CN107103900B - Cross-language emotion voice synthesis method and system - Google Patents
Cross-language emotion voice synthesis method and systemDownload PDFInfo
- Publication number
- CN107103900B CN107103900BCN201710415814.5ACN201710415814ACN107103900BCN 107103900 BCN107103900 BCN 107103900BCN 201710415814 ACN201710415814 ACN 201710415814ACN 107103900 BCN107103900 BCN 107103900B
- Authority
- CN
- China
- Prior art keywords
- language
- labeling
- neutral
- file
- target emotion
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 230000008451emotionEffects0.000titleclaimsabstractdescription111
- 238000001308synthesis methodMethods0.000titleclaimsdescription8
- 241001672694Citrus reticulataSpecies0.000claimsabstractdescription61
- 230000015572biosynthetic processEffects0.000claimsabstractdescription43
- 238000003786synthesis reactionMethods0.000claimsabstractdescription43
- 238000000034methodMethods0.000claimsabstractdescription24
- 238000012549trainingMethods0.000claimsdescription141
- 230000007935neutral effectEffects0.000claimsdescription119
- 238000002372labellingMethods0.000claimsdescription92
- 230000001419dependent effectEffects0.000claimsdescription42
- 230000003044adaptive effectEffects0.000claimsdescription34
- 238000000605extractionMethods0.000claimsdescription29
- 230000009466transformationEffects0.000claimsdescription27
- 239000011159matrix materialSubstances0.000claimsdescription17
- 239000013598vectorSubstances0.000claimsdescription16
- 238000007476Maximum LikelihoodMethods0.000claimsdescription13
- 238000004458analytical methodMethods0.000claimsdescription10
- 238000012417linear regressionMethods0.000claimsdescription10
- 238000013499data modelMethods0.000claimsdescription9
- 238000001228spectrumMethods0.000claimsdescription9
- 238000012360testing methodMethods0.000claimsdescription8
- 230000002194synthesizing effectEffects0.000claimsdescription6
- 230000001788irregularEffects0.000claimsdescription3
- 238000013518transcriptionMethods0.000claimsdescription3
- 230000035897transcriptionEffects0.000claimsdescription3
- 230000001131transforming effectEffects0.000claims2
- 238000005315distribution functionMethods0.000claims1
- 230000002996emotional effectEffects0.000abstractdescription77
- 230000003595spectral effectEffects0.000description9
- 238000005311autocorrelation functionMethods0.000description5
- 230000006870functionEffects0.000description4
- 238000011161developmentMethods0.000description3
- 238000012935AveragingMethods0.000description2
- 230000008859changeEffects0.000description2
- 238000010586diagramMethods0.000description2
- 239000000284extractSubstances0.000description2
- 238000010606normalizationMethods0.000description2
- 238000011160researchMethods0.000description2
- 238000010187selection methodMethods0.000description2
- 208000019901Anxiety diseaseDiseases0.000description1
- 230000036506anxietyEffects0.000description1
- 230000006399behaviorEffects0.000description1
- 238000013136deep learning modelMethods0.000description1
- 230000000694effectsEffects0.000description1
- 238000011156evaluationMethods0.000description1
- 238000002474experimental methodMethods0.000description1
- 238000009499grossingMethods0.000description1
- 230000003993interactionEffects0.000description1
- 230000007787long-term memoryEffects0.000description1
- 238000002715modification methodMethods0.000description1
- 230000000737periodic effectEffects0.000description1
- 238000012545processingMethods0.000description1
- 230000000750progressive effectEffects0.000description1
- 230000006403short-term memoryEffects0.000description1
Images




Classifications
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/02—Methods for producing synthetic speech; Speech synthesisers
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/08—Text analysis or generation of parameters for speech synthesis out of text, e.g. grapheme to phoneme translation, prosody generation or stress or intonation determination
- G10L13/10—Prosody rules derived from text; Stress or intonation
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/06—Creation of reference templates; Training of speech recognition systems, e.g. adaptation to the characteristics of the speaker's voice
- G10L15/063—Training
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/18—Speech classification or search using natural language modelling
- G10L15/1807—Speech classification or search using natural language modelling using prosody or stress
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/18—Speech classification or search using natural language modelling
- G10L15/183—Speech classification or search using natural language modelling using context dependencies, e.g. language models
- G10L15/187—Phonemic context, e.g. pronunciation rules, phonotactical constraints or phoneme n-grams
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/18—Speech classification or search using natural language modelling
- G10L15/183—Speech classification or search using natural language modelling using context dependencies, e.g. language models
- G10L15/19—Grammatical context, e.g. disambiguation of the recognition hypotheses based on word sequence rules
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/06—Creation of reference templates; Training of speech recognition systems, e.g. adaptation to the characteristics of the speaker's voice
- G10L15/063—Training
- G10L2015/0631—Creating reference templates; Clustering
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Artificial Intelligence (AREA)
- Machine Translation (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明涉及多语种情感语音合成技术领域,特别是涉及一种跨语言情感语音合成方法及系统。The invention relates to the technical field of multilingual emotional speech synthesis, in particular to a method and system for cross-language emotional speech synthesis.
背景技术Background technique
目前的语音合成技术,已经能够合成出较自然的中性语音,但当遇到机器人、虚拟助手等这些需要模仿人类行为的人机交互任务时,简单的中性语音合成则不能满足人们的需求。能够模拟表现出人类情感和说话风格的情感语音合成已经成为未来语音合成的发展趋势。The current speech synthesis technology has been able to synthesize more natural neutral speech, but when encountering human-computer interaction tasks such as robots and virtual assistants that need to imitate human behavior, simple neutral speech synthesis cannot meet people's needs. . Emotional speech synthesis capable of simulating human emotion and speaking style has become the development trend of speech synthesis in the future.
对于使用人数众多的大语种汉语、英语等的情感语音合成来说,其研究投入较多,发展水平较高;但对于使用人数较少的小语种如藏语、俄语、西班牙语等情感语音合成来说,其发展却较缓慢,目前还没有一个公认的面向语音合成的高标准、高质量的小语种情感语料库,从而使得小语种情感语音的合成成为了语音合成领域的空白。For the emotional speech synthesis of the large languages such as Chinese and English, which are used by a large number of people, the research investment is more and the development level is relatively high; but for the emotional speech synthesis of small languages such as Tibetan, Russian, and Spanish, which are used by a small number of people However, its development is relatively slow. At present, there is no recognized high-standard and high-quality emotional corpus in small languages for speech synthesis, which makes the synthesis of emotional speech in small languages a blank in the field of speech synthesis.
目前,国内外对情感语音合成的研究技术包括波形拼接方法、韵律单元选择方法和统计参数方法。波形拼接方法需要给情感语音合成系统建立一个庞大的包含每一种情感的情感语料库库,之后对输入的文本进行文本和韵律分析,获得合成语音基本的单元信息,最后根据此单元信息在先前标注好的语料库库中选取合适的语音基元,并进行修改和调整拼接获得目标情感的合成语音,其合成的语音具有较好的情感相似度,但需要提前建立好一个大的、包含各种情感的语音基元语料库库,这在系统的实现中是非常困难的,而且也难以扩展到合成不同说话人、不同语言的情感语音上;韵律特征单元选择方法把韵律或语音体系的策略融入单位选择,用这种规则建立小的或混合的情感语料库库,用于修改目标f0和时长的轮廓,从而获得情感语音。韵律修改方法要对语音信号进行修改,合成语音的音质较差,也不能合成不同人、不同语言的情感语音。以上两种方法由于其局限性,不是现在的主流方法。统计参数语音合成方法虽然成为了主流的语音合成方法,但该方法只能合成出一种语言的情感语音,若需要合成不同语言的情感语音,就需要训练多个情感语音合成系统,每个情感语音合成系统都需要该种语言的情感语音训练语料库。At present, the research techniques of emotional speech synthesis at home and abroad include waveform splicing method, prosodic unit selection method and statistical parameter method. The waveform splicing method needs to build a huge emotional corpus containing each emotion for the emotional speech synthesis system, and then perform text and prosody analysis on the input text to obtain the basic unit information of the synthesized speech, and finally according to the unit information. Select the appropriate speech primitives from a good corpus, and modify and adjust the splicing to obtain the synthesized speech of the target emotion. It is very difficult to implement the system, and it is also difficult to extend to synthesizing the emotional speech of different speakers and languages; the prosodic feature unit selection method integrates the strategy of prosody or phonetic system into unit selection , and use this rule to build a small or mixed emotional corpus for modifying the contours of the target f0 and duration to obtain emotional speech. The prosody modification method needs to modify the speech signal, the sound quality of the synthesized speech is poor, and it cannot synthesize the emotional speech of different people and different languages. The above two methods are not the current mainstream methods due to their limitations. Although the statistical parameter speech synthesis method has become the mainstream speech synthesis method, this method can only synthesize emotional speech in one language. If you need to synthesize emotional speech in different languages, you need to train multiple emotional speech synthesis systems. Speech synthesis systems all require an emotional speech training corpus in that language.
针对上述情感语音合成方法的不足,如何克服上述问题,是目前多语种情感语音合成技术领域急需解决的技术问题。In view of the shortcomings of the above-mentioned emotional speech synthesis methods, how to overcome the above problems is a technical problem that needs to be solved urgently in the field of multilingual emotional speech synthesis technology.
发明内容SUMMARY OF THE INVENTION
本发明的目的是提供一种跨语言情感语音合成方法及系统,以实现用一种多说话人的目标情感普通话训练语料库训练一个普通话说话人目标情感平均声学模型,只需改变待合成文件就能合成同一说话人或不同说话人跨语言的情感语音。The purpose of the present invention is to provide a cross-language emotional speech synthesis method and system, so as to use a multi-speaker target emotion Mandarin training corpus to train a Mandarin speaker target emotion average acoustic model, only need to change the files to be synthesized. Synthesize emotional speech across languages from the same speaker or from different speakers.
为实现上述目的,本发明提供了一种跨语言情感语音合成方法,包括以下步骤:To achieve the above object, the present invention provides a method for cross-language emotional speech synthesis, comprising the following steps:
建立上下文相关标注格式和上下文相关聚类问题集,分别对多说话人的中性第一语言训练语料库、单说话人的中性第二语言训练语料库进行上下文相关文本标注,获得所述中性第一语言训练语料库对应的第一语言标注文件、所述中性第二语言训练语料库对应的第二语言标注文件;分别对所述中性第一语言训练语料库和所述中性第二语言训练语料库进行声学参数提取,获得所述中性第一语言训练语料库对应的第一语言声学参数、所述中性第二语言训练语料库对应的第二语言声学参数;Establish a context-dependent labeling format and a context-dependent clustering problem set, and perform context-dependent text labeling on the multi-speaker neutral first language training corpus and the single-speaker neutral second language training corpus respectively, and obtain the neutral first language training corpus. A first language annotation file corresponding to a language training corpus, a second language annotation file corresponding to the neutral second language training corpus; respectively for the neutral first language training corpus and the neutral second language training corpus extracting acoustic parameters to obtain first language acoustic parameters corresponding to the neutral first language training corpus and second language acoustic parameters corresponding to the neutral second language training corpus;
根据所述上下文相关标注格式和所述上下文相关聚类问题集对多说话人的目标情感普通话训练语料库进行上下文相关文本标注,获得目标情感普通话标注文件;对所述目标情感普通话训练语料库进行声学参数提取,获得目标情感声学参数;According to the context-related annotation format and the context-related clustering question set, context-related text annotation is performed on the target emotional Mandarin training corpus of multiple speakers to obtain a target emotional Mandarin annotation file; acoustic parameters are performed on the target emotional Mandarin training corpus Extraction to obtain target emotional acoustic parameters;
根据所述第一语言标注文件、所述第二语言标注文件、所述目标情感普通话标注文件、所述第一语言声学参数、所述第二语言声学参数和所述目标情感声学参数确定多说话人目标情感平均声学模型;Determine multi-speaking according to the first language annotation file, the second language annotation file, the target emotional Mandarin annotation file, the first language acoustic parameters, the second language acoustic parameters and the target emotional acoustic parameters Human target emotion average acoustic model;
对第一语言或/和第二语言的待合成文件进行上下文相关文本标注获得待合成标注文件;Perform context-sensitive text annotation on the document to be synthesized in the first language or/and the second language to obtain the annotation document to be synthesized;
将所述待合成标注文件输入所述多说话人目标情感平均声学模型获得第一语言或/和第二语言目标情感语音合成文件。Inputting the annotation file to be synthesized into the multi-speaker target emotion average acoustic model to obtain a first language or/and a second language target emotion speech synthesis file.
可选的,所述建立上下文相关标注格式和上下文相关聚类问题集,分别对多说话人的中性第一语言训练语料库、单说话人的中性第二语言训练语料库进行上下文相关文本标注,获得所述中性第一语言训练语料库对应的第一语言标注文件、所述中性第二语言训练语料库对应的第二语言标注文件,具体步骤包括:Optionally, the establishment of a context-related labeling format and a context-related clustering question set, respectively performing context-related text labeling on a multi-speaker neutral first language training corpus and a single-speaker neutral second language training corpus, Obtaining the first language annotation file corresponding to the neutral first language training corpus and the second language annotation file corresponding to the neutral second language training corpus, the specific steps include:
建立第一语言标注规则和第二语言标注规则;Establish first language markup rules and second language markup rules;
根据第一语言标注规则和第二语言标注规则确定上下文相关标注格式,分别对多说话人的中性第一语言训练语料库、单说话人的中性第二语言训练语料库进行上下文相关文本标注,获得所述中性第一语言训练语料库对应的第一语言标注文件、所述中性第二语言训练语料库对应的第二语言标注文件;Determine the context-dependent labeling format according to the first language labeling rules and the second language labeling rules, and perform context-sensitive text labeling on the multi-speaker neutral first language training corpus and the single-speaker neutral second language training corpus respectively, and obtain The first language annotation file corresponding to the neutral first language training corpus, and the second language annotation file corresponding to the neutral second language training corpus;
根据第一语言和第二语言的相似性,建立上下文相关聚类问题集。According to the similarity between the first language and the second language, a context-dependent clustering problem set is established.
可选的,所述建立第一语言标注规则和第二语言标注规则,具体步骤包括:Optionally, the establishment of the first language tagging rule and the second language tagging rule, the specific steps include:
所述建立第一语言标注规则,具体步骤包括:The specific steps for establishing the first language tagging rules include:
将SAMPA-SC普通话机读音标作为所述第一语言标注规则;Using SAMPA-SC Mandarin phone-reading phonetic symbols as the first language marking rule;
所述建立第二语言标注规则,具体步骤包括:The specific steps for establishing the second language tagging rules include:
以国际音标为参考,基于SAMPA-SC普通话机读音标,获得输入第二语言拼音的国际音标;Taking the International Phonetic Alphabet as a reference, based on the phonetic reading of the SAMPA-SC Mandarin phone, obtain the International Phonetic Alphabet for inputting the pinyin of the second language;
判断所述第二语言拼音的国际音标与第一语言拼音的国际音标是否一致;若一致,则直接采用SAMPA-SC普通话机读音标来标记第二语言拼音;否,则按照简单化原则,利用自定义的未使用的键盘符号标记。Determine whether the International Phonetic Alphabet of the second language pinyin is consistent with the International Phonetic Alphabet of the first language pinyin; if consistent, then directly use the SAMPA-SC Mandarin phone reading phonetic symbol to mark the second language pinyin; otherwise, according to the principle of simplification, use Custom unused keysym markers.
可选的,所述根据第一语言标注规则和第二语言标注规则确定上下文相关标注格式,具体步骤包括:Optionally, the determining of the context-dependent tagging format according to the first language tagging rule and the second language tagging rule, the specific steps include:
根据第一语言和第二语言的语法规则知识库和语法词典,对输入的第一语言和第二语言不规范的文本进行文本规范化、语法分析和韵律结构分析获得规范文本,韵律词、短语的长度信息,韵律边界信息,词语相关信息,声调信息;According to the grammar rule knowledge base and grammar dictionary of the first language and the second language, perform text normalization, grammatical analysis and prosodic structure analysis on the input irregular texts in the first language and the second language to obtain canonical texts, prosodic words and phrases. Length information, prosodic boundary information, word related information, tone information;
将所述规范文本带入所述第一语言标注规则获得第一语言的单音素标注文件;或将所述规范文本带入所述第二语言标注规则获得第二语言的单音素标注文件;Bringing the canonical text into the first language annotation rule to obtain a monophone annotation file in the first language; or bringing the canonical text into the second language annotation rule to obtain a monophone annotation file in the second language;
根据韵律词、短语的长度信息,韵律边界信息,词语相关信息,声调信息和单音素标注文件确定上下文相关标注格式。The context-sensitive annotation format is determined according to the length information of prosodic words and phrases, prosodic boundary information, word-related information, tone information and monophone annotation files.
可选的,所述根据第一语言标注文件、第二语言标注文件、目标情感普通话标注文件、第一语言声学参数、第二语言声学参数和目标情感声学参数确定多说话人目标情感平均声学模型,具体步骤包括:Optionally, the multi-speaker target emotion average acoustic model is determined according to the first language annotation file, the second language annotation file, the target emotion Mandarin annotation file, the first language acoustic parameter, the second language acoustic parameter and the target emotion acoustic parameter. , the specific steps include:
将第一语言标注文件、第二语言标注文件、第一语言声学参数、第二语言声学参数作为训练集,基于自适应模型,通过说话人自适应训练,获得混合语言的中性平均声学模型;Using the first language annotation file, the second language annotation file, the first language acoustic parameters, and the second language acoustic parameters as a training set, based on the adaptive model, through speaker adaptive training, a neutral average acoustic model of the mixed language is obtained;
根据混合语言的中性平均声学模型,将目标情感普通话标注文件、目标情感声学参数作为测试集,通过说话人自适应变换,获得多说话人目标情感平均声学模型。According to the neutral average acoustic model of the mixed language, the target emotional Mandarin annotation file and the target emotional acoustic parameters are used as the test set, and the multi-speaker target emotional average acoustic model is obtained through the speaker adaptive transformation.
可选的,所述根据混合语言的中性平均声学模型,将目标情感普通话标注文件、目标情感声学参数作为测试集,通过说话人自适应变换,获得多说话人目标情感普通话说话人目标情感平均声学模型的具体步骤为:Optionally, according to the neutral average acoustic model of the mixed language, the target emotional Mandarin annotation file and the target emotional acoustic parameters are used as the test set, and the target emotional average of the multi-speaker target emotional Mandarin speakers is obtained through the speaker adaptive transformation. The specific steps of the acoustic model are:
采用约束最大似然线性回归算法,计算说话人的状态时长概率分布和状态输出概率分布的协方差矩阵和均值向量,用一组状态时长分布和状态输出分布的变换矩阵将中性平均声学模型的协方差矩阵和均值向量变换为目标说话人模型,具体公式为:The constrained maximum likelihood linear regression algorithm is used to calculate the covariance matrix and mean vector of the speaker's state duration probability distribution and state output probability distribution. The covariance matrix and the mean vector are transformed into the target speaker model, and the specific formula is:
pi(d)=N(d;αmi-β,ασi2α)=|α-1|N(αψ;mi,σi2) (7);pi (d)=N(d;αmi -β,ασi2 α)=|α-1 |N(αψ;mi ,σi2 ) (7);
bi(o)=N(o;Aui-b,AΣiAT)=|A-1|N(Wξ;ui,Σi) (8);bi (o)=N(o; Aui -b,AΣi AT )=|A-1 |N(Wξ; ui ,Σi ) (8);
其中,i为状态,d为状态时长,N为常数,pi(d)为状态时长的变换方程,mi为时长分布均值,σi2为方差,ψ=[d,1]T,o为特征征向量,ξ=[oT,1],ui为状态输出分布均值,∑i为对角协方差矩阵,X=[α-1,β-1]为状态时长概率密度分布的变换矩阵,W=[A-1,b-1]为目标说话人状态输出概率密度分布的线性变换矩阵;Among them, i is the state, d is the state duration, N is a constant, pi (d) is the transformation equation of the state duration, mi is the mean value of duration distribution, σi2 is the variance, ψ=[d,1]T , o is the eigenvector, ξ=[oT ,1],ui is the mean value of the state output distribution, ∑i is the diagonal covariance matrix, X=[α-1 ,β-1 ] is the transformation of the state duration probability density distribution matrix, W=[A-1 ,b-1 ] is the linear transformation matrix of the output probability density distribution of the target speaker state;
通过基于MSD-HSMM的自适应变换算法,可对语音数据的基频、频谱和时长参数进行变换和归一化;对于长度为T的自适应数据O,可变换Λ=(W,X)进行最大似然估计:Through the adaptive transformation algorithm based on MSD-HSMM, the fundamental frequency, spectrum and duration parameters of the speech data can be transformed and normalized; for the adaptive data O of length T, Λ=(W, X) can be transformed to perform Maximum Likelihood Estimation:

其中,λ为MSD-HSMM的参数集,O为长度为T的自适应数据,
对转化和归一化后的时长、频谱和基频参数进行最大似然估计,采用最大后验概率算法对说话人相关模型进行更新和修正,具体公式为:The maximum likelihood estimation is performed on the transformed and normalized duration, spectrum and fundamental frequency parameters, and the maximum posterior probability algorithm is used to update and correct the speaker-related model. The specific formula is:

MAP估计:MAP estimate:


其中,t为时间,λ为给定的MSD-HSMM参数集,T为长度,o为长度为T时自适应数据i为状态,d为状态时长,N为常数,s为训练语音数据模型,ktd(i)为状态i下连续观测序列ot-d+1...ot的概率,αt(i)为向前概率,βt(i)为向后概率,





本发明还提供了一种跨语言情感语音合成系统,所述系统包括:The present invention also provides a cross-language emotional speech synthesis system, the system comprising:
语言语料库文本标注、参数提取模块,用于建立上下文相关标注格式和上下文相关聚类问题集,分别对多说话人的中性第一语言训练语料库、单说话人的中性第二语言训练语料库进行上下文相关文本标注,获得所述中性第一语言训练语料库对应的第一语言标注文件、所述中性第二语言训练语料库对应的第二语言标注文件;分别对中性第一语言训练语料库和中性第二语言训练语料库进行声学参数提取,获得所述中性第一语言训练语料库对应的第一语言声学参数、所述中性第二语言训练语料库对应的第二语言声学参数;The language corpus text annotation and parameter extraction modules are used to establish context-dependent annotation formats and context-dependent clustering problem sets. Context-related text annotation, to obtain the first language annotation file corresponding to the neutral first language training corpus and the second language annotation file corresponding to the neutral second language training corpus; Extracting acoustic parameters from the neutral second language training corpus to obtain first language acoustic parameters corresponding to the neutral first language training corpus and second language acoustic parameters corresponding to the neutral second language training corpus;
目标情感语料库文本标注、参数提取模块,用于根据上下文相关标注格式和上下文相关聚类问题集对多说话人的目标情感普通话训练语料库进行上下文相关文本标注,获得目标情感普通话标注文件;对所述目标情感普通话训练语料库进行声学参数提取,获得目标情感声学参数;The target emotional corpus text annotation and parameter extraction module is used to perform context-related text annotation on the multi-speaker target emotional Mandarin training corpus according to the context-related annotation format and the context-related clustering problem set, and obtain the target emotional Mandarin annotation file; The target emotional Mandarin training corpus is used to extract acoustic parameters to obtain target emotional acoustic parameters;
目标情感平均声学模型确定模块,用于根据所述第一语言标注文件、所述第二语言标注文件、所述目标情感普通话标注文件、所述第一语言声学参数、所述第二语言声学参数和所述目标情感声学参数确定多说话人目标情感平均声学模型;A target emotion average acoustic model determination module, used for the first language annotation file, the second language annotation file, the target emotion Mandarin annotation file, the first language acoustic parameters, the second language acoustic parameters and the target emotion acoustic parameter to determine a multi-speaker target emotion average acoustic model;
待合成标注文件确定模块,用于对第一语言或/和第二语言的待合成文件进行上下文相关文本标注获得待合成标注文件;A to-be-synthesized annotation file determination module, configured to perform context-dependent text annotation on the to-be-synthesized files in the first language or/and the second language to obtain the to-be-synthesized annotation files;
语音合成文件确定模块,用于将所述待合成标注文件输入所述多说话人目标情感平均声学模型获得第一语言或/和第二语言目标情感语音合成文件。A speech synthesis file determination module, configured to input the to-be-synthesized annotation file into the multi-speaker target emotion average acoustic model to obtain a first language or/and a second language target emotion speech synthesis file.
可选的,所述语言语料库文本标注模块,具体包括:Optionally, the language corpus text annotation module specifically includes:
标注规则建立子模块,用于建立第一语言标注规则和第二语言标注规则;The labeling rule establishment sub-module is used to establish the first language labeling rules and the second language labeling rules;
语言语料库文本标注子模块,用于根据第一语言标注规则和第二语言标注规则确定上下文相关标注格式,分别对多说话人的中性第一语言训练语料库、单说话人的中性第二语言训练语料库进行上下文相关文本标注,获得所述中性第一语言训练语料库对应的第一语言标注文件、所述中性第二语言训练语料库对应的第二语言标注文件;The language corpus text labeling sub-module is used to determine the context-dependent labeling format according to the first language labeling rules and the second language labeling rules. The training corpus performs context-related text annotation, and obtains a first language annotation file corresponding to the neutral first language training corpus and a second language annotation file corresponding to the neutral second language training corpus;
标音系统、问题集建立子模块,用于根据第一语言和第二语言的相似性,建立上下文相关聚类问题集。The phonetic system and question set establishment sub-module is used to establish a context-dependent clustering question set according to the similarity between the first language and the second language.
可选的,所述目标情感平均声学模型确定模块,具体包括:Optionally, the target emotion average acoustic model determination module specifically includes:
混合语言的中性平均声学模型确定子模块,用于将藏语标注文件、汉语标注文件、第一语言声学参数、第二语言声学参数作为训练集,基于自适应模型,通过说话人自适应训练,获得混合语言的中性平均声学模型;The sub-module for determining the neutral average acoustic model of mixed languages is used to use Tibetan annotation files, Chinese annotation files, acoustic parameters of the first language, and acoustic parameters of the second language as a training set, based on the adaptive model, through speaker adaptive training , to obtain the neutral average acoustic model of the mixed language;
目标情感平均声学模型确定子模块,用于根据混合语言的中性平均声学模型,将目标情感普通话标注文件、目标情感声学参数作为测试集,通过说话人自适应变换,获得多说话人目标情感平均声学模型。The target emotion average acoustic model determination sub-module is used to obtain the multi-speaker target emotion average by using the target emotion Mandarin annotation file and target emotion acoustic parameters as the test set according to the neutral average acoustic model of the mixed language. acoustic model.
根据本发明提供的具体实施例,本发明公开了以下技术效果:According to the specific embodiments provided by the present invention, the present invention discloses the following technical effects:
1)、本发明利用一种多说话人的目标情感普通话训练语料库就能训练出一种多说话人目标情感平均声学模型,只需改变待合成文件就能合成出另一种语言或多种语言的情感语音合成,从而拓宽了语音合成范围。1) The present invention uses a multi-speaker target emotion Mandarin training corpus to train a multi-speaker target emotion average acoustic model, and can synthesize another language or multiple languages only by changing the files to be synthesized. emotional speech synthesis, thus broadening the scope of speech synthesis.
2)、本发明利用一种多说话人的目标情感普通话训练语料库就能训练出一种多说话人目标情感平均声学模型,既能合成出同一个说话人不同语言的情感语音,还能合成出不同说话人说不同语言的情感语音。2), the present invention can train a multi-speaker target emotion average acoustic model by using a multi-speaker target emotion Mandarin training corpus, which can not only synthesize the emotional speech of the same speaker in different languages, but also synthesize Emotional speech of different speakers in different languages.
附图说明Description of drawings
为了更清楚地说明本发明实施例或现有技术中的技术规则,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。In order to more clearly illustrate the embodiments of the present invention or the technical rules in the prior art, the accompanying drawings required in the embodiments will be briefly introduced below. Obviously, the drawings in the following description are only some of the present invention. In the embodiments, for those of ordinary skill in the art, other drawings can also be obtained according to these drawings without creative labor.
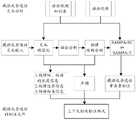
图1为本发明实施例跨语言情感语音合成方法流程图;1 is a flowchart of a method for cross-language emotional speech synthesis according to an embodiment of the present invention;
图2为本发明实施例藏语标注规则的具体流程图;Fig. 2 is the concrete flow chart of the Tibetan language labeling rule according to the embodiment of the present invention;
图3为本发明实施例建立上下文相关标注格式的具体流程图;3 is a specific flowchart of establishing a context-dependent annotation format according to an embodiment of the present invention;
图4为本发明实施例声学参数提取的具体流程图;4 is a specific flowchart of acoustic parameter extraction according to an embodiment of the present invention;
图5为本发明实施例跨语言情感语音合成系统结构框图。FIG. 5 is a structural block diagram of a cross-language emotional speech synthesis system according to an embodiment of the present invention.
具体实施方式Detailed ways
下面将结合本发明实施例中的附图,对本发明实施例中的技术规则进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。The technical rules in the embodiments of the present invention will be clearly and completely described below with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only a part of the embodiments of the present invention, not all of the embodiments. Based on the embodiments of the present invention, all other embodiments obtained by those of ordinary skill in the art without creative efforts shall fall within the protection scope of the present invention.
本发明的目的是提供一种跨语言情感语音合成方法及系统,以实现用一种多说话人的目标情感普通话训练语料库训练一个普通话说话人目标情感平均声学模型,只需改变待合成文件就能合成同一说话人或不同说话人跨语言的情感语音。The purpose of the present invention is to provide a cross-language emotional speech synthesis method and system, so as to use a multi-speaker target emotion Mandarin training corpus to train a Mandarin speaker target emotion average acoustic model, only need to change the files to be synthesized. Synthesize emotional speech across languages from the same speaker or from different speakers.
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。In order to make the above objects, features and advantages of the present invention more clearly understood, the present invention will be described in further detail below with reference to the accompanying drawings and specific embodiments.
本发明公开了第一语言和第二语言,所述第一语言为汉语、英语、德语、法语中任意一种;所述第二语言为藏语、西班牙语、日语、阿拉伯语、韩语、葡萄牙语中任意一种。本发明具体实施例将汉语作为第一语言,将藏语作为第二语言为例进行论述,图1为本发明实施例跨语言情感语音合成方法流程图,具体详见图1。The invention discloses a first language and a second language, the first language is any one of Chinese, English, German and French; the second language is Tibetan, Spanish, Japanese, Arabic, Korean, Portuguese any of the words. The specific embodiment of the present invention takes Chinese as the first language and Tibetan as the second language for discussion. FIG. 1 is a flow chart of a method for cross-language emotional speech synthesis according to an embodiment of the present invention. For details, see FIG. 1 .
本发明具体提供了一种跨语言情感语音合成方法,具体步骤包括:The present invention specifically provides a cross-language emotional speech synthesis method, and the specific steps include:
步骤100:建立汉语和藏语通用的上下文相关标注格式和上下文相关聚类问题集,分别对多说话人的中性汉语训练语料库、单说话人的中性藏语训练语料库进行上下文相关文本标注,获得所述中性汉语训练语料库对应的汉语标注文件、所述中性藏语训练语料库对应的藏语标注文件;分别对所述中性汉语训练语料库和所述中性藏语训练语料库进行声学参数提取,获得所述中性汉语训练语料库对应的汉语声学参数、所述中性藏语训练语料库对应的藏语声学参数。Step 100: Establish a context-dependent labeling format and a context-dependent clustering problem set common to Chinese and Tibetan, and perform context-dependent text labeling on the multi-speaker neutral Chinese training corpus and the single-speaker neutral Tibetan training corpus respectively, Obtain the Chinese annotation files corresponding to the neutral Chinese training corpus and the Tibetan annotation files corresponding to the neutral Tibetan training corpus; respectively perform acoustic parameters on the neutral Chinese training corpus and the neutral Tibetan training corpus Extraction to obtain Chinese acoustic parameters corresponding to the neutral Chinese training corpus and Tibetan acoustic parameters corresponding to the neutral Tibetan training corpus.
步骤200:根据所述上下文相关标注格式和所述上下文相关聚类问题集对多说话人的目标情感普通话训练语料库进行上下文相关文本标注,获得目标情感普通话标注文件;对所述目标情感普通话训练语料库进行声学参数提取,获得目标情感声学参数。Step 200: Perform context-related text annotation on the target emotional Mandarin training corpus of the multi-speaker according to the context-related annotation format and the context-related clustering question set to obtain a target emotional Mandarin annotation file; Perform acoustic parameter extraction to obtain target emotional acoustic parameters.
步骤300:根据所述汉语标注文件、所述藏语标注文件、所述目标情感普通话标注文件、所述汉语声学参数、所述藏语声学参数和所述目标情感声学参数确定多说话人目标情感平均声学模型。Step 300: Determine the multi-speaker target emotion according to the Chinese annotation file, the Tibetan annotation file, the target emotion Mandarin annotation file, the Chinese acoustic parameter, the Tibetan acoustic parameter and the target emotion acoustic parameter Average acoustic model.
步骤400:对汉语或/和藏语的待合成文件进行上下文相关文本标注获得待合成标注文件。Step 400: Perform context-dependent text annotation on the documents to be synthesized in Chinese or/and Tibetan to obtain the annotation files to be synthesized.
步骤500:将所述待合成标注文件输入所述多说话人目标情感平均声学模型获得汉语或/和藏语目标情感语音合成文件。Step 500: Input the annotation file to be synthesized into the multi-speaker target emotion average acoustic model to obtain a Chinese or/and Tibetan target emotion speech synthesis file.
下面对各个步骤进行详细的介绍:Each step is described in detail below:
步骤100:建立汉语和藏语通用的上下文相关标注格式和上下文相关聚类问题集,分别对多说话人的中性汉语训练语料库、单说话人的中性藏语训练语料库进行上下文相关文本标注,获得所述中性汉语训练语料库对应的汉语标注文件、所述中性藏语训练语料库对应的藏语标注文件;分别对所述中性汉语训练语料库和所述中性藏语训练语料库进行声学参数提取,获得所述中性汉语训练语料库对应的汉语声学参数、所述中性藏语训练语料库对应的藏语声学参数。Step 100: Establish a context-dependent labeling format and a context-dependent clustering problem set common to Chinese and Tibetan, and perform context-dependent text labeling on the multi-speaker neutral Chinese training corpus and the single-speaker neutral Tibetan training corpus respectively, Obtain the Chinese annotation files corresponding to the neutral Chinese training corpus and the Tibetan annotation files corresponding to the neutral Tibetan training corpus; respectively perform acoustic parameters on the neutral Chinese training corpus and the neutral Tibetan training corpus Extraction to obtain Chinese acoustic parameters corresponding to the neutral Chinese training corpus and Tibetan acoustic parameters corresponding to the neutral Tibetan training corpus.
步骤101:建立汉语标注规则和藏语标注规则。Step 101: Establish Chinese tagging rules and Tibetan tagging rules.
步骤1011:将SAMPA-SC普通话机读音标作为所述汉语标注规则。Step 1011: Use SAMPA-SC Mandarin phone-reading phonetic symbols as the Chinese marking rule.
步骤1012:所述建立藏语标注规则,具体步骤包括:Step 1012: The specific steps for establishing Tibetan labeling rules include:
目前汉语普通话机读音标SAMPA-SC已趋于成熟并广泛应用,而藏语和汉语在发音上有很多相似之处,例如,汉藏语系中,汉语与藏语在发音上既有共性又有差异,藏语拉萨方言和汉语普通话都是由音节组成,每个音节都包含1个韵母和1个声母,藏语拉萨方言有45个韵母和36个声母,普通话有39个韵母和22个声母,它们共享13个韵母和20个声母,且都有4个声调只是调值不同。因此本发明以SAMPA-SC为基础,根据藏语的发音特点,设计出一套藏语计算机可读音标SAMPA-T,即藏语标注规则。具体详见图2。At present, the Chinese Mandarin phonetic transcription SAMPA-SC has become mature and widely used, while Tibetan and Chinese have many similarities in pronunciation. For example, in the Sino-Tibetan language family, Chinese and Tibetan have common pronunciations and There are differences. Both Tibetan Lhasa dialect and Mandarin Chinese are composed of syllables, and each syllable contains 1 final and 1 initial. Tibetan Lhasa dialect has 45 finals and 36 initials, and Mandarin has 39 finals and 22 initials. Initials, they share 13 finals and 20 initials, and both have 4 tones, but the tones are different. Therefore, the present invention is based on SAMPA-SC, and according to the pronunciation characteristics of Tibetan, a set of Tibetan computer-readable phonetic symbols SAMPA-T, namely Tibetan marking rules, are designed. See Figure 2 for details.
以国际音标为参考,基于SAMPA-SC普通话机读音标,获得输入藏语拼音的国际音标。Taking the International Phonetic Alphabet as a reference, based on SAMPA-SC Mandarin phone-reading phonetic symbols, obtain the International Phonetic Alphabet for inputting Tibetan Pinyin.
判断所述藏语拼音的国际音标与汉语拼音的国际音标是否一致,若一致,则直接采用SAMPA-SC普通话机读音标来标记藏语拼音,否,则按照简单化原则,利用自定义的未使用的键盘符号标记。Judging whether the IPA of the Tibetan Pinyin is consistent with the IPA of the Hanyu Pinyin, if they are consistent, directly use the SAMPA-SC Mandarin phone-reading phonetic symbols to mark the Tibetan Pinyin; Used keyboard symbol tag.
步骤102:根据汉语标注规则和藏语标注规则确定汉语和藏语通用的上下文相关标注格式,根据上下文相关标注格式分别对多说话人的中性汉语训练语料库、单说话人的中性藏语训练语料库进行上下文相关文本标注,分别获得所述中性汉语训练语料库对应的汉语标注文件、所述中性藏语训练语料库对应的藏语标注文件,具体详见图3。Step 102: Determine the context-sensitive labeling format common to Chinese and Tibetan according to the Chinese labeling rules and the Tibetan labeling rules. According to the context-sensitive labeling format, the multi-speaker neutral Chinese training corpus and the single-speaker neutral Tibetan training corpus are respectively The corpus is subjected to context-related text annotation, and the Chinese annotation files corresponding to the neutral Chinese training corpus and the Tibetan language annotation files corresponding to the neutral Tibetan training corpus are respectively obtained, as shown in Figure 3 for details.
步骤1021:根据汉语和藏语的语法规则知识库和语法词典,对输入的汉语和藏语不规范的文本进行文本规范化、语法分析和韵律结构分析获得规范文本,韵律词、短语的长度信息,韵律边界信息,词语相关信息,声调信息。Step 1021: According to the knowledge base of Chinese and Tibetan grammar rules and grammar dictionary, text normalization, grammatical analysis and prosodic structure analysis are performed on the input irregular texts in Chinese and Tibetan to obtain standard text, length information of prosodic words and phrases, Prosodic boundary information, word-related information, and tone information.
步骤1022:将所述规范文本带入所述汉语标注规则获得汉语的单音素标注文件;或将所述规范文本带入所述藏语标注规则获得藏语的单音素标注文件。Step 1022: Bring the canonical text into the Chinese annotation rule to obtain a Chinese monophone annotation file; or bring the canonical text into the Tibetan annotation rule to obtain a Tibetan monophone annotation file.
步骤1023:根据韵律词、短语的长度信息,韵律边界信息,词语相关信息,声调信息和单音素标注文件确定汉语和藏语通用的上下文相关标注格式。Step 1023: Determine a common context-sensitive annotation format for Chinese and Tibetan according to the length information of prosodic words and phrases, prosodic boundary information, word-related information, tone information and monophone annotation files.
上下文相关标注格式用来标注发音基元(声韵母)的上下文信息。上下文相关标注格式包括声韵母音、音节、词、韵律词、韵律短语和语句6层,用来表示发音基元(声韵母)及其在不同语境下的上下文相关信息。The context-sensitive annotation format is used to annotate the contextual information of pronunciation primitives (initials and finals). The context-sensitive annotation format includes six layers of consonants, syllables, words, prosodic words, prosodic phrases and sentences, which are used to represent pronunciation primitives (acoustic vowels) and their context-related information in different contexts.
步骤1024:根据上下文相关标注格式分别对多说话人的中性汉语训练语料库、单说话人的中性藏语训练语料库进行上下文相关文本标注,分别获得所述中性汉语训练语料库对应的汉语标注文件、所述中性藏语训练语料库对应的藏语标注文件。Step 1024: Perform context-dependent text annotation on the multi-speaker neutral Chinese training corpus and the single-speaker neutral Tibetan training corpus respectively according to the context-dependent labeling format, and obtain Chinese labeling files corresponding to the neutral Chinese training corpus respectively , the Tibetan language annotation file corresponding to the neutral Tibetan language training corpus.
步骤103:根据汉语和藏语的相似性,建立汉语和藏语通用的上下文相关聚类问题集。Step 103: According to the similarity between Chinese and Tibetan, establish a context-dependent clustering problem set common to Chinese and Tibetan.
步骤104:分别对中性汉语训练语料库和中性藏语训练语料库进行声学参数提取,获得所述中性汉语训练语料库对应的汉语声学参数、所述中性藏语训练语料库对应的藏语声学参数,具体详见图4。Step 104: Extract acoustic parameters from the neutral Chinese training corpus and the neutral Tibetan training corpus, respectively, to obtain Chinese acoustic parameters corresponding to the neutral Chinese training corpus and Tibetan acoustic parameters corresponding to the neutral Tibetan training corpus , see Figure 4 for details.
声学参数提取时,通过对语音信号进行分析,提取语音信号的基频和谱特征等声学特征。本发明中用广义梅尔倒谱系数(Mel-generalized cepstral,mgc)作为谱特征,用来表示频谱包络,即:源滤波器模型中的滤波器部;用对数基频logF0作为基频特征。因为语音信号不是纯粹的、稳定的周期信号,基频的错误直接影响对频谱包络的提取,因此,提取频谱包络(广义梅尔倒谱系数mgc)同时也要提取基频特征(对数基频logF0)。During the extraction of acoustic parameters, the acoustic features such as fundamental frequency and spectral features of the speech signal are extracted by analyzing the speech signal. In the present invention, the generalized Mel-generalized cepstral coefficient (Mel-generalized cepstral, mgc) is used as the spectral feature to represent the spectral envelope, that is, the filter part in the source filter model; the logarithmic fundamental frequency logF0 is used as the fundamental frequency feature. Because the speech signal is not a pure and stable periodic signal, the error of the fundamental frequency directly affects the extraction of the spectral envelope. Therefore, extracting the spectral envelope (generalized Mel cepstral coefficient mgc) also extracts the fundamental frequency feature (logarithm fundamental frequency logF0).
所述声学参数提取包括:广义梅尔倒谱系数mgc提取,对数基频logF0提取,非周期分量bap提取。The acoustic parameter extraction includes: extraction of generalized Mel cepstral coefficient mgc, extraction of logarithmic fundamental frequency logF0, and extraction of aperiodic component bap.
广义梅尔倒谱系数mgc提取公式具体为:The generalized Mel cepstral coefficient mgc extraction formula is as follows:

其中,
如果γ=0,cα,γ(m)为mgc模型;γ等于-1,则该模型为自回归模型;如果γ等于0,则为指数模型。If γ=0, cα, γ (m) is the mgc model; γ is equal to -1, the model is an autoregressive model; if γ is equal to 0, it is an exponential model.
对数基频logF0提取:Logarithmic fundamental frequency logF0 extraction:
采用归一化自相关函数法提取基频特征,其具体步骤为:The normalized autocorrelation function method is used to extract fundamental frequency features, and the specific steps are as follows:
对于语音信号s(n),n≤N,n∈N+,其自相关函数为:For speech signal s(n), n≤N, n∈N+ , its autocorrelation function is:

其中,k为延时时间,应设置为基音周期的整数倍,s(n+k)为s(n)相邻的语音信号,N整数,K为延时时间的最大数。Among them, k is the delay time, which should be set as an integer multiple of the pitch period, s(n+k) is the speech signal adjacent to s(n), N is an integer, and K is the maximum delay time.
对自相关函数acf(k)进行归一化处理,便得到归一化自相关函数:The normalized autocorrelation function is obtained by normalizing the autocorrelation function acf(k):

其中,
当自相关函数的最大值时,函数的延迟值k即为基音周期。基音周期取倒数就是基频,基频对数就是需要提取的对数基频logF0。When the maximum value of the autocorrelation function, the delay value k of the function is the pitch period. The reciprocal of the pitch period is the base frequency, and the logarithm of the base frequency is the logarithmic base frequency logF0 that needs to be extracted.
非周期分量bap提取:Aperiodic component bap extraction:
语音信号的非周期成分在频域被定义为非周期成分的相对能量水平,并通过非谐波成分的能量与固定基频值结构规整后的谱的总能量的比值计算线性域的非周期成分值ap,也就是说用上下谱包络相减就能确定线性域的非周期成分值ap,具体公式为:The aperiodic component of a speech signal is defined as the relative energy level of the aperiodic component in the frequency domain, and the aperiodic component in the linear domain is calculated by the ratio of the energy of the non-harmonic component to the total energy of the spectrum after the regularization of the fixed fundamental frequency value structure. value ap, that is to say, the aperiodic component value ap of the linear domain can be determined by subtracting the upper and lower spectral envelopes. The specific formula is:

PAP(ω′)为lg域非周期成分值;S(λ′)代表谱能量,SL(λ′)表示谱下包络的谱能量,SU(λ′)为谱上包络的谱能量;wERB(λ′;ω′)为平滑声学滤波器,λ′为基频,ω′为频率。PAP (ω′) is the aperiodic component value in the lg domain; S(λ′) represents the spectral energy,SL (λ′) represents the spectral energy of the envelope under the spectrum, and SU (λ′) is the envelope of the spectrum Spectral energy; wERB (λ′; ω′) is the smoothing acoustic filter, λ′ is the fundamental frequency, and ω′ is the frequency.
在每帧的每个频带内对ap求取平均值就能确定非周期分量bap,具体公式为:The aperiodic component bap can be determined by averaging ap in each frequency band of each frame, and the specific formula is:

其中,bap(ω′)为非周期分量bap。where bap(ω′) is the aperiodic component bap.
步骤200:根据上下文相关标注格式和上下文相关聚类问题集对多说话人的目标情感普通话训练语料库进行上下文相关文本标注,获得目标情感普通话标注文件;对所述目标情感普通话训练语料库进行声学参数提取,获得目标情感声学参数。Step 200: Perform context-related text annotation on the target emotional Mandarin training corpus of the multi-speaker according to the context-related annotation format and the context-related clustering problem set, to obtain a target emotional Mandarin annotation file; perform acoustic parameter extraction on the target emotional Mandarin training corpus , to obtain the target emotional acoustic parameters.
对所述目标情感普通话训练语料库进行声学参数提取与对中性汉语训练语料库和中性藏语训练语料库进行声学参数提取的声学参数提取方式相同。具体详见公式(1)-(4)。The extraction of acoustic parameters for the target emotional Mandarin training corpus is the same as the extraction of acoustic parameters for the neutral Chinese training corpus and the neutral Tibetan training corpus. For details, please refer to formulas (1)-(4).
步骤300:根据所述汉语标注文件、所述藏语标注文件、所述目标情感普通话标注文件、所述汉语声学参数、所述藏语声学参数和所述目标情感声学参数确定多说话人目标情感平均声学模型。Step 300: Determine the multi-speaker target emotion according to the Chinese annotation file, the Tibetan annotation file, the target emotion Mandarin annotation file, the Chinese acoustic parameter, the Tibetan acoustic parameter and the target emotion acoustic parameter Average acoustic model.
步骤301:将汉语标注文件、藏语标注文件、汉语声学参数、藏语声学参数作为训练集,基于自适应模型,通过说话人自适应训练,获得混合语言的中性平均声学模型。所述自适应模型为深度学习模型、长短时记忆模型、隐马尔科夫模型中的任意一种。本发明采用半隐马尔科夫模型进行分析。Step 301 : Using the Chinese annotation files, the Tibetan annotation files, the Chinese acoustic parameters, and the Tibetan acoustic parameters as a training set, based on the adaptive model, through speaker adaptive training, a neutral average acoustic model of the mixed language is obtained. The adaptive model is any one of a deep learning model, a long and short-term memory model, and a hidden Markov model. The present invention adopts semi-hidden Markov model for analysis.
本发明采用约束最大似然线性回归算法,将平均声学模型和训练中说话人的语音数据之间的差异用线性回归函数表示,用一组状态时长分布和状态输出分布的线性回归公式归一化训练说话人之间的差异,训练得到上下文相关的半隐马尔科夫模型(Multi-SpaceHidden semi-Markov models,MSD-HSMM)。采用基于半隐马尔科夫模型MSD-HSMM的说话人自适应训练算法来提高合成语音的音质,减少各说话人之间的差异对合成语音质量的影响。状态时常分布和状态输出分布的线性回归公式具体为:The present invention adopts the constrained maximum likelihood linear regression algorithm, expresses the difference between the average acoustic model and the speech data of the speaker in training with a linear regression function, and normalizes it with a linear regression formula of a set of state duration distribution and state output distribution. The differences between speakers are trained to obtain context-dependent semi-hidden Markov models (Multi-SpaceHidden semi-Markov models, MSD-HSMM). The speaker adaptive training algorithm based on the semi-hidden Markov model MSD-HSMM is used to improve the sound quality of the synthesized speech and reduce the influence of the differences between the speakers on the quality of the synthesized speech. The linear regression formulas of state time distribution and state output distribution are as follows:


其中,公式(5)所示为状态时长分布变换方程,i为状态,右下角的i表示在状态i下,s为训练语音数据模型,s标记在右上角表示属于语音数据模型s的,

步骤302:根据混合语言的中性平均声学模型,将目标情感普通话标注文件、目标情感声学参数作为测试集,通过说话人自适应变换,获得多说话人目标情感平均声学模型;其具体步骤为:Step 302: According to the neutral average acoustic model of the mixed language, the target emotional Mandarin annotation file and the target emotional acoustic parameters are used as the test set, and the multi-speaker target emotional average acoustic model is obtained through the speaker adaptive transformation; the specific steps are:
步骤3021:采用约束最大似然线性回归算法,计算说话人的状态时长概率分布和状态输出概率分布的协方差矩阵和均值向量,用一组状态时长分布和状态输出分布的变换矩阵将中性平均声学模型的协方差矩阵和均值向量变换为目标说话人模型,具体公式为:Step 3021: Use the constrained maximum likelihood linear regression algorithm to calculate the covariance matrix and mean vector of the speaker's state duration probability distribution and state output probability distribution, and use a set of state duration distribution and state output distribution transformation matrices to average the neutral The covariance matrix and mean vector of the acoustic model are transformed into the target speaker model. The specific formula is:
pi(d)=N(d;αmi-β,ασi2α)=|α-1|N(αψ;mi,σi2) (7)pi (d)=N(d;αmi -β,ασi2 α)=|α-1 |N(αψ;mi ,σi2 ) (7)
bi(o)=N(o;Aui-b,AΣiAT)=|A-1|N(Wξ;ui,Σi) (8)bi (o)=N(o; Aui -b,AΣi AT )=|A-1 |N(Wξ; ui ,Σi ) (8)
其中,i为状态,d为状态时长,N为常数,pi(d)为状态时长的变换方程,mi为时长分布均值,σi2为方差,ψ=[d,1]T,o为特征征向量,ξ=[oT,1],ui为状态输出分布均值,∑i为对角协方差矩阵,X=[α-1,β-1]为状态时长概率密度分布的变换矩阵,W=[A-1,b-1]为目标说话人状态输出概率密度分布的线性变换矩阵;Among them, i is the state, d is the state duration, N is a constant, pi (d) is the transformation equation of the state duration, mi is the mean value of duration distribution, σi2 is the variance, ψ=[d,1]T , o is the eigenvector, ξ=[oT ,1],ui is the mean value of the state output distribution, ∑i is the diagonal covariance matrix, X=[α-1 ,β-1 ] is the transformation of the state duration probability density distribution matrix, W=[A-1 ,b-1 ] is the linear transformation matrix of the output probability density distribution of the target speaker state;
步骤3022:通过基于MSD-HSMM的自适应变换算法,可对语音数据的基频、频谱和时长参数进行变换和归一化;对于长度为T的自适应数据O,可变换Λ=(W,X)进行最大似然估计:Step 3022: Through the adaptive transformation algorithm based on MSD-HSMM, the fundamental frequency, spectrum and duration parameters of the speech data can be transformed and normalized; for the adaptive data O whose length is T, it can be transformed Λ=(W, X) for maximum likelihood estimation:

其中,λ为MSD-HSMM的参数集,O为长度为T的自适应数据,
步骤3023:对转化和归一化后的时长、频谱和基频参数进行最大似然估计,采用最大后验概率算法对说话人相关模型进行更新和修正,具体公式为:Step 3023: Perform maximum likelihood estimation on the transformed and normalized duration, spectrum and fundamental frequency parameters, and update and correct the speaker-related model using the maximum a posteriori algorithm. The specific formula is:

MAP估计:MAP estimate:


其中,t为时间,λ为给定的MSD-HSMM参数集,T为长度,o为长度为T时自适应数据i为状态,d为状态时长,N为常数,s为训练语音数据模型,ktd(i)为状态i下连续观测序列ot-d+1...ot的概率,αt(i)为向前概率,βt(i)为向后概率,





步骤400:对汉语或/和藏语的待合成文件进行上下文相关文本标注获得待合成标注文件。Step 400: Perform context-dependent text annotation on the documents to be synthesized in Chinese or/and Tibetan to obtain the annotation files to be synthesized.
所述待合成文件包括汉语和/藏语待合成文件,待合成文件为字、词、短语、句子任意一种,将所述汉语和/藏语待合成文件根据所述上下文相关文本标注格式进行上下文相关文本标注获得待合成标注文件。The documents to be synthesized include Chinese and/Tibetan documents to be synthesized, and the documents to be synthesized are any of characters, words, phrases, and sentences. Context-sensitive text annotations are used to obtain annotation files to be synthesized.
也就是说,当待合成文本为藏语待合成文本时,根据所述上下文相关文本标注格式进行上下文相关文本标注获得藏语待合成标注文件;当待合成文本为汉语待合成文本时,根据所述上下文相关文本标注格式进行上下文相关文本标注获得汉语待合成标注文件;当待合成文本为藏语和汉语待合成文本时,根据所述上下文相关文本标注格式进行上下文相关文本标注获得藏语和汉语待合成标注文件。That is to say, when the text to be synthesized is the text to be synthesized in Tibetan, the context-dependent text annotation is performed according to the context-relevant text annotation format to obtain the annotation file to be synthesized in Tibetan; when the text to be synthesized is the text to be synthesized in Chinese, according to the Use the context-related text annotation format to perform context-related text annotation to obtain Chinese annotation files to be synthesized; when the to-be-synthesized texts are Tibetan and Chinese to be synthesized texts, perform context-dependent text annotation according to the context-dependent text annotation format to obtain Tibetan and Chinese texts. Annotation files to be synthesized.
步骤500:将所述待合成标注文件输入所述多说话人目标情感平均声学模型获得目标情感语音合成文件。Step 500: Input the annotation file to be synthesized into the multi-speaker target emotion average acoustic model to obtain a target emotion speech synthesis file.
对于待合成文本的待合成标注文件,利用问题集,根据每个发音基元(声韵母)的上下文相关信息获得每个发音基元的说话人相关的目标情感平均声学模型,再通过聚类确定整个待合成句子的说话人相关的目标情感平均声学模型,然后根据此说话人相关的目标情感平均声学模型获得普通话和/或藏语的目标情感的声学参数文件,最后利用声学参数文件通过语音波形生成器来合成出藏语和/或汉语目标情感语音合成文件。For the to-be-synthesized labeled files of the text to be synthesized, the question set is used to obtain the average acoustic model of the target emotion related to the speaker of each pronunciation primitive according to the context-related information of each pronunciation primitive (initials and finals), and then determined by clustering. The average acoustic model of the target emotion related to the speaker of the entire sentence to be synthesized, and then the acoustic parameter file of the target emotion of Mandarin and/or Tibetan is obtained according to the average acoustic model of the target emotion related to the speaker, and finally, the acoustic parameter file is used to pass the speech waveform. generator to synthesize Tibetan and/or Chinese target sentiment speech synthesis files.
也就是说,将所述藏语待合成标注文件输入所述多说话人目标情感平均声学模型获得藏语目标情感语音合成文件;将所述汉语待合成标注文件输入所述多说话人目标情感平均声学模型获得汉语目标情感语音合成文件;将所述汉语和藏语待合成标注文件输入所述多说话人目标情感平均声学模型获得汉语和藏语混合目标情感语音合成文件。That is to say, input the Tibetan annotation file to be synthesized into the multi-speaker target emotional average acoustic model to obtain a Tibetan target emotional speech synthesis file; input the Chinese annotation file to be synthesized into the multi-speaker target emotional average The acoustic model obtains a Chinese target emotion speech synthesis file; the Chinese and Tibetan to-be-synthesized annotation files are input into the multi-speaker target emotion average acoustic model to obtain a Chinese and Tibetan mixed target emotion speech synthesis file.
为实现上述目的,本发明还提供了一种跨语言情感语音合成系统。To achieve the above object, the present invention also provides a cross-language emotional speech synthesis system.
图5为本发明实施例跨语言情感语音合成系统结构框图,如图5所示,所述系统包括:语言语料库文本标注、参数提取模块1,目标情感语料库文本标注、参数提取模块2,目标情感平均声学模型确定模块3,待合成标注文件确定模块4,语音合成文件确定模块5。FIG. 5 is a structural block diagram of a cross-language emotional speech synthesis system according to an embodiment of the present invention. As shown in FIG. 5 , the system includes: a language corpus text labeling and
语言语料库文本标注、参数提取模块1,用于建立上下文相关标注格式和上下文相关聚类问题集,分别对多说话人的中性汉语训练语料库、单说话人的中性藏语训练语料库进行上下文相关文本标注,获得所述中性汉语训练语料库对应的汉语标注文件、所述中性藏语训练语料库对应的藏语标注文件;用于分别对中性汉语训练语料库和中性藏语训练语料库进行声学参数提取,获得所述中性汉语训练语料库对应的汉语声学参数、所述中性藏语训练语料库对应的藏语声学参数。The language corpus text annotation and
所述语言语料库文本标注、参数提取模块1具体包括:所述语言语料库文本标注模块和所述语言语料库参数提取模块。The language corpus text annotation and
所述语言语料库文本标注模块,具体包括:标注规则建立子模块,语言语料库文本标注子模块,标音系统、问题集建立子模块。The language corpus text labeling module specifically includes: a labeling rule establishment submodule, a language corpus text labeling submodule, a transcription system, and a question set establishment submodule.
所述标注规则建立子模块,用于建立汉语标注规则和藏语标注规则;The labeling rule establishment submodule is used to establish Chinese labeling rules and Tibetan labeling rules;
所述语言语料库文本标注子模块,用于根据汉语标注规则和藏语标注规则确定上下文相关标注格式,分别对多说话人的中性汉语训练语料库、单说话人的中性藏语训练语料库进行上下文相关文本标注,获得所述中性汉语训练语料库对应的汉语标注文件、所述中性藏语训练语料库对应的藏语标注文件;The language corpus text labeling sub-module is used to determine the context-dependent labeling format according to the Chinese labeling rules and the Tibetan labeling rules, and perform contextual analysis on the multi-speaker neutral Chinese training corpus and the single-speaker neutral Tibetan training corpus respectively. Relevant text annotation, obtaining Chinese annotation files corresponding to the neutral Chinese training corpus and Tibetan annotation files corresponding to the neutral Tibetan training corpus;
所述标音系统、问题集建立子模块,用于根据汉语和藏语的相似性,建立汉语和藏语通用的上下文相关聚类问题集。The phonetic system and question set establishment sub-module is used to establish a context-dependent clustering question set common to Chinese and Tibetan according to the similarity between Chinese and Tibetan.
所述语言语料库参数提取模块,用于分别对中性汉语训练语料库和中性藏语训练语料库进行声学参数提取,获得所述中性汉语训练语料库对应的汉语声学参数、所述中性藏语训练语料库对应的藏语声学参数。The language corpus parameter extraction module is used to extract acoustic parameters from the neutral Chinese training corpus and the neutral Tibetan training corpus, respectively, to obtain Chinese acoustic parameters corresponding to the neutral Chinese training corpus, and the neutral Tibetan training corpus. Tibetan acoustic parameters corresponding to the corpus.
目标情感语料库文本标注、参数提取模块2,用于对多说话人的目标情感普通话训练语料库进行上下文相关文本标注,获得目标情感普通话标注文件;对所述目标情感普通话训练语料库进行声学参数提取,获得目标情感声学参数;The target emotional corpus text annotation and
目标情感平均声学模型确定模块3,用于根据所述汉语标注文件、所述藏语标注文件、所述目标情感普通话标注文件、所述汉语声学参数、所述藏语声学参数和所述目标情感声学参数确定多说话人目标情感平均声学模型;The target emotion average acoustic
所述目标情感平均声学模型确定模块3,具体包括:混合语言的中性平均声学模型确定子模块、目标情感平均声学模型确定子模块。The target emotion average acoustic
所述混合语言的中性平均声学模型确定子模块,用于将藏语标注文件、汉语标注文件、汉语声学参数、藏语声学参数作为训练集,基于自适应模型,通过说话人自适应训练,获得混合语言的中性平均声学模型;The neutral average acoustic model determination sub-module of the mixed language is used to use the Tibetan annotation file, the Chinese annotation file, the Chinese acoustic parameters, and the Tibetan acoustic parameters as a training set, based on the adaptive model, through the speaker adaptive training, Obtain a neutral average acoustic model of the mixed language;
所述目标情感平均声学模型确定子模块,用于根据混合语言的中性平均声学模型,将目标情感普通话标注文件、目标情感声学参数作为测试集,通过说话人自适应变换,获得多说话人目标情感平均声学模型。The target emotion average acoustic model determination sub-module is used to obtain the multi-speaker target by using the target emotion Mandarin annotation file and the target emotion acoustic parameters as the test set according to the neutral average acoustic model of the mixed language. Affective averaging acoustic models.
待合成标注文件确定模块4,用于对汉语或/和藏语的待合成文件进行上下文相关文本标注获得待合成标注文件。The to-be-synthesized annotated file determination module 4 is configured to perform context-dependent text annotation on the Chinese or/and Tibetan to-be-synthesized files to obtain the to-be-synthesized annotated file.
语音合成文件确定模块5,用于将所述待合成标注文件输入所述多说话人目标情感平均声学模型获得汉语或/和藏语目标情感语音合成文件。The speech synthesis
具体举例:Specific examples:
本发明录制一个女性藏语说话人的800句作为单说话人的中性藏语训练语料库,将汉英双语语音数据库作为多说话人的中性汉语训练语料库,录制了一个9个女性说话人11种情感共9900句作为多说话人的目标情感普通话训练语料库,即11中情感包括悲伤、放松、愤怒、焦虑、惊奇、恐惧、轻蔑、温顺、喜悦、厌恶、中性。实验证明,随着普通话目标情感训练语料的增加,合成的目标情感的藏语或汉语语音的情感相似度评测得分(EmotionalMeanOpinionScore,EMOS)逐渐提高。The invention records 800 sentences of a female Tibetan speaker as a neutral Tibetan training corpus for a single speaker, uses a Chinese-English bilingual voice database as a neutral Chinese training corpus for a multi-speaker, and records a 9 female speakers11 A total of 9900 sentences of each emotion were used as the target emotion training corpus for multi-speakers, namely 11 emotions including sadness, relaxation, anger, anxiety, surprise, fear, contempt, meekness, joy, disgust, and neutrality. Experiments show that with the increase of Mandarin target emotion training corpus, the emotional similarity evaluation score (EmotionalMeanOpinionScore, EMOS) of the synthesized Tibetan or Chinese speech of the target emotion gradually increases.
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。The various embodiments in this specification are described in a progressive manner, and each embodiment focuses on the differences from other embodiments, and the same and similar parts between the various embodiments can be referred to each other. For the system disclosed in the embodiment, since it corresponds to the method disclosed in the embodiment, the description is relatively simple, and the relevant part can be referred to the description of the method.
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。In this paper, specific examples are used to illustrate the principles and implementations of the present invention. The descriptions of the above embodiments are only used to help understand the methods and core ideas of the present invention; meanwhile, for those skilled in the art, according to the present invention There will be changes in the specific implementation and application scope. In conclusion, the contents of this specification should not be construed as limiting the present invention.
Claims (9)











Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201710415814.5ACN107103900B (en) | 2017-06-06 | 2017-06-06 | Cross-language emotion voice synthesis method and system |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201710415814.5ACN107103900B (en) | 2017-06-06 | 2017-06-06 | Cross-language emotion voice synthesis method and system |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN107103900A CN107103900A (en) | 2017-08-29 |
| CN107103900Btrue CN107103900B (en) | 2020-03-31 |
Family
ID=59660516
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201710415814.5AActiveCN107103900B (en) | 2017-06-06 | 2017-06-06 | Cross-language emotion voice synthesis method and system |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN107103900B (en) |
Families Citing this family (22)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108831435B (en)* | 2018-06-06 | 2020-10-16 | 安徽继远软件有限公司 | An Emotional Speech Synthesis Method Based on Multi-emotional Speaker Adaptive |
| CN109036370B (en)* | 2018-06-06 | 2021-07-20 | 安徽继远软件有限公司 | A kind of speaker voice adaptive training method |
| CN109192225B (en)* | 2018-09-28 | 2021-07-09 | 清华大学 | Method and device for speech emotion recognition and labeling |
| CN111192568B (en)* | 2018-11-15 | 2022-12-13 | 华为技术有限公司 | Speech synthesis method and speech synthesis device |
| CN111954903B (en)* | 2018-12-11 | 2024-03-15 | 微软技术许可有限责任公司 | Multi-speaker neuro-text-to-speech synthesis |
| CN109949791B (en)* | 2019-03-22 | 2024-07-09 | 平安科技(深圳)有限公司 | HMM-based emotion voice synthesis method, device and storage medium |
| JP7280386B2 (en)* | 2019-05-31 | 2023-05-23 | グーグル エルエルシー | Multilingual speech synthesis and cross-language voice cloning |
| CN110534089B (en)* | 2019-07-10 | 2022-04-22 | 西安交通大学 | Chinese speech synthesis method based on phoneme and prosodic structure |
| CN110853616A (en)* | 2019-10-22 | 2020-02-28 | 武汉水象电子科技有限公司 | Speech synthesis method, system and storage medium based on neural network |
| DE102019216560B4 (en)* | 2019-10-28 | 2022-01-13 | Robert Bosch Gmbh | Method and device for training manipulation skills of a robot system |
| CN113035239A (en)* | 2019-12-09 | 2021-06-25 | 上海航空电器有限公司 | Chinese-English bilingual cross-language emotion voice synthesis device |
| CN112233648B (en)* | 2019-12-09 | 2024-06-11 | 北京来也网络科技有限公司 | Data processing method, device, equipment and storage medium combining RPA and AI |
| CN111145719B (en)* | 2019-12-31 | 2022-04-05 | 北京太极华保科技股份有限公司 | Data labeling method and device for Chinese-English mixing and tone labeling |
| CN113851140B (en)* | 2020-06-28 | 2025-09-30 | 阿里巴巴集团控股有限公司 | Voice conversion related methods, systems and devices |
| CN112151008B (en)* | 2020-09-22 | 2022-07-15 | 中用科技有限公司 | Voice synthesis method, system and computer equipment |
| CN112270168B (en)* | 2020-10-14 | 2023-11-24 | 北京百度网讯科技有限公司 | Dialogue emotional style prediction method, device, electronic device and storage medium |
| CN112634858B (en)* | 2020-12-16 | 2024-01-23 | 平安科技(深圳)有限公司 | Speech synthesis method, device, computer equipment and storage medium |
| CN113539268A (en)* | 2021-01-29 | 2021-10-22 | 南京迪港科技有限责任公司 | End-to-end voice-to-text rare word optimization method |
| CN113345431B (en)* | 2021-05-31 | 2024-06-07 | 平安科技(深圳)有限公司 | Cross-language voice conversion method, device, equipment and medium |
| CN113611286B (en)* | 2021-10-08 | 2022-01-18 | 之江实验室 | Cross-language speech emotion recognition method and system based on common feature extraction |
| CN116092471B (en)* | 2022-09-16 | 2025-08-26 | 西北师范大学 | A multi-style personalized Tibetan speech synthesis model for low-resource conditions |
| CN117496944B (en)* | 2024-01-03 | 2024-03-22 | 广东技术师范大学 | Multi-emotion multi-speaker voice synthesis method and system |
Family Cites Families (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006178063A (en)* | 2004-12-21 | 2006-07-06 | Toyota Central Res & Dev Lab Inc | Dialogue processing device |
| CN101064104B (en)* | 2006-04-24 | 2011-02-02 | 中国科学院自动化研究所 | Emotion voice creating method based on voice conversion |
| CN102005205B (en)* | 2009-09-03 | 2012-10-03 | 株式会社东芝 | Emotional speech synthesizing method and device |
| CN102385858B (en)* | 2010-08-31 | 2013-06-05 | 国际商业机器公司 | Emotional voice synthesis method and system |
| KR101203188B1 (en)* | 2011-04-14 | 2012-11-22 | 한국과학기술원 | Method and system of synthesizing emotional speech based on personal prosody model and recording medium |
| CN102184731A (en)* | 2011-05-12 | 2011-09-14 | 北京航空航天大学 | Method for converting emotional speech by combining rhythm parameters with tone parameters |
| TWI471854B (en)* | 2012-10-19 | 2015-02-01 | Ind Tech Res Inst | Guided speaker adaptive speech synthesis system and method and computer program product |
| US9177549B2 (en)* | 2013-11-01 | 2015-11-03 | Google Inc. | Method and system for cross-lingual voice conversion |
| CN104217713A (en)* | 2014-07-15 | 2014-12-17 | 西北师范大学 | Tibetan-Chinese speech synthesis method and device |
| CN104538025A (en)* | 2014-12-23 | 2015-04-22 | 西北师范大学 | Method and device for converting gestures to Chinese and Tibetan bilingual voices |
| US9665567B2 (en)* | 2015-09-21 | 2017-05-30 | International Business Machines Corporation | Suggesting emoji characters based on current contextual emotional state of user |
| CN105654942A (en)* | 2016-01-04 | 2016-06-08 | 北京时代瑞朗科技有限公司 | Speech synthesis method of interrogative sentence and exclamatory sentence based on statistical parameter |
| CN106128450A (en)* | 2016-08-31 | 2016-11-16 | 西北师范大学 | The bilingual method across language voice conversion and system thereof hidden in a kind of Chinese |
| CN106531150B (en)* | 2016-12-23 | 2020-02-07 | 云知声(上海)智能科技有限公司 | Emotion synthesis method based on deep neural network model |
- 2017
- 2017-06-06CNCN201710415814.5Apatent/CN107103900B/enactiveActive
Also Published As
| Publication number | Publication date |
|---|---|
| CN107103900A (en) | 2017-08-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN107103900B (en) | Cross-language emotion voice synthesis method and system | |
| CN108510976B (en) | Multi-language mixed voice recognition method | |
| CN104217713A (en) | Tibetan-Chinese speech synthesis method and device | |
| Alsharhan et al. | Improved Arabic speech recognition system through the automatic generation of fine-grained phonetic transcriptions | |
| Ekpenyong et al. | Statistical parametric speech synthesis for Ibibio | |
| US11817079B1 (en) | GAN-based speech synthesis model and training method | |
| CN112397056A (en) | Voice evaluation method and computer storage medium | |
| Rebai et al. | Text-to-speech synthesis system with Arabic diacritic recognition system | |
| CN118571229A (en) | Voice labeling method and device for voice feature description | |
| Panda et al. | Text-to-speech synthesis with an Indian language perspective | |
| CN115130457B (en) | Prosodic modeling method and modeling system integrating Amdo Tibetan phoneme vectors | |
| CN119669427A (en) | A method and device for implementing a dual-screen real-time translation machine | |
| TW201937479A (en) | Multilingual mixed speech recognition method | |
| Nair et al. | Indian text to speech systems: A short survey | |
| CN114708848A (en) | Method and device for acquiring size of audio and video file | |
| Chen et al. | A Bilingual Speech Synthesis System of Standard Malay and Indonesian Based on HMM-DNN | |
| Sulír et al. | Development of the Slovak HMM-based tts system and evaluation of voices in respect to the used vocoding techniques | |
| Iyanda et al. | Development of a yorúbà texttospeech system using festival | |
| Bhushan et al. | HMM and Concatenative Synthesis based Text-to-Speech Synthesis | |
| Sultana et al. | Text-to-Speech Synthesis for Hindi Language Using MFCC and LPC Feature Extraction Techniques | |
| Das | Syllabic Speech Synthesis for Marathi Language | |
| CN119889281B (en) | Method and device for synthesizing phonemic knowledge enhanced old-English mixed language speech | |
| Shanavas | Malayalam Text-to-Speech Conversion: An Assistive Tool for Visually Impaired People. | |
| Bu et al. | The Speech Synthesis of Yi Language Based on DNN | |
| Silamu et al. | HMM-based uyghur continuous speech recognition system |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |