CN110795404B - Hadoop distributed file system and operation method and repair method thereof - Google Patents
Hadoop distributed file system and operation method and repair method thereofDownload PDFInfo
- Publication number
- CN110795404B CN110795404BCN201911056278.XACN201911056278ACN110795404BCN 110795404 BCN110795404 BCN 110795404BCN 201911056278 ACN201911056278 ACN 201911056278ACN 110795404 BCN110795404 BCN 110795404B
- Authority
- CN
- China
- Prior art keywords
- name node
- new
- image file
- name
- hadoop distributed
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images






Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/10—File systems; File servers
- G06F16/18—File system types
- G06F16/182—Distributed file systems
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/14—Error detection or correction of the data by redundancy in operation
- G06F11/1402—Saving, restoring, recovering or retrying
- G06F11/1446—Point-in-time backing up or restoration of persistent data
- G06F11/1448—Management of the data involved in backup or backup restore
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/10—File systems; File servers
- G06F16/16—File or folder operations, e.g. details of user interfaces specifically adapted to file systems
- G06F16/162—Delete operations
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/10—File systems; File servers
- G06F16/18—File system types
- G06F16/1805—Append-only file systems, e.g. using logs or journals to store data
- G06F16/1815—Journaling file systems
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02D—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN INFORMATION AND COMMUNICATION TECHNOLOGIES [ICT], I.E. INFORMATION AND COMMUNICATION TECHNOLOGIES AIMING AT THE REDUCTION OF THEIR OWN ENERGY USE
- Y02D10/00—Energy efficient computing, e.g. low power processors, power management or thermal management
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Quality & Reliability (AREA)
- Human Computer Interaction (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本发明涉及数据处理技术领域,尤其涉及一种Hadoop分布式文件系统及其运行方法、修复方法。The invention relates to the technical field of data processing, in particular to a Hadoop distributed file system and its operation method and repair method.
背景技术Background technique
Hadoop集群的存储系统是Hadoop分布式文件系统(Hadoop Distributed FileSystem,HDFS),HDFS可以有效的解决海量数据的存储和管理难题,具体为:将固定于某个地点的某个文件系统,扩展到任意多个地点、多个文件系统,众多的节点组成一个文件系统网络。每个节点可以分布在不同的地点,通过网络进行节点间的通信和数据传输。The storage system of the Hadoop cluster is the Hadoop Distributed File System (Hadoop Distributed File System, HDFS). HDFS can effectively solve the storage and management problems of massive data, specifically: expand a file system fixed at a certain location to any Multiple locations, multiple file systems, and numerous nodes form a file system network. Each node can be distributed in different locations, and the communication and data transmission between nodes can be carried out through the network.
在使用HDFS时,无需关心数据是存储在哪个节点上、或者是从哪个节点获取的,只需要像使用本地文件系统一样管理和存储文件系统中的数据。When using HDFS, you don't need to care about which node the data is stored on or obtained from. You only need to manage and store the data in the file system like a local file system.
发明内容Contents of the invention
本发明的实施例提供一种Hadoop分布式文件系统及其运行方法、修复方法,可以更高频且更多的保存元数据序列,增强数据的安全性。Embodiments of the present invention provide a Hadoop distributed file system and its operation method and repair method, which can store metadata sequences more frequently and more, and enhance data security.
为达到上述目的,本发明的实施例采用如下技术方案:In order to achieve the above object, embodiments of the present invention adopt the following technical solutions:
一方面,提供一种Hadoop分布式文件系统,包括:第一名称节点、与所述第一名称节点连接的第二名称节点;所述第一名称节点,用于存储元数据文件;所述元数据文件包括镜像文件和编辑日志;所述第一名称节点还用于每隔预设的第一时长,将所述镜像文件与所述编辑日志合并,形成新的镜像文件,并启用新的编辑日志;所述第二名称节点,用于每隔预设的第一时长,对所述第一名称节点上新的镜像文件备份;还用于每隔预设的第二时长,对所述第一名称节点上的所述编辑日志备份;所述第二时长小于所述第一时长;其中,所述第一名称节点和所述第二名称节点分别部署于不同的主机。On the one hand, a Hadoop distributed file system is provided, comprising: a first name node, a second name node connected to the first name node; the first name node is used to store metadata files; the metadata The data file includes a mirror image file and an edit log; the first name node is also used to merge the mirror image file with the edit log every preset first time period to form a new mirror image file and enable a new edit log log; the second name node is used to back up the new image file on the first name node every preset first time length; it is also used to backup the first name node every preset second time length The edit log backup on a name node; the second duration is shorter than the first duration; wherein, the first name node and the second name node are respectively deployed on different hosts.
再一方面,提供一种如上所述的Hadoop分布式文件系统的运行方法,包括:启动第一名称节点,加载元数据文件,同时启动第二名称节点;所述元数据文件包括镜像文件和编辑日志;每隔预设的第一时长,所述第一名称节点将所述镜像文件与所述编辑日志合并,形成新的所述镜像文件,同时启用新的编辑日志;所述第二名称节点对所述第一名称节点上新的所述镜像文件备份;每隔预设的第二时长,所述第二名称节点对所述第一名称节点上的所述编辑日志备份;所述第二时长小于所述第一时长;其中,所述第一名称节点与所述第二名称节点分别部署于不同主机。On the other hand, provide a kind of operation method of Hadoop distributed file system as above, comprise: start the first name node, load metadata file, start the second name node simultaneously; Described metadata file comprises image file and editor log; every preset first time length, the first name node merges the image file with the edit log to form a new image file, and at the same time enables a new edit log; the second name node Backing up the new image file on the first name node; every preset second time period, the second name node backs up the edit log on the first name node; the second The duration is shorter than the first duration; wherein, the first namenode and the second namenode are respectively deployed on different hosts.
另一方面,提供一种如上所述的Hadoop分布式文件系统的修复方法,包括:停止受损的第一名称节点,同时停止第二名称节点;备份所述第二名称节点上的元数据文件;所述元数据文件包括所述第二名称节点最后一次从受损的所述第一名称节点上备份的镜像文件和编辑日志;准备部署新的第一名称节点的主机;部署新的第一名称节点的主机与部署所述受损的第一名称节点、部署所述第二名称节点的主机均不同;配置所述主机的名称、IP地址、互信登录、运行环境和集群;对新的所述第一名称节点执行格式化;将备份的所述第二名称节点上的镜像文件和编辑日志,发送至新的所述第一名称节点;修改新的所述第一名称节点的元数据序号。On the other hand, a method for repairing the Hadoop distributed file system as described above is provided, including: stopping the damaged first name node, and stopping the second name node at the same time; backing up the metadata file on the second name node ; The metadata file includes the image file and edit log backed up by the second name node from the damaged first name node for the last time; prepare to deploy the host of the new first name node; deploy the new first name node The host of the name node is different from the host on which the damaged first name node and the second name node are deployed; configure the name, IP address, mutual trust login, operating environment and cluster of the host; Perform formatting on the first name node; send the backup image file and edit log on the second name node to the new first name node; modify the metadata sequence number of the new first name node .
可选地,在修改新的所述第一名称节点的元数据序号之后,还包括:启动新的所述第一名称节点和对应的Hadoop分布式文件系统;执行Hadoop分布式文件系统检查。Optionally, after modifying the metadata sequence number of the new first name node, the method further includes: starting the new first name node and a corresponding Hadoop distributed file system; and performing a Hadoop distributed file system check.
又一方面,提供一种Hadoop分布式文件系统,包括:第一名称节点、与所述第一名称节点连接的第二名称节点;所述第一名称节点,用于存储元数据文件;所述元数据文件包括镜像文件和编辑日志;所述第一名称节点还用于每隔预设的第一时长,启用新的编辑日志;所述第二名称节点,用于每隔预设的第一时长,对所述第一名称节点上原有的所述镜像文件和原有的所述编辑日志备份,将备份的所述镜像文件和所述编辑日志合并,形成新的所述镜像文件,并发送回所述第一名称节点,替换所述第一名称节点原有的镜像文件;所述第二名称节点,还用于每隔预设的第二时长,对所述第一名称节点上的所述编辑日志备份,形成中间编辑日志;所述第二时长小于所述第一时长;其中,所述第一名称节点和所述第二名称节点分别部署于不同的主机。In yet another aspect, a Hadoop distributed file system is provided, including: a first name node, a second name node connected to the first name node; the first name node is used to store metadata files; the The metadata file includes an image file and an edit log; the first name node is also used to enable a new edit log every preset first duration; the second name node is used to enable a new edit log every preset first duration, backup the original image file and the original edit log on the first name node, merge the backup image file and the edit log to form a new image file, and send Returning to the first name node to replace the original image file of the first name node; the second name node is also used to update all the Said edit log backup to form an intermediate edit log; said second duration is shorter than said first duration; wherein said first name node and said second name node are respectively deployed on different hosts.
又一方面,提供一种如上所述的Hadoop分布式文件系统的运行方法,包括:启动第一名称节点,加载元数据文件,同时启动第二名称节点;所述元数据文件包括镜像文件和编辑日志;每隔预设的第一时长,所述第一名称节点启动新的编辑日志;所述第二名称节点对所述第一名称节点上原有的所述镜像文件和原有的所述编辑日志备份,将备份的所述镜像文件与所述编辑日志合并,形成新的所述镜像文件,并发送回所述第一名称节点,替换所述第一名称节点原有的镜像文件;每隔预设的第二时长,所述第二名称节点对所述第一名称节点上的所述编辑日志备份,形成中间编辑日志;所述第二时长小于所述第一时长;其中,所述名称节点与所述第二名称节点分别部署于不同主机。In another aspect, there is provided a method for running the Hadoop distributed file system as described above, including: starting the first name node, loading the metadata file, and starting the second name node at the same time; the metadata file includes the image file and the editor log; every preset first time period, the first name node starts a new edit log; the second name node edits the original image file and the original edit log on the first name node log backup, merging the backup image file with the edit log to form a new image file, and sending it back to the first name node to replace the original image file of the first name node; every A preset second duration, the second name node backs up the edit log on the first name node to form an intermediate edit log; the second duration is shorter than the first duration; wherein, the name The node and the second namenode are respectively deployed on different hosts.
又一方面,提供一种如上所述的Hadoop分布式文件系统的修复方法,包括:停止受损的第一名称节点,同时停止第二名称节点;备份所述第二名称节点上的元数据文件;所述元数据文件包括所述第二名称节点最后一次从受损的所述第一名称节点上备份的镜像文件和编辑日志,以及最后一次形成的中间编辑日志;准备部署新的第一名称节点的主机;部署新的第一名称节点的主机与部署所述受损的第一名称节点、部署所述第二名称节点的主机均不同;配置所述主机的名称、IP地址、互信登录、运行环境和集群;对新的所述第一名称节点执行格式化;将备份的所述第二名称节点上的镜像文件、中间编辑日志和中间编辑日志合并,生成新的镜像文件,发送至新的所述第一名称节点;修改新的所述第一名称节点的元数据序号。In another aspect, a method for repairing the Hadoop distributed file system as described above is provided, including: stopping the damaged first name node, and stopping the second name node at the same time; backing up the metadata file on the second name node ; The metadata file includes the image file and editing log backed up by the second name node from the damaged first name node for the last time, and the intermediate editing log formed last time; prepare to deploy a new first name node The host of the node; the host that deploys the new first name node is different from the host that deploys the damaged first name node and the second name node; configures the name, IP address, mutual trust login, Operating environment and cluster; performing formatting on the new first name node; merging the backup image file, intermediate edit log and intermediate edit log on the second name node to generate a new image file and sending it to the new the first name node; modify the new metadata sequence number of the first name node.
可选地,在修改新的所述第一名称节点的元数据序号之后,还包括:启动新的所述第一名称节点和对应的Hadoop分布式文件系统;执行Hadoop分布式文件系统检查。Optionally, after modifying the metadata sequence number of the new first name node, the method further includes: starting the new first name node and a corresponding Hadoop distributed file system; and performing a Hadoop distributed file system check.
又一方面,提供一种计算机设备,包括存储单元和处理单元;所述存储单元中存储可在所述处理单元上运行的计算机程序并存储结果;所述处理单元执行所述计算机程序时实现如上所述的Hadoop分布式文件系统的运行方法,和/或如上所述的Hadoop分布式文件系统的修复方法。In yet another aspect, a computer device is provided, including a storage unit and a processing unit; the storage unit stores a computer program that can run on the processing unit and stores results; the processing unit implements the above when executing the computer program The operating method of the Hadoop distributed file system, and/or the repair method of the Hadoop distributed file system as described above.
又一方面,提供一种计算机可读介质,其存储有计算机程序,所述计算机程序被处理器执行时实现如上所述的Hadoop分布式文件系统的运行方法,和/或如上所述的Hadoop分布式文件系统的修复方法。In another aspect, a computer-readable medium is provided, which stores a computer program, and when the computer program is executed by a processor, realizes the operating method of the Hadoop distributed file system as described above, and/or the Hadoop distribution as described above How to repair file system.
本发明的实施例提供一种Hadoop分布式文件系统及其运行方法、修复方法,在第一名称节点每隔预设的第一时长,将镜像文件与编辑日志合并,形成新的镜像文件,并启用新的编辑日志的基础上,通过与第一名称节点连接的第二名称节点,每隔预设的第一时长,对第一名称节点上新的镜像文件备份,以及每隔预设的第二时长,对第一名称节点上的编辑日志备份,第二时长小于第一时长,使得编辑日志进行了更高频的备份,保存了更多的元数据序列,增强了Hadoop分布式文件系统中数据的安全性。Embodiments of the present invention provide a Hadoop distributed file system and its operation method and repair method. In the first name node every preset first time length, the image file is merged with the editing log to form a new image file, and On the basis of enabling the new edit log, through the second name node connected to the first name node, every preset first time period, backup the new image file on the first name node, and every preset first name node The second duration is for the backup of the edit log on the first name node. The second duration is shorter than the first duration, so that the edit log is backed up more frequently, more metadata sequences are saved, and the Hadoop distributed file system is enhanced. Data Security.
附图说明Description of drawings
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。In order to more clearly illustrate the technical solutions in the embodiments of the present invention or the prior art, the following will briefly introduce the drawings that need to be used in the description of the embodiments or the prior art. Obviously, the accompanying drawings in the following description are only These are some embodiments of the present invention. Those skilled in the art can also obtain other drawings based on these drawings without creative work.
图1为现有的一种Hadoop分布式文件系统的结构示意图;Fig. 1 is the structural representation of existing a kind of Hadoop distributed file system;
图2为本发明的实施例提供的一种Hadoop分布式文件系统的运行方法的流程示意图;Fig. 2 is the schematic flow chart of the operating method of a kind of Hadoop distributed file system that the embodiment of the present invention provides;
图3为本发明的实施例提供的一种Hadoop分布式文件系统的修复方法的流程示意图;Fig. 3 is the schematic flow sheet of the repair method of a kind of Hadoop distributed file system that the embodiment of the present invention provides;
图4为本发明的实施例提供的再一种Hadoop分布式文件系统的修复方法的流程示意图;Fig. 4 is the schematic flow sheet of another kind of repair method of Hadoop distributed file system that the embodiment of the present invention provides;
图5为本发明的实施例提供的再一种Hadoop分布式文件系统的运行方法的流程示意图;Fig. 5 is the schematic flow chart of another kind of operating method of Hadoop distributed file system that the embodiment of the present invention provides;
图6为本发明的实施例提供的另一种Hadoop分布式文件系统的修复方法的流程示意图;Fig. 6 is the schematic flow sheet of the repair method of another kind of Hadoop distributed file system that the embodiment of the present invention provides;
图7为本发明的实施例提供的又一种Hadoop分布式文件系统的修复方法的流程示意图。FIG. 7 is a schematic flowchart of another method for repairing a Hadoop distributed file system provided by an embodiment of the present invention.
具体实施方式Detailed ways
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。The following will clearly and completely describe the technical solutions in the embodiments of the present invention with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only some, not all, embodiments of the present invention. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts belong to the protection scope of the present invention.
现有技术中,如图1所示,Hadoop分布式文件系统通常包括:第一名称节点(NameNode)、与第一名称节点连接的第二名称节点(Secondary Name Node),与第一名称节点连接的多个数据节点(Data Node)。In the prior art, as shown in Figure 1, the Hadoop distributed file system generally includes: a first name node (NameNode), a second name node (Secondary Name Node) connected to the first name node, connected to the first name node Multiple data nodes (Data Node).
第一名称节点用于存储元数据文件;元数据文件包括镜像文件和编辑日志。The first name node is used to store metadata files; the metadata files include image files and editing logs.
其中,元数据定义为:描述数据的数据,主要是描述数据属性的信息,用于支持如指示存储位置、历史数据、资源查找、文件记录等功能。元数据是一种电子式目录。镜像文件为所有元数据序列化后形成的文件;编辑日志记录客户端更新元数据的每一步操作。Among them, metadata is defined as: data describing data, mainly information describing data attributes, used to support functions such as indicating storage locations, historical data, resource search, and file records. Metadata is an electronic catalog. The image file is a file formed after all metadata is serialized; the editing log records every step of the client updating metadata.
第一名称节点还用于元数据(Meta data)管理,例如查询、修改;以及负责客户端对文件的访问。The first name node is also used for metadata (Meta data) management, such as query and modification; and responsible for client access to files.
第二名称节点是第一名称节点的冷备份。The second namenode is a cold backup of the first namenode.
数据节点为HDFS提供数据块存储数据;数据节点通常以机架的形式组织,机架通过一个交换机将所有系统连接起来。Data nodes provide block storage data for HDFS; data nodes are usually organized in the form of racks, and the racks connect all systems through a switch.
需要说明的是,由于第一名称节点是整个Hadoop分布式文件系统的核心,一旦发生损坏,将危及到整个Hadoop分布式文件系统的数据安全,由此,为了保证第一名称节点的安全,增设第二名称节点定时备份第一名称节点的元数据文件。若名称节点损坏,第二名称节点不代替第一名称节点工作,但是第二名称节点上存储有第一名称节点的一些信息,可发送回第一名称节点,由此,减少第一名称节点损坏造成的损失。It should be noted that since the first name node is the core of the entire Hadoop distributed file system, once it is damaged, the data security of the entire Hadoop distributed file system will be endangered. Therefore, in order to ensure the safety of the first name node, add The second name node regularly backs up the metadata file of the first name node. If the name node is damaged, the second name node does not work instead of the first name node, but some information of the first name node is stored on the second name node, which can be sent back to the first name node, thus reducing the damage of the first name node caused losses.
然而,随着Hadoop分布式文件系统的规模越来越大,第一名称节点会变得非常繁忙,使得元数据文件变得非常大,不适合进行高频次的备份,增加负担。但是,若在备份间隔时间较长,在间隔期间,第一名称节点突然损坏,将会导致第一名称节点从上一次备份到损坏期间的所有元数据改动序列丢失。However, as the size of the Hadoop distributed file system becomes larger and larger, the first name node will become very busy, making the metadata file very large, which is not suitable for high-frequency backup and increases the burden. However, if the backup interval is long and the first namenode is suddenly damaged during the interval, all metadata modification sequences of the first namenode from the last backup to the damage period will be lost.
基于上述问题,本发明的实施例提供一种Hadoop分布式文件系统,包括:第一名称节点、与第一名称节点连接的第二名称节点。Based on the above problems, an embodiment of the present invention provides a Hadoop distributed file system, including: a first name node, and a second name node connected to the first name node.
第一名称节点,用于存储元数据文件;元数据文件包括镜像文件和编辑日志。The first name node is used for storing metadata files; the metadata files include image files and editing logs.
第一名称节点还用于每隔预设的第一时长,将镜像文件与编辑日志合并,形成新的镜像文件;同时,启用新的编辑日志。The first name node is also used for merging the image file and the edit log at intervals of a preset first time period to form a new image file; meanwhile, enabling a new edit log.
其中,启用的新的编辑日志是空文件。where the new edit log enabled is the empty file.
第二名称节点,用于每隔预设的第一时长,对第一名称节点上新的镜像文件备份;还用于每隔预设的第二时长,对第一名称节点上的编辑日志备份;第二时长小于第一时长。The second name node is used to back up the new image file on the first name node every preset first time length; it is also used to back up the edit log on the first name node every preset second time length ;The second duration is less than the first duration.
其中,第一名称节点和第二名称节点分别部署于不同的主机。Wherein, the first name node and the second name node are respectively deployed on different hosts.
需要说明的是,第二名称节点对第一名称节点的元数据文件进行备份时,同时会删除上一次备份的元数据文件。It should be noted that when the second namenode backs up the metadata file of the first namenode, the metadata file backed up last time will be deleted at the same time.
示例的,若预设的第一时长为1小时,预设的第二时长为10分钟,例如2点时,第一名称节点将镜像文件与编辑日志合并,形成新的镜像文件A2,同时,启用新的编辑日志B2,第二名称节点对新的镜像文件A2和新的编辑日志B2备份。For example, if the preset first duration is 1 hour, and the preset second duration is 10 minutes, for example, at 2 o'clock, the first name node will merge the image file with the edit log to form a new image file A2 , and at the same time , enable the new edit log B2 , and the second namenode backs up the new image file A2 and the new edit log B2 .
2点10分时,第二名称节点对第一名称节点上的编辑日志B2′(此时,该编辑日志B2′中存储的是2点到2点10分期间元数据的改动序列)备份,同时,删除上一次2点时备份的编辑日志B2。At 2:10, the second name node edits the edit log B2 ′ on the first name node (at this time, the edit log B2 ′ stores the metadata change sequence from 2:00 to 2:10) Backup, meanwhile, deletes the edit log B2 that was last backed up at 2 o'clock.
2点20分时,第二名称节点对第一名称节点上的编辑日志B2″(此时,该编辑日志B″中存储的是2点到2点20分期间元数据的改动序列)备份,同时,删除上一次2点10分备份的编辑日志B2′。At 2:20, the second namenode backs up the edit log B2 ″ on the first namenode (at this time, the edit log B″ stores the metadata change sequence from 2:00 to 2:20) , and at the same time, delete the last edit log B2 ′ backed up at 2:10.
依次类推,直至3点时,第一名称节点将镜像文件A2和编辑日志B2″″′(此时,该编辑日志中存储的是2点到3点期间元数据的改动序列)合并,形成新的镜像文件A3,同时,启用新的编辑日志B3。第二名称节点对第一名称节点上的新的镜像文件A3和新的编辑日志B3备份,同时,删除2点时备份的镜像文件A2和2点50时备份的编辑日志B2″″′。By analogy, until 3 o'clock, the first name node merges the image file A2 and the edit log B2 ""' (at this time, the edit log stores the metadata modification sequence between 2 o'clock and 3 o'clock), A new image file A3 is formed, and a new edit log B3 is enabled at the same time. The second name node backs up the new image file A3 and the new edit log B3 on the first name node, and at the same time deletes the image file A2 backed up at 2:00 and the edit log B2 backed up at 2:50 ″ "'.
通过在第二名称节点对于第一名称节点上的镜像文件和编辑日志备份时,设置不同的间隔时长,使得相对于镜像文件,较小的编辑日志能单独进行更高频的备份,保存更多的元数据序列,进而减少第一名称节点损坏造成的损失。By setting different intervals when the second name node backs up the image files and edit logs on the first name node, compared with mirror files, smaller edit logs can be independently backed up more frequently and save more metadata sequence, thereby reducing the loss caused by the damage of the first name node.
本发明的实施例提供一种Hadoop分布式文件系统,在第一名称节点每隔预设的第一时长,将镜像文件与编辑日志合并,形成新的镜像文件,并启用新的编辑日志的基础上,通过与第一名称节点连接的第二名称节点,每隔预设的第一时长,对第一名称节点上新的镜像文件备份,以及每隔预设的第二时长,对第一名称节点上的编辑日志备份,第二时长小于第一时长,使得编辑日志进行了更高频的备份,保存了更多的元数据序列,增强了Hadoop分布式文件系统中数据的安全性。Embodiments of the present invention provide a Hadoop distributed file system, which merges the image file and the edit log at the first name node every preset first time length to form a new image file, and enables the basis of the new edit log On, through the second name node connected to the first name node, every preset first time period, the new image file on the first name node is backed up, and every preset second time period, the first name node The edit log backup on the node, the second duration is shorter than the first duration, so that the edit log is backed up more frequently, more metadata sequences are saved, and the data security in the Hadoop distributed file system is enhanced.
本发明的实施例还提供Hadoop分布式文件系统的运行方法,如图2所示,包括:Embodiments of the present invention also provide the operating method of the Hadoop distributed file system, as shown in Figure 2, comprising:
S10、启动第一名称节点,加载元数据文件,同时启动第二名称节点。S10. Start the first name node, load the metadata file, and start the second name node at the same time.
元数据文件包括镜像文件和编辑日志。Metadata files include image files and edit logs.
需要说明的是,若第一名称节点第一次启动,则启用新的镜像文件和编辑日志,若不是第一启动,则直接加载镜像文件和编辑日志。It should be noted that if the first name node is started for the first time, a new image file and edit log will be enabled, and if it is not the first start, the image file and edit log will be directly loaded.
S11、每隔预设的第一时长,第一名称节点将镜像文件与编辑日志合并,形成新的镜像文件,同时启用新的编辑日志。S11. Every preset first time period, the first name node merges the image file with the edit log to form a new image file, and at the same time activates the new edit log.
S12、每隔预设的第一时长,第二名称节点对第一名称节点上新的镜像文件备份。S12. Every preset first time period, the second name node backs up the new image file on the first name node.
S13、每隔预设的第二时长,第二名称节点对第一名称节点上的编辑日志备份。S13. The second name node backs up the edit log on the first name node every preset second time period.
其中,第二时长小于第一时长。第一名称节点与第二名称节点分别部署于不同主机。Wherein, the second duration is shorter than the first duration. The first name node and the second name node are respectively deployed on different hosts.
本发明的实施例提供的Hadoop分布式文件系统的运行方法与上述Hadoop分布式文件系统具有相同的有益效果,在此不再赘述。The operating method of the Hadoop distributed file system provided by the embodiment of the present invention has the same beneficial effects as the above-mentioned Hadoop distributed file system, and will not be repeated here.
本发明的实施例还提供Hadoop分布式文件系统的修复方法,如图3所示,包括:Embodiments of the present invention also provide the repair method of Hadoop distributed file system, as shown in Figure 3, comprising:
S20、停止受损的第一名称节点,同时停止第二名称节点。S20. Stop the damaged first name node and stop the second name node at the same time.
可以理解的是,停止受损的第一名称节点和第二名称节点的相关服务,防止Hadoop分布式文件系统的数据块发生变化。It can be understood that related services of the damaged first name node and second name node are stopped to prevent data blocks of the Hadoop distributed file system from changing.
S21、备份第二名称节点上的元数据文件。S21. Back up the metadata file on the second namenode.
元数据文件包括第二名称节点最后一次从受损的第一名称节点上备份的镜像文件和编辑日志。The metadata file includes the image file and edit log backed up by the second namenode from the damaged first namenode for the last time.
可以理解的是,由于对镜像文件和编辑日志备份的间隔时长不同,最后一次从受损的第一名称节点上备份镜像文件的时间和最后一次备份编辑日志的时间不同。It can be understood that, due to the different intervals between mirror file and edit log backups, the last backup time of the mirror file from the damaged first name node is different from the last time of backing up the edit log.
示例的,若预设的第一时长为1小时,预设的第二时长为10分钟,例如2点时,第一名称节点将镜像文件与编辑日志合并,形成新的镜像文件A2,同时,启用新的编辑日志B2,第二名称节点对新的镜像文件A2和新的编辑日志B2备份;2点10分时,第二名称节点对第一名称节点上的编辑日志B2′备份,此时,该编辑日志B2′中存储的是2点到2点10分期间元数据的改动序列,同时,删除上一次2点时备份的编辑日志B2。For example, if the preset first duration is 1 hour, and the preset second duration is 10 minutes, for example, at 2 o'clock, the first name node will merge the image file with the edit log to form a new image file A2 , and at the same time , enable the new edit log B2 , the second name node backs up the new image file A2 and the new edit log B2 ; at 2:10, the second name node backs up the edit log B2 on the first name node 'Backup, at this time, the editing log B2 ' stores the modification sequence of metadata from 2 o'clock to 2:10, and at the same time, delete the editing log B2 backed up at 2 o'clock last time.
若2点19分第一名称节点损坏,则第二名称节点上最后一次从受损的第一名称节点上备份的元数据文件指的是2点时备份的镜像文件A2,以及2点10分时备份的编辑日志B2′。If the first name node is damaged at 2:19, the last metadata file backed up from the damaged first name node on the second name node refers to the image file A2 backed up at 2:00, and the image file A 2 backed up at 2:10 Edit log B2 ′ for time-sharing backup.
S22、准备部署新的第一名称节点的主机。S22. Prepare to deploy a host of a new first name node.
部署新的第一名称节点的主机与部署受损的第一名称节点、部署第二名称节点的主机均不同。The host on which the new first namenode is deployed is different from the host on which the damaged first namenode is deployed and the host on which the second namenode is deployed.
S23、配置主机的名称、IP地址、互信登录、运行环境和集群。S23. Configure the host name, IP address, mutual trust login, operating environment and cluster.
S24、对新的第一名称节点执行格式化。S24. Perform formatting on the new first name node.
需要说明的是,执行格式化后新的第一名称节点上的元数据序号被清零。It should be noted that after the formatting is performed, the metadata serial number on the new first name node is cleared.
S25、将备份的第二名称节点上的镜像文件和编辑日志,发送至新的第一名称节点。S25. Send the backup image file and edit log on the second namenode to the new first namenode.
示例的,根据S21中的示例可知,第二名称节点上最后一次从受损的第一名称节点上备份的元数据文件指的是2点时备份的镜像文件A2,以及2点10分时备份的编辑日志B2′,将该2点时的镜像文件A2,以及2点10分时备份的编辑日志B2′,发送至第一名称节点。Exemplarily, according to the example in S21, it can be known that the last metadata file backed up on the second namenode from the damaged first namenode refers to the image file A2 backed up at 2:00, and at 2:10 The backup edit log B2 ′ sends the image file A2 at 2:00 and the edit log B2 ′ backed up at 2:10 to the first name node.
S26、修改新的第一名称节点的元数据序号。S26. Modify the metadata sequence number of the new first name node.
可以理解的是,手动修改新的第一名称节点的元数据序号,使得该元数据序号可以与发送回的编辑日志中的元数据序列进行衔接,从而,在新的第一名称节点进行运行时,继续扩展整个元数据序列。It can be understood that manually modifying the metadata sequence number of the new first namenode, so that the metadata sequence number can be connected with the metadata sequence in the edit log sent back, so that when the new first namenode is running , continue expanding the entire metadata sequence.
可选地,在S26之后,如图4所示,Hadoop分布式文件系统的修复方法还包括:Optionally, after S26, as shown in Figure 4, the repair method of Hadoop distributed file system also includes:
S27、启动新的第一名称节点和对应的Hadoop分布式文件系统。S27. Start a new first name node and a corresponding Hadoop distributed file system.
S28、执行Hadoop分布式文件系统检查。S28. Execute Hadoop distributed file system check.
若对Hadoop分布式文件系统进行检查后,确认修复,则修复完成,若检查还未修复,则再次执行S22~S26的步骤,重新进行修复。If the Hadoop distributed file system is checked and the repair is confirmed, the repair is completed; if the check has not been repaired, steps S22 to S26 are executed again to perform the repair again.
本发明的实施例还提供一种Hadoop分布式文件系统,包括:第一名称节点、与第一名称节点连接的第二名称节点。An embodiment of the present invention also provides a Hadoop distributed file system, including: a first name node, and a second name node connected to the first name node.
第一名称节点,用于存储元数据文件;元数据文件包括镜像文件和编辑日志;第一名称节点还用于每隔预设的第一时长,启用新的编辑日志。The first name node is used to store metadata files; the metadata files include image files and edit logs; the first name node is also used to enable new edit logs every preset first time period.
第二名称节点,用于每隔预设的第一时长,对第一名称节点上原有的镜像文件和原有的编辑日志备份,将备份的镜像文件和编辑日志合并,形成新的镜像文件,并发送回第一名称节点,替换第一名称节点原有的镜像文件。The second name node is used to back up the original image file and the original editing log on the first name node every preset first time period, and merge the backup image file and the editing log to form a new image file. And send it back to the first name node to replace the original image file of the first name node.
第二名称节点,还用于每隔预设的第二时长,对第一名称节点上的编辑日志备份,形成中间编辑日志;第二时长小于第一时长。The second name node is also used for backing up the edit log on the first name node every preset second time length to form an intermediate edit log; the second time length is shorter than the first time length.
其中,第一名称节点和第二名称节点分别部署于不同的主机。Wherein, the first name node and the second name node are respectively deployed on different hosts.
示例的,若预设的第一时长为1小时,预设的第二时长为15分钟,例如1点时,第一名称节点启动新的编辑日志b1;第二名称节点对第一名称节点上原有的镜像文件和原有的编辑日志备份,将备份的镜像文件和编辑日志合并,形成新的镜像文件a1,并发送回第一名称节点,替换第一名称节点原有的镜像文件,同时,第二名称节点对第一名称节点上新的编辑日志b1备份,形成中间编辑日志c1。For example, if the preset first duration is 1 hour, and the preset second duration is 15 minutes, for example, at 1:00, the first namenode starts a new edit log b1 ; Upload the original image file and the original edit log backup, merge the backup image file and edit log to form a new image file a1 , and send it back to the first name node to replace the original image file of the first name node, At the same time, the second name node backs up the new edit log b1 on the first name node to form an intermediate edit log c1 .
1点15分时,第二名称节点对第一名称节点上的编辑日志b1′(此时,该编辑日志b1′中存储的是1点到1点15分期间元数据的改动序列)备份,形成中间编辑日志c1′,同时,删除上一次备份的中间编辑日志c1。At 1:15, the second name node edits the edit log b1 ′ on the first name node (at this time, the edit log b1 ′ stores the metadata change sequence from 1:00 to 1:15) Back up to form an intermediate edit log c1 ′, and at the same time, delete the intermediate edit log c1 backed up last time.
1点30分时,第二名称节点对第一名称节点上的编辑日志b1″(此时,该编辑日志b1″中存储的是1点到1点30分期间元数据的改动序列)备份,形成中间编辑日志c1″,同时,删除上一次备份的中间编辑日志c1′。At 1:30, the second name node edits the edit log b1 ″ on the first name node (at this time, the edit log b1 ″ stores the metadata change sequence from 1:00 to 1:30) Back up to form an intermediate edit log c1 ″, and at the same time, delete the intermediate edit log c1 ′ of the previous backup.
依次类推,直至2点时,第一名称节点启动新的编辑日志b2;第二名称节点对第一名称节点上的镜像文件a1和编辑日志b1″′(此时,该编辑日志b1″′中存储的是1点到2点期间元数据的改动序列)备份,将备份的镜像文件a1和编辑日志b1″′合并,形成新的镜像文件a2,并发送回第一名称节点,替换第一名称节点原有的镜像文件a1,同时,第二名称节点对第一名称节点上新的编辑日志b2备份,形成中间编辑日志c2。By analogy, until 2 o'clock, the first name node starts a new edit log b2 ; the second name node performs the mirror file a1 and edit log b1 "' on the first name node (at this time, the edit log b What is stored in1 ″’ is the modification sequence of metadata between 1 o’clock and 2 o’clock) backup, merge the backup image file a1 and edit log b1 ″’ to form a new image file a2 , and send it back to the first The name node replaces the original image file a1 of the first name node, and at the same time, the second name node backs up the new edit log b2 on the first name node to form an intermediate edit log c2 .
通过在第二名称节点对于第一名称节点上的镜像文件和编辑日志备份时,设置不同的间隔时长,使得相对于镜像文件,较小的编辑日志能单独进行更高频的备份,保存更多的元数据序列,进而减少第一名称节点损坏造成的损失。By setting different intervals when the second name node backs up the image files and edit logs on the first name node, compared with mirror files, smaller edit logs can be independently backed up more frequently and save more metadata sequence, thereby reducing the loss caused by the damage of the first name node.
本发明的实施例还提供一种Hadoop分布式文件系统,第一名称节点每隔预设的第一时长,启用新的编辑日志;通过与第一名称节点连接的第二名称节点,每隔预设的第一时长,对第一名称节点上原有的镜像文件和原有的编辑日志备份,将备份的镜像文件和编辑日志合并,形成新的镜像文件,并发送回第一名称节点,替换第一名称节点原有的镜像文件。此外,还通过每隔预设的第二时长,第二名称节点对第一名称节点上的编辑日志备份,形成中间编辑日志;由于第二时长小于第一时长,使得编辑日志单独进行了更高频的备份,保存了更多的元数据序列,增强了Hadoop分布式文件系统中数据的安全性。The embodiment of the present invention also provides a Hadoop distributed file system, the first name node starts a new edit log every preset first time length; through the second name node connected with the first name node, every preset Set the first time length, back up the original image file and the original edit log on the first name node, merge the backup image file and edit log to form a new image file, and send it back to the first name node to replace the first name node An original image file of the name node. In addition, the second name node backs up the edit log on the first name node every preset second time length to form an intermediate edit log; since the second time length is less than the first time length, the edit log is independently higher Frequent backup saves more metadata sequences and enhances data security in the Hadoop distributed file system.
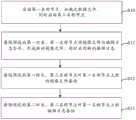
本发明的实施例还提供Hadoop分布式文件系统的运行方法,如图5所示,包括:Embodiments of the present invention also provide the operating method of the Hadoop distributed file system, as shown in Figure 5, including:
S100、启动第一名称节点,加载元数据文件,同时启动第二名称节点。S100. Start the first name node, load the metadata file, and start the second name node at the same time.
元数据文件包括镜像文件和编辑日志。Metadata files include image files and edit logs.
S110、每隔预设的第一时长,第一名称节点启动新的编辑日志。S110. The first name node starts a new edit log every preset first time period.
S120、每隔预设的第一时长,第二名称节点对第一名称节点上原有的镜像文件和原有的编辑日志备份,将备份的镜像文件与编辑日志合并,形成新的镜像文件,并发送回第一名称节点,替换第一名称节点原有的镜像文件。S120. Every preset first time period, the second name node backs up the original image file and the original edit log on the first name node, merges the backup image file and the edit log to form a new image file, and Send back to the first name node to replace the original image file of the first name node.
S130、每隔预设的第二时长,第二名称节点对第一名称节点上的编辑日志备份,形成中间编辑日志。S130. Every second preset time period, the second namenode backs up the edit log on the first namenode to form an intermediate edit log.
其中,第二时长小于第一时长。第一名称节点与第二名称节点分别部署于不同主机。Wherein, the second duration is shorter than the first duration. The first name node and the second name node are respectively deployed on different hosts.
本发明的实施例提供的Hadoop分布式文件系统的运行方法与上述Hadoop分布式文件系统具有相同的有益效果,在此不再赘述。The operating method of the Hadoop distributed file system provided by the embodiment of the present invention has the same beneficial effects as the above-mentioned Hadoop distributed file system, and will not be repeated here.
本发明的实施例还提供Hadoop分布式文件系统的修复方法,如图6所示,包括:Embodiments of the present invention also provide the repair method of Hadoop distributed file system, as shown in Figure 6, comprising:
S200、停止受损的第一名称节点,同时停止第二名称节点。S200. Stop the damaged first name node and stop the second name node at the same time.
S210、备份第二名称节点上的元数据文件。S210. Back up the metadata file on the second namenode.
元数据文件包括第二名称节点最后一次从受损的第一名称节点上备份的镜像文件和编辑日志,以及最后一次形成的中间编辑日志。The metadata file includes the image file and edit log backed up by the second namenode from the damaged first namenode for the last time, and the intermediate edit log formed last time.
可以理解的是,由于对镜像文件和编辑日志备份,和对编辑日志备份形成中间编辑日志的间隔时长不同,所以,最后一次从受损的第一名称节点上对镜像文件和编辑日志备份的时间和最后一次对编辑日志备份,形成中间编辑日志的时间不同。It is understandable that, due to the difference in the interval between the backup of the image file and the edit log and the backup of the edit log to form the intermediate edit log, the time for the last backup of the image file and the edit log from the damaged first name node The time at which the intermediate edit log was formed is different from the last time the edit log was backed up.
示例的,若预设的第一时长为1小时,预设的第二时长为15分钟,例如1点时,第一名称节点启动新的编辑日志b1;第二名称节点对第一名称节点上原有的镜像文件和原有的编辑日志备份,将备份的镜像文件和编辑日志合并,形成新的镜像文件a1,并发送回第一名称节点,替换第一名称节点原有的镜像文件,同时,第二名称节点对第一名称节点上新的编辑日志b1备份,形成中间编辑日志c1。For example, if the preset first duration is 1 hour, and the preset second duration is 15 minutes, for example, at 1:00, the first namenode starts a new edit log b1 ; Upload the original image file and the original edit log backup, merge the backup image file and edit log to form a new image file a1 , and send it back to the first name node to replace the original image file of the first name node, At the same time, the second name node backs up the new edit log b1 on the first name node to form an intermediate edit log c1 .
若1点25分第一名称节点损坏,则第二名称节点上最后一次从受损的第一名称节点上备份的元数据文件指的是1点时备份的镜像文件a0和编辑日志b0,以及1点15分时对编辑日志b1′(此时,该编辑日志b1′存储的是1点到1点15分期间元数据的改动序列)备份,形成的中间编辑日志c1′。If the first name node is damaged at 1:25, the last metadata file backed up from the damaged first name node on the second name node refers to the mirror file a0 and edit log b0 backed up at 1:00 , and back up the edit log b1 ′ at 1:15 (at this time, the edit log b1 ′ stores the metadata change sequence from 1:00 to 1:15 pm) to form an intermediate edit log c1 ′ .
S220、准备部署新的第一名称节点的主机。S220. Prepare to deploy a host of a new first name node.
部署新的第一名称节点的主机与部署受损的第一名称节点、部署第二名称节点的主机均不同。The host on which the new first namenode is deployed is different from the host on which the damaged first namenode is deployed and the host on which the second namenode is deployed.
S230、配置主机的名称、IP地址、互信登录、运行环境和集群。S230, configure the host name, IP address, mutual trust login, operating environment and cluster.
S240、对新的第一名称节点执行格式化。S240. Perform formatting on the new first name node.
S250、将备份的第二名称节点上的镜像文件、编辑日志和中间编辑日志合并,生成新的镜像文件,发送至新的第一名称节点。S250. Merge the backup image file, edit log and intermediate edit log on the second namenode to generate a new image file and send it to the new first namenode.
示例的,根据S210中的示例可知,第二名称节点上最后一次从受损的第一名称节点上备份的元数据文件指的是1点时备份的镜像文件a0和编辑日志b0,以及1点15分时对编辑日志b1′(此时,该编辑日志b1′存储的是1点到1点15分期间元数据的改动序列)备份,形成的中间编辑日志c1′。Exemplarily, according to the example in S210, it can be known that the last metadata file backed up from the damaged first namenode on the second namenode refers to the image file a0 and edit log b0 backed up at 1:00, and Back up the editing log b1 ' at 1:15 (at this time, the editing log b1 ' stores the modification sequence of the metadata from 1:15 to 1:15) to form an intermediate editing log c1 '.
将该镜像文件a0和编辑日志b0、以及中间编辑日志c1′合并,相当于先将镜像文件a0和编辑日志b0合并,生成1点时对应镜像文件a1,再将1点时对应镜像文件a1和中间编辑日志c1′合并,再生成新的镜像文件,发送至新的第一名称节点。Merging the mirror file a0 with the edit log b0 and the intermediate edit log c1 ′ is equivalent to merging the mirror file a0 and the edit log b0 first, generating 1 point corresponding to the mirror file a1 , and then merging the 1 point At this time, the corresponding image file a1 is merged with the intermediate edit log c1 ′ to generate a new image file and send it to the new first name node.
S260、修改新的第一名称节点的元数据序号。S260. Modify the metadata serial number of the new first namenode.
可以理解的是,手动修改新的第一名称节点的元数据序号,使得该元数据序号可以与发送回的镜像文件中的元数据序列进行衔接,从而,在新的第一名称节点进行运行时,继续扩展整个元数据序列。It can be understood that manually modifying the metadata sequence number of the new first namenode, so that the metadata sequence number can be connected with the metadata sequence in the image file sent back, so that when the new first namenode is running , continue expanding the entire metadata sequence.
可选地,在S260之后,如图7所示,Hadoop分布式文件系统的修复方法还包括:Optionally, after S260, as shown in Figure 7, the repair method of the Hadoop distributed file system also includes:
S270、启动新的第一名称节点和对应的Hadoop分布式文件系统。S270. Start a new first name node and a corresponding Hadoop distributed file system.
S280、执行分布式文件系统数据块检查。S280. Execute the distributed file system data block check.
若检查确认修复,则修复完成,若检测未修复,则再次执行S220~S260的步骤,重新进行修复。If it is checked and confirmed to be repaired, the repair is completed. If it is not repaired, the steps S220-S260 are executed again to perform the repair again.
本发明的实施例还提供一种计算机设备,包括存储单元和处理单元;所述存储单元中存储可在所述处理单元上运行的计算机程序并存储结果;所述处理单元执行所述计算机程序时实现如上所述的Hadoop分布式文件系统的运行方法,和/或如上所述的Hadoop分布式文件系统的修复方法。An embodiment of the present invention also provides a computer device, including a storage unit and a processing unit; the storage unit stores a computer program that can run on the processing unit and stores results; when the processing unit executes the computer program Realize the operating method of the above-mentioned Hadoop distributed file system, and/or the repair method of the above-mentioned Hadoop distributed file system.
本发明的实施例还一种计算机可读介质,其存储有计算机程序,所述计算机程序被处理器执行时实现如上所述的Hadoop分布式文件系统的运行方法,和/或如上所述的Hadoop分布式文件系统的修复方法。An embodiment of the present invention is also a computer-readable medium, which stores a computer program, and when the computer program is executed by a processor, it realizes the operating method of the Hadoop distributed file system as described above, and/or the Hadoop as described above Repair methods for distributed file systems.
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。The above is only a specific embodiment of the present invention, but the scope of protection of the present invention is not limited thereto. Anyone skilled in the art can easily think of changes or substitutions within the technical scope disclosed in the present invention. Should be covered within the protection scope of the present invention. Therefore, the protection scope of the present invention should be determined by the protection scope of the claims.
Claims (10)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201911056278.XACN110795404B (en) | 2019-10-31 | 2019-10-31 | Hadoop distributed file system and operation method and repair method thereof |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201911056278.XACN110795404B (en) | 2019-10-31 | 2019-10-31 | Hadoop distributed file system and operation method and repair method thereof |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN110795404A CN110795404A (en) | 2020-02-14 |
| CN110795404Btrue CN110795404B (en) | 2023-04-07 |
Family
ID=69440772
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201911056278.XAActiveCN110795404B (en) | 2019-10-31 | 2019-10-31 | Hadoop distributed file system and operation method and repair method thereof |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN110795404B (en) |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104572357A (en)* | 2014-12-30 | 2015-04-29 | 清华大学 | Backup and recovery method for HDFS (Hadoop distributed filesystem) |
| CN107506260A (en)* | 2017-07-27 | 2017-12-22 | 南京南瑞集团公司 | A kind of dynamic division database incremental backup method |
| CN108804253A (en)* | 2017-05-02 | 2018-11-13 | 中国科学院高能物理研究所 | A kind of concurrent job backup method for mass data backup |
| CN110362381A (en)* | 2019-06-21 | 2019-10-22 | 深圳市汇川技术股份有限公司 | HDFS cluster High Availabitity dispositions method, system, equipment and storage medium |
Family Cites Families (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9367579B1 (en)* | 2005-02-23 | 2016-06-14 | Veritas Technologies Llc | System and method for maintaining a file change log within a distributed file system |
| US9904689B2 (en)* | 2012-07-13 | 2018-02-27 | Facebook, Inc. | Processing a file system operation in a distributed file system |
| US9607001B2 (en)* | 2012-07-13 | 2017-03-28 | Facebook, Inc. | Automated failover of a metadata node in a distributed file system |
| US9514208B2 (en)* | 2012-10-30 | 2016-12-06 | Vekatachary Srinivasan | Method and system of stateless data replication in a distributed database system |
| CN103544045A (en)* | 2013-10-16 | 2014-01-29 | 南京大学镇江高新技术研究院 | HDFS-based virtual machine image storage system and construction method thereof |
| US20170371896A1 (en)* | 2016-06-23 | 2017-12-28 | Ebay Inc. | File system image processing system |
| CN107122238B (en)* | 2017-04-25 | 2018-05-25 | 郑州轻工业学院 | Efficient iterative Mechanism Design method based on Hadoop cloud Computational frame |
| CN109189480B (en)* | 2018-07-02 | 2021-11-09 | 新华三技术有限公司成都分公司 | File system starting method and device |
| CN109407977B (en)* | 2018-09-25 | 2021-08-31 | 佛山科学技术学院 | A method and system for distributed storage management of big data |
- 2019
- 2019-10-31CNCN201911056278.XApatent/CN110795404B/enactiveActive
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104572357A (en)* | 2014-12-30 | 2015-04-29 | 清华大学 | Backup and recovery method for HDFS (Hadoop distributed filesystem) |
| CN108804253A (en)* | 2017-05-02 | 2018-11-13 | 中国科学院高能物理研究所 | A kind of concurrent job backup method for mass data backup |
| CN107506260A (en)* | 2017-07-27 | 2017-12-22 | 南京南瑞集团公司 | A kind of dynamic division database incremental backup method |
| CN110362381A (en)* | 2019-06-21 | 2019-10-22 | 深圳市汇川技术股份有限公司 | HDFS cluster High Availabitity dispositions method, system, equipment and storage medium |
Non-Patent Citations (3)
| Title |
|---|
| Log Pruning in Distributed Event-sourced Systems;Benjamin Erb 等;《ACM》;20180625;第230-233页* |
| 一种Ceph分布式块存储的持续数据保护方法;王胜杰等;《网络安全技术与应用》;20170215(第02期);第84-85页* |
| 基于HDFS的创新知识云平台存储架构的研究与设计;马建红等;《计算机应用与软件》;20160315(第03期);第62-66页* |
Also Published As
| Publication number | Publication date |
|---|---|
| CN110795404A (en) | 2020-02-14 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US12260102B2 (en) | Distributed storage method and device | |
| US10956374B2 (en) | Data recovery method, apparatus, and system | |
| US9578091B2 (en) | Seamless cluster servicing | |
| JP2020518926A (en) | Backup and restore framework for distributed computing systems | |
| CN105824723B (en) | The method and system that a kind of data to publicly-owned cloud storage account are backed up | |
| CN109344006A (en) | An image management method and an image management module | |
| WO2016026306A1 (en) | Data backup method, system, node and computer storage media | |
| CN113934707B (en) | Cloud native database, database expansion method, database reduction method and device | |
| CN106878382B (en) | Method and device for dynamically changing cluster scale in distributed arbitration cluster | |
| CN109271376A (en) | Database upgrade method, apparatus, equipment and storage medium | |
| CN104601366A (en) | Configuration service method and device for control and service nodes | |
| US20250190447A1 (en) | Replica expansion methods, apparatuses, and systems for distributed graph database | |
| CN104793981A (en) | Online snapshot managing method and device for virtual machine cluster | |
| CN110083504B (en) | Running state monitoring method and device for distributed tasks | |
| CN112579550A (en) | Metadata information synchronization method and system of distributed file system | |
| CN106815232A (en) | Catalog management method, apparatus and system | |
| EP2372552B1 (en) | Automated relocation of in-use multi-site protected data storage | |
| CN110795404B (en) | Hadoop distributed file system and operation method and repair method thereof | |
| CN107783826B (en) | A virtual machine migration method, device and system | |
| CN110784353B (en) | Network element equipment configuration data migration method and device | |
| CN112083885A (en) | Data migration method and device, electronic equipment and storage medium | |
| CN111708835A (en) | Blockchain data storage method and device | |
| CN112000850A (en) | Method, device, system and equipment for data processing | |
| CN109241071A (en) | A kind of Android database upgrade method, apparatus and terminal | |
| CN106407320B (en) | File processing method, device and system |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |