CN111325498B - User route generation method and device for VRPSPD, electronic equipment and storage medium - Google Patents
User route generation method and device for VRPSPD, electronic equipment and storage mediumDownload PDFInfo
- Publication number
- CN111325498B CN111325498BCN202010069786.8ACN202010069786ACN111325498BCN 111325498 BCN111325498 BCN 111325498BCN 202010069786 ACN202010069786 ACN 202010069786ACN 111325498 BCN111325498 BCN 111325498B
- Authority
- CN
- China
- Prior art keywords
- sequences
- preset number
- sequence
- user
- initial
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images





Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q10/00—Administration; Management
- G06Q10/08—Logistics, e.g. warehousing, loading or distribution; Inventory or stock management
- G06Q10/083—Shipping
- G06Q10/08355—Routing methods
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/12—Computing arrangements based on biological models using genetic models
- G06N3/126—Evolutionary algorithms, e.g. genetic algorithms or genetic programming
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02T—CLIMATE CHANGE MITIGATION TECHNOLOGIES RELATED TO TRANSPORTATION
- Y02T10/00—Road transport of goods or passengers
- Y02T10/10—Internal combustion engine [ICE] based vehicles
- Y02T10/40—Engine management systems
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Biophysics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Business, Economics & Management (AREA)
- Health & Medical Sciences (AREA)
- Theoretical Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Evolutionary Biology (AREA)
- Economics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Quality & Reliability (AREA)
- Artificial Intelligence (AREA)
- Tourism & Hospitality (AREA)
- Strategic Management (AREA)
- Operations Research (AREA)
- Marketing (AREA)
- Human Resources & Organizations (AREA)
- Entrepreneurship & Innovation (AREA)
- Development Economics (AREA)
- Physiology (AREA)
- Genetics & Genomics (AREA)
- General Business, Economics & Management (AREA)
- Biomedical Technology (AREA)
- Computational Linguistics (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域Technical Field
本发明涉及计算机科学技术领域,特别是涉及一种用于VRPSPD的用户路线生成方法、装置、电子设备及存储介质。The present invention relates to the field of computer science and technology, and in particular to a method, device, electronic device and storage medium for generating a user route for VRPSPD.
背景技术Background Art
面向物质商品的工业生产配送中,广泛存在着运输回程车辆空载的现象,造成运输资源的浪费。在生产配送中,用户往往有换货、退货、或者将废旧材料以及工业生产剩余材料返回至配送仓库的需求,如果在企业原有的配送系统中,配送车辆在将货物配送至用户之后,从用户返回至配送中心的配送车辆还用于装载需要返回配送仓库的货物,这样一来,可以充分利用运输资源,进而能够间接地增加经济效益,针对上述配送方案,如何求取最佳的配送路线即为VRPSPD(Vehicle Routing Problem with Simulta neous Delivery,同时取送货的车辆路径问题)。In the industrial production and distribution of material goods, there is a widespread phenomenon of empty return vehicles, resulting in a waste of transportation resources. In production and distribution, users often have the need to exchange, return, or return waste materials and industrial production surplus materials to the distribution warehouse. If in the original distribution system of the enterprise, after the delivery vehicle delivers the goods to the user, the delivery vehicle returning from the user to the distribution center is also used to load the goods that need to be returned to the distribution warehouse, in this way, the transportation resources can be fully utilized, and the economic benefits can be indirectly increased. For the above distribution plan, how to find the best distribution route is VRPSPD (Vehicle Routing Problem with Simulta neous Delivery).
现有技术中,通常采用遗传算法求解VRPSPD,遗传算法是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法,其具体求解过程为:针对需要配送的多个用户,根据各用户对应的用户标识,生成多个初始序列,每个初始序列中包括多个不同的子序列,各子序列分别表示不同的配送路线,各子序列中包括多个不同的用户标识,接着通过对初始序列进行交叉操作,该交叉操作具体可以为将两个初始序列中的用户标识进行交换,接着对交叉后得到的序列进行变异操作,该变异操作具体可以为改变各初始序列中的部分用户标识,最后在变异后得到的序列中,计算各变异后的序列的适应度,并利用适应度进行选择操作,得到多个新的序列,再将各初始序列更新为新的序列,再次进行交叉、变异以及选择操作,迭代循环多次,最终得到多个目标序列,通过计算各目标序列的适应度,并根据适应度的大小最终确定一个目标序列作为近似最优解。In the prior art, a genetic algorithm is usually used to solve VRPSPD. The genetic algorithm is a computational model of the biological evolution process that simulates the natural selection and genetics mechanism of Darwin's theory of biological evolution. It is a method for searching for the optimal solution by simulating the natural evolution process. The specific solution process is: for multiple users who need delivery, multiple initial sequences are generated according to the user identifiers corresponding to each user. Each initial sequence includes multiple different subsequences, each subsequence represents a different delivery route, and each subsequence includes multiple different user identifiers. Then, a crossover operation is performed on the initial sequence. The crossover operation can be specifically to exchange the user identifiers in the two initial sequences. Then, a mutation operation is performed on the sequence obtained after the crossover. The mutation operation can be specifically to change part of the user identifiers in each initial sequence. Finally, in the sequence obtained after the mutation, the fitness of each mutated sequence is calculated, and a selection operation is performed using the fitness to obtain multiple new sequences. Then, each initial sequence is updated to a new sequence, and crossover, mutation and selection operations are performed again. The iteration cycle is repeated multiple times to finally obtain multiple target sequences. The fitness of each target sequence is calculated, and a target sequence is finally determined as an approximate optimal solution according to the size of the fitness.
由于现有技术中的遗传算法,首先生成初始序列,接着对初始序列进行交叉、变异以及选择操作产生多个新的序列,再将各初始序列更新为新的序列,再次进行交叉、变异以及选择操作,迭代循环多次,最终得到多个目标序列,因此现有技术中,仅包含交叉和变异两个演化过程,整体收敛速度较慢,需要经过较多次的迭代循环,才能得到近似最优解。Since the genetic algorithm in the prior art first generates an initial sequence, then performs crossover, mutation and selection operations on the initial sequence to generate multiple new sequences, then updates each initial sequence to a new sequence, performs crossover, mutation and selection operations again, iterates and cycles multiple times, and finally obtains multiple target sequences. Therefore, the prior art only includes two evolutionary processes, crossover and mutation, and the overall convergence speed is slow. It takes more iterative cycles to obtain an approximate optimal solution.
发明内容Summary of the invention
本发明实施例的目的在于提供一种用于VRPSPD的用户路线生成方法、装置、电子设备及存储介质,以实现加快用户路线生成方法的收敛速度。具体技术方案如下:The purpose of the embodiments of the present invention is to provide a method, device, electronic device and storage medium for generating a user route for VRPSPD, so as to accelerate the convergence speed of the method for generating a user route. The specific technical solution is as follows:
第一方面,本发明实施例提供了一种用于VRPSPD的用户路线生成方法,所述方法包括:In a first aspect, an embodiment of the present invention provides a method for generating a user route for VRPSPD, the method comprising:
针对待进行路线生成的多个用户,生成各用户对应的用户标识,并利用预设的配送车辆最大装载量,以及各所述用户标识对应的用户配送量之和之间的大小关系,生成第一预设数量个初始序列,各所述初始序列中包括多个子序列,各所述子序列中包括多个不同的用户标识,所述子序列用于表示不同的配送路线,子序列对应的配送路线的配送车辆最大装载量,大于或等于该配送路线上各所述用户标识对应的用户配送量之和;For multiple users for whom route generation is to be performed, a user ID corresponding to each user is generated, and a first preset number of initial sequences are generated using a preset maximum load capacity of a delivery vehicle and a size relationship between the sum of user delivery volumes corresponding to each of the user IDs, each of the initial sequences includes multiple subsequences, each of the subsequences includes multiple different user IDs, the subsequences are used to represent different delivery routes, and the maximum load capacity of a delivery vehicle for a delivery route corresponding to a subsequence is greater than or equal to the sum of user delivery volumes corresponding to each of the user IDs on the delivery route;
计算各所述初始序列的适应度,并基于所述适应度从所述第一预设数量个初始序列中选择第二预设数量个初始序列,作为目标序列,并对该第二预设数量个目标序列进行复制操作,得到第二预设数量个复制后的目标序列,所述目标序列的适应度小于所述第一预设数量个初始序列中除所述目标序列之外的其他初始序列的适应度;Calculating the fitness of each of the initial sequences, and selecting a second preset number of initial sequences from the first preset number of initial sequences based on the fitness as target sequences, and performing a copy operation on the second preset number of target sequences to obtain a second preset number of copied target sequences, wherein the fitness of the target sequence is less than the fitness of other initial sequences in the first preset number of initial sequences except the target sequence;
对所述第一预设数量个初始序列进行复制操作,得到第三预设数量个复制后的序列,并对所述第三预设数量个复制后的序列进行交叉操作,得到第三预设数量个交叉后的序列,所述第三预设数量大于所述第一预设数量,所述交叉后的序列中至少存在一个用户标识,该用户标识在交叉后的序列中的位置,与该用户标识在所述复制后的序列中的位置相同;且所述交叉后的序列中至少存在一个用户标识,该用户标识在交叉后的序列中的位置,与该用户标识在所述复制后的序列中位置不同;Performing a copy operation on the first preset number of initial sequences to obtain a third preset number of copied sequences, and performing a crossover operation on the third preset number of copied sequences to obtain a third preset number of crossed sequences, the third preset number being greater than the first preset number, at least one user identifier being present in the crossed sequence, and a position of the user identifier in the crossed sequence being the same as a position of the user identifier in the copied sequence; and at least one user identifier being present in the crossed sequence, and a position of the user identifier in the crossed sequence being different from a position of the user identifier in the copied sequence;
针对所述第三预设数量个交叉后的序列,对各交叉后的序列进行重组操作,得到第三预设数量个重组后的序列,所述重组后的序列中的子序列与所述交叉后的序列中的子序列不同;For the third preset number of crossed sequences, performing a recombination operation on each crossed sequence to obtain a third preset number of recombined sequences, wherein the subsequences in the recombined sequences are different from the subsequences in the crossed sequences;
对所述第三预设数量个重组后的序列,进行变异操作,得到第三预设数量个变异后的序列,所述变异后的序列中至少存在一个用户标识,该用户标识在该序列中所属的子序列,与该用户标识在所述重组后的序列中所属的子序列不同;performing a mutation operation on the third preset number of recombined sequences to obtain a third preset number of mutated sequences, wherein at least one user identifier exists in the mutated sequences, and a subsequence to which the user identifier belongs in the sequence is different from a subsequence to which the user identifier belongs in the recombined sequence;
对第二预设数量个复制后的目标序列进行改进操作,得到第二预设数量个改进后的序列,所述改进后的序列中至少存在一个用户标识,该用户标识在子序列中的位置,与该用户标识在所述复制后的序列中子序列的位置不同;Performing an improvement operation on a second preset number of replicated target sequences to obtain a second preset number of improved sequences, wherein at least one user identifier exists in the improved sequence, and a position of the user identifier in the subsequence is different from a position of the user identifier in the subsequence of the replicated sequence;
计算所述第二预设数量个改进后的序列,以及所述第三预设数量个变异后的序列的适应度,并按照所述适应度的高低顺序,选择得到第一预设数量个选择后的序列,将所述初始序列更新为所述选择后的序列,执行所述计算各所述初始序列的适应度,并基于所述适应度从所述第一预设数量个初始序列中选择第二预设数量个初始序列,作为目标序列的步骤。The fitness of the second preset number of improved sequences and the third preset number of mutated sequences are calculated, and the first preset number of selected sequences are selected in order of the fitness, the initial sequence is updated to the selected sequence, the fitness of each of the initial sequences is calculated, and a second preset number of initial sequences are selected from the first preset number of initial sequences based on the fitness as the target sequence.
可选地,所述针对待进行路线生成的多个用户,生成各用户对应的用户标识,并利用预设的配送车辆最大装载量,以及各所述用户标识对应的用户配送量之和之间的大小关系,生成第一预设数量个初始序列的步骤,包括:Optionally, the step of generating a user identifier corresponding to each user for each of the multiple users for whom route generation is to be performed, and generating a first preset number of initial sequences by using a preset maximum loading capacity of a delivery vehicle and a relationship between the sum of the user delivery capacities corresponding to each of the user identifiers, comprises:
针对待进行路线生成的多个用户,生成各用户对应的用户标识;For multiple users for whom route generation is to be performed, generate user identifiers corresponding to the respective users;
从所述多个用户标识中确定一个用户标识,并利用该用户标识与预先确定的配送中心标识,生成初始子序列,所述配送中心标识用于标识配送中心;Determine a user identifier from the multiple user identifiers, and generate an initial subsequence using the user identifier and a predetermined distribution center identifier, wherein the distribution center identifier is used to identify the distribution center;
从所述多个用户标识中,选择当前用户标识,并计算所述当前用户标识对应的用户配送量与当前子序列中各所述用户标识对应的用户配送量之和,得到货物配送量之和,所述当前子序列是基于所述初始子序列生成的;Selecting a current user identifier from the multiple user identifiers, and calculating the sum of the user delivery amount corresponding to the current user identifier and the user delivery amount corresponding to each of the user identifiers in the current subsequence to obtain the sum of the goods delivery amount, wherein the current subsequence is generated based on the initial subsequence;
判断所述货物配送量之和,是否小于或等于所述配送车辆最大装载量,所述配送车辆用于将所述配送中心的货物,配送至所述子序列中各用户标识对应的用户,或者将各用户标识对应的用户的货物运送至所述配送中心;Determine whether the sum of the cargo delivery quantities is less than or equal to the maximum loading capacity of the delivery vehicle, the delivery vehicle being used to deliver the cargo of the delivery center to the users corresponding to the user identifiers in the subsequence, or to deliver the cargo of the users corresponding to the user identifiers to the delivery center;
如果所述货物配送量之和,小于或等于所述配送车辆最大装载量,则将当前用户标识插入至所述当前子序列中,得到新的子序列,将所述当前子序列更新为所述新的子序列,并执行所述从所述多个用户标识中,选择当前用户标识的步骤;If the sum of the cargo delivery quantities is less than or equal to the maximum loading quantity of the delivery vehicle, inserting the current user identifier into the current subsequence to obtain a new subsequence, updating the current subsequence to the new subsequence, and executing the step of selecting the current user identifier from the multiple user identifiers;
如果所述货物配送量之和,大于所述配送车辆最大装载量,则执行所述从所述多个用户标识中确定一个用户标识,并利用该用户标识与预先确定的配送中心标识,生成初始子序列的步骤。If the sum of the cargo delivery quantities is greater than the maximum loading capacity of the delivery vehicle, the step of determining a user identifier from the multiple user identifiers and generating an initial subsequence using the user identifier and a predetermined distribution center identifier is performed.
可选地,所述将当前用户标识插入至所述当前子序列中,得到新的子序列的步骤,包括:Optionally, the step of inserting the current user identifier into the current subsequence to obtain a new subsequence includes:
将所述当前用户标识插入至所述当前子序列中相邻的两个用户标识之间,或者,将所述当前用户标识插入至所述当前子序列中所述配送中心标识与用户标识之间,得到多个当前子序列;Inserting the current user identifier between two adjacent user identifiers in the current subsequence, or inserting the current user identifier between the distribution center identifier and the user identifier in the current subsequence, to obtain multiple current subsequences;
利用第一预设表达式,计算所述多个当前子序列中各当前子序列的运输成本,所述第一预设表达式为:The transportation cost of each current subsequence in the multiple current subsequences is calculated using a first preset expression, where the first preset expression is:
f1=(2cok+clm)-β(clk+ckm)f1 =(2cok +clm )-β(clk +ckm )
式中,f1表示所述运输成本,cok表示所述配送车辆从所述配送中心行驶至所述当前用户标识对应的当前用户的运输成本,clm表示所述配送车辆从相邻的两个用户之间运输时的运输成本,β表示预设的权重系数,clk表示所述配送车辆从所述相邻的两个用户中的一个用户,行驶至所述当前用户的运输成本,ckm表示所述配送车辆从所述当前用户,行驶至所述相邻的两个用户中的另一个用户的运输成本;Wherein,f1 represents the transportation cost,cok represents the transportation cost of the delivery vehicle from the distribution center to the current user corresponding to the current user identifier,clm represents the transportation cost of the delivery vehicle when transporting between two adjacent users, β represents a preset weight coefficient, clk represents the transportation cost of the delivery vehicle from one of the two adjacent users to the current user, andckm represents the transportation cost of the delivery vehicle from the current user to the other of the two adjacent users;
比较所述多个当前子序列中各当前子序列的运输成本之间的大小,将最小运输成本对应的当前子序列确定为所述新的子序列。The transportation costs of the current subsequences in the multiple current subsequences are compared, and the current subsequence corresponding to the minimum transportation cost is determined as the new subsequence.
可选地,所述计算各所述初始序列的适应度,并基于所述适应度从所述第一预设数量个初始序列中选择第二预设数量个初始序列,作为目标序列的步骤,包括:Optionally, the step of calculating the fitness of each of the initial sequences, and selecting a second preset number of initial sequences from the first preset number of initial sequences based on the fitness as target sequences includes:
按照第二预设表达式,计算各所述初始序列的适应度,所述第二预设表达式为:The fitness of each of the initial sequences is calculated according to a second preset expression, wherein the second preset expression is:
fitness(u)=αTD+(1-α)(Wmax-Wmin)(u)=αTD+(1-α)(W fitnessmax -Wmin )
式中,fitness(u)表示第u个所述初始序列的适应度,α表示预设的平衡系数,TD表示第u个初始序列中所有子序列对应的配送路线的总行驶距离,Wmax表示第u个初始序列中所有子序列对应的配送路线中最大的行驶距离,Wmin表示第u个初始序列中所有子序列对应的配送路线中最小的行驶距离,u∈U,U={1,2,3,……,m},U表示所述初始序列的数量集合,m表示所述第一预设数量;Wherein, fitness(u) represents the fitness of the u-th initial sequence, α represents the preset balance coefficient, TD represents the total driving distance of the delivery routes corresponding to all subsequences in the u-th initial sequence, Wmax represents the maximum driving distance of the delivery routes corresponding to all subsequences in the u-th initial sequence, Wmin represents the minimum driving distance of the delivery routes corresponding to all subsequences in the u-th initial sequence, u∈U, U={1, 2, 3, ..., m}, U represents the number set of the initial sequence, and m represents the first preset number;
将计算得到的各所述适应度进行排序;Sorting the calculated fitnesses;
按照各所述适应度从小到大的顺序,选择第二预设数量个初始序列,作为所述目标序列。A second preset number of initial sequences are selected as the target sequences according to the order of the fitness from small to large.
可选地,所述对所述第一预设数量个初始序列进行复制操作,得到第三预设数量个复制后的序列,并对所述第三预设数量个复制后的序列进行交叉操作,得到第三预设数量个交叉后的序列的步骤,包括:Optionally, the step of performing a copy operation on the first preset number of initial sequences to obtain a third preset number of copied sequences, and performing a crossover operation on the third preset number of copied sequences to obtain a third preset number of crossover sequences includes:
利用所述第三预设数量,以及所述第一预设数量,确定所述第一预设数量个初始序列中各所述初始序列的复制次数;Determine the number of times each of the first preset number of initial sequences is replicated by using the third preset number and the first preset number;
利用各所述初始序列的复制次数,对所述第一预设数量个初始序列进行复制操作,得到第三预设数量个复制后的序列;Using the number of replications of each of the initial sequences, a replication operation is performed on the first preset number of initial sequences to obtain a third preset number of replicated sequences;
针对所述第三预设数量个复制后的序列中的各序列,保持该序列中第四预设数量个子序列不变,获取该序列中除所述第四预设数量个子序列之外的其他子序列中的用户标识,并将所述其他子序列中的用户标识从该序列中删除;For each sequence in the sequence after the third preset number of copies, keep a fourth preset number of subsequences in the sequence unchanged, obtain user identifiers in other subsequences in the sequence except the fourth preset number of subsequences, and delete the user identifiers in the other subsequences from the sequence;
针对所述其他子序列中的用户标识,利用预设的配送车辆最大装载量,以及各所述用户标识对应的用户配送量之和之间的大小关系,生成多个子序列;For the user identifiers in the other subsequences, multiple subsequences are generated using a preset maximum loading capacity of a delivery vehicle and a size relationship between the sum of the user delivery volumes corresponding to the user identifiers;
将所述第四预设数量个子序列和所生成的所述多个子序列,组合为所述交叉后的序列。The fourth preset number of subsequences and the generated multiple subsequences are combined into the crossed sequence.
可选地,所述针对所述第三预设数量个交叉后的序列,对各交叉后的序列进行重组操作,得到第三预设数量个重组后的序列的步骤,包括:Optionally, the step of performing a recombination operation on each of the third preset number of crossed sequences to obtain a third preset number of recombined sequences includes:
针对所述第三预设数量个交叉后的序列中的各序列,从该序列中删除第五预设数量个用户标识;For each sequence in the third preset number of crossed sequences, deleting a fifth preset number of user identifiers from the sequence;
将所删除的所述第五预设数量个用户标识,重新插入至该序列中,得到所述重组后的序列。The deleted fifth preset number of user identifiers are reinserted into the sequence to obtain the reorganized sequence.
可选地,所述对所述第三预设数量个重组后的序列,进行变异操作,得到第三预设数量个变异后的序列的步骤,包括:Optionally, the step of performing a mutation operation on the third preset number of recombined sequences to obtain a third preset number of mutated sequences includes:
针对所述第三预设数量个重组后的序列中的各序列,将该重组后的序列中一个子序列中的用户标识删除,并将该用户标识插入至该重组后的序列中另一个子序列中,得到所述变异后的序列。For each sequence in the third preset number of recombined sequences, the user identifier in a subsequence in the recombined sequence is deleted, and the user identifier is inserted into another subsequence in the recombined sequence to obtain the mutated sequence.
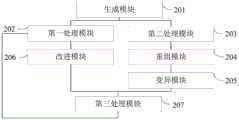
第二方面,本发明实施例提供了一种用于VRPSPD的用户路线生成装置,所述装置包括:In a second aspect, an embodiment of the present invention provides a user route generation device for VRPSPD, the device comprising:
生成模块,用于针对待进行路线生成的多个用户,生成各用户对应的用户标识,并利用预设的配送车辆最大装载量,以及各所述用户标识对应的用户配送量之和之间的大小关系,生成第一预设数量个初始序列,各所述初始序列中包括多个子序列,各所述子序列中包括多个不同的用户标识,所述子序列用于表示不同的配送路线,子序列对应的配送路线的配送车辆最大装载量,大于或等于该配送路线上各所述用户标识对应的用户配送量之和;A generation module, for generating a user ID corresponding to each user for a plurality of users for whom route generation is to be performed, and generating a first preset number of initial sequences by using a preset maximum load capacity of a delivery vehicle and a size relationship between the sum of user delivery volumes corresponding to each of the user IDs, wherein each of the initial sequences includes a plurality of subsequences, each of the subsequences includes a plurality of different user IDs, the subsequences are used to represent different delivery routes, and the maximum load capacity of a delivery vehicle for a delivery route corresponding to a subsequence is greater than or equal to the sum of user delivery volumes corresponding to each of the user IDs on the delivery route;
第一处理模块,用于计算各所述初始序列的适应度,并基于所述适应度从所述第一预设数量个初始序列中选择第二预设数量个初始序列,作为目标序列,并对该第二预设数量个目标序列进行复制操作,得到第二预设数量个复制后的目标序列,所述目标序列的适应度小于所述第一预设数量个初始序列中除所述目标序列之外的其他初始序列的适应度;a first processing module, configured to calculate the fitness of each of the initial sequences, and select a second preset number of initial sequences from the first preset number of initial sequences based on the fitness as target sequences, and perform a copy operation on the second preset number of target sequences to obtain a second preset number of copied target sequences, wherein the fitness of the target sequence is less than the fitness of other initial sequences in the first preset number of initial sequences except the target sequence;
第二处理模块,用于对所述第一预设数量个初始序列进行复制操作,得到第三预设数量个复制后的序列,并对所述第三预设数量个复制后的序列进行交叉操作,得到第三预设数量个交叉后的序列,所述第三预设数量大于所述第一预设数量,所述交叉后的序列中至少存在一个用户标识,该用户标识在交叉后的序列中的位置,与该用户标识在所述复制后的序列中的位置相同;且所述交叉后的序列中至少存在一个用户标识,该用户标识在交叉后的序列中的位置,与该用户标识在所述复制后的序列中位置不同;a second processing module, configured to perform a copy operation on the first preset number of initial sequences to obtain a third preset number of copied sequences, and perform a crossover operation on the third preset number of copied sequences to obtain a third preset number of crossed sequences, wherein the third preset number is greater than the first preset number, and there is at least one user identifier in the crossed sequence, and the position of the user identifier in the crossed sequence is the same as the position of the user identifier in the copied sequence; and there is at least one user identifier in the crossed sequence, and the position of the user identifier in the crossed sequence is different from the position of the user identifier in the copied sequence;
重组模块,用于针对所述第三预设数量个交叉后的序列,对各交叉后的序列进行重组操作,得到第三预设数量个重组后的序列,所述重组后的序列中的子序列与所述交叉后的序列中的子序列不同;a recombination module, configured to perform a recombination operation on each of the third preset number of crossover sequences to obtain a third preset number of recombined sequences, wherein the subsequences in the recombined sequences are different from the subsequences in the crossover sequences;
变异模块,用于对所述第三预设数量个重组后的序列,进行变异操作,得到第三预设数量个变异后的序列,所述变异后的序列中至少存在一个用户标识,该用户标识在该序列中所属的子序列,与该用户标识在所述重组后的序列中所属的子序列不同;a mutation module, configured to perform a mutation operation on the third preset number of recombined sequences to obtain a third preset number of mutated sequences, wherein at least one user identifier exists in the mutated sequences, and a subsequence to which the user identifier belongs in the sequence is different from a subsequence to which the user identifier belongs in the recombined sequence;
改进模块,用于对第二预设数量个复制后的目标序列进行改进操作,得到第二预设数量个改进后的序列,所述改进后的序列中至少存在一个用户标识,该用户标识在子序列中的位置,与该用户标识在所述复制后的序列中子序列的位置不同;an improving module, configured to perform an improving operation on a second preset number of replicated target sequences to obtain a second preset number of improved sequences, wherein at least one user identifier exists in the improved sequence, and a position of the user identifier in the subsequence is different from a position of the user identifier in the subsequence of the replicated sequence;
第三处理模块,用于计算所述第二预设数量个改进后的序列,以及所述第三预设数量个变异后的序列的适应度,并按照所述适应度的高低顺序,选择得到第一预设数量个选择后的序列,将所述初始序列更新为所述选择后的序列,执行所述计算各所述初始序列的适应度,并基于所述适应度从所述第一预设数量个初始序列中选择第二预设数量个初始序列,作为目标序列的步骤。The third processing module is used to calculate the fitness of the second preset number of improved sequences and the third preset number of mutated sequences, and select the first preset number of selected sequences in order of the fitness, update the initial sequence to the selected sequence, execute the step of calculating the fitness of each of the initial sequences, and select the second preset number of initial sequences from the first preset number of initial sequences based on the fitness as the target sequence.
可选地,所述生成模块,包括:Optionally, the generating module includes:
第一生成子模块,用于针对待进行路线生成的多个用户,生成各用户对应的用户标识;A first generating submodule is used to generate a user identifier corresponding to each user for a plurality of users for which route generation is to be performed;
第一处理子模块,用于从所述多个用户标识中确定一个用户标识,并利用该用户标识与预先确定的配送中心标识,生成初始子序列,所述配送中心标识用于标识配送中心;A first processing submodule is used to determine a user identifier from the multiple user identifiers, and generate an initial subsequence using the user identifier and a predetermined distribution center identifier, wherein the distribution center identifier is used to identify the distribution center;
第二处理子模块,用于从所述多个用户标识中,选择当前用户标识,并计算所述当前用户标识对应的用户配送量与当前子序列中各所述用户标识对应的用户配送量之和,得到货物配送量之和,所述当前子序列是基于所述初始子序列生成的;A second processing submodule, configured to select a current user identifier from the multiple user identifiers, and calculate the sum of the user delivery quantity corresponding to the current user identifier and the user delivery quantity corresponding to each of the user identifiers in the current subsequence to obtain the sum of the goods delivery quantity, wherein the current subsequence is generated based on the initial subsequence;
判断子模块,用于判断所述货物配送量之和,是否小于或等于所述配送车辆最大装载量,所述配送车辆用于将所述配送中心的货物,配送至所述子序列中各用户标识对应的用户,或者将各用户标识对应的用户的货物运送至所述配送中心;A judgment submodule, used to judge whether the sum of the goods delivery quantities is less than or equal to the maximum loading capacity of the delivery vehicle, the delivery vehicle is used to deliver the goods of the distribution center to the users corresponding to each user identifier in the subsequence, or to transport the goods of the users corresponding to each user identifier to the distribution center;
第三处理子模块,用于如果所述货物配送量之和,小于或等于所述配送车辆最大装载量,则将当前用户标识插入至所述当前子序列中,得到新的子序列,将所述当前子序列更新为所述新的子序列,并触发所述第二处理子模块执行所述从所述多个用户标识中,选择当前用户标识的步骤;A third processing submodule is configured to insert the current user identifier into the current subsequence to obtain a new subsequence if the sum of the cargo delivery quantities is less than or equal to the maximum loading capacity of the delivery vehicle, update the current subsequence to the new subsequence, and trigger the second processing submodule to execute the step of selecting the current user identifier from the multiple user identifiers;
触发子模块,用于如果所述货物配送量之和,大于所述配送车辆最大装载量,则触发所述第一处理子模块执行所述从所述多个用户标识中确定一个用户标识,并利用该用户标识与预先确定的配送中心标识,生成初始子序列的步骤。The trigger submodule is used to trigger the first processing submodule to execute the step of determining a user identifier from the multiple user identifiers and generating an initial subsequence using the user identifier and a predetermined distribution center identifier if the sum of the cargo distribution quantities is greater than the maximum loading capacity of the distribution vehicle.
可选地,所述第三处理子模块,包括:Optionally, the third processing submodule includes:
插入单元,用于将所述当前用户标识插入至所述当前子序列中相邻的两个用户标识之间,或者,将所述当前用户标识插入至所述当前子序列中所述配送中心标识与用户标识之间,得到多个当前子序列;An inserting unit, used for inserting the current user identifier between two adjacent user identifiers in the current subsequence, or inserting the current user identifier between the distribution center identifier and the user identifier in the current subsequence, to obtain multiple current subsequences;
计算单元,用于利用第一预设表达式,计算所述多个当前子序列中各当前子序列的运输成本,所述第一预设表达式为:A calculation unit is used to calculate the transportation cost of each current subsequence in the multiple current subsequences by using a first preset expression, where the first preset expression is:
f1=(2cok+clm)-β(clk+ckm)f1 =(2cok +clm )-β(clk +ckm )
式中,f1表示所述运输成本,cok表示所述配送车辆从所述配送中心行驶至所述当前用户标识对应的当前用户的运输成本,clm表示所述配送车辆从相邻的两个用户之间运输时的运输成本,β表示预设的权重系数,clk表示所述配送车辆从所述相邻的两个用户中的一个用户,行驶至所述当前用户的运输成本,ckm表示所述配送车辆从所述当前用户,行驶至所述相邻的两个用户中的另一个用户的运输成本;Wherein,f1 represents the transportation cost, cok represents the transportation cost of the delivery vehicle from the distribution center to the current user corresponding to the current user identifier, clm represents the transportation cost of the delivery vehicle when transporting between two adjacent users, β represents a preset weight coefficient, clk represents the transportation cost of the delivery vehicle from one of the two adjacent users to the current user, and ckm represents the transportation cost of the delivery vehicle from the current user to the other of the two adjacent users;
处理单元,用于比较所述多个当前子序列中各当前子序列的运输成本之间的大小,将最小运输成本对应的当前子序列确定为所述新的子序列。The processing unit is used to compare the transportation costs of the current subsequences in the multiple current subsequences, and determine the current subsequence corresponding to the minimum transportation cost as the new subsequence.
可选地,所述第一处理模块,包括:Optionally, the first processing module includes:
计算子模块,用于按照第二预设表达式,计算各所述初始序列的适应度,所述第二预设表达式为:The calculation submodule is used to calculate the fitness of each of the initial sequences according to a second preset expression, where the second preset expression is:
fitness(u)=αTD+(1-α)(Wmax-Wmin)(u)=αTD+(1-α)(W fitnessmax -Wmin )
式中,fitness(u)表示第u个所述初始序列的适应度,α表示预设的平衡系数,TD表示第u个初始序列中所有子序列对应的配送路线的总行驶距离,Wmax表示第u个初始序列中所有子序列对应的配送路线中最大的行驶距离,Wmin表示第u个初始序列中所有子序列对应的配送路线中最小的行驶距离,u∈U,U={1,2,3,……,m},U表示所述初始序列的数量集合,m表示所述第一预设数量;Wherein, fitness(u) represents the fitness of the u-th initial sequence, α represents the preset balance coefficient, TD represents the total driving distance of the delivery routes corresponding to all subsequences in the u-th initial sequence, Wmax represents the maximum driving distance of the delivery routes corresponding to all subsequences in the u-th initial sequence, Wmin represents the minimum driving distance of the delivery routes corresponding to all subsequences in the u-th initial sequence, u∈U, U={1, 2, 3, ..., m}, U represents the number set of the initial sequence, and m represents the first preset number;
排序子模块,用于将计算得到的各所述适应度进行排序;A sorting submodule, used for sorting the calculated fitness values;
选择子模块,用于按照各所述适应度从小到大的顺序,选择第二预设数量个初始序列,作为所述目标序列。The selection submodule is used to select a second preset number of initial sequences as the target sequence according to the order of the fitness from small to large.
可选地,所述第二处理模块,包括:Optionally, the second processing module includes:
确定子模块,用于利用所述第三预设数量,以及所述第一预设数量,确定所述第一预设数量个初始序列中各所述初始序列的复制次数;a determination submodule, configured to determine the number of replications of each of the first preset number of initial sequences by using the third preset number and the first preset number;
复制子模块,用于利用各所述初始序列的复制次数,对所述第一预设数量个初始序列进行复制操作,得到第三预设数量个复制后的序列;a copy submodule, configured to copy the first preset number of initial sequences using the number of copies of each of the initial sequences, to obtain a third preset number of copied sequences;
第四处理子模块,用于针对所述第三预设数量个复制后的序列中的各序列,保持该序列中第四预设数量个子序列不变,获取该序列中除所述第四预设数量个子序列之外的其他子序列中的用户标识,并将所述其他子序列中的用户标识从该序列中删除;a fourth processing submodule, configured to, for each sequence in the sequence after the third preset number of copies, keep a fourth preset number of subsequences in the sequence unchanged, obtain user identifiers in other subsequences in the sequence except the fourth preset number of subsequences, and delete the user identifiers in the other subsequences from the sequence;
第二生成子模块,用于针对所述其他子序列中的用户标识,利用预设的配送车辆最大装载量,以及各所述用户标识对应的用户配送量之和之间的大小关系,生成多个子序列;The second generating submodule is used to generate multiple subsequences for the user identifiers in the other subsequences by using the preset maximum loading capacity of the delivery vehicle and the relationship between the sum of the user delivery quantities corresponding to the user identifiers;
组合子模块,用于将所述第四预设数量个子序列和所生成的所述多个子序列,组合为所述交叉后的序列。A combining submodule is used to combine the fourth preset number of subsequences and the generated multiple subsequences into the crossed sequence.
可选地,所述重组模块,包括:Optionally, the recombination module comprises:
删除子模块,用于针对所述第三预设数量个交叉后的序列中的各序列,从该序列中删除第五预设数量个用户标识;a deleting submodule, configured to delete a fifth preset number of user identifiers from each sequence in the third preset number of crossed sequences;
插入子模块,用于将所删除的所述第五预设数量个用户标识,重新插入至该序列中,得到所述重组后的序列。The inserting submodule is used to reinsert the deleted fifth preset number of user identifiers into the sequence to obtain the reorganized sequence.
可选地,所述变异模块,具体用于:Optionally, the mutation module is specifically used to:
针对所述第三预设数量个重组后的序列中的各序列,将该重组后的序列中一个子序列中的用户标识删除,并将该用户标识插入至该重组后的序列中另一个子序列中,得到所述变异后的序列。For each sequence in the third preset number of recombined sequences, the user identifier in a subsequence in the recombined sequence is deleted, and the user identifier is inserted into another subsequence in the recombined sequence to obtain the mutated sequence.
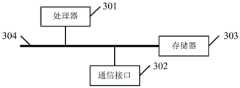
第三方面,本发明实施例还提供了一种电子设备,包括处理器、通信接口、存储器和通信总线,其中,处理器,通信接口,存储器通过通信总线完成相互间的通信;In a third aspect, an embodiment of the present invention further provides an electronic device, including a processor, a communication interface, a memory and a communication bus, wherein the processor, the communication interface and the memory communicate with each other via the communication bus;
存储器,用于存放计算机程序;Memory, used to store computer programs;
处理器,用于执行存储器上所存放的程序时,实现上述任一所述的用于VRPSPD的用户路线生成方法。The processor is used to implement any of the above-mentioned user route generation methods for VRPSPD when executing the program stored in the memory.
第四方面,本发明实施例还提供了一种计算机可读存储介质,其特征在于,所述计算机可读存储介质内存储有计算机程序,所述计算机程序被处理器执行时实现上述任一所述的方法步骤。包含指令的计算机程序产品,当其在计算机上运行时,使得计算机执行上述任一所述的用于VRPSPD的用户路线生成方法。In a fourth aspect, an embodiment of the present invention further provides a computer-readable storage medium, characterized in that a computer program is stored in the computer-readable storage medium, and when the computer program is executed by a processor, the computer program implements any of the above-mentioned method steps. A computer program product containing instructions, when it is run on a computer, enables the computer to execute any of the above-mentioned user route generation methods for VRPSPD.
本发明实施例有益效果:Beneficial effects of the embodiments of the present invention:
本发明实施例提供的一种用于VRPSPD的用户路线生成方法、装置、电子设备及存储介质,可以针对待进行路线生成多个用户,生成各用户对应的用户标识,利用预设的配送车辆最大装载量,以及各用户标识对应的用户配送量之和之间的大小关系,生成第一预设数量个初始序列;针对第一预设数量个初始序列中的第二预设数量个目标序列,进行复制操作,得到第二预设数量个复制后的序列;对第一预设数量个初始序列进行复制操作,得到第三预设数量个复制后的序列,并对第三预设数量个复制后的序列进行交叉操作,得到第三预设数量个交叉后的序列;针对第三预设数量个交叉后的序列,对各交叉后的序列进行重组操作,得到第三预设数量个重组后的序列;对第三预设数量个重组后的序列,进行变异操作,得到第三预设数量个变异后的序列;对第二预设数量个复制后的目标序列进行改进操作,得到第二预设数量个改进后的序列;计算第二预设数量个改进后的序列,以及第三预设数量个变异后的序列的适应度,并按照适应度的高低顺序,选择得到第一预设数量个选择后的序列,将初始序列更新为选择后的序列,进入迭代循环过程。由于在本发明实施例中,在得到初始序列之后,可以对其中一部分进行复制操作和改进操作,对初始序列进行交叉操作、重组操作、变异操作和选择操作,因此能够加快用户路线生成方法的收敛速度。当然,实施本发明的任一产品或方法并不一定需要同时达到以上所述的所有优点。A user route generation method, device, electronic device and storage medium for VRPSPD provided by an embodiment of the present invention can generate multiple users for a route to be performed, generate user identifiers corresponding to each user, and generate a first preset number of initial sequences by using a preset maximum loading capacity of a delivery vehicle and a size relationship between the sum of user delivery quantities corresponding to each user identifier; perform a copy operation on a second preset number of target sequences in the first preset number of initial sequences to obtain a second preset number of copied sequences; perform a copy operation on the first preset number of initial sequences to obtain a third preset number of copied sequences, and perform a cross operation on the third preset number of copied sequences , obtain a third preset number of crossover sequences; for the third preset number of crossover sequences, perform a recombination operation on each crossover sequence to obtain a third preset number of recombined sequences; perform a mutation operation on the third preset number of recombined sequences to obtain a third preset number of mutated sequences; perform an improvement operation on the second preset number of copied target sequences to obtain a second preset number of improved sequences; calculate the fitness of the second preset number of improved sequences and the third preset number of mutated sequences, and select the first preset number of selected sequences in order of fitness, update the initial sequence to the selected sequence, and enter an iterative cycle process. In the embodiment of the present invention, after obtaining the initial sequence, a portion of it can be copied and improved, and the initial sequence can be crossover, recombination, mutation and selection operations can be performed, so the convergence speed of the user route generation method can be accelerated. Of course, any product or method implementing the present invention does not necessarily need to achieve all the advantages described above at the same time.
附图说明BRIEF DESCRIPTION OF THE DRAWINGS
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。In order to more clearly illustrate the embodiments of the present invention or the technical solutions in the prior art, the drawings required for use in the embodiments or the description of the prior art will be briefly introduced below. Obviously, the drawings described below are only some embodiments of the present invention. For ordinary technicians in this field, other drawings can be obtained based on these drawings without paying creative work.
图1为本发明实施例提供的用户路线生成方法的一种流程示意图;FIG1 is a schematic diagram of a flow chart of a method for generating a user route according to an embodiment of the present invention;
图2为本发明实施例提供的序列处理过程的一种示意图;FIG2 is a schematic diagram of a sequence processing process provided by an embodiment of the present invention;
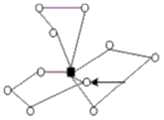
图3a为发明实施例提供的配送方案的一种示意图;FIG3a is a schematic diagram of a distribution solution provided by an embodiment of the invention;
图3b为在配送方案中选择一个配送路线的示意图;FIG3 b is a schematic diagram of selecting a delivery route in a delivery plan;
图3c为变异后的配送方案的一种示意图;FIG3 c is a schematic diagram of a modified distribution plan;
图4为本发明实施例提供的仿真计算的一种结果示意图;FIG4 is a schematic diagram of a result of a simulation calculation provided by an embodiment of the present invention;
图5为本发明实施例提供的用户路线生成装置的一种结构示意图;FIG5 is a schematic diagram of a structure of a user route generating device provided by an embodiment of the present invention;
图6为本发明实施例提供的一种电子设备的结构示意图。FIG6 is a schematic diagram of the structure of an electronic device provided by an embodiment of the present invention.
具体实施方式DETAILED DESCRIPTION
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。The following will be combined with the drawings in the embodiments of the present invention to clearly and completely describe the technical solutions in the embodiments of the present invention. Obviously, the described embodiments are only part of the embodiments of the present invention, not all of the embodiments. Based on the embodiments of the present invention, all other embodiments obtained by ordinary technicians in this field without creative work are within the scope of protection of the present invention.
如图1所示,本发明实施例提供了一种用于VRPSPD的用户路线生成方法,该过程可以包括:As shown in FIG. 1 , an embodiment of the present invention provides a method for generating a user route for VRPSPD, and the process may include:
S101,针对待进行路线生成的多个用户,生成各用户对应的用户标识,并利用预设的配送车辆最大装载量,以及各用户标识对应的用户配送量之和之间的大小关系,生成第一预设数量个初始序列。S101, generating a user ID corresponding to each user for a plurality of users for whom route generation is to be performed, and generating a first preset number of initial sequences by using a preset maximum loading capacity of a delivery vehicle and a relationship between the sum of the user delivery volumes corresponding to each user ID.
在生成的第一预设数量个初始序列中,每个初始序列均可以包括多个用户对应的用户标识,例如,当用户的数量为100个时,各初始序列中用户标识的数量均为100个,第一预设数量个初始序列可以表示,针对多个用户,所生成的第一预设数量个不同的配送方案。第一预设数量可以为预先设置好的数量,该第一预设数量可以根据经验或者实验进行设置,例如,可以将该第一预设数量设置为100。In the generated first preset number of initial sequences, each initial sequence may include user identifiers corresponding to multiple users. For example, when the number of users is 100, the number of user identifiers in each initial sequence is 100. The first preset number of initial sequences may represent a first preset number of different delivery plans generated for multiple users. The first preset number may be a preset number, which may be set based on experience or experiment. For example, the first preset number may be set to 100.
各初始序列中包括多个子序列,各子序列中包括多个不同的用户标识,子序列用于表示不同的配送路线,每个配送路线均由配送车辆将货物从配送中心配送至配送路线上的各用户,即将货物从配送中心配送至子序列中各用户标识对应的用户,或者将用户要返回至配送中心的货物运送至配送中心。针对各配送车辆,预先设置有配送车辆最大装载量,表示该配送车辆能够装载货物的最大重量。针对各子序列,该子序列对应的配送路线的配送车辆最大装载量,大于或等于该配送路线上各用户标识对应的用户配送量之和。Each initial sequence includes multiple subsequences, each subsequence includes multiple different user identifiers, and the subsequences are used to represent different delivery routes. Each delivery route is a delivery vehicle that delivers goods from the delivery center to each user on the delivery route, that is, the goods are delivered from the delivery center to the users corresponding to each user identifier in the subsequence, or the goods that the user wants to return to the delivery center are delivered to the delivery center. For each delivery vehicle, a maximum load capacity of the delivery vehicle is pre-set, indicating the maximum weight of the goods that the delivery vehicle can load. For each subsequence, the maximum load capacity of the delivery vehicle of the delivery route corresponding to the subsequence is greater than or equal to the sum of the user delivery capacities corresponding to each user identifier on the delivery route.
S102,计算各初始序列的适应度,并基于适应度从第一预设数量个初始序列中选择第二预设数量个初始序列,作为目标序列,并对该第二预设数量个目标序列进行复制操作,得到第二预设数量个复制后的目标序列。S102, calculating the fitness of each initial sequence, and selecting a second preset number of initial sequences from the first preset number of initial sequences based on the fitness as target sequences, and performing a copy operation on the second preset number of target sequences to obtain a second preset number of copied target sequences.
在本发明实施例中,目标序列的适应度小于第一预设数量个初始序列中除目标序列之外的其他初始序列的适应度,需要说明的是,适应度通常表示初始序列的优劣程度,即初始序列对应的配送方案是否为较优的方案,且适应度越小,则表明初始序列对应的配送方案较优,相应的,适应度越大,则表明初始序列对应的配送方案较差,因此,目标序列为所有初始序列中较优的配送方案。第二预设数量可以为预先设置的数量,可以根据实验或者经验进行设置,例如,可以将第二预设数量设置为第一预设数量的30%,当第一预设数量为100时,则第二预设数量可以为30。在选择得到第二预设数量个目标序列之后,参见图2,可以对第二预设数量个目标序列进行复制操作,得到第二预设数量个复制后的目标序列。In the embodiment of the present invention, the fitness of the target sequence is less than the fitness of other initial sequences except the target sequence in the first preset number of initial sequences. It should be noted that the fitness usually indicates the quality of the initial sequence, that is, whether the distribution plan corresponding to the initial sequence is a better plan, and the smaller the fitness, the better the distribution plan corresponding to the initial sequence. Correspondingly, the larger the fitness, the worse the distribution plan corresponding to the initial sequence. Therefore, the target sequence is the better distribution plan among all initial sequences. The second preset number can be a preset number, which can be set according to experiments or experience. For example, the second preset number can be set to 30% of the first preset number. When the first preset number is 100, the second preset number can be 30. After selecting and obtaining the second preset number of target sequences, referring to FIG. 2, the second preset number of target sequences can be copied to obtain the second preset number of copied target sequences.
S103,对第一预设数量个初始序列进行复制操作,得到第三预设数量个复制后的序列,并对第三预设数量个复制后的序列进行交叉操作,得到第三预设数量个交叉后的序列。S103, performing a copy operation on the first preset number of initial sequences to obtain a third preset number of copied sequences, and performing a crossover operation on the third preset number of copied sequences to obtain a third preset number of crossover sequences.
第三预设数量大于第一预设数量,为了使得在本发明实施例中,可以从较多数量个序列中选择较优的配送方案,并利用这些较优的配送方案再次进行复制操作、交叉操作等操作,因此,可以将第三预设数量设置为大于第一预设数量的数值,而且可以将第三预设数量设置为第一预设数量的两倍与第二预设数量之间的差值,即,当第一预设数量为100,第二预设数量为30,则第三预设数量可以为170。在本步骤中,首先需要将100个初始序列复制为170个复制后的序列,参见图2,接着对170个复制后的序列进行交叉操作,需要说明的是,具体的交叉操作的过程参见下述内容。The third preset number is greater than the first preset number. In order to select a better distribution plan from a larger number of sequences in the embodiment of the present invention, and use these better distribution plans to perform copy operations, cross operations, etc. again, the third preset number can be set to a value greater than the first preset number, and the third preset number can be set to the difference between twice the first preset number and the second preset number, that is, when the first preset number is 100 and the second preset number is 30, the third preset number can be 170. In this step, first, 100 initial sequences need to be copied into 170 copied sequences, see Figure 2, and then the 170 copied sequences are cross-operated. It should be noted that the specific cross-operation process is shown in the following content.
交叉后的序列中至少存在一个用户标识,该用户标识在交叉后的序列中的位置,与该用户标识在复制后的序列中的位置相同;且交叉后的序列中至少存在一个用户标识,该用户标识在交叉后的序列中的位置,与该用户标识在复制后的序列中位置不同。即在对170个复制后的序列进行交叉操作的过程中,针对各序列,保持一部分用户标识不变,改变另一部分用户标识在序列中的位置。There is at least one user identifier in the crossed sequence, and the position of the user identifier in the crossed sequence is the same as the position of the user identifier in the copied sequence; and there is at least one user identifier in the crossed sequence, and the position of the user identifier in the crossed sequence is different from the position of the user identifier in the copied sequence. That is, in the process of performing the crossover operation on the 170 copied sequences, for each sequence, a part of the user identifiers are kept unchanged, and the positions of the other part of the user identifiers in the sequence are changed.
S104,针对第三预设数量个交叉后的序列,对各交叉后的序列进行重组操作,得到第三预设数量个重组后的序列。S104, for a third preset number of crossed sequences, performing a recombination operation on each crossed sequence to obtain a third preset number of recombined sequences.
参见图2,可以对第三预设数量个交叉后的序列进行重组操作,这样一来,可以改变各序列中的子序列,即重组后的序列中的子序列与交叉后的序列中的子序列不同,此处需要说明的是,重组后的序列中各子序列均与交叉后的序列中的子序列不同,或者重组后的序列中部分子序列,与交叉后的序列中部分子序列不同。还需要说明的是,具体的重组操作的过程参见下述内容。Referring to FIG. 2 , a recombination operation can be performed on the third preset number of crossed sequences, so that the subsequences in each sequence can be changed, that is, the subsequences in the recombined sequence are different from the subsequences in the crossed sequence. It should be noted here that each subsequence in the recombined sequence is different from the subsequence in the crossed sequence, or some subsequences in the recombined sequence are different from some subsequences in the crossed sequence. It should also be noted that the specific recombination operation process is shown in the following content.
S105,对第三预设数量个重组后的序列,进行变异操作,得到第三预设数量个变异后的序列。S105, performing a mutation operation on a third preset number of recombined sequences to obtain a third preset number of mutated sequences.
参见图2,在得到第三预设数量个重组后的序列之后,可以对这些重组后的序列进行变异操作。在本发明实施例中,变异后的序列中至少存在一个用户标识,该用户标识在该序列中所属的子序列,与该用户标识在重组后的序列中所属的子序列不同,即,变异过程可以为,将其中一个用户标识在重组后的序列中的子序列,改变至另一个子序列中。需要说明的是,具体的变异操作的过程参见下述内容。Referring to FIG. 2 , after obtaining the third preset number of recombined sequences, mutation operations may be performed on the recombined sequences. In an embodiment of the present invention, there is at least one user identifier in the mutated sequence, and the subsequence to which the user identifier belongs in the sequence is different from the subsequence to which the user identifier belongs in the recombined sequence, that is, the mutation process may be to change the subsequence of one of the user identifiers in the recombined sequence to another subsequence. It should be noted that the specific mutation operation process is described below.
S106,对第二预设数量个复制后的目标序列进行改进操作,得到第二预设数量个改进后的序列。S106, performing an improvement operation on a second preset number of replicated target sequences to obtain a second preset number of improved sequences.
参见图2,可以对第二预设数量个复制后的目标序列进行改进操作,得到改进后的序列,改进后的序列中至少存在一个用户标识,该用户标识在子序列中的位置,与该用户标识在复制后的序列中子序列的位置不同,即,改变该用户标识在子序列中的位置,即,改变该用户标识对应的用户在配送路线中的位置。Referring to FIG. 2 , an improvement operation may be performed on a second preset number of copied target sequences to obtain an improved sequence, wherein the improved sequence contains at least one user identifier, and the position of the user identifier in the subsequence is different from the position of the user identifier in the subsequence in the copied sequence, that is, the position of the user identifier in the subsequence is changed, that is, the position of the user corresponding to the user identifier in the delivery route is changed.
S107,计算第二预设数量个改进后的序列,以及第三预设数量个变异后的序列的适应度,并按照适应度的高低顺序,选择得到第一预设数量个选择后的序列,将初始序列更新为选择后的序列,然后执行图1所示实施例流程步骤S102。S107, calculate the fitness of the second preset number of improved sequences and the third preset number of mutated sequences, and select the first preset number of selected sequences in order of fitness, update the initial sequence to the selected sequence, and then execute step S102 of the embodiment process shown in Figure 1.
分别计算第二预设数量个改进后的序列,以及第三预设数量个变异后的序列的适应度,参见图2,并按照适应度的高低顺序,选择第一预设数量个选择后的序列,将第一预设数量个初始序列分别更新为该第一预设数量个选择后的序列。接着进入迭代循环过程,即再次针对更新后的序列,进行复制操作、交叉操作、重组操作、变异操作、改进操作以及选择操作,达到预设的截止条件之后,结束迭代过程,预设的截止条件可以为:迭代次数达到预设的迭代次数。在最后一次迭代过程中,经过选择得到第一预设数量个序列,分别计算这第一预设数量个序列的适应度,并按照适应度的高低顺序选择得到一个选择后的序列,该选择后的序列对应的配送路线即为最优的配送路线。此处需要说明的是,可以利用各序列的适应度,按照现有技术中的轮盘赌选择方法,从第二预设数量个改进后的序列,以及第三预设数量个变异后的序列中选择第一预设数量个序列,本发明实施例对此不再赘述。The fitness of the second preset number of improved sequences and the third preset number of mutated sequences are calculated respectively, see FIG2, and the first preset number of selected sequences are selected in the order of fitness, and the first preset number of initial sequences are updated to the first preset number of selected sequences respectively. Then, the iterative cycle process is entered, that is, the copy operation, crossover operation, recombination operation, mutation operation, improvement operation and selection operation are performed again for the updated sequence, and the iterative process is terminated after reaching the preset cutoff condition, and the preset cutoff condition can be: the number of iterations reaches the preset number of iterations. In the last iteration process, the first preset number of sequences are obtained through selection, and the fitness of the first preset number of sequences is calculated respectively, and a selected sequence is selected in the order of fitness, and the distribution route corresponding to the selected sequence is the optimal distribution route. It should be noted here that the fitness of each sequence can be used to select the first preset number of sequences from the second preset number of improved sequences and the third preset number of mutated sequences according to the roulette selection method in the prior art, and the embodiment of the present invention will not be repeated here.
作为本发明实施例一种可选的实施方式,图1所示实施例流程步骤S101,可以包括:As an optional implementation of the embodiment of the present invention, step S101 of the process of the embodiment shown in FIG. 1 may include:
第一步,针对待进行路线生成的多个用户,生成各用户对应的用户标识。The first step is to generate a user ID corresponding to each user for multiple users for whom route generation is to be performed.
可以利用二进制数对多个用户进行编码,得到各用户对应的用户标识,为简化描述过程,示例性的,可以将待进行路线生成的用户的数量设置为4个,各用户的用户标识可以为:001、010、011、100,需要说明的是,不同用户的用户标识应该不同。Binary numbers can be used to encode multiple users to obtain user identifiers corresponding to each user. To simplify the description process, for example, the number of users for which routes are to be generated can be set to 4, and the user identifiers of each user can be: 001, 010, 011, 100. It should be noted that the user identifiers of different users should be different.
第二步,从多个用户标识中确定一个用户标识,并利用该用户标识与预先确定的配送中心标识,生成初始子序列。In the second step, a user ID is determined from the multiple user IDs, and an initial subsequence is generated using the user ID and a predetermined distribution center ID.
配送中心标识可以用于标识配送中心,在生成初始子序列之前,可以对配送中心进行编码,例如,配送中心的标识可以为000。可以从多个用户标识中,随机确定一个用户标识,并利用该用户标识与配送中心标识生成初始子序列,例如,所确定的用户标识为001,则初始子序列为000001。需要说明的是,在实际配送的过程中,初始子序列对应的配送车辆从配送中心出发后,对子序列中的各用户标识对应的用户配送完成后,应返回配送中心。此外,还可以预先设置配送车辆,使得各配送车辆在同一个时刻仅对一个用户进行配送,且配送完一个用户后立即向另一个用户行驶。The distribution center ID can be used to identify the distribution center. Before generating the initial subsequence, the distribution center can be encoded. For example, the distribution center ID can be 000. A user ID can be randomly determined from multiple user IDs, and the initial subsequence can be generated using the user ID and the distribution center ID. For example, if the determined user ID is 001, the initial subsequence is 000001. It should be noted that in the actual distribution process, after the distribution vehicle corresponding to the initial subsequence departs from the distribution center and completes the distribution to the users corresponding to each user ID in the subsequence, it should return to the distribution center. In addition, the distribution vehicles can be pre-set so that each distribution vehicle only delivers to one user at the same time, and immediately drives to another user after delivering to one user.
第三步,从多个用户标识中,选择当前用户标识,并计算当前用户标识对应的用户配送量与当前子序列中各用户标识对应的用户配送量之和,得到货物配送量之和。The third step is to select the current user ID from multiple user IDs, and calculate the sum of the user delivery volume corresponding to the current user ID and the user delivery volume corresponding to each user ID in the current subsequence to obtain the sum of the goods delivery volume.
从多个用户标识中,可以随机选择一个用户标识,作为当前用户标识,例如,选择的当前用户标识为010,当前子序列是基于初始子序列生成的,即,当前子序列可以为初始子序列,也可以为在初始子序列的基础上,插入一个用户标识生成。在本步骤中,以当前子序列为初始子序列为例进行描述,即,当前子序列为000001,表示配送车辆从配送中心出发,行驶至001对应的用户,从001对应的用户返回至配送中心。From multiple user identifiers, a user identifier can be randomly selected as the current user identifier. For example, the selected current user identifier is 010. The current subsequence is generated based on the initial subsequence, that is, the current subsequence can be the initial subsequence, or can be generated by inserting a user identifier on the basis of the initial subsequence. In this step, the current subsequence is described as an example of the initial subsequence, that is, the current subsequence is 000001, indicating that the delivery vehicle starts from the distribution center, travels to the user corresponding to 001, and returns to the distribution center from the user corresponding to 001.
计算101对应的用户的用户配送量,与001对应的用户的用户配送量之和,可以得到货物配送量之和。需要说明的是,不同用户的用户配送量可以以实际需要配送的货物重量为准。The sum of the user delivery volume of the user corresponding to 101 and the user delivery volume of the user corresponding to 001 can be calculated to obtain the sum of the goods delivery volume. It should be noted that the user delivery volume of different users can be based on the actual weight of the goods to be delivered.
第四步,判断货物配送量之和,是否小于或等于配送车辆最大装载量。The fourth step is to determine whether the sum of the cargo delivery quantities is less than or equal to the maximum loading capacity of the delivery vehicle.
在本发明实施例中,配送车辆用于将配送中心的货物,配送至子序列中各用户标识对应的用户,或者将各用户标识对应的用户的货物运送至配送中心。通过判断货物配送量之和,是否小于或等于配送车辆最大装载量,可以确定当前子序列对应的配送路线上的配送车辆是否还有足够的容量,装载当前用户标识对应的用户需要返回的货物。In the embodiment of the present invention, the delivery vehicle is used to deliver the goods of the distribution center to the users corresponding to each user ID in the subsequence, or to deliver the goods of the users corresponding to each user ID to the distribution center. By judging whether the sum of the delivery quantities of goods is less than or equal to the maximum loading capacity of the delivery vehicle, it can be determined whether the delivery vehicle on the delivery route corresponding to the current subsequence has sufficient capacity to load the goods that the user corresponding to the current user ID needs to return.
第五步,如果货物配送量之和,小于或等于配送车辆最大装载量,则将当前用户标识插入至当前子序列中,得到新的子序列,将当前子序列更新为新的子序列,并执行从多个用户标识中,选择当前用户标识的步骤。In the fifth step, if the sum of the cargo delivery quantities is less than or equal to the maximum loading capacity of the delivery vehicle, the current user ID is inserted into the current subsequence to obtain a new subsequence, the current subsequence is updated to the new subsequence, and the step of selecting the current user ID from multiple user IDs is executed.
如果货物配送量之和,小于或等于配送车辆最大装载量,则表明当前子序列对应的配送车辆能够装载当前用户标识对应的用户需要返回的货物,因此,可以将当前用户标识插入至当前子序列中,得到新的子序列,例如,将101插入至000001子序列中,则得到的新的子序列为:000101001,或者000001101,并将当前子序列更新为新的子序列,再次从多个用户标识中选择当前用户标识,直到将多个用户标识全部插入至子序列中。需要说明的是,在生成100个初始序列中各初始序列的过程中,针对已经选择过的用户标识,可以对其进行标记,后续选择当前用户标识的过程中不再选择已标记的用户标识。If the sum of the goods delivered is less than or equal to the maximum loading capacity of the delivery vehicle, it indicates that the delivery vehicle corresponding to the current subsequence can load the goods that the user corresponding to the current user ID needs to return. Therefore, the current user ID can be inserted into the current subsequence to obtain a new subsequence. For example, inserting 101 into the 000001 subsequence will result in a new subsequence of 000101001 or 000001101. The current subsequence is updated to the new subsequence, and the current user ID is selected from multiple user IDs again until all multiple user IDs are inserted into the subsequence. It should be noted that in the process of generating each of the 100 initial sequences, the user ID that has been selected can be marked, and the marked user ID will no longer be selected in the subsequent process of selecting the current user ID.
第六步,如果货物配送量之和,大于配送车辆最大装载量,则执行从多个用户标识中确定一个用户标识,并利用该用户标识与预先确定的配送中心标识,生成初始子序列的步骤。In step 6, if the sum of the delivered quantities is greater than the maximum loading capacity of the delivery vehicle, a step of determining a user ID from multiple user IDs and generating an initial subsequence using the user ID and a predetermined distribution center ID is executed.
如果货物配送量之和,大于配送车辆最大装载量,则表明当前子序列对应的配送车辆无法装载当前用户标识对应的用户需要配送的货物,因此,则需要利用当前用户标识和配送中心标识重新生成一个子序列,即,采用新的配送车辆来运送当前用户标识对应的用户需要返回的货物。If the sum of the delivery quantities of goods is greater than the maximum loading capacity of the delivery vehicle, it means that the delivery vehicle corresponding to the current subsequence cannot load the goods that the user corresponding to the current user ID needs to deliver. Therefore, it is necessary to regenerate a subsequence using the current user ID and the distribution center ID, that is, use a new delivery vehicle to transport the goods that the user corresponding to the current user ID needs to return.
以上步骤为生成一个初始序列的过程,100个待生成的初始序列中的其他初始序列也可以按照上述过程生成,本发明实施例对此不再赘述。The above steps are a process of generating an initial sequence. Other initial sequences among the 100 initial sequences to be generated may also be generated according to the above process, which will not be described in detail in the embodiment of the present invention.
通过比较货物配送量之和,与配送车辆最大装载量之间的大小,并根据两者之间的大小关系,确定是否将当前用户标识插入至当前子序列中,可以使得在生成初始序列的过程中,尽量平衡各初始序列对应的配送车辆的装载量。By comparing the sum of the goods delivery quantities with the maximum load capacity of the delivery vehicles, and determining whether to insert the current user identifier into the current subsequence based on the size relationship between the two, it is possible to balance the load capacities of the delivery vehicles corresponding to each initial sequence as much as possible during the process of generating the initial sequence.
现有技术中,生成初始序列的过程通常为:针对待进行路线生成的多个用户,对多个用户所形成的整个区域进行区域划分,且根据各用户所处的位置,以及各用户对应的用户标识,生成多个初始序列,每个初始序列中包括多个不同的子序列,且每个子序列中的用户标识对应的用户均位于同一个区域内,接着通过交叉、变异以及选择操作产生新的序列,再将初始序列更新为该新的序列,再次进行交叉、变异以及选择操作,迭代循环多次,最终得到多个选择后的序列。由于现有技术中生成初始序列的过程中,每个初始序列中各子序列中的用户标识对应的用户均位于一个区域内,接着针对该初始序列进行多次交叉、变异以及选择操作,最终得到近似最优解,因此通过现有技术的用户路线生成方法得到的最优解,是该区域内的最优解,但是对于位于区域边缘的用户,可能存在将其插入到该区域的隔壁区域的配送路线中得到的配送路线,运输成本更低的情况,因此,现有技术的用户路线生成方法容易产生局部最优解。In the prior art, the process of generating an initial sequence is usually as follows: for multiple users to be routed, the entire area formed by the multiple users is divided into regions, and multiple initial sequences are generated according to the location of each user and the user identifier corresponding to each user, each initial sequence includes multiple different subsequences, and the users corresponding to the user identifiers in each subsequence are all located in the same area, then a new sequence is generated through crossover, mutation and selection operations, and then the initial sequence is updated to the new sequence, and crossover, mutation and selection operations are performed again, and the iteration cycle is repeated multiple times to finally obtain multiple selected sequences. Since in the process of generating the initial sequence in the prior art, the users corresponding to the user identifiers in each subsequence in each initial sequence are all located in one area, and then multiple crossover, mutation and selection operations are performed on the initial sequence to finally obtain an approximate optimal solution, the optimal solution obtained by the user route generation method of the prior art is the optimal solution in the area, but for users located at the edge of the area, there may be a situation where the transportation cost is lower when the user is inserted into the distribution route of the adjacent area of the area, so the user route generation method of the prior art is prone to produce a local optimal solution.
而本发明实施例中,在生成初始序列的过程中,并未对多个用户进行区域划分,因此所生成的初始序列中各子序列中的用户标识对应的用户,可能并未位于现有技术中所划分的同一个区域内,因此,可以解决现有技术中存在的局部最优解的问题。However, in the embodiment of the present invention, multiple users are not divided into regions during the process of generating the initial sequence. Therefore, the users corresponding to the user identifiers in each subsequence in the generated initial sequence may not be located in the same region divided in the prior art. Therefore, the problem of local optimal solution in the prior art can be solved.
另外,在生成初始序列的过程中,除要考虑各配送车辆最大承载量,还可以设置各配送车辆的最大配送距离,可以通过计算当前用户标识对应的用户,与当前子序列中的用户标识对应的用户之间的距离,如果将当前用户标识插入至当前子序列中后,使得当前配送车辆的总行驶距离大于最大配送距离,则不将当前用户标识插入至当前子序列中。这样一来,可以进一步平衡各配送车辆的运输成本,避免因配送车辆行驶距离较远,而导致配送方案中整体运输成本增加的情况。In addition, in the process of generating the initial sequence, in addition to considering the maximum carrying capacity of each delivery vehicle, the maximum delivery distance of each delivery vehicle can also be set. This can be done by calculating the distance between the user corresponding to the current user ID and the user corresponding to the user ID in the current subsequence. If the current user ID is inserted into the current subsequence, the total driving distance of the current delivery vehicle is greater than the maximum delivery distance, then the current user ID will not be inserted into the current subsequence. In this way, the transportation costs of each delivery vehicle can be further balanced, avoiding the situation where the overall transportation cost of the delivery plan increases due to the long driving distance of the delivery vehicle.
作为本发明实施例一种可选的实施方式,图1所示实施例流程步骤S101中的第五步,可以包括:As an optional implementation of the embodiment of the present invention, the fifth step in step S101 of the process of the embodiment shown in FIG. 1 may include:
第一步,将当前用户标识插入至当前子序列中相邻的两个用户标识之间,或者,将当前用户标识插入至当前子序列中配送中心标识与用户标识之间,得到多个当前子序列。In the first step, the current user identifier is inserted between two adjacent user identifiers in the current subsequence, or the current user identifier is inserted between the distribution center identifier and the user identifier in the current subsequence to obtain multiple current subsequences.
在本步骤中,需要将当前用户标识插入至当前子序列中不同的位置,并得到多个当前子序列,例如,将101插入至000001100子序列中,则得到的新的子序列可以为:000101001100,000001101100,以及000001100100。In this step, the current user identifier needs to be inserted into different positions in the current subsequence to obtain multiple current subsequences. For example, if 101 is inserted into the 000001100 subsequence, the obtained new subsequences may be: 000101001100, 000001101100, and 000001100100.
第二步,利用第一预设表达式,计算多个当前子序列中各当前子序列的运输成本,第一预设表达式为:In the second step, the transportation cost of each current subsequence in the multiple current subsequences is calculated using a first preset expression, where the first preset expression is:
f1=(2cok+clm)-β(clk+ckm)f1 =(2cok +clm )-β(clk +ckm )
式中,f1表示运输成本,cok表示配送车辆从配送中心行驶至当前用户标识对应的当前用户的运输成本,clm表示配送车辆从相邻的两个用户之间运输时的运输成本,β表示预设的权重系数,clk表示配送车辆从相邻的两个用户中的一个用户,行驶至当前用户的运输成本,ckm表示配送车辆从当前用户,行驶至相邻的两个用户中的另一个用户的运输成本。Wheref1 represents the transportation cost,cok represents the transportation cost of the delivery vehicle from the distribution center to the current user corresponding to the current user ID,clm represents the transportation cost of the delivery vehicle when transporting between two adjacent users, β represents the preset weight coefficient,clk represents the transportation cost of the delivery vehicle from one of the two adjacent users to the current user, andckm represents the transportation cost of the delivery vehicle from the current user to the other of the two adjacent users.
在本发明实施例中,在计算运输成本之前,可以先获取多个用户和配送中心的坐标位置,利用欧式距离计算公式计算相邻的两个用户之间的距离,并利用第一预设表达式计算各当前子序列的运输成本。在计算的过程中,可以根据实验或者经验对权重系数进行设置,权重系数取值范围可以为0.2~1.4。In an embodiment of the present invention, before calculating the transportation cost, the coordinate positions of multiple users and the distribution center can be obtained, the distance between two adjacent users can be calculated using the Euclidean distance calculation formula, and the transportation cost of each current subsequence can be calculated using the first preset expression. During the calculation process, the weight coefficient can be set according to experiments or experience, and the weight coefficient value range can be 0.2 to 1.4.
第三步,比较多个当前子序列中各当前子序列的运输成本之间的大小,将最小运输成本对应的当前子序列确定为新的子序列。The third step is to compare the transportation costs of the current subsequences in the multiple current subsequences, and determine the current subsequence corresponding to the minimum transportation cost as the new subsequence.
在得到多个当前子序列中各当前子序列的运输成本之后,可以比较各当前子序列运输成本之间大小,并将最小运输成本对应的当前子序列确定为新的子序列。After obtaining the transportation cost of each current subsequence among the multiple current subsequences, the transportation costs of the current subsequences may be compared, and the current subsequence corresponding to the minimum transportation cost may be determined as a new subsequence.
作为本发明实施例一种可选的实施方式,图1所示实施例流程步骤S102,可以包括:As an optional implementation of the embodiment of the present invention, step S102 of the process of the embodiment shown in FIG. 1 may include:
第一步,按照第二预设表达式,计算各初始序列的适应度。The first step is to calculate the fitness of each initial sequence according to the second preset expression.
第二预设表达式为:The second preset expression is:
fitness(u)=αTD+(1-α)(Wmax-Wmin)(u)=αTD+(1-α)(W fitnessmax -Wmin )
式中,fitness(u)表示第u个初始序列的适应度,α表示预设的平衡系数,TD表示第u个初始序列中所有子序列对应的配送路线的总行驶距离,Wmax表示第u个初始序列中所有子序列对应的配送路线中最大的行驶距离,Wmin表示第u个初始序列中所有子序列对应的配送路线中最小的行驶距离,u∈U,U={1,2,3,……,m},U表示初始序列的数量集合,m表示第一预设数量。Wherein, fitness(u) represents the fitness of the u-th initial sequence, α represents the preset balance coefficient, TD represents the total driving distance of the delivery routes corresponding to all subsequences in the u-th initial sequence, Wmax represents the maximum driving distance of the delivery routes corresponding to all subsequences in the u-th initial sequence, Wmin represents the minimum driving distance of the delivery routes corresponding to all subsequences in the u-th initial sequence, u∈U, U={1, 2, 3, …, m}, U represents the number set of initial sequences, and m represents the first preset number.
平衡系数为预先设置的,可以根据经验或实验进行设置,例如,可以将α设置为0.7。需要说明的是,图1所示实施例流程步骤S107中,也可以利用第二预设表达式计算第二预设数量个改进后的序列,以及第三预设数量个变异后的序列的适应度。The balance coefficient is preset and can be set according to experience or experiment. For example, α can be set to 0.7. It should be noted that in step S107 of the process of the embodiment shown in FIG1 , the fitness of the second preset number of improved sequences and the third preset number of mutated sequences can also be calculated using a second preset expression.
第二步,将计算得到的各适应度进行排序。在计算得到各初始序列的适应度之后,可以按照从小到大的顺序,对各适应度进行排序。The second step is to sort the calculated fitnesses. After calculating the fitnesses of the initial sequences, the fitnesses can be sorted in order from small to large.
第三步,按照各适应度从小到大的顺序,选择第二预设数量个初始序列,作为目标序列。The third step is to select a second preset number of initial sequences as target sequences in order of fitness from small to large.
按照从小到大的顺序,从第一预设数量个初始序列中,选择第二预设数量个初始序列,即,从100个初始序列中选择30个初始序列,这30个初始序列相比其他初始序列的适应度小,因此表明这些初始序列中所有子序列对应的配送路线的总行驶距离较小,和/或这些初始序列中所有子序列对应的配送路线中最大行驶距离与最小行驶距离之间的差值较小,因此这些初始序列配送车辆的运输成本较小,即配送方案较优。In order from small to large, a second preset number of initial sequences are selected from the first preset number of initial sequences, that is, 30 initial sequences are selected from 100 initial sequences, and the fitness of these 30 initial sequences is smaller than that of other initial sequences, thus indicating that the total driving distance of the delivery routes corresponding to all subsequences in these initial sequences is smaller, and/or the difference between the maximum driving distance and the minimum driving distance in the delivery routes corresponding to all subsequences in these initial sequences is smaller, so the transportation cost of the delivery vehicles of these initial sequences is smaller, that is, the delivery plan is better.
作为本发明实施例一种可选的实施方式,图1所示实施例流程步骤S103,可以包括:As an optional implementation of the embodiment of the present invention, step S103 of the process of the embodiment shown in FIG1 may include:
第一步,利用第三预设数量,以及第一预设数量,确定第一预设数量个初始序列中各初始序列的复制次数。In the first step, the third preset number and the first preset number are used to determine the number of replications of each initial sequence in the first preset number of initial sequences.
由于第三预设数量通常大于第一预设数量,因此在对初始序列进行复制的过程中,可能部分初始序列仅复制一次,也可能复制多次,因此,可以利用第三预设数量,以及第一预设数量,确定第一预设数量个初始序列中各初始序列的复制次数。例如,当第一预设数量为100,第三预设数量为170,则将从100个初始序列中随机选择的70个初始序列的复制次数设置为2,将另外30个初始序列的复制次数设置为1。Since the third preset number is usually greater than the first preset number, in the process of copying the initial sequence, some of the initial sequences may be copied only once, or may be copied multiple times. Therefore, the third preset number and the first preset number can be used to determine the number of copies of each initial sequence in the first preset number of initial sequences. For example, when the first preset number is 100 and the third preset number is 170, the number of copies of 70 initial sequences randomly selected from the 100 initial sequences is set to 2, and the number of copies of the other 30 initial sequences is set to 1.
第二步,利用各初始序列的复制次数,对第一预设数量个初始序列进行复制操作,得到第三预设数量个复制后的序列。In the second step, a replication operation is performed on a first preset number of initial sequences using the replication times of each initial sequence to obtain a third preset number of replicated sequences.
针对第一预设数量个初始序列中的各初始序列,当初始序列的复制次数为1时,则将该初始序列复制一次,当初始序列的复制次数为2时,则将该初始序列复制两次,得到170个复制后的序列。For each initial sequence in the first preset number of initial sequences, when the number of replications of the initial sequence is 1, the initial sequence is replicated once; and when the number of replications of the initial sequence is 2, the initial sequence is replicated twice, thereby obtaining 170 replicated sequences.
第三步,针对第三预设数量个复制后的序列中的各序列,保持该序列中第四预设数量个子序列不变,获取该序列中除第四预设数量个子序列之外的其他子序列中的用户标识,并将其他子序列中的用户标识从该序列中删除。In the third step, for each sequence in the sequence after the third preset number of copies, keep the fourth preset number of subsequences in the sequence unchanged, obtain the user identifiers in the other subsequences in the sequence except the fourth preset number of subsequences, and delete the user identifiers in the other subsequences from the sequence.
针对经复制后得到的170个复制后的序列中的各序列,保持该序列中一部分子序列不变,并将另一部分子序列中的用户标识从该子序列中取出并删除。需要说明的是,第四预设数量可以根据序列中子序列的数量,以及实验和经验进行设置,例如,当序列中的子序列的数量为10时,则可以将第四预设数量设置为6,因此,在本步骤中,可以保持10个子序列中的6个子序列不变,将剩余4个子序列中的用户标识从子序列中删除。For each of the 170 replicated sequences obtained after replication, a portion of the subsequences in the sequence is kept unchanged, and the user identifiers in the other portion of the subsequences are taken out from the subsequences and deleted. It should be noted that the fourth preset number can be set according to the number of subsequences in the sequence, as well as experiments and experience. For example, when the number of subsequences in the sequence is 10, the fourth preset number can be set to 6. Therefore, in this step, 6 subsequences out of the 10 subsequences can be kept unchanged, and the user identifiers in the remaining 4 subsequences can be deleted from the subsequences.
第四步,针对其他子序列中的用户标识,利用预设的配送车辆最大装载量,以及各用户标识对应的用户配送量之和之间的大小关系,生成多个子序列。The fourth step is to generate multiple subsequences for the user identifiers in other subsequences by using the preset maximum loading capacity of the delivery vehicle and the size relationship between the sum of the user delivery volumes corresponding to each user identifier.
针对获取到的4个子序列中的用户标识,可以利用预设的配送车辆最大装载量,以及各用户标识对应的用户配送量之和之间的大小关系,生成多个子序列,该生成多个子序列的过程可以参考图1所示实施例流程步骤S101中的第一步~第六步,本发明实施例在此不再赘述。需要说明的是,生成的子序列的数量可能不再是4,而是5或者3等其他数量。For the user IDs in the obtained 4 subsequences, multiple subsequences can be generated by using the preset maximum loading capacity of the delivery vehicle and the size relationship between the sum of the user delivery volumes corresponding to each user ID. The process of generating multiple subsequences can refer to the first to sixth steps in the process step S101 of the embodiment shown in FIG1 , and the embodiment of the present invention will not be repeated here. It should be noted that the number of generated subsequences may no longer be 4, but may be 5 or 3 or other numbers.
第五步,将第四预设数量个子序列和所生成的多个子序列,组合为交叉后的序列。在得到多个子序列之后,可以将6个子序列和生成的多个子序列进行组合,生成交叉后的序列。Step 5: Combine the fourth preset number of subsequences and the generated multiple subsequences into a crossover sequence. After obtaining multiple subsequences, the 6 subsequences and the generated multiple subsequences can be combined to generate a crossover sequence.
作为本发明实施例一种可选的实施方式,图1所示实施例流程步骤S104,可以包括:As an optional implementation of the embodiment of the present invention, step S104 of the process of the embodiment shown in FIG. 1 may include:
第一步,针对第三预设数量个交叉后的序列中的各序列,从该序列中删除第五预设数量个用户标识。In the first step, for each sequence in the third preset number of crossed sequences, a fifth preset number of user identifiers are deleted from the sequence.
针对170个交叉后的序列中的各序列,可以从该序列中删除第五预设数量个用户标识,这些用户标识在序列中的位置可以通过随机选择的方法确定。第三预设数量可以为预先设置的数量,例如,可以将第三预设数量设置为序列中所有用户标识数量的五分之一。For each of the 170 crossed sequences, a fifth preset number of user identifiers may be deleted from the sequence, and the positions of these user identifiers in the sequence may be determined by a random selection method. The third preset number may be a preset number, for example, the third preset number may be set to one fifth of the number of all user identifiers in the sequence.
第二步,将所删除的第五预设数量个用户标识,重新插入至该序列中,得到重组后的序列。The second step is to reinsert the deleted fifth preset number of user identifiers into the sequence to obtain a reorganized sequence.
将所删除的五分之一个用户标识,重新插入至删除的序列中,得到重组后的序列,需要说明的是,将删除的五分之一个用户标识重新插入至删除的序列的过程,可以参考图1所示实施例流程步骤第五步所包括的第一步~第三步,本发明实施例对此不再赘述。The deleted one-fifth user identifier is reinserted into the deleted sequence to obtain a reorganized sequence. It should be noted that the process of reinserting the deleted one-fifth user identifier into the deleted sequence can refer to the first to third steps included in the fifth step of the process steps of the embodiment shown in FIG. 1 , and the embodiment of the present invention will not be described in detail.
作为本发明实施例一种可选的实施方式,图1所示实施例流程步骤S105,可以包括:As an optional implementation of the embodiment of the present invention, step S105 of the process of the embodiment shown in FIG. 1 may include:
针对第三预设数量个重组后的序列中的各序列,将该重组后的序列中一个子序列中的用户标识删除,并将该用户标识插入至该重组后的序列中另一个子序列中,得到变异后的序列。For each sequence in the third preset number of recombined sequences, the user identifier in a subsequence in the recombined sequence is deleted, and the user identifier is inserted into another subsequence in the recombined sequence to obtain a mutated sequence.
针对第三预设数量个重组后的序列中的各序列,可以从该序列中随机选择一个用户标识,并将该用户标识从原子序列中删除,将该用户标识插入至另一个子序列中。如图3a所示,箭头所指的用户对应的用户标识即为随机选择的用户标识,其中黑色实心框表示配送中心,随机选择一个子序列,即,选择如图3b所示曲线包围的配送路线,将图3a所示随机选择的用户标识从原子序列中删除,将其插入至图3b中选择的配送路线对应的子序列中,得到如图3c所示的变异后的子序列对应的配送路线。For each sequence in the third preset number of reorganized sequences, a user identifier can be randomly selected from the sequence, and the user identifier can be deleted from the atomic sequence and inserted into another subsequence. As shown in FIG3a, the user identifier corresponding to the user indicated by the arrow is the randomly selected user identifier, wherein the black solid box represents the distribution center, and a subsequence is randomly selected, that is, the distribution route surrounded by the curve shown in FIG3b is selected, and the randomly selected user identifier shown in FIG3a is deleted from the atomic sequence and inserted into the subsequence corresponding to the distribution route selected in FIG3b, so as to obtain the distribution route corresponding to the mutated subsequence shown in FIG3c.
作为本发明实施例一种可选的实施方式,图1所示实施例流程步骤S106,可以包括:As an optional implementation of the embodiment of the present invention, step S106 of the process of the embodiment shown in FIG. 1 may include:
第一步,针对第二预设数量个复制后的序列中的各序列,从该序列中的子序列中,随机选择一个位于两个用户标识之间的用户标识,将该用户标识从这两个用户标识之间删除,重新插入至该子序列中另外的相邻两个用户标识之间,得到多个插入后的子序列。In the first step, for each sequence in the second preset number of replicated sequences, randomly select a user identifier between two user identifiers from a subsequence in the sequence, delete the user identifier from between the two user identifiers, and reinsert the user identifier between another two adjacent user identifiers in the subsequence to obtain multiple inserted subsequences.
第二步,利用第三预设表达式,分别计算各插入后的子序列对应的配送路线的运输成本,第三预设表达式为:In the second step, the transportation cost of the delivery route corresponding to each inserted subsequence is calculated using the third preset expression. The third preset expression is:
f2=(cia+caj+cbc)-(cba+cac+cij)f2 =(cia +caj +cbc )-(cba +cac +cij )
式中,f2表示插入后的子序列对应的配送路线的运输成本,cia表示配送车辆从用户i行驶至用户a的运输成本,caj表示配送车辆从用户a行驶至用户j的运输成本,cbc表示配送车辆从用户b行驶至用户c的运输成本,cba表示配送车辆从用户b行驶至用户a的运输成本,cac表示配送车辆从用户a行驶至用户c的运输成本,cij表示配送车辆从用户i行驶至用户j的运输成本。Wheref2 represents the transportation cost of the delivery route corresponding to the inserted subsequence,cia represents the transportation cost of the delivery vehicle from user i to user a,caj represents the transportation cost of the delivery vehicle from user a to user j,cbc represents the transportation cost of the delivery vehicle from user b to user c,cba represents the transportation cost of the delivery vehicle from user b to user a,cac represents the transportation cost of the delivery vehicle from user a to user c, andcij represents the transportation cost of the delivery vehicle from user i to user j.
第三步,比较各插入后的子序列对应的配送路线的运输成本之间的大小。The third step is to compare the transportation costs of the delivery routes corresponding to each inserted subsequence.
第四步,将最小运输成本的配送路线的子序列确定为该插入操作得到的子序列。The fourth step is to determine the subsequence of the distribution route with the minimum transportation cost as the subsequence obtained by the insertion operation.
或者,图1所示实施例流程步骤S106也可以包括:Alternatively, step S106 of the process of the embodiment shown in FIG. 1 may also include:
第一步,针对第二预设数量个复制后的序列中的各序列,从该序列中的子序列中,随机选择两个用户标识,这两个用户标识中的一个用户标识位于另外两个第一用户标识之间,这两个用户标识中的另一个用户标识位于两个第二用户之间,其中第一用户标识和第二用户标识属于用户标识。In the first step, for each sequence in the second preset number of replicated sequences, two user identifiers are randomly selected from a subsequence in the sequence, one of the two user identifiers is located between the other two first user identifiers, and the other of the two user identifiers is located between the two second users, wherein the first user identifier and the second user identifier are user identifiers.
第二步,交换随机选择的两个用户标识在该子序列中的位置,得到两个交换后的子序列。The second step is to exchange the positions of two randomly selected user IDs in the subsequence to obtain two exchanged subsequences.
第三步,利用第四预设表达式,分别计算两个交换后的子序列的运输成本,第四预设表达式为:The third step is to use the fourth preset expression to calculate the transportation costs of the two exchanged subsequences respectively. The fourth preset expression is:
f3=(cik+ckj+clh+chm)-(clk+ckm+cih+chj)f3 =(cik+ckj+clh+chm)-(clk+ckm+cih+chj)
式中,f3表示交换后的子序列的运输成本,cik表示配送车辆从用户i行驶至用户k的运输成本,ckj表示配送车辆从用户k行驶至用户j的运输成本,clh表示配送车辆从用户l行驶至用户h的运输成本,chm表示配送车辆从用户h行驶至用户m的运输成本,clk表示配送车辆从用户l行驶至用户k的运输成本,ckm表示配送车辆从用户k行驶至用户m的运输成本,cih表示配送车辆从用户i行驶至用户h的运输成本,chj表示配送车辆从用户h行驶至用户j的运输成本。Where f3 represents the transportation cost of the exchanged subsequence, cik represents the transportation cost of the delivery vehicle from useri to user k, ckj represents the transportation cost of the delivery vehicle from user k to user j, clh represents the transportation cost of the delivery vehicle from user l to user h, chm represents the transportation cost of the delivery vehicle from user h to user m, clk represents the transportation cost of the delivery vehicle from user l to user k, ckm represents the transportation cost of the delivery vehicle from user k to user m, cih represents the transportation cost of the delivery vehicle from user i to user h, and chj represents the transportation cost of the delivery vehicle from user h to user j.
第四步,比较两个交换后的子序列的运输成本之间的大小。The fourth step is to compare the transportation costs of the two swapped subsequences.
第五步,将最小运输成本对应的交换后的子序列,确定为最终交换后的子序列。The fifth step is to determine the exchanged subsequence corresponding to the minimum transportation cost as the final exchanged subsequence.
本发明实施例提供的用于VRPSPD的用户路线生成方法,由于在得到初始序列之后,可以对其中一部分进行复制操作和改进操作,对初始序列进行交叉操作、重组操作、变异操作和选择操作,因此能够加快用户路线生成方法的收敛速度。The user route generation method for VRPSPD provided in the embodiment of the present invention can accelerate the convergence speed of the user route generation method because after obtaining the initial sequence, a part of it can be copied and improved, and the initial sequence can be cross-operated, reorganized, mutated and selected.
下面通过仿真计算,进一步描述本发明实施例提供的用于VRPSPD的用户路线生成方法的有益效果,分别取100、200、400个用户进行仿真计算,其中交叉操作的交叉率可以取值0.9,变异操作的变异率可以取值0.09,重组操作的重组率可以取值0.1。第一预设表达式中的权重系数β取值为0.2,第二预设表达式中平衡系数α取值为0.7,仿真结果如表1所示。需要说明的是,本发明实施例中的仿真实验数据参考现有的Solomon扩展VRPSPD算例中的实验数据。The following is a further description of the beneficial effects of the user route generation method for VRPSPD provided by the embodiment of the present invention through simulation calculations. 100, 200, and 400 users are taken for simulation calculations, respectively, where the crossover rate of the crossover operation can be taken as 0.9, the mutation rate of the mutation operation can be taken as 0.09, and the recombination rate of the recombination operation can be taken as 0.1. The weight coefficient β in the first preset expression is taken as 0.2, and the balance coefficient α in the second preset expression is taken as 0.7. The simulation results are shown in Table 1. It should be noted that the simulation experimental data in the embodiment of the present invention refers to the experimental data in the existing Solomon extended VRPSPD example.
表1仿真计算结果Table 1 Simulation results


表1中,算例r101、r201、c101、c201、rc101和rc201中用户数量为100个,算例r1_2_1、r2_2_1、c1_2_1、c2_2_1、rc1_2_1和rc2_2_1中用户数量为200个,算例r1_4_1、r2_4_1、c1_4_1、c2_4_1、rc1_4_1和rc2_4_1中用户数量为400个,且不同算例中所选取的用户的位置,以及用户配送量不同。平均值与最优值的差异为,配送距离平均值与配送距离最优值的差值,与配送距离平均值之间的比值。参照图4,图4为rc101算例中,对100个用户仿真得到的结果示意图,其中不同的曲线表示配送车辆的配送路线,实心原点表示不同的用户,从图4中的结果可以看出,对应于表1中rc101算例,最优配送车辆为9辆,配送总距离为1085.41m。从表1中可以看出,配送距离的最优值与平均值之差小于平均值,因此仿真实验较为稳定。In Table 1, the number of users in the examples r101, r201, c101, c201, rc101 and rc201 is 100, the number of users in the examples r1_2_1, r2_2_1, c1_2_1, c2_2_1, rc1_2_1 and rc2_2_1 is 200, and the number of users in the examples r1_4_1, r2_4_1, c1_4_1, c2_4_1, rc1_4_1 and rc2_4_1 is 400, and the locations of the users selected in different examples and the user delivery volumes are different. The difference between the average value and the optimal value is the ratio of the difference between the average value of the delivery distance and the optimal value of the delivery distance to the average value of the delivery distance. Referring to Figure 4, Figure 4 is a schematic diagram of the simulation results of 100 users in the rc101 example, where different curves represent the delivery routes of the delivery vehicles, and the solid origins represent different users. From the results in Figure 4, it can be seen that corresponding to the rc101 example in Table 1, the optimal delivery vehicles are 9 and the total delivery distance is 1085.41m. From Table 1, it can be seen that the difference between the optimal value and the average value of the delivery distance is smaller than the average value, so the simulation experiment is relatively stable.
本发明实施例提供了一种用于VRPSPD的用户路线生成装置的一种具体实施例,与图1所示流程相对应,参考图5,图5为本发明实施例的一种用于VRPSPD的用户路线生成装置的一种结构示意图,包括:The embodiment of the present invention provides a specific embodiment of a user route generation device for VRPSPD, corresponding to the process shown in FIG1 , with reference to FIG5 , which is a structural schematic diagram of a user route generation device for VRPSPD according to an embodiment of the present invention, including:
生成模块201,用于针对待进行路线生成的多个用户,生成各用户对应的用户标识,并利用预设的配送车辆最大装载量,以及各用户标识对应的用户配送量之和之间的大小关系,生成第一预设数量个初始序列,各初始序列中包括多个子序列,各子序列中包括多个不同的用户标识,子序列用于表示不同的配送路线,子序列对应的配送路线的配送车辆最大装载量,大于或等于该配送路线上各用户标识对应的用户配送量之和。The
第一处理模块202,用于计算各初始序列的适应度,并基于适应度从第一预设数量个初始序列中选择第二预设数量个初始序列,作为目标序列,并对该第二预设数量个目标序列进行复制操作,得到第二预设数量个复制后的目标序列,目标序列的适应度小于第一预设数量个初始序列中除目标序列之外的其他初始序列的适应度。The
第二处理模块203,用于对第一预设数量个初始序列进行复制操作,得到第三预设数量个复制后的序列,并对第三预设数量个复制后的序列进行交叉操作,得到第三预设数量个交叉后的序列,第三预设数量大于第一预设数量,交叉后的序列中至少存在一个用户标识,该用户标识在交叉后的序列中的位置,与该用户标识在复制后的序列中的位置相同;且交叉后的序列中至少存在一个用户标识,该用户标识在交叉后的序列中的位置,与该用户标识在复制后的序列中位置不同。The
重组模块204,用于针对第三预设数量个交叉后的序列,对各交叉后的序列进行重组操作,得到第三预设数量个重组后的序列,重组后的序列中的子序列与交叉后的序列中的子序列不同。The
变异模块205,用于对第三预设数量个重组后的序列,进行变异操作,得到第三预设数量个变异后的序列,变异后的序列中至少存在一个用户标识,该用户标识在该序列中所属的子序列,与该用户标识在重组后的序列中所属的子序列不同。The
改进模块206,用于对第二预设数量个复制后的目标序列进行改进操作,得到第二预设数量个改进后的序列,改进后的序列中至少存在一个用户标识,该用户标识在子序列中的位置,与该用户标识在复制后的序列中子序列的位置不同。The
第三处理模块207,用于计算第二预设数量个改进后的序列,以及第三预设数量个变异后的序列的适应度,并按照适应度的高低顺序,选择得到第一预设数量个选择后的序列,将初始序列更新为选择后的序列,执行计算各初始序列的适应度,并基于适应度从第一预设数量个初始序列中选择第二预设数量个初始序列,作为目标序列的步骤。The
作为本发明实施例一种可选的实施方式,上述生成模块201,可以包括:As an optional implementation of the embodiment of the present invention, the
第一生成子模块,用于针对待进行路线生成的多个用户,生成各用户对应的用户标识。第一处理子模块,用于从多个用户标识中确定一个用户标识,并利用该用户标识与预先确定的配送中心标识,生成初始子序列,配送中心标识用于标识配送中心。第二处理子模块,用于从多个用户标识中,选择当前用户标识,并计算当前用户标识对应的用户配送量与当前子序列中各用户标识对应的用户配送量之和,得到货物配送量之和,当前子序列是基于初始子序列生成的。判断子模块,用于判断货物配送量之和,是否小于或等于配送车辆最大装载量,配送车辆用于将配送中心的货物,配送至子序列中各用户标识对应的用户,或者将各用户标识对应的用户的货物运送至配送中心。第三处理子模块,用于如果货物配送量之和,小于或等于配送车辆最大装载量,则将当前用户标识插入至当前子序列中,得到新的子序列,将当前子序列更新为新的子序列,并触发第二处理子模块执行从多个用户标识中,选择当前用户标识的步骤。触发子模块,用于如果货物配送量之和,大于配送车辆最大装载量,则触发第一处理子模块执行从多个用户标识中确定一个用户标识,并利用该用户标识与预先确定的配送中心标识,生成初始子序列的步骤。The first generation submodule is used to generate user identifiers corresponding to each user for multiple users to generate routes. The first processing submodule is used to determine a user identifier from multiple user identifiers, and use the user identifier and a predetermined distribution center identifier to generate an initial subsequence, and the distribution center identifier is used to identify the distribution center. The second processing submodule is used to select the current user identifier from multiple user identifiers, and calculate the sum of the user distribution volume corresponding to the current user identifier and the user distribution volume corresponding to each user identifier in the current subsequence to obtain the sum of the goods distribution volume, and the current subsequence is generated based on the initial subsequence. The judgment submodule is used to judge whether the sum of the goods distribution volume is less than or equal to the maximum loading volume of the distribution vehicle, and the distribution vehicle is used to distribute the goods of the distribution center to the users corresponding to each user identifier in the subsequence, or to transport the goods of the users corresponding to each user identifier to the distribution center. The third processing submodule is used to insert the current user identifier into the current subsequence if the sum of the goods distribution volume is less than or equal to the maximum loading volume of the distribution vehicle, to obtain a new subsequence, update the current subsequence to the new subsequence, and trigger the second processing submodule to execute the step of selecting the current user identifier from multiple user identifiers. The trigger submodule is used to trigger the first processing submodule to execute the steps of determining a user identifier from multiple user identifiers and generating an initial subsequence using the user identifier and a predetermined distribution center identifier if the sum of the goods distribution quantities is greater than the maximum loading capacity of the distribution vehicle.
作为本发明实施例一种可选的实施方式,上述第三处理子模块,可以包括:As an optional implementation of the embodiment of the present invention, the third processing submodule may include:
插入单元,用于将当前用户标识插入至当前子序列中相邻的两个用户标识之间,或者,将当前用户标识插入至当前子序列中配送中心标识与用户标识之间,得到多个当前子序列。The inserting unit is used to insert the current user identifier between two adjacent user identifiers in the current subsequence, or insert the current user identifier between the distribution center identifier and the user identifier in the current subsequence to obtain multiple current subsequences.
计算单元,用于利用第一预设表达式,计算多个当前子序列中各当前子序列的运输成本,第一预设表达式为:The calculation unit is used to calculate the transportation cost of each current subsequence in the multiple current subsequences by using a first preset expression, where the first preset expression is:
f1=(2cok+clm)-β(clk+ckm)f1 =(2cok +clm )-β(clk +ckm )
式中,f1表示运输成本,cok表示配送车辆从配送中心行驶至当前用户标识对应的当前用户的运输成本,clm表示配送车辆从相邻的两个用户之间运输时的运输成本,β表示预设的权重系数,clk表示配送车辆从相邻的两个用户中的一个用户,行驶至当前用户的运输成本,ckm表示配送车辆从当前用户,行驶至相邻的两个用户中的另一个用户的运输成本。Wheref1 represents the transportation cost, cok represents the transportation cost of the delivery vehicle from the distribution center to the current user corresponding to the current user ID, clm represents the transportation cost of the delivery vehicle when transporting between two adjacent users, β represents the preset weight coefficient, clk represents the transportation cost of the delivery vehicle from one of the two adjacent users to the current user, and ckm represents the transportation cost of the delivery vehicle from the current user to the other of the two adjacent users.
处理单元,用于比较多个当前子序列中各当前子序列的运输成本之间的大小,将最小运输成本对应的当前子序列确定为新的子序列。The processing unit is used to compare the transportation costs of each current subsequence in a plurality of current subsequences, and determine the current subsequence corresponding to the minimum transportation cost as a new subsequence.
作为本发明实施例一种可选的实施方式,上述第一处理模块202,可以包括:As an optional implementation of the embodiment of the present invention, the
计算子模块,用于按照第二预设表达式,计算各初始序列的适应度,第二预设表达式为:The calculation submodule is used to calculate the fitness of each initial sequence according to the second preset expression. The second preset expression is:
fitness(u)=αTD+(1-α)(Wmax-Wmin)(u)=αTD+(1-α)(W fitnessmax -Wmin )
式中,fitness(u)表示第u个初始序列的适应度,α表示预设的平衡系数,TD表示第u个初始序列中所有子序列对应的配送路线的总行驶距离,Wmax表示第u个初始序列中所有子序列对应的配送路线中最大的行驶距离,Wmin表示第u个初始序列中所有子序列对应的配送路线中最小的行驶距离,u∈U,U={1,2,3,……,m},U表示初始序列的数量集合,m表示第一预设数量。排序子模块,用于将计算得到的各适应度进行排序。选择子模块,用于按照各适应度从小到大的顺序,选择第二预设数量个初始序列,作为目标序列。Wherein, fitness(u) represents the fitness of the u-th initial sequence, α represents the preset balance coefficient, TD represents the total driving distance of the delivery routes corresponding to all subsequences in the u-th initial sequence, Wmax represents the maximum driving distance of the delivery routes corresponding to all subsequences in the u-th initial sequence, Wmin represents the minimum driving distance of the delivery routes corresponding to all subsequences in the u-th initial sequence, u∈U, U={1, 2, 3, …, m}, U represents the number set of initial sequences, and m represents the first preset number. The sorting submodule is used to sort the calculated fitnesses. The selection submodule is used to select the second preset number of initial sequences as the target sequence in the order of fitness from small to large.
作为本发明实施例一种可选的实施方式,上述第二处理模块203,可以包括:As an optional implementation of the embodiment of the present invention, the
确定子模块,用于利用第三预设数量,以及第一预设数量,确定第一预设数量个初始序列中各初始序列的复制次数。复制子模块,用于利用各初始序列的复制次数,对第一预设数量个初始序列进行复制操作,得到第三预设数量个复制后的序列。第四处理子模块,用于针对第三预设数量个复制后的序列中的各序列,保持该序列中第四预设数量个子序列不变,获取该序列中除第四预设数量个子序列之外的其他子序列中的用户标识,并将其他子序列中的用户标识从该序列中删除。第二生成子模块,用于针对其他子序列中的用户标识,利用预设的配送车辆最大装载量,以及各用户标识对应的用户配送量之和之间的大小关系,生成多个子序列。组合子模块,用于将第四预设数量个子序列和所生成的多个子序列,组合为交叉后的序列。The determination submodule is used to determine the number of times each initial sequence in the first preset number of initial sequences is copied using the third preset number and the first preset number. The copy submodule is used to copy the first preset number of initial sequences using the number of times each initial sequence is copied to obtain the third preset number of copied sequences. The fourth processing submodule is used to keep the fourth preset number of subsequences in the sequence unchanged for each sequence in the third preset number of copied sequences, obtain the user identifiers in the other subsequences except the fourth preset number of subsequences in the sequence, and delete the user identifiers in the other subsequences from the sequence. The second generation submodule is used to generate multiple subsequences for the user identifiers in the other subsequences using the preset maximum loading capacity of the delivery vehicle and the size relationship between the sum of the user delivery quantities corresponding to each user identifier. The combination submodule is used to combine the fourth preset number of subsequences and the generated multiple subsequences into a crossed sequence.
作为本发明实施例一种可选的实施方式,上述重组模块204,可以包括:As an optional implementation of the embodiment of the present invention, the above-mentioned
删除子模块,用于针对第三预设数量个交叉后的序列中的各序列,从该序列中删除第五预设数量个用户标识。插入子模块,用于将所删除的第五预设数量个用户标识,重新插入至该序列中,得到重组后的序列。作为本发明实施例一种可选的实施方式,上述变异模块205,具体可以用于:The deletion submodule is used to delete the fifth preset number of user identifiers from each sequence in the sequence after the third preset number of crossovers. The insertion submodule is used to reinsert the deleted fifth preset number of user identifiers into the sequence to obtain a recombined sequence. As an optional implementation of the embodiment of the present invention, the above-mentioned
针对第三预设数量个重组后的序列中的各序列,将该重组后的序列中一个子序列中的用户标识删除,并将该用户标识插入至该重组后的序列中另一个子序列中,得到变异后的序列。For each sequence in the third preset number of recombined sequences, the user identifier in a subsequence in the recombined sequence is deleted, and the user identifier is inserted into another subsequence in the recombined sequence to obtain a mutated sequence.
本发明实施例提供的用于VRPSPD的用户路线生成装置,由于在得到初始序列之后,可以对其中一部分进行复制操作和改进操作,对初始序列进行交叉操作、重组操作、变异操作和选择操作,因此能够加快用户路线生成方法的收敛速度。The user route generation device for VRPSPD provided by the embodiment of the present invention can accelerate the convergence speed of the user route generation method because after obtaining the initial sequence, a part of it can be copied and improved, and the initial sequence can be cross-operated, reorganized, mutated and selected.
本发明实施例还提供了一种电子设备,如图6所示,包括处理器301、通信接口302、存储器303和通信总线304,其中,处理器301,通信接口302,存储器303通过通信总线304完成相互间的通信。存储器303,用于存放计算机程序。The embodiment of the present invention further provides an electronic device, as shown in FIG6 , including a
处理器301,用于执行存储器303上所存放的程序时,实现如下步骤:针对待进行路线生成的多个用户,生成各用户对应的用户标识,并利用预设的配送车辆最大装载量,以及各用户标识对应的用户配送量之和之间的大小关系,生成第一预设数量个初始序列,各初始序列中包括多个子序列,各子序列中包括多个不同的用户标识,子序列用于表示不同的配送路线,子序列对应的配送路线的配送车辆最大装载量,大于或等于该配送路线上各用户标识对应的用户配送量之和。计算各初始序列的适应度,并基于适应度从第一预设数量个初始序列中选择第二预设数量个初始序列,作为目标序列,并对该第二预设数量个目标序列进行复制操作,得到第二预设数量个复制后的目标序列,目标序列的适应度小于第一预设数量个初始序列中除目标序列之外的其他初始序列的适应度。对第一预设数量个初始序列进行复制操作,得到第三预设数量个复制后的序列,并对第三预设数量个复制后的序列进行交叉操作,得到第三预设数量个交叉后的序列,第三预设数量大于第一预设数量,交叉后的序列中至少存在一个用户标识,该用户标识在交叉后的序列中的位置,与该用户标识在复制后的序列中的位置相同;且交叉后的序列中至少存在一个用户标识,该用户标识在交叉后的序列中的位置,与该用户标识在复制后的序列中位置不同。针对第三预设数量个交叉后的序列,对各交叉后的序列进行重组操作,得到第三预设数量个重组后的序列,重组后的序列中的子序列与交叉后的序列中的子序列不同。对第三预设数量个重组后的序列,进行变异操作,得到第三预设数量个变异后的序列,变异后的序列中至少存在一个用户标识,该用户标识在该序列中所属的子序列,与该用户标识在重组后的序列中所属的子序列不同。对第二预设数量个复制后的目标序列进行改进操作,得到第二预设数量个改进后的序列,改进后的序列中至少存在一个用户标识,该用户标识在子序列中的位置,与该用户标识在复制后的序列中子序列的位置不同。计算第二预设数量个改进后的序列,以及第三预设数量个变异后的序列的适应度,并按照适应度的高低顺序,选择得到第一预设数量个选择后的序列,将初始序列更新为选择后的序列,执行计算各初始序列的适应度,并基于适应度从第一预设数量个初始序列中选择第二预设数量个初始序列,作为目标序列的步骤。The
上述电子设备提到的通信总线可以是外设部件互连标准(Peripheral ComponentInterconnect,PCI)总线或扩展工业标准结构(Extended Industry StandardArchitecture,EISA)总线等。该通信总线可以分为地址总线、数据总线、控制总线等。为便于表示,图中仅用一条粗线表示,但并不表示仅有一根总线或一种类型的总线。The communication bus mentioned in the above electronic device can be a Peripheral Component Interconnect (PCI) bus or an Extended Industry Standard Architecture (EISA) bus, etc. The communication bus can be divided into an address bus, a data bus, a control bus, etc. For ease of representation, only one thick line is used in the figure, but it does not mean that there is only one bus or one type of bus.
通信接口用于上述电子设备与其他设备之间的通信。存储器可以包括随机存取存储器(Random Access Memory,RAM),也可以包括非易失性存储器(Non-Volatile Memory,NVM),例如至少一个磁盘存储器。可选的,存储器还可以是至少一个位于远离前述处理器的存储装置。The communication interface is used for communication between the above electronic device and other devices. The memory may include a random access memory (RAM) or a non-volatile memory (NVM), such as at least one disk memory. Optionally, the memory may also be at least one storage device located away from the above processor.
上述的处理器可以是通用处理器,包括中央处理器(Central Processing Unit,CPU)、网络处理器(Network Processor,NP)等;还可以是数字信号处理器(Digital SignalProcessing,DSP)、专用集成电路(Application Specific Integrated Circuit,ASIC)、现场可编程门阵列(Field-Programmable Gate Array,FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。The above-mentioned processor can be a general-purpose processor, including a central processing unit (CPU), a network processor (NP), etc.; it can also be a digital signal processor (DSP), an application specific integrated circuit (ASIC), a field programmable gate array (FPGA) or other programmable logic devices, discrete gate or transistor logic devices, discrete hardware components.
在本发明提供的又一实施例中,还提供了一种计算机可读存储介质,该计算机可读存储介质内存储有计算机程序,所述计算机程序被处理器执行时实现上述任一用于VRPSPD的用户路线生成方法的步骤。In another embodiment provided by the present invention, a computer-readable storage medium is also provided, in which a computer program is stored. When the computer program is executed by a processor, the steps of any of the above-mentioned user route generation methods for VRPSPD are implemented.
在上述实施例中,可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用软件实现时,可以全部或部分地以计算机程序产品的形式实现。所述计算机程序产品包括一个或多个计算机指令。在计算机上加载和执行所述计算机程序指令时,全部或部分地产生按照本发明实施例所述的流程或功能。所述计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。所述计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输,例如,所述计算机指令可以从一个网站站点、计算机、服务器或数据中心通过有线(例如同轴电缆、光纤、数字用户线(DSL))或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输。所述计算机可读存储介质可以是计算机能够存取的任何可用介质或者是包含一个或多个可用介质集成的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质,(例如,软盘、硬盘、磁带)、光介质(例如,DVD)、或者半导体介质(例如固态硬盘Solid State Disk(SSD))等。In the above embodiments, it can be implemented in whole or in part by software, hardware, firmware or any combination thereof. When implemented by software, it can be implemented in whole or in part in the form of a computer program product. The computer program product includes one or more computer instructions. When the computer program instructions are loaded and executed on a computer, the process or function described in the embodiment of the present invention is generated in whole or in part. The computer can be a general-purpose computer, a special-purpose computer, a computer network, or other programmable device. The computer instructions can be stored in a computer-readable storage medium, or transmitted from one computer-readable storage medium to another computer-readable storage medium. For example, the computer instructions can be transmitted from one website site, computer, server or data center to another website site, computer, server or data center by wired (e.g., coaxial cable, optical fiber, digital subscriber line (DSL)) or wireless (e.g., infrared, wireless, microwave, etc.) mode. The computer-readable storage medium can be any available medium that a computer can access or a data storage device such as a server or data center that includes one or more available media integrated. The available medium can be a magnetic medium (e.g., a floppy disk, a hard disk, a tape), an optical medium (e.g., a DVD), or a semiconductor medium (e.g., a solid-state hard disk Solid State Disk (SSD)), etc.
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。It should be noted that, in this article, relational terms such as first and second, etc. are only used to distinguish one entity or operation from another entity or operation, and do not necessarily require or imply any such actual relationship or order between these entities or operations. Moreover, the terms "include", "comprise" or any other variants thereof are intended to cover non-exclusive inclusion, so that a process, method, article or device including a series of elements includes not only those elements, but also other elements not explicitly listed, or also includes elements inherent to such process, method, article or device. In the absence of further restrictions, the elements defined by the sentence "comprise a ..." do not exclude the presence of other identical elements in the process, method, article or device including the elements.
本说明书中的各个实施例均采用相关的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于装置实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。以上所述仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内所作的任何修改、等同替换、改进等,均包含在本发明的保护范围内。Each embodiment in this specification is described in a related manner, and the same or similar parts between the embodiments can be referred to each other, and each embodiment focuses on the differences from other embodiments. In particular, for the device embodiment, since it is basically similar to the method embodiment, the description is relatively simple, and the relevant parts can be referred to the partial description of the method embodiment. The above description is only a preferred embodiment of the present invention and is not intended to limit the scope of protection of the present invention. Any modifications, equivalent substitutions, improvements, etc. made within the spirit and principles of the present invention are included in the scope of protection of the present invention.
Claims (10)















Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010069786.8ACN111325498B (en) | 2020-01-21 | 2020-01-21 | User route generation method and device for VRPSPD, electronic equipment and storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010069786.8ACN111325498B (en) | 2020-01-21 | 2020-01-21 | User route generation method and device for VRPSPD, electronic equipment and storage medium |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN111325498A CN111325498A (en) | 2020-06-23 |
| CN111325498Btrue CN111325498B (en) | 2023-04-18 |
Family
ID=71168703
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010069786.8AActiveCN111325498B (en) | 2020-01-21 | 2020-01-21 | User route generation method and device for VRPSPD, electronic equipment and storage medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN111325498B (en) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11386362B1 (en)* | 2020-12-16 | 2022-07-12 | Wm Intellectual Property Holdings, L.L.C. | System and method for optimizing waste / recycling collection and delivery routes for service vehicles |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103279796A (en)* | 2013-06-08 | 2013-09-04 | 苏州大学 | Method for optimizing genetic algorithm evolution quality |
| CN109919376A (en)* | 2019-03-01 | 2019-06-21 | 浙江工业大学 | Multi-yard and multi-model vehicle routing control method |
| CN110109753A (en)* | 2019-04-25 | 2019-08-09 | 成都信息工程大学 | Resource regulating method and system based on various dimensions constraint genetic algorithm |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11106978B2 (en)* | 2017-09-08 | 2021-08-31 | SparkCognition, Inc. | Execution of a genetic algorithm with variable evolutionary weights of topological parameters for neural network generation and training |
- 2020
- 2020-01-21CNCN202010069786.8Apatent/CN111325498B/enactiveActive
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103279796A (en)* | 2013-06-08 | 2013-09-04 | 苏州大学 | Method for optimizing genetic algorithm evolution quality |
| CN109919376A (en)* | 2019-03-01 | 2019-06-21 | 浙江工业大学 | Multi-yard and multi-model vehicle routing control method |
| CN110109753A (en)* | 2019-04-25 | 2019-08-09 | 成都信息工程大学 | Resource regulating method and system based on various dimensions constraint genetic algorithm |
Non-Patent Citations (1)
| Title |
|---|
| 遗传算法局部最优的定向移民策略;李敏等;《兵工自动化》;20041031;第23卷(第05期);第65-66页* |
Also Published As
| Publication number | Publication date |
|---|---|
| CN111325498A (en) | 2020-06-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN108846659B (en) | Block chain-based transfer method and device and storage medium | |
| CN108921472B (en) | Multi-vehicle-type two-stage vehicle and goods matching method | |
| Mukherjee et al. | Asymptotically optimal load balancing topologies | |
| CN106649401A (en) | Data writing method and device of distributed file system | |
| CN111461402B (en) | Logistics scheduling optimization method and device, computer-readable storage medium and terminal | |
| CN110189077A (en) | A Multi-Stage Vehicle-Cargo Matching Method Considering 3D Loading Constraints | |
| CN112465180B (en) | Vehicle path planning method and device | |
| CN111325498B (en) | User route generation method and device for VRPSPD, electronic equipment and storage medium | |
| CN115018197A (en) | Secondary nesting optimization method and system considering residual material utilization | |
| CN117910922A (en) | A product storage method, device, equipment and medium | |
| Keshavarz et al. | Efficient upper and lower bounding methods for flowshop sequence-dependent group scheduling problems | |
| CN109636023B (en) | Task planning system of multiple vehicle platforms under negotiation mechanism | |
| Sadeghiram et al. | Composing distributed data-intensive Web services using a flexible memetic algorithm | |
| CN111369189A (en) | Method and device for generating picking task, storage medium and electronic equipment | |
| CN111882257A (en) | Method and device for modifying delivery address | |
| CN111461395B (en) | Method and system for site selection of temporary distribution center | |
| CN112862520A (en) | Order charging method, system, electronic equipment and storage medium | |
| Li | A selective many-to-many pickup and delivery problem with handling cost in the omni-channel last-mile delivery | |
| CN118674343A (en) | Three-dimensional boxing optimization method and equipment | |
| CN116664035A (en) | Path planning method, device, equipment and storage medium | |
| CN112149910B (en) | Path planning method and device | |
| CN113420970B (en) | Task scheduling method in intelligent warehousing environment | |
| CN114997779A (en) | Storage processing method and device, electronic equipment and computer readable medium | |
| CN113739798B (en) | Path planning method and device | |
| Djordjevic | Unconstrained Optimization Methods: Conjugate Gradient Methods and Trust-Region Methods |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |