CN110673748B - Method and device for providing candidate long sentences in input method - Google Patents
Method and device for providing candidate long sentences in input methodDownload PDFInfo
- Publication number
- CN110673748B CN110673748BCN201910927584.XACN201910927584ACN110673748BCN 110673748 BCN110673748 BCN 110673748BCN 201910927584 ACN201910927584 ACN 201910927584ACN 110673748 BCN110673748 BCN 110673748B
- Authority
- CN
- China
- Prior art keywords
- candidate
- prediction model
- words
- long sentence
- long
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images







Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/01—Input arrangements or combined input and output arrangements for interaction between user and computer
- G06F3/02—Input arrangements using manually operated switches, e.g. using keyboards or dials
- G06F3/023—Arrangements for converting discrete items of information into a coded form, e.g. arrangements for interpreting keyboard generated codes as alphanumeric codes, operand codes or instruction codes
- G06F3/0233—Character input methods
- G06F3/0237—Character input methods using prediction or retrieval techniques
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/044—Recurrent networks, e.g. Hopfield networks
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Software Systems (AREA)
- Mathematical Physics (AREA)
- Computing Systems (AREA)
- Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Human Computer Interaction (AREA)
- Bioinformatics & Computational Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Evolutionary Biology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Machine Translation (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本申请涉及人工智能技术领域,尤其涉及一种输入法中候选长句的提供方法及装置。The present application relates to the technical field of artificial intelligence, in particular to a method and device for providing candidate long sentences in an input method.
背景技术Background technique
目前,在输入法应用中,输入法应用可根据用户输入的拼音序列,提供该拼音序列对应的候选词语以及候选词语对应的下一个字、字、词、短语等较短的文本,然而,在实际应用中在用户需要通过输入法应用输入一个完整句子时,用户需要通过输入法应用多次输入对应完整句子中的相应拼音序列,以完成完整句子的输入,用户输入完整句子的输入成本较高,用户的输入法体验并不理想。At present, in the input method application, the input method application can provide the candidate word corresponding to the pinyin sequence and the next character, word, word, phrase, etc. corresponding to the candidate word according to the pinyin sequence input by the user. However, in In practical applications, when the user needs to input a complete sentence through the input method application, the user needs to input the corresponding pinyin sequence in the complete sentence through the input method application multiple times to complete the input of the complete sentence, and the input cost of the user inputting the complete sentence is relatively high , the user's input method experience is not ideal.
发明内容Contents of the invention
本申请旨在至少在一定程度上解决相关技术中的技术问题之一。This application aims to solve one of the technical problems in the related art at least to a certain extent.
为此,本申请的第一个目的在于提出一种输入法中候选长句的提供方法。For this reason, the first purpose of this application is to propose a method for providing candidate long sentences in an input method.
本申请的第二个目的在于提出一种输入法中候选长句的提供装置。The second purpose of the present application is to propose a device for providing candidate long sentences in an input method.
本申请的第三个目的在于提出一种电子设备。The third object of the present application is to provide an electronic device.
本申请的第四个目的在于提出一种计算机可读存储介质。The fourth object of the present application is to provide a computer-readable storage medium.
本申请的第五个目的在于提出一种计算机程序产品。The fifth object of the present application is to propose a computer program product.
为达上述目的,本申请第一方面实施例提出了一种输入法中候选长句的提供方法,包括:获取用户在输入法应用中输入的当前输入序列;获取与所述当前输入序列相匹配的候选词语;根据预先训练的长句预测模型,获取与所述候选词语相匹配的候选长句;在所述输入法应用上展示候选词语和所述候选长句。In order to achieve the above purpose, the embodiment of the first aspect of the present application proposes a method for providing candidate long sentences in an input method, including: obtaining the current input sequence input by the user in the input method application; obtaining the input sequence that matches the current input sequence the candidate words; obtain the candidate long sentences matching the candidate words according to the pre-trained long sentence prediction model; display the candidate words and the candidate long sentences on the input method application.
本申请实施例的输入法中候选长句的提供方法,获取用户在输入法应用中输入的当前输入序列,并获取与该当前输入序列相匹配的候选词语,以及结合预先训练的长句预测模型和候选词语,获取对应的候选长句,并在输入法应用上展示候选词语的同时显示候选长句,由此,结合预先训练的长句预测模型,快速得到匹配的候选长句,并向用户提供候选长句,方便用户根据候选长句快速完成长句的输入,减少了用户的输入成本,提高了用户体验度。The method for providing candidate long sentences in the input method of the embodiment of the present application obtains the current input sequence input by the user in the input method application, obtains candidate words that match the current input sequence, and combines the pre-trained long sentence prediction model and candidate words, obtain the corresponding candidate long sentences, and display the candidate long sentences while displaying the candidate words on the input method application, thus, combined with the pre-trained long sentence prediction model, quickly get the matching candidate long sentences, and provide the user with Candidate long sentences are provided to facilitate the user to quickly complete the input of long sentences according to the candidate long sentences, which reduces the user's input cost and improves user experience.
为达上述目的,本申请第三方面实施例提出了一种输入法中候选长句的提供装置,包括:第一获取模块,用于获取用户在输入法应用中输入的当前输入序列;第二获取模块,用于获取与所述当前输入序列相匹配的候选词语;第三获取模块,用于根据预先训练的长句预测模型,获取与所述候选词语相匹配的候选长句;展示模块,用于在所述输入法应用上展示候选词语和所述候选长句。In order to achieve the above purpose, the embodiment of the third aspect of the present application proposes a device for providing candidate long sentences in the input method, including: a first acquisition module, used to acquire the current input sequence input by the user in the input method application; The acquisition module is used to obtain the candidate words matched with the current input sequence; the third acquisition module is used to obtain the candidate long sentences matched with the candidate words according to the pre-trained long sentence prediction model; the display module, It is used to display the candidate words and the candidate long sentence on the input method application.
本申请实施例的输入法中候选长句的提供装置,获取用户在输入法应用中输入的当前输入序列,并获取与该当前输入序列相匹配的候选词语,以及结合预先训练的长句预测模型和候选词语,获取对应的候选长句,并在输入法应用上展示候选词语的同时显示候选长句,由此,结合预先训练的长句预测模型,快速得到匹配的候选长句,并向用户提供候选长句,方便用户根据候选长句快速完成长句的输入,减少了用户的输入成本,提高了用户体验度。The device for providing candidate long sentences in the input method of the embodiment of the present application obtains the current input sequence input by the user in the input method application, and obtains candidate words that match the current input sequence, and combines the pre-trained long sentence prediction model and candidate words, obtain the corresponding candidate long sentences, and display the candidate long sentences while displaying the candidate words on the input method application, thus, combined with the pre-trained long sentence prediction model, quickly get the matching candidate long sentences, and provide the user with Candidate long sentences are provided to facilitate the user to quickly complete the input of long sentences according to the candidate long sentences, which reduces the user's input cost and improves user experience.
为达上述目的,本申请第三方面实施例提出了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上所述的输入法中候选长句的提供方法。In order to achieve the above purpose, the embodiment of the third aspect of the present application proposes an electronic device, including a memory, a processor, and a computer program stored on the memory and operable on the processor. When the processor executes the program, the The method for providing the long sentence candidate in the above-mentioned input method.
为了实现上述目的,本申请第四方面实施例提出了一种计算机可读存储介质,当所述存储介质中的指令被处理器执行时,实现如上所述的输入法中候选长句的提供方法。In order to achieve the above purpose, the embodiment of the fourth aspect of the present application proposes a computer-readable storage medium. When the instructions in the storage medium are executed by the processor, the method for providing long sentence candidates in the input method as described above is implemented. .
为了实现上述目的,本申请第五方面实施例提出了一种计算机程序产品,当所述计算机程序产品中的指令处理器执行时,实现如上所述的资质审核方法。In order to achieve the above purpose, the embodiment of the fifth aspect of the present application proposes a computer program product. When the instruction processor in the computer program product executes, the above-mentioned qualification review method is realized.
本申请附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本申请的实践了解到。Additional aspects and advantages of the application will be set forth in part in the description which follows, and in part will be obvious from the description, or may be learned by practice of the application.
附图说明Description of drawings
本申请上述的和/或附加的方面和优点从下面结合附图对实施例的描述中将变得明显和容易理解,其中:The above and/or additional aspects and advantages of the present application will become apparent and easy to understand from the following description of the embodiments in conjunction with the accompanying drawings, wherein:
图1是根据本申请一个实施例的输入法中候选长句的提供方法的流程示意图;Fig. 1 is a schematic flow chart of a method for providing a candidate long sentence in an input method according to an embodiment of the present application;
图2是包含候选长句的用户界面的示例图;Fig. 2 is the example figure that comprises the user interface of candidate long sentence;
图3是图1所示实施例中步骤103的细化流程示意图一;FIG. 3 is a schematic diagram of a detailed flow chart of
图4是图1所示实施例中步骤103的细化流程示意图二;Fig. 4 is a second schematic diagram of the refinement process of
图5是根据本申请另一个实施例的输入法中候选长句的提供方法的流程示意图;Fig. 5 is a schematic flow chart of a method for providing a candidate long sentence in an input method according to another embodiment of the present application;
图6是根据本申请一个实施例的输入法中候选长句的提供装置的结构示意图;Fig. 6 is a schematic structural diagram of a device for providing long sentences in an input method according to an embodiment of the present application;
图7是根据本申请另一个实施例的输入法中候选长句的提供装置的结构示意图;7 is a schematic structural diagram of a device for providing long sentences in an input method according to another embodiment of the present application;
图8是根据本申请另一个实施例的输入法中候选长句的提供装置的结构示意图;Fig. 8 is a schematic structural diagram of an apparatus for providing candidate long sentences in an input method according to another embodiment of the present application;
图9是根据本申请另一个实施例的输入法中候选长句的提供装置的结构示意图Fig. 9 is a schematic structural diagram of a device for providing long sentences in an input method according to another embodiment of the present application
图10是根据本申请一个实施例的电子设备的结构示意图。Fig. 10 is a schematic structural diagram of an electronic device according to an embodiment of the present application.
具体实施方式Detailed ways
下面详细描述本申请的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本申请,而不能理解为对本申请的限制。Embodiments of the present application are described in detail below, examples of which are shown in the drawings, wherein the same or similar reference numerals denote the same or similar elements or elements having the same or similar functions throughout. The embodiments described below by referring to the figures are exemplary, and are intended to explain the present application, and should not be construed as limiting the present application.
下面参考附图描述本申请实施例的输入法中候选长句的提供方法、装置和电子设备。The following describes the method, device and electronic equipment for providing candidate long sentences in the input method of the embodiments of the present application with reference to the accompanying drawings.
图1是根据本申请一个实施例的输入法中候选长句的提供方法的流程示意图。其中,需要说明的是,本实施例提供的输入法中候选长句的提供方法的执行主体为输入法中候选长句的提供装置,该装置可以配置在电子设备或者云端服务器中,该实施例对此不作具体限定。Fig. 1 is a schematic flowchart of a method for providing long sentence candidates in an input method according to an embodiment of the present application. Among them, it should be noted that the execution subject of the method for providing long sentences in the input method provided by this embodiment is the device for providing long sentences in the input method, and this device can be configured in an electronic device or a cloud server. This is not specifically limited.
如图1所示,该输入法中候选长句的提供方法可以包括:As shown in Figure 1, the method for providing a candidate long sentence in the input method may include:
步骤101,获取用户在输入法应用中输入的当前输入序列。
步骤102,获取与当前输入序列相匹配的候选词语。
作为一种示例性的实施方式,在用户需要通过输入法应用输入信息时,终端设备可获取用户在输入法应用中输入的当前输入序列,并将当前输入序列上传至云端服务器,以由云端服务器可对当前输入序列进行转换,以得到与当前输入序列相匹配的候选词语。As an exemplary implementation, when the user needs to input information through the input method application, the terminal device can obtain the current input sequence entered by the user in the input method application, and upload the current input sequence to the cloud server, so that the cloud server can The current input sequence can be converted to obtain candidate words that match the current input sequence.
可以理解的是,获取与当前输入序列相匹配的候选词语除了可以由云端服务器执行外,还可以由终端设备来执行,例如,终端设备可根据用户在输入法应用中输入的当前输入序列,结合按键模型对当前输入序列进行转换,以得到与该当前输入序列相匹配的候选词语,并将对应的候选词语上传至云端服务器,该实施例对此不作限定。It can be understood that the acquisition of candidate words matching the current input sequence can be performed not only by the cloud server, but also by the terminal device. For example, the terminal device can combine the current input sequence entered by the user in the input method application with The button model converts the current input sequence to obtain candidate words matching the current input sequence, and uploads the corresponding candidate words to the cloud server, which is not limited in this embodiment.
其中,终端设备可以包括但不限于个人计算机、平板电脑、手机、智能手机等具有输入法应用的硬件设备,该实施例对此不作具体限定。Wherein, the terminal device may include but not limited to a personal computer, a tablet computer, a mobile phone, a smart phone and other hardware devices with input method applications, which is not specifically limited in this embodiment.
例如,用户在输入法应用中输入的当前输入序列为nihaozai,对当前输入序列“nihaozai”进行转换,可以获取该当前输入序列对应的首先候选词为“你好在”。For example, the current input sequence input by the user in the input method application is nihaozai, and the current input sequence "nihaozai" is converted to obtain the first candidate word corresponding to the current input sequence as "你好在".
又例如,用户在输入法应用中输入的当前输入序列为guonianhao,对当前输入序列“guonianhao”进行转换,可以获取该当前输入序列对应的首先候选词为“过年好”。For another example, the current input sequence entered by the user in the input method application is guonianhao, and the current input sequence "guonianhao" is converted to obtain the first candidate word corresponding to the current input sequence as "Happy Chinese New Year".
步骤103,根据预先训练的长句预测模型,获取与候选词语相匹配的候选长句。
具体地,在获取与当前输入序列相匹配的候选词语后,为了方便用户通过输入法应用快速输入一个完整长句,可结合预先训练的长句预测模型,获取与该候选词语相匹配的候选长句。Specifically, after obtaining candidate words that match the current input sequence, in order to facilitate the user to quickly input a complete long sentence through the input method application, the pre-trained long sentence prediction model can be combined to obtain candidate long sentences that match the candidate words. sentence.
其中,需要说明的是,在不同应用场景中,根据长句预测模型,获取与候选词语相匹配的候选长句的方式不同,例如,可将该候选词语直接输入到长句预测模型中,长句预测模型将直接输出与该候选词语相匹配的候选长句,其中,长句预测模型已学习到候选词语和候选长句之间的对应关系。Among them, it should be noted that in different application scenarios, according to the long sentence prediction model, the way to obtain the candidate long sentence matching the candidate word is different. For example, the candidate word can be directly input into the long sentence prediction model, and the long sentence The sentence prediction model will directly output a candidate long sentence that matches the candidate word, wherein the long sentence prediction model has learned the corresponding relationship between the candidate word and the candidate long sentence.
其中,关于根据长句预测模型,获取与候选词语相匹配的候选长句的其他方式将在后续实施例中描述。Among them, other ways of obtaining candidate long sentences matching candidate words according to the long sentence prediction model will be described in subsequent embodiments.
其中,需要理解的是,候选长句中包括候选词语,以及候选词语之后的后缀词语。Wherein, it should be understood that the candidate long sentence includes candidate words and suffix words after the candidate words.
在实际应用中,不同用户的语句使用习惯会有所不同,为了使得所提供的候选长句更加符合用户需求,作为一种示例性的实施方式,在获取与候选词语相匹配的候选长句之后,可获取该用户的语句偏好特征,并结合语句偏好特征,对所获取的候选长句进行调整,并向终端设备反馈调整后的候选长句。In practical applications, different users have different usage habits of sentences. In order to make the provided candidate long sentences more in line with user needs, as an exemplary implementation, after obtaining the candidate long sentences that match the candidate words , the sentence preference feature of the user can be acquired, and the acquired long sentence candidate can be adjusted in combination with the sentence preference feature, and the adjusted long sentence candidate can be fed back to the terminal device.
步骤104,在输入法应用上展示候选词语和候选长句。
在本实施例中,与候选词语相匹配的候选长句可以为一个或者多个。In this embodiment, there may be one or more candidate long sentences matching the candidate words.
在本实施例中,为了避免候选长句中出现敏感性词语,例如,不文明语句,在获取与候选长句之后,可确定对应候选长句是否包含黑名单词表中的词语,若包含黑名单词表中的词语,则过滤掉对应候选长句,如果不存在,则保存该候选长句。In this embodiment, in order to avoid sensitive words appearing in candidate long sentences, for example, uncivilized sentences, after acquiring and candidate long sentences, it can be determined whether the corresponding candidate long sentences contain words in the blacklist word list, if black Words in the noun vocabulary, then filter out the corresponding candidate long sentence, if it does not exist, then save the candidate long sentence.
其中,黑名单词表中保存了一些预设的不文明词语以及非法词语等。Among them, some preset uncivilized words and illegal words are saved in the black name word table.
作为一种示例性的实施方式,在确定与候选词语相匹配的候选长句为多个时,为了可准确向用户提供候选长句,可获取每个候选长句的得分,并在输入法应用上得分最高的候选长句。As an exemplary implementation, when it is determined that there are multiple candidate long sentences matching the candidate words, in order to accurately provide the user with candidate long sentences, the score of each candidate long sentence can be obtained, and the input method application The candidate long sentence with the highest score.
例如,假设有三个候选长句,候选长句分别为“唉那怎么办”、“唉那怎么了”、“唉那怎么样”,得分依次为8、7、6,如果确定每个候选长句中均不包含黑名单词表中词语,此时,可获取得分最高的候选长句,并将得分最高的候选长句反馈给终端设备进行显示。For example, assuming that there are three candidate long sentences, the candidate long sentences are "Oh, what's the matter", "Oh, what's the matter", and the scores are 8, 7, 6 in turn. If it is determined that each candidate length None of the sentences contain words in the black-name word list. At this time, the candidate long sentence with the highest score can be obtained, and the candidate long sentence with the highest score can be fed back to the terminal device for display.
作为另一种示例性的实施方式,在确定与候选词语相匹配的候选长句为多个,可获取每个候选长句对应的得分,并按照得分由高到低的顺序对候选长句进行排序,并在输入法应用上展示排序后的候选长句。As another exemplary embodiment, when it is determined that there are multiple candidate long sentences matching the candidate words, the score corresponding to each candidate long sentence can be obtained, and the candidate long sentences can be evaluated according to the order of the scores from high to low. sort, and display the sorted candidate long sentences on the input method application.
在本实施例中,为了不影响用户通过输入法输入信息,可在输入法应用上的左上角或者右上角等位置显示候选长句,该实施例对候选长句的展示位置不作具体限定。In this embodiment, in order not to affect the user's input of information through the input method, the candidate long sentences may be displayed in the upper left corner or upper right corner of the input method application. This embodiment does not specifically limit the display position of the candidate long sentences.
例如,用户在输入法应用中当前输入序列“nihaozai”,其在输入法应用中显示候选词语,以及候选词语相匹配的候选长句“你好在吗,我找你有事”,其中,对应的用户界面上的示例图,如图2所示,其中,需要说明的是,图2中以在右上角上显示候选长句进行示例。For example, the user currently inputs the sequence "nihaozai" in the input method application, which displays the candidate words in the input method application, and the candidate long sentence "how are you, I have something to do with you" matching the candidate words, wherein, the corresponding An example diagram on the user interface is shown in FIG. 2 . It should be noted that, in FIG. 2 , the candidate long sentence is displayed on the upper right corner for example.
本申请实施例的输入法中候选长句的提供方法,获取用户在输入法应用中输入的当前输入序列,并获取与该当前输入序列相匹配的候选词语,以及结合预先训练的长句预测模型和候选词语,获取对应的候选长句,并在输入法应用上展示候选词语的同时显示候选长句,由此,结合预先训练的长句预测模型,快速得到匹配的候选长句,并向用户提供候选长句,方便用户根据候选长句快速完成长句的输入,减少了用户的输入成本,提高了用户体验度。The method for providing candidate long sentences in the input method of the embodiment of the present application obtains the current input sequence input by the user in the input method application, obtains candidate words that match the current input sequence, and combines the pre-trained long sentence prediction model and candidate words, obtain the corresponding candidate long sentences, and display the candidate long sentences while displaying the candidate words on the input method application, thus, combined with the pre-trained long sentence prediction model, quickly get the matching candidate long sentences, and provide the user with Candidate long sentences are provided to facilitate the user to quickly complete the input of long sentences according to the candidate long sentences, which reduces the user's input cost and improves user experience.
如图3所示,在一个实施例中,上述步骤103的具体实现过程可以包括:As shown in Figure 3, in one embodiment, the specific implementation process of the
步骤301,将候选词语作为长句预测模型的当前输入。In
在本实施例中,为了可通过长句预测模型准确预测出每个词语之后出现的下一个词语,在将当前输入至长句预测模型中,以获取长句预测模型的当前输出之前,还可结合训练语料数据对长句预测模型进行训练。In this embodiment, in order to accurately predict the next word that appears after each word through the long sentence prediction model, before the current input into the long sentence prediction model to obtain the current output of the long sentence prediction model, you can also Combine the training corpus data to train the long sentence prediction model.
其中,训练长句预测模型的具体过程为:Among them, the specific process of training the long sentence prediction model is as follows:
步骤a,获取训练语料数据,训练语料数据包括前缀样本词语,以及与前缀样本词语对应的后缀样本词语。In step a, the training corpus data is obtained, and the training corpus data includes prefix sample words and suffix sample words corresponding to the prefix sample words.
其中,后缀样本词语为在前缀样本词之后出现的词语。Wherein, the suffix sample word is a word appearing after the prefix sample word.
在本实施例中,可结合即时通信聊天场景中的大量聊天语料,构造出训练语料数据。In this embodiment, the training corpus data can be constructed by combining a large amount of chat corpus in the instant messaging chat scene.
作为一种示例性的实施方式,为保证拥有足够前序信息,在选取聊天语句时,可选择输入字数大于或者等于预设字数阈值的句子,作为聊天语料。As an exemplary implementation, in order to ensure sufficient preamble information, when selecting a chat sentence, a sentence whose word count is greater than or equal to a preset word count threshold may be selected as the chat corpus.
其中,预设字数阈值是预先设置的字数临界值,如果一个聊天语句中的字数等于或者大于该字数临界值,可将该聊天语句作为构造训练语料的句子。例如,预设字数阈值为7个,聊天语句为“我们晚上去哪吃饭”,可以确定该聊天语句的字数超过7个此时,该聊天语句可作为构造训练语料的句子。Wherein, the preset word count threshold is a preset word count threshold, and if the word count in a chat sentence is equal to or greater than the word count threshold, the chat sentence can be used as a sentence for constructing the training corpus. For example, the preset word count threshold is 7, and the chat sentence is "where shall we go for dinner at night", and it can be determined that the chat sentence has more than 7 words. At this time, the chat sentence can be used as a sentence for constructing the training corpus.
其中,根据聊天语料构建训练语料数据的大致过程如下:通过预设分隔符对聊天语料中的聊天语句进行分隔处理,根据分隔处理结果,构建训练语料数据,其中,聊天语句中每个预设分隔符之前的词语为前缀样本词语,对应预设分隔符之后的词语为后缀样本词语。Among them, the general process of constructing the training corpus data according to the chat corpus is as follows: the chat sentences in the chat corpus are separated by the preset separator, and the training corpus data is constructed according to the result of the separation processing, wherein each preset separator in the chat sentence The words before the separator are prefix sample words, and the words after the corresponding preset separator are suffix sample words.
其中,预设分隔符是预先设置的,例如,预设分隔符可以为“|”。Wherein, the preset separator is preset, for example, the preset separator may be "|".
例如,聊天对话为“我们晚上去哪吃饭”,在应用分隔符“|”对聊天语句进行分割后,分割后的聊天对话为“我们|晚上|去哪|吃饭”,对于第一分隔符而言,其对应的前缀样本词语为“我们”,后缀样本词语为“晚上”,第二个分隔符而言,前缀样本词语为“我们晚上”,后缀样本词语为“去哪”,第三个分隔符而言,前缀样本词语为“我们晚上去哪”,后缀样本词语为“吃饭”。For example, the chat conversation is "Where shall we go for dinner at night", after the chat statement is divided by the separator "|", the divided chat conversation is "We | evening | where | dinner", for the first separator and language, the corresponding prefix sample word is "we", the suffix sample word is "evening", for the second separator, the prefix sample word is "we are at night", the suffix sample word is "go where", the third In terms of delimiters, the prefix sample word is "where are we going tonight", and the suffix sample word is "dinner".
步骤b,根据前缀样本词语和后缀样本词语对长句预测模型进行训练。In step b, the long sentence prediction model is trained according to the prefix sample words and the suffix sample words.
具体地,将前缀样本词语作为长句预测模型的输入特征,并将后缀样本词语作为长句预测模型的输出特征,对长句预测模型进行训练。Specifically, the prefix sample words are used as the input features of the long sentence prediction model, and the suffix sample words are used as the output features of the long sentence prediction model to train the long sentence prediction model.
例如,可结合循环神经网络RNN(Recurrent Neural Network)以及前缀样本词语和后缀样本词语对长句预测模型进行训练。For example, the long sentence prediction model can be trained by combining the recurrent neural network RNN (Recurrent Neural Network) and prefix sample words and suffix sample words.
其中,RNN可以使用LSTM或者GRNN等结构,输入特征为汉字,输出特征为下一个汉字。然后通过一层Embedding层,后经RNN层建模。然后经分级hierarchical Softmax输出网络结构,选择其对应的汉字。Among them, RNN can use a structure such as LSTM or GRNN, the input feature is a Chinese character, and the output feature is the next Chinese character. Then pass through a layer of Embedding layer, and then modeled by RNN layer. Then the network structure is output by hierarchical softmax, and the corresponding Chinese characters are selected.
其中,需要说明的是,采用分级Softmax输出网络结构,可降低分类计算量,进而可提高训练模型的效率。Among them, it should be noted that the use of hierarchical Softmax output network structure can reduce the amount of classification calculations, thereby improving the efficiency of training models.
本实施例中,所使用的长句预测模型具有以下优点:输出候选长句的效率较高,并且该长句预测模型所需要的存储空间较小,对存储空间的要求不高,减少了模型所占用的存储资源。In this embodiment, the long sentence prediction model used has the following advantages: the efficiency of outputting candidate long sentences is high, and the storage space required by the long sentence prediction model is small, and the storage space requirement is not high, reducing the number of models. The storage resources used.
其中,在训练模型的过程中,可使用BP算法优化模型中的参数,得到最终的音字的序列转换模型。Wherein, in the process of training the model, BP algorithm can be used to optimize the parameters in the model to obtain the final sequence conversion model of phonetic characters.
其中,需要理解的是,训练后的长句预测模块可以准确预测中每个输入词语之后所出现的下一个词语。Among them, it should be understood that the trained long sentence prediction module can accurately predict the next word that appears after each input word.
步骤302,将当前输入至长句预测模型中,以获取长句预测模型的当前输出,其中,当前输出包括当前输入之后的下一个词语。
步骤303,在确定下一个词语与预设语句终止信息不匹配时,根据当前输出和当前输入更新长句预测模型的当前输入,并通过长句预测模型获取当前输入对应的当前输出,直至长句预测模型的当前输出与预设语句终止信息匹配。
步骤304,在长句预测模型的当前输出与预设语句终止信息匹配时,根据长句预测模型的当前输入,生成与候选词语相匹配的候选长句。
也就是说,本实施例中结合候选词语以及长句预测模型预测出了候选词语之后出现的下一个词语,并将候选词语和下一个词语作为语言模型下一次预测的输入,进一步预测在下一个词,如此反复利用长句预测模型,直至长句预测模型输出语句终止符。That is to say, in this embodiment, the candidate word and the long sentence prediction model are combined to predict the next word that appears after the candidate word, and the candidate word and the next word are used as the input of the next prediction of the language model, and further prediction is made in the next word , so repeatedly use the long sentence prediction model until the long sentence prediction model outputs a sentence terminator.
语句终止信息用于指示语句终止的信息。语句终止信息是预先设置的。例如,语句终止信息可以为语句终止符,语句终止符可以为NULL。Statement termination information is used for information indicating the termination of a statement. Statement termination information is preset. For example, the statement termination information may be a statement terminator, and the statement terminator may be NULL.
举例而言,语句终止信息可以为NULL,假设根据用户在输入法应用中输入的当前输入序列,所获取的候选词语为“我们晚上”,此时,可将候选词语“我们晚上”作为长句预测模型的当前输入,将“我们晚上”输入到长句预测模型后,如果长句预测模型的当前输出为“去哪”,也就是说,“我们晚上”之后出现的下一个词语为“去哪”,此时,可确定当前输出不是语句终止信息,此时,可结合当前输入之后拼接当前输出,以得到更新后的当前输入,更新后的当前输入为“我们晚上去哪”。对应地,长句预测模型的当前输出为“吃饭”。对应地,在当前输入之后再次拼接当前输出,得到更新后的当前输入,更新后的当前输入为“我们晚上去哪吃饭”,此时,长句预测模型的当前输出为“NULL”,长句预测模型对应的当前输入为“我们晚上去哪吃饭”,即为与候选词语相匹配的候选长句。For example, the sentence termination information can be NULL, assuming that according to the current input sequence input by the user in the input method application, the obtained candidate word is "we are at night", at this time, the candidate word "we are at night" can be used as a long sentence The current input of the prediction model, after inputting "we are at night" into the long sentence prediction model, if the current output of the long sentence prediction model is "where to go", that is to say, the next word that appears after "we are at night" is "go to Which", at this time, it can be determined that the current output is not the sentence termination information. At this time, the current output can be combined with the current input to obtain the updated current input. The updated current input is "where are we going at night?" Correspondingly, the current output of the long sentence prediction model is "eating". Correspondingly, after the current input, the current output is spliced again to obtain the updated current input. The updated current input is "where should we go for dinner at night", at this time, the current output of the long sentence prediction model is "NULL", and the long sentence The current input corresponding to the prediction model is "where shall we go for dinner at night", which is a candidate long sentence that matches the candidate word.
如图4所示,在另一个实施例中,上述步骤103的具体实现过程可以包括:As shown in FIG. 4, in another embodiment, the specific implementation process of the
步骤401,通过长句预测模型确定与候选词语相匹配的后缀词语,其中,长句预测模型,已学习得到候选词语与后缀词语之间的对应关系。
在本实施例中,为了可通过长句预测模型准确预测出候选词语相匹配的后缀词语,在将当前输入至长句预测模型中,以获取长句预测模型的当前输出之前,还可结合训练语料数据对长句预测模型进行训练。In this embodiment, in order to accurately predict the suffix words matching the candidate words through the long sentence prediction model, before the current input into the long sentence prediction model to obtain the current output of the long sentence prediction model, it can also be combined with training The corpus data is used to train the long sentence prediction model.
其中,训练长句预测模型的具体过程为:Among them, the specific process of training the long sentence prediction model is as follows:
步骤a,获取训练语料数据,训练语料数据包括前缀样本词语,以及与前缀样本词语对应的后缀样本词语,其中,前缀样本词语和后缀样本词语可组成长句。In step a, the training corpus data is obtained. The training corpus data includes prefix sample words and suffix sample words corresponding to the prefix sample words, wherein the prefix sample words and suffix sample words can form long sentences.
在本实施例中,可结合即时通信聊天场景中的大量聊天语料,构造出训练语料数据。In this embodiment, the training corpus data can be constructed by combining a large amount of chat corpus in the instant messaging chat scene.
作为一种示例性的实施方式,为保证拥有足够前序信息,在选取聊天语句时,可选择输入字数大于或者等于预设字数阈值的句子,作为聊天语料。As an exemplary implementation, in order to ensure sufficient preamble information, when selecting a chat sentence, a sentence whose word count is greater than or equal to a preset word count threshold may be selected as the chat corpus.
其中,预设字数阈值是预先设置的字数临界值,如果一个聊天语句中的字数等于或者大于该字数临界值,可将该聊天语句作为构造训练语料的句子。例如,预设字数阈值为7个,聊天语句为“我们晚上去哪吃饭”,可以确定该聊天语句的字数超过7个此时,该聊天语句可作为构造训练语料的句子。Wherein, the preset word count threshold is a preset word count threshold, and if the word count in a chat sentence is equal to or greater than the word count threshold, the chat sentence can be used as a sentence for constructing the training corpus. For example, the preset word count threshold is 7, and the chat sentence is "where shall we go for dinner at night", and it can be determined that the chat sentence has more than 7 words. At this time, the chat sentence can be used as a sentence for constructing the training corpus.
其中,根据聊天语料构建训练语料数据的大致过程如下,通过预设分隔符对聊天语料中的聊天语句进行分隔处理,根据分隔处理结果,确定训练语料数据。其中,聊天语句中预设分隔符之前的词语为前缀样本词语,对应预设分隔符之后的词语为后缀样本词语。Wherein, the general process of constructing the training corpus data according to the chat corpus is as follows, the chat sentences in the chat corpus are separated by the preset delimiter, and the training corpus data is determined according to the result of the separation processing. The words before the preset separator in the chat sentence are prefix sample words, and the words after the corresponding preset separator are suffix sample words.
其中,预设分隔符是预先设置的,例如,预设分隔符可以为“|”。Wherein, the preset separator is preset, for example, the preset separator may be "|".
例如,聊天对话为“我们晚上去哪吃饭”,在应用分隔符“|”对聊天语句进行分割后,分割后的聊天对话为“我们|晚上|去哪吃饭”,前缀样本词语为“我们晚上”,后缀样本词语为“去哪吃饭”。For example, the chat conversation is "Where shall we go for dinner at night", after the separator "|" is used to split the chat sentence, the divided chat conversation is "We | ", the suffix sample word is "where to eat".
再例如,聊天对话为“我们晚上去哪吃饭”,在应用分隔符“|”对聊天语句进行分割后,分割后的聊天对话为“我们|晚上去哪吃饭”,前缀样本词语为“我们”,后缀样本词语为“晚上去哪吃饭”。For another example, the chat conversation is "Where shall we go for dinner at night", after the chat sentence is divided by the separator "|", the divided chat conversation is "We|Where are we going to eat at night", and the prefix sample word is "We" , the suffix sample word is "where to eat at night".
步骤b,根据前缀样本词语和后缀样本词语对长句预测模型进行训练。In step b, the long sentence prediction model is trained according to the prefix sample words and the suffix sample words.
在本实施例中,可结合典型的序列到序列的神经网络翻译模型,以及前缀词语和后缀词语对长句预测模型进行训练。In this embodiment, the long sentence prediction model can be trained in combination with a typical sequence-to-sequence neural network translation model, as well as prefix words and suffix words.
步骤402,根据候选词语和后缀词语,生成候选长句。
在本实施中,在获取候选词语和后缀词语之后,可将候选词语之后拼接后缀词语,以生成候选长句。In this implementation, after the candidate words and suffix words are obtained, the candidate words can be spliced with suffix words to generate candidate long sentences.
举例而言,假设候选词语为“我们晚上”,如果根据长句预测模型预测出该候选词语之后的后缀词语为“去哪吃饭”,此时,根据候选词语和后缀词语,所生成的候选长句为“我们去哪吃饭”。For example, assuming that the candidate word is "we are at night", if the suffix after the candidate word is predicted as "where to eat" according to the long sentence prediction model, at this time, according to the candidate word and the suffix word, the generated candidate length The sentence is "where shall we go for dinner".
可以理解的是,在实际应用中,在用户通过输入法应用输入该当前输入序列之前,有可能用户已通过输入法在对应用户界面中的文本编辑框中已上屏了一下词语,为了可准确向用户提供候选长句,在上述任意实施例的基础上,可结合已上屏词语和用户在输入法应用中输入的当前输入序列,确定候选长句。It can be understood that, in practical applications, before the user enters the current input sequence through the input method application, the user may have screened the words in the text edit box in the corresponding user interface through the input method. In order to accurately To provide the user with candidate long sentences, on the basis of any of the above-mentioned embodiments, the candidate long sentences may be determined by combining words on the screen and the current input sequence input by the user in the input method application.
下面结合图5对该实施例的输入法中候选长句的提供方法进行进一步描述。The method for providing candidate long sentences in the input method of this embodiment will be further described below with reference to FIG. 5 .
图5是根据本申请另一个实施例的输入法中候选长句的提供方法的流程示意图。Fig. 5 is a schematic flowchart of a method for providing long sentence candidates in an input method according to another embodiment of the present application.
如图5所示,该输入法中候选长句的提供方法可以包括:As shown in Figure 5, the method for providing a candidate long sentence in the input method may include:
步骤501,获取用户在输入法应用中输入的当前输入序列。
步骤502,获取与当前输入序列相匹配的候选词语。
其中,需要说明的是,前述对步骤101-步骤102的解释说明也适用于该实施例的步骤501-步骤502,此处不再赘述。Wherein, it should be noted that the foregoing explanations of
步骤503,获取在当前输入序列之前的已上屏词语。
其中,需要说明的是,本实施例中的步骤502和步骤503的执行顺序不分先后。Wherein, it should be noted that the execution order of
作为一种示例性的实施方式,可获取用户在用户界面中文本编辑框中已输入的文本信息,其中,该文本信息即为已上屏词语。As an exemplary implementation, the text information input by the user in the text editing box in the user interface may be acquired, where the text information is the words that have been uploaded on the screen.
步骤504,采用预先训练的长句预测模型,获取与候选词语和上屏词语相匹配的候选长句。
其中,需要说明的是,在不同应用场景中,采用预先训练的长句预测模型,获取与候选词语和上屏词语相匹配的候选长句的方式不同,举例说明如下:Among them, it should be noted that in different application scenarios, using the pre-trained long sentence prediction model, there are different ways to obtain candidate long sentences that match the candidate words and the words on the screen. Examples are as follows:
在第一种实施场景中,将已上屏词语和候选词语作为长句预测模型的当前输入;将当前输入至长句预测模型中,以获取长句预测模型的当前输出,其中,当前输出包括当前输入之后的下一个词语;在确定下一个词语与预设语句终止信息不匹配时,根据当前输出和当前输入更新长句预测模型的当前输入,并通过长句预测模型获取当前输入对应的当前输出,直至长句预测模型的当前输出与预设语句终止信息匹配;在长句预测模型的当前输出与预设语句终止信息匹配时,根据长句预测模型的当前输入,生成与候选词语相匹配的候选长句。In the first implementation scenario, the words on the screen and candidate words are used as the current input of the long sentence prediction model; the current input is entered into the long sentence prediction model to obtain the current output of the long sentence prediction model, wherein the current output includes The next word after the current input; when it is determined that the next word does not match the preset sentence termination information, the current input of the long sentence prediction model is updated according to the current output and the current input, and the current input corresponding to the current input is obtained through the long sentence prediction model. output until the current output of the long sentence prediction model matches the termination information of the preset sentence; when the current output of the long sentence prediction model matches the termination information of the preset sentence, according to the current input of the long sentence prediction model, a word matching the candidate word is generated candidate long sentences.
作为一种示例,可将已上屏词语之后拼接候选词语,并将拼接所的拼接词语作为长句预测模型的当前输入。As an example, candidate words can be spliced after the words on the screen, and the spliced words can be used as the current input of the long sentence prediction model.
例如,已上屏词语为“我们”,当前输入序列对应的候选词语为“晚上”,可将已上屏词语和候选词语拼接,得到长句预测模型的当前输入为“我们晚上”,将“我们晚上”输入到长句预测模型后,如果长句预测模型的当前输出为“去哪”,也就是说,“我们晚上”之后出现的下一个词语为“去哪”,此时,可确定当前输出不是语句终止符,此时,可结合当前输入之后拼接当前输出,以得到更新后的当前输入,更新后的当前输入为“我们晚上去哪”。对应地,长句预测模型的当前输出为“吃饭”。对应地,在当前输入之后再次拼接当前输出,得到更新后的当前输入,更新后的当前输入为“我们晚上去哪吃饭”,此时,长句预测模型的当前输出为“NULL”,长句预测模型对应的当前输入为“我们晚上去哪吃饭”,即为与候选词语相匹配的候选长句。For example, the word on the screen is "we", and the candidate word corresponding to the current input sequence is "evening". The word on the screen and the candidate word can be concatenated to obtain the current input of the long sentence prediction model as "our evening", and " After "we are at night" is input into the long sentence prediction model, if the current output of the long sentence prediction model is "where to go", that is to say, the next word that appears after "we are at night" is "where to go", at this time, it can be determined The current output is not a statement terminator. At this time, the current output can be combined with the current input to obtain the updated current input. The updated current input is "where are we going at night?" Correspondingly, the current output of the long sentence prediction model is "eating". Correspondingly, after the current input, the current output is spliced again to obtain the updated current input. The updated current input is "where should we go for dinner at night", at this time, the current output of the long sentence prediction model is "NULL", and the long sentence The current input corresponding to the prediction model is "where shall we go for dinner at night", which is a candidate long sentence that matches the candidate word.
第二种实施场景中,通过长句预测模型确定与候选词语和已上屏词语相匹配的后缀词语,其中,长句预测模型,已学习得到候选词语与后缀词语之间的对应关系;根据候选词语和后缀词语,生成候选长句。In the second implementation scenario, the long sentence prediction model is used to determine the suffix words that match the candidate words and the words on the screen, wherein the long sentence prediction model has learned the corresponding relationship between the candidate words and the suffix words; Words and suffix words to generate candidate long sentences.
具体地,可将已上屏词语之后拼接候选词语,得到拼接词语,并将拼接词语输入到长句预测模型,以通过长句预测模型获取该拼接词语对应的后缀词语,然后,在拼接词语之后拼接后缀词语,以得到候选长句。Specifically, the candidate words can be spliced after the words on the screen to obtain the spliced words, and the spliced words can be input into the long sentence prediction model to obtain the suffix words corresponding to the spliced words through the long sentence prediction model, and then, after the spliced words Splicing suffix words to obtain candidate long sentences.
举例而言,假设已上屏词语为“我们”,当前输入序列对应的候选词语为“晚上”,可将已上屏词语和候选词语进行拼接,得到拼接词语为“我们晚上”,如果根据长句预测模型预测出该拼接词之后的后缀词语为“去哪吃饭”,即,“去哪吃饭”为与已上屏词语和候选词语匹配的后缀词语,此时,根据候选词语和后缀词语,所生成的候选长句为“我们去哪吃饭”。For example, assuming that the word on the screen is "we", and the candidate word corresponding to the current input sequence is "evening", the word on the screen and the candidate word can be spliced to obtain the spliced word "we at night". The sentence prediction model predicts that the suffix word after the spliced word is "where to eat", that is, "where to eat" is a suffix word that matches the word on the screen and the candidate word. At this time, according to the candidate word and the suffix word, The generated candidate long sentence is "where shall we go for dinner".
在实际应用中,不同用户的语句使用习惯会有所不同,为了使得所提供的候选长句更加符合用户需求,作为一种示例性的实施方式,在获取与候选词语相匹配的候选长句之后,可获取该用户的语句偏好特征,并结合语句偏好特征,对所获取的候选长句,并向终端设备反馈调整后的候选长句。In practical applications, different users have different usage habits of sentences. In order to make the provided candidate long sentences more in line with user needs, as an exemplary implementation, after obtaining the candidate long sentences that match the candidate words , the user’s sentence preference feature can be obtained, combined with the sentence preference feature, the obtained candidate long sentence is fed back to the terminal device with the adjusted candidate long sentence.
步骤505,在输入法应用上展示候选词语和候选长句。
本申请实施例的输入法中候选长句的提供方法,获取用户在输入法应用中输入的当前输入序列,并获取与该当前输入序列相匹配的候选词语,以及获取在输入当前输入序列之前的已上屏词语,以及结合预先训练的长句预测模型,获取与候选词语和已上屏词语对应的候选长句,并在输入法应用上展示候选词语的同时显示候选长句,由此,结合预先训练的长句预测模型,快速得到匹配的候选长句,并向用户提供候选长句,方便用户根据候选长句快速完成长句的输入,减少了用户的输入成本,提高了用户体验度。The method for providing candidate long sentences in the input method of the embodiment of the present application obtains the current input sequence input by the user in the input method application, obtains the candidate words that match the current input sequence, and obtains the input sequence before the current input sequence Words that have been on the screen, and combined with the pre-trained long sentence prediction model, obtain candidate long sentences corresponding to the candidate words and words that have been on the screen, and display the candidate long sentences while displaying the candidate words on the input method application, thus combining The pre-trained long sentence prediction model quickly obtains matching candidate long sentences and provides candidate long sentences to users, which facilitates users to quickly complete long sentence input according to candidate long sentences, reduces user input costs, and improves user experience.
图6是根据本申请一个实施例的输入法中候选长句的提供装置的结构示意图。Fig. 6 is a schematic structural diagram of an apparatus for providing long sentence candidates in an input method according to an embodiment of the present application.
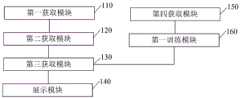
图6所示,该输入法中候选长句的提供装置包括第一获取模块110、第二获取模块120、第三获取模块130和展示模块140,其中:As shown in Fig. 6, the device for providing long sentences of candidates in the input method includes a
第一获取模块110,用于获取用户在输入法应用中输入的当前输入序列。The first acquiring
第二获取模块120,用于获取与当前输入序列相匹配的候选词语。The
第三获取模块130,用于根据预先训练的长句预测模型,获取与候选词语相匹配的候选长句。The
展示模块140,用于在输入法应用上展示候选词语和候选长句。The
在本申请一个实施例中,第三获取模块130,具体用于:将候选词语作为长句预测模型的当前输入。将当前输入至长句预测模型中,以获取长句预测模型的当前输出,其中,当前输出包括当前输入之后的下一个词语。在确定下一个词语与预设语句终止信息不匹配时,根据当前输出和当前输入更新长句预测模型的当前输入,并通过长句预测模型获取当前输入对应的当前输出,直至长句预测模型的当前输出与预设语句终止信息匹配。在长句预测模型的当前输出与预设语句终止信息匹配时,根据长句预测模型的当前输入,生成与候选词语相匹配的候选长句。In an embodiment of the present application, the
在本申请一个实施例中,在图6所示的装置实施例的基础上,如图7所示,该装置可以包括:In one embodiment of the present application, based on the device embodiment shown in FIG. 6, as shown in FIG. 7, the device may include:
第四获取模块150,用于获取训练语料数据,训练语料数据包括前缀样本词语,以及与前缀样本词语对应的后缀样本词语,其中,后缀样本词语为在前缀样本词之后出现的词语。The
第一训练模块160,用于根据前缀样本词语和后缀样本词语对长句预测模型进行训练。The
在本申请一个实施例中,第三获取模块130,具体用于:通过长句预测模型确定与候选词语相匹配的后缀词语,其中,长句预测模型,已学习得到候选词语与后缀词语之间的对应关系。根据候选词语和后缀词语,生成候选长句。In one embodiment of the present application, the
在本申请一个实施例中,在图6所示的装置实施例的基础上,如图8所示,该装置还包括:In one embodiment of the present application, on the basis of the device embodiment shown in FIG. 6, as shown in FIG. 8, the device further includes:
第五获取模块170,用于获取训练语料数据,训练语料数据包括前缀样本词语,以及与前缀样本词语对应的后缀样本词语,其中,前缀样本词语和后缀样本词语可组成长句。The
第二训练模块180,用于根据前缀样本词语和后缀样本词语对长句预测模型进行训练。The
在本申请一个实施例中,在图6所示的装置实施例的基础上,如图9所示,该装置还可以包括:In one embodiment of the present application, on the basis of the device embodiment shown in FIG. 6, as shown in FIG. 9, the device may further include:
第六获取模块190,用于获取在当前输入序列之前的已上屏词语。The sixth acquiring
第三获取模块130,具体用于:采用预先训练的长句预测模型,获取与候选词语和上屏词语相匹配的候选长句。The third obtaining
其中,需要理解的是,前述图9所示装置实施例的第六获取模块190的结构也可以包含在前述图7或图8所示的装置实施例中,该实施对此不作限定。Wherein, it should be understood that the structure of the
其中,需要说明的是,前述对输入法中候选长句的提供方法实施例的解释说明也适用于该实施例的输入法中候选长句的提供装置,其实现原理类似,此处不再赘述。Wherein, it should be noted that, the foregoing explanations to the embodiment of the method for providing long sentences in the input method are also applicable to the device for providing long sentences in the input method of this embodiment, and its implementation principle is similar, and will not be repeated here. .
本申请实施例的输入法中候选长句的提供装置,获取用户在输入法应用中输入的当前输入序列,并获取与该当前输入序列相匹配的候选词语,以及结合预先训练的长句预测模型和候选词语,获取对应的候选长句,并在输入法应用上展示候选词语的同时显示候选长句,由此,结合预先训练的长句预测模型,快速得到匹配的候选长句,并向用户提供候选长句,方便用户根据候选长句快速完成长句的输入,减少了用户的输入成本,提高了用户体验度。The device for providing candidate long sentences in the input method of the embodiment of the present application obtains the current input sequence input by the user in the input method application, and obtains candidate words that match the current input sequence, and combines the pre-trained long sentence prediction model and candidate words, obtain the corresponding candidate long sentences, and display the candidate long sentences while displaying the candidate words on the input method application, thus, combined with the pre-trained long sentence prediction model, quickly get the matching candidate long sentences, and provide the user with Candidate long sentences are provided to facilitate the user to quickly complete the input of long sentences according to the candidate long sentences, which reduces the user's input cost and improves user experience.
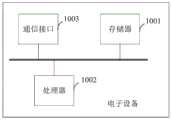
图10是根据本申请一个实施例的电子设备的结构示意图。该电子设备包括:Fig. 10 is a schematic structural diagram of an electronic device according to an embodiment of the present application. This electronic device includes:
存储器1001、处理器1002及存储在存储器1001上并可在处理器1002上运行的计算机程序。A
处理器1002执行程序时实现上述实施例中提供的输入法中候选长句的提供方法。When the
进一步地,电子设备还包括:Further, the electronic equipment also includes:
通信接口1003,用于存储器1001和处理器1002之间的通信。The
存储器1001,用于存放可在处理器1002上运行的计算机程序。The
存储器1001可能包含高速RAM存储器,也可能还包括非易失性存储器(non-volatile memory),例如至少一个磁盘存储器。The
处理器1002,用于执行程序时实现上述实施例的输入法中候选长句的提供方法。The
如果存储器1001、处理器1002和通信接口1003独立实现,则通信接口1003、存储器1001和处理器1002可以通过总线相互连接并完成相互间的通信。总线可以是工业标准体系结构(Industry Standard Architecture,简称为ISA)总线、外部设备互连(PeripheralComponent,简称为PCI)总线或扩展工业标准体系结构(Extended Industry StandardArchitecture,简称为EISA)总线等。总线可以分为地址总线、数据总线、控制总线等。为便于表示,图10中仅用一条粗线表示,但并不表示仅有一根总线或一种类型的总线。If the
可选的,在具体实现上,如果存储器1001、处理器1002及通信接口1003,集成在一块芯片上实现,则存储器1001、处理器1002及通信接口1003可以通过内部接口完成相互间的通信。Optionally, in specific implementation, if the
处理器1002可能是一个中央处理器(Central Processing Unit,简称为CPU),或者是特定集成电路(Application Specific Integrated Circuit,简称为ASIC),或者是被配置成实施本申请实施例的一个或多个集成电路。
本实施例还提供一种计算机可读存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现如上的输入法中候选长句的提供方法。This embodiment also provides a computer-readable storage medium, on which a computer program is stored, and is characterized in that, when the program is executed by a processor, the above method for providing long sentence candidates in the input method is realized.
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本申请的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。In the description of this specification, descriptions referring to the terms "one embodiment", "some embodiments", "example", "specific examples", or "some examples" mean that specific features described in connection with the embodiment or example , structure, material or characteristic is included in at least one embodiment or example of the present application. In this specification, the schematic representations of the above terms are not necessarily directed to the same embodiment or example. Furthermore, the described specific features, structures, materials or characteristics may be combined in any suitable manner in any one or more embodiments or examples. In addition, those skilled in the art can combine and combine different embodiments or examples and features of different embodiments or examples described in this specification without conflicting with each other.
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本申请的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。In addition, the terms "first" and "second" are used for descriptive purposes only, and cannot be interpreted as indicating or implying relative importance or implicitly specifying the quantity of indicated technical features. Thus, the features defined as "first" and "second" may explicitly or implicitly include at least one of these features. In the description of the present application, "plurality" means at least two, such as two, three, etc., unless otherwise specifically defined.
流程图中或在此以其他方式描述的任何过程或方法描述可以被理解为,表示包括一个或更多个用于实现定制逻辑功能或过程的步骤的可执行指令的代码的模块、片段或部分,并且本申请的优选实施方式的范围包括另外的实现,其中可以不按所示出或讨论的顺序,包括根据所涉及的功能按基本同时的方式或按相反的顺序,来执行功能,这应被本申请的实施例所属技术领域的技术人员所理解。Any process or method descriptions in flowcharts or otherwise described herein may be understood to represent a module, segment or portion of code comprising one or more executable instructions for implementing custom logical functions or steps of a process , and the scope of preferred embodiments of the present application includes additional implementations in which functions may be performed out of the order shown or discussed, including in substantially simultaneous fashion or in reverse order depending on the functions involved, which shall It should be understood by those skilled in the art to which the embodiments of the present application belong.
在流程图中表示或在此以其他方式描述的逻辑和/或步骤,例如,可以被认为是用于实现逻辑功能的可执行指令的定序列表,可以具体实现在任何计算机可读介质中,以供指令执行系统、装置或设备(如基于计算机的系统、包括处理器的系统或其他可以从指令执行系统、装置或设备取指令并执行指令的系统)使用,或结合这些指令执行系统、装置或设备而使用。就本说明书而言,"计算机可读介质"可以是任何可以包含、存储、通信、传播或传输程序以供指令执行系统、装置或设备或结合这些指令执行系统、装置或设备而使用的装置。计算机可读介质的更具体的示例(非穷尽性列表)包括以下:具有一个或多个布线的电连接部(电子装置),便携式计算机盘盒(磁装置),随机存取存储器(RAM),只读存储器(ROM),可擦除可编辑只读存储器(EPROM或闪速存储器),光纤装置,以及便携式光盘只读存储器(CDROM)。另外,计算机可读介质甚至可以是可在其上打印程序的纸或其他合适的介质,因为可以例如通过对纸或其他介质进行光学扫描,接着进行编辑、解译或必要时以其他合适方式进行处理来以电子方式获得程序,然后将其存储在计算机存储器中。The logic and/or steps represented in the flowcharts or otherwise described herein, for example, can be considered as a sequenced listing of executable instructions for implementing logical functions, can be embodied in any computer-readable medium, For use with instruction execution systems, devices, or devices (such as computer-based systems, systems including processors, or other systems that can fetch instructions from instruction execution systems, devices, or devices and execute instructions), or in conjunction with these instruction execution systems, devices or equipment used. For the purposes of this specification, a "computer-readable medium" may be any device that can contain, store, communicate, propagate or transmit a program for use in or in conjunction with an instruction execution system, device or device. More specific examples (non-exhaustive list) of computer-readable media include the following: electrical connection with one or more wires (electronic device), portable computer disk case (magnetic device), random access memory (RAM), Read Only Memory (ROM), Erasable and Editable Read Only Memory (EPROM or Flash Memory), Fiber Optic Devices, and Portable Compact Disc Read Only Memory (CDROM). In addition, the computer-readable medium may even be paper or other suitable medium on which the program may be printed, as it may be possible, for example, by optically scanning the paper or other medium, followed by editing, interpretation or other suitable means if necessary. Processing to obtain programs electronically and store them in computer memory.
应当理解,本申请的各部分可以用硬件、软件、固件或它们的组合来实现。在上述实施方式中,多个步骤或方法可以用存储在存储器中且由合适的指令执行系统执行的软件或固件来实现。如,如果用硬件来实现和在另一实施方式中一样,可用本领域公知的下列技术中的任一项或他们的组合来实现:具有用于对数据信号实现逻辑功能的逻辑门电路的离散逻辑电路,具有合适的组合逻辑门电路的专用集成电路,可编程门阵列(PGA),现场可编程门阵列(FPGA)等。It should be understood that each part of the present application may be realized by hardware, software, firmware or a combination thereof. In the above described embodiments, various steps or methods may be implemented by software or firmware stored in memory and executed by a suitable instruction execution system. For example, if implemented in hardware as in another embodiment, it can be implemented by any one or combination of the following techniques known in the art: a discrete Logic circuits, ASICs with suitable combinational logic gates, Programmable Gate Arrays (PGA), Field Programmable Gate Arrays (FPGA), etc.
本技术领域的普通技术人员可以理解实现上述实施例方法携带的全部或部分步骤是可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,该程序在执行时,包括方法实施例的步骤之一或其组合。Those of ordinary skill in the art can understand that all or part of the steps carried by the methods of the above embodiments can be completed by instructing related hardware through a program, and the program can be stored in a computer-readable storage medium. During execution, one or a combination of the steps of the method embodiments is included.
此外,在本申请各个实施例中的各功能单元可以集成在一个处理模块中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个模块中。上述集成的模块既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。所述集成的模块如果以软件功能模块的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。In addition, each functional unit in each embodiment of the present application may be integrated into one processing module, each unit may exist separately physically, or two or more units may be integrated into one module. The above-mentioned integrated modules can be implemented in the form of hardware or in the form of software function modules. If the integrated modules are realized in the form of software function modules and sold or used as independent products, they can also be stored in a computer-readable storage medium.
上述提到的存储介质可以是只读存储器,磁盘或光盘等。尽管上面已经示出和描述了本申请的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本申请的限制,本领域的普通技术人员在本申请的范围内可以对上述实施例进行变化、修改、替换和变型。The storage medium mentioned above may be a read-only memory, a magnetic disk or an optical disk, and the like. Although the embodiments of the present application have been shown and described above, it can be understood that the above embodiments are exemplary and should not be construed as limitations on the present application, and those skilled in the art can make the above-mentioned The embodiments are subject to changes, modifications, substitutions and variations.
Claims (12)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910927584.XACN110673748B (en) | 2019-09-27 | 2019-09-27 | Method and device for providing candidate long sentences in input method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910927584.XACN110673748B (en) | 2019-09-27 | 2019-09-27 | Method and device for providing candidate long sentences in input method |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN110673748A CN110673748A (en) | 2020-01-10 |
| CN110673748Btrue CN110673748B (en) | 2023-04-28 |
Family
ID=69079711
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201910927584.XAActiveCN110673748B (en) | 2019-09-27 | 2019-09-27 | Method and device for providing candidate long sentences in input method |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN110673748B (en) |
Families Citing this family (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113589946B (en)* | 2020-04-30 | 2024-07-26 | 北京搜狗科技发展有限公司 | Data processing method and device and electronic equipment |
| CN113589953B (en)* | 2020-04-30 | 2024-07-26 | 北京搜狗科技发展有限公司 | Information display method and device and electronic equipment |
| CN113589948B (en)* | 2020-04-30 | 2024-10-29 | 北京搜狗科技发展有限公司 | Data processing method and device and electronic equipment |
| CN113589952B (en)* | 2020-04-30 | 2025-05-06 | 北京搜狗科技发展有限公司 | Information display method, device and electronic equipment |
| CN113589947B (en)* | 2020-04-30 | 2024-08-09 | 北京搜狗科技发展有限公司 | Data processing method and device and electronic equipment |
| CN113589949B (en)* | 2020-04-30 | 2025-08-01 | 北京搜狗科技发展有限公司 | Input method and device and electronic equipment |
| CN113589954B (en)* | 2020-04-30 | 2024-09-03 | 北京搜狗科技发展有限公司 | Data processing method and device and electronic equipment |
| CN112052649B (en)* | 2020-10-12 | 2024-05-31 | 腾讯科技(深圳)有限公司 | Text generation method, device, electronic equipment and storage medium |
| CN112506359B (en)* | 2020-12-21 | 2023-07-21 | 北京百度网讯科技有限公司 | Method, device and electronic equipment for providing long sentence candidates in input method |
| CN112527127B (en)* | 2020-12-23 | 2022-01-28 | 北京百度网讯科技有限公司 | Training method and device for input method long sentence prediction model, electronic equipment and medium |
| CN113449515A (en)* | 2021-01-27 | 2021-09-28 | 心医国际数字医疗系统(大连)有限公司 | Medical text prediction method and device and electronic equipment |
| CN113655893B (en)* | 2021-07-08 | 2024-06-18 | 华为技术有限公司 | Word and sentence generation method, model training method and related equipment |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2011128958A (en)* | 2009-12-18 | 2011-06-30 | Chiteki Mirai:Kk | Device, method and program for inputting sentence |
| CN102866782A (en)* | 2011-07-06 | 2013-01-09 | 哈尔滨工业大学 | Input method and input method system for improving sentence generating efficiency |
| CN110187780A (en)* | 2019-06-10 | 2019-08-30 | 北京百度网讯科技有限公司 | Long text prediction method, device, equipment and storage medium |
| CN110286778A (en)* | 2019-06-27 | 2019-09-27 | 北京金山安全软件有限公司 | A Chinese deep learning input method, device and electronic equipment |
Family Cites Families (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE10235548B4 (en)* | 2002-03-25 | 2012-06-28 | Agere Systems Guardian Corp. | Method and device for the prediction of a text message input |
| JP2007034871A (en)* | 2005-07-29 | 2007-02-08 | Sanyo Electric Co Ltd | Character input apparatus and character input apparatus program |
| CN105718070A (en)* | 2016-01-16 | 2016-06-29 | 上海高欣计算机系统有限公司 | Pinyin long sentence continuous type-in input method and Pinyin long sentence continuous type-in input system |
| CN105759984B (en)* | 2016-02-06 | 2019-07-02 | 上海触乐信息科技有限公司 | Method and device for secondary text input |
| CN105929979B (en)* | 2016-06-29 | 2018-09-11 | 百度在线网络技术(北京)有限公司 | Long sentence input method and device |
| CN107688398B (en)* | 2016-08-03 | 2019-09-17 | 中国科学院计算技术研究所 | It determines the method and apparatus of candidate input and inputs reminding method and device |
- 2019
- 2019-09-27CNCN201910927584.XApatent/CN110673748B/enactiveActive
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2011128958A (en)* | 2009-12-18 | 2011-06-30 | Chiteki Mirai:Kk | Device, method and program for inputting sentence |
| CN102866782A (en)* | 2011-07-06 | 2013-01-09 | 哈尔滨工业大学 | Input method and input method system for improving sentence generating efficiency |
| CN110187780A (en)* | 2019-06-10 | 2019-08-30 | 北京百度网讯科技有限公司 | Long text prediction method, device, equipment and storage medium |
| CN110286778A (en)* | 2019-06-27 | 2019-09-27 | 北京金山安全软件有限公司 | A Chinese deep learning input method, device and electronic equipment |
Non-Patent Citations (2)
| Title |
|---|
| IUY ; .拼音输入法词库广度及选词精度全测试.网络与信息.2009,(第10期),第10-11页.* |
| 袁哲 ; .人工智能在拼音输入法中的应用.软件导刊.2010,(第06期),第10-12页.* |
Also Published As
| Publication number | Publication date |
|---|---|
| CN110673748A (en) | 2020-01-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110673748B (en) | Method and device for providing candidate long sentences in input method | |
| US12260854B2 (en) | Response method in human-computer dialogue, dialogue system, and storage medium | |
| JP7204801B2 (en) | Man-machine interaction method, device and medium based on neural network | |
| US10754885B2 (en) | System and method for visually searching and debugging conversational agents of electronic devices | |
| CN104573099B (en) | The searching method and device of topic | |
| CN109359196B (en) | Text multi-modal representation method and device | |
| JP2021197133A (en) | Meaning Matching methods, devices, electronic devices, storage media and computer programs | |
| CN110187780B (en) | Long text prediction method, device, equipment and storage medium | |
| US20160071510A1 (en) | Voice generation with predetermined emotion type | |
| CN107679032A (en) | Voice changes error correction method and device | |
| WO2016197767A2 (en) | Method and device for inputting expression, terminal, and computer readable storage medium | |
| CN108062303A (en) | The recognition methods of refuse messages and device | |
| CN107193807A (en) | Language conversion processing method, device and terminal based on artificial intelligence | |
| CN110413760A (en) | Man-machine dialogue method, device, storage medium and computer program product | |
| WO2017076038A1 (en) | Method and apparatus for search and recommendation | |
| CN110377745B (en) | Information processing method, information retrieval device and server | |
| CN114860910B (en) | Intelligent dialogue method and system | |
| CN106951413A (en) | Segmenting method and device based on artificial intelligence | |
| CN108304376B (en) | Text vector determination method and device, storage medium and electronic device | |
| CN115345669A (en) | Method and device for generating file, storage medium and computer equipment | |
| CN108874789B (en) | Statement generation method, device, storage medium and electronic device | |
| CN112948584A (en) | Short text classification method, device, equipment and storage medium | |
| WO2025209146A1 (en) | Image editing method and apparatus, and device, medium and program product | |
| CN109670047B (en) | Abstract note generation method, computer device and readable storage medium | |
| CN113342179B (en) | Input text processing method, device, electronic device and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |