CN112364641A - Chinese countermeasure sample generation method and device for text audit - Google Patents
Chinese countermeasure sample generation method and device for text auditDownload PDFInfo
- Publication number
- CN112364641A CN112364641ACN202011259475.4ACN202011259475ACN112364641ACN 112364641 ACN112364641 ACN 112364641ACN 202011259475 ACN202011259475 ACN 202011259475ACN 112364641 ACN112364641 ACN 112364641A
- Authority
- CN
- China
- Prior art keywords
- words
- word
- disturbance
- information
- processed
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images






Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/284—Lexical analysis, e.g. tokenisation or collocates
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/166—Editing, e.g. inserting or deleting
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02D—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN INFORMATION AND COMMUNICATION TECHNOLOGIES [ICT], I.E. INFORMATION AND COMMUNICATION TECHNOLOGIES AIMING AT THE REDUCTION OF THEIR OWN ENERGY USE
- Y02D10/00—Energy efficient computing, e.g. low power processors, power management or thermal management
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Machine Translation (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本申请涉及人工智能领域,尤其涉及一种面向文本审核的中文对抗样本生成方法及装置。The present application relates to the field of artificial intelligence, and in particular, to a method and device for generating Chinese adversarial samples for text review.
背景技术Background technique
近年来随着大数据技术的发展以及硬件计算能力的不断提升,深度学习技术在许多领域得到了广泛地应用,例如计算机视觉、语音识别和自然语言处理。然而,伴随着深度学习技术的快速发展,深度学习模型的安全问题逐渐引起了研究者的关注。Szegedy等人首先发现了对抗样本(Adversarial Examples)的存在:即通过在数据集中故意添加微小的干扰所形成的输入样本,导致模型以高置信度给出一个错误的输出。In recent years, with the development of big data technology and the continuous improvement of hardware computing power, deep learning technology has been widely used in many fields, such as computer vision, speech recognition and natural language processing. However, with the rapid development of deep learning technology, the security issues of deep learning models have gradually attracted the attention of researchers. Szegedy et al. first discovered the existence of Adversarial Examples: input samples formed by deliberately adding tiny perturbations to the dataset, causing the model to give an erroneous output with high confidence.
对抗样本揭示了深度学习模型的脆弱性,引发了研究者的极大关注。在自然语言处理(NLP)领域,针对深度学习模型的对抗样本已经威胁到了包括文本审核在内的现实应用。文本审核(即过滤文本中的有害内容,如辱骂、歧视、人身攻击、种族主义言论等)是NLP应用的重要组成部分,其中基于关键词匹配和基于机器学习的文本分类方法是目前最常用的审核方法。然而,有害内容的发布者常常对表达情感的敏感词做一些变形,使处理后的有害信息可以绕过文本审核系统的检测,例如使用“费物”代替“废物”,即可达到上述目的。相关技术中的,基于关键词的文本审核系统无法迅速应对这些变形词,需要额外的人工审核。Adversarial examples reveal the vulnerability of deep learning models, which has attracted great attention from researchers. In the field of natural language processing (NLP), adversarial examples against deep learning models have threatened real-world applications including text moderation. Text moderation (i.e. filtering harmful content in text, such as abuse, discrimination, personal attacks, racist remarks, etc.) is an important part of NLP applications, among which keyword matching and machine learning-based text classification methods are currently the most commonly used. Audit method. However, the publishers of harmful content often make some deformations to the sensitive words expressing emotion, so that the processed harmful information can bypass the detection of the text review system, for example, the above purpose can be achieved by using "fee" instead of "waste". In the related art, the keyword-based text review system cannot deal with these deformed words quickly, and additional manual review is required.
针对相关技术中存在的诸多技术问题,目前尚未提供有效的解决方案。For many technical problems existing in the related technologies, no effective solutions have been provided yet.
发明内容SUMMARY OF THE INVENTION
为了解决上述技术问题或者至少部分地解决上述技术问题,本申请提供了一种面向文本审核的中文对抗样本生成方法及装置。In order to solve the above technical problems or at least partially solve the above technical problems, the present application provides a method and device for generating Chinese adversarial samples for text review.
第一方面,本申请实施例提供了一种面向文本审核的中文对抗样本生成方法,包括:In a first aspect, an embodiment of the present application provides a method for generating Chinese adversarial samples for text review, including:
获取待处理语句信息;Get pending statement information;
对所述待处理语句信息进行分词,得到多个词语;Perform word segmentation on the to-be-processed statement information to obtain a plurality of words;
确定所述词语的第一重要性信息;determining first importance information for the term;
获取各个所述词语对应的扰动词语;obtaining the disturbance words corresponding to each of the words;
根据所述第一重要性信息,依次得到将所述待处理语句信息中各个所述词语替换为对应的扰动词语后的扰动语句信息;According to the first importance information, sequentially obtain disturbed sentence information obtained by replacing each of the words in the to-be-processed sentence information with corresponding disturbed words;
在确定所述扰动语句信息满足预设条件时,根据所述扰动语句信息得到对所述待处理语句信息攻击成功后的对抗样本。When it is determined that the perturbed sentence information satisfies a preset condition, an adversarial sample after successfully attacking the to-be-processed sentence information is obtained according to the perturbed sentence information.
可选的,如前述的方法,所述获取各个所述词语对应的扰动词语,包括:Optionally, as in the foregoing method, the obtaining the disturbed words corresponding to each of the words includes:
确定所述词语的拼音以及字形;Determine the pinyin and glyph of the word;
根据所述拼音,将所述词语中的至少一个字替换为拼音后得到的字符作为所述扰动词语;或者,According to the pinyin, at least one character in the word is replaced by the character obtained after the pinyin is used as the disturbance word; or,
根据所述字形,将所述词语中的至少一个字替换为字形满足预设相似度要求的形近字后得到的字符作为所述扰动词语;或者,According to the glyph, replace at least one character in the word with a character obtained after the glyph meets the preset similarity requirement as the disturbed word; or,
根据所述拼音以及字形,将所述词语中的至少一个字替换为同音和/或字形满足预设相似度要求的同音形近字后得到的字符作为所述扰动词语。According to the pinyin and the glyph, at least one character in the word is replaced with a homophone and/or a character obtained by a homophone with a glyph that meets the preset similarity requirement as the disturbed word.
可选的,如前述的方法,还包括:Optionally, the aforementioned method further includes:
将所述词语按照所述第一重要性信息由高至低进行排列,得到各个词语对应的排列次序信息;Arrange the words according to the first importance information from high to low, and obtain the arrangement order information corresponding to each word;
根据所述排列次序信息,确定与各个所述词语对应的替换次序信息;所述替换次序信息用于确定将所述词语替换为对应的扰动词语的次序。According to the arrangement order information, the replacement order information corresponding to each of the words is determined; the replacement order information is used to determine the order of replacing the words with the corresponding disturbance words.
可选的,如前述的方法,所述根据所述第一重要性信息,依次得到将所述待处理语句信息中各个所述词语替换为对应的扰动词语后的扰动语句信息,包括:Optionally, according to the aforementioned method, according to the first importance information, sequentially obtaining the disturbance sentence information after replacing each of the words in the to-be-processed sentence information with the corresponding disturbance words, including:
在所述词语对应的所有所述扰动词语中,确定重要性最低的最低重要性扰动词语,并得到所述词语与所述最低重要性扰动词语之间的对应关系;Among all the disturbance words corresponding to the word, determine the least important disturbance word with the lowest importance, and obtain the correspondence between the word and the least important disturbance word;
根据所述替换次序信息,依次将各个所述词语按照所述对应关系替换为对应的所述最低重要性扰动词语,并得到所述扰动语句信息。According to the replacement order information, each of the words is sequentially replaced with the corresponding least important disturbance word according to the corresponding relationship, and the disturbance sentence information is obtained.
可选的,如前述的方法,在所述词语对应的所有所述扰动词语中,确定重要性最低的最低重要性扰动词语,包括:Optionally, according to the aforementioned method, among all the disturbance words corresponding to the words, determining the least important disturbance word with the lowest importance, including:
通过所述扰动词语对所述待处理语句信息中的所述词语进行替换后,得到与所述扰动词语对应的替换后语句信息;After the words in the to-be-processed sentence information are replaced by the disturbance words, the replaced sentence information corresponding to the disturbance words is obtained;
在所述替换后语句信息中对所述扰动词语进行删除,得到与所述扰动词语对应的第二缺词语句信息;Deleting the disturbed word in the replaced sentence information to obtain the second missing word sentence information corresponding to the disturbed word;
根据预设的文本审核模型确定所述替换后语句信息对应的第三权重值,以及所述第二缺词语句信息对应的第四权重值;Determine a third weight value corresponding to the replaced sentence information and a fourth weight value corresponding to the second missing word sentence information according to a preset text review model;
根据所述第三权重值分别与第四权重值之间的差值,得到所述扰动词语对应的第二重要性信息;According to the difference between the third weight value and the fourth weight value, the second importance information corresponding to the disturbance word is obtained;
根据与所述词语对应的所述扰动词语对应的第二重要性信息,得到与所述词语对应的所述最低重要性扰动词语。The least important disturbance word corresponding to the word is obtained according to the second importance information corresponding to the disturbance word corresponding to the word.
可选的,如前述的方法,所述确定各个所述词语对应的重要性信息,包括:Optionally, according to the aforementioned method, the determining the importance information corresponding to each of the words includes:
在所述待处理语句信息中分别对所述词语进行删除,得到与所述词语对应的第一缺词语句信息;Deleting the words respectively in the to-be-processed sentence information to obtain the first word-missing sentence information corresponding to the words;
根据预设的文本审核模型确定所述待处理语句信息对应的第一权重值,以及所述第一缺词语句信息对应的第二权重值;Determine a first weight value corresponding to the to-be-processed sentence information and a second weight value corresponding to the first missing word sentence information according to a preset text review model;
根据所述第一权重值分别与第二权重值之间的差值,得到所述词语对应的第一重要性信息。The first importance information corresponding to the word is obtained according to the difference between the first weight value and the second weight value respectively.
可选的,如前述的方法,所述扰动语句信息满足预设条件,包括:Optionally, as in the aforementioned method, the perturbation sentence information satisfies a preset condition, including:
所述扰动语句信息中,所述扰动词语的个数小于或等于预设的扰动词语数量上限阈值;以及,In the disturbance sentence information, the number of the disturbance words is less than or equal to a preset upper limit threshold of the number of disturbance words; and,
所述扰动词语的个数占所述扰动语句信息中词语总数的比例小于预设的扰动比例阈值;以及,The ratio of the number of the disturbance words to the total number of words in the disturbance sentence information is less than a preset disturbance ratio threshold; and,
所述扰动语句信息对应的第一预测标签与所述待处理语句信息对应的第二预测标签不一致;其中,所述第一预测标签通过预设的文本审核模型对所述扰动语句信息进行预测得到,所述第二预测标签通过所述文本审核模型对所述待处理语句信息进行预测得到。The first predicted label corresponding to the disturbance sentence information is inconsistent with the second predicted label corresponding to the to-be-processed sentence information; wherein, the first predicted label is obtained by predicting the disturbance sentence information through a preset text review model , and the second prediction label is obtained by predicting the to-be-processed sentence information by the text review model.
第二方面,本申请实施例提供了一种对抗训练方法,包括:In a second aspect, an embodiment of the present application provides a method for adversarial training, including:
根据如前任一项所述方法生成的对抗样本,得到训练数据以及校验数据;Obtain training data and verification data according to the adversarial samples generated by the method described in any of the preceding items;
通过所述训练数据对预设的文本审核模型进行训练,得到训练后文本审核模型;The preset text review model is trained by the training data to obtain a post-training text review model;
在所述训练后文本审核模型通过所述校验数据进行校验,并满足预设要求时,根据所述训练后文本审核模型得到目标文本审核模型。When the post-training text review model is verified by the verification data and meets preset requirements, a target text review model is obtained according to the post-training text review model.
第三方面,本申请实施例提供了一种面向文本审核的中文对抗样本生成装置,包括:In a third aspect, an embodiment of the present application provides an apparatus for generating Chinese adversarial samples for text review, including:
语句获取模块,用于获取待处理语句信息;The statement acquisition module is used to acquire the information of the statement to be processed;
分词模块,用于对所述待处理语句信息进行分词,得到多个词语;A word segmentation module, used to segment the to-be-processed statement information to obtain a plurality of words;
重要性确定模块,用于确定所述词语的第一重要性信息;an importance determination module, configured to determine the first importance information of the word;
扰动词语模块,用于获取各个所述词语对应的扰动词语;a perturbation word module, used to obtain perturbation words corresponding to each of the words;
替换模块,用于根据所述第一重要性信息,依次得到将所述待处理语句信息中各个所述词语替换为对应的扰动词语后的扰动语句信息;A replacement module, configured to sequentially obtain, according to the first importance information, disturbed sentence information after replacing each of the words in the to-be-processed sentence information with corresponding disturbed words;
样本生成模块,用于在确定所述扰动语句信息满足预设条件时,根据所述扰动语句信息得到对所述待处理语句信息攻击成功后的对抗样本。The sample generation module is configured to obtain, according to the disturbed sentence information, an adversarial sample after the successful attack on the to-be-processed sentence information when it is determined that the disturbed sentence information satisfies a preset condition.
第四方面,本申请实施例提供了一种对抗训练装置,包括:In a fourth aspect, an embodiment of the present application provides a confrontation training device, including:
数据获取模块,用于根据如前任一项所述方法生成的对抗样本,得到训练数据以及校验数据;A data acquisition module, used for obtaining training data and verification data according to the confrontation samples generated by the method described in any of the preceding items;
训练模块,用于通过所述训练数据对预设的文本审核模型进行训练,得到训练后文本审核模型;a training module, used for training a preset text review model through the training data to obtain a post-training text review model;
校验模块,用于在所述训练后文本审核模型通过所述校验数据进行校验,并满足预设要求时,根据所述训练后文本审核模型得到目标文本审核模型。A verification module, configured to obtain a target text verification model according to the post-training text verification model when the post-training text verification model is verified through the verification data and meets preset requirements.
第五方面,本申请实施例提供了一种电子设备,包括:处理器、通信接口、存储器和通信总线,其中,所述处理器、通信接口和存储器通过通信总线完成相互间的通信;In a fifth aspect, an embodiment of the present application provides an electronic device, including: a processor, a communication interface, a memory, and a communication bus, wherein the processor, the communication interface, and the memory communicate with each other through the communication bus;
所述存储器,用于存放计算机程序;the memory for storing computer programs;
所述处理器,用于执行所述计算机程序时,实现如前述任一项所述的处理方法。The processor, when executing the computer program, implements the processing method according to any one of the foregoing.
第六方面,本申请实施例提供了一种存储介质,所述存储介质包括存储的程序,其中,所述程序运行时执行如前任一项所述的方法步骤。In a sixth aspect, an embodiment of the present application provides a storage medium, where the storage medium includes a stored program, wherein the method steps described in any preceding item are executed when the program is run.
本申请实施例提供的上述技术方案与现有技术相比具有如下优点:Compared with the prior art, the above-mentioned technical solutions provided in the embodiments of the present application have the following advantages:
本申请实施例提供的该方法,可以通过对待处理语句进行词语替换的方式得到对抗样本,进而可以增加用于对预测模型进行训练的样本的多样性,同时可以通过自动生成对抗样本,提升训练数据获取的便利性,提升模型训练的效率。The method provided by this embodiment of the present application can obtain adversarial samples by substituting words for the sentences to be processed, thereby increasing the diversity of samples used for training the prediction model, and at the same time, automatically generating adversarial samples to improve training data The convenience of acquisition improves the efficiency of model training.
附图说明Description of drawings
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本发明的实施例,并与说明书一起用于解释本发明的原理。The accompanying drawings, which are incorporated in and constitute a part of this specification, illustrate embodiments consistent with the invention and together with the description serve to explain the principles of the invention.
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。In order to more clearly illustrate the embodiments of the present invention or the technical solutions in the prior art, the following briefly introduces the accompanying drawings that need to be used in the description of the embodiments or the prior art. In other words, on the premise of no creative labor, other drawings can also be obtained from these drawings.
图1为本申请实施例提供的一种面向文本审核的中文对抗样本生成方法的流程图;1 is a flowchart of a method for generating Chinese adversarial samples for text review provided by an embodiment of the present application;
图2为本申请另一实施例提供的一种面向文本审核的中文对抗样本生成方法的流程图;2 is a flowchart of a method for generating Chinese adversarial samples for text review provided by another embodiment of the present application;
图3为本申请应用例提供的一种面向文本审核的中文对抗样本生成方法的流程示意图;3 is a schematic flowchart of a method for generating Chinese adversarial samples for text review provided by an application example of this application;
图4为本申请应用例提供的一种对抗训练的流程示意图;FIG. 4 is a schematic flowchart of a confrontation training provided by the application example of this application;
图5为本申请实施例提供的一种面向文本审核的中文对抗样本生成装置的框图;5 is a block diagram of an apparatus for generating Chinese adversarial samples for text review provided by an embodiment of the present application;
图6为本申请实施例提供的一种对抗训练装置的框图;6 is a block diagram of a confrontation training apparatus provided by an embodiment of the present application;
图7为本申请实施例提供的一种电子设备的结构示意图。FIG. 7 is a schematic structural diagram of an electronic device according to an embodiment of the present application.
具体实施方式Detailed ways
为使本申请实施例的目的、技术方案和优点更加清楚,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本申请的一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本申请保护的范围。In order to make the purposes, technical solutions and advantages of the embodiments of the present application clearer, the technical solutions in the embodiments of the present application will be described clearly and completely below with reference to the drawings in the embodiments of the present application. Obviously, the described embodiments It is a part of the embodiments of the present application, but not all of the embodiments. Based on the embodiments in the present application, all other embodiments obtained by those of ordinary skill in the art without creative work fall within the protection scope of the present application.
目前文本对抗领域绝大多数研究基于英文数据,其中针对英文数据的扰动方法,例如增加、删减、交换相邻字母等,很容易造成中文语义改变,影响理解。本发明结合文本审核中有害文本词形变化多样的特征,提出了一种中文对抗样本的高效生成方法,生成的对抗样本可以很好的保留原始样本的语义。通过在基于深度学习的文本审核模型的训练过程中注入对抗样本,可有效提升模型对有害样本的识别能力和鲁棒性。At present, most of the research in the field of text confrontation is based on English data. Among them, the perturbation methods for English data, such as adding, deleting, and exchanging adjacent letters, can easily cause changes in Chinese semantics and affect understanding. The invention proposes an efficient method for generating Chinese confrontation samples in combination with the diverse features of harmful text morphological changes in text review, and the generated confrontation samples can well retain the semantics of the original samples. By injecting adversarial samples in the training process of the deep learning-based text review model, the recognition ability and robustness of the model to harmful samples can be effectively improved.
图1为本申请实施例提供的一种面向文本审核的中文对抗样本生成方法,包括如下所述步骤S1至S6:FIG. 1 provides a method for generating Chinese adversarial samples for text review provided by an embodiment of the present application, including the following steps S1 to S6:
步骤S1.获取待处理语句信息;Step S1. Obtain the information of the statement to be processed;
具体的,可以通过在网上搜集社交媒体数据进而得到待处理语句信息,社交媒体数据可以包括辱骂言论和正常言论。Specifically, the sentence information to be processed may be obtained by collecting social media data on the Internet, and the social media data may include abusive speech and normal speech.
并且,在得到待处理语句信息之后,可以对待处理语句信息进行预处理,其中,当社交媒体数据的来源是微博等社交媒体时,预处理的方法可以包括:删除hashtag(推文话题,即微博上用前带#号的字词表示推文的话题)、@符号、转发内容、网页链接等。Moreover, after obtaining the sentence information to be processed, the sentence information to be processed may be preprocessed, wherein, when the source of the social media data is social media such as Weibo, the preprocessing method may include: deleting the hashtag (tweet topic, that is, On Weibo, words preceded by a # sign indicate the topic of the tweet), @ symbol, forwarded content, web page links, etc.
步骤S2.对待处理语句信息进行分词,得到多个词语。Step S2. Perform word segmentation on the sentence information to be processed to obtain a plurality of words.
具体的,分词就是将连续的待处理语句信息按照一定的规范重新组合成词序列的过程。举例的,当待处理语句信息中包括词语wi时,可以进行分词得到词语集X,其中X=[w1,w2,…,wn],wi为词语集X中的一个词语。Specifically, word segmentation is the process of recombining continuous sentence information to be processed into a word sequence according to a certain specification. For example, when the sentence information to be processed includes a wordwi , a word set X can be obtained by token segmentation, where X=[w1 , w2 ,...,wn ], andwi is a word in the word set X.
可选的,可以通过自定义分词词典辅助对待处理语句信息的分词。Optionally, a custom word segmentation dictionary can be used to assist the word segmentation of the sentence information to be processed.
进一步的,在进行分词之后,还会删除词语列表中的停用词,然后在得到上述的词语。Further, after the word segmentation, the stop words in the word list are also deleted, and then the above words are obtained.
步骤S3.确定词语的第一重要性信息。Step S3. Determine the first importance information of the word.
第一重要性信息可以是用于表征词语对待处理语句信息的语义造成影响的重要程度的信息。The first importance information may be information for characterizing the importance degree of a word that affects the semantics of the sentence information to be processed.
步骤S4.获取各个词语对应的扰动词语。Step S4. Obtain the disturbance words corresponding to each word.
具体的,扰动词语可以是与原来的词语对应的进行伪装后的词语,例如:对于词语“坏人”来说,“huai人”是对“坏”进行拼音替换后得到的扰动词语。此外,扰动词语还可以采用其他的方式对词语进行处理后得到。Specifically, the disturbed word may be a disguised word corresponding to the original word, for example, for the word "bad person", "huai person" is a disturbed word obtained by replacing "bad" with pinyin. In addition, the perturbed words can also be obtained by processing the words in other ways.
步骤S5.根据第一重要性信息,依次得到将待处理语句信息中各个词语替换为对应的扰动词语后的扰动语句信息。Step S5. According to the first importance information, sequentially obtain disturbed sentence information after replacing each word in the sentence information to be processed with the corresponding disturbed word.
具体的,扰动语句信息是文本中包括扰动词语的语句信息,在进行替换时,可以是按照第一重要性信息,先对待处理语句中的重要性最高的词语替换为扰动词语,然后将重要性次之的词语替换为扰动词语,按此方式逐个替换对应的扰动词语之后,得到扰动语句信息。Specifically, the disturbing sentence information is sentence information including disturbing words in the text. When replacing, it may be that the most important word in the sentence to be processed is first replaced with the disturbing word according to the first importance information, and then the importance The next words are replaced with disturbed words, and after the corresponding disturbed words are replaced one by one in this way, the disturbed sentence information is obtained.
步骤S6.在确定扰动语句信息满足预设条件时,根据扰动语句信息得到对待处理语句信息攻击成功后的对抗样本。Step S6. When it is determined that the perturbed sentence information satisfies the preset condition, the confrontation sample after the successful attack of the to-be-processed sentence information is obtained according to the perturbed sentence information.
具体的,预设条件可以是判定对抗样本成功生成的条件;攻击成功可以是:当待处理语句信息被识别为辱骂语句时,通过对待处理语句信息中的词语替换为对应的扰动词语之后,扰动语句信息被识别为非辱骂语句;即预测的结果与原结果相反或者不一致。Specifically, the preset condition may be a condition for judging that the adversarial sample is successfully generated; the attack success may be: when the sentence information to be processed is identified as an abusive sentence, after the words in the sentence information to be processed are replaced with corresponding disturbance words, the disturbance Sentence information is identified as non-abusive; that is, the predicted outcome is opposite or inconsistent with the original outcome.
通过本实施例中的方法,可以通过对待处理语句进行词语替换的方式得到对抗样本,进而可以增加用于对预测模型进行训练的样本的多样性,同时可以通过自动生成对抗样本,提升训练数据获取的便利性,提升模型训练的效率。With the method in this embodiment, adversarial samples can be obtained by replacing words in the sentences to be processed, thereby increasing the diversity of samples used for training the prediction model, and at the same time, by automatically generating adversarial samples, the acquisition of training data can be improved convenience and improve the efficiency of model training.
在真实场景中,有害文本的发布者为了绕过审核,通常都会对有害信息(例如:辱骂文本)进行变形,包括使用拼音替换,同音形近词替换,象形字替换等。如图2所示,在一些实施例中,为了解决该技术问题,如前述的方法,所述步骤S2获取各个词语对应的扰动词语,包括如下所述步骤S21至S24:In real scenarios, in order to bypass the review, the publishers of harmful texts usually distort harmful information (for example, abusive texts), including using pinyin substitution, homophone substitution, pictographic substitution, etc. As shown in FIG. 2, in some embodiments, in order to solve the technical problem, as in the aforementioned method, the step S2 obtains the disturbed words corresponding to each word, including the following steps S21 to S24:
步骤S21.确定词语的拼音以及字形。Step S21. Determine the pinyin and glyph of the word.
具体的,可以通过对词语进行文字识别,得到各个词语的拼音以及字形;其中,可选的,字形可以包括词语中每个字对应的偏旁部首等信息,以便于后期可以根据对偏旁部首进行替换得到扰动词语。Specifically, the pinyin and glyph of each word can be obtained by character recognition of the words; wherein, optionally, the glyph can include information such as the radicals corresponding to each character in the words, so that the later can be based on the radicals and other information. Make substitutions to get perturbed words.
步骤S22.根据拼音,将词语中的至少一个字替换为拼音后得到的字符作为扰动词语。Step S22. According to pinyin, replace at least one word in the word with a character obtained after pinyin is used as a disturbance word.
也就是说,将词语中的一个字或多个字,通过拼音进行替换,得到扰动词语;举例的:对于词语“坏人”来说,“huai人”是对“坏”进行拼音替换后得到的扰动词语。That is to say, one or more words in the word are replaced by pinyin to obtain disturbed words; for example: for the word "bad person", "huai person" is obtained by replacing "bad" in pinyin disturbing words.
步骤S23.根据字形,将词语中的至少一个字替换为字形满足预设相似度要求的形近字后得到的字符作为扰动词语。Step S23. According to the glyph, replace at least one character in the word with a character obtained after the glyph satisfies the preset similarity requirement, and use the character as a disturbance word.
具体的,预设相似度要求可以通过:确定形近字与被替换的字之间差异部分对应的第一区域大小,以及被替换的字整体对应的第二区域大小;计算第一区域大小与第二区域大小之间的差值;在差值小于预设上限比值阈值时,即判定形近字是与被替换字满足预设相似度要求的。进而可以通过将至少一个字替换为形近字之后,得到扰动词语,且由于该扰动词语与词语之间的差异足够小,因此不会影响人们对文本的理解。但是对于模型来说,由于扰动词语与词语之间的字符是存在差异的,因此其无法准确预测得到扰动词语的含义。举例的:通过将“村花”中的“村”替换为形近字“忖”,进而得到扰动词语“忖花”。Specifically, the preset similarity requirement can be determined by: determining the size of the first region corresponding to the difference between the shape-near word and the word to be replaced, and the size of the second region corresponding to the entire replaced word; calculating the size of the first region and The difference between the sizes of the second regions; when the difference is smaller than the preset upper limit ratio threshold, it is determined that the shape-near word meets the preset similarity requirement with the replaced word. Furthermore, a disturbed word can be obtained by replacing at least one word with a near-shaped word, and since the difference between the disturbed word and the word is small enough, it will not affect people's understanding of the text. However, for the model, since there are differences in the characters between the perturbed words and words, it cannot accurately predict the meaning of the perturbed words. For example: by replacing the "village" in "village flowers" with the approximate word "兖", the disturbance word "忖花" is obtained.
步骤S24.根据拼音以及字形,将词语中的至少一个字替换为同音和/或字形满足预设相似度要求的同音形近字后得到的字符作为扰动词语。Step S24. According to the pinyin and the glyph, replace at least one word in the word with a homophone and/or a character obtained after the glyph meets the preset similarity requirement as a disturbed word.
具体的,同音形近字可以是与被替换字发音相同且字形相近的字。其中同音形近字的获取方法可以是:先确定被替换字的拼音,然后通过被替换字的拼音在字库中查询拼音相同(可以是拼音相同且音调相同,也可以是只需拼音相同即可)的同音字;然后在所有同音字中,按照步骤S23中的方法查询得到对应的形近字,并将其作为同音形近字。举例的:通过对“笨蛋”中的“笨”替换为同音形近字“苯”进而得到扰动词语“苯蛋”。Specifically, a homophone near word may be a word with the same pronunciation as the replaced word and a similar glyph. Wherein, the acquisition method of homophones can be as follows: first determine the pinyin of the replaced word, and then inquire the same pinyin in the word library through the pinyin of the replaced word (it can be the same pinyin and the same pitch, or it can be only the same pinyin) ) of the homophones; then in all homophones, according to the method in step S23, the corresponding shape close words are obtained, and they are used as homophones. For example: by replacing the "stupid" in "stupid" with the homophone "benzene", the perturbed word "benzene egg" is obtained.
通过本实施例中的方法,可以得到多种情况下的扰动词语,本实施例中的扰动词语的获取方法采用字符级替换攻击方法,即对原来的词语中的至少一个字进行替换。并且,本实施例中的替换方法得到的扰动词语基本不会影响人们对文本的理解,可以很好保留句子的语义。经过对抗攻击后,用于进行语义预测的文本审核分类器会被误导,进而将辱骂文本误判为正常文本。The method in this embodiment can obtain disturbed words in various situations. The method for obtaining disturbed words in this embodiment adopts a character-level replacement attack method, that is, at least one word in the original word is replaced. In addition, the disturbed words obtained by the replacement method in this embodiment basically do not affect people's understanding of the text, and the semantics of the sentence can be well preserved. After an adversarial attack, the text moderation classifier used for semantic prediction can be misled and misjudge abusive text as normal text.
举例的,通过一个未通过本实施例中的对抗文本进行训练的文本审核分类器,对包括采用上述方法得到的扰动词语的文本进行预测的结果,如下表所示:For example, by using a text review classifier that has not been trained by the adversarial text in this embodiment, the result of predicting the text including the perturbed words obtained by the above method is shown in the following table:

在一些实施例中,如前述的方法,还包括如下所述步骤P1至P3:In some embodiments, the aforementioned method further comprises steps P1 to P3 as described below:
步骤P1.确定各个词语对应的第一重要性信息。Step P1. Determine the first importance information corresponding to each word.
具体的,第一重要性信息是与词语的重要性对应的信息,且重要性可以是某一特定预测类型对应的预测分值(当预测类型是辱骂时,可以重要性信息可以是对辱骂程度进行评判的分数,例如:“傻蛋”对应的第一重要性信息可以是100,“笨蛋”对应的第一重要性信息可以是80等等)。Specifically, the first importance information is information corresponding to the importance of the word, and the importance may be the prediction score corresponding to a specific prediction type (when the prediction type is abusive, the importance information may be the degree of abuse The score for evaluation, for example, the first importance information corresponding to "idiot" may be 100, the first importance information corresponding to "idiot" may be 80, etc.).
步骤P2.将词语按照第一重要性信息由高至低进行排列,得到各个词语对应的排列次序信息。Step P2. Arrange the words according to the first importance information from high to low, and obtain arrangement order information corresponding to each word.
具体的,由于每个词语都对应有一个第一重要性信息,因此,按照重要性信息对各个词语进行排序可以得到各个词语对应的排列次序信息。Specifically, since each word corresponds to a piece of first importance information, sorting each word according to the importance information can obtain the arrangement order information corresponding to each word.
步骤P3.根据排列次序信息,确定与各个词语对应的替换次序信息;替换次序信息用于确定将词语替换为对应的扰动词语的次序。Step P3. According to the arrangement order information, determine the replacement order information corresponding to each word; the replacement order information is used to determine the order of replacing the words with the corresponding disturbance words.
也就是说,各个词语对应的替换次序信息是根据排列次序信息得到的,因此,替换次序信息也就是根据第一重要性信息高至低进行排列得到的。That is to say, the replacement order information corresponding to each word is obtained according to the arrangement order information. Therefore, the replacement order information is obtained by arranging the first importance information from high to low.
在一些实施例中,如前述的方法,所述步骤S4根据第一重要性信息,依次得到将待处理语句信息中各个词语替换为对应的扰动词语后的扰动语句信息,包括如下所述步骤S51和S52:In some embodiments, as in the aforementioned method, the step S4 sequentially obtains, according to the first importance information, the disturbed sentence information obtained by replacing each word in the to-be-processed sentence information with the corresponding disturbed word, including the following step S51 and S52:
步骤S51.在词语对应的所有扰动词语中,确定重要性最低的最低重要性扰动词语,并得到词语与最低重要性扰动词语之间的对应关系。Step S51. Among all the disturbance words corresponding to the words, determine the least important disturbance words with the lowest importance, and obtain the correspondence between the words and the least important disturbance words.
具体的,在对抗样本生成过程中,由于每个词语会对应多个扰动词语,因此就会存在多个替换选择,考虑到对抗样本的生成效率,本发明采用贪心算法的思路,即对每个词进行替换时,选择当前重要性最低(例如:辱骂性质最低)的最低重要性扰动词语,并且在确定重要性最低的最低重要性扰动词语,并且根据其生成对抗样本,并对待训练模型进行训练之后,训练得到的模型也就可以识别得到重要性更高的扰动词语。Specifically, in the process of adversarial sample generation, since each word corresponds to multiple disturbance words, there will be multiple alternative choices. Considering the generation efficiency of adversarial samples, the present invention adopts the idea of greedy algorithm, that is, for each When replacing words, select the least important perturbation words with the lowest current importance (for example: the least abusive nature), and determine the least important perturbation words with the lowest importance, and generate adversarial samples according to them, and train the model to be trained After that, the trained model can also identify more important perturbation words.
步骤S52.根据替换次序信息,依次将各个词语按照对应关系替换为对应的最低重要性扰动词语,并得到扰动语句信息。Step S52. According to the replacement order information, sequentially replace each word with the corresponding least important disturbance word according to the corresponding relationship, and obtain the disturbance sentence information.
具体的,在得到替换次序信息之后,按照词语重要性从高到低依次对词语进行扰动。确定词语wi对应的最低重要性扰动词语,在替换词语wi之后,得到扰动语句信息,当该扰动语句信息不满足预设条件时,在该扰动语句信息的基础上继续对下一个词语wi+1进行替换,直到触发预设条件。Specifically, after obtaining the replacement order information, the words are perturbed according to the importance of the words from high to low. Determine the least important perturbation word corresponding to the word wi , after replacing the word wi , obtain the perturbation sentence information, when the perturbation sentence information does not meet the preset conditions, continue to the next word w on the basis of the perturbation sentence informationi+1 to replace until the preset condition is triggered.
本实施例中的方法,通过按照替换次序信息依次对各个词语替换为扰动词语,可以达到根据重要性依次对各个词语进行替换的目的,进而可以在诸如对辱骂文本进行分类的情况下,可以更加准确的针对于辱骂的词语,以使得到的对抗文本中的扰动词语可以是对应于辱骂性质最高的词语,提升对抗文本的准确性以及训练价值。In the method in this embodiment, by sequentially replacing each word with a disturbing word according to the replacement order information, the purpose of sequentially replacing each word according to the importance can be achieved, and further, in the case of classifying abusive texts, more Accurately target the abusive words, so that the disturbed words in the obtained adversarial text can correspond to the words with the highest abusive nature, which improves the accuracy and training value of the adversarial text.
在一些实施例中,如前述的方法,所述步骤P1确定各个词语对应的重要性信息,包括如下所述步骤P11至步骤P13:In some embodiments, as in the aforementioned method, the step P1 determines the importance information corresponding to each word, including the following steps P11 to P13:
步骤P11.在待处理语句信息中分别对词语进行删除,得到与词语对应的第一缺词语句信息。Step P11. Deleting words in the sentence information to be processed, respectively, to obtain first word-missing sentence information corresponding to the words.
具体的,第一缺词语句信息是指在待处理语句信息中删除词语之后对应的语句信息。并且,每个词语都对应有一个第一缺词语句信息。Specifically, the first word-missing sentence information refers to sentence information corresponding to after the word is deleted in the sentence information to be processed. Moreover, each word corresponds to a first word-missing sentence information.
步骤P12.根据预设的文本审核模型确定待处理语句信息对应的第一权重值,以及第一缺词语句信息对应的第二权重值。Step P12. Determine a first weight value corresponding to the sentence information to be processed and a second weight value corresponding to the first word-missing sentence information according to a preset text review model.
具体的,权重值可以是某一特定预测类型对应的预测分值。并且,该预测分值是通过文本审核模型对待处理语句信息进行预测得到的。Specifically, the weight value may be a prediction score corresponding to a specific prediction type. Moreover, the predicted score is obtained by predicting the sentence information to be processed through the text review model.
步骤P13.根据第一权重值分别与第二权重值之间的差值,得到词语对应的第一重要性信息。Step P13. Obtain the first importance information corresponding to the word according to the difference between the first weight value and the second weight value respectively.
也就是说,词语对应的第一重要性信息是由待处理语句信息对应的第一权重值以及第一缺词语句信息对应的第二权重值之间的差值得到的。That is to say, the first importance information corresponding to the word is obtained from the difference between the first weight value corresponding to the sentence information to be processed and the second weight value corresponding to the first word-missing sentence information.
其中一种可选的实现方式可以是:One of the optional implementations can be:
参照TextFooler算法,为移除第i个词语前后预测分值的变化,其中i=1,2,…,n。公式详见如下所示公式:Referring to the TextFooler algorithm, to remove the change in the predicted score before and after the i-th word, where i=1,2,...,n. For the formula, please refer to the formula shown below:

其中,






在一些实施例中,如前述的方法,所述步骤S51在词语对应的所有扰动词语中,确定重要性最低的最低重要性扰动词语,包括如下所述步骤S511至步骤S515:In some embodiments, according to the aforementioned method, the step S51 determines the least important disturbance word with the lowest importance among all the disturbance words corresponding to the word, including the following steps S511 to S515:
步骤S511.通过扰动词语对待处理语句信息中的词语进行替换后,得到与扰动词语对应的替换后语句信息。Step S511. After the words in the sentence information to be processed are replaced by the disturbance words, the replaced sentence information corresponding to the disturbance words is obtained.
也就是说,将待处理语句信息中的词语替换为与该词语对应的扰动词语,并得到替换后语句信息;举例的:当待处理语句信息为“林子大了,什么垃圾都有”,待替换的词语为“垃圾”,且对应的扰动词语为“拉圾”时,得到的替换后语句信息为“林子大了,什么拉圾都有”。That is to say, replace the word in the sentence information to be processed with the disturbed word corresponding to the word, and obtain the sentence information after replacement; for example: when the sentence information to be processed is "the forest is big, there are all kinds of garbage", wait for When the replaced word is "garbage" and the corresponding disturbance word is "garbage", the obtained sentence information after replacement is "the forest is big, and there are all kinds of garbage".
步骤S512.在替换后语句信息中对扰动词语进行删除,得到与扰动词语对应的第二缺词语句信息。Step S512 . Delete the disturbed word in the replaced sentence information to obtain second word-missing sentence information corresponding to the disturbed word.
具体的,第二缺词语句信息是指在待处理语句信息中删除扰动词语之后对应的语句信息。并且,每个扰动词语都对应有一个第二缺词语句信息。Specifically, the second word-missing sentence information refers to sentence information corresponding to the sentence information to be processed after the disturbing word is deleted. Moreover, each disturbance word corresponds to a second missing word sentence information.
步骤S513.根据预设的文本审核模型确定替换后语句信息对应的第三权重值,以及第二缺词语句信息对应的第四权重值。Step S513. Determine the third weight value corresponding to the replaced sentence information and the fourth weight value corresponding to the second missing word sentence information according to the preset text review model.
具体的,第三权重值以及第四权重值可以是针对于同一特定预测类型对应的预测分值。并且,该预测分值是通过文本审核模型对待处理语句信息进行预测得到的。Specifically, the third weight value and the fourth weight value may be prediction scores corresponding to the same specific prediction type. Moreover, the predicted score is obtained by predicting the sentence information to be processed through the text review model.
步骤S514.根据第三权重值分别与第四权重值之间的差值,得到扰动词语对应的第二重要性信息。Step S514. Obtain second importance information corresponding to the disturbance word according to the difference between the third weight value and the fourth weight value.
也就是说,扰动词语对应的第二重要性信息是由替换后语句信息对应的第三权重值以及第二缺词语句信息对应的第四权重值之间的差值得到的。That is to say, the second importance information corresponding to the disturbed word is obtained from the difference between the third weight value corresponding to the replaced sentence information and the fourth weight value corresponding to the second word-missing sentence information.
步骤S515.根据与词语对应的扰动词语对应的第二重要性信息,得到与词语对应的最低重要性扰动词语。Step S515. Obtain the least important disturbance word corresponding to the word according to the second importance information corresponding to the disturbance word corresponding to the word.
具体的,在得到与词语对应的各个扰动词语的第二重要性信息之后,即可从词语对应的各个扰动词语中选择得到第二重要性最低的最低重要性扰动词语。Specifically, after obtaining the second importance information of each disturbance word corresponding to the word, the lowest importance disturbance word with the lowest second importance can be selected from the disturbance words corresponding to the word.
在一些实施例中,如前述的方法,所述步骤S6扰动语句信息满足预设条件,包括如下所述步骤S61至S63:In some embodiments, as in the aforementioned method, the step S6 perturbing the sentence information to satisfy a preset condition includes the following steps S61 to S63:
步骤S61.扰动语句信息中,扰动词语的个数小于或等于预设的扰动词语数量上限阈值;以及,Step S61. In the disturbance sentence information, the number of disturbance words is less than or equal to the preset upper limit threshold of the number of disturbance words; and,
步骤S62.扰动词语的个数占扰动语句信息中词语总数的比例小于预设的扰动比例阈值;以及Step S62. The ratio of the number of disturbance words to the total number of words in the disturbance sentence information is less than a preset disturbance ratio threshold; and
步骤S63.扰动语句信息对应的第一预测标签与待处理语句信息对应的第二预测标签不一致;其中,第一预测标签通过预设的文本审核模型对扰动语句信息进行预测得到,第二预测标签通过文本审核模型对待处理语句信息进行预测得到。Step S63. The first predicted label corresponding to the perturbed sentence information is inconsistent with the second predicted label corresponding to the to-be-processed sentence information; wherein, the first predicted label is obtained by predicting the disturbed sentence information through a preset text review model, and the second predicted label is obtained. It is obtained by predicting the to-be-processed sentence information through a text review model.
具体的,当扰动词语的个数过多或者扰动词语的个数占扰动语句信息中词语总数的比例过高时,由于对待处理语句信息的改变过多,可能会造成对抗样本较原样本语义发生较大改变的情况,因此需要设置扰动词语数量上限阈值以及扰动比例阈值。其中,扰动词语数量上限阈值是用于限定待处理语句信息中扰动词语数量的阈值,扰动比例阈值是用于扰动词语的个数占扰动语句信息中词语总数的阈值。Specifically, when the number of perturbation words is too large or the proportion of the number of perturbation words in the total number of words in the perturbation sentence information is too high, due to the excessive changes in the sentence information to be processed, it may cause the adversarial samples to be more semantically inferior than the original samples. In the case of large changes, it is necessary to set the upper threshold of the number of disturbance words and the threshold of disturbance proportion. The upper threshold of the number of disturbance words is a threshold used to limit the number of disturbance words in the sentence information to be processed, and the disturbance proportion threshold is a threshold used to account for the number of disturbance words in the total number of words in the disturbance sentence information.
举例的:当扰动词语数量上限阈值为g(例如:4),且扰动比例阈值为p(例如:50%)时,当扰动词语的个数小于或等于g,且比例小于或等于p,但是预测标签没有反转时,即为满足预设条件,继续对待处理语句信息进行扰动。For example: when the upper threshold of the number of disturbed words is g (for example: 4), and the threshold of the disturbed proportion is p (for example: 50%), when the number of disturbed words is less than or equal to g, and the proportion is less than or equal to p, but When the predicted label is not reversed, that is, to satisfy the preset condition, continue to perturb the information of the sentence to be processed.
当扰动词语的个数小于或等于g,且比例小于或等于p,预测标签已经反转时,即为对待处理语句信息扰动成功;当待处理语句信息被文本审核模型识别为辱骂文本时,扰动成功意味文本审核模型无法正确识别出扰动后的待处理语句信息为辱骂文本。When the number of disturbed words is less than or equal to g, and the proportion is less than or equal to p, and the predicted label has been reversed, the perturbation of the sentence information to be processed is successful; when the sentence information to be processed is identified as abusive text by the text review model, the perturbation Success means that the text review model cannot correctly identify the perturbed to-be-processed sentence information as abusive text.
如果满足扰动词语的个数大于g或者比例大于p其中的一个条件,但是预测标签没有反转时,即为不满足预设条件,停止对本条待处理语句信息的扰动,扰动失败。If the number of disturbed words is greater than g or the ratio is greater than p, but the predicted label is not reversed, it means that the preset condition is not met, and the disturbance of the sentence information to be processed is stopped, and the disturbance fails.
在一般情况下,文本审核模型是一个二分类模型,预测标签一般只存在两种情况,因此,当第一预测标签与第二预测标签不一致时,即意味着第一预测标签与第二预测标签相反。举例的,当待处理语句信息对应的标签为辱骂文本时,扰动语句信息对应的标签则需要是正常文本(即:非辱骂文本)时,说明该文本无法被文本审核模型正确预测,因而可以将其用作于文本审核模型的训练,以使其提升对于对抗样本的预测准确性。In general, the text review model is a two-class model, and there are generally only two cases of predicted labels. Therefore, when the first predicted label is inconsistent with the second predicted label, it means that the first predicted label and the second predicted label. on the contrary. For example, when the label corresponding to the sentence information to be processed is abusive text, and the label corresponding to the disturbing sentence information needs to be normal text (ie: non-abusive text), it means that the text cannot be correctly predicted by the text review model, so it can be It is used to train text moderation models to improve their prediction accuracy for adversarial examples.
应用本实施例中的方法,对待处理语句信息进行攻击得到的攻击结果如下表所示:Using the method in this embodiment, the attack results obtained by attacking the statement information to be processed are shown in the following table:
因此,采用本实施例中的方法可有效生成中文的对抗样本。Therefore, using the method in this embodiment can effectively generate Chinese adversarial samples.
如图3所示应用例中:In the application example shown in Figure 3:
1.结合本自定义分词词典,对输入的句子X进行预处理、分词得到X=[w1,w2,…,wn];其中wi为分词后得到的句子X中的一个词语;1. In combination with this self-defined word segmentation dictionary, the input sentence X is preprocessed, and the word segmentation is performed to obtain X=[w1 , w2 ,...,wn ]; whereinwi is a word in the sentence X obtained after word segmentation;
2.把整句输入和移除第i个词语后的句子输入训练好的文本审核模型(即:辱骂文本分类模型),按照TextFooler算法(一种英文对抗样本生成算法)的重要性计算公式计算每个词语的重要性。2. Input the entire sentence and the sentence after removing the i-th word into the trained text review model (ie: abusive text classification model), and calculate it according to the importance calculation formula of the TextFooler algorithm (an English adversarial sample generation algorithm). The importance of each word.
3.移除词语列表中的停用词,按照词语重要性将词语序列X从高到低排序;3. Remove the stop words in the word list, and sort the word sequence X from high to low according to the importance of the words;
4.按照词语重要性从高到低依次进行词语扰动;对于词wi,遍历当前词语所有替换词,使用TextFooler词重要性分值公式选择替换词中辱骂性质最低的词替换原词,在此基础上继续对下一个词语进行替换,直到满足停止条件时输出对抗样本。4. Perform word perturbation in descending order of word importance; for word wi , traverse all the replacement words of the current word, and use the TextFooler word importance score formula to select the least abusive word among the replacement words to replace the original word, here On the basis, continue to replace the next word until the adversarial sample is output when the stopping condition is met.
5.停止条件:如果同时满足以下三个条件则成功生成对抗样本:1)扰动词语的个数小于等于n;2)扰动词语个数占文本词语总数的比例小于p;3)预测标签反转;否则不生成对抗样本。5. Stopping condition: If the following three conditions are met at the same time, the adversarial sample is successfully generated: 1) The number of disturbed words is less than or equal to n; 2) The ratio of the number of disturbed words to the total number of text words is less than p; 3) The predicted label is reversed ; otherwise no adversarial examples are generated.
根据本申请另一方面的一个实施例,还提供了一种对抗训练方法,包括如下所述步骤S7至S9:According to an embodiment of another aspect of the present application, a method for adversarial training is also provided, including the following steps S7 to S9:
步骤S7.根据如前任一实施例方法生成的对抗样本,得到训练数据以及校验数据。Step S7. Obtain training data and verification data according to the adversarial samples generated by the method in any of the previous embodiments.
具体的,训练数据以及校验数据可以同时包括对抗样本以及原始测试集。其中,原始测试集中的样本可以是未通过扰动词语进行替换的原始语句信息。Specifically, the training data and the verification data may include adversarial samples and the original test set at the same time. The samples in the original test set may be original sentence information that is not replaced by perturbed words.
一般的,在训练数据构建过程中,保留对抗样本对应的待处理语句信息对应的标签(即:待处理语句信息对应的是辱骂文本时,则对抗样本对应的标签也为辱骂文本)。Generally, in the training data construction process, the label corresponding to the to-be-processed sentence information corresponding to the adversarial sample is retained (that is, when the to-be-processed sentence information corresponds to abusive text, the label corresponding to the confrontation sample is also abusive text).
步骤S8.通过训练数据对预设的文本审核模型进行训练,得到训练后文本审核模型;Step S8. The preset text review model is trained through the training data to obtain a post-training text review model;
步骤S9.在训练后文本审核模型通过校验数据进行校验,并满足预设要求时,根据训练后文本审核模型得到目标文本审核模型。Step S9. When the post-training text verification model is verified by the verification data and meets the preset requirements, obtain the target text verification model according to the post-training text verification model.
具体的,预设要求可以是预先设置的与文本审核模型对应的预测的准确率下限阈值。此外,还可以是其他要求,在此不一一进行限定。Specifically, the preset requirement may be a preset lower limit threshold of the accuracy of the prediction corresponding to the text review model. In addition, there may be other requirements, which are not limited here.
也就是说,先通过训练数据对文本审核模型进行训练,得到训练后文本审核模型,然后通过校验数据对训练后文本审核模型进行校验并满足预设要求时,即可得到目标文本审核模型。That is to say, first train the text review model through training data to obtain the post-training text review model, and then use the verification data to verify the post-training text review model and meet the preset requirements, then the target text review model can be obtained. .
当对抗样本对应的文本类型为辱骂文本,且通过本实施例得到的训练数据以及校验数据对BERT模型进行训练时,训练后得到的模型具有如下表所示效果:When the text type corresponding to the adversarial sample is abusive text, and the training data and verification data obtained in this embodiment are used to train the BERT model, the model obtained after training has the effects shown in the following table:

从上表中可见,经过对抗训练后,BERT模型对于对抗样本的识别准确率从86.47%提升到了98.94%,说明对抗训练能有效提升模型对于有害样本的识别能力。As can be seen from the above table, after adversarial training, the recognition accuracy of the BERT model for adversarial samples has increased from 86.47% to 98.94%, indicating that adversarial training can effectively improve the model's ability to recognize harmful samples.
总的来说,对抗样本可以有效增加训练样本的多样性,模型学习到了替换词语(即:扰乱词语)和原始词语间的关联性,改善了模型文本向量表示空间表现不佳的区域。In general, adversarial samples can effectively increase the diversity of training samples, and the model learns the correlation between the replacement words (ie: scrambled words) and the original words, and improves the areas where the model text vector representation space does not perform well.
如图4所示的应用例中:In the application example shown in Figure 4:
1.获取训练数据;1. Obtain training data;
2.对输入的训练数据进行数据预处理;2. Perform data preprocessing on the input training data;
3.得到预处理后的训练数据;3. Obtain the preprocessed training data;
4.将经过预处理后的训练数据输入对抗样本生成模块;4. Input the preprocessed training data into the adversarial sample generation module;
5.获得训练数据的对抗样本,原始样本标签与对抗样本标签保持一致;5. Obtain the adversarial samples of the training data, and the original sample labels are consistent with the adversarial sample labels;
6.混合对抗样本和原始训练数据中作为新的训练数据输入文本审核模型;6. Mix the adversarial samples and the original training data as new training data into the text review model;
7.根据新的训练数据重新对文本审核模型进行微调,获得经过对抗训练的文本审核模型。7. Refine the text review model based on the new training data to obtain a text review model that has been confronted with training.
如图5所示,根据本申请另一方面的一个实施例,还提供了一种面向文本审核的中文对抗样本生成装置,包括:As shown in FIG. 5 , according to an embodiment of another aspect of the present application, a device for generating Chinese adversarial samples for text review is also provided, including:
语句获取模块11,用于获取待处理语句信息;A
分词模块12,用于对待处理语句信息进行分词,得到多个词语;The
重要性确定模块13,用于确定词语的第一重要性信息;an
扰动词语模块14,用于获取各个词语对应的扰动词语;The
替换模块15,用于根据第一重要性信息,依次得到将待处理语句信息中各个词语替换为对应的扰动词语后的扰动语句信息;The
样本生成模块16,用于在确定扰动语句信息满足预设条件时,根据扰动语句信息得到对待处理语句信息攻击成功后的对抗样本。The
具体的,本发明实施例的装置中各模块实现其功能的具体过程可参见方法实施例中的相关描述,此处不再赘述。Specifically, for the specific process of implementing the functions of each module in the apparatus according to the embodiment of the present invention, reference may be made to the relevant description in the method embodiment, which will not be repeated here.
如图6所示,根据本申请另一方面的一个实施例,本申请还提供了一种对抗训练装置,包括:As shown in FIG. 6, according to an embodiment of another aspect of the present application, the present application further provides a confrontation training device, including:
数据获取模块21,用于根据如前任一实施例方法生成的对抗样本,得到训练数据以及校验数据;The
训练模块22,用于通过训练数据对预设的文本审核模型进行训练,得到训练后文本审核模型;The
校验模块23,用于在训练后文本审核模型通过校验数据进行校验,并满足预设要求时,根据训练后文本审核模型得到目标文本审核模型。The
具体的,本发明实施例的装置中各模块实现其功能的具体过程可参见方法实施例中的相关描述,此处不再赘述。Specifically, for the specific process of implementing the functions of each module in the apparatus according to the embodiment of the present invention, reference may be made to the relevant description in the method embodiment, which will not be repeated here.
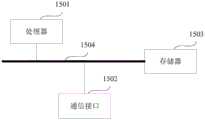
根据本申请的另一个实施例,还提供一种电子设备,包括:如图7所示,电子设备可以包括:处理器1501、通信接口1502、存储器1503和通信总线1504,其中,处理器1501,通信接口1502,存储器1503通过通信总线1504完成相互间的通信。According to another embodiment of the present application, an electronic device is also provided, including: as shown in FIG. 7 , the electronic device may include: a
存储器1503,用于存放计算机程序;The
处理器1501,用于执行存储器1503上所存放的程序时,实现上述方法实施例的步骤。The
上述电子设备提到的总线可以是外设部件互连标准(Peripheral ComponentInterconnect,PCI)总线或扩展工业标准结构(Extended Industry StandardArchitecture,EISA)总线等。该总线可以分为地址总线、数据总线、控制总线等。为便于表示,图中仅用一条粗线表示,但并不表示仅有一根总线或一种类型的总线。The bus mentioned in the above electronic device may be a peripheral component interconnect standard (Peripheral Component Interconnect, PCI) bus or an Extended Industry Standard Architecture (Extended Industry Standard Architecture, EISA) bus or the like. The bus can be divided into address bus, data bus, control bus and so on. For ease of presentation, only one thick line is used in the figure, but it does not mean that there is only one bus or one type of bus.
通信接口用于上述电子设备与其他设备之间的通信。The communication interface is used for communication between the above electronic device and other devices.
存储器可以包括随机存取存储器(Random Access Memory,RAM),也可以包括非易失性存储器(Non-Volatile Memory,NVM),例如至少一个磁盘存储器。可选的,存储器还可以是至少一个位于远离前述处理器的存储装置。The memory may include random access memory (Random Access Memory, RAM), and may also include non-volatile memory (Non-Volatile Memory, NVM), such as at least one disk memory. Optionally, the memory may also be at least one storage device located away from the aforementioned processor.
上述的处理器可以是通用处理器,包括中央处理器(Central Processing Unit,CPU)、网络处理器(Network Processor,NP)等;还可以是数字信号处理器(DigitalSignalProcessing,DSP)、专用集成电路(Application Specific Integrated Circuit,ASIC)、现场可编程门阵列(Field-Programmable Gate Array,FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。The above-mentioned processor may be a general-purpose processor, including a central processing unit (Central Processing Unit, CPU), a network processor (Network Processor, NP), etc.; it may also be a digital signal processor (Digital Signal Processing, DSP), an application-specific integrated circuit ( Application Specific Integrated Circuit, ASIC), Field-Programmable Gate Array (Field-Programmable Gate Array, FPGA) or other programmable logic devices, discrete gate or transistor logic devices, discrete hardware components.
本申请实施例还提供一种存储介质,存储介质包括存储的程序,其中,程序运行时执行上述方法实施例的方法步骤。An embodiment of the present application further provides a storage medium, where the storage medium includes a stored program, wherein the method steps of the foregoing method embodiments are executed when the program runs.
需要说明的是,在本文中,诸如“第一”和“第二”等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。It should be noted that, in this document, relational terms such as "first" and "second" etc. are only used to distinguish one entity or operation from another entity or operation, and do not necessarily require or imply these There is no such actual relationship or sequence between entities or operations. Moreover, the terms "comprising", "comprising" or any other variation thereof are intended to encompass a non-exclusive inclusion such that a process, method, article or device comprising a list of elements includes not only those elements, but also includes not explicitly listed or other elements inherent to such a process, method, article or apparatus. Without further limitation, an element qualified by the phrase "comprising a..." does not preclude the presence of additional identical elements in a process, method, article or apparatus that includes the element.
以上所述仅是本发明的具体实施方式,使本领域技术人员能够理解或实现本发明。对这些实施例的多种修改对本领域的技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所申请的原理和新颖特点相一致的最宽的范围。The above descriptions are only specific embodiments of the present invention, so that those skilled in the art can understand or implement the present invention. Various modifications to these embodiments will be readily apparent to those skilled in the art, and the generic principles defined herein may be implemented in other embodiments without departing from the spirit or scope of the invention. Thus, the present invention is not intended to be limited to the embodiments shown herein, but is to be accorded the widest scope consistent with the principles and novel features claimed herein.
Claims (12)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011259475.4ACN112364641B (en) | 2020-11-12 | 2020-11-12 | Text-audit-oriented Chinese countermeasure sample generation method and device |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011259475.4ACN112364641B (en) | 2020-11-12 | 2020-11-12 | Text-audit-oriented Chinese countermeasure sample generation method and device |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN112364641Atrue CN112364641A (en) | 2021-02-12 |
| CN112364641B CN112364641B (en) | 2024-10-22 |
Family
ID=74514389
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202011259475.4AActiveCN112364641B (en) | 2020-11-12 | 2020-11-12 | Text-audit-oriented Chinese countermeasure sample generation method and device |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN112364641B (en) |
Cited By (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112948887A (en)* | 2021-03-29 | 2021-06-11 | 北京交通大学 | Social engineering defense method based on confrontation sample generation |
| CN113191777A (en)* | 2021-05-13 | 2021-07-30 | 支付宝(杭州)信息技术有限公司 | Risk identification method and device |
| CN113204974A (en)* | 2021-05-14 | 2021-08-03 | 清华大学 | Method, device and equipment for generating confrontation text and storage medium |
| CN113469212A (en)* | 2021-05-07 | 2021-10-01 | 苏州摩多多信息科技有限公司 | Method, system and medium for creating text audit model |
| CN113723506A (en)* | 2021-08-30 | 2021-11-30 | 南京星环智能科技有限公司 | Method and device for generating countermeasure sample and storage medium |
| CN113836297A (en)* | 2021-07-23 | 2021-12-24 | 北京三快在线科技有限公司 | Training method and device for text emotion analysis model |
| CN113868365A (en)* | 2021-09-28 | 2021-12-31 | 北京天融信网络安全技术有限公司 | Method and device for generating adversarial samples, and readable storage medium |
| CN114064891A (en)* | 2021-11-10 | 2022-02-18 | 杭州网易再顾科技有限公司 | Adversarial text generation method, medium, apparatus and computing device |
| CN114254108A (en)* | 2021-12-13 | 2022-03-29 | 重庆邮电大学 | Method, system and medium for generating Chinese text countermeasure sample |
| CN114283797A (en)* | 2021-12-14 | 2022-04-05 | 中国农业银行股份有限公司 | Method, device, medium and equipment for generating voice countermeasure sample of significant sequence |
| CN114444476A (en)* | 2022-01-25 | 2022-05-06 | 腾讯科技(深圳)有限公司 | Information processing method, apparatus and computer readable storage medium |
| CN114626365A (en)* | 2022-03-14 | 2022-06-14 | 腾讯科技(深圳)有限公司 | Composition error correction model defect determination method, apparatus, device and storage medium |
| CN115114910A (en)* | 2022-04-01 | 2022-09-27 | 腾讯科技(深圳)有限公司 | Text processing method, device, equipment, storage medium and product |
| CN115809662A (en)* | 2023-02-03 | 2023-03-17 | 北京匠数科技有限公司 | Text content abnormity detection method, device, equipment and medium |
| CN117058482A (en)* | 2023-08-07 | 2023-11-14 | 上海米哈游天命科技有限公司 | Method and device for detecting challenge sample, electronic equipment and storage medium |
Citations (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2018120889A1 (en)* | 2016-12-28 | 2018-07-05 | 平安科技(深圳)有限公司 | Input sentence error correction method and device, electronic device, and medium |
| US20180261213A1 (en)* | 2017-03-13 | 2018-09-13 | Baidu Usa Llc | Convolutional recurrent neural networks for small-footprint keyword spotting |
| CN109117482A (en)* | 2018-09-17 | 2019-01-01 | 武汉大学 | A kind of confrontation sample generating method towards the detection of Chinese text emotion tendency |
| CN110134942A (en)* | 2019-04-01 | 2019-08-16 | 北京中科闻歌科技股份有限公司 | Text hot spot extracting method and device |
| CN110378474A (en)* | 2019-07-26 | 2019-10-25 | 北京字节跳动网络技术有限公司 | Fight sample generating method, device, electronic equipment and computer-readable medium |
| CN110741388A (en)* | 2019-08-14 | 2020-01-31 | 东莞理工学院 | Confrontation sample detection method and device, computing equipment and computer storage medium |
| CN111026866A (en)* | 2019-10-24 | 2020-04-17 | 北京中科闻歌科技股份有限公司 | Domain-oriented text information extraction clustering method, device and storage medium |
| CN111046176A (en)* | 2019-11-25 | 2020-04-21 | 百度在线网络技术(北京)有限公司 | Countermeasure sample generation method and device, electronic equipment and storage medium |
| CN111160217A (en)* | 2019-12-25 | 2020-05-15 | 中山大学 | Method and system for generating confrontation sample of pedestrian re-identification system |
| CN111209370A (en)* | 2019-12-27 | 2020-05-29 | 同济大学 | Text classification method based on neural network interpretability |
| CN111461226A (en)* | 2020-04-01 | 2020-07-28 | 深圳前海微众银行股份有限公司 | Adversarial sample generation method, device, terminal and readable storage medium |
| CN111709234A (en)* | 2020-05-28 | 2020-09-25 | 北京百度网讯科技有限公司 | Training method, device and electronic device for text processing model |
| CN111783451A (en)* | 2020-06-30 | 2020-10-16 | 北京百度网讯科技有限公司 | Method and apparatus for enhancing text samples |
| CN111783443A (en)* | 2020-06-29 | 2020-10-16 | 百度在线网络技术(北京)有限公司 | Text disturbance detection method, disturbance reduction method, disturbance processing method and device |
| CN111897964A (en)* | 2020-08-12 | 2020-11-06 | 腾讯科技(深圳)有限公司 | Text classification model training method, device, equipment and storage medium |
- 2020
- 2020-11-12CNCN202011259475.4Apatent/CN112364641B/enactiveActive
Patent Citations (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2018120889A1 (en)* | 2016-12-28 | 2018-07-05 | 平安科技(深圳)有限公司 | Input sentence error correction method and device, electronic device, and medium |
| US20180261213A1 (en)* | 2017-03-13 | 2018-09-13 | Baidu Usa Llc | Convolutional recurrent neural networks for small-footprint keyword spotting |
| CN109117482A (en)* | 2018-09-17 | 2019-01-01 | 武汉大学 | A kind of confrontation sample generating method towards the detection of Chinese text emotion tendency |
| CN110134942A (en)* | 2019-04-01 | 2019-08-16 | 北京中科闻歌科技股份有限公司 | Text hot spot extracting method and device |
| CN110378474A (en)* | 2019-07-26 | 2019-10-25 | 北京字节跳动网络技术有限公司 | Fight sample generating method, device, electronic equipment and computer-readable medium |
| CN110741388A (en)* | 2019-08-14 | 2020-01-31 | 东莞理工学院 | Confrontation sample detection method and device, computing equipment and computer storage medium |
| CN111026866A (en)* | 2019-10-24 | 2020-04-17 | 北京中科闻歌科技股份有限公司 | Domain-oriented text information extraction clustering method, device and storage medium |
| CN111046176A (en)* | 2019-11-25 | 2020-04-21 | 百度在线网络技术(北京)有限公司 | Countermeasure sample generation method and device, electronic equipment and storage medium |
| CN111160217A (en)* | 2019-12-25 | 2020-05-15 | 中山大学 | Method and system for generating confrontation sample of pedestrian re-identification system |
| CN111209370A (en)* | 2019-12-27 | 2020-05-29 | 同济大学 | Text classification method based on neural network interpretability |
| CN111461226A (en)* | 2020-04-01 | 2020-07-28 | 深圳前海微众银行股份有限公司 | Adversarial sample generation method, device, terminal and readable storage medium |
| CN111709234A (en)* | 2020-05-28 | 2020-09-25 | 北京百度网讯科技有限公司 | Training method, device and electronic device for text processing model |
| CN111783443A (en)* | 2020-06-29 | 2020-10-16 | 百度在线网络技术(北京)有限公司 | Text disturbance detection method, disturbance reduction method, disturbance processing method and device |
| CN111783451A (en)* | 2020-06-30 | 2020-10-16 | 北京百度网讯科技有限公司 | Method and apparatus for enhancing text samples |
| CN111897964A (en)* | 2020-08-12 | 2020-11-06 | 腾讯科技(深圳)有限公司 | Text classification model training method, device, equipment and storage medium |
Non-Patent Citations (7)
| Title |
|---|
| MOUSTAFA ALZANTOT: "Generating Natural Language Adversarial Examples", 《HTTPS://ARXIV.ORG/ABS/1804.07998》, pages 1 - 9* |
| SHUHUAI REN: "Generating Natural Language Adversarial Examples through Probability Weighted Word Saliency", 《PROCEEDINGS OF THE 57TH ANNUAL MEETING OF THE ASSOCIATION FOR COMPUTATIONAL LINGUISTICS》, 31 July 2019 (2019-07-31), pages 1085 - 1097* |
| SHUHUAI REN: "Generating Natural Language Adversarial Examples through Probability Weighted Word Saliency", 《PROCEEDINGS OF THE 57TH ANNUAL MEETING OF THE ASSOCIATION FOR COMPUTATIONAL LINGUISTICS》, pages 1085 - 1097* |
| 仝鑫: "面向中文文本分类的词级对抗样本生成方法", 《信息网络安全》, vol. 20, no. 09, 10 September 2020 (2020-09-10), pages 12 - 16* |
| 仝鑫: "面向中文文本分类的词级对抗样本生成方法", 信息网络安全, vol. 20, no. 09, pages 12 - 16* |
| 张晓辉: "基于对抗训练的文本表示和分类算法", 计算机科学, vol. 47, no. 1, pages 12 - 16* |
| 王文琦: "面向中文文本倾向性分类的对抗样本生成方法", 软件学报, vol. 30, no. 08, pages 2415 - 2427* |
Cited By (19)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112948887A (en)* | 2021-03-29 | 2021-06-11 | 北京交通大学 | Social engineering defense method based on confrontation sample generation |
| CN112948887B (en)* | 2021-03-29 | 2023-03-28 | 北京交通大学 | Social engineering defense method based on confrontation sample generation |
| CN113469212A (en)* | 2021-05-07 | 2021-10-01 | 苏州摩多多信息科技有限公司 | Method, system and medium for creating text audit model |
| CN113191777A (en)* | 2021-05-13 | 2021-07-30 | 支付宝(杭州)信息技术有限公司 | Risk identification method and device |
| CN113204974B (en)* | 2021-05-14 | 2022-06-17 | 清华大学 | Method, device and equipment for generating confrontation text and storage medium |
| CN113204974A (en)* | 2021-05-14 | 2021-08-03 | 清华大学 | Method, device and equipment for generating confrontation text and storage medium |
| CN113836297A (en)* | 2021-07-23 | 2021-12-24 | 北京三快在线科技有限公司 | Training method and device for text emotion analysis model |
| CN113723506A (en)* | 2021-08-30 | 2021-11-30 | 南京星环智能科技有限公司 | Method and device for generating countermeasure sample and storage medium |
| CN113868365A (en)* | 2021-09-28 | 2021-12-31 | 北京天融信网络安全技术有限公司 | Method and device for generating adversarial samples, and readable storage medium |
| CN114064891A (en)* | 2021-11-10 | 2022-02-18 | 杭州网易再顾科技有限公司 | Adversarial text generation method, medium, apparatus and computing device |
| CN114254108A (en)* | 2021-12-13 | 2022-03-29 | 重庆邮电大学 | Method, system and medium for generating Chinese text countermeasure sample |
| CN114283797A (en)* | 2021-12-14 | 2022-04-05 | 中国农业银行股份有限公司 | Method, device, medium and equipment for generating voice countermeasure sample of significant sequence |
| CN114444476A (en)* | 2022-01-25 | 2022-05-06 | 腾讯科技(深圳)有限公司 | Information processing method, apparatus and computer readable storage medium |
| CN114444476B (en)* | 2022-01-25 | 2024-03-01 | 腾讯科技(深圳)有限公司 | Information processing method, apparatus, and computer-readable storage medium |
| CN114626365A (en)* | 2022-03-14 | 2022-06-14 | 腾讯科技(深圳)有限公司 | Composition error correction model defect determination method, apparatus, device and storage medium |
| CN115114910A (en)* | 2022-04-01 | 2022-09-27 | 腾讯科技(深圳)有限公司 | Text processing method, device, equipment, storage medium and product |
| CN115114910B (en)* | 2022-04-01 | 2024-04-02 | 腾讯科技(深圳)有限公司 | Text processing method, device, equipment, storage medium and product |
| CN115809662A (en)* | 2023-02-03 | 2023-03-17 | 北京匠数科技有限公司 | Text content abnormity detection method, device, equipment and medium |
| CN117058482A (en)* | 2023-08-07 | 2023-11-14 | 上海米哈游天命科技有限公司 | Method and device for detecting challenge sample, electronic equipment and storage medium |
Also Published As
| Publication number | Publication date |
|---|---|
| CN112364641B (en) | 2024-10-22 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN112364641B (en) | Text-audit-oriented Chinese countermeasure sample generation method and device | |
| CN111897970A (en) | Text comparison method, device and equipment based on knowledge graph and storage medium | |
| CN113254643B (en) | Text classification methods, devices, electronic devices and | |
| WO2017167067A1 (en) | Method and device for webpage text classification, method and device for webpage text recognition | |
| CN116150201A (en) | Sensitive data identification method, device, equipment and computer storage medium | |
| CN114528827B (en) | Text-oriented countermeasure sample generation method, system, equipment and terminal | |
| CN110929025A (en) | Junk text recognition method and device, computing equipment and readable storage medium | |
| CN113672731B (en) | Emotion analysis method, device, equipment and storage medium based on field information | |
| CN107341143A (en) | A kind of sentence continuity determination methods and device and electronic equipment | |
| US12164578B2 (en) | Method, apparatus, and computer-readable medium for determining a data domain associated with data | |
| CN113204956B (en) | Multi-model training method, abstract segmentation method, text segmentation method and text segmentation device | |
| CN117454220A (en) | Data hierarchical classification method, device, equipment and storage medium | |
| CN114202443A (en) | Policy classification method, device, equipment and storage medium | |
| CN116975863A (en) | Malicious code detection method based on convolutional neural network | |
| CN114444497B (en) | A text classification method, terminal device and storage medium based on multi-source features | |
| Przystalski et al. | Stylometry recognizes human and LLM-generated texts in short samples | |
| CN114722832A (en) | Abstract extraction method, device, equipment and storage medium | |
| CN111488452A (en) | Webpage tampering detection method, detection system and related equipment | |
| Zhang et al. | Chinese novelty mining | |
| CN110704611B (en) | Illegal text recognition method and device based on feature de-interleaving | |
| CN116362292A (en) | Text classification model training method and device, text classification method and device | |
| Rawat et al. | Hate Speech Detection using Machine Learning Techniques | |
| Daif et al. | AraDIC: Arabic document classification using image-based character embeddings and class-balanced loss | |
| Khan et al. | Hate Speech Detection Using Machine Learning and N-Gram Techniques | |
| TWI897104B (en) | Sensitive data identification method, device, equipment and computer storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| CB02 | Change of applicant information | Address after:100028 room 0715, 7 / F, Yingu building, building 9, North Fourth Ring Road West, Haidian District, Beijing Applicant after:BEIJING ZHONGKE WENGE TECHNOLOGY Co.,Ltd. Applicant after:SHENZHEN ZHONGKE WENGE TECHNOLOGY Co.,Ltd. Applicant after:Guoke Zhian (Beijing) Technology Co.,Ltd. Address before:100028 room 0715, 7 / F, Yingu building, building 9, North Fourth Ring Road West, Haidian District, Beijing Applicant before:BEIJING ZHONGKE WENGE TECHNOLOGY Co.,Ltd. Applicant before:SHENZHEN ZHONGKE WENGE TECHNOLOGY Co.,Ltd. Applicant before:Beijing Zhongke Wenge Zhian Technology Co.,Ltd. | |
| CB02 | Change of applicant information | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |