CN110888944B - 基于多卷积窗尺寸注意力卷积神经网络实体关系抽取方法 - Google Patents
基于多卷积窗尺寸注意力卷积神经网络实体关系抽取方法Download PDFInfo
- Publication number
- CN110888944B CN110888944BCN201911143069.9ACN201911143069ACN110888944BCN 110888944 BCN110888944 BCN 110888944BCN 201911143069 ACN201911143069 ACN 201911143069ACN 110888944 BCN110888944 BCN 110888944B
- Authority
- CN
- China
- Prior art keywords
- layer
- convolution
- sentence
- vector
- word
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images

Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/28—Databases characterised by their database models, e.g. relational or object models
- G06F16/284—Relational databases
- G06F16/288—Entity relationship models
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/36—Creation of semantic tools, e.g. ontology or thesauri
- G06F16/367—Ontology
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Databases & Information Systems (AREA)
- Computational Linguistics (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Biophysics (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- Biomedical Technology (AREA)
- Health & Medical Sciences (AREA)
- Animal Behavior & Ethology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Evolutionary Biology (AREA)
- Machine Translation (AREA)
Abstract
Description
技术领域
本发明涉及中文实体关系抽取领域,更具体地,涉及一种基于多卷积窗尺寸注意力卷积神经网络实体关系抽取方法。
背景技术
实体关系抽取是知识图谱,问答系统,检索系统等自然语言处理任务的一个关键子任务。实体关系抽取任务一般会给定包含两个标记实体的句子,然后要求预测这个句子中两个实体之间的关系。
针对这一任务,目前主流的方法主要包括以下几种类别:第一类,基于特征提取的方法。
这种方法通常需要借助句法依存树、词性标注等语言分析系统或者是类似word-Net的自然语言处理工具来手工抽取特征,这样会产生误差传递的问题,同时也需要花费大量的人力和时间成本。第二类方法是基于核方法,这种方法不需要繁琐的特征工程工作,而是要基于句法和依存结构,设计合适的核函数,因此需要仍然需要借助一些自然语言处理工具,因此也具有误差传递的问题。第三类方法是基于深度神经网络,如卷积神经网络,循环神经网络等。这些网络模型通过自动捕捉句子的特征,从而克服了前两类方法需要借助一些自然语言处理工具而造成误差传播的缺点。但是当前已提出的卷积神经网络模型中,很多网络并没有使用多种卷积窗口尺寸的来提取句子的n-gram特征,而句子一些关键点的n-gram信息对于实体关系抽取任务十分重要,因此当这些特征被忽视时,网络的性能就有可能下降。
发明内容
本发明提供一种基于多卷积窗尺寸注意力卷积神经网络实体关系抽取方法,该方法实现自动提取句子特征。
为了达到上述技术效果,本发明的技术方案如下:
一种基于多卷积窗尺寸注意力卷积神经网络实体关系抽取方法,包括以下步骤:
S1:对于给定的关系抽取数据集;
S2:在输入层将输入句子中的每个单词转化为一个词向量和两个相对位置向量的拼接,得到整个句子的语义向量表示为S;
S3:在卷积池化层使用多个尺寸的卷积核提取特征,得到卷积池化特征P;
S4:根据卷积池化层的输出,使用注意力机制对上一层提取的特征P进行操作;
S5:通过全连接层将上一层获得的句子编码向量r*转化为各类关系的得分s,并用softmax层得到各个关系的条件概率p(yi|S),通过取最大条件概率的关系作为预测值y*。
进一步地,所述步骤S1的具体过程是:首先在输入层将输入句子中的每个单词转化为一个词向量和两个相对位置向量的拼接,得到整个句子的语义向量表示为S,接着,将S输入到卷积层,在卷积池化层使用多个尺寸的卷积核提取特征,并作最大池化,得到卷积池化特征P,然后,使用注意力机制对上一层提取的特征P进行操作,得到处理后的句子编码向量r*,最后,将上一层获得的句子编码向量r*,输入一个全连接层来计算一个得分s,并使用softmax层来预测出文本中两个实体的关系。
进一步地,所述步骤S2中:所述的句子的语义向量S的编码过程如下:
假设输入的文本为一个长度为k的句子s,让s=[v1,v2,…,ve1,…,ve2,…,vk],vi代表句子中第i个单词,ve1和ve2是句子s中的两个标记实体。首先,把句子s中的每个词都转化为一个mv维的词嵌入表示向量形式,把第i个单词vi对应的词嵌入表示向量记为 接着,我们分别计算句子中的每个单词vi和两个命名实体之间的相对距离pi′和pi″并把他们映射成两个md维的相对位置向量
接着,我们分别计算句子中的每个单词vi和两个命名实体之间的相对距离pi′和pi″并把他们映射成两个md维的相对位置向量 最后,对于第i个单词,将词嵌入表示向量
最后,对于第i个单词,将词嵌入表示向量 以及两个相对位置向量
以及两个相对位置向量 拼接成该词最终的语义向量fi,记为
拼接成该词最终的语义向量fi,记为 其中fi的维度为(mv+2md),类似地,可以得到整个句子的语义向量表示为S=[f1,f2,…,fk]。
其中fi的维度为(mv+2md),类似地,可以得到整个句子的语义向量表示为S=[f1,f2,…,fk]。





进一步地,所述步骤S3中:所述卷积池化特征P特征的计算过程如下:
在输入表示层之后,原来的文本内容被转化成为语义向量表示为S=[f1,f2,…,fk],接下来,为了得到句子的高阶的语义特征信息,本发明引入了Ns*Nf个卷积核来对语义向量S进行特征提取,得到高阶语义特征oji,oji的计算如下:
oji=σ(Wji·S) (1)
其中σ是一个激活函数,Ns表示卷积核尺寸的种类数,Nf表示卷积核个数,Wji表示第j种尺寸的第i个卷积核,依据(1),可以得到第j种尺寸的卷积核提取出来的高阶语义特征为 使用最大池化方法对高阶语义特征Oj进行过滤,可以得到第j种尺寸卷积核提取的池化特征pj,即:
使用最大池化方法对高阶语义特征Oj进行过滤,可以得到第j种尺寸卷积核提取的池化特征pj,即:

pj=max(Oj) (2)
由于总共有Ns种不同尺寸卷积核,因此该层最终得到Ns种不同尺寸卷积核输出的池化特征,记为

进一步地,所述步骤S4中使用注意力机制对上一层提取的特征P进行操作过程是:首先,使用tanh激活函数对不同尺寸的卷积核输出特征P进行映射,使其成为T;然后利用T计算权重α;最终通过加权求和的方法得到用关系推断的句子编码向量r*:
T=tanh(P) (3)


r*=tanh(r) (6)
其中,w是一个训练的参数,而参数α,r,w的向量维度大小分别为Nf,Ns和NfNs。
进一步地,通过全连接层将上一层获得的句子编码向量r*转化为各类关系的得分s,并用softmax层得到各个关系的条件概率p(yi|S),通过取最大条件概率的关系作为预测值y*,具体公式如下:
s=Cxr* (7)
p(yi|S)=softmax(s) (8)
y*=arg max p(yi|S) (9)。
与现有技术相比,本发明技术方案的有益效果是:
(1)本发明提出基于卷积窗口尺寸注意力机制的卷积神经网络,在关系分类任务上相比于核方法和特征方法,能够实现自动提取特征,并且可以避免繁杂的特征工程以及相应的误差传播缺点;
(2)本发明提出基于卷积窗口尺寸注意力机制的卷积神经网络,可以有效地关注句子中对关系分类最重要的n-gram信息,提高分类目标的准确率;
(3)本发明采用的基于卷积窗口尺寸注意力机制的卷积神经网络,与基于RNN和词嵌入注意力的神经网络相比,具有相对较低的复杂度,运行速度快的优点。
附图说明
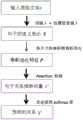
图1是本发明方法流程图;
图2是基于卷积窗口尺寸注意力机制的卷积神经网络的总体框图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
下面结合附图和实施例对本发明的技术方案做进一步的说明。
如图1所示,本申请提出一种基于多卷积窗尺寸注意力卷积神经网络实体关系抽取方法,其整体的网络结构主要分为输入层,卷积池化层,多窗口尺寸注意力层以及全连接层。首先,将输入句子中的每个单词转化为一个词向量和两个相对位置向量。接着,在卷积层使用多个尺寸的卷积核提取特征,并对卷积层的输出作最大池化操作。然后,使用注意力机制提取对于预测最重要的n-gram信息。最后,用一个全连接层结合soft-max层来预测出文本中两个实体的关系。
1、输入表示层
该层主要将文本中的每个词映射成编码的语义向量序列。其中每个词的语义向量序列是由该词的词嵌入表示向量以及两个相对位置向量拼接而成的。
假设给定一个长度为k的句子s,让s=[v1,v1,…,ve1,…,ve2,…,vk],vi代表句子中第i个单词,ve1和ve2是句子s中的两个标记实体。
首先,预训练好的词嵌入表示集Q,这个词嵌入表示集包含文本内容中所有单词的词嵌入表示向量。这样,通过查询词嵌入表示集Q,可以把句子s中的每个词都转化为一个mv维的词嵌入表示向量形式。我们把第i个单词vi对应的词嵌入表示向量记为

接着,我们分别计算单词vi和两个命名实体之间的相对距离pi′和pi″。同样地,我们预定义好一个位置信息嵌入表示集,然后根据这个位置信息嵌入表示集将pi′和pi″映射成两个md维的相对位置向量。
最后,对于第i个单词,将词嵌入表示向量 以及两个相对位置向量
以及两个相对位置向量 拼接成该词最终的语义向量fi。记为
拼接成该词最终的语义向量fi。记为 其中fi的维度为(mv+2md)。类似地,可以得到整个句子的语义向量表示为S=[f1,f2,…,fk]。
其中fi的维度为(mv+2md)。类似地,可以得到整个句子的语义向量表示为S=[f1,f2,…,fk]。



2、卷积池化层
在输入表示层之后,原来的文本内容被转化成为语义向量表示为S=[f1,f2,…,fk]。接下来,为了得到句子的高阶的语义特征信息,本发明引入了多种窗口尺寸的卷积核来对语义向量S进行特征提取。假设共有Ns种尺寸的卷积核,每种尺寸的卷积核共有Nf个。
可以用Wji来表示第j种尺寸的第i个卷积核,利用卷积核Wji对语义向量S进行特征提取,可以得到高阶语义特征oji,oji的计算如下:
oji=σ(Wji·S) (1)
其中σ是一个激活函数。依据(1),可以得到第j种尺寸的卷积核提取出来的高阶语义特征为 使用最大池化方法对高阶语义特征Oj进行更一步筛选,可以得到第j种尺寸卷积核提取的池化特征pj,即:
使用最大池化方法对高阶语义特征Oj进行更一步筛选,可以得到第j种尺寸卷积核提取的池化特征pj,即:

pj=max(Oj) (2)
由于总共有Ns种不同尺寸卷积核,因此该层最终得到Ns种不同尺寸卷积核输出的池化特征,记为

3、基于多窗口尺寸的卷积核注意力机制
在卷积池化层之后,我们得到了Ns种不同尺寸卷积核输出的池化特征P。为了捕捉对关系预测最关键的n-gram信息,本发明在网络中加入了注意力机制。首先,使用tanh激活函数对不同尺寸的卷积核输出特征P进行映射,使其成为T;然后利用T计算权重α;最终通过加权求和的方法得到用关系推断的句子编码向量r*。具体如下:
T=tanh (P) (3)


r*= tanh(r) (6)
其中,w是一个训练的参数,而参数α,r,w的向量维度大小分别为Nf,Ns和NfNs。
4、关系推断
在关系推断部分,本发明将上一层获得的句子编码向量r*,输入一个全连接层来计算一个得分s,并用softmax层得到各个关系的条件概率p(yi|S)。最终,通过取最大条件概率的关系作为预测值y*。具体公式如下:
s =Cx r* (7)
p(yi|S)=softmax(s) (8)
y*= argmax p(yi|S) (9)
5、模型学习
在模型学习阶段,本发明采用的对数极大似然损失作为目标函数,为了抑制模型的过拟合,本发明添加了L2正则化项,其公式可以表示为:

其中β表示L2正则化参数,w代表权重参数,p(yi|S,w)代表在句子S的条件下预测为yi的概率。本发明使用Adam优化算法解决随机最大化问题,并在全连接层采用dropout方法减少过拟合问题。
图1为基于卷积窗口尺寸注意力机制的卷积神经网络的总体框图,本发明提出的基于多卷积窗尺寸注意力的卷积神经网络进行实体关系抽取的方法,其整体的网络结构主要分为输入层,卷积池化层,多窗口尺寸注意力层以及全连接层。首先,在输入层,输入句子中的每个单词被转化为一个词向量和相对位置向量,将两个向量拼接成一个原始输入的句子表示。接着,在卷积层使用多个尺寸的卷积核分别捕捉句子的n-gram信息,并对卷积层的输出作最大池化操作。然后,使用注意力机制提取对于预测最重要的n-gram信息,得到一个特征表示向量。最后,用一个全连接层结合soft-max层来计算每一个关系的条件概率。
表1是关系抽取任务各网络性能对比表,实验数据集为semeval 2010关系抽取任务数据集,模型的性能度量采用F1值,即查准率与查全率的调和平均指标。从实验结果可以看出,基于卷积窗口尺寸注意力机制的卷积神经网络在关系抽取任务上的表现优于传统的支持向量机、双向RNN网络和卷积神经网络等模型。
表1关系抽取任务各网络性能对比表

相同或相似的标号对应相同或相似的部件;
附图中描述位置关系的用于仅用于示例性说明,不能理解为对本专利的限制;
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
Claims (4)
1.一种基于多卷积窗尺寸注意力卷积神经网络实体关系抽取方法,其特征在于,包括以下步骤:
S1:对于给定的关系抽取数据集;
S2:在输入层将输入句子中的每个单词转化为一个词向量和两个相对位置向量的拼接,得到整个句子的语义向量表示为S;
S3:在卷积池化层使用多个尺寸的卷积核提取特征,得到卷积池化特征P;
所述步骤S3中:所述卷积池化特征P特征的计算过程如下:
在输入表示层之后,原来的文本内容被转化成为语义向量表示为S=[f1,f2,…,fk],接下来,为了得到句子的高阶的语义特征信息,本发明引入了Ns*Nf个卷积核来对语义向量S进行特征提取,得到高阶语义特征oji,oji的计算如下:
oji=σ(Wji·S) (1)
其中σ是一个激活函数,Ns表示卷积核尺寸的种类数,Nf表示卷积核个数,Wji表示第j种尺寸的第i个卷积核,依据(1),可以得到第j种尺寸的卷积核提取出来的高阶语义特征为使用最大池化方法对高阶语义特征Oj进行过滤,可以得到第j种尺寸卷积核提取的池化特征pj,即:
pj=max(Oj) (2)
由于总共有Ns种不同尺寸卷积核,因此该层最终得到Ns种不同尺寸卷积核输出的池化特征,记为
S4:根据卷积池化层的输出,使用注意力机制对上一层提取的特征P进行操作;
所述步骤S4中使用注意力机制对上一层提取的特征P进行操作过程是:首先,使用tanh激活函数对不同尺寸的卷积核输出特征P进行映射,使其成为T;然后利用T计算权重α;最终通过加权求和的方法得到用关系推断的句子编码向量r*:
T=tanh(P) (3)
r*=tanh(r) (6)
其中,w是一个训练的参数,而参数α,r,w的向量维度大小分别为Nf,Ns和NfNs;
S5:通过全连接层将上一层获得的句子编码向量r*转化为各类关系的得分s,并用softmax层得到各个关系的条件概率p(yi|S),通过取最大条件概率的关系作为预测值y*。
2.根据权利要求1所述的基于多卷积窗尺寸注意力卷积神经网络实体关系抽取方法,其特征在于,所述步骤S1的具体过程是:首先在输入层将输入句子中的每个单词转化为一个词向量和两个相对位置向量的拼接,得到整个句子的语义向量表示为S,接着,将S输入到卷积层,在卷积池化层使用多个尺寸的卷积核提取特征,并作最大池化,得到卷积池化特征P,然后,使用注意力机制对上一层提取的特征P进行操作,得到处理后的句子编码向量r*,最后,将上一层获得的句子编码向量r*,输入一个全连接层来计算一个得分s,并使用softmax层来预测出文本中两个实体的关系。
3.根据权利要求2所述的基于多卷积窗尺寸注意力卷积神经网络实体关系抽取方法,其特征在于,所述步骤S2中:所述的句子的语义向量S的编码过程如下:
假设输入的文本为一个长度为k的句子s,让s=[v1,v2,…,ve1,…,ve2,…,vk],vi代表句子中第i个单词,ve1和ve2是句子s中的两个标记实体;首先,把句子s中的每个词都转化为一个mv维的词嵌入表示向量形式,把第i个单词vi对应的词嵌入表示向量记为接着,我们分别计算句子中的每个单词vi和两个命名实体之间的相对距离p′i和p″i并把他们映射成两个md维的相对位置向量最后,对于第i个单词,将词嵌入表示向量以及两个相对位置向量拼接成该词最终的语义向量fi,记为其中fi的维度为(mv+2md),类似地,可以得到整个句子的语义向量表示为S=[f1,f2,…,fk]。
4.根据权利要求1所述的基于多卷积窗尺寸注意力卷积神经网络实体关系抽取方法,其特征在于,通过全连接层将上一层获得的句子编码向量r*转化为各类关系的得分s,并用softmax层得到各个关系的条件概率p(yi|S),通过取最大条件概率的关系作为预测值y*,具体公式如下:
s=Cxr* (7)
p(yi|S)=softmax(s) (8)
y*=argmaxp(yi|S) (9)。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201911143069.9ACN110888944B (zh) | 2019-11-20 | 2019-11-20 | 基于多卷积窗尺寸注意力卷积神经网络实体关系抽取方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201911143069.9ACN110888944B (zh) | 2019-11-20 | 2019-11-20 | 基于多卷积窗尺寸注意力卷积神经网络实体关系抽取方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN110888944A CN110888944A (zh) | 2020-03-17 |
| CN110888944Btrue CN110888944B (zh) | 2023-04-28 |
Family
ID=69748090
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201911143069.9AExpired - Fee RelatedCN110888944B (zh) | 2019-11-20 | 2019-11-20 | 基于多卷积窗尺寸注意力卷积神经网络实体关系抽取方法 |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN110888944B (zh) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111666752B (zh)* | 2020-04-20 | 2023-05-09 | 中山大学 | 一种基于关键词注意力机制的电路教材实体关系抽取方法 |
| CN111949802B (zh)* | 2020-08-06 | 2022-11-01 | 平安科技(深圳)有限公司 | 医学领域知识图谱的构建方法、装置、设备及存储介质 |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107180247A (zh)* | 2017-05-19 | 2017-09-19 | 中国人民解放军国防科学技术大学 | 基于选择性注意力卷积神经网络的关系分类器及其方法 |
| CN108664632A (zh)* | 2018-05-15 | 2018-10-16 | 华南理工大学 | 一种基于卷积神经网络和注意力机制的文本情感分类算法 |
| CN108681539A (zh)* | 2018-05-07 | 2018-10-19 | 内蒙古工业大学 | 一种基于卷积神经网络的蒙汉神经翻译方法 |
| CN109376246A (zh)* | 2018-11-07 | 2019-02-22 | 中山大学 | 一种基于卷积神经网络和局部注意力机制的句子分类方法 |
| CN110298037A (zh)* | 2019-06-13 | 2019-10-01 | 同济大学 | 基于增强注意力机制的卷积神经网络匹配的文本识别方法 |
- 2019
- 2019-11-20CNCN201911143069.9Apatent/CN110888944B/zhnot_activeExpired - Fee Related
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107180247A (zh)* | 2017-05-19 | 2017-09-19 | 中国人民解放军国防科学技术大学 | 基于选择性注意力卷积神经网络的关系分类器及其方法 |
| CN108681539A (zh)* | 2018-05-07 | 2018-10-19 | 内蒙古工业大学 | 一种基于卷积神经网络的蒙汉神经翻译方法 |
| CN108664632A (zh)* | 2018-05-15 | 2018-10-16 | 华南理工大学 | 一种基于卷积神经网络和注意力机制的文本情感分类算法 |
| CN109376246A (zh)* | 2018-11-07 | 2019-02-22 | 中山大学 | 一种基于卷积神经网络和局部注意力机制的句子分类方法 |
| CN110298037A (zh)* | 2019-06-13 | 2019-10-01 | 同济大学 | 基于增强注意力机制的卷积神经网络匹配的文本识别方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN110888944A (zh) | 2020-03-17 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN112270379B (zh) | 分类模型的训练方法、样本分类方法、装置和设备 | |
| CN113641820B (zh) | 基于图卷积神经网络的视角级文本情感分类方法及系统 | |
| CN113255320A (zh) | 基于句法树和图注意力机制的实体关系抽取方法及装置 | |
| CN113591483A (zh) | 一种基于序列标注的文档级事件论元抽取方法 | |
| CN111143576A (zh) | 一种面向事件的动态知识图谱构建方法和装置 | |
| CN111984791B (zh) | 一种基于注意力机制的长文分类方法 | |
| CN112232087B (zh) | 一种基于Transformer的多粒度注意力模型的特定方面情感分析方法 | |
| CN108733792A (zh) | 一种实体关系抽取方法 | |
| CN110765260A (zh) | 一种基于卷积神经网络与联合注意力机制的信息推荐方法 | |
| CN111666752B (zh) | 一种基于关键词注意力机制的电路教材实体关系抽取方法 | |
| CN113051886B (zh) | 一种试题查重方法、装置、存储介质及设备 | |
| WO2020232898A1 (zh) | 文本分类方法、装置、电子设备及计算机非易失性可读存储介质 | |
| CN110852066B (zh) | 一种基于对抗训练机制的多语言实体关系抽取方法及系统 | |
| CN110929532B (zh) | 数据处理方法、装置、设备及存储介质 | |
| CN115273815A (zh) | 语音关键词检测的方法、装置、设备及存储介质 | |
| CN112307179A (zh) | 文本匹配方法、装置、设备及存储介质 | |
| KR20250047390A (ko) | 데이터 처리 방법 및 장치, 엔티티 링킹 방법 및 장치, 및 컴퓨터 디바이스 | |
| CN116258147A (zh) | 一种基于异构图卷积的多模态评论情感分析方法及系统 | |
| CN119557424B (zh) | 一种数据分析方法、系统以及存储介质 | |
| CN114444515A (zh) | 一种基于实体语义融合的关系抽取方法 | |
| CN115359799A (zh) | 语音识别方法、训练方法、装置、电子设备及存储介质 | |
| CN117079298A (zh) | 信息提取方法、信息提取系统的训练方法和信息提取系统 | |
| CN115510230A (zh) | 一种基于多维特征融合与比较增强学习机制的蒙古语情感分析方法 | |
| CN114169447A (zh) | 基于自注意力卷积双向门控循环单元网络的事件检测方法 | |
| CN110888944B (zh) | 基于多卷积窗尺寸注意力卷积神经网络实体关系抽取方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| CF01 | Termination of patent right due to non-payment of annual fee | ||
| CF01 | Termination of patent right due to non-payment of annual fee | Granted publication date:20230428 |