CN112256865B - Chinese text classification method based on classifier - Google Patents
Chinese text classification method based on classifierDownload PDFInfo
- Publication number
- CN112256865B CN112256865BCN202011019598.0ACN202011019598ACN112256865BCN 112256865 BCN112256865 BCN 112256865BCN 202011019598 ACN202011019598 ACN 202011019598ACN 112256865 BCN112256865 BCN 112256865B
- Authority
- CN
- China
- Prior art keywords
- text
- category
- feature
- item
- class
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images




Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/35—Clustering; Classification
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02D—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN INFORMATION AND COMMUNICATION TECHNOLOGIES [ICT], I.E. INFORMATION AND COMMUNICATION TECHNOLOGIES AIMING AT THE REDUCTION OF THEIR OWN ENERGY USE
- Y02D10/00—Energy efficient computing, e.g. low power processors, power management or thermal management
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
Translated fromChinese此发明是一种中文文本分类方法,申请号为201910100095.7的专利的分案申请。This invention is a Chinese text classification method, a divisional application of the patent application number 201910100095.7.
技术领域technical field
本发明涉及文本分类领域,更具体的说,它涉及一种基于分类器的中文文本分类方法。The invention relates to the field of text classification, more specifically, it relates to a classifier-based Chinese text classification method.
背景技术Background technique
近年来,化工事故频繁发生,8·12天津滨海新区瑞海国际物流中心危险品仓库发生火灾爆炸事故、11·22山东青岛输油管道泄露爆炸事件等化工事故的发生,带来的不仅是巨大的经济损失,同时也伴随着人员伤亡、环境污染,一些重大的化工事故容易造成人员恐慌,对社会有重大的影响。若能利用某种技术快速准确定位出与化工事故相关报道,为研究化工事故成因、跟踪报道、预防化工事故发生等提供了便利。因此,需要一种可以有效率地管理这些信息的技术,将大量的文本信息自动分类,选择出人们需要的特定领域信息文本。文本分类技术可以分析处理大量文本数据,人工干预大大减少,并且能高效准确定位出特定信息文本,是处理各类文本的有效方式。In recent years, chemical accidents have occurred frequently. The occurrence of chemical accidents such as the fire and explosion accident in the dangerous goods warehouse of Ruihai International Logistics Center in Tianjin Binhai New Area on August 12, and the leakage and explosion incident of Qingdao oil pipeline in Shandong on November 22 have brought not only huge Economic losses are also accompanied by casualties and environmental pollution. Some major chemical accidents are likely to cause panic among personnel and have a major impact on society. If a certain technology can be used to quickly and accurately locate reports related to chemical accidents, it will provide convenience for studying the causes of chemical accidents, tracking reports, and preventing chemical accidents. Therefore, there is a need for a technology that can efficiently manage these information, automatically classify a large amount of text information, and select the information text of a specific field that people need. Text classification technology can analyze and process a large amount of text data, greatly reduce manual intervention, and can efficiently and accurately locate specific information texts, which is an effective way to process various types of texts.
信息技术的发展日益迅猛,互联网技术逐渐成熟,随之产生的数据量呈爆炸性增长,而这些数据大多是半结构化和非结构化的,并且以文本形式呈现。若采用人工方式将一篇文本划分到某个分类中,虽然分类结果准确,但是耗费的人力物力极其巨大,无法快速适应互联网时代信息的极速增加以及社会发展的需求,实现十分困难。实际上,根据特定的需求,人们往往只关心文本信息的某一个领域,快速提取出指定的文本信息对互联网技术的发展具有举足轻重的作用。With the rapid development of information technology and the gradual maturity of Internet technology, the resulting data volume is explosively increasing, and most of these data are semi-structured and unstructured, and are presented in the form of text. If a text is divided into a certain classification manually, although the classification result is accurate, it consumes a huge amount of manpower and material resources, and cannot quickly adapt to the rapid increase of information in the Internet age and the needs of social development, so it is very difficult to achieve. In fact, according to specific needs, people often only care about a certain field of text information, and quickly extracting specified text information plays a decisive role in the development of Internet technology.
我国最早关于文本分类的报告是80年代初,就职于南京工业大学的侯汉清教授首次对其进行了系统性地阐述。随后,多位学者对文本分类方法不断改进,随之我国在文本分类领域的研究取得较大进展。李晓黎、史忠值等人通过将概念推理网引入文本分类,文本分类的准确率和召回率得到较大提升。姜远、周志华等在2006年提出在分类时将词频作为影响因素,复旦大学的李荣陆在构建文本分类器时采用基于最大熵模型的分类方法,黄菁菁等采用独立语种对文本分类进行了广泛扩展。但整体上,仍没有极高的精准分类的方法。如何快速精确地定位是近几年来信息发展的一个重要研究范畴。The earliest report on text classification in my country was in the early 1980s. Professor Hou Hanqing, who worked at Nanjing University of Technology, made a systematic exposition for the first time. Subsequently, many scholars have continuously improved the text classification method, and then our country has made great progress in the field of text classification. Li Xiaoli, Shi Zhongzhi and others introduced the concept reasoning network into text classification, and the accuracy and recall rate of text classification were greatly improved. In 2006, Jiang Yuan, Zhou Zhihua, etc. proposed to use word frequency as an influencing factor in classification. Li Ronglu of Fudan University used the classification method based on the maximum entropy model when constructing a text classifier. Huang Jingjing et al. used independent languages to extensively expand text classification. . But overall, there is still no extremely high-precision classification method. How to quickly and accurately locate is an important research category of information development in recent years.
发明内容Contents of the invention
本发明为文本分类的高效提供了可能,其建模更合理、分类准确率提高、召回率提高,整体精准快捷的一种基于分类器的中文文本分类方法。The present invention provides the possibility for high efficiency of text classification, the modeling is more reasonable, the classification accuracy rate is improved, the recall rate is improved, and the Chinese text classification method based on the classifier is accurate and fast as a whole.
本发明的技术方案如下:Technical scheme of the present invention is as follows:
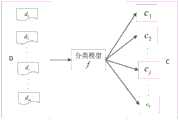
一种基于分类器的中文文本分类方法,包括测试集文本D和训练集的文本类别集合C,将测试集文本D通过文本分类方法映射到训练集的文本类别集合C;其中D={d1,d2,L,dm},其中C={c1,c2,L,cn},m为文本数,n为文本类别数,具体处理步骤如下:A Chinese text classification method based on a classifier, including a test set text D and a text category set C of a training set, and the test set text D is mapped to a text category set C of the training set through a text classification method; where D={d1 ,d2 ,L,dm }, where C={c1 ,c2 ,L,cn }, m is the number of texts, n is the number of text categories, the specific processing steps are as follows:
101)文本预处理步骤:将训练集的文本进行文本标记处理、分词、去除停用词,将处理后的文本通过统计做特征选择,进行特征降维得到训练集的文本类别集合C;101) Text preprocessing step: perform text labeling processing, word segmentation, and removal of stop words on the text of the training set, perform feature selection on the processed text through statistics, and perform feature dimensionality reduction to obtain the text category set C of the training set;
其中,统计采用特征项t与类别Ci的相互关联性进行排序统计,具体包括四种统计:属于类别Ci且包含特征项t的文本数集A,不属于类别Ci但包含特征项t的文本数集B,属于类别Ci但不包含特征项t的文本数集C,不属于类别Ci且不包含特征项t的文本数集D;Ci表示分词后去除相近分词的文本类别集合中的其中一个类别,i为类别标识,其小于等于分词后的分词数量;特征项t为具体的分词;Among them, the statistics use the correlation between the feature item t and the category Ci for sorting statistics, including four types of statistics: the text data set A that belongs to the category Ci and contains the feature item t, does not belong to the category Ci but contains the feature item t The text data set B that belongs to the category Ci but does not contain the feature item t, the text data set D that does not belong to the category Ci and does not contain the feature item t; Ci represents the text category that removes similar word segmentation after word segmentation One of the categories in the set, i is the category identifier, which is less than or equal to the number of word segmentation after word segmentation; the feature item t is the specific word segmentation;
训练集中含有特征项t的文本总数集是A+B,不含有特征项t的文本总数集是C+D,类别Ci的文本数集是A+C,其他类别的文本数集是B+D,训练集文本总数集是N,且N=A+B+C+D,特征项t的概率表示为
由此可得,特征项t与类别Ci的关联性值为:It can be obtained that the correlation value between feature item t and category Ci is:

若特征项t与类别Ci相互独立,AD-CB=0,有X2(t,ci)=0;如果X2(t,ci)的值越大,就表明特征项t与类别Ci相互关系程度越大;AD表示根据特征项t正确判定文档属于Ci类的量化值,CB表示根据特征项t错误判定文档属于Ci类的量化值;If the feature item t and the category Ci are independent of each other, AD-CB=0, there is X2 (t,ci )=0; if the value of X2 (t,ci ) is larger, it indicates that the feature item t and the category The greater the degree of Ci interrelationship; AD represents the quantified value that correctly determines that the document belongs to the Ci class according to the feature item t, and CB represents the quantified value that incorrectly determines that the document belongs to the Ci class according to the feature item t;
在统计排序时以其平均值作为比较,其平均值为如下公式:The average value is used as a comparison in statistical sorting, and the average value is the following formula:

统计排序以平均值从大到小进行排序,从训练集的文本类别集合C中,从大到小选取一定数量的特征项;Statistical sorting is sorted by the average value from large to small, and a certain number of feature items are selected from large to small from the text category set C of the training set;
102)分类器步骤:将步骤101)处理后的数据由文本分类器处理,具体公式如下:102) classifier step: the data processed in step 101) is processed by a text classifier, and the specific formula is as follows:

其中,P(Ci|Dj)表示训练集的文本Dj属于某一类别Ci的概率,文档Dj可以用一组该文档的分词{x1,x2,…,xn}表示,即Dj={x1,x2,…,xn},由于固定的特征词在文本集中出现的次数是常数,所以公式(3)中分母P(x1,x2,L,xn)是常量,因此只需获得公式(3)中分子P(Ci)P(x1,x2,…,xn|Ci)的值,就能判定不同j值时,不同P(Ci|Dj)值间的大小关系;因此公式(3)则最终可表示为:Among them, P(Ci |Dj ) represents the probability that the text Dj of the training set belongs to a certain category Ci , and the document Dj can be represented by a set of word segmentation {x1 ,x2 ,…,xn } , that is, Dj ={x1 ,x2 ,…,xn }, since the number of fixed feature words appearing in the text set is constant, the denominator P(x1 ,x2 ,L,xn ) is a constant, so it is only necessary to obtain the value of the molecule P(Ci )P(x1 ,x2 ,…,xn |Ci ) in the formula (3), and it can be determined that when different values of j, different P( Ci |Dj ) values; therefore formula (3) can be finally expressed as:

其中,xj为文档Dj中的一个分词特征项,n为n个特征项;当某一特征项出现在该文本中,就置权重为1,若未出现就置权重为0,测试文本作为事件,并且该事件为n重事件,即在同样的条件下重复地、相互独立地进行的一种随机事件;用Bxt代表测试文档含有文本特征项t,则得到如下公式:Among them, xj is a word segmentation feature item in document Dj , and n is n feature items; when a feature item appears in the text, set the weight to 1, if it does not appear, set the weight to 0, and test the text As an event, and the event is an n-fold event, that is, a random event that is carried out repeatedly and independently under the same conditions; using Bxt to represent that the test document contains a text feature item t, the following formula is obtained:

在属于类Ci的情况下xj发生的概率用P(xj|Ci)表示,若特征项出现在测试文本中,则只需得到P(xj|Ci),否则需得到1-P(xj|Ci);The probability of occurrence of xj in the case of class Ci is represented by P(xj |Ci ), if the feature item appears in the test text, only P(xj |Ci ) is needed, otherwise 1 is required -P(xj |Ci );
条件概率1-P(xj|Ci)的公式为:The formula for the conditional probability 1-P(xj |Ci ) is:

在训练集中,若类别Ci中的所有文本都不含有特征项xj,则nij是0,从而P(xj|Ci)的值是0,故需要采用加入平滑因子的方法,得如下公式:In the training set, if all the texts in the category Ci do not contain the feature item xj , then nij is 0, so the value of P(xj |Ci ) is 0, so it is necessary to use the method of adding a smoothing factor, and get The following formula:

103)测试与评价步骤:评估分类器的准确率、召回率、F1值、宏平均,调整训练集的文本类别集合C。103) Test and evaluation step: evaluate the accuracy rate, recall rate, F1 value, and macro average of the classifier, and adjust the text category set C of the training set.
进一步的,文本标记处理为用正则表达式去除文中的中文符号、数字和英文,去除中文符号的正则表达式可表示为:[^\\u4e00-\\u9fa5\\w],去除数字和英文的正则表达式为:[a-zA-Z\\d],并用空格代替。Further, the text markup process is to use regular expressions to remove Chinese symbols, numbers and English in the text. The regular expression for removing Chinese symbols can be expressed as: [^\\u4e00-\\u9fa5\\w], remove numbers and English The regular expression is: [a-zA-Z\\d], and replace it with spaces.
进一步的,采用MMSEG4J分词工具包进行分词;停用词为文本中出现多次并且与文本内容无关的词,将停用词整理到停用词表中,并在分词结束后将其删除。Further, the MMSEG4J word segmentation toolkit is used for word segmentation; stop words are words that appear multiple times in the text and have nothing to do with the text content. The stop words are sorted into the stop word list and deleted after word segmentation.
进一步的,准确率,也称查准率,获取测试集中有多少文本的分类结果是正确的,体现分类器分类的准确程度,记为P,具体公式如下:Further, the accuracy rate, also known as the precision rate, obtains the correct classification result of how many texts in the test set, which reflects the accuracy of the classifier classification, and is recorded as P. The specific formula is as follows:

属于类别Ci且包含特征项t的文本数集A,即正确分类到Ci类的文本数;不属于类别Ci但包含特征项t的文本数集B,A+B即实际分类到Ci类的文本总数;The text data set A that belongs to the category Ci and contains the feature item t, that is, the number of texts that are correctly classified into the Ci class; the text data set B that does not belong to the category Ci but contains the feature item t, A+B is actually classified into C the total number of texts in categoryi ;
召回率,也称查全率,获取测试集中在类别Ci中的文本,可以被正确分类到类别Ci所占有的比重,展现出分类器分类的完备性,记为R,具体公式如下:The recall rate, also known as the recall rate, obtains the proportion of the texts in the category Ci in the test set, which can be correctly classified into the category Ci , and shows the completeness of the classifier classification. It is recorded as R, and the specific formula is as follows:

属于类别Ci但不包含特征项t的文本数集C,A+C即所有应归为Ci类的文本;A text data set C that belongs to category Ci but does not contain feature item t, A+C is all texts that should be classified into Ci category;
F1值,也称综合分类率,是准确率P和召回率R的综合评估指标,具体公式如下:The F1 value, also known as the comprehensive classification rate, is a comprehensive evaluation index of the accuracy rate P and the recall rate R. The specific formula is as follows:

宏平均是对分类器的整体分类效果的评价,准确率和召回率的算术平均数就是宏平均,具体公式如下:The macro average is an evaluation of the overall classification effect of the classifier. The arithmetic mean of the accuracy rate and the recall rate is the macro average. The specific formula is as follows:


其中,MacAvg_Precision表示准确率的宏平均,MacAvg_Recall表示召回率的宏平均,|C|表示训练集中包含的文本类别数,Pi表示类别Ci的准确率,Ri表示类别Ci的召回率。Among them, MacAvg_Precision represents the macro average of accuracy, MacAvg_Recall represents the macro average of recall, |C| represents the number of text categories contained in the training set, Pi represents the accuracy of category Ci , and Ri represents the recall rate of category Ci .
本发明相比现有技术优点在于:本发明通过文本训练集,建立特征项,通过准确率、召回率、F1值、宏平均等指标进行评估,从而训练调整选择的特征项。本发明通过特征项与类别的关联性值,进行关系程度量化值的获取和排序,以选择合适的特征项作为分类标准,从而提高准确率、召回率和精准度。本发明方案为文本分类的高效提供了可能,其分类准确率高、召回率高,整体精准快捷。Compared with the prior art, the present invention has the advantages that: the present invention establishes feature items through the text training set, and evaluates through indicators such as accuracy rate, recall rate, F1 value, and macro average, so as to train and adjust the selected feature items. The present invention obtains and sorts the quantitative value of the relationship degree through the correlation value between the feature item and the category, and selects the appropriate feature item as the classification standard, thereby improving the accuracy rate, recall rate and precision. The scheme of the present invention provides the possibility for high efficiency of text classification, and the classification accuracy rate is high, the recall rate is high, and the whole is accurate and fast.
附图说明Description of drawings
图1为本发明的整体模型图;Fig. 1 is an overall model diagram of the present invention;
图2为本发明的文本分类映射模型图;Fig. 2 is a text classification mapping model figure of the present invention;
图3为本发明的训练集中的原始文本;Fig. 3 is the original text in the training set of the present invention;
图4为本发明图3进行文本标记处理后的文本;Fig. 4 is the text after the text mark processing of Fig. 3 of the present invention;
图5为本发明图4分词处理后的文本;Fig. 5 is the text after word segmentation processing of Fig. 4 of the present invention;
图6为本发明图5去除停用词处理后的文本。Fig. 6 is the text after removing stop words in Fig. 5 of the present invention.
具体实施方式Detailed ways
下面结合附图和具体实施方式对本发明进一步说明。The present invention will be further described below in conjunction with the accompanying drawings and specific embodiments.
如图1至图6所示,一种基于分类器的中文文本分类方法,包括测试集文本D和训练集的文本类别集合C,将测试集文本D通过文本分类方法映射到训练集的文本类别集合C;其中D={d1,d2,L,dm},其中C={c1,c2,L,cn},m为文本数,n为文本类别数,具体包括如下步骤:As shown in Figures 1 to 6, a classifier-based Chinese text classification method includes a test set text D and a text category set C of the training set, and the test set text D is mapped to the text category of the training set by the text classification method Set C; where D={d1 ,d2 ,L,dm }, where C={c1 ,c2 ,L,cn }, m is the number of texts, n is the number of text categories, specifically including the following steps :
101)文本预处理步骤:将训练集的文本进行文本标记处理、分词、去除停用词。将处理后的文本通过统计做特征选择,进行特征降维得到训练集的文本类别集合C。具体如下:101) Text preprocessing step: perform text labeling processing, word segmentation, and removal of stop words on the text of the training set. The processed text is used for feature selection through statistics, and feature dimensionality reduction is performed to obtain the text category set C of the training set. details as follows:
如图3所示,为训练集中的原始文本,训练集的文本中含有不包含文本信息的特殊字符、数字等,其对文本的分类没有帮助,属于噪声数据需要文本标记处理,用正则表达式去除中文符号、数字和英文。去除中文符号的正则表达式可表示为:[^\\u4e00-\\u9fa5\\w],去除数字和英文的正则表达式为:[a-zA-Z\\d]。得到如图所示的处理后文本。为了避免去除这些符号后对中文分词的影响,将这些符号以空格代替。As shown in Figure 3, it is the original text in the training set. The text in the training set contains special characters, numbers, etc. that do not contain text information, which is not helpful for text classification. It belongs to noise data and requires text labeling. Use regular expressions Remove Chinese symbols, numbers and English. The regular expression for removing Chinese symbols can be expressed as: [^\\u4e00-\\u9fa5\\w], and the regular expression for removing numbers and English is: [a-zA-Z\\d]. Get the processed text as shown in the figure. In order to avoid the impact on Chinese word segmentation after removing these symbols, replace these symbols with spaces.
中文文本中除了标点符号,没有明显的分隔符标记,因此采用MMSEG4J分词工具包进行分词,将中文文本信息划分为一个个词,这是处理中文文本信息的关键步骤。即得到如图5所示的分词处理后的文本。In addition to punctuation marks, there is no obvious separator mark in Chinese text, so MMSEG4J word segmentation toolkit is used for word segmentation, and Chinese text information is divided into individual words, which is a key step in processing Chinese text information. That is, the word-segmented text as shown in FIG. 5 is obtained.
文本中出现多次并且与文本内容无关的词称为停用词,如“的”、“啊”,“但是”等虚词、无实际意义的实词、连词、语气助词、介词、代词等,这些词几乎出现在每篇文本中,可以将这些词整理到一个停用词表中,在中文分词结束后将这些词删除,得到的文本是文本预处理结束后的文本信息。其中停用词表可以直接来源于百度停用词表。即得到如图6所示的去除停用词处理后的文本。Words that appear many times in the text and have nothing to do with the content of the text are called stop words, such as "'s", "ah", "but" and other function words, content words without practical meaning, conjunctions, modal particles, prepositions, pronouns, etc., these Words appear in almost every text, and these words can be sorted into a stop vocabulary, and these words are deleted after the Chinese word segmentation is completed, and the obtained text is the text information after the text preprocessing is completed. Among them, the stop word list can be directly derived from the Baidu stop word list. That is, the text after removing the stop words as shown in Figure 6 is obtained.
其中,统计采用特征项t与类别Ci的相互关联性进行排序统计,具体包括四种统计:属于类别Ci且包含特征项t的文本数集A,不属于类别Ci但包含特征项t的文本数集B,属于类别Ci但不包含特征项t的文本数集C,不属于类别Ci且不包含特征项t的文本数集D;Ci表示分词后去除相近分词的文本类别集合中的其中一个类别,i为类别标识,其小于等于分词后的分词数量;特征项t为具体的分词;Among them, the statistics use the correlation between the feature item t and the category Ci for sorting statistics, including four types of statistics: the text data set A that belongs to the category Ci and contains the feature item t, does not belong to the category Ci but contains the feature item t The text data set B that belongs to the category Ci but does not contain the feature item t, the text data set D that does not belong to the category Ci and does not contain the feature item t; Ci represents the text category that removes similar word segmentation after word segmentation One of the categories in the set, i is the category identifier, which is less than or equal to the number of word segmentation after word segmentation; the feature item t is the specific word segmentation;
以训练集文本总数N=806,A+B=394,在化工事故新闻报道类别中,A=383,B=11,C=108,D=304,p(化工)=0.609;在非化工事故新闻报道类别中,A=11,B=383,C=304,D=108,p(非化工)=0.391为案例。With the total number of texts in the training set N=806, A+B=394, in the category of chemical accident news reports, A=383, B=11, C=108, D=304, p(chemical industry)=0.609; In the category of news reports, A=11, B=383, C=304, D=108, p (non-chemical industry)=0.391 is the case.
训练集中含有特征项t的文本总数集是A+B,不含有特征项t的文本总数集是C+D,类别Ci的文本数集是A+C,其他类别的文本数集是B+D,训练集文本总数集是N,且N=A+B+C+D,特征项t的概率表示为
由此可得,特征项t与类别Ci的关联性值为:It can be obtained that the correlation value between feature item t and category Ci is:

若特征项t与类别Ci相互独立,AD-CB=0,有X2(t,ci)=0;如果X2(t,ci)的值越大,就表明特征项t与类别Ci相互关系程度越大;AD表示根据特征项t正确判定文档属于Ci类的量化值,CB表示根据特征项t错误判定文档属于Ci类的量化值;If the feature item t and the category Ci are independent of each other, AD-CB=0, there is X2 (t,ci )=0; if the value of X2 (t,ci ) is larger, it indicates that the feature item t and the category The greater the degree of Ci interrelationship; AD represents the quantified value that correctly determines that the document belongs to the Ci class according to the feature item t, and CB represents the quantified value that incorrectly determines that the document belongs to the Ci class according to the feature item t;
在统计排序时以其平均值作为比较,其平均值为如下公式:The average value is used as a comparison in statistical sorting, and the average value is the following formula:

统计排序以平均值从大到小进行排序,从训练集的文本类别集合C中,从大到小选取一定数量的特征项。即将得出的每个特征项t的结果



由公式(2-10)至公式(2-12)可知,“消防”的
102)分类器步骤:将步骤101)处理后的数据由文本分类器处理,即以一篇新闻报道文本经过此步骤处理后选择特征词个数300个时为例,文本预处理后共有128个词,采用统计处理后,一篇文章就剩37个特征词,大大降低了处理量,提高处理精准度。具体公式如下:102) Classifier step: the data processed in step 101) is processed by a text classifier, that is, when a news report text is processed by this step and the number of feature words is selected as 300 as an example, there are 128 in total after the text preprocessing Words, after statistical processing, there are only 37 feature words left in an article, which greatly reduces the processing volume and improves the processing accuracy. The specific formula is as follows:

其中,P(Ci|Dj)表示训练集的文本Dj属于某一类别Ci的概率,文档Dj可以用一组该文档的分词{x1,x2,…,xn}表示,即Dj={x1,x2,…,xn},由于固定的特征词在文本集中出现的次数是常数,所以公式(3)中分母P(x1,x2,L,xn)是常量,因此只需获得公式(3)中分子P(Ci)P(x1,x2,…,xn|Ci)的值,就能判定不同j值时,不同P(Ci|Dj)值间的大小关系。Among them, P(Ci |Dj ) represents the probability that the text Dj of the training set belongs to a certain category Ci , and the document Dj can be represented by a set of word segmentation {x1 ,x2 ,…,xn } , that is, Dj ={x1 ,x2 ,…,xn }, since the number of fixed feature words appearing in the text set is constant, the denominator P(x1 ,x2 ,L,xn ) is a constant, so it is only necessary to obtain the value of the molecule P(Ci )P(x1 ,x2 ,…,xn |Ci ) in the formula (3), and it can be determined that different P( Ci |Dj ) value relationship.
因此公式(3)则最终可表示为:Therefore, formula (3) can finally be expressed as:

其中,xj为文档Dj中的一个分词特征项,n为n个特征项;当某一特征项出现在该文本中,就置权重为1,若未出现就置权重为0,测试文本作为事件,并且该事件为n重事件,即在同样的条件下重复地、相互独立地进行的一种随机事件。Among them, xj is a word segmentation feature item in document Dj , and n is n feature items; when a feature item appears in the text, set the weight to 1, if it does not appear, set the weight to 0, and test the text As an event, and the event is an n-fold event, that is, a random event that occurs repeatedly and independently of each other under the same conditions.
以案例为例可知:P(Ci)为先验概率,
类别Ci的先验概率可表示为:The prior probability of category Ci can be expressed as:

用Bxt代表测试文档含有文本特征项t,则得到如下公式:Using Bxt to represent the test document contains the text feature item t, the following formula is obtained:

在属于类Ci的情况下xj发生的概率用P(xj|Ci)表示,若特征项出现在测试文本中,则只需得到P(xj|Ci),否则需得到1-P(xj|Ci);The probability of occurrence of xj in the case of class Ci is represented by P(xj |Ci ), if the feature item appears in the test text, only P(xj |Ci ) is needed, otherwise 1 is required -P(xj |Ci );
条件概率1-P(xj|Ci)的公式为:The formula for the conditional probability 1-P(xj |Ci ) is:

在训练集中,若类别Ci中的所有文本都不含有特征项xj,则nij是0,从而P(xj|Ci)的值是0,故需要采用加入平滑因子的方法,得如下公式:In the training set, if all the texts in the category Ci do not contain the feature item xj , then nij is 0, so the value of P(xj |Ci ) is 0, so it is necessary to use the method of adding a smoothing factor, and get The following formula:

以训练集文本总数N=806,A+B=394,在化工事故新闻报道类别中,A=383,B=11,C=108,D=304,p(化工)=0.609;在非化工事故新闻报道类别中,A=11,B=383,C=304,D=108,p(非化工)=0.391为例。以训练集文本数806篇,化工事故新闻报道类491篇,非化工事故新闻报道类315篇为例,在化工事故新闻报道类别中,P(化工)=491/806=0.609;在化工事故新闻报道类别中,P(非化工)=315/806=0.391。以图3的新闻报道为例,文本处理后的词如图5所示,ti为图5中的所有词,
103)测试与评价步骤:运用测试集文本测试文本分类器的分类性能,评估其准确率、召回率、综合分类率、宏平均,并进行改进。103) Test and evaluation step: use the test set text to test the classification performance of the text classifier, evaluate its accuracy rate, recall rate, comprehensive classification rate, and macro average, and make improvements.
其中准确率,也称查准率,获取测试集中有多少文本的分类结果是正确的,体现分类器分类的准确程度,记为P,具体公式如下:Among them, the accuracy rate, also known as the precision rate, is the correct classification result of how many texts in the test set, which reflects the accuracy of the classifier classification, and is recorded as P. The specific formula is as follows:

属于类别Ci且包含特征项t的文本数集A,即正确分类到Ci类的文本数;不属于类别Ci但包含特征项t的文本数集B,A+B即实际分类到Ci类的文本总数;The text data set A that belongs to the category Ci and contains the feature item t, that is, the number of texts that are correctly classified into the Ci class; the text data set B that does not belong to the category Ci but contains the feature item t, A+B is actually classified into C the total number of texts in categoryi ;
召回率,也称查全率,获取测试集中在类别Ci中的文本,可以被正确分类到类别Ci所占有的比重,展现出分类器分类的完备性,记为R,具体公式如下:The recall rate, also known as the recall rate, obtains the proportion of the texts in the category Ci in the test set, which can be correctly classified into the category Ci , and shows the completeness of the classifier classification. It is recorded as R, and the specific formula is as follows:

属于类别Ci但不包含特征项t的文本数集C,A+C即所有应归为Ci类的文本;A text data set C that belongs to category Ci but does not contain feature item t, A+C is all texts that should be classified into Ci category;
F1值,也称综合分类率,是准确率P和召回率R的综合评估指标,具体公式如下:The F1 value, also known as the comprehensive classification rate, is a comprehensive evaluation index of the accuracy rate P and the recall rate R. The specific formula is as follows:

宏平均是对分类器的整体分类效果的评价,准确率和召回率的算术平均数就是宏平均,具体公式如下:The macro average is an evaluation of the overall classification effect of the classifier. The arithmetic mean of the accuracy rate and the recall rate is the macro average. The specific formula is as follows:


其中,MacAvg_Precision表示准确率的宏平均,MacAvg_Recall表示召回率的宏平均,|C|表示训练集中包含的文本类别数,Pi表示类别Ci的准确率,Ri表示类别Ci的召回率。Among them, MacAvg_Precision represents the macro average of accuracy, MacAvg_Recall represents the macro average of recall, |C| represents the number of text categories contained in the training set, Pi represents the accuracy of category Ci , and Ri represents the recall rate of category Ci .
以化工训练集文本为例,常用信息增益的方法与本统计方法进行比较的实验数据如下:Taking the chemical training set text as an example, the experimental data of the common information gain method compared with this statistical method is as follows:
表1是否使用统计选词差异比较Table 1 Comparison of whether to use statistical word selection

表2化工事故类别测试Table 2 Chemical Accident Category Test

表3非化工事故类别测试Table 3 Non-chemical accident category test
由上表可知,使用统计方法的分类准确率明显高于未使用统计方法的准确率。对于化工事故类别,本统计方法和信息增益特征选择方法选取特征词的个数大小几乎对该类别的分类准确率无影响,而本统计方法准确率更高均可达到98%以上,信息增益特征选择方法处理后略低。对于非化工事故类别,本统计方法和信息增益特征选择方法在特征词个数为300、500、1000时,分类准确率均较高,本统计方法更是均可达到89%以上,而信息增益特征则体现出特征词的影响,虽然均可达到70%以上,但特征词影响较大,特征词个数越多,准确率才越高。It can be seen from the above table that the classification accuracy rate using the statistical method is significantly higher than that without the statistical method. For the category of chemical accidents, the number of feature words selected by this statistical method and the information gain feature selection method has almost no effect on the classification accuracy of this category, while the accuracy of this statistical method can reach more than 98%, and the information gain feature Slightly lower after selection method treatment. For the category of non-chemical accidents, when the number of feature words is 300, 500, and 1000, the statistical method and the information gain feature selection method have a high classification accuracy rate, and the statistical method can reach more than 89%, while the information gain Features reflect the impact of feature words, although they can reach more than 70%, but the impact of feature words is greater, the more the number of feature words, the higher the accuracy rate.
其中查看训练集的文本,可以发现化工事故类别的文本大部分都会涉及“泄露、火灾、爆炸、中毒”等情况的发生,因此化工事故类别的分类准确率较高;而非化工事故类别的文本包含IT、军事、教育、体育、财经等领域的新闻信息,设计领域较为广泛。非化工事故的测试集分类错误的文本大多是消防演练、化工事故总结等,与化工事故的特征及其相似,导致在分类时将其划分到化工事故类别。Looking at the text of the training set, it can be found that most of the texts of the chemical accident category involve the occurrence of "leakage, fire, explosion, poisoning", etc., so the classification accuracy of the chemical accident category is higher; Contains news information in the fields of IT, military, education, sports, finance and other fields, and the design field is relatively extensive. Most of the wrongly classified texts in the test set of non-chemical accidents are fire drills, chemical accident summaries, etc., which have similar characteristics to chemical accidents, leading to the classification of them into the category of chemical accidents.
104)调整步骤:根据步骤103)的测评结果,调整选择的特征项,进行再次测试评估,直到达到最佳效果。其中上述统计表的对比数据为未进行调整特征词的处理结果。调整后的处理结果数据更高。104) Adjustment step: according to the evaluation result in step 103), adjust the selected feature items, and conduct another test and evaluation until the best effect is achieved. The comparative data in the above statistical table is the processing result of the feature words without adjustment. Adjusted treatment results figures are higher.
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员,在不脱离本发明构思的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明保护范围内。The above is only a preferred embodiment of the present invention, it should be pointed out that for those of ordinary skill in the art, without departing from the concept of the present invention, some improvements and modifications can also be made, and these improvements and modifications should also be considered Within the protection scope of the present invention.
Claims (4)


















Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011019598.0ACN112256865B (en) | 2019-01-31 | 2019-01-31 | Chinese text classification method based on classifier |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011019598.0ACN112256865B (en) | 2019-01-31 | 2019-01-31 | Chinese text classification method based on classifier |
| CN201910100095.7ACN109902173B (en) | 2019-01-31 | 2019-01-31 | Chinese text classification method |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201910100095.7ADivisionCN109902173B (en) | 2019-01-31 | 2019-01-31 | Chinese text classification method |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN112256865A CN112256865A (en) | 2021-01-22 |
| CN112256865Btrue CN112256865B (en) | 2023-03-21 |
Family
ID=66944611
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202011019598.0AActiveCN112256865B (en) | 2019-01-31 | 2019-01-31 | Chinese text classification method based on classifier |
| CN201910100095.7AActiveCN109902173B (en) | 2019-01-31 | 2019-01-31 | Chinese text classification method |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201910100095.7AActiveCN109902173B (en) | 2019-01-31 | 2019-01-31 | Chinese text classification method |
Country Status (1)
| Country | Link |
|---|---|
| CN (2) | CN112256865B (en) |
Families Citing this family (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111798853A (en)* | 2020-03-27 | 2020-10-20 | 北京京东尚科信息技术有限公司 | Method, device, equipment and computer readable medium for speech recognition |
| CN112084308A (en)* | 2020-09-16 | 2020-12-15 | 中国信息通信研究院 | Method, system and storage medium for text type data recognition |
| CN112215002A (en)* | 2020-11-02 | 2021-01-12 | 浙江大学 | A classification method of power system text data based on improved Naive Bayes |
| CN112214605B (en)* | 2020-11-05 | 2025-04-11 | 腾讯科技(深圳)有限公司 | A text classification method and related device |
| CN119202260B (en)* | 2024-11-28 | 2025-02-18 | 国网湖北省电力有限公司技术培训中心 | Power audit text classification method based on large language model |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105512311A (en)* | 2015-12-14 | 2016-04-20 | 北京工业大学 | Chi square statistic based self-adaption feature selection method |
| CN108509471A (en)* | 2017-05-19 | 2018-09-07 | 苏州纯青智能科技有限公司 | A kind of Chinese Text Categorization |
| CN109165294A (en)* | 2018-08-21 | 2019-01-08 | 安徽讯飞智能科技有限公司 | Short text classification method based on Bayesian classification |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP4713870B2 (en)* | 2004-10-13 | 2011-06-29 | ヒューレット−パッカード デベロップメント カンパニー エル.ピー. | Document classification apparatus, method, and program |
| US8346534B2 (en)* | 2008-11-06 | 2013-01-01 | University of North Texas System | Method, system and apparatus for automatic keyword extraction |
| CN101819601B (en)* | 2010-05-11 | 2012-02-08 | 同方知网(北京)技术有限公司 | Method for automatically classifying academic documents |
| CN104063399B (en)* | 2013-03-22 | 2017-03-22 | 杭州娄文信息科技有限公司 | Method and system for automatically identifying emotional probability borne by texts |
| CN105183831A (en)* | 2015-08-31 | 2015-12-23 | 上海德唐数据科技有限公司 | Text classification method for different subject topics |
- 2019
- 2019-01-31CNCN202011019598.0Apatent/CN112256865B/enactiveActive
- 2019-01-31CNCN201910100095.7Apatent/CN109902173B/enactiveActive
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105512311A (en)* | 2015-12-14 | 2016-04-20 | 北京工业大学 | Chi square statistic based self-adaption feature selection method |
| CN108509471A (en)* | 2017-05-19 | 2018-09-07 | 苏州纯青智能科技有限公司 | A kind of Chinese Text Categorization |
| CN109165294A (en)* | 2018-08-21 | 2019-01-08 | 安徽讯飞智能科技有限公司 | Short text classification method based on Bayesian classification |
Non-Patent Citations (2)
| Title |
|---|
| "中文文本分类特征选择方法的研究与实现";林艳峰;《中国优秀硕士学位论文全文数据库 信息科技辑》;20160315;第I138-7803页* |
| "基于朴素贝叶斯方法的中文文本分类研究";李丹;《中国优秀硕士学位论文全文数据库 信息科技辑》;20111115;第I138-519页* |
Also Published As
| Publication number | Publication date |
|---|---|
| CN112256865A (en) | 2021-01-22 |
| CN109902173A (en) | 2019-06-18 |
| CN109902173B (en) | 2020-10-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN112256865B (en) | Chinese text classification method based on classifier | |
| CN107609121B (en) | News text classification method based on LDA and word2vec algorithm | |
| CN106649260B (en) | Product characteristic structure tree construction method based on comment text mining | |
| CN104820629B (en) | A kind of intelligent public sentiment accident emergent treatment system and method | |
| CN104391835B (en) | Feature Words system of selection and device in text | |
| CN107992633A (en) | Electronic document automatic classification method and system based on keyword feature | |
| CN103995876A (en) | Text classification method based on chi square statistics and SMO algorithm | |
| WO2014094332A1 (en) | Method for creating knowledge base engine for emergency management of sudden event and method for querying in knowledge base engine | |
| CN108763348B (en) | Classification improvement method for feature vectors of extended short text words | |
| CN106547864B (en) | A Personalized Information Retrieval Method Based on Query Expansion | |
| CN102576358A (en) | Word pair acquisition device, word pair acquisition method, and program | |
| CN105830064A (en) | Situation generating device and computer program therefor | |
| CN111144106B (en) | Two-stage text feature selection method under unbalanced data set | |
| CN108388660A (en) | A kind of improved electric business product pain spot analysis method | |
| CN107463703A (en) | English social media account number classification method based on information gain | |
| CN110543590A (en) | A detection method for microblog emergencies | |
| CN106104524A (en) | Complex predicate template collection device and be used for its computer program | |
| CN105975518A (en) | Information entropy-based expected cross entropy feature selection text classification system and method | |
| CN107577738A (en) | A FMECA Method for Data Processing by SVM Text Mining | |
| CN107526792A (en) | A kind of Chinese question sentence keyword rapid extracting method | |
| CN104915443A (en) | Extraction method of Chinese Microblog evaluation object | |
| CN110990676A (en) | Social media hotspot topic extraction method and system | |
| CN107506472A (en) | A kind of student browses Web page classification method | |
| CN103218368A (en) | Method and device for discovering hot words | |
| CN106503153B (en) | Computer text classification system |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| TR01 | Transfer of patent right | Effective date of registration:20250124 Address after:237000 Yulan Road, Hangbu Economic Development Zone, Shucheng County, Lu'an City, Anhui Province Patentee after:Anhui Kewen CNC Technology Co.,Ltd. Country or region after:China Address before:266061 Songling Road, Laoshan District, Qingdao, Shandong Province, No. 99 Patentee before:QINGDAO University OF SCIENCE AND TECHNOLOGY Country or region before:China | |
| TR01 | Transfer of patent right |