CN111367282A - A robot navigation method and system based on multimodal perception and reinforcement learning - Google Patents
A robot navigation method and system based on multimodal perception and reinforcement learningDownload PDFInfo
- Publication number
- CN111367282A CN111367282ACN202010157337.9ACN202010157337ACN111367282ACN 111367282 ACN111367282 ACN 111367282ACN 202010157337 ACN202010157337 ACN 202010157337ACN 111367282 ACN111367282 ACN 111367282A
- Authority
- CN
- China
- Prior art keywords
- robot
- network
- reinforcement learning
- perception
- multimodal
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 238000000034methodMethods0.000titleclaimsabstractdescription83
- 230000008447perceptionEffects0.000titleclaimsabstractdescription42
- 230000002787reinforcementEffects0.000titleclaimsabstractdescription40
- 230000011218segmentationEffects0.000claimsabstractdescription63
- 230000004927fusionEffects0.000claimsabstractdescription19
- 238000005259measurementMethods0.000claimsabstractdescription19
- 238000013486operation strategyMethods0.000claimsabstractdescription7
- 238000012549trainingMethods0.000claimsdescription25
- 238000004088simulationMethods0.000claimsdescription18
- 230000008569processEffects0.000claimsdescription14
- 230000003068static effectEffects0.000claimsdescription11
- 238000003860storageMethods0.000claimsdescription4
- 238000012546transferMethods0.000claimsdescription2
- 230000003993interactionEffects0.000abstractdescription3
- 230000007246mechanismEffects0.000abstractdescription3
- 230000009975flexible effectEffects0.000abstractdescription2
- 238000002474experimental methodMethods0.000description8
- 238000012360testing methodMethods0.000description8
- 238000013135deep learningMethods0.000description6
- 230000006870functionEffects0.000description6
- 230000009471actionEffects0.000description5
- 230000008901benefitEffects0.000description4
- 238000013461designMethods0.000description4
- 238000011156evaluationMethods0.000description4
- 238000002679ablationMethods0.000description3
- 238000010586diagramMethods0.000description3
- 239000000284extractSubstances0.000description3
- 238000003709image segmentationMethods0.000description3
- 238000005457optimizationMethods0.000description3
- 238000013459approachMethods0.000description2
- 230000000295complement effectEffects0.000description2
- 238000009826distributionMethods0.000description2
- 238000000605extractionMethods0.000description2
- 238000012545processingMethods0.000description2
- 230000004044responseEffects0.000description2
- 230000000007visual effectEffects0.000description2
- ORILYTVJVMAKLC-UHFFFAOYSA-NAdamantaneNatural productsC1C(C2)CC3CC1CC2C3ORILYTVJVMAKLC-UHFFFAOYSA-N0.000description1
- 230000004913activationEffects0.000description1
- 238000013528artificial neural networkMethods0.000description1
- 230000009286beneficial effectEffects0.000description1
- 238000004590computer programMethods0.000description1
- 238000011217control strategyMethods0.000description1
- 230000000694effectsEffects0.000description1
- 238000009472formulationMethods0.000description1
- 230000007774longtermEffects0.000description1
- 239000000203mixtureSubstances0.000description1
- 238000012986modificationMethods0.000description1
- 230000004048modificationEffects0.000description1
- 239000010813municipal solid wasteSubstances0.000description1
- 238000009877renderingMethods0.000description1
- 230000001953sensory effectEffects0.000description1
- 238000000926separation methodMethods0.000description1
- 230000007704transitionEffects0.000description1
Images









Classifications
- G—PHYSICS
- G05—CONTROLLING; REGULATING
- G05D—SYSTEMS FOR CONTROLLING OR REGULATING NON-ELECTRIC VARIABLES
- G05D1/00—Control of position, course, altitude or attitude of land, water, air or space vehicles, e.g. using automatic pilots
- G05D1/02—Control of position or course in two dimensions
- G05D1/021—Control of position or course in two dimensions specially adapted to land vehicles
- G05D1/0257—Control of position or course in two dimensions specially adapted to land vehicles using a radar
- G—PHYSICS
- G05—CONTROLLING; REGULATING
- G05D—SYSTEMS FOR CONTROLLING OR REGULATING NON-ELECTRIC VARIABLES
- G05D1/00—Control of position, course, altitude or attitude of land, water, air or space vehicles, e.g. using automatic pilots
- G05D1/02—Control of position or course in two dimensions
- G05D1/021—Control of position or course in two dimensions specially adapted to land vehicles
- G05D1/0212—Control of position or course in two dimensions specially adapted to land vehicles with means for defining a desired trajectory
- G05D1/0221—Control of position or course in two dimensions specially adapted to land vehicles with means for defining a desired trajectory involving a learning process
- G—PHYSICS
- G05—CONTROLLING; REGULATING
- G05D—SYSTEMS FOR CONTROLLING OR REGULATING NON-ELECTRIC VARIABLES
- G05D1/00—Control of position, course, altitude or attitude of land, water, air or space vehicles, e.g. using automatic pilots
- G05D1/02—Control of position or course in two dimensions
- G05D1/021—Control of position or course in two dimensions specially adapted to land vehicles
- G05D1/0231—Control of position or course in two dimensions specially adapted to land vehicles using optical position detecting means
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02T—CLIMATE CHANGE MITIGATION TECHNOLOGIES RELATED TO TRANSPORTATION
- Y02T10/00—Road transport of goods or passengers
- Y02T10/10—Internal combustion engine [ICE] based vehicles
- Y02T10/40—Engine management systems
Landscapes
- Engineering & Computer Science (AREA)
- Radar, Positioning & Navigation (AREA)
- Remote Sensing (AREA)
- Physics & Mathematics (AREA)
- Aviation & Aerospace Engineering (AREA)
- General Physics & Mathematics (AREA)
- Automation & Control Theory (AREA)
- Electromagnetism (AREA)
- Traffic Control Systems (AREA)
- Control Of Position, Course, Altitude, Or Attitude Of Moving Bodies (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明涉及机器人导航技术领域,尤其涉及一种基于多模感知与强化学习 的机器人导航方法及系统。The invention relates to the technical field of robot navigation, in particular to a robot navigation method and system based on multimodal perception and reinforcement learning.
背景技术Background technique
本部分的陈述仅仅是提供了与本发明相关的背景技术信息,不必然构成在 先技术。The statements in this section merely provide background information related to the present invention and do not necessarily constitute prior art.
自主导航是移动机器人非常重要的功能,并且一些现有方法已经在结构化 环境中展现出良好的性能。然而,设计一种对于非结构化的真实世界环境可靠 的机器人导航系统仍然具有挑战性,该环境通常包含具有不可预测轨迹的动态 障碍物。这要求机器人以实时智能地处理与障碍物的各种交互作用。Autonomous navigation is a very important function for mobile robots, and some existing methods have demonstrated good performance in structured environments. However, it remains challenging to design a robotic navigation system that is reliable for unstructured real-world environments, which often contain dynamic obstacles with unpredictable trajectories. This requires the robot to intelligently handle various interactions with obstacles in real time.
存在一些依赖于深度学习(DL)的工作来解决复杂环境中机器人导航的挑 战性问题。然而,基于DL的方法典型地更多地集中于对环境的感知,而没有显 式的学习导航策略。少数基于DL的方法在实际的结构化环境中使用离线注释直 接学习策略,但是,此类注释不仅耗时且费力,尤其是在非结构化环境中大规 模生成更困难,而且还受一组固定,有限和离散的动作状态约束。因此,在现 实世界的动态复杂环境中,学习到的策略可能无法满足导航的要求。There are some works that rely on deep learning (DL) to address the challenging problem of robot navigation in complex environments. However, DL-based methods typically focus more on the perception of the environment without explicit learning of navigation strategies. Few DL-based methods use offline annotations to directly learn policies in practical structured environments, however, such annotations are not only time-consuming and labor-intensive, especially more difficult to generate at scale in unstructured environments, but also subject to a fixed set of , finite and discrete action state constraints. Therefore, in the dynamic and complex environment of the real world, the learned policies may not meet the requirements of navigation.
相比之下,强化学习(RL)通过奖励机制直接学习当前环境的最优策略。 实际上,这与人类的决策过程更加一致,在决策过程中,通过与周围环境互动 来制定策略,并根据环境的即时响应通过反复试验直接修改策略模型。此外, RL不需要特别地基于人类受试者提供的策略注释进行监督学习,因为它通过最 大化预期的长期奖励来寻找最佳策略。In contrast, reinforcement learning (RL) directly learns the optimal policy for the current environment through a reward mechanism. In practice, this is more in line with the human decision-making process, where policies are developed by interacting with the surrounding environment, and the policy model is directly modified by trial and error based on the immediate response of the environment. Furthermore, RL does not require supervised learning specifically based on policy annotations provided by human subjects, as it finds the best policy by maximizing the expected long-term reward.
发明人发现,现有技术在RL中使用雷达数据来学习避障策略。但是,雷达 的稀疏点云只能感知特定高度的信息,无法处理包含任意高度和形状的障碍物 的复杂环境,不足以训练实际复杂环境中机器人导航的策略模型。The inventors found that existing techniques use radar data in RL to learn obstacle avoidance strategies. However, the sparse point cloud of radar can only perceive the information of a specific height, and cannot deal with the complex environment containing obstacles of arbitrary height and shape, which is not enough to train the strategy model of robot navigation in the actual complex environment.
现有技术研究了基于视觉的RL作为替代方法,然而,从视觉传感器获得的 图像不能明确提供深度信息,在基于视觉的导航工作中,模拟环境与现实环境 之间的差距是不可避免的。无论仿真引擎多么强大,渲染的图像都不可能完美 地模拟现实世界,因此在模拟环境中训练的导航系统在现实世界中的表现不太 可能达到同样的效果,尤其是当它包含车辆和行人等动态障碍时。Vision-based RL has been studied in the prior art as an alternative approach, however, images obtained from vision sensors do not provide depth information explicitly, and in vision-based navigation work, the gap between simulated and real environments is unavoidable. No matter how powerful the simulation engine is, it is impossible for the rendered image to simulate the real world perfectly, so a navigation system trained in a simulated environment is unlikely to perform as well in the real world, especially when it includes vehicles, pedestrians, etc. During dynamic obstacles.
发明内容SUMMARY OF THE INVENTION
有鉴于此,本发明提出了一种基于多模感知与强化学习的机器人导航方法 及系统,通过深度强化学习框架融合从RGB图像和雷达数据中获得的知识,能 够实现在高动态和拥挤的现实世界环境中可靠的导航和避免碰撞。In view of this, the present invention proposes a robot navigation method and system based on multi-modal perception and reinforcement learning, which can achieve high dynamics and crowded reality by integrating knowledge obtained from RGB images and radar data through a deep reinforcement learning framework. Reliable navigation and collision avoidance in world environments.
为了实现上述目的,在一些实施方式中,采用如下技术方案:In order to achieve the above purpose, in some embodiments, the following technical solutions are adopted:
一种基于多模感知与强化学习的机器人导航方法,包括:A robot navigation method based on multimodal perception and reinforcement learning, including:
获取机器人在设定时刻所观测场景的RGB图片,采用训练好的分割网络将 所述RGB图片转换为二元(道路和非道路)分割图;Obtain the RGB picture of the observed scene of the robot at the set moment, and adopt the trained segmentation network to convert the RGB picture into a binary (road and non-road) segmentation map;
分别采集所述设定时刻的激光雷达数据以及机器人的速度度量数据;Collect the lidar data and the speed measurement data of the robot at the set time respectively;
将所述二元分割图、激光雷达数据以及机器人的速度度量数据输入到训练 好的多模融合深度网络模型中,得到机器人的最优运行策略,实现对机器人的 导航。Input the binary segmentation map, lidar data and the speed measurement data of the robot into the trained multi-mode fusion deep network model to obtain the optimal operation strategy of the robot and realize the navigation of the robot.
本发明将分割图作为RGB图像的中间表示,分割图忽略了低级图像细节的 扰动,在仿真和现实环境中始终保持很高的一致性;将RGB图像分割图和雷达 数据融合作为输入特征数据,能够实现在高动态和拥挤的现实世界环境中可靠 的导航和避免碰撞。The invention uses the segmentation map as the intermediate representation of the RGB image, the segmentation map ignores the disturbance of low-level image details, and always maintains high consistency in simulation and real environments; the RGB image segmentation map and radar data are fused as input feature data, Enables reliable navigation and collision avoidance in highly dynamic and crowded real-world environments.
在另一些实施方式中,采用如下技术方案:In other embodiments, the following technical solutions are adopted:
一种基于多模感知与强化学习的机器人导航系统,包括:A robot navigation system based on multimodal perception and reinforcement learning, including:
用于获取机器人在设定时刻所观测场景的RGB图片,采用训练好的分割网 络将所述RGB图片转换为二元分割图的装置;Be used to obtain the RGB picture of the observed scene of the robot at the set moment, adopt the well-trained segmentation network to convert the RGB picture into the device of the binary segmentation map;
用于分别采集所述设定时刻的激光雷达数据以及机器人的速度度量数据的 装置;A device for collecting the lidar data at the set moment and the speed measurement data of the robot respectively;
用于将所述二元分割图、激光雷达数据以及机器人的速度度量数据输入到 训练好的多模融合深度网络模型中,得到机器人的最优运行策略的装置。A device for inputting the binary segmentation map, lidar data and speed measurement data of the robot into the trained multi-mode fusion deep network model to obtain the optimal operation strategy of the robot.
在另一些实施方式中,采用如下技术方案:In other embodiments, the following technical solutions are adopted:
一种机器人,包括:机器人本体和控制器,所述控制器被配置为执行上述 的基于多模感知与深度强化学习的机器人自主导航方法,实现机器人运行路径 的导航。A robot, comprising: a robot body and a controller, the controller is configured to execute the above-mentioned robot autonomous navigation method based on multimodal perception and deep reinforcement learning, so as to realize the navigation of the robot running path.
一种计算机可读存储介质,其中存储有多条指令,所述指令适于由终端设 备的处理器加载并执行上述的基于多模感知与深度强化学习的机器人自主导航 方法。A computer-readable storage medium, wherein a plurality of instructions are stored, and the instructions are suitable for being loaded by a processor of a terminal device and executing the above-mentioned method for autonomous navigation of a robot based on multimodal perception and deep reinforcement learning.
与现有技术相比,本发明的有益效果是:Compared with the prior art, the beneficial effects of the present invention are:
(1)感知完整性。与单模态模式相比,本发明采用多模机制可确保对环境 更加完整的感知,因为图像和雷达数据在各种场景中都是互补的。这对于基于 RL的策略模块在复杂环境中学习正确的导航策略至关重要,因为其学习过程仅 依赖于在线感知。(1) Perceived integrity. Compared to the single-modal mode, the present invention uses a multi-modal mechanism to ensure a more complete perception of the environment because the image and radar data are complementary in various scenarios. This is crucial for RL-based policy modules to learn correct navigation policies in complex environments, as their learning process only relies on online perception.
(2)模型的可移植性。直接使用RGB图像可能会遇到将在非真实渲染组成 的仿真模拟环境中学习的模型转移到现实环境的问题。本发明使用分割图作为 RGB图像的中间表示,该图像在模拟和真实场景中均具有一致的外观。因此, 可以轻松地从仿真转移到现实世界,而无需进行其他微调。(2) The portability of the model. Working directly with RGB images may run into the problem of transferring a model learned in a simulated simulated environment consisting of non-realistic renderings to a real-world environment. The present invention uses a segmentation map as an intermediate representation of an RGB image that has a consistent appearance in both simulated and real scenes. Therefore, it is easy to move from simulation to the real world without additional fine-tuning.
(3)策略优化。基于DL的方法本质上是通过离线训练来预测可能合适的策 略,这对于当前环境可能不是最佳选择,因为用于搜索策略的一组动作状态受 到限制。相比之下,本发明基于RL的方法可通过在线交互直接学习在无限搜索 空间中围绕周围环境优化的导航策略,从而产生灵活的动作,从而提高了其避 免碰撞的能力。(3) Strategy optimization. DL-based methods essentially predict potentially suitable policies through offline training, which may not be optimal for the current environment because the set of action states used to search for policies is limited. In contrast, the RL-based method of the present invention can directly learn a navigation strategy optimized around the surrounding environment in an infinite search space through online interaction, resulting in flexible actions that improve its ability to avoid collisions.
本发明的附加方面的优点将在下面的描述中部分给出,部分将从下面的描述 中变得明显,或通过本发明的实践了解到。Advantages of additional aspects of the present invention will be set forth in part in the description which follows, and in part will be apparent from the description below, or may be learned by practice of the invention.
附图说明Description of drawings
图1为本发明实施例中基于多模感知与深度强化学习的导航模型示意图;1 is a schematic diagram of a navigation model based on multimodal perception and deep reinforcement learning in an embodiment of the present invention;
图2为本发明实施例中基于多模感知与深度强化学习的导航框架示意图;2 is a schematic diagram of a navigation framework based on multimodal perception and deep reinforcement learning in an embodiment of the present invention;
图3为本发明实施例中基于多模感知与深度强化学习的机器人自主导航方 法流程图;3 is a flowchart of a robot autonomous navigation method based on multimodal perception and deep reinforcement learning in the embodiment of the present invention;
图4(a)-(d)分别为本发明实施例中仿真和真实场景实例示意图;4(a)-(d) are schematic diagrams of simulation and real scene examples in the embodiment of the present invention;
图5为本发明实施方式中仿真场景和真实场景的语义分割结果;Fig. 5 is the semantic segmentation result of simulation scene and real scene in the embodiment of the present invention;
图6(a)-(b)分别为本发明实施方式中两阶段训练场景中的平均奖励。Figures 6(a)-(b) are respectively the average rewards in the two-stage training scenario in the embodiment of the present invention.
具体实施方式Detailed ways
应该指出,以下详细说明都是例示性的,旨在对本申请提供进一步的说明。 除非另有指明,本发明使用的所有技术和科学术语具有与本申请所属技术领域 的普通技术人员通常理解的相同含义。It should be noted that the following detailed description is exemplary and intended to provide further explanation of the application. Unless otherwise defined, all technical and scientific terms used herein have the same meaning as commonly understood by one of ordinary skill in the art to which this application belongs.
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图 限制根据本申请的示例性实施方式。如在这里所使用的,除非上下文另外明确 指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说 明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、 组件和/或它们的组合。It should be noted that the terminology used herein is for the purpose of describing specific embodiments only, and is not intended to limit the exemplary embodiments according to the present application. As used herein, unless the context clearly dictates otherwise, the singular is intended to include the plural as well, furthermore, it is to be understood that when the terms "comprising" and/or "including" are used in this specification, it indicates that There are features, steps, operations, devices, components, and/or combinations thereof.
在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。Embodiments of the invention and features of the embodiments may be combined with each other without conflict.
实施例一Example 1
在一个或多个实施方式中,公开了一种基于多模感知与强化学习的机器人 导航方法,如图2和图3所示,包括以下步骤:In one or more embodiments, a robot navigation method based on multimodal perception and reinforcement learning is disclosed, as shown in Figure 2 and Figure 3, comprising the following steps:
(1)获取机器人在设定时刻所观测场景的RGB图片,采用训练好的分割 网络将所述RGB图片转换为二元分割图;(1) obtain the RGB picture of the observed scene of the robot at the set moment, and adopt the trained segmentation network to convert the RGB picture into a binary segmentation map;
(2)分别采集所述设定时刻的激光雷达数据以及机器人的速度度量数据;(2) respectively collecting the laser radar data and the speed measurement data of the robot at the set time;
(3)将所述二元分割图、激光雷达数据以及机器人的速度度量数据输入到 训练好的多模融合深度网络模型中,得到机器人的最优运行策略。(3) Input the binary segmentation map, lidar data and speed measurement data of the robot into the trained multi-mode fusion deep network model to obtain the optimal operation strategy of the robot.
具体地,本发明实施例设计深度强化学习框架,融合从RGB图像和雷达数 据中获得的知识;参照图1,本发明实施例方法在模拟环境中训练,能够在高动 态和拥挤的现实世界环境中可靠的导航和避免碰撞。Specifically, the embodiment of the present invention designs a deep reinforcement learning framework to fuse the knowledge obtained from RGB images and radar data; with reference to FIG. 1 , the method of the embodiment of the present invention is trained in a simulated environment, and can be used in a highly dynamic and crowded real-world environment. reliable navigation and collision avoidance.
下面对本实施例方法进行详细的说明。The method of this embodiment will be described in detail below.
将本实施例方法的实现过程分成两个部分:感知部分和策略部分。The implementation process of the method in this embodiment is divided into two parts: a perception part and a strategy part.
感知部分将RGB图像转换为语义分割图,并对雷达数据进行规范化,再结 合机器人速度的度量作为基于强化学习的策略部分的输入。最终输出是线速度 和角速度,它们将被输入到机器人控制器中,实现对机器人行驶路径的导航。The perception part converts RGB images into semantic segmentation maps and normalizes the radar data, which is combined with a measure of robot speed as the input to the reinforcement learning-based policy part. The final output is the linear velocity and angular velocity, which will be input into the robot controller to realize the navigation of the robot's travel path.
(1)首先对强化学习进行相关说明:(1) First, the reinforcement learning is explained:
1)问题表述:首先定义强化学习问题以及将在本实施例其余部分中使用的 符号。将导航策略的优化公式化为有限视野部分可观察的马尔可夫决策过程 (POMDP)。在每个离散时间步长t处,RL机器人观察当前状态st∈S并在at∈A处 选择一个动作。在一个时间步长之后,机器人会收到奖励r(st,at)并转换为新状态 st+1∈S。将任务定义为Episode长度为T个时间步长的有限视野问题。因此,该 过程一直持续到T个时间步长或遇到提前终止信号,例如碰撞或驶上人行道。 机器人的目标是学习最终使期望收益最大化的最优控制策略π(at|st;θπ):1) Problem formulation: First define the reinforcement learning problem and the notation that will be used in the rest of this example. The optimization of the navigation strategy is formulated as a partially observable Markov decision process (POMDP) with limited field of view. At each discrete time step t, the RL robot observes the current state st ∈ S and chooses an action at at ∈ A. After one time step, the robot receives a reward r(st , att ) and transitions to a new state st+1 ∈ S. Define the task as a finite field of view problem with episodes of length T time steps. Therefore, the process continues until T time steps or until an early termination signal is encountered, such as a collision or driving onto the sidewalk. The goal of the robot is to learn an optimal control policy π(at |st ; θπ ) that ultimately maximizes the expected return:

这里折扣因子0<γ<1。Here
深度强化学习有几种经典算法。例如DQN,DDPG,A3C和PPO。作为用于处 理复杂任务中连续动作的流行深度强化学习算法,近端策略优化(PPO)算法通 过最大化替代目标函数来搜索最佳策略:There are several classical algorithms for deep reinforcement learning. For example DQN, DDPG, A3C and PPO. As a popular deep reinforcement learning algorithm for handling continuous actions in complex tasks, the Proximal Policy Optimization (PPO) algorithm searches for the best policy by maximizing the surrogate objective function:


其中
2)强化学习设置:2) Reinforcement learning setup:
状态空间。状态st由三部分组成:分割图st1,雷达状态st2和测量状态st3。 分割图由感知模块生成。雷达状态由雷达数据的最后三个连续帧组成,而测量 状态表示当前线速度v和角速度wstate space. The state st consists of three parts: the segmentation map st1 , the radar state st2 and the measurement state st3 . The segmentation map is generated by the perception module. The radar state consists of the last three consecutive frames of radar data, while the measurement state represents the current linear velocity v and angular velocity w
动作空间。为了与实际运动控制更加一致,使用CARLA ROS软件包,该软 件包允许通过线速度和角速度对机器人进行控制。使用离散动作表示运动可能 会导致训练过程更轻松。然而,速度和转向都存在不均匀性,这使得现实世界 中的运动控制变得更加不现实。因此,对v∈[0,2]m/s和w∈[-1,1]rad/s使用连续 值。action space. In order to be more consistent with the actual motion control, the CARLA ROS software package is used, which allows the control of the robot with linear and angular velocities. Using discrete movements to represent movement may result in an easier training process. However, there are inhomogeneities in both speed and steering, which make real-world motion control even more unrealistic. Therefore, use continuous values for v∈[0,2]m/s and w∈[-1,1]rad/s.
奖励设计。我们的目标是避免在拥挤的环境中(包含各种静态和动态对象) 导航时发生碰撞,并最大程度地减少机器人移动到其他车道或人行道的次数。 机器人应遵循右侧交通规则行驶,而其他交通规则将被忽略。Reward design. Our goal is to avoid collisions when navigating in crowded environments (containing a variety of static and dynamic objects) and minimize the number of times the robot moves to other lanes or sidewalks. The robot should follow the traffic rules on the right, and other traffic rules will be ignored.
为了指导机器人实现这一目标,设计了如下的六项奖励函数。To guide the robot to achieve this goal, the following six reward functions are designed.
首先,为确保机器人按照右侧驾驶规则行驶,当机器人走到对面的车道时, 给予负奖励:First, to ensure that the robot drives according to the right-hand driving rule, when the robot walks to the opposite lane, a negative reward is given:
rlane=-1,否则为rlane=0 (4)rlane = -1, otherwise rlane = 0 (4)
其次,为了鼓励机器人尽可能快地行驶,我们将奖励rv设置为与机器人的行 驶速度成比例,因子cv=1.8。为了提高机器人的行驶平稳性,我们还将奖励rw设 置为与其角速度的平方成反比,因子cw=-0.5。因此,驾驶过程中机器人的大转 弯将受到严重惩罚。Second, to encourage the robot to drive as fast as possible, we set the reward rv to be proportional to the robot's travel speed with a factor cv = 1.8. To improve the driving stability of the robot, we also set the reward rw to be inversely proportional to the square of its angular velocity, with a factor cw =-0.5. Therefore, the big turns of the robot during driving will be severely punished.
rv=cv×v,rv =cv ×v,
rw=cw×w2, (5)rw =cw ×w2 , (5)
然后,当机器人与环境中的其他静态或移动物体(例如路障,行人或 车辆)碰撞时,将受到rc的惩罚:Then, when the robot collides with other static or moving objects in the environment (such as roadblocks, pedestrians or vehicles), it will be penalized byrc :
rc=-10,否则为rc=0 (6) 此外,一旦机器人行驶到人行道上,我们将采用大的负奖励roff:rc = -10, otherwise rc = 0 (6) Also, once the robot is on the pavement, we apply a large negative rewardroff :
roff=-10,否则为roff=0 (7)roff = -10, otherwise roff = 0 (7)
最后,为了防止机器人陷入停顿,我们在每次决策时给予较小的恒定损失 rtime,设置为-0.1。Finally, to prevent the robot from stalling, we give a small constant loss rtime at each decision, set to -0.1.
因此,总奖励r(st,at)定义为以上六个项的总和:Therefore, the total reward r(st, at) is defined as the sum of the above six terms:
r(st,at)=rlane+rv+rw+rc+roff+rtime (8)r(st ,at )=rlane +rv +rw +rc +roff +rtime (8)
终止条件。存在三种终止条件:一是机器人与任何障碍物碰撞;二是机器 人行驶到人行道上;三是当前Episode的时间步T累计到2000。Termination condition. There are three termination conditions: first, the robot collides with any obstacle; second, the robot travels to the sidewalk; third, the time step T of the current episode accumulates to 2000.
(2)感知部分(2) Perception part
感知模块旨在感知周围环境,并缓解仿真环境与现实世界之间的差距。将 学习到的策略模块从仿真环境转移到现实中通常失败的主要原因是,在仿真环 境中很难精确模拟现实中的某些因素,例如纹理,照明,传感器噪声。这些因 素导致仿真和现实环境之间的图像细节有很大差异。为了解决此问题,本实施 例将分割图作为中间级别的视觉表征,并将其用作策略模块的输入。这是因为 分割图忽略了低级图像细节的扰动,并在仿真和现实环境中始终保持了很高的 一致性。因此,通过监督学习的范式训练分割网络,将原始RGB图像转换为二 元分割图,即道路和非道路。可以表示为:st1=fseg(Ot;θseg)The perception module is designed to perceive the surrounding environment and alleviate the gap between the simulated environment and the real world. The main reason why the transfer of learned policy modules from the simulated environment to the real world usually fails is that it is difficult to accurately simulate some factors in the real world, such as texture, lighting, sensor noise, in the simulated environment. These factors lead to large differences in image detail between simulated and real-world environments. To address this issue, this embodiment takes the segmentation map as an intermediate-level visual representation and uses it as the input to the policy module. This is because the segmentation map ignores the perturbation of low-level image details and maintains high consistency in both simulated and real-world environments. Therefore, a segmentation network is trained through the paradigm of supervised learning to convert raw RGB images into binary segmentation maps, i.e. roads and non-roads. It can be expressed as: st1 = fseg (Ot ; θseg )
这里,fseg表示分割模型而θseg表示它的参数,Ot是机器人在t时刻所观测场 景的RGB图片。Here, fseg represents the segmentation model and θseg represents its parameters, and Ot is the RGB picture of the scene observed by the robot at time t.
从理论上讲,分割模型fseg需要深度分割网络,例如GSCNN。但是,这样的 网络通常无法利用机器人的机载计算资源来实现实时导航。一种替代方法是使 用轻量级的分割网络,例如ERFNet。然而,由于缺乏足够的训练数据,这种轻 量级的网络很难泛化到复杂的环境。因此,采用老师学生模型将GSCNN嵌入到 ERFNet的训练过程中,以解决此问题。In theory, the segmentation model fseg requires a deep segmentation network such as GSCNN. However, such networks are often unable to utilize the robot's onboard computing resources for real-time navigation. An alternative is to use a lightweight segmentation network such as ERFNet. However, due to the lack of sufficient training data, such lightweight networks are difficult to generalize to complex environments. Therefore, the teacher-student model is adopted to embed GSCNN into the training process of ERFNet to solve this problem.
在实现中,首先使用公开的Cityscapes数据集来训练老师网络GSCNN。然 后,将在现实环境中收集的未标记的RGB图像馈入网络以生成分割图。由GSCNN 生成的分割图用作未标记RGB图像的标签,再结合其他已标记数据以训练学生 网络ERFNet。最后,在模拟和现实环境中都用ERFNet进行机载图像分割。In the implementation, the publicly available Cityscapes dataset is first used to train the teacher network GSCNN. Then, the unlabeled RGB images collected in the real environment are fed into the network to generate segmentation maps. The segmentation maps generated by GSCNN are used as labels for unlabeled RGB images, which are combined with other labeled data to train the student network ERFNet. Finally, airborne image segmentation is performed with ERFNet in both simulated and real-world environments.
当然,本实施例中,老师网络GSCNN和学生网络ERFNet仅是一种示例,本 领域技术人员可以根据需要选择其他分割网络。Of course, in this embodiment, the teacher network GSCNN and the student network ERFNet are only examples, and those skilled in the art can select other segmentation networks as required.
仅依赖RGB图像的语义分割无法提供对于自主导航很重要的准确深度信息。 因此,将激光雷达数据st2引入感知模块。与RGB图像相比,由于从雷达获得的 信息对纹理和照明不敏感,因此它们在仿真和实际环境之间的差异方面相对较 鲁棒。对雷达数据进行归一化操作,并引入最近的历史三帧作为策略模块的输 入。为了获得来自机器人的实时反馈,包括代理的线速度v和角速度w的测量被 引入作为另一个感知输入st3。最后,感知模块将合成状态st输出到策略模块,其 中st=(st1,st2,st3)表示由分割图,雷达数据和测量值组成的状态。Semantic segmentation relying only on RGB images cannot provide accurate depth information that is important for autonomous navigation. Therefore, the lidar datast2 is introduced into the perception module. Compared to RGB images, since the information obtained from radar is insensitive to texture and lighting, they are relatively robust to differences between simulated and real environments. The radar data is normalized and the three most recent historical frames are introduced as the input of the strategy module. To obtain real-time feedback from the robot, measurements including the agent's linear velocity v and angular velocity w are introduced as another sensory input st3 . Finally, the perception module outputs the synthesized statest to the policy module, where s t= (st1 , st2 , st3 ) represents the state consisting of segmentation map, radar data and measurements.
本质上,多模感知模块通过图像分割提取复杂的非结构化环境的结构表示, 这有助于强化学习机器人更好地理解环境的高级语义并加快对最佳策略的搜 索。此外,激光雷达能提供环境准确的深度信息,分割图和雷达数据的结合能 对环境的表示达成互补,因此它们可确保使用更丰富的信息获得完整的感知, 从而显著地使策略模块受益。Essentially, the multimodal perception module extracts the structural representation of complex unstructured environments through image segmentation, which helps reinforcement learning robots to better understand the high-level semantics of the environment and speed up the search for optimal policies. In addition, lidar can provide accurate depth information of the environment, and the combination of segmentation map and radar data can complement the representation of the environment, so they can ensure full perception with richer information, which can significantly benefit the policy module.
(3)策略部分(3) Strategy part
策略模块旨在通过强化学习找到最佳的导航策略。在许多情况下,由于每 种传感技术的固有局限性,通过单模态数据学习的策略不够鲁棒。因此,如图2 所示,利用多模数据,在其中将学习到的多模特征融合到一个深度网络中。首 先,策略模块将感知模块提供的分割图和雷达数据作为输入,并分别提取其特 征。然后融合其特征和测量值,经过全连接网络输出策略π。最后,使用并行 PPO算法来优化策略π。可以表示为π=ffus(Ft1,Ft2,st3;θf)The strategy module aims to find the optimal navigation strategy through reinforcement learning. In many cases, strategies learned from unimodal data are not robust enough due to the inherent limitations of each sensing technology. Therefore, as shown in Figure 2, multimodal data is utilized, in which the learned multimodal features are fused into a deep network. First, the policy module takes the segmentation map and radar data provided by the perception module as input, and extracts their features respectively. Then its features and measured values are fused, and the policy π is output through a fully connected network. Finally, a parallel PPO algorithm is used to optimize the policy π. It can be expressed as π=ffus (Ft1 , Ft2 , st3 ; θf )
其中Ft1和Ft2分别代表处理策略模块中的分割图和雷达数据的两个通道的输 出,以及ffus表示具有可学习参数θf的全连接层和ReLU激活层,将它们融合以 输出策略π。where Ft1 and Ft2 represent the outputs of the two channels processing the segmentation map and radar data in the policy module, respectively, and ffus represents the fully connected layer and ReLU activation layer with learnable parameters θf , which are fused to output the policy pi.
值得注意的是,由于状态空间的扩展,基于多模融合方案的策略网络很难 学习。为了解决这个问题,本实施例提出一种模态分离学习方法作为辅助训练 工具。我们注意到,仿真环境中的雷达特征提取与现实世界高度一致。It is worth noting that the policy network based on the multimodal fusion scheme is difficult to learn due to the expansion of the state space. In order to solve this problem, this embodiment proposes a mode separation learning method as an auxiliary training tool. We note that the radar feature extraction in the simulated environment is highly consistent with the real world.
因此,引入了一个避障网络,在仿真环境中训练基于雷达的避障策略。本 实施例利用现有技术公开的基于雷达的网络模型在Stage仿真器上训练强化学 习机器人。如图4(a)所示,在仿真器上建立了一个新的训练场景。在此仿真 环境中,首先使用基于雷达的避障网络对机器人进行训练。然后,将提取雷达 数据特征的相应层网络参数迁移给多模融合模型并且固定它。以此方式,要学 习的特征的尺寸大大减小。Therefore, an obstacle avoidance network is introduced to train a radar-based obstacle avoidance strategy in a simulated environment. This embodiment uses the radar-based network model disclosed in the prior art to train the reinforcement learning robot on the Stage simulator. As shown in Fig. 4(a), a new training scenario is established on the simulator. In this simulated environment, the robot is first trained using a radar-based obstacle avoidance network. Then, the network parameters of the corresponding layers extracted from the radar data are transferred to the multimodal fusion model and fixed. In this way, the size of the features to be learned is greatly reduced.
此外,本实施例将导航任务分为两个子任务:遵守交通规则和避障。因为 强化学习机器人在包含大量信息的复杂环境中(如同时放置静态和/或动态对 象)直接学习驾驶策略非常困难,为了确保多模融合策略可以有效地学习上述 任务,本实施例采用了简单到复杂的课程学习训练范式。In addition, this embodiment divides the navigation task into two subtasks: obeying traffic rules and avoiding obstacles. Because it is very difficult for reinforcement learning robots to directly learn driving policies in complex environments containing a lot of information (such as placing static and/or dynamic objects at the same time), in order to ensure that the multimodal fusion strategy can effectively learn the above tasks, this embodiment adopts simple to Complex curriculum learning training paradigm.
这种范例使机器人能够通过相对简单的驾驶任务快速学习。This paradigm enables robots to learn quickly from relatively simple driving tasks.
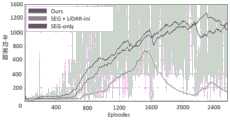
在仿真环境中,道路上不添加任何障碍物,机器人基于实时采集的图像、 激光雷达等数据运用多模感知与深度强化学习的导航模型,不断试错、学习以 快速学会简单的驾驶任务;例如,如何沿着道路驾驶和理解交通规则等;机器 人达到可靠的性能后,将简单的任务停止训练,然后进入复杂任务的阶段,在 该阶段将大量车辆,行人和路障添加进来。不断地训练强化学习机器人以学习 最佳驾驶策略使机器人在驾驶过程中避免潜在的碰撞。In the simulation environment, no obstacles are added on the road. The robot uses multi-modal perception and deep reinforcement learning navigation model based on real-time collected images, lidar and other data to continuously trial and error and learn to quickly learn simple driving tasks; for example , how to drive along the road and understand traffic rules, etc.; after the robot achieves reliable performance, it stops training for simple tasks, and then enters the stage of complex tasks, where a large number of vehicles, pedestrians and roadblocks are added. The reinforcement learning robot is continuously trained to learn the optimal driving policy so that the robot can avoid potential collisions while driving.
(4)实验结果(4) Experimental results
本实施例在仿真和现实环境中进行机器人导航实验,以证明本实施例方法 相对于基线方法的优越性。In this embodiment, robot navigation experiments are carried out in simulation and real environments to prove the superiority of the method of this embodiment relative to the baseline method.
1)实验设置和实施细节1) Experimental setup and implementation details
①仿真环境:Stage仿真器是一个开源的移动机器人模拟器,它提供了由移 动机器人和传感器组成的虚拟世界。首先在Stage中训练了基于雷达的避障策 略,其中使用了长2.3米,宽1.4米的机器人。另外,仅训练8个机器人,如 图4(a)所示,其中每个带激光的矩形代表一个机器人。该模型训练了6000 Episode,总共12个小时。本实施例提出的具有多模融合方案的RL框架最终在 CARLA中训练,CARLA是一种基于Unreal游戏引擎的用于自动驾驶的开源城市 场景仿真器。CARLA目前提供七个高度逼真的复杂城市场景,如图4(b)所示。在我们的实验中,将晴朗白天条件下的Town 2场景用于策略训练,而将Town 1 场景用作机器人未见过的环境进行评估。为了训练感知网络,使用CARLA的自 动驾驶模式收集原始RGB图像及其对应的分割图。此外,为了使机器人能够从 意外漂移中恢复正常,还使用CARLA手动控制模式通过随机远程遥控来收集数 据。所有4.6K仿真图像均以5HZ的频率采集。① Simulation environment: Stage simulator is an open source mobile robot simulator, which provides a virtual world composed of mobile robots and sensors. The radar-based obstacle avoidance strategy is first trained in Stage, in which a robot with a length of 2.3 meters and a width of 1.4 meters is used. Additionally, only 8 robots are trained, as shown in Fig. 4(a), where each rectangle with a laser represents a robot. The model was trained for 6000 Episodes, a total of 12 hours. The RL framework with the multimodal fusion scheme proposed in this embodiment is finally trained in CARLA, an open source urban scene simulator for autonomous driving based on the Unreal game engine. CARLA currently provides seven highly realistic complex urban scenes, as shown in Fig. 4(b). In our experiments, the
②现实环境:图4(c)和图4(d)分别示出了真实的室外和室内环境。采 用老师学生模型将真实世界场景的图像转换为语义分割标签。当在现实世界中 进行实验时,在机器人上安装了高度为1.2米,向下倾斜为12°且视野为60° 的树莓派RGB相机。最终以3HZ的频率通过遥控器收集了1.9K原始RGB图像。 该机器人还配备了2D LiDAR传感器Hokuyo UTM-30LX和车载计算资源NVIDIA Jetson TX2。需要注意的是,为验证本实施例方法的泛化能力,测试环境与收 集的RGB图像以训练分割模型的场景存在显着差异。② Realistic environment: Figure 4(c) and Figure 4(d) show the real outdoor and indoor environments, respectively. A teacher-student model is employed to convert images of real-world scenes into semantic segmentation labels. When conducting experiments in the real world, a Raspberry Pi RGB camera with a height of 1.2 m, a downward tilt of 12° and a field of view of 60° is installed on the robot. Finally, a 1.9K original RGB image was collected through the remote control at a frequency of 3HZ. The robot is also equipped with a 2D LiDAR sensor Hokuyo UTM-30LX and an on-board computing resource NVIDIA Jetson TX2. It should be noted that, in order to verify the generalization ability of the method of this embodiment, there is a significant difference between the test environment and the scene where the RGB images are collected to train the segmentation model.
表1:超参数设置Table 1: Hyperparameter Settings
实现细节:对于感知部分本实施例的目标是获得“道路”和“非道路”区 域,因此语义分割的标签被分为两类:道路和非道路。然后,将公开的Cityscapes 数据集和仿真数据以及真实场景数据进行组合,以训练ERFNet。将所有图像数 据调整为84×84的大小,批量大小设置为48,对模型进行500次迭代训练。使 用ADAM优化器,其初始学习率为0.001,并在150次迭代后将其降低至0.0001。 权重衰减设置为0.0002。图5显示了仿真场景和真实场景的语义分割结果;其 中,图5中的第一行为CARLA中的仿真场景;第二行为真实世界的室内场景; 第三行为真实世界的室外场景。可以看出,本实施例方法可以将室内和室外场 景可靠地划分为“道路”和“非道路”区域。这些二元分割图用作策略模块的 一个输入。对于策略模块,使用表1中列出的超参数来实施培训和测试。尤其 是,策略网络更新的批处理大小在简单阶段设置为256,然后在复杂阶段增加到 1024。复杂阶段有6个并行机器人同时训练。Implementation details: For the perception part, the goal of this embodiment is to obtain "road" and "non-road" regions, so the labels for semantic segmentation are divided into two categories: road and non-road. Then, the public Cityscapes dataset and simulation data and real scene data are combined to train ERFNet. All image data were resized to a size of 84 × 84, the batch size was set to 48, and the model was trained for 500 iterations. An ADAM optimizer was used with an initial learning rate of 0.001 and was reduced to 0.0001 after 150 iterations. Weight decay is set to 0.0002. Figure 5 shows the semantic segmentation results of the simulated and real scenes; among them, the first row in Figure 5 is the simulated scene in CARLA; the second row is the real-world indoor scene; the third row is the real-world outdoor scene. It can be seen that the method of this embodiment can reliably divide indoor and outdoor scenes into "road" and "non-road" areas. These binary segmentation maps are used as an input to the policy module. For the policy module, training and testing are implemented using the hyperparameters listed in Table 1. In particular, the batch size of policy network updates is set to 256 in the simple stage and then increased to 1024 in the complex stage. The complex stage has 6 parallel robots trained simultaneously.
2)基线方法和评估指标2) Baseline methods and evaluation metrics
①基线方法:在实验中,将本实施例方法与4种基线方法进行了比较,如 下所示:1. Baseline method: In the experiment, the method of this embodiment was compared with 4 kinds of baseline methods, as follows:
DroNet:这是一种现有的基于DL的方法,仅使用RGB图像预测控制策略。 尽管已将其应用于现实环境中的机器人导航任务中,但由于遇到障碍物时通常 会终止运动,因此它遭受了停顿问题的困扰。DroNet: This is an existing DL-based method that uses only RGB images to predict control strategies. Although it has been applied to robot navigation tasks in real-world environments, it suffers from the stalling problem because motion is usually terminated when an obstacle is encountered.
DroNet+LiDAR:LiDAR是当前基于RL的最佳避障方法,该方法仅依赖雷 达数据并确保移动的机器人可以避免碰撞障碍物。因此,我们结合DroNet和 LiDA提供了一个基线,该基线可以在现实环境中实现自主导航和避障。DroNet+LiDAR: LiDAR is the current best RL-based obstacle avoidance method, which relies only on radar data and ensures that a moving robot can avoid colliding with obstacles. Therefore, we combine DroNet and LiDA to provide a baseline that enables autonomous navigation and obstacle avoidance in real-world environments.
SEG+LiDAR-ini:这是本实施例方法的消融版本,其中雷达特征提取部分 是从头开始训练的,相比之下,在本实施例方法中,该模型是通过避障网络预 先训练并固定的。SEG+LiDAR-ini: This is the ablation version of the method of this embodiment, in which the radar feature extraction part is trained from scratch, in contrast, in the method of this embodiment, the model is pre-trained and fixed by the obstacle avoidance network of.
SEG-only:表示本实施例方法的另一种消融版本,该方法仅将分割图用作 网络输入,而未考虑雷达数据。因此,它本质上是一种单模态RL方法。SEG-only: Represents another ablation version of the method of this embodiment, which uses only the segmentation map as the network input, without considering radar data. Therefore, it is essentially a unimodal RL method.
②评估指标:在每个测试Episode中,机器人均在随机位置启动,终止条 件为:1)发生任何碰撞;2)达到最大时间(对于仿真场景,设置为100秒; 对于室外场景,设置为150秒,室内场景50秒);3)当机器人到达指定区域 时,会终止其导航。②Evaluation index: In each test episode, the robot starts at a random position, and the termination conditions are: 1) any collision occurs; 2) the maximum time to reach (for the simulation scene, set to 100 seconds; for the outdoor scene, set to 150 seconds, indoor scene 50 seconds); 3) When the robot reaches the designated area, its navigation will be terminated.
距离度量展示Episode中机器人驾驶的长度。总时间记录了机器人在 Episode中驾驶了多长时间。还报告了机器人的平均速度,该速度反映了它是否 可以有效地绕过障碍物。此外,记录车道外时间,该时间定义为机器人在整个 驾驶活动中出现在其他车道或人行道上的时间百分比。The distance metric shows how long the robot drives in the Episode. The total time records how long the robot drives during the episode. Also reported is the robot's average speed, which reflects whether it can efficiently circumvent obstacles. Additionally, out-of-lane time is recorded, which is defined as the percentage of time the robot is present in other lanes or sidewalks throughout its driving activity.
3)仿真环境中的评估3) Evaluation in the simulation environment
①训练过程的消融研究:①Ablation study of training process:
无障碍物的简单阶段。图6(a)显示了在从简单到复杂的学习范例的简单 阶段中,本实施例方法的三个版本的学习曲线。在此阶段,由于机器人的周围 环境没有障碍,因此将RGB图像分为“道路”和“非道路”区域的分割图的学 习为机器人导航提供了最重要的线索。因此,在图6(a)中,观察到SEG-only 版本表现良好。本实施例方法的完整版本也具有与SEG-only相比可观的性能。 这是因为在此版本中,用于从LiDAR数据中学习深度特征的图层具有固定的参 数,因此最终对整个网络进行了训练,以最大程度地学习分割图。相比之下, SEG+LiDAR-ini的训练以网络为结尾,该网络对于学习分段图不是最佳的,但 会损害LiDAR数据的学习。因此,通过SEG+LiDAR-ini网络学习的控制策略 在没有障碍的环境中无法实现较高的平均回报。Simple stage without obstacles. Figure 6(a) shows the learning curves for three versions of the method of this embodiment in the simple phase of the learning paradigm from simple to complex. At this stage, since the robot's surroundings are free of obstacles, the learning of segmentation maps that divide the RGB image into "road" and "non-road" regions provides the most important cues for robot navigation. Therefore, in Fig. 6(a), the SEG-only version is observed to perform well. The full version of the method of this embodiment also has considerable performance compared to SEG-only. This is because in this release, the layers used to learn deep features from LiDAR data have fixed parameters, so the entire network is finally trained to learn segmentation maps to the greatest extent possible. In contrast, the training of SEG+LiDAR-ini ends with a network that is not optimal for learning segmented graphs but impairs learning from LiDAR data. Therefore, the control policy learned through the SEG+LiDAR-ini network cannot achieve high average returns in an environment without obstacles.
具有静态和/或动态障碍的复杂阶段。Complex stages with static and/or dynamic obstacles.
图6(b)显示了复杂阶段的学习曲线,在复杂阶段,机器人经常在场景中 遇到静态和/或动态障碍。我们观察到,在训练速度和平均奖励方面,本实施例 方法的完整版本的性能明显优于SEG+LiDAR-ini。这样的结果也证明了模态分 离学习方案的好处,其中首先仅基于LiDAR数据预先训练了碰撞避免网络,然 后将网络的学习参数转移到多模融合模型中。在实践中,SEG+LiDAR-ini提供 的导航存在一系列问题,包括移至道路左侧,不平顺的行驶路径和意外转弯等。 本实施例方法的完整版本还优于SEG-only的消融版本按训练速度指示。实际上, SEG-only输出的机器人速度v要差得多,因为它遵循均值为0且方差为9的正 态分布。这意味着,机器人在遇到障碍物时必须频繁停车和/或显着减速。相比 之下,本实施例基于多模融合方案的完整方法的v输出分布的平均值为2,方差 为0.1,这表明导航是理想的,因为机器人可以快速地绕过障碍物并安全避免 潜在的碰撞。Figure 6(b) shows the learning curve for the complex stage, where the robot often encounters static and/or dynamic obstacles in the scene. We observe that the full version of the method of this example outperforms SEG+LiDAR-ini significantly in terms of training speed and average reward. Such results also demonstrate the benefits of a modality-separated learning scheme, in which a collision avoidance network is first pre-trained based on LiDAR data only, and then the learned parameters of the network are transferred to a multimodal fusion model. In practice, the navigation provided by SEG+LiDAR-ini suffers from a series of problems, including shifting to the left side of the road, rough driving paths and unexpected turns. The full version of the method of this embodiment also outperforms the SEG-only ablation version as indicated by the training speed. In fact, the robot speed v output by SEG-only is much worse because it follows a normal distribution with
②与基准的定量比较:② Quantitative comparison with benchmark:
通过城市驾驶模拟器将建议的方法与基准方法进行比较。为了测试自主导 航系统是否可以处理涉及静态和动态对象的拥挤场景,设计了不同的任务来评 估机器人在不同场景下的反应模式。The proposed method is compared with a baseline method through an urban driving simulator. To test whether the autonomous navigation system can handle crowded scenarios involving static and dynamic objects, different tasks are designed to evaluate the robot's response patterns in different scenarios.
任务:1)场景中没有障碍物。在此任务中,机器人在驾驶时遵循靠右的交 通规则;2)场景中包含各种静态障碍物,包括静止的车辆,盒子,桶和垃圾箱。 在此任务中,训练机器人避免在行驶中发生碰撞;3)场景包含各种动态障碍物, 包括车辆和行人。这三个任务的起始位置设置相同。每个实验进行了3次,并 报告了平均结果。Tasks: 1) There are no obstacles in the scene. In this task, the robot follows the right-hand traffic rule while driving; 2) the scene contains various static obstacles, including stationary vehicles, boxes, buckets, and trash cans. In this task, the robot is trained to avoid collisions while driving; 3) The scene contains various dynamic obstacles, including vehicles and pedestrians. The start position settings for these three tasks are the same. Each experiment was performed 3 times and the average results are reported.
结果:如表2所示,实验表明,在训练环境中没有障碍物(即任务1)时, 本实施例方法和基准线都可以拉长距离。即使DroNet和DroNet+LiDAR的驱 动策略相对保守,因为它们的平均速度较低。在看不见的测试环境中,使用 DroNet的机器人的驱动速度非常慢,因为它通常需要花费时间来识别道路上的 阴影(例如路灯,建筑物和机器人本身的阴影)。此外,由于DroNet通常倾 向于适应训练现场,因此在看不见的环境中进行测试时,机器人出现在其他车 道上的时间会大大增加。Results: As shown in Table 2, experiments show that when there are no obstacles in the training environment (ie, task 1), the method of this embodiment and the baseline can both extend the distance. Even the driving strategies of DroNet and DroNet+LiDAR are relatively conservative due to their low average speed. In the unseen test environment, the driving speed of the robot using DroNet is very slow, because it usually takes time to recognize the shadows on the road (such as street lights, buildings and shadows of the robot itself). Furthermore, since DroNet generally tends to adapt to the training scene, the time the robot spends in other lanes is greatly increased when tested in unseen environments.
表2在仿真环境中进行定量比较Table 2 Quantitative comparison in simulation environment

在任务2中,本实施例方法可以在训练和测试环境中更好地避免与静态障 碍物的碰撞,而DroNet在遇到障碍物时很大程度上无法避免碰撞,通常会导致 静止或意外碰撞。尽管DroNet+LiDAR可以提高避障性能,但仍然不如本实施 例方法有效。因此,本实施例方法对应于更长的行驶距离和更高的平均速度。In
在任务3中,由于车辆和行人是动态的,因此机器人不会经常处于停顿状 态。对于DroNet方法,机器人运动的平均距离比任务2中的更长。但是,由于 动态场景更加复杂,因此发生碰撞的可能性增加,并且机器人的平均驱动时间 变得更短。In task 3, since vehicles and pedestrians are dynamic, the robot is not always in a standstill state. For the DroNet method, the average distance of robot motion is longer than in
4)真实环境中的评估4) Evaluation in real environment
在这里,将仅使用CARLA模拟器训练的策略模型直接部署到现实世界中, 以验证其健壮性和泛化能力。Here, the policy model trained using only the CARLA simulator is directly deployed into the real world to verify its robustness and generalization ability.
①在室外场景中进行定量比较:① Quantitative comparison in outdoor scenes:
将DroNet和DroNet+LiDAR的方法在具有挑战性的周围环境(包括急转 弯)的多个校园车道中进行比较。图5的底部显示了一些测试方案。如表3所 示,表3的结果中,实际机器人的最大线速度为1m/s;让机器人在室外场景 中分别运行150秒和在室内场景中运行50秒,并报告机器人最终覆盖的导航距 离。The DroNet and DroNet+LiDAR methods are compared across multiple campus lanes in challenging surroundings, including sharp turns. Some test scenarios are shown at the bottom of Figure 5. As shown in Table 3, in the results of Table 3, the maximum linear speed of the actual robot is 1m/s; let the robot run for 150 seconds in the outdoor scene and 50 seconds in the indoor scene, and report the navigation distance that the robot finally covers .
本实施例的方法和两个基线都可以在几乎没有动态障碍的简单方案中完成 任务,而本实施例的方法在导航距离上胜过基线方法。机器人可以在固定时间 内运行的距离。在拥挤的环境中,DroNet和DroNet+LiDAR都无法像本实施例 方法那样驱动长距离路径。这主要是因为本实施例方法可以在具有高动态对象 的场景中找到安全的导航路径,而使用任一基线方法的机器人由于发生碰撞的 可能性较高,因此移动缓慢。Both the method of this embodiment and both baselines can accomplish the task in a simple scheme with few dynamic obstacles, and the method of this embodiment outperforms the baseline method in navigation distance. The distance the robot can travel in a fixed amount of time. In crowded environments, neither DroNet nor DroNet+LiDAR can drive long-distance paths as well as the method of this embodiment. This is mainly because the method of this embodiment can find a safe navigation path in a scene with highly dynamic objects, while the robot using either baseline method moves slowly due to the high possibility of collision.
表3现实世界中的定量比较Table 3 Quantitative comparison in the real world

②室内场景中的定量比较:② Quantitative comparison in indoor scenes:
为了证明多模方法可以将感知部分与策略部分分离,在室内环境中进行了 实验,图5的中间行显示了一些测试场景。这是具有挑战性的,因为训练场景 基于模拟的户外环境CARLA。在实施中,使用室内走廊图像重新训练ERFNet分 割模型。在室内环境中进行测试时,将上述实验中使用的语义分割模型替换为 重新训练的模型,并且策略模型保持不变。结果表明,尽管室内环境与用来训 练策略模型的场景有很大不同,但是本实施例的多模策略模型仍然优于室内环 境中的基线,尤其是在空间有限的拥挤走廊中。To demonstrate that the multimodal approach can separate the perception part from the policy part, experiments are conducted in an indoor environment, and some test scenarios are shown in the middle row of Figure 5. This is challenging because the training scenario is based on the simulated outdoor environment CARLA. In the implementation, the ERFNet segmentation model is retrained using indoor corridor images. When tested in an indoor environment, the semantic segmentation model used in the above experiments was replaced with a retrained model, and the policy model remained unchanged. The results show that even though the indoor environment is quite different from the scene used to train the policy model, the multimodal policy model of this example still outperforms the baselines in the indoor environment, especially in crowded corridors with limited space.
综上所述,本实施例在策略部分提出了一种多模融合方案,以同时利用图 像和雷达数据。但是,由于较大的状态空间,多模策略学习比单模态策略学习 更加困难。而且,RL在具有各种动态障碍的现实环境中很难学习有效的策略。 因此,通过三种方式减轻了多模策略学习的难度。To sum up, this embodiment proposes a multi-mode fusion scheme in the strategy section to utilize both image and radar data. However, multimodal policy learning is more difficult than unimodal policy learning due to the larger state space. Moreover, RL struggles to learn effective policies in real-world environments with various dynamic obstacles. Therefore, the difficulty of multimodal policy learning is alleviated in three ways.
第一,策略部分分别学习图像和雷达数据。训练基于雷达的避障策略,然 后将提取雷达特征的组件迁移到多模策略模块中,同时将从RGB图像派生的语 义分割图直接输入到多模策略模块中。First, the policy part learns from image and radar data separately. The radar-based obstacle avoidance strategy is trained, and then the components that extract radar features are transferred to the multimodal strategy module, while the semantic segmentation maps derived from RGB images are directly input into the multimodal strategy module.
第二,进行从简单到复杂的训练。在简单阶段,在没有障碍的环境中训练, 因此RL机器人可以快速而有效地了解各种驾驶任务和交通规则。然后,在复杂 阶段,机器人专注于在拥挤的场景(包括静态和动态障碍物)中学习可靠的避 免碰撞策略。Second, train from simple to complex. In the simple phase, trained in an environment without obstacles, the RL robot can learn various driving tasks and traffic rules quickly and efficiently. Then, in the complex phase, the robot focuses on learning reliable collision avoidance policies in crowded scenes including static and dynamic obstacles.
第三,基于交通规则,碰撞惩罚和速度平稳性设计了六项奖励函数。Third, six reward functions are designed based on traffic rules, collision penalty and speed smoothness.
考虑到机器人配备的计算资源有限,因此对于感知部分,采用轻量级的神 经网络,该网络可以将RGB图像可靠地划分为道路和非道路区域。生成的分割 图可以视为场景的中级视觉特征,并且在模拟场景和真实场景中均显示一致的 外观。但是,训练网络需要足够大的数据集,否则由于现实环境的多样性而无 法很好地概括。因此,采用老师学生模型提取分割知识,提高网络的泛化能力。Considering that the robot is equipped with limited computing resources, for the perception part, a lightweight neural network is adopted, which can reliably divide the RGB image into road and non-road areas. The generated segmentation maps can be considered as mid-level visual features of the scene and show a consistent appearance in both simulated and real scenes. However, training the network requires a sufficiently large dataset, otherwise it cannot generalize well due to the diversity of real-world environments. Therefore, the teacher-student model is used to extract segmentation knowledge and improve the generalization ability of the network.
实施例二
在一个或多个实施方式中,公开了一种基于多模感知与强化学习的机器人 导航系统,包括:In one or more embodiments, a robot navigation system based on multimodal perception and reinforcement learning is disclosed, including:
用于获取机器人在设定时刻所观测场景的RGB图片,采用训练好的分割网 络将所述RGB图片转换为二元分割图的装置;Be used to obtain the RGB picture of the observed scene of the robot at the set moment, adopt the well-trained segmentation network to convert the RGB picture into the device of the binary segmentation map;
用于分别采集所述设定时刻的激光雷达数据以及机器人的速度度量数据的 装置;A device for collecting the lidar data at the set moment and the speed measurement data of the robot respectively;
用于将所述二元分割图、激光雷达数据以及机器人的速度度量数据输入到 训练好的多模融合深度网络模型中,得到机器人的最优运行策略的装置。A device for inputting the binary segmentation map, lidar data and speed measurement data of the robot into the trained multi-mode fusion deep network model to obtain the optimal operation strategy of the robot.
上述装置的具体实现方式采用实施例一中公开的方法,不再赘述。The specific implementation manner of the above apparatus adopts the method disclosed in the first embodiment, and will not be repeated here.
实施例三Embodiment 3
在一个或多个实施方式中,公开了一种终端设备,包括服务器,所述服务 器包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序, 所述处理器执行所述程序时实现实施例一中公开的基于多模感知与深度强化学 习的机器人自主导航方法,为了简洁,不再赘述。In one or more embodiments, a terminal device is disclosed, including a server, the server including a memory, a processor, and a computer program stored on the memory and executable on the processor, the processor executing the The program implements the autonomous navigation method for a robot based on multimodal perception and deep reinforcement learning disclosed in the first embodiment, which is not repeated for brevity.
应理解,本实施例中,处理器可以是中央处理单元CPU,处理器还可以是 其他通用处理器、数字信号处理器DSP、专用集成电路ASIC,现成可编程门阵 列FPGA或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组 件等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。It should be understood that, in this embodiment, the processor may be a central processing unit CPU, and the processor may also be other general-purpose processors, digital signal processors DSP, application-specific integrated circuits ASIC, off-the-shelf programmable gate array FPGA or other programmable logic devices , discrete gate or transistor logic devices, discrete hardware components, etc. A general purpose processor may be a microprocessor or the processor may be any conventional processor or the like.
存储器可以包括只读存储器和随机存取存储器,并向处理器提供指令和数 据、存储器的一部分还可以包括非易失性随机存储器。例如,存储器还可以存 储设备类型的信息。The memory may include read-only memory and random access memory and provide instructions and data to the processor, and a portion of the memory may also include non-volatile random access memory. For example, the memory may also store information on the type of device.
在实现过程中,上述方法的各步骤可以通过处理器中的硬件的集成逻辑电 路或者软件形式的指令完成。In the implementation process, each step of the above-mentioned method can be completed by an integrated logic circuit of hardware in the processor or an instruction in the form of software.
上述方法可以直接体现为硬件处理器执行完成,或者用处理器中的硬件及 软件模块组合执行完成。软件模块可以位于随机存储器、闪存、只读存储器、 可编程只读存储器或者电可擦写可编程存储器、寄存器等本领域成熟的存储介 质中。该存储介质位于存储器,处理器读取存储器中的信息,结合其硬件完成 上述方法的步骤。为避免重复,这里不再详细描述。The above method can be directly embodied as a hardware processor to execute and complete, or a combination of hardware and software modules in the processor to execute and complete. The software modules can be located in random access memory, flash memory, read-only memory, programmable read-only memory, or electrically erasable programmable memory, registers, and other storage media that are mature in the art. The storage medium is located in the memory, and the processor reads the information in the memory and completes the steps of the above method in combination with its hardware. To avoid repetition, detailed description is omitted here.
本领域普通技术人员可以意识到,结合本实施例描述的各示例的单元即算 法步骤,能够以电子硬件或者计算机软件和电子硬件的结合来实现。这些功能 究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。 专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但 是这种实现不应认为超出本申请的范围。Those of ordinary skill in the art can realize that the unit, that is, the algorithm step of each example described in conjunction with this embodiment, can be implemented by electronic hardware or a combination of computer software and electronic hardware. Whether these functions are performed in hardware or software depends on the specific application and design constraints of the technical solution. Skilled artisans may implement the described functionality using different methods for each particular application, but such implementations should not be considered beyond the scope of this application.
上述虽然结合附图对本发明的具体实施方式进行了描述,但并非对本发明 保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上, 本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明 的保护范围以内。Although the specific embodiments of the present invention have been described above in conjunction with the accompanying drawings, they do not limit the scope of protection of the present invention. Those skilled in the art should understand that on the basis of the technical solutions of the present invention, those skilled in the art do not need to pay creative work. Various modifications or deformations that can be made are still within the protection scope of the present invention.
Claims (10)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010157337.9ACN111367282B (en) | 2020-03-09 | 2020-03-09 | Robot navigation method and system based on multimode perception and reinforcement learning |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010157337.9ACN111367282B (en) | 2020-03-09 | 2020-03-09 | Robot navigation method and system based on multimode perception and reinforcement learning |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN111367282Atrue CN111367282A (en) | 2020-07-03 |
| CN111367282B CN111367282B (en) | 2022-06-07 |
Family
ID=71208662
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010157337.9AActiveCN111367282B (en) | 2020-03-09 | 2020-03-09 | Robot navigation method and system based on multimode perception and reinforcement learning |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN111367282B (en) |
Cited By (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111988220A (en)* | 2020-08-14 | 2020-11-24 | 山东大学 | Multi-target disaster backup method and system among data centers based on reinforcement learning |
| CN111975769A (en)* | 2020-07-16 | 2020-11-24 | 华南理工大学 | Meta-learning-based obstacle avoidance method for mobile robots |
| CN112114592A (en)* | 2020-09-10 | 2020-12-22 | 南京大学 | Method for realizing autonomous crossing of movable frame-shaped barrier by unmanned aerial vehicle |
| CN112130570A (en)* | 2020-09-27 | 2020-12-25 | 重庆大学 | Blind guiding robot of optimal output feedback controller based on reinforcement learning |
| CN112270306A (en)* | 2020-11-17 | 2021-01-26 | 中国人民解放军军事科学院国防科技创新研究院 | Unmanned vehicle track prediction and navigation method based on topological road network |
| CN112304314A (en)* | 2020-08-27 | 2021-02-02 | 中国科学技术大学 | Distributed multi-robot navigation method |
| CN112965081A (en)* | 2021-02-05 | 2021-06-15 | 浙江大学 | Simulated learning social navigation method based on feature map fused with pedestrian information |
| CN112966591A (en)* | 2021-03-03 | 2021-06-15 | 河北工业职业技术学院 | Knowledge map deep reinforcement learning migration system for mechanical arm grabbing task |
| CN113093779A (en)* | 2021-03-25 | 2021-07-09 | 山东大学 | Robot motion control method and system based on deep reinforcement learning |
| CN113848750A (en)* | 2021-09-14 | 2021-12-28 | 清华大学 | Two-wheeled robot simulation system and robot system |
| CN113869482A (en)* | 2021-07-19 | 2021-12-31 | 北京工业大学 | An adaptive energy-saving control method and system for smart street lamps based on deep reinforcement learning |
| CN114564004A (en)* | 2021-10-29 | 2022-05-31 | 泉州装备制造研究所 | Method, system and equipment for end-to-end navigation of mobile robot |
| WO2022160430A1 (en)* | 2021-01-27 | 2022-08-04 | Dalian University Of Technology | Method for obstacle avoidance of robot in the complex indoor scene based on monocular camera |
| CN114859940A (en)* | 2022-07-05 | 2022-08-05 | 北京建筑大学 | Robot movement control method, device, equipment and storage medium |
| CN115062888A (en)* | 2022-03-17 | 2022-09-16 | 中国人民解放军国防科技大学 | A UAV air combat decision optimization training method, system, equipment and medium |
| CN119026779A (en)* | 2024-09-09 | 2024-11-26 | 华南理工大学 | A method and system for collecting and transporting urban garbage based on reinforcement learning |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPWO2024019107A1 (en)* | 2022-07-22 | 2024-01-25 |
Citations (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105157697A (en)* | 2015-07-31 | 2015-12-16 | 天津大学 | Indoor mobile robot pose measurement system and measurement method based on optoelectronic scanning |
| CN109087303A (en)* | 2018-08-15 | 2018-12-25 | 中山大学 | The frame of semantic segmentation modelling effect is promoted based on transfer learning |
| CN109506658A (en)* | 2018-12-26 | 2019-03-22 | 广州市申迪计算机系统有限公司 | Robot autonomous localization method and system |
| CN109764876A (en)* | 2019-02-21 | 2019-05-17 | 北京大学 | Multimodal fusion positioning method for unmanned platform |
| CN110006435A (en)* | 2019-04-23 | 2019-07-12 | 西南科技大学 | A visual aided navigation method for substation inspection robot based on residual network |
| CN110243370A (en)* | 2019-05-16 | 2019-09-17 | 西安理工大学 | A 3D Semantic Map Construction Method for Indoor Environment Based on Deep Learning |
| CN110245567A (en)* | 2019-05-16 | 2019-09-17 | 深圳前海达闼云端智能科技有限公司 | Barrier-avoiding method, device, storage medium and electronic equipment |
| CN110320883A (en)* | 2018-03-28 | 2019-10-11 | 上海汽车集团股份有限公司 | A kind of Vehicular automatic driving control method and device based on nitrification enhancement |
| CN110781976A (en)* | 2019-10-31 | 2020-02-11 | 重庆紫光华山智安科技有限公司 | Extension method of training image, training method and related device |
| CN110795821A (en)* | 2019-09-25 | 2020-02-14 | 的卢技术有限公司 | Deep reinforcement learning training method and system based on scene differentiation |
- 2020
- 2020-03-09CNCN202010157337.9Apatent/CN111367282B/enactiveActive
Patent Citations (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105157697A (en)* | 2015-07-31 | 2015-12-16 | 天津大学 | Indoor mobile robot pose measurement system and measurement method based on optoelectronic scanning |
| CN110320883A (en)* | 2018-03-28 | 2019-10-11 | 上海汽车集团股份有限公司 | A kind of Vehicular automatic driving control method and device based on nitrification enhancement |
| CN109087303A (en)* | 2018-08-15 | 2018-12-25 | 中山大学 | The frame of semantic segmentation modelling effect is promoted based on transfer learning |
| CN109506658A (en)* | 2018-12-26 | 2019-03-22 | 广州市申迪计算机系统有限公司 | Robot autonomous localization method and system |
| CN109764876A (en)* | 2019-02-21 | 2019-05-17 | 北京大学 | Multimodal fusion positioning method for unmanned platform |
| CN110006435A (en)* | 2019-04-23 | 2019-07-12 | 西南科技大学 | A visual aided navigation method for substation inspection robot based on residual network |
| CN110243370A (en)* | 2019-05-16 | 2019-09-17 | 西安理工大学 | A 3D Semantic Map Construction Method for Indoor Environment Based on Deep Learning |
| CN110245567A (en)* | 2019-05-16 | 2019-09-17 | 深圳前海达闼云端智能科技有限公司 | Barrier-avoiding method, device, storage medium and electronic equipment |
| CN110795821A (en)* | 2019-09-25 | 2020-02-14 | 的卢技术有限公司 | Deep reinforcement learning training method and system based on scene differentiation |
| CN110781976A (en)* | 2019-10-31 | 2020-02-11 | 重庆紫光华山智安科技有限公司 | Extension method of training image, training method and related device |
Non-Patent Citations (1)
| Title |
|---|
| 王大方: "基于深度强化学习的机器人导航研究", 《中国优秀硕士学位论文全文数据库 信息科技辑》* |
Cited By (22)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111975769A (en)* | 2020-07-16 | 2020-11-24 | 华南理工大学 | Meta-learning-based obstacle avoidance method for mobile robots |
| CN111988220A (en)* | 2020-08-14 | 2020-11-24 | 山东大学 | Multi-target disaster backup method and system among data centers based on reinforcement learning |
| CN111988220B (en)* | 2020-08-14 | 2021-05-28 | 山东大学 | Method and system for multi-objective disaster backup between data centers based on reinforcement learning |
| CN112304314A (en)* | 2020-08-27 | 2021-02-02 | 中国科学技术大学 | Distributed multi-robot navigation method |
| CN112114592B (en)* | 2020-09-10 | 2021-12-17 | 南京大学 | A method for autonomously crossing movable frame-shaped obstacles by unmanned aerial vehicles |
| CN112114592A (en)* | 2020-09-10 | 2020-12-22 | 南京大学 | Method for realizing autonomous crossing of movable frame-shaped barrier by unmanned aerial vehicle |
| CN112130570A (en)* | 2020-09-27 | 2020-12-25 | 重庆大学 | Blind guiding robot of optimal output feedback controller based on reinforcement learning |
| CN112130570B (en)* | 2020-09-27 | 2023-03-28 | 重庆大学 | Blind guiding robot of optimal output feedback controller based on reinforcement learning |
| CN112270306A (en)* | 2020-11-17 | 2021-01-26 | 中国人民解放军军事科学院国防科技创新研究院 | Unmanned vehicle track prediction and navigation method based on topological road network |
| CN112270306B (en)* | 2020-11-17 | 2022-09-30 | 中国人民解放军军事科学院国防科技创新研究院 | Unmanned vehicle track prediction and navigation method based on topological road network |
| WO2022160430A1 (en)* | 2021-01-27 | 2022-08-04 | Dalian University Of Technology | Method for obstacle avoidance of robot in the complex indoor scene based on monocular camera |
| CN112965081A (en)* | 2021-02-05 | 2021-06-15 | 浙江大学 | Simulated learning social navigation method based on feature map fused with pedestrian information |
| CN112965081B (en)* | 2021-02-05 | 2023-08-01 | 浙江大学 | Simulated learning social navigation method based on feature map fused with pedestrian information |
| CN112966591A (en)* | 2021-03-03 | 2021-06-15 | 河北工业职业技术学院 | Knowledge map deep reinforcement learning migration system for mechanical arm grabbing task |
| CN113093779A (en)* | 2021-03-25 | 2021-07-09 | 山东大学 | Robot motion control method and system based on deep reinforcement learning |
| CN113869482A (en)* | 2021-07-19 | 2021-12-31 | 北京工业大学 | An adaptive energy-saving control method and system for smart street lamps based on deep reinforcement learning |
| CN113848750A (en)* | 2021-09-14 | 2021-12-28 | 清华大学 | Two-wheeled robot simulation system and robot system |
| CN114564004A (en)* | 2021-10-29 | 2022-05-31 | 泉州装备制造研究所 | Method, system and equipment for end-to-end navigation of mobile robot |
| CN115062888A (en)* | 2022-03-17 | 2022-09-16 | 中国人民解放军国防科技大学 | A UAV air combat decision optimization training method, system, equipment and medium |
| CN115062888B (en)* | 2022-03-17 | 2025-05-27 | 中国人民解放军国防科技大学 | A UAV air combat decision optimization training method, system, equipment and medium |
| CN114859940A (en)* | 2022-07-05 | 2022-08-05 | 北京建筑大学 | Robot movement control method, device, equipment and storage medium |
| CN119026779A (en)* | 2024-09-09 | 2024-11-26 | 华南理工大学 | A method and system for collecting and transporting urban garbage based on reinforcement learning |
Also Published As
| Publication number | Publication date |
|---|---|
| CN111367282B (en) | 2022-06-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111367282B (en) | Robot navigation method and system based on multimode perception and reinforcement learning | |
| JP7532615B2 (en) | Planning for autonomous vehicles | |
| Hu et al. | Safe local motion planning with self-supervised freespace forecasting | |
| KR102539942B1 (en) | Method and apparatus for training trajectory planning model, electronic device, storage medium and program | |
| CN112099496A (en) | Automatic driving training method, device, equipment and medium | |
| Haavaldsen et al. | Autonomous vehicle control: End-to-end learning in simulated urban environments | |
| US12037011B2 (en) | Method and system for expanding the operational design domain of an autonomous agent | |
| CN113128381A (en) | Obstacle trajectory prediction method, system and computer storage medium | |
| US11556126B2 (en) | Online agent predictions using semantic maps | |
| CN117631660A (en) | Multi-scenario path planning method and system for robots based on cross-media continuous learning | |
| Li et al. | RDDRL: a recurrent deduction deep reinforcement learning model for multimodal vision-robot navigation | |
| Wijesekara | Deep 3D dynamic object detection towards successful and safe navigation for full autonomous driving | |
| Youssef et al. | Comparative study of end-to-end deep learning methods for self-driving car | |
| Manikandan et al. | Ad hoc-obstacle avoidance-based navigation system using deep reinforcement learning for self-driving vehicles | |
| CN115454085A (en) | Automatic driving control method and automatic driving control device based on navigation map | |
| Kortmann et al. | Watch out, pothole! featuring road damage detection in an end-to-end system for autonomous driving | |
| Huynh et al. | A Method of Deep Reinforcement Learning for Simulation of Autonomous Vehicle Control. | |
| CN118192545A (en) | A method, system and device for autonomous driving trajectory planning to avoid road potholes | |
| Meftah et al. | Improving autonomous vehicles maneuverability and collision avoidance in adverse weather conditions using generative adversarial networks | |
| Sun et al. | Cross validation for CNN based affordance learning and control for autonomous driving | |
| Tippannavar et al. | SDR–Self Driving Car Implemented using Reinforcement Learning & Behavioural Cloning | |
| CN116448134B (en) | Vehicle path planning method and device based on risk field and uncertainty analysis | |
| Chipka et al. | Estimation and navigation methods with limited information for autonomous urban driving | |
| Souza et al. | Template-based autonomous navigation and obstacle avoidance in urban environments | |
| Schörner et al. | Towards multi-modal risk assessment |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |