CN109656963B - Metadata acquisition method, device, device and computer-readable storage medium - Google Patents
Metadata acquisition method, device, device and computer-readable storage mediumDownload PDFInfo
- Publication number
- CN109656963B CN109656963BCN201811551965.4ACN201811551965ACN109656963BCN 109656963 BCN109656963 BCN 109656963BCN 201811551965 ACN201811551965 ACN 201811551965ACN 109656963 BCN109656963 BCN 109656963B
- Authority
- CN
- China
- Prior art keywords
- metadata
- acquisition
- data
- task
- execution
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000034methodMethods0.000titleclaimsabstractdescription140
- 230000008569processEffects0.000claimsdescription76
- 238000006243chemical reactionMethods0.000claimsdescription18
- 238000004458analytical methodMethods0.000claimsdescription7
- 238000001514detection methodMethods0.000claimsdescription5
- 238000007726management methodMethods0.000description54
- 238000012545processingMethods0.000description11
- 230000008859changeEffects0.000description8
- 230000001960triggered effectEffects0.000description7
- 238000004891communicationMethods0.000description5
- 238000010586diagramMethods0.000description3
- 230000006870functionEffects0.000description3
- 238000013523data managementMethods0.000description2
- 238000013500data storageMethods0.000description2
- 230000007547defectEffects0.000description2
- 239000000284extractSubstances0.000description2
- 238000005192partitionMethods0.000description2
- GNFTZDOKVXKIBK-UHFFFAOYSA-N3-(2-methoxyethoxy)benzohydrazideChemical compoundCOCCOC1=CC=CC(C(=O)NN)=C1GNFTZDOKVXKIBK-UHFFFAOYSA-N0.000description1
- FGUUSXIOTUKUDN-IBGZPJMESA-NC1(=CC=CC=C1)N1C2=C(NC([C@H](C1)NC=1OC(=NN=1)C1=CC=CC=C1)=O)C=CC=C2Chemical compoundC1(=CC=CC=C1)N1C2=C(NC([C@H](C1)NC=1OC(=NN=1)C1=CC=CC=C1)=O)C=CC=C2FGUUSXIOTUKUDN-IBGZPJMESA-N0.000description1
- YTAHJIFKAKIKAV-XNMGPUDCSA-N[(1R)-3-morpholin-4-yl-1-phenylpropyl] N-[(3S)-2-oxo-5-phenyl-1,3-dihydro-1,4-benzodiazepin-3-yl]carbamateChemical compoundO=C1[C@H](N=C(C2=C(N1)C=CC=C2)C1=CC=CC=C1)NC(O[C@H](CCN1CCOCC1)C1=CC=CC=C1)=OYTAHJIFKAKIKAV-XNMGPUDCSA-N0.000description1
- 230000009471actionEffects0.000description1
- 238000013070change managementMethods0.000description1
- 238000007405data analysisMethods0.000description1
- 238000013075data extractionMethods0.000description1
- 238000013499data modelMethods0.000description1
- 238000011161developmentMethods0.000description1
- 238000005206flow analysisMethods0.000description1
- 230000008676importEffects0.000description1
- ZLIBICFPKPWGIZ-UHFFFAOYSA-NpyrimethanilChemical compoundCC1=CC(C)=NC(NC=2C=CC=CC=2)=N1ZLIBICFPKPWGIZ-UHFFFAOYSA-N0.000description1
- 238000011160researchMethods0.000description1
- 238000007619statistical methodMethods0.000description1
- 238000012384transportation and deliveryMethods0.000description1
Images


Classifications
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02D—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN INFORMATION AND COMMUNICATION TECHNOLOGIES [ICT], I.E. INFORMATION AND COMMUNICATION TECHNOLOGIES AIMING AT THE REDUCTION OF THEIR OWN ENERGY USE
- Y02D10/00—Energy efficient computing, e.g. low power processors, power management or thermal management
Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本发明涉及大数据技术领域,尤其涉及一种元数据获取方法、装置、设备及计算机可读存储介质。The present invention relates to the technical field of big data, and in particular to a metadata acquisition method, device, equipment, and computer-readable storage medium.
背景技术Background technique
元数据管理为企业建立元数据管理体系提供了可靠、便捷的工具支持,可帮助企业绘制数据血缘、统一数据口径、标明数据方位、分析数据关系、管理模型变更等,便于企业更加有效的发掘和利用信息资产的价值,实现精准高效的分析和决策,推进系统变更管理,降低项目风险。元数据管理的核心功能之一是获取各个数据系统和业务系统的元数据信息,为其建立数据模型并存储到关系型数据库或分布式文件系统中,并对元数据进行版本管理。Metadata management provides reliable and convenient tool support for enterprises to establish a metadata management system. It can help enterprises draw data lineage, unify data caliber, indicate data orientation, analyze data relationship, manage model changes, etc., and facilitate enterprises to more effectively explore and Utilize the value of information assets to achieve accurate and efficient analysis and decision-making, promote system change management, and reduce project risks. One of the core functions of metadata management is to obtain metadata information of various data systems and business systems, build data models for them and store them in relational databases or distributed file systems, and perform version management on metadata.
目前已有的一些元数据管理和数据治理工具如Transwarp Governor和PrimetonMetaCube。Governor是Transwarp Data Hub(TDH)中的元数据管理和数据治理工具。用户可以用它来管理元数据,进行数据血缘分析和影响分析。Primeton(普元)MetaCube。MetaCube是普元基于CWM(Common Warehouse Metamodel,公共仓库元模型)规范的企业级元数据管理产品,为企业建立元数据管理体系提供了可靠、便捷的工具支持,可采集来自企业内数据仓库领域内的元数据,为企业提供了端到端的元数据服务,从而更加有效的发掘和利用信息资产的价值,实现精准高效的分析和决策。Some existing metadata management and data governance tools such as Transwarp Governor and PrimetonMetaCube. Governor is the metadata management and data governance tool in Transwarp Data Hub (TDH). Users can use it to manage metadata, conduct data lineage analysis and impact analysis. Primeton (普元) MetaCube. MetaCube is Puyuan's enterprise-level metadata management product based on CWM (Common Warehouse Metamodel, public warehouse metamodel), which provides reliable and convenient tool support for enterprises to establish a metadata management system, and can collect data from the field of enterprise data warehouse metadata, providing enterprises with end-to-end metadata services, so as to more effectively discover and utilize the value of information assets, and achieve accurate and efficient analysis and decision-making.
当前的元数据管理和数据治理工具在元数据获取过程中,数据组件支持的不够完善,当前主流的大数据平台由各种开源和商业数据组件整合,主要包括流式组件(Kafka)、分布式非关系型数据库(HBase)、数据仓库工具(Hive)、关系型数据库(Oracle/TeradataDatabase/MySQL)、商业智能(Business Intelligence,BI)工具(SAS)等,目前的元数据管理和数据治理工具只能支持关系型数据库,无法获取除关系型数据库外其它数据组件存储的元数据。The current metadata management and data governance tools do not fully support data components in the process of metadata acquisition. The current mainstream big data platforms are integrated by various open source and commercial data components, mainly including streaming components (Kafka), distributed The current metadata management and data governance tools only It can support relational databases, and cannot obtain metadata stored in other data components except relational databases.
发明内容Contents of the invention
本发明的主要目的在于提供一种元数据获取方法、装置、设备及计算机可读存储介质,旨在解决现有的无法获取除关系型数据库外其它数据组件存储的元数据的技术问题。The main purpose of the present invention is to provide a metadata acquisition method, device, equipment and computer-readable storage medium, aiming to solve the existing technical problem of being unable to acquire metadata stored in other data components except relational databases.
为实现上述目的,本发明提供一种元数据获取方法,所述元数据获取方法应用于调度器,所述元数据获取方法包括步骤:In order to achieve the above object, the present invention provides a method for obtaining metadata, the method for obtaining metadata is applied to a scheduler, and the method for obtaining metadata includes the steps of:
当侦测到获取元数据的获取指令后,检测当前时间是否处于所述获取指令对应获取任务的执行时间范围内;After detecting an acquisition instruction for acquiring metadata, detect whether the current time is within the execution time range of the acquisition task corresponding to the acquisition instruction;
若所述当前时间处于所述执行时间范围内,则确定与所述调度器连接的执行器中,资源利用率最小的目标执行器;If the current time is within the execution time range, determine the target executor with the smallest resource utilization among the executors connected to the scheduler;
将所述获取任务发送给所述目标执行器,以供所述目标执行器根据所述获取任务采用对应的获取工具在对应的数据系统中获取所述元数据。Sending the acquisition task to the target executor, so that the target executor acquires the metadata in a corresponding data system by using a corresponding acquisition tool according to the acquisition task.
优选地,所述若所述当前时间处于所述执行时间范围内,则确定与所述调度器连接的执行器中,资源利用率最小的目标执行器的步骤包括:Preferably, if the current time is within the execution time range, the step of determining the target executor with the smallest resource utilization among the executors connected to the scheduler includes:
若所述当时时间处于所述执行时间范围内,则获取与所述调度器连接的各个执行器当前的中央处理器CPU资源利用率;If the current time is within the execution time range, then obtain the current central processing unit CPU resource utilization rate of each executor connected to the scheduler;
将所述CPU资源利用率最小的执行器确定为目标执行器。The executor with the minimum CPU resource utilization is determined as the target executor.
为实现上述目的,本发明提供一种元数据获取方法,所述元数据获取方法应用于执行器,所述元数据获取方法包括步骤:In order to achieve the above object, the present invention provides a method for obtaining metadata, the method for obtaining metadata is applied to an actuator, and the method for obtaining metadata includes the steps of:
当接收到调度器发送的获取任务后,获取所述获取任务对应的执行参数;After receiving the acquisition task sent by the scheduler, acquire the execution parameters corresponding to the acquisition task;
根据所述执行参数连接存储所述获取任务对应元数据的数据系统,并根据所述执行参数确定在所述数据系统中获取元数据的获取工具;connecting to a data system that stores metadata corresponding to the acquisition task according to the execution parameters, and determining an acquisition tool for acquiring metadata in the data system according to the execution parameters;
根据所述获取工具在所连接的所述数据系统中获取所述元数据。The metadata is acquired in the connected data system according to the acquisition tool.
优选地,所述根据所述获取工具在所连接的所述数据系统中获取所述元数据的步骤之后,还包括:Preferably, after the step of obtaining the metadata in the connected data system according to the obtaining tool, it further includes:
将所述元数据存储至大数据平台中,以供所述大数据平台将所述元数据的数据格式转换成元数据存储模型对应的数据格式,得到格式转换后的元数据,并返回格式转换成功的成功消息;storing the metadata in the big data platform for the big data platform to convert the data format of the metadata into a data format corresponding to the metadata storage model, obtain the format-converted metadata, and return the format conversion successful success message;
当接收到所述成功消息后,触发将元数据存储至元数据管理数据库的存储指令,并将所述存储指令发送给所述大数据平台,以供所述大数据平台根据所述存储指令将格式转换后的所述元数据存储至所述元数据管理数据库。After receiving the success message, a storage instruction of storing the metadata to the metadata management database is triggered, and the storage instruction is sent to the big data platform for the big data platform to store the metadata according to the storage instruction The metadata after format conversion is stored in the metadata management database.
优选地,所述当接收到所述成功消息后,触发将元数据存储至元数据管理数据库的存储指令,并将所述存储指令发送给所述大数据平台,以供所述大数据平台根据所述存储指令将格式转换后的所述元数据存储至所述元数据管理数据库的步骤之后,还包括:Preferably, when the success message is received, a storage instruction of storing the metadata to the metadata management database is triggered, and the storage instruction is sent to the big data platform for the big data platform to use according to the After the step of storing the format-converted metadata into the metadata management database, the storage instruction further includes:
检测是否接收到所述大数据平台发送的元数据存储成功的提示信息;Detect whether the prompt message that the metadata storage is successful sent by the big data platform is received;
若接收到所述提示信息,则将所述提示信息发送给所述调度器,以供所述调度器根据所述提示信息记录所述获取任务对应的任务状态。If the prompt information is received, the prompt information is sent to the scheduler, so that the scheduler records the task state corresponding to the acquisition task according to the prompt information.
优选地,当所述获取任务获取的元数据是过程元数据时,所述根据所述获取工具在所连接的所述数据系统中获取所述元数据的步骤之后,还包括:Preferably, when the metadata acquired by the acquisition task is process metadata, after the step of acquiring the metadata in the connected data system according to the acquisition tool, further comprising:
获取所述过程元数据对应的执行记录,并解析所述过程元数据对应的执行记录,以得到所述过程元数据对应执行日志的存储路径;Obtaining an execution record corresponding to the process metadata, and parsing the execution record corresponding to the process metadata to obtain a storage path of an execution log corresponding to the process metadata;
根据所述存储路径获取所述执行日志,并根据所述执行日志确定与所述过程元数据关联的任务标识;Acquiring the execution log according to the storage path, and determining a task identifier associated with the process metadata according to the execution log;
根据所述任务标识确定所述过程元数据对应的输入数据和输出数据,并将所述输入数据名称和所述输出数据名称与对应的技术元数据的数据名称关联,以得到所述输入数据和输出数据与所述技术元数据之间的名称关联信息;Determine the input data and output data corresponding to the process metadata according to the task identifier, and associate the input data name and the output data name with the data name of the corresponding technical metadata, so as to obtain the input data and output data name association information between output data and said technical metadata;
将所述名称关联信息发送给大数据平台,以供所述大数据平台将所述关联信息存储至元数据管理系统数据库中。Send the name association information to the big data platform, so that the big data platform can store the association information in the metadata management system database.
优选地,当所述获取任务获取的元数据是业务元数据时,所述根据所述获取工具在所连接的所述数据系统中获取所述元数据的步骤之后,还包括:Preferably, when the metadata acquired by the acquisition task is business metadata, after the step of acquiring the metadata in the connected data system according to the acquisition tool, further include:
确定所述业务元数据与对应技术元数据的第一关联信息,以及所述业务元数据与对应的业务产品信息的第二关联信息;determining first association information between the business metadata and corresponding technical metadata, and second association information between the business metadata and corresponding business product information;
将所述第一关联信息和所述第二关联信息发送给大数据平台,以供所述大数据平台将所述第一关联信息和所述第二关联信息存储至元数据管理系统数据库。Sending the first association information and the second association information to a big data platform for the big data platform to store the first association information and the second association information in a metadata management system database.
优选地,所述根据所述执行参数连接存储所述获取任务对应元数据的数据系统,并根据所述执行参数确定在所述数据系统中获取元数据的获取工具的步骤包括:Preferably, the step of connecting to the data system that stores the metadata corresponding to the acquisition task according to the execution parameters, and determining the acquisition tool for acquiring metadata in the data system according to the execution parameters includes:
根据所述执行参数确定存储所述获取任务对应元数据的数据系统的接口路径和存储类型;Determine the interface path and storage type of the data system that stores the metadata corresponding to the acquisition task according to the execution parameters;
根据所述接口路径连接所述数据系统,并根据所述存储类型确定在所述数据系统中获取数据的获取工具。The data system is connected according to the interface path, and an acquisition tool for acquiring data in the data system is determined according to the storage type.
此外,为实现上述目的,本发明还提供一种元数据获取装置,所述元数据获取装置应用于调度器,所述元数据获取装置包括:In addition, in order to achieve the above object, the present invention also provides a metadata acquisition device, the metadata acquisition device is applied to a scheduler, and the metadata acquisition device includes:
第一检测模块,用于当侦测到获取元数据的获取指令后,检测当前时间是否处于所述获取指令对应获取任务的执行时间范围内;The first detection module is used to detect whether the current time is within the execution time range of the acquisition task corresponding to the acquisition instruction after detecting the acquisition instruction for acquiring metadata;
第一确定模块,用于若所述当前时间处于所述执行时间范围内,则确定与所述调度器连接的执行器中,资源利用率最小的目标执行器;A first determination module, configured to determine the target executor with the smallest resource utilization among the executors connected to the scheduler if the current time is within the execution time range;
第一发送模块,用于将所述获取任务发送给所述目标执行器,以供所述目标执行器根据所述获取任务采用对应的获取工具在对应的数据系统中获取所述元数据。The first sending module is configured to send the acquisition task to the target executor, so that the target executor acquires the metadata in a corresponding data system by using a corresponding acquisition tool according to the acquisition task.
此外,为实现上述目的,本发明还提供一种元数据获取装置,所述元数据获取装置应用于执行器,所述元数据获取装置包括:In addition, in order to achieve the above object, the present invention also provides a metadata acquisition device, the metadata acquisition device is applied to an actuator, and the metadata acquisition device includes:
获取模块,用于当接收到调度器发送的获取任务后,获取所述获取任务对应的执行参数;An acquisition module, configured to acquire execution parameters corresponding to the acquisition task after receiving the acquisition task sent by the scheduler;
连接模块,用于根据所述执行参数连接存储所述获取任务对应元数据的数据系统;A connection module, configured to connect to a data system that stores metadata corresponding to the acquisition task according to the execution parameters;
第二确定模块,用于根据所述执行参数确定在所述数据系统中获取元数据的获取工具;A second determining module, configured to determine an acquisition tool for acquiring metadata in the data system according to the execution parameters;
所述获取模块还用于根据所述获取工具在所连接的所述数据系统中获取所述元数据。The acquisition module is further configured to acquire the metadata in the connected data system according to the acquisition tool.
此外,为实现上述目的,本发明还提供一种元数据获取设备,所述元数据获取设备包括存储器、处理器和存储在所述存储器上并可在所述处理器上运行的元数据获取程序,所述元数据获取程序被所述处理器执行时实现如上所述的元数据获取方法的步骤。In addition, to achieve the above object, the present invention also provides a metadata acquisition device, the metadata acquisition device includes a memory, a processor, and a metadata acquisition program stored in the memory and operable on the processor When the metadata acquisition program is executed by the processor, the steps of the above-mentioned metadata acquisition method are realized.
此外,为实现上述目的,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有元数据获取程序,所述元数据获取程序被处理器执行时实现如上所述的元数据获取方法的步骤。In addition, in order to achieve the above object, the present invention also provides a computer-readable storage medium, on which a metadata acquisition program is stored, and when the metadata acquisition program is executed by a processor, the above-mentioned The steps of the metadata acquisition method.
本发明通过在侦测到获取元数据的获取指令,且在检测到当前时间处于获取指令对应获取任务的执行时间范围内时,确定与调度器连接的目标执行器,将获取任务发送给目标执行器,以供目标执行器根据获取任务采用对应的获取工具在对应数据系统中获取元数据,通过适配不同数据类型的获取工具获取不同数据类型的元数据,以获取到除关系型数据库外其它数据组件存储的元数据。The present invention determines the target executor connected to the scheduler and sends the acquisition task to the target for execution by detecting an acquisition instruction for acquiring metadata and detecting that the current time is within the execution time range of the acquisition task corresponding to the acquisition instruction For the target executor to use the corresponding acquisition tool to acquire metadata in the corresponding data system according to the acquisition task, and to acquire metadata of different data types by adapting the acquisition tools of different data types, so as to obtain other than relational databases Metadata stored by data components.
附图说明Description of drawings
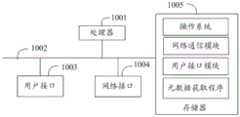
图1是本发明实施例方案涉及的硬件运行环境的结构示意图;Fig. 1 is a schematic structural diagram of the hardware operating environment involved in the solution of the embodiment of the present invention;
图2是本发明元数据获取方法第一实施例的流程示意图;FIG. 2 is a schematic flowchart of the first embodiment of the metadata acquisition method of the present invention;
图3是本发明元数据获取方法第二实施例的流程示意图;FIG. 3 is a schematic flowchart of a second embodiment of the metadata acquisition method of the present invention;
图4是本发明元数据获取方法第三实施例的流程示意图。Fig. 4 is a schematic flowchart of a third embodiment of the metadata acquisition method of the present invention.
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。The realization of the purpose of the present invention, functional characteristics and advantages will be further described in conjunction with the embodiments and with reference to the accompanying drawings.
具体实施方式Detailed ways
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。It should be understood that the specific embodiments described here are only used to explain the present invention, not to limit the present invention.
如图1所示,图1是本发明实施例方案涉及的硬件运行环境的结构示意图。As shown in FIG. 1 , FIG. 1 is a schematic structural diagram of a hardware operating environment involved in the solution of the embodiment of the present invention.
需要说明的是,图1即可为元数据获取设备的硬件运行环境的结构示意图。本发明实施例元数据获取设备可以是PC,便携计算机等终端设备。It should be noted that FIG. 1 is a schematic structural diagram of a hardware operating environment of a metadata acquisition device. The metadata acquisition device in this embodiment of the present invention may be a terminal device such as a PC or a portable computer.
如图1所示,该元数据获取设备可以包括:处理器1001,例如CPU,用户接口1003,网络接口1004,存储器1005,通信总线1002。其中,通信总线1002用于实现这些组件之间的连接通信。用户接口1003可以包括显示屏(Display)、输入单元比如键盘(Keyboard),可选用户接口1003还可以包括标准的有线接口、无线接口。网络接口1004可选的可以包括标准的有线接口、无线接口(如WI-FI接口)。存储器1005可以是高速RAM存储器,也可以是稳定的存储器(non-volatile memory),例如磁盘存储器。存储器1005可选的还可以是独立于前述处理器1001的存储装置。As shown in FIG. 1 , the device for acquiring metadata may include: a
本领域技术人员可以理解,图1中示出的元数据获取设备结构并不构成对元数据获取设备的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。Those skilled in the art can understand that the structure of the metadata acquisition device shown in FIG. layout of the components.
如图1所示,作为一种计算机存储介质的存储器1005中可以包括操作系统、网络通信模块、用户接口模块以及元数据获取程序。其中,操作系统是管理和控制元数据获取设备硬件和软件资源的程序,支持元数据获取程序以及其它软件或程序的运行。As shown in FIG. 1 , the
在图1所示的元数据获取设备中,用户接口1003可用于侦测获取指令等,网络接口1004主要用于连接后台服务器,与后台服务器进行数据通信;当元数据获取设备为调度器时,处理器1001可以用于调用存储器1005中存储的元数据获取程序,并执行以下操作:In the metadata acquisition device shown in Figure 1, the
当侦测到获取元数据的获取指令后,检测当前时间是否处于所述获取指令对应获取任务的执行时间范围内;After detecting an acquisition instruction for acquiring metadata, detect whether the current time is within the execution time range of the acquisition task corresponding to the acquisition instruction;
若所述当前时间处于所述执行时间范围内,则确定与所述调度器连接的执行器中,资源利用率最小的目标执行器;If the current time is within the execution time range, determine the target executor with the smallest resource utilization among the executors connected to the scheduler;
将所述获取任务发送给所述目标执行器,以供所述目标执行器根据所述获取任务采用对应的获取工具在对应的数据系统中获取所述元数据。Sending the acquisition task to the target executor, so that the target executor acquires the metadata in a corresponding data system by using a corresponding acquisition tool according to the acquisition task.
进一步地,所述若所述当前时间处于所述执行时间范围内,则确定与所述调度器连接的执行器中,资源利用率最小的目标执行器的步骤包括:Further, if the current time is within the execution time range, the step of determining the target executor with the smallest resource utilization among the executors connected to the scheduler includes:
若所述当时时间处于所述执行时间范围内,则获取与所述调度器连接的各个执行器当前的中央处理器CPU资源利用率;If the current time is within the execution time range, then obtain the current central processing unit CPU resource utilization rate of each executor connected to the scheduler;
将所述CPU资源利用率最小的执行器确定为目标执行器。The executor with the minimum CPU resource utilization is determined as the target executor.
当元数据获取设备为执行器时,处理器1001可以用于调用存储器1005中存储的元数据获取程序,并执行以下操作:When the metadata acquisition device is an executor, the
当接收到调度器发送的获取任务后,获取所述获取任务对应的执行参数;After receiving the acquisition task sent by the scheduler, acquire the execution parameters corresponding to the acquisition task;
根据所述执行参数连接存储所述获取任务对应元数据的数据系统,并根据所述执行参数确定在所述数据系统中获取元数据的获取工具;connecting to a data system that stores metadata corresponding to the acquisition task according to the execution parameters, and determining an acquisition tool for acquiring metadata in the data system according to the execution parameters;
根据所述获取工具在所连接的所述数据系统中获取所述元数据。The metadata is acquired in the connected data system according to the acquisition tool.
进一步地,所述根据所述获取工具在所连接的所述数据系统中获取所述元数据的步骤之后,处理器1001还可以用于调用存储器1005中存储的基于区块链的元数据获取程序,并执行以下步骤:Further, after the step of acquiring the metadata in the connected data system according to the acquisition tool, the
将所述元数据存储至大数据平台中,以供所述大数据平台将所述元数据的数据格式转换成元数据存储模型对应的数据格式,得到格式转换后的元数据,并返回格式转换成功的成功消息;storing the metadata in the big data platform for the big data platform to convert the data format of the metadata into a data format corresponding to the metadata storage model, obtain the format-converted metadata, and return the format conversion successful success message;
当接收到所述成功消息后,触发将元数据存储至元数据管理数据库的存储指令,并将所述存储指令发送给所述大数据平台,以供所述大数据平台根据所述存储指令将格式转换后的所述元数据存储至所述元数据管理数据库。After receiving the success message, a storage instruction of storing the metadata to the metadata management database is triggered, and the storage instruction is sent to the big data platform for the big data platform to store the metadata according to the storage instruction The metadata after format conversion is stored in the metadata management database.
进一步地,所述当接收到所述成功消息后,触发将元数据存储至元数据管理数据库的存储指令,并将所述存储指令发送给所述大数据平台,以供所述大数据平台根据所述存储指令将格式转换后的所述元数据存储至所述元数据管理数据库的步骤之后,处理器1001还可以用于调用存储器1005中存储的基于区块链的元数据获取程序,并执行以下步骤:Further, when the success message is received, a storage instruction of storing the metadata to the metadata management database is triggered, and the storage instruction is sent to the big data platform for the big data platform to use according to the After the storage instruction stores the format-converted metadata into the metadata management database, the
检测是否接收到所述大数据平台发送的元数据存储成功的提示信息;Detect whether the prompt message that the metadata storage is successful sent by the big data platform is received;
若接收到所述提示信息,则将所述提示信息发送给所述调度器,以供所述调度器根据所述提示信息记录所述获取任务对应的任务状态。If the prompt information is received, the prompt information is sent to the scheduler, so that the scheduler records the task state corresponding to the acquisition task according to the prompt information.
进一步地,当所述获取任务获取的元数据是过程元数据时,所述根据所述获取工具在所连接的所述数据系统中获取所述元数据的步骤之后,处理器1001还可以用于调用存储器1005中存储的基于区块链的元数据获取程序,并执行以下步骤:Further, when the metadata obtained by the obtaining task is process metadata, after the step of obtaining the metadata in the connected data system according to the obtaining tool, the
获取所述过程元数据对应的执行记录,并解析所述过程元数据对应的执行记录,以得到所述过程元数据对应执行日志的存储路径;Obtaining an execution record corresponding to the process metadata, and parsing the execution record corresponding to the process metadata to obtain a storage path of an execution log corresponding to the process metadata;
根据所述存储路径获取所述执行日志,并根据所述执行日志确定与所述过程元数据关联的任务标识;Acquiring the execution log according to the storage path, and determining a task identifier associated with the process metadata according to the execution log;
根据所述任务标识确定所述过程元数据对应的输入数据和输出数据,并将所述输入数据名称和所述输出数据名称与对应的技术元数据的数据名称关联,以得到所述输入数据和输出数据与所述技术元数据之间的名称关联信息;Determine the input data and output data corresponding to the process metadata according to the task identifier, and associate the input data name and the output data name with the data name of the corresponding technical metadata, so as to obtain the input data and output data name association information between output data and said technical metadata;
将所述名称关联信息发送给大数据平台,以供所述大数据平台将所述关联信息存储至元数据管理系统数据库中。Send the name association information to the big data platform, so that the big data platform can store the association information in the metadata management system database.
进一步地,当所述获取任务获取的元数据是业务元数据时,所述根据所述获取工具在所连接的所述数据系统中获取所述元数据的步骤之后,处理器1001还可以用于调用存储器1005中存储的基于区块链的元数据获取程序,并执行以下步骤:Further, when the metadata obtained by the obtaining task is business metadata, after the step of obtaining the metadata in the connected data system according to the obtaining tool, the
确定所述业务元数据与对应技术元数据的第一关联信息,以及所述业务元数据与对应的业务产品信息的第二关联信息;determining first association information between the business metadata and corresponding technical metadata, and second association information between the business metadata and corresponding business product information;
将所述第一关联信息和所述第二关联信息发送给大数据平台,以供所述大数据平台将所述第一关联信息和所述第二关联信息存储至元数据管理系统数据库。Sending the first association information and the second association information to a big data platform for the big data platform to store the first association information and the second association information in a metadata management system database.
进一步地,所述根据所述执行参数连接存储所述获取任务对应元数据的数据系统,并根据所述执行参数确定在所述数据系统中获取元数据的获取工具的步骤包括:Further, the step of connecting to the data system that stores the metadata corresponding to the acquisition task according to the execution parameters, and determining the acquisition tool for acquiring metadata in the data system according to the execution parameters includes:
根据所述执行参数确定存储所述获取任务对应元数据的数据系统的接口路径和存储类型;Determine the interface path and storage type of the data system that stores the metadata corresponding to the acquisition task according to the execution parameters;
根据所述接口路径连接所述数据系统,并根据所述存储类型确定在所述数据系统中获取数据的获取工具。The data system is connected according to the interface path, and an acquisition tool for acquiring data in the data system is determined according to the storage type.
基于上述的结构,提出元数据获取方法的各个实施例。Based on the above structure, various embodiments of the metadata acquisition method are proposed.
参照图2,图2为本发明元数据获取方法第一实施例的流程示意图。Referring to FIG. 2 , FIG. 2 is a schematic flowchart of a first embodiment of a metadata acquisition method according to the present invention.
本发明实施例提供了元数据获取方法的实施例,需要说明的是,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。The embodiment of the present invention provides an embodiment of the metadata acquisition method. It should be noted that although the logic sequence is shown in the flowchart, in some cases, the sequence shown or described steps.
首先,对本发明实施例所需要用到的专业名词进行解释。First, explain the technical terms used in the embodiments of the present invention.
①Hadoop:是一个能够对大量数据进行分布式处理的软件框架。Hadoop包括Common,HDFS(Hadoop Distributed File System,分布式文件系统),YARN(Yet AnotherResource Negotiator,另一种资源协调者)和MapReduce四个模块,其中,Common:是可支持其他模块的公共工具;HDFS是用于提供高吞吐访问性能的分布式文件系统;YARN是提供作业调度和集群资源管理的框架;MapReduce是数据并行计算框架,简称MR。①Hadoop: It is a software framework capable of distributed processing of large amounts of data. Hadoop includes Common, HDFS (Hadoop Distributed File System, distributed file system), YARN (Yet AnotherResource Negotiator, another resource coordinator) and MapReduce four modules, among them, Common: is a public tool that can support other modules; HDFS It is a distributed file system used to provide high-throughput access performance; YARN is a framework that provides job scheduling and cluster resource management; MapReduce is a data parallel computing framework, referred to as MR.
②Hive:是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供SQL(Structured Query Language,结构化查询语言)查询功能,可以将SQL语句转换为MapReduce任务进行运行。Hive对数据仓库的管理包括两方面:一是元数据的管理,二是数据的管理。其中,元数据:Hive将元数据存储在关系型数据库中,如存储至关系型数据库管理系统MySQL中,Hive中的元数据包括表的名字、表的列和分区及其属性、表的属性(是否为外部表等)和表的数据所在HDFS存储目录等;数据:Hive的数据存储在HDFS中,大部分的查询由MapReduce任务计算完成。②Hive: It is a data warehouse tool based on Hadoop, which can map structured data files into a database table, and provide SQL (Structured Query Language, Structured Query Language) query function, which can convert SQL statements into MapReduce tasks for processing run. Hive's management of the data warehouse includes two aspects: one is metadata management, and the other is data management. Among them, metadata: Hive stores metadata in a relational database, such as storing in a relational database management system MySQL, the metadata in Hive includes the name of the table, the columns and partitions of the table and their attributes, and the attributes of the table ( Whether it is an external table, etc.) and the HDFS storage directory where the table data is located; data: Hive data is stored in HDFS, and most queries are calculated by MapReduce tasks.
③Kafka:是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。③Kafka: It is an open source stream processing platform developed by the Apache Software Foundation, written in Scala and Java. Kafka is a high-throughput distributed publish-subscribe messaging system that can handle all action streaming data in consumer-scale websites.
④HBase:是一个分布式、面向列的、高可扩展的key/value大数据存储,存储可基于HDFS,提供对海量结构化数据的高效随机读写访问能力。④HBase: It is a distributed, column-oriented, and highly scalable key/value big data storage. The storage can be based on HDFS, providing efficient random read and write access to massive structured data.
⑤Oracle Database:又名Oracle RDBMS,或简称Oracle,是甲骨文公司的一款关系数据库管理系统。⑤Oracle Database: also known as Oracle RDBMS, or Oracle for short, is a relational database management system of Oracle Corporation.
⑥Teradata database:Teradata公司推出的关系数据库管理系统,Teradata采用标准的SQL查询语言,适用于处理复杂查询数据仓库应用。⑥Teradata database: The relational database management system launched by Teradata Company, Teradata uses standard SQL query language, which is suitable for processing complex query data warehouse applications.
⑦CMDB:Configuration Management Database,配置管理数据库,CMDB存储与管理企业IT架构中设备的各种配置信息,它与所有服务支持和服务交付流程都紧密相联,支持这些流程的运转和发挥配置信息的价值,同时依赖于相关流程保证数据的准确性。⑦CMDB: Configuration Management Database, configuration management database, CMDB stores and manages various configuration information of equipment in the enterprise IT architecture, it is closely related to all service support and service delivery processes, supports the operation of these processes and maximizes the value of configuration information , while relying on relevant processes to ensure the accuracy of the data.
⑧SAS:Statistical Analysis System(SAS),是一个模块化、集成化的大型应用软件系统。它由数十个专用模块构成,功能包括数据访问、数据储存及管理、应用开发、图形处理、数据分析、报告编制、运筹学方法、计量经济学与预测等等,支持标准的SQL语言对数据进行操作,能够制作从简单列表到比较复杂的统计报表。⑧SAS: Statistical Analysis System (SAS), is a modular and integrated large-scale application software system. It consists of dozens of dedicated modules, and its functions include data access, data storage and management, application development, graphics processing, data analysis, report compilation, operations research methods, econometrics and forecasting, etc., and supports standard SQL language for data processing. Operation, can make from simple lists to more complex statistical reports.
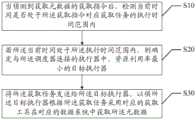
元数据获取方法包括:Metadata acquisition methods include:
步骤S10,当侦测到获取元数据的获取指令后,检测当前时间是否处于所述获取指令对应获取任务的执行时间范围内。Step S10, after detecting an acquisition instruction for acquiring metadata, check whether the current time is within the execution time range of the acquisition task corresponding to the acquisition instruction.
当调度器侦测到获取元数据的获取指令后,调度器获取当前时间,并检测当前时间是否处于获取指令对应获取任务的执行时间范围内。其中,获取指令可由用户根据需要而触发,也可由调度器中预先设置好的定时任务而触发。执行时间范围可根据具体需要而设置,本实施例对执行时间范围不做具体限制。元数据包括技术元数据、业务元数据和过程元数据。技术元数据是描述数据在数据库系统中的存储结构,即数据在数据库系统中存储的字段类型、名称、注释和数据字段长度等;业务元数据是描述数据的业务背景,即描述数据属于那个业务产品,被那些业务产品使用等;过程元数据表示数据是怎么从贴源层表加工到数据集市表的过程,即数据被那些系统调用等。After the scheduler detects an acquisition instruction for acquiring metadata, the scheduler acquires the current time and checks whether the current time is within the execution time range of the acquisition task corresponding to the acquisition instruction. Among them, the acquisition instruction can be triggered by the user according to the needs, or can be triggered by the scheduled task preset in the scheduler. The execution time range can be set according to specific needs, and this embodiment does not specifically limit the execution time range. Metadata includes technical metadata, business metadata and process metadata. Technical metadata is to describe the storage structure of data in the database system, that is, the field type, name, comment, and data field length of data stored in the database system; business metadata is to describe the business background of the data, that is, to describe which business the data belongs to Products, used by those business products, etc.; process metadata indicates how the data is processed from the source layer table to the data mart table, that is, the data is called by those systems, etc.
进一步地,当该获取指令是获取技术元数据时,调度器在侦测到获取技术元数据的获取指令后,调度器判断获取指令对应的技术元数据结构变更频率是否大于预设频率(可选为1天),若确定技术元数据结构变更频率大于预设频率,调度器则采用批量获取方式来获取技术元数据,若确定技术元数据结构变更频率小于或者等于预设频率,调度器则在数据系统中一次导入全量的技术元数据,以初始化数据系统中的技术元数据,然后数据系统通过实时事件消息的方式来实时更新技术元数据。当技术元数据的字段类型、名称、注释和数据字段长度等发生变化时,表明技术元数据结构发生了变更。Further, when the acquisition instruction is to acquire technical metadata, after the scheduler detects the acquisition instruction to acquire technical metadata, the scheduler judges whether the frequency of structural change of the technical metadata corresponding to the acquisition instruction is greater than the preset frequency (optional is 1 day), if it is determined that the change frequency of the technical metadata structure is greater than the preset frequency, the scheduler will obtain the technical metadata in batches; if it is determined that the change frequency of the technical metadata structure is less than or equal to the preset frequency, the scheduler will be in A full amount of technical metadata is imported into the data system at one time to initialize the technical metadata in the data system, and then the data system updates the technical metadata in real time through real-time event messages. When the field type, name, comment, and data field length of technical metadata change, it indicates that the structure of technical metadata has changed.
数据系统通过实时事件消息的方式实时更新技术元数据的过程为:数据系统通过定义一个init.sh脚本调用批量技术元数据更新的ETL(Extract-Transform-Load,抽取、转换、加载)任务将技术元数据初始到元数据管理系统数据库中,即数据系统将其存储的技术元数据写入到元数据管理系统数据库中。具体地,数据系统通过Hook(钩子)获取发生结构变更的技术元数据,并将该技术元数据封装成事件消息发送到消息系统,消息系统将该事件消息发送给流式分析系统。当流式分析系统接收到事件消息后,在该事件消息中解析出结构变更后的技术元数据,并将结构变更后的技术元数据写入到元数据管理系统数据库中。需要说明的是,该Hook实现了Hive的post Execution Hook,通过分析SQL的操作类型,当分析到操作类型是DDL(Update/Alter Table/Partition等)操作的时候触发事件捕获结构变更的技术元数据。可以理解的是,在数据系统执行SQL语句时,可能会产生结构变更的技术元数据。在本发明实施例中,消息系统为Kafka。通过实时获取技术元数据,以便于用户对技术元数据的实时查询。The process for the data system to update technical metadata in real time through real-time event messages is as follows: the data system invokes the ETL (Extract-Transform-Load) task of batch technical metadata update by defining an init.sh script to convert the technical The metadata is initially entered into the database of the metadata management system, that is, the data system writes the stored technical metadata into the database of the metadata management system. Specifically, the data system obtains the technical metadata of the structure change through Hook, and encapsulates the technical metadata into an event message and sends it to the message system, and the message system sends the event message to the streaming analysis system. When the flow analysis system receives the event message, it parses out the technical metadata after the structure change from the event message, and writes the technical metadata after the structure change into the database of the metadata management system. It should be noted that this Hook implements Hive's post Execution Hook. By analyzing the operation type of SQL, when the operation type is analyzed to be a DDL (Update/Alter Table/Partition, etc.) operation, an event is triggered to capture the technical metadata of the structural change . It is understandable that when a data system executes an SQL statement, technical metadata of structural changes may be generated. In the embodiment of the present invention, the message system is Kafka. By obtaining technical metadata in real time, it is convenient for users to query technical metadata in real time.
步骤S20,若所述当前时间处于所述执行时间范围内,则确定与所述调度器连接的执行器中,资源利用率最小的目标执行器。Step S20, if the current time is within the execution time range, determine the target executor with the smallest resource utilization among the executors connected to the scheduler.
若检测到当前时间处于执行时间范围内,调度器则确定与调度器连接的执行器中,资源利用率最小的执行器,并将资源利用率最小的执行器确定为目标执行器。需要说明的是,元数据对于不同数据系统设置了相关联的ETL任务,即元数据对应不同数据系统设置了相关联的获取任务,每个获取任务都设置了对应的执行时间范围。当检测到当前时间处于其对应的执行时间范围时,调度器触发执行指令,将获取任务加入执行队列中。If it is detected that the current time is within the execution time range, the scheduler determines the executor with the minimum resource utilization rate among the executors connected to the scheduler, and determines the executor with the minimum resource utilization rate as the target executor. It should be noted that metadata sets associated ETL tasks for different data systems, that is, metadata sets associated acquisition tasks corresponding to different data systems, and each acquisition task is set with a corresponding execution time range. When it is detected that the current time is within its corresponding execution time range, the scheduler triggers the execution instruction and adds the acquired task to the execution queue.
进一步地,若检测到当前时间未处于执行时间范围内,调度器则继续检测当前时间是否处于执行时间范围内。Further, if it is detected that the current time is not within the execution time range, the scheduler continues to detect whether the current time is within the execution time range.
进一步地,步骤S20包括:Further, step S20 includes:
步骤a,若所述当时时间处于所述执行时间范围内,则获取与所述调度器连接的各个执行器当前的中央处理器CPU资源利用率。Step a, if the current time is within the execution time range, obtain the current CPU resource utilization rate of each executor connected to the scheduler.
步骤b,将所述CPU资源利用率最小的执行器确定为目标执行器。Step b, determining the executor with the smallest CPU resource utilization rate as the target executor.
具体地,调度器确定目标执行器的过程为:若检测到当前时间处于执行时间范围内,调度器则获取与其连接的各个执行器当前的CPU(Central Processing Unit,中央处理器)资源利用率,并将所有执行器中CPU资源利用率最小的执行器确定为目标执行器。Specifically, the process for the scheduler to determine the target executor is: if it is detected that the current time is within the execution time range, the scheduler obtains the current CPU (Central Processing Unit, central processing unit) resource utilization rate of each executor connected to it, And determine the executor with the smallest CPU resource utilization among all executors as the target executor.
进一步地,调度器也可获取所连接的各个执行器当前的内存可用空间(即空间资源利用率),并将所有执行器中内存可用空间最大的执行器(即空间资源利用率最小)确定为目标执行器。进一步地,也可采用内存可用空间和CPU资源利用率结合确定目标执行器。具体地,如可设置空间资源利用率和CPU资源利用率对应的权重,将各个执行器对应的空间资源利用率和CPU资源利用率乘以对应的权重后相加,将相加后所得的值最小的执行器确定为目标执行器,其中,空间资源利用率和CPU资源利用率对应的权重可根据具体需要而设置,本发明实施例对空间资源利用率和CPU资源利用率对应权重的大小不做具体限制。Further, the scheduler can also obtain the current available memory space (i.e. space resource utilization rate) of each connected executor, and determine the executor with the largest memory available space (i.e. the smallest space resource utilization rate) among all executors as target executor. Further, the target executor may also be determined by using a combination of available memory space and CPU resource utilization. Specifically, for example, you can set the weights corresponding to space resource utilization and CPU resource utilization, multiply the corresponding space resource utilization and CPU resource utilization of each executor by the corresponding weight, and then add the value The smallest executor is determined as the target executor, wherein the weights corresponding to the utilization of space resources and the utilization of CPU resources can be set according to specific needs. Make specific restrictions.
步骤S30,将所述获取任务发送给所述目标执行器,以供所述目标执行器根据所述获取任务采用对应的获取工具在对应的数据系统中获取所述元数据。Step S30, sending the acquisition task to the target executor, so that the target executor acquires the metadata in a corresponding data system by using a corresponding acquisition tool according to the acquisition task.
当确定目标执行器后,调度器在执行队列提取获取任务,并将该获取任务发送给目标执行器,以供目标执行器根据该获取任务采用对应的获取工具在所述获取工具对应的数据系统中获取元数据。After determining the target executor, the scheduler extracts the acquisition task from the execution queue, and sends the acquisition task to the target executor, so that the target executor uses the corresponding acquisition tool according to the acquisition task in the data system corresponding to the acquisition tool Get metadata from .
在本实施例中,元数据对于不同数据系统的制定了相关联的获取任务,每个获取任务都有自己定时调度策略,调度器根据获取任务的定时调度策略触发任务执行。一旦满足调度策略的触发条件,调度器会把任务加入执行队列,并根据资源的负载均衡策略将任务从执行队列中取出,以发送至所述目标执行器。In this embodiment, the metadata defines associated acquisition tasks for different data systems, each acquisition task has its own timing scheduling policy, and the scheduler triggers task execution according to the timing scheduling policy of the acquisition task. Once the trigger condition of the scheduling policy is satisfied, the scheduler will add the task to the execution queue, and take the task out of the execution queue according to the resource load balancing policy to send to the target executor.
需要说明的是,在本发明实施例中,执行器为不同的数据系统设置了不同的元数据获取工具(Crawler),其中,所述获取工具根据数据系统的元数据结构设计得到,使得获取工具适配对应的数据系统,获取工具可以连接对应的数据系统,在对应的数据系统中读取元数据。在本发明实施例中,获取工具支持关系型数据库、非关系型数据库、数据仓库系统(Hive)、消息系统(Kafka)和商业BI软件(SAS),其中,关系型数据包括但不限于MySQL、Oracle和Teradata Database。It should be noted that, in the embodiment of the present invention, the executor sets different metadata acquisition tools (Crawler) for different data systems, wherein the acquisition tools are designed according to the metadata structure of the data system, so that the acquisition tools Adapt to the corresponding data system, the acquisition tool can connect to the corresponding data system, and read metadata in the corresponding data system. In the embodiment of the present invention, the acquisition tool supports relational database, non-relational database, data warehouse system (Hive), message system (Kafka) and commercial BI software (SAS), wherein relational data includes but not limited to MySQL, Oracle and Teradata Database.
本实施例通过在侦测到获取元数据的获取指令,且在检测到当前时间处于获取指令对应获取任务的执行时间范围内时,确定与调度器连接的目标执行器,将获取任务发送给目标执行器,以供目标执行器根据获取任务采用对应的获取工具在对应数据系统中获取元数据,通过适配不同数据类型的获取工具获取不同数据类型的元数据,以获取到除关系型数据库外其它数据组件存储的元数据。This embodiment determines the target executor connected to the scheduler and sends the acquisition task to the target by detecting the acquisition instruction for acquiring metadata and detecting that the current time is within the execution time range of the acquisition task corresponding to the acquisition instruction The executor is used for the target executor to obtain metadata in the corresponding data system by using the corresponding acquisition tool according to the acquisition task, and acquire metadata of different data types by adapting the acquisition tools of different data types, so as to obtain the metadata in addition to the relational database Metadata stored by other data components.
需要说明的是,现有的技术方案除了支持的组件较为单一,对元数据的获取存在以下几种缺陷以及本发明能解决的缺陷:It should be noted that, in addition to the single supporting components of the existing technical solutions, there are the following defects in the acquisition of metadata and the defects that the present invention can solve:
元数据类型支持不够丰富,较为单一;而本发明可以支持技术元数据、业务元数据和过程元数据等多种元数据的获取。Metadata type support is not rich enough, relatively simple; and the present invention can support the acquisition of various metadata such as technical metadata, business metadata and process metadata.
当前的元数据更新获取方式单一;而本发明对于变更不频繁的系统,元数据可以每天一次进行增量更新;对于频繁变动的需要结合分布式消息系统实时更新,满足用户的元数据实时查询。The current metadata update acquisition method is single; however, the present invention can incrementally update the metadata once a day for systems with infrequent changes; for frequent changes, it combines real-time updates with the distributed message system to meet the real-time query of metadata by users.
进一步地,提出本发明元数据获取方法第二实施例。Further, a second embodiment of the metadata acquisition method of the present invention is proposed.
所述元数据获取方法第二实施例与所述元数据获取方法第一实施例的区别在于,所述元数据获取方法应用于执行器,参照图3,元数据获取方法还包括:The difference between the second embodiment of the metadata acquisition method and the first embodiment of the metadata acquisition method is that the metadata acquisition method is applied to an executor. Referring to FIG. 3, the metadata acquisition method further includes:
步骤S40,当接收到调度器发送的获取任务后,获取所述获取任务对应的执行参数。Step S40, after receiving the acquisition task sent by the scheduler, acquire the execution parameters corresponding to the acquisition task.
需要说明的是,本发明实施例中的调度器可为第一实施例中目标执行器,也可为与调度器连接的任一执行器。当执行器接收到调度器发送的获取任务后,执行器获取该获取任务对应的执行参数。其中,执行参数包括但不限于数据系统的地址、名称、接口路径和数据系统所存储元数据的数据类型。接口路径为执行器连接数据系统的接口所在位置。It should be noted that the scheduler in this embodiment of the present invention may be the target executor in the first embodiment, or any executor connected to the scheduler. After the executor receives the acquisition task sent by the scheduler, the executor acquires the execution parameters corresponding to the acquisition task. Wherein, the execution parameters include but not limited to the address, name, interface path of the data system and the data type of metadata stored in the data system. The interface path is the location of the interface where the actuator connects to the data system.
步骤S50,根据所述执行参数连接存储所述获取任务对应元数据的数据系统,并根据所述执行参数确定在所述数据系统中获取元数据的获取工具。Step S50, connect to the data system storing metadata corresponding to the acquisition task according to the execution parameters, and determine an acquisition tool for acquiring metadata in the data system according to the execution parameters.
步骤S60,根据所述获取工具在所连接的所述数据系统中获取所述元数据。Step S60, acquiring the metadata in the connected data system according to the acquisition tool.
当执行器获取到获取任务对应的执行参数后,执行器根据执行参数连接存储获取任务对应元数据的数据系统,并根据该执行参数确定在数据系统中获取元数据的获取工具。当确定获取工具后,执行器根据该获取工具在所连接的数据系统中获取元数据。具体地,执行器根据在该获取任务的数据抓取阶段(Extract)在数据系统中获取对应的元数据。After the executor acquires the execution parameters corresponding to the acquisition task, the executor connects to the data system that stores the metadata corresponding to the acquisition task according to the execution parameters, and determines the acquisition tool for acquiring metadata in the data system according to the execution parameters. After determining the acquisition tool, the executor acquires metadata in the connected data system according to the acquisition tool. Specifically, the executor acquires the corresponding metadata in the data system according to the data extraction phase (Extract) of the acquisition task.
进一步地,步骤S50包括:Further, step S50 includes:
步骤c,根据所述执行参数确定存储所述获取任务对应元数据的数据系统的接口路径和存储类型。Step c, determining an interface path and a storage type of a data system storing metadata corresponding to the acquisition task according to the execution parameters.
步骤d,根据所述接口路径连接所述数据系统,并根据所述存储类型确定在所述数据系统中获取数据的获取工具。Step d, connect the data system according to the interface path, and determine an acquisition tool for acquiring data in the data system according to the storage type.
具体地,当执行器获取到获取任务对应的执行参数后,执行器根据执行参数确定存储获取任务对应元数据的数据系统的接口路径和数据系统所存储数据的数据类型,并根据该接口路径连接该数据系统,根据存储类型确定数据系统中获取数据的获取工具。需要说明的是,不同数据系统的接口路径是不一样的。Specifically, after the executor obtains the execution parameters corresponding to the acquisition task, the executor determines the interface path of the data system that stores the metadata corresponding to the acquisition task and the data type of the data stored in the data system according to the execution parameters, and connects the In the data system, an acquisition tool for acquiring data in the data system is determined according to the storage type. It should be noted that the interface paths of different data systems are different.
进一步地,若执行器根据接口路径不能确定所要连接的数据系统,执行器可根据执行参数中接口路径、数据系统的地址和数据系统的名称连接到对应的数据系统中。Further, if the executor cannot determine the data system to be connected according to the interface path, the executor can connect to the corresponding data system according to the interface path, the address of the data system, and the name of the data system in the execution parameters.
本实施例通过接收到调度器发送的获取任务后,获取任务对应的执行参数,根据执行参数连接存储获取任务对应元数据的数据系统,并根据执行参数确定在数据系统中获取元数据的获取工具,根据获取工具在所连接的数据系统中获取元数据,通过适配不同数据类型的获取工具获取不同数据类型的元数据,以获取到除关系型数据库外其它数据组件存储的元数据。In this embodiment, after receiving the acquisition task sent by the scheduler, the execution parameters corresponding to the task are acquired, the data system that stores and acquires the metadata corresponding to the task is connected according to the execution parameter, and the acquisition tool for acquiring metadata in the data system is determined according to the execution parameter , obtain metadata in the connected data system according to the acquisition tool, and obtain metadata of different data types through acquisition tools adapted to different data types, so as to obtain metadata stored in other data components except relational databases.
进一步地,提出本发明元数据获取方法第三实施例。Further, a third embodiment of the metadata acquisition method of the present invention is proposed.
所述元数据获取方法第三实施例与所述元数据获取方法第一或第二实施例的区别在于,参照图4,元数据获取方法还包括:The difference between the third embodiment of the metadata acquisition method and the first or second embodiment of the metadata acquisition method is that, referring to FIG. 4 , the metadata acquisition method further includes:
步骤S70,将所述元数据存储至大数据平台中,以供所述大数据平台将所述元数据的数据格式转换成元数据存储模型对应的数据格式,得到格式转换后的元数据,并返回格式转换成功的成功消息。Step S70, storing the metadata in the big data platform, so that the big data platform can convert the data format of the metadata into a data format corresponding to the metadata storage model to obtain the format-converted metadata, and Returns a success message that the format conversion was successful.
当执行器获取到元数据后,执行器在获取任务的数据转换阶段(Transform),通过bridge插件连接大数据平台,将元数据发送给大数据平台,以将元数据存储至大数据平台中,具体地,将元数据存储至大数据平台的HDFS中。当大数据平台存储元数据后,大数据平台将元数据的数据格式转换成元数据存储模型对应的数据格式,得到格式转换后的元数据,并在元数据格式转换成功后,生成格式转换成功的成功消息,将该成功消息发送给执行器。其中,元数据存储模型是预先设置好,元数据存储模型对应的数据格式也是预先设置好的,如可以将元数据存储模型对应的数据模式设置为MySQL或者设置为HBase等。After the executor obtains the metadata, the executor connects to the big data platform through the bridge plug-in in the data conversion phase (Transform) of the task, and sends the metadata to the big data platform to store the metadata in the big data platform. Specifically, metadata is stored in HDFS of the big data platform. After the big data platform stores the metadata, the big data platform converts the data format of the metadata into the data format corresponding to the metadata storage model, obtains the metadata after the format conversion, and generates the format conversion success after the metadata format conversion is successful , which is sent to the executor. Among them, the metadata storage model is pre-set, and the data format corresponding to the metadata storage model is also pre-set. For example, the data mode corresponding to the metadata storage model can be set to MySQL or HBase.
步骤S80,当接收到所述成功消息后,触发将元数据存储至元数据管理数据库的存储指令,并将所述存储指令发送给所述大数据平台,以供所述大数据平台根据所述存储指令将格式转换后的所述元数据存储至所述元数据管理数据库。Step S80, after receiving the success message, trigger a storage instruction to store the metadata in the metadata management database, and send the storage instruction to the big data platform for the big data platform to use according to the The storage instruction stores the format-converted metadata into the metadata management database.
当执行器接收到大数据平台发送的成功消息后,执行器自动触发将元数据存储至元数据管理数据库的存储指令,并将该存储指令发送给大数据平台。当大数据平台接收到该存储指令后,大数据平台根据该存储指令,调用获取任务的导入(Load)逻辑将格式转换后的元数据存储至元数据管理数据库中。When the executor receives the success message sent by the big data platform, the executor automatically triggers a storage instruction to store the metadata to the metadata management database, and sends the storage instruction to the big data platform. After the big data platform receives the storage instruction, the big data platform calls the import (Load) logic of the acquisition task according to the storage instruction to store the format-converted metadata into the metadata management database.
进一步地,当大数据平台成功将格式转换后的元数据存储至元数据管理数据库中后,大数据平台自动生成元数据存储成功的提示信息,并将该提示信息发送给执行器。Further, when the big data platform successfully stores the format-converted metadata into the metadata management database, the big data platform automatically generates a prompt message indicating that the metadata storage is successful, and sends the prompt message to the executor.
进一步地,所述元数据获取方法还包括:Further, the metadata acquisition method also includes:
步骤e,检测是否接收到所述大数据平台发送的元数据存储成功的提示信息。In step e, it is detected whether the prompt message of successful metadata storage sent by the big data platform is received.
步骤f,若接收到所述提示信息,则将所述提示信息发送给所述调度器,以供所述调度器根据所述提示信息记录所述获取任务对应的任务状态。Step f, if the prompt information is received, send the prompt information to the scheduler, so that the scheduler can record the task state corresponding to the acquisition task according to the prompt information.
当执行器发送存储指令给大数据平台后,执行器检测是否接收到大数据平台发送的元数据存储成功的提示信息。若执行器接收到该提示信息,执行器则根据该提示信息记录该获取任务对应的任务状态,并将提示信息发送给调度器。具体地,执行器根据提示信息将获取任务的状态修改为已执行状态。需要说明的是,若获取任务只存在未执行状态和已执行状态,执行器则根据提示信息将获取任务从未执行状态修改为已执行状态;若获取任务存在未执行状态、执行中状态和已执行状态,执行器则根据该提示信息将获取任务从执行中状态修改为已执行状态。进一步地,执行器该可根据提示信息记录获取任务的执行时长,具体地,执行器记录接收到获取任务的第一接收时间,以及记录接收到提示信息的第二接收时间,计算第一接收时间和第二接收时间之间的时间差,该时间差即为获取任务的执行时长。After the executor sends the storage instruction to the big data platform, the executor detects whether it receives the prompt message of successful metadata storage sent by the big data platform. If the executor receives the prompt information, the executor records the task state corresponding to the acquired task according to the prompt information, and sends the prompt information to the scheduler. Specifically, the executor modifies the state of the acquired task to an executed state according to the prompt information. It should be noted that if the acquired task only has the unexecuted state and the executed state, the executor will modify the acquired task from the unexecuted state to the executed state according to the prompt information; if the acquired task has the unexecuted state, the executing state and the executed state Execution state, the executor will modify the acquired task from the executing state to the executed state according to the prompt information. Further, the executor can record the execution duration of the acquisition task according to the prompt information, specifically, the executor records the first receiving time of receiving the acquisition task, and records the second receiving time of receiving the prompt information, and calculates the first receiving time The time difference between the second receiving time and the second receiving time, the time difference is the execution duration of the acquisition task.
当调度器接收到提示信息后,调度器根据该提示信息记录获取任务对应的任务状态。需要说明的是,调度器根据提示信息记录获取任务对应任务状态的过程和执行器根据提示信息记录获取任务对应任务状态的过程一致,在此不再详细赘述。After the scheduler receives the prompt information, the scheduler records and acquires the task state corresponding to the task according to the prompt information. It should be noted that the process for the scheduler to obtain the task state corresponding to the task according to the prompt information record is the same as the process for the executor to obtain the task state corresponding to the task according to the prompt information record, and will not be described in detail here.
本发明实施例通过将获取的元数据存储至大数据平台中,以供大数据平台将元数据的数据格式转换成元数据存储模型对应的数据格式,并在接收到大数据平台返回的成功消息后,触发将元数据存储至元数据管理数据库的存储指令,并将存储指令发送给大数据平台,以供大数据平台根据存储指令将格式转换后的元数据存储至元数据管理数据库,以便于将不同数据类型的元数据转换成统一的数据格式后存储至元数据管理数据库中,便于元数据管理数据库对元数据的管理。In the embodiment of the present invention, the obtained metadata is stored in the big data platform, so that the big data platform can convert the data format of the metadata into the data format corresponding to the metadata storage model, and after receiving the success message returned by the big data platform Finally, trigger the storage instruction of storing the metadata to the metadata management database, and send the storage instruction to the big data platform, so that the big data platform can store the format-converted metadata in the metadata management database according to the storage instruction, so that Metadata of different data types are converted into a unified data format and stored in the metadata management database, which facilitates the management of metadata by the metadata management database.
进一步地,提出本发明元数据获取方法第四实施例。Further, a fourth embodiment of the metadata acquisition method of the present invention is proposed.
所述元数据获取方法第四实施例与所述元数据获取方法第一、第二或第三实施例的区别在于,当所述获取任务获取的元数据是过程元数据时,元数据获取方法还包括:The difference between the fourth embodiment of the metadata acquisition method and the first, second or third embodiments of the metadata acquisition method is that when the metadata acquired by the acquisition task is process metadata, the metadata acquisition method Also includes:
步骤g,获取所述过程元数据对应的执行记录,并解析所述过程元数据对应的执行记录,以得到所述过程元数据对应执行日志的存储路径。Step g, obtaining the execution record corresponding to the process metadata, and parsing the execution record corresponding to the process metadata, so as to obtain the storage path of the execution log corresponding to the process metadata.
当获取任务获取的元数据是过程元数据时,在执行器通过元数据获取工具Crawler批量获取到过程元数据后,执行器通过调度器的执行日志采集系统的日志接口获取过程元数据对应的执行记录,或者在调度器的数据库中获取过程元数据对应执行记录。当获取到过程元数据对应的执行记录后,执行器解析执行记录,得到过程元数据对应执行日志的存储路径。若执行记录是存储在调度器的数据库中,执行器解析执行记录会得到过程元数据对应执行日志在数据库中的日志标识。可以理解的是,在执行记录中的某个特定字段中,存储有执行日志的存储路径或和日志标识,或者该存储路径和日志标识以特定的形式写在执行记录中。When the metadata acquired by the acquisition task is process metadata, after the executor acquires the process metadata in batches through the metadata acquisition tool Crawler, the executor acquires the execution corresponding to the process metadata through the log interface of the execution log collection system of the scheduler record, or obtain the execution record corresponding to the process metadata in the database of the scheduler. After obtaining the execution record corresponding to the process metadata, the executor parses the execution record to obtain the storage path of the execution log corresponding to the process metadata. If the execution record is stored in the database of the scheduler, the executor will get the log identifier in the database corresponding to the execution log of the process metadata by parsing the execution record. It can be understood that, in a specific field in the execution record, the storage path or the log identifier of the execution log is stored, or the storage path and the log identifier are written in the execution record in a specific form.
需要说明的是,本发明实施例中的元数据获取工具Crawler可适配大数据批量调度系统(Azkaban、Airflow、Oozie),并适配其他自研或者商业的批量调度系统。It should be noted that the metadata acquisition tool Crawler in the embodiment of the present invention can be adapted to big data batch scheduling systems (Azkaban, Airflow, Oozie) and other self-developed or commercial batch scheduling systems.
步骤h,根据所述存储路径获取所述执行日志,并根据所述执行日志确定与所述过程元数据关联的任务标识。Step h, obtaining the execution log according to the storage path, and determining the task identifier associated with the process metadata according to the execution log.
当执行器得到执行日志的存储路径后,执行器根据该存储路径在调度器获取执行日志,分析该执行日志,得到与执行日志对应获取任务管理的任务标识。其中,该任务标识为Hadoop Job ID(MapReduce Job ID),是在Hadoop中执行与获取任务对应任务的任务标识,即该任务标识是获取任务在Hadoop中执行时对应的标识。After the executor obtains the storage path of the execution log, the executor obtains the execution log from the scheduler according to the storage path, analyzes the execution log, and obtains the task ID corresponding to the execution log for task management. Wherein, the task identifier is a Hadoop Job ID (MapReduce Job ID), which is a task identifier for executing a task corresponding to the acquisition task in Hadoop, that is, the task identifier is a corresponding identifier when the acquisition task is executed in Hadoop.
步骤i,根据所述任务标识确定所述过程元数据对应的输入数据和输出数据,并将所述输入数据名称和所述输出数据名称与对应的技术元数据的数据名称关联,以得到所述输入数据和输出数据与所述技术元数据之间的名称关联信息。Step i: Determine the input data and output data corresponding to the process metadata according to the task identifier, and associate the input data name and the output data name with the corresponding technical metadata data name, so as to obtain the Name association information between input data and output data and said technical metadata.
步骤j,将所述名称关联信息发送给大数据平台,以供所述大数据平台将所述关联信息存储至元数据管理系统数据库中。Step j, sending the name association information to the big data platform, so that the big data platform can store the association information in the metadata management system database.
当执行器确定任务标识后,执行器根据该任务标识确定对应的Hadoop任务,分析该Hadoop任务,得到该Hadoop任务对应的输入数据和输出数据,即得到过程元数据对应的输入数据和输出数据。其中,每一Hadoop任务都对应一个唯一的任务标识。当得到过程元数据对应的输入数据和输出数据后,执行器将输入数据名称和输出数据名称与对应的技术元数据的数据名称关联,得到输入数据和输出数据与技术元数据之间的名称关联信息,并将该名称关联信息发送给大数据平台。当大数据平台接收到名称关联信息后,大数据平台将名称关联信息写入元数据管理系统数据库中。需要说明的是,每一输入数据和输出数据都存在对应的技术元数据、业务元数据和过程元数据。After the executor determines the task ID, the executor determines the corresponding Hadoop task according to the task ID, analyzes the Hadoop task, and obtains the input data and output data corresponding to the Hadoop task, that is, the input data and output data corresponding to the process metadata. Wherein, each Hadoop task corresponds to a unique task identifier. After obtaining the input data and output data corresponding to the process metadata, the executor associates the input data name and output data name with the data name of the corresponding technical metadata, and obtains the name association between the input data and output data and the technical metadata information, and send the name association information to the big data platform. After the big data platform receives the name association information, the big data platform writes the name association information into the metadata management system database. It should be noted that each input data and output data has corresponding technical metadata, business metadata and process metadata.
进一步地,执行器可在将过程元数据发送给大数据平台时,一起将名称关联信息发送给大数据平台。Further, when the executor sends the process metadata to the big data platform, it can also send the name association information to the big data platform.
本实施例通过建立过程元数据的输入数据名称和输出数据名称与对应的技术元数据的数据名称之间的关联,以建立获取任务与Hadoop任务之间的关联,Hadoop任务与技术元数据的关系,进而建立了过程元数据和技术元数据之间的关联,以便于用户根据元数据管理数据库中的名称关联信息快速确定数据被那些任务使用,或者数据由那些任务生产。This embodiment establishes the association between the input data name and the output data name of the process metadata and the data name of the corresponding technical metadata to establish the association between the acquisition task and the Hadoop task, the relationship between the Hadoop task and the technical metadata , and then establishes the association between process metadata and technical metadata, so that users can quickly determine which tasks the data is used by or produced by those tasks according to the name association information in the metadata management database.
进一步地,提出本发明元数据获取方法第五实施例。Further, a fifth embodiment of the metadata acquisition method of the present invention is proposed.
所述元数据获取方法第四实施例与所述元数据获取方法第一、第二、第三或第四实施例的区别在于,当所述获取任务获取的元数据是业务元数据时,元数据获取方法还包括:The difference between the fourth embodiment of the metadata acquisition method and the first, second, third or fourth embodiments of the metadata acquisition method is that when the metadata acquired by the acquisition task is business metadata, the metadata Data acquisition methods also include:
步骤k,确定所述业务元数据与对应技术元数据的第一关联信息,以及所述业务元数据与对应的业务产品信息的第二关联信息。Step k, determining first association information between the business metadata and corresponding technical metadata, and second association information between the business metadata and corresponding business product information.
当获取指令是获取业务元数据时,即获取任务获取的元数据是业务元数据时,在执行器获取到业务元数据后,执行器确定所获取的业务元数据与对应技术元数据的第一关联信息,以及业务元数据与对应的业务产品信息的第二关联信息。其中,业务元数据的信息中主要包括数据表的业务属性,业务属性包括:数据表所属的数据系统,数据表所属的业务产品和数据表与数据系统之间的关联信息。需要说明的是,数据表对应着一个数据系统,该数据系统存在多个层级的子数据系统,在最底层的子数据系统中,存储有业务元数据对应的数据表,该数据表中的各个字段的字段类型、表字段名称、注释(包括字段注释和表注释)和字段长度等就是技术元数据。因此,第一关联信息就是数据系统和数据表之间的关联关系,即通过第一关联信息,可确定数据表所在的数据系统,具体地,第一关联信息可为数据系统的名称(包括各个子系统的名称)和关联的数据表名称等;数据表与数据系统之间的关联信息即为数据表与各个数据系统之间的关联关系,通过该关联信息,即可确定业务元数据对应数据表的存储位置。第二关联信息是业务产品信息与数据系统之间的关联关系,即通过第二关联信息,可确定数据系统对应的业务产品,具体地,业务产品信息可包括业务产品名称和产品编码等,第二关联信息可为业务产品名称和关联的数据系统名称。When the acquisition instruction is to acquire business metadata, that is, when the metadata acquired by the acquisition task is business metadata, after the executor acquires the business metadata, the executor determines the first difference between the acquired business metadata and the corresponding technical metadata. Association information, and second association information between the business metadata and the corresponding business product information. Among them, the business metadata information mainly includes the business attributes of the data table, and the business attributes include: the data system to which the data table belongs, the business product to which the data table belongs, and the association information between the data table and the data system. It should be noted that the data table corresponds to a data system, and the data system has multiple levels of sub-data systems. In the bottom sub-data system, the data table corresponding to the business metadata is stored. The field type, table field name, comment (including field comment and table comment) and field length of the field are technical metadata. Therefore, the first association information is the association relationship between the data system and the data table, that is, through the first association information, the data system where the data table is located can be determined. Specifically, the first association information can be the name of the data system (including each name of the subsystem) and the name of the associated data table, etc.; the association information between the data table and the data system is the association relationship between the data table and each data system. Through this association information, the corresponding data of the business metadata can be determined The storage location of the table. The second association information is the association relationship between the business product information and the data system, that is, through the second association information, the business product corresponding to the data system can be determined. Specifically, the business product information can include the business product name and product code, etc., the first The second association information may be the name of the business product and the name of the associated data system.
具体地,当获取业务元数据时,执行器获取业务元数据的数据系统为CMDB和产品目录。在获取业务元数据过程中,执行器通过元数据获取工具在CMDB中获取业务元数据,然后将属于同一数据的业务元数据和技术元数据进行关联,得到业务元数据和对应技术元数据的第一关联信息。执行器通过元数据获取工具在产品目录中读取业务产品信息,并该业务元数据与对应的业务产品信息进行关联,得到第二关联信息。Specifically, when obtaining the business metadata, the data system for the executor to obtain the business metadata is the CMDB and the product catalog. In the process of obtaining business metadata, the executor obtains business metadata in the CMDB through the metadata acquisition tool, and then associates the business metadata and technical metadata belonging to the same data to obtain the business metadata and the corresponding technical metadata. 1. Related information. The executor reads the business product information in the product catalog through the metadata acquisition tool, and associates the business metadata with the corresponding business product information to obtain the second associated information.
步骤l,将所述第一关联信息和所述第二关联信息发送给大数据平台,以供所述大数据平台将所述第一关联信息和所述第二关联信息存储至元数据管理系统数据库。Step 1, sending the first associated information and the second associated information to a big data platform for the big data platform to store the first associated information and the second associated information in a metadata management system database.
当执行器得到第一关联信息和第二关联信息后,执行器将第一关联信息和第二关联信息发送给大数据平台。当大数据平台接收到执行器发送的第一关联信息和第二关联信息后,大数据平台将第一关联信息和第二关联信息存储至元数据关联系统数据库中,即将第一关联信息和第二关联信息写入元数据关联系统数据库中。After the executor obtains the first associated information and the second associated information, the executor sends the first associated information and the second associated information to the big data platform. After the big data platform receives the first association information and the second association information sent by the executor, the big data platform stores the first association information and the second association information in the metadata association system database, that is, the first association information and the second association information Two association information is written into the metadata association system database.
本实施例通过在获取到业务元数据和技术元数据后,建立业务元数据和技术元数据之间的关联,以及建立业务产品和业务元数据之间的关联,通过业务产品和业务元数据之间的关联,可建立业务产品和业务系统之间的关联,并将对应的关联信息发送至元数据管理系统数据库中,以便于在元数据管理系统数据库中快速查找到业务元数据和技术元数据之间的关联关系,以及快速确定业务产品对应的数据系统。In this embodiment, after the business metadata and technical metadata are obtained, the association between the business metadata and the technical metadata is established, and the association between the business product and the business metadata is established, and the relationship between the business product and the business metadata The association between business products and business systems can be established, and the corresponding association information can be sent to the metadata management system database, so as to quickly find business metadata and technical metadata in the metadata management system database The relationship between them, and quickly determine the data system corresponding to the business product.
此外,本发明实施例还提出一种元数据获取装置,所述元数据获取装置应用于调度器,所述元数据获取装置包括:In addition, an embodiment of the present invention also proposes a metadata acquisition device, the metadata acquisition device is applied to a scheduler, and the metadata acquisition device includes:
第一检测模块,用于当侦测到获取元数据的获取指令后,检测当前时间是否处于所述获取指令对应获取任务的执行时间范围内;The first detection module is used to detect whether the current time is within the execution time range of the acquisition task corresponding to the acquisition instruction after detecting the acquisition instruction for acquiring metadata;
第一确定模块,用于若所述当前时间处于所述执行时间范围内,则确定与所述调度器连接的执行器中,资源利用率最小的目标执行器;A first determination module, configured to determine the target executor with the smallest resource utilization among the executors connected to the scheduler if the current time is within the execution time range;
第一发送模块,用于将所述获取任务发送给所述目标执行器,以供所述目标执行器根据所述获取任务采用对应的获取工具在对应的数据系统中获取所述元数据。The first sending module is configured to send the acquisition task to the target executor, so that the target executor acquires the metadata in a corresponding data system by using a corresponding acquisition tool according to the acquisition task.
进一步地,所述第一确定模块包括:Further, the first determination module includes:
第一获取单元,用于若所述当时时间处于所述执行时间范围内,则获取与所述调度器连接的各个执行器当前的中央处理器CPU资源利用率;A first acquisition unit, configured to acquire the current central processing unit CPU resource utilization rate of each executor connected to the scheduler if the current time is within the execution time range;
第一确定单元,用于将所述CPU资源利用率最小的执行器确定为目标执行器。The first determining unit is configured to determine the executor with the smallest CPU resource utilization as the target executor.
此外,本发明实施例还提出一种元数据获取装置,所述元数据获取装置应用于执行器,所述元数据获取装置包括:In addition, an embodiment of the present invention also proposes a metadata acquisition device, the metadata acquisition device is applied to an executor, and the metadata acquisition device includes:
获取模块,用于当接收到调度器发送的获取任务后,获取所述获取任务对应的执行参数;An acquisition module, configured to acquire execution parameters corresponding to the acquisition task after receiving the acquisition task sent by the scheduler;
连接模块,用于根据所述执行参数连接存储所述获取任务对应元数据的数据系统;A connection module, configured to connect to a data system that stores metadata corresponding to the acquisition task according to the execution parameters;
第二确定模块,用于根据所述执行参数确定在所述数据系统中获取元数据的获取工具;A second determining module, configured to determine an acquisition tool for acquiring metadata in the data system according to the execution parameters;
所述获取模块还用于根据所述获取工具在所连接的所述数据系统中获取所述元数据。The acquisition module is further configured to acquire the metadata in the connected data system according to the acquisition tool.
进一步地,所述元数据获取装置还包括:Further, the metadata acquisition device also includes:
存储模块,用于将所述元数据存储至大数据平台中,以供所述大数据平台将所述元数据的数据格式转换成元数据存储模型对应的数据格式,得到格式转换后的元数据,并返回格式转换成功的成功消息;A storage module, configured to store the metadata in the big data platform, so that the big data platform can convert the data format of the metadata into a data format corresponding to the metadata storage model, and obtain the format-converted metadata , and returns a success message indicating that the format conversion is successful;
触发模块,用于当接收到所述成功消息后,触发将元数据存储至元数据管理数据库的存储指令;A trigger module, configured to trigger a storage instruction for storing metadata to a metadata management database after receiving the success message;
第二发送模块,用于将所述存储指令发送给所述大数据平台,以供所述大数据平台根据所述存储指令将格式转换后的所述元数据存储至所述元数据管理数据库。The second sending module is configured to send the storage instruction to the big data platform, so that the big data platform stores the format-converted metadata in the metadata management database according to the storage instruction.
进一步地,所述元数据获取装置还包括:Further, the metadata acquisition device also includes:
第二检测模块,用于检测是否接收到所述大数据平台发送的元数据存储成功的提示信息;The second detection module is used to detect whether the prompt information of successful metadata storage sent by the big data platform is received;
所述第二发送模块还用于若接收到所述提示信息,则将所述提示信息发送给所述调度器,以供所述调度器根据所述提示信息记录所述获取任务对应的任务状态。The second sending module is further configured to send the prompt information to the scheduler if the prompt information is received, so that the scheduler can record the task state corresponding to the acquisition task according to the prompt information .
进一步地,所述元数据获取装置还包括:Further, the metadata acquisition device also includes:
所述获取模块还用于获取所述过程元数据对应的执行记录;The obtaining module is also used to obtain the execution record corresponding to the process metadata;
解析模块,用于解析所述过程元数据对应的执行记录,以得到所述过程元数据对应执行日志的存储路径;An analysis module, configured to analyze the execution record corresponding to the process metadata, so as to obtain the storage path of the execution log corresponding to the process metadata;
所述获取模块还用于根据所述存储路径获取所述执行日志;The acquiring module is further configured to acquire the execution log according to the storage path;
所述第二确定模块还用于根据所述执行日志确定与所述过程元数据关联的任务标识;根据所述任务标识确定所述过程元数据对应的输入数据和输出数据;The second determining module is further configured to determine a task identifier associated with the process metadata according to the execution log; determine input data and output data corresponding to the process metadata according to the task identifier;
关联模块,用于将所述输入数据名称和所述输出数据名称与对应的技术元数据的数据名称关联,以得到所述输入数据和输出数据与所述技术元数据之间的名称关联信息;An associating module, configured to associate the input data name and the output data name with the data name of the corresponding technical metadata, so as to obtain name association information between the input data and output data and the technical metadata;
第三发送模块,用于将所述名称关联信息发送给大数据平台,以供所述大数据平台将所述关联信息存储至元数据管理系统数据库中。The third sending module is configured to send the name association information to a big data platform, so that the big data platform can store the association information in a metadata management system database.
进一步地,所述元数据获取装置还包括:Further, the metadata acquisition device also includes:
所述第二确定模块还用于确定所述业务元数据与对应技术元数据的第一关联信息,以及所述业务元数据与对应的业务产品信息的第二关联信息;The second determination module is also used to determine first association information between the business metadata and corresponding technical metadata, and second association information between the business metadata and corresponding business product information;
第四发送模块,用于将所述第一关联信息和所述第二关联信息发送给大数据平台,以供所述大数据平台将所述第一关联信息和所述第二关联信息存储至元数据管理系统数据库。A fourth sending module, configured to send the first associated information and the second associated information to a big data platform, so that the big data platform can store the first associated information and the second associated information in Metadata management system database.
进一步地,所述获取模块还用于根据所述执行参数确定存储所述获取任务对应元数据的数据系统的接口路径和存储类型;Further, the acquisition module is further configured to determine, according to the execution parameters, the interface path and storage type of the data system storing the metadata corresponding to the acquisition task;
所述连接模块还用于根据所述接口路径连接所述数据系统;The connection module is also used to connect the data system according to the interface path;
所述第二确定模块还用于根据所述存储类型确定在所述数据系统中获取数据的获取工具。The second determination module is further configured to determine an acquisition tool for acquiring data in the data system according to the storage type.
本发明元数据获取装置具体实施方式与上述元数据获取方法各实施例基本相同,在此不再赘述。The specific implementation manners of the metadata acquisition device of the present invention are basically the same as the embodiments of the above metadata acquisition method, and will not be repeated here.
此外,本发明实施例还提出一种计算机可读存储介质,所述计算机可读存储介质上存储有元数据获取程序,所述元数据获取程序被处理器执行时实现如上所述的元数据获取方法的步骤。In addition, an embodiment of the present invention also proposes a computer-readable storage medium, where a metadata acquisition program is stored on the computer-readable storage medium, and when the metadata acquisition program is executed by a processor, the above-mentioned metadata acquisition is realized. method steps.
本发明计算机可读存储介质具体实施方式与上述元数据获取方法各实施例基本相同,在此不再赘述。The specific implementation manners of the computer-readable storage medium of the present invention are basically the same as the above embodiments of the metadata acquisition method, and will not be repeated here.
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者装置不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者装置所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者装置中还存在另外的相同要素。It should be noted that, in this document, the term "comprising", "comprising" or any other variation thereof is intended to cover a non-exclusive inclusion such that a process, method, article or apparatus comprising a set of elements includes not only those elements, It also includes other elements not expressly listed, or elements inherent in the process, method, article, or device. Without further limitations, an element defined by the phrase "comprising a ..." does not preclude the presence of additional identical elements in the process, method, article, or apparatus comprising that element.
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。The serial numbers of the above embodiments of the present invention are for description only, and do not represent the advantages and disadvantages of the embodiments.
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。The above are only preferred embodiments of the present invention, and are not intended to limit the patent scope of the present invention. Any equivalent structure or equivalent process conversion made by using the description of the present invention and the contents of the accompanying drawings, or directly or indirectly used in other related technical fields , are all included in the scope of patent protection of the present invention in the same way.
Claims (16)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201811551965.4ACN109656963B (en) | 2018-12-18 | 2018-12-18 | Metadata acquisition method, device, device and computer-readable storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201811551965.4ACN109656963B (en) | 2018-12-18 | 2018-12-18 | Metadata acquisition method, device, device and computer-readable storage medium |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN109656963A CN109656963A (en) | 2019-04-19 |
| CN109656963Btrue CN109656963B (en) | 2023-06-09 |
Family
ID=66114533
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201811551965.4AActiveCN109656963B (en) | 2018-12-18 | 2018-12-18 | Metadata acquisition method, device, device and computer-readable storage medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN109656963B (en) |
Families Citing this family (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110377568A (en)* | 2019-07-26 | 2019-10-25 | 北京明略软件系统有限公司 | A kind of metadata acquisition method and device |
| CN110516130A (en)* | 2019-08-28 | 2019-11-29 | 北京明略软件系统有限公司 | Metadata processing method and device, storage medium, electronic device |
| CN111182026B (en)* | 2019-11-27 | 2023-05-12 | 广西金慕联行数字科技有限公司 | Intelligent cloud box |
| CN110968592B (en)* | 2019-12-06 | 2023-11-21 | 深圳前海环融联易信息科技服务有限公司 | Metadata acquisition method, metadata acquisition device, computer equipment and computer readable storage medium |
| CN111381951B (en)* | 2020-03-06 | 2023-06-30 | 北京思特奇信息技术股份有限公司 | Dirty data processing method, device and storage medium in system architecture |
| CN111367984B (en)* | 2020-03-11 | 2023-03-21 | 中国工商银行股份有限公司 | Method and system for loading high-timeliness data into data lake |
| CN111651531B (en)* | 2020-06-05 | 2024-04-09 | 深圳前海微众银行股份有限公司 | Data importing method, device, equipment and computer storage medium |
| CN111782886B (en)* | 2020-06-28 | 2024-08-09 | 杭州海康威视数字技术股份有限公司 | Metadata management method and device |
| CN111984380B (en)* | 2020-08-21 | 2024-07-30 | 北京金山云网络技术有限公司 | Stream computing service system and control method and device thereof |
| CN114357254A (en)* | 2021-12-30 | 2022-04-15 | 思必驰科技股份有限公司 | Metadata management method, metadata management terminal, electronic device and storage medium |
| CN114579283B (en)* | 2022-03-25 | 2025-07-25 | 胜斗士(上海)科技技术发展有限公司 | Task scheduling method, system and device |
| CN114936298A (en)* | 2022-07-04 | 2022-08-23 | 抖音视界(北京)有限公司 | Metadata processing method and device, electronic equipment and storage medium |
| CN120218545B (en)* | 2025-03-25 | 2025-09-05 | 成都墨科科技有限公司 | Metadata-driven ubiquitous equipment access and monitoring system |
Family Cites Families (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101566981A (en)* | 2008-04-24 | 2009-10-28 | 长沙创智天马财务软件有限公司 | Method for establishing dynamic virtual data base in analyzing and processing system |
| CN102270225B (en)* | 2011-06-28 | 2015-10-21 | 用友网络科技股份有限公司 | Data change daily record method for supervising and data change daily record supervising device |
| CN103618652B (en)* | 2013-12-17 | 2018-03-20 | 沈阳觉醒软件有限公司 | A kind of audit of business datum and depth analysis system and method |
| CN105045656B (en)* | 2015-06-30 | 2018-11-30 | 深圳清华大学研究院 | Big data storage and management method based on virtual container |
| US10394637B2 (en)* | 2015-09-04 | 2019-08-27 | American Express Travel Related Services Company, Inc. | Systems and methods for data validation and processing using metadata |
| CN108846076A (en)* | 2018-06-08 | 2018-11-20 | 山大地纬软件股份有限公司 | The massive multi-source ETL process method and system of supporting interface adaptation |
- 2018
- 2018-12-18CNCN201811551965.4Apatent/CN109656963B/enactiveActive
Non-Patent Citations (2)
| Title |
|---|
| Metadata integration architecture in enterprise data warehouse system;Yu QianCheng;《The 2nd International Conference on information Science and Engineering》;340-343* |
| Research and Application of Data Modelling and Integration Based on Metadata;Jiecai Zheng,Xueqing Li;《2015 7th International Conference Based on Information Technology in Medicine and Education(ITME)》;525-528* |
Also Published As
| Publication number | Publication date |
|---|---|
| CN109656963A (en) | 2019-04-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN109656963B (en) | Metadata acquisition method, device, device and computer-readable storage medium | |
| US12287794B2 (en) | Data serialization in a distributed event processing system | |
| CN110196888B (en) | Hadoop-based data updating method, device, system and medium | |
| CN110908641B (en) | Visualization-based stream computing platform, method, device and storage medium | |
| JP6266630B2 (en) | Managing continuous queries with archived relations | |
| US9927992B2 (en) | Segmented database migration | |
| US10719506B2 (en) | Natural language query generation | |
| CN112416991A (en) | Data processing method and device and storage medium | |
| US10394805B2 (en) | Database management for mobile devices | |
| US20230185472A1 (en) | Dynamic system workload placement in cloud infrastructures | |
| CN114547206A (en) | Data synchronization method and data synchronization system | |
| US20140006000A1 (en) | Built-in response time analytics for business applications | |
| US11620164B1 (en) | Virtual partitioning of a shared message bus | |
| US8930426B2 (en) | Distributed requests on remote data | |
| US11748441B1 (en) | Serving real-time big data analytics on browser using probabilistic data structures | |
| CN120610804A (en) | Resource scheduling method, device, electronic equipment, computer readable storage medium and computer program product | |
| HK40038255A (en) | Data processing method and apparatus, and storage medium | |
| CN111506459A (en) | Data import method, device, device and computer storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |