CN101916184B - Method for updating branch target address cache in microprocessor and microprocessor thereof - Google Patents
Method for updating branch target address cache in microprocessor and microprocessor thereofDownload PDFInfo
- Publication number
- CN101916184B CN101916184BCN201010260377.2ACN201010260377ACN101916184BCN 101916184 BCN101916184 BCN 101916184BCN 201010260377 ACN201010260377 ACN 201010260377ACN 101916184 BCN101916184 BCN 101916184B
- Authority
- CN
- China
- Prior art keywords
- mentioned
- branch
- branch instruction
- instruction
- target address
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000034methodMethods0.000titleclaimsabstractdescription32
- 238000000605extractionMethods0.000claimsabstractdescription8
- 239000000284extractSubstances0.000claims2
- 238000010586diagramMethods0.000description7
- 239000004065semiconductorSubstances0.000description3
- 238000012986modificationMethods0.000description2
- 230000004048modificationEffects0.000description2
- 230000006870functionEffects0.000description1
- 230000003287optical effectEffects0.000description1
- 238000004088simulationMethods0.000description1
Images




Landscapes
- Advance Control (AREA)
- Memory System Of A Hierarchy Structure (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明是关于微处理器,特别是关于微处理器中的分支目标地址快取(branch target address caches)。The present invention relates to microprocessors, and more particularly to branch target address caches in microprocessors.
背景技术Background technique
传统的分支目标地址快取(branch target address cache;BTAC)大约只能将两个分支指令储存至指令数据的一给定对齐(aligned)的16字节片段中。此设计选择是为了缩短耗时并减少功率消耗与晶粒尺寸。允许储存三个或四个分支指令要比储存两个分支指令复杂的多。虽然从指令快取中提取三个或多个分支指令(其初始字节皆在相同的16字节中)的情况并不多见,但此情况确实会发生并且会对效能产生负面影响。A conventional branch target address cache (BTAC) can only store approximately two branch instructions into a given aligned 16-byte segment of instruction data. This design choice was made to reduce time consumption and reduce power consumption and die size. Allowing storage of three or four branch instructions is more complex than storing two branch instructions. While it is not uncommon for three or more branch instructions (whose initial bytes are all in the same 16 bytes) to be fetched from the instruction cache, it does happen and can have a negative impact on performance.
发明内容Contents of the invention
本发明提供一种微处理器,包括一分支目标地址快取、一执行单元以及一更新逻辑电路。分支目标地址快取中的各个项目用以储存至多N个分支指令的多个分支预测信息。执行单元用以执行事先从一指令快取的一提取总量中提取的一分支指令。更新逻辑电路耦接至分支目标地址快取与执行单元,更新逻辑电路用以判断分支目标地址快取是否已经储存位于提取总量中的N个分支指令的分支预测信息,其中N至少等于二;若分支目标地址快取尚未储存位于提取总量中的N个分支指令的分支预测信息,则使用分支指令的分支信息来更新分支目标地址快取;若分支目标地址快取已经储存位于提取总量中的N个分支指令的分支预测信息,则判断分支指令的替换优先权是否高于分支目标地址快取中的N个分支指令的替换优先权;以及若分支指令的替换优先权高于分支目标地址快取中的N个分支指令的替换优先权,则使用分支指令的分支信息来更新分支目标地址快取。The invention provides a microprocessor, which includes a branch target address cache, an execution unit and an update logic circuit. Each entry in the branch target address cache is used to store a plurality of branch prediction information for at most N branch instructions. The execution unit is used for executing a branch instruction previously fetched from a fetch volume of an instruction cache. The update logic circuit is coupled to the branch target address cache and the execution unit, and the update logic circuit is used for judging whether the branch target address cache has stored branch prediction information of N branch instructions in the fetched total, wherein N is at least equal to two; If the branch target address cache has not yet stored the branch prediction information of the N branch instructions in the fetch total, then use the branch information of the branch instruction to update the branch target address cache; if the branch target address cache has already stored in the fetch total The branch prediction information of the N branch instructions in the branch instruction, then judge whether the replacement priority of the branch instruction is higher than the replacement priority of the N branch instructions in the branch target address cache; and if the replacement priority of the branch instruction is higher than the branch target For the replacement priorities of the N branch instructions in the address cache, use the branch information of the branch instructions to update the branch target address cache.
本发明提供一种更新微处理器中的一分支目标地址快取(BTAC)的方法,其中分支目标地址快取中的各个项目用以储存来自一指令快取的一提取总量中至多N个分支指令的多个分支预测信息。上述方法包括执行事先从指令快取的提取总量中提取的一分支指令。判断分支目标地址快取是否已经储存位于提取总量中的N个分支指令的分支预测信息,其中N至少等于二。若分支目标地址快取尚未储存位于提取总量中的N个分支指令的分支预测信息,则使用分支指令的分支信息来更新分支目标地址快取。若分支目标地址快取已经储存位于提取总量中的N个分支指令的分支预测信息,则判断分支指令的替换优先权是否高于分支目标地址快取中的N个分支指令的替换优先权。若分支指令的替换优先权高于分支目标地址快取中的N个分支指令的替换优先权,则使用分支指令的分支信息来更新分支目标地址快取。The present invention provides a method of updating a branch target address cache (BTAC) in a microprocessor, wherein each entry in the branch target address cache is used to store at most N of a total number of fetches from an instruction cache Multiple branch prediction information for branch instructions. The method described above includes executing a branch instruction previously fetched from the fetch volume of the instruction cache. It is judged whether the branch target address cache has stored the branch prediction information of N branch instructions in the fetched total, wherein N is at least equal to two. If the branch target address cache has not stored the branch prediction information of the N branch instructions in the fetch total, the branch target address cache is updated with the branch information of the branch instructions. If the branch target address cache has stored the branch prediction information of the N branch instructions in the fetched total, it is determined whether the replacement priority of the branch instruction is higher than the replacement priority of the N branch instructions in the branch target address cache. If the replacement priority of the branch instruction is higher than the replacement priorities of the N branch instructions in the branch target address cache, then the branch information of the branch instruction is used to update the branch target address cache.
为让本发明的上述和其它目的、特征、和优点能更明显易懂,下文特举出较佳实施例,并配合所附图式,作详细说明如下。In order to make the above and other objects, features, and advantages of the present invention more comprehensible, preferred embodiments are listed below and described in detail in conjunction with the accompanying drawings.
附图说明Description of drawings
图1为本发明实施例的微处理器的方块图;Fig. 1 is the block diagram of the microprocessor of the embodiment of the present invention;
图2为本发明实施例的指令快取的方块图;Fig. 2 is the block diagram of the command cache of the embodiment of the present invention;
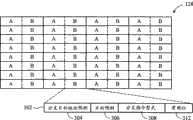
图3为图1中的分支目标地址快取的配置方块图;Fig. 3 is a configuration block diagram of the branch target address cache in Fig. 1;
图4为图1中的更新逻辑电路所使用的分支指令型式优先权的结构图;FIG. 4 is a structural diagram of the branch instruction type priority used by the update logic circuit in FIG. 1;
图5A和5B为图1中的微处理器的操作流程图。5A and 5B are flowcharts of the operation of the microprocessor in FIG. 1 .
[主要元件标号说明][Description of main component labels]
100~微处理器; 102~指令快取;100~microprocessor; 102~instruction cache;
104~提取单元; 106~指令解码器;104~extraction unit; 106~instruction decoder;
108~指令队列; 112~加法器;108~instruction queue; 112~adder;
116~寄存器别名表; 118~保留站;116~register alias table; 118~reservation station;
122~执行单元; 124~引退单元;122~execution unit; 124~retirement unit;
126~第二分支历史表; 128~分支目标地址快取;126~second branch history table; 128~branch target address cache;
132~返回堆栈; 134~控制逻辑电路;132~return stack; 134~control logic circuit;
136~更新逻辑电路; 138~虚拟随机产生器;136~update logic circuit; 138~virtual random generator;
142~提取地址; 144~下一个序列提取地址;142~extraction address; 144~next sequence extraction address;
146~预测分支目标地址;148~预测返回地址;146~predicted branch target address; 148~predicted return address;
152~正确目标地址; 154~分支目标地址;152~correct target address; 154~branch target address;
162~整体分支样式; 164~第一分支历史表;162 ~ overall branch style; 164 ~ first branch history table;
166~虚拟随机指标; 168~通用寄存器;166~virtual random index; 168~general registers;
202~快取线; 302~项目;202~cache line; 302~item;
304~分支目标地址预测;306~方向预测;304~branch target address prediction; 306~direction prediction;
308~分支指令型式; 312~有效位。308~branch instruction type; 312~valid bit.
具体实施方式Detailed ways
为了减少上述问题所造成的效能影响,以下实施例将提供一种替换策略(replacement policy),适用于从指令快取中提取的快取线的相同部分或总量(例如16字节)中具有额外分支指令(例如第三分支指令)的情况。此替换策略为一种以相关分支指令的型式为基础的优先机制(priority scheme),并且具有取代优先机制的虚拟随机措施(pseudo-random provision)用以适应不同的极端状况(corner cases)。In order to reduce the performance impact caused by the above problems, the following embodiments will provide a replacement policy (replacement policy), which is suitable for the same part or the total amount (for example, 16 bytes) of the cache lines extracted from the instruction cache. The case of an additional branch instruction (such as a third branch instruction). The replacement strategy is a priority scheme based on the type of related branch instructions, and has a pseudo-random provision to adapt to different corner cases.
图1为本发明实施例的微处理器100的方块图。微处理器100包括一指令快取102以及一提取单元104,提取单元104提供的提取地址142用以存取指令快取102。提取单元104通过选择不同来源所提供的多个地址中的一者来输出提取地址142,上述来源包括:提取地址142本身、用以递增提取地址142的加法器112所提供的下一个序列提取地址144、分支目标地址快取(BTAC)128提供的预测分支目标地址146、返回堆栈(return stack)132提供的预测返回地址148、执行单元122提供的正确目标地址152,以及指令解码器106提供的分支目标地址154。控制逻辑电路134用以根据来自第一分支历史表164与第二分支历史表126的方向预测以及分支目标地址快取128的信息,控制提取单元104选择多个输入中的一者。举例而言,分支目标地址快取128的信息包括方向预测与分支指令预测的型式(例如呼叫/返回指令、间接分支(indirect branch)指令、条件相对(conditional relative)指令、非条件相对(unconditional relative)指令)。FIG. 1 is a block diagram of a
指令快取102根据提取地址142提供指令字节的快取线202至指令解码器106。指令快取102在每个时钟周期提供部分快取线202而不是整个快取线202。如图2所示,在本实施例中各个快取线202为64字节,并且指令快取102在每个时钟周期提供部分快取线202(16字节)至指令解码器106或指令缓冲器(图未显示)。指令解码器106用以将指令字节解码。在本实施例中,指令解码器106将x86架构指令转译成微指令(microinstructions)并提供至指令队列(instruction queue)108。当指令解码器106将一分支指令解码时(该分支指令的目标地址是以相对于分支指令的地址的偏移量来计算),指令解码器106计算分支目标地址154并将分支目标地址154提供至提取单元104。此外,指令解码器106将分支指令的地址提供至第二分支历史表(branchhistory table)126。第二分支历史表126储存关于先前执行的分支指令的方向历史信息。若分支指令地址命中于(hits in)第二分支历史表126,则分支指令地址预测分支指令会被取用(taken)并将预测结果传送至控制逻辑电路134。控制逻辑电路134使用上述预测来控制提取单元104。The
指令队列108将程序顺序中的指令提供至寄存器别名表(register alias table;RAT)116,寄存器别名表116用以维护并产生各个指令的相依性信息(dependency information)。寄存器别名表116将指令配送(dispatch)至保留站(reservation station)118,保留站118用以将指令(可能是程序顺序外的指令)发送至执行单元122。执行单元122用以执行分支指令。执行单元122也显示不同的分支预测器(分支目标地址快取128、返回堆栈132、第二分支历史表126以及第一分支历史表164)是否已正确地预测分支指令。执行单元122也根据分支指令的执行,使用历史信息来更新上述不同的分支预测器。执行单元122也将正确目标地址152提供至提取单元104。执行单元122也更新微处理器100所储存的整体分支样式(globalbranch pattern)162,当提取地址142出现于第一分支历史表164时,第一分支历史表164会使用整体分支样式162来执行方向预测。在执行单元122执行指令之后,引退单元(retire unit)124用以引退由重排序缓冲器(图未显示)所储存的程序顺序中的指令。The
请参考图3,图3为图1中的分支目标地址快取128的配置方块图。分支目标地址快取128用以储存关于先前执行的分支指令的信息,并且在后续执行期间使用此信息来预测这些分支指令的目标地址、方向以及型式。如图3所示,分支目标地址快取128中的各个项目(entry)302包括一有效位312、一分支目标地址预测304、一方向预测306(即分支指令是否会被取用(taken)或不取用(not taken))以及一分支指令型式308。在一实施例中,分支指令型式308用以指定分支指令是否为一呼叫/返回指令、间接分支指令、条件相对分支指令或非条件相对分支指令。微处理器100中的更新逻辑电路136的优点在于使用分支指令型式308用以明智地替换分支目标地址快取128中的项目302,细节将在以下做进一步说明。如图3所示,分支目标地址快取128可在指令快取102中的快取线202的各个部分或提取总量(fetchquantum)(例如16字节)中储存两个项目302(标记为“A”与“B”)。换言之,分支目标地址快取128可储存部分快取线202中的至多两个分支指令的预测信息。如上所述,在部分快取线202中具有超过两个分支指令的情况下,此限制会降低分支预测的效能。然而,更新逻辑电路136使用一明智的替换策略用以降低效能影响,细节将在以下做进一步说明。在一实施例中,分支目标地址快取128也包括各个A/B项目对(entry pairs)的一最近最少使用(least-recently-used;LRU)位(图未显示),用以显示最近最少使用A侧还是B侧以便决定是否要替换A项目302或B项目302。在本实施例中,虽然分支目标地址快取128储存每个部分快取线202(16字节)中的两个分支指令的预测信息,但可依据设计需要来改变部分快取线202的大小以及每个部分快取线202中的分支指令的数目。Please refer to FIG. 3 , which is a configuration block diagram of the branch
参考回图1,当提取地址142出现于分支目标地址快取128时,分支目标地址快取128将信息提供至提取单元104、指令解码器106、返回堆栈132以及控制逻辑电路134。仔细而言,分支目标地址快取128将作为预测分支目标地址146的分支目标地址预测304提供至提取单元104,并且将方向预测306与分支指令型式308提供至控制逻辑电路134。此外,分支指令型式308沿着具有分支指令的管线传递,并且执行单元122随后将分支指令型式308提供至更新逻辑电路136以便执行分支目标地址快取128的替换策略,细节将在以下做进一步说明。Referring back to FIG. 1 , branch
返回堆栈132用以储存由呼叫指令产生的返回地址。当分支目标地址快取128显示提取地址142所指定的部分快取线202包含一呼叫指令时,返回堆栈132将具有一返回地址。当分支目标地址快取128显示提取地址142所指定的部分快取线202包含一返回指令时,返回堆栈132将预测返回地址148提供至提取单元104。The
微处理器100也包括一虚拟随机产生器138用以提供一虚拟随机指针166至更新逻辑电路136。更新逻辑电路136的优点在于使用虚拟随机指针166来执行分支目标地址快取128的替换策略,用以改善以严格优先权为基础(strictly priority-based)的替换策略,细节将在以下做进一步说明。在一实施例中,虚拟随机产生器138为一15位的线性反馈移位寄存器(linearfeedback shift register;LFSR),用以在虚拟随机顺序中的所有215个状态(除了全为0状态)内循环,并且在虚拟随机产生器138产生相同的重复产生样式(generation pattern repeats)之前,时钟周期数量为32767个时钟周期。当有需要时,可从15位中取样5位来产生虚拟随机指针166。因此,虚拟随机指标166大约每32个时钟周期平均为真值(true)一次。The
请参考图4,图4为图1中的更新逻辑电路136所使用的分支指令型式优先权的结构图。如图4所示,间接型式的分支指令具有最高优先权(表示最后才被替换),呼叫/返回型式的分支指令具有第二高优先权,条件相对型式的分支指令具有第三高优先权,而非条件相对型式的分支指令具有最低优先权(表示可最先被替换)。Please refer to FIG. 4 , which is a structural diagram of the branch instruction type priorities used by the updating
相对型式的分支指令的目标地址是以相对于分支指令的地址的总偏移量来计算,并且偏移量为指令本身中的字段。因此,指令解码器106可正确地计算相对型式的分支指令(包括条件相对分支指令以及非条件相对分支指令)的分支目标地址154。此外,由于已经知道非条件相对分支指令的方向,因此指令解码器106可准确地解析(resolve)非条件相对分支指令。因此,分支目标地址快取128误预测(mispredict)一非条件相对分支指令所产生的代价(penalty),相对小于误预测其它型式的分支指令所产生的代价。在一实施例中,误预测代价在最糟的情况下大约为七个时钟周期,但根据指令队列108的使用率(fullness),误预测代价也会少于七个时钟周期。这就是为什么非条件相对分支指令具有最低优先权(表示可最先被替换)。在一实施例中,分支目标地址快取128的项目302包括一旗标(flag)用以显示分支指令是否为一非条件相对分支指令,因此若部分快取线202中具有超过两个分支指令,则更新逻辑电路136替换分支目标地址快取128中的非条件相对分支指令,并且更新逻辑电路136通常不会将其它型式的分支指令替换为一非条件相对分支指令。The target address of a relative type branch instruction is calculated as a total offset from the address of the branch instruction, and the offset is a field in the instruction itself. Therefore, the
与相对型式的分支指令相比,微处理器100的通用寄存器168中的某些操作数(operand)或存储器位置中的某些操作数可用来计算一间接型式的分支指令目标地址。因此,指令解码器106不会预测间接分支指令,并且是由执行单元122来计算间接分支指令目标地址。因此,分支目标地址快取128误预测一间接分支指令所产生的代价,通常会大于误预测其它型式的分支指令所产生的代价。这就是为什么间接分支指令具有最高优先权(表示最后才被替换)。In contrast to a relative branch instruction, certain operands in the
此外,替换分支目标地址快取128中的呼叫/返回指令(返回堆栈132中具有该呼叫/返回指令的一有效返回地址),会导致返回堆栈132未对齐(misaligned)使得返回堆栈132很有可能在之后会误预测,因而产生负面效能影响。这就是为什么呼叫/返回指令具有第二高优先权。In addition, replacing the call/return instruction in the branch target address cache 128 (with a valid return address for the call/return instruction in the return stack 132), would cause the
最后,虽然通过指令解码器106(目标地址)、第二分支历史表126(方向)以及分支目标地址快取128来预测条件相对分支指令,但由于在本实施例中的分支目标地址快取128的大小大于第二分支历史表126,因此分支目标地址快取128的方向预测会比较准确。此外,从分支目标地址快取128中移除条件相对分支指令会导致整体分支样式162产生误差。基于上述理由,条件相对分支指令是高于非条件相对分支指令因而具有第三高优先权。Finally, although the conditional relative branch instruction is predicted by the instruction decoder 106 (target address), the second branch history table 126 (direction), and the branch
请参考图5,图5为图1中的微处理器100的操作流程图。流程从步骤502开始。Please refer to FIG. 5 , which is a flow chart illustrating the operation of the
在步骤502中,执行单元122执行一全新的分支指令并提供相关信息至更新逻辑电路136。流程前进至步骤504。In step 502 , the
在步骤504中,更新逻辑电路136使用上述分支指令的地址用以在分支目标地址快取128中建立索引。流程前进至判断步骤506。In step 504 , the
在判断步骤506中,更新逻辑电路136检查A项目302与B项目302的有效位312,用以判断快取线202的相同部分(same portion)中是否具有超过两个分支指令。若有,流程前进至步骤512;若没有,流程前进至步骤508。In the
在步骤508中,更新逻辑电路136使用与上述分支指令相关的执行信息来更新分支目标地址快取128。换言之,更新逻辑电路136写入无效的A项目302或B项目302。流程结束于步骤508。In
在步骤512中,更新逻辑电路136检查执行单元122所提供的上述分支指令的分支指令型式308,以及A项目302与B项目302中的两个有效分支指令(根据不同实施例,上述两个有效分支指令是来自于分支目标地址快取128或执行单元122)的分支指令型式308。流程前进至判断步骤514。In
在判断步骤514中,更新逻辑电路136判断上述分支指令的分支指令型式308是否高于A项目302与B项目302中的两个有效分支指令的分支指令型式308。若是,流程前进至步骤516;若否,流程前进至步骤518。In the
在步骤516中,更新逻辑电路136使用与上述分支指令相关的执行信息来更新分支目标地址快取128。换言之,更新逻辑电路136替换A项目302与B项目302中的两个有效分支指令中的一者。在一实施例中,更新逻辑电路136根据LRU位选择索引集合(indexed set)与选择路径(selected way)的A项目302或B项目302。流程结束于步骤516。In
参考步骤518,更新逻辑电路136检查虚拟随机指针166。流程前进至判断步骤522。Referring to step 518 , the
在判断步骤522中,更新逻辑电路136判断上述分支指令是否为一非条件相对型式的分支指令。若是,流程前进至判断步骤524;若否,流程前进至判断步骤532。In the
在判断步骤524中,更新逻辑电路136检查虚拟随机指针166是否为真值。若是,流程前进至步骤526;若否,流程前进至步骤528。In
在步骤526中,更新逻辑电路136使用新执行的分支指令的分支信息来更新分支目标地址快取128。流程结束于步骤526。In
在步骤528中,更新逻辑电路136不使用新执行的分支指令的分支信息来更新分支目标地址快取128。流程结束于步骤528。In
在判断步骤532中,更新逻辑电路136判断三个分支指令(即新执行的分支指令以及A项目302与B项目302中的两个分支指令)是否皆为条件相对分支指令。若是,流程前进至判断步骤534;若否,流程前进至步骤528。In the
在判断步骤534中,更新逻辑电路136判断指令解码器106或第二分支历史表126是否正确地预测新执行的分支指令。若是,流程前进至判断步骤524;若否,流程前进至步骤526。In
本发明人观察到在部分快取线202中具有三个分支指令的情况下,程序有时会按顺序执行其指令而造成重复执行这三个分支指令的情形,因此有可能会替换分支目标地址快取128中的另一个分支指令。然而,大部分的时间只会执行这三个分支指令中的两个(或一个)分支指令,这将影响上述步骤502~516中以严格优先权为基础的替换策略的效能。举例而言,假设程序具有一外循环与一内循环,其中外循环包括一条件相对分支指令(例如第一x86JCC指令),内循环包括一第二x86JCC指令与一非条件相对分支指令(例如x86JMP指令),并且内循环跟随在x86JCC指令之后,x86JMP指令跟随在第二x86JCC指令之后。在此情况下,通常希望分支目标地址快取128的A项目302与B项目302中包含内循环中的分支指令(第二x86JCC指令与x86JMP指令),而不是包含外循环中的分支指令(第一x86JCC指令)。然而,由于x86JCC指令是高于x86JMP指令,因此根据以严格优先权为基础的替换策略,分支目标地址快取128中的A项目302与B项目302会包含两个x86JCC指令,并且更新逻辑电路136不会将这两个x86JCC指令中的任一者替换为x86JMP指令,这种结果是不理想的。The inventor has observed that in the case of having three branch instructions in the partial cache line 202, the program sometimes executes its instructions sequentially to cause repeated execution of the three branch instructions, thus possibly replacing the branch target address cache. Another branch instruction in 128 is taken. However, only two (or one) of the three branch instructions are executed most of the time, which will affect the performance of the replacement strategy based on strict priority in the above steps 502-516. For example, suppose a program has an outer loop and an inner loop, wherein the outer loop includes a conditional relative branch instruction (such as a first x86JCC instruction), and the inner loop includes a second x86JCC instruction and an unconditional relative branch instruction (such as x86JMP instruction), and the inner loop follows the x86JCC instruction, and the x86JMP instruction follows the second x86JCC instruction. In this case, it is generally desirable that the
为了降低效能影响,虚拟随机产生器138提供虚拟随机指针166至更新逻辑电路136,相关细节请参考上述步骤518~528。值得注意的是,虚拟随机指针166随着微处理器100的时钟周期呈现规律性的变化,但由于大部分程序并不随着时钟周期规律地执行一给定的分支指令,因此虚拟随机指针166与分支指令的执行呈现随机性的变化。In order to reduce performance impact, the virtual
因此,假设虚拟随机指标166大约每32个时钟周期平均为真值(true)一次,步骤518~528所实现的替换策略会使得更新逻辑电路136将外循环中的第一x86JCC指令替换为内循环的第32个执行实例(execution instance)中的x86JMP指令,并且内循环中的x86JMP指令会储存在分支目标地址快取128中,直到外循环中的第一x86JCC指令再次被执行。Therefore, assuming that the
此外,若在一给定的部分快取线202中具有三个x86JCC指令,更新逻辑电路136会检查指令解码器106或第二分支历史表126是否正确地预测x86JCC指令,若有正确地预测x86JCC指令,则根据步骤532、534以及528,更新逻辑电路136通常不会替换其它两个x86JCC指令中的一者。由于在本实施例中,第二分支历史表126的大小与所使用的算法复杂度皆小于分支目标地址快取128与第一分支历史表164,因此必须将难以预测(hard-to-predict)的x86JCC指令储存在方向预测最准确的分支目标地址快取128中。然而,为了避免上述类似情况(较常查见(see)三个x86JCC指令中的两者,并且很少执行三个x86JCC指令中的一者),根据步骤532、534以及526,更新逻辑电路136会允许运作良好(well-behaved)的x86JCC指令(即内循环中被指令解码器106或第二分支历史表126所正确预测的x86JCC指令)继续执行(go ahead),并且替换其它x86JCC指令中的一者(通常位于内循环的第32个执行实例(execution instance)中)。Additionally, if there are three x86JCC instructions in a given partial cache line 202, the
本发明虽以各种实施例揭露如上,然其仅为范例参考而非用以限定本发明的范围,任何本领域技术人员,在不脱离本发明的精神和范围内,当可做些许的更动与润饰。举例而言,可使用软件来实现本发明所述的装置与方法的功能、构造、模块化、模拟、描述及/或测试。此目的可通过使用一般程序语言(例如C、C++)、硬件描述语言(包括Verilog或VHDL硬件描述语言等等)、或其它可用的程序来实现。该软件可被设置在任何计算机可用的媒体,例如半导体、磁盘、光盘(例如CD-ROM、DVD-ROM等等)中。本发明实施例中所述的装置与方法可被包括在一半导体智慧财产权核心(semiconductorintellectual property core),例如以硬件描述语言(HDL)实现的微处理器核心中,并被转换为硬件型态的集成电路产品。此外,本发明所描述的装置与方法可通过结合硬件与软件的方式来实现。因此,本发明不应该被本文中的任一实施例所限定,而当视所附的权利要求范围与其等效物所界定者为准。特别是,本发明是实现于一般用途计算机的微处理器装置中。最后,任何本领域技术人员,在不脱离本发明的精神和范围内,当可作些许更动与润饰,因此本发明的保护范围当视所附的权利要求范围所界定者为准。Although the present invention has been disclosed above with various embodiments, they are only exemplary references rather than limiting the scope of the present invention. Anyone skilled in the art may make some modifications without departing from the spirit and scope of the present invention. Move and retouch. For example, software can be used to realize the functions, configurations, modules, simulations, descriptions and/or tests of the devices and methods described in the present invention. This purpose can be achieved by using general programming languages (such as C, C++), hardware description languages (including Verilog or VHDL hardware description languages, etc.), or other available programs. The software can be provided on any computer usable medium such as semiconductor, magnetic disk, optical disk (eg CD-ROM, DVD-ROM, etc.). The device and method described in the embodiments of the present invention can be included in a semiconductor intellectual property core (semiconductor intellectual property core), such as a microprocessor core implemented in a hardware description language (HDL), and converted into a hardware type integrated circuit products. In addition, the devices and methods described in the present invention can be implemented by combining hardware and software. Accordingly, the invention should not be limited by any of the embodiments herein, but rather as defined by the scope of the appended claims and their equivalents. In particular, the invention is implemented in a microprocessor device of a general purpose computer. Finally, any person skilled in the art may make some changes and modifications without departing from the spirit and scope of the present invention. Therefore, the protection scope of the present invention should be defined by the scope of the appended claims.
Claims (14)
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US23792009P | 2009-08-28 | 2009-08-28 | |
| US61/237,920 | 2009-08-28 | ||
| US12/575,951 | 2009-10-08 | ||
| US12/575,951US8832418B2 (en) | 2009-08-28 | 2009-10-08 | Efficient branch target address cache entry replacement |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN101916184A CN101916184A (en) | 2010-12-15 |
| CN101916184Btrue CN101916184B (en) | 2014-02-12 |
Family
ID=43323702
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201010260377.2AActiveCN101916184B (en) | 2009-08-28 | 2010-08-20 | Method for updating branch target address cache in microprocessor and microprocessor thereof |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN101916184B (en) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104252334B (en)* | 2013-06-29 | 2017-07-07 | 华为技术有限公司 | Branch target address acquisition methods and device |
| US11086629B2 (en)* | 2018-11-09 | 2021-08-10 | Arm Limited | Misprediction of predicted taken branches in a data processing apparatus |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP1089169A2 (en)* | 1999-10-01 | 2001-04-04 | Hitachi, Ltd. | System and method for reducing latencies associated with branch instructions |
| CN1397876A (en)* | 2001-05-04 | 2003-02-19 | 智慧第一公司 | Appts. and method for replacing target address in imaginary branch target address high speed buffer storage |
| CN101187863A (en)* | 2006-11-17 | 2008-05-28 | 国际商业机器公司 | Data processing system, processor and method of data processing |
- 2010
- 2010-08-20CNCN201010260377.2Apatent/CN101916184B/enactiveActive
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP1089169A2 (en)* | 1999-10-01 | 2001-04-04 | Hitachi, Ltd. | System and method for reducing latencies associated with branch instructions |
| CN1397876A (en)* | 2001-05-04 | 2003-02-19 | 智慧第一公司 | Appts. and method for replacing target address in imaginary branch target address high speed buffer storage |
| CN101187863A (en)* | 2006-11-17 | 2008-05-28 | 国际商业机器公司 | Data processing system, processor and method of data processing |
Also Published As
| Publication number | Publication date |
|---|---|
| CN101916184A (en) | 2010-12-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US9367471B2 (en) | Fetch width predictor | |
| US7437537B2 (en) | Methods and apparatus for predicting unaligned memory access | |
| US8832418B2 (en) | Efficient branch target address cache entry replacement | |
| US9891923B2 (en) | Loop predictor-directed loop buffer | |
| CN112673346B (en) | Control access to the branch prediction unit for fetching sequence of groups | |
| JP2744890B2 (en) | Branch prediction data processing apparatus and operation method | |
| US11442727B2 (en) | Controlling prediction functional blocks used by a branch predictor in a processor | |
| US10664280B2 (en) | Fetch ahead branch target buffer | |
| US6874081B2 (en) | Selection of link and fall-through address using a bit in a branch address for the selection | |
| US20200081717A1 (en) | Branch prediction circuitry | |
| US10007524B2 (en) | Managing history information for branch prediction | |
| US20100306506A1 (en) | Microprocessor with selective out-of-order branch execution | |
| KR20230084140A (en) | Restoration of speculative history used to make speculative predictions for instructions processed by processors employing control independence techniques | |
| CN113448626B (en) | Speculative branch mode update method and microprocessor | |
| TWI858271B (en) | Microprocessor and branch prediction control method | |
| CN101916184B (en) | Method for updating branch target address cache in microprocessor and microprocessor thereof | |
| CN101840330B (en) | A microprocessor and its information storage method | |
| US20040059899A1 (en) | Effectively infinite branch prediction table mechanism | |
| US20250272104A1 (en) | Switching a predicted branch type following a misprediction of a number of loop iterations | |
| US7100024B2 (en) | Pipelined microprocessor, apparatus, and method for generating early status flags | |
| EP4081899A1 (en) | Controlling accesses to a branch prediction unit for sequences of fetch groups | |
| HK1112983A (en) | Unaligned memory access prediction |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C14 | Grant of patent or utility model | ||
| GR01 | Patent grant |