CN111524226A - Key point detection and 3D reconstruction method for caricature portraits - Google Patents
Key point detection and 3D reconstruction method for caricature portraitsDownload PDFInfo
- Publication number
- CN111524226A CN111524226ACN202010316895.5ACN202010316895ACN111524226ACN 111524226 ACN111524226 ACN 111524226ACN 202010316895 ACN202010316895 ACN 202010316895ACN 111524226 ACN111524226 ACN 111524226A
- Authority
- CN
- China
- Prior art keywords
- dimensional
- face
- model
- vertex
- exaggerated
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images

Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T17/00—Three dimensional [3D] modelling, e.g. data description of 3D objects
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
- G06V40/16—Human faces, e.g. facial parts, sketches or expressions
- G06V40/168—Feature extraction; Face representation
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02T—CLIMATE CHANGE MITIGATION TECHNOLOGIES RELATED TO TRANSPORTATION
- Y02T10/00—Road transport of goods or passengers
- Y02T10/10—Internal combustion engine [ICE] based vehicles
- Y02T10/40—Engine management systems
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Health & Medical Sciences (AREA)
- General Physics & Mathematics (AREA)
- General Health & Medical Sciences (AREA)
- Software Systems (AREA)
- Data Mining & Analysis (AREA)
- Molecular Biology (AREA)
- Oral & Maxillofacial Surgery (AREA)
- Mathematical Physics (AREA)
- General Engineering & Computer Science (AREA)
- Computing Systems (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Evolutionary Computation (AREA)
- Computer Graphics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Multimedia (AREA)
- Human Computer Interaction (AREA)
- Geometry (AREA)
- Processing Or Creating Images (AREA)
- Image Analysis (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明涉及图像处理技术、三维建模技术领域,尤其涉及一种讽刺肖像画的关键点检测与三维重建方法。The invention relates to the fields of image processing technology and three-dimensional modeling technology, in particular to a key point detection and three-dimensional reconstruction method for caricature portraits.
背景技术Background technique
讽刺肖像是一种依托二维图像和三维模型的艺术表达形式。它通过夸张化人脸的某些特征或细节以营造带有幽默色彩的视觉效果,常被用于影视、广告以及社交等生活场景中。这种艺术表现形式同样也在计算机视觉和认知心理学等领域下被证明可以有效地提高人脸识别的精确度。由于其富有潜力的研究前景和广泛用途,讽刺肖像的相关课题正吸引越来越多的科研人员和企业投身其中。A satirical portrait is a form of artistic expression that relies on two-dimensional images and three-dimensional models. It creates humorous visual effects by exaggerating certain features or details of the face, and is often used in life scenes such as film and television, advertising, and social networking. This artistic expression has also been shown to be effective in improving the accuracy of face recognition in areas such as computer vision and cognitive psychology. Due to its potential research prospects and wide range of uses, the subject of satirical portraits is attracting more and more researchers and companies to devote themselves to it.
关于讽刺肖像的关键点检测技术:相较于正常人脸,讽刺肖像更具有夸张性和多样性的特点,所以识别关键点的难度较大。因此,关于讽刺肖像的自动关键点检测算法几乎没有。但另一方面,讽刺肖像的许多研究课题均依赖于关键点,而手工标注关键点不仅枯燥无味,而且费时费力。于是开发一种关于讽刺肖像的关键点检测算法是件有重要意义的事情,不仅能填补这方面研究的空白,也能帮助相关课题的发展。Regarding the key point detection technology of satirical portraits: Compared with normal faces, satirical portraits are more exaggerated and diverse, so it is more difficult to identify key points. As a result, automatic keypoint detection algorithms for sarcastic portraits are few and far between. On the other hand, many research topics in caricature portraits rely on keypoints, and annotating keypoints by hand is tedious and time-consuming. Therefore, it is of great significance to develop a key point detection algorithm for satirical portraits, which can not only fill the gaps in this research, but also help the development of related topics.
目前流行的正常人脸关键点检测算法多为数据驱动的方法,依赖于深度神经网络结构的设计。这类算法通常能从单张图片提取出人脸视觉特征或人脸图像像素统计特征来回归关键点的位置,提取的方法包括基于知识的、基于代数特征的。而夸张人脸根植于正常人脸,它需要满足一张人脸的基本特征,譬如需要具有特定数目的眼睛、嘴巴、鼻子和耳朵等。但夸张人脸在正常人脸的基础上通常对这些特征进行了夸张化,所以不同图片间某一特征差异性较大,例如围绕眼睛的关键点分布。由于夸张出的特征差异化、多样化,关于讽刺肖像的关键点检测算法寥寥无几。Most of the current popular normal face keypoint detection algorithms are data-driven methods and rely on the design of deep neural network structures. This kind of algorithm can usually extract face visual features or face image pixel statistical features from a single image to regress the position of key points. The extraction methods include knowledge-based and algebraic feature-based. The exaggerated face is rooted in the normal face, which needs to meet the basic characteristics of a face, such as the need to have a certain number of eyes, mouth, nose and ears. However, exaggerated faces usually exaggerate these features on the basis of normal faces, so there is a large difference in a certain feature between different pictures, such as the distribution of key points around the eyes. Due to the differentiation and diversity of exaggerated features, there are few key point detection algorithms for satirical portraits.
关于讽刺肖像的三维重建技术:目前人们获取三维夸张人脸模型主要有两类方法:手工建模和基于变形算法的重建。手工建模作为最早的三维建模手段,目前依旧广泛地应用于生成夸张人脸三维模型。但其过程一般需要经过专业学习训练的人员在专业的建模软件如AutoDesk Maya上来完成。虽然有精度高的优点,但由于它需要大量的时间和人力,于是基于变形算法来获取三维夸张人脸模型更受大家欢迎。不过,变形算法虽然具有自动生成的优势,但其生成的模型往往夸张风格局限,同手工建模得到的形态各异的三维夸张人脸相比多样性不足、精度不足。而且现有的变形算法大多依赖于关键点,所以还是需要花费时间、人力在标注关键点上,一旦标注得不准确,生成的模型也很可能与原始的二维讽刺肖像不匹配。Regarding the 3D reconstruction technology of satirical portraits: At present, there are two main methods for obtaining 3D exaggerated face models: manual modeling and reconstruction based on deformation algorithms. As the earliest 3D modeling method, manual modeling is still widely used to generate exaggerated face 3D models. However, the process generally needs to be completed by professional training personnel in professional modeling software such as AutoDesk Maya. Although it has the advantage of high precision, because it requires a lot of time and manpower, it is more popular to obtain 3D exaggerated face models based on deformation algorithms. However, although the deformation algorithm has the advantage of automatic generation, the models generated by it are often limited in exaggerated style, which lacks diversity and accuracy compared with the 3D exaggerated faces of different shapes obtained by manual modeling. Moreover, most of the existing deformation algorithms rely on key points, so it still takes time and manpower to label the key points. Once the labeling is inaccurate, the generated model may not match the original two-dimensional satirical portrait.
传统的基于图像生成正常人脸三维模型的方法,往往先通过相机采集等途径构建出某些人的三维模型,再通过基于统计或降维的方法构造相应的人脸数据库,并建立一个人脸的参数化模型(包括线性模型和非线性模型),进而将复杂的三维人脸参数化到一个低维的参数空间中,通过获取在低维空间中的坐标表示,便可以重建出相应的正常人脸。源自于这个思路,以往的夸张人脸生成思路首先对单张图片标注二维关键点,通过关键点约束和构建好的参数化模型生成相应的夸张人脸。这样的方法非常依赖于关键点,所以不仅要花费时间在标注任务上,一旦标注准确度不高,还会直接影响重建出的三维模型。The traditional method of generating a 3D model of a normal face based on an image often first constructs a 3D model of some people through camera acquisition, etc., and then constructs a corresponding face database through statistical or dimensionality reduction methods, and establishes a face. The parameterized model (including linear model and nonlinear model) of , and then the complex three-dimensional face is parameterized into a low-dimensional parameter space. By obtaining the coordinate representation in the low-dimensional space, the corresponding normal face can be reconstructed. human face. Derived from this idea, the previous idea of exaggerated face generation first marked two-dimensional key points on a single image, and generated corresponding exaggerated faces through key point constraints and a constructed parametric model. Such a method is very dependent on key points, so not only does it take time to label tasks, but once the labeling accuracy is not high, it will directly affect the reconstructed 3D model.
发明内容SUMMARY OF THE INVENTION
本发明的目的是提供一种讽刺肖像画的关键点检测与三维重建方法,可以自动地、快速地检测夸张人脸的关键点以及生成对应的三维模型,在人脸识别、动画生成、表情迁移以及AR\VR等领域具有重要的实际应用价值。The purpose of the present invention is to provide a key point detection and three-dimensional reconstruction method for caricature portraits, which can automatically and quickly detect the key points of exaggerated faces and generate corresponding three-dimensional models. AR\VR and other fields have important practical application value.
本发明的目的是通过以下技术方案实现的:The purpose of this invention is to realize through the following technical solutions:
一种讽刺肖像画的关键点检测与三维重建方法,包括:A key point detection and 3D reconstruction method for caricature portraits, including:
构建卷积神经网络,收集包含三维人脸模板模型、以及由讽刺肖像画、标注好的二维关键点坐标及基于现有方法生成的三维夸张脸模型的数据集;所述三维人脸模板模型与三维夸张脸模型具有相同的拓扑结构;Constructing a convolutional neural network, collecting a data set including a three-dimensional face template model, as well as a caricature portrait, annotated two-dimensional key point coordinates, and a three-dimensional exaggerated face model generated based on existing methods; the three-dimensional face template model and 3D exaggerated face models have the same topology;
训练阶段,以三维人脸模板模型作为模板人脸,计算各讽刺肖像画的变形表示模型,并输出相机投影参数;根据变形表示模型与相机投影参数预测对应的三维夸张脸模型顶点坐标和二维关键点坐标,并以此构造训练阶段的损失函数,从而对网络进行有监督的训练;In the training stage, the 3D face template model is used as the template face to calculate the deformation representation model of each caricature portrait, and output the camera projection parameters; according to the deformation representation model and the camera projection parameters, the corresponding 3D exaggerated face model vertex coordinates and 2D keys are predicted. Point coordinates, and use this to construct the loss function in the training phase, so as to conduct supervised training of the network;
训练完毕后,对于输入的讽刺肖像画得到对应的变形表示模型与相机投影参数,从而预测三维夸张脸模型顶点坐标和二维关键点坐标。After training, the corresponding deformation representation model and camera projection parameters are obtained for the input satirical portrait, so as to predict the vertex coordinates of the three-dimensional exaggerated face model and the two-dimensional key point coordinates.
由上述本发明提供的技术方案可以看出,1)由变形表示来约束的人脸上的变形使得生成的人脸依旧具有人脸的性质,而且强大的变形表示模型还能生成具有夸张风格的人脸。2)通过卷积神经网络结构能直接从单张图片回归人脸变形模型以及相机的投影参数。3)二者共同作用,就获得了比较准确的三维夸张人脸模型。同时也得到了较精确的二维关键点坐标。It can be seen from the above technical solutions provided by the present invention that 1) the deformation of the human face constrained by the deformation representation makes the generated face still have the properties of the human face, and the powerful deformation representation model can also generate exaggerated styles. human face. 2) Through the convolutional neural network structure, the face deformation model and the projection parameters of the camera can be directly returned from a single image. 3) The two work together to obtain a more accurate three-dimensional exaggerated face model. At the same time, more accurate two-dimensional key point coordinates are obtained.
附图说明Description of drawings
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他附图。In order to illustrate the technical solutions of the embodiments of the present invention more clearly, the following briefly introduces the accompanying drawings used in the description of the embodiments. Obviously, the drawings in the following description are only some embodiments of the present invention. For those of ordinary skill in the art, other drawings can also be obtained from these drawings without any creative effort.
图1为本发明实施例提供的一种讽刺肖像画的关键点检测与三维重建方法的流程图;1 is a flowchart of a key point detection and three-dimensional reconstruction method for a caricature portrait provided by an embodiment of the present invention;
图2为本发明实施例提供的卷积神经网络工作过程示意图;2 is a schematic diagram of a working process of a convolutional neural network provided by an embodiment of the present invention;
图3为本发明实施例提供的利用训练好的卷积神经网络进行测试的结果示意图。FIG. 3 is a schematic diagram of a test result using a trained convolutional neural network according to an embodiment of the present invention.
具体实施方式Detailed ways
下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明的保护范围。The technical solutions in the embodiments of the present invention will be clearly and completely described below with reference to the drawings in the embodiments of the present invention. Obviously, the described embodiments are only a part of the embodiments of the present invention, rather than all the embodiments. Based on the embodiments of the present invention, all other embodiments obtained by those of ordinary skill in the art without creative work fall within the protection scope of the present invention.
在讽刺肖像的人脸识别领域,基于正常人脸的关键点检测算法通常因为不同图片间某些面部特征的分布差异过大而识别不够准确,检测后仍需要花费大量的时间调整关键点的位置。在讽刺肖像的三维重建领域,传统的三维重建方法由于基模型的表达能力不够,重建出的人脸模型夸张程度不足;一些基于优化方法及关键点约束的重建算法过度依赖于关键点的标注,一旦标注的不够准确,生成的三维模型与二维图片会存在较大的偏差。为此,本发明实施例提供一种讽刺肖像画的关键点检测与三维重建方法,如图1所示,其主要包括如下步骤:In the field of face recognition for satirical portraits, key point detection algorithms based on normal faces are usually inaccurate due to the large difference in the distribution of certain facial features between different pictures, and it still takes a lot of time to adjust the positions of key points after detection. . In the field of 3D reconstruction of satirical portraits, the traditional 3D reconstruction methods have insufficient expression ability of the base model, and the reconstructed face model is not exaggerated enough; Once the annotation is not accurate enough, the generated 3D model will have a large deviation from the 2D picture. To this end, an embodiment of the present invention provides a key point detection and three-dimensional reconstruction method for caricature portraits, as shown in FIG. 1 , which mainly includes the following steps:
步骤1、构建卷积神经网络,收集包含三维人脸模板模型、以及由讽刺肖像画、标注好的二维关键点坐标及基于现有方法生成的三维夸张脸模型的数据集。
本步骤主要是进行网络构建与数据的收集;由于该数据集存在获取方式的多样性和数据集处理不同的可能性,要求数据集中的三维夸张脸模型要与三维人脸模板模型有相同的拓扑结构,即不同的数据间享有同样的顶点个数和邻接关系,且顶点的顺序在不同模型上是相同的;除此之外,还设定采集的人脸数据足够多样。This step is mainly for network construction and data collection; due to the diversity of acquisition methods and the possibility of different data set processing, the 3D exaggerated face model in the data set is required to have the same topology as the 3D face template model. Structure, that is, different data share the same number of vertices and adjacency relationship, and the order of vertices is the same on different models; in addition, it is also set that the collected face data is sufficiently diverse.
本领域的技术人员可以理解,上述满足此类条件的正常人脸数据集可以通过常规手段获得。Those skilled in the art can understand that the above-mentioned normal face dataset that satisfies such conditions can be obtained by conventional means.
步骤2、训练阶段,以三维人脸模板模型作为模板人脸,计算各讽刺肖像画的变形表示模型,并输出相机投影参数;根据变形表示模型与相机投影参数预测对应的三维夸张脸模型顶点坐标和二维关键点坐标,并以此构造训练阶段的损失函数,从而对网络进行有监督的训练。
首先,针对变形表示模型的计算原理进行介绍。First, the calculation principle of the deformation representation model is introduced.
记三维人脸模板模型上顶点集合为V,V={vi|i=1,...,Nv},即V由单张人脸三维数据上所有顶点vi构成,其中i为索引下标,Nv为顶点的总数;由于获取的数据集满足人脸数据在顶点个数和顶点顺序上相同,同时邻接关系也相同。故知道了所描述的顶点集合V和某个索引下标i后,便可以知道所指代的是哪个顶点。Denote the set of vertices on the 3D face template model as V, V={vi |i=1,...,Nv }, that is, V consists of all vertices vi on the 3D data of a single face, where i is the index Subscript, Nv is the total number of vertices; since the obtained data set satisfies the face data in the same number of vertices and vertex order, and the adjacency relationship is also the same. Therefore, after knowing the described vertex set V and a certain index subscript i, you can know which vertex is referred to.
将三维人脸模板模型作为模板人脸,讽刺肖像画对应的三维夸张脸模型作为变形人脸;构造一个关于变形人脸上索引下标为i的顶点v'i及模板人脸上索引下标为i的顶点vi之间的变形梯度Ti的能量函数,最小化该能量函数求解Ti:Take the 3D face template model as the template face, and the 3D exaggerated face model corresponding to the caricature portrait as the deformed face; construct a vertex v'i with the index index i on the deformed face and the index index on the template face as The energy function of the deformation gradient Ti between the vertices vi of i, minimize this energy function to solve Ti :

其中,Ni指以索引下标为i的顶点为中心的1-邻域顶点的下标集合,模板人脸中集合Ni内索引下标为j的顶点记为vj,变形人脸中集合Ni内索引下标为j的顶点记为v'j;e'ij为变形人脸上顶点v'i到顶点v'j的边,eij为模板人脸上顶点vi到顶点vj的边;cij为模板人脸的余弦拉普拉斯权重;Among them, Ni refers to the index set of 1-neighbor vertices centered on the vertex with index indexi as the center, the vertices with index indexj in the set Ni in the template face are denoted as vj , and in the deformed face The vertex with index index j in the set Ni is denoted as v'j;e'ij is the edge from vertex v'i to vertex v'j on the deformed face, and eij is the vertex vi on the template face to vertex v The edge ofj ; cij is the cosine Laplacian weight of the template face;
获得顶点的形变梯度后,通过矩阵极分解将Ti分解成RiSi,其中Ri代表顶点vi到顶点v'i变形梯度的旋转矩阵分量,Si代表顶点vi到顶点v'i变形梯度的放缩矩阵分量;After obtaining the deformation gradient of the vertex, decompose Ti into Ri Si through matrix polar decomposition, where Ri represents the rotation matrix component of the deformation gradient from vertex vi to vertex v'i , and Si represents vertex vi to vertex v' The scaling matrix component of thei deformation gradient;
通过矩阵运算,将旋转矩阵Ri等效的表示成exp(logRi),则模板人脸到变形人脸的变形表示模型写成:Through matrix operation, the rotation matrix Ri is equivalently expressed as exp(logRi ), then the deformation representation model from the template face to the deformed face is written as:
fn={logRi;Si-I|i=1,...,Nv}fn ={logRi ; Si -I|i=1,...,Nv }
其中,I为单位阵,引入其目的在于构建一个坐标系统,Vn={v'i|i=1,...,Nv}为三维夸张脸模型上的顶点集合;logR的目的是为了使得对于旋转矩阵上的运算RiRj可以表示成exp(logRi+logRj),这样便可以使得乘法运算简化成了加法运算。Among them, I is the unit matrix, the purpose of introducing it is to construct a coordinate system, Vn ={v'i |i=1,...,Nv } is the vertex set on the three-dimensional exaggerated face model; the purpose of logR is to So that the operation Ri Rj on the rotation matrix can be expressed as exp(logRi +logRj ), so that the multiplication operation can be simplified into an addition operation.
通过对所有的变形人脸到模板人脸的变形进行编码,得到三维夸张脸模型数据集上基于模板人脸的变形表示集合F={fn|n=1,...,N},N为变形表示集合中元素的个数,也就是人脸数据集中三维数据的个数。示例性的,F中元素的个数为7800个,即N=7800。By encoding all the deformations of deformed faces to template faces, the deformation representation set based on template faces on the 3D exaggerated face model dataset is obtained F={fn |n=1,...,N}, N Deformation represents the number of elements in the set, that is, the number of three-dimensional data in the face dataset. Exemplarily, the number of elements in F is 7800, that is, N=7800.
将变形表示集合F记为大小为N×M的矩阵,矩阵的第n行代表编号为n的夸张脸基于模板人脸的的变形表示fn;对于每个fn,其第i个顶点v'i的变形表示{logRi;Si-I}记为一个维度为9的向量,所以M=Nv×9,同上,Nv为人脸三维网格上顶点的总数。Denote the deformation representation set F as a matrix of size N×M, and the nth row of the matrix represents the deformation representation fn of the exaggerated face numbered n based on the template face; for each fn , its ith vertex v The deformation of 'i represents {logRi ; Si -I} is denoted as a vector with a dimension of 9, so M=Nv ×9, the same as above, Nv is the total number of vertices on the face three-dimensional mesh.
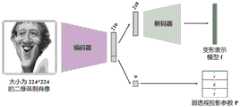
如图2所示,所述卷积神经网络包括编码器与解码器;编码器,用于将讽刺肖像画编码为一个K维的隐向量,该隐向量被切分为两部分,一部分为K1维的向量,即相机投影参数;另一部分为K2维的向量,被解码器解码变为变形表示模型;其中,K1+K2=K。As shown in Figure 2, the convolutional neural network includes an encoder and a decoder; the encoder is used to encode the caricature into a K-dimensional latent vector, the latent vector is divided into two parts, one part is K1-dimensional The vector of , that is, the camera projection parameter; the other part is a K2-dimensional vector, which is decoded by the decoder and becomes a deformed representation model; among them, K1+K2=K.
示例性的,可以采用ResNet34作为编码器,可以采用3层全连接神经网络作为解码器。Exemplarily, ResNet34 can be used as the encoder, and a 3-layer fully connected neural network can be used as the decoder.
示例性的,输入的讽刺肖像画的分辨率可以为224*224,K=216,K1=6,K2=210。Exemplarily, the resolution of the input caricature may be 224*224, K=216, K1=6, K2=210.
基于上述原理,训练过程中,三维人脸模板模型作为模板人脸,输入讽刺肖像画,通过预测出的变形表示模型中的旋转矩阵分量与放缩矩阵分量,得到变形梯度,进而预测讽刺肖像画对应的三维夸张脸模型顶点坐标,再结合网络输出的相机投影参数预测二维关键点坐标。之后,可以利用数据集中相应讽刺肖像画对应的标注好的二维关键点坐标和三维夸张脸模型(真实值)构造损失函数,通过不断训练使得网络预测出的三维夸张脸模型顶点坐标和二维关键点坐标趋近数据集中的真实值。Based on the above principles, in the training process, the 3D face template model is used as the template face, and the caricature portrait is input, and the rotation matrix component and the scaling matrix component in the model are represented by the predicted deformation, and the deformation gradient is obtained, and then the corresponding caricature portrait is predicted. The vertex coordinates of the three-dimensional exaggerated face model are combined with the camera projection parameters output by the network to predict the two-dimensional key point coordinates. After that, the loss function can be constructed by using the labeled two-dimensional key point coordinates and the three-dimensional exaggerated face model (true value) corresponding to the corresponding caricature portraits in the dataset, and through continuous training, the network predicts the vertex coordinates of the three-dimensional exaggerated face model and the two-dimensional key point. Point coordinates approach the true values in the dataset.
网络训练的优选实施方式如下:The preferred implementation of network training is as follows:
对于一幅讽刺肖像画,通过卷积神经网络可以得到变形表示模型,表示为:For a caricature portrait, the deformation representation model can be obtained through the convolutional neural network, which is expressed as:

其中,



根据预测到的变形梯度

其中,


相机投影参数P表示为:





其中,L'是从预测得到的三维夸张脸模型的顶点集合中选出的三维关键点集合;
示例性的,关键点可以是包含轮廓、眉毛、眼睛、鼻子和嘴巴的68关键点,也可以是其他形式的关键点;根据选定的关键点形式可以从三维关键点集合中选出相应的三维关键点,构成集合L'。Exemplarily, the key points can be 68 key points including contour, eyebrows, eyes, nose and mouth, or other forms of key points; according to the selected key point form, the corresponding key point can be selected from the three-dimensional key point set. Three-dimensional key points, constituting the set L'.
在训练过程中,数据集中的数据作为训练时的真值(监督信息)。基于输入的单张讽刺肖像,通过步骤1构造好的卷积神经网络结合本步骤介绍的方式能输出一个变形表示模型f和一个相机投影参数P,并由此得到了预测出的三维模型顶点坐标

本发明实施例中,训练阶段的损失函数包含三个部分:In this embodiment of the present invention, the loss function in the training phase includes three parts:
1)基于顶点的损失函数Ever。1) Vertex-based loss functionEver .
使用数据集中对应讽刺肖像画的三维夸张脸的顶点坐标作为监督信息,相应的损失函数表示为:Using the vertex coordinates of the 3D exaggerated faces corresponding to caricature portraits in the dataset as supervision information, the corresponding loss function is expressed as:

其中,
2)基于二维关键点的损失函数Elan。2) Loss function Elan based on two-dimensional key points.
使用数据集中相应二维关键点坐标作为监督信息,相应的损失函数表示为:Using the corresponding two-dimensional keypoint coordinates in the dataset as supervision information, the corresponding loss function is expressed as:

其中,L'是从预测得到的三维夸张脸模型的顶点集合中选出的三维关键点集合;

3)基于相机投影参数的损失函数Esrt3) Loss functionEsrt based on camera projection parameters
由于关键点损失值不仅涉及三维顶点坐标,还涉及相机参数,因此刚开始训练时需要更多的监督信息对相机参数单独约束,相应的损失函数表示为:Since the keypoint loss value involves not only the three-dimensional vertex coordinates, but also the camera parameters, more supervision information is needed to constrain the camera parameters separately at the beginning of training, and the corresponding loss function is expressed as:

其中,


最终,训练阶段的损失函数为:Finally, the loss function in the training phase is:
E=λ1Ever+λ2Elan+λ3EsrtE=λ1 Ever +λ2 Elan +λ3 Esrt
其中,{λk|k=1,2,3}为权重参数;示例性的,设置λ1=1,λ2=0.00001,λ3=0.0001。Wherein, {λk |k=1, 2, 3} is a weight parameter; exemplarily, λ1 =1, λ2 =0.00001, λ3 =0.0001.
本发明实施例中,可以基于PyTorch深度学习框架训练模型,每次读入多组数据(例如32组)进行有监督地学习,训练多个循环(例如,2000个循环)后训练结束。In this embodiment of the present invention, a model can be trained based on the PyTorch deep learning framework, multiple sets of data (eg, 32 sets) are read in each time for supervised learning, and the training ends after training for multiple cycles (eg, 2000 cycles).
步骤3、训练完毕后,对于输入的讽刺肖像画得到对应的变形表示模型与相机投影参数,从而预测三维夸张脸模型顶点坐标和二维关键点坐标。
测试过程与训练过程的处理方式相同,将讽刺肖像画输入至训练好的卷积神经网络中,可以得到变形表示模型与相机投影参数,从而预测出三维夸张脸模型顶点坐标(由于拓扑结构已知,因而可直接构造三维夸张脸模型)和二维关键点坐标。The testing process is handled in the same way as the training process. The caricature portrait is input into the trained convolutional neural network, and the deformation representation model and camera projection parameters can be obtained, so as to predict the vertex coordinates of the three-dimensional exaggerated face model (due to the known topology, Therefore, a three-dimensional exaggerated face model) and two-dimensional key point coordinates can be directly constructed.
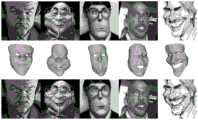
如图3示意性的给出了一些测试结果的示例;第一行是输入的二维讽刺肖像(224*224),第二行是预测得到的三维夸张脸模型,第三行是标注好预测出的二维关键点的图像。Figure 3 schematically shows some examples of test results; the first line is the input 2D sarcastic portrait (224*224), the second line is the predicted 3D exaggerated face model, and the third line is the labeled prediction out the 2D keypoint image.
本发明实施例上述方案,相比于传统的基于图片的关键点检测和三维重建算法,主要具有以下优点:Compared with the traditional image-based key point detection and three-dimensional reconstruction algorithm, the above solution in the embodiment of the present invention mainly has the following advantages:
1)通过参数化三维非线性变形模型,算法增强了卷积神经网络的表达能力,实现了基于夸张人脸的关键点检测任务。1) By parameterizing the three-dimensional nonlinear deformation model, the algorithm enhances the expressive ability of the convolutional neural network and realizes the key point detection task based on exaggerated faces.
2)通过卷积神经网络,算法实现了一种从二维夸张人脸图片端到端重建三维人脸模型的方法。2) Through the convolutional neural network, the algorithm implements a method for end-to-end reconstruction of a 3D face model from a 2D exaggerated face image.
3)基于构建好的大量数据训练,算法模型在不同风格、不同作家的讽刺肖像作品上的识别、建模准确度均较以往算法有大幅度的提高。3) Based on a large amount of data training, the recognition and modeling accuracy of the algorithm model in the satirical portrait works of different styles and authors are greatly improved compared with the previous algorithms.
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例可以通过软件实现,也可以借助软件加必要的通用硬件平台的方式来实现。基于这样的理解,上述实施例的技术方案可以以软件产品的形式体现出来,该软件产品可以存储在一个非易失性存储介质(可以是CD-ROM,U盘,移动硬盘等)中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述的方法。From the description of the above embodiments, those skilled in the art can clearly understand that the above embodiments can be implemented by software or by means of software plus a necessary general hardware platform. Based on this understanding, the technical solutions of the above embodiments may be embodied in the form of software products, and the software products may be stored in a non-volatile storage medium (which may be CD-ROM, U disk, mobile hard disk, etc.), including Several instructions are used to cause a computer device (which may be a personal computer, a server, or a network device, etc.) to execute the methods described in various embodiments of the present invention.
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明披露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求书的保护范围为准。The above description is only a preferred embodiment of the present invention, but the protection scope of the present invention is not limited to this. Substitutions should be covered within the protection scope of the present invention. Therefore, the protection scope of the present invention should be based on the protection scope of the claims.
Claims (5)
























Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010316895.5ACN111524226B (en) | 2020-04-21 | 2020-04-21 | Method for detecting key point and three-dimensional reconstruction of ironic portrait painting |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010316895.5ACN111524226B (en) | 2020-04-21 | 2020-04-21 | Method for detecting key point and three-dimensional reconstruction of ironic portrait painting |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN111524226Atrue CN111524226A (en) | 2020-08-11 |
| CN111524226B CN111524226B (en) | 2023-04-18 |
Family
ID=71903414
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010316895.5AActiveCN111524226B (en) | 2020-04-21 | 2020-04-21 | Method for detecting key point and three-dimensional reconstruction of ironic portrait painting |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN111524226B (en) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112308957A (en)* | 2020-08-14 | 2021-02-02 | 浙江大学 | Optimal fat and thin face portrait image automatic generation method based on deep learning |
| CN112700524A (en)* | 2021-03-25 | 2021-04-23 | 江苏原力数字科技股份有限公司 | 3D character facial expression animation real-time generation method based on deep learning |
| CN113129347A (en)* | 2021-04-26 | 2021-07-16 | 南京大学 | Self-supervision single-view three-dimensional hairline model reconstruction method and system |
| CN113538221A (en)* | 2021-07-21 | 2021-10-22 | Oppo广东移动通信有限公司 | Three-dimensional face processing method, training method, generating method, device and equipment |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH1074271A (en)* | 1996-08-30 | 1998-03-17 | Nippon Telegr & Teleph Corp <Ntt> | Three-dimensional portrait creation method and apparatus |
| CN101751689A (en)* | 2009-09-28 | 2010-06-23 | 中国科学院自动化研究所 | Three-dimensional facial reconstruction method |
| CN108242074A (en)* | 2018-01-02 | 2018-07-03 | 中国科学技术大学 | A 3D exaggerated face generation method based on a single satirical portrait |
| CN108805977A (en)* | 2018-06-06 | 2018-11-13 | 浙江大学 | A kind of face three-dimensional rebuilding method based on end-to-end convolutional neural networks |
| CN109508678A (en)* | 2018-11-16 | 2019-03-22 | 广州市百果园信息技术有限公司 | Training method, the detection method and device of face key point of Face datection model |
| US20190392634A1 (en)* | 2018-10-23 | 2019-12-26 | Hangzhou Qu Wei Technology Co., Ltd. | Real-Time Face 3D Reconstruction System and Method on Mobile Device |
| WO2020001082A1 (en)* | 2018-06-30 | 2020-01-02 | 东南大学 | Face attribute analysis method based on transfer learning |
- 2020
- 2020-04-21CNCN202010316895.5Apatent/CN111524226B/enactiveActive
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH1074271A (en)* | 1996-08-30 | 1998-03-17 | Nippon Telegr & Teleph Corp <Ntt> | Three-dimensional portrait creation method and apparatus |
| CN101751689A (en)* | 2009-09-28 | 2010-06-23 | 中国科学院自动化研究所 | Three-dimensional facial reconstruction method |
| CN108242074A (en)* | 2018-01-02 | 2018-07-03 | 中国科学技术大学 | A 3D exaggerated face generation method based on a single satirical portrait |
| CN108805977A (en)* | 2018-06-06 | 2018-11-13 | 浙江大学 | A kind of face three-dimensional rebuilding method based on end-to-end convolutional neural networks |
| WO2020001082A1 (en)* | 2018-06-30 | 2020-01-02 | 东南大学 | Face attribute analysis method based on transfer learning |
| US20190392634A1 (en)* | 2018-10-23 | 2019-12-26 | Hangzhou Qu Wei Technology Co., Ltd. | Real-Time Face 3D Reconstruction System and Method on Mobile Device |
| CN109508678A (en)* | 2018-11-16 | 2019-03-22 | 广州市百果园信息技术有限公司 | Training method, the detection method and device of face key point of Face datection model |
Non-Patent Citations (2)
| Title |
|---|
| 王海君;杨士颖;王雁飞;: "基于NMF和LS-SVM的肖像漫画生成算法研究"* |
| 董肖莉;李卫军;宁欣;张丽萍;路亚旋;: "应用三角形坐标系的风格化肖像生成算法"* |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112308957A (en)* | 2020-08-14 | 2021-02-02 | 浙江大学 | Optimal fat and thin face portrait image automatic generation method based on deep learning |
| CN112700524A (en)* | 2021-03-25 | 2021-04-23 | 江苏原力数字科技股份有限公司 | 3D character facial expression animation real-time generation method based on deep learning |
| CN112700524B (en)* | 2021-03-25 | 2021-07-02 | 江苏原力数字科技股份有限公司 | 3D character facial expression animation real-time generation method based on deep learning |
| CN113129347A (en)* | 2021-04-26 | 2021-07-16 | 南京大学 | Self-supervision single-view three-dimensional hairline model reconstruction method and system |
| CN113129347B (en)* | 2021-04-26 | 2023-12-12 | 南京大学 | Self-supervision single-view three-dimensional hairline model reconstruction method and system |
| CN113538221A (en)* | 2021-07-21 | 2021-10-22 | Oppo广东移动通信有限公司 | Three-dimensional face processing method, training method, generating method, device and equipment |
Also Published As
| Publication number | Publication date |
|---|---|
| CN111524226B (en) | 2023-04-18 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Zhang | Image engineering | |
| Li et al. | Robust flow-guided neural prediction for sketch-based freeform surface modeling | |
| CN108416840B (en) | A 3D scene dense reconstruction method based on monocular camera | |
| CN111325851B (en) | Image processing method and device, electronic equipment and computer readable storage medium | |
| CN111524226B (en) | Method for detecting key point and three-dimensional reconstruction of ironic portrait painting | |
| Jaklic et al. | Segmentation and recovery of superquadrics | |
| Mehra et al. | Abstraction of man-made shapes | |
| Hu et al. | Robust hair capture using simulated examples | |
| Cong et al. | Fully automatic generation of anatomical face simulation models | |
| Lei et al. | What's the situation with intelligent mesh generation: A survey and perspectives | |
| Demir et al. | Skelneton 2019: Dataset and challenge on deep learning for geometric shape understanding | |
| Qiu et al. | 3dcaricshop: A dataset and a baseline method for single-view 3d caricature face reconstruction | |
| CN110889901B (en) | Large-scene sparse point cloud BA optimization method based on distributed system | |
| CN118470222B (en) | Medical ultrasonic image three-dimensional reconstruction method and system based on SDF diffusion | |
| CN110633628A (en) | 3D model reconstruction method of RGB image scene based on artificial neural network | |
| Shi et al. | Geometric granularity aware pixel-to-mesh | |
| CN108242074B (en) | Three-dimensional exaggeration face generation method based on single irony portrait painting | |
| CN112288859A (en) | Three-dimensional face modeling method based on convolutional neural network | |
| Du et al. | SAniHead: Sketching animal-like 3D character heads using a view-surface collaborative mesh generative network | |
| Leymarie et al. | The SHAPE Lab: New technology and software for archaeologists | |
| Kazmi et al. | Efficient sketch‐based creation of detailed character models through data‐driven mesh deformations | |
| CN117058311A (en) | Hidden representation-based large-scale cloud curved surface reconstruction method for scenic spots of forest scene | |
| Ahmed | Measurement and evaluation of deep learning based 3d reconstruction | |
| CN115439843A (en) | Labeling-free pathological image feature extraction method based on spatial position information | |
| Zhang et al. | UDI-3DVT: A Novel Network for 3D Reconstruction via Uncertainty-Driven Sampling and Incremental Visual-Tactile Fusion |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |