CN112395002B - Operation method, device, computer equipment and storage medium - Google Patents
Operation method, device, computer equipment and storage mediumDownload PDFInfo
- Publication number
- CN112395002B CN112395002BCN201910747969.8ACN201910747969ACN112395002BCN 112395002 BCN112395002 BCN 112395002BCN 201910747969 ACN201910747969 ACN 201910747969ACN 112395002 BCN112395002 BCN 112395002B
- Authority
- CN
- China
- Prior art keywords
- pooling
- data
- instruction
- machine learning
- processed
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images


















Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/3001—Arithmetic instructions
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30145—Instruction analysis, e.g. decoding, instruction word fields
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/34—Addressing or accessing the instruction operand or the result ; Formation of operand address; Addressing modes
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/06—Physical realisation, i.e. hardware implementation of neural networks, neurons or parts of neurons
- G06N3/063—Physical realisation, i.e. hardware implementation of neural networks, neurons or parts of neurons using electronic means
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02D—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN INFORMATION AND COMMUNICATION TECHNOLOGIES [ICT], I.E. INFORMATION AND COMMUNICATION TECHNOLOGIES AIMING AT THE REDUCTION OF THEIR OWN ENERGY USE
- Y02D10/00—Energy efficient computing, e.g. low power processors, power management or thermal management
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Software Systems (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Neurology (AREA)
- Computational Linguistics (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- Evolutionary Computation (AREA)
- Data Mining & Analysis (AREA)
- Mathematical Physics (AREA)
- General Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Computational Mathematics (AREA)
- Mathematical Analysis (AREA)
- Mathematical Optimization (AREA)
- Pure & Applied Mathematics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Advance Control (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本公开涉及计算机技术领域,尤其涉及一种反池化指令处理方法、装置、计算机设备和存储介质。The present disclosure relates to the field of computer technology, and in particular to a method, device, computer equipment and storage medium for processing anti-pooling instructions.
背景技术Background technique
随着科技的不断发展,机器学习,尤其是神经网络算法的使用越来越广泛。其在图像识别、语音识别、自然语言处理等领域中都得到了良好的应用。但由于神经网络算法的复杂度越来越高,所涉及的数据运算种类和数量不断增大。相关技术中,在对数据进行反池化运算的效率低、速度慢。With the continuous development of technology, machine learning, especially neural network algorithms, are used more and more widely. It has been well applied in image recognition, speech recognition, natural language processing and other fields. However, due to the increasing complexity of neural network algorithms, the types and quantities of data operations involved continue to increase. In related technologies, the efficiency and speed of unpooling operations on data are low and slow.
发明内容Contents of the invention
有鉴于此,本公开提出了一种反池化指令处理方法、装置、计算机设备和存储介质,以提高对数据进行反池化运算的效率和速度。In view of this, the present disclosure proposes an anti-pooling instruction processing method, device, computer equipment, and storage medium, so as to improve the efficiency and speed of performing anti-pooling operations on data.
根据本公开的第一方面,提供了一种反池化指令处理装置,所述装置包括:According to a first aspect of the present disclosure, there is provided an anti-pooling instruction processing device, the device comprising:
控制模块,用于对获取到的反池化指令进行解析,得到所述反池化指令的操作码和操作域,并根据所述操作码和所述操作域获取执行所述反池化指令所需的待处理数据、输入索引、池化核和目标地址;A control module, configured to analyze the obtained anti-pooling instruction, obtain the operation code and operation field of the anti-pooling instruction, and obtain the information required to execute the anti-pooling instruction according to the operation code and the operation field. The required data to be processed, input index, pooled core and target address;
运算模块,用于根据所述池化核、所述输入索引对所述待处理数据进行反池化运算,获得运算结果,并将所述运算结果存入所述目标地址中。An operation module, configured to perform an unpooling operation on the data to be processed according to the pooling core and the input index, obtain an operation result, and store the operation result in the target address.
根据本公开的第二方面,提供了一种机器学习运算装置,所述装置包括:According to a second aspect of the present disclosure, a machine learning computing device is provided, the device comprising:
一个或多个上述第一方面所述的反池化指令处理装置,用于从其他处理装置中获取待处理数据和控制信息,并执行指定的机器学习运算,将执行结果通过I/O接口传递给其他处理装置;One or more anti-pooling instruction processing devices described in the first aspect above are used to obtain data to be processed and control information from other processing devices, execute specified machine learning operations, and transfer the execution results through the I/O interface to other processing devices;
当所述机器学习运算装置包含多个所述反池化指令处理装置时,所述多个所述反池化指令处理装置间可以通过特定的结构进行连接并传输数据;When the machine learning computing device includes multiple anti-pooling instruction processing devices, the multiple anti-pooling instruction processing devices can be connected and transmit data through a specific structure;
其中,多个所述反池化指令处理装置通过快速外部设备互连总线PCIE总线进行互联并传输数据,以支持更大规模的机器学习的运算;多个所述反池化指令处理装置共享同一控制系统或拥有各自的控制系统;多个所述反池化指令处理装置共享内存或者拥有各自的内存;多个所述反池化指令处理装置的互联方式是任意互联拓扑。Wherein, a plurality of the anti-pooling instruction processing devices are interconnected and transmit data through the PCIE bus to support larger-scale machine learning operations; a plurality of the anti-pooling instruction processing devices share the same The control system may have its own control system; the multiple anti-pooling instruction processing devices share memory or have their own memory; the interconnection mode of the multiple anti-pooling instruction processing devices is any interconnection topology.
根据本公开的第三方面,提供了一种组合处理装置,所述装置包括:According to a third aspect of the present disclosure, there is provided a combined processing device, the device comprising:
上述第二方面所述的机器学习运算装置、通用互联接口和其他处理装置;The machine learning computing device, universal interconnection interface and other processing devices described in the second aspect above;
所述机器学习运算装置与所述其他处理装置进行交互,共同完成用户指定的计算操作。The machine learning computing device interacts with the other processing devices to jointly complete the computing operation specified by the user.
根据本公开的第四方面,提供了一种机器学习芯片,所述机器学习芯片包括上述第二方面所述的机器学习络运算装置或上述第三方面所述的组合处理装置。According to a fourth aspect of the present disclosure, a machine learning chip is provided, and the machine learning chip includes the machine learning network computing device described in the second aspect above or the combined processing device described in the third aspect above.
根据本公开的第五方面,提供了一种机器学习芯片封装结构,该机器学习芯片封装结构包括上述第四方面所述的机器学习芯片。According to a fifth aspect of the present disclosure, a machine learning chip packaging structure is provided, and the machine learning chip packaging structure includes the machine learning chip described in the fourth aspect above.
根据本公开的第六方面,提供了一种板卡,该板卡包括上述第五方面所述的机器学习芯片封装结构。According to a sixth aspect of the present disclosure, a board is provided, which includes the machine learning chip packaging structure described in the fifth aspect above.
根据本公开的第七方面,提供了一种电子设备,所述电子设备包括上述第四方面所述的机器学习芯片或上述第六方面所述的板卡。According to a seventh aspect of the present disclosure, an electronic device is provided, and the electronic device includes the machine learning chip described in the fourth aspect above or the board described in the sixth aspect above.
根据本公开的第八方面,提供了一种反池化指令处理方法,所述方法应用于反池化指令处理装置,所述方法包括:According to an eighth aspect of the present disclosure, there is provided a method for processing an anti-pooling instruction, the method is applied to an anti-pooling instruction processing device, and the method includes:
对获取到的反池化指令进行解析,得到所述反池化指令的操作码和操作域,并根据所述操作域获取执行所述反池化指令所需的待处理数据、输入索引、池化核和目标地址;Analyzing the obtained anti-pooling instruction to obtain the operation code and operation field of the anti-pooling instruction, and obtaining the data to be processed, input index, and pool required for executing the anti-pooling instruction according to the operation field Nucleus and target address;
根据所述池化核、所述输入索引对所述待处理数据进行反池化运算,获得运算结果,并将所述运算结果存入所述目标地址中。Performing an unpooling operation on the data to be processed according to the pooling core and the input index to obtain an operation result, and store the operation result in the target address.
根据本公开的第九方面,提供了一种非易失性计算机可读存储介质,其上存储有计算机程序指令,所述计算机程序指令被处理器执行时实现上述反池化指令处理方法。According to a ninth aspect of the present disclosure, there is provided a non-volatile computer-readable storage medium, on which computer program instructions are stored, and when the computer program instructions are executed by a processor, the above-mentioned anti-pooling instruction processing method is implemented.
在一些实施例中,所述电子设备包括数据处理装置、机器人、电脑、打印机、扫描仪、平板电脑、智能终端、手机、行车记录仪、导航仪、传感器、摄像头、服务器、云端服务器、相机、摄像机、投影仪、手表、耳机、移动存储、可穿戴设备、交通工具、家用电器、和/或医疗设备。In some embodiments, the electronic equipment includes a data processing device, a robot, a computer, a printer, a scanner, a tablet computer, a smart terminal, a mobile phone, a driving recorder, a navigator, a sensor, a camera, a server, a cloud server, a camera, Video cameras, projectors, watches, headphones, mobile storage, wearable devices, vehicles, home appliances, and/or medical equipment.
在一些实施例中,所述交通工具包括飞机、轮船和/或车辆;所述家用电器包括电视、空调、微波炉、冰箱、电饭煲、加湿器、洗衣机、电灯、燃气灶、油烟机;所述医疗设备包括核磁共振仪、B超仪和/或心电图仪。In some embodiments, the vehicles include airplanes, ships, and/or vehicles; the household appliances include televisions, air conditioners, microwave ovens, refrigerators, rice cookers, humidifiers, washing machines, electric lights, gas stoves, range hoods; the medical Equipment includes MRI machines, ultrasound machines, and/or electrocardiographs.
本公开实施例所提供的反池化指令处理方法、装置、计算机设备和存储介质,该装置包括控制模块和运算模块,控制模块用于对获取到的反池化指令进行解析,得到反池化指令的操作码和操作域,并根据操作域获取执行反池化指令所需的待处理数据、输入索引、池化核和目标地址;运算模块用于根据池化核、输入索引对待处理数据进行反池化运算,获得运算结果,并将运算结果存入目标地址中。本公开实施例所提供的反池化指令处理方法、装置及相关产品的适用范围广,对反池化指令的处理效率高、处理速度快,进行反池化运算的处理效率高、速度快。The anti-pooling command processing method, device, computer equipment and storage medium provided by the embodiments of the present disclosure, the device includes a control module and an operation module, and the control module is used to analyze the acquired anti-pooling command to obtain the anti-pooling command The operation code and operation domain of the instruction, and obtain the data to be processed, input index, pooling core and target address required to execute the unpooling instruction according to the operation domain; the operation module is used to perform processing on the data to be processed according to the pooling core and input index Unpool the operation, obtain the operation result, and store the operation result in the target address. The anti-pooling instruction processing method, device, and related products provided by the embodiments of the present disclosure have a wide range of applications, high processing efficiency and fast processing speed for anti-pooling instructions, and high processing efficiency and fast processing speed for performing anti-pooling operations.
根据下面参考附图对示例性实施例的详细说明,本公开的其它特征及方面将变得清楚。Other features and aspects of the present disclosure will become apparent from the following detailed description of exemplary embodiments with reference to the accompanying drawings.
附图说明Description of drawings
包含在说明书中并且构成说明书的一部分的附图与说明书一起示出了本公开的示例性实施例、特征和方面,并且用于解释本公开的原理。The accompanying drawings, which are incorporated in and constitute a part of the specification, illustrate exemplary embodiments, features, and aspects of the disclosure and, together with the specification, serve to explain the principles of the disclosure.
图1示出根据本公开一实施例的反池化指令处理装置的框图。FIG. 1 shows a block diagram of an anti-pooling instruction processing device according to an embodiment of the present disclosure.
图2a-图2c示出了本公开一实施例的反池化运算的示意图Figures 2a-2c show a schematic diagram of an unpooling operation according to an embodiment of the present disclosure
图2d-图2f示出了本公开一实施例的池化核的索引方式的示意图。2d-2f show schematic diagrams of an indexing manner of pooling kernels according to an embodiment of the present disclosure.
图3a-图3f示出根据本公开一实施例的反池化指令处理装置的框图。3a-3f show block diagrams of an anti-pooling instruction processing device according to an embodiment of the present disclosure.
图4a为示出的一实施例的池化核重叠移动的示意图。Fig. 4a is a schematic diagram illustrating overlapping movement of pooling kernels according to an embodiment.
图4b为示出的一实施例的池化核有间距移动的示意图。Fig. 4b is a schematic diagram showing a moving distance of a pooling kernel according to an embodiment.
图5示出根据本公开一实施例的反池化指令处理装置的应用场景的示意图。Fig. 5 shows a schematic diagram of an application scenario of an anti-pooling instruction processing apparatus according to an embodiment of the present disclosure.
图6a、图6b示出根据本公开一实施例的组合处理装置的框图。6a and 6b show block diagrams of a combination processing device according to an embodiment of the present disclosure.
图7示出根据本公开一实施例的板卡的结构示意图。Fig. 7 shows a schematic structural diagram of a board according to an embodiment of the present disclosure.
图8示出根据本公开一实施例的反池化指令处理方法的流程图。Fig. 8 shows a flowchart of a method for processing an anti-pooling instruction according to an embodiment of the present disclosure.
具体实施方式Detailed ways
下面将结合本披露实施例中的附图,对本披露实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本披露一部分实施例,而不是全部的实施例。基于本披露中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本披露保护的范围。The following will clearly and completely describe the technical solutions in the embodiments of the present disclosure with reference to the drawings in the embodiments of the present disclosure. Obviously, the described embodiments are part of the embodiments of the present disclosure, not all of them. Based on the embodiments in the present disclosure, all other embodiments obtained by those skilled in the art without creative efforts fall within the protection scope of the present disclosure.
应当理解,本披露的权利要求、说明书及附图中的术语“第零”、“第一”、“第二”等是用于区别不同对象,而不是用于描述特定顺序。本披露的说明书和权利要求书中使用的术语“包括”和“包含”指示所描述特征、整体、步骤、操作、元素和/或组件的存在,但并不排除一个或多个其它特征、整体、步骤、操作、元素、组件和/或其集合的存在或添加。It should be understood that the terms "zeroth", "first", and "second" in the claims, specification and drawings of the present disclosure are used to distinguish different objects, rather than to describe a specific order. The terms "comprising" and "comprises" used in the specification and claims of this disclosure indicate the presence of described features, integers, steps, operations, elements and/or components, but do not exclude one or more other features, integers , steps, operations, elements, components, and/or the presence or addition of collections thereof.
还应当理解,在此本披露说明书中所使用的术语仅仅是出于描述特定实施例的目的,而并不意在限定本披露。如在本披露说明书和权利要求书中所使用的那样,除非上下文清楚地指明其它情况,否则单数形式的“一”、“一个”及“该”意在包括复数形式。还应当进一步理解,在本披露说明书和权利要求书中使用的术语“和/或”是指相关联列出的项中的一个或多个的任何组合以及所有可能组合,并且包括这些组合。It should also be understood that the terminology used in this disclosure description is for the purpose of describing specific embodiments only, and is not intended to limit the present disclosure. As used in this disclosure and the claims, the singular forms "a", "an" and "the" are intended to include plural referents unless the context clearly dictates otherwise. It should also be further understood that the term "and/or" used in the present disclosure and the claims refers to any combination and all possible combinations of one or more of the associated listed items, and includes these combinations.
如在本说明书和权利要求书中所使用的那样,术语“如果”可以依据上下文被解释为“当...时”或“一旦”或“响应于确定”或“响应于检测到”。类似地,短语“如果确定”或“如果检测到[所描述条件或事件]”可以依据上下文被解释为意指“一旦确定”或“响应于确定”或“一旦检测到[所描述条件或事件]”或“响应于检测到[所描述条件或事件]”。As used in this specification and claims, the term "if" may be interpreted as "when" or "once" or "in response to determining" or "in response to detecting" depending on the context. Similarly, the phrase "if determined" or "if [the described condition or event] is detected" may be construed, depending on the context, to mean "once determined" or "in response to the determination" or "once detected [the described condition or event] ]” or “in response to detection of [described condition or event]”.
由于神经网络算法的广泛使用,计算机硬件运算人能力的不断提升,实际应用中所涉及到的数据运算的种类和数量不断提高。反池化运算(unpool)是一种根据索引对待处理数据进行上采样的运算。由于编程语言的种类多样,在不同的语言环境下,为实现反池化运算的运算过程,相关技术中,由于现阶段没有能广泛适用于各类编程语言的反池化指令,技术人员需要自定义对应其编程语言环境的多条指令来实现反池化运算,导致进行反池化运算效率低、速度慢。本公开提供一种反池化指令处理方法、装置、计算机设备和存储介质,仅用一个指令即可以实现反池化运算,能够显著提高进行反池化运算的效率和速度。Due to the wide use of neural network algorithms and the continuous improvement of computer hardware computing capabilities, the types and quantities of data operations involved in practical applications continue to increase. The unpooling operation (unpool) is an operation for upsampling the data to be processed according to the index. Due to the variety of programming languages, in order to realize the operation process of anti-pooling operation in different language environments, in the related technologies, there is no anti-pooling instruction that can be widely applied to various programming languages at this stage, and technicians need to use their own Define multiple instructions corresponding to its programming language environment to implement anti-pooling operations, resulting in low efficiency and slow speed for anti-pooling operations. The present disclosure provides an anti-pooling instruction processing method, device, computer equipment, and storage medium, which can implement anti-pooling operations with only one instruction, and can significantly improve the efficiency and speed of anti-pooling operations.
图1示出根据本公开一实施例的反池化指令处理装置的框图。如图1所示,该装置包括控制模块11和运算模块12。FIG. 1 shows a block diagram of an anti-pooling instruction processing device according to an embodiment of the present disclosure. As shown in FIG. 1 , the device includes a
控制模块11,用于对获取到的反池化指令进行解析,得到反池化指令的操作码和操作域,并根据操作码和操作域获取执行反池化指令所需的待处理数据、输入索引、池化核和目标地址。The
运算模块12,用于根据所述池化核、所述输入索引对所述待处理数据进行反池化运算,获得运算结果,并将所述运算结果存入所述目标地址中。The
在本实施例中,控制模块可以从待处理数据地址获得待处理数据。控制模块可以通过数据输入输出单元获得指令和数据,该数据输入输出单元可以为一个或多个数据I/O接口或I/O引脚。In this embodiment, the control module can obtain the data to be processed from the address of the data to be processed. The control module can obtain instructions and data through the data input and output unit, and the data input and output unit can be one or more data I/O interfaces or I/O pins.
在本实施例中,操作码可以是计算机程序中所规定的要执行操作的那一部分指令或字段(通常用代码表示),是指令序列号,用来告知执行指令的装置具体需要执行哪一条指令。操作域可以是执行对应的指令所需的数据的来源,执行对应的指令所需的数据包括待处理数据、输入索引、池化核等参数以及对应的运算方法等等。对于一个反池化指令其必须包括操作码和操作域,其中,操作域至少包括待处理数据地址、输入索引、池化核和目标地址。In this embodiment, the operation code can be the part of the instruction or field (usually represented by code) specified in the computer program to perform the operation, and it is the sequence number of the instruction, which is used to inform the device executing the instruction which instruction needs to be executed. . The operation domain can be the source of the data required to execute the corresponding instruction, and the data required to execute the corresponding instruction includes parameters such as data to be processed, input index, pooled core, and corresponding operation methods. For an unpooling instruction, it must include an operation code and an operation domain, wherein the operation domain includes at least the data address to be processed, the input index, the pooling core and the target address.
应当理解的是,本领域技术人员可以根据需要对反池化指令的指令格式以及所包含的操作码和操作域进行设置,本公开对此不作限制。It should be understood that those skilled in the art can set the instruction format and the included operation code and operation field of the unpooling instruction according to needs, and the present disclosure does not limit this.
在本实施例中,该装置可以包括一个或多个控制模块,以及一个或多个运算模块,可以根据实际需要对控制模块和运算模块的数量进行设置,本公开对此不作限制。在装置包括一个控制模块时,该控制模块可以接收反池化指令,并控制一个或多个运算模块进行反池化运算。在装置包括多个控制模块时,多个控制模块可以分别接收反池化指令,并控制对应的一个或多个运算模块进行反池化运算。In this embodiment, the device may include one or more control modules and one or more computing modules, and the numbers of the control modules and computing modules may be set according to actual needs, which is not limited in the present disclosure. When the device includes a control module, the control module can receive an anti-pooling instruction and control one or more computing modules to perform anti-pooling operations. When the device includes multiple control modules, the multiple control modules can respectively receive anti-pooling instructions, and control one or more corresponding computing modules to perform anti-pooling operations.
本公开实施例所提供的反池化指令处理装置,该装置包括控制模块和运算模块,控制模块用于对获取到的反池化指令进行解析,得到反池化指令的操作码和操作域,并根据操作域获取执行反池化指令所需的待处理数据、输入索引、池化核和目标地址;运算模块用于根据池化核、输入索引对待处理数据进行反池化运算,获得运算结果,并将运算结果存入目标地址中。本公开实施例所提供的反池化指令处理装置的适用范围广,对反池化指令的处理效率高、处理速度快,进行反池化运算的处理效率高、速度快。The anti-pooling instruction processing device provided by the embodiment of the present disclosure includes a control module and an operation module, and the control module is used to analyze the obtained anti-pooling instruction to obtain an operation code and an operation field of the anti-pooling instruction, And obtain the data to be processed, input index, pooling core and target address required for executing the unpooling instruction according to the operation domain; the operation module is used to perform unpooling operation on the data to be processed according to the pooling core and input index, and obtain the operation result , and store the operation result in the target address. The anti-pooling instruction processing device provided by the embodiments of the present disclosure has a wide application range, high processing efficiency and fast processing speed for anti-pooling instructions, and high processing efficiency and fast processing speed for performing anti-pooling operations.
图2a-图2c示出了本公开一实施例的反池化运算的示意图。根据池化核、输入索引对待处理数据进行反池化运算。池化核具有固定的索引方式。根据池化核所在的区域中待处理数据所对应的索引与输入索引进行比较,如果相等,则将该待处理数据作为该位置的运算结果,否则该位置的运算结果为预设的默认值。该预设的默认值可以为零。2a-2c show a schematic diagram of an unpooling operation according to an embodiment of the present disclosure. Perform unpooling operations on the data to be processed according to the pooling kernel and input index. Pooling kernels have a fixed indexing method. Compare the index corresponding to the data to be processed in the area where the pooling core is located with the input index, and if they are equal, use the data to be processed as the operation result of the location, otherwise the operation result of the location is the preset default value. The default value for this preset can be zero.
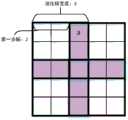
在一种可能的实现方式中,输入索引为一个数据,即待处理数据对应一个输入索引。如图2a所示,假定池化核的尺寸为2×2,其索引以0开始,并且按行依次递增,那么对于该2×2的池化核的索引如图所示。第一步幅和第二步幅值均为2,输入索引为1。运算结果的尺寸为4×4,预设的默认值为0。那么池化核首先位于输出数据的左上角的位置,该位置的索引值为0,与输入索引进行比较,比较结果为不同,根据该比较结果,即不同,得到该处的运算结果为预设的默认值,即0。该池化核所在的区域的第二个值,索引为1,与输入索引进行比较,比较结果为相同,则将待处理数据写入该位置。类似的,比较池化核所在区域的第三个数、第四个数据等。待池化核对应的数据都比较完毕后,以第一步幅以宽度方向移动池化核,即按照宽度方向移动2个单位,重复前述操作,由于输入索引为1个数值,即1,因此对于该区域而言,待处理数据写入到池化核索引为1的位置,其他位置写入默认值,即0。运算完毕后,将池化核跟着第二步幅沿着高度方向进行移动,而后从该高度位置的起始点重新重复前述操作,类似的,将池化核的索引与输入索引,即1,进行比较,通过比较结果得到最终结果。直到全部执行完反向池化运算。In a possible implementation manner, the input index is a piece of data, that is, the data to be processed corresponds to an input index. As shown in Figure 2a, assuming that the size of the pooling kernel is 2×2, its index starts with 0 and increases row by row, then the index of the 2×2 pooling kernel is shown in the figure. The first stride and second stride values are both 2, and the input index is 1. The size of the operation result is 4×4, and the preset default value is 0. Then the pooling kernel is first located at the upper left corner of the output data, and the index value of this position is 0. Compared with the input index, the comparison result is different. According to the comparison result, it is different, and the operation result at this position is preset. The default value, which is 0. The second value of the area where the pooling core is located, the index is 1, is compared with the input index, and if the comparison result is the same, the data to be processed is written to this location. Similarly, compare the third number, fourth data, etc. of the area where the pooling kernel is located. After the data corresponding to the pooling kernel is compared, move the pooling kernel in the width direction in the first step, that is, move 2 units in the width direction, and repeat the above operation. Since the input index is 1 value, that is, 1, so For this area, the data to be processed is written to the position where the pooling core index is 1, and the default value, which is 0, is written to other positions. After the calculation is completed, move the pooling kernel along the height direction with the second step, and then repeat the above operation from the starting point of the height position. Similarly, the index of the pooling kernel and the input index, which is 1, are performed Compare, get the final result by comparing the results. Until all reverse pooling operations are performed.
在一种可能的实现方式中,输入索引为一组数据,其数量与待处理数据相同,即待处理数据与输入索引一一对应。如图2c所示,假定池化核的尺寸为2×2,其索引以0开始,并且按行依次递增,那么对于该2×2的池化核的索引如图所示。第一步幅和第二步幅值均为2,待处理数据的尺寸为2×2,则输入索引也为2×2,与输入索引一一对应。运算结果的尺寸为4×4,预设的默认值为0。那么池化核首先位于输出数据的左上角的位置,该位置的索引值为0,与输入索引进行比较,此时输入索引为2,比较结果为不同,根据该比较结果,即不同,得到该处的运算结果为预设的默认值,即0。该池化核所在的区域的第二个值,索引为1,与输入索引进行比较,比较结果依然不同,则该处的运算结果为0。继续比较第三个值,即索引为2,与输入索引相同,则该处的运算结果为待处理数据。依次类推,待池化核全部运算完毕,以第一步幅以宽度方向移动池化核,即按照宽度方向移动2个单位,重复前述操作,由于输入索引与待处理数据一一对应,则该出的输入索引为1,因此对于该区域而言,待处理数据写入到池化核索引为1的位置,其他位置写入默认值,即0。运算完毕后,将池化核跟着第二步幅沿着高度方向进行移动,而后从该高度位置的起始点重复前述操作,类似的,将池化核的索引与输入索引,即0,进行比较,通过比较结果得到最终结果。再沿着宽度方向移动,将池化核区域与输入索引,即2进行比较,重复执行反向池化运算,直到全部执行完毕。In a possible implementation manner, the input index is a set of data, the number of which is the same as that of the data to be processed, that is, the data to be processed corresponds to the input index one by one. As shown in Figure 2c, assuming that the size of the pooling kernel is 2×2, its index starts with 0 and increases row by row, then the index of the 2×2 pooling kernel is shown in the figure. The values of the first step and the second step are both 2, and the size of the data to be processed is 2×2, so the input index is also 2×2, corresponding to the input index one by one. The size of the operation result is 4×4, and the preset default value is 0. Then the pooling kernel is first located at the upper left corner of the output data, and the index value of this position is 0, which is compared with the input index. At this time, the input index is 2, and the comparison result is different. According to the comparison result, it is different, and the The operation result at is the preset default value, which is 0. The second value of the area where the pooling core is located, the index is 1, is compared with the input index, if the comparison result is still different, then the operation result at this place is 0. Continue to compare the third value, that is, the index is 2, which is the same as the input index, and the operation result here is the data to be processed. By analogy, after all the calculations of the pooling kernel are completed, move the pooling kernel in the width direction with the first step, that is, move 2 units in the width direction, and repeat the above operation. Since the input index corresponds to the data to be processed one by one, the The output index is 1, so for this area, the data to be processed is written to the position where the pooling core index is 1, and the default value, which is 0, is written to other positions. After the calculation is completed, move the pooling kernel along the height direction with the second step, and then repeat the above operation from the starting point of the height position. Similarly, compare the index of the pooling kernel with the input index, which is 0. , to get the final result by comparing the results. Then move along the width direction, compare the pooled core area with the input index, which is 2, and repeat the reverse pooling operation until all are executed.
在一种可能的实现方式中,输入索引为一组数据,待处理数据中的部分数据与输入索引对应。如图2b所示,待处理数据中同一维度的数据对应一个相同的输入索引,即在宽度方向上,同一宽度的数据对应同一个输入索引。其执行过程与上文类似,其区别在于在同一维度的输入索引相同,不同维度的输入索引不同。这里部分数据还可以包括其他方式,例如输入数据为三维,包括输入高度、输入宽度和输入通道,还可以同一输入通道的待处理数据采用同一个输入索引等;例如输入数据被预先处理为多个组,每个组采用同一个输入索引等。In a possible implementation manner, the input index is a set of data, and some data in the data to be processed corresponds to the input index. As shown in Figure 2b, the data of the same dimension in the data to be processed corresponds to the same input index, that is, in the width direction, the data of the same width corresponds to the same input index. Its execution process is similar to the above, the difference is that the input indexes of the same dimension are the same, and the input indexes of different dimensions are different. Part of the data here can also include other methods, for example, the input data is three-dimensional, including input height, input width and input channel, and the same input index can be used for the data to be processed in the same input channel; for example, the input data is pre-processed into multiple groups, each group takes the same input index, etc.
图2d-图2f示出了本公开一实施例的池化核的索引方式的示意图。根据池化核、输入索引对待处理数据进行反池化运算。其中池化核具有固定的索引方式。2d-2f show schematic diagrams of an indexing manner of pooling kernels according to an embodiment of the present disclosure. Perform unpooling operations on the data to be processed according to the pooling kernel and input index. Among them, the pooling kernel has a fixed index method.
在一种可能的实现方式中,池化核的索引方式可以采用行优先的依次递增的方式进行索引,即以一个固定的数据作为起始,而后以行优先的方式依次递增。如图2d所示,其中,以0为起始,一种求(iw,ih)位置的索引值index的方式可以为index=ih*kw+iw。In a possible implementation, the indexing method of the pooling core can be indexed in a row-first and sequentially increasing manner, that is, starting with a fixed data, and then increasing in a row-first manner. As shown in FIG. 2d , where starting from 0, a way to find the index value index of the position (iw, ih) may be index=ih*kw+iw.
在一种可能的实现方式中,池化核的索引方式可以采用列优先的依次递增的方式进行索引。如图2e所示,以0为起始,采用列优先的依次递增的方式进行索引;那么,一种求(iw,ih)位置的索引值index的方式可以为index=iw*kh+ih。In a possible implementation manner, the indexing manner of the pooling core may be indexed in a column-first manner in increasing order. As shown in FIG. 2e , starting from 0, indexing is carried out in a column-first increasing manner; then, a method of finding the index value index of the position (iw, ih) can be index=iw*kh+ih.
在一种可能的实现方式中,池化核的索引方式可以采用根据查找表查找的方式索引,如图2f所示,设置一个查找表,对池化核进行索引。譬如对于c的位置,通过查表得到其索引为10。In a possible implementation manner, the indexing manner of the pooled core may be indexed according to a lookup table. As shown in FIG. 2f, a lookup table is set to index the pooled core. For example, for the position of c, its index is 10 obtained by looking up the table.
应当理解的是,本领域技术人员可以根据需要对反池化指令的中的池化核的索引方式进行设置,本公开对此不作限制。It should be understood that those skilled in the art may set the indexing manner of the pooling cores in the unpooling instruction according to needs, which is not limited in the present disclosure.
图3a示出根据本公开一实施例的反池化指令处理装置的框图。在一种可能的实现方式中,如图3a所示,运算模块12可以包括一个或多个比较器120。比较器120用于对池化核所对应的区域中的待处理数据进行比较运算获得比较结果,获得比较结果的索引作为运算结果。Fig. 3a shows a block diagram of an anti-pooling instruction processing device according to an embodiment of the present disclosure. In a possible implementation manner, as shown in FIG. 3 a , the
在该实现方式中,可以根据所需进行的比较运算的数据量的大小、对比较运算的处理速度、效率等要求对比较器的数量进行设置,本公开对此不作限制。In this implementation manner, the number of comparators may be set according to the size of data required for the comparison operation, the processing speed and efficiency of the comparison operation, etc., which is not limited in the present disclosure.
图3b示出根据本公开多个实施例的反池化指令处理装置的框图。在一种可能的实现方式中,如图3b所示,运算模块12可以包括主运算子模块121和多个从运算子模块122。主运算子模块121包括一个或多个比较器。Fig. 3b shows a block diagram of an anti-pooling instruction processing device according to multiple embodiments of the present disclosure. In a possible implementation manner, as shown in FIG. 3 b , the
在一种可能的实现方式中,主运算子模块121,用于利用所述比较器对所述池化核所对应的区域中的索引与多对应的所述输入索引进行比较运算获得比较结果,根据比较结果获得运算结果,并将所述运算结果存入所述目标地址中。In a possible implementation manner, the
在一种可能的实现方式中,控制模块11,还可以用于对获取到的计算指令进行解析,得到计算指令的操作域和操作码,并根据操作域获取执行计算指令所需的待处理数据。运算模块12,还可以用于根据计算指令对待处理数据进行运算,得到计算指令的计算结果。其中,运算模块还可以包括多个运算器,用于执行与计算指令的运算类型相对应的运算。In a possible implementation, the
在该实现方式中,计算指令可以是其他对标量、向量、矩阵、张量等数据进行算术运算、逻辑运算等运算的指令,本领域技术人员可以根据实际需要对计算指令进行设置,本公开对此不作限制。In this implementation, the calculation instructions can be other instructions for performing arithmetic operations, logical operations, etc. on data such as scalars, vectors, matrices, and tensors. Those skilled in the art can set the calculation instructions according to actual needs. This is not limited.
该实现方式中,运算器可以包括加法器、除法器、乘法器、比较器等能够对数据进行算术运算、逻辑运算等运算的运算器。可以根据所需进行的运算的数据量的大小、运算类型、对数据进行运算的处理速度、效率等要求对运算器的种类及数量进行设置,本公开对此不作限制。In this implementation manner, the arithmetic unit may include an adder, a divider, a multiplier, a comparator, and other arithmetic units capable of performing arithmetic operations, logic operations, and other operations on data. The type and quantity of calculators can be set according to the size of data to be calculated, the type of calculation, the processing speed and efficiency of data calculation, etc., which is not limited in the present disclosure.
在一种可能的实现方式中,如图3b所示,运算模块12可以包括主运算子模块121和多个从运算子模块122。从运算子模块122包括一个或多个比较器。In a possible implementation manner, as shown in FIG. 3 b , the
在一种可能的实现方式中,控制模块11,还用于解析计算指令得到多个运算指令,并将待处理数据和多个运算指令发送至主运算子模块121。In a possible implementation manner, the
主运算子模块121,用于接收控制模块获取的执行所述反池化指令所需的所述待处理数据、所述输入索引、所述池化核和所述目标地址,并向从运算子模块分配和传输各自执行所述反池化指令对应的所需的述待处理数据、所述输入索引、所述池化核和所述目标地址。The
从运算子模块122,用于接收主运算子模块分配和传输的执行所述反池化指令对应的所需的述待处理数据、所述输入索引、所述池化核和所述目标地址,利用所述比较器对所述池化核所对应的区域中的索引与所对应的所述输入索引进行比较运算获得比较结果,根据比较结果得到运算结果,并将所述运算结果存入所述目标地址中。The
在该实现方式中,在计算指令为针对标量、向量数据所进行的运算时,装置可以控制主运算子模块利用其中的运算器进行与计算指令相对应的运算。在计算指令为针对矩阵、张量等维度大于或等于2的数据进行运算时,装置可以控制从运算子模块利用其中的运算器进行与计算指令相对应的运算。In this implementation, when the calculation instruction is an operation on scalar or vector data, the device can control the main operation sub-module to use the arithmetic unit therein to perform the operation corresponding to the calculation instruction. When the calculation instruction is to operate on data whose dimension is greater than or equal to 2, such as matrix and tensor, the device can control the sub-operation sub-module to use the arithmetic unit therein to perform the operation corresponding to the calculation instruction.
需要说明的是,本领域技术人员可以根据实际需要对主运算子模块和多个从运算子模块之间的连接方式进行设置,以实现对运算模块的架构设置,例如,运算模块的架构可以是“H”型架构、阵列型架构、树型架构等,本公开对此不作限制。It should be noted that those skilled in the art can set the connection mode between the main operation sub-module and multiple slave operation sub-modules according to actual needs, so as to realize the architecture setting of the operation module, for example, the architecture of the operation module can be The "H" type architecture, the array type architecture, the tree type architecture, etc., are not limited in this disclosure.
图3c示出根据本公开一实施例的反池化指令处理装置的框图。在一种可能的实现方式中,如图3c所示,运算模块12还可以包括一个或多个分支运算子模块123,该分支运算子模块123用于转发主运算子模块121和从运算子模块122之间的数据和/或运算指令。其中,主运算子模块121与一个或多个分支运算子模块123连接。这样,运算模块中的主运算子模块、分支运算子模块和从运算子模块之间采用“H”型架构连接,通过分支运算子模块转发数据和/或运算指令,节省了对主运算子模块的资源占用,进而提高指令的处理速度。Fig. 3c shows a block diagram of an anti-pooling instruction processing device according to an embodiment of the present disclosure. In a possible implementation, as shown in FIG. 3c, the
图3d示出根据本公开一实施例的反池化指令处理装置的框图。在一种可能的实现方式中,如图3d所示,多个从运算子模块122呈阵列分布。Fig. 3d shows a block diagram of an anti-pooling instruction processing device according to an embodiment of the present disclosure. In a possible implementation manner, as shown in FIG. 3d, multiple
每个从运算子模块122与相邻的其他从运算子模块122连接,主运算子模块121连接多个从运算子模块122中的k个从运算子模块122,k个从运算子模块122为:第1行的n个从运算子模块122、第m行的n个从运算子模块122以及第1列的m个从运算子模块122。Each from
其中,如图3d所示,k个从运算子模块仅包括第1行的n个从运算子模块、第m行的n个从运算子模块以及第1列的m个从运算子模块,即该k个从运算子模块为多个从运算子模块中直接与主运算子模块连接的从运算子模块。其中,k个从运算子模块,用于在主运算子模块以及多个从运算子模块之间的数据以及指令的转发。这样,多个从运算子模块呈阵列分布,可以提高主运算子模块向从运算子模块发送数据和/或运算指令速度,进而提高指令的处理速度。Wherein, as shown in Figure 3d, the k sub-operating sub-modules only include n sub-operating sub-modules in the first row, n sub-operating sub-modules in the m-th row, and m sub-operating sub-modules in the first column, that is The k slave computing sub-modules are slave computing sub-modules directly connected to the master computing sub-module among the multiple slave computing sub-modules. Among them, k slave operation sub-modules are used for forwarding data and instructions between the main operation sub-module and multiple slave operation sub-modules. In this way, the plurality of slave computing sub-modules are distributed in an array, which can increase the speed of sending data and/or computing instructions from the master computing sub-module to the slave computing sub-modules, thereby increasing the processing speed of instructions.
图3e示出根据本公开一实施例的反池化指令处理装置的框图。在一种可能的实现方式中,如图3e所示,运算模块还可以包括树型子模块124。该树型子模块124包括一个根端口401和多个支端口402。根端口401与主运算子模块121连接,多个支端口402与多个从运算子模块122分别连接。其中,树型子模块124具有收发功能,用于转发主运算子模块121和从运算子模块122之间的数据和/或运算指令。这样,通过树型子模块的作用使得运算模块呈树型架构连接,并利用树型子模块的转发功能,可以提高主运算子模块向从运算子模块发送数据和/或运算指令速度,进而提高指令的处理速度。Fig. 3e shows a block diagram of an anti-pooling instruction processing device according to an embodiment of the present disclosure. In a possible implementation manner, as shown in FIG. 3 e , the calculation module may further include a
在一种可能的实现方式中,树型子模块124可以为该装置的可选结果,其可以包括至少一层节点。节点为具有转发功能的线结构,节点本身不具备运算功能。最下层的节点与从运算子模块连接,以转发主运算子模块121和从运算子模块122之间的数据和/或运算指令。特殊地,如树型子模块具有零层节点,该装置则无需树型子模块。In a possible implementation manner, the
在一种可能的实现方式中,树型子模块124可以包括n叉树结构的多个节点,n叉树结构的多个节点可以具有多个层。In a possible implementation manner, the
举例来说,图3f示出根据本公开一实施例的反池化指令处理装置的框图。如图2f所示,n叉树结构可以是二叉树结构,树型子模块包括2层节点01。最下层节点01与从运算子模块122连接,以转发主运算子模块121和从运算子模块122之间的数据和/或运算指令。For example, Fig. 3f shows a block diagram of an anti-pooling instruction processing device according to an embodiment of the present disclosure. As shown in FIG. 2f, the n-ary tree structure may be a binary tree structure, and the tree-type sub-module includes 2 layers of nodes 01 . The lowest layer node 01 is connected to the slave operation sub-module 122 to forward data and/or operation instructions between the
在该实现方式中,n叉树结构还可以是三叉树结构等,n为大于或等于2的正整数。本领域技术人员可以根据需要对n叉树结构中的n以及n叉树结构中节点的层数进行设置,本公开对此不作限制。In this implementation manner, the n-ary tree structure may also be a ternary tree structure, etc., and n is a positive integer greater than or equal to 2. Those skilled in the art can set n in the n-ary tree structure and the number of layers of nodes in the n-ary tree structure according to needs, which is not limited in the present disclosure.
在一种可能的实现方式中,操作域还可以包括输出高度和输出宽度。In a possible implementation manner, the operation domain may also include an output height and an output width.
其中,控制模块,还用于向所述目的地址写入所述运算结果,且所述运算结果的高度为所述输出高度,宽度为所述输出宽度。Wherein, the control module is further configured to write the operation result to the destination address, and the height of the operation result is the output height, and the width is the output width.
在该实现方式中,输出宽度和输出高度可以限定所获得的运算结果的数据量和尺寸。操作域所包括的输出宽度和输出高度可以是具体的数值,还可以是存储输出宽度和输出高度的存储地址。在操作域中直接包括输出宽度和输出高度的具体数值时,将该具体数值分别确定为对应的输出宽度和输出高度。在操作域中包括输出宽度和输出高度的存储地址时,可以分别从输出宽度和输出高度的存储地址中获得输出高度和输出宽度。In this implementation manner, the output width and output height may define the data volume and size of the obtained operation result. The output width and output height included in the operation domain may be specific numerical values, and may also be storage addresses for storing the output width and output height. When the specific numerical values of the output width and output height are directly included in the operation field, the specific numerical values are respectively determined as the corresponding output width and output height. When the storage address of the output width and the output height are included in the operation domain, the output height and the output width can be respectively obtained from the storage addresses of the output width and the output height.
在一种可能的实现方式中,在操作域中不包括输出宽度和输出高度时,可以根据预先设置的默认输出高度和默认输出宽度获取待处理数据,也可以根据输入高度、输入宽度等其他操作域求得。In a possible implementation, when the output width and output height are not included in the operation domain, the data to be processed can be obtained according to the preset default output height and default output width, or other operations such as input height and input width domain obtained.
通过上述方式,可以对运算结果的数据量和尺寸进行限制,保证运算结果的准确性,并保证装置可以执行该反池化指令。Through the above method, the data volume and size of the operation result can be limited, to ensure the accuracy of the operation result, and to ensure that the device can execute the anti-pooling instruction.
在一种可能的实现方式中,操作域还可以包括输出高度和输出宽度。In a possible implementation manner, the operation domain may also include an output height and an output width.
其中,控制模块,还用于根据输出高度得到输入高度,根据输出宽度输入宽度,从所述待处理数据地址中,获取对应所述输入宽度和所述输入高度的待处理数据。Wherein, the control module is further configured to obtain the input height according to the output height, and obtain the data to be processed corresponding to the input width and the input height from the address of the data to be processed according to the output width and input width.
在该实现方式中,输入高度可以根据输出高度获得,一种可能的实现方式为输入高度和输出高度的关系为:In this implementation, the input height can be obtained according to the output height. One possible implementation is that the relationship between the input height and the output height is:
输出高度=(输入高度-1)*第二步幅+池化核高度Output height = (input height - 1) * second stride + pooling kernel height
输出宽度=(输入宽度-1)*第一步幅+池化核宽度Output width = (input width - 1) * first step width + pooling kernel width
在一种可能的实现方式中,在操作域中不包括输出宽度和输出高度时,可以根据预先设置的默认输出高度和默认输出宽度获取待处理数据,也可以根据输入高度、输入宽度等其他操作域求得。In a possible implementation, when the output width and output height are not included in the operation domain, the data to be processed can be obtained according to the preset default output height and default output width, or other operations such as input height and input width domain obtained.
通过上述方式,可以对待处理数据的数据量和尺寸进行限制,保证运算结果的准确性,并保证装置可以执行该反池化指令。Through the above method, the data volume and size of the data to be processed can be limited to ensure the accuracy of the calculation results and ensure that the device can execute the anti-pooling instruction.
在一种可能的实现方式中,操作域还可以包括输入高度和输入宽度。In a possible implementation manner, the operation domain may also include an input height and an input width.
其中,控制模块,还用于从待处理数据地址中,获取对应输入宽度和输入高度的待处理数据。Wherein, the control module is also used to obtain the data to be processed corresponding to the input width and the input height from the address of the data to be processed.
在该实现方式中,输入高度和输入宽度可以限定所获得的待处理数据的数据量和尺寸。操作域所包括的输入高度和输入宽度可以是具体的数值,还可以是存储输入高度和输入宽度的存储地址。在操作域中直接包括输入高度和输入宽度的具体数值时,将该具体数值分别确定为对应的输入高度和输入宽度。在操作域中包括输入高度和输入宽度的存储地址时,可以分别从输入高度和输入宽度的存储地址中获得输入高度和输入宽度。In this implementation manner, the input height and input width may define the data volume and size of the obtained data to be processed. The input height and input width included in the operation field may be specific numerical values, and may also be storage addresses for storing the input height and input width. When the specific numerical values of the input height and input width are directly included in the operation field, the specific numerical values are respectively determined as the corresponding input height and input width. When the storage address of the input height and the input width are included in the operation domain, the input height and the input width can be obtained from the storage addresses of the input height and the input width respectively.
在一种可能的实现方式中,在操作域中不包括输入高度和输入宽度时,可以根据预先设置的默认输入高度和默认输入宽度获取待处理数据,也可以根据输出高度、输出宽度等其他操作域求得。In a possible implementation, when the input height and input width are not included in the operation domain, the data to be processed can be obtained according to the preset default input height and default input width, or other operations such as output height and output width can be used domain obtained.
通过上述方式,可以对待处理数据的数据量和尺寸进行限制,保证运算结果的准确性,并保证装置可以执行该反池化指令。Through the above method, the data volume and size of the data to be processed can be limited to ensure the accuracy of the calculation results and ensure that the device can execute the anti-pooling instruction.
在一种可能的实现方式中,操作域还可以包括输入通道数。In a possible implementation manner, the operation domain may also include the number of input channels.
其中,控制模块,还用于从待处理数据地址中,获取对应输入通道数的待处理数据。Wherein, the control module is also used to obtain the data to be processed corresponding to the number of input channels from the address of the data to be processed.
在该实现方式中,输入通道数可以限定所获得的待处理数据的通道数量,输出通道数与输入通道数相同。操作域所包括的输入通道数可以是具体的数值,还可以是存储输入通道数的存储地址。在操作域中直接包括输入通道数的具体数值时,将该具体数值确定为对应的输入通道数。在操作域中包括输入通道数的存储地址时,可以从输入通道数的存储地址中获得输入通道数度。In this implementation manner, the number of input channels may limit the number of channels of the obtained data to be processed, and the number of output channels is the same as the number of input channels. The number of input channels included in the operation domain may be a specific value, or a storage address for storing the number of input channels. When the specific value of the number of input channels is directly included in the operation field, the specific value is determined as the corresponding number of input channels. When the storage address of the input channel number is included in the operation field, the input channel number can be obtained from the storage address of the input channel number.
在一种可能的实现方式中,在操作域中不包括输入通道数时,可以根据预先设置的默认输入通道数来获取待处理数据。In a possible implementation manner, when the number of input channels is not included in the operation domain, the data to be processed may be obtained according to a preset default number of input channels.
通过上述方式,可以对待处理数据的输入通道数进行限制,保证运算结果的准确性,并保证装置可以执行该反池化指令。Through the above method, the number of input channels of the data to be processed can be limited to ensure the accuracy of the calculation results and ensure that the device can execute the anti-pooling instruction.
在一种可能的实现方式中,操作域还可以包括池化核高度和池化核宽度。In a possible implementation manner, the operation domain may further include pooling kernel height and pooling kernel width.
其中,运算模块12,还用于根据池化核高度和池化核宽度来执行反池化运算。Wherein, the
在一种可能的实现方式中,在操作域中不包括池化核高度、池化核宽度时,可以获取预先设置的默认池化核高度、默认池化核宽度,使得控制模块和运算模块可以执行反池化指令。In a possible implementation, when the pooling core height and pooling core width are not included in the operation domain, the preset default pooling core height and default pooling core width can be obtained, so that the control module and the operation module can Execute the unpooling command.
在一种可能的实现方式中,操作域还可以包括第一步幅。其中,运算模块12,还可以用于按照第一步幅在宽度方向上移动池化核。In a possible implementation manner, the operation domain may also include a first step. Wherein, the
在一种可能的实现方式中,操作域还可以包括第二步幅。其中,运算模块12,还可以用于按照第二步幅在高度方向上移动池化核。In a possible implementation manner, the operating domain may further include a second stride. Wherein, the
在一种可能的实现方式中,操作域还可以包括第一步幅和第二步幅。其中,运算模块12,还可以用于按照第一步幅在宽度方向上移动池化核,按照第二步幅在高度方向上移动池化核。In a possible implementation manner, the operating domain may further include a first stride and a second stride. Wherein, the
在该实现方式中,反池化运算的步幅是在进行反池化运算中每一次移动池化核的幅度。第一步幅可以是在宽度方向上移动池化核的幅度,第二步幅可以是在高度方向上移动池化核的幅度。In this implementation, the stride of the unpooling operation is the magnitude of moving the pooling kernel each time during the unpooling operation. The first step may be the magnitude of moving the pooling kernel in the width direction, and the second step may be the magnitude of moving the pooling kernel in the height direction.
需要说明的是,在本公开中仅以池化核为二维为例,描述了进行反池化运算所需的池化核的高度、宽度、第一步幅和第二步幅等参数,若池化核为多维,在相应地池化核的参数则包括其每个维度的尺寸和步幅。It should be noted that in this disclosure, the pooling kernel is only two-dimensional as an example, and parameters such as the height, width, first step width, and second step size of the pooling kernel required for the unpooling operation are described. If the pooling kernel is multi-dimensional, the parameters of the corresponding pooling kernel include the size and stride of each dimension.
在一种可能的实现方式中,在反池化指令的操作域中并未给出第一步幅和第二步幅时,运算模块可以以池化核的高度和宽度分别为其对应维度的步幅,保证反池化运算的正常进行。In a possible implementation, when the first step and the second step are not given in the operation domain of the unpooling instruction, the operation module can use the height and width of the pooling core as the corresponding dimension The stride is to ensure the normal operation of the unpooling operation.
在一种可能的实现方式中,运算模块12还用于在所述池化核重叠移动时,所述运算结果在重叠处进行累加,其中,所述池化核重叠移动,包括以下至少一项:当所述操作域包含所述第一步幅时,所述第一步幅小于所述池化核宽度;当所述操作域包含所述第二步幅时,所述第二步幅小于所述池化核高度。具体来说,当操作域中只包含第一步幅而不包含第二步幅时,池化核重叠移动指第一步幅小于池化核宽度;当操作域中只包含第二步幅而不包含第一步幅时,池化核重叠移动指第二步幅小于池化核高度;当操作域中同时第一步幅和第二步幅时,且当第一步幅小于池化核宽度和第二步幅小于池化核高度中至少满足一项时,即为池化核重叠移动。In a possible implementation manner, the
如图4a为示出的一种池化核重叠移动的情况,其中池化核尺寸为3×3。第一步幅和第二步幅均为2,那么如图所示的阴影部分即为重叠区域。对于该重叠区域的运算结果,进行累加。例如当池化核的所在区域为左上角的时候,在重叠区域a处的运算结果为1;当池化核移动后,其在重叠区域的运算结果应为2,则此时a处的运算结果将进行累加,即1+2=3。Figure 4a shows a case where the pooling kernels overlap and move, where the size of the pooling kernels is 3×3. The first step and the second step are both 2, then the shaded part shown in the figure is the overlapping area. The calculation results in the overlapping area are accumulated. For example, when the area where the pooling kernel is located is the upper left corner, the operation result at the overlapping area a is 1; when the pooling kernel is moved, the operation result at the overlapping area should be 2, then the operation at a at this time The results will be accumulated,
在一种可能的实现方式中,运算模块12还用于在所述池化核有间距移动时,所述运算结果在间距处写入默认值,其中,所述池化核有间距移动,包括以下至少一项:当所述操作域包含所述第一步幅时,所述第一步幅大于所述池化核宽度;当所述操作域包含所述第二步幅时,所述第二步幅大于所述池化核高度。具体来说,当操作域中只包含第一步幅而不包含第二步幅时,池化核有间距移动指第一步幅大于池化核宽度;当操作域中只包含第二步幅而不包含第一步幅时,池化核有间距移动指第二步幅大于池化核高度;当操作域中同时第一步幅和第二步幅时,且当第一步幅大于池化核宽度和第二步幅大于池化核高度中至少满足一项时,即为池化核有间距移动。In a possible implementation manner, the
在一种可能的实现中,默认值为0。In one possible implementation, the default value is 0.
如图4b为示出的一种池化核有间距移动的情况,其中池化核尺寸为2×2。第一步幅和第二步幅均为3,那么如图所示的阴影部分即为间距区域。Fig. 4b shows a situation where the pooling kernel has pitch movement, where the size of the pooling kernel is 2×2. The first step and the second step are both 3, then the shaded part as shown in the figure is the spacing area.
在一种实现方式中,对于间距区域的数据可以不进行处理。In an implementation manner, no processing may be performed on the data in the distance region.
在一种实现方式中,可以间距区域的运算结果可以视为默认值,默认值可以为零。In an implementation manner, the operation result of the spaceable region may be regarded as a default value, and the default value may be zero.
在一种可能的实现方式中,如图3a-图3f所示,该装置还可以包括存储模块13。存储模块13用于存储待处理数据和池化核。In a possible implementation manner, as shown in FIG. 3 a - FIG. 3 f , the device may further include a
在该实现方式中,存储模块可以为缓存、寄存器中的一种或多种,缓存可以包括速暂存缓存,还可以包括至少一个NRAM(Neuron Random Access Memory,神经元随机存取存储器)。缓存可以用于存储待处理数据和运算结果,寄存器可以用于存储待处理数据、标量数据、参数等。In this implementation, the storage module may be one or more of a cache and a register, and the cache may include a temporary cache, and may also include at least one NRAM (Neuron Random Access Memory, neuron random access memory). Cache can be used to store data to be processed and operation results, and registers can be used to store data to be processed, scalar data, parameters, etc.
在一种可能的实现方式中,缓存可以包括神经元缓存。神经元缓存也即上述神经元随机存取存储器,可以用于存储待处理数据中的神经元数据,神经元数据可以包括神经元向量数据。In a possible implementation manner, the cache may include a neuron cache. The neuron cache, that is, the aforementioned neuron random access memory, may be used to store neuron data in the data to be processed, and the neuron data may include neuron vector data.
在一种可能的实现方式中,该装置还可以包括直接内存访问模块,用于从存储模块中读取或者存储数据。In a possible implementation manner, the device may further include a direct memory access module, configured to read or store data from the storage module.
在一种可能的实现方式中,如图3a-图3f所示,控制模块11可以包括指令存储子模块111、指令处理子模块112和队列存储子模块113。In a possible implementation manner, as shown in FIGS. 3 a - 3 f , the
指令存储子模块111用于存储反池化指令。The instruction storage sub-module 111 is used for storing anti-pooling instructions.
指令处理子模块112用于对反池化指令进行解析,得到反池化指令的操作码和操作域。The
队列存储子模块113用于存储指令队列,指令队列包括按照执行顺序依次排列的多个待执行指令,多个待执行指令可以包括反池化指令。The
在该实现方式中,可以根据待执行指令的接收时间、优先级别等对多个待执行指令的执行顺序进行排列获得指令队列,以便于根据指令队列依次执行多个待执行指令。In this implementation, the execution sequence of the multiple instructions to be executed can be arranged according to the receiving time, priority level, etc. of the instructions to be executed to obtain an instruction queue, so that the multiple instructions to be executed can be sequentially executed according to the instruction queue.
在一种可能的实现方式中,如图3a-图3f所示,控制模块11还可以包括依赖关系处理子模块114。In a possible implementation manner, as shown in FIG. 3 a - FIG. 3 f , the
依赖关系处理子模块114,用于在确定多个待执行命令中的第一待执行指令与第一待执行指令之前的第零待执行指令存在关联关系时,将第一待执行指令缓存在指令存储子模块111中,在第零待执行指令执行完毕后,从指令存储子模块111中提取第一待执行指令发送至运算模块12。The
其中,第一待执行指令与第一待执行指令之前的第零待执行指令存在关联关系包括:存储第一待执行指令所需数据的第一存储地址区间与存储第零待执行指令所需数据的第零存储地址区间具有重叠的区域。反之,第一待执行指令与第一待执行指令之前的第零待执行指令之间没有关联关系可以是第一存储地址区间与第零存储地址区间没有重叠区域。Wherein, the association between the first instruction to be executed and the zeroth instruction to be executed before the first instruction to be executed includes: the first storage address interval storing the data required by the first instruction to be executed and the data required for storing the zeroth instruction to be executed The zeroth memory address range has an overlapping area. On the contrary, there is no correlation between the first instruction to be executed and the zeroth instruction to be executed before the first instruction to be executed may be that the first storage address interval and the zeroth storage address interval have no overlapping area.
通过这种方式,可以根据第一待执行指令与第一待执行指令之前的第零待执行指令之间的依赖关系,使得在先的第零待执行指令执行完毕之后,再执行在后的第一待执行指令,保证运算结果的准确性。In this way, according to the dependency between the first to-be-executed instruction and the zeroth to-be-executed instruction before the first to-be-executed instruction, after the previous zero-th to-be-executed instruction is executed, the following one is executed. Once the instruction is to be executed, the accuracy of the operation result is guaranteed.
在一种可能的实现方式中,反池化指令的指令格式可以是:In a possible implementation manner, the command format of the anti-pooling command may be:
unpool dstsrc0srcChannelsrcHeightsrcWidthdstHeightdstWidthkernelHeightkernelWidthunpool dstsrc0srcChannelsrcHeightsrcWidthdstHeightdstWidthkernelHeightkernelWidth
其中,unpool为反池化指令的操作码,dst、src0、srcChannel、srcHeight、srcWidth为反池化指令的操作域。其中,dst为目标地址,src0为待处理数据地址,srcChannel为输入通道数,srcHeight为输入高度,srcWidth为输入宽度,dstHeight为输出高度,dstWidth为输出宽度,kernelHeight为池化核高度,kernelWidth为池化核宽度。即从src0处获取的待处理数据,待处理数据的尺寸如下,输入通道数是srcChannel、输入高度是srcHeight、输入宽度是srcWidth。池化核的尺寸如下,池化核高度为kernelHeight,池化核宽度为kernelWidth。每次池化核的移动步长为默认值,如宽度方向上每次移动的步长为kernelWidth,高度方向上每次移动的步长为kernalHeight。输出尺寸如下,输出通道数是srcChannel、输出高度是dstHeight、输出宽度是dstWidth。反池化后的运算结果存入地址为dst处。Among them, unpool is the opcode of the anti-pooling instruction, and dst, src0, srcChannel, srcHeight, and srcWidth are the operation fields of the anti-pooling instruction. Among them, dst is the target address, src0 is the address of the data to be processed, srcChannel is the number of input channels, srcHeight is the input height, srcWidth is the input width, dstHeight is the output height, dstWidth is the output width, kernelHeight is the pooled kernel height, and kernelWidth is the pool nuclei width. That is, the data to be processed obtained from src0, the size of the data to be processed is as follows, the number of input channels is srcChannel, the input height is srcHeight, and the input width is srcWidth. The size of the pooling kernel is as follows, the height of the pooling kernel is kernelHeight, and the width of the pooling kernel is kernelWidth. The moving step of each pooling kernel is the default value, for example, the step of each moving in the width direction is kernelWidth, and the step of each moving in the height direction is kernelHeight. The output size is as follows, the number of output channels is srcChannel, the output height is dstHeight, and the output width is dstWidth. The operation result after unpooling is stored at address dst.
在一种可能的实现方式中,反池化指令的指令格式可以是:In a possible implementation manner, the command format of the anti-pooling command may be:
unpool dstsrc0srcChanneldstHeighdstWidthkernelHeightkernelWidthstrideXstrideY indexunpool dstsrc0srcChanneldstHeighdstWidthkernelHeightkernelWidthstrideXstrideY index
其中,unpool为反池化指令的操作码,dst、src0、srcChannel、dstHeight、dstWidth、kernelHeight、kernelWidth、strideX、strideY、index为反池化指令的操作域。其中,dst为目标地址,src0为待处理数据地址,srcChannel为输入通道数,dstHeight为输出高度,dstWidth为输出宽度,kernelHeight为池化核高度,kernelWidth为池化核宽度,strideX为池化核在宽度方向上进行移动的第一步幅,strideY为池化核在高度方向上进行移动的第二步幅。即从src0处获取的待处理数据,待处理数据的尺寸根据输出尺寸获得,即如下,输入通道数是srcChannel、输入高度是srcHeight(srcHeight=(dstHeight-kernelHeight)/strideY+1)、输入宽度是srcWidth(srcWidth=(dstWidth-kernelWidth)/strideX+1)。池化核的尺寸如下,池化核高度为kernelHeight,池化核宽度为kernelWidth。每次池化核在宽度方向上每次移动的步长为strideX,高度方向上每次移动的步长为strideY。输出尺寸如下,输出通道数是srcChannel、输出高度是dstHeight、输出宽度是dstWidth。反池化后的运算结果存入地址为dst处。Among them, unpool is the opcode of the anti-pooling instruction, and dst, src0, srcChannel, dstHeight, dstWidth, kernelHeight, kernelWidth, strideX, strideY, and index are the operating fields of the anti-pooling instruction. Among them, dst is the target address, src0 is the address of the data to be processed, srcChannel is the number of input channels, dstHeight is the output height, dstWidth is the output width, kernelHeight is the height of the pooled core, kernelWidth is the width of the pooled core, and strideX is the width of the pooled core The first step of moving in the width direction, and strideY is the second step of moving the pooling kernel in the height direction. That is, the data to be processed obtained from src0, the size of the data to be processed is obtained according to the output size, namely as follows, the number of input channels is srcChannel, the input height is srcHeight (srcHeight=(dstHeight-kernelHeight)/strideY+1), and the input width is srcWidth(srcWidth=(dstWidth-kernelWidth)/strideX+1). The size of the pooling kernel is as follows, the height of the pooling kernel is kernelHeight, and the width of the pooling kernel is kernelWidth. The step size of each movement of the pooling kernel in the width direction is strideX, and the step size of each movement in the height direction is strideY. The output size is as follows, the number of output channels is srcChannel, the output height is dstHeight, and the output width is dstWidth. The operation result after unpooling is stored at address dst.
应当理解的是,本领域技术人员可以根据需要对反池化指令的操作码、指令格式中操作码和操作域的位置进行设置,本公开对此不作限制。It should be understood that those skilled in the art can set the operation code of the unpooling instruction, the location of the operation code and the operation field in the instruction format according to needs, and the disclosure does not limit this.
在一种可能的实现方式中,该装置可以设置于图形处理器(Graphics ProcessingUnit,简称GPU)、中央处理器(Central Processing Unit,简称CPU)和嵌入式神经网络处理器(Neural-network Processing Unit,简称NPU)的一种或多种之中。In a possible implementation, the device can be set on a graphics processing unit (Graphics Processing Unit, referred to as GPU), a central processing unit (Central Processing Unit, referred to as CPU) and an embedded neural network processor (Neural-network Processing Unit, One or more of NPU).
需要说明的是,尽管以上述实施例作为示例介绍了反池化指令处理装置如上,但本领域技术人员能够理解,本公开应不限于此。事实上,用户完全可根据个人喜好和/或实际应用场景灵活设定各模块,只要符合本公开的技术方案即可。It should be noted that although the above embodiment is used as an example to describe the apparatus for processing an unpooling instruction, those skilled in the art can understand that the present disclosure should not be limited thereto. In fact, users can flexibly set each module according to personal preferences and/or actual application scenarios, as long as they comply with the technical solution of the present disclosure.
应用示例Application example
以下结合“利用反池化指令处理装置进行反池化运算”作为一个示例性应用场景,给出根据本公开实施例的应用示例,以便于理解反池化指令处理装置的流程。本领域技术人员应理解,以下应用示例仅仅是出于便于理解本公开实施例的目的,不应视为对本公开实施例的限制In the following, an application example according to an embodiment of the present disclosure is given in conjunction with "performing an anti-pooling operation by an anti-pooling instruction processing apparatus" as an exemplary application scenario, so as to facilitate understanding of the flow of an anti-pooling instruction processing apparatus. Those skilled in the art should understand that the following application examples are only for the purpose of facilitating the understanding of the embodiments of the present disclosure, and should not be regarded as limiting the embodiments of the present disclosure
图5示出根据本公开一实施例的反池化指令处理装置的应用场景的示意图。如图3所示,反池化指令处理装置对反池化指令进行处理的过程如下:Fig. 5 shows a schematic diagram of an application scenario of an anti-pooling instruction processing apparatus according to an embodiment of the present disclosure. As shown in Figure 3, the process of processing the anti-pooling instruction by the anti-pooling instruction processing device is as follows:
控制模块11对获取到的反池化指令1(如反池化指令1为unpool500100564322112)进行解析,得到反池化指令1的操作码和操作域。其中,反池化指令1的操作码为unpool,目标地址为500,待处理数据地址为100,输入通道数为5,输出高度为64,输出宽度为32,池化核高度为2,池化核宽度为1,第一步幅为1,第二步幅为2。控制模块11根据操作码获取待处理数据规模,一种方式是通过下式计算得到:The
输出高度=(输入高度–1)*第二步幅+池化核高度,输出宽度=(输入宽度–1)*第一步幅+卷积核宽度Output height = (input height – 1) * second stride + pooling kernel height, output width = (input width – 1) * first step width + convolution kernel width
则输入高度为32,输入宽度为32,于是控制模块11从待处理数据地址100中获取32×32×5的待处理数据。Then the input height is 32, and the input width is 32, so the
运算模块12利用池化核分别在5个输入通道上对32×32规模的待处理数据进行反池化运算,得到运算结果,并将运算结果存入目标地址500中。The
以上各模块的工作过程可参考上文的相关描述。For the working process of the above modules, please refer to the relevant description above.
这样,可以高效、快速地对反池化指令进行处理,且进行反池化运算的效率和速度也有显著提高。In this way, the anti-pooling instruction can be processed efficiently and quickly, and the efficiency and speed of the anti-pooling operation are also significantly improved.
本公开提供一种机器学习运算装置,该机器学习运算装置可以包括一个或多个上述反池化指令处理装置,用于从其他处理装置中获取待处理数据和控制信息,执行指定的机器学习运算。该机器学习运算装置可以从其他机器学习运算装置或非机器学习运算装置中获得反池化指令,并将执行结果通过I/O接口传递给外围设备(也可称其他处理装置)。外围设备譬如摄像头,显示器,鼠标,键盘,网卡,wifi接口,服务器。当包含一个以上反池化指令处理装置时,反池化指令处理装置间可以通过特定的结构进行链接并传输数据,譬如,通过PCIE总线进行互联并传输数据,以支持更大规模的神经网络的运算。此时,可以共享同一控制系统,也可以有各自独立的控制系统;可以共享内存,也可以每个加速器有各自的内存。此外,其互联方式可以是任意互联拓扑。The present disclosure provides a machine learning computing device, which may include one or more of the above-mentioned anti-pooling instruction processing devices, which are used to obtain data to be processed and control information from other processing devices, and execute specified machine learning operations . The machine learning computing device can obtain unpooling instructions from other machine learning computing devices or non-machine learning computing devices, and transmit the execution results to peripheral devices (also called other processing devices) through the I/O interface. Peripherals such as cameras, monitors, mice, keyboards, network cards, wifi interfaces, servers. When more than one anti-pooling instruction processing device is included, the anti-pooling instruction processing devices can be linked and transmit data through a specific structure, for example, interconnect and transmit data through a PCIE bus to support a larger-scale neural network. operation. At this time, the same control system can be shared, or there can be independent control systems; the memory can be shared, or each accelerator can have its own memory. In addition, its interconnection method can be any interconnection topology.
该机器学习运算装置具有较高的兼容性,可通过PCIE接口与各种类型的服务器相连接。The machine learning computing device has high compatibility and can be connected with various types of servers through the PCIE interface.
图6a示出根据本公开一实施例的组合处理装置的框图。如图6a所示,该组合处理装置包括上述机器学习运算装置、通用互联接口和其他处理装置。机器学习运算装置与其他处理装置进行交互,共同完成用户指定的操作。Figure 6a shows a block diagram of a combined processing device according to an embodiment of the disclosure. As shown in FIG. 6a, the combined processing device includes the above-mentioned machine learning computing device, a general interconnection interface and other processing devices. The machine learning computing device interacts with other processing devices to jointly complete the operations specified by the user.
其他处理装置,包括中央处理器CPU、图形处理器GPU、神经网络处理器等通用/专用处理器中的一种或以上的处理器类型。其他处理装置所包括的处理器数量不做限制。其他处理装置作为机器学习运算装置与外部数据和控制的接口,包括数据搬运,完成对本机器学习运算装置的开启、停止等基本控制;其他处理装置也可以和机器学习运算装置协作共同完成运算任务。Other processing devices include one or more types of general-purpose/special-purpose processors such as central processing unit CPU, graphics processing unit GPU, and neural network processor. The number of processors included in other processing devices is not limited. Other processing devices serve as the interface between the machine learning computing device and external data and control, including data transfer, and complete the basic control of starting and stopping the machine learning computing device; other processing devices can also cooperate with the machine learning computing device to complete computing tasks.
通用互联接口,用于在机器学习运算装置与其他处理装置间传输数据和控制指令。该机器学习运算装置从其他处理装置中获取所需的输入数据,写入机器学习运算装置片上的存储装置;可以从其他处理装置中获取控制指令,写入机器学习运算装置片上的控制缓存;也可以读取机器学习运算装置的存储模块中的数据并传输给其他处理装置。The universal interconnection interface is used to transmit data and control instructions between the machine learning computing device and other processing devices. The machine learning computing device obtains the required input data from other processing devices, and writes it into the storage device on the machine learning computing device; it can obtain control instructions from other processing devices, and writes it into the control cache on the machine learning computing device chip; The data in the storage module of the machine learning computing device can be read and transmitted to other processing devices.
图6b示出根据本公开一实施例的组合处理装置的框图。在一种可能的实现方式中,如图6b所示,该组合处理装置还可以包括存储装置,存储装置分别与机器学习运算装置和所述其他处理装置连接。存储装置用于保存在机器学习运算装置和所述其他处理装置的数据,尤其适用于所需要运算的数据在本机器学习运算装置或其他处理装置的内部存储中无法全部保存的数据。Fig. 6b shows a block diagram of a combined processing device according to an embodiment of the disclosure. In a possible implementation manner, as shown in FIG. 6b, the combined processing device may further include a storage device, and the storage device is respectively connected to the machine learning computing device and the other processing device. The storage device is used to store data in the machine learning computing device and the other processing devices, and is especially suitable for data that cannot be fully stored in the internal storage of the machine learning computing device or other processing devices.
该组合处理装置可以作为手机、机器人、无人机、视频监控设备等设备的SOC片上系统,有效降低控制部分的核心面积,提高处理速度,降低整体功耗。此情况时,该组合处理装置的通用互联接口与设备的某些部件相连接。某些部件譬如摄像头,显示器,鼠标,键盘,网卡,wifi接口。The combined processing device can be used as a SOC system on a mobile phone, robot, drone, video surveillance equipment and other equipment, effectively reducing the core area of the control part, increasing the processing speed, and reducing the overall power consumption. In this case, the general interconnection interface of the combination processing device is connected with certain components of the equipment. Some components such as camera, monitor, mouse, keyboard, network card, wifi interface.
本公开提供一种机器学习芯片,该芯片包括上述机器学习运算装置或组合处理装置。The present disclosure provides a machine learning chip, which includes the above-mentioned machine learning computing device or combined processing device.
本公开提供一种机器学习芯片封装结构,该机器学习芯片封装结构包括上述机器学习芯片。The present disclosure provides a machine learning chip packaging structure, and the machine learning chip packaging structure includes the above machine learning chip.
本公开提供一种板卡,图5示出根据本公开一实施例的板卡的结构示意图。如图7所示,该板卡包括上述机器学习芯片封装结构或者上述机器学习芯片。板卡除了包括机器学习芯片389以外,还可以包括其他的配套部件,该配套部件包括但不限于:存储器件390、接口装置391和控制器件392。The present disclosure provides a board card, and FIG. 5 shows a schematic structural diagram of the board card according to an embodiment of the present disclosure. As shown in FIG. 7 , the board includes the above-mentioned machine learning chip packaging structure or the above-mentioned machine learning chip. In addition to the machine learning chip 389 , the board may also include other supporting components, including but not limited to: a storage device 390 , an
存储器件390与机器学习芯片389(或者机器学习芯片封装结构内的机器学习芯片)通过总线连接,用于存储数据。存储器件390可以包括多组存储单元393。每一组存储单元393与机器学习芯片389通过总线连接。可以理解,每一组存储单元393可以是DDR SDRAM(英文:Double Data Rate SDRAM,双倍速率同步动态随机存储器)。The storage device 390 is connected to the machine learning chip 389 (or the machine learning chip in the package structure of the machine learning chip) through a bus for storing data. The memory device 390 may include groups of memory cells 393 . Each group of storage units 393 is connected to the machine learning chip 389 via a bus. It can be understood that each group of storage units 393 can be DDR SDRAM (English: Double Data Rate SDRAM, double rate synchronous dynamic random access memory).
DDR不需要提高时钟频率就能加倍提高SDRAM的速度。DDR允许在时钟脉冲的上升沿和下降沿读出数据。DDR的速度是标准SDRAM的两倍。DDR doubles the speed of SDRAM without increasing the clock frequency. DDR allows data to be read out on both rising and falling edges of the clock pulse. DDR is twice as fast as standard SDRAM.
在一个实施例中,存储器件390可以包括4组存储单元393。每一组存储单元393可以包括多个DDR4颗粒(芯片)。在一个实施例中,机器学习芯片389内部可以包括4个72位DDR4控制器,上述72位DDR4控制器中64bit用于传输数据,8bit用于ECC校验。In one embodiment, the memory device 390 may include 4 groups of memory cells 393 . Each group of storage units 393 may include multiple DDR4 particles (chips). In one embodiment, the machine learning chip 389 may include four 72-bit DDR4 controllers, of which 64 bits are used for data transmission and 8 bits are used for ECC verification.
在一个实施例中,每一组存储单元393包括多个并联设置的双倍速率同步动态随机存储器。DDR在一个时钟周期内可以传输两次数据。在机器学习芯片389中设置控制DDR的控制器,用于对每个存储单元393的数据传输与数据存储的控制。In one embodiment, each group of storage units 393 includes a plurality of double-rate synchronous dynamic random access memories arranged in parallel. DDR can transmit data twice in one clock cycle. A controller for controlling DDR is provided in the machine learning chip 389 for controlling data transmission and data storage of each storage unit 393 .
接口装置391与机器学习芯片389(或者机器学习芯片封装结构内的机器学习芯片)电连接。接口装置391用于实现机器学习芯片389与外部设备(例如服务器或计算机)之间的数据传输。例如在一个实施例中,接口装置391可以为标准PCIE接口。比如,待处理的数据由服务器通过标准PCIE接口传递至机器学习芯片289,实现数据转移。在另一个实施例中,接口装置391还可以是其他的接口,本公开并不限制上述其他的接口的具体表现形式,接口装置能够实现转接功能即可。另外,机器学习芯片的计算结果仍由接口装置传送回外部设备(例如服务器)。The
控制器件392与机器学习芯片389电连接。控制器件392用于对机器学习芯片389的状态进行监控。具体的,机器学习芯片389与控制器件392可以通过SPI接口电连接。控制器件392可以包括单片机(Micro Controller Unit,MCU)。如机器学习芯片389可以包括多个处理芯片、多个处理核或多个处理电路,可以带动多个负载。因此,机器学习芯片389可以处于多负载和轻负载等不同的工作状态。通过控制器件可以实现对机器学习芯片中多个处理芯片、多个处理和/或多个处理电路的工作状态的调控。The control device 392 is electrically connected with the machine learning chip 389 . The control device 392 is used to monitor the state of the machine learning chip 389 . Specifically, the machine learning chip 389 and the control device 392 may be electrically connected through an SPI interface. The control device 392 may include a microcontroller (Micro Controller Unit, MCU). For example, the machine learning chip 389 may include multiple processing chips, multiple processing cores, or multiple processing circuits, and may drive multiple loads. Therefore, the machine learning chip 389 can be in different working states such as heavy load and light load. Controlling the working states of multiple processing chips, multiple processing and/or multiple processing circuits in the machine learning chip can be realized through the control device.
本公开提供一种电子设备,该电子设备包括上述机器学习芯片或板卡。The present disclosure provides an electronic device, which includes the above-mentioned machine learning chip or board.
电子设备可以包括数据处理装置、计算机设备、机器人、电脑、打印机、扫描仪、平板电脑、智能终端、手机、行车记录仪、导航仪、传感器、摄像头、服务器、云端服务器、相机、摄像机、投影仪、手表、耳机、移动存储、可穿戴设备、交通工具、家用电器、和/或医疗设备。Electronic equipment may include data processing devices, computer equipment, robots, computers, printers, scanners, tablet computers, smart terminals, mobile phones, driving recorders, navigators, sensors, cameras, servers, cloud servers, cameras, video cameras, projectors , watches, earphones, mobile storage, wearable devices, vehicles, household appliances, and/or medical equipment.
交通工具可以包括飞机、轮船和/或车辆。家用电器可以包括电视、空调、微波炉、冰箱、电饭煲、加湿器、洗衣机、电灯、燃气灶、油烟机。医疗设备可以包括核磁共振仪、B超仪和/或心电图仪。Vehicles may include airplanes, ships, and/or vehicles. Household appliances can include televisions, air conditioners, microwave ovens, refrigerators, rice cookers, humidifiers, washing machines, electric lights, gas stoves, and range hoods. Medical equipment may include MRI machines, B-ultrasound machines and/or electrocardiographs.
图8示出根据本公开一实施例的反池化指令处理方法的流程图。该方法可以应用于包含存储器和处理器的如计算机设备等,其中,存储器用于存储执行方法过程中所使用的数据;处理器用于执行相关的处理、运算步骤,如执行下述步骤S51和步骤S52。如图8所示,该方法应用于上述反池化指令处理装置,该方法包括步骤S51和步骤S52。Fig. 8 shows a flowchart of a method for processing an anti-pooling instruction according to an embodiment of the present disclosure. The method can be applied to a computer device including a memory and a processor, wherein the memory is used to store data used in the process of executing the method; the processor is used to perform related processing and calculation steps, such as performing the following steps S51 and steps S52. As shown in FIG. 8, the method is applied to the above-mentioned anti-pooling instruction processing device, and the method includes step S51 and step S52.
在步骤S51中,对获取到的反池化指令进行解析,得到反池化指令的操作码和操作域,并根据操作域获取执行反池化指令所需的待处理数据、输入索引、池化核和目标地址。其中,操作码用于指示反池化指令对数据所进行的运算为反池化运算,操作域包括待处理数据地址、输入索引、目标地址和池化核。In step S51, the acquired anti-pooling instruction is analyzed to obtain the operation code and operation field of the anti-pooling instruction, and according to the operation field, the data to be processed, input index, pooling core and target addresses. Wherein, the operation code is used to indicate that the operation performed by the anti-pooling instruction on the data is an anti-pooling operation, and the operation domain includes the address of the data to be processed, the input index, the target address, and the pooling core.
在步骤S52中,根据池化核、输入索引对待处理数据进行反池化运算,获得运算结果,并将运算结果存入目标地址中。In step S52, an unpooling operation is performed on the data to be processed according to the pooling core and the input index, and the operation result is obtained, and the operation result is stored in the target address.
在一种可能的实现方式中,包括:所述待处理数据对应一个所述输入索引。In a possible implementation manner, the method includes: the data to be processed corresponds to one input index.
在一种可能的实现方式中,包括:所述待处理数据与所述输入索引一一对应。In a possible implementation manner, the method includes: a one-to-one correspondence between the data to be processed and the input index.
在一种可能的实现方式中,包括:所述待处理数据的部分数据对应一个所述输入索引。In a possible implementation manner, the method includes: the partial data of the data to be processed corresponds to one input index.
在一种可能的实现方式中,根据所述池化核、所述输入索引对所述待处理数据进行反池化运算,获得运算结果,包括:利用所述比较器对所述池化核所对应的区域中的索引与多对应的所述输入索引进行比较运算获得比较结果,根据比较结果获得运算结果。In a possible implementation manner, performing an unpooling operation on the data to be processed according to the pooling kernel and the input index to obtain an operation result includes: using the comparator to The index in the corresponding area is compared with the multi-corresponding input index to obtain a comparison result, and the operation result is obtained according to the comparison result.
在一种可能的实现方式中,包括:所述池化核所对应的区域中的索引按行依次递增、按列依次递增或者根据查找表查找。In a possible implementation manner, it includes: the index in the area corresponding to the pooling core is incremented sequentially by row, sequentially by column, or searched according to a lookup table.
在一种可能的实现方式中,运算模块包括主运算子模块和多个从运算子模块,所述主运算子模块包括所述比较器,In a possible implementation manner, the operation module includes a main operation sub-module and multiple slave operation sub-modules, the main operation sub-module includes the comparator,
其中,所述根据所述池化核、所述输入索引对所述待处理数据进行反池化运算,获得运算结果,并将所述运算结果存入所述目标地址中,包括:Wherein, performing an unpooling operation on the data to be processed according to the pooling core and the input index, obtaining an operation result, and storing the operation result in the target address includes:
利用所述比较器对所述池化核所对应的区域中的索引与多对应的所述输入索引进行比较运算获得比较结果,根据比较结果获得运算结果,并将所述运算结果存入所述目标地址中。Using the comparator to perform a comparison operation on the index in the area corresponding to the pooling core and the corresponding input index to obtain a comparison result, obtain an operation result according to the comparison result, and store the operation result in the in the target address.
在一种可能的实现方式中,运算模块包括主运算子模块和多个从运算子模块,所述从运算子模块包括所述比较器,In a possible implementation manner, the computing module includes a master computing sub-module and multiple slave computing sub-modules, the slave computing sub-modules include the comparator,
其中,所述根据所述池化核、所述输入索引对所述待处理数据进行反池化运算,获得比较结果的索引作为运算结果,并将所述运算结果存入所述目标地址中,包括:Wherein, performing an unpooling operation on the data to be processed according to the pooling core and the input index, obtaining an index of a comparison result as an operation result, and storing the operation result in the target address, include:
利用所述多个比较器对所述池化核所对应的区域中的多个待处理数据进行比较运算获得比较结果,得到运算结果,并将所述运算结果存入所述目标地址中。Using the plurality of comparators to perform a comparison operation on a plurality of data to be processed in the area corresponding to the pooling core to obtain a comparison result, obtain an operation result, and store the operation result in the target address.
接收控制模块获取的执行所述反池化指令所需的所述待处理数据、所述输入索引、所述池化核和所述目标地址,并向从运算子模块分配和传输各自执行所述反池化指令对应的所需的述待处理数据、所述输入索引、所述池化核和所述目标地址;receiving the data to be processed, the input index, the pooling core, and the target address acquired by the control module required for executing the unpooling instruction, and distributing and transmitting the data to be executed respectively to the slave computing sub-modules The required data to be processed corresponding to the anti-pooling instruction, the input index, the pooling core and the target address;
接收主运算子模块分配和传输的执行所述反池化指令对应的所需的所述待处理数据、所述输入索引、所述池化核和所述目标地址,利用所述比较器对所述池化核所对应的区域中的索引与所对应的所述输入索引进行比较运算获得比较结果,根据比较结果得到运算结果,并将所述运算结果存入所述目标地址中。receiving the data to be processed, the input index, the pooling core, and the target address required for executing the unpooling instruction allocated and transmitted by the main operation sub-module, and using the comparator to compare the The index in the area corresponding to the pooling core is compared with the corresponding input index to obtain a comparison result, and the operation result is obtained according to the comparison result, and the operation result is stored in the target address.
在一种可能的实现方式中,操作域还包括输入高度和输入宽度,其中,所述根据所述操作域获取执行所述反池化指令所需的待处理数据、输入索引、池化核和目标地址,包括:从所述待处理数据地址中,获取对应所述输入宽度和所述输入高度的待处理数据。In a possible implementation manner, the operation field further includes an input height and an input width, wherein, according to the operation field, the data to be processed, input index, pooling core, and The target address includes: obtaining the data to be processed corresponding to the input width and the input height from the address of the data to be processed.
在一种可能的实现方式中,操作域还包括输出高度和输出宽度,其中,所述根据所述操作域获取执行所述反池化指令所需的待处理数据、输入索引、池化核和目标地址,包括:向所述目的地址写入所述运算结果,且所述运算结果的高度为所述输出高度,宽度为所述输出宽度。In a possible implementation manner, the operation field further includes an output height and an output width, wherein, according to the operation field, the data to be processed, input index, pooling core, and The target address includes: writing the operation result to the target address, and the height of the operation result is the output height, and the width is the output width.
在一种可能的实现方式中,操作域还包括输出高度和输出宽度,其中,所述根据所述操作域获取执行所述反池化指令所需的待处理数据、输入索引、池化核和目标地址,包括:根据输出高度和输出宽度,分别得到输入高度和输入宽度,从所述待处理数据地址中,获取对应所述输入宽度和所述输入高度的待处理数据。In a possible implementation manner, the operation field further includes an output height and an output width, wherein, according to the operation field, the data to be processed, input index, pooling core, and The target address includes: obtaining an input height and an input width according to the output height and output width respectively, and acquiring data to be processed corresponding to the input width and the input height from the address of the data to be processed.
在一种可能的实现方式中,操作域还包括输入通道数,其中,所述根据所述操作域获取执行所述反池化指令所需的待处理数据、输入索引、池化核和目标地址,包括:从所述待处理数据地址中,获取对应所述输入通道数的待处理数据。In a possible implementation manner, the operation domain also includes the number of input channels, wherein, according to the operation domain, the data to be processed, input index, pooling core and target address required for executing the unpooling instruction are acquired , including: acquiring the data to be processed corresponding to the number of input channels from the address of the data to be processed.
在一种可能的实现方式中,操作域还包括池化核高度和池化核宽度,其中,所述根据所述池化核、所述输入索引对所述待处理数据进行反池化运算,包括:根据所述池化核高度和所述池化核宽度对所述待处理数据进行反池化运算。In a possible implementation manner, the operation domain further includes a pooling kernel height and a pooling kernel width, wherein performing an unpooling operation on the data to be processed according to the pooling kernel and the input index, The method includes: performing an unpooling operation on the data to be processed according to the pooling kernel height and the pooling kernel width.
在一种可能的实现方式中,操作域还可以包括第一步幅。其中,根据池化核、输入索引对待处理数据进行反池化运算,可以包括:按照第一步幅在宽度方向上移动池化核。In a possible implementation manner, the operation domain may also include a first step. Wherein, performing an unpooling operation on the data to be processed according to the pooling kernel and the input index may include: moving the pooling kernel in the width direction according to the width of the first step.
在一种可能的实现方式中,操作域还可以包括第二步幅。其中,根据池化核、输入索引对待处理数据进行反池化运算,可以包括:按照第二步幅在高度方向上移动池化核。In a possible implementation manner, the operating domain may further include a second stride. Wherein, performing an unpooling operation on the data to be processed according to the pooling kernel and the input index may include: moving the pooling kernel in the height direction according to the second stride.
在一种可能的实现方式中,操作域还可以包括第一步幅和第二步幅。其中,根据池化核、输入索引对待处理数据进行反池化运算,可以包括:按照第一步幅在宽度方向上移动池化核和按照第二步幅在高度方向上移动池化核。In a possible implementation manner, the operating domain may further include a first stride and a second stride. Wherein, performing the unpooling operation on the data to be processed according to the pooling kernel and the input index may include: moving the pooling kernel in the width direction according to the first step and moving the pooling kernel in the height direction according to the second step.
在一种可能的实现方式中,根据所述池化核、所述输入索引对所述待处理数据进行反池化运算,还包括:In a possible implementation manner, performing an unpooling operation on the data to be processed according to the pooling kernel and the input index further includes:
在所述池化核重叠移动时,所述运算结果在重叠处进行累加,When the pooling kernel overlaps and moves, the operation results are accumulated at the overlap,
其中,所述池化核重叠移动,包括以下至少一项:Wherein, the overlapping movement of the pooling kernels includes at least one of the following:
当所述操作域包含所述第一步幅时,所述第一步幅小于所述池化核宽度;When the operation domain includes the first step width, the first step width is smaller than the pooling kernel width;
当所述操作域包含所述第二步幅时,所述第二步幅小于所述池化核高度。When the operation domain includes the second stride, the second stride is smaller than the pooling kernel height.
在一种可能的实现方式中,根据所述池化核、所述输入索引对所述待处理数据进行反池化运算,还包括:In a possible implementation manner, performing an unpooling operation on the data to be processed according to the pooling kernel and the input index further includes:
在所述池化核重叠移动时,所述运算结果在重叠处进行累加,When the pooling kernel overlaps and moves, the operation results are accumulated at the overlap,
其中,所述池化核重叠移动,可以为当所述操作域包含所述第一步幅和第二步幅时,所述第一步幅小于所述池化核宽度,或者第二步幅小于所述池化核高度,或者所述第一步幅小于所述池化核宽度并且第二步幅小于所述池化核高度。Wherein, the overlapping movement of the pooling kernel may be that when the operating domain includes the first step and the second step, the first step is smaller than the pooling kernel width, or the second step is smaller than the pooling kernel height, or the first step size is smaller than the pooling kernel width and the second step size is smaller than the pooling kernel height.
在一种可能的实现方式中,根据所述池化核、所述输入索引对所述待处理数据进行反池化运算,还包括:In a possible implementation manner, performing an unpooling operation on the data to be processed according to the pooling kernel and the input index further includes:
在所述池化核有间距移动时,所述运算结果在间距处写入默认值,When the pooling kernel has a gap movement, the operation result is written into a default value at the gap,
其中,所述池化核有间距移动,包括以下至少一项:Wherein, the pooling kernel has pitch movement, including at least one of the following:
当所述操作域包含所述第一步幅时,所述第一步幅大于所述池化核宽度;When the operation domain includes the first step width, the first step width is greater than the pooling kernel width;
当所述操作域包含所述第二步幅时,所述第二步幅大于所述池化核高度。When the operation domain includes the second stride, the second stride is larger than the pooling kernel height.
在一种可能的实现方式中,根据所述池化核、所述输入索引对所述待处理数据进行反池化运算,还包括:In a possible implementation manner, performing an unpooling operation on the data to be processed according to the pooling kernel and the input index further includes:
在所述池化核有间距移动时,所述运算结果在间距处写入默认值,When the pooling kernel has a gap movement, the operation result is written into a default value at the gap,
其中,所述池化核有间距移动,可以为当所述操作域包含所述第一步幅和第二步幅时,所述第一步幅大于所述池化核宽度,或者所述第二步幅大于所述池化核高度,或者所述第一步幅大于所述池化核宽度并且所述第二步幅大于所述池化核高度。Wherein, the pooling kernel has an interval movement, which may be that when the operation domain includes the first step and the second step, the first step is larger than the pooling kernel width, or the first The second stride is greater than the pooling kernel height, or the first step is greater than the pooling kernel width and the second stride is greater than the pooling kernel height.
在一种可能的实现方式中,述根据所述池化核、所述输入索引对所述待处理数据进行反池化运算,还包括:In a possible implementation manner, performing an unpooling operation on the data to be processed according to the pooling kernel and the input index further includes:
所述默认值为零。The default value is zero.
在一种可能的实现方式中,该方法还可以包括:利用装置的存储模块存储待处理数据和运算结果。In a possible implementation manner, the method may further include: using a storage module of the device to store data to be processed and calculation results.
在一种可能的实现方式中,对获取到的反池化指令进行解析,得到反池化指令的操作码和操作域,可以包括:In a possible implementation manner, the obtained anti-pooling instruction is analyzed to obtain the operation code and operation domain of the anti-pooling instruction, which may include:
存储反池化指令;store unpooling instructions;
对反池化指令进行解析,得到反池化指令的操作码和操作域;Analyze the anti-pooling instruction to obtain the operation code and operation domain of the anti-pooling instruction;
存储指令队列,指令队列包括按照执行顺序依次排列的多个待执行指令,多个待执行指令可以包括反池化指令。An instruction queue is stored, and the instruction queue includes a plurality of instructions to be executed sequentially arranged according to an execution order, and the plurality of instructions to be executed may include an anti-pooling instruction.
在一种可能的实现方式中,该方法还可以包括:在确定多个待执行指令中的第一待执行指令与第一待执行指令之前的第零待执行指令存在关联关系时,缓存第一待执行指令,在第零待执行指令执行完毕后,执行第一待执行指令,In a possible implementation, the method may further include: when it is determined that there is an association between the first instruction to be executed among the instructions to be executed and the zeroth instruction to be executed before the first instruction to be executed, caching the first Instructions to be executed, after the execution of the zeroth instruction to be executed, execute the first instruction to be executed,
其中,第一待执行指令与第一待执行指令之前的第零待执行指令存在关联关系包括以下至少一种:Wherein, the association between the first instruction to be executed and the zeroth instruction to be executed before the first instruction to be executed includes at least one of the following:
存储所述第一待执行指令所需数据的第一存储地址区间与存储所述第零待执行指令所需数据的第零存储地址区间具有重叠的区域;The first storage address interval storing the data required by the first instruction to be executed has an overlapping area with the zeroth storage address interval storing the data required by the zeroth instruction to be executed;
执行所述第一待执行指令所需使用的第一运算部件与执行所述第零执行指令所需使用的第零运算部件全部相同或者部分相同。The first computing unit required to execute the first instruction to be executed is all or partly the same as the zeroth computing unit required to execute the zeroth instruction to be executed.
需要说明的是,尽管以上述实施例作为示例介绍了反池化指令处理方法如上,但本领域技术人员能够理解,本公开应不限于此。事实上,用户完全可根据个人喜好和/或实际应用场景灵活设定各步骤,只要符合本公开的技术方案即可。It should be noted that although the above embodiment is used as an example to describe the method for processing an unpooling instruction, those skilled in the art can understand that the present disclosure should not be limited thereto. In fact, the user can flexibly set each step according to personal preferences and/or actual application scenarios, as long as it conforms to the technical solution of the present disclosure.
本公开实施例所提供的反池化指令处理方法的适用范围广,对反池化指令的处理效率高、处理速度快,进行反池化运算的效率高、速度快。The method for processing anti-pooling instructions provided by the embodiments of the present disclosure has a wide application range, high efficiency and fast processing speed for anti-pooling instructions, and high efficiency and fast speed for performing anti-pooling operations.
本公开还提供一种非易失性计算机可读存储介质,其上存储有计算机程序指令,其特征在于,所述计算机程序指令被处理器执行时实现上述反池化指令处理方法。The present disclosure also provides a non-volatile computer-readable storage medium on which computer program instructions are stored, and is characterized in that, when the computer program instructions are executed by a processor, the above-mentioned anti-pooling instruction processing method is implemented.
需要说明的是,对于前述的各方法实施例,为了简单描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本披露并不受所描述的动作顺序的限制,因为依据本披露,某些步骤可以采用其他顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于可选实施例,所涉及的动作和模块并不一定是本披露所必须的。It should be noted that for the foregoing method embodiments, for the sake of simple description, they are expressed as a series of action combinations, but those skilled in the art should know that the present disclosure is not limited by the described action sequence. Because of this disclosure, certain steps may be performed in other orders or simultaneously. Secondly, those skilled in the art should also know that the embodiments described in the specification are all optional embodiments, and the actions and modules involved are not necessarily required by the present disclosure.
进一步需要说明的是,虽然图6的流程图中的各个步骤按照箭头的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,这些步骤可以以其它的顺序执行。而且,图6中的至少一部分步骤可以包括多个子步骤或者多个阶段,这些子步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,这些子步骤或者阶段的执行顺序也不必然是依次进行,而是可以与其它步骤或者其它步骤的子步骤或者阶段的至少一部分轮流或者交替地执行。It should be further noted that although the various steps in the flow chart of FIG. 6 are displayed sequentially as indicated by the arrows, these steps are not necessarily executed sequentially in the order indicated by the arrows. Unless otherwise specified herein, there is no strict order restriction on the execution of these steps, and these steps can be executed in other orders. Moreover, at least some of the steps in Fig. 6 may include multiple sub-steps or multiple stages, these sub-steps or stages are not necessarily executed at the same moment, but may be executed at different moments, the execution of these sub-steps or stages The order is not necessarily performed sequentially, but may be performed alternately or alternately with at least a part of other steps or sub-steps or stages of other steps.
应该理解,上述的装置实施例仅是示意性的,本披露的装置还可通过其它的方式实现。例如,上述实施例中所述单元/模块的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式。例如,多个单元、模块或组件可以结合,或者可以集成到另一个系统,或一些特征可以忽略或不执行。It should be understood that the above device embodiments are only illustrative, and the device disclosed in the present disclosure may also be implemented in other ways. For example, the division of units/modules in the above embodiments is only a logical function division, and there may be other division methods in actual implementation. For example, several units, modules or components may be combined, or may be integrated into another system, or some features may be omitted or not implemented.
另外,若无特别说明,在本披露各个实施例中的各功能单元/模块可以集成在一个单元/模块中,也可以是各个单元/模块单独物理存在,也可以两个或两个以上单元/模块集成在一起。上述集成的单元/模块既可以采用硬件的形式实现,也可以采用软件程序模块的形式实现。In addition, unless otherwise specified, each functional unit/module in each embodiment of the present disclosure may be integrated into one unit/module, each unit/module may exist separately physically, or two or more units/modules may exist separately. Modules are integrated together. The above-mentioned integrated units/modules can be implemented in the form of hardware or in the form of software program modules.
所述集成的单元/模块如果以硬件的形式实现时,该硬件可以是数字电路,模拟电路等等。硬件结构的物理实现包括但不局限于晶体管,忆阻器等等。若无特别说明,若无特别说明,上述存储模块可以是任何适当的磁存储介质或者磁光存储介质,比如,阻变式存储器RRAM(Resistive Random Access Memory)、动态随机存取存储器DRAM(Dynamic RandomAccess Memory)、静态随机存取存储器SRAM(Static Random-Access Memory)、增强动态随机存取存储器EDRAM(Enhanced Dynamic Random Access Memory)、高带宽内存HBM(High-Bandwidth Memory)、混合存储立方HMC(Hybrid Memory Cube)等等。If the integrated unit/module is implemented in the form of hardware, the hardware may be a digital circuit, an analog circuit, or the like. Physical implementations of hardware structures include, but are not limited to, transistors, memristors, and so on. Unless otherwise specified, the above-mentioned storage module can be any suitable magnetic storage medium or magneto-optical storage medium, such as, resistive variable memory RRAM (Resistive Random Access Memory), dynamic random access memory DRAM (Dynamic Random Access Memory) Memory), Static Random-Access Memory SRAM (Static Random-Access Memory), Enhanced Dynamic Random-Access Memory EDRAM (Enhanced Dynamic Random Access Memory), High-Bandwidth Memory HBM (High-Bandwidth Memory), Hybrid Memory Cube HMC (Hybrid Memory Cube) and so on.
所述集成的单元/模块如果以软件程序模块的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储器中。基于这样的理解,本披露的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储器中,包括若干指令用以使得一台计算机设备(可为个人计算机、服务器或者网络设备等)执行本披露各个实施例所述方法的全部或部分步骤。而前述的存储器包括:U盘、只读存储器(ROM,Read-Only Memory)、随机存取存储器(RAM,Random Access Memory)、移动硬盘、磁碟或者光盘等各种可以存储程序代码的介质。If the integrated unit/module is realized in the form of a software program module and sold or used as an independent product, it can be stored in a computer-readable memory. Based on this understanding, the essence of the technical solution disclosed in this disclosure or the part that contributes to the prior art or all or part of the technical solution can be embodied in the form of a software product, and the computer software product is stored in a memory. Several instructions are included to make a computer device (which may be a personal computer, server or network device, etc.) execute all or part of the steps of the methods described in the various embodiments of the present disclosure. The aforementioned memory includes: various media that can store program codes such as U disk, read-only memory (ROM, Read-Only Memory), random access memory (RAM, Random Access Memory), mobile hard disk, magnetic disk or optical disk.
在上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述的部分,可以参见其他实施例的相关描述。上述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。In the foregoing embodiments, the descriptions of each embodiment have their own emphases, and for parts not described in detail in a certain embodiment, reference may be made to relevant descriptions of other embodiments. The various technical features of the above-mentioned embodiments can be combined arbitrarily. For the sake of concise description, all possible combinations of the various technical features in the above-mentioned embodiments are not described. However, as long as there is no contradiction in the combination of these technical features, they should be It is considered to be within the range described in this specification.
依据以下条款可以更好的理解前述内容:The foregoing can be better understood in light of the following terms:
条款A1、一种反池化指令处理装置,所述装置包括:Clause A1. An anti-pooling instruction processing device, the device comprising:
控制模块,用于对获取到的反池化指令进行解析,得到所述反池化指令的操作码和操作域,并根据所述操作域获取执行所述反池化指令所需的待处理数据、输入索引、池化核和目标地址;A control module, configured to analyze the obtained anti-pooling instruction, obtain the operation code and operation field of the anti-pooling instruction, and obtain the data to be processed required to execute the anti-pooling instruction according to the operation field , input index, pooling core and target address;
运算模块,用于根据所述池化核、所述输入索引对所述待处理数据进行反池化运算,获得运算结果,并将所述运算结果存入所述目标地址中。An operation module, configured to perform an unpooling operation on the data to be processed according to the pooling core and the input index, obtain an operation result, and store the operation result in the target address.
条款A2、根据条款A1所述的装置,包括:Clause A2. The device described in Clause A1, comprising:
所述待处理数据对应一个所述输入索引。The data to be processed corresponds to one input index.
条款A3、根据条款A1所述的装置,包括:Clause A3. The device described in Clause A1, comprising:
所述待处理数据与所述输入索引一一对应。The data to be processed corresponds to the input index one by one.
条款A4、根据条款A1所述的装置,包括:Clause A4. The device described in Clause A1, comprising:
所述待处理数据的部分数据对应一个所述输入索引。Part of the data to be processed corresponds to one input index.
条款A5、根据条款A1至条款A4中任一项所述的装置,所述运算模块,包括:Clause A5. The device according to any one of clauses A1 to A4, the computing module comprising:
比较器,用于对所述池化核所对应的区域中的索引与所对应的所述输入索引进行比较运算获得比较结果,根据比较结果得到运算结果。The comparator is configured to perform a comparison operation on the index in the area corresponding to the pooling kernel and the corresponding input index to obtain a comparison result, and obtain an operation result according to the comparison result.
条款A6,根据条款A5所述的装置,所述运算模块包括:Clause A6. The apparatus of clause A5, said computing module comprising:
所述池化核所对应的区域中的索引按行依次递增、按列依次递增或者根据查找表查找。The index in the area corresponding to the pooling core is incremented sequentially by row, sequentially by column, or searched according to a lookup table.
条款A7、根据条款A5或条款A6所述的装置,所述运算模块包括主运算子模块和多个从运算子模块,所述主运算子模块包括所述比较器,Clause A7. The apparatus according to Clause A5 or Clause A6, said computing module comprising a master computing submodule and a plurality of slave computing submodules, said master computing submodule comprising said comparator,
所述主运算子模块,用于利用所述比较器对所述池化核所对应的区域中的索引与多对应的所述输入索引进行比较运算获得比较结果,根据比较结果获得运算结果,并将所述运算结果存入所述目标地址中。The main operation sub-module is used to use the comparator to perform a comparison operation on the index in the area corresponding to the pooling core and the corresponding input index to obtain a comparison result, obtain an operation result according to the comparison result, and Store the operation result into the target address.
条款A8、根据条款A5或条款A6所述的装置,所述运算模块包括主运算子模块和多个从运算子模块,所述从运算子模块包括所述比较器,Clause A8. The apparatus according to Clause A5 or Clause A6, said arithmetic module comprising a master arithmetic submodule and a plurality of slave arithmetic submodules, said slave arithmetic submodules comprising said comparator,
所述主运算子模块,用于接收控制模块获取的执行所述反池化指令所需的所述待处理数据、所述输入索引、所述池化核和所述目标地址,并向从运算子模块分配和传输各自执行所述反池化指令对应的所需的述待处理数据、所述输入索引、所述池化核和所述目标地址;The main computing sub-module is configured to receive the data to be processed, the input index, the pooling core, and the target address required for executing the unpooling instruction acquired by the control module, and send the data to the slave computing The sub-modules allocate and transmit the data to be processed, the input index, the pooling core, and the target address corresponding to the respective execution of the unpooling instruction;
所述从运算子模块,用于接收主运算子模块分配和传输的执行所述反池化指令对应的所需的所述待处理数据、所述输入索引、所述池化核和所述目标地址,利用所述比较器对所述池化核所对应的区域中的索引与所对应的所述输入索引进行比较运算获得比较结果,根据比较结果得到运算结果,并将所述运算结果存入所述目标地址中。The slave computing sub-module is configured to receive the data to be processed, the input index, the pooling core, and the target allocated and transmitted by the main computing sub-module corresponding to the execution of the unpooling instruction address, using the comparator to perform a comparison operation on the index in the area corresponding to the pooling core and the corresponding input index to obtain a comparison result, obtain an operation result according to the comparison result, and store the operation result in in the target address.
条款A9、根据条款A1至条款A8中任一项所述的装置,所述操作域还包括输入高度和输入宽度,Clause A9. The apparatus of any one of Clauses A1 to A8, the operating domain further comprising an input height and an input width,
其中,所述控制模块,还用于从所述待处理数据地址中,获取对应所述输入宽度和所述输入高度的待处理数据。Wherein, the control module is further configured to acquire data to be processed corresponding to the input width and the input height from the address of the data to be processed.
条款A10、根据条款A1至条款A8中任一项所述的装置,所述操作域还包括输出高度和输出宽度,Clause A10. The apparatus of any one of Clauses A1 to A8, said operating domain further comprising an output height and an output width,
其中,所述控制模块,还用于向所述目的地址写入所述运算结果,且所述运算结果的高度为所述输出高度,宽度为所述输出宽度。Wherein, the control module is further configured to write the operation result to the destination address, and the height of the operation result is the output height, and the width is the output width.
条款A11、根据条款A10所述的装置,所述操作域还包括输出高度和输出宽度,Clause A11. The apparatus of Clause A10, said operating domain further comprising an output height and an output width,
其中,所述控制模块,还用于根据输出高度得到输入高度,根据输出宽度输入宽度,从所述待处理数据地址中,获取对应所述输入宽度和所述输入高度的待处理数据。Wherein, the control module is further configured to obtain the input height according to the output height, and obtain the data to be processed corresponding to the input width and the input height from the address of the data to be processed according to the output width and input width.
条款A12、根据条款A1至条款A8中任一项所述的装置,所述操作域还包括输入通道数,Clause A12. The apparatus of any one of Clauses A1 to A8, said operational domain further comprising a number of input channels,
其中,所述控制模块,还用于从所述待处理数据地址中,获取对应所述输入通道数的待处理数据。Wherein, the control module is further configured to acquire data to be processed corresponding to the number of input channels from the data address to be processed.
条款A13、根据条款A1至条款A8中任一项所述的装置,所述操作域还包括池化核高度和池化核宽度,Clause A13. The apparatus of any one of Clauses A1 to A8, the operating domain further comprising a pooling kernel height and a pooling kernel width,
其中,所述运算模块,还用于根据所述池化核高度和所述池化核宽度对所述待处理数据进行反池化运算。Wherein, the operation module is further configured to perform an unpooling operation on the data to be processed according to the pooling kernel height and the pooling kernel width.
条款A14、根据条款A1至条款A8中任一项所述的装置,所述操作域还包括第一步幅和/或第二步幅,Clause A14. The apparatus of any one of clauses A1 to A8, said domain of operation further comprising a first stride and/or a second stride,
其中,所述运算模块,还用于按照所述第一步幅在宽度方向上移动所述池化核和/或按照所述第二步幅在高度方向上移动所述池化核。Wherein, the operation module is further configured to move the pooling kernel in the width direction according to the first step and/or move the pooling kernel in the height direction according to the second step.
条款A15、根据条款A14所述的装置,所述运算模块,还用于在所述池化核重叠移动时,所述运算结果在重叠处进行累加,Clause A15. According to the device described in clause A14, the operation module is further configured to accumulate the operation results at the overlap when the pooling cores overlap and move,
其中,所述池化核重叠移动,包括以下至少一项:Wherein, the overlapping movement of the pooling kernels includes at least one of the following:
当所述操作域包含所述第一步幅时,所述第一步幅小于所述池化核宽度;When the operation domain includes the first step width, the first step width is smaller than the pooling kernel width;
当所述操作域包含所述第二步幅时,所述第二步幅小于所述池化核高度。When the operation domain includes the second stride, the second stride is smaller than the pooling kernel height.
条款A16、根据条款A14所述的装置,所述运算模块,还用于在所述池化核有间距移动时,所述运算结果在间距处写入默认值,Clause A16. According to the device described in Clause A14, the operation module is further configured to write the calculation result into a default value at the gap when the pooling core moves with a gap,
其中,所述池化核有间距移动,包括以下至少一项:Wherein, the pooling kernel has pitch movement, including at least one of the following:
当所述操作域包含所述第一步幅时,所述第一步幅大于所述池化核宽度;When the operation domain includes the first step width, the first step width is greater than the pooling kernel width;
当所述操作域包含所述第二步幅时,所述第二步幅大于所述池化核高度。When the operation domain includes the second stride, the second stride is larger than the pooling kernel height.
条款A17、根据条款A16所述的装置,所述运算模块,包括:Clause A17. The device according to Clause A16, said computing module comprising:
所述默认值为零。The default value is zero.
条款A18、根据条款A1所述的装置,所述装置还包括:Clause A18. The apparatus of Clause A1, further comprising:
存储模块,用于存储所述待处理数据和所述运算结果。A storage module, configured to store the data to be processed and the operation result.
条款A19、根据条款A1所述的装置,所述控制模块,包括:Clause A19. The apparatus of clause A1, said control module comprising:
指令存储子模块,用于存储所述反池化指令;an instruction storage submodule, configured to store the anti-pooling instruction;
指令处理子模块,用于对所述反池化指令进行解析,得到所述反池化指令的操作码和操作域;An instruction processing submodule, configured to parse the anti-pooling instruction to obtain the operation code and operation field of the anti-pooling instruction;
队列存储子模块,用于存储指令队列,所述指令队列包括按照执行顺序依次排列的多个待执行指令,所述多个待执行指令包括所述反池化指令。The queue storage sub-module is used to store an instruction queue, the instruction queue includes a plurality of instructions to be executed arranged in sequence according to the execution order, and the plurality of instructions to be executed include the anti-pooling instruction.
条款A20、根据条款A19所述的装置,所述控制模块,还包括:Clause A20. The apparatus of clause A19, said control module, further comprising:
依赖关系处理子模块,用于在确定所述多个待执行指令中的第一待执行指令与所述第一待执行指令之前的第零待执行指令存在关联关系时,将所述第一待执行指令缓存在所述指令存储子模块中,在所述第零待执行指令执行完毕后,从所述指令存储子模块中提取所述第一待执行指令发送至所述运算模块,The dependency processing submodule is configured to, when it is determined that there is an association between the first instruction to be executed among the plurality of instructions to be executed and the zeroth instruction to be executed before the first instruction to be executed, combine the first instruction to be executed The execution instruction is cached in the instruction storage submodule, and after the execution of the zeroth instruction to be executed is completed, the first instruction to be executed is extracted from the instruction storage submodule and sent to the operation module,
其中,所述第一待执行指令与所述第一待执行指令之前的第零待执行指令存在关联关系包括以下至少一种:Wherein, the association between the first instruction to be executed and the zeroth instruction to be executed before the first instruction to be executed includes at least one of the following:
存储所述第一待执行指令所需数据的第一存储地址区间与存储所述第零待执行指令所需数据的第零存储地址区间具有重叠的区域;The first storage address interval storing the data required by the first instruction to be executed has an overlapping area with the zeroth storage address interval storing the data required by the zeroth instruction to be executed;
执行所述第一待执行指令所需使用的第一运算部件与执行所述第零执行指令所需使用的第零运算部件全部相同或者部分相同。The first computing unit required to execute the first instruction to be executed is all or partly the same as the zeroth computing unit required to execute the zeroth instruction to be executed.
条款A21、一种机器学习运算装置,所述装置包括:Clause A21. A machine learning computing device, said device comprising:
一个或多个如条款A1至条款A20中任一项所述的反池化指令处理装置,用于从其他处理装置中获取待处理数据和控制信息,并执行指定的机器学习运算,将执行结果通过I/O接口传递给其他处理装置;One or more anti-pooling instruction processing devices as described in any one of Clause A1 to Clause A20 are used to obtain data and control information to be processed from other processing devices, and perform specified machine learning operations, and the execution results Pass it to other processing devices through the I/O interface;
当所述机器学习运算装置包含多个所述反池化指令处理装置时,所述多个所述反池化指令处理装置间可以通过特定的结构进行连接并传输数据;When the machine learning computing device includes multiple anti-pooling instruction processing devices, the multiple anti-pooling instruction processing devices can be connected and transmit data through a specific structure;
其中,多个所述反池化指令处理装置通过快速外部设备互连总线PCIE总线进行互联并传输数据,以支持更大规模的机器学习的运算;多个所述反池化指令处理装置共享同一控制系统或拥有各自的控制系统;多个所述反池化指令处理装置共享内存或者拥有各自的内存;多个所述反池化指令处理装置的互联方式是任意互联拓扑。Wherein, a plurality of the anti-pooling instruction processing devices are interconnected and transmit data through the PCIE bus to support larger-scale machine learning operations; a plurality of the anti-pooling instruction processing devices share the same The control system may have its own control system; the multiple anti-pooling instruction processing devices share memory or have their own memory; the interconnection mode of the multiple anti-pooling instruction processing devices is any interconnection topology.
条款A22、一种组合处理装置,所述组合处理装置包括:Clause A22. A combined processing device comprising:
如条款A21所述的机器学习运算装置、通用互联接口和其他处理装置;Machine learning computing devices, universal interconnection interfaces, and other processing devices as described in Clause A21;
所述机器学习运算装置与所述其他处理装置进行交互,共同完成用户指定的计算操作,The machine learning computing device interacts with the other processing devices to jointly complete the computing operation specified by the user,
其中,所述组合处理装置还包括:存储装置,该存储装置分别与所述机器学习运算装置和所述其他处理装置连接,用于保存所述机器学习运算装置和所述其他处理装置的数据。Wherein, the combined processing device further includes: a storage device, which is respectively connected to the machine learning computing device and the other processing device, and is used to save data of the machine learning computing device and the other processing device.
条款A23、一种机器学习芯片,所述机器学习芯片包括:Clause A23. A machine learning chip, said machine learning chip comprising:
如条款A21所述的机器学习运算装置或如条款A22所述的组合处理装置。A machine learning computing device as described in Clause A21 or a combined processing device as described in Clause A22.
条款A24、一种电子设备,所述电子设备包括:Clause A24. An electronic device comprising:
如条款A23所述的机器学习芯片。A machine learning chip as described in Clause A23.
条款A25、一种板卡,所述板卡包括:存储器件、接口装置和控制器件以及如条款A23所述的机器学习芯片;Clause A25. A board comprising: a storage device, an interface device and a control device, and a machine learning chip as described in Clause A23;
其中,所述机器学习芯片与所述存储器件、所述控制器件以及所述接口装置分别连接;Wherein, the machine learning chip is connected to the storage device, the control device and the interface device respectively;
所述存储器件,用于存储数据;The storage device is used to store data;
所述接口装置,用于实现所述机器学习芯片与外部设备之间的数据传输;The interface device is used to implement data transmission between the machine learning chip and external equipment;
所述控制器件,用于对所述机器学习芯片的状态进行监控。The control device is used to monitor the state of the machine learning chip.
条款A26、一种反池化指令处理方法,所述方法应用于反池化指令处理装置,所述方法包括:Clause A26. A method for processing an anti-pooling instruction, the method being applied to an anti-pooling instruction processing device, the method comprising:
对获取到的反池化指令进行解析,得到所述反池化指令的操作码和操作域,并根据所述操作码和所述操作域获取执行所述反池化指令所需的待处理数据、池化核和目标地址;Analyzing the obtained anti-pooling instruction to obtain the operation code and operation field of the anti-pooling instruction, and obtaining the data to be processed required to execute the anti-pooling instruction according to the operation code and the operation field , pooled core and target address;
根据所述池化核、所述输入索引对所述待处理数据进行反池化运算,获得运算结果,并将所述运算结果存入所述目标地址中。Performing an unpooling operation on the data to be processed according to the pooling core and the input index to obtain an operation result, and store the operation result in the target address.
条款A27、根据条款A26所述的方法,包括:Clause A27. The method according to Clause A26, comprising:
所述待处理数据对应一个所述输入索引。The data to be processed corresponds to one input index.
条款A28、根据条款A26所述的方法,包括:Clause A28. The method of clause A26, comprising:
所述待处理数据与所述输入索引一一对应。The data to be processed corresponds to the input index one by one.
条款A29、根据条款A26所述的方法,包括:Clause A29. The method of clause A26, comprising:
所述待处理数据的部分数据对应一个所述输入索引。Part of the data to be processed corresponds to one input index.
条款A30、根据条款A26至条款A29中任一项所述的方法,根据所述池化核、所述输入索引对所述待处理数据进行反池化运算,获得运算结果,包括:Clause A30, according to the method described in any one of Clauses A26 to Clause A29, performing an unpooling operation on the data to be processed according to the pooling kernel and the input index, and obtaining an operation result, including:
利用所述比较器对所述池化核所对应的区域中的索引与多对应的所述输入索引进行比较运算获得比较结果,根据比较结果获得运算结果。Using the comparator to perform a comparison operation on the index in the area corresponding to the pooling core and the corresponding input index to obtain a comparison result, and obtain an operation result according to the comparison result.
条款A31、根据条款A30所述的方法,包括:Clause A31. The method of clause A30, comprising:
所述池化核所对应的区域中的索引按行依次递增、按列依次递增或者根据查找表查找。The index in the area corresponding to the pooling core is incremented sequentially by row, sequentially by column, or searched according to a lookup table.
条款A32、根据条款A30或条款A31所述的方法,所述运算模块包括主运算子模块和多个从运算子模块,所述主运算子模块包括所述比较器,Clause A32. The method of clause A30 or clause A31, said computing module comprising a master computing submodule and a plurality of slave computing submodules, said master computing submodule comprising said comparator,
其中,所述根据所述池化核、所述输入索引对所述待处理数据进行反池化运算,获得运算结果,并将所述运算结果存入所述目标地址中,包括:Wherein, performing an unpooling operation on the data to be processed according to the pooling core and the input index, obtaining an operation result, and storing the operation result in the target address includes:
利用所述比较器对所述池化核所对应的区域中的索引与多对应的所述输入索引进行比较运算获得比较结果,根据比较结果获得运算结果,并将所述运算结果存入所述目标地址中。Using the comparator to perform a comparison operation on the index in the area corresponding to the pooling core and the corresponding input index to obtain a comparison result, obtain an operation result according to the comparison result, and store the operation result in the in the target address.
条款A33、根据条款A30或条款A31所述的方法,所述运算模块包括主运算子模块和多个从运算子模块,所述从运算子模块包括所述比较器,Clause A33. The method of clause A30 or clause A31, said computing module comprising a master computing submodule and a plurality of slave computing submodules, said slave computing submodules comprising said comparator,
其中,所述根据所述池化核、所述输入索引对所述待处理数据进行反池化运算,获得比较结果的索引作为运算结果,并将所述运算结果存入所述目标地址中,包括:Wherein, performing an unpooling operation on the data to be processed according to the pooling core and the input index, obtaining an index of a comparison result as an operation result, and storing the operation result in the target address, include:
利用所述多个比较器对所述池化核所对应的区域中的多个待处理数据进行比较运算获得比较结果,得到运算结果,并将所述运算结果存入所述目标地址中。Using the plurality of comparators to perform a comparison operation on a plurality of data to be processed in the area corresponding to the pooling core to obtain a comparison result, obtain an operation result, and store the operation result in the target address.
接收控制模块获取的执行所述反池化指令所需的所述待处理数据、所述输入索引、所述池化核和所述目标地址,并向从运算子模块分配和传输各自执行所述反池化指令对应的所需的述待处理数据、所述输入索引、所述池化核和所述目标地址;receiving the data to be processed, the input index, the pooling core, and the target address acquired by the control module required for executing the unpooling instruction, and distributing and transmitting the data to be executed respectively to the slave computing sub-modules The required data to be processed corresponding to the anti-pooling instruction, the input index, the pooling core and the target address;
接收主运算子模块分配和传输的执行所述反池化指令对应的所需的述待处理数据、所述输入索引、所述池化核和所述目标地址,利用所述比较器对所述池化核所对应的区域中的索引与所对应的所述输入索引进行比较运算获得比较结果,根据比较结果得到运算结果,并将所述运算结果存入所述目标地址中。receiving the data to be processed, the input index, the pooling core, and the target address corresponding to the unpooling instruction allocated and transmitted by the main operation sub-module, and using the comparator to compare the The index in the area corresponding to the pooling core is compared with the corresponding input index to obtain a comparison result, and the operation result is obtained according to the comparison result, and the operation result is stored in the target address.
条款A34、根据条款A26至条款A33中任一项所述的方法,所述操作域还包括输入高度和输入宽度,Clause A34. The method of any one of Clauses A26 to Clause A33, the operational field further comprising an input height and an input width,
其中,所述根据所述操作域获取执行所述反池化指令所需的待处理数据、输入索引、池化核和目标地址,包括:Wherein, the acquisition of the data to be processed, input index, pooling core and target address required for executing the unpooling instruction according to the operation domain includes:
从所述待处理数据地址中,获取对应所述输入宽度和所述输入高度的待处理数据。Obtain the data to be processed corresponding to the input width and the input height from the address of the data to be processed.
条款A35、根据条款A26至条款A33中任一项所述的方法,所述操作域还包括输出高度和输出宽度,Clause A35. The method of any one of Clauses A26 to Clause A33, the operational domain further comprising an output height and an output width,
其中,所述根据所述操作域获取执行所述反池化指令所需的待处理数据、输入索引、池化核和目标地址,包括:Wherein, the acquisition of the data to be processed, input index, pooling core and target address required for executing the unpooling instruction according to the operation domain includes:
向所述目的地址写入所述运算结果,且所述运算结果的高度为所述输出高度,宽度为所述输出宽度。The operation result is written into the destination address, and the height of the operation result is the output height, and the width is the output width.
条款A36、根据条款A35所述的方法,所述操作域还包括输出高度和输出宽度,Clause A36. The method of clause A35, said operational domain further comprising an output height and an output width,
其中,所述根据所述操作域获取执行所述反池化指令所需的待处理数据、输入索引、池化核和目标地址,包括:Wherein, the acquisition of the data to be processed, input index, pooling core and target address required for executing the unpooling instruction according to the operation domain includes:
根据输出高度和输出宽度,分别得到输入高度和输入宽度,从所述待处理数据地址中,获取对应所述输入宽度和所述输入高度的待处理数据。An input height and an input width are respectively obtained according to the output height and the output width, and data to be processed corresponding to the input width and the input height is acquired from the address of the data to be processed.
条款A37、根据条款A26至条款A33中任一项所述的方法,所述操作域还包括输入通道数,Clause A37. The method of any one of Clauses A26 to A33, said operational domain further comprising a number of input channels,
其中,所述根据所述操作域获取执行所述反池化指令所需的待处理数据、输入索引、池化核和目标地址,包括:Wherein, the acquisition of the data to be processed, input index, pooling core and target address required for executing the unpooling instruction according to the operation domain includes:
从所述待处理数据地址中,获取对应所述输入通道数的待处理数据。Obtain the data to be processed corresponding to the number of input channels from the address of the data to be processed.
条款A38、根据条款A26至条款A33中任一项所述的方法,所述操作域还包括池化核高度和池化核宽度,Clause A38. The method of any one of Clauses A26 to Clause A33, the operational domain further comprising a pooling kernel height and a pooling kernel width,
其中,所述根据所述池化核、所述输入索引对所述待处理数据进行反池化运算,包括:Wherein, performing an unpooling operation on the data to be processed according to the pooling kernel and the input index includes:
根据所述池化核高度和所述池化核宽度对所述待处理数据进行反池化运算。Performing an unpooling operation on the data to be processed according to the pooling kernel height and the pooling kernel width.
条款A39、根据条款A26至条款A33中任一项所述的方法,所述操作域还包括第一步幅和/或第二步幅,Clause A39. The method of any one of Clauses A26 to A33, said domain of operation further comprising a first stride and/or a second stride,
其中,所述根据所述池化核、所述输入索引对所述待处理数据进行反池化运算,包括:Wherein, performing an unpooling operation on the data to be processed according to the pooling kernel and the input index includes:
按照所述第一步幅在宽度方向上移动所述池化核和/或按照所述第二步幅在高度方向上移动所述池化核。Moving the pooling kernel in the width direction according to the first step and/or moving the pooling kernel in the height direction according to the second step.
条款A40、根据条款A39所述的方法,所述根据所述池化核、所述输入索引对所述待处理数据进行反池化运算,还包括:Clause A40, according to the method described in Clause A39, performing an unpooling operation on the data to be processed according to the pooling kernel and the input index, further comprising:
在所述池化核重叠移动时,所述运算结果在重叠处进行累加,When the pooling kernel overlaps and moves, the operation results are accumulated at the overlap,
其中,所述池化核重叠移动,包括以下至少一项:Wherein, the overlapping movement of the pooling kernels includes at least one of the following:
当所述操作域包含所述第一步幅时,所述第一步幅小于所述池化核宽度;When the operation domain includes the first step width, the first step width is smaller than the pooling kernel width;
当所述操作域包含所述第二步幅时,所述第二步幅小于所述池化核高度。When the operation domain includes the second stride, the second stride is smaller than the pooling kernel height.
条款A41、根据条款A39所述的方法,所述根据所述池化核、所述输入索引对所述待处理数据进行反池化运算,还包括:Clause A41. According to the method described in Clause A39, performing an unpooling operation on the data to be processed according to the pooling kernel and the input index, further comprising:
在所述池化核有间距移动时,所述运算结果在间距处写入默认值,When the pooling kernel has a gap movement, the operation result is written into a default value at the gap,
其中,所述池化核有间距移动,包括以下至少一项:Wherein, the pooling kernel has pitch movement, including at least one of the following:
当所述操作域包含所述第一步幅时,所述第一步幅大于所述池化核宽度;When the operation domain includes the first step width, the first step width is greater than the pooling kernel width;
当所述操作域包含所述第二步幅时,所述第二步幅大于所述池化核高度。When the operation domain includes the second stride, the second stride is larger than the pooling kernel height.
条款A42、根据条款A41所述的方法,所述根据所述池化核、所述输入索引对所述待处理数据进行反池化运算,还包括:Clause A42. According to the method described in Clause A41, performing an unpooling operation on the data to be processed according to the pooling kernel and the input index, further comprising:
所述默认值为零。The default value is zero.
条款A43、根据条款A26所述的方法,所述方法还包括:Clause A43. The method of Clause A26, further comprising:
利用所述装置的存储模块存储所述待处理数据和所述运算结果。The storage module of the device is used to store the data to be processed and the operation result.
条款A44、根据条款A26所述的方法,对获取到的反池化指令进行解析,得到所述反池化指令的操作码和操作域,包括:Clause A44. According to the method described in Clause A26, analyze the obtained anti-pooling instruction to obtain the operation code and operation field of the anti-pooling instruction, including:
存储所述反池化指令;storing the unpooling instruction;
对所述反池化指令进行解析,得到所述反池化指令的操作码和操作域;Analyzing the anti-pooling instruction to obtain the operation code and operation field of the anti-pooling instruction;
存储指令队列,所述指令队列包括按照执行顺序依次排列的多个待执行指令,所述多个待执行指令包括所述反池化指令。An instruction queue is stored, the instruction queue includes a plurality of instructions to be executed sequentially arranged in an execution order, and the plurality of instructions to be executed include the anti-pooling instruction.
条款A45、根据条款A26所述的方法,所述方法还包括:Clause A45. The method of Clause A26, further comprising:
在确定所述多个待执行指令中的第一待执行指令与所述第一待执行指令之前的第零待执行指令存在关联关系时,缓存所述第一待执行指令,并在确定所述第零待执行指令执行完毕后,控制进行所述第一待执行指令的执行,When it is determined that the first to-be-executed instruction among the plurality of to-be-executed instructions has an associated relationship with the zeroth to-be-executed instruction before the first to-be-executed instruction, cache the first to-be-executed instruction, and determine the After the execution of the zeroth instruction to be executed is completed, the execution of the first instruction to be executed is controlled,
其中,所述第一待执行指令与所述第一待执行指令之前的第零待执行指令存在关联关系包括以下至少一种:Wherein, the association between the first instruction to be executed and the zeroth instruction to be executed before the first instruction to be executed includes at least one of the following:
存储所述第一待执行指令所需数据的第一存储地址区间与存储所述第零待执行指令所需数据的第零存储地址区间具有重叠的区域;The first storage address interval storing the data required by the first instruction to be executed has an overlapping area with the zeroth storage address interval storing the data required by the zeroth instruction to be executed;
执行所述第一待执行指令所需使用的第一运算部件与执行所述第零执行指令所需使用的第零运算部件全部相同或者部分相同。The first computing unit required to execute the first instruction to be executed is all or partly the same as the zeroth computing unit required to execute the zeroth instruction to be executed.
条款A46、一种非易失性计算机可读存储介质,其上存储有计算机程序指令,所述计算机程序指令被处理器执行时实现条款A26至条款A45任一项所述的方法。Clause A46. A non-transitory computer-readable storage medium having stored thereon computer program instructions that, when executed by a processor, implement the method of any one of clauses A26 to A45.
以上对本申请实施例进行了详细介绍,本文中应用了具体个例对本申请的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本申请的方法及其核心思想;同时,对于本领域的一般技术人员,依据本申请的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本申请的限制。The embodiments of the present application have been introduced in detail above, and specific examples have been used in this paper to illustrate the principles and implementation methods of the present application. The descriptions of the above embodiments are only used to help understand the methods and core ideas of the present application; meanwhile, for Those skilled in the art will have changes in specific implementation methods and application scopes based on the ideas of the present application. In summary, the contents of this specification should not be construed as limiting the present application.
Claims (9)
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910747969.8ACN112395002B (en) | 2019-08-14 | 2019-08-14 | Operation method, device, computer equipment and storage medium |
| PCT/CN2020/088248WO2020233387A1 (en) | 2019-05-17 | 2020-04-30 | Command processing method and apparatus, and related products |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910747969.8ACN112395002B (en) | 2019-08-14 | 2019-08-14 | Operation method, device, computer equipment and storage medium |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN112395002A CN112395002A (en) | 2021-02-23 |
| CN112395002Btrue CN112395002B (en) | 2023-04-18 |
Family
ID=74601334
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201910747969.8AActiveCN112395002B (en) | 2019-05-17 | 2019-08-14 | Operation method, device, computer equipment and storage medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN112395002B (en) |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2010134134A1 (en)* | 2009-05-22 | 2010-11-25 | Hitachi, Ltd. | Storage system comprising plurality of processor units |
| CN108009627A (en)* | 2016-10-27 | 2018-05-08 | 谷歌公司 | Neutral net instruction set architecture |
| EP3346423A1 (en)* | 2017-01-04 | 2018-07-11 | STMicroelectronics Srl | Deep convolutional network heterogeneous architecture system and device |
| WO2018184224A1 (en)* | 2017-04-07 | 2018-10-11 | Intel Corporation | Methods and systems for boosting deep neural networks for deep learning |
| CN110119807A (en)* | 2018-10-12 | 2019-08-13 | 上海寒武纪信息科技有限公司 | Operation method, device, computer equipment and storage medium |
- 2019
- 2019-08-14CNCN201910747969.8Apatent/CN112395002B/enactiveActive
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2010134134A1 (en)* | 2009-05-22 | 2010-11-25 | Hitachi, Ltd. | Storage system comprising plurality of processor units |
| CN108009627A (en)* | 2016-10-27 | 2018-05-08 | 谷歌公司 | Neutral net instruction set architecture |
| EP3346423A1 (en)* | 2017-01-04 | 2018-07-11 | STMicroelectronics Srl | Deep convolutional network heterogeneous architecture system and device |
| WO2018184224A1 (en)* | 2017-04-07 | 2018-10-11 | Intel Corporation | Methods and systems for boosting deep neural networks for deep learning |
| CN110119807A (en)* | 2018-10-12 | 2019-08-13 | 上海寒武纪信息科技有限公司 | Operation method, device, computer equipment and storage medium |
Non-Patent Citations (3)
| Title |
|---|
| Three-dimensional spatial join count exploiting CPU optimized STR R-tree;Ryuya Mitsuhashi等;《2016 IEEE International Conference on Big Data (Big Data)》;IEEE;20170206;全文* |
| WMLScript解释器的原理与实现;尚海忠等;《计算机工程》;20011220(第12期);全文* |
| 具有卷积神经网络扩展指令的微处理器的设计与实现;马珂;《中国优秀硕士学位论文全文数据库》;20181215(第12期);全文* |
Also Published As
| Publication number | Publication date |
|---|---|
| CN112395002A (en) | 2021-02-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110096309B (en) | Computing method, apparatus, computer equipment and storage medium | |
| CN110096310A (en) | Operation method, device, computer equipment and storage medium | |
| CN110096283A (en) | Operation method, device, computer equipment and storage medium | |
| CN110119807B (en) | Operation method, operation device, computer equipment and storage medium | |
| CN111047005A (en) | Computing method, apparatus, computer equipment and storage medium | |
| CN111353124A (en) | Computing method, apparatus, computer equipment and storage medium | |
| CN110458286A (en) | Data processing method, device, computer equipment and storage medium | |
| CN111340202B (en) | Computing method, device and related products | |
| WO2021018313A1 (en) | Data synchronization method and apparatus, and related product | |
| CN111061507A (en) | Operation method, operation device, computer equipment and storage medium | |
| CN112395002B (en) | Operation method, device, computer equipment and storage medium | |
| CN111290789B (en) | Operation method, operation device, computer equipment and storage medium | |
| CN111275197B (en) | Operation method, device, computer equipment and storage medium | |
| CN112396170B (en) | Operation method, device, computer equipment and storage medium | |
| CN114282159B (en) | Data processing device, integrated circuit chip, equipment and implementation method thereof | |
| CN112395009A (en) | Operation method, operation device, computer equipment and storage medium | |
| CN112395008A (en) | Operation method, operation device, computer equipment and storage medium | |
| CN112396169B (en) | Operation method, device, computer equipment and storage medium | |
| CN112395006B (en) | Operation method, device, computer equipment and storage medium | |
| CN111290788B (en) | Computing method, apparatus, computer equipment and storage medium | |
| WO2021027973A1 (en) | Data synchronization method and device, and related products | |
| CN111338694B (en) | Computing method, apparatus, computer equipment and storage medium | |
| CN111339060B (en) | Operation method, device, computer equipment and storage medium | |
| CN111047030A (en) | Operation method, operation device, computer equipment and storage medium | |
| CN111353125B (en) | Operation method, operation device, computer equipment and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |