CN111507910A - Single image reflection removing method and device and storage medium - Google Patents
Single image reflection removing method and device and storage mediumDownload PDFInfo
- Publication number
- CN111507910A CN111507910ACN202010193974.1ACN202010193974ACN111507910ACN 111507910 ACN111507910 ACN 111507910ACN 202010193974 ACN202010193974 ACN 202010193974ACN 111507910 ACN111507910 ACN 111507910A
- Authority
- CN
- China
- Prior art keywords
- image
- loss function
- reflection
- network
- reflective
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images




Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T5/00—Image enhancement or restoration
- G06T5/90—Dynamic range modification of images or parts thereof
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02T—CLIMATE CHANGE MITIGATION TECHNOLOGIES RELATED TO TRANSPORTATION
- Y02T10/00—Road transport of goods or passengers
- Y02T10/10—Internal combustion engine [ICE] based vehicles
- Y02T10/40—Engine management systems
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- General Physics & Mathematics (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- Biomedical Technology (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- Life Sciences & Earth Sciences (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Health & Medical Sciences (AREA)
- Image Analysis (AREA)
- Image Processing (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明涉及图像处理技术领域,尤其涉及一种单图像去反光的方法、装置及存储介质。The present invention relates to the technical field of image processing, and in particular, to a method, a device and a storage medium for de-reflection of a single image.
背景技术Background technique
单张图像的反射去除,通常会利用预先设定的先验信息。首先,最常见的方式为利用自然图像梯度的稀疏特性寻找最小化的边缘和角点来分离图像的图层,例如利用梯度稀疏的约束结合拉普拉斯域的数据保真项来抑制图像反射。但是,这种方式依赖于低级启发式方法,在对于需要对图像的结果进行高等级分析等情况时受到限制。另外一种先验知识为反射层的图像通常是未聚焦的、平滑的。但基于这种假设的算法无法应用于反射图像也具有很强对比度的情况。这些方法均不能有效利用图像的高层次感官信息,且无法解决高对比度的反光图像的去反光问题。The reflection removal of a single image usually uses pre-set prior information. First, the most common way is to use the sparse nature of natural image gradients to find minimized edges and corners to separate image layers, such as using gradient sparse constraints combined with data fidelity terms in the Laplacian domain to suppress image reflections . However, this approach relies on low-level heuristics and is limited in situations such as requiring high-level analysis of the results of the image. Another prior knowledge is that the image of the reflective layer is usually unfocused and smooth. But the algorithm based on this assumption cannot be applied to the case where the reflected image also has strong contrast. None of these methods can effectively utilize the high-level sensory information of images, and cannot solve the problem of de-reflection of high-contrast reflective images.
发明内容SUMMARY OF THE INVENTION
本发明实施例的目的是提供一种单图像去反光的方法、装置及存储介质,能有效提取图像的高层次感官信息加入网络训练,并结合生成对抗网络的优势,能有效解决单图像的去反光问题,对于高对比度的反光图像仍有满意的去反光效果。The purpose of the embodiments of the present invention is to provide a method, device and storage medium for de-reflection of a single image, which can effectively extract high-level sensory information of an image and add it to network training. Reflection problem, still satisfactory de-reflection effect for high-contrast reflective images.
为实现上述目的,本发明一实施例提供了一种单图像去反光的方法,包括以下步骤:In order to achieve the above object, an embodiment of the present invention provides a method for de-reflection of a single image, comprising the following steps:
通过人工拍摄获取背景图像和对应的反射图像,并根据所述背景图像和所述反射图像的叠加,得到反光图像;Obtain a background image and a corresponding reflective image through manual shooting, and obtain a reflective image according to the superposition of the background image and the reflective image;
将所述反光图像输入到预训练的VGG-19网络进行超列特征提取,得到特征集合;Inputting the reflective image into the pre-trained VGG-19 network for hypercolumn feature extraction to obtain a feature set;
将所述特征集合输入到预设的生成网络中,得到预测背景图和预测反射图;其中,所述生成网络的联合损失函数包括超列特征空间的重建损失函数、对抗损失函数和分离损失函数;Inputting the feature set into a preset generation network to obtain a predicted background map and a predicted reflection map; wherein the joint loss function of the generation network includes a reconstruction loss function, an adversarial loss function and a separation loss function of the hypercolumn feature space ;
将所述预测背景图和所述背景图像输入到预设的鉴别网络,以计算得到所述鉴别网络的鉴别损失函数;Inputting the predicted background image and the background image into a preset identification network, to calculate the identification loss function of the identification network;
通过多次迭代计算,直至所述联合损失函数和所述鉴别损失函数均收敛,完成所述生成网络和所述鉴别网络的训练;Through multiple iterative calculations, until both the joint loss function and the discrimination loss function converge, the training of the generating network and the discriminating network is completed;
选取多张所述反光图像进行去反光处理,以定量评估去反光效果。A plurality of the reflective images are selected for de-reflection processing to quantitatively evaluate the de-reflection effect.
优选地,所述根据所述背景图像和所述反射图像的叠加,得到反光图像,具体包括:Preferably, obtaining the reflective image according to the superposition of the background image and the reflective image specifically includes:
获取所述背景图像的第一灰度值;obtaining the first grayscale value of the background image;
获取所述反射图像的第二灰度值;obtaining a second grayscale value of the reflected image;
将所述第一灰度值和所述第二灰度值进行加权计算,得到所述反光图像。The first grayscale value and the second grayscale value are weighted to obtain the reflective image.
优选地,所述VGG-19网络的卷积层包括conv1_2、conv2_2、conv3_2、conv4_2和conv5_2。Preferably, the convolutional layers of the VGG-19 network include conv1_2, conv2_2, conv3_2, conv4_2 and conv5_2.
优选地,所述生成网络包括卷积核为1×1的输入层和8个卷积核为3×3的空洞卷积层;其中,最后一层空洞卷积层利用线性变换产生两幅三通道的RGB图。Preferably, the generation network includes an input layer with a convolution kernel of 1×1 and 8 atrous convolutional layers with a convolution kernel of 3×3; wherein, the last layer of atrous convolutional layers utilizes linear transformation to generate two images and three images. RGB map of the channel.
优选地,所述生成网络的联合损失函数包括超列特征空间的重建损失函数、对抗损失函数和分离损失函数,具体包括:Preferably, the joint loss function of the generation network includes a reconstruction loss function, an adversarial loss function and a separation loss function of the hypercolumn feature space, and specifically includes:
所述超列特征空间的重建损失函数的表达式为
所述对抗损失函数的表达式为
所述分离损失函数的表达式为



所述生成网络的联合损失函数为L(θ)=w1Lfeat(θ)+w2Ladv(θ)+w3Lexcl(θ);其中,L(θ)为所述联合损失函数,w1、w2和w3分别为所述超列特征空间的重建损失函数、所述对抗损失函数和所述分离损失函数对应的系数。The joint loss function of the generation network is L(θ)=w1 Lfeat (θ)+w2 Ladv (θ)+w3 Lexcl (θ); wherein, L(θ) is the joint loss function , w1 , w2 and w3 are the coefficients corresponding to the reconstruction loss function of the hypercolumn feature space, the adversarial loss function and the separation loss function, respectively.
优选地,所述鉴别网络的鉴别损失函数为Ldisc(θ)=log D(I;fT(I;θ))-log D(I,T);其中,Ldisc(θ)为所述鉴别损失函数。Preferably, the discrimination loss function of the discriminant network is Ldisc (θ)=log D(I; fT (I; θ))-log D(I, T); wherein, Ldisc (θ) is the Discriminative loss function.
优选地,所述选取多张反光图像进行去反光处理,以定量评估去反光效果,具体包括:Preferably, selecting a plurality of reflective images for de-reflection processing to quantitatively evaluate the de-reflection effect, specifically including:
选取多张所述反光图像进行去反光处理,计算所述生成网络生成的所述预测背景图与所述背景图之间的峰值信噪比和结构相似性,以定量评估去反光效果Select a plurality of the reflective images for de-reflection processing, and calculate the peak signal-to-noise ratio and structural similarity between the predicted background image generated by the generation network and the background image to quantitatively evaluate the de-reflection effect.
本发明另一实施例提供了一种单图像去反光的装置,所述装置包括:Another embodiment of the present invention provides a single image de-reflection device, the device comprising:
图像集获取模块,用于通过人工拍摄获取背景图像和对应的反射图像,并根据所述背景图像和所述反射图像的叠加,得到反光图像;an image set acquisition module, configured to acquire a background image and a corresponding reflection image through manual shooting, and obtain a reflection image according to the superposition of the background image and the reflection image;
特征提取模块,用于将所述反光图像输入到预训练的VGG-19网络进行超列特征提取,得到特征集合;A feature extraction module, for inputting the reflective image into the pre-trained VGG-19 network to perform hypercolumn feature extraction to obtain a feature set;
预测生成模块,用于将所述特征集合输入到预设的生成网络中,得到预测背景图和预测反射图;其中,所述生成网络的联合损失函数包括超列特征空间的重建损失函数、对抗损失函数和分离损失函数;The prediction generation module is used to input the feature set into the preset generation network to obtain the prediction background map and the prediction reflection map; wherein, the joint loss function of the generation network includes the reconstruction loss function of the hypercolumn feature space, the confrontation loss function and separation loss function;
鉴别模块,用于将所述预测背景图和所述背景图像输入到预设的鉴别网络,以计算得到所述鉴别网络的鉴别损失函数;An identification module, for inputting the predicted background image and the background image into a preset identification network, to calculate the identification loss function of the identification network;
训练模块,用于通过多次迭代计算,直至所述联合损失函数和所述鉴别损失函数均收敛,完成所述生成网络和所述鉴别网络的训练;A training module is used to calculate through multiple iterations until both the joint loss function and the identification loss function converge, and the training of the generation network and the identification network is completed;
评估模块,用于选取多张所述反光图像进行去反光处理,以定量评估去反光效果。The evaluation module is used for selecting a plurality of the reflective images for de-reflection processing, so as to quantitatively evaluate the de-reflection effect.
本发明还有一实施例对应提供了一种使用单图像去反光的方法的装置,包括处理器、存储器以及存储在所述存储器中且被配置为由所述处理器执行的计算机程序,所述处理器执行所述计算机程序时实现上述任一项所述的单图像去反光的方法。Still another embodiment of the present invention provides an apparatus for a method for de-reflection using a single image, comprising a processor, a memory, and a computer program stored in the memory and configured to be executed by the processor, the processing When the computer executes the computer program, the method for de-reflection of a single image described in any one of the above is realized.
本发明另一实施例提供了一种计算机可读存储介质,所述计算机可读存储介质包括存储的计算机程序,其中,在所述计算机程序运行时控制所述计算机可读存储介质所在设备执行如上述任一项所述的单图像去反光的方法。Another embodiment of the present invention provides a computer-readable storage medium, where the computer-readable storage medium includes a stored computer program, wherein, when the computer program runs, the device where the computer-readable storage medium is located is controlled to execute the following The method for de-reflection of a single image according to any one of the above.
与现有技术相比,本发明实施例所提供的一种单图像去反光的方法、装置及存储介质,通过借助深度卷积神经网络有效提取图像的高等级感官信息,并结合生成对抗网络的优化特性,可以得到跟真实背景图像比较接近的预测背景图,有效解决图像采集中遇到的图像反光问题,对于高对比度的反射图像仍有较满意的去反光效果。Compared with the prior art, the method, device and storage medium for single image de-reflection provided by the embodiments of the present invention effectively extract high-level sensory information of an image by means of a deep convolutional neural network, and combine with the method of generative adversarial network. The optimized feature can obtain a predicted background image that is closer to the real background image, effectively solve the image reflection problem encountered in image acquisition, and still have a satisfactory anti-reflection effect for high-contrast reflective images.
附图说明Description of drawings
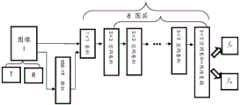
图1是本发明一实施例提供的一种单图像去反光的方法的流程示意图;1 is a schematic flowchart of a method for de-reflection of a single image provided by an embodiment of the present invention;
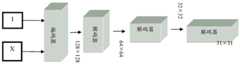
图2是本发明一实施例提供的一种单图像去反光的方法的简单流程示意图;2 is a schematic flowchart of a method for de-reflection of a single image provided by an embodiment of the present invention;
图3是本发明一实施例提供的一种生成网络的结构示意图;3 is a schematic structural diagram of a generation network according to an embodiment of the present invention;
图4是本发明一实施例提供的一种鉴别网络的结构示意图;4 is a schematic structural diagram of an authentication network provided by an embodiment of the present invention;
图5是本发明一实施例提供的4组反光图像、背景图像、预测背景图和反射图像的去反光对比效果图;5 is a de-reflection comparison effect diagram of 4 groups of reflective images, background images, predicted background images and reflective images provided by an embodiment of the present invention;
图6是本发明一实施例提供的一种单图像去反光的装置的结构示意图;FIG. 6 is a schematic structural diagram of a single-image de-reflection device provided by an embodiment of the present invention;
图7是本发明一实施例提供的一种使用单图像去反光的方法的装置的示意图。FIG. 7 is a schematic diagram of a device for a method for de-reflection using a single image provided by an embodiment of the present invention.
具体实施方式Detailed ways
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。The technical solutions in the embodiments of the present invention will be clearly and completely described below with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only a part of the embodiments of the present invention, but not all of the embodiments. Based on the embodiments of the present invention, all other embodiments obtained by those of ordinary skill in the art without creative efforts shall fall within the protection scope of the present invention.
参见图1,是本发明一实施例提供的一种单图像去反光的方法的流程示意图,所述方法包括步骤S1至步骤S6:Referring to FIG. 1, it is a schematic flowchart of a method for de-reflection of a single image provided by an embodiment of the present invention. The method includes steps S1 to S6:
S1、通过人工拍摄获取背景图像和对应的反射图像,并根据所述背景图像和所述反射图像的叠加,得到反光图像;S1, obtaining a background image and a corresponding reflective image by manual shooting, and obtaining a reflective image according to the superposition of the background image and the reflective image;
S2、将所述反光图像输入到预训练的VGG-19网络进行超列特征提取,得到特征集合;S2. Input the reflective image into the pre-trained VGG-19 network to perform hypercolumn feature extraction to obtain a feature set;
S3、将所述特征集合输入到预设的生成网络中,得到预测背景图和预测反射图;其中,所述生成网络的联合损失函数包括超列特征空间的重建损失函数、对抗损失函数和分离损失函数;S3. Input the feature set into a preset generation network to obtain a predicted background map and a predicted reflection map; wherein, the joint loss function of the generation network includes a reconstruction loss function, an adversarial loss function and a separation function of the hypercolumn feature space. loss function;
S4、将所述预测背景图和所述背景图像输入到预设的鉴别网络,以计算得到所述鉴别网络的鉴别损失函数;S4, inputting the predicted background image and the background image to a preset identification network, to calculate the identification loss function of the identification network;
S5、通过多次迭代计算,直至所述联合损失函数和所述鉴别损失函数均收敛,完成所述生成网络和所述鉴别网络的训练;S5, through multiple iterative calculations, until both the joint loss function and the identification loss function converge, complete the training of the generation network and the identification network;
S6、选取多张所述反光图像进行去反光处理,以定量评估去反光效果。S6. Select a plurality of the reflective images for de-reflection processing to quantitatively evaluate the de-reflection effect.
具体地,通过人工拍摄获取背景图像和对应的反射图像,并根据背景图像和反射图像的叠加,得到反光图像。因为在现实生活中,无反光原始图像比较难得到,所以在本发明中,采用人工方式进行制作背景图像,方法:背景图像选择室内图像,将目标物体放到透明玻璃一侧(最好为暗的一侧),拍摄镜头在玻璃另一侧。然后固定物体和镜头位置,拍摄图像得到无反光的背景图像。反射图像可以选择户外图像。得到背景图像和反射图像后,将两张图像设置到同样大小H*W*3,然后进行图像叠加,得到反光图像。最终数据集包含2000张反光图像和其对应的背景图像与反射图像。Specifically, the background image and the corresponding reflection image are obtained by manual shooting, and the reflection image is obtained according to the superposition of the background image and the reflection image. Because in real life, it is difficult to obtain the non-reflective original image, so in the present invention, the background image is made manually. side), the camera lens is on the other side of the glass. Then fix the object and lens position and take the image to get a non-reflective background image. Reflection images can be selected for outdoor images. After getting the background image and the reflection image, set the two images to the same size H*W*3, and then superimpose the images to get the reflection image. The final dataset contains 2000 reflection images and their corresponding background and reflection images.
将反光图像输入到预训练的VGG-19网络进行超列特征提取,得到特征集合。超列特征一共有1472维,然后将反光图像的三个通道与超列特征连接在一起,形成一个1475维的特征集合,记为Φ(x),其中x为输入的反光图像。The reflective image is input to the pre-trained VGG-19 network for hypercolumn feature extraction to obtain a feature set. The hypercolumn feature has a total of 1472 dimensions, and then the three channels of the reflective image are connected with the hypercolumn feature to form a 1475-dimensional feature set, denoted as Φ(x), where x is the input reflective image.
将特征集合输入到预设的生成网络中,得到预测背景图和预测反射图;其中,生成网络的联合损失函数包括超列特征空间的重建损失函数、对抗损失函数和分离损失函数;Input the feature set into the preset generation network to obtain the predicted background map and the predicted reflection map; wherein, the joint loss function of the generation network includes the reconstruction loss function of the hypercolumn feature space, the confrontation loss function and the separation loss function;
将预测背景图和背景图像输入到预设的鉴别网络,以计算得到鉴别网络的鉴别损失函数。鉴别网络的引入是为了对输入的两张图像进行判断,输出这两张图像来源于数据集的概率。Input the predicted background image and background image to the preset discriminant network to calculate the discriminant loss function of the discriminant network. The introduction of the discriminant network is to judge the two input images and output the probability that these two images come from the dataset.
通过多次迭代计算,直至联合损失函数和鉴别损失函数均收敛,完成生成网络和鉴别网络的训练;在训练过程中,鉴别网络的输出概率会影响生成网络的联合损失函数,以优化生成网络。一般地,当鉴别网络的输出概率为0.5时,表示两个函数均收敛。优选地,训练参数为:max_epoch=250,batch_size=1;优化方式为Adam优化算法,学习率为10-4。Through multiple iterative calculations, until both the joint loss function and the discriminant loss function converge, the training of the generative network and the discriminant network is completed; during the training process, the output probability of the discriminator network will affect the joint loss function of the generative network to optimize the generative network. Generally, when the output probability of the discriminant network is 0.5, it means that both functions converge. Preferably, the training parameters are: max_epoch=250, batch_size=1; the optimization method is the Adam optimization algorithm, and the learning rate is 10−4 .
为了评价本发明的方法的优劣,选取多张反光图像进行去反光处理,以定量评估去反光效果。In order to evaluate the pros and cons of the method of the present invention, a plurality of reflective images are selected for de-reflection processing to quantitatively evaluate the de-reflection effect.
为了更清楚地了解本发明的方法的实施过程,参见图2,是本发明该实施例提供的一种单图像去反光的方法的简单流程示意图。In order to understand the implementation process of the method of the present invention more clearly, refer to FIG. 2 , which is a schematic flow chart of a single image de-reflection method provided by this embodiment of the present invention.
本发明实施例1提供的一种单图像去反光的方法,通过借助深度卷积神经网络有效提取图像的高等级感官信息,并结合生成对抗网络的优化特性,可以得到跟真实背景图像比较接近的预测背景图,有效解决图像采集中遇到的图像反光问题,对于高对比度的反射图像仍有较满意的去反光效果。The method for de-reflection of a single image provided in Embodiment 1 of the present invention can effectively extract high-level sensory information of an image by using a deep convolutional neural network, and combine the optimization characteristics of a generative adversarial network to obtain a background image that is closer to the real background image. Predict the background image, effectively solve the image reflection problem encountered in image acquisition, and still have a satisfactory anti-reflection effect for high-contrast reflective images.
作为上述方案的改进,所述根据所述背景图像和所述反射图像的叠加,得到反光图像,具体包括:As an improvement of the above solution, obtaining the reflective image according to the superposition of the background image and the reflective image specifically includes:
获取所述背景图像的第一灰度值;obtaining the first grayscale value of the background image;
获取所述反射图像的第二灰度值;obtaining a second grayscale value of the reflected image;
将所述第一灰度值和所述第二灰度值进行加权计算,得到所述反光图像。The first grayscale value and the second grayscale value are weighted to obtain the reflective image.
具体地,反光图像I可以看作是背景图像T与反射图像R的线形叠加。因此,可以通过获取背景图像的第一灰度值和获取反射图像的第二灰度值,并将第一灰度值和第二灰度值进行加权计算,得到反光图像,用数学表达式表示为:I=(1-α)*T+α*R;其中,I为反光图像,T为背景图像,R为反射图像,α为反射图像对应的加权参数,α∈[0,1],优选地,α=0.5。Specifically, the reflective image I can be regarded as a linear superposition of the background image T and the reflective image R. Therefore, the reflective image can be obtained by obtaining the first gray value of the background image and the second gray value of the reflective image, and performing a weighted calculation on the first gray value and the second gray value, which can be expressed by a mathematical expression is: I=(1-α)*T+α*R; where I is the reflective image, T is the background image, R is the reflective image, α is the weighting parameter corresponding to the reflective image, α∈[0,1], Preferably, a=0.5.
作为上述方案的改进,所述VGG-19网络的卷积层包括conv1_2、conv2_2、conv3_2、conv4_2和conv5_2。As an improvement of the above scheme, the convolutional layers of the VGG-19 network include conv1_2, conv2_2, conv3_2, conv4_2 and conv5_2.
具体地,VGG-19网络的卷积层包括conv1_2、conv2_2、conv3_2、conv4_2和conv5_2。VGG-19网络是在ImageNet上预训练过的,用于提取输入图像的超列特征,使用超列特征的好处在于,输入增加了有用的特征,这些特征抽象了大型数据集(如ImageNet)的视觉感知。给定像素位置的超列特征是该位置的网络选定卷积层上的激活单元的堆栈。Specifically, the convolutional layers of the VGG-19 network include conv1_2, conv2_2, conv3_2, conv4_2, and conv5_2. The VGG-19 network is pretrained on ImageNet to extract hypercolumn features of the input image. The benefit of using hypercolumn features is that the input adds useful features that abstract the features of large datasets such as ImageNet. visual perception. The supercolumn feature at a given pixel location is the stack of activation units on the selected convolutional layer of the network at that location.
作为上述方案的改进,所述生成网络包括卷积核为1×1的输入层和8个卷积核为3×3的空洞卷积层;其中,最后一层空洞卷积层利用线性变换产生两幅三通道的RGB图。As an improvement of the above scheme, the generation network includes an input layer with a convolution kernel of 1×1 and 8 atrous convolutional layers with a convolution kernel of 3×3; wherein, the last layer of atrous convolutional layers is generated by linear transformation Two three-channel RGB images.
具体地,参见图3,是本发明该实施例提供的一种生成网络的结构示意图。由图3可知,生成网络包括卷积核为1×1的输入层和8个卷积核为3×3的空洞卷积层;其中,最后一层空洞卷积层利用线性变换产生两幅三通道的RGB图。输入层可以将VGG-19网络输出的1475维特征降维到64维,8个空洞卷积层的膨胀率取值范围为1到128。生成网络所有中间层的特征层数量为64。Specifically, referring to FIG. 3 , it is a schematic structural diagram of a generation network provided by this embodiment of the present invention. As can be seen from Figure 3, the generation network includes an input layer with a convolution kernel of 1×1 and 8 atrous convolutional layers with a convolution kernel of 3×3; among them, the last layer of atrous convolutional layers uses linear transformation to generate two images and three RGB map of the channel. The input layer can reduce the 1475-dimensional feature output by the VGG-19 network to 64-dimensional, and the dilation rate of the 8 atrous convolutional layers ranges from 1 to 128. The number of feature layers in all intermediate layers of the generative network is 64.
作为上述方案的改进,所述生成网络的联合损失函数包括超列特征空间的重建损失函数、对抗损失函数和分离损失函数,具体包括:As an improvement of the above scheme, the joint loss function of the generation network includes a reconstruction loss function, an adversarial loss function and a separation loss function of the hypercolumn feature space, and specifically includes:
所述超列特征空间的重建损失函数的表达式为
所述对抗损失函数的表达式为
所述分离损失函数的表达式为



所述生成网络的联合损失函数为L(θ)=w1Lfeat(θ)+w2Ladv(θ)+w3Lexcl(θ);其中,L(θ)为所述联合损失函数,w1、w2和w3分别为所述超列特征空间的重建损失函数、所述对抗损失函数和所述分离损失函数对应的系数。The joint loss function of the generation network is L(θ)=w1 Lfeat (θ)+w2 Ladv (θ)+w3 Lexcl (θ); wherein, L(θ) is the joint loss function , w1 , w2 and w3 are the coefficients corresponding to the reconstruction loss function of the hypercolumn feature space, the adversarial loss function and the separation loss function, respectively.
具体地,超列特征空间的重建损失函数,又称Feature reconstruction loss,用于度量生成网络生成的预测背景图与背景图像T在超列空间的距离。一般地,在选定的VGG-19网络层上计算预测图像与目标图像的距离。超列特征空间的重建损失函数的表达式为
对抗损失函数,又称Adversarial loss,其作用是使生成的预测背景图fT(I;θ)与反光图像I差异性更大。对抗损失函数的表达式为
分离损失函数,又称Exclusion loss,是根据观察发现反光图像在图像边缘的规律设计而来。经过观察反光图像的两个图层发现,背景图层与反射图层的边缘一般不会重合。反光图像I中的边缘只能是由背景图像或者反射图像产生,而不可能是两者叠加造成。所以,本发明提出最小化生成网络预测得到的反射图层和背景图层的梯度空间相关性,考虑在两个图层的多个分辨率上计算归一化的梯度信息,以此计算图像边缘相关性作为分离损失函数。The separation loss function, also known as Exclusion loss, is designed based on the observation that the reflective image is at the edge of the image. After observing the two layers of the reflective image, it is found that the edges of the background layer and the reflective layer generally do not coincide. The edge in the reflective image I can only be caused by the background image or the reflective image, and cannot be caused by the superposition of the two. Therefore, the present invention proposes to minimize the gradient spatial correlation between the reflection layer and the background layer predicted by the generation network, and consider calculating the normalized gradient information at multiple resolutions of the two layers to calculate the image edge. Correlation as a separation loss function.
分离损失函数的表达式为




生成网络的联合损失函数为L(θ)=w1Lfeat(θ)+w2Ladv(θ)+w3Lexcl(θ);其中,L(θ)为联合损失函数,w1、w2和w3分别为超列特征空间的重建损失函数、对抗损失函数和分离损失函数对应的系数,用于平衡各个损失函数对生成网络的影响能力。优选地,w1=20,w2=100,w3=1。The joint loss function of the generative network is L(θ)=w1 Lfeat (θ)+w2 Ladv (θ)+w3 Lexcl (θ); among them, L(θ) is the joint loss function, w1 , w2 and w3 are the coefficients corresponding to the reconstruction loss function, the adversarial loss function and the separation loss function of the hypercolumn feature space respectively, which are used to balance the influence of each loss function on the generation network. Preferably, w1 =20, w2 =100, and w3 =1.
作为上述方案的改进,所述鉴别网络的鉴别损失函数为Ldisc(θ)=log D(I;fT(I;θ))-log D(I,T);其中,Ldisc(θ)为所述鉴别损失函数。As an improvement of the above scheme, the discriminant loss function of the discriminant network is Ldisc (θ)=log D(I; fT (I; θ))-log D(I, T); wherein, Ldisc (θ) is the discriminative loss function.
需要说明的是,鉴别网络的构建过程为,首先将输入到鉴别网络的预测背景图和背景图像通过将通道合并得到层叠的输入图像。如果预测背景图和背景图像的大小均为C×W×H,其中C为图像的通道数,W和H分别为图像的宽度和高度,那么经过通道合并后,得到的层叠图像的维度将是2C×W×H。得到的层叠后的输入图像后,将其通过多个级联的下采样单元。这些下采样单元的处理会使输入的层叠图像成为逐渐减小的特征图。这些下采样单元由串联的卷积步长为2的卷积层、批归一化层和非线性激活层组成。步长为2的卷积层会将输入图像的尺寸减小到原来的二分之一,这起到了下采样的作用;批归一化层通过将输入的一个批次的数据归一化到均值为0、方差为1的归一化数据,起到了稳定训练和加速模型收敛的作用;而非线性激活层的加入防止了模型退化为简单的线性模型,提高了模型的描述能力,优选地,将斜率为0.02的Leaky Re LU单元作为非线性激活单元。在经过多个下采样单元后,将得到维度为C×W×H的特征图;其中,C为特征图的通道数,W≤4为特征图的宽度,H≤4为特征图的高度。在得到特征图后,将其映射到一个范围为0到1的标量以指示输入图像的来源为数据集的概率,此过程,使用的是包含一个维度为C×W×H的卷积核的卷积层。在经过这一个卷积层后的处理后,将得到一个标量值,这个标量值将被输入到Sigmoid函数中,得到范围为0到1的概率值。参见图4,是本发明该实施例提供的一种鉴别网络的结构示意图。It should be noted that the construction process of the discriminant network is as follows: firstly, the predicted background image and the background image input to the discriminant network are combined to obtain a layered input image by merging channels. If the size of the predicted background image and the background image are both C×W×H, where C is the number of channels of the image, and W and H are the width and height of the image, respectively, then the dimensions of the resulting stacked image after channel merging will be 2C×W×H. After obtaining the cascaded input image, it is passed through multiple cascaded downsampling units. The processing of these downsampling units results in a progressively smaller feature map from the input stacked image. These downsampling units consist of concatenated convolutional layers with stride 2, batch normalization layers, and nonlinear activation layers. A convolutional layer with stride 2 reduces the size of the input image by half, which acts as a downsampling; a batch normalization layer works by normalizing a batch of input data to The normalized data with a mean of 0 and a variance of 1 plays a role in stabilizing training and accelerating model convergence; while the addition of a nonlinear activation layer prevents the model from degenerating into a simple linear model and improves the model's description ability, preferably , a Leaky Re LU unit with a slope of 0.02 is used as the nonlinear activation unit. After multiple downsampling units, a feature map with dimension C×W×H will be obtained; where C is the number of channels of the feature map, W≤4 is the width of the feature map, and H≤4 is the height of the feature map. After obtaining the feature map, map it to a scalar ranging from 0 to 1 to indicate the probability that the source of the input image is the dataset. This process uses a convolution kernel with a dimension of C×W×H. convolutional layer. After processing through this one convolutional layer, you will get a scalar value, which will be fed into the Sigmoid function to get a probability value ranging from 0 to 1. Referring to FIG. 4 , it is a schematic structural diagram of an authentication network provided by this embodiment of the present invention.
具体地,鉴别网络的鉴别损失函数为Ldisc(θ)=log D(I;fT(I;θ))-log D(I,T);其中,Ldisc(θ)为鉴别损失函数,D(I,x)表示x为反光图像I对应的背景图像的概率,即D(I;fT(I;θ))表示预测背景图fT(I;θ)来源于数据集中的背景图像的概率,D(I,T)表示背景图像T来源于数据集中的背景图像的概率。Specifically, the discriminative loss function of the discriminant network is Ldisc (θ)=log D(I; fT (I; θ))-log D(I, T); wherein, Ldisc (θ) is the discriminative loss function, D(I,x) represents the probability that x is the background image corresponding to the reflective image I, that is, D(I; fT (I; θ)) represents the predicted background image fT (I; θ) comes from the background image in the dataset The probability of , D(I, T) represents the probability that the background image T is derived from the background image in the dataset.
作为上述方案的改进,所述选取多张反光图像进行去反光处理,以定量评估去反光效果,具体包括:As an improvement of the above scheme, the selection of multiple reflective images for de-reflection processing is performed to quantitatively evaluate the de-reflection effect, specifically including:
选取多张所述反光图像进行去反光处理,计算所述生成网络生成的所述预测背景图与所述背景图之间的峰值信噪比和结构相似性,以定量评估去反光效果Select a plurality of the reflective images for de-reflection processing, and calculate the peak signal-to-noise ratio and structural similarity between the predicted background image generated by the generation network and the background image to quantitatively evaluate the de-reflection effect.
具体地,选取多张反光图像进行去反光处理,计算生成网络生成的预测背景图与背景图之间的峰值信噪比和结构相似性,以定量评估去反光效果。其中,峰值信噪比,又称Peak signal-to-noise ratio,缩写为PSNR。结构相似性,又称Structural SimilarityIndex,缩写为SSIM。参见图5,是本发明该实施例提供的4组反光图像、背景图像、预测背景图和反射图像的去反光对比效果图。参见表1,是对应图5的去反光效果评价指标定量评估表。由图5和表1可知,本发明的方法对于单图像去反光具有良好效果。Specifically, multiple reflective images are selected for de-reflection processing, and the peak signal-to-noise ratio and structural similarity between the predicted background image generated by the generation network and the background image are calculated to quantitatively evaluate the de-reflection effect. Among them, peak signal-to-noise ratio, also known as Peak signal-to-noise ratio, abbreviated as PSNR. Structural similarity, also known as Structural SimilarityIndex, abbreviated as SSIM. Referring to FIG. 5 , it is a de-reflection comparison effect diagram of four groups of reflective images, background images, predicted background images, and reflective images provided by this embodiment of the present invention. See Table 1, which is a quantitative evaluation table corresponding to the evaluation index of the anti-reflection effect in FIG. 5 . It can be seen from FIG. 5 and Table 1 that the method of the present invention has a good effect on single image de-reflection.
表1图像去反光效果评价指标定量评估表Table 1 Quantitative evaluation table of evaluation index of image de-reflection effect
参见图6,是本发明一实施例提供的一种单图像去反光的装置的结构示意图,所述装置包括:Referring to FIG. 6 , it is a schematic structural diagram of a device for de-reflection of a single image provided by an embodiment of the present invention, and the device includes:
图像集获取模块11,用于通过人工拍摄获取背景图像和对应的反射图像,并根据所述背景图像和所述反射图像的叠加,得到反光图像;An image set
特征提取模块12,用于将所述反光图像输入到预训练的VGG-19网络进行超列特征提取,得到特征集合;The
预测生成模块13,用于将所述特征集合输入到预设的生成网络中,得到预测背景图和预测反射图;其中,所述生成网络的联合损失函数包括超列特征空间的重建损失函数、对抗损失函数和分离损失函数;The
鉴别模块14,用于将所述预测背景图和所述背景图像输入到预设的鉴别网络,以计算得到所述鉴别网络的鉴别损失函数;The
训练模块15,用于通过多次迭代计算,直至所述联合损失函数和所述鉴别损失函数均收敛,完成所述生成网络和所述鉴别网络的训练;The
评估模块16,用于选取多张所述反光图像进行去反光处理,以定量评估去反光效果。The
本发明实施例所提供的一种单图像去反光的装置能够实现上述任一实施例所述的单图像去反光的方法的所有流程,装置中的各个模块、单元的作用以及实现的技术效果分别与上述实施例所述的单图像去反光的方法的作用以及实现的技术效果对应相同,这里不再赘述。The single-image de-reflection device provided by the embodiment of the present invention can realize all the processes of the single-image de-reflection method described in any of the above-mentioned embodiments, and the functions and technical effects of each module and unit in the device are respectively The functions and technical effects achieved by the method for de-reflection of a single image described in the above-mentioned embodiments correspond to the same, and are not repeated here.
参见图7,是本发明实施例提供的一种使用单图像去反光的方法的装置的示意图,所述使用单图像去反光的方法的装置包括处理器10、存储器20以及存储在所述存储器20中且被配置为由所述处理器10执行的计算机程序,所述处理器10执行所述计算机程序时实现上述任一实施例所述的单图像去反光的方法。Referring to FIG. 7 , it is a schematic diagram of an apparatus for using a method for de-reflection with a single image provided by an embodiment of the present invention, and the apparatus for using a method for de-reflection with a single image includes a
示例性的,计算机程序可以被分割成一个或多个模块/单元,一个或者多个模块/单元被存储在存储器20中,并由处理器10执行,以完成本发明。一个或多个模块/单元可以是能够完成特定功能的一系列计算机程序指令段,该指令段用于描述计算机程序在一种单图像去反光的方法中的执行过程。例如,计算机程序可以被分割成图像集获取模块、特征提取模块、预测生成模块、鉴别模块、训练模块和评估模块,各模块具体功能如下:Exemplarily, the computer program may be divided into one or more modules/units, and the one or more modules/units are stored in the
图像集获取模块11,用于通过人工拍摄获取背景图像和对应的反射图像,并根据所述背景图像和所述反射图像的叠加,得到反光图像;An image set
特征提取模块12,用于将所述反光图像输入到预训练的VGG-19网络进行超列特征提取,得到特征集合;The
预测生成模块13,用于将所述特征集合输入到预设的生成网络中,得到预测背景图和预测反射图;其中,所述生成网络的联合损失函数包括超列特征空间的重建损失函数、对抗损失函数和分离损失函数;The
鉴别模块14,用于将所述预测背景图和所述背景图像输入到预设的鉴别网络,以计算得到所述鉴别网络的鉴别损失函数;The
训练模块15,用于通过多次迭代计算,直至所述联合损失函数和所述鉴别损失函数均收敛,完成所述生成网络和所述鉴别网络的训练;The
评估模块16,用于选取多张所述反光图像进行去反光处理,以定量评估去反光效果。The
所述使用单图像去反光的方法的装置可以是桌上型计算机、笔记本、掌上电脑及云端服务器等计算设备。所述使用单图像去反光的方法的装置可包括,但不仅限于,处理器、存储器。本领域技术人员可以理解,示意图7仅仅是一种使用单图像去反光的方法的装置的示例,并不构成对所述使用单图像去反光的方法的装置的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件,例如所述使用单图像去反光的方法的装置还可以包括输入输出设备、网络接入设备、总线等。The apparatus for using the method for de-reflection of a single image may be a computing device such as a desktop computer, a notebook computer, a palmtop computer, and a cloud server. The apparatus for using the method for de-reflection of a single image may include, but is not limited to, a processor and a memory. Those skilled in the art can understand that the schematic diagram 7 is only an example of an apparatus for using a single-image de-reflection method, and does not constitute a limitation on the apparatus for using a single-image de-reflection method, and may include more than shown in the figure. Or fewer components, or a combination of some components, or different components, for example, the apparatus for using the method for de-reflection of a single image may also include input and output devices, network access devices, buses, and the like.
处理器10可以是中央处理单元(Central Processing Unit,CPU),还可以是其他通用处理器、数字信号处理器(Digital Signal Processor,DSP)、专用集成电路(Application Specific Integrated Circuit,ASIC)、现成可编程门阵列(Field-Programmable Gate Array,FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者处理器10也可以是任何常规的处理器等,处理器10是所述使用单图像去反光的方法的装置的控制中心,利用各种接口和线路连接整个使用单图像去反光的方法的装置的各个部分。The
存储器20可用于存储所述计算机程序和/或模块,处理器10通过运行或执行存储在存储器20内的计算机程序和/或模块,以及调用存储在存储器20内的数据,实现所述使用单图像去反光的方法的装置的各种功能。存储器20可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序等;存储数据区可存储根据程序使用所创建的数据等。此外,存储器20可以包括高速随机存取存储器,还可以包括非易失性存储器,例如硬盘、内存、插接式硬盘,智能存储卡(Smart Media Card,SMC),安全数字(Secure Digital,SD)卡,闪存卡(Flash Card)、至少一个磁盘存储器件、闪存器件、或其他易失性固态存储器件。The
其中,所述使用单图像去反光的方法的装置集成的模块如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明实现上述实施例方法中的全部或部分流程,也可以通过计算机程序来指令相关的硬件来完成,上述的计算机程序可存储于一计算机可读存储介质中,该计算机程序在被处理器执行时,可实现上述各个方法实施例的步骤。其中,上述计算机程序包括计算机程序代码,计算机程序代码可以为源代码形式、对象代码形式、可执行文件或某些中间形式等。计算机可读介质可以包括:能够携带计算机程序代码的任何实体或装置、记录介质、U盘、移动硬盘、磁碟、光盘、计算机存储器、只读存储器(ROM,Read-Only Memory)、随机存取存储器(RAM,Random Access Memory)、电载波信号、电信信号以及软件分发介质等。需要说明的是,计算机可读介质包含的内容可以根据司法管辖区内立法和专利实践的要求进行适当的增减,例如在某些司法管辖区,根据立法和专利实践,计算机可读介质不包括电载波信号和电信信号。Wherein, if the integrated module of the device using the method for de-reflection of a single image is implemented in the form of a software functional unit and sold or used as an independent product, it can be stored in a computer-readable storage medium. Based on this understanding, the present invention can implement all or part of the processes in the methods of the above embodiments, and can also be completed by instructing relevant hardware through a computer program. The above computer program can be stored in a computer-readable storage medium. When executed by the processor, the steps of the above-mentioned various method embodiments may be implemented. Wherein, the above-mentioned computer program includes computer program code, and the computer program code may be in the form of source code, object code, executable file or some intermediate form, and the like. The computer readable medium may include: any entity or device capable of carrying computer program code, recording medium, U disk, removable hard disk, magnetic disk, optical disk, computer memory, read-only memory (ROM, Read-Only Memory), random access Memory (RAM, Random Access Memory), electric carrier signal, telecommunication signal and software distribution medium, etc. It should be noted that the content contained in computer-readable media may be appropriately increased or decreased in accordance with the requirements of legislation and patent practice in the jurisdiction. For example, in some jurisdictions, according to legislation and patent practice, computer-readable media does not include Electrical carrier signals and telecommunication signals.
本发明实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质包括存储的计算机程序,其中,在所述计算机程序运行时控制所述计算机可读存储介质所在设备执行上述任一实施例所述的单图像去反光的方法。Embodiments of the present invention further provide a computer-readable storage medium, where the computer-readable storage medium includes a stored computer program, wherein, when the computer program runs, a device on which the computer-readable storage medium is located is controlled to perform any of the above-mentioned tasks. The method for de-reflection of a single image according to an embodiment.
综上,本发明实施例所提供的一种单图像去反光的方法、装置及存储介质,将反光分离任务看作是图层的分离与评价任务,生成网络的卷积层使用空洞卷积在增大视野的同时不损失细节特征,同时其损失函数充分考虑了图像的高层次特征、图像梯度特征以及预测背景图像与反光图像的差异性;其中,高层次特征是通过VGG-19网络获取得到的,能抽象数据集的视觉感知;鉴别网络则从预测出的背景图像与输入反光图像的差异出发设计损失函数,使预测背景图像与背景图像更像;最后经过验证,本发明对于图像去反光的效果良好,特别是对于高对比度的反射图像仍有较满意的去反光效果。To sum up, in the method, device and storage medium for single image de-reflection provided by the embodiments of the present invention, the reflection separation task is regarded as the separation and evaluation task of layers, and the convolution layer of the generation network uses hole convolution in the It increases the field of view without losing detailed features, and its loss function fully considers the high-level features of the image, the image gradient features, and the difference between the predicted background image and the reflective image; the high-level features are obtained through the VGG-19 network. It can abstract the visual perception of the data set; the discriminant network designs the loss function based on the difference between the predicted background image and the input reflective image, so that the predicted background image is more like the background image; finally, after verification, the present invention can de-reflect the image. The effect is good, especially for high-contrast reflective images, there is still a satisfactory de-reflection effect.
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。The above are the preferred embodiments of the present invention. It should be pointed out that for those skilled in the art, without departing from the principles of the present invention, several improvements and modifications can be made, and these improvements and modifications may also be regarded as It is the protection scope of the present invention.
Claims (10)
Translated fromChinese





Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010193974.1ACN111507910B (en) | 2020-03-18 | 2020-03-18 | A method, device and storage medium for dereflecting a single image |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010193974.1ACN111507910B (en) | 2020-03-18 | 2020-03-18 | A method, device and storage medium for dereflecting a single image |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN111507910Atrue CN111507910A (en) | 2020-08-07 |
| CN111507910B CN111507910B (en) | 2023-06-06 |
Family
ID=71864034
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010193974.1AActiveCN111507910B (en) | 2020-03-18 | 2020-03-18 | A method, device and storage medium for dereflecting a single image |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN111507910B (en) |
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112085671A (en)* | 2020-08-19 | 2020-12-15 | 北京影谱科技股份有限公司 | Background reconstruction method and device, computing equipment and storage medium |
| CN112198483A (en)* | 2020-09-28 | 2021-01-08 | 上海眼控科技股份有限公司 | Data processing method, device and equipment for satellite inversion radar and storage medium |
| CN112634161A (en)* | 2020-12-25 | 2021-04-09 | 南京信息工程大学滨江学院 | Reflected light removing method based on two-stage reflected light eliminating network and pixel loss |
| CN112802076A (en)* | 2021-03-23 | 2021-05-14 | 苏州科达科技股份有限公司 | Reflection image generation model and training method of reflection removal model |
| CN112907466A (en)* | 2021-02-01 | 2021-06-04 | 南京航空航天大学 | Nondestructive testing reflection interference removing method and device and computer readable storage medium |
| CN114926705A (en)* | 2022-05-12 | 2022-08-19 | 网易(杭州)网络有限公司 | Cover design model training method, medium, device and computing equipment |
| WO2022222080A1 (en)* | 2021-04-21 | 2022-10-27 | 浙江大学 | Single-image reflecting layer removing method based on position perception |
| CN117315598A (en)* | 2023-09-27 | 2023-12-29 | 天津大学 | A system and method for eliminating reflection images on automobile glass |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US12299847B2 (en)* | 2022-04-12 | 2025-05-13 | Adobe Inc. | Systems for single image reflection removal |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109993124A (en)* | 2019-04-03 | 2019-07-09 | 深圳市华付信息技术有限公司 | Based on the reflective biopsy method of video, device and computer equipment |
| CN110188776A (en)* | 2019-05-30 | 2019-08-30 | 京东方科技集团股份有限公司 | Image processing method and device, neural network training method, storage medium |
| CN110473154A (en)* | 2019-07-31 | 2019-11-19 | 西安理工大学 | A kind of image de-noising method based on generation confrontation network |
| CN110675336A (en)* | 2019-08-29 | 2020-01-10 | 苏州千视通视觉科技股份有限公司 | Low-illumination image enhancement method and device |
| CN110827217A (en)* | 2019-10-30 | 2020-02-21 | 维沃移动通信有限公司 | Image processing method, electronic device, and computer-readable storage medium |
- 2020
- 2020-03-18CNCN202010193974.1Apatent/CN111507910B/enactiveActive
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109993124A (en)* | 2019-04-03 | 2019-07-09 | 深圳市华付信息技术有限公司 | Based on the reflective biopsy method of video, device and computer equipment |
| CN110188776A (en)* | 2019-05-30 | 2019-08-30 | 京东方科技集团股份有限公司 | Image processing method and device, neural network training method, storage medium |
| CN110473154A (en)* | 2019-07-31 | 2019-11-19 | 西安理工大学 | A kind of image de-noising method based on generation confrontation network |
| CN110675336A (en)* | 2019-08-29 | 2020-01-10 | 苏州千视通视觉科技股份有限公司 | Low-illumination image enhancement method and device |
| CN110827217A (en)* | 2019-10-30 | 2020-02-21 | 维沃移动通信有限公司 | Image processing method, electronic device, and computer-readable storage medium |
Cited By (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112085671A (en)* | 2020-08-19 | 2020-12-15 | 北京影谱科技股份有限公司 | Background reconstruction method and device, computing equipment and storage medium |
| CN112198483A (en)* | 2020-09-28 | 2021-01-08 | 上海眼控科技股份有限公司 | Data processing method, device and equipment for satellite inversion radar and storage medium |
| CN112634161A (en)* | 2020-12-25 | 2021-04-09 | 南京信息工程大学滨江学院 | Reflected light removing method based on two-stage reflected light eliminating network and pixel loss |
| CN112907466A (en)* | 2021-02-01 | 2021-06-04 | 南京航空航天大学 | Nondestructive testing reflection interference removing method and device and computer readable storage medium |
| CN112802076A (en)* | 2021-03-23 | 2021-05-14 | 苏州科达科技股份有限公司 | Reflection image generation model and training method of reflection removal model |
| WO2022222080A1 (en)* | 2021-04-21 | 2022-10-27 | 浙江大学 | Single-image reflecting layer removing method based on position perception |
| CN114926705A (en)* | 2022-05-12 | 2022-08-19 | 网易(杭州)网络有限公司 | Cover design model training method, medium, device and computing equipment |
| CN114926705B (en)* | 2022-05-12 | 2024-05-28 | 网易(杭州)网络有限公司 | Cover design model training method, medium, device and computing equipment |
| CN117315598A (en)* | 2023-09-27 | 2023-12-29 | 天津大学 | A system and method for eliminating reflection images on automobile glass |
| CN117315598B (en)* | 2023-09-27 | 2025-09-02 | 天津大学 | System and method for eliminating reflected images from automobile glass |
Also Published As
| Publication number | Publication date |
|---|---|
| CN111507910B (en) | 2023-06-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111507910A (en) | Single image reflection removing method and device and storage medium | |
| CN109753978B (en) | Image classification method, device and computer-readable storage medium | |
| US20230177641A1 (en) | Neural network training method, image processing method, and apparatus | |
| US20210150678A1 (en) | Very high-resolution image in-painting with neural networks | |
| EP4163831A1 (en) | Neural network distillation method and device | |
| US11887270B2 (en) | Multi-scale transformer for image analysis | |
| US20190087726A1 (en) | Hypercomplex deep learning methods, architectures, and apparatus for multimodal small, medium, and large-scale data representation, analysis, and applications | |
| US20250265808A1 (en) | Image classification method and apparatus | |
| CN112287954B (en) | Image classification method, image classification model training method and device | |
| CN111340077B (en) | Attention mechanism-based disparity map acquisition method and device | |
| Vishwakarma et al. | A novel non-linear modifier for adaptive illumination normalization for robust face recognition | |
| CN113744136B (en) | Image super-resolution reconstruction method and system based on channel-constrained multi-feature fusion | |
| CN112308200A (en) | Neural network searching method and device | |
| CN107679525A (en) | Image classification method, device and computer-readable storage medium | |
| US11967043B2 (en) | Gaming super resolution | |
| CN119130863B (en) | Image recovery method and system based on multiple attention mechanisms | |
| US20230214971A1 (en) | Image processing device and operating method therefor | |
| CN115601820A (en) | Face fake image detection method, device, terminal and storage medium | |
| CN114255190A (en) | Hyperspectral image deblurring method, system and storage medium | |
| US20200184190A1 (en) | Biometric feature reconstruction method, storage medium and neural network | |
| Sun et al. | Randomized nonlinear two-dimensional principal component analysis network for object recognition | |
| US20180114109A1 (en) | Deep convolutional neural networks with squashed filters | |
| CN112749576B (en) | Image recognition method and device, computing equipment and computer storage medium | |
| Bricman et al. | CocoNet: A deep neural network for mapping pixel coordinates to color values | |
| Dai et al. | Adjustable enhancer for low-light image enhancement using multi-expressions fusion and convolutional kernel calibration |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |