CN102013253A - Speech recognition method based on speed difference of voice unit and system thereof - Google Patents
Speech recognition method based on speed difference of voice unit and system thereofDownload PDFInfo
- Publication number
- CN102013253A CN102013253ACN2009101728759ACN200910172875ACN102013253ACN 102013253 ACN102013253 ACN 102013253ACN 2009101728759 ACN2009101728759 ACN 2009101728759ACN 200910172875 ACN200910172875 ACN 200910172875ACN 102013253 ACN102013253 ACN 102013253A
- Authority
- CN
- China
- Prior art keywords
- recognition result
- speech
- voice unit
- voice
- word speed
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images




Landscapes
- Machine Translation (AREA)
Abstract
Translated fromChineseDescription
Translated fromChinese技术领域technical field
本发明涉及语音识别技术,具体地,涉及根据语音单元语速的差异而进行语音识别的方法及相应的语音识别系统。The present invention relates to speech recognition technology, in particular, to a speech recognition method and a corresponding speech recognition system based on differences in speech rates of speech units.
背景技术Background technique
通常,语音识别过程可包括语音信号的预处理、声学特征的提取和搜索解码等。在进行语音识别时,首先对输入的语音信号进行预处理,其包括预滤波、采样和量化、加窗分帧、端点检测、预加重等。然后,对预处理后的语音信号进行特征提取,以获得线性预测系数LPC、倒谱系数CEP、Mel倒谱系数MFCC和感知线性预测PLP等声学特征。根据所获得的声学特征以及预先训练的声学模型,使用诸如Viterbi算法的搜索策略对语音信号进行解码,以获得相应的识别结果。Generally, the speech recognition process may include preprocessing of speech signals, extraction of acoustic features, search and decoding, and so on. When performing speech recognition, the input speech signal is firstly preprocessed, including pre-filtering, sampling and quantization, windowing and framing, endpoint detection, pre-emphasis, etc. Then, feature extraction is performed on the preprocessed speech signal to obtain acoustic features such as linear prediction coefficient LPC, cepstral coefficient CEP, Mel cepstral coefficient MFCC and perceptual linear prediction PLP. According to the obtained acoustic features and the pre-trained acoustic model, a search strategy such as the Viterbi algorithm is used to decode the speech signal to obtain the corresponding recognition results.
在语音识别的过程中,段长信息由于不受噪声或信道的影响,因此对于语音识别的稳健性非常重要。在现有的利用段长信息进行语音识别的方法中,常见的是对语音单元(例如状态、音素、词等)段长用随机分布(例如正态分布、γ分布、高斯混合模型GMM等)进行显式建模,然后将段长得分结合声学得分一起进行语音的解码。这样的方法能够在一定程度上提高语音识别的性能。In the process of speech recognition, segment length information is very important for the robustness of speech recognition because it is not affected by noise or channels. In the existing method of using segment length information for speech recognition, it is common to use random distribution (eg normal distribution, γ distribution, Gaussian mixture model GMM, etc.) Perform explicit modeling, and then combine segment length scores with acoustic scores for speech decoding. Such a method can improve the performance of speech recognition to a certain extent.
例如,在David Burshtern所著的文章“Robust Parametric Modeling of Durations in Hidden Markov Models”(发表于International Conference on Acoustics,Speech and Signal Processing(ICASSP),1995)中详细地描述了使用γ分布对状态建模的方案。在D.Povey所著的文章“Phone Duration Modeling for LVCSR”(发表于International Conference on Acoustics,Speech and Signal Processing(ICASSP),2004)中详细地描述了使用离散分布对音素建模的方案。For example, modeling states using the gamma distribution is described in detail in the paper "Robust Parametric Modeling of Durations in Hidden Markov Models" by David Burshtern (presented at the International Conference on Acoustics, Speech and Signal Processing (ICASSP), 1995) scheme. A scheme for modeling phonemes using discrete distributions is described in detail in the article "Phone Duration Modeling for LVCSR" by D. Povey (published at International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2004).
然而,段长信息本身容易受到语速的影响,因此,将语速信息加入段长模型中可以进一步提高语音识别的性能。然而,如何在语音识别中同时考虑段长信息和语速信息而不增加时间和内存消耗成为研究的重点。However, the segment length information itself is easily affected by the speech rate. Therefore, adding the speech rate information into the segment length model can further improve the performance of speech recognition. However, how to simultaneously consider segment length information and speech rate information in speech recognition without increasing time and memory consumption has become the focus of research.
现有的将语速信息加入段长模型的方法的基本思想是除去语速对段长模型的负面影响。The basic idea of the existing method of adding speech rate information into the segment length model is to remove the negative impact of speech rate on the segment length model.
一种常用的方法是用语速对段长进行归一化处理,其中语速被定义为一句话内所有语音单元的平均段长。然而,由于语速只有在获得整句话才能计算,因此,无法在识别过程中实时地进行段长的归一化。关于这种利用语速对段长归一化的方法,在Gadde和V.R.R.所著的文章“Modeling Word Duration for Better Speech Recognition”(Proc.Of Speech Transcription Workshop,2000)中进行了详细的描述。A common approach is to normalize segment lengths by speech rate, where speech rate is defined as the average segment length of all phonetic units in a sentence. However, since speech rate can only be calculated when the entire sentence is obtained, segment length normalization cannot be performed in real time during the recognition process. Regarding this method of normalizing segment length by speech rate, it is described in detail in the article "Modeling Word Duration for Better Speech Recognition" (Proc.Of Speech Transcription Workshop, 2000) by Gadde and V.R.R.
另一种方法是对不同语速的段长分别建模,例如,对高语速、中语速和慢语速各自建一个模型,然后在识别过程中,选择得分最高的模型。然而,这些模型的精确度不高,并且由于需要分别计算三种模型的概率,因此,将大幅增加计算量和计算时间。关于这种对不同语速分别建模的方法,在Yun Tang、Wenju Liu和Bo Xu所著的文章“Trigram Duration Modeling in Speech Recognition”(发表于International Symposium on Chinese Spoken Language Processing,2004)以及Wern-Jun Wang和Chun-Jen Lee所著的文章“Duration Modeling for Mandarin Speech Recognition Using Prosodic Information,Speech Prosody”(发表于2004)中都进行了详细的描述。Another method is to model the segment lengths of different speech rates separately, for example, build a model for high speech rate, medium speech rate and slow speech rate, and then select the model with the highest score during the recognition process. However, the accuracy of these models is not high, and since the probabilities of the three models need to be calculated separately, the calculation amount and calculation time will be greatly increased. Regarding this method of modeling different speech rates separately, in the article "Trigram Duration Modeling in Speech Recognition" written by Yun Tang, Wenju Liu and Bo Xu (published in International Symposium on Chinese Spoken Language Processing, 2004) and Wern- Both are described in detail in the article "Duration Modeling for Mandarin Speech Recognition Using Prosodic Information, Speech Prosody" by Jun Wang and Chun-Jen Lee (published in 2004).
另一种段长归一化方法是利用前一个语音单元段长对当前语音单元段长进行归一化,然而,在该方法中,需要预先计算并存储所有可能的两个上下文语音单元的归一化段长模型,因此,内存消耗较大。这种方法在美国专利US patent:Masahide Arui,Shinichi Tanaka,Takashi Masuko,“Apparatus,Method and Computer Program Product for Speech Recognition”中进行了详细的描述。Another segment length normalization method is to use the segment length of the previous speech unit to normalize the segment length of the current speech unit. However, in this method, it is necessary to pre-calculate and store all possible normalizations of the two context speech units. A segment-long model, therefore, consumes a lot of memory. This method is described in detail in US patent: Masahide Arui, Shinichi Tanaka, Takashi Masuko, "Apparatus, Method and Computer Program Product for Speech Recognition".
发明内容Contents of the invention
本发明正是基于以上技术问题而提出的,其目的在于提供一种基于语音单元语速的差异的语音识别方法以及语音识别系统,其考虑了语速对于段长的影响,能够提高语音识别性能,但无需对段长进行建模,并且内存消耗和计算时间都很小。The present invention is proposed based on the above technical problems, and its purpose is to provide a speech recognition method and a speech recognition system based on the difference in speech rate of speech units, which considers the influence of speech rate on segment length, and can improve speech recognition performance , but without the need to model segment lengths, and with minimal memory consumption and computation time.
根据本发明的一个方面,提供一种基于语音单元语速的差异的语音识别方法,包括:对所输入的语音进行预处理;提取所述语音的声学特征;基于预先训练的声学模型和所提取的所述语音的声学特征,对所述语音进行解码,以获得所述语音的多个识别结果候选,其中所述多个识别结果候选的每一个具有声学得分以及所包含的语音单元的段长;对于所述多个识别结果候选的每一个,基于所包含的语音单元的段长,计算该识别结果候选的语音单元语速差异值;基于所计算的语音单元语速差异值和声学得分,计算该识别结果候选的综合得分;以及从所述多个识别结果候选中选择所述综合得分最高的识别结果候选,作为所述语音的最终识别结果。According to one aspect of the present invention, there is provided a speech recognition method based on differences in speech rate of speech units, including: preprocessing the input speech; extracting the acoustic features of the speech; based on the pre-trained acoustic model and the extracted Acoustic features of the speech, decoding the speech to obtain a plurality of recognition result candidates of the speech, wherein each of the plurality of recognition result candidates has an acoustic score and a segment length of a speech unit included For each of the plurality of recognition result candidates, based on the segment length of the included speech unit, calculate the speech unit speech rate difference value of the recognition result candidate; based on the calculated speech unit speech rate difference value and the acoustic score, calculating a comprehensive score of the recognition result candidate; and selecting the recognition result candidate with the highest comprehensive score from the plurality of recognition result candidates as the final recognition result of the speech.
根据本发明的另一个方面,提供一种基于语音单元语速的差异的语音识别系统,包括:语音处理模块,用于对所输入的语音进行预处理;特征提取模块,用于提取所述语音的声学特征;解码模块,用于基于预先训练的声学模型和所提取的所述语音的声学特征,对所述语音进行解码,以获得所述语音的多个识别结果候选,其中所述多个识别结果候选的每一个具有声学得分以及所包含的语音单元的段长;语音单元语速差异值计算模块,用于对于所述多个识别结果候选的每一个,基于所包含的语音单元的段长,计算该识别结果候选的语音单元语速差异值;综合得分计算模块,用于对于所述多个识别结果候选的每一个,基于所计算的语音单元语速差异值和声学得分,计算该识别结果候选的综合得分;以及选择模块,用于从所述多个识别结果候选中选择所述综合得分最高的识别结果候选,作为所述语音的最终识别结果。According to another aspect of the present invention, there is provided a speech recognition system based on differences in the speech rate of speech units, including: a speech processing module for preprocessing the input speech; a feature extraction module for extracting the speech The acoustic features; the decoding module is used to decode the speech based on the pre-trained acoustic model and the extracted acoustic features of the speech, so as to obtain multiple recognition result candidates of the speech, wherein the multiple Each of the recognition result candidates has an acoustic score and the segment length of the included speech unit; the speech unit speech rate difference calculation module is used for each of the plurality of recognition result candidates, based on the segment of the included speech unit long, calculate the speech unit speech rate difference value of the recognition result candidate; the comprehensive score calculation module is used for each of the plurality of recognition result candidates, based on the calculated speech unit speech rate difference value and the acoustic score, calculate the a comprehensive score of the recognition result candidate; and a selection module, configured to select the recognition result candidate with the highest comprehensive score from the plurality of recognition result candidates as the final recognition result of the speech.
附图说明Description of drawings
图1是根据本发明的一个实施例的基于语音单元语速的差异的语音识别方法的流程图;Fig. 1 is the flow chart of the speech recognition method based on the difference of speech unit speech rate according to an embodiment of the present invention;
图2是根据本发明的第一个实施例的基于语音单元语速的差异的语音识别系统的示意性方框图;Fig. 2 is the schematic block diagram of the speech recognition system based on the speech rate difference of speech unit according to the first embodiment of the present invention;
图3是根据本发明的第二个实施例的基于语音单元语速的差异的语音识别系统的示意性方框图;Fig. 3 is the schematic block diagram of the speech recognition system based on the speech rate difference of speech unit according to the second embodiment of the present invention;
图4是根据本发明的第三个实施例的基于语音单元语速的差异的语音识别系统的示意性方框图;Fig. 4 is the schematic block diagram of the speech recognition system based on the difference of speech unit speech rate according to the third embodiment of the present invention;
图5是根据本发明的第四个实施例的基于语音单元语速的差异的语音识别系统的示意性方框图。FIG. 5 is a schematic block diagram of a speech recognition system based on differences in speech rates of speech units according to a fourth embodiment of the present invention.
具体实施方式Detailed ways
通过以下结合附图对本发明的具体实施例的详细描述,本发明的上述和其它发明目的、技术特征和优点,将会更加明显。Through the following detailed description of specific embodiments of the present invention in conjunction with the accompanying drawings, the above and other inventive objectives, technical features and advantages of the present invention will be more apparent.
图1示出了根据本发明的一个实施例的基于语音单元语速的差异的语音识别方法的流程图。下面结合附图,对本实施例进行详细的描述。Fig. 1 shows a flow chart of a speech recognition method based on differences in speech rates of speech units according to an embodiment of the present invention. The present embodiment will be described in detail below in conjunction with the accompanying drawings.
在本实施例中,假定一句话内的语速是稳定的,即一句话内每个语音单元的语速基本上相同,因此,对于声学得分相似的语音识别结果候选,语音单元的语速差异小的识别结果候选比语速差异大的识别结果候选更可能是正确的识别结果。本实施例正是基于上述的事实,利用语音单元的语速差异,并结合声学得分来选择最佳的识别结果。In this embodiment, it is assumed that the speech rate in a sentence is stable, that is, the speech rate of each speech unit in a sentence is basically the same. Therefore, for speech recognition result candidates with similar acoustic scores, the speech rate difference of speech units A small recognition result candidate is more likely to be a correct recognition result than a recognition result candidate with a large speech rate difference. This embodiment is based on the above-mentioned facts, using the difference in speech rate of the speech units and combining the acoustic score to select the best recognition result.
如图1所示,在步骤S101,对所输入的语音进行预处理,然后提取所输入的语音的声学特征。语音的预处理和特征提取操作,对于本领域的普通技术人员来说是熟知的,因此,在此省略其详细的说明。通过步骤S101,可以获得语音的声学特征,例如,线性预测系数LPC、倒谱系数CEP、Mel倒谱系数MFCC和感知线性预测PLP等。As shown in FIG. 1 , in step S101 , the input speech is preprocessed, and then the acoustic features of the input speech are extracted. Voice preprocessing and feature extraction operations are well known to those skilled in the art, so detailed descriptions thereof are omitted here. Through step S101, the acoustic features of the speech can be obtained, for example, linear prediction coefficient LPC, cepstral coefficient CEP, Mel cepstral coefficient MFCC, perceptual linear prediction PLP and so on.
接着,在步骤S105,基于预先训练的声学模型并利用所提取的声学特征,对语音进行解码,以获得该语音的多个识别结果候选。通常,语音的解码是根据搜索策略,例如Viterbi算法、N-best搜索、多遍搜索等,寻找所输入的语音的词解码序列。语音的解码对于本领域的普通技术人员来说是熟知的,因此,在此省略其详细说明。在本实施例中,搜索策略可采用Viterbi算法。经过解码后得到的每一个识别结果候选都具有相应的声学得分以及所包含的语音单元的段长。Next, in step S105, the speech is decoded based on the pre-trained acoustic model and the extracted acoustic features, so as to obtain multiple recognition result candidates for the speech. Usually, speech decoding is based on a search strategy, such as Viterbi algorithm, N-best search, multi-pass search, etc., to find the word decoding sequence of the input speech. Speech decoding is well known to those skilled in the art, therefore, its detailed description is omitted here. In this embodiment, the search strategy may use the Viterbi algorithm. Each recognition result candidate obtained after decoding has a corresponding acoustic score and the segment length of the included speech unit.
然后,在步骤S110,对于在步骤S105中得到的多个识别结果候选的每一个,基于所包含的语音单元的段长,计算该识别结果候选的语音单元语速差异值。Then, in step S110, for each of the plurality of recognition result candidates obtained in step S105, based on the segment lengths of the included speech units, the speech rate difference value of the speech unit of the recognition result candidate is calculated.
在本实施例中,语音单元可以是状态、音素、音节、词或者短语中的任意一个。语音单元的语速被定义为在步骤S105中获得的语音单元的实际段长与语音库中对应的语音单元的平均段长的比值,即In this embodiment, the speech unit may be any one of state, phoneme, syllable, word or phrase. The speech rate of the phonetic unit is defined as the ratio of the average segment length of the actual segment length of the phonetic unit obtained in step S105 and the corresponding phonetic unit in the speech bank, namely
其中,ru表示第u个语音单元的语速,du表示第u个语音单元的段长,mu表示语音库中与第u个语音单元对应的语音单元的平均段长。Among them, ru represents the speech rate of the uth speech unit,du represents the segment length of the uth speech unit, andmu represents the average segment length of the speech unit corresponding to the uth speech unit in the speech library.
在步骤S110中,首先,根据公式(1),计算该识别结果候选中的每一个语音单元的语速,然后计算该识别结果候选的语音单元语速差异值。In step S110, first, according to formula (1), the speech rate of each speech unit in the candidate recognition result is calculated, and then the speech rate difference value of the speech unit of the candidate recognition result is calculated.
在一个实施例中,语音单元语速差异值被定义为某个识别结果候选的所有语音单元的语速的最大值与最小值的差值,即语速的极差。假设识别结果候选包括N个语音单元,则语音单元语速差异值可根据以下的公式计算:In one embodiment, the speech rate difference value of a speech unit is defined as the difference between the maximum value and the minimum speech rate of all speech units of a certain recognition result candidate, that is, the extreme difference in speech rate. Assuming that the recognition result candidates include N phonetic units, the speech rate difference value of the phonetic units can be calculated according to the following formula:
sd=max(r1,r2,...,rN)-min(r1,r2,...,rN),sd =max(r1 ,r2 ,...,rN )-min(r1 ,r2 ,...,rN ),
其中,sd表示语音单元语速差异值。在这种情况下,从所计算的所有语音单元的语速中选出最大值和最小值,并计算两者之差。Among them, sd represents the speech rate difference value of the speech unit. In this case, the maximum value and the minimum value are selected from the calculated speech rates of all the speech units, and the difference between them is calculated.
在另一个实施例中,语音单元语速差异值被定义为某个识别结果候选的所有语音单元的语速的方差,即In another embodiment, the speech rate difference value of a speech unit is defined as the variance of the speech rates of all speech units of a certain recognition result candidate, namely
sd=var(r1,r2,...,rN)。sd =var(r1 , r2 , . . . , rN ).
在这种情况下,根据方差公式计算所有语速的方差。In this case, the variance of all speech rates is calculated according to the variance formula.
在另一个实施例中,语音单元语速差异值被定义为某个识别结果候选的所有语音单元的语速的标准差,即In another embodiment, the speech rate difference value of a speech unit is defined as the standard deviation of the speech rates of all speech units of a certain recognition result candidate, namely
sd=stdv(r1,r2,...,rN)。sd =stdv(r1 , r2 , . . . , rN ).
在这种情况下,根据标准差公式计算所有语速的标准差。In this case, the standard deviation of all speech rates was calculated according to the standard deviation formula.
在另一个实施例中,语音单元语速差异值被定义为某个识别结果候选的所有语音单元语速的变异系数,即所有语音单元语速的标准差与平均值的比值,如下列公式所示:In another embodiment, the speech rate difference value of a speech unit is defined as the coefficient of variation of the speech rates of all speech units of a certain recognition result candidate, that is, the ratio of the standard deviation of the speech rates of all speech units to the average value, as shown in the following formula Show:
sd=stdv(r1,r2,...,rN)/mean(r1,r2,rN)sd =stdv(r1 ,r2 ,...,rN )/mean(r1 ,r2 ,rN )
在这种情况下,分别计算所有语音单元语速的标准差以及平均值,并计算两者的比值。In this case, the standard deviation and average of speech rates of all speech units are calculated respectively, and the ratio of the two is calculated.
虽然以上描述了几种计算语音单元语速差异值的方法,但本领域的普通技术人员应当理解,还可以使用其它的计算语音单元语速差异值的方法,只要能够获得所有语音单元语速的总体差异即可。Although several methods for calculating the speech rate differences of speech units have been described above, those of ordinary skill in the art should understand that other methods for calculating the speech rate differences of speech units can also be used, as long as the speech rates of all speech units can be obtained. overall difference.
这样,通过步骤S110,能够得到每个识别结果候选的语音单元语速差异值。然后,在步骤S115,根据所计算的每个识别结果候选的语音单元语速差异值以及声学得分,计算每个识别结果候选的综合得分。In this way, through step S110, the speech rate difference value of each speech unit of each recognition result candidate can be obtained. Then, in step S115 , according to the calculated speech rate difference value of each speech unit and the acoustic score of each candidate recognition result, the comprehensive score of each candidate recognition result is calculated.
对于综合得分的计算,考虑到对于最佳的识别结果,其声学得分应当越高越好,而语音单元语速差异值越低越好,因此,在基于语音单元语速差异值和声学得分计算综合得分时,通常对语音单元语速差异值进行取反操作,再结合声学得分进行计算。下面给出几种计算综合得分的实施例。当然,本领域的普通技术人员应当理解,除了以下所述的计算综合得分的方法,还可以采用其它的方法计算综合得分。For the calculation of the comprehensive score, considering that for the best recognition results, the higher the acoustic score, the better, and the lower the speech rate difference value of the speech unit, the better. Therefore, in the calculation based on the speech unit speech rate difference and the acoustic score When scoring comprehensively, the speech rate difference value of the speech unit is usually negated, and then combined with the acoustic score for calculation. Several examples of calculating the composite score are given below. Of course, those of ordinary skill in the art should understand that, in addition to the method for calculating the comprehensive score described below, other methods can also be used to calculate the comprehensive score.
在一个实施例中,对于每个识别结果候选,首先计算语音单元语速差异值的倒数值,再根据预先确定的权重系数对该倒数值进行加权,然后将加权后的倒数值与声学得分相加,从而得到该识别结果候选的综合得分。In one embodiment, for each recognition result candidate, the reciprocal value of the speech rate difference value of the speech unit is first calculated, and then the reciprocal value is weighted according to a predetermined weight coefficient, and then the weighted reciprocal value is compared with the acoustic score Add, so as to get the comprehensive score of the recognition result candidate.
在另一个实施例中,首先计算语音单元语速差异值的相反数,再根据预先确定的权重系数对该相反数进行加权,然后将加权后的相反数与声学得分相加,从而得到该识别结果候选的综合得分。In another embodiment, the inverse number of speech rate difference value of the speech unit is firstly calculated, then the inverse number is weighted according to a predetermined weight coefficient, and then the weighted inverse number is added to the acoustic score to obtain the identification The composite score of the result candidate.
在另一个实施例中,首先计算语音单元语速差异值的倒数值,再根据预先确定的权重系数对该倒数值进行加权,然后将加权后的倒数值与声学得分相乘,从而得到该识别结果候选的综合得分。In another embodiment, the reciprocal value of the speech rate difference value of the speech unit is firstly calculated, and then the reciprocal value is weighted according to a predetermined weight coefficient, and then the weighted reciprocal value is multiplied by the acoustic score to obtain the recognition The composite score of the result candidate.
在上述的计算综合得分的实施例中,权重系数可以根据不同的识别任务进行调整。In the above embodiment of calculating the comprehensive score, the weight coefficient can be adjusted according to different recognition tasks.
最后,在步骤S120,根据每个识别结果候选的综合得分,选择综合得分最高的识别结果候选,作为所输入的语音的最终识别结果。Finally, in step S120, according to the comprehensive score of each recognition result candidate, the recognition result candidate with the highest comprehensive score is selected as the final recognition result of the input speech.
通过以上描述可以看出,本实施例的基于语音单元语速的差异的语音识别方法考虑了语音识别中语速对段长的影响,从而能够提高语音识别的性能,并且避免了对段长的建模。另外,本实施例的方法只需预先存储每个语音单元的平均段长,内存消耗较少,而且语音单元语速差异值的计算简单,计算时间短。本实施例的方法适用于任何语音识别系统,特别是小词汇量语音识别系统。As can be seen from the above description, the speech recognition method based on the difference in speech rate of the speech units of the present embodiment takes into account the influence of the speech rate on the segment length in speech recognition, thereby improving the performance of speech recognition and avoiding the impact on the segment length. modeling. In addition, the method of this embodiment only needs to store the average segment length of each speech unit in advance, which consumes less memory, and the calculation of the speech rate difference value of the speech units is simple and the calculation time is short. The method of this embodiment is applicable to any speech recognition system, especially a small vocabulary speech recognition system.
在同一个发明构思下,图2示出了根据本发明的第一个实施例的基于语音单元语速的差异的语音识别系统200的示意性方框图。下面结合附图,对本实施例进行详细的描述,其中对于与前面实施例相同的部分,适当省略其说明。Under the same inventive concept, FIG. 2 shows a schematic block diagram of a
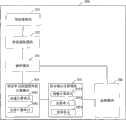
如图2所示,本实施例的基于语音单元语速的差异的语音识别系统200包括:预处理模块201,其对所输入的语音进行预处理;特征提取模块202,其提取该语音的声学特征;解码模块203,其基于预先训练的声学模型并利用所提取的语音的声学特征,对语音进行解码,以获得该语音的多个识别结果候选;语音单元语速差异值计算模块204,其对于多个识别结果候选的每一个,基于所包含的语音单元的段长,计算该识别结果候选的语音单元语速差异值;综合得分计算模块205,其对于多个识别结果候选的每一个,基于所计算的语音单元语速差异值和声学得分,计算该识别结果候选的综合得分;以及选择模块206,其从多个识别结果候选中选择综合得分最高的识别结果候选,作为所输入的语音的最终识别结果。As shown in Figure 2, the
在本实施例中,当语音被输入预处理模块201后,进行语音的预处理,然后特征提取模块202提取该语音的声学特征。所提取的声学特征与预先训练的声学模型一起被提供给解码模块203,由解码模块203根据搜索策略对语音进行解码,以获得多个识别结果候选,其中每一个识别结果候选都具有声学得分以及所包含的语音单元的段长。如前所述,语音单元可以是状态、音素、音节、词或者短语中的任意一个。In this embodiment, after the voice is input into the
在解码模块203输出多个识别结果候选后,语音单元语速差异值计算模块204对每一个识别结果候选,基于所包含的语音单元的段长,计算语音单元语速差异值。After the
在本实施例中,在语音单元语速差异值计算模块204中,首先,语速计算单元2041对于每一个识别结果候选中的每一个语音单元,计算该语音单元的语速。如前所述,语速被定义为语音单元的段长(即通过解码模块203获得的语音单元的实际段长)与语音库中对应的语音单元的平均段长的比值。然后,极差计算单元2042计算所有语音单元的语速中最大值与最小值的差值,作为该识别结果候选的语音单元语速差异值。In this embodiment, in the speech unit speech rate
然后,在综合得分计算模块205中,根据每个识别结果候选的语音单元语速差异值和声学得分,计算该识别结果候选的综合得分。在本实施例中,首先,倒数计算单元2051计算该识别结果候选的语音单元语速差异值的倒数值,然后,加权单元2052根据预先确定的权重系数对所计算的倒数值进行加权,最后,求和单元2053将加权后的倒数值与声学得分相加,以作为该识别结果候选的综合得分。Then, in the comprehensive
可选地,在计算识别结果候选的综合得分时,还可以用相反数代替倒数值,即,在综合得分计算模块205中,首先相反数计算单元计算该识别结果候选的语音单元语速差异值的相反数,接着,加权单元根据预先确定的权重系数对所计算的相反数进行加权,然后求和单元将加权后的相反数与声学得分相加,以作为该识别结果候选的综合得分。Optionally, when calculating the comprehensive score of the recognition result candidate, the inverse number can also be used instead of the reciprocal value, that is, in the comprehensive
另外,可选地,综合得分计算模块205也可以包括:倒数计算单元,其计算该识别结果候选的语音单元语速差异值的倒数值;加权单元,其根据预先确定的权重系数对所计算的倒数值进行加权;以及乘积计算单元,其将加权后的倒数值与声学得分相乘,以作为该识别结果候选的综合得分。In addition, optionally, the comprehensive
在上述的综合得分计算模块205中,权重系数可以根据不同的语音识别任务进行调整。In the aforementioned comprehensive
最后,所有的识别结果候选及其综合得分都被提供给选择模块206,由选择模块206根据综合得分,从多个识别结果候选中选择综合得分最高的识别结果候选,作为语音的最终识别结果。Finally, all the recognition result candidates and their comprehensive scores are provided to the
图3示出了根据本发明的第二个实施例的基于语音单元语速的差异的语音识别系统300的示意性方框图,其中,与前面实施例相同的部分使用相同的附图标记,并适当省略其说明。下面结合附图,对本实施例进行详细描述。Fig. 3 shows a schematic block diagram of a
本实施例的语音识别系统300的结构与图2所示的语音识别系统200的基本相同,区别在于:语音单元语速差异值计算模块304的结构不同。The structure of the
在本实施例的语音单元语速差异值计算模块304中,首先,语速计算单元3041对于每个识别结果候选中的每一个语音单元,计算该语音单元的语速。然后,由方差计算单元3042计算每个识别结果候选的所有语音单元的语速的方差,以作为该识别结果候选的语音单元语速差异值。In the speech unit speech rate
同样,图4所示出的根据本发明的第三个实施例的基于语音单元语速的差异的语音识别系统400与图2和图3所示的语音识别系统200、300的区别也在于:语音单元语速差异值计算模块404的结构不同。Similarly, the difference between the
在本实施例的语音单元语速差异值计算模块404中,首先,语速计算单元4041对于每个识别结果候选中的每一个语音单元,计算该语音单元的语速。然后,标准差计算单元4042计算每个识别结果候选的所有语音单元的语速的标准差,作为该识别结果候选的语音单元语速差异值。In the speech unit speech rate
同样,图5所示出的根据本发明的第四个实施例的基于语音单元语速的差异的语音识别系统500与图2、图3和图4所示的语音识别系统200、300、400的区别也在于:语音单元语速差异值计算模块504的结构不同。Similarly, the
在本实施例的语音单元语速差异值计算模块504中,首先,语速计算单元5041对于每个识别结果候选中的每一个语音单元,计算该语音单元的语速。然后,标准差计算单元5042和平均值计算单元5043分别计算每个识别结果候选的所有语音单元的语速的标准差和平均值,再由比值计算单元5044计算上述标准差与平均值的比值,作为该识别结果候选的语音单元语速差异值。In the speech unit speech rate
应当指出,上述实施例的基于语音单元语速的差异的语音识别系统200、300、400和500及其各个组成部分可以用专用的电路或芯片构成,也可以通过计算机(处理器)执行相应的程序来实现。并且,上述实施例的基于语音单元语速的差异的语音识别系统在操作上可以实现图1所示的基于语音单元语速的差异的语音识别方法。It should be pointed out that the
以上虽然通过一些示例性的实施例详细描述了本发明的各个实施例的基于语音单元语速的差异的语音识别方法及语音识别系统,但是以上这些实施例并不是穷举的,本领域技术人员可以在本发明的精神和范围内实现各种变化和修改。因此,本发明并不限于这些实施例,本发明的范围仅由所附的权利要求限定。Although the speech recognition method and the speech recognition system based on the difference in speech rate of speech units of various embodiments of the present invention have been described in detail through some exemplary embodiments above, these above embodiments are not exhaustive, and those skilled in the art Various changes and modifications can be made within the spirit and scope of the invention. Therefore, the present invention is not limited to these embodiments, and the scope of the present invention is defined only by the appended claims.
Claims (10)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN2009101728759ACN102013253B (en) | 2009-09-07 | 2009-09-07 | Speech recognition method based on speed difference of voice unit and system thereof |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN2009101728759ACN102013253B (en) | 2009-09-07 | 2009-09-07 | Speech recognition method based on speed difference of voice unit and system thereof |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN102013253Atrue CN102013253A (en) | 2011-04-13 |
| CN102013253B CN102013253B (en) | 2012-06-06 |
Family
ID=43843398
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN2009101728759AExpired - Fee RelatedCN102013253B (en) | 2009-09-07 | 2009-09-07 | Speech recognition method based on speed difference of voice unit and system thereof |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN102013253B (en) |
Cited By (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103137127A (en)* | 2011-11-30 | 2013-06-05 | 北京德信互动网络技术有限公司 | Intelligent electronic device based on voice control and voice control method |
| CN103137125A (en)* | 2011-11-30 | 2013-06-05 | 北京德信互动网络技术有限公司 | Intelligent electronic device based on voice control and voice control method |
| CN103137126A (en)* | 2011-11-30 | 2013-06-05 | 北京德信互动网络技术有限公司 | Intelligent electronic device based on voice control and voice control method |
| CN104021786A (en)* | 2014-05-15 | 2014-09-03 | 北京中科汇联信息技术有限公司 | Speech recognition method and speech recognition device |
| CN104424290A (en)* | 2013-09-02 | 2015-03-18 | 佳能株式会社 | Voice based question-answering system and method for interactive voice system |
| CN104751847A (en)* | 2015-03-31 | 2015-07-01 | 刘畅 | Data acquisition method and system based on overprint recognition |
| CN104823235A (en)* | 2013-11-29 | 2015-08-05 | 三菱电机株式会社 | Speech recognition device |
| CN105989839A (en)* | 2015-06-03 | 2016-10-05 | 乐视致新电子科技(天津)有限公司 | Speech recognition method and speech recognition device |
| WO2018014537A1 (en)* | 2016-07-22 | 2018-01-25 | 百度在线网络技术(北京)有限公司 | Voice recognition method and apparatus |
| CN108428446A (en)* | 2018-03-06 | 2018-08-21 | 北京百度网讯科技有限公司 | Audio recognition method and device |
| CN109065051A (en)* | 2018-09-30 | 2018-12-21 | 珠海格力电器股份有限公司 | Voice recognition processing method and device |
| CN109102810A (en)* | 2017-06-21 | 2018-12-28 | 北京搜狗科技发展有限公司 | Method for recognizing sound-groove and device |
| WO2021134546A1 (en)* | 2019-12-31 | 2021-07-08 | 李庆远 | Input method for increasing speech recognition rate |
| WO2021134549A1 (en)* | 2019-12-31 | 2021-07-08 | 李庆远 | Human merging and training of multiple artificial intelligence outputs |
| CN113782014A (en)* | 2021-09-26 | 2021-12-10 | 联想(北京)有限公司 | Voice recognition method and device |
| CN115482822A (en)* | 2021-05-31 | 2022-12-16 | 株式会社东芝 | Speech recognition device, method and program |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| TWI627626B (en)* | 2017-04-27 | 2018-06-21 | 醫療財團法人徐元智先生醫藥基金會亞東紀念醫院 | Voice rehabilitation and therapy system and method thereof |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN1221937C (en)* | 2002-12-31 | 2005-10-05 | 北京天朗语音科技有限公司 | Voice identification system of voice speed adaption |
| CN1835076B (en)* | 2006-04-07 | 2010-05-12 | 安徽中科大讯飞信息科技有限公司 | Speech evaluating method of integrally operating speech identification, phonetics knowledge and Chinese dialect analysis |
- 2009
- 2009-09-07CNCN2009101728759Apatent/CN102013253B/ennot_activeExpired - Fee Related
Cited By (23)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103137125A (en)* | 2011-11-30 | 2013-06-05 | 北京德信互动网络技术有限公司 | Intelligent electronic device based on voice control and voice control method |
| CN103137126A (en)* | 2011-11-30 | 2013-06-05 | 北京德信互动网络技术有限公司 | Intelligent electronic device based on voice control and voice control method |
| CN103137127A (en)* | 2011-11-30 | 2013-06-05 | 北京德信互动网络技术有限公司 | Intelligent electronic device based on voice control and voice control method |
| CN104424290A (en)* | 2013-09-02 | 2015-03-18 | 佳能株式会社 | Voice based question-answering system and method for interactive voice system |
| CN104823235A (en)* | 2013-11-29 | 2015-08-05 | 三菱电机株式会社 | Speech recognition device |
| CN104823235B (en)* | 2013-11-29 | 2017-07-14 | 三菱电机株式会社 | Voice recognition device |
| CN104021786A (en)* | 2014-05-15 | 2014-09-03 | 北京中科汇联信息技术有限公司 | Speech recognition method and speech recognition device |
| CN104021786B (en)* | 2014-05-15 | 2017-05-24 | 北京中科汇联信息技术有限公司 | Speech recognition method and speech recognition device |
| CN104751847A (en)* | 2015-03-31 | 2015-07-01 | 刘畅 | Data acquisition method and system based on overprint recognition |
| CN105989839B (en)* | 2015-06-03 | 2019-12-13 | 乐融致新电子科技(天津)有限公司 | Speech recognition method and device |
| CN105989839A (en)* | 2015-06-03 | 2016-10-05 | 乐视致新电子科技(天津)有限公司 | Speech recognition method and speech recognition device |
| WO2018014537A1 (en)* | 2016-07-22 | 2018-01-25 | 百度在线网络技术(北京)有限公司 | Voice recognition method and apparatus |
| CN109102810A (en)* | 2017-06-21 | 2018-12-28 | 北京搜狗科技发展有限公司 | Method for recognizing sound-groove and device |
| CN109102810B (en)* | 2017-06-21 | 2021-10-15 | 北京搜狗科技发展有限公司 | Voiceprint recognition method and device |
| CN108428446A (en)* | 2018-03-06 | 2018-08-21 | 北京百度网讯科技有限公司 | Audio recognition method and device |
| US10978047B2 (en) | 2018-03-06 | 2021-04-13 | Beijing Baidu Netcom Science And Technology Co., Ltd. | Method and apparatus for recognizing speech |
| CN109065051A (en)* | 2018-09-30 | 2018-12-21 | 珠海格力电器股份有限公司 | Voice recognition processing method and device |
| CN109065051B (en)* | 2018-09-30 | 2021-04-09 | 珠海格力电器股份有限公司 | Voice recognition processing method and device |
| WO2021134546A1 (en)* | 2019-12-31 | 2021-07-08 | 李庆远 | Input method for increasing speech recognition rate |
| WO2021134549A1 (en)* | 2019-12-31 | 2021-07-08 | 李庆远 | Human merging and training of multiple artificial intelligence outputs |
| CN115482822A (en)* | 2021-05-31 | 2022-12-16 | 株式会社东芝 | Speech recognition device, method and program |
| CN113782014A (en)* | 2021-09-26 | 2021-12-10 | 联想(北京)有限公司 | Voice recognition method and device |
| CN113782014B (en)* | 2021-09-26 | 2024-03-26 | 联想(北京)有限公司 | Speech recognition method and device |
Also Published As
| Publication number | Publication date |
|---|---|
| CN102013253B (en) | 2012-06-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN102013253B (en) | Speech recognition method based on speed difference of voice unit and system thereof | |
| Bhardwaj et al. | Effect of pitch enhancement in Punjabi children's speech recognition system under disparate acoustic conditions | |
| Hu et al. | A new DNN-based high quality pronunciation evaluation for computer-aided language learning (CALL). | |
| CN101030369B (en) | Embedded Speech Recognition Method Based on Subword Hidden Markov Model | |
| Chang et al. | Large vocabulary Mandarin speech recognition with different approaches in modeling tones. | |
| Shahnawazuddin et al. | Pitch-Adaptive Front-End Features for Robust Children's ASR. | |
| Kumar et al. | A comprehensive view of automatic speech recognition system-a systematic literature review | |
| Bhatt et al. | Continuous speech recognition technologies—a review | |
| Mistry et al. | Overview: Speech recognition technology, mel-frequency cepstral coefficients (mfcc), artificial neural network (ann) | |
| CN114627896B (en) | Voice evaluation method, device, equipment and storage medium | |
| Sinha et al. | Continuous density hidden markov model for context dependent Hindi speech recognition | |
| Sinha et al. | Empirical analysis of linguistic and paralinguistic information for automatic dialect classification | |
| Hachkar et al. | A comparison of DHMM and DTW for isolated digits recognition system of Arabic language | |
| JP3660512B2 (en) | Voice recognition method, apparatus and program recording medium | |
| Yousfi et al. | Holy Qur'an speech recognition system Imaalah checking rule for warsh recitation | |
| Zolnay et al. | Using multiple acoustic feature sets for speech recognition | |
| Furui | Selected topics from 40 years of research on speech and speaker recognition. | |
| Sawada et al. | The NITech text-to-speech system for the blizzard challenge 2016 | |
| Singhal et al. | Automatic speech recognition for connected words using DTW/HMM for English/Hindi languages | |
| Fu et al. | A survey on Chinese speech recognition | |
| Sinha et al. | Continuous density hidden markov model for hindi speech recognition | |
| Rebai et al. | Linto platform: A smart open voice assistant for business environments | |
| Gerosa et al. | Acoustic analysis and automatic recognition of spontaneous children’s speech | |
| Tripathi et al. | Robust vowel region detection method for multimode speech | |
| Qian et al. | A Multi-Space Distribution (MSD) and two-stream tone modeling approach to Mandarin speech recognition |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C14 | Grant of patent or utility model | ||
| GR01 | Patent grant | ||
| CF01 | Termination of patent right due to non-payment of annual fee | ||
| CF01 | Termination of patent right due to non-payment of annual fee | Granted publication date:20120606 Termination date:20160907 |