CN112185187B - Learning method and intelligent device for social language - Google Patents
Learning method and intelligent device for social languageDownload PDFInfo
- Publication number
- CN112185187B CN112185187BCN201910596768.2ACN201910596768ACN112185187BCN 112185187 BCN112185187 BCN 112185187BCN 201910596768 ACN201910596768 ACN 201910596768ACN 112185187 BCN112185187 BCN 112185187B
- Authority
- CN
- China
- Prior art keywords
- target
- learning
- video
- social
- learning video
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images





Classifications
- G—PHYSICS
- G09—EDUCATION; CRYPTOGRAPHY; DISPLAY; ADVERTISING; SEALS
- G09B—EDUCATIONAL OR DEMONSTRATION APPLIANCES; APPLIANCES FOR TEACHING, OR COMMUNICATING WITH, THE BLIND, DEAF OR MUTE; MODELS; PLANETARIA; GLOBES; MAPS; DIAGRAMS
- G09B5/00—Electrically-operated educational appliances
- G09B5/06—Electrically-operated educational appliances with both visual and audible presentation of the material to be studied
- G09B5/065—Combinations of audio and video presentations, e.g. videotapes, videodiscs, television systems
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q50/00—Information and communication technology [ICT] specially adapted for implementation of business processes of specific business sectors, e.g. utilities or tourism
- G06Q50/10—Services
- G06Q50/20—Education
- G06Q50/205—Education administration or guidance
- G—PHYSICS
- G09—EDUCATION; CRYPTOGRAPHY; DISPLAY; ADVERTISING; SEALS
- G09B—EDUCATIONAL OR DEMONSTRATION APPLIANCES; APPLIANCES FOR TEACHING, OR COMMUNICATING WITH, THE BLIND, DEAF OR MUTE; MODELS; PLANETARIA; GLOBES; MAPS; DIAGRAMS
- G09B7/00—Electrically-operated teaching apparatus or devices working with questions and answers
- G09B7/02—Electrically-operated teaching apparatus or devices working with questions and answers of the type wherein the student is expected to construct an answer to the question which is presented or wherein the machine gives an answer to the question presented by a student
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
- G10L2015/225—Feedback of the input speech
Landscapes
- Engineering & Computer Science (AREA)
- Business, Economics & Management (AREA)
- Educational Administration (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Educational Technology (AREA)
- General Physics & Mathematics (AREA)
- Multimedia (AREA)
- Strategic Management (AREA)
- Health & Medical Sciences (AREA)
- Tourism & Hospitality (AREA)
- Acoustics & Sound (AREA)
- Human Computer Interaction (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- Economics (AREA)
- General Health & Medical Sciences (AREA)
- Human Resources & Organizations (AREA)
- Marketing (AREA)
- Primary Health Care (AREA)
- General Business, Economics & Management (AREA)
- Electrically Operated Instructional Devices (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本发明属于智能产品技术领域,特别涉及一种社交语言的学习方法及智能装置。The invention belongs to the technical field of intelligent products, and particularly relates to a social language learning method and an intelligent device.
背景技术Background technique
在现代社会,由于经济的迅猛发展,人们之间的交往日益频繁,社交语言的重要性也日益增强,好的语言表达能力越来越被认为是现代人所应具有的必备能力。对于孩子来说,其社交语言能力同样重要。从小培养孩子的社交语言能力,不仅能使小孩更好的适应各种环境,协调好与他人、与集体的关系;而且更有利于孩子的身心健康。In modern society, due to the rapid development of economy, people communicate more and more frequently, and the importance of social language is also increasing. Good language expression ability is more and more considered as a necessary ability for modern people. For children, their social language skills are equally important. Cultivating children's social language ability from an early age not only enables children to better adapt to various environments and coordinate their relationship with others and the collective; it is also more conducive to children's physical and mental health.
随着智能终端和网络技术的迅速发展,越来越多的语言学习设备涌现,比如复读机、点读机等。但是,这些语言学习设备都是针对英文等外文语言的学习,目前还没有语言学习设备来辅导儿童进行社交语言的学习,导致儿童的社交语言能力无法得到很好的培养和提高。With the rapid development of intelligent terminals and network technology, more and more language learning devices have emerged, such as repeaters and point-readers. However, these language learning devices are all aimed at the learning of foreign languages such as English. At present, there is no language learning device to guide children in social language learning, resulting in children's social language ability cannot be well cultivated and improved.
发明内容SUMMARY OF THE INVENTION
本发明的目的是提供一种社交语言的学习方法及智能装置,通过播放学习视频,可供用户进行特定场景、特定角色的社交语言练习和学习,以提高用户的社交语言能力。The purpose of the present invention is to provide a social language learning method and an intelligent device. By playing a learning video, users can practice and learn social language in specific scenes and roles, so as to improve the user's social language ability.
本发明提供的技术方案如下:The technical scheme provided by the present invention is as follows:
一方面,提供一种社交语言的学习方法,包括:On the one hand, a social language learning method is provided, including:
获取用户选择的目标社交场景和所述目标社交场景中的目标角色;Obtain the target social scene selected by the user and the target character in the target social scene;
在预先构建的视频库中选取与所述目标社交场景对应的目标学习视频集,所述目标学习视频集包括多个学习不同角色的社交语言的学习视频;Selecting a target learning video set corresponding to the target social scene from a pre-built video library, where the target learning video set includes a plurality of learning videos for learning social languages of different roles;
在所述目标学习视频集中选取与所述目标角色对应的目标学习视频,并获取所述目标角色在所述目标学习视频中的标准音频,所述目标学习视频中不包含所述目标角色的音频信息;Select the target learning video corresponding to the target character in the target learning video set, and obtain the standard audio of the target character in the target learning video, and the target learning video does not contain the audio of the target character information;
播放所述目标学习视频;play the target learning video;
播放所述目标学习视频时,采集用户输入的回复信息;When the target learning video is played, the reply information input by the user is collected;
根据所述标准音频,判断所述回复信息是否正确,若不正确,发出提示信息。According to the standard audio, it is judged whether the reply information is correct, if not, a prompt message is sent out.
进一步优选地,所述视频库的构建方法为:Further preferably, the construction method of described video library is:
获取各社交场景对应的对话视频;Obtain conversation videos corresponding to each social scene;
从当前社交场景对应的对话视频中删除当前角色的音频信息,形成所述当前角色对应的学习视频;Delete the audio information of the current character from the dialogue video corresponding to the current social scene to form a learning video corresponding to the current character;
根据所述当前社交场景下各角色对应的各学习视频,生成所述当前社交场景对应的学习视频集;According to each learning video corresponding to each character in the current social scene, a learning video set corresponding to the current social scene is generated;
根据各社交场景对应的学习视频集,构建所述视频库。The video library is constructed according to the learning video set corresponding to each social scene.
进一步优选地,还包括:Further preferably, it also includes:
当所述回复信息不正确时,根据所述标准音频,确定回复错误的地方在所述对话视频中的播放时间;When the reply information is incorrect, according to the standard audio, determine the playback time of the wrong place in the dialogue video;
控制所述目标社交场景对应的对话视频按照所述播放时间进行播放。Controlling the dialogue video corresponding to the target social scene to be played according to the playback time.
进一步优选地,所述根据所述标准音频,判断所述回复信息是否正确具体包括:Further preferably, the judging whether the reply information is correct according to the standard audio specifically includes:
识别所述回复信息的语义;identify the semantics of the reply message;
识别所述标准音频的语义;identifying the semantics of the standard audio;
将所述回复信息的语义和所述标准音频的语义进行比对;Compare the semantics of the reply information with the semantics of the standard audio;
当所述回复信息的语义与所述标准音频的语义相同时,则所述回复信息正确;否则,所述回复信息不正确。When the semantics of the reply information is the same as the semantics of the standard audio, the reply information is correct; otherwise, the reply information is incorrect.
进一步优选地,还包括:Further preferably, it also includes:
根据判断结果,对所述回复信息进行评分;According to the judgment result, score the reply information;
根据所述评分,向所述用户推送对应社交场景的学习视频集。According to the score, a learning video set corresponding to the social scene is pushed to the user.
另一方面,还提供一种智能装置,包括:In another aspect, an intelligent device is also provided, comprising:
获取模块,用于获取用户选择的目标社交场景和所述目标社交场景中的目标角色;an acquisition module for acquiring a target social scene selected by the user and a target role in the target social scene;
查找模块,用于在预先构建的视频库中选取与所述目标社交场景对应的目标学习视频集,所述目标学习视频集包括多个学习不同角色的社交语言的学习视频;A search module for selecting a target learning video set corresponding to the target social scene in a pre-built video library, where the target learning video set includes a plurality of learning videos for learning social languages of different roles;
所述查找模块,还用于在所述目标学习视频集中选取与所述目标角色对应的目标学习视频,并获取所述目标角色在所述目标学习视频中的标准音频,所述目标学习视频中不包含所述目标角色的音频信息;The search module is further configured to select the target learning video corresponding to the target role in the target learning video set, and obtain the standard audio of the target role in the target learning video, in the target learning video. does not contain the audio information of the target character;
播放模块,用于播放所述目标学习视频;a playing module, used for playing the target learning video;
采集模块,用于播放所述目标学习视频时,采集用户输入的回复信息;a collection module, configured to collect the reply information input by the user when the target learning video is played;
判断模块,用于根据所述标准音频,判断所述回复信息是否正确;a judging module for judging whether the reply information is correct according to the standard audio;
提示模块,用于当所述回复信息不正确时,发出提示信息。The prompting module is used for sending prompt information when the reply information is incorrect.
进一步优选地,还包括构建模块;Further preferably, it also includes building blocks;
所述构建模块包括:The building blocks include:
获取单元,用于获取各社交场景对应的对话视频;an obtaining unit, used for obtaining the dialogue video corresponding to each social scene;
处理单元,用于从当前社交场景对应的对话视频中删除当前角色的音频信息,形成所述当前角色对应的学习视频;a processing unit, configured to delete the audio information of the current character from the dialogue video corresponding to the current social scene, and form a learning video corresponding to the current character;
存储单元,用于根据所述当前社交场景下各角色对应的各学习视频,生成所述当前社交场景对应的学习视频集;a storage unit, configured to generate a learning video set corresponding to the current social scene according to each learning video corresponding to each character in the current social scene;
所述存储单元,用于根据各社交场景对应的学习视频集,构建所述视频库。The storage unit is configured to construct the video library according to the learning video set corresponding to each social scene.
进一步优选地,还包括:Further preferably, it also includes:
确定模块,用于当所述回复信息不正确时,根据所述标准音频,确定回复错误的地方在所述对话视频中的播放时间;a determining module, configured to determine, according to the standard audio, the playback time of the wrong place in the dialogue video when the reply information is incorrect;
控制模块,用于控制所述目标社交场景对应的对话视频按照所述播放时间进行播放。A control module, configured to control the dialogue video corresponding to the target social scene to be played according to the play time.
进一步优选地,所述判断模块包括:Further preferably, the judging module includes:
识别单元,用于识别所述回复信息的语义;an identification unit for identifying the semantics of the reply information;
所述识别单元,用于识别所述标准音频的语义;the identifying unit, for identifying the semantics of the standard audio;
比对单元,用于将所述回复信息的语义和所述标准音频的语义进行比对;a comparison unit, configured to compare the semantics of the reply information with the semantics of the standard audio;
判断单元,用于当所述回复信息的语义与所述标准音频的语义相同时,判断所述回复信息正确;否则,判断所述回复信息不正确。A judging unit, configured to judge that the reply information is correct when the semantics of the reply information is the same as the semantics of the standard audio; otherwise, judge that the reply information is incorrect.
进一步优选地,还包括:Further preferably, it also includes:
评分模块,用于根据判断结果,对所述回复信息进行评分;a scoring module, used for scoring the reply information according to the judgment result;
推送模块,用于根据所述评分,向所述用户推送对应社交场景的学习视频集。A push module, configured to push a learning video set corresponding to a social scene to the user according to the score.
与现有技术相比,本发明提供的一种社交语言的学习方法及智能装置具有以下有益效果:本发明通过播放学习视频,让用户以特定角色与学习视频中的其他角色进行对话,以供用户进行特定场景、特定角色的社交语言练习和学习,并在用户回复错误时,提醒用户,以便用户知晓回复错误的地方,并思考该如何进行回复,进而提高用户的社交语言能力。Compared with the prior art, a social language learning method and an intelligent device provided by the present invention have the following beneficial effects: the present invention allows the user to have a dialogue with other characters in the learning video with a specific role by playing the learning video, for the purpose of Users perform social language practice and learning in specific scenarios and roles, and remind users when users reply incorrectly, so that users know where the reply is wrong, and think about how to reply, thereby improving the user's social language ability.
附图说明Description of drawings
下面将以明确易懂的方式,结合附图说明优选实施方式,对一种社交语言的学习方法及智能装置的上述特性、技术特征、优点及其实现方式予以进一步说明。The preferred embodiments will be described below in a clear and easy-to-understand manner with reference to the accompanying drawings, and further description will be given of the above-mentioned characteristics, technical features, advantages and implementation methods of a social language learning method and an intelligent device.
图1是本发明一种社交语言的学习方法的一个实施例的流程示意图;1 is a schematic flowchart of an embodiment of a social language learning method of the present invention;
图2是本发明一种社交语言的学习方法的另一实施例的流程示意图;2 is a schematic flowchart of another embodiment of a social language learning method of the present invention;
图3是本发明一种社交语言的学习方法的另一实施例的流程示意图;3 is a schematic flowchart of another embodiment of a social language learning method of the present invention;
图4是本发明一种社交语言的学习方法的另一实施例的流程示意图;4 is a schematic flowchart of another embodiment of a social language learning method of the present invention;
图5是本发明一种社交语言的学习方法的另一实施例的流程示意图;5 is a schematic flowchart of another embodiment of a social language learning method of the present invention;
图6是本发明一种智能装置的一个实施例的结构示意框图。FIG. 6 is a schematic structural block diagram of an embodiment of a smart device of the present invention.
附图标号说明Explanation of reference numerals
10、获取模块;20、查找模块;30、播放模块;40、采集模块;50、判断模块;60、提示模块。10. Obtaining module; 20. Searching module; 30. Playing module; 40. Collecting module; 50. Judging module; 60. Prompting module.
具体实施方式Detailed ways
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对照附图说明本发明的具体实施方式。显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图,并获得其他的实施方式。In order to more clearly describe the embodiments of the present invention or the technical solutions in the prior art, the specific embodiments of the present invention will be described below with reference to the accompanying drawings. Obviously, the accompanying drawings in the following description are only some embodiments of the present invention. For those of ordinary skill in the art, other drawings can also be obtained from these drawings without creative efforts, and obtain other implementations.
应当理解,当在本说明书中使用时,术语“包括”指示所述描述特征、整体、步骤、操作、元素和/或组件的存在,但并不排除一个或多个其他特征、整体、步骤、操作、元素、组件和/或集合的存在或添加。It should be understood that, when used in this specification, the term "comprising" indicates the presence of the described features, integers, steps, operations, elements and/or components, but does not exclude one or more other features, integers, steps, The existence or addition of operations, elements, components, and/or collections.
为使图面简洁,各图中只示意性地表示出了与本发明相关的部分,它们并不代表其作为产品的实际结构。另外,以使图面简洁便于理解,在有些图中具有相同结构或功能的部件,仅示意性地绘示了其中的一个,或仅标出了其中的一个。在本文中,“一个”不仅表示“仅此一个”,也可以表示“多于一个”的情形。In order to keep the drawings concise, the drawings only schematically show the parts related to the present invention, and they do not represent its actual structure as a product. In addition, in order to make the drawings concise and easy to understand, in some drawings, only one of the components having the same structure or function is schematically shown, or only one of them is marked. As used herein, "one" not only means "only one", but also "more than one".
图1是本发明提供的一种社交语言的学习方法的一个实施例的流程图,该社交语言的学习方法包括:1 is a flowchart of an embodiment of a social language learning method provided by the present invention, and the social language learning method includes:
S100获取用户选择的目标社交场景和所述目标社交场景中的目标角色;S100 obtains the target social scene selected by the user and the target role in the target social scene;
S200在预先构建的视频库中选取与所述目标社交场景对应的目标学习视频集,所述目标学习视频集包括多个学习不同角色的社交语言的学习视频;S200 selects a target learning video set corresponding to the target social scene in a pre-built video library, and the target learning video set includes a plurality of learning videos for learning social languages of different roles;
S300在所述目标学习视频集中选取与所述目标角色对应的目标学习视频,并获取所述目标角色在所述目标学习视频中的标准音频,所述目标学习视频中不包含所述目标角色的音频信息;S300 selects the target learning video corresponding to the target character in the target learning video set, and obtains the standard audio of the target character in the target learning video, and the target learning video does not include the target character's audio audio information;
S400播放所述目标学习视频;S400 plays the target learning video;
S500播放所述目标学习视频时,采集用户输入的回复信息;S500 collects the reply information input by the user when playing the target learning video;
S600根据所述标准音频,判断所述回复信息是否正确,若不正确,发出提示信息。S600 judges whether the reply information is correct according to the standard audio, and if not, sends a prompt message.
具体地,本发明的社交语言的学习方法可应用于各智能终端,如家教机、平板电脑、智能台灯等。Specifically, the social language learning method of the present invention can be applied to various smart terminals, such as tutoring machines, tablet computers, smart desk lamps, and the like.
当儿童需要进行社交语言学习时,可在智能终端上选择需要学习的目标社交场景和目标社交场景中的目标角色。When children need to learn social language, they can select the target social scene to be learned and the target role in the target social scene on the smart terminal.
社交场景是指在不同的场景下与不同的人进行对话。例如,向老师请教题目时的对话场景;向朋友请教学习时的对话场景;与小朋友分享玩具时的对话场景;与朋友玩耍时的对话场景;在路上遇到熟人时的对话场景;向老师问好时的对话场景等。Social scenarios refer to having conversations with different people in different scenarios. For example, a conversation scene when asking a teacher for a topic; a conversation scene when asking a friend for advice on learning; a conversation scene when sharing toys with children; a conversation scene when playing with friends; a conversation scene when meeting an acquaintance on the road; saying hello to the teacher dialogue scenes, etc.
每个对话场景中都包括多个角色,可以是两个角色,即一对一对话;也可以是三个以上角色,即多人对话。用户可以选择其中任意一个角色作为目标角色进行社交语言学习。当然,为了更好地培养和提高用户的社交语言能力,最好选择和自己身份相符合的角色进行社交语言学习。例如,在与老师的对话场景中,当用户是儿童时,最好选择儿童角色进行社交语言学习,以便更好地学习和掌握与自己身份相符合的社交语言。Each dialogue scene includes multiple characters, which can be two characters, that is, one-to-one dialogue; or more than three characters, that is, multi-person dialogue. Users can choose any one of the roles as the target role for social language learning. Of course, in order to better cultivate and improve the social language ability of users, it is best to choose a role that matches your own identity for social language learning. For example, in a dialogue scene with a teacher, when the user is a child, it is better to choose a child character for social language learning, so as to better learn and master the social language that is in line with their own identity.
智能终端获取用户选择地目标社交场景和目标社交场景中的目标角色后,可在预先构建的视频库中选取目标社交场景对应的目标学习视频集。每个社交场景对应一个或多个学习视频集,即在同一社交场景下,可有多种表现形式。当目标社交场景对应多个学习视频集时,若这多个学习视频集用户都没有学习过,则从这多个学习视频集中随机选取一个学习视频集作为目标学习视频集;若用户已经学习过这多个学习视频集中的某些学习视频集时,可随机选取一个用户未学习过的学习视频集作为目标学习视频集。After acquiring the target social scene selected by the user and the target character in the target social scene, the intelligent terminal can select a target learning video set corresponding to the target social scene from the pre-built video library. Each social scene corresponds to one or more learning video sets, that is, in the same social scene, there can be multiple manifestations. When the target social scene corresponds to multiple learning video sets, if the users of these multiple learning video sets have not studied, a learning video set is randomly selected from the multiple learning video sets as the target learning video set; if the user has already learned When there are some learning video sets in the multiple learning video sets, a learning video set that has not been learned by the user may be randomly selected as the target learning video set.
学习视频集中包括多个学习视频,每个学习视频可用于学习一个角色的社交语言。选取目标学习视频集后,根据用户选择的目标角色,在目标学习视频集的多个学习视频中选择对应的目标学习视频,然后播放该目标学习视频。The learning video set includes multiple learning videos, each of which can be used to learn the social language of a character. After the target learning video set is selected, according to the target role selected by the user, a corresponding target learning video is selected from multiple learning videos in the target learning video set, and then the target learning video is played.
目标学习视频中不包含目标角色的音频信息,只包含其他角色的音频信息。在播放目标学习视频时,目标学习视频中的其他角色的对话音频正常播放,在对话中,当需要目标角色回话时,用户可输入回复信息,使用户作为目标角色与目标学习视频中的其他角色进行对话。目标学习视频中的其他角色的对话信息可作为对社交场景的限定,以及对用户的回复信息的一个引导,引导用户进行回复和交流。The target learning video does not contain the audio information of the target character, only the audio information of other characters. When playing the target learning video, the dialogue audio of other characters in the target learning video is played normally. During the dialogue, when the target character needs to talk back, the user can enter reply information, so that the user can act as the target character and other characters in the target learning video. Have a conversation. The dialogue information of other characters in the target learning video can be used as a limitation on the social scene and as a guide for the user's reply information, so as to guide the user to reply and communicate.
示例性的,假设目标学习视频中包含角色A和角色B,用户选择的目标角色为角色A,目标学习视频中正常播放角色A和角色B的视频画面,并播放角色B的音频信息,用户在角色B的对话引导下,输入针对角色B的音频的回复信息。Exemplarily, it is assumed that the target learning video contains character A and character B, the target character selected by the user is character A, the video images of character A and character B are normally played in the target learning video, and the audio information of character B is played. Under the guidance of the dialogue of character B, enter the reply information for the audio of character B.
在用户作为角色A输入回复信息时,采集用户的回复信息,然后根据角色A的标准音频,判断用户输入的回复信息是否正确,若正确,则输出夸奖信息,若不正确,则输出提示信息,提示用户哪些地方回答的不对,以便用户思考应该如何回复,提高用户的社交语言能力。When the user enters reply information as role A, collect the user's reply information, and then judge whether the reply information input by the user is correct according to the standard audio of role A. If it is correct, output the compliment information, if not, output the prompt information. Prompt the user where the answer is wrong, so that the user can think about how to reply, and improve the user's social language ability.
本发明通过播放学习视频,让用户以特定角色与学习视频中的其他角色进行对话,以供用户进行特定场景、特定角色的社交语言练习和学习,并在用户回复错误时,提醒用户,以便用户知晓回复错误的地方,并思考该如何进行回复,进而提高用户的社交语言能力;同时,还可判断出用户已掌握哪些社交语言,未掌握哪些社交语言,以便用户进一步加强学习。By playing the learning video, the present invention allows the user to have a dialogue with other characters in the learning video in a specific role, so that the user can practice and learn social language in a specific scene and a specific role, and when the user replies to an error, the user is reminded, so that the user can Know the wrong place to reply, and think about how to reply, so as to improve the user's social language ability; at the same time, it can also judge which social language the user has mastered and which social language has not been mastered, so that the user can further strengthen the learning.
图2是本发明提供的一种社交语言的学习方法的另一个实施例的流程图,该社交语言的学习方法包括:2 is a flowchart of another embodiment of a social language learning method provided by the present invention, and the social language learning method includes:
S010获取各社交场景对应的对话视频;S010 obtains dialogue videos corresponding to each social scene;
S020从当前社交场景对应的对话视频中删除当前角色的音频信息,形成所述当前角色对应的学习视频;S020 deletes the audio information of the current role from the dialogue video corresponding to the current social scene, and forms a learning video corresponding to the current role;
S030根据所述当前社交场景下各角色对应的各学习视频,生成所述当前社交场景对应的学习视频集;S030, according to each learning video corresponding to each character under the current social scene, generate a learning video set corresponding to the current social scene;
S040根据各社交场景对应的学习视频集,构建视频库;S040 constructs a video library according to the learning video set corresponding to each social scene;
S100获取用户选择的目标社交场景和所述目标社交场景中的目标角色;S100 obtains the target social scene selected by the user and the target role in the target social scene;
S200在预先构建的视频库中选取与所述目标社交场景对应的目标学习视频集,所述目标学习视频集包括多个学习不同角色的社交语言的学习视频;S200 selects a target learning video set corresponding to the target social scene in a pre-built video library, and the target learning video set includes a plurality of learning videos for learning social languages of different roles;
S300在所述目标学习视频集中选取与所述目标角色对应的目标学习视频,并获取所述目标角色在所述目标学习视频中的标准音频,所述目标学习视频中不包含所述目标角色的音频信息;S300 selects the target learning video corresponding to the target character in the target learning video set, and obtains the standard audio of the target character in the target learning video, and the target learning video does not include the target character's audio audio information;
S400播放所述目标学习视频;S400 plays the target learning video;
S500播放所述目标学习视频时,采集用户输入的回复信息;S500 collects the reply information input by the user when playing the target learning video;
S600根据所述标准音频,判断所述回复信息是否正确,若不正确,发出提示信息。S600 judges whether the reply information is correct according to the standard audio, and if not, sends a prompt message.
具体地,视频库中包括各社交场景对应的学习视频集,每个社交场景对应一个或多个学习视频集。各社交场景对应的学习视频集的构建方法为:先获取各社交场景对应的对话视频,每个社交场景可获取多个对话视频。其中,对话视频可以是由真人根据标准社交用语拍摄而成,也可以是根据标准社交用语通过动画制作而成。Specifically, the video library includes learning video sets corresponding to each social scene, and each social scene corresponds to one or more learning video sets. The method for constructing the learning video set corresponding to each social scene is as follows: firstly acquire the dialogue videos corresponding to each social scene, and each social scene may acquire multiple dialogue videos. Among them, the dialogue video may be shot by a real person according to standard social terms, or may be produced by animation according to standard social terms.
从对话视频中分别提取出各角色的音频信息,然后删除某一角色的音频信息,生成该角色的学习视频。例如,对话视频中包括角色A和角色B,从对话视频中删除角色A的音频信息,即可生成角色A的学习视频;从对话视频中删除角色B的音频信息,即可生成角色B的学习视频。角色A的学习视频和角色B的学习视频即可形成一个学习视频集。若对话视频中包括三个角色,则可生成三个角色分别对应的学习视频,这三个学习视频也可形成一个学习视频集。The audio information of each character is extracted from the dialogue video, and then the audio information of a certain character is deleted to generate a learning video of the character. For example, a dialogue video includes character A and character B. Deleting the audio information of character A from the dialogue video can generate a learning video for character A; deleting the audio information of character B from the dialogue video can generate a learning video for character B video. The learning video of character A and the learning video of character B can form a learning video set. If the dialogue video includes three characters, learning videos corresponding to the three characters can be generated, and the three learning videos can also form a learning video set.
根据各个社交场景的对话视频,即可生成各个社交场景对应的学习视频集,然后将生成的学习视频集全部存储在新建的视频库中,形成构建好的视频库。在构建好的视频库中,建立各个学习视频集与社交场景的关联关系。在获取到用户选择的目标社交场景后,可根据社交场景与学习视频集之间的关联关系,在视频库中查找到与目标社交场景对应的目标学习视频集。According to the conversation videos of each social scene, a learning video set corresponding to each social scene can be generated, and then all the generated learning video sets are stored in the newly created video library to form a constructed video library. In the constructed video library, establish the relationship between each learning video set and the social scene. After acquiring the target social scene selected by the user, a target learning video set corresponding to the target social scene can be found in the video library according to the relationship between the social scene and the learning video set.
图3是本发明提供的一种社交语言的学习方法的另一个实施例的流程图,该社交语言的学习方法包括:3 is a flowchart of another embodiment of a social language learning method provided by the present invention, and the social language learning method includes:
S010获取各社交场景对应的对话视频;S010 obtains dialogue videos corresponding to each social scene;
S020从当前社交场景对应的对话视频中删除当前角色的音频信息,形成所述当前角色对应的学习视频;S020 deletes the audio information of the current role from the dialogue video corresponding to the current social scene, and forms a learning video corresponding to the current role;
S030根据所述当前社交场景下各角色对应的各学习视频,生成所述当前社交场景对应的学习视频集;S030, according to each learning video corresponding to each character under the current social scene, generate a learning video set corresponding to the current social scene;
S040根据各社交场景对应的学习视频集,构建视频库;S040 constructs a video library according to the learning video set corresponding to each social scene;
S100获取用户选择的目标社交场景和所述目标社交场景中的目标角色;S100 obtains the target social scene selected by the user and the target role in the target social scene;
S200在预先构建的视频库中选取与所述目标社交场景对应的目标学习视频集,所述目标学习视频集包括多个学习不同角色的社交语言的学习视频;S200 selects a target learning video set corresponding to the target social scene in a pre-built video library, and the target learning video set includes a plurality of learning videos for learning social languages of different roles;
S300在所述目标学习视频集中选取与所述目标角色对应的目标学习视频,并获取所述目标角色在所述目标学习视频中的标准音频,所述目标学习视频中不包含所述目标角色的音频信息;S300 selects the target learning video corresponding to the target character in the target learning video set, and obtains the standard audio of the target character in the target learning video, and the target learning video does not include the target character's audio audio information;
S400播放所述目标学习视频;S400 plays the target learning video;
S500播放所述目标学习视频时,采集用户输入的回复信息;S500 collects the reply information input by the user when playing the target learning video;
S600根据所述标准音频,判断所述回复信息是否正确,若不正确,发出提示信息;S600, according to the standard audio, determine whether the reply information is correct, if not, send a prompt message;
S710当所述回复信息不正确时,根据所述标准音频,确定回复错误的地方在所述对话视频中的播放时间;S710, when the reply information is incorrect, according to the standard audio, determine the playback time of the wrong place in the dialogue video;
S720控制所述目标社交场景对应的对话视频按照所述播放时间进行播放。S720 controls the dialogue video corresponding to the target social scene to be played according to the play time.
具体地,用户在与目标学习视频中的其他角色对话时,可能会回复多次,因此,回复信息中可能包括多句话。将回复信息中的每句话与标准音频中对应的语句进行比对,判断回复信息中是否存在不正确的地方,若存在,则根据标准音频,确定回复错误的地方在目标社交场景对应的对话视频中的播放时间,该播放时间包括播放开始时间和播放结束时间。Specifically, the user may reply multiple times when talking with other characters in the target learning video, so the reply information may include multiple sentences. Compare each sentence in the reply message with the corresponding sentence in the standard audio, and determine whether there is an incorrect place in the reply message. If there is, then according to the standard audio, determine that the wrong place in the reply is in the dialogue corresponding to the target social scene The playback time in the video, which includes the playback start time and playback end time.
目标社交场景对应的学习视频集中还可存储该目标社交场景对应的对话视频。根据确定的播放时间,控制目标社交场景对应的对话视频进行播放,以播放错误回复对应的正确回复,以供用户进行模仿学习,对于年级较小的孩子来说,模仿学习也是非常重要的学习过程。The learning video set corresponding to the target social scene may also store a dialogue video corresponding to the target social scene. According to the determined playback time, the dialogue video corresponding to the target social scene is controlled to be played, and the correct response corresponding to the wrong response is played for the user to imitate learning. For younger children, imitation learning is also a very important learning process. .
本发明在用户回复错误时,仅播放该错误回复对应的正确回复,不仅可节省用户的时间,而且可供用户进行模仿学习,以提高孩子的社交语言能力,以便更好地与他人进行交流。When the user replies wrongly, the present invention only plays the correct reply corresponding to the wrong reply, which not only saves the user's time, but also allows the user to imitate and learn, so as to improve the child's social language ability, so as to better communicate with others.
图4是本发明提供的一种社交语言的学习方法的另一个实施例的流程图,该社交语言的学习方法包括:4 is a flowchart of another embodiment of a social language learning method provided by the present invention, and the social language learning method includes:
S100获取用户选择的目标社交场景和所述目标社交场景中的目标角色;S100 obtains the target social scene selected by the user and the target role in the target social scene;
S200在预先构建的视频库中选取与所述目标社交场景对应的目标学习视频集,所述目标学习视频集包括多个学习不同角色的社交语言的学习视频;S200 selects a target learning video set corresponding to the target social scene in a pre-built video library, and the target learning video set includes a plurality of learning videos for learning social languages of different roles;
S300在所述目标学习视频集中选取与所述目标角色对应的目标学习视频,并获取所述目标角色在所述目标学习视频中的标准音频,所述目标学习视频中不包含所述目标角色的音频信息;S300 selects the target learning video corresponding to the target character in the target learning video set, and obtains the standard audio of the target character in the target learning video, and the target learning video does not include the target character's audio audio information;
S400播放所述目标学习视频;S400 plays the target learning video;
S500播放所述目标学习视频时,采集用户输入的回复信息;S500 collects the reply information input by the user when playing the target learning video;
S610识别所述回复信息的语义;S610 identifies the semantics of the reply information;
S620识别所述标准音频的语义;S620 identifies the semantics of the standard audio;
S630将所述回复信息的语义和所述标准音频的语义进行比对;S630 compares the semantics of the reply information with the semantics of the standard audio;
S640当所述回复信息的语义与所述标准音频的语义相同时,则所述回复信息正确;否则,所述回复信息不正确;S640, when the semantics of the reply information is the same as the semantics of the standard audio, the reply information is correct; otherwise, the reply information is incorrect;
S650若不正确,发出提示信息。If the S650 is incorrect, a prompt message will be sent.
具体地,将回复信息与标准音频进行比对,以判断回复信息是否正确时,先识别回复信息的语义,并识别标准音频的语义,然后将回复信息的语义与标准音频的语义进行比对,当回复信息的语义与标准音频的语义相同时,回复信息正确,若两者语义不同,则回复信息不正确。Specifically, when comparing the reply information with the standard audio to determine whether the reply information is correct, first identify the semantics of the reply information, and identify the semantics of the standard audio, and then compare the semantics of the reply information with the semantics of the standard audio, When the semantics of the reply information is the same as that of the standard audio, the reply information is correct; if the semantics of the two are different, the reply information is incorrect.
当回复信息中包含多句话时,将回复信息中的每句话的语义与标准音频中对应语句的语义进行比对,以判断回复信息中的哪句话回复正确,哪句话回复不正确。对于不正确的回复,可发出提示信息提醒用户,并且提醒用户后,还可再次采集用户输入的语音信息,该再次输入的语音信息是用户对回复错误的地方的再次回复,并根据该错误回复的标准音频判断用户再次输入的语音信息是否正确。在用户多次回复,仍不正确时,可播放对话视频中该错误回复对应的正确回复,在播放对话视频时,只播放该错误回复对应的正确回复部分,对于其他已回复正确的地方,可不再进行播放;当然,若用户希望播放完整的对话视频,则进行播放。When the reply message contains multiple sentences, compare the semantics of each sentence in the reply message with the semantics of the corresponding sentence in the standard audio to determine which sentence in the reply message is correct and which is incorrect. . For an incorrect reply, a prompt message can be sent to remind the user, and after reminding the user, the voice information input by the user can be collected again. The standard audio to determine whether the voice information input by the user again is correct. When the user replies multiple times and is still incorrect, the correct reply corresponding to the incorrect reply in the conversation video can be played. When playing the conversation video, only the correct reply part corresponding to the incorrect reply is played. Play again; of course, if the user wants to play the complete dialogue video, play it.
本实施例中,根据回复信息的语义以及标准音频的语义,来判断回复信息是否正确,可防止出现语义相同,但因使用文字不同而被判断错误的情况,进而提高判断的准确率。In this embodiment, it is judged whether the reply information is correct according to the semantics of the reply information and the semantics of the standard audio, which can prevent the situation that the semantics are the same, but the judgment is wrong due to different words, thereby improving the accuracy of the judgment.
图5是本发明提供的一种社交语言的学习方法的另一个实施例的流程图,该社交语言的学习方法包括:5 is a flowchart of another embodiment of a social language learning method provided by the present invention, and the social language learning method includes:
S100获取用户选择的目标社交场景和所述目标社交场景中的目标角色;S100 obtains the target social scene selected by the user and the target role in the target social scene;
S200在预先构建的视频库中选取与所述目标社交场景对应的目标学习视频集,所述目标学习视频集包括多个学习不同角色的社交语言的学习视频;S200 selects a target learning video set corresponding to the target social scene in a pre-built video library, and the target learning video set includes a plurality of learning videos for learning social languages of different roles;
S300在所述目标学习视频集中选取与所述目标角色对应的目标学习视频,并获取所述目标角色在所述目标学习视频中的标准音频,所述目标学习视频中不包含所述目标角色的音频信息;S300 selects the target learning video corresponding to the target character in the target learning video set, and obtains the standard audio of the target character in the target learning video, and the target learning video does not include the target character's audio audio information;
S400播放所述目标学习视频;S400 plays the target learning video;
S500播放所述目标学习视频时,采集用户输入的回复信息;S500 collects the reply information input by the user when playing the target learning video;
S600根据所述标准音频,判断所述回复信息是否正确,若不正确,发出提示信息;S600, according to the standard audio, determine whether the reply information is correct, if not, send a prompt message;
S810根据判断结果,对所述回复信息进行评分;S810, according to the judgment result, score the reply information;
S820根据所述评分,向所述用户推送对应社交场景的学习视频集。S820, according to the score, push a learning video set corresponding to the social scene to the user.
具体地,在根据标准音频,判断回复信息是否正确后,还可根据判断结果,对回复信息进行评分。例如,当回复信息中包含五句话时,其中有三句回复正确,有两句回复错误,则回复信息的评分为60分。Specifically, after judging whether the reply information is correct according to the standard audio, the reply information can also be scored according to the judgment result. For example, when the reply message contains five sentences, three of which are correct and two are wrong, the reply message is scored as 60 points.
若回复信息的评分较高,则说明用户已掌握该社交场景的社交语言;若回复信息的评分较低,则说明用户未掌握该社交场景的社交语言。若用户已掌握该社交场景的社交语言,则可向用户推送更高难度的社交场景的学习视频集。若用户未掌握该社交场景的社交语言,则向用户推送该社交场景对应的其它学习视频集,或向用户推送与该社交场景相关联的社交场景的学习视频集。If the score of the reply message is high, it indicates that the user has mastered the social language of the social scene; if the score of the reply message is low, it indicates that the user has not mastered the social language of the social scene. If the user has mastered the social language of the social scene, a learning video set of a more difficult social scene can be pushed to the user. If the user does not master the social language of the social scene, other learning video sets corresponding to the social scene are pushed to the user, or a learning video set of the social scene associated with the social scene is pushed to the user.
本实施例中,根据回复信息的评分,向用户推送对应的学习视频集,使得推送的学习视频集更符合用户的当前水平,以便更好的帮助用户进行社交语言的学习。In this embodiment, according to the score of the reply information, a corresponding learning video set is pushed to the user, so that the pushed learning video set is more in line with the user's current level, so as to better help the user to learn social language.
应理解,在上述各实施例中,各步骤序号的大小并不意味着执行顺序的先后,各步骤的执行顺序应以功能和内在逻辑确定,而不应对本发明实施例的实施过程构成任何限定。It should be understood that, in the above embodiments, the size of the sequence numbers of the steps does not mean the sequence of execution, and the execution sequence of the steps should be determined by functions and internal logic, and should not constitute any limitation to the implementation process of the embodiments of the present invention .
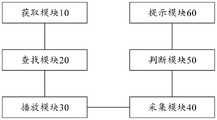
图6是本发明提供的一种智能装置的一个实施例的结构示意框图,该智能装置包括:6 is a schematic structural block diagram of an embodiment of a smart device provided by the present invention, and the smart device includes:
获取模块10,用于获取用户选择的目标社交场景和所述目标社交场景中的目标角色;an acquisition module 10, configured to acquire the target social scene selected by the user and the target role in the target social scene;
查找模块20,用于在预先构建的视频库中选取与所述目标社交场景对应的目标学习视频集,所述目标学习视频集包括多个学习不同角色的社交语言的学习视频;The search module 20 is used to select a target learning video set corresponding to the target social scene in a pre-built video library, and the target learning video set includes a plurality of learning videos for learning social languages of different roles;
查找模块20,还用于在所述目标学习视频集中选取与所述目标角色对应的目标学习视频,并获取所述目标角色在所述目标学习视频中的标准音频,所述目标学习视频中不包含所述目标角色的音频信息;The search module 20 is further configured to select the target learning video corresponding to the target role in the target learning video set, and obtain the standard audio of the target role in the target learning video, and the target learning video does not contains audio information of the target character;
播放模块30,用于播放所述目标学习视频;A playing module 30 is used to play the target learning video;
采集模块40,用于播放所述目标学习视频时,采集用户输入的回复信息;The collection module 40 is used to collect the reply information input by the user when the target learning video is played;
判断模块50,用于根据所述标准音频,判断所述回复信息是否正确;Judging module 50, for judging whether the reply information is correct according to the standard audio;
提示模块60,用于当所述回复信息不正确时,发出提示信息。The prompting module 60 is configured to issue prompting information when the reply information is incorrect.
具体地,本发明的智能装置可以为各种智能终端,如家教机、平板电脑、智能台灯等。Specifically, the smart device of the present invention can be various smart terminals, such as a tutoring machine, a tablet computer, a smart desk lamp, and the like.
当儿童需要进行社交语言学习时,可在智能终端上选择需要学习的目标社交场景和目标社交场景中的目标角色。When children need to learn social language, they can select the target social scene to be learned and the target role in the target social scene on the smart terminal.
社交场景是指在不同的场景下与不同的人进行对话。例如,向老师请教题目时的对话场景;向朋友请教学习时的对话场景;与小朋友分享玩具时的对话场景;与朋友玩耍时的对话场景;在路上遇到熟人时的对话场景;向老师问好时的对话场景等。Social scenarios refer to having conversations with different people in different scenarios. For example, a conversation scene when asking a teacher for a topic; a conversation scene when asking a friend for advice on learning; a conversation scene when sharing toys with children; a conversation scene when playing with friends; a conversation scene when meeting an acquaintance on the road; saying hello to the teacher dialogue scenes, etc.
每个对话场景中都包括多个角色,可以是两个角色,即一对一对话;也可以是三个以上角色,即多人对话。用户可以选择其中任意一个角色作为目标角色进行社交语言学习。当然,为了更好地培养和提高用户的社交语言能力,最好选择和自己身份相符合的角色进行社交语言学习。例如,在与老师的对话场景中,当用户是儿童时,最好选择儿童角色进行社交语言学习,以便更好地学习和掌握与自己身份相符合的社交语言。Each dialogue scene includes multiple characters, which can be two characters, that is, one-to-one dialogue; or more than three characters, that is, multi-person dialogue. Users can choose any one of the roles as the target role for social language learning. Of course, in order to better cultivate and improve the social language ability of users, it is best to choose a role that matches your own identity for social language learning. For example, in a dialogue scene with a teacher, when the user is a child, it is better to choose a child character for social language learning, so as to better learn and master the social language that is in line with their own identity.
智能终端获取用户选择地目标社交场景和目标社交场景中的目标角色后,可在预先构建的视频库中选取目标社交场景对应的目标学习视频集。每个社交场景对应一个或多个学习视频集,即在同一社交场景下,可有多种表现形式。当目标社交场景对应多个学习视频集时,若这多个学习视频集用户都没有学习过,则从这多个学习视频集中随机选取一个学习视频集作为目标学习视频集;若用户已经学习过这多个学习视频集中的某些学习视频集时,可随机选取一个用户未学习过的学习视频集作为目标学习视频集。After acquiring the target social scene selected by the user and the target character in the target social scene, the intelligent terminal can select a target learning video set corresponding to the target social scene from the pre-built video library. Each social scene corresponds to one or more learning video sets, that is, in the same social scene, there can be multiple manifestations. When the target social scene corresponds to multiple learning video sets, if the users of these multiple learning video sets have not studied, a learning video set is randomly selected from the multiple learning video sets as the target learning video set; if the user has already learned When there are some learning video sets in the multiple learning video sets, a learning video set that has not been learned by the user may be randomly selected as the target learning video set.
学习视频集中包括多个学习视频,每个学习视频可用于学习一个角色的社交语言。选取目标学习视频集后,根据用户选择的目标角色,在目标学习视频集的多个学习视频中选择对应的目标学习视频,然后播放该目标学习视频。The learning video set includes multiple learning videos, each of which can be used to learn the social language of a character. After the target learning video set is selected, according to the target role selected by the user, a corresponding target learning video is selected from multiple learning videos in the target learning video set, and then the target learning video is played.
目标学习视频中不包含目标角色的音频信息,只包含其他角色的音频信息。在播放目标学习视频时,目标学习视频中的其他角色的对话音频正常播放,在对话中,当需要目标角色回话时,用户可输入回复信息,使用户作为目标角色与目标学习视频中的其他角色进行对话。目标学习视频中的其他角色的对话信息可作为对社交场景的限定,以及对用户的回复信息的一个引导,引导用户进行回复和交流。The target learning video does not contain the audio information of the target character, only the audio information of other characters. When the target learning video is played, the dialogue audio of other characters in the target learning video is played normally. During the dialogue, when the target character needs to talk back, the user can enter the reply information, so that the user can act as the target character and other characters in the target learning video. Have a conversation. The dialogue information of other characters in the target learning video can be used as a limitation on the social scene and as a guide for the user's reply information, so as to guide the user to reply and communicate.
示例性的,假设目标学习视频中包含角色A和角色B,用户选择的目标角色为角色A,目标学习视频中正常播放角色A和角色B的视频画面,并播放角色B的音频信息,用户在角色B的对话引导下,输入针对角色B的音频的回复信息。Exemplarily, it is assumed that the target learning video contains character A and character B, the target character selected by the user is character A, the video images of character A and character B are normally played in the target learning video, and the audio information of character B is played. Under the guidance of the dialogue of character B, enter the reply information for the audio of character B.
在用户作为角色A输入回复信息时,采集用户的回复信息,然后根据角色A的标准音频,判断用户输入的回复信息是否正确,若正确,则输出夸奖信息,若不正确,则输出提示信息,提示用户哪些地方回答的不对,以便用户思考应该如何回复,提高用户的社交语言能力。When the user enters reply information as role A, collect the user's reply information, and then judge whether the reply information input by the user is correct according to the standard audio of role A. If it is correct, output the compliment information, if not, output the prompt information. Prompt the user where the answer is wrong, so that the user can think about how to reply, and improve the user's social language ability.
本发明通过播放学习视频,让用户以特定角色与学习视频中的其他角色进行对话,以供用户进行特定场景、特定角色的社交语言练习和学习,并在用户回复错误时,提醒用户,以便用户知晓回复错误的地方,并思考该如何进行回复,进而提高用户的社交语言能力;同时,还可判断出用户已掌握哪些社交语言,未掌握哪些社交语言,以便用户进一步加强学习。By playing the learning video, the present invention allows the user to have a dialogue with other roles in the learning video with a specific role, so that the user can practice and learn social language in a specific scene and a specific role, and when the user replies to an error, the user is reminded, so that the user can Know the wrong place to reply, and think about how to reply, so as to improve the user's social language ability; at the same time, it can also judge which social language the user has mastered and which social language has not been mastered, so that the user can further strengthen the learning.
优选地,还包括构建模块;构建模块包括:Preferably, it also includes a building block; the building block includes:
获取单元,用于获取各社交场景对应的对话视频;an obtaining unit, used for obtaining the dialogue video corresponding to each social scene;
处理单元,用于从当前社交场景对应的对话视频中删除当前角色的音频信息,形成所述当前角色对应的学习视频;a processing unit, configured to delete the audio information of the current character from the dialogue video corresponding to the current social scene, and form a learning video corresponding to the current character;
存储单元,用于根据所述当前社交场景下各角色对应的各学习视频,生成所述当前社交场景对应的学习视频集;a storage unit, configured to generate a learning video set corresponding to the current social scene according to each learning video corresponding to each character in the current social scene;
所述存储单元,用于根据各社交场景对应的学习视频集,构建所述视频库。The storage unit is configured to construct the video library according to the learning video set corresponding to each social scene.
具体地,视频库中包括各社交场景对应的学习视频集,每个社交场景对应一个或多个学习视频集。各社交场景对应的学习视频集的构建方法为:先获取各社交场景对应的对话视频,每个社交场景可获取多个对话视频。其中,对话视频可以是由真人根据标准社交用语拍摄而成,也可以是根据标准社交用语通过动画制作而成。Specifically, the video library includes learning video sets corresponding to each social scene, and each social scene corresponds to one or more learning video sets. The method for constructing the learning video set corresponding to each social scene is as follows: firstly acquire the dialogue videos corresponding to each social scene, and each social scene may acquire multiple dialogue videos. Among them, the dialogue video may be shot by a real person according to standard social terms, or may be produced by animation according to standard social terms.
从对话视频中分别提取出各角色的音频信息,然后删除某一角色的音频信息,生成该角色的学习视频。例如,对话视频中包括角色A和角色B,从对话视频中删除角色A的音频信息,即可生成角色A的学习视频;从对话视频中删除角色B的音频信息,即可生成角色B的学习视频。角色A的学习视频和角色B的学习视频即可形成一个学习视频集。若对话视频中包括三个角色,则可生成三个角色分别对应的学习视频,这三个学习视频也可形成一个学习视频集。The audio information of each character is extracted from the dialogue video, and then the audio information of a certain character is deleted to generate a learning video of the character. For example, a dialogue video includes character A and character B. Deleting the audio information of character A from the dialogue video can generate a learning video for character A; deleting the audio information of character B from the dialogue video can generate a learning video for character B video. The learning video of character A and the learning video of character B can form a learning video set. If the dialogue video includes three characters, learning videos corresponding to the three characters can be generated, and the three learning videos can also form a learning video set.
根据各个社交场景的对话视频,即可生成各个社交场景对应的学习视频集,然后将生成的学习视频集全部存储在新建的视频库中,形成构建好的视频库。在构建好的视频库中,建立各个学习视频集与社交场景的关联关系。在获取到用户选择的目标社交场景后,可根据社交场景与学习视频集之间的关联关系,在视频库中查找到与目标社交场景对应的目标学习视频集。According to the conversation videos of each social scene, a learning video set corresponding to each social scene can be generated, and then all the generated learning video sets are stored in the newly created video library to form a constructed video library. In the constructed video library, establish the relationship between each learning video set and the social scene. After acquiring the target social scene selected by the user, a target learning video set corresponding to the target social scene can be found in the video library according to the relationship between the social scene and the learning video set.
优选地,还包括:Preferably, it also includes:
确定模块,用于当所述回复信息不正确时,根据所述标准音频,确定回复错误的地方在所述对话视频中的播放时间;a determining module, configured to determine, according to the standard audio, the playback time of the wrong place in the dialogue video when the reply information is incorrect;
控制模块,用于控制所述目标社交场景对应的对话视频按照所述播放时间进行播放。A control module, configured to control the dialogue video corresponding to the target social scene to be played according to the play time.
具体地,用户在与目标学习视频中的其他角色对话时,可能会回复多次,因此,回复信息中可能包括多句话。将回复信息中的每句话与标准音频中对应的语句进行比对,判断回复信息中是否存在不正确的地方,若存在,则根据标准音频,确定回复错误的地方在目标社交场景对应的对话视频中的播放时间,该播放时间包括播放开始时间和播放结束时间。Specifically, the user may reply multiple times when talking with other characters in the target learning video, and therefore, the reply information may include multiple sentences. Compare each sentence in the reply message with the corresponding sentence in the standard audio to determine whether there is an incorrect place in the reply message. If there is, then according to the standard audio, determine that the wrong place in the reply is in the dialogue corresponding to the target social scene The playback time in the video, which includes the playback start time and playback end time.
目标社交场景对应的学习视频集中还可存储该目标社交场景对应的对话视频。根据确定的播放时间,控制目标社交场景对应的对话视频进行播放,以播放错误回复对应的正确回复,以供用户进行模仿学习。The learning video set corresponding to the target social scene may also store a dialogue video corresponding to the target social scene. According to the determined play time, the dialogue video corresponding to the target social scene is controlled to play, so as to play the correct reply corresponding to the wrong reply, so that the user can imitate and learn.
本发明在用户回复错误时,仅播放该错误回复对应的正确回复,不仅可节省用户的时间,而且可供用户进行模仿学习,以提高孩子的社交语言能力,以便更好地与他人进行交流。When the user replies wrongly, the present invention only plays the correct reply corresponding to the wrong reply, which not only saves the user's time, but also allows the user to imitate and learn, so as to improve the child's social language ability, so as to better communicate with others.
优选地,判断模块50包括:Preferably, the judgment module 50 includes:
识别单元,用于识别所述回复信息的语义;an identification unit for identifying the semantics of the reply information;
所述识别单元,用于识别所述标准音频的语义;the identifying unit, for identifying the semantics of the standard audio;
比对单元,用于将所述回复信息的语义和所述标准音频的语义进行比对;a comparison unit, configured to compare the semantics of the reply information with the semantics of the standard audio;
判断单元,用于当所述回复信息的语义与所述标准音频的语义相同时,判断所述回复信息正确;否则,判断所述回复信息不正确。A judging unit, configured to judge that the reply information is correct when the semantics of the reply information is the same as the semantics of the standard audio; otherwise, judge that the reply information is incorrect.
具体地,将回复信息与标准音频进行比对,以判断回复信息是否正确时,先识别回复信息的语义,并识别标准音频的语义,然后将回复信息的语义与标准音频的语义进行比对,当回复信息的语义与标准音频的语义相同时,回复信息正确,若两者语义不同,则回复信息不正确。Specifically, when comparing the reply information with the standard audio to determine whether the reply information is correct, first identify the semantics of the reply information, and identify the semantics of the standard audio, and then compare the semantics of the reply information with the semantics of the standard audio, When the semantics of the reply information is the same as that of the standard audio, the reply information is correct; if the semantics of the two are different, the reply information is incorrect.
当回复信息中包含多句话时,将回复信息中的每句话的语义与标准音频中对应语句的语义进行比对,以判断回复信息中的哪句话回复正确,哪句话回复不正确。对于不正确的回复,可发出提示信息提醒用户,并且提醒用户后,还可再次采集用户输入的语音信息,该再次输入的语音信息是用户对回复错误的地方的再次回复,并根据该错误回复的标准音频判断用户再次输入的语音信息是否正确。在用户多次回复,仍不正确时,可播放对话视频中该错误回复对应的正确回复,在播放对话视频时,只播放该错误回复对应的正确回复部分,对于其他已回复正确的地方,可不再进行播放;当然,若用户希望播放完整的对话视频,则进行播放。When the reply message contains multiple sentences, compare the semantics of each sentence in the reply message with the semantics of the corresponding sentence in the standard audio to determine which sentence in the reply message is correct and which is incorrect. . For an incorrect reply, a prompt message can be sent to remind the user, and after reminding the user, the voice information input by the user can be collected again. The standard audio to determine whether the voice information input by the user again is correct. When the user replies multiple times and is still incorrect, the correct reply corresponding to the incorrect reply in the conversation video can be played. When playing the conversation video, only the correct reply part corresponding to the incorrect reply is played. Play again; of course, if the user wants to play the complete dialogue video, play it.
本实施例中,根据回复信息的语义以及标准音频的语义,来判断回复信息是否正确,可防止出现语义相同,但因使用文字不同而被判断错误的情况,进而提高判断的准确率。In this embodiment, it is judged whether the reply information is correct according to the semantics of the reply information and the semantics of the standard audio, which can prevent the situation that the semantics are the same, but the judgment is wrong due to different words, thereby improving the accuracy of the judgment.
优选地,还包括:Preferably, it also includes:
评分模块,用于根据判断结果,对所述回复信息进行评分;a scoring module, used for scoring the reply information according to the judgment result;
推送模块,用于根据所述评分,向所述用户推送对应社交场景的学习视频集。A push module, configured to push a learning video set corresponding to a social scene to the user according to the score.
具体地,在根据标准音频,判断回复信息是否正确后,还可根据判断结果,对回复信息进行评分。例如,当回复信息中包含五句话时,其中有三句回复正确,有两句回复错误,则回复信息的评分为60分。Specifically, after judging whether the reply information is correct according to the standard audio, the reply information can also be scored according to the judgment result. For example, when the reply message contains five sentences, three of which are correct and two are wrong, the reply message is scored as 60 points.
若回复信息的评分较高,则说明用户已掌握该社交场景的社交语言;若回复信息的评分较低,则说明用户未掌握该社交场景的社交语言。若用户已掌握该社交场景的社交语言,则可向用户推送更高难度的社交场景的学习视频集。若用户未掌握该社交场景的社交语言,则向用户推送该社交场景对应的其它学习视频集,或向用户推送与该社交场景相关联的社交场景的学习视频集。If the score of the reply message is high, it indicates that the user has mastered the social language of the social scene; if the score of the reply message is low, it indicates that the user has not mastered the social language of the social scene. If the user has mastered the social language of the social scene, a learning video set of a more difficult social scene can be pushed to the user. If the user does not master the social language of the social scene, other learning video sets corresponding to the social scene are pushed to the user, or a learning video set of the social scene associated with the social scene is pushed to the user.
本实施例中,根据回复信息的评分,向用户推送对应的学习视频集,使得推送的学习视频集更符合用户的当前水平,以便更好的帮助用户进行社交语言的学习。In this embodiment, according to the score of the reply information, a corresponding learning video set is pushed to the user, so that the pushed learning video set is more in line with the user's current level, so as to better help the user to learn social language.
应当说明的是,上述实施例均可根据需要自由组合。以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。It should be noted that the above embodiments can be freely combined as required. The above are only the preferred embodiments of the present invention. It should be pointed out that for those skilled in the art, without departing from the principles of the present invention, several improvements and modifications can be made. It should be regarded as the protection scope of the present invention.
Claims (6)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910596768.2ACN112185187B (en) | 2019-07-02 | 2019-07-02 | Learning method and intelligent device for social language |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910596768.2ACN112185187B (en) | 2019-07-02 | 2019-07-02 | Learning method and intelligent device for social language |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN112185187A CN112185187A (en) | 2021-01-05 |
| CN112185187Btrue CN112185187B (en) | 2022-05-20 |
Family
ID=73915990
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201910596768.2AActiveCN112185187B (en) | 2019-07-02 | 2019-07-02 | Learning method and intelligent device for social language |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN112185187B (en) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112669658A (en)* | 2021-01-25 | 2021-04-16 | 杨涵予 | English learning real scene dialogue training device |
| CN112560512B (en)* | 2021-02-24 | 2021-08-06 | 南京酷朗电子有限公司 | Intelligent Speech Analysis and Assisted Communication Methods for Foreign Language Learning |
| CN114913307A (en)* | 2022-05-16 | 2022-08-16 | 深圳慧安康科技有限公司 | Information interaction method, device and equipment for language learning |
| CN119577068A (en)* | 2023-08-22 | 2025-03-07 | 杭州阿里云飞天信息技术有限公司 | Reply generation system, method and device |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5930757A (en)* | 1996-11-21 | 1999-07-27 | Freeman; Michael J. | Interactive two-way conversational apparatus with voice recognition |
| CN208796480U (en)* | 2018-05-16 | 2019-04-26 | 侯院凤 | A kind of multi-functional early education robot |
Family Cites Families (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8009966B2 (en)* | 2002-11-01 | 2011-08-30 | Synchro Arts Limited | Methods and apparatus for use in sound replacement with automatic synchronization to images |
| US20070015121A1 (en)* | 2005-06-02 | 2007-01-18 | University Of Southern California | Interactive Foreign Language Teaching |
| TW200811769A (en)* | 2006-08-25 | 2008-03-01 | Inventec Besta Co Ltd | Method of scenario language learning |
| WO2008119078A2 (en)* | 2007-03-28 | 2008-10-02 | Breakthrough Performance Technologies, Llc | Systems and methods for computerized interactive training |
| CN101123043A (en)* | 2007-09-13 | 2008-02-13 | 无敌科技(西安)有限公司 | Scenario foreign language learning method |
| US20130073964A1 (en)* | 2011-09-20 | 2013-03-21 | Brian Meaney | Outputting media presentations using roles assigned to content |
| CN103117057B (en)* | 2012-12-27 | 2015-10-21 | 安徽科大讯飞信息科技股份有限公司 | The application process of a kind of particular person speech synthesis technique in mobile phone cartoon is dubbed |
| WO2014186346A1 (en)* | 2013-05-13 | 2014-11-20 | Mango Languages | Method and system for motion picture assisted foreign language learning |
| CN103426335A (en)* | 2013-08-26 | 2013-12-04 | 苏州跨界软件科技有限公司 | Social language learning method |
| US10272349B2 (en)* | 2016-09-07 | 2019-04-30 | Isaac Davenport | Dialog simulation |
| CN106952515A (en)* | 2017-05-16 | 2017-07-14 | 宋宇 | The interactive learning methods and system of view-based access control model equipment |
| CN207425137U (en)* | 2017-08-30 | 2018-05-29 | 湖南安全技术职业学院 | English study training device based on the dialogue of VR real scenes |
| CN108040289A (en)* | 2017-12-12 | 2018-05-15 | 天脉聚源(北京)传媒科技有限公司 | A kind of method and device of video playing |
- 2019
- 2019-07-02CNCN201910596768.2Apatent/CN112185187B/enactiveActive
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5930757A (en)* | 1996-11-21 | 1999-07-27 | Freeman; Michael J. | Interactive two-way conversational apparatus with voice recognition |
| CN208796480U (en)* | 2018-05-16 | 2019-04-26 | 侯院凤 | A kind of multi-functional early education robot |
Also Published As
| Publication number | Publication date |
|---|---|
| CN112185187A (en) | 2021-01-05 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN112185187B (en) | Learning method and intelligent device for social language | |
| US12050574B2 (en) | Artificial intelligence platform with improved conversational ability and personality development | |
| CN105975622B (en) | Multi-role intelligent chatting method and system | |
| Serban et al. | A survey of available corpora for building data-driven dialogue systems | |
| Hopper | Telephone conversation | |
| CN112015852B (en) | Providing responses in conversation about events | |
| WO2022121601A1 (en) | Live streaming interaction method and apparatus, and device and medium | |
| CN109643325B (en) | Recommending friends in automatic chat | |
| WO2019184103A1 (en) | Person ip-based human-computer interaction method and system, medium and device | |
| US20180181855A1 (en) | Systems and methods for a mathematical chat bot | |
| JP4889690B2 (en) | Conversation display method and server apparatus | |
| CN106294582A (en) | Man-machine interaction method based on natural language and system | |
| TW201117114A (en) | System, apparatus and method for message simulation | |
| CN109582700A (en) | A kind of voice room user matching method, device and equipment | |
| CN110249325A (en) | Input system with traffic model | |
| CN104462122A (en) | Test question data processing method and device | |
| Koh | “Date me date me”: AI chatbot interactions as a resource for the online construction of masculinity | |
| CN111767386A (en) | Conversation processing method and device, electronic equipment and computer readable storage medium | |
| Clavel-Arroitia et al. | A qualitative meta-analysis of intercultural research into audio-visual synchronous communication between language learners | |
| CN112820265B (en) | Speech synthesis model training method and related device | |
| Kennedy et al. | Learning and reusing dialog for repeated interactions with a situated social agent | |
| Hendershott-Kraetzer | Juliet, I prosume? or Shakespeare and the social network | |
| CN114520003A (en) | Voice interaction method and device, electronic equipment and storage medium | |
| CN107154173B (en) | Language learning method and system | |
| CN117271290B (en) | Fair and efficient multi-dialogue system evaluation system and method |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |