CN101894558A - Lost frame recovering method and equipment as well as speech enhancing method, equipment and system - Google Patents
Lost frame recovering method and equipment as well as speech enhancing method, equipment and systemDownload PDFInfo
- Publication number
- CN101894558A CN101894558ACN2010102448832ACN201010244883ACN101894558ACN 101894558 ACN101894558 ACN 101894558ACN 2010102448832 ACN2010102448832 ACN 2010102448832ACN 201010244883 ACN201010244883 ACN 201010244883ACN 101894558 ACN101894558 ACN 101894558A
- Authority
- CN
- China
- Prior art keywords
- frame
- lost
- frames
- type
- lost frame
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images
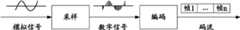











Landscapes
- Compression, Expansion, Code Conversion, And Decoders (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本发明涉及通信技术领域,尤其涉及一种丢帧恢复方法、设备以及一种语音增强方法、设备和系统。The present invention relates to the field of communication technology, in particular to a frame loss recovery method, equipment and a voice enhancement method, equipment and system.
背景技术Background technique
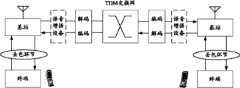
语音传输在通信领域有着广泛的应用,一个常见的语音传输系统如图1所示:原始语音数据(模拟信号)经过采样得到基于样点值的波形信号(数字信号),再经过编码后形成以帧为基本单元的码流,并通过相应的传输网络(如IP网、TFO网)进行传输。由于受各种网络环境因素的制约,会出现网络拥塞以及抖动等现象,导致帧丢失,从而对语音质量造成影响。Voice transmission has a wide range of applications in the field of communication. A common voice transmission system is shown in Figure 1: the original voice data (analog signal) is sampled to obtain a waveform signal (digital signal) based on sample points, and then encoded to form the following The frame is the code stream of the basic unit, and is transmitted through the corresponding transmission network (such as IP network, TFO network). Due to the constraints of various network environment factors, there will be phenomena such as network congestion and jitter, resulting in frame loss, which will affect the voice quality.
为了实现语音增强(即提高语音质量),现有技术一般都采用线性域(波形域)补偿的方法来对丢失的帧进行恢复,即先将编码后的相关帧进行完全解码,得到基于样点值的信号波形,再根据前一帧或后一帧的波形来恢复当前帧的波形,将恢复出来的波形(基于样点值)进行编码,恢复生成丢失的帧数据。In order to achieve speech enhancement (i.e. improve speech quality), the prior art generally adopts a linear domain (waveform domain) compensation method to restore the lost frame, that is, firstly decode the encoded related frame completely, and obtain a sample-based Value signal waveform, and then restore the waveform of the current frame according to the waveform of the previous frame or the next frame, encode the recovered waveform (based on the sample point value), and restore and generate the lost frame data.
发明人在实现本发明的过程中,发现现有技术至少存在如下缺点:In the process of realizing the present invention, the inventor finds that the prior art has at least the following disadvantages:
由于现有技术在进行帧恢复时,需要先对相关帧进行解码,然后再根据解码后的相关帧的波形进行恢复;而解码过程往往需要消耗较多的系统资源(如内存占用、CPU占用率等),因此,如果当网络条件较差,需要恢复的帧数据较多时,需要执行多次解码操作,从而大大增加了系统资源消耗。Because the prior art needs to decode relevant frames earlier when performing frame recovery, and then recover according to the waveform of the decoded relevant frames; and the decoding process often needs to consume more system resources (such as memory usage, CPU usage rate, etc.) etc.), therefore, if the network condition is poor and there is a lot of frame data to be recovered, multiple decoding operations need to be performed, thereby greatly increasing the consumption of system resources.
发明内容Contents of the invention
本发明实施例提供一种丢帧恢复方法、设备及语音增强方法、设备及系统,用于降低丢帧恢复过程中消耗的系统资源以及实现语音增强。Embodiments of the present invention provide a frame loss recovery method, device, and voice enhancement method, device, and system, which are used to reduce system resources consumed in the frame loss recovery process and implement voice enhancement.
其中,本发明实施例提供了一种丢帧恢复方法,包括如下步骤:Wherein, the embodiment of the present invention provides a frame loss recovery method, including the following steps:
根据与丢失帧相邻的相邻帧类型确定丢失帧的类型;determining the type of the lost frame based on the type of adjacent frames adjacent to the lost frame;
获取对相邻帧进行解参数后得到的特征参数,特征参数用于确定帧中编码数据的特征信息;Obtaining the characteristic parameters obtained after deparameterizing the adjacent frames, the characteristic parameters are used to determine the characteristic information of the encoded data in the frame;
根据相邻帧的特征参数以及所述丢失帧与所述相邻帧中编码数据特征信息之间的相关性,构建与丢失帧类型相符的特征参数;Constructing a characteristic parameter consistent with the type of the missing frame according to the characteristic parameter of the adjacent frame and the correlation between the missing frame and the characteristic information of the encoded data in the adjacent frame;
根据构建的丢失帧的特征参数恢复丢失帧。The lost frame is recovered according to the constructed characteristic parameters of the lost frame.
本发明实施例还提供了一种语音增强方法,包括上述丢帧恢复方法,用于对语音帧进行丢失帧恢复,还包括:The embodiment of the present invention also provides a voice enhancement method, including the above lost frame recovery method for recovering the lost frame of the voice frame, and also includes:
在对丢失帧进行恢复后,通过在参数域实现自动回声控制、自动噪声抑制、抗削波、自动电平控制以及自动噪声补偿中的一种或多种技术对进行丢失帧恢复后的语音帧信号进行语音增强。After recovering the lost frame, implement one or more technologies in automatic echo control, automatic noise suppression, anti-clipping, automatic level control and automatic noise compensation in the parameter domain to recover the lost frame speech frame signal for speech enhancement.
本发明实施例还提供了一种丢帧恢复设备,包括:The embodiment of the present invention also provides a lost frame recovery device, including:
帧信息确定单元,用于根据与丢失帧相邻的相邻帧类型确定丢失帧的类型;A frame information determination unit, configured to determine the type of the lost frame according to the type of adjacent frames adjacent to the lost frame;
解参数单元,用于获取对相邻帧进行解参数后得到的特征参数,特征参数用于确定帧中编码数据的特征信息;The solution parameter unit is used to obtain the characteristic parameters obtained after solving the parameters of the adjacent frames, and the characteristic parameters are used to determine the characteristic information of the encoded data in the frame;
特征参数构建单元,用于根据相邻帧的特征参数以及所述丢失帧与所述相邻帧中编码数据特征信息之间的相关性,构建与丢失帧类型相符的特征参数;A characteristic parameter construction unit, configured to construct a characteristic parameter consistent with the type of the lost frame according to the characteristic parameter of the adjacent frame and the correlation between the lost frame and the characteristic information of the encoded data in the adjacent frame;
恢复单元,用于根据构建的丢失帧的特征参数恢复丢失帧。A recovery unit is used for recovering the lost frame according to the constructed characteristic parameters of the lost frame.
本发明实施例还包括一种语音增强设备,包括以上丢帧恢复设备,还包括以下几个语音增强单元中的一个或多个::The embodiment of the present invention also includes a speech enhancement device, including the above lost frame recovery device, and also includes one or more of the following speech enhancement units:
自动回声控制单元,用于自动回声控制;automatic echo control unit for automatic echo control;
自动噪声抑制单元,用于自动噪声抑制;Automatic noise suppression unit for automatic noise suppression;
抗削波单元,用于抗削波;Anti-clipping unit for anti-clipping;
自动电平控制单元,用于自动电平控制;Automatic level control unit for automatic level control;
自动噪声补偿单元,用于自动噪声补偿;Automatic noise compensation unit for automatic noise compensation;
上述一个或多个语音增强单元对丢帧恢复设备进行丢失帧恢复后的语音帧进行解参数后得到特征参数,并利用解参数后得到的特征参数进行语音增强处理。The above-mentioned one or more speech enhancement units deparameterize the speech frames after the lost frame restoration by the lost frame recovery device to obtain characteristic parameters, and use the characteristic parameters obtained after deparameterization to perform speech enhancement processing.
本发明实施例还提供了一种语音增强系统,包括:The embodiment of the present invention also provides a speech enhancement system, including:
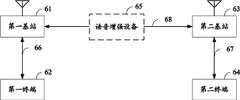
第一基站,第一终端;第二基站,第二终端;上述丢帧恢复设备;The first base station, the first terminal; the second base station, the second terminal; the above-mentioned frame loss recovery device;
其中,第一基站与第一终端之间通过第一链路进行连接;第二基站与第二终端之间通过第二链路进行连接;第一基站与第二基站之间通过第三链路进行连接;Wherein, the connection between the first base station and the first terminal is through the first link; the connection between the second base station and the second terminal is through the second link; the connection between the first base station and the second base station is through the third link make a connection;
丢帧恢复设备用于对第一链路、第二链路或者第三链路中的一个或多个环节出现的丢帧进行恢复。The frame loss recovery device is used for recovering the frame loss occurred in one or more links in the first link, the second link or the third link.
本发明实施例还提供了一种语音增强系统,包括:The embodiment of the present invention also provides a speech enhancement system, including:
第一基站,第一终端;第二基站,第二终端;上述语音增强设备;The first base station, the first terminal; the second base station, the second terminal; the above-mentioned voice enhancement device;
其中,第一基站与第一终端之间通过第一链路进行连接;第二基站与第二终端之间通过第二链路进行连接;第一基站与第二基站之间通过第三链路进行连接;Wherein, the connection between the first base station and the first terminal is through the first link; the connection between the second base station and the second terminal is through the second link; the connection between the first base station and the second base station is through the third link make a connection;
语音增强设备用于对第一链路、第二链路或者第三链路中的一个或多个环节出现的丢帧进行恢复及实现上述一个或多个环节出现的语音增强。The speech enhancement device is used for recovering the frame loss in one or more links in the first link, the second link or the third link and realizing the speech enhancement in the above one or more links.
上述技术方案中具有如下的优点:The above technical solution has the following advantages:
本发明实施例中丢帧恢复方法及设备中,通过利用相邻帧的类型与特征参数来恢复丢失帧,由于解参数过程相比于完全解码到波形域的过程所消耗的资源要少得多,因此,通过本发明实施例恢复方法可以大大降低系统消耗的资源,在网络条件较差,存在很多丢失帧的情况下,这种效果更加明显。In the lost frame recovery method and device in the embodiment of the present invention, the lost frame is recovered by using the type and characteristic parameters of the adjacent frame, because the deparameterization process consumes much less resources than the process of completely decoding to the waveform domain Therefore, the resource consumed by the system can be greatly reduced through the recovery method of the embodiment of the present invention, and this effect is more obvious when the network condition is poor and there are many lost frames.
同时,本发明实施例语音增强方法、设备及系统中,在基于丢帧恢复的基础上进行对帧进行解参数,并对解参数后得到的特征参数进行语音增强,可以在降低系统消耗的资源上更一步提升语音的质量。At the same time, in the speech enhancement method, device and system of the embodiment of the present invention, the frame is deparameterized on the basis of frame loss recovery, and the characteristic parameters obtained after deparameterization are speech enhanced, which can reduce the resources consumed by the system. Further improve the quality of voice.
附图说明Description of drawings
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。In order to more clearly illustrate the technical solutions in the embodiments of the present invention, the following will briefly introduce the accompanying drawings that need to be used in the descriptions of the embodiments or the prior art. Obviously, the accompanying drawings in the following description are only of the present invention. For some embodiments, those of ordinary skill in the art can also obtain other drawings based on these drawings without any creative effort.
图1为现有技术常见语音传输系统示意图;FIG. 1 is a schematic diagram of a common voice transmission system in the prior art;
图2为本发明实施例一方法流程示意图;Fig. 2 is a schematic flow chart of a method according to Embodiment 1 of the present invention;
图3为本发明实施例一方法流程图;Fig. 3 is a flow chart of a method according to Embodiment 1 of the present invention;
图4为本发明实施例二加入模式选择的方法流程图;FIG. 4 is a flowchart of a method for adding mode selection in Embodiment 2 of the present invention;
图5为本发明实施例三采用AMR-NB进行语音增强示意图;FIG. 5 is a schematic diagram of speech enhancement using AMR-NB in Embodiment 3 of the present invention;
图6为本发明实施例三采用AMR-NB对丢失帧特征参数进行恢复的方法;FIG. 6 is a method for recovering characteristic parameters of lost frames by using AMR-NB in Embodiment 3 of the present invention;
图7为本发明实施例四在基于丢失帧恢复基础上通过其他参数域进行语音增强的方法示意图;FIG. 7 is a schematic diagram of a method for speech enhancement through other parameter domains based on lost frame recovery in Embodiment 4 of the present invention;
图8为本发明实施例四中加入信号分类器对信号进行分类示意图;8 is a schematic diagram of adding a signal classifier to classify signals in Embodiment 4 of the present invention;
图9为本发明实施例在参数域进行抗削波方法流程图;FIG. 9 is a flowchart of an anti-clipping method in the parameter domain according to an embodiment of the present invention;
图10为本发明实施例五丢帧恢复设备结构示意图;FIG. 10 is a schematic structural diagram of a lost frame recovery device according to Embodiment 5 of the present invention;
图11为本发明实施例五丢帧恢复设备中帧信息确定单元结构示意图;FIG. 11 is a schematic structural diagram of a frame information determination unit in a frame loss recovery device according to Embodiment 5 of the present invention;
图12为本发明实施例五丢帧恢复设备包括模式选择单元时的结构示意图;FIG. 12 is a schematic structural diagram when the lost frame recovery device includes a mode selection unit according to Embodiment 5 of the present invention;
图13为本发明实施例五语音增强设备结构示意图;13 is a schematic structural diagram of a speech enhancement device according to Embodiment 5 of the present invention;
图14为本发明实施例五语音增强设备一个具体硬件实现示意图;FIG. 14 is a schematic diagram of a specific hardware implementation of a speech enhancement device according to Embodiment 5 of the present invention;
图15为本发明实施例五语音增强设备另一个具体硬件实现示意图;FIG. 15 is a schematic diagram of another specific hardware implementation of the speech enhancement device according to Embodiment 5 of the present invention;
图16为本发明实施例六应用语音增强设备系统的示意图;FIG. 16 is a schematic diagram of a voice enhancement device system according to Embodiment 6 of the present invention;
图17为本发明实施例六在全IP组网下TrFO场景下应用示意图;FIG. 17 is a schematic diagram of the application of Embodiment 6 of the present invention in a TrFO scenario in an all-IP network;
图18为本发明实施例六在TFO场景下应用示意图;FIG. 18 is a schematic diagram of the application of Embodiment 6 of the present invention in a TFO scenario;
图19为本发明实施例六在TDM场景下应用示意图。FIG. 19 is a schematic diagram of application of Embodiment 6 of the present invention in a TDM scenario.
具体实施方式Detailed ways
为使本发明的目的、技术方案及优点更加清楚明白,以下将通过具体实施例和相关附图,对本发明作进一步详细说明。In order to make the object, technical solution and advantages of the present invention clearer, the present invention will be further described in detail below through specific embodiments and related drawings.
实施例一Embodiment one
本发明实施例一提供了一种语音增强方法,参见图2,为本发明实施例一个流程示意图,在接收码流后,首先根据相邻帧的类型确定该丢失帧的类型,再利用对相邻帧进行解参数后得到的特征参数来构建丢失帧的特征参数,最后对构建的丢失帧的特征参数进行编码,恢复丢失帧。由于本发明实施例是通过解参数后通过得到特征参数来恢复丢失帧,因此,可以看成是一个在“参数域”进行恢复的过程。具体的,参见图3,本发明实施例包括如下步骤:Embodiment 1 of the present invention provides a speech enhancement method. Referring to FIG. 2 , it is a schematic flowchart of an embodiment of the present invention. After receiving the code stream, first determine the type of the lost frame according to the type of the adjacent frame, and then use the corresponding The characteristic parameters obtained after deparameterization of adjacent frames are used to construct the characteristic parameters of the lost frame, and finally the characteristic parameters of the constructed lost frame are encoded to restore the lost frame. Since the embodiment of the present invention restores the lost frame by obtaining the characteristic parameters after solving the parameters, it can be regarded as a restoration process in the "parameter domain". Specifically, referring to FIG. 3, this embodiment of the present invention includes the following steps:
S101、根据与丢失帧相邻的相邻帧类型确定丢失帧的类型;S101. Determine the type of the lost frame according to the type of the adjacent frame adjacent to the lost frame;
在确定根据相邻的帧的类型确定丢失帧类型之前,首先要确定丢失帧是哪一帧,以及丢失帧相邻的帧,以及这些相邻帧的类型。Before determining the type of the lost frame according to the type of the adjacent frame, it is first necessary to determine which frame the lost frame is, the frames adjacent to the lost frame, and the types of these adjacent frames.
其中,确定丢失帧以与其相邻的帧可以通过检测收到的帧中的帧序号,或者时间戳是否符合预设规则等方法来确定。Wherein, the frame adjacent to the lost frame can be determined by detecting the frame sequence number in the received frame, or whether the time stamp conforms to a preset rule or the like.
具体的,通过帧序号实现的方法是将每个帧按一定规则(如顺序递增)编上序号,如果接收到发现收到的多个帧序号不满足该规则(如顺序递增过程中中间少了个号),则认为发生了丢帧,那么,该帧的前一帧或前几帧,后一帧或后几帧为该丢失帧的相邻帧。Specifically, the method realized by the frame number is to number each frame according to a certain rule (such as increasing in order), and if it is received, it is found that the received multiple frame numbers do not satisfy the rule (for example, there are fewer frames in the middle of the sequence increasing process). number), it is considered that a frame loss has occurred, then the previous frame or a few frames before the frame, and the next frame or a few frames are the adjacent frames of the lost frame.
上述收到的多个帧序号可以通过在收到帧数据时先对帧进行缓存,判断是否丢失帧时,解析缓存的帧数据得到;或者也可以在收到帧数据时先解析得到帧序号,将其缓存,在判断时直接读取缓存的帧序号时得到。后续其他与帧相关的数据(如时间戳、帧类型标志、特征参数等)都可以采用先缓存帧,使用时解析帧提取相关数据;或者直接在收到帧时先解析出这些数据进行缓存,需要用到时直接使用这些缓存的数据。The multiple frame numbers received above can be obtained by first caching the frame when receiving the frame data, and parsing the cached frame data when judging whether the frame is lost; or the frame number can be obtained by first analyzing the frame data when receiving the frame data. It is cached and obtained when directly reading the cached frame number when judging. Subsequent other data related to the frame (such as timestamp, frame type flag, characteristic parameters, etc.) can be cached first, and parsed to extract relevant data during use; or directly parse out the data for caching when receiving the frame. Use these cached data directly when needed.
具体的,当采用时间戳实现时,每个帧在发送时会打上时间戳,接收端收到多个帧后,根据这些时间戳的先后顺序来判断是否发生丢帧。例如,假设正常时每隔1ms就会打上一个时间戳,接收端收到两个帧后,发现两帧间隔了2ms或2ms以上,则认为在这两个帧之间有帧丢失,这两个帧可认为是相邻帧,可以理解的是,前一相邻帧再往前的一帧或多帧以及再往后一相邻帧再往后一帧的一帧或多帧也可认为是相邻帧。Specifically, when timestamping is used, each frame will be stamped with a timestamp when it is sent, and after receiving multiple frames, the receiving end will judge whether frame loss occurs according to the order of these timestamps. For example, assuming that a time stamp is stamped every 1ms under normal conditions, after receiving two frames, the receiving end finds that the interval between the two frames is 2ms or more, then it is considered that there is a frame loss between the two frames. A frame can be considered as an adjacent frame, and it can be understood that one or more frames before the previous adjacent frame and one or more frames after an adjacent frame and then one frame after that can also be considered as adjacent frames.
此外,在某一些情况下,如果通过检测发现收到的为错帧,则也可将这种情况认为该帧为丢失帧;当然,实际应用中,也可以不认为是丢失帧,而是按错帧的情况进行处理。In addition, in some cases, if it is found that the received frame is an error frame, this situation can also be considered as a lost frame; of course, in practical applications, it may not be considered a lost frame, but according to Handle frame errors.
需要说明的是,上述丢失帧可以是一个或者多个,如果是多个,则恢复时先恢复第一个,然后再依次利用恢复的帧(也可以是一个或多个)来恢复后面的丢失帧。It should be noted that the above lost frames can be one or more. If there are more than one, the first one should be recovered first, and then the recovered frames (or one or more) can be used in turn to recover the subsequent lost frames. frame.
在确定了帧丢失的情况,以及丢失帧的相邻帧后,便可以通过相邻帧的类型来确定丢失帧的类型。After determining the frame loss situation and the adjacent frames of the lost frame, the type of the lost frame can be determined according to the type of the adjacent frame.
其中,在确定帧的类型时,可以通过帧中的相应标志位来确定。例如,基于AMR-NB编码方式的帧在编码过程中,编码器在将语音数据编码成帧数据时,会在帧特定的位置通过标志位来表示帧的类型(如话音帧、舒适噪声帧、空帧等);接收端只要接收到帧数据,便可以根据相应的标志位来确定帧的类型;基于EVRC(Enhanced Variable Rate Codec,增强型变速率语音编解码)的帧通过速率标志位以速率为类型区分不同类型的帧(如1/8速率,半速率,全速率等)。Wherein, when determining the type of the frame, it can be determined through a corresponding flag bit in the frame. For example, during the encoding process of a frame based on the AMR-NB encoding method, when the encoder encodes speech data into frame data, it will indicate the type of the frame (such as voice frame, comfort noise frame, Empty frame, etc.); as long as the receiving end receives the frame data, it can determine the type of frame according to the corresponding flag bit; based on EVRC (Enhanced Variable Rate Codec, Enhanced Variable Rate Voice Codec), the frame passing rate flag bit Differentiate between different types of frames for type (such as 1/8 rate, half rate, full rate, etc.).
通过以上方法确定丢失帧的相邻帧后,可以根据这些相邻帧的类型来确定丢失帧的类型。具体的,可以根据相邻帧的类型并结合实际帧传输情形,估计丢失帧最可能的类型,例如,假设码流中的帧类型包括A、B、C三种,实际应用中,大多数情况下这几种类型的帧会按A、B、C三种类型先后顺序传输,此时,如果丢失帧的前一帧为A、后一帧为C,那么丢失帧为B的概率为最大,可以在这种情况下认为该丢失帧的类型为B;或者,再结合根据最佳帧类型确定丢失帧的类型,例如,针对B帧,可能是好帧(没有损失的数据),也可能是坏帧(如某一位或几位出错,但有一部分也能用),这种情况下,都按是好帧(即最佳帧类型)的情况进行恢复。实际使用过程中,一般都会使用上述两种方案的结合,当然,也可以只基于其中一种方法进行恢复,本发明实施例并不进行限定。After the adjacent frames of the lost frame are determined through the above method, the type of the lost frame can be determined according to the types of these adjacent frames. Specifically, the most likely type of the lost frame can be estimated according to the type of adjacent frames combined with the actual frame transmission situation. For example, assuming that the frame types in the code stream include A, B, and C, in practical applications, most cases The following types of frames will be transmitted in sequence according to the three types of A, B, and C. At this time, if the previous frame of the lost frame is A and the next frame is C, then the probability of the lost frame being B is the greatest. In this case, the type of the lost frame can be considered as B; or, combined with the optimal frame type to determine the type of the lost frame, for example, for the B frame, it may be a good frame (no loss of data), or it may be Bad frames (such as a certain bit or several bits are wrong, but some of them can also be used), in this case, they are all restored according to the situation of good frames (ie, the best frame type). In actual use, a combination of the above two solutions is generally used. Of course, recovery can also be performed based on only one of the methods, which is not limited in this embodiment of the present invention.
S102、获取对相邻帧进行解参数后得到的特征参数,特征参数用于确定帧中编码数据的特征信息;S102. Obtain the characteristic parameters obtained after deparameterizing the adjacent frames, and the characteristic parameters are used to determine the characteristic information of the encoded data in the frame;
在进行解参数的过程中,由于进行编解码时基于的语音数字信号的模型可能不同,因此,进行解参数后得到的特征参数也会不同。例如,以基于CELP(Code Excited Linear Prediction,码激励线性预测编码)模型的解码器为例,输出的特征参数可以包括:线谱频率(LSF,Line Spectrum Frequency)或线谱对(LSP,Line Spectrum Pair)、基音延迟、自适应码书增益(Gain Pit)、固定码书增益(Gain Code)、反射系数等信息,其中,线谱频率以及线谱对是用于描述同一信息采用的两种不同表示方法,两者之间可以相互转化。以基于VSELP(Vector Sum Excited Linear Prediction,矢量和激励线性预测编码)模型为例,解参数后可以得到谱包络、帧能量等参数。上述特征参数的具体定义以及解参数的方法都已在相应的标准中有定义,本领域技术人员可以根据标准中的定义完成解参数的步骤,在此不再赘述。In the process of deparameterizing, since the model of the speech digital signal based on encoding and decoding may be different, the characteristic parameters obtained after deparameterizing will also be different. For example, taking a decoder based on the CELP (Code Excited Linear Prediction) model as an example, the output feature parameters can include: line spectrum frequency (LSF, Line Spectrum Frequency) or line spectrum pair (LSP, Line Spectrum Pair), pitch delay, adaptive codebook gain (Gain Pit), fixed codebook gain (Gain Code), reflection coefficient and other information, among which, line spectrum frequency and line spectrum pair are two different types used to describe the same information. Representation methods, the two can be transformed into each other. Taking the VSELP (Vector Sum Excited Linear Prediction) model as an example, parameters such as spectral envelope and frame energy can be obtained after solving the parameters. The specific definitions of the above-mentioned characteristic parameters and the method of solving the parameters have been defined in the corresponding standards, and those skilled in the art can complete the steps of solving the parameters according to the definitions in the standards, and will not repeat them here.
其中,上述各个特征参数用于确定帧中编码数据的特征信息;这里的编码数据即对语音信号进行采样、编码后得到的数据;编码数据中的特征信息用于描述编码信号所对应的时域或频域的一些信息,而解参数后得到的特征参数即用于对这些特征信息进行描述或表示。例如,LSF/LSP描述了信号在频域上的包络特性;基音延迟描述了当前帧的基音与前一帧的差值;自适应码书增益描述了频域周期性最强的频谱分量的能量特性;固定码书增益描述了其他周期性较弱的频谱分量的能量特性。如果一个帧的特征参数确定了,那么就可以根据这些特征参数来对该帧进行恢复。Among them, the above-mentioned characteristic parameters are used to determine the characteristic information of the encoded data in the frame; the encoded data here is the data obtained after sampling and encoding the speech signal; the characteristic information in the encoded data is used to describe the time domain corresponding to the encoded signal Or some information in the frequency domain, and the characteristic parameters obtained after solving the parameters are used to describe or represent these characteristic information. For example, LSF/LSP describes the envelope characteristics of the signal in the frequency domain; the pitch delay describes the difference between the pitch of the current frame and the previous frame; the adaptive codebook gain describes the spectral component with the strongest periodicity in the frequency domain Energy characteristics; fixed codebook gain describes the energy characteristics of other less periodic spectral components. If the characteristic parameters of a frame are determined, then the frame can be restored according to these characteristic parameters.
需要说明的是,当本发明实施例基于一个独立的设备时,上述解参数过程的由该独立设备的解参数单元来完成。而如果本发明实施例基于一个现有的设备,那么解参数功能可以由现有设备来完成,例如,现有设备为了转码或兼容需求,已有一个解码器,而该解码器在解码(解码到波形)过程中,也会输出特征参数,那么,就可以利用该解码器输出的特征参数;当然,这种情况下也可以不使用原有设备输出的特征参数,而是在本设备上通过一个解参数单元来完成特征参数的输出。It should be noted that when the embodiment of the present invention is based on an independent device, the above parameterization process is completed by the parameterization unit of the independent device. However, if the embodiment of the present invention is based on an existing device, then the deparameterization function can be completed by the existing device. For example, the existing device has a decoder for transcoding or compatibility requirements, and the decoder is decoding ( In the process of decoding to waveform), the characteristic parameters will also be output, so the characteristic parameters output by the decoder can be used; of course, in this case, the characteristic parameters output by the original equipment can also be used instead of the original equipment. The output of characteristic parameters is completed through a solution parameter unit.
S103、根据相邻帧的特征参数以及所述丢失帧与相邻帧中编码数据特征信息之间的相关性,构建与丢失帧类型相符的特征参数;S103. According to the characteristic parameters of the adjacent frame and the correlation between the missing frame and the characteristic information of the encoded data in the adjacent frame, construct a characteristic parameter consistent with the type of the missing frame;
确定丢失帧的类型后,需要构建与丢失帧类型相符的特征参数,例如,对于一些类型的丢失帧(话音帧),恢复时只需要使用相邻帧中解参数出来的一种特征参数;而对于另一些类型的丢失帧(如信号帧),需要使用多种特征参数。因此,根据不同类型的帧,需要构建与其类型相符的特征参数,这样才能根据这些构建的特征参数对丢失帧进行恢复。After determining the type of the lost frame, it is necessary to construct a characteristic parameter consistent with the lost frame type, for example, for some types of lost frame (voice frame), only need to use a kind of characteristic parameter that solution parameter in the adjacent frame comes out when restoring; And For other types of lost frames (such as signal frames), various characteristic parameters need to be used. Therefore, according to different types of frames, it is necessary to construct characteristic parameters corresponding to the types, so that lost frames can be restored according to these constructed characteristic parameters.
需要说明的是,对于另一些类型的丢失帧(如静音帧等),可以不进行恢复,直接透传到后级进行处理(如后级进行一些数据的填充),具体处理方法在本发明实施例中不进行详细描述。It should be noted that, for other types of lost frames (such as silent frames, etc.), it may not be restored, and directly transparently transmitted to the subsequent stage for processing (such as the subsequent stage to fill some data), the specific processing method is implemented in the present invention Examples are not described in detail.
构建与丢失帧类型相符的特征参数根据相邻帧的特征参数以及各帧中编码数据特征信息之间的相关性来完成。这里的相关性也可以理解为表征各帧中编码数据的特征信息变化趋势。实际应用中,各帧中的编码数据的特征信息并非完全孤立的,很多情况下都是具有相关性的,如多个帧中编码数据的包络特性(通过LSF/LSP特征参数体现)会表现出增加,或者减少,或者有规律变化的趋势等,通过这种相关性(或变化趋势),可以利用某一些帧来对另一些帧进行恢复。本发明实施例中,丢失帧中编码数据特征信息与相邻帧中的编码数据特征信息也会存在相关性,因此,可以通过相邻帧的特征参数(用于表征相邻帧中的特征信息)以及这种相关性来得到丢失帧的特征参数,例如,前2帧相邻帧特征参数(也可理解为特征信息,在此并不严格区分)为分别为2、4;后2帧分别为7,10,则可以看到各帧的相关性(变化趋势)为呈现增加的趋势,因此,可得到丢失帧在很大概率上为4-7之间的一个值。Constructing the characteristic parameters consistent with the type of the lost frame is completed according to the characteristic parameters of adjacent frames and the correlation between the characteristic information of the encoded data in each frame. The correlation here can also be understood as characterizing the change trend of the feature information of the encoded data in each frame. In practical applications, the feature information of the coded data in each frame is not completely isolated, and is correlated in many cases. For example, the envelope characteristics of the coded data in multiple frames (reflected by LSF/LSP feature parameters) will show The output increases, or decreases, or has a regular change trend, etc. Through this correlation (or change trend), some frames can be used to restore other frames. In the embodiment of the present invention, there is also a correlation between the characteristic information of the encoded data in the lost frame and the characteristic information of the encoded data in the adjacent frame. Therefore, the characteristic parameters of the adjacent frame (used to characterize the characteristic information in the adjacent frame ) and this correlation to obtain the characteristic parameters of the lost frame, for example, the characteristic parameters of the adjacent frames of the first two frames (also can be understood as characteristic information, which is not strictly distinguished here) are 2 and 4 respectively; the latter two frames are respectively If it is 7 or 10, it can be seen that the correlation (change trend) of each frame shows an increasing trend. Therefore, it can be obtained that the lost frame is a value between 4-7 with a high probability.
在根据多个帧中编码数据特征信息之间的相关性进行丢失帧特征参数恢复时,选取的相邻帧数越多,判断这种相关性(或变化趋势)的准确度也越高,但同时引入的时延以及算法复杂度也会增加,实际使用中可以根据应用需求选择合适数量的相邻帧(如前2帧,或前后各一帧)来恢复丢失帧。When recovering the characteristic parameters of the lost frame based on the correlation between the characteristic information of the encoded data in multiple frames, the more adjacent frames are selected, the higher the accuracy of judging the correlation (or change trend), but At the same time, the time delay introduced and the complexity of the algorithm will also increase. In actual use, an appropriate number of adjacent frames (such as the previous two frames, or one frame before and after) can be selected according to the application requirements to restore the lost frame.
恢复丢失帧所采用的算法的实现形式并不唯一,例如,想恢复LSF/LSF参数时,一个简单的算法是将丢失帧的前后各一帧的LSF/LSF参数相加后取算术平均,来得到当前帧的LSF/LSF参数;或者,想恢复基音延迟参数时,将前一帧的基音延迟参数加上一固定值或者直接使用前一帧的基音延迟参数。The implementation form of the algorithm used to restore the lost frame is not unique. For example, when you want to restore the LSF/LSF parameters, a simple algorithm is to add the LSF/LSF parameters of the frames before and after the lost frame and take the arithmetic mean to obtain Get the LSF/LSF parameter of the current frame; or, when you want to restore the pitch delay parameter, add a fixed value to the pitch delay parameter of the previous frame or directly use the pitch delay parameter of the previous frame.
实际应用当中,为了取得更好性能的恢复效果,可以在利用丢失帧与相邻帧之间的相关性的基础上结合引入影响因子(或加权系数)等方式创建更优的算法,实现对丢失帧特征参数更准确的构建,例如,虽然有多个帧会与丢失帧相关,但因为相关性不同,所以需要对相关的帧的相关程度通过影响因子进行限定(加权)。影响因子的确定可以通过历史经验值或者测试值来得到,通过结合影响子,可以取得更好的恢复效果。In practical applications, in order to achieve better recovery performance, it is possible to use the correlation between the lost frame and adjacent frames to create a better algorithm by introducing influence factors (or weighting coefficients) to realize the recovery of lost frames. More accurate construction of frame feature parameters, for example, although there are multiple frames that are related to the lost frame, but because the correlation is different, it is necessary to limit (weight) the correlation degree of the related frames through the influence factor. The determination of the impact factor can be obtained through historical experience or test values. By combining the impact factors, better recovery effects can be achieved.
S104、根据构建的特征参数恢复丢失帧S104. Restoring lost frames according to the constructed feature parameters
构建完丢失帧的特征参数之后,便可以根据这些构建的特征参数恢复丢失帧,其具体实现也可参见标准相关定义,将这些特征参数编码后恢复成新的帧。同时,与解参数过程类型,根据本发明实施例基于的设备可以是由一个独立设备中的相关功能单元来完成,也可以基于原有设备中具有相应功能的单元来完成,在此并不限定。After the characteristic parameters of the lost frame are constructed, the lost frame can be restored according to the constructed characteristic parameters. For the specific implementation, please refer to the relevant definition of the standard, and these characteristic parameters are encoded and restored into a new frame. At the same time, with regard to the type of parameter solution process, the device based on the embodiment of the present invention can be completed by a related functional unit in an independent device, or it can be completed based on a unit with corresponding functions in the original device, which is not limited here .
本发明实施例中,通过利用相邻帧的类型与特征参数来恢复丢失帧,由于解参数过程相比于完全解码到波形域的过程所消耗的资源要少得多,因此,通过本发明实施例恢复方法可以大大降低系统消耗的资源,在网络条件较差,存在很多丢失帧的情况下,这种效果更加明显。In the embodiment of the present invention, the lost frame is recovered by using the type and characteristic parameters of adjacent frames, since the deparameterization process consumes much less resources than the process of fully decoding to the waveform domain, therefore, through the implementation of the present invention The example recovery method can greatly reduce the resources consumed by the system, and this effect is more obvious when the network condition is poor and there are many lost frames.
实施例二Embodiment two
本发明实施例基于上述实施例一,提供了一种基于不同工作模式的语音增强方法,为了应对实际应用中对传输质量与延迟的要求,在确定有丢失帧且需要对丢失帧进行恢复时,通过进入不同的模式来应对不同的实际应用场景。Based on the first embodiment above, the embodiment of the present invention provides a speech enhancement method based on different working modes. In order to meet the requirements for transmission quality and delay in practical applications, when it is determined that there is a lost frame and the lost frame needs to be recovered, By entering different modes to deal with different practical application scenarios.
这里的系统指的是应用了本发明实施例语音增强技术的系统;在该系统中,为了防止网络抖动(Jitter),可能会设立抖动缓存(Jitter Buffer),通过缓存一定量的帧,并进行重排序来防止抖动,通过抖动缓存的设置,使得传输更加稳定,提高了传输质量,但在另一方面却会造成延时。The system here refers to the system that has applied the voice enhancement technology of the embodiment of the present invention; in this system, in order to prevent network jitter (Jitter), a jitter buffer (Jitter Buffer) may be set up, by buffering a certain amount of frames, and performing Reordering to prevent jitter, through the setting of the jitter buffer, makes the transmission more stable and improves the transmission quality, but on the other hand it will cause delay.
当系统提供了Jitter Buffer时,在获取跟帧有关的数据(如序号、时间戳、类型等)时也可以从Jitter Buffer中去取(在这种情况下,Jitter Buffer需要支持提供某一接口,如标志位、接口函数等来供其他单元获取相关的信息)。通过利用系统提供的Jitter Buffer,可以不必再开辟一块缓存区缓存相关的数据,节省了存储空间,实现起来也更简单。当然,本发明实施例也可以不使用系统提供的Jitter Buffer,而再设计一个缓存(类似于实施例一中的用于缓存帧的缓存)来实现相应的功能。When the system provides a Jitter Buffer, it can also be obtained from the Jitter Buffer when obtaining frame-related data (such as serial number, timestamp, type, etc.) (in this case, the Jitter Buffer needs to support providing a certain interface, Such as flag bits, interface functions, etc. for other units to obtain relevant information). By using the Jitter Buffer provided by the system, there is no need to open up a buffer area to cache related data, which saves storage space and is easier to implement. Certainly, the embodiment of the present invention may not use the Jitter Buffer provided by the system, but design a buffer (similar to the buffer for buffering frames in Embodiment 1) to realize the corresponding function.
由于系统的实际应用场景并不固定,不同的场景对传输质量与传输延时要求并不相同,有的应用场景对传输延时的要求比较高,有的则对传输质量要求比较高,因此,本发明实施例引入了两种工作模式来针对实际中可能会遇到的两种场景来满足可能会出现的场景,具体包括:延时模式(Delay Mode)以及非延时模式(Non-Delay Mode),当进入延时模式时,用前一帧(或前几帧)和后一帧(后几帧)进行恢复,以保证对质量的要求;当进入非延时模式时,只用前一帧(或前几帧)进行恢复,以保证对时延的要求。Since the actual application scenarios of the system are not fixed, different scenarios have different requirements for transmission quality and transmission delay. Some application scenarios have relatively high requirements for transmission delay, while others have relatively high requirements for transmission quality. Therefore, The embodiment of the present invention introduces two working modes to meet the two scenarios that may be encountered in practice, specifically including: delay mode (Delay Mode) and non-delay mode (Non-Delay Mode) ), when entering the delay mode, use the previous frame (or the first few frames) and the next frame (the next few frames) to restore to ensure the quality requirements; when entering the non-delay mode, only use the previous frame Frames (or the first few frames) are restored to ensure the delay requirements.
具体的,参见图4;包括如下步骤:Specifically, see Figure 4; including the following steps:
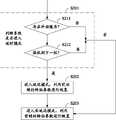
S201、判断系统是否进入延时模式,如果是,执行步骤S202;否执,执行步骤S203;S201. Determine whether the system enters the delay mode, if yes, execute step S202; if not, execute step S203;
其中,是否进入延时模式可以根据是否有抖动缓存(或者抖动缓存是否工作),以及是否接收到下一帧来判断。具体的,包括如下步骤:Wherein, whether to enter the delay mode can be judged according to whether there is a jitter buffer (or whether the jitter buffer is working), and whether the next frame is received. Specifically, the following steps are included:
S211、判断是否存在抖动缓存(Jitter Buffer);如果是,执行步骤S212,否则,判断为进入非延迟模式执行步骤S203;S211, judging whether there is a jitter buffer (Jitter Buffer); if yes, execute step S212, otherwise, judge to enter non-delay mode and execute step S203;
S212、判断是否接收到下一帧;如果是,执行步骤S202,否则,判断为进入非延迟模式,执行步骤S203;S212. Determine whether the next frame is received; if yes, perform step S202, otherwise, determine to enter the non-delay mode, and perform step S203;
如果在准备发送最近接收到的帧数据时,已经收到下一帧,则判定进行入延迟模式,利用前后帧的特征参数进行恢复;否则,为了减少延时,进入非延迟模式,仅使用前帧(前一帧或前几帧)的特征参数进行恢复。If the next frame has been received when preparing to send the most recently received frame data, it is determined to enter the delay mode and use the characteristic parameters of the previous and subsequent frames to recover; otherwise, in order to reduce the delay, enter the non-delay mode and only use the previous The feature parameters of the frame (the previous frame or the previous few frames) are restored.
S202、进入延迟模式,利用前后帧的特征参数进行恢复;S202, enter the delay mode, and use the characteristic parameters of the preceding and following frames to restore;
在延迟模式下,可以利用前后帧的特征参数进行恢复,此时,相邻帧包括前后帧。本发明例中,仅使用前后各一帧的特征参数进行恢复,但实际使用中,也可以使用前一帧或多帧以及后一帧或多帧的特征参数来恢复。由于用到了前后相邻帧的数据,因此,准确性相对较高,满足了对质量的要求。In the delay mode, the feature parameters of the previous and subsequent frames can be used for restoration, and at this time, the adjacent frames include the previous and subsequent frames. In the example of the present invention, only the characteristic parameters of one frame before and after are used for restoration, but in actual use, the characteristic parameters of the previous frame or frames and the following frame or frames can also be used for restoration. Since the data of adjacent frames are used, the accuracy is relatively high, which meets the quality requirements.
S203、进入非延迟模式,利用前帧的特征参数进行恢复;S203, enter the non-delay mode, and use the characteristic parameters of the previous frame to restore;
在非延迟模式下,对延时的要求比较严格,因此,仅使用前一帧(或前几帧)来恢复,此时,相邻帧指的是前帧。由于只使用前一帧(或前几帧),相比于S202中的方案,需要缓存的帧也会减少(不需要缓存后几帧),因此,引入的时延也会减少;同时,少了后一帧或后几帧的特征参数作为参考,在算法实现上也会更加快捷,从而能更快地进行恢复,但由于少了后一帧或后几帧的特征参数作为参考,其准确性可能会不如延迟模式下得到的结果。In the non-delay mode, the requirement for delay is relatively strict, therefore, only the previous frame (or several previous frames) is used for recovery, and at this time, the adjacent frame refers to the previous frame. Since only the previous frame (or the first few frames) is used, compared with the scheme in S202, the frames to be cached will also be reduced (no need to cache the last few frames), so the time delay introduced will also be reduced; at the same time, less If the feature parameters of the next frame or the next few frames are used as a reference, the algorithm implementation will be faster, so that the recovery can be performed faster, but because the feature parameters of the next frame or the next few frames are missing as a reference, its accuracy Performance may not be as good as results obtained in delayed mode.
实际使用过程中,除了上述判断方法外,也可以通过其他类似的方法来选择进入的模式,在此并不限定。例如:可以通过手动配套结合自动检测的方法来进入相应的模式,具体的,用户可以通过相应的程序接口根据实际需求配置某个参数来决定要进入的模式,系统运行时读取该参数来决定选择进入哪种模式;In actual use, in addition to the above-mentioned judging method, other similar methods may also be used to select the entry mode, which is not limited here. For example: the corresponding mode can be entered through manual matching combined with automatic detection. Specifically, the user can configure a certain parameter according to the actual demand through the corresponding program interface to determine the mode to enter, and the system reads the parameter to determine when it is running. choose which mode to enter;
或者,结合上述两种方法,系统通过步骤S201的方法以及读取用户手动配置的参数,判断是否一致,如果一致,则进入相应的模式;如果不一致,则根据一定的算法(如通过判断两种方法的优先级)选择其中一个模式。Or, in combination with the above two methods, the system judges whether they are consistent through the method of step S201 and reading the parameters manually configured by the user, and if they are consistent, then enter the corresponding mode; method priority) select one of the modes.
本发明实施例通过设定两种模式(延迟模式以及非延迟模式),在系统运行时,可以根据实际情况自动选择或者通过人工手动配置进入哪种模式,满足了不同场景下对传输质量及传输时延的要求。In the embodiment of the present invention, by setting two modes (delay mode and non-delay mode), when the system is running, which mode can be automatically selected according to the actual situation or entered through manual configuration, which satisfies the requirements for transmission quality and transmission in different scenarios. Latency requirements.
实施例三Embodiment three
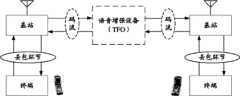
本发明实施例基于上述实施例,以系统采用AMR-NB(Adaptive Multi-RateNarrow-Band,自适应多码率-窄带)编码为例对语音增强技术进行详细说明,参见图5,包括如下步骤:The embodiment of the present invention is based on the above-mentioned embodiment, taking the system adopting AMR-NB (Adaptive Multi-RateNarrow-Band, Adaptive Multi-Rate Narrow-Band) coding as an example to describe the speech enhancement technology in detail, referring to Figure 5, including the following steps:
S301、获取帧数据;S301. Obtain frame data;
获取帧数据可以是直接获取前端处理后的帧数据,或者在本端增加一个接收单元通过解析网络传输的数据包(Packet)得到。在实际应用中,为了适应各种网络传输协议,编码后的帧都会根据网络传输类型进行打包(如打成IP包、RTP包等),每个包一般包括只包含一个帧,这样即使发生丢包的情形式,损失的帧也比较少,可以提高传输的可靠性;在一些需要传输多路数据的应用场景下,一个包也可能包含多个帧,但多个帧分别属于多个用户,即一个用户对应于包中的一帧数据,这样也是为了在发生丢包情形时不至于损失过多的帧数据。Obtaining the frame data can be obtained by directly obtaining the frame data processed by the front end, or by adding a receiving unit at the local end by analyzing the data packets (Packet) transmitted by the network. In practical applications, in order to adapt to various network transmission protocols, the encoded frames will be packaged according to the network transmission type (such as IP packets, RTP packets, etc.). In the form of packets, the loss of frames is relatively small, which can improve the reliability of transmission; in some application scenarios that need to transmit multiple channels of data, a packet may also contain multiple frames, but multiple frames belong to multiple users. That is, one user corresponds to one frame of data in the packet, so that too much frame data will not be lost when packet loss occurs.
在本发明实施例中,为了说明方便,以一个数据包只含有一帧为例来进行说明,在这种情况下,无论是“丢包”还是“丢帧”,都意味着那一帧语音数据的失丢,只不过“丢包”是从协议传输层面上来讲,而“丢帧”是从数据层面上来讲。因此,本发明实施例并不对“丢包”以及“丢帧”作严格区分,可以认为“丢包”即意味着出现了“丢帧”,而“丢帧”则意味着是因为“丢包”进而导致了“丢帧”。In this embodiment of the present invention, for the convenience of description, a data packet contains only one frame as an example. In this case, whether it is "packet loss" or "frame loss", it means that the frame of voice Data loss, but "packet loss" is from the protocol transmission level, while "frame loss" is from the data level. Therefore, the embodiment of the present invention does not strictly distinguish between "packet loss" and "frame loss". It can be considered that "packet loss" means "frame loss" and "frame loss" means that "packet loss" ” which in turn leads to “dropped frames”.
需要指出的是,如果一个包中包含有多个属于同一用户的帧时,只需通过解析出包中的多个帧数据即可,本发明实施例中其余步骤也完全对这种情况适用,后续恢复步骤都可以参考一个包只包含一个帧情况的步骤进行。此外,如果一帧数据由多个包构成,则只需要解析多个包后得到该帧数据,后续步骤也可以参考一个包只包含一个帧情况的步骤进行。It should be pointed out that if a packet contains multiple frames belonging to the same user, it only needs to parse out the multiple frame data in the packet, and the remaining steps in the embodiment of the present invention are also completely applicable to this situation. Subsequent recovery steps can be performed with reference to the steps in the case that a packet contains only one frame. In addition, if a frame of data consists of multiple packets, it is only necessary to parse the multiple packets to obtain the frame of data, and the subsequent steps can also be performed by referring to the steps in the case of a packet containing only one frame.
本发明实施例中,解析包的过程由具体的传输协议进行定义,解析后得到的包中的净荷(Payload)部分一般就是有效的帧数据。In the embodiment of the present invention, the process of parsing the packet is defined by a specific transmission protocol, and the payload (Payload) part of the packet obtained after parsing is generally valid frame data.
S302、判断是否有帧丢失,如果是,执行步骤S303,否则,执行步骤S308、解参数后得到特征参数,更新缓存的特征参数;后续执行步骤S307、按正常帧的处理流程来进行处理。S302, judge whether there is a frame loss, if yes, execute step S303, otherwise, execute step S308, obtain the characteristic parameters after solving the parameters, and update the cached characteristic parameters; subsequently execute step S307, and process according to the normal frame processing flow.
其中,步骤S308中,用于对帧进行解参数,得到特征参数,并更新缓存的特征参数。这里“缓存的特征参数”是指在系统开辟的一块缓存区域中存储的之前帧的特征参数;因为构建当前帧的特征参数需要用到相邻帧的特征参数,因此,需要将这些相邻帧进行解参数后进行缓存。缓存的大小可以视恢复时使用到的帧数而定,例如,在恢复丢失帧时,需要用到丢失帧前面3帧的特征参数来构建丢失帧的特征参数,则可以缓存3帧或3帧以上(具体可视实际用而定)的特征参数。当本次有新数据时,更新缓存区,丢弃掉最老的数据,得到最近的一帧或几帧数据的特征参数。Wherein, in step S308, it is used to deparameterize the frame to obtain characteristic parameters, and update the cached characteristic parameters. Here "cached characteristic parameters" refers to the characteristic parameters of the previous frame stored in a cache area opened by the system; because the characteristic parameters of the current frame need to use the characteristic parameters of the adjacent frames, therefore, these adjacent frames need to be Cache after solving parameters. The size of the cache can depend on the number of frames used for recovery. For example, when recovering a lost frame, the feature parameters of the 3 frames before the lost frame need to be used to construct the feature parameters of the lost frame, and then 3 or 3 frames can be cached The characteristic parameters above (depending on actual use). When there is new data this time, the buffer area is updated, the oldest data is discarded, and the characteristic parameters of the latest frame or frames of data are obtained.
需要说明的是,本发明实施例中,缓存的数据是解参数后得到的特征参数,实现使用中,也可以缓存帧数据,在需要进行帧恢复时,取出缓存的帧数据,再进行解参数,得到相应的特征参数。这两种方法都有各自的特点,当采用缓存特征参数时,在每一次收到正常帧时都需要执行解参数的步骤,会增加平均资源消耗,但在对丢失帧进行恢复时,可以直接使用缓存的特征参数,不再执行解参数的动作,此时就会降低峰值的资源消耗;而采用缓存帧的方法时,在收到正常帧时并不需要执行解参数,会降低平均资源消耗,但在恢复过程中,需要进行解参数,并执行恢复算法,会增加峰值的资源消耗。在系统设计过程当中,设计指标一般都会以峰值的资源消耗作为参考,如系统总的资源为12,每个用户在峰值时消耗为4,则可以设计3路用户,如果用户峰值资源消耗为2,则可以设计6路用户。而本发明实施例中,使用缓存解参数的方法,可以使得在恢复过程中不需要再进行解参数,从而降低系统在峰值的资源消耗,以便更好地满足系统设计需求。It should be noted that, in the embodiment of the present invention, the cached data is the characteristic parameter obtained after solving the parameters. During the implementation, the frame data can also be cached. When frame recovery is required, the cached frame data is taken out, and then the parameters are solved. , to get the corresponding characteristic parameters. These two methods have their own characteristics. When the cache feature parameters are used, the step of solving the parameters needs to be performed every time a normal frame is received, which will increase the average resource consumption. However, when recovering the lost frame, it can be directly Using the cached characteristic parameters, no longer perform the action of solving the parameters, and the peak resource consumption will be reduced at this time; while using the method of caching frames, it is not necessary to execute the solution parameters when receiving normal frames, which will reduce the average resource consumption , but in the recovery process, it is necessary to solve the parameters and execute the recovery algorithm, which will increase the peak resource consumption. During the system design process, the design indicators generally use the peak resource consumption as a reference. For example, if the total system resources are 12, and each user consumes 4 at the peak, then 3 users can be designed. If the user peak resource consumption is 2 , you can design 6-way users. However, in the embodiment of the present invention, using the method of caching solution parameters can make it unnecessary to perform parameter solution during the recovery process, thereby reducing the resource consumption of the system at the peak, so as to better meet the system design requirements.
判断的具体方法可以参见实施例一中的相关描述,例如,通过序号、时间戳等方法来进行判断。For the specific method of judging, please refer to the relevant description in Embodiment 1, for example, judging by serial number, time stamp and other methods.
S302′、确定进入的模式;具体的方法可以参见上述实施例二,在此不再赘述;该步骤为可选步骤,实际应用中也可以不进行判断,而直接进入某一种模式,使用前一帧(前几帧)和/或后一帧(后几帧)的特征参数来恢复。S302', determine the mode to enter; the specific method can refer to the second embodiment above, and will not be repeated here; this step is an optional step, and it is not necessary to judge in actual applications, but directly enter a certain mode, before use The feature parameters of one frame (the first few frames) and/or the next frame (the last few frames) are restored.
S303、确定丢失帧的类型;S303. Determine the type of the lost frame;
具体的,通过与丢失帧相邻的帧(相邻帧)来确定丢失帧的类型。Specifically, the type of the lost frame is determined from frames adjacent to the lost frame (adjacent frames).
参见表1,本发明实施例基于实施一步骤S101中介绍的帧类型确定方法给出了一种基于AMR-NB编码的帧类型确定方法。Referring to Table 1, the embodiment of the present invention provides a frame type determination method based on AMR-NB coding based on the frame type determination method introduced in step S101.
表1AMR-NB帧类型确定对应表Table 1 AMR-NB frame type determination correspondence table

表1中,第一列为系统所处的工作模式,即对应实施例二中的非延时模式以及延时模式;第二、第三列为在各种模式下丢失帧前一帧以及后一帧的类型,采用非延时模式时,后一帧类型为空;最后一列为根据前一帧,或者根据前一帧以及后一帧后确定的丢失帧类型。In Table 1, the first column is the working mode of the system, which corresponds to the non-delay mode and the delay mode in the second embodiment; the second and third columns are the previous frame and the subsequent frame lost in various modes The type of a frame. When the non-delay mode is used, the type of the next frame is empty; the last column is the type of the lost frame determined according to the previous frame, or according to the previous frame and the next frame.
具体的,以RX_SPEECH打头的为话音帧,包括RX_SPEECH_GOOD、RX_SPEECH_DEGRADED及RX_SPEECH_BAD等类型,表中的RX_SPEECH_xxx包括上述三种类型;Specifically, voice frames starting with RX_SPEECH include types such as RX_SPEECH_GOOD, RX_SPEECH_DEGRADED, and RX_SPEECH_BAD, and RX_SPEECH_xxx in the table includes the above three types;
以RX_SID打头的为信号帧,包括RX_SID_FIRST、RX_SID_UPDATE及RX_SID_BAD等类型,表中RX_SID_xxx包括上述三种类型;The signal frame starting with RX_SID includes RX_SID_FIRST, RX_SID_UPDATE and RX_SID_BAD and other types. RX_SID_xxx in the table includes the above three types;
此外,RX_NO_DATA表示静音帧;In addition, RX_NO_DATA indicates a silent frame;
通过本发明实施例中的表格中的对应关系,可以根据前一帧(或结合后一帧)的类型来决定丢失帧的类型,例如,在非延时模式下,如果前一帧类型为RX_SPEECH_xxx类型,则丢失帧类型为RX_SPEECH_GOOD(尽量以好帧类型去恢复,以得到更好的效果);在延时模式下,如果前一帧类型为RX_SPEECH_xxx,后一帧类型为RX_SID_xxx,则丢失帧类型为RX_SPEECH_GOOD。Through the corresponding relationship in the table in the embodiment of the present invention, the type of the lost frame can be determined according to the type of the previous frame (or combined with the next frame), for example, in the non-delay mode, if the previous frame type is RX_SPEECH_xxx type, the lost frame type is RX_SPEECH_GOOD (try to recover with a good frame type to get better results); in the delay mode, if the previous frame type is RX_SPEECH_xxx and the next frame type is RX_SID_xxx, the lost frame type is RX_SPEECH_GOOD.
需要说明的是,上述表格只是本实施例中的一个具体实现形式,具体的需要用到的相邻帧个数(如不采用一帧数据,而采用前几帧和/或后几帧)以及具体定义方法(如前一帧为RX_SPEECH_DEGRADED时,丢失帧不为RX_SPEECH_GOOD,而是RX_SPEECH_DEGRADED)都不限定。It should be noted that the above table is only a specific implementation form in this embodiment, and the specific number of adjacent frames to be used (such as not using one frame of data, but using the first few frames and/or the next few frames) and The specific definition method (for example, when the previous frame is RX_SPEECH_DEGRADED, the lost frame is not RX_SPEECH_GOOD, but RX_SPEECH_DEGRADED) is not limited.
通过对帧类型的确定,后续可以对类型为话音帧的丢失帧进行恢复;而对于信号帧以及静音帧,本发明实施例可以不需要通过恢复算法进行恢复(即可认为没发生丢帧),后续由其他后级单元通过噪声补偿等方法来实现数据恢复,在此并不赘述。By determining the frame type, the lost frame of the voice frame type can be recovered subsequently; and for the signal frame and the silent frame, the embodiment of the present invention does not need to recover through the recovery algorithm (that is, it can be considered that no frame loss occurs), Subsequent data recovery is implemented by other subsequent units through methods such as noise compensation, which will not be described in detail here.
S304、获取相邻帧的特征参数;S304. Acquiring characteristic parameters of adjacent frames;
通过对相关的相邻帧进行解参数,获取相邻帧的特征参数;解参数的具体方法可以通过AMR-NB解码器来完成,AMR-NB解码器基于CELP模型,生成的特征参数主要包括LSF/LSP、基音延迟、自适应码书增益、固定码书增益等。The characteristic parameters of the adjacent frames are obtained by deparameterizing the relevant adjacent frames; the specific method of deparameterization can be completed by the AMR-NB decoder, which is based on the CELP model, and the generated characteristic parameters mainly include LSF /LSP, pitch delay, adaptive codebook gain, fixed codebook gain, etc.
S305、构建与丢失帧类型相符的特征参数;S305. Construct characteristic parameters that match the type of the lost frame;
即通过根据相邻帧的特征参数以及多个帧中编码数据特征信息之间的相关性,构建与丢失帧类型相符的特征参数。That is, according to the characteristic parameters of adjacent frames and the correlation between the characteristic information of encoded data in multiple frames, the characteristic parameters consistent with the type of the lost frame are constructed.
例如,以构建丢失帧的LSF参数为例,假设丢失帧的LSF参数为LSF(n),选取该帧前N帧以及后一帧相邻帧的LSF参数进行构建,则前N帧及后一帧的LSF参数分别为LSF(n-N)、LSF(n-N+1)...LSF(n-1)以及LSF(n+1),总共N+1个值;这里的n可以为整数,N可以为正整数;则可以通过如下公式进行恢复:For example, taking the construction of the LSF parameters of the lost frame as an example, assuming that the LSF parameters of the lost frame are LSF(n), and selecting the LSF parameters of the previous N frames of the frame and the adjacent frames of the next frame to construct, then the previous N frames and the next frame The LSF parameters of the frame are LSF(n-N), LSF(n-N+1)...LSF(n-1) and LSF(n+1), with a total of N+1 values; n here can be an integer, N can be a positive integer; then it can be restored by the following formula:
其中,公式中的mean_lsf表示经过大量语音数据训练得到的LSF平均值(即取大量数据的LSF参数的平均值);fac(n)为影响因子(也可认为是“加权系数”),其值也由大量语音数据训练得到,例如,想确定fac(1)时,可以先取一段大量的语音数据,如1000帧,然后,假设第1帧丢失,此时,先取fac(1)为其中一个数,利用公式恢复出第1帧的LSF参数后,与真实的第1帧LSF参数值做差,此时,一般差值都会较大;然后,再继续调整fac(1)为另一个数,再算LSF参数,再与真实值做差,如此反复,直到通过公式逼近的第1帧LSF参数与真实的LSF参数差在一个阈值范围内,则此时fac(1)即为训练后得到的fac(1)值。同理,其余影响因子也可以通过类似方法进行确定。Among them, mean_lsf in the formula represents the average value of LSF obtained through a large amount of speech data training (that is, the average value of LSF parameters obtained by taking a large amount of data); It is also trained by a large amount of speech data. For example, when you want to determine fac(1), you can first take a large amount of speech data, such as 1000 frames, and then assume that the first frame is lost. At this time, first take fac(1) as one of the numbers , after using the formula to recover the LSF parameters of the first frame, make a difference with the real LSF parameter value of the first frame. Calculate the LSF parameters, and then make a difference with the real value, and so on, until the difference between the first frame LSF parameters approximated by the formula and the real LSF parameters is within a threshold range, then fac(1) at this time is the fac obtained after training (1) Value. Similarly, other impact factors can also be determined by similar methods.
需要说明的是,上述公式及各参数及实现形式并不唯一,例如,可以取不同数量的相邻帧,或者使用其他加权的方法,只要能利用各帧相关性来构建丢失帧的算法都可以。It should be noted that the above formulas, parameters and implementation forms are not unique. For example, different numbers of adjacent frames can be used, or other weighting methods can be used, as long as the correlation of each frame can be used to construct an algorithm for missing frames. .
再次,以需要构建出丢失帧的基音延迟参数时,首先需要得到前后帧的基音周期,然后再生成基音延迟,其中,如果根据基音周期生成基音延迟的方法为本领域技术人员熟知的技术,在此不再赘述。Again, when it is necessary to construct the pitch delay parameter of the lost frame, it is first necessary to obtain the pitch periods of the preceding and following frames, and then generate the pitch delay. Wherein, if the method of generating the pitch delay according to the pitch period is a technique well known to those skilled in the art, in This will not be repeated here.
在获取基音周期时,由于语音的基音周期具有较好的平稳性,因此,可以利用丢失帧前几帧和后几帧的变化趋势来判断丢失帧基音的几种变化趋势。这里以丢失帧前两帧和后一帧为例来判断丢失帧基音的5种变化趋势(快速上升,快速下降,平稳上升,平稳下降,持平)。When acquiring the pitch period, since the pitch period of speech has good stability, several changing trends of the pitch of the lost frame can be judged by using the changing trend of several frames before and after the lost frame. Here we take the first two frames and the next frame of the lost frame as an example to judge the 5 changing trends of the pitch of the lost frame (rapid rise, fast fall, steady rise, steady fall, and flat).
假设丢失帧的基音周期为Delay(n),(n为整数),丢失帧前两帧的基音周期为Delay(n-2),Delay(n-1),丢失帧后一帧的基音周期为Delay(n+1),则构建丢失帧基音周期的方法如下:Assume that the pitch period of the lost frame is Delay(n), (n is an integer), the pitch periods of the two frames before the lost frame are Delay(n-2), Delay(n-1), and the pitch period of the frame after the lost frame is Delay(n+1), the method of constructing the pitch period of the lost frame is as follows:
首先,判决定上升还是上降:如果丢失帧前一帧的基音周期大于丢失帧后一帧的基音周期(即Delay(n-1)-Delay(n+1)>0),则判决为下降情况;如果小于0,则为上升情景;如果等于0,则为持平情景。First, determine whether to rise or fall: if the pitch period of the frame before the lost frame is greater than the pitch period of the frame after the lost frame (ie Delay(n-1)-Delay(n+1)>0), the decision is to fall Scenario; if less than 0, it is an up-scenario; if equal to 0, it is a flat-scenario.
其次,判断变化趋势是快速还是平稳:如果丢失帧前两帧的基音周期差值的绝对值Delay_abs(Delay_abs=|Delay(n-2)-Delay(n-1)|)大于等于设定的门限值Delay_set,则判断为快速变化,否则,判断为平稳变化;门限值的设定并不限定,可以根据实际情况进行调整。Secondly, judge whether the change trend is fast or stable: if the absolute value of the pitch period difference Delay_abs(Delay_abs=|Delay(n-2)-Delay(n-1)|) of the two frames before the lost frame is greater than or equal to the set gate The limit value Delay_set is judged to be a rapid change, otherwise, it is judged to be a steady change; the setting of the threshold value is not limited, and can be adjusted according to the actual situation.
最后,根据分类结果进行恢复,具体的:Finally, restore according to the classification results, specifically:

实际应用过程中,由于解码出的基音周期分为整数基音周期T0和分数基音周期T0_frac两部分(分数基音周期的变化单位为1/3或1/6个整数基音周期单位),为了取得更好的构建效果,在快速变化时,还可以以整数基音为单位套用公式2,用T0套用公式2后,得到的公式如下:In the actual application process, since the decoded pitch period is divided into two parts, the integer pitch period T0 and the fractional pitch period T0_frac (the change unit of the fractional pitch period is 1/3 or 1/6 integer pitch period units), in order to obtain better The construction effect of , in the case of rapid changes, formula 2 can also be applied in units of integer pitches. After applying formula 2 with T0, the obtained formula is as follows:
(公式3) (Formula 3)
本发明实施例中,构建丢失帧恢复自适应码书增益以及固定码书增益的方法与上述需要构建出丢失帧的基音周期的方法类型,也是先判断上升或下降,再判断平稳或快速,最后参考前后帧参数进行构建,在此不再赘述。In the embodiment of the present invention, the method of constructing the lost frame recovery adaptive codebook gain and the fixed codebook gain is the same as the above-mentioned method that needs to construct the pitch period of the lost frame. Refer to the front and rear frame parameters for construction, so I won’t repeat them here.
由于丢失帧的类型不同,因此,需要构建的与其类型相符的特征参数也不同。参见图6,为本发明实施例AMR-NB基于不同的帧类型对丢失帧特征参数进行恢复的方法,包括:Since the types of lost frames are different, the feature parameters that need to be constructed to match the types are also different. Referring to FIG. 6, it is a method for recovering characteristic parameters of lost frames based on different frame types by AMR-NB according to an embodiment of the present invention, including:
S351、判断帧的类型;当为RX_SPEECH_GOOD时,执行步骤S352;当为RX_SID_FIRST时,执行步骤S352′;当为RX_NO_DATA时,不进行丢帧恢复操作,直接透传至后级,由后级(相对于丢失帧恢复这一级)处理单元来完成相应的操作;S351, judge the type of frame; when it is RX_SPEECH_GOOD, execute step S352; when it is RX_SID_FIRST, execute step S352′; when it is RX_NO_DATA, do not carry out the lost frame recovery operation, directly transparently transmit to the subsequent stage, by the latter stage (relatively At the level of lost frame recovery) processing unit to complete the corresponding operation;
S352、构建LSF参数;S352. Construct LSF parameters;
S353、构建基音延迟参数;S353. Construct pitch delay parameters;
S354、构建自适应码书增益以及固定码书增益参数;S354. Construct an adaptive codebook gain and a fixed codebook gain parameter;
S352′、构建LSF参数,与S352类似,也构建LSF参数,只是此处针对RX_SID_FIRST帧;S352', constructing LSF parameters, similar to S352, also constructing LSF parameters, only for the RX_SID_FIRST frame here;
从以上步骤可看到,当帧类型为RX_SPEECH_GOOD时,需要构建LSF、基音延迟、自适应码书增益以及固定码书增益等与该帧类型相符的特征参数;而当帧类型为RX_SID_FIRST时,只需构建LSF特征参数。其中,上述各参数的具体恢复方法在本实施例中相应部分已经进行描述,在此不再赘述。From the above steps, it can be seen that when the frame type is RX_SPEECH_GOOD, it is necessary to construct LSF, pitch delay, adaptive codebook gain and fixed codebook gain, etc. The LSF feature parameters need to be constructed. Wherein, the specific restoration methods of the above parameters have been described in corresponding parts in this embodiment, and will not be repeated here.
在构建与丢失帧类型相符的特征参数后,继续执行如下步骤:After constructing the feature parameters that match the type of lost frame, proceed to the following steps:
S306、对丢失帧特征参数进行编码得到恢复后的新帧;S306. Encode the characteristic parameters of the lost frame to obtain a restored new frame;
即对构建的丢失帧的特征参数进行编码,得到恢复后的新帧;编码由系统的编码器来完成。That is, the characteristic parameters of the constructed lost frame are encoded to obtain the restored new frame; the encoding is completed by the encoder of the system.
S307、执行正常帧处理流程。S307. Execute a normal frame processing flow.
恢复后的新帧可认为是正常帧,后续执行正常帧的处理流程;当步骤S302判断没有帧丢失时,执行步骤S308后也执行该步骤。The restored new frame can be regarded as a normal frame, and the processing flow of the normal frame is subsequently executed; when step S302 judges that no frame is lost, this step is also executed after step S308 is executed.
本发明实施例中,通过利用相邻帧的类型与特征参数来恢复丢失帧,由于解参数过程相比于完全解码到波形域的过程所消耗的资源要少得多,因此,通过本发明实施例恢复方法可以大大降低系统消耗的资源,在网络条件较差,存在很多丢失帧的情况下,这种效果更加明显。In the embodiment of the present invention, the lost frame is recovered by using the type and characteristic parameters of adjacent frames, since the deparameterization process consumes much less resources than the process of fully decoding to the waveform domain, therefore, through the implementation of the present invention The example recovery method can greatly reduce the resources consumed by the system, and this effect is more obvious when the network condition is poor and there are many lost frames.
此外,本发明实施例还通过设定两种模式(延迟模式以及非延迟模式),在系统运行时,可以根据实际情况自动选择或者通过人工手动配置进入哪种模式,满足了不同场景下对传输质量及传输时延的要求。In addition, the embodiment of the present invention also sets two modes (delay mode and non-delay mode). When the system is running, which mode can be automatically selected according to the actual situation or manually configured to meet the needs of transmission in different scenarios. Quality and transmission delay requirements.
实施例四Embodiment four
本发明实施例基于上述实施例对丢失帧进行恢复的基础上,通过结合其他参数域的语音增强技术以达到更好的语音增强效果。In the embodiment of the present invention, on the basis of recovering the lost frame in the foregoing embodiments, a better speech enhancement effect is achieved by combining speech enhancement technologies in other parameter domains.
参见图7,本发明实施例在基于丢失帧恢复的基础上,还通过其他参数域语音增强方法来实现语音增强,即对经过丢帧恢复后的语音帧再进行解参数,得到特征参数,根据得到的特征参数进行语音增强。Referring to FIG. 7 , the embodiment of the present invention implements speech enhancement through other parameter domain speech enhancement methods on the basis of lost frame recovery, that is, deparameterizes the speech frame after lost frame recovery to obtain characteristic parameters, according to The obtained feature parameters are used for speech enhancement.
如图7所示,这里本发明实施例应用在网络中间网元设备中的示意图,在该设备中,接收到的码流可分为上行码流以及下行码流。其中,上行处理过程中,在丢失帧恢复后,可以先对信号进行分类,然后根据分类结果执行后续AEC、ANR、ACLP以及ALC各语音增强功能模块的处理流程。其中,上述各功能模块的含义如下:As shown in FIG. 7 , here is a schematic diagram of an embodiment of the present invention applied to an intermediate network element device in a network. In this device, a received code stream can be divided into an uplink code stream and a downlink code stream. Wherein, during the uplink processing, after the lost frame is recovered, the signal may be classified first, and then the subsequent processing procedures of the speech enhancement function modules of AEC, ANR, ACLP and ALC are executed according to the classification result. Among them, the meanings of the above functional modules are as follows:
AEC(Acoustic Echo Control,自动回声控制);AEC (Acoustic Echo Control, automatic echo control);
ANR(Automatic Noise Reduction,自动噪声抑制);ANR (Automatic Noise Reduction, automatic noise suppression);
ACLP(Anti-clip,抗削波);ACLP (Anti-clip, anti-clipping);
ALC(Automatic Level Control,自动电平控制);ALC (Automatic Level Control, automatic level control);
需要说明的是,本发明实施例各语音增强步骤之间用虚线箭头连接仅表示后续可能执行这些步骤中的一个或多个(按箭头顺序),并不代表后续某个功能模块的输出是另一个的输入,如上行处理过程中,AEC的输出并不代表ANR的输入。It should be noted that, in the embodiments of the present invention, the speech enhancement steps are connected by dotted arrows only to indicate that one or more of these steps may be executed in the future (according to the order of the arrows), and it does not mean that the output of a certain subsequent functional module is another One input, such as the uplink processing, the output of AEC does not represent the input of ANR.
下行处理过程与上行处理过程类似,在进行丢失帧恢复后,先对信号进行分类,然后根据分类结果执行后续ANR、ACLP、ALC以及ANC中的一个或多个功能模块的处理流程。其中,ANR、ALP、ALC的定义在文已经介绍,在些不再赘述;这里的ANC表示Automatic Noise Compensation,即自动噪声补偿。The downlink processing process is similar to the uplink processing process. After the lost frame is recovered, the signal is first classified, and then the subsequent processing flow of one or more functional modules in ANR, ACLP, ALC, and ANC is executed according to the classification result. Among them, the definitions of ANR, ALP, and ALC have been introduced in the text, and will not be repeated here; ANC here means Automatic Noise Compensation, that is, automatic noise compensation.
本发明实施例中,上下行的处理并不完全相同,例如,考虑到回声主要来自于终端侧,因此,上行过程当中增加了AEC模块,而下行中并没有增加AEC模块。当然,实际使用中也可以使用相同的处理方法,在此并不限定。另外,上下行也可以使用其中一种或多种语音增强方法,如上行只使用AEC,下行只使用ACL等。In the embodiment of the present invention, the uplink and downlink processes are not completely the same. For example, considering that the echo mainly comes from the terminal side, an AEC module is added in the uplink process, but not in the downlink process. Of course, the same processing method can also be used in actual use, which is not limited here. In addition, one or more voice enhancement methods can also be used in the uplink and downlink, such as only AEC in the uplink and ACL in the downlink.
当上行或下行需要使用多种增强处理方式时,可以根据每个功能模块处理方式的特点对处理顺序进行排序。例如,AEC用于回声控制,一般放在最前面,这样可以先去掉回声,否则,信号在处理过程当中始终会带着回声,在进行信号增强时会把回声也增强了,给后续回声控制增加难度;而ALC一般放在最后,这是因为ALC用于将语音的幅值调到目标范围内,如果放在前面,则后续其他模块处理后,又会引起语音幅值的变化,还得进行ALC调整,浪费了前面一次ALC处理过程。When multiple enhanced processing methods are required for the uplink or downlink, the processing order can be sorted according to the characteristics of the processing methods of each functional module. For example, AEC is used for echo control, and it is generally placed at the front, so that the echo can be removed first, otherwise, the signal will always carry echo during the processing process, and the echo will be enhanced when the signal is enhanced, which will increase the subsequent echo control. Difficulty; and ALC is generally placed at the end, because ALC is used to adjust the amplitude of the voice to the target range. If it is placed in the front, the subsequent processing of other modules will cause changes in the amplitude of the voice, and it has to be carried out The ALC adjustment wastes the previous ALC processing.
此外,还需要说明的是,上下行的数据可以是独立的,也可以是相关的(即其中有些数据需要相互交互),当上下行的数据是独立时,完全可以只使用上行模块或者下行模块;或者,如果实际应用只需要处理上行或下行数据,则本发明实施例可以只设置对应的上行或下行处理模块。In addition, it should be noted that the uplink and downlink data can be independent or related (that is, some of the data needs to interact with each other). When the uplink and downlink data are independent, only the uplink module or the downlink module can be used. ; Or, if the actual application only needs to process uplink or downlink data, the embodiment of the present invention may only set the corresponding uplink or downlink processing module.
为了更好地对信号分类进行说明,下面结合图8来进行详细阐述。参见图8,为本发明实施例进行信号分类处理的一个示意图,本发明实施例中,输入的码流首先通过一个信号分类器,区分是静音、噪声、语音、音乐、回声以及信号音中的哪种,实际应用中,用户也可以添加其他自定义的分类,或者删除一些分类。信号分类器区分是哪种信号可以通过分析各种特征参数来得到,例如,如果分析到某些帧没有能量,则可以判决为静音;如果某些帧的参数符合话音帧或音乐帧的特征,则可以判决为话音帧或音乐帧。In order to better describe the signal classification, it will be described in detail below in conjunction with FIG. 8 . Referring to FIG. 8 , it is a schematic diagram of signal classification processing in the embodiment of the present invention. In the embodiment of the present invention, the input code stream first passes through a signal classifier to distinguish between silence, noise, voice, music, echo and signal tones. Which, in practical applications, users can also add other custom categories, or delete some categories. The signal classifier distinguishes which kind of signal can be obtained by analyzing various characteristic parameters. For example, if it is analyzed that some frames have no energy, it can be judged as silent; if the parameters of some frames conform to the characteristics of speech frames or music frames, Then it can be judged as a speech frame or a music frame.
当由信号分类器确定是哪种类型后,送到相应的功能模块进行处理,例如,当确定是静音或噪声后,通过噪声电平跟踪后送到ANR功能模块进行处理;当确定是语音或音乐时,通过语音电平跟踪送至ALC以及ANC功能模块进行处理;需要说明的是,这里为了方便将噪声电平跟踪以及语音电平跟踪以单独的模块形式呈现,实际应用中,噪声电平跟踪以及语音电平跟踪都由分别由ANC,ALC或ANC内部实现,例如ALC和ANC每个单元内部都有一个语音电平跟踪功能模块来实现对语音电平的跟踪;当确定是回声时,直接送到AEC进行处理;当收到的是信号音时,不进行处理,直接输出。各功能模块具体处理步骤可以参考上述描述,在此不再赘述。When the type is determined by the signal classifier, it is sent to the corresponding functional module for processing. For example, when it is determined to be silence or noise, it is sent to the ANR function module for processing after tracking through the noise level; when it is determined to be voice or During music, it is sent to the ALC and ANC functional modules for processing through voice level tracking; Tracking and voice level tracking are implemented by ANC, ALC or ANC respectively. For example, each unit of ALC and ANC has a voice level tracking function module to track the voice level; when it is determined that it is an echo, It is directly sent to AEC for processing; when the received signal tone is not processed, it is directly output. For the specific processing steps of each functional module, reference may be made to the above description, which will not be repeated here.
本发明实施例中,与丢失帧恢复处理方法类似,每个功能模块的处理也在参数域进行,通过缓存的解参数后得到的相关特征参数并通过一定的算法进行恢复,算法实现过程中,也可以利用一些相邻帧的相关性并引入一定的经验值或影响因子,使得恢复结果更加准确。In the embodiment of the present invention, similar to the lost frame recovery processing method, the processing of each functional module is also carried out in the parameter domain, and the relevant characteristic parameters obtained after the cached solution parameters are restored through a certain algorithm. During the algorithm implementation process, It is also possible to use the correlation of some adjacent frames and introduce a certain experience value or impact factor to make the restoration result more accurate.
例如,以ACLP(抗削波)处理为例,参见图9,包括如下步骤:For example, take ACLP (anti-clipping) processing as an example, see Figure 9, including the following steps:
S401、削波状态识别;S401, clipping state recognition;
具体的,可以基于缓存的帧得到出现削波帧的比例,当比例达到一定阈值,认为需要进行削波处理;其中,削波帧的判断方法通过解参数后得到的特征参数来判断,例如,可以通过固定码书增益或自适应码书增益等参数来判断能量是否溢出(即是否超过一定阈值),如果是,则判断为削波帧。Specifically, the ratio of clipped frames can be obtained based on the cached frames. When the ratio reaches a certain threshold, it is considered that clipping processing is required; wherein, the judgment method of clipped frames is judged by the characteristic parameters obtained after solving the parameters, for example, Whether the energy overflows (that is, exceeds a certain threshold) can be judged by parameters such as the fixed codebook gain or the adaptive codebook gain, and if so, it is judged as a clipping frame.
S402、判断当前帧是否为削波;S402. Determine whether the current frame is clipping;
在进行削波状态识别后,如果状态是需要进行削波处理,则后续针对每一帧判断是否为削波判断后输出三种结果,分别为否、弱、以及强;After the clipping state is identified, if the state needs to be clipped, then three results are output after judging whether it is clipping for each frame, which are no, weak, and strong;
如果为否,执行步骤S403;如果为弱,执行步骤S404;如果为强,执行步骤S405;If not, execute step S403; if weak, execute step S404; if strong, execute step S405;
S403、更新缓存的正常帧参数;S403. Update the cached normal frame parameters;
如果为否,则进行透传处理,不需要恢复,更新完缓存的正常帧参数即可;If not, perform transparent transmission processing, no need to restore, just update the cached normal frame parameters;
S404、削波恢复因子弱更新;后续执行步骤S406;S404. Weakly update the clipping recovery factor; follow up with step S406;
这里的削波恢复因子是指跟恢复有关的影响因子,类似于实施例三中在进行丢失帧LSF参数构建时公式中的影响因子fac(),这里的削波恢复因子也是一个经验值,用于决定削波恢复的程度,例如,如果削波增益只超阈值一点点,则恢复时也只需要将削波增益减少一点点,此时,削波恢复因子就可以设得平稳一些(即变化不需要太大);反之,如果削波情况比较严重,恢复时需要将削波增益大大减少,则此时需要将削波恢复因子设得剧烈一些(即变化需要大一点)。The clipping recovery factor here refers to the impact factor related to recovery, similar to the impact factor fac () in the formula when the lost frame LSF parameter is constructed in the third embodiment, the clipping recovery factor here is also an empirical value, used It depends on the degree of clipping recovery. For example, if the clipping gain is only a little bit higher than the threshold value, it is only necessary to reduce the clipping gain a little bit during recovery. At this time, the clipping recovery factor can be set to be stable (that is, the change Conversely, if the clipping is serious and the clipping gain needs to be greatly reduced during recovery, then the clipping recovery factor needs to be set a little more violently (that is, the change needs to be larger).
当判断为“弱”时,表示虽然有削波发生,但不是非常严重,因此,弱更新时,削波恢复因子可以选择一个比较平稳的值。When it is judged as "weak", it means that although clipping occurs, it is not very serious. Therefore, when the update is weak, the clipping recovery factor can choose a relatively stable value.
S405、削波特征参数强更新;后续执行步骤S406;S405, strong update of the clipping characteristic parameters; subsequent execution of step S406;
与判断为“强”时,表示削波情况比较严重,因此,需要通过强更新来将削波恢复因子设置成一个比较剧烈的值。When it is judged to be "strong", it indicates that the clipping situation is relatively serious. Therefore, it is necessary to set the clipping recovery factor to a relatively severe value through strong update.
S405、进行削波恢复;S405. Perform clipping recovery;
削波恢复因子更新后,便可以根据削波恢复因子以及解参数后得到的一些特征参数(如自适应码书增益、固定码书增益等)来进行削波恢复。通过上述步骤,即可以得到进行削波恢复,在进行其他处理时(如AEC、ALC),也可以利用参数域中的特征参数并结合一些影响因子通过一定的算法来实现各种对应的功能。After the clipping recovery factor is updated, the clipping recovery can be performed according to the clipping recovery factor and some characteristic parameters (such as adaptive codebook gain, fixed codebook gain, etc.) obtained after solving the parameters. Through the above steps, clipping recovery can be obtained. When performing other processing (such as AEC, ALC), it is also possible to use the characteristic parameters in the parameter domain and combine some influencing factors to realize various corresponding functions through certain algorithms.
本发明实施例通过在对丢失帧恢复的基础上,通过分类器判断信号属于哪种类型,并进行相应的处理,可以针对不同类型进行相应的处理,从而进一步提升了语音质量。In the embodiment of the present invention, on the basis of recovering the lost frame, the classifier determines which type the signal belongs to, and performs corresponding processing, and corresponding processing can be performed for different types, thereby further improving the voice quality.
通过本发明实施例,可以实现对语音进一步的增强,同时,由于也在参数域进行语音增强,因此,也能降低系统消耗的资源;结合前面实施例中的丢帧恢复技术,能取得更好的效果。Through the embodiment of the present invention, it is possible to further enhance the voice. At the same time, since the voice is also enhanced in the parameter domain, the resources consumed by the system can also be reduced; combined with the lost frame recovery technology in the previous embodiment, better results can be obtained. Effect.
同时,本发明实施例当有多个语音增强模块(如AEC、ANC等)时,可以根据实际情况对各增强单元在顺序上进行调整,并且通过信号分类器对信号进行划分,以取得更好的效果。At the same time, when there are multiple speech enhancement modules (such as AEC, ANC, etc.) in the embodiment of the present invention, the order of each enhancement unit can be adjusted according to the actual situation, and the signal can be divided by a signal classifier to obtain better Effect.
实施例五、Embodiment five,
本发明实施例提供了一种丢帧恢复设备51,用于对丢失帧进行恢复,参见图10,包括;An embodiment of the present invention provides a lost
帧信息确定单元511,用于根据与丢失帧相邻的相邻帧类型确定丢失帧的类型;A frame
解参数单元512,用于获取对相邻帧进行解参数后得到的特征参数,该特征参数用于确定帧中编码数据的特征信息;The
特征参数构建单元513,用于根据相邻帧的特征参数以及多个帧中编码数据特征信息之间的相关性,构建与丢失帧类型相符的特征参数;A characteristic parameter construction unit 513, configured to construct a characteristic parameter consistent with the type of the lost frame according to the characteristic parameters of adjacent frames and the correlation between the characteristic information of the encoded data in multiple frames;
恢复单元514,用于根据构建的丢失帧的特征参数恢复丢失帧。A
参见图11,具体的,上述帧信息确定单元511还可以包括丢失帧确定单元5111、帧类型确定单元5112以及丢失帧类型确定单元5113;其中,Referring to FIG. 11, specifically, the frame
丢失帧确定单元5111用于,通过检测收到的帧中的帧序号,或者时间戳确定是否符合预设规则的方法来确定丢失帧及与相邻帧;The lost
帧类型确定单元5112用于,通过帧中相关标志位确定帧的类型;The frame
丢失帧类型确定单元5113用于,根据相邻帧类型确定丢失帧类型,其中,相邻帧的类型可由帧类型确定单元5112来完成,而丢失帧的确定可由丢失帧确定单元5111来完成;The lost frame
参见图12,上述语音增强设备还可以包括:Referring to Fig. 12, the above-mentioned speech enhancement device may also include:
模式选择单元515,用于当丢失帧确定单元确定有丢失帧且需要恢复时,判断是否进入延时模式,如果是,则特征参数构建单元513使用前后帧的特征参数进行恢复,此时,相邻帧包括前后帧;否则,进入非延时模式,特征参数构建单元513使用前帧的特征参数进行恢复,此时,相邻帧指前帧。The
上述各单元具体执行的步骤可以参见上述实施例一、二、三中的相关描述,本领域技术人员可以从以上实施例中描述来实现本发明实施例各单元具体执行步骤。For the specific execution steps of the above-mentioned units, refer to the relevant descriptions in the above-mentioned embodiments 1, 2, and 3. Those skilled in the art can realize the specific execution steps of each unit in the embodiment of the present invention from the descriptions in the above embodiments.
参见图13,本发明实施例还可以提供了一种语音增强设备,包括丢帧恢复设备51,还包括以下几个语音增强单元中的一个或多个(也可以全部):Referring to FIG. 13 , an embodiment of the present invention can also provide a speech enhancement device, including a lost
自动回声控制(AEC)单元52,用于自动回声控制;an automatic echo control (AEC)
用于自动噪声抑制(ANR)单元53,用于自动噪声抑制;For Automatic Noise Reduction (ANR)
抗削波(ACLP)单元54,用于抗削波;Anti-clipping (ACLP)
自动电平控制(ALC)单元55,用于自动电平控制;an automatic level control (ALC)
自动噪声补偿(ANC)单元56,用于自动噪声补偿。An automatic noise compensation (ANC)
当有多个单元时,还可以包括:When there are multiple units, you can also include:
分类单元57,用于对输入的信号进行分类,确定信号的类型,并根据确定的类型送至上述一个或多个对应的功能单元进行处理。如果只使用其中一个单元,则可以不使用分类单元,直接根据信号的类型进行相应处理。The
分类单元521及上述AEC、ANR、ACLP、ALC、ANC等单元都是基于参数域进行信号处理,即对码流进行解参数后得到特征参数,根据特征参数对信号进行自动回声控制、自动噪声抑制、抗削波、自动电平控制或者自动噪声补偿中的一种或多种语音增强处理。其具体处理方法可以参见实施例四中的相关说明,本领域技术人员可以根据实施例四中描述来实现各单元的功能,在此不再赘述。The classification unit 521 and the above-mentioned AEC, ANR, ACLP, ALC, ANC and other units are all based on the parameter domain for signal processing, that is, the characteristic parameters are obtained after deparameterizing the code stream, and automatic echo control and automatic noise suppression are performed on the signal according to the characteristic parameters , anti-clipping, automatic level control or automatic noise compensation in one or more speech enhancement processing. For the specific processing method, please refer to the relevant descriptions in Embodiment 4, and those skilled in the art can realize the functions of each unit according to the description in Embodiment 4, and details are not repeated here.
在具体硬件实现上,本发明实施例可以各单元可以通过通用处理器(如DSP、FPGA等)来实现,也可以采用ASIC专用电路来实现,在此并不限定。同时,如果本发明实施例中设备可以是独立的设备,也可以与其他设备进行集成,例如,如果原来有设备中的相应解参数单元(如通过自带解码器实现解参数功能)也可以完成解参数的功能,则本发明实施例解参数单元也可以采用原有设备中的解码单元来完成解参数;如果是独立的设备,则可以通过设计相应的解参数模块来完成需要的功能。In terms of specific hardware implementation, each unit in the embodiment of the present invention can be implemented by a general-purpose processor (such as DSP, FPGA, etc.), or can be implemented by using an ASIC special circuit, which is not limited here. Meanwhile, if the device in the embodiment of the present invention can be an independent device, it can also be integrated with other devices. For the function of parameter resolution, the parameter resolution unit in the embodiment of the present invention can also use the decoding unit in the original device to complete the parameter resolution; if it is an independent device, the required function can be completed by designing a corresponding parameter resolution module.
参见图14,为本发明实施例中一个具体实现的硬件示意图,包括DSP、存储器、接口单元、附属电路等部分;其中,DSP为主要处理芯片,用于运行处理代码,实现上述各单元的功能;存储器用于为程序运行提供所需的存储空间,如DDR、flash等;接口单元用于该设备与其他设备进行通信,如通过串口、以太网或其他接口进行通信;附属电路可以是系统运行所需一些电路,如电源电路,晶振电路、监控电路等,在此不再赘述。Referring to Fig. 14, it is a schematic diagram of a specific implementation of hardware in the embodiment of the present invention, including DSP, memory, interface unit, auxiliary circuit and other parts; wherein, DSP is the main processing chip, which is used to run the processing code and realize the functions of the above-mentioned units ;The memory is used to provide the required storage space for program operation, such as DDR, flash, etc.; the interface unit is used for the device to communicate with other devices, such as communication through serial ports, Ethernet or other interfaces; the auxiliary circuit can be used for system operation Some circuits required, such as power supply circuit, crystal oscillator circuit, monitoring circuit, etc., will not be repeated here.
在图14所示的实施例中,DSP负责所有的程序代码执行,包括对码流进行解参数;在另一个实施例中,如果系统内的其他设备已经带有解参数功能的话,那么DSP可以直接使用该设备解参数后得到的特征参数,而不需要自己再执行解参数。参见图15,为本发明另一实施例DSP直接使用另一设备(如编解码器,也可以用DSP实现)解参数后输出的特征参数示意图。In the embodiment shown in Figure 14, the DSP is responsible for all program code execution, including deparameterizing the code stream; in another embodiment, if other devices in the system have deparameterization function, then the DSP can Directly use the characteristic parameters obtained after solving the parameters of the device, without needing to perform the parameter solving by yourself. Referring to FIG. 15 , it is a schematic diagram of characteristic parameters output after the DSP directly uses another device (such as a codec, which can also be realized by DSP) to solve the parameters according to another embodiment of the present invention.
本发明实施例通过在参数域进行丢失帧恢复,可以降低系统消耗的资源,同时,通过模式选择单元选择不同的模式进行恢复,可以满足系统对延时或质量的要求;并且,本发明实施例还可以加入其他语音增强单元,以达到更好的语音增强效果。The embodiment of the present invention can reduce the resources consumed by the system by recovering the lost frame in the parameter field, and at the same time, select different modes for recovery through the mode selection unit, which can meet the system's requirements for delay or quality; and, the embodiment of the present invention Other voice enhancement units can also be added to achieve better voice enhancement effects.
实施例六Embodiment six
本发明实施例提供了一种语音增强系统,参见图16,包括:An embodiment of the present invention provides a speech enhancement system, see Figure 16, including:
第一基站61,第一终端62;第二基站63,第二终端64;丢帧恢复设备(或语音增强设备)65;A
其中,第一基站61与第一终端62之间通过第一链路66进行连接;第二基站63与第二终端64之间通过第二链路67进行连接;第一基站61与第二基站64之间通过第三链路68进行连接;Wherein, the
其中,丢帧恢复设备(或语音增强设备)65为上述实施例中提供的丢帧恢复设备或语音增强设备(以下统一称为语音增强设备,并不对两者进行严格区分),用于对第一链路、第二链路或者第三链路中的一个或多个环节出现的丢帧进行恢复;或者还可以对码流进行解参数后得到的特征参数,根据特征参数对信号进行自动回声控制、自动噪声抑制、抗削波、自动电平控制或者自动噪声补偿中的一种或多种语音增强处理。Wherein, the frame loss recovery device (or speech enhancement device) 65 is the frame loss recovery device or speech enhancement device provided in the above-mentioned embodiments (hereinafter collectively referred to as the speech enhancement device, and the two are not strictly distinguished), and is used for the first The frame loss in one or more links in the first link, the second link or the third link can be recovered; or the characteristic parameters obtained after deparameterizing the code stream can be automatically echoed to the signal according to the characteristic parameters One or more speech enhancement processes from among control, automatic noise suppression, anti-clipping, automatic level control, or automatic noise compensation.
具体的,语音增强设备根据应用场景不同位于系统中的位置也不同,下面通过几种常用的场景进行介绍。Specifically, the position of the speech enhancement device in the system varies according to different application scenarios, and several commonly used scenarios are introduced below.
参见图17,为全IP组网下TrFO(Transcoder Free Operation,免编解码级联操作)场景应用示意图,包括IP网(图中Internet)以及位于IP网两侧的基站和终端。TrFO的特点在于通信双方(如图中两个终端)采用相同的编码形式,因此,在传输过程当中不需要进行编码转换,都是以码流的形式进行传输(不包括通过Internet传输时打包),这些码流都可以作为本发明实施例中的输入。See Figure 17, which is a schematic diagram of the application of the TrFO (Transcoder Free Operation, codec-free cascading operation) scenario under the all-IP network, including the IP network (Internet in the figure) and base stations and terminals located on both sides of the IP network. The characteristic of TrFO is that the two parties in the communication (the two terminals in the figure) adopt the same encoding form. Therefore, no encoding conversion is required during the transmission process, and all are transmitted in the form of code streams (excluding packaging when transmitting via the Internet) , these code streams can be used as the input in the embodiment of the present invention.
如图17所示,在网络传输过程中,会有几个丢包(丢帧)环节,如丢包环节1表示在IP网络出现丢包;丢包环节2表示终端跟基站上行或下行也会出现丢包的情况。As shown in Figure 17, during network transmission, there will be several packet loss (frame loss) links. For example, packet loss link 1 indicates that packet loss occurs on the IP network; A packet loss occurs.
如图17所示,为了解决IP网络中的丢包环节1导致的丢包情况,将语音增强设备放在位于基站至IP网中的相关网元中,例如,放在BSC(Base StationController,基站控制器)或核心网中的相关网元;As shown in Figure 17, in order to solve the packet loss situation caused by the packet loss link 1 in the IP network, the voice enhancement equipment is placed in the relevant network elements from the base station to the IP network, for example, placed in the BSC (Base Station Controller, base station controller) or related network elements in the core network;
或者,也可以将语音增强设备放在基站或终端中,以解决丢包环节2导致的丢包情况;Alternatively, the voice enhancement device can also be placed in the base station or terminal to solve the packet loss situation caused by the packet loss link 2;
或者也可以在几个位置都增加语音增强设备。Alternatively, speech enhancement devices can be added at several locations.
参见图18,为另一应用语音增强设备的系统示意图,图18所示的应用场景为TFO(Tandem Free Operation,免级联操作),在TFO应用场景中,两侧终端对应的编码类型也相同,在传输过程中不需要进行编码转换,都以码流的形式进行传输,这些码流也可以作为语音增强设备的输入。Refer to Figure 18, which is a schematic diagram of another application of voice enhancement equipment. The application scenario shown in Figure 18 is TFO (Tandem Free Operation, cascading-free operation). In the TFO application scenario, the encoding types corresponding to the terminals on both sides are also the same , there is no need for code conversion in the transmission process, and they are all transmitted in the form of code streams, and these code streams can also be used as the input of speech enhancement equipment.
其中,丢包环节可能发生在终端与基站上下行传输过程当中,语音增强设备的位置并不固定,例如可以位于终端或基站上,解决上下行丢包的问题;或者也可以如图18所示,位于两个基站之间,解决其中一侧产生的丢包问题;或者也可以在几个位置都增加语音增强设备。Among them, the packet loss link may occur during the uplink and downlink transmission between the terminal and the base station, and the location of the voice enhancement device is not fixed, for example, it can be located on the terminal or the base station to solve the problem of uplink and downlink packet loss; or it can also be shown in Figure 18 , located between two base stations, to solve the problem of packet loss on one side; or add voice enhancement devices at several locations.
参见图19,为本发明另一实施例应用语音增强设备的系统示意图,图19所示的应用场景为TDM(Time Division Multiplex,时分复用)传统组网。在TDM应用场景中,两侧终端的编解码类型可能不同(如一侧是GSM,另一侧是CDMA),此时,需要通过编解码器来对不同类型的码流进行转化,如图中TC所示。此时,语音增强设备位于TC的前端,经过处理后输出给TC的都是经语音增强设备处理(丢帧恢复及其他语音增强处理)过的好帧。Referring to FIG. 19 , it is a schematic diagram of a system applying a speech enhancement device according to another embodiment of the present invention. The application scenario shown in FIG. 19 is a TDM (Time Division Multiplex, time division multiplexing) traditional networking. In a TDM application scenario, the codec types of terminals on both sides may be different (such as GSM on one side and CDMA on the other side). shown. At this time, the speech enhancement device is located at the front end of the TC, and all the good frames processed by the speech enhancement device (loss frame recovery and other speech enhancement processing) are output to the TC after processing.
当然,与前面几个应用场景类似,语音增强设备也可以位于基站或终端或者几个地方都进行部署。Of course, similar to the previous application scenarios, voice enhancement devices can also be deployed in base stations or terminals, or in several places.
通过上述应用场景可知,本发明实施中的语音增强设备可以位于全IP组网下的TrFO、以及TFO、TDM等应用场景,具有非常好的适用性;同时,通过本语音增强设备,可以基于输入的码流解决不同环节出现的丢包问题,提升了语音质量,并且与现有技术基于波形的恢复方法相比,大大降低了消耗的资源。It can be seen from the above application scenarios that the speech enhancement device in the implementation of the present invention can be located in TrFO, TFO, TDM and other application scenarios under the all-IP networking, and has very good applicability; at the same time, through the speech enhancement device, it can be based on the input The code stream solves the packet loss problem in different links, improves the voice quality, and greatly reduces the resource consumption compared with the waveform-based recovery method in the prior art.
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,所述的存储介质可为磁碟、光盘、只读存储记忆体(Read-Only Memory,ROM)或随机存储记忆体(Random Access Memory,RAM)等。Those of ordinary skill in the art can understand that all or part of the processes in the methods of the above embodiments can be implemented through computer programs to instruct related hardware, and the programs can be stored in a computer-readable storage medium. During execution, it may include the processes of the embodiments of the above-mentioned methods. Wherein, the storage medium may be a magnetic disk, an optical disk, a read-only memory (Read-Only Memory, ROM) or a random access memory (Random Access Memory, RAM), etc.
上列较佳实施例,对本发明的目的、技术方案和优点进行了进一步详细说明,所应理解的是,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。The above-listed preferred embodiments have further described the purpose, technical solutions and advantages of the present invention in detail. It should be understood that the above descriptions are only preferred embodiments of the present invention, and are not intended to limit the present invention. Within the spirit and principles of the present invention, any modifications, equivalent replacements, improvements, etc., shall be included within the protection scope of the present invention.
Claims (15)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN2010102448832ACN101894558A (en) | 2010-08-04 | 2010-08-04 | Lost frame recovering method and equipment as well as speech enhancing method, equipment and system |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN2010102448832ACN101894558A (en) | 2010-08-04 | 2010-08-04 | Lost frame recovering method and equipment as well as speech enhancing method, equipment and system |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN101894558Atrue CN101894558A (en) | 2010-11-24 |
Family
ID=43103729
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN2010102448832APendingCN101894558A (en) | 2010-08-04 | 2010-08-04 | Lost frame recovering method and equipment as well as speech enhancing method, equipment and system |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN101894558A (en) |
Cited By (49)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102355484A (en)* | 2011-08-05 | 2012-02-15 | 多玩娱乐信息技术(北京)有限公司 | Audio data transmission method |
| CN102740064A (en)* | 2012-06-15 | 2012-10-17 | 福建星网视易信息系统有限公司 | Packing method for streaming media transmission in intercom system |
| CN102752602A (en)* | 2012-06-19 | 2012-10-24 | 清华大学 | Video sequence loss frame recovery method and device |
| CN102833037A (en)* | 2012-07-18 | 2012-12-19 | 华为技术有限公司 | Speech data packet loss compensation method and device |
| WO2013016986A1 (en)* | 2011-07-31 | 2013-02-07 | 中兴通讯股份有限公司 | Compensation method and device for frame loss after voiced initial frame |
| CN103065636A (en)* | 2011-10-24 | 2013-04-24 | 中兴通讯股份有限公司 | Voice frequency signal frame loss compensation method and device |
| CN103413553A (en)* | 2013-08-20 | 2013-11-27 | 腾讯科技(深圳)有限公司 | Audio coding method, audio decoding method, coding terminal, decoding terminal and system |
| CN103794221A (en)* | 2012-10-26 | 2014-05-14 | 索尼公司 | Signal processing device and method, and program |
| CN104240715A (en)* | 2013-06-21 | 2014-12-24 | 华为技术有限公司 | Method and device for recovering lost data |
| CN104934040A (en)* | 2014-03-17 | 2015-09-23 | 华为技术有限公司 | Duration adjustment method and device for audio signal |
| WO2015139521A1 (en)* | 2014-03-21 | 2015-09-24 | 华为技术有限公司 | Voice frequency code stream decoding method and device |
| CN104980253A (en)* | 2015-05-28 | 2015-10-14 | 南京科力威电子设备有限公司 | Forward direction frame-loss resistance wireless transmission method of waveform data for measuring vital signs |
| CN105245496A (en)* | 2015-08-26 | 2016-01-13 | 广州市百果园网络科技有限公司 | Audio data play method and device |
| CN105378831A (en)* | 2013-06-21 | 2016-03-02 | 弗朗霍夫应用科学研究促进协会 | Device and method for improving signal fading in error concealment process of switchable audio coding system |
| CN105654957A (en)* | 2015-12-24 | 2016-06-08 | 武汉大学 | Stereo error code concealment method through combination of inter-track and intra-track prediction and system thereof |
| CN105681653A (en)* | 2016-01-12 | 2016-06-15 | 深圳市云智易联科技有限公司 | Video file generation method and device |
| CN103065636B (en)* | 2011-10-24 | 2016-12-14 | 南京中兴软件有限责任公司 | The frame losing compensation method of voice frequency signal and device |
| CN106341698A (en)* | 2015-07-07 | 2017-01-18 | 腾讯科技(深圳)有限公司 | Video live broadcast processing method and device |
| US20170187635A1 (en)* | 2015-12-28 | 2017-06-29 | Qualcomm Incorporated | System and method of jitter buffer management |
| WO2017161998A1 (en)* | 2016-03-24 | 2017-09-28 | 腾讯科技(深圳)有限公司 | Video processing method and device and computer storage medium |
| CN107256709A (en)* | 2012-11-15 | 2017-10-17 | 株式会社Ntt都科摩 | Audio coding apparatus |
| US10121484B2 (en) | 2013-12-31 | 2018-11-06 | Huawei Technologies Co., Ltd. | Method and apparatus for decoding speech/audio bitstream |
| CN108962276A (en)* | 2018-07-24 | 2018-12-07 | 北京三听科技有限公司 | A kind of speech separating method and device |
| WO2019000178A1 (en)* | 2017-06-26 | 2019-01-03 | 华为技术有限公司 | Frame loss compensation method and device |
| CN110033776A (en)* | 2019-03-08 | 2019-07-19 | 佛山市云米电器科技有限公司 | A kind of virtual image interactive system and method applied to screen equipment |
| CN110096493A (en)* | 2018-11-02 | 2019-08-06 | 深圳市科信南方信息技术有限公司 | Flying quality modification method, data processing system and storage medium |
| CN110164456A (en)* | 2013-10-29 | 2019-08-23 | 株式会社Ntt都科摩 | Audio signal processor, acoustic signal processing method and storage medium |
| CN111326166A (en)* | 2020-02-25 | 2020-06-23 | 网易(杭州)网络有限公司 | Voice processing method and device, computer readable storage medium and electronic equipment |
| CN112532349A (en)* | 2020-11-24 | 2021-03-19 | 广州技象科技有限公司 | Data processing method and device based on decoding abnormity |
| US10997982B2 (en) | 2018-05-31 | 2021-05-04 | Shure Acquisition Holdings, Inc. | Systems and methods for intelligent voice activation for auto-mixing |
| US11297426B2 (en) | 2019-08-23 | 2022-04-05 | Shure Acquisition Holdings, Inc. | One-dimensional array microphone with improved directivity |
| US11297423B2 (en) | 2018-06-15 | 2022-04-05 | Shure Acquisition Holdings, Inc. | Endfire linear array microphone |
| US11303981B2 (en) | 2019-03-21 | 2022-04-12 | Shure Acquisition Holdings, Inc. | Housings and associated design features for ceiling array microphones |
| CN114339445A (en)* | 2021-12-16 | 2022-04-12 | 以萨技术股份有限公司 | Real-time video stream self-adaptive coordination system and method |
| US11302347B2 (en) | 2019-05-31 | 2022-04-12 | Shure Acquisition Holdings, Inc. | Low latency automixer integrated with voice and noise activity detection |
| US11310596B2 (en) | 2018-09-20 | 2022-04-19 | Shure Acquisition Holdings, Inc. | Adjustable lobe shape for array microphones |
| US11310592B2 (en) | 2015-04-30 | 2022-04-19 | Shure Acquisition Holdings, Inc. | Array microphone system and method of assembling the same |
| US11438691B2 (en) | 2019-03-21 | 2022-09-06 | Shure Acquisition Holdings, Inc. | Auto focus, auto focus within regions, and auto placement of beamformed microphone lobes with inhibition functionality |
| US11445294B2 (en) | 2019-05-23 | 2022-09-13 | Shure Acquisition Holdings, Inc. | Steerable speaker array, system, and method for the same |
| US11477327B2 (en) | 2017-01-13 | 2022-10-18 | Shure Acquisition Holdings, Inc. | Post-mixing acoustic echo cancellation systems and methods |
| US11523212B2 (en) | 2018-06-01 | 2022-12-06 | Shure Acquisition Holdings, Inc. | Pattern-forming microphone array |
| US11552611B2 (en) | 2020-02-07 | 2023-01-10 | Shure Acquisition Holdings, Inc. | System and method for automatic adjustment of reference gain |
| US11558693B2 (en) | 2019-03-21 | 2023-01-17 | Shure Acquisition Holdings, Inc. | Auto focus, auto focus within regions, and auto placement of beamformed microphone lobes with inhibition and voice activity detection functionality |
| US11678109B2 (en) | 2015-04-30 | 2023-06-13 | Shure Acquisition Holdings, Inc. | Offset cartridge microphones |
| US11706562B2 (en) | 2020-05-29 | 2023-07-18 | Shure Acquisition Holdings, Inc. | Transducer steering and configuration systems and methods using a local positioning system |
| US11785380B2 (en) | 2021-01-28 | 2023-10-10 | Shure Acquisition Holdings, Inc. | Hybrid audio beamforming system |
| US12028678B2 (en) | 2019-11-01 | 2024-07-02 | Shure Acquisition Holdings, Inc. | Proximity microphone |
| US12250526B2 (en) | 2022-01-07 | 2025-03-11 | Shure Acquisition Holdings, Inc. | Audio beamforming with nulling control system and methods |
| US12289584B2 (en) | 2021-10-04 | 2025-04-29 | Shure Acquisition Holdings, Inc. | Networked automixer systems and methods |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2004059894A2 (en)* | 2002-12-31 | 2004-07-15 | Nokia Corporation | Method and device for compressed-domain packet loss concealment |
| US7117156B1 (en)* | 1999-04-19 | 2006-10-03 | At&T Corp. | Method and apparatus for performing packet loss or frame erasure concealment |
| CN101155140A (en)* | 2006-10-01 | 2008-04-02 | 华为技术有限公司 | Method, device and system for audio stream error concealment |
| CN101170827A (en)* | 2007-11-23 | 2008-04-30 | 中兴通讯股份有限公司 | Configuration method for voice enhanced function |
| CN101207459A (en)* | 2007-11-05 | 2008-06-25 | 华为技术有限公司 | Method and device of signal processing |
| CN101394660A (en)* | 2007-09-17 | 2009-03-25 | 华为技术有限公司 | A method and device for determining downlink transmission mode |
- 2010
- 2010-08-04CNCN2010102448832Apatent/CN101894558A/enactivePending
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7117156B1 (en)* | 1999-04-19 | 2006-10-03 | At&T Corp. | Method and apparatus for performing packet loss or frame erasure concealment |
| WO2004059894A2 (en)* | 2002-12-31 | 2004-07-15 | Nokia Corporation | Method and device for compressed-domain packet loss concealment |
| CN101155140A (en)* | 2006-10-01 | 2008-04-02 | 华为技术有限公司 | Method, device and system for audio stream error concealment |
| CN101394660A (en)* | 2007-09-17 | 2009-03-25 | 华为技术有限公司 | A method and device for determining downlink transmission mode |
| CN101207459A (en)* | 2007-11-05 | 2008-06-25 | 华为技术有限公司 | Method and device of signal processing |
| CN101170827A (en)* | 2007-11-23 | 2008-04-30 | 中兴通讯股份有限公司 | Configuration method for voice enhanced function |
Non-Patent Citations (4)
| Title |
|---|
| 《IEEE TRANSACTION ON AUDIO,SPEECH AND LANGUAGE PROCESSING》 20070531 Milan Jelinek et.al Wideband Speech Coding Advances in VMR-WB Standard 第1167-1179页 第15卷, 第4期* |
| 《IEEE TRANSACTION ON AUDIO,SPEECH AND LANGUAGE PROCESSING》 20070531 Milan Jelinek et.al Wideband Speech Coding Advances in VMR-WB Standard 第1167-1179页 第15卷, 第4期 2* |
| 《Recommendation ITU-T G.718: Frame error robust narrow-band and wideband embedded variable bit-rate coding of speech and audio from 8-32 kbit/s》 20091231 ITU-T Recommendation ITU-T G.718: Frame error robust narrow-band and wideband embedded variable bit-rate coding of speech and audio from 8-32 kbit/s ,* |
| 《Recommendation ITU-T G.718: Frame error robust narrow-band and wideband embedded variable bit-rate coding of speech and audio from 8-32 kbit/s》 20091231 ITU-T Recommendation ITU-T G.718: Frame error robust narrow-band and wideband embedded variable bit-rate coding of speech and audio from 8-32 kbit/s , 1* |
Cited By (102)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2013016986A1 (en)* | 2011-07-31 | 2013-02-07 | 中兴通讯股份有限公司 | Compensation method and device for frame loss after voiced initial frame |
| CN102915737B (en)* | 2011-07-31 | 2018-01-19 | 中兴通讯股份有限公司 | The compensation method of frame losing and device after a kind of voiced sound start frame |
| CN102355484A (en)* | 2011-08-05 | 2012-02-15 | 多玩娱乐信息技术(北京)有限公司 | Audio data transmission method |
| CN102355484B (en)* | 2011-08-05 | 2018-12-04 | 广州华多网络科技有限公司 | A kind of method of audio data transmission |
| US9330672B2 (en) | 2011-10-24 | 2016-05-03 | Zte Corporation | Frame loss compensation method and apparatus for voice frame signal |
| CN103065636B (en)* | 2011-10-24 | 2016-12-14 | 南京中兴软件有限责任公司 | The frame losing compensation method of voice frequency signal and device |
| CN103065636A (en)* | 2011-10-24 | 2013-04-24 | 中兴通讯股份有限公司 | Voice frequency signal frame loss compensation method and device |
| WO2013060223A1 (en)* | 2011-10-24 | 2013-05-02 | 中兴通讯股份有限公司 | Frame loss compensation method and apparatus for voice frame signal |
| CN102740064A (en)* | 2012-06-15 | 2012-10-17 | 福建星网视易信息系统有限公司 | Packing method for streaming media transmission in intercom system |
| CN102740064B (en)* | 2012-06-15 | 2015-02-18 | 福建星网视易信息系统有限公司 | Packing method for streaming media transmission in intercom system |
| CN102752602A (en)* | 2012-06-19 | 2012-10-24 | 清华大学 | Video sequence loss frame recovery method and device |
| CN102752602B (en)* | 2012-06-19 | 2014-11-26 | 清华大学 | Video sequence loss frame recovery method and device |
| CN102833037B (en)* | 2012-07-18 | 2015-04-29 | 华为技术有限公司 | Speech data packet loss compensation method and device |
| US9571424B2 (en) | 2012-07-18 | 2017-02-14 | Huawei Technologies Co., Ltd. | Method and apparatus for compensating for voice packet loss |
| CN102833037A (en)* | 2012-07-18 | 2012-12-19 | 华为技术有限公司 | Speech data packet loss compensation method and device |
| CN103794221A (en)* | 2012-10-26 | 2014-05-14 | 索尼公司 | Signal processing device and method, and program |
| CN103794221B (en)* | 2012-10-26 | 2017-07-14 | 索尼公司 | Signal processing apparatus and method |
| CN107256709A (en)* | 2012-11-15 | 2017-10-17 | 株式会社Ntt都科摩 | Audio coding apparatus |
| US10672404B2 (en) | 2013-06-21 | 2020-06-02 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V. | Apparatus and method for generating an adaptive spectral shape of comfort noise |
| US11501783B2 (en) | 2013-06-21 | 2022-11-15 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V. | Apparatus and method realizing a fading of an MDCT spectrum to white noise prior to FDNS application |
| US12125491B2 (en) | 2013-06-21 | 2024-10-22 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V. | Apparatus and method realizing improved concepts for TCX LTP |
| US11869514B2 (en) | 2013-06-21 | 2024-01-09 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V. | Apparatus and method for improved signal fade out for switched audio coding systems during error concealment |
| CN105378831A (en)* | 2013-06-21 | 2016-03-02 | 弗朗霍夫应用科学研究促进协会 | Device and method for improving signal fading in error concealment process of switchable audio coding system |
| CN104240715A (en)* | 2013-06-21 | 2014-12-24 | 华为技术有限公司 | Method and device for recovering lost data |
| US11776551B2 (en) | 2013-06-21 | 2023-10-03 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V. | Apparatus and method for improved signal fade out in different domains during error concealment |
| US10607614B2 (en) | 2013-06-21 | 2020-03-31 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V. | Apparatus and method realizing a fading of an MDCT spectrum to white noise prior to FDNS application |
| US11462221B2 (en) | 2013-06-21 | 2022-10-04 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V. | Apparatus and method for generating an adaptive spectral shape of comfort noise |
| CN104240715B (en)* | 2013-06-21 | 2017-08-25 | 华为技术有限公司 | Method and apparatus for recovering loss data |
| US10867613B2 (en) | 2013-06-21 | 2020-12-15 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V. | Apparatus and method for improved signal fade out in different domains during error concealment |
| US10854208B2 (en) | 2013-06-21 | 2020-12-01 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V. | Apparatus and method realizing improved concepts for TCX LTP |
| US10679632B2 (en) | 2013-06-21 | 2020-06-09 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V. | Apparatus and method for improved signal fade out for switched audio coding systems during error concealment |
| CN105378831B (en)* | 2013-06-21 | 2019-05-31 | 弗朗霍夫应用科学研究促进协会 | Device and method for improving signal fading during error concealment in switched audio coding system |
| US9812139B2 (en) | 2013-08-20 | 2017-11-07 | Tencent Technology (Shenzhen) Company Limited | Method, terminal, system for audio encoding/decoding/codec |
| CN103413553A (en)* | 2013-08-20 | 2013-11-27 | 腾讯科技(深圳)有限公司 | Audio coding method, audio decoding method, coding terminal, decoding terminal and system |
| CN103413553B (en)* | 2013-08-20 | 2016-03-09 | 腾讯科技(深圳)有限公司 | Audio coding method, audio-frequency decoding method, coding side, decoding end and system |
| US9997166B2 (en) | 2013-08-20 | 2018-06-12 | Tencent Technology (Shenzhen) Company Limited | Method, terminal, system for audio encoding/decoding/codec |
| CN110164456A (en)* | 2013-10-29 | 2019-08-23 | 株式会社Ntt都科摩 | Audio signal processor, acoustic signal processing method and storage medium |
| CN110164456B (en)* | 2013-10-29 | 2023-11-14 | 株式会社Ntt都科摩 | Audio signal processing device, audio signal processing method and storage medium |
| US10121484B2 (en) | 2013-12-31 | 2018-11-06 | Huawei Technologies Co., Ltd. | Method and apparatus for decoding speech/audio bitstream |
| CN104934040A (en)* | 2014-03-17 | 2015-09-23 | 华为技术有限公司 | Duration adjustment method and device for audio signal |
| US11031020B2 (en) | 2014-03-21 | 2021-06-08 | Huawei Technologies Co., Ltd. | Speech/audio bitstream decoding method and apparatus |
| WO2015139521A1 (en)* | 2014-03-21 | 2015-09-24 | 华为技术有限公司 | Voice frequency code stream decoding method and device |
| CN107369454B (en)* | 2014-03-21 | 2020-10-27 | 华为技术有限公司 | Method and device for decoding voice frequency code stream |
| AU2015234068B2 (en)* | 2014-03-21 | 2017-11-02 | Huawei Technologies Co., Ltd. | Speech/audio bitstream decoding method and apparatus |
| US10269357B2 (en) | 2014-03-21 | 2019-04-23 | Huawei Technologies Co., Ltd. | Speech/audio bitstream decoding method and apparatus |
| CN107369454A (en)* | 2014-03-21 | 2017-11-21 | 华为技术有限公司 | The coding/decoding method and device of language audio code stream |
| RU2644512C1 (en)* | 2014-03-21 | 2018-02-12 | Хуавэй Текнолоджиз Ко., Лтд. | Method and device of decoding speech/audio bitstream |
| CN107369455A (en)* | 2014-03-21 | 2017-11-21 | 华为技术有限公司 | The coding/decoding method and device of language audio code stream |
| US12262174B2 (en) | 2015-04-30 | 2025-03-25 | Shure Acquisition Holdings, Inc. | Array microphone system and method of assembling the same |
| US11678109B2 (en) | 2015-04-30 | 2023-06-13 | Shure Acquisition Holdings, Inc. | Offset cartridge microphones |
| US11310592B2 (en) | 2015-04-30 | 2022-04-19 | Shure Acquisition Holdings, Inc. | Array microphone system and method of assembling the same |
| US11832053B2 (en) | 2015-04-30 | 2023-11-28 | Shure Acquisition Holdings, Inc. | Array microphone system and method of assembling the same |
| CN104980253A (en)* | 2015-05-28 | 2015-10-14 | 南京科力威电子设备有限公司 | Forward direction frame-loss resistance wireless transmission method of waveform data for measuring vital signs |
| CN104980253B (en)* | 2015-05-28 | 2018-07-27 | 南京科力威电子设备有限公司 | The anti-frame losing radio transmitting method of forward direction for life sign measurement Wave data |
| CN106341698B (en)* | 2015-07-07 | 2020-11-03 | 腾讯科技(深圳)有限公司 | Video live broadcast processing method and device, storage medium and terminal equipment |
| CN106341698A (en)* | 2015-07-07 | 2017-01-18 | 腾讯科技(深圳)有限公司 | Video live broadcast processing method and device |
| CN105245496B (en)* | 2015-08-26 | 2019-03-12 | 广州市百果园网络科技有限公司 | A kind of method and apparatus of playing audio-fequency data |
| CN105245496A (en)* | 2015-08-26 | 2016-01-13 | 广州市百果园网络科技有限公司 | Audio data play method and device |
| CN105654957A (en)* | 2015-12-24 | 2016-06-08 | 武汉大学 | Stereo error code concealment method through combination of inter-track and intra-track prediction and system thereof |
| CN105654957B (en)* | 2015-12-24 | 2019-05-24 | 武汉大学 | Between joint sound channel and the stereo error concellment method and system of sound channel interior prediction |
| US20170187635A1 (en)* | 2015-12-28 | 2017-06-29 | Qualcomm Incorporated | System and method of jitter buffer management |
| CN105681653A (en)* | 2016-01-12 | 2016-06-15 | 深圳市云智易联科技有限公司 | Video file generation method and device |
| WO2017161998A1 (en)* | 2016-03-24 | 2017-09-28 | 腾讯科技(深圳)有限公司 | Video processing method and device and computer storage medium |
| US10791379B2 (en) | 2016-03-24 | 2020-09-29 | Tencent Technology (Shenzhen) Company Limited | Video processing method and apparatus, and computer storage medium |
| US12309326B2 (en) | 2017-01-13 | 2025-05-20 | Shure Acquisition Holdings, Inc. | Post-mixing acoustic echo cancellation systems and methods |
| US11477327B2 (en) | 2017-01-13 | 2022-10-18 | Shure Acquisition Holdings, Inc. | Post-mixing acoustic echo cancellation systems and methods |
| WO2019000178A1 (en)* | 2017-06-26 | 2019-01-03 | 华为技术有限公司 | Frame loss compensation method and device |
| CN109496333A (en)* | 2017-06-26 | 2019-03-19 | 华为技术有限公司 | A kind of frame loss compensation method and device |
| US11798575B2 (en) | 2018-05-31 | 2023-10-24 | Shure Acquisition Holdings, Inc. | Systems and methods for intelligent voice activation for auto-mixing |
| US10997982B2 (en) | 2018-05-31 | 2021-05-04 | Shure Acquisition Holdings, Inc. | Systems and methods for intelligent voice activation for auto-mixing |
| US11800281B2 (en) | 2018-06-01 | 2023-10-24 | Shure Acquisition Holdings, Inc. | Pattern-forming microphone array |
| US11523212B2 (en) | 2018-06-01 | 2022-12-06 | Shure Acquisition Holdings, Inc. | Pattern-forming microphone array |
| US11770650B2 (en) | 2018-06-15 | 2023-09-26 | Shure Acquisition Holdings, Inc. | Endfire linear array microphone |
| US11297423B2 (en) | 2018-06-15 | 2022-04-05 | Shure Acquisition Holdings, Inc. | Endfire linear array microphone |
| CN108962276A (en)* | 2018-07-24 | 2018-12-07 | 北京三听科技有限公司 | A kind of speech separating method and device |
| CN108962276B (en)* | 2018-07-24 | 2020-11-17 | 杭州听测科技有限公司 | Voice separation method and device |
| US11310596B2 (en) | 2018-09-20 | 2022-04-19 | Shure Acquisition Holdings, Inc. | Adjustable lobe shape for array microphones |
| CN110096493A (en)* | 2018-11-02 | 2019-08-06 | 深圳市科信南方信息技术有限公司 | Flying quality modification method, data processing system and storage medium |
| CN110033776A (en)* | 2019-03-08 | 2019-07-19 | 佛山市云米电器科技有限公司 | A kind of virtual image interactive system and method applied to screen equipment |
| US11558693B2 (en) | 2019-03-21 | 2023-01-17 | Shure Acquisition Holdings, Inc. | Auto focus, auto focus within regions, and auto placement of beamformed microphone lobes with inhibition and voice activity detection functionality |
| US12425766B2 (en) | 2019-03-21 | 2025-09-23 | Shure Acquisition Holdings, Inc. | Auto focus, auto focus within regions, and auto placement of beamformed microphone lobes with inhibition and voice activity detection functionality |
| US11438691B2 (en) | 2019-03-21 | 2022-09-06 | Shure Acquisition Holdings, Inc. | Auto focus, auto focus within regions, and auto placement of beamformed microphone lobes with inhibition functionality |
| US11778368B2 (en) | 2019-03-21 | 2023-10-03 | Shure Acquisition Holdings, Inc. | Auto focus, auto focus within regions, and auto placement of beamformed microphone lobes with inhibition functionality |
| US11303981B2 (en) | 2019-03-21 | 2022-04-12 | Shure Acquisition Holdings, Inc. | Housings and associated design features for ceiling array microphones |
| US12284479B2 (en) | 2019-03-21 | 2025-04-22 | Shure Acquisition Holdings, Inc. | Auto focus, auto focus within regions, and auto placement of beamformed microphone lobes with inhibition functionality |
| US11445294B2 (en) | 2019-05-23 | 2022-09-13 | Shure Acquisition Holdings, Inc. | Steerable speaker array, system, and method for the same |
| US11800280B2 (en) | 2019-05-23 | 2023-10-24 | Shure Acquisition Holdings, Inc. | Steerable speaker array, system and method for the same |
| US11302347B2 (en) | 2019-05-31 | 2022-04-12 | Shure Acquisition Holdings, Inc. | Low latency automixer integrated with voice and noise activity detection |
| US11688418B2 (en) | 2019-05-31 | 2023-06-27 | Shure Acquisition Holdings, Inc. | Low latency automixer integrated with voice and noise activity detection |
| US11750972B2 (en) | 2019-08-23 | 2023-09-05 | Shure Acquisition Holdings, Inc. | One-dimensional array microphone with improved directivity |
| US11297426B2 (en) | 2019-08-23 | 2022-04-05 | Shure Acquisition Holdings, Inc. | One-dimensional array microphone with improved directivity |
| US12028678B2 (en) | 2019-11-01 | 2024-07-02 | Shure Acquisition Holdings, Inc. | Proximity microphone |
| US11552611B2 (en) | 2020-02-07 | 2023-01-10 | Shure Acquisition Holdings, Inc. | System and method for automatic adjustment of reference gain |
| CN111326166A (en)* | 2020-02-25 | 2020-06-23 | 网易(杭州)网络有限公司 | Voice processing method and device, computer readable storage medium and electronic equipment |
| US11706562B2 (en) | 2020-05-29 | 2023-07-18 | Shure Acquisition Holdings, Inc. | Transducer steering and configuration systems and methods using a local positioning system |
| US12149886B2 (en) | 2020-05-29 | 2024-11-19 | Shure Acquisition Holdings, Inc. | Transducer steering and configuration systems and methods using a local positioning system |
| CN112532349A (en)* | 2020-11-24 | 2021-03-19 | 广州技象科技有限公司 | Data processing method and device based on decoding abnormity |
| US11785380B2 (en) | 2021-01-28 | 2023-10-10 | Shure Acquisition Holdings, Inc. | Hybrid audio beamforming system |
| US12289584B2 (en) | 2021-10-04 | 2025-04-29 | Shure Acquisition Holdings, Inc. | Networked automixer systems and methods |
| CN114339445A (en)* | 2021-12-16 | 2022-04-12 | 以萨技术股份有限公司 | Real-time video stream self-adaptive coordination system and method |
| CN114339445B (en)* | 2021-12-16 | 2023-09-05 | 以萨技术股份有限公司 | Real-time video stream self-adaptive coordination system and method |
| US12250526B2 (en) | 2022-01-07 | 2025-03-11 | Shure Acquisition Holdings, Inc. | Audio beamforming with nulling control system and methods |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN101894558A (en) | Lost frame recovering method and equipment as well as speech enhancing method, equipment and system | |
| JP6546897B2 (en) | Method of performing coding for frame loss concealment for multi-rate speech / audio codecs | |
| JP6151405B2 (en) | System, method, apparatus and computer readable medium for criticality threshold control | |
| RU2701707C2 (en) | Encoder, decoder and audio content encoding and decoding method using parameters to improve masking | |
| JP2012529243A (en) | System and method for preventing loss of information in speech frames | |
| WO2008040250A1 (en) | A method, a device and a system for error concealment of an audio stream | |
| US8787490B2 (en) | Transmitting data in a communication system | |
| US20050143984A1 (en) | Multirate speech codecs | |
| CN103229544B (en) | Source Signal Adaptive Frame Aggregation | |
| CN105188075B (en) | Voice quality optimization method and device, terminal | |
| JP2005534984A (en) | Voice communication unit and method for reducing errors in voice frames | |
| CN116388930A (en) | Codec control method, device and electronic equipment for self-organizing network |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C12 | Rejection of a patent application after its publication | ||
| RJ01 | Rejection of invention patent application after publication | Application publication date:20101124 |