CN111598065A - Depth image acquisition method, living body identification method, apparatus, circuit, and medium - Google Patents
Depth image acquisition method, living body identification method, apparatus, circuit, and mediumDownload PDFInfo
- Publication number
- CN111598065A CN111598065ACN202010720275.8ACN202010720275ACN111598065ACN 111598065 ACN111598065 ACN 111598065ACN 202010720275 ACN202010720275 ACN 202010720275ACN 111598065 ACN111598065 ACN 111598065A
- Authority
- CN
- China
- Prior art keywords
- image
- infrared
- living body
- recognized
- determining
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images











Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
- G06V40/16—Human faces, e.g. facial parts, sketches or expressions
- G06V40/172—Classification, e.g. identification
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T5/00—Image enhancement or restoration
- G06T5/50—Image enhancement or restoration using two or more images, e.g. averaging or subtraction
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/50—Depth or shape recovery
- G06T7/55—Depth or shape recovery from multiple images
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/10—Image acquisition
- G06V10/12—Details of acquisition arrangements; Constructional details thereof
- G06V10/14—Optical characteristics of the device performing the acquisition or on the illumination arrangements
- G06V10/143—Sensing or illuminating at different wavelengths
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/20—Image preprocessing
- G06V10/25—Determination of region of interest [ROI] or a volume of interest [VOI]
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
- G06V40/16—Human faces, e.g. facial parts, sketches or expressions
- G06V40/168—Feature extraction; Face representation
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/40—Spoof detection, e.g. liveness detection
- G06V40/45—Detection of the body part being alive
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/10—Image acquisition modality
- G06T2207/10048—Infrared image
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20212—Image combination
- G06T2207/20221—Image fusion; Image merging
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Multimedia (AREA)
- Human Computer Interaction (AREA)
- Health & Medical Sciences (AREA)
- Oral & Maxillofacial Surgery (AREA)
- Computer Vision & Pattern Recognition (AREA)
- General Health & Medical Sciences (AREA)
- Image Analysis (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本申请涉及人工智能技术领域,特别涉及一种深度图像获取方法及活体识别方法、设备、电路和介质。The present application relates to the technical field of artificial intelligence, and in particular, to a depth image acquisition method and a living body recognition method, device, circuit and medium.
背景技术Background technique
随着人工智能地不断发展,人脸识别作为一种生物识别技术,广泛地应用在安防、支付等领域。在人脸识别技术中,为了防止被人脸照片攻破,需要利用人脸的深度图像进行活体识别。根据相关公开,可以利用结构光技术和飞行时间(Time of flight,简称“TOF”)技术来获取人脸的深度图像。With the continuous development of artificial intelligence, face recognition, as a biometric technology, is widely used in security, payment and other fields. In face recognition technology, in order to prevent being attacked by face photos, it is necessary to use the depth image of the face to perform living body recognition. According to relevant disclosures, a depth image of a human face can be acquired by using structured light technology and time of flight ("TOF" for short) technology.
结构光技术的基本原理是:通过近红外激光器,将具有一定结构特征(例如散斑图案)的光线投射到被拍摄物体上,再由专门的红外摄像头进行采集。这种具备一定结构的光线,会因被摄物体的不同深度区域反射,而采集不同的图像相位信息。然后通过运算单元将这种结构的变化换算成深度信息,以此来获得三维图像。再将获取到的信息进行更深入的应用。The basic principle of structured light technology is: through a near-infrared laser, light with certain structural features (such as speckle patterns) is projected onto the object to be photographed, and then collected by a special infrared camera. This kind of light with a certain structure will collect different image phase information due to the reflection of different depth areas of the subject. Then, the change of the structure is converted into depth information by the arithmetic unit, so as to obtain a three-dimensional image. The obtained information is then used for more in-depth application.
TOF技术的基本原理是:激光源发射一定视野角激光,碰到物体以后会反射回来。收光器件为带电荷保持的光敏二极管阵列(CCD)。通过捕捉激光来回的时间,能快速准确计算出到距离信息(即深度信息),以此来获得三维结构。The basic principle of TOF technology is: the laser source emits a laser with a certain viewing angle, and it will be reflected back after hitting an object. The light-receiving device is a photodiode array (CCD) with charge retention. By capturing the back and forth time of the laser, the distance information (ie depth information) can be quickly and accurately calculated to obtain the three-dimensional structure.
上述两种技术都是通过光学手段来获取被拍摄物体的深度图像,对光学仪器要求较高。The above two technologies both obtain the depth image of the photographed object by optical means, and have high requirements on optical instruments.
在此部分中描述的方法不一定是之前已经设想到或采用的方法。除非另有指明,否则不应假定此部分中描述的任何方法仅因其包括在此部分中就被认为是现有技术。类似地,除非另有指明,否则此部分中提及的问题不应认为在任何现有技术中已被公认。The approaches described in this section are not necessarily approaches that have been previously conceived or employed. Unless otherwise indicated, it should not be assumed that any of the approaches described in this section qualify as prior art merely by virtue of their inclusion in this section. Similarly, unless otherwise indicated, the issues raised in this section should not be considered to be recognized in any prior art.
发明内容SUMMARY OF THE INVENTION
根据本公开的一方面,提供一种深度图像获取方法,包括:开启红外光源,以提供双目红外相机拍摄所需的光照,其中所述双目红外相机包括第一红外相机和第二红外相机;获取所述双目红外相机在所述光照下拍摄的红外目标图像,所述红外目标图像包括第一红外图像和第二红外图像,所述第一红外图像为所述第一红外相机拍摄的图像,所述第二红外图像为所述第二红外相机拍摄的图像,所述第一红外图像和第二红外图像均包括待识别对象;以及基于所述第一红外图像和第二红外图像,确定包括所述待识别对象的深度图像;其中,基于所述第一红外图像和第二红外图像,确定包括所述待识别对象的深度图像包括:获取包围所述第一红外图像中的所述待识别对象的第一边界框,以及包围所述第二红外图像中的所述待识别对象的第二边界框;以及基于所述第一红外图像、第二红外图像、所述第一边界框和第二边界框,确定包括所述待识别对象的深度图像。According to an aspect of the present disclosure, a method for acquiring a depth image is provided, including: turning on an infrared light source to provide illumination required for shooting by a binocular infrared camera, wherein the binocular infrared camera includes a first infrared camera and a second infrared camera ; Acquire an infrared target image captured by the binocular infrared camera under the illumination, the infrared target image includes a first infrared image and a second infrared image, and the first infrared image is captured by the first infrared camera an image, the second infrared image is an image captured by the second infrared camera, the first infrared image and the second infrared image both include the object to be identified; and based on the first infrared image and the second infrared image, Determining a depth image including the object to be identified; wherein, based on the first infrared image and the second infrared image, determining the depth image including the object to be identified includes: acquiring the depth image surrounding the first infrared image a first bounding box of the object to be identified, and a second bounding box surrounding the object to be identified in the second infrared image; and based on the first infrared image, the second infrared image, the first bounding box and a second bounding box to determine a depth image that includes the object to be identified.
根据本公开的另一方面,提供一种活体识别方法,包括:执行上述的深度图像获取方法;以及至少部分地基于所述深度图像,确定第三识别结果,所述第三识别结果指示所述待识别对象是否为活体。According to another aspect of the present disclosure, there is provided a living body recognition method, comprising: performing the above-described depth image acquisition method; and determining a third recognition result based at least in part on the depth image, the third recognition result indicating the Whether the object to be identified is a living body.
根据本公开的另一方面,提供一种电子电路,包括被配置为执行上述的深度图像获取方法的步骤的电路。According to another aspect of the present disclosure, there is provided an electronic circuit comprising a circuit configured to perform the steps of the above-described depth image acquisition method.
根据本公开的另一方面,提供一种深度图像获取设备,包括:红外光源,被配置为提供双目红外相机拍摄所需的光照;双目红外相机,包括第一红外相机和第二红外相机,被配置为拍摄红外目标图像,所述红外目标图像包括第一红外图像和第二红外图像,所述第一红外图像为所述第一红外相机拍摄的图像,所述第二红外图像为所述第二红外相机拍摄的图像,所述第一红外图像和第二红外图像均包括待识别对象;以及上述的电子电路。According to another aspect of the present disclosure, a depth image acquisition device is provided, including: an infrared light source configured to provide illumination required for shooting by a binocular infrared camera; a binocular infrared camera including a first infrared camera and a second infrared camera , is configured to capture an infrared target image, the infrared target image includes a first infrared image and a second infrared image, the first infrared image is the image captured by the first infrared camera, and the second infrared image is the The image captured by the second infrared camera, the first infrared image and the second infrared image both include the object to be identified; and the above electronic circuit.
根据本公开的另一方面,提供一种电子电路,包括:被配置为执行上述的活体识别方法的步骤的电路。According to another aspect of the present disclosure, there is provided an electronic circuit comprising: a circuit configured to perform the steps of the above-described living body identification method.
根据本公开的另一方面,提供一种活体识别设备,包括:红外光源,被配置为提供双目红外相机拍摄所需的光照;双目红外相机,包括第一红外相机和第二红外相机,被配置为拍摄红外目标图像,所述红外目标图像包括第一红外图像和第二红外图像,所述第一红外图像为所述第一红外相机拍摄的图像,所述第二红外图像为所述第二红外相机拍摄的图像,所述第一红外图像和第二红外图像均包括待识别对象;以及上述的电子电路。According to another aspect of the present disclosure, there is provided a living body recognition device, comprising: an infrared light source configured to provide illumination required for shooting by a binocular infrared camera; the binocular infrared camera including a first infrared camera and a second infrared camera, is configured to capture an infrared target image, the infrared target image includes a first infrared image and a second infrared image, the first infrared image is an image captured by the first infrared camera, and the second infrared image is the The image captured by the second infrared camera, the first infrared image and the second infrared image both include the object to be identified; and the above-mentioned electronic circuit.
根据本公开的另一方面,提供一种电子设备,包括:处理器;以及存储程序的存储器,所述程序包括指令,所述指令在由所述处理器执行时使所述处理器执行上述的深度图像获取方法或上述的活体识别方法。According to another aspect of the present disclosure, there is provided an electronic device comprising: a processor; and a memory storing a program, the program including instructions that, when executed by the processor, cause the processor to perform the above-described The depth image acquisition method or the above-mentioned living body recognition method.
根据本公开的另一方面,提供一种存储程序的非暂态计算机可读存储介质,所述程序包括指令,所述指令在由电子设备的处理器执行时,致使所述电子设备执行上述的深度图像获取方法或上述的活体识别方法。According to another aspect of the present disclosure, there is provided a non-transitory computer-readable storage medium storing a program, the program comprising instructions that, when executed by a processor of an electronic device, cause the electronic device to perform the above-described The depth image acquisition method or the above-mentioned living body recognition method.
附图说明Description of drawings
附图示例性地示出了实施例并且构成说明书的一部分,与说明书的文字描述一起用于讲解实施例的示例性实施方式。所示出的实施例仅出于例示的目的,并不限制权利要求的范围。在所有附图中,相同的附图标记指代类似但不一定相同的要素。The accompanying drawings illustrate the embodiments by way of example and constitute a part of the specification, and together with the written description of the specification serve to explain exemplary implementations of the embodiments. The shown embodiments are for illustrative purposes only and do not limit the scope of the claims. Throughout the drawings, the same reference numbers refer to similar but not necessarily identical elements.
图1是示出根据本公开示例性实施例的深度图像获取方法的流程图;FIG. 1 is a flowchart illustrating a depth image acquisition method according to an exemplary embodiment of the present disclosure;
图2是示出根据示例性实施例的双目视觉的原理示意图;FIG. 2 is a schematic diagram illustrating the principle of binocular vision according to an exemplary embodiment;
图3和图4是示出根据本公开示例性实施例的深度图像获取方法的流程图;3 and 4 are flowcharts illustrating a depth image acquisition method according to an exemplary embodiment of the present disclosure;
图5是示出根据本公开示例性实施例的单步多框检测神经网络模型的检测原理示意图;5 is a schematic diagram illustrating a detection principle of a neural network model for single-step multi-frame detection according to an exemplary embodiment of the present disclosure;
图6是示出根据本公开示例性实施例的深度图像获取方法的流程图;6 is a flowchart illustrating a depth image acquisition method according to an exemplary embodiment of the present disclosure;
图7-图9是示出根据本公开示例性实施例的活体识别方法的流程图;7-9 are flowcharts illustrating a method for living body recognition according to an exemplary embodiment of the present disclosure;
图10-图14是示出根据示例性实施例的比对方法的流程图;Figures 10-14 are flow charts illustrating alignment methods according to exemplary embodiments;
图15是示出能够应用于示例性实施例的示例性计算设备的结构框图。15 is a block diagram illustrating an example computing device that can be applied to example embodiments.
具体实施方式Detailed ways
在本公开中,除非另有说明,否则使用术语“第一”、“第二”等来描述各种要素不意图限定这些要素的位置关系、时序关系或重要性关系,这种术语只是用于将一个元件与另一元件区分开。在一些示例中,第一要素和第二要素可以指向该要素的同一实例,而在某些情况下,基于上下文的描述,它们也可以指代不同实例。In the present disclosure, unless otherwise specified, the use of the terms "first", "second", etc. to describe various elements is not intended to limit the positional relationship, timing relationship or importance relationship of these elements, and such terms are only used for Distinguish one element from another. In some examples, the first element and the second element may refer to the same instance of the element, while in some cases they may refer to different instances based on the context of the description.
在本公开中对各种所述示例的描述中所使用的术语只是为了描述特定示例的目的,而并非旨在进行限制。除非上下文另外明确地表明,如果不特意限定要素的数量,则该要素可以是一个也可以是多个。此外,本公开中所使用的术语“和/或”涵盖所列出的项目中的任何一个以及全部可能的组合方式。The terminology used in the description of the various described examples in this disclosure is for the purpose of describing particular examples only and is not intended to be limiting. Unless the context clearly dictates otherwise, if the number of an element is not expressly limited, the element may be one or more. Furthermore, as used in this disclosure, the term "and/or" covers any and all possible combinations of the listed items.
在人脸识别技术中,基于深度图像可以实现活体识别,能够达到防攻击的目的。根据相关技术,获取深度图像的技术可以包括结构光技术和TOF技术。结构光技术和TOF技术都是采用主动向人脸投射具有一定结构的光线,通过采集的人脸反射的光线来获取深度信息,由此来获取人脸的深度图像。通过投射具有一定结构特征的光线来获取深度信息的方式,对光学仪器的要求较高,诸如结构光技术采用的散斑投射仪,导致成本较高。In face recognition technology, living body recognition can be realized based on depth images, which can achieve the purpose of preventing attacks. According to the related art, the technology of acquiring the depth image may include structured light technology and TOF technology. Both structured light technology and TOF technology use actively projecting light with a certain structure to the face, and obtain depth information through the collected light reflected by the face, thereby obtaining the depth image of the face. The method of acquiring depth information by projecting light with certain structural features requires high optical instruments, such as speckle projectors used in structured light technology, resulting in high costs.
为了解决上述技术问题,本公开提供一种深度图像获取方法,通过红外光源提供拍摄所需的光照,获取双目红外相机在所述光照下拍摄的两个包括待识别对象的红外图像。然后基于所述两个红外图像,可以利用双目视觉原理来获取包括待识别对象的深度图像。由此,不需要能够投射具有一定结构特征光线的光学仪器,仅用红外光源直接提供拍摄待识别对象所需的光照即可,成本较低。通过红外光源照射待识别对象能够保证双目红外相机拍摄得到清晰的红外图像,从而能够基于两个红外图像来获取深度图像,而且环境适应性强,适用于弱光和强光拍摄场景。In order to solve the above technical problems, the present disclosure provides a depth image acquisition method, which provides illumination required for shooting through an infrared light source, and acquires two infrared images including an object to be recognized captured by a binocular infrared camera under the illumination. Then, based on the two infrared images, the principle of binocular vision can be used to obtain a depth image including the object to be recognized. Therefore, an optical instrument capable of projecting light with certain structural characteristics is not required, and only the infrared light source can be used to directly provide the illumination required for photographing the object to be recognized, and the cost is low. Irradiating the object to be recognized by the infrared light source can ensure that the binocular infrared camera can obtain a clear infrared image, so that the depth image can be obtained based on two infrared images, and the environment adaptability is strong, suitable for low-light and strong-light shooting scenes.
本公开的深度图像获取方法可以应用于智能识别领域(例如人脸识别)、机器视觉领域和自动驾驶领域等。The depth image acquisition method of the present disclosure can be applied to the field of intelligent recognition (eg, face recognition), the field of machine vision, the field of automatic driving, and the like.
根据具体的应用领域,所述待识别对象可以不同。例如,在智能识别领域,所述待识别对象可以为人脸、动物等。在机器视觉领域,所述待识别对象可以为机器人所处场景中的任一对象。在自动驾驶领域,所述待识别对象可以为汽车、行人、自行车等。The objects to be identified may be different according to specific application fields. For example, in the field of intelligent recognition, the object to be recognized may be a human face, an animal, or the like. In the field of machine vision, the object to be recognized may be any object in the scene where the robot is located. In the field of automatic driving, the object to be recognized may be a car, a pedestrian, a bicycle, or the like.
以下将结合附图对根据本公开实施例的深度图像获取方法进行进一步描述。The depth image acquisition method according to the embodiments of the present disclosure will be further described below with reference to the accompanying drawings.
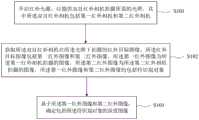
图1是示出根据本公开示例性实施例的深度图像获取方法的流程图。如图1所示,所述深度图像获取方法可以包括:步骤S101、开启红外光源,以提供双目红外相机拍摄所需的光照,其中所述双目红外相机包括第一红外相机和第二红外相机;步骤S102、获取所述双目红外相机在所述光照下拍摄的红外目标图像,所述红外目标图像包括第一红外图像和第二红外图像,所述第一红外图像为所述第一红外相机拍摄的图像,所述第二红外图像为所述第二红外相机拍摄的图像,所述第一红外图像和第二红外图像均包括待识别对象;以及步骤S103、基于所述第一红外图像和第二红外图像,确定包括所述待识别对象的深度图像。FIG. 1 is a flowchart illustrating a depth image acquisition method according to an exemplary embodiment of the present disclosure. As shown in FIG. 1 , the depth image acquisition method may include: step S101 , turning on an infrared light source to provide illumination required for shooting by a binocular infrared camera, wherein the binocular infrared camera includes a first infrared camera and a second infrared camera camera; Step S102, acquiring an infrared target image captured by the binocular infrared camera under the illumination, the infrared target image includes a first infrared image and a second infrared image, and the first infrared image is the first infrared image an image captured by an infrared camera, the second infrared image is an image captured by the second infrared camera, and both the first infrared image and the second infrared image include an object to be identified; and step S103, based on the first infrared image image and the second infrared image, and determine the depth image including the object to be identified.
所述红外光源可以为近红外光源,发出的近红外光线的波长为0.75-1.4微米,例如可以为940纳米或850纳米。近红外光线对影像的增强非常敏锐,能够使得双目红外相机在晚上也能够获得清晰图像。The infrared light source can be a near-infrared light source, and the wavelength of the near-infrared light emitted is 0.75-1.4 micrometers, for example, 940 nanometers or 850 nanometers. Near-infrared light is very sensitive to image enhancement, enabling binocular infrared cameras to obtain clear images at night.
所述双目红外相机可以是独立装置(例如照相机、视频摄像机、摄像头等),也可以包括在各类电子设备(例如移动电话、计算机、个人数字助理、平板电脑、可穿戴设备等)中。The binocular infrared camera may be an independent device (eg, camera, video camera, camera, etc.), or may be included in various electronic devices (eg, mobile phone, computer, personal digital assistant, tablet computer, wearable device, etc.).
所述红外目标图像可以是通过双目红外相机获取的电子图像数据。所述红外目标图像也可以是经过了一些预处理的图像,所述预处理例如可以包括但不限于图像增强、去噪、模糊去除等等。The infrared target image may be electronic image data obtained by a binocular infrared camera. The infrared target image may also be an image that has undergone some preprocessing, for example, the preprocessing may include, but is not limited to, image enhancement, denoising, blur removal, and the like.
如图2所示,双目视觉的原理可以为:双目红外相机包括第一红外相机和第二红外相机,第一红外相机的第一光心Ol和第二红外相机的第二光心Or在x轴上的间隔距离为T。图2中长为L的两条线段分别表示第一红外相机的像面和第二红外相机的像面,第一光心Ol和第二光心Or到相应的像面的最短距离为焦距f。待识别对象上的一点P,其在第一红外相机上的成像点(可以对应一个像素)为PL,在第二红外相机上的成像点(可以对应一个像素)为PR。PL和PR与各自像面的左边缘的距离分别为xl和xr。可以定义点P在第一红外相机和第二红外相机中的成像视差为xl-xr或者是xr-xl。在双目红外相机标定和匹配后,f、T、xl、xr都能够直接得到。根据三角关系可以得到:As shown in FIG. 2, the principle of binocular vision can be as follows: the binocular infrared camera includes a first infrared camera and a second infrared camera, a first optical centerO1 of the firstinfrared camera and a second optical center of the second infrared cameraOr isspaced a distanceT on thex -axis. The two line segments with a length ofL in FIG. 2 respectively represent the image plane of the first infrared camera and the image plane of the second infrared camera, and the shortest distances from the first optical centerO1 and the secondopticalcenterOr to the corresponding image planes are focal lengthf . For a point P on the object to be identified, its imaging point (which may correspond to one pixel) on the first infrared camera is PL, and the imaging point (which may correspond to one pixel) on the second infrared camera is PR.The distances of PL and PR from the left edge of the respective image planes arexl andxr ,respectively . The imaging parallax of the point P in the first infrared camera and the second infrared camera may be defined asxl -xr orxr -xl . After the binocular infrared camera is calibrated and matched,f ,T , xl , andxr can be obtained directly. According to the triangular relationship, we can get:

根据上述公式可以计算得到点P与第一红外相机和第二红外相机之间的距离Z(即深度)。According to the above formula, the distance Z (ie depth) between the point P and the first infrared camera and the second infrared camera can be calculated.
以所述待识别对象为人脸为例,所述点P例如可以为眼睛的瞳孔中心、眼角、鼻尖、嘴角等特征点。通过获取瞳孔中心在第一红外目标图像中的第一像素坐标和在第二红外红标图像中的第二像素坐标,可以计算得到瞳孔中心在两个红外相机中的成像视差。然后可以利用上述公式计算得到瞳孔中心的深度Z。同样地,可以利用上述方法计算得到眼角、鼻尖、嘴角等特征点的深度。根据多个特征点的深度信息,能够获取人脸的深度图像。Taking the object to be recognized as a human face as an example, the point P may be, for example, a feature point such as the center of the pupil of the eye, the corner of the eye, the tip of the nose, and the corner of the mouth. By acquiring the first pixel coordinates of the pupil center in the first infrared target image and the second pixel coordinates in the second infrared red mark image, the imaging parallax of the pupil center in the two infrared cameras can be calculated. Then the depth Z of the center of the pupil can be calculated by using the above formula. Similarly, the depth of feature points such as the corner of the eye, the tip of the nose, and the corner of the mouth can be obtained by using the above method. According to the depth information of a plurality of feature points, a depth image of a human face can be obtained.
根据一些实施例,如图3所示,所述深度图像获取方法还可以包括:步骤S104、将所述深度图像与所述第一红外图像或第二红外图像进行融合,得到融合图像。从而得到的融合图像既具有深度信息又具有红外图像的灰度、亮度等信息,基于融合图像能够提高后续控制或识别的准确性。例如,在机器视觉、自动驾驶等领域,基于融合图像能够提高控制的准确性。在智能识别等领域,基于融合图像能够提高识别的准确性。According to some embodiments, as shown in FIG. 3 , the depth image acquisition method may further include: step S104 , fusing the depth image with the first infrared image or the second infrared image to obtain a fused image. The obtained fusion image has both depth information and information such as grayscale and brightness of the infrared image, and the accuracy of subsequent control or recognition can be improved based on the fusion image. For example, in the fields of machine vision and autonomous driving, the accuracy of control can be improved based on fused images. In areas such as intelligent recognition, the accuracy of recognition can be improved based on fusion images.
根据一些实施例,结合图1和图4所示,步骤S103可以包括:步骤S1031、获取包围所述第一红外图像中的所述待识别对象的第一边界框,以及包围所述第二红外图像中的所述待识别对象的第二边界框;以及步骤S1032、基于所述第一红外图像、第二红外图像、所述第一边界框和第二边界框,确定包括所述待识别对象的深度图像。由此,能够实现待识别对象位于边界框限定的有效图像区域内,从而能够仅针对红外图像的有效图像区域来确定包括待识别对象的深度图像。由于第一红外图像和第二红外图像中待识别对象的视差可能存在大于设定的视差阈值(可以根据硬件的计算能力和存储空间来设定)的情况,这样会导致重建深度图像的计算量过大,计算过程中也会产生更多的中间数据,需要更大的存储空间,从而导致硬件上不能满足需求,影响深度图像的重建。上述技术方案通过仅针对第一红外图像和第二红外图像中相应的两个有效图像区域来重建深度图像,而两个有效图像区域中待识别对象的视差小于第一红外图像和第二红外图像中待识别对象的视差,从而能够解决视差过大会影响重建深度图像的问题。另外,仅基于红外图像的有效图像区域来重建深度图像,能够减少计算量,从而能够提高运算速度,缩短重建深度图像的时间。According to some embodiments, as shown in FIG. 1 and FIG. 4 , step S103 may include: step S1031 , acquiring a first bounding box surrounding the object to be recognized in the first infrared image, and surrounding the second infrared image the second bounding box of the object to be identified in the image; and step S1032, determining that the object to be identified is included based on the first infrared image, the second infrared image, the first bounding box and the second bounding box depth image. Thereby, it can be realized that the object to be recognized is located in the effective image area defined by the bounding box, so that the depth image including the object to be recognized can be determined only for the effective image area of the infrared image. Since the parallax of the object to be identified in the first infrared image and the second infrared image may be larger than the set parallax threshold (which can be set according to the computing power and storage space of the hardware), this will lead to the calculation amount of the reconstructed depth image. If it is too large, more intermediate data will be generated in the calculation process, and more storage space will be required, which will lead to the inability to meet the requirements on the hardware and affect the reconstruction of the depth image. The above technical solution reconstructs the depth image only for the corresponding two effective image areas in the first infrared image and the second infrared image, and the parallax of the object to be recognized in the two effective image areas is smaller than the first infrared image and the second infrared image. The parallax of the object to be recognized can be solved, so that the problem that the parallax will affect the reconstructed depth image can be solved. In addition, the depth image is reconstructed only based on the effective image area of the infrared image, which can reduce the amount of calculation, thereby improving the operation speed and shortening the time for reconstructing the depth image.
根据一些实施例,所述第一边界框和第二边界框可以为包围所述待识别对象的最小矩形框,或将包围待识别对象的最小矩形框向上、下、左和/或右膨胀一定的倍数后得到的矩形框。当然,所述第一边界框和第二边界框也可以为其它形状的多边形框、圆形框或不规则的曲线框等,只要能够包围所述待识别对象并且限定的区域内除所述待识别对象以外不具有较复杂背景即可,在此不作限定。According to some embodiments, the first bounding box and the second bounding box may be the smallest rectangular box surrounding the object to be recognized, or the smallest rectangular box surrounding the object to be recognized may be expanded upward, downward, left and/or right by a certain amount The rectangular box obtained after a multiple of . Of course, the first bounding box and the second bounding box can also be polygonal boxes, circular boxes or irregular curved boxes of other shapes, etc., as long as they can enclose the object to be recognized and the defined area excludes the object to be recognized. Other than the recognition object, it suffices not to have a relatively complex background, which is not limited here.
根据一些实施例,包围所述初始图像中的所述待识别对象的边界框可以由用户标记,或采用其它可根据待识别对象的形状来获取边界框的方式获得,只要能够实现所述边界框包围所述初始图像中的所述待识别对象即可。例如:可以检测待识别对象的边界特征,然后根据所述边界特征确定包围待识别对象的最小矩形框为所述边界框,或将包围待识别对象的最小矩形框向上、下、左和/或右膨胀一定的倍数后得到所述边界框。According to some embodiments, the bounding box surrounding the to-be-recognized object in the initial image may be marked by a user, or obtained in other ways that can obtain the bounding box according to the shape of the to-be-identified object, as long as the bounding box can be realized It is sufficient to surround the object to be recognized in the initial image. For example, the boundary features of the object to be recognized can be detected, and then the minimum rectangular frame surrounding the object to be recognized can be determined as the boundary frame according to the boundary features, or the minimum rectangular frame surrounding the object to be recognized can be set up, down, left and/or The bounding box is obtained after the right expansion by a certain multiple.
根据一些实施例,也可以通过将包括待识别对象的红外图像输入单步多框检测(英文全名为Single Shot Multi-Box Detector,简称为“SSD”)神经网络模型,来获取包围所述红外图像中的所述待识别对象的边界框。相应地,步骤S1031可以包括:将所述第一红外图像输入第一单步多框检测神经网络模型;获取所述第一单步多框检测神经网络模型输出的所述第一边界框;将所述第二红外图像输入所述第一单步多框检测神经网络模型;以及获取所述第一单步多框检测神经网络模型输出的所述第二边界框。由于SSD神经网络能够对多个不同尺度的特征图进行检测,错误率低。而且只需要一步即可完成对输入图像中的对象进行分类和位置检测,检测速度快。According to some embodiments, an infrared image including an object to be recognized can also be input into a single-step multi-box detection (English full name Single Shot Multi-Box Detector, referred to as "SSD") neural network model, to obtain the infrared image surrounding the object. The bounding box of the object to be recognized in the image. Correspondingly, step S1031 may include: inputting the first infrared image into a first single-step multi-frame detection neural network model; acquiring the first bounding box output by the first single-step multi-frame detection neural network model; The second infrared image is input to the first single-step multi-frame detection neural network model; and the second bounding box output by the first single-step multi-frame detection neural network model is obtained. Since the SSD neural network can detect multiple feature maps of different scales, the error rate is low. And it only takes one step to complete the classification and position detection of the objects in the input image, and the detection speed is fast.
下面对SSD神经网络的检测原理和训练过程进行描述。The detection principle and training process of the SSD neural network are described below.
SSD 神经网络的结构可以建立在VGG、mobileNet、ResNet等卷积神经网络的基础上,以实现特征提取。图5中示出的SSD 神经网络的结构是建立在 VGG-16 的基础上,VGG-16是一种经典的卷积神经网络结构,可以提供高质量的图像分类和迁移学习来改善输出结果。SSD 神经网络在 VGG-16 的基础上进行了如下修改:取消全连接层,替换为一系列辅助卷积层(Conv6~Conv11)。通过使用辅助卷积层,并逐步减小每个辅助卷积层的尺寸(像素数),可以提取图像多个尺度的特征图。不同特征图设置不同尺度的预检测框,同一特征图设置多个不同长宽比的预检测框,采用卷积对不同的特征图直接进行检测,输出预测的边界框。输出的预测的边界框包括其类别置信度和位置参数。大尺度(即大尺寸)特征图可以用来检测小物体,而小尺度特征图用来检测大物体。因此,SSD神经网络只需要一步即可完成分类和位置检测,检测速度快、错误率低。其中,类别置信度和边界框位置各采用一次卷积来检测。下面以一个示例性实施例来说明SSD神经网络的检测原理:假设一特征图100所采用的预检测框的数目为n,特征图中对象的类别数为c,那么类别置信度需要数量为n×c的卷积核来检测,而边界框的位置(可以由边界框的中心坐标、宽和高四个参数表示)需要数量为n×4的卷积核来检测。VGG-16 的卷积层Conv4输出的特征图可以作为用于检测的第一个特征图。新增的辅助卷积层中可以提取Conv7,Conv8,Conv9,Conv10,Conv11输出的特征图作为检测所用的特征图,加上Conv4,共提取了6个特征图,其大小分别是38×38、19×19、10×10、5×5、3×3、1×1。由于每个预检测框都会预测一个边界框, SSD神经网络一共可以预测(即输出)38×38×(4)+19×19×(6)+10×10×(6)+5×5×(6)+3×3×(4)+1×1×(4)=8732个边界框,其中,括号里的数字代表该特征图设置的预检测框的数目。然后,通过检测器200对预测的边界框进行分类和回归。最后通过非极大值抑制(英文全称为Non-maximum suppression,简称为NMS)算法过滤掉非极大值,输出每一对象对应的边界框,包括其类别(类别置信度最大)和位置参数。 The structure of the SSD neural network can be built on the basis of convolutional neural networks such as VGG, mobileNet, and ResNet to achieve feature extraction. The structure of the SSD neural network shown in Figure 5 is built on the basis of VGG-16, a classic convolutional neural network structure that can provide high-quality image classification and transfer learning to improve output results. The SSD neural network is modified as follows on the basis of VGG-16: the fully connected layer is cancelled and replaced with a series of auxiliary convolutional layers (Conv6~Conv11). By using auxiliary convolutional layers and gradually reducing the size (number of pixels) of each auxiliary convolutional layer, feature maps at multiple scales of the image can be extracted. Different feature maps are set with different scales of pre-detection boxes, the same feature map is set with multiple pre-detection boxes with different aspect ratios, and convolution is used to directly detect different feature maps, and output the predicted bounding box. The output predicted bounding box includes its class confidence and location parameters. Large-scale (ie, large-scale) feature maps can be used to detect small objects, while small-scale feature maps are used to detect large objects. Therefore, the SSD neural network only needs one step to complete the classification and position detection, and the detection speed is fast and the error rate is low. Among them, the category confidence and the bounding box position are each detected by one convolution. The detection principle of the SSD neural network is described below with an exemplary embodiment: Assuming that the number of pre-detection frames used in a
根据一些实施例,所述边界框可以为矩形框。SSD神经网络模型输出的边界框可以包括边界框的特征点(可以为边界框的中心或顶点等)位置、宽和高。当然,所述边界框也可以包括其它能够表示位置信息的参数组合,在此不作限定。在抠图处理过程中,可以根据具体的需求来选择使用边界框的哪类位置参数。According to some embodiments, the bounding box may be a rectangular box. The bounding box output by the SSD neural network model can include the position, width and height of the feature points of the bounding box (which can be the center or vertex of the bounding box, etc.). Of course, the bounding box may also include other parameter combinations capable of representing position information, which are not limited here. In the process of matting, you can choose which type of position parameters of the bounding box to use according to specific requirements.
根据一些实施例,所述单步多框检测神经网络模型的训练过程可以包括:获取包括所述待识别对象的样本图像,并在所述样本图像中标记包围所述待识别对象的目标框;将所述样本图像输入至单步多框检测神经网络,输出包括类别为所述待识别对象的边界框;利用损失函数计算所述边界框和对应的目标框之间的损失值;根据所述损失值调整所述单步多框检测神经网络的参数。训练的目的是调整SSD神经网络的参数使得边界框的位置逼近目标框,同时提高类别置信度。According to some embodiments, the training process of the single-step multi-frame detection neural network model may include: acquiring a sample image including the object to be recognized, and marking a target frame surrounding the object to be recognized in the sample image; Input the sample image into a single-step multi-frame detection neural network, and the output includes a bounding box whose category is the object to be recognized; use a loss function to calculate the loss value between the bounding box and the corresponding target box; according to the The loss value adjusts the parameters of the single-step multi-frame detection neural network. The purpose of training is to adjust the parameters of the SSD neural network so that the position of the bounding box is close to the target box, while improving the class confidence.
根据一些实施例,所述损失函数可以为边界框的类别置信度误差和边界框位置误差的加权和。在训练过程中可以通过梯度下降法以及反向传播机制不断减少所述损失值,使得边界框的位置逼近目标框,同时提高类别置信度。通过多次优化,不断增强网络模型检测对象的效果,最终得到一个最优的对象检测模型。According to some embodiments, the loss function may be a weighted sum of bounding box class confidence error and bounding box position error. During the training process, the loss value can be continuously reduced by the gradient descent method and the back-propagation mechanism, so that the position of the bounding box is close to the target box, and the category confidence is improved at the same time. Through multiple optimizations, the effect of the network model for object detection is continuously enhanced, and an optimal object detection model is finally obtained.
根据一些实施例,所述目标框可以为包围所述待识别对象的最小矩形框。因此,所述边界框也相应为包围所述待识别对象的最小矩形框。According to some embodiments, the target frame may be the smallest rectangular frame surrounding the object to be recognized. Therefore, the bounding box is also correspondingly the smallest rectangular box surrounding the object to be recognized.
根据一些实施例,SSD神经网络模型的训练过程中采用的样本图像集例如可以包括在不同拍摄背景下调整摄像机和待识别对象之间的相对距离获取的包括待识别对象的多个样本图像,以及在不同拍摄背景下调整摄像机和待识别对象之间的相对角度获取的包括待识别对象的多个样本图像。According to some embodiments, the sample image set used in the training process of the SSD neural network model may include, for example, a plurality of sample images including the object to be recognized obtained by adjusting the relative distance between the camera and the object to be recognized under different shooting backgrounds, and A plurality of sample images including the object to be recognized obtained by adjusting the relative angle between the camera and the object to be recognized under different shooting backgrounds.
本公开的上述技术方案通过将包括待识别对象的红外图像输入SSD神经网络模型,能够快速、准确获取包围待识别对象的边界框。The above-mentioned technical solution of the present disclosure can quickly and accurately obtain a bounding box surrounding the object to be recognized by inputting the infrared image including the object to be recognized into the SSD neural network model.
根据一些实施例,步骤S1032、基于所述第一红外图像、第二红外图像、所述第一边界框和第二边界框,确定包括所述待识别对象的深度图像可以包括:基于所述第一红外图像和所述第一边界框,修改所述第一红外图像中的除所述第一边界框限定的第一有效图像区域以外的区域的像素值;基于所述第二红外图像和所述第二边界框,修改所述第二红外图像中除所述第二边界框限定的第二有效图像区域以外的区域的像素值;以及基于所述第一有效图像区域和所述第二有效图像区域,确定包括所述待识别对象的深度图像。由此,通过修改红外图像的除包括待识别对象的有效抠图像区域以外的区域的像素值,可以克服拍摄背景可能会影响获取包括待识别对象的深度图像的问题。According to some embodiments, step S1032, based on the first infrared image, the second infrared image, the first bounding box, and the second bounding box, determining the depth image including the object to be recognized may include: based on the first an infrared image and the first bounding box, modifying pixel values of areas in the first infrared image other than the first effective image area defined by the first bounding box; based on the second infrared image and the the second bounding box, modifying pixel values of areas in the second infrared image other than the second effective image area defined by the second bounding box; and based on the first effective image area and the second effective image area The image area is determined to include the depth image of the object to be recognized. Thus, by modifying the pixel values of areas of the infrared image other than the effective matte area including the object to be recognized, the problem that the shooting background may affect the acquisition of a depth image including the object to be recognized can be overcome.
根据一些实施例,可以修改所述第一红外图像中除第一有效图像区域以外的区域的像素值以获得第一背景区域,以及修改所述第二红外图像中除第二有效图像区域以外的区域的像素值以获得第二背景区域。例如,可以将所述第一红外图像中除第一有效图像区域以外的区域的像素值修改为位于0~255之间的灰色像素值,以获得第一背景区域。可以将所述第二红外图像中除第二有效图像区域以外的区域的像素值修改为位于0~255之间的灰色像素值,以获得第二背景区域。还可以将所述第一红外图像中除第一有效图像区域以外的区域的像素值以及所述第二红外图像中除第二有效图像区域以外的区域的像素值修改为“0”或“255”,以获得全黑或全白的背景区域。还可以通过对所述第一红外图像中除第一有效图像区域以外的区域以及所述第二红外图像中除第二有效图像区域以外的区域进行透明化或模糊化等处理以获得背景区域。According to some embodiments, pixel values of areas in the first infrared image other than the first effective image area may be modified to obtain a first background area, and areas in the second infrared image other than the second effective image area may be modified The pixel value of the area to obtain the second background area. For example, pixel values of regions other than the first effective image region in the first infrared image may be modified to gray pixel values between 0 and 255 to obtain the first background region. The pixel values of the regions other than the second effective image region in the second infrared image may be modified to gray pixel values between 0 and 255 to obtain the second background region. It is also possible to modify the pixel value of the area other than the first effective image area in the first infrared image and the pixel value of the area other than the second effective image area in the second infrared image to "0" or "255". ” to get an all black or all white background area. The background area can also be obtained by performing transparent or blurring processing on the area other than the first effective image area in the first infrared image and the area other than the second effective image area in the second infrared image.
根据另一些实施例,也可以直接将包括待识别对象的有效图像区域从拍摄得到的红外图像中提取出来,并基于提取出来的图像来包括待识别对象的深度图像,也能够解决视差过大会影响重建深度图像的问题,并缩短重建深度图像的时间。According to other embodiments, it is also possible to directly extract the effective image area including the object to be recognized from the captured infrared image, and to include the depth image of the object to be recognized based on the extracted image, which can also solve the effect of excessive parallax. The problem of reconstructing depth images and shortening the time to reconstruct depth images.
根据一些实施例,步骤S1032、基于所述第一红外图像、第二红外图像、所述第一边界框和第二边界框,确定包括所述待识别对象的深度图像可以包括:基于所述第一红外图像和所述第一边界框,确定所述第一红外图像中的与所述待识别对象相关联的多个第一关键点;基于所述第二红外图像和所述第二边界框,确定所述第二红外图像中的与所述多个第一关键点中的每一个第一关键点对应的第二关键点;根据所述多个第一关键点中的每一个第一关键点与多个第二关键点中的与该第一关键点对应的第二关键点之间的视差,确定所述待识别对象的多个特征点的深度信息;以及基于所述多个特征点的深度信息,确定包括所述待识别对象的深度图像。由此,能够基于包围所述待识别对象的边界框来提高获取的与待识别对象相关联的多个关键点的准确性,克服拍摄背景可能会影响准确获取与待识别对象相关联的多个关键点的问题,从而能够提高获取的深度图像的质量。According to some embodiments, step S1032, based on the first infrared image, the second infrared image, the first bounding box, and the second bounding box, determining the depth image including the object to be recognized may include: based on the first an infrared image and the first bounding box, determining a plurality of first key points associated with the object to be identified in the first infrared image; based on the second infrared image and the second bounding box , determine a second key point in the second infrared image corresponding to each of the first key points in the plurality of first key points; The disparity between the point and the second key point corresponding to the first key point among the plurality of second key points, determining the depth information of the plurality of feature points of the object to be recognized; and based on the plurality of feature points The depth information is determined to include the depth image of the object to be recognized. In this way, the accuracy of acquiring multiple key points associated with the object to be identified can be improved based on the bounding box surrounding the object to be identified, and the shooting background may affect the accurate acquisition of multiple key points associated with the object to be identified. key points, so that the quality of the acquired depth images can be improved.
所述第一关键点和第二关键点可以为所述待识别对象的同一特征点分别在所述第一红外图像和第二红外图像中对应的一个像素。以所述待识别对象为人脸为例,所述多个第一关键点和多个第二关键点可以包括眼睛的瞳孔中心、眼角、鼻尖或嘴角分别在所述第一红外图像和第二红外图像中对应的像素。需要说明的是,在此仅是举例说明关键点的含义,并不限定所述待识别对象只能为人脸。The first key point and the second key point may be a pixel corresponding to the same feature point of the object to be recognized in the first infrared image and the second infrared image, respectively. Taking the object to be recognized as a human face as an example, the plurality of first key points and the plurality of second key points may include the pupil center of the eye, the corner of the eye, the tip of the nose or the corner of the mouth, respectively, in the first infrared image and the second infrared image. the corresponding pixel in the image. It should be noted that, the meanings of the key points are only illustrated here, and it is not limited that the object to be recognized can only be a human face.
根据一些实施例,步骤S104中可以基于相应的所述多个第一关键点(或多个第二关键点),将所述深度图像与所述第一红外图像(或第二红外图像)进行融合,得到融合图像。从而能够提高融合效率和准确性。According to some embodiments, in step S104, the depth image and the first infrared image (or the second infrared image) may be performed based on the corresponding first key points (or second key points). Fusion to get a fused image. Thus, the fusion efficiency and accuracy can be improved.
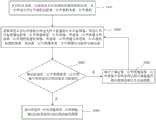
在双目红外相机执行拍摄时,所述待识别对象可能存在被遮挡的问题,这可能会影响后续准确获取包括待识别对象的深度图像。基于此,根据一些实施例,如图6所示,所述深度图像获取方法还可以包括:步骤S201、确定所述第一红外图像和第二红外图像中的所述待识别对象是否被遮挡;以及步骤S202、响应于确定第一红外图像或第二红外图像中的所述待识别对象被遮挡,提示重新获取红外目标图像。可以响应于确定所述第一红外图像和第二红外图像中的所述待识别对象均未被遮挡,执行步骤S103、基于所述第一红外图像和第二红外图像,确定包括待识别对象的深度图像。当然,也可以先确定第一红外图像中的所述待识别对象是否被遮挡,可以响应于确定第一红外图像中的所述待识别对象被遮挡,提示重新获取红外目标图像,而响应于确定第一红外图像中的所述待识别对象未被遮挡,再确定第二红外图像中的所述待识别对象是否被遮挡。或者,可以仅基于所述第一红外图像来确定所述待识别对象是否被遮挡,即,响应于确定所述第一红外图像中的所述待识别对象被遮挡,提示重新获取红外目标图像,而响应于确定所述第一红外图像中的所述待识别对象未被遮挡,执行步骤S103。When the binocular infrared camera performs shooting, the object to be recognized may be occluded, which may affect the subsequent accurate acquisition of a depth image including the object to be recognized. Based on this, according to some embodiments, as shown in FIG. 6 , the depth image acquisition method may further include: step S201 , determining whether the to-be-identified object in the first infrared image and the second infrared image is blocked; And step S202, in response to determining that the object to be identified in the first infrared image or the second infrared image is blocked, prompting to re-acquire the infrared target image. In response to determining that the object to be identified in the first infrared image and the second infrared image is not blocked, step S103 is performed, and based on the first infrared image and the second infrared image, it is determined that the object to be identified includes the object to be identified. depth image. Of course, it is also possible to first determine whether the object to be identified in the first infrared image is blocked, and in response to determining that the object to be identified in the first infrared image is blocked, prompting to re-acquire the infrared target image, and in response to determining that the object to be identified is blocked The object to be identified in the first infrared image is not blocked, and then it is determined whether the object to be identified in the second infrared image is blocked. Alternatively, it may be determined whether the object to be identified is blocked only based on the first infrared image, that is, in response to determining that the object to be identified in the first infrared image is blocked, prompting to re-acquire an infrared target image, In response to determining that the object to be identified in the first infrared image is not blocked, step S103 is performed.
根据一些示例性实施例,步骤S201中可以并行执行确定所述第一红外图像中的所述待识别对象是否被遮挡,以及确定所述第二红外图像中的所述待识别对象是否被遮挡。According to some exemplary embodiments, step S201 may be performed in parallel to determine whether the object to be recognized in the first infrared image is blocked, and to determine whether the object to be recognized in the second infrared image is blocked.
根据另一些示例性实施例,步骤S201中也可以依次确定所述第一红外图像和所述第二红外图像中的所述待识别对象是否被遮挡。例如,先确定所述第一红外图像中的所述待识别对象是否被遮挡,然后确定所述第二红外图像中的所述待识别对象是否被遮挡。According to other exemplary embodiments, in step S201, it may also be determined sequentially whether the object to be identified in the first infrared image and the second infrared image is blocked. For example, it is first determined whether the object to be recognized in the first infrared image is blocked, and then it is determined whether the object to be recognized in the second infrared image is blocked.
根据一些实施例,可以通过训练得到第二单步多框检测神经网络模型。通过将红外图像输入第二单步多框检测神经网络模型,能够同时输出包围红外图像中的待识别对象的边界框和指示所述待识别对象是否被遮挡的识别结果。According to some embodiments, the second single-step multi-frame detection neural network model can be obtained through training. By inputting the infrared image into the second single-step multi-frame detection neural network model, the bounding box surrounding the object to be recognized in the infrared image and the recognition result indicating whether the object to be recognized is occluded can be output simultaneously.
在一个示例性实施例中,可以依次确定第一红外相机拍摄的第一红外图像和第二红外相机拍摄的第二红外图像中的所述待识别对象是否被遮挡,并且可以响应于确定第一红外图像或第二红外图像中的所述待识别对象被遮挡,确定所述待识别对象是否被遮挡。以先确定第一红外相机拍摄的第一红外图像中的所述待识别对象是否被遮挡为例,相应地,步骤S1031中获取所述第一边界框可以包括:将所述第一红外图像输入所述第二单步多框检测神经网络模型;以及获取所述第二单步多框检测神经网络模型输出的所述第一边界框和第一识别结果,所述第一识别结果指示所述待识别对象是否被遮挡。所述深度图像获取方法还可以包括:响应于所述第一识别结果指示所述待识别对象被遮挡,确定所述待识别对象被遮挡;响应于确定所述待识别对象被遮挡,提示重新获取红外目标图像。可以响应于所述第一识别结果指示所述待识别对象未被遮挡,再确定第二红外相机拍摄的第二红外图像中的所述待识别对象是否被遮挡,具体的实现方式可以与上述相同。从而能够在基于第一红外图像确定所述待识别对象被遮挡的情况下,不需要再确定所述第二红外图像中的所述待识别对象是否被遮挡,提高检测效率。In an exemplary embodiment, whether the object to be identified in the first infrared image captured by the first infrared camera and the second infrared image captured by the second infrared camera may be sequentially determined, and may be responsive to determining the first The object to be identified in the infrared image or the second infrared image is blocked, and it is determined whether the object to be identified is blocked. Taking determining whether the object to be recognized in the first infrared image captured by the first infrared camera is blocked as an example, correspondingly, acquiring the first bounding box in step S1031 may include: inputting the first infrared image into the second single-step multi-frame detection neural network model; and obtaining the first bounding box and the first recognition result output by the second single-step multi-frame detection neural network model, the first recognition result indicating the Whether the object to be recognized is occluded. The depth image acquisition method may further include: in response to the first recognition result indicating that the object to be recognized is blocked, determining that the object to be recognized is blocked; in response to determining that the object to be recognized is blocked, prompting re-acquisition Infrared target image. In response to the first recognition result indicating that the object to be recognized is not blocked, it can be determined whether the object to be recognized in the second infrared image captured by the second infrared camera is blocked, and the specific implementation can be the same as the above. . Therefore, when it is determined based on the first infrared image that the object to be identified is blocked, it is unnecessary to determine whether the object to be identified in the second infrared image is blocked, thereby improving detection efficiency.
在另一个示例性实施例中,可以在获取指示所述第一红外图像和第二红外图像中的待识别对象是否被遮挡的指示结果之后,基于所述第一红外图像和第二红外图像相应的两个指示结果来确定所述待识别对象是否被遮挡。相应地,步骤S1031、获取所述第一边界框和第二边界框可以包括:将所述第一红外图像输入第二单步多框检测神经网络模型;获取所述第二单步多框检测神经网络模型输出的所述第一边界框和第一识别结果,所述第一识别结果指示所述待识别对象是否被遮挡;将所述第二红外图像输入所述第二单步多框检测神经网络模型;以及获取所述第二单步多框检测神经网络模型输出的所述第二边界框和第二识别结果,所述第二识别结果指示所述待识别对象是否被遮挡。所述深度图像获取方法还可以包括:响应于所述第一识别结果和/或第二识别结果指示所述待识别对象被遮挡,确定所述待识别对象被遮挡;响应于确定所述待识别对象被遮挡,提示重新获取红外目标图像。根据一些实施例,可以将所述第一红外图像和第二红外图像同时输入第二单步多框检测神经网络模型,以获取所述第一识别结果和第二识别结果,能够提高检测效率。In another exemplary embodiment, after obtaining an indication result indicating whether the object to be identified in the first infrared image and the second infrared image is occluded, a corresponding response based on the first infrared image and the second infrared image may be obtained. to determine whether the object to be recognized is occluded. Correspondingly, in step S1031, obtaining the first bounding box and the second bounding box may include: inputting the first infrared image into a second single-step multi-frame detection neural network model; obtaining the second single-step multi-frame detection The first bounding box and the first recognition result output by the neural network model, the first recognition result indicates whether the object to be recognized is occluded; the second infrared image is input into the second single-step multi-frame detection a neural network model; and acquiring the second bounding box and a second recognition result output by the second single-step multi-frame detection neural network model, the second recognition result indicating whether the object to be recognized is occluded. The depth image acquisition method may further include: in response to the first recognition result and/or the second recognition result indicating that the object to be recognized is blocked, determining that the object to be recognized is blocked; in response to determining that the object to be recognized is blocked; The object is occluded, prompting to reacquire the IR target image. According to some embodiments, the first infrared image and the second infrared image may be simultaneously input into a second single-step multi-frame detection neural network model to obtain the first recognition result and the second recognition result, which can improve detection efficiency.
根据本公开的另一方面还提供一种电子电路,包括被配置为执行上述的深度图像获取方法的步骤的电路。According to another aspect of the present disclosure, there is also provided an electronic circuit comprising a circuit configured to perform the steps of the above-described depth image acquisition method.
根据本公开的另一方面还提供一种深度图像获取设备,包括:红外光源,被配置为提供双目红外相机拍摄所需的光照;双目红外相机,包括第一红外相机和第二红外相机,被配置为拍摄红外目标图像,所述红外目标图像包括第一红外图像和第二红外图像,所述第一红外图像为所述第一红外相机拍摄的图像,所述第二红外图像为所述第二红外相机拍摄的图像,所述第一红外图像和第二红外图像均包括待识别对象;如上所述的电子电路。According to another aspect of the present disclosure, there is also provided a depth image acquisition device, including: an infrared light source configured to provide illumination required for shooting by a binocular infrared camera; a binocular infrared camera including a first infrared camera and a second infrared camera , is configured to capture an infrared target image, the infrared target image includes a first infrared image and a second infrared image, the first infrared image is the image captured by the first infrared camera, and the second infrared image is the The image captured by the second infrared camera, the first infrared image and the second infrared image both include the object to be identified; the electronic circuit as described above.
下面以基于人脸图像的活体识别为例来对根据本公开实施例的深度图像获取方法的具体应用进行进一步描述。需要说明的是,在此仅是以人脸识别为例来进行说明,并不是限定本公开的活体识别方法仅能适用于人脸活体识别。The specific application of the depth image acquisition method according to the embodiment of the present disclosure will be further described below by taking the living body recognition based on the face image as an example. It should be noted that the description here is only taking face recognition as an example, and it is not limited that the living body recognition method of the present disclosure is only applicable to face living body recognition.
图7是示出根据本公开示例性实施例的活体识别方法的流程图。如图7所示,所述活体识别方法可以包括:执行上述的深度图像获取方法;以及步骤S105、至少部分地基于所述深度图像,确定第三识别结果,所述第三识别结果指示所述待识别对象是否为活体。由此,不需要能够投射具有一定结构特征光线的光学仪器,仅用普通的红外光源直接提供拍摄待识别对象所需的光照即可,成本较低,并且利用双目视觉原理来获取包括待识别对象的深度图像,用于活体识别,环境适应性强,适用于弱光和强光拍摄场景。FIG. 7 is a flowchart illustrating a living body recognition method according to an exemplary embodiment of the present disclosure. As shown in FIG. 7 , the living body recognition method may include: performing the above-mentioned depth image acquisition method; and step S105 , based at least in part on the depth image, determining a third recognition result, the third recognition result indicating the Whether the object to be identified is a living body. Therefore, there is no need for an optical instrument capable of projecting light with certain structural characteristics, and only ordinary infrared light sources are used to directly provide the illumination required for photographing the object to be identified, which is low in cost, and the principle of binocular vision is used to obtain information including objects to be identified. The depth image of the object, used for living body recognition, has strong environmental adaptability, and is suitable for low-light and strong-light shooting scenes.
根据一些实施例,结合图7和图8所示,当所述深度图像获取方法包括:将所述深度图像与所述第一红外图像或第二红外图像进行融合,得到融合图像时,步骤S105可以包括:步骤S1051、至少部分地基于所述深度图像与所述第一红外图像或第二红外图像融合得到的融合图像,确定所述第三识别结果。由于所述融合图像既具有深度信息又具有红外图像的灰度、亮度等信息,能够提高活体识别的准确性。According to some embodiments, as shown in FIG. 7 and FIG. 8 , when the depth image acquisition method includes: fusing the depth image with the first infrared image or the second infrared image to obtain a fused image, step S105 The method may include: step S1051 , determining the third recognition result based at least in part on a fusion image obtained by fusion of the depth image and the first infrared image or the second infrared image. Since the fusion image has both depth information and information such as grayscale and brightness of the infrared image, the accuracy of living body recognition can be improved.
根据一些示例性实施例,步骤S105中至少部分地基于所述融合图像,确定所述第三识别结果可以包括:基于所述融合图像以及所述第一红外图像中的与所述待识别对象相关联的多个第一关键点,确定所述第三识别结果。从而活体识别过程与待识别对象的关键点相关,能够提高识别的准确性和效率。在一个示例性实施例中,基于所述融合图像以及所述多个第一关键点,确定所述第三识别结果可以包括:将所述融合图像以及所述多个第一关键点输入第一卷积神经网络模型;以及获取所述第一卷积神经网络模型输出的所述第三识别结果。通过神经网络模型能够快速得到识别结果,并且提高识别准确性。所述第一卷积神经网络模型可以为:LeNet-5、AlexNet、ZFNet、VGG-16、GoogLeNet、ResNet、MobileNet等等。例如,MobileNet具有更小的体积,更少的计算量,更快的速度,更高的精度。因此,MobileNet网络在轻量级神经网络中拥有优势,可适用于终端设备。可以理解的是,并不局限于利用神经网络模型来对融合图像中的待识别对象进行活体识别,利用还可以基于传统的分类器(如支持向量机SVM)来进行活体识别,在此不作限定。According to some exemplary embodiments, determining the third recognition result based at least in part on the fused image in step S105 may include: based on the fused image and the first infrared image related to the object to be recognized A plurality of first key points are connected to determine the third recognition result. Therefore, the living body recognition process is related to the key points of the object to be recognized, and the accuracy and efficiency of the recognition can be improved. In an exemplary embodiment, based on the fused image and the plurality of first key points, determining the third recognition result may include: inputting the fused image and the plurality of first key points into a first a convolutional neural network model; and obtaining the third recognition result output by the first convolutional neural network model. The recognition results can be obtained quickly through the neural network model, and the recognition accuracy can be improved. The first convolutional neural network model may be: LeNet-5, AlexNet, ZFNet, VGG-16, GoogLeNet, ResNet, MobileNet, and so on. For example, MobileNet has smaller volume, less computation, faster speed, and higher accuracy. Therefore, MobileNet network has advantages in lightweight neural network, which can be applied to end devices. It can be understood that it is not limited to use the neural network model to carry out living body recognition to the object to be identified in the fusion image, and the use can also be based on traditional classifiers (such as support vector machine SVM) to carry out living body recognition, which is not limited here. .
根据一些实施例,可以基于所述第一红外图像和包围所述第一红外图像中的待识别对象的第一边界框,来确定所述第一红外图像中的与所述待识别对象相关联的多个第一关键点。其中,所述第一边界框的获取方法已经在上面内容中描述。所述多个第一关键点可以包括人脸的瞳孔中心、眼角、鼻尖、嘴角等特征点对应的像素。According to some embodiments, it may be determined that the object to be identified in the first infrared image is associated with the object to be identified in the first infrared image based on the first infrared image and a first bounding box surrounding the object to be identified in the first infrared image of multiple first key points. The method for obtaining the first bounding box has been described above. The plurality of first key points may include pixels corresponding to feature points such as the center of the pupil, the corner of the eye, the tip of the nose, and the corner of the mouth of the human face.
根据另一些实施例,步骤S105也可以包括:基于深度图像以及所述第一红外图像中的与所述待识别对象相关联的多个第一关键点,确定所述第三识别结果。与上述实施例不同的是,不再将所述深度图像与第一红外图像或第二红外图像进行融合,同样也能够实现活体识别过程与待识别对象的关键点相关,能够提高识别的准确性和效率。在一个示例性实施例中,基于深度图像以及所述第一红外图像中的与所述待识别对象相关联的多个第一关键点,确定所述第三识别结果可以包括:将所述深度图像以及所述多个第一关键点输入第二卷积神经网络模型;以及获取所述第二卷积神经网络模型输出的所述第三识别结果。通过神经网络模型能够快速得到识别结果,并且提高识别准确性。所述第二卷积神经网络模型可以为:LeNet-5、AlexNet、ZFNet、VGG-16、GoogLeNet、ResNet、MobileNet等等。例如,MobileNet具有更小的体积,更少的计算量,更快的速度,更高的精度。因此,MobileNet网络在轻量级神经网络中拥有优势,可适用于终端设备。可以理解的是,并不局限于利用神经网络模型来对深度图像中的待识别对象进行活体识别,利用还可以基于传统的分类器(如支持向量机SVM)来进行活体识别,在此不作限定。According to other embodiments, step S105 may also include: determining the third recognition result based on the depth image and a plurality of first key points associated with the object to be recognized in the first infrared image. Different from the above-mentioned embodiment, the depth image is no longer fused with the first infrared image or the second infrared image, and it is also possible to realize that the process of living body recognition is related to the key points of the object to be recognized, which can improve the accuracy of recognition. and efficiency. In an exemplary embodiment, determining the third recognition result based on the depth image and a plurality of first key points associated with the object to be recognized in the first infrared image may include: converting the depth The image and the plurality of first key points are input into a second convolutional neural network model; and the third recognition result output by the second convolutional neural network model is obtained. The recognition results can be obtained quickly through the neural network model, and the recognition accuracy can be improved. The second convolutional neural network model may be: LeNet-5, AlexNet, ZFNet, VGG-16, GoogLeNet, ResNet, MobileNet, and so on. For example, MobileNet has smaller volume, less computation, faster speed, and higher accuracy. Therefore, MobileNet network has advantages in lightweight neural network, which can be applied to end devices. It can be understood that, it is not limited to use the neural network model to carry out living body recognition to the object to be identified in the depth image, and the use can also be based on traditional classifiers (such as support vector machine SVM) to carry out living body recognition, which is not limited here. .
根据一些实施例,在执行步骤S105以基于深度图像进行活体识别的同时,还可以基于双目红外相机拍摄得到的两个红外图像中的至少其中之一,来进行活体识别,并基于两个识别结果进行决策来判定待识别对象是否为活体。从而能够提高活体识别的准确性。相应地,如图9所示,所述活体识别方法还可以包括:步骤S106、至少部分地基于所述第一红外图像,确定第四识别结果,所述第四识别结果指示所述待识别对象是否为活体;步骤S107、至少部分地基于所述第二红外图像,确定第五识别结果,所述第五识别结果指示所述待识别对象是否为活体;以及步骤S108、根据所述第四识别结果和第五识别结果中的至少其中之一以及所述第三识别结果进行决策,判定所述待识别对象是否为活体。According to some embodiments, while performing step S105 to perform living body recognition based on the depth image, living body recognition may also be performed based on at least one of the two infrared images captured by the binocular infrared camera, and based on the two As a result, a decision is made to determine whether the object to be identified is a living body. Thereby, the accuracy of living body recognition can be improved. Correspondingly, as shown in FIG. 9 , the living body recognition method may further include: step S106 , determining a fourth recognition result based at least in part on the first infrared image, where the fourth recognition result indicates the object to be recognized Whether it is a living body; step S107, based at least in part on the second infrared image, determine a fifth recognition result, the fifth recognition result indicates whether the object to be recognized is a living body; and step S108, according to the fourth recognition At least one of the result and the fifth identification result and the third identification result make a decision to determine whether the object to be identified is a living body.
需要说明的是,在此并不限定步骤S103和步骤S105(基于深度图像进行活体识别)与步骤S106-步骤S107(基于红外图像进行活体识别)的执行顺序,例如,步骤S103和步骤S105可以与步骤S106-步骤S107并行执行,或者,也可以先执行步骤S106和S107,然后再执行步骤S103和步骤S105。It should be noted that the execution sequence of steps S103 and S105 (living body recognition based on depth images) and steps S106 to S107 (living body recognition based on infrared images) is not limited here. For example, steps S103 and S105 can be combined with Steps S106 to S107 are performed in parallel, or, steps S106 and S107 may be performed first, and then steps S103 and S105 may be performed.
可以理解的是,若只根据所述第四识别结果(或所述第五识别结果)以及所述第三识别结果进行决策,也可以只确定所述第四识别结果(或所述五识别结果),并不限定必须要同时确定所述第四识别结果和所述五识别结果。也就是说,图9中也可以不同时包括步骤S106和步骤S107,而仅包括步骤S106和步骤S107中的其中之一。It can be understood that, if the decision is made only according to the fourth identification result (or the fifth identification result) and the third identification result, only the fourth identification result (or the fifth identification result) may be determined. ), it does not limit that the fourth identification result and the fifth identification result must be determined at the same time. That is to say, in FIG. 9 , steps S106 and S107 may not be included at the same time, but only one of steps S106 and S107 may be included.
根据一些实施例,在根据所述第四识别结果和第五识别结果以及所述第三识别结果进行决策的情况下,可以在所述第四识别结果和第五识别结果以及所述第三识别结果均指示所述待识别对象为活体时,才判定所述待识别对象为活体,只要所述第四识别结果、第五识别结果和所述第三识别结果中的至少其中一个指示所述待识别对象不为活体,则判定所述待识别对象不为活体。当然,根据所述第四识别结果和第五识别结果以及所述第三识别结果进行决策的策略并不局限于上述一种,例如:还可以在所述第四识别结果、第五识别结果和所述第三识别结果中的至少其中两个指示所述待识别对象为活体时,判定所述待识别对象为活体。或者,为所述第四识别结果、第五识别结果和所述第三识别结果设定不同的权重,可以将所述第四识别结果、第五识别结果和所述第三识别结果与相应的权重相乘之后,再进行求和得到加权和。当计算得到的所述加权和不小于设定阈值时,判定所述待识别对象为活体。否则,当计算得到的所述加权和小于所述设定阈值时,判定所述待识别对象不为活体。According to some embodiments, in the case of making a decision according to the fourth identification result, the fifth identification result and the third identification result, the fourth identification result and the fifth identification result and the third identification Only when the results indicate that the object to be identified is a living body, the object to be identified is determined to be a living body, as long as at least one of the fourth identification result, the fifth identification result and the third identification result indicates the object to be identified. If the recognized object is not a living body, it is determined that the object to be recognized is not a living body. Of course, the decision-making strategy based on the fourth identification result, the fifth identification result and the third identification result is not limited to the above one, for example, the fourth identification result, the fifth identification result and the When at least two of the third identification results indicate that the object to be identified is a living body, it is determined that the object to be identified is a living body. Alternatively, different weights are set for the fourth identification result, the fifth identification result, and the third identification result, and the fourth identification result, the fifth identification result, and the third identification result can be compared with the corresponding After the weights are multiplied, they are summed to obtain a weighted sum. When the calculated weighted sum is not less than a set threshold, it is determined that the object to be identified is a living body. Otherwise, when the calculated weighted sum is less than the set threshold, it is determined that the object to be identified is not a living body.
根据一些示例性实施例,确定所述第四识别结果和第五识别结果可以包括:将所述第一红外图像输入第三单步多框检测神经网络模型;获取所述第三单步多框检测神经网络模型输出的第四识别结果;将所述第二红外图像输入所述第三单步多框检测神经网络模型;以及获取所述第三单步多框检测神经网络模型输出的第五识别结果。从而能够通过神经网络模型能够快速得到识别结果,并且提高识别准确性。当然,也可以利用其它类型的卷积神经网络来对输入的红外图像中的待识别对象进行活体识别,并不局限于利用SSD神经网络模型。可以理解的是,并不局限于利用神经网络模型来进行活体识别,利用还可以基于传统的分类器(如支持向量机SVM)来进行活体识别,在此不作限定。According to some exemplary embodiments, determining the fourth recognition result and the fifth recognition result may include: inputting the first infrared image into a third single-step multi-frame detection neural network model; obtaining the third single-step multi-frame detection Detecting the fourth identification result output by the neural network model; inputting the second infrared image into the third single-step multi-frame detection neural network model; and obtaining the fifth single-step multi-frame detection neural network model output Identify the results. Therefore, the recognition result can be obtained quickly through the neural network model, and the recognition accuracy can be improved. Of course, other types of convolutional neural networks can also be used to perform living body recognition on the object to be recognized in the input infrared image, and the use of the SSD neural network model is not limited. It can be understood that, it is not limited to use the neural network model to perform living body recognition, and can also use traditional classifiers (such as support vector machine SVM) to perform living body recognition, which is not limited here.
根据一些实施例,所述第三单步多框检测神经网络模型可以与所述第二单步多框检测神经网络模型为同一神经网络模型。也就是说,在通过将包括待识别对象的红外图像输入单步多框检测神经网络模型,来获取包围所述红外图像中的所述待识别对象的边界框以及指示所述待识别对象是否被遮挡的识别结果的同时,还可以获取指示所述待识别对象是否为活体的识别结果。相应地,获取所述第一边界框和第二边界框以及确定所述第四识别结果和第五识别结果可以包括:将所述第一红外图像输入第二单步多框检测神经网络模型;获取所述第一单步多框检测神经网络模型输出的所述第一边界框、第一识别结果和第四识别结果;将所述第二红外图像输入所述第二单步多框检测神经网络模型;以及获取所述第一单步多框检测神经网络模型输出的所述第二边界框、第二识别结果和第五识别结果。由于SSD神经网络能够对多个不同尺度的特征图进行检测,错误率低。而且只需要一步即可完成对输入图像中的对象进行识别和位置检测,检测速度快。According to some embodiments, the third single-step multi-frame detection neural network model may be the same neural network model as the second single-step multi-frame detection neural network model. That is to say, by inputting an infrared image including an object to be recognized into a single-step multi-frame detection neural network model, a bounding box surrounding the object to be recognized in the infrared image is obtained and an indication of whether the object to be recognized is At the same time as the recognition result of the occlusion, the recognition result indicating whether the object to be recognized is a living body can also be obtained. Correspondingly, acquiring the first bounding box and the second bounding box and determining the fourth recognition result and the fifth recognition result may include: inputting the first infrared image into a second single-step multi-frame detection neural network model; Obtain the first bounding box, the first recognition result and the fourth recognition result output by the first single-step multi-frame detection neural network model; input the second infrared image into the second single-step multi-frame detection neural network a network model; and acquiring the second bounding box, the second recognition result and the fifth recognition result output by the first single-step multi-frame detection neural network model. Since the SSD neural network can detect multiple feature maps of different scales, the error rate is low. And it only needs one step to complete the recognition and position detection of the object in the input image, and the detection speed is fast.
可以理解的是,所述第三单步多框检测神经网络模型也可以与所述第一单步多框检测神经网络模型为同一神经网络模型。也就是说,在通过将包括待识别对象的红外图像输入单步多框检测神经网络模型,来获取包围所述红外图像中的所述待识别对象的边界框的同时,还可以获取指示所述待识别对象是否为活体的识别结果。相应地,获取所述第一边界框和第二边界框以及确定所述第四识别结果和第五识别结果可以包括:将所述第一红外图像输入第一单步多框检测神经网络模型;获取所述第一单步多框检测神经网络模型输出的所述第一边界框和第四识别结果;将所述第二红外图像输入所述第一单步多框检测神经网络模型;以及获取所述第一单步多框检测神经网络模型输出的所述第二边界框和第五识别结果。It can be understood that the third single-step multi-frame detection neural network model may also be the same neural network model as the first single-step multi-frame detection neural network model. That is to say, by inputting an infrared image including an object to be recognized into a single-step multi-frame detection neural network model to obtain a bounding box surrounding the object to be recognized in the infrared image, it is also possible to obtain an indication of the object to be recognized. The recognition result of whether the object to be recognized is a living body. Correspondingly, acquiring the first bounding box and the second bounding box and determining the fourth identification result and the fifth identification result may include: inputting the first infrared image into a first single-step multi-frame detection neural network model; obtaining the first bounding box and the fourth recognition result output by the first single-step multi-frame detection neural network model; inputting the second infrared image into the first single-step multi-frame detection neural network model; and obtaining The second bounding box and the fifth recognition result output by the first single-step multi-frame detection neural network model.
在对待识别对象进行活体识别的一些应用场景中,还需要将待识别对象与一个或多个目标对象进行比对,只有当所述待识别对象为活体并且比对结果表明所述待识别对象与其中一个目标对象匹配,才能完成整个识别过程。也就是说,活体识别可以包括确定待识别对象是否为活体的活体判定过程和确定待识别对象是否为目标对象的比对过程。例如,在人脸识别门禁应用场景中,需要针对获取的待识别人脸的图像进行活体判定,还需要通过比对确定待识别人脸是否为目标对象,才能够完成识别过程。只有在待识别人脸判定为活体并且待识别人脸为目标对象时,才打开门禁。在人脸识别支付应用场景中,也需要针对获取的待识别人脸的图像进行活体判定,还需要通过比对确定待识别人脸是否为目标对象,才能够完成识别过程。只有在判定待识别人脸为活体并且待识别人脸为目标对象时,才执行支付。在身份认证应用场景中,也需要针对获取的待识别人脸的图像进行活体判定,还需要通过比对确定待识别人脸是否为目标对象,才能够完成识别过程。只有在判定待识别人脸为活体并且待识别人脸为目标对象时,才认证成功。In some application scenarios in which the object to be recognized is recognized as a living body, it is also necessary to compare the object to be recognized with one or more target objects. One of the target objects is matched to complete the entire recognition process. That is, the living body identification may include a living body determination process of determining whether the object to be identified is a living body and a comparison process of determining whether the object to be identified is a target object. For example, in the face recognition access control application scenario, it is necessary to determine the living body of the obtained image of the face to be recognized, and it is also necessary to determine whether the face to be recognized is the target object through comparison, and then the recognition process can be completed. The door is opened only when the face to be recognized is determined to be alive and the face to be recognized is the target object. In the face recognition payment application scenario, it is also necessary to carry out in vivo determination on the obtained image of the face to be recognized, and it is also necessary to determine whether the face to be recognized is the target object through comparison, and then the recognition process can be completed. Payment is performed only when it is determined that the face to be recognized is a living body and the face to be recognized is the target object. In the application scenario of identity authentication, it is also necessary to perform in vivo determination on the obtained image of the face to be recognized, and it is also necessary to determine whether the face to be recognized is the target object through comparison, and then the recognition process can be completed. The authentication succeeds only when it is determined that the face to be recognized is a living body and the face to be recognized is the target object.
基于此,根据一些实施例,如图10所示,所述活体识别方法还可以包括:步骤S301、获取比对目标图像,所述比对目标图像包括所述待识别对象;步骤S302、获取所述比对目标图像中的所述待识别对象的第一图像信息;步骤S303、将所述第一图像信息和至少一个第二图像信息进行比对;以及步骤S304、基于比对结果确定所述待识别对象是否为目标对象。Based on this, according to some embodiments, as shown in FIG. 10 , the living body recognition method may further include: step S301 , obtaining a comparison target image, where the comparison target image includes the object to be recognized; step S302 , obtaining the comparing the first image information of the object to be identified in the target image; step S303, comparing the first image information with at least one second image information; and step S304, determining the Whether the object to be recognized is the target object.
所述比对目标图像可以为上述双目红外相机拍摄得到的第一红外图像或第二红外图像,也可以为独立设置的彩色相机拍摄得到的彩色图像。The comparison target image may be the first infrared image or the second infrared image captured by the binocular infrared camera, or may be a color image captured by an independently set color camera.
在获取待识别对象的第一图像信息之前,还可以对比对目标图像进行预处理。所述预处理可以包括人脸检测、人脸对齐等。所述第一图像信息可以但不局限于为整个待识别对象的图像编码信息(例如人脸编码信息)。Before acquiring the first image information of the object to be recognized, the target image may also be preprocessed by comparison. The preprocessing may include face detection, face alignment, and the like. The first image information may be, but is not limited to, image encoding information (eg, face encoding information) of the entire object to be recognized.
根据一些实施例,如图10所示,在将所述第一图像信息和第二图像信息进行比对之前还可以包括:步骤S401、确定所述比对目标图像的图像质量是否符合预设标准。其中,将所述第一图像信息和第二图像信息进行比对可以为响应于确定比对目标图像的图像质量符合预设标准而执行。从而能够保证比对目标图像的质量,提高比对结果的准确性。所述活体识别方法还可以包括:步骤S402、响应于比对目标图像的图像质量不符合预设标准,提示重新获取比对目标图像。According to some embodiments, as shown in FIG. 10 , before the comparison between the first image information and the second image information may further include: Step S401 , determining whether the image quality of the comparison target image meets a preset standard . The comparison of the first image information and the second image information may be performed in response to determining that the image quality of the comparison target image meets a preset standard. Therefore, the quality of the comparison target image can be guaranteed, and the accuracy of the comparison result can be improved. The living body recognition method may further include: Step S402, in response to the image quality of the comparison target image not meeting the preset standard, prompting to re-acquire the comparison target image.
以人脸识别为例,确定所述比对目标图像的图像质量是否符合预设标准包括以下各项中的至少一个:确定所述比对目标图像中的所述待识别对象是否被遮挡;确定所述比对目标图像的分辨率是否高于预设分辨率;确定所述比对目标图像中的所述待识别对象的瞳间距是否大于预设距离;确定所述比对目标图像是否曝光不足或过曝;确定所述比对目标图像是否清晰;确定所述比对目标图像中的所述待识别对象是否具有预设表情;以及确定所述比对目标图像中的所述待识别对象的转角是否不大于预设角度。Taking face recognition as an example, determining whether the image quality of the comparison target image meets a preset standard includes at least one of the following: determining whether the object to be recognized in the comparison target image is occluded; determining Whether the resolution of the comparison target image is higher than a preset resolution; determining whether the interpupillary distance of the object to be identified in the comparison target image is greater than a preset distance; determining whether the comparison target image is underexposed determine whether the comparison target image is clear; determine whether the object to be recognized in the comparison target image has a preset expression; and determine whether the object to be recognized in the comparison target image is Whether the corner is not greater than the preset angle.
根据一些实施例,在所述比对目标图像为第一红外图像(或第二红外图像)的情况下,可以根据上述内容中描述的,通过将所述第一红外图像(或第二红外图像)输入所述第二单步多框检测神经网络模型,来获取所述第二单步多框检测神经网络模型输出的所述第一边界框(或第二边界框,即人脸框)和指示所述待识别对象是否被遮挡的第一识别结果(或第二识别结果)。从而能够在确定人脸框的同时,并确定人脸是否被遮挡。还可以基于所述比对目标图像和人脸框,确定与人脸相关联的多个第一关键点(或第二关键点)。所述多个第一关键点(或第二关键点)可以包括瞳孔中心,从而能够确定瞳间距是否大于预设距离,以使得所述比对目标图像中的人脸足够大,能够保证后续比对结果的准确性。According to some embodiments, when the comparison target image is the first infrared image (or the second infrared image), the first infrared image (or the second infrared image) may be ) input the second single-step multi-frame detection neural network model to obtain the first bounding box (or the second bounding box, that is, the face frame) output by the second single-step multi-frame detection neural network model and the The first recognition result (or the second recognition result) indicating whether the object to be recognized is occluded. Therefore, it can be determined whether the face is blocked while determining the face frame. A plurality of first key points (or second key points) associated with the face may also be determined based on the comparison target image and the face frame. The plurality of first key points (or second key points) may include the center of the pupil, so that it can be determined whether the interpupillary distance is greater than a preset distance, so that the face in the comparison target image is large enough to ensure subsequent comparisons. accuracy of results.
根据一些实施例,在所述比对目标图像为彩色图像的情况下,确定所述比对目标图像的图像质量是否符合预设标准可以包括:将所述彩色图像输入第四单步多框检测神经网络模型;以及获取所述第四单步多框检测神经网络模型输出的第四边界框(即人脸框)和第六识别结果。所述第四边界框能够包围所述彩色图像中的人脸。所述第六识别结果指示所述彩色图像中的人脸是否被遮挡。由于SSD神经网络能够对多个不同尺度的特征图进行检测,错误率低。而且只需要一步即可完成对输入图像中的对象进行分类和位置检测,检测速度快。还可以基于所述彩色图像和人脸框(第四边界框)确定与人脸相关联的多个第四关键点,所述多个第四关键点可以包括瞳孔中心,从而能够确定瞳间距是否大于预设距离,以使得所述比对目标图像中的人脸足够大,能够保证后续比对结果的准确性。According to some embodiments, when the comparison target image is a color image, determining whether the image quality of the comparison target image meets a preset standard may include: inputting the color image into a fourth single-step multi-frame detection a neural network model; and acquiring a fourth bounding box (ie, a face frame) and a sixth recognition result output by the fourth single-step multi-frame detection neural network model. The fourth bounding box can enclose a human face in the color image. The sixth recognition result indicates whether the face in the color image is occluded. Since the SSD neural network can detect multiple feature maps of different scales, the error rate is low. And it only takes one step to complete the classification and position detection of the objects in the input image, and the detection speed is fast. A plurality of fourth keypoints associated with the face may also be determined based on the color image and the face frame (fourth bounding box), the plurality of fourth keypoints may include the pupil center, thereby enabling a determination of whether the interpupillary distance is is greater than the preset distance, so that the face in the comparison target image is large enough to ensure the accuracy of the subsequent comparison result.
针对所述比对目标图像的分辨率是否高于预设分辨率、是否曝光不出或过曝、是否清晰,可以根据所述比对目标图像来直接确定。如果所述比对目标图像的分辨率不高于预设分辨率,则可以提示重新获取比对目标图像。如果所述比对目标图像欠曝或过曝,则可以提示重新获取比对目标图像。如果所述比对目标图像不清晰,则可以提示重新获取比对目标图像。Whether the resolution of the comparison target image is higher than the preset resolution, whether it is underexposed or overexposed, and whether it is clear or not can be directly determined according to the comparison target image. If the resolution of the comparison target image is not higher than the preset resolution, it may prompt to re-acquire the comparison target image. If the comparison target image is underexposed or overexposed, it may prompt to re-acquire the comparison target image. If the comparison target image is not clear, it may prompt to re-acquire the comparison target image.
所述预设表情例如可以包括大笑、歪嘴、歪脸、闭眼等。如果所述比对目标图像中的待识别对象具有上述预设表情,则可以提示重新获取比对目标图像。The preset expressions may include, for example, laughing, crooked mouth, crooked face, closed eyes, and the like. If the object to be identified in the comparison target image has the above-mentioned preset expression, a prompt may be given to re-acquire the comparison target image.
可以基于模型的方法、基于表观的方法或基于分类的方法来获取人脸的转角。如果人脸的转角大于预设角度,则可以提示重新获取比对目标图像。The corners of the face can be obtained by a model-based method, an appearance-based method, or a classification-based method. If the rotation angle of the face is larger than the preset angle, it can prompt to re-acquire the comparison target image.
当确定所述比对目标图像的图像质量符合预设标准,执行将所述第一图像信息和第二图像信息进行比对,能够保证比对结果的准确性。When it is determined that the image quality of the comparison target image meets a preset standard, the comparison between the first image information and the second image information is performed, which can ensure the accuracy of the comparison result.
上述比对过程可以与活体判定过程并行执行。也可以先进行比对,可以响应于确定所述待识别对象为目标对象,执行步骤S101-S105,以进行活体判定。也可以先执行步骤S101-步骤S105进行活体判定,响应于确定所述待识别对象为活体,执行所述步骤S301-步骤S304进行比对。当上述比对过程与活体判定过程并行执行时,可以设置两个数据处理器进行并行数据处理,更加高效。当上述比对过程与活体判定过程为串行执行时,可以仅设置一个数据处理器进行串行数据处理,能够降低功耗。可以根据具体的应用场景来选择上述比对过程与活体判定过程的执行顺序,在此不作限定。The above-described comparison process may be performed in parallel with the living body determination process. The comparison may also be performed first, and steps S101-S105 may be performed in response to determining that the object to be identified is the target object to perform living body determination. Steps S101 to S105 may also be performed first to determine a living body, and in response to determining that the object to be identified is a living body, steps S301 to S304 are performed to perform comparison. When the above comparison process and the living body determination process are performed in parallel, two data processors can be set to perform parallel data processing, which is more efficient. When the above-mentioned comparison process and the living body determination process are performed serially, only one data processor may be set to perform serial data processing, which can reduce power consumption. The execution order of the above comparison process and the living body determination process may be selected according to a specific application scenario, which is not limited here.
以下内容中将结合几种示例性应用场景来具体描述如何选择上述比对过程与活体判定过程的执行顺序。The following content will specifically describe how to select the execution order of the comparison process and the living body determination process in combination with several exemplary application scenarios.
当上述比对过程中待比对的所述至少一个第二图像信息的数量不大于预设数值时,可以先进行比对,响应于确定所述待识别对象为目标对象,执行步骤S101-S105,以进行活体判定。当上述比对过程中待比对的所述至少一个第二图像信息的数量大于预设数值时,可以先执行步骤S101- S105进行活体判定,响应于确定所述待识别对象为活体,执行所述步骤S301-步骤S304进行比对。所述预设数值可以根据实际需求设定,在此不作限定。When the quantity of the at least one second image information to be compared in the above comparison process is not greater than the preset value, the comparison may be performed first, and in response to determining that the object to be identified is the target object, steps S101-S105 are executed , for in vivo determination. When the quantity of the at least one second image information to be compared in the above comparison process is greater than a preset value, steps S101-S105 may be performed first to determine a living body, and in response to determining that the object to be identified is a living body, performing all The above steps S301-S304 are compared. The preset value can be set according to actual needs, which is not limited here.
在人脸识别技术领域中,根据待比对的所述至少一个第二图像信息的数量N,可以划分为N=1、N不大于预设数值和N大于预设数值三种应用场景。N=1的应用场景例如可以但不局限于为身份认证应用场景;N不大于预设数值的应用场景例如可以但不局限于为门禁应用场景或公司考勤应用场景;N大于预设数值的应用场景例如可以但不局限于为支付应用场景或监控应用场景。In the technical field of face recognition, according to the quantity N of the at least one second image information to be compared, it can be divided into three application scenarios: N=1, N is not greater than a preset value, and N is greater than a preset value. The application scenario of N=1 can be, for example, but not limited to the identity authentication application scenario; the application scenario where N is not greater than the preset value can be, for example, but not limited to the access control application scenario or the company attendance application scenario; the application scenario where N is greater than the preset value The scenarios can be, for example, but not limited to, payment application scenarios or monitoring application scenarios.
根据一些示例性实施例,在N=1的情况下,如图11所示,步骤S303、将所述第一图像信息和至少一个第二图像信息进行比对之前还可以包括:步骤S501、获取包括所述目标对象的采集图像;以及步骤S502、从所述采集图像中确定所述目标对象的所述第二图像信息。从而能够验证所述待识别对象是否为采集图像中的目标对象,能够实现身份认证。所述采集图像可以为包括目标对象的人脸图像的身份证、驾照等的图像。在这种情况下,可以在实现身份认证后,再进行活体判定。因为所述第一图像信息仅需与一个第二图像信息进行比对,可以快速完成比对过程。According to some exemplary embodiments, in the case of N=1, as shown in FIG. 11 , step S303 , before comparing the first image information with at least one second image information, may further include: step S501 , obtaining Including the captured image of the target object; and step S502, determining the second image information of the target object from the captured image. Therefore, it can be verified whether the object to be identified is the target object in the captured image, and identity authentication can be realized. The captured image may be an image of an ID card, a driver's license, etc. including a face image of the target object. In this case, the living body determination can be performed after the identity authentication is realized. Because the first image information only needs to be compared with one second image information, the comparison process can be completed quickly.
根据一些示例性实施例,在N不大于预设数值的情况下,如图12所示,步骤S303、将所述第一图像信息和至少一个第二图像信息进行比对之前还可以包括:步骤S601、获取所述待识别对象的标识码;以及步骤S602、从预先建立的第一数据库中获取与所述标识码对应的第二图像信息。可以将所述将第一图像信息和该第二图像信息进行比对。其中,基于比对结果确定所述待识别对象是否为目标对象可以包括:响应于比对结果表明所述第一图像信息和该第二图像信息匹配,确定所述待识别对象为该第二图像信息对应的目标对象。从而能够根据唯一标识码来验证所述待识别对象是否为数据库中相应的目标对象,能够快速完成比对过程。在这种情况下,可以先进行比对,再执行步骤S101-S105进行活体判定。因为数据库中存储的第二图像信息的数量不大于预设数值,可以快速完成比对过程。该示例性实施例可以适用于N较大的应用场景,例如公司考勤应用场景,具有更高的比对效率。According to some exemplary embodiments, when N is not greater than a preset value, as shown in FIG. 12 , step S303 , before comparing the first image information with the at least one second image information, may further include: step S303 S601 , acquiring the identification code of the object to be identified; and step S602 , acquiring second image information corresponding to the identification code from a pre-established first database. The first image information and the second image information may be compared. Wherein, determining whether the object to be recognized is the target object based on the comparison result may include: in response to the comparison result indicating that the first image information matches the second image information, determining that the object to be recognized is the second image The target object corresponding to the information. Therefore, it can be verified whether the object to be identified is the corresponding target object in the database according to the unique identification code, and the comparison process can be completed quickly. In this case, the comparison can be performed first, and then steps S101-S105 are performed to determine the living body. Because the quantity of the second image information stored in the database is not greater than the preset value, the comparison process can be completed quickly. This exemplary embodiment can be applied to an application scenario with a large N, such as a company attendance application scenario, and has higher comparison efficiency.
所述标识码例如可以为条形码、二维码等。所述第一数据库可以存储在本地。The identification code may be, for example, a barcode, a two-dimensional code, or the like. The first database may be stored locally.
根据另一些示例性实施例,在N不大于预设数值的情况下,如图13所示,在步骤S303、将所述第一图像信息和至少一个第二图像信息进行比对之前还可以包括:步骤S701、建立第二数据库,所述第二数据库包括至少一个第二图像信息。步骤S303可以将所述第一图像信息与预先建立的第二数据库中的至少一个第二图像信息进行比对。其中,基于比对结果确定所述待识别对象是否为目标对象可以包括:响应于比对结果表明所述第一图像信息与所述至少一个第二图像信息中的其中一个第二图像信息匹配,确定所述待识别对象为该第二图像信息对应的目标对象。与上述实施例不同的是,该示例性实施例直接将待识别对象的第一图像信息与数据库中的至少一个第二图像信息进行比对。根据一些实施例,可以将所述第一图像信息依次与数据库中的至少一个第二图像信息进行比对,直至所述第一图像信息与其中一个第二图像信息的比对结果表明所述第一图像信息与该第二图像信息匹配,结束比对。也可以将所述第一图像信息依次与数据库中的至少一个第二图像信息进行比对,获取所述至少一个第二图像信息对应的比对结果,并根据所有比对结果来确定所述第一图像信息与其中一个第二图像信息匹配。例如,可以根据所述第一图像信息与所述至少一个第二图像信息中的每一个第二图像的比对结果进行打分,获取所述至少一个第二图像信息对应的多个比对评分,并确定对应的比对评分最高的第二图像信息与所述第一图像信息匹配。与上述示例性实施例相同的是,在这种情况下,可以先进行比对,再执行步骤S101-S105进行活体判定。该示例性实施例可以适用于N较小的应用场景,例如家用门禁应用场景,待比对的第二图像信息数量较少,能够快速完成比对过程。According to some other exemplary embodiments, when N is not greater than a preset value, as shown in FIG. 13 , in step S303 , before comparing the first image information with the at least one second image information, the method may further include: : Step S701 , establishing a second database, where the second database includes at least one second image information. Step S303 may compare the first image information with at least one second image information in a pre-established second database. Wherein, determining whether the object to be identified is the target object based on the comparison result may include: in response to the comparison result indicating that the first image information matches one of the at least one second image information, It is determined that the object to be recognized is the target object corresponding to the second image information. Different from the above-mentioned embodiment, this exemplary embodiment directly compares the first image information of the object to be recognized with at least one second image information in the database. According to some embodiments, the first image information may be sequentially compared with at least one second image information in the database, until the comparison result of the first image information and one of the second image information indicates that the first image information One image information matches the second image information, and the comparison ends. It is also possible to sequentially compare the first image information with at least one second image information in the database, obtain a comparison result corresponding to the at least one second image information, and determine the first image information according to all the comparison results. An image information matches one of the second image information. For example, scoring may be performed according to a comparison result between the first image information and each second image in the at least one second image information, to obtain multiple comparison scores corresponding to the at least one second image information, And it is determined that the corresponding second image information with the highest comparison score matches the first image information. Similar to the above-mentioned exemplary embodiment, in this case, the comparison can be performed first, and then steps S101-S105 are performed to perform the living body determination. This exemplary embodiment may be applicable to an application scenario with a small N, such as a home access control application scenario, where the amount of second image information to be compared is small, and the comparison process can be completed quickly.
所述第二数据库可以存储在本地。The second database may be stored locally.
根据一些示例性实施例,在N大于预设数值的情况下,如图14所示,所述活体识别方法还可以包括:步骤S801、获取比对目标图像,所述比对目标图像包括所述待识别对象;步骤S802、将包括所述比对目标图像的比对数据发送至远程服务器,以确定所述待识别对象是否为所述目标对象;以及步骤S803、接收所述远程服务器发送的比对结果。从而能够利用远程服务器来实现比对过程,一方面可以降低对本地资源的要求,另一方面通过将数据库存储在远程服务器,可以保证数据的安全性。在这种情况下,可以先执行步骤S101-S105进行活体判定,可以响应于确定所述待识别对象为活体,执行将包括所述比对目标图像的比对数据发送至远程服务器。According to some exemplary embodiments, when N is greater than a preset value, as shown in FIG. 14 , the living body recognition method may further include: step S801 , acquiring a comparison target image, where the comparison target image includes the object to be identified; step S802, sending the comparison data including the comparison target image to a remote server to determine whether the object to be identified is the target object; and step S803, receiving the comparison data sent by the remote server to the results. Therefore, a remote server can be used to implement the comparison process, on the one hand, the requirements for local resources can be reduced, and on the other hand, by storing the database in the remote server, data security can be ensured. In this case, steps S101-S105 may be performed first to determine a living body, and in response to determining that the object to be identified is a living body, the comparison data including the comparison target image may be sent to a remote server.
所述比对数据还可以包括所述比对目标图像中的与所述待识别对象相关联的多个第三关键点,和/或,包围所述比对目标图像中的所述待识别对象的第三边界框。可以根据远程服务器的比对需求,将所需的比对数据发送至远程服务器,在此不作限定。The comparison data may further include a plurality of third key points associated with the object to be recognized in the comparison target image, and/or surrounding the object to be recognized in the comparison target image the third bounding box. The required comparison data can be sent to the remote server according to the comparison requirements of the remote server, which is not limited here.
根据一些实施例,在将包括所述比对目标图像的比对数据发送至远程服务器之前还可以执行步骤S401、确定所述比对目标图像的图像质量是否符合预设标准。其中,将包括所述比对目标图像的比对数据发送至远程服务器可以为响应于确定所述比对目标图像的图像质量符合预设标准而执行。可以响应于确定所述比对目标图像的图像质量不符合预设标准,执行步骤S402、提示重新获取比对目标图像。从而能够保证发送至远程服务器的比对目标图像的质量,能够保证比对结果的准确性。其中确定所述比对目标图像的图像质量是否符合预设标准的方法已经在上面内容中描述。According to some embodiments, before sending the comparison data including the comparison target image to the remote server, step S401 may also be performed to determine whether the image quality of the comparison target image meets a preset standard. The sending of the comparison data including the comparison target image to the remote server may be performed in response to determining that the image quality of the comparison target image meets a preset standard. In response to determining that the image quality of the comparison target image does not meet the preset standard, step S402 may be performed to prompt to re-acquire the comparison target image. Therefore, the quality of the comparison target image sent to the remote server can be guaranteed, and the accuracy of the comparison result can be ensured. The method for determining whether the image quality of the comparison target image meets the preset standard has been described above.
需要说明的是,在N不大于预设数值的情况下,也可以将数据库(上述的第一数据库和第二数据库)存储在远程服务器,以保证数据的安全性。同样也可以将所述待识别对象的第一图像信息发送至远程服务器,以确定所述待识别对象是否为所述目标对象,并接收所述远程服务器发送的比对结果。It should be noted that, in the case where N is not greater than the preset value, the databases (the above-mentioned first database and second database) may also be stored in a remote server to ensure data security. Similarly, the first image information of the object to be recognized can also be sent to a remote server to determine whether the object to be recognized is the target object, and a comparison result sent by the remote server can be received.
根据本公开的另一方面,还提供一种电子电路,包括:被配置为执行上述的活体识别方法的步骤的电路。According to another aspect of the present disclosure, there is also provided an electronic circuit, comprising: a circuit configured to perform the steps of the above-mentioned method for identifying a living body.
根据本公开的另一方面,还提供一种活体识别设备,包括:红外光源,被配置为提供双目红外相机拍摄所需的光照;双目红外相机,包括第一红外相机和第二红外相机,被配置为拍摄红外目标图像,所述红外目标图像包括第一红外图像和第二红外图像,所述第一红外图像为所述第一红外相机拍摄的图像,所述第二红外图像为所述第二红外相机拍摄的图像,所述第一红外图像和第二红外图像均包括待识别对象;以及上述的电子电路。According to another aspect of the present disclosure, there is also provided a living body recognition device, comprising: an infrared light source configured to provide illumination required for shooting by a binocular infrared camera; a binocular infrared camera including a first infrared camera and a second infrared camera , is configured to capture an infrared target image, the infrared target image includes a first infrared image and a second infrared image, the first infrared image is the image captured by the first infrared camera, and the second infrared image is the The image captured by the second infrared camera, the first infrared image and the second infrared image both include the object to be identified; and the above-mentioned electronic circuit.
根据本公开的另一方面,还提供一种电子设备,包括:处理器;以及存储程序的存储器,所述程序包括指令,所述指令在由所述处理器执行时使所述处理器执行上述的深度图像获取方法或上述的活体识别方法。According to another aspect of the present disclosure, there is also provided an electronic device, comprising: a processor; and a memory storing a program, the program including instructions that, when executed by the processor, cause the processor to perform the above-mentioned The depth image acquisition method or the above-mentioned living body recognition method.
根据本公开的另一方面,还提供一种存储程序的非暂态计算机可读存储介质,所述程序包括指令,所述指令在由电子设备的处理器执行时,致使所述电子设备执行上述的深度图像获取方法或上述的活体识别方法。According to another aspect of the present disclosure, there is also provided a non-transitory computer-readable storage medium storing a program, the program comprising instructions that, when executed by a processor of an electronic device, cause the electronic device to perform the above-mentioned The depth image acquisition method or the above-mentioned living body recognition method.
参见图15所示,现将描述计算设备2000,其是可以应用于本公开的各方面的硬件设备(电子设备)的示例。计算设备2000可以是被配置为执行处理和/或计算的任何机器,可以是但不限于工作站、服务器、台式计算机、膝上型计算机、平板计算机、个人数字助理、机器人、智能电话、车载计算机或其任何组合。上述深度图像获取方法和活体识别方法可以全部或至少部分地由计算设备2000或类似设备或系统实现。Referring to Figure 15, a
计算设备2000可以包括(可能经由一个或多个接口)与总线2002连接或与总线2002通信的元件。例如,计算设备2000可以包括总线2002、一个或多个处理器2004、一个或多个输入设备2006以及一个或多个输出设备2008。一个或多个处理器2004可以是任何类型的处理器,并且可以包括但不限于一个或多个通用处理器和/或一个或多个专用处理器(例如特殊处理芯片)。输入设备2006可以是能向计算设备2000输入信息的任何类型的设备,并且可以包括但不限于鼠标、键盘、触摸屏、麦克风和/或遥控器。输出设备2008可以是能呈现信息的任何类型的设备,并且可以包括但不限于显示器、扬声器、视频/音频输出终端、振动器和/或打印机。计算设备2000还可以包括非暂时性存储设备2010或者与非暂时性存储设备2010连接,非暂时性存储设备可以是非暂时性的并且可以实现数据存储的任何存储设备,并且可以包括但不限于磁盘驱动器、光学存储设备、固态存储器、软盘、柔性盘、硬盘、磁带或任何其他磁介质,光盘或任何其他光学介质、ROM(只读存储器)、RAM(随机存取存储器)、高速缓冲存储器和/或任何其他存储器芯片或盒、和/或计算机可从其读取数据、指令和/或代码的任何其他介质。非暂时性存储设备2010可以从接口拆卸。非暂时性存储设备2010可以具有用于实现上述方法和步骤的数据/程序(包括指令)/代码。计算设备2000还可以包括通信设备2012。通信设备2012可以是使得能够与外部设备和/或与网络通信的任何类型的设备或系统,并且可以包括但不限于调制解调器、网卡、红外通信设备、无线通信设备和/或芯片组,例如蓝牙TM设备、1302.11设备、WiFi设备、WiMax设备、蜂窝通信设备和/或类似物。
计算设备2000还可以包括工作存储器2014,其可以是可以存储对处理器2004的工作有用的程序(包括指令)和/或数据的任何类型的工作存储器,并且可以包括但不限于随机存取存储器和/或只读存储器设备。
软件要素(程序)可以位于工作存储器2014中,包括但不限于操作系统2016、一个或多个应用程序2018、驱动程序和/或其他数据和代码。用于执行上述方法和步骤的指令可以被包括在一个或多个应用程序2018中,并且上述深度获取方法和活体识别方法可以通过由处理器2004读取和执行一个或多个应用程序2018的指令来实现。更具体地,上述深度获取方法和活体识别方法中,步骤S101-步骤S108以及步骤S301-步骤S304可以例如通过处理器2004执行具有步骤S101-步骤S108以及步骤S301-步骤S304的指令的应用程序2018而实现。此外,上述深度获取方法和活体识别方法中的其它步骤可以例如通过处理器2004执行具有执行相应步骤中的指令的应用程序2018而实现。软件要素(程序)的指令的可执行代码或源代码可以存储在非暂时性计算机可读存储介质(例如上述存储设备2010)中,并且在执行时可以被存入工作存储器2014中(可能被编译和/或安装)。软件要素(程序)的指令的可执行代码或源代码也可以从远程位置下载。Software elements (programs) may be located in working memory 2014, including, but not limited to, operating system 2016, one or
还应该理解,可以根据具体要求而进行各种变型。 例如,也可以使用定制硬件,和/或可以用硬件、软件、固件、中间件、微代码,硬件描述语言或其任何组合来实现特定元件。例如,所公开的方法和设备中的一些或全部可以通过使用根据本公开的逻辑和算法,用汇编语言或硬件编程语言(诸如VERILOG,VHDL,C ++)对硬件(例如,包括现场可编程门阵列(FPGA)和/或可编程逻辑阵列(PLA)的可编程逻辑电路)进行编程来实现。It should also be understood that various modifications may be made according to specific requirements. For example, custom hardware may also be used, and/or particular elements may be implemented in hardware, software, firmware, middleware, microcode, hardware description languages, or any combination thereof. For example, some or all of the disclosed methods and apparatus may be implemented in assembly language or hardware programming languages (such as VERILOG, VHDL, C++) on hardware (eg, including field programmable logic) using logic and algorithms in accordance with the present disclosure. Gate Array (FPGA) and/or Programmable Logic Array (PLA) Programmable Logic Circuits) are implemented by programming.
还应该理解,前述方法可以通过服务器-客户端模式来实现。例如,客户端可以接收用户输入的数据并将所述数据发送到服务器。客户端也可以接收用户输入的数据,进行前述方法中的一部分处理,并将处理所得到的数据发送到服务器。服务器可以接收来自客户端的数据,并且执行前述方法或前述方法中的另一部分,并将执行结果返回给客户端。客户端可以从服务器接收到方法的执行结果,并例如可以通过输出设备呈现给用户。It should also be understood that the aforementioned methods may be implemented in a server-client pattern. For example, a client may receive data entered by a user and send the data to a server. The client can also receive the data input by the user, perform part of the processing in the foregoing method, and send the data obtained from the processing to the server. The server may receive data from the client, execute the aforementioned method or another part of the aforementioned method, and return the execution result to the client. The client can receive the execution result of the method from the server, and can present it to the user, for example, through an output device.
还应该理解,计算设备2000的组件可以分布在网络上。 例如,可以使用一个处理器执行一些处理,而同时可以由远离该一个处理器的另一个处理器执行其他处理。计算系统2000的其他组件也可以类似地分布。这样,计算设备2000可以被解释为在多个位置执行处理的分布式计算系统。It should also be understood that components of
虽然已经参照附图描述了本公开的实施例或示例,但应理解,上述的方法、系统和设备仅仅是示例性的实施例或示例,本发明的范围并不由这些实施例或示例限制,而是仅由授权后的权利要求书及其等同范围来限定。实施例或示例中的各种要素可以被省略或者可由其等同要素替代。此外,可以通过不同于本公开中描述的次序来执行各步骤。进一步地,可以以各种方式组合实施例或示例中的各种要素。重要的是随着技术的演进,在此描述的很多要素可以由本公开之后出现的等同要素进行替换。Although the embodiments or examples of the present disclosure have been described with reference to the accompanying drawings, it should be understood that the above-described methods, systems and devices are merely exemplary embodiments or examples, and the scope of the present invention is not limited by these embodiments or examples, but is limited only by the appended claims and their equivalents. Various elements of the embodiments or examples may be omitted or replaced by equivalents thereof. Furthermore, the steps may be performed in an order different from that described in this disclosure. Further, various elements of the embodiments or examples may be combined in various ways. Importantly, as technology evolves, many of the elements described herein may be replaced by equivalent elements that appear later in this disclosure.
Claims (31)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010720275.8ACN111598065B (en) | 2020-07-24 | 2020-07-24 | Depth image acquisition method and living body recognition method, device, circuit and medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010720275.8ACN111598065B (en) | 2020-07-24 | 2020-07-24 | Depth image acquisition method and living body recognition method, device, circuit and medium |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN111598065Atrue CN111598065A (en) | 2020-08-28 |
| CN111598065B CN111598065B (en) | 2024-06-18 |
Family
ID=72190277
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010720275.8AActiveCN111598065B (en) | 2020-07-24 | 2020-07-24 | Depth image acquisition method and living body recognition method, device, circuit and medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN111598065B (en) |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112115886A (en)* | 2020-09-22 | 2020-12-22 | 北京市商汤科技开发有限公司 | Image detection method and related device, equipment and storage medium |
| CN112883791A (en)* | 2021-01-15 | 2021-06-01 | 北京小米移动软件有限公司 | Object recognition method, object recognition device, and storage medium |
| CN112926489A (en)* | 2021-03-17 | 2021-06-08 | 北京市商汤科技开发有限公司 | Living body detection method, living body detection device, living body detection equipment, living body detection medium, living body detection system and transportation means |
| CN113128429A (en)* | 2021-04-24 | 2021-07-16 | 新疆爱华盈通信息技术有限公司 | Stereo vision based living body detection method and related equipment |
| CN113160210A (en)* | 2021-05-10 | 2021-07-23 | 深圳市水务工程检测有限公司 | Drainage pipeline defect detection method and device based on depth camera |
Citations (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101673395A (en)* | 2008-09-10 | 2010-03-17 | 深圳华为通信技术有限公司 | Image mosaic method and image mosaic device |
| KR20130107981A (en)* | 2012-03-23 | 2013-10-02 | 경북대학교 산학협력단 | Device and method for tracking sight line |
| CN103679699A (en)* | 2013-10-16 | 2014-03-26 | 南京理工大学 | Stereo matching method based on translation and combined measurement of salient images |
| CN106529502A (en)* | 2016-08-01 | 2017-03-22 | 深圳奥比中光科技有限公司 | Lip language identification method and apparatus |
| CN106934394A (en)* | 2017-03-09 | 2017-07-07 | 深圳奥比中光科技有限公司 | Double-wavelength images acquisition system and method |
| CN107609383A (en)* | 2017-10-26 | 2018-01-19 | 深圳奥比中光科技有限公司 | 3D face identity authentications and device |
| CN107798694A (en)* | 2017-11-23 | 2018-03-13 | 海信集团有限公司 | A kind of pixel parallax value calculating method, device and terminal |
| CN108830819A (en)* | 2018-05-23 | 2018-11-16 | 青柠优视科技(北京)有限公司 | A kind of image interfusion method and device of depth image and infrared image |
| CN109034102A (en)* | 2018-08-14 | 2018-12-18 | 腾讯科技(深圳)有限公司 | Human face in-vivo detection method, device, equipment and storage medium |
| CN109101871A (en)* | 2018-08-07 | 2018-12-28 | 北京华捷艾米科技有限公司 | A kind of living body detection device based on depth and Near Infrared Information, detection method and its application |
| CN109120861A (en)* | 2018-09-29 | 2019-01-01 | 成都臻识科技发展有限公司 | A kind of high quality imaging method and system under extremely low illumination |
| CN110278356A (en)* | 2019-06-10 | 2019-09-24 | 北京迈格威科技有限公司 | Smart camera equipment and information processing method, information processing equipment and medium |
- 2020
- 2020-07-24CNCN202010720275.8Apatent/CN111598065B/enactiveActive
Patent Citations (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101673395A (en)* | 2008-09-10 | 2010-03-17 | 深圳华为通信技术有限公司 | Image mosaic method and image mosaic device |
| KR20130107981A (en)* | 2012-03-23 | 2013-10-02 | 경북대학교 산학협력단 | Device and method for tracking sight line |
| CN103679699A (en)* | 2013-10-16 | 2014-03-26 | 南京理工大学 | Stereo matching method based on translation and combined measurement of salient images |
| CN106529502A (en)* | 2016-08-01 | 2017-03-22 | 深圳奥比中光科技有限公司 | Lip language identification method and apparatus |
| CN106934394A (en)* | 2017-03-09 | 2017-07-07 | 深圳奥比中光科技有限公司 | Double-wavelength images acquisition system and method |
| CN107609383A (en)* | 2017-10-26 | 2018-01-19 | 深圳奥比中光科技有限公司 | 3D face identity authentications and device |
| CN107798694A (en)* | 2017-11-23 | 2018-03-13 | 海信集团有限公司 | A kind of pixel parallax value calculating method, device and terminal |
| CN108830819A (en)* | 2018-05-23 | 2018-11-16 | 青柠优视科技(北京)有限公司 | A kind of image interfusion method and device of depth image and infrared image |
| CN109101871A (en)* | 2018-08-07 | 2018-12-28 | 北京华捷艾米科技有限公司 | A kind of living body detection device based on depth and Near Infrared Information, detection method and its application |
| CN109034102A (en)* | 2018-08-14 | 2018-12-18 | 腾讯科技(深圳)有限公司 | Human face in-vivo detection method, device, equipment and storage medium |
| CN109120861A (en)* | 2018-09-29 | 2019-01-01 | 成都臻识科技发展有限公司 | A kind of high quality imaging method and system under extremely low illumination |
| CN110278356A (en)* | 2019-06-10 | 2019-09-24 | 北京迈格威科技有限公司 | Smart camera equipment and information processing method, information processing equipment and medium |
Non-Patent Citations (2)
| Title |
|---|
| IN LU: "实时目标检测之SSD(单步多框检测)", 《HTTPS://ZHUANLAN.ZHIHU.COM/P/40273459》* |
| 孙水发等: "《3D打印逆向建模技术及应用》", 31 May 2016, 南京师范大学出版社* |
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112115886A (en)* | 2020-09-22 | 2020-12-22 | 北京市商汤科技开发有限公司 | Image detection method and related device, equipment and storage medium |
| JP2022552754A (en)* | 2020-09-22 | 2022-12-20 | ベイジン・センスタイム・テクノロジー・デベロップメント・カンパニー・リミテッド | IMAGE DETECTION METHOD AND RELATED DEVICE, DEVICE, STORAGE MEDIUM, AND COMPUTER PROGRAM |
| CN112883791A (en)* | 2021-01-15 | 2021-06-01 | 北京小米移动软件有限公司 | Object recognition method, object recognition device, and storage medium |
| CN112883791B (en)* | 2021-01-15 | 2024-04-16 | 北京小米移动软件有限公司 | Object recognition method, object recognition device and storage medium |
| CN112926489A (en)* | 2021-03-17 | 2021-06-08 | 北京市商汤科技开发有限公司 | Living body detection method, living body detection device, living body detection equipment, living body detection medium, living body detection system and transportation means |
| CN113128429A (en)* | 2021-04-24 | 2021-07-16 | 新疆爱华盈通信息技术有限公司 | Stereo vision based living body detection method and related equipment |
| CN113160210A (en)* | 2021-05-10 | 2021-07-23 | 深圳市水务工程检测有限公司 | Drainage pipeline defect detection method and device based on depth camera |
| CN113160210B (en)* | 2021-05-10 | 2024-09-27 | 深圳市水务工程检测有限公司 | Drainage pipeline defect detection method and device based on depth camera |
Also Published As
| Publication number | Publication date |
|---|---|
| CN111598065B (en) | 2024-06-18 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6844038B2 (en) | Biological detection methods and devices, electronic devices and storage media | |
| US10872420B2 (en) | Electronic device and method for automatic human segmentation in image | |
| US10956714B2 (en) | Method and apparatus for detecting living body, electronic device, and storage medium | |
| TWI766201B (en) | Methods and devices for biological testing and storage medium thereof | |
| CN111598065B (en) | Depth image acquisition method and living body recognition method, device, circuit and medium | |
| CN116324878A (en) | Segmentation for Image Effects | |
| CN112232155B (en) | Non-contact fingerprint identification method and device, terminal and storage medium | |
| WO2020018359A1 (en) | Three-dimensional living-body face detection method, face authentication recognition method, and apparatuses | |
| CN110598710A (en) | Certificate identification method and device | |
| CN110163899A (en) | Image matching method and image matching apparatus | |
| WO2020134528A1 (en) | Target detection method and related product | |
| GB2609723A (en) | Exposure defects classification of images using a neural network | |
| CN112232163B (en) | Fingerprint acquisition method and device, fingerprint comparison method and device, and equipment | |
| CN112016525A (en) | Non-contact fingerprint acquisition method and device | |
| TW202418218A (en) | Removal of objects from images | |
| CN112926461B (en) | Neural network training, driving control method and device | |
| CN112232159B (en) | Fingerprint identification method, device, terminal and storage medium | |
| WO2022068931A1 (en) | Non-contact fingerprint recognition method and apparatus, terminal, and storage medium | |
| CN113128428A (en) | Depth map prediction-based in vivo detection method and related equipment | |
| CN113824884A (en) | Photographing method and apparatus, photographing device and computer-readable storage medium | |
| CN116051736A (en) | Three-dimensional reconstruction method, device, edge equipment and storage medium | |
| KR20220127188A (en) | Object detection device with custom object detection model | |
| CN112232152B (en) | Non-contact fingerprint identification method and device, terminal and storage medium | |
| CN112232157B (en) | Fingerprint area detection method, device, equipment and storage medium | |
| CN113095347A (en) | Deep learning-based mark recognition method and training method, system and electronic equipment thereof |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| PE01 | Entry into force of the registration of the contract for pledge of patent right | ||
| PE01 | Entry into force of the registration of the contract for pledge of patent right | Denomination of invention:Depth image acquisition methods and live recognition methods, devices, circuits, and media Granted publication date:20240618 Pledgee:Zheshang Bank Limited by Share Ltd. Shanghai branch Pledgor:NEXTVPU (SHANGHAI) Co.,Ltd. Registration number:Y2025310000067 |