CN102318372A - Sound system - Google Patents
Sound systemDownload PDFInfo
- Publication number
- CN102318372A CN102318372ACN2010800066263ACN201080006626ACN102318372ACN 102318372 ACN102318372 ACN 102318372ACN 2010800066263 ACN2010800066263 ACN 2010800066263ACN 201080006626 ACN201080006626 ACN 201080006626ACN 102318372 ACN102318372 ACN 102318372A
- Authority
- CN
- China
- Prior art keywords
- sound
- transformation
- audio signal
- spatial audio
- format
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images




Classifications
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S7/00—Indicating arrangements; Control arrangements, e.g. balance control
- H04S7/30—Control circuits for electronic adaptation of the sound field
- H04S7/308—Electronic adaptation dependent on speaker or headphone connection
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/02—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders
- G10L19/0212—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders using orthogonal transformation
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/10—Complex mathematical operations
- G06F17/14—Fourier, Walsh or analogous domain transformations, e.g. Laplace, Hilbert, Karhunen-Loeve, transforms
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S1/00—Two-channel systems
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S3/00—Systems employing more than two channels, e.g. quadraphonic
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S3/00—Systems employing more than two channels, e.g. quadraphonic
- H04S3/02—Systems employing more than two channels, e.g. quadraphonic of the matrix type, i.e. in which input signals are combined algebraically, e.g. after having been phase shifted with respect to each other
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S7/00—Indicating arrangements; Control arrangements, e.g. balance control
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S7/00—Indicating arrangements; Control arrangements, e.g. balance control
- H04S7/30—Control circuits for electronic adaptation of the sound field
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S2420/00—Techniques used stereophonic systems covered by H04S but not provided for in its groups
- H04S2420/01—Enhancing the perception of the sound image or of the spatial distribution using head related transfer functions [HRTF's] or equivalents thereof, e.g. interaural time difference [ITD] or interaural level difference [ILD]
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S2420/00—Techniques used stereophonic systems covered by H04S but not provided for in its groups
- H04S2420/11—Application of ambisonics in stereophonic audio systems
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Signal Processing (AREA)
- Acoustics & Sound (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Pure & Applied Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Mathematical Optimization (AREA)
- Mathematical Analysis (AREA)
- Algebra (AREA)
- Data Mining & Analysis (AREA)
- Computational Mathematics (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Human Computer Interaction (AREA)
- Multimedia (AREA)
- General Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Databases & Information Systems (AREA)
- Stereophonic System (AREA)
- Circuit For Audible Band Transducer (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本发明涉及用于处理音频数据的系统和方法。特别地,本发明涉及用于处理空间音频数据的系统和方法。The present invention relates to systems and methods for processing audio data. In particular, the present invention relates to systems and methods for processing spatial audio data.
背景技术Background technique
音频数据最简单的形式是采用表现声音特征(诸如,频率和音量)的单声道数据的形式;这被称为单声道信号。立体音频数据是一种非常成功的音频数据格式,其包括双声道音频数据,并因此在一定程度上包含该音频数据表现的声音的方向特征。最近,包括环绕声格式的音频格式日益流行,其可包括两个声道以上的音频数据并包括所表现声音的二维或三维方向特征。The simplest form of audio data is in the form of monaural data representing sound characteristics such as frequency and volume; this is called a monaural signal. Stereo audio data is a very successful audio data format that includes binaural audio data, and thus contains, to some extent, the directional characteristics of the sound represented by the audio data. More recently, audio formats have grown in popularity, including surround sound formats, which may include more than two channels of audio data and include two- or three-dimensional directional characteristics of the represented sound.
本文使用的术语“空间音频数据”是指包含与所表现的声音的方向特征信息有关的任何数据。空间音频数据可以各种不同格式表示,每种格式具有规定数量的音频声道,并需要不同的解译以再现所表现的声音。这种格式的例子包括立体声、5.1环绕声及使用声场的球谐函数表达式的格式,诸如Ambisonic B格式和高阶Ambisonic(HOA)格式。在一阶B格式中,声场信息被编码至四个声道,通常标记为W、X、Y和Z,其中,W声道代表全向信号级,X、Y和Z声道代表三维中的方向分量。HOA格式使用更多的声道,这可以例如产生更大的甜区(即,用户听到基本达到预期的声音的区域),并在更高频率处产生更精确的声场再现。Ambisonic数据可使用声场麦克风通过现场录音创建,可使用ambisonic移动立体声录音法在录音室中混合,或通过(例如)游戏软件生成。As used herein, the term "spatial audio data" refers to any data containing information about the directional characteristics of represented sound. Spatial audio data can be represented in a variety of different formats, each format having a specified number of audio channels and requiring different interpretations to reproduce the represented sound. Examples of such formats include stereo, 5.1 surround, and formats using spherical harmonic representations of sound fields, such as the Ambisonic B format and the Higher Order Ambisonic (HOA) format. In the first-order B format, sound field information is encoded into four channels, usually labeled W, X, Y, and Z, where the W channel represents the omnidirectional signal level and the X, Y, and Z channels represent the three-dimensional direction component. The HOA format uses more channels, which can, for example, result in a larger sweet spot (ie, the area where the user hears substantially what is expected) and a more accurate reproduction of the sound field at higher frequencies. Ambisonic data can be created from field recordings using sound field microphones, can be mixed in the studio using ambisonic mobile stereo recording, or can be generated by, for example, gaming software.
Ambisonic格式和一些其他格式使用声场的球谐函数表达式。球谐函数是拉普拉斯方程的一组正交解的角度部分。The ambisonic format and some others use spherical harmonic representations of the sound field. Spherical harmonics are the angular parts of a set of orthogonal solutions to Laplace's equations.
球谐函数可以多种方式定义。球谐函数的实值形式可定义如下:Spherical harmonics can be defined in various ways. The real-valued form of spherical harmonics can be defined as follows:
其中,l≥0、-l≥m≥l,l和m通常分别被称为特定球谐函数的“阶”和“指数”,
n=l(l+1)+m (ii)n=l(l+1)+m (ii)
这些Yn(θ,φ)可用于表示在整个球面上定义的任何分段连续函数f(θ,φ),使:TheseYn (θ,φ) can be used to represent any piecewise continuous function f(θ,φ) defined over the entire sphere such that:
因为球谐函数Yi(θ,φ)在对于球面的积分下为正交,由此可见,ai可从以下方程得出:Because the spherical harmonic function Yi (θ, φ) is orthogonal under the integral with respect to the spherical surface, it can be seen that ai can be obtained from the following equation:
其可用解析法或数值法求解。It can be solved analytically or numerically.
可用如方程iii)所示的数列表示处于时域或频域的原点的中心收听点的周围的声场。以一些有限阶L对方程iii)的数列进行截取,可使用有限数目的分量给出函数f(θ,φ)的近似值。这种截取近似值通常为原函数的平滑形式:The sound field around a central listening point at the origin of the time or frequency domain can be represented by a sequence as shown in equation iii). Intercepting the sequence of equation iii) with some finite order L gives an approximation of the function f(θ,φ) using a finite number of components. This truncated approximation is usually a smoothed version of the original function:
可对该表达式进行解释,使函数f(θ,φ)代表平面波从该方向入射的方向,因此,从特定方向入射的平面波源被编码为:This expression can be interpreted so that the function f(θ, φ) represents the direction from which the plane wave is incident, so that a plane wave source from a particular direction is encoded as:
ai=4πYi(θ,φ) (vi)ai =4πYi (θ, φ) (vi)
进一步,可将多个源的输出相加以合成更复杂的声场。还可通过将曲面波前分解为平面波,以表示到达中心收听点的曲面波前。Further, the outputs of multiple sources can be summed to synthesize more complex sound fields. A surface wavefront arriving at a central listening point can also be represented by decomposing the surface wavefront into plane waves.
因此,代表任意数目的声音分量的方程vi)的截取ai数列可用于对时间点或频率点处的声场行为进行近似。一般情况下,这种ai(t)的时间数列被提供为用于重放的编码空间音频流,然后利用解码器算法根据新收听者的身体原则或心理声学原则对声音进行重构。可通过录音技术和/或声音合成获取这种空间音频流。四声道Ambisonic B格式表达式可示为L=1截取数列v)的简单线性变换。Thus, the sequence of intercepts ai of equation vi) representing any number of sound components can be used to approximate the behavior of the sound field at time points or frequency points. Typically, this temporal series of ai (t) is provided as an encoded spatial audio stream for playback, and decoder algorithms are then used to reconstruct the sound according to the new listener's physical or psychoacoustic principles. Such spatial audio streams may be obtained through recording techniques and/or sound synthesis. The four-channel Ambisonic B format expression can be shown as a simple linear transformation of L=1 truncated sequence v).
可替换地,时间数列可(例如)通过加窗快速傅里叶变换技术变换至频域,提供ai(ω)形式的数据,其中,ω=2πf,f为频率。这种情况下,ai(ω)的值通常是复数。Alternatively, the time series can be transformed to the frequency domain, eg, by windowed Fast Fourier Transform techniques, providing data in the form ai (ω), where ω = 2πf and f is the frequency. In this case, the value of ai (ω) is usually a complex number.
进一步,可用以下方程将单音频流m(t)编码为空间音频流,作为从方向(θ,φ)入射的平面波:Further, the following equation can be used to encode a single audio stream m(t) into a spatial audio stream as a plane wave incident from the direction (θ, φ):
ai(t)=4πYi(θ,φ)m(t) (vii)ai (t) = 4πYi (θ, φ)m(t) (vii)
其可写为时间相关矢量a(t)。It can be written as a time-dependent vector a(t).
重放之前,必须对空间音频数据进行解码,以提供扬声器馈送,即,用于重放声音数据以再现声音的每个单独扬声器的数据。可在将解码数据写入用于供应消费者的(例如)DVD之前执行解码;这种情况下,假定消费者将使用包括预定数目扬声器的预定扬声器布局。在其他情况下,该空间音频数据可在重放期间实时地(on the fly)被解码。Before playback, the spatial audio data must be decoded to provide speaker feeds, ie data for each individual speaker that is used to playback the sound data to reproduce the sound. Decoding may be performed prior to writing the decoded data to, for example, a DVD for supply to the consumer; in this case it is assumed that the consumer will use a predetermined speaker layout comprising a predetermined number of speakers. In other cases, the spatial audio data may be decoded on the fly during playback.
解码空间音频数据(例如,ambisonic(环境声)音频数据)的方法一般涉及计算时域或频域内的扬声器输出,可能对于再现由空间音频数据代表的声场的、给定扬声器布局中的每个扬声器使用隔离高频解码和低频解码的时域滤波器。在任何指定时间,所有扬声器一般都能有效地再现声场,而与声场的源的方向无关。这要求扬声器布局的精确装配,可以看出,关于扬声器的位置缺乏稳定性,特别是在较高频率下。Methods of decoding spatial audio data (e.g., ambisonic (ambient sound) audio data) generally involve computing speaker outputs in the time or frequency domain, possibly for each speaker in a given speaker arrangement that reproduces the sound field represented by the spatial audio data Use a time-domain filter that isolates high-frequency decoding from low-frequency decoding. At any given time, all loudspeakers are generally capable of effectively reproducing a sound field, regardless of the direction of the sound field's source. This requires precise fitting of the loudspeaker layout, and it can be seen that there is a lack of stability with respect to the placement of the loudspeakers, especially at higher frequencies.
众所周知,对空间音频数据进行变换,该变换可改变所代表的声场的空间特征。例如,通过对ambisonic声道的矢量表达式应用矩阵变换,可以对处于ambisonic格式的整个声场进行旋转或镜像。It is well known to perform transformations on spatial audio data which alter the spatial characteristics of the represented sound field. For example, an entire sound field in ambisonic format can be rotated or mirrored by applying a matrix transformation to a vector representation of an ambisonic channel.
本发明的目的在于提供用于处理和/或解码音频数据的方法和系统,以增强收听者的收听体验。本发明进一步的目的在于提供用于处理和解码空间音频数据、不对正在使用的音频系统造成过度负担的方法和系统。It is an object of the present invention to provide methods and systems for processing and/or decoding audio data to enhance the listening experience of the listener. It is a further object of the present invention to provide methods and systems for processing and decoding spatial audio data that do not place an undue burden on the audio system being used.
发明内容Contents of the invention
根据本发明的第一方面,提供了处理空间音频信号的方法,该方法包括:According to a first aspect of the present invention, a method of processing a spatial audio signal is provided, the method comprising:
接收空间音频信号,该空间音频信号代表一个或多个声音分量,该声音分量具有规定方向特征和一个或多个声音特征;receiving a spatial audio signal representing one or more sound components having a prescribed directional characteristic and one or more sound characteristics;
提供变换,用于更改一个或多个声音分量的一个或多个声音特征,该声音分量的规定方向特征与方向特征的规定范围相关;providing a transform for modifying one or more sound characteristics of one or more sound components having a specified directional characteristic associated with a specified range of directional characteristics;
对空间音频信号应用该变换,从而生成更改的空间音频信号,其中,一个或多个声音分量的一个或多个声音特征被更改,对给定声音分量的更改与给定分量的规定方向特征与方向特征的规定范围之间的关系有关;以及applying the transformation to a spatial audio signal, thereby generating a modified spatial audio signal in which one or more sound characteristics of one or more sound components are modified, the modification to a given sound component being in the same way as the prescribed directional characteristics of the given component relationship between specified ranges of directional features; and
输出经更改的空间音频信号。Output a modified spatial audio signal.
这允许对空间音频数据进行处理,使诸如频率特征和音量特征的声音特征可根据其方向来进行选择性地改变。This allows spatial audio data to be processed so that sound characteristics such as frequency characteristics and volume characteristics can be selectively changed according to its direction.
本文的术语“声音分量”指,例如,从规定方向入射的平面波,或属于特定声源(不论该源是静止或是移动(例如,人走动的情况))的声音。The term "sound component" herein refers to, for example, a plane wave incident from a prescribed direction, or a sound belonging to a specific sound source whether the source is stationary or moving (for example, in the case of a person walking).
根据本发明的第二方面,提供了解码空间音频信号的方法,该方法包括:According to a second aspect of the present invention, there is provided a method of decoding a spatial audio signal, the method comprising:
接收空间音频信号,该空间音频信号代表一个或多个声音分量,该声音分量具有预定方向特征,该信号处于使用该声音分量的球谐函数表达式的格式;receiving a spatial audio signal representing one or more sound components having predetermined directional characteristics, the signal being in a format using spherical harmonic expressions of the sound components;
对球谐函数表达式进行变换,该变换基于预定扬声器布局和预定规则,该预定规则表示当再现从给定方向入射的声音时根据预定扬声器布局而布置的每个扬声器的扬声器增益,给定扬声器的扬声器增益与给定方向有关;该变换的执行产生多个扬声器信号,每个扬声器信号定义了扬声器的输出,该扬声器信号能够控制根据预定扬声器布局而布置的扬声器,以根据规定方向特征生成一个或多个声音分量;以及performing a transformation on the spherical harmonic expression based on a predetermined speaker layout and a predetermined rule representing the speaker gain of each speaker arranged according to the predetermined speaker layout when reproducing sound incident from a given direction, the given speaker The loudspeaker gain of is related to a given direction; the execution of this transformation produces a plurality of loudspeaker signals, each defining a loudspeaker output, capable of controlling loudspeakers arranged according to a predetermined loudspeaker layout to generate a or multiple sound components; and
输出经解码的信号。Output the decoded signal.
本文所称的规则可为平移规则(panning rule)。The rule referred to herein may be a panning rule.
这对现有的、使用球谐函数表达式的音频数据解码技术提供了替代方法,其中,由扬声器生成的声音提供对方向的敏锐感知,并对于扬声器设置和扬声器意外移动较为稳固。This provides an alternative to existing audio data decoding techniques that use spherical harmonic expressions, where the sound generated by the speakers provides a keen sense of direction and is robust to speaker settings and accidental speaker movement.
根据本发明的第三方面,提供了处理音频信号的方法,该方法包括:According to a third aspect of the present invention, there is provided a method of processing an audio signal, the method comprising:
接收对于更改音频信号的请求,该更改包括:对于预定格式和一个或多个规定声音特征这两者中的至少一个的更改;receiving a request to modify the audio signal, the modification comprising: a modification to at least one of a predetermined format and one or more prescribed sound characteristics;
响应于对该请求的接收,对存储多个矩阵变换的数据存储装置进行存取,每个矩阵变换用于更改音频流的格式和声音特征中的至少一个;In response to receiving the request, accessing a data storage device storing a plurality of matrix transformations, each matrix transformation for changing at least one of the format and sound characteristics of the audio stream;
确定矩阵变换的多个组合,每个经确定的组合用于执行所请求的更改;determining a plurality of combinations of matrix transformations, each determined combination for performing the requested alteration;
响应于对组合的选择,将选出的组合的矩阵变换组合为组合变换;In response to selecting a combination, combining matrix transformations of the selected combination into a combined transformation;
对接收的音频信号应用组合变换,从而生成更改的音频信号;以及applying a combined transformation to the received audio signal, thereby generating an altered audio signal; and
输出更改的音频信号。Output the changed audio signal.
确定用于执行所请求的更改的、矩阵变换的多种组合以在选择矩阵变换的步骤时,例如将用户偏好纳入考虑;组合所选组合的矩阵变换允许快速有效地处理复杂的变换操作。Multiple combinations of matrix transformations for performing the requested changes are determined to take into account eg user preference when selecting the step of matrix transformation; combining the matrix transformations of the selected combinations allows complex transformation operations to be processed quickly and efficiently.
本发明的进一步特征和优点将根据以下对于参考附图仅通过示例方式给出的本发明的优先实施方式的说明变得显而易见。Further features and advantages of the invention will become apparent from the following description of a preferred embodiment of the invention, given by way of example only with reference to the accompanying drawings.
附图说明Description of drawings
图1是第一系统的示意图,在该系统中可以实现本发明的实施方式以提供对于空间音频数据的再现;1 is a schematic diagram of a first system in which embodiments of the present invention may be implemented to provide reproduction of spatial audio data;
图2是第二系统的示意图,在该系统中可以实现本发明的实施方式以记录空间音频数据;Figure 2 is a schematic diagram of a second system in which embodiments of the present invention may be implemented to record spatial audio data;
图3是被布置为根据本发明的任意实施方式执行解码操作的部件的示意图;Figure 3 is a schematic diagram of components arranged to perform a decoding operation according to any embodiment of the invention;
图4是示出了根据本发明的实施方式执行着色变换(tinting transform)的流程图;FIG. 4 is a flowchart illustrating performing a tinting transform in accordance with an embodiment of the present invention;
图5是被布置为根据本发明的实施方式执行着色变换的部件的示意图;以及Figure 5 is a schematic diagram of components arranged to perform a shading transformation according to an embodiment of the invention; and
图6是根据本发明的实施方式由变换引擎执行的处理的流程图。Figure 6 is a flow diagram of processing performed by a transformation engine in accordance with an embodiment of the invention.
具体实施方式Detailed ways
图1示出了根据本发明实施方式用于处理和播放音频信号的示例系统100。图1中所示的每个部件可实现为硬件部件,或实现为在相同或不同硬件上运行的软件部件。该系统包括DVD播放机110和游戏装置120,这两者均将输出提供至变换引擎104。游戏装置播放机120可以是通用个人计算机,或诸如“Xbox”的游戏机。FIG. 1 shows an example system 100 for processing and playing audio signals according to an embodiment of the present invention. Each of the components shown in Figure 1 may be implemented as a hardware component, or as a software component running on the same or different hardware. The system includes a DVD player 110 and a gaming device 120 , both of which provide output to the
游戏装置120将输出(例如)以来自正在玩的游戏的OpenAL调用的形式提供给描绘器(renderer)112,并利用这些输出以诸如Ambisonic B格式的格式构造表示游戏声场的多声道音频流;然后,该Ambisonic B格式流输出至变换引擎104。Game device 120 provides output to renderer 112, for example in the form of OpenAL calls from the game being played, and utilizes these outputs to construct a multi-channel audio stream representing the game's sound field in a format such as Ambisonic B format; Then, the Ambisonic B format stream is output to the
DVD播放机110能够以(例如)5.1环绕声或立体声将输出提供至变换引擎104。DVD player 110 can provide output to
变换引擎104根据下文描述技术的其中之一对于从游戏装置120和/或DVD播放机110接收的信号进行处理,以不同格式提供音频信号输出,和/或表现具有与输入音频流代表的特征不同的声音。附加地或可替代地,变换引擎104可根据下文描述的技术解码音频信号。用于该处理的变换可存储于变换数据库106;用户可设计变换,并可经由用户界面108将这些变换存储于变换数据库106。变换引擎104可从一个或多个处理插件114接收变换,该处理插件114可提供用于对声场执行空间操作(例如,旋转)的变换。
用户界面108还可用于对变换引擎104的操作方面进行控制,例如,选择在变换引擎104中使用的变换。
然后,由变换引擎执行的处理所产生的信号从该处理输出至输出管理器132,该输出管理器通过(例如)选择要使用的音频驱动器并提供适用于所使用的扬声器布局的扬声器馈送,从而对变换引擎104使用的格式与可用于重放的输出声道之间的关系进行管理。在图1所示的系统100中,来自输出管理器132的输出可提供给耳机150和/或扬声器阵列140。The signals resulting from the processing performed by the transformation engine are then output from the processing to the output manager 132 which, for example, selects the audio driver to be used and provides speaker feeds appropriate for the speaker layout used, thereby The relationship between the format used by the
图2示出了可在其中实现本发明实施方式的可替换系统200。图2的系统用于对音频数据进行编码和/或记录。在该系统中,诸如空间麦克风录音和/或其他输入的音频输入连接到数字音频工作站(DAW)204,其允许对音频数据进行编辑和重放。该DAW可与变换引擎104、变换数据库106和/或处理插件114结合使用,以根据下文描述的技术处理音频输入,从而将接收的音频输入编辑为预期形式。一旦音频数据被编辑为预期形式,就将其发送至出口管理器208,该出口管理器执行添加诸如与音频数据创作者相关的元数据等功能。该音频数据随后传输给音频文件写入器212,以写入记录介质。Figure 2 shows an
现在将对变换引擎104的功能进行详细说明。变换引擎104处理音频流输入,以生成改变的音频流,其中,该改变可包括对所表现的声音的改变和/或空间音频流格式的改变;附加地或可替代地,变换引擎执行空间音频流解码。在一些情况下,该改变可包括:对多个声道中的每个声道应用相同滤波器。The function of the
变换引擎104被布置为将两个以上变换连在一起,以创建组合变换,这使得与单独执行每个变换的现有系统相比实现更快速且更少资源密集处理。可从用户可配置的处理插件提供的变换数据库106中检索被组合以形成组合变换的单独变换。一些情况下,可直接计算变换,以提供(例如)声音旋转,旋转角度可由用户通过用户界面108选择。The
变换可表示为有限脉冲响应(FIR)卷积滤波器的矩阵。在时域中,我们将这些矩阵的元索引为pij(t)。为了进行说明,假设FIR为长度T的数字因果滤波器。给出具有m个声道的多声道信号ai(t),具有n个声道的多声道输出bj(t)可由以下方程得出:The transform can be represented as a matrix of finite impulse response (FIR) convolution filters. In the time domain, we index the elements of these matrices as pij (t). For illustration, assume that the FIR is a digital causal filter of length T. Given a multi-channel signal ai (t) with m channels, the multi-channel output bj (t) with n channels can be obtained by the following equation:
通过对每个矩阵分量执行可逆离散傅里叶变换(DFT),可以提供时域变换的等价表达式。然后,分量可表示为其中,ω=2πf以及f为频率。An equivalent expression for the time-domain transform is provided by performing an invertible discrete Fourier transform (DFT) on each matrix component. Then, the components can be expressed as where ω=2πf and f is the frequency.
在该表达式中,输入音频流
注意,这种形式(对于每个ω)与复杂矩阵乘法等价。因此,可以矩阵形式将变换表示为:Note that this form (for each ω) is equivalent to complex matrix multiplication. Therefore, the transformation can be expressed in matrix form as:
其中,



同样,如果对音频流


将方程(3)代入方程(4),可得出:Substituting Equation (3) into Equation (4), we get:
因此,可为每个频率查找单矩阵Therefore, a single matrix can be found for each frequency
使方程(3)和(4)的变换可以作为单变换而进行:The transformation of equations (3) and (4) can be performed as a single transformation:
其可表示为:It can be expressed as:
应理解的是,通过对关于方程(3)至(7)的上述步骤进行迭代,从而可以将该方法延伸为将任何数量的变换组合为等价组合变换。一旦形成新频域变换,就可以将其变换回时域。可替代地,如此处所述,可在频域内执行变换。It will be appreciated that by iterating the steps described above with respect to equations (3) to (7), the method can thus be extended to combine any number of transformations into equivalently combined transformations. Once a new frequency domain transform is formed, it can be transformed back to the time domain. Alternatively, the transform may be performed in the frequency domain, as described herein.
可以使用诸如在快速卷积算法中经常使用的开窗技术通过(例如)DFT将音频流切成块并传输至频域。随后,可使用方程(8)在频域中实现变换,这比在时域中执行变换更高效,原因在于不对s求和(方程(1)与(8)比较)。随后可对生成的块执行可逆离散傅里叶变换(IDFT),然后可以将块组合为新的音频流,并将该新的音频流输出至输出管理器。The audio stream can be sliced and transferred to the frequency domain by eg DFT using windowing techniques such as are often used in fast convolution algorithms. The transformation can then be implemented in the frequency domain using equation (8), which is more efficient than performing the transformation in the time domain because s are not summed (compare equation (1) to (8)). An Inverse Discrete Fourier Transform (IDFT) may then be performed on the resulting blocks, and the blocks may then be combined into a new audio stream and output to the output manager.
以这种方式将变换连在一起允许将多个变换作为单个、线性变换来执行,意味着可快速执行复杂的数据操作,而没有对处理装置的资源造成沉重负担。Linking transforms together in this way allows multiple transforms to be performed as a single, linear transform, meaning that complex data manipulations can be performed quickly without taxing the resources of the processing device.
现在将提供可使用变换引擎104实现的变换的一些实施例。Some examples of transformations that may be implemented using the
格式变换format conversion
在输入音频流与扬声器布局不兼容的情况下,例如,在输入音频流为HOA流,但扬声器为一对耳机的情况下,可能需要改变音频流的格式。可替代地或附加地,可能需要改变格式以执行要求音频流的球谐函数表达式的操作,例如,着色(见下文)。现在,将提供格式变换的一些实施例。In cases where the input audio stream is not compatible with the speaker layout, for example, where the input audio stream is an HOA stream but the speakers are a pair of headphones, it may be necessary to change the format of the audio stream. Alternatively or additionally, the format may need to be changed to perform operations requiring spherical harmonic representations of the audio stream, eg coloring (see below). Now, some examples of format conversion will be provided.
矩阵编码音频Matrix encoded audio
一些立体声格式通过操作相位来编码空间信息;例如,杜比立体声将四声道扬声器信号编码为立体声。矩阵编码音频的其他实施例包括:MatrixQS、Matrix SQ和Ambisonic UHJ立体声。变换为或变换自这些格式的变换可使用变换引擎104实现。Some stereo formats encode spatial information by manipulating phase; for example, Dolby Stereo encodes a quad-speaker signal as stereo. Other embodiments of matrix encoded audio include: MatrixQS, Matrix SQ, and Ambisonic UHJ stereo. Transformation to or from these formats may be accomplished using the
Ambisonic A-B格式转换Ambisonic A-B format conversion
Ambisonic麦克风通常具有产生A格式信号的振膜舱四面体排列。在现有系统中,该A格式信号通常是通过一组滤波器、矩阵混音器、以及一些其他滤波器转换为B格式空间音频流。在根据本发明实施方式的变换引擎104中,该操作组合可组合为从A格式到B格式的单个变换。Ambisonic microphones typically have a tetrahedral arrangement of capsules that produce an A-format signal. In existing systems, the A-format signal is usually converted into a B-format spatial audio stream through a set of filters, a matrix mixer, and some other filters. In a
虚拟声源virtual sound source
给定扬声器馈送格式(例如,5.1环绕声数据),可通过位于特定方向的虚拟声向这些扬声器声道的每个声道馈送音频,从而合成抽象空间表达式。Given a speaker feed format (eg, 5.1 surround sound data), an abstract spatial expression can be synthesized by feeding audio to each of these speaker channels with a virtual sound located in a particular direction.
这使矩阵从扬声器馈送格式变换为空间音频表达式;构造空间音频流的另一种方法见下文名为“用平移资料构造空间音频流”一节。This transforms the matrix from a speaker feed format to a spatial audio representation; see the section below entitled "Constructing a Spatial Audio Stream from Panning Data" for an alternative approach to constructing a spatial audio stream.
虚拟麦克风virtual microphone
给定音频流的抽象空间表示,通常可合成特定方向的麦克风响应。例如,可使用指向用户指定方向的一对虚拟心形方向性麦克风由Ambisonic信号构造立体声馈送。Given an abstract spatial representation of an audio stream, it is often possible to synthesize directional-specific microphone responses. For example, a stereo feed can be constructed from an ambisonic signal using a pair of virtual cardioid directional microphones pointing in a direction specified by the user.
恒等变换identity transformation
有时在数据库中包含恒等变换(即,该变换实际上不会更改声音)是有用的,以帮助用户在格式之间进行变换;这可用于(例如)声音可明显地用不同方式表示的情况。例如,可将杜比立体声数据转换为立体声,用于烧录到CD。Sometimes it is useful to include an identity transform (i.e., a transform that does not actually change the sound) in the database to help the user transform between formats; this can be used (for example) when the sound can clearly be represented differently . For example, Dolby Stereo data can be converted to stereo for burning to CD.
其他简单矩阵变换Other Simple Matrix Transformations
简单变换的其他实施例包括,(例如)通过简单地增加新(无声)低音声道,从5.0环绕声格式转换为5.1环绕声格式,或通过增加无声三阶声道将二阶Ambisonic流上采样为三阶。Other examples of simple transformations include, for example, converting from a 5.0 surround format to a 5.1 surround format by simply adding a new (silent) bass channel, or upsampling a second-order ambisonic stream by adding a silent third-order channel for the third order.
同样,简单线性组合,例如,从左/右标准立体声向中/侧表达式的转换为表示为简单矩阵变换。Likewise, simple linear combinations, eg, conversion from left/right standard stereo to mid/side representations are represented as simple matrix transformations.
HRTF立体声HRTF Stereo
抽象空间音频流可转换为适用于使用HRTF(头部相关传输函数)数据的耳机的立体声。此处,滤波器通常相当复杂,因为最终频率组成与基础声源的方向有关。Abstracted spatial audio streams can be converted to stereo suitable for headphones using HRTF (Head Related Transfer Function) data. Here, the filter is usually quite complex, since the final frequency content depends on the direction of the underlying sound source.
Ambisonic解码Ambisonic decoding
Ambisonic解码变换一般包括采取Ambisonic空间音频流以及针对特定扬声器布局进行转换的矩阵操作。这可称为简单矩阵变换。双频段解码器也可由通过使用交迭FIR或IIR滤波器组合的两个矩阵表示。Ambisonic decoding transforms generally include matrix operations that take an ambisonic spatial audio stream and transform it for a specific loudspeaker layout. This may be called a simple matrix transformation. A dual-band decoder can also be represented by two matrices combined by using overlapping FIR or IIR filters.
这种解码技术尝试重新构造对音频信号代表的声场的感知。Ambisonic解码的结果是对于该布局中的每个扬声器的扬声器馈送;无论对声场产生作用的声源的方向如何,每个扬声器通常都会对声场产生作用。这在假定听众所处的区域(“甜区”)的中心和非常靠近中心的位置产生精确的声场再现。但是,由ambisonic解码产生的甜区的尺寸通常是正被再现的声音的波长的数量级。人类的听觉范围为约17mm至17m的波长范围;特别地,在小波长下,由此形成的甜区的面积较小,意味着需要如上所述的、精确的扬声器设置。This decoding technique attempts to reconstruct the perception of the sound field represented by the audio signal. The result of ambisonic decoding is a speaker feed for each speaker in the layout; each speaker generally contributes to the sound field regardless of the direction of the sound source contributing to the sound field. This produces an accurate reproduction of the sound field at and very close to the center of the area where the listener is assumed to be (the "sweet spot"). However, the size of the sweet spot produced by ambisonic decoding is usually of the order of the wavelength of the sound being reproduced. The human hearing range is in the wavelength range of about 17mm to 17m; especially at small wavelengths, the resulting sweet spot is smaller in size, implying the need for precise loudspeaker setup as described above.
投影平移projection translation
根据本发明的一些实施方式,提供了对使用球谐函数表达式的空间音频流进行解码的方法,其中,根据平移规则将空间音频流解码为扬声器馈送。以下描述涉及Ambisonic音频流,但此处描述的平移技术可用于使用球谐函数表达式的任何空间音频流;在输入音频流并非球谐函数格式的情况下,可使用(例如)上文中名为“虚拟声源”一节中所描述的技术转换,通过变换引擎104将该输入音频流转换为该形式。According to some embodiments of the present invention, there is provided a method of decoding a spatial audio stream using a spherical harmonic expression, wherein the spatial audio stream is decoded into a speaker feed according to a panning rule. The following description refers to ambisonic audio streams, but the panning technique described here can be used with any spatial audio stream that uses spherical harmonic expressions; in cases where the input audio stream is not in spherical harmonic format, use (for example) the The technique conversion described in the section "Virtual Sound Source" converts the input audio stream to this form by the
在平移技术中,重新创建一个或多个虚拟声源;平移技术并非基于上文所描述的ambisonic解码技术中使用的声源再现。通常称为平移规则的规则被定义如下,其对于给定的扬声器布局指定了当再现以给定方向从声源入射的声音时每个扬声器的扬声器增益。因此,根据声源的叠加对声场进行重新构造。In panning techniques, one or more virtual sound sources are recreated; panning techniques are not based on the reproduction of sound sources used in the ambisonic decoding techniques described above. A rule, commonly referred to as a panning rule, is defined that specifies, for a given speaker layout, the speaker gain of each speaker when reproducing sound incident from a sound source in a given direction. Therefore, the sound field is reconstructed according to the superposition of sound sources.
一个示例是矢量基幅度平移(VBAP),其通常使用一大组扬声器中的、靠近声源的预期方向的两个或三个扬声器。One example is Vector Basal Amplitude Panning (VBAP), which typically uses two or three speakers in a large group of speakers close to the intended direction of the sound source.
对于任何给定的平移规则,存在着针对每个扬声器j的一些实增益函数或复增益函数sj(θ,φ),该函数可用于代表在(θ,φ)方向上扬声器对于给定声源应产生的增益。由正在使用的特定平移规则和扬声器布局对sj(θ,φ)进行定义。例如,在VBAP的情况下,除了方向(θ,φ)靠近所讨论的扬声器的情况之外,sj(θ,φ)在大部分单位球面上为零。For any given translation rule, there exists some real gain function or complex gain function sj (θ, φ) for each loudspeaker j, which can be used to represent the The gain the source should produce. sj (θ, φ) is defined by the particular panning rule and loudspeaker layout being used. For example, in the case of VBAP, sj (θ, φ) is zero on most of the unit sphere except for the case where the direction (θ, φ) is close to the loudspeaker in question.
这些sj(θ,φ)中的每个可表示为球谐函数分量Yi(θ,φ)的和:Each of these sj (θ, φ) can be expressed as a sum of spherical harmonic components Yi (θ, φ):
因此,对于从特定方向(θ,φ)入射的声音,实际扬声器输出可由以下方程得出:Therefore, for sound incident from a specific direction (θ, φ), the actual speaker output can be given by the following equation:
vj(t)=sj(θ,φ)m(t) (10)vj (t) = sj (θ, φ)m(t) (10)
其中,m(t)为单音频流。vj(t)可表示为球谐函数分量数列:Among them, m(t) is a single audio stream. vj (t) can be expressed as a sequence of spherical harmonic function components:
qi,j可由以下方程得出,以解析法或数值法执行所需要的积分:qi,j can be derived from the following equations to perform the required integration analytically or numerically:
如果将所使用的表达式截取为一定阶的球谐函数,可以构造矩阵P使得每个元由以下方程定义:If the expressions used are truncated as spherical harmonics of a certain order, the matrix P can be constructed such that each element is defined by the following equation:
根据方程vii),声音可在空间音频流中表示为:According to equation vii), sound can be represented in a spatial audio stream as:
ai(t)=4πYi(θ,φ)m(t) (14)ai (t) = 4πYi (θ, φ)m(t) (14)
因此,可利用以下方程产生扬声器输出音频流:Therefore, the speaker output audio stream can be generated using the following equation:
wT=aTP (15)wT =aT P (15)
P仅与平移规则和扬声器位置有关,而与特定空间音频流无关,因此,其可在音频重放开始之前确定。P is only related to panning rules and speaker positions, not to a specific spatial audio stream, so it can be determined before audio playback starts.
如果音频流a仅包含来自单平面波的分量,则w矢量内的分量现在具有以下值:If the audio stream a contains only components from a single plane wave, the components within the w vector now have the following values:
对于所使用的数列截取精度而言,方程(18)与根据方程(11)由平移技术提供的扬声器输出相同。Equation (18) is the same as the loudspeaker output provided by the panning technique according to Equation (11) for the sequence truncation precision used.
这提供了增益矩阵,当其应用于空间音频流时产生一组扬声器输出。如果将声音分量以特定方向记录至空间音频流,则对应的扬声器输出将处于与在声音直接平移时到达的方向相同或相似的方向。This provides a gain matrix which when applied to a spatial audio stream produces a set of speaker outputs. If a sound component is recorded to a spatial audio stream in a particular direction, the corresponding speaker output will be in the same or similar direction as it would have arrived if the sound had been panned directly.
由于方程(15)为线性,可以看出,其适用于可表示为平面波源叠加的任何声场。另外,如上所述,可将以上分析延伸至考虑波前的曲率。Since equation (15) is linear, it can be seen that it applies to any sound field that can be expressed as a superposition of plane wave sources. Additionally, as noted above, the above analysis can be extended to consider the curvature of the wavefront.
与上文所描述的ambisonic解码技术相比,该方法将平移法则的使用与所使用的空间音频流完全分离,目的在于重新构造单独的声源,而不是重新构造对声场的感知。因此,可对记录的或合成的空间音频流进行处理,潜在地,包括了在没有关于要用于播放空间音频流的后续扬声器的任何信息的情况下以其它方式(例如,旋转或着色——见下文)被操纵的其他分量(例如,真实或合成混响产生的附加资料)和多个声源。然后,将平移矩阵P直接应用到空间音频流,以得出用于实际扬声器的音频流。In contrast to the ambisonic decoding techniques described above, this method completely separates the use of panning laws from the spatial audio stream used, with the aim of reconstructing individual sound sources rather than reconstructing the perception of a sound field. Thus, a recorded or synthesized spatial audio stream can be processed, potentially including in other ways (e.g., rotating or coloring— See below) manipulated other components (for example, real or synthetic reverbs to generate additional material) and multiple sound sources. Then, the translation matrix P is directly applied to the spatial audio stream to derive the audio stream for the actual speakers.
由于在本文采用的平移技术中,一般仅使用两个或三个扬声器对来自任何给定角度的声源进行再现,可以看出,可获得灵敏的方向感应;这意味着,甜区较大,并且相对于扬声器布局较为稳固。在本发明的某些实施方式中,本文所描述的平移技术可用于解码较高频率的信号,上文所描述的Ambisonic解码技术用于较低频率。Since in the panning technique employed in this paper, only two or three loudspeakers are generally used to reproduce the sound source from any given angle, it can be seen that a good sense of direction is obtained; this means that the sweet spot is larger, And it is relatively stable relative to the speaker layout. In some embodiments of the invention, the translation techniques described herein can be used to decode higher frequency signals, and the ambisonic decoding techniques described above are used for lower frequencies.
进一步,在某些实施方式中,不同解码技术可应用于不同球谐函数阶数;例如,平移技术可应用于较高阶数,Ambisonic解码可应用于较低阶数。进一步,由于平移矩阵P的项仅与所使用的平移规则有关,因此可选择适于正在使用的特定扬声器布局的平移规则;某些情况下,采用VBAP,在其他情况下,采用诸如线性平移和/或恒功率平移的其他平移规则。某些情况下,不同频段可应用不同的平移规则。Further, in some embodiments, different decoding techniques may be applied to different spherical harmonic orders; for example, translation techniques may be applied to higher orders and ambisonic decoding may be applied to lower orders. Further, since the entries of the panning matrix P are only related to the panning rule used, one can choose a panning rule appropriate to the particular loudspeaker layout being used; /or other translation rules for constant power translation. In some cases, different panning rules may apply to different frequency bands.
方程(18)中的数列截取一般会产生轻微混淆扬声器音频流的效应。在某些情况下,由于声音在靠近真实扬声器方向的位置通过时某些平移算法会经历感知间断,上述效应可作为一个有用特征。Sequence truncation in equation (18) generally has the effect of slightly obfuscating the speaker audio stream. In some cases, this effect can be a useful feature due to the perceptual discontinuity that some panning algorithms experience when sound passes close to the direction of the real speaker.
作为数列截取的替代方法,还可使用某些其他技术得出qi,j,例如,Nelder和Mead提出的下山单纯形方法的多维优化方法。As an alternative to sequence truncation, qi,j can also be derived using some other technique, for example, the multidimensional optimization method of the downhill simplex method proposed by Nelder and Mead.
在某些实施方式中,利用时域中的延时和施加给扬声器输出的增益、或频域中的相位和增益修正对扬声器距离和增益进行补偿。还可采用数字式房间校正。这些处理可以以下方式表示:在得出qi,j项之前将上述sj(θ,φ)函数乘以(潜在频率相关)项,对sj(θ,φ)函数进行扩展。可替代地,可在应用平移矩阵之后进行相乘。这种情况下,可通过时域延时和/或其他数字式房间校正技术应用相位修正。In some embodiments, speaker distance and gain are compensated with delay in the time domain and gain applied to the speaker output, or phase and gain correction in the frequency domain. Digital room correction is also available. These processes can be expressed by extending the sj (θ, φ) function by multiplying the above s j (θ, φ) function by a (potentially frequency dependent) term before deriving the qi ,j term. Alternatively, the multiplication can be done after applying the translation matrix. In this case, phase correction can be applied by time domain delay and/or other digital room correction techniques.
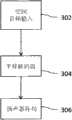
可将方程(15)的平移变换与作为变换引擎104的处理的一部分的其他变换组合,以提供代表单独扬声器馈送的解码输出。但是,在本发明的某些实施方式中,可使用如图3所示的平移解码器来独立于其他变换执行平移变换。在图3的实施例中,将空间音频信号302提供给平移解码器304,该平移解码器可为独立硬件或软件部件,并根据上述平移技术对信号进行解码并且适于所使用的扬声器阵列306。随后,将解码的单独扬声器馈送发送给扬声器阵列306。The translational transform of equation (15) may be combined with other transforms as part of the processing of the
根据平移资料构造空间音频流Construct spatial audio streams from translational data
多种常用格式的环绕声采用一组预定扬声器位置(例如,针对ITU5.1环绕声),录音室中的声音平移一般利用正在使用的混音台或软件所提供的单平移技术(例如,成对矢量平移)。产生的扬声器输出s提供给消费者,例如,通过DVD。Surround sound in many common formats employs a predetermined set of speaker positions (e.g. for ITU5. vector translation). The resulting speaker outputs s are provided to consumers, for example, via a DVD.
平移技术已知时,可经所使用的录音室平移技术近似于上述的矩阵P。When the translation technique is known, the matrix P above can be approximated via the studio translation technique used.
然后,可使用以下方程反演矩阵P,以得出可应用于扬声器馈送s的矩阵R,从而构造空间音频馈送:The matrix P can then be inverted using the following equation to obtain a matrix R that can be applied to the speaker feed s to construct a spatial audio feed:
aT=sTR (19)aT =sT R (19)
应注意的是,矩阵P的反演可能为非平凡反演,因为在大多数情况下,P为奇异矩阵。由于这个原因,矩阵R一般并非严格逆矩阵,而是通过单值分解(SVD)、正则化或其他技术得出的伪逆矩阵或其他逆替代矩阵。It should be noted that the inversion of the matrix P may be non-trivial since in most cases P is singular. For this reason, the matrix R is generally not a strict inverse matrix, but a pseudo-inverse matrix or other inverse surrogate matrix obtained by singular value decomposition (SVD), regularization, or other techniques.
可使用在DVD或类似物上向使用的播放软件提供的数据流内的标记确定采用的平移技术,以避免播放器对平移技术进行推测,或需要收听者选择平移技术。可替代地,可将P或R的表示或描述包含在流中。The panning technique employed can be determined using markers within the data stream provided on the DVD or the like to the playback software used, to avoid guesswork by the player, or to require the listener to select the panning technique. Alternatively, a representation or description of P or R may be included in the stream.
随后可根据本文所描述的一个或多个技术对产生的空间音频馈送aT进行处理,和/或根据收听环境中实际存在的扬声器使用Ambisonic解码器或平移矩阵、或其他解码方法进行解码。The resulting spatial audio feed aT may then be processed according to one or more techniques described herein, and/or decoded using an ambisonic decoder or panning matrix, or other decoding methods, based on the speakers actually present in the listening environment.
通用变换Universal transformation
某些变换基本上可应用于任何格式,不需改变格式。例如,可对形成具有固定值的对角矩阵的音频流施加简单增益,从而对任何馈送进行放大。还可使用应用于某些或所有声道的随机FIR对任何给定馈送进行过滤。Certain transformations can be applied to essentially any format without changing the format. For example, any feed can be amplified by applying simple gains to the audio streams forming a diagonal matrix of fixed values. Any given feed can also be filtered using a randomized FIR applied to some or all channels.
空间变换space transformation
本节对可使用球谐函数代表的空间音频数据执行的一组处理进行描述。数据保持空间音频格式。This section describes a set of processing that can be performed on spatial audio data represented using spherical harmonics. The data remains in spatial audio format.
旋转与反射Rotation and Reflection
可使用一个或多个矩阵变换对声像进行旋转、反射和/或翻转;例如在“Rotation Matrices for Real Spherical Harmonics.Direct Determination byRecursion”,Joseph Ivanic and Klaus Ruedenberg,J.Phys.Chem.,1996,100(15),pp 6342-6347中说明的旋转。The acoustic image can be rotated, reflected and/or flipped using one or more matrix transformations; for example in "Rotation Matrices for Real Spherical Harmonics. Direct Determination by Recursion", Joseph Ivanic and Klaus Ruedenberg, J.Phys.Chem., 1996, 100(15), rotation as described in pp 6342-6347.
着色coloring
根据本发明的实施方式,提供了在特定方向改变声音特征的方法。例如,其可用于增强或减弱特定方向的声级。以下说明涉及ambisonic音频流;但是,应理解的是,该技术可用于使用球谐函数表达式的任何空间音频流。通过首先将音频流转换为采用球谐函数表达式的格式,该技术还可用于不采用这种表达式的音频流。According to an embodiment of the present invention, a method of changing sound characteristics in a specific direction is provided. For example, it can be used to increase or decrease sound levels in certain directions. The following description refers to ambisonic audio streams; however, it should be understood that the technique can be used with any spatial audio stream using spherical harmonic expressions. This technique can also be used for audio streams that do not use spherical harmonic expressions by first converting the audio stream to a format that uses spherical harmonic expressions.
假设输入音频流aT在时域或频域中采用声场f(θ,φ)的球谐函数表达式,并且预期生成代表一个或多个方向上的声级有所改变的声场g(θ,φ)的输出音频流bT,可将函数h(θ,φ)定义如下:Assume that the input audio stream aT adopts the spherical harmonic function expression of the sound field f(θ, φ) in the time domain or the frequency domain, and is expected to generate a sound field g(θ, φ) that represents a change in the sound level in one or more directions φ) output audio stream bT , the function h(θ, φ) can be defined as follows:
g(θ,φ)=f(θ,φ)h(θ,φ) (20)g(θ,φ)=f(θ,φ)h(θ,φ) (20)
例如,h(θ,φ)可定义为:For example, h(θ,φ) can be defined as:
其产生的结果是使g(θ,φ)在左侧比f(θ,φ)宏亮一倍,在右侧为无声。换句话说,对规定方向处于φ<π的角度范围内的声音分量施加增益2,对规定方向处于φ≥π的角度范围内的声音分量施加增益0。The result is that g(θ, φ) is twice as loud as f(θ, φ) on the left and silent on the right. In other words, a gain of 2 is applied to a sound component whose predetermined direction falls within an angular range of φ<π, and a gain of 0 is applied to a sound component whose predetermined direction falls within an angular range of φ≥π.
假设f(θ,φ)和h(θ,φ)都为分段连续函数,则其乘积g(θ,φ)也为分段连续函数,意味着三个函数都可用球谐函数表示。Assuming that both f(θ, φ) and h(θ, φ) are piecewise continuous functions, their product g(θ, φ) is also a piecewise continuous function, which means that all three functions can be expressed by spherical harmonics.
可用方程iv)得出bj的值,如下所示:The value of bj can be obtained from equation iv) as follows:
用方程(20):Using equation (20):
用方程(22)和(24):Using equations (22) and (24):
其中in
这些ωi,j,k项与f、g和h无关,可用解析法(可用量子系统研究中使用的维格纳3j符号表示)或数值法得出。在实践中,这些项可制成表。These ωi, j, k terms are independent of f, g, and h, and can be derived analytically (which can be represented by the Wigner 3j notation used in the study of quantum systems) or numerically. In practice, these terms can be tabulated.
如果对用于代表函数f(θ,φ)、g(θ,φ)和h(θ,φ)的数列进行截取,则方程(29)采用矩阵乘法的形式。如果将ai项代入矢量aT,将bj项代入bT,则:Equation (29) takes the form of matrix multiplication if the sequence used to represent the functions f(θ,φ), g(θ,φ) and h(θ,φ) is intercepted. If the term ai is substituted into vector aT and the term bj into bT , then:
bT=aTC (31)bT = aT C (31)
其中in
应注意的是,在方程(31)中,根据输入音频流aT中的音频声道的数量截取数列;如果要求更精确的处理,可附加零,以增加aT中的项数,并将数列扩展到要求的阶数,从而实现该目的。进一步,如果没有将着色函数h(θ,φ)规定为足够高的阶数,其截取数列也可通过附加零而扩展到要求的阶数。It should be noted that in equation (31), the sequence is truncated according to the number of audio channels in the input audio stream aT ; if more precise processing is required, zeros can be appended to increase the number of terms in aT , and The sequence is extended to the required order to achieve this. Furthermore, if the coloring function h(θ, φ) is not specified to be of a sufficiently high order, its truncated sequence can also be extended to the required order by adding zeros.
矩阵C与f(θ,φ)或f(θ,φ)无关,仅与着色函数h(θ,φ)有关。因此,可在时域或频域中查找固定线性变换,其可用于对使用球谐函数表达式的空间音频流进行处理。应注意的是,在频域中,每个频率可能需要不同的矩阵。The matrix C has nothing to do with f(θ, φ) or f(θ, φ), only with the shading function h(θ, φ). Therefore, fixed linear transformations can be found in the time or frequency domain, which can be used to process spatial audio streams using spherical harmonic expressions. It should be noted that in the frequency domain, a different matrix may be required for each frequency.
虽然在该实施例中,着色函数h规定为在固定角度范围内具有固定值,但本发明的实施方式并不限于这种情况。在某些实施方式中,着色函数的值可随规定角度范围内角度的不同而不同,或着色函数可规定为在所有角度下具有非零值。该着色函数可随时间变化。Although in this embodiment, the shading function h is specified to have a fixed value within a fixed angle range, the embodiment of the present invention is not limited to this case. In some embodiments, the value of the shading function may vary from angle to angle within a specified range of angles, or the shading function may be specified to have a non-zero value at all angles. This shading function can vary over time.
进一步,在(例如)可对处于较大角度范围内、和/或随时间和/或频率变化的声源指定声音分量的情况下,着色函数的方向特征与声音分量的方向特征之间的关系可能是复数。Further, the relationship between the directional characteristics of the shading function and the directional characteristics of the sound components where, for example, sound components can be assigned to sound sources over a large angular range, and/or over time and/or frequency May be plural.
采用这种技术,可根据用于处理采用球谐函数表达式的空间音频流的所定义的着色函数来生成着色变换。因此,可用预定函数增强或减弱特定方向的声级,以(例如)改变录音的空间均衡,以实现无噪声独奏者,在输入音频流中该独奏者是收听者噪音中唯一能听不见的。这要求独奏者的方向已知;这可通过(例如)观察录音位置而确定。With this technique, a shading transformation is generated from a defined shading function for processing a spatial audio stream using a spherical harmonic expression. Thus, the sound level in a particular direction can be boosted or attenuated with a predetermined function to, for example, change the spatial balance of the recording to achieve a noiseless soloist that is the only thing inaudible to the listener's noise in the input audio stream. This requires that the orientation of the soloist is known; this can be determined, for example, by observing the recording position.
在着色技术用于游戏系统的情况下,例如,用于图1所示的游戏装置120和变换引擎104时,该游戏装置120可为变换引擎提供游戏环境的变化信息,随后变换引擎104利用该变化信息生成和/或检索适用的变换。例如,游戏装置120可为变换引擎提供如下数据:该数据表明在游戏环境中驾驶车辆的用户正在靠墙驾驶。随后,变换引擎104可选择并使用变换来改变声音特征,并将墙壁的接近程度加以考虑。In the case that the rendering technology is used in a game system, for example, when used in the game device 120 and the
在h(θ,φ)处于频域的情况下,对声场空间行为所作的改变可与频率相关。这可用于在指定方向进行均衡化,或改变来自特定方向的声音的频率特征,使(例如)特定声音分量的声音更清楚,或过滤掉特定方向的无用音高。Where h(θ,φ) is in the frequency domain, changes made to the spatial behavior of the sound field can be frequency dependent. This can be used to equalize in a specific direction, or to change the frequency characteristics of sounds coming from a specific direction, to make (for example) the sound of a specific sound component clearer, or to filter out unwanted pitches from a specific direction.
进一步,着色函数可在解码器(包括Ambisonic解码器)设计期间用作加权变换,以优先考虑特定方向和/或特定频率下的解码精度。Further, shading functions may be used as weighting transforms during the design of decoders (including ambisonic decoders) to prioritize decoding accuracy in certain directions and/or at certain frequencies.
通过对h(θ,φ)进行适当定义,可将代表已知方向的单独声源的数据从空间音频流中提取出来,对提取数据进行某种处理,并将处理后的数据重新引入音频流中。例如,可通过将除了与目标管弦乐队组对应的角度之外的所有角度下的h(θ,φ)定义为0,提取管弦乐队的特定组的声音。随后,可对提取数据进行处理,使得在将数据重新引入空间音频流之前,改变来自管弦乐队组的声音的角分布(例如,管弦乐队组的声音的特定部分进一步靠后)。可替代地或附加地,可在与提取方向相同或不同的方向处理和引入提取数据。例如,可将对左侧讲话的人的声音进行提取和处理,以消除背景噪声,并在左侧将其重新引入空间音频流中。With an appropriate definition of h(θ, φ), data representing individual sound sources of known orientation can be extracted from the spatial audio stream, some processing is done on the extracted data, and the processed data is reintroduced into the audio stream middle. For example, the sound of a specific group of an orchestra can be extracted by defining h(θ, φ) as 0 at all angles except the angle corresponding to the target orchestra group. The extracted data may then be processed such that the angular distribution of the sounds from the orchestra group is altered (eg, certain parts of the orchestra group's sounds are further back) before the data is reintroduced into the spatial audio stream. Alternatively or additionally, the extracted data may be processed and introduced in the same or a different direction than the extracted direction. For example, the voice of a person speaking to the left can be extracted and processed to remove background noise and reintroduced into the spatial audio stream on the left.
HRTF着色HRTF coloring
作为频域着色的一个实施例,我们考虑使用h(θ,φ)代表HRTF数据的情况。可使收听者感知到声源方向的重要提示包括两耳时差(ITD)和两耳强度差(IID),其中,两耳时差(ITD)是到达左耳与到达右耳的声音之间的时差,两耳强度差(IID)是左耳与右耳处的声音强度差。ITD和IID效应是由双耳的身体间距以及人的头部对入射声波的效应产生的。HRTF一般用于通过仿效人的头部对入射声波的效应的滤波器模拟这些效应,以(特别通过耳机)产生针对左耳和右耳的音频流,从而为收听者提供了改进的声源方向感,特别是对于声源高度的感知。但是,现有技术中的方法没有对空间音频流进行更改以包含这种数据;在现有技术的方法中,在再现时对解码信号进行更改。As an example of frequency domain coloring, we consider the case of using h(θ, φ) to represent HRTF data. Important cues that allow a listener to perceive the direction of a sound source include Interaural Time Difference (ITD) and Interaural Intensity Difference (IID), where Interaural Time Difference (ITD) is the time difference between the sound reaching the left ear and the right ear , the interaural intensity difference (IID) is the difference in sound intensity at the left and right ear. The ITD and IID effects are produced by the body spacing of the ears and the effect of the person's head on incident sound waves. HRTFs are generally used to simulate the effects of the human head on incident sound waves through filters that emulate these effects, to produce (particularly with headphones) an audio stream directed at the left and right ear, thus providing the listener with an improved direction of the sound source sense, especially the perception of the height of the sound source. However, prior art methods do not modify the spatial audio stream to contain such data; in prior art methods, modifications are made to the decoded signal upon reproduction.
此处假设针对左耳和右耳的HRTF有对称表达的形式:Here it is assumed that the HRTFs for the left and right ears have symmetrical expressions:
hR(θ,φ)=hL(θ,2π-φ) (34)hR (θ, φ) = hL (θ, 2π-φ) (34)
代表hL的ci分量可以形成矢量cL,单左耳流可由空间分量ai代表的空间音频流f(θ,φ)得出。可用标积得出用于左耳的适合音频流:The ci components representing hL can form a vector cL , and the single left ear stream can be obtained from the spatial audio stream f(θ, φ) represented by the spatial component ai . The scalar product can be used to derive the appropriate audio stream for the left ear:
dL=a.cL (35)dL =acL (35)
这将完整空间音频流减少为适用于一对耳机及其他中的一个的单音频流。这是一项有用的技术,但不能产生空间音频流。This reduces the full spatial audio stream to a single audio stream for a pair of headphones and one of the other. This is a useful technique, but does not produce spatial audio streams.
根据本发明的某些实施方式,使用上文描述的着色技术将HRTF数据应用于空间音频流,并将hL转换为方程(31)形式的着色矩阵,获取着色的空间音频流,作为处理结果。其作用在于,将HRTF的特征添加至音频流。随后,可通过各种方式,例如,利用Ambisonic解码器在收听之前对该流继续进行解码。According to some embodiments of the present invention, HRTF data is applied to the spatial audio stream using the coloring technique described above, and hL is converted into a coloring matrix in the form of equation (31), and the colored spatial audio stream is obtained as the processing result . Its role is to add the features of HRTF to the audio stream. The stream can then be further decoded in various ways, eg, using an Ambisonic decoder, before listening.
例如,将该技术用于耳机时,如果直接将hL应用到空间音频流,用左耳的专有信息对空间音频流进行着色。在大多数对称应用中,该流对于右耳没有用,因此,利用方程(34)对声场也进行着色,以生成针对右耳的单独空间音频流。For example, when using this technique for headphones, if hL is directly applied to the spatial audio stream, the spatial audio stream is colored with the information specific to the left ear. In most symmetric applications, this stream is not useful for the right ear, so the sound field is also colored using equation (34) to generate a separate spatial audio stream for the right ear.
在随后进行了处理的情况下,这种形式的着色音频流可用于驱动耳机(例如,与简单的头部模型结合使用,以形成ITD提示等)。同样,潜在地,其也可用于串声消除技术,以减少对旨在用于一只耳朵的声音被另一只耳朵拾取的影响。With subsequent processing, this form of colored audio stream can be used to drive headphones (e.g. in combination with a simple head model for ITD cues, etc.). Also, potentially, it can be used in crosstalk cancellation techniques to reduce the effect of sound intended for one ear being picked up by the other.
进一步,根据本发明的某些实施方式,hL可分解为两个函数aL和pL的乘积,这两个函数分别对于每个频率的振幅和相位分量进行管理,其中,aL为实值,并捕获特定方向的频率组成,pL捕获相位形式的相对的两耳时延(ITD),并且:|pL|=1。Further, according to some embodiments of the present invention, hL can be decomposed into the product of two functions aL and pL that manage the amplitude and phase components of each frequency respectively, where aL is the real value, and captures the frequency composition in a particular direction, pL captures the relative binaural delay (ITD) in phase form, and: |pL |=1.
hL(θ,φ)=aL(θ,φ)pL(θ,φ) (36)hL (θ, φ) = aL (θ, φ) pL (θ, φ) (36)
可将aL和pL分解为着色函数,并探测其截取表达中产生的误差。在较高频率下,pL表达越来越不精确,|PL|逐渐偏离1,从而对hL的整体振幅容量产生影响。aL and pL can be decomposed into shading functions and errors in their truncated representations can be detected. At higher frequencies, pL expression becomes less and less precise, and |PL | gradually deviates from 1, thus having an impact on the overall amplitude capacity of hL.
由于在较高频率下ITD提示重要性较低而IID提示的重要性较高,可对pL进行更改,使其在较高频率下为1,因此,上述误差不会引入振幅容量。对于每个方向,可用相位数据构造应用于每个频率f的延时
pL(θ,φ,f)=e-2πfd(θ,φ,f) (37)pL (θ, φ, f) = e-2πfd(θ, φ, f) (37)
随后,可用以下方程构造限于特定频率范围[f1,f2]内的新版本的相位信息:Subsequently, a new version of the phase information limited to a certain frequency range [f1 , f2 ] can be constructed using the following equation:

应注意的是,对于f>f2的情况,
可将d值进行缩放,以模拟不同大小的头部。The d value can be scaled to simulate different sized heads.
可从记录的HRTF数据集中导出上述d值。可替代地,可使用头部的简单数学模型。例如,可将头部模拟为球体,将两个麦克风插入相对侧。左耳的相对时延则可由以下方程得出:The above d values can be derived from recorded HRTF datasets. Alternatively, a simple mathematical model of the head can be used. For example, the head can be modeled as a sphere with two microphones plugged into opposite sides. The relative time delay of the left ear can be obtained by the following equation:

其中,r为球体半径,c为声音速度。where r is the radius of the sphere and c is the speed of sound.
如上所述,ITD和IID效应为提供感知声源方向提供了重要提示。但是,声源可自多个点上产生相同的ITD和IID提示。例如,在<1,1,0>、<-1,1,0>和<0,1,1>(相对于笛卡儿坐标系而定义,x向前为正、y向左为正、z向上为正,三者都为相对于收听者而言)三点上的声音将在人的头部的对称模型中产生相同的ITD和IID提示。这些点中的每组已知为“干扰锥形”,众所周知,人类听觉系统利用HRTF型提示(在包括头部移动的其他提示中)帮助确定这种情况下的声音位置。As mentioned above, the ITD and IID effects provide important cues for providing perceived sound source direction. However, sound sources can generate the same ITD and IID cues from multiple points. For example, in <1, 1, 0>, <-1, 1, 0> and <0, 1, 1> (defined relative to the Cartesian coordinate system, x is positive forward, y is positive to the left, z up is positive and all three are relative to the listener) Sounds on three points will produce the same ITD and IID cues in a symmetrical model of the human head. Each set of these points is known as a "cone of interference" and it is well known that the human auditory system utilizes HRTF-type cues (among other cues including head movement) to help determine sound location in this case.
对于hL,可对数据进行处理,以除去所有非左右对称的ci分量。这产生新的空间函数,该函数实际上仅包含hL与hR共有的分量。这可通过将方程(30)中所有与非左右对称的球面函数对应的ci分量设为零而实现。这是有用的方法,原因在于消除了会被左耳和右耳混淆在一起而拾取的分量。For hL , the data can be processed to remove any non-left-right symmetricci components. This produces a new spatial function that actually contains only the components thathL has in common withhR . This can be achieved by setting allci components in equation (30) corresponding to non-left-right symmetric spherical functions to zero. This is useful because it removes components that would be picked up by mixing the left and right ears together.
这会产生新矢量代表的新着色函数,可用于对空间音频流进行着色,并增强提示,以帮助收听者通过对双耳同等有效的方式解决干扰锥形的问题。该流随后可在线索完整无缺的情况下馈送给Ambisonics或其他重放装置,即使相关方向没有设置扬声器,例如,声源处于收听者上方或后面,相关方向没有设置扬声器,但仍可更敏锐地感知声源方向。This results in new shading functions represented by new vectors that can be used to colorize spatial audio streams and enhance cues to help listeners resolve interference cones in a way that is equally effective for both ears. This stream can then be fed to an ambisonics or other playback device with the cues intact, even if there are no speakers in the relevant direction, for example, if the sound source is above or behind the listener, and the relevant direction does not have a speaker, but still more acutely. Perceive the direction of the sound source.
在已知收听者朝向特定方向的情况下,例如,观看电影或看舞台,或玩计算机游戏时,该方法特别有效。可将进一步的分量丢弃,仅保留关于垂直轴对称的分量(即,与θ无关的分量)。This method works especially well in situations where the listener is known to be facing a certain direction, for example, while watching a movie or a stage, or playing a computer game. Further components can be discarded, leaving only components that are symmetric about the vertical axis (ie, not related to Θ).
这可产生着色函数,该函数可仅对高度提示进行增强。该方法对收听者的朝向进行较少假设;要求的唯一假设为,头部垂直。应注意的是,根据应用情况的不同,期望将一定量的高度和干扰锥形着色这两者或这些着色函数的某些定向分量应用于空间音频流。This results in a shading function that augments only the height cues. This method makes fewer assumptions about the listener's orientation; the only assumption required is that the head is vertical. It should be noted that, depending on the application, it may be desirable to apply some amount of both height and interference cone shading, or some directional component of these shading functions, to the spatial audio stream.
应注意的是,根据应用情况的不同,可将高度和干扰锥形着色这两者,或这些函数的某些定向分量应用于空间音频流。It should be noted that, depending on the application, both height and interference cone shading, or some directional component of these functions, may be applied to the spatial audio stream.
可替代地,或附加地,如上所述的丢弃HRTF表达的分量的技术还可用于成对平移技术,以及不采用球谐函数空间音频流的其他应用情况。此处,可用上述方程(30)直接根据HRTF函数进行处理,并生成适用的HRTF提示。Alternatively, or in addition, the techniques described above for discarding components of HRTF representations can also be used for pairwise panning techniques, and other application cases where spherical harmonics are not employed for spatial audio streams. Here, the above equation (30) can be used to directly process according to the HRTF function and generate applicable HRTF hints.
增益控制gain control
根据应用情况的不同,期望能对应用的着色量进行控制,以使效果较弱或较强。我们注意到,着色函数可写为:Depending on the application, it is desirable to be able to control the amount of tint applied to make the effect weaker or stronger. We note that the shading function can be written as:
h(θ,φ)=l+(h(θ,φ)-1) (40)h(θ,φ)=l+(h(θ,φ)-1) (40)
随后,可如下将增益系数p代入方程:The gain factor p can then be substituted into the equation as follows:
h(θ,φ)=l+p(h(θ,φ)-1) (41)h(θ,φ)=l+p(h(θ,φ)-1) (41)
应用上述方程(18)至(29),最终得出着色矩阵Cp,可由以下方程得出:Applying the above equations (18) to (29), the coloring matrix Cp is finally obtained, which can be obtained by the following equation:
Cp=I+p(C-I) (42)Cp = I+p(CI) (42)
其中,I为相关大小的恒等矩阵,p可用作控制所应用的着色量的增益控制;p=0可使着色完全消失。where I is an identity matrix of relative size and p can be used as a gain control to control the amount of shading applied; p=0 makes the shading disappear completely.
进一步,如果希望在特定方向提供不同的着色量,可将着色应用到h自身,或应用到h与上文
虽然上文所描述的着色变换可方便地作为变换引擎所执行的处理的一部分来实现,存储在变换数据库106内,或作为(例如)处理插件114提供,在本发明的某些实施方式中,着色变换独立于上文图1和图2所描述的系统而实现,如本文图4和图5所描述的。While the shading transformations described above may conveniently be implemented as part of the processing performed by the transformation engine, stored within the
图4显示了作为软件插件实现的着色。在步骤S402中,从软件包,例如Nuendo中接收空间音频数据。在步骤S404中,在返回到软件音频包(步骤S406)之前,根据上文所描述的着色技术对其进行处理。Figure 4 shows the colorization implemented as a software plugin. In step S402, spatial audio data is received from a software package, such as Nuendo. In step S404, it is processed according to the rendering technique described above before returning to the software audio package (step S406).
图5显示了在进行转换、用于耳机之前,将着色应用于空间音频流。声音文件播放器502将空间音频数据传输给多声道HRTF着色部件504,该部件根据上述技术之一执行HRTF着色,使空间音频流的IID提示增强。该增强的空间音频流随后传输给立体声转换器506,该立体声转换器可采用简单的立体声头部模型进一步引入ITD提示,并将空间音频流减少为立体声。该立体声随后被传输给数模转换器508,并输出给耳机510,为收听者进行重放。此处参考图5所描述的部件可为软件或硬件部件。Figure 5 shows the application of coloring to a spatial audio stream before conversion for use in headphones. The
应理解的是,上述着色技术可在多种其他场境中应用。例如,软件和/或硬件部件可与游戏软件结合使用,作为Hi-Fi系统或音频录制专用的硬件装置的一部分。It should be understood that the above-described shading techniques can be applied in a variety of other contexts. For example, software and/or hardware components may be used in conjunction with game software, as part of a Hi-Fi system or a dedicated hardware device for audio recording.
对于变换引擎104的功能,现在将参考图6提供实施例,其中,变换引擎104用于处理和解码用于给定扬声器阵列140的空间音频信号。An embodiment will now be provided with reference to FIG. 6 as to the functionality of the
在步骤S602中,变换引擎104接收音频数据流。如上所述,该音频数据流可以是来自游戏、CD播放器,或能提供这种数据的任何其他源。在步骤S604中,变换引擎104确定输入格式,即,输入音频数据流的格式。在某些实施方式中,输入格式由用户通过用户界面设置。在某些实施方式中,自动检测输入格式;这可通过音频数据中包含的标记而实现,或者变换引擎可利用统计技术检测格式。In step S602, the
在步骤S606中,变换引擎104确定是否需要进行空间变换,例如,上述着色变换。空间变换可由用户通过用户界面108进行选择,和/或可通过软件部件选择;如为后者,空间变换则为(例如)用户进入不同声音环境(例如,从洞穴出来,进入开阔空间)的游戏中的提示,要求具有不同声音特征。In step S606, the
如果需要进行空间变换,可从变换数据库106中进行检索;在使用插件114的情况下,附加地或可替代地,可从插件中检索变换。If a spatial transformation is required, it may be retrieved from the
在步骤S610中,变换引擎104确定是否需要进行一个或多个格式变换。同样,这可由用户通过用户界面108指定。例如,如果输入格式不采用球谐函数表达式,将采用着色变换,附加地或可替代地,可要求进行格式变换,以执行空间变换。在步骤S611中,如果要求进行一个或多个格式变换,可从变换数据库106和/或插件114中进行检索。In step S610, the
在步骤S612中,变换引擎104确定要使用的平移矩阵。这与采用的扬声器布局以及要用于扬声器布局的平移规则有关,一般情况下,两者都由用户通过用户界面108指定。In step S612, the
在步骤S614中,通过对步骤S608、S611和S612中检索到的变换进行卷积,可形成组合矩阵变换。在步骤S616中执行变换,在步骤S618中输出解码数据。由于此处采用平移矩阵,因此输出为解码扬声器馈送的形式;某些情况下,变换引擎104的输出为编码空间音频流,该音频流随后被解码。In step S614, a combined matrix transform may be formed by convolving the transforms retrieved in steps S608, S611 and S612. Transformation is performed in step S616, and decoded data is output in step S618. Since a translation matrix is used here, the output is in the form of a decoded speaker feed; in some cases, the output of the
应理解的是,变换引擎104作为录音系统的一部分时,其将进行相似步骤。这种情况下,空间变换一般都由用户指定;虽然变换引擎104可确定转换用户指定格式所需的变换,用户一般还可选择输入和输出格式。It should be understood that the
在步骤S606至S612中,对变换进行选择,用于在步骤S614中组合为组合变换,在某些情况下,变换数据库106中可能存储多于一个的变换或变换组合,从而能够进行要求的数据转换。例如,如果用户或软件部件指定将输入的B格式音频流转换为环绕声7.1格式,变换数据库106可能存储有多个变换组合,可用于执行这种转换。变换数据库106可存储格式的指示,每个域变换在这些格式之间转换,允许变换引擎104确定第一格式到第二格式的多种“路径”。In steps S606 to S612, transformations are selected for combination into a combined transformation in step S614. In some cases, more than one transformation or combination of transformations may be stored in the
在某些实施方式中,接收到对指定(例如)格式转换的请求时,变换引擎104在变换数据库106中搜索变换的备选组合(例如,串),以执行请求的转换。存储于变换数据库106中的变换可被标记,或与指示每个变换的函数的信息相关联,例如,给定格式变换转换为或转换自的格式;该信息可由变换引擎104用于查找适用的变换组合,用于进行请求的转换。在某些实施方式中,变换引擎104生成备选变换组合列表,以供用户选择,并将生成的列表提供给用户界面108。在某些实施方式中,如此处所描述的,变换引擎104对备选变换组合进行分析。In some implementations, upon receiving a request for a specified (eg,) format conversion, the
存储于数据库106中的变换可被标记,或与等级值相关联,两者都指定了特定变换的使用偏好。可根据(例如)有多少信息损失与给定变换相关联(例如,B格式到单音频格式的转换会产生较高信息损失),和/或针对变换的用户偏好的指示对等级值进行分配。某些情况下,可对每个变换分配指示使用变换的总体期望的单个值。某些情况下,用户可使用用户界面108改变等级值。Transforms stored in
接收到对给定(例如)格式转换的请求时,变换引擎104可在数据库106中搜索适合于所请求的转换的备选变换组合,如上所述。一旦获得备选变换组合列表,变换引擎104就可根据上述等级值对列表进行分析。例如,如果将参数值设置为较高值表明对于使用给定变换的较低偏好,则可计算每个组合中包含的值的总和,并选择具有最低值的组合。某些情况下,将涉及的变换数量大于给定变换数量的组合丢弃。Upon receiving a request for a given, eg, format conversion,
在某些实施方式中,变换组合的选择由变换引擎104执行。在其他实施方式中,变换引擎104根据上述分析对备选变换列表进行排序,并将该排序列表发送给用户界面108,以供用户选择。In some implementations, the selection of the transformation combination is performed by the
因此,在变换组合选择的实施例中,在预定了扬声器布局的情况下,用户通过用户界面108上的菜单选择给定输入格式(例如,B格式)和期望的输出格式(例如,环绕声7.1)。响应于该选择,变换引擎104随后在变换数据库106中搜索用于将B格式转换为环绕声7.1的变换组合,根据上述等级值将结果进行排序,并将据此排序的列表呈现给用户,以供选择。一旦用户做出了他或她的选择,所选变换组合的变换被组合为如上所述的单个变换,用于处理音频流输入的音频流。Thus, in an embodiment of changing combination selection, with a predetermined speaker layout, the user selects a given input format (e.g., B format) and a desired output format (e.g., surround sound 7.1 ). In response to this selection, the
上述实施方式应理解为本发明的示例性实施例。设想本发明的其他实施方式。应注意的是,上述技术不依赖于球谐函数的任何特定表示;通过使用(例如)球谐函数的任何其他表示或球谐函数分量的线性组合,也可获得相同结果。应理解的是,有关任何一个实施方式所描述的任意特征可单独使用或与所描述的其他特征结合使用,并可与任何其他实施方式的一个或多个特征,或任何其他实施方式的任何组合结合使用。另外,在不背离所附权利要求限定的本发明的范围的情况下,可采用上文没有描述的等同物和变型。The above-described embodiments are to be understood as exemplary embodiments of the present invention. Other embodiments of the invention are contemplated. It should be noted that the technique described above does not rely on any particular representation of spherical harmonics; the same result can also be obtained by using, for example, any other representation of spherical harmonics or a linear combination of spherical harmonic components. It should be understood that any feature described in relation to any one embodiment may be used alone or in combination with other features described, and with one or more features of any other embodiment, or any combination of any other embodiment In conjunction with. Furthermore, equivalents and modifications not described above may be employed without departing from the scope of the invention as defined in the appended claims.
权利要求书(按照条约第19条的修改)Claims (as amended under Article 19 of the Treaty)
1.一种处理空间音频信号的方法,所述方法包括:1. A method of processing a spatial audio signal, the method comprising:
接收空间音频信号,所述空间音频信号代表一个或多个声音分量,所述声音分量具有规定方向特征和一个或多个声音特征;receiving a spatial audio signal representing one or more sound components having a prescribed directional characteristic and one or more sound characteristics;
提供用于更改一个或多个所述声音分量的变换,所述变换用于更改其规定方向特征与方向特征的规定范围相关的声音分量的一个或多个声音特征;providing a transformation for modifying one or more of said sound components, said transformation for modifying one or more sound characteristics of a sound component whose prescribed directional characteristic is associated with a prescribed range of directional characteristics;
将所述变换应用于所述空间音频信号,从而生成其中由所述空间音频信号代表的一个或多个所述声音分量的一个或多个声音特征被更改了的更改的空间音频信号,对于给定声音分量的更改依赖于所述给定分量的规定方向特征与方向特征的规定范围之间的关系;以及applying the transform to the spatial audio signal, thereby generating a modified spatial audio signal in which one or more sound characteristics of one or more of the sound components represented by the spatial audio signal are altered, for a given The modification of a given sound component is dependent on the relationship between a prescribed directional characteristic of said given component and a prescribed range of directional characteristics; and
输出更改的所述空间音频信号。The modified spatial audio signal is output.
2.根据权利要求1所述的方法,其中,接收的所述空间音频信号包括所述声音分量的球谐函数表达式,输出的所述空间音频信号包括所述声音分量的球谐函数表达式。2. The method according to claim 1, wherein the received spatial audio signal comprises a spherical harmonic function expression of the sound component, and the output spatial audio signal comprises a spherical harmonic function expression of the sound component .
3.根据权利要求2所述的方法,其中,接收的所述空间音频信号包括ambisonic信号,输出的所述空间音频信号包括ambisonic信号。3. The method of claim 2, wherein the received spatial audio signal comprises an ambisonic signal and the output spatial audio signal comprises an ambisonic signal.
4.根据权利要求1所述的方法,其中,接收的所述音频信号具有不使用所述声音分量的球谐函数表达式的格式,所述方法包括:将该空间音频信号转换为使用所述声音分量的球谐函数表达式的格式。4. The method according to claim 1 , wherein the received audio signal has a format that does not use spherical harmonic expressions of the sound components, the method comprising: converting the spatial audio signal to use the The format of the spherical harmonic expression for the sound components.
5.根据前述权利要求任一项所述的方法,其中,一个或多个被更改了的声音特征包括增益特征。5. A method as claimed in any preceding claim, wherein the one or more altered sound characteristics comprise a gain characteristic.
6.根据前述权利要求任一项所述的方法,其中,一个或多个被更改了的声音特征包括频率特征。6. A method as claimed in any preceding claim, wherein the one or more altered sound characteristics comprise frequency characteristics.
7.根据前述权利要求任一项所述的方法,其中,所述变换在时域中执行。7. A method according to any one of the preceding claims, wherein the transformation is performed in the time domain.
8.根据权利要求1至6任一项所述的方法,其中,所述变换在频域中执行。8. The method according to any one of claims 1 to 6, wherein the transformation is performed in the frequency domain.
9.根据权利要求8所述的方法,其中,所述变换包括多个变换,所述多个变换中的每个与不同的频率范围相关。9. The method of claim 8, wherein the transform comprises a plurality of transforms, each of the plurality of transforms being associated with a different frequency range.
10.根据权利要求9所述的方法,其中,所述更改依赖于频率。10. The method of claim 9, wherein the altering is frequency dependent.
11.根据前述权利要求任一项所述的方法,其中,所述变换使在所述方向特征的规定范围中声场均衡。11. A method according to any one of the preceding claims, wherein the transformation equalizes the sound field in a prescribed range of the directional characteristics.
12.根据前述权利要求任一项所述的方法,其中,所述变换基于头部相关传输函数(HRTF),所述变换的应用包括:向所述音频信号添加表明所述声音分量的方向特征的提示。12. A method according to any one of the preceding claims, wherein the transformation is based on a head related transfer function (HRTF), the application of the transformation comprising: adding to the audio signal a directional characteristic indicative of the sound component tips.
13.根据权利要求12所述的方法,其中,所述提示基于两耳时差(ITD)。13. The method of claim 12, wherein the prompt is based on Interaural Time Difference (ITD).
14.根据权利要求12或13所述的方法,其中,所述提示基于两耳强度差(IID)。14. The method of claim 12 or 13, wherein the cue is based on an interaural intensity difference (IID).
15.根据前述权利要求任一项所述的方法,其中,接收的所述空间音频信号代表第一所述声音分量和第二所述声音分量,所述更改包括:15. A method according to any one of the preceding claims, wherein said received spatial audio signal is representative of a first said sound component and a second said sound component, said modifying comprising:
基本消除所述第一分量并保留所述第二分量,使更改的所述空间音频信号包括所述第一分量。The first component is substantially eliminated and the second component is retained such that the modified spatial audio signal includes the first component.
16.根据权利要求15所述的方法,包括:16. The method of claim 15, comprising:
改变与所述第一分量关联的规定方向特征;以及changing a prescribed directional characteristic associated with the first component; and
将改变的所述第一分量与所述第二分量组合。The changed first component is combined with the second component.
17.一种用于游戏系统的方法,该游戏系统包括:用于控制用户交互游戏环境的游戏功能,以及用于处理与所述游戏环境关联的空间音频信号的声音功能,所述方法包括:在所述声音功能处从所述游戏功能接收输入,所述输入表明所述游戏环境的变化,以及,响应于对所述信号的接收,按照根据前述权利要求任一项所述的方法处理与变化后的所述游戏环境关联的声音信号。17. A method for a gaming system comprising: gaming functionality for controlling a user-interactive gaming environment, and sound functionality for processing spatial audio signals associated with said gaming environment, said method comprising: Receiving input from said game function at said sound function, said input indicating a change in said game environment, and, in response to receiving said signal, processing according to a method according to any one of the preceding claims and A sound signal associated with the changed game environment.
18.根据权利要求17所述的方法,其中,所述输入包括表明所述游戏环境的特征变化的数据,所述提供变换包括:根据所述特征变化选择变换。18. The method of claim 17, wherein the input includes data indicative of a change in a characteristic of the gaming environment, and the providing a transformation comprises selecting a transformation based on the characteristic change.
19.一种提供用于控制扬声器的多个扬声器信号的方法,所述方法包括:19. A method of providing a plurality of speaker signals for controlling a speaker, the method comprising:
根据预定扬声器布局和预定规则提供根据所述预定扬声器布局所布置的每个扬声器的扬声器增益,所述预定规则表明当产生来自给定方向的声音时根据所述预定扬声器布局所布置的每个扬声器的扬声器增益,给定扬声器的扬声器增益依赖于所述给定方向;providing a speaker gain for each speaker arranged according to a predetermined speaker layout and a predetermined rule indicating that each speaker arranged according to the predetermined speaker layout when producing sound from a given direction The loudspeaker gain of a given loudspeaker depends on the given direction;
将所述扬声器增益表示为球谐函数分量的总和,每个所述球谐函数分量具有关联系数;expressing said loudspeaker gain as a sum of spherical harmonic function components, each of said spherical harmonic function components having an associated coefficient;
计算多个所述系数中每个的值;calculating a value for each of a plurality of said coefficients;
生成包括多个元的矩阵变换,每个所述元基于计算得到的所述值;generating a matrix transformation comprising a plurality of elements, each said element being based on said computed said value;
接收空间音频信号,所述空间音频信号代表一个或多个声音分量,所述声音分量具有规定方向特征,所述信号处于使用所述声音分量的球谐函数表达式的格式;receiving a spatial audio signal representing one or more sound components having prescribed directional characteristics, the signal being in a format using spherical harmonic function expressions of the sound components;
对所述球谐函数表达式执行所述矩阵变换,所述变换的执行产生多个扬声器信号,每个所述扬声器信号规定了扬声器的输出,所述扬声器信号能够控制根据所述预定扬声器布局所布置的扬声器,以根据所述规定方向特征生成所述一个或多个声音分量;以及performing said matrix transformation on said spherical harmonic expression, said transformation being performed to generate a plurality of loudspeaker signals, each said loudspeaker signal specifying an output of a loudspeaker, said loudspeaker signals capable of controlling a loudspeaker arranged to generate said one or more sound components according to said prescribed directional characteristics; and
输出多个所述扬声器信号。A plurality of said speaker signals are output.
20.根据权利要求19所述的方法,其中,所述空间音频信号包括ambisonic信号。20. The method of claim 19, wherein the spatial audio signal comprises an ambisonic signal.
21.根据权利要求19或20所述的方法,包括:接收处于不使用声音分量的球谐函数表达式的格式的空间音频信号,以及,将该音频信号转换为接收的所述空间音频信号。21. A method according to claim 19 or 20, comprising receiving a spatial audio signal in a format that does not use spherical harmonic expressions of sound components, and converting the audio signal into the received spatial audio signal.
22.根据权利要求19至21中任一项所述的方法,包括:根据各个所述扬声器距预期收听点的相应距离,在两个以上所述扬声器信号之间应用相对时延。22. A method as claimed in any one of claims 19 to 21, comprising applying a relative time delay between two or more of said loudspeaker signals according to the respective distance of each said loudspeaker from an intended listening point.
23.根据权利要求19至22中任一项所述的方法,包括:根据所述预定扬声器布局确定所述规则。23. A method as claimed in any one of claims 19 to 22, comprising determining said rules from said predetermined loudspeaker layout.
24.根据权利要求19至23中任一项所述的方法,其中,所述声音分量包括具有多个频率的声音,所述方法包括:对为规定频率的声音执行ambisonic解码技术。24. A method as claimed in any one of claims 19 to 23, wherein the sound components comprise sounds having a plurality of frequencies, the method comprising: performing an ambisonic decoding technique on sounds having a specified frequency.
25.根据权利要求24所述的方法,包括:对具有低于规定阈频率的频率的声音执行所述ambisonic解码技术。25. The method of claim 24, comprising performing the ambisonic decoding technique on sounds having frequencies below a prescribed threshold frequency.
26.一种处理音频信号的方法,所述方法包括:26. A method of processing an audio signal, the method comprising:
接收音频信号,所述音频信号具有预定格式并代表一个或多个规定声音特征,其中,所述音频信号是可再现的以生成具有所述一个或多个规定特征的声音;receiving an audio signal having a predetermined format and representing one or more prescribed sound characteristics, wherein the audio signal is reproducible to generate sound having the one or more prescribed characteristics;
接收对所述音频信号进行更改的请求,所述更改包括:更改所述预定格式和所述一个或多个规定声音特征这两者中的至少一个;receiving a request to modify the audio signal, the modification comprising: modifying at least one of the predetermined format and the one or more prescribed sound characteristics;
响应于对所述请求的接收,对存储多个矩阵变换的数据存储装置进行存取,每个所述矩阵变换用于更改音频流的格式和声音特征这两者中的至少一个;In response to receiving the request, accessing data storage storing a plurality of matrix transformations, each of the matrix transformations for modifying at least one of the format and the sound characteristics of the audio stream;
确定所述矩阵变换的多个组合,每个确定的所述组合用于执行请求的所述更改;determining a plurality of combinations of said matrix transformations, each determined said combination being used to perform said alteration requested;
响应于对所述组合的选择,将选定的所述组合的矩阵变换组合为组合变换;In response to selecting the combination, combining the selected matrix transformations of the combination into a combined transformation;
将所述组合变换应用于接收的所述音频信号,从而生成更改的音频信号;以及applying said combined transform to said received audio signal, thereby generating a modified audio signal; and
输出更改的所述音频信号。The modified audio signal is output.
27.根据权利要求26所述的方法,其中,所述选择包括用户选择,所述方法包括:27. The method of claim 26, wherein the selection comprises a user selection, the method comprising:
生成所确定的所述组合的列表;以及generating a list of said determined combinations; and
将生成的所述列表提供给用户界面,以供用户选择。The generated list is provided to the user interface for selection by the user.
28.根据权利要求27所述的方法,其中,存储的所述矩阵变换与一个或多个等级值相关联,所述列表的生成包括:28. The method of claim 27, wherein the stored matrix transformations are associated with one or more rank values, the generating of the list comprising:
根据所述等级值分析所确定的多个所述组合;以及analyzing the determined plurality of said combinations according to said rank value; and
根据所述分析对所述列表进行排序。The list is sorted according to the analysis.
29.根据权利要求26至28中任一项所述的方法,其中,接收的所述音频信号和更改的所述音频信号中的至少一个包括代表一个或多个声音分量的空间音频信号,所述声音分量具有规定方向特征。29. A method according to any one of claims 26 to 28, wherein at least one of the received audio signal and the modified audio signal comprises a spatial audio signal representing one or more sound components, the The sound components have a prescribed directional characteristic.
30.根据权利要求29所述的方法,其中,接收的所述音频信号和更改的所述音频信号中的至少一个具有使用所述声音分量的球谐函数表达式的格式。30. The method of claim 29, wherein at least one of the received audio signal and the modified audio signal has a format using spherical harmonic expressions of the sound components.
31.根据权利要求30所述的方法,其中,接收的所述音频信号和更改的所述音频信号中的至少一个具有Ambisonic格式。31. The method of claim 30, wherein at least one of the received audio signal and the modified audio signal has an ambisonic format.
32.根据权利要求29至31中任一项所述的方法,其中,多个所述矩阵变换中的至少一个包括空间变换,所述更改包括:更改所述方向特征中的至少一个。32. A method according to any one of claims 29 to 31 , wherein at least one of said plurality of matrix transformations comprises a spatial transformation and said altering comprises altering at least one of said directional features.
33.根据权利要求26至32中任一项所述的方法,其中,多个所述矩阵变换中的至少一个包括信号格式变换。33. A method as claimed in any one of claims 26 to 32, wherein at least one of said plurality of matrix transformations comprises a signal format transformation.
34.一种包括变换功能的变换系统,所述变换功能被布置为执行根据权利要求26至33中任一项所述的方法。34. A transformation system comprising a transformation function arranged to perform a method according to any one of claims 26 to 33.
35.根据权利要求34所述的变换系统,包括用户界面,其中,所述变换系统被布置为使得所述用户可经由所述用户界面选择所述变换功能使用的变换。35. A transformation system according to claim 34, comprising a user interface, wherein the transformation system is arranged such that the user can select a transformation to be used by the transformation function via the user interface.
36.根据权利要求35或36所述的变换系统,包括所述数据存储装置。36. A transformation system as claimed in claim 35 or 36, comprising the data storage means.
37.根据权利要求34至36中任一项所述的变换系统,被布置为执行根据权利要求1至25中任一项所述的方法。37. A transformation system as claimed in any one of claims 34 to 36, arranged to perform a method as claimed in any one of claims 1 to 25.
38.一种游戏系统,包括根据权利要求34至37中任一项所述的变换系统,所述游戏系统包括用于控制用户交互游戏环境的游戏功能,其中,所述系统被布置为根据来自所述游戏环境的数据确定所述变换系统使用的变换。38. A gaming system comprising a transformation system according to any one of claims 34 to 37, said gaming system comprising gaming functionality for controlling a user-interactive gaming environment, wherein said system is arranged to The game environment data determines the transformations used by the transformation system.
39.一种系统,被布置为执行根据权利要求1至25中任一项所述的方法。39. A system arranged to perform a method according to any one of claims 1 to 25.
40.一种生成头部相关传输函数(HRTF)变换的方法,该HRTF变换可用于根据权利要求1至18中任一项所述的方法,所述生成头部相关传输函数变换的方法包括:40. A method of generating a head-related transfer function (HRTF) transformation, which can be used in the method according to any one of claims 1 to 18, the method of generating a head-related transfer function transformation comprising:
接收代表HRTF数据的函数h,其中θ为;Receive a function h representing HRTF data, where θ is;
生成接收的所述函数的球谐函数表达式,所述表达式具有以下形式:generates a spherical harmonic expression for the function received, the expression having the following form:
其中,Yi(θ,φ)为球谐函数;Among them, Yi (θ, φ) is a spherical harmonic function;
确定至少一些所述ci的值;determining values for at least some of saidci ;
根据确定的所述ci值生成矩阵变换,生成的所述变换可用于根据权利要求1至18中任一项所述的方法;Generating a matrix transformation based on the determined values ofci , the generated transformation being usable in the method according to any one of claims 1 to 18;
在记录介质上记录生成的所述矩阵变换。The generated matrix transformation is recorded on a recording medium.
41.根据权利要求40所述的方法,包括:41. The method of claim 40, comprising:
更改至少一个所述ci的值,从而减少对至少一个以下函数的h的影响:Change the value of at least one of saidci , thereby reducing the effect on h of at least one of the following functions:
非左右对称的球谐函数;以及spherical harmonics that are not left-right symmetric; and
关于垂直轴不对称的球谐函数。Spherical harmonics that are asymmetric about the vertical axis.
42.根据权利要求40或41所述的方法,包括:将h分解为频率相关分量和相位相关分量。42. A method as claimed in claim 40 or 41 , comprising decomposing h into a frequency-dependent component and a phase-dependent component.
43.一种计算机程序,被布置为使处理装置适合执行根据权利要求1至33或权利要求38至40中任一项所述的方法。43. A computer program arranged to adapt processing means to carry out the method according to any one of claims 1 to 33 or claims 38 to 40.
Claims (43)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201410555492.0ACN104349267B (en) | 2009-02-04 | 2010-02-04 | sound system |
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| GB0901722.9AGB2467534B (en) | 2009-02-04 | 2009-02-04 | Sound system |
| GB0901722.9 | 2009-02-04 | ||
| PCT/EP2010/051390WO2010089357A2 (en) | 2009-02-04 | 2010-02-04 | Sound system |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201410555492.0ADivisionCN104349267B (en) | 2009-02-04 | 2010-02-04 | sound system |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN102318372Atrue CN102318372A (en) | 2012-01-11 |
Family
ID=40469490
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN2010800066263APendingCN102318372A (en) | 2009-02-04 | 2010-02-04 | Sound system |
| CN201410555492.0AActiveCN104349267B (en) | 2009-02-04 | 2010-02-04 | sound system |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201410555492.0AActiveCN104349267B (en) | 2009-02-04 | 2010-02-04 | sound system |
Country Status (5)
| Country | Link |
|---|---|
| US (3) | US9078076B2 (en) |
| EP (1) | EP2394445A2 (en) |
| CN (2) | CN102318372A (en) |
| GB (3) | GB2476747B (en) |
| WO (1) | WO2010089357A2 (en) |
Cited By (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103888889A (en)* | 2014-04-07 | 2014-06-25 | 北京工业大学 | Multi-channel conversion method based on spherical harmonic expansion |
| CN104604256A (en)* | 2012-08-31 | 2015-05-06 | 杜比实验室特许公司 | Reflected sound rendering of object-based audio |
| CN105308989A (en)* | 2013-04-17 | 2016-02-03 | J-L·奥莱斯 | Method for playing back sound of digital audio signal |
| CN105340298A (en)* | 2013-05-29 | 2016-02-17 | 高通股份有限公司 | Stereo rendering of spherical harmonic coefficients |
| CN106971738A (en)* | 2012-05-14 | 2017-07-21 | 杜比国际公司 | Method and apparatus for compressing and decompressing a Higher Order Ambisonics signal representation |
| CN107403625A (en)* | 2012-07-16 | 2017-11-28 | 杜比国际公司 | Method, apparatus and computer readable medium for decoding HOA audio signals |
| CN107623894A (en)* | 2013-03-29 | 2018-01-23 | 三星电子株式会社 | Methods for rendering audio signals |
| CN107690123A (en)* | 2012-12-04 | 2018-02-13 | 三星电子株式会社 | Audio provides method |
| CN108834038A (en)* | 2014-03-28 | 2018-11-16 | 三星电子株式会社 | Method and apparatus for rendering acoustic signal |
| CN110767242A (en)* | 2013-05-29 | 2020-02-07 | 高通股份有限公司 | Compression of decomposed representations of sound fields |
| CN110972033A (en)* | 2018-09-28 | 2020-04-07 | 硅实验室公司 | System and method for modifying audio data information based on one or more Radio Frequency (RF) signal reception and/or transmission characteristics |
| CN111312263A (en)* | 2014-05-16 | 2020-06-19 | 高通股份有限公司 | Method and apparatus to obtain multiple Higher Order Ambisonic (HOA) coefficients |
Families Citing this family (46)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20120203723A1 (en)* | 2011-02-04 | 2012-08-09 | Telefonaktiebolaget Lm Ericsson (Publ) | Server System and Method for Network-Based Service Recommendation Enhancement |
| EP2541547A1 (en)* | 2011-06-30 | 2013-01-02 | Thomson Licensing | Method and apparatus for changing the relative positions of sound objects contained within a higher-order ambisonics representation |
| EP2600637A1 (en)* | 2011-12-02 | 2013-06-05 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Apparatus and method for microphone positioning based on a spatial power density |
| WO2013117806A2 (en) | 2012-02-07 | 2013-08-15 | Nokia Corporation | Visual spatial audio |
| EP2829083B1 (en)* | 2012-03-23 | 2016-08-10 | Dolby Laboratories Licensing Corporation | System and method of speaker cluster design and rendering |
| WO2013149867A1 (en)* | 2012-04-02 | 2013-10-10 | Sonicemotion Ag | Method for high quality efficient 3d sound reproduction |
| GB201211512D0 (en) | 2012-06-28 | 2012-08-08 | Provost Fellows Foundation Scholars And The Other Members Of Board Of The | Method and apparatus for generating an audio output comprising spartial information |
| US9190065B2 (en) | 2012-07-15 | 2015-11-17 | Qualcomm Incorporated | Systems, methods, apparatus, and computer-readable media for three-dimensional audio coding using basis function coefficients |
| US9288603B2 (en) | 2012-07-15 | 2016-03-15 | Qualcomm Incorporated | Systems, methods, apparatus, and computer-readable media for backward-compatible audio coding |
| US9473870B2 (en) | 2012-07-16 | 2016-10-18 | Qualcomm Incorporated | Loudspeaker position compensation with 3D-audio hierarchical coding |
| KR102131810B1 (en) | 2012-07-19 | 2020-07-08 | 돌비 인터네셔널 에이비 | Method and device for improving the rendering of multi-channel audio signals |
| EP2717263B1 (en) | 2012-10-05 | 2016-11-02 | Nokia Technologies Oy | Method, apparatus, and computer program product for categorical spatial analysis-synthesis on the spectrum of a multichannel audio signal |
| US9736609B2 (en)* | 2013-02-07 | 2017-08-15 | Qualcomm Incorporated | Determining renderers for spherical harmonic coefficients |
| CN104010265A (en) | 2013-02-22 | 2014-08-27 | 杜比实验室特许公司 | Audio space rendering device and method |
| EP2974384B1 (en)* | 2013-03-12 | 2017-08-30 | Dolby Laboratories Licensing Corporation | Method of rendering one or more captured audio soundfields to a listener |
| WO2014151813A1 (en) | 2013-03-15 | 2014-09-25 | Dolby Laboratories Licensing Corporation | Normalization of soundfield orientations based on auditory scene analysis |
| US9723305B2 (en) | 2013-03-29 | 2017-08-01 | Qualcomm Incorporated | RTP payload format designs |
| US9466305B2 (en)* | 2013-05-29 | 2016-10-11 | Qualcomm Incorporated | Performing positional analysis to code spherical harmonic coefficients |
| US9788135B2 (en) | 2013-12-04 | 2017-10-10 | The United States Of America As Represented By The Secretary Of The Air Force | Efficient personalization of head-related transfer functions for improved virtual spatial audio |
| US9489955B2 (en) | 2014-01-30 | 2016-11-08 | Qualcomm Incorporated | Indicating frame parameter reusability for coding vectors |
| US9922656B2 (en) | 2014-01-30 | 2018-03-20 | Qualcomm Incorporated | Transitioning of ambient higher-order ambisonic coefficients |
| US10770087B2 (en) | 2014-05-16 | 2020-09-08 | Qualcomm Incorporated | Selecting codebooks for coding vectors decomposed from higher-order ambisonic audio signals |
| US9620137B2 (en) | 2014-05-16 | 2017-04-11 | Qualcomm Incorporated | Determining between scalar and vector quantization in higher order ambisonic coefficients |
| CN105208501A (en) | 2014-06-09 | 2015-12-30 | 杜比实验室特许公司 | Method for modeling frequency response characteristic of electro-acoustic transducer |
| US9838819B2 (en)* | 2014-07-02 | 2017-12-05 | Qualcomm Incorporated | Reducing correlation between higher order ambisonic (HOA) background channels |
| US9536531B2 (en)* | 2014-08-01 | 2017-01-03 | Qualcomm Incorporated | Editing of higher-order ambisonic audio data |
| US9782672B2 (en)* | 2014-09-12 | 2017-10-10 | Voyetra Turtle Beach, Inc. | Gaming headset with enhanced off-screen awareness |
| US9774974B2 (en) | 2014-09-24 | 2017-09-26 | Electronics And Telecommunications Research Institute | Audio metadata providing apparatus and method, and multichannel audio data playback apparatus and method to support dynamic format conversion |
| US9747910B2 (en) | 2014-09-26 | 2017-08-29 | Qualcomm Incorporated | Switching between predictive and non-predictive quantization techniques in a higher order ambisonics (HOA) framework |
| US10140996B2 (en) | 2014-10-10 | 2018-11-27 | Qualcomm Incorporated | Signaling layers for scalable coding of higher order ambisonic audio data |
| EP3251116A4 (en)* | 2015-01-30 | 2018-07-25 | DTS, Inc. | System and method for capturing, encoding, distributing, and decoding immersive audio |
| US9961475B2 (en)* | 2015-10-08 | 2018-05-01 | Qualcomm Incorporated | Conversion from object-based audio to HOA |
| US10249312B2 (en) | 2015-10-08 | 2019-04-02 | Qualcomm Incorporated | Quantization of spatial vectors |
| US9961467B2 (en)* | 2015-10-08 | 2018-05-01 | Qualcomm Incorporated | Conversion from channel-based audio to HOA |
| US20200267490A1 (en)* | 2016-01-04 | 2020-08-20 | Harman Becker Automotive Systems Gmbh | Sound wave field generation |
| EP3188504B1 (en) | 2016-01-04 | 2020-07-29 | Harman Becker Automotive Systems GmbH | Multi-media reproduction for a multiplicity of recipients |
| KR102640940B1 (en) | 2016-01-27 | 2024-02-26 | 돌비 레버러토리즈 라이쎈싱 코오포레이션 | Acoustic environment simulation |
| US11128973B2 (en)* | 2016-06-03 | 2021-09-21 | Dolby Laboratories Licensing Corporation | Pre-process correction and enhancement for immersive audio greeting card |
| US9865274B1 (en)* | 2016-12-22 | 2018-01-09 | Getgo, Inc. | Ambisonic audio signal processing for bidirectional real-time communication |
| CN107147975B (en)* | 2017-04-26 | 2019-05-14 | 北京大学 | A kind of Ambisonics matching pursuit coding/decoding method put towards irregular loudspeaker |
| US20180315437A1 (en)* | 2017-04-28 | 2018-11-01 | Microsoft Technology Licensing, Llc | Progressive Streaming of Spatial Audio |
| US10129648B1 (en)* | 2017-05-11 | 2018-11-13 | Microsoft Technology Licensing, Llc | Hinged computing device for binaural recording |
| US10251014B1 (en)* | 2018-01-29 | 2019-04-02 | Philip Scott Lyren | Playing binaural sound clips during an electronic communication |
| US11843792B2 (en)* | 2020-11-12 | 2023-12-12 | Istreamplanet Co., Llc | Dynamic decoder configuration for live transcoding |
| CN114173256B (en)* | 2021-12-10 | 2024-04-19 | 中国电影科学技术研究所 | Method, device and equipment for restoring sound field space and posture tracking |
| CN114949856B (en)* | 2022-04-14 | 2024-12-27 | 北京字跳网络技术有限公司 | Game sound effect processing method, device, storage medium and terminal device |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5757927A (en)* | 1992-03-02 | 1998-05-26 | Trifield Productions Ltd. | Surround sound apparatus |
| US6259795B1 (en)* | 1996-07-12 | 2001-07-10 | Lake Dsp Pty Ltd. | Methods and apparatus for processing spatialized audio |
| US20040111171A1 (en)* | 2002-10-28 | 2004-06-10 | Dae-Young Jang | Object-based three-dimensional audio system and method of controlling the same |
| CN1735922A (en)* | 2002-11-19 | 2006-02-15 | 法国电信局 | Method for processing audio data and sound acquisition device implementing this method |
Family Cites Families (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB9204485D0 (en)* | 1992-03-02 | 1992-04-15 | Trifield Productions Ltd | Surround sound apparatus |
| JPH06334986A (en)* | 1993-05-19 | 1994-12-02 | Sony Corp | Weighted cosine transform method |
| US6072878A (en)* | 1997-09-24 | 2000-06-06 | Sonic Solutions | Multi-channel surround sound mastering and reproduction techniques that preserve spatial harmonics |
| AUPP272598A0 (en)* | 1998-03-31 | 1998-04-23 | Lake Dsp Pty Limited | Wavelet conversion of 3-d audio signals |
| US7231054B1 (en)* | 1999-09-24 | 2007-06-12 | Creative Technology Ltd | Method and apparatus for three-dimensional audio display |
| US7031474B1 (en)* | 1999-10-04 | 2006-04-18 | Srs Labs, Inc. | Acoustic correction apparatus |
| EP1275272B1 (en)* | 2000-04-19 | 2012-11-21 | SNK Tech Investment L.L.C. | Multi-channel surround sound mastering and reproduction techniques that preserve spatial harmonics in three dimensions |
| GB2379147B (en)* | 2001-04-18 | 2003-10-22 | Univ York | Sound processing |
| US7020304B2 (en)* | 2002-01-22 | 2006-03-28 | Digimarc Corporation | Digital watermarking and fingerprinting including synchronization, layering, version control, and compressed embedding |
| JP4114583B2 (en) | 2003-09-25 | 2008-07-09 | ヤマハ株式会社 | Characteristic correction system |
| US7298925B2 (en)* | 2003-09-30 | 2007-11-20 | International Business Machines Corporation | Efficient scaling in transform domain |
| US7634092B2 (en)* | 2004-10-14 | 2009-12-15 | Dolby Laboratories Licensing Corporation | Head related transfer functions for panned stereo audio content |
| US20090041254A1 (en)* | 2005-10-20 | 2009-02-12 | Personal Audio Pty Ltd | Spatial audio simulation |
| WO2008039339A2 (en)* | 2006-09-25 | 2008-04-03 | Dolby Laboratories Licensing Corporation | Improved spatial resolution of the sound field for multi-channel audio playback systems by deriving signals with high order angular terms |
| US20080298610A1 (en)* | 2007-05-30 | 2008-12-04 | Nokia Corporation | Parameter Space Re-Panning for Spatial Audio |
| ITMI20071133A1 (en) | 2007-06-04 | 2008-12-05 | No El Srl | METHOD AND EQUIPMENT FOR CORRUGATION AND WINDING OF PLASTIC FILM COILS |
- 2009
- 2009-02-04GBGB1104233.0Apatent/GB2476747B/enactiveActive
- 2009-02-04GBGB0901722.9Apatent/GB2467534B/enactiveActive
- 2009-02-04GBGB1104237.1Apatent/GB2478834B/enactiveActive
- 2010
- 2010-02-04CNCN2010800066263Apatent/CN102318372A/enactivePending
- 2010-02-04CNCN201410555492.0Apatent/CN104349267B/enactiveActive
- 2010-02-04WOPCT/EP2010/051390patent/WO2010089357A2/enactiveApplication Filing
- 2010-02-04EPEP10706562Apatent/EP2394445A2/ennot_activeWithdrawn
- 2011
- 2011-07-28USUS13/192,717patent/US9078076B2/enactiveActive
- 2015
- 2015-06-02USUS14/728,565patent/US9773506B2/enactiveActive
- 2017
- 2017-08-29USUS15/689,814patent/US10490200B2/enactiveActive
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5757927A (en)* | 1992-03-02 | 1998-05-26 | Trifield Productions Ltd. | Surround sound apparatus |
| US6259795B1 (en)* | 1996-07-12 | 2001-07-10 | Lake Dsp Pty Ltd. | Methods and apparatus for processing spatialized audio |
| US20040111171A1 (en)* | 2002-10-28 | 2004-06-10 | Dae-Young Jang | Object-based three-dimensional audio system and method of controlling the same |
| CN1735922A (en)* | 2002-11-19 | 2006-02-15 | 法国电信局 | Method for processing audio data and sound acquisition device implementing this method |
Non-Patent Citations (1)
| Title |
|---|
| VILLE PULKKI AND TONI HIRVONEN: "Localization of Virtual Sources in Multichannel Audio Reproduction", 《IEEE TRANSACTIONS ON SPEECH ANO AUOIO PROCESSING》* |
Cited By (42)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US12245012B2 (en) | 2012-05-14 | 2025-03-04 | Dolby Laboratories Licensing Corporation | Method and apparatus for compressing and decompressing a higher order ambisonics signal representation |
| US11792591B2 (en) | 2012-05-14 | 2023-10-17 | Dolby Laboratories Licensing Corporation | Method and apparatus for compressing and decompressing a higher order Ambisonics signal representation |
| US11234091B2 (en) | 2012-05-14 | 2022-01-25 | Dolby Laboratories Licensing Corporation | Method and apparatus for compressing and decompressing a Higher Order Ambisonics signal representation |
| CN107180638B (en)* | 2012-05-14 | 2021-01-15 | 杜比国际公司 | Method and apparatus for compressing and decompressing a higher order ambisonics signal representation |
| CN106971738A (en)* | 2012-05-14 | 2017-07-21 | 杜比国际公司 | Method and apparatus for compressing and decompressing a Higher Order Ambisonics signal representation |
| CN107180638A (en)* | 2012-05-14 | 2017-09-19 | 杜比国际公司 | Method and apparatus for compressing and decompressing a higher order ambisonics signal representation |
| CN107403625A (en)* | 2012-07-16 | 2017-11-28 | 杜比国际公司 | Method, apparatus and computer readable medium for decoding HOA audio signals |
| CN107403625B (en)* | 2012-07-16 | 2021-06-04 | 杜比国际公司 | Method, apparatus and computer readable medium for decoding HOA audio signals |
| CN107424618B (en)* | 2012-07-16 | 2021-01-08 | 杜比国际公司 | Method, apparatus and computer readable medium for decoding HOA audio signals |
| CN107591160A (en)* | 2012-07-16 | 2018-01-16 | 杜比国际公司 | Method, apparatus and computer readable medium for decoding HOA audio signals |
| CN107424618A (en)* | 2012-07-16 | 2017-12-01 | 杜比国际公司 | Method, apparatus and computer readable medium for decoding HOA audio signals |
| CN107509141B (en)* | 2012-08-31 | 2019-08-27 | 杜比实验室特许公司 | Audio processing apparatus with channel remapper and object renderer |
| CN104604256A (en)* | 2012-08-31 | 2015-05-06 | 杜比实验室特许公司 | Reflected sound rendering of object-based audio |
| CN107454511A (en)* | 2012-08-31 | 2017-12-08 | 杜比实验室特许公司 | Loudspeakers for reflecting sound from viewing screens or display surfaces |
| CN107509141A (en)* | 2012-08-31 | 2017-12-22 | 杜比实验室特许公司 | Audio processing apparatus with channel remapper and object renderer |
| CN104604256B (en)* | 2012-08-31 | 2017-09-15 | 杜比实验室特许公司 | Reflected sound rendering of object-based audio |
| US9794718B2 (en) | 2012-08-31 | 2017-10-17 | Dolby Laboratories Licensing Corporation | Reflected sound rendering for object-based audio |
| US11277703B2 (en) | 2012-08-31 | 2022-03-15 | Dolby Laboratories Licensing Corporation | Speaker for reflecting sound off viewing screen or display surface |
| US10743125B2 (en) | 2012-08-31 | 2020-08-11 | Dolby Laboratories Licensing Corporation | Audio processing apparatus with channel remapper and object renderer |
| CN107454511B (en)* | 2012-08-31 | 2024-04-05 | 杜比实验室特许公司 | Loudspeaker for reflecting sound from a viewing screen or display surface |
| US10341800B2 (en) | 2012-12-04 | 2019-07-02 | Samsung Electronics Co., Ltd. | Audio providing apparatus and audio providing method |
| CN107690123A (en)* | 2012-12-04 | 2018-02-13 | 三星电子株式会社 | Audio provides method |
| CN107690123B (en)* | 2012-12-04 | 2021-04-02 | 三星电子株式会社 | Audio delivery method |
| US10405124B2 (en) | 2013-03-29 | 2019-09-03 | Samsung Electronics Co., Ltd. | Audio apparatus and audio providing method thereof |
| CN107623894B (en)* | 2013-03-29 | 2019-10-15 | 三星电子株式会社 | Methods for rendering audio signals |
| CN107623894A (en)* | 2013-03-29 | 2018-01-23 | 三星电子株式会社 | Methods for rendering audio signals |
| CN105308989A (en)* | 2013-04-17 | 2016-02-03 | J-L·奥莱斯 | Method for playing back sound of digital audio signal |
| CN105308989B (en)* | 2013-04-17 | 2017-06-20 | J-L·奥莱斯 | Method for playing back sound of digital audio signal |
| CN110767242B (en)* | 2013-05-29 | 2024-05-24 | 高通股份有限公司 | Compression of decomposed representations of sound fields |
| CN105340298B (en)* | 2013-05-29 | 2017-05-31 | 高通股份有限公司 | The stereo presentation of spherical harmonics coefficient |
| CN105340298A (en)* | 2013-05-29 | 2016-02-17 | 高通股份有限公司 | Stereo rendering of spherical harmonic coefficients |
| CN110767242A (en)* | 2013-05-29 | 2020-02-07 | 高通股份有限公司 | Compression of decomposed representations of sound fields |
| US10687162B2 (en) | 2014-03-28 | 2020-06-16 | Samsung Electronics Co., Ltd. | Method and apparatus for rendering acoustic signal, and computer-readable recording medium |
| CN108834038B (en)* | 2014-03-28 | 2021-08-03 | 三星电子株式会社 | Method and apparatus for rendering acoustic signals |
| CN108834038A (en)* | 2014-03-28 | 2018-11-16 | 三星电子株式会社 | Method and apparatus for rendering acoustic signal |
| CN103888889B (en)* | 2014-04-07 | 2016-01-13 | 北京工业大学 | A Multi-channel Conversion Method Based on Spherical Harmonic Expansion |
| CN103888889A (en)* | 2014-04-07 | 2014-06-25 | 北京工业大学 | Multi-channel conversion method based on spherical harmonic expansion |
| CN111312263A (en)* | 2014-05-16 | 2020-06-19 | 高通股份有限公司 | Method and apparatus to obtain multiple Higher Order Ambisonic (HOA) coefficients |
| CN111312263B (en)* | 2014-05-16 | 2024-05-24 | 高通股份有限公司 | Method and apparatus to obtain multiple higher order ambisonic HOA coefficients |
| US11906642B2 (en) | 2018-09-28 | 2024-02-20 | Silicon Laboratories Inc. | Systems and methods for modifying information of audio data based on one or more radio frequency (RF) signal reception and/or transmission characteristics |
| CN110972033B (en)* | 2018-09-28 | 2023-08-22 | 硅实验室公司 | System and method for modifying audio data |
| CN110972033A (en)* | 2018-09-28 | 2020-04-07 | 硅实验室公司 | System and method for modifying audio data information based on one or more Radio Frequency (RF) signal reception and/or transmission characteristics |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2010089357A3 (en) | 2010-11-11 |
| GB2478834B (en) | 2012-03-07 |
| US9078076B2 (en) | 2015-07-07 |
| GB2467534A (en) | 2010-08-11 |
| WO2010089357A2 (en) | 2010-08-12 |
| GB201104233D0 (en) | 2011-04-27 |
| WO2010089357A4 (en) | 2011-02-03 |
| CN104349267B (en) | 2017-06-06 |
| US20170358308A1 (en) | 2017-12-14 |
| GB2478834A (en) | 2011-09-21 |
| US20150262586A1 (en) | 2015-09-17 |
| US9773506B2 (en) | 2017-09-26 |
| US10490200B2 (en) | 2019-11-26 |
| GB0901722D0 (en) | 2009-03-11 |
| EP2394445A2 (en) | 2011-12-14 |
| GB2476747B (en) | 2011-12-21 |
| US20120014527A1 (en) | 2012-01-19 |
| CN104349267A (en) | 2015-02-11 |
| GB2467534B (en) | 2014-12-24 |
| GB201104237D0 (en) | 2011-04-27 |
| GB2476747A (en) | 2011-07-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10490200B2 (en) | Sound system | |
| US9973874B2 (en) | Audio rendering using 6-DOF tracking | |
| RU2533437C2 (en) | Method and apparatus for encoding and optimal reconstruction of three-dimensional acoustic field | |
| US9197977B2 (en) | Audio spatialization and environment simulation | |
| RU2444154C2 (en) | Method and device to generate stereo signal with improved perception property | |
| US8175280B2 (en) | Generation of spatial downmixes from parametric representations of multi channel signals | |
| KR101341523B1 (en) | How to Generate Multi-Channel Audio Signals from Stereo Signals | |
| CN114503606B (en) | Audio Processing | |
| Farina et al. | Ambiophonic principles for the recording and reproduction of surround sound for music | |
| TW202029186A (en) | Apparatus, method and computer program for encoding, decoding, scene processing and other procedures related to dirac based spatial audio coding using diffuse compensation | |
| KR20150013073A (en) | Binaural rendering method and apparatus for decoding multi channel audio | |
| CN115226022A (en) | Content-Based Spatial Remixing | |
| US20250168587A1 (en) | System for and method of controlling a three-dimensional audio engine | |
| Drossos et al. | Stereo goes mobile: Spatial enhancement for short-distance loudspeaker setups | |
| Tsakostas et al. | Binaural rendering for enhanced 3d audio perception | |
| WO2025036543A1 (en) | Devices and methods for binaural audio rendering | |
| Rumsey | Ambisonics comes of age | |
| Tom | Automatic mixing systems for multitrack spatialization based on unmasking properties and directivity patterns | |
| CN118511545A (en) | Multi-channel audio processing for upmix/remix/downmix applications | |
| GB2609667A (en) | Audio rendering | |
| Kan et al. | Psychoacoustic evaluation of different methods for creating individualized, headphone-presented virtual auditory space from B-format room impulse responses | |
| KR20060131806A (en) | Sound Synthesis and Spatialization Methods |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C12 | Rejection of a patent application after its publication | ||
| RJ01 | Rejection of invention patent application after publication | Application publication date:20120111 |