CN111461151A - Multi-group sample construction method and device - Google Patents
Multi-group sample construction method and deviceDownload PDFInfo
- Publication number
- CN111461151A CN111461151ACN201910049706.XACN201910049706ACN111461151ACN 111461151 ACN111461151 ACN 111461151ACN 201910049706 ACN201910049706 ACN 201910049706ACN 111461151 ACN111461151 ACN 111461151A
- Authority
- CN
- China
- Prior art keywords
- sample
- feature
- tuple
- feature set
- features
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images




Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
Landscapes
- Engineering & Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Theoretical Computer Science (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Biology (AREA)
- Evolutionary Computation (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Image Analysis (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明涉及机器学习与图像识别技术领域,具体而言,涉及一种样本获取方法及装置。The present invention relates to the technical field of machine learning and image recognition, and in particular, to a sample acquisition method and device.
背景技术Background technique
在度量学习任务中,通常通过构造由相似图和不相似图组成的多元组来监督网络学习到图片之间的相似性。在多元组样本中分别包括了参考样本(anchor)、正样本(positive)和负样本(negative)。其中参考样本与正样本相似,而与负样本不像似。In metric learning tasks, the supervised network learns the similarity between pictures by constructing a tuple consisting of similar and dissimilar graphs. Reference samples (anchor), positive samples (positive) and negative samples (negative) are included in the tuple samples, respectively. The reference sample is similar to the positive sample, but not similar to the negative sample.
目前的多元组样本构建策略中,通常在一固定的样本训练集中对样本进行遍历计算完成,由于计算效率低,仅能在样本训练集的一小范围中构建多元组样本,这样构建的样本质量较低,无法有效的引导待训练模型不同阶段的学习。In the current tuple sample construction strategy, the samples are usually traversed and calculated in a fixed sample training set. Due to the low computational efficiency, tuple samples can only be constructed in a small range of the sample training set. The quality of the samples constructed in this way is low, it cannot effectively guide the learning of the different stages of the model to be trained.
发明内容SUMMARY OF THE INVENTION
有鉴于此,本发明实施例的目的在于提供一种多元组样本构建方法及装置,本发明提高了多元组样本构建的质量;使用该方法构建的多元组样本可适应待训练模型不同阶段的学习,提高了待训练模型的收敛速度和效果。In view of this, the purpose of the embodiments of the present invention is to provide a method and device for constructing a tuple sample. The present invention improves the quality of constructing a tuple sample; the tuple sample constructed by using the method can adapt to different stages of learning of the model to be trained. , which improves the convergence speed and effect of the model to be trained.
第一方面,本申请通过本申请的一实施例提供如下技术方案:In the first aspect, the present application provides the following technical solutions through an embodiment of the present application:
一种多元组样本构建方法,包括:A tuple sample construction method, comprising:
获取由第一样本特征组成的第一特征集合;根据所述第一特征集合,获得预设的待训练模型当前次训练所需的第一多元组样本;通过所述待训练模型,根据所述第一多元组样本进行前向计算,获得第二样本特征;在所述第一特征集合中,将所述第一多元组样本所对应的第一样本特征更新为所述第二样本特征,获得第二特征集合;根据所述第二特征集合,获得所述待训练模型下一次训练时所需的第二多元组样本。Obtain a first feature set consisting of first sample features; according to the first feature set, obtain a preset first tuple sample required for the current training of the to-be-trained model; through the to-be-trained model, according to Perform forward calculation on the first tuple sample to obtain the second sample feature; in the first feature set, update the first sample feature corresponding to the first tuple sample to the first tuple sample Two-sample features, obtain a second feature set; according to the second feature set, obtain the second tuple samples required for the next training of the to-be-trained model.
优选地,所述根据所述第一特征集合,获得预设的待训练模型当前次训练所需的第一多元组样本的步骤,包括:Preferably, the step of obtaining the preset first tuple samples required for the current training of the model to be trained according to the first feature set includes:
根据随机特征,从所述第一特征集合中抽取参考特征,并基于所述参考特征获得参考样本,其中,所述随机特征为从所述第一特征集合中随机选取获得,在所述第一特征集合中与所述参考特征相似的第一样本特征均被标记有识别标识;根据所述参考样本和标记有所述识别标识的第一样本特征,获得与所述参考样本对应的正样本;根据所述参考样本和未标记所述识别标识的第一样本特征,获得与所述参考样本对应的负样本;根据所述参考样本,与所述参考样本对应的正样本,以及与所述参考样本对应的负样本获得第一多元组样本,每个所述参考样本对应一个多元组样本。According to random features, a reference feature is extracted from the first feature set, and a reference sample is obtained based on the reference feature, wherein the random feature is randomly selected from the first feature set, and in the first feature set The first sample features in the feature set that are similar to the reference features are marked with identification marks; according to the reference samples and the first sample features marked with the identification marks, a positive sample corresponding to the reference sample is obtained. sample; obtain a negative sample corresponding to the reference sample according to the reference sample and the first sample feature not marked with the identification mark; according to the reference sample, a positive sample corresponding to the reference sample, and The negative samples corresponding to the reference samples obtain the first tuple samples, and each of the reference samples corresponds to a tuple sample.
优选地,所述根据随机特征,从所述第一特征集合中抽取参考特征,并基于所述参考特征获得参考样本的步骤,包括:Preferably, the step of extracting reference features from the first feature set according to random features, and obtaining reference samples based on the reference features, includes:
获取所述随机特征与每一个第一样本特征之间的第一相似度;当所述第一相似度属于预设的第一范围时,抽取属于所述第一范围的所述第一相似度对应的第一样本特征作为参考特征;将所述参考特征所对应的样本作为所述参考样本。Obtain the first similarity between the random feature and each first sample feature; when the first similarity belongs to a preset first range, extract the first similarity belonging to the first range The first sample feature corresponding to the degree is taken as the reference feature; the sample corresponding to the reference feature is taken as the reference sample.
优选地,所述根据所述参考样本和标记有所述识别标识的第一样本特征,获得与所述参考样本对应的正样本的步骤,包括:Preferably, the step of obtaining a positive sample corresponding to the reference sample according to the reference sample and the first sample feature marked with the identification mark includes:
对同一个参考样本,获取所述参考样本对应的参考特征与标记有所述识别标识的第一样本特征之间的第二相似度;当所述第二相似度属于预设的第二范围时,抽取属于所述第二范围的所述第二相似度对应的第一样本特征,作为所述参考样本对应的正样本的特征;根据所述正样本的特征,获得该个参考样本对应的正样本。For the same reference sample, obtain the second similarity between the reference feature corresponding to the reference sample and the first sample feature marked with the identification mark; when the second similarity belongs to a preset second range , extract the first sample feature corresponding to the second similarity belonging to the second range as the feature of the positive sample corresponding to the reference sample; obtain the corresponding feature of the reference sample according to the feature of the positive sample positive sample.
优选地,所述根据所述参考样本和未标记所述识别标识的第一样本特征,获得与所述参考样本对应的负样本的步骤,包括:Preferably, the step of obtaining a negative sample corresponding to the reference sample according to the reference sample and the first sample feature not marked with the identification mark includes:
对同一个参考样本,获取所述参考样本对应的参考特征与未标记有所述识别标识的第一样本特征的第三相似度;当所述第三相似度属于预设的第三范围时,抽取属于所述第三范围的所述第三相似度对应的第一样本特征,作为所述参考样本对应的负样本的特征;根据所述负样本的特征,获得该个参考样本对应的负样本。For the same reference sample, obtain the third similarity between the reference feature corresponding to the reference sample and the first sample feature not marked with the identification mark; when the third similarity belongs to a preset third range , extract the first sample feature corresponding to the third degree of similarity belonging to the third range as the feature of the negative sample corresponding to the reference sample; obtain the feature corresponding to the reference sample according to the feature of the negative sample negative sample.
优选地,所述第一样本特征与所述第二样本特征均为图片的特征。Preferably, both the first sample feature and the second sample feature are features of a picture.
第二方面,基于同一发明构思,本申请通过本申请的一实施例提供如下技术方案:In the second aspect, based on the same inventive concept, the present application provides the following technical solutions through an embodiment of the present application:
一种多元组样本构建装置,包括:A multi-group sample construction device, comprising:
第一特征集合获取模块,用于获取由第一样本特征组成的第一特征集合;第一样本获取模块,用于根据所述第一特征集合,获得预设的待训练模型当前次训练所需的第一多元组样本;前向计算模块,用于通过所述待训练模型,根据所述第一多元组样本进行前向计算,获得第二样本特征;更新模块,用于在所述第一特征集合中,将所述第一多元组样本所对应的第一样本特征更新为所述第二样本特征,获得第二特征集合;第二样本获取模块,用于根据所述第二特征集合,获得所述待训练模型下一次训练时所需的第二多元组样本。The first feature set acquisition module is used to acquire a first feature set composed of first sample features; the first sample acquisition module is used to obtain the current training of the preset to-be-trained model according to the first feature set The required first tuple samples; the forward calculation module is used to perform forward calculation according to the first tuple samples through the to-be-trained model to obtain the second sample features; the update module is used to In the first feature set, the first sample feature corresponding to the first tuple sample is updated to the second sample feature to obtain a second feature set; the second sample acquisition module is used for The second feature set is obtained, and the second tuple samples required for the next training of the to-be-trained model are obtained.
优选地,所述第一样本获取模块,还用于:Preferably, the first sample acquisition module is further used for:
根据随机特征,从所述第一特征集合中抽取参考特征,并基于所述参考特征获得参考样本,其中,所述随机特征为从所述第一特征集合中随机选取获得,在所述第一特征集合中与所述参考特征相似的第一样本特征均被标记有识别标识;根据所述参考样本和标记有所述识别标识的第一样本特征,获得与所述参考样本对应的正样本;根据所述参考样本和未标记所述识别标识的第一样本特征,获得与所述参考样本对应的负样本;根据所述参考样本,与所述参考样本对应的正样本,以及与所述参考样本对应的负样本获得第一多元组样本,每个所述参考样本对应一个多元组样本。According to random features, a reference feature is extracted from the first feature set, and a reference sample is obtained based on the reference feature, wherein the random feature is randomly selected from the first feature set, and in the first feature set The first sample features in the feature set that are similar to the reference features are marked with identification marks; according to the reference samples and the first sample features marked with the identification marks, a positive sample corresponding to the reference sample is obtained. sample; obtain a negative sample corresponding to the reference sample according to the reference sample and the first sample feature not marked with the identification mark; according to the reference sample, a positive sample corresponding to the reference sample, and The negative samples corresponding to the reference samples obtain the first tuple samples, and each of the reference samples corresponds to a tuple sample.
优选地,所述第一样本获取模块,还用于:Preferably, the first sample acquisition module is further used for:
获取所述随机特征与每一个第一样本特征之间的第一相似度;当所述第一相似度属于预设的第一范围时,抽取属于所述第一范围的所述第一相似度对应的第一样本特征作为参考特征;将所述参考特征所对应的样本作为所述参考样本。Obtain the first similarity between the random feature and each first sample feature; when the first similarity belongs to a preset first range, extract the first similarity belonging to the first range The first sample feature corresponding to the degree is taken as the reference feature; the sample corresponding to the reference feature is taken as the reference sample.
优选地,所述第一样本获取模块,还用于:Preferably, the first sample acquisition module is further used for:
对同一个参考样本,获取所述参考样本对应的参考特征与标记有所述识别标识的第一样本特征之间的第二相似度;当所述第二相似度属于预设的第二范围时,抽取属于所述第二范围的所述第二相似度对应的第一样本特征,作为所述参考样本对应的正样本的特征;根据所述正样本的特征,获得该个参考样本对应的正样本。For the same reference sample, obtain the second similarity between the reference feature corresponding to the reference sample and the first sample feature marked with the identification mark; when the second similarity belongs to a preset second range , extract the first sample feature corresponding to the second similarity belonging to the second range as the feature of the positive sample corresponding to the reference sample; obtain the corresponding feature of the reference sample according to the feature of the positive sample positive sample.
优选地,所述第一样本获取模块,还用于:Preferably, the first sample acquisition module is further used for:
对同一个参考样本,获取所述参考样本对应的参考特征与未标记有所述识别标识的第一样本特征的第三相似度;当所述第三相似度属于预设的第三范围时,抽取属于所述第三范围的所述第三相似度对应的第一样本特征,作为所述参考样本对应的负样本的特征;根据所述负样本的特征,获得该个参考样本对应的负样本。For the same reference sample, obtain the third similarity between the reference feature corresponding to the reference sample and the first sample feature not marked with the identification mark; when the third similarity belongs to a preset third range , extract the first sample feature corresponding to the third degree of similarity belonging to the third range as the feature of the negative sample corresponding to the reference sample; obtain the feature corresponding to the reference sample according to the feature of the negative sample negative sample.
优选地,所述第一样本特征与所述第二样本特征均为图片的特征。Preferably, both the first sample feature and the second sample feature are features of a picture.
第三方面,基于同一发明构思,本申请通过本申请的一实施例提供如下技术方案:In the third aspect, based on the same inventive concept, the present application provides the following technical solutions through an embodiment of the present application:
一种多元组样本构建装置,包括有存储器,以及一个或者一个以上的程序,其中一个或者一个以上程序存储于存储器中,且经配置以由一个或者一个以上处理器执行所述一个或者一个以上程序包含用于进行以下操作的指令:A tuple sample construction device comprising a memory, and one or more programs, wherein the one or more programs are stored in the memory and configured to be executed by one or more processors to execute the one or more programs Contains instructions for doing the following:
获取由第一样本特征组成的第一特征集合;根据所述第一特征集合,获得预设的待训练模型当前次训练所需的第一多元组样本;通过所述待训练模型,根据所述第一多元组样本进行前向计算,获得第二样本特征;在所述第一特征集合中,将所述第一多元组样本所对应的第一样本特征更新为所述第二样本特征,获得第二特征集合;根据所述第二特征集合,获得所述待训练模型下一次训练时所需的第二多元组样本。Obtain a first feature set consisting of first sample features; according to the first feature set, obtain a preset first tuple sample required for the current training of the to-be-trained model; through the to-be-trained model, according to Perform forward calculation on the first tuple sample to obtain the second sample feature; in the first feature set, update the first sample feature corresponding to the first tuple sample to the first tuple sample Two-sample features, obtain a second feature set; according to the second feature set, obtain the second tuple samples required for the next training of the to-be-trained model.
第四方面,基于同一发明构思,本申请通过本申请的一实施例提供如下技术方案:In the fourth aspect, based on the same inventive concept, the present application provides the following technical solutions through an embodiment of the present application:
一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现以下步骤:A computer-readable storage medium on which a computer program is stored, and when the program is executed by a processor, the following steps are implemented:
获取由第一样本特征组成的第一特征集合;根据所述第一特征集合,获得预设的待训练模型当前次训练所需的第一多元组样本;通过所述待训练模型,根据所述第一多元组样本进行前向计算,获得第二样本特征;在所述第一特征集合中,将所述第一多元组样本所对应的第一样本特征更新为所述第二样本特征,获得第二特征集合;根据所述第二特征集合,获得所述待训练模型下一次训练时所需的第二多元组样本。Obtain a first feature set consisting of first sample features; according to the first feature set, obtain a preset first tuple sample required for the current training of the to-be-trained model; through the to-be-trained model, according to Perform forward calculation on the first tuple sample to obtain the second sample feature; in the first feature set, update the first sample feature corresponding to the first tuple sample to the first tuple sample Two-sample features, obtain a second feature set; according to the second feature set, obtain the second tuple samples required for the next training of the to-be-trained model.
本申请实施例中提供的一个或多个技术方案,至少具有如下技术效果或优点:One or more technical solutions provided in the embodiments of this application have at least the following technical effects or advantages:
本发明通过在待训练模型的训练过程中,使用的第一多元组样本训练时获得的第二样本特征,对第一特征集合中的第一样本特征进行更新获得第二特征集合。保证了待训练模型在不同的训练阶段挖掘学习样本时,样本特征的距离分布在不断更新变化。当在第二多元组样本挖掘时将更加有针对性,可挖掘到质量更高、更加适合当前训练阶段的多元组样本。使用本发明中的方法获得的多元组样本可适应待训练模型不同阶段的学习,更快的引导待训练模型达到较优解,提高了待训练模型的收敛速度和效果。The present invention obtains the second feature set by updating the first sample feature in the first feature set by using the second sample feature obtained during the training of the first tuple samples used in the training process of the model to be trained. It is ensured that when the model to be trained mines learning samples in different training stages, the distance distribution of sample features is constantly updated and changed. When mining the second tuple samples, it will be more targeted, and the tuple samples of higher quality and more suitable for the current training stage can be mined. The tuple samples obtained by the method of the present invention can adapt to the learning of the model to be trained in different stages, guide the model to be trained to achieve a better solution faster, and improve the convergence speed and effect of the model to be trained.
为使本发明的上述目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合所附附图,作详细说明如下。In order to make the above-mentioned objects, features and advantages of the present invention more obvious and easy to understand, preferred embodiments are given below, and are described in detail as follows in conjunction with the accompanying drawings.
附图说明Description of drawings
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。In order to illustrate the technical solutions of the embodiments of the present invention more clearly, the following briefly introduces the accompanying drawings used in the embodiments. It should be understood that the following drawings only show some embodiments of the present invention, and therefore do not It should be regarded as a limitation of the scope, and for those of ordinary skill in the art, other related drawings can also be obtained according to these drawings without any creative effort.
图1为本发明第一实施例提供的一种多元组样本构建方法的流程图;1 is a flowchart of a method for constructing a tuple sample according to a first embodiment of the present invention;
图2为本图1中步骤S20的具体流程图;Fig. 2 is the concrete flow chart of step S20 in Fig. 1;
图3为本发明第二实施例提供的一种多元组样本构建装置的功能模块框图;FIG. 3 is a functional block diagram of a tuple sample construction device according to a second embodiment of the present invention;
图4为本发明第三实施例提供的一种多元组样本构建装置的结构框图;4 is a structural block diagram of an apparatus for constructing a tuple sample provided by a third embodiment of the present invention;
图5为本发明第四实施例提供的示例性的服务器的结构框图。FIG. 5 is a structural block diagram of an exemplary server provided by a fourth embodiment of the present invention.
具体实施方式Detailed ways
下面将结合本发明实施例中附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。The technical solutions in the embodiments of the present invention will be clearly and completely described below with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only a part of the embodiments of the present invention, but not all of the embodiments.
为了便于说明和理解,下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能解释为对本发明的限制。For ease of illustration and understanding, embodiments of the present invention are described in detail below, examples of which are illustrated in the accompanying drawings, wherein the same or similar reference numerals refer to the same or similar elements or elements having the same or similar functions throughout. The embodiments described below with reference to the accompanying drawings are exemplary and are only used to explain the present invention, but not to be construed as a limitation of the present invention.
本技术领域技术人员可以理解,除非特意声明,这里使用的单数形式“一”、“一个”、“所述”和“该”也可包括复数形式。应该进一步理解的是,本发明的说明书中使用的措辞“包括”是指存在所述特征、整数、步骤、操作、元件和/或组件,但是并不排除存在或添加一个或多个其他特征、整数、步骤、操作、元件、组件和/或它们的组。应该理解,当我们称元件被“连接”或“耦接”到另一元件时,它可以直接连接或耦接到其他元件,或者也可以存在中间元件。此外,这里使用的“连接”或“耦接”可以包括无线连接或无线耦接。这里使用的措辞“和/或”包括一个或更多个相关联的列出项的全部或任一单元和全部组合。It will be understood by those skilled in the art that the singular forms "a", "an", "the" and "the" as used herein can include the plural forms as well, unless expressly stated otherwise. It should be further understood that the word "comprising" used in the description of the present invention refers to the presence of stated features, integers, steps, operations, elements and/or components, but does not exclude the presence or addition of one or more other features, Integers, steps, operations, elements, components and/or groups thereof. It will be understood that when we refer to an element as being "connected" or "coupled" to another element, it can be directly connected or coupled to the other element or intervening elements may also be present. Furthermore, "connected" or "coupled" as used herein may include wirelessly connected or wirelessly coupled. As used herein, the term "and/or" includes all or any element and all combination of one or more of the associated listed items.
本技术领域技术人员可以理解,除非另外定义,这里使用的所有术语(包括技术术语和科学术语),具有与本发明所属领域中的普通技术人员的一般理解相同的意义。还应该理解的是,诸如通用字典中定义的那些术语,应该被理解为具有与现有技术的上下文中的意义一致的意义,并且除非像这里一样被特定定义,否则不会用理想化或过于正式的含义来解释。It will be understood by those skilled in the art that, unless otherwise defined, all terms (including technical and scientific terms) used herein have the same meaning as commonly understood by one of ordinary skill in the art to which this invention belongs. It should also be understood that terms, such as those defined in a general dictionary, should be understood to have meanings consistent with their meanings in the context of the prior art and, unless specifically defined as herein, should not be interpreted in idealistic or overly formal meaning to explain.
第一实施例first embodiment
请参照图1,在本实施例中提供一种多元组样本构建方法。图1示出了本实施例中方法的具体流程,在本实施例中将结合附图对所述方法的各步骤进行详细阐述。所述多元组样本构建方法具体包括:Referring to FIG. 1 , a method for constructing a tuple sample is provided in this embodiment. FIG. 1 shows a specific flow of the method in this embodiment. In this embodiment, each step of the method will be described in detail with reference to the accompanying drawings. The tuple sample construction method specifically includes:
步骤S10:获取由第一样本特征组成的第一特征集合。Step S10: Obtain a first feature set consisting of first sample features.
步骤S20:根据所述第一特征集合,获得预设的待训练模型当前次训练所需的第一多元组样本。Step S20: According to the first feature set, obtain a preset first tuple sample required for the current training of the model to be trained.
步骤S30:通过所述待训练模型根据所述第一多元组样本进行前向计算获得第二样本特征。Step S30 : obtaining second sample features by performing forward calculation on the model to be trained according to the first tuple samples.
步骤S40:在所述第一特征集合中,将所述第一多元组样本所对应的第一样本特征更新为所述第二样本特征,获得第二特征集合。Step S40: In the first feature set, update the first sample feature corresponding to the first tuple sample to the second sample feature to obtain a second feature set.
步骤S50:根据所述第二特征集合,获得所述待训练模型下一次训练时所需的第二多元组样本。Step S50: According to the second feature set, obtain a second tuple sample required for the next training of the to-be-trained model.
在步骤S10中,获取由第一样本特征组成的第一特征集合。In step S10, a first feature set consisting of first sample features is acquired.
每个第一样本特征均对应一个样本。第一样本特征可在网络模型前向计算时获得,也可将样本进行向量化学习获得,第一样本特征的表现形式可以为特征向量。第一特征集合对应一样本集合。Each first sample feature corresponds to a sample. The first sample feature may be obtained during forward calculation of the network model, or may be obtained by performing vectorized learning on the sample, and the expression form of the first sample feature may be a feature vector. The first feature set corresponds to a sample set.
在本实施例中,所述的网络模型包括但不限于,各种架构的卷积神经网络模型,如:VGG16,VGG19(Visual Geometry Group,VGG),ResNet50模型,Inception V3模型,Xception模型等,上述各模型的训练和使用为所属技术领域内的普通技术人员可直接实施的,不再赘述。In this embodiment, the network models include, but are not limited to, convolutional neural network models of various architectures, such as: VGG16, VGG19 (Visual Geometry Group, VGG), ResNet50 model, Inception V3 model, Xception model, etc., The training and use of the above models can be directly implemented by those of ordinary skill in the technical field, and will not be repeated here.
在步骤S20中,根据所述第一特征集合,获得预设的待训练模型当前次训练所需的第一多元组样本。In step S20, according to the first feature set, the preset first tuple samples required for the current training of the model to be trained are obtained.
在步骤S20中,待训练模型可为上述的任一网络模型。在待训练模型的训练过程中,可针对该待训练模型不同的训练阶段分批次进行训练样本的构建,以使待训练模型快速收敛到较优值。因此,待训练模型的训练过程可分解为多次,每次训练时使用一批多元组样本。In step S20, the model to be trained may be any of the above-mentioned network models. During the training process of the to-be-trained model, training samples may be constructed in batches for different training stages of the to-be-trained model, so that the to-be-trained model quickly converges to a better value. Therefore, the training process of the model to be trained can be decomposed into multiple times, using a batch of tuple samples for each training.
步骤S20中所述的当前次可为多次训练中的任意不为末次的训练次。The current time described in step S20 may be any training time that is not the last time among the multiple training times.
具体的,本实施例提供一种具体实施方式,用于获取当前次的第一多元组样本。请参阅图2,该方式包括:Specifically, this embodiment provides a specific implementation manner for acquiring the current first tuple sample. Referring to Figure 2, this approach includes:
步骤S21:根据随机特征,从所述第一特征集合中抽取参考特征,并基于所述参考特征获得参考样本。其中,所述随机特征为从所述第一特征集合中随机选取获得,在所述第一特征集合中与所述参考特征相似的第一样本特征均被标记有识别标识。Step S21: Extract reference features from the first feature set according to random features, and obtain reference samples based on the reference features. The random feature is obtained by randomly selecting from the first feature set, and the first sample features in the first feature set that are similar to the reference feature are marked with identification marks.
步骤S22:根据所述参考样本和标记有所述识别标识的第一样本特征,获得与所述参考样本对应的正样本;Step S22: obtaining a positive sample corresponding to the reference sample according to the reference sample and the first sample feature marked with the identification mark;
步骤S23:根据所述参考样本和未标记所述识别标识的第一样本特征,获得与所述参考样本对应的负样本;Step S23: obtaining a negative sample corresponding to the reference sample according to the reference sample and the first sample feature not marked with the identification mark;
步骤S24:根据所述参考样本,与所述参考样本对应的正样本,以及与所述参考样本对应的负样本获得第一多元组样本,每个所述参考样本对应一个多元组样本。Step S24: Obtain a first tuple sample according to the reference sample, the positive sample corresponding to the reference sample, and the negative sample corresponding to the reference sample, each of the reference samples corresponding to a tuple sample.
在步骤S21中,所述随机特征为从所述第一特征集合中随机选取获得,在本实施例中第一特征集合中包含有对应的一个参考集合,随机特征可为在参考集合中随机选取的一个特征。同样的,也可在样本集合中随机的抽取一个样本,作为随机样本,然后将该随机样本对应于第一特征集合中的第一样本特征作为随机特征。此外,在某些实施方式中随机特征也可由第一特征集合之外获得。例如:随机确定一图片作为随机样本,然后将图片进行向量化学习获得该图片的特征向量,可将该特征向量用于与第一特征集合中的后续计算,即该图片的特征向量为随机特征。In step S21, the random feature is randomly selected from the first feature set. In this embodiment, the first feature set includes a corresponding reference set, and the random feature can be randomly selected from the reference set. a feature of . Similarly, a sample can also be randomly selected from the sample set as a random sample, and then the random sample corresponds to the first sample feature in the first feature set as a random feature. Furthermore, random features may also be obtained outside of the first set of features in some embodiments. For example: randomly determine a picture as a random sample, and then perform vectorized learning on the picture to obtain the feature vector of the picture, which can be used for subsequent calculations in the first feature set, that is, the feature vector of the picture is a random feature .
第一特征集合中与所述参考特征相似的第一样本特征均被标记有识别标识,以便于更准确的选取参考样本对应的正样本和负样本;在第一特征集合中,对于相似的同一系列的第一样本特征均可标记一个可与其他第一样本特征作区分的标识。The first sample features that are similar to the reference features in the first feature set are marked with identification marks, so as to more accurately select positive samples and negative samples corresponding to the reference samples; in the first feature set, for similar The first sample features of the same series can be marked with an identifier that can be distinguished from other first sample features.
参考样本获取的一种具体实施方式为:A specific implementation of reference sample acquisition is:
首先,获取所述随机特征与每一个第一样本特征之间的第一相似度。一般来说,可直接计算随机特征与参考集合中的每一个第一样本特征之间的第一相似度。若参考集合较大,可在参考集合中随机取样一子集来计算第一相似度,子集大小可为构建的一批多元组样本大小的50-100倍,或100-200倍均可。第一相似度(后文所述的第二相似度与第三相似度亦同)的具体表示方式可包括:余弦距离、欧氏距离、马氏距离等,不作限制。优选地,在本实施例中,第一样本特征的表示形式可采用特征向量,则第一相似度、第二相似度、第三相似度均可采用余弦距离进行度量和表示。First, a first similarity between the random feature and each first sample feature is obtained. In general, the first similarity between the random feature and each first sample feature in the reference set can be directly calculated. If the reference set is large, a subset may be randomly sampled in the reference set to calculate the first similarity, and the size of the subset may be 50-100 times or 100-200 times the size of the constructed batch of tuple samples. The specific representation of the first similarity (the second similarity and the third similarity described later are also the same) may include: cosine distance, Euclidean distance, Mahalanobis distance, etc., which are not limited. Preferably, in this embodiment, the representation form of the first sample feature may be a feature vector, and the first similarity, the second similarity, and the third similarity may be measured and represented by cosine distance.
然后,当所述第一相似度属于预设的第一范围时,抽取属于所述第一范围的所述第一相似度对应的第一样本特征作为参考特征。第一范围的大小区间可进行自定义。其中所述的抽取可为全部抽取,也可为部分抽取,例如在指定的第一范围内随机抽取一定数量的第一样本特征作为参考特征。在较佳的实施方式中,为保证同一批次的参考样本相似,可将所述第一范围确定在第一相似度表示较为相似或距离较近的区间。Then, when the first similarity belongs to a preset first range, a first sample feature corresponding to the first similarity belonging to the first range is extracted as a reference feature. The size range of the first range can be customized. The extraction may be full extraction or partial extraction, for example, a certain number of first sample features are randomly selected within a specified first range as reference features. In a preferred embodiment, in order to ensure that the reference samples of the same batch are similar, the first range may be determined in an interval where the first similarity indicates relatively similar or relatively close distances.
最后,将所述参考特征所对应的样本作为所述参考样本。Finally, the sample corresponding to the reference feature is used as the reference sample.
以一实例说明步骤S21:Step S21 is described with an example:
以图片样本为例,首先在样本集合中随机选取一个随机图片(对应随机特征)。对第一特征集合中的参考集合进行随机抽样构建大小为batch size(样本批次大小)50倍的第一特征集合的子集。再计算随机特征和该抽样出的子集中所有第一样本特征的距离(即随机图片与样本集合中对应样本的距离),从子集中召回距离最小的batch size大小的集合。将召回的第一样本特征对应的样本作为当前批次的所有参考样本,满足当前批次中所有参考样本是较为相似的,且实现了批量获取参考样本。Taking a picture sample as an example, first randomly select a random picture (corresponding to a random feature) in the sample set. Randomly sample the reference set in the first feature set to construct a subset of the first feature set 50 times the size of the batch size (sample batch size). Then calculate the distance between the random feature and all the first sample features in the sampled subset (that is, the distance between the random image and the corresponding sample in the sample set), and recall the set of batch size with the smallest distance from the subset. The samples corresponding to the recalled first sample feature are used as all reference samples of the current batch, which satisfies all reference samples in the current batch are relatively similar, and realizes batch acquisition of reference samples.
在获取参考样本之后,还需要获取参考样本对应的正样本和负样本才能构建为多元组样本。进一步的:After obtaining the reference samples, it is also necessary to obtain the positive samples and negative samples corresponding to the reference samples to construct a tuple sample. further:
步骤S22:根据所述参考样本和标记有所述识别标识的第一样本特征,获得与所述参考样本对应的正样本。Step S22: Obtain a positive sample corresponding to the reference sample according to the reference sample and the first sample feature marked with the identification mark.
在步骤S22中具体的实施过程中,对于每一个参考样本,都需要选择与参考样本相似的样本作为正样本,与参考样本不像似的样本作为负样本。具体的是否相似可通过第二相似度或第三相似度进行衡量。一个参考样本可对应一个正样本或负样本,也可对应多个正样本或负样本。In the specific implementation process in step S22, for each reference sample, a sample similar to the reference sample needs to be selected as a positive sample, and a sample not similar to the reference sample needs to be selected as a negative sample. Whether the specific similarity can be measured by the second similarity or the third similarity. A reference sample can correspond to one positive sample or negative sample, or can correspond to multiple positive samples or negative samples.
具体的,正样本的获取:Specifically, the acquisition of positive samples:
首先,对同一个参考样本,获取所述参考样本对应的参考特征与标记有所述识别标识的第一样本特征之间的第二相似度。其中,若一个参考样本对应的标记有识别标志的第一样本特征数量较多时,可在该参考样本对应的标记有识别标志的第一样本特征中随机抽取一子集计算第二相似度,子集大小可为构建的一批多元组样本大小的50-100倍,或100-200倍均可。First, for the same reference sample, a second degree of similarity between the reference feature corresponding to the reference sample and the first sample feature marked with the identification identifier is obtained. Wherein, if the number of first sample features marked with identification marks corresponding to a reference sample is large, a subset may be randomly selected from the first sample features marked with identification marks corresponding to the reference sample to calculate the second similarity , the subset size can be 50-100 times or 100-200 times the size of the constructed batch of tuple samples.
然后,当所述第二相似度属于预设的第二范围时,抽取属于所述第二范围的所述第二相似度对应的第一样本特征,作为所述参考样本对应的正样本的特征。Then, when the second similarity belongs to a preset second range, extract the first sample feature corresponding to the second similarity belonging to the second range as a feature of the positive sample corresponding to the reference sample feature.
最后,根据所述正样本的特征,获得该个参考样本对应的正样本。Finally, according to the feature of the positive sample, a positive sample corresponding to the reference sample is obtained.
在步骤S22中,所述的抽取可为全部抽取,也可为部分抽取,例如在指定的第二范围内随机抽取一定数量的第一样本特征作为参考样本对应的正样本。第二范围的确定不作限制,可根据应用场景的需求进行确定。In step S22, the extraction may be full extraction or partial extraction, for example, a certain number of first sample features are randomly selected within a specified second range as positive samples corresponding to the reference samples. The determination of the second range is not limited, and may be determined according to the requirements of the application scenario.
若多元组样本中相似样本和不相似样本的相似度过小,会导致构造的多元组对于网络的学习过于简单,网络学习不到具有强判别力的特征在优选的实施方式中,为了提高训练效果,就需要构建多元组样本中的难样本。难样本中,包括参考样本,与参考样本不太相似的正样本,与参考样本比较相似的负样本。此时,可将第二范围定义在第二相似度表示不相似或距离较远的区间,以获取与参考样本不太相似的正样本。总的来说,在本实施例优选的实施方式中,在与参考样本相似的样本中选取不太相似的样本作为正样本。If the similarity between similar samples and dissimilar samples in the tuple samples is too small, the constructed tuple will be too simple for the network to learn, and the network cannot learn the features with strong discriminative power. In the preferred embodiment, in order to improve the training effect, it is necessary to construct the difficult samples in the tuple samples. Difficult samples include reference samples, positive samples that are not very similar to the reference samples, and negative samples that are more similar to the reference samples. At this time, the second range may be defined in an interval where the second degree of similarity indicates dissimilarity or a relatively far distance, so as to obtain a positive sample that is not very similar to the reference sample. In general, in a preferred implementation of this embodiment, a sample that is not very similar to the reference sample is selected as a positive sample.
步骤S23:根据所述参考样本和未标记所述识别标识的第一样本特征,获得与所述参考样本对应的负样本。Step S23: Obtain a negative sample corresponding to the reference sample according to the reference sample and the first sample feature not marked with the identification mark.
在步骤S23中,具体包括以下实施步骤:In step S23, the following implementation steps are specifically included:
首先,对同一个参考样本,获取所述参考样本对应的参考特征与未标记有所述识别标识的第一样本特征的第三相似度。其中,若一个参考样本对应的未标记有识别标志的第一样本特征数量较多时,可在该参考样本对应的未标记有识别标志的第一样本特征中随机抽取一子集计算第三相似度,子集大小可为构建的一批多元组样本大小的50-100倍,或100-200倍均可。First, for the same reference sample, a third degree of similarity between the reference feature corresponding to the reference sample and the first sample feature not marked with the identification mark is obtained. Wherein, if the number of first sample features that are not marked with identification marks corresponding to a reference sample is large, a subset may be randomly selected from the first sample features that are not marked with identification marks corresponding to the reference sample to calculate the third Similarity, the subset size can be 50-100 times or 100-200 times the size of the constructed batch of tuple samples.
然后,当所述第三相似度属于预设的第三范围时,抽取属于所述第三范围的所述第三相似度对应的第一样本特征,作为所述参考样本对应的负样本的特征。Then, when the third similarity belongs to a preset third range, extract the first sample feature corresponding to the third similarity belonging to the third range as the negative sample corresponding to the reference sample. feature.
最后,根据所述负样本的特征,获得该个参考样本对应的负样本。Finally, according to the characteristics of the negative sample, a negative sample corresponding to the reference sample is obtained.
在步骤S23中,所述的抽取可为全部抽取,也可为部分抽取,例如在指定的第三范围内随机抽取一定数量的第一样本特征作为参考样本对应的负样本。第三范围的确定不作限制,可根据应用场景的需求进行确定。In step S23, the extraction may be full extraction or partial extraction, for example, a certain number of first sample features are randomly selected within a specified third range as negative samples corresponding to the reference samples. The determination of the third range is not limited, and can be determined according to the requirements of the application scenario.
在本实施例优选的实施方式中,构建难样本时,可将第三范围定义在第三相似度表示相似或距离较近的区间,以获取与参考样本比较相似的负样本。总的来说,在与参考样本不相似的样本中选取比较相似的样本作为负样本。In a preferred implementation of this embodiment, when constructing a difficult sample, the third range may be defined in an interval where the third degree of similarity indicates similarity or a short distance, so as to obtain a negative sample that is more similar to the reference sample. In general, the samples that are not similar to the reference samples are selected as negative samples.
通过步骤S22与步骤S23构建的难样本,避免了相似样本和不相似样本的相似度过高,导致多元组对于网络的学习过难,使得网络难以收敛的问题。The difficult samples constructed in step S22 and step S23 avoid the problem that the similarity between similar samples and dissimilar samples is too high, which makes it difficult for the tuple to learn the network and makes the network difficult to converge.
为了方便计算,在计算上述的第一相似度、第二相似度和第三相似度之前均可对第一样本特征、第二样本特征和/或第三样本特征(如后文所述)进行归一化处理。For the convenience of calculation, before calculating the above-mentioned first similarity, second similarity and third similarity, the first sample feature, second sample feature and/or third sample feature (as described later) Normalize.
本实施例中,所述的第一范围、第二范围及第三范围均可为一个或多个分段的范围。例如,取样的时候在多个分段的、不相邻的第一范围中取样,通过该种分段的方式,选择了不过于相邻的样本,可避免样本的局部缺陷问题。In this embodiment, the first range, the second range, and the third range can all be ranges of one or more segments. For example, when sampling, sampling is performed in a plurality of segmented, non-adjacent first ranges, and by this segmentation method, samples that are not too adjacent are selected, which can avoid the problem of local defects of the samples.
步骤S24:根据所述参考样本,与所述参考样本对应的正样本,以及与所述参考样本对应的负样本获得第一多元组样本。其中,每个所述参考样本对应一个第一多元组样本。当前次的多元组样本构建中,所有的第一多元组样本构成了待训练模型当前次训练所需的批量样本集合。Step S24: Obtain a first tuple sample according to the reference sample, the positive sample corresponding to the reference sample, and the negative sample corresponding to the reference sample. Wherein, each of the reference samples corresponds to a first tuple sample. In the current tuple sample construction, all the first tuple samples constitute the batch sample set required for the current training of the model to be trained.
在步骤S20的计算中,由于第一特征集合的存在,可以直接从第一特征集合中选出对应的特征计算相似度,而不需要重新经过网络模型的前向计算得到特征,提高了计算效率。In the calculation of step S20, due to the existence of the first feature set, the corresponding features can be directly selected from the first feature set to calculate the similarity, without the need to obtain the features through the forward calculation of the network model again, which improves the calculation efficiency .
步骤S30:通过所述待训练模型根据所述第一多元组样本进行前向计算获得第二样本特征。Step S30 : obtaining second sample features by performing forward calculation on the model to be trained according to the first tuple samples.
在步骤S30中,第一多元组样本的前向计算包括了参考样本,参考样本对应的正样本、负样本。在待训练模型的前向计算中可学习到样本新的特征,即为第二样本特征。In step S30, the forward calculation of the first tuple samples includes reference samples, positive samples and negative samples corresponding to the reference samples. In the forward calculation of the model to be trained, a new feature of the sample can be learned, that is, the second sample feature.
步骤S40:在所述第一特征集合中,将所述第一多元组样本所对应的第一样本特征更新为所述第二样本特征,获得第二特征集合。Step S40: In the first feature set, update the first sample feature corresponding to the first tuple sample to the second sample feature to obtain a second feature set.
在步骤S40中,第二特征集合用于替换第一特征集合,由于第一样本特征与第二样本特征均为同一样本在前向计算中得到,因此可在第一特征集合中寻找到与第二样本特征对应的第一样本特征。举个例子:In step S40, the second feature set is used to replace the first feature set. Since both the first sample feature and the second sample feature are obtained from the same sample in the forward calculation, the first feature set can be found in the first feature set. The first sample feature corresponding to the second sample feature. for example:
表1更新前Before Table 1 was updated
若表1中,样本2、样本5、样本6为选中的一多元组样本,在待训练模型的前向计算后分别得到特征b、特征e和特征f即第二样本特征;那么执行步骤S40将第一特征集合中,样本2、样本5、样本6对应的特征B、特征E、特征F更新为特征b、特征e、特征f,获得第二特征集合:If in Table 1, sample 2, sample 5, and sample 6 are selected one-tuple samples, after the forward calculation of the model to be trained, feature b, feature e and feature f are obtained respectively, that is, the second sample feature; then execute the steps S40, in the first feature set, the feature B, feature E, and feature F corresponding to sample 2, sample 5, and sample 6 are updated to feature b, feature e, and feature f, to obtain a second feature set:
表2更新后Table 2 after the update
由此,特征b、特征e和特征f对应的样本2、样本5、样本6相对于其他样本之间的距离或分布发生了改变。以上表1,表2仅为示例性说明,不对特征集合的存储形式、大小等构成限制。As a result, the distances or distributions between samples 2, 5, and 6 corresponding to feature b, feature e, and feature f are changed relative to other samples. The above Table 1 and Table 2 are only exemplary descriptions, and do not limit the storage form and size of the feature set.
步骤S50:根据所述第二特征集合,获得所述待训练模型下一次训练时所需的第二多元组样本。Step S50: According to the second feature set, obtain a second tuple sample required for the next training of the to-be-trained model.
在步骤S50中,所述第二多元组样本的获取方式可参考第一多元组样本的获取方式进行,确定一随机特征、根据随机特征在第二特征集合中抽取参考特征、根据参考特征获得参考样本、根据参考特征和在第二特征集合中的样本特征获取参考样本对应的正、负样本,即组成第二多元组样本。In step S50, the acquisition method of the second tuple sample can be performed with reference to the acquisition method of the first tuple sample, determining a random feature, extracting a reference feature from the second feature set according to the random feature, and selecting the reference feature according to the reference feature. Obtaining reference samples, and obtaining positive and negative samples corresponding to the reference samples according to the reference features and the sample features in the second feature set, that is, forming the second tuple samples.
同样,使用第二多元组样本训练待训练模型的时候,在前向计算中可获得对应的第三样本特征,然后替换/更新第二特征集合中对应的样本特征,获得新的集合,可作为第三特征集合。Similarly, when using the second tuple samples to train the model to be trained, the corresponding third sample features can be obtained in the forward calculation, and then the corresponding sample features in the second feature set are replaced/updated to obtain a new set, which can be as the third feature set.
以上,循环执行,在每次待训练模型的前向计算中获得新的样本特征,不断维持特征集合的更新。The above is performed in a loop, new sample features are obtained in each forward calculation of the model to be trained, and the feature set is continuously updated.
在待训练模型的整个训练过程中,包括前向计算过程,还包括反向传播过程,直至满足收敛条件后停止训练。During the entire training process of the model to be trained, including the forward calculation process and the back propagation process, the training is stopped until the convergence condition is satisfied.
由于本实施例中的方法在构建第一多元组样本的过程中均是采用第一样本特征进行计算,因此对该第一样本特征替换更新后就可改变第一样本特征/第二样本特征对应的样本与其他样本之间的计算距离/相似度,即间接的使样本分布发生了变化。从而在每次待训练模型训练的过程中均可维护特征集合的更新。获得的第二多元组样本可更快的引导待训练模型收敛。Since the method in this embodiment uses the first sample feature for calculation in the process of constructing the first tuple sample, after the first sample feature is replaced and updated, the first sample feature/first sample feature can be changed. The calculated distance/similarity between the sample corresponding to the two-sample feature and other samples, that is, indirectly changes the sample distribution. Therefore, the update of the feature set can be maintained during each training process of the to-be-trained model. The obtained second tuple samples can guide the model to be trained to converge faster.
需要说明的是,对应不用的应用场景,本实施例中提到的样本包括但不限于各种形式的图片以及文字。在待训练模型的整个训练阶段中,步骤S10-S50为循环执行,每次训练可对特征集合更新一次。It should be noted that, corresponding to different application scenarios, the samples mentioned in this embodiment include, but are not limited to, pictures and texts in various forms. In the entire training stage of the model to be trained, steps S10-S50 are performed in a loop, and the feature set can be updated once for each training.
综上,本发明通过在待训练模型的训练过程中,使用的第一多元组样本训练时获得的第二样本特征,对第一特征集合中的第一样本特征进行更新获得第二特征集合。保证了待训练模型在不同的训练阶段挖掘学习样本时,样本特征的距离分布在不断更新变化。当在第二多元组样本挖掘时将更加有针对性,可挖掘到质量更高、更加适合当前训练阶段的多元组样本。使用本发明中的方法获得的多元组样本可适应待训练模型不同阶段的学习,更快的引导待训练模型达到较优解,提高了待训练模型的收敛速度和效果。In summary, the present invention obtains the second feature by updating the first sample feature in the first feature set by using the second sample feature obtained during the training of the first tuple samples used in the training process of the model to be trained gather. It is ensured that when the model to be trained mines learning samples in different training stages, the distance distribution of sample features is constantly updated and changed. When mining the second tuple samples, it will be more targeted, and the tuple samples of higher quality and more suitable for the current training stage can be mined. The tuple samples obtained by the method of the present invention can adapt to the learning of the model to be trained in different stages, guide the model to be trained to achieve a better solution faster, and improve the convergence speed and effect of the model to be trained.
第二实施例Second Embodiment
请参阅图3,基于同一发明构思,在本实施例中提供一种多元组样本构建装置400,所述装置400包括:Referring to FIG. 3 , based on the same inventive concept, a tuple
第一特征集合获取模块401,用于获取由第一样本特征组成的第一特征集合。The first feature set obtaining
第一样本获取模块402,用于根据所述第一特征集合,获得预设的待训练模型当前次训练所需的第一多元组样本。The first
前向计算模块403,用于通过所述待训练模型,根据所述第一多元组样本进行前向计算,获得第二样本特征。The
更新模块404,用于在所述第一特征集合中,将所述第一多元组样本所对应的第一样本特征更新为所述第二样本特征,获得第二特征集合。The updating module 404 is configured to, in the first feature set, update the first sample feature corresponding to the first tuple sample to the second sample feature to obtain a second feature set.
第二样本获取模块405,用于根据所述第二特征集合,获得所述待训练模型下一次训练时所需的第二多元组样本。The second
作为一种可选的实施方式,所述第一样本获取模块402,还用于:As an optional implementation manner, the first
根据随机特征,从所述第一特征集合中抽取参考特征,并基于所述参考特征获得参考样本,其中,所述随机特征为从所述第一特征集合中随机选取获得,在所述第一特征集合中与所述参考特征相似的第一样本特征均被标记有识别标识;根据所述参考样本和标记有所述识别标识的第一样本特征,获得与所述参考样本对应的正样本;根据所述参考样本和未标记所述识别标识的第一样本特征,获得与所述参考样本对应的负样本;根据所述参考样本,与所述参考样本对应的正样本,以及与所述参考样本对应的负样本获得第一多元组样本,每个所述参考样本对应一个多元组样本。According to random features, a reference feature is extracted from the first feature set, and a reference sample is obtained based on the reference feature, wherein the random feature is randomly selected from the first feature set, and in the first feature set The first sample features in the feature set that are similar to the reference features are marked with identification marks; according to the reference samples and the first sample features marked with the identification marks, a positive sample corresponding to the reference sample is obtained. sample; obtain a negative sample corresponding to the reference sample according to the reference sample and the first sample feature not marked with the identification mark; according to the reference sample, a positive sample corresponding to the reference sample, and The negative samples corresponding to the reference samples obtain the first tuple samples, and each of the reference samples corresponds to a tuple sample.
作为一种可选的实施方式,所述第一样本获取模块402,还用于:As an optional implementation manner, the first
获取所述随机特征与每一个第一样本特征之间的第一相似度;当所述第一相似度属于预设的第一范围时,抽取属于所述第一范围的所述第一相似度对应的第一样本特征作为参考特征;将所述参考特征所对应的样本作为所述参考样本。Obtain the first similarity between the random feature and each first sample feature; when the first similarity belongs to a preset first range, extract the first similarity belonging to the first range The first sample feature corresponding to the degree is taken as the reference feature; the sample corresponding to the reference feature is taken as the reference sample.
作为一种可选的实施方式,所述第一样本获取模块402,还用于:As an optional implementation manner, the first
对同一个参考样本,获取所述参考样本对应的参考特征与标记有所述识别标识的第一样本特征之间的第二相似度;当所述第二相似度属于预设的第二范围时,抽取属于所述第二范围的所述第二相似度对应的第一样本特征,作为所述参考样本对应的正样本的特征;根据所述正样本的特征,获得该个参考样本对应的正样本。For the same reference sample, obtain the second similarity between the reference feature corresponding to the reference sample and the first sample feature marked with the identification mark; when the second similarity belongs to a preset second range , extract the first sample feature corresponding to the second similarity belonging to the second range as the feature of the positive sample corresponding to the reference sample; obtain the corresponding feature of the reference sample according to the feature of the positive sample positive sample.
作为一种可选的实施方式,所述第一样本获取模块402,还用于:As an optional implementation manner, the first
对同一个参考样本,获取所述参考样本对应的参考特征与未标记有所述识别标识的第一样本特征的第三相似度;当所述第三相似度属于预设的第三范围时,抽取属于所述第三范围的所述第三相似度对应的第一样本特征,作为所述参考样本对应的负样本的特征;根据所述负样本的特征,获得该个参考样本对应的负样本。For the same reference sample, obtain the third similarity between the reference feature corresponding to the reference sample and the first sample feature not marked with the identification mark; when the third similarity belongs to a preset third range , extract the first sample feature corresponding to the third degree of similarity belonging to the third range as the feature of the negative sample corresponding to the reference sample; obtain the feature corresponding to the reference sample according to the feature of the negative sample negative sample.
作为一种可选的实施方式,所述第一样本特征与所述第二样本特征均为图片的特征。As an optional implementation manner, both the first sample feature and the second sample feature are features of a picture.
关于上述实施例中的装置,其中各个模块执行操作的具体方式已经在有关该方法的实施例中进行了详细描述,此处将不做详细阐述说明。Regarding the apparatus in the above-mentioned embodiment, the specific manner in which each module performs operations has been described in detail in the embodiment of the method, and will not be described in detail here.
第三实施例Third Embodiment
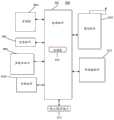
图4是根据一示例性实施例示出的一种多元组样本构建装置800的框图。例如,装置800可以是移动电话,计算机,数字广播终端,消息收发设备,游戏控制台,平板设备,医疗设备,健身设备,个人数字助理等。Fig. 4 is a block diagram of an
参照图4,装置800可以包括以下一个或多个组件:处理组件802,存储器804,电源组件806,多媒体组件808,音频组件810,输入/输出(I/O)的接口812,传感器组件814,以及通信组件816。4, the
处理组件802通常控制装置800的整体操作,诸如与显示,电话呼叫,数据通信,相机操作和记录操作相关联的操作。处理元件802可以包括一个或多个处理器820来执行指令,以完成上述的方法的全部或部分步骤。此外,处理组件802可以包括一个或多个模块,便于处理组件802和其他组件之间的交互。例如,处理部件802可以包括多媒体模块,以方便多媒体组件808和处理组件802之间的交互。The
存储器804被配置为存储各种类型的数据以支持在设备800的操作。这些数据的示例包括用于在装置800上操作的任何应用程序或方法的指令,联系人数据,电话簿数据,消息,图片,视频等。存储器804可以由任何类型的易失性或非易失性存储设备或者它们的组合实现,如静态随机存取存储器(SRAM),电可擦除可编程只读存储器(EEPROM),可擦除可编程只读存储器(EPROM),可编程只读存储器(PROM),只读存储器(ROM),磁存储器,快闪存储器,磁盘或光盘。
电力组件806为装置800的各种组件提供电力。电力组件806可以包括电源管理系统,一个或多个电源,及其他与为装置800生成、管理和分配电力相关联的组件。
多媒体组件808包括在所述装置800和用户之间的提供一个输出接口的屏幕。在一些实施例中,屏幕可以包括液晶显示器(LCD)和触摸面板(TP)。如果屏幕包括触摸面板,屏幕可以被实现为触摸屏,以接收来自用户的输入信号。
触摸面板包括一个或多个触摸传感器以感测触摸、滑动和触摸面板上的手势。所述触摸传感器可以不仅感测触摸或滑动动作的边界,而且还检测与所述触摸或滑动操作相关的持续时间和压力。在一些实施例中,多媒体组件808包括一个前置摄像头和/或后置摄像头。当设备800处于操作模式,如拍摄模式或视频模式时,前置摄像头和/或后置摄像头可以接收外部的多媒体数据。每个前置摄像头和后置摄像头可以是一个固定的光学透镜系统或具有焦距和光学变焦能力。The touch panel includes one or more touch sensors to sense touch, swipe, and gestures on the touch panel. The touch sensor may not only sense the boundaries of a touch or swipe action, but also detect the duration and pressure associated with the touch or swipe action. In some embodiments, the
音频组件810被配置为输出和/或输入音频信号。例如,音频组件810包括一个麦克风(MIC),当装置800处于操作模式,如呼叫模式、记录模式和语音识别模式时,麦克风被配置为接收外部音频信号。所接收的音频信号可以被进一步存储在存储器804或经由通信组件816发送。在一些实施例中,音频组件810还包括一个扬声器,用于输出音频信号。
I/O接口812为处理组件802和外围接口模块之间提供接口,上述外围接口模块可以是键盘,点击轮,按钮等。这些按钮可包括但不限于:主页按钮、音量按钮、启动按钮和锁定按钮。The I/
传感器组件814包括一个或多个传感器,用于为装置800提供各个方面的状态评估。例如,传感器组件814可以检测到设备800的打开/关闭状态,组件的相对定位,例如所述组件为装置800的显示器和小键盘,传感器组件814还可以检测装置800或装置800一个组件的位置改变,用户与装置800接触的存在或不存在,装置800方位或加速/减速和装置800的温度变化。传感器组件814可以包括接近传感器,被配置用来在没有任何的物理接触时检测附近物体的存在。传感器组件814还可以包括光传感器,如CMOS或CCD图像传感器,用于在成像应用中使用。在一些实施例中,该传感器组件814还可以包括加速度传感器,陀螺仪传感器,磁传感器,压力传感器或温度传感器。
通信组件816被配置为便于装置800和其他设备之间有线或无线方式的通信。装置800可以接入基于通信标准的无线网络,如WiFi,2G或3G,或它们的组合。在一个示例性实施例中,通信部件816经由广播信道接收来自外部广播管理系统的广播信号或广播相关信息。在一个示例性实施例中,所述通信部件816还包括近场通信(NFC)模块,以促进短程通信。例如,在NFC模块可基于射频识别(RFID)技术,红外数据协会(IrDA)技术,超宽带(UWB)技术,蓝牙(BT)技术和其他技术来实现。
在示例性实施例中,装置800可以被一个或多个应用专用集成电路(ASIC)、数字信号处理器(DSP)、数字信号处理设备(DSPD)、可编程逻辑器件(PLD)、现场可编程门阵列(FPGA)、控制器、微控制器、微处理器或其他电子元件实现,用于执行上述第一实施例所述的方法。In an exemplary embodiment,
第四实施例Fourth Embodiment
在示例性实施例中,还提供了一种包括指令的非临时性计算机可读存储介质,例如包括指令的存储器804,上述指令可由装置800的处理器820执行以完成上述方法。例如,所述非临时性计算机可读存储介质可以是ROM、随机存取存储器(RAM)、CD-ROM、磁带、软盘和光数据存储设备等。In an exemplary embodiment, there is also provided a non-transitory computer-readable storage medium including instructions, such as a
一种计算机可读存储介质,具体为一种非临时性计算机可读存储介质,当所述存储介质中的指令由移动终端的处理器执行时,使得移动终端能够执行一种多元组样本构建方法,所述方法包括:A computer-readable storage medium, specifically a non-transitory computer-readable storage medium, when an instruction in the storage medium is executed by a processor of a mobile terminal, the mobile terminal can execute a method for constructing a tuple sample , the method includes:
获取由第一样本特征组成的第一特征集合;根据所述第一特征集合,获得预设的待训练模型当前次训练所需的第一多元组样本;通过所述待训练模型,根据所述第一多元组样本进行前向计算,获得第二样本特征;在所述第一特征集合中,将所述第一多元组样本所对应的第一样本特征更新为所述第二样本特征,获得第二特征集合;根据所述第二特征集合,获得所述待训练模型下一次训练时所需的第二多元组样本。Obtain a first feature set consisting of first sample features; according to the first feature set, obtain a preset first tuple sample required for the current training of the to-be-trained model; through the to-be-trained model, according to Perform forward calculation on the first tuple sample to obtain the second sample feature; in the first feature set, update the first sample feature corresponding to the first tuple sample to the first tuple sample Two-sample features, obtain a second feature set; according to the second feature set, obtain the second tuple samples required for the next training of the to-be-trained model.
图5是本发明实施例中服务器的结构示意图。该服务器1900可因配置或性能不同而产生比较大的差异,可以包括一个或一个以上中央处理器(central processing units,CPU)1922(例如,一个或一个以上处理器)和存储器1932,一个或一个以上存储应用程序1942或数据1944的存储介质1930(例如一个或一个以上海量存储设备)。其中,存储器1932和存储介质1930可以是短暂存储或持久存储。存储在存储介质1930的程序可以包括一个或一个以上模块(图示没标出),每个模块可以包括对服务器中的一系列指令操作。更进一步地,中央处理器1922可以设置为与存储介质1930通信,在服务器1900上执行存储介质1930中的一系列指令操作。FIG. 5 is a schematic structural diagram of a server in an embodiment of the present invention. The
服务器1900还可以包括一个或一个以上电源1926,一个或一个以上有线或无线网络接口1950,一个或一个以上输入输出接口1958,一个或一个以上键盘1956,和/或,一个或一个以上操作系统1941,例如Windows ServerTM,Mac OS XTM,UnixTM,LinuxTM,FreeBSDTM等等。
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本发明的其它实施方案。本申请旨在涵盖本发明的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本发明的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本发明的真正范围和精神由下面的权利要求指出。Other embodiments of the invention will readily occur to those skilled in the art upon consideration of the specification and practice of the invention disclosed herein. This application is intended to cover any variations, uses, or adaptations of the invention that follow the general principles of the invention and include common knowledge or conventional techniques in the art not disclosed by this disclosure . The specification and examples are to be regarded as exemplary only, with the true scope and spirit of the invention being indicated by the following claims.
应当理解的是,本发明并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本发明的范围仅由所附的权利要求来限制。It should be understood that the present invention is not limited to the precise structures described above and illustrated in the accompanying drawings, and that various modifications and changes may be made without departing from its scope. The scope of the present invention is limited only by the appended claims.
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应所述以权利要求的保护范围为准。The above are only specific embodiments of the present invention, but the protection scope of the present invention is not limited thereto. Any person skilled in the art can easily think of changes or substitutions within the technical scope disclosed by the present invention. should be included within the protection scope of the present invention. Therefore, the protection scope of the present invention should be based on the protection scope of the claims.
Claims (10)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910049706.XACN111461151B (en) | 2019-01-18 | 2019-01-18 | A multi-group sample construction method and device |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910049706.XACN111461151B (en) | 2019-01-18 | 2019-01-18 | A multi-group sample construction method and device |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN111461151Atrue CN111461151A (en) | 2020-07-28 |
| CN111461151B CN111461151B (en) | 2025-01-03 |
Family
ID=71678201
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201910049706.XAActiveCN111461151B (en) | 2019-01-18 | 2019-01-18 | A multi-group sample construction method and device |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN111461151B (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112466334A (en)* | 2020-12-14 | 2021-03-09 | 腾讯音乐娱乐科技(深圳)有限公司 | Audio identification method, equipment and medium |
| CN113792104A (en)* | 2021-09-16 | 2021-12-14 | 平安科技(深圳)有限公司 | Medical data error detection method and device based on artificial intelligence and storage medium |
Citations (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9129216B1 (en)* | 2013-07-15 | 2015-09-08 | Xdroid Kft. | System, method and apparatus for computer aided association of relevant images with text |
| CN105608450A (en)* | 2016-03-01 | 2016-05-25 | 天津中科智能识别产业技术研究院有限公司 | Heterogeneous face identification method based on deep convolutional neural network |
| CN106845330A (en)* | 2016-11-17 | 2017-06-13 | 北京品恩科技股份有限公司 | A kind of training method of the two-dimension human face identification model based on depth convolutional neural networks |
| CN107679078A (en)* | 2017-08-29 | 2018-02-09 | 银江股份有限公司 | A kind of bayonet socket image vehicle method for quickly retrieving and system based on deep learning |
| CN108229532A (en)* | 2017-10-30 | 2018-06-29 | 北京市商汤科技开发有限公司 | Image-recognizing method, device and electronic equipment |
| CN108319686A (en)* | 2018-02-01 | 2018-07-24 | 北京大学深圳研究生院 | Antagonism cross-media retrieval method based on limited text space |
| WO2018137357A1 (en)* | 2017-01-24 | 2018-08-02 | 北京大学 | Target detection performance optimization method |
| CN108537181A (en)* | 2018-04-13 | 2018-09-14 | 盐城师范学院 | A kind of gait recognition method based on the study of big spacing depth measure |
| CN108596010A (en)* | 2017-12-31 | 2018-09-28 | 厦门大学 | The implementation method of pedestrian's weight identifying system |
| CN108805185A (en)* | 2018-05-29 | 2018-11-13 | 腾讯科技(深圳)有限公司 | Training method, device, storage medium and the computer equipment of model |
| CN108830385A (en)* | 2018-07-10 | 2018-11-16 | 北京京东金融科技控股有限公司 | deep learning model training method and device and computer readable storage medium |
- 2019
- 2019-01-18CNCN201910049706.XApatent/CN111461151B/enactiveActive
Patent Citations (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9129216B1 (en)* | 2013-07-15 | 2015-09-08 | Xdroid Kft. | System, method and apparatus for computer aided association of relevant images with text |
| CN105608450A (en)* | 2016-03-01 | 2016-05-25 | 天津中科智能识别产业技术研究院有限公司 | Heterogeneous face identification method based on deep convolutional neural network |
| CN106845330A (en)* | 2016-11-17 | 2017-06-13 | 北京品恩科技股份有限公司 | A kind of training method of the two-dimension human face identification model based on depth convolutional neural networks |
| WO2018137357A1 (en)* | 2017-01-24 | 2018-08-02 | 北京大学 | Target detection performance optimization method |
| CN107679078A (en)* | 2017-08-29 | 2018-02-09 | 银江股份有限公司 | A kind of bayonet socket image vehicle method for quickly retrieving and system based on deep learning |
| CN108229532A (en)* | 2017-10-30 | 2018-06-29 | 北京市商汤科技开发有限公司 | Image-recognizing method, device and electronic equipment |
| CN108596010A (en)* | 2017-12-31 | 2018-09-28 | 厦门大学 | The implementation method of pedestrian's weight identifying system |
| CN108319686A (en)* | 2018-02-01 | 2018-07-24 | 北京大学深圳研究生院 | Antagonism cross-media retrieval method based on limited text space |
| CN108537181A (en)* | 2018-04-13 | 2018-09-14 | 盐城师范学院 | A kind of gait recognition method based on the study of big spacing depth measure |
| CN108805185A (en)* | 2018-05-29 | 2018-11-13 | 腾讯科技(深圳)有限公司 | Training method, device, storage medium and the computer equipment of model |
| CN108830385A (en)* | 2018-07-10 | 2018-11-16 | 北京京东金融科技控股有限公司 | deep learning model training method and device and computer readable storage medium |
Non-Patent Citations (2)
| Title |
|---|
| CARMEN LAI 等: "Random subspace method for multivariate feature selection", PATTERN RECOGNITION LETTERS, vol. 27, no. 10, 15 July 2006 (2006-07-15)* |
| 李振东;钟勇;曹冬平;: "深度卷积特征向量用于快速人脸图像检索", 计算机辅助设计与图形学学报, no. 12, 15 December 2018 (2018-12-15)* |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112466334A (en)* | 2020-12-14 | 2021-03-09 | 腾讯音乐娱乐科技(深圳)有限公司 | Audio identification method, equipment and medium |
| CN113792104A (en)* | 2021-09-16 | 2021-12-14 | 平安科技(深圳)有限公司 | Medical data error detection method and device based on artificial intelligence and storage medium |
| CN113792104B (en)* | 2021-09-16 | 2024-03-01 | 平安科技(深圳)有限公司 | Medical data error detection method and device based on artificial intelligence and storage medium |
Also Published As
| Publication number | Publication date |
|---|---|
| CN111461151B (en) | 2025-01-03 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11455491B2 (en) | Method and device for training image recognition model, and storage medium | |
| WO2020134556A1 (en) | Image style transfer method, device, electronic apparatus, and storage medium | |
| CN112001364A (en) | Image recognition method and device, electronic device and storage medium | |
| CN111461304B (en) | Classification neural network training methods, text classification methods, devices and equipment | |
| CN110458102A (en) | A face image recognition method and device, electronic device and storage medium | |
| KR20150117202A (en) | Clustering method and device related to the same | |
| CN110941727B (en) | Resource recommendation method and device, electronic equipment and storage medium | |
| WO2021036382A1 (en) | Image processing method and apparatus, electronic device and storage medium | |
| CN111259967A (en) | Image classification and neural network training method, device, equipment and storage medium | |
| CN111160448A (en) | An image classification model training method and device | |
| CN113486978B (en) | Training method and device for text classification model, electronic equipment and storage medium | |
| CN106203306A (en) | Age prediction method, device and terminal | |
| CN107341509A (en) | The training method and device of convolutional neural networks | |
| CN107832691B (en) | Micro-expression identification method and device | |
| CN110765943A (en) | Network training and recognition method and device, electronic equipment and storage medium | |
| CN112116095A (en) | A method and related device for training a multi-task learning model | |
| CN111554271A (en) | End-to-end awakening word detection method and device | |
| CN111461151B (en) | A multi-group sample construction method and device | |
| CN114663901A (en) | Image processing method, image recognition device, electronic apparatus, and medium | |
| CN104850855B (en) | The method and apparatus for calculating confidence level | |
| CN104268149A (en) | Clustering method and clustering device | |
| CN112130839A (en) | Method for constructing database, method for voice programming and related device | |
| CN104090915B (en) | Method and device for updating user data | |
| CN112825247A (en) | Data processing method and device and electronic equipment | |
| CN110659625A (en) | Training method and device of object recognition network, electronic equipment and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| TA01 | Transfer of patent application right | ||
| TA01 | Transfer of patent application right | Effective date of registration:20220812 Address after:100084. Room 9, floor 01, cyber building, building 9, building 1, Zhongguancun East Road, Haidian District, Beijing Applicant after:BEIJING SOGOU TECHNOLOGY DEVELOPMENT Co.,Ltd. Address before:310016 room 1501, building 17, No.57, kejiyuan Road, Baiyang street, Hangzhou Economic and Technological Development Zone, Zhejiang Province Applicant before:SOGOU (HANGZHOU) INTELLIGENT TECHNOLOGY Co.,Ltd. Applicant before:BEIJING SOGOU TECHNOLOGY DEVELOPMENT Co.,Ltd. | |
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| TG01 | Patent term adjustment | ||
| TG01 | Patent term adjustment |