CN103778206A - Method for providing network service resources - Google Patents
Method for providing network service resourcesDownload PDFInfo
- Publication number
- CN103778206A CN103778206ACN201410015647.1ACN201410015647ACN103778206ACN 103778206 ACN103778206 ACN 103778206ACN 201410015647 ACN201410015647 ACN 201410015647ACN 103778206 ACN103778206 ACN 103778206A
- Authority
- CN
- China
- Prior art keywords
- interest
- user
- classification
- document
- attribute
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images

Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/95—Retrieval from the web
- G06F16/953—Querying, e.g. by the use of web search engines
- G06F16/9535—Search customisation based on user profiles and personalisation
Landscapes
- Engineering & Computer Science (AREA)
- Databases & Information Systems (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Translated fromChineseDescription
Translated fromChinese技术领域technical field
本发明涉及到互联网服务资源的提供领域,具体的说是一种网络服务资源的提供方法。The invention relates to the field of providing Internet service resources, in particular to a method for providing network service resources.
背景技术Background technique
服务资源分类是指对网络中各种已存在的服务和资源按照其各自的属性和特点进行分析,并划分使其归属于特定的类别。随着互联网技术的高速发展以及计算机技术的不断普及,促使人们对网络服务资源的依赖愈加强烈,而服务资源的分类是一个复杂的加工处理过程,其涉及到服务资源的预处理、特征向量集合的提取和分类等技术环节,服务资源分类则可理解为采用一定的方法与模式,按照一定的规则将网络上的各种资源进行全面的分析、优选、加工、排列组合、整理、分类等加工处理,使其形成一个有序的、便于用户高效获取并利用的服务资源体的系统过程。服务资源的分类使得繁杂零散的资源集合形成了有序化的结构,使之转化为一个有意义的整体,便于服务资源能依据某一特定形式的规则进行更高层次的存取和利用。目前网络上的服务和资源十分丰富,如何将海量的服务资源准确的分类,这已成为资源分类技术要处理的一个关键问题。Classification of service resources refers to analyzing various existing services and resources in the network according to their respective attributes and characteristics, and classifying them into specific categories. With the rapid development of Internet technology and the continuous popularization of computer technology, people have become more and more dependent on network service resources, and the classification of service resources is a complex processing process, which involves preprocessing of service resources and feature vector collection. Service resource classification can be understood as the use of certain methods and models to conduct comprehensive analysis, optimization, processing, permutation, sorting, and classification of various resources on the network according to certain rules. It is a systematic process of forming an orderly service resource body that is convenient for users to obtain and utilize efficiently. The classification of service resources makes the complex and scattered resource collections form an orderly structure, transforming them into a meaningful whole, so that service resources can be accessed and utilized at a higher level according to a specific form of rules. At present, there are abundant services and resources on the Internet. How to accurately classify massive service resources has become a key issue to be dealt with by resource classification technology.
当前服务资源分类方法基本是用户依据一定规则自行手动进行人工分类。在资源量过大的时候,使用这种方法必定将消耗大量人力,并且效率相当低下。当用户定义新类别时,又要对原先未定义种类的服务资源进行再次分类,若再进行人工分类,代价过大。近年来,一些学者使用智能学习的方法来进行分类,取得了一定的成果。现在一些常用的智能分类方法有聚类算法、决策树算法等。聚类算法由于具有无监督的学习能力,但在高维数据空间中,聚类往往只存在于某些子空间中,并且不同的聚类所关联的子空间也存在差异。受“维度效应”的影响,传统的聚类算法一般无法直接对高维数据进行有效的聚类,需要通过一些特殊的处理。决策树分类的直观表示方法较容易转化为标准的数据库查询,其归纳的方法行之有效,尤其适合大型数据集。但其算法的伸缩性太差,随着数据量的增大其运行时间大大增加。The current classification method of service resources is basically manual classification by users themselves according to certain rules. When the amount of resources is too large, using this method will consume a lot of manpower, and the efficiency is quite low. When the user defines a new category, it is necessary to classify the service resources of the original undefined category again. If the manual classification is performed again, the cost is too high. In recent years, some scholars have used intelligent learning methods to classify and achieved certain results. Now some commonly used intelligent classification methods include clustering algorithm, decision tree algorithm and so on. Clustering algorithms have unsupervised learning ability, but in high-dimensional data space, clusters often only exist in certain subspaces, and the subspaces associated with different clusters are also different. Affected by the "dimension effect", traditional clustering algorithms generally cannot effectively cluster high-dimensional data directly, and require some special processing. The visual representation method of decision tree classification is easier to transform into standard database query, and its inductive method is effective, especially suitable for large data sets. However, the scalability of its algorithm is too poor, and its running time increases greatly with the increase of data volume.
目前,个性化检索是服务资源检索领域的热点和难点。这一领域的研究范围很广,涉及到的问题也很多。许多学者从不同的角度,提出多种技术方法,主要有:①网络数据库技术(web Database),构建用户等相关数据库;②过程跟踪技术(Process Tracking),如Cookies技术等;③代理技术(Agent),代理指在分布式系统中持续自主的发挥作用的计算实体,他有独立性、自主性和交互性等特性,,借助代理,可以很好地完成用户与系统的交互;④数据挖掘技术(Data Mining),从海量数据中采掘出隐含的、先前未知的、对决策有潜在价值的知识和规则,并根据这些规则,预测用户即将发生的行为;⑤推送技术(Push),根据用户定义的准则,自动搜索用户感兴趣的服务资源,并主动传递至用户指定“地点”;⑥信息过滤技术(Information Filtering),信息过滤是一种用来过滤大量信息流,为用户提供相关信息子集的技术。信息过滤可以分为:基于规则的过滤、基于协作的过滤、基于内容的过滤,它们的目标都是根据用户兴趣需要将最有价值的服务资源信息自动推荐给用户,并最大限度地节省用户的阅读时间。At present, personalized retrieval is a hot and difficult point in the field of service resource retrieval. The scope of research in this field is very wide, and there are many problems involved. Many scholars have proposed a variety of technical methods from different angles, mainly including: ① web database technology (web Database), constructing user-related databases; ② process tracking technology (Process Tracking), such as Cookies technology; ③ agent technology (Agent ), an agent refers to a computing entity that continuously and autonomously plays a role in a distributed system. It has the characteristics of independence, autonomy, and interactivity. With the help of an agent, the interaction between the user and the system can be well completed; ④ data mining technology (Data Mining), which extracts implicit, previously unknown, and potentially valuable knowledge and rules for decision-making from massive data, and predicts the upcoming behavior of users based on these rules; ⑤ Push technology (Push), according to user Defined criteria, automatically search for service resources that users are interested in, and actively deliver them to the user-specified "place"; set of technologies. Information filtering can be divided into: rule-based filtering, collaboration-based filtering, and content-based filtering. Their goals are to automatically recommend the most valuable service resource information to users according to their interests and needs, and to save users' time and money to the greatest extent. reading time.
传统的服务资源检索技术满足了人们一定的检索需要,但受通用性限制,无法满足用户一些复杂的查询需求。随着信息爆炸出现,人们对检索系统的功能、智能化程度以及检索效果有了更高的要求,希望能提供更准确、更精炼和更符合个人需要的检索结果。The traditional service resource retrieval technology meets people's certain retrieval needs, but due to the limitation of versatility, it cannot meet some complex query needs of users. With the emergence of the information explosion, people have higher requirements for the function, intelligence and retrieval effect of the retrieval system, hoping to provide more accurate, refined and more personal retrieval results.
发明内容Contents of the invention
为解决传统的检索技术难以满足人们对检索系统功能、智能化程度以及检索效果的要求的问题,本发明提供了一种网络服务资源的提供方法,来满足用户多样化的实时需求,更加快捷的为用户提供更优质的服务。In order to solve the problem that the traditional retrieval technology is difficult to meet people's requirements for retrieval system functions, intelligence and retrieval effects, the present invention provides a method for providing network service resources to meet the diverse real-time needs of users. To provide users with better services.
本发明为解决上述技术问题采用的技术方案为:一种网络服务资源的提供方法,首先对网络服务资源进行分类,然后根据用户的兴趣提供检索方案,并根据该检索方案提供分类后的网络服务资源,所述对网络服务资源进行分类包括以下步骤:The technical solution adopted by the present invention to solve the above technical problems is: a method for providing network service resources, which first classifies the network service resources, then provides a search plan according to the user's interest, and provides the classified network service according to the search plan Resources, the classification of network service resources includes the following steps:
1)预定义m个类别,类标号为 

2)针对n维特征向量中每个属性






3)确定n维特征向量中每个属性

方法如下:首先,定义两个对象空间






式中:






其中


然后,定义类别






按照升序排列属性





属性


由下式计算每个属性的权重The weight of each attribute is calculated by

4)根据步骤2)和步骤3 )所得结果,利用加权朴素贝叶斯公式

所述步骤4)的加权朴素贝叶斯公式






所述步骤1)中提取待分类服务资源X的若干特征向量,特征向量包括文件名、文件后缀名、文本内容和文件大小。In the step 1), several feature vectors of the service resource X to be classified are extracted, and the feature vectors include file name, file extension, text content and file size.
所述根据用户的兴趣提供检索方案,首先,定义文档集合D中的文档总数为N,任一属于集合D的文档都可以表示为t维向量的形式:
其中,t是索引词的个数,向量分量


步骤一、获取用户兴趣信息,然后用向量或图形的方法将兴趣信息进行形式化的表示,即形成用户兴趣剖像;Step 1. Obtain user interest information, and then use vector or graphic methods to formally represent the interest information, that is, to form a user interest profile;
步骤二、借助分类目录表征用户兴趣,并将分类目录映射为树状结构形成用户兴趣树,用户兴趣树中的节点表示类目,该节点的权值表示用户对该节点表示的类目的感兴趣程度;Step 2: Represent user interest with the help of classification directory, and map the classification directory into a tree structure to form a user interest tree. The nodes in the user interest tree represent categories, and the weight of the node represents the user's sentiment on the category represented by the node. level of interest;
步骤三、使用二元组兴趣向量

式中,




步骤四、由公式Step 4, by the formula



步骤五、提取用户检索请求中的提问向量


步骤六、从用户兴趣剖像库




式中,为兴趣权数,
步骤七、根据步骤六得出的兴趣相似度SCOREi的大小对这m篇文档进行排序并在界面上显示,优先推荐这m篇文章中与用户兴趣相关的文档;Step 7. According to the interest similarity SCOREi obtained in step 6, the m documents are sorted and displayed on the interface, and the documents related to the user's interests in the m articles are preferentially recommended;
步骤八、跟踪并记录用户对检索结果的访问情况,以此来更新该用户的兴趣剖像库。Step 8: Track and record the user's access to the retrieval results, so as to update the user's interest profile library.
所述步骤八中更新该用户的兴趣剖像库,其具体步骤如下:In said step eight, update the user's interest profile library, and its specific steps are as follows:
①初始化用户兴趣树,使每个节点均对应一原始权值
②叶子节点权值不变,重新计算每一个非叶子节点的权值: 其中
所述叶子节点是指用户兴趣树中最小的分类类目,非叶子节点是指用户兴趣树中具有子分类的分类类目;The leaf node refers to the smallest classification category in the user interest tree, and the non-leaf node refers to the classification category with sub-categories in the user interest tree;
③若用户访问某些节点中的文档,则重复以上两个步骤;③ If the user accesses documents in some nodes, repeat the above two steps;
④根据步骤②中更新后的非叶子节点的权值来更新用户兴趣剖像④Update the user interest profile according to the weights of non-leaf nodes updated in step ②

式中



有益效果:本发明与现有技术相比,具有以下优点:Beneficial effect: compared with the prior art, the present invention has the following advantages:
1)本发明通过引入数学中的相似度的概念,利用加权朴素贝斯公式,将属性相似度的计算应用到加权朴素贝叶斯公式中,用来确定出每个特征属性的权值,将此算法应用到服务资源分类上,对于未知的服务资源数据样本按加权朴素贝叶斯公式计算其属于每一个类别的概率,然后选择其中概率最大的类别作为其类别,以得到基于属性相似度的服务资源分类方法,大大提高了服务资源分类的准确率;1) The present invention introduces the concept of similarity in mathematics and uses the weighted naive Bayesian formula to apply the calculation of attribute similarity to the weighted naive Bayesian formula to determine the weight of each feature attribute. The algorithm is applied to the classification of service resources. For unknown service resource data samples, the probability of belonging to each category is calculated according to the weighted naive Bayesian formula, and then the category with the highest probability is selected as its category to obtain a service based on attribute similarity. The resource classification method greatly improves the accuracy of service resource classification;
2)在对服务资源进行检索时,通过对用户兴趣的提取并分析,并使用兴趣路径上各节点权值的和作为兴趣相关因子,准确建立用户兴趣模型,随着时间推移,用户兴趣也在不断变化,及时对该用户兴趣模型进行更新,保证了用户兴趣模型的时间可靠性,使得检索更加符合用户的实际需要,实现了基于用户兴趣的个性化服务资源检索,明显改善了检索效果;2) When retrieving service resources, by extracting and analyzing user interests, and using the sum of the weights of each node on the interest path as an interest-related factor, an accurate user interest model is established. As time goes by, user interests also Constantly changing, updating the user interest model in time ensures the time reliability of the user interest model, makes the retrieval more in line with the actual needs of the user, realizes the personalized service resource retrieval based on the user interest, and significantly improves the retrieval effect;
3)本发明通过对服务资源的分类和检索这两种方法的有效结合,提出了一种基于分类的服务资源提供方案,该方案在对用户提供服务时,提高了网络服务资源分类的准确性,降低了对海量的网络服务资源检索的时间,效率有明显的提高。3) Through the effective combination of the two methods of classification and retrieval of service resources, the present invention proposes a classification-based service resource provision scheme, which improves the accuracy of network service resource classification when providing services to users , reducing the time for searching massive network service resources, and the efficiency is obviously improved.
附图说明Description of drawings
图1为本发明所用到的朴素贝叶斯模型示意图;Fig. 1 is the naive Bayesian model schematic diagram used in the present invention;
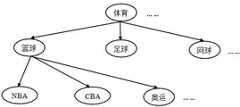
图2为本发明所述的用户兴趣树的示意图;FIG. 2 is a schematic diagram of a user interest tree according to the present invention;
图3为本发明对分类服务资源进行检索时的检索流程图。Fig. 3 is a retrieval flow chart of the present invention when retrieving classified service resources.
具体实施方式Detailed ways
一种网络服务资源的提供方法,首先对网络服务资源进行分类,然后根据用户的兴趣提供检索方案,并根据该检索方案提供分类后的网络服务资源,所述对网络服务资源进行分类包括以下步骤:A method for providing network service resources, firstly classifying the network service resources, then providing a search plan according to the interests of users, and providing classified network service resources according to the search plan, said classifying the network service resources includes the following steps :
1)预定义m个类别,类标号为

2)针对n维特征向量中每个属性





3)确定n维特征向量中每个属性

方法如下:首先,定义两个对象空间







式中:



其中和

然后,定义类别









按照升序排列属性




属性归一化的属性相似度为

由下式计算每个属性的权重The weight of each attribute is calculated by

4)根据步骤2)和步骤3 )所得结果,利用加权朴素贝叶斯公式
所述步骤4)的加权朴素贝叶斯公式

表示该n维特征向量属于某一个类




所述步骤1)中提取待分类服务资源X的若干特征向量,特征向量包括文件名、文件后缀名、文本内容和文件大小。一个文件的特征向量集合可能涉及到近百个特征,特征集合的表述质量会直接影响分类的效果,所以要尽量选择能够代表文件特性的属性作为特征属性,但又不能选择太多,属性太多会增加分类计算量并且带来噪声影响,从而造成分类准确率的下降。对此,经过综合分析,选取了以下文件的特征属性向量进行分析:In the step 1), several feature vectors of the service resource X to be classified are extracted, and the feature vectors include file name, file extension, text content and file size. The feature vector set of a file may involve nearly a hundred features, and the expression quality of the feature set will directly affect the classification effect, so try to choose the attributes that can represent the characteristics of the file as feature attributes, but you can’t choose too many, too many attributes It will increase the amount of classification calculations and bring noise effects, resulting in a decline in classification accuracy. In this regard, after comprehensive analysis, the characteristic attribute vectors of the following files are selected for analysis:
a、文件名,可以通过文件名内的关键词进行分析从而进行分类;a. The file name can be classified by analyzing the keywords in the file name;
b、文件后缀名,可以对文件后缀名进行筛选并进行分类;b. File suffixes, which can filter and classify file suffixes;
c、文本内容,如果文件后缀名是文本类型文件再根据文本内容进行分析并分类;c. Text content, if the file suffix name is a text type file, analyze and classify according to the text content;
d、文件大小,获取文件的大小并赋以权重再进行分类。d. File size, obtain the size of the file and assign weights to classify.
本发明上述的根据用户的兴趣提供检索方案,首先,定义文档集合D中的文档总数为N,任一属于集合D的文档都可以表示为t维向量的形式:
其中,t是索引词的个数,向量分量代表第i个索引词

步骤一、获取用户兴趣信息,然后用向量或图形的方法将兴趣信息进行形式化的表示,即形成用户兴趣剖像;Step 1. Obtain user interest information, and then use vector or graphic methods to formally represent the interest information, that is, to form a user interest profile;
步骤二、借助分类目录表征用户兴趣,并将分类目录映射为树状结构形成用户兴趣树,用户兴趣树中的节点表示类目,该节点的权值表示用户对该节点表示的类目的感兴趣程度;Step 2: Represent user interest with the help of classification directory, and map the classification directory into a tree structure to form a user interest tree. The nodes in the user interest tree represent categories, and the weight of the node represents the user's sentiment on the category represented by the node. level of interest;
步骤三、使用二元组兴趣向量

式中,
为

步骤四、由公式Step 4, by the formula




步骤五、提取用户检索请求中的提问向量


步骤六、从用户兴趣剖像库



式中,

步骤七、根据步骤六得出的兴趣相似度SCOREi的大小对这m篇文档进行排序并在界面上显示,优先推荐这m篇文章中与用户兴趣相关的文档;Step 7. According to the interest similarity SCOREi obtained in step 6, the m documents are sorted and displayed on the interface, and the documents related to the user's interests in the m articles are preferentially recommended;
步骤八、跟踪并记录用户对检索结果的访问情况,以此来更新该用户的兴趣剖像库。Step 8: Track and record the user's access to the retrieval results, so as to update the user's interest profile database.
所述步骤八中更新该用户的兴趣剖像库,其具体步骤如下:In said step eight, update the user's interest profile library, and its specific steps are as follows:
①初始化用户兴趣树,使每个节点均对应一原始权值
②叶子节点权值不变,重新计算每一个非叶子节点的权值: 其中
所述叶子节点是指用户兴趣树中最小的分类类目,非叶子节点是指用户兴趣树中具有子分类的分类类目;The leaf node refers to the smallest classification category in the user interest tree, and the non-leaf node refers to the classification category with sub-categories in the user interest tree;
③若用户访问某些节点中的文档,则重复以上两个步骤;③ If the user accesses documents in some nodes, repeat the above two steps;
④根据步骤②中更新后的非叶子节点的权值来更新用户兴趣剖像④Update the user interest profile according to the weights of non-leaf nodes updated in step ②

式中
本发明上述步骤一中,所述的获取用户兴趣信息是指采用特定的方法获取能够反映用户兴趣的信息,以生成能表示用户兴趣的特征文件,即用户兴趣剖像。如果用户经常访问某一页面或文档,或者用户在某一页面或文档上停留较长的时间,则说明用户对该页面或该文档感兴趣。这表明,用户对检索结果的访问情况等用户行为能够反映用户的兴趣。为了学习用户的兴趣,可以使用计算机对这些访问信息进行跟踪和记录并进行挖掘,从中抽取出能反映用户兴趣的信息,进而生成用户兴趣剖像;In the above step 1 of the present invention, the acquisition of user interest information refers to the use of specific methods to obtain information that can reflect user interest, so as to generate a feature file that can represent user interest, that is, user interest profile. If the user frequently visits a certain page or document, or the user stays on a certain page or document for a long time, it means that the user is interested in the page or document. This shows that user behavior such as user access to search results can reflect user interest. In order to learn the interests of users, computers can be used to track, record and mine these access information, extract information that can reflect the interests of users, and then generate user interest profiles;
将获取到的用户兴趣信息用向量或图形的方法进行形式化的表示,即形成用户兴趣剖像。它存储在计算机上,是高度结构化的,并且能够自动生成和动态更新。本文提到的用户兴趣剖像或兴趣剖像均指用户个人兴趣剖像。建立用户兴趣剖像是实现个性化检索的基础和关键。Formally represent the obtained user interest information with vector or graphic methods, that is, form a user interest profile. It is stored on the computer, is highly structured, and can be automatically generated and dynamically updated. The user interest profile or interest profile mentioned in this article refers to the user's personal interest profile. Establishing user interest profiles is the basis and key to realize personalized retrieval.
本发明上述步骤二中,所述的用户兴趣树的具体含义如下:In the above-mentioned step 2 of the present invention, the specific meaning of the described user interest tree is as follows:
在多数检索中,用户其实是对某一主题感兴趣。如果用户对检出的某篇文档感兴趣,则他对同一主题的其它文档应当有相同的兴趣。而分类法中同一类目下的文档拥有相同的主题,因此借助分类目录来表示用户兴趣,并将其映射为树状结构,即用户兴趣树(如附图2所示)。用户兴趣树中的节点表示类目。在实际检索中,用户对每个分类的兴趣并不相同,因此在兴趣树中,代表用户兴趣度的节点权值也不同。对语料库中的文档进行分类,则每篇文档均包含在兴趣树的某一节点中;相应地,兴趣树中每篇文档都有其“兴趣路径”。如附图2的兴趣树中,文档《姚明伤愈复出重返火箭》的兴趣路径是:体育~篮球~NBA。文档的兴趣相关因子表示用户对这篇文档的偏好程度,它等于文档所在的兴趣路径上的所有节点的权值的和。上例中,((姚明伤愈复出重返火箭》的兴趣相关因子为:J=w[体育]+w[篮球]+w[NBA]。In most searches, the user is actually interested in a certain topic. If a user is interested in a document checked out, he should be interested in other documents on the same topic. In the taxonomy, the documents under the same category have the same subject, so the user interest is represented by the taxonomy, and it is mapped into a tree structure, that is, the user interest tree (as shown in Figure 2). Nodes in the user interest tree represent categories. In actual retrieval, users have different interests in each category, so in the interest tree, the node weights representing user interest are also different. To classify the documents in the corpus, each document is included in a certain node of the interest tree; correspondingly, each document in the interest tree has its "interest path". As shown in the interest tree in Figure 2, the interest path of the document "Yao Ming returns from injury and returns to the Rockets" is: sports ~ basketball ~ NBA. The interest correlation factor of a document represents the user's preference for this document, which is equal to the sum of the weights of all nodes on the interest path where the document is located. In the above example, ((Yao Ming returned from injury and returned to the Rockets) The correlation factor of interest is: J=w[sports]+w[basketball]+w[NBA].
Claims (5)

















































































Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201410015647.1ACN103778206A (en) | 2014-01-14 | 2014-01-14 | Method for providing network service resources |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201410015647.1ACN103778206A (en) | 2014-01-14 | 2014-01-14 | Method for providing network service resources |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN103778206Atrue CN103778206A (en) | 2014-05-07 |
Family
ID=50570441
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201410015647.1APendingCN103778206A (en) | 2014-01-14 | 2014-01-14 | Method for providing network service resources |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN103778206A (en) |
Cited By (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104102875A (en)* | 2014-07-22 | 2014-10-15 | 河海大学 | Software service quality monitoring method and system based on weighted naive Bayes classifier |
| CN106204083A (en)* | 2015-04-30 | 2016-12-07 | 中国移动通信集团山东有限公司 | A kind of targeted customer's sorting technique, Apparatus and system |
| CN106407445A (en)* | 2016-09-29 | 2017-02-15 | 重庆邮电大学 | Unstructured data resource identification and locating method based on URL (Uniform Resource Locator) |
| CN108229748A (en)* | 2018-01-16 | 2018-06-29 | 北京三快在线科技有限公司 | For the matching process, device and electronic equipment of rideshare service |
| CN108256827A (en)* | 2018-01-10 | 2018-07-06 | 广东轩辕网络科技股份有限公司 | Target job analysis method and system |
| CN108897802A (en)* | 2018-06-14 | 2018-11-27 | 桂林电子科技大学 | A kind of intelligent information browsing method based on data mining |
| CN109063209A (en)* | 2018-09-20 | 2018-12-21 | 新乡学院 | A kind of webpage recommending solution based on probabilistic model |
| CN111414556A (en)* | 2020-02-10 | 2020-07-14 | 华北电力大学 | A service discovery method based on knowledge graph |
| CN114880548A (en)* | 2021-01-21 | 2022-08-09 | 广州视源电子科技股份有限公司 | User interest multi-level processing method, device, equipment and storage medium |
- 2014
- 2014-01-14CNCN201410015647.1Apatent/CN103778206A/enactivePending
Cited By (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104102875A (en)* | 2014-07-22 | 2014-10-15 | 河海大学 | Software service quality monitoring method and system based on weighted naive Bayes classifier |
| CN104102875B (en)* | 2014-07-22 | 2017-05-03 | 河海大学 | Software service quality monitoring method and system based on weighted naive Bayes classifier |
| CN106204083A (en)* | 2015-04-30 | 2016-12-07 | 中国移动通信集团山东有限公司 | A kind of targeted customer's sorting technique, Apparatus and system |
| CN106407445A (en)* | 2016-09-29 | 2017-02-15 | 重庆邮电大学 | Unstructured data resource identification and locating method based on URL (Uniform Resource Locator) |
| CN108256827A (en)* | 2018-01-10 | 2018-07-06 | 广东轩辕网络科技股份有限公司 | Target job analysis method and system |
| CN108229748A (en)* | 2018-01-16 | 2018-06-29 | 北京三快在线科技有限公司 | For the matching process, device and electronic equipment of rideshare service |
| CN108897802A (en)* | 2018-06-14 | 2018-11-27 | 桂林电子科技大学 | A kind of intelligent information browsing method based on data mining |
| CN108897802B (en)* | 2018-06-14 | 2021-04-06 | 桂林电子科技大学 | Intelligent information browsing method based on data mining |
| CN109063209A (en)* | 2018-09-20 | 2018-12-21 | 新乡学院 | A kind of webpage recommending solution based on probabilistic model |
| CN111414556A (en)* | 2020-02-10 | 2020-07-14 | 华北电力大学 | A service discovery method based on knowledge graph |
| CN111414556B (en)* | 2020-02-10 | 2023-11-21 | 华北电力大学 | Knowledge graph-based service discovery method |
| CN114880548A (en)* | 2021-01-21 | 2022-08-09 | 广州视源电子科技股份有限公司 | User interest multi-level processing method, device, equipment and storage medium |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN106997382B (en) | Automatic labeling method and system for innovative creative labels based on big data | |
| CN111680173A (en) | A CMR Model for Unified Retrieval of Cross-Media Information | |
| CN103838833B (en) | Text retrieval system based on correlation word semantic analysis | |
| CN103778206A (en) | Method for providing network service resources | |
| CN103514183B (en) | Information search method and system based on interactive document clustering | |
| CN109829104A (en) | Pseudo-linear filter model information search method and system based on semantic similarity | |
| CN111061939B (en) | Scientific research academic news keyword matching recommendation method based on deep learning | |
| CN108647322B (en) | Method for identifying similarity of mass Web text information based on word network | |
| CN106547864B (en) | A Personalized Information Retrieval Method Based on Query Expansion | |
| CN103425740B (en) | A kind of material information search method based on Semantic Clustering of internet of things oriented | |
| CN110633365A (en) | A hierarchical multi-label text classification method and system based on word vectors | |
| CN101174273A (en) | News Event Detection Method Based on Metadata Analysis | |
| CN112597305B (en) | Scientific literature author name disambiguation method and web end disambiguation device based on deep learning | |
| Karthikeyan et al. | Probability based document clustering and image clustering using content-based image retrieval | |
| CN103761286B (en) | A kind of Service Source search method based on user interest | |
| CN107688870A (en) | A kind of the classification factor visual analysis method and device of the deep neural network based on text flow input | |
| CN113962293A (en) | A Name Disambiguation Method and System Based on LightGBM Classification and Representation Learning | |
| CN104199826A (en) | Heterogeneous media similarity calculation method and retrieval method based on correlation analysis | |
| De Boom et al. | Semantics-driven event clustering in Twitter feeds | |
| CN107291895A (en) | A kind of quick stratification document searching method | |
| CN118445406A (en) | Integration system based on massive polymorphic circuit heritage information | |
| CN117196716A (en) | Digital signage advertising theme recommendation method based on Transformer network model | |
| CN105677830B (en) | A kind of dissimilar medium similarity calculation method and search method based on entity mapping | |
| CN112948544A (en) | Book retrieval method based on deep learning and quality influence | |
| Kinariwala et al. | Onto_TML: Auto-labeling of topic models |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| RJ01 | Rejection of invention patent application after publication | ||
| RJ01 | Rejection of invention patent application after publication | Application publication date:20140507 |