CN108089918B - A Graph Computing Load Balancing Method for Heterogeneous Server Structure - Google Patents
A Graph Computing Load Balancing Method for Heterogeneous Server StructureDownload PDFInfo
- Publication number
- CN108089918B CN108089918BCN201711274503.8ACN201711274503ACN108089918BCN 108089918 BCN108089918 BCN 108089918BCN 201711274503 ACN201711274503 ACN 201711274503ACN 108089918 BCN108089918 BCN 108089918B
- Authority
- CN
- China
- Prior art keywords
- node
- migration
- vertex
- computing
- graph
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images



Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/48—Program initiating; Program switching, e.g. by interrupt
- G06F9/4806—Task transfer initiation or dispatching
- G06F9/4843—Task transfer initiation or dispatching by program, e.g. task dispatcher, supervisor, operating system
- G06F9/485—Task life-cycle, e.g. stopping, restarting, resuming execution
- G06F9/4856—Task life-cycle, e.g. stopping, restarting, resuming execution resumption being on a different machine, e.g. task migration, virtual machine migration
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5061—Partitioning or combining of resources
- G06F9/5072—Grid computing
Landscapes
- Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
- Computer And Data Communications (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明属于图计算技术领域,更具体地,涉及一种面向异构服务器结构的图计算负载均衡方法。The invention belongs to the technical field of graph computing, and more particularly, relates to a graph computing load balancing method oriented to a heterogeneous server structure.
背景技术Background technique
分布式图计算技术被广泛应用在社交网络分析、自然语言处理、网页信息检索等众多领域,其组成体系通常包含三个部分:图算法、图数据集和图计算系统。大多数图计算系统采用BSP(Bulk Synchronization Barrier)计算模型,在此模型下,图计算过程通常被分为若干次迭代,每一次迭代又称为一个超级步。在每次超级步中,激活顶点根据在上次超级步中接收的消息更新顶点数值,并将更新后的数值以消息的形式发送给对应的邻居顶点。相邻的两次超级步间设有同步障碍,以保证所有激活顶点在下次超级步开始前已经完成当前超级步中的数值更新操作。Distributed graph computing technology is widely used in social network analysis, natural language processing, web page information retrieval and many other fields. Its composition system usually includes three parts: graph algorithm, graph dataset and graph computing system. Most graph computing systems use the BSP (Bulk Synchronization Barrier) computing model. Under this model, the graph computing process is usually divided into several iterations, and each iteration is also called a super step. In each superstep, the active vertex updates the vertex value according to the message received in the last superstep, and sends the updated value to the corresponding neighbor vertices in the form of a message. There is a synchronization barrier between two adjacent super steps to ensure that all active vertices have completed the value update operation in the current super step before the next super step.
现有的图计算系统出于负载均衡的考虑,在计算节点导入图数据集阶段为所有计算节点分配数量相当的顶点。然而,当前的数据中心或集群通常采用异构的服务器结构,这使得不同处理能力的计算节点在每次超级步中的处理时间不同,即处理能力强的计算节点在每次超级步中总是比处理能力弱的计算节点优先完成本地计算,并在同步障碍处等待同步。此外,在处理图计算任务的过程中,分布在各计算节点上的激活顶点数会发生变化,因而各计算节点在每次超级中的负载量也会动态变化。以上两个原因,导致大多数图计算系统很难保证各计算节点在每次超级步中的处理时间是均衡的。For the consideration of load balancing, the existing graph computing system allocates a comparable number of vertices to all computing nodes during the stage of importing a graph dataset. However, the current data center or cluster usually adopts a heterogeneous server structure, which makes the processing time of computing nodes with different processing capabilities in each superstep different, that is, computing nodes with strong processing capabilities always have different processing times in each superstep. Computational nodes with weaker processing power are given priority to complete local computations and wait for synchronization at synchronization barriers. In addition, in the process of processing graph computing tasks, the number of active vertices distributed on each computing node will change, so the load of each computing node in each super will also change dynamically. The above two reasons make it difficult for most graph computing systems to ensure that the processing time of each computing node in each superstep is balanced.
针对处理图计算任务时计算节点间负载不均衡的问题,少数图计算系统(例如Mizan和GPS)提出采用顶点迁移的方法来均衡每次超级步中各计算节点上的负载。然而,这些图计算系统通常利用顶点级的参数(例如顶点在一次超级步中接受的消息数)来拟定迁移计划,从而导致迁移效果不理想,计算节点间的负载在顶点迁移后仍然不均衡。另外,这些图计算系统通常采用较敏感的迁移策略,即使检测到轻微的负载不均衡也会执行顶点迁移,导致顶点迁移的开销(如迁移时间、资源占用等)远大于负载均衡的收益。A few graph computing systems (such as Mizan and GPS) propose a method of vertex migration to balance the load on each computing node in each superstep. However, these graph computing systems usually use vertex-level parameters (such as the number of messages received by a vertex in a superstep) to formulate a migration plan, resulting in an unsatisfactory migration effect, and the load among computing nodes is still unbalanced after vertex migration. In addition, these graph computing systems usually adopt a more sensitive migration strategy, and perform vertex migration even if a slight load imbalance is detected, resulting in the vertex migration overhead (such as migration time, resource occupation, etc.) far greater than the benefits of load balancing.
发明内容SUMMARY OF THE INVENTION
针对现有技术的以上缺陷或改进需求,本发明提供一种面向异构服务器结构的图计算负载均衡方法,用于均衡分布式图计算系统中所有计算节点在每次超级步中的处理时间,从而降低计算节点在每次超级步中的同步开销,缩短图计算任务的运行时间,解决在现有的异构服务器结构下处理图计算任务时存在的计算节点负载量不均衡和处理时间不同步问题。In view of the above defects or improvement requirements of the prior art, the present invention provides a graph computing load balancing method oriented to a heterogeneous server structure, which is used to balance the processing time of all computing nodes in a distributed graph computing system in each super step, Thereby, the synchronization overhead of computing nodes in each super step is reduced, the running time of graph computing tasks is shortened, and the unbalanced load of computing nodes and the asynchronous processing time that exist when processing graph computing tasks under the existing heterogeneous server structure are solved. question.
本发明提出的一种面向异构服务器结构的图计算负载均衡方法,包括如下阶段:A graph computing load balancing method oriented to a heterogeneous server structure proposed by the present invention includes the following stages:
检测不均衡阶段:在图计算任务运行时,主控节点监测每次超级步中各计算节点的处理时间,并根据本次超级步中所有计算节点处理时间的变异系数和用户预设的阈值,判断各计算节点上的图计算负载是否均衡;所述变异系数为反映一组数据值离散程度的参数;对于一个图算法,如果用户不知道其运行时的特征,即用户对于运行时激活顶点个数的变化未知,则阈值默认为0.10;而对于稳定的图算法,即运行时激活顶点的个数不变,则应该设定一个小于0.10的阈值;而对于不稳定的图算法,即运行时激活顶点的个数持续变化,则应该设定一个大于0.10的阈值;本发明默认阈值可以设为0.10,对于不同图算法的具体阈值选取则不在本发明的讨论范围内。Unbalanced detection stage: When the graph computing task is running, the master control node monitors the processing time of each computing node in each superstep, and according to the coefficient of variation of the processing time of all computing nodes in this superstep and the threshold preset by the user, Determine whether the graph computing load on each computing node is balanced; the coefficient of variation is a parameter that reflects the degree of dispersion of a set of data values; for a graph algorithm, if the user does not know its runtime characteristics, that is, the user has an If the change of the number is unknown, the threshold defaults to 0.10; for stable graph algorithms, that is, the number of activated vertices remains unchanged at runtime, a threshold less than 0.10 should be set; and for unstable graph algorithms, that is, runtime If the number of activated vertices continues to change, a threshold greater than 0.10 should be set; the default threshold of the present invention can be set to 0.10, and the selection of specific thresholds for different graph algorithms is not within the scope of the present invention.
拟定迁移计划阶段:各计算节点确定各自需要迁移的顶点,主控节点确定这些顶点对应的迁入节点;In the stage of preparing the migration plan: each computing node determines the vertices that need to be migrated, and the main control node determines the migration nodes corresponding to these vertices;
实施迁移阶段:所有迁出节点采用延迟迁移的方式传输顶点信息到对应的迁入节点上,主控节点更新顶点迁移后的位置信息;所述延迟迁移指迁出节点在本次超级步结束后只对顶点的ID、数值、邻接边表进行迁移,而将尺寸较大的顶点传入消息在迁出节点上本地处理后再进行迁移;顶点的位置信息,指的是顶点当前所在的节点,知道该顶点的位置信息,其它顶点才能向它发送消息。Implementation of the migration stage: all the outgoing nodes transmit vertex information to the corresponding ingress nodes by means of delayed migration, and the master node updates the location information after the vertex migration; Only the ID, value, and adjacent edge table of the vertices are migrated, and the incoming messages of larger vertices are processed locally on the migrating node and then migrated; the location information of the vertex refers to the node where the vertex is currently located. Knowing the position of the vertex, other vertices can send messages to it.
进一步的,所述方法,包括以下步骤:Further, the method includes the following steps:
步骤1所有计算节点导入图算法和图数据集;一般而言,图算法和图数据集组成了计算负载;Step 1 All computing nodes import graph algorithms and graph datasets; in general, graph algorithms and graph datasets constitute the computational load;
步骤2所有计算节点执行图算法的一次超级步;(图算法通常是系统提供的或用户编写的,图算法用于对图数据集进行信息提取,其提取信息的过程通常可分为若干次超级步);Step 2 All computing nodes execute a super step of the graph algorithm; (The graph algorithm is usually provided by the system or written by the user, and the graph algorithm is used to extract information from the graph data set. The process of extracting information can usually be divided into several super steps. step);
步骤3主控节点判断各计算节点上的图计算负载是否均衡;Step 3: The master control node judges whether the graph computing load on each computing node is balanced;
步骤4若步骤3中判定结果为负载不均衡,则进入拟定迁移计划阶段,转步骤5;否则,转步骤7,所有计算节点进入下一次超级步;Step 4 If the result of the judgment in step 3 is that the load is unbalanced, enter the stage of drawing up the migration plan, and go to step 5; otherwise, go to step 7, and all computing nodes enter the next super step;
步骤5各计算节点确定各自需要迁移的顶点,主控节点确定这些顶点对应的迁入节点;In step 5, each computing node determines the vertices that need to be migrated, and the main control node determines the corresponding migration nodes of these vertices;
步骤6所有计算节点采用延迟迁移的方式,传输顶点信息到对应的迁入节点上,主控节点更新并汇总顶点迁移后的位置信息;In step 6, all computing nodes adopt a delayed migration method to transmit the vertex information to the corresponding inbound node, and the master control node updates and summarizes the position information after the vertex migration;
步骤7重复步骤2至步骤6,直至图算法收敛。Step 7 Repeat steps 2 to 6 until the graph algorithm converges.
进一步的,所这步骤3中检测不平衡阶段包括以下子步骤:Further, the unbalance detection stage in step 3 includes the following sub-steps:
步骤3-1各计算节点将本次超级步中监测的处理时间发送给主控节点(各计算节点在运行过程中会监测每次超级步中的处理时间);Step 3-1 Each computing node sends the processing time monitored in this super step to the master control node (each computing node will monitor the processing time in each super step during operation);
步骤3-2主控节点计算本次超级步中所有处理时间的变异系数CV:Step 3-2 The main control node calculates the coefficient of variation CV of all processing times in this super step:

其中u为本次超级步中所有计算节点的平均处理时间,N为计算节点的总个数,ti为计算节点i在本次超级步中监测的处理时间;where u is the average processing time of all computing nodes in this superstep, N is the total number of computing nodes, and ti is the processing time monitored by computing node i in this superstep;
步骤3-3若上次和本次超级步中计算所得的变异系数CV都大于用户预设的阈值CVthr,则主控节点判定各计算节点上的图计算负载不均衡;否则,认定各计算节点上的图计算负载为是均衡的;如果是第一次超级步中,计算所得的CV大于阈值,仍不进行顶点迁移;唯有连续两次超级步中的CV都大于阈值时,才可进行顶点迁移;Step 3-3 If the coefficient of variation CV calculated in the last and this super step is greater than the threshold CVthr preset by the user, the master control node determines that the graph computing load on each computing node is unbalanced; otherwise, it is determined that each computing The graph calculation load on the node is balanced; if the calculated CV is greater than the threshold in the first super step, the vertex migration is still not performed; only when the CV in two consecutive super steps are greater than the threshold, can the perform vertex migration;
步骤3-4主控节点将判定的结果发送给所有计算节点。Step 3-4 The master node sends the judgment result to all computing nodes.
进一步的,所述步骤5中拟定迁移计划阶段包括以下子步骤:Further, the stage of drawing up the migration plan in the step 5 includes the following sub-steps:
步骤5-1主控节点将本次超级步中平均处理时间u发送给各计算节点;Step 5-1 The master node sends the average processing time u in this super step to each computing node;
步骤5-2各计算节点根据平均处理时间u,判定自身是迁出节点即处理时间大于平均处理时间,还是迁入节点即处理时间小于平均处理时间;Step 5-2 Each computing node determines, according to the average processing time u, whether it is an outgoing node, that is, the processing time is greater than the average processing time, or whether it is an in-migrating node, that is, the processing time is less than the average processing time;
若是迁出节点,则计算其需要迁出的边数Eout,并进一步根据Eout确定需要迁出的顶点;迁出的顶点也就是迁入的顶点,这些顶点在迁移过程中从一个计算节点上被转移到了另一个计算节点上;If it is an outgoing node, calculate the number of edges Eout that it needs to move out, and further determine the vertices that need to be moved out according to Eout ; was transferred to another computing node;
若是迁入节点,则计算其需要迁入的边数Ein;Eout和Ein分别描述了一个计算节点最多能迁出的边数和最多能迁入的边数;If it is a moving-in node, calculate the number of edges E in that it needs to movein ; Eout and Ein describe the maximum number of edges that a computing node can move out and the maximum number of edges that can be moved in respectively;
步骤5-3计算节点将各自需要迁出或迁入的边数即Eout或Ein发送给主控节点;Step 5-3: The computing node sends the number of edges that need to be moved out or moved in, namely Eout or Ein to the master control node;
步骤5-4主控节点根据各计算节点需要迁出或迁入的边数,即Eout或Ein,确定迁移顶点对应的迁入节点;迁出节点上的迁移顶点已经确定了,即步骤5-2的工作,当前主控节点需要确定这些迁移顶点应该被转移到哪些节点上;Step 5-4 The master control node determines the inbound node corresponding to the migration vertex according to the number of edges that each computing node needs to migrate out or in, that is, Eout or Ein ; the migration vertex on the migration node has been determined, that is, the step In the work of 5-2, the current master node needs to determine which nodes these migration vertices should be transferred to;
步骤5-5主控节点将迁移顶点对应的迁入节点信息发送给相应的迁出节点。Step 5-5: The master control node sends the inbound node information corresponding to the migration vertex to the corresponding outbound node.
进一步的,步骤5-2中各迁出节点确定各自需要迁出的顶点时操作如下:Further, in step 5-2, when each outgoing node determines the vertices to be outgoing, the operations are as follows:
各计算节点按照顶点所连接的边数,对其所维护的顶点降序排列(计算节点对一个顶点进行维护,指的是计算节点需要保存该顶点的所有信息,并在每次超级步中对该顶点的数值进行更新操作);当计算节点i接收到主控节点发来的平均处理时间u后,计算本次超级步中其处理时间ti与平均处理时间u的差值Δt=ti-u;当Δt为正时,表示计算节点i的图计算负载高于平均负载水平,该节点需要迁出的边数为Eout=(ti-μ)*EPSi,其中EPSi为计算节点i在本次超级步中平均每秒所处理的边数;计算节点可以统计每次超级步中处理的边数,再用这个边数除以处理时间就可以获得本次超级步中的EPSi;Each computing node arranges the vertices it maintains in descending order according to the number of edges connected to the vertices (the computing node maintains a vertex, which means that the computing node needs to save all the information of the vertex, and in each super step, The value of the vertex is updated); when the computing node i receives the average processing time u sent by the master node, it calculates the difference between the processing time ti and the average processing time u in this super step Δt=ti − u; When Δt is positive, it means that the graph computing load of computing node i is higher than the average load level, and the number of edges that this node needs to migrate out is Eout =(ti -μ)*EPSi , where EPSi is the computing node The average number of edges processed by i per second in this super step; the computing node can count the number of edges processed in each super step, and then divide the number of edges by the processing time to obtain EPSi in this super step ;
当Δt为负时,表示计算节点i的图计算负载低于平均负载水平,该节点需要迁入的边数为Ein=(μ-ti)*EPSi;When Δt is negative, it means that the graph computing load of computing node i is lower than the average load level, and the number of edges that this node needs to migrate in is Ein =(μ-ti )*EPSi ;
迁出节点需要迁出的边数Eout确定后,则需要迁出的顶点可以从该迁出节点所维护的顶点中按照所连接的边数降序选出,直至选出顶点的边数总和达到Eout;(确定的迁出顶点也是迁入顶点,因为这些顶点的信息在迁移过程中会被迁出节点发送给迁入节点,而迁入节点上需要迁入的顶点不需要计算,因为迁入顶点就是其它节点上的迁出顶点)After the number of edges Eout that the outgoing node needs to move out is determined, the vertices that need to be moved out can be selected from the vertices maintained by the outgoing node in descending order of the number of connected edges, until the sum of the edges of the selected vertices reaches Eout ; (The determined outgoing vertices are also incoming vertices, because the information of these vertices will be sent by the outgoing node to the ingoing node during the migration process, and the vertices that need to be moved in on the incoming node do not need to be calculated, because the migration process Incoming vertices are outgoing vertices on other nodes)
进一步的,所述步骤5-4中主控节点确定迁移顶点对应的迁入节点时操作如下:Further, in the step 5-4, when the master control node determines the migration node corresponding to the migration vertex, the operation is as follows:
当主控节点接收到各计算节点发来的需要迁出或迁入的边数即Eout或Ein时,根据对应的Eout或Ein数值为所有计算节点排序;When the master control node receives the number of edges that need to be moved out or moved in from each computing node, that is, Eout or Ein , it sorts all the computing nodes according to the corresponding Eout or Ein value;
主控节点首先将负载最重的即|Eout|数值最大的计算节点上的迁移顶点指派给负载最轻的即|Ein|数值最大的计算节点,若此重负载计算节点上仍有迁移顶点没有被指派迁入节点即该重负载计算节点迁出的边数暂时还未达到|Eout|,则将这些未被指派的迁移顶点指派给下一个轻负载计算节点;而当此轻负载计算节点上有多余的空间(每个迁入节点都有一个Ein值,表示其最多能容纳多少个迁入的边)容纳更多的迁移顶点时即该轻负载计算节点迁入的边数暂时还未达到|Ein|,则将下一个重负载计算节点上的迁移顶点指派给该轻负载计算节点;The master node first assigns the migration vertex on the computing node with the heaviest load, that is, the largest |Eout | value, to the computing node with the lightest load, that is, the largest |Ein | value. If there is still migration on the heavily loaded computing node If the vertices are not assigned to the migration node, that is, the number of edges migrated from the heavily loaded computing node has not reached |Eout | for the time being, then these unassigned migration vertices are assigned to the next lightly loaded computing node; There is excess space on the computing node (each inbound node has an Ein value, indicating how many inbound edges it can accommodate at most) when more migrating vertices are accommodated, that is, the number of edges that the lightly loaded computing node migrates in If |Ein | has not been reached yet, the migration vertex on the next heavy-load computing node is assigned to the light-load computing node;
主控节点按照前述方法为所有迁移顶点指派对应的迁入节点;由于各|Eout|是由相应的迁出节点计算所得,而各|Ein|是由相应的迁入节点计算所得,故所有|Eout|的总和与所有|Ein|的总和未必相等;当|Eout|的总和与|Ein|的总和不相等时,则剩余未匹配的Eout或Ein将被主控节点忽略。The master node assigns the corresponding in-migration nodes to all the migration vertices according to the aforementioned method; since each |Eout | is calculated by the corresponding in-migration node, and each |Ein | is calculated by the corresponding in-migration node, so The sum of all |Eout | is not necessarily equal to the sum of all |Ein |; when the sum of |Eout | is not equal to the sum of |Ein |, the remaining unmatched Eout or Ein will be mastered Node ignored.
进一步的,所述步骤6中实施迁移阶段包括以下子步骤:Further, the implementation of the migration phase in the step 6 includes the following sub-steps:
步骤6-1各迁出节点发送迁移顶点信息给对应的迁入节点;Step 6-1 Each outgoing node sends the migration vertex information to the corresponding incoming node;
步骤6-2顶点迁移完成后,各迁出节点将迁移顶点的ID和位置信息即该迁移顶点的迁入节点发送给主控节点;Step 6-2 After the vertex migration is completed, each migrating node sends the ID and location information of the migrating vertex, that is, the migrating node of the migrating vertex, to the main control node;
步骤6-3主控节点在一个表结构中汇总各迁移顶点ID和迁移后的位置信息;该表结构在第一次顶点迁移时创建,而在后面的顶点迁移中更新表结构中的内容;由于有多个迁出节点都对各自维护的顶点进行了迁移,因此所有迁移顶点的位置信息都需要在主控节点处进行汇总;Step 6-3 The master control node summarizes each migration vertex ID and the position information after migration in a table structure; the table structure is created during the first vertex migration, and the content in the table structure is updated in the subsequent vertex migration; Since there are multiple migrating nodes that have migrated the vertices they maintain, the location information of all migrating vertices needs to be aggregated at the master node;
步骤6-4主控节点将汇总后的位置信息表发送给各计算节点;步骤6-2、步骤6-3和步骤6-4更新了迁移顶点的位置信息。In step 6-4, the master control node sends the aggregated location information table to each computing node; in step 6-2, step 6-3 and step 6-4, the location information of the migrated vertex is updated.
进一步的,所述步骤6-1中迁出节点向迁入节点迁移顶点时使用如下方法:Further, in the step 6-1, the following method is used when migrating vertices from the outgoing node to the ingoing node:
迁出节点在本次超级步结束后,将迁移顶点的ID、数值和邻接边表传输给对应的迁入节点,并通过更改迁移顶点位置信息方式的(首先迁出节点把该顶点的迁入节点发送给主控节点,主控节点在汇总后,再把这个顶点的迁入节点广播给所有其它计算节点),使得在下次超级步中该顶点新的传入消息即其它顶点发送给该顶点的消息被导向给迁入节点;而迁移顶点在本次超级步中接收的传入消息,由迁出节点在下次超级步中本地处理,即本次超级步中接受的消息,在迁移过程中并没有被立即发送,而是被迁出节点处理之后再被发送,这是因为消息的尺寸很大,通过网络传输消息的开销巨大;处理后得到的新顶点数值在下次超级步完成后由迁出节点发送给迁入节点;这种迁移顶点的方法使得顶点的传入消息被迁出节点本地处理,并将更新后的顶点数值在下次超级步完成后发送给迁入节点,因此总共需要连续两次超级步才能完成一次顶点的迁移,故称为延迟迁移;迁移过程中,发送迁移顶点的节点称为迁出节点,接受迁移顶点的节点称为迁入节点。After the end of this super step, the outgoing node transmits the ID, value and adjacent edge table of the migrated vertex to the corresponding ingress node, and changes the position information of the migrated vertex (first the outgoing node transfers the ingress of the vertex). The node sends the node to the master node, and the master node broadcasts the incoming node of this vertex to all other computing nodes after summarizing), so that in the next super step, the new incoming message of this vertex, that is, other vertices, are sent to this vertex. The message is directed to the inbound node; and the incoming message received by the migration vertex in this superstep is processed locally by the outbound node in the next superstep, that is, the message received in this superstep will be processed during the migration process. It is not sent immediately, but is sent after being processed by the migrated node. This is because the size of the message is very large, and the overhead of transmitting the message through the network is huge; the new vertex value obtained after processing will be migrated after the next super step is completed. The outgoing node sends it to the incoming node; this method of migrating vertices makes the incoming message of the vertex be processed locally by the outgoing node, and the updated vertex value is sent to the incoming node after the next super step is completed, so a total of continuous Only two super steps can complete a vertex migration, so it is called delayed migration; during the migration process, the node that sends the migrated vertex is called the migration node, and the node that accepts the migration vertex is called the migration node.
总体说来,本发明提出的方法包括三个主要阶段,分别是检测不均衡阶段、拟定迁移计划阶段和实施迁移阶段。本发明的技术构思是:在图计算任务运行时监测每次超级步中各计算节点的处理时间,并根据上次和本次超级步中所有计算节点处理时间的变异系数和用户预设的阈值,来判断各计算节点上的图计算负载是否均衡;若判断结果为图计算负载不均衡,则各计算节点之间采用延迟迁移的方式迁移相应数量的顶点,以均衡下次超级步中各计算节点的处理时间。Generally speaking, the method proposed by the present invention includes three main stages, namely, the stage of detecting imbalance, the stage of making migration plan and the stage of implementing migration. The technical idea of the present invention is to monitor the processing time of each computing node in each super step when the graph computing task is running, and according to the coefficient of variation of the processing time of all computing nodes in the last and this super step and the threshold value preset by the user , to judge whether the graph computing load on each computing node is balanced; if the judgment result is that the graph computing load is unbalanced, the corresponding number of vertices will be migrated between the computing nodes by means of delayed migration to balance the computations in the next super step. The processing time of the node.
本发明所构思的以上技术方案与现有技术相比,具有以下优点:Compared with the prior art, the above technical scheme conceived by the present invention has the following advantages:
使用本发明能均衡分布式图计算系统中所有计算节点在每次超级步中的处理时间,从而降低计算节点在每次超级步中的同步开销,缩短图计算任务的运行时间。另外,在本发明中处理能力强的计算节点在每次超级步中被分配了更重的图计算负载,因此各计算节点的硬件资源得以充分使用以加速图算法的收敛。The invention can balance the processing time of all computing nodes in the distributed graph computing system in each super step, thereby reducing the synchronization overhead of computing nodes in each super step and shortening the running time of graph computing tasks. In addition, in the present invention, a computing node with strong processing capability is assigned a heavier graph computing load in each superstep, so the hardware resources of each computing node can be fully utilized to accelerate the convergence of the graph algorithm.
附图说明Description of drawings
图1为本发明的结构示意图;Fig. 1 is the structural representation of the present invention;
图2为本发明均衡图计算负载的主要步骤示意图;FIG. 2 is a schematic diagram of the main steps of the balance graph calculation load of the present invention;
图3为本发明拟定迁移计划阶段中确定迁入节点的示意图;3 is a schematic diagram of determining a migration node in the stage of preparing a migration plan according to the present invention;
图4为本发明实施迁移阶段中延迟迁移的示意图。FIG. 4 is a schematic diagram of delayed migration in the implementation migration stage of the present invention.
具体实施方式Detailed ways
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。In order to make the objectives, technical solutions and advantages of the present invention clearer, the present invention will be further described in detail below with reference to the accompanying drawings and embodiments. It should be understood that the specific embodiments described herein are only used to explain the present invention, but not to limit the present invention. In addition, the technical features involved in the various embodiments of the present invention described below can be combined with each other as long as they do not conflict with each other.
本发明实施例中将会用到一些定义,其中的名词解释如下:Some definitions will be used in the embodiments of the present invention, and the nouns therein are explained as follows:
异构服务器结构:由处理能力或硬件配置不同的服务器所组成的数据中心或集群。Heterogeneous server structure: A data center or cluster consisting of servers with different processing capabilities or hardware configurations.
主控节点:数据中心或集群中,负责资源管理和任务调度的节点。Master node: A node in a data center or cluster that is responsible for resource management and task scheduling.
计算节点:数据中心或集群中,除主控节点外负责处理局部任务的节点。Compute node: In a data center or cluster, other than the master node, the node responsible for processing local tasks.
图计算:是一种计算模式。它将真实世界中的物体及其关系分别抽象为图结构中的顶点和边,并在图结构上应用相应的图算法,以提取图结构中用户感兴趣的深层信息。Graph computing: is a computing mode. It abstracts objects and their relationships in the real world into vertices and edges in the graph structure, respectively, and applies corresponding graph algorithms on the graph structure to extract the deep information that users are interested in in the graph structure.
图数据集:由真实世界中的物体及其关系抽象而成的图结构。Graph datasets: graph structures abstracted from real-world objects and their relationships.
图算法:由开发者或用户编写以提取图中深层信息的挖掘算法。Graph Algorithms: Mining algorithms written by developers or users to extract deep information in graphs.
超级步:图计算过程通常被分为若干次迭代,一次迭代被称为一个超级步。Superstep: The graph computation process is usually divided into several iterations, and an iteration is called a superstep.
同步障碍:相邻两次超级步之间设有一个同步障碍,以同步每次超级步中激活顶点的数值更新。Synchronization Barrier: A synchronization barrier is placed between two adjacent supersteps to synchronize the numerical updates of the active vertices in each superstep.
标准偏差DS:一种衡量一组数据{x1,x2...xN}离散程度的参数,其计算公式为
变异系数CV:一种衡量一组数据{x1,x2...xN}离散程度的参数,其计算公式为
迁出节点:顶点迁移中,发送迁移顶点的计算节点。Migration node: During vertex migration, the computing node that sends the migrated vertices.
迁入节点:顶点迁移中,接受迁移顶点的计算节点。Migration node: During vertex migration, the computing node that accepts the migrated vertices.
邻接边表:一个顶点通常连接了一条或多条边,邻接边表记录了一个顶点所连接的各条边和这些边的权值。Adjacent edge table: A vertex usually connects one or more edges, and the adjacency edge table records the edges connected by a vertex and the weights of these edges.
一、负载均衡算法设计方案1. Design scheme of load balancing algorithm
在图计算任务运行过程中,当计算节点上的图计算负载在一次超级步中出现不均衡时,最直接的结果就是各计算节点的处理时间不同。为描述计算节点间的负载不均衡问题,需要一个参数来量化一次超级步中处理时间的离散程度。最常用的参数是标准偏差,其大小同时受数据项的绝对值和离散程度的影响。然而,各种图算法在一次超级步中处理时间的绝对值相差很大,对于处理时间长的图算法所得的标准偏差也较大。为了不考虑一组时间值绝对大小的影响而只考虑其离散程度,本发明选取变异系数C作为量化处理时间离散程度的关键性参数。在一次超级步结束后,处理时间的变异系数越大,则代表本次超级步中处理时间离散程度越高,即计算节点间的图计算负载不均衡越严重。一次超级步中处理时间的变异系数计算公式为:In the process of running a graph computing task, when the graph computing load on a computing node is unbalanced in a superstep, the most direct result is that the processing time of each computing node is different. To describe the problem of load imbalance among computing nodes, a parameter is needed to quantify the dispersion of processing time in a superstep. The most commonly used parameter is the standard deviation, whose magnitude is affected by both the absolute value of the data items and the degree of dispersion. However, the absolute value of processing time in a superstep varies greatly among various graph algorithms, and the standard deviation obtained for graph algorithms with long processing time is also large. In order not to consider the influence of the absolute size of a group of time values but only to consider the degree of dispersion, the present invention selects the coefficient of variation C as a key parameter for quantifying the degree of time dispersion. After a super step, the larger the variation coefficient of processing time, the higher the discrete degree of processing time in this super step, that is, the more serious the imbalance of graph computing load between computing nodes. The formula for calculating the coefficient of variation of the processing time in a superstep is:

其中u为本次超级步中的平均处理时间,N为计算节点的总个数,ti为计算节点i在本次超级步中的处理时间。为使每次超级步中计算节点间的图计算负载均衡,本发明通过顶点迁移的方式来降低每次超级步中处理时间的变异系数。where u is the average processing time in this super step, N is the total number of computing nodes, and ti is the processing time of computing node i in this super step. In order to balance the graph computing load among computing nodes in each super step, the present invention reduces the variation coefficient of processing time in each super step by means of vertex migration.
对于某些轻微的负载不均衡,其顶点迁移带来的开销远大于负载均衡的收益。为避免此类无收益的顶点迁移,本发明规定用户在运行图算法前为该算法指定一个阈值CVthr(默认可以设为0.10),用于判断每次超级步中负载不均衡的程度是否超出了用户可接受的范围;若一次超级步结束后算得的变异系数大于该阈值(CV>CVthr),则判定各计算节点在运行时的图计算负载不均衡,需要在本次超级步结束后对计算节点上的图计算负载重新分配,否则所有计算节点将继续执行下次超级步。另外,由于某些图算法(例如单源最短路径算法)的特性,其运行过程中各计算节点上的激活顶点数变化剧烈,致使变异系数在一次超级步中陡增,而在下一次超级步中恢复较低的水平。当出现这种情况时,会导致在连续的超级步中计算节点间来回迁移相同的顶点。为降低这类图算法运行过程中的迁移开销,本发明规定只有当上次和本次超级步中的变异系数都大于预设的阈值时,才对计算节点执行一次顶点迁移,以均衡后续超级步中的处理时间。For some slight load imbalances, the overhead of vertex migration is far greater than the benefits of load balancing. In order to avoid such unprofitable vertex migration, the present invention stipulates that the user specifies a threshold CVthr for the algorithm before running the graph algorithm (can be set to 0.10 by default), which is used to judge whether the load imbalance in each super step exceeds the threshold. If the coefficient of variation calculated after the end of a super step is greater than the threshold (CV>CVthr ), it is determined that the graph computing load of each computing node during runtime is not balanced, which needs to be done after the end of this super step. Redistribute the graph computation load on compute nodes, otherwise all compute nodes will proceed to the next superstep. In addition, due to the characteristics of some graph algorithms (such as the single-source shortest path algorithm), the number of active vertices on each computing node changes drastically during its operation, causing the coefficient of variation to increase sharply in one super step, and in the next super step. return to lower levels. When this happens, it causes the same vertices to be migrated back and forth between compute nodes in successive supersteps. In order to reduce the migration overhead during the operation of this kind of graph algorithm, the present invention stipulates that only when the coefficient of variation in the previous and current supersteps is greater than a preset threshold, a vertex migration is performed on the computing node to balance the subsequent supersteps. processing time in the step.
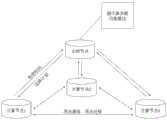
为此,本发明所提供的一种面向异构服务器结构的图计算负载均衡算法,主要适用于满足主从结构的分布式图计算系统。如图1所示,各计算节点负责存储本地顶点的信息并对顶点数值进行更新操作,将更新后的顶点值以消息的形式发送给其它节点,以及在顶点迁移阶段并行地迁移顶点信息到其它节点上;主控节点负责收集各计算节点的状态信息包括每次超级步中的处理时间,拟定迁移计划并将迁移计划通知给所有计算节点,并负责更新和汇总迁移后顶点的位置信息。负载均衡算法的主体逻辑被实现于主控节点中。Therefore, a graph computing load balancing algorithm oriented to a heterogeneous server structure provided by the present invention is mainly suitable for a distributed graph computing system satisfying a master-slave structure. As shown in Figure 1, each computing node is responsible for storing local vertex information and updating vertex values, sending the updated vertex values to other nodes in the form of messages, and migrating vertex information to other nodes in parallel in the vertex migration stage. The master node is responsible for collecting the status information of each computing node, including the processing time in each super step, formulating a migration plan and notifying all computing nodes of the migration plan, and is responsible for updating and summarizing the position information of the vertices after migration. The main logic of the load balancing algorithm is implemented in the master node.
如图2所示,本发明均衡分布在异构服务器结构上的图计算负载,方法包括以下步骤:As shown in FIG. 2, the present invention balances the graph computing load distributed on the heterogeneous server structure, and the method includes the following steps:
步骤1所有计算节点导入图算法和图数据集;Step 1 All computing nodes import graph algorithms and graph datasets;
步骤2所有计算节点执行图算法的一次超级步;Step 2: All computing nodes execute a super step of the graph algorithm;
步骤3主控节点判断各计算节点上的图计算负载是否均衡;Step 3: The master control node judges whether the graph computing load on each computing node is balanced;
步骤4若步骤3中判定结果为负载不均衡,则进入拟定迁移计划阶段,转步骤5;否则,转步骤7,所有计算节点进入下一次超级步;Step 4 If the result of the judgment in step 3 is that the load is unbalanced, enter the stage of drawing up the migration plan, and go to step 5; otherwise, go to step 7, and all computing nodes enter the next super step;
步骤5各计算节点确定各自需要迁移的顶点,主控节点确定这些顶点对应的迁入节点;In step 5, each computing node determines the vertices that need to be migrated, and the main control node determines the corresponding migration nodes of these vertices;
步骤6所有计算节点采用延迟迁移的方式,传输顶点信息到对应的迁入节点上,主控节点更新并汇总顶点迁移后的位置信息;In step 6, all computing nodes adopt a delayed migration method to transmit the vertex information to the corresponding inbound node, and the master control node updates and summarizes the position information after the vertex migration;
步骤7重复步骤2至步骤6,直至图算法收敛。Step 7 Repeat steps 2 to 6 until the graph algorithm converges.
本发明所提供的一种面向异构服务器结构的图计算负载均衡算法,独立于用户所执行的具体图算法和图数据集,其能在任何满足主从结构的分布式图计算系统(如Giraph、PowerGraph)上使用。A graph computing load balancing algorithm oriented to a heterogeneous server structure provided by the present invention is independent of the specific graph algorithm and graph data set executed by the user, and can be used in any distributed graph computing system (such as Giraph) that satisfies the master-slave structure. , PowerGraph).
二、拟定迁移计划阶段2. Drafting the migration plan stage
当主控节点在连续两次超级步中计算所得的变异系数都大于预设的阈值时,则判定计算节点上的图计算负载不均衡,需要对计算节点上的顶点进行迁移,以均衡下次超级步中计算节点间的处理时间。为此,图计算系统进入拟定迁移计划阶段,该阶段所做的主要工作是确定各计算节点上需要迁移的顶点以及这些顶点对应的迁入节点。When the coefficient of variation calculated by the master control node in two consecutive super steps is greater than the preset threshold, it is determined that the graph computing load on the computing node is unbalanced, and the vertices on the computing node need to be migrated to balance the next time. Processing time between compute nodes in a superstep. To this end, the graph computing system enters the stage of drawing up the migration plan, and the main work in this stage is to determine the vertices that need to be migrated on each computing node and the migration nodes corresponding to these vertices.
首先,主控节点将本次超级步中计算所得的平均处理时间u发送给各计算节点。当计算节点i接收到主控节点发来的平均处理时间u后,计算本次超级步中其处理时间ti与平均处理时间的差值Δt=ti-u;当Δt为正时,表示计算节点i的图计算负载高于平均负载水平,该节点需要迁出的边数为Eout=(ti-μ)*EPSi,其中EPSi为计算节点i在本次超级步中平均每秒所处理的边数;当Δt为负时,表示计算节点i的图计算负载低于平均负载水平,该节点需要迁入的边数为Ein=(μ-ti)*EPSi。迁出节点需要迁出的边数Eout确定后,则需要迁出的顶点可以从该迁出节点所维护的顶点中按照所连接的边数降序选出,直至选出顶点的边数总和达到Eout。这里,采用一次超级步中每秒钟处理的边数而不是每秒钟处理的顶点数来定义计算节点的吞吐率,是因为真实世界中的图数据集大多服从幂律分布,即少数顶点连接着图中大多数边。处理一个顶点的时间随着其连接的边数而不同,而处理一条边的时间通常是稳定的,所以这里使用每秒钟处理的边数来定义计算节点的吞吐率,以对各计算节点的吞吐率做相对公平的量化。First, the master node sends the average processing time u calculated in this super step to each computing node. When the computing node i receives the average processing time u sent by the main control node, it calculates the difference between its processing time ti and the average processing time Δt = ti -u in this super step; when Δt is positive, it means The graph computing load of computing node i is higher than the average load level, and the number of edges that this node needs to migrate out is Eout =(ti -μ)*EPSi , where EPSi is the average per-cycle of computing node i in this super step. The number of edges processed per second; when Δt is negative, it means that the graph computing load of computing node i is lower than the average load level, and the number of edges that this node needs to move in is Ein =(μ-ti )*EPSi . After the number of edges Eout that the outgoing node needs to move out is determined, the vertices that need to be moved out can be selected from the vertices maintained by the outgoing node in descending order of the number of connected edges, until the sum of the edges of the selected vertices reaches Eout . Here, the number of edges processed per second in a superstep rather than the number of vertices processed per second is used to define the throughput rate of computing nodes, because most graph datasets in the real world obey a power-law distribution, that is, a small number of vertices are connected most of the edges in the graph. The time to process a vertex varies with the number of edges it connects, and the time to process one edge is usually stable, so here the number of edges processed per second is used to define the throughput rate of the computing node, so as to determine the throughput of each computing node. Throughput is relatively fair to quantify.
各计算节点将各自需要迁出或迁入的边数(即Eout或Ein)发送给主控节点,主控节点根据Eout或Ein的数值为所有计算节点排序。如图3所示,迁出节点1的|Eout|数值最大,所以其在本次超级步中的负载最重,需要迁出的顶点数目最多;相似地,迁入节点1的|Ein|数值最大,所以其在本次超级步中的负载最轻,需要迁入的顶点数目最多。首先将负载最重的计算节点(即迁出节点1)上的迁移顶点指派给负载最轻的计算节点(即迁入节点1),若重负载计算节点上仍有迁移顶点没有被指派迁入节点时,则将这些未指派的迁移顶点指派给下一个轻负载计算节点(例如,迁出节点1的顶点被指派给迁入节点1、2);相反,当轻负载计算节点上有多余的空间容纳更多的迁移顶点时,则将下一个重负载计算节点上的迁移顶点指派给该轻负载计算节点(例如迁出节点2、3的顶点被指派给迁入节点3)。主控节点依照这种装箱式的方法为所有迁移顶点指派迁入节点,当所有|Eout|的总和与所有|Ein|的总和不等时(例如

最后,主控节点将指派迁入节点的结果发送给对应的迁出节点,从而完成拟定迁移计划阶段,转而进入实施迁移阶段。Finally, the master control node sends the result of assigning the ingress node to the corresponding outgoing node, thereby completing the stage of preparing the migration plan, and then entering the stage of implementing the migration.
三、实施迁移阶段Third, the implementation of the migration phase
在实施迁移阶段中,图计算系统需要完成两个工作,即迁出节点迁移顶点信息到对应的迁入节点上,以及主控节点更新并汇总迁移后顶点的位置信息。由于各迁移顶点都有明确的迁入节点,迁出节点可以同时向一个或多个迁入节点发送顶点信息。对于大多数图算法而言,顶点的信息可以分为两类:尺寸不变的和尺寸变化的。顶点的ID、数值和邻接边表在运行时通常是不变的,例如可以用一个整型表示顶点ID,用一个浮点型表示顶点数值。而由于激活顶点数目的变化,一个顶点在每次超级步中接收到的消息数目也随之变化。此外,一个顶点连接的边数可以很大,也就是说该顶点在一次超级步中接收的消息数目可能很多。所以,顶点的传入消息相对于其它类型的顶点信息而言尺寸巨大,将顶点消息通过网络在计算节点间传输是消耗大量的时间和资源,并将严重影响图算法运行的时间。During the migration phase, the graph computing system needs to complete two tasks, that is, the migration node migrates vertex information to the corresponding migration node, and the master node updates and summarizes the position information of the migrated vertices. Since each migrating vertex has a clear ingress node, the outgoing node can send vertex information to one or more ingress nodes at the same time. For most graph algorithms, vertex information can be divided into two categories: size-invariant and size-changing. Vertex IDs, values, and adjacency edge lists are usually constant at runtime. For example, an integer can be used to represent the vertex ID, and a floating-point value can be used to represent the vertex value. As the number of active vertices changes, the number of messages a vertex receives in each superstep also changes. In addition, the number of edges connected by a vertex can be very large, which means that the number of messages received by the vertex in one superstep can be very large. Therefore, the incoming messages of vertices are huge in size compared to other types of vertex information. The transmission of vertex messages between computing nodes through the network consumes a lot of time and resources, and will seriously affect the running time of the graph algorithm.
为避免顶点迁移中传输顶点消息的巨额开销,本发明采用延迟迁移的方式迁移顶点信息。如图4所示,计算节点在超级步1中发生负载不均衡,主控节点检测到该不均衡并拟定了迁移计划。在同步障碍1,迁出节点将尺寸相对较小的顶点ID、顶点消息和邻接边表发送给迁入节点,而尺寸相对较大的传入消息被保留在迁出节点上,与此同时,迁移顶点的位置信息变为迁入节点(该位置信息被主控节点广播给其它的计算节点)。在超级步2中,由于迁移顶点的位置信息改变,所有该顶点的传入消息被导向到迁入节点上,而该顶点在超级步1中接收的传入消息则被迁出节点本地处理,并产生新的顶点值。在同步障碍2中,迁出节点将计算得到的新顶点值发送给迁入节点。在超级步3开始前,该顶点完成了从迁出节点到迁入节点的迁移。延迟迁移使得顶点的传入消息被迁出节点本地处理后,在下一次超级步完成后才被发送给迁入节点,因此总共需要连续两次超级步才能完成一次顶点的迁移。同时,为保证顶点数值的一致性,本发明规定只有一个顶点的延迟迁移全部完成后,该顶点才能被安排进行下次延迟迁移。In order to avoid the huge overhead of transmitting the vertex message in the vertex migration, the present invention adopts the mode of delayed migration to migrate the vertex information. As shown in Figure 4, the load imbalance of the computing nodes occurs in super step 1, and the master node detects the imbalance and draws up a migration plan. At synchronization barrier 1, the outgoing node sends vertex IDs, vertex messages, and adjacency edge lists of relatively small size to the ingoing node, while the incoming messages of relatively large size are retained on the outgoing node. At the same time, The location information of the migrated vertex becomes the inbound node (the location information is broadcast by the master node to other computing nodes). In super step 2, due to the change of the position information of the migrating vertex, all incoming messages of the vertex are directed to the in-migrating node, while the incoming messages received by the vertex in super-step 1 are processed locally by the in-migrating node, and generate new vertex values. In synchronization barrier 2, the outgoing node sends the calculated new vertex value to the ingoing node. Before the start of superstep 3, the vertex has completed the migration from the outgoing node to the ingoing node. Delayed migration makes the incoming messages of vertices processed locally by the migrating node, and then sent to the migrating node after the next superstep is completed. Therefore, two consecutive supersteps are required to complete a vertex migration. At the same time, in order to ensure the consistency of vertex values, the present invention stipulates that only after the delayed migration of a vertex is completed, the vertex can be arranged for the next delayed migration.
顶点迁移后的位置信息应该被及时更新,以保证迁移后该顶点的传入消息被发送到正确的计算节点上。为减少更新顶点位置信息的开销,本发明规定主控节点更新并汇总迁移后所有顶点的位置信息。在顶点ID、顶点数值和邻接边表被发送到迁入节点后,迁出节点向主控节点发送迁移顶点的ID和对应的迁入节点。主控节点在一个表结构中汇总各迁移顶点的ID和迁移后的位置信息,并在所有顶点都完成迁移后将该表结构发送给所有计算节点,各计算节点记录迁移顶点最新的位置信息。至此,各计算节点完成了顶点的迁移。The location information of the vertex after migration should be updated in time to ensure that the incoming message of the vertex is sent to the correct computing node after the migration. In order to reduce the overhead of updating vertex position information, the present invention specifies that the master control node updates and summarizes the position information of all vertices after migration. After the vertex ID, vertex value and adjacent edge list are sent to the ingress node, the outgoing node sends the ID of the migrated vertex and the corresponding ingress node to the master node. The master control node summarizes the IDs of the migrated vertices and the migrated location information in a table structure, and sends the table structure to all computing nodes after all vertices have been migrated, and each computing node records the latest location information of the migrated vertices. So far, each computing node has completed the migration of vertices.
四、特点4. Features
本发明提供了一种面向异构服务器结构的图计算负载均衡算法。该算法中共包括三个主要阶段:检测不均衡阶段,主控节点根据本次超级步中所有计算节点处理时间的变异系数和用户预设的阈值,来判断计算节点上的图计算负载是否均衡;拟定迁移计划阶段,各计算节点确定各自需要迁移的顶点,主控节点确定这些顶点对应的迁入节点;实施迁移阶段,所有计算节点采用延迟迁移的方式并行地传输顶点信息到对应的迁入节点上,主控节点更新并汇总顶点迁移后的位置信息。The invention provides a graph computing load balancing algorithm oriented to a heterogeneous server structure. The algorithm includes three main stages: the detection imbalance stage, the master control node judges whether the graph computing load on the computing nodes is balanced according to the coefficient of variation of the processing time of all computing nodes in this super step and the threshold value preset by the user; In the migration planning stage, each computing node determines the vertices that need to be migrated, and the master control node determines the ingress nodes corresponding to these vertices; in the migration stage, all computing nodes transmit vertex information to the corresponding ingress nodes in parallel by means of delayed migration. , the master node updates and summarizes the position information of the vertex after migration.
与现有的同类发明相比,该算法将一次超级步中处理时间的变异系数作为量化负载不均衡的关键性参数,能够准确反映异构服务器结构中计算节点间图计算负载的真实分布;当连续两次超级步中处理时间的变异系数大于预设的阈值时才执行顶点迁移,可以有效地降低执行某些图算法时的迁移开销;计算节点间采用延迟迁移的方式迁移顶点信息,可以极大降低迁移所需的时间和网络带宽;采用主控节点来更新并汇总顶点迁移后的位置信息,可以降低更新位置信息的开销。Compared with the existing similar inventions, the algorithm uses the variation coefficient of processing time in a superstep as a key parameter to quantify load imbalance, which can accurately reflect the real distribution of graph computing load among computing nodes in a heterogeneous server structure; Vertex migration is performed only when the coefficient of variation of the processing time in two consecutive super steps is greater than the preset threshold, which can effectively reduce the migration overhead when executing some graph algorithms. It greatly reduces the time and network bandwidth required for migration; using the master node to update and summarize the location information after vertex migration can reduce the cost of updating location information.
总地来说,本发明所提供的一种面向异构服务器结构的图计算负载均衡算法,能够自适应地均衡每次超级步中各计算节点的处理时间,并尽可能地降低顶点迁移过程中的各类开销,从而大幅度地降低图计算任务的运行时间。另外,在本发明所提供的图计算负载均衡算法中,处理能力强的计算节点在每次超级步中被分配了更重的图计算负载,因此各计算节点的硬件资源得以充分利用以加速图算法的收敛。In general, a graph computing load balancing algorithm oriented to a heterogeneous server structure provided by the present invention can adaptively balance the processing time of each computing node in each superstep, and minimize the time required for vertex migration. All kinds of overhead, thereby greatly reducing the running time of graph computing tasks. In addition, in the graph computing load balancing algorithm provided by the present invention, a computing node with strong processing capability is assigned a heavier graph computing load in each super step, so the hardware resources of each computing node can be fully utilized to speed up the graph Convergence of the algorithm.
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。Those skilled in the art can easily understand that the above are only preferred embodiments of the present invention, and are not intended to limit the present invention. Any modifications, equivalent replacements and improvements made within the spirit and principles of the present invention, etc., All should be included within the protection scope of the present invention.
Claims (7)

Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201711274503.8ACN108089918B (en) | 2017-12-06 | 2017-12-06 | A Graph Computing Load Balancing Method for Heterogeneous Server Structure |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201711274503.8ACN108089918B (en) | 2017-12-06 | 2017-12-06 | A Graph Computing Load Balancing Method for Heterogeneous Server Structure |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN108089918A CN108089918A (en) | 2018-05-29 |
| CN108089918Btrue CN108089918B (en) | 2020-07-14 |
Family
ID=62174116
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201711274503.8AActiveCN108089918B (en) | 2017-12-06 | 2017-12-06 | A Graph Computing Load Balancing Method for Heterogeneous Server Structure |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN108089918B (en) |
Families Citing this family (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110489229B (en)* | 2019-07-17 | 2020-06-30 | 长沙学院 | A multi-objective task scheduling method and system |
| CN110515729B (en)* | 2019-08-19 | 2022-05-24 | 中国人民解放军国防科技大学 | Graphical processor-based vector load balancing method and device for graph computing nodes |
| CN110532091B (en)* | 2019-08-19 | 2022-02-22 | 中国人民解放军国防科技大学 | Graph computation edge vector load balancing method and device based on graph processor |
| TWI729606B (en)* | 2019-12-05 | 2021-06-01 | 財團法人資訊工業策進會 | Load balancing device and method for an edge computing network |
| CN111459914B (en)* | 2020-03-31 | 2023-09-05 | 北京金山云网络技术有限公司 | Optimization method and device of distributed graph database and electronic equipment |
| CN115292039A (en)* | 2022-07-29 | 2022-11-04 | 北京神舟航天软件技术股份有限公司 | Multitask distributed scheduling load balancing method for heterogeneous computing platform |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102244685A (en)* | 2011-08-11 | 2011-11-16 | 中国科学院软件研究所 | Distributed type dynamic cache expanding method and system supporting load balancing |
| CN103081416A (en)* | 2010-09-08 | 2013-05-01 | 瑞典爱立信有限公司 | Automated Traffic Engineering of Multiprotocol Label Switching (MPLS) with Link Utilization as Feedback into Tie-Breaking Mechanisms |
| CN103546530A (en)* | 2013-06-20 | 2014-01-29 | 江苏大学 | Peer-to-peer network node load balancing method and system based on group resource management |
| CN104270402A (en)* | 2014-08-25 | 2015-01-07 | 浪潮电子信息产业股份有限公司 | A Method for Heterogeneous Cluster Storage Adaptive Data Load |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8792633B2 (en)* | 2012-09-07 | 2014-07-29 | Genesys Telecommunications Laboratories, Inc. | Method of distributed aggregation in a call center |
| US9934323B2 (en)* | 2013-10-01 | 2018-04-03 | Facebook, Inc. | Systems and methods for dynamic mapping for locality and balance |
- 2017
- 2017-12-06CNCN201711274503.8Apatent/CN108089918B/enactiveActive
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103081416A (en)* | 2010-09-08 | 2013-05-01 | 瑞典爱立信有限公司 | Automated Traffic Engineering of Multiprotocol Label Switching (MPLS) with Link Utilization as Feedback into Tie-Breaking Mechanisms |
| CN102244685A (en)* | 2011-08-11 | 2011-11-16 | 中国科学院软件研究所 | Distributed type dynamic cache expanding method and system supporting load balancing |
| CN103546530A (en)* | 2013-06-20 | 2014-01-29 | 江苏大学 | Peer-to-peer network node load balancing method and system based on group resource management |
| CN104270402A (en)* | 2014-08-25 | 2015-01-07 | 浪潮电子信息产业股份有限公司 | A Method for Heterogeneous Cluster Storage Adaptive Data Load |
Also Published As
| Publication number | Publication date |
|---|---|
| CN108089918A (en) | 2018-05-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN108089918B (en) | A Graph Computing Load Balancing Method for Heterogeneous Server Structure | |
| CN101593133B (en) | Method and device for load balancing of resources of virtual machine | |
| CN107992353B (en) | Container dynamic migration method and system based on minimum migration volume | |
| CN103631657B (en) | A kind of method for scheduling task based on MapReduce | |
| CN102195886B (en) | Service scheduling method on cloud platform | |
| CN101719081B (en) | Method for scheduling virtual machines | |
| CN105279027B (en) | A kind of virtual machine deployment method and device | |
| CN104375897B (en) | Cloud computing resource scheduling method based on the unbalanced degree of minimum relative load | |
| WO2018000991A1 (en) | Data balancing method and device | |
| CN103401939A (en) | Load balancing method adopting mixing scheduling strategy | |
| CN113347027B (en) | Virtual instance placement method facing network virtual twin | |
| Madsen et al. | Integrative dynamic reconfiguration in a parallel stream processing engine | |
| CN115167984B (en) | Virtual machine load balancing placement method considering physical resource competition based on cloud computing platform | |
| CN106775949A (en) | A kind of Application of composite feature that perceives migrates optimization method online with the virtual machine of the network bandwidth | |
| CN115022926A (en) | A multi-objective optimized container migration method based on resource balance | |
| CN110990160A (en) | A load prediction-based static security analysis container cloud elastic scaling method | |
| CN116089083A (en) | Multi-target data center resource scheduling method | |
| CN105635285B (en) | A kind of VM migration scheduling method based on state aware | |
| Lu et al. | An efficient load balancing algorithm for heterogeneous grid systems considering desirability of grid sites | |
| Kumar et al. | A priority based dynamic load balancing approach in a grid based distributed computing network | |
| CN105260245A (en) | Resource scheduling method and device | |
| CN114595052A (en) | A Distributed Communication Load Balancing Method Based on Graph Partitioning Algorithm | |
| CN107479968A (en) | A kind of equally loaded method and system towards Dynamic Graph incremental computations | |
| Yuan et al. | A DRL-Based Container Placement Scheme with Auxiliary Tasks. | |
| CN105138391B (en) | The multitasking virtual machine distribution method of cloud system justice is distributed towards wide area |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |