CN103685041A - Programmable router and routing method based on bit granularity - Google Patents
Programmable router and routing method based on bit granularityDownload PDFInfo
- Publication number
- CN103685041A CN103685041ACN201210324804.8ACN201210324804ACN103685041ACN 103685041 ACN103685041 ACN 103685041ACN 201210324804 ACN201210324804 ACN 201210324804ACN 103685041 ACN103685041 ACN 103685041A
- Authority
- CN
- China
- Prior art keywords
- programmable
- data
- packet
- virtual
- bit
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images





Landscapes
- Data Exchanges In Wide-Area Networks (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明涉及互联网技术领域,具体涉及可编程路由器结构,尤其涉及一种基于比特粒度可编程的路由器及路由方法。The invention relates to the technical field of the Internet, in particular to a programmable router structure, in particular to a programmable router based on bit granularity and a routing method.
背景技术Background technique
互联网经历了30余年的发展,取得了巨大的成功,已经成为整个世界不可或缺的信息交流和获取的途径。随着计算机和通信技术的迅速发展,催生了大量新业务以及新协议,比如P2P,VOD,云计算,社交网络,移动互联网等;除此之外,针对以上互联网发展中遇到的问题,互联网领域的研究者们提出了各种新型网络体系结构及改进方案,如内容命名网络(Named Data Network)、服务导向网络、面向移动的网络等,新型网络体系架构在命名编址、路由转发等方面都引入了新的机制,为了满足新协议的需求,网络中传输的数据包格式已经不局限于IP的格式,研究人员不得不加入或减少现有的包头字段或引入自定义的包格式。但是现有的路由器设备难以支持这些新型的数据包处理,这就需要在路由器的数据平面上做相应的创新,使得路由器能够支持各种类型数据包的处理和转发。After more than 30 years of development, the Internet has achieved great success and has become an indispensable way for the entire world to exchange and acquire information. With the rapid development of computer and communication technology, a large number of new services and new protocols have been born, such as P2P, VOD, cloud computing, social networking, mobile Internet, etc.; Researchers in the field have proposed various new network architectures and improvement schemes, such as Named Data Network (Named Data Network), service-oriented network, and mobile-oriented network. A new mechanism has been introduced. In order to meet the requirements of the new protocol, the format of the data packet transmitted in the network is not limited to the IP format. Researchers have to add or reduce the existing packet header fields or introduce a custom packet format. However, it is difficult for existing router equipment to support these new types of data packet processing, which requires corresponding innovations on the data plane of the router, so that the router can support the processing and forwarding of various types of data packets.
现在已经涌现出一些设计结构来提供路由器的可编程能力,它们的可编程的能力和程度由其内部结构决定的。不同的结构具有不同的编程接口和不同的编程复杂度。Click,SwitchBlade采用基于模块的可编程结构,当用户需要添加新的处理功能时,需要了解设备编程原理以及C、Verilog等编程语言,并根据需要重新进行设计并编译整合,这样的编程结构带来较高的设计复杂度,并且在添加新功能时需要设备暂停工作,不提供在线的可编程能力。OpenFlow采用基于流表的结构可在线配置转发的规则,具有很高的灵活性,但OpenFlow的数据平面结构不能变动,如果需要在OpenFlow中添加与转发相关的新协议或功能,如部署非IP协议或基于TCP序号分流等功能则只能在控制器中编写软件实现,不能得到数据平面高速转发的支持,包转发速度将成为瓶颈,而基于IP数据包的十元组编程结构不能提供足够的编程灵活性。今后的数据包结构的改变可能出现在数据包的各个位置,因此需要数据平面具有处理任意类型数据包的能力。Some design structures have emerged to provide routers with programmable capabilities, and their programmable capabilities and degrees are determined by their internal structures. Different structures have different programming interfaces and different programming complexities. Click, SwitchBlade adopts a module-based programmable structure. When users need to add new processing functions, they need to understand the principles of device programming and programming languages such as C and Verilog, and redesign and compile and integrate as needed. This programming structure brings High design complexity, and requires the device to suspend work when adding new functions, and does not provide online programmability. OpenFlow uses a flow table-based structure to configure forwarding rules online, which has high flexibility, but the data plane structure of OpenFlow cannot be changed. If you need to add new protocols or functions related to forwarding in OpenFlow, such as deploying non-IP protocols Or based on TCP serial number distribution and other functions, it can only be realized by writing software in the controller, and cannot be supported by high-speed forwarding of the data plane. The packet forwarding speed will become a bottleneck, and the ten-tuple programming structure based on IP data packets cannot provide enough programming. flexibility. Changes in the future data packet structure may appear in various positions of the data packet, so the data plane is required to have the ability to process any type of data packet.
发明内容Contents of the invention
(一)技术问题(1) Technical issues
本发明要解决的问题是如何提供处理任意类型数据包的数据平面和在线编程能力。The problem to be solved by the present invention is how to provide data plane and online programming capability for processing any type of data packets.
(二)技术方案(2) Technical solution
本发明提供一种可编程虚拟路由器,其包括可编程硬件板卡、PCI/PCI-E总线以及主机,所述硬件板卡通过所述总线与所述主机相连接,通过所述可编程硬件板卡实现比特粒度可编程的数据平面结构,所述数据平面结构支持数据包中任意比特的提取,支持在跨总线长度的边界部分任意比特长度的组合,从而数据包中任意域被进行提取组合,通过多流水线的设计实现多个虚拟路由器;所述主机用于实现虚拟的控制平面,所述虚拟的控制平面与可编程硬件板卡中的多个虚拟路由器动态地连接来形成映射关系。The present invention provides a programmable virtual router, which includes a programmable hardware board, a PCI/PCI-E bus and a host, the hardware board is connected to the host through the bus, and the programmable hardware board The card implements a data plane structure with programmable bit granularity. The data plane structure supports the extraction of any bit in the data packet, and supports the combination of any bit length at the boundary part across the length of the bus, so that any field in the data packet is extracted and combined. Multiple virtual routers are realized through multi-pipeline design; the host computer is used to realize a virtual control plane, and the virtual control plane is dynamically connected with multiple virtual routers in the programmable hardware board to form a mapping relationship.
可选的,所述可编程硬件板卡包括:Optionally, the programmable hardware board includes:
多个输入端口,用于输入数据包,每个输入端口对应有各自的输入队列;Multiple input ports are used to input data packets, and each input port has its own input queue;
输入仲裁模块,用于以轮询或加权轮询的方式分流数据包到各个数据处理单元;The input arbitration module is used to distribute data packets to each data processing unit in a round-robin or weighted round-robin manner;
多个数据处理单元,用于提取数据包的对应时序比特位,并处理固定位宽的数据;A plurality of data processing units are used to extract the corresponding timing bits of the data packet and process data with a fixed bit width;
转发单元,用于进行编程定制转发。The forwarding unit is used for programming and customizing forwarding.
可选的,所述可编程硬件板卡为FPGA板卡。Optionally, the programmable hardware board is an FPGA board.
可选的,所述可编程硬件板卡还包括交换单元,用于在数据包通过转发单元确定转发端口后,对确定转发端口的数据包再选择输出端口。Optionally, the programmable hardware board further includes a switch unit, configured to select an output port for the data packet whose forwarding port is determined after the data packet passes through the forwarding unit to determine the forwarding port.
可选的,所述输入端口和输出端口在网口和PCI/PCI-E总线接口中进行选择。Optionally, the input port and the output port are selected from a network port and a PCI/PCI-E bus interface.
可选的,所述多个数据处理单元结构相同,而且相互级联。Optionally, the multiple data processing units have the same structure and are cascaded with each other.
本发明还提供一种可编程的路由方法,其包括下列步骤:The present invention also provides a programmable routing method, which includes the following steps:
1)利用可编程硬件板卡实现比特粒度可编程的数据平面结构,所述数据平面结构支持数据包中任意比特的提取,支持在跨总线长度的边界部分任意比特长度的组合,从而数据包中任意域被进行提取组合;1) Use the programmable hardware board to realize the data plane structure with programmable bit granularity. The data plane structure supports the extraction of any bit in the data packet, and supports the combination of any bit length in the boundary part of the cross-bus length, so that the data packet Arbitrary fields are extracted and combined;
2)实现虚拟的控制平面,所述虚拟的控制平面与可编程硬件板卡中的多个虚拟路由器动态地连接来形成映射关系。2) A virtual control plane is realized, and the virtual control plane is dynamically connected with multiple virtual routers in the programmable hardware board to form a mapping relationship.
3)通过所述控制平面,对数据平面进行配置和编程。3) Configure and program the data plane through the control plane.
可选的,所述控制平面还用于生成多个虚拟机来运行不同的控制平面协议,虚拟机的端口和可编程硬件板卡中的多个虚拟路由器动态地连接来形成映射关系。Optionally, the control plane is also used to generate multiple virtual machines to run different control plane protocols, and the ports of the virtual machines are dynamically connected to multiple virtual routers in the programmable hardware board to form a mapping relationship.
可选的,所述步骤1)进一步包括:Optionally, said step 1) further includes:
10)通过输入端口输入数据包,每个输入端口对应有各自的输入队列;10) Input the data packet through the input port, and each input port has its own input queue;
11)以轮询或加权轮询的方式分流数据包到各个数据处理单元;11) Distribute data packets to each data processing unit in a polling or weighted polling manner;
12)利用所述数据处理单元提取数据包的对应时序比特位,并处理固定位宽的数据;12) Using the data processing unit to extract the corresponding timing bits of the data packet, and process data with a fixed bit width;
13)利用转发单元进行编程定制转发。13) Use the forwarding unit to program and customize forwarding.
可选的,所述步骤13)进一步包括:Optionally, said step 13) further includes:
131)用户通过编程接口定义数据包的格式和数据域处理方式;131) The user defines the format of the data packet and the processing method of the data field through the programming interface;
132)采用统一定义的可扩展流水线结构来处理数据包的各个数据域,采用将条件表达式映射到TCAM的编程方案来实现转发的可编程控制。132) Use a uniformly defined scalable pipeline structure to process each data field of a data packet, and use a programming scheme that maps conditional expressions to TCAM to realize programmable control of forwarding.
133)通过用户设定的规则来选择控制的内部的处理功能。133) The internal processing function of the control is selected through the rules set by the user.
(三)技术效果(3) Technical effects
本发明通过采用比特粒度可编程和虚拟化的技术手段使得路由器结构能够提供在线的可编程、数据平面高速并行转发、能够处理任意类型数据包的功能。The present invention enables the router structure to provide online programmable, high-speed parallel forwarding of data planes, and the ability to process arbitrary types of data packets by adopting technical means of bit granularity programming and virtualization.
附图说明Description of drawings
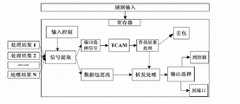
图1表示本发明的基于比特粒度可编程的路由器的整体结构;Fig. 1 shows the overall structure of the programmable router based on bit granularity of the present invention;
图2表示表示本发明的所述路由器的数据平面结构;Fig. 2 shows the data plane structure representing the router of the present invention;
图3表示表示本发明的所述路由器的包处理单元内部结构;Fig. 3 shows the internal structure of the packet processing unit of the router of the present invention;
图4表示本发明的所述路由器的处理级编程的格式;Figure 4 represents the format of the process-level programming of the router of the present invention;
图5表示本发明的所述路由器的转发级的内部结构;Fig. 5 represents the internal structure of the forwarding stage of the router of the present invention;
图6表示本发明的所述路由器的转发级的编程原理;Fig. 6 shows the programming principle of the forwarding stage of the router of the present invention;
图7表示IP数据包在数据平面中的处理格式;Fig. 7 represents the processing format of IP packet in the data plane;
图8表示编程配置IPv4路由器的处理级编程脚本格式;Fig. 8 represents the processing level programming script format of programming configuration IPv4 router;
图9表示编程配置IPv4路由器的转发级编程脚本格式。Figure 9 shows the format of a forwarding level programming script to programmatically configure an IPv4 router.
具体实施方式Detailed ways
实施例1:Example 1:
本发明提供一种可编程虚拟路由器,其包括可编程硬件板卡、PCI/PCI-E总线以及主机,所述硬件板卡通过所述总线与所述主机相连接,通过所述可编程硬件板卡实现比特粒度可编程的数据平面结构,所述数据平面结构支持数据包中任意比特的提取,支持在跨总线长度的边界部分任意比特长度的组合,从而数据包中任意域被提取和组合,通过多流水线的设计实现多个虚拟路由器;所述主机用于实现虚拟的控制平面,所述虚拟的控制平面与可编程硬件板卡中的多个虚拟路由器动态地连接形成映射关系。The present invention provides a programmable virtual router, which includes a programmable hardware board, a PCI/PCI-E bus and a host, the hardware board is connected to the host through the bus, and the programmable hardware board The card implements a data plane structure with programmable bit granularity. The data plane structure supports the extraction of any bit in the data packet, and supports the combination of any bit length at the boundary part across the length of the bus, so that any field in the data packet is extracted and combined. Multiple virtual routers are realized through multi-pipeline design; the host computer is used to realize a virtual control plane, and the virtual control plane is dynamically connected with multiple virtual routers in the programmable hardware board to form a mapping relationship.
可选的,所述可编程硬件板卡包括:Optionally, the programmable hardware board includes:
多个输入端口,用于输入数据包,每个输入端口对应有各自的输入队列;Multiple input ports are used to input data packets, and each input port has its own input queue;
输入仲裁模块,用于以轮询或加权轮询的方式分流数据包到各个数据处理单元;The input arbitration module is used to distribute data packets to each data processing unit in a round-robin or weighted round-robin manner;
多个数据处理单元,用于提取数据包的对应时序比特位,并处理固定位宽的数据;A plurality of data processing units are used to extract the corresponding timing bits of the data packet and process data with a fixed bit width;
转发单元,用于进行编程定制转发。The forwarding unit is used for programming and customizing forwarding.
可选的,所述可编程硬件板卡为FPGA板卡。Optionally, the programmable hardware board is an FPGA board.
可选的,所述可编程硬件板卡还包括交换单元,用于在数据包通过转发单元确定转发端口后,对确定转发端口的数据包再选择输出端口。Optionally, the programmable hardware board further includes a switch unit, configured to select an output port for the data packet whose forwarding port is determined after the data packet passes through the forwarding unit to determine the forwarding port.
可选的,所述输入端口和输出端口在网口和PCI/PCI-E总线中进行选择。Optionally, the input port and the output port are selected from a network port and a PCI/PCI-E bus.
可选的,所述多个数据处理单元结构相同,而且相互级联。Optionally, the multiple data processing units have the same structure and are cascaded with each other.
本发明还提供一种基于比特粒度可编程的路由方法,其包括下列步骤:The present invention also provides a programmable routing method based on bit granularity, which includes the following steps:
1)利用可编程硬件板卡实现比特粒度可编程的数据平面结构,所述数据平面结构支持数据包中任意比特的提取,支持在跨总线长度的边界部分任意比特长度的组合,数据包中任意域都可以被提取和组合;1) Use programmable hardware boards to realize a data plane structure with programmable bit granularity. The data plane structure supports the extraction of any bit in the data packet, supports the combination of any bit length in the boundary part of the cross-bus length, and any bit in the data packet. domains can be extracted and combined;
2)实现虚拟的控制平面,所述虚拟的控制平面与可编程硬件板卡中的多个虚拟路由器动态地连接来形成映射关系。2) A virtual control plane is realized, and the virtual control plane is dynamically connected with multiple virtual routers in the programmable hardware board to form a mapping relationship.
3)通过所述控制平面,对数据平面进行配置和编程。3) Configure and program the data plane through the control plane.
可选的,所述控制平面还用于生成多个虚拟机来运行不同的控制平面协议,虚拟机的端口和可编程硬件板卡中的多个虚拟路由器动态地连接来形成映射关系。Optionally, the control plane is also used to generate multiple virtual machines to run different control plane protocols, and the ports of the virtual machines are dynamically connected to multiple virtual routers in the programmable hardware board to form a mapping relationship.
可选的,所述步骤1)进一步包括:Optionally, said step 1) further includes:
10)通过输入端口输入数据包,每个输入端口对应有各自的输入队列;10) Input the data packet through the input port, and each input port has its own input queue;
11)以轮询或加权轮询的方式分流数据包到各个数据处理单元;11) Distribute data packets to each data processing unit in a polling or weighted polling manner;
12)利用所述数据处理单元提取数据包的对应时序比特位,并处理固定位宽的数据;12) Using the data processing unit to extract the corresponding timing bits of the data packet, and process data with a fixed bit width;
13)利用转发单元进行编程定制转发。13) Use the forwarding unit to program and customize forwarding.
可选的,所述步骤13)进一步包括:Optionally, said step 13) further includes:
131)用户通过编程接口定义数据包的格式和数据域处理方式;131) The user defines the format of the data packet and the processing method of the data field through the programming interface;
132)采用统一定义的可扩展流水线结构来处理数据包的各个数据域,采用将条件表达式映射到TCAM的编程方案来实现转发的可编程控制。132) Use a uniformly defined scalable pipeline structure to process each data field of a data packet, and use a programming scheme that maps conditional expressions to TCAM to realize programmable control of forwarding.
133)通过用户设定的规则来选择控制的内部的处理功能。133) The internal processing function of the control is selected through the rules set by the user.
实施例2:Example 2:
本实施例与交换芯片,网络处理器等ASIC结构的方案不同,采用可编程硬件如FPGA来构建数据平面的功能可以实现比特粒度可编程的数据平面结构,这是因为FPGA的内部逻辑都可以由开发人员定义,这样可以保证每个处理环节按照我们的思想进行设计和部署。This embodiment is different from the schemes of ASIC structures such as switching chips and network processors. The function of using programmable hardware such as FPGA to build the data plane can realize the data plane structure with programmable bit granularity. This is because the internal logic of the FPGA can be configured by Defined by developers, this ensures that each processing link is designed and deployed according to our ideas.
(1)总体结构(1) Overall structure
图1中所示为可编程数据平面的硬件结构,数据平面基于可编程硬件,如FPGA等,数据包通过输入端口如网口,PCI等总线接口输入到板卡中,每个输入端口对应有各自的输入队列,数据包在其中以FIFO方式排队。一个高速的输入仲裁模块以轮询或加权轮询的方式分流数据包到各个虚拟的数据平面,即相互分离的转发流水线中,这些流水线都是同构的。流水线的包头处理部分是由相同结构的包处理单元构成,为了实现数据包的比特粒度的可编程能力,处理流水线的每个处理单元可以将数据包的对应时序比特位提取出来,每个单元可以处理固定位宽的数据,前后级的处理单元也可组合成更长的处理宽度,用户可以通过配置处理规则来对各个处理单元的功能进行配置。在处理功能上可以选择TCAM查表,哈希匹配,基本运算等来处理比特组合成的数据域,所有处理单元的处理结果都会最终汇聚输出到转发级;在转发级,用户可以通过配置TCAM查找转发表来实现编程定制转发功能,但数据包的转发端口确定后,数据包发送到交换单元进行交换输出,输出的选择与输入端口一样可以在网口以及PCI等总线中选择。硬件板卡通过PCI/PCI-E与主机相连接,控制平面的功能位于主机中,主要的功能包括控制平面的虚拟化机制,虚拟机的端口和数据平面板卡的动态映射机制以及对数据平面的配置和控制功能。控制平面可以生成多个虚拟机来运行不同的控制平面协议,这些虚拟的控制平面可以与硬件中的多个虚拟路由器动态地连接来形成映射关系。数据平面的配置和编程也是通过控制平面实现,控制平面可以通过对硬件中寄存器配置来实现数据平面的编程功能。Figure 1 shows the hardware structure of the programmable data plane. The data plane is based on programmable hardware, such as FPGA, etc. Data packets are input to the board through input ports such as network ports, PCI bus interfaces, etc. Each input port corresponds to a Respective input queues in which packets are queued in FIFO fashion. A high-speed input arbitration module distributes data packets to each virtual data plane in a polling or weighted polling manner, that is, separate forwarding pipelines, and these pipelines are isomorphic. The packet header processing part of the pipeline is composed of packet processing units with the same structure. In order to realize the programmability of the bit granularity of the data packet, each processing unit of the processing pipeline can extract the corresponding timing bits of the data packet, and each unit can To process data with a fixed bit width, the processing units of the front and rear stages can also be combined to form a longer processing width. Users can configure the functions of each processing unit by configuring the processing rules. In terms of processing functions, TCAM table lookup, hash matching, and basic operations can be selected to process the data field composed of bits. The processing results of all processing units will be aggregated and output to the forwarding level; at the forwarding level, users can configure TCAM The forwarding table is used to realize the programming custom forwarding function, but after the forwarding port of the data packet is determined, the data packet is sent to the switching unit for switching output, and the selection of the output can be selected in the network port and PCI bus like the input port. The hardware board is connected to the host through PCI/PCI-E. The function of the control plane is located in the host. The main functions include the virtualization mechanism of the control plane, the dynamic mapping mechanism of the port of the virtual machine and the data plane board, and the data plane configuration and control functions. The control plane can generate multiple virtual machines to run different control plane protocols, and these virtual control planes can be dynamically connected with multiple virtual routers in the hardware to form a mapping relationship. The configuration and programming of the data plane are also realized through the control plane, and the control plane can realize the programming function of the data plane by configuring the registers in the hardware.
(2)处理级流水线详细结构及编程规则(2) Detailed structure and programming rules of the processing-level pipeline
流水线结构图如图2所示,处理级部分是由完全同构的包处理单元级联而成的,数据包输入到处理级有两条路径,一条是进入包处理单元进行查找,判断等操作,处理结果供转发级判断输出的端口和目的地址;还有另一条路径是基于这样的考虑:输出的端口判断是在包头处理完毕后才能决定,而此时的总线数据已经没有了包头的数据,就需要包头的数据在FIFO中缓存以供输出。The pipeline structure diagram is shown in Figure 2. The processing stage is formed by cascading completely isomorphic packet processing units. There are two paths for data packets to be input to the processing stage. One is to enter the packet processing unit for search, judgment and other operations. , the processing results are used by the forwarding stage to judge the output port and destination address; there is another path based on the consideration that the output port judgment can only be determined after the packet header is processed, and the bus data at this time has no packet header data. , the data of the header needs to be buffered in the FIFO for output.
每个包处理单元在时序控制模块的统一控制下实现对应数据域的处理,每个模块中都有很多寄存器来分别存储可编程的信息,这些寄存器的位宽和功能也是不同的,如两种输入的掩码选择,处理的运算选择,运算的操作数,输出的目的模块选择,输出的结果选择,以及输出的偏移量等等。对数据域的选择和处理都是基于用户对这些寄存器的编程控制,整个处理单元结构如图3所示,它的数据输入包括两个部分:当前总线上需要处理的数据和前一级处理完后的数据,这两部分的数据可根据输入规则进行任意组合,组合后的数据可以选择匹配规则及相应的处理方式,预定义的匹配规则包括哈希匹配、TCAM查找以及比较操作,哈希匹配用于最基本的匹配情况,如MAC地址的分类,包类型的识别,都只需要将某一数据域与特定的数值进行比较;TCAM查找功能用于路由表查找,ARP表查找等需要进行高速查表操作的情况;比较操作用于TTL比较等需要进行数据比较的场合。处理结果有两个输出方向,某些规则的处理结果会输出到下一级,如最长前缀匹配的结果;其他规则的处理结果会输出到转发级,这些处理结果会决定数据包的最终输出格式及输出端口。Each packet processing unit realizes the processing of the corresponding data field under the unified control of the timing control module. There are many registers in each module to store programmable information respectively. The bit width and function of these registers are also different, such as two Input mask selection, processing operation selection, operation operands, output destination module selection, output result selection, and output offset, etc. The selection and processing of the data fields are based on the user's programming control of these registers. The structure of the entire processing unit is shown in Figure 3. Its data input includes two parts: the data that needs to be processed on the current bus and the data that has been processed by the previous stage. These two parts of data can be combined arbitrarily according to the input rules. The combined data can choose matching rules and corresponding processing methods. The predefined matching rules include hash matching, TCAM search and comparison operations, and hash matching It is used for the most basic matching situations, such as the classification of MAC addresses and the identification of packet types. It only needs to compare a certain data field with a specific value; the TCAM lookup function is used for routing table lookup, ARP table lookup, etc. The case of table lookup operation; the comparison operation is used in occasions where data comparison is required, such as TTL comparison. The processing results have two output directions. The processing results of some rules will be output to the next level, such as the result of the longest prefix match; the processing results of other rules will be output to the forwarding level, and these processing results will determine the final output of the packet format and output port.
处理级的配置规则格式如图4所示,整体来讲它包括13个域,分别为字选择,用于选择当前规则使用的处理流水单元所处位置;偏移量用于选择所需要处理的比特在两种输入数据部分所处位置;匹配模式用于选择匹配操作的类型;操作部分定义了操作的类型以及操作数的数值;输出控制部分主要用于选择输出的格式以及输出方向,每条规则都可以定义自己处理后的输出在整个输出数据中的偏移量,输出目的的选择是为了确定模块的输出是到下一级还是最终的转发级。The configuration rule format of the processing level is shown in Figure 4. Generally speaking, it includes 13 fields, which are word selections, which are used to select the location of the processing pipeline unit used by the current rule; the offset is used to select the required processing The position of the bit in the two input data parts; the matching mode is used to select the type of matching operation; the operation part defines the type of operation and the value of the operand; the output control part is mainly used to select the output format and output direction, each Each rule can define the offset of the processed output in the entire output data. The selection of the output purpose is to determine whether the output of the module is to the next level or the final forwarding level.
(3)转发级详细结构及编程规则(3) Forwarding level detailed structure and programming rules
转发级由单个模块构成,其结构如图5所示,来自各个处理单元的输出结果作为该模块的输入,这些输入包括了用于数据包更改的信息以及用于确定输出端口的判断选择信息,该模块内部也有寄存器来区分这两部分的数据,包括每个输入的偏移量,功能和处理方式可以在寄存器中做相应的控制。用于更改数据包的信息可以在输出时直接替换所需更改的数据域;而用于输出端口判断的信息会一般经过复杂的逻辑选择来确定最终的输出端口,对于普通的路由器或中间盒来讲,这些输入会在有限状态机中以条件表达式的方式进行处理,但是这种方式不易于可编程的实现,为了解决这一问题,我们采用了条件表达式映射的方式来解决这一问题。以图5为例,输入信号包括L,M,N三个判断信号,每个占用1比特的宽度,条件表达式如最左侧代码所示,不同的逻辑组合导致丢包,转发到网络端口以及转发到控制平面等决策。这样一个结构很容易通过树形结构的决策树来表示,如中间的图形所示,而我们知道为了表示3个比特的所有组合关系需要用到23=8个树节点来表示,当比特宽度增加时,需要表示的节点数将会指数增加,这就意味着需要与节点数目相同的表项来表示,使得编程的复杂度和资源占用率极高,为了解决这一问题进而我们利用TCAM的三态查找的特点来进行可编程能力的优化,以图中表达式为例,与所需要的状态无关的组合可以用TCAM中的不定态来替代,这样就可以将8条规则压缩到4条,而当比特宽度增加时,压缩比将会进一步增大。通过这种方式可以实现转发目的端口的可编程选择。The forwarding stage is composed of a single module, and its structure is shown in Figure 5. The output results from each processing unit are used as the input of the module, and these inputs include information for data packet modification and judgment and selection information for determining the output port. There are also registers inside the module to distinguish the two parts of data, including the offset of each input, and the functions and processing methods can be controlled in the registers accordingly. The information used to change the data packet can directly replace the data field that needs to be changed when outputting; while the information used to judge the output port will usually go through complex logic selection to determine the final output port. For ordinary routers or middle boxes In other words, these inputs will be processed in the form of conditional expressions in the finite state machine, but this method is not easy to implement programmable. In order to solve this problem, we use the method of conditional expression mapping to solve this problem . Taking Figure 5 as an example, the input signal includes three judgment signals L, M, and N, each occupying a width of 1 bit, and the conditional expression is shown in the leftmost code, and different logical combinations cause packet loss, which is forwarded to the network port And decisions like forwarding to the control plane. Such a structure is easily represented by a tree-structured decision tree, as shown in the middle figure, and we know that 23=8 tree nodes are required to represent all the combination relationships of 3 bits. When the bit width increases When , the number of nodes that need to be represented will increase exponentially, which means that the same number of entries as the number of nodes is required to represent, which makes the programming complexity and resource occupancy rate extremely high. In order to solve this problem, we use the three The characteristics of state search are used to optimize the programmability. Taking the expression in the figure as an example, the combination that has nothing to do with the required state can be replaced by the indeterminate state in TCAM, so that 8 rules can be compressed to 4. And when the bit width increases, the compression ratio will further increase. In this way, the programmable selection of the forwarding destination port can be realized.
为了使得我们的结构能够与集中式的网络协议和控制系统相匹配,如OpenFlow等协议,数据平面允许利用流表的格式进行配置,比如OpenFlow的十元组流表匹配域可以先转换成处理级的对应比特的操作,而流表的Action域则可以转化为TCAM表形式进行转发,这样我们的数据平面既可以基于分布式的路由协议进行编程又可以基于集中式的控制器进行流表等配置实现集中控制。In order to make our structure match with centralized network protocols and control systems, such as OpenFlow and other protocols, the data plane allows configuration using the format of the flow table. For example, OpenFlow’s ten-tuple flow table matching domain can be converted to The corresponding bit operation of the flow table, and the Action field of the flow table can be converted into a TCAM table form for forwarding, so that our data plane can be programmed based on a distributed routing protocol and can be configured based on a centralized controller such as a flow table Realize centralized control.
实施例3:Example 3:
本发明具体可实施的场景包括:Specific implementable scenarios of the present invention include:
实施场景一:商用网络,包括当前基于IPv4的互联网以及基于IPv6的网络,路由器的灵活可编程性兼容当前的网络协议和标准。Implementation Scenario 1: Commercial networks, including the current IPv4-based Internet and IPv6-based networks, the flexible programmability of routers is compatible with current network protocols and standards.
实施场景二:网络创新实验平台,网络体系结构的创新需要实验平台来进行实验测试,它有内在的可编程路由器的需求。Implementation Scenario 2: Network Innovation Experimental Platform. The innovation of network architecture requires an experimental platform for experimental testing, which has an inherent requirement for programmable routers.
实施场景三:数据中心网络,为了使得数据中心内部的网络高效运行,研究人员提出很多新的协议,这些协议也对中间盒的可编程能力提出了要求。Implementation Scenario 3: Data center network. In order to make the network inside the data center run efficiently, researchers have proposed many new protocols. These protocols also put forward requirements for the programmability of the middle box.
我们以最常用的商用网络中IPv4路由器为例来描述可编程能力,IP包在数据平面中的处理格式如图7所示,图中每64比特划分为一个字,每个字单独由一个包处理单元处理,以每个字需要处理的内容我们划分每个字的功能:字0是数据包的控制字,包括包长度以及包的输入端口信息,这一部分由于不是包头信息,所以不用处理;字1包括目的MAC地址(63位-16位),路由器需要判断目的MAC地址是否发到本地以及是否为广播数据包,如果是广播包则需要发送的控制平面;字2中需要判断数据包的类型(31位-16位),确定它是否为IP包或非IP如ARP包;字3中需要判断TTL的数值(15位-8位)是否正确,如果正确的话需要做TTL减一的操作;字4中需要判断校验值(63位-48位)是否正确,并且把目的IP地址高16位(15位-0位)发送到下一级;字5需要将目的IP地址低16位(63-48位)与上级的输入组合成32位的目的IP地址,并进行LPM的查找,查找结果输出到下一级(第6级)进行ARP查找的处理。我们定义的规则如图8所示,这些处理的输出最终汇聚到转发级。We take the most commonly used IPv4 router in commercial networks as an example to describe the programmability. The processing format of IP packets in the data plane is shown in Figure 7. In the figure, each 64 bits is divided into a word, and each word consists of a packet Processing unit processing, we divide the function of each word according to the content that each word needs to process:
转发级将判断信号分离出来后会得到9种判断信号,路由器需要根据这些信号来进行转发的处理,用户可以通过图9中所示的TCAM查找表的规则来定义数据包的转发目的端口及地址。第一条规则描述了从控制平面发来的数据可以直接从相应端口输出,第二条到第七条规则做了如下定义,以下类型的包需要发送到控制平面:非IP包、校验错误的数据包、指定发到控制平面、包头有选项、TTL错误以及LPM查找未命中和ARP查找未命中的都会发送到控制平面,只有正常的数据包在LPM和ARP查找都命中后才会从查找后的端口输出。After the forwarding stage separates the judgment signals, it will get 9 kinds of judgment signals. The router needs to perform forwarding processing according to these signals. The user can define the forwarding destination port and address of the data packet through the rules of the TCAM lookup table shown in Figure 9. . The first rule describes that the data sent from the control plane can be directly output from the corresponding port. The second to seventh rules are defined as follows. The following types of packets need to be sent to the control plane: non-IP packets, checksum errors The data packets that are specified to be sent to the control plane, have options in the header, TTL errors, LPM lookup misses and ARP lookup misses will all be sent to the control plane. Only normal data packets will be sent from the lookup after both LPM and ARP lookups are hit After the port output.
由前面的详细说明可知,本发明提出的基于比特粒度可编程虚拟路由器由两部分组成,基于在操作系统运行软件构成控制平面及基于可编程硬件构成数据平面。本发明设计的比特粒度可编程的路由器结构上可以部署各种已有的和今后可能的协议。As can be seen from the foregoing detailed description, the programmable virtual router based on bit granularity proposed by the present invention consists of two parts, a control plane based on software running in an operating system and a data plane based on programmable hardware. Various existing and future possible protocols can be deployed on the structure of the programmable router with bit granularity designed by the present invention.
它具有如下的特性:It has the following characteristics:
比特粒度可编程:为了适应网络发展的需求,路由器需要支持新业务和新体系架构的创新,网络中间盒不能仅在控制平面有所创新,更需要数据平面的创新来支持各种类型数据包的处理。数据平面允许任意比特的提取,在跨总线长度的边界部分允许任意比特长度的组合,实现数据包中任意域的提取组合能力,提取出的数据域允许用户定义处理功能,比如TCAM查找,哈希匹配,比较,运算等操作,以实现数据包处理的可编程能力;包的转发目的端口和目的地址决定于包头的处理结果,为了使得包转发的方式也能够通过编程实现,数据平面将包头处理结果编码并利用TCAM的三态查找能力来确定数据包的最终输出。Programmable bit granularity: In order to meet the needs of network development, routers need to support innovations in new services and new architectures. Network middleboxes cannot only innovate in the control plane, but also require innovations in the data plane to support various types of data packets. deal with. The data plane allows the extraction of arbitrary bits, and allows the combination of arbitrary bit lengths in the boundary part across the length of the bus to realize the ability to extract and combine arbitrary fields in the data packet. The extracted data fields allow users to define processing functions, such as TCAM lookup, hash Matching, comparison, operation and other operations to realize the programmable capability of data packet processing; the forwarding destination port and destination address of the packet are determined by the processing result of the packet header. The result is encoded and utilizes the TCAM's tri-state lookup capability to determine the final output of the packet.
虚拟化支持:为了使得路由器可以允许多个不同网络同时运行,这些网络既可以是同构的也可以是异构的,路由器需要能够支持虚拟化,即多个路由器实例同时运行。路由器需要在控制平面上需要完全分离的功能,功能独立运行,可以分别配置各自协议,他们之间互不影响,具有良好隔离性;在数据平面上,各路由器实例中的数据能够分别进行高速的处理,处理后的数据能够以一种有效地方式进行重新聚合。Virtualization support: In order for the router to allow multiple different networks to run at the same time, these networks can be either homogeneous or heterogeneous, the router needs to be able to support virtualization, that is, multiple router instances run at the same time. The router needs to have completely separated functions on the control plane, the functions can run independently, and their respective protocols can be configured separately, and they do not affect each other and have good isolation; on the data plane, the data in each router instance can be separately high-speed Processing, the processed data can be re-aggregated in an efficient manner.
以上实施方式仅用于说明本发明,而并非对本发明的限制,如本发明还可用于收割其他农作物,有关技术领域的普通技术人员,在不脱离本发明的精神和范围的情况下,还可以做出各种变化和变型,因此所有等同的技术方案也属于本发明的范畴,本发明的专利保护范围应由权利要求限定。The above embodiments are only used to illustrate the present invention, rather than limitation of the present invention, as the present invention can also be used for harvesting other crops, those of ordinary skill in the relevant technical field, without departing from the spirit and scope of the present invention, can also Various changes and modifications are made, so all equivalent technical solutions also belong to the category of the present invention, and the scope of patent protection of the present invention should be defined by the claims.
Claims (10)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201210324804.8ACN103685041B (en) | 2012-09-04 | 2012-09-04 | Programmable router and routing method based on bit granularity |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201210324804.8ACN103685041B (en) | 2012-09-04 | 2012-09-04 | Programmable router and routing method based on bit granularity |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN103685041Atrue CN103685041A (en) | 2014-03-26 |
| CN103685041B CN103685041B (en) | 2017-04-19 |
Family
ID=50321397
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201210324804.8AExpired - Fee RelatedCN103685041B (en) | 2012-09-04 | 2012-09-04 | Programmable router and routing method based on bit granularity |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN103685041B (en) |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104009924A (en)* | 2014-05-19 | 2014-08-27 | 北京东土科技股份有限公司 | A message processing method and device based on TCAM and FPGA |
| CN107528786A (en)* | 2017-07-19 | 2017-12-29 | 杜景钦 | Intelligent router based on parallel processing and the Internet of Things application system built with this |
| CN108768892A (en)* | 2018-03-26 | 2018-11-06 | 西安电子科技大学 | A kind of programmable data plane based on P4 exchanges the design and realization of prototype |
| CN108989203A (en)* | 2017-05-31 | 2018-12-11 | 瞻博网络公司 | Selected structural path of the notice for the service routing in dummy node |
| CN114221849A (en)* | 2020-09-18 | 2022-03-22 | 芯启源(南京)半导体科技有限公司 | Method for realizing intelligent network card by combining FPGA with TCAM |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109873769A (en)* | 2018-12-28 | 2019-06-11 | 安徽中瑞通信科技股份有限公司 | A kind of intelligent router based on 5G communication |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN1516840A (en)* | 2001-04-25 | 2004-07-28 | �ź㴫 | Adaptive Multiprotocol Communication System |
| CN1674557A (en)* | 2005-04-01 | 2005-09-28 | 清华大学 | Parallel IP packet sorter matched with settling range based on TCAM and method thereof |
| CN1728702A (en)* | 2004-07-29 | 2006-02-01 | 国家数字交换系统工程技术研究中心 | Method for separating control plane of router from hardware of data plane |
| CN101877671A (en)* | 2009-12-02 | 2010-11-03 | 北京星网锐捷网络技术有限公司 | Sending method of mirror image message, switch chip and Ethernet router |
| CN102065021A (en)* | 2011-01-28 | 2011-05-18 | 北京交通大学 | IPSecVPN (Internet Protocol Security Virtual Private Network) realizing system and method based on NetFPGA (Net Field Programmable Gate Array) |
| CN102231708A (en)* | 2011-07-04 | 2011-11-02 | 清华大学 | Virtual routing device and routing method thereof |
- 2012
- 2012-09-04CNCN201210324804.8Apatent/CN103685041B/ennot_activeExpired - Fee Related
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN1516840A (en)* | 2001-04-25 | 2004-07-28 | �ź㴫 | Adaptive Multiprotocol Communication System |
| CN1728702A (en)* | 2004-07-29 | 2006-02-01 | 国家数字交换系统工程技术研究中心 | Method for separating control plane of router from hardware of data plane |
| CN1674557A (en)* | 2005-04-01 | 2005-09-28 | 清华大学 | Parallel IP packet sorter matched with settling range based on TCAM and method thereof |
| CN101877671A (en)* | 2009-12-02 | 2010-11-03 | 北京星网锐捷网络技术有限公司 | Sending method of mirror image message, switch chip and Ethernet router |
| CN102065021A (en)* | 2011-01-28 | 2011-05-18 | 北京交通大学 | IPSecVPN (Internet Protocol Security Virtual Private Network) realizing system and method based on NetFPGA (Net Field Programmable Gate Array) |
| CN102231708A (en)* | 2011-07-04 | 2011-11-02 | 清华大学 | Virtual routing device and routing method thereof |
Non-Patent Citations (2)
| Title |
|---|
| ZHONGJIN LIU等: "Grainflow : A Per-bit Customizable Scheme For Data Plane Innovation on Programmable Hardware", 《PROCEEDINGS OF THE ACM CONEXT STUDENT WORKSHOP》* |
| 杨懋等: "基于可编程硬件的虚拟路由器控制平面", 《清华大学学报(自然科学版)》* |
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104009924A (en)* | 2014-05-19 | 2014-08-27 | 北京东土科技股份有限公司 | A message processing method and device based on TCAM and FPGA |
| CN104009924B (en)* | 2014-05-19 | 2017-04-12 | 北京东土科技股份有限公司 | Message processing method and device based on TCAM and FPGA |
| CN108989203A (en)* | 2017-05-31 | 2018-12-11 | 瞻博网络公司 | Selected structural path of the notice for the service routing in dummy node |
| CN108989203B (en)* | 2017-05-31 | 2021-06-18 | 瞻博网络公司 | Advertise selected fabric paths for service routing in virtual nodes |
| CN107528786A (en)* | 2017-07-19 | 2017-12-29 | 杜景钦 | Intelligent router based on parallel processing and the Internet of Things application system built with this |
| CN108768892A (en)* | 2018-03-26 | 2018-11-06 | 西安电子科技大学 | A kind of programmable data plane based on P4 exchanges the design and realization of prototype |
| CN114221849A (en)* | 2020-09-18 | 2022-03-22 | 芯启源(南京)半导体科技有限公司 | Method for realizing intelligent network card by combining FPGA with TCAM |
| CN114221849B (en)* | 2020-09-18 | 2024-03-19 | 芯启源(南京)半导体科技有限公司 | Method for realizing intelligent network card by combining FPGA with TCAM |
Also Published As
| Publication number | Publication date |
|---|---|
| CN103685041B (en) | 2017-04-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11546189B2 (en) | Access node for data centers | |
| US10812378B2 (en) | System and method for improved service chaining | |
| US20240264964A1 (en) | Multi-plane, multi-protocol memory switch fabric with configurable transport | |
| US20200265005A1 (en) | Network traffic routing in distributed computing systems | |
| CN108833299B (en) | Large-scale network data processing method based on reconfigurable switching chip architecture | |
| CN103685041B (en) | Programmable router and routing method based on bit granularity | |
| US8599863B2 (en) | System and method for using a multi-protocol fabric module across a distributed server interconnect fabric | |
| US20190109793A1 (en) | Network server systems, architectures, components and related methods | |
| US20190116133A1 (en) | Ruled-based network traffic interception and distribution scheme | |
| CN102334112A (en) | Method and system for virtual machine networking | |
| Hojabr et al. | Customizing clos network-on-chip for neural networks | |
| US9160659B2 (en) | Paravirtualized IP over infiniband bridging | |
| CN103516633B (en) | Method and apparatus for providing service in distribution switch | |
| CN114697276A (en) | Broadcast switch system in network on chip (NoC) | |
| US9331935B2 (en) | Network device selection | |
| Koldehofe et al. | Tutorial: Event-based systems meet software-defined networking | |
| US9898069B1 (en) | Power reduction methods for variable sized tables | |
| CN107566238A (en) | A kind of method of User space configuration physical interface automatic identification vlan frames and non-vlan frames | |
| Ahmad et al. | Protection of centralized SDN control plane from high-rate Packet-In messages | |
| CN116156027B (en) | Action execution engine supporting RMT and execution method thereof | |
| Lant et al. | Enabling shared memory communication in networks of MPSoCs | |
| Biswas et al. | Implementing a partial group based routing for homogeneous fat tree network on chip architecture | |
| Duan et al. | Separating VNF and Network Control for Hardware‐Acceleration of SDN/NFV Architecture | |
| CN115701060A (en) | Message transmission method and related device | |
| Toyohara et al. | Distributed MQTT brokers infrastructure with network transparent hardware broker |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant | ||
| CF01 | Termination of patent right due to non-payment of annual fee | ||
| CF01 | Termination of patent right due to non-payment of annual fee | Granted publication date:20170419 Termination date:20210904 |