CN111353519A - User behavior recognition method and system, device with AR function and control method thereof - Google Patents
User behavior recognition method and system, device with AR function and control method thereofDownload PDFInfo
- Publication number
- CN111353519A CN111353519ACN201811585707.8ACN201811585707ACN111353519ACN 111353519 ACN111353519 ACN 111353519ACN 201811585707 ACN201811585707 ACN 201811585707ACN 111353519 ACN111353519 ACN 111353519A
- Authority
- CN
- China
- Prior art keywords
- user
- frame
- image
- video
- behavior
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images



















Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/01—Input arrangements or combined input and output arrangements for interaction between user and computer
- G06F3/011—Arrangements for interaction with the human body, e.g. for user immersion in virtual reality
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/002—Specific input/output arrangements not covered by G06F3/01 - G06F3/16
- G06F3/005—Input arrangements through a video camera
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0464—Convolutional networks [CNN, ConvNet]
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T19/00—Manipulating 3D models or images for computer graphics
- G06T19/006—Mixed reality
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/10—Segmentation; Edge detection
- G06T7/11—Region-based segmentation
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/20—Image preprocessing
- G06V10/25—Determination of region of interest [ROI] or a volume of interest [VOI]
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/20—Movements or behaviour, e.g. gesture recognition
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Human Computer Interaction (AREA)
- Multimedia (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Software Systems (AREA)
- Health & Medical Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Computer Graphics (AREA)
- Computer Hardware Design (AREA)
- Artificial Intelligence (AREA)
- Life Sciences & Earth Sciences (AREA)
- Social Psychology (AREA)
- Psychiatry (AREA)
- Mathematical Physics (AREA)
- Computing Systems (AREA)
- Molecular Biology (AREA)
- Computational Linguistics (AREA)
- Biophysics (AREA)
- Biomedical Technology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Evolutionary Biology (AREA)
- Image Analysis (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本公开涉及增强现实(AR)技术领域,更具体地,涉及一种用户行为识别方法和用户行为识别系统、具有AR功能的设备及其控制方法。The present disclosure relates to the field of augmented reality (AR) technology, and more particularly, to a user behavior recognition method and user behavior recognition system, a device with AR function, and a control method thereof.
背景技术Background technique
在日常生活中,一个人每天要产生很多不同的生活工作行为,每种行为所需的信息、以及相应的需要增强现实(AR)设备实现的信息增强功能互不相同。如果对这些不同行为所需的增强现实功能逐一进行手动设置和控制将花费用户大量时间精力,严重影响用户的流程体验,并干扰用户的正常日常生活的行为习惯。In daily life, a person produces many different life and work behaviors every day, and the information required for each behavior and the corresponding information enhancement functions that need to be implemented by augmented reality (AR) devices are different from each other. If the augmented reality functions required for these different behaviors are manually set and controlled one by one, the user will spend a lot of time and energy, seriously affect the user's process experience, and interfere with the user's normal daily behavior habits.
目前,已经针对用户行为预测(即,用户行为识别,在本文中,“预测”与“识别”可以互换使用)提出了解决方案。例如,Google公司提出了一种基于双流(two stream)和感兴趣区域池化(ROI pooling)的行为识别方法(AVA:A Video Dataset of Spatio-temporallyLocalized Atomic Visual Actions,CVPR,2018),该方法的流程图如图1所示。参见图1,该方法从视频输入中分别提取彩色图像序列3D-CNN(三维卷积神经元网络)特征、关键帧行为ROI、以及光流图像序列3D-CNN特征,并分别对彩色图像序列3D-CNN和关键帧行为ROI、以及光流图像序列3D-CNN特征和关键帧行为ROI进行池化处理,将池化后的特征进行行为特征融合分类,以对用户行为进行识别。Currently, solutions have been proposed for user behavior prediction (ie, user behavior recognition, in this paper, "prediction" and "recognition" are used interchangeably). For example, Google proposed an action recognition method based on two streams and ROI pooling (AVA: A Video Dataset of Spatio-temporallyLocalized Atomic Visual Actions, CVPR, 2018). The flow chart is shown in Figure 1. Referring to Fig. 1, the
然而,上述基于双流和ROI池化的行为识别方法具有以下缺点:只使用RGB图像和光流信息,缺少人体部位模型,难以区分相似行为;只使用包含人体的ROI,缺少判断人物交互及人人交互时所需的图像周边上下文信息;且光流计算耗时,不适于实时性AR交互场景。However, the above-mentioned behavior recognition methods based on dual-stream and ROI pooling have the following shortcomings: only use RGB images and optical flow information, lack of human body part models, and it is difficult to distinguish similar behaviors; only use ROIs containing human bodies, lack of judging human interaction and human-human interaction In addition, the optical flow calculation is time-consuming, which is not suitable for real-time AR interaction scenarios.
此外,目前通常需要用户通过用户交互界面有意识地执行对AR设备的控制,通过例如触摸、声音、手势、视线等方式选择、打开或关闭特定的AR功能应用。这些会分散用户的注意力,从一定程度上影响用户的正常的日常生活。例如,Microsoft公司在US9727132B2中提出了一种通过用户交互界面控制一个或多个增强现实显示功能应用的方法,该方法需要用户的主动交互来启动或关闭特定的AR应用,且不涉及对用户行为的理解。In addition, currently, users are usually required to consciously perform control of AR devices through a user interface, and select, turn on or off specific AR function applications through methods such as touch, sound, gesture, sight, and the like. These will distract the user's attention and affect the user's normal daily life to a certain extent. For example, Microsoft Corporation in US9727132B2 proposes a method for controlling one or more augmented reality display function applications through a user interaction interface. The method requires the user's active interaction to start or close a specific AR application, and does not involve user behavior. understanding.
发明内容SUMMARY OF THE INVENTION
为了至少克服现有技术的上述不足,本公开提供了一种用户行为识别方案,通过增加人体解析处理来提供对人体姿态的精细分析,从而可以区分视觉特征相似的不同行为;通过将从图像整体上提取的特征和从局部图像上提取的特征融合,协同进行行为识别,将在人物周围的图像特征也包含进来,因而对于涉及人和物体交互以及涉及人和人交互的行为具有更好的识别能力;而且,通过将从多种用户行为分类方式得到的行为识别特征进行融合,能够取得更好的行为识别效果。In order to at least overcome the above-mentioned deficiencies of the prior art, the present disclosure provides a user behavior recognition scheme, which provides a fine analysis of the human body posture by adding human body analysis processing, so that different behaviors with similar visual features can be distinguished; The features extracted from the above and the features extracted from the local images are fused, and the behavior recognition is performed collaboratively, and the image features around the characters are also included, so it has better recognition for behaviors involving human-object interaction and human-human interaction. Moreover, by fusing the behavior identification features obtained from various user behavior classification methods, a better behavior identification effect can be achieved.
此外本公开还提出,可以基于上述用户行为识别方案,在用户行为开始的时候识别出用户行为的类别,支持AR功能的系统借此可以获取对用户行为的感知,并以此自动地根据用户的行为需求控制AR的显示功能,从而以智能化的方式实现了根据用户的行为自动地对AR显示功能进行选择和控制。In addition, the present disclosure also proposes that, based on the above-mentioned user behavior identification scheme, the category of user behavior can be identified when the user behavior begins, so that the system supporting the AR function can obtain the perception of the user behavior, and automatically according to the user's behavior. The AR display function is controlled by the behavior requirement, so that the AR display function can be automatically selected and controlled according to the user's behavior in an intelligent way.
根据本公开的第一方面,提供了一种用户行为识别方法。所述用户行为识别方法包括:According to a first aspect of the present disclosure, a user behavior identification method is provided. The user behavior identification method includes:
从视频中包含用户的图像帧中获得基于帧的局部特征图像;Obtain frame-based local feature images from image frames containing the user in the video;
通过以下三种方式中的至少一种来对图像帧中的用户行为进行分类:Classify user behavior in image frames in at least one of three ways:
根据所述基于帧的局部特征图像和人体姿态特征来对用户行为进行分类;classifying user behaviors according to the frame-based local feature images and human gesture features;
根据所述基于帧的局部特征图像来获得基于视频的局部特征图像,并根据所述基于视频的局部特征图像来对用户行为进行分类;Obtaining a video-based local feature image according to the frame-based local feature image, and classifying user behaviors according to the video-based local feature image;
根据所述基于帧的局部特征图像来获得基于视频的局部特征图像,并根据所述基于视频的局部特征图像和基于视频的整体特征图像来对用户行为进行分类;以及obtaining a video-based local feature image according to the frame-based local feature image, and classifying user behavior according to the video-based local feature image and the video-based overall feature image; and
通过将所述三种方式中的至少一种得到的用户行为分类的结果进行融合,以识别用户行为。The user behavior is identified by fusing the user behavior classification results obtained in at least one of the three methods.
在一示例性实施例中,获取基于帧的局部特征图像包括:根据所述图像帧,获得基于帧的整体特征图像;从所述基于帧的整体特征图像中提取ROI候选;以及根据所述基于帧的整体特征图像和ROI候选,获得所述基于帧的局部特征图像。In an exemplary embodiment, obtaining a frame-based local feature image includes: obtaining a frame-based overall feature image according to the image frame; extracting ROI candidates from the frame-based overall feature image; and The overall feature image and ROI candidates of the frame are obtained to obtain the frame-based local feature image.
在一示例性实施例中,获得基于帧的整体特征图像包括:通过3D CNN,根据所述图像帧的空间域和不同时刻的图像帧的时间域获得不同时刻的图像帧的基于帧的整体特征图像;提取ROI候选包括:通过区域推荐网络RPN,从每个基于帧的整体特征图像中提取出ROI候选,以得到ROI候选序列,其中所述ROI候选序列由各个图像帧上的指示包含相同用户相关内容的图像区域的ROI候选构成;以及获得所述基于帧的局部特征图像包括:根据所述ROI候选序列,从所述所述基于帧的整体特征图像上截取所述基于帧的局部特征图像。In an exemplary embodiment, obtaining the frame-based overall feature image includes: obtaining, through a 3D CNN, the frame-based overall feature of the image frame at different times according to the spatial domain of the image frame and the temporal domain of the image frame at different times. Image; extracting ROI candidates includes: extracting ROI candidates from each frame-based overall feature image through the regional recommendation network RPN to obtain ROI candidate sequences, wherein the ROI candidate sequences are indicated by the respective image frames to contain the same user. ROI candidate composition of the image region of the related content; and obtaining the frame-based local feature image comprises: according to the ROI candidate sequence, intercepting the frame-based local feature image from the frame-based overall feature image .
在一示例性实施例中,所述用户行为识别方法还包括:根据基于视频的局部特征图像进行用户行为定位,以从多个基于视频的局部特征图像中选择出一个基于视频的局部特征图像。In an exemplary embodiment, the user behavior identification method further includes: performing user behavior localization according to the video-based local feature images, so as to select a video-based local feature image from a plurality of video-based local feature images.
在一示例性实施例中,根据所述基于帧的局部特征图像和人体姿态特征来对用户行为进行分类包括:根据所述基于帧的局部特征图像来获得基于视频的局部特征图像;以及通过人体部位解析对人体部位进行定位,使得所选的基于视频的局部特征图像包含基于人体部位的人体姿态特征,并根据包含基于所述人体姿态特征的基于视频的局部特征图像来对用户行为进行分类。In an exemplary embodiment, classifying the user behavior according to the frame-based local feature image and the human body gesture feature includes: obtaining a video-based local feature image according to the frame-based local feature image; The part analysis locates the human body part so that the selected video-based local feature image contains the human body part-based human pose feature, and classifies the user behavior according to the video-based local feature image including the human body pose feature.
在一示例性实施例中,根据包含基于所述人体姿态特征的基于视频的局部特征图像来对用户行为进行分类包括:分别通过以用户姿势动作作为分类标签的3D CNN和以用户交互动作作为分类标签的3D CNN,从包含基于所述人体姿态特征的基于视频的局部特征图像中提取与用户姿势动作有关的特征和与用户交互动作有关的特征;以及将所提取的与用户姿势动作有关的特征和与用户交互动作有关的特征进行融合,以对用户行为进行分类,其中针对用户姿势动作使用类别互斥的多标签姿势动作分类损失函数进行训练,针对用户交互动作使用类别非互斥的多标签交互动作分类损失函数进行训练。In an exemplary embodiment, classifying the user behavior according to the video-based local feature image including the human gesture feature includes: using the 3D CNN with the user gesture action as the classification label and the user interaction action as the classification respectively. Labeled 3D CNN, extracting features related to user gestures and actions and features related to user interaction from the video-based local feature images containing the human gesture features; and extracting the extracted features related to user gestures and actions Fusion with features related to user interaction actions to classify user behaviors, in which the multi-label gesture-action classification loss function with mutually exclusive categories is used for user gesture actions, and the multi-label non-mutually exclusive categories are used for user interaction actions. Interactive action classification loss function for training.
在一示例性实施例中,获得基于帧的整体特征图像包括:通过2D CNN,根据所述图像帧获得基于帧的整体特征图像。In an exemplary embodiment, obtaining a frame-based overall feature image includes: obtaining a frame-based overall feature image according to the image frame through a 2D CNN.
在一示例性实施例中,所述用户行为识别方法还包括:根据基于帧的局部特征图像进行用户行为定位,以从多个基于帧的局部特征图像中选择出一个基于帧的局部特征图像。In an exemplary embodiment, the user behavior identification method further includes: performing user behavior positioning according to the frame-based local feature images, so as to select a frame-based local feature image from a plurality of frame-based local feature images.
在一示例性实施例中,所述用户行为识别方法还包括:在根据每个图像帧的所选的基于帧的局部特征图像和人体姿态特征来对用户行为进行分类之后,将针对每个图像帧的用户行为分类结果进行组合,其中根据每个图像帧的基于帧的局部特征图像和人体姿态特征来对用户行为进行分类包括:通过人体部位解析对人体部位进行定位,使得所选的基于帧的局部特征图像包含基于人体部位的人体姿态特征,并根据包含基于所述人体姿态特征的基于帧的局部特征图像来对用户行为进行分类。In an exemplary embodiment, the user behavior recognition method further includes: after classifying the user behavior according to the selected frame-based local feature images and human gesture features of each image frame, classifying the user behavior for each image frame. The user behavior classification results of the frames are combined, wherein classifying the user behavior according to the frame-based local feature image and the human body pose feature of each image frame includes: locating the human body parts through the human body part analysis, so that the selected frame-based The local feature image of the includes body pose features based on body parts, and user behavior is classified according to the frame-based local feature images including the frame-based local feature images based on the body pose features.
在一示例性实施例中,根据包含基于所述人体姿态特征的基于帧的局部特征图像来对用户行为进行分类包括:分别通过以用户姿势动作作为分类标签的2D CNN和以用户交互动作作为分类标签的2D CNN,从包含基于所述人体姿态特征的基于帧的局部特征图像中提取与用户姿势动作有关的特征和与用户交互动作有关的特征;以及将所提取的与用户姿势动作有关的特征和与用户交互动作有关的特征进行融合,以对用户行为进行分类,其中针对用户姿势动作使用类别互斥的多标签姿势动作分类损失函数进行训练,针对用户交互动作使用类别非互斥的多标签交互动作分类损失函数进行训练。In an exemplary embodiment, classifying the user behavior according to the frame-based local feature image containing the human gesture feature includes: using the 2D CNN with the user gesture action as the classification label and the user interaction action as the classification respectively. Labeled 2D CNN, extracts features related to user gestures and actions and features related to user interaction actions from frame-based local feature images containing the human pose features; and extracts the extracted features related to user gestures and actions Fusion with features related to user interaction actions to classify user behaviors, in which the multi-label gesture-action classification loss function with mutually exclusive categories is used for user gesture actions, and the multi-label non-mutually exclusive categories are used for user interaction actions. Interactive action classification loss function for training.
在一示例性实施例中,通过人体部位解析对人体部位进行定位包括:确定所述视频的每个人体实例在每个图像帧上的图像区域;对从所确定的图像区域中提取的人体图像区域候选进行粗略的部分语义分割,以得到粗略语义分割结果;预测每个图像帧上的每个像素相对于其所属的人体中心的方向以得到方向预测结果;根据所述粗略语义分割结果与所述方向预测结果,得到人体部位解析结果。In an exemplary embodiment, locating the human body part by analyzing the human body part includes: determining an image area of each human body instance of the video on each image frame; The region candidate performs rough partial semantic segmentation to obtain a rough semantic segmentation result; predicts the direction of each pixel on each image frame relative to the center of the human body to which it belongs to obtain a direction prediction result; The above direction prediction results are obtained, and the analysis results of human body parts are obtained.
在一示例性实施例中,根据所述基于视频的局部特征图像来对用户行为进行分类包括:分别通过以用户姿势动作作为分类标签的相应的CNN和以用户交互动作作为分类标签的相应的CNN,从所选的基于视频的局部特征图像中提取与用户姿势动作有关的特征和与用户交互动作有关的特征;以及将所提取的与用户姿势动作有关的特征和与用户交互动作有关的特征进行融合,以对用户行为进行分类,其中针对用户姿势动作使用类别互斥的多标签姿势动作分类损失函数进行训练,针对用户交互动作使用类别非互斥的多标签交互动作分类损失函数进行训练。In an exemplary embodiment, classifying the user behavior according to the video-based local feature image comprises: using a corresponding CNN with a user gesture action as a classification label and a corresponding CNN with a user interaction action as a classification label, respectively. , extract features related to user gestures and actions and features related to user interaction from the selected video-based local feature images; and perform the extracted features related to user gestures and features related to user interaction. Fusion to classify user behavior, in which the multi-label gesture action classification loss function with mutually exclusive categories is used for training for user gesture actions, and the multi-label interaction action classification loss function with non-mutually exclusive categories is used for training for user interaction actions.
在一示例性实施例中,根据所述基于视频的局部特征图像和基于视频的整体特征图像来对用户行为进行分类包括:根据基于帧的整体特征图像,获得基于视频的整体特征图像;将所述基于视频的整体特征图像与所选的基于视频的局部特征图像进行特征组合,以根据组合后的特征图像对用户行为进行分类。In an exemplary embodiment, classifying the user behavior according to the video-based local feature image and the video-based overall feature image includes: obtaining a video-based overall feature image according to the frame-based overall feature image; The said overall video-based feature image and the selected video-based local feature image are feature combined, so as to classify user behavior according to the combined feature image.
在一示例性实施例中,根据组合后的特征图像对用户行为进行分类包括:分别通过以用户姿势动作作为分类标签的相应的CNN和以用户交互动作作为分类标签的相应的CNN,从组合后的特征图像中提取与用户姿势动作有关的特征和与用户交互动作有关的特征;以及将所提取的与用户姿势动作有关的特征和与用户交互动作有关的特征进行融合,以对用户行为进行分类,其中针对用户姿势动作使用类别互斥的多标签姿势动作分类损失函数进行训练,针对用户交互动作使用类别非互斥的多标签交互动作分类损失函数进行训练。In an exemplary embodiment, classifying the user behavior according to the combined feature images includes: using the corresponding CNN with the user gesture action as the classification label and the corresponding CNN with the user interaction action as the classification label, respectively, from the combined feature image. Extract features related to user gestures and actions and features related to user interaction actions from the feature image; and fuse the extracted features related to user gesture actions and features related to user interaction actions to classify user behaviors , in which the multi-label gesture action classification loss function with mutually exclusive categories is used for training, and the multi-label interaction action classification loss function with non-mutually exclusive categories is used for training for user interaction actions.
根据本公开的第二方面,提供了一种用户行为识别系统。所述用户行为识别系统包括:局部特征获得单元,被配置为从视频中包含用户的图像帧中获得基于帧的局部特征图像;用户行为识别装置,被配置为通过以下三种方式中的至少一种来对用户行为进行分类:根据所述基于帧的局部特征图像和人体姿态特征来对用户行为进行分类;根据所述基于帧的局部特征图像来获得基于视频的局部特征图像,并根据所述基于视频的局部特征图像来对用户行为进行分类;根据所述基于帧的局部特征图像来获得基于视频的局部特征图像,并根据所述基于视频的局部特征图像和基于视频的整体特征图像来对用户行为进行分类;以及特征融合单元,被配置为通过将所述三种方式中的至少一种得到的用户行为分类的结果进行融合,以识别用户行为。According to a second aspect of the present disclosure, a user behavior recognition system is provided. The user behavior recognition system includes: a local feature obtaining unit configured to obtain a frame-based local feature image from an image frame containing the user in the video; a user behavior recognition device configured to perform at least one of the following three ways. to classify user behaviors: classify user behaviors according to the frame-based local feature images and human posture features; obtain video-based local feature images according to the frame-based local feature images, and Classify user behavior based on the local feature image of the video; obtain the local feature image based on the video according to the local feature image based on the frame, and classify the local feature image based on the video and the overall feature image based on the video. classifying user behaviors; and a feature fusion unit configured to identify user behaviors by fusing the results of classifying user behaviors obtained in at least one of the three ways.
在一示例性实施例中,局部特征获得单元包括:特征提取单元,被配置为根据所述图像帧,获得基于帧的整体特征图像;ROI提取单元,被配置为从所述基于帧的整体特征图像中提取ROI候选;ROI池化单元,被配置为根据所述基于帧的整体特征图像和ROI候选,获得所述基于帧的局部特征图像。In an exemplary embodiment, the local feature obtaining unit includes: a feature extraction unit configured to obtain a frame-based overall feature image according to the image frame; a ROI extraction unit configured to obtain a frame-based overall feature image from the frame-based overall feature ROI candidates are extracted from the images; the ROI pooling unit is configured to obtain the frame-based local feature images according to the frame-based overall feature images and the ROI candidates.
在一示例性实施例中,所述特征提取单元通过三维卷积神经元网络3D CNN根据所述图像帧获得基于帧的整体特征图像;所述ROI提取单元通过RPN,从每个基于帧的整体特征图像中提取出ROI候选,以得到ROI候选序列,其中所述ROI候选序列由各个图像帧上的指示包含相同用户相关内容的图像区域的ROI候选构成;以及所述ROI池化单元根据所述ROI候选序列,从所述所述基于帧的整体特征图像上截取所述基于帧的局部特征图像。In an exemplary embodiment, the feature extraction unit obtains a frame-based overall feature image according to the image frame through a three-dimensional convolutional
在一示例性实施例中,所述用户行为识别系统还包括:行为定位单元,被配置为根据基于视频的局部特征图像进行用户行为定位,以从多个基于视频的局部特征图像中选择出一个基于视频的局部特征图像。In an exemplary embodiment, the user behavior recognition system further includes: a behavior locating unit configured to perform user behavior locating according to the video-based local feature images, so as to select one from a plurality of video-based local feature images. Video-based local feature images.
在一示例性实施例中,所述用户行为识别系统还包括:ROI对齐单元,被配置为根据所述基于帧的局部特征图像来获得基于视频的局部特征图像;以及所述用户行为识别装置通过人体姿态注意单元根据所述基于视频的局部特征图像和人体姿态特征来对用户行为进行分类,所述人体姿态注意单元包括:3D CNN解码器,被配置为通过人体部位解析对人体部位进行定位,使得所选的基于视频的局部特征图像包含基于人体部位的人体姿态特征;以及用户行为分类单元,被配置为根据包含基于所述人体姿态特征的基于视频的局部特征图像来对用户行为进行分类。In an exemplary embodiment, the user behavior recognition system further includes: an ROI alignment unit configured to obtain a video-based local feature image according to the frame-based local feature image; The human body posture attention unit classifies the user behavior according to the video-based local feature image and the human body posture feature, and the human body posture attention unit includes: a 3D CNN decoder, configured to locate the human body parts by analyzing the human body parts, The selected video-based local feature image includes human body pose features based on body parts; and a user behavior classification unit configured to classify user actions according to the video-based local feature images including the human pose features.
在一示例性实施例中,所述用户行为分类单元还包括:以用户姿势动作作为分类标签的第一3D CNN模块,被配置为通过以用户姿势动作作为分类标签的3D CNN,从包含基于所述人体姿态特征的基于视频的局部特征图像中提取与用户姿势动作有关的特征;以用户交互动作作为分类标签的第二3D CNN模块,被配置为通过以用户交互动作作为分类标签的CNN,从包含基于所述人体姿态特征的基于视频的局部特征图像中提取与用户交互动作有关的特征;以及融合模块,被配置为将所提取的与用户姿势动作有关的特征和与用户交互动作有关的特征进行融合,以对用户行为进行分类,其中针对用户姿势动作使用类别互斥的多标签姿势动作分类损失函数进行训练,针对用户交互动作使用类别非互斥的多标签交互动作分类损失函数进行训练。In an exemplary embodiment, the user behavior classification unit further includes: a first 3D CNN module that uses the user gesture action as a classification label, and is configured to use the user gesture action as a classification label. The features related to user gestures and actions are extracted from the video-based local feature images of the human body pose features; the second 3D CNN module with user interaction actions as classification labels is configured to use the CNN with user interaction actions as classification labels. Extracting features related to user interaction actions from the video-based local feature images based on the human gesture features; and a fusion module configured to combine the extracted features related to user gesture actions and features related to user interaction actions Fusion is performed to classify user behavior, in which the multi-label gesture action classification loss function with mutually exclusive categories is used for training for user gesture actions, and the multi-label interaction action classification loss function with non-mutually exclusive categories is used for training for user interaction actions.
在一示例性实施例中,所述特征提取单元通过二维卷积神经元网络2D CNN根据所述图像帧获得基于帧的整体特征图像。In an exemplary embodiment, the feature extraction unit obtains a frame-based overall feature image according to the image frame through a two-dimensional
在一示例性实施例中,所述用户行为识别系统还包括:行为定位单元,被配置为根据基于帧的局部特征图像进行用户行为定位,以从多个基于帧的局部特征图像中选择出一个基于帧的局部特征图像。In an exemplary embodiment, the user behavior recognition system further includes: a behavior locating unit configured to perform user behavior locating according to the frame-based local feature images, so as to select one from a plurality of frame-based local feature images. Frame-based local feature images.
在一示例性实施例中,所述用户行为识别装置通过人体姿态注意单元根据每个图像帧的所选的基于帧的局部特征图像和人体姿态特征来对用户行为进行分类,并通过组合单元将针对每个图像帧的用户行为分类结果进行组合,其中所述人体姿态注意单元包括:2D CNN解码器,被配置为通过人体部位解析对人体部位进行定位,使得所选的基于帧的局部特征图像包含基于人体部位的人体姿态特征;以及用户行为分类单元,被配置为根据包含基于所述人体姿态特征的基于帧的局部特征图像来对用户行为进行分类。In an exemplary embodiment, the user behavior recognition device classifies the user behavior according to the selected frame-based local feature image and the human gesture feature of each image frame by the human gesture attention unit, and uses the combination unit to classify the user behavior. The user behavior classification results for each image frame are combined, wherein the human pose attention unit includes: a 2D CNN decoder configured to locate human body parts through human body part analysis, so that the selected frame-based local feature image including human body pose features based on human body parts; and a user behavior classification unit configured to classify user actions according to the frame-based local feature images including the human body pose features.
在一示例性实施例中,所述用户行为分类单元还包括:以用户姿势动作作为分类标签的第一2D CNN模块,被配置为通过以用户姿势动作作为分类标签的2D CNN,从包含基于所述人体姿态特征的基于帧的局部特征图像中提取与用户姿势动作有关的特征;以用户交互动作作为分类标签的第二2D CNN模块,被配置为通过以用户交互动作作为分类标签的2D CNN,从包含基于所述人体姿态特征的基于帧的局部特征图像中提取与用户交互动作有关的特征;以及融合模块,被配置为将所提取的与用户姿势动作有关的特征和与用户交互动作有关的特征进行融合,以对用户行为进行分类,其中针对用户姿势动作使用类别互斥的多标签姿势动作分类损失函数进行训练,针对用户交互动作使用类别非互斥的多标签交互动作分类损失函数进行训练。In an exemplary embodiment, the user behavior classification unit further includes: a first 2D CNN module that uses the user gesture action as a classification label, and is configured to use the 2D CNN that uses the user gesture action as a classification label. Extracting features related to user gestures and actions from the frame-based local feature images of the human body pose features; the second 2D CNN module with user interaction as the classification label is configured to use the user interaction as the
在一示例性实施例中,所述用户行为识别系统还包括人体部位定位装置,所述人体部位定位装置包括:人体检测单元,被配置为确定所述视频的每个人体实例在每个图像帧上的图像区域;人体语义分割单元,被配置为对从所确定的图像区域中提取的人体图像区域候选进行粗略的部分语义分割,以得到粗略语义分割结果;方向预测单元,被配置为预测每个图像帧上的每个像素相对于其所属的人体中心的方向以得到方向预测结果;卷积模块,被配置为根据所述粗略语义分割结果与所述方向预测结果,得到人体部位解析结果。In an exemplary embodiment, the user behavior recognition system further includes a human body part positioning device, and the human body part positioning device includes: a human body detection unit configured to determine that each human body instance of the video is in each image frame. The human body semantic segmentation unit is configured to perform rough partial semantic segmentation on the human body image region candidates extracted from the determined image regions, so as to obtain a rough semantic segmentation result; the direction prediction unit is configured to predict each The direction of each pixel on each image frame relative to the center of the human body to which it belongs to obtain a direction prediction result; the convolution module is configured to obtain a body part analysis result according to the rough semantic segmentation result and the direction prediction result.
在一示例性实施例中,所述用户行为识别装置通过局部行为识别单元根据所述基于视频的局部特征图像来对用户行为进行分类,其中所述局部行为识别单元包括:以用户姿势动作作为分类标签的第一CNN模块,被配置为通过以用户姿势动作作为分类标签的相应的CNN,从所述基于局部视频的多层特征图像中提取与用户姿势动作有关的特征;以用户交互动作作为分类标签的第二CNN模块,被配置为通过以用户交互动作作为分类标签的相应的CNN,从所述基于局部视频的多层特征图像中提取与用户交互动作有关的特征;以及融合模块,被配置为将所提取的与用户姿势动作有关的特征和与用户交互动作有关的特征进行融合,以对用户行为进行分类,其中针对用户姿势动作使用类别互斥的多标签姿势动作分类损失函数进行训练,针对用户交互动作使用类别非互斥的多标签交互动作分类损失函数进行训练。In an exemplary embodiment, the user behavior recognition device classifies the user behavior according to the video-based local feature image through a local behavior recognition unit, wherein the local behavior recognition unit includes: using the user gesture action as the classification; The first CNN module of the label is configured to extract features related to the user's gesture and action from the multi-layer feature image based on the partial video through the corresponding CNN using the user's gesture and action as the classification label; using the user's interaction action as the classification The second CNN module of the label is configured to extract features related to the user interaction from the multi-layer feature image based on the partial video through the corresponding CNN with the user interaction as the classification label; and the fusion module is configured In order to fuse the extracted features related to user gestures and actions and features related to user interaction actions to classify user behaviors, a multi-label gesture action classification loss function with mutually exclusive categories is used for training on user gestures and actions, A multi-label interaction action classification loss function with non-mutually exclusive categories is used for training on user interactions.
在一示例性实施例中,所述用户行为识别装置通过整体-局部融合行为识别单元根据所述基于局部视频的多层特征图像和所述多个基于帧的多层特征图像来对用户行为进行分类,其中所述整体-局部融合行为识别单元包括:CNN模块,被配置为根据基于帧的整体特征图像,获得基于视频的整体特征图像;特征组合单元,被配置为将所述基于视频的整体特征图像与所选的基于视频的局部特征图像进行特征组合,以根据组合后的特征图像对用户行为进行分类In an exemplary embodiment, the user behavior recognition device performs the user behavior recognition according to the partial video-based multi-layer feature images and the multiple frame-based multi-layer feature images through the global-local fusion behavior recognition unit. classification, wherein the overall-local fusion behavior recognition unit includes: a CNN module configured to obtain a video-based overall feature image according to a frame-based overall feature image; a feature combining unit configured to combine the video-based overall feature image Feature images are combined with selected video-based local feature images to classify user behaviors based on the combined feature images
在一示例性实施例中,所述用户行为分类单元包括:以用户姿势动作作为分类标签的第一CNN模块,被配置为通过以用户姿势动作作为分类标签的相应的CNN,从特征组合后的多层特征图像中提取与用户姿势动作有关的特征;以用户交互动作作为分类标签的第二CNN模块,被配置为通过以用户交互动作作为分类标签的相应的CNN,从特征组合后的多层特征图像中提取与用户交互动作有关的特征;以及融合模块,被配置为将所提取的与用户姿势动作有关的特征和与用户交互动作有关的特征进行融合,以对用户行为进行分类,其中针对用户姿势动作使用类别互斥的多标签姿势动作分类损失函数进行训练,针对用户交互动作使用类别非互斥的多标签交互动作分类损失函数进行训练。In an exemplary embodiment, the user behavior classification unit includes: a first CNN module that uses the user gesture action as a classification label, and is configured to use a corresponding CNN that uses the user gesture action as a classification label. The features related to user gestures and actions are extracted from the multi-layer feature images; the second CNN module with the user interaction action as the classification label is configured to pass the corresponding CNN with the user interaction action as the classification label, from the multi-layer after feature combination. Extracting features related to user interaction actions from the feature image; and a fusion module configured to fuse the extracted features related to user gesture actions and features related to user interaction actions to classify user behaviors, wherein for The user gestures and actions are trained using the multi-label gesture and action classification loss function with mutually exclusive categories, and the multi-label interaction action classification loss function with non-mutually exclusive categories is used for training for user interaction actions.
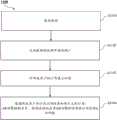
根据本公开的第三方面,提供了一种用于控制具有AR功能的设备的方法。所述方法包括:获取视频;从所获取的视频中检测用户;对所述用户的行为进行识别;以及根据所述用户的行为识别结果和预定义的行为-AR功能映射关系,控制关联的具有AR功能的设备执行对应的AR功能。According to a third aspect of the present disclosure, there is provided a method for controlling an AR-enabled device. The method includes: acquiring a video; detecting a user from the acquired video; recognizing the behavior of the user; The AR-enabled device executes the corresponding AR function.
在一示例性实施例中,所述行为-AR功能映射关系包括以下至少一组映射:In an exemplary embodiment, the behavior-AR function mapping relationship includes at least one set of the following mappings:
1)唱歌行为、以及与所述唱歌行为相匹配的以下AR功能中的至少一个:1) Singing behavior, and at least one of the following AR functions that match the singing behavior:
识别歌曲并通过因特网检索或在本地存储的歌曲库中检索,identify songs and retrieve them via the Internet or in a locally stored song library,
在设备中显示歌词,display lyrics in the device,
在设备中显示歌名和/或歌手名,Display the song title and/or artist name in the device,
在设备中同步播放歌曲的伴奏音乐;Play the accompaniment music of the song synchronously in the device;
2)吸烟行为、以及与所述吸烟行为相匹配的以下AR功能中的至少一个:2) Smoking behavior, and at least one of the following AR functions that match the smoking behavior:
在设备中显示该用户所处地点是否允许吸烟,Display on the device whether smoking is allowed in the user's location,
如果此处不允许吸烟,则显示最近的可吸烟区的相关信息;If smoking is not allowed here, information about the nearest smoking area is displayed;
3)握手行为、以及与所述握手行为相匹配AR功能的至少一个:3) handshake behavior, and at least one of AR functions matching the handshake behavior:
识别与握手人的身份;identify the person shaking hands;
在握手人附近显示该握手人的信息;Display the information of the handshake near the handshake;
4)演奏乐器行为、以及与所述演奏乐器行为相匹配AR功能的至少一个:4) At least one of the behavior of playing an instrument and an AR function that matches the behavior of playing an instrument:
识别乐器;identify musical instruments;
显示乐器名;display the name of the instrument;
在乐器旁边同步显示音乐的乐谱。Displays the music score in sync next to the instrument.
在一示例性实施例中,根据所述用户的行为识别结果和预定义的行为-AR功能映射关系控制关联的具有AR功能的设备执行对应的AR功能包括:根据所述设备所处的场景、所述用户的行为识别结果和预定义的行为-AR功能映射关系,确定对应的AR功能,并控制所述设备执行对应的AR功能。In an exemplary embodiment, controlling the associated device with the AR function to execute the corresponding AR function according to the user's behavior recognition result and the predefined behavior-AR function mapping relationship includes: according to the scene where the device is located, The user's behavior recognition result and the predefined behavior-AR function mapping relationship determine the corresponding AR function, and control the device to execute the corresponding AR function.
在一示例性实施例中,对所述用户的行为进行识别包括:使用前述根据本公开的第一方面所述的方法,对所述用户的行为进行识别。In an exemplary embodiment, identifying the behavior of the user includes identifying the behavior of the user using the aforementioned method according to the first aspect of the present disclosure.
在一示例性实施例中,所述视频通过以下方式之一获取:In an exemplary embodiment, the video is obtained in one of the following ways:
通过设置在所述设备之外的相机捕获;Captured by a camera located outside the device;
通过所述设备上的相机捕获;captured by a camera on said device;
通过所述设备上的视频应用呈现。Presented through a video application on the device.
在一示例性实施例中,当存在与所识别的用户的行为相匹配的多个AR功能时,从所述多个AR功能中选择一个或多个AR功能,控制所述设备执行所选的一个或多个AR功能。In an exemplary embodiment, when there are multiple AR functions that match the behavior of the identified user, one or more AR functions are selected from the multiple AR functions, and the device is controlled to perform the selected AR functions. One or more AR features.
在一示例性实施例中,所述方法还包括:根据所述用户的行为识别结果更新当前用户行为的状态,并根据所述行为-AR功能映射关系,控制所述设备关闭与当前用户行为不匹配的AR功能。In an exemplary embodiment, the method further includes: updating the status of the current user behavior according to the behavior recognition result of the user, and controlling the device to turn off the current user behavior according to the behavior-AR function mapping relationship. Matching AR features.
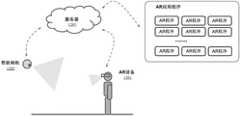
在一示例性实施例中,在通过设置在所述设备之外的相机捕获所述视频的情况下,所述方法由服务器执行,还包括:从视频中执行人体跟踪;对跟踪到的人体执行人脸检测,以得到人脸图像区域;通过人脸识别从登记的AR用户数据库中搜索匹配的用户,其中所述AR用户数据库至少包括:用户的人脸图像,用户的设备信息;当在AR用户数据库中搜索到匹配的用户时,获得与所述用户相关联的设备信息。In an exemplary embodiment, in the case where the video is captured by a camera provided outside the device, the method is performed by a server, further comprising: performing human body tracking from the video; performing the tracking on the tracked human body Face detection to obtain a face image area; searching for matching users from the registered AR user database through face recognition, wherein the AR user database at least includes: the user's face image, the user's equipment information; When a matching user is found in the user database, device information associated with the user is obtained.
在一示例性实施例中,在通过所述设备上的相机捕获所述视频、或通过所述设备上的视频应用呈现所述视频的情况下,所述方法由所述设备执行。In an exemplary embodiment, the method is performed by the device where the video is captured by a camera on the device or rendered by a video application on the device.
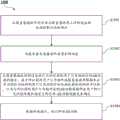
根据本公开的第四方面,提供了一种用于控制具有AR功能的设备的方法。所述方法包括:从服务器接收针对启动与所述服务器协同工作的设备自动控制方法的请求;向所述服务器发送接受所述请求的响应;从所述服务器接收控制所述设备执行与所识别的用户行为相对应的AR功能的指令,其中与所识别的用户行为相对应的AR功能根据所述用户的行为识别结果和预定义的行为-AR功能映射关系来确定;以及根据所述控制,执行所述AR功能。According to a fourth aspect of the present disclosure, there is provided a method for controlling an AR-enabled device. The method includes: receiving a request from a server for initiating an automatic control method for a device working in cooperation with the server; sending a response to the server accepting the request; receiving from the server controlling the device to perform and identify the an instruction of an AR function corresponding to a user behavior, wherein the AR function corresponding to the identified user behavior is determined according to the user's behavior recognition result and a predefined behavior-AR function mapping relationship; and according to the control, executing The AR function.
在一示例性实施例中,所述行为-AR功能映射关系包括以下至少一组映射:In an exemplary embodiment, the behavior-AR function mapping relationship includes at least one set of the following mappings:
1)唱歌行为、以及与所述唱歌行为相匹配的以下AR功能中的至少一个:1) Singing behavior, and at least one of the following AR functions that match the singing behavior:
识别歌曲并通过因特网检索或在本地存储的歌曲库中检索,identify songs and retrieve them via the Internet or in a locally stored song library,
在设备中显示歌词,display lyrics in the device,
在设备中显示歌名和/或歌手名,Display the song title and/or artist name in the device,
在设备中同步播放歌曲的伴奏音乐;Play the accompaniment music of the song synchronously in the device;
2)吸烟行为、以及与所述吸烟行为相匹配的以下AR功能中的至少一个:2) Smoking behavior, and at least one of the following AR functions that match the smoking behavior:
在设备中显示该用户所处地点是否允许吸烟,Display on the device whether smoking is allowed in the user's location,
如果此处不允许吸烟,则显示最近的可吸烟区的相关信息;If smoking is not allowed here, information about the nearest smoking area is displayed;
3)握手行为、以及与所述握手行为相匹配AR功能的至少一个:3) handshake behavior, and at least one of AR functions matching the handshake behavior:
识别与握手人的身份;identify the person shaking hands;
在握手人附近显示该握手人的信息;Display the information of the handshake near the handshake;
4)演奏乐器行为、以及与所述演奏乐器行为相匹配AR功能的至少一个:4) At least one of the behavior of playing an instrument and an AR function that matches the behavior of playing an instrument:
识别乐器;identify musical instruments;
显示乐器名;display the name of the instrument;
在乐器旁边同步显示音乐的乐谱。Displays the music score in sync next to the instrument.
在一示例性实施例中,所述与所识别的用户行为相对应的AR功能还根据所述设备所处的场景来确定。In an exemplary embodiment, the AR function corresponding to the identified user behavior is further determined according to a scene in which the device is located.
在一示例性实施例中,当接收到控制所述设备执行与所识别的用户行为相对应的多个AR功能的指令时,从所述多个AR功能中选择并执行一个或多个AR功能。In an exemplary embodiment, upon receiving an instruction to control the device to perform a plurality of AR functions corresponding to the identified user behavior, selecting and executing one or more AR functions from the plurality of AR functions .
在一示例性实施例中,当当前用户行为的状态被更新时,从服务器接收控制所述设备关闭与当前用户行为不匹配的AR功能的指令;以及根据所述指令,关闭与当前用户行为不匹配的AR功能。In an exemplary embodiment, when the state of the current user behavior is updated, an instruction is received from the server to control the device to turn off the AR function that does not match the current user behavior; and according to the instruction, close the AR function that does not match the current user behavior. Matching AR features.
根据本公开的第五方面,提供了一种用于控制具有AR功能的设备。所述设备包括:处理器;以及存储器,存储有计算机可执行指令,所述指令在被处理器执行时,使所述设备执行前述根据本公开的第三或第四方面所述的方法。According to a fifth aspect of the present disclosure, there is provided a device for controlling an AR function. The apparatus includes: a processor; and a memory storing computer-executable instructions that, when executed by the processor, cause the apparatus to perform the aforementioned method according to the third or fourth aspect of the present disclosure.
在一示例性实施例中,所述设备是服务器。In an exemplary embodiment, the device is a server.
本公开提供的上述用户行为识别方案通过增加人体解析处理来提供对人体姿态的精细分析,由此可以区分视觉特征相似的不同行为。此外,本公开提供的上述用户行为识别方法将从图像整体上提取的特征和从局部图像上提取的特征融合,协同进行行为识别。由于在人物周围的图像特征也可以被包含进来,对于涉及人和物体交互、以及涉及人和人交互的行为具有更好的识别能力。而且,本公开提供的上述用户行为识别方法将采用多种方式的行为识别特征融合,能够取得更好的行为识别效果。The above-mentioned user behavior recognition solution provided by the present disclosure provides a fine analysis of the human body posture by adding human body analysis processing, so that different behaviors with similar visual features can be distinguished. In addition, the above-mentioned user behavior recognition method provided by the present disclosure fuses the features extracted from the overall image and the features extracted from the partial images to perform behavior recognition collaboratively. Since image features around people can also be included, it has better recognition ability for behaviors involving human-object interaction, as well as human-human interaction. Moreover, the above-mentioned user behavior identification method provided by the present disclosure integrates behavior identification features in various ways, and can achieve better behavior identification effect.
本公开提供了速度快识别精度好的用户行为识别方法、以及自动控制AR显示系统显示的内容和方式,提高了用户使用AR显示系统的体验。本公开可以应用于AR眼镜或基于手机等移动设备的具有AR功能的设备,也可以应用于一般的人机交互界面,在物联网设备中用于对用户行为的感知。The present disclosure provides a user behavior recognition method with high speed and good recognition accuracy, and automatic control of the content and method displayed by the AR display system, thereby improving the user experience of using the AR display system. The present disclosure can be applied to AR glasses or devices with AR functions based on mobile devices such as mobile phones, and can also be applied to general human-computer interaction interfaces, used in IoT devices to perceive user behavior.
附图说明Description of drawings
为了更清楚地说明本公开实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本公开的一些实施例,对于本领域技术人员,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。In order to illustrate the technical solutions in the embodiments of the present disclosure more clearly, the following briefly introduces the accompanying drawings used in the description of the embodiments. Obviously, the accompanying drawings in the following description are only some embodiments of the present disclosure. For those skilled in the art, other drawings can also be obtained from these drawings without creative effort.
图1示意性地示出了现有技术中的基于双流3D CNN和ROI池化方法的行为识别方法的流程图;Fig. 1 schematically shows the flow chart of the behavior recognition method based on dual-
图2示意性地示出了根据本公开示例性实施例的用户行为识别方法的概述过程的流程图;FIG. 2 schematically shows a flowchart of an overview process of a user behavior recognition method according to an exemplary embodiment of the present disclosure;
图3示意性地示出了根据本公开一示例性实施例的基于3D CNN的用户行为识别方法的具体过程流图;3 schematically shows a specific process flow diagram of a 3D CNN-based user behavior recognition method according to an exemplary embodiment of the present disclosure;
图4示意性地示出了根据本公开示例性实施例的用户行为识别方法中结合人体部位解析对用户行为进行分类的过程;FIG. 4 schematically shows a process of classifying user behavior in combination with human body part analysis in a user behavior recognition method according to an exemplary embodiment of the present disclosure;
图5示意性地示出了图4的过程中得到的方向特征量化示意图;FIG. 5 schematically shows a schematic diagram of directional feature quantization obtained in the process of FIG. 4;
图6(a)示意性地示出了根据本公开示例性实施例的用户行为识别方法中采用多任务方式对用户行为进行分类的过程;FIG. 6( a ) schematically shows a process of classifying user behaviors in a multi-task manner in the method for identifying user behaviors according to an exemplary embodiment of the present disclosure;
图6(b)示意性地示出了根据本公开示例性实施例的用户行为定位分支训练过程;Fig. 6(b) schematically shows a branch training process of user behavior localization according to an exemplary embodiment of the present disclosure;
图6(c)示意性地示出了根据本公开示例性实施例的用户行为分类分支训练过程;Fig. 6(c) schematically shows a branch training process of user behavior classification according to an exemplary embodiment of the present disclosure;
图7示意性地示出了根据本公开另一示例性实施例的基于2D CNN的用户行为识别方法的具体过程流图;7 schematically shows a specific process flow diagram of a 2D CNN-based user behavior recognition method according to another exemplary embodiment of the present disclosure;
图8示意性地示出了根据本公开示例性实施例的用户行为识别系统的结构框图;FIG. 8 schematically shows a structural block diagram of a user behavior recognition system according to an exemplary embodiment of the present disclosure;
图9示意性地示出了根据本公开一示例性实施例的基于3D CNN的用户行为识别系统的结构框图;9 schematically shows a structural block diagram of a 3D CNN-based user behavior recognition system according to an exemplary embodiment of the present disclosure;
图10示意性地示出了根据本公开另一示例性实施例的基于2D CNN的用户行为识别系统的结构框图;10 schematically shows a structural block diagram of a 2D CNN-based user behavior recognition system according to another exemplary embodiment of the present disclosure;
图11示意性地示出了根据本公开示例性实施例的用于控制具有AR功能的设备的方法的流程图;FIG. 11 schematically shows a flowchart of a method for controlling an AR-enabled device according to an exemplary embodiment of the present disclosure;
图12示意性地示出了根据本公开示例性实施例的用于控制具有AR功能的设备的方法的示例性应用场景;FIG. 12 schematically shows an exemplary application scenario of the method for controlling an AR-enabled device according to an exemplary embodiment of the present disclosure;
图13示意性地示出了根据本公开示例性实施例的在服务器处执行的用于控制具有AR功能的设备的方法的流程图;FIG. 13 schematically shows a flowchart of a method for controlling an AR-enabled device executed at a server according to an exemplary embodiment of the present disclosure;
图14示意性地示出了应用于本公开示例性实施例的示例性行为-AR功能映射关系;FIG. 14 schematically shows an exemplary behavior-AR function mapping relationship applied to an exemplary embodiment of the present disclosure;
图15示意性地示出了根据本公开示例性实施例的具有AR功能的设备处执行的受控方法的流程图;FIG. 15 schematically shows a flowchart of a controlled method executed at an AR-capable device according to an exemplary embodiment of the present disclosure;
图16示意性地示出了应用图13和15的方法的用相机观察用户并通过用户行为控制AR设备执行AR功能的示例性场景效果图;FIG. 16 schematically shows an exemplary scene rendering diagram of observing the user with a camera and controlling the AR device to perform AR functions through the user behavior by applying the methods of FIGS. 13 and 15;
图17示意性地示出了根据本公开示例性实施例的服务器的结构框图;FIG. 17 schematically shows a structural block diagram of a server according to an exemplary embodiment of the present disclosure;
图18示意性地示出了根据本公开示例性实施例的采用图13的方法的具有AR功能的设备的结构框图。FIG. 18 schematically shows a structural block diagram of an AR-capable device using the method of FIG. 13 according to an exemplary embodiment of the present disclosure.
图19示意性地示出了根据本公开示例性实施例的在具有AR功能的设备处执行的用于控制该设备的方法的示例性应用场景;FIG. 19 schematically shows an exemplary application scenario of a method for controlling an AR-capable device executed at an AR-capable device according to an exemplary embodiment of the present disclosure;
图20示意性地示出了根据本公开示例性实施例的在具有AR功能的设备处执行的用于控制该设备的方法的流程图;FIG. 20 schematically shows a flowchart of a method for controlling an AR-capable device performed at an AR-enabled device according to an exemplary embodiment of the present disclosure;
图21示意性地示出了根据本公开一示例性实施例的在移动设备视频播放场景中采用图20的方法的示例性场景效果图;Fig. 21 schematically shows an exemplary scene effect diagram of adopting the method of Fig. 20 in a video playback scene of a mobile device according to an exemplary embodiment of the present disclosure;
图22示意性地示出了根据本公开一示例性实施例的在AR设备中采用图20的方法的示例性场景效果图;以及FIG. 22 schematically shows an exemplary scene effect diagram of using the method of FIG. 20 in an AR device according to an exemplary embodiment of the present disclosure; and
图23示意性地示出了根据本公开示例性实施例的采用图20的方法的具有AR功能的设备的结构框图。FIG. 23 schematically shows a structural block diagram of an AR-capable device using the method of FIG. 20 according to an exemplary embodiment of the present disclosure.
具体实施方式Detailed ways
为了使本技术领域的人员更好地理解本公开的方案,下面将结合本公开实施例中的附图,对本公开实施例中的技术方案进行清楚、完整地描述。In order for those skilled in the art to better understand the solutions of the present disclosure, the technical solutions in the embodiments of the present disclosure will be clearly and completely described below with reference to the accompanying drawings in the embodiments of the present disclosure.
在本公开的说明书和权利要求书及上述附图中的描述的一些流程中,包含了按照特定顺序出现的多个操作,但是应该清楚了解,这些操作可以不按照其在本文中出现的顺序来执行或并行执行,操作的序号如101、102等,仅仅是用于区分开各个不同的操作,序号本身不代表任何的执行顺序。另外,这些流程可以包括更多或更少的操作,并且这些操作可以按顺序执行或并行执行。需要说明的是,本文中的“第一”、“第二”等描述,是用于区分不同的消息、设备、模块等,不代表先后顺序,也不限定“第一”和“第二”是不同的类型。In some of the processes described in the specification and claims of the present disclosure and the above-mentioned figures, various operations are included in a specific order, but it should be clearly understood that the operations may be performed out of the order in which they appear in the text. For execution or parallel execution, the sequence numbers of the operations, such as 101, 102, etc., are only used to distinguish different operations, and the sequence numbers themselves do not represent any execution order. Additionally, these flows may include more or fewer operations, and these operations may be performed sequentially or in parallel. It should be noted that the descriptions such as "first" and "second" in this document are used to distinguish different messages, devices, modules, etc., and do not represent a sequence, nor do they limit "first" and "second" are different types.
下面将结合本公开实施例中的附图,对本公开实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本公开一部分实施例,而不是全部的实施例。基于本公开中的实施例,本领域技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本公开保护的范围。The technical solutions in the embodiments of the present disclosure will be clearly and completely described below with reference to the accompanying drawings in the embodiments of the present disclosure. Obviously, the described embodiments are only a part of the embodiments of the present disclosure, but not all of the embodiments. Based on the embodiments in the present disclosure, all other embodiments obtained by those skilled in the art without creative efforts shall fall within the protection scope of the present disclosure.
本公开提出了一种高效的用户行为预测/识别方法,用于从视频中预测/识别用户行为。该方法基于深度神经元网络模型,通过加入人体部位解析方法和局部-整体特征融合方法,可以有效区分细微动作差别,并可以有效区分涉及人与物交互的行为和涉及人与人交互的行为。The present disclosure proposes an efficient user behavior prediction/recognition method for predicting/identifying user behavior from video. The method is based on the deep neural network model, and by adding the human body part analysis method and the local-global feature fusion method, it can effectively distinguish the subtle action differences, and can effectively distinguish the behaviors involving human-object interaction and human-human interaction.
以下参照图2,对根据本公开示例性实施例的用户行为识别方法进行概述。Referring to FIG. 2 below, a user behavior recognition method according to an exemplary embodiment of the present disclosure will be summarized.
图2示意性地示出了根据本公开示例性实施例的用户行为识别方法200的概述过程的流程图。FIG. 2 schematically shows a flowchart of an overview process of a user
如图2所示,在步骤S201中,从视频中包含用户的图像帧中获得基于帧的局部特征图像。As shown in FIG. 2 , in step S201 , a frame-based local feature image is obtained from an image frame containing the user in the video.
在一示例性实施例中,步骤S201可以包括:In an exemplary embodiment, step S201 may include:
步骤S2011:根据所述图像帧,获得基于帧的整体特征图像;Step S2011: According to the image frame, obtain a frame-based overall feature image;
步骤S2012:从所述基于帧的整体特征图像中提取ROI候选;以及Step S2012: extracting ROI candidates from the frame-based overall feature image; and
步骤S2013:根据所述基于帧的整体特征图像和ROI候选,获得所述基于帧的局部特征图像。Step S2013: Obtain the frame-based local feature image according to the frame-based overall feature image and the ROI candidate.
具体地,在一示例中,在步骤S2011中,针对从输入的视频中选择的N个图像帧的每个图像帧进行特征提取,以得到N个基于帧的整体特征图像,其中N为正整数。在本文中,基于帧的整体特征图像指示该图像帧的多层具有多种抽象程度的特征图像。这里,“基于帧”的含义为,所获得的多层特征图像是对应于某一图像帧的多层特征图像。Specifically, in an example, in step S2011, feature extraction is performed for each image frame of N image frames selected from the input video to obtain N frame-based overall feature images, where N is a positive integer . In this paper, a frame-based overall feature image refers to a feature image that has multiple levels of abstraction for multiple layers of the image frame. Here, "frame-based" means that the obtained multi-layer feature image is a multi-layer feature image corresponding to a certain image frame.
在步骤S2012中,从N个基于帧的整体特征图像中的每个基于帧的整体特征图像中提取出至少一个ROI候选。在本文中,ROI候选指示用户在一图像帧上的包含用户相关内容的图像区域。例如,ROI候选可以是一图像帧上的用户位置方框,其边界包括了发生某行为的用户的图像区域。ROI候选可以在该图像帧上的位置和大小进行表征。In step S2012, at least one ROI candidate is extracted from each frame-based overall feature image of the N frame-based overall feature images. Herein, a ROI candidate indicates a user's image region on an image frame that contains user-related content. For example, a ROI candidate may be a user location box on an image frame, the boundary of which includes the image area of the user who performed a certain action. ROI candidates can be characterized by their location and size on the image frame.
在步骤S2013中,根据N个基于帧的整体特征图像和从每个基于帧的整体特征图像中提取出的至少一个ROI候选中的每个ROI候选,获得N个基于帧的局部特征图像。在本文中,基于帧的局部特征图像指示基于帧的整体特征图像上与ROI候选相对应的局部部分,而获得的N个基于帧的局部特征图像指示所述N个基于帧的整体特征图像上与指示包含相同的用户相关内容的图像区域的N个ROI候选相对应的局部部分。这里,“基于帧的局部特征图像”的含义为,所获得的多层特征图像是每帧图像的局部部分的多层特征图像。In step S2013, N frame-based local feature images are obtained according to each of the N frame-based global feature images and at least one ROI candidate extracted from each frame-based global feature image. In this paper, the frame-based local feature image indicates a local part on the frame-based overall feature image corresponding to the ROI candidate, and the obtained N frame-based local feature images indicate the N frame-based overall feature images on the N frame-based overall feature images. Local parts corresponding to N ROI candidates indicating image regions containing the same user-related content. Here, the "frame-based local feature image" means that the obtained multi-layer feature image is a multi-layer feature image of a local part of each frame image.
在步骤S202中,通过以下三种方式中的至少一种来对用户行为进行分类:In step S202, the user behavior is classified by at least one of the following three ways:
根据所述基于帧的局部特征图像和人体姿态特征来对用户行为进行分类;具体地,根据所述N个基于帧的局部特征图像和通过人体部位解析得到的基于人体部位的人体姿态特征来对用户行为进行分类,也称为“基于人体姿态特征的用户行为分类方式”;The user behavior is classified according to the frame-based local feature images and the human body posture features; specifically, according to the N frame-based local feature images and the human body part-based human body posture features obtained by analyzing the body parts User behavior classification, also known as "user behavior classification method based on human posture features";
根据所述基于帧的局部特征图像来获得基于视频的局部特征图像,并根据所述基于视频的局部特征图像来对用户行为进行分类;具体地,根据所述N个基于帧的局部特征图像来获得基于视频的局部特征图像,并根据所述基于视频的局部特征图像来对用户行为进行分类,也称为“基于局部特征的用户行为分类方式”;A video-based local feature image is obtained according to the frame-based local feature image, and user behavior is classified according to the video-based local feature image; Obtaining a video-based local feature image, and classifying user behavior according to the video-based local feature image, also known as a "local feature-based user behavior classification method";
根据所述基于帧的局部特征图像来获得基于视频的局部特征图像,并根据所述基于视频的局部特征图像和基于视频的整体特征图像来对用户行为进行分类;具体地,根据所述N个基于帧的局部特征图像来获得基于视频的局部特征图像,并根据所述基于视频的局部特征图像和所述N个基于帧的整体特征图像来对用户行为进行分类,也称为“基于整体-局部特征融合的用户行为分类方式”。A video-based local feature image is obtained according to the frame-based local feature image, and user behavior is classified according to the video-based local feature image and the video-based overall feature image; Obtaining video-based local feature images based on frame-based local feature images, and classifying user behaviors based on the video-based local feature images and the N frame-based overall feature images, also known as “overall-based User Behavior Classification by Local Feature Fusion".
在本文中,基于视频的局部特征图像是所述N个基于帧的局部特征图像的特征变换或特征组合。这里,“基于视频的局部特征图像”的含义为,所获得的多层特征图像是视频中的所述N个图像帧上对应的局部部分的多层特征图像的特征变换或特征组合。Herein, a video-based local feature image is a feature transformation or feature combination of the N frame-based local feature images. Here, "video-based local feature image" means that the obtained multi-layer feature image is the feature transformation or feature combination of the multi-layer feature images of corresponding local parts on the N image frames in the video.
在步骤S203中,通过将上述三种方式中的至少一种得到的用户行为分类的结果进行融合,以识别用户行为。In step S203, the user behavior is identified by fusing the user behavior classification results obtained in at least one of the above three manners.
用户行为识别方法200可以采用3D CNN(三维卷积神经元网络)来进行各图像帧的特征提取,也可以采用2D CNN(二维卷积神经元网络)来进行各图像帧的特征提取,以下将分别进行描述。The user
在下面的示例性说明中,将以这样的实施方式为例,对本公开的用户行为识别方法进行描述,在该实施方式中,分别采用上述三种对用户行为进行分类的方法得到三个用户行为分类的结果,并对这三个用户行为分类的结果进行融合,以识别用户行为。然而应理解,采用上述三种对用户行为进行分类的方法中的至少一种得到的用户行为分类的结果进行融合以识别用户行为的方案均在本公开意在保护的范围之内。In the following exemplary description, the user behavior identification method of the present disclosure will be described by taking such an implementation manner as an example. In this implementation manner, the above three methods for classifying user behaviors are respectively used to obtain three user behaviors. classification results, and fuse the results of the three user behavior classifications to identify user behaviors. However, it should be understood that the solution of fusing the results of user behavior classification obtained by at least one of the above three methods for classifying user behaviors to identify user behaviors is within the intended protection scope of the present disclosure.
图3示意性地示出了根据本公开一示例性实施例的基于3D CNN的用户行为识别方法的具体过程的流图,其中对应的处理步骤以与图2的概述方法200的各步骤相对应的数字进行标记,具体地,图3中的S3011、S3012、S3013、S302、S303分别对应于图2的方法200中的S2011、S2012、S2013、S202、S203,图3中的S3021、S3022、S3023对应于图2的方法200中的S202。FIG. 3 schematically shows a flow chart of a specific process of a 3D CNN-based user behavior recognition method according to an exemplary embodiment of the present disclosure, wherein the corresponding processing steps correspond to the steps of the
如图3所示,首先在S3011通过3D-CNN,根据所述图像帧的空间域和不同时刻的图像帧的时间域获得不同时刻的图像帧的基于帧的整体特征图像。As shown in FIG. 3 , firstly, in S3011, through 3D-CNN, frame-based overall feature images of image frames at different times are obtained according to the spatial domain of the image frame and the temporal domain of image frames at different times.
具体地,结合先前的示例,在S3011中,视频输入的N个图像帧通过3D-CNN,从每个图像帧的空间域和时间域中提取该图像帧的特征,以得到N个基于帧的整体特征图像。Specifically, in combination with the previous example, in S3011, the N image frames of the video input are passed through 3D-CNN to extract the features of the image frame from the spatial and temporal domains of each image frame to obtain N frame-based image frames. Overall feature image.
接下来,在S3012,通过RPN(区域推荐网络),从每个基于帧的整体特征图像中提取出ROI候选,以得到ROI候选序列。假设从每个基于帧的整体特征图像中提取出M个ROI候选,得到M个ROI候选序列,其中M为正整数。每个ROI候选序列由指示N个图像帧上包含相同的用户相关内容的图像区域的N个ROI候选构成。例如,每个ROI候选序列是随时间变化位置的N个方框,各个方框的边界包括相同的用户相关内容。Next, in S3012, ROI candidates are extracted from each frame-based overall feature image through RPN (Regional Recommendation Network) to obtain ROI candidate sequences. Assuming that M ROI candidates are extracted from each frame-based overall feature image, M ROI candidate sequences are obtained, where M is a positive integer. Each ROI candidate sequence consists of N ROI candidates indicating image regions on N image frames that contain the same user-related content. For example, each ROI candidate sequence is N boxes with time-varying positions, and the boundaries of each box include the same user-related content.
在S3013,根据所述ROI候选序列,从所述所述基于帧的整体特征图像上截取所述基于帧的局部特征图像。In S3013, according to the ROI candidate sequence, the frame-based local feature image is intercepted from the frame-based overall feature image.
具体地,在S3013中,通过ROI池化操作,根据每个ROI候选序列,从所述N个基于帧的整体特征图像上分别截取所述N个基于帧的局部特征图像。Specifically, in S3013, through the ROI pooling operation, according to each ROI candidate sequence, the N frame-based local feature images are respectively intercepted from the N frame-based overall feature images.
在S304,针对M个ROI候选序列中的每一个,通过ROI对齐操作,将所述N个基于帧的局部特征图像基于相应的ROI候选序列进行对齐,并通过3D CNN进一步进行特征提取,以分别获得M个基于视频的局部特征图像。In S304, for each of the M ROI candidate sequences, through the ROI alignment operation, the N frame-based local feature images are aligned based on the corresponding ROI candidate sequences, and further feature extraction is performed through the 3D CNN to respectively Obtain M video-based local feature images.
在S305,根据基于视频的局部特征图像进行用户行为定位,以从多个基于视频的局部特征图像中选择出一个基于视频的局部特征图像。具体地,可以根据这M个基于视频的局部特征图像进行用户行为定位。S305的输出是施行某行为的用户的位置方框。例如,发生“吸烟”行为的用户的图像区域的方框。S305的处理经过FC(全连接)网络,其包括分类的FC分支和回归的FC分支。分类的分支用来判断某个ROI候选是否包含用户,该分支采用逻辑回归函数作为分类损失函数进行训练。回归的分支用来学习包含用户的方框的位置,该分支采用位置偏差损失函数作为回归损失函数进行训练。通过训练,S305可以从M个所述基于视频的局部特征图像中选择出一个基于视频的局部特征图像,以便根据所选的基于视频的局部特征图像对用户行为进行分类。In S305, user behavior positioning is performed according to the video-based local feature images, so as to select a video-based local feature image from a plurality of video-based local feature images. Specifically, user behavior localization can be performed according to the M video-based local feature images. The output of S305 is the location box of the user who performed a certain action. For example, a box in the image area of a user who is "smoking". The processing of S305 goes through an FC (Fully Connected) network, which includes a classification FC branch and a regression FC branch. The classification branch is used to judge whether a ROI candidate contains a user, and the branch uses the logistic regression function as the classification loss function for training. The branch of regression is used to learn the position of the box containing the user, and the branch is trained with the position bias loss function as the regression loss function. Through training, S305 may select a video-based local feature image from the M video-based local feature images, so as to classify the user behavior according to the selected video-based local feature image.
接下来,将所选的基于视频的局部特征图像作为输入,在S3021、S3022和S3023,分别通过基于人体姿态特征的用户行为分类方式、基于局部特征的用户行为分类方式、以及基于整体-局部特征融合的用户行为分类方式对用户行为进行分类,得到用户行为分类的结果,该结果的输出是该用户的行为概率向量,该向量中的每个元素表示用户施行某行为的概率,之后将详细描述。Next, the selected video-based local feature image is used as input, and in S3021, S3022 and S3023, the user behavior classification method based on human body posture features, the user behavior classification method based on local features, and the overall-local feature-based method are respectively used. The fused user behavior classification method classifies user behavior, and obtains the result of user behavior classification. The output of the result is the behavior probability vector of the user. Each element in the vector represents the probability that the user performs a certain behavior, which will be described in detail later. .
在S303,通过将分别采用上述三种方式得到的用户行为分类的结果进行融合,以识别用户行为。具体地,可以将分别采用上述三种方式得到的用户的三个行为概率向量经过1×1卷积融合,然后通过一个全连接层进行行为分类,分类的结果作为最终的用户行为识别结果输出。分类的输出具有最大概率的行为标签,例如握手、吸烟等行为。In S303, the user behavior is identified by fusing the user behavior classification results obtained in the above three manners respectively. Specifically, the three behavior probability vectors of the user obtained by the above three methods can be fused through 1×1 convolution, and then behavior classification is performed through a fully connected layer, and the classification result is output as the final user behavior recognition result. The output of the classification has the most probable action labels, such as handshake, smoking, etc.
以下将分别对通过上述三种方式进行用户行为分类的过程进行详细描述。The process of classifying user behavior through the above three methods will be described in detail below.
基于人体姿态特征的用户行为分类方式Classification of user behavior based on human pose features
在S3021,通过人体部位解析对人体部位进行定位,使得对所选的基于视频的局部特征图像进行3D CNN解码得到的3D CNN解码后的基于视频的局部特征图像包含基于人体部位的人体姿态特征,并根据包含基于所述人体姿态特征的3D CNN解码后的基于视频的局部特征图像来对用户行为进行分类。In S3021, the human body parts are located by analyzing the human body parts, so that the video-based local feature images decoded by the 3D CNN obtained by performing 3D CNN decoding on the selected video-based local feature images contain the human body pose features based on the human body parts, The user behavior is classified according to the video-based local feature image containing the decoded 3D CNN based on the human pose feature.
在一示例性实施例中,通过人体部位解析对人体部位进行定位可以包括:In an exemplary embodiment, locating body parts through body part analysis may include:
确定所述视频的多个图像帧内的每个人体实例在每个图像帧上的图像区域;determining the image area on each image frame of each human body instance within the plurality of image frames of the video;
对从所确定的图像区域中提取的人体图像区域候选进行粗略的部分语义分割,以得到粗略语义分割结果;Perform rough partial semantic segmentation on the human body image region candidates extracted from the determined image regions to obtain a rough semantic segmentation result;
预测每个图像帧上的每个像素相对于其所属的人体中心的方向以得到方向预测结果;Predict the direction of each pixel on each image frame relative to the center of the human body to which it belongs to obtain the direction prediction result;
对所述粗略语义分割结果与所述方向预测结果进行卷积操作,以得到人体部位解析结果。A convolution operation is performed on the rough semantic segmentation result and the direction prediction result to obtain a human body part analysis result.
图4示意性地示出了根据本公开示例性实施例的用户行为识别方法中结合人体部位解析对用户行为进行分类的过程。FIG. 4 schematically shows a process of classifying user behaviors in combination with human body part analysis in a user behavior identification method according to an exemplary embodiment of the present disclosure.
人体部位解析的目的是将图像中出现的多个人体实例分割开来,同时,对每一个分割后的人体实例,分割出更为详细的部位(如头、胳膊、腿等)。通过对图像中每个像素都分配一个部位的类标,可以为用户行为预测方法提供更为精确的人体姿态注意特征,从而达到更高的行为预测准确率。The purpose of human body part analysis is to segment multiple human body instances appearing in the image, and at the same time, for each segmented human body instance, more detailed parts (such as head, arms, legs, etc.) are segmented. By assigning a class label to each pixel in the image, it can provide more accurate human pose attention features for the user behavior prediction method, so as to achieve a higher behavior prediction accuracy.
在一示例性实施例中,提出了一种将人体检测和分割相结合的方法,以进行人体部位解析。该方法使用3D-CNN从时空域图像序列中提取特征,具体包括:In an exemplary embodiment, a method combining human body detection and segmentation is proposed for human body part parsing. The method uses 3D-CNN to extract features from spatiotemporal image sequences, including:
将S304之后得到的基于视频的局部特征图像分别输入3个分支:Input the video-based local feature images obtained after S304 into three branches:
·第一个分支是人体检测分支,用于将提取到的ROI候选进行位置回归,确定所述视频的多个图像帧内的每个人体实例在每个图像帧上的图像区域;The first branch is the human body detection branch, which is used to perform position regression on the extracted ROI candidates, and determine the image area of each human body instance on each image frame in the multiple image frames of the video;
·第二个分支是人体语义分割分支,用于对第一个分支中位置确定的图像区域中提取的人体图像区域候选进行粗略的部分语义分割,以得到粗略语义分割结果;The second branch is the human body semantic segmentation branch, which is used to perform rough partial semantic segmentation on the human body image region candidates extracted from the image regions whose positions are determined in the first branch to obtain a rough semantic segmentation result;
·第三个分支是方向预测分支,用于预测每个图像帧上的每个像素相对于其所属的人体中心的方向,这个特征将被用于帮助分开不同的人体实例,这个分支输出方向预测的结果;The third branch is the orientation prediction branch, which is used to predict the orientation of each pixel on each image frame relative to the center of the human body to which it belongs. This feature will be used to help separate different human instances. This branch outputs orientation predictions the result of;
最后,将第二个分支粗略语义分割的结果和第三个分支方向预测的结果组合,进行1*1的卷积操作,得到最终的人体部位解析结果。Finally, the result of the coarse semantic segmentation of the second branch and the result of the direction prediction of the third branch are combined, and a 1*1 convolution operation is performed to obtain the final analysis result of human body parts.
以上描述对应于测试阶段的处理流程。The above description corresponds to the processing flow of the test phase.
在训练阶段,将S304之后得到的基于视频的局部特征图像分别输入3个分支:In the training phase, the video-based local feature images obtained after S304 are input into three branches:
·第一个分支是人体检测分支,这个分支使用回归损失作为损失函数,将提取到的ROI候选进行位置回归,确定所述视频的多个图像帧内的每个人体实例在每个图像帧上的图像区域;The first branch is the human body detection branch. This branch uses regression loss as the loss function to perform position regression on the extracted ROI candidates, and determine that each human instance in the multiple image frames of the video is on each image frame. the image area;
·第二个分支是人体语义分割分支,这个分支使用交叉熵作为损失函数,对第一个分支中中提取的人体图像区域候选进行粗略的部分语义分割,输出粗略语义分割的结果;The second branch is the human body semantic segmentation branch. This branch uses the cross entropy as the loss function to perform rough partial semantic segmentation on the human body image region candidates extracted in the first branch, and outputs the results of the rough semantic segmentation;
·第三个分支是方向预测分支,这个分支仍然使用交叉熵作为损失函数,预测每个图像帧上的每个像素相对于其所属的人体中心的方向,然后输出方向预测的结果;在训练阶段,本公开根据像素对其所属的人体实例的相对方向和距离远近做出量化,如图5所示。The third branch is the orientation prediction branch, which still uses cross-entropy as the loss function, predicts the orientation of each pixel on each image frame relative to the center of the human body to which it belongs, and then outputs the result of orientation prediction; in the training phase , the present disclosure quantifies the relative direction and distance of the human body instance to which the pixel belongs, as shown in FIG. 5 .
最后,将第二个分支粗略语义分割的结果和第三个分支方向预测的结果组合,进行1*1的卷积操作,使得到最终的人体部位解析结果和数据集标定的人体部位解析结果计算交叉熵损失函数,进行训练整个网络参数。Finally, the result of the rough semantic segmentation of the second branch and the result of the direction prediction of the third branch are combined, and a 1*1 convolution operation is performed, so that the final human body part analysis result and the human body part analysis result calibrated by the dataset are calculated. The cross-entropy loss function is used to train the entire network parameters.
在一示例性实施例中,根据包含基于所述人体姿态特征的3D CNN解码后的基于视频的局部特征图像来对用户行为进行分类可以包括:In an exemplary embodiment, classifying the user behavior according to the video-based local feature image containing the decoded 3D CNN based on the human pose feature may include:
分别通过以用户姿势动作作为分类标签的3D CNN和以用户交互动作作为分类标签的3D CNN,从包含基于所述人体姿态特征的3D CNN解码后的基于视频的局部特征图像中提取与用户姿势动作有关的特征和与用户交互动作有关的特征;以及Using the 3D CNN with the user pose action as the classification label and the 3D CNN with the user interaction action as the classification label, respectively, from the video-based local feature image decoded by the 3D CNN based on the human pose feature, extract the image with the user pose action. related features and features related to user interactions; and
将所提取的与用户姿势动作有关的特征和与用户交互动作有关的特征进行融合,以对用户行为进行分类,The extracted features related to user gestures and actions related to user interaction are fused to classify user behaviors,
其中针对用户姿势动作使用类别互斥的多标签姿势动作分类损失函数进行训练,针对用户交互动作使用类别非互斥的多标签交互动作分类损失函数进行训练。Among them, the multi-label gesture and action classification loss function with mutually exclusive categories is used for training for user gesture actions, and the multi-label interaction action classification loss function with non-mutually exclusive categories is used for training for user interaction actions.
图6(a)示意性地示出了根据本公开示例性实施例的用户行为识别方法中采用多任务方式对用户行为进行分类的过程。FIG. 6( a ) schematically shows a process of classifying user behaviors in a multi-task manner in the method for recognizing user behaviors according to an exemplary embodiment of the present disclosure.
图6(a)所示的方法所使用的深度神经元网络模型采用了一种多任务的网络结构,其任务分别是用户定位任务、用户行为分类任务。用户定位分支估计用户在视频中的空间位置,输出为用户区域的矩形框。用户行为分类分支预测矩形框内的用户行为。其中:用户行为根据类别可分为用户姿势动作和用户交互动作。用户姿势动作包括:坐、站、跑等动作。用户姿势动作的多个类别相互排斥,即多个用户姿势动作中只有一个是成立的,不能多个动作同时成立。例如:一个用户不能既“坐”又“站”。对于这类行为使用类别互斥的多标签姿势动作分类损失函数,例如Softmax函数。用户交互动作的多个类别不相互排斥,例如:一个用户可以同时“吸烟”和“看书”。对于这类行为使用类别非互斥的多标签交互动作分类损失函数,如多个逻辑回归函数。The deep neural network model used in the method shown in Fig. 6(a) adopts a multi-task network structure, and its tasks are user localization task and user behavior classification task respectively. The user localization branch estimates the spatial position of the user in the video and outputs a rectangular box of the user area. The user behavior classification branch predicts user behavior within a rectangular box. Among them: user behavior can be divided into user gesture actions and user interaction actions according to categories. User posture actions include: sitting, standing, running and other actions. Multiple categories of user gesture actions are mutually exclusive, that is, only one of multiple user gesture actions is established, and multiple actions cannot be established at the same time. For example: a user cannot both "sit" and "stand". For this type of behavior use a class-exclusive multi-label pose-action classification loss function, such as the Softmax function. The multiple categories of user interaction actions are not mutually exclusive, eg: a user can "smoke" and "read a book" at the same time. For this type of behavior use a non-mutually exclusive multi-label interaction action classification loss function, such as multiple logistic regression functions.
用户行为分类分支包含两个3D CNN和一个融合网络。在基于人体姿态特征的用户行为分类方式中,将包含基于所述人体姿态特征的3D CNN解码后的基于视频的局部特征图像作为该用户行为分类分支的输入,即,使包含基于所述人体姿态特征的3D CNN解码后的基于视频的局部特征图像分别通过以用户姿势动作作为分类标签的3D CNN(S601)和以用户交互动作作为分类标签的3D CNN(S602),使得可以通过这两个3D CNN分别学习特定的动作特征,从包含基于所述人体姿态特征的3D CNN解码后的基于视频的局部特征图像中提取与用户姿势动作有关的特征和与用户交互动作有关的特征;然后在S603,融合网络将两个3D CNN输出特征融合后进一步对用户行为分类。The user behavior classification branch contains two 3D CNNs and a fusion network. In the user behavior classification method based on human pose features, the video-based local feature image decoded by the 3D CNN based on the human pose features is used as the input of the user behavior classification branch, that is, the
以上描述对应于测试阶段的处理流程。The above description corresponds to the processing flow of the test phase.
在训练阶段,(1)将视频中的多个图像帧作为输入,训练共享3D CNN和用户定位分支的RPN,不训练用户行为分类分支的网络。模型训练过程如图6(b)所示,RPN优化两个损失函数:矩形框分类损失和回归损失。In the training phase, (1) take multiple image frames in the video as input, train the RPN that shares the 3D CNN and the user localization branch, and not train the network of the user behavior classification branch. The model training process is shown in Figure 6(b), where RPN optimizes two loss functions: box classification loss and regression loss.
(2)将视频中的多个图像帧作为输入,经过RPN产生ROI候选,训练共享3D CNN和用户行为分类分支的网络,不训练用户定位分支。模型前向过程如图6(c)所示:输入数据经过共享3D CNN提取基于帧的整体特征图像,该基于帧的整体特征图像与产生的ROI候选做池化操作输出基于帧的局部特征图像,该基于帧的局部特征图像经过ROI对齐得到基于视频的局部特征图像,经过用户分类分支输出用户行为。用户行为分类分支优化三个损失函数:类别互斥的多标签姿势动作分类损失函数、类别非互斥的多标签交互动作分类损失函数、以及多标签用户行为分类损失函数。(2) Taking multiple image frames in the video as input, generating ROI candidates through RPN, training the network sharing the 3D CNN and the user behavior classification branch, and not training the user localization branch. The forward process of the model is shown in Figure 6(c): the input data is passed through the shared 3D CNN to extract the frame-based overall feature image, and the frame-based overall feature image and the generated ROI candidates are pooled to output the frame-based local feature image. , the frame-based local feature image is ROI aligned to obtain a video-based local feature image, and the user behavior is output through the user classification branch. The user behavior classification branch optimizes three loss functions: a multi-label gesture action classification loss function with mutually exclusive categories, a multi-label interaction action classification loss function with non-mutually exclusive categories, and a multi-label user behavior classification loss function.
(3)将视频中的多个图像帧作为输入,固定共享3D CNN,单独训练用户定位分支的RPN。(3) Using multiple image frames in the video as input, a fixed shared 3D CNN, and the RPN of the user localization branch is separately trained.
(4)将视频中的多个图像帧作为输入,固定共享3D CNN,单独训练用户行为分类分支的网络。(4) Taking multiple image frames in the video as input, fixedly sharing the 3D CNN, and separately training the network of the user behavior classification branch.
基于局部特征的用户行为分类方式User behavior classification based on local features
在S3022,根据所选的基于视频的局部特征图像来对用户行为进行分类。At S3022, the user behavior is classified according to the selected video-based local feature images.
与基于人体姿态特征的用户行为分类方式中采用多任务方式对用户行为进行分类的过程类似,在基于局部特征的用户行为分类方式中,也可以采用多任务方式对用户行为进行分类。Similar to the process of classifying user behavior in a multi-task manner in the user behavior classification method based on human posture features, in the user behavior classification method based on local features, the user behavior can also be classified in a multi-task manner.
在这样的示例性实施例中,根据所选的基于视频的局部特征图像来对用户行为进行分类包括:In such an exemplary embodiment, classifying user behavior according to selected video-based local feature images includes:
分别通过以用户姿势动作作为分类标签的3D CNN和以用户交互动作作为分类标签的3D CNN,从所选的基于视频的局部特征图像中提取与用户姿势动作有关的特征和与用户交互动作有关的特征;以及The features related to user gestures and user interaction actions are extracted from the selected video-based local feature images through a 3D CNN with user gesture actions as classification labels and a 3D CNN with user interaction actions as classification labels, respectively. features; and
将所提取的与用户姿势动作有关的特征和与用户交互动作有关的特征进行融合,以对用户行为进行分类,The extracted features related to user gestures and actions related to user interaction are fused to classify user behaviors,
其中针对用户姿势动作使用类别互斥的多标签姿势动作分类损失函数进行训练,针对用户交互动作使用类别非互斥的多标签交互动作分类损失函数进行训练。Among them, the multi-label gesture and action classification loss function with mutually exclusive categories is used for training for user gesture actions, and the multi-label interaction action classification loss function with non-mutually exclusive categories is used for training for user interaction actions.
该过程所使用的多任务的网络结构仍然如图6(a)所示,其区别仅在于,在基于局部特征的用户行为分类方式中,将所选的基于视频的局部特征图像作为该用户行为分类分支的输入,即,使所选的基于视频的局部特征图像分别通过以用户姿势动作作为分类标签的3D CNN(S601)和以用户交互动作作为分类标签的3D CNN(S602),使得可以通过这两个3DCNN分别学习特定的动作特征,从所选的基于视频的局部特征图像中提取与用户姿势动作有关的特征和与用户交互动作有关的特征;然后在S603,融合网络将两个3D CNN输出特征融合后进一步对用户行为分类。The multi-task network structure used in this process is still as shown in Figure 6(a), the only difference is that in the local feature-based user behavior classification method, the selected video-based local feature image is used as the user behavior. The input of the classification branch, that is, making the selected video-based local feature images pass through the 3D CNN with user gesture actions as classification labels (S601) and the 3D CNN with user interaction actions as classification labels (S602), respectively, so that the The two 3D CNNs learn specific action features respectively, and extract features related to user gestures and actions and features related to user interaction actions from the selected video-based local feature images; then in S603, the fusion network combines the two 3D CNNs with After the output features are fused, the user behavior is further classified.
在训练阶段的处理流程与基于人体姿态特征的用户行为分类方式中对于多任务网络的训练过程相同,在此不再赘述。The processing flow in the training phase is the same as the training process for the multi-task network in the user behavior classification method based on the human posture feature, and will not be repeated here.
基于整体-局部特征融合的用户行为分类方式User behavior classification based on global-local feature fusion
在S3023,根据所选的基于视频的局部特征图像和所述N个基于帧的整体特征图像来对用户行为进行分类。At S3023, classify the user behavior according to the selected video-based local feature images and the N frame-based overall feature images.
具体地,根据所选的基于视频的局部特征图像和所述N个基于帧的整体特征图像来对用户行为进行分类包括:Specifically, classifying user behavior according to the selected video-based local feature images and the N frame-based overall feature images includes:
通过3D CNN,从所述N个基于帧的整体特征图像中进一步进行特征提取,以得到基于视频的整体特征图像,这里,“基于视频的整体特征图像”的含义为,所获得的多层特征图像是视频中的所述N个图像帧上对应的整幅图像的多层特征图像的特征变换;以及Through 3D CNN, further feature extraction is performed from the N frame-based overall feature images to obtain video-based overall feature images. Here, the meaning of "video-based overall feature images" means that the obtained multi-layer features The image is the feature transformation of the multi-layer feature images of the corresponding whole image on the N image frames in the video; and
将所述基于视频的整体特征图像与所选的基于视频的局部特征图像进行特征组合,以根据特征组合后的多层特征图像对用户行为进行分类。The feature combination of the video-based overall feature image and the selected video-based local feature image is performed to classify user behaviors according to the feature-combined multi-layer feature images.
与基于人体姿态特征的用户行为分类方式、基于局部特征的用户行为分类方式中采用多任务方式对用户行为进行分类的过程类似,在基于整体-局部特征融合的用户行为分类方式中,也可以采用多任务方式对用户行为进行分类。Similar to the user behavior classification method based on human posture features and the user behavior classification method based on local features, the multi-task method is used to classify user behavior. In the user behavior classification method based on global-local feature fusion, it can also be used A multitasking approach classifies user behavior.
在这样的示例性实施例中,根据特征组合后的多层特征图像对用户行为进行分类包括:In such an exemplary embodiment, classifying user behavior according to the feature-combined multi-layer feature image includes:
分别通过以用户姿势动作作为分类标签的3D CNN和以用户交互动作作为分类标签的3D CNN,从特征组合后的多层特征图像中提取与用户姿势动作有关的特征和与用户交互动作有关的特征;以及Through the 3D CNN with the user gesture action as the classification label and the 3D CNN with the user interaction action as the classification label, the features related to the user pose and action are extracted from the multi-layer feature image after feature combination. ;as well as
将所提取的与用户姿势动作有关的特征和与用户交互动作有关的特征进行融合,以对用户行为进行分类,The extracted features related to user gestures and actions related to user interaction are fused to classify user behaviors,
其中针对用户姿势动作使用类别互斥的多标签姿势动作分类损失函数进行训练,针对用户交互动作使用类别非互斥的多标签交互动作分类损失函数进行训练。Among them, the multi-label gesture and action classification loss function with mutually exclusive categories is used for training for user gesture actions, and the multi-label interaction action classification loss function with non-mutually exclusive categories is used for training for user interaction actions.
该过程所使用的多任务的网络结构仍然如图6(a)所示,其区别仅在于,在基于整体-局部特征融合的用户行为分类方式中,将特征组合后的多层特征图像作为该用户行为分类分支的输入,即,使特征组合后的多层特征图像分别通过以用户姿势动作作为分类标签的3D CNN(S601)和以用户交互动作作为分类标签的3D CNN(S602),使得可以通过这两个3D CNN分别学习特定的动作特征,从特征组合后的多层特征图像中提取与用户姿势动作有关的特征和与用户交互动作有关的特征;然后在S603,融合网络将两个3D CNN输出特征融合后进一步对用户行为分类。The multi-task network structure used in this process is still shown in Figure 6(a). The only difference is that in the user behavior classification method based on global-local feature fusion, the multi-layer feature image after feature combination is used as The input of the user behavior classification branch, that is, the multi-layer feature image after feature combination is passed through the 3D CNN (S601) with the user gesture action as the classification label and the 3D CNN (S602) with the user interaction action as the classification label, so that it can be The two 3D CNNs learn specific action features respectively, and extract features related to user gestures and actions and features related to user interaction actions from the combined multi-layer feature image; then in S603, the fusion network combines the two 3D features. The CNN output features are fused to further classify user behaviors.
在训练阶段的处理流程与基于人体姿态特征的用户行为分类方式中对于多任务网络的训练过程相同,在此不再赘述。The processing flow in the training phase is the same as the training process for the multi-task network in the user behavior classification method based on the human posture feature, and will not be repeated here.
以上对根据本公开一示例性实施例的基于3D CNN的用户行为识别方法进行了详细描述。在另一示例性实施例中,可以采用2D CNN来进行各个图像帧的特征提取。The 3D CNN-based user behavior recognition method according to an exemplary embodiment of the present disclosure has been described above in detail. In another exemplary embodiment, a 2D CNN may be employed for feature extraction of each image frame.
图7示意性地示出了根据本公开一示例性实施例的基于2D CNN的用户行为识别方法700的具体过程的流图,其中对应的处理步骤以与图2的概述方法200、以及图3的基于3DCNN的用户行为识别方法300的各步骤相对应的数字进行标记,具体地,图7中的S7011、S7012、S7013、S702、S703分别对应于图2的方法200中的S2011、S2012、S2013、S202、S203,并分别对应于图3中的S3011、S3012、S3013、S302、S303;图7中的S704、S705分别对应于图3中的S304、S305;图7中的S7021、S7022、S7023分别对应于图3中的S3021、S3022、S3023、并对应于图2的方法200中的S202。FIG. 7 schematically shows a flow chart of a specific process of a 2D CNN-based user behavior recognition method 700 according to an exemplary embodiment of the present disclosure, wherein the corresponding processing steps are the same as those of the
如图7所示,可以从视频输入中选择多个图像帧,例如,选择第一帧、中间帧、以及最后一帧三图像帧。在S7011,通过2D-CNN,根据所述图像帧获得基于帧的整体特征图像。具体地,结合先前的示例,通过2D-CNN,从N个图像帧中的每个图像帧中分别提取特征,以得到N个基于帧的整体特征图像。As shown in FIG. 7, a plurality of image frames can be selected from the video input, for example, three image frames of the first frame, the middle frame, and the last frame are selected. In S7011, a frame-based overall feature image is obtained according to the image frame through 2D-CNN. Specifically, combined with the previous examples, through 2D-CNN, features are separately extracted from each of the N image frames to obtain N frame-based overall feature images.
在S7012,通过RPN,从每个图像帧的基于帧的整体特征图像中提取出例如M个ROI候选。At S7012, for example, M ROI candidates are extracted from the frame-based overall feature image of each image frame through RPN.
在S7013,针对多个图像帧中的每个图像帧,通过ROI池化操作,根据所述M个ROI候选中的每个ROI候选,从该图像帧的基于帧的整体特征图像上截取基于帧的局部特征图像。由此,可以获得与M个ROI候选相对应的M个基于帧的局部特征图像。At S7013, for each image frame in the plurality of image frames, through the ROI pooling operation, according to each ROI candidate in the M ROI candidates, intercept the frame-based overall feature image from the frame-based overall feature image of the image frame. local feature image. Thereby, M frame-based local feature images corresponding to the M ROI candidates can be obtained.
在S704,通过2D CNN进一步进行特征提取。At S704, feature extraction is further performed by 2D CNN.
在S705,根据基于帧的局部特征图像进行用户行为定位,以从多个基于帧的局部特征图像中选择出一个基于帧的局部特征图像。具体地,结合先前的示例,可以根据每个图像帧的M个基于帧的局部特征图像进行用户行为定位。与基于3D CNN的用户行为识别方法类似,S705的处理也经过FC网络,其包括分类的FC分支和回归的FC分支。分类的分支用来判断某个ROI候选是否包含用户,该分支采用逻辑回归函数作为分类损失函数进行训练。回归的分支用来学习包含用户的方框的位置,该分支采用位置偏差损失函数作为回归损失函数进行训练。通过训练,S705可以从所述M个基于帧的局部特征图像中选择出一个基于帧的局部特征图像,以便根据所选的基于帧的局部特征图像对用户行为进行分类。In S705, user behavior localization is performed according to the frame-based local feature images, so as to select a frame-based local feature image from a plurality of frame-based local feature images. Specifically, in combination with the previous examples, user behavior localization can be performed according to M frame-based local feature images of each image frame. Similar to the 3D CNN-based user behavior recognition method, the processing of S705 also goes through the FC network, which includes a classification FC branch and a regression FC branch. The classification branch is used to judge whether a ROI candidate contains a user, and the branch uses the logistic regression function as the classification loss function for training. The branch of regression is used to learn the position of the box containing the user, and the branch is trained with the position bias loss function as the regression loss function. Through training, S705 may select a frame-based local feature image from the M frame-based local feature images, so as to classify the user behavior according to the selected frame-based local feature image.
接下来,在S7021,针对每个图像帧,将所选的基于帧的局部特征图像作为输入,通过基于人体姿态特征的用户行为分类方式对用户行为进行分类。Next, in S7021, for each image frame, the selected frame-based local feature image is used as input, and the user behavior is classified by the user behavior classification method based on the human body posture feature.
基于人体姿态特征的用户行为分类方式Classification of user behavior based on human pose features
在S7021,根据每个图像帧的所选的基于帧的局部特征图像和通过人体部位解析得到的基于人体部位的人体姿态特征来对用户行为进行分类,然后将针对每个图像帧的用户行为分类结果进行组合,At S7021, classify the user behavior according to the selected frame-based local feature image of each image frame and the human body part-based body pose feature obtained by analyzing the body part, and then classify the user behavior for each image frame The results are combined,
在一示例性实施例中,根据每个图像帧的基于帧的局部特征图像和通过人体部位解析得到的基于人体部位的人体姿态特征来对用户行为进行分类包括:In an exemplary embodiment, classifying the user behavior according to the frame-based local feature image of each image frame and the human body part-based human pose feature obtained by analyzing the human body part includes:
通过人体部位解析对人体部位进行定位,使得对所述基于帧的局部特征图像进行2D CNN解码得到的3D CNN解码后的基于帧的局部特征图像包含基于人体部位的人体姿态特征,并根据包含基于所述人体姿态特征的2D CNN解码后的基于帧的局部特征图像来对用户行为进行分类。The human body parts are located through the human body part analysis, so that the frame-based local feature image decoded by the 3D CNN obtained by performing 2D CNN decoding on the frame-based local feature image contains the human body pose feature based on the human body part, and according to the The frame-based local feature images decoded by the 2D CNN of the human pose features are used to classify user behaviors.
在一示例性实施例中,通过人体部位解析对人体部位进行定位可以包括:In an exemplary embodiment, locating body parts through body part analysis may include:
确定所述视频的多个图像帧内的每个人体实例在每个图像帧上的图像区域;determining the image area on each image frame of each human body instance within the plurality of image frames of the video;
对从所确定的图像区域中提取的人体图像区域候选进行粗略的部分语义分割,以得到粗略语义分割结果;Perform rough partial semantic segmentation on the human body image region candidates extracted from the determined image regions to obtain a rough semantic segmentation result;
预测每个图像帧上的每个像素相对于其所属的人体中心的方向以得到方向预测结果;Predict the direction of each pixel on each image frame relative to the center of the human body to which it belongs to obtain the direction prediction result;
对所述粗略语义分割结果与所述方向预测结果进行卷积操作,以得到人体部位解析结果。A convolution operation is performed on the rough semantic segmentation result and the direction prediction result to obtain a human body part analysis result.
具体的过程可以参照图4。图4示意性地示出了根据本公开示例性实施例的用户行为识别方法中结合人体部位解析对用户行为进行分类的过程。The specific process can refer to FIG. 4 . FIG. 4 schematically shows a process of classifying user behaviors in combination with human body part analysis in a user behavior identification method according to an exemplary embodiment of the present disclosure.
人体部位解析的目的是将图像中出现的多个人体实例分割开来,同时,对每一个分割后的人体实例,分割出更为详细的部位(如头、胳膊、腿等)。通过对图像中每个像素都分配一个部位的类标,可以为用户行为预测方法提供更为精确的人体姿态注意特征,从而达到更高的行为预测准确率。The purpose of human body part analysis is to segment multiple human body instances appearing in the image, and at the same time, for each segmented human body instance, more detailed parts (such as head, arms, legs, etc.) are segmented. By assigning a class label to each pixel in the image, it can provide more accurate human pose attention features for the user behavior prediction method, so as to achieve a higher behavior prediction accuracy.
在一示例性实施例中,提出了一种将人体检测和分割相结合的方法,以进行人体部位解析。该方法使用2D-CNN从每个图像帧中提取特征,具体包括:In an exemplary embodiment, a method combining human body detection and segmentation is proposed for human body part parsing. The method uses 2D-CNN to extract features from each image frame, including:
将S704之后得到的基于帧的局部特征图像分别输入3个分支:The frame-based local feature images obtained after S704 are respectively input into three branches:
·第一个分支是人体检测分支,用于将提取到的ROI候选进行位置回归,确定所述视频的多个图像帧内的每个人体实例在每个图像帧上的图像区域;The first branch is the human body detection branch, which is used to perform position regression on the extracted ROI candidates, and determine the image area of each human body instance on each image frame in the multiple image frames of the video;
·第二个分支是人体语义分割分支,用于对第一个分支中位置确定的图像区域中提取的人体图像区域候选进行粗略的部分语义分割,以得到粗略语义分割结果;The second branch is the human body semantic segmentation branch, which is used to perform rough partial semantic segmentation on the human body image region candidates extracted from the image regions whose positions are determined in the first branch to obtain a rough semantic segmentation result;
·第三个分支是方向预测分支,用于预测每个图像帧上的每个像素相对于其所属的人体中心的方向,这个特征将被用于帮助分开不同的人体实例,这个分支输出方向预测的结果;The third branch is the orientation prediction branch, which is used to predict the orientation of each pixel on each image frame relative to the center of the human body to which it belongs. This feature will be used to help separate different human instances. This branch outputs orientation predictions the result of;
最后,将第二个分支粗略语义分割的结果和第三个分支方向预测的结果组合到一起,进行1*1的卷积操作,得到最终的人体部位解析结果。Finally, the results of the second branch's rough semantic segmentation and the third branch's direction prediction results are combined, and a 1*1 convolution operation is performed to obtain the final human body part analysis result.
以上描述对应于测试阶段的处理流程。The above description corresponds to the processing flow of the test phase.
在训练阶段,将S704之后得到的基于帧的局部特征图像分别输入3个分支:In the training phase, the frame-based local feature images obtained after S704 are input into three branches:
·第一个分支是人体检测分支,这个分支使用回归损失作为损失函数,将提取到的ROI候选进行位置回归,确定所述视频的多个图像帧内的每个人体实例在每个图像帧上的图像区域;The first branch is the human body detection branch. This branch uses regression loss as the loss function to perform position regression on the extracted ROI candidates, and determine that each human instance in the multiple image frames of the video is on each image frame. the image area;
·第二个分支是人体语义分割分支,这个分支使用交叉熵作为损失函数,对第一个分支中中提取的人体图像区域候选进行粗略的部分语义分割,输出粗略语义分割的结果;The second branch is the human body semantic segmentation branch. This branch uses the cross entropy as the loss function to perform rough partial semantic segmentation on the human body image region candidates extracted in the first branch, and outputs the results of the rough semantic segmentation;
·第三个分支是方向预测分支,这个分支仍然使用交叉熵作为损失函数,预测每个图像帧上的每个像素相对于其所属的人体中心的方向,然后输出方向预测的结果;在训练阶段,本公开根据像素对其所属的人体实例的相对方向和距离远近做出量化,如图5所示。The third branch is the orientation prediction branch, which still uses cross-entropy as the loss function, predicts the orientation of each pixel on each image frame relative to the center of the human body to which it belongs, and then outputs the result of orientation prediction; in the training phase , the present disclosure quantifies the relative direction and distance of the human body instance to which the pixel belongs, as shown in FIG. 5 .
最后,将第二个分支粗略语义分割的结果和第三个分支方向预测的结果组合,进行1*1的卷积操作,使得到最终的人体部位解析结果和数据集标定的人体部位解析结果计算交叉熵损失函数,进行训练整个网络参数。Finally, the result of the rough semantic segmentation of the second branch and the result of the direction prediction of the third branch are combined, and a 1*1 convolution operation is performed, so that the final human body part analysis result and the human body part analysis result calibrated by the dataset are calculated. The cross-entropy loss function is used to train the entire network parameters.
在一示例性实施例中,根据包含基于所述人体姿态特征的2D CNN解码后的基于帧的局部特征图像来对用户行为进行分类可以包括:In an exemplary embodiment, classifying the user behavior according to the frame-based local feature image containing the decoded 2D CNN based on the human pose feature may include:
分别通过以用户姿势动作作为分类标签的2D CNN和以用户交互动作作为分类标签的2D CNN,从包含基于所述人体姿态特征的2D CNN解码后的基于帧的局部特征图像中提取与用户姿势动作有关的特征和与用户交互动作有关的特征;以及Using the 2D CNN with the user pose action as the classification label and the 2D CNN with the user interaction action as the classification label, respectively, from the frame-based local feature image decoded by the 2D CNN based on the human pose feature, extract the image with the user pose action. related features and features related to user interactions; and
将所提取的与用户姿势动作有关的特征和与用户交互动作有关的特征进行融合,以对用户行为进行分类,The extracted features related to user gestures and actions related to user interaction are fused to classify user behaviors,
其中针对用户姿势动作使用类别互斥的多标签姿势动作分类损失函数进行训练,针对用户交互动作使用类别非互斥的多标签交互动作分类损失函数进行训练。Among them, the multi-label gesture and action classification loss function with mutually exclusive categories is used for training for user gesture actions, and the multi-label interaction action classification loss function with non-mutually exclusive categories is used for training for user interaction actions.
与基于3D CNN的用户行为识别方法类似,所使用的深度神经元网络模型采用了一种多任务的网络结构,其任务分别是用户定位任务、用户行为分类任务。用户定位分支估计用户在视频中的空间位置,输出为用户区域的矩形框。用户行为分类分支预测矩形框内的用户行为。其中:用户行为根据类别可分为用户姿势动作和用户交互动作。用户姿势动作包括:坐、站、跑等动作。用户姿势动作的多个类别相互排斥,即多个用户姿势动作中只有一个是成立的,不能多个动作同时成立。例如:一个用户不能既“坐”又“站”。对于这类行为使用类别互斥的多标签姿势动作分类损失函数,例如Softmax函数。用户交互动作的多个类别不相互排斥,例如:一个用户可以同时“吸烟”和“看书”。对于这类行为使用类别非互斥的多标签交互动作分类损失函数,如多个逻辑回归函数。Similar to the user behavior recognition method based on 3D CNN, the deep neural network model used adopts a multi-task network structure, and its tasks are user localization task and user behavior classification task. The user localization branch estimates the spatial position of the user in the video and outputs a rectangular box of the user area. The user behavior classification branch predicts user behavior within a rectangular box. Among them: user behavior can be divided into user gesture actions and user interaction actions according to categories. User posture actions include: sitting, standing, running and other actions. Multiple categories of user gesture actions are mutually exclusive, that is, only one of multiple user gesture actions is established, and multiple actions cannot be established at the same time. For example: a user cannot both "sit" and "stand". For this type of behavior use a class-exclusive multi-label pose-action classification loss function, such as the Softmax function. The multiple categories of user interaction actions are not mutually exclusive, eg: a user can "smoke" and "read a book" at the same time. For this type of behavior use a non-mutually exclusive multi-label interaction action classification loss function, such as multiple logistic regression functions.
用户行为分类分支包含两个2D CNN和一个融合网络。尽管没有示出,但仍可参照图6(a)中从S304输出的箭头之后的部分。在基于人体姿态特征的用户行为分类方式中,将包含基于所述人体姿态特征的2D CNN解码后的基于帧的局部特征图像作为该用户行为分类分支的输入,即,使包含基于所述人体姿态特征的2D CNN解码后的基于帧的局部特征图像分别通过以用户姿势动作作为分类标签的2D CNN和以用户交互动作作为分类标签的2DCNN,使得可以通过这两个2D CNN分别学习特定的动作特征,从包含基于所述人体姿态特征的2D CNN解码后的基于帧的局部特征图像中提取与用户姿势动作有关的特征和与用户交互动作有关的特征;然后,融合网络将两个2D CNN输出特征融合后进一步对用户行为分类。The user behavior classification branch contains two 2D CNNs and a fusion network. Although not shown, reference may be made to the portion following the arrow output from S304 in FIG. 6(a). In the user behavior classification method based on human pose features, the frame-based local feature image decoded by the 2D CNN based on the human pose features is used as the input of the user behavior classification branch, that is, the The frame-based local feature images decoded by the 2D CNN of the features are respectively passed through a 2D CNN with user gesture actions as classification labels and a 2D CNN with user interaction actions as classification labels, so that specific action features can be learned through these two 2D CNNs respectively. , extract features related to user gestures and actions and features related to user interaction from the frame-based local feature images decoded by the 2D CNN based on the human pose features; then, the fusion network combines the two 2D CNN output features After the fusion, the user behavior is further classified.
以上描述对应于测试阶段的处理流程。The above description corresponds to the processing flow of the test phase.
在训练阶段,(1)将视频中的多个图像帧作为输入,训练共享2D CNN和用户定位分支的RPN,不训练用户行为分类分支的网络。类似于基于2D CNN的用户识别方法中使用模型训练过程,RPN优化两个损失函数:矩形框分类损失和回归损失。In the training phase, (1) take multiple image frames in the video as input, train the RPN that shares the 2D CNN and the user localization branch, and do not train the network of the user behavior classification branch. Similar to the model training process used in 2D CNN-based user identification methods, RPN optimizes two loss functions: box classification loss and regression loss.
(2)将视频中的多个图像帧作为输入,经过RPN产生ROI候选,训练共享2D CNN和用户行为分类分支的网络,不训练用户定位分支。类似于基于3D CNN的用户识别方法中使用的模型训练过程:输入数据经过共享2D CNN提取基于帧的整体特征图像,该基于帧的整体特征图像与产生的ROI候选做池化操作输出基于帧的局部特征图像,该基于帧的局部特征图像经过用户分类分支输出用户行为。用户行为分类分支优化三个损失函数:类别互斥的多标签姿势动作分类损失函数、类别非互斥的多标签交互动作分类损失函数、以及多标签用户行为分类损失函数。(2) Taking multiple image frames in the video as input, generating ROI candidates through RPN, training the network sharing the 2D CNN and the user behavior classification branch, and not training the user localization branch. Similar to the model training process used in the 3D CNN-based user identification method: the input data is passed through a shared 2D CNN to extract a frame-based overall feature image, and the frame-based overall feature image is pooled with the generated ROI candidates. Local feature image, the frame-based local feature image outputs user behavior through the user classification branch. The user behavior classification branch optimizes three loss functions: a multi-label gesture action classification loss function with mutually exclusive categories, a multi-label interaction action classification loss function with non-mutually exclusive categories, and a multi-label user behavior classification loss function.
(3)将视频中的多个图像帧作为输入,固定共享2D CNN,单独训练用户定位分支的RPN。(3) Using multiple image frames in the video as input, a fixed shared 2D CNN is used to separately train the RPN of the user localization branch.
(4)将视频中的多个图像帧作为输入,固定共享2D CNN,单独训练用户分类分支的网络。(4) Taking multiple image frames in the video as input, fixedly sharing the 2D CNN, and separately training the network of the user classification branch.
实际训练中,上述步骤的顺序可以变化或交替进行。In actual training, the order of the above steps can be changed or performed alternately.
基于局部特征的用户行为分类方式User behavior classification based on local features
在S7022,根据针对N个图像帧分别选择的N个基于帧的局部特征图像来获得基于视频的局部特征图像,其中所述N个基于帧的局部特征图像指示所述N个基于帧的整体特征图像上与指示包含相同用户相关内容的图像区域的N个ROI候选相对应的局部部分。这里,基于视频的局部特征图像是所述N个基于帧的局部特征图像的特征组合。然后,根据所述基于视频的局部特征图像来对用户行为进行分类。In S7022, video-based local feature images are obtained according to N frame-based local feature images selected for the N image frames respectively, wherein the N frame-based local feature images indicate the N frame-based global features The local portion on the image corresponding to N ROI candidates indicating image regions containing the same user-related content. Here, the video-based local feature image is a feature combination of the N frame-based local feature images. Then, the user behavior is classified according to the video-based local feature images.
与基于人体姿态特征的用户行为分类方式中采用多任务方式对用户行为进行分类的过程类似,在基于局部特征的用户行为分类方式中,也可以采用多任务方式对用户行为进行分类。Similar to the process of classifying user behavior in a multi-task manner in the user behavior classification method based on human posture features, in the user behavior classification method based on local features, the user behavior can also be classified in a multi-task manner.
在这样的示例性实施例中,根据所选的基于视频的局部特征图像来对用户行为进行分类包括:In such an exemplary embodiment, classifying user behavior according to selected video-based local feature images includes:
分别通过以用户姿势动作作为分类标签的2D CNN和以用户交互动作作为分类标签的2D CNN,从所选的基于视频的局部特征图像中提取与用户姿势动作有关的特征和与用户交互动作有关的特征;以及The features related to user gestures and user interaction actions are extracted from the selected video-based local feature images through a 2D CNN with user gesture actions as classification labels and a 2D CNN with user interaction actions as classification labels, respectively. features; and
将所提取的与用户姿势动作有关的特征和与用户交互动作有关的特征进行融合,以对用户行为进行分类,The extracted features related to user gestures and actions related to user interaction are fused to classify user behaviors,
其中针对用户姿势动作使用类别互斥的多标签姿势动作分类损失函数进行训练,针对用户交互动作使用类别非互斥的多标签交互动作分类损失函数进行训练。Among them, the multi-label gesture and action classification loss function with mutually exclusive categories is used for training for user gesture actions, and the multi-label interaction action classification loss function with non-mutually exclusive categories is used for training for user interaction actions.
该过程所使用的多任务的网络结构仍然可参照图6(a)中从S304输出的箭头之后的部分,其区别仅在于,在基于局部特征的用户行为分类方式中,将所选的基于视频的局部特征图像作为该用户行为分类分支的输入,即,使所选的基于视频的局部特征图像分别通过以用户姿势动作作为分类标签的2D CNN和以用户交互动作作为分类标签的2D CNN,使得可以通过这两个2D CNN分别学习特定的动作特征,从所选的基于视频的局部特征图像中提取与用户姿势动作有关的特征和与用户交互动作有关的特征;然后,融合网络将两个2DCNN输出特征融合后进一步对用户行为分类。The multi-task network structure used in this process can still refer to the part after the arrow output from S304 in FIG. The local feature image is used as the input of this user behavior classification branch, that is, the selected video-based local feature image is passed through the 2D CNN with the user gesture action as the classification label and the 2D CNN with the user interaction action as the classification label, so that The specific action features can be learned separately through these two 2D CNNs, and the features related to user gestures and actions and the features related to user interaction actions are extracted from the selected video-based local feature images; then, the fusion network combines the two 2DCNNs. After the output features are fused, the user behavior is further classified.
在训练阶段的处理流程与基于人体姿态特征的用户行为分类方式中对于多任务网络的训练过程相同,在此不再赘述。The processing flow in the training phase is the same as the training process for the multi-task network in the user behavior classification method based on the human posture feature, and will not be repeated here.
基于整体-局部特征融合的用户行为分类方式User behavior classification based on global-local feature fusion
在S7023,根据针对N个图像帧分别选择的N个基于帧的局部特征图像来获得基于视频的局部特征图像,其中所述N个基于帧的局部特征图像指示所述N个基于帧的整体特征图像上与指示包含相同用户相关内容的图像区域的N个ROI候选相对应的局部部分。这里,基于视频的局部特征图像是所述N个基于帧的局部特征图像的特征组合。然后,根据所选的基于视频的局部特征图像和所述N个基于帧的整体特征图像来对用户行为进行分类。At S7023, video-based local feature images are obtained according to N frame-based local feature images respectively selected for the N image frames, wherein the N frame-based local feature images indicate the N frame-based global features The local portion on the image corresponding to N ROI candidates indicating image regions containing the same user-related content. Here, the video-based local feature image is a feature combination of the N frame-based local feature images. Then, the user behavior is classified according to the selected video-based local feature images and the N frame-based global feature images.
具体地,根据所选的基于视频的局部特征图像和所述N个基于帧的整体特征图像来对用户行为进行分类包括:Specifically, classifying user behavior according to the selected video-based local feature images and the N frame-based overall feature images includes:
通过2D CNN,从所述N个基于帧的整体特征图像中进一步进行特征提取,以得到基于视频的整体特征图像,这里,“基于视频的整体特征图像”的含义为,所获得的多层特征图像是视频中的所述N个图像帧上对应的整幅图像的多层特征图像的特征变换;以及Through 2D CNN, further feature extraction is performed from the N frame-based overall feature images to obtain video-based overall feature images. Here, the meaning of "video-based overall feature images" means that the obtained multi-layer features The image is the feature transformation of the multi-layer feature images of the corresponding whole image on the N image frames in the video; and
将所述基于视频的整体特征图像与所选的基于视频的局部特征图像进行特征组合,以根据特征组合后的多层特征图像对用户行为进行分类。The feature combination of the video-based overall feature image and the selected video-based local feature image is performed to classify user behaviors according to the feature-combined multi-layer feature images.
与基于人体姿态特征的用户行为分类方式、基于局部特征的用户行为分类方式中采用多任务方式对用户行为进行分类的过程类似,在基于整体-局部特征融合的用户行为分类方式中,也可以采用多任务方式对用户行为进行分类。Similar to the user behavior classification method based on human posture features and the user behavior classification method based on local features, the multi-task method is used to classify user behavior. In the user behavior classification method based on global-local feature fusion, it can also be used A multitasking approach classifies user behavior.
在这样的示例性实施例中,根据特征组合后的多层特征图像对用户行为进行分类包括:In such an exemplary embodiment, classifying user behavior according to the feature-combined multi-layer feature image includes:
分别通过以用户姿势动作作为分类标签的2D CNN和以用户交互动作作为分类标签的2D CNN,从特征组合后的多层特征图像中提取与用户姿势动作有关的特征和与用户交互动作有关的特征;以及Using the 2D CNN with the user gesture action as the classification label and the 2D CNN with the user interaction action as the classification label, respectively, the features related to the user pose and action are extracted from the multi-layer feature image after feature combination. ;as well as
将所提取的与用户姿势动作有关的特征和与用户交互动作有关的特征进行融合,以对用户行为进行分类,The extracted features related to user gestures and actions related to user interaction are fused to classify user behaviors,
其中针对用户姿势动作使用类别互斥的多标签姿势动作分类损失函数进行训练,针对用户交互动作使用类别非互斥的多标签交互动作分类损失函数进行训练。Among them, the multi-label gesture and action classification loss function with mutually exclusive categories is used for training for user gesture actions, and the multi-label interaction action classification loss function with non-mutually exclusive categories is used for training for user interaction actions.
该过程所使用的多任务的网络结构仍然可参照图6(a)中从S304输出的箭头之后的部分,其区别仅在于,在基于整体-局部特征融合的用户行为分类方式中,将特征组合后的多层特征图像作为该用户行为分类分支的输入,即,使特征组合后的多层特征图像分别通过以用户姿势动作作为分类标签的2D CNN和以用户交互动作作为分类标签的2D CNN,使得可以通过这两个2D CNN分别学习特定的动作特征,从特征组合后的多层特征图像中提取与用户姿势动作有关的特征和与用户交互动作有关的特征;然后,融合网络将两个2D CNN输出特征融合后进一步对用户行为分类。The multi-task network structure used in this process can still refer to the part after the arrow output from S304 in FIG. The latter multi-layer feature image is used as the input of the user behavior classification branch, that is, the multi-layer feature image after feature combination is passed through the 2D CNN with the user gesture action as the classification label and the 2D CNN with the user interaction action as the classification label, respectively. It makes it possible to learn specific action features separately through these two 2D CNNs, and extract features related to user gestures and actions and features related to user interaction actions from the combined multi-layer feature image; then, the fusion network combines the two 2D The CNN output features are fused to further classify user behaviors.
在训练阶段的处理流程与基于人体姿态特征的用户行为分类方式中对于多任务网络的训练过程相同,在此不再赘述。The processing flow in the training phase is the same as the training process for the multi-task network in the user behavior classification method based on the human posture feature, and will not be repeated here.
以上分别对通过基于人体姿态特征的用户行为分类方式、基于局部特征的用户行为分类方式、以及基于整体-局部特征融合的用户行为分类方式对用户行为进行分类,得到用户行为分类的结果,该结果的输出是该用户的行为概率向量,该向量中的每个元素表示用户施行某行为的概率。The user behavior classification method based on human posture features, the user behavior classification method based on local features, and the user behavior classification method based on global-local feature fusion are respectively classified above, and the result of user behavior classification is obtained. The output of is the user's behavior probability vector, each element in the vector represents the probability of the user performing a certain behavior.
在S703,通过将分别采用上述三种方式得到的用户行为分类的结果进行融合,以识别用户行为。具体地,可以将分别采用上述三种方式得到的用户的三个行为概率向量经过1×1卷积融合,然后通过一个全连接层进行行为分类,分类的结果作为最终的用户行为识别结果输出。分类的输出具有最大概率的行为标签,例如握手、吸烟等行为。In S703, the user behavior is identified by fusing the user behavior classification results obtained in the above three manners respectively. Specifically, the three behavior probability vectors of the user obtained by the above three methods can be fused through 1×1 convolution, and then behavior classification is performed through a fully connected layer, and the classification result is output as the final user behavior recognition result. The output of the classification has the most probable action labels, such as handshake, smoking, etc.
以下参照图8,对根据本公开示例性实施例的用户行为识别系统的结构进行描述。Referring to FIG. 8 below, the structure of the user behavior recognition system according to an exemplary embodiment of the present disclosure will be described.
图8示意性地示出了根据本公开示例性实施例的用户行为识别系统800的结构框图。FIG. 8 schematically shows a structural block diagram of a user behavior recognition system 800 according to an exemplary embodiment of the present disclosure.
如图8所示,用户行为识别系统800包括:局部特征获得单元801、用户行为识别装置802和特征融合单元803。As shown in FIG. 8 , the user behavior recognition system 800 includes: a local feature obtaining unit 801 , a user
局部特征获得单元801可以被配置为从视频中包含用户的图像帧中获得基于帧的局部特征图像。The local feature obtaining unit 801 may be configured to obtain frame-based local feature images from image frames containing the user in the video.
在一示例性实施例中,局部特征获得单元801可以包括:In an exemplary embodiment, the local feature obtaining unit 801 may include:
特征提取单元8011,被配置为根据所述图像帧,获得基于帧的整体特征图像;A
ROI提取单元8012,被配置为从所述基于帧的整体特征图像中提取ROI候选;以及an ROI extraction unit 8012, configured to extract ROI candidates from the frame-based overall feature image; and
ROI池化单元8013,被配置为根据所述基于帧的整体特征图像和ROI候选,获得所述基于帧的局部特征图像。The
具体地,结合先前的示例,特征提取单元801可以被配置为针对从视频中选择的N个图像帧的每个图像帧进行特征提取,以得到N个基于帧的整体特征图像;Specifically, in conjunction with the previous example, the feature extraction unit 801 may be configured to perform feature extraction for each of the N image frames selected from the video to obtain N frame-based overall feature images;
ROI提取单元802可以被配置为从N个基于帧的整体特征图像中的每个基于帧的整体特征图像中提取出至少一个感兴趣区域ROI候选;The
ROI池化单元803可以被配置为根据N个基于帧的整体特征图像和从每个基于帧的整体特征图像中提取出的至少一个ROI候选中的每个ROI候选,获得N个基于帧的局部特征图像。The
用户行为识别装置802可以被配置为通过以下三种方式中的至少一种来对用户行为进行分类:The user
根据所述基于帧的局部特征图像和人体姿态特征来对用户行为进行分类;具体地,结合先前的示例,根据所述N个基于帧的局部特征图像和通过人体部位解析得到的基于人体部位的人体姿态特征来对用户行为进行分类;Classify user behaviors according to the frame-based local feature images and human body posture features; specifically, in combination with the previous examples, according to the N frame-based local feature images and the human body part-based Human pose features to classify user behavior;
根据所述基于帧的局部特征图像来获得基于视频的局部特征图像,并根据所述基于视频的局部特征图像来对用户行为进行分类;具体地,结合先前的示例,根据所述N个基于帧的局部特征图像来获得基于视频的局部特征图像,并根据所述基于视频的局部特征图像来对用户行为进行分类;A video-based local feature image is obtained according to the frame-based local feature image, and user behavior is classified according to the video-based local feature image; to obtain a video-based local feature image, and classify user behavior according to the video-based local feature image;
根据所述基于帧的局部特征图像来获得基于视频的局部特征图像,并根据所述基于视频的局部特征图像和基于视频的整体特征图像来对用户行为进行分类;具体地,结合先前的示例,根据所述N个基于帧的局部特征图像来获得基于视频的局部特征图像,并根据所述基于视频的局部特征图像和所述N个基于帧的整体特征图像来对用户行为进行分类。A video-based local feature image is obtained according to the frame-based local feature image, and user behavior is classified according to the video-based local feature image and the video-based overall feature image; specifically, in conjunction with the previous examples, Video-based local feature images are obtained according to the N frame-based local feature images, and user behavior is classified according to the video-based local feature images and the N frame-based overall feature images.
特征融合单元803可以被配置为通过将所述三种方式中的至少一种得到的用户行为分类的结果进行融合,以识别用户行为。The
图9示意性地示出了根据本公开示例性实施例的基于3D CNN的用户行为识别系统900的结构框图。对应于图8所示的用户行为识别系统800,用户行为识别系统900包括:特征提取单元9011、ROI提取单元9012、ROI池化单元9013、用户行为识别装置902、以及特征融合单元903。FIG. 9 schematically shows a structural block diagram of a 3D CNN-based user behavior recognition system 900 according to an exemplary embodiment of the present disclosure. Corresponding to the user behavior recognition system 800 shown in FIG. 8 , the user behavior recognition system 900 includes: a
如图9所示,特征提取单元9011可以通过3D CNN,根据所述图像帧的空间域和不同时刻的图像帧的时间域获得不同时刻的图像帧的基于帧的整体特征图像。As shown in FIG. 9 , the
具体地,结合先前的示例,特征提取单元9011可以被配置为将视频输入的N个图像帧通过3D CNN,从每个图像帧的空间域和时间域中提取该图像帧的特征,以得到所述N个基于帧的整体特征图像。Specifically, in conjunction with the previous example, the
ROI提取单元9012可以通过RPN,从每个基于帧的整体特征图像中提取出ROI候选,以得到ROI候选序列。假设从每个基于帧的整体特征图像中提取出M个ROI候选,以得到M个ROI候选序列。每个ROI候选序列由所述N个ROI候选构成。The
ROI池化单元9013可以根据所述ROI候选序列,从所述所述基于帧的整体特征图像上截取所述基于帧的局部特征图像。具体地,结合先前的示例,ROI池化单元9013被进一步配置为:通过ROI池化操作,根据每个ROI候选序列,从所述N个基于帧的整体特征图像上分别截取所述N个基于帧的局部特征图像。The
在一示例性实施例中,用户行为识别系统900还包括:行为定位单元904,被配置为根据基于视频的局部特征图像进行用户行为定位,以从多个基于视频的局部特征图像中选择出一个基于视频的局部特征图像。根据M个基于视频的局部特征图像进行用户行为定位,以从M个所述基于视频的局部特征图像中选择出一个基于视频的局部特征图像,以便根据所选的基于视频的局部特征图像对用户行为进行分类。In an exemplary embodiment, the user behavior recognition system 900 further includes: a behavior locating unit 904 configured to perform user behavior localization according to the video-based local feature images, so as to select one from a plurality of video-based local feature images. Video-based local feature images. Perform user behavior localization according to the M video-based local feature images, so as to select a video-based local feature image from the M video-based local feature images, so that the user can be identified according to the selected video-based local feature images. Behaviour is classified.
在一示例性实施例中,用户行为识别系统900还包括:ROI对齐单元905,被配置为根据所述基于帧的局部特征图像来获得基于视频的局部特征图像。具体地,结合先前的示例,ROI对齐单元905可以针对M个ROI候选序列中的每一个,通过ROI对齐操作,将所述N个基于帧的局部特征图像基于相应的ROI候选序列进行对齐。然后,通过3D CNN进一步进行特征提取,以分别获得M个基于视频的局部特征图像。In an exemplary embodiment, the user behavior recognition system 900 further includes: an
在一示例性实施例中,用户行为识别装置902包括:人体姿态注意单元9021,被配置为根据所述基于视频的局部特征图像和通过人体部位解析得到的基于人体部位的人体姿态特征来对用户行为进行分类。In an exemplary embodiment, the user behavior recognition device 902 includes: a human body posture attention unit 9021, which is configured to pay attention to the user according to the video-based local feature image and the human body part-based human body posture feature obtained by analyzing the human body parts. Behaviour is classified.
在一示例性实施例中,人体姿态注意单元9021包括:In an exemplary embodiment, the human pose attention unit 9021 includes:
3D CNN解码器9211,通过人体部位解析对人体部位进行定位,使得所选的基于视频的局部特征图像包含基于人体部位的人体姿态特征。具体地,3D CNN解码器9211可以由3D反卷积网络构成,通过反卷积和上采样,逐渐提高基于视频的局部特征图像的分辨率,并通过人体部位解析对人体部位进行定位,使得对从所述M个基于视频的局部特征图像中选择的一个基于视频的局部特征图像进行3D CNN解码得到的3D CNN解码后的基于视频的局部特征图像包含基于人体部位的人体姿态特征;以及The
用户行为分类单元9212,被配置为根据包含基于所述人体姿态特征的3D CNN解码后的基于视频的局部特征图像来对用户行为进行分类。The user
在一示例性实施例中,用户行为分类单元9212还包括:In an exemplary embodiment, the user
以用户姿势动作作为分类标签的第一3D CNN模块92121,被配置为通过以用户姿势动作作为分类标签的3D CNN,从包含基于所述人体姿态特征的3D CNN解码后的基于视频的局部特征图像中提取与用户姿势动作有关的特征;The first
以用户交互动作作为分类标签的第二3D CNN模块92122,被配置为通过以用户交互动作作为分类标签的CNN,从包含基于所述人体姿态特征的CNN解码后的基于视频的局部特征图像中提取与用户交互动作有关的特征;以及The second
融合模块92123,被配置为将所提取的与用户姿势动作有关的特征和与用户交互动作有关的特征进行融合,以对用户行为进行分类,The fusion module 92123 is configured to fuse the extracted features related to user gestures and actions and features related to user interaction actions to classify user behaviors,
其中针对用户姿势动作使用类别互斥的多标签姿势动作分类损失函数进行训练,针对用户交互动作使用类别非互斥的多标签交互动作分类损失函数进行训练。Among them, the multi-label gesture and action classification loss function with mutually exclusive categories is used for training for user gesture actions, and the multi-label interaction action classification loss function with non-mutually exclusive categories is used for training for user interaction actions.
在一示例性实施例中,用户行为识别系统900还包括人体部位定位装置906,所述人体部位定位装置906包括:In an exemplary embodiment, the user behavior recognition system 900 further includes a human body part positioning device 906, and the human body part positioning device 906 includes:
人体检测单元9061,被配置为确定所述视频的多个图像帧内的每个人体实例在每个图像帧上的图像区域;a human body detection unit 9061, configured to determine the image area on each image frame of each human body instance in the multiple image frames of the video;
人体语义分割单元9062,被配置为对从所确定的图像区域中提取的人体图像区域候选进行粗略的部分语义分割,以得到粗略语义分割结果;The human body semantic segmentation unit 9062 is configured to perform rough partial semantic segmentation on the human body image region candidates extracted from the determined image region to obtain a rough semantic segmentation result;
方向预测单元9063,被配置为预测每个图像帧上的每个像素相对于其所属的人体中心的方向以得到方向预测结果;The direction prediction unit 9063 is configured to predict the direction of each pixel on each image frame relative to the center of the human body to which it belongs to obtain a direction prediction result;
卷积模块9064,被配置为对所述粗略语义分割结果与所述方向预测结果进行卷积操作,以得到人体部位解析结果。The convolution module 9064 is configured to perform a convolution operation on the rough semantic segmentation result and the direction prediction result to obtain a human body part analysis result.
在一示例性实施例中,用户行为识别装置902还包括:局部行为识别单元9022,被配置为根据所述基于视频的局部特征图像来对用户行为进行分类。In an exemplary embodiment, the user behavior recognition device 902 further includes: a local behavior recognition unit 9022, configured to classify user behaviors according to the video-based local feature images.
在一示例性实施例中,所述局部行为识别单元9022还包括:In an exemplary embodiment, the local behavior identification unit 9022 further includes:
以用户姿势动作作为分类标签的第一CNN模块9221,被配置为通过以用户姿势动作作为分类标签的相应的CNN,从所述基于视频的局部特征图像中提取与用户姿势动作有关的特征;The
以用户交互动作作为分类标签的第二CNN模块9222,被配置为通过以用户交互动作作为分类标签的相应的CNN,从所述基于视频的局部特征图像中提取与用户交互动作有关的特征;以及a second CNN module 9222 with the user interaction as the classification label, configured to extract features related to the user interaction from the video-based local feature image through the corresponding CNN with the user interaction as the classification label; and
融合模块9223,被配置为将所提取的与用户姿势动作有关的特征和与用户交互动作有关的特征进行融合,以对用户行为进行分类,The
其中针对用户姿势动作使用类别互斥的多标签姿势动作分类损失函数进行训练,针对用户交互动作使用类别非互斥的多标签交互动作分类损失函数进行训练。Among them, the multi-label gesture and action classification loss function with mutually exclusive categories is used for training for user gesture actions, and the multi-label interaction action classification loss function with non-mutually exclusive categories is used for training for user interaction actions.
在一示例性实施例中,用户行为识别装置902还包括:整体-局部融合行为识别单元9023,被配置为根据所述基于视频的局部特征图像和所述多个基于帧的整体特征图像来对用户行为进行分类。In an exemplary embodiment, the user behavior recognition device 902 further includes: a global-local fusion behavior recognition unit 9023, configured to identify the image based on the video-based local feature image and the plurality of frame-based global feature images. User behavior is classified.
所述整体-局部融合行为识别单元9023包括:The overall-local fusion behavior identification unit 9023 includes:
3D CNN模块9231,被配置为通过3D CNN,从所述多个基于帧的整体特征图像中进一步进行特征提取,以得到基于视频的整体特征图像;The
特征组合单元9232,被配置为将所述基于视频的整体特征图像与所述基于视频的局部特征图像进行特征组合;以及A
用户行为分类单元9233,被配置为根据特征组合后的多层特征图像对用户行为进行分类。The user
在一示例性实施例中,用户行为分类单元9233包括:In an exemplary embodiment, the user
以用户姿势动作作为分类标签的第一3D CNN模块92331,被配置为通过以用户姿势动作作为分类标签的3D CNN,从特征组合后的多层特征图像中提取与用户姿势动作有关的特征;The first
以用户交互动作作为分类标签的第二3D CNN模块92332,被配置为通过以用户交互动作作为分类标签的3D CNN,从特征组合后的多层特征图像中提取与用户交互动作有关的特征;以及The second
融合模块92333,被配置为将所提取的与用户姿势动作有关的特征和与用户交互动作有关的特征进行融合,以对用户行为进行分类,The fusion module 92333 is configured to fuse the extracted features related to user gestures and actions and features related to user interaction actions to classify user behaviors,
其中针对用户姿势动作使用类别互斥的多标签姿势动作分类损失函数进行训练,针对用户交互动作使用类别非互斥的多标签交互动作分类损失函数进行训练。Among them, the multi-label gesture and action classification loss function with mutually exclusive categories is used for training for user gesture actions, and the multi-label interaction action classification loss function with non-mutually exclusive categories is used for training for user interaction actions.
图10示意性地示出了根据本公开示例性实施例的基于2D CNN的用户行为识别系统1000的结构框图。对应于图8所示的用户行为识别系统800、以及图9所示的基于3D CNN的用户行为识别系统900,用户行为识别系统1000包括:特征提取单元1011、ROI提取单元1012、ROI池化单元1013、用户行为识别装置1002、以及特征融合单元1003。FIG. 10 schematically shows a structural block diagram of a 2D CNN-based user behavior recognition system 1000 according to an exemplary embodiment of the present disclosure. Corresponding to the user behavior recognition system 800 shown in FIG. 8 and the 3D CNN-based user behavior recognition system 900 shown in FIG. 9 , the user behavior recognition system 1000 includes: a feature extraction unit 1011, a ROI extraction unit 1012, and a
如图10所示,特征提取单元1011可以被配置为通过2D CNN,根据所述图像帧获得基于帧的整体特征图像。As shown in FIG. 10 , the feature extraction unit 1011 may be configured to obtain a frame-based overall feature image according to the image frame through a 2D CNN.
具体地,结合先前的示例,特征提取单元1011可以通过2D CNN,从每个图像帧中提取特征,以分别得到N个基于帧的整体特征图像。Specifically, in combination with the previous example, the feature extraction unit 1011 can extract features from each image frame through 2D CNN to obtain N frame-based overall feature images respectively.
ROI提取单元1002可以被配置为通过RPN,从每个图像帧的基于帧的整体特征图像中提取出例如M个ROI候选。The ROI extraction unit 1002 may be configured to extract, for example, M ROI candidates from the frame-based overall feature image of each image frame through RPN.
ROI池化单元1003可以被配置为:针对多个图像帧中的每个图像帧,通过ROI池化操作,根据所述M个ROI候选中的每个ROI候选,从该图像帧的基于帧的整体特征图像上截取基于帧的局部特征图像。The
在一示例性实施例中,用户行为识别系统1000还包括:行为定位单元1006,被配置为根据基于帧的局部特征图像进行用户行为定位,以从多个基于帧的局部特征图像中选择出一个基于帧的局部特征图像。具体地,结合先前的示例,可以根据每个图像帧的M个基于帧的局部特征图像进行用户行为定位,以从所述M个基于帧的局部特征图像中选择出一个基于帧的局部特征图像,以便根据所选的基于帧的局部特征图像对用户行为进行分类。In an exemplary embodiment, the user behavior recognition system 1000 further includes: a behavior localization unit 1006 configured to perform user behavior localization according to the frame-based local feature images, so as to select one from a plurality of frame-based local feature images. Frame-based local feature images. Specifically, in combination with the previous examples, user behavior localization may be performed according to M frame-based local feature images of each image frame, so as to select a frame-based local feature image from the M frame-based local feature images , to classify user behavior based on selected frame-based local feature images.
在一示例性实施例中,用户行为识别装置1002包括:In an exemplary embodiment, the user behavior recognition device 1002 includes:
人体姿态注意单元10021,被配置为根据每个图像帧的所选的基于帧的局部特征图像和通过人体部位解析得到的基于人体部位的人体姿态特征来对用户行为进行分类;以及a human body pose attention unit 10021 configured to classify user behaviors according to the selected frame-based local feature images of each image frame and the human body part-based human pose features obtained by analyzing the human body parts; and
组合单元10022,被配置为将针对每个图像帧的用户行为分类结果进行组合。The combining unit 10022 is configured to combine the user behavior classification results for each image frame.
在一示例性实施例中,人体姿态注意单元10021包括:In an exemplary embodiment, the human pose attention unit 10021 includes:
2D CNN解码器10211,被配置为通过人体部位解析对人体部位进行定位,使得所选的基于帧的局部特征图像包含基于人体部位的人体姿态特征。具体地,2D CNN解码器10211可以由2D反卷积网络构成,通过反卷积和上采样,逐渐提高基于帧的局部特征图像的分辨率,并通过人体部位解析对人体部位进行定位,使得对所述基于帧的局部特征图像进行2DCNN解码得到的2D CNN解码后的基于帧的局部特征图像包含基于人体部位的人体姿态特征;以及The
用户行为分类单元10212,被配置为根据包含基于所述人体姿态特征的CNN解码后的基于帧的局部特征图像来对用户行为进行分类。The user
在一示例性实施例中,用户行为分类单元10212还包括:In an exemplary embodiment, the user
以用户姿势动作作为分类标签的第一2D CNN模块102121,被配置为通过以用户姿势动作作为分类标签的2D CNN,从包含基于所述人体姿态特征的2D CNN解码后的基于帧的局部特征图像中提取与用户姿势动作有关的特征;The first
以用户交互动作作为分类标签的第二2D CNN模块102122,被配置为通过以用户交互动作作为分类标签的2D CNN,从包含基于所述人体姿态特征的2D CNN解码后的基于帧的局部特征图像中提取与用户交互动作有关的特征;以及The second
融合模块102123,被配置为将所提取的与用户姿势动作有关的特征和与用户交互动作有关的特征进行融合,以对用户行为进行分类,The fusion module 102123 is configured to fuse the extracted features related to user gestures and actions and features related to user interaction actions to classify user behaviors,
其中针对用户姿势动作使用类别互斥的多标签姿势动作分类损失函数进行训练,针对用户交互动作使用类别非互斥的多标签交互动作分类损失函数进行训练。Among them, the multi-label gesture and action classification loss function with mutually exclusive categories is used for training for user gesture actions, and the multi-label interaction action classification loss function with non-mutually exclusive categories is used for training for user interaction actions.
在一示例性实施例中,用户行为识别系统1000还包括人体部位定位装置1006,所述人体部位定位装置1006包括:In an exemplary embodiment, the user behavior recognition system 1000 further includes a human body part locating device 1006, and the human body part locating device 1006 includes:
人体检测单元10061,被配置为确定所述视频的多个图像帧内的每个人体实例在每个图像帧上的图像区域;a human body detection unit 10061, configured to determine the image area on each image frame of each human body instance in the multiple image frames of the video;
人体语义分割单元10062,被配置为对从所确定的图像区域中提取的人体图像区域候选进行粗略的部分语义分割,以得到粗略语义分割结果;The human body semantic segmentation unit 10062 is configured to perform rough partial semantic segmentation on the human body image region candidates extracted from the determined image region to obtain a rough semantic segmentation result;
方向预测单元10063,被配置为预测每个图像帧上的每个像素相对于其所属的人体中心的方向以得到方向预测结果;The
卷积模块10064,被配置为对所述粗略语义分割结果与所述方向预测结果进行卷积操作,以得到人体部位解析结果。The convolution module 10064 is configured to perform a convolution operation on the rough semantic segmentation result and the direction prediction result to obtain a human body part analysis result.
在一示例性实施例中,用户行为识别装置1002还包括:局部行为识别单元10022,被配置为根据所述基于视频的局部特征图像来对用户行为进行分类。In an exemplary embodiment, the user behavior recognition apparatus 1002 further includes: a local behavior recognition unit 10022, configured to classify the user behavior according to the video-based local feature images.
在一示例性实施例中,所述局部行为识别单元10022还包括:In an exemplary embodiment, the local behavior recognition unit 10022 further includes:
以用户姿势动作作为分类标签的第一CNN模块10221,被配置为通过以用户姿势动作作为分类标签的相应的CNN,从所述基于视频的局部特征图像中提取与用户姿势动作有关的特征;The
以用户交互动作作为分类标签的第二CNN模块10222,被配置为通过以用户交互动作作为分类标签的相应的CNN,从所述基于视频的局部特征图像中提取与用户交互动作有关的特征;以及a second CNN module 10222 with the user interaction action as the classification label, configured to extract features related to the user interaction action from the video-based local feature image through the corresponding CNN with the user interaction action as the classification label; and
融合模块10223,被配置为将所提取的与用户姿势动作有关的特征和与用户交互动作有关的特征进行融合,以对用户行为进行分类,The
其中针对用户姿势动作使用类别互斥的多标签姿势动作分类损失函数进行训练,针对用户交互动作使用类别非互斥的多标签交互动作分类损失函数进行训练。Among them, the multi-label gesture and action classification loss function with mutually exclusive categories is used for training for user gesture actions, and the multi-label interaction action classification loss function with non-mutually exclusive categories is used for training for user interaction actions.
在一示例性实施例中,用户行为识别装置1002还包括:整体-局部融合行为识别单元10023,被配置为根据所述基于视频的局部特征图像和所述多个基于帧的整体特征图像来对用户行为进行分类。In an exemplary embodiment, the user behavior recognition device 1002 further includes: a global-local fusion behavior recognition unit 10023, configured to identify the video-based local feature images and the plurality of frame-based global feature images according to the video-based local feature images. User behavior is classified.
所述整体-局部融合行为识别单元10023包括:The overall-local fusion behavior recognition unit 10023 includes:
2D CNN模块10231,被配置为通过2D CNN,从所述多个基于帧的整体特征图像中进一步进行特征提取,以得到基于视频的整体特征图像;The
特征组合单元10232,被配置为将所述基于视频的整体特征图像与所述基于视频的局部特征图像进行特征组合;以及A
用户行为分类单元10233,被配置为根据特征组合后的多层特征图像对用户行为进行分类。The user
在一示例性实施例中,用户行为分类单元10233包括:In an exemplary embodiment, the user
以用户姿势动作作为分类标签的第一2D CNN模块102331,被配置为通过以用户姿势动作作为分类标签的2D CNN,从特征组合后的多层特征图像中提取与用户姿势动作有关的特征;The first
以用户交互动作作为分类标签的第二2D CNN模块102332,被配置为通过以用户交互动作作为分类标签的2D CNN,从特征组合后的多层特征图像中提取与用户交互动作有关的特征;以及The second
融合模块102333,被配置为将所提取的与用户姿势动作有关的特征和与用户交互动作有关的特征进行融合,以对用户行为进行分类,The fusion module 102333 is configured to fuse the extracted features related to user gestures and actions and features related to user interaction actions to classify user behaviors,
其中针对用户姿势动作使用类别互斥的多标签姿势动作分类损失函数进行训练,针对用户交互动作使用类别非互斥的多标签交互动作分类损失函数进行训练。Among them, the multi-label gesture and action classification loss function with mutually exclusive categories is used for training for user gesture actions, and the multi-label interaction action classification loss function with non-mutually exclusive categories is used for training for user interaction actions.
上述根据本公开示例性实施例的用户行为识别方法可以将各种类型的视频作为其输入,对该视频中的用户行为进行识别,并可根据所识别的用户行为来自动控制具有AR功能的设备。The above-mentioned user behavior recognition method according to the exemplary embodiment of the present disclosure can take various types of videos as its input, recognize the user behavior in the video, and automatically control the device with AR function according to the recognized user behavior. .
以下参照图11,对根据本公开示例性实施例的用于控制具有AR功能的设备的方法进行描述。Referring to FIG. 11 , a method for controlling an AR-capable device according to an exemplary embodiment of the present disclosure will be described below.
图11示意性地示出了根据本公开示例性实施例的用于控制具有AR功能的设备的方法1100的流程图。FIG. 11 schematically shows a flowchart of a
如图11所示,在步骤S1101中,获取视频;在步骤S1102中,从所获取的视频中检测用户;在步骤S1103中,对所述用户的行为进行识别;以及在步骤S1104中,根据所述用户的行为识别结果和预定义的行为-AR功能映射关系,控制关联的具有AR功能的设备执行对应的AR功能。As shown in FIG. 11, in step S1101, a video is acquired; in step S1102, a user is detected from the acquired video; in step S1103, the behavior of the user is identified; and in step S1104, according to the Describe the user's behavior recognition result and the predefined behavior-AR function mapping relationship, and control the associated AR-enabled device to execute the corresponding AR function.
在一示例性实施例中,所述行为-AR功能映射关系包括以下至少一组映射:In an exemplary embodiment, the behavior-AR function mapping relationship includes at least one set of the following mappings:
1)唱歌行为、以及与所述唱歌行为相匹配的以下AR功能中的至少一个:1) Singing behavior, and at least one of the following AR functions that match the singing behavior:
识别歌曲并通过因特网检索或在本地存储的歌曲库中检索,identify songs and retrieve them via the Internet or in a locally stored song library,
在设备中显示歌词,display the lyrics in the device,
在设备中显示歌名和/或歌手名,Display the song title and/or artist name in the device,
在设备中同步播放歌曲的伴奏音乐;Play the accompaniment music of the song synchronously in the device;
2)吸烟行为、以及与所述吸烟行为相匹配的以下AR功能中的至少一个:2) Smoking behavior, and at least one of the following AR functions that match the smoking behavior:
在设备中显示该用户所处地点是否允许吸烟,Display on the device whether smoking is allowed in the user's location,
如果此处不允许吸烟,则显示最近的可吸烟区的相关信息;If smoking is not allowed here, information about the nearest smoking area is displayed;
3)握手行为、以及与所述握手行为相匹配AR功能的至少一个:3) handshake behavior, and at least one of AR functions matching the handshake behavior:
识别与握手人的身份;identify the person shaking hands;
在握手人附近显示该握手人的信息;Display the information of the handshake near the handshake;
4)演奏乐器行为、以及与所述演奏乐器行为相匹配AR功能的至少一个:4) At least one of the behavior of playing an instrument and an AR function that matches the behavior of playing an instrument:
识别乐器;identify musical instruments;
显示乐器名;display the name of the instrument;
在乐器旁边同步显示音乐的乐谱。Displays the music score in sync next to the instrument.
在一示例性实施例中,根据所述用户的行为识别结果和预定义的行为-AR功能映射关系控制关联的具有AR功能的设备执行对应的AR功能包括:根据所述设备所处的场景、所述用户的行为识别结果和预定义的行为-AR功能映射关系,确定对应的AR功能,并控制所述设备执行对应的AR功能。In an exemplary embodiment, controlling the associated device with the AR function to execute the corresponding AR function according to the user's behavior recognition result and the predefined behavior-AR function mapping relationship includes: according to the scene where the device is located, The user's behavior recognition result and the predefined behavior-AR function mapping relationship determine the corresponding AR function, and control the device to execute the corresponding AR function.
在一示例性实施例中,步骤S1103包括:使用前述根据本公开的示例性实施例所述的用户行为识别方法,对所述用户的行为进行识别。In an exemplary embodiment, step S1103 includes: identifying the user's behavior by using the user behavior identification method described above according to the exemplary embodiment of the present disclosure.
在一示例性实施例中,所述视频通过以下方式之一获取:In an exemplary embodiment, the video is obtained in one of the following ways:
通过设置在所述设备之外的相机捕获;Captured by a camera located outside the device;
通过所述设备上的相机捕获;captured by a camera on said device;
通过所述设备上的视频应用呈现。Presented through a video application on the device.
在一示例性实施例中,当存在与所识别的用户的行为相匹配的多个AR功能时,从所述多个AR功能中选择一个或多个AR功能,控制所述设备执行所选的一个或多个AR功能。In an exemplary embodiment, when there are multiple AR functions that match the behavior of the identified user, one or more AR functions are selected from the multiple AR functions, and the device is controlled to perform the selected AR functions. One or more AR features.
在一示例性实施例中,所述方法还包括:根据所述用户的行为识别结果更新当前用户行为的状态,并根据所述行为-AR功能映射关系,控制所述设备关闭与当前用户行为不匹配的AR功能。In an exemplary embodiment, the method further includes: updating the status of the current user behavior according to the behavior recognition result of the user, and controlling the device to turn off the current user behavior according to the behavior-AR function mapping relationship. Matching AR features.
在一示例性实施例中,在通过设置在所述设备之外的相机捕获所述视频的情况下,所述方法由服务器执行,还包括:从视频中执行人体跟踪;对跟踪到的人体执行人脸检测,以得到人脸图像区域;通过人脸识别从登记的AR用户数据库中搜索匹配的用户,其中所述AR用户数据库至少包括:用户的人脸图像,用户的设备信息;当在AR用户数据库中搜索到匹配的用户时,获得与所述用户相关联的设备信息。In an exemplary embodiment, in the case where the video is captured by a camera provided outside the device, the method is performed by a server, further comprising: performing human body tracking from the video; performing the tracking on the tracked human body Face detection to obtain a face image area; searching for matching users from the registered AR user database through face recognition, wherein the AR user database at least includes: the user's face image, the user's equipment information; When a matching user is found in the user database, device information associated with the user is obtained.
在一示例性实施例中,在通过所述设备上的相机捕获所述视频、或通过所述设备上的视频应用呈现所述视频的情况下,所述方法由所述设备执行。In an exemplary embodiment, the method is performed by the device where the video is captured by a camera on the device or rendered by a video application on the device.
例如,视频的类型可以包括:For example, types of videos can include:
-第三人称视频,其指通过与使用具有AR功能的设备的用户存在一定距离的相机(即,在所述具有AR功能的设备之外的相机)对用户进行拍摄而获得的视频,该相机可以是物联网系统中安装在用户家居环境中的相机,也可以是办公室商场等公共环境中的监控相机;相应地,第三人称视频中识别的用户行为是使用所述具有AR功能的设备的用户发生的行为,其示例性应用场景如图11所示;- Third-person video, which refers to a video obtained by capturing a user with a camera at a distance from the user using the AR-enabled device (ie, a camera outside of the AR-enabled device), which camera can It is a camera installed in the user's home environment in the Internet of Things system, or it can be a surveillance camera in a public environment such as an office shopping mall; accordingly, the user behavior identified in the third-person video is the user using the AR-enabled device. behavior, and its exemplary application scenario is shown in Figure 11;
-第一人称视频,其指通过具有AR功能的设备上的相机拍摄的视频或在具有AR功能的设备上显示的视频;相应地,第一人称视频中识别的用户行为不是使用所述具有AR功能的设备的用户发生的行为,而是通过所述具有AR功能的设备上的相机或者在所述具有AR功能的设备上显示的视频中捕捉到的其他用户发生的行为,其示例性应用场景如图15所示。- First-person video, which refers to a video captured by a camera on an AR-enabled device or displayed on an AR-enabled device; accordingly, the user behavior identified in the first-person video is not the use of said AR-enabled device The behavior of the user of the device, but the behavior of other users captured by the camera on the AR-enabled device or the video displayed on the AR-enabled device. An exemplary application scenario is shown in the figure 15 shown.
以下将分别对基于第三人称视频、第一人称视频的针对具有AR功能的设备进行自动控制的方案进行描述。The following will respectively describe the solutions for automatic control of devices with AR functions based on third-person video and first-person video.
基于第三人称视频的针对具有AR功能的设备的自动控制方法An automatic control method for AR-enabled devices based on third-person video
参见图12示出的示例性应用场景,位于具有AR功能的设备(也称为AR设备)1201之外的相机1202对使用AR设备1201的用户进行监控,并将获取的有关该用户的视频(即,第三人称视频)提供给服务器1203。服务器1203获取上述场景中相机1202监控到的视频,从该视频中进行用户检测,对检测到的用户识别该用户使用的具有AR功能的设备1201。当识别出该用户是经过注册的AR用户时,服务器1203和用户的AR设备建立通信并且和其中的AR程序管理器取得联系。AR程序管理器根据用户的设备1201的设定来确定是否接受启动和服务器1203协同工作的设备自动控制方法。如果设备1201接受该请求,则服务器1203基于相机1202的视频对用户的行为进行识别,并根据行为识别的结果和预定义的行为-AR功能映射关系向用户的设备1201发送控制指令。用户的设备1201接收该控制指令,并进行相应的AR显示。Referring to the exemplary application scenario shown in FIG. 12 , a
以下将参照图13,对根据本公开示例性实施例的在服务器处执行的用于控制具有AR功能的设备的方法进行描述。Referring to FIG. 13 , a method for controlling an AR-capable device executed at a server according to an exemplary embodiment of the present disclosure will be described below.
图13示意性地示出了根据本公开示例性实施例的在服务器1203处执行的用于控制具有AR功能的设备1201的方法1300的流程图。FIG. 13 schematically shows a flowchart of a
在步骤S1301中,服务器1203通过位于具有AR功能的设备1201之外的相机1202获取使用设备1201的用户的视频。In step S1301, the
在步骤S1302中,服务器1203从所获取的视频中检测用户,并将检测到的用户和所述用户使用的设备1201进行关联。In step S1302, the
在一示例性实施例中,从所获取的视频中检测用户并将检测到的用户和所述用户使用的设备1201进行关联可以包括以下步骤:In an exemplary embodiment, detecting a user from the acquired video and associating the detected user with the
从视频中执行人体跟踪;perform human tracking from video;
对跟踪到的人体执行人脸检测,以得到人脸图像区域;通过人脸识别从登记的AR用户数据库中搜索匹配的用户,其中所述AR用户数据库至少包括:用户的人脸图像,用户的设备信息;Perform face detection on the tracked human body to obtain a face image area; search for matching users from the registered AR user database through face recognition, wherein the AR user database at least includes: the user's face image, the user's Device Information;
当无法在AR用户数据库中搜索到匹配的用户时,结束当前的操作;When a matching user cannot be found in the AR user database, end the current operation;
而当在AR用户数据库中搜索到匹配的用户时,获得与所述用户相关联的设备信息,例如,设备型号、设备ID、无线通信地址、网卡地址等,以便由此与所述用户的具有AR功能的设备建立通信联系。When a matching user is searched in the AR user database, the device information associated with the user is obtained, such as device model, device ID, wireless communication address, network card address, etc. The AR-enabled device establishes a communication link.
由此,在步骤S1302中,服务器1203可以与所述用户的设备1201建立通信,并请求设备1201中的AR程序管理器接受启动与服务器1203协同工作的设备自动控制方法。Thus, in step S1302, the
在步骤S1303中,服务器1203响应于所述AR程序管理器接受所述请求,使用根据以上详细讨论的根据本公开示例性实施例的用户行为识别方法,从相机1202获取的视频中对所述用户的行为进行识别。In step S1303, in response to the AR program manager accepting the request, the
在步骤S1304中,服务器1203根据所述用户的行为识别结果和预定义的行为-AR功能映射关系,向设备1201发送控制该设备1201执行与所识别的用户行为相匹配的AR功能的指令。In step S1304, the
所述行为-AR功能映射关系定义了在特定定义的用户行为下使用哪种或哪些AR显示功能。The behavior-AR function mapping relationship defines which AR display function or functions are used under a specific defined user behavior.
在一示例性实施例中,所述行为-AR功能映射关系可以包括以下至少一组映射:In an exemplary embodiment, the behavior-AR function mapping relationship may include at least one set of the following mappings:
1)唱歌行为、以及与所述唱歌行为相匹配的以下AR功能中的至少一个:1) Singing behavior, and at least one of the following AR functions that match the singing behavior:
识别歌曲并通过因特网检索或在本地存储的歌曲库中检索,identify songs and retrieve them via the Internet or in a locally stored song library,
在设备中显示歌词,display lyrics in the device,
在设备中显示歌名和/或歌手名,Display the song title and/or artist name in the device,
在设备中同步播放歌曲的伴奏音乐;Play the accompaniment music of the song synchronously in the device;
2)吸烟行为、以及与所述吸烟行为相匹配的以下AR功能中的至少一个:2) Smoking behavior, and at least one of the following AR functions that match the smoking behavior:
在设备中显示该用户所处地点是否允许吸烟,Display on the device whether smoking is allowed in the user's location,
如果此处不允许吸烟,则显示最近的可吸烟区的相关信息;If smoking is not allowed here, information about the nearest smoking area is displayed;
3)握手行为、以及与所述握手行为相匹配AR功能的至少一个:3) handshake behavior, and at least one of AR functions matching the handshake behavior:
识别与握手人的身份;identify the person shaking hands;
在握手人附近显示该握手人的信息;Display the information of the handshake near the handshake;
4)演奏乐器行为、以及与所述演奏乐器行为相匹配AR功能的至少一个:4) At least one of the behavior of playing an instrument and an AR function that matches the behavior of playing an instrument:
识别乐器;identify musical instruments;
显示乐器名;display the name of the instrument;
在乐器旁边同步显示音乐的乐谱。Displays the music score in sync next to the instrument.
图14示意性地示出了应用于本公开示例性实施例的示例性行为-AR功能映射关系。如图14所示,该示例性行为-AR功能映射关系中描述了对于第一列中的特定用户行为执行第二列中的哪些AR功能,相应地,在该表的第三列中示意性地给出了可能在设备1201中显示的内容。FIG. 14 schematically illustrates an exemplary behavior-AR function mapping relationship applied to an exemplary embodiment of the present disclosure. As shown in FIG. 14 , the exemplary behavior-AR function mapping relationship describes which AR functions in the second column are executed for the specific user behavior in the first column, and correspondingly, in the third column of the table, the The content that may be displayed in
例如,当服务器1203根据所述用户的行为识别结果确定所述用户做出唱歌行为时,根据所述行为-AR功能映射关系,向设备1201发送控制设备1201执行与唱歌行为相匹配的例如以下AR功能的指令:For example, when the
识别歌曲并通过因特网检索或在本地存储的歌曲库中检索,identify songs and retrieve them via the Internet or in a locally stored song library,
在设备中显示歌词,display lyrics in the device,
在设备中显示歌名和/或歌手名,Display the song title and/or artist name in the device,
在设备中同步播放歌曲的伴奏音乐。Play the backing music of the song in sync on the device.
由此,接收到该指令的设备1201可以执行例如图14第三列“示意图”中对应于“唱歌”的AR功能。Thus, the
当服务器1203根据所述用户的行为识别结果确定所述用户做出吸烟行为时,根据所述行为-AR功能映射关系,向设备1201发送控制设备1201执行与吸烟行为相匹配的例如以下AR功能的指令:When the
在设备中显示该用户所处地点是否允许吸烟,Display on the device whether smoking is allowed in the user's location,
如果此处不允许吸烟,则显示最近的可吸烟区的相关信息,例如,从用户所在地点到达吸烟区的路线信息。If smoking is not allowed here, information about the nearest smoking area is displayed, for example, the route information from the user's location to the smoking area.
由此,接收到该指令的设备1001可以执行例如图14第三列“示意图”中对应于“吸烟”的AR功能。Thus, the device 1001 that has received the instruction can perform, for example, the AR function corresponding to "smoking" in the third column "Schematic" of FIG. 14 .
当服务器1203根据所述用户的行为识别结果确定所述用户做出握手行为时,根据所述行为-AR功能映射关系,向设备1201发送控制设备1201执行与握手行为相匹配的例如以下AR功能的指令:When the
识别与握手人的身份;identify the person shaking hands;
在握手人附近显示该握手人的信息。Displays information about the handshake near the handshake.
由此,接收到该指令的设备1201可以执行例如图14第三列“示意图”中对应于“握手”的AR功能。Thus, the
当服务器1203根据所述用户的行为识别结果确定所述用户做出演奏乐器行为时,根据所述行为-AR功能映射关系,向设备1201发送控制设备1201执行与演奏乐器行为相匹配的例如以下AR功能的指令:When the
识别乐器;identify musical instruments;
显示乐器名;display the name of the instrument;
在乐器旁边同步显示音乐的乐谱。Displays the music score in sync next to the instrument.
由此,接收到该指令的设备1201可以执行例如图14第三列“示意图”中对应于“演奏乐器”的AR功能。Thus, the
图16示意性地示出了应用图13和15的方法的用AR设备1201之外的相机1202观察用户并通过用户行为识别自动控制AR设备1201执行AR功能的示例性场景效果图。FIG. 16 schematically shows an exemplary scene effect diagram of observing the user with a
在一示例性实施例中,当存在与所识别的用户的行为相匹配的多个AR功能时,服务器1203可以根据存储在服务器1203中与设备1201的用户登记的资料相关联的用户预先设置,从所述多个AR功能中选择一个或多个AR功能,并向设备1201发送控制设备1001执行所选的一个或多个AR功能的指令。In an exemplary embodiment, when there are multiple AR functions that match the behavior of the identified user, the
在另一示例性实施例中,所述用户预先设置也可以存储在设备1201的存储器上,服务器1203可以向设备1201发送控制设备1201执行与所识别的用户的行为相匹配的多个AR功能,而由设备1201根据其存储的用户预先设置来选择并执行一个或多个AR功能。In another exemplary embodiment, the user preset may also be stored on the memory of the
在一示例性实施例中,服务器1203可以根据所述用户的行为识别结果更新当前用户行为的状态,并根据所述行为-AR功能映射关系,向设备1201发送控制设备1201关闭与当前用户行为不匹配的AR功能的指令。In an exemplary embodiment, the
以下将参照图15,对根据本公开示例性实施例的在具有AR功能的设备1201处执行的用于控制设备1201的方法进行描述。A method for controlling the
图15示出了根据本公开示例性实施例的在具有AR功能的设备1201处执行的用于控制设备1201的方法1500的流程图。15 shows a flowchart of a
在步骤S1501中,设备1201,具体地,其中的AR程序管理器,从服务器1203接收针对启动与所述服务器1203协同工作的设备自动控制方法的请求。In step S1501, the
AR程序管理器可以根据设备1201的设定来确定是否接受启动和服务器1203协同工作的设备自动控制方法。如果接受,则设备1201在步骤S1502中向所述服务器发送接受所述请求的响应。The AR program manager may determine whether or not to accept the device automatic control method that works in cooperation with the
在步骤S1503中,设备1201从所述服务器接收控制设备1201执行与所识别的用户行为相对应的AR功能的指令,其中所识别的用户行为由服务器1203使用根据以上详细讨论的根据本公开示例性实施例的用户行为识别方法从相机获取的视频中识别,以及与所识别的用户行为相对应的AR功能根据所述用户的行为识别结果和预定义的行为-AR功能映射关系来确定。In step S1503, the
在步骤S1504中,设备1201可以根据所述指令来执行所述AR功能。In step S1504, the
结合图14所述的行为-AR功能映射关系的示例,当服务器1203根据所述用户的行为识别结果确定所述用户做出唱歌行为时,根据所述行为-AR功能映射关系,向设备1201发送控制设备1201执行与唱歌行为相匹配的例如以下AR功能的指令:With reference to the example of the behavior-AR function mapping relationship described in FIG. 14 , when the
识别歌曲并通过因特网检索或在本地存储的歌曲库中检索,identify songs and retrieve them via the Internet or in a locally stored song library,
在设备中显示歌词,display lyrics in the device,
在设备中显示歌名和/或歌手名,Display the song title and/or artist name in the device,
在设备中同步播放歌曲的伴奏音乐。Play the backing music of the song in sync on the device.
由此,接收到该指令的设备1001可以执行例如图14第三列“示意图”中对应于“唱歌”的AR功能。Thus, the device 1001 that has received the instruction can perform, for example, the AR function corresponding to "singing" in the third column "Schematic" in FIG. 14 .
当服务器1203根据所述用户的行为识别结果确定所述用户做出吸烟行为时,根据所述行为-AR功能映射关系,向设备1201发送控制设备1201执行与吸烟行为相匹配的例如以下AR功能的指令:When the
在设备中显示该用户所处地点是否允许吸烟,Display on the device whether smoking is allowed in the user's location,
如果此处不允许吸烟,则显示最近的可吸烟区的相关信息,例如,从用户所在地点到达吸烟区的路线信息。If smoking is not allowed here, information about the nearest smoking area is displayed, for example, the route information from the user's location to the smoking area.
由此,接收到该指令的设备1201可以执行例如图14第三列“示意图”中对应于“吸烟”的AR功能。Thus, the
当服务器1203根据所述用户的行为识别结果确定所述用户做出握手行为时,根据所述行为-AR功能映射关系,向设备1201发送控制设备1201执行与握手行为相匹配的例如以下AR功能的指令:When the
识别与握手人的身份;identify the person shaking hands;
在握手人附近显示该握手人的信息。Displays information about the handshake near the handshake.
由此,接收到该指令的设备1201可以执行例如图14第三列“示意图”中对应于“握手”的AR功能。Thus, the
当服务器1203根据所述用户的行为识别结果确定所述用户做出演奏乐器行为时,根据所述行为-AR功能映射关系,向设备1201发送控制设备1201执行与演奏乐器行为相匹配的例如以下AR功能的指令:When the
识别乐器;identify musical instruments;
显示乐器名;display instrument name;
在乐器旁边同步显示音乐的乐谱。Displays the music score in sync next to the instrument.
由此,接收到该指令的设备1201可以执行例如图14第三列“示意图”中对应于“演奏乐器”的AR功能。Thus, the
图16示意性地示出了应用图13和15的方法的用AR设备1201之外的相机1202观察用户并通过用户行为识别自动控制AR设备1201执行AR功能的示例性场景效果图。FIG. 16 schematically shows an exemplary scene effect diagram of observing the user with a
在一示例性实施例中,当接收到控制所述设备执行与所识别的用户行为相对应的多个AR功能时,可以根据在设备1201的存储器上存储用户预先设置,从所述多个AR功能中选择并执行一个或多个AR功能。In an exemplary embodiment, when a control of the device to perform a plurality of AR functions corresponding to the identified user behavior is received, the plurality of AR functions may be retrieved from the plurality of AR functions according to a user preset stored on the memory of the
在一示例性实施例中,当当前用户行为的状态被更新时,设备1201可以从服务器1203接收控制设备1201关闭与当前用户行为不匹配的AR功能的指令;并根据所述指令,关闭与当前用户行为不匹配的AR功能。In an exemplary embodiment, when the state of the current user behavior is updated, the
以下将参照图17,对根据本公开示例性实施例的服务器的结构进行描述。The structure of a server according to an exemplary embodiment of the present disclosure will be described below with reference to FIG. 17 .
图17示意性地示出了根据本公开示例性实施例的服务器1600的结构框图。服务器1700可以用于执行如前参考图13描述的方法1300。FIG. 17 schematically shows a structural block diagram of a server 1600 according to an exemplary embodiment of the present disclosure. Server 1700 may be used to perform
如图17所示,服务器1700包括处理单元或处理器1701,所述处理器1701可以是单个单元或者多个单元的组合,用于执行方法的不同步骤;存储器1702,其中存储有计算机可执行指令,所述指令在被处理器1701执行时,使服务器1700执行方法1300。为了简明,在此仅对根据本公开示例性实施例的服务器的示意性结构进行描述,而省略了如前参考图13描述的方法1300中已经详述过的细节。As shown in Figure 17, the server 1700 includes a processing unit or processor 1701, which may be a single unit or a combination of multiple units, for performing different steps of the method; a memory 1702, in which computer-executable instructions are stored , the instructions, when executed by the processor 1701, cause the server 1700 to perform the
所述指令在被处理器1701执行时,使服务器1700执行以下操作:The instructions, when executed by the processor 1701, cause the server 1700 to perform the following operations:
通过相机获取的视频;video captured by the camera;
从通过相机所获取的视频中检测用户,并将检测到的用户和所述相应用户使用的具有AR功能的设备进行关联;Detecting a user from the video obtained by the camera, and associating the detected user with the AR-enabled device used by the corresponding user;
请求所述设备中的AR程序管理器接受启动与服务器协同工作的设备自动控制方法;Requesting the AR program manager in the device to accept the device automatic control method that works in conjunction with the server;
响应于所述AR程序管理器接受所述请求,使用前述根据本公开示例性实施例的用户行为识别方法,基于从所述相机获取的视频中对所述用户的行为进行识别;以及In response to the AR program manager accepting the request, the user's behavior is identified based on the video obtained from the camera using the aforementioned user behavior recognition method according to an exemplary embodiment of the present disclosure; and
根据所述用户的行为识别结果和预定义的行为-AR功能映射关系,向所述设备发送控制所述设备执行与所识别的用户行为相匹配的AR功能的指令。According to the behavior identification result of the user and the predefined behavior-AR function mapping relationship, an instruction to control the device to execute the AR function matching the identified user behavior is sent to the device.
在一示例性实施例中,从所获取的视频中检测用户并将检测到的用户和所述用户使用的具有AR功能的设备进行关联包括:In an exemplary embodiment, detecting a user from the acquired video and associating the detected user with an AR-enabled device used by the user includes:
从视频中执行人体跟踪;perform human tracking from video;
对跟踪到的人体执行人脸检测,以得到人脸图像区域;Perform face detection on the tracked human body to obtain the face image area;
通过人脸识别从登记的AR用户数据库中搜索匹配的用户,其中所述AR用户数据库至少包括:用户的人脸图像,用户的设备信息;Search for matching users from the registered AR user database through face recognition, wherein the AR user database at least includes: the user's face image and the user's device information;
当在AR用户数据库中搜索到匹配的用户时,获得与所述用户相关联的设备信息。When a matching user is searched in the AR user database, device information associated with the user is obtained.
在一示例性实施例中,所述指令在被处理器1701执行时还使服务器1700执行以下操作:当存在与所识别的用户的行为相匹配的多个AR功能时,从所述多个AR功能中选择一个或多个AR功能,并向所述设备发送控制所述设备执行所选的一个或多个AR功能的指令。In an exemplary embodiment, the instructions, when executed by the processor 1701, further cause the server 1700 to perform the following operations: when there are multiple AR functions matching the identified user's behavior, from the multiple AR functions One or more AR functions are selected from among the functions, and an instruction to control the device to perform the selected one or more AR functions is sent to the device.
在一示例性实施例中,所述指令在被处理器1701执行时还使服务器1700执行以下操作:根据所述用户的行为识别结果更新当前用户行为的状态,并根据所述行为-AR功能映射关系,向所述设备发送控制所述设备关闭与当前用户行为不匹配的AR功能的指令。In an exemplary embodiment, the instructions, when executed by the processor 1701, further cause the server 1700 to perform the following operations: update the status of the current user behavior according to the user's behavior recognition result, and map the behavior-AR function according to the behavior relationship, sending an instruction to control the device to turn off the AR function that does not match the current user behavior to the device.
图18示意性地示出了根据本公开示例性实施例的具有AR功能的设备1800的结构框图。设备1800可以用于执行如前参考图15描述的方法1500。FIG. 18 schematically shows a structural block diagram of an AR-enabled device 1800 according to an exemplary embodiment of the present disclosure. The apparatus 1800 may be used to perform the
如图18所示,设备1800包括处理单元或处理器1801,所述处理器1801可以是单个单元或者多个单元的组合,用于执行方法的不同步骤;存储器1802,其中存储有计算机可执行指令,所述指令在被处理器1801执行时,使设备1800执行方法1500。为了简明,在此仅对根据本公开示例性实施例的设备的示意性结构进行描述,而省略了如前参考图15描述的方法1500中已经详述过的细节。As shown in Figure 18, apparatus 1800 includes a processing unit or processor 1801, which may be a single unit or a combination of units, for performing different steps of a method; a memory 1802, in which computer-executable instructions are stored , the instructions, when executed by the processor 1801, cause the device 1800 to perform the
所述指令在被处理器1801执行时,使设备1800执行以下操作:The instructions, when executed by the processor 1801, cause the device 1800 to perform the following operations:
从服务器接收针对启动与所述服务器协同工作的设备自动控制方法的请求;receiving, from a server, a request for initiating an automatic control method for a device working in conjunction with the server;
向所述服务器发送接受所述请求的响应;sending a response to the server accepting the request;
从所述服务器接收控制所述设备执行与所识别的用户行为相对应的AR功能的指令,其中所识别的用户行为由所述服务器使用前述根据本公开示例性实施例的用户行为识别方法从相机获取的视频中识别,以及与所识别的用户行为相对应的AR功能根据所述用户的行为识别结果和预定义的行为-AR功能映射关系来确定;以及An instruction to control the device to perform an AR function corresponding to an identified user behavior is received from the server, wherein the identified user behavior is retrieved from the camera by the server using the aforementioned user behavior identification method according to an exemplary embodiment of the present disclosure Identify in the acquired video, and the AR function corresponding to the identified user behavior is determined according to the user's behavior identification result and a predefined behavior-AR function mapping relationship; and
根据所述指令,执行所述AR功能。According to the instruction, the AR function is executed.
在一示例性实施例中,所述指令在被处理器1801执行时,还使设备1800执行以下操作:In an exemplary embodiment, the instructions, when executed by processor 1801, also cause device 1800 to perform the following operations:
当接收到控制所述设备执行与所识别的用户行为相对应的多个AR功能时,从所述多个AR功能中选择并执行一个或多个AR功能。When receiving control of the device to perform a plurality of AR functions corresponding to the identified user behavior, selecting and executing one or more AR functions from the plurality of AR functions.
在一示例性实施例中,所述指令在被处理器1801执行时,还使设备1800执行以下操作:In an exemplary embodiment, the instructions, when executed by processor 1801, also cause device 1800 to perform the following operations:
当当前用户行为的状态被更新时,从服务器接收控制所述设备关闭与当前用户行为不匹配的AR功能的指令;以及When the state of the current user behavior is updated, receiving an instruction from the server to control the device to turn off AR functions that do not match the current user behavior; and
根据所述指令,关闭与当前用户行为不匹配的AR功能。According to the instruction, turn off the AR function that does not match the current user behavior.
基于第一人称视频的针对具有AR功能的设备的自动控制方法An automatic control method for AR-enabled devices based on first-person video
参见图19示出的示例性应用场景。See the exemplary application scenario shown in FIG. 19 .
在一示例性实施例中,具有AR功能的设备可以是移动设备1901,如图19中的(a)所示,在移动设备1901的视频应用中呈现视频,根据所呈现的视频中的人体行为来控制移动设备1901的视频应用执行相应的AR功能。In an exemplary embodiment, the device with AR function may be a
在另一示例性实施例中,具有AR功能的设备可以是AR设备1902,如图19中的(b)所示,通过用户的AR设备1902上的相机拍摄视频,根据拍摄到的视频中的人体行为,来控制AR设备1902执行相应的AR功能,即,在用户的视野中显示相应的AR效果。In another exemplary embodiment, the device with AR function may be an AR device 1902. As shown in (b) of FIG. 19, a video is captured by a camera on the user's AR device 1902, and according to the captured video Human behavior is used to control the AR device 1902 to perform the corresponding AR function, that is, to display the corresponding AR effect in the user's field of vision.
以下参照图20,对根据本公开示例性实施例的在具有AR功能的设备处执行的用于控制该设备的方法进行描述。Referring to FIG. 20 , a method for controlling an AR-capable device performed at an AR-capable device according to an exemplary embodiment of the present disclosure will be described below.
图20示意性地示出了根据本公开示例性实施例的在具有AR功能的设备1901/1902处执行的用于控制该设备的方法2000的流程图。Figure 20 schematically illustrates a flow chart of a
在步骤S2001中,设备1901/1902从视频中执行人体跟踪;In step S2001, the
在步骤S2002中,设备1901/1902使用前述根据本公开示例性实施例的用户行为识别方法,基于所述视频对跟踪到的人体的行为进行识别;以及In step S2002, the
在步骤S2003中,设备1901/1902根据所述人体的行为识别结果和预定义的行为-AR功能映射关系,在设备1901/1902上执行与所识别的行为相匹配的AR功能。In step S2003, the
在所述设备是移动设备1901的示例性实施例中,移动设备1901包括具有AR功能的视频应用,所述视频通过所述视频应用在所述移动设备1801上显示。In the exemplary embodiment where the device is a
在所述设备是AR设备1902的示例性实施例中,AR设备1902包括相机,所述视频通过AR设备1902的相机捕获。In an exemplary embodiment where the device is an AR device 1902, the AR device 1902 includes a camera, and the video is captured by the AR device 1902 camera.
结合图14所述的行为-AR功能映射关系的示例,当设备1901/1902根据所述用户的行为识别结果确定视频中的人体做出唱歌行为时,根据所述行为-AR功能映射关系,在设备1901/1902上执行与唱歌行为相匹配的例如图14第三列“示意图”中对应于“唱歌”的以下AR功能:With reference to the example of the behavior-AR function mapping relationship described in FIG. 14, when the
识别歌曲并通过因特网检索或在本地存储的歌曲库中检索,identify songs and retrieve them via the Internet or in a locally stored song library,
在设备中显示歌词,display lyrics in the device,
在设备中显示歌名和/或歌手名,Display the song title and/or artist name in the device,
在设备中同步播放歌曲的伴奏音乐。Play the backing music of the song in sync on the device.
当设备1901/1902根据所述用户的行为识别结果确定视频中的人体做出吸烟行为时,根据所述行为-AR功能映射关系,在设备1901/1902上执行与吸烟行为相匹配的例如图14第三列“示意图”中对应于“吸烟”的以下AR功能:When the
在设备中显示该用户所处地点是否允许吸烟,Display on the device whether smoking is allowed in the user's location,
如果此处不允许吸烟,则显示最近的可吸烟区的相关信息,例如,从用户所在地点到达吸烟区的路线信息。If smoking is not allowed here, information about the nearest smoking area is displayed, for example, the route information from the user's location to the smoking area.
当设备1901/1902根据所述用户的行为识别结果确定视频中的人体做出握手行为时,根据所述行为-AR功能映射关系,在设备1901/1902上执行与握手行为相匹配的例如图14第三列“示意图”中对应于“握手”的以下AR功能:When the
识别与握手人的身份;identify the person shaking hands;
在握手人附近显示该握手人的信息。Displays information about the handshake near the handshake.
当设备1901/1902根据所述用户的行为识别结果确定视频中的人体做出演奏乐器行为时,根据所述行为-AR功能映射关系,在设备1901/1902上执行与演奏乐器行为相匹配的例如图14第三列“示意图”中对应于“演奏乐器”的以下AR功能:When the
识别乐器;identify musical instruments;
显示乐器名;display the name of the instrument;
在乐器旁边同步显示音乐的乐谱。Displays the music score in sync next to the instrument.
图21和图22分别示意性地示出了根据本公开示例性实施例的在移动设备1801的视频播放场景中和在AR设备1802的视频捕获场景中采用图19的方法的示例性场景效果图。FIGS. 21 and 22 schematically illustrate exemplary scene renderings using the method of FIG. 19 in the video playback scene of the mobile device 1801 and in the video capture scene of the AR device 1802, respectively, according to an exemplary embodiment of the present disclosure. .
图23示意性地示出了根据本公开示例性实施例的具有AR功能的设备2200的结构框图。设备2300可以用于执行如前参考图20描述的方法2000。FIG. 23 schematically shows a structural block diagram of an AR-enabled device 2200 according to an exemplary embodiment of the present disclosure. Apparatus 2300 may be used to perform
如图23所示,设备2300包括处理单元或处理器2301,所述处理器2301可以是单个单元或者多个单元的组合,用于执行方法的不同步骤;存储器2302,其中存储有计算机可执行指令,所述指令在被处理器2301执行时,使设备2300执行方法2000。为了简明,在此仅对根据本公开示例性实施例的设备的示意性结构进行描述,而省略了如前参考图20描述的方法2000中已经详述过的细节。As shown in Figure 23, the apparatus 2300 includes a processing unit or processor 2301, which may be a single unit or a combination of multiple units, for performing different steps of the method; a memory 2302, in which computer-executable instructions are stored , the instructions, when executed by the processor 2301, cause the device 2300 to perform the
所述指令在被处理器2301执行时,使设备2300执行以下操作:The instructions, when executed by the processor 2301, cause the device 2300 to perform the following operations:
从视频中执行人体跟踪;perform human tracking from video;
使用前述根据本公开示例性实施例的用户行为识别方法,基于所述视频对跟踪到的人体的行为进行识别;以及Using the aforementioned method for recognizing user behavior according to an exemplary embodiment of the present disclosure, identifying the behavior of the tracked human body based on the video; and
根据所述人体的行为识别结果和预定义的行为-AR功能映射关系,在所述设备上执行与所识别的行为相匹配的AR功能。According to the behavior recognition result of the human body and the predefined behavior-AR function mapping relationship, an AR function matching the recognized behavior is executed on the device.
运行在根据本公开的设备上的程序可以是通过控制中央处理单元(CPU)来使计算机实现本公开的实施例功能的程序。该程序或由该程序处理的信息可以临时存储在易失性存储器(如随机存取存储器RAM)、硬盘驱动器(HDD)、非易失性存储器(如闪速存储器)、或其他存储器系统中。The program running on the device according to the present disclosure may be a program that causes a computer to implement the functions of the embodiments of the present disclosure by controlling a central processing unit (CPU). The program or information processed by the program may be temporarily stored in volatile memory (eg, random access memory RAM), a hard disk drive (HDD), non-volatile memory (eg, flash memory), or other memory systems.
用于实现本公开各实施例功能的程序可以记录在计算机可读记录介质上。可以通过使计算机系统读取记录在所述记录介质上的程序并执行这些程序来实现相应的功能。此处的所谓“计算机系统”可以是嵌入在该设备中的计算机系统,可以包括操作系统或硬件(如外围设备)。“计算机可读记录介质”可以是半导体记录介质、光学记录介质、磁性记录介质、短时动态存储程序的记录介质、或计算机可读的任何其他记录介质。A program for realizing the functions of the embodiments of the present disclosure can be recorded on a computer-readable recording medium. The corresponding functions can be realized by causing a computer system to read programs recorded on the recording medium and execute the programs. The so-called "computer system" as used herein may be a computer system embedded in the device, and may include an operating system or hardware (eg, peripheral devices). The "computer-readable recording medium" may be a semiconductor recording medium, an optical recording medium, a magnetic recording medium, a recording medium that dynamically stores a program for a short period of time, or any other recording medium readable by a computer.
用在上述实施例中的设备的各种特征或功能模块可以通过电路(例如,单片或多片集成电路)来实现或执行。设计用于执行本说明书所描述的功能的电路可以包括通用处理器、数字信号处理器(DSP)、专用集成电路(ASIC)、现场可编程门阵列(FPGA)、或其他可编程逻辑器件、分立的门或晶体管逻辑、分立的硬件组件、或上述器件的任意组合。通用处理器可以是微处理器,也可以是任何现有的处理器、控制器、微控制器、或状态机。上述电路可以是数字电路,也可以是模拟电路。因半导体技术的进步而出现了替代现有集成电路的新的集成电路技术的情况下,本公开的一个或多个实施例也可以使用这些新的集成电路技术来实现。The various features or functional blocks of the devices used in the above-described embodiments may be implemented or performed by electrical circuits (eg, monolithic or multi-chip integrated circuits). Circuits designed to perform the functions described in this specification may include general purpose processors, digital signal processors (DSPs), application specific integrated circuits (ASICs), field programmable gate arrays (FPGAs), or other programmable logic devices, discrete gate or transistor logic, discrete hardware components, or any combination of the above. A general-purpose processor may be a microprocessor or any existing processor, controller, microcontroller, or state machine. The above circuit may be a digital circuit or an analog circuit. In the event that new integrated circuit technologies emerge as a result of advances in semiconductor technology to replace existing integrated circuits, one or more embodiments of the present disclosure may also be implemented using these new integrated circuit technologies.
如上,已经参考附图对本公开的实施例进行了详细描述。但是,具体的结构并不局限于上述实施例,本公开也包括不偏离本公开主旨的任何设计改动。另外,可以在权利要求的范围内对本公开进行多种改动,通过适当地组合不同实施例所公开的技术手段所得到的实施例也包含在本公开的技术范围内。此外,上述实施例中所描述的具有相同效果的组件可以相互替代。As above, the embodiments of the present disclosure have been described in detail with reference to the accompanying drawings. However, the specific structure is not limited to the above embodiments, and the present disclosure also includes any design changes that do not deviate from the gist of the present disclosure. In addition, various modifications can be made to the present disclosure within the scope of the claims, and embodiments obtained by appropriately combining technical means disclosed in different embodiments are also included in the technical scope of the present disclosure. In addition, the components described in the above-described embodiments having the same effect may be substituted for each other.
以上描述仅为本申请的较佳实施例以及对所运用技术原理的说明。本领域技术人员应当理解,本申请中所涉及的发明范围,并不限于上述技术特征的特定组合而成的技术方案,同时也应涵盖在不脱离所述发明构思的情况下,由上述技术特征或其等同特征进行任意组合而形成的其它技术方案。例如上述特征与本申请中公开的(但不限于)具有类似功能的技术特征进行互相替换而形成的技术方案。The above description is only a preferred embodiment of the present application and an illustration of the applied technical principles. Those skilled in the art should understand that the scope of the invention involved in this application is not limited to the technical solution formed by the specific combination of the above-mentioned technical features, and should also cover the above-mentioned technical features without departing from the inventive concept. Other technical solutions formed by any combination of its equivalent features. For example, a technical solution is formed by replacing the above-mentioned features with the technical features disclosed in this application (but not limited to) with similar functions.
Claims (20)
Translated fromChinesePriority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201811585707.8ACN111353519A (en) | 2018-12-24 | 2018-12-24 | User behavior recognition method and system, device with AR function and control method thereof |
| KR1020190135393AKR102830486B1 (en) | 2018-12-24 | 2019-10-29 | Method and apparatus for controlling ar apparatus based on action prediction |
| US16/718,404US11315354B2 (en) | 2018-12-24 | 2019-12-18 | Method and apparatus that controls augmented reality (AR) apparatus based on action prediction |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201811585707.8ACN111353519A (en) | 2018-12-24 | 2018-12-24 | User behavior recognition method and system, device with AR function and control method thereof |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN111353519Atrue CN111353519A (en) | 2020-06-30 |
Family
ID=71193945
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201811585707.8APendingCN111353519A (en) | 2018-12-24 | 2018-12-24 | User behavior recognition method and system, device with AR function and control method thereof |
Country Status (2)
| Country | Link |
|---|---|
| KR (1) | KR102830486B1 (en) |
| CN (1) | CN111353519A (en) |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112329719A (en)* | 2020-11-25 | 2021-02-05 | 江苏云从曦和人工智能有限公司 | Behavior recognition method, behavior recognition device and computer-readable storage medium |
| CN112883817A (en)* | 2021-01-26 | 2021-06-01 | 咪咕文化科技有限公司 | Action positioning method and device, electronic equipment and storage medium |
| CN113518201A (en)* | 2020-07-14 | 2021-10-19 | 阿里巴巴集团控股有限公司 | Video processing method, device and equipment |
| CN114511908A (en)* | 2022-01-27 | 2022-05-17 | 北京百度网讯科技有限公司 | Face living body detection method and device, electronic equipment and storage medium |
| CN119380602A (en)* | 2024-12-30 | 2025-01-28 | 杭州数栾安全科技有限公司 | Safety training simulation rehearsal method and system based on digital twin |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR102488969B1 (en)* | 2020-12-28 | 2023-01-13 | 한국로봇융합연구원 | Apparatus for labeling data for early screening of developmental disabilities based on learning model and method therefor |
| CN114445628B (en)* | 2021-12-30 | 2025-05-30 | 中原动力智能机器人有限公司 | Video instance segmentation method, device, mobile terminal and storage medium |
| CN117976226B (en)* | 2023-10-12 | 2024-10-18 | 上海中医药大学附属曙光医院 | Traumatic brain injury prediction method, device and equipment based on marking data |
| CN119200845B (en)* | 2024-09-12 | 2025-03-18 | 北京三月雨文化传播有限责任公司 | Interactive projection optimization method for exhibition halls |
Citations (19)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20110182469A1 (en)* | 2010-01-28 | 2011-07-28 | Nec Laboratories America, Inc. | 3d convolutional neural networks for automatic human action recognition |
| US20130007668A1 (en)* | 2011-07-01 | 2013-01-03 | James Chia-Ming Liu | Multi-visor: managing applications in head mounted displays |
| US20130234962A1 (en)* | 2012-03-06 | 2013-09-12 | Lenovo (Beijing) Co., Ltd. | Method Of Identifying A To-Be-Identified Object And An Electronic Device Of The Same |
| CN103854016A (en)* | 2014-03-27 | 2014-06-11 | 北京大学深圳研究生院 | Human body behavior classification and identification method and system based on directional common occurrence characteristics |
| CN104616028A (en)* | 2014-10-14 | 2015-05-13 | 北京中科盘古科技发展有限公司 | Method for recognizing posture and action of human limbs based on space division study |
| KR20150088157A (en)* | 2014-01-23 | 2015-07-31 | 삼성전자주식회사 | Method of generating feature vector, generating histogram, and learning classifier for recognition of behavior |
| CN105045398A (en)* | 2015-09-07 | 2015-11-11 | 哈尔滨市一舍科技有限公司 | Virtual reality interaction device based on gesture recognition |
| CN106066996A (en)* | 2016-05-27 | 2016-11-02 | 上海理工大学 | The local feature method for expressing of human action and in the application of Activity recognition |
| US20170236302A1 (en)* | 2016-02-11 | 2017-08-17 | AR4 GmbH | Image processing method, mobile device and method for generating a video image database |
| CN107341471A (en)* | 2017-07-04 | 2017-11-10 | 南京邮电大学 | A kind of Human bodys' response method based on Bilayer condition random field |
| CN107506712A (en)* | 2017-08-15 | 2017-12-22 | 成都考拉悠然科技有限公司 | Method for distinguishing is known in a kind of human behavior based on 3D depth convolutional networks |
| CN107679522A (en)* | 2017-10-31 | 2018-02-09 | 内江师范学院 | Action identification method based on multithread LSTM |
| CN107707839A (en)* | 2017-09-11 | 2018-02-16 | 广东欧珀移动通信有限公司 | Image processing method and device |
| CN108241849A (en)* | 2017-08-28 | 2018-07-03 | 北方工业大学 | Human interaction action recognition method based on video |
| CN108280436A (en)* | 2018-01-29 | 2018-07-13 | 深圳市唯特视科技有限公司 | A kind of action identification method based on the multi-grade remnant network for stacking recursive unit |
| CN108288015A (en)* | 2017-01-10 | 2018-07-17 | 武汉大学 | Human motion recognition method and system in video based on THE INVARIANCE OF THE SCALE OF TIME |
| CN108399380A (en)* | 2018-02-12 | 2018-08-14 | 北京工业大学 | A kind of video actions detection method based on Three dimensional convolution and Faster RCNN |
| CN108416288A (en)* | 2018-03-04 | 2018-08-17 | 南京理工大学 | The first visual angle interactive action recognition methods based on overall situation and partial situation's network integration |
| CN108681695A (en)* | 2018-04-26 | 2018-10-19 | 北京市商汤科技开发有限公司 | Video actions recognition methods and device, electronic equipment and storage medium |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20130053466A (en)* | 2011-11-14 | 2013-05-24 | 한국전자통신연구원 | Apparatus and method for playing contents to provide an interactive augmented space |
| KR20180079943A (en)* | 2017-01-03 | 2018-07-11 | 서울여자대학교 산학협력단 | Apparatus and method for room control based on wearable device and spatial augmented reality |
- 2018
- 2018-12-24CNCN201811585707.8Apatent/CN111353519A/enactivePending
- 2019
- 2019-10-29KRKR1020190135393Apatent/KR102830486B1/enactiveActive
Patent Citations (19)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20110182469A1 (en)* | 2010-01-28 | 2011-07-28 | Nec Laboratories America, Inc. | 3d convolutional neural networks for automatic human action recognition |
| US20130007668A1 (en)* | 2011-07-01 | 2013-01-03 | James Chia-Ming Liu | Multi-visor: managing applications in head mounted displays |
| US20130234962A1 (en)* | 2012-03-06 | 2013-09-12 | Lenovo (Beijing) Co., Ltd. | Method Of Identifying A To-Be-Identified Object And An Electronic Device Of The Same |
| KR20150088157A (en)* | 2014-01-23 | 2015-07-31 | 삼성전자주식회사 | Method of generating feature vector, generating histogram, and learning classifier for recognition of behavior |
| CN103854016A (en)* | 2014-03-27 | 2014-06-11 | 北京大学深圳研究生院 | Human body behavior classification and identification method and system based on directional common occurrence characteristics |
| CN104616028A (en)* | 2014-10-14 | 2015-05-13 | 北京中科盘古科技发展有限公司 | Method for recognizing posture and action of human limbs based on space division study |
| CN105045398A (en)* | 2015-09-07 | 2015-11-11 | 哈尔滨市一舍科技有限公司 | Virtual reality interaction device based on gesture recognition |
| US20170236302A1 (en)* | 2016-02-11 | 2017-08-17 | AR4 GmbH | Image processing method, mobile device and method for generating a video image database |
| CN106066996A (en)* | 2016-05-27 | 2016-11-02 | 上海理工大学 | The local feature method for expressing of human action and in the application of Activity recognition |
| CN108288015A (en)* | 2017-01-10 | 2018-07-17 | 武汉大学 | Human motion recognition method and system in video based on THE INVARIANCE OF THE SCALE OF TIME |
| CN107341471A (en)* | 2017-07-04 | 2017-11-10 | 南京邮电大学 | A kind of Human bodys' response method based on Bilayer condition random field |
| CN107506712A (en)* | 2017-08-15 | 2017-12-22 | 成都考拉悠然科技有限公司 | Method for distinguishing is known in a kind of human behavior based on 3D depth convolutional networks |
| CN108241849A (en)* | 2017-08-28 | 2018-07-03 | 北方工业大学 | Human interaction action recognition method based on video |
| CN107707839A (en)* | 2017-09-11 | 2018-02-16 | 广东欧珀移动通信有限公司 | Image processing method and device |
| CN107679522A (en)* | 2017-10-31 | 2018-02-09 | 内江师范学院 | Action identification method based on multithread LSTM |
| CN108280436A (en)* | 2018-01-29 | 2018-07-13 | 深圳市唯特视科技有限公司 | A kind of action identification method based on the multi-grade remnant network for stacking recursive unit |
| CN108399380A (en)* | 2018-02-12 | 2018-08-14 | 北京工业大学 | A kind of video actions detection method based on Three dimensional convolution and Faster RCNN |
| CN108416288A (en)* | 2018-03-04 | 2018-08-17 | 南京理工大学 | The first visual angle interactive action recognition methods based on overall situation and partial situation's network integration |
| CN108681695A (en)* | 2018-04-26 | 2018-10-19 | 北京市商汤科技开发有限公司 | Video actions recognition methods and device, electronic equipment and storage medium |
Non-Patent Citations (8)
| Title |
|---|
| BYUNGIN YOO 等: "Randomized decision bush: Combining global shape parameters and local scalable descriptors for human body parts recognition", 2014 IEEE INTERNATIONAL CONFERENCE ON IMAGE PROCESSING (ICIP), pages 1560 - 1564* |
| GUILHEM CHÉRON 等: "P-CNN: Pose-Based CNN Features for Action Recognition", 2015 IEEE INTERNATIONAL CONFERENCE ON COMPUTER VISION (ICCV), pages 3 - 5* |
| LIANG-CHIEH CHEN 等: "MaskLab: Instance Segmentation by Refining Object Detection with Semantic and Direction Features", 2018 IEEE/CVF CONFERENCE ON COMPUTER VISION AND PATTERN RECOGNITION, pages 2* |
| LIANGLIANG WANG 等: "Three-stream CNNs for action recognition", PATTERN RECOGNITION LETTERS, pages 33 - 40* |
| YEMIN SHI 等: "Sequential Deep Trajectory Descriptor for Action Recognition With Three-Stream CNN", IEEE TRANSACTIONS ON MULTIMEDIA, vol. 19, no. 7, pages 1510 - 1520, XP011653819, DOI: 10.1109/TMM.2017.2666540* |
| 唐超 等: "融合局部与全局特征的人体动作识别", 系统仿真学报, vol. 30, no. 7, pages 2497 - 2506* |
| 郑潇 等: "基于姿态时空特征的人体行为识别方法", 计算机辅助设计与图形学学报, vol. 30, no. 9, pages 1615 - 1624* |
| 钱银中 等: "姿态特征与深度特征在图像动作识别中的混合应用", 自动化学报, vol. 44, pages 1 - 11* |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113518201A (en)* | 2020-07-14 | 2021-10-19 | 阿里巴巴集团控股有限公司 | Video processing method, device and equipment |
| CN112329719A (en)* | 2020-11-25 | 2021-02-05 | 江苏云从曦和人工智能有限公司 | Behavior recognition method, behavior recognition device and computer-readable storage medium |
| CN112883817A (en)* | 2021-01-26 | 2021-06-01 | 咪咕文化科技有限公司 | Action positioning method and device, electronic equipment and storage medium |
| CN114511908A (en)* | 2022-01-27 | 2022-05-17 | 北京百度网讯科技有限公司 | Face living body detection method and device, electronic equipment and storage medium |
| CN119380602A (en)* | 2024-12-30 | 2025-01-28 | 杭州数栾安全科技有限公司 | Safety training simulation rehearsal method and system based on digital twin |
Also Published As
| Publication number | Publication date |
|---|---|
| KR102830486B1 (en) | 2025-07-08 |
| KR20200079175A (en) | 2020-07-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11315354B2 (en) | Method and apparatus that controls augmented reality (AR) apparatus based on action prediction | |
| CN111353519A (en) | User behavior recognition method and system, device with AR function and control method thereof | |
| US10769438B2 (en) | Augmented reality | |
| US10846534B1 (en) | Systems and methods for augmented reality navigation | |
| US10970334B2 (en) | Navigating video scenes using cognitive insights | |
| KR102585234B1 (en) | Vision Intelligence Management for Electronic Devices | |
| KR101796008B1 (en) | Sensor-based mobile search, related methods and systems | |
| KR101832693B1 (en) | Intuitive computing methods and systems | |
| US10019779B2 (en) | Browsing interface for item counterparts having different scales and lengths | |
| CN111491187B (en) | Video recommendation method, device, equipment and storage medium | |
| US20190158927A1 (en) | Smart closed caption positioning system for video content | |
| US20170109615A1 (en) | Systems and Methods for Automatically Classifying Businesses from Images | |
| US9881084B1 (en) | Image match based video search | |
| US9691183B2 (en) | System and method for dynamically generating contextual and personalized digital content | |
| JP2019075124A (en) | Method and system for providing camera effect | |
| WO2014000645A1 (en) | Interacting method, apparatus and server based on image | |
| CN110431514A (en) | System and method for context driven intelligence | |
| WO2021213067A1 (en) | Object display method and apparatus, device and storage medium | |
| US20220300066A1 (en) | Interaction method, apparatus, device and storage medium | |
| US10650814B2 (en) | Interactive question-answering apparatus and method thereof | |
| EP3486796A1 (en) | Search method and device | |
| WO2019214019A1 (en) | Online teaching method and apparatus based on convolutional neural network | |
| US20140286624A1 (en) | Method and apparatus for personalized media editing | |
| CN114842488A (en) | Image title text determination method and device, electronic equipment and storage medium | |
| CN116301311A (en) | Interactive information acquisition method, device, electronic device and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| RJ01 | Rejection of invention patent application after publication | ||
| RJ01 | Rejection of invention patent application after publication | Application publication date:20200630 |