CN111738003B - Named entity recognition model training method, named entity recognition method and medium - Google Patents
Named entity recognition model training method, named entity recognition method and mediumDownload PDFInfo
- Publication number
- CN111738003B CN111738003BCN202010541415.5ACN202010541415ACN111738003BCN 111738003 BCN111738003 BCN 111738003BCN 202010541415 ACN202010541415 ACN 202010541415ACN 111738003 BCN111738003 BCN 111738003B
- Authority
- CN
- China
- Prior art keywords
- module
- model
- training
- data set
- named entity
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images



Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/289—Phrasal analysis, e.g. finite state techniques or chunking
- G06F40/295—Named entity recognition
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Artificial Intelligence (AREA)
- Health & Medical Sciences (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Image Analysis (AREA)
Abstract
Description
Translated fromChinese技术领域Technical Field
本发明涉及自然语言处理技术领域,具体来说涉及命名实体识别技术领域,更具体地说,涉及命名实体识别模型训练方法、命名实体识别方法和介质。The present invention relates to the field of natural language processing technology, specifically to the field of named entity recognition technology, and more specifically to a named entity recognition model training method, a named entity recognition method and a medium.
背景技术Background Art
自然语言处理是为了让计算机理解人类的语言,从而更好地实现人与计算之间的交互(如语音助手、消息自动回复、翻译软件等应用与人的交互)。自然语言处理通常包括分词、词性标注、命名实体识别和语法分析等。命名实体识别(Named Entity Recognition,简称NER)是自然语言处理(Natural Language Processing,简称NLP)的一个重要组成部分。命名实体识别是指识别文本中具有特定意义的事物名称或者符号的过程,命名实体主要包括人名、地名、机构名、日期、专有名词等。许多下游NLP任务或应用程序都依赖NER进行信息提取,例如问题回答、关系提取、事件提取和实体链接等。若能更准确地识别出文本中的命名实体,有助于计算机更好地理解语言的语义、更好地执行任务,从而提高人机交互体验。Natural language processing is to enable computers to understand human language, so as to better realize the interaction between people and computers (such as the interaction between voice assistants, automatic message replies, translation software and other applications and people). Natural language processing usually includes word segmentation, part-of-speech tagging, named entity recognition and grammatical analysis. Named entity recognition (NER) is an important part of natural language processing (NLP). Named entity recognition refers to the process of identifying the names or symbols of things with specific meanings in text. Named entities mainly include names of people, places, institutions, dates, proper nouns, etc. Many downstream NLP tasks or applications rely on NER for information extraction, such as question answering, relationship extraction, event extraction and entity linking. If the named entities in the text can be identified more accurately, it will help the computer better understand the semantics of the language and perform tasks better, thereby improving the human-computer interaction experience.
基于深度神经网络的命名实体识别方法通常将命名实体识别看做多分类任务或序列标注任务,可以分为输入的分布式表示、语义编码和标签解码三个过程,其中输入的分布式表示根据编码对象可以分为字符级别、词级别和混合三种,可以得到每个词的向量表示;语义编码通常应用深度神经网络,比如双向长短记忆神经网络,基于Transform的双向编码器表示(Bidirectional Encoder Representation from Transformers,简称BERT)以及迁移学习网络等,可以利用文本中每个词的词向量得到文本的向量表示;标签解码由分类器完成,分类器常利用全连接神经网络+Softmax层或者条件随机场+维特比算法(Viterbi算法)来得到每个词的标签。Named entity recognition methods based on deep neural networks usually regard named entity recognition as a multi-classification task or a sequence labeling task, which can be divided into three processes: distributed representation of input, semantic encoding, and label decoding. The distributed representation of input can be divided into three types according to the encoding object: character level, word level, and mixed, and the vector representation of each word can be obtained; semantic encoding usually uses deep neural networks, such as bidirectional long short-term memory neural networks, bidirectional encoder representation from Transformers (BERT), and transfer learning networks, etc., and the word vector of each word in the text can be used to obtain the vector representation of the text; label decoding is completed by the classifier, and the classifier often uses a fully connected neural network + Softmax layer or a conditional random field + Viterbi algorithm to obtain the label of each word.
命名实体识别当前并不是一个大热的研究方向,因为学术界部分认为这是一个已经解决了的问题。但是,也有很多研究者认为这个问题还没有得到很好地解决,原因主要是命名实体识别只是在有限的文本类型(主要是新闻语料中)和实体类别(主要是人名、地名、组织机构名)中取得了不错的效果;而在其他自然语言处理领域,命名实体评测语料较小,容易产生过拟合,通用的识别多种类型的命名实体的系统性能还很差。Named entity recognition is not a hot research topic at present, because some academics believe that this is a solved problem. However, many researchers believe that this problem has not been well solved, mainly because named entity recognition has only achieved good results in limited text types (mainly news corpus) and entity categories (mainly names of people, places, and organizations); in other natural language processing fields, the named entity evaluation corpus is small, which is prone to overfitting, and the performance of general systems for recognizing multiple types of named entities is still poor.
基于深度学习的命名实体识别在英语新闻语料上已经达到不错的效果(F1值在90%以上),但深度学习方法一般需要大量标注数据,在真实世界中很多语言和领域通常标记数据比较少,因此出现了低资源命名实体识别问题。迁移学习是目前解决低资源命名实体识别问题的常用方法,但目前应用于低资源命名实体识别问题的迁移学习存在数据量、标签资源不平衡问题,共同学习时会更加偏向于高资源数据(数据量更大的数据集)的问题,使得命名实体识别模型的识别效果不好。因此,有必要对现有技术进行改进。Named entity recognition based on deep learning has achieved good results on English news corpus (F1 value is above 90%), but deep learning methods generally require a large amount of labeled data. In the real world, many languages and fields usually have relatively little labeled data, so the problem of low-resource named entity recognition arises. Transfer learning is currently a common method to solve the problem of low-resource named entity recognition, but the transfer learning currently applied to the problem of low-resource named entity recognition has problems with data volume and label resources imbalance. When learning together, it will be more biased towards high-resource data (data sets with larger data volumes), resulting in poor recognition effects of named entity recognition models. Therefore, it is necessary to improve the existing technology.
发明内容Summary of the invention
因此,本发明的目的在于克服上述现有技术的缺陷,提供命名实体识别模型训练方法、命名实体识别方法和介质。Therefore, the purpose of the present invention is to overcome the defects of the above-mentioned prior art and provide a named entity recognition model training method, a named entity recognition method and a medium.
本发明的目的是通过以下技术方案实现的:The objective of the present invention is achieved through the following technical solutions:
根据本发明的第一方面,提供一种命名实体识别模型训练方法,所述方法包括:A1、构建第一训练模型,所述第一训练模型包括特征提取模块、识别模块和领域区分模块;A2、对第一训练模型进行多轮训练,其中,每轮训练中,用第一数据集对识别模块进行训练、用第一数据集和第二数据集对特征提取模块和领域区分模块进行对抗训练,每轮训练后至少根据识别模块的损失函数和领域区分模块的损失函数对特征提取模块的参数进行调整,同时更新第一数据集和第二数据集,以更新后的第一数据集和第二数据集进行下一轮训练,其中,第一数据集是以单词向量形式表示的有实体标签的源领域标记数据集,第二数据集是以单词向量形式表示的无实体标签的目标领域未标记数据集;A3、构建第二训练模型,所述第二训练模型包括特征提取模块和识别模块,第二训练模型的特征提取模块的初始参数采用经步骤A2训练后的第一训练模型的特征提取模块的参数进行设置,识别模块的初始参数采用随机初始化的方式进行设置;A4、用第三数据集以监督训练的方式对由步骤A3构建的第二训练模型的特征提取模块和识别模块的进行参数微调,将经参数微调后的第二训练模型作为命名实体识别模型,其中,第三数据集是以单词向量形式表示的有实体标签的目标领域标记数据集。According to a first aspect of the present invention, a method for training a named entity recognition model is provided, the method comprising: A1, constructing a first training model, the first training model comprising a feature extraction module, a recognition module and a domain distinction module; A2, performing multiple rounds of training on the first training model, wherein in each round of training, the recognition module is trained with a first data set, and the feature extraction module and the domain distinction module are adversarially trained with the first data set and the second data set, after each round of training, the parameters of the feature extraction module are adjusted at least according to the loss function of the recognition module and the loss function of the domain distinction module, and the first data set and the second data set are updated at the same time, and the next round of training is performed with the updated first data set and the second data set, wherein the first data set is represented in the form of word vectors with entity labels. A source domain labeled dataset, the second dataset is a target domain unlabeled dataset without entity labels represented in the form of word vectors; A3, constructing a second training model, the second training model includes a feature extraction module and a recognition module, the initial parameters of the feature extraction module of the second training model are set using the parameters of the feature extraction module of the first training model trained in step A2, and the initial parameters of the recognition module are set using random initialization; A4, using a third dataset to fine-tune the parameters of the feature extraction module and the recognition module of the second training model constructed in step A3 in a supervised training manner, and using the second training model after parameter fine-tuning as a named entity recognition model, wherein the third dataset is a target domain labeled dataset with entity labels represented in the form of word vectors.
优选的,所述源领域标记数据集的规模与所述目标领域未标记数据集的规模相同或者大致相同,所述目标领域标记数据集的规模小于所述目标领域未标记数据集的规模。Preferably, the size of the source domain labeled dataset is the same or approximately the same as the size of the target domain unlabeled dataset, and the size of the target domain labeled dataset is smaller than the size of the target domain unlabeled dataset.
优选的,规模相同或者大致相同是指源领域标记数据集与目标领域未标记数据集的数据量之比为:10:14~10:9。Preferably, the same or approximately the same scale means that the ratio of the data volume of the source domain labeled data set to the target domain unlabeled data set is 10:14 to 10:9.
在本发明的一些实施例中,所述第一训练模型中的特征提取模块包括预处理层、CNN模型、Word2Vec模型、包含前向LSTM和后向LSTM的BiLSTM模型,其中,前向LSTM、后向LSTM分别包括多个依次连接的LSTM单元;该特征提取模块分别对非单词向量形式表示的源领域标记数据集、目标领域未标记数据集、目标领域标记数据集进行如下处理以获得第一数据集、第二数据集、第三数据集:用所述预处理层对数据集的单词进行包含统一大小写和去除停用词的预处理;用CNN模型提取数据集中各单词的字符级别嵌入特征;用Word2Vec模型提取数据集中各单词的单词嵌入特征;对数据集中各单词的字符级别嵌入特征和单词嵌入特征进行串联拼接,得到各单词的向量表示;将数据集中各单词的向量表示输入特征提取模块的BiLSTM模型中进行处理,得到包含上下文信息的以单词向量形式表示的数据集。In some embodiments of the present invention, the feature extraction module in the first training model includes a preprocessing layer, a CNN model, a Word2Vec model, and a BiLSTM model including a forward LSTM and a backward LSTM, wherein the forward LSTM and the backward LSTM respectively include a plurality of LSTM units connected in sequence; the feature extraction module respectively processes the source domain labeled data set, the target domain unlabeled data set, and the target domain labeled data set represented in the form of non-word vectors as follows to obtain the first data set, the second data set, and the third data set: using the preprocessing layer to preprocess the words in the data set including unifying the case and removing stop words; using the CNN model to extract the character-level embedding features of each word in the data set; using the Word2Vec model to extract the word embedding features of each word in the data set; concatenating the character-level embedding features and the word embedding features of each word in the data set to obtain the vector representation of each word; inputting the vector representation of each word in the data set into the BiLSTM model of the feature extraction module for processing to obtain a data set represented in the form of a word vector containing context information.
在本发明的一些实施例中,第一训练模型和第二训练模型的识别模块均包括BiLSTM-CRF模型,其中,采用源领域标记数据的实体标签设置第一训练模型中识别模块的BiLSTM-CRF模型的CRF层的标签取值空间,采用的目标领域标记数据集的实体标签设置第二训练模型的识别模块的BiLSTM-CRF模型的CRF层的标签设置。In some embodiments of the present invention, the recognition modules of the first training model and the second training model both include a BiLSTM-CRF model, wherein the label value space of the CRF layer of the BiLSTM-CRF model of the recognition module in the first training model is set using the entity labels of the source domain label data, and the label setting of the CRF layer of the BiLSTM-CRF model of the recognition module of the second training model is set using the entity labels of the target domain label data set.
在本发明的一些实施例中,所述第一训练模型还包括梯度反转层,对特征提取模块和领域区分模块进行对抗训练过程中,在正向传播时通过梯度反转层对第一训练模型的特征提取模块和领域区分模块执行标准随机梯度下降操作,并且在反向传播时,在将领域区分模块的损失函数返回到特征提取模块之前将梯度反转层的参数自动取反,以使特征提取模块提取源领域标记数据集和目标领域未标记数据集中单词的通用特征。In some embodiments of the present invention, the first training model further includes a gradient reversal layer. During adversarial training of the feature extraction module and the domain distinction module, a standard stochastic gradient descent operation is performed on the feature extraction module and the domain distinction module of the first training model through the gradient reversal layer during forward propagation, and during back propagation, the parameters of the gradient reversal layer are automatically reversed before the loss function of the domain distinction module is returned to the feature extraction module, so that the feature extraction module extracts common features of words in the source domain labeled dataset and the target domain unlabeled dataset.
在本发明的一些实施例中,所述第一训练模型还包括自动编码模块,用第二数据集对自动编码模块进行训练,每轮训练后,根据自动编码模块的损失函数、识别模块的损失函数和领域区分模块的损失函数共同更新特征提取模块的参数。In some embodiments of the present invention, the first training model also includes an automatic encoding module, which is trained with a second data set. After each round of training, the parameters of the feature extraction module are jointly updated according to the loss function of the automatic encoding module, the loss function of the recognition module, and the loss function of the domain distinction module.
在本发明的一些实施例中,所述自动编码模块包含编码器和解码器,其中,每轮训练中,编码器获取用特征提取模块的BiLSTM模型提取到目标领域未标记数据集的单词的前向LSTM中最后一个LSTM和后向LSTM中最后一个LSTM的隐藏状态并组合为解码器的初始状态特征,并使用该初始状态特征和其前一个单词嵌入特征作为解码器的输入以训练自动编码模块提取目标领域的私有特征。In some embodiments of the present invention, the automatic encoding module includes an encoder and a decoder, wherein, in each round of training, the encoder obtains the hidden states of the last LSTM in the forward LSTM and the last LSTM in the backward LSTM of the words of the unlabeled data set of the target domain extracted by the BiLSTM model of the feature extraction module and combines them into the initial state features of the decoder, and uses the initial state features and the previous word embedding features as the input of the decoder to train the automatic encoding module to extract private features of the target domain.
在本发明的一些实施例中,按照以下方式对第一训练模型的特征提取模块的参数进行调整:In some embodiments of the present invention, the parameters of the feature extraction module of the first training model are adjusted in the following manner:

其中,θf表示本次调整后特征提取模块的参数,θ’f表示本次调整前特征提取模块的参数,μ表示学习率,Ltask表示识别模块的损失函数,Ltype表示领域区分模块的损失函数,Ltarget表示自动编码模块的损失函数,-ω表示梯度翻转参数,α、β、γ表示用户设置的权重。Among them, θf represents the parameters of the feature extraction module after this adjustment, θ'f represents the parameters of the feature extraction module before this adjustment, μ represents the learning rate, Ltask represents the loss function of the recognition module, Ltype represents the loss function of the domain distinction module, Ltarget represents the loss function of the automatic encoding module, -ω represents the gradient flipping parameter, and α, β, and γ represent the weights set by the user.
在本发明的一些实施例中,所述步骤A2还包括:在每轮训练后按照以下方式对第一训练模型的识别模块、领域区分模块和自动编码模块的参数进行调整:In some embodiments of the present invention, step A2 further includes: adjusting the parameters of the recognition module, the domain distinction module and the automatic encoding module of the first training model after each round of training in the following manner:
识别模块对应的参数调整方式为:
领域区分模块对应的参数调整方式为:
自动编码模块对应的参数调整方式为:
其中,θy表示本次调整后识别模块的参数,θ’y表示本次调整前识别模块的参数,θd表示本次调整后领域区分模块的参数,θ’d表示本次调整前领域区分模块的参数,θr表示本次调整后自动编码模块的参数,θ’r表示本次调整前自动编码模块的参数,μ表示学习率,α、β、γ表示用户设置的权重。Among them, θy represents the parameters of the recognition module after this adjustment, θ'y represents the parameters of the recognition module before this adjustment, θd represents the parameters of the domain distinction module after this adjustment, θ'd represents the parameters of the domain distinction module before this adjustment, θr represents the parameters of the automatic encoding module after this adjustment, θ'r represents the parameters of the automatic encoding module before this adjustment, μ represents the learning rate, and α, β, and γ represent the weights set by the user.
根据本发明的第二方面,提供一种基于如第一方面所述的命名实体识别模型训练方法训练得到的命名实体识别模型的命名实体识别方法,所述命名实体识别模型包括特征提取模块和识别模块,所述命名实体识别方法包括:B1、通过命名实体识别模型的特征提取模块获取待识别文本的字符级别嵌入特征和单词嵌入特征并进行串联拼接,得到待识别文本中各单词的单词向量;B2、将单词向量的形式表示的待识别文本输入命名实体识别模型的识别模块,得到所述待识别文本的命名实体识别结果。According to a second aspect of the present invention, there is provided a named entity recognition method based on a named entity recognition model trained by the named entity recognition model training method as described in the first aspect, wherein the named entity recognition model comprises a feature extraction module and a recognition module, and the named entity recognition method comprises: B1, obtaining character-level embedding features and word embedding features of a text to be recognized through the feature extraction module of the named entity recognition model and concatenating them in series to obtain word vectors of each word in the text to be recognized; B2, inputting the text to be recognized represented in the form of word vectors into the recognition module of the named entity recognition model to obtain a named entity recognition result of the text to be recognized.
根据本发明的第三方面,提供一种电子设备,包括:一个或多个处理器;以及存储器,其中存储器用于存储一个或多个可执行指令;所述一个或多个处理器被配置为经由执行所述一个或多个可执行指令以实现第一方面或者第二方面所述方法的步骤。According to a third aspect of the present invention, there is provided an electronic device comprising: one or more processors; and a memory, wherein the memory is used to store one or more executable instructions; the one or more processors are configured to implement the steps of the method described in the first aspect or the second aspect by executing the one or more executable instructions.
与现有技术相比,本发明的优点在于:Compared with the prior art, the advantages of the present invention are:
本发明考虑先用源领域标记数据和目标领域未标记数据集对第一训练模型进行训练,基于第一训练模型的参数设置第二训练模型,再用目标领域标记数据集对第二训练模型进行微调,从而得到最终的命名实体识别模型。由此,避免了需要大量标记目标领域的样本用于训练的问题,训练出的命名实体识别模型对目标领域未标记数据集中的单词进行命名实体识别时的识别效果也得到了提升。The present invention considers first training a first training model with source domain labeled data and target domain unlabeled data set, setting a second training model based on the parameters of the first training model, and then fine-tuning the second training model with the target domain labeled data set, thereby obtaining a final named entity recognition model. Thus, the problem of requiring a large number of labeled samples of the target domain for training is avoided, and the recognition effect of the trained named entity recognition model when performing named entity recognition on words in the target domain unlabeled data set is also improved.
附图说明BRIEF DESCRIPTION OF THE DRAWINGS
以下参照附图对本发明实施例作进一步说明,其中:The embodiments of the present invention are further described below with reference to the accompanying drawings, in which:
图1为根据本发明实施例的命名实体识别模型训练方法的简化示意图;FIG1 is a simplified schematic diagram of a named entity recognition model training method according to an embodiment of the present invention;
图2为根据本发明实施例的命名实体识别模型的结构原理示意图;FIG2 is a schematic diagram of the structural principle of a named entity recognition model according to an embodiment of the present invention;
图3为根据本发明实施例的鞍点的示意图;FIG3 is a schematic diagram of a saddle point according to an embodiment of the present invention;
图4为作为本发明的基线实验的现有模型进行命名实体识别的示意图;FIG4 is a schematic diagram of named entity recognition using an existing model as a baseline experiment of the present invention;
图5为作为本发明的对比实验的两种现有方法的示意图。FIG. 5 is a schematic diagram of two existing methods used as a comparative experiment of the present invention.
具体实施方式DETAILED DESCRIPTION
为了使本发明的目的,技术方案及优点更加清楚明白,以下结合附图通过具体实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。In order to make the purpose, technical solution and advantages of the present invention more clearly understood, the present invention is further described in detail by specific embodiments in conjunction with the accompanying drawings. It should be understood that the specific embodiments described herein are only used to explain the present invention and are not used to limit the present invention.
如在背景技术部分提到的,目前的命名实体识别模型是在特定领域的经过标记(即标记出数据集中哪些字词是命名实体)的数据集上经过监督训练得到的,其能够在特定领域实现较高的识别准确性,但是如果把该模型直接应用到其他领域时,存在泛化能力较差、识别准确性不高的问题。而在真实世界中很多语言和领域通常标记数据比较少,难以通过监督训练得到该领域所需的命名实体识别模型,而如果通过人工对这些领域的数据进行标记,不仅需要负责人工标记的人员具有对各领域的各类命名实体的名称有清晰的认识,还需要其从海量的数据中准确标记出各类命名实体,其工作量大且成本高。而如果直接用规模相对较大的源领域标记数据集和规模较小的目标领域标记数据集进行迁移学习,会存在标签资源不平衡问题,导致共同学习时会更加偏向于高资源数据的问题,使训练得到的模型在目标领域的识别效果不佳。As mentioned in the background technology section, the current named entity recognition model is obtained through supervised training on a labeled data set in a specific field (i.e., which words in the data set are named entities) and can achieve high recognition accuracy in a specific field. However, if the model is directly applied to other fields, there are problems of poor generalization ability and low recognition accuracy. In the real world, many languages and fields usually have relatively few labeled data, and it is difficult to obtain the named entity recognition model required in the field through supervised training. If the data in these fields are manually labeled, not only does the person responsible for manual labeling need to have a clear understanding of the names of various named entities in various fields, but he also needs to accurately label various named entities from massive data, which is labor-intensive and costly. If a relatively large-scale source field labeled data set and a smaller-scale target field labeled data set are directly used for transfer learning, there will be a problem of imbalanced label resources, resulting in a problem of being more biased towards high-resource data during joint learning, so that the trained model has poor recognition effect in the target field.
因此,本发明考虑先用源领域标记数据和目标领域未标记数据集对第一训练模型进行训练,基于第一训练模型的参数设置第二训练模型,再用目标领域标记数据集对第二训练模型进行微调,从而得到最终的命名实体识别模型。由此,可以将目标领域数据分为目标领域未标记数据集和目标领域标记数据集两部分对模型进行训练,从而可以将目标领域未标记数据集与源领域标记数据集的规模设置为大致相同以避免最终训练的模型参数偏向数据量大的数据集;训练后用规模比目标领域未标记数据集小的目标领域标记数据集对第二训练模型进行微调,从而得到最终的命名实体识别模型,避免了需要大量标记目标领域的样本用于训练的问题。Therefore, the present invention considers first training the first training model with the source domain labeled data and the target domain unlabeled data set, setting the second training model based on the parameters of the first training model, and then fine-tuning the second training model with the target domain labeled data set, so as to obtain the final named entity recognition model. Thus, the target domain data can be divided into two parts, the target domain unlabeled data set and the target domain labeled data set, to train the model, so that the scale of the target domain unlabeled data set and the source domain labeled data set can be set to be roughly the same to avoid the final training model parameters being biased towards the data set with a large amount of data; after training, the target domain labeled data set with a smaller scale than the target domain unlabeled data set is used to fine-tune the second training model, so as to obtain the final named entity recognition model, avoiding the problem of requiring a large number of labeled samples of the target domain for training.
在对本发明的实施例进行具体介绍之前,先对其中使用到的部分术语作如下解释:Before specifically introducing the embodiments of the present invention, some of the terms used therein are explained as follows:
对抗训练,也称对抗学习,是由Goodfellow等人提出,基本思想是基于两个模型:一个生成模型和一个判别模型。判别模型的任务是判断一张给定的图片是真实的还是经过人工修饰,生成模型的任务是模拟生成与图集中的图片相似的合成图片。在训练过程中通过反复对抗,生成模型和判别模型的能力都会不断增强,直到达成一个平衡。我们可以把这个过程看作一种零和游戏。目前对抗学习已成功用于图像生成、半监督学习以及域自适应。领域自适应对抗学习网络的关键思想是在优化特征提取模块的过程中对抗领域区分模块,来构建通用不变的特征。Adversarial training, also known as adversarial learning, was proposed by Goodfellow et al. The basic idea is based on two models: a generative model and a discriminative model. The task of the discriminative model is to determine whether a given picture is real or artificially modified, and the task of the generative model is to simulate and generate synthetic pictures similar to the pictures in the atlas. Through repeated confrontation during the training process, the capabilities of the generative model and the discriminative model will continue to increase until a balance is reached. We can think of this process as a zero-sum game. At present, adversarial learning has been successfully used in image generation, semi-supervised learning, and domain adaptation. The key idea of the domain adaptive adversarial learning network is to construct universal and invariant features by adversarially distinguishing the domain in the process of optimizing the feature extraction module.
迁移学习,是将已经学习到的知识迁移到另一种未知的知识的学习,即从源领域迁移到目标领域。Transfer learning is the process of transferring already learned knowledge to another unknown knowledge, that is, from the source domain to the target domain.
源领域标记数据集,是指源领域的经过实体标记而带有实体标签的数据集。换言之,源领域标记数据集中的实体对象带有其对应类型的实体标签。The source domain labeled dataset refers to a dataset in the source domain that has been labeled with entity labels. In other words, the entity objects in the source domain labeled dataset have entity labels of their corresponding types.
目标领域未标记数据集,是指目标领域的没有经过实体标记的数据集。没有经过标记是指无需在本发明的训练过程前对其进行标记。即使收集的部分数据带有其原来他人标记的实体标签,也被视为不带有实体标签的数据集,因为这部分实体标签在对抗训练的过程中不考虑或者不会被使用。The target domain unlabeled dataset refers to a dataset in the target domain that has not been labeled with entities. Unlabeled means that it does not need to be labeled before the training process of the present invention. Even if part of the collected data has entity labels that were originally labeled by others, it is considered as a dataset without entity labels, because these entity labels are not considered or will not be used in the adversarial training process.
目标领域标记数据集,是指目标领域的经过实体标记而带有实体标签的数据集。The target domain labeled dataset refers to a dataset in the target domain that has been labeled with entity tags.
CNN(Convolutional Neural Networks),表示卷积神经网络,是一类包含卷积计算且具有深度结构的前馈神经网络。CNN (Convolutional Neural Networks) stands for convolutional neural network, which is a type of feedforward neural network that includes convolution calculations and has a deep structure.
Word2Vec(Word to Vector)模型,是一种将词汇向量化的自然语言处理模型。Word2Vec模型的工作原理是从大量文本语料中以无监督的方式学习词的语义信息,并输出词向量来表征词的语义信息。The Word2Vec (Word to Vector) model is a natural language processing model that vectorizes vocabulary. The working principle of the Word2Vec model is to learn the semantic information of words from a large amount of text corpus in an unsupervised manner and output word vectors to represent the semantic information of words.
LSTM(Long Short-Term Memory),表示长短期记忆网络,是一种递归循环神经网络。LSTM的出现主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。相比于普通的循环神经网络(Recurrent Neural Network,简称RNN),LSTM在长序列中学习长期依赖信息方面具有更好的表现。LSTM (Long Short-Term Memory) is a recursive neural network. LSTM was developed to solve the gradient vanishing and gradient exploding problems in long sequence training. Compared with ordinary recurrent neural networks (RNN), LSTM performs better in learning long-term dependent information in long sequences.
BiLSTM(Bi-directional Long Short-Term Memory),表示双向长短期记忆网络。BiLSTM (Bi-directional Long Short-Term Memory) stands for bidirectional long short-term memory network.
CRF(Conditional Random Fields),表示条件随机场,是一种给定输入随机变量x,求解条件概率P(y│x)的概率无向图模型。条件随机场模型需要建模的是输入变量和输出变量的条件概率分布。条件随机场常用于标注或分析序列资料,如自然语言文字或是生物序列。用于序列标注时,输入输出随机变量为两个等长的序列。CRF (Conditional Random Fields), which stands for conditional random fields, is a probabilistic undirected graph model that solves the conditional probability P(y│x) given an input random variable x. The conditional random field model needs to model the conditional probability distribution of the input and output variables. Conditional random fields are often used to annotate or analyze sequence data, such as natural language text or biological sequences. When used for sequence annotation, the input and output random variables are two sequences of equal length.
MLP(Multilayer Perceptron),表示多层感知机,是一种前馈人工神经网络模型,用于进行多层线性或非线性变换。MLP (Multilayer Perceptron), which stands for Multilayer Perceptron, is a feedforward artificial neural network model used for multi-layer linear or nonlinear transformation.
停用词,是指在处理自然语言数据(或文本)之前或之后会自动过滤掉的无明确意义的字或词。比如,语气助词、副词、介词、连接词等。去除停用词可以节省存储空间、提高处理效率。Stop words refer to words or characters without clear meaning that are automatically filtered out before or after processing natural language data (or text). For example, modal particles, adverbs, prepositions, conjunctions, etc. Removing stop words can save storage space and improve processing efficiency.
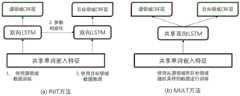
参见图1,本发明的命名实体模型训练方法的训练过程主要包括以下几个阶段:先用规模相同或者大致相同的第一数据集和第二数据集训练第一训练模型,训练完成后将第一训练模型的知识通过迁移学习的方式传递给第二训练模型后用规模小于第二数据集的第三数据集对第二训练模型进行微调,得到命名实体识别模型。Referring to Figure 1, the training process of the named entity model training method of the present invention mainly includes the following stages: first, a first training model is trained with a first data set and a second data set of the same or approximately the same size. After the training is completed, the knowledge of the first training model is transferred to the second training model through transfer learning, and then the second training model is fine-tuned with a third data set that is smaller than the second data set to obtain a named entity recognition model.
根据本发明的一个实施例,提供一种命名实体识别模型训练方法,包括步骤A1、A2、A3、A4。为了更好地理解本发明,下面结合具体的实施例针对每一个步骤分别进行详细说明。According to an embodiment of the present invention, a method for training a named entity recognition model is provided, comprising steps A1, A2, A3, and A4. In order to better understand the present invention, each step is described in detail below in conjunction with a specific embodiment.
步骤A1:构建第一训练模型,第一训练模型包括特征提取模块11、识别模块12和领域区分模块13。Step A1: construct a first training model, which includes a
根据本发明的一个实施例,第一训练模型中的特征提取模块11包括预处理层、CNN模型、Word2Vec模型和包含前向LSTM和后向LSTM的BiLSTM模型,其中,前向LSTM、后向LSTM分别包括多个依次连接的LSTM单元;该特征提取模块11分别对非单词向量形式表示的源领域标记数据集、目标领域未标记数据集、目标领域标记数据集进行如下处理以获得第一数据集、第二数据集、第三数据集:用所述预处理层对数据集的单词进行包含统一大小写和去除停用词的预处理;用CNN模型提取数据集中各单词的字符级别嵌入特征;用Word2Vec模型提取数据集中各单词的单词嵌入特征;对数据集中各单词的字符级别嵌入特征和单词嵌入特征进行串联拼接,得到各单词的向量表示;将数据集中各单词的向量表示输入到特征提取模块11的BiLSTM模型中进行处理,得到包含上下文信息的以单词向量形式表示的数据集。简单地说,特征提取模块11可以提取源领域和目标领域共同的字符级别嵌入特征和单词嵌入特征以及包含上下文信息的单词向量。参见图2,源领域和目标领域为一些句子组成的样本,将其输入到特征提取模块11。特征提取模块11利用CNN提取字符级别嵌入特征


根据本发明的一个实施例,第一训练模型的识别模块12包括BiLSTM-CRF模型。其中,采用源领域标记数据集的实体标签设置第一训练模型中识别模块12的BiLSTM-CRF模型的CRF层的标签取值空间。标签例如图2识别模块12内示出的示意性结果,B-GPE表示一种示意性的实体标签,例如为国家、城市、州这类实体,O表示非实体的标签,识别模块12用于进行命名实体识别标注。识别模块12以F(x)作为输入,使用CRF层,最大似然估计计算损失函数以及Viterbi算法将F(x)中的每个单词向量F(xi)映射到其实体标签,CRF层的CRF算法使用特征函数来更抽象地表达特征,其中,CRF算法的目标函数为:According to one embodiment of the present invention, the

其中,x表示输入单词序列,y表示输出实体标签序列,θy为特征函数权重,Z(x)为归一化因子,i为当前单词的位置,M为输入单词序列长度,j表示特征函数的个数,θyj表示第j个特征函数的权重,f(x,i,yi,yi-1)表示特征函数,yi为当前位置的输出实体标签,yi-1为前一个位置的输出实体标签。该目标函数所表达的含义是:给定输入单词序列x和特征函数权重θy,输出标签序列y出现的条件概率,将概率最高的实体标签作为单词序列x中对应单词的实体标签yi。Where x represents the input word sequence, y represents the output entity label sequence,θy is the feature function weight, Z(x) is the normalization factor, i is the position of the current word, M is the length of the input word sequence, j represents the number of feature functions,θyj represents the weight of the jth feature function, f(x,i,yi ,yi-1 ) represents the feature function,yi is the output entity label of the current position, and yi-1 is the output entity label of the previous position. The objective function means: given the input word sequence x and the feature function weightθy , the conditional probability of the output label sequence y appears, and the entity label with the highest probability is used as the entity labelyi of the corresponding word in the word sequence x.
上述归一化因子Z(x)表示为:
识别模块12的参数即为特征函数的权重θy,对参数的求解用最大似然估计,假设源领域训练集为


用以下公式计算对数似然作为损失函数以对识别模块12进行训练:The log-likelihood is calculated as the loss function to train the

其中,k表示当前样本的序号。Where k represents the sequence number of the current sample.
根据本发明的一个实施例,第一训练模型的领域区分模块13包括多层感知机MLP,多层感知机包括Softmax层。领域区分模块13以F(x)作为输入,是标准的前馈网络。领域区分模块13的训练目标为尽量不能对样本来自源领域和目标领域进行区分。领域区分模块13将相同的隐藏状态h映射到域标签,将该映射的参数记作θd。领域区分模块13旨在通过以下损失函数来识别域标签:According to one embodiment of the present invention, the

其中,dk是样本k的标准域标签,

根据本发明的一个实施例,第一训练模型还包括梯度反转层。对特征提取模块11和领域区分模块13进行对抗训练过程中,在正向传播时通过梯度反转层对第一训练模型的特征提取模块11和领域区分模块13执行标准随机梯度下降操作。在反向传播时,在将领域区分模块13的损失函数返回到特征提取模块11之前将梯度反转层的参数自动取反,以使特征提取模块11提取源领域标记数据集和目标领域未标记数据集中单词的通用特征。According to one embodiment of the present invention, the first training model further includes a gradient reversal layer. During the adversarial training of the
根据本发明的一个实施例,再次参见图2,第一训练模型还包括自动编码模块14,用第二数据集对自动编码模块14进行训练,每轮训练后,根据自动编码模块14的损失函数、识别模块12的损失函数和领域区分模块13的损失函数共同更新特征提取模块11的参数。优选的,所述自动编码模块14包含编码器和解码器,其中,每轮训练中,编码器获取用特征提取模块11的BiLSTM模型提取到目标领域未标记数据集的单词的前向LSTM中最后一个LSTM和后向LSTM中最后一个LSTM的隐藏状态并组合为解码器的初始状态特征,并使用该初始状态特征和其前一个单词嵌入特征作为解码器的输入以训练自动编码模块14提取目标领域的私有特征。对抗学习试图将隐藏表示优化为通用表示hcommon,通过对抗学习的这一优化过程得到的识别模块12的参数初始化第二训练模型的识别模块12的参数,而目标域自动编码模块14通过调整通用表示使其既包括一部分源领域和目标领域的通用特征,又包括一部分目标领域数据的领域私有特征,得到包含目标领域信息的领域特征表示,作为最终模型的特征提取模块11,抵消了对抗学习网络去除目标领域特征的趋势。换言之,自动编码模块14进行目标领域的特征学习,保留其领域特性。通过训练由特征提取模块11和领域区分模块13组成的对抗学习网络,可以获得源领域和目标领域的通用特征hcommon,但是它将削弱一些对命名实体识别有用的领域特定特征,可见,仅获得领域通用特征将限制分类能力。因此,本发明通过引入目标领域的自动编码模块14来解决该缺陷,自动编码模块14试图重建目标领域数据。本发明用自动编码模块14的编码器获取特征提取模块11中的BiLSTM模型中前向LSTM和后向LSTM的最后隐藏状态组合为解码器LSTM的初始状态h0(dec)。因此,本发明不需要颠倒输入句子(单词序列)的单词顺序,并且该模型避免了在输入和输出之间建立交流的困难。使用h0(dec)和前一个单词嵌入特征作为解码器的输入。假设



其中,每个
本发明的目标是针对自动编码模块14的参数θr最小化如以下公式所示的损失函数:The goal of the present invention is to minimize the loss function as shown in the following formula for the parametersθr of the auto-encoding module 14:

其中,
步骤A2:对第一训练模型进行多轮训练,其中,每轮训练中,用第一数据集对识别模块12进行训练、用第一数据集和第二数据集对特征提取模块11和领域区分模块13进行对抗训练,每轮训练后至少根据识别模块12的损失函数和领域区分模块13的损失函数对特征提取模块11的参数进行调整,同时更新第一数据集和第二数据集,以更新后的第一数据集和第二数据集进行下一轮训练,其中,第一数据集是以单词向量形式表示的有实体标签的源领域标记数据集,第二数据集是以单词向量形式表示的无实体标签的目标领域未标记数据集。Step A2: Perform multiple rounds of training on the first training model, wherein in each round of training, the
其中,源领域标记数据集的规模与目标领域未标记数据集的规模相同或者大致相同。目标领域标记数据集的规模小于目标领域未标记数据集的规模。优选的,规模相同或者大致相同是指源领域标记数据集与目标领域未标记数据集的数据量之比为:10:14~10:9。源领域标记数据集的规模与目标领域未标记数据集的规模相同或者大致相同可以避免在对抗训练时训练的模型的参数不至于因为资源不均衡而偏向其中数据量较大的领域,使得最终的模型在目标领域上获得更好的命名实体识别的效果。Among them, the scale of the source domain labeled dataset is the same or approximately the same as the scale of the target domain unlabeled dataset. The scale of the target domain labeled dataset is smaller than the scale of the target domain unlabeled dataset. Preferably, the same or approximately the same scale means that the ratio of the data volume of the source domain labeled dataset to the target domain unlabeled dataset is: 10:14 to 10:9. The same or approximately the same scale of the source domain labeled dataset and the target domain unlabeled dataset can avoid the parameters of the model trained during adversarial training from being biased towards the field with a larger amount of data due to resource imbalance, so that the final model can obtain better named entity recognition effect in the target field.
优选的,用第一数据集对识别模块12进行训练的过程包括用以单词向量表示的单词序列以及单词序列中各单词的实体标签训练识别模块12以使其能够根据单词向量识别单词所属的实体标签。Preferably, the process of training the
优选的,用第一数据集和第二数据集对特征提取模块11和领域区分模块13进行对抗训练的过程包括:在一轮训练时,领域区分模块13以特征提取模块11生成的包含上下文信息的单词序列F(x)为输入,训练领域区分模块13输出单词序列是来自源领域还是目标领域的分类结果;在反向传播过程中,至少根据前一步训练得到的领域区分模块13的损失函数对特征提取模块11的参数进行调整,从而拥有新的参数的特征提取模块11能够生成新的包含上下文信息的单词序列F(x),根据新的包含上下文信息的单词序列F(x),重复上述步骤进行下一轮训练。Preferably, the process of using the first data set and the second data set to perform adversarial training on the
优选的,在每轮训练后按照以下方式对第一训练模型的特征提取模块11的参数进行调整:Preferably, after each round of training, the parameters of the

其中,θf表示本次调整后特征提取模块11的参数,θ’f表示本次调整前特征提取模块11的参数,μ表示学习率,Ltask表示识别模块12的损失函数,Ltype表示领域区分模块13的损失函数,Ltarget表示自动编码模块14的损失函数,-ω表示梯度翻转参数,α、β、γ表示用户设置的权重。Among them, θf represents the parameters of the
优选的,在每轮训练后按照以下方式对第一训练模型的识别模块12、领域区分模块13和自动编码模块14的参数进行调整:Preferably, after each round of training, the parameters of the
识别模块12对应的参数调整方式为:
领域区分模块13对应的参数调整方式为:
自动编码模块14对应的参数调整方式为:
其中,θt表示本次调整后识别模块12的参数,θ’y表示本次调整前识别模块12的参数,θd表示本次调整后领域区分模块13的参数,θ’d表示本次调整前领域区分模块13的参数,θr表示本次调整后自动编码模块14的参数,θ’r表示本次调整前自动编码模块14的参数,μ表示学习率,α、β、γ表示用户设置的权重。Among them, θt represents the parameters of the
优选的,训练第一训练模型的目标是将其训练至收敛,其中一个判断标准就是训练至使第一训练模型的特征提取模块11、识别模块12、领域区分模块13对应的损失函数的加权求和结果最小化,即最小化以下总损失函数:Preferably, the goal of training the first training model is to train it to convergence, and one of the judgment criteria is to train it to minimize the weighted sum of the loss functions corresponding to the
Ltotal=αLtask+βLtarget+γLtype;Ltotal =αLtask +βLtarget +γLtype ;
其中,α、β、γ表示用户设置的权重。或者说,α、β、γ表示用户设置的用于权衡第一训练模型的特征提取模块11、识别模块12、领域区分模块13的损失函数的影响的权重。Among them, α, β, and γ represent weights set by the user. In other words, α, β, and γ represent weights set by the user for weighing the influence of the loss functions of the
步骤A3:构建第二训练模型,所述第二训练模型包括特征提取模块21和识别模块22,第二训练模型的特征提取模块21的初始参数采用经步骤A2训练后的第一训练模型的特征提取模块11的参数进行设置,识别模块22的初始参数采用随机初始化的方式进行设置。识别模块22的初始参数采用随机初始化的方式进行设置可以生成均匀分布的参数,减少将模型训练至收敛的时间,也会更容易将模型训练到最优效果而不是次优效果。Step A3: Construct a second training model, the second training model includes a
第二训练模型的特征提取模块21的结构和第一训练模型的特征提取模块11的结构相同,即,包括预处理层、CNN模型、Word2Vec模型和包含前向LSTM和后向LSTM的BiLSTM模型。在完成对第一训练模型的训练后,通过迁移学习的方式将训练第一训练模型的特征提取模块11得到的参数用于设置第二训练模型的特征提取模块21。此外,第二训练模型的识别模块22包括BiLSTM-CRF模型。其中,与第一训练模型的识别模块12不同,第二训练模型采用的目标领域标记数据集的实体标签设置其识别模块22的BiLSTM-CRF模型的CRF层的标签,由此,以根据目标领域的实体标签对目标领域的数据进行命名实体识别。The structure of the
步骤A4:用第三数据集以监督训练的方式对由步骤A3构建的第二训练模型的特征提取模块21和识别模块22的进行参数微调,将经参数微调后的第二训练模型作为命名实体识别模型,其中,第三数据集是以单词向量形式表示的有实体标签的目标领域标记数据集。第三数据集带有目标领域的实体标签,可以用于对第二训练模型进行监督训练,以对第二训练模型的特征提取模块21和识别模块22的参数进行调整,从而使最终得到的命名实体识别模型对目标领域的数据进行命名实体识别的准确性得到进一步地改善。应当理解地是,命名实体识别模型包括特征提取模块31和识别模块32。其中,命名实体识别模型的特征提取模块31是由第二训练模型的特征提取模块21经参数微调后得到的。命名实体识别模型的识别模块32是由第二训练模型的识别模块22经参数微调后得到的。Step A4: Use the third data set to fine-tune the parameters of the
下面通过一个具体实验示例来说明本发明。The present invention is described below by means of a specific experimental example.
第一部分:数据集设置Part 1: Dataset Setup
源领域标记数据:为了训练对抗学习网络(第一训练模型的特征提取模块和领域区分模块)进行命名实体识别,使用了Ontonotes5.0英文数据集。Source domain labeled data: In order to train the adversarial learning network (the feature extraction module and domain distinction module of the first training model) for named entity recognition, the Ontonotes5.0 English dataset was used.
目标领域标记数据:为了训练和评估提出的模型,使用了Ritter11数据集。Target Domain Labeled Data: To train and evaluate the proposed model, the Ritter11 dataset is used.
目标领域未标记数据:为了训练对抗学习网络保留通用特征,本发明需要使用具有大规模未标记推文的数据集;因此,本发明使用Twitter的接口从Twitter构造了大规模的Twitter领域未标记数据集作为目标领域未标记数据。Target domain unlabeled data: In order to train the adversarial learning network to retain common features, the present invention needs to use a dataset with large-scale unlabeled tweets; therefore, the present invention uses the Twitter interface to construct a large-scale Twitter domain unlabeled dataset from Twitter as the target domain unlabeled data.
Ontonotes5.0和Ritter11数据集的统计信息如表1所示,可以看到Ontonotes5.0的训练数据集单词数量(Token数量)为848,220,Ritter11的训练数据集单词数量为37,098。构造的Twitter领域未标记数据的验证数据集单词数量为1,177,746。The statistics of the Ontonotes5.0 and Ritter11 datasets are shown in Table 1. It can be seen that the number of words (tokens) in the Ontonotes5.0 training dataset is 848,220, and the number of words in the Ritter11 training dataset is 37,098. The number of words in the constructed Twitter domain unlabeled data validation dataset is 1,177,746.
表1 Ontonotes5.0和Ritter11数据集统计信息Table 1 Statistics of Ontonotes5.0 and Ritter11 datasets
在本领域,获取到数据集后,通常会将数据集分为表1所示的三个部分,分别是训练数据集(简称训练集)、验证数据集(简称验证集)和测试数据集(简称测试集)。训练集用于训练模型,训练中会用训练集中的样本对各个模型或者模块多轮训练,训练至收敛。满足以下评价规则中任意一个则视为模型已训练至收敛:第一评价规则:训练轮数达到自定义的上限轮数;第二评价规则:命名实体识别模型对应的F1值在一轮训练后与其前一轮训练后相比变化幅度小于等于预设变化幅度阈值;第三评价规则:训练轮数已达到自定义的下限轮数,并且命名实体识别模型在验证集上识别的精确率在某一轮训练后与其前一轮训练后相比没有提升。例如,下限轮数设为2,上限轮数设为30,变化幅度阈值设为设为±0.5%。验证集用于统计评估指标、调节参数、选择算法。测试集用于在最后整体评估模型的性能。In this field, after obtaining the data set, the data set is usually divided into three parts as shown in Table 1, namely, the training data set (referred to as the training set), the validation data set (referred to as the validation set), and the test data set (referred to as the test set). The training set is used to train the model. During the training, the samples in the training set are used to train each model or module for multiple rounds until convergence. The model is considered to have been trained to convergence if any of the following evaluation rules is met: the first evaluation rule: the number of training rounds reaches the custom upper limit number of rounds; the second evaluation rule: the F1 value corresponding to the named entity recognition model after one round of training is less than or equal to the preset change range threshold compared with the previous round of training; the third evaluation rule: the number of training rounds has reached the custom lower limit number of rounds, and the accuracy of the named entity recognition model on the validation set has not improved after a certain round of training compared with the previous round of training. For example, the lower limit number of rounds is set to 2, the upper limit number of rounds is set to 30, and the change range threshold is set to ±0.5%. The validation set is used to statistically evaluate indicators, adjust parameters, and select algorithms. The test set is used to evaluate the performance of the model as a whole at the end.
对于表1中Ontonotes5.0数据集的18个命名实体类别和Ritter11数据集的10个命名实体类别对应的实体标签可分别参见下面的表2和表3。此外,通常用标签O(Outside)表示非实体。The entity labels corresponding to the 18 named entity categories of the Ontonotes5.0 dataset and the 10 named entity categories of the Ritter11 dataset in Table 1 can be found in Tables 2 and 3 below. In addition, the label O (Outside) is usually used to represent non-entities.
表2 Ontonotes5.0数据集实体标签Table 2 Entity labels of Ontonotes5.0 dataset

表3 Ritter11数据集实体标签Table 3 Entity labels of the Ritter11 dataset

第二部分:实验设置Part II: Experimental Setup
因为标记的Ontonotes5.0数据集的大小是标记的Ritter11数据集的20倍以上,所以如果直接使用合并的数据集训练模型,最终结果会更加偏向于Ontonotes5.0数据集,使得训练结果较差。因此,本发明首先在Ontonotes5.0数据集和Twitter领域未标记数据集上进行对抗训练,然后使用Ritter11数据集来以低学习率微调(fine-tune)第二训练模型的参数。微调(fine-tune)就是使用已经训练好的模型参数当做训练的起点,在新的数据上重新训练一遍的过程。Because the size of the labeled Ontonotes5.0 dataset is more than 20 times that of the labeled Ritter11 dataset, if the merged dataset is used directly to train the model, the final result will be more biased towards the Ontonotes5.0 dataset, resulting in poor training results. Therefore, the present invention first performs adversarial training on the Ontonotes5.0 dataset and the Twitter domain unlabeled dataset, and then uses the Ritter11 dataset to fine-tune the parameters of the second training model at a low learning rate. Fine-tuning is the process of using the trained model parameters as the starting point of training and retraining on new data.
本示例的实验中,模型使用的超参数如下:目前的优化器主要有AdaGrad、RMSProp、Adam以及AdaDelta。经过进行实验对使用各个优化器的效果对比,本发明中对抗学习过程选择AdaGrad优化器,学习率设置范围为(0~1],本示例用0.1作为默认学习率。微调(fine-tune)过程选择Adam优化器,学习率设置范围为(0~1],本示例中用0.0001作为默认学习率,并且使用早停机制(early stop)训练轮数设置范围例如为(0~100],本示例中设置为100。单词嵌入特征使用Google发布的将字词转换成多维向量的Word2Vec技术进行训练,Word2Vec模型的维数设为默认的200维。字符级别嵌入特征使用CNN训练,维数设置范围为(0~300],本示例中设置为25维。使用BiLSTM进行编码,每层隐藏的神经元的个数的设置范围例如为(0~300],本示例中每层包含250个隐藏的神经元。使用三层标准LSTM进行解码,每个LSTM层的隐藏的神经元的个数的设置范围例如为(0~1000],本示例中由500个隐藏的神经元组成。本示例中,权重α、β、γ均设置为1。应当注意的是,以上训练轮数、维度、神经元个数等的设置范围仅是示意性的,在计算资源充足的情况下也可设置为更大数值,本发明对此不作任何限制。In the experiment of this example, the hyperparameters used in the model are as follows: The current optimizers mainly include AdaGrad, RMSProp, Adam, and AdaDelta. After conducting experiments to compare the effects of using various optimizers, the adversarial learning process in this invention selects the AdaGrad optimizer, and the learning rate setting range is (0-1]. In this example, 0.1 is used as the default learning rate. The fine-tuning process selects the Adam optimizer, and the learning rate setting range is (0-1). In this example, 0.0001 is used as the default learning rate, and the early stopping mechanism is used. The setting range of the number of training rounds is, for example, (0-100], and is set to 100 in this example. The word embedding feature is trained using the Word2Vec technology released by Google that converts words into multidimensional vectors, and the dimension of the Word2Vec model is set to the default 200 dimensions. The character level embedding feature is trained using CNN, and the dimension setting range is (0-300], and is set to 25 dimensions in this example. BiLSTM is used for encoding, and the setting range of the number of hidden neurons in each layer is, for example, (0-300], and each layer contains 250 hidden neurons in this example. Three-layer standard LSTM is used for decoding, and the setting range of the number of hidden neurons in each LSTM layer is, for example, (0-1000], and in this example, it consists of 500 hidden neurons. In this example, the weights α, β, and γ are all set to 1. It should be noted that the setting ranges of the above training rounds, dimensions, number of neurons, etc. are only schematic, and can also be set to larger values if computing resources are sufficient. The present invention does not impose any restrictions on this.
基线实验为如图4所示的使用本章提出的特征提取模块的基础BiLSTM-CRF模型在Ritter11数据集上的训练结果,记作In-domain。即,直接将Bob Dylan visited Sweden这类样本的字符级别嵌入特征和单词嵌入特征进行拼接后输入BiLSTM-CRF模型的BiLSTM层和CRF层,得到命名实体识别结果。比如,对样本Bob Dylan visited Sweden的命名实体识别结果分别为:B-PER I-PER O B-GPE。B-PER表示Bob是人名实体(Begin,开始),I-PER表示Dylan是人名实体(Inside,内部),O表示visited是非实体,B-GPE表示Sweden是国家、城市、州这类实体(Begin,开始)。The baseline experiment is the training result of the basic BiLSTM-CRF model on the Ritter11 dataset using the feature extraction module proposed in this chapter, as shown in Figure 4, denoted as In-domain. That is, the character-level embedding features and word embedding features of samples such as Bob Dylan visited Sweden are directly concatenated and input into the BiLSTM layer and CRF layer of the BiLSTM-CRF model to obtain the named entity recognition results. For example, the named entity recognition results of the sample Bob Dylan visited Sweden are: B-PER I-PER O B-GPE. B-PER means that Bob is a person name entity (Begin, start), I-PER means that Dylan is a person name entity (Inside, inside), O means that visited is a non-entity, and B-GPE means that Sweden is an entity such as a country, city, or state (Begin, start).
此外,本发明也使用了如图5所示的现有的参数初始化方法(INIT)和多任务学习方法(MULT)作为对比试验。这两个现有方法的具体描述如下:In addition, the present invention also uses the existing parameter initialization method (INIT) and multi-task learning method (MULT) as shown in Figure 5 as a comparative experiment. The specific descriptions of these two existing methods are as follows:
参数初始化方法:首先使用源领域训练数据DS训练源模型MS。接下来,构造目标模型MT并重建最后的CRF层,以解决输出空间(标签)不同的问题。使用学习到的MS的参数来初始化MT(不包括CRF层)。最后,继续使用目标领域训练数据DT训练MT。Parameter initialization method: First, train the source modelMS using the source domain training data DS. Next, construct the target modelMT and rebuild the final CRF layer to solve the problem of different output spaces (labels). Use the learned parameters ofMS to initializeMT (excluding the CRF layer). Finally, continue to trainMT using the target domain training data DT.
多任务学习方法:多任务学习同时使用DS和DT训练MS和MT。MS和MT的参数(不包括CRF层)在训练过程中共享。在一些现有技术方案中都使用超参数λ,作为从DS而非DT中选择实例的概率来优化模型参数。通过选择超参数λ,多任务学习过程在目标领域中表现更好。但是,其存在源领域大、目标领域小,偏向源领域,效果不好。Multi-task learning method: Multi-task learning usesDS andDT to trainMS andMT at the same time. The parameters ofMS andMT (excluding the CRF layer) are shared during the training process. In some existing technical solutions, a hyperparameter λ is used as the probability of selecting an instance fromDS instead ofDT to optimize the model parameters. By selecting the hyperparameter λ, the multi-task learning process performs better in the target domain. However, it has the problem of large source domain and small target domain, biased towards the source domain, and poor effect.
第三部分:评价方法和指标Part III: Evaluation methods and indicators
评价方法采用CoNLL03会议规定的完全匹配,即实体的边界和类型均匹配才算作正确匹配(正确标注)。The evaluation method adopts the complete match specified by the CoNLL03 conference, that is, the entity boundary and type must match to be considered a correct match (correct labeling).
评价指标使用精确率(Precision),召回率(Recall)和F1值(F1-score),计算方式如下:The evaluation indicators used are precision, recall and F1-score, which are calculated as follows:
精确率:
召回率:
F1值:
其中,TP表示True Positive(TP),是指被模型预测为正的正样本(实体单词被正确标注);可以称作判断为真的正确率;TP stands for True Positive (TP), which refers to the positive samples predicted by the model as positive (the entity words are correctly labeled); it can be called the accuracy rate of the judgment as true;
FP表示False Positive(FP),是指被模型预测为正的负样本(非实体单词被标注为实体);可以称作误报率;FP stands for False Positive (FP), which refers to negative samples predicted as positive by the model (non-entity words are marked as entities); it can be called the false alarm rate;
FN表示False Negative(FN),是指被模型预测为负的正样本(实体单词被标注为非实体);可以称作漏报率。FN stands for False Negative (FN), which refers to positive samples predicted as negative by the model (entity words are marked as non-entities); it can be called the false negative rate.
该示例的实验结果如表4所示:The experimental results of this example are shown in Table 4:
表4实验结果Table 4 Experimental results


从表4可以看出,只使用特征提取模块和NER分类模块进行微调(fine-tune)的本发明模型(即表4第5行)与In-domain方法、INIT方法和MULT方法效果相近,因为只使用特征提取模块和NER分类模块进行微调(fine-tune)本质上就是标准迁移学习方法。而在此基础上增加领域区分模块和特征提取模块组成对抗学习网络(即表4第6行)可以提高性能,并且增加领域区分模块和目标域自动编码模块(即表4第7行)比单独增加领域区分模块性能更高,表明通过在目标领域中引入自动编码模块,可以保留特定于域的特征以获得更好的性能。实验结果表明本发明提出的模型可以极大地帮助执行跨域命名实体识别。As can be seen from Table 4, the model of the present invention that uses only the feature extraction module and the NER classification module for fine-tuning (i.e., the 5th row of Table 4) has similar effects to the In-domain method, the INIT method, and the MULT method, because only using the feature extraction module and the NER classification module for fine-tuning (fine-tuning) is essentially a standard transfer learning method. On this basis, adding a domain distinction module and a feature extraction module to form an adversarial learning network (i.e., the 6th row of Table 4) can improve the performance, and adding a domain distinction module and a target domain automatic encoding module (i.e., the 7th row of Table 4) has higher performance than adding a domain distinction module alone, indicating that by introducing an automatic encoding module in the target domain, domain-specific features can be retained to obtain better performance. The experimental results show that the model proposed by the present invention can greatly help perform cross-domain named entity recognition.
根据本发明的一个实施例,提供一种基于前述实施例的命名实体识别模型训练方法训练得到的命名实体识别模型的命名实体识别方法,其特征在于,所述命名实体识别模型包括特征提取模块31和识别模块32,所述命名实体识别方法包括:B1、通过命名实体识别模型的特征提取模块31获取待识别文本的字符级别嵌入特征和单词嵌入特征并进行串联拼接,得到待识别文本中各单词的单词向量;B2、将单词向量的形式表示的待识别文本输入命名实体识别模型的识别模块32,得到所述待识别文本的命名实体识别结果。According to one embodiment of the present invention, there is provided a named entity recognition method based on a named entity recognition model trained by the named entity recognition model training method of the aforementioned embodiment, characterized in that the named entity recognition model includes a
需要说明的是,虽然上文按照特定顺序描述了各个步骤,但是并不意味着必须按照上述特定顺序来执行各个步骤,实际上,这些步骤中的一些可以并发执行,甚至改变顺序,只要能够实现所需要的功能即可。It should be noted that although the above describes the various steps in a specific order, it does not mean that the various steps must be executed in the above specific order. In fact, some of these steps can be executed concurrently or even in a different order as long as the required functions can be achieved.
本发明可以是系统、方法和/或计算机程序产品。计算机程序产品可以包括计算机可读存储介质,其上载有用于使处理器实现本发明的各个方面的计算机可读程序指令。The present invention may be a system, a method and/or a computer program product. The computer program product may include a computer-readable storage medium carrying computer-readable program instructions for causing a processor to implement various aspects of the present invention.
计算机可读存储介质可以是保持和存储由指令执行设备使用的指令的有形设备。计算机可读存储介质例如可以包括但不限于电存储设备、磁存储设备、光存储设备、电磁存储设备、半导体存储设备或者上述的任意合适的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:便携式计算机盘、硬盘、随机存取存储器(RAM)、只读存储器(ROM)、可擦式可编程只读存储器(EPROM或闪存)、静态随机存取存储器(SRAM)、便携式压缩盘只读存储器(CD-ROM)、数字多功能盘(DVD)、记忆棒、软盘、机械编码设备、例如其上存储有指令的打孔卡或凹槽内凸起结构、以及上述的任意合适的组合。Computer readable storage medium can be a tangible device that holds and stores instructions used by an instruction execution device. Computer readable storage medium can include, for example, but is not limited to, an electrical storage device, a magnetic storage device, an optical storage device, an electromagnetic storage device, a semiconductor storage device, or any suitable combination thereof. More specific examples (non-exhaustive list) of computer readable storage medium include: a portable computer disk, a hard disk, a random access memory (RAM), a read-only memory (ROM), an erasable programmable read-only memory (EPROM or flash memory), a static random access memory (SRAM), a portable compact disk read-only memory (CD-ROM), a digital versatile disk (DVD), a memory stick, a floppy disk, a mechanical encoding device, for example, a punch card or a protruding structure in a groove on which instructions are stored, and any suitable combination thereof.
以上已经描述了本发明的各实施例,上述说明是示例性的,并非穷尽性的,并且也不限于所披露的各实施例。在不偏离所说明的各实施例的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。本文中所用术语的选择,旨在最好地解释各实施例的原理、实际应用或对市场中的技术改进,或者使本技术领域的其它普通技术人员能理解本文披露的各实施例。The embodiments of the present invention have been described above, and the above description is exemplary, not exhaustive, and is not limited to the disclosed embodiments. Many modifications and variations will be apparent to those of ordinary skill in the art without departing from the scope and spirit of the described embodiments. The selection of terms used herein is intended to best explain the principles of the embodiments, practical applications, or technical improvements in the market, or to enable other persons of ordinary skill in the art to understand the embodiments disclosed herein.
Claims (12)
Translated fromChinese



Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010541415.5ACN111738003B (en) | 2020-06-15 | 2020-06-15 | Named entity recognition model training method, named entity recognition method and medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010541415.5ACN111738003B (en) | 2020-06-15 | 2020-06-15 | Named entity recognition model training method, named entity recognition method and medium |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN111738003A CN111738003A (en) | 2020-10-02 |
| CN111738003Btrue CN111738003B (en) | 2023-06-06 |
Family
ID=72649103
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010541415.5AActiveCN111738003B (en) | 2020-06-15 | 2020-06-15 | Named entity recognition model training method, named entity recognition method and medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN111738003B (en) |
Families Citing this family (18)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112215007B (en)* | 2020-10-22 | 2022-09-23 | 上海交通大学 | Method and System for Normalization of Institution Named Entity Based on LEAM Model |
| CN114548103B (en)* | 2020-11-25 | 2024-03-29 | 马上消费金融股份有限公司 | A training method for a named entity recognition model and a method for recognizing named entities |
| CN112597774B (en)* | 2020-12-14 | 2023-06-23 | 山东师范大学 | Chinese medical named entity recognition method, system, storage medium and equipment |
| CN113515942A (en)* | 2020-12-24 | 2021-10-19 | 腾讯科技(深圳)有限公司 | Text processing method, device, computer equipment and storage medium |
| CN112906857B (en)* | 2021-01-21 | 2024-03-19 | 商汤国际私人有限公司 | Network training method and device, electronic equipment and storage medium |
| CN112926665A (en)* | 2021-03-02 | 2021-06-08 | 安徽七天教育科技有限公司 | Text line recognition system based on domain self-adaptation and use method |
| CN113761924B (en)* | 2021-04-19 | 2025-01-28 | 腾讯科技(深圳)有限公司 | A training method, device, equipment and storage medium for a named entity model |
| CN113221575B (en)* | 2021-05-28 | 2022-08-02 | 北京理工大学 | PU reinforcement learning remote supervision named entity identification method |
| CN113723102B (en)* | 2021-06-30 | 2024-04-26 | 平安国际智慧城市科技股份有限公司 | Named entity recognition method, named entity recognition device, electronic equipment and storage medium |
| CN113516196B (en)* | 2021-07-20 | 2024-04-12 | 云知声智能科技股份有限公司 | Named entity recognition data enhancement method, named entity recognition data enhancement device, electronic equipment and named entity recognition data enhancement medium |
| CN113887227B (en)* | 2021-09-15 | 2023-05-02 | 北京三快在线科技有限公司 | Model training and entity identification method and device |
| CN114580415B (en)* | 2022-02-25 | 2024-03-22 | 华南理工大学 | A cross-domain graph matching entity recognition method for educational examinations |
| CN114626380B (en)* | 2022-03-25 | 2025-09-19 | 北京明略昭辉科技有限公司 | Entity identification method and device, electronic equipment and storage medium |
| CN114548109B (en)* | 2022-04-24 | 2022-09-23 | 阿里巴巴达摩院(杭州)科技有限公司 | Named entity recognition model training method and named entity recognition method |
| CN114925697A (en)* | 2022-05-24 | 2022-08-19 | 山东理工大学 | Inspection and detection service method based on semantic analysis |
| CN115048933A (en)* | 2022-06-07 | 2022-09-13 | 东南大学 | Semi-supervised named entity identification method for insufficiently marked data |
| CN116720519B (en)* | 2023-06-08 | 2023-12-19 | 吉首大学 | Seedling medicine named entity identification method |
| CN118446218B (en)* | 2024-05-16 | 2024-11-01 | 西南交通大学 | Method for identifying nested named entities by antagonism type reading understanding |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108664589A (en)* | 2018-05-08 | 2018-10-16 | 苏州大学 | Text message extracting method, device, system and medium based on domain-adaptive |
| CN109918644A (en)* | 2019-01-26 | 2019-06-21 | 华南理工大学 | A Transfer Learning-Based Named Entity Recognition Method for TCM Health Consultation Text |
| CN110765775A (en)* | 2019-11-01 | 2020-02-07 | 北京邮电大学 | A Domain Adaptation Method for Named Entity Recognition Fusing Semantics and Label Differences |
| CN111222339A (en)* | 2020-01-13 | 2020-06-02 | 华南理工大学 | A Named Entity Recognition Method for Medical Consultation Based on Adversarial Multi-Task Learning |
| CN111241837A (en)* | 2020-01-04 | 2020-06-05 | 大连理工大学 | Theft case legal document named entity identification method based on anti-migration learning |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9971763B2 (en)* | 2014-04-08 | 2018-05-15 | Microsoft Technology Licensing, Llc | Named entity recognition |
- 2020
- 2020-06-15CNCN202010541415.5Apatent/CN111738003B/enactiveActive
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108664589A (en)* | 2018-05-08 | 2018-10-16 | 苏州大学 | Text message extracting method, device, system and medium based on domain-adaptive |
| CN109918644A (en)* | 2019-01-26 | 2019-06-21 | 华南理工大学 | A Transfer Learning-Based Named Entity Recognition Method for TCM Health Consultation Text |
| CN110765775A (en)* | 2019-11-01 | 2020-02-07 | 北京邮电大学 | A Domain Adaptation Method for Named Entity Recognition Fusing Semantics and Label Differences |
| CN111241837A (en)* | 2020-01-04 | 2020-06-05 | 大连理工大学 | Theft case legal document named entity identification method based on anti-migration learning |
| CN111222339A (en)* | 2020-01-13 | 2020-06-02 | 华南理工大学 | A Named Entity Recognition Method for Medical Consultation Based on Adversarial Multi-Task Learning |
Non-Patent Citations (1)
| Title |
|---|
| 迁移学习在命名实体识别中的应用;盛剑;《中国优秀硕士学位论文全文数据库信息科技辑》;第I138-2350页* |
Also Published As
| Publication number | Publication date |
|---|---|
| CN111738003A (en) | 2020-10-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111738003B (en) | Named entity recognition model training method, named entity recognition method and medium | |
| US12271701B2 (en) | Method and apparatus for training text classification model | |
| CN111783462B (en) | Chinese Named Entity Recognition Model and Method Based on Double Neural Network Fusion | |
| Logeswaran et al. | Sentence ordering and coherence modeling using recurrent neural networks | |
| CN110598713B (en) | Intelligent image automatic description method based on deep neural network | |
| CN108733792B (en) | An Entity Relationship Extraction Method | |
| CN111061843B (en) | A Fake News Detection Method Guided by Knowledge Graph | |
| CN108984526B (en) | A deep learning-based document topic vector extraction method | |
| CN116127953B (en) | Chinese spelling error correction method, device and medium based on contrast learning | |
| CN109992780B (en) | Specific target emotion classification method based on deep neural network | |
| CN113591483A (en) | Document-level event argument extraction method based on sequence labeling | |
| CN110196978A (en) | A kind of entity relation extraction method for paying close attention to conjunctive word | |
| CN112699216A (en) | End-to-end language model pre-training method, system, device and storage medium | |
| CN114064918A (en) | Multi-modal event knowledge graph construction method | |
| CN107992597A (en) | A kind of text structure method towards electric network fault case | |
| CN110765775A (en) | A Domain Adaptation Method for Named Entity Recognition Fusing Semantics and Label Differences | |
| CN111125367B (en) | Multi-character relation extraction method based on multi-level attention mechanism | |
| CN113051886B (en) | Test question duplicate checking method, device, storage medium and equipment | |
| CN116049406A (en) | Cross-domain emotion classification method based on contrast learning | |
| CN114818717A (en) | Chinese named entity recognition method and system fusing vocabulary and syntax information | |
| CN114881038B (en) | Chinese entity and relation extraction method and device based on span and attention mechanism | |
| CN114781380A (en) | Chinese named entity recognition method, equipment and medium fusing multi-granularity information | |
| CN114428850A (en) | Text retrieval matching method and system | |
| CN116720519B (en) | Seedling medicine named entity identification method | |
| CN115510230A (en) | Mongolian emotion analysis method based on multi-dimensional feature fusion and comparative reinforcement learning mechanism |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |