CN111310058A - Information theme recommendation method and device, terminal and storage medium - Google Patents
Information theme recommendation method and device, terminal and storage mediumDownload PDFInfo
- Publication number
- CN111310058A CN111310058ACN202010227922.1ACN202010227922ACN111310058ACN 111310058 ACN111310058 ACN 111310058ACN 202010227922 ACN202010227922 ACN 202010227922ACN 111310058 ACN111310058 ACN 111310058A
- Authority
- CN
- China
- Prior art keywords
- information
- topic
- topics
- user
- similarity
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images





Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/95—Retrieval from the web
- G06F16/953—Querying, e.g. by the use of web search engines
- G06F16/9535—Search customisation based on user profiles and personalisation
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/22—Matching criteria, e.g. proximity measures
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- Databases & Information Systems (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Computation (AREA)
- Evolutionary Biology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Bioinformatics & Computational Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本申请涉及数据处理技术领域中的智能搜索技术,尤其涉及一种资讯主题的推荐方法、装置、终端及存储介质。The present application relates to an intelligent search technology in the technical field of data processing, and in particular, to a method, device, terminal and storage medium for recommending information topics.
背景技术Background technique
随着互联网的发展,现在网络上的资讯内容越来越丰富。可以为使用者用户推荐符合使用者用户要求的资讯。With the development of the Internet, the information content on the Internet is becoming more and more abundant. Information that meets the user's requirements can be recommended for the user.
目前,为使用者用户,推荐符合使用者用户要求的资讯的时候,可以采用基于各个使用者用户的历史搜索记录的方式,确定出搜索率较高的资讯;进而将搜索率较高的资讯,推荐给使用者用户。At present, when recommending information that meets the user's requirements for users, it is possible to determine the information with a higher search rate based on the historical search records of each user; Recommended for user users.
但是,上述方式只适合于使用者用户,对于推荐者用户(作者)来说,推荐者用户需要及时的掌握合适的主题,进而撰写出该主题对应的资讯;然后,使用者用户才可以观看到资讯。然而现有技术中,无法为推荐者用户提供合适的主题,进而使得推荐者用户不能提供出热度较高、时效性较高的资讯。However, the above method is only suitable for user users. For recommender users (authors), recommender users need to grasp the appropriate topic in time, and then write the information corresponding to the topic; then, the user user can watch the News. However, in the prior art, it is impossible to provide the recommender user with a suitable topic, so that the recommender user cannot provide information with high popularity and high timeliness.
发明内容SUMMARY OF THE INVENTION
本申请提供一种资讯主题的推荐方法、装置、终端及存储介质,可以对全网资讯进行智能搜索,向推荐者用户提供热度和时效性较高的主题,进而使得推荐者用户能够创作出热度较高、时效性较高的资讯。The present application provides a method, device, terminal and storage medium for recommending information topics, which can intelligently search for information on the entire network, and provide recommender users with topics with high popularity and timeliness, thereby enabling recommender users to create popular topics. Higher and more timely information.
第一方面,本申请实施例提供一种资讯主题的推荐方法,所述方法包括:In a first aspect, an embodiment of the present application provides a method for recommending information topics, the method comprising:
确定资讯的主题;determine the subject of the information;
确定所述主题的写作度;determine the degree of writing on the subject;
根据所述主题之间的相似度和所述主题的写作度,筛选出目标主题;According to the similarity between the themes and the writing degree of the theme, filter out the target theme;
将所述目标主题发送给推荐者用户。The target topic is sent to the recommender user.
本实施例中,通过确定资讯的主题;确定所述主题的写作度;根据所述主题之间的相似度和所述主题的写作度,筛选出目标主题;将所述目标主题发送给推荐者用户。从而可以根据主题之间的相似度和写作度对主题进行筛选,从全网中搜索出热度和时效性较高的主题,进而使得推荐者用户能够创作出热度较高、时效性较高的资讯。In this embodiment, by determining the topic of the information; determining the writing degree of the topic; filtering out the target topic according to the similarity between the topics and the writing degree of the topic; sending the target topic to the recommender user. In this way, topics can be filtered according to the similarity and writing degree between topics, and topics with high popularity and timeliness can be searched from the whole network, so that recommender users can create information with high popularity and timeliness. .
在一种可能的设计中,所述确定资讯的主题,包括:In one possible design, the topic of determining the information includes:
获取待处理的资讯;obtain pending information;
通过而分类模型对所述待处理的资讯进行分类处理,得到质量分数大于第一预设值的资讯;Through the classification model, the information to be processed is classified and processed to obtain information whose quality score is greater than the first preset value;
确定分类处理后每一篇资讯所对应的N个主题;所述N个主题包括M个实体型主题和N-M个话题型主题。N topics corresponding to each piece of information after the classification process are determined; the N topics include M entity-type topics and N-M topic-type topics.
本实施例中,通过分类模型对资讯进行分类处理,例如构建广告判别的二分类模型、黄反判别的二分类模型、盘点类资讯的二分类模型,从而可以通过这些模型将资讯分为高质量资讯和低质量资讯。滤除低质量的资讯,将高质量的资讯进行主题确定处理,从而可以筛选出高质量的资讯内容,降低后续步骤的数据处理量。In this embodiment, the information is classified and processed by a classification model, such as constructing a two-class model for advertisement discrimination, a two-class model for yellow anti-discrimination, and a two-class model for inventory information, so that information can be classified into high-quality information through these models. information and low-quality information. Filter out low-quality information, and subject high-quality information to subject determination processing, so that high-quality information content can be filtered out and data processing in subsequent steps can be reduced.
在一种可能的设计中,所述确定分类处理后每一篇资讯所对应的N个主题,包括:In a possible design, the determining N topics corresponding to each piece of information after the classification process includes:
根据已有的通用知识图谱,对资讯的内容进行知识的提取和表示,得到实体链接关系;According to the existing general knowledge graph, the content of the information is extracted and represented by knowledge, and the entity link relationship is obtained;
根据实体链接关系,从知识图谱中找到与输入内容相关的实体知识、实体关联信息,得到所述资讯的实体型主题;According to the entity link relationship, find the entity knowledge and entity association information related to the input content from the knowledge graph, and obtain the entity-type topic of the information;
提取资讯的关键字;keywords for extracting information;
根据关键字在资讯中统计信息,确定所述资讯对应的话题型主题;其中,所述统计信息包括:关键字的频次、关键字的词性、关键字与文章主旨符合程度。According to the statistical information of the keywords in the information, the topic-type topic corresponding to the information is determined; wherein the statistical information includes: the frequency of the keywords, the part of speech of the keywords, and the degree of conformity between the keywords and the subject of the article.
本实施例中,针对每一篇资讯,基于已有的通用知识图谱,对资讯内容进行知识的提取和表示,基于实体链接从知识图谱中找到与输入内容相关的实体知识、实体关联信息,确定出该资讯的实体型主题。即,采用知识图谱实体关联的方式,根据每一个资讯的关键字,从每一个资讯中提取出每一个资讯的实体型主题。针对每一篇资讯,提取该资讯的关键字;依据该资讯中的关键字的频次、关键字的词性、关键字与文章主旨符合程度、等等这些统计信息,分析出该资讯的话题标签主题。从而可以准确地对资讯的主题进行划分,方便用户对资讯内容进行分类阅读。In this embodiment, for each piece of information, based on the existing general knowledge graph, knowledge is extracted and represented on the information content, and the entity knowledge and entity association information related to the input content are found from the knowledge graph based on the entity link, and determined. The entity-type subject of this information. That is, the entity-type topic of each information is extracted from each information according to the keyword of each information by adopting the method of knowledge graph entity association. For each piece of information, extract the keyword of the information; according to the frequency of the keyword in the information, the part of speech of the keyword, the degree of conformity between the keyword and the subject of the article, etc., analyze the topic tag of the information. . Therefore, the subject of the information can be accurately divided, and it is convenient for the user to classify and read the information content.
在一种可能的设计中,所述确定所述主题的写作度,包括:In one possible design, the determining the degree of writing on the topic includes:
提取所述主题的主题特征,所述主题特征包括:主题下的资讯数量、主题下的资讯在时间窗口内的用户行为数据、主题在时间窗口内的点击率、主题与用户领域的语义距离打分、主题的事件概率得分;Extract the theme features of the theme, the theme features include: the amount of information under the theme, the user behavior data of the information under the theme within the time window, the click rate of the theme within the time window, and the semantic distance score between the theme and the user field , the event probability score of the topic;
将所述主题特征输入主题点击率模型,得到所述主题的写作度分数;其中,所述主题点击率模型是通过预先标注有点击率和写作度分数的第一主题数据集迭代训练得到的。Inputting the topic features into a topic click-through rate model to obtain a writing degree score of the topic; wherein, the topic click-through rate model is obtained by iterative training of the first topic data set pre-marked with click-through rate and writing degree scores.
本实施例中,通过提取主题的主题特征输入点击率模型中,输出每一个主题的写作度分数,从而可以直观地对各个主题进行写作度评判,其中,写作度分数越高,则对应主题的热度和时效性越强。In this embodiment, by extracting the topic features of the topics and inputting them into the click-through rate model, the writing degree score of each topic is output, so that each topic can be judged intuitively. The heat and timeliness are stronger.
在一种可能的设计中,所述根据所述主题之间的相似度和所述主题的写作度,筛选出目标主题,包括:In a possible design, according to the similarity between the topics and the writing degree of the topics, the target topic is screened, including:
通过相似度判别模型,确定两两主题之间的相似度;其中,所述相似度判别模型是通过预先标注有相似度的第二主题数据集迭代训练得到的,所述第二主题数据集中的元素为两两主题构成的子集;The similarity between the two topics is determined by the similarity discrimination model; wherein, the similarity discrimination model is obtained by iterative training of the second subject data set marked with the similarity in advance. Elements are subsets of pairs of topics;
对相似度大于第二预设值的主题进行去重处理,得到候选主题;Perform de-duplication processing on topics with a similarity greater than the second preset value to obtain candidate topics;
按照写作度分数从高到低的顺序,从所述候选主题中选择至少一个候选主题作为所述目标主题。At least one candidate topic is selected from the candidate topics as the target topic in descending order of writing degree scores.
本实施例中,将第二主题样本数据集(被标注了每2个主题的相似度的主题所构成的数据集)输入到主题相似判别模型中,得到经过训练的主题相似判别模型。针对待处理的主题,将每2个主题输入到经过训练的主题相似判别模型中,得到每2个主题之间的相似度(即,相似概率)。根据主题的写作度分数的由高到低的顺序,对相似度较高(相似度大于预设阈值)的主题进行去重处理,进而过滤掉重复的主题,得到过滤后的主题。从而可以得到热度高,时效性强的目标主题。In this embodiment, the second subject sample data set (a data set composed of subjects marked with the similarity of every two subjects) is input into the subject similarity discriminating model to obtain a trained subject similarity discriminating model. For the topics to be processed, each 2 topics are input into the trained topic similarity discriminant model, and the similarity (ie, similarity probability) between each 2 topics is obtained. According to the order of the writing degree scores of the topics from high to low, the topics with high similarity (similarity greater than a preset threshold) are deduplicated, and then duplicate topics are filtered out to obtain filtered topics. In this way, a target theme with high popularity and strong timeliness can be obtained.
在一种可能的设计中,在将所述目标主题发送给推荐者用户之前,还包括:In a possible design, before sending the target topic to the recommender user, it further includes:
获取所述推荐者用户的用户信息;obtaining user information of the recommender user;
确定与所述用户信息匹配的目标主题。A target topic matching the user information is determined.
本实施例中,还可以进一步地根据用户信息对目标主题作一个匹配校验,使得最终推荐的目标主题与推荐者用户擅长写作的领域相符,实现更加精准地信息推荐。In this embodiment, a matching check can be further performed on the target topic according to the user information, so that the final recommended target topic is consistent with the field where the recommender user is good at writing, so as to achieve more accurate information recommendation.
在一种可能的设计中,在确定所述主题的写作度之前,还包括:In one possible design, before determining the degree of writing on the topic, also include:
确定每一个主题对应的领域标签;Determine the domain label corresponding to each topic;
根据所述推荐者用户的用户信息,选取出与所述用户信息匹配的领域标签所对应的主题。According to the user information of the recommender user, the topic corresponding to the domain tag matching the user information is selected.
本实施例中,在对主题的写作度进行分析之前,通过对主题的领域标签进行标注,得到更加细粒度的领域划分主题。从而可以实现更加精准地主题筛选。In this embodiment, before analyzing the writing degree of the topic, a more fine-grained domain division topic is obtained by labeling the domain label of the topic. This allows for more precise topic filtering.
在一种可能的设计中,所述确定每一个主题对应的领域标签,包括:In a possible design, the determining the domain label corresponding to each topic includes:
按照主题将资讯进行整合,得到同一主题下的多篇资讯;Integrate the information according to the theme to get multiple pieces of information under the same theme;
通过多分类模型,对所述多篇资讯进行分类处理,标注出每一篇资讯的领域标签;其中,所述多分类模型是通过标注有领域标签的资讯数据集迭代训练得到的;Using a multi-classification model, the multiple pieces of information are classified and processed, and the domain label of each piece of information is marked; wherein, the multi-classification model is obtained by iterative training of the information data set marked with the domain label;
将出现频次排在前P位的领域标签作为所述主题对应的领域标签。The field tags whose appearance frequency ranks in the top P positions are used as field tags corresponding to the topic.
本实施例中,实现了对主题的领域标签的细分度的划分,即,将主题的领域更加细化了,解决了现有技术中对主题“细分度不足”的问题。In this embodiment, the division of the subdivision of the topic's field label is achieved, that is, the topic field is further refined, and the problem of "insufficient subdivision" of the topic in the prior art is solved.
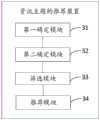
第二方面,本申请实施例提供一种资讯主题的推荐装置,所述装置包括:In a second aspect, an embodiment of the present application provides a device for recommending information topics, and the device includes:
第一确定模块,用于确定资讯的主题;The first determination module is used to determine the subject of the information;
第二确定模块,用于确定所述主题的写作度;The second determining module is used to determine the writing degree of the topic;
筛选模块,用于根据所述主题之间的相似度和所述主题的写作度,筛选出目标主题;A screening module, used for screening out the target topic according to the similarity between the topics and the writing degree of the topic;
推荐模块,用于将所述目标主题发送给推荐者用户。The recommendation module is used for sending the target topic to the recommender user.
本实施例中,通过确定资讯的主题;确定所述主题的写作度;根据所述主题之间的相似度和所述主题的写作度,筛选出目标主题;将所述目标主题发送给推荐者用户。从而可以根据主题之间的相似度和写作度对主题进行筛选,从全网中搜索出热度和时效性较高的主题,进而使得推荐者用户能够创作出热度较高、时效性较高的资讯。In this embodiment, by determining the topic of the information; determining the writing degree of the topic; filtering out the target topic according to the similarity between the topics and the writing degree of the topic; sending the target topic to the recommender user. In this way, topics can be filtered according to the similarity and writing degree between topics, and topics with high popularity and timeliness can be searched from the whole network, so that recommender users can create information with high popularity and timeliness. .
在一种可能的设计中,所述第一确定模块,具体用于:In a possible design, the first determining module is specifically used for:
获取待处理的资讯;obtain pending information;
通过而分类模型对所述待处理的资讯进行分类处理,得到质量分数大于第一预设值的资讯;Through the classification model, the information to be processed is classified and processed to obtain information whose quality score is greater than the first preset value;
确定分类处理后每一篇资讯所对应的N个主题;所述N个主题包括M个实体型主题和N-M个话题型主题。N topics corresponding to each piece of information after the classification process are determined; the N topics include M entity-type topics and N-M topic-type topics.
本实施例中,通过分类模型对资讯进行分类处理,例如构建广告判别的二分类模型、黄反判别的二分类模型、盘点类资讯的二分类模型,从而可以通过这些模型将资讯分为高质量资讯和低质量资讯。滤除低质量的资讯,将高质量的资讯进行主题确定处理,从而可以筛选出高质量的资讯内容,降低后续步骤的数据处理量。In this embodiment, the information is classified and processed by a classification model, such as constructing a two-class model for advertisement discrimination, a two-class model for yellow anti-discrimination, and a two-class model for inventory information, so that information can be classified into high-quality information through these models. information and low-quality information. Filter out low-quality information, and subject high-quality information to subject determination processing, so that high-quality information content can be filtered out and data processing in subsequent steps can be reduced.
在一种可能的设计中,所述第一确定模块,具体用于:In a possible design, the first determining module is specifically used for:
根据已有的通用知识图谱,对资讯的内容进行知识的提取和表示,得到实体链接关系;According to the existing general knowledge graph, the content of the information is extracted and represented by knowledge, and the entity link relationship is obtained;
根据实体链接关系,从知识图谱中找到与输入内容相关的实体知识、实体关联信息,得到所述资讯的实体型主题;According to the entity link relationship, find the entity knowledge and entity association information related to the input content from the knowledge graph, and obtain the entity-type topic of the information;
提取资讯的关键字;keywords for extracting information;
根据关键字在资讯中统计信息,确定所述资讯对应的话题型主题;其中,所述统计信息包括:关键字的频次、关键字的词性、关键字与文章主旨符合程度。According to the statistical information of the keywords in the information, the topic-type topic corresponding to the information is determined; wherein the statistical information includes: the frequency of the keywords, the part of speech of the keywords, and the degree of conformity between the keywords and the subject of the article.
本实施例中,针对每一篇资讯,基于已有的通用知识图谱,对资讯内容进行知识的提取和表示,基于实体链接从知识图谱中找到与输入内容相关的实体知识、实体关联信息,确定出该资讯的实体型主题。即,采用知识图谱实体关联的方式,根据每一个资讯的关键字,从每一个资讯中提取出每一个资讯的实体型主题。针对每一篇资讯,提取该资讯的关键字;依据该资讯中的关键字的频次、关键字的词性、关键字与文章主旨符合程度、等等这些统计信息,分析出该资讯的话题标签主题。从而可以准确地对资讯的主题进行划分,方便用户对资讯内容进行分类阅读。In this embodiment, for each piece of information, based on the existing general knowledge graph, knowledge is extracted and represented on the information content, and the entity knowledge and entity association information related to the input content are found from the knowledge graph based on the entity link, and determined. The entity-type subject of this information. That is, the entity-type topic of each information is extracted from each information according to the keyword of each information by adopting the method of knowledge graph entity association. For each piece of information, extract the keyword of the information; according to the frequency of the keyword in the information, the part of speech of the keyword, the degree of conformity between the keyword and the subject of the article, etc., analyze the topic tag of the information. . Therefore, the subject of the information can be accurately divided, and it is convenient for the user to classify and read the information content.
在一种可能的设计中,所述第二确定模块,具体用于:In a possible design, the second determining module is specifically used for:
提取所述主题的主题特征,所述主题特征包括:主题下的资讯数量、主题下的资讯在时间窗口内的用户行为数据、主题在时间窗口内的点击率、主题与用户领域的语义距离打分、主题的事件概率得分;Extract the theme features of the theme, the theme features include: the amount of information under the theme, the user behavior data of the information under the theme within the time window, the click rate of the theme within the time window, and the semantic distance score between the theme and the user field , the event probability score of the topic;
将所述主题特征输入主题点击率模型,得到所述主题的写作度分数;其中,所述主题点击率模型是通过预先标注有点击率和写作度分数的第一主题数据集迭代训练得到的。Inputting the topic features into a topic click-through rate model to obtain a writing degree score of the topic; wherein, the topic click-through rate model is obtained by iterative training of the first topic data set pre-marked with click-through rate and writing degree scores.
本实施例中,通过提取主题的主题特征输入点击率模型中,输出每一个主题的写作度分数,从而可以直观地对各个主题进行写作度评判,其中,写作度分数越高,则对应主题的热度和时效性越强。In this embodiment, by extracting the topic features of the topics and inputting them into the click-through rate model, the writing degree score of each topic is output, so that each topic can be judged intuitively. The heat and timeliness are stronger.
在一种可能的设计中,所述筛选模块,具体用于:In a possible design, the screening module is specifically used to:
通过相似度判别模型,确定两两主题之间的相似度;其中,所述相似度判别模型是通过预先标注有相似度的第二主题数据集迭代训练得到的,所述第二主题数据集中的元素为两两主题构成的子集;The similarity between the two topics is determined by the similarity discrimination model; wherein, the similarity discrimination model is obtained by iterative training of the second subject data set marked with the similarity in advance. Elements are subsets of pairs of topics;
对相似度大于第二预设值的主题进行去重处理,得到候选主题;Perform de-duplication processing on topics with a similarity greater than the second preset value to obtain candidate topics;
按照写作度分数从高到低的顺序,从所述候选主题中选择至少一个候选主题作为所述目标主题。At least one candidate topic is selected from the candidate topics as the target topic in descending order of writing degree scores.
本实施例中,将第二主题样本数据集(被标注了每2个主题的相似度的主题所构成的数据集)输入到主题相似判别模型中,得到经过训练的主题相似判别模型。针对待处理的主题,将每2个主题输入到经过训练的主题相似判别模型中,得到每2个主题之间的相似度(即,相似概率)。根据主题的写作度分数的由高到低的顺序,对相似度较高(相似度大于预设阈值)的主题进行去重处理,进而过滤掉重复的主题,得到过滤后的主题。从而可以得到热度高,时效性强的目标主题。In this embodiment, the second subject sample data set (a data set composed of subjects marked with the similarity of every two subjects) is input into the subject similarity discriminating model to obtain a trained subject similarity discriminating model. For the topics to be processed, each 2 topics are input into the trained topic similarity discriminant model, and the similarity (ie, similarity probability) between each 2 topics is obtained. According to the order of the writing degree scores of the topics from high to low, the topics with high similarity (similarity greater than a preset threshold) are deduplicated, and then duplicate topics are filtered out to obtain filtered topics. In this way, a target theme with high popularity and strong timeliness can be obtained.
在一种可能的设计中,还包括:获取模块,用于:In one possible design, it also includes: an acquisition module for:
获取所述推荐者用户的用户信息;obtaining user information of the recommender user;
确定与所述用户信息匹配的目标主题。A target topic matching the user information is determined.
本实施例中,还可以进一步地根据用户信息对目标主题作一个匹配校验,使得最终推荐的目标主题与推荐者用户擅长写作的领域相符,实现更加精准地信息推荐。In this embodiment, a matching check can be further performed on the target topic according to the user information, so that the final recommended target topic is consistent with the field where the recommender user is good at writing, so as to achieve more accurate information recommendation.
在一种可能的设计中,还包括:第三确定模块,用于:In a possible design, it also includes: a third determination module for:
确定每一个主题对应的领域标签;Determine the domain label corresponding to each topic;
根据所述推荐者用户的用户信息,选取出与所述用户信息匹配的领域标签所对应的主题。According to the user information of the recommender user, the topic corresponding to the domain tag matching the user information is selected.
本实施例中,在对主题的写作度进行分析之前,通过对主题的领域标签进行标注,得到更加细粒度的领域划分主题。从而可以实现更加精准地主题筛选。In this embodiment, before analyzing the writing degree of the topic, a more fine-grained domain division topic is obtained by labeling the domain label of the topic. This allows for more precise topic filtering.
在一种可能的设计中,所述第三确定模块,具体用于:In a possible design, the third determining module is specifically used for:
按照主题将资讯进行整合,得到同一主题下的多篇资讯;Integrate the information according to the theme to get multiple pieces of information under the same theme;
通过多分类模型,对所述多篇资讯进行分类处理,标注出每一篇资讯的领域标签;其中,所述多分类模型是通过标注有领域标签的资讯数据集迭代训练得到的;Using a multi-classification model, the multiple pieces of information are classified and processed, and the domain label of each piece of information is marked; wherein, the multi-classification model is obtained by iterative training of the information data set marked with the domain label;
将出现频次排在前P位的领域标签作为所述主题对应的领域标签。The field tags whose appearance frequency ranks in the top P positions are used as field tags corresponding to the topic.
本实施例中,实现了对主题的领域标签的细分度的划分,即,将主题的领域更加细化了,解决了现有技术中对主题“细分度不足”的问题。In this embodiment, the division of the subdivision of the topic's field label is achieved, that is, the topic field is further refined, and the problem of "insufficient subdivision" of the topic in the prior art is solved.
第三方面,本申请提供一种终端,包括:处理器和存储器;存储器中存储有所述处理器的可执行指令;其中,所述处理器配置为经由执行所述可执行指令来执行如第一方面中任一项所述的资讯主题的推荐方法。In a third aspect, the present application provides a terminal, comprising: a processor and a memory; executable instructions of the processor are stored in the memory; wherein the processor is configured to execute the execution as described in the first step by executing the executable instructions. The method for recommending information topics according to any one of the aspects.
第四方面,本申请提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现第一方面中任一项所述的资讯主题的推荐方法。In a fourth aspect, the present application provides a computer-readable storage medium on which a computer program is stored, and when the program is executed by a processor, implements the method for recommending an information topic described in any one of the first aspect.
第五方面,本申请实施例提供一种程序产品,所述程序产品包括:计算机程序,所述计算机程序存储在可读存储介质中,服务器的至少一个处理器可以从所述可读存储介质读取所述计算机程序,所述至少一个处理器执行所述计算机程序使得服务器执行第一方面中任一所述的资讯主题的推荐方法。In a fifth aspect, an embodiment of the present application provides a program product, where the program product includes: a computer program, where the computer program is stored in a readable storage medium, and at least one processor of a server can read from the readable storage medium Taking the computer program, the at least one processor executes the computer program to cause the server to execute the method for recommending an information topic according to any one of the first aspects.
上述申请中的一个实施例具有如下优点或有益效果:可以对全网资讯进行智能搜索,向推荐者用户提供热度和时效性较高的主题,进而使得推荐者用户能够创作出热度较高、时效性较高的资讯。因为采用确定所述主题的写作度;根据所述主题之间的相似度和所述主题的写作度,筛选出目标主题;将所述目标主题发送给推荐者用户的技术手段,所以克服了无法为推荐者用户提供合适的主题,进而使得推荐者用户不能提供出热度较高、时效性较高的资讯的技术问题,通过根据主题之间的相似度和写作度对主题进行筛选,从全网中搜索出热度和时效性较高的主题,进而使得推荐者用户能够创作出热度较高、时效性较高的资讯的技术效果。上述可选方式所具有的其他效果将在下文中结合具体实施例加以说明。An embodiment in the above application has the following advantages or beneficial effects: intelligent search for information on the entire network can be performed, and topics with high popularity and timeliness are provided to recommender users, thereby enabling the recommender users to create highly popular and time-sensitive topics. Sexual information. Because the technical means of determining the writing degree of the topic; filtering out the target topic according to the similarity between the topics and the writing degree of the topic; sending the target topic to the recommender user, it overcomes the inability to The technical problem of providing suitable topics for recommender users, so that recommender users cannot provide information with high popularity and high timeliness. Topics with high popularity and timeliness are searched in the search engine, so that recommender users can create the technical effect of information with higher popularity and timeliness. Other effects of the above-mentioned optional manners will be described below with reference to specific embodiments.
附图说明Description of drawings
附图用于更好地理解本方案,不构成对本申请的限定。其中:The accompanying drawings are used for better understanding of the present solution, and do not constitute a limitation to the present application. in:
图1是可以实现本申请实施例的资讯主题的推荐方法的原理示意图;FIG. 1 is a schematic diagram of a principle that can implement a method for recommending information topics according to an embodiment of the present application;
图2是根据本申请第一实施例的示意图;Fig. 2 is a schematic diagram according to the first embodiment of the present application;
图3是根据本申请第二实施例的示意图;3 is a schematic diagram according to a second embodiment of the present application;
图4是根据本申请第三实施例的示意图;4 is a schematic diagram according to a third embodiment of the present application;
图5是根据本申请第四实施例的示意图;5 is a schematic diagram according to a fourth embodiment of the present application;
图6是根据本申请第五实施例的示意图;6 is a schematic diagram according to a fifth embodiment of the present application;
图7是根据本申请第六实施例的示意图;7 is a schematic diagram according to a sixth embodiment of the present application;
图8是用来实现本申请实施例的终端的框图。FIG. 8 is a block diagram of a terminal used to implement an embodiment of the present application.
具体实施方式Detailed ways
以下结合附图对本申请的示范性实施例做出说明,其中包括本申请实施例的各种细节以助于理解,应当将它们认为仅仅是示范性的。因此,本领域普通技术人员应当认识到,可以对这里描述的实施例做出各种改变和修改,而不会背离本申请的范围和精神。同样,为了清楚和简明,以下的描述中省略了对公知功能和结构的描述。Exemplary embodiments of the present application are described below with reference to the accompanying drawings, which include various details of the embodiments of the present application to facilitate understanding, and should be considered as exemplary only. Accordingly, those of ordinary skill in the art will recognize that various changes and modifications of the embodiments described herein can be made without departing from the scope and spirit of the present application. Also, descriptions of well-known functions and constructions are omitted from the following description for clarity and conciseness.
本申请的说明书和权利要求书及上述附图中的术语“第一”、“第二”、“第三”、“第四”等(如果存在)是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本申请的实施例例如能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。The terms "first", "second", "third", "fourth", etc. (if any) in the description and claims of this application and the above-mentioned drawings are used to distinguish similar objects and are not necessarily used to describe a specific order or sequence. It is to be understood that the data so used may be interchanged under appropriate circumstances such that the embodiments of the application described herein can, for example, be practiced in sequences other than those illustrated or described herein. Furthermore, the terms "comprising" and "having" and any variations thereof, are intended to cover non-exclusive inclusion, for example, a process, method, system, product or device comprising a series of steps or units is not necessarily limited to those expressly listed Rather, those steps or units may include other steps or units not expressly listed or inherent to these processes, methods, products or devices.
下面以具体地实施例对本申请的技术方案进行详细说明。下面这几个具体的实施例可以相互结合,对于相同或相似的概念或过程可能在某些实施例不再赘述。The technical solutions of the present application will be described in detail below with specific examples. The following specific embodiments may be combined with each other, and the same or similar concepts or processes may not be repeated in some embodiments.
现有技术中,为使用者用户,推荐符合使用者用户要求的资讯的时候,可以采用基于各个使用者用户的历史搜索记录的方式,确定出搜索率较高的资讯;进而将搜索率较高的资讯,推荐给使用者用户。对于推荐者用户(作者)来说,推荐者用户需要及时的掌握合适的主题,进而撰写出该主题对应的资讯;然后,使用者用户才可以观看到资讯。然而现有技术中,无法为推荐者用户提供合适的主题,进而使得推荐者用户不能提供出热度较高、时效性较高的资讯。In the prior art, when recommending information that meets user requirements for users, information with a higher search rate can be determined based on the historical search records of each user user; information, recommended to users. For the recommender user (author), the recommender user needs to grasp a suitable topic in time, and then write information corresponding to the topic; then, the user user can view the information. However, in the prior art, it is impossible to provide the recommender user with a suitable topic, so that the recommender user cannot provide information with high popularity and high timeliness.
针对上述技术问题,本申请旨在提供一种资讯主题的推荐方法、装置、终端及存储介质,可以对全网资讯进行智能搜索,向推荐者用户提供热度和时效性较高的主题,进而使得推荐者用户能够创作出热度较高、时效性较高的资讯。本申请提供的方法可以应用于终端设备,例如:手机、平板电脑,计算机等等。In view of the above technical problems, this application aims to provide a method, device, terminal and storage medium for recommending information topics, which can intelligently search for information on the entire network, and provide recommender users with topics with high popularity and timeliness, thereby enabling Recommender users can create information with high popularity and high timeliness. The method provided in this application can be applied to terminal devices, such as mobile phones, tablet computers, computers, and so on.
图1是可以实现本申请实施例的资讯主题的推荐方法的原理示意图,如图1所示,首先从全部网络获取待处理的资讯,包括从百度搜索、微博热搜、论坛等各个渠道获取海量资讯。这样就可以从多个角度建立全网资讯的完整视图,资讯的主题更加丰富,也避免了站点受用户群体关注点的影响,更加客观地反映真实情况。然后,通过分类模型对资讯进行分类处理,例如构建广告判别的二分类模型、黄反判别的二分类模型、盘点类资讯的二分类模型,从而可以通过这些模型将资讯分为高质量资讯和低质量资讯。滤除低质量的资讯,将高质量的资讯进行主题确定处理,从而可以筛选出高质量的资讯内容,降低后续步骤的数据处理量。然后,从这些高质量资讯中抽取出资讯对应的多个主题。确定分类处理后每一篇资讯所对应的N个主题,包括:根据已有的通用知识图谱,对资讯的内容进行知识的提取和表示,得到实体链接关系;根据实体链接关系,从知识图谱中找到与输入内容相关的实体知识、实体关联信息,得到资讯的实体型主题;提取资讯的关键字;根据关键字在资讯中统计信息,确定资讯对应的话题型主题;其中,统计信息包括:关键字的频次、关键字的词性、关键字与文章主旨符合程度。然后,可以从多个主题特征维度对主题进行描述,进行主题写作度打分。例如,主题相关资讯数量、主题相关资讯在时间窗口内(最近一小时、最近一天、最近一周、历史)用户行为数据(评论数、浏览数、点赞量、用户量)、主题在时间窗口内(最近一小时、最近一天、最近一周、历史)的点击率(这是主题的真实的点击率,不是资讯的点击率,例如作者是否点击了该点击率)、主题与用户领域语义距离打分、主题事件概率得分(事件,指的是业界的研究方向;例如每一个事情,是否是事件)等。用户领域,指的是推荐者用户(作者)所归属的领域,例如,作者在使用百度的“百家号”时,会选择下自己归属的领域,例如是娱乐、药品、历史;可以将主题与用户领域之间,从语义上进行分析,进而得到两者之间的语义距离的分数。然后,将主题特征输入主题点击率模型,得到主题的写作度分数。主题点击率模型使用包括但不限于逻辑回归(Logistic Regression,简称LR)模型、梯度提升随机树(Gradient Boosting Decision Tree,简称GBDT)模型、深度神经网络(Deep NeuralNetworks,简称DNN)模型等多种模型结构,通过预先标注有点击率和写作度分数的第一主题数据集迭代训练得到的。通过这种方式可以提取主题的主题特征输入点击率模型中,输出每一个主题的写作度分数,从而可以直观地对各个主题进行写作度评判,其中,写作度分数越高,则对应主题的热度和时效性越强。最后,可以通过相似度判别模型,确定两两主题之间的相似度。其中,相似度判别模型是通过预先标注有相似度的第二主题数据集迭代训练得到的,第二主题数据集中的元素为两两主题构成的子集。然后,对相似度大于第二预设值的主题进行去重处理,得到候选主题。最后,按照写作度分数从高到低的顺序,从候选主题中选择至少一个候选主题作为目标主题,并将目标主题发送给用户。Fig. 1 is a schematic diagram of the principle that can implement the method for recommending information topics according to an embodiment of the present application. As shown in Fig. 1, information to be processed is firstly obtained from all networks, including obtaining from various channels such as Baidu search, Weibo hot search, and forums. Massive information. In this way, a complete view of the entire network information can be established from multiple angles, the topics of the information are more abundant, and the site is prevented from being affected by the concerns of the user group, and the real situation is more objectively reflected. Then, classify the information through the classification model, such as constructing a two-class model for advertising discrimination, a two-class model for yellow anti-discrimination, and a two-class model for inventory information, so that information can be classified into high-quality information and low-quality information through these models. quality information. Filter out low-quality information, and subject high-quality information to subject determination processing, so that high-quality information content can be filtered out and data processing in subsequent steps can be reduced. Then, multiple topics corresponding to the information are extracted from these high-quality information. Determine the N topics corresponding to each piece of information after classification processing, including: extracting and expressing knowledge from the content of the information according to the existing general knowledge map, and obtaining the entity link relationship; according to the entity link relationship, from the knowledge map Find the entity knowledge and entity related information related to the input content, and obtain the entity-type topic of the information; extract the keywords of the information; according to the keyword statistics in the information, determine the topic-type topic corresponding to the information; wherein, the statistical information includes: key The frequency of the word, the part of speech of the keyword, and the degree to which the keyword matches the subject of the article. Then, the topic can be described from multiple topic feature dimensions, and the topic writing degree can be scored. For example, the number of topic-related information, the topic-related information within the time window (the last hour, the last day, the last week, the history), the user behavior data (the number of comments, the number of views, the number of likes, the number of users), the topic within the time window (last hour, last day, last week, history) click-through rate (this is the real click-through rate of the topic, not the click-through rate of information, such as whether the author clicked on the click-through rate), the semantic distance score between the topic and the user domain, The subject event probability score (event, refers to the research direction of the industry; such as each thing, whether it is an event), etc. User field refers to the field to which the recommender user (author) belongs. For example, when the author uses Baidu's "Baijia Account", he will choose the field to which he belongs, such as entertainment, medicine, and history; And the user domain is analyzed semantically, and then the score of the semantic distance between the two is obtained. Then, input the topic features into the topic click-through rate model to get the topic's writing degree score. The topic click rate model uses a variety of models including but not limited to Logistic Regression (LR) model, Gradient Boosting Decision Tree (GBDT) model, Deep Neural Networks (DNN) model, etc. structure, obtained by iterative training on the first topic dataset pre-annotated with click-through rate and writing degree scores. In this way, the topic features of the topic can be extracted and input into the click-through rate model, and the writing degree score of each topic can be output, so that the writing degree of each topic can be judged intuitively. The higher the writing degree score, the more popular the corresponding topic is. and time-sensitive. Finally, the similarity between two topics can be determined through the similarity discrimination model. Wherein, the similarity discrimination model is obtained by iterative training of a second subject data set marked with similarity in advance, and the elements in the second subject data set are subsets formed by two subjects. Then, deduplication processing is performed on topics with a similarity greater than the second preset value to obtain candidate topics. Finally, according to the order of writing degree scores from high to low, at least one candidate topic is selected from the candidate topics as the target topic, and the target topic is sent to the user.
应用上述方法可以根据主题之间的相似度和写作度对主题进行筛选,从全网中搜索出热度和时效性较高的主题,进而使得推荐者用户能够创作出热度较高、时效性较高的资讯。Applying the above method can filter topics according to the similarity and writing degree between topics, and search for topics with high popularity and timeliness from the whole network, so that recommender users can create topics with higher popularity and timeliness. information.
图2是根据本申请第一实施例的示意图,如图2所示,本实施例中的方法可以包括:FIG. 2 is a schematic diagram according to the first embodiment of the present application. As shown in FIG. 2 , the method in this embodiment may include:
S101、确定资讯的主题。S101. Determine the subject of the information.
本实施例中,可以首先获取待处理的资讯。然后,通过而分类模型对待处理的资讯进行分类处理,得到质量分数大于第一预设值的资讯。最后,确定分类处理后每一篇资讯所对应的N个主题。其中,N个主题包括M个实体型主题和N-M个话题型主题。In this embodiment, the information to be processed may be acquired first. Then, the information to be processed is classified and processed by the classification model to obtain information whose quality score is greater than the first preset value. Finally, N topics corresponding to each piece of information after classification processing are determined. Among them, the N topics include M entity-type topics and N-M topic-type topics.
具体地,首先从全部网络获取待处理的资讯,包括从百度搜索、微博热搜、论坛等各个渠道获取海量资讯。这样就可以从多个角度建立全网资讯的完整视图,资讯的主题更加丰富,也避免了站点受用户群体关注点的影响,更加客观地反映真实情况。然后,通过分类模型对资讯进行分类处理,例如构建广告判别的二分类模型、黄反判别的二分类模型、盘点类资讯的二分类模型,从而可以通过这些模型将资讯分为高质量资讯和低质量资讯。滤除低质量的资讯,将高质量的资讯进行主题确定处理,从而可以筛选出高质量的资讯内容,降低后续步骤的数据处理量。最后,从这些高质量资讯中抽取出资讯对应的多个主题。Specifically, the information to be processed is first obtained from all networks, including massive information obtained from various channels such as Baidu search, Weibo hot search, and forums. In this way, a complete view of the entire network information can be established from multiple angles, the topics of the information are more abundant, and the site is prevented from being affected by the concerns of the user group, and the real situation is more objectively reflected. Then, classify the information through the classification model, such as constructing a two-class model for advertising discrimination, a two-class model for yellow anti-discrimination, and a two-class model for inventory information, so that information can be classified into high-quality information and low-quality information through these models. quality information. Filter out low-quality information, and subject high-quality information to subject determination processing, so that high-quality information content can be filtered out and data processing in subsequent steps can be reduced. Finally, multiple topics corresponding to the information are extracted from these high-quality information.
可选地,确定分类处理后每一篇资讯所对应的N个主题,包括:根据已有的通用知识图谱,对资讯的内容进行知识的提取和表示,得到实体链接关系;根据实体链接关系,从知识图谱中找到与输入内容相关的实体知识、实体关联信息,得到资讯的实体型主题;提取资讯的关键字;根据关键字在资讯中统计信息,确定资讯对应的话题型主题;其中,统计信息包括:关键字的频次、关键字的词性、关键字与文章主旨符合程度。Optionally, determining the N topics corresponding to each piece of information after the classification process includes: extracting and representing knowledge on the content of the information according to an existing general knowledge graph, and obtaining an entity link relationship; according to the entity link relationship, Find the entity knowledge and entity related information related to the input content from the knowledge graph, and obtain the entity-type topic of the information; extract the keywords of the information; according to the keyword statistics in the information, determine the topic-type topic corresponding to the information; The information includes: the frequency of the keyword, the part of speech of the keyword, and the degree to which the keyword matches the subject of the article.
具体地,主题可以分为实体型主题和话题型主题。其中,实体型主题是一种粗粒度的主题,话题型主题是一种细粒度的主题。针对每一篇资讯,基于已有的通用知识图谱,对资讯内容进行知识的提取和表示,基于实体链接从知识图谱中找到与输入内容相关的实体知识、实体关联信息,确定出该资讯的实体型主题。即,采用知识图谱实体关联的方式,根据每一个资讯的关键字,从每一个资讯中提取出每一个资讯的实体型主题。针对每一篇资讯,提取该资讯的关键字;依据该资讯中的关键字的频次、关键字的词性、关键字与文章主旨符合程度、等等这些统计信息,分析出该资讯的话题标签主题。例如,杨幂是一个实体型主题,事件B是话题型主题。一般来说,实体型主题有百度百科。也可以简单地根据是否有百度百科来判断是否是实体型主题。通过这种方式,可以准确地对资讯的主题进行划分,方便用户对资讯内容进行分类阅读。Specifically, topics can be divided into entity-type topics and topic-type topics. Among them, the entity-type topic is a coarse-grained topic, and the topic-type topic is a fine-grained topic. For each piece of information, based on the existing general knowledge graph, the information content is extracted and represented, and the entity knowledge and entity association information related to the input content are found from the knowledge graph based on the entity link, and the entity of the information is determined. type theme. That is, the entity-type topic of each information is extracted from each information according to the keyword of each information by adopting the method of knowledge graph entity association. For each piece of information, extract the keyword of the information; according to the frequency of the keyword in the information, the part of speech of the keyword, the degree of conformity between the keyword and the subject of the article, etc., analyze the topic tag of the information. . For example, Yang Mi is an entity-type topic, and event B is a topic-type topic. Generally speaking, entity-type topics have Baidu Encyclopedia. You can also simply judge whether it is an entity theme based on whether there is Baidu Encyclopedia. In this way, the subject of the information can be accurately divided, and it is convenient for the user to classify and read the information content.
S102、确定主题的写作度。S102. Determine the writing degree of the theme.
本实施例中,可以首先提取主题的主题特征。其中,主题特征包括:主题下的资讯数量、主题下的资讯在时间窗口内的用户行为数据、主题在时间窗口内的点击率、主题与用户领域的语义距离打分、主题的事件概率得分等。然后,将主题特征输入主题点击率模型,得到主题的写作度分数。其中,主题点击率模型是通过预先标注有点击率和写作度分数的第一主题数据集迭代训练得到的。In this embodiment, the subject feature of the subject may be extracted first. Among them, the topic features include: the amount of information under the topic, the user behavior data of the information under the topic in the time window, the click rate of the topic in the time window, the semantic distance score between the topic and the user domain, the event probability score of the topic, etc. Then, input the topic features into the topic click-through rate model to get the topic's writing score. Among them, the topic click rate model is obtained by iterative training of the first topic dataset pre-annotated with click rate and writing score.
具体地,可以从多个主题特征维度对主题进行描述。例如,主题相关资讯数量、主题相关资讯在时间窗口内(最近一小时、最近一天、最近一周、历史)用户行为数据(评论数、浏览数、点赞量、用户量)、主题在时间窗口内(最近一小时、最近一天、最近一周、历史)的点击率(这是主题的真实的点击率,不是资讯的点击率,例如作者是否点击了该点击率)、主题与用户领域语义距离打分、主题事件概率得分(事件,指的是业界的研究方向;例如每一个事情,是否是事件)等。用户领域,指的是推荐者用户(作者)所归属的领域,例如,作者在使用百度的“百家号”时,会选择下自己归属的领域,例如是娱乐、药品、历史;可以将主题与用户领域之间,从语义上进行分析,进而得到两者之间的语义距离的分数。然后,将主题特征输入主题点击率模型,得到主题的写作度分数。主题点击率模型使用包括但不限于逻辑回归(Logistic Regression,简称LR)模型、梯度提升随机树(Gradient Boosting DecisionTree,简称GBDT)模型、深度神经网络(Deep Neural Networks,简称DNN)模型等多种模型结构,通过预先标注有点击率和写作度分数的第一主题数据集迭代训练得到的。通过这种方式可以提取主题的主题特征输入点击率模型中,输出每一个主题的写作度分数,从而可以直观地对各个主题进行写作度评判,其中,写作度分数越高,则对应主题的热度和时效性越强。Specifically, a topic can be described from multiple topic feature dimensions. For example, the number of topic-related information, the topic-related information within the time window (the last hour, the last day, the last week, the history), the user behavior data (the number of comments, the number of views, the number of likes, the number of users), the topic within the time window (last hour, last day, last week, history) click-through rate (this is the real click-through rate of the topic, not the click-through rate of information, such as whether the author clicked on the click-through rate), the semantic distance score between the topic and the user domain, The subject event probability score (event, refers to the research direction of the industry; such as each thing, whether it is an event), etc. User field refers to the field to which the recommender user (author) belongs. For example, when the author uses Baidu's "Baijia Account", he will choose the field to which he belongs, such as entertainment, medicine, and history; And the user domain is analyzed semantically, and then the score of the semantic distance between the two is obtained. Then, input the topic features into the topic click-through rate model to get the topic's writing score. The topic click-through rate model uses a variety of models, including but not limited to Logistic Regression (LR) model, Gradient Boosting DecisionTree (GBDT) model, Deep Neural Networks (DNN) model, etc. structure, obtained by iterative training on the first topic dataset pre-annotated with click-through rate and writing degree scores. In this way, the topic features of the topic can be extracted and input into the click-through rate model, and the writing degree score of each topic can be output, so that the writing degree of each topic can be judged intuitively. The higher the writing degree score, the more popular the corresponding topic is. and time-sensitive.
S103、根据主题之间的相似度和主题的写作度,筛选出目标主题。S103: Screen out the target topic according to the similarity between the topics and the writing degree of the topic.
本实施例中,可以通过相似度判别模型,确定两两主题之间的相似度。其中,相似度判别模型是通过预先标注有相似度的第二主题数据集迭代训练得到的,第二主题数据集中的元素为两两主题构成的子集。然后,对相似度大于第二预设值的主题进行去重处理,得到候选主题。最后,按照写作度分数从高到低的顺序,从候选主题中选择至少一个候选主题作为目标主题。In this embodiment, the similarity between two topics can be determined through a similarity discrimination model. Wherein, the similarity discrimination model is obtained by iterative training of the second subject data set marked with the similarity in advance, and the elements in the second subject data set are subsets formed by two subjects. Then, deduplication processing is performed on topics with a similarity greater than the second preset value to obtain candidate topics. Finally, at least one candidate topic is selected as the target topic from the candidate topics in order of writing degree score from high to low.
具体地,可以将第二主题样本数据集(被标注了每2个主题的相似度的主题所构成的数据集)输入到主题相似判别模型中,得到经过训练的主题相似判别模型。针对待处理的主题,将每2个主题输入到经过训练的主题相似判别模型中,得到每2个主题之间的相似度(即,相似概率)。根据主题的写作度分数的由高到低的顺序,对相似度较高(相似度大于预设阈值)的主题进行去重处理,进而过滤掉重复的主题,得到过滤后的主题。从而可以得到热度高,时效性强的目标主题。Specifically, the second subject sample data set (a data set composed of subjects marked with the similarity of each two subjects) may be input into the subject similarity discrimination model to obtain a trained subject similarity discrimination model. For the topics to be processed, each 2 topics are input into the trained topic similarity discriminant model, and the similarity (ie, similarity probability) between each 2 topics is obtained. According to the order of the writing degree scores of the topics from high to low, the topics with high similarity (similarity greater than a preset threshold) are deduplicated, and then duplicate topics are filtered out to obtain filtered topics. In this way, a target theme with high popularity and strong timeliness can be obtained.
S104、将目标主题发送给推荐者用户。S104. Send the target topic to the recommender user.
本实施例中,可以将目标主题发送给推荐者用户,从而可以根据主题之间的相似度和写作度对快速地对主题进行筛选,从全网中搜索出热度和时效性较高的主题,进而使得推荐者用户能够创作出热度较高、时效性较高的资讯。In this embodiment, the target topic can be sent to the recommender user, so that the topics can be quickly screened according to the similarity and writing degree between the topics, and the topics with high popularity and timeliness can be searched from the whole network, In turn, recommender users can create information with high popularity and high timeliness.
本实施例,通过确定资讯的主题;确定主题的写作度;根据主题之间的相似度和主题的写作度,筛选出目标主题;将目标主题发送给推荐者用户。从而可以根据主题之间的相似度和写作度对主题进行筛选,从全网中搜索出热度和时效性较高的主题,进而使得推荐者用户能够创作出热度较高、时效性较高的资讯。In this embodiment, the topic of the information is determined; the writing degree of the topic is determined; the target topic is selected according to the similarity between topics and the writing degree of the topic; and the target topic is sent to the recommender user. In this way, topics can be filtered according to the similarity and writing degree between topics, and topics with high popularity and timeliness can be searched from the whole network, so that recommender users can create information with high popularity and timeliness. .
图3是根据本申请第二实施例的示意图,如图3所示,本实施例中的方法可以包括:FIG. 3 is a schematic diagram according to a second embodiment of the present application. As shown in FIG. 3 , the method in this embodiment may include:
S201、确定资讯的主题。S201. Determine the subject of the information.
S202、确定主题的写作度。S202. Determine the writing degree of the theme.
S203、根据主题之间的相似度和主题的写作度,筛选出目标主题。S203 , according to the similarity between the topics and the writing degree of the topics, filter out the target topic.
S204、获取推荐者用户的用户信息;确定与用户信息匹配的目标主题。S204. Obtain user information of the recommender user; determine a target theme matching the user information.
本实施例中,还可以进一步地获取推荐者用户的用户信息,并根据推荐者用户信息对目标主题作一个匹配校验,使得最终推荐的目标主题与推荐者用户擅长写作的领域相符,实现更加精准地信息推荐。In this embodiment, the user information of the recommender user can be further obtained, and a matching check is made on the target topic according to the recommender user information, so that the final recommended target topic is consistent with the field where the recommender user is good at writing. Accurate information recommendation.
S205、将目标主题发送给推荐者用户。S205. Send the target topic to the recommender user.
本实施例中,步骤S201~步骤S203、步骤S205的具体实现过程和技术原理请参见图2所示的方法中步骤S101~步骤S104中的相关描述,此处不再赘述。In this embodiment, for the specific implementation process and technical principles of steps S201 to S203 and step S205, please refer to the relevant descriptions in steps S101 to S104 in the method shown in FIG. 2, which will not be repeated here.
本实施例,通过确定资讯的主题;确定主题的写作度;根据主题之间的相似度和主题的写作度,筛选出目标主题;将目标主题发送给推荐者用户。从而可以根据主题之间的相似度和写作度对主题进行筛选,从全网中搜索出热度和时效性较高的主题,进而使得推荐者用户能够创作出热度较高、时效性较高的资讯。In this embodiment, the topic of the information is determined; the writing degree of the topic is determined; the target topic is selected according to the similarity between topics and the writing degree of the topic; and the target topic is sent to the recommender user. In this way, topics can be filtered according to the similarity and writing degree between topics, and topics with high popularity and timeliness can be searched from the whole network, so that recommender users can create information with high popularity and timeliness. .
另外,本实施例还可以获取推荐者用户的用户信息,并根据推荐者用户信息对目标主题作一个匹配校验,使得最终推荐的目标主题与推荐者用户擅长写作的领域相符,实现更加精准地信息推荐。In addition, this embodiment can also obtain user information of the recommender user, and perform a matching check on the target topic according to the recommender user information, so that the final recommended target topic is consistent with the field where the recommender user is good at writing, so as to achieve a more accurate Information recommendation.
图4是根据本申请第三实施例的示意图,如图4所示,本实施例中的方法可以包括:FIG. 4 is a schematic diagram according to a third embodiment of the present application. As shown in FIG. 4 , the method in this embodiment may include:
S301、确定资讯的主题。S301. Determine the subject of the information.
S302、确定主题的写作度。S302. Determine the writing degree of the theme.
S303、根据主题之间的相似度和主题的写作度,筛选出目标主题。S303, according to the similarity between the topics and the writing degree of the topics, filter out the target topic.
S304、确定每一个主题对应的领域标签;根据推荐者用户的用户信息,选取出与用户信息匹配的领域标签所对应的主题。S304 , determining the domain label corresponding to each topic; and selecting the topic corresponding to the domain label matching the user information according to the user information of the recommender user.
本实施例中,在对主题的写作度进行分析之前,还可以通过对主题的领域标签进行标注,得到更加细粒度的领域划分主题。并根据推荐者用户的用户信息,选取出与用户信息匹配的领域标签所对应的主题,从而可以实现更加精准地主题筛选。In this embodiment, before analyzing the writing degree of the topic, a more fine-grained domain division topic may be obtained by labeling the domain label of the topic. And according to the user information of the recommender user, the topic corresponding to the domain tag matching the user information is selected, so that more accurate topic screening can be realized.
可选地,确定每一个主题对应的领域标签,包括:按照主题将资讯进行整合,得到同一主题下的多篇资讯;通过多分类模型,对多篇资讯进行分类处理,标注出每一篇资讯的领域标签;其中,多分类模型是通过标注有领域标签的资讯数据集迭代训练得到的;将出现频次排在前P位的领域标签作为主题对应的领域标签。Optionally, determining the domain label corresponding to each topic includes: integrating information according to the topic to obtain multiple pieces of information under the same topic; classifying and processing multiple pieces of information through a multi-classification model, and marking each piece of information The domain label of ; among them, the multi-classification model is obtained by iterative training of information datasets marked with domain labels; the domain labels with the top P occurrence frequency are used as the domain labels corresponding to the topics.
本实施例中,可以将资讯按照主题进行整合,得到同一主题下的多篇资讯。然后,将主题领域判别任务转换成多个资讯领域判别任务,即通过资讯领域分类模型对主题所有相关资讯进行领域分类,并将结果进行聚合,选取出现频次最高的5个领域作为主题最终的领域分类结果。从而实现了对主题的领域标签的细分度的划分,即,将主题的领域更加细化了,解决了现有技术中对主题“细分度不足”的问题。In this embodiment, the information can be integrated according to the theme to obtain multiple pieces of information under the same theme. Then, convert the subject domain discrimination task into multiple information domain discrimination tasks, that is, classify all relevant information of the subject through the information domain classification model, and aggregate the results, and select the five domains with the highest frequency as the final domain of the subject. Classification results. Thereby, the division of the subdivision of the subject field tags is realized, that is, the subject field is further refined, and the problem of "insufficient subdivision" of the subject in the prior art is solved.
S305、将目标主题发送给推荐者用户。S305. Send the target topic to the recommender user.
本实施例中,步骤S301~步骤S303、步骤S305的具体实现过程和技术原理请参见图2所示的方法中步骤S101~步骤S104中的相关描述,此处不再赘述。In this embodiment, for the specific implementation process and technical principles of steps S301 to S303 and S305, please refer to the relevant descriptions of steps S101 to S104 in the method shown in FIG. 2 , which will not be repeated here.
本实施例,通过确定资讯的主题;确定主题的写作度;根据主题之间的相似度和主题的写作度,筛选出目标主题;将目标主题发送给推荐者用户。从而可以根据主题之间的相似度和写作度对主题进行筛选,从全网中搜索出热度和时效性较高的主题,进而使得推荐者用户能够创作出热度较高、时效性较高的资讯。In this embodiment, the topic of the information is determined; the writing degree of the topic is determined; the target topic is selected according to the similarity between topics and the writing degree of the topic; and the target topic is sent to the recommender user. In this way, topics can be filtered according to the similarity and writing degree between topics, and topics with high popularity and timeliness can be searched from the whole network, so that recommender users can create information with high popularity and timeliness. .
另外,本实施例还可以对主题的领域标签的细分度的划分,即,将主题的领域更加细化了,解决了现有技术中对主题“细分度不足”的问题。In addition, this embodiment can also divide the subdivision degree of the subject field tags, that is, the subject field is further refined, which solves the problem of "insufficient subdivision degree" of the subject in the prior art.
图5是根据本申请第四实施例的示意图;如图5所示,本实施例中的装置可以包括:FIG. 5 is a schematic diagram according to a fourth embodiment of the present application; as shown in FIG. 5 , the apparatus in this embodiment may include:
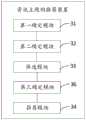
第一确定模块31,用于确定资讯的主题;The
第二确定模块32,用于确定主题的写作度;The
筛选模块33,用于根据主题之间的相似度和主题的写作度,筛选出目标主题;The
推荐模块34,用于将目标主题发送给推荐者用户。The
本实施例中,通过确定资讯的主题;确定主题的写作度;根据主题之间的相似度和主题的写作度,筛选出目标主题;将目标主题发送给推荐者用户。从而可以根据主题之间的相似度和写作度对主题进行筛选,从全网中搜索出热度和时效性较高的主题,进而使得推荐者用户能够创作出热度较高、时效性较高的资讯。In this embodiment, the topic of the information is determined; the writing degree of the topic is determined; the target topic is selected according to the similarity between topics and the writing degree of the topic; and the target topic is sent to the recommender user. In this way, topics can be filtered according to the similarity and writing degree between topics, and topics with high popularity and timeliness can be searched from the whole network, so that recommender users can create information with high popularity and timeliness. .
在一种可能的设计中,第一确定模块31,具体用于:In a possible design, the
获取待处理的资讯;obtain pending information;
通过而分类模型对待处理的资讯进行分类处理,得到质量分数大于第一预设值的资讯;Through the classification model, the information to be processed is classified and processed to obtain information whose quality score is greater than the first preset value;
确定分类处理后每一篇资讯所对应的N个主题;N个主题包括M个实体型主题和N-M个话题型主题。N topics corresponding to each piece of information after the classification process are determined; the N topics include M entity-type topics and N-M topic-type topics.
本实施例中,通过分类模型对资讯进行分类处理,例如构建广告判别的二分类模型、黄反判别的二分类模型、盘点类资讯的二分类模型,从而可以通过这些模型将资讯分为高质量资讯和低质量资讯。滤除低质量的资讯,将高质量的资讯进行主题确定处理,从而可以筛选出高质量的资讯内容,降低后续步骤的数据处理量。In this embodiment, the information is classified and processed by a classification model, such as constructing a two-class model for advertisement discrimination, a two-class model for yellow anti-discrimination, and a two-class model for inventory information, so that information can be classified into high-quality information through these models. information and low-quality information. Filter out low-quality information, and subject high-quality information to subject determination processing, so that high-quality information content can be filtered out and data processing in subsequent steps can be reduced.
在一种可能的设计中,第一确定模块31,具体用于:In a possible design, the
根据已有的通用知识图谱,对资讯的内容进行知识的提取和表示,得到实体链接关系;According to the existing general knowledge graph, the content of the information is extracted and represented by knowledge, and the entity link relationship is obtained;
根据实体链接关系,从知识图谱中找到与输入内容相关的实体知识、实体关联信息,得到资讯的实体型主题;According to the entity link relationship, find the entity knowledge and entity association information related to the input content from the knowledge graph, and obtain the entity-type topic of the information;
提取资讯的关键字;keywords for extracting information;
根据关键字在资讯中统计信息,确定资讯对应的话题型主题;其中,统计信息包括:关键字的频次、关键字的词性、关键字与文章主旨符合程度。According to the statistical information of the keywords in the information, the topic-type topics corresponding to the information are determined; wherein, the statistical information includes: the frequency of the keywords, the part of speech of the keywords, and the degree of conformity between the keywords and the subject of the article.
本实施例中,针对每一篇资讯,基于已有的通用知识图谱,对资讯内容进行知识的提取和表示,基于实体链接从知识图谱中找到与输入内容相关的实体知识、实体关联信息,确定出该资讯的实体型主题。即,采用知识图谱实体关联的方式,根据每一个资讯的关键字,从每一个资讯中提取出每一个资讯的实体型主题。针对每一篇资讯,提取该资讯的关键字;依据该资讯中的关键字的频次、关键字的词性、关键字与文章主旨符合程度、等等这些统计信息,分析出该资讯的话题标签主题。从而可以准确地对资讯的主题进行划分,方便用户对资讯内容进行分类阅读。In this embodiment, for each piece of information, based on the existing general knowledge graph, knowledge is extracted and represented on the information content, and the entity knowledge and entity association information related to the input content are found from the knowledge graph based on the entity link, and determined. The entity-type subject of this information. That is, the entity-type topic of each information is extracted from each information according to the keyword of each information by adopting the method of knowledge graph entity association. For each piece of information, extract the keyword of the information; according to the frequency of the keyword in the information, the part of speech of the keyword, the degree of conformity between the keyword and the subject of the article, etc., analyze the topic tag of the information. . Therefore, the subject of the information can be accurately divided, and it is convenient for the user to classify and read the information content.
在一种可能的设计中,第二确定模块32,具体用于:In a possible design, the
提取主题的主题特征,主题特征包括:主题下的资讯数量、主题下的资讯在时间窗口内的用户行为数据、主题在时间窗口内的点击率、主题与用户领域的语义距离打分、主题的事件概率得分;Extract the topic features of the topic. The topic features include: the amount of information under the topic, the user behavior data of the information under the topic in the time window, the click rate of the topic in the time window, the semantic distance score between the topic and the user field, and the events of the topic probability score;
将主题特征输入主题点击率模型,得到主题的写作度分数;其中,主题点击率模型是通过预先标注有点击率和写作度分数的第一主题数据集迭代训练得到的。Input the topic features into the topic click-through rate model to obtain the topic's writing degree score; wherein, the topic click-through rate model is obtained by iterative training of the first topic data set pre-marked with click-through rate and writing degree score.
本实施例中,通过提取主题的主题特征输入点击率模型中,输出每一个主题的写作度分数,从而可以直观地对各个主题进行写作度评判,其中,写作度分数越高,则对应主题的热度和时效性越强。In this embodiment, by extracting the topic features of the topics and inputting them into the click-through rate model, the writing degree score of each topic is output, so that each topic can be judged intuitively. The heat and timeliness are stronger.
在一种可能的设计中,筛选模块33,具体用于:In one possible design, the
通过相似度判别模型,确定两两主题之间的相似度;其中,相似度判别模型是通过预先标注有相似度的第二主题数据集迭代训练得到的,第二主题数据集中的元素为两两主题构成的子集;The similarity between two topics is determined by the similarity discrimination model; wherein, the similarity discrimination model is obtained by iterative training of the second subject data set marked with similarity in advance, and the elements in the second subject data set are pairwise a subset of topics;
对相似度大于第二预设值的主题进行去重处理,得到候选主题;Perform de-duplication processing on topics with a similarity greater than the second preset value to obtain candidate topics;
按照写作度分数从高到低的顺序,从候选主题中选择至少一个候选主题作为目标主题。Select at least one candidate topic from the candidate topics as the target topic in order of writing degree score from high to low.
本实施例中,将第二主题样本数据集(被标注了每2个主题的相似度的主题所构成的数据集)输入到主题相似判别模型中,得到经过训练的主题相似判别模型。针对待处理的主题,将每2个主题输入到经过训练的主题相似判别模型中,得到每2个主题之间的相似度(即,相似概率)。根据主题的写作度分数的由高到低的顺序,对相似度较高(相似度大于预设阈值)的主题进行去重处理,进而过滤掉重复的主题,得到过滤后的主题。从而可以得到热度高,时效性强的目标主题。In this embodiment, the second subject sample data set (a data set composed of subjects marked with the similarity of every two subjects) is input into the subject similarity discriminating model to obtain a trained subject similarity discriminating model. For the topics to be processed, each 2 topics are input into the trained topic similarity discriminant model, and the similarity (ie, similarity probability) between each 2 topics is obtained. According to the order of the writing degree scores of the topics from high to low, the topics with high similarity (similarity greater than a preset threshold) are deduplicated, and then duplicate topics are filtered out to obtain filtered topics. In this way, a target theme with high popularity and strong timeliness can be obtained.
本实施例的资讯主题的推荐装置,可以执行图2所示方法中的技术方案,其具体实现过程和技术原理参见图2所示方法中的相关描述,此处不再赘述。The apparatus for recommending information topics in this embodiment can implement the technical solutions in the method shown in FIG. 2 , and the specific implementation process and technical principles thereof refer to the related descriptions in the method shown in FIG. 2 , which will not be repeated here.
本实施例,通过确定资讯的主题;确定主题的写作度;根据主题之间的相似度和主题的写作度,筛选出目标主题;将目标主题发送给推荐者用户。从而可以根据主题之间的相似度和写作度对主题进行筛选,从全网中搜索出热度和时效性较高的主题,进而使得推荐者用户能够创作出热度较高、时效性较高的资讯。In this embodiment, the topic of the information is determined; the writing degree of the topic is determined; the target topic is selected according to the similarity between topics and the writing degree of the topic; and the target topic is sent to the recommender user. In this way, topics can be filtered according to the similarity and writing degree between topics, and topics with high popularity and timeliness can be searched from the whole network, so that recommender users can create information with high popularity and timeliness. .
图6是根据本申请第五实施例的示意图;如图6所示,本实施例中的装置在图5所示装置的基础上,还可以包括:FIG. 6 is a schematic diagram according to a fifth embodiment of the present application; as shown in FIG. 6 , on the basis of the device shown in FIG. 5 , the device in this embodiment may further include:
获取模块35,具体用于:Get
获取推荐者用户的用户信息;Obtain the user information of the recommender user;
确定与用户信息匹配的目标主题。Identify target topics that match user information.
本实施例中,还可以进一步地根据用户信息对目标主题作一个匹配校验,使得最终推荐的目标主题与推荐者用户擅长写作的领域相符,实现更加精准地信息推荐。In this embodiment, a matching check can be further performed on the target topic according to the user information, so that the final recommended target topic is consistent with the field where the recommender user is good at writing, so as to achieve more accurate information recommendation.
本实施例的资讯主题的推荐装置,可以执行图2、图3所示方法中的技术方案,其具体实现过程和技术原理参见图2、图3所示方法中的相关描述,此处不再赘述。The device for recommending information topics in this embodiment can implement the technical solutions in the methods shown in FIG. 2 and FIG. 3 . For the specific implementation process and technical principles, please refer to the relevant descriptions in the methods shown in FIG. 2 and FIG. 3 , which are not repeated here. Repeat.
本实施例,通过确定资讯的主题;确定主题的写作度;根据主题之间的相似度和主题的写作度,筛选出目标主题;将目标主题发送给推荐者用户。从而可以根据主题之间的相似度和写作度对主题进行筛选,从全网中搜索出热度和时效性较高的主题,进而使得推荐者用户能够创作出热度较高、时效性较高的资讯。In this embodiment, the topic of the information is determined; the writing degree of the topic is determined; the target topic is selected according to the similarity between topics and the writing degree of the topic; and the target topic is sent to the recommender user. In this way, topics can be filtered according to the similarity and writing degree between topics, and topics with high popularity and timeliness can be searched from the whole network, so that recommender users can create information with high popularity and timeliness. .
另外,本实施例还可以获取推荐者用户的用户信息,并根据推荐者用户信息对目标主题作一个匹配校验,使得最终推荐的目标主题与推荐者用户擅长写作的领域相符,实现更加精准地信息推荐。In addition, this embodiment can also obtain user information of the recommender user, and perform a matching check on the target topic according to the recommender user information, so that the final recommended target topic is consistent with the field where the recommender user is good at writing, so as to achieve a more accurate Information recommendation.
图7是根据本申请第六实施例的示意图;如图7所示,本实施例中的装置在图5所示装置的基础上,还可以包括:FIG. 7 is a schematic diagram according to a sixth embodiment of the present application; as shown in FIG. 7 , on the basis of the device shown in FIG. 5 , the device in this embodiment may further include:
第三确定模块36,具体用于:The
确定每一个主题对应的领域标签;Determine the domain label corresponding to each topic;
根据推荐者用户的用户信息,选取出与用户信息匹配的领域标签所对应的主题。According to the user information of the recommender user, the topic corresponding to the domain tag matching the user information is selected.
本实施例中,在对主题的写作度进行分析之前,通过对主题的领域标签进行标注,得到更加细粒度的领域划分主题。从而可以实现更加精准地主题筛选。In this embodiment, before analyzing the writing degree of the topic, a more fine-grained domain division topic is obtained by labeling the domain label of the topic. This allows for more precise topic filtering.
在一种可能的设计中,第三确定模块36,具体用于:In a possible design, the
按照主题将资讯进行整合,得到同一主题下的多篇资讯;Integrate the information according to the theme to get multiple pieces of information under the same theme;
通过多分类模型,对多篇资讯进行分类处理,标注出每一篇资讯的领域标签;其中,多分类模型是通过标注有领域标签的资讯数据集迭代训练得到的;Through the multi-classification model, multiple pieces of information are classified and processed, and the domain label of each piece of information is marked; wherein, the multi-classification model is obtained by iterative training of the information data set marked with the domain label;
将出现频次排在前P位的领域标签作为主题对应的领域标签。The domain label with the top P in the frequency of occurrence is used as the domain label corresponding to the topic.
本实施例中,实现了对主题的领域标签的细分度的划分,即,将主题的领域更加细化了,解决了现有技术中对主题“细分度不足”的问题。In this embodiment, the division of the subdivision of the topic's field label is achieved, that is, the topic field is further refined, and the problem of "insufficient subdivision" of the topic in the prior art is solved.
本实施例的资讯主题的推荐装置,可以执行图2、图4所示方法中的技术方案,其具体实现过程和技术原理参见图2、图4所示方法中的相关描述,此处不再赘述。The device for recommending information topics in this embodiment can implement the technical solutions in the methods shown in FIG. 2 and FIG. 4 . For the specific implementation process and technical principles, refer to the relevant descriptions in the methods shown in FIG. 2 and FIG. 4 , which are not repeated here. Repeat.
本实施例,通过确定资讯的主题;确定主题的写作度;根据主题之间的相似度和主题的写作度,筛选出目标主题;将目标主题发送给推荐者用户。从而可以根据主题之间的相似度和写作度对主题进行筛选,从全网中搜索出热度和时效性较高的主题,进而使得推荐者用户能够创作出热度较高、时效性较高的资讯。In this embodiment, the topic of the information is determined; the writing degree of the topic is determined; the target topic is selected according to the similarity between topics and the writing degree of the topic; and the target topic is sent to the recommender user. In this way, topics can be filtered according to the similarity and writing degree between topics, and topics with high popularity and timeliness can be searched from the whole network, so that recommender users can create information with high popularity and timeliness. .
另外,本实施例还可以对主题的领域标签的细分度的划分,即,将主题的领域更加细化了,解决了现有技术中对主题“细分度不足”的问题。In addition, this embodiment can also divide the subdivision degree of the subject field tags, that is, the subject field is further refined, which solves the problem of "insufficient subdivision degree" of the subject in the prior art.
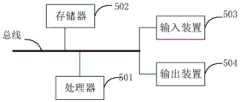
图8是用来实现本申请实施例的终端的框图;如图8所示,是根据本申请实施例的图8终端的框图。电子设备旨在表示各种形式的数字计算机,诸如,膝上型计算机、台式计算机、工作台、个人数字助理、服务器、刀片式服务器、大型计算机、和其它适合的计算机。电子设备还可以表示各种形式的移动装置,诸如,个人数字处理、蜂窝电话、智能电话、可穿戴设备和其它类似的计算装置。本文所示的部件、它们的连接和关系、以及它们的功能仅仅作为示例,并且不意在限制本文中描述的和/或者要求的本申请的实现。FIG. 8 is a block diagram of a terminal used to implement an embodiment of the present application; as shown in FIG. 8 , it is a block diagram of the terminal in FIG. 8 according to an embodiment of the present application. Electronic devices are intended to represent various forms of digital computers, such as laptops, desktops, workstations, personal digital assistants, servers, blade servers, mainframe computers, and other suitable computers. Electronic devices may also represent various forms of mobile devices, such as personal digital processors, cellular phones, smart phones, wearable devices, and other similar computing devices. The components shown herein, their connections and relationships, and their functions are by way of example only, and are not intended to limit implementations of the application described and/or claimed herein.
如图8所示,该终端包括:一个或多个处理器501、存储器502,以及用于连接各部件的接口,包括高速接口和低速接口。各个部件利用不同的总线互相连接,并且可以被安装在公共主板上或者根据需要以其它方式安装。处理器可以对在电子设备内执行的指令进行处理,包括存储在存储器中或者存储器上以在外部输入/输出装置(诸如,耦合至接口的显示设备)上显示GUI的图形信息的指令。在其它实施方式中,若需要,可以将多个处理器和/或多条总线与多个存储器和多个存储器一起使用。同样,可以连接多个电子设备,各个设备提供部分必要的操作(例如,作为服务器阵列、一组刀片式服务器、或者多处理器系统)。图8中以一个处理器501为例。As shown in FIG. 8, the terminal includes: one or
存储器502即为本申请所提供的非瞬时计算机可读存储介质。其中,存储器存储有可由至少一个处理器执行的指令,以使至少一个处理器执行本申请所提供的图8终端的资讯主题的推荐方法。本申请的非瞬时计算机可读存储介质存储计算机指令,该计算机指令用于使计算机执行本申请所提供的图8资讯主题的推荐方法。The
存储器502作为一种非瞬时计算机可读存储介质,可用于存储非瞬时软件程序、非瞬时计算机可执行程序以及模块,如本申请实施例中的图8资讯主题的推荐方法对应的程序指令/模块。处理器501通过运行存储在存储器502中的非瞬时软件程序、指令以及模块,从而执行服务器的各种功能应用以及数据处理,即实现上述方法实施例中的图8资讯主题的推荐方法。As a non-transitory computer-readable storage medium, the
存储器502可以包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需要的应用程序;存储数据区可存储根据图8终端的使用所创建的数据等。此外,存储器502可以包括高速随机存取存储器,还可以包括非瞬时存储器,例如至少一个磁盘存储器件、闪存器件、或其他非瞬时固态存储器件。在一些实施例中,存储器502可选包括相对于处理器501远程设置的存储器,这些远程存储器可以通过网络连接至图8终端。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。The
图8终端还可以包括:输入装置503和输出装置504。处理器501、存储器502、输入装置503和输出装置504可以通过总线或者其他方式连接,图8中以通过总线连接为例。The terminal in FIG. 8 may further include: an
输入装置503可接收输入的数字或字符信息,以及产生与图8终端的用户设置以及功能控制有关的键信号输入,例如触摸屏、小键盘、鼠标、轨迹板、触摸板、指示杆、一个或者多个鼠标按钮、轨迹球、操纵杆等输入装置。输出装置504可以包括显示设备、辅助照明装置(例如,LED)和触觉反馈装置(例如,振动电机)等。该显示设备可以包括但不限于,液晶显示器(LCD)、发光二极管(LED)显示器和等离子体显示器。在一些实施方式中,显示设备可以是触摸屏。The
此处描述的系统和技术的各种实施方式可以在数字电子电路系统、集成电路系统、专用ASIC(专用集成电路)、GPU(图形处理器)、FPGA(现场可编程门阵列)设备、计算机硬件、固件、软件、和/或它们的组合中实现。这些各种实施方式可以包括:实施在一个或者多个计算机程序中,该一个或者多个计算机程序可在包括至少一个可编程处理器的可编程系统上执行和/或解释,该可编程处理器可以是专用或者通用可编程处理器,可以从存储系统、至少一个输入装置、和至少一个输出装置接收数据和指令,并且将数据和指令传输至该存储系统、该至少一个输入装置、和该至少一个输出装置。Various implementations of the systems and techniques described herein may be implemented in digital electronic circuitry, integrated circuit systems, application specific ASICs (application specific integrated circuits), GPUs (graphics processing units), FPGA (field programmable gate array) devices, computer hardware , firmware, software, and/or combinations thereof. These various embodiments may include being implemented in one or more computer programs executable and/or interpretable on a programmable system including at least one programmable processor that The processor, which may be a special purpose or general-purpose programmable processor, may receive data and instructions from a storage system, at least one input device, and at least one output device, and transmit data and instructions to the storage system, the at least one input device, and the at least one output device an output device.
这些计算程序(也称作程序、软件、软件应用、或者代码)包括可编程处理器的机器指令,并且可以利用高级过程和/或面向对象的编程语言、和/或汇编/机器语言来实施这些计算程序。如本文使用的,术语“机器可读介质”和“计算机可读介质”指的是用于将机器指令和/或数据提供给可编程处理器的任何计算机程序产品、设备、和/或装置(例如,磁盘、光盘、存储器、可编程逻辑装置(PLD)),包括,接收作为机器可读信号的机器指令的机器可读介质。术语“机器可读信号”指的是用于将机器指令和/或数据提供给可编程处理器的任何信号。These computational programs (also referred to as programs, software, software applications, or codes) include machine instructions for programmable processors, and may be implemented using high-level procedural and/or object-oriented programming languages, and/or assembly/machine languages calculation program. As used herein, the terms "machine-readable medium" and "computer-readable medium" refer to any computer program product, apparatus, and/or apparatus for providing machine instructions and/or data to a programmable processor ( For example, magnetic disks, optical disks, memories, programmable logic devices (PLDs), including machine-readable media that receive machine instructions as machine-readable signals. The term "machine-readable signal" refers to any signal used to provide machine instructions and/or data to a programmable processor.
为了提供与用户的交互,可以在计算机上实施此处描述的系统和技术,该计算机具有:用于向用户显示信息的显示装置(例如,CRT(阴极射线管)或者LCD(液晶显示器)监视器);以及键盘和指向装置(例如,鼠标或者轨迹球),用户可以通过该键盘和该指向装置来将输入提供给计算机。其它种类的装置还可以用于提供与用户的交互;例如,提供给用户的反馈可以是任何形式的传感反馈(例如,视觉反馈、听觉反馈、或者触觉反馈);并且可以用任何形式(包括声输入、语音输入或者、触觉输入)来接收来自用户的输入。To provide interaction with a user, the systems and techniques described herein may be implemented on a computer having a display device (eg, a CRT (cathode ray tube) or LCD (liquid crystal display) monitor) for displaying information to the user ); and a keyboard and pointing device (eg, a mouse or trackball) through which a user can provide input to the computer. Other kinds of devices can also be used to provide interaction with the user; for example, the feedback provided to the user can be any form of sensory feedback (eg, visual feedback, auditory feedback, or tactile feedback); and can be in any form (including acoustic input, voice input, or tactile input) to receive input from the user.
可以将此处描述的系统和技术实施在包括后台部件的计算系统(例如,作为数据服务器)、或者包括中间件部件的计算系统(例如,应用服务器)、或者包括前端部件的计算系统(例如,具有图形用户界面或者网络浏览器的用户计算机,用户可以通过该图形用户界面或者该网络浏览器来与此处描述的系统和技术的实施方式交互)、或者包括这种后台部件、中间件部件、或者前端部件的任何组合的计算系统中。可以通过任何形式或者介质的数字数据通信(例如,通信网络)来将系统的部件相互连接。通信网络的示例包括:局域网(LAN)、广域网(WAN)和互联网。The systems and techniques described herein may be implemented on a computing system that includes back-end components (eg, as a data server), or a computing system that includes middleware components (eg, an application server), or a computing system that includes front-end components (eg, a user's computer having a graphical user interface or web browser through which a user may interact with implementations of the systems and techniques described herein), or including such backend components, middleware components, Or any combination of front-end components in a computing system. The components of the system may be interconnected by any form or medium of digital data communication (eg, a communication network). Examples of communication networks include: Local Area Networks (LANs), Wide Area Networks (WANs), and the Internet.
计算机系统可以包括客户端和服务器。客户端和服务器一般远离彼此并且通常通过通信网络进行交互。通过在相应的计算机上运行并且彼此具有客户端-服务器关系的计算机程序来产生客户端和服务器的关系。A computer system can include clients and servers. Clients and servers are generally remote from each other and usually interact through a communication network. The relationship of client and server arises by computer programs running on the respective computers and having a client-server relationship to each other.
应该理解,可以使用上面所示的各种形式的流程,重新排序、增加或删除步骤。例如,本发申请中记载的各步骤可以并行地执行也可以顺序地执行也可以不同的次序执行,只要能够实现本申请公开的技术方案所期望的结果,本文在此不进行限制。It should be understood that steps may be reordered, added or deleted using the various forms of flow shown above. For example, the steps described in the present application can be performed in parallel, sequentially or in different orders, and as long as the desired results of the technical solutions disclosed in the present application can be achieved, no limitation is imposed herein.
上述具体实施方式,并不构成对本申请保护范围的限制。本领域技术人员应该明白的是,根据设计要求和其他因素,可以进行各种修改、组合、子组合和替代。任何在本申请的精神和原则之内所作的修改、等同替换和改进等,均应包含在本申请保护范围之内。The above-mentioned specific embodiments do not constitute a limitation on the protection scope of the present application. It should be understood by those skilled in the art that various modifications, combinations, sub-combinations and substitutions may occur depending on design requirements and other factors. Any modifications, equivalent replacements and improvements made within the spirit and principles of this application shall be included within the protection scope of this application.
Claims (12)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010227922.1ACN111310058B (en) | 2020-03-27 | 2020-03-27 | Information theme recommendation method, device, terminal and storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010227922.1ACN111310058B (en) | 2020-03-27 | 2020-03-27 | Information theme recommendation method, device, terminal and storage medium |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN111310058Atrue CN111310058A (en) | 2020-06-19 |
| CN111310058B CN111310058B (en) | 2023-08-08 |
Family
ID=71147430
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010227922.1AActiveCN111310058B (en) | 2020-03-27 | 2020-03-27 | Information theme recommendation method, device, terminal and storage medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN111310058B (en) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112395498A (en)* | 2020-11-02 | 2021-02-23 | 北京五八信息技术有限公司 | Topic recommendation method and device, electronic equipment and storage medium |
| CN113343083A (en)* | 2021-05-25 | 2021-09-03 | 北京字节跳动网络技术有限公司 | Theme pushing method and device, storage medium and computer equipment |
| CN113378555A (en)* | 2021-06-22 | 2021-09-10 | 富途网络科技(深圳)有限公司 | Intelligent association method for individual stock and related product |
| CN114930319A (en)* | 2020-08-31 | 2022-08-19 | 华为技术有限公司 | Music recommendation method and device |
Citations (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20100306249A1 (en)* | 2009-05-27 | 2010-12-02 | James Hill | Social network systems and methods |
| US20130066862A1 (en)* | 2011-09-12 | 2013-03-14 | Microsoft Corporation | Multi-factor correlation of internet content resources |
| US20130080534A1 (en)* | 2011-04-01 | 2013-03-28 | Kento Ogawa | Content processing device, content processing method, computer-readable recording medium, and integrated circuit |
| CN103577579A (en)* | 2013-11-08 | 2014-02-12 | 南方电网科学研究院有限责任公司 | Resource recommendation method and system based on potential demands of users |
| CN103678474A (en)* | 2013-09-24 | 2014-03-26 | 浙江大学 | Method for acquiring large number of hot topics fast in social network |
| CN105095202A (en)* | 2014-04-17 | 2015-11-25 | 华为技术有限公司 | Method and device for message recommendation |
| CN105740468A (en)* | 2016-03-07 | 2016-07-06 | 达而观信息科技(上海)有限公司 | Individuation recommendation method and system combined with content publisher information |
| US20170161393A1 (en)* | 2015-12-08 | 2017-06-08 | Samsung Electronics Co., Ltd. | Terminal, server and event suggesting methods thereof |
| US20170300535A1 (en)* | 2016-04-15 | 2017-10-19 | Google Inc. | Systems and methods for suggesting content to a writer based on contents of a document |
| CN109460518A (en)* | 2018-12-07 | 2019-03-12 | 杭州东信北邮信息技术有限公司 | A kind of book recommendation method based on user website access record |
| US20190286673A1 (en)* | 2016-11-21 | 2019-09-19 | Comcast Cable Communications, Llc | Content Recommendation System With Weighted Metadata Annotations |
| US20190294657A1 (en)* | 2018-03-26 | 2019-09-26 | Adobe Inc. | Defining and delivering personalized entity recommendations |
| CN110457439A (en)* | 2019-08-06 | 2019-11-15 | 北京如优教育科技有限公司 | One-stop intelligent writes householder method, device and system |
| CN110457581A (en)* | 2019-08-02 | 2019-11-15 | 达而观信息科技(上海)有限公司 | An information recommendation method, device, electronic device and storage medium |
| US20190362384A1 (en)* | 2013-03-14 | 2019-11-28 | Clipfile Corporation | Tagging and ranking content |
- 2020
- 2020-03-27CNCN202010227922.1Apatent/CN111310058B/enactiveActive
Patent Citations (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20100306249A1 (en)* | 2009-05-27 | 2010-12-02 | James Hill | Social network systems and methods |
| US20130080534A1 (en)* | 2011-04-01 | 2013-03-28 | Kento Ogawa | Content processing device, content processing method, computer-readable recording medium, and integrated circuit |
| US20130066862A1 (en)* | 2011-09-12 | 2013-03-14 | Microsoft Corporation | Multi-factor correlation of internet content resources |
| US20190362384A1 (en)* | 2013-03-14 | 2019-11-28 | Clipfile Corporation | Tagging and ranking content |
| CN103678474A (en)* | 2013-09-24 | 2014-03-26 | 浙江大学 | Method for acquiring large number of hot topics fast in social network |
| CN103577579A (en)* | 2013-11-08 | 2014-02-12 | 南方电网科学研究院有限责任公司 | Resource recommendation method and system based on potential demands of users |
| CN105095202A (en)* | 2014-04-17 | 2015-11-25 | 华为技术有限公司 | Method and device for message recommendation |
| US20170161393A1 (en)* | 2015-12-08 | 2017-06-08 | Samsung Electronics Co., Ltd. | Terminal, server and event suggesting methods thereof |
| CN105740468A (en)* | 2016-03-07 | 2016-07-06 | 达而观信息科技(上海)有限公司 | Individuation recommendation method and system combined with content publisher information |
| US20170300535A1 (en)* | 2016-04-15 | 2017-10-19 | Google Inc. | Systems and methods for suggesting content to a writer based on contents of a document |
| US20190286673A1 (en)* | 2016-11-21 | 2019-09-19 | Comcast Cable Communications, Llc | Content Recommendation System With Weighted Metadata Annotations |
| US20190294657A1 (en)* | 2018-03-26 | 2019-09-26 | Adobe Inc. | Defining and delivering personalized entity recommendations |
| CN109460518A (en)* | 2018-12-07 | 2019-03-12 | 杭州东信北邮信息技术有限公司 | A kind of book recommendation method based on user website access record |
| CN110457581A (en)* | 2019-08-02 | 2019-11-15 | 达而观信息科技(上海)有限公司 | An information recommendation method, device, electronic device and storage medium |
| CN110457439A (en)* | 2019-08-06 | 2019-11-15 | 北京如优教育科技有限公司 | One-stop intelligent writes householder method, device and system |
Non-Patent Citations (1)
| Title |
|---|
| 黎万英;黄瑞章;丁志远;陈艳平;徐立洋;: "基于用户行为特征的多维度文本聚类", 计算机应用, no. 11* |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114930319A (en)* | 2020-08-31 | 2022-08-19 | 华为技术有限公司 | Music recommendation method and device |
| CN112395498A (en)* | 2020-11-02 | 2021-02-23 | 北京五八信息技术有限公司 | Topic recommendation method and device, electronic equipment and storage medium |
| CN113343083A (en)* | 2021-05-25 | 2021-09-03 | 北京字节跳动网络技术有限公司 | Theme pushing method and device, storage medium and computer equipment |
| CN113343083B (en)* | 2021-05-25 | 2024-08-13 | 北京字节跳动网络技术有限公司 | Theme pushing method and device, storage medium and computer equipment |
| CN113378555A (en)* | 2021-06-22 | 2021-09-10 | 富途网络科技(深圳)有限公司 | Intelligent association method for individual stock and related product |
| CN113378555B (en)* | 2021-06-22 | 2023-06-27 | 富途网络科技(深圳)有限公司 | Intelligent association method of individual strands and related products |
Also Published As
| Publication number | Publication date |
|---|---|
| CN111310058B (en) | 2023-08-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN112507715B (en) | Methods, devices, equipment and storage media for determining association relationships between entities | |
| CN111967262B (en) | Method and device for determining entity tags | |
| CN111522967B (en) | Knowledge graph construction method, device, equipment and storage medium | |
| CN111104514B (en) | Training method and device for document tag model | |
| CN111310058B (en) | Information theme recommendation method, device, terminal and storage medium | |
| CN111597433B (en) | Resource searching method and device and electronic equipment | |
| CN111709247A (en) | Data set processing method, apparatus, electronic device and storage medium | |
| US20200110842A1 (en) | Techniques to process search queries and perform contextual searches | |
| JP7096919B2 (en) | Entity word recognition method and device | |
| CN111931500B (en) | Search information processing method and device | |
| JP2022040026A (en) | Entity linking methods, devices, electronic devices and storage media | |
| WO2017040436A1 (en) | Distributed server system for language understanding | |
| CN111428049A (en) | Method, device, equipment and storage medium for generating event topic | |
| EP3832486A2 (en) | Text query method and apparatus, device and storage medium | |
| CN111831821A (en) | Method, device and electronic device for generating training samples for text classification model | |
| WO2022095892A1 (en) | Method and apparatus for generating push information | |
| CN111737501A (en) | A content recommendation method and device, electronic device, and storage medium | |
| CN111984774B (en) | Searching method, searching device, searching equipment and storage medium | |
| CN112380104A (en) | User attribute identification method and device, electronic equipment and storage medium | |
| CN111460289A (en) | News information push method and device | |
| CN112860840A (en) | Search processing method, device, equipment and storage medium | |
| CN111783463A (en) | Knowledge extraction method and device | |
| CN111737966A (en) | Document duplication detection method, apparatus, device and readable storage medium | |
| CN111400456B (en) | Information recommendation method and device | |
| CN115809334B (en) | Training method, text processing method and device for event correlation classification model |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |