CN111949657A - A real-time data warehouse width meter processing method and system - Google Patents
A real-time data warehouse width meter processing method and systemDownload PDFInfo
- Publication number
- CN111949657A CN111949657ACN202010760035.0ACN202010760035ACN111949657ACN 111949657 ACN111949657 ACN 111949657ACN 202010760035 ACN202010760035 ACN 202010760035ACN 111949657 ACN111949657 ACN 111949657A
- Authority
- CN
- China
- Prior art keywords
- data
- kafka
- cluster
- real
- application
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images



Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/22—Indexing; Data structures therefor; Storage structures
- G06F16/2282—Tablespace storage structures; Management thereof
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/245—Query processing
- G06F16/2457—Query processing with adaptation to user needs
- G06F16/24578—Query processing with adaptation to user needs using ranking
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/245—Query processing
- G06F16/2458—Special types of queries, e.g. statistical queries, fuzzy queries or distributed queries
- G06F16/2471—Distributed queries
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/27—Replication, distribution or synchronisation of data between databases or within a distributed database system; Distributed database system architectures therefor
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q30/00—Commerce
- G06Q30/06—Buying, selling or leasing transactions
- G06Q30/0601—Electronic shopping [e-shopping]
- G06Q30/0633—Managing shopping lists, e.g. compiling or processing purchase lists
- G06Q30/0635—Managing shopping lists, e.g. compiling or processing purchase lists replenishment orders; recurring orders
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Databases & Information Systems (AREA)
- General Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- General Engineering & Computer Science (AREA)
- Business, Economics & Management (AREA)
- Software Systems (AREA)
- Finance (AREA)
- Accounting & Taxation (AREA)
- Computational Linguistics (AREA)
- Probability & Statistics with Applications (AREA)
- Mathematical Physics (AREA)
- Fuzzy Systems (AREA)
- Development Economics (AREA)
- Economics (AREA)
- Marketing (AREA)
- Strategic Management (AREA)
- General Business, Economics & Management (AREA)
- Computing Systems (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明涉及数据查询技术领域,更具体的说,本发明涉及一种实时数仓宽表加工处理方法及系统。The invention relates to the technical field of data query, and more particularly, the invention relates to a real-time data warehouse width table processing method and system.
背景技术Background technique
目前无论在电商还是金融领域很多数据都是分布在不同业务部门不同业务库下的,比如在电商里面订单可能在业务部订单库里面,支付信息可能存储在支付部的支付库下。很多时候我们需要对外实时提供查询服务,那就涉及跨库访问问题,随着业务的增长业务划分愈加细,那么跨部门访问问题越加突出。传统的解决方案偏向于增加代理(中间件),通过中间件去和不同数据库交互然后汇集数据。但是这种解决方案实时性很大程度上受到硬件制约,查询开销较大。At present, many data in both e-commerce and financial fields are distributed in different business departments and different business databases. For example, in e-commerce, orders may be stored in the business department's order database, and payment information may be stored in the payment department's payment database. In many cases, we need to provide external query services in real time, which involves cross-database access problems. As the business grows, the business division becomes more and more detailed, so the cross-departmental access problem becomes more and more prominent. Traditional solutions tend to add agents (middleware) to interact with different databases and aggregate data through middleware. However, the real-time performance of this solution is largely restricted by hardware, and the query overhead is large.
目前对于大多数中小企业都倾向于将需要的不同业务数据抽取出来整合成一张宽表,对外提供服务。但是这其中面临很多技术点:接收多个消息,消息先后顺序无法保证;如何保证时效性的同时不丢失数据。At present, most small and medium-sized enterprises tend to extract and integrate the different business data they need into a wide table to provide external services. However, there are many technical points in this: receiving multiple messages, the sequence of messages cannot be guaranteed; how to ensure timeliness without losing data.
发明内容SUMMARY OF THE INVENTION
为了克服现有技术的不足,本发明提供一种实时数仓宽表加工处理方法及系统,能够快速关联到维表信息并获取到对应字段。In order to overcome the deficiencies of the prior art, the present invention provides a real-time data warehouse wide table processing method and system, which can quickly associate with dimension table information and obtain corresponding fields.
本发明解决其技术问题所采用的技术方案是:一种实时数仓宽表加工处理方法,其改进之处在于,该方法包括以下的步骤:The technical scheme adopted by the present invention to solve the technical problem is: a real-time data warehouse width table processing method, and its improvement lies in that the method comprises the following steps:
S1、数据的同步,将Oracle数据库中的数据实时同步到Kafka集群中,同时将Oracle数据库中的数据实时同步至mongodb数据库,mongodb数据库设置有线上接口;S1, data synchronization, synchronize the data in the Oracle database to the Kafka cluster in real time, and synchronize the data in the Oracle database to the mongodb database in real time, and the mongodb database is set with an online interface;
S2、基础表信息的同步,将Oracle数据库中的基础表信息同步到Redis集群中,作为缓存数据;S2, the synchronization of basic table information, the basic table information in the Oracle database is synchronized to the Redis cluster as cached data;
S3、数据的消费,Kafka应用程序消费Kafka集群中的数据,在数据查询时, Kafka应用程序先行查询Redis集群中的缓存数据,如未查询到缓存数据,则通过线上接口查询mongodb数据库中的数据;S3. Data consumption. The Kafka application consumes the data in the Kafka cluster. When querying data, the Kafka application first queries the cached data in the Redis cluster. If the cached data is not queried, it queries the mongodb database through the online interface. data;
S4、数据的下发,当Kafka应用程序查询到数据时,则将查询结果下方至宽表;当Kafka应用程序未查询到数据时,则将查询结果存储至Hbase集群中。S4. Data delivery. When the Kafka application queries the data, the query result is placed below the wide table; when the Kafka application does not query the data, the query result is stored in the Hbase cluster.
进一步的,所述的步骤S1中,通过Ogg将Oracle数据库中的数据实时同步到 Kafka集群中。Further, in the described step S1, the data in the Oracle database is synchronized to the Kafka cluster in real time through Ogg.
进一步的,所述的步骤S2中,基础表信息包括部门前一天新增的数据。Further, in the step S2, the basic table information includes data newly added by the department on the previous day.
进一步的,所述的步骤S2中,基础表信息包括但不限于部门表、权限表、商户表以及商品种类表。Further, in the step S2, the basic table information includes but is not limited to a department table, a permission table, a merchant table, and a commodity category table.
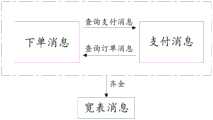
进一步的,所述的步骤S3中,Kafka应用程序消费的数据包括订单支付金额,该订单支付金额包括下单消息数据和支付消息数据,其数据查询包括以下的步骤:Further, in the step S3, the data consumed by the Kafka application includes the order payment amount, the order payment amount includes the order message data and the payment message data, and the data query includes the following steps:
S31、如下单消息数据进入Kafka应用程序,则Kafka应用程序查询对应的支付消息数据,如查询到支付消息数据,则将查询结果下发至宽表,如未查询到支付消息数据,则将查询结果存储至Hbase集群中;S31. The following single message data enters the Kafka application, and the Kafka application queries the corresponding payment message data. If the payment message data is queried, the query result will be sent to the wide table. If the payment message data is not queried, the query will be The results are stored in the Hbase cluster;
S32、如支付消息数据先行进入Kafka应用程序,则Kafka应用程序查询对应的下单消息数据,如查询到下单消息数据,则将查询结果下发至宽表,如未查询到下单消息数据,则将查询结果存储至Hbase集群中。S32. If the payment message data first enters the Kafka application, the Kafka application queries the corresponding order message data. If the order message data is queried, the query result is sent to the wide table. If the order message data is not queried , the query results are stored in the HBase cluster.
另一方面,本发明还提供了一种实时数仓宽表加工处理系统,其改进之处在于,该系统包括Oracle数据库、mongodb数据库、Kafka集群、Redis集群、Hbase集群以及宽表;On the other hand, the present invention also provides a real-time data warehouse wide table processing system, the improvement is that the system includes Oracle database, mongodb database, Kafka cluster, Redis cluster, Hbase cluster and wide table;
所述的Oracle数据库分别同Kafka集群和Redis集群相连接,Kafka集群用于接收Oracle数据库中实时同步的数据,Redis集群用于接收Oracle数据库中同步的基础表信息;所述的Oracle数据库与mongodb数据库之间实现数据同步,mongodb 数据库上设置有线上接口;Described Oracle database is connected with Kafka cluster and Redis cluster respectively, Kafka cluster is used for receiving real-time synchronized data in Oracle database, Redis cluster is used for receiving basic table information synchronized in Oracle database; Described Oracle database and mongodb database To achieve data synchronization between them, a wired interface is set on the mongodb database;
Kafka应用程序连接在Kafka集群和Redis集群上,Kafka应用程序用于消费 Kafka集群中的数据,同时对Redis集群的数据进行查询,Kafka应用程序还连接至线上接口,用于在Redis集群中未查询数据时,实现在mongodb数据库中实现数据查询;The Kafka application is connected to the Kafka cluster and the Redis cluster. The Kafka application is used to consume the data in the Kafka cluster and query the data of the Redis cluster. The Kafka application is also connected to the online interface, which is used for unattended data in the Redis cluster. When querying data, realize data query in mongodb database;
所述的Hbase集群和宽表均连接在Kafka应用程序,所述的宽表用于接收经 Kafka应用程序查询到的数据,Hbase集群用于存储Kafka应用程序未查询到数据的查询结果。The HBase cluster and the wide table are all connected to the Kafka application, the wide table is used to receive the data queried by the Kafka application, and the HBase cluster is used to store the query result that the Kafka application does not query the data.
在上述的系统中,所述的Oracle数据库与Kafka集群通过Ogg实现数据同步。In the above system, the Oracle database and the Kafka cluster realize data synchronization through Ogg.
在上述的系统中,所述Redis集群在接收Oracle数据库中同步的基础表信息后,形成缓存数据,Kafka应用程序则对该缓存数据进行查询。In the above system, the Redis cluster forms cached data after receiving the synchronized basic table information in the Oracle database, and the Kafka application program queries the cached data.
本发明的有益效果是:本发明的一种实时数仓宽表加工处理方法及系统,能够快速关联到维表信息并获取到对应字段;即使消息不保证先后顺序的情况下,也可以实现消息的幂等处理;数据处理过程异常可追踪,重试机制保障数据不丢失。The beneficial effects of the present invention are: a real-time data warehouse width table processing method and system of the present invention can quickly associate with dimension table information and obtain corresponding fields; even if the message does not guarantee the sequence, the message can also be realized idempotent processing; data processing exceptions can be traced, and the retry mechanism ensures that data is not lost.
附图说明Description of drawings
图1为本发明的一种实时数仓宽表加工处理方法的流程示意图。FIG. 1 is a schematic flowchart of a processing method for a real-time data warehouse width meter according to the present invention.
图2为本发明的一种实时数仓宽表加工处理系统的框架结构示意图。FIG. 2 is a schematic diagram of the frame structure of a real-time data warehouse width meter processing system of the present invention.
图3为本发明中维表A和维表B的具体实施例图。FIG. 3 is a diagram of a specific embodiment of dimension table A and dimension table B in the present invention.
图4为本发明的一种实时数仓宽表加工处理方法的订单场景的具体实施例图。FIG. 4 is a diagram of a specific embodiment of an order scenario of a real-time warehouse width table processing method of the present invention.
具体实施方式Detailed ways
下面结合附图和实施例对本发明进一步说明。The present invention will be further described below in conjunction with the accompanying drawings and embodiments.
以下将结合实施例和附图对本发明的构思、具体结构及产生的技术效果进行清楚、完整地描述,以充分地理解本发明的目的、特征和效果。显然,所描述的实施例只是本发明的一部分实施例,而不是全部实施例,基于本发明的实施例,本领域的技术人员在不付出创造性劳动的前提下所获得的其他实施例,均属于本发明保护的范围。另外,专利中涉及到的所有联接/连接关系,并非单指构件直接相接,而是指可根据具体实施情况,通过添加或减少联接辅件,来组成更优的联接结构。本发明创造中的各个技术特征,在不互相矛盾冲突的前提下可以交互组合。The concept, specific structure and technical effects of the present invention will be clearly and completely described below with reference to the embodiments and accompanying drawings, so as to fully understand the purpose, characteristics and effects of the present invention. Obviously, the described embodiments are only a part of the embodiments of the present invention, rather than all the embodiments. Based on the embodiments of the present invention, other embodiments obtained by those skilled in the art without creative efforts are all within the scope of The scope of protection of the present invention. In addition, all the coupling/connection relationships involved in the patent do not mean that the components are directly connected, but refer to a better coupling structure by adding or reducing coupling accessories according to the specific implementation. Various technical features in the present invention can be combined interactively on the premise of not contradicting each other.
参照图1所示,本发明揭示了一种实时数仓宽表加工处理方法,具体的,该方法包括以下的步骤:Referring to Figure 1, the present invention discloses a real-time data warehouse width table processing method. Specifically, the method includes the following steps:
S1、数据的同步,将Oracle数据库中的数据实时同步到Kafka集群中,同时将Oracle数据库中的数据实时同步至mongodb数据库,mongodb数据库设置有线上接口;本实施例中,通过Ogg将Oracle数据库中的数据实时同步到Kafka集群中;S1. Data synchronization, synchronize the data in the Oracle database to the Kafka cluster in real time, and synchronize the data in the Oracle database to the mongodb database in real time. The mongodb database is set with an online interface; in this embodiment, the Oracle database is The data is synchronized to the Kafka cluster in real time;
S2、基础表信息的同步,将Oracle数据库中的基础表信息同步到Redis集群中,作为缓存数据;本实施例中,基础表信息包括但不限于部门表、权限表、商户表以及商品种类表;在本发明的一个具体实施例中,基础表信息包括部门前一天新增的数据;S2. Synchronization of basic table information, synchronizing the basic table information in the Oracle database to the Redis cluster as cached data; in this embodiment, the basic table information includes but is not limited to department table, authority table, merchant table and commodity category table ; In a specific embodiment of the present invention, the basic table information includes data newly added by the department the day before;
S3、数据的消费,Kafka应用程序消费Kafka集群中的数据,在数据查询时, Kafka应用程序先行查询Redis集群中的缓存数据,如未查询到缓存数据,则通过线上接口查询mongodb数据库中的数据;S3. Data consumption. The Kafka application consumes the data in the Kafka cluster. When querying data, the Kafka application first queries the cached data in the Redis cluster. If the cached data is not queried, it queries the mongodb database through the online interface. data;
S4、数据的下发,当Kafka应用程序查询到数据时,则将查询结果下方至宽表;当Kafka应用程序未查询到数据时,则将查询结果存储至Hbase集群中。S4. Data delivery. When the Kafka application queries the data, the query result is placed below the wide table; when the Kafka application does not query the data, the query result is stored in the Hbase cluster.
如图2所示,本发明还提供了一种实时数仓宽表加工处理系统,该系统包括Oracle数据库10、mongodb数据库20、Kafka集群30、Redis集群40、Hbase集群 50以及宽表60;所述的Oracle数据库10分别同Kafka集群30和Redis集群40 相连接,Kafka集群30用于接收Oracle数据库10中实时同步的数据,Redis集群 40用于接收Oracle数据库10中同步的基础表信息;所述的Oracle数据库10与mongodb数据库20之间实现数据同步,mongodb数据库20上设置有线上接口;Kafka 应用程序70连接在Kafka集群30和Redis集群40上,Kafka应用程序70用于消费Kafka集群30中的数据,同时对Redis集群40的数据进行查询,Kafka应用程序70还连接至线上接口,用于在Redis集群40中未查询数据时,实现在mongodb 数据库20中实现数据查询;所述的Hbase集群50和宽表60均连接在Kafka应用程序70,所述的宽表60用于接收经Kafka应用程序70查询到的数据,Hbase集群 50用于存储Kafka应用程序70未查询到数据的查询结果。As shown in FIG. 2 , the present invention also provides a real-time data warehouse wide table processing system, which includes an
本实施例中,所述的Oracle数据库10与Kafka集群30通过Ogg实现数据同步。所述Redis集群40在接收Oracle数据库10中同步的基础表信息后,形成缓存数据,Kafka应用程序70则对该缓存数据进行查询。In this embodiment, the
结合上述的步骤,参照图3所示,我们对本发明如何关联维表信息的问题进行详细说明,本实施例中,当需要计算订单相关数据时,需要查询部门信息和收获地址信息,需要关联部门相关的部门信息维表和地址信息维表,即分别为维表A和维表B。本实施例中,将基础信息表同步到Redis集群40中作为缓存数据,查询时先行查询Redis集群40中的缓存数据,当没有查询到时,则再通过线上接口,查询 mongodb数据库20中的数据,能够快速关联到维表信息并获取到对应字段,有效减少线上接口的压力。In combination with the above steps, referring to Fig. 3, we will describe in detail the problem of how to associate dimension table information in the present invention. In this embodiment, when order-related data needs to be calculated, it is necessary to query department information and harvest address information, and it is necessary to associate departments The related department information dimension table and address information dimension table are dimension table A and dimension table B respectively. In this embodiment, the basic information table is synchronized to the
对于多个消息无法保证先后顺序的问题,结合图1、图4所示,以订单场景为例进行详细解释说明,Kafka应用程序70消费的数据包括订单支付金额,该订单支付金额包括下单消息数据和支付消息数据,在正常情况下时,下单消息数据会先到,但下单消息数据和支付消息数据的先后顺序没有办法保证。在本实施例中,通过将查询的消息放入Hbase集群50,具体包括以下的步骤:For the problem that the sequence of multiple messages cannot be guaranteed, the order scenario is taken as an example to explain in detail with reference to Figures 1 and 4. The data consumed by the
S31、如下单消息数据进入Kafka应用程序70,则Kafka应用程序70查询对应的支付消息数据,如查询到支付消息数据,则将查询结果下发至宽表60,如未查询到支付消息数据,则将查询结果存储至Hbase集群50中;S31. The following single message data enters the
S32、如支付消息数据先行进入Kafka应用程序70,则Kafka应用程序70查询对应的下单消息数据,如查询到下单消息数据,则将查询结果下发至宽表60,如未查询到下单消息数据,则将查询结果存储至Hbase集群50中。S32. If the payment message data first enters the
通过这种步骤,在消息不保证先后顺序的情况下时,也可以实现消息的幂等处理。Through this step, idempotent processing of messages can also be achieved when the message sequence is not guaranteed.
需要进一步说明的是,在订单场景下,一个订单包括有多个消息,例如下单消息A、支付消息B以及取消消息C等,在本方案中,无论消息是否已经到达kafka 消费程序,都将消息存储至Hbase集群50中,同时,取出该订单相关的所有消息进行下方至宽表60。It needs to be further explained that in the order scenario, an order includes multiple messages, such as order message A, payment message B, and cancellation message C, etc. In this solution, regardless of whether the message has reached the kafka consumer program, it will be sent to the Kafka consumer program. The message is stored in the
另外,Kafka应用程序70通过偏移量来维护数据的完整性,当遇到异常时会有重试机制,Kafka应用程序70异常退出后只需要重启程序,应用程序会自动从上一次未提交的偏移量处开始进行处理;由于宽表60采用主健约束因此可以保证消息处理的幂等性。In addition, the
综上所述,本发明的一种实时数仓宽表60加工处理方法及系统,能够快速关联到维表信息并获取到对应字段;即使消息不保证先后顺序的情况下,也可以实现消息的幂等处理;数据处理过程异常可追踪,重试机制保障数据不丢失;高并发下系统也能够快速响应查询数据。To sum up, a method and system for processing a real-time data warehouse width table 60 of the present invention can quickly associate with dimension table information and obtain corresponding fields; Idempotent processing; abnormal data processing can be traced, and the retry mechanism ensures that data is not lost; the system can also quickly respond to query data under high concurrency.
以上是对本发明的较佳实施进行了具体说明,但本发明创造并不限于所述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可做出种种的等同变形或替换,这些等同的变形或替换均包含在本申请权利要求所限定的范围内。The above is a specific description of the preferred implementation of the present invention, but the present invention is not limited to the described embodiments, and those skilled in the art can also make various equivalent deformations or replacements on the premise that does not violate the spirit of the present invention , these equivalent modifications or substitutions are all included within the scope defined by the claims of the present application.
Claims (8)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010760035.0ACN111949657A (en) | 2020-07-31 | 2020-07-31 | A real-time data warehouse width meter processing method and system |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010760035.0ACN111949657A (en) | 2020-07-31 | 2020-07-31 | A real-time data warehouse width meter processing method and system |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN111949657Atrue CN111949657A (en) | 2020-11-17 |
Family
ID=73338645
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010760035.0APendingCN111949657A (en) | 2020-07-31 | 2020-07-31 | A real-time data warehouse width meter processing method and system |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN111949657A (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113051275A (en)* | 2021-03-31 | 2021-06-29 | 银盛支付服务股份有限公司 | Storage architecture method compatible with real-time and offline data processing |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109189835A (en)* | 2018-08-21 | 2019-01-11 | 北京京东尚科信息技术有限公司 | The method and apparatus of the wide table of data are generated in real time |
| CN110209677A (en)* | 2018-02-06 | 2019-09-06 | 北京京东尚科信息技术有限公司 | The method and apparatus of more new data |
| CN110781203A (en)* | 2019-09-09 | 2020-02-11 | 国网电子商务有限公司 | Method and device for determining data width table |
| CN111008521A (en)* | 2019-12-06 | 2020-04-14 | 北京三快在线科技有限公司 | Method and device for generating wide table and computer storage medium |
- 2020
- 2020-07-31CNCN202010760035.0Apatent/CN111949657A/enactivePending
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110209677A (en)* | 2018-02-06 | 2019-09-06 | 北京京东尚科信息技术有限公司 | The method and apparatus of more new data |
| CN109189835A (en)* | 2018-08-21 | 2019-01-11 | 北京京东尚科信息技术有限公司 | The method and apparatus of the wide table of data are generated in real time |
| CN110781203A (en)* | 2019-09-09 | 2020-02-11 | 国网电子商务有限公司 | Method and device for determining data width table |
| CN111008521A (en)* | 2019-12-06 | 2020-04-14 | 北京三快在线科技有限公司 | Method and device for generating wide table and computer storage medium |
Non-Patent Citations (1)
| Title |
|---|
| "实时数仓宽表加工解决方案", Retrieved from the Internet <URL:https://blog.csdn.net/weixin_43291055/article/details/100112790?ops_request_misc=&request_id=&biz_id=102&utm_term=%E5%AE%BD%E8%A1%A8%20%E5%B9%82%E7%AD%89&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-3-100112790.142^v100^pc_search_result_base7&spm=1018.2226.3001.4187>* |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113051275A (en)* | 2021-03-31 | 2021-06-29 | 银盛支付服务股份有限公司 | Storage architecture method compatible with real-time and offline data processing |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11281665B2 (en) | Read/write split database query routing | |
| US8762420B2 (en) | Aggregation of data stored in multiple data stores | |
| US20150032695A1 (en) | Client and server integration for replicating data | |
| CN109189835A (en) | The method and apparatus of the wide table of data are generated in real time | |
| Spirovska et al. | Wren: Nonblocking reads in a partitioned transactional causally consistent data store | |
| EP2797013A1 (en) | Database update execution according to power management schemes | |
| US20140359029A1 (en) | Message index subdivided based on time intervals | |
| EP3480705B1 (en) | Database data modification request processing method and apparatus | |
| US20200104405A1 (en) | Data warehouse management and synchronization systems and methods | |
| CN111028074A (en) | Overdue bill updating and inquiring method, system, server and storage medium | |
| CN115292414A (en) | A method for synchronizing business data to data warehouse | |
| CN116910079A (en) | Method, system, device and storage medium for realizing delay association of Flink with respect to CDC data dimension table | |
| CN111949657A (en) | A real-time data warehouse width meter processing method and system | |
| US10303552B2 (en) | Method for optimizing index, master database node and subscriber database node | |
| CN111708808A (en) | Distributed service system and service summarizing and inquiring method, device and equipment thereof | |
| CN112907336A (en) | Method and server for realizing order state synchronization based on mybatis interceptor | |
| US7680838B1 (en) | Maintaining data synchronization in a file-sharing environment | |
| CN109635042B (en) | OLTP and OLAP integrated automobile financial big data system | |
| CN111930889A (en) | Rapid query method based on large-range date span of unstructured database | |
| CN117668083A (en) | Heterogeneous database synchronization method and device, electronic equipment and storage medium | |
| CN117971968A (en) | A storage system and data synchronization method based on multiple heterogeneous databases | |
| CN117194572A (en) | A data synchronization processing method and terminal | |
| CN114443773A (en) | Distributed system data synchronization method, device, equipment and storage medium | |
| CN102193976B (en) | Method for implementing transaction rollback mechanism in online transaction of graphic database | |
| CN104933623A (en) | Mechanical non-standard component design service platform |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| RJ01 | Rejection of invention patent application after publication | Application publication date:20201117 |