CN110211599B - Application wake-up method, device, storage medium and electronic device - Google Patents
Application wake-up method, device, storage medium and electronic deviceDownload PDFInfo
- Publication number
- CN110211599B CN110211599BCN201910478400.6ACN201910478400ACN110211599BCN 110211599 BCN110211599 BCN 110211599BCN 201910478400 ACN201910478400 ACN 201910478400ACN 110211599 BCN110211599 BCN 110211599B
- Authority
- CN
- China
- Prior art keywords
- audio data
- preset
- processor
- electronic device
- adaptive filter
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images







Classifications
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/26—Speech to text systems
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
- G10L2021/02082—Noise filtering the noise being echo, reverberation of the speech
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
- G10L21/0216—Noise filtering characterised by the method used for estimating noise
- G10L2021/02161—Number of inputs available containing the signal or the noise to be suppressed
- G10L2021/02165—Two microphones, one receiving mainly the noise signal and the other one mainly the speech signal
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Quality & Reliability (AREA)
- Signal Processing (AREA)
- Circuit For Audible Band Transducer (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本申请涉及语音处理技术领域,具体涉及一种应用唤醒方法、装置、存储介质及电子设备。The present application relates to the technical field of voice processing, and in particular, to an application wake-up method, device, storage medium and electronic device.
背景技术Background technique
目前,随着语音识别技术的发展,电子设备(比如手机、平板电脑等)通过运行的语音交互应用可与用户进行语音交互,比如,用户可以说出“我要听**歌曲”,则语音交互应用对用户的语音进行识别,并识别出用户想要听**歌曲的意图之后,即播放**歌曲。可以理解的是,用户与电子设备进行语音交互的前提是唤醒语音交互应用,然而,在实际使用环境中,往往存在各种噪声,使得语音交互应用的唤醒率较低。At present, with the development of speech recognition technology, electronic devices (such as mobile phones, tablet computers, etc.) can perform voice interaction with users through running voice interaction applications. After the interactive application recognizes the user's voice and recognizes the user's intention to listen to the ** song, the ** song is played. It can be understood that the premise of the voice interaction between the user and the electronic device is to wake up the voice interactive application. However, in an actual use environment, there are often various noises, which makes the wake-up rate of the voice interactive application low.
发明内容SUMMARY OF THE INVENTION
本申请实施例提供了一种应用唤醒方法、装置、存储介质及电子设备,能够提高语音交互应用的唤醒率。Embodiments of the present application provide an application wake-up method, apparatus, storage medium, and electronic device, which can improve the wake-up rate of a voice interactive application.
第一方面,本申请实施例提供了一种应用唤醒方法,应用于电子设备,所述电子设备包括两个麦克风,所述应用唤醒方法包括:In a first aspect, an embodiment of the present application provides an application wake-up method, which is applied to an electronic device, where the electronic device includes two microphones, and the application wake-up method includes:
通过所述两个麦克风采集得到两路音频数据,以及获取音频采集期间所播放的背景音频数据;Obtain two-way audio data through the collection of the two microphones, and obtain the background audio data played during the audio collection;
根据所述背景音频数据对两路所述音频数据进行回声消除处理,得到回声消除后的两路音频数据;Perform echo cancellation processing on the audio data of two channels according to the background audio data to obtain two channels of audio data after echo cancellation;
对所述回声消除后的两路音频数据进行波束形成处理,得到增强音频数据;Perform beamforming processing on the two channels of audio data after the echo cancellation to obtain enhanced audio data;
对所述增强音频数据的文本特征以及声纹特征进行一级校验,并在一级校验通过后对所述增强音频数据的文本特征以及声纹特征进行二级校验;The text feature and the voiceprint feature of the enhanced audio data are subjected to a first-level verification, and after the first-level verification is passed, the text feature and the voiceprint feature of the enhanced audio data are subjected to a second-level verification;
若二级校验通过,则唤醒语音交互应用。If the second-level verification is passed, the voice interactive application will be awakened.
第二方面,本申请实施例提供了一种应用唤醒装置,应用于电子设备,所述电子设备包括两个麦克风,所述应用唤醒装置包括:In a second aspect, an embodiment of the present application provides an application wake-up device, which is applied to an electronic device, where the electronic device includes two microphones, and the application wake-up device includes:
音频采集模块,用于通过所述两个麦克风采集得到两路音频数据,以及获取音频采集期间所播放的背景音频数据;an audio acquisition module, used for acquiring two channels of audio data through the acquisition of the two microphones, and acquiring background audio data played during audio acquisition;
回声消除模块,用于根据所述背景音频数据对两路所述音频数据进行回声消除处理,得到回声消除后的两路音频数据;an echo cancellation module, configured to perform echo cancellation processing on the two channels of the audio data according to the background audio data to obtain two channels of audio data after echo cancellation;
波束形成模块,用于对所述回声消除后的两路音频数据进行波束形成处理,得到增强音频数据;a beamforming module, configured to perform beamforming processing on the two channels of audio data after echo cancellation to obtain enhanced audio data;
音频校验模块,用于对所述增强音频数据的文本特征以及声纹特征进行一级校验,并在一级校验通过后对所述增强音频数据的文本特征以及声纹特征进行二级校验;The audio verification module is used to perform a first-level verification on the text feature and the voiceprint feature of the enhanced audio data, and after the first-level verification is passed, the text feature and the voiceprint feature of the enhanced audio data are subjected to a second-level verification. check;
应用唤醒模块,用于在二级校验通过时,唤醒语音交互应用。The application wake-up module is used to wake up the voice interactive application when the second-level verification is passed.
第三方面,本申请实施例提供了一种存储介质,其上存储有计算机程序,当所述计算机程序在包括两个麦克风的电子设备运行时,使得所述电子设备执行本申请实施例提供的应用唤醒方法。In a third aspect, an embodiment of the present application provides a storage medium on which a computer program is stored, and when the computer program runs on an electronic device including two microphones, the electronic device is made to execute the storage medium provided by the embodiment of the present application. Apply the wake-up method.
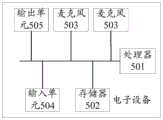
第四方面,本申请实施例还提供了一种电子设备,所述电子设备包括处理器、存储器和两个麦克风,所述存储器储存有计算机程序,所述处理器通过调用所述处理器,用于执行本申请实施例提供的应用唤醒方法。In a fourth aspect, an embodiment of the present application further provides an electronic device, the electronic device includes a processor, a memory, and two microphones, the memory stores a computer program, and the processor invokes the processor to use for executing the application wake-up method provided by the embodiment of the present application.
本申请实施例中,电子设备包括两个麦克风,其可以通过两个麦克风采集得到两路音频数据,以及获取到音频采集期间所播放的背景音频数据;然后,根据背景音频数据对两路音频数据进行回声消除处理,以消除自噪声;然后,对回声消除后的两路音频数据进行波束形成处理,以消除外部噪声,得到增强音频数据;然后,对增强音频数据的文本特征以及声纹特征进行一级校验,并在一级校验通过后对增强音频数据的文本特征以及声纹特征进行二级校验;最后,若二级校验通过,则唤醒语音交互应用,从而实现电子设备与用户之间的语音交互。由此,本申请能够排除自噪声和外部噪声的干扰,并利用两级校验确保校验准确性,达到提高语音交互应用唤醒率的目的。In the embodiment of the present application, the electronic device includes two microphones, which can collect two channels of audio data through the two microphones, and acquire background audio data played during the audio collection; then, according to the background audio data, the two channels of audio data are Perform echo cancellation processing to eliminate self-noise; then, perform beamforming processing on the two channels of audio data after echo cancellation to eliminate external noise to obtain enhanced audio data; then, perform text features and voiceprint features on the enhanced audio data. First-level verification, and after the first-level verification is passed, the text features and voiceprint features of the enhanced audio data are subjected to second-level verification; finally, if the second-level verification is passed, the voice interactive application will be awakened, so that the electronic device can communicate with each other. Voice interaction between users. Therefore, the present application can eliminate the interference of self-noise and external noise, and utilize two-level verification to ensure verification accuracy, so as to achieve the purpose of improving the wake-up rate of voice interactive applications.
附图说明Description of drawings
为了更清楚地说明本申请实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。In order to illustrate the technical solutions in the embodiments of the present application more clearly, the following briefly introduces the drawings that are used in the description of the embodiments. Obviously, the drawings in the following description are only some embodiments of the present application. For those skilled in the art, other drawings can also be obtained from these drawings without creative effort.
图1是本申请实施例提供的应用唤醒方法的一流程示意图。FIG. 1 is a schematic flowchart of an application wake-up method provided by an embodiment of the present application.
图2是本申请实施例中两个麦克风的设置位置示意图。FIG. 2 is a schematic diagram of the arrangement positions of two microphones in an embodiment of the present application.
图3是本申请实施例中训练声纹特征提取模型的流程示意图。FIG. 3 is a schematic flowchart of training a voiceprint feature extraction model in an embodiment of the present application.
图4是本申请实施例中提取的语谱图的示意图。FIG. 4 is a schematic diagram of the spectrogram extracted in the embodiment of the present application.
图5是本申请实施例提供的应用唤醒方法的另一流程示意图。FIG. 5 is another schematic flowchart of an application wake-up method provided by an embodiment of the present application.
图6是本申请实施例提供的应用唤醒装置的结构示意图。FIG. 6 is a schematic structural diagram of an application wake-up device provided by an embodiment of the present application.
图7是本申请实施例提供的电子设备的结构示意图。FIG. 7 is a schematic structural diagram of an electronic device provided by an embodiment of the present application.
图8是本申请实施例提供的电子设备的另一结构示意图。FIG. 8 is another schematic structural diagram of an electronic device provided by an embodiment of the present application.
具体实施方式Detailed ways
请参照图式,其中相同的组件符号代表相同的组件,本申请的原理是以实施在一适当的运算环境中来举例说明。以下的说明是基于所例示的本申请具体实施例,其不应被视为限制本申请未在此详述的其它具体实施例。Please refer to the drawings, wherein the same component symbols represent the same components, and the principles of the present application are exemplified by being implemented in a suitable computing environment. The following description is based on illustrated specific embodiments of the present application and should not be construed as limiting other specific embodiments of the present application not detailed herein.
本申请实施例首先提供一种应用唤醒方法,该应用唤醒方法的执行主体可以是本申请实施例提供的电子设备,该电子设备包括两个麦克风,该电子设备可以是智能手机、平板电脑、掌上电脑、笔记本电脑、或者台式电脑等配置有处理器而具有处理能力的设备。Embodiments of the present application first provide an application wake-up method. The execution body of the application wake-up method may be the electronic device provided by the embodiment of the present application. The electronic device includes two microphones, and the electronic device may be a smart phone, a tablet computer, a palmtop A computer, notebook computer, or desktop computer, etc., is a device that is equipped with a processor and has processing power.
请参照图1,图1为本申请实施例提供的应用唤醒方法的流程示意图。该应用唤醒方法应用于本申请提供的电子设备,该电子设备包括两个麦克风,如图1所示,本申请实施例提供的应用唤醒方法的流程可以如下:Please refer to FIG. 1 , which is a schematic flowchart of an application wake-up method provided by an embodiment of the present application. The application wake-up method is applied to the electronic device provided by the present application, and the electronic device includes two microphones. As shown in FIG. 1 , the process of the application wake-up method provided by the embodiment of the present application may be as follows:
在101中,通过两个麦克风采集得到两路音频数据,以及获取音频采集期间所播放的背景音频数据。In 101, two channels of audio data are acquired through two microphones, and background audio data played during audio acquisition is acquired.
比如,电子设备所包括的两个麦克风背靠背设置且间隔预设距离,其中,两个麦克风背靠背设置是指这两个麦克风的拾音孔朝向相反。比如,请参照图2,电子设备包括两个麦克风,分别为设置在电子设备下侧边的麦克风1和设置在电子设备上侧边的麦克风2,其中,麦克风1的拾音孔朝下,麦克风2的拾音孔朝上,且麦克风2和麦克风1的连线与电子设备左/右侧边平行。此外,电子设备所包括的两个麦克风可以为无指向性麦克风(或者说,全指向性麦克风)。For example, the two microphones included in the electronic device are arranged back-to-back and separated by a preset distance, wherein, the back-to-back arrangement of the two microphones means that the sound pickup holes of the two microphones face oppositely. For example, referring to FIG. 2 , the electronic device includes two microphones, namely a microphone 1 arranged on the lower side of the electronic device and a microphone 2 arranged on the upper side of the electronic device. The pickup hole of 2 is facing upward, and the connection between microphone 2 and microphone 1 is parallel to the left/right side of the electronic device. In addition, the two microphones included in the electronic device may be omnidirectional microphones (or omnidirectional microphones).
本申请实施例中,电子设备可以在播放音视频期间,通过背靠背设置的两个麦克风进行声音采集,从而采集得到两路相同时长的音频数据。此外,电子设备还获取音频采集期间播放的音频数据,可以是独立的音频数据,比如播放的音频文件、歌曲等,还可以是附加在视频数据中的音频数据等。应当说明的是,为便于区分进行声音采集所得到的音频数据以及音频采集期间所播放的音频数据,本申请将获取到音频采集期间播放的音频数据记为背景音频数据。In the embodiment of the present application, the electronic device may collect sound through two microphones arranged back-to-back during the playback of audio and video, so as to collect two channels of audio data of the same duration. In addition, the electronic device also acquires audio data played during the audio collection, which may be independent audio data, such as played audio files, songs, etc., or audio data attached to video data. It should be noted that, in order to facilitate the distinction between the audio data obtained by sound collection and the audio data played during the audio collection, the present application records the acquired audio data played during the audio collection as background audio data.
在102中,根据背景音频数据对两路音频数据进行回声消除处理,得到回声消除后的两路音频数据。In 102, echo cancellation processing is performed on the two channels of audio data according to the background audio data to obtain the two channels of audio data after echo cancellation.
应当说明的是,电子设备在播放音视频期间通过两个麦克风进行声音采集,将会采集得到其播放背景音频数据的声音,即回声(或称自噪声)。本申请中,为了消除采集得到的两路音频数据中的回声,进一步根据背景音频数据,采用回声消除算法对两路音频数据进行回声消除处理,以消除两路音频数据中的回声,得到回声消除后的两路音频数据。应当说明的是,本申请实施例中对于采用何种回声消除算法不做具体限制,可由本领域普通技术人员根据实际需要选择。It should be noted that, the electronic device collects sound through two microphones during playback of audio and video, and will collect the sound of the background audio data played by the electronic device, that is, echo (or self-noise). In the present application, in order to eliminate the echoes in the two channels of audio data collected, further according to the background audio data, an echo cancellation algorithm is used to perform echo cancellation processing on the two channels of audio data, so as to eliminate the echoes in the two channels of audio data, and obtain echo cancellation After the two-channel audio data. It should be noted that there is no specific limitation on which echo cancellation algorithm to be used in the embodiments of the present application, which can be selected by those of ordinary skill in the art according to actual needs.
比如,电子设备可以对背景音频数据进行反相位处理,得到反相位的背景音频数据,然后将反相位的背景音频数据分别与两路音频数据进行叠加,以消除两路音频数据中的回声,得到回声消除后的两路音频数据。For example, the electronic device can perform reverse-phase processing on the background audio data to obtain the reverse-phase background audio data, and then superimpose the reverse-phase background audio data with the two channels of audio data to eliminate the inverse phase of the two channels of audio data. echo, and obtain two channels of audio data after echo cancellation.
通俗的说,以上进行的回声消除处理消除了音频数据中携带的自噪声。In layman's terms, the echo cancellation process performed above removes self-noise carried in the audio data.
在103中,对回声消除后的两路音频数据进行波束形成处理,得到增强音频数据。In 103, beamforming is performed on the echo-cancelled two channels of audio data to obtain enhanced audio data.
电子设备在完成对两路音频数据的回声消除处理,得到回声消除后的两路音频数据之后,进一步对回声消除后的两路音频数据做波束形成处理,得到一路信噪比更高的音频数据,记为增强音频数据。After the electronic equipment completes the echo cancellation processing on the two channels of audio data and obtains the two channels of audio data after echo cancellation, it further performs beamforming processing on the two channels of audio data after echo cancellation to obtain one channel of audio data with a higher signal-to-noise ratio. , denoted as enhanced audio data.
通俗的说,以上进行的波束形成处理消除了音频数据中携带的外部噪声。至此,电子设备通过对采集得到的两路音频数据进行的回声消除处理以及波束形成处理,得到了消除了自噪声和外部噪声的增强音频数据。In layman's terms, the beamforming processing performed above removes the external noise carried in the audio data. So far, the electronic device obtains enhanced audio data from which self-noise and external noise are eliminated by performing echo cancellation processing and beamforming processing on the collected two-channel audio data.
在104中,对增强音频数据的文本特征以及声纹特征进行一级校验,并在一级校验通过后对增强音频数据的文本特征以及声纹特征进行二级校验。In 104, the first-level verification is performed on the text feature and the voiceprint feature of the enhanced audio data, and after the first-level verification is passed, the second-level verification is performed on the text feature and the voiceprint feature of the enhanced audio data.
如上所述,增强音频数据相较于采集的原始两路音频数据消除了自噪声和外部噪声,其具有较高的信噪比。此时,电子设备进一步对增强音频数据的文本特征和声纹特征进行两级校验,其中,电子设备基于第一唤醒算法对增强音频数据的文本特征以及声纹特征进行一级校验,若一级校验通过,则电子设备基于第二唤醒算法对增强音频数据的文本特征以及声纹特征进行二级校验。As described above, the enhanced audio data has a higher signal-to-noise ratio than the acquired original two-channel audio data, which eliminates self-noise and external noise. At this time, the electronic device further performs two-level verification on the text features and voiceprint features of the enhanced audio data, wherein the electronic device performs a first-level verification on the text features and voiceprint features of the enhanced audio data based on the first wake-up algorithm. If the first-level verification is passed, the electronic device performs the second-level verification on the text features and voiceprint features of the enhanced audio data based on the second wake-up algorithm.
应当说明的是,在本申请实施例中,无论是对增强音频数据的文本特征以及声纹特征所进行的一级校验还是二级校验,均是校验增强音频数据中是否包括预设用户(比如,电子设备的机主,或者机主授权使用电子设备的其他用户)说出的预设唤醒词,若增强音频数据中包括预设用户说出的预设唤醒词,则增强音频数据的文本特征以及声纹特征校验通过,否则校验不通过。比如,增强音频数据包括了预设用户设置的预设唤醒词,且该预设唤醒词由预设用户说出,则增强音频数据的文本特征以及声纹特征将校验通过。又比如,增强音频数据包括了预设用户之外的其他用户说出的预设唤醒词,或者增强音频数据不包括任何用户说出的预设唤醒词时,将校验失败(或者说未校验通过)。It should be noted that, in this embodiment of the present application, whether it is the first-level verification or the second-level verification performed on the text features and voiceprint features of the enhanced audio data, it is to verify whether the enhanced audio data includes presets. The preset wake-up word spoken by the user (for example, the owner of the electronic device, or other users authorized by the owner to use the electronic device), if the enhanced audio data includes the preset wake-up word spoken by the preset user, the enhanced audio data The verification of text features and voiceprint features passed, otherwise the verification failed. For example, if the enhanced audio data includes a preset wake-up word set by a preset user, and the preset wake-up word is spoken by the preset user, the text feature and voiceprint feature of the enhanced audio data will be verified. For another example, when the enhanced audio data includes a preset wake-up word spoken by a user other than the preset user, or the enhanced audio data does not include a preset wake-up word spoken by any user, the verification will fail (or uncorrected). pass).
此外,还应当说明的是,在本申请实施例中,电子设备所采用的第一唤醒算法和第二唤醒算法不同。比如,第一语音唤醒算法为基于高斯混合模型的语音唤醒算法,第二语音唤醒算法为基于神经网络的语音唤醒算法。In addition, it should also be noted that, in this embodiment of the present application, the first wake-up algorithm and the second wake-up algorithm adopted by the electronic device are different. For example, the first voice wake-up algorithm is a voice wake-up algorithm based on a Gaussian mixture model, and the second voice wake-up algorithm is a neural network-based voice wake-up algorithm.
在105中,若二级校验通过,则唤醒语音交互应用。In 105, if the secondary verification is passed, the voice interactive application is awakened.
其中,语音交互应用即俗称的语音助手,比如欧珀的语音助手“小欧”等。Among them, voice interaction applications are commonly known as voice assistants, such as Opal's voice assistant "Xiaoou".
基于以上描述,本领域普通技术人员可以理解的是,在对增强音频数据的的二级校验通过时,说明当前有预设用户说出了预设唤醒词,此时唤醒语音交互应用,实现电子设备与用户之间的语音交互。Based on the above description, those of ordinary skill in the art can understand that when the second-level verification of the enhanced audio data is passed, it means that a preset wake-up word is spoken by a preset user. At this time, the voice interactive application is awakened to realize Voice interaction between electronic device and user.
由上可知,本申请实施例中,电子设备可以通过两个麦克风采集得到两路音频数据,以及获取到音频采集期间所播放的背景音频数据;然后,根据背景音频数据对两路音频数据进行回声消除处理,以消除自噪声;然后,对回声消除后的两路音频数据进行波束形成处理,以消除外部噪声,得到增强音频数据;然后,对增强音频数据的文本特征以及声纹特征进行一级校验,并在一级校验通过后对增强音频数据的文本特征以及声纹特征进行二级校验;最后,若二级校验通过,则唤醒语音交互应用,从而实现电子设备与用户之间的语音交互。由此,本申请能够排除自噪声和外部噪声的干扰,并利用两级校验确保校验准确性,达到提高语音交互应用唤醒率的目的。As can be seen from the above, in the embodiment of the present application, the electronic device can collect two channels of audio data through two microphones, and obtain the background audio data played during the audio collection; then, echo the two channels of audio data according to the background audio data. Elimination processing to eliminate self-noise; then, the two channels of audio data after echo cancellation are subjected to beamforming processing to eliminate external noise to obtain enhanced audio data; then, the text features and voiceprint features of the enhanced audio data are first-level After the first-level verification is passed, the text features and voiceprint features of the enhanced audio data are subjected to the second-level verification; finally, if the second-level verification is passed, the voice interactive application will be awakened, so as to realize the communication between the electronic device and the user. voice interaction between. Therefore, the present application can eliminate the interference of self-noise and external noise, and utilize two-level verification to ensure verification accuracy, so as to achieve the purpose of improving the wake-up rate of voice interactive applications.
在一实施例中,“根据背景音频数据对两路音频数据进行回声消除处理”,包括:In one embodiment, "carrying out echo cancellation processing on two channels of audio data according to background audio data" includes:
(1)获取初始的自适应滤波器系数,根据背景音频数据以及音频数据迭代更新初始的自适应滤波器系数,得到目标自适应滤波器系数;(1) obtain the initial adaptive filter coefficients, iteratively update the initial adaptive filter coefficients according to the background audio data and the audio data, and obtain the target adaptive filter coefficients;
(2)根据目标自适应滤波器系数以及对音频数据进行回声消除处理。(2) Perform echo cancellation processing on the audio data according to the target adaptive filter coefficients.
本申请实施例中,电子设备在根据背景音频数据对两路音频数据进行回声消除处理时,以下以对一路音频数据的回声消除处理为例进行说明。In the embodiments of the present application, when the electronic device performs echo cancellation processing on two channels of audio data according to the background audio data, the following takes the echo cancellation processing on one channel of audio data as an example for description.
其中,电子设备首先获取到初始的自适应滤波器系数,然后根据背景音频数据以及一路音频数据对初始的自适应滤波器系数进行迭代更新,得到目标自适应滤波器系数。然后,电子设备根据迭代更新得到的目标自适应滤波器系数估计该路音频数据中携带的回声音频数据,从而消除该路音频数据中携带的回声音频数据,完成对该路音频数据的回声消除处理,如下公式所示:The electronic device first obtains the initial adaptive filter coefficients, and then iteratively updates the initial adaptive filter coefficients according to the background audio data and one channel of audio data to obtain the target adaptive filter coefficients. Then, the electronic device estimates the echo audio data carried in the audio data of the road according to the target adaptive filter coefficients obtained by iterative updating, thereby eliminating the echo audio data carried in the audio data of the road, and completing the echo cancellation processing of the audio data of the road , as shown in the following formula:
X’=X-WT*X;X'=XWT *X;
其中,X’表示回声消除后的音频数据,X表示回声消除前的音频数据,W表示目标自适应滤波器系数,T表示转置。Among them, X' represents the audio data after echo cancellation, X represents the audio data before echo cancellation, W represents the target adaptive filter coefficient, and T represents the transposition.
在一实施例中,“根据背景音频数据以及音频数据迭代更新初始的自适应滤波器系数,得到目标自适应滤波器系数”,包括:In one embodiment, "iteratively update the initial adaptive filter coefficients according to the background audio data and the audio data to obtain the target adaptive filter coefficients", including:
(1)根据初始的自适应滤波器系数获取当前时刻的自适应滤波器系数;(1) Obtain the adaptive filter coefficients of the current moment according to the initial adaptive filter coefficients;
(2)根据当前时刻的自适应滤波器系数,估计音频数据中携带的对应当前时刻的回声音频数据;(2) according to the adaptive filter coefficient of the current moment, estimate the echo audio data of the corresponding current moment carried in the audio data;
(3)根据背景音频数据以及估计得到的回声音频数据,获取当前时刻的误差音频数据;(3) according to the background audio data and the estimated echo audio data, obtain the error audio data of the current moment;
(4)识别当前时刻的自适应滤波器系数的活跃部分,根据当前时刻的误差音频数据更新当前时刻的自适应滤波器系数的活跃部分,并调整当前时刻的自适应滤波器系数的阶数,得到下一时刻的自适应滤波器系数。(4) identify the active part of the adaptive filter coefficient at the current moment, update the active part of the adaptive filter coefficient at the current moment according to the error audio data at the current moment, and adjust the order of the adaptive filter coefficient at the current moment, Get the adaptive filter coefficients at the next moment.
以下以一次更新过程中说明如何迭代更新初始的自适应滤波器系数。The following describes how to iteratively update the initial adaptive filter coefficients in one update process.
其中,当前时刻并不特指某一时刻,而是代指对初始的自适应滤波器系数进行一次更新的时刻。Wherein, the current time does not specifically refer to a certain time, but refers to the time when the initial adaptive filter coefficients are updated once.
以对初始的自适应滤波器系数进行的第一次更新为例,电子设备获取到初始的自适应滤波器系数,将其作为当前时刻k的自适应滤波器系数。比如,获取到当前时刻k的自适应滤波器系数为W(k)=[w0,w1,w3...wL-1]T,其长度为L。Taking the first update of the initial adaptive filter coefficients as an example, the electronic device obtains the initial adaptive filter coefficients and uses them as the adaptive filter coefficients at the current moment k. For example, the adaptive filter coefficient obtained at the current moment k is W(k) =[w0 , w1 , w3 . . . wL-1 ]T , and its length is L.
然后,电子设备根据当前时刻k的自适应滤波器系数,估计音频数据中携带对应当前时刻的回声音频数据,如下公式所示:Then, the electronic device estimates that the audio data carries the echo audio data corresponding to the current moment according to the adaptive filter coefficient of the current moment k, as shown in the following formula:

其中,
然后,电子设备根据背景音频数据对应当前时刻k的部分以及估计得到的回声音频数据,获取当前时刻k的误差音频数据,如下公式所示:Then, the electronic device obtains the error audio data at the current time k according to the part of the background audio data corresponding to the current time k and the estimated echo audio data, as shown in the following formula:

其中,e(k)表示当前时刻k的误差音频数据,r(k)表示背景音频数据对应当前时刻k的部分。Among them, e(k) represents the error audio data at the current time k, and r(k) represents the part of the background audio data corresponding to the current time k.
应当说明的是,较大的滤波器阶数会增加计算复杂度,而较小的滤波器阶数则无法完全收敛回声。本申请中考虑到自适应滤波器系数很多都是0,只有一小部分起到迭代更新的作用,因此,可以仅对自适应滤波器的活跃部分进行迭代更新,并实时调整自适应滤波器的阶数。It should be noted that larger filter orders increase the computational complexity, while smaller filter orders cannot fully converge the echoes. Considering that many adaptive filter coefficients are 0 in this application, and only a small part plays the role of iterative update, only the active part of the adaptive filter can be iteratively updated, and the adaptive filter can be adjusted in real time. Order.
相应的,在本申请实施例中,电子设备在获取到当前时刻的误差音频数据之后,进一步识别出当前时刻k的自适应滤波器系数的活跃部分,从而根据当前时刻的误差音频数据更新当前时刻的自适应滤波器系数的活跃部分,如下公式所示:Correspondingly, in the embodiment of the present application, after acquiring the error audio data at the current moment, the electronic device further identifies the active part of the adaptive filter coefficient at the current moment k, thereby updating the current moment according to the error audio data at the current moment. The active part of the adaptive filter coefficients of , as follows:
W(k+1)=W(k)+ux(k)e(k);W(k+1)=W(k)+ux(k)e(k);
其中,u表示预设的收敛步长,可由本领域普通技术人员根据实际需要进行设置,本申请实施例对此不做具体限制。需要强调的是,在对当前时刻k的自适应滤波器系数W(k)进行更新时,仅更新其活跃部分。比如,W(k)=[w0,w1,w3...wL-1]T,其中[w0,w1,w3...wL-3]被确定为活跃部分,则电子设备按照如上公式对[w0,w1,w3...wL-3]进行更新。Wherein, u represents a preset convergence step size, which can be set by a person of ordinary skill in the art according to actual needs, which is not specifically limited in this embodiment of the present application. It should be emphasized that when updating the adaptive filter coefficient W(k) at the current time k, only its active part is updated. For example, W(k) = [w0 , w1 , w3 ... wL-1 ]T , where [w0 , w1 , w3 ... wL-3 ] is determined as the active part, Then, the electronic device updates [w0 , w1 , w3 . . . wL-3 ] according to the above formula.
另外,电子设备还根据识别出的活跃部分调整当前时刻的自适应滤波器系数的阶数,从而得到下一时刻的自适应滤波器系数W(k+1)。In addition, the electronic device also adjusts the order of the adaptive filter coefficient at the current moment according to the identified active part, so as to obtain the adaptive filter coefficient W(k+1) at the next moment.
在一实施例中,“识别当前时刻的自适应滤波器系数的活跃部分”,包括:In one embodiment, "identifying the active part of the adaptive filter coefficients at the current moment" includes:
(1)将当前时刻的自适应滤波器系数划分为等长度的多个子滤波器系数;(1) dividing the adaptive filter coefficient at the current moment into multiple sub-filter coefficients of equal length;
(2)由后向前的顺序获取各子滤波器系数的平均值及方差,将平均值大于预设平均值且对方差大于预设方差的首个子滤波器系数及其之前的子滤波器系数确定为活跃部分;(2) Obtain the average value and variance of each sub-filter coefficient in the order from back to front, and set the average value greater than the preset average value and the variance greater than the preset variance for the first sub-filter coefficient and its previous sub-filter coefficients identified as an active part;
调整当前时刻的自适应滤波器系数的阶数,包括:Adjust the order of the adaptive filter coefficients at the current moment, including:
(3)判断首个子滤波器系数是否为最后一个子滤波器系数,是则增加当前时刻的自适应滤波器系数的阶数,否则减少当前时刻的自适应滤波器系数的阶数。(3) Determine whether the first sub-filter coefficient is the last sub-filter coefficient, if yes, increase the order of the adaptive filter coefficient at the current moment, otherwise decrease the order of the adaptive filter coefficient at the current moment.
本申请实施例中,电子设备在识别当前时刻的自适应滤波器系数的活跃部分时,首先将当前时刻的自适应滤波器系数划分为等长度(该长度大于1)的多个子滤波器系数,比如,电子设备将当前时刻的自适应滤波器系数W=[w0,w1,w2...wL-1]T划分为等长度的M个子滤波器系数,每个子滤波器系数的长度为L/M,则第m个子滤波器系数Wm=[wmL/M,wmL/M+1,wmL/M+2…w(m+1)L/M]T,m的取值范围为[0,M]。In this embodiment of the present application, when identifying the active part of the adaptive filter coefficients at the current moment, the electronic device first divides the adaptive filter coefficients at the current moment into multiple sub-filter coefficients of equal length (the length is greater than 1), For example, the electronic device divides the adaptive filter coefficient W=[w0 , w1 , w2 ... wL-1 ]T at the current moment into M sub-filter coefficients of equal length, and the The length is L/M, then the mth sub-filter coefficient Wm =[wmL/M ,wmL/M+1 ,wmL/M+2 …w(m+1)L/M ]T , m’s The value range is [0, M].
然后,电子设备由后向前的顺序获取各子滤波器系数的平均值及方差,即首先获取第M个子滤波器系数的平均值及方差,再获取第M-1个子滤波器系数的平均值及方案,直至获取到平均值大于预设平均值且对方差大于预设方差的首个子滤波器系数,将该首个子滤波器系数及其之前的子滤波器系数确定为当前时刻的自适应滤波器系数的活跃部分。Then, the electronic device obtains the average value and variance of each sub-filter coefficient in order from back to front, that is, first obtains the average value and variance of the M-th sub-filter coefficient, and then obtains the average value of the M-1 th sub-filter coefficient and scheme, until the first sub-filter coefficient whose average value is greater than the preset average value and whose variance is greater than the preset variance is obtained, the first sub-filter coefficient and its previous sub-filter coefficients are determined as the adaptive filtering at the current moment The active part of the coefficients of the filter.
其中,预设平均值和预设方差可由本领域普通技术人员取经验调试值,本申请实施例对此不做具体限制,比如,本申请实施例中,可以取预设平均值为0.000065,取预设方差为0.003。Wherein, the preset average value and the preset variance can be debugged from experience by those of ordinary skill in the art, which are not specifically limited in this embodiment of the present application. The default variance is 0.003.
另外,在调整当前时刻的自适应滤波器系数的阶数,电子设备可以判断前述首个子滤波器系数是否为最后一个子滤波器系数,是则说明当前时刻的自适应滤波器系数的阶数不够,增加当前时刻的自适应滤波器系数的阶数,否则说明当前时刻的自适应滤波器系数的阶数足够,可以减少当前时刻的自适应滤波器系数的阶数。In addition, when adjusting the order of the adaptive filter coefficients at the current moment, the electronic device can determine whether the first sub-filter coefficient is the last sub-filter coefficient, and if so, it means that the order of the adaptive filter coefficients at the current moment is not enough , increase the order of the adaptive filter coefficients at the current moment, otherwise it indicates that the order of the adaptive filter coefficients at the current moment is sufficient, and the order of the adaptive filter coefficients at the current moment can be reduced.
其中,对于增加或减少阶数的变化量,可由本领域普通技术人员根据实际需要取经验值,本申请实施例对此不做具体限制。Wherein, for the change amount of increasing or decreasing the order, a person of ordinary skill in the art can take an empirical value according to actual needs, which is not specifically limited in this embodiment of the present application.
在一实施例中,“对回声消除后的两路音频数据进行波束形成处理,得到增强音频数据”,包括:In one embodiment, "beamforming the two channels of audio data after echo cancellation to obtain enhanced audio data" includes:
采用预设波束形成算法分别在多个预设角度对回声消除后的两路音频数据进行波束形成处理,得到多个增强音频数据。A preset beamforming algorithm is used to respectively perform beamforming processing on the two channels of audio data after echo cancellation at multiple preset angles to obtain multiple enhanced audio data.
其中,本申请实施例中,相对于电子设备的麦克风设置有多个预设角度,比如,电子设备在与用户进行语音交互的过程中,对用户语音的来波角度进行统计,得到用户使用概率达到预设概率的多个来波角度,将前述多个来波角度作为多个预设角度。Among them, in the embodiment of the present application, a plurality of preset angles are set relative to the microphone of the electronic device. For example, in the process of the electronic device performing voice interaction with the user, the incoming wave angle of the user's voice is counted to obtain the probability of the user's use. For the multiple incoming wave angles that reach the preset probability, the aforementioned multiple incoming wave angles are used as the multiple preset angles.
由此,电子设备即可预设波束形成算法分别在多个预设角度对回声消除后的两路音频数据进行波束形成处理,得到多个增强音频数据。Thus, the electronic device can preset the beamforming algorithm to respectively perform beamforming processing on the two channels of audio data after echo cancellation at multiple preset angles to obtain multiple enhanced audio data.
比如,假设设置有3个预设角度,分别为θ1,θ2和θ3,可以采用GSC算法进行波束形成处理,由于GSC算法需要预先进行波束形成角度的估计,电子设备将将θ1,θ2和θ3作为GSC算法估计得到的波束形成角度,采用GSC算法分别针对θ1,θ2和θ3进行波束形成处理,得到3路增强音频数据。For example, assuming that there are 3 preset angles, θ1 , θ2 and θ3 respectively, the GSC algorithm can be used for beamforming processing. Since the GSC algorithm needs to estimate the beamforming angle in advance, the electronic device will use θ 1 , θ1 , θ2 and θ3 are used as the beam forming angles estimated by the GSC algorithm, and the GSC algorithm is used to perform beam forming processing for θ1 , θ2 and θ3 respectively, and obtain 3 channels of enhanced audio data.
如上所述,本申请实施例中使用预设角度代替角度估计的波束形成角度,无需进行费时的角度估计,能够提高波束形成的整体效率。As described above, in the embodiment of the present application, a preset angle is used instead of the angle-estimated beamforming angle, which eliminates the need for time-consuming angle estimation, and can improve the overall efficiency of beamforming.
在一实施例中,“对增强音频数据的文本特征以及声纹特征进行一级校验,”包括:In one embodiment, "the first-level verification of the text features and voiceprint features of the enhanced audio data," includes:
(1)提取各预设角度对应的增强音频数据的梅尔频率倒谱系数;(1) extract the Mel frequency cepstral coefficients of the enhanced audio data corresponding to each preset angle;
(2)调用与预设文本相关的目标声纹特征模型对提取的各梅尔频率倒谱系数进行匹配;(2) calling the target voiceprint feature model related to the preset text to match the extracted cepstral coefficients of each Mel frequency;
(3)若存在匹配的梅尔频率倒谱系数,则判定一级校验通过;(3) If there is a matching Mel frequency cepstral coefficient, it is determined that the first-level verification is passed;
其中,目标声纹特征模型由与预设文本相关的高斯混合通用背景模型根据预设音频数据的梅尔频率倒谱系数自适应得到,预设音频数据为预设用户说出预设文本的音频数据。Wherein, the target voiceprint feature model is adaptively obtained by a Gaussian mixture general background model related to the preset text according to the Mel frequency cepstral coefficients of the preset audio data, and the preset audio data is the audio of the preset user speaking the preset text. data.
以下对一级唤醒算法进行说明。The first-level wake-up algorithm is described below.
应当说明的是,本申请实施例中预先训练与预设文本相关的高斯混合通用背景模型。其中,预设文本即以上提及的预设唤醒词。比如,可以预先采集多人(比如200人)说出预设唤醒词的音频数据,然后分别提取这些音频数据的梅尔频率倒谱系数,再根据这些音频数据的梅尔频率倒谱系数训练得到一个与预设文本(即预设唤醒词)相关的高斯混合通用背景模型。It should be noted that in the embodiment of the present application, a Gaussian mixture general background model related to the preset text is pre-trained. The preset text is the preset wake-up word mentioned above. For example, the audio data of multiple people (such as 200 people) speaking the preset wake-up word can be collected in advance, and then the Mel-frequency cepstral coefficients of these audio data are extracted separately, and then obtained by training according to the Mel-frequency cepstral coefficients of these audio data. A Gaussian mixture general background model associated with preset text (i.e. preset wake words).
然后,对高斯混合通用背景模型做进一步训练,其中,由高斯混合通用背景模型根据预设音频数据的梅尔频率倒谱系数进行自适应处理(比如最大后验概率MAP,最大似然线性回归MLLR等自适应算法),预设音频数据为预设用户说出预设文本(即预设唤醒词)的音频数据,由此,使得高斯混合通用背景模型的每个高斯分布向预设用户对应的梅尔频率倒谱系数靠近,使得高斯混合通用背景模型携带预设用户的声纹特征,并将这个携带了预设用户的声纹特征的高斯混合通用背景模型记为目标声纹特征模型。Then, the Gaussian mixture general background model is further trained, wherein the Gaussian mixture general background model performs adaptive processing according to the Mel frequency cepstral coefficients of the preset audio data (such as maximum a posteriori probability MAP, maximum likelihood linear regression MLLR and other adaptive algorithms), the preset audio data is the audio data of the preset user speaking the preset text (ie the preset wake-up word), thereby making each Gaussian distribution of the Gaussian mixture general background model to the preset user corresponding to the audio data The Mel frequency cepstral coefficients are close, so that the Gaussian mixture general background model carries the preset user's voiceprint features, and the Gaussian mixture general background model carrying the preset user's voiceprint features is recorded as the target voiceprint feature model.
由此,电子设备在对增强音频数据的文本特征以及声纹特征进行一级校验时,分别提取各预设角度对应的增强音频数据的梅尔频率倒谱系数,然后调用与预设文本相关的目标声纹特征模型分别对提取的各梅尔频率倒谱系数进行匹配,其中,电子设备将提取的各梅尔频率倒谱系数输入目标声纹特征模型中,由目标声纹特征模型对输入的梅尔频率倒谱系数进行识别,并输出一个分值,当输出的分值达到预设阈值时,即可判定输入的梅尔频率倒谱系数与目标声纹特征模型匹配,否则不匹配。比如,本申请实施例中,目标声纹特征模型的输出分值的区间为[0,1],预设阈值配置为0.28,也即是当输入目标声纹特征模型的梅尔频率倒谱系数所对应的分值达到0.28时,电子设备将判定该梅尔频率倒谱系数与目标声纹特征模型匹配。Therefore, when the electronic device performs the first-level verification on the text features and voiceprint features of the enhanced audio data, it extracts the Mel frequency cepstral coefficients of the enhanced audio data corresponding to each preset angle, and then calls the corresponding preset text. The target voiceprint feature model matches the extracted Mel-frequency cepstral coefficients, wherein the electronic device inputs the extracted Mel-frequency cepstral coefficients into the target voiceprint feature model, and the target voiceprint feature model matches the input The Mel-frequency cepstral coefficient of the input is identified, and a score is output. When the output score reaches the preset threshold, it can be determined that the input Mel-frequency cepstral coefficient matches the target voiceprint feature model, otherwise it does not match. For example, in the embodiment of the present application, the output score range of the target voiceprint feature model is [0, 1], and the preset threshold is configured as 0.28, that is, when the Mel frequency cepstral coefficient of the target voiceprint feature model is input When the corresponding score reaches 0.28, the electronic device will determine that the Mel-frequency cepstral coefficient matches the target voiceprint feature model.
电子设备在调用与预设文本相关的目标声纹特征模型对提取的各梅尔频率倒谱系数进行匹配之后,若存在匹配的梅尔频率倒谱系数,则电子设备判定一级校验通过。After the electronic device calls the target voiceprint feature model related to the preset text to match the extracted Mel-frequency cepstral coefficients, if there is a matching Mel-frequency cepstral coefficient, the electronic device determines that the first-level verification is passed.
在一实施例中,“对增强音频数据的文本特征以及声纹特征进行二级校验”,包括:In one embodiment, the "second-level verification of text features and voiceprint features of the enhanced audio data" includes:
(1)将前述预设角度对应的增强音频数据划分为多个子音频数据;(1) the enhanced audio data corresponding to the aforementioned preset angle is divided into a plurality of sub-audio data;
(2)根据与预设文本相关的声纹特征提取模型提取各子音频数据的声纹特征向量;(2) extract the voiceprint feature vector of each sub-audio data according to the voiceprint feature extraction model relevant to the preset text;
(3)获取各声纹特征向量与目标声纹特征向量之间的相似度,目标声纹特征向量为预设音频数据的声纹特征向量;(3) obtaining the similarity between each voiceprint feature vector and the target voiceprint feature vector, and the target voiceprint feature vector is the voiceprint feature vector of the preset audio data;
(4)根据各子音频数据对应的相似度,校验前述预设角度对应的增强音频数据文本特征以及声纹特征;(4) according to the similarity corresponding to each sub-audio data, verify the enhanced audio data text feature and voiceprint feature corresponding to the aforementioned preset angle;
(5)若存在校验通过的预设角度对应的增强音频数据,则判定二级校验通过。(5) If there is enhanced audio data corresponding to the preset angle that has passed the verification, it is determined that the second-level verification has passed.
以下对二级唤醒算法进行说明。The second-level wake-up algorithm is described below.
本申请实施例中,考虑到增强音频数据可能并不仅包括预设唤醒词,比如预设唤醒词为“小欧小欧”,而增强音频数据为“你好小欧小欧”。为此,本申请实施例中,根据预设唤醒词的长度,将语音部分划分为多个子音频数据,其中,各子音频数据的长度大于或等于预设唤醒词的长度,且相邻两个子音频数据具有重合部分,对于重合部分的长度可由本领域普通技术人员根据实际需要设置,比如,本申请实施例中设置为子音频数据长度的25%。In the embodiment of the present application, it is considered that the enhanced audio data may not only include the preset wake-up word, for example, the preset wake-up word is "Xiaoou Xiaoou", and the enhanced audio data is "Hello Xiaoou Xiaoou". To this end, in the embodiment of the present application, according to the length of the preset wake-up word, the speech part is divided into a plurality of sub-audio data, wherein the length of each sub-audio data is greater than or equal to the length of the preset wake-up word, and two adjacent sub-audio data The audio data has overlapping parts, and the length of the overlapping parts can be set by those skilled in the art according to actual needs.
应当说明的是,本申请实施例中还预先训练有与预设文本(即预设唤醒词)相关的声纹特征提取模型。比如,本申请实施例中训练基于卷积神经网络的声纹特征提取模型,如图3所示,预先采集多人(比如200人)说出预设唤醒词的音频数据,然后对这些音频数据进行端点检测,分割出其中的预设唤醒词部分,然后对分割出的预设唤醒词部分进行预处理(比如高通滤波)和加窗,再进行傅里叶变换(比如短时傅里叶变换)后计算其能量密度,生成灰度的语谱图(如图4所示,其中横轴表示时间,纵轴表示频率,灰度值表示能量值),最后,利用卷积神经网络对生成的语谱图进行训练,生成与预设文本相关的声纹特征提取模型。另外,本申请实施例中还提取预设用户说出预设唤醒词(即预设文本)的音频数据的语谱图,并输入到之前训练的声纹特征提取模型中,经过声纹特征提取模型的多个卷积层、池化层以及全连接层后,将输出对应的一组特征向量,将其记为目标声纹特征向量。It should be noted that, in this embodiment of the present application, a voiceprint feature extraction model related to a preset text (ie, a preset wake-up word) is also pre-trained. For example, in the embodiment of the present application, a voiceprint feature extraction model based on a convolutional neural network is trained. As shown in FIG. 3 , audio data of multiple people (for example, 200 people) speaking a preset wake-up word are collected in advance, and then the audio data is analyzed. Perform endpoint detection, segment the preset wake-up word part, and then perform preprocessing (such as high-pass filtering) and windowing on the segmented preset wake-up word part, and then perform Fourier transform (such as short-time Fourier transform) ) and then calculate its energy density to generate a grayscale spectrogram (as shown in Figure 4, where the horizontal axis represents time, the vertical axis represents frequency, and the gray value represents energy value). The spectrogram is trained to generate a voiceprint feature extraction model related to the preset text. In addition, in the embodiment of the present application, the spectrogram of the audio data of the preset user speaking the preset wake-up word (that is, the preset text) is also extracted, and input into the previously trained voiceprint feature extraction model. After the voiceprint feature extraction After multiple convolutional layers, pooling layers and fully connected layers of the model, a corresponding set of feature vectors will be output, which is recorded as the target voiceprint feature vector.
相应的,电子设备将前述预设角度对应的增强音频数据划分为多个子音频数据之后,分别提取各子音频数据的语谱图。其中,对于如何提取语谱图,此处不再赘述,具体可参照以上相关描述。在提取到前述多个子音频数据的语谱图之后,电子设备分别将前述多个子音频数据的语谱图输入到之前训练的声纹特征提取模型,从而提取得到各子音频数据的声纹特征向量。Correspondingly, after dividing the enhanced audio data corresponding to the preset angle into a plurality of sub-audio data, the electronic device extracts the spectrogram of each sub-audio data respectively. Among them, how to extract the spectrogram will not be repeated here, and for details, please refer to the above related description. After extracting the spectrograms of the plurality of sub-audio data, the electronic device respectively inputs the spectrograms of the foregoing plurality of sub-audio data into the previously trained voiceprint feature extraction model, thereby extracting the voiceprint feature vector of each sub-audio data. .
在提取得到各子音频数据的声纹特征向量之后,电子设备分别获取各子音频数据的声纹特征向量与目标声纹特征向量之间的相似度,然后,根据各子音频数据对应的相似度来校验前述预设角度对应的增强音频数据的文本特征以及声纹特征。比如,电子设备可以判断是否存在声纹特征向量与目标声纹特征向量之间的相似度达到预设相似度(可由本领域普通技术人员根据实际需要取经验值,比如可以设置为75%)的子音频数据,若存在,则判定前述预设角度对应的增强音频数据的文本特征以及声纹特征。After extracting the voiceprint feature vector of each sub-audio data, the electronic device obtains the similarity between the voiceprint feature vector of each sub-audio data and the target voiceprint feature vector respectively, and then, according to the similarity corresponding to each sub-audio data to verify the text features and voiceprint features of the enhanced audio data corresponding to the aforementioned preset angles. For example, the electronic device can determine whether there is a similarity between the voiceprint feature vector and the target voiceprint feature vector that reaches a preset similarity (experience values can be obtained by those of ordinary skill in the art according to actual needs, for example, it can be set to 75%) If the sub-audio data exists, the text feature and voiceprint feature of the enhanced audio data corresponding to the preset angle are determined.
电子设备在完成对前述预设角度对应的增强音频数据文本特征以及声纹特征的校验之后,若存在校验通过的预设角度对应的增强音频数据,则判定二级校验通过。After the electronic device completes the verification of the enhanced audio data text features and voiceprint features corresponding to the aforementioned preset angles, if there is enhanced audio data corresponding to the preset angles that pass the verification, it is determined that the secondary verification is passed.
在一实施例中,“根据各子音频数据对应的相似度,校验前述预设角度对应的增强音频数据文本特征以及声纹特征”,包括:In one embodiment, "checking the enhanced audio data text features and voiceprint features corresponding to the aforementioned preset angles according to the similarity corresponding to each sub-audio data" includes:
根据各子音频数据对应的相似度以及预设的识别函数,校验前述预设角度对应的增强音频数据的文本特征以及声纹特征;According to the similarity corresponding to each sub-audio data and the preset recognition function, verify the text feature and voiceprint feature of the enhanced audio data corresponding to the aforementioned preset angle;
其中,预设的识别函数为γn=γn-1+f(ln),γn表示第n个子音频数据对应的识别函数状态值,γn-1表示第n-1个子音频数据对应的识别函数状态值,
应当说明的是,识别函数中a的取值可由本领域普通技术人员根据实际需要取经验值,比如,可以将a取值为1。It should be noted that, the value of a in the identification function can be taken as an empirical value by those skilled in the art according to actual needs, for example, a can be taken as 1.
另外,识别函数中b的取值与声纹特征提取模型的识别率正相关,根据实际训练得到的声纹特征提取模型的识别率确定b的取值。In addition, the value of b in the recognition function is positively correlated with the recognition rate of the voiceprint feature extraction model, and the value of b is determined according to the recognition rate of the voiceprint feature extraction model obtained by actual training.
另外,预设识别函数状态值也可由本领域普通技术人员根据实际需要取经验值,其取值越大,对语音部分校验的准确度也就也大。In addition, the state value of the preset recognition function can also be taken as an empirical value by a person of ordinary skill in the art according to actual needs.
由此,通过该识别函数,即使当增强音频数据中包括预设唤醒词之外的其它信息,也能够准确的对其进行校验。Therefore, through the identification function, even when the enhanced audio data includes other information than the preset wake-up word, it can be verified accurately.
可选的,在获取各子音频数据的声纹特征向量与目标声纹特征训练之间的相似度时,可按照动态时间规整算法计算各子音频数据的声纹特征向量与目标声纹特征向量之间的相似度。Optionally, when obtaining the similarity between the voiceprint feature vector of each sub-audio data and the target voiceprint feature training, the voiceprint feature vector of each sub-audio data and the target voiceprint feature vector can be calculated according to the dynamic time warping algorithm. similarity between.
或者,可计算各子音频数据的声纹特征向量与目标声纹特征向量之间的特征距离作为相似度,对于采用何种特征距离来衡量两个向量之间的相似度,本申请实施例中不做具体限制,比如,可以采用欧几里得距离来衡量子音频数据的声纹特征向量与目标声纹特征向量之间的相似度。Alternatively, the feature distance between the voiceprint feature vector of each sub-audio data and the target voiceprint feature vector can be calculated as the similarity. As to which feature distance is used to measure the similarity between the two vectors, in the embodiment of the present application There is no specific limitation, for example, the Euclidean distance can be used to measure the similarity between the voiceprint feature vector of the sub-audio data and the target voiceprint feature vector.
图5为本申请实施例提供的应用唤醒方法的另一流程示意图。该应用唤醒方法应用于本申请提供的电子设备,该电子设备包括两个麦克风,如图5所示,本申请实施例提供的应用唤醒方法的流程可以如下:FIG. 5 is another schematic flowchart of an application wake-up method provided by an embodiment of the present application. The application wake-up method is applied to the electronic device provided by the present application, and the electronic device includes two microphones. As shown in FIG. 5 , the process of the application wake-up method provided by the embodiment of the present application may be as follows:
在201中,电子设备基于处理器判断其是否处于音视频播放状态,是则转入202,否则转入206。In 201 , the electronic device determines whether it is in an audio and video playback state based on the processor, and if yes, goes to 202 , otherwise, goes to 206 .
本申请实施例中,电子设备首先基于处理器判断其是否处于音视频播放状态,比如,以安卓系统为例,电子设备基于处理器接收安卓内部消息,根据该安卓内部消息判断其是否处于音视频播放状态。In the embodiment of the present application, the electronic device first determines whether it is in the audio and video playback state based on the processor. For example, taking the Android system as an example, the electronic device receives the Android internal message based on the processor, and determines whether it is in the audio and video state according to the Android internal message. Playing status.
在202中,电子设备通过两个麦克风采集得到两路音频数据,以及获取音频采集期间所播放的背景音频数据。In 202, the electronic device acquires two channels of audio data through two microphones, and acquires background audio data played during the audio acquisition.
比如,电子设备所包括的两个麦克风背靠背设置且间隔预设距离,其中,两个麦克风背靠背设置是指这两个麦克风的拾音孔朝向相反。比如,请参照图2,电子设备包括两个麦克风,分别为设置在电子设备下侧边的麦克风1和设置在电子设备上侧边的麦克风2,其中,麦克风1的拾音孔朝下,麦克风2的拾音孔朝上,且麦克风2和麦克风1的连线与电子设备左/右侧边平行。此外,电子设备所包括的两个麦克风可以为无指向性麦克风(或者说,全指向性麦克风)。For example, the two microphones included in the electronic device are arranged back-to-back and separated by a preset distance, wherein, the back-to-back arrangement of the two microphones means that the sound pickup holes of the two microphones face oppositely. For example, referring to FIG. 2 , the electronic device includes two microphones, namely a microphone 1 arranged on the lower side of the electronic device and a microphone 2 arranged on the upper side of the electronic device. The pickup hole of 2 is facing upward, and the connection between microphone 2 and microphone 1 is parallel to the left/right side of the electronic device. In addition, the two microphones included in the electronic device may be omnidirectional microphones (or omnidirectional microphones).
本申请实施例中,电子设备可以在播放音视频期间,通过背靠背设置的两个麦克风进行声音采集,从而采集得到两路相同时长的音频数据。此外,电子设备还获取音频采集期间播放的音频数据,可以是独立的音频数据,比如播放的音频文件、歌曲等,还可以是附加在视频数据中的音频数据等。应当说明的是,为便于区分进行声音采集所得到的音频数据以及音频采集期间所播放的音频数据,本申请将获取到音频采集期间播放的音频数据记为背景音频数据。In the embodiment of the present application, the electronic device may collect sound through two microphones arranged back-to-back during the playback of audio and video, so as to collect two channels of audio data of the same duration. In addition, the electronic device also acquires audio data played during the audio collection, which may be independent audio data, such as played audio files, songs, etc., or audio data attached to video data. It should be noted that, in order to facilitate the distinction between the audio data obtained by sound collection and the audio data played during the audio collection, the present application records the acquired audio data played during the audio collection as background audio data.
在203中,电子设备根据背景音频数据,基于处理器对两路音频数据进行回声消除处理,得到回声消除后的两路音频数据。In 203, the electronic device performs echo cancellation processing on the two channels of audio data based on the background audio data and the processor to obtain the two channels of audio data after echo cancellation.
应当说明的是,电子设备在播放音视频期间通过两个麦克风进行声音采集,将会采集得到其播放背景音频数据的声音,即回声(或称自噪声)。本申请中,为了消除采集得到的两路音频数据中的回声,进一步根据背景音频数据,基于处理器调用回声消除算法对两路音频数据进行回声消除处理,以消除两路音频数据中的回声,得到回声消除后的两路音频数据。应当说明的是,本申请实施例中对于采用何种回声消除算法不做具体限制,可由本领域普通技术人员根据实际需要选择。It should be noted that, the electronic device collects sound through two microphones during playback of audio and video, and will collect the sound of the background audio data played by the electronic device, that is, echo (or self-noise). In the present application, in order to eliminate the echoes in the two channels of audio data collected, further according to the background audio data, the processor invokes an echo cancellation algorithm to perform echo cancellation processing on the two channels of audio data, so as to eliminate the echoes in the two channels of audio data, Obtain the two-channel audio data after echo cancellation. It should be noted that there is no specific limitation on which echo cancellation algorithm to be used in the embodiments of the present application, which can be selected by those of ordinary skill in the art according to actual needs.
比如,电子设备可基于处理器对背景音频数据进行反相位处理,得到反相位的背景音频数据,然后将反相位的背景音频数据分别与两路音频数据进行叠加,以消除两路音频数据中的回声,得到回声消除后的两路音频数据。For example, the electronic device can perform anti-phase processing on the background audio data based on the processor to obtain the anti-phase background audio data, and then superimpose the anti-phase background audio data with the two channels of audio data to eliminate the two channels of audio data. The echo in the data is obtained, and the two channels of audio data after echo cancellation are obtained.
通俗的说,以上进行的回声消除处理消除了音频数据中携带的自噪声。In layman's terms, the echo cancellation process performed above removes self-noise carried in the audio data.
在204中,电子设备基于处理器对回声消除后的两路音频数据进行波束形成处理,得到增强音频数据。In 204, the electronic device performs beamforming processing on the two channels of audio data after echo cancellation based on the processor to obtain enhanced audio data.
电子设备在完成对两路音频数据的回声消除处理,得到回声消除后的两路音频数据之后,进一步基于处理器对回声消除后的两路音频数据做波束形成处理,得到一路信噪比更高的音频数据,记为增强音频数据。After the electronic device completes the echo cancellation processing on the two channels of audio data and obtains the two channels of audio data after echo cancellation, the electronic device further performs beamforming processing on the two channels of audio data after echo cancellation based on the processor, and obtains one channel with a higher signal-to-noise ratio. The audio data is recorded as enhanced audio data.
通俗的说,以上进行的波束形成处理消除了音频数据中携带的外部噪声。至此,电子设备通过对采集得到的两路音频数据进行的回声消除处理以及波束形成处理,得到了消除了自噪声和外部噪声的增强音频数据。In layman's terms, the beamforming processing performed above removes the external noise carried in the audio data. So far, the electronic device obtains enhanced audio data from which self-noise and external noise are eliminated by performing echo cancellation processing and beamforming processing on the collected two-channel audio data.
在205中,电子设备基于处理器对增强音频数据的文本特征以及声纹特征进行一级校验,并在一级校验通过后基于处理器对增强音频数据的文本特征以及声纹特征进行二级校验,若二级校验通过,则基于处理器唤醒语音交互应用。In 205, the electronic device performs a first-level verification on the text feature and the voiceprint feature of the enhanced audio data based on the processor, and after the first-level verification is passed, the electronic device performs a second-level verification on the text feature and the voiceprint feature of the enhanced audio data based on the processor. First-level verification, if the second-level verification is passed, the voice interactive application will be woken up based on the processor.
如上所述,增强音频数据相较于采集的原始两路音频数据消除了自噪声和外部噪声,其具有较高的信噪比。此时,电子设备进一步基于处理器对增强音频数据的文本特征和声纹特征进行两级校验,其中,基于处理器调用第一唤醒算法对增强音频数据的文本特征以及声纹特征进行一级校验,若一级校验通过,则基于处理器调用第二唤醒算法对增强音频数据的文本特征以及声纹特征进行二级校验。As described above, the enhanced audio data has a higher signal-to-noise ratio than the acquired original two-channel audio data, which eliminates self-noise and external noise. At this time, the electronic device further performs two-level verification on the text features and voiceprint features of the enhanced audio data based on the processor, wherein the first wake-up algorithm is called based on the processor to perform a first-level verification on the text features and voiceprint features of the enhanced audio data. Verification, if the first-level verification is passed, the second-level verification is performed on the text feature and voiceprint feature of the enhanced audio data based on the processor calling the second wake-up algorithm.
应当说明的是,在本申请实施例中,无论是对增强音频数据的文本特征以及声纹特征所进行的一级校验还是二级校验,均是校验增强音频数据中是否包括预设用户(比如,电子设备的机主,或者机主授权使用电子设备的其他用户)说出的预设唤醒词,若增强音频数据中包括预设用户说出的预设唤醒词,则增强音频数据的文本特征以及声纹特征校验通过,否则校验不通过。比如,增强音频数据包括了预设用户设置的预设唤醒词,且该预设唤醒词由预设用户说出,则增强音频数据的文本特征以及声纹特征将校验通过。又比如,增强音频数据包括了预设用户之外的其他用户说出的预设唤醒词,或者增强音频数据不包括任何用户说出的预设唤醒词时,将校验失败(或者说未校验通过)。It should be noted that, in this embodiment of the present application, whether it is the first-level verification or the second-level verification performed on the text features and voiceprint features of the enhanced audio data, it is to verify whether the enhanced audio data includes presets. The preset wake-up word spoken by the user (for example, the owner of the electronic device, or other users authorized by the owner to use the electronic device), if the enhanced audio data includes the preset wake-up word spoken by the preset user, the enhanced audio data The verification of text features and voiceprint features passed, otherwise the verification failed. For example, if the enhanced audio data includes a preset wake-up word set by a preset user, and the preset wake-up word is spoken by the preset user, the text feature and voiceprint feature of the enhanced audio data will be verified. For another example, when the enhanced audio data includes a preset wake-up word spoken by a user other than the preset user, or the enhanced audio data does not include a preset wake-up word spoken by any user, the verification will fail (or uncorrected). pass).
此外,还应当说明的是,在本申请实施例中,电子设备所采用的第一唤醒算法和第二唤醒算法不同。比如,第一语音唤醒算法为基于高斯混合模型的语音唤醒算法,第二语音唤醒算法为基于神经网络的语音唤醒算法。In addition, it should also be noted that, in this embodiment of the present application, the first wake-up algorithm and the second wake-up algorithm adopted by the electronic device are different. For example, the first voice wake-up algorithm is a voice wake-up algorithm based on a Gaussian mixture model, and the second voice wake-up algorithm is a neural network-based voice wake-up algorithm.
在206中,电子设备通过任一麦克风采集得到一路音频数据。In 206, the electronic device acquires a channel of audio data through any microphone.
电子设备在未播放音视频期间,通过任一麦克风进行声音采集,得到一路音频数据。When the audio and video are not played, the electronic device collects sound through any microphone to obtain a channel of audio data.
在207中,电子设备基于专用语音识别芯片对前述一路音频数据进行一级校验,并在一级校验通过后基于处理器对前述一路音频数据进行二级校验。In 207, the electronic device performs a first-level verification on the aforementioned channel of audio data based on a dedicated speech recognition chip, and performs a second-level verification on the aforementioned channel of audio data based on the processor after the first-level verification is passed.
其中,专用语音识别芯片是以语音识别为目的而设计的专用芯片,比如以语音为目的而设计的数字信号处理芯片,以语音为目的而设计的专用集成电路芯片等,其相较于通用的处理器,具有更低的功耗。Among them, the dedicated speech recognition chip is a dedicated chip designed for the purpose of speech recognition, such as a digital signal processing chip designed for the purpose of speech, an application-specific integrated circuit chip designed for the purpose of speech, etc. processor with lower power consumption.
电子设备在采集得到前述一路音频数据之后,基于专用语音识别芯片调用第三唤醒算法对前述一路音频数据进行校验,其中,可以同时校验前述一路音频数据的文本特征和声纹特征,也可以仅校验前述一路音频数据的文本特征。After the electronic device collects the aforementioned one channel of audio data, it calls the third wake-up algorithm based on the dedicated speech recognition chip to verify the aforementioned one channel of audio data, wherein the text features and voiceprint features of the aforementioned one channel of audio data can be verified simultaneously, or Only the text features of the aforementioned audio data are checked.
比如,电子设备可以基于专用语音识别芯片提取前述一路音频数据的梅尔频率倒谱系数;然后,基于专用语音识别芯片调用与预设文本相关的高斯混合通用背景模型对提取的梅尔频率倒谱系数进行匹配;若匹配成功,则判定前述前述一路音频数据的文本特征校验通过。For example, the electronic device can extract the Mel-frequency cepstral coefficients of the aforementioned one channel of audio data based on a dedicated speech recognition chip; If the matching is successful, it is determined that the text feature verification of the aforementioned channel of audio data has passed.
在对前述一路音频数据的一级校验通过后,电子设备进一步基于处理器对前述一路音频数据进行二级校验,其中,电子设备在基于处理器对前述一路音频数据进行二级校验时,基于处理器调用第一唤醒算法或第二唤醒算法校验前述一路音频数据的文本特征和声纹特征。After the first-level verification of the aforementioned channel of audio data is passed, the electronic device further performs second-level verification on the aforementioned channel of audio data based on the processor, wherein the electronic device performs second-level verification on the aforementioned channel of audio data based on the processor. , based on the processor calling the first wake-up algorithm or the second wake-up algorithm to verify the text features and voiceprint features of the aforementioned channel of audio data.
在208中,若二级校验通过,则电子设备基于处理器唤醒语音交互应用。In 208, if the secondary verification is passed, the electronic device wakes up the voice interactive application based on the processor.
在对前述一路音频数据的二级校验通过时,电子设备即可基于处理器唤醒语音交互应用,实现电子设备与用户的语音交互。When the second-level verification of the aforesaid channel of audio data is passed, the electronic device can wake up the voice interaction application based on the processor, so as to realize the voice interaction between the electronic device and the user.
请参照图6,图6为本申请实施例提供的应用唤醒装置的结构示意图。该应用唤醒装置可以应用于电子设备,该电子设备包括两个麦克风。应用唤醒装置可以包括音频采集模块401、回声消除模块402、波束形成模块403、音频校验模块404以及应用唤醒模块405,其中,Please refer to FIG. 6 , which is a schematic structural diagram of an application wake-up device provided by an embodiment of the present application. The application wake-up device can be applied to an electronic device, and the electronic device includes two microphones. The application wake-up device may include an audio acquisition module 401, an echo cancellation module 402, a beamforming module 403, an audio verification module 404, and an application wake-up module 405, wherein,
音频采集模块401,用于通过两个麦克风采集得到两路音频数据,以及获取音频采集期间所播放的背景音频数据;The audio collection module 401 is used to collect two channels of audio data through two microphones, and obtain background audio data played during the audio collection;
回声消除模块402,用于根据背景音频数据对两路音频数据进行回声消除处理,得到回声消除后的两路音频数据;The echo cancellation module 402 is used to perform echo cancellation processing on the two-channel audio data according to the background audio data, and obtain the two-channel audio data after the echo cancellation;
波束形成模块403,用于对回声消除后的两路音频数据进行波束形成处理,得到增强音频数据;a beamforming module 403, configured to perform beamforming processing on the two channels of audio data after echo cancellation to obtain enhanced audio data;
音频校验模块404,用于对增强音频数据的文本特征以及声纹特征进行一级校验,并在一级校验通过后对增强音频数据的文本特征以及声纹特征进行二级校验;The audio verification module 404 is used to perform a first-level verification on the text feature and the voiceprint feature of the enhanced audio data, and after the first-level verification is passed, the text feature and the voiceprint feature of the enhanced audio data are subjected to a second-level verification;
应用唤醒模块405,用于在二级校验通过,唤醒语音交互应用。The application wake-up module 405 is configured to wake up the voice interactive application when the second-level verification is passed.
在一实施例中,在根据背景音频数据对两路音频数据进行回声消除处理时,回声消除模块402可以用于:In one embodiment, when performing echo cancellation processing on two channels of audio data according to the background audio data, the echo cancellation module 402 may be used to:
获取初始的自适应滤波器系数,根据背景音频数据以及音频数据迭代更新初始的自适应滤波器系数,得到目标自适应滤波器系数;Obtain the initial adaptive filter coefficients, iteratively update the initial adaptive filter coefficients according to the background audio data and the audio data, and obtain the target adaptive filter coefficients;
根据目标自适应滤波器系数以及对音频数据进行回声消除处理。Echo cancellation processing is performed on the audio data according to the target adaptive filter coefficients.
在一实施例中,在根据背景音频数据以及音频数据迭代更新初始的自适应滤波器系数,得到目标自适应滤波器系数时,回声消除模块402可以用于:In one embodiment, when the initial adaptive filter coefficients are iteratively updated according to the background audio data and the audio data to obtain the target adaptive filter coefficients, the echo cancellation module 402 may be used to:
根据初始的自适应滤波器系数获取当前时刻的自适应滤波器系数;Obtain the adaptive filter coefficients of the current moment according to the initial adaptive filter coefficients;
根据当前时刻的自适应滤波器系数,估计音频数据中携带的对应当前时刻的回声音频数据;According to the adaptive filter coefficients at the current moment, the echo audio data corresponding to the current moment carried in the audio data is estimated;
根据背景音频数据以及估计得到的回声音频数据,获取当前时刻的误差音频数据;Acquire the error audio data at the current moment according to the background audio data and the estimated echo audio data;
识别当前时刻的自适应滤波器系数的活跃部分,根据当前时刻的误差音频数据更新当前时刻的自适应滤波器系数的活跃部分,并调整当前时刻的自适应滤波器系数的阶数,得到下一时刻的自适应滤波器系数。Identify the active part of the adaptive filter coefficient at the current moment, update the active part of the adaptive filter coefficient at the current moment according to the error audio data at the current moment, and adjust the order of the adaptive filter coefficient at the current moment to obtain the next Adaptive filter coefficients at time.
在一实施例中,在识别当前时刻的自适应滤波器系数的活跃部分时,回声消除模块402可以用于:In one embodiment, when identifying the active portion of the adaptive filter coefficients at the current moment, the echo cancellation module 402 may be used to:
将当前时刻的自适应滤波器系数划分为等长度的多个子滤波器系数;Divide the adaptive filter coefficients at the current moment into multiple sub-filter coefficients of equal length;
由后向前的顺序获取各子滤波器系数的平均值及方差,将平均值大于预设平均值且对方差大于预设方差的首个子滤波器系数及其之前的子滤波器系数确定为活跃部分;Obtain the average value and variance of each sub-filter coefficient in the order from back to front, and determine the first sub-filter coefficient and its previous sub-filter coefficients whose average value is greater than the preset average value and whose variance is greater than the preset variance as active. part;
而在调整当前时刻的自适应滤波器系数的阶数时,回声消除模块402可以用于:When adjusting the order of the adaptive filter coefficients at the current moment, the echo cancellation module 402 can be used to:
判断首个子滤波器系数是否为最后一个子滤波器系数,是则增加当前时刻的自适应滤波器系数的阶数,否则减少当前时刻的自适应滤波器系数的阶数。It is judged whether the first sub-filter coefficient is the last sub-filter coefficient, and if so, the order of the adaptive filter coefficient at the current moment is increased, otherwise the order of the adaptive filter coefficient at the current moment is decreased.
在一实施例中,在对回声消除后的两路音频数据进行波束形成处理,得到增强音频数据时,波束形成模块403可以用于:In one embodiment, when performing beamforming processing on the two channels of audio data after echo cancellation to obtain enhanced audio data, the beamforming module 403 may be used to:
采用预设波束形成算法分别在多个预设角度对回声消除后的两路音频数据进行波束形成处理,得到多个增强音频数据。A preset beamforming algorithm is used to respectively perform beamforming processing on the two channels of audio data after echo cancellation at multiple preset angles to obtain multiple enhanced audio data.
在一实施例中,在对增强音频数据的文本特征以及声纹特征进行一级校验时,音频校验模块404可以用于:In one embodiment, when performing first-level verification on the text features and voiceprint features of the enhanced audio data, the audio verification module 404 can be used to:
提取各预设角度对应的增强音频数据的梅尔频率倒谱系数;extracting the Mel frequency cepstral coefficients of the enhanced audio data corresponding to each preset angle;
调用与预设文本相关的目标声纹特征模型对提取的各梅尔频率倒谱系数进行匹配;Call the target voiceprint feature model related to the preset text to match the extracted cepstral coefficients of each Mel frequency;
若存在匹配的梅尔频率倒谱系数,则判定一级校验通过;If there is a matching Mel frequency cepstral coefficient, it is determined that the first-level verification is passed;
其中,目标声纹特征模型由与预设文本相关的高斯混合通用背景模型根据预设音频数据的梅尔频率倒谱系数自适应得到,预设音频数据为预设用户说出预设文本的音频数据。Wherein, the target voiceprint feature model is adaptively obtained by a Gaussian mixture general background model related to the preset text according to the Mel frequency cepstral coefficients of the preset audio data, and the preset audio data is the audio of the preset user speaking the preset text. data.
在一实施例中,在对增强音频数据的文本特征以及声纹特征进行二级校验时,音频校验模块404可以用于:In one embodiment, when performing secondary verification on the text features and voiceprint features of the enhanced audio data, the audio verification module 404 may be used to:
将前述预设角度对应的增强音频数据划分为多个子音频数据;dividing the enhanced audio data corresponding to the aforementioned preset angle into a plurality of sub-audio data;
根据与预设文本相关的声纹特征提取模型提取各子音频数据的声纹特征向量;Extract the voiceprint feature vector of each sub-audio data according to the voiceprint feature extraction model related to the preset text;
获取各声纹特征向量与目标声纹特征向量之间的相似度,目标声纹特征向量为预设音频数据的声纹特征向量;Obtain the similarity between each voiceprint feature vector and the target voiceprint feature vector, where the target voiceprint feature vector is the voiceprint feature vector of the preset audio data;
根据各子音频数据对应的相似度,校验前述预设角度对应的增强音频数据文本特征以及声纹特征;According to the similarity corresponding to each sub-audio data, verify the enhanced audio data text feature and voiceprint feature corresponding to the aforementioned preset angle;
若存在校验通过的预设角度对应的增强音频数据,则判定二级校验通过。If there is enhanced audio data corresponding to the preset angle that has passed the verification, it is determined that the second-level verification has passed.
在一实施例中,在根据各子音频数据对应的相似度,校验前述预设角度对应的增强音频数据文本特征以及声纹特征时,音频校验模块404可以用于:In one embodiment, when verifying the enhanced audio data text features and voiceprint features corresponding to the aforementioned preset angles according to the similarity corresponding to each sub-audio data, the audio verification module 404 can be used for:
根据各子音频数据对应的相似度以及预设的识别函数,校验前述预设角度对应的增强音频数据的文本特征以及声纹特征;According to the similarity corresponding to each sub-audio data and the preset recognition function, verify the text feature and voiceprint feature of the enhanced audio data corresponding to the aforementioned preset angle;
其中,预设的识别函数为γn=γn-1+f(ln),γn表示第n个子音频数据对应的识别函数状态值,γ-1表示第n-1个子音频数据对应的识别函数状态值,
在一实施例中,获取各子音频数据的声纹特征向量与目标声纹特征训练之间的相似度时,音频校验模块404可以用于:In one embodiment, when acquiring the similarity between the voiceprint feature vector of each sub-audio data and the target voiceprint feature training, the audio verification module 404 can be used to:
按照动态时间规整算法计算各子音频数据的声纹特征向量与目标声纹特征向量之间的相似度;Calculate the similarity between the voiceprint feature vector of each sub-audio data and the target voiceprint feature vector according to the dynamic time warping algorithm;
或者,计算各子音频数据的声纹特征向量与目标声纹特征向量之间的特征距离作为相似度。Alternatively, the feature distance between the voiceprint feature vector of each sub-audio data and the target voiceprint feature vector is calculated as the similarity.
本申请实施例提供一种存储介质,其上存储有指令执行程序,当其存储的指令执行程序在本申请实施例提供的电子设备上执行时,使得电子设备执行如本申请实施例提供的应用唤醒方法中的步骤。其中,存储介质可以是磁碟、光盘、只读存储器(Read OnlyMemory,ROM)或者随机存取器(Random Access Memory,RAM)等。An embodiment of the present application provides a storage medium on which an instruction execution program is stored. When the stored instruction execution program is executed on the electronic device provided by the embodiment of the present application, the electronic device is made to execute the application provided by the embodiment of the present application. Steps in a wakeup method. The storage medium may be a magnetic disk, an optical disk, a read only memory (Read Only Memory, ROM), or a random access device (Random Access Memory, RAM), or the like.
本申请实施例还提供一种电子设备,请参照图7,电子设备包括处理器501、存储器502和麦克风503。An embodiment of the present application further provides an electronic device. Please refer to FIG. 7 . The electronic device includes a
本申请实施例中的处理器501是通用处理器,比如ARM架构的处理器。The
存储器502中存储有指令执行程序,其可以为高速随机存取存储器,还可以为非易失性存储器,比如至少一个磁盘存储器件、闪存器件、或其他易失性固态存储器件等。相应地,存储器502还可以包括存储器控制器,以提供处理器501对存储器502的访问,实现如下功能:The
通过两个麦克风采集得到两路音频数据,以及获取音频采集期间所播放的背景音频数据;Acquire two channels of audio data through the acquisition of two microphones, and acquire the background audio data played during audio acquisition;
根据背景音频数据对两路音频数据进行回声消除处理,得到回声消除后的两路音频数据;Perform echo cancellation processing on the two channels of audio data according to the background audio data to obtain the two channels of audio data after echo cancellation;
对回声消除后的两路音频数据进行波束形成处理,得到增强音频数据;Perform beamforming processing on the two channels of audio data after echo cancellation to obtain enhanced audio data;
对增强音频数据的文本特征以及声纹特征进行一级校验,并在一级校验通过后对增强音频数据的文本特征以及声纹特征进行二级校验;Perform first-level verification on the text features and voiceprint features of the enhanced audio data, and perform second-level verification on the text features and voiceprint features of the enhanced audio data after the first-level verification is passed;
若二级校验通过,则唤醒语音交互应用。If the second-level verification is passed, the voice interactive application will be awakened.
请参照图8,图8为本申请实施例提供的电子设备的另一结构示意图,与图7所示电子设备的区别在于,电子设备还包括输入单元504和输出单元505等组件。Please refer to FIG. 8 , which is another schematic structural diagram of an electronic device provided by an embodiment of the present application. The difference from the electronic device shown in FIG. 7 is that the electronic device further includes components such as an input unit 504 and an output unit 505 .
其中,输入单元504可用于接收输入的数字、字符信息或用户特征信息(比如指纹),以及产生与用户设置以及功能控制有关的键盘、鼠标、操作杆、光学或者轨迹球信号输入等。The input unit 504 can be used to receive input numbers, character information or user feature information (such as fingerprints), and generate keyboard, mouse, joystick, optical or trackball signal input related to user settings and function control.
输出单元505可用于显示由用户输入的信息或提供给用户的信息,如屏幕。The output unit 505 may be used to display information input by the user or information provided to the user, such as a screen.
在本申请实施例中,电子设备中的处理器501会按照如下的步骤,将一个或一个以上的计算机程序的进程对应的指令加载到存储器502中,并由处理器501运行存储在存储器502中的计算机程序,从而实现各种功能,如下:In this embodiment of the present application, the
通过两个麦克风采集得到两路音频数据,以及获取音频采集期间所播放的背景音频数据;Acquire two channels of audio data through the acquisition of two microphones, and acquire the background audio data played during audio acquisition;
根据背景音频数据对两路音频数据进行回声消除处理,得到回声消除后的两路音频数据;Perform echo cancellation processing on the two channels of audio data according to the background audio data to obtain the two channels of audio data after echo cancellation;
对回声消除后的两路音频数据进行波束形成处理,得到增强音频数据;Perform beamforming processing on the two channels of audio data after echo cancellation to obtain enhanced audio data;
对增强音频数据的文本特征以及声纹特征进行一级校验,并在一级校验通过后对增强音频数据的文本特征以及声纹特征进行二级校验;Perform first-level verification on the text features and voiceprint features of the enhanced audio data, and perform second-level verification on the text features and voiceprint features of the enhanced audio data after the first-level verification is passed;
若二级校验通过,则唤醒语音交互应用。If the second-level verification is passed, the voice interactive application will be awakened.
在一实施例中,在根据背景音频数据对两路音频数据进行回声消除处理时,处理器501可以执行:In one embodiment, when performing echo cancellation processing on two channels of audio data according to the background audio data, the
获取初始的自适应滤波器系数,根据背景音频数据以及音频数据迭代更新初始的自适应滤波器系数,得到目标自适应滤波器系数;Obtain the initial adaptive filter coefficients, iteratively update the initial adaptive filter coefficients according to the background audio data and the audio data, and obtain the target adaptive filter coefficients;
根据目标自适应滤波器系数以及对音频数据进行回声消除处理。Echo cancellation processing is performed on the audio data according to the target adaptive filter coefficients.
在一实施例中,在根据背景音频数据以及音频数据迭代更新初始的自适应滤波器系数,得到目标自适应滤波器系数时,处理器501可以执行:In one embodiment, when the initial adaptive filter coefficients are iteratively updated according to the background audio data and the audio data to obtain the target adaptive filter coefficients, the
根据初始的自适应滤波器系数获取当前时刻的自适应滤波器系数;Obtain the adaptive filter coefficients of the current moment according to the initial adaptive filter coefficients;
根据当前时刻的自适应滤波器系数,估计音频数据中携带的对应当前时刻的回声音频数据;According to the adaptive filter coefficients at the current moment, the echo audio data corresponding to the current moment carried in the audio data is estimated;
根据背景音频数据以及估计得到的回声音频数据,获取当前时刻的误差音频数据;Acquire the error audio data at the current moment according to the background audio data and the estimated echo audio data;
识别当前时刻的自适应滤波器系数的活跃部分,根据当前时刻的误差音频数据更新当前时刻的自适应滤波器系数的活跃部分,并调整当前时刻的自适应滤波器系数的阶数,得到下一时刻的自适应滤波器系数。Identify the active part of the adaptive filter coefficient at the current moment, update the active part of the adaptive filter coefficient at the current moment according to the error audio data at the current moment, and adjust the order of the adaptive filter coefficient at the current moment to obtain the next Adaptive filter coefficients at time.
在一实施例中,在识别当前时刻的自适应滤波器系数的活跃部分时,处理器501可以执行:In one embodiment, when identifying the active part of the adaptive filter coefficients at the current moment, the
将当前时刻的自适应滤波器系数划分为等长度的多个子滤波器系数;Divide the adaptive filter coefficients at the current moment into multiple sub-filter coefficients of equal length;
由后向前的顺序获取各子滤波器系数的平均值及方差,将平均值大于预设平均值且对方差大于预设方差的首个子滤波器系数及其之前的子滤波器系数确定为活跃部分;Obtain the average value and variance of each sub-filter coefficient in the order from back to front, and determine the first sub-filter coefficient and its previous sub-filter coefficients whose average value is greater than the preset average value and whose variance is greater than the preset variance as active. part;
而在调整当前时刻的自适应滤波器系数的阶数时,处理器501可以执行:When adjusting the order of the adaptive filter coefficients at the current moment, the
判断首个子滤波器系数是否为最后一个子滤波器系数,是则增加当前时刻的自适应滤波器系数的阶数,否则减少当前时刻的自适应滤波器系数的阶数。It is judged whether the first sub-filter coefficient is the last sub-filter coefficient, and if so, the order of the adaptive filter coefficient at the current moment is increased, otherwise the order of the adaptive filter coefficient at the current moment is decreased.
在一实施例中,在对回声消除后的两路音频数据进行波束形成处理,得到增强音频数据时,处理器501可以执行:In one embodiment, when performing beamforming processing on the two channels of audio data after echo cancellation to obtain enhanced audio data, the
采用预设波束形成算法分别在多个预设角度对回声消除后的两路音频数据进行波束形成处理,得到多个增强音频数据。A preset beamforming algorithm is used to respectively perform beamforming processing on the two channels of audio data after echo cancellation at multiple preset angles to obtain multiple enhanced audio data.
在一实施例中,在对增强音频数据的文本特征以及声纹特征进行一级校验时,处理器501可以执行:In one embodiment, when the first-level verification is performed on the text feature and the voiceprint feature of the enhanced audio data, the
提取各预设角度对应的增强音频数据的梅尔频率倒谱系数;extracting the Mel frequency cepstral coefficients of the enhanced audio data corresponding to each preset angle;
调用与预设文本相关的目标声纹特征模型对提取的各梅尔频率倒谱系数进行匹配;Call the target voiceprint feature model related to the preset text to match the extracted cepstral coefficients of each Mel frequency;
若存在匹配的梅尔频率倒谱系数,则判定一级校验通过;If there is a matching Mel frequency cepstral coefficient, it is determined that the first-level verification is passed;
其中,目标声纹特征模型由与预设文本相关的高斯混合通用背景模型根据预设音频数据的梅尔频率倒谱系数自适应得到,预设音频数据为预设用户说出预设文本的音频数据。Wherein, the target voiceprint feature model is adaptively obtained by a Gaussian mixture general background model related to the preset text according to the Mel frequency cepstral coefficients of the preset audio data, and the preset audio data is the audio of the preset user speaking the preset text. data.
在一实施例中,在对增强音频数据的文本特征以及声纹特征进行二级校验时,处理器501可以执行:In one embodiment, when performing secondary verification on the text feature and voiceprint feature of the enhanced audio data, the
将前述预设角度对应的增强音频数据划分为多个子音频数据;dividing the enhanced audio data corresponding to the aforementioned preset angle into a plurality of sub-audio data;
根据与预设文本相关的声纹特征提取模型提取各子音频数据的声纹特征向量;Extract the voiceprint feature vector of each sub-audio data according to the voiceprint feature extraction model related to the preset text;
获取各声纹特征向量与目标声纹特征向量之间的相似度,目标声纹特征向量为预设音频数据的声纹特征向量;Obtain the similarity between each voiceprint feature vector and the target voiceprint feature vector, where the target voiceprint feature vector is the voiceprint feature vector of the preset audio data;
根据各子音频数据对应的相似度,校验前述预设角度对应的增强音频数据文本特征以及声纹特征;According to the similarity corresponding to each sub-audio data, verify the enhanced audio data text feature and voiceprint feature corresponding to the aforementioned preset angle;
若存在校验通过的预设角度对应的增强音频数据,则判定二级校验通过。If there is enhanced audio data corresponding to the preset angle that has passed the verification, it is determined that the second-level verification has passed.
在一实施例中,在根据各子音频数据对应的相似度,校验前述预设角度对应的增强音频数据文本特征以及声纹特征时,处理器501可以执行:In one embodiment, when checking the text feature and voiceprint feature of the enhanced audio data corresponding to the aforementioned preset angles according to the similarity corresponding to each sub-audio data, the
根据各子音频数据对应的相似度以及预设的识别函数,校验前述预设角度对应的增强音频数据的文本特征以及声纹特征;According to the similarity corresponding to each sub-audio data and the preset recognition function, verify the text feature and voiceprint feature of the enhanced audio data corresponding to the aforementioned preset angle;
其中,预设的识别函数为γn=γn-1+f(ln),γn表示第n个子音频数据对应的识别函数状态值,γn-1表示第n-1个子音频数据对应的识别函数状态值,
在一实施例中,获取各子音频数据的声纹特征向量与目标声纹特征训练之间的相似度时,处理器501可以执行:In one embodiment, when acquiring the similarity between the voiceprint feature vector of each sub-audio data and the target voiceprint feature training, the
按照动态时间规整算法计算各子音频数据的声纹特征向量与目标声纹特征向量之间的相似度;Calculate the similarity between the voiceprint feature vector of each sub-audio data and the target voiceprint feature vector according to the dynamic time warping algorithm;
或者,计算各子音频数据的声纹特征向量与目标声纹特征向量之间的特征距离作为相似度。Alternatively, the feature distance between the voiceprint feature vector of each sub-audio data and the target voiceprint feature vector is calculated as the similarity.
应当说明的是,本申请实施例提供的电子设备与上文实施例中的应用唤醒方法属于同一构思,在电子设备上可以运行应用唤醒方法实施例中提供的任一方法,其具体实现过程详见特征提取方法实施例,此处不再赘述。It should be noted that the electronic device provided by the embodiment of the present application and the application wake-up method in the above embodiments belong to the same concept, and any method provided in the application wake-up method embodiment can be executed on the electronic device, and the specific implementation process is detailed. See the embodiment of the feature extraction method, which will not be repeated here.
需要说明的是,对本申请实施例的应用唤醒方法而言,本领域普通测试人员可以理解实现本申请实施例的应用唤醒方法的全部或部分流程,是可以通过计算机程序来控制相关的硬件来完成,所述计算机程序可存储于一计算机可读取存储介质中,如存储在电子设备的存储器中,并被该电子设备内的处理器和专用语音识别芯片执行,在执行过程中可包括如应用唤醒方法的实施例的流程。其中,所述的存储介质可为磁碟、光盘、只读存储器、随机存取记忆体等。It should be noted that, for the application wake-up method of the embodiment of the present application, ordinary testers in the art can understand that all or part of the process of implementing the application wake-up method of the embodiment of the present application can be completed by controlling the relevant hardware through a computer program. , the computer program can be stored in a computer-readable storage medium, such as in the memory of an electronic device, and executed by a processor and a dedicated speech recognition chip in the electronic device, and the execution process can include applications such as A flow of an embodiment of a wake-up method. The storage medium may be a magnetic disk, an optical disk, a read-only memory, a random access memory, or the like.
以上对本申请实施例所提供的一种应用唤醒方法、存储介质及电子设备进行了详细介绍,本文中应用了具体个例对本申请的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本申请的方法及其核心思想;同时,对于本领域的技术人员,依据本申请的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本申请的限制。An application wake-up method, a storage medium, and an electronic device provided by the embodiments of the present application have been described in detail above. The principles and implementations of the present application are described with specific examples. The descriptions of the above embodiments are only used for Help to understand the method of the present application and its core idea; meanwhile, for those skilled in the art, according to the idea of the present application, there will be changes in the specific implementation and application scope. In summary, the content of this specification does not It should be understood as a limitation of this application.
Claims (9)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910478400.6ACN110211599B (en) | 2019-06-03 | 2019-06-03 | Application wake-up method, device, storage medium and electronic device |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201910478400.6ACN110211599B (en) | 2019-06-03 | 2019-06-03 | Application wake-up method, device, storage medium and electronic device |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN110211599A CN110211599A (en) | 2019-09-06 |
| CN110211599Btrue CN110211599B (en) | 2021-07-16 |
Family
ID=67790514
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201910478400.6AActiveCN110211599B (en) | 2019-06-03 | 2019-06-03 | Application wake-up method, device, storage medium and electronic device |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN110211599B (en) |
Families Citing this family (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111048071B (en)* | 2019-11-11 | 2023-05-30 | 京东科技信息技术有限公司 | Voice data processing method, device, computer equipment and storage medium |
| CN111179931B (en)* | 2020-01-03 | 2023-07-21 | 青岛海尔科技有限公司 | Method, device and household appliance for voice interaction |
| CN112307161B (en)* | 2020-02-26 | 2022-11-22 | 北京字节跳动网络技术有限公司 | Method and apparatus for playing audio |
| CN111369992A (en)* | 2020-02-27 | 2020-07-03 | Oppo(重庆)智能科技有限公司 | Instruction execution method and device, storage medium and electronic equipment |
| CN111755002B (en)* | 2020-06-19 | 2021-08-10 | 北京百度网讯科技有限公司 | Speech recognition device, electronic apparatus, and speech recognition method |
| CN112581972B (en)* | 2020-10-22 | 2024-08-02 | 广东美的白色家电技术创新中心有限公司 | Voice interaction method, related device and corresponding relation establishment method |
| CN115148197A (en)* | 2021-03-31 | 2022-10-04 | 华为技术有限公司 | Voice wake-up method, device, storage medium and system |
| CN114333877B (en)* | 2021-12-20 | 2025-03-25 | 北京声智科技有限公司 | A voice processing method, device, equipment and storage medium |
| CN115171703B (en)* | 2022-05-30 | 2024-05-24 | 青岛海尔科技有限公司 | Distributed voice awakening method and device, storage medium and electronic device |
Citations (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2002374588A (en)* | 2001-06-15 | 2002-12-26 | Sony Corp | Device and method for reducing acoustic noise |
| CN101763858A (en)* | 2009-10-19 | 2010-06-30 | 瑞声声学科技(深圳)有限公司 | Method for processing double-microphone signal |
| CN101917527A (en)* | 2010-09-02 | 2010-12-15 | 杭州华三通信技术有限公司 | Method and device of echo elimination |
| CN103680515A (en)* | 2013-11-21 | 2014-03-26 | 苏州大学 | Proportional adaptive filter coefficient vector updating method using coefficient reusing |
| CN104520925A (en)* | 2012-08-01 | 2015-04-15 | 杜比实验室特许公司 | Percentile filtering of noise reduction gains |
| CN105575395A (en)* | 2014-10-14 | 2016-05-11 | 中兴通讯股份有限公司 | Voice wake-up method and apparatus, terminal, and processing method thereof |
| CN105654959A (en)* | 2016-01-22 | 2016-06-08 | 韶关学院 | Self-adaptive filtering coefficient updating method and device |
| CN107123430A (en)* | 2017-04-12 | 2017-09-01 | 广州视源电子科技股份有限公司 | Echo cancellation method, device, conference tablet and computer storage medium |
| CN107464565A (en)* | 2017-09-20 | 2017-12-12 | 百度在线网络技术(北京)有限公司 | A kind of far field voice awakening method and equipment |
| US9842606B2 (en)* | 2015-09-15 | 2017-12-12 | Samsung Electronics Co., Ltd. | Electronic device, method of cancelling acoustic echo thereof, and non-transitory computer readable medium |
| US10013995B1 (en)* | 2017-05-10 | 2018-07-03 | Cirrus Logic, Inc. | Combined reference signal for acoustic echo cancellation |
| CN109218882A (en)* | 2018-08-16 | 2019-01-15 | 歌尔科技有限公司 | The ambient sound monitor method and earphone of earphone |
| US20190074025A1 (en)* | 2017-09-01 | 2019-03-07 | Cirrus Logic International Semiconductor Ltd. | Acoustic echo cancellation (aec) rate adaptation |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10194259B1 (en)* | 2018-02-28 | 2019-01-29 | Bose Corporation | Directional audio selection |
- 2019
- 2019-06-03CNCN201910478400.6Apatent/CN110211599B/enactiveActive
Patent Citations (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2002374588A (en)* | 2001-06-15 | 2002-12-26 | Sony Corp | Device and method for reducing acoustic noise |
| CN101763858A (en)* | 2009-10-19 | 2010-06-30 | 瑞声声学科技(深圳)有限公司 | Method for processing double-microphone signal |
| CN101917527A (en)* | 2010-09-02 | 2010-12-15 | 杭州华三通信技术有限公司 | Method and device of echo elimination |
| CN104520925A (en)* | 2012-08-01 | 2015-04-15 | 杜比实验室特许公司 | Percentile filtering of noise reduction gains |
| CN103680515A (en)* | 2013-11-21 | 2014-03-26 | 苏州大学 | Proportional adaptive filter coefficient vector updating method using coefficient reusing |
| CN105575395A (en)* | 2014-10-14 | 2016-05-11 | 中兴通讯股份有限公司 | Voice wake-up method and apparatus, terminal, and processing method thereof |
| US9842606B2 (en)* | 2015-09-15 | 2017-12-12 | Samsung Electronics Co., Ltd. | Electronic device, method of cancelling acoustic echo thereof, and non-transitory computer readable medium |
| CN105654959A (en)* | 2016-01-22 | 2016-06-08 | 韶关学院 | Self-adaptive filtering coefficient updating method and device |
| CN107123430A (en)* | 2017-04-12 | 2017-09-01 | 广州视源电子科技股份有限公司 | Echo cancellation method, device, conference tablet and computer storage medium |
| US10013995B1 (en)* | 2017-05-10 | 2018-07-03 | Cirrus Logic, Inc. | Combined reference signal for acoustic echo cancellation |
| US20190074025A1 (en)* | 2017-09-01 | 2019-03-07 | Cirrus Logic International Semiconductor Ltd. | Acoustic echo cancellation (aec) rate adaptation |
| CN107464565A (en)* | 2017-09-20 | 2017-12-12 | 百度在线网络技术(北京)有限公司 | A kind of far field voice awakening method and equipment |
| CN109218882A (en)* | 2018-08-16 | 2019-01-15 | 歌尔科技有限公司 | The ambient sound monitor method and earphone of earphone |
Non-Patent Citations (2)
| Title |
|---|
| 《基于预测残差和自适应阶数的回声消除方法研究》;王正腾等;《中国优秀硕士学位论文全文数据库(电子期刊)》;20170215;第4.3-4.4小节* |
| 《自 适应回声消除的初期迭代统计学模型及改进算法》;文昊翔等;《数据采集与处理》;20120131;全文* |
Also Published As
| Publication number | Publication date |
|---|---|
| CN110211599A (en) | 2019-09-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110211599B (en) | Application wake-up method, device, storage medium and electronic device | |
| US11823679B2 (en) | Method and system of audio false keyphrase rejection using speaker recognition | |
| CN110400571B (en) | Audio processing method, device, storage medium and electronic device | |
| CN109599124B (en) | Audio data processing method, device and storage medium | |
| CN110021307B (en) | Audio verification method and device, storage medium and electronic equipment | |
| CN106486131B (en) | Method and device for voice denoising | |
| CN110232933B (en) | Audio detection method and device, storage medium and electronic equipment | |
| CN106663446B (en) | Acoustic noise reduction that is aware of the user's environment | |
| CN108417224B (en) | Method and system for training and recognition of bidirectional neural network model | |
| CN110600048B (en) | Audio verification method and device, storage medium and electronic equipment | |
| EP4004906A1 (en) | Per-epoch data augmentation for training acoustic models | |
| US20190172480A1 (en) | Voice activity detection systems and methods | |
| CN108806707B (en) | Voice processing method, device, equipment and storage medium | |
| CN107644638A (en) | Audio recognition method, device, terminal and computer-readable recording medium | |
| US11081115B2 (en) | Speaker recognition | |
| CN110689887B (en) | Audio verification method and device, storage medium and electronic equipment | |
| CN110491373A (en) | Model training method, device, storage medium and electronic equipment | |
| CN110544468B (en) | Application awakening method and device, storage medium and electronic equipment | |
| CN116453537B (en) | Method and system for improving audio information transmission effect | |
| CN115620739A (en) | Speech enhancement method for specified direction, electronic device and storage medium | |
| Delcroix et al. | Cluster-based dynamic variance adaptation for interconnecting speech enhancement pre-processor and speech recognizer | |
| CN111192569B (en) | Double-microphone voice feature extraction method and device, computer equipment and storage medium | |
| CN118301518A (en) | Voiceprint noise reduction method, electronic device and storage medium | |
| WO2020015546A1 (en) | Far-field speech recognition method, speech recognition model training method, and server | |
| CN117174082A (en) | Training and execution method, device, equipment and storage medium of voice wake-up model |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |