CN106204083B - A target user classification method, device and system - Google Patents
A target user classification method, device and systemDownload PDFInfo
- Publication number
- CN106204083B CN106204083BCN201510219456.1ACN201510219456ACN106204083BCN 106204083 BCN106204083 BCN 106204083BCN 201510219456 ACN201510219456 ACN 201510219456ACN 106204083 BCN106204083 BCN 106204083B
- Authority
- CN
- China
- Prior art keywords
- user
- category
- probability
- feature attribute
- attribute group
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000034methodMethods0.000titleclaimsabstractdescription30
- 238000012954risk controlMethods0.000claimsdescription23
- 238000010586diagramMethods0.000description8
- 238000013398bayesian methodMethods0.000description6
- 238000004590computer programMethods0.000description6
- 230000006870functionEffects0.000description6
- 238000005516engineering processMethods0.000description3
- 238000012986modificationMethods0.000description3
- 230000004048modificationEffects0.000description3
- 238000004422calculation algorithmMethods0.000description2
- 238000007418data miningMethods0.000description2
- 238000007635classification algorithmMethods0.000description1
- 238000003066decision treeMethods0.000description1
- 230000000694effectsEffects0.000description1
- 230000006872improvementEffects0.000description1
- 238000004519manufacturing processMethods0.000description1
- 230000008569processEffects0.000description1
- 230000001737promoting effectEffects0.000description1
- 238000005070samplingMethods0.000description1
- 239000007787solidSubstances0.000description1
Images

Landscapes
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明涉及信息技术领域,尤其涉及一种目标用户分类方法、装置及系统。The present invention relates to the field of information technology, and in particular, to a target user classification method, device and system.
背景技术Background technique
数据挖掘技术近几年得到了广泛应用,分类是数据挖掘技术的主要内容之一,随着相关算法的不断完善,分类算法已经应用在各个领域。银行、运营商、超市等服务行业在进行新产品或相关活动的推介时,会对不同的用户进行针对性的宣传,准确的目标用户是准确营销的基础,只有确定消费群体中的某类目标用户,才能展开有效的具有针对性的营销事务。因此,如何对目标用户进行有效的分类成为各行业关注的重点。Data mining technology has been widely used in recent years, and classification is one of the main contents of data mining technology. With the continuous improvement of related algorithms, classification algorithms have been applied in various fields. Banks, operators, supermarkets and other service industries will carry out targeted publicity for different users when promoting new products or related activities. Accurate target users are the basis of accurate marketing, and only certain types of targets in the consumer group can be determined. Users can carry out effective targeted marketing affairs. Therefore, how to effectively classify target users has become the focus of various industries.
现有的对目标用户进行分类的分类方法主要采用决策树方法和贝叶斯方法。其中,由于贝叶斯方法是无环图和概率理论的有机结合,具有坚实的概率理论基础而被广泛应用。对所有的用户数据来说,特征属性表征了用户的相关信息,以移动电话用户为例:用户的性别、年龄、网龄、月均流量、流量套餐价值、通话次数、通话费等都是特征属性。而向用户推送产品等服务时,会根据不同类别的用户进行推送,例如:可以将年龄大于30岁的用户作为第一目标用户类别,年龄不大于30岁的用户作为第二目标用户类别。在对目标用户进行分类时,首先确定每个类别在数据样本中出现的概率,以及每个特征属性对每个类别的条件概率估计即先验概率,通过贝叶斯算法,使用已确定的条件概率估计,计算待分类目标用户在每个类别的后验概率,将最大后验概率对应的类别作为待分类目标用户的类别。The existing classification methods for classifying target users mainly use decision tree method and Bayesian method. Among them, because the Bayesian method is an organic combination of acyclic graph and probability theory, it has a solid probability theory foundation and is widely used. For all user data, feature attributes represent the relevant information of the user. Take mobile phone users as an example: the user's gender, age, Internet age, monthly average traffic, data package value, number of calls, and call charges are all features. Attributes. When pushing products and other services to users, it will be pushed according to different categories of users. For example, users who are older than 30 years old can be used as the first target user category, and users who are not older than 30 years old can be used as the second target user category. When classifying target users, first determine the probability of each category appearing in the data sample, and the conditional probability estimation of each feature attribute for each category, that is, the prior probability, through the Bayesian algorithm, using the determined conditions Probability estimation: Calculate the posterior probability of the target user to be classified in each category, and use the category corresponding to the maximum posterior probability as the category of the target user to be classified.
上述对目标用户分类使用的贝叶斯方法需要假设各个特征属性是相互独立,但实际上用户数据的特征属性之间是具有一定的相关性的,因此这种独立性的假设使得目标用户分类不准确。The above Bayesian method for classifying target users needs to assume that each feature attribute is independent of each other, but in fact there is a certain correlation between the feature attributes of user data, so this independence assumption makes the target user classification difficult. precise.
发明内容SUMMARY OF THE INVENTION
本发明实施例提供一种目标用户分类方法、装置及系统,用以解决现有技术中存在的目标用户分类准确性低的问题。Embodiments of the present invention provide a target user classification method, device, and system, so as to solve the problem of low classification accuracy of target users in the prior art.
本发明实施例提供一种目标用户分类方法,包括:An embodiment of the present invention provides a target user classification method, including:
确定训练样本中各用户类别的概率,以及在每个用户类别下各特征属性组的条件概率估计,所述用户类别的概率为该用户类别下训练样本的数量与训练样本总数量的比值,所述每个用户类别下特征属性组的条件概率估计为在该用户类别下的训练样本中,该特征属性组中各特征属性满足该特征属性组对应的预设条件的训练样本数量与该用户类别的训练样本数量的比值;所述特征属性组包括所述训练样本的所有特征属性中提取的具有相关性的特征属性,且各特征属性组之间相互独立,所述特征属性表征训练样本数据的特点;Determine the probability of each user category in the training sample, and estimate the conditional probability of each feature attribute group under each user category, the probability of the user category is the ratio of the number of training samples under the user category to the total number of training samples, so The conditional probability of the feature attribute group under each user category is estimated as, in the training samples under the user category, the number of training samples for which each feature attribute in the feature attribute group satisfies the preset conditions corresponding to the feature attribute group and the user category The ratio of the number of training samples; the feature attribute group includes the relevant feature attributes extracted from all the feature attributes of the training sample, and each feature attribute group is independent of each other, and the feature attribute represents the training sample data. characteristics;
采用贝叶斯公式,根据确定的各用户类别的概率和每个用户下各特征属性组的条件概率估计,确定待分类目标用户在每个类别的后验概率;Using Bayesian formula, according to the determined probability of each user category and the conditional probability estimation of each feature attribute group under each user, determine the posterior probability of the target user to be classified in each category;
将后验概率最大对应的类别确定为所述待分类目标用户的用户类别。The category corresponding to the maximum posterior probability is determined as the user category of the target user to be classified.
通过本发明实施例提供的上述方法,将具有相关性的特征属性组成特征属性组,且特征属性组之间相互独立,符合使用贝叶斯方法的各参量相互独立的假设条件,因此对目标用户分类时,提高了目标用户分类的准确性。Through the above method provided by the embodiment of the present invention, the feature attributes with correlation are formed into feature attribute groups, and the feature attribute groups are independent of each other, which conforms to the assumption that the parameters of the Bayesian method are independent of each other. Therefore, for the target user When classifying, the accuracy of target user classification is improved.
进一步的,所述待分类目标用户在每个类别的后验概率采用如下公式确定:Further, the posterior probability of the target user to be classified in each category is determined by the following formula:

其中,Ci为第i个用户类别,1≤i≤m,m为用户类别的总数量,P(Xkj|Ci)表示第k个特征属性组的各特征属性在预设条件j时,在用户类别Ci下第k个特征属性组的条件概率估计,n为特征属性组的数量,r为预设条件的个数,P(Ci)表示用户类别Ci出现的概率,P(X|Ci)表示待分类目标用户X在用户类别Ci的后验概率。Among them, Ci is the i-th user category, 1≤i≤m, m is the total number of user categories, and P(Xkj |Ci ) indicates that each characteristic attribute of the k-th characteristic attribute group is in the preset condition j , the conditional probability estimation of the k-th feature attribute group under the user category Ci , n is the number of feature attribute groups, r is the number of preset conditions, P(Ci ) represents the probability of the user category Ci appearing, P (X|Ci ) represents the posterior probability of the target user X to be classified in the user category Ci .
进一步的,上述方法,还包括:Further, the above method also includes:
在将后验概率最大对应的类别确定为所述待分类目标用户的类别之前,将确定的最大的后验概率与预设的风险控制系数进行比较,并确定所述最大的后验概率大于预设的风险控制系数。Before determining the category corresponding to the maximum posterior probability as the category of the target user to be classified, the determined maximum posterior probability is compared with a preset risk control coefficient, and it is determined that the maximum posterior probability is greater than the preset risk control coefficient. The set risk control coefficient.
进一步的,上述方法,还包括:Further, the above method also includes:
当确定所述最大的后验概率不大于预设的风险控制系数时,舍弃对所述待分类目标用户的分类判定。When it is determined that the maximum posterior probability is not greater than a preset risk control coefficient, the classification determination of the target user to be classified is discarded.
这样,将最大的后验概率不大于预设的风险控制系数的待分类目标用户舍弃,降低了营销风险,可以提高营销成功率。In this way, the target users to be classified whose maximum posterior probability is not greater than the preset risk control coefficient are discarded, which reduces the marketing risk and can improve the marketing success rate.
本发明实施例还提供了一种目标用户分类装置,包括:The embodiment of the present invention also provides a target user classification device, including:
第一确定单元,用于确定训练样本中各用户类别的概率,以及在每个用户类别下各特征属性组的条件概率估计,所述用户类别的概率为该用户类别下训练样本的数量与训练样本总数量的比值,所述每个用户类别下特征属性组的条件概率估计为在该用户类别下的训练样本中,该特征属性组中各特征属性满足该特征属性组对应的预设条件的训练样本数量与该用户类别的训练样本数量的比值;所述特征属性组包括所述训练样本的所有特征属性中提取的具有相关性的特征属性,且各特征属性组之间相互独立,所述特征属性表征训练样本数据的特点;The first determination unit is used to determine the probability of each user category in the training sample, and the conditional probability estimation of each feature attribute group under each user category, where the probability of the user category is the number of training samples under the user category and the training The ratio of the total number of samples, the conditional probability of the feature attribute group under each user category is estimated as in the training samples under the user category, each feature attribute in the feature attribute group satisfies the preset condition corresponding to the feature attribute group. The ratio of the number of training samples to the number of training samples of the user category; the feature attribute group includes relevant feature attributes extracted from all feature attributes of the training sample, and each feature attribute group is independent of each other, the Feature attributes characterize the characteristics of training sample data;
第二确定单元,用于采用贝叶斯公式,根据确定的各用户类别的概率和每个用户下各特征属性组的条件概率估计,确定待分类目标用户在每个类别的后验概率;The second determination unit is used for adopting the Bayesian formula to determine the posterior probability of the target user to be classified in each category according to the determined probability of each user category and the conditional probability estimation of each feature attribute group under each user;
第三确定单元,用于将后验概率最大对应的类别确定为所述待分类目标用户的用户类别。The third determining unit is configured to determine the category corresponding to the maximum posterior probability as the user category of the target user to be classified.
通过本发明实施例提供的上述装置,将具有相关性的特征属性组成特征属性组,且特征属性组之间相互独立,符合使用贝叶斯方法的各参量相互独立的假设条件,因此对目标用户分类时,提高了目标用户分类的准确性。With the above-mentioned device provided by the embodiment of the present invention, the feature attributes with correlation are formed into feature attribute groups, and the feature attribute groups are independent of each other, which conforms to the assumption that the parameters of the Bayesian method are independent of each other. When classifying, the accuracy of target user classification is improved.
进一步的,所述第二确定单元,具体用于采用如下公式确定所述待分类目标用户在每个类别的后验概率:Further, the second determining unit is specifically configured to adopt the following formula to determine the posterior probability of the target user to be classified in each category:

其中,Ci为第i个用户类别,1≤i≤m,m为用户类别的总数量,P(Xkj|Ci)表示第k个特征属性组的各特征属性在预设条件j时,在用户类别Ci下第k个特征属性组的条件概率估计,n为特征属性组的数量,r为预设条件的个数,P(Ci)表示用户类别Ci出现的概率,P(X|Ci)表示待分类目标用户X在用户类别Ci的后验概率。Among them, Ci is the i-th user category, 1≤i≤m, m is the total number of user categories, and P(Xkj |Ci ) indicates that each characteristic attribute of the k-th characteristic attribute group is in the preset condition j , the conditional probability estimation of the k-th feature attribute group under the user category Ci , n is the number of feature attribute groups, r is the number of preset conditions, P(Ci ) represents the probability of the user category Ci appearing, P (X|Ci ) represents the posterior probability of the target user X to be classified in the user category Ci .
进一步的,上述装置,还包括:Further, the above-mentioned device also includes:
比较单元,用于在将后验概率最大对应的类别确定为所述待分类目标用户的类别之前,将确定的最大的后验概率与预设的风险控制系数进行比较,并确定所述最大的后验概率大于预设的风险控制系数。The comparison unit is configured to compare the determined maximum posterior probability with a preset risk control coefficient before determining the category corresponding to the maximum posterior probability as the category of the target user to be classified, and determine the maximum posterior probability. The posterior probability is greater than the preset risk control coefficient.
进一步的,上述装置,还包括:Further, the above-mentioned device also includes:
舍弃单元,用于当确定所述最大的后验概率不大于预设的风险控制系数时,舍弃对所述待分类目标用户的分类判定。A discarding unit, configured to discard the classification determination of the target user to be classified when it is determined that the maximum posterior probability is not greater than a preset risk control coefficient.
这样,将最大的后验概率不大于预设的风险控制系数的待分类目标用户舍弃,降低了营销风险,可以提高营销成功率。In this way, the target users to be classified whose maximum posterior probability is not greater than the preset risk control coefficient are discarded, which reduces the marketing risk and can improve the marketing success rate.
本发明实施例还提供了一种目标用户分类系统,包括:The embodiment of the present invention also provides a target user classification system, including:
如上述实施例提供的目标用户分类装置。The target user classification device provided by the above embodiment.
本申请的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本申请而了解。本申请的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。Other features and advantages of the present application will be set forth in the description which follows, and in part will be apparent from the description, or may be learned by practice of the present application. The objectives and other advantages of the application may be realized and attained by the structure particularly pointed out in the written description, claims, and drawings.
附图说明Description of drawings
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:The accompanying drawings are used to provide a further understanding of the present invention, and constitute a part of the specification, and are used to explain the present invention together with the embodiments of the present invention, and do not constitute a limitation to the present invention. In the attached image:
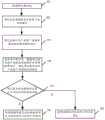
图1为本发明实施例提供的目标用户分类方法的流程图;1 is a flowchart of a target user classification method provided by an embodiment of the present invention;
图2为本发明实施例1提供的目标用户分类方法的流程图;2 is a flowchart of a target user classification method provided in Embodiment 1 of the present invention;
图3为本发明实施例2提供的目标用户分类装置的结构示意图。FIG. 3 is a schematic structural diagram of an apparatus for classifying target users according to Embodiment 2 of the present invention.
具体实施方式Detailed ways
为了给出提高目标用户分类准确性的实现方案,本发明实施例提供了一种目标用户分类方法、装置及系统,以下结合说明书附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。并且在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。In order to provide a solution for improving the classification accuracy of target users, the embodiments of the present invention provide a method, device and system for classifying target users. The preferred embodiments of the present invention will be described below with reference to the accompanying drawings. It should be understood that the description herein The preferred embodiments are only used to illustrate and explain the present invention, not to limit the present invention. And the embodiments in this application and the features in the embodiments may be combined with each other without conflict.
本发明实施例提供一种目标用户分类方法,如图1所示,包括:An embodiment of the present invention provides a target user classification method, as shown in FIG. 1 , including:
步骤101、确定训练样本中各用户类别的概率,以及在每个用户类别下各特征属性组的概率,该用户类别的概率为该用户类别下训练样本的数量与训练样本总数量的比值,该每个用户类别下特征属性组的概率为在该用户类别下的训练样本中,该特征属性组中各特征属性满足该特征属性组对应的预设条件的训练样本数量与该用户类别的训练样本数量的比值,该特征属性组包括训练样本的所有特征属性中提取的具有相关性的特征属性,且各特征属性组之间相互独立,该特征属性表征训练样本数据的特点。Step 101, determine the probability of each user category in the training sample, and the probability of each feature attribute group under each user category, the probability of the user category is the ratio of the number of training samples to the total number of training samples under the user category, the The probability of a feature attribute group under each user category is the number of training samples for which each feature attribute in the feature attribute group satisfies the preset conditions corresponding to the feature attribute group among the training samples under the user category and the number of training samples for the user category. The feature attribute group includes relevant feature attributes extracted from all the feature attributes of the training sample, and each feature attribute group is independent of each other, and the feature attribute represents the characteristics of the training sample data.
步骤102、采用贝叶斯公式,根据确定的各用户类别的概率和每个用户下各特征属性组的概率,确定待分类目标用户在每个类别的后验概率。Step 102: Determine the posterior probability of the target user to be classified in each category according to the determined probability of each user category and the probability of each feature attribute group under each user by using the Bayesian formula.
步骤103、将后验概率最大对应的类别确定为该待分类目标用户的用户类别。Step 103: Determine the category corresponding to the maximum posterior probability as the user category of the target user to be classified.
本发明实施例中,目标用户的分类方法可以应用在各商家或企业的精确营销服务中,对于一种营销服务,训练样本可以为对该营销服务下的前期已使用过该服务的各用户的基础数据,通过随机抽样的方式获取得到。在该营销服务下,一个用户数据即为一个实例。其中,特征属性表征训练样本的特点,以移动服务为例,训练样本包括前期用户分别使用移动服务的各种数据,特征属性可以包括:用户性别、年龄、网龄、月均流量、流量套餐价值、通话次数、通话费等。In the embodiment of the present invention, the classification method of target users can be applied to the precise marketing services of various businesses or enterprises. For a marketing service, the training samples can be the training samples of users who have used the service in the previous stage of the marketing service. The basic data are obtained by random sampling. Under this marketing service, one user data is an instance. Among them, the characteristic attributes represent the characteristics of the training samples. Taking mobile services as an example, the training samples include various data of previous users using mobile services respectively. The characteristic attributes can include: user gender, age, Internet age, average monthly traffic, and data package value. , number of calls, call charges, etc.
对于一种营销服务的训练样本中所有的特征属性,提取具有相关性的特征属性,将具有相关性的特征属性构成特征属性组,特征属性组之间相互独立。具体的,特征属性组的数量可以根据不同的营销服务进行灵活设置。For all the feature attributes in the training sample of a marketing service, extract the relevant feature attributes, and form the relevant feature attributes into a feature attribute group, and the feature attribute groups are independent of each other. Specifically, the number of characteristic attribute groups can be flexibly set according to different marketing services.
其中,用户类别为预先设定的为用户推送具体产品的类型。The user category is a preset type of a specific product that is pushed to the user.
下面结合附图,用具体实施例对本发明提供的方法及装置和相应系统进行详细描述。The method, the device and the corresponding system provided by the present invention will be described in detail below with specific embodiments in conjunction with the accompanying drawings.
实施例1:Example 1:
图2为本发明实施例1提供的目标用户分类方法的流程图,具体包括如下处理步骤:2 is a flowchart of a target user classification method provided in Embodiment 1 of the present invention, which specifically includes the following processing steps:
步骤201、构建特征属性组。
本实施例中,针对一种营销服务,将该营销服务下的前期已使用过该服务的各用户的基础数据作为原始样本数据,每个用户的基础数据为一条原始样本数据,随机抽取预设样本数量的原始样本数据作为训练样本。原始样本数据中包括各种特征属性,结合该营销服务的数据特点,在所有的特征属性中选择具有相关性的特征属性构成特征属性组。例如:以移动服务为例,可以将具有相关性的特征属性分为几个组,流量组(包含流量ARPU(Average Revenue Per-User,每用户平均收入)、月均流量、超套餐流量,流量套餐价值),终端组(包含终端制式,机龄),通话组(包含通话次数、通话费),用户费用组(用户月均费用)。上述这种方式是将所有具有相关性的特征属性分为一个特征属性组,进一步的,还可以从具有相关性的所有特征属性中选择部分特征属性作为特征属性组,例如:可以选择流量组(月均流量,流量ARPU),终端组((机龄),通话组(通话次数,通话费),用户费用组(用户月均费用)作为特征属性组。In this embodiment, for a marketing service, the basic data of each user who has used the service in the early stage of the marketing service is used as the original sample data, and the basic data of each user is a piece of original sample data, which is randomly selected and preset The raw sample data of the sample size is used as the training sample. The original sample data includes various characteristic attributes. Combined with the data characteristics of the marketing service, the relevant characteristic attributes are selected from all the characteristic attributes to form a characteristic attribute group. For example, taking mobile services as an example, the relevant feature attributes can be divided into several groups, traffic group (including traffic ARPU (Average Revenue Per-User, average revenue per user), monthly average traffic, super package traffic, traffic Package value), terminal group (including terminal standard and age), call group (including number of calls and call charges), user fee group (user monthly average fee). In the above method, all relevant feature attributes are divided into a feature attribute group. Further, some feature attributes can be selected from all related feature attributes as a feature attribute group. For example, a traffic group ( Monthly average traffic, traffic ARPU), terminal group ((machine age), call group (number of calls, call fee), user cost group (user monthly average cost) as feature attribute groups.
假设s个特征属性分别为A1,A2,……As,用户类别的数量为m个,分别为C1,C2,……Cm,在训练样本据中,各个特征属性值分别为(X1,X2,……Xs),构建n个特征属性组分别为B1=(A1,A2,A3),B2=(A4,A6),B3=(A5)……Bn。下面以具体训练样本为例,假设将训练样本分为2个用户类别,C1为4G套餐用户,C2为非4G套餐用户,训练样本的数量为5万个用户,其中,5000个用户是4G套餐用户,45000个用户是非4G套餐用户。Assuming that the s feature attributes are A1 , A2 , ... Ass , and the number of user categories is m, which are C1 , C2 , ... Cm respectively, in the training sample data, the values of each feature attribute are respectively For (X1 , X2 ,...Xs ), construct n feature attribute groups as B1 =(A1 , A2 , A3 ), B2 =(A4 , A6 ), B3 = (A5 )...Bn . The following takes specific training samples as an example, assuming that the training samples are divided into 2 user categories, C1 is a 4G package user, C2 is a non-4G package user, and the number of training samples is 50,000 users, of which 5,000 users are 4G package users, 45,000 users are non-4G package users.
步骤202、确定在该训练样本中各用户类别的概率。Step 202: Determine the probability of each user category in the training sample.
本步骤中,用户类别C1出现的概率P(C1)=5000/50000=0.1,用户类别C2出现的概率P(C2)=45000/50000=0.9。In this step, the probability P(C1 ) of the appearance of the user category C1 = 5000/50000 = 0.1, and the probability of the appearance of the user category C2 P(C2 ) = 45000/50000 = 0.9.
步骤203、确定在每个用户类别下各特征属性组的条件概率估计。Step 203: Determine the conditional probability estimates of each feature attribute group under each user category.
本步骤中,每个用户类别下各特征属性组的条件概率估计,为在每一个用户类别下的训练样本中,针对该特征属性组中各特征属性满足该特征属性组对应的预设条件的训练样本数量与该用户类别的训练样本数量的比值。其中,特征属性组对应的预设条件可以为多个预设条件。In this step, the conditional probability estimation of each feature attribute group under each user category is, in the training samples under each user category, for each feature attribute group in the feature attribute group that satisfies the preset conditions corresponding to the feature attribute group The ratio of the number of training samples to the number of training samples for this user category. The preset conditions corresponding to the feature attribute group may be multiple preset conditions.
例如:第k个特征属性组中包括2个特征属性,月均流量-A1和流量APRU-A2,该特征属性组对应的预设条件有4种:(1)A1≤10,A2≤10;(2)A1≤10,A2>10;(3)A1>10,A2≤10;(4)A1>10,A2>10。4G套餐用户的训练样本数据中,分别满足上述4中预设条件的4G套餐用户数量分别为500、2500、1000、1000,那么,第k个特征属性组中各特征属性满足第一种预设条件时,在用户类别C1下第k个特征属性组的条件概率估计P(Xk1|C1)=500/5000=0.1;第k个特征属性组中各特征属性满足第二种预设条件时,在用户类别C1下第k个特征属性组的条件概率估计P(Xk2|C1)=2500/5000=0.5,第k个特征属性组中各特征属性满足第三种预设条件时在用户类别C1下第k个特征属性组的条件概率估计P(Xk3|C1)=1000/5000=0.2;第k个特征属性组中各特征属性满足第四种预设条件时在用户类别C1下第k个特征属性组的条件概率估计P(Xk4|C1)=1000/5000=0.2。类似的,可以确定第k个特征属性组中各特征属性分别满足上述4中预设条件时,在用户类别C2下第k个特征属性组的条件概率估计。For example, the k-th characteristic attribute group includes 2 characteristic attributes, monthly average flow rate -A1 and flow rate APRU-A2 . There are 4 preset conditions corresponding to this characteristic attribute group: (1) A1 ≤10, A2 ≤ 10; (2) A1 ≤ 10, A2 >10; (3) A1 >10, A2 ≤ 10; (4) A1 >10, A2 > 10. Training sample data for 4G package users , the number of 4G package users who meet the preset conditions in the above 4 are 500, 2500, 1000, and 1000 respectively. Then, when each feature attribute in the k-th feature attribute group satisfies the first preset condition, the user category C The conditional probability estimation P(Xk1 |C1 )=500/5000=0.1 of the k-th feature attribute group under1 ; when each feature attribute in the k-th feature attribute group satisfies the second preset condition, in the user category C The conditional probability estimation P(Xk2 |C1 )=2500/5000=0.5 of the k-th feature attribute group under1 , when each feature attribute in the k-th feature attribute group satisfies the third preset condition, the user category C1 The conditional probability estimation P(Xk3 |C1 )=1000/5000=0.2 of the k-th feature attribute group; when each feature attribute in the k-th feature attribute group satisfies the fourth preset condition, it is under the user category C1 The conditional probability estimate of the k-th feature attribute group is P(Xk4 |C1 )=1000/5000=0.2. Similarly, it can be determined that when each feature attribute in the kth feature attribute group satisfies the preset conditions in the above 4 respectively, the conditional probability estimation of the kth feature attribute group under the user categoryC2 can be determined.
采用上述相同的方式,可以确定其它各特征属性组满足该特征属性组对应的预设条件时,在每一个用户类别下该特征属性组的条件概率估计,确定的条件概率估计即为特征属性组对每个用户类别的先验概率,也就相当于,通过对训练样本数据采用步骤201-步骤203的方式进行训练生成了分类器。In the same manner as above, it can be determined that when other characteristic attribute groups satisfy the preset conditions corresponding to the characteristic attribute group, the conditional probability estimation of the characteristic attribute group under each user category is determined, and the determined conditional probability estimate is the characteristic attribute group. The prior probability of each user category is equivalent to generating a classifier by performing training on the training sample data in the manner of
步骤204、采用贝叶斯公式,根据确定的各用户类别出现的概率和条件概率估计,确定待分类目标用户在每个类别的后验概率。Step 204: Determine the posterior probability of the target user to be classified in each category according to the determined probability of occurrence of each user category and the conditional probability estimation by using the Bayesian formula.
本步骤中,采用如下公式确定待分类目标用户在每个类别的后验概率:In this step, the following formula is used to determine the posterior probability of the target user to be classified in each category:
其中,Ci为第i个用户类别,1≤i≤m,m为用户类别的总数量,P(Xkj|Ci)表示第k个特征属性组的各特征属性在预设条件j时,在用户类别Ci下第k个特征属性组的条件概率估计,n为特征属性组的数量,r为预设条件的个数,P(Ci)表示用户类别Ci出现的概率,P(X|Ci)表示待分类目标用户X在用户类别Ci的后验概率。Among them, Ci is the i-th user category, 1≤i≤m, m is the total number of user categories, and P(Xkj |Ci ) indicates that each characteristic attribute of the k-th characteristic attribute group is in the preset condition j , the conditional probability estimation of the k-th feature attribute group under the user category Ci , n is the number of feature attribute groups, r is the number of preset conditions, P(Ci ) represents the probability of the user category Ci appearing, P (X|Ci ) represents the posterior probability of the target user X to be classified in the user category Ci .
步骤205、确定最大的后验概率是否大于预设的风险控制系数,如果是,进入步骤206,如果否,进入步骤207。
其中,预设的风险控制系数可以根据实际情况进行灵活设置。Among them, the preset risk control coefficient can be flexibly set according to the actual situation.
步骤206、将后验概率最大对应的类别确定为该待分类目标用户的类别。Step 206: Determine the category corresponding to the maximum posterior probability as the category of the target user to be classified.
步骤207、舍弃该待分别目标用户的分类判定。Step 207: Discard the classification determination of the target users to be separated.
本发明实施例中,由于在进行营销服务时,需要向不同类别的目标用户推送该类别对应的服务,即使确定了最大的后验概率对应的类别,该类别对应的服务也有可能是该待分类目标用户不希望被推送的,因此预设的风险控制系数用来判定该类别具有的风险程度,如果最大的后验概率不大于该风险控制系数,则认为该待分类目标用户的类别是有风险的,该分类也是不准确的,舍弃该待分别目标用户的分类判定,后续不再向该待分类目标用户推送服务。In the embodiment of the present invention, since it is necessary to push the service corresponding to the category to target users of different categories when performing marketing services, even if the category corresponding to the largest posterior probability is determined, the service corresponding to the category may be the one to be classified. The target user does not want to be pushed, so the preset risk control coefficient is used to determine the risk level of the category. If the maximum posterior probability is not greater than the risk control coefficient, it is considered that the category of the target user to be classified is risky If the classification is inaccurate, the classification determination of the target user to be classified is discarded, and the service will not be pushed to the target user to be classified subsequently.
通过本发明实施例1提供的方法,将具有相关性的特征属性组成特征属性组,且特征属性组之间相互独立,符合使用贝叶斯方法的各参量相互独立的假设条件,因此对目标用户分类时,提高了目标用户分类的准确性。并且,将最大的后验概率不大于预设的风险控制系数的待分类目标用户舍弃,降低了营销风险,可以提高营销成功率。With the method provided in Embodiment 1 of the present invention, feature attributes with correlation are formed into feature attribute groups, and the feature attribute groups are independent of each other, which conforms to the assumption that the parameters of the Bayesian method are independent of each other. When classifying, the accuracy of target user classification is improved. In addition, the target users to be classified whose maximum posterior probability is not greater than the preset risk control coefficient are discarded, which reduces the marketing risk and can improve the marketing success rate.
实施例2:Example 2:
基于同一发明构思,根据本发明上述实施例提供的目标用户分类方法,相应地,本发明实施例2还提供了一种目标用户分类装置,其结构示意图如图3所示,具体包括:Based on the same inventive concept, according to the target user classification method provided by the above embodiments of the present invention, correspondingly, Embodiment 2 of the present invention also provides a target user classification device, the schematic diagram of which is shown in FIG. 3 , and specifically includes:
第一确定单元301,用于确定训练样本中各用户类别的概率,以及在每个用户类别下各特征属性组的条件概率估计,所述用户类别的概率为该用户类别下训练样本的数量与训练样本总数量的比值,所述每个用户类别下特征属性组的条件概率估计为在该用户类别下的训练样本中,该特征属性组中各特征属性满足该特征属性组对应的预设条件的训练样本数量与该用户类别的训练样本数量的比值;所述特征属性组包括所述训练样本的所有特征属性中提取的具有相关性的特征属性,且各特征属性组之间相互独立,所述特征属性表征训练样本数据的特点;The first determination unit 301 is used to determine the probability of each user category in the training sample, and the conditional probability estimation of each feature attribute group under each user category, where the probability of the user category is the number of training samples under the user category and The ratio of the total number of training samples, the conditional probability of the feature attribute group under each user category is estimated to be in the training samples under the user category, and each feature attribute in the feature attribute group satisfies the preset condition corresponding to the feature attribute group The ratio of the number of training samples to the number of training samples of the user category; the feature attribute group includes the relevant feature attributes extracted from all the feature attributes of the training sample, and each feature attribute group is independent of each other, so Describe the feature attributes to characterize the characteristics of the training sample data;
第二确定单元302,用于采用贝叶斯公式,根据确定的各用户类别的概率和每个用户下各特征属性组的条件概率估计,确定待分类目标用户在每个类别的后验概率;The second determining unit 302 is configured to adopt the Bayesian formula to determine the posterior probability of the target user to be classified in each category according to the determined probability of each user category and the conditional probability estimation of each feature attribute group under each user;
第三确定单元303,用于将后验概率最大对应的类别确定为所述待分类目标用户的用户类别。The third determining unit 303 is configured to determine the category corresponding to the maximum posterior probability as the user category of the target user to be classified.
进一步的,所述确定各特征属性组中的各特征属性满足该特征属性组对应的预设条件时在每一个用户类别的条件概率估计为在每一个用户类别下的训练样本数据中,针对每一个特征属性组中各特征属性满足该特征属性组对应的预设条件的训练样本数量与所述用户类别下的训练样本数量的比值。Further, when it is determined that each feature attribute in each feature attribute group satisfies the preset condition corresponding to the feature attribute group, the conditional probability of each user category is estimated as in the training sample data under each user category, for each user category. The ratio of the number of training samples for which each feature attribute in a feature attribute group satisfies the preset condition corresponding to the feature attribute group to the number of training samples under the user category.
进一步的,第二确定单元302,具体用于采用如下公式确定所述待分类目标用户在每个类别的后验概率:Further, the second determining unit 302 is specifically configured to adopt the following formula to determine the posterior probability of the target user to be classified in each category:

其中,Ci为第i个用户类别,1≤i≤m,m为用户类别的总数量,P(Xkj|Ci)表示第k个特征属性组的各特征属性在预设条件j时,在用户类别Ci下第k个特征属性组的条件概率估计,n为特征属性组的数量,r为预设条件的个数,P(Ci)表示用户类别Ci出现的概率,P(X|Ci)表示待分类目标用户X在用户类别Ci的后验概率。Among them, Ci is the i-th user category, 1≤i≤m, m is the total number of user categories, and P(Xkj |Ci ) indicates that each characteristic attribute of the k-th characteristic attribute group is in the preset condition j , the conditional probability estimation of the k-th feature attribute group under the user category Ci , n is the number of feature attribute groups, r is the number of preset conditions, P(Ci ) represents the probability of the user category Ci appearing, P (X|Ci ) represents the posterior probability of the target user X to be classified in the user category Ci .
进一步的,上述装置,还包括:Further, the above-mentioned device also includes:
比较单元304,用于在将后验概率最大对应的类别确定为所述待分类目标用户的类别之前,将确定的最大的后验概率与预设的风险控制系数进行比较,并确定所述最大的后验概率大于预设的风险控制系数。The comparison unit 304 is configured to compare the determined maximum posterior probability with a preset risk control coefficient before determining the category corresponding to the maximum posterior probability as the category of the target user to be classified, and determine the maximum posterior probability. The posterior probability of is greater than the preset risk control coefficient.
进一步的,上述装置,还包括:Further, the above-mentioned device also includes:
舍弃单元305,用于当确定所述最大的后验概率不大于预设的风险控制系数时,舍弃对所述待分类目标用户的分类判定。The discarding unit 305 is configured to discard the classification determination of the target user to be classified when it is determined that the maximum posterior probability is not greater than a preset risk control coefficient.
本发明实施例2还提供了一种目标用户分类系统,包括:Embodiment 2 of the present invention also provides a target user classification system, including:
本发明实施例2提供的上述目标用户分类装置。The foregoing apparatus for classifying target users provided in Embodiment 2 of the present invention.
上述各单元的功能可对应于图1或图2所示流程中的相应处理步骤,在此不再赘述。The functions of the above units may correspond to the corresponding processing steps in the flow shown in FIG. 1 or FIG. 2 , which will not be repeated here.
综上所述,本发明实施例提供的方案,包括:确定训练样本中各用户类别的概率,以及在每个用户类别下各特征属性组的概率,该用户类别的概率为该用户类别下训练样本的数量与训练样本总数量的比值,该每个用户类别下特征属性组的概率为在该用户类别下的训练样本中,该特征属性组中各特征属性满足该特征属性组对应的预设条件的训练样本数量与该用户类别的训练样本数量的比值,该特征属性组包括训练样本的所有特征属性中提取的具有相关性的特征属性,且各特征属性组之间相互独立,该特征属性表征训练样本数据的特点;采用贝叶斯公式,根据确定的各用户类别的概率和每个用户下各特征属性组的条件概率估计,确定待分类目标用户在每个类别的后验概率;将后验概率最大对应的类别确定为所述待分类目标用户的用户类别。采用本发明实施例的方案,提高了目标用户分类的准确性。To sum up, the solution provided by the embodiment of the present invention includes: determining the probability of each user category in the training sample, and the probability of each feature attribute group under each user category, and the probability of the user category is the training under the user category. The ratio of the number of samples to the total number of training samples, the probability of the feature attribute group under each user category is in the training samples under the user category, and each feature attribute in the feature attribute group satisfies the preset corresponding to the feature attribute group. The ratio of the number of training samples of the condition to the number of training samples of the user category, the feature attribute group includes the relevant feature attributes extracted from all the feature attributes of the training sample, and each feature attribute group is independent of each other, the feature attribute Characterize the characteristics of the training sample data; use the Bayesian formula to determine the posterior probability of the target user to be classified in each category according to the determined probability of each user category and the conditional probability estimation of each feature attribute group under each user; The category corresponding to the maximum posterior probability is determined as the user category of the target user to be classified. By adopting the solution of the embodiment of the present invention, the classification accuracy of the target user is improved.
本申请的实施例所提供的目标用户分类装置可通过计算机程序实现。本领域技术人员应该能够理解,上述的模块划分方式仅是众多模块划分方式中的一种,如果划分为其他模块或不划分模块,只要目标用户分类装置具有上述功能,都应该在本申请的保护范围之内。The target user classification apparatus provided by the embodiments of the present application may be implemented by a computer program. Those skilled in the art should be able to understand that the above-mentioned module division method is only one of many module division methods. If it is divided into other modules or not divided into modules, as long as the target user classification device has the above functions, it should be protected under the protection of the present application. within the range.
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。The present application is described with reference to flowchart illustrations and/or block diagrams of methods, apparatus (systems), and computer program products according to embodiments of the present application. It will be understood that each flow and/or block in the flowchart illustrations and/or block diagrams, and combinations of flows and/or blocks in the flowchart illustrations and/or block diagrams, can be implemented by computer program instructions. These computer program instructions may be provided to the processor of a general purpose computer, special purpose computer, embedded processor or other programmable data processing device to produce a machine such that the instructions executed by the processor of the computer or other programmable data processing device produce Means for implementing the functions specified in a flow or flow of a flowchart and/or a block or blocks of a block diagram.
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。These computer program instructions may also be stored in a computer-readable memory capable of directing a computer or other programmable data processing apparatus to function in a particular manner, such that the instructions stored in the computer-readable memory result in an article of manufacture comprising instruction means, the instructions The apparatus implements the functions specified in the flow or flow of the flowcharts and/or the block or blocks of the block diagrams.
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。These computer program instructions can also be loaded on a computer or other programmable data processing device to cause a series of operational steps to be performed on the computer or other programmable device to produce a computer-implemented process such that The instructions provide steps for implementing the functions specified in the flow or blocks of the flowcharts and/or the block or blocks of the block diagrams.
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。It will be apparent to those skilled in the art that various modifications and variations can be made in the present invention without departing from the spirit and scope of the invention. Thus, provided that these modifications and variations of the present invention fall within the scope of the claims of the present invention and their equivalents, the present invention is also intended to include these modifications and variations.
Claims (9)
Translated fromChinese
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201510219456.1ACN106204083B (en) | 2015-04-30 | 2015-04-30 | A target user classification method, device and system |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201510219456.1ACN106204083B (en) | 2015-04-30 | 2015-04-30 | A target user classification method, device and system |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN106204083A CN106204083A (en) | 2016-12-07 |
| CN106204083Btrue CN106204083B (en) | 2020-02-18 |
Family
ID=57458538
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201510219456.1AActiveCN106204083B (en) | 2015-04-30 | 2015-04-30 | A target user classification method, device and system |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN106204083B (en) |
Families Citing this family (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108229989B (en)* | 2016-12-14 | 2020-09-22 | 北京国双科技有限公司 | Method and device for determining attribute category of user attribute |
| CN109919790A (en)* | 2017-12-13 | 2019-06-21 | 腾讯科技(深圳)有限公司 | Group type recognition methods, device, electronic equipment and storage medium |
| CN109962956B (en)* | 2017-12-26 | 2022-06-07 | 中国电信股份有限公司 | Method and system for recommending communication services to a user |
| CN110580483A (en)* | 2018-05-21 | 2019-12-17 | 上海大唐移动通信设备有限公司 | indoor and outdoor user distinguishing method and device |
| CN110442722B (en)* | 2019-08-13 | 2022-05-13 | 北京金山数字娱乐科技有限公司 | Method and device for training classification model and method and device for data classification |
| CN111324641B (en)* | 2020-02-19 | 2022-09-09 | 腾讯科技(深圳)有限公司 | Personnel estimation method and device, computer-readable storage medium and terminal equipment |
| CN111797942A (en)* | 2020-07-23 | 2020-10-20 | 深圳壹账通智能科技有限公司 | User information classification method and device, computer equipment and storage medium |
| CN113111284B (en)* | 2021-04-12 | 2024-07-16 | 中国铁塔股份有限公司 | Classification information display method, device, electronic device and readable storage medium |
| CN113591018A (en)* | 2021-07-30 | 2021-11-02 | 中国联合网络通信集团有限公司 | Communication client classification management method, system, electronic device and storage medium |
| CN113888316A (en)* | 2021-10-19 | 2022-01-04 | 平安银行股份有限公司 | A Bayesian Network-Based Target Person Recognition Method and Related Equipment |
| CN114330578A (en)* | 2021-12-31 | 2022-04-12 | 北京字跳网络技术有限公司 | Object classification method and device, readable medium and electronic equipment |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101685458A (en)* | 2008-09-27 | 2010-03-31 | 华为技术有限公司 | Recommendation method and system based on collaborative filtering |
Family Cites Families (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101577866A (en)* | 2008-05-07 | 2009-11-11 | 中国移动通信集团公司 | User classification method, advertisement release method and device |
| US8346689B2 (en)* | 2010-01-21 | 2013-01-01 | National Cheng Kung University | Recommendation system using rough-set and multiple features mining integrally and method thereof |
| CN102081655B (en)* | 2011-01-11 | 2013-06-05 | 华北电力大学 | Information retrieval method based on Bayesian classification algorithm |
| CN103778206A (en)* | 2014-01-14 | 2014-05-07 | 河南科技大学 | Method for providing network service resources |
| CN104281635A (en)* | 2014-03-13 | 2015-01-14 | 电子科技大学 | Method for predicting basic attributes of mobile user based on privacy feedback |
| CN104298719B (en)* | 2014-09-23 | 2018-02-27 | 新浪网技术(中国)有限公司 | Category division, advertisement placement method and the system of user is carried out based on Social behaviors |
- 2015
- 2015-04-30CNCN201510219456.1Apatent/CN106204083B/enactiveActive
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101685458A (en)* | 2008-09-27 | 2010-03-31 | 华为技术有限公司 | Recommendation method and system based on collaborative filtering |
Also Published As
| Publication number | Publication date |
|---|---|
| CN106204083A (en) | 2016-12-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN106204083B (en) | A target user classification method, device and system | |
| CN110175595B (en) | Human body attribute recognition method, recognition model training method and device | |
| CN108304435B (en) | Information recommendation method and device, computer equipment and storage medium | |
| Dey et al. | Estimating age privacy leakage in online social networks | |
| CN103793484B (en) | The fraud identifying system based on machine learning in classification information website | |
| Wong et al. | Quantifying political leaning from tweets and retweets | |
| US8799306B2 (en) | Recommendation of search keywords based on indication of user intention | |
| CN108427690B (en) | Information delivery method and device | |
| CN107944593A (en) | A kind of resource allocation methods and device, electronic equipment | |
| CN107563757A (en) | The method and device of data risk control | |
| CN108052862A (en) | Age predictor method and device | |
| CN104750829B (en) | A kind of customer location sorting technique and system based on feature of registering | |
| CN111260416B (en) | Method and apparatus for determining associated users of an object | |
| WO2022142903A1 (en) | Identity recognition method and apparatus, electronic device, and related product | |
| CN111325067A (en) | Identification method, device and electronic equipment of illegal video | |
| CN104111970B (en) | Count page mean residence time, the method and apparatus for determining Page user stickiness | |
| CN107896153A (en) | A kind of flow package recommendation method and device based on mobile subscriber's internet behavior | |
| CN107909038A (en) | A kind of social networks disaggregated model training method, device, electronic equipment and medium | |
| US9332031B1 (en) | Categorizing accounts based on associated images | |
| WO2020024444A1 (en) | Group performance grade recognition method and apparatus, and storage medium and computer device | |
| CN114399352A (en) | Information recommendation method and device, electronic equipment and storage medium | |
| CN107257419A (en) | One kind quantifies estimation method based on Bayesian analysis interpersonal relationships | |
| CN105335363A (en) | Object pushing method and system | |
| CN109359689B (en) | Data identification method and device | |
| CN110032596A (en) | Traffic Anomaly user identification method and system |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |