CN111259142B - Specific target emotion classification method based on attention coding and graph convolution network - Google Patents
Specific target emotion classification method based on attention coding and graph convolution networkDownload PDFInfo
- Publication number
- CN111259142B CN111259142BCN202010036470.9ACN202010036470ACN111259142BCN 111259142 BCN111259142 BCN 111259142BCN 202010036470 ACN202010036470 ACN 202010036470ACN 111259142 BCN111259142 BCN 111259142B
- Authority
- CN
- China
- Prior art keywords
- context
- specific target
- coding
- attention
- word
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images






Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/35—Clustering; Classification
- G06F16/353—Clustering; Classification into predefined classes
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/044—Recurrent networks, e.g. Hopfield networks
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Biophysics (AREA)
- Evolutionary Computation (AREA)
- Biomedical Technology (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- Computational Linguistics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Health & Medical Sciences (AREA)
- Databases & Information Systems (AREA)
- Machine Translation (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明涉及自然语言处理技术领域,特别是涉及一种基于注意力编码和图卷积网络的特定目标情感分类方法。The invention relates to the technical field of natural language processing, in particular to a specific target emotion classification method based on attention coding and graph convolution network.
背景技术Background technique
情感分析是自然语言处理(Natural Language Processing,NLP)中的重要任务,其目的在于对带有情感色彩的主观性文本进行分析。其中,特定目标的情感分析属于细粒度情感分析,与传统的情感分析不同,其目的主要在于识别句子中特定目标的情感极性。Sentiment analysis is an important task in Natural Language Processing (NLP), and its purpose is to analyze subjective texts with emotional colors. Among them, the sentiment analysis of a specific target belongs to fine-grained sentiment analysis. Different from the traditional sentiment analysis, its purpose is mainly to identify the sentiment polarity of a specific target in a sentence.
目前,有众多神经网络与注意力机制相结合的方法用以解决特定目标的情感分析问题,这些方法虽然能够克服浅层学习模型的缺陷,区分了不同词对于特定目标情感分析任务的重要性,但是依旧存在如下问题:一方面,现有方法不能充分捕捉上下文的语义信息,没有关注长距离信息依赖和信息并行计算的问题;另一方面,现有方法均没有考虑上下文和特定目标与句法信息之间的联系,且由于缺乏句法的约束技术,可能会将句法上不相关的上下文单词识别为判断目标情感分类的线索,降低了分类的准确性。At present, there are many methods combining neural network and attention mechanism to solve the problem of sentiment analysis of specific targets. Although these methods can overcome the shortcomings of shallow learning models and distinguish the importance of different words for specific target sentiment analysis tasks, However, the following problems still exist: on the one hand, the existing methods cannot fully capture the semantic information of the context, and do not pay attention to the problems of long-distance information dependence and information parallel computing; on the other hand, the existing methods do not consider the context, specific targets and syntactic information. Moreover, due to the lack of syntactic constraint technology, syntactically irrelevant context words may be identified as clues for judging the target sentiment classification, reducing the classification accuracy.
发明内容SUMMARY OF THE INVENTION
为克服相关技术中存在的问题,本发明实施例提供了一种基于注意力编码和图卷积网络的特定目标情感分类方法及装置。In order to overcome the problems existing in the related art, the embodiments of the present invention provide a specific target emotion classification method and device based on attention coding and graph convolutional network.
根据本发明实施例的第一方面,提供一种基于注意力编码和图卷积网络的特定目标情感分类方法,包括如下步骤:According to a first aspect of the embodiments of the present invention, there is provided a specific target emotion classification method based on attention coding and graph convolutional network, including the following steps:
获取上下文对应的词向量和特定目标对应的词向量;Obtain the word vector corresponding to the context and the word vector corresponding to a specific target;
将所述上下文对应的词向量和特定目标对应的词向量输入预设双向循环神经网络模型,得到上下文对应的隐藏状态向量和特定目标对应的隐藏状态向量;Inputting the word vector corresponding to the context and the word vector corresponding to the specific target into a preset two-way cyclic neural network model to obtain the hidden state vector corresponding to the context and the hidden state vector corresponding to the specific target;
基于结合逐点卷积的预设图卷积神经网络,提取所述上下文对应的句法依存树中的句法向量;extracting a syntax vector in the syntax dependency tree corresponding to the context based on a preset graph convolutional neural network combined with point-by-point convolution;
对所述上下文对应的隐藏状态向量、所述特定目标对应的隐藏状态向量和所述句法向量进行多头自注意力编码,分别得到上下文语义信息编码、特定目标语义信息编码和句法信息编码;Perform multi-head self-attention coding on the hidden state vector corresponding to the context, the hidden state vector corresponding to the specific target, and the syntax vector, to obtain the context semantic information coding, the specific target semantic information coding and the syntax information coding respectively;
对所述上下文语义信息编码和句法信息编码、所述特定目标语义信息编码和句法信息编码分别进行多头交互注意力编码,得到上下文-句法信息编码和特定目标-句法信息编码;Perform multi-head interactive attention coding on the context semantic information coding and syntax information coding, the specific target semantic information coding and the syntactic information coding, respectively, to obtain the context-syntax information coding and the specific target-syntax information coding;
将所述上下文语义信息编码、所述上下文-句法信息编码和所述特定目标-句法信息编码取平均池化后再进行拼接,得到所述特定目标对应的特征表示;The context semantic information encoding, the context-syntax information encoding and the specific target-syntax information encoding are averaged and pooled before splicing to obtain a feature representation corresponding to the specific target;
将所述特征表示输入预设归一化指数函数中,得到特定目标的情感分类结果。The feature representation is input into the preset normalized exponential function to obtain the sentiment classification result of the specific target.
可选的,将所述上下文对应的词向量



其中,n表示上下文对应的词向量的维度,m表示特定目标对应的词向量的维度,

可选的,根据特定目标在上下文中的位置和位置权重分配函数,得到上下文中每个单词对应的位置权重;Optionally, according to the position of the specific target in the context and the position weight assignment function, the position weight corresponding to each word in the context is obtained;
获取上下文对应的句法依存树;Get the syntactic dependency tree corresponding to the context;
根据所述句法依存树,得到所述上下文中的单词对应的邻接矩阵,其中,所述邻接矩阵反应所述上下文中的单词的邻接关系;According to the syntactic dependency tree, an adjacency matrix corresponding to the word in the context is obtained, wherein the adjacency matrix reflects the adjacency relationship of the word in the context;
将所述邻接矩阵和所述每个单词对应的位置权重输入预设图卷积神经网络,得到输出层的输出结果;Inputting the adjacency matrix and the position weight corresponding to each word into a preset graph convolutional neural network to obtain the output result of the output layer;
对所述输出结果进行逐点卷积,得到所述句法向量。Perform point-by-point convolution on the output result to obtain the syntax vector.
可选的,根据特定目标在上下文中的位置和位置权重分配函数,得到上下文中每个单词对应的位置权重;其中,所述位置权重分配函数F(·)如下:Optionally, according to the position of the specific target in the context and the position weight assignment function, the position weight corresponding to each word in the context is obtained; wherein, the position weight assignment function F( ) is as follows:

τ+1表示特定目标的起始位置,m表示特定目标中单词的个数,n表示上下文中单词的个数,qi表示上下文中第i个单词的位置权重。τ+1 represents the starting position of the specific target, m represents the number of words in the specific target, n represents the number of words in the context, and qi represents the position weight of theith word in the context.
可选的,将所述邻接矩阵、每个单词的位置权重和上一层的输出结果输入至预设图卷积运算公式中,得到当前层的输出结果,重复执行输入操作直至得到输出层的输出结果;其中,所述预设图卷积运算公式如下:Optionally, input the adjacency matrix, the position weight of each word and the output result of the previous layer into the preset graph convolution operation formula to obtain the output result of the current layer, and repeat the input operation until the output layer is obtained. Output result; wherein, the preset graph convolution operation formula is as follows:



Aij表示邻接矩阵的第i行第j列的值,A∈Rn×n表示邻接矩阵A为n行n列的矩阵,Aij表示预设图卷积神经网络的上一层输出结果,qj表示上下文中第j个单词的位置权重,

可选的,将预设图卷积网络的输出层的输出结果输入预设逐点卷积公式,得到所述句法向量;其中,所述预设逐点卷积公式如下:Optionally, input the output result of the output layer of the preset graph convolution network into a preset point-by-point convolution formula to obtain the syntax vector; wherein, the preset point-by-point convolution formula is as follows:

PWC(h)=σ(h*Wpwc+bpwc)PWC(h)=σ(h*Wpwc +bpwc )
hl表示预设图卷积网络的输出层的输出结果,


可选的,将所述上下文对应的隐藏状态向量Hc、所述特定目标对应的隐藏状态向量Ht和所述句法向量
Hcs=MHA(Hc,Hc)Hcs =MHA(Hc ,Hc )
Hts=MHA(Ht,Ht)Hts =MHA(Ht ,Ht )


oh=Attentionh(k,q)oh = Attentionh (k,q)
Attention(k,q)=soft max(fs(k,q))kAttention(k,q)=soft max(fs (k,q))k

fs(ki,qj)=tanh([ki;qj]·Watt)fs (ki , qj )=tanh([ki ; qj ]·Watt )
fs(ki,qj)表示多头注意力的第一输入向量k={k1,k2,...,kn}与多头注意力的第二输入向量q={q1,q2,...,qm}的语义相关性,当进行多头自注意力编码时k=q,当进行多头交互注意力编码时k≠q,“;”是指向量的拼接,



可选的,将所述上下文语义信息编码Hcs和句法信息编码Hgs、所述特定目标语义信息编码Hts和句法信息编码Hgs分别输入预设多头注意力编码公式,得到上下文-句法信息编码Hgt和特定目标-句法信息编码Hcg;其中,Optionally, the context semantic information encoding Hcs and the syntax information encoding Hgs , the specific target semantic information encoding Hts and the syntax information encoding Hgs are respectively input into a preset multi-head attention encoding formula to obtain the context-syntax information. encode Hgt and specific object-syntax information encode Hcg ; where,
Hgt=MHA(Hgs,Hts)Hgt =MHA(Hgs ,Hts )
Hcg=MHA(Hgs,Hcs)Hcg =MHA(Hgs ,Hcs )

可选的,对上下文-句法信息编码Hcg,特定目标-句法信息编码Hgt以及上下文语义编码Hcs输入预设平均池化计算公式,并将输出结果进行拼接,得到所述特定目标对应的特征表示u;其中,预设平均池化计算公式如下:Optionally, a preset average pooling calculation formula is input into the context-syntax information coding Hcg , the specific target-syntax information coding Hgt and the context semantic coding Hcs , and the output results are spliced to obtain the corresponding specific target. The feature represents u; among them, the preset average pooling calculation formula is as follows:







可选的,将所述特征表示先输入预设转换公式,再将特征表示的转换结果输入预设归一化指数函数中,得到特定目标的情感分类结果,其中,所述预设转换公式和预设归一化指数函数如下:Optionally, the feature representation is first input into a preset conversion formula, and then the conversion result of the feature representation is input into a preset normalized exponential function to obtain the sentiment classification result of the specific target, wherein the preset conversion formula and The default normalized exponential function is as follows:




相对于现有技术,本发明实施例通过预设双向循环神经网络模型,得到上下文对应的隐藏状态向量和特定目标对应的隐藏状态向量,再结合多头自注意力的并行计算和长距离依赖的优点,对上下文对应的隐藏状态向量和特定目标对应的隐藏状态向量进行多头自注意编码,提取到丰富充分的上下文语义信息和特定目标语义信息。再通过逐点卷积的图卷积神经网络,提取所述上下文对应的句法依存树中的句法向量,并对句法向量进行多头自注意力编码,得到句法信息编码,之后,使用多头交互注意力分别对句法信息编码和上下文语义信息编码、句法信息编码和特定目标语义信息编码进行交互融合,将融合后的结果与上下文语义信息编码拼接,得到最终的特征表示,使得该特征表示充分考虑了上下文和特定目标与句法信息之间的联系,防止了将句法上不相关的上下文单词识别为判断目标情感分类的线索,提高了情感分类的准确性。Compared with the prior art, the embodiment of the present invention obtains the hidden state vector corresponding to the context and the hidden state vector corresponding to the specific target by presetting a bidirectional cyclic neural network model, and then combines the advantages of parallel computing of multi-head self-attention and long-distance dependence. , perform multi-head self-attention coding on the hidden state vector corresponding to the context and the hidden state vector corresponding to a specific target, and extract rich and sufficient contextual semantic information and specific target semantic information. Then, through the point-by-point convolution graph convolutional neural network, the syntax vector in the syntactic dependency tree corresponding to the context is extracted, and the multi-head self-attention encoding is performed on the syntax vector to obtain the syntax information encoding. After that, the multi-head interactive attention is used. The syntactic information coding and the context semantic information coding, the syntactic information coding and the specific target semantic information coding are interactively fused, respectively, and the fusion result is spliced with the context semantic information coding to obtain the final feature representation, so that the feature representation fully considers the context. The connection between the specific target and the syntactic information prevents the recognition of syntactically irrelevant context words as clues for judging the target sentiment classification, and improves the accuracy of sentiment classification.
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本发明。It is to be understood that both the foregoing general description and the following detailed description are exemplary and explanatory only and are not restrictive of the invention.
为了更好地理解和实施,下面结合附图详细说明本发明。For better understanding and implementation, the present invention is described in detail below with reference to the accompanying drawings.
附图说明Description of drawings
图1为本发明一个示例性实施例提供的基于注意力编码和图卷积网络的特定目标情感分类方法的流程示意图;1 is a schematic flowchart of a specific target sentiment classification method based on attention coding and graph convolutional network provided by an exemplary embodiment of the present invention;
图2为本发明一个示例性实施例提供的基于注意力编码和图卷积网络的特定目标情感分类方法中S103的流程示意图;FIG. 2 is a schematic flowchart of S103 in the specific target emotion classification method based on attention coding and graph convolution network provided by an exemplary embodiment of the present invention;
图3为本发明一个示例性实施例提供的句法依存树的示意图;3 is a schematic diagram of a syntax dependency tree provided by an exemplary embodiment of the present invention;
图4为本发明一个示例性实施例提供的邻接矩阵的示意图;4 is a schematic diagram of an adjacency matrix provided by an exemplary embodiment of the present invention;
图5为本发明一个示例性实施例提供的基于注意力编码和图卷积网络的特定目标情感分类模型的整体结构示意图;5 is a schematic diagram of the overall structure of a specific target emotion classification model based on attention coding and graph convolutional networks provided by an exemplary embodiment of the present invention;
图6为本发明一个示例性实施例提供的图卷积神经网络的示意图;6 is a schematic diagram of a graph convolutional neural network provided by an exemplary embodiment of the present invention;
图7为本发明一个示例性实施例提供的基于注意力编码和图卷积网络的特定目标情感分类装置的结构示意图;FIG. 7 is a schematic structural diagram of a specific target emotion classification device based on attention coding and graph convolution network provided by an exemplary embodiment of the present invention;
图8为本发明一个示例性实施例提供的基于注意力编码和图卷积网络的特定目标情感分类设备的结构示意图。FIG. 8 is a schematic structural diagram of a specific target emotion classification device based on attention coding and graph convolutional network provided by an exemplary embodiment of the present invention.
具体实施方式Detailed ways
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本发明相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本发明的一些方面相一致的装置和方法的例子。Exemplary embodiments will be described in detail herein, examples of which are illustrated in the accompanying drawings. Where the following description refers to the drawings, the same numerals in different drawings refer to the same or similar elements unless otherwise indicated. The implementations described in the illustrative examples below are not intended to represent all implementations consistent with the present invention. Rather, they are merely examples of apparatus and methods consistent with some aspects of the invention as recited in the appended claims.
在本发明使用的术语是仅仅出于描述特定实施例的目的,而非旨在限制本发明。在本发明和所附权利要求书中所使用的单数形式的“一种”、“所述”和“该”也旨在包括多数形式,除非上下文清楚地表示其他含义。还应当理解,本文中使用的术语“和/或”是指并包含一个或多个相关联的列出项目的任何或所有可能组合。The terminology used in the present invention is for the purpose of describing particular embodiments only and is not intended to limit the present invention. As used in this specification and the appended claims, the singular forms "a," "the," and "the" are intended to include the plural forms as well, unless the context clearly dictates otherwise. It will also be understood that the term "and/or" as used herein refers to and includes any and all possible combinations of one or more of the associated listed items.
应当理解,尽管在本发明可能采用术语第一、第二、第三等来描述各种信息,但这些信息不应限于这些术语。这些术语仅用来将同一类型的信息彼此区分开。例如,在不脱离本发明范围的情况下,第一信息也可以被称为第二信息,类似地,第二信息也可以被称为第一信息。取决于语境,如在此所使用的词语“如果”/“若”可以被解释成为“在……时”或“当……时”或“响应于确定”。It should be understood that although the terms first, second, third, etc. may be used in the present invention to describe various information, such information should not be limited by these terms. These terms are only used to distinguish the same type of information from each other. For example, the first information may also be referred to as the second information, and similarly, the second information may also be referred to as the first information, without departing from the scope of the present invention. Depending on the context, the words "if"/"if" as used herein may be interpreted as "at the time of" or "when" or "in response to determining".
请参阅图1,图1为本发明一个示例性实施例提供的基于注意力编码和图卷积网络的特定目标情感分类方法的流程示意图,所述方法由情感分类设备执行,包括如下步骤:Please refer to FIG. 1. FIG. 1 is a schematic flowchart of a specific target emotion classification method based on attention coding and graph convolutional network provided by an exemplary embodiment of the present invention. The method is executed by an emotion classification device and includes the following steps:
S101:获取上下文对应的词向量和特定目标对应的词向量。S101: Obtain a word vector corresponding to the context and a word vector corresponding to a specific target.
词嵌入是单词的一种数字化表示方式,其是将一个单词映射到一个高维的向量中以实现对单词的表示,这个向量被称为词向量。Word embedding is a digital representation of words, which is to map a word into a high-dimensional vector to represent the word. This vector is called a word vector.
在本申请实施例中,情感分类设备首先确定文本内的上下文和特定目标,其中,上下文可以为文本中的一句话,特定目标为上下文中的至少一个单词,例如:上下文为“theprice is reasonable while the service is poor”,特定目标为“price”和“service”。之后,情感分类设备通过词嵌入工具将该上下文和特定目标转换为对应的词向量,若上下文中包括n个单词,上下文对应的词向量则为n个高维向量,若特定目标包括m个单词,特定目标对应的词向量则为m个高维向量。In the embodiment of the present application, the emotion classification device first determines the context and a specific target in the text, wherein the context can be a sentence in the text, and the specific target is at least one word in the context, for example: the context is "the price is reasonable while the service is poor", with specific targets "price" and "service". After that, the sentiment classification device converts the context and the specific target into the corresponding word vector through the word embedding tool. If the context includes n words, the word vector corresponding to the context is n high-dimensional vectors. If the specific target includes m words , and the word vector corresponding to a specific target is m high-dimensional vectors.
词嵌入工具可以为GloVe或word2vec等,在本申请实施例中,基于GloVe的并行化处理以及利于处理大数据集的优势,采用GloVe对上下文和特定目标进行词向量转换,获取上下文对应的词向量和特定目标对应的词向量。The word embedding tool can be GloVe or word2vec, etc. In the embodiment of this application, based on the parallel processing of GloVe and the advantages of being conducive to processing large data sets, GloVe is used to convert the context and specific targets to word vectors, and obtain the word vectors corresponding to the context. word vector corresponding to a specific target.
S102:将所述上下文对应的词向量和特定目标对应的词向量输入预设双向循环神经网络模型,得到上下文对应的隐藏状态向量和特定目标对应的隐藏状态向量。S102: Input the word vector corresponding to the context and the word vector corresponding to the specific target into a preset bidirectional recurrent neural network model to obtain a hidden state vector corresponding to the context and a hidden state vector corresponding to the specific target.
循环神经网络(Recurrent Neural Network,RNN)是一类以序列数据为输入,在序列的演进方向进行递归且所有节点(循环单元)按链式连接的递归神经网络,常见的循环神经网络包括双向循环神经网络(Bidirectional RNN,Bi-RNN)、长短期记忆网络(LongShort-Term Memory networks,LSTM)、双向长短期记忆网络(Bidirectional Long Short-Term Memory networks,Bi-LSTM)等。Recurrent Neural Network (RNN) is a type of recurrent neural network that takes sequence data as input, performs recursion in the evolution direction of the sequence, and all nodes (recurrent units) are connected in a chain. Common recurrent neural networks include bidirectional loops. Neural network (Bidirectional RNN, Bi-RNN), long short-term memory network (LongShort-Term Memory networks, LSTM), bidirectional long short-term memory network (Bidirectional Long Short-Term Memory networks, Bi-LSTM) and so on.
本申请实施例中,可以采用双向循环神经网络(Bidirectional RNN,Bi-RNN)或双向长短期记忆网络(Bidirectional Long Short-Term Memory networks,Bi-LSTM)作为预设双向循环神经网络模型,得到上下文对应的隐藏状态向量和特定目标对应的隐藏状态向量,初步获取上下文及特定目标中所包含的语义信息。双向的循环神经网络模型的隐藏层要保存两个值,一个值参与正向计算,另一个值参与反向计算,即在一个循环网络包括前向循环神经网络和后向神经网络,双向的循环神经网络更适用于对时序数据的建模,更利于捕捉双向的语义依赖。In the embodiment of the present application, a bidirectional cyclic neural network (Bidirectional RNN, Bi-RNN) or a bidirectional long short-term memory network (Bidirectional Long Short-Term Memory networks, Bi-LSTM) may be used as a preset bidirectional cyclic neural network model to obtain the context The corresponding hidden state vector and the hidden state vector corresponding to the specific target are used to preliminarily obtain the context and semantic information contained in the specific target. The hidden layer of the bidirectional recurrent neural network model needs to save two values, one value participates in the forward calculation, and the other value participates in the reverse calculation, that is, in a recurrent network including a forward recurrent neural network and a backward neural network, a two-way cycle Neural networks are more suitable for modeling time series data and are more conducive to capturing bidirectional semantic dependencies.
在一个可选的实施例中,由于在进行特定情感目标分类的过程中,需要考虑单词在上下文中的前后顺序,因而若采用Bi-LSTM,则能够传递相隔较远的信息,同时避免长期依赖的问题。例如,上下文“我不觉得这个画展好”,通过Bi-LSTM模型中的前向神经网络能够获知“不”字是对后面“好”的否定,从而得出该句子的情感极性是贬义。再例如:“我觉得这个酒店房间脏得不行,没有前面那家好”,通过Bi-LSTM中的后向神经网络,能够获知“不行”是对“脏”的程度的一种修饰。因而,通过利用Bi-LSTM预设双向循环神经网络模型,能够使得到的上下文对应的隐藏状态向量和特定目标对应的隐藏状态向量更准确地描述上下文及特定目标中所包含的语义信息。In an optional embodiment, since the sequence of words in the context needs to be considered in the process of classifying specific emotional targets, if Bi-LSTM is used, information that is far apart can be transmitted while avoiding long-term dependencies The problem. For example, in the context of "I don't think this exhibition is good", the forward neural network in the Bi-LSTM model can learn that the word "no" is a negation of the following "good", so that the emotional polarity of the sentence is derogatory. Another example: "I think this hotel room is not as dirty as the previous one." Through the backward neural network in Bi-LSTM, we can know that "no" is a modification of the degree of "dirty". Therefore, by using Bi-LSTM to preset a bidirectional recurrent neural network model, the hidden state vector corresponding to the obtained context and the hidden state vector corresponding to the specific target can more accurately describe the context and the semantic information contained in the specific target.
具体地,将所述上下文对应的词向量



其中,n表示上下文对应的词向量的维度,m表示特定目标对应的词向量的维度,

S103:基于结合逐点卷积的预设图卷积神经网络,提取所述上下文对应的句法依存树中的句法向量。S103: Extract a syntax vector in the syntax dependency tree corresponding to the context based on a preset graph convolutional neural network combined with point-by-point convolution.
语义依存分析(Semantic Dependency Parsing,SDP)又称依存树,用于分析上下文中单词之间的语义关联,并将语义关联以依存结构呈现。具体过程为:(1)对上下文进行分词,例如:“猴子喜欢吃香蕉。”,分词后为“猴子喜欢吃香蕉。”;(2)对每个单词进行词性标注,例如:猴子/NN喜欢/VV吃/VV香蕉/NN。/PU;(3)由词性标注生成短语句法树;(4)将短语句法树转化成句法依存树。Semantic Dependency Parsing (SDP), also known as dependency tree, is used to analyze the semantic associations between words in the context and present the semantic associations in a dependency structure. The specific process is: (1) Perform word segmentation on the context, for example: "Monkey likes to eat bananas." After the word segmentation is "Monkey likes to eat bananas."; (2) Tag each word with part of speech, for example: Monkey/NN likes /VV Eat /VV Bananas /NN. /PU; (3) generate a short syntax tree from part-of-speech tagging; (4) convert the short syntax tree into a syntax dependency tree.
图卷积神经网络(GCN)用于对图结构类型的数据进行处理,其中图结构即拓扑结构,也可以称之为非欧几里得结构,常见的图结构包括例如社交网络、信息网络等。逐点卷积是将图卷积神经网络的输出结果再进行一次卷积操作,以更好的整合句子中的句法。Graph Convolutional Neural Network (GCN) is used to process data of graph structure type, in which graph structure is topological structure, which can also be called non-Euclidean structure. Common graph structures include, for example, social networks, information networks, etc. . Point-by-point convolution is to perform a convolution operation on the output of the graph convolutional neural network to better integrate the syntax in the sentence.
在本申请实施例中,情感分类设备获取上下文对应的句法依存树,并利用先利用预设图卷积神经网络获取句法依存树中的初始句法向量,之后再对初始句法向量进行逐点卷积,得到上下文对应的句法向量。其中,将训练好的图卷积神经网络作为预设图卷积神经网络,具体训练方式与现有神经网络的训练方式相同。In the embodiment of the present application, the sentiment classification device obtains the syntactic dependency tree corresponding to the context, and first uses a preset graph convolutional neural network to obtain the initial syntax vector in the syntax dependency tree, and then performs point-by-point convolution on the initial syntax vector , get the syntactic vector corresponding to the context. Among them, the trained graph convolutional neural network is used as the preset graph convolutional neural network, and the specific training method is the same as that of the existing neural network.
结合逐点卷积的预设图卷积神经网络能够把句法依存树中展示的句法信息提取出来,得到句法向量,从而在后续避免将句法上不相关的单词作为判断情感极性的线索,提高特定目标情感分类的准确性。The preset graph convolutional neural network combined with point-by-point convolution can extract the syntactic information displayed in the syntactic dependency tree and obtain the syntactic vector, so as to avoid using syntactically irrelevant words as clues for judging emotional polarity in the future. The accuracy of sentiment classification for a specific target.
在一个可选的实施例中,为准确获取所述句法向量,步骤S103具体包括S1031~S1035,请参阅图2,图2为本发明一个示例性实施例提供的基于注意力编码和图卷积网络的特定目标情感分类方法中S103的流程示意图,步骤S1031~S1035如下:In an optional embodiment, in order to accurately obtain the syntax vector, step S103 specifically includes S1031 to S1035, please refer to FIG. 2 , which is the attention-based coding and graph convolution provided by an exemplary embodiment of the present invention A schematic flowchart of S103 in the network specific target sentiment classification method, steps S1031 to S1035 are as follows:
S1031:根据特定目标在上下文中的位置和位置权重分配函数,得到上下文中每个单词对应的位置权重。S1031: Obtain the position weight corresponding to each word in the context according to the position of the specific target in the context and the position weight assignment function.
根据特定目标在上下文中的位置的不同,因而上下文中每个单词对于特定目标的情感分类的重要程度也不同。具体地,根据特定目标在上下文中的位置和位置权重分配函数,得到上下文中每个单词对应的位置权重。位置权重分配函数可以根据不同特定目标情感分类的需求不同进行预先设置。例如:可以设置位置权重分配函数为F(a),a为上下文中每个单词与最近的特定目标之间相隔单词个数,从而根据相隔的单词个数,得到不同的位置权重。According to the different positions of the specific target in the context, the importance of each word in the context to the sentiment classification of the specific target is also different. Specifically, according to the position of the specific target in the context and the position weight assignment function, the position weight corresponding to each word in the context is obtained. The location weight assignment function can be preset according to the different needs of different specific target sentiment classification. For example, the position weight assignment function can be set as F(a), where a is the number of words separated between each word in the context and the nearest specific target, so that different position weights can be obtained according to the number of separated words.
在一个可选的实施例中,根据特定目标在上下文中的位置和位置权重分配函数,得到上下文中每个单词对应的位置权重词向量;其中,所述位置权重分配函数F(·)如下:In an optional embodiment, according to the position of the specific target in the context and the position weight distribution function, the position weight word vector corresponding to each word in the context is obtained; wherein, the position weight distribution function F( ) is as follows:

τ+1表示特定目标的起始位置,m表示特定目标中单词的个数,n表示上下文中单词的个数,qi表示上下文中第i个单词的位置权重。τ+1 represents the starting position of the specific target, m represents the number of words in the specific target, n represents the number of words in the context, and qi represents the position weight of theith word in the context.
通过上述置权重分配函数F(·)得到更准确地分析出不同位置的单词的重要程度,更合理地分配上下文中每个单词对应的位置权重。Through the above-mentioned weight assignment function F(·), the importance of words in different positions can be analyzed more accurately, and the position weight corresponding to each word in the context can be allocated more reasonably.
S1032:获取上下文对应的句法依存树。S1032: Obtain a syntactic dependency tree corresponding to the context.
情感分类设备获取上下文对应的句法依存树。The sentiment classification device obtains the syntactic dependency tree corresponding to the context.
在本申请实施例中,可以通过spaCy进行句法依存树的获取。句法依存树能够形象的体现出上下文中单词的依存关系。请参阅图3,图3为本发明一个示例性实施例提供的句法依存树的示意图。如图所示,上下文为“我今天很不开心”,构建的句法依存树中,开心为句法依存树的根部,其包括三个分枝分别为“我”(主语)、“今天”(状语)和“不”(状语),“不”的分枝为“很”(状语),用于进一步修饰“不”。In this embodiment of the present application, the syntax dependency tree can be obtained through spaCy. The syntactic dependency tree can vividly reflect the dependencies of words in the context. Please refer to FIG. 3 , which is a schematic diagram of a syntax dependency tree provided by an exemplary embodiment of the present invention. As shown in the figure, the context is "I am very unhappy today". In the constructed syntactic dependency tree, happy is the root of the syntactic dependency tree, which includes three branches: "I" (subject) and "today" (adverbial). ) and "bu" (adverb), the branch of "bu" is "very" (adverb), which is used to further modify "bu".
S1033:根据所述句法依存树,得到所述上下文中的单词对应的邻接矩阵,其中,所述邻接矩阵反应所述上下文中的单词的邻接关系。S1033: Obtain an adjacency matrix corresponding to a word in the context according to the syntactic dependency tree, where the adjacency matrix reflects the adjacency relationship of the words in the context.
在本申请实施例中,情感分类设备根据所述句法依存树,得到所述上下文中的单词对应的邻接矩阵。其中,邻接矩阵反应上下文中的单词的邻接关系。需要说明的是,单词与自身默认存在邻接关系。In the embodiment of the present application, the emotion classification device obtains the adjacency matrix corresponding to the word in the context according to the syntactic dependency tree. Among them, the adjacency matrix reflects the adjacency relationship of words in the context. It should be noted that a word has an adjacency relationship with itself by default.
请参阅图4,图4为本发明一个示例性实施例提供的邻接矩阵的示意图,图4所示的邻接矩阵对应图3所示的句法依存树。如图所示,其对角线上的数值均为1,表示每个单词与自身均存在邻接关系。图3中句法依存树的根部为“开心”,其包括三个分枝分别为“我”、“今天”和“不”,因而在对应的邻接矩阵中,“开心”所在行与“我”、“今天”、“不”所在列值的交叉位置处,值均为1。通过上下文中的单词对应的邻接矩阵,能够精准快速地获取单词之间的邻接关系。Please refer to FIG. 4 , which is a schematic diagram of an adjacency matrix provided by an exemplary embodiment of the present invention. The adjacency matrix shown in FIG. 4 corresponds to the syntax dependency tree shown in FIG. 3 . As shown in the figure, the values on the diagonal line are all 1, indicating that each word has an adjacency relationship with itself. The root of the syntactic dependency tree in Figure 3 is "happy", which includes three branches, namely "me", "today" and "no", so in the corresponding adjacency matrix, the row where "happy" is located is the same as "me" , "Today", "No" at the intersection of the column value, the value is 1. Through the adjacency matrix corresponding to the words in the context, the adjacency relationship between words can be obtained accurately and quickly.
S1034:将所述邻接矩阵和所述每个单词对应的位置权重输入预设图卷积神经网络,得到输出层的输出结果。S1034: Input the adjacency matrix and the position weight corresponding to each word into a preset graph convolutional neural network to obtain an output result of the output layer.
在本申请实施例中,情感分类设备将所述邻接矩阵和所述每个单词对应的位置权重输入预设图卷积神经网络,得到输出层的输出结果。其中,预设图卷积神经网络的隐藏层设置为1层,激活函数可根据实际情况进行设置。In the embodiment of the present application, the emotion classification device inputs the adjacency matrix and the position weight corresponding to each word into a preset graph convolutional neural network to obtain the output result of the output layer. Among them, the hidden layer of the preset graph convolutional neural network is set to 1 layer, and the activation function can be set according to the actual situation.
具体地,情感分类设备将邻接矩阵、每个单词的位置权重以及上下文对应的隐藏状态向量Hc输入预设图卷积神经网络的输入层,并将输入层的输出结果、邻接矩阵和每个单词的位置权重传入隐藏层,隐藏层再将其输出结果、邻接矩阵和每个单词的位置权重传递至输出层,最终得到输出层的输出结果,即句法依存树中的初始句法向量。Specifically, the sentiment classification device inputs the adjacency matrix, the position weight of each word, and the hidden state vector Hc corresponding to the context into the input layer of the preset graph convolutional neural network, and inputs the output result of the input layer, the adjacency matrix and each The position weight of the word is passed to the hidden layer, and the hidden layer transmits its output result, the adjacency matrix and the position weight of each word to the output layer, and finally the output result of the output layer is obtained, that is, the initial syntactic vector in the syntactic dependency tree.
在一个可选的实施例中,预设图卷积神经网络的隐藏层可以为多层,激活函数为RELU()。In an optional embodiment, the hidden layer of the preset graph convolutional neural network may be multi-layered, and the activation function is RELU().
具体地,情感分类设备将所述邻接矩阵、每个单词的位置权重和上一层的输出结果输入至预设图卷积运算公式中,得到当前层的输出结果,重复执行输入操作直至得到输出层的输出结果;其中,所述预设图卷积运算公式如下:Specifically, the emotion classification device inputs the adjacency matrix, the position weight of each word, and the output result of the previous layer into the preset graph convolution operation formula, obtains the output result of the current layer, and repeats the input operation until the output is obtained. The output result of the layer; wherein, the preset graph convolution operation formula is as follows:



Aij表示邻接矩阵的第i行第j列的值,A∈Rn×n表示邻接矩阵A为n行n列的矩阵,Aij表示预设图卷积神经网络的上一层输出结果,qj表示上下文中第j个单词的位置权重,

S1035:对所述输出结果进行逐点卷积,得到所述句法向量。S1035: Perform point-by-point convolution on the output result to obtain the syntax vector.
情感分类设备对对所述输出结果(即初始句法向量)进行逐点卷积,得到所述句法向量。其中,逐点卷积操作是指逐个对初始句法向量

在一个可选的实施例中,情感分类设备将预设图卷积网络的输出层的输出结果输入预设逐点卷积公式,得到所述句法向量;其中,所述预设逐点卷积公式如下:In an optional embodiment, the emotion classification device inputs the output result of the output layer of the preset graph convolution network into a preset point-by-point convolution formula to obtain the syntax vector; wherein, the preset point-by-point convolution The formula is as follows:

PWC(h)=σ(h*Wpwc+bpwc)PWC(h)=σ(h*Wpwc +bpwc )
hl表示预设图卷积网络的输出层的输出结果,


S104:对所述上下文对应的隐藏状态向量、所述特定目标对应的隐藏状态向量和所述句法向量进行多头自注意力编码,分别得到上下文语义信息编码、特定目标语义信息编码和句法信息编码。S104: Perform multi-head self-attention encoding on the hidden state vector corresponding to the context, the hidden state vector corresponding to the specific target, and the syntax vector, to obtain context semantic information encoding, specific target semantic information encoding, and syntax information encoding, respectively.
注意力机制的本质来自于人类视觉注意力机制,将注意力机制应用于情感分类,目的在于能够使在分类过程中分配更多的注意力到关键单词。具体地,可以将一句文本想象成是由一系列的<Key,Value>数据对组成,此时给定某个元素Query(查询),通过计算Query和各个Key的相似性或者相关性,得到每个Key对应的Value的权重系数,再通过softmax函数归一化后,对权重系数和相应Value进行加权求和,得到注意力结果。目前的研究中,Key和Value常常都是相等的,即Key=Value。The essence of the attention mechanism comes from the human visual attention mechanism, and the attention mechanism is applied to emotion classification in order to allocate more attention to key words in the classification process. Specifically, a sentence of text can be imagined as consisting of a series of <Key, Value> data pairs. At this time, given a certain element Query (query), by calculating the similarity or correlation between Query and each Key, each key is obtained. The weight coefficient of the Value corresponding to each Key is normalized by the softmax function, and the weight coefficient and the corresponding Value are weighted and summed to obtain the attention result. In the current research, Key and Value are often equal, that is, Key=Value.
多头注意力编码(Multi-head Attention)表示进行多次注意力编码运算,每运算一次代表一头,头之间的参数不进行共享,最后将结果进行拼接,在进行一次线性变换得到多头编码结果。Multi-head attention coding (Multi-head Attention) means to perform multiple attention coding operations, each operation represents one head, the parameters between the heads are not shared, and finally the results are spliced, and a linear transformation is performed to obtain the multi-head coding result.
多头注意力编码又分为多头自注意力编码和多头交互注意力编码。其中,多头自注意力的Query与Key相同,多头交互注意力编码的Query与Key不相同。对于多头自注意力编码,其需要实现某一句文本中的每个词与该句文本的所有词之间的注意力值的计算;对于多头交互注意力编码,其需要实现某一句文本中的每个词与其他文本的所有词之间的注意力值的计算。Multi-head attention coding is further divided into multi-head self-attention coding and multi-head interactive attention coding. Among them, the multi-head self-attention Query is the same as the Key, and the multi-head interactive attention encoding is different from the Key. For multi-head self-attention coding, it needs to realize the calculation of the attention value between each word in a certain text and all words in the sentence; for multi-head interactive attention coding, it needs to realize each word in a certain text. Calculation of attention value between a word and all words of other texts.
本申请实施例中,情感分类设备对所述上下文对应的隐藏状态向量、所述特定目标对应的隐藏状态向量和所述句法向量进行多头自注意力编码,分别得到上下文语义信息编码、特定目标语义信息编码和句法信息编码。In the embodiment of the present application, the emotion classification device performs multi-head self-attention encoding on the hidden state vector corresponding to the context, the hidden state vector corresponding to the specific target, and the syntax vector, and obtains the context semantic information encoding and the specific target semantic information respectively. Information encoding and syntactic information encoding.
具体地,(1)情感分类设备以上下文对应的隐藏状态向量为Query和Key,进行多头自注意力编码,得到上下文语义信息编码;(2)情感分类设备以特定目标对应的隐藏状态向量为Query和Key,进行多头自注意力编码,得到特定目标语义信息编码;(3)情感分类设备以句法向量为Query和Key,进行多头自注意力编码,得到句法信息编码。Specifically, (1) the emotion classification device uses the hidden state vector corresponding to the context as Query and Key, and performs multi-head self-attention encoding to obtain the contextual semantic information encoding; (2) The emotion classification device uses the hidden state vector corresponding to the specific target as Query and Key, perform multi-head self-attention encoding, and obtain the semantic information encoding of the specific target; (3) The sentiment classification device uses the syntax vectors as Query and Key, and performs multi-head self-attention encoding to obtain the syntax information encoding.
通过对所述上下文对应的隐藏状态向量、所述特定目标对应的隐藏状态向量和所述句法向量进行多头自注意力编码,能够提取到更为丰富的语义信息和情感信息。By performing multi-head self-attention encoding on the hidden state vector corresponding to the context, the hidden state vector corresponding to the specific target, and the syntax vector, richer semantic information and emotional information can be extracted.
在一个可选的实施例中,情感分类设备将所述上下文对应的隐藏状态向量Hc、所述特定目标对应的隐藏状态向量Ht和所述句法向量
Hcs=MHA(Hc,Hc)Hcs =MHA(Hc ,Hc )
Hts=MHA(Ht,Ht)Hts =MHA(Ht ,Ht )


oh=Attentionh(k,q)oh = Attentionh (k,q)
Attention(k,q)=soft max(fs(k,q))kAttention(k,q)=soft max(fs (k,q))k

fs(ki,qj)=tanh([ki;qj]·Watt)fs (ki , qj )=tanh([ki ; qj ]·Watt )
fs(ki,qj)表示多头注意力的第一输入向量k={k1,k2,...,kn}与多头注意力的第二输入向量q={q1,q2,...,qm}的语义相关性,当进行多头自注意力编码时k=q,当进行多头交互注意力编码时k≠q,“;”是指向量的拼接,




S105:对所述上下文语义信息编码和句法信息编码、所述特定目标语义信息编码和句法信息编码分别进行多头交互注意力编码,得到上下文-句法信息编码和特定目标-句法信息编码。S105: Perform multi-head interactive attention coding on the context semantic information coding and syntax information coding, the specific target semantic information coding and the syntactic information coding, respectively, to obtain context-syntax information coding and specific target-syntax information coding.
情感分类设备对上下文语义信息编码和句法信息编码、所述特定目标语义信息编码和句法信息编码分别进行多头交互注意力编码,得到上下文-句法信息编码和特定目标-句法信息编码。The sentiment classification device performs multi-head interactive attention encoding on the context semantic information encoding and the syntactic information encoding, the specific target semantic information encoding and the syntactic information encoding, respectively, to obtain the context-syntax information encoding and the specific target-syntax information encoding.
具体地,(1)情感分类设备以句法信息编码为Key,以上下文语义信息编码为Query,进行多头交互注意编码,得到上下文-句法信息编码,使句法信息编码与上下文语义编码进行交互融合,充分考虑句法信息与上下文的紧密联系。(2)情感分类设备以句法信息编码为Key,以特定目标语义信息编码为Query,进行多头交互注意编码,得到特定目标-句法信息编码,使句法信息编码与上特定目标语义信息编码进行交互融合,充分考虑句法信息与特定目标的紧密联系。Specifically, (1) the sentiment classification device uses the syntactic information encoding as the Key and the context semantic information encoding as the Query, performs multi-head interactive attention encoding, and obtains the context-syntax information encoding, so that the syntactic information encoding and the context semantic encoding are interactively fused, fully Consider the close connection of syntactic information to context. (2) The sentiment classification device uses the syntactic information as Key and the specific target semantic information as Query, performs multi-head interactive attention encoding, and obtains the specific target-syntax information code, so that the syntactic information code and the specific target semantic information code are interactively fused , fully considering the close relationship between syntactic information and specific goals.
在一个可选的实施例中,情感分类设备将所述上下文语义信息编码Hcs和句法信息编码Hgs、所述特定目标语义信息编码Hts和句法信息编码Hgs分别输入预设多头注意力编码公式,得到上下文-句法信息编码Hgt和特定目标-句法信息编码Hcg;其中,In an optional embodiment, the emotion classification device inputs the contextual semantic information encoding Hcs and the syntactic information encoding Hgs , the specific target semantic information encoding Hts and the syntax information encoding Hgs respectively into preset multi-head attention coding formula, obtain the context-syntax information code Hgt and the specific target-syntax information code Hcg ; wherein,
Hgt=MHA(Hgs,Hts)Hgt =MHA(Hgs ,Hts )
Hcg=MHA(Hgs,Hcs)Hcg =MHA(Hgs ,Hcs )

S106:将所述上下文语义信息编码、所述上下文-句法信息编码和所述特定目标-句法信息编码取平均池化后再进行拼接,得到所述特定目标对应的特征表示。S106 : Average and pool the context semantic information encoding, the context-syntax information encoding, and the specific target-syntax information encoding, and then perform splicing to obtain a feature representation corresponding to the specific target.
情感分类设备将所述上下文语义信息编码、所述上下文-句法信息编码和所述特定目标-句法信息编码取平均池化后再进行拼接,得到所述特定目标对应的特征表示。其中,平均池化操作为同一维度的值进行平均值化,拼接操作为将向量首尾相接,例如:向量[1,1],[2,2],[3,3],拼接后得到[1,1,2,2,3,3]。The sentiment classification device averages and pools the context semantic information encoding, the context-syntax information encoding, and the specific target-syntax information encoding, and then performs splicing to obtain a feature representation corresponding to the specific target. Among them, the average pooling operation is to average the values of the same dimension, and the splicing operation is to connect the vectors end to end. 1,1,2,2,3,3].
在一个可选的实施例中,情感分类设备对上下文-句法信息编码Hcg,特定目标-句法信息编码Hgt以及上下文语义编码Hcs输入预设平均池化计算公式,并将输出结果进行拼接,得到所述特定目标对应的特征表示u;其中,预设平均池化计算公式如下:In an optional embodiment, the sentiment classification device inputs a preset average pooling calculation formula into the context-syntax information encoding Hcg , the specific target-syntax information encoding Hgt and the context semantic encoding Hcs , and splices the output results , to obtain the feature representation u corresponding to the specific target; wherein, the preset average pooling calculation formula is as follows:







S107:将所述特征表示输入预设归一化指数函数中,得到特定目标的情感分类结果。S107: Input the feature representation into a preset normalized exponential function to obtain a sentiment classification result of a specific target.
情感分类设备将所述特征表示输入预设归一化指数函数中,得到特定目标的情感分类结果。其中,预设归一化指数函数为softmax()函数,通过该预设归一化指数函数,得到不同特定目标下情感极性的概率分布,从而得到特定目标的情感分类结果。The emotion classification device inputs the feature representation into a preset normalized exponential function to obtain an emotion classification result of a specific target. Wherein, the preset normalized exponential function is the softmax() function, and through the preset normalized exponential function, the probability distribution of the emotion polarity under different specific targets is obtained, thereby obtaining the emotion classification result of the specific target.
在一个可选的实施例中,情感分类设备将所述特征表示先输入预设转换公式,再将特征表示的转换结果输入预设归一化指数函数中,得到特定目标的情感分类结果,其中,所述预设转换公式和预设归一化指数函数如下:In an optional embodiment, the emotion classification device first inputs the feature representation into a preset conversion formula, and then inputs the conversion result of the feature representation into a preset normalized exponential function to obtain the emotion classification result of the specific target, wherein , the preset conversion formula and the preset normalized exponential function are as follows:




请同时参阅图5和图6,图5为本发明一个示例性实施例提供的基于注意力编码和图卷积网络的特定目标情感分类模型的整体结构示意图,图6为本发明一个示例性实施例提供的图卷积神经网络的示意图。基于注意力编码和图卷积网络的特定目标情感分类模型(以下简称AEGCN模型)对应本申请实施例中所提出的基于注意力编码和图卷积网络的特定目标情感分类方法,例如:步骤S101~S107。具体地,该模型首先通过预设双向循环神经网络模型,得到上下文对应的隐藏状态向量和特定目标对应的隐藏状态向量,再结合多头自注意力的并行计算和长距离依赖的优点,对上下文对应的隐藏状态向量和特定目标对应的隐藏状态向量进行多头自注意编码,提取到丰富充分的上下文语义信息和特定目标语义信息。再通过结合逐点卷积的图卷积神经网络,提取所述上下文对应的句法依存树中的句法向量,并对句法向量进行多头自注意力编码,得到句法信息编码,之后,使用多头交互注意力分别对句法信息编码和上下文语义信息编码、句法信息编码和特定目标语义信息编码进行交互融合,将融合后的结果与上下文语义信息编码拼接,得到最终的特征表示,使得该特征表示充分考虑了上下文和特定目标与句法信息之间的联系,防止了将句法上不相关的上下文单词识别为判断目标情感分类的线索,提高了情感分类的准确性。Please refer to FIG. 5 and FIG. 6 at the same time. FIG. 5 is a schematic diagram of the overall structure of a specific target emotion classification model based on attention coding and graph convolutional network provided by an exemplary embodiment of the present invention, and FIG. 6 is an exemplary implementation of the present invention. The example provides a schematic diagram of a graph convolutional neural network. The specific target emotion classification model based on attention coding and graph convolutional network (hereinafter referred to as AEGCN model) corresponds to the specific target emotion classification method based on attention coding and graph convolutional network proposed in the embodiment of this application, for example: step S101 ~S107. Specifically, the model first obtains the hidden state vector corresponding to the context and the hidden state vector corresponding to a specific target through the preset bidirectional recurrent neural network model, and then combines the advantages of parallel computing and long-distance dependence of multi-head self-attention, to the context corresponding The hidden state vector and the hidden state vector corresponding to the specific target are encoded by multi-head self-attention, and rich and sufficient contextual semantic information and specific target semantic information are extracted. Then, by combining the graph convolutional neural network with point-by-point convolution, the syntax vector in the syntactic dependency tree corresponding to the context is extracted, and the multi-head self-attention encoding is performed on the syntax vector to obtain the syntax information encoding. After that, the multi-head interactive attention is used. The power of syntactic information coding and context semantic information coding, syntactic information coding and specific target semantic information coding are interactively fused, and the fusion result is spliced with the context semantic information coding to obtain the final feature representation, which fully considers the feature representation. The connection between context and specific target and syntactic information prevents the recognition of syntactically irrelevant context words as clues for judging target sentiment classification, and improves the accuracy of sentiment classification.
下面将对本申请实施例提出的基于注意力编码和图卷积网络的特定目标情感分类方法进行实验论证,论证过程如下:The following will experimentally demonstrate the specific target sentiment classification method based on attention coding and graph convolution network proposed in the embodiment of the present application, and the demonstration process is as follows:
(1)选取五个数据集TWITTER,REST14和LAP14(SemEval 2014task4),REST15(SemEval 2015task 12),REST16(SemEval 2016task 5)。(1) Select five datasets TWITTER, REST14 and LAP14 (SemEval 2014task4), REST15 (SemEval 2015task 12), REST16 (SemEval 2016task 5).
其中,TWITTER数据集最初由Tang等人建立,包含了来自社交软件twitter的推文,一共包括6940条评论,每条评论都有标记出其中的特定目标以及特定目标的情感极性。Among them, the TWITTER dataset was originally established by Tang et al. It contains tweets from the social software twitter, including a total of 6940 comments, each comment marked with a specific target and the emotional polarity of the specific target.
SemEval-2014 Task4数据集主要用于细粒度情感分析,包含LAP14和REST14,每个领域的数据集都分为训练数据、验证数据(从训练数据分离出来)和测试数据,一共包含7794条评论,每条评论都有标记出其中的特定目标以及特定目标的情感极性。The SemEval-2014 Task4 dataset is mainly used for fine-grained sentiment analysis, including LAP14 and REST14. The dataset in each field is divided into training data, validation data (separated from training data) and test data, with a total of 7794 comments. Each comment is marked with a specific target and the emotional polarity of the specific target.
SemEval-2015task 12数据集主要用于细粒度情感分析,包含REST15,每个领域的数据集都分为训练数据、验证数据(从训练数据分离出来)和测试数据,一共包含1746条评论,每条评论都有标记出其中的特定目标以及特定目标的情感极性。The SemEval-2015task 12 dataset is mainly used for fine-grained sentiment analysis, including REST15. The datasets in each field are divided into training data, validation data (separated from training data) and test data, with a total of 1746 comments, each Comments are marked with a specific target and the emotional polarity of the specific target.
SemEval-2016task 5,数据集主要用于细粒度情感分析,包含REST16,每个领域的数据集都分为训练数据、验证数据(从训练数据分离出来)和测试数据,一共包含2454条评论,每条评论都有标记出其中的特定目标以及特定目标的情感极性。SemEval-2016task 5, the data set is mainly used for fine-grained sentiment analysis, including REST16, the data set in each field is divided into training data, validation data (separated from training data) and test data, a total of 2454 comments, each Each comment is marked with a specific target and the emotional polarity of the specific target.
(2)对数据集中的数据进行预处理,具体地,在GloVe工具中进行初始化处理,将数据中的每个单词均转化成维度为300的高维向量。并利用均匀分布对实验中利用到的模型进行权重的初始化设置。(2) Preprocess the data in the dataset, specifically, perform initialization processing in the GloVe tool, and convert each word in the data into a high-dimensional vector with a dimension of 300. And use uniform distribution to initialize the weight of the model used in the experiment.
(3)搭建图卷积神经网络结构,所有隐藏层维度大小均为300。Adam为优化器,其学习率为0.001。L2正则项的权重设置为0.00001。同时为了防止过拟合,参数dropout rate为0.5。参数batch size的系数为32。多头注意力中head的个数为3,GCN层数设定为2。(3) Build a graph convolutional neural network structure, and all hidden layers have a dimension size of 300. Adam is an optimizer with a learning rate of 0.001.The weight of the L2 regular term is set to 0.00001. At the same time, in order to prevent overfitting, the parameter dropout rate is 0.5. The coefficient of the parameter batch size is 32. The number of heads in the multi-head attention is 3, and the number of GCN layers is set to 2.
(4)对比实验结果。(4) Comparison of experimental results.
本发明选用Accuracy和Macro-Averaged F1作为评价指标。其中,Accuracy为二分类评价指标,其计算方式为正确分类的句子数与句子总数的比值,Macro-Averaged F1为多分类评价指标,其计算方式如下:The present invention selects Accuracy and Macro-Averaged F1 as evaluation indexes. Among them, Accuracy is a two-class evaluation index, and its calculation method is the ratio of the number of correctly classified sentences to the total number of sentences. Macro-Averaged F1 is a multi-class evaluation index, and its calculation method is as follows:





其中,TPi是指分类i的True Positive,True Positive指被预测分类为i且真实分类为i的句子的数量,FPi是指分类i的False Positive,False Positive指被预测分类为i但真实分类不为i的句子的数量,TNi是指分类i的True Negative,True Negative指被预测分类不为i且真实分类不为i的句子的数量,FNi是指分类i的False Negative,FalseNegative指被预测分类不为i但真实分为i的句子的数量,n为句子的总数量。Among them, TPi refers to the True Positive of the category i, True Positive refers to the number of sentences predicted to be classified as i and actually classified as i, FPi refers to the False Positive of the category i, False Positive refers to the predicted category i but true The number of sentences that are not classified as i, TNi refers to the True Negative of class i, True Negative refers to the number of sentences that are predicted to be classified as not i and the true class is not i, FNi refers to the False Negative of class i, False Negative Refers to the number of sentences that are not predicted to be classified as i but are actually classified as i, and n is the total number of sentences.
请参阅下方表1,通过表1可以得出,本申请提出的基于注意力编码和图卷积网络的特定目标情感分类方法,性能要优于传统的机器学习的方法。在表中SVM模型是使用支持向量机进行分类,它依赖大量人工特征提取。本申请提出的基于注意力编码和图卷积网络的特定目标情感分类方法无人工特征提取,并且在Twitter,lap14和restaurant数据集上相比于SVM准确率分别高出9.76%,5.42%和0.88%。说明基于注意力编码和图卷积网络的特定目标情感分类方法更适用于特定目标情感分析的研究。Please refer to Table 1 below. From Table 1, it can be concluded that the specific target sentiment classification method based on attention coding and graph convolutional network proposed in this application has better performance than traditional machine learning methods. The SVM model in the table uses support vector machines for classification, which relies on a lot of manual feature extraction. The target-specific sentiment classification method based on attention coding and graph convolutional network proposed in this application has no artificial feature extraction, and the accuracy is 9.76%, 5.42% and 0.88% higher than that of SVM on Twitter, lap14 and restaurant datasets, respectively %. It shows that the specific target sentiment classification method based on attention coding and graph convolutional network is more suitable for the research of specific target sentiment analysis.
本申请提出的基于注意力编码和图卷积网络的特定目标情感分类方法使用双向LSTM结合多头注意力机制对语义编码,相比标准多注意力机制的方法以及只使用多头注意力机制进行语义编码的方法效果较好。以MemNet为例,其在五个数据集上的准确率和F1值均低于本文方法。以AEN为例,在三个数据集(TWITTER,LAP14和REST14)中本文方法仅有一项指标(REST14,F1)低(0.82%)。The target-specific sentiment classification method based on attention encoding and graph convolutional network proposed in this application uses bidirectional LSTM combined with multi-head attention mechanism to encode semantics, compared with the standard multi-attention mechanism method and only using multi-head attention mechanism for semantic encoding method works better. Taking MemNet as an example, its accuracy and F1 value on five datasets are lower than our method. Taking AEN as an example, in three datasets (TWITTER, LAP14 and REST14), only one indicator (REST14, F1) of our method is low (0.82%).
由于结合了句法信息,比起没有考虑句法信息的方法,本申请提出的基于注意力编码和图卷积网络的特定目标情感分类方法所取得的效果也较好。以AOA为例,在五个数据集上的准确率和F1值中仅有REST16的准确率略高于本申请提出的方法(高出0.11%)。此外,IAN在五个数据集上的准确率和F1值都低于本申请提出的方法,本申请提出的方法在其中四个数据集上表现又都优于TNet-LF。Due to the combination of syntactic information, the target-specific sentiment classification method based on attention coding and graph convolutional network proposed in this application also achieves better results than methods that do not consider syntactic information. Taking AOA as an example, among the five datasets in terms of accuracy and F1 value, only the accuracy of REST16 is slightly higher than that of the method proposed in this application (0.11% higher). In addition, the accuracy and F1 value of IAN on five datasets are lower than those of the method proposed in this application, and the performance of the method proposed in this application is better than TNet-LF on four of the datasets.
本发明提出的结合逐点卷积的GCN表现优于结合了aspect-specific maskinglayer的GCN。ASGCN模型在GCN的顶部强加apect-specific masking layer,以此来获得融入了句法信息的特定目标的表示。但是这样就损失了带有句法信息的上下文表示。在五个数据集的准确率和F1值中,本文方法仅在REST14的F1,REST15的F1以及REST16的准确率这三个指标低于(0.87%,1.02%and 1.60%respectively)ASGCN,其他七项指标均优于ASGCN,证实了本申请提出的方法的有效性。The GCN combined with point-wise convolution proposed by the present invention outperforms the GCN combined with aspect-specific masking layer. The ASGCN model imposes an apect-specific masking layer on top of the GCN to obtain object-specific representations incorporating syntactic information. But this loses contextual representation with syntactic information. In the accuracy and F1 value of the five datasets, the method in this paper is only lower than (0.87%, 1.02% and 1.60% respectively) ASGCN in the three indicators of REST14 F1, REST15 F1 and REST16 accuracy, and the other seven All indicators are better than ASGCN, which confirms the effectiveness of the method proposed in this application.

表1Table 1
同上,针对本申请提出的基于注意力编码和图卷积网络的特定目标情感分类方法进行消融研究,结果如表2所示。The same as above, the ablation research is carried out on the specific target sentiment classification method based on attention coding and graph convolutional network proposed in this application, and the results are shown in Table 2.
首先,在移除了GCN后,有三个数据集(LAP14,REST14和REST15)的表现出现了下滑,但TWITTER和REST16表现更好。由于TWITTER数据集中句子比较口语化,以及结合前述实验结果所观察到的TNet-LF方法在数据集REST16的两个指标上都取得了最好的表现,可以推断出TWITTER数据集以及REST16数据集对于句法信息不是非常的敏感。First, there are three datasets (LAP14, REST14 and REST15) that show a drop in performance after GCN is removed, but TWITTER and REST16 perform better. Since the sentences in the TWITTER dataset are relatively colloquial, and the TNet-LF method observed in combination with the aforementioned experimental results achieves the best performance on both indicators of the dataset REST16, it can be inferred that the TWITTER dataset and the REST16 dataset are important for Syntactic information is not very sensitive.
其次,在没有多头自注意力的情况下,TWITTER数据集的表现并不是很好,但是REST15数据集的结果却有所上升,这也反映出了TWITTER数据集非常依赖于语义信息以及本发明对于多头自注意力机制的应用能够很好地提取到丰富的语义信息,也可以推测出REST15数据集相比于其他数据集对句法信息更加敏感。Second, in the absence of multi-head self-attention, the performance of the TWITTER dataset is not very good, but the results of the REST15 dataset have risen, which also reflects that the TWITTER dataset relies heavily on semantic information and the The application of the multi-head self-attention mechanism can well extract rich semantic information, and it can also be inferred that the REST15 dataset is more sensitive to syntactic information than other datasets.
最后,可以看出如果移除了多头交互注意力,本发明在五个数据集上的表现都不好,这也说明多头交互注意力对于本发明非常重要,也可以看出句法信息和语义信息的交互对于类似于LAP14,REST14以及REST15这样的数据集来说非常重要。Finally, it can be seen that if the multi-head interaction attention is removed, the performance of the present invention on the five data sets is not good, which also shows that multi-head interaction attention is very important to the present invention, and it can also be seen that syntactic information and semantic information The interaction is very important for datasets like LAP14, REST14 and REST15.
消融研究的实验结果表明,本申请实施例中提出的基于注意力编码和图卷积网络的特定目标情感分类方法中每一步骤都是必不可缺并且有效的。The experimental results of the ablation study show that each step in the target-specific sentiment classification method based on attention coding and graph convolutional network proposed in the embodiments of this application is indispensable and effective.

表2Table 2
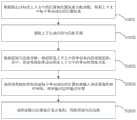
请参见图7,图7为本发明一个示例性实施例提供的基于注意力编码和图卷积网络的特定目标情感分类装置的结构示意图。包括的各单元用于执行图1和图2对应的实施例中的各步骤,具体请参阅图1和图2各自对应的实施例中的相关描述。为了便于说明,仅示出了与本实施例相关的部分。参见图7,基于注意力编码和图卷积网络的特定目标情感分类装置7包括:Please refer to FIG. 7 , which is a schematic structural diagram of a specific target emotion classification apparatus based on attention coding and graph convolutional network provided by an exemplary embodiment of the present invention. The included units are used to execute the steps in the embodiments corresponding to FIG. 1 and FIG. 2 . For details, please refer to the relevant descriptions in the respective embodiments corresponding to FIG. 1 and FIG. 2 . For convenience of explanation, only the parts related to this embodiment are shown. Referring to Fig. 7, the specific target emotion classification device 7 based on attention coding and graph convolutional network includes:
获取单元71,用于获取上下文对应的词向量和特定目标对应的词向量;Obtaining
第一神经网络单元72,用于将所述上下文对应的词向量和特定目标对应的词向量输入预设双向循环神经网络模型,得到上下文对应的隐藏状态向量和特定目标对应的隐藏状态向量;The first
第二神经网络单元73,用于基于结合逐点卷积的预设图卷积神经网络,提取所述上下文对应的句法依存树中的句法向量;The second
第一编码单元74,用于对所述上下文对应的隐藏状态向量、所述特定目标对应的隐藏状态向量和所述句法向量进行多头自注意力编码,分别得到上下文语义信息编码、特定目标语义信息编码和句法信息编码;The
第二编码单元75,用于对所述上下文语义信息编码和句法信息编码、所述特定目标语义信息编码和句法信息编码分别进行多头交互注意力编码,得到上下文-句法信息编码和特定目标-句法信息编码;The
拼接单元76,用于将所述上下文语义信息编码、所述上下文-句法信息编码和所述特定目标-句法信息编码取平均池化后再进行拼接,得到所述特定目标对应的特征表示;The
分类单元77,用于将所述特征表示输入预设归一化指数函数中,得到特定目标的情感分类结果。The
可选的,第二神经网络单元73包括:Optionally, the second
位置权重分配单元731,用于根据特定目标在上下文中的位置和位置权重分配函数,得到上下文中每个单词对应的位置权重;The position weight assignment unit 731 is used to obtain the position weight corresponding to each word in the context according to the position of the specific target in the context and the position weight assignment function;
第一获取单元732,用于获取上下文对应的句法依存树;a first obtaining unit 732, configured to obtain a syntactic dependency tree corresponding to the context;
第二获取单元733,用于根据所述句法依存树,得到所述上下文中的单词对应的邻接矩阵,其中,所述邻接矩阵反应所述上下文中的单词的邻接关系;The second obtaining unit 733 is configured to obtain the adjacency matrix corresponding to the word in the context according to the syntactic dependency tree, wherein the adjacency matrix reflects the adjacency relationship of the word in the context;
第三神经网络单元734,用于将所述邻接矩阵和所述每个单词对应的位置权重输入预设图卷积神经网络,得到输出层的输出结果;The third neural network unit 734 is configured to input the adjacency matrix and the position weight corresponding to each word into a preset graph convolutional neural network to obtain the output result of the output layer;
逐点卷积单元735,用于对所述输出结果进行逐点卷积,得到所述句法向量。The point-by-point convolution unit 735 is configured to perform point-by-point convolution on the output result to obtain the syntax vector.
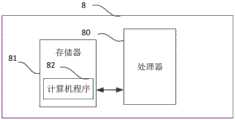
请参见图8,图8是本发明一个示例性实施例提供的基于注意力编码和图卷积网络的特定目标情感分类设备的示意图。如图8所示,该实施例的基于注意力编码和图卷积网络的特定目标情感分类设备8包括:处理器80、存储器81以及存储在所述存储器81中并可在所述处理器80上运行的计算机程序82,例如基于注意力编码和图卷积网络的特定目标情感分类程序。所述处理器80执行所述计算机程序82时实现上述各个基于注意力编码和图卷积网络的特定目标情感分类方法实施例中的步骤,例如图1所示的步骤S101至S107。或者,所述处理器80执行所述计算机程序82时实现上述各装置实施例中各模块/单元的功能,例如图5所示单元71至77的功能。Please refer to FIG. 8. FIG. 8 is a schematic diagram of a specific target emotion classification device based on attention coding and graph convolutional network provided by an exemplary embodiment of the present invention. As shown in FIG. 8 , the specific target
示例性的,所述计算机程序82可以被分割成一个或多个模块/单元,所述一个或者多个模块/单元被存储在所述存储器81中,并由所述处理器80执行,以完成本发明。所述一个或多个模块/单元可以是能够完成特定功能的一系列计算机程序指令段,该指令段用于描述所述计算机程序82在所述基于注意力编码和图卷积网络的特定目标情感分类设备8中的执行过程。例如,所述计算机程序82可以被分割成获取单元、第一神经网络单元、第二神经网络单元、第一编码单元、第二编码单元、拼接单元和分类单元,各单元功能如下:Exemplarily, the
获取单元,用于获取上下文对应的词向量和特定目标对应的词向量;an acquisition unit for acquiring the word vector corresponding to the context and the word vector corresponding to the specific target;
第一神经网络单元,用于将所述上下文对应的词向量和特定目标对应的词向量输入预设双向循环神经网络模型,得到上下文对应的隐藏状态向量和特定目标对应的隐藏状态向量;The first neural network unit is used to input the word vector corresponding to the context and the word vector corresponding to the specific target into a preset two-way cyclic neural network model to obtain the hidden state vector corresponding to the context and the hidden state vector corresponding to the specific target;
第二神经网络单元,用于基于结合逐点卷积的预设图卷积神经网络,提取所述上下文对应的句法依存树中的句法向量;The second neural network unit is used to extract the syntax vector in the syntax dependency tree corresponding to the context based on the preset graph convolutional neural network combined with point-by-point convolution;
第一编码单元,用于对所述上下文对应的隐藏状态向量、所述特定目标对应的隐藏状态向量和所述句法向量进行多头自注意力编码,分别得到上下文语义信息编码、特定目标语义信息编码和句法信息编码;The first coding unit is used to perform multi-head self-attention coding on the hidden state vector corresponding to the context, the hidden state vector corresponding to the specific target, and the syntax vector, to obtain the context semantic information coding and the specific target semantic information coding respectively. and syntactic information encoding;
第二编码单元,用于对所述上下文语义信息编码和句法信息编码、所述特定目标语义信息编码和句法信息编码分别进行多头交互注意力编码,得到上下文-句法信息编码和特定目标-句法信息编码;The second coding unit is configured to perform multi-head interactive attention coding on the context semantic information coding and syntax information coding, the specific target semantic information coding and the syntactic information coding, respectively, to obtain the context-syntax information coding and the specific target-syntax information coding;
拼接单元,用于将所述上下文语义信息编码、所述上下文-句法信息编码和所述特定目标-句法信息编码取平均池化后再进行拼接,得到所述特定目标对应的特征表示;a splicing unit, configured to perform splicing after averaging and pooling the context semantic information coding, the context-syntax information coding and the specific target-syntax information coding to obtain a feature representation corresponding to the specific target;
分类单元,用于将所述特征表示输入预设归一化指数函数中,得到特定目标的情感分类结果。The classification unit is used for inputting the feature representation into the preset normalized exponential function to obtain the sentiment classification result of the specific target.
所述基于注意力编码和图卷积网络的特定目标情感分类设备8可包括,但不仅限于,处理器80、存储器81。本领域技术人员可以理解,图8仅仅是基于注意力编码和图卷积网络的特定目标情感分类设备8的示例,并不构成对基于注意力编码和图卷积网络的特定目标情感分类设备8的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件,例如所述基于注意力编码和图卷积网络的特定目标情感分类设备8还可以包括输入输出设备、网络接入设备、总线等。The specific target
所称处理器80可以是中央处理单元(Central Processing Unit,CPU),还可以是其他通用处理器、数字信号处理器(Digital Signal Processor,DSP)、专用集成电路(Application SpecificIntegrated Circuit,ASIC)、现成可编程门阵列(Field-Programmable Gate Array,FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。The so-called
所述存储器81可以是所述基于注意力编码和图卷积网络的特定目标情感分类设备8的内部存储单元,例如基于注意力编码和图卷积网络的特定目标情感分类设备8的硬盘或内存。所述存储器81也可以是所述基于注意力编码和图卷积网络的特定目标情感分类设备8的外部存储设备,例如所述基于注意力编码和图卷积网络的特定目标情感分类设备8上配备的插接式硬盘,智能存储卡(Smart Media Card,SMC),安全数字(Secure Digital,SD)卡,闪存卡(Flash Card)等。进一步地,所述存储器81还可以既包括所基于注意力编码和图卷积网络的特定目标情感分类设备8的内部存储单元也包括外部存储设备。所述存储器81用于存储所述计算机程序以及所述基于注意力编码和图卷积网络的特定目标情感分类设备所需的其他程序和数据。所述存储器81还可以用于暂时地存储已经输出或者将要输出的数据。The
所属领域的技术人员可以清楚地了解到,为了描述的方便和简洁,仅以上述各功能单元、模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能单元、模块完成,即将所述装置的内部结构划分成不同的功能单元或模块,以完成以上描述的全部或者部分功能。实施例中的各功能单元、模块可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中,上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。另外,各功能单元、模块的具体名称也只是为了便于相互区分,并不用于限制本申请的保护范围。上述系统中单元、模块的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。Those skilled in the art can clearly understand that, for the convenience and simplicity of description, only the division of the above-mentioned functional units and modules is used as an example for illustration. In practical applications, the above-mentioned functions can be allocated to different functional units, Module completion, that is, dividing the internal structure of the device into different functional units or modules to complete all or part of the functions described above. Each functional unit and module in the embodiment may be integrated in one processing unit, or each unit may exist physically alone, or two or more units may be integrated into one unit, and the above-mentioned integrated units may adopt hardware. It can also be realized in the form of software functional units. In addition, the specific names of the functional units and modules are only for the convenience of distinguishing from each other, and are not used to limit the protection scope of the present application. For the specific working processes of the units and modules in the above-mentioned system, reference may be made to the corresponding processes in the foregoing method embodiments, which will not be repeated here.
在上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述或记载的部分,可以参见其它实施例的相关描述。In the foregoing embodiments, the description of each embodiment has its own emphasis. For parts that are not described or described in detail in a certain embodiment, reference may be made to the relevant descriptions of other embodiments.
本领域普通技术人员可以意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、或者计算机软件和电子硬件的结合来实现。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。Those of ordinary skill in the art can realize that the units and algorithm steps of each example described in conjunction with the embodiments disclosed herein can be implemented in electronic hardware, or a combination of computer software and electronic hardware. Whether these functions are performed in hardware or software depends on the specific application and design constraints of the technical solution. Skilled artisans may implement the described functionality using different methods for each particular application, but such implementations should not be considered beyond the scope of the present invention.
在本发明所提供的实施例中,应该理解到,所揭露的装置/终端设备和方法,可以通过其它的方式实现。例如,以上所描述的装置/终端设备实施例仅是示意性的,例如,所述模块或单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通讯连接可以是通过一些接口,装置或单元的间接耦合或通讯连接,可以是电性,机械或其它的形式。In the embodiments provided by the present invention, it should be understood that the disclosed apparatus/terminal device and method may be implemented in other manners. For example, the apparatus/terminal device embodiments described above are only illustrative. For example, the division of the modules or units is only a logical function division. In actual implementation, there may be other division methods, such as multiple units. Or components may be combined or may be integrated into another system, or some features may be omitted, or not implemented. On the other hand, the shown or discussed mutual coupling or direct coupling or communication connection may be through some interfaces, indirect coupling or communication connection of devices or units, and may be in electrical, mechanical or other forms.
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。The units described as separate components may or may not be physically separated, and components displayed as units may or may not be physical units, that is, may be located in one place, or may be distributed to multiple network units. Some or all of the units may be selected according to actual needs to achieve the purpose of the solution in this embodiment.
另外,在本发明各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。In addition, each functional unit in each embodiment of the present invention may be integrated into one processing unit, or each unit may exist physically alone, or two or more units may be integrated into one unit. The above-mentioned integrated units may be implemented in the form of hardware, or may be implemented in the form of software functional units.
所述集成的模块/单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明实现上述实施例方法中的全部或部分流程,也可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一计算机可读存储介质中,该计算机程序在被处理器执行时,可实现上述各个方法实施例的步骤。其中,所述计算机程序包括计算机程序代码,所述计算机程序代码可以为源代码形式、对象代码形式、可执行文件或某些中间形式等。所述计算机可读介质可以包括:能够携带所述计算机程序代码的任何实体或装置、记录介质、U盘、移动硬盘、磁碟、光盘、计算机存储器、只读存储器(ROM,Read-Only Memory)、随机存取存储器(RAM,RandomAccess Memory)、电载波信号、电信信号以及软件分发介质等。需要说明的是,所述计算机可读介质包含的内容可以根据司法管辖区内立法和专利实践的要求进行适当的增减,例如在某些司法管辖区,根据立法和专利实践,计算机可读介质不包括电载波信号和电信信号。本发明并不局限于上述实施方式,如果对本发明的各种改动或变形不脱离本发明的精神和范围,倘若这些改动和变形属于本发明的权利要求和等同技术范围之内,则本发明也意图包含这些改动和变形。The integrated modules/units, if implemented in the form of software functional units and sold or used as independent products, may be stored in a computer-readable storage medium. Based on this understanding, the present invention can implement all or part of the processes in the methods of the above embodiments, and can also be completed by instructing relevant hardware through a computer program. The computer program can be stored in a computer-readable storage medium, and the computer When the program is executed by the processor, the steps of the foregoing method embodiments can be implemented. Wherein, the computer program includes computer program code, and the computer program code may be in the form of source code, object code, executable file or some intermediate form, and the like. The computer-readable medium may include: any entity or device capable of carrying the computer program code, a recording medium, a U disk, a removable hard disk, a magnetic disk, an optical disk, a computer memory, a read-only memory (ROM, Read-Only Memory) , Random Access Memory (RAM, RandomAccess Memory), electric carrier signal, telecommunication signal and software distribution medium, etc. It should be noted that the content contained in the computer-readable media may be appropriately increased or decreased according to the requirements of legislation and patent practice in the jurisdiction, for example, in some jurisdictions, according to legislation and patent practice, the computer-readable media Electric carrier signals and telecommunication signals are not included. The present invention is not limited to the above-mentioned embodiments. If various changes or modifications of the present invention do not depart from the spirit and scope of the present invention, and if these changes and modifications belong to the claims of the present invention and the equivalent technical scope, then the present invention is also Intended to contain these alterations and variants.
Claims (10)







































Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010036470.9ACN111259142B (en) | 2020-01-14 | 2020-01-14 | Specific target emotion classification method based on attention coding and graph convolution network |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010036470.9ACN111259142B (en) | 2020-01-14 | 2020-01-14 | Specific target emotion classification method based on attention coding and graph convolution network |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN111259142A CN111259142A (en) | 2020-06-09 |
| CN111259142Btrue CN111259142B (en) | 2020-12-25 |
Family
ID=70948730
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010036470.9AActiveCN111259142B (en) | 2020-01-14 | 2020-01-14 | Specific target emotion classification method based on attention coding and graph convolution network |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN111259142B (en) |
Families Citing this family (55)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111680159B (en)* | 2020-06-11 | 2023-08-29 | 华东交通大学 | Data processing method and device and electronic equipment |
| CN111710428B (en)* | 2020-06-19 | 2022-05-31 | 华中师范大学 | Biomedical text representation method for modeling global and local context interaction |
| CN111797763A (en)* | 2020-07-02 | 2020-10-20 | 北京灵汐科技有限公司 | A scene recognition method and system |
| CN111783474B (en)* | 2020-07-16 | 2023-04-07 | 厦门市美亚柏科信息股份有限公司 | Comment text viewpoint information processing method and device and storage medium |
| US12039270B2 (en) | 2020-08-05 | 2024-07-16 | Baldu USA LLC | Disentangle syntax and semantics in sentence representation with decomposable variational autoencoder |
| CN112035661B (en)* | 2020-08-24 | 2024-09-24 | 北京大学深圳研究生院 | Text sentiment analysis method, system and electronic device based on graph convolutional network |
| CN112131383B (en)* | 2020-08-26 | 2021-05-18 | 华南师范大学 | Sentiment Polarity Classification Methods for Specific Targets |
| CN112001187B (en)* | 2020-08-26 | 2021-05-28 | 重庆理工大学 | A sentiment classification system based on Chinese syntax and graph convolutional neural network |
| CN112001186A (en)* | 2020-08-26 | 2020-11-27 | 重庆理工大学 | Emotion classification method using graph convolution neural network and Chinese syntax |
| CN112001185B (en)* | 2020-08-26 | 2021-07-20 | 重庆理工大学 | A sentiment classification method combining Chinese syntax and graph convolutional neural network |
| US12299566B2 (en) | 2020-09-23 | 2025-05-13 | Beijing Wodong Tianjun Information Technology Co., Ltd. | Method and system for relation learning by multi-hop attention graph neural network |
| CN112132223B (en)* | 2020-09-27 | 2024-02-27 | 腾讯科技(深圳)有限公司 | Method, device, equipment and storage medium for pooling |
| CN111881665B (en)* | 2020-09-27 | 2021-01-05 | 华南师范大学 | Word embedding representation method, device and equipment |
| CN112214601B (en)* | 2020-10-21 | 2022-06-10 | 厦门市美亚柏科信息股份有限公司 | Social short text sentiment classification method and device and storage medium |
| CN114386389B (en)* | 2020-10-22 | 2023-06-06 | 四川大学 | Aspect Sentiment Analysis Method Based on Federated Learning |
| CN112528672B (en)* | 2020-12-14 | 2021-07-30 | 北京邮电大学 | Aspect-level sentiment analysis method and device based on graph convolutional neural network |
| CN112417157B (en)* | 2020-12-15 | 2022-04-26 | 华南师范大学 | A sentiment classification method for text attribute words based on deep learning network |
| CN112579778B (en)* | 2020-12-23 | 2022-08-26 | 重庆邮电大学 | Aspect-level emotion classification method based on multi-level feature attention |
| CN112633010B (en)* | 2020-12-29 | 2023-08-04 | 山东师范大学 | Aspect-level sentiment analysis method and system based on multi-head attention and graph convolutional network |
| CN112733764A (en)* | 2021-01-15 | 2021-04-30 | 天津大学 | Method for recognizing video emotion information based on multiple modes |
| CN112926337B (en)* | 2021-02-05 | 2022-05-17 | 昆明理工大学 | End-to-end aspect level emotion analysis method combined with reconstructed syntax information |
| CN112560503B (en) | 2021-02-19 | 2021-07-02 | 中国科学院自动化研究所 | A Semantic Sentiment Analysis Method Fusing Deep Features and Temporal Models |
| CN114973231B (en)* | 2021-02-25 | 2025-06-24 | 微软技术许可有限责任公司 | 3D Object Detection |
| CN112801219B (en)* | 2021-03-22 | 2021-06-18 | 华南师范大学 | A multimodal emotion classification method, device and equipment |
| CN112686056B (en)* | 2021-03-22 | 2021-07-06 | 华南师范大学 | Emotion classification method |
| CN112686034B (en)* | 2021-03-22 | 2021-07-13 | 华南师范大学 | A kind of emotion classification method, device and equipment |
| CN112860907B (en)* | 2021-04-27 | 2021-06-29 | 华南师范大学 | Emotion classification method and equipment |
| CN113177562B (en)* | 2021-04-29 | 2024-02-06 | 京东科技控股股份有限公司 | Vector determination method and device for merging context information based on self-attention mechanism |
| CN112883741B (en)* | 2021-04-29 | 2021-07-27 | 华南师范大学 | Target-specific sentiment classification method based on dual-channel graph neural network |
| CN113326739B (en)* | 2021-05-07 | 2022-08-09 | 山东大学 | Online learning participation degree evaluation method based on space-time attention network, evaluation system, equipment and storage medium |
| CN112966074B (en)* | 2021-05-17 | 2021-08-03 | 华南师范大学 | Emotion analysis method and device, electronic equipment and storage medium |
| CN113033215B (en)* | 2021-05-18 | 2021-08-13 | 华南师范大学 | Emotion detection method, device, device and storage medium |
| CN113505583B (en)* | 2021-05-27 | 2023-07-18 | 山东交通学院 | Extraction Method of Sentiment Reason Clause Pairs Based on Semantic Decision Graph Neural Network |
| CN113220887B (en)* | 2021-05-31 | 2022-03-15 | 华南师范大学 | A sentiment classification method using target knowledge to enhance the model |
| CN113468874B (en)* | 2021-06-09 | 2024-04-16 | 大连理工大学 | Biomedical relation extraction method based on graph convolution self-coding |
| CN113609267B (en)* | 2021-07-21 | 2023-11-07 | 上海交通大学 | Speech relation recognition method and system based on GCNDT-MacBERT neural network framework |
| CN113535904B (en)* | 2021-07-23 | 2022-08-09 | 重庆邮电大学 | Aspect level emotion analysis method based on graph neural network |
| CN113887213A (en)* | 2021-09-30 | 2022-01-04 | 深圳市检验检疫科学研究院 | Event detection method and device based on multilayer graph attention network |
| CN113868425B (en)* | 2021-10-20 | 2024-06-28 | 西安邮电大学 | Aspect-level emotion classification method |
| CN113688212B (en)* | 2021-10-27 | 2022-02-08 | 华南师范大学 | Sentence emotion analysis method, device and equipment |
| CN113988052A (en)* | 2021-11-03 | 2022-01-28 | 深圳市检验检疫科学研究院 | A method and device for event detection based on graph perturbation strategy |
| CN114398479B (en)* | 2021-11-13 | 2024-12-20 | 北京国简科技有限公司 | Text classification method, device and medium based on temporal interactive graph neural network |
| CN114429122B (en)* | 2022-01-25 | 2024-06-11 | 重庆大学 | Aspect-level emotion analysis system and method based on circulating attention |
| CN114579707B (en)* | 2022-03-07 | 2023-07-28 | 桂林旅游学院 | Aspect-level emotion analysis method based on BERT neural network and multi-semantic learning |
| CN114863917A (en)* | 2022-04-02 | 2022-08-05 | 深圳市大梦龙途文化传播有限公司 | Game voice detection method, device, equipment and computer readable storage medium |
| CN114662503B (en)* | 2022-04-07 | 2024-06-07 | 重庆邮电大学 | An aspect-level sentiment analysis method based on LSTM and grammatical distance |
| CN114677234B (en)* | 2022-04-26 | 2024-04-30 | 河南大学 | A graph convolutional neural network social recommendation method and system integrating multi-channel attention mechanism |
| CN114881042B (en)* | 2022-06-02 | 2023-05-02 | 电子科技大学 | A Chinese Sentiment Analysis Method Based on Graph Convolutional Network Fusion of Syntactic Dependency and Part of Speech |
| CN114707518B (en)* | 2022-06-08 | 2022-08-16 | 四川大学 | Semantic fragment-oriented target emotion analysis method, device, equipment and medium |
| CN115054270B (en)* | 2022-06-17 | 2024-10-15 | 上海大学绍兴研究院 | Sleep stage method and system for extracting sleep spectrogram characteristics based on GCN |
| CN115391529B (en)* | 2022-08-23 | 2025-04-04 | 重庆邮电大学 | A text sentiment multi-classification method based on dual-graph convolutional network with fused label graph |
| CN115860006B (en)* | 2023-02-13 | 2023-04-25 | 广东工业大学 | Aspect-level emotion prediction method and device based on semantic syntax |
| CN117034059A (en)* | 2023-07-21 | 2023-11-10 | 中国银联股份有限公司 | Data clustering method and device and computer readable storage medium |
| CN117592460A (en)* | 2024-01-17 | 2024-02-23 | 西安邮电大学 | An end-to-end aspect-level sentiment analysis method based on feature fusion |
| CN119380743B (en)* | 2024-12-26 | 2025-03-25 | 之江实验室 | Mixed sound source separation method, device, computer equipment and readable storage medium |
Family Cites Families (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10510018B2 (en)* | 2013-09-30 | 2019-12-17 | Manyworlds, Inc. | Method, system, and apparatus for selecting syntactical elements from information as a focus of attention and performing actions to reduce uncertainty |
| US10839790B2 (en)* | 2017-02-06 | 2020-11-17 | Facebook, Inc. | Sequence-to-sequence convolutional architecture |
| CN108399158B (en)* | 2018-02-05 | 2021-05-14 | 华南理工大学 | Attribute emotion classification method based on dependency tree and attention mechanism |
| CN108549646B (en)* | 2018-04-24 | 2022-04-15 | 中译语通科技股份有限公司 | Neural network machine translation system based on capsule and information data processing terminal |
| CN108664632B (en)* | 2018-05-15 | 2021-09-21 | 华南理工大学 | Text emotion classification algorithm based on convolutional neural network and attention mechanism |
| CN109408823B (en)* | 2018-10-31 | 2019-08-06 | 华南师范大学 | A Target-Specific Sentiment Analysis Method Based on Multi-Channel Model |
| CN109558487A (en)* | 2018-11-06 | 2019-04-02 | 华南师范大学 | Document Classification Method based on the more attention networks of hierarchy |
| CN109582764A (en)* | 2018-11-09 | 2019-04-05 | 华南师范大学 | Interaction attention sentiment analysis method based on interdependent syntax |
| CN109446331B (en)* | 2018-12-07 | 2021-03-26 | 华中科技大学 | Text emotion classification model establishing method and text emotion classification method |
| CN109657246B (en)* | 2018-12-19 | 2020-10-16 | 中山大学 | Method for establishing extraction type machine reading understanding model based on deep learning |
| CN109885670A (en)* | 2019-02-13 | 2019-06-14 | 北京航空航天大学 | A Sentiment Analysis Method for Topic Text-Oriented Interactive Attention Coding |
- 2020
- 2020-01-14CNCN202010036470.9Apatent/CN111259142B/enactiveActive
Also Published As
| Publication number | Publication date |
|---|---|
| CN111259142A (en) | 2020-06-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111259142B (en) | Specific target emotion classification method based on attention coding and graph convolution network | |
| CN112183747B (en) | Neural network training method, neural network compression method and related equipment | |
| CN112131383A (en) | Sentiment Polarity Classification Methods for Specific Targets | |
| CN109033068B (en) | Method and device for reading and understanding based on attention mechanism and electronic equipment | |
| CN113704460B (en) | Text classification method and device, electronic equipment and storage medium | |
| CN111738001B (en) | Training method of synonym recognition model, synonym determination method and equipment | |
| CN112732915A (en) | Emotion classification method and device, electronic equipment and storage medium | |
| CN111353310A (en) | Artificial intelligence-based named entity recognition method, device and electronic device | |
| CN113239169A (en) | Artificial intelligence-based answer generation method, device, equipment and storage medium | |
| CN113722474A (en) | Text classification method, device, equipment and storage medium | |
| CN112699686B (en) | Semantic understanding method, device, equipment and medium based on task type dialogue system | |
| CN115169333B (en) | Text entity recognition method, device, equipment, storage medium and program product | |
| CN111522936A (en) | Intelligent customer service dialogue reply generation method and device containing emotion and electronic equipment | |
| CN114626463A (en) | Language model training method, text matching method and related device | |
| CN115759254A (en) | Question-answering method, system and medium based on knowledge-enhanced generative language model | |
| WO2024098524A1 (en) | Text and video cross-searching method and apparatus, model training method and apparatus, device, and medium | |
| CN116956866A (en) | Scenario data processing method, apparatus, device, storage medium and program product | |
| CN118427215A (en) | Method for generating structured query statement, method for processing question and answer and corresponding device | |
| WO2024239755A1 (en) | Method and apparatus for determining picture generation model, method and apparatus for picture generation, computing device, storage medium, and program product | |
| CN116955704A (en) | Searching method, searching device, searching equipment and computer readable storage medium | |
| CN113326383B (en) | Short text entity linking method, device, computing equipment and storage medium | |
| CN115238077A (en) | Artificial intelligence-based text analysis method, device, equipment and storage medium | |
| CN118797058A (en) | Data processing method, model training method and device | |
| US20230368571A1 (en) | Training Method of Facial Expression Embedding Model, Facial Expression Embedding Method and Facial Expression Embedding Device | |
| CN116680401A (en) | Document processing method, document processing device, equipment and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| CB03 | Change of inventor or designer information | ||
| CB03 | Change of inventor or designer information | Inventor after:Xiao Luwei Inventor after:Hu Xiaohui Inventor after:Liu Yifan Inventor after:Xue Yun Inventor after:Gu Donghong Inventor after:Chen Bingliang Inventor before:Xiao Luwei Inventor before:Liu Yifan Inventor before:Hu Xiaohui Inventor before:Xue Yun Inventor before:Gu Donghong Inventor before:Chen Bingliang | |
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| TR01 | Transfer of patent right | ||
| TR01 | Transfer of patent right | Effective date of registration:20210708 Address after:210012 4th floor, building C, Wanbo Science Park, 20 Fengxin Road, Yuhuatai District, Nanjing City, Jiangsu Province Patentee after:NANJING SILICON INTELLIGENCE TECHNOLOGY Co.,Ltd. Address before:Room 614-615, No.1, Lane 2277, Zuchongzhi Road, China (Shanghai) pilot Free Trade Zone, Pudong New Area, Shanghai, 200120 Patentee before:Shanghai Airlines Intellectual Property Services Ltd. Effective date of registration:20210708 Address after:Room 614-615, No.1, Lane 2277, Zuchongzhi Road, China (Shanghai) pilot Free Trade Zone, Pudong New Area, Shanghai, 200120 Patentee after:Shanghai Airlines Intellectual Property Services Ltd. Address before:School of physics and telecommunication engineering, South China Normal University, No. 378, Waihuan West Road, Panyu District, Guangzhou City, Guangdong Province, 510006 Patentee before:SOUTH CHINA NORMAL University | |
| CP03 | Change of name, title or address | ||
| CP03 | Change of name, title or address | Address after:5th Floor, Building C, Wanbo Science and Technology Park, No. 20 Fengxin Road, Yuhuatai District, Nanjing City, Jiangsu Province, China 210012 Patentee after:Nanjing Silicon based Intelligent Technology Group Co.,Ltd. Country or region after:China Address before:210012 4th floor, building C, Wanbo Science Park, 20 Fengxin Road, Yuhuatai District, Nanjing City, Jiangsu Province Patentee before:NANJING SILICON INTELLIGENCE TECHNOLOGY Co.,Ltd. Country or region before:China |