CN111797296A - Method and system for knowledge mining of poison-target literature based on web crawling - Google Patents
Method and system for knowledge mining of poison-target literature based on web crawlingDownload PDFInfo
- Publication number
- CN111797296A CN111797296ACN202010654561.9ACN202010654561ACN111797296ACN 111797296 ACN111797296 ACN 111797296ACN 202010654561 ACN202010654561 ACN 202010654561ACN 111797296 ACN111797296 ACN 111797296A
- Authority
- CN
- China
- Prior art keywords
- target
- poison
- literature
- information
- relationship
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images
Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/95—Retrieval from the web
- G06F16/951—Indexing; Web crawling techniques
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/3331—Query processing
- G06F16/334—Query execution
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02D—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN INFORMATION AND COMMUNICATION TECHNOLOGIES [ICT], I.E. INFORMATION AND COMMUNICATION TECHNOLOGIES AIMING AT THE REDUCTION OF THEIR OWN ENERGY USE
- Y02D10/00—Energy efficient computing, e.g. low power processors, power management or thermal management
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Databases & Information Systems (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本发明涉及互联网技术领域,具体涉及一种基于网络爬取的毒物-靶标文献知识挖掘方法及系统。The invention relates to the field of Internet technology, in particular to a method and system for mining poison-target literature knowledge based on web crawling.
背景技术Background technique
随着毒理学及分子生物学等学科的快速发展,互联网上涌现出了大量与毒物和靶标相关的数据集,但目前这些数据集的资源存储分散,格式异构,不同毒物与靶标数据集存在着大量重复冗余信息,毒物名称与别名信息混乱,缺乏统一的命名规范。这些数据集的出现虽然为广大毒物科研人员提供了参考,但是因为数据标准不统一,缺乏必要的数据过滤与质量控制机制,造成了手动检索、查询存在效率低下,冗余信息太多和知识发现困难等问题。因此,如何有序高效的整合现有的毒物与靶标数据集,建立一个包括目前已知数据集的综合毒物靶标数据集就显示的尤其重要。With the rapid development of disciplines such as toxicology and molecular biology, a large number of data sets related to poisons and targets have emerged on the Internet. However, at present, the resources of these data sets are scattered, the formats are heterogeneous, and different poison and target data sets exist. With a lot of repeated redundant information, poison names and alias information are confusing, and there is a lack of unified naming conventions. Although the emergence of these data sets provides a reference for the majority of toxicological researchers, due to inconsistent data standards and the lack of necessary data filtering and quality control mechanisms, manual retrieval and query efficiency is low, too much redundant information and knowledge discovery. difficulties, etc. Therefore, how to integrate existing poison and target data sets in an orderly and efficient manner and establish a comprehensive poison target data set including currently known data sets is particularly important.
毒物与靶标现有文献检索系统是基于用户输入的关键字如毒物名称、靶标名称或二者组合在后台文献数据库中进行信息检索与模糊匹配,找到相似度高的文献返回给用户,此种文献检索方式还停留在静态内容查找匹配层面,很难获得文献中隐藏的知识,更难以从海量生物医学文献中进行知识挖掘,严重影响毒物研发与科研工作者的工作效率。The existing literature retrieval system for poisons and targets is based on the keywords input by the user, such as poison name, target name or a combination of the two, to perform information retrieval and fuzzy matching in the background literature database, and find the literature with high similarity and return it to the user. The retrieval method is still at the level of static content search and matching. It is difficult to obtain the knowledge hidden in the literature, and it is even more difficult to mine knowledge from the massive biomedical literature, which seriously affects the work efficiency of poison research and development and scientific research workers.
因此,亟需提出一种效率高、准确、智能化的毒物-靶标文献知识挖掘方法及系统。Therefore, there is an urgent need to propose an efficient, accurate and intelligent poison-target literature knowledge mining method and system.
发明内容SUMMARY OF THE INVENTION
(一)要解决的技术问题(1) Technical problems to be solved
鉴于上述问题,本发明的主要目的在于提供一种基于网络爬取的毒物-靶标文献知识挖掘方法及系统,以期至少部分地解决上述提及的技术问题中的至少之一。In view of the above problems, the main purpose of the present invention is to provide a method and system for mining poison-target literature knowledge based on web crawling, in order to at least partially solve at least one of the above-mentioned technical problems.
(二)技术方案(2) Technical solutions
根据本发明的一个方面,提供了一种基于网络爬取的毒物-靶标文献知识挖掘方法,包括:According to one aspect of the present invention, a method for mining poison-target literature knowledge based on web crawling is provided, including:
获取毒物及靶标数据信息并处理以建立综合数据集;Obtain toxicant and target data information and process it to create a comprehensive dataset;
开发网络爬虫工具;Develop web crawler tools;
基于所述综合数据集,利用所述网络爬虫工具爬取毒物及靶标文献文本信息并处理以建立文献文本数据库;Based on the comprehensive data set, using the web crawler tool to crawl the poison and target literature text information and process it to establish a literature text database;
基于所述文献文本数据库,利用自然语言处理技术确定毒物-靶标潜在作用关系,形成毒物-靶标关系知识库;Based on the literature text database, natural language processing technology is used to determine the potential role relationship between the poison and the target, and a knowledge base of the relationship between the poison and the target is formed;
利用所述文献文本数据库及毒物-靶标关系知识库进行毒物-靶标文献知识挖掘。Using the literature text database and the poison-target relationship knowledge base to perform poison-target literature knowledge mining.
进一步的,获取毒物及靶标数据信息并处理以建立综合数据集,包括:Further, toxic and target data information is obtained and processed to create a comprehensive data set, including:
获取已知毒物及靶标数据信息;Obtain known toxicants and target data information;
对已知毒物及靶标数据信息进行信息去重、数据过滤及规范处理,建立毒物及靶标综合数据集。Perform information deduplication, data filtering and standardized processing of known poisons and target data information, and establish a comprehensive data set of poisons and targets.
进一步的,所述综合数据集中包括毒物的信息和靶标的信息;其中,所述毒物的信息包括毒物名称、CAS编号、化学结构、分子式基本信息,所述靶标的信息包括靶标名称、Uniprot序列编号信息。Further, the comprehensive data set includes poison information and target information; wherein, the poison information includes poison name, CAS number, chemical structure, and basic information of molecular formula, and the target information includes target name, Uniprot sequence number. information.
进一步的,开发网络爬虫工具,包括:基于Python语言和Scapy架构开发网络爬虫工具。Further, develop web crawler tools, including: developing web crawler tools based on Python language and Scapy architecture.
进一步的,基于所述综合数据集,利用所述网络爬虫工具爬取毒物及靶标文献文本信息并处理以建立文献文本数据库,包括:Further, based on the comprehensive data set, the web crawler tool is used to crawl the poison and target literature text information and process it to establish a literature text database, including:
基于所述综合数据集中的毒物名称和靶标名称,利用所述网络爬虫工具自动从文献网站Pubmed上爬取毒物及靶标文献文本信息;Based on the poison names and target names in the comprehensive data set, the web crawler tool is used to automatically crawl the poison and target literature text information from the literature website Pubmed;
对所述毒物及靶标文献文本信息进行数据清洗,利用清洗后的文献文本信息建立毒物及靶标的文献文本数据库。Data cleaning is performed on the literature text information of the poison and the target, and a literature text database of the poison and the target is established by using the cleaned literature text information.
进一步的,基于所述文献文本数据库,利用自然语言处理技术确定毒物-靶标潜在作用关系,形成毒物-靶标关系知识库,包括:基于相似性分析、聚类分析、主题挖掘、实体关系抽取和深度学习算法确定文献毒物-靶标的关系,并形成毒物-靶标关系知识库。Further, based on the literature text database, use natural language processing technology to determine the potential role relationship of poison-target, and form a knowledge base of poison-target relationship, including: based on similarity analysis, cluster analysis, topic mining, entity relationship extraction and depth. The learning algorithm determines the poison-target relationship in literature and forms a knowledge base of poison-target relationship.
进一步的,基于相似性分析、聚类分析、主题挖掘、实体关系抽取和深度学习算法确定文献毒物-靶标的关系,并形成毒物-靶标关系知识库,包括:Further, based on similarity analysis, cluster analysis, topic mining, entity relationship extraction and deep learning algorithm to determine the relationship between toxicants and targets in literature, and form a toxicant-target relationship knowledge base, including:
基于相似性分析、聚类分析、主题挖掘对爬取的文献和建立的文献文本数据库中数据进行处理,得到多维的文献定量数据;Based on similarity analysis, cluster analysis and topic mining, the crawled documents and the data in the established document text database are processed to obtain multi-dimensional quantitative document data;
基于实体关系抽取采用数据挖掘技术确定毒物和靶标关系的统计分析模型;Statistical analysis model that uses data mining technology to determine the relationship between poison and target based on entity relationship extraction;
基于深度学习算法采用词向量、多层神经网络技术优化所述模型参数;The model parameters are optimized by using word vector and multi-layer neural network technology based on deep learning algorithm;
基于多维的文献定量数据,利用优化后的统计分析模型确定文献毒物-靶标的关系,并形成毒物-靶标关系知识库。Based on multi-dimensional literature quantitative data, the optimized statistical analysis model was used to determine the relationship between toxicants and targets in literature, and a knowledge base of toxicant-target relationships was formed.
进一步的,利用所述文献文本数据库及毒物-靶标关系知识库进行毒物-靶标文献知识挖掘,包括:Further, using the literature text database and the poison-target relationship knowledge base to perform poison-target literature knowledge mining, including:
利用所述文献文本数据库及毒物-靶标关系知识库进行检索及定向文献查询,从而对毒物-靶标文献知识进行挖掘。The literature text database and the poison-target relationship knowledge base are used for retrieval and directional literature query, so as to mine poison-target literature knowledge.
进一步的,利用所述文献文本数据库及毒物-靶标关系知识库进行检索及定向文献查询,从而对毒物-靶标文献知识进行挖掘,包括:Further, using the literature text database and the poison-target relationship knowledge base for retrieval and directional literature query, so as to mine poison-target literature knowledge, including:
通过在所述文献文本数据库中检索毒物,获取毒物的名称、CAS编号、化学结构、分子式基本信息;Obtain the basic information of the name, CAS number, chemical structure and molecular formula of the poison by retrieving the poison in the literature text database;
通过在所述文献文本数据库中检索靶标,获取靶标的名称、DNA名称、受体名称、Uniprot序列编号、分子重量、别名、基因序列、蛋白ID信息;Obtain the name, DNA name, receptor name, Uniprot sequence number, molecular weight, alias, gene sequence, and protein ID information of the target by retrieving the target in the literature text database;
通过在毒物-靶标关系知识库中进行毒物、靶标检索,获取毒物、靶标对靶蛋白、受体或人体靶器官的潜在作用关系。By performing poison and target retrieval in the poison-target relationship knowledge base, the potential effect relationships of poisons and targets on target proteins, receptors or human target organs can be obtained.
根据本发明的另一个方面,提供了一种基于网络爬取的毒物-靶标文献知识挖掘系统,包括处理器,用于执行所述的方法。According to another aspect of the present invention, there is provided a knowledge mining system for poison-target literature based on web crawling, including a processor for executing the method.
(三)有益效果(3) Beneficial effects
从上述技术方案可以看出,本发明一种基于网络爬取的毒物-靶标文献知识挖掘方法及系统至少具有以下有益效果其中之一:It can be seen from the above technical solutions that a method and system for mining poison-target literature knowledge based on web crawling of the present invention have at least one of the following beneficial effects:
(1)本发明基于已知的毒物、靶标数据,对已知的毒物、靶标数据进行处理,建立综合数据集,解决了现有数据集存在的数据重复冗余,信息混乱,命名不规范的问题,有利于提高挖掘效率和准确性。(1) The present invention processes the known poison and target data based on the known poison and target data, establishes a comprehensive data set, and solves the data repetition redundancy, information confusion, and irregular naming existing in the existing data set. It is beneficial to improve the mining efficiency and accuracy.
(2)本发明基于综合数据集中的毒物靶标信息进行网络海量生物医学文献的自动爬取,建立起文献文本数据库,能够获得文献中隐藏的知识,便于从海量生物医学文献中进行知识挖掘。(2) The present invention automatically crawls the massive biomedical documents on the network based on the poison target information in the comprehensive data set, establishes a document text database, can obtain the knowledge hidden in the documents, and facilitates knowledge mining from the massive biomedical documents.
(3)本发明基于机器学习和深度学习算法从海量文献中挖掘出毒物靶标潜在作用关系,有利于提高挖掘的智能化程度和有效性。(3) The present invention mines the potential role relationship of the poison target from the massive literature based on the machine learning and the deep learning algorithm, which is beneficial to improve the intelligence and effectiveness of the mining.
附图说明Description of drawings
构成本发明的一部分的附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:The accompanying drawings constituting a part of the present invention are used to provide further understanding of the present invention, and the exemplary embodiments of the present invention and their descriptions are used to explain the present invention and do not constitute an improper limitation of the present invention. In the attached image:
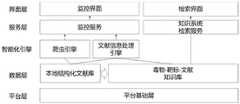
图1为本发明毒物-靶标文献知识挖掘系统结构示意图。FIG. 1 is a schematic structural diagram of the poison-target literature knowledge mining system of the present invention.
具体实施方式Detailed ways
为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明作进一步的详细说明。In order to make the objectives, technical solutions and advantages of the present invention more clearly understood, the present invention will be further described in detail below in conjunction with specific embodiments and with reference to the accompanying drawings.
本发明提出一种基于网络爬取的毒物-靶标文献知识挖掘方法,包括:The present invention proposes a poison-target literature knowledge mining method based on web crawling, including:
获取毒物及靶标数据信息并处理以建立综合数据集;Obtain toxicant and target data information and process it to create a comprehensive dataset;
开发网络爬虫工具;Develop web crawler tools;
基于所述综合数据集,利用所述网络爬虫工具爬取毒物及靶标文献文本信息并处理以建立文献文本数据库;Based on the comprehensive data set, using the web crawler tool to crawl the poison and target literature text information and process it to establish a literature text database;
基于所述文献文本数据库,利用自然语言处理技术确定毒物-靶标潜在作用关系,形成毒物-靶标关系知识库;Based on the literature text database, natural language processing technology is used to determine the potential role relationship between the poison and the target, and a knowledge base of the relationship between the poison and the target is formed;
利用所述文献文本数据库及毒物-靶标关系知识库进行毒物-靶标文献知识挖掘。Using the literature text database and the poison-target relationship knowledge base to perform poison-target literature knowledge mining.
其中,获取的所述毒物及靶标数据信息即未经处理的原始已知毒物及靶标数据(现有的各数据库中的毒物及靶标数据,这些数据存在重复、冗余,混乱,命名不规范等问题);所述综合数据集即所述原始已知毒物及靶标数据信息经处理后构成的数据集合;对获取的所述毒物及靶标数据信息进行处理即进行去重、过滤、规范、统一处理等。本发明基于已知的毒物、靶标数据,对已知的毒物、靶标数据进行处理,建立综合数据集,解决了现有数据集存在的数据重复冗余,信息混乱,命名不规范的问题,有利于提高挖掘效率和准确性Among them, the obtained poison and target data information is the raw known poison and target data that have not been processed (the poison and target data in the existing databases, these data have repetition, redundancy, confusion, and irregular naming, etc. problem); the comprehensive data set is the data set formed by processing the original known poison and target data information; the processing of the obtained poison and target data information means deduplication, filtering, standardization, and unified processing Wait. Based on the known poison and target data, the present invention processes the known poison and target data, establishes a comprehensive data set, and solves the problems of data repetition and redundancy, information confusion and non-standard naming in the existing data set. Conducive to improving mining efficiency and accuracy
具体的,获取毒物及靶标数据信息并处理以建立综合数据集,包括:获取已知毒物及靶标数据信息;以及对已知毒物及靶标数据信息进行信息去重、数据过滤及规范处理,建立毒物及靶标综合数据集。Specifically, obtaining and processing data information on poisons and targets to establish a comprehensive data set, including: obtaining data information on known poisons and targets; and deduplicating, filtering and standardizing data on known poisons and targets, and establishing poisons and target synthesis datasets.
开发网络爬虫工具,包括:基于Python语言和Scapy架构开发网络爬虫工具。Develop web crawler tools, including: developing web crawler tools based on Python language and Scapy architecture.
基于所述综合数据集,利用所述网络爬虫工具爬取毒物及靶标文献文本信息并处理以建立文献文本数据库,包括:基于所述综合数据集中的毒物名称和靶标名称,利用所述网络爬虫工具自动从文献网站Pubmed上爬取毒物及靶标文献文本信息;以及对所述毒物及靶标文献文本信息进行数据清洗,利用清洗后的文献文本信息建立毒物及靶标的文献文本数据库。Based on the comprehensive data set, using the web crawler tool to crawl and process document text information on poisons and targets to establish a document text database, including: using the web crawler tool based on the poison names and target names in the comprehensive data set Automatically crawl the poison and target literature text information from the literature website Pubmed; and perform data cleaning on the poison and target literature text information, and use the cleaned literature text information to build a poison and target literature text database.
基于所述文献文本数据库,利用自然语言处理技术确定毒物-靶标潜在作用关系,形成毒物-靶标关系知识库,包括:基于相似性分析、聚类分析、主题挖掘、实体关系抽取和深度学习算法确定文献毒物-靶标的关系,并形成毒物-靶标关系知识库。本发明基于机器学习和深度学习算法从海量文献中挖掘出毒物靶标潜在作用关系,有利于提高挖掘的智能化程度和有效性。Based on the literature text database, natural language processing technology is used to determine the potential role relationship between toxicants and targets, and a knowledge base for toxicant-target relationships is formed, including: determination based on similarity analysis, cluster analysis, topic mining, entity relationship extraction, and deep learning algorithms Document poison-target relationships and form a knowledge base of poison-target relationships. Based on machine learning and deep learning algorithms, the present invention excavates the potential role relationship of poison targets from massive documents, which is beneficial to improve the intelligence and effectiveness of excavation.
利用所述文献文本数据库及毒物-靶标关系知识库进行毒物-靶标文献知识挖掘,包括:通过在所述文献文本数据库中检索毒物,获取毒物的名称、CAS编号、化学结构、分子式基本信息;通过在所述文献文本数据库中检索靶标,获取靶标的名称、DNA名称、受体名称、Uniprot序列编号、分子重量、别名、基因序列、蛋白ID信息;以及通过在毒物-靶标关系知识库中进行毒物、靶标检索,获取毒物、靶标对靶蛋白、受体或人体靶器官的潜在作用关系。Using the literature text database and the poison-target relationship knowledge base to perform poison-target literature knowledge mining, including: by retrieving poisons in the literature text database, obtaining the name, CAS number, chemical structure, and molecular formula basic information of the poison; Searching the target in the literature text database to obtain the target's name, DNA name, receptor name, Uniprot sequence number, molecular weight, alias, gene sequence, protein ID information; , Target retrieval, to obtain the potential relationship between toxicants and targets on target proteins, receptors or human target organs.
相较于直接通过现有的网络上分散的数据资源获取毒物-靶标文献知识,本发明对已知毒物及靶标数据信息进行处理,形成综合数据集,构建文献文本数据库及毒物-靶标关系知识库,在文献文本数据库及毒物-靶标关系知识库中进行毒物和/或靶标检索,效率更高、准确性更好。Compared with the direct acquisition of poison-target literature knowledge through the existing scattered data resources on the network, the present invention processes the known poison and target data information to form a comprehensive data set, and constructs a literature text database and a poison-target relationship knowledge base. , to perform poison and/or target retrieval in the literature text database and poison-target relationship knowledge base, with higher efficiency and better accuracy.
下面结合附图详细介绍本发明实施例。本实施例所述基于网络爬取的毒物-靶标文献知识挖掘方法包括以下步骤:The embodiments of the present invention will be described in detail below with reference to the accompanying drawings. The method for mining poison-target literature knowledge based on web crawling described in this embodiment includes the following steps:
步骤1:毒物及靶标数据信息的获取及综合数据集建立;Step 1: Acquisition of poison and target data information and establishment of a comprehensive data set;
具体的,收集、整理、挖掘目前已知的毒物及靶标的相关数据信息,建立包含毒物及靶标基本信息的综合数据集。更具体而言,通过检索查询各种现有的数据库,包括但不限于美国国立医学图书馆授权的TOXNET数据库、Drugbank数据库、TDD数据库、NRDB药物蛋白质数据库和药物-靶点相互作用信息数据库Supertarget等,对目前已知的所有毒物及靶标的相关数据信息,进行数据信息收集、整理和挖掘,并进行信息去重、数据过滤等处理过程,建立一个毒物及靶标基本信息的综合数据集。综合数据集中包括毒物的信息和靶标的信息,其中,毒物的信息包括名称、CAS编号、化学结构、分子式等基本信息,靶标的信息包括靶标名称、Uniprot序列编号等基本信息。构建的毒物和靶标基本信息的综合数据集,为下一步的文献文本信息的爬取和挖掘提供准确、有效的信息依据。Specifically, collect, organize and mine the relevant data information of currently known poisons and targets, and establish a comprehensive data set containing basic information of poisons and targets. More specifically, various existing databases, including but not limited to the TOXNET database authorized by the US National Library of Medicine, the Drugbank database, the TDD database, the NRDB drug protein database, and the drug-target interaction information database Supertarget, etc. , to collect, organize and mine the data information of all known poisons and targets, and carry out information deduplication, data filtering and other processing processes to establish a comprehensive data set of the basic information of poisons and targets. The comprehensive data set includes information on toxicants and targets. The information on toxicants includes basic information such as name, CAS number, chemical structure, and molecular formula. The information on targets includes basic information such as target name and Uniprot sequence number. The constructed comprehensive data set of basic information of poisons and targets provides accurate and effective information basis for the next step of crawling and mining the literature text information.
步骤2:网络爬虫工具开发,毒物-靶标文献爬取和文本信息预处理,建立文献文本数据库;Step 2: Web crawler tool development, poison-target literature crawling and text information preprocessing, to establish a literature text database;
具体的,开发网络爬虫工具,自动从文献网站Pubmed上获取与毒物和靶标相关的文献文本信息,也即利用所述综合数据集中的毒物和靶标的名称,自动从文献网站Pubmed上爬取毒物和靶标相关的文献文本信息,将爬取的所有文献文本进行初步整理、收集,建立一个文献文本数据库。更具体而言,可通过分别开发文献采集站点管理模块、文献采集模板管理模块、文献采集模块和采集监控模块,实现在Pubmed网站上的针对所有毒物和靶标的文献文本自动爬取,由此获取毒物和靶标的文献文本数据集,针对毒物和靶标的文献文本数据集进行数据抽取、交换以及加载等数据清洗过程,实现文献文本数据的结构化存储预处理过程,并建立毒物和靶标的文献文本数据库。Specifically, a web crawler tool is developed to automatically obtain literature text information related to poisons and targets from the literature website Pubmed, that is, using the names of poisons and targets in the comprehensive data set, to automatically crawl poisons and targets from the literature website Pubmed. Target-related literature text information, preliminarily organize and collect all the crawled literature texts, and establish a literature text database. More specifically, the literature collection site management module, literature collection template management module, literature collection module and collection monitoring module can be developed respectively to realize automatic crawling of literature texts for all poisons and targets on the Pubmed website. Document text datasets of poisons and targets, perform data cleaning processes such as data extraction, exchange and loading for the document text datasets of poisons and targets, realize the structured storage preprocessing process of document text data, and establish document texts of poisons and targets. database.
优选的,基于python语言和Scapy架构开发网络爬虫工具,针对特定网站进行特定功能开发,基于Scapy架构的网络爬虫工具的各模块功能如下:Preferably, a web crawler tool is developed based on the python language and Scapy architecture, and specific functions are developed for a specific website. The functions of each module of the web crawler tool based on the Scapy architecture are as follows:
引擎(Scrapy Engine):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等;Engine (Scrapy Engine): responsible for the communication between Spider, ItemPipeline, Downloader, Scheduler, signal, data transmission, etc.;
调度器(Scheduler):负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎;Scheduler (Scheduler): Responsible for accepting the Request requests sent by the engine, arrange them in a certain way, enter the queue, and return them to the engine when the engine needs it;
下载器(Downloader):负责下载Scrapy Engine发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine,由引擎交给Spider来处理;Downloader (Downloader): Responsible for downloading all Requests requests sent by Scrapy Engine, and returning the obtained Responses to Scrapy Engine, which is handed over to Spider for processing;
爬虫(Spider):负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler;Spider: Responsible for processing all Responses, analyzing and extracting data from it, obtaining the data required by the Item field, submitting the URL that needs to be followed up to the engine, and entering the Scheduler again;
Item Pipeline(管道):负责处理Spider中获取到的Item,并进行后期处理(详细分析、过滤、存储等)的地方;Item Pipeline: The place responsible for processing the items obtained in the Spider and performing post-processing (detailed analysis, filtering, storage, etc.);
Downloader Middlewares(下载中间件):可以是一个可自定义扩展下载功能的组件;Downloader Middlewares: It can be a component that can customize the extended download function;
Spider Middlewares(Spider中间件):可以是一个可自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)。Spider Middlewares (Spider Middleware): It can be a functional component that can be customized to extend and operate the engine and the intermediate communication between the Spider (such as the Responses entering the Spider; and the Requests going out from the Spider).
步骤3:文献文本数据挖掘处理及知识库建立,具体的,基于所述文献文本数据库,利用自然语言处理技术确定毒物-靶标潜在作用关系,形成毒物-靶标关系知识库;Step 3: document text data mining processing and knowledge base establishment, specifically, based on the document text database, use natural language processing technology to determine the potential role relationship of poison-target, and form a knowledge base of poison-target relationship;
更具体而言,基于相似性分析、聚类分析、主题挖掘、实体关系抽取等数据挖掘和深度学习算法,确定文献毒物-靶标的关系,形成毒物-靶标关系知识库,过程如下:More specifically, based on data mining and deep learning algorithms such as similarity analysis, cluster analysis, topic mining, entity relationship extraction, etc., the relationship between toxicants and targets in literature is determined, and a knowledge base of toxicant-target relationships is formed. The process is as follows:
首先对爬取的文献和建立的文献库数据进行处理,得到一种多维的文献数据定量数据;Firstly, the crawled documents and the established document database data are processed to obtain a multi-dimensional quantitative data of document data;
采用数据挖掘技术建立毒物和靶标关系的统计分析模型,采用词向量、多层神经网络(深度学习)技术优化模型参数,并采用现有的文献关系数据库对结果进行验证性测试;优选的,本发明采用基于双向GRU和双层Attention机制的深度学习,提高了精度,具有更好的效果;Data mining technology is used to establish a statistical analysis model of the relationship between poisons and targets, word vectors and multi-layer neural network (deep learning) technology are used to optimize model parameters, and the existing literature relational database is used to test the results. The invention adopts deep learning based on two-way GRU and double-layer Attention mechanism, which improves the accuracy and has better effects;
基于所述优化和测试后的模型,利用所述文献数据定量数据构建毒物-靶标关系,形成毒物-靶标关系知识库。Based on the optimized and tested model, a toxicant-target relationship is constructed using the quantitative data of the literature data, and a toxicant-target relationship knowledge base is formed.
步骤4:毒物-靶标文献知识挖掘;Step 4: Poison-target literature knowledge mining;
利用所述文献文本数据库及毒物-靶标关系知识库进行毒物-靶标文献知识挖掘;具体的,基于所述文献文本数据库及毒物-靶标关系知识库对毒物-靶标关系和文献文本信息进行检索及定向文献查询,从而对毒物-靶标文献知识进行挖掘。Using the literature text database and the poison-target relationship knowledge base to perform poison-target literature knowledge mining; specifically, based on the literature text database and the poison-target relationship knowledge base, the poison-target relationship and literature text information are retrieved and directed Literature query to mine poison-target literature knowledge.
本发明还提出一种基于网络爬取的毒物-靶标文献知识挖掘系统,包括处理器,用于执行所述基于网络爬取的毒物-靶标文献知识挖掘方法。通过将建立的毒物和靶标信息综合数据集、文献文本数据库、毒物-靶标关系知识库及基于网络的文献爬虫工具、文献数据挖掘算法等进行无缝整合,建立集毒物、靶标信息检索和文献文本信息检索及定向文献查询为一体的在线毒物-靶标文献知识挖掘系统,其具有可扩展、跨平台、多用户等特点。The present invention also provides a web crawling-based poison-target literature knowledge mining system, comprising a processor for executing the web crawling-based poison-target literature knowledge mining method. Through the seamless integration of the established poison and target information comprehensive dataset, literature text database, poison-target relationship knowledge base, web-based literature crawler tools, literature data mining algorithms, etc., a collection of poison and target information retrieval and literature text are established. It is an online poison-target literature knowledge mining system integrating information retrieval and directional literature query. It is scalable, cross-platform, and multi-user.
图1中示出了本发明毒物-靶标文献知识挖掘系统结构。Figure 1 shows the structure of the poison-target literature knowledge mining system of the present invention.
所述系统的人机交互包括两部分:爬虫和文献知识挖掘监控界面、以及毒物-靶标知识库检索界面。请参照图1,所述知识挖掘系统为基于浏览器-服务-智能化引擎-数据层的四层系统架构,包括:界面层,采用web浏览器,采用标准的MVC框架(如Vus.js);服务层,采用支持CRUD标准操作的RESTFul服务接口(如SprintBoot等)智能化引擎:用Python开发,采用Python开发语言,Numpy,Scipy,NLTK,SpaCy,Gensim开发包,Tensorflow和Keras开发平台。实现网络爬虫和数据挖掘(深度学习);数据层,采用MongoDB和Neo4j分别实现文献文档库和知识库;平台层,基础的网络、OS平台,系统在Windows平台开发和运行,易于部署、维护和操作。The human-computer interaction of the system includes two parts: a crawler and literature knowledge mining monitoring interface, and a poison-target knowledge base retrieval interface. Please refer to FIG. 1, the knowledge mining system is a four-layer system architecture based on browser-service-intelligent engine-data layer, including: interface layer, using a web browser, using a standard MVC framework (such as Vus.js) ; Service layer, using RESTFul service interface (such as SprintBoot, etc.) that supports CRUD standard operations. Intelligent engine: developed in Python, using Python development language, Numpy, Scipy, NLTK, SpaCy, Gensim development kit, Tensorflow and Keras development platform. Realize web crawler and data mining (deep learning); data layer, use MongoDB and Neo4j to realize document database and knowledge base respectively; platform layer, basic network, OS platform, the system is developed and run on Windows platform, easy to deploy, maintain and operate.
请继续参照图1,对不同来源的现有的毒物靶标数据进行数据整合、数据清洗、去重然后建立毒物及靶标综合数据集,此综合数据集作为图1中的爬虫引擎的数据输入,爬虫引擎根据这些数据输入自动从Pubmed生物医学网站(当然并不仅限于此)获取相关文献信息,经文献数据预处理后存入本地结构化文献库(毒物和靶标的文献文本数据库)。对本地结构化文献库首先进行词频分析得到高频文献数据集,然后运用句子分割器和分词器对文献摘要进行分割,得到词的元组列表,对词元组列表进行词性标注,进而得到所有词列表的词性信息,经由分块器处理后,进行命名实体识别和实体之间关系的抽取,最终生成毒物-靶标文献知识库(也称毒物-靶标关系知识库)。Please continue to refer to Figure 1, perform data integration, data cleaning, and deduplication on the existing poison target data from different sources, and then establish a comprehensive data set of poisons and targets. This comprehensive data set is used as the data input of the crawler engine in Figure 1. The engine automatically obtains relevant literature information from the Pubmed biomedical website (of course not limited to this) according to these data inputs, and stores the literature data into a local structured literature database (a literature text database of poisons and targets) after literature data preprocessing. For the local structured literature database, first perform word frequency analysis to obtain high-frequency literature data sets, and then use sentence segmenter and tokenizer to segment the literature abstracts to obtain a list of word tuples, tag the word tuple list, and then obtain all After the part-of-speech information of the word list is processed by the blocker, named entity recognition and relationship extraction between entities are performed, and finally a poison-target literature knowledge base (also called a poison-target relationship knowledge base) is generated.
基于上述本地结构化文献库和毒物-靶标关系知识库,可对毒物和靶标进行快速全文检索。本发明提供毒物、靶标、通路、毒物靶标作用关系等不同类型的本地文献数据库检索和毒物-靶标关系知识库检索,不同类型数据检索展示样式不同。Based on the above-mentioned local structured literature library and poison-target relationship knowledge base, a fast full-text search of poisons and targets can be performed. The present invention provides different types of local document database retrieval and poison-target relationship knowledge base retrieval of poisons, targets, pathways, and poison-target action relationships, and different types of data retrieval display styles are different.
在本地结构化文献库中检索毒物时,本发明可以全文检索出所有包含此毒物或者毒物别名的文献信息,展示出的文献信息列表按照关键字在文献中出现的权重比例大小进行排序。点击毒物可以查看毒物的名称、CAS编号、化学结构、分子式等基本信息,以及常用的外部毒物参考链接。When retrieving a poison in a local structured document database, the present invention can search out all document information containing the poison or the alias of the poison in full text, and the displayed document information list is sorted according to the weight ratio of the keywords appearing in the document. Click on the poison to view the basic information such as the name, CAS number, chemical structure, molecular formula, etc. of the poison, as well as the commonly used external poison reference links.
在本地结构化文献库中检索靶标时,本发明可以全文检索所有包含此靶标名称、DNA名称、受体名称的所有文献信息,展示出的文献信息同样以靶标出现的权重进行排序,点击靶标可以得到相关的靶标名称、Uniprot序列编号、基因名称、分子重量、别名、基因序列、蛋白ID及常用外部靶标链接信息。When retrieving a target in the local structured document library, the present invention can search all document information including the target name, DNA name and receptor name in full text, and the displayed document information is also sorted by the weight of the target appearance. Get related target name, Uniprot sequence number, gene name, molecular weight, alias, gene sequence, protein ID and commonly used external target link information.
在毒物-靶标关系知识库中进行毒物或靶标检索时,本发明能给出基于海量网络生物医学文献数据,通过数据挖掘得到该毒物或靶标对其它靶蛋白、受体或人体靶器官的潜在作用关系,并给出相关的文献链接便于查看详细文献信息。When the poison or target is searched in the poison-target relationship knowledge base, the present invention can provide data based on massive network biomedical literature, and obtain the potential effect of the poison or target on other target proteins, receptors or human target organs through data mining. Relationships, and related literature links are given for easy viewing of detailed literature information.
至此,已经结合附图对本发明进行了详细描述。依据以上描述,本领域技术人员应当对本发明有了清楚的认识。So far, the present invention has been described in detail with reference to the accompanying drawings. From the above description, those skilled in the art should have a clear understanding of the present invention.
需要说明的是,在附图或说明书正文中,未绘示或描述的实现方式,均为所属技术领域中普通技术人员所知的形式,并未进行详细说明。此外,上述对各元件的定义并不仅限于实施例中提到的各种具体结构、形状或方式,本领域普通技术人员可对其进行简单地更改或替换。It should be noted that, in the accompanying drawings or the text of the description, the implementations that are not shown or described are in the form known to those of ordinary skill in the technical field, and are not described in detail. In addition, the above definitions of each element are not limited to various specific structures, shapes or manners mentioned in the embodiments, and those of ordinary skill in the art can simply modify or replace them.
当然,根据实际需要,本发明还可以包含其他的部分,由于同本发明的创新之处无关,此处不再赘述。Of course, according to actual needs, the present invention may also include other parts. Since it has nothing to do with the innovation of the present invention, it will not be repeated here.
类似地,应当理解,为了精简本发明并帮助理解各个发明方面中的一个或多个,在上面对本发明的示例性实施例的描述中,本发明的各个特征有时被一起分组到单个实施例、图、或者对其的描述中。然而,并不应将该发明的方法解释成反映如下意图:即所要求保护的本发明要求比在每个权利要求中所明确记载的特征更多的特征。更确切地说,如下面的权利要求书所反映的那样,发明方面在于少于前面发明的单个实施例的所有特征。因此,遵循具体实施方式的权利要求书由此明确地并入该具体实施方式,其中每个权利要求本身都作为本发明的单独实施例。Similarly, it is to be understood that in the above description of exemplary embodiments of the invention, various features of the invention are sometimes grouped together into a single embodiment, figure, or its description. However, this method of the invention should not be construed to reflect the intention that the invention as claimed requires more features than are expressly recited in each claim. Rather, as the following claims reflect, inventive aspects lie in less than all features of a single preceding embodiment of the invention. Thus, the claims following the Detailed Description are hereby expressly incorporated into this Detailed Description, with each claim standing on its own as a separate embodiment of this invention.
此外,在附图或说明书描述中,相似或相同的部分都使用相同的图号。说明书中示例的各个实施例中的技术特征在无冲突的前提下可以进行自由组合形成新的方案,另外每个权利要求可以单独作为一个实施例或者各个权利要求中的技术特征可以进行组合作为新的实施例,且在附图中,实施例的形状或是厚度可扩大,并以简化或是方便标示。再者,附图中未绘示或描述的元件或实现方式,为所属技术领域中普通技术人员所知的形式。另外,虽然本文可提供包含特定值的参数的示范,但应了解,参数无需确切等于相应的值,而是可在可接受的误差容限或设计约束内近似于相应的值。In addition, in the drawings or the description of the specification, the same reference numerals are used for similar or identical parts. The technical features in the various embodiments exemplified in the specification can be freely combined to form new solutions under the premise of no conflict. In addition, each claim can be used as an embodiment alone or the technical features in each claim can be combined as a new solution. and in the accompanying drawings, the shape or thickness of the embodiments may be enlarged and marked for simplification or convenience. Furthermore, elements or implementations not shown or described in the drawings are in the form known to those of ordinary skill in the art. Additionally, although examples of parameters including specific values may be provided herein, it should be understood that the parameters need not be exactly equal to the corresponding values, but may be approximated within acceptable error tolerances or design constraints.
除非存在技术障碍或矛盾,本发明的上述各种实施方式可以自由组合以形成另外的实施例,这些另外的实施例均在本发明的保护范围中。Unless there are technical obstacles or contradictions, the above-mentioned various embodiments of the present invention can be freely combined to form additional embodiments, and these additional embodiments are all within the protection scope of the present invention.
虽然结合附图对本发明进行了说明,但是附图中公开的实施例旨在对本发明优选实施方式进行示例性说明,而不能理解为对本发明的一种限制。附图中的尺寸比例仅仅是示意性的,并不能理解为对本发明的限制。Although the present invention has been described with reference to the accompanying drawings, the embodiments disclosed in the accompanying drawings are intended to illustrate the preferred embodiments of the present invention and should not be construed as a limitation of the present invention. The dimension ratios in the drawings are only schematic and should not be construed as limiting the present invention.
虽然本发明总体构思的一些实施例已被显示和说明,本领域普通技术人员将理解,在不背离本总体发明构思的原则和精神的情况下,可对这些实施例做出改变,本发明的范围以权利要求和它们的等同物限定。Although some embodiments of the present general inventive concept have been shown and described, those of ordinary skill in the art will understand that The scope is defined by the claims and their equivalents.
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。The above descriptions are only preferred embodiments of the present invention, and are not intended to limit the present invention. Any modification, equivalent replacement, improvement, etc. made within the spirit and principle of the present invention shall be included in the scope of the present invention. within the scope of protection.
Claims (10)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010654561.9ACN111797296B (en) | 2020-07-08 | 2020-07-08 | Poison-target literature knowledge mining method and system based on web crawling |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010654561.9ACN111797296B (en) | 2020-07-08 | 2020-07-08 | Poison-target literature knowledge mining method and system based on web crawling |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN111797296Atrue CN111797296A (en) | 2020-10-20 |
| CN111797296B CN111797296B (en) | 2024-04-09 |
Family
ID=72811357
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010654561.9AActiveCN111797296B (en) | 2020-07-08 | 2020-07-08 | Poison-target literature knowledge mining method and system based on web crawling |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN111797296B (en) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114927168A (en)* | 2022-05-31 | 2022-08-19 | 四川大学 | Method for constructing biomechanically regulated bone reconstruction text mining interactive website |
| CN114996465A (en)* | 2022-08-01 | 2022-09-02 | 中国传媒大学 | Information propagation dynamics document classification knowledge base establishing method, system and equipment |
| CN115687296A (en)* | 2022-10-13 | 2023-02-03 | 核动力运行研究所 | A method for constructing nuclear power plant chemical knowledge base based on crawler technology |
| CN115827948A (en)* | 2023-02-09 | 2023-03-21 | 中南大学 | Single-reflectivity intelligent agent for crawling literature data and literature data crawling method |
Citations (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20030220860A1 (en)* | 2002-05-24 | 2003-11-27 | Hewlett-Packard Development Company,L.P. | Knowledge discovery through an analytic learning cycle |
| CN102521337A (en)* | 2011-12-08 | 2012-06-27 | 华中科技大学 | Academic community system based on massive knowledge network |
| CN104572709A (en)* | 2013-10-18 | 2015-04-29 | 北京中海纪元数字技术发展股份有限公司 | Data mining system used for enterprise innovation system |
| JP2016192198A (en)* | 2015-03-30 | 2016-11-10 | 国立研究開発法人情報通信研究機構 | Term sharing classifier learning device, language knowledge collection device, and anaphora / omission analysis device |
| CN106156286A (en)* | 2016-06-24 | 2016-11-23 | 广东工业大学 | Type extraction system and method towards technical literature knowledge entity |
| CN106156335A (en)* | 2016-07-07 | 2016-11-23 | 苏州大学 | A kind of discovery and arrangement method and system of teaching material knowledge point |
| CN106649272A (en)* | 2016-12-23 | 2017-05-10 | 东北大学 | Named entity recognizing method based on mixed model |
| CN108984761A (en)* | 2018-07-19 | 2018-12-11 | 南昌工程学院 | A kind of information processing system driven based on model and domain knowledge |
| CN110309393A (en)* | 2019-03-28 | 2019-10-08 | 平安科技(深圳)有限公司 | Data processing method, device, equipment and readable storage medium storing program for executing |
| CN110334220A (en)* | 2019-07-15 | 2019-10-15 | 中国人民解放军战略支援部队航天工程大学 | A knowledge map construction method based on multiple data sources |
| CN110347844A (en)* | 2019-07-15 | 2019-10-18 | 中国人民解放军战略支援部队航天工程大学 | A kind of space object knowledge map construction system |
| CN110347894A (en)* | 2019-05-31 | 2019-10-18 | 平安科技(深圳)有限公司 | Knowledge mapping processing method, device, computer equipment and storage medium based on crawler |
| CN110489395A (en)* | 2019-07-27 | 2019-11-22 | 西南电子技术研究所(中国电子科技集团公司第十研究所) | Automatically the method for multi-source heterogeneous data knowledge is obtained |
| CN110929165A (en)* | 2019-12-17 | 2020-03-27 | 云南大学 | JAVA Doc knowledge graph-based multidimensional evaluation recommendation method |
- 2020
- 2020-07-08CNCN202010654561.9Apatent/CN111797296B/enactiveActive
Patent Citations (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20030220860A1 (en)* | 2002-05-24 | 2003-11-27 | Hewlett-Packard Development Company,L.P. | Knowledge discovery through an analytic learning cycle |
| CN102521337A (en)* | 2011-12-08 | 2012-06-27 | 华中科技大学 | Academic community system based on massive knowledge network |
| CN104572709A (en)* | 2013-10-18 | 2015-04-29 | 北京中海纪元数字技术发展股份有限公司 | Data mining system used for enterprise innovation system |
| JP2016192198A (en)* | 2015-03-30 | 2016-11-10 | 国立研究開発法人情報通信研究機構 | Term sharing classifier learning device, language knowledge collection device, and anaphora / omission analysis device |
| CN106156286A (en)* | 2016-06-24 | 2016-11-23 | 广东工业大学 | Type extraction system and method towards technical literature knowledge entity |
| CN106156335A (en)* | 2016-07-07 | 2016-11-23 | 苏州大学 | A kind of discovery and arrangement method and system of teaching material knowledge point |
| CN106649272A (en)* | 2016-12-23 | 2017-05-10 | 东北大学 | Named entity recognizing method based on mixed model |
| CN108984761A (en)* | 2018-07-19 | 2018-12-11 | 南昌工程学院 | A kind of information processing system driven based on model and domain knowledge |
| CN110309393A (en)* | 2019-03-28 | 2019-10-08 | 平安科技(深圳)有限公司 | Data processing method, device, equipment and readable storage medium storing program for executing |
| CN110347894A (en)* | 2019-05-31 | 2019-10-18 | 平安科技(深圳)有限公司 | Knowledge mapping processing method, device, computer equipment and storage medium based on crawler |
| CN110334220A (en)* | 2019-07-15 | 2019-10-15 | 中国人民解放军战略支援部队航天工程大学 | A knowledge map construction method based on multiple data sources |
| CN110347844A (en)* | 2019-07-15 | 2019-10-18 | 中国人民解放军战略支援部队航天工程大学 | A kind of space object knowledge map construction system |
| CN110489395A (en)* | 2019-07-27 | 2019-11-22 | 西南电子技术研究所(中国电子科技集团公司第十研究所) | Automatically the method for multi-source heterogeneous data knowledge is obtained |
| CN110929165A (en)* | 2019-12-17 | 2020-03-27 | 云南大学 | JAVA Doc knowledge graph-based multidimensional evaluation recommendation method |
Non-Patent Citations (2)
| Title |
|---|
| A. MONTAZERI 等: "A Data-Driven Statistical Approach for Monitoring and Analysis of Large Industrial Processes", 《IFAC-PAPERSONLINE》, pages 2354 - 2359* |
| 李枫林 等: "基于深度学习框架的实体关系抽取研究进展", 《情报科学》, pages 169 - 176* |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114927168A (en)* | 2022-05-31 | 2022-08-19 | 四川大学 | Method for constructing biomechanically regulated bone reconstruction text mining interactive website |
| CN114927168B (en)* | 2022-05-31 | 2023-08-29 | 四川大学 | Construction method of biomechanical regulation and control bone reconstruction text mining interaction website |
| CN114996465A (en)* | 2022-08-01 | 2022-09-02 | 中国传媒大学 | Information propagation dynamics document classification knowledge base establishing method, system and equipment |
| CN115687296A (en)* | 2022-10-13 | 2023-02-03 | 核动力运行研究所 | A method for constructing nuclear power plant chemical knowledge base based on crawler technology |
| CN115827948A (en)* | 2023-02-09 | 2023-03-21 | 中南大学 | Single-reflectivity intelligent agent for crawling literature data and literature data crawling method |
| CN115827948B (en)* | 2023-02-09 | 2023-05-02 | 中南大学 | A Single Reflective Agent for Crawling Document Data and a Document Data Crawling Method |
Also Published As
| Publication number | Publication date |
|---|---|
| CN111797296B (en) | 2024-04-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111797296B (en) | Poison-target literature knowledge mining method and system based on web crawling | |
| US8510302B2 (en) | System, method, and computer program for a consumer defined information architecture | |
| JP3891909B2 (en) | Information search support system, application server, information search method, and program | |
| US9092504B2 (en) | Clustered information processing and searching with structured-unstructured database bridge | |
| US8375014B1 (en) | Database query builder | |
| US7246128B2 (en) | Data storage, retrieval, manipulation and display tools enabling multiple hierarchical points of view | |
| US20020042789A1 (en) | Internet search engine with interactive search criteria construction | |
| US20030233365A1 (en) | System and method for semantics driven data processing | |
| US20090019000A1 (en) | Query based rule sets | |
| Stuckenschmidt et al. | Exploring large document repositories with RDF technology: The DOPE project | |
| CN101681351A (en) | System and method for knowledge navigation and discovery of wiki content | |
| CN108363798A (en) | Knowledge capture and discovery system | |
| JPH09503088A (en) | Device and method for retrieving information | |
| CN111460095A (en) | Question and answer processing method and device, electronic equipment and storage medium | |
| CN111243748A (en) | Needle pushing health data standardization system | |
| Sellami et al. | Keyword-based faceted search interface for knowledge graph construction and exploration | |
| Gollapalli et al. | Automated discovery of multi-faceted ontologies for accurate query answering and future semantic reasoning | |
| Tirado et al. | Web data knowledge extraction | |
| Khurana et al. | Survey of techniques for deep web source selection and surfacing the hidden web content | |
| Kettouch | A new approach for interlinking and integrating semi-structured and linked data | |
| Maxim et al. | Enhancing User-Centric Information Retrieval: A Unified Dual-DBMS Strategy for Integrating Full-Text and Knowledge Graph Searches | |
| Gavankar et al. | A comparative study of semantic search systems | |
| US20250284688A1 (en) | Automated Prompt Augmentation And Engineering Using ML Automation In SQL Query Engine | |
| Zhang et al. | Natural Language Querying on NoSQL Databases: Opportunities and Challenges [Vision Paper] | |
| Zhang et al. | TAIJI: MCP-based Multi-Modal Data Analytics on Data Lakes |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |