CN112132238A - A method, apparatus, device and readable medium for identifying private data - Google Patents
A method, apparatus, device and readable medium for identifying private dataDownload PDFInfo
- Publication number
- CN112132238A CN112132238ACN202011322577.6ACN202011322577ACN112132238ACN 112132238 ACN112132238 ACN 112132238ACN 202011322577 ACN202011322577 ACN 202011322577ACN 112132238 ACN112132238 ACN 112132238A
- Authority
- CN
- China
- Prior art keywords
- data
- identified
- classification model
- metadata
- belongs
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images




Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/243—Classification techniques relating to the number of classes
- G06F18/2431—Multiple classes
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/24765—Rule-based classification
Landscapes
- Engineering & Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Theoretical Computer Science (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Biology (AREA)
- Evolutionary Computation (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本申请涉及计算机技术领域,尤其涉及一种识别隐私数据的方法、装置、设备和可读介质。The present application relates to the field of computer technology, and in particular, to a method, apparatus, device and readable medium for identifying private data.
背景技术Background technique
现有技术中,当进行隐私数据识别时,通常可以采用与该类型对应的内置规则或基于机器学习的多分类模型来进行识别。内置规则可以是特定的正则表达式或基于敏感数据自身结构特征而构造的识别规则。然而,隐私数据的类型是多样的。这些预先准备的内置规则无法涵盖全部的数据类型。当用户想要识别的数据并不具有对应的预设内置规则时,就无法实现对目标数据的识别。现有的基于机器学习的多分类模型大多基于数据的具体内容进行训练和识别,而这种只基于数据的具体内容训练得到的多分类模型,模型维度单一,并不能充分挖掘出待识别数据多维度的属性,从而导致其识别准确率较低,而且由于待识别数据的具体内容所包含的数据量大,模型在训练阶段和测试阶段开销较大。In the prior art, when identifying private data, the built-in rules corresponding to the type or a multi-classification model based on machine learning can usually be used for identification. Built-in rules can be specific regular expressions or identification rules constructed based on the structural characteristics of sensitive data itself. However, the types of private data are diverse. These pre-prepared built-in rules cannot cover all data types. When the data the user wants to identify does not have corresponding preset built-in rules, the target data cannot be identified. Most of the existing multi-classification models based on machine learning are trained and recognized based on the specific content of the data, and this multi-classification model, which is only trained based on the specific content of the data, has a single model dimension and cannot fully mine the data to be recognized. Due to the attributes of the dimension, the recognition accuracy rate is low, and due to the large amount of data contained in the specific content of the data to be recognized, the model has a large overhead in the training phase and the testing phase.
基于此,如何提供一种准确率和效率都比较高的识别隐私数据的方法成为亟需解决的技术问题。Based on this, how to provide a method for identifying private data with high accuracy and efficiency has become a technical problem that needs to be solved urgently.
发明内容SUMMARY OF THE INVENTION
本说明书实施例提供一种识别隐私数据的方法、装置、设备和可读介质,以提高隐私数据识别的准确率和效率。The embodiments of this specification provide a method, apparatus, device, and readable medium for identifying private data, so as to improve the accuracy and efficiency of identifying private data.
为解决上述技术问题,本说明书实施例是这样实现的:In order to solve the above-mentioned technical problems, the embodiments of this specification are implemented as follows:
本说明书实施例提供的一种识别隐私数据的方法,包括:A method for identifying private data provided by the embodiments of this specification includes:
获取待识别数据的元数据;Obtain metadata of the data to be identified;
将所述元数据输入第一多分类模型以对所述待识别数据的数据类型进行识别,得到第一识别结果;所述第一多分类模型是基于隐私类型数据对应的元数据进行训练得到的;The metadata is input into the first multi-classification model to identify the data type of the data to be identified, and a first recognition result is obtained; the first multi-classification model is obtained by training based on the metadata corresponding to the privacy type data ;
若所述第一识别结果表示所述待识别数据属于隐私数据,则根据所述第一识别结果确定所述待识别数据所属的隐私类型;If the first identification result indicates that the to-be-identified data belongs to private data, determining the privacy type to which the to-be-identified data belongs according to the first identification result;
若所述第一识别结果表示所述待识别数据不属于隐私数据,则将所述元数据和所述待识别数据输入第二多分类模型,得到第二识别结果;根据所述第二识别结果确定所述待识别数据所属的隐私类型。If the first identification result indicates that the data to be identified does not belong to private data, the metadata and the data to be identified are input into a second multi-classification model to obtain a second identification result; according to the second identification result Determine the privacy type to which the data to be identified belongs.
本说明书实施例提供的一种识别隐私数据的装置,包括:An apparatus for identifying private data provided by an embodiment of this specification includes:
数据获取模块,用于获取待识别数据的元数据;A data acquisition module for acquiring metadata of the data to be identified;
第一识别结果确定模块,用于将所述元数据输入第一多分类模型以对所述待识别数据的数据类型进行识别,得到第一识别结果;所述第一多分类模型是基于隐私类型数据对应的元数据进行训练得到的;若所述第一识别结果表示所述待识别数据属于隐私数据,则根据所述第一识别结果确定所述待识别数据所属的隐私类型;a first recognition result determination module, configured to input the metadata into a first multi-classification model to identify the data type of the data to be recognized, and obtain a first recognition result; the first multi-classification model is based on the privacy type The metadata corresponding to the data is obtained by training; if the first identification result indicates that the data to be identified belongs to private data, then the privacy type to which the data to be identified belongs is determined according to the first identification result;
第二识别结果确定模块,用于若所述第一识别结果表示所述待识别数据不属于隐私数据,则将所述元数据和所述待识别数据输入第二多分类模型,得到第二识别结果;根据所述第二识别结果确定所述待识别数据所属的隐私类型。A second identification result determination module, configured to input the metadata and the data to be identified into a second multi-classification model to obtain a second identification if the first identification result indicates that the data to be identified does not belong to private data Result: determining the privacy type to which the data to be identified belongs according to the second identification result.
本说明书实施例提供的一种识别隐私数据的设备,包括:A device for identifying private data provided by the embodiments of this specification includes:
至少一个处理器;以及,at least one processor; and,
与所述至少一个处理器通信连接的存储器;其中,a memory communicatively coupled to the at least one processor; wherein,
所述处理器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够:The processor stores instructions executable by the at least one processor, the instructions being executed by the at least one processor to enable the at least one processor to:
获取待识别数据的元数据;Obtain metadata of the data to be identified;
将所述元数据输入第一多分类模型以对所述待识别数据的数据类型进行识别,得到第一识别结果;所述第一多分类模型是基于隐私类型数据对应的元数据进行训练得到的;The metadata is input into the first multi-classification model to identify the data type of the data to be identified, and a first recognition result is obtained; the first multi-classification model is obtained by training based on the metadata corresponding to the privacy type data ;
若所述第一识别结果表示所述待识别数据属于隐私数据,则根据所述第一识别结果确定所述待识别数据所属的隐私类型;If the first identification result indicates that the to-be-identified data belongs to private data, determining the privacy type to which the to-be-identified data belongs according to the first identification result;
若所述第一识别结果表示所述待识别数据不属于隐私数据,则将所述元数据和所述待识别数据输入第二多分类模型,得到第二识别结果;根据所述第二识别结果确定所述待识别数据所属的隐私类型。If the first identification result indicates that the data to be identified does not belong to private data, the metadata and the data to be identified are input into a second multi-classification model to obtain a second identification result; according to the second identification result Determine the privacy type to which the data to be identified belongs.
本说明书实施例提供的一种计算机可读介质,其上存储有计算机可读指令,所述计算机可读指令可被处理器执行以实现一种识别隐私数据的方法。A computer-readable medium provided by an embodiment of the present specification stores computer-readable instructions thereon, and the computer-readable instructions can be executed by a processor to implement a method for identifying private data.
本说明书中提供的至少一个实施例能够达到以下有益效果:At least one embodiment provided in this specification can achieve the following beneficial effects:
本说明书实施例优先采用基于已知隐私类型的数据的元数据训练得到的第一多分类模型来判断待识别数据是否属于隐私数据及所属的隐私类型,如果判断为否,则再采用基于已知隐私类型的数据样本的元数据和所述已知隐私类型的数据样本的组合结果进行训练得到的第二多分类模型对待识别数据进行进一步判断。一方面,可以节省计算资源,减少计算时间,提高隐私数据识别模型的整体识别效率,另一方面,由于可以获得更多的特征信息,提高隐私数据识别模型的准确率,从而本方案可以同时兼顾隐私数据识别的准确率和效率。The embodiments of this specification preferentially use the first multi-classification model obtained by training metadata based on data of known privacy types to determine whether the data to be identified belongs to privacy data and the privacy type to which it belongs. The second multi-classification model obtained by training the metadata of the data samples of the privacy type and the combined result of the data samples of the known privacy type performs further judgment on the data to be identified. On the one hand, it can save computing resources, reduce computing time, and improve the overall recognition efficiency of the privacy data recognition model. Accuracy and efficiency of private data identification.
附图说明Description of drawings
为了更清楚地说明本说明书实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请中记载的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。In order to more clearly illustrate the technical solutions in the embodiments of the present specification or the prior art, the following briefly introduces the accompanying drawings required in the description of the embodiments or the prior art. Obviously, the accompanying drawings in the following description are only These are some embodiments described in this application. For those of ordinary skill in the art, other drawings can also be obtained based on these drawings without any creative effort.
图1为本说明书实施例中一种识别隐私数据的方法的整体方案流程示意图;FIG. 1 is a schematic flowchart of an overall scheme of a method for identifying private data in an embodiment of this specification;
图2为本说明书实施例中另一种识别隐私数据的方法的整体方案流程示意图;2 is a schematic flowchart of an overall solution of another method for identifying private data in the embodiment of this specification;
图3为本说明书实施例提供的一种识别隐私数据的方法的流程示意图;3 is a schematic flowchart of a method for identifying private data provided by an embodiment of the present specification;
图4为本说明书实施例提供的对应于图3的一种识别隐私数据的装置的结构示意图;FIG. 4 is a schematic structural diagram of an apparatus for identifying private data corresponding to FIG. 3 provided by an embodiment of the present specification;
图5为本说明书实施例提供的对应于图3的一种识别隐私数据的设备的结构示意图。FIG. 5 is a schematic structural diagram of a device for identifying private data corresponding to FIG. 3 according to an embodiment of the present specification.
具体实施方式Detailed ways
为使本说明书一个或多个实施例的目的、技术方案和优点更加清楚,下面将结合本说明书具体实施例及相应的附图对本说明书一个或多个实施例的技术方案进行清楚、完整地描述。显然,所描述的实施例仅是本说明书的一部分实施例,而不是全部的实施例。基于本说明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本说明书一个或多个实施例保护的范围。In order to make the objectives, technical solutions and advantages of one or more embodiments of this specification clearer, the technical solutions of one or more embodiments of this specification will be clearly and completely described below with reference to the specific embodiments of this specification and the corresponding drawings. . Obviously, the described embodiments are only some of the embodiments of the present specification, but not all of the embodiments. All other embodiments obtained by persons of ordinary skill in the art based on the embodiments in the present specification without creative efforts fall within the protection scope of one or more embodiments of the present specification.
对隐私数据进行识别的目的是对其实施更有效的保护,隐私数据保护首先需要从海量数据表中识别出潜在隐私数据字段;其次,针对识别出的隐私数据字段,利用相应的手段进行脱敏处理,从而有效防范隐私数据的泄露。The purpose of identifying private data is to protect it more effectively. To protect private data, it is first necessary to identify potential private data fields from massive data tables; secondly, for the identified private data fields, corresponding means are used to desensitize them. processing, so as to effectively prevent the leakage of private data.
目前,当进行隐私数据识别时,用户可以根据想要识别的隐私数据的类型,采用相应的预设正则表达式、或者相应的提前训练的多分类模型来进行识别。Currently, when identifying private data, a user can use a corresponding preset regular expression or a corresponding pre-trained multi-classification model to perform the identification according to the type of private data to be identified.
正则表达式(Regular Expression),又称正则表示式、正则表示法、规则表达式、常规表示法,其基于约定的语法规则,构建单个字符串来描述、匹配一系列符合某个句法规则的字符串。例如,对于手机号可以用正则表达式“^1[3-9][0-9]{9}$”来表示,只要匹配这个正则表达式的字段就可以被识别为手机号字段。目前,若采用基于规则的隐私数据识别方案,在扫描数据库时,会将数据库的抽样数据通过每一条正则表达式来判断隐私数据的类型,然后将所有抽样数据的识别结果进行汇总后,再做最终的判断。由于需要通过每一条规则来达到判断的效果,因此当隐私数据类型很多的情况下,匹配的效率非常低;并且,由于内置规则无法覆盖全部的隐私数据类型,适用范围非常受限,当用户想要识别的隐私类型没有相应的预设规则时,用户需求无法满足;再者,内置规则的撰写需要专业人士参与,人力资源损耗较大。Regular Expression (Regular Expression), also known as regular expression, regular notation, regular expression, regular notation, is based on the agreed grammar rules and constructs a single string to describe and match a series of characters that conform to a certain syntactic rule string. For example, a mobile phone number can be represented by the regular expression "^1[3-9][0-9]{9}$", as long as a field matching this regular expression can be identified as a mobile phone number field. At present, if a rule-based privacy data identification scheme is adopted, when scanning the database, the sampled data of the database will be judged by each regular expression to determine the type of privacy data, and then the identification results of all the sampled data will be aggregated, and then final judgment. Since each rule needs to be used to achieve the effect of judgment, when there are many types of private data, the matching efficiency is very low; and because the built-in rules cannot cover all types of private data, the scope of application is very limited. When there is no corresponding preset rule for the privacy type to be identified, user needs cannot be met; moreover, the writing of built-in rules requires the participation of professionals, and the loss of human resources is large.
基于多分类模型(Multi-classification)的隐私数据识别方法,是有监督学习(Supervised Learning)方法的一种。现有的基于机器学习的多分类模型大多基于数据的具体内容进行训练和识别,而这种只基于数据的具体内容训练得到的多分类模型,模型维度单一,并不能充分挖掘出待识别数据多维度的属性,从而导致其识别准确率较低,而且由于待识别数据的具体内容所包含的数据量大,模型在训练阶段和测试阶段开销较大,需要耗费较多的GPU或CPU资源。The privacy data identification method based on the multi-classification model is a kind of supervised learning method. Most of the existing multi-classification models based on machine learning are trained and recognized based on the specific content of the data, and this multi-classification model, which is only trained based on the specific content of the data, has a single model dimension and cannot fully mine the data to be recognized. Due to the attributes of the dimension, the recognition accuracy is low, and due to the large amount of data contained in the specific content of the data to be recognized, the model has a large overhead in the training and testing phases, and requires more GPU or CPU resources.
本方案中提供的识别隐私数据的方法优先采用基于已知隐私类型的数据的元数据训练得到的第一多分类模型来判断待识别数据是否属于隐私数据及所属的隐私类型,如果判断为否,则再采用基于已知隐私类型的数据样本的元数据和所述已知隐私类型的数据样本的组合结果进行训练得到的第二多分类模型对待识别数据进行进一步判断。这样,一方面,可以节省计算资源,减少计算时间,提高隐私数据识别模型的整体识别效率,另一方面,由于可以获得更多的特征信息,提高隐私数据识别模型的准确率,从而本方案可以同时兼顾隐私数据识别的准确率和效率。The method for identifying private data provided in this solution preferentially uses the first multi-classification model trained based on metadata of data of known privacy types to determine whether the data to be identified belongs to private data and the type of privacy to which it belongs. Then, a second multi-classification model obtained by training based on the metadata of the data samples of the known privacy type and the combined result of the data samples of the known privacy type is used to further judge the data to be identified. In this way, on the one hand, computing resources can be saved, computing time can be reduced, and the overall recognition efficiency of the private data identification model can be improved. At the same time, the accuracy and efficiency of private data identification are taken into account.
为使本说明书中一个或多个实施例的目的、技术方案和优点更加清楚,下面将结合本说明书具体实施例及相应的附图对本说明书一个或多个实施例的技术方案进行清楚、完整地描述。显然,所描述的实施例仅是本说明书的一部分实施例,而不是全部的实施例。基于本说明书中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本说明书一个或多个实施例的保护范围。应当理解,尽管在本说明书中可能采用术语第一、第二、第三等来描述各种信息,但这些信息不应限于这些术语,这些术语仅用来将同一类型的信息彼此区分开来。In order to make the objectives, technical solutions and advantages of one or more embodiments in this specification clearer, the following will clearly and completely describe the technical solutions of one or more embodiments in this specification in conjunction with the specific embodiments of this specification and the corresponding drawings. describe. Obviously, the described embodiments are only some of the embodiments of the present specification, but not all of the embodiments. Based on the embodiments in this specification, all other embodiments obtained by those of ordinary skill in the art without creative efforts shall fall within the protection scope of one or more embodiments of this specification. It should be understood that although the terms first, second, third, etc. may be used in this specification to describe various information, these information should not be limited to these terms, which are only used to distinguish the same type of information from each other.
以下结合附图,详细说明本说明书各实施例所提供的技术方案。The technical solutions provided by the embodiments of the present specification will be described in detail below with reference to the accompanying drawings.
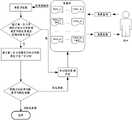
图1为本说明书实施例中一种识别隐私数据的方法的整体方案流程示意图。如图1所示,当用户对数据库中某个字段下的多条数据进行查询时,首先需进行数据预处理,即从该待识别的多条数据所属的字段的全部数据中抽取预定比例的数据,或者从待识别的多条数据所属的字段的全部数据中抽取预定条数的数据,得到抽样数据,同时获取该待识别的多条数据所属的字段的元数据。经过数据预处理阶段后,首先采用基于已知隐私类型的数据的元数据训练得到的第一多分类模型来判断抽样数据是否属于隐私数据及所属的隐私类型,如果通过第一多分类模型就能判断出抽样数据所属的隐私类型,则首先对抽样数据所属的整个字段的全部数据进行隐私类型标记,再采用与抽样数据所属的隐私类型相应的脱敏规则对抽样数据所属的整个字段的全部数据进行脱敏处理,再将查询结果输出给用户。如果通过第一多分类模型不能判断出抽样数据是否属于隐私数据及所属的隐私类型,则再采用基于已知隐私类型的数据样本的元数据和所述已知隐私类型的数据样本的组合结果进行训练得到的第二多分类模型对抽样数据进行进一步判断,如果通过第二多分类模型能够判断出抽样数据为隐私数据及所属的隐私类型,则为提高隐私数据识别的准确率,需再采用与抽样数据的隐私类型相应的校验规则对抽样数据进而二次校验(在本实施例方案中,根据掌握的隐私数据类型的经验,预先设置了若干条校验规则,即规则1、规则2、…、规则n),采用与抽样数据所属的隐私类型相应的校验规则对抽样数据进行二次校验,然后对二次校验的结果进行比例分析,即如果抽样数据通过二次校验的比例大于预定的第一阈值且抽样数据属于所述隐私类型的概率大于预先设定的第二阈值时,则可以采用与抽样数据所属的隐私类型相应的脱敏规则对抽样数据所属的整个字段的全部数据进行脱敏处理。需要说明的是,在本方案中,在数据预处理阶段,从用户欲查询的多条数据所属的字段中进行了数据抽样,再将抽样得到的抽样数据进行后续的识别处理,考虑到用户欲查询的数据的条数可能较少,比如可能少于50条,此时如果不从用户欲查询的多条数据所属的字段中进行数据抽样,而是直接将用户欲查询的多条数据进行后续的经过第一多分类模型进行识别以及根据第一多分类模型的识别结果决定是否再经过第二多分类模型进行进一步识别,则在二次校验阶段,可能由于数据条数较少,统计规律不明显,使得此多条数据通过二次校验的比例的比例值不具有统计规律性,从而在统计意义上,此多条数据中通过二次校验的数据的条数相对全部所述多条数据的比例值不能说明此多条数据是否为隐私数据。而当用户欲查询的数据的条数较多,比如大于等于50条时,在数据预处理阶段,就不用从用户欲查询的多条数据所属的字段中进行数据抽样,但需获取该待识别的多条数据所属的字段的元数据,后续的经过第一多分类模型进行识别以及根据第一多分类模型的识别结果决定是否再经过第二多分类模型进行进一步识别和二次校验的内容,前文已有交待,在此不再赘述。FIG. 1 is a schematic flowchart of an overall solution of a method for identifying private data in an embodiment of the specification. As shown in Figure 1, when a user queries multiple pieces of data under a certain field in the database, data preprocessing is first required, that is, a predetermined proportion of data, or extract a predetermined number of data from all the data of the fields to which the pieces of data to be identified belong, to obtain sample data, and at the same time obtain the metadata of the fields to which the pieces of data to be identified belong. After the data preprocessing stage, the first multi-classification model trained based on the metadata of data of known privacy types is used to judge whether the sampled data belongs to privacy data and the privacy type to which it belongs. To determine the privacy type to which the sampled data belongs, first mark the privacy type of all data in the entire field to which the sampled data belongs, and then use the desensitization rule corresponding to the privacy type to which the sampled data belongs to all data in the entire field to which the sampled data belongs. Perform desensitization processing, and then output the query results to the user. If the first multi-classification model cannot determine whether the sampled data belongs to the privacy data and the privacy type to which it belongs, then use the combination result of the metadata of the data sample based on the known privacy type and the data sample of the known privacy type to conduct The second multi-classification model obtained by training further judges the sampled data. If the second multi-classification model can determine that the sampled data is private data and the privacy type it belongs to, in order to improve the accuracy of private data identification, it is necessary to use the same The verification rules corresponding to the privacy type of the sampled data further verify the sampled data (in this embodiment, according to the experience of the privacy data type, a number of verification rules are preset, namely
图2为本说明书实施例中另一种识别隐私数据的方法的整体方案流程示意图。在该方案中当用户对数据库中某个字段下的多条数据进行查询时,首先需进行数据预处理,即从该待识别的多条数据所属的字段的全部数据中抽样预定比例的数据,或者从待识别的多条数据所属的字段的全部数据中抽样预定条数的数据,得到抽样数据。采用基于已知隐私类型的数据的元数据训练得到的第一多分类模型来判断抽样数据是否属于隐私数据及所属的隐私类型,如果通过第一多分类模型就能判断出抽样数据所属的隐私类型,则首先对抽样数据所属的整个字段的全部数据进行隐私类型标记,再采用与抽样数据所属的隐私类型相应的脱敏规则对抽样数据所属的整个字段的全部数据进行脱敏处理,再将处理结果输出给用户;如果通过第一多分类模型不能判断出抽样数据是否属于隐私数据及所属的隐私类型,则采用基于已知隐私类型的数据样本的元数据和所述已知隐私类型的数据样本的组合结果进行训练得到的第二多分类模型对抽样数据进行进一步判断,如果通过第二多分类模型能够判断出抽样数据为隐私数据及所属的隐私类型,对于所述抽样数据所属字段中的全部数据采用与所述抽样数据所属的隐私类型相应的隐私类型标识进行隐私类型标记,再采用与抽样数据所属的隐私类型相应的脱敏规则对抽样数据所属的整个字段的全部数据进行脱敏处理,再将查询结果输出给用户。图2中技术方案与图1中技术方案的区别在于,如果通过第二多分类模型能够判断抽样数据是否属于隐私数据及所属的隐私类型,就不再对抽样数据进行二次校验,而是直接将抽样数据视为隐私数据,直接将抽样数据所属的字段中的全部数据视为隐私数据,然后进行后续的隐私类型标记及脱敏处理,然后再将脱敏处理后的数据返回给用户。FIG. 2 is a schematic flowchart of an overall solution of another method for identifying private data in an embodiment of the present specification. In this solution, when a user queries multiple pieces of data under a certain field in the database, data preprocessing is first required, that is, a predetermined proportion of data is sampled from all the data in the fields to which the multiple pieces of data to be identified belong. Alternatively, a predetermined number of pieces of data are sampled from all the data of the fields to which the pieces of data to be identified belong to obtain the sampled data. The first multi-classification model trained based on the metadata of data of known privacy types is used to determine whether the sampled data belongs to privacy data and the privacy type to which it belongs. If the first multi-classification model is used, the privacy type to which the sampled data belongs can be determined. , first mark all data of the entire field to which the sampled data belongs to the privacy type, and then use the desensitization rule corresponding to the privacy type to which the sampled data belongs to desensitize all the data of the entire field to which the sampled data belongs, and then desensitize all the data of the entire field to which the sampled data belongs. The result is output to the user; if it is impossible to judge whether the sampled data belongs to privacy data and the privacy type it belongs to through the first multi-classification model, the metadata of the data sample based on the known privacy type and the data sample of the known privacy type are used. The second multi-classification model obtained by training the combined results of the data further judges the sampled data. If the second multi-classification model can determine that the sampled data is private data and the privacy type to which it belongs, for all the fields to which the sampled data belongs The data is marked with a privacy type identifier corresponding to the privacy type to which the sampled data belongs, and then desensitizes all data in the entire field to which the sampled data belongs by using a desensitization rule corresponding to the privacy type to which the sampled data belongs. Then output the query result to the user. The difference between the technical solution in FIG. 2 and the technical solution in FIG. 1 is that if the second multi-classification model can determine whether the sampled data belongs to privacy data and the privacy type to which it belongs, the sampled data will not be checked twice, but Directly regard the sampled data as private data, directly regard all data in the fields to which the sampled data belongs as private data, and then perform subsequent privacy type marking and desensitization processing, and then return the desensitized data to the user.
图3为本说明书实施例提供的一种识别隐私数据的方法的流程示意图。从程序角度而言,流程的执行主体可以为搭载于应用服务器或应用终端的程序。FIG. 3 is a schematic flowchart of a method for identifying private data according to an embodiment of the present specification. From a program perspective, the execution body of the process may be a program mounted on an application server or an application terminal.
如图3所示,该流程可以包括以下步骤:As shown in Figure 3, the process can include the following steps:
步骤302:获取待识别数据的元数据。Step 302: Obtain metadata of the data to be identified.
数据,尤其是大批量数据,大多数情况下是采用结构化形式进行存储的,这些数据可以通过基于关系模型的表结构存储在数据库中。数据库中包括大量表结构,以表结构为组织单位来对数据进行存储。每个表结构有一个或者多个字段。用户可以通过数据库查询语言与数据库系统进行交互,进而获取所需要的数据。需要说明的是,这里的待识别数据可以指的是用户希望从数据库表结构的一个字段中查询的一条数据。例如:数据库表结构中可以包含“姓名”、“年龄”、“手机号”、“身份证号”等多个字段,每个字段可以对应多条数据。在实际应用中,一个字段对应的字段属性应该是相同的,比如,“手机号”这一字段中包含的所有数据都应是用户的手机号。本实施例中,用户通过数据库查询语言对存储在数据库中的数据进行检索,在将检索后得到的数据提供给用户之前,需要预先判断显示给用户的数据所属的隐私类型数据。如果判断是隐私数据,则需对这些数据进行相应的适当的脱敏处理,以避免隐私数据泄露可能带来的风险。Data, especially in large batches, is mostly stored in a structured form, which can be stored in a database through a table structure based on a relational model. The database includes a large number of table structures, and the table structure is used as an organizational unit to store data. Each table structure has one or more fields. Users can interact with the database system through the database query language to obtain the required data. It should be noted that the data to be identified here may refer to a piece of data that the user wishes to query from a field of the database table structure. For example, the database table structure can contain multiple fields such as "name", "age", "mobile phone number", "ID card number", and each field can correspond to multiple pieces of data. In practical applications, the field attributes corresponding to a field should be the same, for example, all data contained in the field "mobile phone number" should be the user's mobile phone number. In this embodiment, the user retrieves the data stored in the database through the database query language. Before providing the retrieved data to the user, it is necessary to pre-determine the privacy type data to which the data displayed to the user belongs. If it is judged to be private data, appropriate desensitization processing should be performed on these data to avoid the possible risks of private data leakage.
元数据(Metadata)是结构化的、被编码的数据,或者说是用于提供某种资源的相关信息的结构数据,可以用以协助对被描述实体的识别、发现、评估和管理。举例来说,对于一个word文档,通过点击鼠标右键查看其属性,可以得到此word文档的文件类型、打开方式、位置、大小、占用空间、创建时间、修改时间、访问时间、作者、最后一次保存者、是否被设置为只读等大量文档属性信息,即使不打开此word文档查看其记载的具体内容,也能在一定程度上从这些属性信息中得到关于此word文档的一些重要信息。具体到数据库领域中,元数据是用于描述数据仓库内存储的数据的结构和建立方法的数据,一般表示数据库、表、字段的相关属性信息。例如项目名、数据库名、数据库描述信息、表名、字段名、注释、字段的数据类型(整型、浮点型、字符型)等。元数据最基本的功能就是对数据库中存储的信息资源对象进行描述,即是对数据的解释和说明,可以描述信息资源的主题、内容、属性和特点等,从而即使不具体查看元数据所描述的信息的具体内容,也能从一定程度上对其所描述的数据对象的属性有所了解。Metadata is structured, encoded data, or structured data used to provide relevant information about a resource, which can be used to assist in the identification, discovery, evaluation and management of the described entity. For example, for a word document, by clicking the right mouse button to view its properties, you can get the file type, opening method, location, size, space occupied, creation time, modification time, access time, author, and last save of the word document. Even if you do not open the word document to view the specific content of its records, you can get some important information about the word document from these attribute information to a certain extent. Specifically in the database field, metadata is data used to describe the structure and establishment method of data stored in a data warehouse, and generally represents the relevant attribute information of databases, tables, and fields. For example, project name, database name, database description information, table name, field name, comment, field data type (integer, floating point, character), etc. The most basic function of metadata is to describe the information resource objects stored in the database, that is, to explain and describe the data. The specific content of the information can also be understood to a certain extent about the attributes of the data objects it describes.
步骤304:将所述元数据输入第一多分类模型以对所述待识别数据的数据类型进行识别,得到第一识别结果;所述第一多分类模型是基于隐私类型数据对应的元数据进行训练得到的。Step 304: Input the metadata into the first multi-classification model to identify the data type of the data to be identified, and obtain a first recognition result; the first multi-classification model is based on the metadata corresponding to the privacy type data. obtained by training.
统计学习技术中的监督学习的任务是学习一个模型,使模型能够对任意给定的输入,对其相应的输出做出一个好的预测。第一多分类模型可以是有监督学习算法中的一种,可以根据已知样本的某些特征,判断一个新的样本属于哪种已知的样本类型。更具体地,多分类模型可以根据已知的训练集提供的样本数据,通过计算选择特征参数,创建判别函数对样本进行分类。所述第一多分类模型是基于隐私类型数据对应的元数据进行训练得到的,是指预先将数据的带有类别标签的元数据作为训练样本,利用元数据对多分类模型进行训练,让多分类模型学习这些带有类别标签的元数据训练样本中所蕴含的向量特征,最后得到训练完毕的第一多分类模型。其中所述元数据包含有表征待识别数据的语义特征信息。这样在遇到待识别数据的类别标签未知的元数据时,就可以将此待识别数据的元数据输入到此训练完毕的第一多分类模型进行识别,判断其所属的隐私类型。需要说明的是,本实施例技术方案中在获取待识别数据的元数据时,可以只选取与判断待识别数据隐私属性密切相关的部分元数据即可,而不必选取待识别数据的全部元数据。这里的第一多分类模型可以包括:基于决策树算法的多分类模型、基于随机森林算法的多分类模型、基于逻辑回归的多分类模型、基于Xgboost算法的多分类模型、基于梯度提升树算法的多分类模型、基于最大熵算法的多分类模型、基于卷积神经网络(Convolutional Neural Networks,CNN)的多分类模型或基于循环神经网络(Recurrent Neural Network,RNN)的多分类模型等。The task of supervised learning in statistical learning techniques is to learn a model that, for any given input, makes a good prediction about its corresponding output. The first multi-classification model may be one of supervised learning algorithms, which may determine which known sample type a new sample belongs to according to certain characteristics of known samples. More specifically, the multi-classification model can select feature parameters by calculation according to the sample data provided by the known training set, and create a discriminant function to classify the samples. The first multi-classification model is obtained by training based on the metadata corresponding to the privacy type data, which means that the metadata with category labels of the data is used as a training sample in advance, and the multi-classification model is trained by using the metadata, so that the multi-classification model can be trained by using the metadata. The classification model learns the vector features contained in these metadata training samples with category labels, and finally obtains the first multi-classification model after training. The metadata includes semantic feature information representing the data to be identified. In this way, when encountering metadata with unknown category labels of the data to be identified, the metadata of the data to be identified can be input into the trained first multi-classification model for identification, and the privacy type to which it belongs can be determined. It should be noted that, in the technical solution of this embodiment, when obtaining the metadata of the data to be identified, only part of the metadata that is closely related to judging the privacy attributes of the data to be identified can be selected, and it is not necessary to select all the metadata of the data to be identified. . The first multi-classification model here may include: a multi-classification model based on a decision tree algorithm, a multi-classification model based on a random forest algorithm, a multi-classification model based on logistic regression, a multi-classification model based on the Xgboost algorithm, and a multi-classification model based on the gradient boosting tree algorithm. Multi-classification model, multi-classification model based on maximum entropy algorithm, multi-classification model based on Convolutional Neural Networks (CNN) or multi-classification model based on Recurrent Neural Network (RNN), etc.
需要说明的是,本实施例中第一多分类模型具有识别多种隐私类型的功能,例如:多分类模型可识别出身份证号、银行卡号、手机号、IP地址、系统账号等多种隐私类型。因为元数据包含有表征待识别数据的语义的特征信息,从而从这些特征信息中能够分析出待识别数据是否为隐私数据以及具体属于哪种类型的隐私数据。将待识别数据的元数据输入第一多分类模型后,能够得到待识别数据属于各种隐私类型的概率。例如:需要识别数据A的隐私类型,此时,将待识别数据A的元数据输入到第一多分类模型中,可以识别出数据A可能对应的隐私类型集合为:手机号、系统账号、电子邮箱,待识别数据对应的隐私类型为手机号、系统账号、电子邮箱的概率分别为60%、30%和10%。上述步骤中的隐私类型集合中可以包含一种隐私类型、也可以包含多种隐私类型,还可以不包含隐私类型。本实施例中,将对应概率最大的那种隐私类型作为待识别数据所属的隐私类型,即对于数据A,本实施例的技术方案能够判断其为隐私数据,且其隐私类型为手机号。It should be noted that the first multi-classification model in this embodiment has the function of identifying multiple types of privacy. For example, the multi-classification model can identify various types of privacy such as ID card numbers, bank card numbers, mobile phone numbers, IP addresses, and system account numbers. type. Because the metadata contains feature information representing the semantics of the data to be identified, whether the data to be identified is private data and what type of private data it belongs to can be analyzed from the feature information. After the metadata of the data to be identified is input into the first multi-classification model, the probability that the data to be identified belongs to various privacy types can be obtained. For example, the privacy type of data A needs to be identified. At this time, the metadata of data A to be identified is input into the first multi-classification model, and the set of privacy types that may correspond to data A can be identified as: mobile phone number, system account number, electronic Email, the probability that the privacy type corresponding to the data to be identified is mobile phone number, system account number, and email address are 60%, 30%, and 10%, respectively. The privacy type set in the above steps may include one privacy type, may include multiple privacy types, or may not include privacy types. In this embodiment, the privacy type with the highest corresponding probability is used as the privacy type of the data to be identified, that is, for data A, the technical solution of this embodiment can determine that it is private data, and its privacy type is a mobile phone number.
隐私数据(Private Data)即秘密数据,可以指不想被他人或无关人等获知的数据。从隐私数据的所有者的角度出发,可以将隐私数据分为个人隐私数据和共同隐私数据。在本申请的实施例中,只要是用户想要识别和保护的数据均可称为隐私数据。例如,隐私数据可以包括用来定位或者识别个人的个人特征信息(例如,电话号码、地址、信用卡号等)、敏感信息(例如,个人健康情况、财务信息、公司重要文件等)等,也可以包括家庭隐私数据(例如,家庭年收入情况等)、法人隐私数据等。Private data is secret data, which can refer to data that you do not want to be known by others or unrelated people. From the perspective of the owner of privacy data, privacy data can be divided into personal privacy data and common privacy data. In the embodiments of the present application, as long as the data that the user wants to identify and protect can be referred to as private data. For example, private data may include personal characteristic information (eg, phone number, address, credit card number, etc.) used to locate or identify an individual, sensitive information (eg, personal health, financial information, important company documents, etc.), etc., or Including family privacy data (for example, family annual income, etc.), legal person privacy data, etc.
隐私数据可以包括个人基本信息、个人身份信息、个人生物识别信息、网络身份标识信息、个人健康生理信息、个人教育工作信息、个人财产信息、个人通信信息、联系人信息、个人上网记录、个人常用设备信息、个人位置信息等。Privacy data may include basic personal information, personal identification information, personal biometric information, network identification information, personal health and physiological information, personal education and work information, personal property information, personal communication information, contact information, personal online records, personal commonly used information Device information, personal location information, etc.
其中,个人基本信息类隐私数据可以包括个人姓名、生日、性别、民族、国籍、家庭关系、住址、个人电话号码、电子邮箱等具体信息类型。个人身份信息类隐私数据可以包括身份证、军官证、护照、驾驶证、工作证、出入证、社保卡、居住证等具体信息类型。个人生物识别信息类隐私数据可以包括个人基因、指纹、声纹、眼纹、掌纹、耳廓、虹膜、面部特征等具体信息类型。网络身份标识信息类隐私数据可以包括系统账号、IP地址、邮箱地址及与前述有关的密码、口令、口令保护答案、个人数字证书等具体信息类型。个人健康生理信息类隐私数据可以包括个人因生病医治等产生的相关记录,如病症、住院志、医嘱单、检验报告、手术及麻醉记录、护理记录、用药记录、药物食物过敏信息、生育信息、以往病史、诊治情况、家族病史、现病史、传染病史等,以及与个人身体健康状况相关的其他信息;以及,体重、身高、肺活量等具体信息类型。个人教育工作信息类隐私数据可以包括个人职业、职位、工作单位、学历、学位、教育经历、工作经历、培训记录、成绩单等具体信息类型。个人财产信息类隐私数据可以包括银行账号、鉴别信息(口令)、存款信息(包括资金数量、支付收款记录等)、房产信息、信贷记录、征信信息、交易和消费记录、流水记录等,以及虚拟货币、虚拟交易、游戏类兑换码等虚拟财产信息等具体信息类型。个人通信信息类隐私数据可以包括通信记录和内容、短信、彩信、电子邮件,以及描述个人通信的数据(通常称为元数据)等具体信息类型。联系人信息类隐私数据可以包括通讯录、好友列表、群列表、电子邮件地址列表等具体信息类型。个人上网记录类隐私数据可以指通过日志储存的操作记录,可以包括网站浏览记录、软件使用记录、点击记录等具体信息类型。个人常用设备信息类隐私数据可以指用于描述个人常用设备基本情况的信息,可以包括硬件序列号、设备MAC地址、软件列表、唯一设备识别码(如IMEI/android ID/IDFA/OPENUDID/GUID、SIM卡IMSI信息等)等具体信息类型。个人位置信息类隐私数据可以包括行踪轨迹、精准定位信息、住宿信息、经纬度等具体信息类型。此外,隐私数据还可以包括婚史、宗教信仰、性取向、未公开的违法犯罪记录等具体信息类型。Among them, the private data of personal basic information may include personal name, birthday, gender, ethnicity, nationality, family relationship, address, personal phone number, e-mail and other specific information types. Personally identifiable private data can include specific types of information such as ID cards, military IDs, passports, driver's licenses, work permits, entry and exit cards, social security cards, and residence permits. Personal biometric information privacy data may include specific information types such as personal genes, fingerprints, voiceprints, eyeprints, palmprints, auricles, irises, and facial features. The private data of network identification information may include system account numbers, IP addresses, email addresses, and specific types of information such as passwords, passwords, password-protected answers, and personal digital certificates related to the foregoing. Personal health and physiological information privacy data may include personal records related to illness and treatment, such as symptoms, hospital records, doctor’s orders, inspection reports, surgery and anesthesia records, nursing records, medication records, drug and food allergy information, fertility information, Past medical history, diagnosis and treatment, family medical history, current disease history, infectious disease history, etc., as well as other information related to personal health status; and specific information types such as weight, height, and vital capacity. Personal education and work information privacy data may include specific types of information such as personal occupation, position, work unit, education, degree, educational experience, work experience, training records, and transcripts. Personal property information privacy data may include bank account numbers, identification information (passwords), deposit information (including the amount of funds, payment and collection records, etc.), real estate information, credit records, credit information, transaction and consumption records, running water records, etc., As well as specific types of information such as virtual currency, virtual transactions, game exchange codes and other virtual property information. Personal communication information privacy data may include communication records and content, text messages, multimedia messages, emails, and specific information types such as data describing personal communications (usually referred to as metadata). Contact information privacy data may include specific information types such as address book, friend list, group list, and email address list. Personal Internet record private data may refer to operation records stored in logs, and may include specific types of information such as website browsing records, software usage records, and click records. Personal common device information privacy data can refer to the information used to describe the basic situation of personal common devices, which can include hardware serial number, device MAC address, software list, unique device identification code (such as IMEI/android ID/IDFA/OPENUDID/GUID, SIM card IMSI information, etc.) and other specific information types. Personal location information privacy data may include specific types of information such as whereabouts, precise positioning information, accommodation information, latitude and longitude. In addition, private data can also include specific types of information such as marriage history, religious beliefs, sexual orientation, and undisclosed criminal records.
以上罗列的信息仅是作为本申请的实施例可识别的隐私数据的示例,并不限于上述示例。The information listed above is only an example of privacy data identifiable by the embodiments of the present application, and is not limited to the above examples.
步骤306:若所述第一识别结果表示所述待识别数据属于隐私数据,则根据所述第一识别结果确定所述待识别数据所属的隐私类型。Step 306: If the first identification result indicates that the data to be identified belongs to private data, determine the privacy type to which the data to be identified belongs according to the first identification result.
第一多分类模型具有识别多种隐私类型的功能,如果在步骤304中能够识别出待识别数据为隐私数据,则在本步骤306中能够进一步确定待识别数据所属的隐私类型。The first multi-classification model has the function of identifying multiple privacy types. If the data to be identified can be identified as private data in
步骤304和步骤306中,将待识别数据的元数据输入到预先训练好的第一多分类模型中进行判断,由于待识别数据的元数据的数据量要比待识别数据的具体文本的数据量要少很多,但是包含了其所描述的数据的大量关键属性信息,从而从计算复杂度的角度来说,较之于现有技术中基于字段内容的多分类模型,本方案的计算代价和耗时都要小很多。这样本方案中在步骤304和步骤306阶段就可以将大部分实际为隐私数据的待识别数据准确识别出来。在实践中,元数据只是从宏观层面描述数据的属性信息,并不包含所属数据的具体内容方面的信息,而且部分表结构的元数据可能不含有表征待识别数据的语义特征信息,为了进一步提高本实施例整体技术方案对识别隐私数据的准确率,本方案中将步骤304中判断为不是隐私数据的数据进行如下步骤308所描述的进一步识别处理。In
步骤308:若所述第一识别结果表示所述待识别数据不属于隐私数据,则将所述元数据和所述待识别数据输入第二多分类模型,得到第二识别结果;根据所述第二识别结果确定所述待识别数据所属的隐私类型。Step 308: If the first identification result indicates that the data to be identified does not belong to private data, input the metadata and the data to be identified into a second multi-classification model to obtain a second identification result; 2. The identification result determines the privacy type to which the data to be identified belongs.
在本实施例步骤306中,将步骤304中判断为非隐私数据的待识别数据进行进一步识别,即将待识别数据和所述待识别数据的元数据输入到第二多分类模型中进行识别。其中第二多分类模型是指预先将元数据和此元数据所属的数据的文本进行组合,得到组合结果,确定此组合结果的类型标签(即,如果元数据所对应的数据是隐私数据,则此类型标签为此元数据所对应的数据的具体隐私类型,如果元数据所对应的数据不是隐私数据,则此类型标签表示此元数据所对应的数据不属于隐私数据),然后利用带标签的组合结果作为训练样本对第二多分类模型进行训练,让第二多分类模型学习这些带有类别标签的组合结果中所蕴含的向量特征,最后得到训练完毕的第二多分类模型。从而对于第一多分类模型判断为不是隐私数据的待识别数据,利用此训练完毕的第二多分类模型对其进一步判断,得到第二识别结果。由于在训练阶段,第二多分类模型学习到了带类型标签的元数据和此元数据所对应的数据中所蕴含的向量特征,从而利用所述第二结果,能够确定所述待识别数据属于隐私数据及所述待识别数据所属的隐私类型。需要说明的是,本步骤中的第二多分类模型的具体类型根据需要同样可以采用步骤304中记载的多分类模型之一,此处不再赘述。In
在步骤304中能够将大部分隐私数据识别出来,在第一多分类模型将待识别数据识别为非隐私数据的情况下,在本步骤306中,再采用基于已知隐私类型的数据样本的元数据和所述已知隐私类型的数据样本的组合结果进行训练得到的第二多分类模型对待识别数据进行进一步识别,这样能够将步骤304中实际上为隐私数据但被第一多分类模型判定为非隐私数据的待识别数据准确识别出来,从而本实施例的整体技术方案对隐私数据识别的准确率和效率都较高。In
应当理解,本说明书一个或多个实施例所述的方法中,部分步骤的顺序可以根据实际需要调整,或者可以省略部分步骤。It should be understood that, in the method described in one or more embodiments of this specification, the order of some steps may be adjusted according to actual needs, or some steps may be omitted.
基于图3的方法,本说明书实施例还提供了该方法的一些具体实施方式。下面进行说明。Based on the method in FIG. 3 , some specific implementations of the method are also provided in the embodiments of the present specification. The following description will be made.
步骤304中需要将待识别数据的元数据输入到第一多分类模型中,在将待识别数据的元数据输入到第一多分类模型前,需要对此元数据进行分词处理,然后将分词处理后的结果进行特征提取,将特征提取的结果组成第一特征向量,然后将此第一特征向量标记上与所述元数据所属的数据的隐私类型相应的标签,再将带类型标签的第一特征向量输入到所述第一多分类模型中进行识别,得到第一识别结果。In
具体地,本实施例中元数据经过分词处理并进行特征提取后可形式化表示为,其中,n表示特征的数目,表示样本x的第i个特征,提取这些特征的特征提取方法包括但不限于:采用One-hot编码方法对分词处理后的结果进行特征提取、采用词频特征方法对分词处理后的结果进行特征提取或者采用tf-idf方法对分词处理后的结果进行特征提取等。例如一个数据库表结构包括若干字段。其中这个表结构的部分元数据信息包括:表名:contact_info;表注释:联系人信息表;字段名1:name;字段1注释:联系人姓名;字段名2:phone_num;字段2注释:联系人手机号。这个表结构的其中两个字段的字段名分别为name、phone_num,相应的字段内容部分信息如下:name:张三、李四、王五,phone_num:1861X898293、1861X898294、1861X898295。假设当前欲识别的字段为phone_num字段中的一条数据,由于只需要判断phone_num字段中的数据是否为隐私数据,只需要从此表结构中选取与phone_num字段相关的元数据即可,所以选取的元数据只需包括:联系人信息表、联系人手机号、contact_info、phone_num,将这些元数据信息进行分词处理,分词处理结果为:联系人、信息表、联系人、手机号、contact、info、phone、num,将分词处理的结果组成第一特征向量x=[联系人、信息表、联系人、手机号、contact、info、phone、num]T,然后将此第一特征向量输入到训练好的第一多分类模型中,可以识别出待识别的数据属于隐私数据,且其隐私类型为“手机号”。Specifically, in this embodiment, after word segmentation and feature extraction, the metadata can be formally expressed as, where n represents the number of features, and represents the i-th feature of the sample x, and the feature extraction method for extracting these features includes but does not It is limited to: using the One-hot encoding method to extract features from the result of word segmentation processing, using the word frequency feature method to extract features from the results of word segmentation processing, or using tf-idf method to extract features from the results after word segmentation processing, etc. For example, a database table structure includes several fields. Part of the metadata information of this table structure includes: table name: contact_info; table note: contact information table; field name 1: name;
在步骤304和步骤306中,如果通过第一多分类模型不能判断出待识别数据所属的隐私类型或将待识别数据识别为非隐私数据,则还需经过步骤308中的第二多分类模型的进一步识别。具体地,步骤308中,第二多分类模型的输入为待识别数据的元数据和待识别数据的文本进行组合后的分词结果。其中,如果待识别数据为一条,则需先将这一条待识别数据的元数据和此条数据的文本先进行组合,再进行分词,再将分词结果输入到第二多分类模型中进行识别;如果待识别数据为数据库表结构一个字段中的多条数据,则可以在这多条待识别数据中进行随机抽样,抽样出部分待识别数据,再将这多条待识别数据的元数据和这部分待识别数据的文本进行组合,得到组合结果,再对组合结果进行分词处理,将分词结果输入到第二多分类模型中进行识别。In
需要说明的是,在机器学习领域中,传统机器学习的流程往往由多个独立的模块组成,比如在一个典型的自然语言处理(Natural Language Processing)问题中,包括分词、词性标注、句法分析、语义分析等多个独立步骤,每个步骤是一个独立的任务,其结果的好坏会影响到下一步骤,从而影响整个训练的结果,这是非端到端的。而对于深度学习,训练过程中,从输入端(输入数据)到输出端会得到一个预测结果,与真实结果相比较会得到一个误差,这个误差会在模型中的每一层传递(反向传播),每一层的表示都会根据这个误差来做调整,直到模型收敛或达到预期的效果才结束,这是端到端的,因此本实施例的技术方案中,如果第一多分类模型是基于深度学习模型进行训练得到的,则在步骤304中,待识别数据的元数据可以不需要进行分词处理,而是可以按照元数据的字符内容直接转换为One-hot特征向量,然后输入第一多分类模型中进行识别;同理在步骤306中,如果第二多分类模型是基于深度学习模型进行训练得到的,则对于待识别数据的元数据和待识别数据的文本进行组合后,也可以不进行分词处理,将组合结果的字符内容直接转换为One-hot特征向量,然后输入第二多分类模型中进行识别。It should be noted that in the field of machine learning, the traditional machine learning process is often composed of multiple independent modules. For example, in a typical Natural Language Processing problem, it includes word segmentation, part-of-speech tagging, syntax analysis, Semantic analysis and other independent steps, each step is an independent task, the quality of the result will affect the next step, thus affecting the result of the entire training, which is not end-to-end. For deep learning, during the training process, a prediction result will be obtained from the input end (input data) to the output end, and an error will be obtained when compared with the actual result, and this error will be passed through each layer in the model (backpropagation). ), the representation of each layer will be adjusted according to this error, and it will not end until the model converges or achieves the expected effect. This is end-to-end. Therefore, in the technical solution of this embodiment, if the first multi-classification model is based on depth obtained by training the learning model, in
本实施例方案中隐私数据识别的目的,是为了对相应的隐私数据进行脱敏处理,以防止隐私数据的泄露,不同隐私类型的数据可以对应不同的脱敏方法。因此,在确定了待识别数据的隐私类型后,可以确定隐私类型对应的脱敏方法,采用相应的脱敏方法对待识别的数据进行脱敏处理。The purpose of identifying the private data in the solution of this embodiment is to perform desensitization processing on the corresponding private data to prevent the leakage of the private data. Different privacy types of data may correspond to different desensitization methods. Therefore, after the privacy type of the data to be identified is determined, the desensitization method corresponding to the privacy type can be determined, and the corresponding desensitization method is used to desensitize the data to be identified.
具体地,在根据所述第一识别结果确定所述待识别数据所属的隐私类型之后,采用与所述待识别数据所属的隐私类型相应的处理方式对所述待识别数据进行脱敏处理;或者,在根据所述第二识别结果确定所述待识别数据所属的隐私类型之后,采用与所述待识别数据所属的隐私类型相应的处理方式对所述待识别数据进行脱敏处理。Specifically, after the privacy type to which the data to be identified belongs is determined according to the first identification result, the data to be identified is desensitized using a processing method corresponding to the privacy type to which the data to be identified belongs; or , after the privacy type to which the data to be identified belongs is determined according to the second identification result, the data to be identified is desensitized using a processing method corresponding to the privacy type to which the data to be identified belongs.
例如,可以对需要脱敏处理的数据中的部分信息进行掩盖,比如:需要对用户的身份证号以及手机号进行脱敏处理时,可以直接采用如“******”的符号代替身份证号中的部分数字,例如:张三,身份证号为:5303******12。通过上述方法,利用数据脱敏技术对信息进行脱敏,实现信息隐蔽,从而起到保护信息的安全的作用。For example, part of the information in the data that needs to be desensitized can be masked. For example, when desensitization of the user's ID number and mobile phone number is required, a symbol such as "******" can be used instead. Part of the number in the ID number, for example: Zhang San, ID number: 5303******12. Through the above method, the information is desensitized by using the data desensitization technology, so as to realize the concealment of the information, thereby playing the role of protecting the security of the information.
在实际应用中,上述步骤中用到的第一多分类模型和第二多分类模型可以通过预先进行训练得到。In practical applications, the first multi-classification model and the second multi-classification model used in the above steps can be obtained by pre-training.
具体地,所述将所述元数据输入第一多分类模型以对所述待识别数据是否属于隐私数据进行识别,得到第一识别结果之前,还可以包括:Specifically, inputting the metadata into the first multi-classification model to identify whether the data to be identified belongs to private data, and before obtaining the first identification result, may further include:
获取待识别数据的元数据样本,所述元数据样本包含表征所述待识别数据的语义特征信息;根据所述元数据样本对初始的第一多分类模型进行训练,得到训练后的第一多分类模型。Obtaining metadata samples of the data to be identified, the metadata samples containing semantic feature information representing the data to be identified; training the initial first multi-classification model according to the metadata samples, and obtaining the trained first multi-class model. classification model.
所述将所述元数据和所述待识别数据输入第二多分类模型,得到第二识别结果之前,还包括:获取已知隐私类型的数据样本及所述已知隐私类型的数据样本的元数据;将所述已知隐私类型的数据样本的元数据和所述已知隐私类型的数据样本进行组合,根据组合后的结果对初始的第二多分类模型进行训练,得到训练后的第二多分类模型。Before inputting the metadata and the data to be identified into the second multi-classification model and obtaining the second identification result, the method further includes: obtaining a data sample of a known privacy type and a metadata of the data sample of the known privacy type. data; combine the metadata of the data samples of the known privacy type and the data samples of the known privacy type, train the initial second multi-classification model according to the combined result, and obtain the second Multiclass model.
基于同样的思路,本说明书实施例还提供了上述方法对应的装置。图4为本说明书实施例提供的对应于图3的一种隐私数据的识别装置的结构示意图。如图4所示,该装置可以包括:Based on the same idea, the embodiments of the present specification also provide a device corresponding to the above method. FIG. 4 is a schematic structural diagram of an apparatus for identifying private data corresponding to FIG. 3 according to an embodiment of the present specification. As shown in Figure 4, the apparatus may include:
数据获取模块402,用于获取待识别数据的元数据;a
第一识别结果确定模块404,用于将所述元数据输入第一多分类模型以对所述待识别数据的数据类型进行识别,得到第一识别结果;所述第一多分类模型是基于隐私类型数据对应的元数据进行训练得到的;若所述第一识别结果表示所述待识别数据属于隐私数据,则根据所述第一识别结果确定所述待识别数据所属的隐私类型;A first identification
第二识别结果确定模块406,用于若所述第一识别结果表示所述待识别数据不属于隐私数据,则将所述元数据和所述待识别数据输入第二多分类模型,得到第二识别结果;根据所述第二识别结果确定所述待识别数据所属的隐私类型。The second identification
基于图4的装置,本说明书实施例还提供了该方法的一些具体实施方案,下面进行说明。Based on the device in FIG. 4 , some specific implementations of the method are also provided in the embodiments of this specification, which will be described below.
在本申请的至少一个实施例中,所述第一识别结果确定模块404,具体用于:将所述元数据进行分词处理,将分词处理后的结果进行特征提取,得到第一特征向量;将所述第一特征向量输入到所述第一多分类模型中进行识别,得到第一识别结果。In at least one embodiment of the present application, the first recognition
在本申请的至少一个实施例中,所述第二识别结果确定模块406,具体可用于:将所述元数据和所述待识别数据的文本进行组合,得到组合结果;对所述组合结果进行分词处理,将分词处理后的结果进行特征提取,得到第二特征向量;将所述第二特征向量输入到所述第二多分类模型中进行识别,得到第二识别结果。In at least one embodiment of the present application, the second recognition
所述装置还包括:The device also includes:
脱敏模块,用于:在根据所述第一识别结果确定所述待识别数据所属的隐私类型之后,采用与所述待识别数据所属的隐私类型相应的处理方式对所述待识别数据进行脱敏处理;或者,在根据所述第二识别结果确定所述待识别数据所属的隐私类型之后,采用与所述待识别数据所属的隐私类型相应的处理方式对所述待识别数据进行脱敏处理。A desensitization module, configured to: after determining the privacy type to which the data to be identified belongs according to the first identification result, desensitize the data to be identified by using a processing method corresponding to the privacy type to which the data to be identified belongs. or, after the privacy type to which the data to be identified belongs is determined according to the second identification result, the data to be identified is desensitized using a processing method corresponding to the privacy type to which the data to be identified belongs. .
第一多分类模型训练模块,用于获取待识别数据的元数据样本,所述元数据样本包含表征所述待识别数据的语义特征信息;根据所述元数据样本对初始的第一多分类模型进行训练,得到训练后的第一多分类模型。The first multi-classification model training module is used to obtain metadata samples of the data to be identified, the metadata samples include semantic feature information representing the data to be identified; according to the metadata samples, the initial first multi-classification model is Perform training to obtain the first multi-classification model after training.
第二多分类模型训练模块,用于获取已知隐私类型的数据样本及所述已知隐私类型的数据样本的元数据;将所述已知隐私类型的数据样本的元数据和所述已知隐私类型的数据样本进行组合,根据组合后的结果对初始的第二多分类模型进行训练,得到训练后的第二多分类模型。The second multi-classification model training module is configured to obtain data samples of known privacy types and metadata of the data samples of known privacy types; combine the metadata of the data samples of known privacy types with the known privacy types The data samples of the privacy type are combined, the initial second multi-classification model is trained according to the combined result, and the trained second multi-classification model is obtained.
可以理解,上述的各模块是指计算机程序或者程序段,用于执行某一项或多项特定的功能。此外,上述各模块的区分并不代表实际的程序代码也必须是分开的。It can be understood that the above-mentioned modules refer to computer programs or program segments, which are used to perform one or more specific functions. In addition, the above-mentioned distinction of each module does not mean that the actual program code must also be separated.
基于同样的思路,本说明书实施例还提供了上述方法对应的设备。图5为本说明书实施例提供的对应于图3的一种识别隐私数据的设备的结构示意图。如图5所示,设备500可以包括:Based on the same idea, the embodiments of this specification also provide a device corresponding to the above method. FIG. 5 is a schematic structural diagram of a device for identifying private data corresponding to FIG. 3 according to an embodiment of the present specification. As shown in FIG. 5,
至少一个处理器510;以及,at least one processor 510; and,
与所述至少一个处理器通信连接的存储器530;其中,a memory 530 in communication with the at least one processor; wherein,
所述存储器530存储有可被所述至少一个处理器510执行的指令520,所述指令被所述至少一个处理器510执行。The memory 530 stores instructions 520 executable by the at least one processor 510 that are executed by the at least one processor 510 .
所述指令可以使所述至少一个处理器510能够:The instructions may enable the at least one processor 510 to:
获取待识别数据的元数据;Obtain metadata of the data to be identified;
将所述元数据输入第一多分类模型以对所述待识别数据的数据类型进行识别,得到第一识别结果;所述第一多分类模型是基于隐私类型数据对应的元数据进行训练得到的;The metadata is input into the first multi-classification model to identify the data type of the data to be identified, and a first recognition result is obtained; the first multi-classification model is obtained by training based on the metadata corresponding to the privacy type data ;
若所述第一识别结果表示所述待识别数据属于隐私数据,则根据所述第一识别结果确定所述待识别数据所属的隐私类型;If the first identification result indicates that the to-be-identified data belongs to private data, determining the privacy type to which the to-be-identified data belongs according to the first identification result;
若所述第一识别结果表示所述待识别数据不属于隐私数据,则将所述元数据和所述待识别数据输入第二多分类模型,得到第二识别结果;根据所述第二识别结果确定所述待识别数据所属的隐私类型。If the first identification result indicates that the data to be identified does not belong to private data, the metadata and the data to be identified are input into a second multi-classification model to obtain a second identification result; according to the second identification result Determine the privacy type to which the data to be identified belongs.
基于同样的思路,本说明书实施例还提供了上述方法对应的计算机可读介质。计算机可读介质上存储有计算机可读指令,所述计算机可读指令可被处理器执行以实现以下方法:Based on the same idea, the embodiments of the present specification also provide a computer-readable medium corresponding to the above method. The computer-readable medium has computer-readable instructions stored thereon, and the computer-readable instructions are executable by a processor to implement the following methods:
获取待识别数据的元数据;Obtain metadata of the data to be identified;
将所述元数据输入第一多分类模型以对所述待识别数据的数据类型进行识别,得到第一识别结果;所述第一多分类模型是基于隐私类型数据对应的元数据进行训练得到的;The metadata is input into the first multi-classification model to identify the data type of the data to be identified, and a first recognition result is obtained; the first multi-classification model is obtained by training based on the metadata corresponding to the privacy type data ;
若所述第一识别结果表示所述待识别数据属于隐私数据,则根据所述第一识别结果确定所述待识别数据所属的隐私类型;If the first identification result indicates that the to-be-identified data belongs to private data, determining the privacy type to which the to-be-identified data belongs according to the first identification result;
若所述第一识别结果表示所述待识别数据不属于隐私数据,则将所述元数据和所述待识别数据输入第二多分类模型,得到第二识别结果;根据所述第二识别结果确定所述待识别数据所属的隐私类型。If the first identification result indicates that the data to be identified does not belong to private data, the metadata and the data to be identified are input into a second multi-classification model to obtain a second identification result; according to the second identification result Determine the privacy type to which the data to be identified belongs.
上述对本说明书特定实施例进行了描述。其他实施例在所附权利要求书的范围内。在一些情况下,在权利要求书中记载的动作或步骤可以按照不同于实施例中的顺序来执行并且仍然可以实现期望的结果。另外,在附图中描绘的过程不一定要求示出的特定顺序或者连续顺序才能实现期望的结果。在某些实施方式中,多任务处理和并行处理也是可以的或者可能是有利的。The foregoing describes specific embodiments of the present specification. Other embodiments are within the scope of the appended claims. In some cases, the actions or steps recited in the claims can be performed in an order different from that in the embodiments and still achieve desirable results. Additionally, the processes depicted in the figures do not necessarily require the particular order shown, or sequential order, to achieve desirable results. In some embodiments, multitasking and parallel processing are also possible or may be advantageous.
在20世纪90年代,对于一个技术的改进可以很明显地区分是硬件上的改进(例如,对二极管、晶体管、开关等电路结构的改进)还是软件上的改进(对于方法流程的改进)。然而,随着技术的发展,当今的很多方法流程的改进已经可以视为硬件电路结构的直接改进。设计人员几乎都通过将改进的方法流程编程到硬件电路中来得到相应的硬件电路结构。因此,不能说一个方法流程的改进就不能用硬件实体模块来实现。例如,可编程逻辑器件(Programmable Logic Device, PLD)(例如现场可编程门阵列(Field Programmable GateArray,FPGA))就是这样一种集成电路,其逻辑功能由用户对器件编程来确定。由设计人员自行编程来把一个数字符系统“集成”在一片PLD上,而不需要请芯片制造厂商来设计和制作专用的集成电路芯片。而且,如今,取代手工地制作集成电路芯片,这种编程也多半改用“逻辑编译器(logic compiler)”软件来实现,它与程序开发撰写时所用的软件编译器相类似,而要编译之前的原始代码也得用特定的编程语言来撰写,此称之为硬件描述语言(Hardware Description Language,HDL),而HDL也并非仅有一种,而是有许多种,如ABEL(Advanced Boolean Expression Language)、AHDL(Altera Hardware DescriptionLanguage)、Confluence、CUPL(Cornell University Programming Language)、HDCal、JHDL(Java Hardware Description Language)、Lava、Lola、MyHDL、PALASM、RHDL(RubyHardware Description Language)等,目前最普遍使用的是VHDL(Very-High-SpeedIntegrated Circuit Hardware Description Language)与Verilog。本领域技术人员也应该清楚,只需要将方法流程用上述几种硬件描述语言稍作逻辑编程并编程到集成电路中,就可以很容易得到实现该逻辑方法流程的硬件电路。In the 1990s, an improvement in a technology could be clearly differentiated between improvements in hardware (for example, improvements in circuit structures such as diodes, transistors, switches, etc.) or improvements in software (improvements in method flow). However, with the development of technology, the improvement of many methods and processes today can be regarded as a direct improvement of the hardware circuit structure. Designers almost get the corresponding hardware circuit structure by programming the improved method flow into the hardware circuit. Therefore, it cannot be said that the improvement of a method flow cannot be realized by hardware entity modules. For example, a Programmable Logic Device (PLD) such as a Field Programmable Gate Array (FPGA) is an integrated circuit whose logical function is determined by the user programming the device. It is programmed by the designer to "integrate" a digital character system on a PLD, without the need for a chip manufacturer to design and manufacture a dedicated integrated circuit chip. And, instead of making integrated circuit chips by hand, these days, most of this programming is done using software called a "logic compiler", which is similar to the software compilers used in program development and writing, but before compiling The original code also has to be written in a specific programming language, which is called Hardware Description Language (HDL), and there is not only one HDL, but many kinds, such as ABEL (Advanced Boolean Expression Language) , AHDL (Altera Hardware Description Language), Confluence, CUPL (Cornell University Programming Language), HDCal, JHDL (Java Hardware Description Language), Lava, Lola, MyHDL, PALASM, RHDL (Ruby Hardware Description Language), etc. The most commonly used ones are VHDL (Very-High-Speed Integrated Circuit Hardware Description Language) and Verilog. It should also be clear to those skilled in the art that a hardware circuit for implementing the logic method process can be easily obtained by simply programming the method process in the above-mentioned several hardware description languages and programming it into the integrated circuit.
控制器可以按任何适当的方式实现,例如,控制器可以采取例如微处理器或处理器以及存储可由该(微)处理器执行的计算机可读程序代码(例如软件或固件)的计算机可读介质、逻辑门、开关、专用集成电路(Application Specific Integrated Circuit,ASIC)、可编程逻辑控制器和嵌入微控制器的形式,控制器的例子包括但不限于以下微控制器:ARC 625D、Atmel AT91SAM、Microchip PIC18F26K20 以及Silicone Labs C8051F320,存储器控制器还可以被实现为存储器的控制逻辑的一部分。本领域技术人员也知道,除了以纯计算机可读程序代码方式实现控制器以外,完全可以通过将方法步骤进行逻辑编程来使得控制器以逻辑门、开关、专用集成电路、可编程逻辑控制器和嵌入微控制器等的形式来实现相同功能。因此这种控制器可以被认为是一种硬件部件,而对其内包括的用于实现各种功能的装置也可以视为硬件部件内的结构。或者甚至,可以将用于实现各种功能的装置视为既可以是实现方法的软件模块又可以是硬件部件内的结构。The controller may be implemented in any suitable manner, for example, the controller may take the form of eg a microprocessor or processor and a computer readable medium storing computer readable program code (eg software or firmware) executable by the (micro)processor , logic gates, switches, application specific integrated circuits (ASICs), programmable logic controllers and embedded microcontrollers, examples of controllers include but are not limited to the following microcontrollers: ARC 625D, Atmel AT91SAM, Microchip PIC18F26K20 and Silicon Labs C8051F320, the memory controller can also be implemented as part of the control logic of the memory. Those skilled in the art also know that, in addition to implementing the controller in the form of pure computer-readable program code, the controller can be implemented as logic gates, switches, application-specific integrated circuits, programmable logic controllers and embedded devices by logically programming the method steps. The same function can be realized in the form of a microcontroller, etc. Therefore, such a controller can be regarded as a hardware component, and the devices included therein for realizing various functions can also be regarded as a structure within the hardware component. Or even, the means for implementing various functions can be regarded as both a software module implementing a method and a structure within a hardware component.
上述实施例阐明的系统、装置、模块或单元,具体可以由计算机芯片或实体实现,或者由具有某种功能的产品来实现。一种典型的实现设备为计算机。具体的,计算机例如可以为个人计算机、膝上型计算机、蜂窝电话、相机电话、智能电话、个人数字符助理、媒体播放器、导航设备、电子邮件设备、游戏控制台、平板计算机、可穿戴设备或者这些设备中的任何设备的组合。The systems, devices, modules or units described in the above embodiments may be specifically implemented by computer chips or entities, or by products with certain functions. A typical implementation device is a computer. Specifically, the computer may be, for example, a personal computer, a laptop computer, a cellular phone, a camera phone, a smart phone, a personal digital assistant, a media player, a navigation device, an email device, a game console, a tablet computer, a wearable device Or a combination of any of these devices.
为了描述的方便,描述以上装置时以功能分为各种单元分别描述。当然,在实施本申请时可以把各单元的功能在同一个或多个软件和/或硬件中实现。For the convenience of description, when describing the above device, the functions are divided into various units and described respectively. Of course, when implementing the present application, the functions of each unit may be implemented in one or more software and/or hardware.
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。As will be appreciated by one skilled in the art, embodiments of the present invention may be provided as a method, system, or computer program product. Accordingly, the present invention may take the form of an entirely hardware embodiment, an entirely software embodiment, or an embodiment combining software and hardware aspects. Furthermore, the present invention may take the form of a computer program product embodied on one or more computer-usable storage media (including, but not limited to, disk storage, CD-ROM, optical storage, etc.) having computer-usable program code embodied therein.
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。The present invention is described with reference to flowchart illustrations and/or block diagrams of methods, apparatus (systems), and computer program products according to embodiments of the invention. It will be understood that each flow and/or block in the flowcharts and/or block diagrams, and combinations of flows and/or blocks in the flowcharts and/or block diagrams, can be implemented by computer program instructions. These computer program instructions may be provided to the processor of a general purpose computer, special purpose computer, embedded processor or other programmable data processing device to produce a machine such that the instructions executed by the processor of the computer or other programmable data processing device produce Means for implementing the functions specified in one or more of the flowcharts and/or one or more blocks of the block diagrams.
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。These computer program instructions may also be stored in a computer-readable memory capable of directing a computer or other programmable data processing apparatus to function in a particular manner, such that the instructions stored in the computer-readable memory result in an article of manufacture comprising instruction means, the instructions An apparatus implements the functions specified in a flow or flows of the flowcharts and/or a block or blocks of the block diagrams.
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。These computer program instructions can also be loaded on a computer or other programmable data processing device to cause a series of operational steps to be performed on the computer or other programmable device to produce a computer-implemented process such that The instructions provide steps for implementing the functions specified in one or more of the flowcharts and/or one or more blocks of the block diagrams.
在一个典型的配置中,计算设备包括一个或多个处理器(CPU)、输入/输出接口、网络接口和内存。In a typical configuration, a computing device includes one or more processors (CPUs), input/output interfaces, network interfaces, and memory.
内存可能包括计算机可读介质中的非永久性存储器,随机存取存储器(RAM)和/或非易失性内存等形式,如只读存储器(ROM)或闪存(flash RAM)。内存是计算机可读介质的示例。Memory may include non-persistent memory in computer readable media, random access memory (RAM) and/or non-volatile memory in the form of, for example, read only memory (ROM) or flash memory (flash RAM). Memory is an example of a computer-readable medium.
计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(PRAM)、静态随机存取存储器(SRAM)、动态随机存取存储器(DRAM)、其他类型的随机存取存储器(RAM)、只读存储器(ROM)、电可擦除可编程只读存储器(EEPROM)、快闪记忆体或其他内存技术、只读光盘只读存储器(CD-ROM)、数字符多功能光盘(DVD)或其他光学存储、磁盒式磁带,磁带式磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。按照本文中的界定,计算机可读介质不包括暂存电脑可读媒体(transitory media),如调制的数据信号和载波。Computer-readable media includes both persistent and non-permanent, removable and non-removable media, and storage of information may be implemented by any method or technology. Information may be computer readable instructions, data structures, modules of programs, or other data. Examples of computer storage media include, but are not limited to, phase-change memory (PRAM), static random access memory (SRAM), dynamic random access memory (DRAM), other types of random access memory (RAM), read only memory (ROM), Electrically Erasable Programmable Read Only Memory (EEPROM), Flash Memory or other memory technology, Compact Disc Read Only Memory (CD-ROM), Digital Versatile Disc (DVD), or other optical storage , magnetic tape cartridges, magnetic tape-disk storage or other magnetic storage devices or any other non-transmission medium that can be used to store information that can be accessed by a computing device. Computer-readable media, as defined herein, excludes transitory computer-readable media, such as modulated data signals and carrier waves.
还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、商品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、商品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、商品或者设备中还存在另外的相同要素。It should also be noted that the terms "comprising", "comprising" or any other variation thereof are intended to encompass a non-exclusive inclusion such that a process, method, article or device comprising a series of elements includes not only those elements, but also Other elements not expressly listed or inherent to such a process, method, article of manufacture or apparatus are also included. Without further limitation, an element qualified by the phrase "comprising a..." does not preclude the presence of additional identical elements in the process, method, article of manufacture, or device that includes the element.
本领域技术人员应明白,本申请的实施例可提供为方法、系统或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。It will be appreciated by those skilled in the art that the embodiments of the present application may be provided as a method, a system or a computer program product. Accordingly, the present application may take the form of an entirely hardware embodiment, an entirely software embodiment, or an embodiment combining software and hardware aspects. Furthermore, the present application may take the form of a computer program product embodied on one or more computer-usable storage media (including, but not limited to, disk storage, CD-ROM, optical storage, etc.) having computer-usable program code embodied therein.
本申请可以在由计算机执行的计算机可执行指令的一般上下文中描述,例如程序模块。一般地,程序模块包括执行特定任务或实现特定抽象数据类型的例程、程序、对象、组件、数据结构等等。也可以在分布式计算环境中实践本申请,在这些分布式计算环境中,由通过通信网络而被连接的远程处理设备来执行任务。在分布式计算环境中,程序模块可以位于包括存储设备在内的本地和远程计算机存储介质中。The application may be described in the general context of computer-executable instructions, such as program modules, being executed by a computer. Generally, program modules include routines, programs, objects, components, data structures, etc. that perform particular tasks or implement particular abstract data types. The application may also be practiced in distributed computing environments where tasks are performed by remote processing devices that are linked through a communications network. In a distributed computing environment, program modules may be located in both local and remote computer storage media including storage devices.
以上所述仅为本申请的实施例而已,并不用于限制本申请。对于本领域技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本申请的权利要求范围之内。The above descriptions are merely examples of the present application, and are not intended to limit the present application. Various modifications and variations of this application are possible for those skilled in the art. Any modification, equivalent replacement, improvement, etc. made within the spirit and principle of the present application shall be included within the scope of the claims of the present application.
Claims (21)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011322577.6ACN112132238A (en) | 2020-11-23 | 2020-11-23 | A method, apparatus, device and readable medium for identifying private data |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011322577.6ACN112132238A (en) | 2020-11-23 | 2020-11-23 | A method, apparatus, device and readable medium for identifying private data |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN112132238Atrue CN112132238A (en) | 2020-12-25 |
Family
ID=73852254
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202011322577.6APendingCN112132238A (en) | 2020-11-23 | 2020-11-23 | A method, apparatus, device and readable medium for identifying private data |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN112132238A (en) |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112818390A (en)* | 2021-01-26 | 2021-05-18 | 支付宝(杭州)信息技术有限公司 | Data information publishing method, device and equipment based on privacy protection |
| CN113672653A (en)* | 2021-08-09 | 2021-11-19 | 支付宝(杭州)信息技术有限公司 | Method and apparatus for identifying private data in a database |
| CN113987309A (en)* | 2021-12-29 | 2022-01-28 | 深圳红途科技有限公司 | Personal privacy data identification method and device, computer equipment and storage medium |
| CN114169004A (en)* | 2021-12-10 | 2022-03-11 | 泰康保险集团股份有限公司 | Data processing method and device, electronic equipment and computer readable storage medium |
| CN114565787A (en)* | 2022-02-11 | 2022-05-31 | 北京旷视科技有限公司 | Document identification methods, equipment, media and products |
| JP2022179952A (en)* | 2021-05-24 | 2022-12-06 | 日本電気株式会社 | Management device, management method, and program |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104731976A (en)* | 2015-04-14 | 2015-06-24 | 海量云图(北京)数据技术有限公司 | Method for finding and sorting private data in data table |
| CN106897459A (en)* | 2016-12-14 | 2017-06-27 | 中国电子科技集团公司第三十研究所 | A kind of text sensitive information recognition methods based on semi-supervised learning |
| CN108776762A (en)* | 2018-06-08 | 2018-11-09 | 北京中电普华信息技术有限公司 | A kind of processing method and processing device of data desensitization |
| CN109800600A (en)* | 2019-01-23 | 2019-05-24 | 中国海洋大学 | Ocean big data susceptibility assessment system and prevention method towards privacy requirements |
| CN111079186A (en)* | 2019-12-20 | 2020-04-28 | 百度在线网络技术(北京)有限公司 | Data analysis method, device, equipment and storage medium |
| CN111539021A (en)* | 2020-04-26 | 2020-08-14 | 支付宝(杭州)信息技术有限公司 | Data privacy type identification method, device and equipment |
| CN111709052A (en)* | 2020-06-01 | 2020-09-25 | 支付宝(杭州)信息技术有限公司 | A method, apparatus, device and readable medium for identifying and processing private data |
- 2020
- 2020-11-23CNCN202011322577.6Apatent/CN112132238A/enactivePending
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104731976A (en)* | 2015-04-14 | 2015-06-24 | 海量云图(北京)数据技术有限公司 | Method for finding and sorting private data in data table |
| CN106897459A (en)* | 2016-12-14 | 2017-06-27 | 中国电子科技集团公司第三十研究所 | A kind of text sensitive information recognition methods based on semi-supervised learning |
| CN108776762A (en)* | 2018-06-08 | 2018-11-09 | 北京中电普华信息技术有限公司 | A kind of processing method and processing device of data desensitization |
| CN109800600A (en)* | 2019-01-23 | 2019-05-24 | 中国海洋大学 | Ocean big data susceptibility assessment system and prevention method towards privacy requirements |
| CN111079186A (en)* | 2019-12-20 | 2020-04-28 | 百度在线网络技术(北京)有限公司 | Data analysis method, device, equipment and storage medium |
| CN111539021A (en)* | 2020-04-26 | 2020-08-14 | 支付宝(杭州)信息技术有限公司 | Data privacy type identification method, device and equipment |
| CN111709052A (en)* | 2020-06-01 | 2020-09-25 | 支付宝(杭州)信息技术有限公司 | A method, apparatus, device and readable medium for identifying and processing private data |
Cited By (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112818390A (en)* | 2021-01-26 | 2021-05-18 | 支付宝(杭州)信息技术有限公司 | Data information publishing method, device and equipment based on privacy protection |
| JP2022179952A (en)* | 2021-05-24 | 2022-12-06 | 日本電気株式会社 | Management device, management method, and program |
| JP7676945B2 (en) | 2021-05-24 | 2025-05-15 | 日本電気株式会社 | Management device, management method, and program |
| CN113672653A (en)* | 2021-08-09 | 2021-11-19 | 支付宝(杭州)信息技术有限公司 | Method and apparatus for identifying private data in a database |
| CN114169004A (en)* | 2021-12-10 | 2022-03-11 | 泰康保险集团股份有限公司 | Data processing method and device, electronic equipment and computer readable storage medium |
| CN114169004B (en)* | 2021-12-10 | 2024-08-20 | 泰康保险集团股份有限公司 | Data processing method, device, electronic equipment and computer readable storage medium |
| CN113987309A (en)* | 2021-12-29 | 2022-01-28 | 深圳红途科技有限公司 | Personal privacy data identification method and device, computer equipment and storage medium |
| CN113987309B (en)* | 2021-12-29 | 2022-03-11 | 深圳红途科技有限公司 | Personal privacy data identification method and device, computer equipment and storage medium |
| CN114565787A (en)* | 2022-02-11 | 2022-05-31 | 北京旷视科技有限公司 | Document identification methods, equipment, media and products |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111783126B (en) | Private data identification method, device, equipment and readable medium | |
| Hulsebos et al. | Sherlock: A deep learning approach to semantic data type detection | |
| CN111709052B (en) | Private data identification and processing method, device, equipment and readable medium | |
| Verma et al. | MCred: multi-modal message credibility for fake news detection using BERT and CNN | |
| TWI735782B (en) | Model training method, data similarity determination method, device and equipment | |
| CN112132238A (en) | A method, apparatus, device and readable medium for identifying private data | |
| Geman et al. | Visual turing test for computer vision systems | |
| US20190156206A1 (en) | Analyzing Spatially-Sparse Data Based on Submanifold Sparse Convolutional Neural Networks | |
| CN112313642A (en) | Intent recognition for agent matching by assistant system | |
| WO2022222942A1 (en) | Method and apparatus for generating question and answer record, electronic device, and storage medium | |
| US12211598B1 (en) | Configuring a generative machine learning model using a syntactic interface | |
| CN113761125B (en) | Dynamic summary determination method and device, computing device and computer storage medium | |
| Ahmed et al. | Automated detection of unstructured context-dependent sensitive information using deep learning | |
| Truong et al. | Sensitive data detection with high-throughput neural network models for financial institutions | |
| CN116756762A (en) | Method, device and equipment for identifying abnormal privacy attribute information | |
| CN111738358B (en) | A data identification method, apparatus, device and readable medium | |
| Ngueajio et al. | Decoding fake news and hate speech: A survey of explainable ai techniques | |
| CN115129864A (en) | Text classification method and device, computer equipment and storage medium | |
| CN114510944A (en) | Name matching method, training method, device and storage medium | |
| Acharya et al. | LegoNet-classification and extractive summarization of Indian legal judgments with capsule networks and sentence embeddings | |
| Farrelly et al. | Current topological and machine learning applications for bias detection in text | |
| Ghosal et al. | CatRevenge: towards effective revenge text detection in online social media with paragraph embedding and CATBoost | |
| Gambarelli et al. | Is your model sensitive? SPeDaC: A new benchmark for detecting and classifying sensitive personal data | |
| CN116680401A (en) | Document processing method, document processing device, equipment and storage medium | |
| Leghari et al. | Online signature verification using deep learning based aggregated convolutional feature representation |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| REG | Reference to a national code | Ref country code:HK Ref legal event code:DE Ref document number:40043795 Country of ref document:HK | |
| TA01 | Transfer of patent application right | ||
| TA01 | Transfer of patent application right | Effective date of registration:20241120 Address after:Room 302, 3rd Floor, Building 1, Courtyard 1, Leng Street, Haidian District, Beijing 100080 Applicant after:Sasi Digital Technology (Beijing) Co.,Ltd. Country or region after:China Address before:310012 801-11, Section B, floor 8, No. 556, Xixi Road, Xihu District, Hangzhou City, Zhejiang Province Applicant before:Alipay (Hangzhou) Information Technology Co.,Ltd. Country or region before:China | |
| RJ01 | Rejection of invention patent application after publication | ||
| RJ01 | Rejection of invention patent application after publication | Application publication date:20201225 |