CN111247581A - Method, device, equipment and storage medium for synthesizing voice by multi-language text - Google Patents
Method, device, equipment and storage medium for synthesizing voice by multi-language textDownload PDFInfo
- Publication number
- CN111247581A CN111247581ACN201980003170.6ACN201980003170ACN111247581ACN 111247581 ACN111247581 ACN 111247581ACN 201980003170 ACN201980003170 ACN 201980003170ACN 111247581 ACN111247581 ACN 111247581A
- Authority
- CN
- China
- Prior art keywords
- text
- encoding
- multilingual
- joint
- synthesized
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 238000000034methodMethods0.000titleclaimsabstractdescription37
- 230000002194synthesizing effectEffects0.000titledescription5
- 230000003595spectral effectEffects0.000claimsabstractdescription114
- 230000015572biosynthetic processEffects0.000claimsabstractdescription59
- 238000003786synthesis reactionMethods0.000claimsabstractdescription59
- 238000012545processingMethods0.000claimsabstractdescription24
- 238000001308synthesis methodMethods0.000claimsabstractdescription21
- 238000013528artificial neural networkMethods0.000claimsdescription59
- 230000015654memoryEffects0.000claimsdescription27
- PXFBZOLANLWPMH-UHFFFAOYSA-N16-EpiaffinineNatural productsC1C(C2=CC=CC=C2N2)=C2C(=O)CC2C(=CC)CN(C)C1C2COPXFBZOLANLWPMH-UHFFFAOYSA-N0.000claimsdescription24
- 238000000605extractionMethods0.000claimsdescription24
- 230000009466transformationEffects0.000claimsdescription24
- 230000007246mechanismEffects0.000claimsdescription9
- 238000001228spectrumMethods0.000claimsdescription7
- 230000002457bidirectional effectEffects0.000claimsdescription6
- 238000013527convolutional neural networkMethods0.000claimsdescription6
- 125000004122cyclic groupChemical group0.000claimsdescription3
- 238000012549trainingMethods0.000description8
- 238000004590computer programMethods0.000description6
- 238000010586diagramMethods0.000description6
- 230000000306recurrent effectEffects0.000description6
- 230000000694effectsEffects0.000description5
- 238000006243chemical reactionMethods0.000description4
- 230000008569processEffects0.000description4
- 230000006403short-term memoryEffects0.000description3
- 230000009471actionEffects0.000description2
- 238000013135deep learningMethods0.000description2
- 238000010606normalizationMethods0.000description2
- 238000012805post-processingMethods0.000description2
- 238000007781pre-processingMethods0.000description2
- 230000001360synchronised effectEffects0.000description2
- 230000009286beneficial effectEffects0.000description1
- 230000008859changeEffects0.000description1
- 230000001419dependent effectEffects0.000description1
- 238000011161developmentMethods0.000description1
- 230000018109developmental processEffects0.000description1
- 238000005516engineering processMethods0.000description1
- 239000012634fragmentSubstances0.000description1
- 230000003993interactionEffects0.000description1
- 238000013507mappingMethods0.000description1
- 238000012986modificationMethods0.000description1
- 230000004048modificationEffects0.000description1
- 230000000717retained effectEffects0.000description1
- 230000011218segmentationEffects0.000description1
- 230000003068static effectEffects0.000description1
Images






Classifications
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/02—Methods for producing synthetic speech; Speech synthesisers
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/02—Methods for producing synthetic speech; Speech synthesisers
- G10L13/04—Details of speech synthesis systems, e.g. synthesiser structure or memory management
- G10L13/047—Architecture of speech synthesisers
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/08—Text analysis or generation of parameters for speech synthesis out of text, e.g. grapheme to phoneme translation, prosody generation or stress or intonation determination
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
- G10L19/16—Vocoder architecture
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/03—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters
- G10L25/18—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters the extracted parameters being spectral information of each sub-band
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/03—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters
- G10L25/24—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters the extracted parameters being the cepstrum
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/27—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the analysis technique
- G10L25/30—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the analysis technique using neural networks
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Health & Medical Sciences (AREA)
- Computational Linguistics (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Computation (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Machine Translation (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本申请涉及语音技术领域,尤其涉及一种多语言文本的语音合成方法、装置、设备及存储介质。The present application relates to the field of speech technology, and in particular, to a method, apparatus, device and storage medium for speech synthesis of multilingual text.
背景技术Background technique
语音合成是语音交互中一个重要的任务,它的目标是将文本信息合成出自然的像真人发出来的声音。传统的语音合成系统包括两个部分:前端和后端。前端的作用是对文本进行分析和语言学信息的提取,比如:分词,词性标注,韵律结构预测等。后端是将从前端获取的语言学信息合成出语音。Speech synthesis is an important task in speech interaction, and its goal is to synthesize textual information into a natural human voice. A traditional speech synthesis system consists of two parts: front-end and back-end. The role of the front-end is to analyze the text and extract linguistic information, such as: word segmentation, part-of-speech tagging, prosodic structure prediction, etc. The back-end is to synthesize speech from the linguistic information obtained from the front-end.
在过去十多年,语音拼接合成和参数合成被广泛的应用,并且取得了不错的效果。拼接合成需要大量的语料,从语料中选取语音片段合成所需要的语音。虽然合成出的每个片段的语音自然度比较高,但是语音内的连续性不够好。参数合成虽然相对拼接合成需要更少的语料,但是往往因为模型比较复杂,包含了大量的参数,修改起来很费时费力。In the past ten years, speech splicing synthesis and parametric synthesis have been widely used and achieved good results. A large amount of corpus is required for splicing and synthesis, and speech fragments are selected from the corpus to synthesize the required speech. Although the speech naturalness of each segment synthesized is relatively high, the continuity within the speech is not good enough. Although parameter synthesis requires less corpus than splicing synthesis, it is often time-consuming and laborious to modify because the model is more complex and contains a large number of parameters.
最近几年,随着深度学习的发展,端到端的语音合成系统被提出来,比如:Tacotron(端到端的深度学习语音合成模型)和Tacotron2,它们使用神经网络简化了传统语音合成的前端。Tacotron和Tacotron2首先直接从文本中生成频谱特征(Melspectrograms)然后使用声码器,比如:Griffin-Lim(采用Griffin-Lim算法音频生成模型)和WaveNet(原始音频生成模型)将频谱特征合成出语音。这种基于神经网络的端到端的模型很大程度上提高了合成的语音质量,其中,这里的端到端模型指的就是带有注意力机制的序列到序列的模型。将文本序列使用编码器映射到语义空间并生成一系列编码器隐藏状态,然后解码器使用注意力机制将这些语义空间的隐藏状态作为上下文信息,构造解码器隐藏状态,然后输出频谱特征帧。其中注意力机制中常常包括循环神经网络。循环神经网络可以由输入的序列生成输出的序列,输出的当前序列由之前所有的输出序列和当前的隐含状态共同决定。对于某一个特定的频谱帧,由于编码器的输入信息不足或者编码器的编码不充分,可能经过多次的循环之后,还是与实际有偏差。在合成的语音的表现上来看,听起来可能会是漏词或跳词。In recent years, with the development of deep learning, end-to-end speech synthesis systems have been proposed, such as: Tacotron (end-to-end deep learning speech synthesis model) and Tacotron2, which use neural networks to simplify the front-end of traditional speech synthesis. Tacotron and Tacotron2 first generate spectral features (Melspectrograms) directly from text and then use vocoders such as: Griffin-Lim (audio generation model using Griffin-Lim algorithm) and WaveNet (original audio generation model) to synthesize the spectral features into speech. This neural network-based end-to-end model greatly improves the quality of synthesized speech, where the end-to-end model here refers to a sequence-to-sequence model with an attention mechanism. The text sequence is mapped to the semantic space using the encoder and a series of encoder hidden states are generated, and then the decoder uses the attention mechanism to take the hidden states of these semantic spaces as context information, construct the decoder hidden state, and then output the spectral feature frame. The attention mechanism often includes recurrent neural networks. A recurrent neural network can generate an output sequence from an input sequence, and the current output sequence is jointly determined by all previous output sequences and the current hidden state. For a certain spectral frame, due to insufficient input information of the encoder or insufficient encoding of the encoder, it may still deviate from the actual after many cycles. In terms of the performance of the synthesized speech, it may sound like missing words or skip words.
同时虽然在大多数场景下这种单一语言的语音合成系统已经能够满足日常的需求,但是对于一些特定的场景,比如机器人,翻译机等需要多种语言的语音合成系统。如果针对每一种语言训练一个系统,会给模型的部署带来很大的消耗。因此,开发一种不会漏词或跳词、部署简单的多语言文本的语音合成方法显得尤为重要。At the same time, although this single-language speech synthesis system has been able to meet daily needs in most scenarios, for some specific scenarios, such as robots, translators, etc., multi-language speech synthesis systems are required. If a system is trained for each language, it will bring a lot of consumption to the deployment of the model. Therefore, it is particularly important to develop a speech synthesis method that does not miss or skip words and deploys simple multilingual texts.
发明内容SUMMARY OF THE INVENTION
基于此,有必要针对上述问题,提出了一种多语言文本的语音合成方法、装置、设备及存储介质,用于解决现有技术中漏词或跳词、部署复杂的技术问题。Based on this, it is necessary to address the above problems and propose a multilingual text speech synthesis method, apparatus, device and storage medium, which are used to solve the technical problems of missing or skipped words and complex deployment in the prior art.
第一方面,本发明一种多语言文本的语音合成方法,所述方法包括:In a first aspect, the present invention provides a speech synthesis method for multilingual text, the method comprising:
获取待合成多语言文本;Get multilingual text to be synthesized;
将所述待合成多语言文本分别输入至少两个编码规则不同的编码器中进行编码,得到与编码规则对应的文本编码;The multilingual texts to be synthesized are respectively input into at least two encoders with different encoding rules for encoding, and the text encoding corresponding to the encoding rules is obtained;
将所有所述编码规则对应的文本编码转换为联合文本编码;Convert all text encodings corresponding to the encoding rules to joint text encodings;
将所述联合文本编码、标准频谱特征数据输入解码器进行预测解码,得到预测频谱特征;Inputting the joint text encoding and standard spectral feature data into a decoder for predictive decoding to obtain predicted spectral features;
将所述预测频谱特征输入声码器进行合成处理,得到与所述待合成多语言文本对应的目标语音。The predicted spectral features are input into a vocoder for synthesis processing to obtain target speech corresponding to the multilingual text to be synthesized.
在一个实施例中,所述将所有所述编码规则对应的文本编码转换为联合文本编码,包括:In one embodiment, converting the text encodings corresponding to all the encoding rules to joint text encodings includes:
将所有所述编码规则对应的文本编码进行拼接,得到拼接文本编码;Splicing the text codes corresponding to all the coding rules to obtain the splicing text codes;
将所述拼接文本编码进行线性仿射变换,得到联合文本编码。Linear affine transformation is performed on the spliced text encoding to obtain a joint text encoding.
在一个实施例中,所述将所述联合文本编码、标准频谱特征数据输入解码器进行预测解码,得到预测频谱特征,包括:In one embodiment, inputting the joint text encoding and standard spectral feature data into a decoder for predictive decoding to obtain predicted spectral features includes:
将所述联合文本编码进行高层特征提取得到联合文本编码高层特征;performing high-level feature extraction on the joint text encoding to obtain high-level features of the joint text encoding;
将所述联合文本编码高层特征、所述标准频谱特征数据输入解码器进行预测解码,得到所述预测频谱特征。The joint text encoding high-level feature and the standard spectral feature data are input into a decoder for predictive decoding to obtain the predicted spectral feature.
在一个实施例中,所述将所述待合成多语言文本分别输入至少两个编码规则不同的编码器中进行编码,得到与编码规则对应的文本编码,包括:In one embodiment, the described multilingual text to be synthesized is respectively input into at least two encoders with different encoding rules for encoding, and the text encoding corresponding to the encoding rules is obtained, including:
将所述待合成多语言文本输入One-hot编码器进行编码,得到与One-hot编码器对应的One-hot文本编码;Inputting the multilingual text to be synthesized into the One-hot encoder for encoding to obtain the One-hot text encoding corresponding to the One-hot encoder;
将所述待合成多语言文本输入UTF-8编码器进行编码,得到与UTF-8编码器对应的UTF-8文本编码;Inputting the multilingual text to be synthesized into a UTF-8 encoder for encoding to obtain a UTF-8 text encoding corresponding to the UTF-8 encoder;
将所述待合成多语言文本输入音素编码器进行编码,得到与音素编码器对应的音素文本编码。The multilingual text to be synthesized is input into a phoneme encoder for encoding, and a phoneme text encoding corresponding to the phoneme encoder is obtained.
在一个实施例中,所述将所有所述编码规则对应的文本编码进行拼接,得到拼接文本编码,包括:In one embodiment, the text codes corresponding to all the encoding rules are spliced to obtain the spliced text codes, including:
将所述One-hot文本编码、所述UTF-8文本编码、所述音素文本编码在通道维度上进行拼接,得到拼接文本编码,所述拼接文本编码包括三维数据;其中,第一维数据为所述One-hot文本编码,第二维数据为所述UTF-8文本编码,第三维数据为所述音素文本编码。The One-hot text encoding, the UTF-8 text encoding, and the phoneme text encoding are spliced in the channel dimension to obtain a spliced text encoding, and the spliced text encoding includes three-dimensional data; wherein, the first dimension data is For the One-hot text encoding, the second dimension data is the UTF-8 text encoding, and the third dimension data is the phoneme text encoding.
在一个实施例中,所述将所述拼接文本编码进行线性仿射变换,得到联合文本编码,包括:In one embodiment, performing linear affine transformation on the spliced text encoding to obtain a joint text encoding, comprising:
将多维的所述拼接文本编码输入第一神经网络进行线性仿射变换对所述编码规则对应的文本编码进行选择,得到联合文本编码。The multi-dimensional spliced text codes are input into the first neural network to perform linear affine transformation to select the text codes corresponding to the coding rules to obtain joint text codes.
在一个实施例中,所述将所述联合文本编码进行高层特征提取,得到联合文本编码高层特征,包括:In one embodiment, performing high-level feature extraction on the joint text encoding to obtain high-level features of the joint text encoding, including:
将所述联合文本编码输入第二神经网络进行高层特征提取,得到联合文本编码高层特征。The joint text encoding is input into the second neural network for high-level feature extraction to obtain joint text encoding high-level features.
在一个实施例中,所述第二神经网络包括依次设置的字符级卷积神经网络、三个卷积层及双向长短时记忆循环神经网络。In one embodiment, the second neural network includes a character-level convolutional neural network, three convolutional layers, and a bidirectional long-short-term memory recurrent neural network arranged in sequence.
在一个实施例中,所述将所述联合文本编码高层特征、所述标准频谱特征数据输入解码器进行预测解码,得到所述预测频谱特征,包括:In one embodiment, inputting the joint text encoding high-level feature and the standard spectral feature data into a decoder for predictive decoding to obtain the predicted spectral feature includes:
获取标准频谱特征数据;Obtain standard spectral characteristic data;
将所述联合文本编码高层特征、所述标准频谱特征数据输入解码器,所述解码器包括第三神经网络;Inputting the joint text encoding high-level feature and the standard spectral feature data into a decoder, and the decoder includes a third neural network;
所述解码器的第三神经网络根据所述联合文本编码、所述标准频谱特征数据结合注意力机制进行频谱特征预测,得到预测频谱特征。The third neural network of the decoder performs spectral feature prediction according to the joint text encoding, the standard spectral feature data and the attention mechanism to obtain the predicted spectral feature.
在一个实施例中,所述获取待合成多语言文本之前,还包括:In one embodiment, before the acquiring the multilingual text to be synthesized, the method further includes:
获取待处理多语言文本;Get multilingual text to be processed;
根据所述待处理多语言文本进行语言标准化处理,得到待合成多语言文本。Perform language standardization processing according to the multilingual text to be processed to obtain multilingual text to be synthesized.
第二方面,本发明还提出了一种多语言文本的语音合成装置,所述装置包括:In a second aspect, the present invention also provides a multilingual text speech synthesis device, the device comprising:
联合编码模块,用于获取待合成多语言文本,将所述待合成多语言文本分别输入至少两个编码规则不同的编码器中进行编码,得到与编码规则对应的文本编码,将所有所述编码规则对应的文本编码转换为联合文本编码;The joint encoding module is used to obtain the multilingual text to be synthesized, input the multilingual text to be synthesized into at least two encoders with different encoding rules for encoding, obtain the text encoding corresponding to the encoding rules, and encode all the encoding The text encoding corresponding to the rule is converted into a joint text encoding;
语音合成模块,用于将所述联合文本编码、标准频谱特征数据输入解码器进行预测解码,得到预测频谱特征,将所述预测频谱特征输入声码器进行合成处理,得到与所述待合成多语言文本对应的目标语音。The speech synthesis module is used for inputting the joint text encoding and standard spectral feature data into a decoder for predictive decoding, to obtain predicted spectral features, and inputting the predicted spectral features into a vocoder for synthesis processing to obtain the same as the multi-component to be synthesized. The target speech corresponding to the language text.
在一个实施例中,所述联合编码模块包括分别编码子模块、联合编码子模块;In one embodiment, the joint encoding module includes a separate encoding sub-module and a joint encoding sub-module;
所述分别编码子模块用于获取待合成多语言文本,将所述待合成多语言文本分别输入至少两个编码规则不同的编码器中进行编码,得到与编码规则对应的文本编码;The separate encoding sub-module is used to obtain the multilingual text to be synthesized, and input the multilingual text to be synthesized into at least two encoders with different encoding rules for encoding, so as to obtain the text encoding corresponding to the encoding rules;
所述联合编码子模块用于将所有所述编码规则对应的文本编码进行拼接,得到拼接文本编码,将所述拼接文本编码进行线性仿射变换,得到联合文本编码。The joint coding submodule is used for splicing all the text codes corresponding to the coding rules to obtain the spliced text codes, and performing linear affine transformation on the spliced text codes to obtain the joint text codes.
在一个实施例中,所述语音合成模块包括高层特征提取子模块、频谱特征预测子模块;In one embodiment, the speech synthesis module includes a high-level feature extraction sub-module and a spectral feature prediction sub-module;
所述高层特征提取子模块用于将所述联合文本编码进行高层特征提取得到联合文本编码高层特征;The high-level feature extraction submodule is used to extract high-level features of the joint text encoding to obtain high-level features of the joint text encoding;
所述频谱特征预测子模块用于将所述联合文本编码高层特征、所述标准频谱特征数据输入解码器进行预测解码,得到所述预测频谱特征。The spectral feature prediction sub-module is configured to input the joint text coding high-level feature and the standard spectral feature data into a decoder for predictive decoding to obtain the predicted spectral feature.
第三方面,本发明还提出了一种存储介质,存储有计算机指令程序,所述计算机指令程序被处理器执行时,使得所述处理器执行第一方面任一项所述方法的步骤。In a third aspect, the present invention also provides a storage medium storing a computer instruction program, which, when executed by a processor, causes the processor to execute the steps of any one of the methods in the first aspect.
第四方面,本发明还提出了一种多语言文本的语音合成设备,包括至少一个存储器、至少一个处理器,所述存储器存储有计算机指令程序,所述计算机指令程序被所述处理器执行时,使得所述处理器执行第一方面任一项所述方法的步骤。In a fourth aspect, the present invention also provides a multilingual text speech synthesis device, comprising at least one memory and at least one processor, wherein the memory stores a computer instruction program, and when the computer instruction program is executed by the processor , so that the processor executes the steps of any one of the methods in the first aspect.
综上所述,本发明的多语言文本的语音合成方法将所述待合成多语言文本分别输入至少两个编码规则不同的编码器中进行编码得到与编码规则对应的文本编码,再将所有所述编码规则对应的文本编码转换为联合文本编码;通过至少两个编码规则不同的编码器进行不同规则的编码,能更充分的保留文本的特征,也有利于多语言文本的处理;通过至少两个编码规则不同的编码器进行不同规则的编码后再经过转换得到联合文本编码,提高了文本合成语音的效果的稳定性,同时也降低了部署难度,降低了部署成本。因此,本发明能更充分的保留文本的特征,有利于多语言文本的处理,降低了部署难度,降低了部署成本。To sum up, in the multilingual text speech synthesis method of the present invention, the multilingual text to be synthesized is respectively input into at least two encoders with different encoding rules for encoding to obtain text encoding corresponding to the encoding rules, and then all the The text encoding corresponding to the above encoding rules is converted into joint text encoding; encoding with different rules by at least two encoders with different encoding rules can more fully retain the characteristics of the text, and is also conducive to the processing of multilingual text; Encoders with different encoding rules encode different rules and then convert to obtain joint text encoding, which improves the stability of the effect of text-to-speech synthesis, reduces deployment difficulty, and reduces deployment costs. Therefore, the present invention can more fully retain the characteristics of the text, which is beneficial to the processing of multi-language text, reduces the difficulty of deployment, and reduces the cost of deployment.
附图说明Description of drawings
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。In order to explain the embodiments of the present invention or the technical solutions in the prior art more clearly, the following briefly introduces the accompanying drawings that need to be used in the description of the embodiments or the prior art. Obviously, the accompanying drawings in the following description are only These are some embodiments of the present invention. For those of ordinary skill in the art, other drawings can also be obtained according to these drawings without creative efforts.
其中:in:
图1为一个实施例中多语言文本的语音合成方法的流程图;Fig. 1 is the flow chart of the speech synthesis method of multilingual text in one embodiment;
图2为图1的多语言文本的语音合成方法的确定联合文本编码的流程图;Fig. 2 is the flow chart of the determination joint text encoding of the speech synthesis method of the multilingual text of Fig. 1;
图3为图1的多语言文本的语音合成方法的预测解码的流程图;Fig. 3 is the flow chart of the predictive decoding of the multilingual text speech synthesis method of Fig. 1;
图4为另一个实施例中多语言文本的语音合成方法的流程图;Fig. 4 is the flow chart of the speech synthesis method of multilingual text in another embodiment;
图5为一个实施例中多语言文本的语音合成装置的结构框图;5 is a structural block diagram of an apparatus for speech synthesis of multilingual text in one embodiment;
图6为图5的多语言文本的语音合成装置的联合编码模块的结构框图;Fig. 6 is the structural block diagram of the joint coding module of the multilingual text speech synthesis apparatus of Fig. 5;
图7为图5的多语言文本的语音合成装置的语音合成模块的结构框图;Fig. 7 is the structural block diagram of the speech synthesis module of the speech synthesis device of the multilingual text of Fig. 5;
图8为一个实施例中计算机设备的结构框图。FIG. 8 is a structural block diagram of a computer device in one embodiment.
具体实施方式Detailed ways
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。The technical solutions in the embodiments of the present invention will be clearly and completely described below with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only a part of the embodiments of the present invention, but not all of the embodiments. Based on the embodiments of the present invention, all other embodiments obtained by those of ordinary skill in the art without creative efforts shall fall within the protection scope of the present invention.
如图1所示,在一个实施例中,提出了一种多语言文本的语音合成方法,所述方法包括:As shown in FIG. 1, in one embodiment, a method for speech synthesis of multilingual text is proposed, and the method includes:
S102、获取待合成多语言文本;S102, acquiring the multilingual text to be synthesized;
所述多语言文本是指文本中同时包含至少两个种类的语言,比如,多语言文本包括中文、英文、法文、阿拉伯数字混合而成,在此举例不作具体限定。The multilingual text refers to that the text contains at least two kinds of languages at the same time, for example, the multilingual text includes Chinese, English, French, and Arabic numerals mixed together, which is not specifically limited in this example.
具体而言,从文本输入设备或数据库或网络中获取多语言文本,将所述多语言文本作为所述待合成多语言文本,以便对所述待合成多语言文本进行合成,并将其合成为语音的形式,在合成语音之前所述待合成多语言文本和合成语音之后的语音表达的内容不发生改变。Specifically, acquiring multilingual text from a text input device or database or network, and using the multilingual text as the multilingual text to be synthesized, so as to synthesize the multilingual text to be synthesized, and synthesizing it into In the form of speech, the multilingual text to be synthesized before the speech is synthesized and the content of the speech expression after the synthesized speech does not change.
用户可以通过文本输入设备触发文本的输入,当用户开始输入时则文本输入设备开始采集文本,当用户停止输入时则文本输入设备停止采集文本,从而使文本输入设备可以采集一段文本。The user can trigger text input through the text input device. When the user starts inputting, the text input device starts to collect text, and when the user stops inputting, the text input device stops collecting text, so that the text input device can collect a piece of text.
S104、将所述待合成多语言文本分别输入至少两个编码规则不同的编码器中进行编码,得到与编码规则对应的文本编码;S104, inputting the multilingual text to be synthesized into at least two encoders with different encoding rules for encoding, to obtain text encoding corresponding to the encoding rules;
具体而言,将所述待合成多语言文本的按阅读顺序依次分别输入至少两个编码规则不同的编码器中进行编码,得到与编码规则对应的文本编码。其中,编码规则不同的编码器可以是两个、三个、四个、五个、六个、七个,在此举例不作具体限定。可以理解的是,不同编码规则的编码器在编码时获取的语言特征的维度不同,通过至少两个编码规则不同的编码器进行编码,可以从多个维度充分获取了所述待合成多语言文本的语言特征,避免了单一编码器获取语言特征不充分或输出信息不充足的问题。Specifically, the multilingual texts to be synthesized are sequentially input into at least two encoders with different encoding rules in order of reading for encoding, so as to obtain text encodings corresponding to the encoding rules. The number of encoders with different encoding rules may be two, three, four, five, six, and seven, which are not specifically limited by examples herein. It can be understood that the dimensions of language features obtained by encoders with different encoding rules are different during encoding. By encoding at least two encoders with different encoding rules, the multilingual text to be synthesized can be fully obtained from multiple dimensions. It avoids the problem of insufficient language features obtained by a single encoder or insufficient output information.
可以理解的是,每个编码器都需要对所述待合成多语言文本按阅读顺序单独进行编码。It can be understood that each encoder needs to encode the multilingual text to be synthesized separately in reading order.
可选的,将所述待合成多语言文本中的字符或字形分别输入至少两个编码规则不同的编码器中进行编码,得到与编码规则对应的文本编码。Optionally, the characters or glyphs in the multilingual text to be synthesized are respectively input into at least two encoders with different encoding rules for encoding, so as to obtain text encoding corresponding to the encoding rules.
所述编码器可以从现有技术中选择对文本进行编码获取语言特征,比如One-hot编码器、UTF-8编码器、音素编码器,在此举例不作具体限定。The encoder may select from the prior art to encode text to obtain language features, such as One-hot encoder, UTF-8 encoder, and phoneme encoder, which are not specifically limited by examples herein.
其中,可以根据所述待合成多语言文本中的语言的种类选择编码器,也可以根据所述待合成多语言文本的内容涉及的领域选择编码器,在此举例不作具体限定。Wherein, the encoder may be selected according to the type of language in the multilingual text to be synthesized, or the encoder may be selected according to the field involved in the content of the multilingual text to be synthesized, which is not specifically limited by this example.
S106、将所有所述编码规则对应的文本编码转换为联合文本编码;S106, converting the text encoding corresponding to all the encoding rules into joint text encoding;
具体而言,将至少两个编码规则不同的编码器编码得到的所有所述编码规则对应的文本编码进行联合编码转换,得到联合文本编码。Specifically, joint encoding conversion is performed on all the text encodings corresponding to the encoding rules encoded by at least two encoders with different encoding rules to obtain joint text encoding.
可选的,将至少两个编码规则不同的编码器编码进行拼接及线性仿射变换,得到联合文本编码,所述联合文本编码的维度为一维。Optionally, splicing and linear affine transformation are performed on at least two encoder codes with different coding rules to obtain a joint text encoding, and the dimension of the joint text encoding is one dimension.
S108、将所述联合文本编码、标准频谱特征数据输入解码器进行预测解码,得到预测频谱特征;S108, inputting the joint text encoding and standard spectral feature data into a decoder for predictive decoding to obtain predicted spectral features;
具体而言,将所述标准频谱特征数据输入解码器供解码器学习,解码器通过对所述联合文本编码进行解码处理,得到与联合文本编码对应的频谱特征,将与联合文本编码对应的频谱特征作为预测频谱特征。Specifically, the standard spectral feature data is input into the decoder for the decoder to learn, and the decoder obtains the spectral features corresponding to the joint text encoding by decoding the joint text encoding, and converts the spectrum corresponding to the joint text encoding features as predicted spectral features.
所述频谱特征可以实现为梅尔频谱,在此举例不作具体限定。The spectral feature may be implemented as a Mel spectrum, which is not specifically limited by an example herein.
所述标准频谱特征数据是通过神经网络预训练出的标准的频谱特征数据库。The standard spectral feature data is a standard spectral feature database pre-trained by a neural network.
S110、将所述预测频谱特征输入声码器进行合成处理,得到与所述待合成多语言文本对应的目标语音。S110. Input the predicted spectral features into a vocoder for synthesis processing to obtain a target speech corresponding to the multilingual text to be synthesized.
可选的,将所述频谱特征实现为梅尔频谱,将梅尔频谱通过声码器进行语音合成处理,得到与所述预测频谱特征对应的目标语音,将与所述预测频谱特征对应的目标语音作为与所述待合成多语言文本对应的目标语音。Optionally, the spectral feature is implemented as a mel spectrum, and the mel spectrum is subjected to speech synthesis processing through a vocoder to obtain a target speech corresponding to the predicted spectral feature, and the target speech corresponding to the predicted spectral feature is obtained. The speech is used as the target speech corresponding to the multilingual text to be synthesized.
当所述频谱特征实现为梅尔频谱时,所述声码器可以从现有技术中选择Universal Vocoding声码器,在此举例不作具体限定。When the spectral feature is implemented as a mel spectrum, the vocoder may select a Universal Vocoding vocoder from the prior art, which is not specifically limited by an example herein.
本实施例的多语言文本的语音合成方法将所述待合成多语言文本分别输入至少两个编码规则不同的编码器中进行编码得到与编码规则对应的文本编码,再将所有所述编码规则对应的文本编码转换为联合文本编码;通过至少两个编码规则不同的编码器进行不同规则的编码,能更充分的保留文本的特征,也有利于多语言文本的处理;通过至少两个编码规则不同的编码器进行不同规则的编码后再经过转换得到联合文本编码,提高了文本合成语音的效果的稳定性,同时也降低了部署难度,降低了部署成本。In the multilingual text speech synthesis method of the present embodiment, the multilingual text to be synthesized is input into at least two encoders with different encoding rules for encoding to obtain the text encoding corresponding to the encoding rules, and then all the encoding rules are corresponding to the encoding rules. The text encoding is converted into joint text encoding; at least two encoders with different encoding rules are used to encode different rules, which can more fully retain the characteristics of the text, and is also conducive to the processing of multilingual texts; through at least two different encoding rules The encoder performs encoding with different rules and then converts to obtain joint text encoding, which improves the stability of the effect of text-to-speech synthesis, reduces deployment difficulty, and reduces deployment costs.
如图2所示,在一个实施例中,所述将所有所述编码规则对应的文本编码转换为联合文本编码,包括:As shown in FIG. 2, in one embodiment, the converting the text encoding corresponding to all the encoding rules to the joint text encoding includes:
S202、将所有所述编码规则对应的文本编码进行拼接,得到拼接文本编码;S202, splicing the text codes corresponding to all the coding rules to obtain the spliced text codes;
具体而言,将每个所述编码规则对应的文本编码作为一维数据,再将所有所述编码规则对应的文本编码的一维数据进行依次拼接,得到拼接文本编码。Specifically, the text code corresponding to each of the encoding rules is used as one-dimensional data, and then the one-dimensional data of the text codes corresponding to all the encoding rules are sequentially spliced to obtain a spliced text code.
可以理解的是,对齐所有所述编码规则对应的文本编码的一维数据的头端,将所有所述编码规则对应的文本编码的一维数据拼接成多维数据,得到拼接文本编码。It can be understood that the head ends of the text-encoded one-dimensional data corresponding to all the encoding rules are aligned, and the text-encoded one-dimensional data corresponding to all the encoding rules are spliced into multi-dimensional data to obtain the spliced text encoding.
S204、将所述拼接文本编码进行线性仿射变换,得到联合文本编码。S204. Perform linear affine transformation on the spliced text encoding to obtain a joint text encoding.
具体而言,将多维的所述拼接文本编码进行线性仿射变换对用于所述编码规则对应的文本编码进行选择,得到联合文本编码,所述联合文本编码的维度为一维。Specifically, linear affine transformation is performed on the multi-dimensional spliced text encoding to select the text encoding corresponding to the encoding rule to obtain a joint text encoding, and the dimension of the joint text encoding is one dimension.
线性仿射变换用于针对每个文本单元选择其中一个所述编码规则对应的文本编码作为与文本单元对应的目标文本编码,将所有所述目标文本编码依次进行拼接,得到联合文本编码。The linear affine transformation is used for selecting one of the text codes corresponding to the encoding rules for each text unit as the target text code corresponding to the text unit, and splicing all the target text codes in sequence to obtain a joint text code.
在一个实施例中,所述将所述待合成多语言文本分别输入至少两个编码规则不同的编码器中进行编码,得到与编码规则对应的文本编码,包括:将所述待合成多语言文本输入One-hot编码器进行编码,得到与One-hot编码器对应的One-hot文本编码;将所述待合成多语言文本输入UTF-8编码器进行编码,得到与UTF-8编码器对应的UTF-8文本编码;将所述待合成多语言文本输入音素编码器进行编码,得到与音素编码器对应的音素文本编码。In one embodiment, the step of inputting the multilingual text to be synthesized into at least two encoders with different encoding rules for encoding, and obtaining the text encoding corresponding to the encoding rules, includes: inputting the multilingual text to be synthesized. Input the One-hot encoder for encoding, and obtain the One-hot text encoding corresponding to the One-hot encoder; input the multilingual text to be synthesized into the UTF-8 encoder for encoding, and obtain the corresponding UTF-8 encoder. UTF-8 text encoding; input the multilingual text to be synthesized into a phoneme encoder for encoding, and obtain a phoneme text encoding corresponding to the phoneme encoder.
所述One-Hot编码即独热编码,又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。One-Hot编码可以将不同语言的字符或字形的集合放在一起作为输入的字典。The One-Hot encoding is one-hot encoding, also known as one-bit effective encoding. The method is to use an N-bit state register to encode N states, each state has its own register bit, and at any time, Only one of them is valid. One-Hot encoding can put together a collection of characters or glyphs from different languages as a dictionary of input.
所述UTF-8(8位元,Universal Character Set/Unicode TransformationFormat)是针对Unicode的一种可变长度字符编码,可以用来表示Unicode标准中的任何字符,由128个字符组成,包括大小写字母、数字0-9、标点符号、非打印字符(换行符、制表符等4个)以及控制字符(退格、响铃等)组成,能适应全球所有字符。The UTF-8 (8-bit, Universal Character Set/Unicode TransformationFormat) is a variable-length character encoding for Unicode, which can be used to represent any character in the Unicode standard, consisting of 128 characters, including upper and lower case letters , numbers 0-9, punctuation marks, non-printing characters (linefeed, tab, etc. 4) and control characters (backspace, bell, etc.), which can adapt to all characters in the world.
所述音素是根据语音的自然属性划分出来的最小语音单位,依据音节里的发音动作来分析,一个动作构成一个音素。The phoneme is the smallest phonetic unit divided according to the natural attributes of the voice, and is analyzed according to the pronunciation action in the syllable, and an action constitutes a phoneme.
所述One-hot编码器是采用One-hot编码的方式采用神经网络训练得到,训练方法可以从现有技术中选择,在此不作赘述。The One-hot encoder is obtained by training a neural network in a One-hot encoding manner, and the training method can be selected from the prior art, which will not be repeated here.
所述UTF-8编码器是采用UTF-8编码的方式采用神经网络训练得到,训练方法可以从现有技术中选择,在此不作赘述。用于可以将输入的字符或字形映射到一个具有256个可能值的词条进行编码器输入。The UTF-8 encoder is obtained by using neural network training in the manner of UTF-8 encoding, and the training method can be selected from the prior art, which will not be repeated here. Used for encoder input that can map an input character or glyph to a term with 256 possible values.
所述音素编码器是采用音素编码的方式采用神经网络训练得到,训练方法可以从现有技术中选择。音素编码器不需要学习复杂的发音规则,相同的音素可以在不同的语言中共享。The phoneme encoder is obtained by training a neural network in a phoneme encoding manner, and the training method can be selected from the prior art. Phoneme encoders do not need to learn complex pronunciation rules, and the same phonemes can be shared across different languages.
One-hot编码器、UTF-8编码器、音素编码器是目前应用比较广泛的提取文本编码的编码器,本方法通过采用这三种编码器,提高了保留的文本的语言特征,也更有利于多语言文本的处理。可以理解的是,本方法还可以采取其他提取文本编码的编码器,在此举例不作具体限定。One-hot encoder, UTF-8 encoder, and phoneme encoder are currently widely used encoders for extracting text encoding. By using these three encoders, this method improves the language characteristics of the retained text, and also has more Facilitate the processing of multilingual texts. It can be understood that this method may also adopt other encoders for extracting text encoding, which is not specifically limited by this example.
在一个实施例中,所述将所有所述编码规则对应的文本编码进行拼接,得到拼接文本编码,包括:In one embodiment, the text codes corresponding to all the encoding rules are spliced to obtain the spliced text codes, including:
将所述One-hot文本编码、所述UTF-8文本编码、所述音素文本编码在通道维度上进行拼接,得到拼接文本编码,所述拼接文本编码包括三维数据;其中,第一维数据为所述One-hot文本编码,第二维数据为所述UTF-8文本编码,第三维数据为所述音素文本编码。The One-hot text encoding, the UTF-8 text encoding, and the phoneme text encoding are spliced in the channel dimension to obtain a spliced text encoding, and the spliced text encoding includes three-dimensional data; wherein, the first dimension data is For the One-hot text encoding, the second dimension data is the UTF-8 text encoding, and the third dimension data is the phoneme text encoding.
在一个实施例中,所述将所述拼接文本编码进行线性仿射变换,得到联合文本编码,包括:In one embodiment, performing linear affine transformation on the spliced text encoding to obtain a joint text encoding, comprising:
将多维的所述拼接文本编码输入第一神经网络进行线性仿射变换对所述编码规则对应的文本编码进行选择,得到联合文本编码,所述联合文本编码的维度为一维。The multi-dimensional spliced text encoding is input into the first neural network to perform linear affine transformation to select the text encoding corresponding to the encoding rule to obtain a joint text encoding, and the dimension of the joint text encoding is one dimension.
具体而言,以文本单元为独立单元通过已训练的所述第一神经网络从多维的所述拼接文本编码对所述编码规则对应的文本编码进行选择,选择其中一个所述编码规则对应的文本编码作为与文本单元对应的目标文本编码,将所有所述目标文本编码依次进行拼接,得到联合文本编码;其中,所述编码规则对应的文本编码选择的规则是所述第一神经网络经过训练得到的。比如,选择One-hot编码器、UTF-8编码器、音素编码器提取与编码规则对应的文本编码时,通过编码得到与One-hot编码器对应的One-hot文本编码、与UTF-8编码器对应的UTF-8文本编码、与音素编码器对应的音素文本编码,对每个文本单元从与One-hot编码器对应的One-hot文本编码、与UTF-8编码器对应的UTF-8文本编码、与音素编码器对应的音素文本编码中选择其中一种作为与文本单元对应的目标文本编码。Specifically, using the text unit as an independent unit, select the text code corresponding to the encoding rule from the multi-dimensional spliced text code through the trained first neural network, and select the text corresponding to one of the encoding rules The encoding is used as the target text encoding corresponding to the text unit, and all the target text encodings are spliced in turn to obtain a joint text encoding; wherein, the text encoding selection rule corresponding to the encoding rule is obtained by the first neural network after training. of. For example, when selecting the One-hot encoder, UTF-8 encoder, and phoneme encoder to extract the text encoding corresponding to the encoding rule, the One-hot text encoding corresponding to the One-hot encoder, and the UTF-8 encoding corresponding to the One-hot encoder are obtained through encoding. UTF-8 text encoding corresponding to the encoder, phoneme text encoding corresponding to the phoneme encoder, for each text unit from the One-hot text encoding corresponding to the One-hot encoder, the UTF-8 corresponding to the UTF-8 encoder One of the text encoding and the phoneme text encoding corresponding to the phoneme encoder is selected as the target text encoding corresponding to the text unit.
所述第一神经网络可以从现有技术中选择可以进行线性仿射变换的神经网络,在此不做赘述。For the first neural network, a neural network capable of performing linear affine transformation can be selected from the prior art, and details are not described here.
在一个实施例中,所述将所述联合文本编码、标准频谱特征数据输入解码器进行预测解码,得到预测频谱特征,包括:将所述联合文本编码进行高层特征提取得到联合文本编码高层特征;将所述联合文本编码高层特征、所述标准频谱特征数据输入解码器进行预测解码,得到所述预测频谱特征。In one embodiment, inputting the joint text encoding and standard spectral feature data into a decoder for predictive decoding to obtain predicted spectral features includes: performing high-level feature extraction on the joint text encoding to obtain joint text encoding high-level features; The joint text encoding high-level feature and the standard spectral feature data are input into a decoder for predictive decoding to obtain the predicted spectral feature.
所述高层特征是指所述待合成多语言文本包含的与语言分类、语义信息等相关的特征。The high-level features refer to features related to language classification, semantic information, etc. contained in the multilingual text to be synthesized.
高层特征是包含的与语言分类、语义信息等相关的特征,通过包含高层特征的所述联合文本编码预测解码得到预测频谱特征保留了待合成多语言文本的语言分类、语义信息,从而进一步提高了最终合成出的与所述待合成多语言文本对应的目标语音的准确性。High-level features are features related to language classification, semantic information, etc., and the predicted spectral features obtained by the joint text encoding prediction and decoding containing high-level features retain the language classification and semantic information of the multilingual text to be synthesized, thereby further improving. The accuracy of the final synthesized target speech corresponding to the multilingual text to be synthesized.
在一个实施例中,所述从所述联合文本编码进行高层特征提取得到联合文本编码高层特征,包括:In one embodiment, the high-level feature extraction of the joint text encoding to obtain the high-level features of the joint text encoding includes:
将所述联合文本编码输入第二神经网络进行高层特征提取,得到联合文本编码高层特征。对所述联合文本编码进行高层特征提取的规则,可以通过对所述第二神经网络经过训练得到的。The joint text encoding is input into the second neural network for high-level feature extraction to obtain joint text encoding high-level features. The rules for extracting high-level features for the joint text encoding can be obtained by training the second neural network.
所述第二神经网络可以从现有技术中选择可以对文本编码进行高层特征提取的神经网络,在此不做赘述。The second neural network can be selected from the prior art as a neural network capable of performing high-level feature extraction for text encoding, which will not be repeated here.
在一个实施例中,所述第二神经网络包括依次设置的字符级卷积神经网络、三个卷积层及双向长短时记忆循环神经网络。In one embodiment, the second neural network includes a character-level convolutional neural network, three convolutional layers, and a bidirectional long-short-term memory recurrent neural network arranged in sequence.
所述字符级卷积神经网络用于实现字符嵌入,详细结构可以从现有技术中选择,在此不做赘述。The character-level convolutional neural network is used to implement character embedding, and the detailed structure can be selected from the prior art, which will not be repeated here.
所述三个卷积层用于实现高层特征提取,详细结构可以从现有技术中选择,在此不做赘述。The three convolutional layers are used to implement high-level feature extraction, and the detailed structure can be selected from the prior art, which will not be repeated here.
所述双向长短时记忆循环神经网络用于语义关系识别,利用循环神经网络直接从词学习问句的语义特征表示,详细结构可以从现有技术中选择,在此不做赘述。The bidirectional long-short-term memory cyclic neural network is used for semantic relationship recognition, and the cyclic neural network is used to directly learn the semantic feature representation of the question sentence from words. The detailed structure can be selected from the prior art, which will not be repeated here.
如图3所示,在一个实施例中,所述将所述联合文本编码高层特征、所述标准频谱特征数据输入解码器进行预测解码,得到所述预测频谱特征,包括:As shown in FIG. 3 , in one embodiment, inputting the joint text encoding high-level feature and the standard spectral feature data into a decoder for predictive decoding to obtain the predicted spectral feature includes:
S302、获取标准频谱特征数据;S302. Obtain standard spectrum characteristic data;
S304、将所述联合文本编码高层特征、所述标准频谱特征数据输入解码器,所述解码器包括第三神经网络;S304, inputting the joint text encoding high-level feature and the standard spectral feature data into a decoder, where the decoder includes a third neural network;
S306、所述解码器的第三神经网络根据所述联合文本编码高层特征、所述标准频谱特征数据结合注意力机制进行频谱特征预测,得到预测频谱特征。S306: The third neural network of the decoder performs spectral feature prediction according to the joint text coding high-level feature, the standard spectral feature data, and an attention mechanism to obtain the predicted spectral feature.
具体而言,将所述标准频谱特征数据输入第三神经网络进行学习,对第三神经网络进行学习训练得到解码器,解码器根据注意力机制将所述联合文本编码高层特征映射成频谱特征序列,将所述频谱特征序列作为预测频谱特征。通过对第三神经网络进行学习训练得到的解码器,可以捕捉单词的发音,还可以捕捉人类语音的各种细微变化,包括音量、语速和语调。Specifically, the standard spectral feature data is input into a third neural network for learning, the third neural network is learned and trained to obtain a decoder, and the decoder maps the joint text encoding high-level features into a spectral feature sequence according to an attention mechanism , and the spectral feature sequence is used as the predicted spectral feature. The decoder, which is learned and trained by the third neural network, can capture the pronunciation of words, as well as various subtle changes in human speech, including volume, speed and intonation.
所述第三神经网络可以从现有技术中选择可以对文本编码进行提取的神经网络,在此不做赘述。The third neural network can be selected from the prior art as a neural network capable of extracting text codes, and details are not described here.
在一个实施例中,所述第三神经网络包括2层预处理神经网络、2层长短期记忆网络、线性仿射变换神经网络、5层卷积后处理神经网络。2层预处理神经网络、2层长短期记忆网络、线性仿射变换神经网络、5层卷积后处理神经网络的详细结构可以从现有技术中选择,在此不做赘述。In one embodiment, the third neural network includes a 2-layer preprocessing neural network, a 2-layer long short-term memory network, a linear affine transformation neural network, and a 5-layer convolutional post-processing neural network. The detailed structures of the 2-layer preprocessing neural network, the 2-layer long short-term memory network, the linear affine transformation neural network, and the 5-layer convolutional post-processing neural network can be selected from the prior art, which will not be repeated here.
所述长短时记忆网络用于在输入和输出序列之间的映射过程中利用上下文相关信息。The long short-term memory network is used to utilize context-dependent information in the mapping process between input and output sequences.
如图4所示,在一个实施例中,还提出了一种多语言文本的语音合成方法,所述方法包括:As shown in FIG. 4, in one embodiment, a method for speech synthesis of multilingual text is also proposed, and the method includes:
S402、获取待处理多语言文本;S402. Obtain the multilingual text to be processed;
所述多语言文本是指文本中同时包含多个种类的语言,比如,多语言文本包括中文、英文、法文、阿拉伯数字混合而成,在此举例不作具体限定。The multilingual text refers to that the text contains multiple kinds of languages at the same time, for example, the multilingual text includes Chinese, English, French, and Arabic numerals mixed together, which is not specifically limited by this example.
所述待处理多语言文本是指从文本输入设备或数据库或网络中获取多语言文本。The multilingual text to be processed refers to acquiring the multilingual text from a text input device, a database or a network.
S404、根据所述待处理多语言文本进行语言标准化处理,得到待合成多语言文本;S404, performing language standardization processing according to the multilingual text to be processed to obtain multilingual text to be synthesized;
在语言的使用过程中,存在非标准化的使用,比如:英文单词的缩写、简写、多个单词通过连接符连接在一起等,这些非标准化的使用在从文本合成语音的时可能出现漏词或跳词的问题。In the process of using language, there are non-standard uses, such as: abbreviations, abbreviations of English words, multiple words are connected together by connectors, etc. These non-standard uses may occur when synthesizing speech from text. Missing words or The problem of skipping words.
所述语言标准化处理包括把缩写还原、简写还原、连接在一起的多个单词拆开,在此举例不做具体限定。The language standardization process includes restoring abbreviations, restoring abbreviations, and separating multiple words that are connected together, which are not specifically limited by examples herein.
S406、获取待合成多语言文本;S406, acquiring the multilingual text to be synthesized;
S408、将所述待合成多语言文本分别输入至少两个编码规则不同的编码器中进行编码,得到与编码规则对应的文本编码;S408, the multilingual text to be synthesized is respectively input into at least two encoders with different encoding rules for encoding, to obtain the text encoding corresponding to the encoding rules;
S410、将所有所述编码规则对应的文本编码转换为联合文本编码;S410, converting the text encoding corresponding to all the encoding rules into joint text encoding;
S412、将所述联合文本编码、标准频谱特征数据输入解码器进行预测解码,得到预测频谱特征;S412, inputting the joint text encoding and standard spectral feature data into a decoder for predictive decoding to obtain predicted spectral features;
S414、将所述预测频谱特征输入声码器进行合成处理,得到与所述待合成多语言文本对应的目标语音。S414. Input the predicted spectral features into a vocoder for synthesis processing to obtain a target speech corresponding to the multilingual text to be synthesized.
本实施例通过将所述待处理多语言文本进行语言标准化处理后得到待合成多语言文本,再把待合成多语言文本作为输入用于合成语音,进一步避免了漏词或跳词的现象,进一步提成合成语音的质量。In this embodiment, the multilingual text to be synthesized is obtained by performing language standardization on the multilingual text to be processed, and then the multilingual text to be synthesized is used as input for synthesizing speech, thereby further avoiding the phenomenon of missing words or skipping words, and further The quality of the synthesized speech.
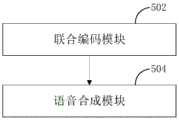
如图5所示,在一个实施例中,本发明提出了一种多语言文本的语音合成装置,所述装置包括:As shown in FIG. 5 , in one embodiment, the present invention provides a multilingual text speech synthesis device, the device includes:
联合编码模块502,用于获取待合成多语言文本,将所述待合成多语言文本分别输入至少两个编码规则不同的编码器中进行编码,得到与编码规则对应的文本编码,将所有所述编码规则对应的文本编码转换为联合文本编码;The
语音合成模块504,用于将所述联合文本编码、标准频谱特征数据输入解码器进行预测解码,得到预测频谱特征,将所述预测频谱特征输入声码器进行合成处理,得到与所述待合成多语言文本对应的目标语音。The
本实施例的多语言文本的语音合成装置将所述待合成多语言文本分别输入至少两个编码规则不同的编码器中进行编码得到与编码规则对应的文本编码,再将所有所述编码规则对应的文本编码转换为联合文本编码;通过至少两个编码规则不同的编码器进行不同规则的编码,能更充分的保留文本的特征,也有利于多语言文本的处理;通过至少两个编码规则不同的编码器进行不同规则的编码后再经过转换得到联合文本编码,提高了文本合成语音的效果的稳定性,同时也降低了部署难度,降低了部署成本。The multilingual text speech synthesis apparatus of this embodiment inputs the multilingual text to be synthesized into at least two encoders with different encoding rules for encoding to obtain text codes corresponding to the encoding rules, and then converts all the encoding rules corresponding to the encoding rules. The text encoding is converted into joint text encoding; at least two encoders with different encoding rules are used to encode different rules, which can more fully retain the characteristics of the text, and is also conducive to the processing of multilingual texts; through at least two different encoding rules The encoder performs encoding with different rules and then converts to obtain joint text encoding, which improves the stability of the effect of text-to-speech synthesis, reduces deployment difficulty, and reduces deployment costs.
如图6所示,在一个实施例中,所述联合编码模块包括分别编码子模块5022、编码联合转换子模块5024;As shown in FIG. 6 , in one embodiment, the joint encoding module includes a
所述分别编码子模块5022用于获取待合成多语言文本,将所述待合成多语言文本分别输入至少两个编码规则不同的编码器中进行编码,得到与编码规则对应的文本编码;The
所述联合编码子模块5024用于将所有所述编码规则对应的文本编码进行拼接,得到拼接文本编码,将所述拼接文本编码进行线性仿射变换,得到联合文本编码。The
如图7所示,在一个实施例中,所述语音合成模块包括高层特征提取子模块5042、频谱特征预测子模块5044;As shown in FIG. 7 , in one embodiment, the speech synthesis module includes a high-level
所述高层特征提取子模块5042用于将所述联合文本编码进行高层特征提取得到联合文本编码高层特征;The high-level
所述频谱特征预测子模块5044用于将所述联合文本编码高层特征、所述标准频谱特征数据输入解码器进行预测解码,得到所述预测频谱特征。The spectral
图8示出了一个实施例中计算机设备的内部结构图。该计算机设备具体可以是终端,也可以是服务器。如图8所示,该计算机设备包括通过系统总线连接的处理器、存储器和网络接口。其中,存储器包括非易失性存储介质和内存储器。该计算机设备的非易失性存储介质存储有操作系统,还可存储有计算机程序,该计算机程序被处理器执行时,可使得处理器实现多语言文本的语音合成方法。该内存储器中也可储存有计算机程序,该计算机程序被处理器执行时,可使得处理器执行多语言文本的语音合成方法。本领域技术人员可以理解,图8中示出的结构,仅仅是与本申请方案相关的部分结构的框图,并不构成对本申请方案所应用于其上的计算机设备的限定,具体的计算机设备可以包括比图中所示更多或更少的部件,或者组合某些部件,或者具有不同的部件布置。Figure 8 shows an internal structure diagram of a computer device in one embodiment. Specifically, the computer device may be a terminal or a server. As shown in FIG. 8, the computer device includes a processor, memory, and a network interface connected by a system bus. Wherein, the memory includes a non-volatile storage medium and an internal memory. The non-volatile storage medium of the computer device stores an operating system, and also stores a computer program, which, when executed by the processor, enables the processor to implement a method for synthesizing speech in multiple languages. A computer program can also be stored in the internal memory, and when the computer program is executed by the processor, the processor can execute the method of speech synthesis of multilingual text. Those skilled in the art can understand that the structure shown in FIG. 8 is only a block diagram of a part of the structure related to the solution of the present application, and does not constitute a limitation on the computer equipment to which the solution of the present application is applied. Include more or fewer components than shown in the figures, or combine certain components, or have a different arrangement of components.
在一个实施例中,本申请提供的一种多语言文本的语音合成方法可以实现为一种计算机程序的形式,计算机程序可在如图8所示的计算机设备上运行。计算机设备的存储器中可存储组成的一种多语言文本的语音合成装置的各个程序模板。比如,联合编码模块502、语音合成模块504。In one embodiment, the multilingual text speech synthesis method provided by the present application can be implemented in the form of a computer program, and the computer program can be executed on a computer device as shown in FIG. 8 . The memory of the computer device can store various program templates that constitute a multilingual text speech synthesis apparatus. For example, the
在一个实施例中,本发明提出了一种存储介质,存储有计算机指令程序,所述计算机指令程序被处理器执行时,使得所述处理器执行时实现如下方法步骤:In one embodiment, the present invention provides a storage medium that stores a computer instruction program. When the computer instruction program is executed by a processor, the processor implements the following method steps when executed:
获取待合成多语言文本;Get multilingual text to be synthesized;
将所述待合成多语言文本分别输入至少两个编码规则不同的编码器中进行编码,得到与编码规则对应的文本编码;The multilingual texts to be synthesized are respectively input into at least two encoders with different encoding rules for encoding, and the text encoding corresponding to the encoding rules is obtained;
将所有所述编码规则对应的文本编码转换为联合文本编码;Convert all text encodings corresponding to the encoding rules to joint text encodings;
将所述联合文本编码、标准频谱特征数据输入解码器进行预测解码,得到预测频谱特征;Inputting the joint text encoding and standard spectral feature data into a decoder for predictive decoding to obtain predicted spectral features;
将所述预测频谱特征输入声码器进行合成处理,得到与所述待合成多语言文本对应的目标语音。The predicted spectral features are input into a vocoder for synthesis processing to obtain target speech corresponding to the multilingual text to be synthesized.
本实施例的方法步骤执行时将所述待合成多语言文本分别输入至少两个编码规则不同的编码器中进行编码得到与编码规则对应的文本编码,再将所有所述编码规则对应的文本编码转换为联合文本编码;通过至少两个编码规则不同的编码器进行不同规则的编码,能更充分的保留文本的特征,也有利于多语言文本的处理;通过至少两个编码规则不同的编码器进行不同规则的编码后再经过转换得到联合文本编码,提高了文本合成语音的效果的稳定性,同时也降低了部署难度,降低了部署成本。When the method steps of this embodiment are executed, the multilingual texts to be synthesized are respectively input into at least two encoders with different encoding rules for encoding to obtain text encodings corresponding to the encoding rules, and then all the text encodings corresponding to the encoding rules are encoded. Convert to joint text encoding; use at least two encoders with different encoding rules to encode different rules, which can more fully retain the characteristics of the text, and is also conducive to the processing of multilingual text; through at least two encoders with different encoding rules After encoding with different rules, the joint text encoding is obtained after conversion, which improves the stability of the effect of text-to-speech synthesis, reduces the difficulty of deployment, and reduces the cost of deployment.
在一个实施例中,所述将所有所述编码规则对应的文本编码转换为联合文本编码,包括:将所有所述编码规则对应的文本编码进行拼接,得到拼接文本编码;将所述拼接文本编码进行线性仿射变换,得到联合文本编码。In one embodiment, the converting the text codes corresponding to all the coding rules to the joint text codes includes: splicing the text codes corresponding to all the coding rules to obtain the spliced text codes; coding the spliced texts A linear affine transformation is performed to obtain a joint text encoding.
在一个实施例中,所述将所述联合文本编码、标准频谱特征数据输入解码器进行预测解码,得到预测频谱特征,包括:将所述联合文本编码进行高层特征提取得到联合文本编码高层特征;将所述联合文本编码高层特征、所述标准频谱特征数据输入解码器进行预测解码,得到所述预测频谱特征。In one embodiment, inputting the joint text encoding and standard spectral feature data into a decoder for predictive decoding to obtain predicted spectral features includes: performing high-level feature extraction on the joint text encoding to obtain joint text encoding high-level features; The joint text encoding high-level feature and the standard spectral feature data are input into a decoder for predictive decoding to obtain the predicted spectral feature.
在一个实施例中,所述将所述待合成多语言文本分别输入至少两个编码规则不同的编码器中进行编码,得到与编码规则对应的文本编码,包括:将所述待合成多语言文本输入One-hot编码器进行编码,得到与One-hot编码器对应的One-hot文本编码;将所述待合成多语言文本输入UTF-8编码器进行编码,得到与UTF-8编码器对应的UTF-8文本编码;将所述待合成多语言文本输入音素编码器进行编码,得到与音素编码器对应的音素文本编码。In one embodiment, the step of inputting the multilingual text to be synthesized into at least two encoders with different encoding rules for encoding, and obtaining the text encoding corresponding to the encoding rules, includes: inputting the multilingual text to be synthesized. Input the One-hot encoder for encoding, and obtain the One-hot text encoding corresponding to the One-hot encoder; input the multilingual text to be synthesized into the UTF-8 encoder for encoding, and obtain the corresponding UTF-8 encoder. UTF-8 text encoding; input the multilingual text to be synthesized into a phoneme encoder for encoding, and obtain a phoneme text encoding corresponding to the phoneme encoder.
在一个实施例中,所述将所有所述编码规则对应的文本编码进行拼接,得到拼接文本编码,包括:将所述One-hot文本编码、所述UTF-8文本编码、所述音素文本编码在通道维度上进行拼接,得到拼接文本编码,所述拼接文本编码包括三维数据;其中,第一维数据为所述One-hot文本编码,第二维数据为所述UTF-8文本编码,第三维数据为所述音素文本编码。In one embodiment, the splicing of the text codes corresponding to all the encoding rules to obtain the spliced text codes includes: splicing the One-hot text codes, the UTF-8 text codes, and the phoneme text codes Splicing is performed in the channel dimension to obtain a spliced text code, where the spliced text code includes three-dimensional data; wherein the first dimension data is the One-hot text code, the second dimension data is the UTF-8 text code, and the third dimension data is the UTF-8 text code. Three-dimensional data encodes the phoneme text.
在一个实施例中,所述将所述拼接文本编码进行线性仿射变换,得到联合文本编码,包括:将多维的所述拼接文本编码输入第一神经网络进行线性仿射变换对所述编码规则对应的文本编码进行选择,得到联合文本编码。In one embodiment, performing linear affine transformation on the spliced text encoding to obtain a joint text encoding includes: inputting the multi-dimensional spliced text encoding into a first neural network to perform linear affine transformation on the encoding rules The corresponding text encoding is selected to obtain a joint text encoding.
在一个实施例中,所述将所述联合文本编码进行高层特征提取,得到联合文本编码高层特征,包括:将所述联合文本编码输入第二神经网络进行高层特征提取,得到联合文本编码高层特征。In one embodiment, performing high-level feature extraction on the joint text encoding to obtain the joint text encoding high-level features includes: inputting the joint text encoding into a second neural network for high-level feature extraction to obtain the joint text encoding high-level features .
在一个实施例中,所述第二神经网络包括依次设置的字符级卷积神经网络、三个卷积层及双向长短时记忆循环神经网络。In one embodiment, the second neural network includes a character-level convolutional neural network, three convolutional layers, and a bidirectional long-short-term memory recurrent neural network arranged in sequence.
在一个实施例中,所述将所述联合文本编码高层特征、所述标准频谱特征数据输入解码器进行预测解码,得到所述预测频谱特征,包括:获取标准频谱特征数据;将所述联合文本编码高层特征、所述标准频谱特征数据输入解码器,所述解码器包括第三神经网络;所述解码器的第三神经网络根据所述联合文本编码、所述标准频谱特征数据结合注意力机制进行频谱特征预测,得到预测频谱特征。In one embodiment, the step of inputting the joint text-encoded high-level feature and the standard spectral feature data into a decoder for predictive decoding to obtain the predicted spectral feature includes: obtaining standard spectral feature data; The encoded high-level features and the standard spectral feature data are input into the decoder, and the decoder includes a third neural network; the third neural network of the decoder is based on the joint text encoding, the standard spectral feature data combined with the attention mechanism Perform spectral feature prediction to obtain predicted spectral features.
在一个实施例中,所述获取待合成多语言文本之前,还包括:获取待处理多语言文本;根据所述待处理多语言文本进行语言标准化处理,得到待合成多语言文本。In one embodiment, before acquiring the multilingual text to be synthesized, the method further includes: acquiring the multilingual text to be processed; and performing language normalization processing according to the multilingual text to be processed to obtain the multilingual text to be synthesized.
在一个实施例中,本发明提出了一种多语言文本的语音合成设备,包括至少一个存储器、至少一个处理器,所述存储器存储有计算机指令程序,所述计算机指令程序被所述处理器执行时,使得所述处理器执行实现如下方法步骤:In one embodiment, the present invention provides a multilingual text speech synthesis device, comprising at least one memory and at least one processor, wherein the memory stores a computer instruction program, and the computer instruction program is executed by the processor , causing the processor to execute the following method steps:
获取待合成多语言文本;Get multilingual text to be synthesized;
将所述待合成多语言文本分别输入至少两个编码规则不同的编码器中进行编码,得到与编码规则对应的文本编码;The multilingual texts to be synthesized are respectively input into at least two encoders with different encoding rules for encoding, and the text encoding corresponding to the encoding rules is obtained;
将所有所述编码规则对应的文本编码转换为联合文本编码;Convert all text encodings corresponding to the encoding rules to joint text encodings;
将所述联合文本编码、标准频谱特征数据输入解码器进行预测解码,得到预测频谱特征;Inputting the joint text encoding and standard spectral feature data into a decoder for predictive decoding to obtain predicted spectral features;
将所述预测频谱特征输入声码器进行合成处理,得到与所述待合成多语言文本对应的目标语音。The predicted spectral features are input into a vocoder for synthesis processing to obtain target speech corresponding to the multilingual text to be synthesized.
本实施例的方法步骤执行时将所述待合成多语言文本分别输入至少两个编码规则不同的编码器中进行编码得到与编码规则对应的文本编码,再将所有所述编码规则对应的文本编码转换为联合文本编码;通过至少两个编码规则不同的编码器进行不同规则的编码,能更充分的保留文本的特征,也有利于多语言文本的处理;通过至少两个编码规则不同的编码器进行不同规则的编码后再经过转换得到联合文本编码,提高了文本合成语音的效果的稳定性,同时也降低了部署难度,降低了部署成本。When the method steps of this embodiment are executed, the multilingual texts to be synthesized are respectively input into at least two encoders with different encoding rules for encoding to obtain text encodings corresponding to the encoding rules, and then all the text encodings corresponding to the encoding rules are encoded. Convert to joint text encoding; use at least two encoders with different encoding rules to encode different rules, which can more fully retain the characteristics of the text, and is also conducive to the processing of multilingual text; through at least two encoders with different encoding rules After encoding with different rules, the joint text encoding is obtained after conversion, which improves the stability of the effect of text-to-speech synthesis, reduces the difficulty of deployment, and reduces the cost of deployment.
在一个实施例中,所述将所有所述编码规则对应的文本编码转换为联合文本编码,包括:将所有所述编码规则对应的文本编码进行拼接,得到拼接文本编码;将所述拼接文本编码进行线性仿射变换,得到联合文本编码。In one embodiment, the converting the text codes corresponding to all the coding rules to the joint text codes includes: splicing the text codes corresponding to all the coding rules to obtain the spliced text codes; coding the spliced texts A linear affine transformation is performed to obtain a joint text encoding.
在一个实施例中,所述将所述联合文本编码、标准频谱特征数据输入解码器进行预测解码,得到预测频谱特征,包括:将所述联合文本编码进行高层特征提取得到联合文本编码高层特征;将所述联合文本编码高层特征、所述标准频谱特征数据输入解码器进行预测解码,得到所述预测频谱特征。In one embodiment, inputting the joint text encoding and standard spectral feature data into a decoder for predictive decoding to obtain predicted spectral features includes: performing high-level feature extraction on the joint text encoding to obtain joint text encoding high-level features; The joint text encoding high-level feature and the standard spectral feature data are input into a decoder for predictive decoding to obtain the predicted spectral feature.
在一个实施例中,所述将所述待合成多语言文本分别输入至少两个编码规则不同的编码器中进行编码,得到与编码规则对应的文本编码,包括:将所述待合成多语言文本输入One-hot编码器进行编码,得到与One-hot编码器对应的One-hot文本编码;将所述待合成多语言文本输入UTF-8编码器进行编码,得到与UTF-8编码器对应的UTF-8文本编码;将所述待合成多语言文本输入音素编码器进行编码,得到与音素编码器对应的音素文本编码。In one embodiment, the step of inputting the multilingual text to be synthesized into at least two encoders with different encoding rules for encoding, and obtaining the text encoding corresponding to the encoding rules, includes: inputting the multilingual text to be synthesized. Input the One-hot encoder for encoding, and obtain the One-hot text encoding corresponding to the One-hot encoder; input the multilingual text to be synthesized into the UTF-8 encoder for encoding, and obtain the corresponding UTF-8 encoder. UTF-8 text encoding; input the multilingual text to be synthesized into a phoneme encoder for encoding, and obtain a phoneme text encoding corresponding to the phoneme encoder.
在一个实施例中,所述将所有所述编码规则对应的文本编码进行拼接,得到拼接文本编码,包括:将所述One-hot文本编码、所述UTF-8文本编码、所述音素文本编码在通道维度上进行拼接,得到拼接文本编码,所述拼接文本编码包括三维数据;其中,第一维数据为所述One-hot文本编码,第二维数据为所述UTF-8文本编码,第三维数据为所述音素文本编码。In one embodiment, the splicing of the text codes corresponding to all the encoding rules to obtain the spliced text codes includes: splicing the One-hot text codes, the UTF-8 text codes, and the phoneme text codes Splicing is performed in the channel dimension to obtain a spliced text code, where the spliced text code includes three-dimensional data; wherein the first dimension data is the One-hot text code, the second dimension data is the UTF-8 text code, and the third dimension data is the UTF-8 text code. Three-dimensional data encodes the phoneme text.
在一个实施例中,所述将所述拼接文本编码进行线性仿射变换,得到联合文本编码,包括:将多维的所述拼接文本编码输入第一神经网络进行线性仿射变换对所述编码规则对应的文本编码进行选择,得到联合文本编码。In one embodiment, performing linear affine transformation on the spliced text encoding to obtain a joint text encoding includes: inputting the multi-dimensional spliced text encoding into a first neural network to perform linear affine transformation on the encoding rules The corresponding text encoding is selected to obtain a joint text encoding.
在一个实施例中,所述将所述联合文本编码进行高层特征提取,得到联合文本编码高层特征,包括:将所述联合文本编码输入第二神经网络进行高层特征提取,得到联合文本编码高层特征。In one embodiment, performing high-level feature extraction on the joint text encoding to obtain the joint text encoding high-level features includes: inputting the joint text encoding into a second neural network for high-level feature extraction to obtain the joint text encoding high-level features .
在一个实施例中,所述第二神经网络包括依次设置的字符级卷积神经网络、三个卷积层及双向长短时记忆循环神经网络。In one embodiment, the second neural network includes a character-level convolutional neural network, three convolutional layers, and a bidirectional long-short-term memory recurrent neural network arranged in sequence.
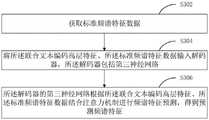
在一个实施例中,所述将所述联合文本编码高层特征、所述标准频谱特征数据输入解码器进行预测解码,得到所述预测频谱特征,包括:获取标准频谱特征数据;将所述联合文本编码高层特征、所述标准频谱特征数据输入解码器,所述解码器包括第三神经网络;所述解码器的第三神经网络根据所述联合文本编码、所述标准频谱特征数据结合注意力机制进行频谱特征预测,得到预测频谱特征。In one embodiment, the step of inputting the joint text-encoded high-level feature and the standard spectral feature data into a decoder for predictive decoding to obtain the predicted spectral feature includes: obtaining standard spectral feature data; The encoded high-level features and the standard spectral feature data are input into the decoder, and the decoder includes a third neural network; the third neural network of the decoder is based on the joint text encoding, the standard spectral feature data combined with the attention mechanism Perform spectral feature prediction to obtain predicted spectral features.
在一个实施例中,所述获取待合成多语言文本之前,还包括:获取待处理多语言文本;根据所述待处理多语言文本进行语言标准化处理,得到待合成多语言文本。In one embodiment, before acquiring the multilingual text to be synthesized, the method further includes: acquiring the multilingual text to be processed; and performing language normalization processing according to the multilingual text to be processed to obtain the multilingual text to be synthesized.
需要说明的是,上述一种多语言文本的语音合成方法、一种多语言文本的语音合成装置、存储介质及多语言文本的语音合成设备属于一个总的发明构思,一种多语言文本的语音合成方法、一种多语言文本的语音合成装置、存储介质及多语言文本的语音合成设备实施例中的内容可相互适用。It should be noted that the above-mentioned speech synthesis method for multilingual text, speech synthesis device for multilingual text, storage medium and speech synthesis device for multilingual text belong to a general inventive concept. The content in the embodiments of the synthesis method, a multilingual text speech synthesis apparatus, the storage medium and the multilingual text speech synthesis apparatus can be mutually applicable.
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一非易失性计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,本申请所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可包括只读存储器(ROM)、可编程ROM(PROM)、电可编程ROM(EPROM)、电可擦除可编程ROM(EEPROM)或闪存。易失性存储器可包括随机存取存储器(RAM)或者外部高速缓冲存储器。作为说明而非局限,RAM以多种形式可得,诸如静态RAM(SRAM)、动态RAM(DRAM)、同步DRAM(SDRAM)、双数据率SDRAM(DDRSDRAM)、增强型SDRAM(ESDRAM)、同步链路(Synchlink)DRAM(SLDRAM)、存储器总线(Rambus)直接RAM(RDRAM)、直接存储器总线动态RAM(DRDRAM)、以及存储器总线动态RAM(RDRAM)等。Those of ordinary skill in the art can understand that all or part of the processes in the methods of the above embodiments can be implemented by instructing relevant hardware through a computer program, and the program can be stored in a non-volatile computer-readable storage medium , when the program is executed, it may include the flow of the above-mentioned method embodiments. Wherein, any reference to memory, storage, database or other medium used in the various embodiments provided in this application may include non-volatile and/or volatile memory. Nonvolatile memory may include read only memory (ROM), programmable ROM (PROM), electrically programmable ROM (EPROM), electrically erasable programmable ROM (EEPROM), or flash memory. Volatile memory may include random access memory (RAM) or external cache memory. By way of illustration and not limitation, RAM is available in various forms such as static RAM (SRAM), dynamic RAM (DRAM), synchronous DRAM (SDRAM), double data rate SDRAM (DDRSDRAM), enhanced SDRAM (ESDRAM), synchronous chain Road (Synchlink) DRAM (SLDRAM), memory bus (Rambus) direct RAM (RDRAM), direct memory bus dynamic RAM (DRDRAM), and memory bus dynamic RAM (RDRAM), etc.
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。The technical features of the above embodiments can be combined arbitrarily. In order to make the description simple, all possible combinations of the technical features in the above embodiments are not described. However, as long as there is no contradiction in the combination of these technical features It is considered to be the range described in this specification.
以上所述实施例仅表达了本申请的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本申请专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。因此,本申请专利的保护范围应以所附权利要求为准。The above-mentioned embodiments only represent several embodiments of the present application, and the descriptions thereof are relatively specific and detailed, but should not be construed as a limitation on the scope of the patent of the present application. It should be pointed out that for those skilled in the art, without departing from the concept of the present application, several modifications and improvements can be made, which all belong to the protection scope of the present application. Therefore, the scope of protection of the patent of the present application shall be subject to the appended claims.
Claims (15)
Translated fromChineseApplications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/CN2019/127334WO2021127817A1 (en) | 2019-12-23 | 2019-12-23 | Speech synthesis method, device, and apparatus for multilingual text, and storage medium |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN111247581Atrue CN111247581A (en) | 2020-06-05 |
| CN111247581B CN111247581B (en) | 2023-10-10 |
Family
ID=70880890
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201980003170.6AActiveCN111247581B (en) | 2019-12-23 | 2019-12-23 | Multi-language text voice synthesizing method, device, equipment and storage medium |
Country Status (2)
| Country | Link |
|---|---|
| CN (1) | CN111247581B (en) |
| WO (1) | WO2021127817A1 (en) |
Cited By (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112133282A (en)* | 2020-10-26 | 2020-12-25 | 厦门大学 | Lightweight multi-speaker speech synthesis system and electronic equipment |
| CN112365878A (en)* | 2020-10-30 | 2021-02-12 | 广州华多网络科技有限公司 | Speech synthesis method, device, equipment and computer readable storage medium |
| CN112634865A (en)* | 2020-12-23 | 2021-04-09 | 爱驰汽车有限公司 | Speech synthesis method, apparatus, computer device and storage medium |
| CN112634858A (en)* | 2020-12-16 | 2021-04-09 | 平安科技(深圳)有限公司 | Speech synthesis method, speech synthesis device, computer equipment and storage medium |
| CN112652294A (en)* | 2020-12-25 | 2021-04-13 | 深圳追一科技有限公司 | Speech synthesis method, apparatus, computer device and storage medium |
| CN112712789A (en)* | 2020-12-21 | 2021-04-27 | 深圳市优必选科技股份有限公司 | Cross-language audio conversion method and device, computer equipment and storage medium |
| CN112735373A (en)* | 2020-12-31 | 2021-04-30 | 科大讯飞股份有限公司 | Speech synthesis method, apparatus, device and storage medium |
| CN113033150A (en)* | 2021-03-18 | 2021-06-25 | 深圳市元征科技股份有限公司 | Method and device for coding program text and storage medium |
| CN113160792A (en)* | 2021-01-15 | 2021-07-23 | 广东外语外贸大学 | Multi-language voice synthesis method, device and system |
| WO2021227707A1 (en)* | 2020-05-13 | 2021-11-18 | 腾讯科技(深圳)有限公司 | Audio synthesis method and apparatus, computer readable medium, and electronic device |
| CN113870834A (en)* | 2021-09-26 | 2021-12-31 | 平安科技(深圳)有限公司 | Multi-language speech synthesis method, system, apparatus and storage medium |
| WO2022133630A1 (en)* | 2020-12-21 | 2022-06-30 | 深圳市优必选科技股份有限公司 | Cross-language audio conversion method, computer device and storage medium |
| CN118506764A (en)* | 2024-07-17 | 2024-08-16 | 成都索贝数码科技股份有限公司 | Controllable output method and device based on autoregressive deep learning speech synthesis |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114328817B (en)* | 2021-11-24 | 2025-08-26 | 腾讯科技(深圳)有限公司 | Text processing method and device |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20180114522A1 (en)* | 2016-10-24 | 2018-04-26 | Semantic Machines, Inc. | Sequence to sequence transformations for speech synthesis via recurrent neural networks |
| US20180268806A1 (en)* | 2017-03-14 | 2018-09-20 | Google Inc. | Text-to-speech synthesis using an autoencoder |
| CN109326283A (en)* | 2018-11-23 | 2019-02-12 | 南京邮电大学 | Many-to-many speech conversion method based on text encoder under the condition of non-parallel text |
| JP2019032529A (en)* | 2017-08-07 | 2019-02-28 | 国立研究開発法人情報通信研究機構 | Front-end learning method for speech synthesis, computer program, speech synthesis system, and front-end processing method for speech synthesis |
| CN109767755A (en)* | 2019-03-01 | 2019-05-17 | 广州多益网络股份有限公司 | A kind of phoneme synthesizing method and system |
| WO2019139428A1 (en)* | 2018-01-11 | 2019-07-18 | 네오사피엔스 주식회사 | Multilingual text-to-speech synthesis method |
| CN110050302A (en)* | 2016-10-04 | 2019-07-23 | 纽昂斯通讯有限公司 | Speech synthesis |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP3707153B2 (en)* | 1996-09-24 | 2005-10-19 | ソニー株式会社 | Vector quantization method, speech coding method and apparatus |
| US20140025381A1 (en)* | 2012-07-20 | 2014-01-23 | Microsoft Corporation | Evaluating text-to-speech intelligibility using template constrained generalized posterior probability |
| CN104732542B (en)* | 2015-03-27 | 2018-07-13 | 巢湖学院 | The image processing method of panorama Vehicle security system based on multi-cam self-calibration |
| US10083685B2 (en)* | 2015-10-13 | 2018-09-25 | GM Global Technology Operations LLC | Dynamically adding or removing functionality to speech recognition systems |
| CN105390141B (en)* | 2015-10-14 | 2019-10-18 | 科大讯飞股份有限公司 | Sound converting method and device |
- 2019
- 2019-12-23WOPCT/CN2019/127334patent/WO2021127817A1/ennot_activeCeased
- 2019-12-23CNCN201980003170.6Apatent/CN111247581B/enactiveActive
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110050302A (en)* | 2016-10-04 | 2019-07-23 | 纽昂斯通讯有限公司 | Speech synthesis |
| US20180114522A1 (en)* | 2016-10-24 | 2018-04-26 | Semantic Machines, Inc. | Sequence to sequence transformations for speech synthesis via recurrent neural networks |
| US20180268806A1 (en)* | 2017-03-14 | 2018-09-20 | Google Inc. | Text-to-speech synthesis using an autoencoder |
| JP2019032529A (en)* | 2017-08-07 | 2019-02-28 | 国立研究開発法人情報通信研究機構 | Front-end learning method for speech synthesis, computer program, speech synthesis system, and front-end processing method for speech synthesis |
| WO2019139428A1 (en)* | 2018-01-11 | 2019-07-18 | 네오사피엔스 주식회사 | Multilingual text-to-speech synthesis method |
| CN109326283A (en)* | 2018-11-23 | 2019-02-12 | 南京邮电大学 | Many-to-many speech conversion method based on text encoder under the condition of non-parallel text |
| CN109767755A (en)* | 2019-03-01 | 2019-05-17 | 广州多益网络股份有限公司 | A kind of phoneme synthesizing method and system |
Cited By (24)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2021227707A1 (en)* | 2020-05-13 | 2021-11-18 | 腾讯科技(深圳)有限公司 | Audio synthesis method and apparatus, computer readable medium, and electronic device |
| US12106746B2 (en) | 2020-05-13 | 2024-10-01 | Tencent Technology (Shenzhen) Company Limited | Audio synthesis method and apparatus, computer readable medium, and electronic device |
| CN112133282A (en)* | 2020-10-26 | 2020-12-25 | 厦门大学 | Lightweight multi-speaker speech synthesis system and electronic equipment |
| CN112133282B (en)* | 2020-10-26 | 2022-07-08 | 厦门大学 | Lightweight multi-speaker speech synthesis system and electronic equipment |
| CN112365878A (en)* | 2020-10-30 | 2021-02-12 | 广州华多网络科技有限公司 | Speech synthesis method, device, equipment and computer readable storage medium |
| CN112365878B (en)* | 2020-10-30 | 2024-01-23 | 广州华多网络科技有限公司 | Speech synthesis method, device, equipment and computer readable storage medium |
| CN112634858A (en)* | 2020-12-16 | 2021-04-09 | 平安科技(深圳)有限公司 | Speech synthesis method, speech synthesis device, computer equipment and storage medium |
| CN112634858B (en)* | 2020-12-16 | 2024-01-23 | 平安科技(深圳)有限公司 | Speech synthesis method, device, computer equipment and storage medium |
| CN112712789B (en)* | 2020-12-21 | 2024-05-03 | 深圳市优必选科技股份有限公司 | Cross-language audio conversion method, device, computer equipment and storage medium |
| CN112712789A (en)* | 2020-12-21 | 2021-04-27 | 深圳市优必选科技股份有限公司 | Cross-language audio conversion method and device, computer equipment and storage medium |
| WO2022133630A1 (en)* | 2020-12-21 | 2022-06-30 | 深圳市优必选科技股份有限公司 | Cross-language audio conversion method, computer device and storage medium |
| CN112634865A (en)* | 2020-12-23 | 2021-04-09 | 爱驰汽车有限公司 | Speech synthesis method, apparatus, computer device and storage medium |
| CN112634865B (en)* | 2020-12-23 | 2022-10-28 | 爱驰汽车有限公司 | Speech synthesis method, apparatus, computer device and storage medium |
| CN112652294B (en)* | 2020-12-25 | 2023-10-24 | 深圳追一科技有限公司 | Speech synthesis method, device, computer equipment and storage medium |
| CN112652294A (en)* | 2020-12-25 | 2021-04-13 | 深圳追一科技有限公司 | Speech synthesis method, apparatus, computer device and storage medium |
| CN112735373B (en)* | 2020-12-31 | 2024-05-03 | 科大讯飞股份有限公司 | Speech synthesis method, device, equipment and storage medium |
| CN112735373A (en)* | 2020-12-31 | 2021-04-30 | 科大讯飞股份有限公司 | Speech synthesis method, apparatus, device and storage medium |
| CN113160792B (en)* | 2021-01-15 | 2023-11-17 | 广东外语外贸大学 | A multilingual speech synthesis method, device and system |
| CN113160792A (en)* | 2021-01-15 | 2021-07-23 | 广东外语外贸大学 | Multi-language voice synthesis method, device and system |
| CN113033150A (en)* | 2021-03-18 | 2021-06-25 | 深圳市元征科技股份有限公司 | Method and device for coding program text and storage medium |
| CN113870834A (en)* | 2021-09-26 | 2021-12-31 | 平安科技(深圳)有限公司 | Multi-language speech synthesis method, system, apparatus and storage medium |
| CN113870834B (en)* | 2021-09-26 | 2024-10-18 | 平安科技(深圳)有限公司 | Multilingual speech synthesis method, system, apparatus, and storage medium |
| CN118506764A (en)* | 2024-07-17 | 2024-08-16 | 成都索贝数码科技股份有限公司 | Controllable output method and device based on autoregressive deep learning speech synthesis |
| CN118506764B (en)* | 2024-07-17 | 2024-10-11 | 成都索贝数码科技股份有限公司 | Controllable output method and device based on autoregressive deep learning voice synthesis |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2021127817A1 (en) | 2021-07-01 |
| CN111247581B (en) | 2023-10-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111247581B (en) | Multi-language text voice synthesizing method, device, equipment and storage medium | |
| CN111798832B (en) | Speech synthesis method, apparatus and computer readable storage medium | |
| CN114038447B (en) | Speech synthesis model training method, speech synthesis method, device and medium | |
| CN112352275B (en) | Neural text-to-speech synthesis with multi-level text information | |
| CN111341293B (en) | Text voice front-end conversion method, device, equipment and storage medium | |
| CN113205792A (en) | Mongolian speech synthesis method based on Transformer and WaveNet | |
| CN115424604B (en) | Training method of voice synthesis model based on countermeasure generation network | |
| CN113129862B (en) | Voice synthesis method, system and server based on world-tacotron | |
| CN112464649A (en) | Pinyin conversion method and device for polyphone, computer equipment and storage medium | |
| CN113160793A (en) | Speech synthesis method, device, equipment and storage medium based on low resource language | |
| CN119314466B (en) | Speech synthesis method, device and equipment based on AI large model under multi-language scene | |
| CN118298803B (en) | Speech cloning method | |
| CN114360525A (en) | Voice recognition method and system | |
| CN114242038A (en) | A kind of speech synthesis method and system | |
| CN117037769A (en) | Text processing method and system for speech synthesis | |
| CN116469370A (en) | Target language speech synthesis method and device, electronic equipment, storage medium | |
| CN111583902B (en) | Speech synthesis system, method, electronic device and medium | |
| CN118057522A (en) | Speech synthesis method, model training method, device, equipment and storage medium | |
| CN115294961A (en) | Voice synthesis method and device, electronic equipment and storage medium | |
| Akinwonmi | Rule-induced misanalysis of nasal syllables in yoruba declarative syllabification algorithm | |
| Carson-Berndsen | Multilingual time maps: portable phonotactic models for speech technology | |
| CN117524193B (en) | Training method, device, equipment and medium for Chinese-English mixed speech recognition system | |
| Saychum et al. | A great reduction of wer by syllable toneme prediction for thai grapheme to phoneme conversion | |
| US12374329B2 (en) | System and method for speech to text conversion | |
| CN119763538A (en) | Data augmentation method, device and electronic equipment |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |