CN111931809A - Data processing method and device, storage medium and electronic equipment - Google Patents
Data processing method and device, storage medium and electronic equipmentDownload PDFInfo
- Publication number
- CN111931809A CN111931809ACN202010605188.8ACN202010605188ACN111931809ACN 111931809 ACN111931809 ACN 111931809ACN 202010605188 ACN202010605188 ACN 202010605188ACN 111931809 ACN111931809 ACN 111931809A
- Authority
- CN
- China
- Prior art keywords
- data
- feature
- information
- attribute information
- user terminal
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images




Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- General Engineering & Computer Science (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Life Sciences & Earth Sciences (AREA)
- Software Systems (AREA)
- Medical Informatics (AREA)
- Computing Systems (AREA)
- Mathematical Physics (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本申请涉及计算机技术领域,尤其涉及一种数据的处理方法、装置、存储介质及电子设备。The present application relates to the field of computer technology, and in particular, to a data processing method, apparatus, storage medium, and electronic device.
背景技术Background technique
随着互联网的发展,数据处理在互联网行业扮演着越来越重要的角色,在多个领域过程中,均需要通过对海量数据进行分析处理,但在现有技术中,存在处理过程繁琐,数据特征提取不充分、运算结果并不精准等问题。With the development of the Internet, data processing plays an increasingly important role in the Internet industry. In many fields, it is necessary to analyze and process massive data. However, in the existing technology, the processing process is cumbersome and the data Insufficient feature extraction and inaccurate calculation results.
发明内容SUMMARY OF THE INVENTION
本申请实施例提供了一种数据的处理方法、装置、存储介质及电子设备,可以解决对数据的特征提取不充分,处理结果不精确的问题。所述技术方案如下:The embodiments of the present application provide a data processing method, apparatus, storage medium and electronic device, which can solve the problems of insufficient feature extraction of data and inaccurate processing results. The technical solution is as follows:
第一方面,本申请实施例提供了一种数据的处理方法,所述方法包括:In a first aspect, an embodiment of the present application provides a data processing method, the method comprising:
获取数据的属性信息;其中,所述属性信息包括所述数据的基本信息和互动信息;Obtain attribute information of the data; wherein, the attribute information includes basic information and interaction information of the data;
对所述属性信息进行特征提取得到特征组集合;其中,所述特征组集合包括至少一个特征组,所述特征组中包括至少一个数据特征;Perform feature extraction on the attribute information to obtain a feature group set; wherein, the feature group set includes at least one feature group, and the feature group includes at least one data feature;
基于预测模型对所述特征组集合进行处理得到预测值;The predicted value is obtained by processing the feature set set based on the prediction model;
根据所述预测值为所述数据标注上目标数据标签。Label the data with a target data label according to the predicted value.
第二方面,本申请实施例提供了一种数据的处理装置,所述数据的处理装置包括:In a second aspect, an embodiment of the present application provides a data processing device, where the data processing device includes:
获取模块,用于获取数据的属性信息;其中,所述属性信息包括所述数据的基本信息和互动信息;an acquisition module, configured to acquire attribute information of the data; wherein the attribute information includes basic information and interaction information of the data;
提取模块,用于对所述属性信息进行特征提取得到特征组集合;其中,所述特征组集合包括至少一个特征组,所述特征组中包括至少一个数据特征;an extraction module, configured to perform feature extraction on the attribute information to obtain a feature group set; wherein, the feature group set includes at least one feature group, and the feature group includes at least one data feature;
预测模块,用于基于预测模型对所述特征组集合进行处理得到预测值;a prediction module, used for processing the feature group set based on the prediction model to obtain a prediction value;
标注模块,用于根据所述预测值为所述数据标注上目标数据标签。A labeling module, configured to label the data with a target data label according to the predicted value.
第三方面,本申请实施例提供一种计算机存储介质,所述计算机存储介质存储有多条指令,所述指令适于由处理器加载并执行上述的方法步骤。In a third aspect, an embodiment of the present application provides a computer storage medium, where the computer storage medium stores a plurality of instructions, and the instructions are suitable for being loaded by a processor and executing the above method steps.
第四方面,本申请实施例提供一种电子设备,可包括:处理器、存储器和显示屏;其中,所述存储器存储有计算机程序,所述计算机程序适于由所述处理器加载并执行上述的方法步骤。In a fourth aspect, an embodiment of the present application provides an electronic device, which may include: a processor, a memory, and a display screen; wherein, the memory stores a computer program, and the computer program is adapted to be loaded by the processor and execute the above-mentioned method steps.
本申请一些实施例提供的技术方案带来的有益效果至少包括:The beneficial effects brought by the technical solutions provided by some embodiments of the present application include at least:
本申请实施例的方案在执行时,服务器获取数据的属性信息,属性信息包括数据的基本信息和互动信息,对属性信息进行特征提取得到特征组集合,特征组集合包括至少一个特征组,特征组中包括至少一个数据特征,基于预测模型对特征组集合进行处理得到预测值,根据预测值为数据标注上目标数据标签,通过分析数据的基本信息、互动信息等属性信息,能充分提取数据特征,并精确地识别出该数据是否需要标注上目标数据标签,以便后续能基于该目标数据标签为用户提供更好的服务。When the solution of the embodiment of the present application is executed, the server obtains attribute information of the data, the attribute information includes the basic information and interaction information of the data, and performs feature extraction on the attribute information to obtain a feature group set. The feature group set includes at least one feature group, and the feature group It includes at least one data feature. Based on the prediction model, the feature set is processed to obtain the predicted value. According to the predicted value, the data is labeled with the target data label. By analyzing the basic information of the data, interactive information and other attribute information, the data features can be fully extracted. And accurately identify whether the data needs to be marked with a target data label, so that the user can be provided with better services based on the target data label in the future.
附图说明Description of drawings
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。In order to more clearly illustrate the embodiments of the present application or the technical solutions in the prior art, the following briefly introduces the accompanying drawings required for the description of the embodiments or the prior art. Obviously, the drawings in the following description are only These are some embodiments of the present application. For those of ordinary skill in the art, other drawings can also be obtained based on these drawings without any creative effort.
图1是本申请实施例提供的一种系统架构图;1 is a system architecture diagram provided by an embodiment of the present application;
图2是本申请实施例提供的数据的处理方法的流程示意图;2 is a schematic flowchart of a data processing method provided by an embodiment of the present application;
图3是本申请实施例提供的数据的处理方法的另一流程示意图;3 is another schematic flowchart of a data processing method provided by an embodiment of the present application;
图4是本申请实施例提供的一种装置的结构示意图;4 is a schematic structural diagram of a device provided by an embodiment of the present application;
图5是本申请实施例提供的一种电子设备的结构示意图。FIG. 5 is a schematic structural diagram of an electronic device provided by an embodiment of the present application.
具体实施方式Detailed ways
为使本申请的目的、技术方案和优点更加清楚,下面将结合附图对本申请实施例方式作进一步地详细描述。In order to make the objectives, technical solutions and advantages of the present application clearer, the embodiments of the present application will be described in further detail below with reference to the accompanying drawings.
下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本申请相一致的所有实施方式。相反,它们仅是如所附权利要求书中所详述的、本申请的一些方面相一致的装置和方法的例子。Where the following description refers to the drawings, the same numerals in different drawings refer to the same or similar elements unless otherwise indicated. The implementations described in the illustrative examples below are not intended to represent all implementations consistent with this application. Rather, they are merely examples of apparatus and methods consistent with some aspects of the present application, as recited in the appended claims.
在本申请的描述中,需要理解的是,术语“第一”、“第二”等仅用于描述目的,而不能理解为指示或暗示相对重要性。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本申请中的具体含义。“和/或”,描述关联对象的关联关系,表示可以存在三种关系,例如,A和/或B,可以表示:单独存在A,同时存在A和B,单独存在B这三种情况。字符“/”一般表示前后关联对象是一种“或”的关系。In the description of the present application, it should be understood that the terms "first", "second" and the like are used for descriptive purposes only, and should not be construed as indicating or implying relative importance. For those of ordinary skill in the art, the specific meanings of the above terms in this application can be understood in specific situations. "And/or", which describes the association relationship of the associated objects, means that there can be three kinds of relationships, for example, A and/or B, which can mean that A exists alone, A and B exist at the same time, and B exists alone. The character "/" generally indicates that the associated objects are an "or" relationship.
为使本申请的目的、技术方案和优点更加清楚,下面将结合附图对本申请实施例方式作进一步地详细描述。In order to make the objectives, technical solutions and advantages of the present application clearer, the embodiments of the present application will be described in further detail below with reference to the accompanying drawings.
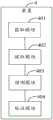
图1示出了可以应用本申请实施例的数据的处理方法或数据的处理装置的示例性系统架构100的示意图。FIG. 1 shows a schematic diagram of an
如图1所示,系统架构100可以包括终端设备101、102、103中的一种或多种,网络104和服务器105。网络104用以在终端设备101、102、103和服务器105之间提供通信链路的介质。网络104可以包括各种连接类型,例如有线、无线通信链路或者光纤电缆等等。As shown in FIG. 1 , the
应该理解,图1中的终端设备、网络和服务器的数目仅仅是示意性的。根据实现需要,可以具有任意数目的终端设备、网络和服务器。比如服务器105可以是多个服务器组成的服务器集群等。It should be understood that the numbers of terminal devices, networks and servers in FIG. 1 are merely illustrative. There can be any number of terminal devices, networks and servers according to implementation needs. For example, the
工作人员(如:教师,销售人员)与用户(如:学生,家长)可以使用终端设备101、102、103通过网络104与服务器105交互,以接收或发送消息等。终端设备101、102、103可以是具有显示屏的各种电子设备,包括但不限于智能手机、平板电脑、便携式计算机和台式计算机等等。本申请中的终端设备101、102、103可以为提供各种服务的终端设备。可通过服务器105获取数据的属性信息,属性信息包括数据的基本信息和互动信息,对属性信息进行特征提取得到特征组集合,特征组集合包括至少一个特征组,特征组中包括至少一个数据特征,基于预测模型对特征组集合进行处理得到预测值,根据预测值为数据标注上目标数据标签。Staff (eg: teachers, sales staff) and users (eg: students, parents) can use the
在此需要说明的是,本申请实施例所提供的数据的处理方法可以由终端设备101、102、103中的一个或多个,和/或,服务器105执行,相应地,本申请实施例所提供的数据的处理装置一般设置于对应终端设备中,和/或,服务器105中,但本申请不限于此。It should be noted here that the data processing methods provided in the embodiments of the present application may be executed by one or more of the
应理解,图1中的终端设备、网络和服务器的数目仅是示意性的。根据现实需要,可以是任意数量的终端设备、网络和服务器。It should be understood that the numbers of terminal devices, networks and servers in FIG. 1 are only illustrative. According to actual needs, it can be any number of terminal devices, networks and servers.
下面将结合附图2和附图3,对本申请实施例提供的数据的处理方法进行详细介绍。在这里需要说明的是,为了方便描述,实施例以在线教育行业中的目标用户识别为例进行说明,但本领域技术人员明白,本申请的适用并不局限于在线教育行业,本申请所描述的数据的处理方法可以有效应用于互联网各个行业领域。The data processing method provided by the embodiment of the present application will be described in detail below with reference to FIG. 2 and FIG. 3 . It should be noted here that, for the convenience of description, the embodiment takes target user identification in the online education industry as an example for description, but those skilled in the art understand that the application of this application is not limited to the online education industry. The data processing method can be effectively applied to various fields of the Internet.
请参见图2,为本申请实施例提供了一种数据的处理方法的流程示意图。如图2所示,本申请实施例的所述方法可以包括以下步骤:Referring to FIG. 2 , a schematic flowchart of a data processing method is provided in an embodiment of the present application. As shown in FIG. 2 , the method of the embodiment of the present application may include the following steps:
S201,获取数据的属性信息。S201, acquire attribute information of the data.
其中,属性信息可以是多个维度的数据,属性信息包括数据的基本信息和互动信息等,如:在目标用户识别中属性信息可以包括用户的基本信息、学习记录和学习互动数据等,属性信息可以是通过对与用户相关的音频、视频、文本和图片等形式的数据进行分析后得到的信息,获取用户的属性信息便于后续对用户进行识别分析。Among them, the attribute information can be data of multiple dimensions, and the attribute information includes the basic information and interactive information of the data. It may be information obtained by analyzing data in the form of audio, video, text, and pictures related to the user, and the attribute information of the user is acquired to facilitate subsequent identification and analysis of the user.
S202,对属性信息进行特征提取得到特征组集合。S202, perform feature extraction on the attribute information to obtain a feature group set.
其中,特征组集合是指包括至少一个特征组的集合,特征组中包括至少一个数据特征,在对数据的属性信息进行特征提取后,可得到多个数据相关的特征,根据不同特征类型对多个数据相关的特征进行归类得到多个特征组,多个特征组共同组成了特征组集合。The feature group set refers to a set including at least one feature group, and the feature group includes at least one data feature. After feature extraction is performed on the attribute information of the data, multiple data-related features can be obtained. The data-related features are classified to obtain multiple feature groups, and the multiple feature groups together form a feature group set.
一般的,可对属性信息进行特征工程处理,清除属性信息中的异常数据得到至少一个有效特征数据,对至少一个有效特征数据进行预处理得到有效数据信息,获取有效数据信息中的至少一个特征,从至少一个特征中选取特征发散或相关性高于预设阈值的至少一个目标特征,对至少一个目标特征分类处理得到特征组集合。特征工程处理是利用数据领域的相关知识创建能使机器学习算法达到最佳性能特征的过程,也即将原始数据转变成特征的过程,得到的特征可较好的描述该原始数据,并且利用这些特征建立的模型在未知数据上的表现性能可以达到最优(或者接近最佳性能)。典型的特征工程包括数据清理、特征离散化、特征提取、特征选择等过程。Generally, feature engineering can be performed on the attribute information, at least one valid feature data can be obtained by clearing abnormal data in the attribute information, at least one valid feature data can be preprocessed to obtain valid data information, and at least one feature in the valid data information can be obtained, At least one target feature whose feature divergence or correlation is higher than a preset threshold is selected from the at least one feature, and the at least one target feature is classified and processed to obtain a feature group set. Feature engineering is the process of creating features that enable machine learning algorithms to achieve the best performance by using relevant knowledge in the data field, that is, the process of converting raw data into features. The obtained features can better describe the original data, and use these features. The performance of the established model on unknown data can be optimal (or close to optimal performance). Typical feature engineering includes data cleaning, feature discretization, feature extraction, feature selection and other processes.
特征工程中对数据预处理过程常用方法可以包括:归一化:MinMaxScaler,X_std=(X-X.min(axis=0))/(X.max(axis=0)-X.min(axis=0)),X_scaled=X_std/(max-min)+min;标准化:(X-mean)/std,标准化的前提是特征值服从正态分布,在标准化后转换成标准正态分布,通常是z-score标准化,即零-均值标准化y=(x-μ)/σ,经过处理后的数据均值为0,标准差为1;离散化:对连续型的数值型特征分段,每一段内的数据都可以作为一个新的特征,定量特征二值化的核心在于设定一个阈值,大于阈值的赋值为1,小于等于阈值的赋值为0;On-hot:利用二进制的位来表示某个定性特征的出现与否,N个维度来对N个类别进行编码,且对于每个类别,只有一个维度有效,记作数字1;其它维度均记作数字0。Common methods for data preprocessing in feature engineering include: Normalization: MinMaxScaler, X_std=(X-X.min(axis=0))/(X.max(axis=0)-X.min(axis=0) ), X_scaled=X_std/(max-min)+min; Standardization: (X-mean)/std, the premise of standardization is that the eigenvalues obey the normal distribution, and are converted into standard normal distribution after standardization, usually z-score Standardization, that is, zero-mean standardization y=(x-μ)/σ, the processed data has a mean value of 0 and a standard deviation of 1; discretization: for continuous numerical feature segmentation, the data in each segment is It can be used as a new feature. The core of quantitative feature binarization is to set a threshold. The value greater than the threshold is assigned as 1, and the value less than or equal to the threshold is assigned as 0; On-hot: use binary bits to represent a qualitative feature. Appear or not, N dimensions are used to encode N categories, and for each category, only one dimension is valid, denoted as number 1; other dimensions are denoted as number 0.
S203,基于预测模型对特征组集合进行处理得到预测值。S203, processing the feature group set based on the prediction model to obtain a prediction value.
其中,预测模型是在采用定量预测法进行预测时建立的预测数学模型,可利用数学语言或公式的方式描述预测事物间的数量关系,该数量关系在一定程度上揭示了事物间的内在规律性,预测时可将该数量关系作为计算预测值的直接依据。预测方法的种类很多,不同的预测方法种类对应不同的预测模型。本申请实施例中的预测模型是基于样本数据经过预先训练后建立的模型,预测值是用于表示数据(用户)倾向性的数值。Among them, the forecasting model is a forecasting mathematical model established when using quantitative forecasting method for forecasting. It can use mathematical language or formulas to describe the quantitative relationship between predicted things, and the quantitative relationship reveals the inherent regularity between things to a certain extent. , the quantitative relationship can be used as a direct basis for calculating the predicted value during prediction. There are many types of forecasting methods, and different types of forecasting methods correspond to different forecasting models. The prediction model in the embodiment of the present application is a model established after pre-training based on sample data, and the prediction value is a numerical value used to represent the tendency of the data (user).
一般的,建立预测模型的过程可以是通过获取多个样本数据各自的属性信息,对多个样本数据各自的属性信息进行特征提取,得到多个样本数据各自对应的特征组集合,利用XGBoost算法对多个样本数据各自对应的特征组集合训练得到预测模型。建模过程需要先对样本数据进行基本的特征工程处理,然后用经过特征工程处理的数据集进行模型训练。特征工程是指从原始数据转换为特征向量的过程,特征工程是机器学习中最重要的起始步骤,会直接影响机器学习的效果,并通常需要大量的时间。典型的特征工程包括数据清理、特征离散化、特征提取、特征选择等过程。Generally, the process of establishing a prediction model can be obtained by acquiring the respective attribute information of multiple sample data, and performing feature extraction on the respective attribute information of multiple sample data, so as to obtain the corresponding feature group sets of multiple sample data, and using the XGBoost algorithm to A prediction model is obtained by training a set of feature groups corresponding to each of the plurality of sample data. The modeling process needs to perform basic feature engineering on the sample data, and then use the feature-engineered dataset for model training. Feature engineering refers to the process of converting raw data into feature vectors. Feature engineering is the most important initial step in machine learning, which directly affects the effect of machine learning and usually takes a lot of time. Typical feature engineering includes data cleaning, feature discretization, feature extraction, feature selection and other processes.
XGBoost是一个优化的分布式梯度增强库,旨在实现高效,灵活和便携;其在Gradient Boosting框架下实现机器学习算法。XGBoost算法是对梯度提升算法的改进,求解损失函数极值时使用牛顿法,将损失函数泰勒展开到二阶,另外损失函数中加入了正则化项。XGBoost算法可以看成是由K棵树组成的加法模型:


S204,根据预测值为数据标注上目标数据标签。S204, label the data with a target data label according to the predicted value.
其中,目标数据标签是用于区分数据为目标数据还是非目标数据的标记,如:在目标用户识别中目标数据标签也即目标用户标签,标注上目标用户标签的用户数据表明其对应的用户为预测值符合预设条件的用户,通过对用户的属性信息进行分析后,可得到该用户对应的倾向性的数值,即预测值,基于该预测值可判定是否需要为该用户数据标注上目标用户标签。Among them, the target data label is a label used to distinguish whether the data is target data or non-target data. For example, in target user identification, the target data label is also the target user label, and the user data marked with the target user label indicates that the corresponding user is For a user whose predicted value meets the preset conditions, after analyzing the user's attribute information, the value of the user's corresponding tendency, that is, the predicted value, can be obtained. Based on the predicted value, it can be determined whether the target user needs to be marked for the user data. Label.
一般的,基于预测模型对特征组集合进行预测可得到预测值,预测值可以是Leads分数,Leads分数是指通过交流得到的关于某人购买某种产品或服务的可能性的数据,根据Leads分数可识别符合预设购买意向分值的目标对象,即目标用户。通过判断预测值是否大于或等于预设阈值,可确定是否需要为该数据标注上目标数据标签;若预测值大于或等于预设阈值,可为所述数据标注上所述目标数据标签,则从用户终端集合中确定处于在线状态的至少一个候选用户终端,获取至少一个候选用户终端的工作状态,从至少一个候选用户终端中选择工作状态满足预设条件的候选用户终端作为用户终端,将具有所述目标数据标签的数据对应的用户描述信息发送至用户终端,使用户终端处的工作人员可获取该用户描述信息,以便能为该用户描述信息对应的目标用户提供更好的服务。In general, predicting a set of feature groups based on a predictive model can obtain a predicted value, and the predicted value can be the Leads score. The Leads score refers to the data obtained through communication about the possibility of someone buying a certain product or service. According to the Leads score It can identify target objects that meet the preset purchase intention score, that is, target users. By judging whether the predicted value is greater than or equal to the preset threshold, it can be determined whether the data needs to be labeled with the target data label; if the predicted value is greater than or equal to the preset threshold, the data can be labeled with the target data label, then from the Determine at least one candidate user terminal in the online state in the user terminal set, obtain the working state of the at least one candidate user terminal, select a candidate user terminal whose working state meets the preset condition from the at least one candidate user terminal as the user terminal, and use all the candidate user terminals. The user description information corresponding to the data of the target data tag is sent to the user terminal, so that the staff at the user terminal can obtain the user description information, so as to provide better services for the target user corresponding to the user description information.
本申请实施例的方案在执行时,服务器获取数据的属性信息,属性信息包括数据的基本信息和互动信息,对属性信息进行特征提取得到特征组集合,特征组集合包括至少一个特征组,特征组中包括至少一个数据特征,基于预测模型对特征组集合进行处理得到预测值,根据预测值为数据标注上目标数据标签,通过分析数据的基本信息、互动信息等属性信息,能充分提取数据特征,并精确地识别出该数据是否需要标注上目标数据标签,以便后续能基于该目标数据标签为用户提供更好的服务。When the solution of the embodiment of the present application is executed, the server obtains attribute information of the data, the attribute information includes the basic information and interaction information of the data, and performs feature extraction on the attribute information to obtain a feature group set. The feature group set includes at least one feature group, and the feature group It includes at least one data feature. Based on the prediction model, the feature set is processed to obtain the predicted value. According to the predicted value, the data is labeled with the target data label. By analyzing the basic information of the data, interactive information and other attribute information, the data features can be fully extracted. And accurately identify whether the data needs to be marked with a target data label, so that the user can be provided with better services based on the target data label in the future.
请参见图3,为本申请实施例提供了一种数据的处理方法的流程示意图。本实施例以数据的处理方法应用于电子设备中来举例说明,电子设备可以是服务器或终端设备。该数据的处理方法可以包括以下步骤:Referring to FIG. 3 , a schematic flowchart of a data processing method is provided in an embodiment of the present application. In this embodiment, the data processing method is applied to an electronic device as an example, and the electronic device may be a server or a terminal device. The data processing method may include the following steps:
S301,获取数据的属性信息。S301, acquire attribute information of the data.
其中,属性信息可以是多个维度的数据,属性信息包括数据的基本信息和互动信息等,如:在目标用户识别中属性信息可以包括用户的基本信息、学习记录和学习互动数据等,属性信息可以是通过对与用户相关的音频、视频、文本和图片等形式的数据进行分析后得到的信息,获取用户的属性信息便于后续对用户进行识别分析。Among them, the attribute information can be data of multiple dimensions, and the attribute information includes the basic information and interactive information of the data. It may be information obtained by analyzing data in the form of audio, video, text, and pictures related to the user, and the attribute information of the user is acquired to facilitate subsequent identification and analysis of the user.
S302,对属性信息进行特征工程处理,清除属性信息中的异常数据得到至少一个有效特征数据。S302 , perform feature engineering processing on the attribute information, and remove abnormal data in the attribute information to obtain at least one valid feature data.
其中,在目标用户识别中用户的属性信息中可能会包含一些冗余或不相关的特征,故可在不造成大量信息丢失的情况下清除这些特征,而有效特征数据则是在对用户的属性信息进行异常数据进行清除后得到的特征数据。Among them, the attribute information of the user in the target user identification may contain some redundant or irrelevant features, so these features can be cleared without causing a large amount of information loss, and the effective feature data is the attribute information of the user. The characteristic data obtained after the abnormal data is removed from the information.
一般的,对属性信息进行特征工程处理,清除属性信息中的异常数据得到至少一个有效特征数据,对至少一个有效特征数据进行预处理得到有效数据信息,获取有效数据信息中的至少一个特征,从至少一个特征中选取特征发散或相关性高于预设阈值的至少一个目标特征,对至少一个目标特征分类处理得到特征组集合。特征工程处理是利用数据领域的相关知识创建能使机器学习算法达到最佳特征的过程,也即将原始数据转变成特征的过程,得到的特征可较好的描述该原始数据,并且利用这些特征建立的模型在未知数据上的表现性能可以达到最优(或者接近最佳性能)。典型的特征工程包括数据清理、特征离散化、特征提取、特征选择等过程。Generally, feature engineering is performed on attribute information, at least one valid feature data is obtained by removing abnormal data in the attribute information, valid data information is obtained by preprocessing at least one valid feature data, at least one feature in the valid data information is obtained, and From the at least one feature, at least one target feature whose feature divergence or correlation is higher than a preset threshold is selected, and the at least one target feature is classified and processed to obtain a feature group set. Feature engineering is the process of using relevant knowledge in the data field to create the best features for machine learning algorithms, that is, the process of transforming original data into features, and the obtained features can better describe the original data, and use these features to establish The performance of the model on unknown data can be optimal (or close to optimal performance). Typical feature engineering includes data cleaning, feature discretization, feature extraction, feature selection and other processes.
特征工程中对数据预处理过程常用方法可以包括:归一化:MinMaxScaler,X_std=(X-X.min(axis=0))/(X.max(axis=0)-X.min(axis=0)),X_scaled=X_std/(max-min)+min;标准化:(X-mean)/std,标准化的前提是特征值服从正态分布,在标准化后转换成标准正态分布,通常是z-score标准化,即零-均值标准化y=(x-μ)/σ,经过处理后的数据均值为0,标准差为1;离散化:对连续型的数值型特征分段,每一段内的数据都可以作为一个新的特征,定量特征二值化的核心在于设定一个阈值,大于阈值的赋值为1,小于等于阈值的赋值为0;On-hot:利用二进制的位来表示某个定性特征的出现与否,N个维度来对N个类别进行编码,且对于每个类别,只有一个维度有效,记作数字1;其它维度均记作数字0。Common methods for data preprocessing in feature engineering include: Normalization: MinMaxScaler, X_std=(X-X.min(axis=0))/(X.max(axis=0)-X.min(axis=0) ), X_scaled=X_std/(max-min)+min; Standardization: (X-mean)/std, the premise of standardization is that the eigenvalues obey the normal distribution, and are converted into standard normal distribution after standardization, usually z-score Standardization, that is, zero-mean standardization y=(x-μ)/σ, the processed data has a mean value of 0 and a standard deviation of 1; discretization: for continuous numerical feature segmentation, the data in each segment is It can be used as a new feature. The core of quantitative feature binarization is to set a threshold. The value greater than the threshold is assigned as 1, and the value less than or equal to the threshold is assigned as 0; On-hot: use binary bits to represent a qualitative feature. Appear or not, N dimensions are used to encode N categories, and for each category, only one dimension is valid, denoted as number 1; other dimensions are denoted as number 0.
S303,对至少一个有效特征数据进行预处理得到有效数据信息。S303: Preprocess at least one valid feature data to obtain valid data information.
其中,有效特征数据相较于原始数据的属性信息存在不同量纲、信息冗余、定性特征不能直接使用、存在缺失值、信息利用率较低和特征缺失的问题,如:在目标用户识别中需要对有效特征数据进行预处理以补充得到完整的用户信息,即有效用户信息,也即有效数据信息。Among them, compared with the attribute information of the original data, the effective feature data has different dimensions, information redundancy, qualitative features cannot be used directly, there are missing values, low information utilization and missing features, such as: in target user identification The valid feature data needs to be preprocessed to supplement complete user information, that is, valid user information, that is, valid data information.
一般的,在对属性信息进行特征工程处理,清除属性信息中的异常数据得到至少一个有效特征数据后,可得到未经处理的特征数据,这时的特征可能存在不同量纲、信息冗余、定性特征不能直接使用、存在缺失值、信息利用率较低和特征缺失的问题,需要对有效特征数据进行数据预处理以得到有效数据信息。Generally, after feature engineering is performed on attribute information and at least one valid feature data is obtained by removing abnormal data in the attribute information, unprocessed feature data can be obtained. At this time, the features may have different dimensions, information redundancy, Qualitative features cannot be used directly, there are missing values, low information utilization, and missing features. It is necessary to perform data preprocessing on valid feature data to obtain valid data information.
对有效特征数据进行数据预处理可以包括以下过程:Data preprocessing on valid feature data can include the following processes:
对有效特征数据进行无量纲化可使不同规格的数据转换到同一规格,常见的无量纲化方法有标准化和区间缩放法;标准化的前提是特征值服从正态分布,在标准化后可转换成标准正态分布;区间缩放法利用边界值信息,将特征的取值区间缩放到某个特点的范围,例如[0,1]等。Dimensionalization of valid feature data can convert data of different specifications to the same specification. Common dimensionless methods include standardization and interval scaling. The premise of standardization is that the eigenvalues obey a normal distribution, which can be converted into a standard after standardization. Normal distribution; the interval scaling method uses the boundary value information to scale the value interval of the feature to the range of a certain feature, such as [0,1].
对有效特征数据进行标准化的常用方法是z-score标准化,经过处理后的数据均值为0,标准差为1,处理方法是:x′=x-μδx′=x-μδ(x’是标准化后的特征,x是原始特征值,μ是样本均值,σ是样本标准差),可以通过现有样本进行估计,在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景。A common method for standardizing effective feature data is z-score standardization. The mean value of the processed data is 0 and the standard deviation is 1. The processing method is: x'=x-μδx'=x-μδ(x' is the normalized value. , x is the original eigenvalue, μ is the sample mean, σ is the sample standard deviation), which can be estimated by existing samples, and is relatively stable when there are enough existing samples, which is suitable for modern noisy big data scenarios.
对有效特征数据进行定量特征二值化(离散化),其核心在于设定一个阈值,大于阈值的赋值为1,小于等于阈值的赋值为0。The core of quantitative feature binarization (discretization) of valid feature data is to set a threshold, and the value greater than the threshold is assigned 1, and the value less than or equal to the threshold is assigned 0.
对有效特征数据的定性特征进行独热编码,使用二进制的位来表示某个定性特征的出现与否。One-hot encoding is performed on the qualitative features of the valid feature data, and binary bits are used to represent the presence or absence of a qualitative feature.
对有效特征数据的缺失值处理的方法可以包括:删除属性或者删除样本(如果一个样本大部分属性缺失,可以选择放弃该样本,适用于数据集中缺失较少的情况);统计填充(分析缺失值的属性,如数值类型的属性,可基于所有样本关于这维属性的统计值对其进行填充,如使用平均数、中位数、众数、最大值、最小值等进行填,具体选择哪种统计值需要具体问题具体分析);统一填充(对于含缺失值的属性,把所有缺失值统一填充为自定义值,如何选择自定义值需要具体问题具体分析,常用的统一填充值有:“空”、“0”、“正无穷”、“负无穷”等);预测填充(通过预测模型利用不存在缺失值的属性来预测缺失值,也即先利用预测模型将数据填充后再做进一步的工作,如统计、学习等);具体分析(属性缺失有时并不意味着数据缺失,缺失本身是包含信息的,需要根据不同应用场景下缺失值可能包含的信息进行合理填充)。The methods for dealing with missing values of valid feature data may include: deleting attributes or deleting samples (if most of the attributes of a sample are missing, you can choose to abandon the sample, which is suitable for cases where there are few missing values in the data set); statistical filling (analyzing missing values) Attributes, such as numeric attributes, can be filled based on the statistical values of all samples about this dimension attribute, such as using the mean, median, mode, maximum value, minimum value, etc., which one to choose. Statistical values require specific analysis of specific problems); unified filling (for attributes with missing values, all missing values are uniformly filled as custom values, how to select custom values requires specific analysis of specific problems, commonly used uniform filling values are: "null" ", "0", "positive infinity", "negative infinity", etc.); prediction filling (using the prediction model to predict the missing value by using the attribute without missing value, that is, first use the prediction model to fill the data and then do further work, such as statistics, learning, etc.); specific analysis (missing attributes sometimes does not mean that data is missing, the missing itself contains information, and it needs to be filled reasonably according to the information that the missing values may contain in different application scenarios).
对有效特征数据的数据变换可以是基于多项式的数据变换、基于指数函数的数据变换、基于对数函数的数据变换;多项式的数据变换,目标是将特征两两组合起来,使得特征和目标变量之间的的关系更接近线性,从而提高预测的效果。The data transformation of effective feature data can be polynomial-based data transformation, exponential function-based data transformation, logarithmic function-based data transformation; polynomial data transformation, the goal is to combine the features in pairs, so that the feature and the target variable are combined. The relationship between them is closer to linear, thereby improving the prediction effect.
S304,获取有效数据信息中的至少一个特征。S304, at least one feature in the valid data information is acquired.
S305,从至少一个特征中选取特征发散或相关性高于预设阈值的至少一个目标特征。S305: Select at least one target feature whose feature divergence or correlation is higher than a preset threshold from at least one feature.
一般的,在对有效特征数据进行数据预处理后,得到的有效数据信息中包含多个特征,需要从中选择有意义的特征输入机器学习的算法和模型进行训练。通常可从两个方面考虑来选择特征:特征是否发散,如果一个特征不发散,如方差接近于0,也即表示样本在该特征上基本上没有差异,该特征对于样本的区分无用;特征与目标的相关性,与目标相关性高的特征需要优选选择。根据特征选择的形式又可以将特征选择方法分为三种:Generally, after data preprocessing is performed on the valid feature data, the obtained valid data information contains multiple features, and it is necessary to select meaningful features from them and input them into a machine learning algorithm and model for training. Features can usually be selected from two aspects: whether the feature is divergent, if a feature is not divergent, such as the variance is close to 0, it means that the sample has basically no difference in the feature, and the feature is useless for distinguishing samples; The correlation of the target, the features with high correlation with the target need to be preferentially selected. According to the form of feature selection, feature selection methods can be divided into three types:
Filter:过滤法,按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数以选择特征。Filter: The filtering method, which scores each feature according to divergence or correlation, and sets a threshold or the number of thresholds to be selected to select features.
Wrapper:包装法,根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。Wrapper: The wrapping method, according to the objective function (usually the prediction effect score), selects several features at a time, or excludes several features.
Embedded:嵌入法,先利用机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。Embedded: Embedded method, first use machine learning algorithms and models for training, get the weight coefficients of each feature, and select features from large to small according to the coefficients.
S306,对至少一个目标特征分类处理得到特征组集合。S306, classifying at least one target feature to obtain a feature group set.
其中,特征组集合是指包括至少一个特征组的集合,特征组中包括至少一个数据特征,在对数据的属性信息进行特征提取后,可得到多个数据相关的特征,根据不同特征类型对多个数据相关的特征进行归类得到多个特征组,多个特征组共同组成了特征组集合,不同的特征组可反映与数据相关且不同维度的信息。如:在目标用户识别中特征类别可以包括用户的注册信息类别、联系信息类别、沟通信息类别、频率频次类别、用户的基本信息类别、与用户沟通过的工作人员信息类别等。The feature group set refers to a set including at least one feature group, and the feature group includes at least one data feature. After feature extraction is performed on the attribute information of the data, multiple data-related features can be obtained. The features related to the data are classified to obtain multiple feature groups, and the multiple feature groups together form a feature group set, and different feature groups can reflect information related to the data and with different dimensions. For example, in target user identification, feature categories may include the user's registration information category, contact information category, communication information category, frequency frequency category, user's basic information category, and staff information category that has communicated with the user.
S307,获取多个样本数据各自的属性信息。S307: Acquire respective attribute information of a plurality of sample data.
其中,在目标用户识别中样本数据是指包含预先设定的用户身份数据的样本用户数据,通常会预先设定多个样本用户数据。属性信息可以是多个维度的数据,属性信息包括数据的基本信息和互动信息等,如:在目标用户识别中属性信息可以包括用户的基本信息、学习记录和学习互动数据等,属性信息可以是通过对与用户相关的音频、视频、文本和图片等形式的数据进行分析后得到的信息,获取用户的属性信息便于后续对用户进行识别分析。The sample data in target user identification refers to sample user data including preset user identity data, and usually multiple sample user data are preset. The attribute information can be data of multiple dimensions, and the attribute information includes the basic information and interaction information of the data. Through the information obtained by analyzing the data in the form of audio, video, text, and pictures related to the user, the attribute information of the user is obtained to facilitate the subsequent identification and analysis of the user.
S308,对多个样本数据各自的属性信息进行特征提取,得到多个样本数据各自对应的特征组集合。S308 , perform feature extraction on the respective attribute information of the plurality of sample data to obtain a feature group set corresponding to each of the plurality of sample data.
一般的,特征提取过程为对样本数据的属性信息进行特征工程处理的过程,对样本数据的属性信息进行特征工程处理,清除样本数据的属性信息中的异常数据得到至少一个有效样本特征数据,对至少一个有效样本特征数据进行预处理得到有效样本数据信息,获取有效样本数据信息中的至少一个样本特征,从至少一个样本特征中选取特征发散或相关性高于预设阈值的至少一个目标样本特征,对至少一个目标样本特征分类处理得到样本数据对应的特征组集合。Generally, the feature extraction process is a process of performing feature engineering processing on the attribute information of the sample data, performing feature engineering processing on the attribute information of the sample data, and removing abnormal data in the attribute information of the sample data to obtain at least one valid sample feature data. At least one valid sample feature data is preprocessed to obtain valid sample data information, at least one sample feature in the valid sample data information is obtained, and at least one target sample feature whose feature divergence or correlation is higher than a preset threshold is selected from the at least one sample feature , classifying and processing at least one target sample feature to obtain a feature group set corresponding to the sample data.
S309,利用XGBoost算法对多个样本数据各自对应的特征组集合训练得到预测模型。S309 , using the XGBoost algorithm to train the respective feature group sets corresponding to the plurality of sample data to obtain a prediction model.
其中,预测模型是在采用定量预测法进行预测时建立的预测数学模型,可利用数学语言或公式的方式描述预测事物间的数量关系,该数量关系在一定程度上揭示了事物间的内在规律性,预测时可将该数量关系作为计算预测值的直接依据。预测方法的种类很多,不同的预测方法种类对应不同的预测模型。本申请实施例中的预测模型是基于样本数据经过预先训练后建立的模型。Among them, the forecasting model is a forecasting mathematical model established when using quantitative forecasting method for forecasting. It can use mathematical language or formulas to describe the quantitative relationship between predicted things, and the quantitative relationship reveals the inherent regularity between things to a certain extent. , the quantitative relationship can be used as a direct basis for calculating the predicted value during prediction. There are many types of forecasting methods, and different types of forecasting methods correspond to different forecasting models. The prediction model in the embodiment of the present application is a model established after pre-training based on sample data.
一般的,建立预测模型的过程可以是通过获取多个样本数据各自的属性信息,对多个样本数据户各自的属性信息进行特征提取,得到多个样本数据各自对应的特征组集合,利用XGBoost算法对多个样本数据各自对应的特征组集合训练得到预测模型。建模过程需要先对样本数据进行基本的特征工程处理,然后用经过特征工程处理的数据集进行模型训练。特征工程是指从原始数据转换为特征向量的过程,特征工程是机器学习中最重要的起始步骤,会直接影响机器学习的效果,并通常需要大量的时间。典型的特征工程包括数据清理、特征离散化、特征提取、特征选择等过程。Generally, the process of establishing a prediction model can be obtained by acquiring the respective attribute information of multiple sample data, and performing feature extraction on the respective attribute information of multiple sample data users to obtain respective feature sets corresponding to multiple sample data, using the XGBoost algorithm. The prediction model is obtained by training the respective feature set sets corresponding to the plurality of sample data. The modeling process needs to perform basic feature engineering on the sample data, and then use the feature-engineered dataset for model training. Feature engineering refers to the process of converting raw data into feature vectors. Feature engineering is the most important initial step in machine learning, which directly affects the effect of machine learning and usually takes a lot of time. Typical feature engineering includes data cleaning, feature discretization, feature extraction, feature selection and other processes.
XGBoost是一个优化的分布式梯度增强库,旨在实现高效,灵活和便携;其在Gradient Boosting框架下实现机器学习算法。XGBoost算法是对梯度提升算法的改进,求解损失函数极值时使用牛顿法,将损失函数泰勒展开到二阶,另外损失函数中加入了正则化项。XGBoost算法可以看成是由K棵树组成的加法模型:




S310,基于预测模型对特征组集合进行处理得到预测值。S310, processing the feature group set based on the prediction model to obtain a prediction value.
其中,预测模型是基于样本数据经过预先训练后建立的模型,预测值是用于表示数据(用户)倾向性的数值。The prediction model is a model established after pre-training based on sample data, and the prediction value is a numerical value used to represent the tendency of the data (user).
S311,判断预测值是否大于或等于预设阈值。S311, determine whether the predicted value is greater than or equal to a preset threshold.
其中,预设阈值是指预先设定预测值的下限值,可用于判定是否需要为该预测值对应的数据标注上目标数据标签;在预测值大于或等于预设阈值时,可为该数据标注上目标数据标签;在预测值小于预设阈值时,则不为该数据标注上目标数据标签。Among them, the preset threshold refers to the lower limit of the preset predicted value, which can be used to determine whether the data corresponding to the predicted value needs to be marked with a target data label; when the predicted value is greater than or equal to the preset threshold, it can be used for the data. Label the target data; when the predicted value is less than the preset threshold, the data is not labelled with the target data.
S312,在预测值小于预设阈值时,则不为数据标注上目标数据标签。S312, when the predicted value is less than the preset threshold, do not label the data with a target data label.
S313,在预测值大于或等于预设阈值时,则为数据标注上目标数据标签。S313, when the predicted value is greater than or equal to the preset threshold, label the data with a target data label.
其中,目标数据标签是用于区分数据为目标数据还是非目标数据的标记,如:在目标用户识别中目标数据标签也即目标用户标签,标注上目标用户标签的用户数据表明其对应的用户为预测值符合预设条件的用户,通过对用户的属性信息进行分析后,可得到该用户对应的倾向性的数值,即预测值,基于该预测值可判定是否需要为该用户数据标注上目标用户标签。Among them, the target data label is a label used to distinguish whether the data is target data or non-target data. For example, in target user identification, the target data label is also the target user label, and the user data marked with the target user label indicates that the corresponding user is For a user whose predicted value meets the preset conditions, after analyzing the user's attribute information, the value of the user's corresponding tendency, that is, the predicted value, can be obtained. Based on the predicted value, it can be determined whether the target user needs to be marked for the user data. Label.
一般的,基于预测模型对特征组集合进行预测可得到预测值,预测值可以是Leads分数,如:在目标用户识别中Leads分数是指通过交流得到的关于某人购买某种产品或服务的可能性的数据,根据Leads分数可识别符合预设购买意向分值的目标对象,即目标用户。In general, predicting a set of feature groups based on a predictive model can obtain a predicted value, and the predicted value can be the Leads score. For example, in target user identification, the Leads score refers to the possibility of someone purchasing a product or service obtained through communication. According to the Leads score, the target object that meets the preset purchase intention score, that is, the target user can be identified.
S314,从用户终端集合中确定处于在线状态的至少一个候选用户终端。S314, at least one candidate user terminal in an online state is determined from the set of user terminals.
其中,用户终端集合是指包括N个用户终端的集合,N为大于等于1的正整数,在用户终端集合中的各用户终端的线上状态有在线状态、忙绿状态、离线状态、请勿打扰状态等。用户终端是指开设在线课程的工作人员(如:销售人员或销售顾问)可用于与目标用户沟通的终端,也可以是用于向目标用户提供服务的终端。The user terminal set refers to a set including N user terminals, where N is a positive integer greater than or equal to 1, and the online status of each user terminal in the user terminal set includes online status, busy green status, offline status, do not disturbance status, etc. The user terminal refers to a terminal that can be used by staff (eg, salespersons or sales consultants) who offer online courses to communicate with target users, and can also be terminals used to provide services to target users.
一般的,可从用户终端集合中确定在线状态的候选用户终端集合,用户终端集合是由不同线上状态的用户终端组成,候选用户终端集合由至少一个在线状态的用户终端组成,即至少一个候选用户务终端组成。Generally, the set of candidate user terminals in the online state can be determined from the set of user terminals, the set of user terminals is composed of user terminals in different online states, and the set of candidate user terminals is composed of at least one user terminal in the online state, that is, at least one candidate User service terminal composition.
例如,系统中有10台用户终端,它们共同构成了用户终端集合,其中,有2台用户终端处于忙碌状态,有1台用户终端处于离线状态,7台用户终端处于在线状态,则这7台用户终端共同组成了候选用户终端集合,该候选用户终端集合中的候选用户终端都是处于在线状态。For example, there are 10 user terminals in the system, which together constitute a user terminal set. Among them, 2 user terminals are in a busy state, 1 user terminal is offline, and 7 user terminals are online. The user terminals together form a candidate user terminal set, and the candidate user terminals in the candidate user terminal set are all in an online state.
S315,获取至少一个候选用户终端的工作状态。S315: Acquire the working status of at least one candidate user terminal.
其中,工作状态表示用户终端正在执行规定功能时的状态,可以包括:忙碌、空闲、会议、请勿打扰、隐身等工作状态。Wherein, the working state indicates the state when the user terminal is executing a prescribed function, and may include working states such as busy, idle, conference, do not disturb, and invisible.
S316,从至少一个候选用户终端中选择工作状态满足预设条件的候选用户终端作为用户终端。S316 , from at least one candidate user terminal, select a candidate user terminal whose working state satisfies a preset condition as a user terminal.
其中,预设条件可根据需要设置任意工作状态作为选择用户终端需要满足的条件,如:预设条件可以是工作状态为空闲,则可从至少一个候选用户终端中筛选出工作状态为空闲状态的用户终端,若所筛选出来的用户终端数量为多个,则可对用户终端进行进一步的筛选,可以是对多个用户终端完成的任务量进行分析,以从中选择完成任务量较少的用户终端作为所选择的用户终端。Among them, the preset condition can be set to any working state as required as the condition to be satisfied by the selection of the user terminal, for example: the preset condition can be that the working state is idle, then the working state of the at least one candidate user terminal can be selected from the idle state. User terminals, if the number of user terminals screened out is multiple, the user terminals may be further screened, which may be to analyze the amount of tasks completed by the multiple user terminals, so as to select a user terminal that has completed fewer tasks. as the selected user terminal.
S317,将具有目标数据标签的数据对应的用户描述信息发送至用户终端。S317: Send the user description information corresponding to the data with the target data tag to the user terminal.
其中,在目标用户识别中用户描述信息是指包含用户相关数据的信息,如:用户的年龄、上课课龄、已学习课程记录、用户上课频率、用户的联系方式等信息。Among them, the user description information in the target user identification refers to information including user-related data, such as: the user's age, class age, lessons learned, the user's class frequency, the user's contact information and other information.
一般的,在为该数据标注上目标数据标签后,可将具有目标数据标签的数据对应的用户描述信息发送给用户终端,使工作人员可通过用户终端查看到该具有目标数据标签的数据的相关信息,如:在目标用户识别中的相关信息可以是与该数据对应的用户的年龄、上课课龄、已学习课程记录、用户上课频率、用户的联系方式等信息,辅助工作人员对与该数据对应的用户进行全面的了解,也能在后续为与该数据对应的用户提供更全面,且符合与该数据对应的用户实际需求的服务。Generally, after marking the data with the target data tag, the user description information corresponding to the data with the target data tag can be sent to the user terminal, so that the staff can view the relevant data of the data with the target data tag through the user terminal. Information, such as: the relevant information in the target user identification can be the user's age, class age, learned course records, user's class frequency, user's contact information and other information corresponding to the data. A comprehensive understanding of the corresponding users can also provide the users corresponding to the data with a more comprehensive service that meets the actual needs of the users corresponding to the data in the future.
本申请实施例的方案在执行时,在服务器,获取数据的属性信息,对属性信息进行特征工程处理,清除属性信息中的异常数据得到至少一个有效特征数据,对至少一个有效特征数据进行预处理得到有效数据信息,获取有效数据信息中的至少一个特征,从至少一个特征中选取特征发散或相关性高于预设阈值的至少一个目标特征,对至少一个目标特征分类处理得到特征组集合,获取多个样本数据各自的属性信息,对多个样本数据各自的属性信息进行特征提取,得到多个样本数据各自对应的特征组集合,利用XGBoost算法对多个样本数据各自对应的特征组集合训练得到预测模型,基于预测模型对特征组集合进行处理得到预测值,判断预测值是否大于或等于预设阈值,在预测值大于或等于预设阈值时,则为数据标注上目标数据标签,并从用户终端集合中确定处于在线状态的至少一个候选用户终端,获取至少一个候选用户终端的工作状态,从至少一个候选用户终端中选择工作状态满足预设条件的候选用户终端作为用户终端,将具有目标数据标签的数据对应的用户描述信息发送至用户终端,通过分析数据的基本信息、互动信息等属性信息,能充分提取数据特征,并精确地识别出该数据是否需要标注上目标数据标签,以便后续能基于该目标数据标签为用户提供更好的服务。When the solutions of the embodiments of the present application are executed, the server obtains attribute information of the data, performs feature engineering processing on the attribute information, clears abnormal data in the attribute information to obtain at least one valid feature data, and preprocesses the at least one valid feature data Obtain valid data information, obtain at least one feature in the valid data information, select at least one target feature whose feature divergence or correlation is higher than a preset threshold from the at least one feature, classify and process the at least one target feature to obtain a feature group set, and obtain The respective attribute information of multiple sample data, the feature extraction is performed on the respective attribute information of multiple sample data, and the respective feature group sets corresponding to multiple sample data are obtained, and the XGBoost algorithm is used to train the respective feature set sets corresponding to multiple sample data. Prediction model: Based on the prediction model, the set of feature groups is processed to obtain the predicted value, and it is judged whether the predicted value is greater than or equal to the preset threshold. Determining at least one candidate user terminal in an online state in the terminal set, acquiring the working state of the at least one candidate user terminal, selecting a candidate user terminal whose working state satisfies a preset condition from the at least one candidate user terminal as a user terminal, and using target data The user description information corresponding to the tag data is sent to the user terminal. By analyzing the basic information, interaction information and other attribute information of the data, the data features can be fully extracted, and whether the data needs to be tagged with the target data tag can be accurately identified, so that the follow-up can be used. Provide better service to users based on the target data tag.
下述为本申请装置实施例,可以用于执行本申请方法实施例。对于本申请装置实施例中未披露的细节,请参照本申请方法实施例。The following are apparatus embodiments of the present application, which can be used to execute the method embodiments of the present application. For details not disclosed in the device embodiments of the present application, please refer to the method embodiments of the present application.
请参见图4,其示出了本申请一个示例性实施例提供的数据的处理装置的结构示意图。以下简称装置4,装置4可以通过软件、硬件或者两者的结合实现成为终端的全部或一部分。装置4包括获取模块401、提取模块402、预测模块403和标注模块404。Please refer to FIG. 4 , which shows a schematic structural diagram of a data processing apparatus provided by an exemplary embodiment of the present application. The device 4 is hereinafter referred to as the device 4, and the device 4 can be implemented as all or a part of the terminal through software, hardware or a combination of the two. The apparatus 4 includes an
获取模块401,用于获取数据的属性信息;其中,所述属性信息包括所述数据的基本信息和互动信息;an
提取模块402,用于对所述属性信息进行特征提取得到特征组集合;其中,所述特征组集合包括至少一个特征组,所述特征组中包括至少一个数据特征;An
预测模块403,用于基于预测模型对所述特征组集合进行处理得到预测值;A
标注模块404,用于根据所述预测值为所述数据标注上目标数据标签。The
可选地,所述装置4还包括:Optionally, the device 4 also includes:
第一获取单元,用于获取多个样本数据各自的属性信息;a first acquiring unit, configured to acquire respective attribute information of a plurality of sample data;
第一提取单元,用于对所述多个样本数据各自的属性信息进行特征提取,得到所述多个样本数据各自对应的特征组集合;a first extraction unit, configured to perform feature extraction on the respective attribute information of the plurality of sample data to obtain a feature group set corresponding to each of the plurality of sample data;
训练单元,用于利用XGBoost算法对所述多个样本数据各自对应的特征组集合训练得到所述预测模型。The training unit is configured to use the XGBoost algorithm to train the respective feature group sets corresponding to the plurality of sample data to obtain the prediction model.
可选地,所述提取模块402包括:Optionally, the
第一处理单元,用于对所述属性信息进行特征工程处理,清除所述属性信息中的异常数据得到至少一个有效特征数据;a first processing unit, configured to perform feature engineering processing on the attribute information, and remove abnormal data in the attribute information to obtain at least one valid feature data;
预处理单元,用于对所述至少一个有效特征数据进行预处理得到有效数据信息;a preprocessing unit, configured to preprocess the at least one valid feature data to obtain valid data information;
第二提取单元,用于基于预设规则对所述有效数据信息进行特征提取得到所述特征组集合。The second extraction unit is configured to perform feature extraction on the valid data information based on a preset rule to obtain the feature group set.
可选地,所述提取模块402包括:Optionally, the
第二获取单元,用于获取所述有效数据信息中的至少一个特征;a second acquiring unit, configured to acquire at least one feature in the valid data information;
第一选择单元,用于从所述至少一个特征中选取特征发散或相关性高于预设阈值的至少一个目标特征;a first selection unit, configured to select at least one target feature whose feature divergence or correlation is higher than a preset threshold from the at least one feature;
第二处理单元,用于对所述至少一个目标特征分类处理得到所述特征组集合。The second processing unit is configured to classify and process the at least one target feature to obtain the feature group set.
可选地,所述标注模块404包括:Optionally, the
判断单元,用于判断所述预测值是否大于或等于预设阈值;a judging unit for judging whether the predicted value is greater than or equal to a preset threshold;
标注单元,用于若为是,则为所述数据标注上所述目标数据标签。A labeling unit, configured to label the data with the target data label if yes.
可选地,所述装置4还包括:Optionally, the device 4 also includes:
确定单元,用于从用户终端集合中确定处于在线状态的至少一个候选用户终端;a determining unit, configured to determine at least one candidate user terminal in an online state from the set of user terminals;
第二选择单元,用于基于预设规则,从所述至少一个候选用户终端中选择用户终端;a second selection unit, configured to select a user terminal from the at least one candidate user terminal based on a preset rule;
发送单元,用于将具有所述目标数据标签的数据对应的用户描述信息发送至所述用户终端。A sending unit, configured to send user description information corresponding to the data with the target data tag to the user terminal.
可选地,所述装置4还包括:Optionally, the device 4 also includes:
第三获取单元,用于获取所述至少一个候选用户终端的工作状态;a third acquiring unit, configured to acquire the working state of the at least one candidate user terminal;
第三选择单元,用于从所述至少一个候选用户终端中选择所述工作状态满足预设条件的候选用户终端作为所述用户终端。A third selection unit, configured to select, from the at least one candidate user terminal, a candidate user terminal whose working state satisfies a preset condition as the user terminal.
需要说明的是,上述实施例提供的装置4在执行数据的处理方法时,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将设备的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。另外,上述实施例提供的数据的处理方法实施例属于同一构思,其体现实现过程详见方法实施例,这里不再赘述。It should be noted that, when the device 4 provided in the above embodiment executes the data processing method, only the division of the above functional modules is used as an example for illustration. In practical applications, the above functions may be allocated to different functional modules as required. , that is, dividing the internal structure of the device into different functional modules to complete all or part of the functions described above. In addition, the embodiments of the data processing method provided by the above embodiments belong to the same concept, and the implementation process of the embodiment is detailed in the method embodiments, which will not be repeated here.
上述本申请实施例序号仅仅为了描述,不代表实施例的优劣。The above-mentioned serial numbers of the embodiments of the present application are only for description, and do not represent the advantages or disadvantages of the embodiments.
本申请实施例还提供了一种计算机存储介质,所述计算机存储介质可以存储有多条指令,所述指令适于由处理器加载并执行如上述图2、图3所示实施例的方法步骤,具体执行过程可以参见图2、图3所示实施例的具体说明,在此不进行赘述。An embodiment of the present application further provides a computer storage medium, where the computer storage medium can store multiple instructions, and the instructions are suitable for being loaded by a processor and executing the method steps of the embodiments shown in FIG. 2 and FIG. 3 above. , and the specific execution process may refer to the specific description of the embodiments shown in FIG. 2 and FIG. 3 , which will not be repeated here.
图5为本申请实施例提供的一种数据的处理的电子设备结构示意图,以下简称装置5,装置5可以集成于前述服务器或终端设备中,如图5所示,该装置包括:存储器502、处理器501、输入装置503、输出装置504和通信接口。FIG. 5 is a schematic structural diagram of an electronic device for data processing provided by an embodiment of the present application, hereinafter referred to as device 5. Device 5 may be integrated into the aforementioned server or terminal equipment. As shown in FIG. 5 , the device includes: a memory 502, A processor 501, an
存储器502可以是独立的物理单元,与处理器501、输入装置503和输出装置504可以通过总线连接。存储器502、处理器501、输入装置503和输出装置504也可以集成在一起,通过硬件实现等。The memory 502 may be an independent physical unit, and may be connected to the processor 501, the
存储器502用于存储实现以上方法实施例,或者装置实施例各个模块的程序,处理器501调用该程序,执行以上方法实施例的操作。The memory 502 is used to store a program for implementing the above method embodiments or each module of the apparatus embodiment, and the processor 501 invokes the program to execute the operations of the above method embodiments.
输入装置502包括但不限于键盘、鼠标、触摸面板、摄像头和麦克风;输出装置包括但限于显示屏。The input device 502 includes but is not limited to a keyboard, a mouse, a touch panel, a camera and a microphone; the output device includes but is not limited to a display screen.
通信接口用于收发各种类型的消息,通信接口包括但不限于无线接口或有线接口。The communication interface is used to send and receive various types of messages, and the communication interface includes but is not limited to a wireless interface or a wired interface.
可选地,当上述实施例的数据的处理方法中的部分或全部通过软件实现时,装置也可以只包括处理器。用于存储程序的存储器位于装置之外,处理器通过电路/电线与存储器连接,用于读取并执行存储器中存储的程序。Optionally, when part or all of the data processing methods in the foregoing embodiments are implemented by software, the apparatus may only include a processor. The memory for storing the program is located outside the device, and the processor is connected to the memory through a circuit/wire for reading and executing the program stored in the memory.
处理器可以是中央处理器(central processing unit,CPU),网络处理器(network processor,NP)或者CPU和NP的组合。The processor may be a central processing unit (CPU), a network processor (NP), or a combination of CPU and NP.
处理器还可以进一步包括硬件芯片。上述硬件芯片可以是专用集成电路(application-specific integrated circuit,ASIC),可编程逻辑器件(programmablelogic device,PLD)或其组合。上述PLD可以是复杂可编程逻辑器件(complexprogrammable logic device,CPLD),现场可编程逻辑门阵列(field-programmable gatearray,FPGA),通用阵列逻辑(generic array logic,GAL)或其任意组合。The processor may further include a hardware chip. The above hardware chip may be an application-specific integrated circuit (ASIC), a programmable logic device (PLD) or a combination thereof. The above-mentioned PLD may be a complex programmable logic device (CPLD), a field-programmable gate array (FPGA), a generic array logic (GAL) or any combination thereof.
存储器可以包括易失性存储器(volatile memory),例如存取存储器(random-access memory,RAM);存储器也可以包括非易失性存储器(non-volatile memory),例如快闪存储器(flash memory),硬盘(hard disk drive,HDD)或固态硬盘(solid-state drive,SSD);存储器还可以包括上述种类的存储器的组合。The memory may include volatile memory (volatile memory), such as access memory (random-access memory, RAM); the memory may also include non-volatile memory (non-volatile memory), such as flash memory (flash memory), A hard disk drive (HDD) or a solid-state drive (SSD); the memory may also include a combination of the above types of memory.
其中,处理器501调用存储器502中的程序代码用于执行以下步骤:Wherein, the processor 501 invokes the program code in the memory 502 to perform the following steps:
获取数据的属性信息;其中,所述属性信息包括所述数据的基本信息和互动信息;Obtain attribute information of the data; wherein, the attribute information includes basic information and interaction information of the data;
对所述属性信息进行特征提取得到特征组集合;其中,所述特征组集合包括至少一个特征组,所述特征组中包括至少一个数据特征;Perform feature extraction on the attribute information to obtain a feature group set; wherein, the feature group set includes at least one feature group, and the feature group includes at least one data feature;
基于预测模型对所述特征组集合进行处理得到预测值;The predicted value is obtained by processing the feature set set based on the prediction model;
根据所述预测值为所述数据标注上目标数据标签。Label the data with a target data label according to the predicted value.
在一个或多个实施例中,处理器501还用于:In one or more embodiments, the processor 501 is further configured to:
获取多个样本数据各自的属性信息;Obtain the respective attribute information of multiple sample data;
对所述多个样本数据各自的属性信息进行特征提取,得到所述多个样本数据各自对应的特征组集合;Perform feature extraction on the respective attribute information of the plurality of sample data to obtain a feature group set corresponding to each of the plurality of sample data;
利用XGBoost算法对所述多个样本数据各自对应的特征组集合训练得到所述预测模型。The prediction model is obtained by training the feature group sets corresponding to each of the multiple sample data by using the XGBoost algorithm.
在一个或多个实施例中,处理器501还用于:In one or more embodiments, the processor 501 is further configured to:
对所述属性信息进行特征工程处理,清除所述属性信息中的异常数据得到至少一个有效特征数据;Perform feature engineering processing on the attribute information, and remove abnormal data in the attribute information to obtain at least one valid feature data;
对所述至少一个有效特征数据进行预处理得到有效数据信息;Preprocessing the at least one valid feature data to obtain valid data information;
基于第一预设规则对所述有效数据信息进行特征提取得到所述特征组集合。The feature group set is obtained by performing feature extraction on the valid data information based on the first preset rule.
在一个或多个实施例中,处理器501还用于:In one or more embodiments, the processor 501 is further configured to:
获取所述有效数据信息中的至少一个特征;Obtain at least one feature in the valid data information;
从所述至少一个特征中选取特征发散或相关性高于预设阈值的至少一个目标特征;Select at least one target feature whose feature divergence or correlation is higher than a preset threshold from the at least one feature;
对所述至少一个目标特征分类处理得到所述特征组集合。The feature group set is obtained by classifying the at least one target feature.
在一个或多个实施例中,处理器501还用于:In one or more embodiments, the processor 501 is further configured to:
判断所述预测值是否大于或等于预设阈值;judging whether the predicted value is greater than or equal to a preset threshold;
若为是,则为所述数据标注上所述目标数据标签。If yes, label the data with the target data label.
在一个或多个实施例中,处理器501还用于:In one or more embodiments, the processor 501 is further configured to:
从用户终端集合中确定处于在线状态的至少一个候选用户终端;determining at least one candidate user terminal in an online state from the set of user terminals;
基于第二预设规则,从所述至少一个候选用户终端中选择用户终端;selecting a user terminal from the at least one candidate user terminal based on a second preset rule;
将具有所述目标数据标签的数据对应的用户描述信息发送至所述用户终端。The user description information corresponding to the data with the target data tag is sent to the user terminal.
在一个或多个实施例中,处理器501还用于:In one or more embodiments, the processor 501 is further configured to:
获取所述至少一个候选用户终端的工作状态;acquiring the working status of the at least one candidate user terminal;
从所述至少一个候选用户终端中选择所述工作状态满足预设条件的候选用户终端作为所述用户终端。A candidate user terminal whose working state satisfies a preset condition is selected from the at least one candidate user terminal as the user terminal.
本申请实施例还提供了一种计算机存储介质,存储有计算机程序,该计算机程序用于执行上述实施例提供的数据的处理方法。The embodiments of the present application further provide a computer storage medium storing a computer program, where the computer program is used to execute the data processing method provided by the above-mentioned embodiments.
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。As will be appreciated by those skilled in the art, the embodiments of the present application may be provided as a method, a system, or a computer program product. Accordingly, the present application may take the form of an entirely hardware embodiment, an entirely software embodiment, or an embodiment combining software and hardware aspects. Furthermore, the present application may take the form of a computer program product embodied on one or more computer-usable storage media (including, but not limited to, disk storage, CD-ROM, optical storage, etc.) having computer-usable program code embodied therein.
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。The present application is described with reference to flowchart illustrations and/or block diagrams of methods, apparatus (systems), and computer program products according to embodiments of the present application. It will be understood that each flow and/or block in the flowchart illustrations and/or block diagrams, and combinations of flows and/or blocks in the flowchart illustrations and/or block diagrams, can be implemented by computer program instructions. These computer program instructions may be provided to the processor of a general purpose computer, special purpose computer, embedded processor or other programmable data processing device to produce a machine such that the instructions executed by the processor of the computer or other programmable data processing device produce Means for implementing the functions specified in a flow or flow of a flowchart and/or a block or blocks of a block diagram.
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。These computer program instructions may also be stored in a computer-readable memory capable of directing a computer or other programmable data processing apparatus to function in a particular manner, such that the instructions stored in the computer-readable memory result in an article of manufacture comprising instruction means, the instructions The apparatus implements the functions specified in the flow or flows of the flowcharts and/or the block or blocks of the block diagrams.
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。These computer program instructions can also be loaded on a computer or other programmable data processing device to cause a series of operational steps to be performed on the computer or other programmable device to produce a computer-implemented process such that The instructions provide steps for implementing the functions specified in the flow or blocks of the flowcharts and/or the block or blocks of the block diagrams.
Claims (10)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010605188.8ACN111931809A (en) | 2020-06-29 | 2020-06-29 | Data processing method and device, storage medium and electronic equipment |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010605188.8ACN111931809A (en) | 2020-06-29 | 2020-06-29 | Data processing method and device, storage medium and electronic equipment |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN111931809Atrue CN111931809A (en) | 2020-11-13 |
Family
ID=73316693
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010605188.8APendingCN111931809A (en) | 2020-06-29 | 2020-06-29 | Data processing method and device, storage medium and electronic equipment |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN111931809A (en) |
Cited By (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113178258A (en)* | 2021-04-28 | 2021-07-27 | 青岛百洋智能科技股份有限公司 | Preoperative risk assessment method and system for surgical operation |
| CN113407549A (en)* | 2021-08-19 | 2021-09-17 | 清华四川能源互联网研究院 | Data processing method and device, electronic equipment and readable storage medium |
| CN113569955A (en)* | 2021-07-29 | 2021-10-29 | 中国工商银行股份有限公司 | A model training method, user portrait generation method, device and equipment |
| CN113610503A (en)* | 2021-08-11 | 2021-11-05 | 中国平安人寿保险股份有限公司 | Resume information processing method, device, equipment and medium |
| CN113837727A (en)* | 2021-09-30 | 2021-12-24 | 平安银行股份有限公司 | Event reminding method, device, equipment and medium |
| CN114334696A (en)* | 2021-12-30 | 2022-04-12 | 中国电信股份有限公司 | Quality detection method and device, electronic equipment and computer readable storage medium |
| CN114385700A (en)* | 2022-01-10 | 2022-04-22 | 腾讯科技(深圳)有限公司 | Method, device and equipment for determining seed object and storage medium |
| CN114444618A (en)* | 2022-02-28 | 2022-05-06 | 中国科学院上海微系统与信息技术研究所 | Intelligent recognition method and system for bionic fruit flies and computer storage medium |
| CN114444788A (en)* | 2022-01-17 | 2022-05-06 | 北京卡路里信息技术有限公司 | Prediction method and device of FTP, storage medium and processor |
| CN116737726A (en)* | 2023-07-03 | 2023-09-12 | 中电数创(北京)科技有限公司 | A method and device for grading data resources based on data fingerprints |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2019100724A1 (en)* | 2017-11-24 | 2019-05-31 | 华为技术有限公司 | Method and device for training multi-label classification model |
| CN109858970A (en)* | 2019-02-02 | 2019-06-07 | 中国银行股份有限公司 | A kind of user's behavior prediction method, apparatus and storage medium |
| CN110688553A (en)* | 2019-08-13 | 2020-01-14 | 平安科技(深圳)有限公司 | Information pushing method and device based on data analysis, computer equipment and storage medium |
| CN111046262A (en)* | 2019-12-17 | 2020-04-21 | 清华大学 | Data annotation method and device and computer storage medium |
- 2020
- 2020-06-29CNCN202010605188.8Apatent/CN111931809A/enactivePending
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2019100724A1 (en)* | 2017-11-24 | 2019-05-31 | 华为技术有限公司 | Method and device for training multi-label classification model |
| CN109858970A (en)* | 2019-02-02 | 2019-06-07 | 中国银行股份有限公司 | A kind of user's behavior prediction method, apparatus and storage medium |
| CN110688553A (en)* | 2019-08-13 | 2020-01-14 | 平安科技(深圳)有限公司 | Information pushing method and device based on data analysis, computer equipment and storage medium |
| CN111046262A (en)* | 2019-12-17 | 2020-04-21 | 清华大学 | Data annotation method and device and computer storage medium |
Non-Patent Citations (2)
| Title |
|---|
| 孟洁 等: "《数据合规入门、实战与进阶》", 31 May 2020, 机械工业出版社, pages: 183* |
| 方积乾: "医学统计学手册", 31 May 2018, 中国统计出版社, pages: 292* |
Cited By (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113178258A (en)* | 2021-04-28 | 2021-07-27 | 青岛百洋智能科技股份有限公司 | Preoperative risk assessment method and system for surgical operation |
| CN113569955A (en)* | 2021-07-29 | 2021-10-29 | 中国工商银行股份有限公司 | A model training method, user portrait generation method, device and equipment |
| CN113610503A (en)* | 2021-08-11 | 2021-11-05 | 中国平安人寿保险股份有限公司 | Resume information processing method, device, equipment and medium |
| CN113407549A (en)* | 2021-08-19 | 2021-09-17 | 清华四川能源互联网研究院 | Data processing method and device, electronic equipment and readable storage medium |
| CN113837727A (en)* | 2021-09-30 | 2021-12-24 | 平安银行股份有限公司 | Event reminding method, device, equipment and medium |
| CN113837727B (en)* | 2021-09-30 | 2024-03-29 | 平安银行股份有限公司 | Event reminding method, device, equipment and medium |
| CN114334696B (en)* | 2021-12-30 | 2024-03-05 | 中国电信股份有限公司 | Quality detection method and device, electronic equipment and computer readable storage medium |
| CN114334696A (en)* | 2021-12-30 | 2022-04-12 | 中国电信股份有限公司 | Quality detection method and device, electronic equipment and computer readable storage medium |
| CN114385700A (en)* | 2022-01-10 | 2022-04-22 | 腾讯科技(深圳)有限公司 | Method, device and equipment for determining seed object and storage medium |
| CN114444788A (en)* | 2022-01-17 | 2022-05-06 | 北京卡路里信息技术有限公司 | Prediction method and device of FTP, storage medium and processor |
| CN114444618A (en)* | 2022-02-28 | 2022-05-06 | 中国科学院上海微系统与信息技术研究所 | Intelligent recognition method and system for bionic fruit flies and computer storage medium |
| CN114444618B (en)* | 2022-02-28 | 2025-09-16 | 中国科学院上海微系统与信息技术研究所 | Intelligent identification method, system and computer storage medium for bionic drosophila |
| CN116737726A (en)* | 2023-07-03 | 2023-09-12 | 中电数创(北京)科技有限公司 | A method and device for grading data resources based on data fingerprints |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111931809A (en) | Data processing method and device, storage medium and electronic equipment | |
| CN110995459B (en) | Abnormal object identification method, device, medium and electronic equipment | |
| CN108629358B (en) | Object class prediction method and device | |
| CA3066029A1 (en) | Image feature acquisition | |
| US20230214679A1 (en) | Extracting and classifying entities from digital content items | |
| CN113704389B (en) | Data evaluation method, device, computer equipment and storage medium | |
| CN108319720A (en) | Man-machine interaction method, device based on artificial intelligence and computer equipment | |
| CN108665293B (en) | Feature importance acquisition method and device | |
| CN111427974A (en) | Data quality evaluation management method and device | |
| CN110856037A (en) | Video cover determination method and device, electronic equipment and readable storage medium | |
| CN112348321A (en) | Risk user identification method and device and electronic equipment | |
| CN112905885B (en) | Method, apparatus, device, medium and program product for recommending resources to user | |
| CN111191825A (en) | User default prediction method and device and electronic equipment | |
| CN112883990A (en) | Data classification method and device, computer storage medium and electronic equipment | |
| CN114219562A (en) | Model training method, enterprise credit evaluation method and device, equipment and medium | |
| CN113850666A (en) | Service scheduling method, device, equipment and storage medium | |
| CN115632874A (en) | Threat detection method, device, equipment and storage medium of a physical object | |
| CN113837836A (en) | Model recommendation method, device, equipment and storage medium | |
| CN114693409A (en) | Product matching method, device, computer equipment, storage medium and program product | |
| CN113052635A (en) | Population attribute label prediction method, system, computer device and storage medium | |
| CN115238816B (en) | User classification method and related equipment based on multivariate data fusion | |
| CN114330720B (en) | Knowledge graph construction method, device and storage medium for cloud computing | |
| CN114298241A (en) | Classification method, device and storage medium of user data | |
| CN114329022A (en) | A kind of training of pornographic classification model, image detection method and related device | |
| CN113888265A (en) | Product recommendation method, device, equipment and computer-readable storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| RJ01 | Rejection of invention patent application after publication | ||
| RJ01 | Rejection of invention patent application after publication | Application publication date:20201113 |