CN108764517B - A kind of blast furnace hot metal silicon content change trend prediction method, equipment and storage medium - Google Patents
A kind of blast furnace hot metal silicon content change trend prediction method, equipment and storage mediumDownload PDFInfo
- Publication number
- CN108764517B CN108764517BCN201810305865.7ACN201810305865ACN108764517BCN 108764517 BCN108764517 BCN 108764517BCN 201810305865 ACN201810305865 ACN 201810305865ACN 108764517 BCN108764517 BCN 108764517B
- Authority
- CN
- China
- Prior art keywords
- silicon content
- trend
- blast furnace
- model
- molten iron
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images





Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q10/00—Administration; Management
- G06Q10/04—Forecasting or optimisation specially adapted for administrative or management purposes, e.g. linear programming or "cutting stock problem"
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/10—Complex mathematical operations
- G06F17/18—Complex mathematical operations for evaluating statistical data, e.g. average values, frequency distributions, probability functions, regression analysis
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Business, Economics & Management (AREA)
- Theoretical Computer Science (AREA)
- Human Resources & Organizations (AREA)
- Strategic Management (AREA)
- Computational Mathematics (AREA)
- Mathematical Analysis (AREA)
- Mathematical Optimization (AREA)
- Operations Research (AREA)
- Economics (AREA)
- Pure & Applied Mathematics (AREA)
- Mathematical Physics (AREA)
- Game Theory and Decision Science (AREA)
- Evolutionary Biology (AREA)
- Software Systems (AREA)
- General Engineering & Computer Science (AREA)
- Bioinformatics & Computational Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Development Economics (AREA)
- Probability & Statistics with Applications (AREA)
- Databases & Information Systems (AREA)
- Algebra (AREA)
- Life Sciences & Earth Sciences (AREA)
- Entrepreneurship & Innovation (AREA)
- Marketing (AREA)
- Quality & Reliability (AREA)
- Tourism & Hospitality (AREA)
- General Business, Economics & Management (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
- Manufacture Of Iron (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明涉及及高炉冶炼自动化控制技术领域,更具体地,涉及一种高炉铁水硅含量变化趋势预测方法、设备和存储介质。The invention relates to the technical field of blast furnace smelting automation control, and more particularly, to a method, equipment and storage medium for predicting the change trend of silicon content in blast furnace molten iron.
背景技术Background technique
高炉冶炼是一个连续的生产过程,炉内运行情况复杂,各种物理、化学反应众多。高炉炉温,即炉缸内的铁水温度,是衡量高炉炉况的重要参数之一,过高和过低都会造成铁水质量的下降和炉况的不顺。炉温低,铁水物理热不足,炉缸热储备不够,容易造成炉缸冻结事故;炉温高,炉缸煤气流太过旺盛,导致悬料、崩料等炉况故障及原材料的浪费。因此实现炉温的在线预测对保证高炉炉况安全稳定顺行具有重大的意义。Blast furnace smelting is a continuous production process with complex operation conditions in the furnace and numerous physical and chemical reactions. The blast furnace temperature, that is, the temperature of molten iron in the hearth, is one of the important parameters to measure the furnace condition of the blast furnace. Too high or too low will cause the quality of molten iron to decline and the furnace condition to be unsatisfactory. If the furnace temperature is low, the physical heat of molten iron is insufficient, and the heat reserve of the hearth is insufficient, which may easily cause a hearth freezing accident; if the furnace temperature is high, the gas flow in the hearth is too strong, resulting in furnace conditions such as overhang and collapse, and waste of raw materials. Therefore, it is of great significance to realize the online prediction of furnace temperature to ensure the safety and stability of blast furnace conditions.
由于高炉封闭的生产过程,无法直接检测炉缸内铁水的温度,在撇渣器处用热电偶测得的温度具有一定的热损失不能准确代表高炉炉温。研究表明,铁水从炉缸流向撇渣器的过程中,铁水硅含量的信息不存在丢失,并且铁水硅含量与炉缸内铁水的温度具有较强的正相关关系,因此可以将炉温的预报问题转换为高炉铁水硅含量的预报。但在实际的生产过程中,高炉操作者并不会因为前后两次硅含量的值的变化而且频繁的调节参数,只有当硅含量的变化趋势超出一定的允许范围时,才会采取相应的调控手段,从对现场提供指导的方面来看,高炉铁水硅含量变化趋势的预测对现场高炉炉温精细化的调控具有重大意义。特别是在钢铁大规模定制化生产和我国炼铁所需原材料日益劣化的条件下,高炉炼铁的外界环境呈现明显的不确定性,而高炉铁水硅含量的变化趋势呈现出明显的高动态性,高炉的稳定控制难度明显增大,因此实时准确的预报铁水硅含量的趋势对稳定高炉炉况、保障高炉顺行具有重要的意义。Due to the closed production process of the blast furnace, the temperature of the molten iron in the hearth cannot be directly detected, and the temperature measured by the thermocouple at the skimmer has a certain heat loss and cannot accurately represent the blast furnace temperature. The research shows that in the process of the molten iron flowing from the hearth to the skimmer, the information of the silicon content of the molten iron is not lost, and the silicon content of the molten iron has a strong positive correlation with the temperature of the molten iron in the hearth, so the prediction of the furnace temperature can be used. The problem is transformed into the prediction of silicon content in blast furnace hot metal. However, in the actual production process, the blast furnace operator will not frequently adjust the parameters due to the change of the silicon content value twice before and after. From the perspective of providing guidance to the site, the prediction of the change trend of the silicon content in the hot metal of the blast furnace is of great significance to the fine control of the furnace temperature of the blast furnace. Especially under the conditions of large-scale customized production of iron and steel and the increasingly deteriorating raw materials required for ironmaking in my country, the external environment of blast furnace ironmaking presents obvious uncertainties, and the change trend of silicon content in blast furnace molten iron presents obvious high dynamics Therefore, the real-time and accurate prediction of the trend of the silicon content in the molten iron is of great significance for stabilizing the furnace conditions and ensuring the forward run of the blast furnace.
铁水硅含量趋势的预报主要是通过建立机理和数据模型,机理模型预测的准确率高,应用范围广,能直观的反应高炉内部硅含量趋势与炼铁过程中检测参数之间的关系,但建立准确的机理模型费时费力,建模条件要求严格且模型所需的参数无法准确获得。因此建立基于数据驱动的智能预报模型成为另外一种好的方法,通过利用炼铁过程中丰富的在线和离线历史数据,建立炼铁过程中检测参数和硅含量趋势之间的预报模型,实现硅含量趋势在线、实时、准确的预报。公开专利号CN105574297A的中国发明专利提出了一种自适应的高炉铁水硅含量趋势预报方法,基于在线最小二乘支持向量机,建立基于在线最小二乘支持向量机(Least Squares Support Vector Machines,LS-SVMS)模型的自适应预报器,通过不断采集新样本对趋势预报模型进行自适应性更新,追踪高炉冶炼过程的动态变化,实时性和可靠性好;但该专利高炉铁水硅含量采集的数据转化为趋势是通过前后前后两炉次硅含量的差值来决定的,差值为正表示上升趋势,差值为负表示下降趋势。这样做可预报趋势的周期短,并且趋势划分的不够全面,只能提供硅含量变化趋势的方向并不能提供变化幅度的信息。公开专利号CN104899463A的中国发明专利提出了一种高炉铁水硅含量四分类趋势预报模型,利用高炉现场采集的丰富的在线离线数据,依据模糊C均值聚类的方法对铁水硅含量样本有效的聚类,得到模型输出变量四类变化趋势区间的划分标准,并利用极限学习机建立四分类趋势预报模型。但其使用的极限学习机是一种单隐含层的前向神经网络,通过随机的方式给输入节点和隐含节点权值从而保证模型的快速性,但输出权值是在输入权值和隐层节点权值的基础上求得的,输出权值是非最优使得模型的准确度得不到保证。综上所述,现有的硅含量趋势预方法主要存在两个方面的不足,一是硅含量的趋势只通过前后两炉次的差来定义趋势,这种划分方法划分较为粗糙且不能反应全面的信息;二是用来预报的模型准确度得不到保证。The prediction of the trend of silicon content in hot metal is mainly through the establishment of mechanism and data models. The prediction of the mechanism model has high accuracy and wide application range, and can intuitively reflect the relationship between the trend of silicon content in the blast furnace and the detection parameters in the ironmaking process. An accurate mechanism model is time-consuming and labor-intensive, the modeling conditions are strict and the parameters required by the model cannot be obtained accurately. Therefore, establishing a data-driven intelligent forecasting model has become another good method. By using the rich online and offline historical data in the ironmaking process, a forecasting model between the detection parameters and the silicon content trend in the ironmaking process is established to realize the silicon content trend. Online, real-time and accurate forecast of content trends. The Chinese invention patent with the published patent number CN105574297A proposes an adaptive method for predicting the trend of silicon content in blast furnace hot metal. The adaptive predictor of the SVMS) model can adaptively update the trend forecast model by continuously collecting new samples to track the dynamic changes of the blast furnace smelting process, with good real-time and reliability; The trend is determined by the difference between the silicon content of the two heats before and after, a positive difference indicates an upward trend, and a negative difference indicates a downward trend. In this way, the period of the forecast trend is short, and the trend division is not comprehensive enough. It can only provide the direction of the silicon content change trend but not the information of the change range. The Chinese invention patent with the published patent number CN104899463A proposes a four-category trend forecasting model for the silicon content of hot metal in blast furnaces, using the rich online and offline data collected on the blast furnace site, according to the fuzzy C-means clustering method to effectively cluster the silicon content samples in the molten iron , to obtain the division criteria of the four types of variation trend intervals of the model output variables, and use the extreme learning machine to establish a four-category trend forecast model. However, the extreme learning machine it uses is a forward neural network with a single hidden layer. It gives weights to the input nodes and hidden nodes in a random way to ensure the speed of the model, but the output weights are between the input weights and the hidden nodes. Based on the hidden layer node weights, the output weights are non-optimal, so the accuracy of the model cannot be guaranteed. To sum up, the existing pre-method of silicon content trend mainly has two shortcomings. First, the trend of silicon content is only defined by the difference between the two heats before and after. Second, the accuracy of the model used for forecasting cannot be guaranteed.
发明内容SUMMARY OF THE INVENTION
本发明提供一种克服上述问题或者至少部分地解决上述问题的一种高炉铁水硅含量变化趋势预测方法、设备和存储介质,解决了现有技术中硅含量趋势预方法中硅含量的趋势只通过前后两炉次的差来定义趋势,划分方法划分较为粗糙、不能反应全面的信息,且用来预报的模型准确度得不到保证的问题。The present invention provides a method, equipment and storage medium for predicting the change trend of silicon content in blast furnace molten iron that overcomes the above problems or at least partially solves the above problems, and solves the problem that the trend of silicon content in the prior art silicon content trend pre-method only passes through The difference between the two heats before and after is used to define the trend. The division method is relatively rough, cannot reflect comprehensive information, and the accuracy of the model used for prediction cannot be guaranteed.
根据本发明的一个方面,提供一种高炉铁水硅含量变化趋势预测方法,包括:According to one aspect of the present invention, there is provided a method for predicting the variation trend of silicon content in blast furnace hot metal, comprising:
获取炼铁过程中与高炉铁水中硅含量变化相关的特征参数,基于已训练的高炉铁水硅含量预测模型,对硅含量变化趋势进行预测;Obtain the characteristic parameters related to the change of silicon content in blast furnace molten iron during the ironmaking process, and predict the change trend of silicon content based on the trained blast furnace molten iron silicon content prediction model;
其中,所述高炉铁水含量预测模型包括第一层预测模型和第二层预测模型,所述第一层预测模型用于根据原始样本对硅含量变化趋势进行初步预测,所述第二层预测模型根据所述第一层预测模型的预测结果进行二次预测,得到硅含量变化趋势。Wherein, the blast furnace molten iron content prediction model includes a first-layer prediction model and a second-layer prediction model, the first-layer prediction model is used to preliminarily predict the change trend of silicon content according to the original sample, and the second-layer prediction model A secondary prediction is performed according to the prediction result of the first-layer prediction model to obtain the variation trend of silicon content.
一种高炉铁水硅含量变化趋势预测设备,包括:A device for predicting the change trend of silicon content in blast furnace molten iron, comprising:
至少一个处理器、至少一个存储器、通信接口和总线;其中,at least one processor, at least one memory, a communication interface, and a bus; wherein,
所述处理器、存储器、通信接口通过所述总线完成相互间的通信;The processor, the memory, and the communication interface communicate with each other through the bus;
所述通信接口用于该测试设备与显示装置的通信设备之间的信息传输;The communication interface is used for information transmission between the test equipment and the communication equipment of the display device;
所述存储器存储有可被所述处理器执行的程序指令,所述处理器调用所述程序指令能够执行如上述高炉铁水硅含量变化趋势预测方法。The memory stores program instructions executable by the processor, and the processor invokes the program instructions to execute the above-mentioned method for predicting the change trend of silicon content in hot metal of a blast furnace.
一种高炉铁水硅含量变化趋势预测设备,包括:A device for predicting the change trend of silicon content in blast furnace molten iron, comprising:
至少一个处理器;以及at least one processor; and
与所述处理器通信连接的至少一个存储器,其中:at least one memory communicatively coupled to the processor, wherein:
所述存储器存储有可被所述处理器执行的程序指令,所述处理器调用所述程序指令能够执行如上述高炉铁水硅含量变化趋势预测方法。The memory stores program instructions executable by the processor, and the processor invokes the program instructions to execute the above-mentioned method for predicting the change trend of silicon content in hot metal of a blast furnace.
一种非暂态计算机可读存储介质,所述非暂态计算机可读存储介质存储计算机指令,所述计算机指令使所述计算机执行如上述高炉铁水硅含量变化趋势预测方法。A non-transitory computer-readable storage medium, the non-transitory computer-readable storage medium stores computer instructions, the computer instructions cause the computer to execute the above method for predicting the change trend of silicon content in blast furnace hot metal.
本发明提出一种高炉铁水硅含量变化趋势预测方法、设备和存储介质,通过数据驱动的方法来预测高炉铁水硅含量的趋势,通过数据预处理构建输入样本,通过对滑动窗口内硅含量值通过回归线性拟合的方法确定输出趋势类别;并建立了基于极限梯度提升和长短期记忆网络的融合模型对铁水硅含量的趋势进行预测;充分利用高炉可检测到的影响铁水硅含量的数据对半个炼铁班次内铁水硅含量趋势的方向和幅度进行预测,为高炉操作者提前判断炉况的变化趋势以及调控幅度提供参考依据,进而保证炼铁过程顺行和铁水质量保持在正常范围内。The invention provides a method, equipment and storage medium for predicting the change trend of silicon content in blast furnace molten iron. The trend of silicon content in blast furnace molten iron is predicted by a data-driven method, an input sample is constructed through data preprocessing, and an input sample is constructed through data preprocessing. Regression linear fitting method is used to determine the output trend category; and a fusion model based on extreme gradient boosting and long short-term memory network is established to predict the trend of hot metal silicon content; make full use of the data that can be detected in the blast furnace that affects the silicon content of molten iron. Predicting the direction and magnitude of the trend of the silicon content in the molten iron in each ironmaking shift provides a reference for the blast furnace operator to judge the changing trend of the furnace condition and the adjustment range in advance, so as to ensure that the ironmaking process runs smoothly and the molten iron quality remains within the normal range.
附图说明Description of drawings
图1为根据本发明实施例的高炉铁水硅含量变化趋势预测方法示意图;1 is a schematic diagram of a method for predicting the variation trend of silicon content in blast furnace hot metal according to an embodiment of the present invention;
图2为根据本发明实施例的硅含量趋势划分流程图;Fig. 2 is a flow chart of silicon content trend division according to an embodiment of the present invention;
图3为根据本发明实施例的多模型融合示意图;3 is a schematic diagram of multi-model fusion according to an embodiment of the present invention;
图4(a)为根据本发明实施例的实际案例中部分硅含量趋势预报结果命中图;FIG. 4(a) is a hit map of part of silicon content trend prediction results in an actual case according to an embodiment of the present invention;
图4(b)为根据本发明实施例的实际案例中另一部分硅含量趋势预报结果命中图;Figure 4(b) is a hit map of another part of silicon content trend prediction results in a practical case according to an embodiment of the present invention;
图5为根据本发明实施例的高炉铁水硅含量变化趋势预测设备示意图。5 is a schematic diagram of a device for predicting the change trend of silicon content in blast furnace molten iron according to an embodiment of the present invention.
具体实施方式Detailed ways
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。The specific embodiments of the present invention will be described in further detail below with reference to the accompanying drawings and embodiments. The following examples are intended to illustrate the present invention, but not to limit the scope of the present invention.
本实施例中示出了一种高炉铁水硅含量变化趋势预测方法,如图1所示,包括:This embodiment shows a method for predicting the change trend of silicon content in blast furnace molten iron, as shown in Figure 1, including:
获取炼铁过程中与高炉铁水中硅含量变化相关的特征参数,基于已训练的高炉铁水硅含量预测模型,对硅含量变化趋势进行预测;Obtain the characteristic parameters related to the change of silicon content in blast furnace molten iron during the ironmaking process, and predict the change trend of silicon content based on the trained blast furnace molten iron silicon content prediction model;
其中,所述高炉铁水含量预测模型包括第一层预测模型和第二层预测模型,所述第一层预测模型用于根据原始样本对硅含量变化趋势进行初步预测,所述第二层预测模型根据所述第一层预测模型的预测结果进行二次预测,得到硅含量变化趋势。Wherein, the blast furnace molten iron content prediction model includes a first-layer prediction model and a second-layer prediction model, the first-layer prediction model is used to preliminarily predict the change trend of silicon content according to the original sample, and the second-layer prediction model A secondary prediction is performed according to the prediction result of the first-layer prediction model to obtain the variation trend of silicon content.
在本实施例中,铁水中硅含量的变化趋势与整个炼铁过程中众多参数的变化密切相关,这些参数可以分为两类:一类是部分可测的、同时可以反映高炉冶炼过程状态的状态参数;另一类是高炉炉况出现失常时,现场工人进行调控的控制参数。主要包括富氧率、透气性指数、标准风速、富氧流量、冷风流量、喷煤量、铁水成分、煤气成分、顶压、全压差、热风压力、实际风速、冷风压力、理论燃烧温度、热风温度、鼓风动能、富氧流量、富氧压力、炉腹煤气量等等。In this embodiment, the change trend of the silicon content in the molten iron is closely related to the changes of many parameters in the whole ironmaking process. These parameters can be divided into two categories: one is partially measurable and can reflect the state of the blast furnace smelting process at the same time. State parameters; the other is the control parameters that are regulated by on-site workers when the blast furnace condition is abnormal. Mainly include oxygen enrichment rate, air permeability index, standard wind speed, oxygen enrichment flow, cold air flow, coal injection volume, molten iron composition, gas composition, top pressure, total pressure difference, hot air pressure, actual wind speed, cold air pressure, theoretical combustion temperature, Hot air temperature, blast kinetic energy, oxygen-enriched flow, oxygen-enriched pressure, belly gas volume, etc.
在本实施例中,通过极限梯度提升模型和循环神经网络的一种变体长短期记忆模型建立第一层预测模型,将特征参数数据输入到极限梯度提升模型中,得到模型的预测结果和影响硅含量趋势的特征参数重要性排序;In this embodiment, the first-layer prediction model is established by using the extreme gradient boosting model and a variant long short-term memory model of the recurrent neural network, and the characteristic parameter data is input into the extreme gradient boosting model, and the prediction results and influence of the model are obtained. The order of importance of characteristic parameters of silicon content trend;
从重要性排序中选出重要性高的特征参数数据,输入到长短期记忆模型中得到模型的预测结果;Select the feature parameter data with high importance from the importance ranking and input it into the long short-term memory model to obtain the prediction result of the model;
建立极限梯度提升模型和长短期记忆模型的融合模型,得到硅含量七分类趋势预测结果。The fusion model of the limit gradient boosting model and the long short-term memory model was established, and the prediction result of the seven classification trend of silicon content was obtained.
高炉的历史数据库中保存了大量的历史数据,其中有些数据是实时在线采集的,而有些数据则是通过化验后经过高炉操作工人手动输入的。数据在采集的过程中由于设备故障或者人工操作失误等多种原因造成数据不能真实准确的反应炉况,因此需要对数据进行预处理来消除上述问题和提高数据的质量以及后续模型的精度。A large amount of historical data is stored in the blast furnace's historical database, some of which are collected online in real time, while some are manually input by blast furnace operators after testing. In the process of data collection, due to various reasons such as equipment failure or manual operation error, the data cannot be the true and accurate reaction furnace condition. Therefore, it is necessary to preprocess the data to eliminate the above problems and improve the quality of data and the accuracy of subsequent models.
因此,在本实施例中,获取炼铁过程中与高炉铁水中硅含量变化相关的特征参数前,还包括:Therefore, in this embodiment, before acquiring the characteristic parameters related to the change of silicon content in the blast furnace molten iron during the ironmaking process, the method further includes:
获取历史炼铁过程中与高炉铁水中硅含量变化相关的特征参数及硅含量变化趋势,对所述高炉铁水含量预测模型进行训练;Obtaining characteristic parameters related to the change of silicon content in blast furnace molten iron and the change trend of silicon content in the historical ironmaking process, and training the blast furnace molten iron content prediction model;
通过所述特征参数及硅含量变化趋势对所述第一层预测模型进行训练,通过训练后第一层预测模型的预测结果对所述第二层预测模型进行训练。The first-layer prediction model is trained according to the characteristic parameter and the silicon content change trend, and the second-layer prediction model is trained according to the prediction result of the first-layer prediction model after training.
获取炼铁过程中的现场数据,对所述特征参数进行异常值剔除、缺失值填补、归一化处理,建模所需的高质量数据;Obtain the field data in the ironmaking process, and perform outlier elimination, missing value filling, and normalization processing on the characteristic parameters, and high-quality data required for modeling;
通过滑动窗口对高炉铁水中硅含量在时间轴上进行分割,得到高炉铁水中硅含量变化趋势。The silicon content in blast furnace molten iron was divided on the time axis by sliding window, and the variation trend of silicon content in blast furnace molten iron was obtained.
具体的,包括:Specifically, including:
1)、异常值处理1), outlier processing
当高炉出现故障时,或者由于一些异常的炉况就会导致采集到的特征参数数据偏离正常范围。因此需要多异常值进行剔除。首先对于序列中明显异常数据直接剔除,对于那些不明显的数据,通过箱线图法直接剔除。箱形图的绘制仅依靠实际数据,不需要事先假定数据服从特定的分布形式,没有对数据作任何限制性要求,对异常值识别的结果比较客观。When the blast furnace fails, or due to some abnormal furnace conditions, the collected characteristic parameter data will deviate from the normal range. Therefore, multiple outliers need to be eliminated. First of all, the obvious abnormal data in the sequence is directly eliminated, and for those insignificant data, it is directly eliminated by the boxplot method. The drawing of the box plot only relies on the actual data. It does not need to assume that the data obeys a specific distribution form in advance. It does not make any restrictive requirements for the data, and the results of outlier identification are relatively objective.
2)、缺失值填补2), missing value filling
步骤1)删除的异常值,人工失误、休风以及设备故障等原因都会造成数据的缺失。若不对缺失的数据进行合理的删除和填补必然会对模型的精度造成一定的影响。Step 1) Deleted outliers, manual errors, wind breaks and equipment failures will cause data loss. If the missing data is not properly deleted and filled, it will inevitably affect the accuracy of the model.
直接把缺失值全部删除必然会丢失一部分信息,因此需要对缺失值进行有选择的删除和填补。首先按行统计每个样本的属性缺失值的个数,将缺失值的个数按照从小到大排序,以序号为横坐标,缺失值的个数为纵坐标。分别画出训练集和测试集缺失值个数统计的散点图。从模型的角度来说,训练集和测试集的分布越一致就越能防止过拟合现象的发生,找出散点图中分布不一致的地方,这些点可以认为是离群点,将其整行数据剔除。Directly deleting all missing values will inevitably lose some information, so it is necessary to selectively delete and fill missing values. First, count the number of attribute missing values of each sample by row, sort the number of missing values from small to large, take the serial number as the abscissa, and the number of missing values as the ordinate. Draw a scatterplot of the number of missing values in the training set and test set, respectively. From the perspective of the model, the more consistent the distribution of the training set and the test set, the more it can prevent the occurrence of overfitting. Find out the inconsistent distribution in the scatter plot. These points can be considered as outliers, and they can be integrated into row data culling.
对于剩下的缺失值应对其进行填补,假设第l时刻的数据缺失,利用该数据前一时刻的数据xim和后一时刻的数据xin进行估算:The remaining missing values should be filled, assuming that the data at the lth moment is missing, use the data xim at the previous moment and the data xin at the next moment to estimate:

3)、归一化处理3), normalization processing
由于现场采集的数据量纲相差比较大,量纲大的对模型的影响会比较大,因此在建模之前需要对数据进行归一化处理,通过如下公式归一化:Since the dimensions of the data collected on site are quite different, the larger dimension will have a greater impact on the model, so the data needs to be normalized before modeling, and normalized by the following formula:

xnorm表示变量归一化之后的结果,xmax,xmin分别表示第i个变量的最大值和最小值。xnorm represents the result after the variable is normalized, and xmax and xmin represent the maximum and minimum values of the i-th variable, respectively.
通过滑动窗口对高炉铁水中硅含量在时间轴上进行分割,得到高炉铁水中硅含量变化趋势。The silicon content in blast furnace molten iron was divided on the time axis by sliding window, and the variation trend of silicon content in blast furnace molten iron was obtained.
在实际冶炼操作过程中,每个班次(8个小时),工长并不会因为铁水硅含量的小幅度波动而频繁的调节相应的控制参数。只有在炉况偏离正常范围时,操作者才会调控鼓风动能、热风温度、喷煤量等控制参数。所以预测周期过短,对现场工人的指导意义不大,预测周期过长,炉况发生异常又不能及时得到相应的调控。一般情况下,各个参数都有不同的滞后时间,如送风对铁水硅含量有2-3小时的滞后、喷煤量对铁水硅含量有3-4小时的滞后,这将会使得调控结果大概在几个小时之后才会有相应的体现。且根据现场专家的经验,预测半个班次的趋势对现场指导意义较大。综合上述原因,本实施例中选取半个班次(4个小时)的时间段作为分析铁水硅含量趋势预测的周期,为高炉工长提供接下来4个小时硅含量的变化趋势,有利于工长全面把握炉况在未来的变化方向,适时的采取合适的调控手段,保证高炉的稳定顺行。During the actual smelting operation, for each shift (8 hours), the foreman will not frequently adjust the corresponding control parameters due to the small fluctuation of the silicon content in the molten iron. Only when the furnace condition deviates from the normal range, the operator will adjust the control parameters such as blast kinetic energy, hot air temperature, and coal injection amount. Therefore, if the forecast period is too short, it has little guiding significance for the on-site workers. If the forecast period is too long, the abnormal furnace conditions cannot be regulated in time. In general, each parameter has a different lag time. For example, the air supply has a lag of 2-3 hours for the silicon content of the molten iron, and the amount of coal injection has a lag of 3-4 hours for the silicon content of the molten iron, which will make the control result approximately It will be reflected in a few hours. And according to the experience of on-site experts, predicting the trend of half a shift is of great significance for on-site guidance. Based on the above reasons, in this embodiment, the time period of half a shift (4 hours) is selected as the period for analyzing the trend prediction of the silicon content in the molten iron, so as to provide the foreman of the blast furnace with the change trend of the silicon content in the next 4 hours, which is beneficial to the foreman. Fully grasp the changing direction of the furnace conditions in the future, and take appropriate control measures in a timely manner to ensure the stability of the blast furnace.
从一个月的硅含量的时间序列图上可以看出铁水硅含量的值没有明确的周期性和聚类性,很难直接在原始数据上挖掘趋势的信息。因此可以通过对铁水硅含量的值在时间轴上用滑动窗口进行分割,并对滑动窗口内的数据采用多项式回归拟合的方法得到其方程,通过拟合方程的一阶跟二阶导数的正负来确定硅含量的趋势信息。当一阶导数为0时,表示平稳不变趋势;而当一阶导数为正数时,表示线性上升趋势;当一阶导数为负数时,表示线性下降趋势。二阶导数则反映了变量的变化形状,二阶导数为正数时为上凸状;二阶导数为负数为下凹状。根据一阶导数与二阶导数的组合,可以将趋势划分为7种类型:凹型上升、线性上升、凸形上升、平稳不变、凹型下降、线性下降、凸形下降。硅含量趋势划分的整体流程图如图2所示,具体步骤如下:From the time series chart of silicon content in one month, it can be seen that the value of silicon content in hot metal has no clear periodicity and clustering, and it is difficult to directly mine trend information from the original data. Therefore, the value of the silicon content in the molten iron can be divided on the time axis with a sliding window, and the data in the sliding window can be fitted by polynomial regression to obtain its equation. Negative to determine trend information for silicon content. When the first derivative is 0, it indicates a stable and constant trend; when the first derivative is positive, it indicates a linear upward trend; when the first derivative is negative, it indicates a linear downward trend. The second-order derivative reflects the changing shape of the variable. When the second-order derivative is positive, it is upwardly convex; when the second-order derivative is negative, it is downwardly concave. According to the combination of the first derivative and the second derivative, the trend can be divided into 7 types: concave rise, linear rise, convex rise, steady and constant, concave fall, linear fall, and convex fall. The overall flow chart of silicon content trend division is shown in Figure 2, and the specific steps are as follows:
Step1:设定总窗口宽度,并根据炼铁班次确定高炉铁水中硅含量变化的预测周期,根据所述预测周期设定滑动窗口宽度;在本实施例中,确定总窗口宽度M,即所研究问题的总时间序列中有M个数据((x1,y1),(x2,y2)...(xM,yM)),根据预测周期确定滑动窗口的宽度N=8(N<M);Step1: set the total window width, and determine the prediction period of the change of silicon content in the blast furnace molten iron according to the ironmaking shift, and set the sliding window width according to the prediction period; In the present embodiment, determine the total window width M, that is, the researched There are M data in the total time series of the problem ((x1 , y1 ), (x2 , y2 )...(xM , yM )), and the width of the sliding window N=8 ( N<M);
Step2:对每个滑动窗口,通过零阶多项式对所述滑动窗口内的硅含量值进行拟合,得到拟合方程,并通过方差比率检验(F-test,F显著性检验)判断拟合效果,若拟合方程不显著,则记录所述滑动窗口内的硅含量为平稳不变趋势,否则转入Step3;Step2: For each sliding window, the silicon content value in the sliding window is fitted by a zero-order polynomial to obtain a fitting equation, and the fitting effect is judged by the variance ratio test (F-test, F significance test). , if the fitting equation is not significant, record the silicon content in the sliding window as a stable and constant trend, otherwise go to
Step3:通过一阶多项式对所述滑动窗口内的硅含量值进行拟合,得到拟合方程,并通过F显著性检验判断拟合效果,若拟合方程不显著,则根据斜率正负判断所述滑动窗口内硅含量为线性上升趋势或线性下降趋势,否则转入Step4;Step3: Fit the silicon content value in the sliding window through a first-order polynomial to obtain a fitting equation, and judge the fitting effect through the F significance test. The silicon content in the sliding window is a linear upward trend or a linear downward trend, otherwise, go to
Step4:通过二阶多项式对所述滑动窗口内的硅含量值进行拟合,得到拟合方程,求出所述拟合方程的一阶导数和二阶导数,若一阶导数正且二阶导数正,则判断所述滑动窗口内硅含量为凸形上升趋势;若一阶导数正且二阶导数负,则判断所述滑动窗口内硅含量为凹形上升趋势;若一阶导数负且二阶导数正,则判断所述滑动窗口内硅含量为凸形下降趋势;若一阶导数负且二阶导数负,则判断所述滑动窗口内硅含量为凹形下降趋势;Step4: Fit the silicon content value in the sliding window by a second-order polynomial, obtain a fitting equation, and obtain the first-order derivative and the second-order derivative of the fitting equation, if the first-order derivative is positive and the second-order derivative positive, the silicon content in the sliding window is judged to be a convex upward trend; if the first derivative is positive and the second derivative is negative, it is judged that the silicon content in the sliding window is a concave upward trend; if the first derivative is negative and the second derivative is negative If the order derivative is positive, it is judged that the silicon content in the sliding window has a convex downward trend; if the first order derivative is negative and the second order derivative is negative, it is judged that the silicon content in the sliding window has a concave downward trend;
Step5:对每个滑动窗口内的数据通过上述步骤进行操作,得到每个滑动窗口内硅含量变化趋势,终止条件为总窗口内的数据都被拟合完。Step 5: The data in each sliding window is operated through the above steps, and the variation trend of silicon content in each sliding window is obtained, and the termination condition is that the data in the total window has been fitted.
通过所述特征参数及硅含量变化趋势对所述第一层预测模型进行训练,通过训练后第一层预测模型的预测结果对所述第二层预测模型进行训练。The first-layer prediction model is trained according to the characteristic parameter and the silicon content change trend, and the second-layer prediction model is trained according to the prediction result of the first-layer prediction model after training.
在本实施例中,所述第一层预测模型包括极限梯度提升模型和循环神经网络的一个变体长短期记忆模型;In this embodiment, the first-layer prediction model includes an extreme gradient boosting model and a variant long short-term memory model of a recurrent neural network;
所述第一层预测模型通过原始样本进行训练,包括:The first-layer prediction model is trained with original samples, including:
通过所述特征参数和硅含量变化趋势对极限梯度提升模型进行训练,得到训练后的极限梯度提升模型和影响硅含量变化趋势的过程变量参数重要性排序;The extreme gradient boosting model is trained by the characteristic parameters and the variation trend of silicon content, and the extreme gradient boosting model after training and the importance ranking of process variable parameters affecting the variation trend of silicon content are obtained;
基于长短期记忆模型对过程变量参数重要性排序中排序靠前的多个过程变量特征参数进行训练,在本实施例中,选择影响硅含量趋势中特征重要性排名前15个的特征参数,输入到长短期记忆模型(LSTM)中,预测铁水硅含量的趋势。Based on the long-term and short-term memory model, training is performed on a plurality of process variable characteristic parameters that are ranked first in the ranking of the importance of process variable parameters. into a long short-term memory model (LSTM) to predict the trend of silicon content in hot metal.
选择极限梯度提升模型(XGboost)作为预测模型的可行性分析,从数据的角度来看,高炉检测设备众多,获得的实际生产数据量大,数据存在多元性和层次性。XGboost采用并行式和分布式的计算,使得模型的学习速度加快。从模型的角度来看,XGboost作为机器学习算法(Gradient Boosting Machine,GBM)类算法的一种有效的高性能实现,计算复杂度不高,在工业界有大量的应用,并在在分类、回归和排序问题上,计算性能、准确度、运行时间方面优势显著。The feasibility analysis of selecting the extreme gradient boosting model (XGboost) as the prediction model. From the perspective of data, there are many blast furnace testing equipment, and the actual production data obtained is large, and the data has diversity and hierarchy. XGboost uses parallel and distributed computing to accelerate the learning speed of the model. From the model point of view, XGboost, as an effective high-performance implementation of Gradient Boosting Machine (GBM) algorithms, has low computational complexity and has a large number of applications in the industry. On the problem of sorting and sorting, it has significant advantages in terms of computational performance, accuracy, and running time.
XGboost通过一组弱分类器的迭代计算来实现准确的预测效果,基本的分类器是分类和回归。为了保证模型的精度,常见的解决思路是采用树的集成模型,把多颗树的预测结果综合在一起。假设给定的数据集有n个样本m个特征

其中,

其中l是预测值


其中,


根据二阶泰勒展开,简化目标中的损失函数,于是目标函数可以近似为:According to the second-order Taylor expansion, simplify the loss function in the target, so the target function can be approximated as:

其中,

目标函数中的训练误差部分已确定,接下来定义树的复杂度,假设fk是决策树,把树拆分为结构部分q和叶子节点ω,结构函数q把输入映射到叶子的索引号上面去,而ω给定了每个索引号对应的叶子分数。The training error part of the objective function has been determined. Next, define the complexity of the tree. Suppose fk is a decision tree, and split the tree into a structural part q and a leaf node ω. The structural function q maps the input to the index number of the leaf. go, and ω gives the leaf score corresponding to each index number.
f(x)=ωq(x),ω∈RT,q:Rd→{1,2...T}f(x)=ωq(x) ,ω∈RT ,q:Rd →{1,2...T}
把决策树做了如上定义后,树的复杂度就可以做如下定义:After the decision tree is defined as above, the complexity of the tree can be defined as follows:

其中I被定义为每个叶子上面样本集合Ij={i|q(xi)=j},可把目标函数进行如下改写:where I is defined as the set of samples above each leaf Ij = {i|q(xi) =j}, the objective function can be rewritten as follows:

目标函数包含了T个互相独立的单变量二次函数,定义


假设树的结构q(x)固定,对ωj求导,就能得到叶子节点的最优权值和目标函数的最优值:Assuming that the structure q(x) of the tree is fixed, the optimal weight of the leaf node and the optimal value of the objective function can be obtained by derivation of ωj :


上式中,obj(t)为代表树的结构分数,obj(t)越小代表树的结构越好,利用打分函数来寻找出一个最优结构的树,加入到我们的模型中,再重复这样的操作。不过枚举所有树结构这个操作不太可行,所以常用的方法是贪心法,每一次尝试去对已有的叶子加入一个分割,选择目标函数最小、增益最大的划分,增益公式如下:In the above formula, obj(t) represents the structural score of the tree. The smaller obj(t) is, the better the structure of the tree is. Use the scoring function to find a tree with an optimal structure, add it to our model, and repeat such an operation. However, it is not feasible to enumerate all tree structures, so the commonly used method is the greedy method. Each time you try to add a partition to the existing leaves, select the partition with the smallest objective function and the largest gain. The gain formula is as follows:

其中,GL,GR分别表示左边树、右边树的增益之和,这个公式用来选出分裂的候选变量。Among them,GL andGR respectively represent the sum of the gains of the left tree and the right tree, and this formula is used to select the candidate variable for splitting.
对循环神经网络进行训练,由于高炉的冶炼是一个动态时间序列的过程,具有大时滞、强滞后等特点,而且高炉的冶炼过程是渐变的,当前的炉况与历史的炉况具有一定的相关性,因此铁水硅含量的趋势不仅与当前的参数有关,还与以前面时刻的参数有关。循环神经网络能在学习新信息同时保存历史信息有选择的持久化,本实施例中选择循环神经网络的一个变体长短期记忆模型(Long Short-Term Memory ,LSTM)来预测铁水硅含量的趋势。For training the recurrent neural network, since the smelting of blast furnace is a dynamic time series process, it has the characteristics of large time delay and strong lag, and the smelting process of blast furnace is gradual, and the current furnace conditions and historical furnace conditions have certain differences. Therefore, the trend of the silicon content in the hot metal is not only related to the current parameters, but also related to the parameters of the previous time. The recurrent neural network can learn new information while saving historical information for selective persistence. In this embodiment, a long short-term memory model (Long Short-Term Memory, LSTM), a variant of the recurrent neural network, is selected to predict the trend of hot metal silicon content .
为了克服循环神经网络梯度消失的问题,提出了长短期记忆模型(LSTM),LSTM构建了专门的记忆存贮单元,可以解决隐藏层在新的时间节点状态下将不断叠加输入序列而导致前面的信息模糊,而无法继续向后传播的问题,更适合时间序列方面的预测。长短期记忆模型(LSTM)基本结构如下:In order to overcome the problem of the gradient disappearance of the recurrent neural network, a long short-term memory model (LSTM) is proposed. LSTM builds a special memory storage unit, which can solve the problem that the hidden layer will continue to superimpose the input sequence in the new time node state and cause the previous The problem that the information is ambiguous and cannot continue to propagate backward is more suitable for time series forecasting. The basic structure of the long short-term memory model (LSTM) is as follows:
长短期记忆模型(LSTM)定义为:输入时间序列X={x1,x2...xn},每个输入都有对应的输入门,遗忘门和输出门来保护和控制细胞状态。细胞状态控制长期记忆单元的记忆与遗忘。The long short-term memory model (LSTM) is defined as: input time series X = {x1 , x2 ... xn }, each input has a corresponding input gate, forget gate and output gate to protect and control the cell state. Cell state controls memory and forgetting in long-term memory cells.
在长短期记忆模型(LSTM)中,遗忘门ft第一步决定从细胞状态中丢弃什么信息:In a long short-term memory model (LSTM), the forget gate ft first decides what information to discard from the cell state:
ft=σ(ωf[ht-1,xt]+bf)ft =σ(ωf [ht-1 ,xt ]+bf )
ht-1代表上一个时刻的输出,xt代表当前时刻的输入。ft输出一个在0-1之间的数值给细胞状态ct-1,若输出为1,则完全保留,若输出为0,则完全舍弃。ht-1 represents the output at the previous moment, and xt represents the input at the current moment. ft outputs a value between 0-1 to the cell state ct-1 , if the output is 1, it is completely reserved, and if the output is 0, it is completely discarded.
下一步就是确定什么样的信息被存放在细胞状态中:The next step is to determine what information is stored in the cell state:
it=σ(ωi[ht-1,xt]+bi)it =σ(ωi [ht-1 ,xt ]+bi )


输入门it输出0-1之间的数确定什么值被更新,

再确定最后的输出,这个输出依赖于我们之前的细胞状态:Then determine the final output, which depends on our previous cell state:
Ot=σ(ωo[ht-1,xt]+bo)Ot =σ(ωo [ht-1 ,xt ]+bo )
ht=Ot*tanh(Ct)ht =Ot *tanh(Ct )
首先通过一个Sigmoid函数确定细胞状态哪部分输出,接着,把细胞状态通过tanh处理和输出门的输出相乘,最终得到确定的输出部分。上述控制门和记忆细胞允许LSTM单元自适应地忘记、记忆和展示记忆内容。遗忘门的开闭可以同时发生在不同的LSTM单元。基于循环神经网络的长短期记忆模型可以发现和建立输入值和输出值之间的长期依赖关系。First, a Sigmoid function is used to determine which part of the cell state is output. Then, the cell state is multiplied by the output of the output gate through tanh processing, and finally the determined output part is obtained. The aforementioned control gates and memory cells allow the LSTM unit to adaptively forget, memorize, and display memory contents. The opening and closing of the forget gate can occur simultaneously in different LSTM units. Long and short-term memory models based on recurrent neural networks can discover and establish long-term dependencies between input and output values.
在本实施例中,两个模型经过简单的调参以后都可以达到一个较好的分类效果,但想进一步提高模型的精度就需要进行复杂的调参过程,为了避免这种费时费力且效果不一定有显著提高的调参过程,模型融合就成了一种提高模型预测精度的好办法。模型融合充分利用了多个现有模型的特点,具有较好的拟合能力且能形成两个模型的互补关系。In this embodiment, both models can achieve a good classification effect after simple parameter adjustment. However, to further improve the accuracy of the model, a complex parameter adjustment process is required. In order to avoid this time-consuming and laborious and ineffective There must be a significantly improved parameter tuning process, and model fusion has become a good way to improve the prediction accuracy of the model. Model fusion makes full use of the characteristics of multiple existing models, has good fitting ability and can form a complementary relationship between the two models.
本实施例中采用堆叠(stacking)的方式进行模型融合,堆叠(也称为元组合)是用于组合来自多个预测模型的信息以生成新模型的模型组合技术。堆叠模型也称为二级模型,因为它的平滑性和突出每个基本模型在其中执行得最好的能力,并且抹黑其执行不佳的每个基本模型,所以将优于每个单个模型。具体融合过程如图3所示,第一层预测模型是极限梯度提升模型和长短期记忆模型,第二层预测模型为逻辑回归模型,堆叠(stacking)具体步骤如下:In this embodiment, the model fusion is performed in a stacking manner. Stacking (also called meta-combination) is a model combination technique used to combine information from multiple prediction models to generate a new model. A stacked model, also known as a secondary model, will outperform every single model because of its smoothness and ability to highlight where each base model performs best, and discredit each base model where it performs poorly. The specific fusion process is shown in Figure 3. The first-layer prediction model is an extreme gradient boosting model and a long short-term memory model, and the second-layer prediction model is a logistic regression model. The specific steps of stacking are as follows:
Step1:把原始样本集按一定比例分成训练集和测试集,把训练集平均分成五份;Step1: Divide the original sample set into training set and test set according to a certain proportion, and divide the training set into five parts on average;
Step2:将训练集中的四份对第一层预测模型的极限梯度提升模型进行训练,第五份数据在训练好的极限梯度提升模型上进行预测并且保留预测结果,此过程迭代五次;Step2: Train the extreme gradient boosting model of the first-layer prediction model with four copies of the training set, and predict the fifth data on the trained extreme gradient boosting model and retain the prediction results. This process is iterated five times;
Step3:将Step2中的极限梯度提升模型换成长短期记忆模型,并执行Step2的操作;Step3: Replace the extreme gradient boosting model in Step2 with a long short-term memory model, and perform the operation of Step2;
Step4:将极限梯度提升模型和成长短期记忆模型的预测结果合成一列,输入到第二层预测模型的逻辑回归模型中,完成模型的训练;Step4: Combine the prediction results of the extreme gradient boosting model and the growing short-term memory model into one column, and input them into the logistic regression model of the second-layer prediction model to complete the training of the model;
Step5:利用训练好的第一层预测模型对测试集进行预测并把结果保留下来,每一个模型经过五次迭代后得到五组不同的预测结果,把五组结果对于位置上的值取众数得到一组预测结果;Step5: Use the trained first-layer prediction model to predict the test set and keep the results. After five iterations of each model, five sets of different prediction results are obtained, and the five sets of results are taken as the mode of the value at the position. get a set of prediction results;
Step6:将第一层预测模型中的两个模型的预测结果合成一列,并输入到第二层预测模型中的逻辑回归模型中,得到最终的预测结果。Step6: Combine the prediction results of the two models in the first-layer prediction model into one column, and input it into the logistic regression model in the second-layer prediction model to obtain the final prediction result.
本实施例中的方法应用到某钢厂2650m3高炉进行试验测试,具体包括如下步骤:The method in the present embodiment is applied to a2650m3 blast furnace in a certain steel mill for test testing, which specifically includes the following steps:
1)数据预处理。将高炉检测装置上的采集来的数据进行相关处理提高数据的质量,本案例获取了2017年1月到2017年6月的数据,具体步骤如下:1) Data preprocessing. The data collected from the blast furnace detection device is processed to improve the quality of the data. In this case, the data from January 2017 to June 2017 was obtained. The specific steps are as follows:
采用箱线图法剔除异常数据,通过异常值处理,本实施例共剔除248个异常数据。The boxplot method is used to remove abnormal data, and through outlier processing, a total of 248 abnormal data are removed in this embodiment.
按行统计每个样本的属性缺失值的个数,将缺失值的个数按照从小到大排序,以序号为横坐标,缺失值的个数为纵坐标。分别画出训练集和测试集缺失值个数统计的散点图,把散点图中不一致的地方当做离群点删掉,再把其他的缺失值根据前后两时刻的值进行填补,本实施例共填补582个缺失数据。The number of attribute missing values of each sample is counted by row, and the number of missing values is sorted from small to large, with the serial number as the abscissa and the number of missing values as the ordinate. Draw the scatter plots of the statistics of missing values in the training set and the test set respectively, delete the inconsistencies in the scatter plots as outliers, and then fill in the other missing values according to the values at the two times before and after. This implementation A total of 582 missing data were filled.
归一化处理。Normalized processing.
2)铁水硅含量变化趋势的确定。根据现场专家的经验、时滞分析确定预测周期为半个班次(四个小时),对每四个小时内的硅含量的数值用n阶多项式方程(n<3)去拟合,得到方程的一阶跟二阶导数,当一阶导数为0时,表示处于平稳不变趋势;而当一阶导数为正数时,表示具有线性上升趋势;当一阶导数为负数时,表示具有线性下降趋势;一阶导数正二阶导数正则为凸形上升趋势;一阶导数正二阶导数负则为凹形上升趋势;一阶导数负二阶导数正则为凸形下降趋势;一阶导数负二阶导数负则为凹形下降趋势。2) Determination of changing trend of silicon content in molten iron. According to the experience of on-site experts and time-delay analysis, the prediction period is determined to be half a shift (four hours). For the first and second derivatives, when the first derivative is 0, it indicates a stable and constant trend; when the first derivative is positive, it indicates a linear upward trend; when the first derivative is negative, it indicates a linear decline Trend; first derivative positive second derivative is a convex upward trend; first derivative positive second derivative negative is a concave upward trend; first derivative negative second derivative is a convex downward trend; first derivative negative second derivative Negative is a concave downtrend.
3)建立极限梯度预报模型。将经过上述过程处理的样本按照一定比例组成训练集和测试集,用于模型的训练和预测。把数据输入到极限梯度提升模型中,通过网格搜索法找到模型的最优参数,得到铁水硅含量趋势的预测结果,测试集共100个,总共命中了67个,命中率为67%。并得到输入特征的重要度预排序,根据极限梯度预报模型重要度排序,选出特征预排名考前的15个,即:富氧压力、热风温度、鼓风温度、CO2、理论燃烧温度、H2、拱温东北、CO、透气性指数、拱温东南、冷风流量、上小时喷煤量、拱温西南、富氧流量、富氧率输入到循环神经网络中。3) Establish a limit gradient prediction model. The samples processed by the above process are composed of training set and test set according to a certain proportion, which are used for model training and prediction. Input the data into the extreme gradient boosting model, find the optimal parameters of the model by grid search method, and obtain the prediction result of the trend of silicon content in molten iron. There are 100 test sets, and 67 hits in total, with a hit rate of 67%. And get the pre-ranking of the importance of the input features, according to the importance of the extreme gradient prediction model, select the 15 features before the pre-ranking test, namely: oxygen-enriched pressure, hot air temperature, blast temperature, CO2 , theoretical combustion temperature, H2 , northeast arch temperature, CO, air permeability index, arch temperature southeast, cold air flow, coal injection volume in the last hour, arch temperature southwest, oxygen-enriched flow, and oxygen-enriched rate are input into the cyclic neural network.
4)建立循环神经网络预报模型。将经过上述过程处理的样本按照一定比例组成训练集和测试集,把数据输入到长短期记忆模型(Long-Short Term Memory,LSTM)中,得到铁水硅含量趋势的预测结果,测试集共100个,总共命中了62个,命中率为62%。4) Establish a cyclic neural network prediction model. The samples processed by the above process are composed of training set and test set according to a certain proportion, and the data is input into the long-short term memory model (Long-Short Term Memory, LSTM) to obtain the prediction result of the trend of silicon content in molten iron. There are 100 test sets in total. , hit a total of 62 for a 62 percent hit rate.
5)建立极限梯度提升和长短期记忆模型的融合模型,融合模型预测的结果如图4(a)和图4(b)所示,图4(a)和图4(b)中各包含50个结果,0代表平稳不变趋势,1代表凸形上升趋势,2代表线性上升趋势,3代表凹型上升趋势,-1代表凸形下降趋势,-2代表线性下降趋势,-3代表凹型下降趋势。图中,圆形为实际类别,五角星为预测类别,五角星和圆形重合则表示预测命中,测试集共100个,总共命中了75个,命中率为75%,可以看出预测精度有了一定的提高,综合了极限梯度提升(XGboost)预测模型和长短期记忆模型(LSTM)的优势,实现了铁水硅含量趋势的智能预报,为高炉操作者调节炉况指导生产提供了重要的信息。5) Establish a fusion model of extreme gradient boosting and long short-term memory model. The results of the fusion model prediction are shown in Figure 4(a) and Figure 4(b). Figure 4(a) and Figure 4(b) each contain 50 0 represents a stable and constant trend, 1 represents a convex upward trend, 2 represents a linear upward trend, 3 represents a concave upward trend, -1 represents a convex downward trend, -2 represents a linear downward trend, and -3 represents a concave downward trend . In the figure, the circle is the actual category, the five-pointed star is the predicted category, and the coincidence of the five-pointed star and the circle indicates that the prediction hits. There are 100 test sets, and 75 hits in total, and the hit rate is 75%. It can be seen that the prediction accuracy is To a certain extent, the advantages of the extreme gradient boosting (XGboost) prediction model and the long short-term memory model (LSTM) are combined to realize the intelligent prediction of the trend of the silicon content in the molten iron, and provide important information for the blast furnace operator to adjust the furnace condition and guide the production. .
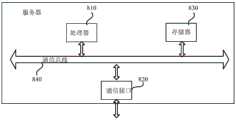
图5是示出本申请实施例的高炉铁水硅含量变化趋势预测设备的结构框图。FIG. 5 is a block diagram showing the structure of the apparatus for predicting the change trend of silicon content in blast furnace hot metal according to an embodiment of the present application.
参照图5,所述高炉铁水硅含量变化趋势预测设备,包括:处理器(processor)810、存储器(memory)830、通信接口(Communications Interface)820和总线840;Referring to FIG. 5 , the apparatus for predicting the change trend of silicon content in hot metal of blast furnace includes: a processor (processor) 810, a memory (memory) 830, a communications interface (Communications Interface) 820 and a
其中,in,
所述处理器810、存储器830、通信接口820通过所述总线840完成相互间的通信;The
所述通信接口820用于该测试设备与显示装置的通信设备之间的信息传输;The
所述处理器810用于调用所述存储器830中的程序指令,以执行上述各方法实施例所提供的高炉铁水硅含量变化趋势预测方法,例如包括:The
获取炼铁过程中与高炉铁水中硅含量变化相关的特征参数,基于已训练的高炉铁水硅含量预测模型,对硅含量变化趋势进行预测;Obtain the characteristic parameters related to the change of silicon content in blast furnace molten iron during the ironmaking process, and predict the change trend of silicon content based on the trained blast furnace molten iron silicon content prediction model;
其中,所述高炉铁水含量预测模型包括第一层预测模型和第二层预测模型,所述第一层预测模型用于根据原始样本对硅含量变化趋势进行初步预测,所述第二层预测模型根据所述第一层预测模型的预测结果进行二次预测,得到硅含量变化趋势。Wherein, the blast furnace molten iron content prediction model includes a first-layer prediction model and a second-layer prediction model, the first-layer prediction model is used to preliminarily predict the change trend of silicon content according to the original sample, and the second-layer prediction model A secondary prediction is performed according to the prediction result of the first-layer prediction model to obtain the variation trend of silicon content.
本实施例公开一种高炉铁水硅含量变化趋势预测设备,包括:The present embodiment discloses a device for predicting the change trend of silicon content in blast furnace molten iron, including:
至少一个处理器;以及at least one processor; and
与所述处理器通信连接的至少一个存储器,其中:at least one memory communicatively coupled to the processor, wherein:
所述存储器存储有可被所述处理器执行的程序指令,所述处理器调用所述程序指令能够执行如上述高炉铁水硅含量变化趋势预测方法。The memory stores program instructions executable by the processor, and the processor invokes the program instructions to execute the above-mentioned method for predicting the change trend of silicon content in hot metal of a blast furnace.
本实施例公开一种计算机程序产品,所述计算机程序产品包括存储在非暂态计算机可读存储介质上的计算机程序,所述计算机程序包括程序指令,当所述程序指令被计算机执行时,计算机能够执行上述各方法实施例所提供的高炉铁水硅含量变化趋势预测方法,例如包括:This embodiment discloses a computer program product, the computer program product includes a computer program stored on a non-transitory computer-readable storage medium, the computer program includes program instructions, and when the program instructions are executed by a computer, the computer program The method for predicting the change trend of silicon content in blast furnace molten iron provided by the above method embodiments can be implemented, for example, including:
获取炼铁过程中与高炉铁水中硅含量变化相关的特征参数,基于已训练的高炉铁水硅含量预测模型,对硅含量变化趋势进行预测;Obtain the characteristic parameters related to the change of silicon content in blast furnace molten iron during the ironmaking process, and predict the change trend of silicon content based on the trained blast furnace molten iron silicon content prediction model;
其中,所述高炉铁水含量预测模型包括第一层预测模型和第二层预测模型,所述第一层预测模型用于根据原始样本对硅含量变化趋势进行初步预测,所述第二层预测模型根据所述第一层预测模型的预测结果进行二次预测,得到硅含量变化趋势。Wherein, the blast furnace molten iron content prediction model includes a first-layer prediction model and a second-layer prediction model, the first-layer prediction model is used to preliminarily predict the change trend of silicon content according to the original sample, and the second-layer prediction model A secondary prediction is performed according to the prediction result of the first-layer prediction model to obtain the variation trend of silicon content.
本实施例提供一种非暂态计算机可读存储介质,所述非暂态计算机可读存储介质存储计算机指令,所述计算机指令使所述计算机执行上述各方法实施例所提供的高炉铁水硅含量变化趋势预测方法,例如包括:This embodiment provides a non-transitory computer-readable storage medium, the non-transitory computer-readable storage medium stores computer instructions, and the computer instructions cause the computer to execute the blast furnace hot metal silicon content provided by the above method embodiments Change trend forecasting methods, for example, include:
获取炼铁过程中与高炉铁水中硅含量变化相关的特征参数,基于已训练的高炉铁水硅含量预测模型,对硅含量变化趋势进行预测;Obtain the characteristic parameters related to the change of silicon content in blast furnace molten iron during the ironmaking process, and predict the change trend of silicon content based on the trained blast furnace molten iron silicon content prediction model;
其中,所述高炉铁水含量预测模型包括第一层预测模型和第二层预测模型,所述第一层预测模型用于根据原始样本对硅含量变化趋势进行初步预测,所述第二层预测模型根据所述第一层预测模型的预测结果进行二次预测,得到硅含量变化趋势。Wherein, the blast furnace molten iron content prediction model includes a first-layer prediction model and a second-layer prediction model, the first-layer prediction model is used to preliminarily predict the change trend of silicon content according to the original sample, and the second-layer prediction model A secondary prediction is performed according to the prediction result of the first-layer prediction model to obtain the variation trend of silicon content.
综上所述,本发明提出一种高炉铁水硅含量变化趋势预测方法、设备和存储介质,通过数据驱动的方法来预测高炉铁水硅含量的趋势,通过对影响硅含量趋势的特征参数进行预处理提高输入样本的质量,通过对滑动窗口内硅含量的值回归拟合确定输出趋势类别;并建立了极限梯度提升和长短期记忆网络的融合模型对铁水硅含量的趋势进行预测;充分利用高炉可检测到的影响铁水硅含量的数据对半个炼铁班次内(四个小时)铁水硅含量趋势的方向和幅度进行预测,为高炉操作者提前判断炉况的变化趋势以及调控幅度提供参考依据,进而保证炼铁过程顺行和铁水质量保持在正常范围内。In summary, the present invention proposes a method, equipment and storage medium for predicting the change trend of silicon content in blast furnace molten iron. The trend of silicon content in blast furnace molten iron is predicted by a data-driven method, and the characteristic parameters that affect the trend of silicon content are preprocessed. To improve the quality of the input samples, the output trend category is determined by the regression fitting of the silicon content in the sliding window; and a fusion model of extreme gradient boosting and long short-term memory network is established to predict the trend of molten iron silicon content; making full use of the blast furnace can The detected data affecting the silicon content of molten iron can predict the direction and magnitude of the trend of silicon content in molten iron within half an ironmaking shift (four hours), and provide a reference for blast furnace operators to judge the changing trend of furnace conditions and the adjustment range in advance. This ensures that the ironmaking process runs smoothly and the quality of molten iron remains within the normal range.
本领域普通技术人员可以理解:实现上述方法实施例的全部或部分步骤可以通过程序指令相关的硬件来完成,前述的程序可以存储于一计算机可读取存储介质中,该程序在执行时,执行包括上述方法实施例的步骤;而前述的存储介质包括:ROM、RAM、磁碟或者光盘等各种可以存储程序代码的介质。Those of ordinary skill in the art can understand that all or part of the steps of implementing the above method embodiments can be completed by program instructions related to hardware, the aforementioned program can be stored in a computer-readable storage medium, and when the program is executed, execute It includes the steps of the above method embodiments; and the aforementioned storage medium includes: ROM, RAM, magnetic disk or optical disk and other media that can store program codes.
以上所描述的显示装置的测试设备等实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性的劳动的情况下,即可以理解并实施。The above-described embodiments such as the test equipment of the display device are only schematic, wherein the units described as separate components may or may not be physically separated, and the components displayed as units may or may not be physically separated unit, that is, it can be located in one place, or it can be distributed over multiple network units. Some or all of the modules may be selected according to actual needs to achieve the purpose of the solution in this embodiment. Those of ordinary skill in the art can understand and implement it without creative effort.
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到各实施方式可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件。基于这样的理解,上述技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在计算机可读存储介质中,如ROM/RAM、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行各个实施例或者实施例的某些部分所述的方法。From the description of the above embodiments, those skilled in the art can clearly understand that each embodiment can be implemented by means of software plus a necessary general hardware platform, and certainly can also be implemented by hardware. Based on this understanding, the above-mentioned technical solutions can be embodied in the form of software products in essence or the parts that make contributions to the prior art, and the computer software products can be stored in computer-readable storage media, such as ROM/RAM, magnetic A disc, an optical disc, etc., includes several instructions for causing a computer device (which may be a personal computer, a server, or a network device, etc.) to perform the methods described in various embodiments or some parts of the embodiments.
最后应说明的是:以上各实施例仅用以说明本发明的实施例的技术方案,而非对其限制;尽管参照前述各实施例对本发明的实施例进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明的实施例各实施例技术方案的范围。Finally, it should be noted that the above embodiments are only used to illustrate the technical solutions of the embodiments of the present invention, but not to limit them; although the embodiments of the present invention have been described in detail with reference to the foregoing embodiments, ordinary The skilled person should understand that it is still possible to modify the technical solutions described in the foregoing embodiments, or to perform equivalent replacements on some or all of the technical features; and these modifications or replacements do not make the essence of the corresponding technical solutions deviate from the present invention. The scope of the technical solutions of the embodiments of each embodiment.
最后,本发明的方法仅为较佳的实施方案,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。Finally, the method of the present invention is only a preferred embodiment, and is not intended to limit the protection scope of the present invention. Any modification, equivalent replacement, improvement, etc. made within the spirit and principle of the present invention shall be included within the protection scope of the present invention.
Claims (6)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810305865.7ACN108764517B (en) | 2018-04-08 | 2018-04-08 | A kind of blast furnace hot metal silicon content change trend prediction method, equipment and storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810305865.7ACN108764517B (en) | 2018-04-08 | 2018-04-08 | A kind of blast furnace hot metal silicon content change trend prediction method, equipment and storage medium |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN108764517A CN108764517A (en) | 2018-11-06 |
| CN108764517Btrue CN108764517B (en) | 2020-12-04 |
Family
ID=63981135
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201810305865.7AActiveCN108764517B (en) | 2018-04-08 | 2018-04-08 | A kind of blast furnace hot metal silicon content change trend prediction method, equipment and storage medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN108764517B (en) |
Families Citing this family (23)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109657285A (en)* | 2018-11-27 | 2019-04-19 | 中国科学院空间应用工程与技术中心 | The detection method of turbine rotor transient stress |
| CN109325640B (en)* | 2018-12-07 | 2022-04-26 | 中山大学 | User value prediction method, device, storage medium and equipment |
| CN109656918A (en)* | 2019-01-04 | 2019-04-19 | 平安科技(深圳)有限公司 | Prediction technique, device, equipment and the readable storage medium storing program for executing of epidemic disease disease index |
| CN110147525B (en)* | 2019-05-21 | 2023-02-14 | 内蒙古蒙树生态环境有限公司 | Method, device and equipment for predicting growth state of nursery stock and storage medium |
| CN110288096B (en)* | 2019-06-28 | 2021-06-08 | 满帮信息咨询有限公司 | Prediction model training method, prediction model training device, prediction model prediction method, prediction model prediction device, electronic equipment and storage medium |
| CN111103420B (en)* | 2019-11-20 | 2022-05-10 | 华东理工大学 | A method for predicting the quality of phenolic resin products under uncertainty of raw materials |
| CN111679584B (en)* | 2020-06-23 | 2022-05-03 | 武汉钢铁有限公司 | Regulating and controlling method and device for blast furnace smelting |
| CN111832703B (en)* | 2020-06-29 | 2022-05-13 | 中南大学 | A Dynamic Sequence Modeling Method for Irregular Sampling in Process Manufacturing Industry |
| CN111984907B (en)* | 2020-07-31 | 2022-03-22 | 新兴铸管股份有限公司 | Method for judging development trend of blast furnace temperature |
| CN111949135B (en)* | 2020-08-31 | 2022-06-17 | 福州大学 | Touch communication fault tolerance method and system based on hybrid prediction |
| CN112434961B (en)* | 2020-12-01 | 2022-04-15 | 内蒙古科技大学 | Method, device and terminal equipment for predicting temperature drop of molten iron at iron-steel interface |
| CN113223634B (en)* | 2021-03-22 | 2022-09-16 | 浙江大学 | Prediction method of silicon content in blast furnace hot metal based on two-dimensional self-attention enhanced GRU model |
| CN113325811B (en)* | 2021-05-20 | 2022-03-22 | 杭州电子科技大学 | An online detection method for industrial process anomalies based on memory and forgetting strategy |
| CN113205368B (en)* | 2021-05-25 | 2022-11-29 | 合肥供水集团有限公司 | Industrial and commercial customer clustering method based on time sequence water consumption data |
| CN113656930B (en)* | 2021-06-24 | 2023-11-17 | 华北理工大学 | Prediction method for smelting endpoint phosphorus content by adopting machine learning algorithm |
| CN114626303A (en)* | 2022-03-18 | 2022-06-14 | 山东莱钢永锋钢铁有限公司 | Blast furnace temperature prediction and operation guidance method based on neural network |
| CN114398140B (en)* | 2022-03-25 | 2022-05-31 | 深圳市鼎阳科技股份有限公司 | Dynamic generation method of trend graph, electronic measurement device and storage medium |
| CN114943186A (en)* | 2022-07-19 | 2022-08-26 | 数皮科技(湖北)有限公司 | Granite thermal conductivity limit lifting gradient prediction method based on whole-rock chemical data |
| CN115758189B (en)* | 2022-10-26 | 2025-02-07 | 山东蓝想环境科技股份有限公司 | A data identification method for circulating water operation status |
| CN116665803B (en)* | 2023-05-24 | 2024-10-22 | 阿里云计算有限公司 | Control method and system of waste treatment equipment, electronic equipment and storage medium |
| CN118011835B (en)* | 2024-04-08 | 2024-06-25 | 唐山阿诺达自动化有限公司 | Blast furnace ironmaking control system based on machine learning |
| CN118016202B (en)* | 2024-04-10 | 2024-06-25 | 华能山东发电有限公司白杨河发电厂 | A chemical equipment operation analysis method and system based on soda quality |
| CN119828573B (en)* | 2025-03-17 | 2025-07-15 | 江苏沙钢钢铁有限公司 | Closed-loop control and early warning method and system for molten iron storage of blast furnace hearth |
Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104778361A (en)* | 2015-04-14 | 2015-07-15 | 浙江大学 | Improved method for predicting hot-metal silicon content by EMD-Elman (empirical mode decomposition-Elman) neural network |
| CN105574297A (en)* | 2016-02-16 | 2016-05-11 | 中国石油大学(华东) | Self-adaption blast-furnace melt silicon content tendency forecasting method |
| WO2016101182A1 (en)* | 2014-12-23 | 2016-06-30 | 清华大学 | Interval type indicator forecasting method based on bayesian network and extreme learning machine |
| CN106096637A (en)* | 2016-06-06 | 2016-11-09 | 浙江大学 | Molten iron silicon content Forecasting Methodology based on the strong predictor of Elman Adaboost |
| CN106250403A (en)* | 2016-07-19 | 2016-12-21 | 北京奇艺世纪科技有限公司 | Customer loss Forecasting Methodology and device |
| CN106709197A (en)* | 2016-12-31 | 2017-05-24 | 浙江大学 | Molten iron silicon content predicting method based on slide window T-S fuzzy neural network model |
| CN106909705A (en)* | 2016-12-22 | 2017-06-30 | 上海交通大学 | A kind of blast-melted quality prediction method and its system |
| CN107704966A (en)* | 2017-10-17 | 2018-02-16 | 华南理工大学 | A kind of Energy Load forecasting system and method based on weather big data |
- 2018
- 2018-04-08CNCN201810305865.7Apatent/CN108764517B/enactiveActive
Patent Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2016101182A1 (en)* | 2014-12-23 | 2016-06-30 | 清华大学 | Interval type indicator forecasting method based on bayesian network and extreme learning machine |
| CN104778361A (en)* | 2015-04-14 | 2015-07-15 | 浙江大学 | Improved method for predicting hot-metal silicon content by EMD-Elman (empirical mode decomposition-Elman) neural network |
| CN105574297A (en)* | 2016-02-16 | 2016-05-11 | 中国石油大学(华东) | Self-adaption blast-furnace melt silicon content tendency forecasting method |
| CN106096637A (en)* | 2016-06-06 | 2016-11-09 | 浙江大学 | Molten iron silicon content Forecasting Methodology based on the strong predictor of Elman Adaboost |
| CN106250403A (en)* | 2016-07-19 | 2016-12-21 | 北京奇艺世纪科技有限公司 | Customer loss Forecasting Methodology and device |
| CN106909705A (en)* | 2016-12-22 | 2017-06-30 | 上海交通大学 | A kind of blast-melted quality prediction method and its system |
| CN106709197A (en)* | 2016-12-31 | 2017-05-24 | 浙江大学 | Molten iron silicon content predicting method based on slide window T-S fuzzy neural network model |
| CN107704966A (en)* | 2017-10-17 | 2018-02-16 | 华南理工大学 | A kind of Energy Load forecasting system and method based on weather big data |
Also Published As
| Publication number | Publication date |
|---|---|
| CN108764517A (en) | 2018-11-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN108764517B (en) | A kind of blast furnace hot metal silicon content change trend prediction method, equipment and storage medium | |
| CN118197463B (en) | A method for predicting the end-point quality of metallurgical processes based on a stacking ensemble strategy | |
| CN110739031B (en) | Supervised prediction method, device and storage medium for metallurgical sintering process | |
| CN115130741A (en) | Multi-model fusion based multi-factor power demand medium and short term prediction method | |
| CN113096388A (en) | Short-term traffic flow prediction method based on gradient lifting decision tree | |
| CN111444942B (en) | Intelligent forecasting method and system for silicon content of blast furnace molten iron | |
| CN114015825A (en) | Method for monitoring abnormal state of blast furnace heat load based on attention mechanism | |
| CN111310965A (en) | A method of aircraft track prediction based on LSTM network | |
| CN113095550A (en) | Air quality prediction method based on variational recursive network and self-attention mechanism | |
| CN108875118B (en) | A method and equipment for evaluating the accuracy of a prediction model for silicon content in blast furnace molten iron | |
| CN115796936A (en) | Method, system and storage medium for predicting cigarette sales based on combination model | |
| CN116862079B (en) | Enterprise pollutant emission prediction method and prediction system | |
| CN113377075A (en) | Method and device for optimizing rare earth extraction process in real time and computer readable storage medium | |
| CN117139380A (en) | Camber control method based on self-learning of regulation experience | |
| CN108647772A (en) | A method of it is rejected for slope monitoring data error | |
| CN117521511A (en) | A granary temperature prediction method based on improved gray wolf algorithm optimized LSTM | |
| CN119289672B (en) | Intelligent control system and method for smelting furnace | |
| CN114202106B (en) | A method for air conditioning system load forecasting based on deep learning | |
| JP7519453B2 (en) | Method for generating a trained prediction model for predicting the energy efficiency of a melting furnace, method for predicting the energy efficiency of a melting furnace, and computer program | |
| Li et al. | Long short-term memory based on random forest-recursive feature eliminated for hot metal silcion content prediction of blast furnace | |
| Jiang et al. | A trend prediction method based on fusion model and its application | |
| CN114662677A (en) | Method for predicting intrinsic viscosity of polyester fiber in polymerization process | |
| CN114462668A (en) | Material consumption prediction method based on artificial neural network time sequence prediction | |
| CN119598011B (en) | Personalized recommendation method in intelligent auxiliary design system of robot | |
| US20250164952A1 (en) | Method for generating trained prediction model that predicts amount of dross generated in melting furnace, method for predicting amount of dross generated in melting furnace, and computer program |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |