CN108829657B - Smoothing method and system - Google Patents
Smoothing method and systemDownload PDFInfo
- Publication number
- CN108829657B CN108829657BCN201810344157.4ACN201810344157ACN108829657BCN 108829657 BCN108829657 BCN 108829657BCN 201810344157 ACN201810344157 ACN 201810344157ACN 108829657 BCN108829657 BCN 108829657B
- Authority
- CN
- China
- Prior art keywords
- occurrence
- probability
- missing
- occurrences
- words
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images


Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/284—Lexical analysis, e.g. tokenisation or collocates
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Machine Translation (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本发明涉及自然语言处理技术领域,特别是涉及一种平滑处理方法和系统。The present invention relates to the technical field of natural language processing, in particular to a smoothing processing method and system.
背景技术Background technique
语言模型是处理自然语言过程中,根据语言客观事实而进行的语言抽象数学建模。语言模型会出现数据缺失,对于数据缺失,需要通过平滑算法来解决。平滑算法通过劫取已出现词语的概率,获得用于再分配的剩余概率,将可用于分配的概率按照一定规则分配给缺失词语,缺失词语分配而得的概率称为平滑概率。Language model is an abstract mathematical modeling of language based on the objective facts of language in the process of processing natural language. There will be missing data in the language model. For the missing data, it needs to be solved by a smoothing algorithm. The smoothing algorithm obtains the remaining probability for redistribution by robbing the probability of the words that have appeared, and assigns the probability that can be used for distribution to the missing words according to certain rules.
发明人发现在传统技术中存在以下问题,以Good Turing平滑算法为例,在 GoodTuring平滑算法中,通过平均分配的方式分配剩余频率,缺失数据进行平滑,但是平均分配的方式未必符合真实情况。因为数据缺失来自两种情况,一是词语本身出错,稀有词语在任何语料中都不可能出现,二是可能只是因为语料本身覆盖不够,出现未登录词语。传统的Good Turing平滑算法无法区分词语本身出错和语料本身覆盖不足这两种情况,导致GoodTuring平滑算法在实际应用中会造成大量误判。The inventor found that there are the following problems in the traditional technology. Taking the Good Turing smoothing algorithm as an example, in the Good Turing smoothing algorithm, the remaining frequencies are allocated by means of average distribution, and the missing data is smoothed, but the way of average allocation may not conform to the real situation. Because the missing data comes from two situations, one is that the words themselves are wrong, and rare words cannot appear in any corpus, and the other is that unregistered words appear simply because the corpus itself is not covered enough. The traditional Good Turing smoothing algorithm cannot distinguish between the error of the word itself and the insufficient coverage of the corpus itself, which leads to a large number of misjudgments in the practical application of the Good Turing smoothing algorithm.
综上所述,传统的平滑处理方式效果差。To sum up, the traditional smoothing method is ineffective.
发明内容SUMMARY OF THE INVENTION
基于此,有必要针对传统的平滑处理方式效果差问题,提供一种平滑处理方法和系统。Based on this, it is necessary to provide a smoothing method and system for the problem of poor effect of traditional smoothing methods.
一种平滑处理方法,包括以下步骤:统计缺失词语在目标语料库中的第一出现次数,其中,缺失词语为在原语料库中出现次数为0的词语;根据第一出现次数计算缺失词语的归一化频率指标;根据归一化频率指标和剩余概率计算缺失词语的平滑概率,并根据平滑概率对缺失词语进行平滑处理,其中,剩余概率为从原语料库中出现次数小于或等于k次的词语的出现概率之和,k为正整数。A smoothing processing method, comprising the following steps: counting the first occurrences of missing words in a target corpus, wherein the missing words are words with 0 occurrences in the original corpus; calculating the normalization of the missing words according to the first occurrences Frequency index; calculate the smoothing probability of the missing words according to the normalized frequency index and the residual probability, and smooth the missing words according to the smoothing probability, where the residual probability is the occurrence of words that appear less than or equal to k times from the original corpus The sum of probabilities, k is a positive integer.
上述平滑处理方法,统计缺失词语在目标语料库中的第一出现次数,根据第一出现次数计算缺失词语的归一化频率指标,根据归一化频率指标和剩余概率计算缺失词语的平滑概率,并根据平滑概率对缺失词语进行平滑处理;通过引入缺失词语在目标语料库中的第一出现次数,计算缺失词语的归一化频率指标,由缺失词语的归一化频率指标分配剩余概率,区分缺失词语可能出现的词语本身出错和语料本身覆盖不足这两种情况,获得反映缺失词语真实情况的平滑概率,对缺失词语进行平滑处理,减少误判,增强平滑处理效果。The above smoothing processing method counts the first occurrences of the missing words in the target corpus, calculates the normalized frequency index of the missing words according to the first occurrences, and calculates the smoothing probability of the missing words according to the normalized frequency index and the remaining probability, and The missing words are smoothed according to the smoothing probability; by introducing the first occurrence of the missing words in the target corpus, the normalized frequency index of the missing words is calculated, and the remaining probability is assigned by the normalized frequency index of the missing words to distinguish the missing words. In the case of possible errors in the words themselves and insufficient coverage of the corpus itself, a smooth probability reflecting the real situation of the missing words is obtained, and the missing words are smoothed to reduce misjudgments and enhance the smoothing effect.
进一步地,缺失词语为多个;根据第一出现次数计算缺失词语的归一化频率指标的步骤,包括以下步骤:计算各第一出现次数的对数值;对对数值求和,得到对数值之和;分别将各第一出现次数的对数值分别除以对数值之和,得到对应各缺失词语的归一化频率指标。Further, the number of missing words is multiple; the step of calculating the normalized frequency index of the missing words according to the first occurrence number includes the following steps: calculating the logarithm value of each first occurrence number; summing the logarithmic values to obtain the sum of the logarithmic values. and; divide the logarithmic value of each first occurrence by the sum of the logarithmic values to obtain the normalized frequency index corresponding to each missing word.
上述平滑处理方法,通过对各第一出现次数进行数值处理获得归一化频率指标,使得第一出现次数的归一化处理简便,另外对数的处理可以适合出现次数数值较大的情况。The above-mentioned smoothing processing method obtains the normalized frequency index by performing numerical processing on each first occurrence number, so that the normalization processing of the first occurrence number is simple, and the logarithmic processing can be suitable for the case where the numerical value of the occurrence number is relatively large.
进一步地,计算各第一出现次数的对数值的步骤,包括以下步骤:将各第一出现次数分别增加数值N,获得各个绝对出现次数;计算各绝对出现次数的对数值,将各绝对出现次数的对数值分别作为各第一出现次数的对数值,其中,N为大于1的正整数。Further, the step of calculating the logarithm value of each first number of occurrences includes the following steps: increasing each first number of occurrences by numerical value N to obtain each absolute number of occurrences; The logarithmic value of , respectively, is used as the logarithmic value of each first occurrence, where N is a positive integer greater than 1.
上述平滑处理方法,通过对选取的各第一出现次数分别增加数值N后,进行对数处理,可以避免第一出现次数为0导致无法进行对数处理的情况。In the above-mentioned smoothing processing method, the logarithmic processing is performed after adding the numerical value N to each of the selected first occurrence times, so as to avoid the situation that the logarithmic processing cannot be performed due to the first occurrence times being 0.
进一步地,根据归一化频率指标和剩余概率计算缺失词语的平滑概率的步骤,包括以下步骤:将缺失词语的归一化频率指标与第一剩余频率的乘积作为缺失词语的平滑概率。Further, the step of calculating the smoothing probability of the missing word according to the normalized frequency index and the residual probability includes the following steps: taking the product of the normalized frequency index of the missing word and the first residual frequency as the smoothing probability of the missing word.
上述平滑处理方法,通过乘法处理,按照缺失词语的归一化频率指标分配剩余概率,对缺失词语进行平滑处理,增强平滑处理效果。In the above-mentioned smoothing processing method, the residual probability is allocated according to the normalized frequency index of the missing words through multiplication processing, and the missing words are smoothed to enhance the smoothing processing effect.
进一步地,k为大于1的正整数;在根据归一化频率指标和剩余概率计算缺失词语的平滑概率的步骤之前,还包括以下步骤:获取各n元词语在原语料库中的第二出现次数,并计算各第二出现次数的和值;统计第二出现次数小于或等于k次的各n元词语的第三出现次数,并计算各第三出现次数的和值;根据各第二出现次数的和值以及各第三出现次数的和值计算剩余概率。Further, k is a positive integer greater than 1; before the step of calculating the smooth probability of the missing word according to the normalized frequency index and the residual probability, the following steps are also included: obtaining the second occurrence of each n-gram word in the original corpus, And calculate the sum of each second occurrence; count the third occurrence of each n-gram word whose second occurrence is less than or equal to k times, and calculate the sum of each third occurrence; The remaining probability is calculated from the sum and the sum of each third occurrence.
上述平滑处理方法,通过统计第二出现次数小于或等于k次的词语的第三出现次数以及各n元词语在原语料库中的第二出现次数,计算剩余概率,对缺失词语进行平滑处理,增强了平滑处理效果。The above smoothing processing method calculates the remaining probability by counting the third occurrence of words whose second occurrence is less than or equal to k times and the second occurrence of each n-gram word in the original corpus, and smoothing the missing words, which enhances Smooth processing effect.
进一步地,剩余概率为从原语料库中出现次数等于1次的词语的出现概率之和;在根据归一化频率指标和剩余概率计算缺失词语的平滑概率的步骤之前,还包括以下步骤:获取各n元词语在原语料库中的第二出现次数并计算各第二出现次数的和值;统计第二出现次数为1的单次出现词语个数;根据各第二出现次数的和值以及单次出现词语个数计算剩余概率。Further, the residual probability is the sum of the occurrence probabilities of words whose number of occurrences is equal to one from the original corpus; before the step of calculating the smooth probability of the missing words according to the normalized frequency index and the residual probability, the following steps are also included: obtaining each The second occurrences of n-gram words in the original corpus and the sum of the second occurrences are calculated; the number of single occurrences of which the second occurrence is 1 is counted; according to the sum of the second occurrences and the single occurrence The number of words calculates the remaining probability.
上述平滑处理方法,通过统计第二出现次数为1的单次出现词语个数及计算各第二出现次数的和值,计算剩余概率,对缺失词语进行平滑处理,增强了平滑处理效果。In the above smoothing method, by counting the number of single-occurring words whose second occurrence is 1 and calculating the sum of the second occurrences, calculating the remaining probability, and smoothing the missing words, the smoothing effect is enhanced.
进一步地,在根据归一化频率指标和剩余概率计算缺失词语的平滑概率的步骤之后,还包括以下步骤:获取n元词语在原语料库中的第二出现次数;根据第二出现次数计算已出现词语劫取后的第一出现概率;根据平滑概率和第一出现概率,对缺失词语所在的n元语法模型进行训练。Further, after the step of calculating the smooth probability of the missing word according to the normalized frequency index and the residual probability, it also includes the following steps: obtaining the second occurrence of the n-gram word in the original corpus; calculating the occurrence of the word according to the second occurrence. The first occurrence probability after hijacking; according to the smooth probability and the first occurrence probability, the n-gram model where the missing word is located is trained.
上述平滑处理方法,通过计算第一出现概率,根据平滑概率和第一出现概率,对缺失词语所在的n元语法模型进行训练,建立平滑处理后的n元语法模型,对n元语法模型进行平滑处理,增强平滑处理效果。In the above smoothing method, by calculating the first occurrence probability, according to the smoothing probability and the first occurrence probability, the n-gram model where the missing word is located is trained, the smoothed n-gram model is established, and the n-gram model is smoothed. processing to enhance the smoothing effect.
进一步地,目标语料库为以搜索引擎网站为入口的互联网语料库;第一出现次数为缺失词语在搜索引擎网站中搜索后的相关结果数。Further, the target corpus is an Internet corpus with a search engine website as an entrance; the first occurrence number is the number of relevant results after the missing word is searched on the search engine website.
上述平滑处理方法,借助互联网搜索引擎在互联网数据网络的数据库搜索缺失词语,可以扩大语料的覆盖范围,获得的第一出现次数能够符合真实情况,对数据缺失出现的两种情况进行区分,增强平滑处理效果。The above smoothing processing method can expand the coverage of the corpus by searching for the missing words in the database of the Internet data network with the help of the Internet search engine, and the obtained first occurrence times can conform to the real situation. processing effect.
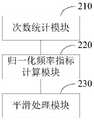
一种平滑处理系统,包括:次数统计模块,用于统计缺失词语在目标语料库中的第一出现次数,其中,缺失词语为在原语料库中出现次数为0的词语;归一化频率指标计算模块,用于根据第一出现次数计算缺失词语的归一化频率指标;平滑处理模块,用于根据归一化频率指标和剩余概率计算缺失词语的平滑概率,并根据平滑概率对缺失词语进行平滑处理,其中,剩余概率为从原语料库中出现次数小于或等于k次的词语的出现概率之和,k为正整数。A smoothing processing system, comprising: a frequency counting module for counting the first occurrences of missing words in a target corpus, wherein the missing words are words with 0 occurrences in the original corpus; a normalized frequency index calculation module, It is used to calculate the normalized frequency index of the missing words according to the first occurrence number; the smoothing processing module is used to calculate the smoothing probability of the missing words according to the normalized frequency index and the remaining probability, and smooth the missing words according to the smoothing probability, Among them, the residual probability is the sum of the occurrence probabilities of words whose occurrence times are less than or equal to k times from the original corpus, and k is a positive integer.
上述平滑处理系统,统计缺失词语在目标语料库中的第一出现次数,根据第一出现次数计算缺失词语的归一化频率指标,根据归一化频率指标和剩余概率计算缺失词语的平滑概率,并根据平滑概率对缺失词语进行平滑处理;通过引入缺失词语在目标语料库中的第一出现次数,计算缺失词语的归一化频率指标,由缺失词语的归一化频率指标分配剩余概率,区分缺失词语可能出现的词语本身出错和语料本身覆盖不足这两种情况,获得反映缺失词语真实情况的平滑概率,对缺失词语进行平滑处理,减少误判,增强平滑处理效果。The above smoothing processing system counts the first occurrences of the missing words in the target corpus, calculates the normalized frequency index of the missing words according to the first occurrences, calculates the smoothing probability of the missing words according to the normalized frequency index and the remaining probability, and The missing words are smoothed according to the smoothing probability; by introducing the first occurrence of the missing words in the target corpus, the normalized frequency index of the missing words is calculated, and the remaining probability is assigned by the normalized frequency index of the missing words to distinguish the missing words. In the case of possible errors in the words themselves and insufficient coverage of the corpus itself, a smooth probability reflecting the real situation of the missing words is obtained, and the missing words are smoothed to reduce misjudgments and enhance the smoothing effect.
一种计算机设备,包括存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序,处理器执行计算机程序时实现如上述平滑处理方法。A computer device includes a memory, a processor, and a computer program stored in the memory and executable on the processor, and the processor implements the above-mentioned smooth processing method when the computer program is executed.
一种计算机存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上述平滑处理方法。A computer storage medium on which a computer program is stored, and when the program is executed by a processor, implements the above-mentioned smoothing processing method.
附图说明Description of drawings
图1为本发明一个实施例的平滑处理方法的流程图;1 is a flowchart of a smoothing method according to an embodiment of the present invention;
图2为本发明一个实施例的平滑处理系统的结构示意图;2 is a schematic structural diagram of a smoothing processing system according to an embodiment of the present invention;
图3为本发明一个具体实施例的平滑处理方法的流程图。FIG. 3 is a flowchart of a smoothing processing method according to a specific embodiment of the present invention.
具体实施方式Detailed ways
为了便于理解本发明,下面将参照相关附图对本发明进行更全面的描述。In order to facilitate understanding of the present invention, the present invention will be described more fully hereinafter with reference to the related drawings.
参见图1所示,为本发明一个实施例的平滑处理方法的流程图。该实施例中的平滑处理方法,包括以下步骤:Referring to FIG. 1 , it is a flowchart of a smoothing processing method according to an embodiment of the present invention. The smoothing processing method in this embodiment includes the following steps:
步骤S110:统计缺失词语在目标语料库中的第一出现次数,其中,缺失词语为在原语料库中出现次数为0的词语。Step S110: Count the first occurrences of the missing words in the target corpus, where the missing words are words whose occurrences in the original corpus are 0.
本步骤中,由于缺失词语为在原语料库中出现次数为0的词语,在分配平滑概率的过程,无法区分数据缺失中的词语本身出错和语料本身覆盖不足这两种情况,因此需要引入可以区分上述两种情况的参数来分配平滑概率。于是,在目标语料库中,统计缺失词语的出现次数,获得第一出现次数。缺失词语在目标语料库中出现,可以反映出语料本身覆盖不足;缺失词语在目标语料库中不出现,或者出现次数极少,反映出词语本身出错。在带有搜索或查找功能的目标语料库中,可以通过搜索或查找缺失词语,将查找结果数作为第一出现次数。其中,缺失词语为n元词语,n元词语是n元语法模型中由n个字组成的词语,n-1元词语是指n元语法模型中由n-1个字组成的词语,n为大于1的正整数。In this step, since the missing words are words with 0 occurrences in the original corpus, in the process of assigning the smooth probability, it is impossible to distinguish between the errors of the words in the missing data and the insufficient coverage of the corpus itself. parameters for both cases to assign smoothing probabilities. Therefore, in the target corpus, the number of occurrences of the missing words is counted to obtain the first number of occurrences. The missing words appear in the target corpus, which can reflect the lack of coverage of the corpus itself; the missing words do not appear in the target corpus, or the number of occurrences is very small, reflecting that the words themselves are wrong. In a target corpus with a search or find function, the number of search results can be used as the first occurrence by searching or finding missing words. Among them, missing words are n-gram words, n-gram words are words composed of n characters in the n-gram model, n-1-gram words are words composed of n-1 words in the n-gram model, and n is A positive integer greater than 1.
在一个实施例中,目标语料库是数据量较大的语料库。In one embodiment, the target corpus is a corpus with a relatively large amount of data.
可选地,目标语料库可以是互联网数据网络的数据库,还可以是知识领域数据库,如专利数据库、学术文献数据库等,或者自建的数据库,如存储业务文件的数据库等;目标语料库也可以是书籍或文本的内容,如字典、各个行业的技术手册、世界名著等。缺失词语可以是某个知识领域中常见词语,由于语料覆盖的领域不同,会导致数据缺失的情况,因此可以针对特定知识领域的目标语料库获得第一出现次数,针对特定知识领域的缺失词语进行平滑处理。另外,针对特定知识领域的平滑处理,能够增强对应语言模型在特定知识领域的应用效果,提高语言处理能力。Optionally, the target corpus can be a database of the Internet data network, or a knowledge domain database, such as a patent database, an academic literature database, etc., or a self-built database, such as a database for storing business documents, etc.; the target corpus can also be a book. Or the content of text, such as dictionaries, technical manuals of various industries, world famous books, etc. Missing words can be common words in a certain knowledge field. Due to the different fields covered by the corpus, data will be missing. Therefore, the first occurrence can be obtained for the target corpus of a specific knowledge field, and the missing words in a specific knowledge field can be smoothed. deal with. In addition, the smoothing processing for a specific knowledge field can enhance the application effect of the corresponding language model in the specific knowledge field and improve the language processing capability.
步骤S120:根据第一出现次数计算缺失词语的归一化频率指标。Step S120: Calculate the normalized frequency index of the missing word according to the first number of occurrences.
在本步骤中,为了按照一定比例对剩余概率进行分配,需要对第一出现次数进行归一化处理,获得归一化频率指标,在后续处理中按照归一化频率指标对剩余概率进行分配。按照缺失词语的第一出现次数在所有第一出现次数中所占的比例,计算缺失词语的归一化频率指标。归一化处理后,所有缺失词语的归一化频率指标之和等于1。In this step, in order to allocate the remaining probability according to a certain proportion, it is necessary to normalize the first occurrence number to obtain a normalized frequency index, and in the subsequent processing, the remaining probability is allocated according to the normalized frequency index. According to the proportion of the first occurrence of the missing word in all the first occurrences, the normalized frequency index of the missing word is calculated. After normalization, the sum of the normalized frequency indices of all missing words is equal to 1.
步骤S130:根据归一化频率指标和剩余概率计算缺失词语的平滑概率,并根据平滑概率对缺失词语进行平滑处理,其中,剩余概率为从原语料库中出现次数小于或等于k次的词语的出现概率之和,k为正整数。Step S130: Calculate the smoothing probability of the missing words according to the normalized frequency index and the residual probability, and perform smoothing processing on the missing words according to the smoothing probability, wherein the residual probability is the occurrence of words whose occurrence times are less than or equal to k times from the original corpus The sum of probabilities, k is a positive integer.
将原语料库中已出现词语的出现概率按照一定比例进行降低,使得所有已出现词语的概率之和小于1,概率的分布出现余量,出现的余量为剩余概率,即为从原语料库中出现次数小于或等于k次的词语的出现概率之和,k为正整数。假设原语料库中已出现词语A、B、C、D、E的概率分别为0.5、0.4、0.3、0.2 和0.1,分别按照10%、20%、30%、40%和50%的比例进行降低,出现的余量等于0.5×0.1+0.4×0.2+0.3×0.3+0.2×0.4+0.1×0.5=0.35,即剩余概率为0.35。The probability of occurrence of words that have appeared in the original corpus is reduced according to a certain proportion, so that the sum of the probabilities of all words that have appeared is less than 1, and the probability distribution has a margin. Sum of occurrence probabilities of words whose times are less than or equal to k times, where k is a positive integer. Assume that the probabilities of words A, B, C, D, and E appearing in the original corpus are 0.5, 0.4, 0.3, 0.2, and 0.1, respectively, which are reduced by 10%, 20%, 30%, 40%, and 50%, respectively. , the margin of occurrence is equal to 0.5×0.1+0.4×0.2+0.3×0.3+0.2×0.4+0.1×0.5=0.35, that is, the residual probability is 0.35.
在本步骤中,根据归一化频率指标分配剩余概率,获得缺失词语的平滑概率。将剩余概率,按照归一化频率指标的比例进行分配,计算后获得缺失词语的平滑概率。In this step, the remaining probability is assigned according to the normalized frequency index, and the smooth probability of the missing word is obtained. The remaining probability is distributed according to the proportion of the normalized frequency index, and the smooth probability of the missing word is obtained after calculation.
上述平滑处理方法,统计缺失词语在目标语料库中的第一出现次数,根据第一出现次数计算缺失词语的归一化频率指标,根据归一化频率指标和剩余概率计算缺失词语的平滑概率,并根据平滑概率对缺失词语进行平滑处理;通过引入缺失词语在目标语料库中的第一出现次数,计算缺失词语的归一化频率指标,由缺失词语的归一化频率指标分配剩余概率,区分缺失词语可能出现的词语本身出错和语料本身覆盖不足这两种情况,获得反映缺失词语真实情况的平滑概率,对缺失词语进行平滑处理,减少误判,增强平滑处理效果。The above smoothing processing method counts the first occurrences of the missing words in the target corpus, calculates the normalized frequency index of the missing words according to the first occurrences, and calculates the smoothing probability of the missing words according to the normalized frequency index and the remaining probability, and The missing words are smoothed according to the smoothing probability; by introducing the first occurrence of the missing words in the target corpus, the normalized frequency index of the missing words is calculated, and the remaining probability is assigned by the normalized frequency index of the missing words to distinguish the missing words. In the case of possible errors in the words themselves and insufficient coverage of the corpus itself, a smooth probability reflecting the real situation of the missing words is obtained, and the missing words are smoothed to reduce misjudgments and enhance the smoothing effect.
进一步地,缺失词语为多个;根据第一出现次数计算缺失词语的归一化频率指标的步骤,包括以下步骤:Further, there are multiple missing words; the step of calculating the normalized frequency index of the missing words according to the first number of occurrences includes the following steps:
步骤S121:计算各第一出现次数的对数值;步骤S122:对对数值求和,得到对数值之和;步骤S123:分别将各第一出现次数的对数值分别除以对数值之和,得到对应各缺失词语的归一化频率指标。Step S121: Calculate the logarithm value of each first occurrence; Step S122: Sum the logarithms to obtain the sum of the logarithms; Step S123: Divide the logarithms of the first occurrences by the sum of the logarithms to obtain The normalized frequency index corresponding to each missing word.
假如,缺失词语AA、AB、BC、BD和CE的第一出现次数分别为1000、90000、85000、6000和450,则缺失词语AA的第一出现次数对数值 fAA=log1000=3,对数值之和为19.3150,则缺失词语AA的归一化频率指标为 0.155。If the first occurrences of the missing words AA, AB, BC, BD and CE are 1000, 90000, 85000, 6000 and 450 respectively, then the logarithmic value of the first occurrence of the missing word AA fAA =log1000=3, the logarithmic value The sum is 19.3150, and the normalized frequency index of the missing word AA is 0.155.
上述平滑处理方法,通过对各第一出现次数进行数值处理获得归一化频率指标,使得第一出现次数的归一化处理简便,另外对数的处理可以适合出现次数数值较大的情况。The above-mentioned smoothing processing method obtains the normalized frequency index by performing numerical processing on each first occurrence number, so that the normalization processing of the first occurrence number is simple, and the logarithmic processing can be suitable for the case where the numerical value of the occurrence number is relatively large.
进一步地,计算各第一出现次数的对数值的步骤,包括以下步骤:Further, the step of calculating the logarithmic value of each first occurrence includes the following steps:
步骤S1211:将各第一出现次数分别增加数值N,获得各个绝对出现次数;步骤S1212:计算各绝对出现次数的对数值,将各绝对出现次数的对数值分别作为各第一出现次数的对数值,其中,N为大于1的正整数。Step S1211: increase the number N of each first occurrence respectively to obtain each absolute number of occurrences; Step S1212: calculate the logarithm value of each absolute number of occurrences, and use the logarithmic value of each absolute number of occurrences as the logarithm value of each first occurrence number respectively , where N is a positive integer greater than 1.
假如,对于未出现的二元词语wjwi,第一出现次数为


上述平滑处理方法,通过对选取的各第一出现次数分别增加数值N后,进行对数处理,可以避免第一出现次数为0导致无法进行对数处理的情况。In the above-mentioned smoothing processing method, the logarithmic processing is performed after adding the numerical value N to each of the selected first occurrence times, so as to avoid the situation that the logarithmic processing cannot be performed due to the first occurrence times being 0.
进一步地,根据归一化频率指标和剩余概率计算缺失词语的平滑概率的步骤,包括以下步骤:Further, the step of calculating the smooth probability of missing words according to the normalized frequency index and the residual probability includes the following steps:
将缺失词语的归一化频率指标与第一剩余频率的乘积作为缺失词语的平滑概率。The product of the normalized frequency index of the missing word and the first remaining frequency is taken as the smoothed probability of the missing word.
假如,第一剩余频率为0.43,当缺失词语AA的归一化频率指标为0.155时,缺失词语AA的平滑概率为0.0665。Assuming that the first residual frequency is 0.43, when the normalized frequency index of the missing word AA is 0.155, the smoothed probability of the missing word AA is 0.0665.
本步骤中,将缺失词语的归一化频率指标与第一剩余频率的乘积作为缺失词语的平滑概率。通过乘法处理,按照缺失词语的归一化频率指标分配剩余概率。In this step, the product of the normalized frequency index of the missing word and the first residual frequency is used as the smoothing probability of the missing word. Through the multiplication process, the remaining probability is assigned according to the normalized frequency index of the missing word.
上述平滑处理方法,通过乘法处理,按照缺失词语的归一化频率指标分配剩余概率,对缺失词语进行平滑处理,增强平滑处理效果。In the above-mentioned smoothing processing method, the residual probability is allocated according to the normalized frequency index of the missing words through multiplication processing, and the missing words are smoothed to enhance the smoothing processing effect.
进一步地,k为大于1的正整数;Further, k is a positive integer greater than 1;
在根据归一化频率指标和剩余概率计算缺失词语的平滑概率的步骤之前,还包括以下步骤:Before the step of calculating the smoothed probability of missing words based on the normalized frequency index and the residual probability, the following steps are also included:
步骤S141:获取各n元词语在原语料库中的第二出现次数,并计算各第二出现次数的和值;步骤S142:统计第二出现次数小于或等于k次的各n元词语的第三出现次数,并计算各第三出现次数的和值;步骤S143:根据各第二出现次数的和值以及各第三出现次数的和值计算剩余概率。Step S141: Obtain the second occurrences of each n-gram in the original corpus, and calculate the sum of the second occurrences; Step S142: Count the third occurrences of each n-gram whose second occurrence is less than or equal to k times and calculate the sum of the third occurrences; Step S143: Calculate the remaining probability according to the sum of the second occurrences and the third occurrences.
假如,k等于2,统计n元词语在原语料库中的第二出现次数,并计算各第二出现次数的和值,即获得所有出现词语的出现总次数;统计第二出现次数为2 的出现词语个数n2和第二出现次数为1的出现词语个数n1,则第二出现次数为 2的出现词语的第三出现次数为2n2,第二出现次数为1的出现词语的第三出现次数为1n1,2n2+n1为各第三出现次数的和值,各第三出现次数的和值除以各第二出现次数的和值的商即为计算的剩余概率。If k is equal to 2, count the second occurrences of n-gram words in the original corpus, and calculate the sum of the second occurrences, that is, to obtain the total number of occurrences of all words; count the occurrences of words whose second occurrence is 2 The number n2 and the number n1 of the words with the second occurrence of 1, then the third occurrence of the word with the second occurrence of 2 is 2n2 , and the third occurrence of the word with the second occurrence of 1 is 2n 2 . The number of occurrences is 1n1 , 2n2 +n1 is the sum of the third occurrences, and the quotient of dividing the sum of the third occurrences by the sum of the second occurrences is the calculated residual probability.
上述平滑处理方法,通过统计第二出现次数小于或等于k次的词语的第三出现次数以及各n元词语在原语料库中的第二出现次数,计算剩余概率,对缺失词语进行平滑处理,增强了平滑处理效果。The above smoothing processing method calculates the remaining probability by counting the third occurrence of words whose second occurrence is less than or equal to k times and the second occurrence of each n-gram word in the original corpus, and smoothing the missing words, which enhances Smooth processing effect.
进一步地,剩余概率为从原语料库中出现次数等于1次的词语的出现概率之和;Further, the remaining probability is the sum of the occurrence probabilities of the words whose number of occurrences is equal to one from the original corpus;
在根据归一化频率指标和剩余概率计算缺失词语的平滑概率的步骤之前,还包括以下步骤:Before the step of calculating the smoothed probability of missing words based on the normalized frequency index and the residual probability, the following steps are also included:
步骤S144:获取各n元词语在原语料库中的第二出现次数并计算各第二出现次数的和值;步骤S145:统计第二出现次数为1的单次出现词语个数;步骤 S146:根据各第二出现次数的和值以及单次出现词语个数计算剩余概率。Step S144: Obtain the second occurrences of each n-gram word in the original corpus and calculate the sum of the second occurrences; Step S145: Count the number of single occurrences of which the second occurrence is 1; Step S146: According to each The sum of the second occurrences and the number of words in a single occurrence calculate the remaining probability.
假如以n元语法模型为例,r为n元词语在原语料库中的第二出现次数,nr是原语料库中恰好出现r次的n元词语的个数,nr+1是原语料库中恰好出现r+1 次的n元词语的个数,根据nr降低r,获得降低后的出现次数r*。降低r相当于从原语料库中已出现词语的出现概率中劫取概率,将已出现词语的出现概率按照一定比例进行降低,使得所有已出现词语的概率之和小于1,概率的分布出现余量。r*满足以下公式:Taking the n-gram model as an example, r is the second occurrence of the n-gram in the original corpus, nr is the number of n-grams that appear exactly r times in the original corpus, and nr+1 is the exact number of n-grams in the original corpus. For the number of n-gram words that appear r+1 times, reduce r according to nr to obtain the reduced number of occurrences r* . Reducing r is equivalent to taking the probability from the occurrence probability of the words that have appeared in the original corpus, and reducing the occurrence probability of the words that have appeared according to a certain proportion, so that the sum of the probabilities of all the words that have appeared is less than 1, and the probability distribution appears margin . r* satisfies the following formula:

对于第二出现次数为r的n元词语在原语料库中按照一定比例进行降低后的第一出现概率为:




上述平滑处理方法,通过统计第二出现次数为1的单次出现词语个数及计算各第二出现次数的和值,计算剩余概率,对缺失词语进行平滑处理,增强了平滑处理效果。In the above smoothing method, by counting the number of single-occurring words whose second occurrence is 1 and calculating the sum of the second occurrences, calculating the remaining probability, and smoothing the missing words, the smoothing effect is enhanced.
进一步地,在根据归一化频率指标和剩余概率计算缺失词语的平滑概率的步骤之后,还包括以下步骤:Further, after the step of calculating the smooth probability of missing words according to the normalized frequency index and the residual probability, the following steps are also included:
步骤S151:获取n元词语在原语料库中的第二出现次数;步骤S152:根据第二出现次数计算已出现词语劫取后的第一出现概率;步骤S153:根据平滑概率和第一出现概率,对缺失词语所在的n元语法模型进行训练。Step S151: Obtain the second occurrence of the n-gram word in the original corpus; Step S152: Calculate the first occurrence probability after the word has been hijacked according to the second occurrence; Step S153: According to the smooth probability and the first occurrence probability, for The n-gram model where the missing words are located is trained.
假如以n元语法模型为例,进行本发明一个实施例的平滑处理方法前的2 元语法模型中,获取n元词语在原语料库中的第二出现次数r,nr是原语料库中恰好出现r次的n元词语的个数,根据nr降低r,获得降低后的出现次数r*。降低r相当于从原语料库中已出现词语的出现概率中劫取概率,将已出现词语的出现概率按照一定比例进行降低,使得所有已出现词语的概率之和小于1,概率的分布出现余量。r*满足以下公式:If an n-gram model is taken as an example, in the 2-gram model before the smoothing method of an embodiment of the present invention is performed, the second occurrence number r of the n-gram word in the original corpus is obtained, where nr is the occurrence of r in the original corpus. The number of n-gram words of times, reduce r according to nr , and obtain the reduced number of occurrences r* . Reducing r is equivalent to taking the probability from the occurrence probability of the words that have appeared in the original corpus, and reducing the occurrence probability of the words that have appeared according to a certain proportion, so that the sum of the probabilities of all the words that have appeared is less than 1, and the probability distribution appears margin . r* satisfies the following formula:

对于第二出现次数为r的n元词语在原语料库中按照一定比例进行降低后的第一出现概率为:

根据平滑概率和第一出现概率,对缺失词语所在的n元语法模型进行训练,建立平滑处理后的n元语法模型。According to the smoothing probability and the first occurrence probability, the n-gram model where the missing word is located is trained, and the smoothed n-gram model is established.
上述平滑处理方法,通过计算第一出现概率,根据平滑概率和第一出现概率,对缺失词语所在的n元语法模型进行训练,建立平滑处理后的n元语法模型,对n元语法模型进行平滑处理,增强平滑处理效果。In the above smoothing method, by calculating the first occurrence probability, according to the smoothing probability and the first occurrence probability, the n-gram model where the missing word is located is trained, the smoothed n-gram model is established, and the n-gram model is smoothed. processing to enhance the smoothing effect.
进一步地,目标语料库为以搜索引擎网站为入口的互联网语料库;第一出现次数为缺失词语在搜索引擎网站中搜索后的相关结果数。Further, the target corpus is an Internet corpus with a search engine website as an entrance; the first occurrence number is the number of relevant results after the missing word is searched on the search engine website.
目标语料库可以是以搜索引擎网站为入口的互联网数据网络的数据库,并且可以借助互联网搜索引擎网站中搜索后的相关结果数,作为缺失词语在目标语料库的第一出现次数。The target corpus can be a database of the Internet data network with the search engine website as the entrance, and the number of relevant results after searching on the Internet search engine website can be used as the first occurrence of the missing word in the target corpus.
上述平滑处理方法,借助互联网搜索引擎在互联网数据网络的数据库搜索缺失词语,可以扩大语料的覆盖范围,获得的第一出现次数能够符合真实情况,对数据缺失出现的两种情况进行区分,增强平滑处理效果。The above smoothing processing method can expand the coverage of the corpus by searching for the missing words in the database of the Internet data network with the help of the Internet search engine, and the obtained first occurrence times can conform to the real situation. processing effect.
参见图2所示,为本发明一个实施例的平滑处理系统的结构示意图。该实施例中的平滑处理系统,包括:Referring to FIG. 2 , it is a schematic structural diagram of a smoothing processing system according to an embodiment of the present invention. The smoothing processing system in this embodiment includes:
次数统计模块210,用于统计缺失词语在目标语料库中的第一出现次数,其中,缺失词语为在原语料库中出现次数为0的词语;The number of
归一化频率指标计算模块220,用于根据第一出现次数计算缺失词语的归一化频率指标;The normalized frequency
平滑处理模块230,用于根据归一化频率指标和剩余概率计算缺失词语的平滑概率,并根据平滑概率对缺失词语进行平滑处理,其中,剩余概率为从原语料库中出现次数小于或等于k次的词语的出现概率之和,k为正整数。The smoothing
上述平滑处理系统,统计缺失词语在目标语料库中的第一出现次数,根据第一出现次数计算缺失词语的归一化频率指标,根据归一化频率指标和剩余概率计算缺失词语的平滑概率,并根据平滑概率对缺失词语进行平滑处理;通过引入缺失词语在目标语料库中的第一出现次数,计算缺失词语的归一化频率指标,由缺失词语的归一化频率指标分配剩余概率,区分缺失词语可能出现的词语本身出错和语料本身覆盖不足这两种情况,获得反映缺失词语真实情况的平滑概率,对缺失词语进行平滑处理,减少误判,增强平滑处理效果。The above smoothing processing system counts the first occurrences of the missing words in the target corpus, calculates the normalized frequency index of the missing words according to the first occurrences, calculates the smoothing probability of the missing words according to the normalized frequency index and the remaining probability, and The missing words are smoothed according to the smoothing probability; by introducing the first occurrence of the missing words in the target corpus, the normalized frequency index of the missing words is calculated, and the remaining probability is assigned by the normalized frequency index of the missing words to distinguish the missing words. In the case of possible errors in the words themselves and insufficient coverage of the corpus itself, a smooth probability reflecting the real situation of the missing words is obtained, and the missing words are smoothed to reduce misjudgments and enhance the smoothing effect.
进一步地,缺失词语为多个,归一化频率指标计算模块220计算各第一出现次数的对数值;对对数值求和,得到对数值之和;分别将各第一出现次数的对数值分别除以对数值之和,得到对应各缺失词语的归一化频率指标。Further, if there are multiple missing words, the normalized frequency
上述平滑处理系统,通过对各第一出现次数进行数值处理获得归一化频率指标,使得第一出现次数的归一化处理简便,另外对数的处理可以适合出现次数数值较大的情况。The above-mentioned smoothing processing system obtains the normalized frequency index by performing numerical processing on each first occurrence number, so that the normalization processing of the first occurrence number is simple, and the logarithmic processing can be suitable for the case where the numerical value of the occurrence number is relatively large.
进一步地,归一化频率指标计算模块220将各第一出现次数分别增加数值N,获得绝对出现次数;计算各绝对出现次数的对数值,将各绝对出现次数的对数值分别作为第一出现次数的对数值,其中,N为大于1的正整数。Further, the normalized frequency
上述平滑处理系统,通过对选取的各第一出现次数分别增加数值N后,进行对数处理,可以避免第一出现次数为0导致无法进行对数处理的情况。In the above-mentioned smoothing processing system, the logarithmic processing is performed after adding a numerical value N to each of the selected first occurrence times, so as to avoid the situation that the logarithmic processing cannot be performed due to the first occurrence times being 0.
进一步地,平滑处理模块230将缺失词语的归一化频率指标与第一剩余频率的乘积作为缺失词语的平滑概率。Further, the smoothing
上述平滑处理系统,通过乘法处理,按照缺失词语的归一化频率指标分配剩余概率,对缺失词语进行平滑处理,增强平滑处理效果。The above-mentioned smoothing processing system, through multiplication processing, assigns the remaining probability according to the normalized frequency index of the missing words, performs smoothing processing on the missing words, and enhances the smoothing processing effect.
进一步地,k为大于1的正整数,平滑处理模块230获取各n元词语在原语料库中的第二出现次数,并计算各第二出现次数的和值;统计第二出现次数小于或等于k次的各n元词语的第三出现次数,并计算各第三出现次数的和值;根据各第二出现次数的和值以及各第三出现次数的和值计算剩余概率。Further, k is a positive integer greater than 1, and the smoothing
上述平滑处理系统,通过统计第二出现次数小于或等于k次的词语的第三出现次数以及各n元词语在原语料库中的第二出现次数,计算剩余概率,对缺失词语进行平滑处理,增强了平滑处理效果。The above smoothing processing system calculates the remaining probability by counting the third occurrence of words whose second occurrence is less than or equal to k times and the second occurrence of each n-gram word in the original corpus, and smoothes the missing words, enhancing Smooth processing effect.
进一步地,剩余概率为从原语料库中出现次数等于1次的词语的出现概率之和,平滑处理模块230获取各n元词语在原语料库中的第二出现次数并计算各第二出现次数的和值;统计第二出现次数为1的单次出现词语个数;根据各第二出现次数的和值以及单次出现词语个数计算剩余概率。Further, the remaining probability is the sum of the occurrence probabilities of words whose number of occurrences is equal to 1 from the original corpus, and the
上述平滑处理系统,通过统计第二出现次数为1的单次出现词语个数及计算各第二出现次数的和值,计算剩余概率,对缺失词语进行平滑处理,增强了平滑处理效果。The above-mentioned smoothing processing system, by counting the number of single-occurring words with the second occurrence number of 1 and calculating the sum of the second occurrence times, calculates the remaining probability, and performs smoothing processing on the missing words, thereby enhancing the smoothing processing effect.
进一步地,平滑处理模块230获取n元词语在原语料库中的第二出现次数;Further, the smoothing
根据第二出现次数计算已出现词语劫取后的第一出现概率;根据平滑概率和第一出现概率,对缺失词语所在的n元语法模型进行训练。According to the second occurrence times, the first occurrence probability after the occurrence of the word has been hijacked is calculated; according to the smooth probability and the first occurrence probability, the n-gram model where the missing word is located is trained.
上述平滑处理系统,通过计算第一出现概率,根据平滑概率和第一出现概率,对缺失词语所在的n元语法模型进行训练,建立平滑处理后的n元语法模型,对n元语法模型进行平滑处理,增强平滑处理效果。The above smoothing processing system, by calculating the first occurrence probability, according to the smoothing probability and the first occurrence probability, trains the n-gram grammar model where the missing words are located, establishes the smoothed n-gram grammar model, and smoothes the n-gram grammar model. processing to enhance the smoothing effect.
进一步地,次数统计模块210中目标语料库为以搜索引擎网站为入口的互联网语料库;第一出现次数为缺失词语在搜索引擎网站中搜索后的相关结果数。Further, the target corpus in the
上述平滑处理系统,借助互联网搜索引擎在互联网数据网络的数据库搜索缺失词语,可以扩大语料的覆盖范围,获得的第一出现次数能够符合真实情况,对数据缺失出现的两种情况进行区分,增强平滑处理效果。The above-mentioned smoothing processing system can expand the coverage of the corpus by searching for missing words in the database of the Internet data network with the help of an Internet search engine, and the obtained first occurrence times can conform to the real situation. processing effect.
一种计算机设备,包括存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序,处理器执行计算机程序时实现如上述平滑处理方法。A computer device includes a memory, a processor, and a computer program stored in the memory and executable on the processor, and the processor implements the above-mentioned smooth processing method when the computer program is executed.
一种计算机存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上述平滑处理方法。A computer storage medium on which a computer program is stored, and when the program is executed by a processor, implements the above-mentioned smoothing processing method.
根据上述本发明的平滑处理方法,本发明还提供一种计算机设备和计算机存储介质,用于通过程序实现上述的平滑处理方法。According to the above-mentioned smoothing processing method of the present invention, the present invention also provides a computer device and a computer storage medium for implementing the above-mentioned smoothing processing method through a program.
参见图3所示,为本发明一个具体实施例的平滑处理方法的流程图。该实施例中的平滑处理方法,包括以下步骤:Referring to FIG. 3 , it is a flowchart of a smoothing processing method according to a specific embodiment of the present invention. The smoothing processing method in this embodiment includes the following steps:
计算剩余概率。在n元语法模型中,将已出现词语的出现概率按照一定比例进行降低,使得所有已出现词语的概率之和小于1,概率的分布出现余量,获得剩余概率。获取n元词语在原语料库中的第二出现次数r,nr是原语料库中恰好出现r次的n元词语的个数,nr+1是原语料库中恰好出现r+1次的n元词语的个数,根据nr降低r,获得降低后的出现次数r*。降低r相当于从原语料库中已出现词语的出现概率中劫取概率,将已出现词语的出现概率按照一定比例进行降低。r*满足以下公式:Calculate the remaining probability. In the n-gram model, the occurrence probability of the words that have appeared is reduced according to a certain proportion, so that the sum of the probabilities of all the words that have appeared is less than 1, and the probability distribution has a margin, and the remaining probability is obtained. Obtain the second occurrence r of the n-gram word in the original corpus, where nr is the number of n-gram words that appear exactly r times in the original corpus, and nr+1 is the n-gram word that occurs exactly r+1 times in the original corpus The number of , reduce r according to nr to obtain the reduced number of occurrences r* . Reducing r is equivalent to taking the probability from the occurrence probability of the words that have appeared in the original corpus, and reducing the occurrence probability of the words that have appeared according to a certain proportion. r* satisfies the following formula:

对于第二出现次数为r的n元词语在原语料库中按照一定比例进行降低后的第一出现概率为:




统计缺失词语,将缺失词语输入目标语料库,将缺失词语输入搜索引擎,获得每一个缺失词语的结果数,将结果数作为第一出现次数。缺失词语可以为多个。Count the missing words, input the missing words into the target corpus, input the missing words into the search engine, obtain the number of results for each missing word, and take the number of results as the number of first occurrences. There can be multiple missing words.
根据各第一出现次数计算对应各缺失词语的归一化频率指标。计算选取的各第一出现次数的对数值;对对数值求和,得到对数值之和;分别将各个选取的第一出现次数的对数值分别除以对数值之和,得到对应各缺失词语的归一化频率指标。The normalized frequency index corresponding to each missing word is calculated according to each first occurrence. Calculate the logarithmic value of each selected first occurrence; sum the logarithmic values to obtain the sum of the logarithmic values; divide the logarithmic value of each selected first occurrence by the sum of the logarithmic values to obtain the corresponding value of each missing word. Normalized frequency indicator.
对于缺失词语wjwi,归一化的频度指标率为For missing words wj wi , the normalized frequency index is

其中
根据归一化频率指标和剩余概率计算缺失词语的平滑概率,并根据平滑概率对缺失词语进行平滑处理。将各缺失词语的归一化频率指标与第一剩余频率的乘积作为各缺失词语的平滑概率。Calculate the smoothing probability of missing words according to the normalized frequency index and residual probability, and smooth the missing words according to the smoothing probability. The product of the normalized frequency index of each missing word and the first residual frequency is taken as the smoothing probability of each missing word.

其中,
如表1所示,表1为原语料库中二元词语的出现次数与个数的关系。As shown in Table 1, Table 1 shows the relationship between the number of occurrences and the number of binary words in the original corpus.
表1原语料库中二元词语的出现次数与个数的关系Table 1 The relationship between the number of occurrences and the number of binary words in the original corpus
根据
表2原语料库中二元词语的频率分布Table 2 Frequency distribution of bigram words in original corpus
如表2所示,表2为原语料库中二元词语的频率分布,则可以计算第二出现次数为1的单次出现词语个数n1=2053,各第二出现次数的和值N=4855,剩余概率为
对于未出现的二元词语“文量”得到的第一出现次数为939000,“文量”的第一出现次数的对数值为:The number of first occurrences of the non-occurring binary word "literature" is 939000, and the logarithm of the first occurrence of "literature" is:
f文量=log939000=5.97ftext volume = log939000 = 5.97
假设所有的二元词语的出现次数的对数值总和为5000,那么缺失词语“文量”的平滑概率为:Assuming that the sum of the logarithms of the occurrences of all binary words is 5000, the smoothed probability of the missing word "literature" is:

本发明的平滑处理系统与本发明的平滑处理方法一一对应,在上述平滑处理方法的实施例阐述的技术特征及其有益效果均适用于平滑处理系统的实施例中,特此声明。The smoothing system of the present invention is in one-to-one correspondence with the smoothing method of the present invention, and the technical features and beneficial effects described in the embodiments of the smoothing method are applicable to the embodiments of the smoothing system, which are hereby declared.
除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本文中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本发明。本文所使用的术语“及/或”包括一个或多个相关的所列项目的任意的和所有的组合。Unless otherwise defined, all technical and scientific terms used herein have the same meaning as commonly understood by one of ordinary skill in the art to which this invention belongs. The terms used herein in the description of the present invention are for the purpose of describing specific embodiments only, and are not intended to limit the present invention. As used herein, the term "and/or" includes any and all combinations of one or more of the associated listed items.
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。本领域普通技术人员可以理解实现上述实施例方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,所述的程序可以存储于计算机可读取存储介质中,该程序在执行时,包括以上方法所述的步骤,所述的存储介质,如:ROM/RAM、磁碟、光盘等。The technical features of the above-described embodiments can be combined arbitrarily. For the sake of brevity, all possible combinations of the technical features in the above-described embodiments are not described. However, as long as there is no contradiction between the combinations of these technical features, All should be regarded as the scope described in this specification. Those of ordinary skill in the art can understand that all or part of the steps in the methods of the above embodiments can be completed by instructing relevant hardware through a program, and the program can be stored in a computer-readable storage medium, and when the program is executed , including the steps described in the above method, and the storage medium, such as: ROM/RAM, magnetic disk, optical disk, etc.
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。The above-mentioned embodiments only represent several embodiments of the present invention, and the descriptions thereof are more specific and detailed, but should not be construed as a limitation on the scope of the invention patent. It should be pointed out that for those skilled in the art, without departing from the concept of the present invention, several modifications and improvements can be made, which all belong to the protection scope of the present invention. Therefore, the protection scope of the patent of the present invention shall be subject to the appended claims.
Claims (11)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810344157.4ACN108829657B (en) | 2018-04-17 | 2018-04-17 | Smoothing method and system |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810344157.4ACN108829657B (en) | 2018-04-17 | 2018-04-17 | Smoothing method and system |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN108829657A CN108829657A (en) | 2018-11-16 |
| CN108829657Btrue CN108829657B (en) | 2022-05-03 |
Family
ID=64154406
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201810344157.4AActiveCN108829657B (en) | 2018-04-17 | 2018-04-17 | Smoothing method and system |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN108829657B (en) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN118536495B (en)* | 2024-07-23 | 2024-10-11 | 北京匠数科技有限公司 | Text error correction method and device based on character existence index, computer equipment and storage medium |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101295294A (en)* | 2008-06-12 | 2008-10-29 | 昆明理工大学 | Improved Bayesian Word Sense Disambiguation Method Based on Information Gain |
| CN103116578A (en)* | 2013-02-07 | 2013-05-22 | 北京赛迪翻译技术有限公司 | Translation method integrating syntactic tree and statistical machine translation technology and translation device |
| CN103488629A (en)* | 2013-09-24 | 2014-01-01 | 南京大学 | Method for extracting translation unit table in machine translation |
| CN104408087A (en)* | 2014-11-13 | 2015-03-11 | 百度在线网络技术(北京)有限公司 | Method and system for identifying cheating text |
| CN106649269A (en)* | 2016-12-16 | 2017-05-10 | 广州视源电子科技股份有限公司 | Method and device for extracting spoken sentences |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7379867B2 (en)* | 2003-06-03 | 2008-05-27 | Microsoft Corporation | Discriminative training of language models for text and speech classification |
| US7630976B2 (en)* | 2005-05-10 | 2009-12-08 | Microsoft Corporation | Method and system for adapting search results to personal information needs |
| CN104484322A (en)* | 2010-09-24 | 2015-04-01 | 新加坡国立大学 | Methods and systems for automated text correction |
| US9606986B2 (en)* | 2014-09-29 | 2017-03-28 | Apple Inc. | Integrated word N-gram and class M-gram language models |
- 2018
- 2018-04-17CNCN201810344157.4Apatent/CN108829657B/enactiveActive
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101295294A (en)* | 2008-06-12 | 2008-10-29 | 昆明理工大学 | Improved Bayesian Word Sense Disambiguation Method Based on Information Gain |
| CN103116578A (en)* | 2013-02-07 | 2013-05-22 | 北京赛迪翻译技术有限公司 | Translation method integrating syntactic tree and statistical machine translation technology and translation device |
| CN103488629A (en)* | 2013-09-24 | 2014-01-01 | 南京大学 | Method for extracting translation unit table in machine translation |
| CN104408087A (en)* | 2014-11-13 | 2015-03-11 | 百度在线网络技术(北京)有限公司 | Method and system for identifying cheating text |
| CN106649269A (en)* | 2016-12-16 | 2017-05-10 | 广州视源电子科技股份有限公司 | Method and device for extracting spoken sentences |
Non-Patent Citations (4)
| Title |
|---|
| Combining Naive Bayes and n-Gram Language Models for Text Classification;Fuchun Peng,Dale Schuurmans;《ECIR 2003: Advances in Information Retrieval》;20030415;全文* |
| 基于互信息的统计语言模型平滑技术;黄永文;《中国优秀博硕士学位论文全文数据库(硕士)信息科技辑》;20051215;全文* |
| 基于数据聚类的语言模型研究;楚彦凌;《中国优秀博硕士学位论文全文数据库(硕士)信息科技辑》;20110315;全文* |
| 统计语言模型的研究与应用;文娟;《中国优秀博硕士学位论文全文数据库(博士)信息科技辑》;20101115;全文* |
Also Published As
| Publication number | Publication date |
|---|---|
| CN108829657A (en) | 2018-11-16 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11017178B2 (en) | Methods, devices, and systems for constructing intelligent knowledge base | |
| CN109101620B (en) | Similarity calculation method, clustering method, device, storage medium and electronic equipment | |
| CN107704625B (en) | Method and device for field matching | |
| CN109918660B (en) | A method and device for keyword extraction based on TextRank | |
| US9311389B2 (en) | Finding indexed documents | |
| CN110489757A (en) | A keyword extraction method and device | |
| CN114417116A (en) | Search method, apparatus, device, medium, and program product based on search word | |
| Pusateri et al. | Connecting and comparing language model interpolation techniques | |
| CN108829657B (en) | Smoothing method and system | |
| CN109299887B (en) | Data processing method and device and electronic equipment | |
| CN113220838A (en) | Method and device for determining key information, electronic equipment and storage medium | |
| CN108733648B (en) | Smoothing method and system | |
| CN110287284B (en) | Semantic matching method, device and device | |
| CN113204613A (en) | Address generation method, device, equipment and storage medium | |
| CN117499340A (en) | Communication resource name matching method, device, equipment and medium | |
| CN110083835A (en) | A kind of keyword extracting method and device based on figure and words and phrases collaboration | |
| CN113010517B (en) | Data table management method and device | |
| CN110471901B (en) | Data importing method and terminal equipment | |
| CN109684442B (en) | Text retrieval method, device, equipment and program product | |
| CN115248807A (en) | Information retrieval method and system for small data sets | |
| CN111625579A (en) | Information processing method, device and system | |
| CN117033759B (en) | Data matching method, device, equipment, storage medium and program product | |
| CN114840724B (en) | A query method, device, electronic device and storage medium | |
| CN114138951B (en) | Question and answer processing method, device, electronic device and storage medium | |
| TWI524196B (en) | Cloud-based periodical recommendation system and operation method thereof |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |