CN111368534A - Application log noise reduction method and device - Google Patents
Application log noise reduction method and deviceDownload PDFInfo
- Publication number
- CN111368534A CN111368534ACN201811587244.9ACN201811587244ACN111368534ACN 111368534 ACN111368534 ACN 111368534ACN 201811587244 ACN201811587244 ACN 201811587244ACN 111368534 ACN111368534 ACN 111368534A
- Authority
- CN
- China
- Prior art keywords
- word segmentation
- noise
- log
- application
- application log
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images


Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
Landscapes
- Engineering & Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Theoretical Computer Science (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Biology (AREA)
- Evolutionary Computation (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Machine Translation (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明实施例涉及计算机软件技术领域,尤其涉及一种应用日志降噪方法及装置。Embodiments of the present invention relate to the technical field of computer software, and in particular, to a method and device for noise reduction of application logs.
背景技术Background technique
应用日志目前被视作系统故障诊断定位的重要运维窗口之一,通过对日志事件行为特征的提取聚合等可以实现对大多数故障的实时定位。除此之外,应用日志也被广泛应用于各类经营分析,如对用户访问日志等的深度挖掘及关联分析可以建立不同人群的行为肖像,从而开展多层次的营销活动。然而,随着系统规模的不断增长,系统复杂度不断提高,基于日志的故障诊断、经营分析等受到各类环境因素、代码质量等影响,如注入大量与故障、经分需求无关的日志,系统开发时对日志级别设定不准确导致的杂乱日志等,这些类型的日志在后续日志分析的时候会造成极大的干扰,因此被视作“噪声数据”。为了构建有效的故障特征模型及聚合准确的运营指标数据,必须要在分析前将这些噪声日志滤除。Application logs are currently regarded as one of the important operation and maintenance windows for system fault diagnosis and location, and most faults can be located in real time through the extraction and aggregation of log event behavior characteristics. In addition, application logs are also widely used in various business analysis, such as in-depth mining and correlation analysis of user access logs, etc., can establish behavioral portraits of different groups of people, so as to carry out multi-level marketing activities. However, with the continuous growth of the system scale and the increasing complexity of the system, log-based fault diagnosis and business analysis are affected by various environmental factors, code quality, etc. The cluttered logs caused by inaccurate log level settings during development, etc. These types of logs will cause great interference in subsequent log analysis, so they are regarded as "noise data". In order to build an effective fault signature model and aggregate accurate operational indicator data, these noisy logs must be filtered out before analysis.
目前关于应用日志降噪的相关技术方案如下:方案一:基于人为经验标注的日志噪声过滤方法,基于经验标注的方法主要通过运维等系统负责人员定期整理分析应用吐出的日志数据,并根据自己长期的工作经验对各类日志进行分类筛选,并对判定为无用噪声的日志进行标注,在日志采集或者入库的时候进行强制性过滤。而过滤的方式多数采用关键字匹配,模板正则等形式。该方法适合小型等日志量不大的应用系统,见效相对彻底。方案二:基于应用日志级别的噪声过滤方法,基于应用日志级别的噪声过滤方法主要是借用当前各类编程语言的日志级别管理标准,如Java Log4j中的5大日志级别(debug、info、warn、error、fatal),其分别针对细粒度的应用调试日志、运行日志、潜在错误、运行错误、严重事件日志进行分级打印。而依照类似的日志级别规范,开发者通过对潜在噪声日志的输出划界,定义为info甚至以上或自定义级别。在后续日志分析的时候针对无益的噪声日志过滤只需要实现对该日志级别上的整体控制即可。方案三:基于噪声模板跳表的日志过滤方法,该方案主要基于日志时间序列相似度特征提取判别,首先通过将噪声采样信息按照特定类型标识建模为时间序列,使用Haar小波变换提取序列特征,基于跳表构造噪声模板库。目标日志时间序列通过与噪声模板进行相似度比较来确定其是否为噪声日志。基于真实云计算平台的实验表明,提出的方法能够有效提高故障特征的有效性。At present, the relevant technical solutions for application log noise reduction are as follows: Option 1: Log noise filtering method based on human experience annotation. The experience-based method mainly organizes and analyzes the log data spit out by the application through operation and maintenance and other system responsible personnel. Long-term work experience classifies and filters various types of logs, marks logs that are judged to be useless noise, and conducts mandatory filtering when logs are collected or stored. Most of the filtering methods are in the form of keyword matching, template regularization, etc. This method is suitable for small and other application systems with a small amount of logs, and the effect is relatively complete. Option 2: Noise filtering method based on application log level. The noise filtering method based on application log level mainly borrows the current log level management standards of various programming languages, such as the five log levels in Java Log4j (debug, info, warn, error, fatal), which respectively perform hierarchical printing for fine-grained application debug logs, running logs, potential errors, running errors, and serious event logs. In accordance with similar log level specifications, developers define the output of potentially noisy logs as info or above or a custom level. In the subsequent log analysis, it is only necessary to realize the overall control of the log level to filter unhelpful noise logs. Scheme 3: Log filtering method based on noise template skip table. This scheme is mainly based on log time series similarity feature extraction and discrimination. First, the noise sampling information is modeled as a time series according to a specific type of identification, and Haar wavelet transform is used to extract sequence features. The noise template library is constructed based on the skip table. The target log time series is determined by comparing the similarity with the noise template to determine whether it is a noise log. Experiments based on a real cloud computing platform show that the proposed method can effectively improve the effectiveness of fault features.
现有技术方案主要存在以下几个问题:(1)方案一针对人为经验标注的方式存在的问题:随着目前各类系统集群规模的不断扩大,单纯的人工标注已经成为一项艰巨的任务,更不用说由于敏捷开发的落地导致应用的代码变动与日俱增,从而带来的日志量及类型上的暴增。线性增长的日志噪声无法快速准确地得到识别滤除,而且马太效应会越来越严重。准确来说,该方式对于中大型的项目成本过大。(2)方案二针对应用日志级别的噪声过滤方法存在的问题:该方案实现的前提是保证日志级别规范的准确性和全面性,需要准确的对现有及预计会发生的日志类型进行级别分类,同时需要保证开发对日志级别设定的准确理解和执行。然而随着系统的复杂迭代,关于新生日志有效和噪声的区分在原有规范的边界上会逐渐模糊,并导致系统开发在后续的设定上不再准确,即噪声日志数据在原有级别上不断往其余级别溢出,最终无法区分。因此,该方式存在实际上的应用缺陷。(3)方案三基于噪声模板跳表的日志过滤方式存在的问题:基于噪声模板跳表的过滤方式首先需要对原始日志序列进行小波变化,并进一步的计算与噪声模板相似度差值,最后根据设定阈值进行噪声判定,这里带来最大的问题是噪声模板的提取和相似度计算阈值的设定。综上,现有的技术方案过于复杂、费时,且耗费大量成本。The existing technical solutions mainly have the following problems: (1) Solution 1 addresses the problems in the way of human experience labeling: with the continuous expansion of the scale of various system clusters, simple manual labeling has become a arduous task. Not to mention that due to the implementation of agile development, the code changes of the application are increasing day by day, which brings about a surge in the amount and type of logs. The linearly growing log noise cannot be quickly and accurately identified and filtered, and the Matthew effect will become more and more serious. To be precise, this method is too costly for medium and large projects. (2)
发明内容SUMMARY OF THE INVENTION
本发明实施例提供一种应用日志降噪方法及装置,用以解决现有技术过于复杂、费时,且耗费大量成本。Embodiments of the present invention provide an application log noise reduction method and device, which are used to solve the problem that the prior art is too complicated, time-consuming, and costs a lot of money.
第一方面,本发明实施例提供了一种应用日志降噪方法,包括:In a first aspect, an embodiment of the present invention provides an application log noise reduction method, including:
采集应用日志;Collect application logs;
根据预先得到的分词规则对所述应用日志进行分词处理得到特征向量;Perform word segmentation processing on the application log according to the pre-obtained word segmentation rule to obtain a feature vector;
根据所述特征向量和预先根据主题模型得到的噪声识别规则,若判定所述应用日志为噪声,则将所述应用日志去除。According to the feature vector and the noise identification rule obtained in advance according to the topic model, if it is determined that the application log is noise, the application log is removed.
第二方面,本发明实施例提供了一种用于应用日志降噪装置,包括:In a second aspect, an embodiment of the present invention provides an apparatus for denoising an application log, including:
日志语料库模块,用于采集应用日志;The log corpus module is used to collect application logs;
分词模块,用于根据预先得到的分词规则对所述应用日志进行分词处理得到特征向量;A word segmentation module, configured to perform word segmentation processing on the application log according to a pre-obtained word segmentation rule to obtain a feature vector;
噪声识别模块,用于根据所述特征向量和预先根据主题模型得到的噪声识别规则,若判定所述应用日志为噪声,则将所述应用日志去除。The noise identification module is configured to remove the application log if it is determined that the application log is noise according to the feature vector and the noise identification rule obtained in advance according to the topic model.
第三方面,本发明实施例还提供了一种电子设备,包括:In a third aspect, an embodiment of the present invention also provides an electronic device, including:
处理器、存储器、通信接口和通信总线;其中,processors, memories, communication interfaces and communication buses; wherein,
所述处理器、存储器、通信接口通过所述通信总线完成相互间的通信;The processor, the memory, and the communication interface communicate with each other through the communication bus;
所述通信接口用于该电子设备的通信设备之间的信息传输;The communication interface is used for information transmission between communication devices of the electronic device;
所述存储器存储有可被所述处理器执行的计算机程序指令,所述处理器调用所述程序指令能够执行如下方法:The memory stores computer program instructions executable by the processor, and the processor invokes the program instructions to perform the following methods:
采集应用日志;Collect application logs;
根据预先得到的分词规则对所述应用日志进行分词处理得到特征向量;Perform word segmentation processing on the application log according to the pre-obtained word segmentation rule to obtain a feature vector;
根据所述特征向量和预先根据主题模型得到的噪声识别规则,若判定所述应用日志为噪声,则将所述应用日志去除。According to the feature vector and the noise identification rule obtained in advance according to the topic model, if it is determined that the application log is noise, the application log is removed.
第四方面,本发明实施例还提供了一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如下方法:In a fourth aspect, an embodiment of the present invention further provides a non-transitory computer-readable storage medium, on which a computer program is stored, and when the computer program is executed by a processor, the following method is implemented:
采集应用日志;Collect application logs;
根据预先得到的分词规则对所述应用日志进行分词处理得到特征向量;Perform word segmentation processing on the application log according to the pre-obtained word segmentation rule to obtain a feature vector;
根据所述特征向量和预先根据主题模型得到的噪声识别规则,若判定所述应用日志为噪声,则将所述应用日志去除。According to the feature vector and the noise identification rule obtained in advance according to the topic model, if it is determined that the application log is noise, the application log is removed.
本发明实施例提供的应用日志降噪方法及装置,通过预先确认的分词规则对得到的应用日志进行分词,再采用预先得到的噪声识别规则对分词后得到的特征向量进行判定,从而可以简单、方便、准确得对各种应用日志进行噪声识别。In the application log noise reduction method and device provided by the embodiments of the present invention, the obtained application log is segmented according to the pre-confirmed word segmentation rules, and then the feature vector obtained after the word segmentation is determined by using the pre-obtained noise identification rules, so that simple, It is convenient and accurate to perform noise identification on various application logs.
附图说明Description of drawings
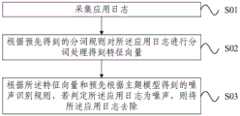
图1为本发明实施例的应用日志降噪方法流程图;1 is a flowchart of an application log noise reduction method according to an embodiment of the present invention;
图2为本发明实施例的另一应用日志降噪方法流程图;2 is a flowchart of another application log noise reduction method according to an embodiment of the present invention;
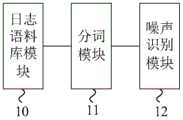
图3为本发明实施例的用于应用日志降噪装置结构示意图;3 is a schematic structural diagram of an apparatus for denoising an application log according to an embodiment of the present invention;
图4为本发明实施例的另一用于应用日志降噪装置结构示意图;4 is a schematic structural diagram of another device for applying log noise reduction according to an embodiment of the present invention;
图5示例了一种电子设备的实体结构示意图。FIG. 5 illustrates a schematic diagram of the physical structure of an electronic device.
具体实施方式Detailed ways
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。In order to make the purposes, technical solutions and advantages of the embodiments of the present invention clearer, the technical solutions in the embodiments of the present invention will be clearly and completely described below with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments These are some embodiments of the present invention, but not all embodiments. Based on the embodiments of the present invention, all other embodiments obtained by those of ordinary skill in the art without creative efforts shall fall within the protection scope of the present invention.
图1为本发明实施例的应用日志降噪方法流程图,如图1所示,所述方法包括:FIG. 1 is a flowchart of an application log noise reduction method according to an embodiment of the present invention. As shown in FIG. 1 , the method includes:
步骤S01、采集应用日志。Step S01, collecting application logs.
从网络中实时采集应用日志,并存入日志语料库中。Collect application logs from the network in real time and store them in the log corpus.
步骤S02、根据预先得到的分词规则对所述应用日志进行分词处理得到特征向量。Step S02: Perform word segmentation processing on the application log according to the pre-obtained word segmentation rule to obtain a feature vector.
由于所述应用日志来源的不同会存在各种不同的格式和规范,且包括不规则、破碎的文本数据,以及过度冗余,不精确的日志信息。现有技术中需要根据不同的格式和规范来对噪声识别进行相应的调整。而本发明实施例采用基于词频统计的无词典分词方式进行对实时应用日志的分词处理,不再需要遵循在日志格式和规范上的硬性约束。Due to the different sources of the application logs, there are various formats and specifications, including irregular and fragmented text data, as well as excessively redundant and inaccurate log information. In the prior art, the noise identification needs to be adjusted according to different formats and specifications. However, in the embodiment of the present invention, a dictionary-free word segmentation method based on word frequency statistics is used to process the word segmentation of the real-time application log, and it is no longer necessary to follow the hard constraints on the log format and specification.
将每条应用日志视作一篇短文档,根据预先得到的分词规则对所述应用日志进行分词处理,具体对该应用日志进行词语的切分,并得到每个词语的特征值,提取主要词语和特征值组建与该应用日志对应的特征向量。Treat each application log as a short document, perform word segmentation processing on the application log according to the pre-obtained word segmentation rules, specifically perform word segmentation on the application log, obtain the feature value of each word, and extract the main words and eigenvalues to form a eigenvector corresponding to the application log.
步骤S03、根据所述特征向量和预先根据主题模型得到的噪声识别规则,若判定所述应用日志为噪声,则将所述应用日志去除。Step S03 , according to the feature vector and the noise identification rule obtained in advance according to the topic model, if it is determined that the application log is noise, remove the application log.
通过主题模型可以得到所述主题模型中不同主题的判定规则,在本发明实施例中,在预先确认主题模型中通过词频及文档特征等建立噪声主题,因此通过该主题模型可以得到噪声识别规则。Judgment rules for different topics in the topic model can be obtained through the topic model. In the embodiment of the present invention, noise topics are established by word frequency and document features in the pre-confirmed topic model, so noise identification rules can be obtained through the topic model.
采用所述噪声识别规则对所述应用日志的特征向量进行判定,若所述特征向量与所述噪声识别规则相符,则判定该应用日志为噪声,需要在所述应用日志中加入噪声标记,否则不作任何操作或者加入非噪声标记。The feature vector of the application log is determined by using the noise identification rule. If the feature vector matches the noise identification rule, the application log is determined to be noise, and a noise mark needs to be added to the application log. Otherwise, the application log is determined to be noise. Do nothing or add non-noise markers.
通过对标记的识别就可以对应用日志是否为噪声进行判断,若判定对应的应用日志为噪声,则需要在对应用日志进行后续数据挖掘和关联分析前加以去除。Whether the application log is noise can be judged by identifying the tag. If the corresponding application log is judged to be noise, it needs to be removed before subsequent data mining and correlation analysis are performed on the application log.
本发明实施例通过预先确认的分词规则对得到的应用日志进行分词,再采用预先得到的噪声识别规则对分词后得到的特征向量进行判定,从而可以简单、方便、准确得对各种应用日志进行噪声识别。The embodiment of the present invention performs word segmentation on the obtained application log through pre-confirmed word segmentation rules, and then uses the pre-obtained noise recognition rule to determine the feature vector obtained after the word segmentation, so that various application logs can be analyzed simply, conveniently and accurately. noise identification.
图2为本发明实施例的另一应用日志降噪方法流程图,如图2所示,所述方法还包括:FIG. 2 is a flowchart of another application log noise reduction method according to an embodiment of the present invention. As shown in FIG. 2 , the method further includes:
步骤S10、根据语料库中训练集保存的历史应用日志,采用统计分词模型得到所述分词规则。Step S10, according to the historical application log saved in the training set in the corpus, using a statistical word segmentation model to obtain the word segmentation rule.
为了能够预先得到所述分词规则,需要先收集各种应用日志的历史数据并存入语料库中,而将其中的一部分历史应用日志组成训练集。In order to obtain the word segmentation rules in advance, historical data of various application logs need to be collected and stored in the corpus, and a part of the historical application logs is formed into a training set.
根据训练集中所有的历史应用日志,采用预设的统计分词模型,来得到所述分词规则。According to all historical application logs in the training set, a preset statistical word segmentation model is used to obtain the word segmentation rules.
步骤S11、根据所述分词规则对所述历史应用日志中的每个历史应用日志进行分词处理以得到对应的特征向量。Step S11: Perform word segmentation processing on each historical application log in the historical application log according to the word segmentation rule to obtain a corresponding feature vector.
根据得到的分词规则可以对每条历史应用日志进行词语的切分,并根据词频特征进行筛选及向量化,以得到对应的特征向量。According to the obtained word segmentation rules, words can be segmented for each historical application log, and filtered and vectorized according to word frequency features to obtain corresponding feature vectors.
进一步地,所述统计分词模型为N元文法(N-gram)语言模型。Further, the statistical word segmentation model is an N-gram language model.
所述统计分词模型有很多,在本发明实施例中仅给出了其中的一种举例说明,N-gram语言模型。该模型根据相邻字在训练集中出现的概率或频率来反应切分词的可信度。其中所述N可以根据实际的需要来进行设定,下面仅以3为例进行举例说明。在处理一条历史应用日志时,利用3字滑动窗口依次提取3个gram,即英文单词,统计出现次数,利用贝叶斯公式计算相应概率,再利用最大似然法,使得训练样本的概率取得最大值。最终根据计算结果提取高频gram作为分好的词。以每个词为维度,每个词在该条训练集中出现频率或概率信息为值,构建与该历史应用日志数据向量化后的特征向量。There are many statistical word segmentation models, and only one of them, the N-gram language model, is given as an example in the embodiment of the present invention. The model reflects the credibility of segmented words according to the probability or frequency of adjacent words appearing in the training set. The N can be set according to actual needs, and 3 is taken as an example for illustration below. When processing a historical application log, use a 3-word sliding window to extract 3 grams, namely English words, count the number of occurrences, use the Bayesian formula to calculate the corresponding probability, and then use the maximum likelihood method to maximize the probability of the training sample value. Finally, according to the calculation results, high-frequency gram is extracted as a good word. Taking each word as the dimension and the frequency or probability information of each word in the training set as the value, construct a feature vector that is vectorized with the historical application log data.
步骤S12、根据所述历史应用日志的特征向量,通过训练得到主题模型;其中,所述主题模型至少包括噪声主题。Step S12: Obtain a topic model through training according to the feature vector of the historical application log; wherein, the topic model includes at least a noise topic.
根据得到的所有历史应用日志的特征向量来进行主题建模,借用自然语言学习中的主题分类思想,将整个训练集中的主题指定为噪声和非噪声两类,将噪声识别问题转换为文体分类中的概率问题。Topic modeling is carried out according to the obtained feature vectors of all historical application logs, borrowing the idea of topic classification in natural language learning, the topics in the entire training set are designated as noise and non-noise, and the noise recognition problem is transformed into stylistic classification. probability problem.
进一步地,所述主题模型为隐含狄利克雷分配(Latent Dirichlet Allocation,LDA)模型。Further, the topic model is a Latent Dirichlet Allocation (LDA) model.
主题模型的具体应用有很多种,在此仅以LDA模型为例进行举例说明。LDA模型在确定主题类型为噪声主题和非噪声主题后,根据上述实施例中得到的特征向量,获得每个主题在训练集中所有词上的多项式分布,即狄利克雷分布。其次对于每一条历史应用日志,获得该历史应用日志在所有主题上的狄利克雷分布,然后根据预设的超参数,通过迭代优化,得到每个特征向量对应的主题,从而建立了主题模型。There are many specific applications of the topic model, and only the LDA model is used as an example to illustrate. After determining that the topic types are noise topics and non-noise topics, the LDA model obtains the multinomial distribution of each topic on all words in the training set, that is, the Dirichlet distribution, according to the feature vector obtained in the above embodiment. Secondly, for each historical application log, the Dirichlet distribution of the historical application log on all topics is obtained, and then according to the preset hyperparameters, through iterative optimization, the topic corresponding to each feature vector is obtained, thereby establishing a topic model.
步骤S13、所述根据主题模型得到所述噪声识别规则。Step S13, the noise identification rule is obtained according to the topic model.
通过建立的主题模型的分析,可以得到所述噪声识别规则。Through the analysis of the established topic model, the noise identification rule can be obtained.
本发明实施例通过训练集中的历史应用日志,采用统计分词模型得到所述分词规则、主题模型,以及噪声识别规则,从而可以简单、方便、准确得对各种应用日志进行噪声识别。The embodiment of the present invention obtains the word segmentation rules, topic models, and noise identification rules through historical application logs in the training set and a statistical word segmentation model, so that noise identification of various application logs can be performed simply, conveniently and accurately.
基于上述实施例,进一步地,所述语料库还包括测试集,所述测试集至少包括一条测试应用日志;相应地,所述方法还包括:Based on the above embodiment, further, the corpus further includes a test set, and the test set includes at least one test application log; correspondingly, the method further includes:
根据所述分词规则对所述测试集中的每个测试应用日志进行分词处理以得到对应的特征向量;Perform word segmentation processing on each test application log in the test set according to the word segmentation rule to obtain a corresponding feature vector;
根据所述特征向量和所述噪声识别规则进行噪声识别,并与预设的标准进行比对,若存在偏差,则根据所述偏差对所述主题模型进行优化。Noise identification is performed according to the feature vector and the noise identification rule, and is compared with a preset standard. If there is a deviation, the topic model is optimized according to the deviation.
所述语料库中除了训练集外,还包括由其它历史应用日志作为测试应用日志组成的测试集。In addition to the training set, the corpus also includes a test set composed of other historical application logs as test application logs.
在由所述统计分词模型根据所述训练集得到分词规则,且根据主题模型得到噪声识别规则后。将所述测试集中的测试应用日志也同样放入统计分词模型中,根据得到的分词规则得到对应特征向量,再通过确定的主题模型,由噪声识别规则得到每个测试应用日志的主题。After the statistical word segmentation model obtains word segmentation rules according to the training set, and obtains noise identification rules according to the topic model. The test application logs in the test set are also put into the statistical word segmentation model, corresponding feature vectors are obtained according to the obtained word segmentation rules, and then the subject of each test application log is obtained from the noise identification rules through the determined topic model.
将得到的结果与预设的标准进行比对,若存在偏差,则需要根据偏差对所述主题模型再次进行优化,以得到更加准确的噪声识别规则。The obtained result is compared with a preset standard, and if there is a deviation, the subject model needs to be optimized again according to the deviation, so as to obtain a more accurate noise identification rule.
本发明实施例通过测试集对所述分词规则和噪声识别规则进行测试,若结果出现偏差,则再次对所述主题模型进行优化,从而可以简单、方便、准确得对各种应用日志进行噪声识别。In this embodiment of the present invention, the word segmentation rules and the noise identification rules are tested through a test set, and if the results are deviated, the topic model is optimized again, so that noise identification can be performed on various application logs in a simple, convenient and accurate manner. .
基于上述实施例,进一步地,所述方法还包括:Based on the above embodiment, further, the method further includes:
定期将采集到的所有应用日志存入所述语料库中,用于进一步对所述优化所述分词规则和噪声识别规则。All the collected application logs are periodically stored in the corpus for further optimizing the word segmentation rules and noise identification rules.
在实际的应用过程中,可能会出现新的应用,得到新的应用日志,或者出现新的习惯用词,所以为了能够让所述分词规则和噪声识别规则能够随时适应当前应用日志的新变化,所以需要定期将采集到的所有应用日志作为历史应用日志存入所述语料库中,分别收录到训练集或测试集,从而通过更新后的训练集来优化所述分词规则,同时来优化所述主题模型,进而得到优化后的噪声识别规则。In the actual application process, new applications may appear, new application logs may be obtained, or new idioms may appear. Therefore, in order to enable the word segmentation rules and noise identification rules to adapt to new changes in the current application log at any time, Therefore, it is necessary to regularly store all the collected application logs into the corpus as historical application logs, and record them into the training set or test set respectively, so as to optimize the word segmentation rules through the updated training set, and at the same time optimize the topic model, and then get the optimized noise identification rules.
本发明实施例通过定期向所述语料库补充历史应用日志,从而使不断优化所述分词规则和所述噪声识别规则,从而可以简单、方便、准确得对各种应用日志进行噪声识别。In the embodiment of the present invention, by regularly supplementing the corpus with historical application logs, the word segmentation rules and the noise identification rules are continuously optimized, so that noise identification of various application logs can be performed simply, conveniently and accurately.
图3为本发明实施例的用于应用日志降噪装置结构示意图,如图3所示,所述装置包括:日志语料库模块10、分词模块11和噪声识别模块12,其中,所述日志语料库模块10用于采集应用日志;所述分词模块11用于根据预先得到的分词规则对所述应用日志进行分词处理得到特征向量;所述噪声识别模块12用于根据所述特征向量和预先根据主题模型得到的噪声识别规则,若判定所述应用日志为噪声,则将所述应用日志去除。具体地:3 is a schematic structural diagram of an apparatus for applying log noise reduction according to an embodiment of the present invention. As shown in FIG. 3 , the apparatus includes: a
所述日志语料库模块10从网络中实时采集应用日志,并存入日志语料库中。同时所述日志语料库模块10实时向所述分词模块11发送采集到的应用日志。The
所述分词模块11将每条应用日志视作一篇短文档,根据预先得到的分词规则对所述应用日志进行分词处理,具体对该应用日志进行词语的切分,并得到每个词语的特征值,提取主要词语和特征值组建与该应用日志对应的特征向量,并将该特征向量发送给所述噪声识别模块12。The
通过主题模型可以得到所述主题模型中不同主题的判定规则,在本发明实施例中,在预先确认主题模型中通过词频及文档特征等建立噪声主题,因此通过该主题模型可以得到噪声识别规则。Judgment rules for different topics in the topic model can be obtained through the topic model. In the embodiment of the present invention, noise topics are established by word frequency and document features in the pre-confirmed topic model, so noise identification rules can be obtained through the topic model.
所述噪声识别模块12采用所述噪声识别规则对所述应用日志的特征向量进行判定,若所述特征向量与所述噪声识别规则相符,则判定该应用日志为噪声,需要在所述应用日志中加入噪声标记,否则不作任何操作或者加入非噪声标记。The
通过对标记的识别就可以对应用日志是否为噪声进行判断,若判定对应的应用日志为噪声,则需要在对应用日志进行后续数据挖掘和关联分析前通过过滤模块加以去除。Whether the application log is noise can be judged by identifying the tag. If the corresponding application log is judged to be noise, it needs to be removed by the filtering module before subsequent data mining and correlation analysis are performed on the application log.
本发明实施例提供的装置用于执行上述方法,其功能具体参考上述方法实施例,其具体方法流程在此处不再赘述。The apparatus provided in the embodiment of the present invention is used to execute the foregoing method, and its function refers to the foregoing method embodiment for details, and the specific method flow is not repeated here.
本发明实施例通过预先确认的分词规则对得到的应用日志进行分词,再采用预先得到的噪声识别规则对分词后得到的特征向量进行判定,从而可以简单、方便、准确得对各种应用日志进行噪声识别。The embodiment of the present invention performs word segmentation on the obtained application log through pre-confirmed word segmentation rules, and then uses the pre-obtained noise recognition rule to determine the feature vector obtained after the word segmentation, so that various application logs can be analyzed simply, conveniently and accurately. noise identification.
图4为本发明实施例的另一用于应用日志降噪装置结构示意图,如图4所示,所述装置还包括:训练分词模块20、建模模块21和分类构造模块22,其中,FIG. 4 is a schematic structural diagram of another device for applying log noise reduction according to an embodiment of the present invention. As shown in FIG. 4 , the device further includes: a training
所述训练分词模块20用于根据语料库中训练集保存的历史应用日志,采用统计分词模型得到所述分词规则;所述训练分词模块20还用于根据所述分词规则对所述历史应用日志中的每个历史应用日志进行分词处理以得到对应的特征向量;所述建模模块21用于根据所述历史应用日志的特征向量,通过训练得到主题模型;其中,所述主题模型至少包括噪声主题;所述分类构造模块22用于所述根据主题模型得到所述噪声识别规则。具体地:The training
为了能够预先得到所述分词规则,需要先收集各种应用日志的历史数据并存入语料库中,而将其中的一部分历史应用日志组成训练集。In order to obtain the word segmentation rules in advance, historical data of various application logs need to be collected and stored in the corpus, and a part of the historical application logs is formed into a training set.
所述训练分词模块20根据训练集中所有的历史应用日志,采用预设的统计分词模型,来得到所述分词规则。所述训练分词模块20将分词规则发送给所述分词模块11。The training
所述训练分词模块20根据得到的分词规则可以对每条历史应用日志进行词语的切分,并根据词频特征进行筛选及向量化,以得到对应的特征向量。The training
进一步地,所述统计分词模型为N元文法(N-gram)语言模型。Further, the statistical word segmentation model is an N-gram language model.
所述统计分词模型有很多,在本发明实施例中仅给出了其中的一种举例说明,N-gram语言模型。该模型根据相邻字在训练集中出现的概率或频率来反应切分词的可信度。其中所述N可以根据实际的需要来进行设定,下面仅以3为例进行举例说明。在处理一条历史应用日志时,利用3字滑动窗口依次提取3个gram,即英文单词,统计出现次数,利用贝叶斯公式计算相应概率,再利用最大似然法,使得训练样本的概率取得最大值。最终根据计算结果提取高频gram作为分好的词。以每个词为维度,每个词在该条训练集中出现频率或概率信息为值,构建与该历史应用日志数据向量化后的特征向量。There are many statistical word segmentation models, and only one of them, the N-gram language model, is given as an example in the embodiment of the present invention. The model reflects the credibility of segmented words according to the probability or frequency of adjacent words appearing in the training set. The N can be set according to actual needs, and 3 is taken as an example for illustration below. When processing a historical application log, use a 3-word sliding window to extract 3 grams, namely English words, count the number of occurrences, use the Bayesian formula to calculate the corresponding probability, and then use the maximum likelihood method to maximize the probability of the training sample value. Finally, according to the calculation results, high-frequency gram is extracted as a good word. Taking each word as the dimension and the frequency or probability information of each word in the training set as the value, construct a feature vector that is vectorized with the historical application log data.
所述建模模块21根据由训练分词模块20得到的所有历史应用日志的特征向量来进行主题建模,借用自然语言学习中的主题分类思想,将整个训练集中的主题指定为噪声和非噪声两类,将噪声识别问题转换为文体分类中的概率问题。The
进一步地,所述主题模型为隐含狄利克雷分配(Latent Dirichlet Allocation,LDA)模型。Further, the topic model is a Latent Dirichlet Allocation (LDA) model.
主题模型的具体应用有很多种,在此仅以LDA模型为例进行举例说明。LDA模型在确定主题类型为噪声主题和非噪声主题后,根据上述实施例中得到的特征向量,获得每个主题在训练集中所有词上的多项式分布,即狄利克雷分布。其次对于每一条历史应用日志,获得该历史应用日志在所有主题上的狄利克雷分布,然后根据预设的超参数,通过迭代优化,得到每个特征向量对应的主题,从而建立了主题模型。There are many specific applications of the topic model, and only the LDA model is used as an example to illustrate. After determining that the topic types are noise topics and non-noise topics, the LDA model obtains the multinomial distribution of each topic on all words in the training set, that is, the Dirichlet distribution, according to the feature vector obtained in the above embodiment. Secondly, for each historical application log, the Dirichlet distribution of the historical application log on all topics is obtained, and then according to the preset hyperparameters, through iterative optimization, the topic corresponding to each feature vector is obtained, thereby establishing a topic model.
所述分类构造模块22通过建立的主题模型的分析,可以得到所述噪声识别规则,并将所述噪声识别规则发送给所述噪声识别模块12。The classification and construction module 22 can obtain the noise identification rules by analyzing the established topic model, and send the noise identification rules to the
本发明实施例提供的装置用于执行上述方法,其功能具体参考上述方法实施例,其具体方法流程在此处不再赘述。The apparatus provided in the embodiment of the present invention is used to execute the foregoing method, and its function refers to the foregoing method embodiment for details, and the specific method flow is not repeated here.
本发明实施例通过训练集中的历史应用日志,采用统计分词模型得到所述分词规则、主题模型,以及噪声识别规则,从而可以简单、方便、准确得对各种应用日志进行噪声识别。The embodiment of the present invention obtains the word segmentation rules, topic models, and noise identification rules through historical application logs in the training set and a statistical word segmentation model, so that noise identification of various application logs can be performed simply, conveniently and accurately.
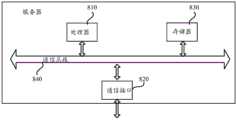
图5示例了一种电子设备的实体结构示意图,如图5所示,该服务器可以包括:处理器(processor)810、通信接口(Communications Interface)820、存储器(memory)830和通信总线840,其中,处理器810,通信接口820,存储器830通过通信总线840完成相互间的通信。处理器810可以调用存储器830中的逻辑指令,以执行如下方法:采集应用日志;根据预先得到的分词规则对所述应用日志进行分词处理得到特征向量;根据所述特征向量和预先根据主题模型得到的噪声识别规则,若判定所述应用日志为噪声,则将所述应用日志去除。FIG. 5 illustrates a schematic diagram of the physical structure of an electronic device. As shown in FIG. 5 , the server may include: a processor (processor) 810, a communication interface (Communications Interface) 820, a memory (memory) 830 and a
进一步地,本发明实施例公开一种计算机程序产品,所述计算机程序产品包括存储在非暂态计算机可读存储介质上的计算机程序,所述计算机程序包括程序指令,当所述程序指令被计算机执行时,计算机能够执行上述各方法实施例所提供的方法,例如包括:采集应用日志;根据预先得到的分词规则对所述应用日志进行分词处理得到特征向量;根据所述特征向量和预先根据主题模型得到的噪声识别规则,若判定所述应用日志为噪声,则将所述应用日志去除。Further, an embodiment of the present invention discloses a computer program product, the computer program product includes a computer program stored on a non-transitory computer-readable storage medium, the computer program includes program instructions, and when the program instructions are executed by a computer During execution, the computer can execute the methods provided by the above method embodiments, for example, including: collecting application logs; performing word segmentation processing on the application logs according to pre-obtained word segmentation rules to obtain feature vectors; According to the noise identification rule obtained by the model, if it is determined that the application log is noise, the application log is removed.
进一步地,本发明实施例提供一种非暂态计算机可读存储介质,所述非暂态计算机可读存储介质存储计算机指令,所述计算机指令使所述计算机执行上述各方法实施例所提供的方法,例如包括:采集应用日志;根据预先得到的分词规则对所述应用日志进行分词处理得到特征向量;根据所述特征向量和预先根据主题模型得到的噪声识别规则,若判定所述应用日志为噪声,则将所述应用日志去除。Further, an embodiment of the present invention provides a non-transitory computer-readable storage medium, where the non-transitory computer-readable storage medium stores computer instructions, and the computer instructions cause the computer to execute the methods provided by the foregoing method embodiments. The method, for example, includes: collecting application logs; performing word segmentation processing on the application logs according to pre-obtained word segmentation rules to obtain feature vectors; noise, the application log is removed.
本领域普通技术人员可以理解:此外,上述的存储器830中的逻辑指令可以通过软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(ROM,Read-Only Memory)、随机存取存储器(RAM,Random AccessMemory)、磁碟或者光盘等各种可以存储程序代码的介质。Those skilled in the art can understand that: in addition, the above-mentioned logic instructions in the
以上所描述的电子设备等实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性的劳动的情况下,即可以理解并实施。The above-described electronic equipment and other embodiments are only illustrative, wherein the units described as separate components may or may not be physically separated, and the components displayed as units may or may not be physical units, that is, It can be located in one place, or it can be distributed over multiple network elements. Some or all of the modules may be selected according to actual needs to achieve the purpose of the solution in this embodiment. Those of ordinary skill in the art can understand and implement it without creative effort.
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到各实施方式可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件。基于这样的理解,上述技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在计算机可读存储介质中,如ROM/RAM、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行各个实施例或者实施例的某些部分所述的方法。From the description of the above embodiments, those skilled in the art can clearly understand that each embodiment can be implemented by means of software plus a necessary general hardware platform, and certainly can also be implemented by hardware. Based on this understanding, the above-mentioned technical solutions can be embodied in the form of software products in essence or the parts that make contributions to the prior art, and the computer software products can be stored in computer-readable storage media, such as ROM/RAM, magnetic A disc, an optical disc, etc., includes several instructions for causing a computer device (which may be a personal computer, a server, or a network device, etc.) to perform the methods described in various embodiments or some parts of the embodiments.
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。Finally, it should be noted that the above embodiments are only used to illustrate the technical solutions of the present invention, but not to limit them; although the present invention has been described in detail with reference to the foregoing embodiments, those of ordinary skill in the art should understand that it can still be The technical solutions described in the foregoing embodiments are modified, or some technical features thereof are equivalently replaced; and these modifications or replacements do not make the essence of the corresponding technical solutions deviate from the spirit and scope of the technical solutions of the embodiments of the present invention.
Claims (10)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201811587244.9ACN111368534A (en) | 2018-12-25 | 2018-12-25 | Application log noise reduction method and device |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201811587244.9ACN111368534A (en) | 2018-12-25 | 2018-12-25 | Application log noise reduction method and device |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN111368534Atrue CN111368534A (en) | 2020-07-03 |
Family
ID=71205896
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201811587244.9APendingCN111368534A (en) | 2018-12-25 | 2018-12-25 | Application log noise reduction method and device |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN111368534A (en) |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114564473A (en)* | 2022-04-28 | 2022-05-31 | 江苏益柏锐信息科技有限公司 | Data processing method, equipment and medium based on ERP enterprise management system |
| CN114896236A (en)* | 2022-05-25 | 2022-08-12 | 中卫市昊科电子技术有限公司 | Big data denoising optimization method and big data system applying artificial intelligence analysis |
| CN115757068A (en)* | 2022-11-17 | 2023-03-07 | 中电云数智科技有限公司 | Process log acquisition and automatic noise reduction method and system based on eBPF |
| CN116578534A (en)* | 2023-04-11 | 2023-08-11 | 华能信息技术有限公司 | Log message data format identification method and system |
| CN118626463A (en)* | 2024-08-12 | 2024-09-10 | 国能大渡河大数据服务有限公司 | A method for noise reduction of alarm logs based on multi-source threat intelligence |
Citations (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20120101965A1 (en)* | 2010-10-26 | 2012-04-26 | Microsoft Corporation | Topic models |
| CN102902752A (en)* | 2012-09-20 | 2013-01-30 | 新浪网技术(中国)有限公司 | Method and system for monitoring log |
| CN103678282A (en)* | 2014-01-07 | 2014-03-26 | 苏州思必驰信息科技有限公司 | Word segmentation method and device |
| CN105045812A (en)* | 2015-06-18 | 2015-11-11 | 上海高欣计算机系统有限公司 | Text topic classification method and system |
| CN106844424A (en)* | 2016-12-09 | 2017-06-13 | 宁波大学 | A kind of file classification method based on LDA |
| CN107092650A (en)* | 2017-03-13 | 2017-08-25 | 网宿科技股份有限公司 | A kind of Web Log Analysis method and device |
| CN107943791A (en)* | 2017-11-24 | 2018-04-20 | 北京奇虎科技有限公司 | A kind of recognition methods of refuse messages, device and mobile terminal |
| CN108170818A (en)* | 2017-12-29 | 2018-06-15 | 深圳市金立通信设备有限公司 | A kind of file classification method, server and computer-readable medium |
| CN108268560A (en)* | 2017-01-03 | 2018-07-10 | 中国移动通信有限公司研究院 | A kind of file classification method and device |
| CN108509793A (en)* | 2018-04-08 | 2018-09-07 | 北京明朝万达科技股份有限公司 | A kind of user's anomaly detection method and device based on User action log data |
| CN108667678A (en)* | 2017-03-29 | 2018-10-16 | 中国移动通信集团设计院有限公司 | A method and device for security detection of operation and maintenance logs based on big data |
- 2018
- 2018-12-25CNCN201811587244.9Apatent/CN111368534A/enactivePending
Patent Citations (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20120101965A1 (en)* | 2010-10-26 | 2012-04-26 | Microsoft Corporation | Topic models |
| CN102902752A (en)* | 2012-09-20 | 2013-01-30 | 新浪网技术(中国)有限公司 | Method and system for monitoring log |
| CN103678282A (en)* | 2014-01-07 | 2014-03-26 | 苏州思必驰信息科技有限公司 | Word segmentation method and device |
| CN105045812A (en)* | 2015-06-18 | 2015-11-11 | 上海高欣计算机系统有限公司 | Text topic classification method and system |
| CN106844424A (en)* | 2016-12-09 | 2017-06-13 | 宁波大学 | A kind of file classification method based on LDA |
| CN108268560A (en)* | 2017-01-03 | 2018-07-10 | 中国移动通信有限公司研究院 | A kind of file classification method and device |
| CN107092650A (en)* | 2017-03-13 | 2017-08-25 | 网宿科技股份有限公司 | A kind of Web Log Analysis method and device |
| CN108667678A (en)* | 2017-03-29 | 2018-10-16 | 中国移动通信集团设计院有限公司 | A method and device for security detection of operation and maintenance logs based on big data |
| CN107943791A (en)* | 2017-11-24 | 2018-04-20 | 北京奇虎科技有限公司 | A kind of recognition methods of refuse messages, device and mobile terminal |
| CN108170818A (en)* | 2017-12-29 | 2018-06-15 | 深圳市金立通信设备有限公司 | A kind of file classification method, server and computer-readable medium |
| CN108509793A (en)* | 2018-04-08 | 2018-09-07 | 北京明朝万达科技股份有限公司 | A kind of user's anomaly detection method and device based on User action log data |
Non-Patent Citations (1)
| Title |
|---|
| ANTON A.CHUVAKIN ET AL.: "日志管理与分析权威指南", vol. 1, 机械工业出版社, pages: 96 - 98* |
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114564473A (en)* | 2022-04-28 | 2022-05-31 | 江苏益柏锐信息科技有限公司 | Data processing method, equipment and medium based on ERP enterprise management system |
| CN114564473B (en)* | 2022-04-28 | 2022-07-12 | 江苏益柏锐信息科技有限公司 | Data processing method, equipment and medium based on ERP enterprise management system |
| CN114896236A (en)* | 2022-05-25 | 2022-08-12 | 中卫市昊科电子技术有限公司 | Big data denoising optimization method and big data system applying artificial intelligence analysis |
| CN115757068A (en)* | 2022-11-17 | 2023-03-07 | 中电云数智科技有限公司 | Process log acquisition and automatic noise reduction method and system based on eBPF |
| CN115757068B (en)* | 2022-11-17 | 2024-03-05 | 中电云计算技术有限公司 | Process log acquisition and automatic noise reduction method and system based on eBPF |
| CN116578534A (en)* | 2023-04-11 | 2023-08-11 | 华能信息技术有限公司 | Log message data format identification method and system |
| CN116578534B (en)* | 2023-04-11 | 2024-06-04 | 华能信息技术有限公司 | Log message data format identification method and system |
| CN118626463A (en)* | 2024-08-12 | 2024-09-10 | 国能大渡河大数据服务有限公司 | A method for noise reduction of alarm logs based on multi-source threat intelligence |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111368534A (en) | Application log noise reduction method and device | |
| CN107808011B (en) | Information classification and extraction method, device, computer equipment and storage medium | |
| CN109783631B (en) | Verification method, device, computer equipment and storage medium for community question and answer data | |
| CN110347840B (en) | Prediction method, system, equipment and storage medium for complaint text category | |
| CN110084289B (en) | Image annotation method, device, electronic device and storage medium | |
| CN112445775B (en) | Fault analysis method, device, equipment and storage medium of photoetching machine | |
| KR101948634B1 (en) | Failure prediction method of system resource for smart computing | |
| US20180067973A1 (en) | Column weight calculation for data deduplication | |
| CN107301120B (en) | Method and device for processing unstructured log | |
| CN109858029A (en) | A kind of data preprocessing method improving corpus total quality | |
| CN108804558A (en) | A kind of defect report automatic classification method based on semantic model | |
| CN114037478A (en) | Advertisement abnormal flow detection method and system, electronic equipment and readable storage medium | |
| CN114416511A (en) | System abnormity detection method, device, medium and electronic equipment based on log | |
| CN115858785A (en) | A sensitive data identification method and system based on big data | |
| CN116795977A (en) | Data processing methods, devices, equipment and computer-readable storage media | |
| CN116841779A (en) | Abnormality log detection method, abnormality log detection device, electronic device and readable storage medium | |
| CN112685374A (en) | Log classification method and device and electronic equipment | |
| Geetika et al. | An optimized hybrid deep learning model for code clone detection | |
| CN116721713B (en) | Data set construction method and device oriented to chemical structural formula identification | |
| CN117909970A (en) | Data processing method, device, equipment and medium | |
| CN108647263B (en) | Network address confidence evaluation method based on webpage segmentation crawling | |
| CN118797041A (en) | Classification model training method, device, equipment, medium and product | |
| CN117315694A (en) | Automatic medicine universal name recognition and classification system based on deep learning | |
| CN111581199B (en) | Intelligent data analysis system and method | |
| CN115904964A (en) | Error reporting test script classification method and device |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| RJ01 | Rejection of invention patent application after publication | Application publication date:20200703 | |
| RJ01 | Rejection of invention patent application after publication |