CN111767710A - Sentiment classification methods, devices, equipment and media in Indonesian - Google Patents
Sentiment classification methods, devices, equipment and media in IndonesianDownload PDFInfo
- Publication number
- CN111767710A CN111767710ACN202010402298.4ACN202010402298ACN111767710ACN 111767710 ACN111767710 ACN 111767710ACN 202010402298 ACN202010402298 ACN 202010402298ACN 111767710 ACN111767710 ACN 111767710A
- Authority
- CN
- China
- Prior art keywords
- indonesia
- general representation
- indonesian
- processed
- representation information
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images

Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/205—Parsing
- G06F40/211—Syntactic parsing, e.g. based on context-free grammar [CFG] or unification grammars
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/35—Clustering; Classification
- G06F16/355—Creation or modification of classes or clusters
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明涉及印尼语情感分类技术领域,尤其涉及一种印尼语的情感分类方法、装置、设备及介质。The invention relates to the technical field of Indonesian language emotion classification, in particular to a method, device, equipment and medium for Indonesian language emotion classification.
背景技术Background technique
目前,在印尼语情感分析研究中,主要分为两种任务:构建情感词典与文本情感识别,但是构建情感词典与文本情感识别只能应用于单个领域的情感分类任务。而现有的多领域情感分类任务的研究开展仍然有限,且大部分工作集中在英语研究上,但是由于印尼语与英语差别较大,无法将现有的多领域情感分类任务直接应用于印尼语上,因此,无法对多个领域的印尼语进行分类。At present, in Indonesian sentiment analysis research, it is mainly divided into two tasks: building sentiment dictionary and text sentiment recognition, but building sentiment dictionary and text sentiment recognition can only be applied to sentiment classification tasks in a single field. However, the research on the existing multi-domain sentiment classification tasks is still limited, and most of the work focuses on English research. However, due to the large difference between Indonesian and English, the existing multi-domain sentiment classification tasks cannot be directly applied to Indonesian. , therefore, it is not possible to classify Indonesian in multiple domains.
发明内容SUMMARY OF THE INVENTION
本发明实施例提供一种印尼语的情感分类方法、装置、设备及介质,使得在多个领域都可对印尼语进行情感分类。Embodiments of the present invention provide a method, device, device, and medium for sentiment classification in Indonesian, so that sentiment can be classified in Indonesian in various fields.
本发明一实施例提供一种印尼语的情感分类方法,包括:An embodiment of the present invention provides a sentiment classification method in Indonesian, including:
获取待处理的印尼语句子,并确定所述待处理的印尼语句子对应的领域描述符;Acquire the Indonesian sentence to be processed, and determine the domain descriptor corresponding to the Indonesian sentence to be processed;
根据预设的CNN-BILSTM模型对所述待处理的印尼语句子进行计算,得到所述待处理的印尼语句子对应的通用表示信息;Calculate the Indonesian sentence to be processed according to the preset CNN-BILSTM model, and obtain the general representation information corresponding to the Indonesian sentence to be processed;
根据所述领域描述符以及所述通用表示信息计算得到领域通用表示信息;Calculate and obtain domain general representation information according to the domain descriptor and the general representation information;
将所述领域通用表示信息在当前领域对应的记忆网络样本库中进行加权计算,得到文本特征信息;Perform weighted calculation on the general representation information of the field in the memory network sample library corresponding to the current field to obtain text feature information;
根据所述文本特征信息确定对应的情感分类结果。The corresponding sentiment classification result is determined according to the text feature information.
作为上述方案的改进,所述根据预设的CNN-BILSTM模型对所述待处理的印尼语句子进行计算,得到所述待处理的印尼语句子对应的通用表示信息,具体包括:As an improvement of the above scheme, the Indonesian sentence sentence to be processed is calculated according to the preset CNN-BILSTM model, and the general representation information corresponding to the Indonesian sentence sentence to be processed is obtained, which specifically includes:
根据多尺度卷积核获取所述待处理的印尼语句子的n-gram特征;Obtain the n-gram feature of the Indonesian sentence to be processed according to the multi-scale convolution kernel;
根据BILSTM层对所述n-gram特征进行计算得到所述待处理的印尼语句子对应的通用表示信息。The general representation information corresponding to the Indonesian sentence to be processed is obtained by calculating the n-gram feature according to the BILSTM layer.
作为上述方案的改进,所述根据所述领域描述符以及所述通用表示信息计算得到领域通用表示信息,具体包括:As an improvement of the above solution, the calculation to obtain the general representation information of the domain according to the domain descriptor and the general representation information specifically includes:
根据所述领域描述符以及所述通用表示信息的计算相似度;Calculate the similarity according to the domain descriptor and the general representation information;
根据所述相似度以及所述通用表示信息进行回归处理得到领域通用表示信息。Perform regression processing according to the similarity and the general representation information to obtain domain general representation information.
作为上述方案的改进,所述将所述领域通用表示信息在当前领域对应的记忆网络样本库中进行加权计算,得到文本特征信息,具体包括:As an improvement of the above solution, the weighted calculation of the general representation information of the field in the memory network sample library corresponding to the current field is performed to obtain text feature information, which specifically includes:
根据dot product attention对所述领域通用表示信息与对应的记忆网络样本库中的通用信息进行加权计算,得到文本特征信息。According to the dot product attention, the general information in the field and the general information in the corresponding memory network sample library are weighted and calculated to obtain text feature information.
作为上述方案的改进,所述根据所述文本特征信息确定对应的情感分类结果,具体包括:As an improvement of the above solution, the determination of the corresponding sentiment classification result according to the text feature information specifically includes:
将所述文本特征信息通过全连接层映射为对应的三维向量;mapping the text feature information to a corresponding three-dimensional vector through a fully connected layer;
根据softmax函数将所述三维向量正则化,确定对应的情感分类结果;其中,情感分类结果包括:正向情感、中性情感以及负向情感。The three-dimensional vector is normalized according to the softmax function, and the corresponding sentiment classification result is determined; wherein, the sentiment classification result includes: positive sentiment, neutral sentiment and negative sentiment.
作为上述方案的改进,在所述根据预设的CNN-BILSTM模型对所述待处理的印尼语句子进行计算,得到所述待处理的印尼语句子对应的通用表示信息,之后还包括:As an improvement of the above scheme, after calculating the Indonesian sentence sentence to be processed according to the preset CNN-BILSTM model, the general representation information corresponding to the Indonesian sentence sentence to be processed is obtained, and further includes:
将所述通用表示信息根据预设的对抗学习法进行对抗训练,以使通用表示信息中不包含领域信息。The general representation information is subjected to adversarial training according to a preset adversarial learning method, so that the general representation information does not contain domain information.
本发明另一实施例对应提供了一种印尼语的情感分类装置,包括:Another embodiment of the present invention correspondingly provides an Indonesian language emotion classification device, including:
获取模块,用于获取待处理的印尼语句子,并确定所述待处理的印尼语句子对应的领域描述符;an acquisition module, configured to acquire the Indonesian sentence to be processed, and to determine the domain descriptor corresponding to the Indonesian sentence to be processed;
第一处理模块,用于根据预设的CNN-BILSTM模型对所述待处理的印尼语句子进行计算,得到所述待处理的印尼语句子对应的通用表示信息;The first processing module is used to calculate the Indonesian sentence sentence to be processed according to the preset CNN-BILSTM model, and obtain the general representation information corresponding to the Indonesian sentence sentence to be processed;
第二处理模块,用于根据所述领域描述符以及所述通用表示信息计算得到领域通用表示信息;a second processing module, configured to calculate and obtain domain general representation information according to the domain descriptor and the general representation information;
第三处理模块,用于将所述领域通用表示信息在当前领域对应的记忆网络样本库中进行加权计算,得到文本特征信息;The third processing module is used to perform weighted calculation on the general representation information of the field in the memory network sample library corresponding to the current field to obtain text feature information;
分类模块,用于根据所述文本特征信息确定对应的情感分类结果。A classification module, configured to determine a corresponding sentiment classification result according to the text feature information.
本发明另一实施例提供了一种印尼语的情感分类设备,包括处理器、存储器以及存储在所述存储器中且被配置为由所述处理器执行的计算机程序,所述处理器执行所述计算机程序时实现上述发明实施例所述的印尼语的情感分类方法。Another embodiment of the present invention provides an Indonesian language emotion classification device, comprising a processor, a memory, and a computer program stored in the memory and configured to be executed by the processor, the processor executing the The computer program implements the Indonesian sentiment classification method described in the above embodiments of the invention.
本发明另一实施例提供了一种存储介质,所述计算机可读存储介质包括存储的计算机程序,其中,在所述计算机程序运行时控制所述计算机可读存储介质所在设备执行上述发明实施例所述的印尼语的情感分类方法。Another embodiment of the present invention provides a storage medium, where the computer-readable storage medium includes a stored computer program, wherein when the computer program runs, a device on which the computer-readable storage medium is located is controlled to execute the foregoing embodiments of the invention The described sentiment classification method in Indonesian.
与现有技术相比,本发明实施例公开的印尼语的情感分类方法、装置、设备及介质,通过获取待处理的印尼语句子,并确定所述待处理的印尼语句子对应的领域描述符;根据预设的CNN-BILSTM模型对所述待处理的印尼语句子进行计算,得到所述待处理的印尼语句子对应的通用表示信息;根据所述领域描述符以及所述通用表示信息计算得到领域通用表示信息;将所述领域通用表示信息在所述领域描述符对应的记忆网络样本库中进行加权计算,得到文本特征信息;从而根据所述文本特征信息确定对应的情感分类结果。使得印尼语的通用表示可以适用于于多个领域,从而可以对在多个领域都可对印尼语进行情感分类。Compared with the prior art, the Indonesian language emotion classification method, device, device and medium disclosed in the embodiments of the present invention obtain Indonesian sentences to be processed and determine the domain descriptor corresponding to the Indonesian sentences to be processed. ; Calculate the Indonesian sentence to be processed according to the preset CNN-BILSTM model, and obtain the general representation information corresponding to the Indonesian sentence to be processed; Calculate according to the domain descriptor and the general representation information Domain general representation information; weighted calculation is performed on the domain general representation information in the memory network sample library corresponding to the domain descriptor to obtain text feature information; thus, the corresponding sentiment classification result is determined according to the text feature information. The general representation of Indonesian can be applied to many fields, so that the sentiment classification of Indonesian can be carried out in many fields.
附图说明Description of drawings
图1是本发明一实施例提供的一种印尼语的情感分类方法的流程示意图;1 is a schematic flowchart of a method for classifying sentiments in Indonesian according to an embodiment of the present invention;
图2是本发明一实施例提供的一种印尼语的情感分类装置的结构示意图;2 is a schematic structural diagram of a device for classifying emotions in Indonesian according to an embodiment of the present invention;
图3是本发明一实施例提供的一种印尼语的情感分类设备的结构示意图。FIG. 3 is a schematic structural diagram of an Indonesian language emotion classification device according to an embodiment of the present invention.
具体实施方式Detailed ways
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。The technical solutions in the embodiments of the present invention will be clearly and completely described below with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only a part of the embodiments of the present invention, but not all of the embodiments. Based on the embodiments of the present invention, all other embodiments obtained by those of ordinary skill in the art without creative efforts shall fall within the protection scope of the present invention.
参见图1,是本发明一实施例提供的一种印尼语的情感分类方法的流程示意图。Referring to FIG. 1 , it is a schematic flowchart of a method for sentiment classification in Indonesian according to an embodiment of the present invention.
本发明一实施例提供一种印尼语的情感分类方法,包括:An embodiment of the present invention provides a sentiment classification method in Indonesian, including:
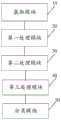
S10,获取待处理的印尼语句子,并确定所述待处理的印尼语句子对应的领域描述符。S10: Acquire the Indonesian sentence to be processed, and determine the domain descriptor corresponding to the Indonesian sentence to be processed.
S20,根据预设的CNN-BILSTM模型对所述待处理的印尼语句子进行计算,得到所述待处理的印尼语句子对应的通用表示信息。S20, calculate the Indonesian sentence sentence to be processed according to the preset CNN-BILSTM model, and obtain the general representation information corresponding to the Indonesian sentence sentence to be processed.
S30,根据所述领域描述符以及所述通用表示信息计算得到领域通用表示信息。S30: Calculate and obtain domain general representation information according to the domain descriptor and the general representation information.
S40,将所述领域通用表示信息在当前领域对应的记忆网络样本库中进行加权计算,得到文本特征信息。S40, performing weighted calculation on the general representation information of the field in the memory network sample library corresponding to the current field to obtain text feature information.
S50,根据所述文本特征信息确定对应的情感分类结果。S50: Determine a corresponding sentiment classification result according to the text feature information.
需要说明的是,在分类的过程中每一个待处理的印尼语句子对应一个领域,即可获得领域描述符。可以理解的是,可以是用户直接设定的领域,还可以是根据领域分类器进行识别。在本实施例中,领域包括:酒店、饭店等。It should be noted that in the process of classification, each Indonesian sentence to be processed corresponds to a field, and the field descriptor can be obtained. It can be understood that, it may be a field directly set by the user, or it may be identified according to a field classifier. In this embodiment, the fields include hotels, restaurants, and the like.
在训练模型时,根据领域分类器对待训练的印尼语句进行识别,不断自身训练,以使通过领域分类器可以更准确的获取领域描述符。在本实施例中,采用self-attention进行训练,同时更新相似域的领域描述符。When training the model, the Indonesian sentence to be trained is identified according to the domain classifier, and it is continuously trained by itself, so that the domain descriptor can be obtained more accurately through the domain classifier. In this embodiment, self-attention is used for training, and domain descriptors of similar domains are updated at the same time.
综上所述,通过识别印尼语中的描述符,再将描述符与通用信息进行结合得到领域描述符,使得印尼语的通用表示可以适用于于多个领域,从而可以对在多个领域都可对印尼语进行情感分类。In summary, by identifying the descriptors in Indonesian, and then combining the descriptors with general information to obtain domain descriptors, the general representation of Indonesian can be applied to many fields, so that it can be used in many fields. Sentiment classification for Indonesian.
在上述实施例中,优选地,所述根据预设的CNN-BILSTM模型对所述待处理的印尼语句子进行计算,得到所述待处理的印尼语句子对应的通用表示信息,步骤S20具体包括:In the above embodiment, preferably, according to the preset CNN-BILSTM model, the Indonesian sentence to be processed is calculated to obtain the general representation information corresponding to the to-be-processed Indonesian sentence. Step S20 specifically includes: :
根据多尺度卷积核获取所述待处理的印尼语句子的n-gram特征。The n-gram features of the Indonesian sentence to be processed are obtained according to the multi-scale convolution kernel.
具体地,在CNN的卷积操作中,存在着多个不同尺度的卷积核同时对文本进行特征提取,从而提取出不同粒度的n-gram特征。Specifically, in the convolution operation of CNN, there are multiple convolution kernels of different scales to perform feature extraction on the text at the same time, thereby extracting n-gram features of different granularities.
根据BILSTM层对所述n-gram特征进行计算得到所述待处理的印尼语句子对应的通用表示信息。The general representation information corresponding to the Indonesian sentence to be processed is obtained by calculating the n-gram feature according to the BILSTM layer.
具体地,设输入的句子矩阵为C,其中每个词的维度为d(包括dw维的词向量表示和dp维的位置向量)。为了得到输入句子的特征表示,模型初始化窗口大小为k的滤波器用于卷积操作,其宽度与词向量维度一致。卷积操作如下所示:Specifically, let the input sentence matrix be C, in which the dimension of each word is d (including the word vector representation of dw dimension and the position vector of dp dimension). To obtain the feature representation of the input sentence, the model initializes a filter with a window size of k for the convolution operation, whose width is consistent with the word vector dimension. The convolution operation looks like this:

其中,“·”代表点乘,σ表示sigmoid激活函数,C[i:i+k]表示第i到i+k的词向量序列,Hk为宽度为k的卷积核,b为偏置参数。为了保证不同的卷积核抽取的特征图长度一致,采用了SAME的padding策略,以使不同粒度特征输出和输入序列长度一致。为了更好地捕捉特征序列间的整体信息,将BiLSTM置于CNN之后,通过BiLSTM捕获特征序列的上下文关系,经过BiLSTM层后输出为:Among them, "·" represents the dot product, σ represents the sigmoid activation function, C[i:i+k] represents the word vector sequence i to i+k, Hk is the convolution kernel of width k, and b is the bias parameter. In order to ensure that the lengths of the feature maps extracted by different convolution kernels are consistent, the padding strategy of SAME is adopted to make the output of different granularity features consistent with the length of the input sequence. In order to better capture the overall information between feature sequences, BiLSTM is placed after CNN, and the context relationship of feature sequences is captured by BiLSTM. After the BiLSTM layer, the output is:

其中

作为上述方案的改进,所述根据所述领域描述符以及所述通用表示信息计算得到领域通用表示信息,步骤S30具体包括:As an improvement of the above solution, the calculation to obtain the domain general representation information according to the domain descriptor and the general representation information, step S30 specifically includes:
根据所述领域描述符以及所述通用表示信息的计算相似度;Calculate the similarity according to the domain descriptor and the general representation information;
根据所述相似度以及所述通用表示信息进行回归处理得到领域通用表示信息。Perform regression processing according to the similarity and the general representation information to obtain domain general representation information.
具体地,self-attention中采用采用dot product attentionSpecifically, self-attention adopts dot product attention

计算Ni与每个领域描述符之间的点积,点积后的值使用softmax函数归一化,

基于additiveattention融合领域表示去获取具有领域信息的文本表示。领域描述符用来捕获领域特征,其维度为N∈R2K*m,每个领域描述符对于N中的每一列,长度为2K。该矩阵在训练过程中也同步自动更新训练。The domain representation is fused based on additive attention to obtain text representation with domain information. Domain descriptors are used to capture domain features, and their dimension is N∈R2K*m , and each domain descriptor is 2K in length for each column in N. This matrix is also automatically updated during training synchronously.
训练时,给定一个输入








作为上述方案的改进,所述将所述领域通用表示信息在当前领域对应的记忆网络样本库中进行加权计算,得到文本特征信息,步骤S40具体包括:As an improvement of the above scheme, the weighted calculation of the general representation information of the field in the memory network sample library corresponding to the current field is performed to obtain text feature information, and step S40 specifically includes:
根据dot product attention对所述领域通用表示信息与对应的记忆网络样本库中的通用信息进行加权计算,得到文本特征信息。其中,记忆网络样本库为memorynetwork。According to the dot product attention, the general information in the field and the general information in the corresponding memory network sample library are weighted and calculated to obtain text feature information. Among them, the memory network sample library is memorynetwork.
具体地,采用一个

设





需要说明的是,在训练时,将文本特征信息保存至记忆网络样本库。It should be noted that during training, the text feature information is saved to the memory network sample library.
具体地,将文本特征信息保存至记忆网络样本库,便于继续对memorynetwork进行训练,以使得到的文本特征信息更加准确。Specifically, the text feature information is saved to the memory network sample library, so as to continue to train the memory network, so that the obtained text feature information is more accurate.
作为上述方案的改进,所述根据所述文本特征信息确定对应的情感分类结果,具体包括:As an improvement of the above solution, the determination of the corresponding sentiment classification result according to the text feature information specifically includes:
将所述文本特征信息通过全连接层映射为对应的三维向量。The text feature information is mapped to a corresponding three-dimensional vector through a fully connected layer.
根据softmax函数将所述三维向量正则化,确定对应的情感分类结果;其中,情感分类结果包括:正向情感、负向情感以及中性情感。The three-dimensional vector is normalized according to the softmax function, and the corresponding sentiment classification result is determined; wherein, the sentiment classification result includes: positive sentiment, negative sentiment and neutral sentiment.
具体地,文本特征信息,即为文本特征向量经过一层全连接层映射到三维向量,并采用softmax函数正则化,得到最后的情感分类结果。Specifically, the text feature information, that is, the text feature vector is mapped to a three-dimensional vector through a fully connected layer, and the softmax function is used for regularization to obtain the final sentiment classification result.
作为上述方案的改进,在所述根据预设的CNN-BILSTM模型对所述待处理的印尼语句子进行计算,得到所述待处理的印尼语句子对应的通用表示信息,之后还包括:As an improvement of the above scheme, after calculating the Indonesian sentence sentence to be processed according to the preset CNN-BILSTM model, the general representation information corresponding to the Indonesian sentence sentence to be processed is obtained, and further includes:
将所述通用表示信息根据预设的对抗学习法进行对抗训练,以使通用表示信息中不包含领域信息。The general representation information is subjected to adversarial training according to a preset adversarial learning method, so that the general representation information does not contain domain information.
具体地,预测输入序列





θds为各个领域的参数,包括领域描述符、attention权重以及Softmax参数。对抗部分通过更新θdc使损失最大化:θds is the parameter of each domain, including domain descriptor, attention weight and Softmax parameter. The adversarial part maximizes the loss by updating θdc :

两个部分迭代执行以生成域不变表示来增强通用表示。The two parts are executed iteratively to generate a domain-invariant representation to augment the general representation.
参见图2,是本发明一实施例提供的一种印尼语的情感分类装置的结构示意图。Referring to FIG. 2 , it is a schematic structural diagram of an Indonesian language emotion classification device according to an embodiment of the present invention.
本发明另一实施例对应提供了一种印尼语的情感分类装置,包括:Another embodiment of the present invention correspondingly provides an Indonesian language emotion classification device, including:
获取模块10,用于获取待处理的印尼语句子,并确定所述待处理的印尼语句子对应的领域描述符。The acquiring
第一处理模块20,用于根据预设的CNN-BILSTM模型对所述待处理的印尼语句子进行计算,得到所述待处理的印尼语句子对应的通用表示信息。The
第二处理模块30,用于根据所述领域描述符以及所述通用表示信息计算得到领域通用表示信息。The
第三处理模块40,用于将所述领域通用表示信息在当前领域对应的记忆网络样本库中进行加权计算,得到文本特征信息。The
分类模块50,用于根据所述文本特征信息确定对应的情感分类结果。The
本发明实施例提供的一种印尼语的情感分类装置,通过识别印尼语中的描述符,再将描述符与通用信息进行结合得到领域描述符,使得印尼语的通用表示可以适用于于多个领域,从而可以对在多个领域都可对印尼语进行情感分类。An Indonesian language emotion classification device provided by an embodiment of the present invention obtains domain descriptors by recognizing descriptors in Indonesian, and then combining the descriptors with general information, so that the general Indonesian expression can be applied to multiple domain, so that sentiment classification of Indonesian can be done in multiple domains.
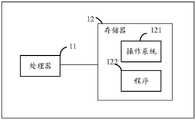
参见图3,是本发明一实施例提供的印尼语的情感分类设备的示意图。该实施例的印尼语的情感分类设备包括:处理器11、存储器12以及存储在所述存储器12中并可在所述处理器11上运行的计算机程序。所述处理器11执行所述计算机程序时实现上述各个印尼语的语法纠错方法实施例中的步骤。或者,所述处理器11执行所述计算机程序时实现上述各装置实施例中各模块/单元的功能。Referring to FIG. 3 , it is a schematic diagram of an Indonesian language emotion classification device provided by an embodiment of the present invention. The Indonesian language emotion classification device of this embodiment includes: a
示例性的,所述计算机程序可以被分割成一个或多个模块/单元,所述一个或者多个模块/单元被存储在所述存储器12中,并由所述处理器11执行,以完成本发明。所述一个或多个模块/单元可以是能够完成特定功能的一系列计算机程序指令段,该指令段用于描述所述计算机程序在所述印尼语的情感分类设备中的执行过程。Exemplarily, the computer program can be divided into one or more modules/units, and the one or more modules/units are stored in the
所述印尼语的情感分类设备可以是桌上型计算机、笔记本、掌上电脑及云端服务器等计算设备。所述印尼语的情感分类设备可包括,但不仅限于,处理器、存储器。本领域技术人员可以理解,所述示意图仅仅是印尼语的情感分类设备的示例,并不构成对印尼语的情感分类设备的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件,例如所述印尼语的情感分类设备还可以包括输入输出设备、网络接入设备、总线等。The Indonesian language emotion classification device may be a computing device such as a desktop computer, a notebook, a palmtop computer, and a cloud server. The Indonesian language emotion classification device may include, but is not limited to, a processor and a memory. Those skilled in the art can understand that the schematic diagram is only an example of the Indonesian language emotion classification device, and does not constitute a limitation to the Indonesian language emotion classification device, and may include more or less components than the one shown in the figure, or a combination of certain Some components, or different components, for example, the Indonesian language emotion classification device may also include input and output devices, network access devices, buses, and the like.
所称处理器11可以是中央处理单元(Central Processing Unit,CPU),还可以是其他通用处理器、数字信号处理器(Digital Signal Processor,DSP)、专用集成电路(Application Specific Integrated Circuit,ASIC)、现成可编程门阵列(Field-Programmable Gate Array,FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等,所述处理器是所述印尼语的情感分类设备的控制中心,利用各种接口和线路连接整个印尼语的情感分类设备的各个部分。The so-called
所述存储器12可用于存储所述计算机程序和/或模块,所述处理器通过运行或执行存储在所述存储器内的计算机程序和/或模块,以及调用存储在存储器内的数据,实现所述印尼语的情感分类设备的各种功能。所述存储器可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序(比如声音播放功能、图像播放功能等)等;存储数据区可存储根据手机的使用所创建的数据(比如音频数据、电话本等)等。此外,存储器可以包括高速随机存取存储器,还可以包括非易失性存储器,例如硬盘、内存、插接式硬盘,智能存储卡(Smart Media Card,SMC),安全数字(Secure Digital,SD)卡,闪存卡(Flash Card)、至少一个磁盘存储器件、闪存器件、或其他易失性固态存储器件。The
其中,所述印尼语的情感分类设备集成的模块/单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明实现上述实施例方法中的全部或部分流程,也可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一计算机可读存储介质中,该计算机程序在被处理器执行时,可实现上述各个方法实施例的步骤。其中,所述计算机程序包括计算机程序代码,所述计算机程序代码可以为源代码形式、对象代码形式、可执行文件或某些中间形式等。所述计算机可读介质可以包括:能够携带所述计算机程序代码的任何实体或装置、记录介质、U盘、移动硬盘、磁碟、光盘、计算机存储器、只读存储器(ROM,Read-OnlyMemory)、随机存取存储器(RAM,Random Access Memory)、电载波信号、电信信号以及软件分发介质等。Wherein, if the integrated modules/units of the Indonesian language emotion classification device are implemented in the form of software functional units and sold or used as independent products, they may be stored in a computer-readable storage medium. Based on this understanding, the present invention can implement all or part of the processes in the methods of the above embodiments, and can also be completed by instructing relevant hardware through a computer program, and the computer program can be stored in a computer-readable storage medium. When the program is executed by the processor, the steps of the foregoing method embodiments can be implemented. Wherein, the computer program includes computer program code, and the computer program code may be in the form of source code, object code, executable file or some intermediate form, and the like. The computer-readable medium may include: any entity or device capable of carrying the computer program code, a recording medium, a U disk, a removable hard disk, a magnetic disk, an optical disk, a computer memory, a read-only memory (ROM, Read-Only Memory), Random Access Memory (RAM, Random Access Memory), electric carrier signal, telecommunication signal and software distribution medium, etc.
需说明的是,以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。另外,本发明提供的装置实施例附图中,模块之间的连接关系表示它们之间具有通信连接,具体可以实现为一条或多条通信总线或信号线。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。It should be noted that the device embodiments described above are only schematic, wherein the units described as separate components may or may not be physically separated, and the components displayed as units may or may not be physical unit, that is, it can be located in one place, or it can be distributed over multiple network units. Some or all of the modules may be selected according to actual needs to achieve the purpose of the solution in this embodiment. In addition, in the drawings of the apparatus embodiments provided by the present invention, the connection relationship between the modules indicates that there is a communication connection between them, which may be specifically implemented as one or more communication buses or signal lines. Those of ordinary skill in the art can understand and implement it without creative effort.
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。The above are the preferred embodiments of the present invention. It should be pointed out that for those skilled in the art, without departing from the principles of the present invention, several improvements and modifications can be made, and these improvements and modifications may also be regarded as It is the protection scope of the present invention.
Claims (9)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010402298.4ACN111767710B (en) | 2020-05-13 | 2020-05-13 | Indonesia emotion classification method, device, equipment and medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010402298.4ACN111767710B (en) | 2020-05-13 | 2020-05-13 | Indonesia emotion classification method, device, equipment and medium |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN111767710Atrue CN111767710A (en) | 2020-10-13 |
| CN111767710B CN111767710B (en) | 2023-03-28 |
Family
ID=72719067
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010402298.4AActiveCN111767710B (en) | 2020-05-13 | 2020-05-13 | Indonesia emotion classification method, device, equipment and medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN111767710B (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113657446A (en)* | 2021-07-13 | 2021-11-16 | 广东外语外贸大学 | Processing method, system and storage medium for multi-label emotion classification model |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20180165554A1 (en)* | 2016-12-09 | 2018-06-14 | The Research Foundation For The State University Of New York | Semisupervised autoencoder for sentiment analysis |
| CN110678881A (en)* | 2017-05-19 | 2020-01-10 | 易享信息技术有限公司 | Natural language processing using context-specific word vectors |
- 2020
- 2020-05-13CNCN202010402298.4Apatent/CN111767710B/enactiveActive
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20180165554A1 (en)* | 2016-12-09 | 2018-06-14 | The Research Foundation For The State University Of New York | Semisupervised autoencoder for sentiment analysis |
| CN110678881A (en)* | 2017-05-19 | 2020-01-10 | 易享信息技术有限公司 | Natural language processing using context-specific word vectors |
Non-Patent Citations (2)
| Title |
|---|
| AQSATH RASYID NARADHIPA ET AL.: "Sentiment Classification for Indonesian Message in Social Media", 《2011 INTERNATIONAL CONFERENCE ON ELECTRICAL ENGINEERING AND INFORMATICS》* |
| YITAO CAI ET AL.: "Multi-Domain Sentiment Classification Based on Domain-Aware Embedding and Attention", 《PROCEEDINGS OF THE TWENTY-EIGHTH INTERNATIONAL JOINT CONFERENCE ON ARTIFICIAL INTELLIGENCE (IJCAI-19)》* |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113657446A (en)* | 2021-07-13 | 2021-11-16 | 广东外语外贸大学 | Processing method, system and storage medium for multi-label emotion classification model |
Also Published As
| Publication number | Publication date |
|---|---|
| CN111767710B (en) | 2023-03-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10621971B2 (en) | Method and device for extracting speech feature based on artificial intelligence | |
| CN111831826B (en) | Training method, classification method and device of cross-domain text classification model | |
| CN111368037B (en) | Text similarity calculation method and device based on Bert model | |
| EP3620982B1 (en) | Sample processing method and device | |
| CN113987188B (en) | A kind of short text classification method, device and electronic equipment | |
| CN110879938A (en) | Text sentiment classification method, device, equipment and storage medium | |
| WO2022042043A1 (en) | Machine learning model training method and apparatus, and electronic device | |
| CN111753863A (en) | An image classification method, device, electronic device and storage medium | |
| CN109271624B (en) | Target word determination method, device and storage medium | |
| CN111340097A (en) | Image fine-granularity classification method and device, storage medium and equipment | |
| CN111858999B (en) | Retrieval method and device based on segmentation difficult sample generation | |
| CN106611015A (en) | Tag processing method and apparatus | |
| CN112529029B (en) | Information processing method, device and storage medium | |
| CN115186133A (en) | Video generation method, device, electronic device and medium | |
| US11410016B2 (en) | Selective performance of deterministic computations for neural networks | |
| CN115062621A (en) | Label extraction method, device, electronic device and storage medium | |
| CN114373212A (en) | Face recognition model construction method, face recognition method and related equipment | |
| CN112560463B (en) | Text multi-labeling method, device, equipment and storage medium | |
| WO2025091983A1 (en) | Method and apparatus for sample generation, and device and storage medium | |
| US10504002B2 (en) | Systems and methods for clustering of near-duplicate images in very large image collections | |
| CN114419378B (en) | Image classification method, device, electronic device and medium | |
| CN111767710B (en) | Indonesia emotion classification method, device, equipment and medium | |
| CN111382243A (en) | Category matching method, category matching device and terminal for text | |
| CN115115920B (en) | Graph data self-supervision training method and device | |
| CN113868424B (en) | Method, device, computer equipment and storage medium for determining text topic |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |