CN102546034B - Method and equipment for processing voice signals - Google Patents
Method and equipment for processing voice signalsDownload PDFInfo
- Publication number
- CN102546034B CN102546034BCN 201210026441CN201210026441ACN102546034BCN 102546034 BCN102546034 BCN 102546034BCN 201210026441CN201210026441CN 201210026441CN 201210026441 ACN201210026441 ACN 201210026441ACN 102546034 BCN102546034 BCN 102546034B
- Authority
- CN
- China
- Prior art keywords
- data
- function
- group data
- group
- function group
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
- 238000000034methodMethods0.000titleclaimsdescription27
- 238000012545processingMethods0.000titleclaimsdescription14
- 238000003672processing methodMethods0.000claimsabstractdescription15
- 238000013139quantizationMethods0.000claimsdescription9
- 238000006243chemical reactionMethods0.000claimsdescription6
- 238000005070samplingMethods0.000claimsdescription4
- 230000003044adaptive effectEffects0.000claimsdescription2
- 230000005236sound signalEffects0.000claims1
- 238000004519manufacturing processMethods0.000abstractdescription4
- 230000006870functionEffects0.000description33
- 125000000524functional groupChemical group0.000description30
- 230000008569processEffects0.000description15
- 238000010586diagramMethods0.000description4
- 238000001208nuclear magnetic resonance pulse sequenceMethods0.000description4
- 238000004422calculation algorithmMethods0.000description3
- 230000004044responseEffects0.000description3
- 238000004364calculation methodMethods0.000description2
- 238000013075data extractionMethods0.000description2
- 238000001514detection methodMethods0.000description2
- 238000011161developmentMethods0.000description2
- 230000003993interactionEffects0.000description2
- 238000012986modificationMethods0.000description2
- 230000004048modificationEffects0.000description2
- 238000007781pre-processingMethods0.000description2
- 241001672694Citrus reticulataSpecies0.000description1
- 238000012217deletionMethods0.000description1
- 230000037430deletionEffects0.000description1
- 238000003780insertionMethods0.000description1
- 230000037431insertionEffects0.000description1
- 230000007257malfunctionEffects0.000description1
- 230000003287optical effectEffects0.000description1
- 238000001228spectrumMethods0.000description1
Images








Landscapes
- Selective Calling Equipment (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明涉及信号处理领域,尤其涉及一种语音信号处理方法及设备。 The invention relates to the field of signal processing, in particular to a voice signal processing method and equipment. the
背景技术Background technique
作为数字设备的一种,现在机顶盒在开发生产的过程中都要进行人机交互,人机交互的方式一般有两种,其一是采用遥控器进行遥控操作,其二是通过前面板进行按键操作。 As a kind of digital equipment, human-computer interaction is required in the development and production process of set-top boxes. There are generally two ways of human-computer interaction. operate. the
遥控器虽然便携,但随着社会的发展,家用电器越来越多,遥控器也越来越多。其结果是容易混淆和丢失,遥控器还比容易较损坏或失灵,既增加了成本和让客户使用不方便。前面板用户操作起来就更不方便了。特别对于无法手动操作的残疾人,遥控器或前面板的操作更加不便。 Although the remote control is portable, with the development of society, there are more and more household appliances, and there are more and more remote controls. As a result, it is easy to be confused and lost, and the remote control is relatively easy to damage or malfunction, which not only increases the cost but also makes it inconvenient for customers to use. It is even more inconvenient for the front panel user to operate. Especially for disabled persons who cannot operate manually, the operation of the remote control or the front panel is more inconvenient. the
发明内容Contents of the invention
本发明实施例所要解决的技术问题在于,提供一种语音信号处理方法及设备,以方便用户进行数字设备的控制操作。 The technical problem to be solved by the embodiments of the present invention is to provide a voice signal processing method and device, so as to facilitate users to perform control operations on digital devices. the
为了解决上述技术问题,本发明实施例提出了一种语音信号处理方法,包括: In order to solve the above technical problems, the embodiment of the present invention proposes a voice signal processing method, including:
采集输入的当前语音信号; Collect the current voice signal input;
对所述当前语音信号进行量化编码得到当前组数据; Quantize and encode the current voice signal to obtain the current group data;
从由与语音控制功能对应的功能组数据所形成集合中,查找得到与所述当前组数据匹配的功能组数据; From the set formed by the functional group data corresponding to the voice control function, find the functional group data matching the current group data;
执行与所述查找得到的功能组数据对应的语音控制功能。 Execute the voice control function corresponding to the searched function group data. the
相应地,本发明实施例还提供了一种语音信号处理设备,包括: Correspondingly, the embodiment of the present invention also provides a voice signal processing device, including:
采集模块,用于采集输入的当前语音信号; Acquisition module, for collecting the current voice signal of input;
编码模块,用于对所述当前语音信号进行量化编码得到当前组数据; An encoding module, configured to quantize and encode the current speech signal to obtain the current group data;
数据库模块,用于存储由与语音控制功能对应的功能组数据所形成集合; The database module is used to store the set formed by the function group data corresponding to the voice control function;
查找模块,用于从所述集合中,查找得到与所述当前组数据匹配的功能组数据; A search module, configured to search for functional group data that matches the current group data from the set;
执行模块,用于执行与所述查找得到的功能组数据对应的语音控制功能。 An executing module, configured to execute the voice control function corresponding to the found function group data. the
本发明实施例通过提供一种语音信号处理方法及设备,对采集输入的当前语音信号进行量化编码得到当前组数据,其次从由与语音控制功能对应的功能组数据所形成集合中,查找得到与所述当前组数据匹配的功能组数据,然后执行与所述查找得到的功能组数据对应的语音控制功能,从而用户可实现对数字设备的语音控制,使用户操作更加方便,不再为遥控器多和坏犯愁,降低了数字设备的制造成本,可以不用配遥控器,更为残疾人提供了便利。 The embodiment of the present invention provides a voice signal processing method and device, quantizes and encodes the collected and inputted current voice signal to obtain the current group data, and then finds and obtains from the set formed by the function group data corresponding to the voice control function. The function group data matched by the current group data, and then perform the voice control function corresponding to the function group data obtained by the search, so that the user can realize the voice control of the digital device, making the user's operation more convenient, no longer a remote control Too many and bad to worry about, reducing the manufacturing cost of digital equipment, can not be equipped with remote control, more convenient for the disabled. the
附图说明Description of drawings
图1是本发明实施例的语音信号处理方法的主要流程图。 FIG. 1 is a main flow chart of a speech signal processing method according to an embodiment of the present invention. the
图2是本发明实施例的功能组数据的设定过程。 Fig. 2 is the setting process of functional group data in the embodiment of the present invention. the
图3是本发明实施例的语音信号处理方法中103步骤的子流程图。 Fig. 3 is a sub-flowchart of
图4是本发明实施例的语音信号处理方法中101步骤的子流程图。 Fig. 4 is a sub-flowchart of
图5是本发明实施例的语音信号处理方法中的预加重处理流程图。 Fig. 5 is a flow chart of pre-emphasis processing in the speech signal processing method according to the embodiment of the present invention. the
图6是本发明实施例的功能组数据的设定过程的流程图。 FIG. 6 is a flow chart of the setting process of function group data according to the embodiment of the present invention. the
图7是本发明实施例的语音信号处理方法的一种应用示图。 Fig. 7 is an application diagram of the speech signal processing method according to the embodiment of the present invention. the
图8是本发明实施例的另一种语音信号处理方法的流程示意图。 Fig. 8 is a schematic flowchart of another speech signal processing method according to an embodiment of the present invention. the
图9是本发明实施例的语音信号处理设备的主要结构图。 FIG. 9 is a main structural diagram of the speech signal processing device of the embodiment of the present invention. the
图10是本发明实施例的语音信号处理设备的查找模块904的结构图。 Fig. 10 is a structural diagram of the
图11是本发明实施例的语音信号处理设备的元件组装图。 Fig. 11 is an assembly diagram of components of the speech signal processing device of the embodiment of the present invention. the
具体实施方式Detailed ways
下面结合附图,对本发明实施例进行详细说明。 Embodiments of the present invention will be described in detail below in conjunction with the accompanying drawings. the
参照图1,本发明实施例的语音信号处理方法主要包括如下流程: With reference to Fig. 1, the speech signal processing method of the embodiment of the present invention mainly comprises following flow process:
101,采集输入的当前语音信号; 101, collect the current input voice signal;
102,对当前语音信号进行量化编码得到当前组数据; 102. Quantize and encode the current voice signal to obtain the current group data;
103,从由与语音控制功能对应的功能组数据所形成集合中,查找得到与当前组数据匹配的功能组数据; 103. From the set formed by the functional group data corresponding to the voice control function, search for the functional group data matching the current group data;
104,执行与查找得到的功能组数据对应的语音控制功能。 104. Execute the voice control function corresponding to the found function group data. the
具体地,用户通过麦克风输入当前语音信号后,通过对其进行量化编码,并进行功能组数据的匹配,从而对匹配所得的功能组数据执行对应的语音控制功能,实现了对数字设备的语音控制,使用户操作更加方便,不再为遥控器多和坏犯愁,降低了数字设备的制造成本,可以不用配遥控器,更为残疾人提供 了便利。 Specifically, after the user inputs the current voice signal through the microphone, quantization and coding are performed on it, and the functional group data is matched, so that the corresponding voice control function is performed on the matched functional group data, and the voice control of the digital device is realized. , making the user's operation more convenient, no longer worrying about too many and bad remote controllers, reducing the manufacturing cost of digital equipment, eliminating the need for remote controllers, and providing convenience for the disabled. the
作为一种实施方式,上述方法还包括如图2所示的功能组数据的设定过程,设定过程与101-102类似: As an implementation, the above method also includes the setting process of the functional group data as shown in Figure 2, the setting process is similar to 101-102:
201,采集输入的功能语音信号; 201, collecting the input functional voice signal;
202,对所述功能语音信号进行量化编码,得到所述功能组数据。 202. Quantize and encode the functional voice signal to obtain the functional group data. the
具体地,用户通过麦克风输入功能语音信号后,通过对其进行量化编码,即可得到功能组数据以供图1所示流程的查找所用。 Specifically, after the user inputs the functional voice signal through the microphone, by quantizing and encoding it, the functional group data can be obtained for the search process shown in FIG. 1 . the
作为一种实施方式,103可具体包括如图3所示的流程: As an implementation manner, 103 may specifically include a process as shown in Figure 3:
301,确定当前组数据A与备选的功能组数据B的编辑距离LD(A,B),以及当前组数据A与功能组数据B的最长公共子组数据长度LCS(A,B); 301. Determine the edit distance LD(A, B) between the current group data A and the functional group data B, and the longest common subgroup data length LCS(A, B) between the current group data A and the functional group data B;
302,根据编辑距离LD(A,B)与最长公共子组数据长度LCS(A,B)的比值,确定当前组数据A与备选的功能组数据B的近似度S(A,B),近似度S(A,B)可由如下式(1)确定: 302. According to the ratio of the edit distance LD(A, B) to the longest common subgroup data length LCS(A, B), determine the degree of approximation S(A, B) between the current group data A and the candidate functional group data B , the degree of approximation S(A, B) can be determined by the following formula (1):
303,根据近似度S(A,B),查找得到与当前组数据A匹配的功能组数据B。 303. Find the functional group data B matching the current group data A according to the degree of approximation S(A, B). the
具体地,在度量当前组数据A与备选的功能组数据B的近似度时,比较合理的相似度应该满足下列性质: Specifically, when measuring the similarity between the current group data A and the alternative functional group data B, a reasonable similarity should satisfy the following properties:
性质一:0≤S(A,B)≤100%,0表示完全不相似,100%表示完全相等, Property 1: 0≤S(A, B)≤100%, 0 means completely dissimilar, 100% means completely equal,
性质二:S(A,B)=S(B,A)。 Property 2: S(A, B) = S(B, A). the
采用上式(1)能准确地满足性质一及性质二,例如: Using the above formula (1) can accurately satisfy the first and second properties, for example:
当前组数据A=GGATCGA,B=GAATTCAGTTA,通过计算,LD(A,B)=5,LCS(A,B)=2,当前组数据A与备选的功能组数据B匹配如下表1所示: The current group data A=GGATCGA, B=GAATTCAGTTA, through calculation, LD(A, B)=5, LCS(A, B)=2, the current group data A matches the optional functional group data B as shown in Table 1 below :
表1 Table 1
式(1)中LD(A,B)+LCS(A,B)表示当前组数据A与备选的功能组数据B的最佳匹配组数据的长度,这是唯一的。另外还要注意的是,LD(A,B)+LCS(A,B)与Max(Len(A),Len(B))并不完全相等。 In formula (1), LD(A, B)+LCS(A, B) represents the length of the best matching group data between the current group data A and the alternative functional group data B, which is unique. Also note that LD(A, B)+LCS(A, B) is not exactly equal to Max(Len(A), Len(B)). the
编辑距离LD(A,B)在计算时采用的是编辑距离算法(Edit Distance,ED),它 是以当前组数据A通过插入、删除、替换数据变成备选的功能组数据B的操作次数来表示当前组数据A与备选的功能组数据B之间的差异。其算法可如下述: The edit distance LD(A, B) is calculated using the edit distance algorithm (Edit Distance, ED), which is the number of operations that the current group data A becomes an alternative functional group data B through insertion, deletion, and replacement data to represent the difference between the current group data A and the alternative functional group data B. Its algorithm can be as follows:

最长公共子组数据长度LCS(A,B)的计算算法可如下述: The calculation algorithm of the longest common subgroup data length LCS(A, B) can be as follows:
作为一种实施方式,101可包括如图4所示的流程: As an implementation manner, 101 may include a process as shown in Figure 4:
401,对当前语音信号以9kbit/s的频率进行采样; 401, sampling the current voice signal at a frequency of 9kbit/s;
402,对采样的第一级信号采用12位模/数转换器进行模/数转换; 402, using a 12-bit analog/digital converter to perform analog/digital conversion on the sampled first-level signal;
403,对模/数转换后的第二级信号利用一阶滤波器进行预加重处理。 403. Perform pre-emphasis processing on the second-stage signal after the analog/digital conversion by using a first-order filter. the
具体地,上述101为信号预处理部分,主要完成输入的当前语音信号的采样、模/数转换等处理。采样频率为9kbit/s,模/数转换由内嵌12位模/数转换器实现。因为语音信号频谱的高频部分能量较小,其幅度较小,容易受到干扰的影响,在进行102之前,先可对其高频部分进行增强,即采用一阶滤波器(1-az-1)利用软件进行预加重,其中a可取0.95或其他数值,过程可如图5所示。 Specifically, the above-mentioned 101 is a signal preprocessing part, which mainly completes processing such as sampling and analog-to-digital conversion of the input current speech signal. The sampling frequency is 9kbit/s, and the analog/digital conversion is realized by an embedded 12-bit analog/digital converter. Because the energy of the high-frequency part of the speech signal spectrum is small, its amplitude is small, and it is easily affected by interference. Before performing 102, the high-frequency part can be enhanced, that is, a first-order filter (1-az-1 ) is pre-emphasized using software, where a can be 0.95 or other values, and the process can be shown in Figure 5. the
而对当前语音信号进行量化编码得到当前组数据可为采用自适应差分脉冲编码调制(Adaptive Differential Pulse-Code Modulation,ADPCM)对当前语音信号进行量化编码。具体地,在GSM标准中,规则码采用APCM对所选的规则脉冲序列进行量化编码,规则脉冲序列有13个样点Xm(i)组成,先找到|Xm(i)|中最大的Xmax,对Xmax用6bit对数量化编码得到,对Xmax解码后得到的X′max用来对13个非零样值作归一化处理得到X′(i),即: The current group of data obtained by performing quantization and coding on the current voice signal may be quantization and coding on the current voice signal by using Adaptive Differential Pulse-Code Modulation (ADPCM). Specifically, in the GSM standard, the regular code uses APCM to quantize and encode the selected regular pulse sequence. The regular pulse sequence consists of 13 sample points Xm (i), first find the largest |Xm (i)| Xmax is obtained by 6-bit logarithmic coding for Xmax , and X′max obtained after decoding Xmax is used to normalize 13 non-zero samples to obtain X′(i), namely:
X′(i)=X′m(i)/X′max,i=0,1,2,...,12X'(i)=X'm (i)/X'max , i=0, 1, 2,..., 12
然后,用3bit均匀量化X′(i),每帧需要180bit对脉冲序列进行编码。由于每个样本信号的位数太大,直接对输入信号的幅值进行量化编码时,耗用CPU资源较多,再加上机顶盒等数字终端设备只是用数据来存储较对,不需要恢复语音,所以语音质量不是很重要。本发明实施例中采用ADPCM方式加以改进,对实际的规则脉冲与预测的规则脉冲之差进行编码,每个非零样值仅用2bit进行编码,而每帧用104bit对脉冲序列进行编码,使编码速率从13kbit/s降为9kbit/s,同时也降低了耗用资源数量。 Then, X'(i) is uniformly quantized with 3 bits, and each frame needs 180 bits to encode the pulse sequence. Because the number of bits of each sample signal is too large, when directly quantizing and encoding the amplitude of the input signal, it consumes more CPU resources. In addition, digital terminal equipment such as set-top boxes only use data to store relatively, and do not need to restore voice , so voice quality is not very important. In the embodiment of the present invention, the ADPCM mode is adopted to improve, and the difference between the actual regular pulse and the predicted regular pulse is encoded, and each non-zero sample value is only encoded with 2 bits, and each frame is encoded with 104 bits to the pulse sequence, so that The encoding rate is reduced from 13kbit/s to 9kbit/s, which also reduces the amount of resources consumed. the
在应用时,上述功能组数据的设定过程可包括如图6所示的过程: In application, the setting process of the above-mentioned functional group data may include the process shown in Figure 6:
601,机顶盒前面板选择用户录制,其中,用户数可配置; 601. Select a user to record on the front panel of the set-top box, where the number of users is configurable;
602,检测“我是XXX”的语音输入; 602, detecting the voice input of "I am XXX";
603,进行数据提取和GSM编码; 603, perform data extraction and GSM encoding;
604,GSM编码并存储用户音频数据库; 604, GSM encoding and storing the user audio database;
605,判断采集次数是否为3次,若是,则执行604,否则,执行602; 605, determine whether the number of acquisitions is 3 times, if so, execute 604, otherwise, execute 602;
606,前面板选择设置功能录制; 606, select the setting function recording on the front panel;
607,检测功能语音输入; 607, detection function voice input;
608,GSM编码并存储功能音频数据库; 608, GSM codes and stores functional audio database;
609,判断采集次数是否为3次,若是,则执行610,否则,执行607; 609, determine whether the number of acquisitions is 3, if so, execute 610, otherwise, execute 607;
610,判断功能录制是否已经完成,若是,则结束,否则,执行606。 610, determine whether the function recording has been completed, if so, end, otherwise, go to 606. the
在应用时,上述101-104的语音信号处理方法可包括如图7所示的过程: In application, the speech signal processing method of above-mentioned 101-104 can comprise the process as shown in Figure 7:
701,检测用户“我是XXX”登入是否有效,若是,则执行702,否则重新执行701; 701, check whether the login of the user "I am XXX" is valid, if so, execute 702, otherwise execute 701 again;
702,检测功能语音输入; 702, detection function voice input;
703,数据提取和GSM编码; 703, data extraction and GSM encoding;
704,和数据库中已录制用户语音进行匹配,若匹配成功,则执行705,否则,执行702; 704, match with the recorded user voice in the database, if the match is successful, then execute 705, otherwise, execute 702;
705,功能语音响应处理,并返回执行701。 705 , process the function voice response, and return to execute 701 . the
为了提高查找的准确度,每一个语音控制功能对应存在至少两个功能组数据,这样,有多个功能组数据供与当前组数据进行匹配查找,准确率会提高,但同时会使设备响应变慢,如图8所示,例如: In order to improve the accuracy of the search, there are at least two function group data for each voice control function. In this way, there are multiple function group data for matching search with the current group data, the accuracy rate will be improved, but at the same time, the device response will be slowed down. , as shown in Figure 8, for example:
801,判断当前组数据与3个功能组数据的近似度值S(A,B)是否均大于70,若是,则比较成功,否则,执行802; 801, judge whether the approximation value S (A, B) of current group data and 3 function group data is all greater than 70, if so, then compare success, otherwise, execute 802;
802,判断当前组数据与3个功能组数据的近似度值S(A,B)是否均小于30,若是,则比较失败,否则,执行803; 802, judge whether the approximation value S (A, B) of current group data and 3 functional group data is all less than 30, if so, then comparison fails, otherwise, execution 803;
803,判断是否存在当前组数据与3个功能组数据中其中一个的近似度值S(A,B)大于70,若是,则比较成功,否则,比较失败。 803. Determine whether there is an approximate value S(A, B) greater than 70 between the current group data and one of the three functional group data. If yes, the comparison is successful; otherwise, the comparison fails. the
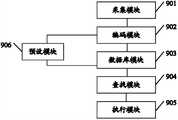
相应地,本发明实施例的语音信号处理设备主要包括如图9所示的结构: Correspondingly, the speech signal processing equipment of the embodiment of the present invention mainly includes the structure as shown in Figure 9:
采集模块901,用于采集输入的当前语音信号,当前语音信号可由麦克风输入;
编码模块902,用于对当前语音信号进行量化编码得到当前组数据;
数据库模块903,用于存储由与语音控制功能对应的功能组数据所形成集合,该集合可以数据库或列表等形式进行存储; The
查找模块904,用于从集合中,查找得到与当前组数据匹配的功能组数据; Finding
执行模块905,用于执行与查找得到的功能组数据对应的语音控制功能; The
预设模块906,用于在采集模块901采集的输入的功能语音信号之后,将编码模块902对功能语音信号进行量化编码得到的功能组数据存入数据库模块903。 The
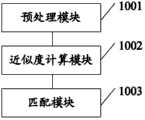
具体地,查找模块904可包括如图10所示的结构: Specifically, the
预处理模块1001,用于确定当前组数据与功能组数据的编辑距离,以及当前组数据与功能组数据的最长公共子组数据长度; The
近似度计算模块1002,用于根据编辑距离与最长公共子组数据长度的比值,确定当前组数据与功能组数据的近似度; The
匹配模块1003,用于根据近似度,查找得到与当前组数据匹配的功能组数据。 The
上述本发明实施例的语音信号处理设备其元件组装可如图11所示,其主要包括有作为核心控制处理器的LM386,以及其他电容电阻元件。 The speech signal processing device of the above-mentioned embodiment of the present invention can be assembled as shown in FIG. 11 , which mainly includes LM386 as the core control processor, and other capacitive and resistive elements. the
需要说明的是,上述语音信号处理设备可以为机顶盒、数字电视、计算机或其他数字终端设备。 It should be noted that the above-mentioned voice signal processing device may be a set-top box, a digital TV, a computer or other digital terminal devices. the
上述语音信号处理方法及设备在应用时,可采用如下操作手段: When the above-mentioned speech signal processing method and equipment are applied, the following operating means can be adopted:
首先,用户录音前需要选择用户编号,录制自己的用户名“我是XXX”,用户数为4或可随机顶盒硬件配置而定; First of all, the user needs to select the user number before recording, and record his own user name "I am XXX". The number of users is 4 or it can be determined by the hardware configuration of the top box;
其次,通过前面板操作进入机顶盒OSD设置,依次对常用功能发音进行录音,录音功能主要是依据按键为主,差不多是用口代替遥控器,不一定要标准普通话。常用功能录音有(登陆用户名、0-9、确认、取消、上下左右、退出、待机、),其它功能录音有(菜单、信息、EPG、录制、时移、快进、快退、停止、前一个、下一个、TV/RADIO、游戏等); Secondly, enter the OSD settings of the set-top box through the front panel operation, and record the pronunciation of common functions in turn. The recording function is mainly based on the buttons, almost using the mouth instead of the remote control, and does not necessarily need standard Mandarin. Commonly used function recordings include (login user name, 0-9, confirm, cancel, up, down, left, right, exit, standby,), other function recordings include (menu, information, EPG, recording, time shift, fast forward, rewind, stop, previous, next, TV/RADIO, game, etc.);
然后,每个录音采集3次,采集次数用户设置(视机顶盒硬件配置定),采 集次数越多,准确率会越高,但机顶盒响应会变慢; Then, each recording is collected 3 times, and the number of collections is set by the user (depending on the hardware configuration of the set-top box). The more the number of collections, the higher the accuracy, but the response of the set-top box will be slower;
之后,“我是XXX”声控登陆后,用户就可以声控了,机顶盒检测登陆用户每声的音频数据,匹配音频数据库,成功后做出对应处理。 Afterwards, after the "I am XXX" voice control login, the user can voice control. The set-top box detects the audio data of each voice of the logged-in user, matches the audio database, and makes corresponding processing after success. the
这种声控智能终端系统特性能使用户使用更为方便,不再为遥控器多和坏犯愁,产品成本减少可以不用配遥控器,更为残疾人提供了便利。 The characteristics of this voice-activated intelligent terminal system can make users more convenient to use, no longer need to worry about too many and broken remote controls, and the product cost can be reduced without the need for remote controls, which provides convenience for the disabled. the
另外,本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过程序来指令相关的硬件来完成,所述的程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,所述的存储介质可为磁碟、光盘、只读存储记忆体(Read-Only Memory,ROM)或随机存储记忆体(Radom Access Memory,RAM)等。 In addition, those of ordinary skill in the art can understand that all or part of the processes in the methods of the above embodiments can be implemented by instructing related hardware through a program, and the program can be stored in a computer-readable storage medium. When the program is executed, it may include the processes of the embodiments of the above-mentioned methods. Wherein, the storage medium may be a magnetic disk, an optical disk, a read-only memory (Read-Only Memory, ROM) or a random access memory (Radom Access Memory, RAM), etc. the
以上所述是本发明的具体实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。 The above are specific implementations of the present invention. It should be pointed out that for those of ordinary skill in the art, without departing from the principle of the present invention, some improvements and modifications can also be made, and these improvements and modifications are also considered Be the protection scope of the present invention. the
Claims (7)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN 201210026441CN102546034B (en) | 2012-02-07 | 2012-02-07 | Method and equipment for processing voice signals |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN 201210026441CN102546034B (en) | 2012-02-07 | 2012-02-07 | Method and equipment for processing voice signals |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN102546034A CN102546034A (en) | 2012-07-04 |
| CN102546034Btrue CN102546034B (en) | 2013-12-18 |
Family
ID=46352077
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN 201210026441Expired - Fee RelatedCN102546034B (en) | 2012-02-07 | 2012-02-07 | Method and equipment for processing voice signals |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN102546034B (en) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP2903703A1 (en) | 2012-10-04 | 2015-08-12 | Disney Enterprises, Inc. | Interactive objects for immersive environment |
| WO2017020211A1 (en)* | 2015-08-02 | 2017-02-09 | 李强生 | Method and remote controller for information reminder when matching voice to household electrical appliance |
| CN106815196B (en)* | 2015-11-27 | 2020-07-31 | 北京国双科技有限公司 | Method and device for counting the number of press releases |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN1223508A (en)* | 1998-01-13 | 1999-07-21 | 黄金富 | Sound-controlled infrared ray remote controller |
| US7138927B2 (en)* | 2000-03-10 | 2006-11-21 | Fang Calvin C | Universal remote controller with voice and digital memory |
| CN101178897A (en)* | 2007-12-05 | 2008-05-14 | 浙江大学 | Speaker Recognition Method Based on Fundamental Band Envelope Removal of Emotional Speech |
| CN101516005A (en)* | 2008-02-23 | 2009-08-26 | 华为技术有限公司 | Speech recognition channel selecting system, method and channel switching device |
| CN102023854A (en)* | 2009-09-18 | 2011-04-20 | 上海智问软件技术有限公司 | Template-based semantic variable extraction method |
- 2012
- 2012-02-07CNCN 201210026441patent/CN102546034B/ennot_activeExpired - Fee Related
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN1223508A (en)* | 1998-01-13 | 1999-07-21 | 黄金富 | Sound-controlled infrared ray remote controller |
| US7138927B2 (en)* | 2000-03-10 | 2006-11-21 | Fang Calvin C | Universal remote controller with voice and digital memory |
| CN101178897A (en)* | 2007-12-05 | 2008-05-14 | 浙江大学 | Speaker Recognition Method Based on Fundamental Band Envelope Removal of Emotional Speech |
| CN101516005A (en)* | 2008-02-23 | 2009-08-26 | 华为技术有限公司 | Speech recognition channel selecting system, method and channel switching device |
| CN102023854A (en)* | 2009-09-18 | 2011-04-20 | 上海智问软件技术有限公司 | Template-based semantic variable extraction method |
Also Published As
| Publication number | Publication date |
|---|---|
| CN102546034A (en) | 2012-07-04 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| TWI508057B (en) | Speech recognition system and method | |
| KR102614021B1 (en) | Audio content recognition method and device | |
| CN1042790A (en) | The method and apparatus that the real-time voice of recognizing people and do not recognize people is discerned | |
| CN102568478A (en) | Video play control method and system based on voice recognition | |
| CN105489221A (en) | Voice recognition method and device | |
| CN104391924A (en) | Mixed audio and video search method and system | |
| CN109473103A (en) | A kind of meeting summary generation method | |
| WO2016119604A1 (en) | Voice information search method and apparatus, and server | |
| US12300218B2 (en) | Method and apparatus for training acoustic network model, and electronic device | |
| CN102546034B (en) | Method and equipment for processing voice signals | |
| JP2020527255A (en) | Audio fingerprint extraction method and equipment | |
| US20230252986A1 (en) | Systems and methods for avoiding inadvertently triggering a voice assistant | |
| CN110111811A (en) | Audio signal detection method, device and storage medium | |
| US20160034247A1 (en) | Extending Content Sources | |
| CN108320740B (en) | Voice recognition method and device, electronic equipment and storage medium | |
| CN102136001B (en) | A Fuzzy Retrieval Method for Multimedia Information | |
| CN106550268B (en) | Video processing method and video processing device | |
| CN110889010A (en) | Audio matching method, device, medium and electronic equipment | |
| RU2633097C2 (en) | Methods and devices for signal coding and decoding | |
| Zhang et al. | Selected features for classifying environmental audio data with random forest | |
| CN101222703A (en) | Identity verification method for mobile terminal based on voice identification | |
| WO2021139772A1 (en) | Audio information processing method and apparatus, electronic device, and storage medium | |
| US20160275077A1 (en) | Method and apparatus for automatically sending multimedia file, mobile terminal, and storage medium | |
| CN109862408B (en) | User voice recognition control method for intelligent television voice remote controller | |
| CN110688859B (en) | Semantic analysis method, device, medium and electronic equipment based on machine learning |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C53 | Correction of patent of invention or patent application | ||
| CB03 | Change of inventor or designer information | Inventor after:Cao Lihua Inventor after:Dong Xuefeng Inventor before:Shu Guoling Inventor before:Cao Lihua Inventor before:Dong Xuefeng | |
| C14 | Grant of patent or utility model | ||
| GR01 | Patent grant | ||
| CF01 | Termination of patent right due to non-payment of annual fee | ||
| CF01 | Termination of patent right due to non-payment of annual fee | Granted publication date:20131218 |