CN111681059B - Training method and device for behavior prediction model - Google Patents
Training method and device for behavior prediction modelDownload PDFInfo
- Publication number
- CN111681059B CN111681059BCN202010819192.4ACN202010819192ACN111681059BCN 111681059 BCN111681059 BCN 111681059BCN 202010819192 ACN202010819192 ACN 202010819192ACN 111681059 BCN111681059 BCN 111681059B
- Authority
- CN
- China
- Prior art keywords
- vector
- sample
- user
- behavior
- node
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images







Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q30/00—Commerce
- G06Q30/02—Marketing; Price estimation or determination; Fundraising
- G06Q30/0201—Market modelling; Market analysis; Collecting market data
- G06Q30/0202—Market predictions or forecasting for commercial activities
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/23—Clustering techniques
- G06F18/232—Non-hierarchical techniques
- G06F18/2321—Non-hierarchical techniques using statistics or function optimisation, e.g. modelling of probability density functions
- G06F18/23213—Non-hierarchical techniques using statistics or function optimisation, e.g. modelling of probability density functions with fixed number of clusters, e.g. K-means clustering
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/241—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches
- G06F18/2415—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches based on parametric or probabilistic models, e.g. based on likelihood ratio or false acceptance rate versus a false rejection rate
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/243—Classification techniques relating to the number of classes
- G06F18/24323—Tree-organised classifiers
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/25—Fusion techniques
- G06F18/253—Fusion techniques of extracted features
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Computation (AREA)
- General Engineering & Computer Science (AREA)
- Life Sciences & Earth Sciences (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Evolutionary Biology (AREA)
- Bioinformatics & Computational Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Business, Economics & Management (AREA)
- Accounting & Taxation (AREA)
- Development Economics (AREA)
- Strategic Management (AREA)
- Finance (AREA)
- Molecular Biology (AREA)
- General Health & Medical Sciences (AREA)
- Computing Systems (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Health & Medical Sciences (AREA)
- Probability & Statistics with Applications (AREA)
- Biomedical Technology (AREA)
- Entrepreneurship & Innovation (AREA)
- Computational Linguistics (AREA)
- Biophysics (AREA)
- Game Theory and Decision Science (AREA)
- Economics (AREA)
- Marketing (AREA)
- General Business, Economics & Management (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本说明书实施例涉及计算机技术领域,尤其涉及一种行为预测模型的训练方法及装置。The embodiments of the present specification relate to the field of computer technology, and in particular, to a method and apparatus for training a behavior prediction model.
背景技术Background technique
当前,服务平台通常会向用户进行产品或内容等业务对象的推荐或推送,例如,推荐一些网络课程、服装商品、广告图片等。随着业务对象数量的累积增长,以及不断涌现新的业务对象,为了提高用户体验,需要及时、准确地向用户推荐符合其需求和偏好的业务对象,相应地,服务平台可以利用机器学习模型预测用户行为,具体预测某用户是否会对某业务对象做出特定行为,从而根据预测结果确定是否向该某用户推荐该某业务对象,例如,通过预测某用户是否会对某篇文章进行浏览,确定是否向该用户推送该篇文章,又例如,通过预测某用户是否会购买某商品,确定是否向该用户推荐该商品。At present, service platforms usually recommend or push business objects such as products or content to users, for example, recommend some online courses, clothing products, advertising pictures, etc. With the cumulative growth of the number of business objects and the continuous emergence of new business objects, in order to improve user experience, it is necessary to promptly and accurately recommend business objects that meet their needs and preferences. Accordingly, the service platform can use machine learning models to predict User behavior, specifically predicting whether a user will perform a specific behavior on a business object, so as to determine whether to recommend the business object to the user according to the prediction result. For example, by predicting whether a user will browse an article, determine Whether to push the article to the user, for another example, by predicting whether a user will purchase a certain product, it is determined whether to recommend the product to the user.
显然,希望上述针对用户行为的预测能够尽可能的及时、准确。然而,目前预测用户行为的方式较为单一,预测的速度和准确度也十分有限。因此,需要一种方案,可以有效提高用户行为预测的及时性和准确性。Obviously, it is hoped that the above prediction on user behavior can be as timely and accurate as possible. However, the current method of predicting user behavior is relatively simple, and the speed and accuracy of prediction are also very limited. Therefore, there is a need for a solution that can effectively improve the timeliness and accuracy of user behavior prediction.
发明内容SUMMARY OF THE INVENTION
采用本说明书描述的行为预测模型的训练方法及装置,可以同时有效提高行为预测模型的训练速度和模型性能,从而提高用户行为预测的及时性和准确性。Using the behavior prediction model training method and device described in this specification can effectively improve the training speed and model performance of the behavior prediction model, thereby improving the timeliness and accuracy of user behavior prediction.
根据第一方面,提供一种行为预测模型的训练方法,包括:确定针对目标对象的多个样本用户,其中任一的第一样本用户对应第一样本硬标签,该第一样本硬标签指示该第一样本用户是否对所述目标对象做出特定行为;基于预先确定的嵌入向量集,确定对应于所述第一样本用户的样本用户特征向量,并且,确定对应于所述目标对象的目标对象特征向量;其中,所述嵌入向量集是利用训练后的图神经网络对构建的二部图进行图嵌入处理而确定;所述二部图包括对应于多个用户的多个用户节点,对应于多个对象的多个对象节点,以及用户节点向对象节点做出所述特定行为而形成的连接边,所述嵌入向量集中包括所述多个用户的多个用户特征向量和所述多个对象的多个对象特征向量;将所述样本用户特征向量输入第一行为预测模型中,得到行为预测结果;基于所述行为预测结果和所述第一样本硬标签,确定第一损失项;基于所述样本用户特征向量和所述目标对象特征向量,确定所述第一样本用户对该目标对象做出该特定行为的特定行为概率,作为第一样本软标签;基于所述行为预测结果和所述第一样本软标签,确定第二损失项;利用所述第一损失项和第二损失项,训练所述第一行为预测模型。According to a first aspect, a method for training a behavior prediction model is provided, including: determining a plurality of sample users for a target object, wherein any of the first sample users corresponds to a first sample hard label, and the first sample hard label The label indicates whether the first sample user performs a specific behavior on the target object; based on a predetermined set of embedded vectors, a sample user feature vector corresponding to the first sample user is determined, and a sample user feature vector corresponding to the first sample user is determined. The target object feature vector of the target object; wherein, the embedding vector set is determined by using the trained graph neural network to perform graph embedding processing on the constructed bipartite graph; the bipartite graph includes a plurality of A user node, a plurality of object nodes corresponding to a plurality of objects, and a connection edge formed by the user node performing the specific behavior to the object node, the embedding vector set includes a plurality of user feature vectors of the plurality of users and Multiple object feature vectors of the multiple objects; input the sample user feature vector into the first behavior prediction model to obtain a behavior prediction result; determine the first sample based on the behavior prediction result and the first sample hard label. a loss term; based on the sample user feature vector and the target object feature vector, determine the specific behavior probability that the first sample user performs the specific behavior on the target object, as a first sample soft label; based on The behavior prediction result and the first sample soft label are used to determine a second loss term; the first behavior prediction model is trained by using the first loss term and the second loss term.
根据第二方面,提供一种行为预测模型的训练方法,包括:针对目标对象,获取基于多个种子用户形成的多个正样本,其中任意的第一正样本包括,与第一种子用户对应的第一用户特征和正例标签,该正例标签指示出,对应用户是被确定为对所述目标对象做出特定行为的用户;基于所述多个种子用户各自的用户特征,采用无监督的离群点检测算法,确定所述第一种子用户的离群分数,作为针对行为预测任务的第一训练权重;利用针对所述行为预测任务的训练样本集,对第一行为预测模型进行第一训练,所述训练样本集包括所述多个正样本以及预先获取的多个负样本;所述第一训练具体包括:将所述第一用户特征输入第一行为预测模型中,得到对应的行为预测结果;基于所述行为预测结果和所述正例标签,确定行为预测损失,并利用所述第一训练权重对该行为预测损失进行加权处理,得到加权损失;利用所述加权损失,训练所述第一行为预测模型。According to a second aspect, a method for training a behavior prediction model is provided, comprising: for a target object, acquiring multiple positive samples formed based on multiple seed users, wherein any first positive sample includes a A first user feature and a positive example label, the positive example label indicates that the corresponding user is a user who is determined to perform a specific behavior on the target object; based on the respective user features of the multiple seed users, an unsupervised separation The cluster detection algorithm determines the outlier score of the first seed user as the first training weight for the behavior prediction task; uses the training sample set for the behavior prediction task to perform the first training on the first behavior prediction model , the training sample set includes the multiple positive samples and the multiple negative samples obtained in advance; the first training specifically includes: inputting the first user characteristics into the first behavior prediction model to obtain corresponding behavior predictions result; based on the behavior prediction result and the positive example label, determine the behavior prediction loss, and use the first training weight to weight the behavior prediction loss to obtain a weighted loss; use the weighted loss to train the The first acts as a predictive model.
根据第三方面,提供一种行为预测模型的训练装置,包括:样本用户确定单元,配置为确定针对目标对象的多个样本用户,其中任一的第一样本用户对应第一样本硬标签,该第一样本硬标签指示该第一样本用户是否对所述目标对象做出特定行为;特征向量确定单元,配置为基于预先确定的嵌入向量集,确定对应于所述第一样本用户的样本用户特征向量,并且,确定对应于所述目标对象的目标对象特征向量;其中,所述嵌入向量集是利用训练后的图神经网络对构建的二部图进行图嵌入处理而确定;所述二部图包括对应于多个用户的多个用户节点,对应于多个对象的多个对象节点,以及用户节点向对象节点做出所述特定行为而形成的连接边,所述嵌入向量集中包括所述多个用户的多个用户特征向量和所述多个对象的多个对象特征向量;行为预测单元,配置为将所述样本用户特征向量输入第一行为预测模型中,得到行为预测结果;第一损失确定单元,配置为基于所述行为预测结果和所述第一样本硬标签,确定第一损失项;软标签确定单元,配置为基于所述样本用户特征向量和所述目标对象特征向量,确定所述第一样本用户对该目标对象做出该特定行为的特定行为概率,作为第一样本软标签;第二损失确定单元,配置为基于所述行为预测结果和所述第一样本软标签,确定第二损失项;第一行为训练单元,配置为利用所述第一损失项和第二损失项,训练所述第一行为预测模型。According to a third aspect, a training device for a behavior prediction model is provided, comprising: a sample user determination unit configured to determine a plurality of sample users for a target object, wherein any first sample user corresponds to a first sample hard label , the first sample hard label indicates whether the first sample user has performed a specific behavior on the target object; the feature vector determination unit is configured to determine the first sample corresponding to the first sample based on a predetermined embedding vector set The sample user feature vector of the user, and the target object feature vector corresponding to the target object is determined; wherein, the embedding vector set is determined by using the trained graph neural network to perform graph embedding processing on the constructed bipartite graph; The bipartite graph includes a plurality of user nodes corresponding to a plurality of users, a plurality of object nodes corresponding to a plurality of objects, and connecting edges formed by the user nodes performing the specific behavior to the object nodes, and the embedding vector The collection includes multiple user feature vectors of the multiple users and multiple object feature vectors of the multiple objects; the behavior prediction unit is configured to input the sample user feature vectors into the first behavior prediction model to obtain behavior predictions Results; a first loss determination unit, configured to determine a first loss term based on the behavior prediction result and the first sample hard label; a soft label determination unit, configured to determine a first loss term based on the sample user feature vector and the target The object feature vector, which determines the specific behavior probability that the first sample user performs the specific behavior on the target object, as the first sample soft label; the second loss determining unit is configured to be based on the behavior prediction result and all The first sample soft label is used to determine the second loss item; the first behavior training unit is configured to use the first loss item and the second loss item to train the first behavior prediction model.
根据第四方面,提供一种行为预测模型的训练装置,包括:样本获取单元,配置为针对目标对象,获取基于多个种子用户形成的多个正样本,其中任意的第一正样本包括,与第一种子用户对应的第一用户特征和正例标签,该正例标签指示出,对应用户是被确定为对所述目标对象做出特定行为的用户;样本权重确定单元,配置为基于所述多个种子用户各自的用户特征,采用无监督的离群点检测算法,确定所述第一种子用户的离群分数,作为针对行为预测任务的第一训练权重;第一模型训练单元,配置为利用针对所述行为预测任务的训练样本集,对第一行为预测模型进行第一训练,所述训练样本集包括所述多个正样本以及预先获取的多个负样本;所述第一模型训练单元具体包括以下模块:第一预测模块,配置为将所述第一用户特征输入第一行为预测模型中,得到对应的行为预测结果;第一损失确定模块,配置为基于所述行为预测结果和所述正例标签,确定行为预测损失;第一损失加权模块,配置为利用所述第一训练权重对该行为预测损失进行加权处理,得到加权损失;第一训练模块,配置为利用所述加权损失,训练所述第一行为预测模型。According to a fourth aspect, a training device for a behavior prediction model is provided, comprising: a sample acquisition unit configured to acquire, for a target object, a plurality of positive samples formed based on a plurality of seed users, wherein any first positive sample includes, The first user feature corresponding to the first seed user and the positive example label, the positive example label indicates that the corresponding user is a user who is determined to perform a specific behavior on the target object; the sample weight determination unit is configured to be based on the multiple The user characteristics of each seed user are used to determine the outlier score of the first seed user by using an unsupervised outlier detection algorithm as the first training weight for the behavior prediction task; the first model training unit is configured to use For the training sample set of the behavior prediction task, the first training is performed on the first behavior prediction model, and the training sample set includes the multiple positive samples and the multiple pre-acquired negative samples; the first model training unit Specifically, it includes the following modules: a first prediction module, configured to input the first user feature into a first behavior prediction model to obtain a corresponding behavior prediction result; a first loss determination module, configured to be based on the behavior prediction result and all The positive example label is used to determine the behavior prediction loss; the first loss weighting module is configured to use the first training weight to perform weighting processing on the behavior prediction loss to obtain a weighted loss; the first training module is configured to use the weighted loss , train the first behavior prediction model.
根据第五方面,提供了一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行第一方面或第二方面所描述的方法。According to a fifth aspect, there is provided a computer-readable storage medium on which a computer program is stored, and when the computer program is executed in a computer, causes the computer to execute the method described in the first aspect or the second aspect.
根据第六方面,提供了一种计算设备,包括存储器和处理器,其特征在于,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现第一方面或第二方面所描述的方法。According to a sixth aspect, a computing device is provided, comprising a memory and a processor, wherein executable code is stored in the memory, and when the processor executes the executable code, the first aspect or the first aspect is implemented. The method described in the second aspect.
综上,采用本说明书实施例披露的行为预测模型的训练方法,在训练针对目标对象的第一行为预测模型的过程中,通过将GNN模型输出的特征向量作为先验知识,可以减少多个样本用户中种子用户存在的覆盖偏差,有效提高模型性能,加快训练速度,并且,因为第一行为预测模型可以实现为轻量级模型,因此,可以大大减少后续行为预测过程中的计算量。To sum up, using the training method of the behavior prediction model disclosed in the embodiments of this specification, in the process of training the first behavior prediction model for the target object, by using the feature vector output by the GNN model as prior knowledge, multiple samples can be reduced. The coverage bias of seed users among users can effectively improve model performance and speed up training. Moreover, because the first behavior prediction model can be implemented as a lightweight model, it can greatly reduce the amount of computation in the subsequent behavior prediction process.
此外,在人群定向的冷启动阶段,利用无监督的离群点检测算法,对上述多个正样本中的各个正样本进行权重分配,从而降低噪标签对第一行为预测模型的性能影响。进一步地,在获得用户反馈数据后,利用用户反馈数据训练第二行为预测模型,实现更加精准的人群重定向,使用户被推荐到符合自身需求的目标对象,从而有效提高用户体验。In addition, in the cold start stage of crowd orientation, an unsupervised outlier detection algorithm is used to assign weights to each positive sample in the above-mentioned multiple positive samples, thereby reducing the impact of noise labels on the performance of the first behavior prediction model. Further, after obtaining user feedback data, use the user feedback data to train a second behavior prediction model to achieve more accurate crowd redirection, so that users are recommended to target objects that meet their own needs, thereby effectively improving user experience.
附图说明Description of drawings
为了更清楚地说明本说明书披露的多个实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本说明书披露的多个实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。In order to more clearly illustrate the technical solutions of the various embodiments disclosed in the present specification, the accompanying drawings required in the description of the embodiments will be briefly introduced below. Obviously, the accompanying drawings in the following description are only disclosed in the present specification. For various embodiments, for those of ordinary skill in the art, other drawings can also be obtained according to these drawings without any creative effort.
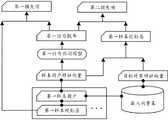
图1示出根据一个实施例的GNN模型的训练架构示意图;1 shows a schematic diagram of a training architecture of a GNN model according to one embodiment;
图2示意根据一个实施例的用户-对象二部图;Figure 2 illustrates a user-object bipartite graph according to one embodiment;
图3示出根据一个实施例的行为预测模型的训练架构示意图;3 shows a schematic diagram of a training architecture of a behavior prediction model according to one embodiment;
图4示出根据一个实施例的行为预测模型的训练方法流程图;Fig. 4 shows the training method flow chart of the behavior prediction model according to one embodiment;
图5示出根据一个实施例的GNN模型的训练方法流程图;Fig. 5 shows the training method flow chart of the GNN model according to one embodiment;
图6示出根据另一个实施例的行为预测模型的训练方法流程图;6 shows a flowchart of a training method for a behavior prediction model according to another embodiment;
图7示出根据一个实施例的行为预测模型的训练装置结构图;7 shows a structural diagram of a training device for a behavior prediction model according to an embodiment;
图8示出根据另一个实施例的行为预测模型的训练装置结构图。FIG. 8 shows a structural diagram of a training device for a behavior prediction model according to another embodiment.
具体实施方式Detailed ways
下面结合附图,对本说明书披露的多个实施例进行描述。The various embodiments disclosed in this specification will be described below with reference to the accompanying drawings.
本说明书实施例披露一种行为预测模型的训练方法,下面,先对该训练方法的发明构思进行介绍,具体如下:The embodiment of this specification discloses a training method for a behavior prediction model. Below, the inventive concept of the training method is first introduced, and the details are as follows:
如前所述,希望能提高用户行为预测的准确性、及时性。然而,预测的准确性与及时性之间往往是存在冲突的,因为机器学习的参数越多,预测的准确性会越高,但是较多的参数会带来较多的计算量,从而导致预测速度的下降,尤其是在用户数量庞大的情况下,产生的时延愈发明显。As mentioned above, it is hoped to improve the accuracy and timeliness of user behavior prediction. However, there is often a conflict between the accuracy and timeliness of prediction, because the more parameters of machine learning, the higher the accuracy of prediction, but more parameters will bring more computation, which will lead to prediction The decrease in speed, especially in the case of a large number of users, has become more and more obvious.
为了解决准确性和及时性之间存在的矛盾冲突,实现二者的同时提升,发明人提出借鉴KD(Knowledge Distillation,知识蒸馏)的框架,首先,利用多个业务对象(以下或将业务对象简称为对象)和多个用户的特征数据,训练一个重量级(主要指模型参数较多)的用于对上述多个对象进行用户行为预测的老师模型(teacher model);然后,利用训练后的老师模型指导轻量级(主要指模型参数较少)的学生模型(student model)的训练,具体在训练学生模型的过程中,老师模型中的先验知识被传递到学生模型中,从而使得即使学生模型的参数较少,学出来的模型效果也会较优,同时,因学生模型的模型参数较少,故而可以实现快速学习,另外,可以为若干目标对象中的每个目标对象分别训练一个学生模型,作为针对该每个目标对象的行为预测模型,如此可以实现对老师模型中先验知识的高效复用。此外,因为学生模型的训练和使用所占用的计算资源均较少,计算效率高,因此学生模型的训练和使用均可以在线上实现,这也使得预测结果具有高时效性。In order to solve the conflict between accuracy and timeliness, and achieve the simultaneous improvement of the two, the inventor proposes to draw on the framework of KD (Knowledge Distillation), first of all, use multiple business objects (hereinafter referred to as business objects for short). object) and the feature data of multiple users, train a heavyweight (mainly referring to more model parameters) teacher model (teacher model) for predicting user behavior of the above multiple objects; then, use the trained teacher model The model guides the training of a lightweight (mainly referring to less model parameters) student model (student model). Specifically, in the process of training the student model, the prior knowledge in the teacher model is transferred to the student model, so that even if the students The model has fewer parameters, and the learned model will have better effect. At the same time, because the model parameters of the student model are less, it can achieve fast learning. In addition, a student can be trained for each target object among several target objects. The model, as a behavior prediction model for each target object, can achieve efficient reuse of prior knowledge in the teacher model. In addition, because the training and use of the student model takes up less computing resources and has high computational efficiency, both the training and use of the student model can be implemented online, which also makes the prediction results highly time-sensitive.
此外,发明人还发现,在用户行为预测领域,通常只是简单地引入用户和对象的基础属性特征,并没有有效地引入用户和对象之间的历史交互数据,使得在对用户和对象进行表征时,无法捕捉更多更丰富的高阶用户特征和高阶对象特征。因此,发明人进一步提出,采用GNN(Graph Neural Networks,图神经网络)作为上述老师模型,具体地,先利用多个用户和多个业务对象之间的历史交互数据,构建用户-业务对象二部图,然后,在训练过程中,利用GNN模型(文中或称图神经网络,或称GNN)对该二部图进行图嵌入处理,得到用户表征向量和对象的表征向量,进而基于图神经网络中的链路预测任务,实现对该GNN模型的训练,进一步地,训练好的GNN模型输出的用户表征向量和对象表征向量,可以作为先验知识指导学生模型的学习。In addition, the inventor also found that in the field of user behavior prediction, the basic attribute characteristics of users and objects are usually simply introduced, and the historical interaction data between users and objects is not effectively introduced, so that when characterizing users and objects, the historical interaction data is not effectively introduced. , which cannot capture more and richer higher-order user features and higher-order object features. Therefore, the inventor further proposes to use GNN (Graph Neural Networks, Graph Neural Networks) as the above-mentioned teacher model. Then, in the training process, the GNN model (or graph neural network, or GNN) is used to embed the bipartite graph to obtain the user representation vector and the object representation vector, and then based on the graph neural network To achieve the training of the GNN model, the user representation vector and object representation vector output by the trained GNN model can be used as prior knowledge to guide the learning of the student model.
由上可知,发明人提出借鉴KD的训练算法框架,先训练GNN模型作为老师模型,再利用训练好的GNN模型指导学生模型,即针对目标对象的行为预测模型的训练,训练好的行为预测模型用于确定目标对象的推荐人群。It can be seen from the above that the inventor proposes to learn from the training algorithm framework of KD, first train the GNN model as the teacher model, and then use the trained GNN model to guide the student model, that is, the training of the behavior prediction model for the target object, the trained behavior prediction model. Recommended population for identifying target audience.
以上对本说明书实施例披露的训练方法的发明构思进行介绍,为便于理解,下面再结合实施例,对上述训练方法的实施进行简要介绍。The inventive concept of the training method disclosed in the embodiments of the present specification has been introduced above. For ease of understanding, the implementation of the above-mentioned training method will be briefly introduced below with reference to the embodiments.
在一个实施例中,在老师模型训练阶段,基于用户-对象二部图和训练样本,训练GNN模型。具体地,图1示出根据一个实施例的GNN模型的训练架构示意图,如图1所示,首先,一方面,获取预先构建的用户-对象二部图,例如,可参见图2中示出的用户-对象二部图,其中包括对应于多个用户的多个用户节点,以及对应于多个对象的多个对象节点,以及用户节点向对象节点做出特定行为而形成的连接边;回到图1,另一方面,获取针对该多个对象的训练样本集,其中任一的第一训练样本中包括第一用户的用户标识、第一对象的对象标识和第一样本标签,该第一样本标签指示该第一用户是否向该第一对象做出该特定行为;接着,通过GNN模型对该二部图进行图嵌入处理,确定该第一用户的第一用户特征向量和该第一对象的第一对象特征向量;进一步地,基于该第一用户特征向量和第一对象特征向量,确定该第一用户对该第一对象做出该特定行为的第一行为概率,进而结合该第一样本标签,确定行为预测损失,以训练该图神经网络。进一步地,可以利用训练后的GNN模型对上述二部图进行嵌入处理,得到上述多个用户对应的多个用户特征向量,以及上述多个对象对应的多个对象特征向量,归到嵌入向量集。如此,可以得到老师模型输出的含义丰富的特征向量。In one embodiment, in the teacher model training phase, the GNN model is trained based on the user-object bipartite graph and training samples. Specifically, FIG. 1 shows a schematic diagram of a training architecture of a GNN model according to an embodiment. As shown in FIG. 1 , first, on the one hand, a pre-built user-object bipartite graph is obtained. For example, see the diagram shown in FIG. 2 The user-object bipartite graph of the 1, on the other hand, a training sample set for the multiple objects is obtained, wherein any of the first training samples includes the user identifier of the first user, the object identifier of the first object and the first sample label, the The first sample label indicates whether the first user makes the specific behavior to the first object; then, the graph embedding process is performed on the bipartite graph through the GNN model to determine the first user feature vector and the first user feature vector of the first user. The first object feature vector of the first object; further, based on the first user feature vector and the first object feature vector, determine the first behavior probability that the first user performs the specific behavior on the first object, and then combine The first sample label determines the behavior prediction loss to train the graph neural network. Further, the trained GNN model can be used to embed the above-mentioned bipartite graph to obtain multiple user feature vectors corresponding to the multiple users and multiple object feature vectors corresponding to the multiple objects, which are classified into the embedding vector set. . In this way, a meaningful feature vector output by the teacher model can be obtained.
在学生模型训练阶段,可以确定针对目标对象的多个样本用户,其中任一的第一样本用户对应第一样本硬标签,指示该第一样本用户是否对所述目标对象做出特定行为。因该第一样本硬标签通常为是和否,从概率值来说就是1和0,这样的标签是较硬,或者说是绝对化的,其包含的信息量是有限的,简单来说,对一张图片,标签是1是指图片中的物体是苹果,标签是0是指图片中的物体是梨子,这就将两个物体绝对化了,实际苹果和梨子是有一些相似之处的,假定标签是0.85,则可以告诉我们图片中的物体85%是苹果,还有15%的可能是梨,这样标签0.85就提供了更多的信息量,有助于提高模型的泛化性能,尤其是在用户行为预测场景下,可以拓展到更多差异化的用户,实现对海量用户的准确预测。那么,如何拿到标签0.85(文中将这类标签称为软标签),在本说明书实施例中,可以利用训练后的GNN模型获得,从而将确定出的软标签用于学生模型的训练,也就实现了老师模型中先验知识的传递,具体地,对于上述第一样本用户,可以根据上述嵌入向量集确定对应的样本用户特征向量,并结合根据该嵌入向量集确定出的目标对象的目标对象特征向量,确定对应第一样本软标签,用于行为预测模型的训练。In the training stage of the student model, a plurality of sample users for the target object can be determined, and any of the first sample users corresponds to the first sample hard label, indicating whether the first sample user has made a specific application to the target object. Behavior. Because the hard labels of the first sample are usually yes and no, in terms of probability values, they are 1 and 0. Such labels are relatively hard, or absolute, and the amount of information they contain is limited. , For a picture, the label is 1 means that the object in the picture is an apple, and the label is 0 means that the object in the picture is a pear, which makes the two objects absolute, the actual apple and pear have some similarities Yes, assuming the label is 0.85, it can tell us that 85% of the objects in the picture are apples, and 15% may be pears, so the label of 0.85 provides more information and helps to improve the generalization performance of the model , especially in the user behavior prediction scenario, it can be extended to more differentiated users and achieve accurate prediction of massive users. Then, how to get a label of 0.85 (this type of label is called a soft label in the text), in the embodiment of this specification, it can be obtained by using the trained GNN model, so that the determined soft label is used for the training of the student model, and also It realizes the transfer of prior knowledge in the teacher model. Specifically, for the above-mentioned first sample user, the corresponding sample user feature vector can be determined according to the above-mentioned embedding vector set, and combined with the target object determined according to the embedding vector set. The feature vector of the target object is determined to correspond to the first sample soft label, which is used for the training of the behavior prediction model.
图3示出根据一个实施例的行为预测模型的训练架构示意图,如图3所示,首先,基于预先确定的嵌入向量集,确定对应于上述第一样本用户的样本用户特征向量,并且,确定对应于上述目标对象的目标对象特征向量;接着,将该样本用户特征向量输入第一行为预测模型中,得到第一行为概率,一方面,结合该第一行为概率和上述第一样本硬标签,确定第一损失项;另一方面,基于该样本用户特征向量和目标对象特征向量,确定第一用户对该目标对象做出该特定行为的特定行为概率,作为第一样本软标签,进而结合该第一样本软标签和上述第一行为概率,确定第二损失项;然后,利用该第一损失项和第二损失项,训练该第一行为预测模型。如此,可以实现对第一行为预测模型的训练,从而通过对目标对象的候选用户进行行为预测,确定出目标对象的目标用户群体,并向该目标用户群体推荐该目标对象。FIG. 3 shows a schematic diagram of a training architecture of a behavior prediction model according to an embodiment. As shown in FIG. 3 , first, based on a predetermined set of embedding vectors, a sample user feature vector corresponding to the above-mentioned first sample user is determined, and, Determine the target object feature vector corresponding to the above target object; then, input the sample user feature vector into the first behavior prediction model to obtain the first behavior probability, on the one hand, combine the first behavior probability and the above-mentioned first sample hard. label, determine the first loss item; on the other hand, based on the sample user feature vector and the target object feature vector, determine the specific behavior probability that the first user performs the specific behavior to the target object, as the first sample soft label, Then, a second loss item is determined in combination with the first sample soft label and the first behavior probability; then, the first behavior prediction model is trained by using the first loss item and the second loss item. In this way, the training of the first behavior prediction model can be realized, thereby determining the target user group of the target object by performing behavior prediction on the candidate users of the target object, and recommending the target object to the target user group.
接下来,对本说明书实施例披露的行为预测模型的训练方法进行更具体的介绍。Next, the training method of the behavior prediction model disclosed in the embodiment of the present specification will be introduced in more detail.
图4示出根据一个实施例的行为预测模型的训练方法流程图,所述方法的执行主体可以为任何具有计算、处理能力的平台、服务器、设备集群等。如图4所示,所述方法包括以下步骤:FIG. 4 shows a flowchart of a training method for a behavior prediction model according to an embodiment, and the execution body of the method may be any platform, server, device cluster, etc. with computing and processing capabilities. As shown in Figure 4, the method includes the following steps:
步骤S410,确定针对目标对象的多个样本用户,其中任一的第一样本用户对应第一样本硬标签,该第一样本硬标签指示该第一样本用户是否对该目标对象做出特定行为;步骤S420,基于预先确定的嵌入向量集,确定对应于该第一样本用户的样本用户特征向量,并且,确定对应于该目标对象的目标对象特征向量;其中,该嵌入向量集是利用训练后的图神经网络对构建的二部图进行图嵌入处理而确定;该二部图包括对应于多个用户的多个用户节点,对应于多个对象的多个对象节点,以及用户节点向对象节点做出该特定行为而形成的连接边,该嵌入向量集中包括该多个用户的多个用户特征向量和该多个对象的多个对象特征向量;步骤S430,将该样本用户特征向量输入第一行为预测模型中,得到行为预测结果;步骤S440,基于该行为预测结果和该第一样本硬标签,确定第一损失项;步骤S450,基于该样本用户特征向量和该目标对象特征向量,确定该第一样本用户对该目标对象做出该特定行为的特定行为概率,作为第一样本软标签;步骤S460,基于该行为预测结果和该第一样本软标签,确定第二损失项;步骤S470,利用该第一损失项和第二损失项,训练该第一行为预测模型。Step S410, determining a plurality of sample users for the target object, any one of the first sample users corresponds to a first sample hard label, and the first sample hard label indicates whether the first sample user does anything to the target object. In step S420, a sample user feature vector corresponding to the first sample user is determined based on a predetermined embedding vector set, and a target object feature vector corresponding to the target object is determined; wherein, the embedding vector set It is determined by using the trained graph neural network to perform graph embedding processing on the constructed bipartite graph; the bipartite graph includes multiple user nodes corresponding to multiple users, multiple object nodes corresponding to multiple objects, and user nodes. The connection edge formed by the node performing the specific behavior to the object node, the embedding vector set includes multiple user feature vectors of the multiple users and multiple object feature vectors of the multiple objects; step S430, the sample user feature vector The vector is input into the first behavior prediction model, and the behavior prediction result is obtained; step S440, based on the behavior prediction result and the first sample hard label, determine the first loss term; step S450, based on the sample user feature vector and the target object Feature vector, determine the specific behavior probability of the first sample user to perform the specific behavior to the target object, as the first sample soft label; Step S460, based on the behavior prediction result and the first sample soft label, determine The second loss item; Step S470, using the first loss item and the second loss item to train the first behavior prediction model.
针对以上步骤,首先需要说明的是,上述“第一样本用户”、“第一样本硬标签”等中的“第一”,以及文中别处“第二”、“第三”等类似用语,均是为了描述的清楚而用于区分同类事物,不具有其他限定作用。For the above steps, it should be noted that the "first" in the above "first sample user", "first sample hard label", etc., as well as similar terms such as "second" and "third" elsewhere in the text , are used to distinguish similar things for the clarity of description, and have no other limiting effect.
另外,为了便于理解,先对上述步骤S420中嵌入向量集的确定进行介绍,具体地,在执行步骤S420之前,利用预先构建的二部图和采集的训练样本集训练GNN模型,再利用训练后的GNN模型对该二部图进行图嵌入处理,得到上述嵌入向量集。In addition, in order to facilitate understanding, the determination of the embedding vector set in the above step S420 is introduced first. Specifically, before step S420 is performed, the GNN model is trained by using the pre-built bipartite graph and the collected training sample set, and then the post-training model is used to train the GNN model. The GNN model of the graph embeds the bipartite graph to obtain the above embedding vector set.
对于上述二部图,在一种构建方式中,可以采集多个用户的用户特征、多个对象的对象特征,以及多个用户和多个对象之间的交互数据,然后,基于这些数据构建二部图。在一个实施例中,上述多个用户中的任一用户可以体现为账户名、用户ID(Identity,标识)、用户终端设备ID。在一个实施例中,上述用户特征数据可以包括用户属性特征,如性别、年龄、职业、地址(公司地址、常住地址、物流收货地址、实时位置等)、兴趣爱好(如运动、画画等)。在另一个实施例中,上述用户特征数据可以包括基于用户的历史行为数据而确定出的用户行为特征,例如,平台活跃度(如日均登录次数、日均登录时长)、交易偏好特征(如商品类别、交易时段)等。For the above bipartite graph, in one construction method, the user characteristics of multiple users, the object characteristics of multiple objects, and the interaction data between multiple users and multiple objects can be collected, and then, based on these data, a bipartite graph can be constructed. Department map. In one embodiment, any one of the above-mentioned multiple users may be embodied as an account name, a user ID (Identity, identification), and a user terminal device ID. In one embodiment, the above-mentioned user characteristic data may include user attribute characteristics, such as gender, age, occupation, address (company address, resident address, logistics delivery address, real-time location, etc.), hobbies (such as sports, painting, etc.) ). In another embodiment, the above-mentioned user characteristic data may include user behavior characteristics determined based on the user's historical behavior data, for example, platform activity (such as daily average number of logins, average daily login time), transaction preference characteristics (such as commodity category, trading hours), etc.
在一个实施例中,上述多个对象中的任一对象可以属于以下中的任一种:内容信息、业务登录界面、业务注册界面、商品、服务、用户。在一个具体的实施例中,其中内容信息的形式包括以下中的至少一种:图片、文本、视频。在一些具体的例子中,业务对象可以是超链接文本(如链接到目标页面的广告文本)、超链接图片(如连接到目标页面的广告图片)、公众号的文章、支付宝登录和注册界面、服装、书籍(电子书或纸质书)、线上生活缴费服务、平台推荐关注的个人用户、公众号或内容领域。需要说明,某个业务对象可以是某一篇文章、某一张广告图片、某一个商品等等,训练样本中的业务对象是指单个业务对象。In one embodiment, any one of the above-mentioned multiple objects may belong to any one of the following: content information, service login interface, service registration interface, commodity, service, and user. In a specific embodiment, the form of the content information includes at least one of the following: picture, text, and video. In some specific examples, business objects can be hyperlink text (such as advertising text linked to the target page), hyperlink images (such as advertising images linked to the target page), articles on official accounts, Alipay login and registration interfaces, Clothing, books (e-books or paper books), online life payment services, individual users recommended by the platform, public accounts or content areas. It should be noted that a certain business object may be an article, an advertisement image, a certain commodity, etc., and the business object in the training sample refers to a single business object.
在一个实施例中,上述对象特征可以包括业务对象的介绍文本(可以是从网络中爬取或由工作人员输入的)、业务对象ID(Identity,标识)(例如,可以是系统分配得到的)、其所属的业务类别(如视频播放类、交友类、游戏类等)、其所针对的目标人群(如青年、学生、在职人员等)。在一个具体的实施例中,若业务对象属于内容信息,则其对象特征还可以包括基于所对应的内容信息确定的特征。在一个例子中,业务对象为一篇内容资讯,则其对象特征还可以包括该篇内容资讯的关键词或摘要文本。在另一个例子中,业务对象为某张图片(或称第一图片),该第一图片中包括多个像素,共同对应多个不同的像素值,相应地,该第一图片的对象特征还可以包括多个不同的像素值,以及其中各个像素值所对应的像素块个数。In one embodiment, the above-mentioned object features may include the introduction text of the business object (which may be crawled from the network or input by staff), the ID (Identity) of the business object (for example, may be assigned by the system) , the business category it belongs to (such as video playback, dating, games, etc.), and the target group it targets (such as youth, students, in-service personnel, etc.). In a specific embodiment, if the business object belongs to content information, the object characteristics thereof may further include characteristics determined based on the corresponding content information. In an example, if the business object is a piece of content information, the object feature may further include keywords or abstract text of the piece of content information. In another example, the business object is a certain picture (or called the first picture), and the first picture includes multiple pixels, which together correspond to multiple different pixel values. Correspondingly, the object characteristics of the first picture also include It may include multiple different pixel values and the number of pixel blocks corresponding to each pixel value.
在一个实施例中,多个用户和多个对象之间的交互数据可以包括,某个对象被曝光给哪些用户,某个用户对哪些对象做出上述特定行为。在一个实施例中,上述特定行为可以包括:点击行为、浏览达到预设时长的行为、注册行为、登录行为、购买行为和关注行为。其中特定行为可以由工作人员根据业务对象和实际经验进行设定。例如,若业务对象为广告图片,则特定行为可以被设定为点击行为。又例如,若业务对象为商品,则特定行为可以被设定为购买行为。再例如,若业务对象为新闻资讯,则特定行为可以被设定为浏览时长达到预设时长(如5min)。还例如,若业务对象为公众号,则特定行为可以被设定为关注行为。再又例如,若业务对象为应用APP,则特定行为可以被设定为登录行为或下载行为或注册行为。In one embodiment, the interaction data between multiple users and multiple objects may include, to which users a certain object is exposed, and to which objects a certain user performs the above-mentioned specific behavior. In one embodiment, the above-mentioned specific behaviors may include click behaviors, browsing behaviors for a preset duration, registration behaviors, login behaviors, purchase behaviors, and attention behaviors. Among them, specific behaviors can be set by the staff according to business objects and actual experience. For example, if the business object is an advertisement image, the specific action can be set as a click action. For another example, if the business object is a commodity, the specific behavior can be set as a purchase behavior. For another example, if the business object is news information, the specific behavior can be set so that the browsing duration reaches a preset duration (eg, 5 minutes). For another example, if the business object is an official account, the specific behavior can be set as the attention behavior. For another example, if the business object is an application APP, the specific behavior may be set as a login behavior, a download behavior, or a registration behavior.
以上对采集的多个用户的用户特征、多个对象的对象特征,以及用户和对象之间的交互数据进行介绍。进一步地,可以基于这些数据构建二部图。在一个实施例中,创建对应于多个用户的多个用户节点,并将各个用户的用户特征作为对应用户节点的节点特征,同理,创建对应于多个对象的多个对象节点,并将各个对象的对象特征作为对应对象节点的节点特征;然后,基于交互数据,在用户节点和对象节点之间建立连接边,具体包括:假定根据该交互数据判断出某个用户曾对某个对象做出上述特定行为,则在该某个用户对应的用户节点和该某个对象对应的对象节点之间建立连接边。需要理解,用户节点之间不会存在连接边,对象节点之间也不会存在连接边。如此,可以实现用户-对象二部图的构建。The collected user characteristics of multiple users, object characteristics of multiple objects, and interaction data between users and objects are introduced above. Further, a bipartite graph can be constructed based on these data. In one embodiment, multiple user nodes corresponding to multiple users are created, and the user characteristics of each user are used as the node characteristics of the corresponding user nodes. Similarly, multiple object nodes corresponding to multiple objects are created, and The object feature of each object is used as the node feature of the corresponding object node; then, based on the interaction data, a connection edge is established between the user node and the object node, which specifically includes: assuming that it is determined according to the interaction data that a user has done something to an object. If the above specific behavior occurs, a connection edge is established between the user node corresponding to the certain user and the object node corresponding to the certain object. It needs to be understood that there will be no connecting edges between user nodes, and no connecting edges between object nodes. In this way, the construction of user-object bipartite graph can be realized.
对于上述训练样本集,需要理解,训练样本集涉及的用户属于上述多个用户,并且,训练样本集涉及的对象属于上述多个对象。此外,该训练样本集可以基于上述交互数据而构建,比如,若根据该交互数据判断出某对象被曝光给某用户,则可以基于该某对象和某用户构建训练样本,进一步地,若该某用户向该某用户做出特定行为,则将对应的样本标签设定为正例标签,若该某用户没有向该某用户做出特定行为,则将对应的样本标签设定为负例标签。另外,上述用户标识和对象标识可以分别映射到二部图中对应的用户节点和对象节点。Regarding the above training sample set, it should be understood that the users involved in the training sample set belong to the above-mentioned multiple users, and the objects involved in the training sample set belong to the above-mentioned multiple objects. In addition, the training sample set can be constructed based on the above interaction data. For example, if it is determined according to the interaction data that an object is exposed to a certain user, a training sample can be constructed based on the certain object and a certain user. If the user makes a specific behavior to the certain user, the corresponding sample label is set as the positive example label, and if the certain user does not perform the specific behavior to the certain user, the corresponding sample label is set as the negative example label. In addition, the above-mentioned user identifiers and object identifiers may be mapped to corresponding user nodes and object nodes in the bipartite graph, respectively.
以上,对用户-对象二部图和训练样本集的构建进行介绍。另一方面,对于GNN模型的训练,可以采用图5中示出的以下步骤实现:Above, the construction of user-object bipartite graph and training sample set is introduced. On the other hand, for the training of the GNN model, the following steps shown in Figure 5 can be adopted:
步骤S51,获取训练样本集,其中任意的第一训练样本中包括第一用户的用户标识、第一对象的对象标识和第一样本标签。其中第一样本标签指示该第一用户是否向该第一对象做出特定行为,即,该第一样本标签为上述正例标签或负例标签。Step S51 , acquiring a training sample set, wherein any first training sample includes a user identifier of a first user, an object identifier of a first object, and a first sample label. The first sample label indicates whether the first user performs a specific behavior to the first object, that is, the first sample label is the positive example label or the negative example label.
步骤S52,通过图神经网络对该二部图进行图嵌入处理,确定上述第一用户的第一用户特征向量和第一对象的第一对象特征向量。Step S52, performing a graph embedding process on the bipartite graph through a graph neural network to determine the first user feature vector of the first user and the first object feature vector of the first object.
需要说明,利用图神经网络对二部图中的任一节点进行图嵌入的过程是相同的。基于此,下面以对二部图中任意的第一节点进行图嵌入,从而得到与第一节点对应的特征向量为例,对上述图嵌入处理的过程进行说明。It should be noted that the process of using a graph neural network to embed any node in a bipartite graph is the same. Based on this, the process of the above graph embedding processing is described below by taking the graph embedding of any first node in the bipartite graph to obtain a feature vector corresponding to the first node as an example.
在一个实施例中,可以采用多级聚合的方式对第一节点进行图嵌入,比如,一级聚合可以包括,对该第一节点的一阶邻居节点的节点特征进行聚合,二级聚合可以包括,对该第二节点的二阶邻居节点的节点特征进行聚合。In one embodiment, the first node may be graph embedded in a multi-level aggregation manner. For example, the first-level aggregation may include aggregating the node features of the first-order neighbor nodes of the first node, and the second-level aggregation may include , and aggregate the node features of the second-order neighbor nodes of the second node.
然而,一方面,发明人发现,若采用常规的图嵌入方式,则对应得到的用户特征向量是耦合的,无法表征用户对多个对象分属的不同领域的意图(intentions),例如,用户对于电影领域和理财领域,可能具有不同的偏好和行为倾向。因此,为了得到含义更加丰富的用户表征向量,发明人提出采用以下图嵌入方式,实现对用户特征向量的解耦(disantangle),也就是使得确定出的用户特征向量能够反映用户对上述不同领域的意图。However, on the one hand, the inventor found that if a conventional graph embedding method is used, the corresponding user feature vectors are coupled and cannot represent the user's intentions for different fields to which multiple objects belong. The film field and the financial field may have different preferences and behavioral tendencies. Therefore, in order to obtain a more meaningful user characterization vector, the inventor proposes to use the following graph embedding method to realize the decoupling (disantangle) of the user characterization vector, that is, the determined user characterization vector can reflect the user's perception of the above-mentioned different fields. intention.
具体地,上述图神经网络包括L个隐层,相应地,上述图嵌入处理可以包括:针对第一节点,在每个隐层,获取上一隐层输出的隐向量




在一个实施例中,上述对该K个子隐向量分别进行T次迭代更新包括,对K个子隐向量中任意的第j子隐向量进行任一次迭代更新,显然,其中j为不大于K的正整数。更具体地,对其中第j子隐向量
首先,一方面,获取上述第一节点的第j子映射向量

对此,根据一个实施例,当前隐层中,在对上一隐层输出的隐向量
在一个示例中,对于N+1个节点中的第i个节点,将其映射至第


其中,




相应地,可以获取上述第j子映射向量
接着,针对上述N个邻居节点中任一的第二节点,分别计算该第二节点对应的K个子映射向量与上述第j子隐向量之间的K个相似度,并利用其和值对其中第j个相似度进行归一化处理,得到第一权重。在一个示例中,可以通过计算两个向量之间的点积、欧式距离、余弦距离等,得到相似度。在一个示例中,可以利用softmax函数、求数值占比等方式,实现上述归一化处理,进而得到第一权重。Next, for any second node among the above-mentioned N neighbor nodes, calculate the K similarities between the K sub-map vectors corresponding to the second node and the above-mentioned j-th sub-implicit vector, and use the sum value to compare the The jth similarity is normalized to obtain the first weight. In one example, the similarity can be obtained by calculating the dot product, Euclidean distance, cosine distance, etc. between two vectors. In an example, the above-mentioned normalization process may be implemented by using a softmax function, calculating the ratio of values, and the like, thereby obtaining the first weight.
根据一个具体的示例,可以通过以下公式计算第一权重:According to a specific example, the first weight can be calculated by the following formula:

其中,






如此,可以得到对应于N个邻居节点的N个第一权重。然后,利用对应于N个邻居节点的N个第一权重,对该N个邻居节点所对应的N个第j子映射向量进行加权处理,得到加权向量,并将上述第j子隐向量更新为,上述第j子映射向量和上述加权向量的和向量所对应的单位向量。在一个示例中,可以表示为以下计算式:In this way, N first weights corresponding to N neighbor nodes can be obtained. Then, use the N first weights corresponding to the N neighbor nodes to perform weighting processing on the N jth sub-map vectors corresponding to the N neighbor nodes to obtain a weighted vector, and update the above jth sub-implicit vector as , the unit vector corresponding to the sum vector of the above jth sub-mapping vector and the above weighting vector. In one example, it can be expressed as the following calculation:

其中,






如此,可以得到任一次迭代更新后的


进一步地,考虑到上述二部图中或多或少引入了一些噪声,会影响节点嵌入的准确性,例如,用于构建二部图的交互数据中,存在某个用户手滑点击了某张广告图片的点击数据,而导致在二部图中建立了一条噪声连接边。对此,发明人提出,在对第一节点的隐向量进行更新时,引入注意力机制,对其N个邻居节点进行注意力打分,从而减缓或消除二部图中噪声的影响。Further, considering that the above-mentioned bipartite graph introduces some noise more or less, it will affect the accuracy of node embedding. The click data of the advertisement image, resulting in the establishment of a noise connection edge in the bipartite graph. In this regard, the inventor proposes that when updating the hidden vector of the first node, an attention mechanism is introduced to score the attention of its N neighbor nodes, thereby reducing or eliminating the influence of noise in the bipartite graph.
根据一种实施方式,在当前隐层中,可以在对上述第一节点的第j子隐向量进行T次迭代更新前,计算引入注意力机制得到的N个邻居节点对应的N个第二权重,再在当前隐层的每次迭代更新中,对该N个第二权重进行取用。According to an embodiment, in the current hidden layer, N second weights corresponding to the N neighbor nodes obtained by introducing the attention mechanism can be calculated before the j-th sub-hidden vector of the first node is iteratively updated for T times. , and then use the N second weights in each iterative update of the current hidden layer.
对于上述N个第二权重的确定和使用分别进行如下介绍。在一个实施例中,先根据第一节点的节点特征和N个邻居节点中任意的第二节点的节点特征,对第二节点进行注意力打分,然后,对得到的对应于N个邻居节点的N个注意分数进行归一化处理,得到上述N个第二权重。The determination and use of the above-mentioned N second weights are respectively introduced as follows. In one embodiment, the second node is firstly scored according to the node feature of the first node and the node feature of any second node among the N neighbor nodes, and then the obtained node features corresponding to the N neighbor nodes are scored. The N attention scores are normalized to obtain the above N second weights.
在一个示例中,可以通过以下公式计算第二节点的第二权重:In one example, the second weight of the second node can be calculated by the following formula:

其中,







在另一个示例中,也可以通过以下公式计算第二节点的第二权重:In another example, the second weight of the second node can also be calculated by the following formula:

其中,








如此,可以在对第一节点的隐向量进行更新前,得到N个邻居节点对应的N个第二权重,用于结合上述N个第一权重,实现T次迭代更新中的各次迭代更新。在一个实施例中,对于上述任一次迭代更新包括的利用N个第一权重计算加权向量的步骤,可以被进一步实施为:获取上述N个第二权重,对上述N个第一权重和上述N个第二权重进行对应位置的权重相乘处理,得到N个第三权重;再利用该N个第三权重,对上述N个第j子映射向量进行加权处理,得到上述加权向量。需要理解,其中对应位置的权重相乘处理的本质在于,对应位置的第一权重和第二权重对应相同的邻居节点。在一个示例中,其中进一步实施可以用以下计算式实现:In this way, before updating the hidden vector of the first node, N second weights corresponding to the N neighbor nodes can be obtained, which are used to realize each iteration of the T iterations of the iterative update in combination with the above-mentioned N first weights. In an embodiment, the step of calculating a weight vector by using N first weights included in any one of the above iterative updates may be further implemented as: acquiring the above N second weights, and comparing the above N first weights and the above N The weights of the corresponding positions are multiplied by the second weights to obtain N third weights; and then the N third weights are used to perform weighting processing on the N jth sub-mapping vectors to obtain the weighting vectors. It should be understood that the essence of the multiplication process of the weights of the corresponding positions is that the first weight and the second weight of the corresponding positions correspond to the same neighbor node. In one example, where further implementation can be achieved with the following calculation:

其中,






如此,在隐向量的更新过程中,可以同时实现用户领域意图的解耦和二部图中噪声信息的消除。以上主要对在L个隐层的任一隐层中对第一节点的第j子隐向量的T次迭代更新中的任一次迭代更新进行说明,由此,可以得到第L个层输出的隐向量,作为第一节点的特征向量。此外需要说明,上述图嵌入处理还可以实现为:针对K个推荐领域设计对应的K个GNN模型,相应地,K个GNN模型的隐层可以实现对各自对应的子隐向量的更新,再将K个GNN模型输出的K个子隐向量进行拼接,作为第一节点对应的特征向量。In this way, in the updating process of the hidden vector, the decoupling of the user's domain intention and the elimination of the noise information in the bipartite graph can be realized at the same time. The above mainly describes any iterative update in the T iteration updates of the jth sub-hidden vector of the first node in any hidden layer of the L hidden layers. From this, the hidden output of the Lth layer can be obtained. vector, as the feature vector of the first node. In addition, it should be noted that the above graph embedding process can also be implemented as follows: K GNN models corresponding to the K recommendation fields are designed. Correspondingly, the hidden layers of the K GNN models can update their corresponding sub-hidden vectors, and then update the corresponding sub-hidden vectors. The K sub-implicit vectors output by the K GNN models are spliced together as the feature vector corresponding to the first node.
根据另一方面的实施例,也可以不考虑用户领域意图的解耦,而是只考虑二部图中噪声信息的消除,同样可以提高节点嵌入向量的表征准确度。相应地,上述图嵌入处理过程可以实现为:针对上述二部图中任意的第一节点,在每个隐层,获取上一隐层输出的隐向量

首先,获取第一节点及其N个邻居节点各自对应的映射向量,该映射向量是将其对应节点的节点特征映射至预设特征空间而得到。在一个示例中,对于第一节点及其N个邻居节点中的第i个节点,将其映射至预设特征空间(需理解,其中预设是指空间维数是预先设定的)而得到对应的映射向量

其中,



接着,计算上述N个邻居节点各自对应的映射向量与所述隐向量之间的相似度,得到N个相似度,并对该N个相似度进行归一化处理,得到N个第一权重。在一个示例中,其中任一个第一权重可以通过下式计算得到:Next, the similarity between the mapping vectors corresponding to the N neighbor nodes and the hidden vector is calculated to obtain N similarities, and the N similarities are normalized to obtain N first weights. In an example, any one of the first weights can be calculated by the following formula:

其中,








然后,获取对N个注意力分数进行归一化处理而得到的N个第二权重,该N个注意力分数对应所述N个邻居节点,其中各个注意力分数是基于其对应的邻居节点的节点特征和所述第一节点的节点特征而确定。Then, N second weights obtained by normalizing the N attention scores are obtained, the N attention scores correspond to the N neighbor nodes, and each attention score is based on its corresponding neighbor node. The node feature and the node feature of the first node are determined.
需要说明,对N个注意力分数和N个第二权重的确定,可以参见上述相关描述,如公式(4)和(5)等,在此不作赘述。It should be noted that, for the determination of the N attention scores and the N second weights, reference may be made to the above-mentioned related descriptions, such as formulas (4) and (5), etc., which will not be repeated here.
再接着,对上述N个第一权重和N个第二权重进行对应位置的权重相乘处理,得到N个第三权重,并利用上述N个第三权重,对上述N个邻居节点对应的N个映射向量进行加权处理,得到加权向量;最后,将上述隐向量更新为,第一节点的映射向量与该加权向量的和向量所对应的单位向量。在一个示例中,具体可以实现为以下公式的计算:Next, multiply the weights of the corresponding positions on the N first weights and the N second weights to obtain N third weights, and use the N third weights to calculate the N corresponding to the N neighbor nodes. Perform weighting processing on each of the mapping vectors to obtain a weighted vector; finally, the above-mentioned hidden vector is updated to a unit vector corresponding to the sum vector of the mapping vector of the first node and the weighted vector. In one example, it can be implemented as the calculation of the following formula:

在上式中,










采用以上方式更新隐向量,可以实现对二部图中所引入噪声信息的消除。By updating the hidden vector in the above manner, the noise information introduced in the bipartite graph can be eliminated.
以上,对步骤S52中通过图神经网络对用户-对象二部图进行图嵌入处理,确定任一的第一节点的特征向量进行介绍。由此可自然推出,对与第一用户对应的第一用户节点进行图嵌入得到第一用户特征向量,以及,对与第一对象对应的第一对象节点进行图嵌入得到第一对象特征向量的过程。In the above, in step S52, the graph embedding process is performed on the user-object bipartite graph through the graph neural network, and the feature vector of any first node is determined. From this, it can be naturally deduced that the graph embedding of the first user node corresponding to the first user is performed to obtain the first user feature vector, and the graph embedding of the first object node corresponding to the first object is performed to obtain the first object feature vector. process.
然后,在步骤S53,基于该第一用户特征向量和第一对象特征向量,确定该第一用户对该第一对象做出该特定行为的第一行为概率,进而结合该第一样本标签,确定行为预测损失。Then, in step S53, based on the first user feature vector and the first object feature vector, determine the first behavior probability that the first user performs the specific behavior to the first object, and then combine the first sample label, Determining behavioral prediction losses.
对于其中第一行为概率的确定,在一个实施例中,可以计算第一用户特征向量和第一对象特征向量的第一相似度,并对该第一相似度进行归一化处理,得到该第一行为概率。需要理解,其中归一化处理是指把一个数值映射为区间[0,1]中的一个数值。在一个具体的实施例中,可以采用取值区间在[0,1]内的分段函数,对第一相似度进行映射处理,得到第一行为概率。在另一个具体的实施例中,可以采用取值区间在[0,1]内的单调函数,如sigmoid函数,将第一相似度归一化为第一行为概率,具体可以表示为以下公式:For the determination of the first behavior probability, in one embodiment, the first similarity between the first user feature vector and the first object feature vector may be calculated, and the first similarity may be normalized to obtain the first similarity. A behavior probability. It should be understood that the normalization process refers to mapping a value to a value in the interval [0,1]. In a specific embodiment, a piecewise function with a value interval in [0, 1] may be used to perform mapping processing on the first similarity to obtain the first behavior probability. In another specific embodiment, a monotonic function with a value interval in [0, 1], such as a sigmoid function, can be used to normalize the first similarity to the first behavior probability, which can be specifically expressed as the following formula:

其中,


在另一个实施例中,可以对第一用户特征向量和第一对象特征向量进行融合,得到第一融合向量;再将第一融合向量输入分类网络中,得到第一行为概率。在一个具体的实施例中,其中向量的融合可以通过拼接、加和或求平均实现。在一个具体的实施例中,其中分类网络可以用若干全连接层实现。In another embodiment, the first user feature vector and the first object feature vector may be fused to obtain a first fusion vector; and then the first fusion vector is input into a classification network to obtain a first behavior probability. In a specific embodiment, the fusion of the vectors may be achieved by concatenation, summing or averaging. In a specific embodiment, the classification network can be implemented with several fully connected layers.
在以上确定出第一行为概率后,结合上述第一样本标签,确定行为预测损失。在一个具体的实施例中,可以利用交叉熵损失函数、铰链损失函数、或欧式距离等,计算该行为预测损失。在一个示例中,可以采用交叉熵损失函数计算行为预测损失,具体的计算式如下After the first behavior probability is determined above, the behavior prediction loss is determined in combination with the above first sample label. In a specific embodiment, the behavior prediction loss may be calculated using a cross-entropy loss function, a hinge loss function, or Euclidean distance, or the like. In an example, the behavioral prediction loss can be calculated using the cross-entropy loss function, and the specific calculation formula is as follows

其中,


由上,可以确定出行为预测损失,进而在步骤S54,利用该行为预测损失,训练该图神经网络。在一个实施例中,利用行为预测损失,训练上述分类网络和图神经网络。需要说明,训练过程中的调参可以采用反向传播法实现,在此不作赘述。From the above, the behavior prediction loss can be determined, and then in step S54, the graph neural network is trained by using the behavior prediction loss. In one embodiment, the above-described classification network and graph neural network are trained using a behavior prediction loss. It should be noted that the parameter adjustment in the training process can be realized by the back-propagation method, which is not repeated here.
通过执行以上步骤S51至步骤S52,可以实现对GNN模型的训练,并在训练至收敛或者达到预定迭代次数后,利用训练好的GNN模型对二部图中的各个节点进行图嵌入处理,得到包括对应于多个用户的多个用户特征向量,以及对应于多个对象的多个对象特征向量的嵌入向量集,用于指导学生模型,即,行为预测模型的训练。By performing the above steps S51 to S52, the training of the GNN model can be realized, and after the training has converged or reached a predetermined number of iterations, the trained GNN model is used to perform graph embedding processing on each node in the bipartite graph, and the results include: Multiple user feature vectors corresponding to multiple users, and an embedding vector set of multiple object feature vectors corresponding to multiple objects are used to guide the training of the student model, ie, the behavior prediction model.
现在回到图4,图4中包括的步骤具体如下:Returning now to Figure 4, the steps included in Figure 4 are as follows:
首先,在步骤S410,确定针对目标对象的多个样本用户,其中任一的第一样本用户对应第一样本硬标签,该第一样本硬标签指示该第一样本用户是否对该目标对象做出特定行为。First, in step S410, a plurality of sample users for the target object are determined, any one of the first sample users corresponds to a first sample hard label, and the first sample hard label indicates whether the first sample user has the The target object performs a specific behavior.
在一种实施情况下,目标对象历史推荐对象,也就是目标对象曾经被推荐给一些用户,此时,其属于上述多个对象,相应地,可以根据相关的历史反馈数据或者历史行为数据,确定上述多个样本用户。在另一种实施情况下,目标对象是新对象,也就意味着不存在与之相关的历史数据,相应地,可以获取人工构建的多个样本用户。对于人工构建的过程,在一种可能的方式中,工作人员可以根据与目标对象相关的历史推荐对象的历史数据,确定上述多个样本用户。例如,假定目标对象是即将上映的一部电影,名为XX系列的第二部,此时,可以筛选出看过XX系列的第一部的用户,将其归入上述多个样本用户,并将这部分用户对应的样本硬标签设定为正例标签,即指示用户对目标对象做出特定行为,同时,在没有看过XX系列的第一部的用户中,随机抽取一部分用户归入上述多个样本用户中,并将这部分用户的样本硬标签设定为负例标签,即指示用户没有对目标对象做出特定行为。In an implementation situation, the historically recommended object of the target object, that is, the target object has been recommended to some users, at this time, it belongs to the above-mentioned multiple objects, and accordingly, it can be determined according to the relevant historical feedback data or historical behavior data. Multiple sample users above. In another implementation situation, the target object is a new object, which means that there is no historical data related to it, and accordingly, a plurality of manually constructed sample users can be obtained. For the manual construction process, in a possible manner, the staff may determine the above-mentioned multiple sample users according to the historical data of historical recommended objects related to the target object. For example, assuming that the target object is an upcoming movie named the second part of the XX series, at this time, users who have watched the first part of the XX series can be filtered out, classified into the above-mentioned multiple sample users, and The sample hard labels corresponding to these users are set as positive labels, that is, users are instructed to perform specific behaviors on the target object. Among multiple sample users, the sample hard labels of these users are set as negative labels, that is, it indicates that the users do not perform specific behaviors on the target object.
由上,可以确定针对目标对象的多个样本用户,以及获知其中任一的第一样本用户对应的第一样本硬标签。From the above, multiple sample users for the target object can be determined, and the first sample hard label corresponding to any one of the first sample users can be obtained.
接着,在步骤S420,基于预先确定的嵌入向量集,确定对应于该第一样本用户的样本用户特征向量,并且,确定对应于该目标对象的目标对象特征向量。需要理解,第一样本用户属于二部图中的多个用户,因此,可以从嵌入向量集中直接查询得到该第一样本用户的样本用户特征向量。Next, in step S420, a sample user feature vector corresponding to the first sample user is determined based on a predetermined embedding vector set, and a target object feature vector corresponding to the target object is determined. It should be understood that the first sample user belongs to multiple users in the bipartite graph. Therefore, the sample user feature vector of the first sample user can be obtained by direct query from the embedding vector set.
对于目标对象,在一种实施情况下,其属于二部图中的多个对象,此时,可以从嵌入向量集中直接查询得到该第一目标对象的目标对象特征向量。在另一种情况下,目标对象是新的对象,其不属于上述多个对象。此时,可以根据上述多个样本用户中样本硬标签指示对目标对象做出特定行为的用户(为便于描述,称为种子用户),确定目标对象的目标对象特征向量。For the target object, in an implementation situation, it belongs to multiple objects in the bipartite graph. In this case, the target object feature vector of the first target object can be obtained by direct query from the embedding vector set. In another case, the target object is a new object that does not belong to the above-mentioned plurality of objects. At this time, the target object feature vector of the target object can be determined according to the user (for convenience of description, referred to as a seed user) who has performed a specific behavior on the target object indicated by the sample hard label among the above-mentioned multiple sample users.
具体地,先确定多个(M个)种子用户对应的多个种子特征向量;再根据该多个种子特征向量,以及上述多个(N个)对象对应的多个对象特征向量,确定目标对象特征向量,其中M和N均为大于1的整数。Specifically, first determine multiple seed feature vectors corresponding to multiple (M) seed users; then determine the target object according to the multiple seed feature vectors and multiple object feature vectors corresponding to the multiple (N) objects Eigenvectors, where M and N are both integers greater than 1.
在一个实施例中,计算M个种子特征向量中各个种子向量与N个对象特征向量中各个对象向量之间的相似度,得到M*N个相似度;再确定该M*N个相似度中在预定范围内的若干相似度,并将该若干相似度所对应的若干对象特征向量的平均向量,作为上述目标对象特征向量。在一个具体的实施例中,其中预定范围可是排名在前多少名(如前10名)以内,或者,排名在前多少百分比(如前1%)以内。In one embodiment, the similarity between each seed vector in the M seed feature vectors and each object vector in the N object feature vectors is calculated, and M*N similarities are obtained; and then the M*N similarities are determined. several similarities within a predetermined range, and the average vector of several object feature vectors corresponding to the several similarities is taken as the above-mentioned target object feature vector. In a specific embodiment, the predetermined range may be within the top ranking (eg, the top 10), or within the top percentage (eg, the top 1%).
在另一个实施例中,考虑到计算M*N个相似度的计算量比较大,可以利用聚类优化目标向量的计算过程,有效减少计算量。具体地,先对上述多个种子特征向量进行聚类处理,得到Q(Q为正整数)个类簇;接着,针对该Q个类簇中任一的第一类簇,对其中所包含的种子特征向量进行平均处理,得到第一平均向量,并计算该第一平均向量与上述N个对象特征向量中各个向量之间的相似度,得到N个第三相似度,并确定其中的最大相似度所对应的对象特征向量,作为第一相似对象特征向量;再基于对应于所述Q个类簇的Q个相似对象特征向量,确定上述目标对象特征向量。In another embodiment, considering that the calculation amount for calculating the M*N similarities is relatively large, the calculation process of the target vector can be optimized by using clustering to effectively reduce the calculation amount. Specifically, the above-mentioned multiple seed feature vectors are clustered to obtain Q (Q is a positive integer) clusters; then, for any first cluster in the Q clusters, the The seed feature vector is averaged to obtain a first average vector, and the similarity between the first average vector and each of the above-mentioned N object feature vectors is calculated to obtain N third similarities, and determine the maximum similarity among them The object feature vector corresponding to the degree is used as the first similar object feature vector; and the above target object feature vector is determined based on the Q similar object feature vectors corresponding to the Q clusters.
在一个具体的实施中,其中聚类处理可以采用K-Means聚类算法,DBSCAN聚类算法等聚类算法,具体不作限定。在一个具体的实施例中,其中基于对应于所述Q个类簇的Q个相似对象特征向量,确定上述目标对象特征向量,可以包括:将该Q个相似对象特征向量的平均向量,确定为目标对象特征向量,或者,将该Q个相似对象特征向量,共同作为目标对象特征向量。In a specific implementation, the clustering process may adopt clustering algorithms such as K-Means clustering algorithm, DBSCAN clustering algorithm, etc., which is not specifically limited. In a specific embodiment, determining the above-mentioned target object feature vector based on Q similar object feature vectors corresponding to the Q clusters may include: determining the average vector of the Q similar object feature vectors as The target object feature vector, or the Q similar object feature vectors are taken together as the target object feature vector.
由上,可以确定对应于第一样本用户的样本用户特征向量,以及对应于目标对象的目标对象特征向量。From the above, the sample user feature vector corresponding to the first sample user and the target object feature vector corresponding to the target object can be determined.
进一步地,在步骤S430,将该样本用户特征向量输入第一行为预测模型中,得到行为预测结果。在一个实施例中,其中第一行为预测模型可以为轻量级模型,例如,隐层数量小于阈值的多层感知机,如包含2个全连接层的多层感知机,又例如,逻辑回归模型或支持向量机等。Further, in step S430, the sample user feature vector is input into the first behavior prediction model to obtain a behavior prediction result. In one embodiment, the first behavior prediction model may be a lightweight model, for example, a multi-layer perceptron with a number of hidden layers less than a threshold, such as a multi-layer perceptron including 2 fully connected layers, or, for example, logistic regression models or support vector machines, etc.
在得到第一行为预测结果后,一方面,可以在步骤S440,基于该行为预测结果和该第一样本硬标签,确定第一损失项。在一个实施例中,可以根据交叉熵损失函数,或铰链损失函数,或欧式距离等,计算第一损失项。After the first behavior prediction result is obtained, on the one hand, in step S440, a first loss term may be determined based on the behavior prediction result and the first sample hard label. In one embodiment, the first loss term may be calculated according to a cross-entropy loss function, or a hinge loss function, or Euclidean distance, or the like.
另一方面,可以在步骤S450,基于该样本用户特征向量和该目标对象特征向量,确定该第一样本用户对该目标对象做出该特定行为的特定行为概率,作为第一样本软标签。并且,在步骤S460,基于该行为预测结果和该第一样本软标签,确定第二损失项。On the other hand, in step S450, based on the feature vector of the sample user and the feature vector of the target object, the specific behavior probability of the specific behavior performed by the first sample user to the target object may be determined, as the first sample soft label . And, in step S460, a second loss term is determined based on the behavior prediction result and the first sample soft label.
对于上述特定行为概率的确定,在一个实施例中,可以计算样本用户特征向量和目标对象特征向量的第二相似度,并对该第二相似度进行归一化处理,得到特定行为概率。在另一个实施例中,目标对象特征向量包括上述Q个对象特征向量,相应地,可以计算样本用户特征向量和上述Q个对象特征向量中各个向量之间的第四相似度,并对该第四相似度进行归一化处理,得到Q个归一化概率,进而计算该Q个归一化概率的均值,作为特定行为概率。在还一个实施例中,可以对样本用户特征向量和目标对象特征向量进行融合,得到第二融合向量,再将该第二融合向量输入训练后的上述分类网络中,得到特定行为概率。For the determination of the above specific behavior probability, in one embodiment, the second similarity between the sample user feature vector and the target object feature vector may be calculated, and the second similarity may be normalized to obtain the specific behavior probability. In another embodiment, the target object feature vector includes the above-mentioned Q object feature vectors, and accordingly, a fourth similarity between the sample user feature vector and each of the above-mentioned Q object feature vectors can be calculated, and the first The four similarities are normalized to obtain Q normalized probabilities, and then the mean of the Q normalized probabilities is calculated as the specific behavior probability. In yet another embodiment, the sample user feature vector and the target object feature vector may be fused to obtain a second fusion vector, and the second fusion vector may be input into the above-mentioned classification network after training to obtain the specific behavior probability.
对于第二损失项的确定,可以参见对第一损失项的相关描述,不作赘述。For the determination of the second loss item, reference may be made to the relevant description of the first loss item, and details are not repeated here.
以上可以确定出第一损失项和第二损失项,进而在步骤S470,利用该第一损失项和第二损失项,训练该第一行为预测模型。在一个实施例中,可以直接将第一损失项和第二损失项的加和结果,作为综合损失,训练第一行为预测模型。在另一个实施例中,可以为第一损失项和第二损失项人工分配不同的权重,再将加权求和的结果作为综合损失,训练第一行为预测模型。The first loss term and the second loss term can be determined above, and then in step S470, the first behavior prediction model is trained by using the first loss term and the second loss term. In one embodiment, the summation result of the first loss term and the second loss term may be directly used as a comprehensive loss to train the first behavior prediction model. In another embodiment, different weights may be manually assigned to the first loss item and the second loss item, and the result of the weighted summation is used as a comprehensive loss to train the first behavior prediction model.
如此,可以实现第一行为预测模型的训练,并且,在训练至迭代收敛或者迭代次数达到预定数值后,可以得到训练好的第一行为预测模型,用于确定目标对象的推荐人群,实现人群定向。In this way, the training of the first behavior prediction model can be realized, and after the training reaches the iteration convergence or the number of iterations reaches a predetermined value, the trained first behavior prediction model can be obtained, which is used to determine the recommended crowd of the target object and realize crowd orientation .
综上,采用本说明书实施例披露的行为预测模型的训练方法,在训练针对目标对象的第一行为预测模型的过程中,通过将GNN模型输出的特征向量作为先验知识,可以减少多个样本用户中种子用户存在的覆盖偏差,有效提高模型性能,加快训练速度,并且,因为第一行为预测模型可以实现为轻量级模型,因此,可以大大减少后续行为预测过程中的计算量。To sum up, using the training method of the behavior prediction model disclosed in the embodiments of this specification, in the process of training the first behavior prediction model for the target object, by using the feature vector output by the GNN model as prior knowledge, multiple samples can be reduced. The coverage bias of seed users among users can effectively improve model performance and speed up training. Moreover, because the first behavior prediction model can be implemented as a lightweight model, it can greatly reduce the amount of computation in the subsequent behavior prediction process.
根据另一方面的实施例,一者,考虑到上述针对目标对象的多个种子用户(对应样本标签为正例标签)存在一些噪声,例如,种子用户是根据目标对象的历史推荐情况确定的,而用户自身是一个不断变化的个体,其偏好可能发生改变导致标签不准确,或者,种子用户是根据人工设定的规则筛选得到的,这也会引入噪声标签;二者,考虑到不同的种子用户具有的可拓展性不同,例如,基于种子用户A拓展得到的50个推广用户中,有30个对目标对象做出特定行为,而基于种子用户B拓展得到的50个推广用户中,只有5个对目标对象做出特定行为,则种子用户A相较于种子用户B明显具有更高的拓展性。因此,发明人提出,在训练针对目标对象的行为预测模型时,可以为不同种子用户对应的正样本赋予不同的样本权重,从而降低噪声影响,提高模型拓展能力。According to another embodiment, on the one hand, considering that there is some noise in the above-mentioned multiple seed users for the target object (the corresponding sample labels are positive example labels), for example, the seed users are determined according to the historical recommendation situation of the target object, The user itself is a constantly changing individual, and its preferences may change, resulting in inaccurate labels, or the seed users are filtered according to manually set rules, which will also introduce noise labels; both, considering different seeds Users have different scalability. For example, among the 50 promoted users based on seed user A, 30 perform specific actions on the target object, while among the 50 promoted users based on seed user B, only 5 Compared with the seed user B, the seed user A has a higher scalability than the seed user B. Therefore, the inventor proposes that, when training a behavior prediction model for a target object, different sample weights can be assigned to positive samples corresponding to different seed users, thereby reducing the influence of noise and improving the model expansion capability.
具体地,图6示出根据另一个实施例的行为预测模型的训练方法流程图,所述方法的执行主体可以为任何具有计算、处理能力的平台、服务器、设备集群等。如图6所示,所述方法包括以下步骤:Specifically, FIG. 6 shows a flowchart of a training method for a behavior prediction model according to another embodiment, and the execution body of the method can be any platform, server, device cluster, etc. with computing and processing capabilities. As shown in Figure 6, the method includes the following steps:
步骤S610,针对目标对象,获取基于多个种子用户形成的多个正样本,其中任意的第一正样本包括,与第一种子用户对应的第一用户特征和正例标签,该正例标签指示出,对应用户是被确定为对该目标对象做出特定行为的用户;步骤S620,基于该多个种子用户各自的用户特征,采用无监督的离群点检测算法,确定该第一种子用户的离群分数,作为针对行为预测任务的第一训练权重;步骤S630,利用针对该行为预测任务的训练样本集,对第一行为预测模型进行第一训练,该训练样本集包括所述多个正样本以及预先获取的多个负样本;其中第一训练具体包括:步骤S631,将该第一用户特征输入第一行为预测模型中,得到对应的行为预测结果;步骤S632,基于该行为预测结果和该正例标签,确定行为预测损失,并利用该第一训练权重对该行为预测损失进行加权处理,得到加权损失;步骤S633,利用该加权损失,训练该第一行为预测模型。Step S610, for the target object, obtain a plurality of positive samples formed based on a plurality of seed users, wherein any first positive sample includes a first user feature corresponding to the first seed user and a positive example label, the positive example label indicates that , the corresponding user is a user who is determined to perform a specific behavior on the target object; step S620, based on the respective user characteristics of the multiple seed users, an unsupervised outlier detection algorithm is used to determine the distance of the first seed user. Group score, as the first training weight for the behavior prediction task; Step S630, use the training sample set for the behavior prediction task to perform the first training on the first behavior prediction model, and the training sample set includes the multiple positive samples and a plurality of negative samples obtained in advance; wherein the first training specifically includes: step S631, inputting the first user feature into the first behavior prediction model to obtain a corresponding behavior prediction result; step S632, based on the behavior prediction result and the Positive example label, determine the behavior prediction loss, and use the first training weight to weight the behavior prediction loss to obtain a weighted loss; step S633, use the weighted loss to train the first behavior prediction model.
针对以上步骤,首先需要说明的是,在一种实施情况下,图6中的第一行为预测模型可以是图4中提及的第一行为预测模型,此时,图6示出的方法是基于图4示出的方法做出的进一步改进。在另一种实施情况下,图6中的第一行为预测模型不同于图4中提及的第一行为预测模型,此时,图6示出的方法可以看作一个单独的方法流程,其并不依托于图4示出的方法流程;进一步地,在一种实施例中,第一行为预测模型可以实现为DNN(Deep NeuralNetworks,深度神经网络),或者CNN(Convolutional Neural Networks,卷积神经网络)。Regarding the above steps, it should be noted first that, in an implementation situation, the first behavior prediction model in FIG. 6 may be the first behavior prediction model mentioned in FIG. 4 . In this case, the method shown in FIG. 6 is A further improvement based on the method shown in FIG. 4 . In another implementation situation, the first behavior prediction model in FIG. 6 is different from the first behavior prediction model mentioned in FIG. 4 . In this case, the method shown in FIG. 6 can be regarded as a separate method flow, which It does not rely on the method flow shown in FIG. 4; further, in an embodiment, the first behavior prediction model may be implemented as DNN (Deep Neural Networks, deep neural network), or CNN (Convolutional Neural Networks, convolutional neural network) network).
以上步骤具体如下:The above steps are as follows:
首先,在步骤S610,针对目标对象,获取基于多个种子用户形成的多个正样本,其中任意的第一正样本包括,与第一种子用户对应的第一用户特征和正例标签,该正例标签指示出,对应用户是被确定为对该目标对象做出特定行为的用户。First, in step S610, for the target object, obtain multiple positive samples formed based on multiple seed users, wherein any first positive sample includes a first user feature corresponding to the first seed user and a positive example label, the positive example The label indicates that the corresponding user is the user determined to perform a specific action on the target object.
在一个实施例中,上述目标对象是历史推荐对象,此时,可以直接根据相关的历史数据,确定出曾经对该目标对象做出特定行为的历史用户,归为上述多个种子用户。在另一个实施例中,上述目标对象是新的待推荐对象,此时,尚不存在相关历史数据,此时,可以由工作人员根据目标对象的特点(例如,目标对象是江浙美食),设定筛选规则(消费记录中包括对江浙美食的交易),从海量用户中筛选出具有较高的可能性对该目标对象做出特定行为的用户,归为上述多个种子用户。In one embodiment, the above-mentioned target object is a historical recommendation object. In this case, historical users who have performed specific behaviors on the target object can be directly determined according to relevant historical data, and are classified as the above-mentioned multiple seed users. In another embodiment, the above-mentioned target object is a new object to be recommended. At this time, there is no relevant historical data. At this time, the staff can set the target object according to the characteristics of the target object (for example, the target object is Jiangsu and Zhejiang cuisine). According to the screening rules (consumption records include transactions of Jiangsu and Zhejiang cuisine), users who have a high possibility of doing specific behaviors to the target object are screened out from a large number of users, and they are classified as the above-mentioned multiple seed users.
相应地,可以获取多个种子用户形成的多个正样本。接着,在步骤S620,基于该多个种子用户各自的用户特征,采用无监督的离群点检测算法,确定该第一种子用户的离群分数,作为针对该行为预测任务的第一训练权重。需要理解,其中离群分数所对应的值域为[0,1],其中行为预测任务是指,预测用户是否会对目标对象做出特定行为的任务。Accordingly, multiple positive samples formed by multiple seed users can be obtained. Next, in step S620, based on the respective user characteristics of the multiple seed users, an unsupervised outlier detection algorithm is used to determine the outlier score of the first seed user as the first training weight for the behavior prediction task. It should be understood that the value range corresponding to the outlier score is [0, 1], and the behavior prediction task refers to the task of predicting whether the user will perform a specific behavior on the target object.
需要说明,发明人通过对多个对象的历史反馈数据进行统计分析发现,将多个历史种子用户映射至用户空间后,分布在稀疏区域的历史种子用户,相较于分布在密集区域的历史种子用户而言,可拓展性更强,并且,越稀疏越强。基于此,发明人提出,可以采用无监督的离群点检测算法(也称异常检测算法),给上述多个种子用户打分,进而确定针对行为预测任务的训练权重。需强调,种子用户的离群分数越高,说明其所在区域种子用户分布越稀疏,相应地,为其分配的权重越高。It should be noted that the inventor found through statistical analysis of the historical feedback data of multiple objects that after mapping multiple historical seed users to the user space, the historical seed users distributed in the sparse area are compared with the historical seeds distributed in the dense area. For users, the scalability is stronger, and the more sparse, the stronger. Based on this, the inventor proposes that an unsupervised outlier detection algorithm (also called anomaly detection algorithm) can be used to score the above-mentioned multiple seed users, and then determine the training weight for the behavior prediction task. It should be emphasized that the higher the outlier score of seed users, the sparser the distribution of seed users in their area, and the higher the weight assigned to them accordingly.
具体地,在一个实施例中,采用的离群点检测算法可以是孤立森林(IsolationForest)算法,相应地,本步骤中可以包括:首先,利用多个种子用户各自的用户特征,构建孤立森林模型,该孤立森林模型中包括多棵孤立树,其中每棵孤立树包括用于对种子用户进行划分的多个节点和节点之间的多条边;接着,将该第一用户特征输入该孤立森林模型,得到多条路径,其中各条路径为该第一种子用户在对应的孤立树中从根节点到叶节点经过的边;然后,将该各条路径中所包含边的数量输入与该孤立森林模型对应的离群评估函数,得到该第一种子用户的离群分数,作为上述第一训练权重。Specifically, in one embodiment, the adopted outlier detection algorithm may be an isolation forest (Isolation Forest) algorithm. Accordingly, this step may include: first, using the respective user characteristics of multiple seed users to construct an isolation forest model , the isolated forest model includes a plurality of isolated trees, wherein each isolated tree includes a plurality of nodes for dividing the seed users and a plurality of edges between the nodes; then, the first user feature is input into the isolated forest model to obtain multiple paths, where each path is the edge that the first seed user passes through from the root node to the leaf node in the corresponding isolated tree; then, input the number of edges contained in each path and the isolated tree The outlier evaluation function corresponding to the forest model is used to obtain the outlier score of the first seed user as the above-mentioned first training weight.
在另一个实施例中,采用的离群点检测算法可以是密度估计(DensityEstimation)算法,相应地,本步骤可以包括:基于多个种子用户各自的用户特征,利用密度估计算法,确定该多个种子用户对应的概率密度函数;然后,利用该概率密度函数,确定所述第一种子用户对应的概率密度;再利用预设的减函数对该概率密度进行运算,得到上述离群分数,作为上述第一训练权重。进一步地,在一个具体的实施例中,其中密度估计算法可以采用最大似然估计算法或核密度估计(Kernel Density Estimation)算法等。在一个具体的实施例中,其中预设的减函数可以是:y=1-x等,其中y表示离群分数,x表示概率密度。In another embodiment, the adopted outlier detection algorithm may be a density estimation (DensityEstimation) algorithm, and accordingly, this step may include: using a density estimation algorithm based on the respective user characteristics of multiple seed users to determine the multiple The probability density function corresponding to the seed user; then, use the probability density function to determine the probability density corresponding to the first seed user; and then use the preset subtraction function to calculate the probability density to obtain the above-mentioned outlier score, which is used as the above-mentioned The first training weight. Further, in a specific embodiment, the density estimation algorithm may adopt a maximum likelihood estimation algorithm or a kernel density estimation (Kernel Density Estimation) algorithm or the like. In a specific embodiment, the preset decreasing function may be: y=1-x, etc., where y represents the outlier score, and x represents the probability density.
由上,可以得到第一种子用户对应的第一训练权重,相应可得到多个种子用户对应的多个训练权重。From the above, the first training weight corresponding to the first seed user can be obtained, and correspondingly, multiple training weights corresponding to multiple seed users can be obtained.
然后在步骤S630,利用针对上述行为预测任务的训练样本集,对第一行为预测模型进行第一训练,该训练样本集包括所述多个正样本以及预先获取的多个负样本。需要理解,其中任意的第一负样本中包括对应用户的用户特征和负例标签,该负例标签指示出,对应用户是被确定为不对目标对象做出特定行为的用户。Then in step S630, first training is performed on the first behavior prediction model by using the training sample set for the above behavior prediction task, where the training sample set includes the plurality of positive samples and the plurality of pre-acquired negative samples. It should be understood that any first negative sample includes user characteristics of the corresponding user and a negative example label, and the negative example label indicates that the corresponding user is a user who is determined not to perform a specific behavior on the target object.
上述第一训练具体包括:在步骤S631,将第一用户特征输入第一行为预测模型中,得到对应的行为预测结果;接着在步骤S632,基于该行为预测结果和上述正例标签,确定行为预测损失,并利用上述第一训练权重对该行为预测损失进行加权处理,得到加权损失;然后在步骤S633,利用该加权损失,训练该第一行为预测模型。在一个实施例中,其中行为预测损失可以基于交叉熵损失函数、铰链损失函数、欧式距离等确定。The above-mentioned first training specifically includes: in step S631, inputting the first user characteristics into the first behavior prediction model to obtain a corresponding behavior prediction result; then in step S632, based on the behavior prediction result and the above positive example label, determine the behavior prediction loss, and use the above-mentioned first training weight to perform weighting processing on the behavior prediction loss to obtain a weighted loss; then in step S633, use the weighted loss to train the first behavior prediction model. In one embodiment, where the behavior prediction loss may be determined based on a cross-entropy loss function, a hinge loss function, Euclidean distance, or the like.
根据一个具体的实施例,在利用某批次样本对第一行为预测模型进行训练时,计算出的损失如下:According to a specific embodiment, when using a batch of samples to train the first behavior prediction model, the calculated loss is as follows:

其中,











如此,可以实现对第一行为预测模型的训练,从而利用训练好的第一行为预测模型,确定出目标对象适用的推荐人群。具体地,在一个实施例中,在步骤S630之后,上述方法还可以包括:先获取多个候选用户的多个用户特征,并将该多个用户特征分别输入训练后的第一行为预测模型中,得到对应的多个行为预测结果;接着基于该多个行为预测结果,从多个候选用户中选出多个目标用户;再向该多个目标用户推送目标对象。In this way, the training of the first behavior prediction model can be realized, so that the recommended group suitable for the target object is determined by using the trained first behavior prediction model. Specifically, in one embodiment, after step S630, the above method may further include: first acquiring multiple user characteristics of multiple candidate users, and inputting the multiple user characteristics into the trained first behavior prediction model respectively , to obtain multiple corresponding behavior prediction results; then, based on the multiple behavior prediction results, select multiple target users from multiple candidate users; and then push target objects to the multiple target users.
对于上述多个候选用户的确定,在一个具体的实施例中,可以是根据预置规则确定的,例如,可以是从未被推送过目标对象的用户中,随机选取预定数量的用户作为该多个候选用户,又例如,假定该目标对象适合被推送给开通了某项服务的用户,则可以将开通了该某项服务的用户归为该多个候选用户。For the determination of the above-mentioned multiple candidate users, in a specific embodiment, it may be determined according to a preset rule, for example, it may be that a predetermined number of users are randomly selected as the multiple users who have never been pushed to the target object. For another example, if the target object is suitable for being pushed to a user who has activated a certain service, the users who have activated the certain service can be classified as the multiple candidate users.
对于上述多个目标用户的选取,在一个具体的实施例中,对于某个候选用户,如果其对应的行为预测结果指示其会对目标对象做出特定行为,则将该某个候选对象归入多个目标用户。在另一个具体的实施例中,上述多个行为预测结果对应多个行为预测概率,可以基于该多个行为预测概率对多个候选用户进行排序,再将排在预设范围(如前10万名)内的候选用户确定为多个目标用户。For the selection of the above-mentioned multiple target users, in a specific embodiment, for a certain candidate user, if the corresponding behavior prediction result indicates that it will perform a specific behavior on the target object, the certain candidate object is classified into the Multiple target users. In another specific embodiment, the above-mentioned multiple behavior prediction results correspond to multiple behavior prediction probabilities, and the multiple candidate users can be sorted based on the multiple behavior prediction probabilities, and then ranked in a preset range (such as the top 100,000 users) The candidate users within the name) are identified as multiple target users.
在选取出多个目标用户后,向该多个目标用户推送目标对象。进一步地,在一个实施例中,在向该多个目标用户推送目标对象之后,可以对该多个目标用户针对该目标对象的反馈数据进行采集,然后利用反馈数据训练行为预测模型,进行人群重定向。需要理解,基于反馈数据构建的训练数据具有更高的时效性和准确性,因此利用反馈数据训练行为预测模型,能够得到较好的预测效果。After the multiple target users are selected, the target objects are pushed to the multiple target users. Further, in one embodiment, after the target object is pushed to the multiple target users, the feedback data of the multiple target users on the target object can be collected, and then the behavior prediction model can be trained by using the feedback data, and the crowd re-evaluation can be performed. Orientation. It should be understood that the training data constructed based on the feedback data has higher timeliness and accuracy, so using the feedback data to train the behavior prediction model can obtain better prediction results.
具体地,先获取针对多个目标用户采集的行为反馈数据,接着基于该行为反馈数据构建多个训练样本,其中各个训练样本中包括对应目标用户的用户特征和样本标签,该样本标签指示该对应目标用户是否对所述目标对象做出所述特定行为;再利用该多个训练样本,训练第二行为预测模型。需要说明,其中第二行为预测模型可以独立于上述第一行为预测模型,或者,第二行为预测模型也可以是上述训练后的第一行为预测模型,相应地,训练第二行为预测模型实际就是对第一行为预测模型进行再训练。如此,可以利用训练后的第二行为预测模型确定针对目标对象的目标推荐用户,进行目标对象的后续推送。Specifically, first obtain behavior feedback data collected for multiple target users, and then construct multiple training samples based on the behavior feedback data, wherein each training sample includes user characteristics and sample labels corresponding to the target users, and the sample labels indicate the corresponding target users. Whether the target user performs the specific behavior on the target object; and then use the multiple training samples to train a second behavior prediction model. It should be noted that the second behavior prediction model may be independent of the first behavior prediction model described above, or the second behavior prediction model may also be the first behavior prediction model after training. Correspondingly, training the second behavior prediction model is actually Retrain the first behavior prediction model. In this way, the target recommended user for the target object can be determined by using the trained second behavior prediction model, and the subsequent push of the target object can be performed.
需要说明,发明人在对历史反馈数据进行研究的过程中发现,在连续多个采集周期(如每个采集周期可以为1天)内采集到的多批反馈数据,其中不同批次的反馈数据中做出特定行为的用户存在分布差异,这就会导致基于某批次或某几批次反馈数据构建的多个训练样本中的正样本存在覆盖偏差(例如,某些用户难以被拓展到)。因此,发明人想到,上述冷启动阶段确定的多个种子用户,其中用户量比较丰富,覆盖偏差相对较小,因此可以结合反馈数据和多个种子用户共同训练第二行为预测模型。然而,发明人还考虑到,上述多个种子用户存在一些噪声用户,如果只是简单的将两部分数据混在一起进行模型训练,可能会导致相较于单独使用反馈数据,训练出的模型预测性能会有所降低。因此,发明人进一步提出,对上述多个种子用户进行筛选,筛选出其中较优质的种子用户,再结合基于反馈数据构建的上述多个训练样本,对上述第二行为预测模型进行训练。It should be noted that in the process of researching the historical feedback data, the inventor found that among the multiple batches of feedback data collected in multiple consecutive collection periods (for example, each collection period can be 1 day), the feedback data of different batches There are differences in the distribution of users who have performed specific behaviors in the network, which will lead to coverage bias in the positive samples in multiple training samples constructed based on a certain batch or batches of feedback data (for example, some users are difficult to be extended to) . Therefore, the inventor thinks that the number of seed users determined in the cold start phase is relatively abundant, and the coverage deviation is relatively small, so the second behavior prediction model can be jointly trained by combining the feedback data and multiple seed users. However, the inventor also considers that there are some noisy users in the above-mentioned multiple seed users. If the model training is performed by simply mixing the two parts of the data together, the prediction performance of the trained model may be lower than that of using the feedback data alone. somewhat reduced. Therefore, the inventor further proposes that the above-mentioned multiple seed users are screened to select the better-quality seed users, and then the above-mentioned second behavior prediction model is trained in combination with the above-mentioned multiple training samples constructed based on the feedback data.
在一个具体的实施例中,从对应于多个种子用户的多个正样本中,确定多个选中正样本,再利用该多个选中正样本和上述多个训练样本,训练第二行为预测模型。在一个更具体的实施例中,其中确定多个选中正样本可以包括:利用上述多个训练样本,训练第三行为预测模型;再将多个正样本中包含的多个用户特征,分别输入训练后的第三行为预测模型中,得到多个预测概率,进而确定该多个预测概率中排在预定靠前范围内的预测概率,并将对应的正样本归为所述多个选中正样本。需要说明,第三行为预测模型用于筛选优质种子用户,其是利用多个训练样本训练得到,不同于第二行为预测模型,用于进行人群重定向,需要利用多个训练样本和筛选出的优质正样本进行训练。在一个例子中,其中预定靠前范围可以是一个比例范围(如前10%),也可以是一个具体的名次范围(如前10万名)。在另一个更具体的实施例中,其中确定多个选中正样本可以包括:获取工作人员从多个正样本中确定出的多个选中正样本。In a specific embodiment, a plurality of selected positive samples are determined from a plurality of positive samples corresponding to a plurality of seed users, and the second behavior prediction model is trained by using the plurality of selected positive samples and the above-mentioned plurality of training samples . In a more specific embodiment, determining a plurality of selected positive samples may include: using the above-mentioned plurality of training samples to train a third behavior prediction model; and then inputting a plurality of user features contained in the plurality of positive samples into training In the latter third behavior prediction model, a plurality of predicted probabilities are obtained, and then the predicted probabilities ranked in the predetermined front range among the multiple predicted probabilities are determined, and the corresponding positive samples are classified as the plurality of selected positive samples. It should be noted that the third behavior prediction model is used to screen high-quality seed users, which is obtained by training with multiple training samples. Unlike the second behavior prediction model, which is used for crowd redirection, multiple training samples and selected High-quality positive samples for training. In an example, the predetermined top range may be a proportional range (eg, the top 10%), or a specific ranking range (eg, the top 100,000). In another more specific embodiment, determining a plurality of selected positive samples may include: acquiring a plurality of selected positive samples determined by a staff member from the plurality of positive samples.
如此,可以利用多个选中正样本和上述基于反馈数据构建的多个训练样本,训练第二行为预测模型。进一步地,发明人还考虑到,多个选中正样本中仍然存在一定的噪声,为了更进一步优化第二行为预测模型的训练性能,可以为多个选中正样本分配权重,从而削弱噪声的影响。In this way, the second behavior prediction model can be trained by using multiple selected positive samples and multiple training samples constructed based on the feedback data. Further, the inventor also considers that there is still a certain amount of noise in multiple selected positive samples, in order to further optimize the training performance of the second behavior prediction model, weights can be assigned to multiple selected positive samples, thereby weakening the influence of noise.
根据一个具体的实施例,上述利用多个训练样本以及多个选中正样本,训练第二行为预测模型,可以包括:将所述多个选中正样本中第一选中正样本所包含的用户特征,输入第二行为预测模型中,得到第一预测结果,进而结合所述正例标签,确定第一预测损失;然后,利用第一选中正样本对应的第一权重对该第一预测损失进行加权,得到第一加权损失;再利用该第一加权损失,训练第二行为预测模型。在一个更具体的实施例中,其中多个选中正样本对应的权重可以是由工作人员预先设定,具体可以设定成统一的权重,如0.8或0.6。According to a specific embodiment, the above-mentioned using multiple training samples and multiple selected positive samples to train the second behavior prediction model may include: using the user characteristics included in the first selected positive sample among the multiple selected positive samples, Input the second behavior prediction model to obtain the first prediction result, and then combine the positive example label to determine the first prediction loss; then, use the first weight corresponding to the first selected positive sample to weight the first prediction loss, The first weighted loss is obtained; and the second behavior prediction model is trained by using the first weighted loss. In a more specific embodiment, the weights corresponding to the plurality of selected positive samples may be preset by the staff, and may be specifically set as a uniform weight, such as 0.8 or 0.6.
在另一个更具体的实施例中,可以利用反馈数据指导多个选中样本中各样本的权重的设定,从而使得权重设定的可信度更高,并且,训练出的第二行为预测模型的预测性能更好,具体地,可以采用元学习(meta-learning)的方式,相关描述如下:In another more specific embodiment, the feedback data can be used to guide the setting of the weight of each sample in the plurality of selected samples, so that the credibility of the weight setting is higher, and the trained second behavior prediction model The prediction performance is better. Specifically, the meta-learning method can be used. The relevant descriptions are as follows:
发明人通过对行为反馈数据进行分析得到:产生时间越靠后的反馈数据,其反映的用户覆盖偏差越小,据此,针对上述基于行为反馈数据构建的多个训练样本,按照时间方向(time direction),从中划分出基于该行为反馈数据中在预定时刻之后产生的部分构建的部分训练样本,作为无偏差(no bias)的元数据(meta-data)。例如,对于最近24小时内产生的行为反馈数据,将基于其中最近1小时内的数据构建的训练样本,作为元数据。The inventor obtained by analyzing the behavior feedback data: the feedback data generated later in time, the smaller the user coverage deviation reflected by the feedback data. Accordingly, for the above-mentioned multiple training samples constructed based on the behavior feedback data, according to the time direction (time direction). direction), from which part of the training samples constructed based on the part generated after a predetermined time in the behavioral feedback data are divided as no bias metadata (meta-data). For example, for the behavior feedback data generated within the last 24 hours, the training samples constructed based on the data within the last 1 hour will be used as metadata.
为便于描述,将元数据表示为












其中,


在公式(13)和(14)中,









由公式(13)和公式(14)可以看出,其中存在嵌套循环(Nested Loop),为了避免出现这一问题,可以采用以下策略实现对

首先,将上述多个选中正样本中第二选中正样本所包含的用户特征,输入第二行为预测模型中,得到第二预测结果,进而结合正例标签,确定第二预测损失;然后,利用权重函数,确定第二选中样本所对应的权重表达式(其中包含变量而非数值形式的

其中,







在以上得到更新后参数表达式后,利用该更新后参数表达式,确定元数据中的第一训练样本对应的训练损失表达式,并利用训练损失表达式更新权重函数中参数

其中
由此可以得到第一权重

需要说明,若


由上,可以实现利用元学习,对多个选中样本的权重进行可靠设定,从而进一步提高第二行为预测模型的预测性能。From the above, meta-learning can be used to reliably set the weights of multiple selected samples, thereby further improving the prediction performance of the second behavior prediction model.
综上,采用本说明书实施例披露的行为预测模型的训练方法,在人群定向的冷启动阶段,利用无监督的离群点检测算法,对上述多个正样本中的各个正样本进行权重分配,从而降低噪标签对第一行为预测模型的性能影响。进一步地,在获得用户反馈数据后,利用用户反馈数据训练第二行为预测模型,实现更加精准的人群重定向,使用户被推荐到符合自身需求的目标对象,从而有效提高用户体验。To sum up, using the training method of the behavior prediction model disclosed in the embodiment of this specification, in the cold start stage of crowd orientation, the unsupervised outlier detection algorithm is used to assign weights to each positive sample in the above-mentioned multiple positive samples, Thereby, the impact of noisy labels on the performance of the first behavior prediction model is reduced. Further, after obtaining user feedback data, use the user feedback data to train a second behavior prediction model to achieve more accurate crowd redirection, so that users are recommended to target objects that meet their own needs, thereby effectively improving user experience.
与上述行为预测模型的训练方法相对应地,本说明书实施例还披露训练装置,具体如下:Corresponding to the training method of the above-mentioned behavior prediction model, the embodiment of this specification also discloses a training device, which is as follows:
图7示出根据一个实施例的行为预测模型的训练装置结构图。如图7所示,所述装置700包括:FIG. 7 shows a structural diagram of a training device for a behavior prediction model according to an embodiment. As shown in FIG. 7, the
样本用户确定单元710,配置为确定针对目标对象的多个样本用户,其中任一的第一样本用户对应第一样本硬标签,该第一样本硬标签指示该第一样本用户是否对所述目标对象做出特定行为。特征向量确定单元720,配置为基于预先确定的嵌入向量集,确定对应于所述第一样本用户的样本用户特征向量,并且,确定对应于所述目标对象的目标对象特征向量;其中,所述嵌入向量集是利用训练后的图神经网络对构建的二部图进行图嵌入处理而确定;所述二部图包括对应于多个用户的多个用户节点,对应于多个对象的多个对象节点,以及用户节点向对象节点做出所述特定行为而形成的连接边,所述嵌入向量集中包括所述多个用户的多个用户特征向量和所述多个对象的多个对象特征向量。行为预测单元730,配置为将所述样本用户特征向量输入第一行为预测模型中,得到行为预测结果。第一损失确定单元740,配置为基于所述行为预测结果和所述第一样本硬标签,确定第一损失项。软标签确定单元750,配置为基于所述样本用户特征向量和所述目标对象特征向量,确定所述第一样本用户对该目标对象做出该特定行为的特定行为概率,作为第一样本软标签。第二损失确定单元760,配置为基于所述行为预测结果和所述第一样本软标签,确定第二损失项。第一行为训练单元770,配置为利用所述第一损失项和第二损失项,训练所述第一行为预测模型。The sample
在一个实施例中,所述目标对象属于以下中的任一种:内容信息、业务登录界面、商品、服务、用户;其中内容信息的形式包括以下中的至少一种:图片、文本、视频。In one embodiment, the target object belongs to any one of the following: content information, business login interface, commodity, service, and user; wherein the content information includes at least one of the following forms: picture, text, and video.
在一个实施例中,所述特定行为包括以下中的任一种:点击行为、浏览达到预设时长的行为、注册行为、登录行为、购买行为和关注行为。In one embodiment, the specific behavior includes any one of the following: click behavior, browsing behavior for a preset duration, registration behavior, login behavior, purchase behavior, and attention behavior.
在一个实施例中,所述图神经网络包括L个隐层,所述图嵌入处理基于图嵌入单元780而实现,其中图嵌入单元780配置为:针对所述二部图中任意的第一节点,在每个隐层,获取上一隐层输出的隐向量,所述隐向量包括对应于K个特征子空间的K个子隐向量,对所述K个子隐向量分别进行T次迭代更新得到本层输出的隐向量,将第L个隐层输出的隐向量作为所述第一节点对应的特征向量。In one embodiment, the graph neural network includes L hidden layers, and the graph embedding process is implemented based on a
在一个具体的实施例中,所述图嵌入单元780具体配置为:对所述K个子隐向量中任意的第j子隐向量进行T次迭代更新,其中任一次迭代更新通过所述图嵌入单元中包含的以下模块实现:In a specific embodiment, the
映射向量获取模块781,配置为获取所述第一节点的第j子映射向量,其是将所述第一节点的节点特征映射至第j个子特征空间而得到;并且,获取所述第一节点的N个邻居节点各自对应的K个子映射向量,该K个子映射向量是将对应的邻居节点的节点特征映射至所述K个特征子空间而得到。权重计算模块782,配置为针对所述N个邻居节点中任一的第二节点,分别计算该第二节点对应的K个子映射向量与所述第j子隐向量之间的K个相似度,并利用其和值对其中第j个相似度进行归一化处理,得到第一权重。映射向量加权模块783,配置为利用对应于N个邻居节点的N个第一权重,对该N个邻居节点所对应的N个第j子映射向量进行加权处理,得到加权向量。隐向量更新模块784,配置为将所述第j子隐向量更新为,所述第一节点的第j子映射向量和所述加权向量的和向量所对应的单位向量。The mapping
在一个更具体的实施例中,所述映射向量加权模块783具体配置为:获取对N个注意力分数进行归一化处理而得到的N个第二权重,所述N个注意力分数对应所述N个邻居节点,其中各个注意力分数是基于其对应的邻居节点的节点特征和所述第一节点的节点特征而确定;对所述N个第一权重和所述N个第二权重进行对应位置的权重相乘处理,得到N个第三权重;利用N个第三权重,对所述N个第j子映射向量进行加权处理,得到所述加权向量。In a more specific embodiment, the mapping
在一个实施例中,所述图神经网络包括L个隐层,所述图嵌入处理基于图嵌入单元780而实现,其中图嵌入单元780配置为:针对所述二部图中任意的第一节点,在每个隐层,获取上一隐层输出的隐向量,对该隐向量进行T次迭代更新作为本层输出,将第L个隐层输出的隐向量作为所述第一节点对应的特征向量;其中,所述T次迭代更新中的任一次迭代更新包括:In one embodiment, the graph neural network includes L hidden layers, and the graph embedding process is implemented based on a
获取所述第一节点及其N个邻居节点各自对应的映射向量,该映射向量是将其对应节点的节点特征映射至预设特征空间而得到;计算所述N个邻居节点各自对应的映射向量与所述隐向量之间的相似度,得到N个相似度,并对该N个相似度进行归一化处理,得到N个第一权重;获取对N个注意力分数进行归一化处理而得到的N个第二权重,所述N个注意力分数对应所述N个邻居节点,其中各个注意力分数是基于其对应的邻居节点的节点特征和所述第一节点的节点特征而确定;对所述N个第一权重和所述N个第二权重进行对应位置的权重相乘处理,得到N个第三权重;利用所述N个第三权重,对所述N个邻居节点对应的N个映射向量进行加权处理,得到所述加权向量;将所述隐向量更新为,所述第一节点的映射向量与所述加权向量的和向量所对应的单位向量。Obtain the mapping vectors corresponding to the first node and its N neighbor nodes, which are obtained by mapping the node features of the corresponding nodes to a preset feature space; calculate the mapping vectors corresponding to the N neighbor nodes. The similarity with the hidden vector, N similarities are obtained, and the N similarities are normalized to obtain N first weights; the N attention scores are normalized to obtain The obtained N second weights, the N attention scores correspond to the N neighbor nodes, wherein each attention score is determined based on the node characteristics of its corresponding neighbor nodes and the node characteristics of the first node; The N first weights and the N second weights are multiplied by the weights of the corresponding positions to obtain N third weights; using the N third weights, the corresponding positions of the N neighbor nodes are Perform weighting processing on the N mapping vectors to obtain the weighting vector; and update the latent vector to a unit vector corresponding to the sum vector of the mapping vector of the first node and the weighting vector.
在一个实施例中,所述图神经网络通过图神经网络训练单元包含的以下模块进行训练得到:In one embodiment, the graph neural network is obtained by training the following modules included in the graph neural network training unit:
样本集获取模块,配置为获取训练样本集,其中任一的第一训练样本中包括第一用户的用户标识、第一对象的对象标识和第一样本标签,该第一样本标签指示所述第一用户是否向所述第一对象做出所述特定行为;图嵌入模块,配置为通过所述图神经网络对所述二部图进行图嵌入处理,确定所述第一用户的第一用户特征向量和所述第一对象的第一对象特征向量;概率确定模块,配置为基于所述第一用户特征向量和第一对象特征向量,确定所述第一用户对所述第一对象做出所述特定行为的第一行为概率;损失确定模块,配置为基于所述第一行为概率和所述第一样本标签,确定行为预测损失;图神经网络训练模块,配置为利用所述行为预测损失,训练所述图神经网络。The sample set acquisition module is configured to acquire a training sample set, wherein any of the first training samples includes the user ID of the first user, the object ID of the first object, and a first sample label, the first sample label indicating the whether the first user performs the specific behavior to the first object; the graph embedding module is configured to perform graph embedding processing on the bipartite graph through the graph neural network, and determine the first user's first The user feature vector and the first object feature vector of the first object; the probability determination module is configured to determine, based on the first user feature vector and the first object feature vector, what the first user does to the first object; the first behavior probability of the specific behavior; the loss determination module is configured to determine the behavior prediction loss based on the first behavior probability and the first sample label; the graph neural network training module is configured to use the behavior To predict the loss, train the graph neural network.
在一个具体的实施例中,所述概率确定模块具体配置为:计算所述第一用户特征向量和第一对象特征向量的第一相似度,并对该第一相似度进行归一化处理,得到所述第一行为概率;其中,所述软标签确定单元750具体配置为:计算所述样本用户特征向量和目标对象特征向量的第二相似度,并对该第二相似度进行归一化处理,得到所述特定行为概率。In a specific embodiment, the probability determination module is specifically configured to: calculate a first similarity between the first user feature vector and the first object feature vector, and perform normalization processing on the first similarity, Obtain the first behavior probability; wherein, the soft
在另一个具体的实施例中,所述概率确定模块配置为:对所述第一用户特征向量和第一对象特征向量进行融合,得到第一融合向量;将所述第一融合向量输入所述分类网络中,得到所述第一行为概率;其中,所述图神经网络训练模块具体配置为:利用所述行为预测损失,训练分类网络和所述图神经网络;其中,所述软标签确定单元750具体配置为:对所述样本用户特征向量和所述目标对象特征向量进行融合,得到第二融合向量;将所述第二融合向量输入训练后的分类网络中,得到所述特定行为概率。In another specific embodiment, the probability determination module is configured to: fuse the first user feature vector and the first object feature vector to obtain a first fusion vector; input the first fusion vector into the In the classification network, the first behavior probability is obtained; wherein, the graph neural network training module is specifically configured to: use the behavior prediction loss to train the classification network and the graph neural network; wherein, the soft
在一个实施例中,所述多个样本用户中包括多个种子用户,其中各个种子用户对应的样本硬标签均指示对所述目标对象做出所述特定行为。In one embodiment, the multiple sample users include multiple seed users, wherein the sample hard tags corresponding to each seed user indicate that the specific behavior is performed on the target object.
进一步地,在一个具体的实施例中,其中,所述目标对象不属于所述二部图中包含的所述多个对象;其中,所述特征向量确定单元720通过其包含的以下模块确定所述目标对象特征向量:Further, in a specific embodiment, the target object does not belong to the plurality of objects included in the bipartite graph; wherein, the feature
种子向量确定模块721,配置为确定所述多个种子用户对应的多个种子特征向量;对象向量确定模块722,配置为根据所述多个种子特征向量和所述多个对象特征向量,确定所述目标对象特征向量。The seed
在一个更具体的实施例中,所述多个种子用户为M个,所述多个对象特征向量为N个;所述对象向量确定模块722具体配置为:In a more specific embodiment, the number of the multiple seed users is M, and the number of the multiple object feature vectors is N; the object vector determination module 722 is specifically configured as:
计算M个种子特征向量中各个向量与N个对象特征向量中各个向量之间的相似度,得到M*N个相似度;确定所述M*N个相似度中在预定范围内的若干相似度,并将该若干相似度所对应的若干对象特征向量的平均向量,作为所述目标对象特征向量。Calculate the similarity between each vector in the M seed feature vectors and each vector in the N object feature vectors to obtain M*N similarities; determine a number of similarities within a predetermined range in the M*N similarities , and the average vector of several object feature vectors corresponding to the several similarities is taken as the target object feature vector.
在另一个更具体的实施例中,所述多个对象特征向量为N个;所述对象向量确定模块722具体包括:向量聚类子模块,配置为对所述多个种子特征向量进行聚类处理,得到Q个类簇;相似对象确定子模块,配置为针对所述Q个类簇中任一的第一类簇,对其中所包含的种子特征向量进行平均处理,得到第一平均向量,并计算该第一平均向量与N个对象特征向量中各个向量之间的相似度,得到N个第三相似度,并确定其中的最大相似度所对应的对象特征向量,作为第一相似对象特征向量;对象向量确定子模块,配置为基于对应于所述Q个类簇的Q个相似对象特征向量,确定所述目标对象特征向量。In another more specific embodiment, the plurality of object feature vectors is N; the object vector determination module 722 specifically includes: a vector clustering sub-module configured to cluster the plurality of seed feature vectors processing to obtain Q clusters; the similar object determination submodule is configured to perform averaging processing on the seed feature vectors contained in any of the first clusters in the Q clusters to obtain the first mean vector, And calculate the similarity between the first average vector and each of the N object feature vectors, obtain N third similarities, and determine the object feature vector corresponding to the maximum similarity among them, as the first similar object feature vector; an object vector determination submodule, configured to determine the target object feature vector based on the Q similar object feature vectors corresponding to the Q clusters.
更进一步地,在一个例子中,所述对象向量确定子模块具体配置为:将该Q个相似对象特征向量的平均向量,确定为所述目标对象特征向量。在另一个例子中,其中,所述对象向量确定子模块具体配置为:将所述Q个对象特征向量共同作为所述目标对象特征向量;其中,所述软标签确定单元750具体配置为:计算所述样本用户特征向量和所述Q个对象特征向量中各个向量之间的第四相似度,并对该第四相似度进行归一化处理,得到Q个归一化概率;计算所述Q个归一化概率的均值,作为所述特定行为概率。Further, in an example, the object vector determination submodule is specifically configured to: determine the average vector of the Q similar object feature vectors as the target object feature vector. In another example, the object vector determination sub-module is specifically configured to: take the Q object feature vectors together as the target object feature vector; wherein, the soft
在一个实施例中,所述装置还包括权重确定单元790,配置为:基于对应于所述多个种子用户的多个种子用户特征向量,采用无监督的离群点检测算法,确定其中任一的第一种子用户的离群分数,作为第一训练权重;其中,所述第一行为训练单元770具体配置为:在所述第一样本用户为所述第一种子用户的情况下,利用所述第一训练权重对所述第一损失项和第二损失项的相加结果进行加权,得到加权损失;利用所述加权损失,训练所述第一行为预测模型。In one embodiment, the apparatus further includes a weight determination unit 790, configured to: based on a plurality of seed user feature vectors corresponding to the plurality of seed users, using an unsupervised outlier detection algorithm, determine any one of the The outlier score of the first seed user is used as the first training weight; wherein, the first
在一个实施例中,所述装置700还包括目标用户确定单元791,配置为:获取多个候选用户的多个用户特征,并将该多个用户特征分别输入训练后的第一行为预测模型中,得到对应的多个行为预测结果;基于所述多个行为预测结果,从所述多个候选用户中选出多个目标用户;向所述多个目标用户推送所述目标对象。In one embodiment, the
在一个具体的实施例中,所述装置700还包括第二行为训练单元792,配置为:获取针对所述多个目标用户采集的行为反馈数据;基于所述行为反馈数据构建多个训练样本,其中各个训练样本中包括对应目标用户的用户特征和样本标签,该样本标签指示该对应目标用户是否对所述目标对象做出所述特定行为;利用所述多个训练样本,训练第二行为预测模型。In a specific embodiment, the
综上,采用本说明书实施例披露的行为预测模型的训练装置,在训练针对目标对象的第一行为预测模型的过程中,通过将GNN模型输出的特征向量作为先验知识,可以减少多个样本用户中种子用户存在的覆盖偏差,有效提高模型性能,加快训练速度,并且,因为第一行为预测模型可以实现为轻量级模型,因此,可以大大减少后续行为预测过程中的计算量。To sum up, using the behavior prediction model training device disclosed in the embodiments of this specification, in the process of training the first behavior prediction model for the target object, by using the feature vector output by the GNN model as prior knowledge, multiple samples can be reduced. The coverage bias of seed users among users can effectively improve model performance and speed up training. Moreover, because the first behavior prediction model can be implemented as a lightweight model, it can greatly reduce the amount of computation in the subsequent behavior prediction process.
图8示出根据另一个实施例的行为预测模型的训练装置结构图,如图8所示,所述装置800包括:FIG. 8 shows a structural diagram of a training apparatus for a behavior prediction model according to another embodiment. As shown in FIG. 8 , the
样本获取单元810,配置为针对目标对象,获取基于多个种子用户形成的多个正样本,其中任意的第一正样本包括,与第一种子用户对应的第一用户特征和正例标签,该正例标签指示出,对应用户是被确定为对所述目标对象做出特定行为的用户;样本权重确定单元820,配置为基于所述多个种子用户各自的用户特征,采用无监督的离群点检测算法,确定所述第一种子用户的离群分数,作为针对行为预测任务的第一训练权重;第一模型训练单元830,配置为利用针对所述行为预测任务的训练样本集,对第一行为预测模型进行第一训练,所述训练样本集包括所述多个正样本以及预先获取的多个负样本;所述第一模型训练单元具体包括以下模块:第一预测模块831,配置为将所述第一用户特征输入第一行为预测模型中,得到对应的行为预测结果;第一损失确定模块832,配置为基于所述行为预测结果和所述正例标签,确定行为预测损失;第一损失加权模块833,配置为利用所述第一训练权重对该行为预测损失进行加权处理,得到加权损失;第一训练模块834,配置为利用所述加权损失,训练所述第一行为预测模型。The
在一个实施例中,所述样本权重确定单元820具体配置为:利用所述多个种子用户各自的用户特征,构建孤立森林模型,所述孤立森林模型中包括多棵孤立树,其中每棵孤立树包括用于对种子用户进行划分的多个节点和节点之间的多条边;将所述第一用户特征输入所述孤立森林模型,得到多条路径,其中各条路径为所述第一种子用户在对应的孤立树中从根节点到叶节点经过的边;将所述各条路径中所包含边的数量输入与所述孤立森林模型对应的离群评估函数,得到所述第一种子用户的离群分数。In one embodiment, the sample
在一个实施例中,所述样本权重确定单元820具体配置为:基于所述多个种子用户各自的用户特征,利用密度估计算法,确定所述多个种子用户对应的概率密度函数;利用所述概率密度函数,确定所述第一种子用户对应的概率密度;利用预设的减函数对所述概率密度进行运算,得到所述离群分数。In one embodiment, the sample
在一个实施例中,所述装置800还包括目标用户确定单元,配置为:获取多个候选用户的多个用户特征,并将该多个用户特征分别输入训练后的第一行为预测模型中,得到对应的多个行为预测结果;基于所述多个行为预测结果,从所述多个候选用户中选出多个目标用户;向所述多个目标用户推送所述目标对象。In one embodiment, the
在一个具体的实施例中,所述装置800还包括第二模型训练单元840,该第二模型训练单元包括以下模块:反馈数据获取模块841,配置为获取针对所述多个目标用户采集的行为反馈数据;样本构建模块842,配置为基于所述行为反馈数据构建多个训练样本,其中各个训练样本中包括对应目标用户的用户特征和样本标签,该样本标签指示该对应目标用户是否对所述目标对象做出所述特定行为;第二训练模块843,配置为利用所述多个训练样本,训练第二行为预测模型。In a specific embodiment, the
在一个更具体的实施例中,所述第二训练模块843具体包括:样本选取子模块8431,配置为从所述多个正样本中确定多个选中正样本;第二训练子模块8432,配置为利用所述多个训练样本以及所述多个选中正样本,训练第二行为预测模型。In a more specific embodiment, the
进一步地,在一个例子中,所述样本选取子模块8431具体配置为:利用所述多个训练样本,训练第三行为预测模型;将所述多个正样本中包含的多个用户特征,分别输入训练后的第三行为预测模型中,得到多个预测概率;确定所述多个预测概率中排在预定靠前范围内的预测概率,并将对应的正样本归为所述多个选中正样本。Further, in one example, the
在另一个例子中,所述第二训练子模块8432具体配置为:将所述多个选中正样本中第一选中正样本所包含的用户特征,输入所述第二行为预测模型中,得到第一预测结果,进而结合所述正例标签,确定第一预测损失;采用元学习的方式,确定所述第一选中正样本对应的第一权重,并利用该第一权重对所述第一预测损失进行加权,得到第一加权损失;利用所述第一加权损失,训练所述第二行为预测模型。In another example, the
在一个更具体的例子中,所述多个训练样本包括第一训练样本,其基于所述行为反馈数据中在预定时刻之后产生的部分而构建;其中,所述第二训练子模块8432进一步配置为通过执行以下内容实现所述采用元学习的方式,确定所述第一选中正样本对应的第一权重:将所述多个选中正样本中第二选中正样本所包含的用户特征,输入所述第二行为预测模型中,得到第二预测结果,进而结合所述正例标签,确定第二预测损失;利用权重变量对所述第二预测结果进行加权,得到加权损失表达式;基于所述加权损失表达式,对所述第二行为预测模型中的模型参数进行更新计算,得到所述模型参数的更新后参数表达式;利用所述更新后参数表达式,确定所述第一训练样本对应的训练损失表达式;利用所述训练损失表达式更新所述权重变量对应的数值,得到所述第一权重。In a more specific example, the plurality of training samples include a first training sample, which is constructed based on a portion of the behavioral feedback data generated after a predetermined time; wherein the
更进一步地,在一个示例中,所述第二训练子模块进一步配置为通过执行以下内容实现所述利用该第一权重对所述第一预测损失进行加权,得到第一加权损失:利用所述第一权重和0中的较大值对所述第一预测损失进行加权,得到所述第一加权损失。Further, in one example, the second training sub-module is further configured to implement the weighting of the first prediction loss by using the first weight to obtain a first weighted loss by performing the following content: using the The first prediction loss is weighted by the first weight and the larger value of 0 to obtain the first weighted loss.
另一方面,在另一个例子中,所述多个训练样本包括第二训练样本,其基于所述行为反馈数据中在预定时刻之前产生的部分而构建;其中,所述第二训练子模块8432还配置为:利用所述第二训练样本,训练所述第二行为预测模型。On the other hand, in another example, the plurality of training samples includes a second training sample constructed based on a portion of the behavioral feedback data generated before a predetermined time; wherein the
综上,采用本说明书实施例披露的行为预测模型的训练装置,在人群定向的冷启动阶段,利用无监督的离群点检测算法,对上述多个正样本中的各个正样本进行权重分配,从而降低噪标签对第一行为预测模型的性能影响。进一步地,在获得用户反馈数据后,利用用户反馈数据训练第二行为预测模型,实现更加精准的人群重定向,使用户被推荐到符合自身需求的目标对象,从而有效提高用户体验。To sum up, using the training device for the behavior prediction model disclosed in the embodiments of this specification, in the cold start stage of crowd orientation, the unsupervised outlier detection algorithm is used to assign weights to each positive sample in the above-mentioned multiple positive samples, Thereby, the impact of noisy labels on the performance of the first behavior prediction model is reduced. Further, after obtaining user feedback data, use the user feedback data to train a second behavior prediction model to achieve more accurate crowd redirection, so that users are recommended to target objects that meet their own needs, thereby effectively improving user experience.
如上,根据又一方面的实施例,还提供一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行结合图4或图5或图6所描述的方法。As above, according to an embodiment of another aspect, there is also provided a computer-readable storage medium, on which a computer program is stored, and when the computer program is executed in a computer, the computer is made to execute in conjunction with FIG. 4 or FIG. 5 or FIG. 6 . the described method.
根据又一方面的实施例,还提供一种计算设备,包括存储器和处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现结合图4或图5或图6所描述的方法。According to yet another embodiment, there is also provided a computing device, including a memory and a processor, where executable code is stored in the memory, and when the processor executes the executable code, the implementation is combined with FIG. 4 or FIG. 5 . or the method described in Figure 6.
本领域技术人员应该可以意识到,在上述一个或多个示例中,本说明书披露的多个实施例所描述的功能可以用硬件、软件、固件或它们的任意组合来实现。当使用软件实现时,可以将这些功能存储在计算机可读介质中或者作为计算机可读介质上的一个或多个指令或代码进行传输。Those skilled in the art should realize that, in the above one or more examples, the functions described in the various embodiments disclosed in this specification may be implemented by hardware, software, firmware or any combination thereof. When implemented in software, the functions may be stored on or transmitted over as one or more instructions or code on a computer-readable medium.
以上所述的具体实施方式,对本说明书披露的多个实施例的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本说明书披露的多个实施例的具体实施方式而已,并不用于限定本说明书披露的多个实施例的保护范围,凡在本说明书披露的多个实施例的技术方案的基础之上,所做的任何修改、等同替换、改进等,均应包括在本说明书披露的多个实施例的保护范围之内。The specific embodiments described above further describe in detail the purposes, technical solutions and beneficial effects of the various embodiments disclosed in this specification. It should be understood that the above description is only for the various embodiments disclosed in this specification The specific description is only for the specific implementation, and is not intended to limit the protection scope of the multiple embodiments disclosed in this specification. Any modifications, equivalent replacements, improvements, etc. made on the basis of the technical solutions of the multiple embodiments disclosed in this specification are made. , all should be included within the protection scope of the multiple embodiments disclosed in this specification.
Claims (40)
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202011626281.3ACN112581191B (en) | 2020-08-14 | 2020-08-14 | Training method and device of behavior prediction model |
| CN202010819192.4ACN111681059B (en) | 2020-08-14 | 2020-08-14 | Training method and device for behavior prediction model |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010819192.4ACN111681059B (en) | 2020-08-14 | 2020-08-14 | Training method and device for behavior prediction model |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202011626281.3ADivisionCN112581191B (en) | 2020-08-14 | 2020-08-14 | Training method and device of behavior prediction model |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN111681059A CN111681059A (en) | 2020-09-18 |
| CN111681059Btrue CN111681059B (en) | 2020-11-13 |
Family
ID=72438626
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202011626281.3AActiveCN112581191B (en) | 2020-08-14 | 2020-08-14 | Training method and device of behavior prediction model |
| CN202010819192.4AActiveCN111681059B (en) | 2020-08-14 | 2020-08-14 | Training method and device for behavior prediction model |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202011626281.3AActiveCN112581191B (en) | 2020-08-14 | 2020-08-14 | Training method and device of behavior prediction model |
Country Status (1)
| Country | Link |
|---|---|
| CN (2) | CN112581191B (en) |
Families Citing this family (46)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112150199B (en)* | 2020-09-21 | 2024-07-12 | 北京小米松果电子有限公司 | Method and device for determining vertical characteristics and storage medium |
| CN112085615B (en)* | 2020-09-23 | 2024-10-11 | 支付宝(杭州)信息技术有限公司 | Training method and device for graphic neural network |
| CN112165496B (en)* | 2020-10-13 | 2021-11-02 | 清华大学 | Network Security Anomaly Detection Algorithm and Detection System Based on Cluster Graph Neural Network |
| CN112308211B (en)* | 2020-10-29 | 2024-03-08 | 中科(厦门)数据智能研究院 | Domain increment method based on meta learning |
| CN112508085B (en)* | 2020-12-05 | 2023-04-07 | 西安电子科技大学 | Social network link prediction method based on perceptual neural network |
| CN112541530B (en)* | 2020-12-06 | 2023-06-20 | 支付宝(杭州)信息技术有限公司 | Data preprocessing method and device for clustering model |
| CN112541575B (en)* | 2020-12-06 | 2023-03-10 | 支付宝(杭州)信息技术有限公司 | Method and device for training graph neural network |
| CN112668716B (en)* | 2020-12-29 | 2024-12-13 | 奥比中光科技集团股份有限公司 | A training method and device for a neural network model |
| CN112633607B (en)* | 2021-01-05 | 2023-06-30 | 西安交通大学 | Dynamic space-time event prediction method and system |
| CN112784157B (en)* | 2021-01-20 | 2025-01-14 | 网易传媒科技(北京)有限公司 | Behavior prediction model training method, behavior prediction method and device, and equipment |
| CN112837095A (en)* | 2021-02-01 | 2021-05-25 | 支付宝(杭州)信息技术有限公司 | Object distribution method and system |
| CN112836128A (en)* | 2021-02-10 | 2021-05-25 | 脸萌有限公司 | Information recommendation method, apparatus, device and storage medium |
| CN112989169B (en)* | 2021-02-23 | 2023-07-25 | 腾讯科技(深圳)有限公司 | Target object identification method, information recommendation method, device, equipment and medium |
| CN115204381A (en)* | 2021-03-26 | 2022-10-18 | 北京三快在线科技有限公司 | Weak supervision model training method and device and electronic equipment |
| CN113159834B (en)* | 2021-03-31 | 2022-06-07 | 支付宝(杭州)信息技术有限公司 | Commodity information sorting method, device and equipment |
| CN113222139B (en)* | 2021-04-27 | 2024-06-14 | 商汤集团有限公司 | Neural network training method and device, equipment, and computer storage medium |
| CN113222700B (en)* | 2021-05-17 | 2023-04-18 | 中国人民解放军国防科技大学 | Session-based recommendation method and device |
| CN113283861B (en)* | 2021-05-18 | 2024-04-16 | 上海示右智能科技有限公司 | Method for constructing compliance of intelligent enterprise |
| CN113313314B (en)* | 2021-06-11 | 2024-05-24 | 北京沃东天骏信息技术有限公司 | Model training method, device, equipment and storage medium |
| CN113282807B (en)* | 2021-06-29 | 2022-09-02 | 中国平安人寿保险股份有限公司 | Keyword expansion method, device, equipment and medium based on bipartite graph |
| CN113641896A (en)* | 2021-07-23 | 2021-11-12 | 北京三快在线科技有限公司 | Model training and recommendation probability prediction method and device |
| CN113538108B (en)* | 2021-07-27 | 2025-02-21 | 北京沃东天骏信息技术有限公司 | Resource information determination method, device, electronic device and storage medium |
| CN113807515A (en)* | 2021-08-23 | 2021-12-17 | 网易(杭州)网络有限公司 | Model training method and device, computer equipment and storage medium |
| CN113656699B (en)* | 2021-08-25 | 2024-02-13 | 平安科技(深圳)有限公司 | User feature vector determining method, related equipment and medium |
| CN113688323B (en)* | 2021-09-03 | 2024-07-19 | 支付宝(杭州)信息技术有限公司 | Method and device for constructing intent trigger strategy and intent recognition |
| CN113792798B (en)* | 2021-09-16 | 2024-07-09 | 平安科技(深圳)有限公司 | Model training method and device based on multi-source data and computer equipment |
| CN113988175B (en)* | 2021-10-27 | 2024-06-11 | 支付宝(杭州)信息技术有限公司 | Clustering processing method and device |
| CN116150425B (en) | 2021-11-19 | 2025-08-29 | 腾讯科技(深圳)有限公司 | Method, device, equipment, storage medium and program product for selecting recommended content |
| CN114154575A (en)* | 2021-12-03 | 2022-03-08 | 京东科技信息技术有限公司 | Recognition model training method, device, computer equipment and storage medium |
| CN114428887B (en)* | 2021-12-30 | 2024-06-21 | 北京百度网讯科技有限公司 | Click data denoising method, device, electronic device and storage medium |
| CN114692972B (en)* | 2022-03-31 | 2024-09-24 | 支付宝(杭州)信息技术有限公司 | Training method and device of behavior prediction system |
| CN114925199B (en)* | 2022-04-19 | 2025-06-10 | 上海有旺信息科技有限公司 | Image construction method, image construction device, electronic device, and storage medium |
| CN114943284A (en)* | 2022-05-17 | 2022-08-26 | 阿里巴巴(中国)有限公司 | Data processing system and method of behavior prediction model |
| CN115099988B (en)* | 2022-06-28 | 2024-10-15 | 腾讯科技(深圳)有限公司 | Model training method, data processing method, device and computer medium |
| CN115169583A (en)* | 2022-07-13 | 2022-10-11 | 支付宝(杭州)信息技术有限公司 | Training method and device for user behavior prediction system |
| CN116151834A (en)* | 2022-08-02 | 2023-05-23 | 马上消费金融股份有限公司 | Dialogue feature representation method and device, and model training method and device |
| CN115223104B (en)* | 2022-09-14 | 2022-12-02 | 深圳市睿拓新科技有限公司 | Method and system for detecting illegal operation behaviors based on scene recognition |
| CN116028708A (en)* | 2022-10-12 | 2023-04-28 | 支付宝(杭州)信息技术有限公司 | Training method and device for recommendation model |
| CN116187411A (en)* | 2022-12-16 | 2023-05-30 | 支付宝(杭州)信息技术有限公司 | Model training method, recommendation method and device based on meta-learning |
| CN115759183B (en)* | 2023-01-06 | 2023-05-16 | 浪潮电子信息产业股份有限公司 | Correlation method and correlation device for multi-structure text graph neural network |
| CN116432039B (en)* | 2023-06-13 | 2023-09-05 | 支付宝(杭州)信息技术有限公司 | Collaborative training method and device, business prediction method and device |
| CN116975686A (en)* | 2023-07-21 | 2023-10-31 | 支付宝(杭州)信息技术有限公司 | Method for training student model, behavior prediction method and device |
| CN116955816A (en)* | 2023-07-21 | 2023-10-27 | 支付宝(杭州)信息技术有限公司 | Data augmentation method and device for training article recommendation model |
| CN116662814B (en)* | 2023-07-28 | 2023-10-31 | 腾讯科技(深圳)有限公司 | Object intention prediction method, device, computer equipment and storage medium |
| CN117349775B (en)* | 2023-10-30 | 2024-04-26 | 浙江大学 | A method and device for identifying abnormal subtasks in cluster computing |
| CN117151346B (en)* | 2023-10-30 | 2024-02-09 | 中国民航大学 | A civil aviation professional teaching and training system based on smart learning |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3680823A1 (en)* | 2019-01-10 | 2020-07-15 | Visa International Service Association | System, method, and computer program product for incorporating knowledge from more complex models in simpler models |
| CN111462137A (en)* | 2020-04-02 | 2020-07-28 | 中科人工智能创新技术研究院(青岛)有限公司 | Point cloud scene segmentation method based on knowledge distillation and semantic fusion |
Family Cites Families (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8655307B1 (en)* | 2012-10-26 | 2014-02-18 | Lookout, Inc. | System and method for developing, updating, and using user device behavioral context models to modify user, device, and application state, settings and behavior for enhanced user security |
| CN105373806A (en)* | 2015-10-19 | 2016-03-02 | 河海大学 | Outlier detection method based on uncertain data set |
| CN107730286A (en)* | 2016-08-10 | 2018-02-23 | 中国移动通信集团黑龙江有限公司 | A kind of target customer's screening technique and device |
| CN108550077A (en)* | 2018-04-27 | 2018-09-18 | 信雅达系统工程股份有限公司 | A kind of individual credit risk appraisal procedure and assessment system towards extensive non-equilibrium collage-credit data |
| CN109345302B (en)* | 2018-09-27 | 2023-04-18 | 腾讯科技(深圳)有限公司 | Machine learning model training method and device, storage medium and computer equipment |
| CN109598331A (en)* | 2018-12-04 | 2019-04-09 | 北京芯盾时代科技有限公司 | A kind of fraud identification model training method, fraud recognition methods and device |
| CN110009012B (en)* | 2019-03-20 | 2023-06-16 | 创新先进技术有限公司 | Risk sample identification method and device and electronic equipment |
| CN110046665A (en)* | 2019-04-17 | 2019-07-23 | 成都信息工程大学 | Based on isolated two abnormal classification point detecting method of forest, information data processing terminal |
| CN110363346B (en)* | 2019-07-12 | 2024-07-23 | 腾讯科技(北京)有限公司 | Click rate prediction method, training method, device and equipment of prediction model |
| CN110659686A (en)* | 2019-09-23 | 2020-01-07 | 西南交通大学 | Fuzzy coarse grain outlier detection method for mixed attribute data |
| CN111401963B (en)* | 2020-03-20 | 2022-06-07 | 支付宝(杭州)信息技术有限公司 | Method and device for training user behavior prediction model |
| CN111310860B (en)* | 2020-03-26 | 2023-04-18 | 清华大学深圳国际研究生院 | Method and computer-readable storage medium for improving performance of gradient boosting decision trees |
- 2020
- 2020-08-14CNCN202011626281.3Apatent/CN112581191B/enactiveActive
- 2020-08-14CNCN202010819192.4Apatent/CN111681059B/enactiveActive
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3680823A1 (en)* | 2019-01-10 | 2020-07-15 | Visa International Service Association | System, method, and computer program product for incorporating knowledge from more complex models in simpler models |
| CN111462137A (en)* | 2020-04-02 | 2020-07-28 | 中科人工智能创新技术研究院(青岛)有限公司 | Point cloud scene segmentation method based on knowledge distillation and semantic fusion |
Non-Patent Citations (2)
| Title |
|---|
| Knowledge Distillation and Student-teacher Learning for Visual Intelligence:A Review and New Outlooks;Lin Wang等;《arXiv:2004.05937v3[cs.CV]》;20200504;第14卷(第8期);第1-38页* |
| Learning to Transfer Graph Embeddings for Inductive Graph based Recommendation;Le Wu等;《http://arxiv.org/abs/2005.11724》;20200524;第1-10页* |
Also Published As
| Publication number | Publication date |
|---|---|
| CN112581191B (en) | 2022-07-19 |
| CN111681059A (en) | 2020-09-18 |
| CN112581191A (en) | 2021-03-30 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111681059B (en) | Training method and device for behavior prediction model | |
| Zhang et al. | Artificial intelligence in recommender systems | |
| CN110162703B (en) | Content recommendation method, training device, content recommendation equipment and storage medium | |
| CN111966914B (en) | Content recommendation method and device based on artificial intelligence and computer equipment | |
| CN110969516A (en) | Product recommendation method and device | |
| Bauer et al. | Recommender systems based on quantitative implicit customer feedback | |
| CN113051468B (en) | Movie recommendation method and system based on knowledge graph and reinforcement learning | |
| Selvi et al. | A novel Adaptive Genetic Neural Network (AGNN) model for recommender systems using modified k-means clustering approach | |
| CN111429161B (en) | Feature extraction method, feature extraction device, storage medium and electronic equipment | |
| WO2023284516A1 (en) | Information recommendation method and apparatus based on knowledge graph, and device, medium, and product | |
| Wang et al. | A spatiotemporal graph neural network for session-based recommendation | |
| Afoudi et al. | An enhanced recommender system based on heterogeneous graph link prediction | |
| Liu et al. | Effective public service delivery supported by time-decayed Bayesian personalized ranking | |
| Kübler et al. | Machine learning and big data | |
| Wu | Application of improved boosting algorithm for art image classification | |
| Kumar et al. | Recent trends in recommender systems: a survey | |
| Nedjah et al. | Client profile prediction using convolutional neural networks for efficient recommendation systems in the context of smart factories | |
| Peng et al. | Robust and dynamic graph convolutional network for multi-view data classification | |
| US20240070741A1 (en) | Providing visual indications of time sensitive real estate listing information on a graphical user interface (gui) | |
| Sahni et al. | Recommender system based on unsupervised clustering and supervised deep learning | |
| Liu | Restricted Boltzmann machine collaborative filtering recommendation algorithm based on project tag improvement | |
| CN115880024A (en) | Method for recommending lightweight graph convolutional neural network based on pre-training | |
| Guo et al. | Collaborative Filtering Recommender System for Online Learning Resources with Integrated Dynamic Time Weighting and Trust Value Calculation | |
| HK40049831A (en) | Behavior prediction model training method and device | |
| HK40049831B (en) | Behavior prediction model training method and device |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |