CN102419973B - Tone evaluating method - Google Patents
Tone evaluating methodDownload PDFInfo
- Publication number
- CN102419973B CN102419973BCN2011103700384ACN201110370038ACN102419973BCN 102419973 BCN102419973 BCN 102419973BCN 2011103700384 ACN2011103700384 ACN 2011103700384ACN 201110370038 ACN201110370038 ACN 201110370038ACN 102419973 BCN102419973 BCN 102419973B
- Authority
- CN
- China
- Prior art keywords
- tone
- feature
- evaluation
- recognition
- model
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000034methodMethods0.000titleclaimsabstractdescription28
- 238000011156evaluationMethods0.000claimsabstractdescription69
- 238000012549trainingMethods0.000claimsabstractdescription21
- 238000012360testing methodMethods0.000claimsdescription19
- 238000013210evaluation modelMethods0.000description9
- 230000008569processEffects0.000description9
- 238000002372labellingMethods0.000description8
- 230000006872improvementEffects0.000description6
- 238000013209evaluation strategyMethods0.000description5
- 238000002474experimental methodMethods0.000description5
- 230000011218segmentationEffects0.000description5
- 230000008447perceptionEffects0.000description4
- 230000006870functionEffects0.000description3
- 230000003044adaptive effectEffects0.000description2
- 230000009286beneficial effectEffects0.000description2
- 230000000694effectsEffects0.000description2
- 230000006978adaptationEffects0.000description1
- 230000007423decreaseEffects0.000description1
- 238000013461designMethods0.000description1
- 238000003745diagnosisMethods0.000description1
- 238000010586diagramMethods0.000description1
- 238000012850discrimination methodMethods0.000description1
- 238000012986modificationMethods0.000description1
- 230000004048modificationEffects0.000description1
- 238000012545processingMethods0.000description1
- 238000011160researchMethods0.000description1
Images




Landscapes
- Machine Translation (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明涉及计算机辅助语言教学中语音信号处理领域,尤其涉及一种声调评测方法。The invention relates to the field of speech signal processing in computer-aided language teaching, in particular to a tone evaluation method.
背景技术Background technique
近年来,利用计算机进行普通话水平测试(PSC)、汉语水平考试(HSK)、少数民族汉语考试(MHK)已经获得广泛应用,相应的发音教学软件也逐渐增多。汉语是一种声调语言(Tonal Language)。这是汉语区别于印欧语系的突出特点之一。同时,声调作为汉语的三大要素(声母、韵母、声调)之一,是各种汉语口语考试的必考内容。因此,准确可靠地进行声调诊断至关重要。In recent years, the use of computers for Putonghua Proficiency Test (PSC), Chinese Proficiency Test (HSK), and Minority Chinese Test (MHK) has been widely used, and the corresponding pronunciation teaching software has gradually increased. Chinese is a tonal language. This is one of the outstanding features that distinguish Chinese from Indo-European languages. At the same time, tone, as one of the three major elements of Chinese (initials, finals, and tones), is a compulsory content for various oral Chinese tests. Therefore, accurate and reliable tone diagnosis is crucial.
专利200810107118公开了一种发音和声调自适应评测方法,其思想是利用后验概率挑选出比较可靠的数据进行模型自适应,将自适应后的模型再次应用于发音和声调的评测,以期获得评测性能的提升。Patent 200810107118 discloses a pronunciation and tone adaptive evaluation method, the idea is to use the posterior probability to select more reliable data for model adaptation, and apply the adaptive model again to the evaluation of pronunciation and tone, in order to obtain evaluation Performance improvements.
该方法对声调的评测实际上暗示了四个前提假设:第一,声韵母切分的边界几乎没有误差;第二,基频曲线是连续不断的;第三,基频曲线对声调的贡献处处一致;第四,声调仅用基频特征即可。The evaluation of the tone by this method actually implies four assumptions: first, there is almost no error in the boundary of the consonant and final segmentation; second, the fundamental frequency curve is continuous; third, the contribution of the fundamental frequency curve to the tone is everywhere. Consistent; Fourth, the tone can only use the fundamental frequency characteristics.
发明人在研究中发现,以上假设过于严格,有必要进一步放宽要求。The inventor found in the research that the above assumptions are too strict, and it is necessary to further relax the requirements.
首先,无论声学模型如何完善,声韵母的边界都无法完全切分准确。采用全人工标注声韵母边界,标注误差50毫秒以内的边界约占全部标注边界的95%左右。采用机器进行声韵母边界标注的性能则更差,受声学模型好坏的影响不同,边界标注性能差异较大,边界准确率在70-92%之间。First of all, no matter how perfect the acoustic model is, the boundaries of consonants and finals cannot be completely segmented and accurate. The boundaries of consonants and finals are marked manually, and the boundaries within 50 milliseconds of labeling error account for about 95% of all labeling boundaries. The performance of using machines to mark the boundaries of consonants and finals is even worse, depending on the quality of the acoustic model, the performance of boundary marking varies greatly, and the boundary accuracy rate is between 70-92%.
其次,发明人发现大量的韵母不存在基频(图1)或者韵母的部分位置不存在基频(图2)。图1中“绸子”的“子”字整个字完全没有基频,图2中“光彩”的“彩”字后半段没有基频。可见,在同一个声调内部,基频不一定完全连续,可以有丢失,还可以完全没有基频。Secondly, the inventors found that there is no fundamental frequency in a large number of finals (Fig. 1) or part of the finals (Fig. 2). The word "zi" in "Silk" in Figure 1 has no base frequency at all, and the second half of the character "Cai" in "Guangcai" in Figure 2 has no base frequency. It can be seen that within the same tone, the fundamental frequency is not necessarily completely continuous, there may be loss, and there may be no fundamental frequency at all.
第三,提取所得的基频曲线中只有部分对人耳听感有用。图3中“脚印”的“印”字,只有前半段基频对声调感知有用,后半段的基频曲线实际上是鼻音的拖音,该拖音导致基频曲线先降、后升、再降,而实际上只有前半段的下降曲线对声调感知有用。Third, only part of the extracted fundamental frequency curve is useful to the human ear. In the word "印" of "footprint" in Figure 3, only the first half of the fundamental frequency is useful for tone perception, and the second half of the fundamental frequency curve is actually a dragging sound of the nasal sound, which causes the fundamental frequency curve to drop first, then rise, Then drop again, but in fact only the first half of the drop curve is useful for tone perception.
第四,大量实验表明,即使没有基频的耳语声,人耳也能辨别出正确的声调。因此专利200810123713公开了一种基于声道增益轨迹的声调辨别方法。Fourth, numerous experiments have shown that the human ear can discern the correct pitch even without a whisper at the fundamental frequency. Therefore, patent 200810123713 discloses a tone discrimination method based on the channel gain trajectory.
针对上述第一个假设的缺点,专利200910186154提出在网格(Lattice)上确定最优边界的方法。该方案仅有效地解决了上述第一假设带来的问题,但依旧无法解决第二、三、四个假设导致的问题。而专利200810123713是专门针对耳语设计的,对正常语音声调识别性能不佳。因此,一种可以解决上述四种类问题的声调评测方法显得非常重要。本发明的方案较为灵活,其优选方案采用MLP为分类器,隐式地解决了问题二和问题三,其特征融合了基频、能量、时长三大特征,有效地避免了问题四。Aiming at the shortcomings of the above first assumption, patent 200910186154 proposes a method of determining the optimal boundary on a grid (Lattice). This solution only effectively solves the problems caused by the above-mentioned first assumption, but still cannot solve the problems caused by the second, third, and fourth assumptions. And the patent 200810123713 is specially designed for whispering, and the recognition performance of normal speech tone is not good. Therefore, a tone evaluation method that can solve the above four types of problems is very important. The scheme of the present invention is relatively flexible, and the preferred scheme adopts MLP as the classifier, which implicitly solves the second and third problems. Its features combine the three characteristics of fundamental frequency, energy and duration, and effectively avoid the fourth problem.
此外,在实际操作过程中,发明人发现,标注人员对声调的感知并不完全一致,在声调不标准的情况下,不同标注员对声调感知差异巨大。除此以外,标注员的标注性能还随着工作时间的延长和疲劳程度的增加而下降。传统的解决方案是请多位标注员对同一批数据进行多次标注。这样做的直接影响是大大减缓了标注的进度。同时,即使经过了多次标注之后,标注员之间的一致性有逐步提高,但标注员的标注一致性在到达特定位置之后无法继续提升,也就是说,人的标注性能是有上限的。因此,一种可以在不可靠标注条件下获得可靠声学模型的方法显得非常重要。发明人多次实验表明,利用本发明的训练方法,可以从不可靠数据获取可靠模型,利用本发明的方法进行评测,其错误率比直接采用声调识别的方法要低相对50%以上。In addition, in the actual operation process, the inventors found that the perception of the tones by the annotators is not completely consistent, and when the tones are not standard, different annotators have huge differences in the perception of the tones. In addition, the labeling performance of labelers also decreases with the extension of working hours and the increase of fatigue. The traditional solution is to ask multiple labelers to label the same batch of data multiple times. The direct effect of this is to greatly slow down the progress of labeling. At the same time, even after multiple annotations, the consistency among the annotators has gradually improved, but the annotation consistency of the annotators cannot continue to improve after reaching a specific position, that is to say, there is an upper limit to the human annotation performance. Therefore, a method that can obtain a reliable acoustic model under unreliable labeling conditions is very important. The inventor's multiple experiments have shown that using the training method of the present invention, a reliable model can be obtained from unreliable data, and the method of the present invention is used for evaluation, and the error rate is relatively lower than the method of directly using tone recognition by more than 50%.
发明内容Contents of the invention
(一)要解决的技术问题(1) Technical problems to be solved
为解决上述的一个或多个问题,本发明提供了一种声调评测方法,以获得更加良好的声调识别性能。To solve one or more of the above problems, the present invention provides a tone evaluation method to obtain better tone recognition performance.
(二)技术方案(2) Technical solution
根据本发明的一个方面,提出了一种声调评测方法。该方法包括:从待评测语音中提取声调识别特征,声调识别特征包含基频曲线特征;将声调识别特征送入训练后的声调识别模型,获得每一个声调的识别得分;提取得分最高的声调及其识别得分作为第一评测特征,标准声调和标准声调识别得分作为第二评测特征;将第一声调评测特征和第二声调评测特征合并成4维的声调评测特征,送入训练后的声调评测模型,获得待评测语音的声调评测得分。According to one aspect of the present invention, a tone evaluation method is proposed. The method includes: extracting tone recognition features from the speech to be evaluated, and the tone recognition features include fundamental frequency curve features; sending the tone recognition features into the trained tone recognition model to obtain the recognition score of each tone; extracting the tone with the highest score and Its recognition score is used as the first evaluation feature, and the standard tone and the standard tone recognition score are used as the second evaluation feature; the first tone evaluation feature and the second tone evaluation feature are combined into a 4-dimensional tone evaluation feature, which is sent to the tone evaluation after training model to obtain the tone evaluation score of the speech to be evaluated.
(三)有益效果(3) Beneficial effects
本发明的提出,解决了声韵母边界不准导致识别性能不高的问题,解决了基频曲线断开导致识别性能不高的问题,解决了基频曲线对声调识别贡献率处处一致假设导致的识别性能不高的问题,解决了声调即基频曲线假设导致的识别性能不高的问题,具体来讲:The proposal of the present invention solves the problem of low recognition performance caused by inaccurate boundaries of consonants and finals, solves the problem of low recognition performance caused by disconnection of the fundamental frequency curve, and solves the problem caused by the assumption that the contribution rate of the fundamental frequency curve to tone recognition is consistent everywhere. The problem of low recognition performance solves the problem of low recognition performance caused by the assumption that the tone is the fundamental frequency curve. Specifically:
1.采用了两级模型进行声调评测的策略。在第一层级,先采用声调识别器进行声调识别,将识别声调的得分和标准声调的得分作为新的输入,在第二层级采用识别器进行再次决策。多次实验结果表明,这种分两层级进行声调评测的策略,具有好的性能。在标注不准确的情况下,依然可以获得稳定的性能提升。1. A two-level model is used for the tone evaluation strategy. In the first level, the tone recognizer is used to recognize the tone, and the score of the recognized tone and the score of the standard tone are used as new inputs, and the recognizer is used to make another decision in the second level. The results of multiple experiments show that this two-level tone evaluation strategy has good performance. In the case of inaccurate labeling, a stable performance improvement can still be obtained.
2.采用能量曲线辅助基频曲线进行声调识别,可以比单独使用基频曲线获得更好的识别性能。采用基频曲线和能量曲线,通过训练模型的过程让模型自动决定声调曲线在不同能量条件下的加权方式,可以获得比基频曲线更优的识别性能。另外,能量曲线还具有区分轻声的作用。轻声的能量通常要比正常音节的能量更低。2. Using the energy curve to assist the fundamental frequency curve for tone recognition can achieve better recognition performance than using the fundamental frequency curve alone. Using the fundamental frequency curve and energy curve, the model can automatically determine the weighting method of the tone curve under different energy conditions through the process of training the model, which can obtain better recognition performance than the fundamental frequency curve. In addition, the energy curve also has the function of distinguishing soft sounds. Soft syllables usually have lower energy than normal syllables.
3.采用时长辅助基频曲线进行声调识别,可以比单独使用基频曲线获得更好的识别性能。轻声具有多种基频曲线表现形式,可以有基频,也可以无基频。但通常伴随着的显著特点是时长比正常音节短,通常是正常音节的一半。3. Using duration-assisted fundamental frequency curves for tone recognition can achieve better recognition performance than using fundamental frequency curves alone. The soft voice has a variety of fundamental frequency curves, which can have a fundamental frequency or no fundamental frequency. But it is usually accompanied by a distinctive feature that the duration is shorter than normal syllables, usually half of normal syllables.
附图说明Description of drawings
图1为现有技术中韵母不存在基频实例的频谱图;Fig. 1 is the spectrogram that there is no fundamental frequency example in the prior art;
图2为现有技术中韵母部分位置不存在基频实例的频谱图;Fig. 2 is the spectrogram that there is no fundamental frequency example in the vowel of a Chinese syllable part position in the prior art;
图3为现有技术中基频曲线中只有部分对人耳听感有用实例的频谱图;Fig. 3 is the spectrogram of only some examples useful to the human ear in the fundamental frequency curve in the prior art;
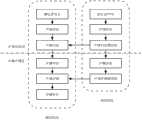
图4为本发明实施例声调评测方法的流程图;Fig. 4 is the flow chart of the tone evaluation method of the embodiment of the present invention;
图5为本发明实施例声调评测方法的流程图。Fig. 5 is a flow chart of a tone evaluation method according to an embodiment of the present invention.
具体实施方式Detailed ways
为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明进一步详细说明。虽然本文可提供包含特定值的参数的示范,但应了解,参数无需确切等于相应的值,而是可在可接受的误差容限或设计约束内近似于所述值。In order to make the object, technical solution and advantages of the present invention clearer, the present invention will be described in further detail below in conjunction with specific embodiments and with reference to the accompanying drawings. While illustrations of parameters including particular values may be provided herein, it should be understood that parameters need not be exactly equal to the corresponding values, but rather may approximate the values within acceptable error margins or design constraints.
在本发明的一个示例性实施例中,提供了一种声调评测方法。图4为本发明实施例声调评测方法的流程图。如图4所示,本实施例包括如下训练阶段和测试阶段:In an exemplary embodiment of the present invention, a tone evaluation method is provided. Fig. 4 is a flow chart of a tone evaluation method according to an embodiment of the present invention. As shown in Figure 4, this embodiment includes the following training phase and testing phase:
一、在训练阶段,采用如下步骤建立声调识别模型M1和声调评测模型M2。1. In the training phase, the tone recognition model M1 and the tone evaluation model M2 are established using the following steps.
步骤A1:从标注语料库中提取声调识别特征。该特征包括如下特征的一种或多种:基频曲线、能量曲线、时长。Step A1: Extract tone recognition features from the tagged corpus. The feature includes one or more of the following features: fundamental frequency curve, energy curve, and duration.
基频曲线是进行声调识别的最佳特征,也是最本质的特征。本实施例中,基频曲线为必选特征,能量曲线和时长为可选特征。The fundamental frequency curve is the best feature for tone recognition, and it is also the most essential feature. In this embodiment, the fundamental frequency curve is a mandatory feature, and the energy curve and duration are optional features.
在本发明优选的实施例中,采用能量曲线辅助基频曲线进行声调识别,可以比单独使用基频曲线获得更好的识别性能。在没有基频的条件下(耳语声),能量曲线也具有区分声调的作用。另外,能量曲线还能够辅助解决边界不准的问题。一般来说,音节末尾的能量较低,而且是一个渐变过程,因此音节结束边界难以断定。由于音节结尾的能量低,人耳对该部分感知不灵敏,此处的基频也通常没有区分声调的能力。采用基频曲线和能量曲线,通过训练模型的过程让模型自动决定声调曲线在不同能量条件下的加权方式,可以获得比基频曲线更优的识别性能。另外,能量曲线还具有区分轻声的作用。轻声的能量通常要比正常音节的能量更低。In a preferred embodiment of the present invention, using the energy curve to assist the fundamental frequency curve for tone recognition can achieve better recognition performance than using the fundamental frequency curve alone. In the absence of fundamental frequency (whispering), the energy curve also has the effect of distinguishing tones. In addition, the energy curve can also assist in solving the problem of inaccurate boundaries. Generally speaking, the energy at the end of a syllable is low, and it is a gradual process, so the boundary of the end of a syllable is difficult to determine. Due to the low energy at the end of the syllable, the human ear is not sensitive to this part, and the fundamental frequency here usually has no ability to distinguish the tone. Using the fundamental frequency curve and energy curve, the model can automatically determine the weighting method of the tone curve under different energy conditions through the process of training the model, which can obtain better recognition performance than the fundamental frequency curve. In addition, the energy curve also has the function of distinguishing soft sounds. Soft syllables usually have lower energy than normal syllables.
在本发明另一个优选的实施例中,采用时长辅助基频曲线进行声调识别,可以比单独使用基频曲线获得更好的识别性能。轻声具有多种基频曲线表现形式,可以有基频,也可以无基频。但通常伴随着的显著特点是时长比正常音节短,通常是正常音节的一半。增加时长作为声调识别特征可以改善声调识别性能,但性能提升不大。工程应用时,可以根据需要决定是否增加时长作为辅助特征。In another preferred embodiment of the present invention, using the duration-assisted fundamental frequency curve for tone recognition can achieve better recognition performance than using the fundamental frequency curve alone. The soft voice has a variety of fundamental frequency curves, which can have a fundamental frequency or no fundamental frequency. But it is usually accompanied by a distinctive feature that the duration is shorter than normal syllables, usually half of normal syllables. Adding duration as a tone recognition feature can improve the performance of tone recognition, but the performance improvement is not significant. In engineering applications, you can decide whether to add duration as an auxiliary feature according to your needs.
步骤A2:利用上述声调识别特征训练用于声调识别模型M1。该声调识别模型M1可以是上下文有关的模型,可以是上下文无关的模型。Step A2: Use the above tone recognition features to train the tone recognition model M1. The tone recognition model M1 may be a context-sensitive model or a context-independent model.
在进行单字声调评测时,采用单字建立的UniTone模型,UniTone模型指的是不考虑上下文,只考虑当前的声调的模型。进行双字声调评测时,采用双字建立的BiTone模型;BiTone模型指的是在考虑当前声调的基础上,附加考虑上文声调或者附加考虑下文声调的模型。进行多字词和句子声调评测时,采用上下文相关的TriTone模型。TriTone模型指的是在当前声调的基础上,同时考虑上文声调和下文声调的模型。更优选地,采用多层感知机(Multilayer Perceptron,简称MLP)作为声调识别模型。When performing single-character tone evaluation, the UniTone model established by the single character is used. The UniTone model refers to a model that does not consider the context, but only considers the current tone. When evaluating the double-character tone, the BiTone model established by the double-character is used; the BiTone model refers to a model that considers the above tone or the following tone in addition to the current tone. When evaluating multi-word and sentence tone, the context-sensitive TriTone model is used. The TriTone model refers to a model that considers both the above tone and the following tone on the basis of the current tone. More preferably, a multilayer perceptron (MLP for short) is used as the tone recognition model.
步骤A3:利用A2训练得到的模型对待评测的声调特征进行识别,从声调识别结果中提取声调评测特征。将该评测特征分为两部分:第一声调评测特征和第二声调评测特征。Step A3: Use the model trained in A2 to identify the tone features to be evaluated, and extract the tone evaluation features from the tone recognition results. The evaluation feature is divided into two parts: the first tone evaluation feature and the second tone evaluation feature.
第一评测特征指的是利用识别器识别出来的声调标签ToneREC,以及该标签对应的识别得分ScoreREC。第二评测特征指的是汉字的标准声调ToneSTD,以及该标准声调在识别器中的对应得分ScoreSTD。以汉字“吗”为例,训练含有1声、2声、3声、4声、5声(轻声)共5个声调的识别器,识别“吗”的声调结果为1声0.8分,2声0.5分,3声0.3分,4声0.3分,轻声0.7分。那么,识别结果应该是1声,识别得分为0.8分,标准声调应该是5声(轻声),标准声调得分0.7分。那么声调评测特征为(1,0.8,5,0.7),将此特征送入声调评测模型,可以获得该字读轻声的评测得分为0.88分。The first evaluation feature refers to the tone label ToneREC recognized by the recognizer, and the recognition score ScoreREC corresponding to the label. The second evaluation feature refers to the standard tone of Chinese characters ToneSTD and the corresponding score ScoreSTD of the standard tone in the recognizer. Taking the Chinese character "Do" as an example, train a recognizer with 5 tones including 1 tone, 2 tone, 3 tone, 4 tone and 5 tone (soft tone). The result of recognizing the tone of "Do" is 0.8 points for 1 tone, 2 tone 0.5 points, 0.3 points for 3 sounds, 0.3 points for 4 sounds, and 0.7 points for soft sounds. Then, the recognition result should be 1 tone, the recognition score is 0.8 points, the standard tone should be 5 sounds (soft tone), and the standard tone score is 0.7 points. Then the tone evaluation feature is (1, 0.8, 5, 0.7), and this feature is sent to the tone evaluation model, and the evaluation score of the word can be obtained as 0.88 points.
步骤A4:用步骤A3的4维特征训练评测模型。该模型的输入为上述4维特征,输出为每个声调的人工评分。优选地,采用MLP作为声调评测模型。Step A4: Use the 4-dimensional features of step A3 to train the evaluation model. The input of the model is the above 4-dimensional features, and the output is the human score of each tone. Preferably, MLP is used as the tone evaluation model.
二、在测试阶段,采用如下步骤评测说话者的声调水平。2. In the test phase, the following steps are used to evaluate the speaker's tone level.
步骤B1:从说话者语音中提取声调识别特征。该特征与训练阶段的A1步骤的特征保持一致。Step B1: Extract tone recognition features from the speaker's voice. This feature is consistent with that of the A1 step in the training phase.
步骤B2:将提取的声调识别特征送入训练阶段生成的声调识别模型M1,获得声调识别结果。Step B2: Send the extracted tone recognition features to the tone recognition model M1 generated in the training stage to obtain the tone recognition result.
步骤B3:从B2的识别结果中获得声调评测特征。该特征与A3步骤保持一致。Step B3: Obtain tone evaluation features from the recognition results of B2. This feature is consistent with step A3.
步骤B4:将声调评测特征送入训练阶段生成的声调评测模型M2,获得声调评测得分。Step B4: Send the tone evaluation features into the tone evaluation model M2 generated in the training stage to obtain the tone evaluation score.
从上述的技术方案可以看出,本实施例声调评测方法采用了两级模型进行声调评测的策略。在第一层级,先采用声调识别器进行声调识别,将识别声调的得分和标准声调的得分作为新的输入,在第二层级采用识别器进行再次决策。多次实验结果表明,这种分两层级进行声调评测的策略,具有好的性能。在标注不准确的情况下,依然可以获得稳定的性能提升。It can be seen from the above technical solutions that the tone evaluation method of this embodiment adopts a strategy of two-level model for tone evaluation. In the first level, the tone recognizer is used to recognize the tone, and the score of the recognized tone and the score of the standard tone are used as new inputs, and the recognizer is used to make another decision in the second level. The results of multiple experiments show that this two-level tone evaluation strategy has good performance. In the case of inaccurate labeling, a stable performance improvement can still be obtained.
在本发明的另一个实施例中,提出了一种仅考虑基频特征的声调评测方法。图5为本发明实施例声调评测方法的示意图。如图5所示,本实施例同样包括训练阶段和测试阶段:In another embodiment of the present invention, a tone evaluation method that only considers fundamental frequency features is proposed. Fig. 5 is a schematic diagram of a tone evaluation method according to an embodiment of the present invention. As shown in Figure 5, this embodiment also includes a training phase and a testing phase:
训练阶段:Training phase:
步骤S201,对于已知文本的语音,利用语音识别领域的强制切分(ForceAlignment)技术,可以解码得到每个单词、汉字、声母、韵母的开始时间点和结束时间点;Step S201, for the voice of the known text, use the forced segmentation (ForceAlignment) technology in the field of speech recognition to decode and obtain the start time point and end time point of each word, Chinese character, initial consonant, and final syllable;
步骤S202,利用强制切分的结果,可以知道每个声母和韵母的边界,并从每个韵母段截取该段落的基频曲线作为声调特征;Step S202, using the result of forced segmentation, the boundary of each initial and final can be known, and the fundamental frequency curve of the paragraph is intercepted from each final section as a tone feature;
步骤S203,由于实际说话过程中每个汉字的时间长度有长有短,上述曲线基频曲线长度是不固定的,实施时将基频曲线线性地10等分,取每个等分段落的中点位置对应的基频,形成10维的特征,将该特征作为声调识别特征;Step S203, because the time length of each Chinese character in the actual speaking process is long or short, the length of the fundamental frequency curve of the above-mentioned curve is not fixed. The fundamental frequency corresponding to the point position forms a 10-dimensional feature, which is used as a tone recognition feature;
步骤S204,从外部输入每个字的实际声调标注;Step S204, input the actual tone label of each character from the outside;
步骤S205,将S203的声调识别特征和S204的实际声调标注对应起来,可以训练出用于声调识别的模型;Step S205, corresponding the tone recognition feature of S203 and the actual tone label of S204, a model for tone recognition can be trained;
步骤S206,利用S205的声调识别模型对训练语音进行声调识别,可以获得每个字的如下信息:标准声调ToneSTD,识别声调ToneREC,标准声调得分ScoreSTD,识别声调得分ScoreREC,这4维特征构成声调评测特征;Step S206, using the tone recognition model of S205 to perform tone recognition on the training speech, the following information of each word can be obtained: standard tone ToneSTD , recognition tone ToneREC , standard tone score ScoreSTD , recognition tone score ScoreREC , these 4 dimensions The feature constitutes the tone evaluation feature;
步骤S207,从外部输入每个字的评测信息,即每个字的声调是对的(1分)还是错的(0分);Step S207, input the evaluation information of each word from the outside, that is, whether the tone of each word is correct (1 point) or wrong (0 point);
步骤S208,将S206的声调评测特征按照S207的信息训练评测模型,该模型可以评测出0至1之间的分数。In step S208, the tone evaluation feature in S206 is used to train an evaluation model according to the information in S207, and the model can evaluate a score between 0 and 1.
至此,训练阶段结束。At this point, the training phase ends.
在测试阶段:During testing phase:
步骤S209,被测试的语音通过自动语音识别(ASR)或者强制切分(Force Alignment),可以获得每个单词、汉字、声母、韵母的开始时间点和结束时间点;Step S209, the tested speech can obtain the start time point and the end time point of each word, Chinese character, initial consonant and final syllable through automatic speech recognition (ASR) or forced segmentation (Force Alignment);
步骤S210,从S209获得每个声母和韵母的边界,并从每个韵母段截取该段落的基频曲线作为声调特征;Step S210, obtains the boundary of each initial consonant and final syllable from S209, and intercepts the fundamental frequency curve of this paragraph from each final syllable section as tone feature;
步骤S211,由于实际说话过程中每个汉字的时间长度有长有短,上述曲线基频曲线长度是不固定的,实施时将基频曲线线性地10等分,取每个等分段落的中点位置对应的基频,形成10维的特征,将该特征作为声调识别特征;Step S211, because the time length of each Chinese character in the actual speaking process is long or short, the length of the fundamental frequency curve of the above-mentioned curve is not fixed. The fundamental frequency corresponding to the point position forms a 10-dimensional feature, which is used as a tone recognition feature;
步骤S212,从外部查询获得每个字的标准声调;Step S212, obtain the standard tone of each word from external query;
步骤S213,利用S205的声调识别模型对S211获得的声调识别特征进行识别,结合S212处获得的标准声调可以对每个汉字提取如下信息:标准声调ToneSTD,识别声调ToneREC,标准声调得分ScoreSTD,识别声调得分ScoreREC,这4维特征构成声调评测特征;Step S213, using the tone recognition model of S205 to identify the tone recognition features obtained in S211, combined with the standard tone obtained at S212, the following information can be extracted for each Chinese character: standard tone ToneSTD , recognition tone ToneREC , standard tone score ScoreSTD , the recognition tone score ScoreREC , these 4-dimensional features constitute the tone evaluation feature;
步骤S214,将S213的声调评测特征输入声调评测模型,获得评测结果。Step S214, input the tone evaluation features of S213 into the tone evaluation model to obtain evaluation results.
在本发明的再一个实施例中,提出了一种考虑基频特征、能量特征和时长特征的声调评测方法。本实施例同样结合图5进行说明。本实施例包括:In yet another embodiment of the present invention, a tone evaluation method considering fundamental frequency features, energy features and duration features is proposed. This embodiment is also described in conjunction with FIG. 5 . This example includes:
步骤S201,对于已知文本的语音,利用语音识别领域的强制切分(ForceAlignment)技术,可以解码得到每个单词、汉字、声母、韵母的开始时间点和结束时间点。Step S201, for the speech of the known text, use the Force Alignment technology in the field of speech recognition to decode and obtain the start time point and end time point of each word, Chinese character, initial consonant, and final vowel.
步骤S202,从S201的结果可以获得每个声母和韵母的边界,并从每个韵母段提取该段落的基频曲线、能量曲线、时长作为声调特征。In step S202, the boundary of each initial and final can be obtained from the results of S201, and the fundamental frequency curve, energy curve, and duration of each final section are extracted as tone features.
步骤S203,由于实际说话过程中每个汉字的时间长度有长有短,上述曲线基频曲线长度是不固定的,实施时将基频曲线线性地10等分,取每个等分段落的中点位置对应的基频,形成10维的基频特征。同理,将能量曲线也变成10维的能量特征。加上时长共计21维特征作为声调识别特征;Step S203, because the time length of each Chinese character in the actual speaking process is long or short, the length of the fundamental frequency curve of the above-mentioned curve is not fixed. The fundamental frequency corresponding to the point position forms a 10-dimensional fundamental frequency feature. In the same way, turn the energy curve into a 10-dimensional energy feature. A total of 21-dimensional features plus duration are used as tone recognition features;
步骤S204,从外部输入每个字的实际声调标注;Step S204, input the actual tone label of each character from the outside;
步骤S205,将S203的声调识别特征和S204的实际声调标注对应起来,可以训练出用于声调识别的模型;Step S205, corresponding the tone recognition feature of S203 and the actual tone label of S204, a model for tone recognition can be trained;
步骤S206,利用S205的声调识别模型对训练语音进行声调识别,可以获得每个字的如下信息:标准声调ToneSTD,识别声调ToneREC,标准声调得分ScoreSTD,识别声调得分ScoreREC,这4维特征构成声调评测特征;Step S206, using the tone recognition model of S205 to perform tone recognition on the training speech, the following information of each word can be obtained: standard tone ToneSTD , recognition tone ToneREC , standard tone score ScoreSTD , recognition tone score ScoreREC , these 4 dimensions The feature constitutes the tone evaluation feature;
步骤S207,从外部输入每个字的评测信息,即每个字的声调是对的(1分)还是错的(0分)。Step S207, input the evaluation information of each character from the outside, that is, whether the tone of each character is correct (1 point) or wrong (0 point).
步骤S208,将S206的声调评测特征按照S207的信息分训练评测模型,该模型可以评测出0至1之间的分数。In step S208, the tone evaluation feature in S206 is used to train an evaluation model according to the information in S207, and the model can evaluate a score between 0 and 1.
在测试阶段:During testing phase:
步骤S209,被测试的语音通过自动语音识别(ASR)或者强制切分(Force Alignment),可以获得每个单词、汉字、声母、韵母的开始时间点和结束时间点。In step S209, the tested voice can obtain the start time and end time of each word, Chinese character, initial consonant, and final through automatic speech recognition (ASR) or forced segmentation (Force Alignment).
步骤S210,从S209获得每个声母和韵母的边界,并从每个韵母段提取该段落的基频曲线、能量曲线、时长作为声调特征。Step S210, obtain the boundaries of each initial and final from S209, and extract the fundamental frequency curve, energy curve, and duration of each final segment as tone features.
步骤S211,由于实际说话过程中每个汉字的时间长度有长有短,上述曲线基频曲线长度是不固定的,实施时将基频曲线线性地10等分,取每个等分段落的中点位置对应的基频,形成10维的基频特征。同理,将能量曲线也变成10维的能量特征。加上时长共计21维特征作为声调识别特征;Step S211, because the time length of each Chinese character in the actual speaking process is long or short, the length of the fundamental frequency curve of the above-mentioned curve is not fixed. The fundamental frequency corresponding to the point position forms a 10-dimensional fundamental frequency feature. In the same way, turn the energy curve into a 10-dimensional energy feature. A total of 21-dimensional features plus duration are used as tone recognition features;
步骤S212,从外部查询获得每个字的标准声调;Step S212, obtain the standard tone of each word from external query;
步骤S213,利用S205的声调识别模型对S211获得的声调识别特征进行识别,结合S212可以提取每个汉字的如下信息:标准声调ToneSTD,识别声调ToneREC,标准声调得分ScoreSTD,识别声调得分ScoreREC,这4维特征构成声调评测特征。Step S213, using the tone recognition model of S205 to identify the tone recognition features obtained in S211, combined with S212, the following information of each Chinese character can be extracted: standard tone ToneSTD , recognition tone ToneREC , standard tone score ScoreSTD , recognition tone score ScoreREC , these 4-dimensional features constitute the tone evaluation features.
步骤S214,将S213的声调评测特征输入声调评测模型,获得评测得分。Step S214, input the tone evaluation features of S213 into the tone evaluation model to obtain evaluation scores.
本发明的提出,解决了声韵母边界不准导致识别性能不高的问题,解决了基频曲线断开导致识别性能不高的问题,解决了基频曲线对声调识别贡献率处处一致假设导致的识别性能不高的问题,解决了声调即基频曲线假设导致的识别性能不高的问题,具体来讲:The proposal of the present invention solves the problem of low recognition performance caused by inaccurate boundaries of consonants and finals, solves the problem of low recognition performance caused by disconnection of the fundamental frequency curve, and solves the problem caused by the assumption that the contribution rate of the fundamental frequency curve to tone recognition is consistent everywhere. The problem of low recognition performance solves the problem of low recognition performance caused by the assumption that the tone is the fundamental frequency curve. Specifically:
1.采用了两级模型进行声调评测的策略。在第一层级,先采用声调识别器进行声调识别,将识别声调的得分和标准声调的得分作为新的输入,在第二层级采用识别器进行再次决策。多次实验结果表明,这种分两层级进行声调评测的策略,具有好的性能。在标注不准确的情况下,依然可以获得稳定的性能提升。1. A two-level model is used for the tone evaluation strategy. In the first level, the tone recognizer is used to recognize the tone, and the score of the recognized tone and the score of the standard tone are used as new inputs, and the recognizer is used to make another decision in the second level. The results of multiple experiments show that this two-level tone evaluation strategy has good performance. In the case of inaccurate labeling, a stable performance improvement can still be obtained.
2.采用能量曲线辅助基频曲线进行声调识别,可以比单独使用基频曲线获得更好的识别性能。采用基频曲线和能量曲线,通过训练模型的过程让模型自动决定声调曲线在不同能量条件下的加权方式,可以获得比基频曲线更优的识别性能。另外,能量曲线还具有区分轻声的作用。轻声的能量通常要比正常音节的能量更低。2. Using the energy curve to assist the fundamental frequency curve for tone recognition can achieve better recognition performance than using the fundamental frequency curve alone. Using the fundamental frequency curve and energy curve, the model can automatically determine the weighting method of the tone curve under different energy conditions through the process of training the model, which can obtain better recognition performance than the fundamental frequency curve. In addition, the energy curve also has the function of distinguishing soft sounds. Soft syllables usually have lower energy than normal syllables.
3.采用时长辅助基频曲线进行声调识别,可以比单独使用基频曲线获得更好的识别性能。轻声具有多种基频曲线表现形式,可以有基频,也可以无基频。但通常伴随着的显著特点是时长比正常音节短,通常是正常音节的一半。3. Using duration-assisted fundamental frequency curves for tone recognition can achieve better recognition performance than using fundamental frequency curves alone. The soft voice has a variety of fundamental frequency curves, which can have a fundamental frequency or no fundamental frequency. But it is usually accompanied by a distinctive feature that the duration is shorter than normal syllables, usually half of normal syllables.
以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。The specific embodiments described above have further described the purpose, technical solutions and beneficial effects of the present invention in detail. It should be understood that the above descriptions are only specific embodiments of the present invention and are not intended to limit the present invention. Any modifications, equivalent replacements, improvements, etc. made within the spirit and principles of the present invention shall be included within the protection scope of the present invention.
Claims (6)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN2011103700384ACN102419973B (en) | 2011-11-18 | 2011-11-18 | Tone evaluating method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN2011103700384ACN102419973B (en) | 2011-11-18 | 2011-11-18 | Tone evaluating method |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN102419973A CN102419973A (en) | 2012-04-18 |
| CN102419973Btrue CN102419973B (en) | 2013-06-19 |
Family
ID=45944356
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN2011103700384AActiveCN102419973B (en) | 2011-11-18 | 2011-11-18 | Tone evaluating method |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN102419973B (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3036000A4 (en)* | 2013-08-19 | 2017-05-03 | MED-EL Elektromedizinische Geräte GmbH | Auditory prosthesis stimulation rate as a multiple of intrinsic oscillation |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101727902A (en)* | 2008-10-29 | 2010-06-09 | 中国科学院自动化研究所 | Method for estimating tone |
| CN102124515A (en)* | 2008-06-17 | 2011-07-13 | 声感有限公司 | Speaker characterization through speech analysis |
- 2011
- 2011-11-18CNCN2011103700384Apatent/CN102419973B/enactiveActive
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102124515A (en)* | 2008-06-17 | 2011-07-13 | 声感有限公司 | Speaker characterization through speech analysis |
| CN101727902A (en)* | 2008-10-29 | 2010-06-09 | 中国科学院自动化研究所 | Method for estimating tone |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3036000A4 (en)* | 2013-08-19 | 2017-05-03 | MED-EL Elektromedizinische Geräte GmbH | Auditory prosthesis stimulation rate as a multiple of intrinsic oscillation |
Also Published As
| Publication number | Publication date |
|---|---|
| CN102419973A (en) | 2012-04-18 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110675854B (en) | Chinese and English mixed speech recognition method and device | |
| CN103578467B (en) | Acoustic model building method, speech recognition method and electronic device thereof | |
| US9711138B2 (en) | Method for building language model, speech recognition method and electronic apparatus | |
| CN111341305B (en) | Audio data labeling method, device and system | |
| US9613621B2 (en) | Speech recognition method and electronic apparatus | |
| CN107103900B (en) | Cross-language emotion voice synthesis method and system | |
| US9471568B2 (en) | Speech translation apparatus, speech translation method, and non-transitory computer readable medium thereof | |
| CN103345922B (en) | A kind of large-length voice full-automatic segmentation method | |
| CN103177733B (en) | Standard Chinese suffixation of a nonsyllabic "r" sound voice quality evaluating method and system | |
| CN112908360B (en) | Online spoken pronunciation evaluation method, device and storage medium | |
| CN109863554B (en) | Acoustic grapheme models and acoustic grapheme-phoneme models for computer-aided pronunciation training and speech processing | |
| KR102442020B1 (en) | Automatic fluency assessment method and device for speaking | |
| CN103035241A (en) | Model complementary Chinese rhythm interruption recognition system and method | |
| Harrison et al. | Improving mispronunciation detection and diagnosis of learners' speech with context-sensitive phonological rules based on language transfer. | |
| CN115358219A (en) | Chinese spelling error correction method integrating unsupervised learning and self-supervised learning | |
| CN105895076B (en) | A kind of phoneme synthesizing method and system | |
| CN102419973B (en) | Tone evaluating method | |
| TW201937479A (en) | Multilingual mixed speech recognition method | |
| Prakash et al. | Acoustic Analysis of Syllables Across Indian Languages. | |
| CN110992986B (en) | Method, device, electronic device and storage medium for error detection of word syllable stress | |
| CN116013250A (en) | Audio labeling method, training method, equipment and medium of speech synthesis model | |
| CN115099222A (en) | Method, device, equipment and storage medium for detecting and correcting misuse of punctuation marks | |
| Pan et al. | Improvements in tone pronunciation scoring for strongly accented mandarin speech | |
| CN114203158A (en) | A method and device for evaluating and detecting and correcting errors in children's spoken Chinese | |
| Slifka et al. | A landmark-based model of speech perception: History and recent developments |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C14 | Grant of patent or utility model | ||
| GR01 | Patent grant |