CN108399435B - A video classification method based on dynamic and static features - Google Patents
A video classification method based on dynamic and static featuresDownload PDFInfo
- Publication number
- CN108399435B CN108399435BCN201810237226.1ACN201810237226ACN108399435BCN 108399435 BCN108399435 BCN 108399435BCN 201810237226 ACN201810237226 ACN 201810237226ACN 108399435 BCN108399435 BCN 108399435B
- Authority
- CN
- China
- Prior art keywords
- frame
- video
- motion
- dynamic
- vector
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images


Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/25—Fusion techniques
- G06F18/253—Fusion techniques of extracted features
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/23—Clustering techniques
- G06F18/232—Non-hierarchical techniques
- G06F18/2321—Non-hierarchical techniques using statistics or function optimisation, e.g. modelling of probability density functions
- G06F18/23213—Non-hierarchical techniques using statistics or function optimisation, e.g. modelling of probability density functions with fixed number of clusters, e.g. K-means clustering
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/241—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/20—Analysis of motion
- G06T7/246—Analysis of motion using feature-based methods, e.g. the tracking of corners or segments
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/40—Extraction of image or video features
- G06V10/50—Extraction of image or video features by performing operations within image blocks; by using histograms, e.g. histogram of oriented gradients [HoG]; by summing image-intensity values; Projection analysis
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/10—Image acquisition modality
- G06T2207/10016—Video; Image sequence
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20024—Filtering details
- G06T2207/20032—Median filtering
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20081—Training; Learning
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20084—Artificial neural networks [ANN]
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Evolutionary Biology (AREA)
- Evolutionary Computation (AREA)
- General Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Probability & Statistics with Applications (AREA)
- Image Analysis (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明涉及一种基于动静特征的视频分类方法,属于行为识别、机器学习等交叉技术领域。The invention relates to a video classification method based on dynamic and static features, belonging to the cross technical fields of behavior recognition, machine learning and the like.
背景技术Background technique
近年来,视频中的行为识别和分类计算机视觉领域中的一个重要研究课题,具有重要的理论意义与实际应用价值。In recent years, behavior recognition and classification in video is an important research topic in the field of computer vision, which has important theoretical significance and practical application value.
随着我国经济社会的发展和科技的进步,对视频中任务的识别分析和理解已经成为社会科学和自然科学领域的重要内容,在安防监控、智慧城市建设、体育项目和生命健康等诸多领域都具有广泛的应用。与静态图片中的行为识别相比较而言,视频中背景的变化、动态对象的跟踪和高维度的数据处理等更加复杂,因而具有更大的挑战性。With the development of my country's economy and society and the advancement of science and technology, the identification, analysis and understanding of tasks in videos has become an important part of the social and natural sciences. Has a wide range of applications. Compared with action recognition in still pictures, background changes, dynamic object tracking, and high-dimensional data processing in videos are more complex and therefore more challenging.
对于视频中的人物行为识别主要分为两个部分,一是对于类似背景之类的静态信息的处理,二是对于动态对象的跟踪和识别。就视频分类来说,如何使视频中的静态信息和动态信息互不影响特征提取的同时又能保持这两者可以相互结合,以及结合的过程中动态特征向量和静态特征向量的贡献律是多少是需要确定的。The human behavior recognition in the video is mainly divided into two parts, one is the processing of static information such as background, and the other is the tracking and recognition of dynamic objects. As far as video classification is concerned, how to make the static information and dynamic information in the video not affect the feature extraction while keeping the two can be combined with each other, and what is the contribution law of the dynamic feature vector and the static feature vector in the process of combining is to be determined.
目前常用的跟踪方法主要是光流法,而常用的神经网络包括RNN神经网络,LSTM神经网络等。光流法的优点是在不需要知道场景任何信息的情况下,能够检测出运动目标,但是计算复杂度高,实时性差,对硬件有较高的要求。而训练标准的RNN来解决需要学习长期时间依赖性的问题是不理想的。At present, the commonly used tracking method is mainly the optical flow method, and the commonly used neural networks include RNN neural network, LSTM neural network and so on. The advantage of the optical flow method is that it can detect moving targets without knowing any information about the scene, but it has high computational complexity, poor real-time performance, and high hardware requirements. Training a standard RNN to solve problems that require learning long-term temporal dependencies is not ideal.
目前为止,对于视频中的行为和识别的分类的方法,还需要进行大量的研究工作。To date, there is still a lot of research work to be done on methods for the classification of behavior and recognition in videos.
发明内容SUMMARY OF THE INVENTION
技术问题:发明所要解决的技术问题是视频中动态特征和静态特征的提取并完成二者信息的融合,以有效的提高对视频中行为分类的准确度。Technical problem: The technical problem to be solved by the invention is to extract dynamic features and static features in the video and complete the fusion of the two information, so as to effectively improve the accuracy of the behavior classification in the video.
技术方案:本发明的一种基于动静特征的视频分类方法包括以下步骤:Technical solution: a video classification method based on dynamic and static features of the present invention includes the following steps:
步骤1)输入1个视频,所述视频是用户输入的视频,将该视频分解成具有l帧的视频片段,其中每个视频片段的间隔为5帧;Step 1) input 1 video, the video is the video input by the user, and this video is decomposed into a video clip with 1 frame, and the interval of each video clip is 5 frames;
步骤2)通过密集轨迹跟踪算法即DT算法对步骤1)输入视频中运动的对象进行跟踪,并使用基于密度的噪声空间聚类算法(DBSCAN聚类算法)对来隔离每帧视频,实现对上述视频中动态信息的捕获和跟踪;所述的DT算法是通过网格划分的方式在图片的多个尺度上分别密集采样特征点;DBSCAN聚类算法是从某个选定的核心点出发,不断向密度可达的区域扩张,得到一个包含核心点和边界点的最大化区域;Step 2) Track the moving objects in the input video in step 1) through the dense trajectory tracking algorithm, namely the DT algorithm, and use the density-based noise space clustering algorithm (DBSCAN clustering algorithm) to isolate each frame of video to achieve the above The capture and tracking of dynamic information in the video; the DT algorithm is to densely sample feature points on multiple scales of the picture through grid division; the DBSCAN clustering algorithm starts from a selected core point and continuously Expand to the density-reachable area to get a maximized area containing core points and boundary points;
步骤3)在每个视频片段的每一帧图像中构建运动框,通过增加和删除运动管中运动框的数量使每帧图像中包含的运动框的数量一致,通过步骤2)中跟踪的运动轨迹,将每帧中的运动框连接,生成运动管;Step 3) Constructing a motion frame in each frame of each video clip, by adding and deleting the number of motion frames in the motion tube, the number of motion frames contained in each frame of image is consistent, and by the motion tracked in step 2) Track, connect the motion frames in each frame to generate motion tubes;
步骤4)通过计算运动管中的光流矢量,利用方向梯度直方图HoG特征的方法为每个运动管统计运动管运动的方向,再通过k均值聚类法即k-means聚类法选取100000个描述方向的向量,从而生成对动态信息的描述;HoG特征是是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子,通过计算和统计图像局部区域的梯度方向直方图来构成特征;k-means聚类法是数据点到原型的某种距离作为优化的目标函数,利用函数求极值的方法得到迭代运算的调整规则;Step 4) By calculating the optical flow vector in the motion tube, use the method of the HoG feature of the directional gradient histogram to count the direction of motion of the motion tube for each motion tube, and then select 100,000 by the k-means clustering method, that is, the k-means clustering method. A vector describing the direction to generate a description of dynamic information; HoG feature is a feature descriptor used for object detection in computer vision and image processing. Constitute features; k-means clustering method uses a certain distance from the data point to the prototype as the objective function of optimization, and uses the method to find the extreme value of the function to obtain the adjustment rules of the iterative operation;
步骤5)处理静态特征的步骤如下:在数据集ImageNet上训练一个卷积神经网络即CNN神经网络,所述CNN神经网络包括5层卷积层,2层完全链接层和一个softmax模型的输出层,线性整流函数即ReLU函数作为激活函数;将此CNN神经网络应用到最初的分解的视频片断的每个帧,从中检索到深度特征后从CNN中的softmax层输出静态特征向量;输出的静态特征向量为每个视频片段建立一个静态描述,产生的静态特征的时间序列为:C=[ct0,ct1,...,ctn-1];其中n代表视频的片段;Step 5) The steps of processing static features are as follows: train a convolutional neural network, namely a CNN neural network, on the dataset ImageNet, the CNN neural network includes 5 layers of convolution layers, 2 layers of fully linked layers and an output layer of a softmax model , the linear rectification function is the ReLU function as the activation function; this CNN neural network is applied to each frame of the initial decomposed video segment, and the deep features are retrieved from it, and the static feature vector is output from the softmax layer in the CNN; the output static feature The vector establishes a static description for each video segment, and the time sequence of the generated static features is: C=[ct0 ,ct1 ,...,ctn-1 ]; where n represents the segment of the video;
步骤6)通过乔里斯基变换即Cholesky变换将静态描述和动态描述进行融合,然后将融合的向量通过门控循环单元GRU神经网络,完成视频的分类;所述Cholesky变换是指通过代数的变换找到两个未知关系的变量之间的数学关系,通过矩阵的变换找到另外一个向量使得这个向量与动态描述向量和静态描述向量都用联系,从而就用这个向量来表示静态描述向量和动态描述向量;Step 6) fuse static description and dynamic description through Cholesky transformation, and then pass the fused vector through the gated recurrent unit GRU neural network to complete the classification of the video; the Cholesky transformation refers to finding through algebraic transformation. The mathematical relationship between two variables with unknown relationship, find another vector through the transformation of the matrix, so that this vector is related to the dynamic description vector and the static description vector, so that this vector is used to represent the static description vector and dynamic description vector;
其中,in,
所述步骤2)具体如下:Described step 2) is as follows:
步骤21)采用步长为5*5的采样框对每帧中的关键点进行采样,设置第t帧关键点的坐标为Pt(xt,yt),则t+1帧的坐标为

步骤22)在步骤21)中5*5的采样框没有包括特征点,则手动增加这个特征点到跟踪的轨迹中;Step 22) In step 21), the sampling frame of 5*5 does not include the feature point, then manually add this feature point to the tracked track;
步骤23)记录每个视频片段中每帧的关键点的坐标,得到序列S=(ΔPt,ΔPt+1,...ΔPt+l-1);产生的矢量通过位移矢量的大小之和来归一化得到
步骤24)分离帧内的每一个区域,选取领域半径ε和核心点MinPoints;去除离集群中最远的20%的点保证DT算法作用在整个区域。Step 24) Separate each area in the frame, select the field radius ε and the core point MinPoints; remove the 20% points farthest from the cluster to ensure that the DT algorithm acts on the entire area.
所述步骤3)具体如下:Described step 3) is as follows:
步骤31)以关键点P为中心,建立运动框,用向量b=(x,y,r,f)表示关键点P的运动框;所述x、y是这个运动框的左上角的横坐标和纵坐标,r是这个运动框的边长,f表示这个帧;Step 31) With the key point P as the center, a motion frame is established, and the motion frame of the key point P is represented by a vector b=(x, y, r, f); the x, y are the abscissas of the upper left corner of the motion frame and the ordinate, r is the side length of the motion frame, and f represents the frame;
步骤32)计算每个视频片段中帧内的平均动作框数量n,假设从第一帧到第w帧的动作框的数达到了n,舍弃w帧内的其余动作框,从w+1帧开始重新找到包含n个动作框的某帧,重复这个步骤,直到每帧包含的动作框数一样;通过一个序列表示:Step 32) Calculate the average number of action boxes in each video clip, n, assuming that the number of action boxes from the first frame to the wth frame reaches n, discard the rest of the action boxes in the w frame, and start from w+1 frame. Start to re-find a frame containing n action boxes, and repeat this step until each frame contains the same number of action boxes; represented by a sequence:
g(vi,t)={[bt,1,1,bt,1,2,...,bt,1,k],[bt,2,1,bt,2,2,...,bt,2,k],...,[bt,n,1,bt,n,2,...,bt,n,k]};g(vi,t )={[bt,1,1 ,bt,1,2 ,...,bt,1,k ],[bt,2,1 ,bt,2,2 ,...,bt,2,k ],...,[bt,n,1 ,bt,n,2 ,...,bt,n,k ]};
其中bt,j,k是第t个视频片段中第j帧中的第k个动作框;通过步骤32)使每个帧包含的动作框数都为k;Wherein bt, j, k is the k-th action frame in the j-th frame in the t-th video clip; through step 32), the number of action frames contained in each frame is k;
步骤33)在保证每帧包含的运动框数一致后,开始建立运动管;设置每个视频片段的距离矩阵:Step 33) After ensuring that the number of motion frames contained in each frame is consistent, start to build a motion tube; set the distance matrix of each video segment:

所述Di,j是第k帧的第i个动作框与第k+1帧的第j个动作框之间的欧几里得距离;此距离矩阵选出在相邻帧中两个距离最短的运动框,每帧之间最短的动作框通过运动管连接这些帧;为每个运动管构造一个包含帧数、运动框数、运动框坐标和运动框大小的5列的矩阵Mi:The Di,j is the Euclidean distance between the i-th action frame of the k-th frame and the j-th action frame of the k+1-th frame; this distance matrix selects two distances in adjacent frames. The shortest motion frame, the shortest action frame between each frame, connects these frames through motion tubes; construct a 5-column matrixMi for each motion tube containing the number of frames, the number of motion frames, the coordinates of the motion frame, and the size of the motion frame:

所述距离矩阵表示为第Mi个视频片段的第k帧视频的动作框信息,所述n代表动作框的个数,x、y代表动作框的左上角坐标信息,r代表动作框的边长,z表示与第k帧相连的下一帧。The distance matrix is represented as the action frame information of the kth frame of the video of the Mi th video segment, the n represents the number of action frames, x and y represent the upper left corner coordinate information of the action frame, and r represents the edge of the action frame. long, z denotes the next frame connected to the kth frame.
所述步骤4)具体如下:Described step 4) is as follows:
步骤41)识别每个视频片段的每个运动管并计算运动管的光流矢量,创建HoG特征后取一个合适的bin值,统计运动管运动的方向在每个角度区域的数量,为每一个运动管建立直方图;上述HoG方法是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子,通过计算和统计图像局部区域的梯度方向直方图来构成特征;Step 41) Identify each motion tube of each video segment and calculate the optical flow vector of the motion tube, take an appropriate bin value after creating the HoG feature, and count the number of motion tube motion directions in each angle area, for each The motion tube establishes a histogram; the above HoG method is a feature descriptor used for object detection in computer vision and image processing, and features are formed by calculating and counting the gradient direction histogram of the local area of the image;
步骤42)在所有视频中选取100000个HoG向量,使用k-means聚类法对这100000个向量进行聚类,对每个视频片段使用以下公式:Step 42) Select 100,000 HoG vectors in all videos, use the k-means clustering method to cluster these 100,000 vectors, and use the following formula for each video segment:
p=argmin(Tj-hn,k),j={1,2,...1000};p=argmin(Tj-hn,k ),j ={1,2,...1000};
所述hn,k为第n个视频片段的第k个HoG向量,Tj是第j个簇头整个动态信息在时间上的序列;得直方图H=[Ht0,Ht1,...,Htn-1],其中n代表视频片段。The hn,k is the k-th HoG vector of the n-th video segment, and Tj is the temporal sequence of the entire dynamic information of the j-th cluster head; the histogram H=[Ht0 , Ht1 , .. .,Htn-1 ], where n represents the video segment.
所述步骤6)具体如下:Described step 6) is as follows:
步骤61)设置H代表静态向量,M代表动态向量;使用Cholesky变换将动态和静态矢量融合,得到动态和静态特征描述的融合时间序列C=[ct0,ct1,...ctn-1];Step 61) Set H to represent a static vector and M to represent a dynamic vector; use Cholesky transform to fuse the dynamic and static vectors to obtain a fusion time series C=[ct0 ,ct1 ,...ctn-1 described by dynamic and static features ];
步骤62)设置参数Ct,表示每个视频片段的融合矢量,使用GRU神经网络中的更新门和重置门处理输入的数据信息;将生成的时间序列C=[ct0,ct1,...ctn-1]输入到GRU神经网络中完成最后的视频分类。Step 62) Set the parameter Ct to represent the fusion vector of each video segment, and use the update gate and reset gate in the GRU neural network to process the input data information; the generated time series C=[ct0 ,ct1 ,. ..ctn-1 ] input into the GRU neural network to complete the final video classification.
所述步骤1)中,l按照经验取15。In described step 1), l is 15 according to experience.
所述步骤24)中,ε和MinPoints按照经验取8和10。In the step 24), ε and MinPoints are 8 and 10 according to experience.
所述步骤41)中,bin按照经验取100。In the step 41), bin is taken as 100 according to experience.
所述步骤42)中,k按照经验取1000。In the step 42), k is 1000 according to experience.
有益效果:本发明采用以上技术方案与现有技术相比,具有以下技术效果:Beneficial effect: the present invention adopts the above technical scheme compared with the prior art, has the following technical effects:
本发明使用DT跟踪算法和DBSCAN算法对视频帧的关键点进行跟踪和聚类,通过光流法构造运动管对视频帧进行连接,并利用Cholesky变换对动态描述信息和静态描述信息进行融合,采用GRU神经网络完成最后的视频分类。通过这些方法的应用能够对视频中的运动对象完成分类,具有良好的准确性和有效性,具体来说:The invention uses the DT tracking algorithm and the DBSCAN algorithm to track and cluster the key points of the video frame, constructs motion tubes through the optical flow method to connect the video frames, and uses the Cholesky transformation to fuse the dynamic description information and the static description information. The GRU neural network completes the final video classification. The application of these methods can complete the classification of moving objects in videos with good accuracy and effectiveness, specifically:
(1)本发明通过使用DT跟踪算法和DBSCAN算法,可以有效的排除视频背景的干扰,对所需要跟踪的关键点进行跟踪,增加了对于关键点捕获的准确性。(1) By using the DT tracking algorithm and the DBSCAN algorithm, the present invention can effectively eliminate the interference of the video background, track the key points that need to be tracked, and increase the accuracy of capturing the key points.
(2)本发明通过找出相邻帧中关键点的最短欧几里得距离,连接距离最短的两个帧,从而将视频片段里面的所有帧连接起来,更准确的完成了对关键运动物体运动轨迹的跟踪(2) The present invention connects all the frames in the video clip by finding the shortest Euclidean distance of the key points in the adjacent frames, and connecting the two frames with the shortest distance, so as to more accurately complete the detection of key moving objects. Tracking of motion trajectories
(3)本发明通过使用随机Cholesky变换,将静态和动态特征描述向量融合,找出最佳的融合精度后,提高了视频分类的准确性。(3) The present invention fuses static and dynamic feature description vectors by using random Cholesky transform, and improves the accuracy of video classification after finding the best fusion accuracy.
附图说明Description of drawings
图1是基于动静特征的视频分类方法流程。Figure 1 is a flow of a video classification method based on dynamic and static features.
图2是HoG生成动态信息直方图。Figure 2 is a histogram of dynamic information generated by HoG.
图3是GRU神经网路示意图。Figure 3 is a schematic diagram of the GRU neural network.
具体实施方式Detailed ways
下面结合附图对本发明的技术方案做进一步的详细说明:Below in conjunction with accompanying drawing, the technical scheme of the present invention is described in further detail:
本发明的一种基于动静特征的视频分类方法包括以下步骤:A video classification method based on dynamic and static features of the present invention comprises the following steps:
步骤1)输入1个视频,所述视频是用户输入的视频,将该视频分解成具有l帧的视频片段,其中每个视频片段的间隔为5帧;Step 1)
步骤2)通过密集轨迹跟踪算法即DT算法对步骤1)输入视频中运动的对象进行跟踪,并使用基于密度的噪声空间聚类算法(DBSCAN聚类算法)对来隔离每帧视频,实现对上述视频中动态信息的捕获和跟踪;所述的DT算法是通过网格划分的方式在图片的多个尺度上分别密集采样特征点;DBSCAN聚类算法是从某个选定的核心点出发,不断向密度可达的区域扩张,得到一个包含核心点和边界点的最大化区域;Step 2) Track the moving objects in the input video in step 1) through the dense trajectory tracking algorithm, namely the DT algorithm, and use the density-based noise space clustering algorithm (DBSCAN clustering algorithm) to isolate each frame of video to achieve the above The capture and tracking of dynamic information in the video; the DT algorithm is to densely sample feature points on multiple scales of the picture through grid division; the DBSCAN clustering algorithm starts from a selected core point and continuously Expand to the density-reachable area to get a maximized area containing core points and boundary points;
步骤3)在每个视频片段的每一帧图像中构建运动框,通过增加和删除运动管中运动框的数量使每帧图像中包含的运动框的数量一致,通过步骤2)中跟踪的运动轨迹,将每帧中的运动框连接,生成运动管;Step 3) Constructing a motion frame in each frame of each video clip, by adding and deleting the number of motion frames in the motion tube, the number of motion frames contained in each frame of image is consistent, and by the motion tracked in step 2) Track, connect the motion frames in each frame to generate motion tubes;
步骤4)通过计算运动管中的光流矢量,利用方向梯度直方图HoG特征的方法为每个运动管统计运动管运动的方向,再通过k均值聚类法即k-means聚类法选取100000个描述方向的向量,从而生成对动态信息的描述;HoG特征是是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子,通过计算和统计图像局部区域的梯度方向直方图来构成特征;k-means聚类法是数据点到原型的某种距离作为优化的目标函数,利用函数求极值的方法得到迭代运算的调整规则;Step 4) By calculating the optical flow vector in the motion tube, use the method of the HoG feature of the directional gradient histogram to count the direction of motion of the motion tube for each motion tube, and then select 100,000 by the k-means clustering method, that is, the k-means clustering method. A vector describing the direction to generate a description of dynamic information; HoG feature is a feature descriptor used for object detection in computer vision and image processing. Constitute features; k-means clustering method uses a certain distance from the data point to the prototype as the objective function of optimization, and uses the method to find the extreme value of the function to obtain the adjustment rules of the iterative operation;
步骤5)处理静态特征的步骤如下:在数据集ImageNet上训练一个卷积神经网络即CNN神经网络,所述CNN神经网络包括5层卷积层,2层完全链接层和一个softmax模型的输出层,线性整流函数即ReLU函数作为激活函数;将此CNN神经网络应用到最初的分解的视频片断的每个帧,从中检索到深度特征后从CNN中的softmax层输出静态特征向量;输出的静态特征向量为每个视频片段建立一个静态描述,产生的静态特征的时间序列为:C=[ct0,ct1,...,ctn-1];其中n代表视频的片段;Step 5) The steps of processing static features are as follows: train a convolutional neural network, namely a CNN neural network, on the dataset ImageNet, the CNN neural network includes 5 layers of convolution layers, 2 layers of fully linked layers and an output layer of a softmax model , the linear rectification function is the ReLU function as the activation function; this CNN neural network is applied to each frame of the initial decomposed video segment, and the deep features are retrieved from it, and the static feature vector is output from the softmax layer in the CNN; the output static feature The vector establishes a static description for each video segment, and the time sequence of the generated static features is: C=[ct0 ,ct1 ,...,ctn-1 ]; where n represents the segment of the video;
步骤6)通过乔里斯基变换即Cholesky变换将静态描述和动态描述进行融合,然后将融合的向量通过门控循环单元GRU神经网络,完成视频的分类;所述Cholesky变换是指通过代数的变换找到两个未知关系的变量之间的数学关系,通过矩阵的变换找到另外一个向量使得这个向量与动态描述向量和静态描述向量都用联系,从而就用这个向量来表示静态描述向量和动态描述向量;Step 6) fuse static description and dynamic description through Cholesky transformation, and then pass the fused vector through the gated recurrent unit GRU neural network to complete the classification of the video; the Cholesky transformation refers to finding through algebraic transformation. The mathematical relationship between two variables with unknown relationship, find another vector through the transformation of the matrix, so that this vector is related to the dynamic description vector and the static description vector, so that this vector is used to represent the static description vector and dynamic description vector;
其中,in,
所述步骤2)具体如下:Described step 2) is as follows:
步骤21)采用步长为5*5的采样框对每帧中的关键点进行采样,设置第t帧关键点的坐标为Pt(xt,yt),则t+1帧的坐标为

步骤22)在步骤21)中5*5的采样框没有包括特征点,则手动增加这个特征点到跟踪的轨迹中;Step 22) In step 21), the sampling frame of 5*5 does not include the feature point, then manually add this feature point to the tracked track;
步骤23)记录每个视频片段中每帧的关键点的坐标,得到序列S=(ΔPt,ΔPt+1,...ΔPt+l-1);产生的矢量通过位移矢量的大小之和来归一化得到
步骤24)通过DBSCAN聚类算法分离帧内的每一个区域,选取领域半径ε和核心点MinPoints;通过边界噪音移除算法去除离集群中最远的20%的点保证DT算法作用在整个区域。Step 24) Separate each area in the frame by DBSCAN clustering algorithm, select the field radius ε and core point MinPoints; remove the 20% points farthest from the cluster by the boundary noise removal algorithm to ensure that the DT algorithm acts on the entire area.
所述步骤3)具体如下:Described step 3) is as follows:
步骤31)以关键点P为中心,建立运动框,用向量b=(x,y,r,f)表示关键点P的运动框;所述x、y是这个运动框的左上角的横坐标和纵坐标,r是这个运动框的边长,f表示这个帧;Step 31) With the key point P as the center, a motion frame is established, and the motion frame of the key point P is represented by a vector b=(x, y, r, f); the x, y are the abscissas of the upper left corner of the motion frame and the ordinate, r is the side length of the motion frame, and f represents the frame;
步骤32)计算每个视频片段中帧内的平均动作框数量n,假设从第一帧到第w帧的动作框的数达到了n,舍弃w帧内的其余动作框,从w+1帧开始重新找到包含n个动作框的某帧,重复这个步骤,直到每帧包含的动作框数一样;通过一个序列表示:Step 32) Calculate the average number of action boxes in each video clip, n, assuming that the number of action boxes from the first frame to the wth frame reaches n, discard the rest of the action boxes in the w frame, and start from w+1 frame. Start to re-find a frame containing n action boxes, and repeat this step until each frame contains the same number of action boxes; represented by a sequence:
g(vi,t)={[bt,1,1,bt,1,2,...,bt,1,k],[bt,2,1,bt,2,2,...,bt,2,k],...,[bt,n,1,bt,n,2,...,bt,n,k]};其中bt,j,k是第t个视频片段中第j帧中的第k个动作框;通过步骤32)使每个帧包含的动作框数都为k;g(vi,t )={[bt,1,1 ,bt,1,2 ,...,bt,1,k ],[bt,2,1 ,bt,2,2 ,...,bt,2,k ],...,[bt,n,1 ,bt,n,2 ,...,bt,n,k ]}; where bt,j , k is the k-th action frame in the j-th frame in the t-th video clip; through step 32), the number of action frames contained in each frame is k;
步骤33)在保证每帧包含的运动框数一致后,开始建立运动管;设置每个视频片段的距离矩阵:Step 33) After ensuring that the number of motion frames contained in each frame is consistent, start to build a motion tube; set the distance matrix of each video segment:

所述Di,j是第k帧的第i个动作框与第k+1帧的第j个动作框之间的欧几里得距离;此距离矩阵选出在相邻帧中两个距离最短的运动框,每帧之间最短的动作框通过运动管连接这些帧;为每个运动管构造一个包含帧数、运动框数、运动框坐标和运动框大小的5列的矩阵Mi:The Di,j is the Euclidean distance between the i-th action frame of the k-th frame and the j-th action frame of the k+1-th frame; this distance matrix selects two distances in adjacent frames. The shortest motion frame, the shortest action frame between each frame, connects these frames through motion tubes; construct a 5-column matrixMi for each motion tube containing the number of frames, the number of motion frames, the coordinates of the motion frame, and the size of the motion frame:

所述距离矩阵表示为第Mi个视频片段的第k帧视频的动作框信息,所述n代表动作框的个数,x、y代表动作框的左上角坐标信息,r代表动作框的边长,z表示与第k帧相连的下一帧。The distance matrix is represented as the action frame information of the kth frame of the video of the Mi th video segment, the n represents the number of action frames, x and y represent the upper left corner coordinate information of the action frame, and r represents the edge of the action frame. long, z denotes the next frame connected to the kth frame.
所述步骤4)具体如下:Described step 4) is as follows:
步骤41)识别每个视频片段的每个运动管并计算运动管的光流矢量,创建HoG特征后取一个合适的bin值,统计运动管运动的方向在每个角度区域的数量,为每一个运动管建立直方图;上述HoG方法是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子,通过计算和统计图像局部区域的梯度方向直方图来构成特征;Step 41) Identify each motion tube of each video segment and calculate the optical flow vector of the motion tube, take an appropriate bin value after creating the HoG feature, and count the number of motion tube motion directions in each angle area, for each The motion tube establishes a histogram; the above HoG method is a feature descriptor used for object detection in computer vision and image processing, and features are formed by calculating and counting the gradient direction histogram of the local area of the image;
步骤42)在所有视频中选取100000个HoG向量,使用k-means聚类法对这100000个向量进行聚类,对每个视频片段使用以下公式:Step 42) Select 100,000 HoG vectors in all videos, use the k-means clustering method to cluster these 100,000 vectors, and use the following formula for each video segment:
p=argmin(Tj-hn,k),j={1,2,...1000};p=argmin(Tj-hn,k ),j ={1,2,...1000};
所述hn,k为第n个视频片段的第k个HoG向量,Tj是第j个簇头整个动态信息在时间上的序列;得直方图H=[Ht0,Ht1,...,Htn-1],其中n代表视频片段。The hn,k is the k-th HoG vector of the n-th video segment, and Tj is the temporal sequence of the entire dynamic information of the j-th cluster head; the histogram H=[Ht0 , Ht1 , .. .,Htn-1 ], where n represents the video segment.
所述步骤6)具体如下:Described step 6) is as follows:
步骤61)设置H代表静态向量,M代表动态向量;使用Cholesky变换将动态和静态矢量融合,得到动态和静态特征描述的融合时间序列C=[ct0,ct1,...ctn-1];Step 61) Set H to represent a static vector and M to represent a dynamic vector; use Cholesky transform to fuse the dynamic and static vectors to obtain a fusion time series C=[ct0 ,ct1 ,...ctn-1 described by dynamic and static features ];
步骤62)设置参数Ct,表示每个视频片段的融合矢量,使用GRU神经网络中的更新门和重置门处理输入的数据信息。将生成的时间序列C=[ct0,ct1,...ctn-1]输入到GRU神经网络中完成最后的视频分类。Step 62) Set the parameter Ct to represent the fusion vector of each video segment, and use the update gate and reset gate in the GRU neural network to process the input data information. The generated time series C=[ct0 ,ct1 ,...ctn-1 ] are input into the GRU neural network to complete the final video classification.
在具体实施中,图1是基于动静特征的视频分类的方法流程。首先用户输入1个视频,然后将该视频分成帧数为15帧的片段。In a specific implementation, FIG. 1 is a flowchart of a method for video classification based on dynamic and static features. First the
通过DT跟踪算法和DBSCAN聚类算法对每帧视频的特征点进行捕获和跟踪,所述的DT算法是通过网格划分的方式在图片的多个尺度上分别密集采样特征点。DBSCAN算法是从某个选定的核心点出发,不断向密度可达的区域扩张,从而得到一个包含核心点和边界点的最大化区域,区域中任意两点相连。The feature points of each frame of video are captured and tracked by the DT tracking algorithm and the DBSCAN clustering algorithm. The DT algorithm densely samples the feature points on multiple scales of the picture by grid division. The DBSCAN algorithm starts from a selected core point and continuously expands to the density-reachable area, so as to obtain a maximized area including the core point and the boundary point, and any two points in the area are connected.
为了对运动对象构造运动管,这里需要用到欧几里得距离矩阵,找出相邻帧间欧几里得距离最短的两个运动框,从而在每个视频片段中通过构造运动管来连接每一帧。这样就可以做到跟踪每个视频片段的特征点的运动轨迹。In order to construct a motion tube for a moving object, we need to use the Euclidean distance matrix to find the two motion frames with the shortest Euclidean distance between adjacent frames, so as to connect each video segment by constructing a motion tube. every frame. In this way, the motion trajectory of the feature points of each video clip can be tracked.
接下来需要对这些视频片段里面运动管中的运动框的坐标进行记录,为每个运动管构造了一个包含帧数,运动框数,运动框坐标和运动框大小的5列的矩阵Mi:Next, it is necessary to record the coordinates of the motion frames in the motion tubes in these video clips, and construct a 5-column matrix Mi for each motion tube that contains the number of frames, the number of motion frames, the coordinates of the motion frame and the size of the motion frame:

其中矩阵内各参数的意义为:第Mi个视频片段的第k帧视频的动作框信息如上所示,其中n代表动作框的个数,x,y代表动作框的左上角坐标信息,r代表动作框的边长。The meanings of the parameters in the matrix are: the action frame information of the kth frame video of the Mi video clip is as shown above, where n represents the number of action frames, x and y represent the coordinate information of the upper left corner of the action frame, r Represents the side length of the action box.
识别了每个视频片段的每个运动管后,计算运动管的光流矢量。如图2所示创建HoG,取bin=100,每个区域的角度为3.6度,统计运动管运动的方向在每个角度区域的数量,所以对于每一个运动管都可以建立直方图。上述HoG方法是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子,通过计算和统计图像局部区域的梯度方向直方图来构成特征。然后选取100000个HoG向量,使用k-means聚类法对这100000个向量进行聚类,取k=1000(这是为了和融合静态信息所取得)。上述k-means算法是硬聚类算法,是典型的基于原型的目标函数聚类方法的代表,它是数据点到原型的某种距离作为优化的目标函数,利用函数求极值的方法得到迭代运算的调整规则。通过对每个视频片段使用以下公式After identifying each motion tube of each video clip, calculate the optical flow vector of the motion tube. Create HoG as shown in Figure 2, take bin=100, the angle of each area is 3.6 degrees, and count the number of motion tube motion directions in each angle area, so a histogram can be established for each motion tube. The above HoG method is a feature descriptor used for object detection in computer vision and image processing, and features are formed by calculating and counting the gradient direction histograms of local regions of the image. Then select 100,000 HoG vectors, use k-means clustering method to cluster these 100,000 vectors, and take k = 1000 (this is obtained for integrating static information). The above k-means algorithm is a hard clustering algorithm, which is a typical representative of the prototype-based objective function clustering method. It uses a certain distance from the data point to the prototype as the optimized objective function, and uses the function to find the extreme value method to obtain iterations. Adjustment rules for operations. By using the following formula for each video clip
p=argmin(Tj-hn,k),j={1,2,...1000}可以得到直方图。其中hn,k为第n个视频片段的第k个HoG向量,Tj是第j个簇头整个动态信息在时间上的序列就可以得到了:H=[Ht0,Ht1,...,Htn-1];p=argmin(Tj -hn,k ), j={1,2,...1000} can get the histogram. Where hn,k is the k-th HoG vector of the n-th video clip, and Tj is the temporal sequence of the entire dynamic information of the j-th cluster head: H=[Ht0 , Ht1 , .. ., Htn-1 ];
在ImageNet上训练一个深度CNN神经网络,将静态特征也通过时间序列表示出来,I=[it0,it1,...,itn-1];其中n代表视频的片段。使用Cholesky变换将动态和静态矢量融合,得到动态描述和静态描述融合的时间序列C=[ct0,ct1,...ctn-1],将生成的时间序列C=[ct0,ct1,...ctn-1]输入到GRU神经网络中完成最后的视频分类。A deep CNN neural network is trained on ImageNet, and the static features are also represented by time series, I=[it0 , it1 ,..., itn-1 ]; where n represents the segment of the video. Use the Cholesky transform to fuse the dynamic and static vectors to obtain a time series C=[ct0 ,ct1 ,...ctn-1 ] that combines the dynamic description and the static description, and the generated time series C=[ct0 ,ct1 ,...ctn-1 ] are input to the GRU neural network to complete the final video classification.
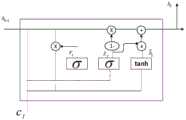
图3是GRU神经网络每个cell单元的具体构造,序列中前一个向量分别通过重置门rt和更新门zt后,得到rt=σ(Wr·[ht-1,ct])和zt=σ(Wt·[ht-1,ct]);重置门r和前一次结果ht-1再连接这次输入的序列ct进行卷积通过权值




通过最后的GRU网络,就完成了视频的分类。Through the final GRU network, the video classification is completed.
Claims (8)
Translated fromChinese




Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810237226.1ACN108399435B (en) | 2018-03-21 | 2018-03-21 | A video classification method based on dynamic and static features |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810237226.1ACN108399435B (en) | 2018-03-21 | 2018-03-21 | A video classification method based on dynamic and static features |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN108399435A CN108399435A (en) | 2018-08-14 |
| CN108399435Btrue CN108399435B (en) | 2020-09-25 |
Family
ID=63091556
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201810237226.1AActiveCN108399435B (en) | 2018-03-21 | 2018-03-21 | A video classification method based on dynamic and static features |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN108399435B (en) |
Families Citing this family (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109446872B (en)* | 2018-08-24 | 2022-04-19 | 南京理工大学 | A Group Action Recognition Method Based on Recurrent Neural Network |
| CN109522937B (en)* | 2018-10-23 | 2021-02-19 | 北京市商汤科技开发有限公司 | Image processing method and device, electronic equipment and storage medium |
| CN109523993B (en)* | 2018-11-02 | 2022-02-08 | 深圳市网联安瑞网络科技有限公司 | Voice language classification method based on CNN and GRU fusion deep neural network |
| ES3036162T3 (en) | 2019-02-28 | 2025-09-15 | Stats Llc | System and method for player reidentification in broadcast video |
| CN109903339B (en)* | 2019-03-26 | 2021-03-05 | 南京邮电大学 | A video group person location detection method based on multi-dimensional fusion features |
| CN111309035B (en)* | 2020-05-14 | 2022-03-04 | 浙江远传信息技术股份有限公司 | Multi-robot cooperative movement and dynamic obstacle avoidance method, device, equipment and medium |
| CN112308306A (en)* | 2020-10-27 | 2021-02-02 | 贵州工程应用技术学院 | Multi-mode input coal and gas outburst risk prediction method |
| CN112633261A (en)* | 2021-03-09 | 2021-04-09 | 北京世纪好未来教育科技有限公司 | Image detection method, device, equipment and storage medium |
| CN113221694B (en) | 2021-04-29 | 2023-08-01 | 苏州大学 | A method of action recognition |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN106778854B (en)* | 2016-12-07 | 2019-12-24 | 西安电子科技大学 | Action Recognition Method Based on Trajectory and Convolutional Neural Network Feature Extraction |
| CN107169415B (en)* | 2017-04-13 | 2019-10-11 | 西安电子科技大学 | Human Action Recognition Method Based on Convolutional Neural Network Feature Coding |
| CN107346414B (en)* | 2017-05-24 | 2020-06-12 | 北京航空航天大学 | Pedestrian attribute recognition method and device |
| CN107330362B (en)* | 2017-05-25 | 2020-10-09 | 北京大学 | Video classification method based on space-time attention |
| CN107316005B (en)* | 2017-06-06 | 2020-04-14 | 西安电子科技大学 | Behavior Recognition Method Based on Dense Trajectory Kernel Covariance Descriptor |
- 2018
- 2018-03-21CNCN201810237226.1Apatent/CN108399435B/enactiveActive
Also Published As
| Publication number | Publication date |
|---|---|
| CN108399435A (en) | 2018-08-14 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN108399435B (en) | A video classification method based on dynamic and static features | |
| CN112200111B (en) | An Occlusion Robust Pedestrian Re-identification Method Based on Global and Local Feature Fusion | |
| CN109858390B (en) | Human skeleton behavior recognition method based on end-to-end spatiotemporal graph learning neural network | |
| Si et al. | Skeleton-based action recognition with spatial reasoning and temporal stack learning | |
| CN108898620B (en) | Target Tracking Method Based on Multiple Siamese Neural Networks and Regional Neural Networks | |
| CN106056628B (en) | Target tracking method and system based on deep convolutional neural network feature fusion | |
| CN102930302B (en) | Incremental human behavior identification method based on online sequential extreme learning machine | |
| CN107633226B (en) | Human body motion tracking feature processing method | |
| CN108764308A (en) | Pedestrian re-identification method based on convolution cycle network | |
| CN109948561A (en) | Method and system for unsupervised image and video person re-identification based on transfer network | |
| CN110163127A (en) | A kind of video object Activity recognition method from thick to thin | |
| CN108960140A (en) | The pedestrian's recognition methods again extracted and merged based on multi-region feature | |
| CN110781790A (en) | Visual SLAM closed loop detection method based on convolutional neural network and VLAD | |
| Li et al. | Pedestrian detection based on deep learning model | |
| CN107067410B (en) | Manifold regularization related filtering target tracking method based on augmented samples | |
| CN106909938B (en) | Perspective-independent behavior recognition method based on deep learning network | |
| CN107767416B (en) | Method for identifying pedestrian orientation in low-resolution image | |
| CN108764269A (en) | A kind of cross datasets pedestrian recognition methods again based on space-time restriction incremental learning | |
| CN109801311B (en) | A Visual Object Tracking Method Based on Deep Residual Network Features | |
| CN106296734B (en) | Method for tracking target based on extreme learning machine and boosting Multiple Kernel Learnings | |
| CN107977660A (en) | Region of interest area detecting method based on background priori and foreground node | |
| CN110827304A (en) | A TCM tongue image localization method and system based on deep convolutional network and level set method | |
| CN107609509A (en) | A kind of action identification method based on motion salient region detection | |
| Su et al. | Transfer learning for video recognition with scarce training data for deep convolutional neural network | |
| CN103065158A (en) | Action identification method of independent subspace analysis (ISA) model based on relative gradient |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| CB02 | Change of applicant information | ||
| CB02 | Change of applicant information | Address after:No.66 xinmodel Road, Gulou District, Nanjing City, Jiangsu Province Applicant after:NANJING University OF POSTS AND TELECOMMUNICATIONS Address before:No. 9, Wen Yuan Road, Xincheng, Ya Dong, Nanjing, Jiangsu Applicant before:NANJING University OF POSTS AND TELECOMMUNICATIONS | |
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| EE01 | Entry into force of recordation of patent licensing contract | ||
| EE01 | Entry into force of recordation of patent licensing contract | Application publication date:20180814 Assignee:Hongzhen Technology Co.,Ltd. Assignor:NANJING University OF POSTS AND TELECOMMUNICATIONS Contract record no.:X2020980007073 Denomination of invention:A video classification method based on dynamic and static features Granted publication date:20200925 License type:Common License Record date:20201023 | |
| EC01 | Cancellation of recordation of patent licensing contract | ||
| EC01 | Cancellation of recordation of patent licensing contract | Assignee:Hongzhen Technology Co.,Ltd. Assignor:NANJING University OF POSTS AND TELECOMMUNICATIONS Contract record no.:X2020980007073 Date of cancellation:20220304 |