CN110610006B - A Morphological Dual-Channel Chinese Word Embedding Method Based on Stroke and Glyph - Google Patents
A Morphological Dual-Channel Chinese Word Embedding Method Based on Stroke and GlyphDownload PDFInfo
- Publication number
- CN110610006B CN110610006BCN201910881062.0ACN201910881062ACN110610006BCN 110610006 BCN110610006 BCN 110610006BCN 201910881062 ACN201910881062 ACN 201910881062ACN 110610006 BCN110610006 BCN 110610006B
- Authority
- CN
- China
- Prior art keywords
- word
- chinese
- stroke
- morphological
- feature
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images


Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/36—Creation of semantic tools, e.g. ontology or thesauri
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02D—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN INFORMATION AND COMMUNICATION TECHNOLOGIES [ICT], I.E. INFORMATION AND COMMUNICATION TECHNOLOGIES AIMING AT THE REDUCTION OF THEIR OWN ENERGY USE
- Y02D10/00—Energy efficient computing, e.g. low power processors, power management or thermal management
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Computational Linguistics (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Document Processing Apparatus (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本发明涉及自然语言处理领域,尤其涉及一种基于笔画和字形的形态学双通道中文词嵌入方法。The invention relates to the field of natural language processing, in particular to a morphological dual-channel Chinese word embedding method based on strokes and font shapes.
背景技术Background technique
自然语言是人类用来表达和传递信息的一套复杂系统。在这套系统中,词是表义的基本单元。词向量,顾名思义,是用来表示词的向量,也可被认为是词的特征向量或表征。把词映射为实数域向量的技术也叫词嵌入。作为自然语言任务的基石,词嵌入一直是一个被广泛研究的课题。Natural language is a complex system used by humans to express and transmit information. In this system, word is the basic unit of meaning. Word vectors, as the name suggests, are vectors used to represent words, and can also be considered as feature vectors or representations of words. The technique of mapping words to real field vectors is also called word embedding. As the cornerstone of natural language tasks, word embedding has been a widely studied topic.
近些年,信息全球化使得互联网上的文本信息呈现爆炸式的增长,其中汉语文本的比例和影响力与日俱增,针对中文的自然语言处理方法,尤其是作为任务基础的词嵌入方法越来越受到人们的关注。汉语作为一种由象形文字衍生而来的语言,其形态学含义极为丰富,不仅在一维笔顺特征上有体现,而且在二维空间上的字形中也有所反映。近年来的研究已经证明,刻画形态学特征有助于词嵌入的特征捕捉。因此,利用形态学信息来增强中文词嵌入的效果成为中文自然语言处理任务的一个重要问题。In recent years, the globalization of information has led to an explosive growth of text information on the Internet, among which the proportion and influence of Chinese texts are increasing day by day. Natural language processing methods for Chinese, especially word embedding methods as the basis of tasks, are becoming more and more popular. people's attention. As a language derived from pictographs, Chinese has extremely rich morphological meanings, which are not only reflected in the characteristics of one-dimensional stroke order, but also in the shape of characters in two-dimensional space. Research in recent years has proved that characterizing morphological features is helpful for feature capture of word embeddings. Therefore, using morphological information to enhance the effect of Chinese word embeddings becomes an important issue for Chinese natural language processing tasks.
目前,可用于中文的词嵌入方法或是将以英语为代表的字母语言所设计的方法迁移过来,或是独立刻画中文的形态学特征,例如笔画、字形。前者忽略了中文是一种语素语言,和英语等字母语言有着本质的区别,因此在应用于中文文本处理时效果欠佳。后者则是将形态学特征割裂开来,无法有效捕捉形态学各维度的特征,因此也十分局限。所以,如何充分利用形态学特征来增强中文词嵌入的效果依然有着很多的机遇和挑战。At present, the word embedding methods that can be used in Chinese either migrate the method designed for the alphabetic language represented by English, or independently describe the morphological features of Chinese, such as strokes and font shapes. The former ignores that Chinese is a morpheme language, which is fundamentally different from alphabetic languages such as English, so it is not effective when applied to Chinese text processing. The latter separates the morphological features and cannot effectively capture the characteristics of each dimension of morphology, so it is also very limited. Therefore, how to make full use of morphological features to enhance the effect of Chinese word embedding still has many opportunities and challenges.
发明内容Contents of the invention
本发明的目的是提供一种基于笔画和字形的形态学双通道中文词嵌入方法,可以增强词嵌入的效果,为汉语自然语言处理、文本挖掘等领域的实践提供一定的技术支持。The purpose of the present invention is to provide a morphological dual-channel Chinese word embedding method based on strokes and glyphs, which can enhance the effect of word embedding, and provide certain technical support for the practice of Chinese natural language processing, text mining and other fields.
本发明的目的是通过以下技术方案实现的:The purpose of the present invention is achieved by the following technical solutions:
一种基于笔画和字形的形态学双通道中文词嵌入方法,包括:A morphological dual-channel Chinese word embedding method based on strokes and glyphs, including:
获取中文文本,并通过预处理得到相应的词序列;Get the Chinese text and get the corresponding word sequence through preprocessing;
将词序列中的每个单词拆分为若干个汉字,再根据汉字的笔顺信息与字形图片信息,针对字级形态学特征、字级特征与词级特征的提取过程进行建模,从而获得适用于汉语自身特点的词嵌入表达。Split each word in the word sequence into several Chinese characters, and then model the extraction process of word-level morphological features, word-level features and word-level features according to the stroke order information and glyph image information of Chinese characters, so as to obtain the applicable The word embedding expression based on the characteristics of Chinese itself.
由上述本发明提供的技术方案可以看出,基于笔画和字形的形态学双通道中文词嵌入方法来对中文文本进行词嵌入建模,相比于传统的处理方法,可以更有效地借助于笔顺、字形信息对中文文本进行向量表征,从而提供更丰富的形态学信息,以及良好的可解释性,为互联网的自然语言处理任务提供更好的下游特征数据。具有一定实际应用价值,并且能够给一些相关的文本信息平台带来一定的潜在经济效益。It can be seen from the above-mentioned technical solution provided by the present invention that the Chinese word embedding method based on stroke and glyph morphology dual-channel Chinese word embedding modeling for Chinese text, compared with the traditional processing method, can more effectively rely on stroke order , Glyph information to perform vector representation of Chinese text, thereby providing richer morphological information and good interpretability, and providing better downstream feature data for Internet natural language processing tasks. It has certain practical application value and can bring certain potential economic benefits to some related text information platforms.
附图说明Description of drawings
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他附图。In order to more clearly illustrate the technical solutions of the embodiments of the present invention, the following will briefly introduce the accompanying drawings that need to be used in the description of the embodiments. Obviously, the accompanying drawings in the following description are only some embodiments of the present invention. For Those of ordinary skill in the art can also obtain other drawings based on these drawings on the premise of not paying creative efforts.
图1为本发明实施例提供的一种基于笔画和字形的形态学双通道中文词嵌入方法的流程图;Fig. 1 is the flow chart of a kind of morphological dual-channel Chinese word embedding method based on stroke and font provided by the embodiment of the present invention;
图2为本发明实施例提供的汉字形态学特征的形式化描述图;Fig. 2 is the formal description diagram of the Chinese character morphological feature that the embodiment of the present invention provides;
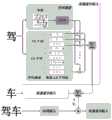
图3为本发明实施例提供的基于笔画和字形的形态学双通道中文词嵌入方法的模型框架图。Fig. 3 is a model framework diagram of a morphological dual-channel Chinese word embedding method based on strokes and glyphs provided by an embodiment of the present invention.
具体实施方式Detailed ways
下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明的保护范围。The technical solutions in the embodiments of the present invention will be clearly and completely described below in conjunction with the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only some of the embodiments of the present invention, not all of them. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts belong to the protection scope of the present invention.
如图1所示,为本发明实施例提供一种基于笔画和字形的形态学双通道中文词嵌入方法;如图2所示,为该方法对应的模型框架。该方法主要包括:As shown in FIG. 1 , a morphological dual-channel Chinese word embedding method based on strokes and glyphs is provided for the embodiment of the present invention; as shown in FIG. 2 , it is the model framework corresponding to the method. The method mainly includes:
步骤1、获取中文文本,并通过预处理得到相应的词序列。
本发明实施例中,预先从开源中文语料库爬取指定数量的中文文本语料数据集(用于模型训练,具体数量可根据实际情况来选择);从开源字典数据中爬取汉字的笔顺信息,包括汉字及其笔画顺序(32画);生成汉字的字形图片信息(28X 28,1BIT)。In the embodiment of the present invention, the Chinese text corpus data set (for model training, concrete quantity can be selected according to actual situation) of specified quantity is climbed from open source Chinese corpus in advance; Crawled stroke order information of Chinese character from open source dictionary data, includes Chinese characters and their stroke order (32 strokes); generate Chinese character glyph image information (28X 28, 1BIT).
为了保证模型效果,在建模之前需要进行预处理。In order to ensure the effect of the model, preprocessing is required before modeling.
1)将中文文本进行分词处理。1) Segment the Chinese text.
本发明实例中,需要先将中文文本划分为词序列。In the example of the present invention, the Chinese text needs to be divided into word sequences first.
2)去除分词结果中词数小于设定值的文本。2) Remove texts whose number of words is less than the set value in the word segmentation result.
本发明实例中,需要去除某些质量较低的数据。通常认为文本内容中的词数小于设定数量的文本中仅包含较小信息量,质量较低。示例性的,此处的设定数量可以为5。In the example of the present invention, some low-quality data need to be removed. It is generally considered that the text with less than the set number of words in the text contains only a small amount of information and low quality. Exemplarily, the set number here may be 5.
3)去除停用词,得到相应的词序列。3) Remove the stop words to get the corresponding word sequence.
本发明实例中,需要去除某些停用词,例如“你”,“的”,“这个”等。通常认为文本内容中的停用词是高频指代性词汇,语义变化性较大,不适合词嵌入任务,需要去除。In the example of the present invention, some stop words need to be removed, such as "you", "the", "this" and so on. It is generally considered that stop words in text content are high-frequency referential words with large semantic variability, which are not suitable for word embedding tasks and need to be removed.
步骤2、将词序列中的每个单词拆分为若干个汉字,再根据汉字的笔顺信息与字形信息,针对字级形态学特征、字级特征与词级特征的提取过程进行建模,从而获得适用于汉语自身特点的词嵌入表达。
词嵌入表达,就是用数学实值向量来表征人类社会抽象的语言概念和语义单元(词),使得这些实值向量尽可能准确地反映不同词之间的语义联系。高质量的词嵌入表达是自然语言处理领域下游任务的基石,因为任意一个自然语言任务(比如:文本分类)都需要先对文本进行“抽象概念”到“计算机能处理的数学实值向量”的转换,得到文本的实值向量表示之后,才能进行后续的深度学习建模流程(每种自然语言下游任务对应一种处理流程)。而对于一个文本来说,其是由一个个词组成的,故文本的表示最终依赖于词嵌入表示的叠加(如何叠加,以及叠加的方式则对应于一个个的词嵌入模型和算法)。Word embedding expression is to use mathematical real-valued vectors to represent abstract language concepts and semantic units (words) in human society, so that these real-valued vectors can reflect the semantic connection between different words as accurately as possible. High-quality word embedding expression is the cornerstone of downstream tasks in the field of natural language processing, because any natural language task (such as: text classification) needs to convert the text from "abstract concepts" to "mathematical real-valued vectors that can be processed by computers". After conversion, the real-valued vector representation of the text can be obtained before the subsequent deep learning modeling process (each natural language downstream task corresponds to a processing process). For a text, it is composed of words, so the representation of the text ultimately depends on the superposition of word embedding representations (how to superimpose and the way of superposition correspond to each word embedding model and algorithm).
需要说明的是,本发明实施例只针对词嵌入表达提取方式进行保护,而利用提取到的词嵌入表达做具体的自然语言任务可以由本领域技术人员根据自身需求来决定。例如,可以是前文提到的文本分类任务,所涉及的后续流程也可以参照常规技术来实现。It should be noted that the embodiment of the present invention only protects the word embedding expression extraction method, and using the extracted word embedding expression to perform specific natural language tasks can be determined by those skilled in the art according to their own needs. For example, it may be the text classification task mentioned above, and the subsequent processes involved may also be implemented with reference to conventional technologies.
实际上,汉语和英语无论是在语言本质上还是文字系统上都存在着巨大的差异,尤其是在形态学特征的刻画上。但是,传统的词嵌入方法不能很好捕获中文的形态学特征。为了对中文词汇复杂的形态学结构和特点进行建模,设计了该基于笔画和字形的形态学双通道中文词嵌入模型(DWE)。如图2所示,DWE模型刻画了三个粒度的特征:字级形态学特征(笔顺、字形),字级特征(笔顺特征和字形特征的融合),词级特征(字级特征的融合)。对于每个输入的单词,首先将其拆分成若干个汉字,再根据前述收集的笔顺、字形信息,得到每个汉字的笔画序列、字形图片,之后逐级提取字级形态学特征、字级特征、词级特征。In fact, there are huge differences between Chinese and English both in language essence and writing system, especially in the description of morphological features. However, traditional word embedding methods cannot capture the morphological features of Chinese very well. In order to model the complex morphological structure and characteristics of Chinese vocabulary, this morphological dual-channel Chinese word embedding model (DWE) based on strokes and glyphs is designed. As shown in Figure 2, the DWE model depicts three granular features: word-level morphological features (stroke order, font shape), word-level features (fusion of stroke order features and font features), word-level features (fusion of word-level features) . For each input word, it is first split into several Chinese characters, and then according to the stroke order and font shape information collected above, the stroke sequence and font picture of each Chinese character are obtained, and then the word-level morphological features and character-level features are extracted step by step. features, word-level features.
1、字级形态学特征。1. Character-level morphological features.
所述字级形态学特征主要包括:一维序列通道的笔顺特征和二维空间通道的字形特征。The character-level morphological features mainly include: the stroke order feature of the one-dimensional sequence channel and the font feature of the two-dimensional space channel.
1)一维序列通道的笔顺特征1) Stroke order feature of one-dimensional sequence channel
每个汉字都可以被分解成一个确定不变的笔画序列,即通常所说的笔顺,笔顺中的笔画进行组合,就可以得到偏旁、部首等形态学组件,这一点和英文的前缀、后缀以及词根是类似的。这些特定的笔画序列,或者说形态学组件,可以反映固有、共享的语义。如图3的上半部分所示,汉字“驾”可以分解成八个笔画的序列,其中最后三个笔画一起对应其部首“马”(马),同时其开头两画(力)和中间三画(口)则描绘了“驾”这一动作的原意真实场景的特点(用力拉缰绳,同时口中发出指令)。Each Chinese character can be decomposed into a definite sequence of strokes, which is commonly referred to as the order of strokes. By combining the strokes in the order of strokes, morphological components such as radicals and radicals can be obtained. This is similar to English prefixes and suffixes. And the roots are similar. These specific stroke sequences, or morphological components, can reflect inherent, shared semantics. As shown in the upper part of Figure 3, the Chinese character "drive" can be decomposed into a sequence of eight strokes, in which the last three strokes together correspond to its radical "horse" (horse), while its first two strokes (force) and the middle The three paintings (mouth) depict the characteristics of the original meaning of the action of "driving" (pull the rein hard, and at the same time issue instructions from the mouth).
本发明实施例中,所述字级形态学特征中一维序列通道的笔顺特征的提取方式主要包括:In the embodiment of the present invention, the extraction method of the stroke order feature of the one-dimensional sequence channel in the word-level morphological feature mainly includes:
对于汉字c,根据汉字的笔顺信息,确定汉字c的笔顺,得到相应的笔画序列;For the Chinese character c, according to the stroke order information of the Chinese character, determine the stroke order of the Chinese character c, and obtain the corresponding stroke sequence;
设定一个大小为n的滑动窗口来提取笔顺的子词组合;Set a sliding window with a size of n to extract the subword combination of the stroke order;
向汉字c的笔画序列的头、尾分别添加边界符号<、>,得到新的笔画序列;Add border symbols <, > respectively to the head and tail of the stroke sequence of Chinese character c to obtain a new stroke sequence;
从前往后,以n个笔画为一组,顺序拆解出多个笔画组合,同时将添加边界符的笔顺作为一个特殊子词(subword);From front to back, take n strokes as a group, sequentially disassemble a plurality of stroke combinations, and at the same time use the stroke order of adding boundary symbols as a special subword (subword);
最终汉字c所包含的子词组合记为G(c)。The subword combination contained in the final Chinese character c is denoted as G(c).
示例性的,对于一个汉字“打”来说,如果n选为1,则表示一画一画地拆解,得到的均为横竖撇捺等笔画单元,以及边界符“<”和“>”;如果n选为2,则表示两画两画地拆解,两画的组合方式中就会含有“<一”、“一亅”…“一亅”、“亅>”;如果n选为3,则表示三画三画地拆解,其中就会含有可以表达特定语义的部首:提手旁(扌)。Exemplarily, for a Chinese character "打", if n is selected as 1, it means that it will be disassembled one by one, and all the stroke units obtained are horizontal and vertical strokes, as well as boundary symbols "<" and ">". ; If n is selected as 2, it means that two paintings and two paintings are disassembled, and the combination of two paintings will contain "<一", "一亅"..."一亅", "一亅>"; if n is selected as 3, it means that three paintings and three paintings are dismantled, which will contain radicals that can express specific semantics: beside the handle (扌).
使用子词嵌入的方式提取笔顺特征,以“驾”字(笔顺:丿丨一
设定n=3的滑动窗口,向笔顺Stoke的头尾添加两个特殊的边界符号“<”和“>”,得到新的笔画序列:Set the sliding window of n=3, add two special boundary symbols "<" and ">" to the head and tail of the stroke order Stoke to get a new stroke sequence:
<丿丨一
从前往后,以三个笔画为一组,顺序拆解出多个笔画组合:From front to back, take three strokes as a group, and sequentially disassemble multiple stroke combinations:
<丿,丿丨,丿丨,丨一,一,一


同时将添加边界符的笔顺作为一个特殊子词,即:At the same time, the stroke order of the added boundary character is taken as a special subword, namely:
<丿丨一
记所有汉字中的子词组合集合为G,对任意汉字c,其包含的子词组合为G(c),对每一个子词g∈G(c),赋予一个子词特征向量
本领域技术人员可以理解,边界符顾名思义就是区分不同汉字的边界,是额外加上的“<”和“>”,如汉字“驾”是8画,在“驾”拆成的8画序列前加上“<”,末尾加上“>”,这样一共是10画,而提取笔画n-gram时就以n为窗口大小从左到右n个n个进行扫描,当n在一个取值区间内取不同的值时,就会得到一个笔画n-gram集合,这个集合就是汉字c对应的所有子词组合G(c)。n-gram是子词组的特指名词,子词组是一类特殊的词组,通过对笔顺进行处理得到,用来作为词嵌入方法中的一种特征。在此段前的一段中,具体解释了3-gram是如何进行操作,并得到3-gram子词组的。Those skilled in the art can understand that the boundary character, as the name suggests, is to distinguish the boundaries of different Chinese characters, which are additionally added "<" and ">". Add "<" and ">" at the end, so that there are 10 strokes in total, and when extracting the stroke n-gram, use n as the window size to scan n from left to right, when n is in a value range When different values are taken, a stroke n-gram set will be obtained, which is all subword combinations G(c) corresponding to the Chinese character c. n-gram is a specific noun for a sub-phrase, and a sub-phrase is a special type of phrase that is obtained by processing the stroke order and used as a feature in the word embedding method. In the paragraph before this paragraph, it is explained in detail how 3-gram is operated and 3-gram subphrases are obtained.
2)字形特征2) Font features
由于中文是一种源自甲骨文(一种象形文字)的语素语言,其空间结构,即字形,也可以传达丰富的语义信息。汉字在形态信息方面如此丰富的关键原因在于同样的笔画在二维空间中不同组合方式可以传达出不同的语义信息。如图3的下半部分所示,三个汉字“人”,“入”和“八”,它们有完全相同的笔画序列,但它们具有完全不同的语义,因为它们笔画空间组合是不同的。使用卷积神经网络来提取字形特征,方法如下:Since Chinese is a morpheme language derived from oracle bone inscriptions (a type of pictograph), its spatial structure, i.e., glyphs, can also convey rich semantic information. The key reason why Chinese characters are so rich in morphological information is that different combinations of the same stroke in two-dimensional space can convey different semantic information. As shown in the lower part of Fig. 3, three Chinese characters "人", "入" and "八", they have exactly the same sequence of strokes, but they have completely different semantics because their stroke-space combinations are different. Use a convolutional neural network to extract glyph features as follows:
对于汉字c,根据字形图片信息,得到相应的字形图片Ic,使用LeNet卷积神经网络提取字形特征:For the Chinese character c, according to the glyph image information, the corresponding glyph image Ic is obtained, and the glyph features are extracted using the LeNet convolutional neural network:

下面示例性的给出CNN网络的结构及相关参数。The structure and related parameters of the CNN network are exemplarily given below.
CNN网络包括:输入层,C1层(第一卷积层),S2层(第一池化层),C3层(第二卷积层),S4层(第二池化层),F5层(全连接层),输出层。CNN network includes: input layer, C1 layer (first convolutional layer), S2 layer (first pooling layer), C3 layer (second convolutional layer), S4 layer (second pooling layer), F5 layer ( fully connected layer), the output layer.
各层参数如下:The parameters of each layer are as follows:
C1层:20个卷积核,每个卷积核大小5x5;C1 layer: 20 convolution kernels, each convolution kernel size 5x5;
S2层:最大池化核(MaxPooling),池化核大小2x2;S2 layer: maximum pooling core (MaxPooling), pooling core size 2x2;
C3层:50个卷积核,每个卷积核大小5x5;C3 layer: 50 convolution kernels, each convolution kernel size 5x5;
S4层:最大池化核(MaxPooling),池化核大小2x2;S4 layer: maximum pooling core (MaxPooling), pooling core size 2x2;
F5层:输出维度500。F5 layer: output dimension 500.
2、字级特征2. Character-level features
汉语中的形态信息由两部分组成:笔顺代表的一维序列信息和字形代表的二维空间信息,在表征字级特征时,需要将两者结合。Morphological information in Chinese consists of two parts: one-dimensional sequence information represented by stroke order and two-dimensional spatial information represented by glyphs. When character-level features are represented, the two need to be combined.
本发明实施例中,采用成分组合的操作来结合两者,具体如下:In the embodiment of the present invention, the operation of combination of components is used to combine the two, as follows:
对于汉字c,一维序列通道的笔顺特征为子词组合G(c),每个元素包含一个子词特征向量


其中,*为成分组合操作符,有多种选择,例如加法和点乘等。Among them, * is a component combination operator, and there are many choices, such as addition and dot product.
3、词级特征3. Word-level features
所述词级特征为通过融合字级特征得到:将每个单词中的汉字进行累加求和(Nc为每个单词含的汉字数量),得到词级特征中的字级特征表示




这里


在训练阶段,利用预先爬取的指定数量的中文文本语料数据集D,对模型进行优化和训练;In the training phase, the model is optimized and trained using the pre-crawled specified number of Chinese text corpus data sets D;
对于单词w,根据分布P(一般为一元模型分布unigram distribution),抽取大小为λ(一般为5)的负样本集合,使用最大似然估计优化最终的优化目标:For the word w, according to the distribution P (generally a unigram distribution), a negative sample set with a size of λ (generally 5) is extracted, and the final optimization goal is optimized using maximum likelihood estimation:

其中,s(w,e)表示跳字模型中的相似度函数,其中的w为中心词,e为中心词w的窗口背景词,T(w)是中心词w的上下文窗口词集合,λ是每个中心词w的负样本数量,e′是负采样得到的负样本噪声词,
本发明实施例中,跳字模型中的相似度函数表示为:In the embodiment of the present invention, the similarity function in the word skipping model is expressed as:

其中,

训练完毕后,利用测试任务数据集对模型性能进行评估。After training, use the test task dataset to evaluate the model performance.
本领域技术人员可以理解,训练阶段与测试阶段均参照前述步骤1~步骤2所述的方式执行。Those skilled in the art can understand that both the training phase and the testing phase are executed in the manner described in
本发明实施例上述方案,对于一个中文文本,利用中文分词工具以及汉字的笔顺、字形特征,可以将该文本切分、映射为三种粒度特征,即:词序列、每个词包含的字序列、每个字对应的笔顺序列和字形图片。其中,词序列和字序列是词嵌入任务中最常用的两种特征,而字的笔顺序列和字形图片是中文形态学中极为重要的两种特征,它们分别刻画了中文的一维序列形态特征和二维空间形态特征,含有的更多是汉语较为隐式和低层次的语义信息。将低层的笔顺特征和字形特征融合,然后逐级向上合并,从而将中文形态学特征融入到词嵌入的建模过程中,为词嵌入模型提供了更丰富的语言特征。The above scheme of the embodiment of the present invention, for a Chinese text, using the Chinese word segmentation tool and the stroke order and shape features of Chinese characters, the text can be segmented and mapped into three granular features, namely: word sequence, word sequence contained in each word , the stroke sequence and glyph picture corresponding to each character. Among them, word sequence and word sequence are the two most commonly used features in word embedding tasks, and the stroke order sequence and glyph picture of words are two extremely important features in Chinese morphology, which respectively describe the one-dimensional sequence morphological characteristics of Chinese and two-dimensional spatial morphological features, which contain more implicit and low-level semantic information in Chinese. The low-level stroke order features and glyph features are fused, and then merged step by step, so that the Chinese morphological features are integrated into the modeling process of word embedding, which provides richer language features for the word embedding model.
从上述发明提供的技术方案可以看出,用基于笔画和字形的形态学双通道中文词嵌入方法来对中文文本进行词嵌入建模,相比于传统的处理方法,可以更有效地借助于笔顺、字形信息对中文文本进行向量表征,从而提供更丰富的形态学信息,以及良好的可解释性,为互联网的自然语言处理任务提供更好的下游特征数据。具有一定实际应用价值,并且能够给一些相关的文本信息平台带来一定的潜在经济效益。From the technical solution provided by the above invention, it can be seen that using the morphological dual-channel Chinese word embedding method based on strokes and glyphs to model Chinese text word embedding, compared with traditional processing methods, can more effectively rely on stroke order , Glyph information to perform vector representation of Chinese text, thereby providing richer morphological information and good interpretability, and providing better downstream feature data for Internet natural language processing tasks. It has certain practical application value and can bring certain potential economic benefits to some related text information platforms.
以上主要针对本发明相关方案进行介绍,下面针对词嵌入任务做相关的技术介绍,以便于理解本发明。The above mainly introduces the relevant solutions of the present invention, and the following introduces the relevant technologies for the word embedding task, so as to facilitate the understanding of the present invention.
对于词嵌入任务来说,其目的是将文本中的每个词表示成一个固定维度的向量,并使得这些向量能较好地表达不同词之间的相似和类比关系,即对于两个词x,y。其相似度定义为它们的向量化表征x,y之间夹角的余弦值,即余弦相似度:
沿用跳字模型的表达式,以一段文本为例“百灵鸟从蓝天飞过”,记为S。首先用分词工具,将其切分为词序列T,“百灵鸟从蓝天飞过”。以蓝天为中心词c,设背景词窗口大小为2。则问题具体化为,给定中心词c,生成与它距离不超过两个词的背景词的条件概率。更具体一些,将每个词表示为两个d维向量,用来计算条件概率。假设单词在词典中索引为i,当它为中心词时向量表示为




其中词典索引集

忽略所有小于1和大于N的时间步。目标是最大化上述似然函数。All time steps less than 1 and greater than N are ignored. The goal is to maximize the above likelihood function.
然而,以上模型中包含的事件仅考虑了正类样本。这导致当所有词向量相等且值为无穷大时,以上的联合概率才被最大化为1。很明显,这样的词向量毫无意义。因此,对每个单词w,我们根据分布P(一般为一元分布),抽取大小为λ(一般为5)的负样本集合T(w),同时含有正类样本和负类样本的事件相互独立,同时令:However, the events included in the above models only considered positive samples. This leads to the above joint probability being maximized to 1 when all word vectors are equal and the value is infinity. Obviously, such word vectors are meaningless. Therefore, for each word w, we extract a negative sample set T(w) of size λ (generally 5) according to the distribution P (generally a univariate distribution), and the events containing both positive samples and negative samples are independent of each other , while ordering:

其中P(D=1|w(t),w(t+j))=σ(s(w(t),w(t+j)))代表背景词w(t+j)出现在中心词w(t)的背景窗口,σ是sigmoid函数
将前述需要最大化考虑正类样本的联合概率改写为对数似然函数,得到待优化目标函数

其中,


通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例可以通过软件实现,也可以借助软件加必要的通用硬件平台的方式来实现。基于这样的理解,上述实施例的技术方案可以以软件产品的形式体现出来,该软件产品可以存储在一个非易失性存储介质(可以是CD-ROM,U盘,移动硬盘等)中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述的方法。Through the above description of the implementation manners, those skilled in the art can clearly understand that the above embodiments can be implemented by software, or by means of software plus a necessary general-purpose hardware platform. Based on this understanding, the technical solutions of the above-mentioned embodiments can be embodied in the form of software products, which can be stored in a non-volatile storage medium (which can be CD-ROM, U disk, mobile hard disk, etc.), including Several instructions are used to make a computer device (which may be a personal computer, a server, or a network device, etc.) execute the methods described in various embodiments of the present invention.
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明披露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求书的保护范围为准。The above is only a preferred embodiment of the present invention, but the scope of protection of the present invention is not limited thereto. Any person familiar with the technical field can easily conceive of changes or changes within the technical scope disclosed in the present invention. Replacement should be covered within the protection scope of the present invention. Therefore, the protection scope of the present invention should be determined by the protection scope of the claims.
Claims (4)
Translated fromChinese














Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910881062.0ACN110610006B (en) | 2019-09-18 | 2019-09-18 | A Morphological Dual-Channel Chinese Word Embedding Method Based on Stroke and Glyph |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910881062.0ACN110610006B (en) | 2019-09-18 | 2019-09-18 | A Morphological Dual-Channel Chinese Word Embedding Method Based on Stroke and Glyph |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN110610006A CN110610006A (en) | 2019-12-24 |
| CN110610006Btrue CN110610006B (en) | 2023-06-20 |
Family
ID=68892871
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201910881062.0AActiveCN110610006B (en) | 2019-09-18 | 2019-09-18 | A Morphological Dual-Channel Chinese Word Embedding Method Based on Stroke and Glyph |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN110610006B (en) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111476036A (en)* | 2020-04-10 | 2020-07-31 | 电子科技大学 | A Word Embedding Learning Method Based on Chinese Word Feature Substrings |
| CN111539437B (en)* | 2020-04-27 | 2022-06-28 | 西南大学 | Detection and identification method of oracle-bone inscription components based on deep learning |
| CN113505784B (en)* | 2021-06-11 | 2024-07-12 | 清华大学 | Automatic nail labeling analysis method and device, electronic equipment and storage medium |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107273355A (en)* | 2017-06-12 | 2017-10-20 | 大连理工大学 | A kind of Chinese word vector generation method based on words joint training |
| CN109408814A (en)* | 2018-09-30 | 2019-03-01 | 中国地质大学(武汉) | Across the language vocabulary representative learning method and system of China and Britain based on paraphrase primitive word |
| CN109858039A (en)* | 2019-03-01 | 2019-06-07 | 北京奇艺世纪科技有限公司 | A kind of text information identification method and identification device |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101408873A (en)* | 2007-10-09 | 2009-04-15 | 劳英杰 | Full scope semantic information integrative cognition system and application thereof |
| CN109992783B (en)* | 2019-04-03 | 2020-10-30 | 同济大学 | Chinese word vector modeling method |
- 2019
- 2019-09-18CNCN201910881062.0Apatent/CN110610006B/enactiveActive
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107273355A (en)* | 2017-06-12 | 2017-10-20 | 大连理工大学 | A kind of Chinese word vector generation method based on words joint training |
| CN109408814A (en)* | 2018-09-30 | 2019-03-01 | 中国地质大学(武汉) | Across the language vocabulary representative learning method and system of China and Britain based on paraphrase primitive word |
| CN109858039A (en)* | 2019-03-01 | 2019-06-07 | 北京奇艺世纪科技有限公司 | A kind of text information identification method and identification device |
Also Published As
| Publication number | Publication date |
|---|---|
| CN110610006A (en) | 2019-12-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110750959B (en) | Text information processing method, model training method and related device | |
| Bahdanau et al. | Learning to compute word embeddings on the fly | |
| CN107220235B (en) | Speech recognition error correction method and device based on artificial intelligence and storage medium | |
| WO2019214145A1 (en) | Text sentiment analyzing method, apparatus and storage medium | |
| CN108804423B (en) | Medical text feature extraction and automatic matching method and system | |
| CN111444721A (en) | Chinese text key information extraction method based on pre-training language model | |
| CN106407211B (en) | Method and device for classifying semantic relationship of entity words | |
| CN110134954B (en) | Named entity recognition method based on Attention mechanism | |
| CN108647191B (en) | A Sentiment Dictionary Construction Method Based on Supervised Sentiment Text and Word Vectors | |
| CN101253514A (en) | Grammatical Analysis of Document Visual Structure | |
| CN104239289B (en) | Syllabification method and syllabification equipment | |
| CN110610006B (en) | A Morphological Dual-Channel Chinese Word Embedding Method Based on Stroke and Glyph | |
| US10810467B2 (en) | Flexible integrating recognition and semantic processing | |
| CN102681981A (en) | Natural language lexical analysis method, device and analyzer training method | |
| CN112347761B (en) | BERT-based drug relation extraction method | |
| CN111597807B (en) | Word segmentation data set generation method, device, equipment and storage medium thereof | |
| CN114927177B (en) | Medical entity identification method and system integrating Chinese medical field characteristics | |
| CN114943230A (en) | A Chinese Domain-Specific Entity Linking Method Integrating Common Sense Knowledge | |
| CN116842168B (en) | Cross-domain problem processing method and device, electronic equipment and storage medium | |
| CN110457691B (en) | Script role based emotional curve analysis method and device | |
| CN116186241A (en) | Event element extraction method and device based on semantic analysis and prompt learning, electronic equipment and storage medium | |
| CN114254645B (en) | An artificial intelligence-assisted writing system | |
| CN114780577B (en) | SQL statement generation method, device, equipment and storage medium | |
| CN113869037B (en) | Learning method of topic label representation based on content-enhanced network embedding | |
| CN115481599A (en) | Document processing method and device, electronic equipment and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |