CN106971704B - Audio processing method and mobile terminal - Google Patents
Audio processing method and mobile terminalDownload PDFInfo
- Publication number
- CN106971704B CN106971704BCN201710288677.3ACN201710288677ACN106971704BCN 106971704 BCN106971704 BCN 106971704BCN 201710288677 ACN201710288677 ACN 201710288677ACN 106971704 BCN106971704 BCN 106971704B
- Authority
- CN
- China
- Prior art keywords
- frequency
- preset
- audio data
- audio
- voice
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000003672processing methodMethods0.000titleclaimsabstractdescription12
- 230000001755vocal effectEffects0.000claimsabstractdescription215
- 238000000034methodMethods0.000claimsabstractdescription46
- 230000008569processEffects0.000claimsabstractdescription17
- 238000011156evaluationMethods0.000claimsdescription9
- 238000004364calculation methodMethods0.000claimsdescription4
- 230000002708enhancing effectEffects0.000claims2
- 239000012634fragmentSubstances0.000claims1
- 230000000694effectsEffects0.000abstractdescription24
- 230000006870functionEffects0.000description10
- 238000010586diagramMethods0.000description8
- 238000012545processingMethods0.000description8
- 238000004891communicationMethods0.000description4
- 230000001360synchronised effectEffects0.000description4
- 230000008859changeEffects0.000description3
- 230000008878couplingEffects0.000description3
- 238000010168coupling processMethods0.000description3
- 238000005859coupling reactionMethods0.000description3
- 238000001514detection methodMethods0.000description3
- 238000004458analytical methodMethods0.000description2
- 230000005236sound signalEffects0.000description2
- 238000001228spectrumMethods0.000description2
- 210000001260vocal cordAnatomy0.000description2
- KLDZYURQCUYZBL-UHFFFAOYSA-N2-[3-[(2-hydroxyphenyl)methylideneamino]propyliminomethyl]phenolChemical compoundOC1=CC=CC=C1C=NCCCN=CC1=CC=CC=C1OKLDZYURQCUYZBL-UHFFFAOYSA-N0.000description1
- 241001342895ChorusSpecies0.000description1
- 241000699666Mus <mouse, genus>Species0.000description1
- 241000699670Mus sp.Species0.000description1
- 230000005540biological transmissionEffects0.000description1
- HAORKNGNJCEJBX-UHFFFAOYSA-NcyprodinilChemical compoundN=1C(C)=CC(C2CC2)=NC=1NC1=CC=CC=C1HAORKNGNJCEJBX-UHFFFAOYSA-N0.000description1
- 201000001098delayed sleep phase syndromeDiseases0.000description1
- 208000033921delayed sleep phase type circadian rhythm sleep diseaseDiseases0.000description1
- 238000013461designMethods0.000description1
- 230000003287optical effectEffects0.000description1
- 230000004044responseEffects0.000description1
- 230000003068static effectEffects0.000description1
- 238000010897surface acoustic wave methodMethods0.000description1
- 230000007704transitionEffects0.000description1
- 230000000007visual effectEffects0.000description1
Images





Classifications
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H1/00—Details of electrophonic musical instruments
- G10H1/36—Accompaniment arrangements
- G10H1/361—Recording/reproducing of accompaniment for use with an external source, e.g. karaoke systems
- G10H1/366—Recording/reproducing of accompaniment for use with an external source, e.g. karaoke systems with means for modifying or correcting the external signal, e.g. pitch correction, reverberation, changing a singer's voice
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10H—ELECTROPHONIC MUSICAL INSTRUMENTS; INSTRUMENTS IN WHICH THE TONES ARE GENERATED BY ELECTROMECHANICAL MEANS OR ELECTRONIC GENERATORS, OR IN WHICH THE TONES ARE SYNTHESISED FROM A DATA STORE
- G10H2210/00—Aspects or methods of musical processing having intrinsic musical character, i.e. involving musical theory or musical parameters or relying on musical knowledge, as applied in electrophonic musical tools or instruments
- G10H2210/031—Musical analysis, i.e. isolation, extraction or identification of musical elements or musical parameters from a raw acoustic signal or from an encoded audio signal
- G10H2210/066—Musical analysis, i.e. isolation, extraction or identification of musical elements or musical parameters from a raw acoustic signal or from an encoded audio signal for pitch analysis as part of wider processing for musical purposes, e.g. transcription, musical performance evaluation; Pitch recognition, e.g. in polyphonic sounds; Estimation or use of missing fundamental
Landscapes
- Physics & Mathematics (AREA)
- Engineering & Computer Science (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Telephonic Communication Services (AREA)
- Reverberation, Karaoke And Other Acoustics (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明实施例涉及通信领域,尤其涉及一种音频处理方法及移动终端。Embodiments of the present invention relate to the field of communications, and in particular, to an audio processing method and a mobile terminal.
背景技术Background technique
目前在很多终端上集成有家庭影院、卡拉OK等功能,方便用户K歌。而K歌的用户往往是业余的歌唱者,在歌唱过程中,经常无法按照原唱的频率演唱歌曲中的高音部分或低音部分。导致无法展现出优质的演唱效果。例如,当用户演唱到歌曲的高音部分时,往往会使用假音以达到较高的频率,但由于假音难以准确控制,因此容易出现频率突然降低的情况,即容易出现破音。At present, many terminals are integrated with functions such as home theater and karaoke, which is convenient for users to karaoke songs. The users of K-song are often amateur singers. During the singing process, they often cannot sing the high-pitched part or the low-pitched part of the song according to the frequency of the original singing. As a result, the high-quality singing effect cannot be displayed. For example, when the user sings to the high-pitched part of the song, the falsetto is often used to achieve a higher frequency, but because the falsetto is difficult to accurately control, it is prone to a sudden decrease in frequency, that is, a broken sound is prone to occur.
由此可见,现有技术中,只有通过提高用户的演唱水平,才能展现出优质的演唱效果,若用户演唱水平不足,容易出现破音,导致影响演唱效果。It can be seen that, in the prior art, only by improving the user's singing level, can a high-quality singing effect be exhibited. If the user's singing level is insufficient, broken sounds are likely to occur, which will affect the singing effect.
发明内容SUMMARY OF THE INVENTION
本发明实施例提供一种音频处理方法及移动终端,以解决由于用户演唱水平不足,容易出现破音,导致影响演唱效果的问题。Embodiments of the present invention provide an audio processing method and a mobile terminal, so as to solve the problem that due to insufficient singing level of a user, broken sound is likely to occur, which affects the singing effect.
一方面,提供了一种音频处理方法,方法包括:In one aspect, an audio processing method is provided, the method comprising:
在用户演唱歌曲过程中,采集所述用户的人声音频数据;In the process of the user singing a song, collecting the user's vocal audio data;
判断所述人声音频数据在所述歌曲中对应的时间段是否位于预设时间段内;Judging whether the time period corresponding to the vocal audio data in the song is within a preset time period;
若所述人声音频数据在所述歌曲中对应的时间段位于预设时间段内,则判断所述人声音频数据的频率是否达到原唱的频率;If the time period corresponding to the vocal audio data in the song is within a preset time period, then determine whether the frequency of the vocal audio data reaches the frequency of the original singing;
若所述人声音频数据的频率未达到原唱的频率,则将所述采集的人声音频数据的频率调整至所述原唱的频率,输出频率调整后的人声音频数据;If the frequency of the vocal audio data does not reach the frequency of the original singing, then adjusting the frequency of the collected vocal audio data to the frequency of the original singing, and outputting the frequency-adjusted vocal audio data;
其中,所述预设时间段为所述歌曲的预设音频片段对应的时间段,所述预设音频片段为所述歌曲原唱的频率在预设人声频率范围内的音频片段,所述预设人声频率范围包括预设的高音人声频率范围和预设的低音人声频率范围。Wherein, the preset time period is a time period corresponding to a preset audio clip of the song, and the preset audio clip is an audio clip whose frequency of the original singing of the song is within the preset vocal frequency range, and the preset audio clip The preset vocal frequency range includes a preset treble vocal frequency range and a preset bass vocal frequency range.
另一方面,本发明实施例还提供了一种移动终端,包括:On the other hand, an embodiment of the present invention also provides a mobile terminal, including:
声音采集模块,用于在用户演唱歌曲过程中,采集所述用户的人声音频数据;a sound collection module, used for collecting the user's vocal audio data during the user's singing of songs;
音频位置确定模块,用于判断所述人声音频数据在所述歌曲中对应的时间段是否位于预设时间段内;An audio position determination module for judging whether the time period corresponding to the vocal audio data in the song is within a preset time period;
评估模块,用于若所述人声音频数据在所述歌曲中对应的时间段位于预设时间段内,则判断所述人声音频数据的频率是否达到原唱的频率;The evaluation module is used to judge whether the frequency of the vocal audio data reaches the frequency of the original singing if the time period corresponding to the vocal audio data in the song is within a preset time period;
音频调整模块,用于若所述人声音频数据的频率未达到原唱的频率,则将所述采集的人声音频数据的频率调整至所述原唱的频率;an audio adjustment module, for adjusting the frequency of the collected vocal audio data to the frequency of the original singing if the frequency of the vocal audio data does not reach the frequency of the original singing;
输出模块,用于输出频率调整后的人声音频数据;The output module is used to output the frequency-adjusted vocal audio data;
其中,所述预设时间段为所述歌曲的预设音频片段对应的时间段,所述预设音频片段为所述歌曲原唱的频率在预设人声频率范围内的音频片段,所述预设人声频率范围包括预设的高音人声频率范围和预设的低音人声频率范围。Wherein, the preset time period is a time period corresponding to a preset audio clip of the song, and the preset audio clip is an audio clip whose frequency of the original singing of the song is within the preset vocal frequency range, and the preset audio clip The preset vocal frequency range includes a preset treble vocal frequency range and a preset bass vocal frequency range.
综上,本发明实施例通过在用户演唱歌曲过程中,采集用户的人声音频数据,并判断该人声音频数据在歌曲中对应的时间段是否位于预设时间段内。若该人声音频数据在歌曲中对应的时间段位于预设时间段内,则判断该人声音频数据的频率是否达到原唱的频率,若该人声音频数据的频率未达到原唱的频率,则将采集的人声音频数据的频率调整至原唱的频率,再输出频率调整后的人声音频数据。从而对用户歌声的频率进行有效调节,避免用户声音的频率与原唱声音频率差值过大影响演唱效果,进而使用户在不具备专业演唱能力的情况下,仍能够体现较好的演唱水平,优化了演唱者的演唱效果。To sum up, the embodiment of the present invention collects the user's vocal audio data during the user's singing of a song, and determines whether the time period corresponding to the vocal audio data in the song is within a preset time period. If the time period corresponding to the vocal audio data in the song is within the preset time period, it is determined whether the frequency of the vocal audio data reaches the frequency of the original singing, and if the frequency of the vocal audio data does not reach the frequency of the original singing , the frequency of the collected vocal audio data is adjusted to the frequency of the original singing, and then the frequency-adjusted vocal audio data is output. In this way, the frequency of the user's singing voice can be effectively adjusted to avoid the excessive difference between the frequency of the user's voice and the original singing voice, which affects the singing effect, so that the user can still reflect a better singing level even if he does not have professional singing ability. Optimized the singer's singing effect.
附图说明Description of drawings
为了更清楚地说明本发明实施例的技术方案,下面将对本发明实施例的描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。In order to illustrate the technical solutions of the embodiments of the present invention more clearly, the following briefly introduces the drawings that are used in the description of the embodiments of the present invention. Obviously, the drawings in the following description are only some embodiments of the present invention. , for those of ordinary skill in the art, other drawings can also be obtained from these drawings without creative labor.
图1是本发明实施例的一种音频处理方法的流程图;1 is a flowchart of an audio processing method according to an embodiment of the present invention;
图2是本发明实施例的另一种音频处理方法的流程图;2 is a flowchart of another audio processing method according to an embodiment of the present invention;
图3是本发明实施例的移动终端的框图之一;3 is one of the block diagrams of a mobile terminal according to an embodiment of the present invention;
图4是本发明实施例的移动终端的框图之二;4 is the second block diagram of a mobile terminal according to an embodiment of the present invention;
图5是本发明实施例的移动终端的框图之三;5 is a third block diagram of a mobile terminal according to an embodiment of the present invention;
图6是本发明实施例的移动终端的框图之四。FIG. 6 is a fourth block diagram of a mobile terminal according to an embodiment of the present invention.
具体实施方式Detailed ways
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。The technical solutions in the embodiments of the present invention will be clearly and completely described below with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are part of the embodiments of the present invention, but not all of the embodiments. Based on the embodiments of the present invention, all other embodiments obtained by those of ordinary skill in the art without creative efforts shall fall within the protection scope of the present invention.
参照图1,示出了本发明实施例中一种音频处理方法的流程图,本实施例所提供的方法可以由移动终端执行,音频处理方法包括:Referring to FIG. 1, a flowchart of an audio processing method in an embodiment of the present invention is shown. The method provided in this embodiment can be executed by a mobile terminal, and the audio processing method includes:
步骤101,在用户演唱歌曲过程中,采集用户的人声音频数据。
其中,该采集的人声音频数据可以为设定时间长度的一个或一个以上的音频帧。为保证该段时间内人声音频数据的频率不存在明显波动,可以根据人声音频的变化规律,确定该设定时间长度。The collected human voice audio data may be one or more audio frames of a set time length. In order to ensure that the frequency of the human voice audio data does not fluctuate significantly during the period, the set time length may be determined according to the change rule of the human voice audio.
在实际应用中,采集的人声音频数据可以为用户输入的任一设定时间长度的音频。其中,设定时间长度可由本领域技术人员根据经验设置,例如,可设置为5毫秒。In practical applications, the collected human voice audio data may be audio of any set time length input by the user. Wherein, the set time length can be set by those skilled in the art according to experience, for example, it can be set as 5 milliseconds.
在采集到人声音频数据后,可以通过对人声音频数据的分析,获取该段人声音频数据的频率值,以便与音频源文件进行比较。After the vocal audio data is collected, the frequency value of the segment of vocal audio data can be obtained by analyzing the vocal audio data, so as to be compared with the audio source file.
步骤102,判断人声音频数据在歌曲中对应的时间段是否位于预设时间段内。
人声是指通过声带的振动而发出的声音。在一定时间内,声带振动的次数越多则声调越高,即人声频率越高。通常将频率处于高音人声频率范围的人声称为高音,将频率处于低音人声频率范围的人声称为低音。从发音难度而言,通常难于发出高音和低音。因此,可以针对这一特点,判断人声音频数据在歌曲中对应的时间段是否位于预设时间段内。若该人声音频数据在歌曲中对应的时间段位于预设时间段内,则执行步骤103,判断人声音频数据的频率是否达到原唱的频率。若该人声音频数据在歌曲中对应的时间段并不位于预设时间段内,则可以无需对采集的人声音频数据进行干预,直接输出即可,从而保留并体现用户真实的演唱风格。The human voice is the sound produced by the vibration of the vocal cords. In a certain period of time, the more times the vocal cords vibrate, the higher the tone, that is, the higher the frequency of the human voice. People whose frequencies are in the frequency range of high-pitched vocals are generally referred to as treble, and those whose frequencies are in the frequency range of low-pitched vocals are referred to as bass. In terms of pronunciation difficulty, it is usually difficult to produce high and low notes. Therefore, according to this feature, it can be determined whether the time period corresponding to the vocal audio data in the song is within the preset time period. If the time period corresponding to the vocal audio data in the song is within the preset time period,
其中,该预设时间段为歌曲的预设音频片段对应的时间段,该预设音频片段为歌曲原唱的频率在预设人声频率范围内的音频片段,该预设人声频率范围包括预设的高音人声频率范围和预设的低音人声频率范围。Wherein, the preset time period is the time period corresponding to the preset audio clip of the song, and the preset audio clip is the audio clip whose frequency of the original singing of the song is within the preset vocal frequency range, and the preset vocal frequency range includes Preset treble vocal frequency range and preset bass vocal frequency range.
例如,当人声音频数据在歌曲中对应的时间段位于歌曲的高音片段范围内时,即用户演唱到了歌曲的高音部分时,很容易因为用户高音唱不上去,导致降低用户的演唱效果。本发明实施例可以在该时段对采集的人声音频数据进行调整,以避免用户演唱时因声音频率较低影响演唱效果。For example, when the time period corresponding to the vocal audio data in the song is within the range of the high-pitched segment of the song, that is, when the user sings to the high-pitched part of the song, the user's singing effect is easily reduced because the user cannot sing the high-pitched voice. In the embodiment of the present invention, the collected vocal audio data can be adjusted in this period, so as to avoid the singing effect being affected by the low frequency of the voice when the user sings.
步骤103,判断人声音频数据的频率是否达到原唱的频率。Step 103: Determine whether the frequency of the vocal audio data reaches the frequency of the original singing.
当人声音频数据在歌曲中对应的时间段位于预设时间段内时,由于用户通常难于以原唱的频率演唱该段歌曲,因此,可以在该时段判断人声音频数据的频率是否达到原唱的频率。When the time period corresponding to the vocal audio data in the song is within the preset time period, since it is usually difficult for the user to sing the song at the original singing frequency, it can be determined whether the frequency of the vocal audio data reaches the original singing frequency in this period. frequency of singing.
具体的,可以计算人声音频数据的频率与原唱的频率之间的频率差值,并判断该频率差值是否小于阈值频率,若该频率差值小于阈值频率,则确定该人声音频数据的频率达到原唱的频率。即确定用户演唱的频率与原唱相近似,能够达到较好的演唱效果,该情况下可以不对采集的人声音频数据进行调整。直接执行步骤105,输出采集的人声音频数据。Specifically, the frequency difference between the frequency of the vocal audio data and the frequency of the original song can be calculated, and it is determined whether the frequency difference is less than the threshold frequency, and if the frequency difference is less than the threshold frequency, the vocal audio data is determined. The frequency reaches the frequency of the original singing. That is, it is determined that the frequency of the user's singing is similar to the original singing, and a better singing effect can be achieved. In this case, the collected vocal audio data may not be adjusted. Step 105 is directly executed to output the collected human voice audio data.
反之,若人声音频数据的频率未达到原唱的频率,则可以执行步骤104,将采集的人声音频数据的频率调整至原唱的频率,输出频率调整后的人声音频数据。以保障用户的演唱效果。Conversely, if the frequency of the vocal audio data does not reach the frequency of the original singing,
步骤104,将采集的人声音频数据的频率调整至原唱的频率,输出频率调整后的人声音频数据。
当采集的人声音频数据的频率未达到原唱时,可以通过对采集的人声音频数据的频率进行调整,以达到原唱的频率。When the frequency of the collected vocal audio data does not reach the original singing, the frequency of the collected vocal audio data can be adjusted to achieve the frequency of the original singing.
具体的,在对采集的人声音频数据的频率进行调整时,若原唱的频率处于高音人声频率范围,可以对发音较低的人声音频数据提高频率。若原唱的频率处于低音人声频率范围,可以对发音较高的人声音频数据降低频率。从而将采集的人声音频数据的频率调整至原唱的频率,使采集的人声音频数据通过移动终端播放出来的效果更加接近原唱的演唱效果。例如,可以使用频域均衡器对采集的人声音频数据的频率进行频域增强。其中,频域均衡器一种均衡补偿设备,用于完成对数据传输信道中的频率特性失真进行均衡补偿,从而起到调整采集的人声音频数据的频率的作用。对于多个音轨的音频数据,需要对每个音轨进行单独调节。Specifically, when the frequency of the collected vocal audio data is adjusted, if the frequency of the original singing is in the high-pitched vocal frequency range, the frequency of the vocal audio data with lower pronunciation can be increased. If the frequency of the original singing is in the frequency range of the low-pitched vocal, the frequency of the vocal audio data with higher pronunciation can be reduced. Therefore, the frequency of the collected vocal audio data is adjusted to the frequency of the original singing, so that the effect played by the collected vocal audio data through the mobile terminal is closer to the singing effect of the original singing. For example, a frequency domain equalizer can be used to perform frequency domain enhancement on the frequencies of the captured vocal audio data. Among them, the frequency domain equalizer is an equalization compensation device used for equalizing and compensating the frequency characteristic distortion in the data transmission channel, so as to adjust the frequency of the collected human voice audio data. For audio data of multiple tracks, each track needs to be adjusted individually.
步骤105,输出采集的人声音频数据。
综上所述,本发明实施例中,通过在用户演唱歌曲过程中,采集用户的人声音频数据,并判断该人声音频数据在歌曲中对应的时间段是否位于预设时间段内。若该人声音频数据在歌曲中对应的时间段位于预设时间段内,则判断该人声音频数据的频率是否达到原唱的频率,若该人声音频数据的频率未达到原唱的频率,则将采集的人声音频数据的频率调整至原唱的频率,再输出频率调整后的人声音频数据。从而对用户歌声的频率进行有效调节,避免用户声音的频率与原唱声音频率差值过大影响演唱效果,进而使用户在不具备专业演唱能力的情况下,仍能够体现较好的演唱水平,优化了演唱者的演唱效果。To sum up, in this embodiment of the present invention, the user's vocal audio data is collected during the user's singing of a song, and it is determined whether the time period corresponding to the vocal audio data in the song is within a preset time period. If the time period corresponding to the vocal audio data in the song is within the preset time period, it is determined whether the frequency of the vocal audio data reaches the frequency of the original singing, and if the frequency of the vocal audio data does not reach the frequency of the original singing , the frequency of the collected vocal audio data is adjusted to the frequency of the original singing, and then the frequency-adjusted vocal audio data is output. In this way, the frequency of the user's singing voice can be effectively adjusted to avoid the excessive difference between the frequency of the user's voice and the original singing voice, which affects the singing effect, so that the user can still reflect a better singing level even if he does not have professional singing ability. Optimized the singer's singing effect.
参照图2,示出了本发明实施例的另一种音频处理方法的流程图。本实施例所提供的方法可以由移动终端执行,控制音频处理方法包括:Referring to FIG. 2 , a flowchart of another audio processing method according to an embodiment of the present invention is shown. The method provided in this embodiment can be executed by a mobile terminal, and the method for controlling audio processing includes:
步骤201,确定歌曲的音频源文件中的预设音频片段。Step 201: Determine a preset audio segment in the audio source file of the song.
为了确定采集的人声音频数据是否位于预设时间段内,可以先根据预设人声频率范围和音频源文件的数据对应关系,确定歌曲的音频源文件中频率在预设人声频率范围内的目标时间段;再将该目标时间段内的音频片段确定为预设音频片段。从而为判断人声音频数据在歌曲中对应的时间段是否位于预设时间段内提供依据。其中,音频源文件的数据对应关系可以为频谱图。In order to determine whether the collected vocal audio data is within the preset time period, it can be determined that the frequency in the audio source file of the song is within the preset vocal frequency range according to the corresponding relationship between the preset vocal frequency range and the audio source file. target time period; and then determine the audio segment within the target time segment as the preset audio segment. Thus, a basis is provided for judging whether the time period corresponding to the vocal audio data in the song is within the preset time period. The data corresponding relationship of the audio source file may be a spectrogram.
具体的,由于不同性别的人发音特点不同,对应的预设人声频率范围也不同,因此可以先确定音频源文件中每个时间段的音频数据对应的原唱的性别,再根据各段音频数据对应的原唱的性别和不同性别对应的预设人声频率范围,分别确定各段音频数据中频率在预设人声频率范围内的目标时间段。从而能够针对不同性别做出更加准确的判断。Specifically, due to the different pronunciation characteristics of people of different genders, the corresponding preset vocal frequency ranges are also different. Therefore, it is possible to first determine the gender of the original singer corresponding to the audio data of each time period in the audio source file, and then according to each segment of audio The gender of the original singer corresponding to the data and the preset vocal frequency range corresponding to different genders are used to determine the target time period in which the frequency in each piece of audio data is within the preset vocal frequency range. Thus, more accurate judgments can be made for different genders.
例如,若男性演唱者的预设人声频率范围为164~698Hz,女性演唱者的预设人声频率范围为220~1.1KHz。则对于原唱为男性演唱者的歌曲,音频源文件的数据对应关系中频率幅值在164~698Hz范围内的音频片段即为预设音频片段。同样,对于原唱为女性演唱者的歌曲,音频源文件的数据对应关系中频率幅值在220~1.1KHz范围内的音频片段即为预设音频片段。当音频源文件为男女合唱的歌曲时,可以针对每段音频片段标注的性别,根据对应的预设人声频率范围,分别确定各段音频的预设音频片段。For example, if the preset vocal frequency range of a male singer is 164-698 Hz, and the preset vocal frequency range of a female singer is 220-1.1 KHz. Then, for a song originally sung by a male singer, the audio segment whose frequency amplitude is in the range of 164-698 Hz in the data correspondence of the audio source file is the preset audio segment. Similarly, for a song originally sung by a female singer, an audio segment with a frequency amplitude in the range of 220-1.1 KHz in the data correspondence of the audio source file is a preset audio segment. When the audio source file is a male and female chorus song, the preset audio segment of each audio segment may be determined according to the corresponding preset vocal frequency range according to the gender marked in each audio segment.
在实际应用中,为了提升分析判断的效率,可以预先根据音频源文件,制成预设音频片段划分数据,并存储在云端服务器中或移动终端本地。从而在确定歌曲的音频源文件中的预设音频片段这一步骤之前,可以从云端服务器中获取预设音频片段划分数据,或从移动终端本地获取预设音频片段划分数据。其中,该预设音频片段划分数据用于表征音频源文件中预设音频片段所在时间段。因此,在执行步骤203时,只需将人声音频数据在歌曲中对应的时间段与设音频片段划分数据直接对比即可,从而节省运算能力,避免大量频繁运算影响系统响应速度。In practical applications, in order to improve the efficiency of analysis and judgment, preset audio segment division data may be prepared in advance according to the audio source file, and stored in the cloud server or locally on the mobile terminal. Therefore, before the step of determining the preset audio segment in the audio source file of the song, the preset audio segment division data can be obtained from the cloud server, or the preset audio segment division data can be obtained locally from the mobile terminal. Wherein, the preset audio segment division data is used to represent the time period in which the preset audio segment in the audio source file is located. Therefore, when performing
步骤202,在用户演唱歌曲过程中,采集用户的人声音频数据。
在实际应用中,可以利用如麦克风等声音采集设备,实时采集用户演唱歌曲时的音频信号,再对该音频信号进行处理,从而获得对应的人声音频数据。In practical applications, a sound collection device such as a microphone can be used to collect the audio signal when the user sings a song in real time, and then process the audio signal to obtain corresponding vocal audio data.
步骤203,判断人声音频数据在歌曲中对应的时间段是否位于预设时间段内。
为了判断人声音频数据在歌曲中对应的时间段是否位于预设时间段内,可以根据预设人声频率范围和音频源文件的数据对应关系,确定歌曲的音频源文件中频率在预设人声频率范围内的目标时间段,再将目标时间段内的音频片段确定为预设音频片段。也可以从云端服务器或移动终端本地直接获取预先确定的预设音频片段划分数据,即只获取音频源文件中各预设音频片段所在时间段,并通过各预设音频片段所在时间段,判断人声音频数据在歌曲中对应的时间段是否位于预设时间段内。具体的,在利用音频源文件的数据对应关系对音频源文件的频谱进行分析时,为防止受到伴奏声音的干扰,对频谱的分析可以只对音频源文件的人声音轨进行鉴别。In order to determine whether the time period corresponding to the vocal audio data in the song is within the preset time period, it can be determined that the frequency in the audio source file of the song is within the preset vocal frequency range according to the corresponding relationship between the preset vocal frequency range and the audio source file. A target time period within the sound frequency range is determined, and then the audio segment within the target time period is determined as the preset audio segment. The pre-determined preset audio segment division data can also be obtained directly from the cloud server or the mobile terminal locally, that is, only the time period of each preset audio segment in the audio source file is obtained, and the person is judged based on the time period of each preset audio segment. Whether the time period corresponding to the audio data in the song is within the preset time period. Specifically, when analyzing the frequency spectrum of the audio source file by using the data corresponding relationship of the audio source file, in order to prevent interference by the accompaniment sound, the analysis of the frequency spectrum may only identify the vocal track of the audio source file.
若该人声音频数据在歌曲中对应的时间段位于预设时间段内,则执行步骤204,判断人声音频数据的频率是否达到原唱的频率。若该人声音频数据在歌曲中对应的时间段并不位于预设时间段内,则可以无需对采集的人声音频数据进行干预,直接输出即可,从而保留并体现用户真实的演唱风格。If the time period corresponding to the vocal audio data in the song is within the preset time period,
步骤204,判断人声音频数据的频率是否达到原唱的频率。
为了准确判断人声音频数据的频率是否达到原唱的频率,可以计算人声音频数据的频率与原唱的频率之间的频率差值,并判断该频率差值是否小于阈值频率,若该频率差值小于阈值频率,则确定该人声音频数据的频率达到原唱的频率。在该情况下,直接执行步骤206,输出采集的人声音频数据即可。否则执行步骤205,将采集的人声音频数据的频率调整至原唱的频率,输出频率调整后的人声音频数据。In order to accurately judge whether the frequency of the vocal audio data reaches the frequency of the original singing, the frequency difference between the frequency of the vocal audio data and the frequency of the original singing can be calculated, and whether the frequency difference is less than the threshold frequency, if the frequency If the difference is smaller than the threshold frequency, it is determined that the frequency of the vocal audio data reaches the frequency of the original singing. In this case,
具体的,由于不同用户对频率准确度的要求不同,可以由用户设定该阈值频率。也可以由本领域技术人员根据经验进行设置。例如,若用户需要确保表现出较好的演唱效果,可以将该阈值频率设置得较小,从而使得用户在该时间段的演唱效果更为接近原唱的演唱效果。如果用户在演唱时更希望凸显个人的演唱效果,可以将该阈值频率设置得较大,从而在用户演唱时采集的人声音频数据的频率明显低于原唱的频率时才进行调整。Specifically, since different users have different requirements on frequency accuracy, the threshold frequency can be set by the user. It can also be set empirically by those skilled in the art. For example, if the user needs to ensure a better singing effect, the threshold frequency can be set smaller, so that the user's singing effect in this time period is closer to the original singing effect. If the user prefers to highlight the personal singing effect when singing, the threshold frequency can be set higher, so that the frequency of the vocal audio data collected when the user is singing is significantly lower than the frequency of the original singing.
步骤205,将采集的人声音频数据的频率调整至原唱的频率,输出频率调整后的人声音频数据。Step 205: Adjust the frequency of the collected vocal audio data to the frequency of the original singing, and output the frequency-adjusted vocal audio data.
在将采集的人声音频数据的频率调整至原唱的频率时,可以根据预设音频片段的长度,确定平缓调节时长。并在该平缓调节时长内,先将采集的人声音频数据的频率平缓地调整至原唱的频率,再在将采集的人声音频数据的频率平缓地调整至原唱的频率后,持续对采集的人声音频数据的频率进行增强,直至预设音频片段结束或采集的人声音频数据中断。从而使得频率调整的过程较为平缓,避免频率调整后输出的声音过于突兀影响演唱效果。When the frequency of the collected vocal audio data is adjusted to the frequency of the original singing, the duration of the gentle adjustment may be determined according to the length of the preset audio segment. And within the gentle adjustment period, firstly adjust the frequency of the collected vocal audio data to the frequency of the original singing, and then adjust the frequency of the collected vocal audio data to the frequency of the original singing, and continue to adjust the frequency of the original singing. The frequency of the collected vocal audio data is enhanced until the preset audio segment ends or the collected vocal audio data is interrupted. Thereby, the process of frequency adjustment is relatively smooth, and the output sound after frequency adjustment is prevented from being too abrupt and affecting the singing effect.
具体的,在根据预设音频片段的长度确定平缓调节时长过程中,当预设音频片段的长度超过阈值时间长度时,将阈值时间长度确定为平缓调节时长;当预设音频片段的长度未超过阈值时间长度时,将预设音频片段的长度确定为平缓调节时长。即在预设音频片段时间较长时,可以用充足的时间平缓地将采集的人声音频数据的频率调整至原唱的频率;在预设音频片段时间较短时,没有充足的时间进行调整,可以将整个预设音频片段时间作为平缓过渡的平缓调节时长。从而为频率调整最大化地提供充足的时间。Specifically, in the process of determining the duration of the smooth adjustment according to the length of the preset audio clip, when the length of the preset audio clip exceeds the threshold time length, the threshold time length is determined as the duration of the smooth adjustment; when the length of the preset audio clip does not exceed the threshold duration When the threshold time length is set, the length of the preset audio clip is determined as the smooth adjustment time length. That is, when the preset audio clip is long, you can use sufficient time to smoothly adjust the frequency of the collected vocal audio data to the frequency of the original singing; when the preset audio clip is short, there is not enough time to adjust. , you can use the entire preset audio clip time as the smooth adjustment duration of the smooth transition. Thereby sufficient time is provided for maximum frequency adjustment.
在对频率进行调整的过程中,可以在该平缓调节时长内,以调节幅度δ=(f2-f1)*t/T对采集的人声音频数据的频率进行调节,得到调节后的频率f=f1+δ,直至t=T。其中,t为平缓调节时长内当前时刻距所述预设音频片段开始时刻的时间长度,T为所述平缓调节时长,f1为所述采集的人声音频数据的频率,f2为所述原唱的频率。从而保证在各种情况下,都能使采集的人声音频数据的频率能够平缓地调整至原唱的频率。In the process of adjusting the frequency, the frequency of the collected vocal audio data can be adjusted with the adjustment amplitude δ=(f2-f1)*t/T within the gentle adjustment period, and the adjusted frequency f= f1+δ until t=T. Wherein, t is the time length from the current moment to the start time of the preset audio segment within the smooth adjustment duration, T is the smooth adjustment duration, f1 is the frequency of the collected vocal audio data, and f2 is the original song Frequency of. Therefore, it is ensured that the frequency of the collected vocal audio data can be smoothly adjusted to the frequency of the original singing under various circumstances.
此外,由于部分用户在演唱至某一音频片段结束时,并不会按照音频源文件中结束的时间及时停止演唱,而是会继续延长一段时间。例如“青藏高原”这首歌的“原”字原唱假设会持续4秒,某些用户持续可能会5秒,此时,如果按照原唱结束的时间停止对采集的人声音频数据的调整,那么当原唱唱到第5秒的时候就会由于频率增强关闭造成人声音频的频率突然下降,给用户不好的体验。因此,为了防止在该情况下音频调整突然中断,可以在预设音频片段结束时,检测采集的人声音频数据是否中断。若检测到采集的人声音频数据未中断,则持续对采集的人声音频数据的频率进行调节,以稳定至原唱的频率,或平缓地降低对采集的人声音频数据的频率调节的幅度。In addition, when some users sing to the end of an audio segment, they will not stop singing in time according to the ending time in the audio source file, but will continue to extend for a period of time. For example, the original singing of the word "Original" of the song "Qinghai-Tibet Plateau" is assumed to last for 4 seconds, and some users may last for 5 seconds. At this time, if the adjustment of the collected vocal audio data is stopped according to the time when the original singing ends , then when the original singer sings for the 5th second, the frequency of the vocal audio will suddenly drop due to the frequency enhancement and shutdown, which will give the user a bad experience. Therefore, in order to prevent the audio adjustment from being interrupted suddenly in this case, it may be detected whether the collected human voice audio data is interrupted when the preset audio segment ends. If it is detected that the collected vocal audio data is not interrupted, the frequency of the collected vocal audio data is continuously adjusted to stabilize to the frequency of the original singing, or the amplitude of the frequency adjustment to the collected vocal audio data is gradually reduced. .
步骤206,输出采集的人声音频数据。
综上所述,本发明实施例中,通过根据各段音频数据对应的原唱的性别和不同性别对应的预设人声频率范围,分别确定各段音频数据中频率在预设人声频率范围内的目标时间段。从而能够针对不同性别做出更加准确的判断。而且通过从云端服务器或移动终端本地中获取预先确定的预设音频片段划分数据,使得计算速度更快,对采集的人声音频数据的频率的增强更加及时有效。另外,对音频的逐步增强,以及对段落结束部分的持续增强也使得变化更为平缓,避免变化效果过于突兀。从而大幅提升用户的使用体验。To sum up, in this embodiment of the present invention, according to the gender of the original singer corresponding to each segment of audio data and the preset vocal frequency range corresponding to different genders, it is determined that the frequency in each segment of audio data is within the preset vocal frequency range. target time period within . Thus, more accurate judgments can be made for different genders. Moreover, by acquiring the predetermined preset audio segment division data locally from the cloud server or the mobile terminal, the calculation speed is faster, and the frequency enhancement of the collected vocal audio data is more timely and effective. In addition, the gradual enhancement of the audio and the continuous enhancement of the end of the paragraph also make the changes more gradual and avoid too abrupt changes. This greatly improves the user experience.
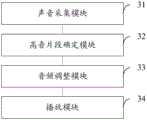
参照图3,示出了本发明实施例中一种移动终端的框图。移动终端包括:声音采集模块31、音频位置确定模块32、评估模块33、音频调整模块34和输出模块35。Referring to FIG. 3, a block diagram of a mobile terminal in an embodiment of the present invention is shown. The mobile terminal includes: a
其中,声音采集模块31,用于在用户演唱歌曲过程中,采集用户的人声音频数据;Among them, the
音频位置确定模块32,用于判断人声音频数据在歌曲中对应的时间段是否位于预设时间段内;The audio
评估模块33,用于若人声音频数据在歌曲中对应的时间段位于预设时间段内,则判断人声音频数据的频率是否达到原唱的频率;The
音频调整模块34,用于若人声音频数据的频率未达到原唱的频率,则将采集的人声音频数据的频率调整至原唱的频率;The audio
输出模块35,用于输出频率调整后的人声音频数据。The
其中,预设时间段为歌曲的预设音频片段对应的时间段,预设音频片段为歌曲原唱的频率在预设人声频率范围内的音频片段,预设人声频率范围包括预设的高音人声频率范围和预设的低音人声频率范围。Among them, the preset time period is the time period corresponding to the preset audio clip of the song, the preset audio clip is the audio clip whose frequency of the original singing of the song is within the preset vocal frequency range, and the preset vocal frequency range includes the preset vocal frequency range. Treble vocal frequency range and preset bass vocal frequency range.
综上,本发明实施例中,通过声音采集模块31在用户演唱歌曲过程中,采集用户的人声音频数据,并由音频位置确定模块32判断该人声音频数据在歌曲中对应的时间段是否位于预设时间段内。若该人声音频数据在歌曲中对应的时间段位于预设时间段内,则由评估模块33判断该人声音频数据的频率是否达到原唱的频率,若该人声音频数据的频率未达到原唱的频率,则由音频调整模块34将采集的人声音频数据的频率调整至原唱的频率,再由输出模块35输出频率调整后的人声音频数据。从而对用户歌声的频率进行有效调节,避免用户声音的频率与原唱声音频率差值过大影响演唱效果,进而使用户在不具备专业演唱能力的情况下,仍能够体现较好的演唱水平。To sum up, in the embodiment of the present invention, the user's voice audio data is collected by the
参照图4,在本发明的一个优选的实施例中,在图3的基础上,移动终端还包括:预设音频片段确定模块36和获取模块37。Referring to FIG. 4 , in a preferred embodiment of the present invention, on the basis of FIG. 3 , the mobile terminal further includes: a preset audio
其中,预设音频片段确定模块36,用于确定歌曲的音频源文件中的预设音频片段。Wherein, the preset audio
获取模块37,用于从云端服务器中获取预设音频片段划分数据;或从移动终端本地获取预设音频片段划分数据;其中,预设音频片段划分数据用于表征音频源文件中预设音频片段所在时间段。The obtaining
具体的,预设音频片段确定模块36,又包括:Specifically, the preset audio
时间段确定子模块361,用于根据预设人声频率范围和音频源文件的数据对应关系,确定歌曲的音频源文件中频率在预设人声频率范围内的目标时间段;The time period determination sub-module 361 is used to determine the target time period in which the frequency in the audio source file of the song is within the preset vocal frequency range according to the data correspondence between the preset vocal frequency range and the audio source file;
预设音频片段确定子模块362,用于将目标时间段内的音频片段确定为预设音频片段。The preset audio
其中,时间段确定子模块361,包括:Wherein, the time period determination sub-module 361 includes:
性别确定单元3611,用于确定音频源文件中每个时间段的音频数据对应的原唱的性别;
时间段确定单元3612,用于根据各段音频数据对应的原唱的性别和不同性别对应的预设人声频率范围,分别确定各段音频数据中频率在预设人声频率范围内的目标时间段。The time
此外,音频调整模块34,包括:In addition, the
平缓调节时长确定子模块341,用于根据预设音频片段的长度,确定平缓调节时长;The smooth adjustment
调整子模块342,用于在平缓调节时长内,逐步将采集的人声音频数据的频率调整至原唱的频率;并在将采集的人声音频数据的频率平缓地调整至原唱的频率后,持续对采集的人声音频数据的频率进行增强,直至预设音频片段结束或采集的人声音频数据中断。The
其中,平缓调节时长确定子模块341,具体用于当预设音频片段的长度超过阈值时间长度时,将阈值时间长度确定为平缓调节时长;当预设音频片段的长度未超过阈值时间长度时,将预设音频片段的长度确定为平缓调节时长。The sub-module 341 for determining the duration of the smooth adjustment is specifically configured to determine the threshold duration as the duration of the smooth adjustment when the length of the preset audio clip exceeds the threshold duration; when the length of the preset audio clip does not exceed the threshold duration, Determines the length of the preset audio clip as a smooth adjustment duration.
调整子模块342,具体用于在平缓调节时长内,以调节幅度δ=(f2-f1)*t/T对采集的人声音频数据的频率进行调节,得到调节后的频率f=f1+δ,直至t=T;其中,t为平缓调节时长内当前时刻距预设音频片段开始时刻的时间长度,T为平缓调节时长,f1为采集的人声音频数据的频率,f2为原唱的频率。The
而且,调整子模块342,还用于检测采集的人声音频数据是否中断;若检测到采集的人声音频数据未中断,则持续对采集的人声音频数据的频率进行调节,以稳定至原唱的频率,或平缓地降低对采集的人声音频数据的频率调节的幅度。Moreover, the
具体的,评估模块33,包括:Specifically, the
频率差值计算子模块331,用于计算人声音频数据的频率与原唱的频率之间的频率差值;The frequency
频率差值评估子模块332,用于判断频率差值是否小于阈值频率;若频率差值小于阈值频率,则确定人声音频数据的频率达到原唱的频率。The frequency
综上,本发明实施例中,通过音频片段确定模块36根据各段音频数据对应的原唱的性别和不同性别对应的预设人声频率范围,分别确定各段音频数据中频率在预设人声频率范围内的目标时间段。从而能够针对不同性别做出更加准确的判断。而且通过获取模块37从云端服务器或移动终端本地中获取预先确定的预设音频片段划分数据,使得计算速度更快,对采集的人声音频数据的频率的增强更加及时有效。另外,通过音频调整模块34对音频的逐步增强,以及对段落结束部分的持续增强也使得变化更为平缓,避免变化效果过于突兀。To sum up, in this embodiment of the present invention, the audio
图5是本发明实施例的又一种移动终端的框图。图5所示的移动终端500包括:至少一个处理器501、存储器502、至少一个网络接口504和其他用户接口503。移动终端500中的各个组件通过总线系统505耦合在一起。可理解,总线系统505用于实现这些组件之间的连接通信。总线系统505除包括数据总线之外,还包括电源总线、控制总线和状态信号总线。但是为了清楚说明起见,在图5中将各种总线都标为总线系统505。FIG. 5 is a block diagram of another mobile terminal according to an embodiment of the present invention. The
其中,用户接口503可以包括显示器、键盘或者点击设备(例如,鼠标,轨迹球(trackball)、触感板或者触摸屏等。Among them, the
可以理解,本发明实施例中的存储器502可以是易失性存储器或非易失性存储器,或可包括易失性和非易失性存储器两者。其中,非易失性存储器可以是只读存储器(Read-OnlyMemory,ROM)、可编程只读存储器(ProgrammableROM,PROM)、可擦除可编程只读存储器(ErasablePROM,EPROM)、电可擦除可编程只读存储器(ElectricallyEPROM,EEPROM)或闪存。易失性存储器可以是随机存取存储器(RandomAccessMemory,RAM),其用作外部高速缓存。通过示例性但不是限制性说明,许多形式的RAM可用,例如静态随机存取存储器(StaticRAM,SRAM)、动态随机存取存储器(DynamicRAM,DRAM)、同步动态随机存取存储器(SynchronousDRAM,SDRAM)、双倍数据速率同步动态随机存取存储器(DoubleDataRateSDRAM,DDRSDRAM)、增强型同步动态随机存取存储器(Enhanced SDRAM,ESDRAM)、同步连接动态随机存取存储器(SynchlinkDRAM,SLDRAM)和直接内存总线随机存取存储器(DirectRambusRAM,DRRAM)。本发明实施例描述的系统和方法的存储器502旨在包括但不限于这些和任意其它适合类型的存储器。It can be understood that the
在一些实施方式中,存储器502存储了如下的元素,可执行模块或者数据结构,或者他们的子集,或者他们的扩展集:操作系统5021和应用程序5022。In some embodiments,
其中,操作系统5021,包含各种系统程序,例如框架层、核心库层、驱动层等,用于实现各种基础业务以及处理基于硬件的任务。应用程序5022,包含各种应用程序,例如媒体播放器(MediaPlayer)、浏览器(Browser)等,用于实现各种应用业务。实现本发明实施例方法的程序可以包含在应用程序5022中。The
在本发明实施例中,通过调用存储器502存储的程序或指令,具体的,可以是应用程序5022中存储的程序或指令,处理器501用于在用户演唱歌曲过程中,采集用户的人声音频数据,并判断该人声音频数据在歌曲中对应的时间段是否位于预设时间段内。若该人声音频数据在歌曲中对应的时间段位于预设时间段内,则判断该人声音频数据的频率是否达到原唱的频率,若该人声音频数据的频率未达到原唱的频率,则将采集的人声音频数据的频率调整至原唱的频率,再输出频率调整后的人声音频数据。In this embodiment of the present invention, by calling the program or instruction stored in the
上述本发明实施例揭示的方法可以应用于处理器501中,或者由处理器501实现。处理器501可能是一种集成电路芯片,具有信号的处理能力。在实现过程中,上述方法的各步骤可以通过处理器501中的硬件的集成逻辑电路或者软件形式的指令完成。上述的处理器501可以是通用处理器、数字信号处理器(DigitalSignalProcessor,DSP)、专用集成电路(ApplicationSpecificIntegratedCircuit,ASIC)、现成可编程门阵列(FieldProgrammableGateArray,FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。可以实现或者执行本发明实施例中的公开的各方法、步骤及逻辑框图。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。结合本发明实施例所公开的方法的步骤可以直接体现为硬件译码处理器执行完成,或者用译码处理器中的硬件及软件模块组合执行完成。软件模块可以位于随机存储器,闪存、只读存储器,可编程只读存储器或者电可擦写可编程存储器、寄存器等本领域成熟的存储介质中。该存储介质位于存储器502,处理器501读取存储器502中的信息,结合其硬件完成上述方法的步骤。The methods disclosed in the above embodiments of the present invention may be applied to the
可以理解的是,本发明实施例描述的这些实施例可以用硬件、软件、固件、中间件、微码或其组合来实现。对于硬件实现,处理单元可以实现在一个或多个专用集成电路(ApplicationSpecificIntegratedCircuits,ASIC)、数字信号处理器(DigitalSignalProcessing,DSP)、数字信号处理设备(DSPDevice,DSPD)、可编程逻辑设备(ProgrammableLogicDevice,PLD)、现场可编程门阵列(Field-ProgrammableGateArray,FPGA)、通用处理器、控制器、微控制器、微处理器、用于执行本申请功能的其它电子单元或其组合中。It can be understood that the embodiments described in the embodiments of the present invention may be implemented by hardware, software, firmware, middleware, microcode or a combination thereof. For hardware implementation, the processing unit can be implemented in one or more application specific integrated circuits (Application Specific Integrated Circuits, ASIC), digital signal processors (Digital Signal Processing, DSP), digital signal processing devices (DSP Device, DSPD), Programmable Logic Device (Programmable Logic Device, PLD) ), a Field-Programmable Gate Array (FPGA), a general-purpose processor, a controller, a microcontroller, a microprocessor, other electronic units for performing the functions of the present application, or a combination thereof.
对于软件实现,可通过执行本发明实施例功能的模块(例如过程、函数等)来实现本发明实施例的技术。软件代码可存储在存储器中并通过处理器执行。存储器可以在处理器中或在处理器外部实现。For software implementation, the techniques of the embodiments of the present invention may be implemented through modules (eg, procedures, functions, etc.) that perform the functions of the embodiments of the present invention. Software codes may be stored in memory and executed by a processor. The memory can be implemented in the processor or external to the processor.
可选地,处理器501还用于,确定歌曲的音频源文件中的预设音频片段。Optionally, the
可选地,处理器501还具体用于,根据预设人声频率范围和音频源文件的数据对应关系,确定歌曲的音频源文件中频率在预设人声频率范围内的目标时间段;将目标时间段内的音频片段确定为预设音频片段。Optionally, the
可选地,处理器501还具体用于,确定音频源文件中每个时间段的音频数据对应的原唱的性别;根据各段音频数据对应的原唱的性别和不同性别对应的预设人声频率范围,分别确定各段音频数据中频率在预设人声频率范围内的目标时间段。Optionally, the
可选地,处理器501还用于,从云端服务器中获取预设音频片段划分数据;或从移动终端本地获取预设音频片段划分数据;其中,预设音频片段划分数据用于表征音频源文件中预设音频片段所在时间段。Optionally, the
可选地,处理器501还用于,根据预设音频片段的长度,确定平缓调节时长;在平缓调节时长内,将采集的人声音频数据的频率平缓地调整至原唱的频率;在将采集的人声音频数据的频率平缓地调整至原唱的频率后,持续对采集的人声音频数据的频率进行增强,直至预设音频片段结束或采集的人声音频数据中断。Optionally, the
可选地,处理器501还具体用于,当预设音频片段的长度超过阈值时间长度时,将阈值时间长度确定为平缓调节时长;当预设音频片段的长度未超过阈值时间长度时,将预设音频片段的长度确定为平缓调节时长。Optionally, the
可选地,处理器501还具体用于,在平缓调节时长内,以调节幅度δ=(f2-f1)*t/T对采集的人声音频数据的频率进行调节,得到调节后的频率f=f1+δ,直至t=T;其中,t为平缓调节时长内当前时刻距预设音频片段开始时刻的时间长度,T为平缓调节时长,f1为采集的人声音频数据的频率,f2为原唱的频率。Optionally, the
可选地,处理器501还具体用于,检测采集的人声音频数据是否中断;若检测到采集的人声音频数据未中断,则持续对采集的人声音频数据的频率进行调节,以稳定至原唱的频率,或平缓地降低对采集的人声音频数据的频率调节的幅度。Optionally, the
可选地,处理器501还用于,计算人声音频数据的频率与原唱的频率之间的频率差值;判断频率差值是否小于阈值频率;若频率差值小于阈值频率,则确定人声音频数据的频率达到原唱的频率。Optionally, the
移动终端500能够实现前述实施例中移动终端实现的各个过程,为避免重复,这里不再赘述。The
综上,本发明实施例通过在用户演唱歌曲过程中,采集用户的人声音频数据,并判断该人声音频数据在歌曲中对应的时间段是否位于预设时间段内。若该人声音频数据在歌曲中对应的时间段位于预设时间段内,则判断该人声音频数据的频率是否达到原唱的频率,若该人声音频数据的频率未达到原唱的频率,则将采集的人声音频数据的频率调整至原唱的频率,再输出频率调整后的人声音频数据。从而对用户歌声的频率进行有效调节,避免用户声音的频率与原唱声音频率差值过大影响演唱效果,进而使用户在不具备专业演唱能力的情况下,仍能够体现较好的演唱水平。To sum up, the embodiment of the present invention collects the user's vocal audio data during the user's singing of a song, and determines whether the time period corresponding to the vocal audio data in the song is within a preset time period. If the time period corresponding to the vocal audio data in the song is within the preset time period, it is determined whether the frequency of the vocal audio data reaches the frequency of the original singing, and if the frequency of the vocal audio data does not reach the frequency of the original singing , the frequency of the collected vocal audio data is adjusted to the frequency of the original singing, and then the frequency-adjusted vocal audio data is output. Thereby, the frequency of the user's singing voice is effectively adjusted to avoid the excessive difference between the frequency of the user's voice and the original singing voice from affecting the singing effect, so that the user can still reflect a better singing level even if he does not have the professional singing ability.
图6是本发明实施例的再一种移动终端的框图。具体地,图6中的移动终端可以为手机、平板电脑、个人数字助理(PersonalDigital Assistant,PDA)、或车载电脑等。FIG. 6 is a block diagram of still another mobile terminal according to an embodiment of the present invention. Specifically, the mobile terminal in FIG. 6 may be a mobile phone, a tablet computer, a personal digital assistant (Personal Digital Assistant, PDA), or a vehicle-mounted computer.
图6中的移动终端包括射频(RadioFrequency,RF)电路610、存储器620、输入单元630、显示单元640、处理器660、音频电路670、WiFi(WirelessFidelity)模块680和电源690。The mobile terminal in FIG. 6 includes a radio frequency (RF)
其中,输入单元630可用于接收用户输入的数字或字符信息,以及产生与移动终端的用户设置以及功能控制有关的信号输入。具体地,本发明实施例中,该输入单元630可以包括触控面板631。触控面板631,也称为触摸屏,可收集用户在其上或附近的触摸操作(比如用户使用手指、触笔等任何适合的物体或附件在触控面板631上的操作),并根据预先设定的程式驱动相应的连接装置。可选的,触控面板631可包括触摸检测装置和触摸控制器两个部分。其中,触摸检测装置检测用户的触摸方位,并检测触摸操作带来的信号,将信号传送给触摸控制器;触摸控制器从触摸检测装置上接收触摸信息,并将它转换成触点坐标,再送给该处理器660,并能接收处理器660发来的命令并加以执行。此外,可以采用电阻式、电容式、红外线以及表面声波等多种类型实现触控面板631。除了触控面板631,输入单元630还可以包括其他输入设备632,其他输入设备632可以包括但不限于物理键盘、功能键(比如音量控制按键、开关按键等)、轨迹球、鼠标、操作杆等中的一种或多种。Wherein, the
其中,显示单元640可用于显示由用户输入的信息或提供给用户的信息以及移动终端的各种菜单界面。显示单元640可包括显示面板641,可选的,可以采用LCD或有机发光二极管(OrganicLight-EmittingDiode,OLED)等形式来配置显示面板641。The
应注意,触控面板631可以覆盖显示面板641,形成触摸显示屏,当该触摸显示屏检测到在其上或附近的触摸操作后,传送给处理器660以确定触摸事件的类型,随后处理器660根据触摸事件的类型在触摸显示屏上提供相应的视觉输出。It should be noted that the
触摸显示屏包括应用程序界面显示区及常用控件显示区。该应用程序界面显示区及该常用控件显示区的排列方式并不限定,可以为上下排列、左右排列等可以区分两个显示区的排列方式。该应用程序界面显示区可以用于显示应用程序的界面。每一个界面可以包含至少一个应用程序的图标和/或widget桌面控件等界面元素。该应用程序界面显示区也可以为不包含任何内容的空界面。该常用控件显示区用于显示使用率较高的控件,例如,设置按钮、界面编号、滚动条、电话本图标等应用程序图标等。The touch screen includes the application program interface display area and the commonly used controls display area. The arrangement of the application program interface display area and the common control display area is not limited, and may be an arrangement that can distinguish the two display areas, such as up-down arrangement, left-right arrangement, or the like. The application program interface display area can be used to display the interface of the application program. Each interface may contain at least one application icon and/or interface elements such as widget desktop controls. The application program interface display area can also be an empty interface that does not contain any content. The commonly used control display area is used to display controls with high usage rate, such as setting buttons, interface numbers, scroll bars, phonebook icons and other application icons.
其中处理器660是移动终端的控制中心,利用各种接口和线路连接整个手机的各个部分,通过运行或执行存储在第一存储器621内的软件程序和/或模块,以及调用存储在第二存储器622内的数据,执行移动终端的各种功能和处理数据,从而对移动终端进行整体监控。可选的,处理器660可包括一个或多个处理单元。The
在本发明实施例中,通过调用存储该第一存储器621内的软件程序和/或模块和/或该第二存储器622内的数据,处理器660用于在用户演唱歌曲过程中,采集用户的人声音频数据,并判断该人声音频数据在歌曲中对应的时间段是否位于预设时间段内。若该人声音频数据在歌曲中对应的时间段位于预设时间段内,则判断该人声音频数据的频率是否达到原唱的频率,若该人声音频数据的频率未达到原唱的频率,则将采集的人声音频数据的频率调整至原唱的频率,再输出频率调整后的人声音频数据。In this embodiment of the present invention, by calling and storing software programs and/or modules in the
可选地,处理器660还用于,确定歌曲的音频源文件中的预设音频片段。Optionally, the
可选地,处理器660还具体用于,根据预设人声频率范围和音频源文件的数据对应关系,确定歌曲的音频源文件中频率在预设人声频率范围内的目标时间段;将目标时间段内的音频片段确定为预设音频片段。Optionally, the
可选地,处理器660还具体用于,确定音频源文件中每个时间段的音频数据对应的原唱的性别;根据各段音频数据对应的原唱的性别和不同性别对应的预设人声频率范围,分别确定各段音频数据中频率在预设人声频率范围内的目标时间段。Optionally, the
可选地,处理器660还用于,从云端服务器中获取预设音频片段划分数据;或从移动终端本地获取预设音频片段划分数据;其中,预设音频片段划分数据用于表征音频源文件中预设音频片段所在时间段。Optionally, the
可选地,处理器660还用于,根据预设音频片段的长度,确定平缓调节时长;在平缓调节时长内,将采集的人声音频数据的频率平缓地调整至原唱的频率;在将采集的人声音频数据的频率平缓地调整至原唱的频率后,持续对采集的人声音频数据的频率进行增强,直至预设音频片段结束或采集的人声音频数据中断。Optionally, the
可选地,处理器660还具体用于,当预设音频片段的长度超过阈值时间长度时,将阈值时间长度确定为平缓调节时长;当预设音频片段的长度未超过阈值时间长度时,将预设音频片段的长度确定为平缓调节时长。Optionally, the
可选地,处理器660还具体用于,在平缓调节时长内,以调节幅度δ=(f2-f1)*t/T对采集的人声音频数据的频率进行调节,得到调节后的频率f=f1+δ,直至t=T;其中,t为平缓调节时长内当前时刻距预设音频片段开始时刻的时间长度,T为平缓调节时长,f1为采集的人声音频数据的频率,f2为原唱的频率。Optionally, the
可选地,处理器660还具体用于,检测采集的人声音频数据是否中断;若检测到采集的人声音频数据未中断,则持续对采集的人声音频数据的频率进行调节,以稳定至原唱的频率,或平缓地降低对采集的人声音频数据的频率调节的幅度。Optionally, the
可选地,处理器660还用于,计算人声音频数据的频率与原唱的频率之间的频率差值;判断频率差值是否小于阈值频率;若频率差值小于阈值频率,则确定人声音频数据的频率达到原唱的频率。Optionally, the
移动终端能够实现前述实施例中移动终端实现的各个过程,为避免重复,这里不再赘述。The mobile terminal can implement each process implemented by the mobile terminal in the foregoing embodiments, and in order to avoid repetition, details are not repeated here.
可见,本发明实施例中的移动终端,通过处理器660在用户演唱歌曲过程中,采集用户的人声音频数据,并判断该人声音频数据在歌曲中对应的时间段是否位于预设时间段内。若该人声音频数据在歌曲中对应的时间段位于预设时间段内,则判断该人声音频数据的频率是否达到原唱的频率,若该人声音频数据的频率未达到原唱的频率,则将采集的人声音频数据的频率调整至原唱的频率,再输出频率调整后的人声音频数据。从而对用户歌声的频率进行有效调节,避免用户声音的频率与原唱声音频率差值过大影响演唱效果,进而使用户在不具备专业演唱能力的情况下,仍能够体现较好的演唱水平。It can be seen that the mobile terminal in the embodiment of the present invention collects the user's vocal audio data through the
本领域普通技术人员可以意识到,结合本发明实施例中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、或者计算机软件和电子硬件的结合来实现。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。Those skilled in the art can realize that the units and algorithm steps of each example described in conjunction with the embodiments disclosed in the embodiments of the present invention can be implemented by electronic hardware, or a combination of computer software and electronic hardware. Whether these functions are performed in hardware or software depends on the specific application and design constraints of the technical solution. Skilled artisans may implement the described functionality using different methods for each particular application, but such implementations should not be considered beyond the scope of the present invention.
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统、装置和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。Those skilled in the art can clearly understand that, for the convenience and brevity of description, the specific working process of the above-described systems, devices and units may refer to the corresponding processes in the foregoing method embodiments, which will not be repeated here.
在本申请所提供的实施例中,应该理解到,所揭露的装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。In the embodiments provided in this application, it should be understood that the disclosed apparatus and method may be implemented in other manners. For example, the apparatus embodiments described above are only illustrative. For example, the division of units is only a logical function division. In actual implementation, there may be other division methods, for example, multiple units or components may be combined or integrated. to another system, or some features can be ignored, or not implemented. On the other hand, the shown or discussed mutual coupling or direct coupling or communication connection may be through some interfaces, indirect coupling or communication connection of devices or units, and may be in electrical, mechanical or other forms.
作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。Units described as separate components may or may not be physically separated, and components shown as units may or may not be physical units, that is, may be located in one place, or may be distributed to multiple network units. Some or all of the units may be selected according to actual needs to achieve the purpose of the solution in this embodiment.
另外,在本发明各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。In addition, each functional unit in each embodiment of the present invention may be integrated into one processing unit, or each unit may exist physically alone, or two or more units may be integrated into one unit.
功能如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、ROM、RAM、磁碟或者光盘等各种可以存储程序代码的介质。The functions, if implemented in the form of software functional units and sold or used as stand-alone products, may be stored in a computer-readable storage medium. Based on this understanding, the technical solution of the present invention can be embodied in the form of a software product in essence, or the part that contributes to the prior art or the part of the technical solution. The computer software product is stored in a storage medium, including Several instructions are used to cause a computer device (which may be a personal computer, a server, or a network device, etc.) to execute all or part of the steps of the methods of various embodiments of the present invention. The aforementioned storage medium includes: a U disk, a removable hard disk, a ROM, a RAM, a magnetic disk, or an optical disk, and other media that can store program codes.
以上,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。The above are only specific embodiments of the present invention, but the protection scope of the present invention is not limited to this. Any person skilled in the art who is familiar with the technical scope disclosed by the present invention can easily think of changes or replacements, which should cover within the protection scope of the present invention. Therefore, the protection scope of the present invention should be subject to the protection scope of the claims.
Claims (16)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201710288677.3ACN106971704B (en) | 2017-04-27 | 2017-04-27 | Audio processing method and mobile terminal |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201710288677.3ACN106971704B (en) | 2017-04-27 | 2017-04-27 | Audio processing method and mobile terminal |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN106971704A CN106971704A (en) | 2017-07-21 |
| CN106971704Btrue CN106971704B (en) | 2020-03-17 |
Family
ID=59333616
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201710288677.3AActiveCN106971704B (en) | 2017-04-27 | 2017-04-27 | Audio processing method and mobile terminal |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN106971704B (en) |
Families Citing this family (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108074557B (en)* | 2017-12-11 | 2021-11-23 | 深圳Tcl新技术有限公司 | Tone adjusting method, device and storage medium |
| CN108665881A (en)* | 2018-03-30 | 2018-10-16 | 北京小唱科技有限公司 | Repair sound controlling method and device |
| CN111046226B (en)* | 2018-10-15 | 2023-05-05 | 阿里巴巴集团控股有限公司 | Tuning method and device for music |
| CN109949783B (en)* | 2019-01-18 | 2021-01-29 | 苏州思必驰信息科技有限公司 | Song synthesis method and system |
| CN109979485B (en)* | 2019-04-29 | 2023-05-23 | 北京小唱科技有限公司 | Audio evaluation method and device |
| CN110459196A (en)* | 2019-09-05 | 2019-11-15 | 长沙市回音科技有限公司 | A kind of method, apparatus and system adjusting singing songs difficulty |
| CN111370024B (en)* | 2020-02-21 | 2023-07-04 | 腾讯科技(深圳)有限公司 | Audio adjustment method, device and computer readable storage medium |
| CN116170632B (en)* | 2022-12-29 | 2025-05-16 | 深圳市鸿合创新信息技术有限责任公司 | A sound compensation method and device |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2008227680A (en)* | 2007-03-09 | 2008-09-25 | Yamaha Corp | Acoustic characteristic correction system |
| JP2015072431A (en)* | 2013-10-04 | 2015-04-16 | ブラザー工業株式会社 | Singing result display device, and program |
| CN104538011A (en)* | 2014-10-30 | 2015-04-22 | 华为技术有限公司 | Tone adjusting method and device and terminal device |
| CN105338449A (en)* | 2015-11-26 | 2016-02-17 | 宁波柏人艾电子有限公司 | Sound effect processing circuit |
| CN106024035A (en)* | 2016-05-04 | 2016-10-12 | 珠海市魅族科技有限公司 | Audio processing method and terminal |
- 2017
- 2017-04-27CNCN201710288677.3Apatent/CN106971704B/enactiveActive
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2008227680A (en)* | 2007-03-09 | 2008-09-25 | Yamaha Corp | Acoustic characteristic correction system |
| JP2015072431A (en)* | 2013-10-04 | 2015-04-16 | ブラザー工業株式会社 | Singing result display device, and program |
| CN104538011A (en)* | 2014-10-30 | 2015-04-22 | 华为技术有限公司 | Tone adjusting method and device and terminal device |
| CN105338449A (en)* | 2015-11-26 | 2016-02-17 | 宁波柏人艾电子有限公司 | Sound effect processing circuit |
| CN106024035A (en)* | 2016-05-04 | 2016-10-12 | 珠海市魅族科技有限公司 | Audio processing method and terminal |
Also Published As
| Publication number | Publication date |
|---|---|
| CN106971704A (en) | 2017-07-21 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN106971704B (en) | Audio processing method and mobile terminal | |
| CN106027809B (en) | A volume adjustment method and mobile terminal | |
| CN105827849A (en) | Method for adjusting sound effect and mobile terminal | |
| CN108174031B (en) | Volume adjusting method, terminal equipment and computer readable storage medium | |
| CN106331371A (en) | A volume adjustment method and mobile terminal | |
| CN103714824B (en) | A kind of audio-frequency processing method, device and terminal device | |
| CN106024007B (en) | A sound processing method and mobile terminal | |
| CN107277268B (en) | A kind of audio playback method and mobile terminal | |
| CN106357871A (en) | Voice amplifying method and mobile terminal | |
| CN107623776A (en) | A volume control method, system and mobile terminal | |
| CN102640092B (en) | Adjustment of audio device settings based on touch input | |
| CN107249080A (en) | A kind of method, device and mobile terminal for adjusting audio | |
| US9269341B1 (en) | Method for processing music to match runners tempo | |
| CN106101929A (en) | A kind of protection human ear audition method and mobile terminal | |
| CN101241414A (en) | User interface method of multimedia player with touch screen | |
| KR102084979B1 (en) | Audio file rerecording method, device and storage media | |
| CN105204761B (en) | A kind of volume adjusting method and user terminal | |
| WO2017028686A1 (en) | Information processing method, terminal device and computer storage medium | |
| CN106714038B (en) | A sound loudness control method and mobile terminal | |
| CN105528113A (en) | Touch control method and terminal based on curved-surface touch screen | |
| CN105611458A (en) | Directed recording control method and device of mobile terminal | |
| CN110175015B (en) | Method and device for controlling volume of terminal equipment and terminal equipment | |
| WO2022089098A1 (en) | Pitch adjustment method and device, and computer storage medium | |
| CN107450883A (en) | A kind of audio data processing method, device and mobile terminal | |
| CN106354520A (en) | Interface background switching method and mobile terminal |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |