CN109344845B - A Feature Matching Method Based on Triplet Deep Neural Network Structure - Google Patents
A Feature Matching Method Based on Triplet Deep Neural Network StructureDownload PDFInfo
- Publication number
- CN109344845B CN109344845BCN201811112938.7ACN201811112938ACN109344845BCN 109344845 BCN109344845 BCN 109344845BCN 201811112938 ACN201811112938 ACN 201811112938ACN 109344845 BCN109344845 BCN 109344845B
- Authority
- CN
- China
- Prior art keywords
- feature
- matching
- neural network
- deep neural
- image
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images


Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/40—Extraction of image or video features
- G06V10/44—Local feature extraction by analysis of parts of the pattern, e.g. by detecting edges, contours, loops, corners, strokes or intersections; Connectivity analysis, e.g. of connected components
- G06V10/443—Local feature extraction by analysis of parts of the pattern, e.g. by detecting edges, contours, loops, corners, strokes or intersections; Connectivity analysis, e.g. of connected components by matching or filtering
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Biophysics (AREA)
- Evolutionary Computation (AREA)
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- Biomedical Technology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Computational Linguistics (AREA)
- Data Mining & Analysis (AREA)
- Multimedia (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Image Analysis (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明属于图像处理技术领域,涉及一种基于深度学习的图像特征匹配方法。The invention belongs to the technical field of image processing, and relates to an image feature matching method based on deep learning.
背景技术Background technique
在计算机视觉应用中,计算良好的特征描述是图像匹配、目标定位、三维重建等的一个重要的组成部分,对最终算法的准确性起了非常关键的作用。在过去的十几年里,计算特征描述一直是图像处理领域的研究热点。一般来说,计算特征描述可以分为人工设计和基于学习的方法。利用人工设计的方法进行特征提取时,很难做到综合考虑各种因素从而得到有效的描述;在复杂情况下很难达到良好的性能,而且调节需要大量的时间。采用基于学习的方法来计算特征描述,可以自动学习良好的特征,免去人工设计过程。传统的SIFT及基于深度学习的TFeat、HardNet等特征描述方法在匹配性能上较差,影响图像匹配的应用价值。In computer vision applications, well-computed feature descriptions are an important part of image matching, target localization, 3D reconstruction, etc., and play a critical role in the accuracy of the final algorithm. Computational feature description has been a research hotspot in the field of image processing over the past decade. In general, computational feature descriptions can be divided into human-designed and learning-based methods. When using artificially designed methods for feature extraction, it is difficult to comprehensively consider various factors to obtain an effective description; it is difficult to achieve good performance in complex situations, and adjustment requires a lot of time. Using a learning-based approach to compute feature descriptions can automatically learn good features, eliminating the need for manual design processes. Traditional SIFT and deep learning-based TFeat, HardNet and other feature description methods have poor matching performance, which affects the application value of image matching.
发明内容SUMMARY OF THE INVENTION
本发明要解决的技术问题是:本发明的目的在于解决现有技术的SIFT及基于深度学习的TFeat、HardNet等特征描述方法存在匹配性能较差的问题,提出一种基于Triplet深度神经网络结构的特征匹配方法。The technical problem to be solved by the present invention is: the purpose of the present invention is to solve the problem of poor matching performance in feature description methods such as SIFT and deep learning-based TFeat, HardNet, etc. Feature matching method.
本发明为解决上述技术问题采取的技术方案是:The technical scheme that the present invention takes for solving the above-mentioned technical problems is:
一种基于Triplet深度神经网络结构的特征匹配方法,所述方法包括如下步骤:A feature matching method based on Triplet deep neural network structure, the method comprises the steps:
步骤一:训练基于Triplet结构的深度神经网络Step 1: Train a Deep Neural Network Based on Triplet Structure
Triplet结构的深度神经网络输入为三元组,该三元组由三个样本构成:一个是从训练数据集中随机选一个样本,该样本称为参考样本,然后再随机选取一个和参考样本属于同一类的样本和不同类的样本,这两个样本分别称为同类样本和异类样本;三个样本构成一个三元组,通过损失函数来训练整个网络;The input of the triplet structure of the deep neural network is a triplet, and the triplet consists of three samples: one is to randomly select a sample from the training data set, which is called a reference sample, and then randomly select a sample that belongs to the same reference sample. Class samples and samples of different classes, these two samples are called homogeneous samples and heterogeneous samples respectively; three samples form a triple, and the entire network is trained through the loss function;
基于Triplet结构的深度神经网络训练过程如下:The training process of deep neural network based on Triplet structure is as follows:
从训练数据库中生成三元组,其中


训练一个深度神经网络,由网络输出得到每组样本相应的特征表达,分别记为:











该不等式定义了同类样本和异类样本之间的距离关系,即:所有同类样本之间的距离加上最小间隔λ,要小于异类样本之间的距离;当距离关系不满足上述不等式时,可通过求解下列损失函数:This inequality defines the distance relationship between similar samples and heterogeneous samples, that is: the distance between all similar samples plus the minimum interval λ is smaller than the distance between heterogeneous samples; when the distance relationship does not satisfy the above inequality, it can be passed through Solve the following loss function:

+表示[]内的值大于零的时候,取该值为误差,小于零的时候,误差为零;+ means that when the value in [] is greater than zero, take the value as the error, and when it is less than zero, the error is zero;
根据对正负匹配对距离分布的分析,对正负匹配对的均值和方差做约束以减小重叠区域面积,其中均值采用如下约束:According to the analysis of the distance distribution of the positive and negative matching pairs, the mean and variance of the positive and negative matching pairs are constrained to reduce the area of the overlapping area, and the mean value adopts the following constraints:

其中m是两分布均值之间的最小距离的间隔因子,μneg表示负匹配对的距离均值,μpos表示正匹配对的距离均值;where m is the interval factor of the minimum distance between the means of the two distributions, μneg represents the distance mean of negative matching pairs, and μpos represents the distance mean of positive matching pairs;
对分布的方差做如下约束:The variance of the distribution is constrained as follows:
Lvar=σpos+σneg (4)Lvar =σpos +σneg (4)
其中σpos表示正匹配对的方差,σneg表示负匹配对的方差;where σpos represents the variance of positive matching pairs, and σneg represents the variance of negative matching pairs;
将三元组误差函数、均值约束、方差约束结合起来得到最终损失函数:Combine the triplet error function, mean constraint, and variance constraint to get the final loss function:
Lloss=Ltri+Lmean+Lvar (5)Lloss =Ltri +Lmean +Lvar (5)
利用损失函数Lloss分别对



步骤二:图像的特征点检测Step 2: Feature point detection of the image
对目标图像和待匹配图像分别进行特征点检测,Feature point detection is performed on the target image and the image to be matched, respectively.
利用FAST(Features from Accelerated Segment Test)算法做图像特征点检测:先通过图像上各像素点与其对应圆周上像素的差值是否满足设定阈值来快速筛选出可能的兴趣点,然后,使用ID3(Iterative Dichotomiser 3)算法训练一个决策树,将特征点圆周上的16个像素输入决策树中,进一步筛选出最优的特征点;Use the FAST (Features from Accelerated Segment Test) algorithm to detect image feature points: first, the possible points of interest are quickly screened out by whether the difference between each pixel on the image and the pixel on the corresponding circumference meets the set threshold, and then, using ID3 ( Iterative Dichotomiser 3) The algorithm trains a decision tree, and inputs 16 pixels on the circumference of the feature point into the decision tree, and further filters out the optimal feature point;
使用非极大值抑制(NMS)算法去除局部密集特征点以减小局部特征点聚集;计算每一个特征点的响应大小,对临近特征点比较,保留响应值大的特征点,删除其余特征点;分别得到目标图像、待匹配图像的特征点;Use non-maximum suppression (NMS) algorithm to remove local dense feature points to reduce local feature point aggregation; calculate the response size of each feature point, compare adjacent feature points, retain feature points with large response values, and delete the rest. ; Obtain the feature points of the target image and the image to be matched respectively;
步骤三:用训练好的神经网络计算目标图像、待匹配图像上各特征点的特征描述子,Step 3: Use the trained neural network to calculate the target image and the feature descriptors of each feature point on the image to be matched,
以每个特征点为中心提取一个分辨率为32*32大小的正方形图像块,将其输入到训练好的深度神经网络中,得到输出为128维的特征描述子;Extract a square image block with a resolution of 32*32 centered on each feature point, input it into the trained deep neural network, and obtain a 128-dimensional feature descriptor as the output;
步骤四:使用高维数据的近似最近邻(FLANN)算法进行快速匹配Step 4: Use the Approximate Nearest Neighbor (FLANN) algorithm for high-dimensional data for fast matching
利用FLANN算法计算目标图像上每个特征点与待匹配图像上所有特征点的128维特征描述子的欧式距离以实现快速匹配,欧式距离越小,则相似度越高,当欧式距离小于等于设定的阈值时,判定为匹配成功;The FLANN algorithm is used to calculate the Euclidean distance between each feature point on the target image and the 128-dimensional feature descriptor of all feature points on the image to be matched to achieve fast matching. The smaller the Euclidean distance, the higher the similarity. When the Euclidean distance is less than or equal to set When the set threshold is reached, it is determined that the matching is successful;
FLANN算法是一种利用k-d树实现快速最近邻搜索算法,适用于高维特征的快速匹配。该发明的特征点匹配是利用FLANN算法,通过计算两组特征点的128维特征描述子的欧式距离实现的。欧式距离越小,则相似度越高,当欧式距离小于设定的阈值时,可以判定为匹配成功;FLANN algorithm is a fast nearest neighbor search algorithm using k-d tree, which is suitable for fast matching of high-dimensional features. The feature point matching of the invention is realized by using the FLANN algorithm by calculating the Euclidean distance of the 128-dimensional feature descriptors of the two sets of feature points. The smaller the Euclidean distance, the higher the similarity. When the Euclidean distance is less than the set threshold, it can be determined that the matching is successful;
步骤五:计算仿射变换矩阵,完成特征匹配Step 5: Calculate the affine transformation matrix to complete feature matching
由于特征匹配的结果中往往包含一些错误的匹配对,在特征匹配的基础上,利用随机抽样一致性(RANSAC)算法计算两幅图像的仿射变换矩阵。Since the result of feature matching often contains some wrong matching pairs, on the basis of feature matching, the affine transformation matrix of the two images is calculated by using the random sampling consistency (RANSAC) algorithm.
在步骤四中,特征点匹配是利用FLANN算法,通过计算两组特征点的128维特征描述子的欧式距离实现,具体过程为:In step 4, the feature point matching is realized by using the FLANN algorithm by calculating the Euclidean distance of the 128-dimensional feature descriptors of the two sets of feature points. The specific process is as follows:
(1)计算待匹配的特征点各维度的方差,选取方差最大一维将特征集合划分成两部分,再在各子集重复相同的过程,以此方式建立k-d树保存特征;(1) Calculate the variance of each dimension of the feature points to be matched, select the one with the largest variance to divide the feature set into two parts, and then repeat the same process in each subset, and establish a k-d tree in this way to save the feature;
(2)做特征匹配时,进行基于k-d树的特征搜索,通过二叉查找和回溯操作找到最近邻匹配。(2) When doing feature matching, perform feature search based on k-d tree, and find nearest neighbor matching through binary search and backtracking operations.
步骤五的具体实现过程为:The specific implementation process of step 5 is as follows:
(1)从目标图像、待匹配图像的所有特征匹配结果中每次随机选出3组不共线点对,计算仿射变换矩阵,并测试其他所有匹配结果在此仿射变换矩阵下的误差,并统计小于设定误差阈值的匹配数目;(1) Randomly select 3 sets of non-collinear point pairs from all the feature matching results of the target image and the image to be matched, calculate the affine transformation matrix, and test the errors of all other matching results under this affine transformation matrix , and count the number of matches less than the set error threshold;
(2)重复第(1)步n次,并从最终结果中选择匹配数目最多的一组参数作为最终的仿射变换矩阵。(2) Repeat step (1) n times, and select a set of parameters with the largest number of matches from the final result as the final affine transformation matrix.
本发明的有益效果是:The beneficial effects of the present invention are:
本发明方法用高斯分布近似匹配特征对(正匹配对)与不匹配特征对(负匹配对)的距离分布,通过分析,得到两个匹配特征对重叠区域面积与两个分布统计信息的关系。由于两个匹配特征对距离分布中的重叠区域是容易产生误判的部分,即在这一区间的距离无法准确判定成匹配或者不匹配,因此减小这一混淆区域有利于提高特征度量时的准确性。为减小两个匹配特征对距离分布的重叠区域,本发明提出了一个新的损失函数,结合Triplet深度神经网络,可得到性能优异的特征描述,提高图像的特征匹配准确度。The method of the invention uses Gaussian distribution to approximate the distance distribution of matching feature pairs (positive matching pairs) and unmatched feature pairs (negative matching pairs). Since the overlapping area of the distance distribution of two matching feature pairs is a part that is prone to misjudgment, that is, the distance in this interval cannot be accurately determined as matching or mismatching, so reducing this confusion area is beneficial to improve the feature measurement. accuracy. In order to reduce the overlapping area of the distance distribution of the two matching feature pairs, the present invention proposes a new loss function, combined with the Triplet deep neural network, to obtain a feature description with excellent performance and improve the feature matching accuracy of the image.
本发明所述的方法弥补了图像匹配中人工设计特征描述时难于考虑各种综合因素、需要大量时间的不足。通过提出的一个对训练样本均值和方差做约束的新型损失函数,结合Triplet深度神经网络,可以自动学习到性能优异的图像特征点的特征描述,可大大提高图像的匹配准确度,可完全应用于实际的图像匹配中。The method of the present invention makes up for the shortcomings that it is difficult to consider various comprehensive factors and requires a lot of time when manually designing feature descriptions in image matching. Through the proposed new loss function that constrains the mean and variance of the training samples, combined with the Triplet deep neural network, the feature descriptions of image feature points with excellent performance can be automatically learned, which can greatly improve the matching accuracy of images, and can be fully applied to actual image matching.
本发明提出的基于Triplet深度神经网络结构的特征匹配方法,设计了一个对训练样本均值和方差做约束的新型损失函数,结合Triplet深度神经网络,可得到性能优异的特征描述。该方法用高斯分布描述匹配特征对和不匹配特征对的距离分布,根据减小特征匹配误差等价于减小两个匹配特征对距离分布重叠面积这一原则,得出对训练样本均值和方差做约束的新型损失函数。实验结果表明,与传统SIFT及基于深度学习的TFeat、HardNet等特征描述方法相比,所提出的基于Triplet深度神经网络结构的特征描述方法,在匹配性能上得到了提升,在实际的图像匹配上具有一定的应用价值。The feature matching method based on the triplet deep neural network structure proposed by the present invention designs a new loss function that constrains the mean and variance of the training samples, and combined with the triplet deep neural network, a feature description with excellent performance can be obtained. The method uses Gaussian distribution to describe the distance distribution of matched feature pairs and mismatched feature pairs. According to the principle that reducing the feature matching error is equivalent to reducing the overlapping area of the distance distribution of the two matching feature pairs, the mean and variance of the training samples are obtained. A novel loss function for constraints. The experimental results show that, compared with traditional SIFT and deep learning-based TFeat, HardNet and other feature description methods, the proposed feature description method based on Triplet deep neural network structure has been improved in matching performance, and in actual image matching. It has certain application value.
经测试,本发明训练的基于Triplet结构的深度神经网络的性能优于现有方法(参见表1)。用FPR95指标来评价网络性能。训练好网络后,输入从测式数据集中产生的匹配对,计算各匹配对的特征并计算匹配对的距离,基于所有匹配对的距离利用FPR95指标来评价网络性能;即对计算出来的所有距离从小到大排序,设定一距离阈值μ,在μ从最小移动到最大过程中,将小于阈值的匹配对都看作是正匹配,超过阈值的则认为是负匹配对,这样正匹配对的召回率将从0逐步增加到1。在召回率达到0.95时,低于阈值μ的匹配对中包含负匹配对的比例就是FPR95值。显然,该值越小表示误分类的样本越少,网络对距离的计算越准确。After testing, the performance of the deep neural network based on the triplet structure trained by the present invention is better than that of the existing method (see Table 1). Use the FPR95 metric to evaluate network performance. After training the network, input the matching pairs generated from the test data set, calculate the characteristics of each matching pair and calculate the distance of the matching pairs, and use the FPR95 indicator to evaluate the network performance based on the distances of all matching pairs; Sort from small to large, set a distance threshold μ, in the process of moving μ from the smallest to the largest, the matching pairs smaller than the threshold are regarded as positive matching, and those exceeding the threshold are regarded as negative matching pairs, so that the recall of positive matching pairs The rate will gradually increase from 0 to 1. When the recall rate reaches 0.95, the proportion of matching pairs below the threshold μ containing negative matching pairs is the FPR95 value. Obviously, the smaller the value is, the less misclassified samples are, and the more accurate the network calculates the distance.
附图说明Description of drawings
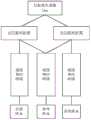
图1是本发明的图像匹配的流程图;Fig. 1 is the flow chart of the image matching of the present invention;
图2是本发明的Triplet深度神经网络结构;Fig. 2 is the Triplet deep neural network structure of the present invention;
图3是本发明的特征匹配的对比图,图中(a)为SIFT算法匹配,(b)为Triplet方法匹配。FIG. 3 is a comparison diagram of the feature matching of the present invention, in which (a) is the SIFT algorithm matching, and (b) is the Triplet method matching.
具体实施方式Detailed ways
下面结合本发明的附图,对本发明进行说明。The present invention will be described below with reference to the accompanying drawings of the present invention.
如图1至图3所示,一种基于Triplet深度神经网络结构的特征匹配方法,包括如下步骤:As shown in Figure 1 to Figure 3, a feature matching method based on Triplet deep neural network structure includes the following steps:
步骤一,利用UBC图像块匹配数据库,生成大量三元组训练数据,结合本发明中所提出的目标损失函数Lloss训练Triplet结构的深度神经网络并进行测试,triplet深度神经网络结构如图2所示。所用的网络结构为:三个卷积层加一个全连接层,前两个卷积层之后做非线性变换并接最大池化层,最后一层全连接层之后将特征归一化到单位向量。Step 1: UBC image block matching database is used to generate a large number of triplet training data, combined with the target loss function Lloss proposed in the present invention to train and test the deep neural network of the Triplet structure. The structure of the triplet deep neural network is shown in Figure 2. Show. The network structure used is: three convolutional layers plus a fully connected layer, the first two convolutional layers are followed by nonlinear transformation and the maximum pooling layer is connected, and the features are normalized to unit vectors after the last fully connected layer. .
步骤二,分别在原图像与目标图像中利用FAST算法检测特征点,使用ID3算法训练一个决策树,将特征点圆周上的16个像素输入决策树中,进筛选出最优的特征点,并用NMS算法去除局部密集特征点。Step 2: Use the FAST algorithm to detect the feature points in the original image and the target image respectively, use the ID3 algorithm to train a decision tree, input the 16 pixels on the circumference of the feature point into the decision tree, filter out the optimal feature points, and use NMS The algorithm removes local dense feature points.
步骤三,分别以原图像与目标图像上得到的特征点为中心,提取一个32*32大小的正方形图像块,将其输入到训练好的深度神经网络中,得到相应为128维的特征描述子。Step 3: Take the feature points obtained on the original image and the target image as the center, extract a square image block of size 32*32, input it into the trained deep neural network, and obtain a corresponding 128-dimensional feature descriptor .
步骤四,利用FLANN算法,通过计算两组特征点的128维特征描述子的欧式距离实现特征匹配。Step 4: Using the FLANN algorithm, feature matching is achieved by calculating the Euclidean distance of the 128-dimensional feature descriptors of the two sets of feature points.
步骤五,利用随机抽样一致性(RANSAC)算法计算两幅图像的仿射变换矩阵,计算出正确的特征匹配。Step 5: Use the random sampling consistency (RANSAC) algorithm to calculate the affine transformation matrix of the two images, and calculate the correct feature matching.
图3和表1分别给出本发明方法与其他方法的定性和定量比较结果。Figure 3 and Table 1 show the qualitative and quantitative comparison results of the method of the present invention and other methods, respectively.
如图3所示的特征匹配图对比图,本发明的Triplet方法实现的图像匹配正确性明显高于基于SIFT描述子的图像匹配。As shown in the feature matching diagram comparison diagram shown in FIG. 3 , the accuracy of the image matching realized by the Triplet method of the present invention is obviously higher than that of the image matching based on the SIFT descriptor.
如表1所示,与传统SIFT及基于深度学习的TFeat、HardNet等特征描述方法在UBC数据库中Notredame、Yosemite和Liberty公共数据集上做相比,本发明的Triplet方法,匹配准确度均有所提高。其中的数值表示在真正率达到95%时假正率的大小,该数值越小表示性能越好。As shown in Table 1, compared with the traditional SIFT and deep learning-based TFeat, HardNet and other feature description methods on the public data sets of Notredame, Yosemite and Liberty in the UBC database, the Triplet method of the present invention has better matching accuracy. improve. The value in it indicates the size of the false positive rate when the true rate reaches 95%, and the smaller the value, the better the performance.
实验表明,本发明一种基于Triplet深度神经网络结构的特征匹配方法,通过提出的一个对训练样本均值和方差做约束的新型损失函数,结合Triplet深度神经网络,得到性能优异的特征描述,大大提高图像的匹配的准确度,在实际图像匹配中具有一定的应用价值。Experiments show that a feature matching method based on the triplet deep neural network structure of the present invention can obtain a feature description with excellent performance through a proposed new loss function that constrains the mean and variance of the training samples, combined with the triplet deep neural network, and greatly improves the performance of the feature description. The accuracy of image matching has certain application value in actual image matching.
表1Table 1

表1是本发明的特征匹配的性能对比。Table 1 is a performance comparison of the feature matching of the present invention.
Claims (3)




















Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201811112938.7ACN109344845B (en) | 2018-09-21 | 2018-09-21 | A Feature Matching Method Based on Triplet Deep Neural Network Structure |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201811112938.7ACN109344845B (en) | 2018-09-21 | 2018-09-21 | A Feature Matching Method Based on Triplet Deep Neural Network Structure |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN109344845A CN109344845A (en) | 2019-02-15 |
| CN109344845Btrue CN109344845B (en) | 2020-06-09 |
Family
ID=65306260
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201811112938.7AExpired - Fee RelatedCN109344845B (en) | 2018-09-21 | 2018-09-21 | A Feature Matching Method Based on Triplet Deep Neural Network Structure |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN109344845B (en) |
Families Citing this family (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109948577B (en)* | 2019-03-27 | 2020-08-04 | 无锡雪浪数制科技有限公司 | Cloth identification method and device and storage medium |
| CN110135474A (en)* | 2019-04-26 | 2019-08-16 | 武汉市土地利用和城市空间规划研究中心 | A kind of oblique aerial image matching method and system based on deep learning |
| CN110148120B (en)* | 2019-05-09 | 2020-08-04 | 四川省农业科学院农业信息与农村经济研究所 | Intelligent disease identification method and system based on CNN and transfer learning |
| CN111915480B (en)* | 2020-07-16 | 2023-05-23 | 抖音视界有限公司 | Method, apparatus, device and computer readable medium for generating feature extraction network |
| CN113505929B (en)* | 2021-07-16 | 2024-04-16 | 中国人民解放军军事科学院国防科技创新研究院 | Topological optimal structure prediction method based on embedded physical constraint deep learning technology |
| CN114529739A (en)* | 2022-01-10 | 2022-05-24 | 武汉图科智能科技有限公司 | Image matching method |
| CN114972740A (en)* | 2022-07-29 | 2022-08-30 | 上海鹰觉科技有限公司 | Automatic ship sample collection method and system |
| CN115546521B (en)* | 2022-11-07 | 2024-05-07 | 佳木斯大学 | Point matching method based on key point response constraint |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105574215B (en)* | 2016-03-04 | 2019-11-12 | 哈尔滨工业大学深圳研究生院 | A kind of instance-level image search method indicated based on multilayer feature |
| CN106845330A (en)* | 2016-11-17 | 2017-06-13 | 北京品恩科技股份有限公司 | A kind of training method of the two-dimension human face identification model based on depth convolutional neural networks |
| CN106780906B (en)* | 2016-12-28 | 2019-06-21 | 北京品恩科技股份有限公司 | A kind of testimony of a witness unification recognition methods and system based on depth convolutional neural networks |
| CN106980641B (en)* | 2017-02-09 | 2020-01-21 | 上海媒智科技有限公司 | Unsupervised Hash quick picture retrieval system and unsupervised Hash quick picture retrieval method based on convolutional neural network |
| CN108399428B (en)* | 2018-02-09 | 2020-04-10 | 哈尔滨工业大学深圳研究生院 | Triple loss function design method based on trace ratio criterion |
- 2018
- 2018-09-21CNCN201811112938.7Apatent/CN109344845B/ennot_activeExpired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| CN109344845A (en) | 2019-02-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN109344845B (en) | A Feature Matching Method Based on Triplet Deep Neural Network Structure | |
| CN108921130B (en) | Video key frame extraction method based on saliency region | |
| CN109697692B (en) | Feature matching method based on local structure similarity | |
| CN107437246B (en) | Common significance detection method based on end-to-end full-convolution neural network | |
| CN112364881B (en) | An Advanced Sampling Consistency Image Matching Method | |
| CN103793702A (en) | Pedestrian re-identifying method based on coordination scale learning | |
| CN110738695B (en) | A Method for Eliminating Mismatched Image Feature Points Based on Local Transformation Model | |
| CN110909643B (en) | Remote sensing ship image small sample classification method based on nearest neighbor prototype representation | |
| CN104992177A (en) | Network pornographic image detection method based on deep convolutional neural network | |
| CN108765465A (en) | A kind of unsupervised SAR image change detection | |
| WO2021082428A1 (en) | Semi-supervised learning-based image classification method and apparatus, and computer device | |
| WO2023087953A1 (en) | Method and apparatus for searching for neural network ensemble model, and electronic device | |
| CN109903282B (en) | Cell counting method, system, device and storage medium | |
| CN107239792A (en) | A method and device for workpiece recognition based on binary descriptors | |
| Lin et al. | Hypergraph optimization for multi-structural geometric model fitting | |
| CN111339924A (en) | A Polarimetric SAR Image Classification Method Based on Superpixels and Fully Convolutional Networks | |
| CN110727819A (en) | A Scale-adaptive Pathological Whole Section Image Database Retrieval Method | |
| CN103823887B (en) | Based on low-order overall situation geometry consistency check error match detection method | |
| Xie et al. | Learning to find good correspondences of multiple objects | |
| CN114722226B (en) | A matching image adaptive retrieval method, device and storage medium | |
| CN115984178A (en) | Counterfeit image detection method, electronic device and computer-readable storage medium | |
| CN105095923A (en) | Image processing method and device | |
| CN118688599B (en) | Circuit system for measuring thyristors and capacitors in series inverter circuits | |
| CN107578445B (en) | Image Discriminant Region Extraction Method Based on Convolution Feature Spectrum | |
| CN115170793A (en) | Small sample image segmentation self-calibration method for industrial product quality inspection |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| CF01 | Termination of patent right due to non-payment of annual fee | ||
| CF01 | Termination of patent right due to non-payment of annual fee | Granted publication date:20200609 |