CN112256834B - A content and literature-based marine scientific data recommendation system - Google Patents
A content and literature-based marine scientific data recommendation systemDownload PDFInfo
- Publication number
- CN112256834B CN112256834BCN202011173700.2ACN202011173700ACN112256834BCN 112256834 BCN112256834 BCN 112256834BCN 202011173700 ACN202011173700 ACN 202011173700ACN 112256834 BCN112256834 BCN 112256834B
- Authority
- CN
- China
- Prior art keywords
- data
- marine
- similarity
- recommendation
- module
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images

Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/3331—Query processing
- G06F16/334—Query execution
- G06F16/3344—Query execution using natural language analysis
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/335—Filtering based on additional data, e.g. user or group profiles
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/194—Calculation of difference between files
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Artificial Intelligence (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Audiology, Speech & Language Pathology (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本发明涉及海洋科学观测数据,尤其涉及一种基于内容及文献的海洋科学数据推荐系统。The invention relates to marine scientific observation data, in particular to a marine scientific data recommendation system based on content and documents.
背景技术Background technique
随着海洋科学观测技术的发展,海洋观测数据呈现了海量的增长。用户在寻找数据的过程中,会遭受到大量无关数据的干扰,这个过程会花费用户大量的时间。将数据个性化推荐算法结合到海洋科学数据共享系统,是帮助数据用户更准确、迅速的在网站中获得感兴趣的科学数据的一种高效方法。With the development of marine scientific observation technology, marine observation data has shown a massive growth. In the process of searching for data, users will be interfered by a large amount of irrelevant data, and this process will take users a lot of time. Combining the data personalized recommendation algorithm with the marine scientific data sharing system is an efficient method to help data users obtain the scientific data of interest in the website more accurately and quickly.
目前常用的个性化推荐算法有协同过滤算法和基于内容的推荐算法。协同过滤算法利用具有相同兴趣的用户群体对数据的感兴趣程度进行数据推荐,通过大量用户信息对数据评分,进行用户个性化推荐。该方法存在典型的问题,如缺少信息的新用户获得的推荐质量差,新数据难得到推荐。基于内容的推荐算法是基于数据自身的相关信息计算数据的相似度,解决了推荐算法的冷启动问题。但是该方法只推荐内容相似的数据,不同种类的数据难以获得推荐。相比于传统领域,海洋科学数据更为复杂,常用的推荐算法在海洋科学数据共享领域的应用还有待商榷。海洋科学数据为多维的空间数据,具有复杂的空间属性和时间属性,需要考虑多维信息。而且海洋科学数据面向的用户多为教育、科研用户,且用户对数据的需求更为复杂。此外海洋数据共享网站往往缺少评价打分系统,用户的行为偏好也更难获取,难以获得足够的用户评分。这些使得目前常用的推荐算法无法在海洋科学数据领域得到较好的应用,故需要一种针对海洋科学数据的个性化推荐方法,综合考虑海洋科学数据的三维地理空间信息、时间尺度信息及用户使用需求,提高海洋科学数据推荐的效率,为海洋科学数据共享提供支撑。At present, the commonly used personalized recommendation algorithms include collaborative filtering algorithm and content-based recommendation algorithm. The collaborative filtering algorithm uses the interest degree of the user groups with the same interest in the data to recommend data, and scores the data through a large amount of user information to make user personalized recommendation. There are typical problems with this method, such as the poor quality of recommendations obtained by new users lacking information, and it is difficult to get recommendations for new data. The content-based recommendation algorithm calculates the similarity of the data based on the relevant information of the data itself, which solves the cold start problem of the recommendation algorithm. However, this method only recommends data with similar content, and it is difficult to obtain recommendations for different types of data. Compared with traditional fields, marine scientific data is more complex, and the application of commonly used recommendation algorithms in the field of marine scientific data sharing remains to be discussed. Marine scientific data is multi-dimensional spatial data with complex spatial and temporal attributes, and multi-dimensional information needs to be considered. Moreover, the users of marine scientific data are mostly education and scientific research users, and the users' needs for data are more complex. In addition, marine data sharing websites often lack an evaluation and scoring system, and it is more difficult to obtain users' behavioral preferences, making it difficult to obtain sufficient user scores. These make the currently commonly used recommendation algorithms unable to be well applied in the field of marine scientific data. Therefore, a personalized recommendation method for marine scientific data is required, which comprehensively considers the three-dimensional geospatial information, time scale information and user usage of marine scientific data. requirements, improve the efficiency of marine scientific data recommendation, and provide support for marine scientific data sharing.
发明内容SUMMARY OF THE INVENTION
本发明的目的在于克服在海洋科学数据检索及共享方面存在的技术缺陷,提出了一种基于内容及文献的海洋科学数据推荐系统。The purpose of the present invention is to overcome the technical defects in marine scientific data retrieval and sharing, and propose a marine scientific data recommendation system based on content and documents.
为了实现上述目的,本发明提出了一种基于内容及文献的海洋科学数据推荐系统,数据获取模块、内容相似度计算模块、初始推荐模块、文献定期检索模块、文献读取模块、文献分析模块、最终推荐模块和个性化推荐模块;In order to achieve the above purpose, the present invention proposes a marine scientific data recommendation system based on content and documents, including a data acquisition module, a content similarity calculation module, an initial recommendation module, a periodic document retrieval module, a document reading module, a document analysis module, Final recommendation module and personalized recommendation module;
所述数据获取模块,用于获取多个海洋科学数据集的类别、来源、空间范围和时间范围属性,并分别对每个海洋科学数据集进行标准化处理;The data acquisition module is used to acquire the attributes of category, source, spatial range and time range of a plurality of marine scientific data sets, and to standardize each marine scientific data set respectively;
所述内容相似度计算模块,用于根据类别、来源、空间范围和时间范围属性分别计算海洋科学数据集之间的主题相似度、来源相似度、空间相似度和时间相似度,再通过设置内容相似度模型的参数,根据主题相似度、来源相似度、空间相似度和时间相似度计算得到海洋科学数据集之间的内容相似度;The content similarity calculation module is used to calculate the subject similarity, source similarity, spatial similarity and temporal similarity between marine scientific datasets according to the attributes of category, source, spatial range and time range, and then set the content by setting the content similarity. The parameters of the similarity model are calculated according to the subject similarity, source similarity, spatial similarity and temporal similarity to obtain the content similarity between marine science datasets;
所述初始推荐模块,用于根据海洋科学数据集之间的内容相似度,对海洋科学数据集进行数据推荐,得到多个海洋科学数据集对应的数据推荐列表;The initial recommendation module is used to perform data recommendation on the marine scientific data set according to the content similarity between the marine scientific data sets, and obtain a data recommendation list corresponding to a plurality of marine scientific data sets;
所述文献定期检索模块,用于定期在文献数据库中根据海洋科学数据集的主题进行检索,获取相关文献信息;The document periodic retrieval module is used to periodically retrieve the subject matter of the marine science data set in the document database to obtain relevant document information;
所述文献读取模块,用于根据获取的相关文献信息,统计每个海洋科学数据集具有的相同文献数量;The literature reading module is used to count the same number of literatures in each marine scientific data set according to the obtained relevant literature information;
所述文献分析模块,用于分析多个海洋科学数据集之间的相关文献的同现概率,计算得到海洋科学数据集之间的数据关联度;The literature analysis module is used to analyze the co-occurrence probability of relevant literature among multiple marine scientific data sets, and calculate the data correlation degree between marine scientific data sets;
所述最终推荐模块,用于基于海洋科学数据集之间的数据关联度对数据推荐列表进行重排,得到多个海洋科学数据集对应的数据最终推荐列表;The final recommendation module is used to rearrange the data recommendation list based on the data correlation between the marine scientific data sets, and obtain the final data recommendation list corresponding to the plurality of marine scientific data sets;
所述个性化推荐模块,用于基于用户的信息,结合每个海洋科学数据集对应的数据最终推荐列表,提供推荐结果。The personalized recommendation module is used to provide a recommendation result based on the user's information in combination with a final recommendation list of data corresponding to each marine science dataset.
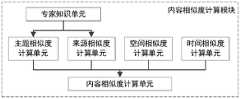
作为上述系统的一种改进,所述内容相似度计算模块包括:专家知识单元、主题相似度计算单元、来源相似度计算单元、空间相似度计算单元、时间相似度计算单元和内容相似度计算单元;其中,As an improvement of the above system, the content similarity calculation module includes: an expert knowledge unit, a topic similarity calculation unit, a source similarity calculation unit, a spatial similarity calculation unit, a temporal similarity calculation unit and a content similarity calculation unit ;in,
所述专家知识单元,用于对提前构建好的海洋数据类别层次树和来源层次树进行管理,并进行层次树各深度的权重值设置;The expert knowledge unit is used to manage the marine data category hierarchy tree and the source hierarchy tree constructed in advance, and to set the weight value of each depth of the hierarchy tree;
所述主题相似度计算单元,用于根据获取的海洋科学数据集的类别和主题类别层次树,计算得到第i个海洋科学数据集Xi和第j个海洋科学数据集Xj之间的主题相似度Simtop(Xi,Xj):The subject similarity calculation unit is used to calculate the subject between the i-th marine scientific data set Xi and the j-th marine scientific data set Xj according to the obtained marine scientific data set category and subject category hierarchy tree Similarity Simtop (Xi ,Xj ):

其中,cn为主题类别层次树的总层数,
所述来源相似度计算单元,用于根据获取的海洋科学数据集的来源和来源层次树,计算得到第i个海洋科学数据集Xi和第j个海洋科学数据集Xj之间的来源相似度Simsou(Xi,Xj):The source similarity calculation unit is used to calculate the source similarity between the i-th marine scientific data set Xi and the j-th marine scientific data set Xj according to the source of the acquired marine scientific data set and the source hierarchy tree Degree Simsou (Xi , Xj ):

其中,sn为来源类别层次树的总层数,
所述空间相似度计算单元,用于按照几何类型对海洋科学数据集进行分类,根据不同几何类型的数据空间相似度计算公式,计算得到第i个海洋科学数据集Xi和第j个海洋科学数据集Xj之间的空间相似度;The spatial similarity calculation unit is used for classifying marine scientific data sets according to geometric types, and calculates the ith marine scientific data set Xi and the jth marine scientific data set according to the data space similarity calculation formulas of different geometric types. Spatial similarity between datasets Xj ;
所述时间相似度计算单元,用于根据获取的海洋科学数据集的时间范围,判断海洋科学数据集的时间尺度是否兼容,对海洋科学数据集的观测时间进行分级,根据数据时间相似度计算公式,计算得到第i个海洋科学数据集Xi和第j个海洋科学数据集Xj之间的时间相似度;The time similarity calculation unit is used to judge whether the time scale of the marine scientific data set is compatible according to the time range of the marine scientific data set obtained, classify the observation time of the marine scientific data set, and calculate the time similarity of the data according to the formula. , calculate the time similarity between the i-th marine scientific data set Xi and the j-th marine scientific data set Xj ;
所述内容相似度计算单元,用于根据专家知识单元设定的权重值,结合主题相似度、来源相似度、空间相似度和时间相似度,计算得到第i个海洋科学数据集Xi和第j个海洋科学数据集Xj之间的内容相似度。The content similarity calculation unit is used to calculate the ith marine scientific data set X i and the ith marine science data set Xi and the Content similarity between j marine science datasets Xj .
作为上述系统的一种改进,所述空间相似度计算单元的具体实现过程为:As an improvement of the above system, the specific implementation process of the spatial similarity calculation unit is:
按照几何类型对海洋科学数据集进行分类,所述几何类型包括:点数据、线数据、面数据和三维体数据;Categorize marine science datasets according to geometry types including: point data, line data, area data, and 3D volume data;
如果两个海洋科学数据集中有一个海洋科学数据集为点数据,根据距离公式计算得到第i个海洋科学数据集Xi和第j个海洋科学数据集Xj之间的距离

其中,
如果两个海洋科学数据集均为线数据或一个海洋科学数据集为线数据并且另一个海洋科学数据集为面数据时,以0.5千米范围计算缓冲区,将线数据转换为面数据,从而得到第i个海洋科学数据集Xi的分布面积


如果两个海洋科学数据集均为面数据时,根据以下公式计算得到空间相似度Simspa(Xi,Xj):If the two marine science datasets are surface data, the spatial similarity Simspa (Xi , Xj ) is calculated according to the following formula:

其中,

如果一个海洋科学数据集为三维体数据并且另一个海洋科学数据集为线数据、面数据或三维体数据时,根据以下公式计算得到空间相似度Simspa(x,y):If one ocean science dataset is 3D volume data and the other ocean science dataset is line data, area data or 3D volume data, the spatial similarity Simspa (x, y) is calculated according to the following formula:

其中,

如果一个海洋科学数据集为点数据,另一个海洋科学数据集为线数据、面数据或三维体数据时,空间相似度Simspa(Xi,Xj)=0;If one marine scientific data set is point data and the other marine scientific data set is line data, area data or three-dimensional volume data, the spatial similarity Simspa (Xi , Xj )=0;
如果一个海洋科学数据集为线数据,另一个海洋科学数据集为面数据或三维体数据时,空间相似度Simspa(Xi,Xj)=0;If one marine scientific data set is line data, and the other marine scientific data set is surface data or three-dimensional volume data, the spatial similarity Simspa (Xi , Xj )=0;
如果一个海洋科学数据集为面数据,另一个海洋科学数据集为三维体数据时,空间相似度Simspa(Xi,Xj)=0。If one marine scientific data set is surface data and the other marine scientific data set is three-dimensional volume data, the spatial similarity Simspa (Xi , Xj )=0.
作为上述系统的一种改进,所述时间相似度计算单元的具体实现过程为:As an improvement of the above system, the specific implementation process of the time similarity calculation unit is:
如果两个海洋科学数据集的时间尺度不相同,判断时间尺度是否兼容,如果时间尺度不能兼容,则相似度为0;If the time scales of the two marine science datasets are different, judge whether the time scales are compatible; if the time scales are not compatible, the similarity is 0;
如果时间尺度兼容,则对每个海洋科学数据集的观测时间进行分级,其中秒对应级别为1,分对应级别为2,小时对应级别为3,日对应级别为4,旬对应级别为5,月对应级别为6,年对应级别为7;If the time scales are compatible, the observation time of each marine science dataset is graded, where seconds correspond to level 1, minutes correspond to level 2, hours correspond to level 3, days correspond to level 4, ten days correspond to level 5, The month corresponds to level 6, and the year corresponds to level 7;
根据以下公式计算得到第i个海洋科学数据集Xi和第j个海洋科学数据集Xj之间的时间相似度SimTim(Xi,Xj):The temporal similarity SimTim (Xi , Xj ) between the i-th marine scientific data set Xi and the j-th marine scientific data set Xj is calculated according to the following formula:

其中,



作为上述系统的一种改进,所述内容相似度计算单元的具体实现过程为:As an improvement of the above system, the specific implementation process of the content similarity calculation unit is as follows:
根据下式计算得到第i个海洋科学数据集Xi和第j个海洋科学数据集Xj之间的内容相似度Sim(Xi,Xj):The content similarity Sim(Xi , Xj ) between the i-th marine scientific data set Xi and the j-th marine scientific data set Xj is calculated according to the following formula:
Sim(Xi,Xj)=W1Simtop(Xi,Xj)+W2Simsou(Xi,Xj)+W3Simspa(Xi,Xj)+W4Simtim(Xi,Xj)Sim(Xi , Xj )=W1 Simtop (Xi , Xj )+W2 Simsou (Xi , Xj )+W3 Simspa (Xi , Xj )+W4 Simtim ( Xi , Xj )
其中,W1为专家知识单元对主题相似度Simtop(Xi,Xj)设置的权重值,W2为专家知识单元对来源相似度Simsou(Xi,Xj)设置的权重值,W3为专家知识单元对空间相似度Simspa(Xi,Xj)设置的权重值,W4为专家知识单元对时间相似度Simtim(Xi,Xj)设置的权重值。Among them, W1 is the weight value set by the expert knowledge unit to the topic similarity Simtop (Xi , Xj ), W2 is the weight value set by the expert knowledge unit to the source similarity Simsou (Xi , Xj ), W3 is the weight value set by the expert knowledge unit to the spatial similarity Simspa (Xi , Xj ), and W4 is the weight value set by the expert knowledge unit to the temporal similarity Simtim (Xi , Xj ).
作为上述系统的一种改进,所述初始推荐模块的具体实现过程为:As an improvement of the above system, the specific implementation process of the initial recommendation module is:
将第i个海洋科学数据集Xi与其他每一个海洋科学数据集的内容相似度组成内容相似度矩阵L1:The content similarity between the i-th marine science dataset Xi and every other marine science dataset is formed into a content similarity matrix L1:

对内容相似度矩阵L1的每一行按照内容相似度的数值从高到低进行排序,分别得到第i个海洋科学数据集Xi对应的数据推荐列表R1(Xi)。Sort each row of the content similarity matrix L1 according to the value of the content similarity from high to low, and obtain the data recommendation list R1 (Xi ) corresponding to the i-th marine scientific data set Xi respectively.
作为上述系统的一种改进,所述文献分析模块的具体实现过程为:As an improvement of the above system, the specific implementation process of the document analysis module is:
根据下式计算得到第i个海洋科学数据集Xi和第j个海洋科学数据集Xj之间的数据关联度Ass(Xi,Xj):The data association degree Ass(Xi , Xj ) between the i-th marine scientific data set Xi and the j-th marine scientific data set Xj is calculated according to the following formula:

其中,


将Xi与其他每一个海洋科学数据集的数据关联度组成数据关联度矩阵L2:The data correlation degree ofXi and each other marine science data set is composed of the data correlation degree matrix L2:

作为上述系统的一种改进,所述最终推荐模块的具体实现过程为:As an improvement of the above system, the specific implementation process of the final recommendation module is as follows:
综合考虑数据的内容相似度矩阵L1和数据关联度矩阵L2的贡献度,设置权重,构建数据推荐模型,得到推荐矩阵L:Considering the contribution of the data content similarity matrix L1 and the data correlation matrix L2 comprehensively, set the weights, build the data recommendation model, and obtain the recommendation matrix L:

其中,Ws为内容相似度矩阵L1的权重,Wa为数据关联度矩阵L2的权重;P(Xi,Xj)为最终推荐值:Among them, Ws is the weight of the content similarity matrix L1, Wa is the weight of the data relevance matrix L2; P(Xi , Xj ) is the final recommended value:
P(Xi,Xj)=WsSim(Xi,Xj)+WaAss(Xi,Xj);P(Xi , Xj )=Ws Sim(Xi , Xj )+Wa Ass(Xi , Xj );
对推荐矩阵L的每一行按照最终推荐值的数值从高到低进行排序,对数据推荐列表R1(Xi)进行重排,分别得到第i个海洋科学数据集Xi对应的最终数据推荐列表R2(Xi)。Sort each row of the recommendation matrix L according to the value of the final recommendation value from high to low, rearrange the data recommendation list R1(Xi ), and obtain the final data recommendation list corresponding to the i-th marine science data set Xi respectively. R2(Xi ).
与现有技术相比,本发明的优势在于:Compared with the prior art, the advantages of the present invention are:
1、本发明构建了基于数据内容相似度和数据关联度的海洋科学数据推荐模型,该发明计算海洋科学数据四个方面的属性相似度,包括主题内容相似度、数据来源相似度、空间相似度、时间相似度,通过对四个方面的数据属性分析,对海洋科学数据的内容相似性的计算更加精确,提高对海洋科学数据的推荐质量;1. The present invention builds a marine scientific data recommendation model based on data content similarity and data correlation, and the invention calculates the attribute similarity in four aspects of marine scientific data, including subject content similarity, data source similarity, and spatial similarity. , time similarity, through the analysis of data attributes in four aspects, the calculation of the content similarity of marine scientific data is more accurate, and the recommendation quality of marine scientific data is improved;
2、本发明利用文献检索网站,以科学数据为主题检索相关文章的发表情况,统计分析海洋科学数据共同使用的情况,以此作为数据关联度计算的依据,通过该操作,满足海洋交叉学科用户对数据的需求,提高推荐数据的多样性;2. The present invention uses the literature retrieval website to retrieve the publications of relevant articles on the subject of scientific data, and statistically analyzes the common use of marine scientific data, which is used as the basis for the calculation of data correlation. The demand for data increases the diversity of recommended data;
3、本发明解决了推荐系统常有的冷启动问题和推荐单一性的问题,极大提高了推荐数据的有效性。3. The present invention solves the common cold start problem and the single recommendation problem of the recommendation system, and greatly improves the validity of the recommendation data.
附图说明Description of drawings
图1是本发明实施例1的基于内容及文献的海洋科学数据推荐系统组成图;1 is a composition diagram of a marine scientific data recommendation system based on content and documents according to Embodiment 1 of the present invention;
图2是本发明实施例1的内容相似度计算模块组成图。FIG. 2 is a composition diagram of a content similarity calculation module according to Embodiment 1 of the present invention.
具体实施方式Detailed ways
本发明针对海洋科学数据量大、类型杂、高维属性等特点,构建一套服务于海洋科学数据的推荐方法及系统。通过融合海洋科学数据的类别、来源、时间和空间属性,获得数据内容的相似度,从而得到推荐序列,然后通过统计分析数据相关文献发表情况,分析不同海洋科学数据的交叉应用情况,得到数据之间的关联性,对推荐序列进行重排得到优化推荐序列。该发明从多方面考虑数据的内容,保证数据推荐的正确性,并通过数据的交叉应用分析,提高数据推荐多样性。Aiming at the characteristics of large amount of marine scientific data, various types, high-dimensional attributes, and the like, the present invention constructs a set of recommendation methods and systems serving marine scientific data. By fusing the category, source, time and space attributes of marine scientific data, the similarity of data content is obtained, so as to obtain the recommended sequence, and then through statistical analysis of the publication of relevant literature data, the cross-application of different marine scientific data is analyzed, and the data is obtained. The correlation between the recommended sequences is rearranged to obtain optimized recommended sequences. The invention considers the content of the data from various aspects, ensures the correctness of the data recommendation, and improves the diversity of the data recommendation through the cross-application analysis of the data.
本发明基于海洋科学数据属性数据和检索的文献数据实现海洋科学数据个性化推荐方法及系统。首先通过分析海洋科学数据的属性信息计算数据的相似度,包括主题内容相似度、空间信息相似度和时间信息相似度,得到数据推荐列表。然后,通过检索网站,检索每类海洋科学数据的相关文献,对比分析每类海洋科学数据的文献重叠度,分析不同海洋科学数据的关联度。最后,融合相似度和数据关联度,得到数据的推荐序列。The invention realizes the method and system for personalized recommendation of marine scientific data based on the attribute data of marine scientific data and the retrieved document data. Firstly, the similarity of the data is calculated by analyzing the attribute information of the marine scientific data, including the similarity of the subject content, the similarity of the spatial information and the similarity of the time information, and the data recommendation list is obtained. Then, by retrieving websites, relevant documents of each type of marine scientific data were retrieved, and the degree of overlapping of documents of each type of marine scientific data was compared and analyzed, and the correlation degree of different marine scientific data was analyzed. Finally, the similarity and data correlation are fused to obtain the recommended sequence of data.
1、内容相似度1. Content similarity
本发明从四个方面来定义海洋科学数据之间的相似性,即主题内容相似度、数据来源相似度、空间相似度、时间相似度。数据的总体相似度将通过上述四个方面的相似度加权求和获得,并设置权重值。计算方法如下:The invention defines the similarity between marine scientific data from four aspects, ie, the similarity of subject content, the similarity of data sources, the similarity of space and the similarity of time. The overall similarity of the data will be obtained through the weighted summation of the above four aspects, and the weight value will be set. The calculation method is as follows:
Sim(Xi,Xj)=W1Simtop(Xi,Xj)+W2Simsou(Xi,Xj)+W3Simspa(Xi,Xj)+W4Simtim(Xi,Xj)其中,W1为主题相似度Simtop(Xi,Xj)的权重值,W2为来源相似度Simsou(Xi,Xj)的权重值,W3为空间相似度Simspa(Xi,Xj)的权重值,W4为时间相似度Simtim(Xi,Xj)的权重值。Sim(Xi , Xj )=W1 Simtop (Xi , Xj )+W2 Simsou (Xi , Xj )+W3 Simspa (Xi , Xj )+W4 Simtim ( Xi , Xj ) where W1 is the weight value of the topic similarity Simtop (Xi , Xj ), W2 is the weight value of the source similarity Simsou (Xi , Xj ), and W3 is the space The weight value of the similarity Simspa (Xi , Xj ), and W4 is the weight value of the time similarity Simtim (Xi , Xj ).
其中,Xi和Xj为两个数据集,Simtop(x,y)为两个数据的主题相似度,Simsou(x,y)为来源相似度,Simspa(x,y)为空间相似度,Simtim(x,y)为时间相似度。Among them, Xi and Xj are two datasets, Simtop (x, y) is the topic similarity of the two data, Simsou (x, y) is the source similarity, Simspa (x, y) is the space Similarity, Simtim (x, y) is the temporal similarity.
1)主题相似度1) Topic similarity
主题内容相似度指的是数据归属类别的相似度。通常来说,海洋科学中相对独立的四个基础分支学科:海洋物理学、海洋化学、海洋地质学和海洋生物学。四个学科下有不同的研究主题,如海洋气象学、海洋声学、海洋电磁学、海洋光学等,不同的研究主题包含不同的观测要素。根据数据的分类,构建类别层次树,计算公式如下:The similarity of the subject content refers to the similarity of the category of the data to which it belongs. Generally speaking, there are four relatively independent basic sub-disciplines in marine science: marine physics, marine chemistry, marine geology and marine biology. There are different research themes under the four disciplines, such as marine meteorology, marine acoustics, marine electromagnetism, marine optics, etc. Different research themes contain different observation elements. According to the classification of the data, a category hierarchy tree is constructed, and the calculation formula is as follows:

其中,cn为数据主题类别层次树总层数,
来源相似度source similarity
随着海洋技术的发展,海洋观测手段越来越多,不同观测手段获取的数据各有不同,因此数据来源相似度也至关重要。数据来源的分类包括不同的观测手段和不同的观测设备。从大的方面,观测手段分为天基、岸基、空基、海基、船基和海底基,每种观测手段包含的观测设备各不相同,如天基主要是指不同的海洋卫星,海基和海底基则包括CTD、ADCP等不同的原位观测仪器,且大多包含多个仪器。和主题内容相似度的计算方式类似,构建数据来源层次树,计算公式如下:With the development of marine technology, there are more and more ocean observation methods, and the data obtained by different observation methods are different, so the similarity of data sources is also very important. The classification of data sources includes different observational means and different observational equipment. From a large perspective, observation methods are divided into space-based, shore-based, space-based, sea-based, ship-based and submarine-based. Each observation method contains different observation equipment. For example, space-based mainly refers to different ocean satellites. Sea-based and submarine-based include different in-situ observation instruments such as CTD and ADCP, and most of them include multiple instruments. Similar to the calculation method of topic content similarity, the data source hierarchy tree is constructed, and the calculation formula is as follows:

其中,sn为数据来源类别层次树总层数,
2)空间相似度2) Spatial similarity
海洋科学数据最为显著的特征就是其三维空间属性。海洋数据空间范围分为水平面和垂直面。空间范围相似度最直接的方法是计算两个数据的空间尺度的兼容性以及空间范围重合度。按照几何类型来分,数据可分为点数据、线数据、面数据及三维体数据三种。The most notable feature of marine scientific data is its three-dimensional spatial properties. The spatial extent of ocean data is divided into horizontal plane and vertical plane. The most direct method of spatial scale similarity is to calculate the spatial scale compatibility and spatial scale coincidence of the two data. According to the type of geometry, the data can be divided into three types: point data, line data, surface data and 3D volume data.
a)对于相同几何类型的数据,则直接判断两个数据的距离或覆盖度。a) For data of the same geometry type, the distance or coverage of the two data is directly judged.
根据需求,设置数据的有效距离D,即如果两个点数据距离超过D千米,则两个数据的空间相似度为0。相似度计算公式如下:According to the requirements, set the effective distance D of the data, that is, if the distance between the two point data exceeds D kilometers, the spatial similarity of the two data is 0. The similarity calculation formula is as follows:

其中,Dxy为点数据集Xi和Xj的距离,单位为千米。Among them, Dxy is the distance between the point datasets Xi and Xj , in kilometers.
线数据则以0.5千米范围计算缓冲区,将线数据转化成面数据。和面数据一样,计算两个面的重叠度。For line data, the buffer is calculated with a range of 0.5 kilometers, and the line data is converted into area data. As with the polygon data, the degree of overlap between the two polygons is calculated.

其中,

三维体数据则需要计算两个数据的重叠体积。For 3D volume data, the overlapping volume of the two data needs to be calculated.

其中,

b)对于不同几何类型的数据,则直接以0.5千米范围计算数据的缓冲区,计算两个数据的重叠度。但是点和线数据、线和面数据,由于类型不同、尺度不同,相似度都是单向的,如对线数据来说,点数据的相似度为0。对于点数据来说,线数据的相似度则按照点到线的距离计算。数据重叠度计算式,缓冲区统一按照0.5千米计算。b) For data of different geometric types, the data buffer is directly calculated in the range of 0.5 kilometers, and the overlap degree of the two data is calculated. But point and line data, line and area data, due to different types and scales, the similarity is one-way. For example, for line data, the similarity of point data is 0. For point data, the similarity of line data is calculated according to the distance from the point to the line. The data overlap calculation formula, the buffer area is uniformly calculated according to 0.5 kilometers.
综上所述,数据的空间相似度具体计算方法如下表所示。In summary, the specific calculation method of the spatial similarity of the data is shown in the following table.
表1数据空间相似度计算公式Table 1 Data space similarity calculation formula

3)时间相似度3) Time similarity
从两个维度考虑数据的时间相似度,首先需要判断时间尺度,观测数据集一般包括秒、分、小时、日、旬、月、年尺度,分别对应1到7个级别。如果时间尺度不相同,确定时间尺度是否兼容。如果时间尺度不能兼容,则相似度为0;如果时间尺度兼容,则按照时间打分制度,并分析时间重叠度进行时间尺度相似度计算。Considering the temporal similarity of data from two dimensions, it is first necessary to judge the time scale. The observation data set generally includes seconds, minutes, hours, days, ten days, months, and years, corresponding to 1 to 7 levels respectively. If the timescales are not the same, determine if the timescales are compatible. If the time scales are not compatible, the similarity is 0; if the time scales are compatible, the time scale similarity is calculated according to the time scoring system and the time overlap is analyzed.

其中,

2、初始推荐2. Initial recommendation
将第i个海洋科学数据集Xi(i=1,2,...,n)与其他每一个海洋科学数据集的内容相似度组成内容相似度矩阵L1:The content similarity between the i-th marine science data set Xi (i=1, 2,...,n) and each other marine science data set is formed into a content similarity matrix L1:

对内容相似度矩阵L1的每一行按照内容相似度的数值从高到低进行排序,分别得到第i个海洋科学数据集Xi(i=1,2,...,n)对应的数据推荐列表R1(Xi)。Sort each row of the content similarity matrix L1 according to the value of the content similarity from high to low, and obtain the data recommendation corresponding to the i-th marine science data set Xi (i=1, 2, ..., n) respectively List R1(Xi ).
3、数据关联度3. Data Relevance
由于很多科研数据共享网站平台未提供评分系统,且大多数据共享网站的数据并不能直接下载。因此本研究通过研究科研用户发表的论文中对数据的使用情况,分析海洋科学数据之间的关联度。基于权威文献数据库,对海洋科学数据的使用情况进行统计和分析,全面反映海洋科学数据在国内外的使用情况。检索策略为:主题=“数据x”,研究领域设定为海洋学。通过分析搜集的文献,然后统计检索的文献数量。分析不同数据同时出现在同一文献的概率,以此来表示数据之间的关联。利用同现相似度来计算数据之间的关联,具体计算公式如下:Because many scientific research data sharing website platforms do not provide a scoring system, and most data sharing websites cannot directly download the data. Therefore, this study analyzes the correlation between marine science data by studying the use of data in papers published by scientific research users. Based on the authoritative literature database, statistics and analysis are carried out on the use of marine scientific data, which comprehensively reflects the use of marine scientific data at home and abroad. The retrieval strategy is: subject="data x", and the research field is set to oceanography. By analyzing the collected literature, and then counting the number of retrieved literature. Analyze the probability of different data appearing in the same document at the same time, in order to represent the relationship between the data. The co-occurrence similarity is used to calculate the correlation between data, and the specific calculation formula is as follows:

其中,


将Xi,(i=1,2,...,n)与其他每一个海洋科学数据集的数据关联度组成数据关联度矩阵L2:The Xi , (i=1, 2, .

4、最终推荐模型4. The final recommendation model
综合考虑数据的内容相似度矩阵L1和数据关联度矩阵L2的贡献度,设置权重,构建数据推荐模型,得到推荐矩阵L:Considering the contribution of the data content similarity matrix L1 and the data correlation matrix L2 comprehensively, set the weights, build the data recommendation model, and obtain the recommendation matrix L:

其中,Ws为内容相似度矩阵L1的权重,Wa为数据关联度矩阵L2的权重;P(Xi,Xj)为最终推荐值:Among them, Ws is the weight of the content similarity matrix L1, Wa is the weight of the data relevance matrix L2; P(Xi , Xj ) is the final recommended value:
P(Xi,Xj)=WsSim(Xi,Xj)+WaAss(Xi,Xj);P(Xi , Xj )=Ws Sim(Xi , Xj )+Wa Ass(Xi , Xj );
对推荐矩阵L的每一行按照最终推荐值的数值从高到低进行排序,分别得到第i个海洋科学数据集Xi,(i=1,2,...,n)对应的最终数据推荐列表R2(Xi)下面结合附图和实施例对本发明的技术方案进行详细的说明。Sort each row of the recommendation matrix L according to the value of the final recommendation value from high to low, and obtain the final data recommendation corresponding to the i-th marine science data set Xi , (i=1, 2,...,n) respectively List R2(Xi ) The technical solutions of the present invention will be described in detail below with reference to the accompanying drawings and embodiments.
实施例1Example 1
如图1所示,本发明的实施例1提出了一种基于内容及文献的海洋科学数据推荐系统,该推荐系统包括数据获取模块、内容相似度计算模块、初始推荐模块、文献定期检索模块、文献读取模块、文献分析模块、最终推荐模块和个性化推荐模块;As shown in FIG. 1 , Embodiment 1 of the present invention proposes a marine scientific data recommendation system based on content and documents. The recommendation system includes a data acquisition module, a content similarity calculation module, an initial recommendation module, a periodic document retrieval module, Literature reading module, literature analysis module, final recommendation module and personalized recommendation module;
其中内容相似度计算模块如图2所示,包括主题相似度计算单元、来源相似度计算单元、空间相似度计算单元、时间相似度计算单元和内容相似度计算单元五部分。The content similarity calculation module is shown in Figure 2, including five parts: topic similarity calculation unit, source similarity calculation unit, spatial similarity calculation unit, temporal similarity calculation unit and content similarity calculation unit.
专家知识单元,用于构建和管理海洋数据类别层次树、来源层次树,并进行层次树各深度的权重值设置。The expert knowledge unit is used to construct and manage the marine data category hierarchy tree and source hierarchy tree, and set the weight value of each depth of the hierarchy tree.
数据获取模块,用于获取数据集的类别、来源、时间范围和空间范围属性,并进行数据的标准化处理。The data acquisition module is used to acquire the category, source, time range and spatial range properties of the dataset, and to standardize the data.
主题相似度计算单元,用于根据获取的数据集的类别和类别层次树,计算出数据集间的主题相似度。The topic similarity calculation unit is used to calculate the topic similarity between the datasets according to the category and category hierarchy tree of the acquired dataset.
来源相似度计算单元,用于根据获取的数据集的来源和来源层次树,计算出数据集之间的来源相似度。The source similarity calculation unit is used to calculate the source similarity between the datasets according to the source of the acquired dataset and the source hierarchy tree.
空间相似度计算单元,用于根据获取的数据集的空间范围,判断数据的空间类型(点、线、面或三维),根据不同类型的数据空间相似度计算公式,计算出数据集之间的空间相似度。The spatial similarity calculation unit is used to judge the spatial type (point, line, surface or three-dimensional) of the data according to the spatial range of the obtained data set, and calculate the spatial similarity between the data sets according to the calculation formula of the spatial similarity of different types of data. spatial similarity.
时间相似度计算单元,用于根据获取的数据集的时间范围,判断数据集时间范围的覆盖范围,根据数据时间相似度计算公式,计算数据集之间的时间相似度。The time similarity calculation unit is used to determine the coverage of the time range of the data set according to the time range of the obtained data set, and calculate the time similarity between the data sets according to the calculation formula of the data time similarity.
内容相似度计算单元,用于内容相似度模型的参数设置,并根据计算的主题、来源、空间和时间相似度计算数据集之间的内容相似度计算。The content similarity calculation unit is used for parameter setting of the content similarity model, and calculates the content similarity calculation between the datasets according to the calculated subject, source, space and time similarity.
初始推荐模块,用于根据数据集之间的内容相似度对每一海洋科学数据集进行数据推荐。The initial recommendation module is used to recommend data for each marine science dataset according to the content similarity between datasets.
文献定期检索模块,用于定期进行权威文献数据库中数据集相关发表文献检索,获取相关文献信息。The regular literature retrieval module is used to regularly search the published literature related to the dataset in the authoritative literature database to obtain relevant literature information.
文献读取模块,用于获取文献定期检索结果。The literature reading module is used to obtain regular retrieval results of literature.
文献分析模块,用于分析两个数据集的相关文献的同现概率,从而获得数据关联度。The literature analysis module is used to analyze the co-occurrence probability of the related literatures of the two data sets, so as to obtain the data correlation degree.
最终推荐模块,用于基于数据关联度进行初始推荐结果的重排,从而获得数据最终推荐列表。The final recommendation module is used to rearrange the initial recommendation results based on the data relevance, so as to obtain the final recommendation list of data.
个性化推荐模块,用于基于用户的信息,提供合适的推荐结果。The personalized recommendation module is used to provide appropriate recommendation results based on user information.
举例说明for example
以20个模拟数据集为测试数据(D1-D20),分别对20个数据集进行推荐,得到推荐列表。Taking 20 simulated datasets as test data (D1 -D20 ), recommend the 20 datasets respectively to obtain a recommendation list.
步骤1:读取20个模拟数据的属性信息,包括海洋科学数据的类别、来源、数据类型、空间范围、时间范围等。Step 1: Read the attribute information of 20 simulated data, including the category, source, data type, spatial range, time range, etc. of marine scientific data.
步骤2:计算20个数据集两两之间的主题相似度Simtop(Di,Dj)。Step 2: Calculate the topic similarity Simtop (Di , Dj ) between the 20 datasets.
步骤2.1根据海洋数据的分类,构建类别层次树,分为分支、主题、元素、数据集4级,按照类别层次深度给每一层进行赋值,前3个级别的参数分别为1、2、3。Step 2.1 According to the classification of marine data, build a category hierarchy tree, which is divided into four levels: branch, theme, element, and data set. Assign values to each layer according to the depth of the category hierarchy. The parameters of the first three levels are 1, 2, and 3 respectively. .
步骤2.2依据类别层次数和海洋科学数据的类别,确定海洋科学数据的类别值。In step 2.2, the category value of marine scientific data is determined according to the number of category layers and the category of marine scientific data.
步骤2.3根据主题相似度计算公式,分别计算20个数据集两两之间的主题相似度矩阵Simtop(Di,Dj)。Step 2.3 According to the topic similarity calculation formula, the topic similarity matrix Simtop (Di , Dj ) between the 20 datasets is calculated respectively.
步骤3:计算20个数据集两两之间的来源相似度Simsou(Di,Dj)。Step 3: Calculate the source similarity Simsou (Di , Dj ) between the 20 datasets.
步骤3.1根据海洋数据的来源分类,构建数据来源层次树,分为观测系统、观测手段、观测设备、具体观测设备、数据集5级。按照层次深度给每一层进行赋值,前4个级别的参数分别为1、2、3和4。Step 3.1 According to the source classification of ocean data, build a data source hierarchy tree, which is divided into five levels: observation system, observation method, observation equipment, specific observation equipment, and data set. Assign values to each layer according to the depth of the layer, and the parameters of the first 4 levels are 1, 2, 3 and 4 respectively.
步骤3.2依据来源层次树和海洋科学数据的来源,确定海洋科学数据的来源赋值。Step 3.2 determines the source assignment of marine scientific data according to the source hierarchy tree and the source of marine scientific data.
步骤3.3根据来源相似度计算公式分别计算20个数据集两两之间的来源相似度矩阵Simsou(Di,Dj)。Step 3.3: Calculate the source similarity matrix Simsou (Di , Dj ) between the 20 data sets, respectively, according to the source similarity calculation formula.
步骤4:计算20个数据集两两之间的空间相似度Simspa(Di,Dj)。Step 4: Calculate the spatial similarity Simspa (Di , Dj ) between the 20 datasets.
步骤4.1读取海洋科学数据Di和Dj的数据类型。Step 4.1 Read the data types of marine science data Di and Dj .
步骤4.2如果数据类型一致,如果是点数据,则计算Di和Dj的距离;如果是线数据,则生成Di和Dj的缓冲区,然后计算两个缓冲区的重叠度;如果是面数据,则计算两个数据的重叠度;如果是三维体数据,则计算两个数据的体积重叠度。距离或重叠度即代表两个数据的相似度。Step 4.2 If the data types are the same, if it is point data, calculate the distance between Di and Dj ; if it is line data, generate buffers of Di and Dj , and then calculate the degree of overlap between the two buffers; if it is For surface data, calculate the overlap of the two data; if it is 3D volume data, calculate the volume overlap of the two data. Distance or overlap represents the similarity of two data.
步骤4.3如果数据类型不一致,首先判断Di和Dj的类型兼容度,如果Dj的数据类型不可兼容Di的数据类型,则数据空间相似度为0。如果可兼容,则按照表1的公式进行计算相似度。Step 4.3 If the data types are inconsistent, first determine the type compatibility of Di and Dj . If the data type of Dj is not compatible with the data type of Di , the data space similarity is 0. If it is compatible, calculate the similarity according to the formula in Table 1.
步骤4.4得到20个数据集两两之间的空间相似度矩阵Simspa(Di,Dj)。Step 4.4 obtains the spatial similarity matrix Simspa (Di , Dj ) between the 20 datasets.
步骤5:计算20个数据集两两之间的时间相似度SimTim(Di,Dj)。Step 5: Calculate the temporal similarity SimTim (Di , Dj ) between the 20 datasets.
步骤5.1确定海洋科学数据x的时间范围,确定是尺度级别。读取其他所有数据y的时间范围及尺度级别。Step 5.1 Determine the time range of marine scientific data x, and determine the scale level. Read the time range and scale level of all other data y.
步骤5.2如果数据时间尺度一致,则按照时间范围重叠度进行时间尺度相似度计算。Step 5.2 If the data time scales are consistent, calculate the time scale similarity according to the overlapping degree of the time range.
步骤5.3如果数据时间尺度不一致,判断时间尺度兼容度。如果Di的时间尺度级别小于Dj的时间尺度级别,则相似度为0。如果可以兼容,则按照时间尺度的差别和时间范围的重叠度计算数据的时间相似度。Step 5.3 If the data time scales are inconsistent, judge the time scale compatibility. If the time scale level of Di is smaller than that of Dj , the similarity is 0. If it is compatible, the temporal similarity of the data is calculated according to the difference of time scales and the overlap of time ranges.
步骤5.4得到20个数据集两两之间的内容相似度矩阵Sim(Di,Dj)。Step 5.4 obtains the content similarity matrix Sim(Di , Dj ) between the 20 data sets.
步骤6:按照相似度加权求和方法,将计算方法中W1、W2、W3和W4分别设置为0.2、0.2、0.3和0.3,将主题相似度矩阵、来源相似度矩阵、空间相似度矩阵和时间相似度矩阵加权求和,得到20个数据集两两之间的内容相似度矩阵Sim(Di,Dj)。Step 6: According to the similarity weighted summation method, set W1 , W2 , W3 and W4 in the calculation method to 0.2, 0.2, 0.3 and 0.3 respectively, and set the subject similarity matrix, source similarity matrix and spatial similarity The weighted summation of the degree matrix and the time similarity matrix is used to obtain the content similarity matrix Sim(Di , Dj ) between the 20 data sets.
步骤7:根据数据的内容相似度矩阵,对矩阵每一行按照从高到低排序,得到20个数据的数据推荐列表R1(Di)。Step 7: According to the content similarity matrix of the data, sort each row of the matrix from high to low to obtain a data recommendation list R1(Di ) of 20 data.
步骤8:计算20个数据集两两之间的关联度Ass(Di,Dj)。Step 8: Calculate the association degree Ass(Di , Dj ) between the 20 data sets.
步骤8.1:分析20个数据集属于的观测要素类,例如温度、盐度、地形等不同要素,20个数据集分属10个不同的观测要素。Step 8.1: Analyze the observation element classes that the 20 datasets belong to, such as different elements such as temperature, salinity, and terrain, and the 20 datasets belong to 10 different observation elements.
步骤8.2:通过检索网站,检索主题=“观测要素”的发表文献,研究领域设定为海洋学,获得数据某观测要素相关文献。此后,可定期进行文献检索,按照周或月的频率进行,及时获取更新文献的相关信息。Step 8.2: By searching the website, search the published literature with the subject=“observation element”, set the research field to oceanography, and obtain the data related to a certain observation element. After that, literature searches can be carried out on a regular basis, on a weekly or monthly basis, to obtain relevant information on updated literature in a timely manner.
步骤8.3:读取两个数据集所属要素的文献发表情况,统计分析各相同文献的数量。Step 8.3: Read the publications of the elements to which the two datasets belong, and statistically analyze the number of identical documents.
步骤8.4:利用同现相似度计算数据之间的关联,得到观测要素关联度矩阵,进一步得到20个数据集的关联度矩阵Ass(Di,Dj)。Step 8.4: Calculate the correlation between the data by using the co-occurrence similarity to obtain the correlation matrix of the observed elements, and further obtain the correlation matrix Ass(Di , Dj ) of the 20 data sets.
步骤9:设置内容相似度和关联度的权重分别为0.6和0.4,融合20个数据集的内容相似度矩阵和关联度矩阵,获得数据推荐度矩阵P(Di,Dj)。Step 9: Set the weights of content similarity and relevance to 0.6 and 0.4 respectively, and fuse the content similarity matrix and relevance matrix of 20 data sets to obtain a data recommendation matrix P(Di , Dj ).
步骤11:按照数据推荐度矩阵P(Di,Dj),对矩阵每一行按照从高到低排序,得到20个数据的数据推荐列表R2(Di)。Step 11: According to the data recommendation degree matrix P(Di , Dj ), sort each row of the matrix from high to low to obtain a data recommendation list R2(Di ) of 20 data.
步骤12:新用户在初次使用系统时,向用户推荐系统中的热门数据,然后根据用户选择的数据或用户搜索的数据,按照推荐列表推荐。老用户登陆后,获取用户的历史数据,首先按照用户最近访问的数据进行推荐,然后根据用户选择的数据或用户搜索的数据。Step 12: When a new user uses the system for the first time, it recommends popular data in the system to the user, and then recommends it according to the recommendation list according to the data selected by the user or the data searched by the user. After the old user logs in, the historical data of the user is obtained, and the recommendation is first based on the data recently accessed by the user, and then based on the data selected by the user or the data searched by the user.
其中,步骤1至步骤11是在初次构建系统时,系统对数据的处理。此后,系统定期进行步骤8至步骤11,从而定期更新数据推荐列表R2,保证推荐列表的正确性。Among them, steps 1 to 11 are the processing of data by the system when the system is initially constructed. After that, the system regularly performs steps 8 to 11, thereby regularly updating the data recommendation list R2 to ensure the correctness of the recommendation list.
本发明基于数据内容的相似度和数据之间的关联度提出了针对海洋科学数据的个性化推荐方法,该方法不仅考虑了海洋科学数据的时空特性,而且考虑了交叉学科数据的实际利用情况。一方面,本发明在计算数据相似度时,充分考虑到了海洋科学数据特有的时空属性,通过加入了空间相似度、时间相似度的计算提高了海洋科学数据的推荐质量。另一方面,本发明利用已发表的海洋学科的文献代替数据共享网站的用户信息和用户打分系统,通过海洋科学数据的共同使用情况,获得数据的关联性,以此解决了海洋科学共享网站缺少打分系统、用户评分信息难以获取等问题。The invention proposes a personalized recommendation method for marine scientific data based on the similarity of data content and the correlation between the data. On the one hand, the present invention fully considers the unique spatiotemporal attributes of marine scientific data when calculating data similarity, and improves the recommendation quality of marine scientific data by adding spatial similarity and temporal similarity calculation. On the other hand, the present invention replaces the user information and user scoring system of the data sharing website with published marine science documents, and obtains the relevance of the data through the common use of marine scientific data, thereby solving the problem of lack of marine science sharing websites. Problems such as the scoring system and the difficulty in obtaining user scoring information.
最后所应说明的是,以上实施例仅用以说明本发明的技术方案而非限制。尽管参照实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,对本发明的技术方案进行修改或者等同替换,都不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。Finally, it should be noted that the above embodiments are only used to illustrate the technical solutions of the present invention and not to limit them. Although the present invention has been described in detail with reference to the embodiments, those of ordinary skill in the art should understand that any modification or equivalent replacement of the technical solutions of the present invention will not depart from the spirit and scope of the technical solutions of the present invention, and should be included in the present invention. within the scope of the claims.
Claims (7)
Translated fromChinese



























Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011173700.2ACN112256834B (en) | 2020-10-28 | 2020-10-28 | A content and literature-based marine scientific data recommendation system |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011173700.2ACN112256834B (en) | 2020-10-28 | 2020-10-28 | A content and literature-based marine scientific data recommendation system |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN112256834A CN112256834A (en) | 2021-01-22 |
| CN112256834Btrue CN112256834B (en) | 2021-06-08 |
Family
ID=74262729
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202011173700.2AActiveCN112256834B (en) | 2020-10-28 | 2020-10-28 | A content and literature-based marine scientific data recommendation system |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN112256834B (en) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113076481B (en)* | 2021-04-22 | 2022-05-13 | 同济大学 | Document recommendation system and method based on maturity technology |
| CN114595383B (en)* | 2022-02-24 | 2024-11-01 | 中国海洋大学 | Marine environment data recommendation method and system based on session sequence |
| CN115238174B (en)* | 2022-06-28 | 2025-08-12 | 河钢股份有限公司 | User-collaborative similar material recommendation method |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104182450A (en)* | 2013-05-20 | 2014-12-03 | 株式会社日立制作所 | Information structuring system |
| CN107562896A (en)* | 2017-09-06 | 2018-01-09 | 华中师范大学 | A kind of the resource tissue and methods of exhibiting of knowledge based association |
| CN107832312A (en)* | 2017-01-03 | 2018-03-23 | 北京工业大学 | A kind of text based on deep semantic discrimination recommends method |
| CN111831786A (en)* | 2020-07-24 | 2020-10-27 | 刘秀萍 | Full-text database accurate and efficient retrieval method for perfecting subject term |
Family Cites Families (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10073835B2 (en)* | 2013-12-03 | 2018-09-11 | International Business Machines Corporation | Detecting literary elements in literature and their importance through semantic analysis and literary correlation |
| CN111523010B (en)* | 2019-02-03 | 2023-04-28 | 阿里巴巴集团控股有限公司 | Recommendation method, recommendation device, terminal equipment and computer storage medium |
| CN111754278A (en)* | 2019-03-27 | 2020-10-09 | 北京京东尚科信息技术有限公司 | Item recommendation method, apparatus, computer storage medium and electronic device |
| CN111026957B (en)* | 2019-11-21 | 2023-05-05 | 北京网聘咨询有限公司 | Recommender system and its method based on multidimensional similarity |
| CN111241412B (en)* | 2020-04-24 | 2020-08-07 | 支付宝(杭州)信息技术有限公司 | Method, system and device for determining map for information recommendation |
| CN111737420A (en)* | 2020-08-07 | 2020-10-02 | 四川大学 | A similar case retrieval method, system, device and medium based on dispute focus |
- 2020
- 2020-10-28CNCN202011173700.2Apatent/CN112256834B/enactiveActive
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104182450A (en)* | 2013-05-20 | 2014-12-03 | 株式会社日立制作所 | Information structuring system |
| CN107832312A (en)* | 2017-01-03 | 2018-03-23 | 北京工业大学 | A kind of text based on deep semantic discrimination recommends method |
| CN107562896A (en)* | 2017-09-06 | 2018-01-09 | 华中师范大学 | A kind of the resource tissue and methods of exhibiting of knowledge based association |
| CN111831786A (en)* | 2020-07-24 | 2020-10-27 | 刘秀萍 | Full-text database accurate and efficient retrieval method for perfecting subject term |
Also Published As
| Publication number | Publication date |
|---|---|
| CN112256834A (en) | 2021-01-22 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Şahin | A comprehensive analysis of weighting and multicriteria methods in the context of sustainable energy | |
| Le Bagousse-Pinguet et al. | Phylogenetic, functional, and taxonomic richness have both positive and negative effects on ecosystem multifunctionality | |
| CN112256834B (en) | A content and literature-based marine scientific data recommendation system | |
| CN109918563B (en) | Book recommendation method based on public data | |
| US8706742B1 (en) | System for enhancing expert-based computerized analysis of a set of digital documents and methods useful in conjunction therewith | |
| EP1995669A1 (en) | Ontology-content-based filtering method for personalized newspapers | |
| CN112989215B (en) | A Knowledge Graph Enhanced Recommendation System Based on Sparse User Behavior Data | |
| US20140207786A1 (en) | System and methods for computerized information governance of electronic documents | |
| US20100131496A1 (en) | Predictive indexing for fast search | |
| CN102081668A (en) | Information retrieval optimizing method based on domain ontology | |
| CN107291939A (en) | The clustering match method and system of hotel information | |
| CN117556118B (en) | Visual recommendation system and method based on scientific research big data prediction | |
| CN111079009A (en) | User interest detection method and system for government map service | |
| CN112434024A (en) | Relational database-oriented data dictionary generation method, device, equipment and medium | |
| CN102254025B (en) | Information memory retrieving method | |
| CN119576862B (en) | A surveying and mapping results management method and system based on big data | |
| CN113920366B (en) | A comprehensive weighted master data identification method based on machine learning | |
| van Erp et al. | Georeferencing animal specimen datasets | |
| CN112506930B (en) | Data insight system based on machine learning technology | |
| Çekim et al. | The impact of google trends on the tourist arrivals: a case of antalya tourism | |
| CN114676206B (en) | Unified organization, expression and retrieval method of multi-heterogeneous spatiotemporal elements of silk heritage | |
| CN112685452A (en) | Enterprise case retrieval method, device, equipment and storage medium | |
| CN117272995A (en) | Repeated work order recommendation method and device | |
| CN117827754A (en) | Data processing method and device for marketing, electronic equipment and storage medium | |
| CN102651014B (en) | Retrieval method for conceptual relation-based field data semantics |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |