CN101807398B - Speech recognition device and operating method thereof - Google Patents
Speech recognition device and operating method thereofDownload PDFInfo
- Publication number
- CN101807398B CN101807398BCN2009100063762ACN200910006376ACN101807398BCN 101807398 BCN101807398 BCN 101807398BCN 2009100063762 ACN2009100063762 ACN 2009100063762ACN 200910006376 ACN200910006376 ACN 200910006376ACN 101807398 BCN101807398 BCN 101807398B
- Authority
- CN
- China
- Prior art keywords
- voice
- training
- model
- host
- recognition device
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
- 238000011017operating methodMethods0.000titleclaimsdescription5
- 238000012545processingMethods0.000claimsabstractdescription45
- 238000012549trainingMethods0.000claimsdescription139
- 238000000034methodMethods0.000claimsdescription20
- 238000004088simulationMethods0.000abstractdescription2
- 238000010586diagramMethods0.000description12
- 230000003287optical effectEffects0.000description7
- 239000002131composite materialSubstances0.000description5
- 230000008569processEffects0.000description5
- 238000012790confirmationMethods0.000description3
- 238000012217deletionMethods0.000description2
- 230000037430deletionEffects0.000description2
- 230000005540biological transmissionEffects0.000description1
- 238000006243chemical reactionMethods0.000description1
- 230000006872improvementEffects0.000description1
- 238000012986modificationMethods0.000description1
- 230000004048modificationEffects0.000description1
- 230000009467reductionEffects0.000description1
- 230000001960triggered effectEffects0.000description1
Images







Landscapes
- User Interface Of Digital Computer (AREA)
- Machine Translation (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本发明是有关于一种语音识别装置及其操作方法,且特别是有关于一种具可移植性、个人化与智能型的语音识别装置及其操作方法。The present invention relates to a speech recognition device and its operating method, and in particular to a portable, personalized and intelligent speech recognition device and its operating method.
背景技术Background technique
近年来,语音识别系统由于具有使用方便,提高效率及节省成本的几项优势,因此广泛地被应用在各行各业。例如,使用者对着麦克风输入指令语音,例如是“复制”,然后经语音软件比对出对应的装置码,例如是代表复制功能的装置码。因此,在识别过程中,用口述方式就能取代键盘的操作,相当便利。In recent years, speech recognition systems have been widely used in various industries due to their advantages of ease of use, efficiency improvement and cost savings. For example, the user inputs an instruction voice into the microphone, such as "copy", and then compares the corresponding device code through the voice software, such as the device code representing the copy function. Therefore, in the recognition process, the operation of the keyboard can be replaced by dictation, which is quite convenient.
一般而言,在进行语音识别前须先安装语音软件至主机内并进行语音训练。语音软件在计算出训练语音的训练特征值后,将训练特征值储存在主机内。当使用者进行语音识别时,对着麦克风输入指令语音,然后由主机内的语音软件计算出指令语音的指令特征值后,将指令特征值与主机内的多个训练特征值进行比对,以比对出对应的语音特征值。然后,再输出与语音特征值对应的装置码。Generally speaking, before performing speech recognition, speech software must be installed in the host and speech training must be performed. After the voice software calculates the training feature value of the training voice, the training feature value is stored in the host. When the user performs speech recognition, he inputs the command voice into the microphone, and then the voice software in the host computer calculates the command feature value of the command voice, and then compares the command feature value with multiple training feature values in the host machine to obtain Compare the corresponding speech feature values. Then, output the device code corresponding to the voice feature value.
然而,由于语音软件必须安装在主机内且训练特征值也储存于主机内,若主机损坏或使用者更换到另一台主机使用,则必须重新安装语音软件且必须重新进行语音训练。此外,每次用来输入指令语音的麦克风不一定是同一支,由于每支麦克风对声音的音频撷取都有些差异,若使用到与进行语音训练时用的麦克风差异过大的麦克风来进行语音识别操作,为达到高识别率的语音识别,则须重新进行语音训练,相当地不便。However, since the voice software must be installed in the host and the training feature values are also stored in the host, if the host is damaged or the user replaces it with another host, the voice software must be reinstalled and the voice training must be performed again. In addition, the microphone used to input the command voice is not necessarily the same one each time, because each microphone has some differences in the audio capture of the sound, if the microphone used for voice training is too different In the recognition operation, in order to achieve high recognition rate speech recognition, speech training must be carried out again, which is quite inconvenient.
发明内容Contents of the invention
本发明是有关于一种语音识别装置及其操作方法,是将运算出的训练特征值储存于一语音识别装置内。如此,使用者可随身携带语音识别装置,就算是更换不同的主机,亦不须重新进行语音训练。如此,不但省时且相当便利。The present invention relates to a voice recognition device and its operation method. The calculated training feature value is stored in a voice recognition device. In this way, the user can carry the speech recognition device with him, even if he changes a different host, he does not need to carry out speech training again. This saves time and is quite convenient.
根据本发明的第一方面,提出一种语音识别装置。语音识别装置包括人机界面(HID Interface)、语音输入界面、语音转码单元、语音数据库及装置处理单元。人机界面用以向主机列举语音识别装置为操作装置。语音输入界面用以撷取模拟指令语音。语音转码单元用以转换模拟指令语音为数字指令语音。语音数据库包括数个模型特征值及数个模型装置码,模型特征值对应于模型装置码。以及,装置处理单元用以比对数字指令语音的指令特征值与模型特征值,并输出对应的模型装置码至主机。According to a first aspect of the present invention, a speech recognition device is proposed. The speech recognition device includes a human-machine interface (HID Interface), a speech input interface, a speech transcoding unit, a speech database and a device processing unit. The man-machine interface is used to enumerate the voice recognition device as an operating device to the host. The voice input interface is used for capturing the simulated command voice. The voice transcoding unit is used for converting the analog command voice into digital command voice. The speech database includes several model feature values and several model device codes, and the model feature values correspond to the model device codes. And, the device processing unit is used for comparing the command feature value of the digital command voice with the model feature value, and outputting the corresponding model device code to the host.
根据本发明的第二方面,提出一种语音识别装置的操作方法。操作方法包括以下步骤。向主机列举语音识别装置为操作装置。其中,语音识别装置储存有语音数据库,语音数据库包括数个模型特征值及数个模型装置码,模型特征值对应至模型装置码;撷取模拟指令语音;转换模拟指令语音为数字指令语音;比对数字指令语音的指令特征值与模型特征值;以及,输出对应的模型装置码至主机。According to a second aspect of the present invention, a method for operating a speech recognition device is proposed. The operation method includes the following steps. List the voice recognition device as the operating device to the host. Wherein, the voice recognition device stores a voice database, and the voice database includes several model feature values and several model device codes, and the model feature values correspond to the model device codes; captures the analog command voice; converts the analog command voice into a digital command voice; The command feature value and the model feature value of the digital command voice; and output the corresponding model device code to the host.
根据本发明的第三方面,提出一种语音识别装置。语音识别装置包括大量储存界面、语音输入界面、语音转码单元、语音数据库及装置处理单元。大量储存界面用以与主机电性连接并向主机将语音识别装置列举为大量储存装置(Mass Storage Device)。语音输入界面用以撷取模拟指令语音。语音转码单元用以转换模拟指令语音为数字指令语音。语音数据库包括数个模型特征值及数个模型装置码,模型特征值对应于模型装置码。以及,装置处理单元用以传送语音数据库及应用程序至主机。其中,主机用以加载应用程序并比对数字指令语音的指令特征值与模型特征值,以传送对应的模型装置码。According to a third aspect of the present invention, a speech recognition device is provided. The speech recognition device includes a mass storage interface, a speech input interface, a speech transcoding unit, a speech database and a device processing unit. The mass storage interface is used to electrically connect with the host and enumerate the speech recognition device as a mass storage device to the host. The voice input interface is used for capturing the simulated command voice. The voice transcoding unit is used for converting the analog command voice into digital command voice. The speech database includes several model feature values and several model device codes, and the model feature values correspond to the model device codes. And, the device processing unit is used to transmit the voice database and the application program to the host. Wherein, the host computer is used to load the application program and compare the command feature value and the model feature value of the digital command voice to transmit the corresponding model device code.
根据本发明的第四方面,提出一种语音识别装置的操作方法。操作方法包括以下步骤。向主机列举语音识别装置为大量储存装置。其中,语音撷取装置储存有应用程序、数个模型特征值及数个模型装置码,模型特征值对应至模型装置码;传送语音数据库与应用程序至主机;主机加载应用程序;撷取模拟指令语音;转换模拟指令语音为数字指令语音;主机比对数字指令语音的指令特征值与此些模型特征值;以及,主机传送对应的模型装置码。According to a fourth aspect of the present invention, a method for operating a speech recognition device is provided. The operation method includes the following steps. The voice recognition device is enumerated to the host as a mass storage device. Among them, the voice capture device stores the application program, several model feature values and several model device codes, the model feature values correspond to the model device codes; transmit the voice database and the application program to the host; the host loads the application program; captures the simulation command voice; converting the analog command voice into digital command voice; the host compares the command feature value of the digital command voice with these model feature values; and the host sends the corresponding model device code.
为让本发明的上述内容能更明显易懂,下文特举较佳实施例,并配合所附图式,作详细说明如下:In order to make the above content of the present invention more obvious and understandable, the following preferred embodiments are specifically cited below, and in conjunction with the accompanying drawings, the detailed description is as follows:
附图说明Description of drawings
图1绘示依照本发明第一实施例的语音识别装置的功能方块图。FIG. 1 is a functional block diagram of a speech recognition device according to a first embodiment of the present invention.
图2绘示依照本发明第一实施例的语音识别装置的操作流程图。FIG. 2 is a flowchart illustrating the operation of the speech recognition device according to the first embodiment of the present invention.
图3绘示依照本发明第二实施例的语音识别装置的功能方块图。FIG. 3 is a functional block diagram of a speech recognition device according to a second embodiment of the present invention.
图4绘示依照本发明第二实施例的语音识别装置的操作流程图。FIG. 4 is a flowchart illustrating the operation of the speech recognition device according to the second embodiment of the present invention.
图5绘示第二实施例的语音训练窗口的示意图。FIG. 5 is a schematic diagram of the speech training window of the second embodiment.
图6绘示依照本发明第三实施例的语音识别装置的功能方块图。FIG. 6 is a functional block diagram of a speech recognition device according to a third embodiment of the present invention.
图7绘示依照本发明第三实施例的语音识别装置的操作流程图。FIG. 7 is a flowchart illustrating the operation of the speech recognition device according to the third embodiment of the present invention.
图8绘示依照本发明第四实施例的语音识别装置的功能方块图。FIG. 8 is a functional block diagram of a speech recognition device according to a fourth embodiment of the present invention.
图9绘示依照本发明第四实施例的语音识别装置的操作流程图。FIG. 9 is a flowchart illustrating the operation of the speech recognition device according to the fourth embodiment of the present invention.
图10绘示本发明另一实施例的语音识别装置的功能方块图。FIG. 10 is a functional block diagram of a speech recognition device according to another embodiment of the present invention.
[主要元件标号说明][Description of main component labels]
100、300、600、800、900:语音识别装置100, 300, 600, 800, 900: voice recognition device
102、902:人机界面102, 902: Man-machine interface
104、616:语音输入界面104, 616: voice input interface
106、606:语音转码单元106, 606: Speech transcoding unit
108、608:储存单元108, 608: storage unit
110、610:装置处理单元110, 610: device processing unit
112、612:语音数据库112, 612: voice database
114、614:主机114, 614: Host
302、602、802:应用程序302, 602, 802: application
304、604:大量储存界面304, 604: mass storage interface
308、904:复合式装置308, 904: composite device
K1:训练装置码K1: Trainer Code
S1:模拟指令语音S1: Analog command voice
S2:数字指令语音S2: digital command voice
T1:模拟训练语音T1: simulated training voice
T2:数字训练语音T2: Digital training voice
W:语音训练窗口W: voice training window
W11、W12、W13:语音字段W11, W12, W13: Speech fields
W21、W22、W23:装置码字段W21, W22, W23: device code field
具体实施方式Detailed ways
依照本发明的语音识别装置及其操作方法,是将计算出的训练特征值储存于语音数据库内,而语音数据库储存于语音识别装置内。如此,使用者可随身携带语音识别装置,就算是更换不同的主机,亦不须重新进行语音训练。如此,不但省时且相当便利。底下以多组应用实例来作说明。然此些实施例仅为本发明的发明精神下的几种实施方式,其说明的文字与图标并不会对本发明的欲保护范围进行限缩。According to the speech recognition device and its operation method of the present invention, the calculated training feature values are stored in the speech database, and the speech database is stored in the speech recognition device. In this way, the user can carry the speech recognition device with him, even if he changes a different host, he does not need to carry out speech training again. This saves time and is quite convenient. In the following, several groups of application examples are used for illustration. However, these embodiments are only several implementation modes under the inventive spirit of the present invention, and the description words and icons thereof will not limit the protection scope of the present invention.
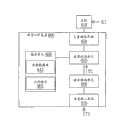
请参照图1,其绘示依照本发明第一实施例的语音识别装置的功能方块图。语音识别装置100,例如是麦克风,其包括人机界面102、语音输入界面104、语音转码单元106、储存单元108及装置处理单元110。Please refer to FIG. 1 , which shows a functional block diagram of a speech recognition device according to a first embodiment of the present invention. The speech recognition device 100 is, for example, a microphone, and includes a man-machine interface 102 , a
人机界面102用以向主机114列举语音识别装置为操作装置,操作装置例如是键盘或鼠标。其中,人机界面102可为通用串行总线标准界面(Universal Serial Bus,USB)或PS/2界面,而第一实施例的人机界面102以通用串行总线标准界面为例作说明。语音输入界面104用以撷取模拟指令语音S1。语音转码单元106用以转换模拟指令语音S1为数字指令语音S2。The man-machine interface 102 is used to enumerate the voice recognition device to the
储存单元108用以储存语音数据库112,语音数据库112包括数个模型特征值(未绘示)及数个模型装置码(未绘示),而模型特征值对应于模型装置码,模型装置码为键盘码(未绘示)或鼠标码(未绘示)。举例来说,模型特征值包括语音“复制”的特征值及语音“删除”的特征值,而模型装置码包括对应于“复制”的模型特征值的模型装置码及对应于“删除”的模型特征值的模型装置码。The storage unit 108 is used to store the
装置处理单元110用以运算出数字指令语音S2的指令特征值(未绘示)并比对指令特征值与模型特征值,并从模型特征值中比对出与指令特征值相似的模型特征值。当比对出与指令特征值相似的模型特征值后,装置处理单元110输出对应于相似的模型特征值的模型装置码至主机114。The
如上所述的装置处理单元110,其比对功能与传送模型装置码的功能是可以固件(firmware)形式实现。因此,第一实施例的语音识别装置100在执行语音识别操作时,并不需要另外安装任何应用程序。如此,只要携带着语音识别装置100,到哪里都能进行语音识别操作,不用担心主机是否有安装语音识别软件,相当方便。As mentioned above, the
由于语音识别装置100具有可移植性,使用者可随身携带语音识别装置100。也就是说,可随身携带语音数据库112。如此,不管换到哪一台主机,都能通过储存于语音识别装置100的语音数据库112内的模型特征值来进行语音识别操作,而无需重新再进行语音训练。Since the voice recognition device 100 is portable, users can carry the voice recognition device 100 with them. That is to say, the
并且,由于语音识别装置100本身就包括语音输入界面104及语音转码单元106,所以不需通过其它的语音撷取装置,例如是其它的麦克风来输入模拟指令语音。如此,便排除了不同的语音撷取装置的差异性所造成的语音识别率下降的问题。Moreover, since the voice recognition device 100 itself includes the
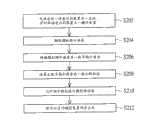
请参照图2,其绘示依照本发明的第一实施例的语音识别装置的操作流程图。操作方法包括以下步骤。首先,于步骤S202中,电性连接语音识别装置100与主机114,人机界面102并向主机114列举语音识别装置100为操作装置。接着,于步骤S204中,语音输入界面104撷取模拟指令语音S1,例如是使用者对着语音输入界面104讲出“复制”。Please refer to FIG. 2 , which shows a flow chart of the operation of the speech recognition device according to the first embodiment of the present invention. The operation method includes the following steps. First, in step S202 , the speech recognition device 100 is electrically connected to the
再来,于步骤S206中,语音转码单元106转换模拟指令语音S1为数字指令语音S2。Next, in step S206 , the
接着,于步骤S208中,装置处理单元110运算出数字指令语音S2的指令特征值。Next, in step S208 , the
然后,于步骤S210中,装置处理单元110比对指令特征值与模型特征值,并从模型特征值中比对出与指令特征值相似的模型特征值。例如,装置处理单元110将指令特征值与语音数据库112中“复制”的模型特征值与“删除”的模型特征值进行比对后,发现“复制”的模型特征值与指令特征值相似。Then, in step S210 , the
然后,于步骤S212中,装置处理单元110通过人机界面102,输出语音数据库112的多个模型装置码中与“复制”的模型特征值相对应的模型装置码至主机114。Then, in step S212 , the
请参照图3,其绘示依照本发明第二实施例的语音识别装置的功能方块图。第二实施例与第一实施例不同之处在于,第二实施例的语音识别装置300的储存单元108还储存有应用程序302,而应用程序302用以进行语音训练。此外,语音识别装置300还包括大量储存界面(Mass Storage Interface)304,应用程序302即通过大量储存界面304被传送至主机114,以让主机114加载以进行语音训练操作。其余相同之处沿用相同标号,在此就不再赘述。Please refer to FIG. 3 , which shows a functional block diagram of a speech recognition device according to a second embodiment of the present invention. The difference between the second embodiment and the first embodiment is that the storage unit 108 of the speech recognition device 300 of the second embodiment further stores an
大量储存界面304,例如是通用串行总线标准界面,用以与主机114电性连接并向主机114将语音识别装置300列举为大量储存装置。大量储存装置例如是含应用程序光盘片的光驱或随身碟,第二实施例的大量储存装置是以列举成光驱为例作说明。The mass storage interface 304 , such as a USB standard interface, is used to electrically connect with the
此外,语音输入界面104于第二实施例的语音识别装置300还用以撷取模拟训练语音T1,而语音转码单元106还用以转换模拟训练语音T1为数字训练语音T2。此外,装置处理单元110通过大量储存界面传送应用程序302至主机114,且用以运算出数字训练语音T2的训练特征值(未绘示)。较佳地,运算出训练特征值所采用的语音算法与运算出指令特征值所采用的语音算法是相同的。In addition, the
当装置处理单元110传送应用程序302至主机后,主机114的处理单元(未绘示)加载应用程序302。之后,主机114还用以撷取训练装置码K1,训练装置码K1为键盘码或鼠标码。其中,训练装置码K1对应于训练特征值。After the
通过第二实施例的应用程序,可进行语音训练及装置码的输入。并由装置处理单元110运算出数字训练语音T2的训练特征值后,将训练特征值储存进语音识别装置300内的语音数据库112,使训练特征值成为数个模型特征值之一。并且,装置处理单元110将对应的装置码,即对应于训练特征值的训练装置码K1储存进语音识别装置300内的语音数据库112,使训练装置码K1成为数个模型装置码之一。Voice training and device code input can be performed through the application program of the second embodiment. After calculating the training feature value of the digital training speech T2 by the
此外,由于语音识别装置300包含人机界面102与大量储存界面304,所以语音识别装置300向主机114列举为一包含操作装置与大量储存装置的复合式装置308。因此,语音识别装置300除了可与主机114配合以进行语音训练操作外,语音识别装置300的装置处理单元110还可进行语音识别的操作并通过人机界面102输出模型装置码至主机114。也就是说,语音识别装置300为同时具有语音训练功能及语音识别功能的装置。In addition, since the speech recognition device 300 includes the man-machine interface 102 and the mass storage interface 304 , the speech recognition device 300 is listed to the
请参照图4,其绘示依照本发明第二实施例的语音识别装置的操作流程图。操作方法包括以下步骤。首先,于步骤S402中,电性连接语音识别装置300与主机114,大量储存界面304并向主机114列举语音识别装置300为大量储存装置,而人机界面102向主机114列举语音识别装置300为操作装置,使语音识别装置300成为包含操作装置与大量储存装置的复合式装置308。Please refer to FIG. 4 , which shows a flow chart of the operation of the speech recognition device according to the second embodiment of the present invention. The operation method includes the following steps. First, in step S402, the voice recognition device 300 is electrically connected to the
接着,于步骤S404中,语音识别装置300传送应用程序302至主机114,以让主机114加载。由于语音识别装置300被列举成光驱,所以语音识别装置300的储存单元108可储存有自动执行设定文件,例如是文件名为“autorun.inf”的文件。文件“autorun.inf”记录有执行应用程序302的路径及指令。当主机114发现语音识别装置300内有文件“autorun.inf”时,便自动执行此文件所指向的应用程序302。也就是说,在应用程序302被主机114加载的过程中,是自动完成的,并不需使用者手动设定或点取。Next, in step S404 , the voice recognition device 300 transmits the
此外,当语音识别装置300被列举为随身碟时也可以执行语音训练操作。举例来说,当语音识别装置300被列举为随身碟时,使用者可以自行点选储存单元108内的应用程序302,在连续双击或按下键盘的确认键(Enter)后,主机114就加载应用程序302。如此,一样可以完成启动应用程序302的操作。In addition, voice training operations can also be performed when the voice recognition device 300 is listed as a flash drive. For example, when the voice recognition device 300 is listed as a flash drive, the user can click on the
再来,请参照图5,其绘示第二实施例的语音训练窗口的示意图。于步骤S406中,主机114加载装置处理单元110所传来的应用程序302,并开启语音训练窗口W,语音训练窗口W包括数个语音字段,例如是语音字段W11、W12及W13及数个装置码字段,例如是装置码字段W21、W22及W23。语音字段用以记录数字训练语音T2,装置码字段用以记录训练装置码K1。Next, please refer to FIG. 5 , which shows a schematic diagram of the speech training window of the second embodiment. In step S406, the
然后,于步骤S408中,语音输入界面104撷取模拟训练语音T1,例如是使用者对着语音识别装置300讲出“复制”。Then, in step S408 , the
然后,于步骤S410中,语音转码单元106转换模拟训练语音T1为数字训练语音T2。转换完成之后,主机114可将代表数字训练语音T2已转换完成的消息记录于语音字段的一者,例如是记录于语音字段W11。记录形式例如是文件名形式或符号形式。Then, in step S410, the
然后,于步骤S412中,装置处理单元110运算出数字训练语音T2的训练特征值。或者,运算出数字训练语音T2的训练特征值的操作也可以由主机114来完成。更进一步地说,若运算出训练特征值的操作系由主机114来完成的话,应用程序302还包含了语音的特征值的运算功能。较佳地,不管运算特征值的操作是由主机114或装置处理单元110执行,所使用的语音算法是相同的。Then, in step S412, the
然后,于步骤S414中,主机114撷取训练装置码K1,训练装置码K1对应于训练特征值。训练装置码K1例如是使用者触发与主机114相连接的键盘(未绘示)的按键后,由主机114撷取而得。主机114在撷取完训练装置码K1后,将其记录于装置码字段的一者,例如是记录于装置码字段W21。记录形式例如是符号形式或训练装置码K1的码号。Then, in step S414, the
使用者在触发与主机114相连接的键盘上的按键之前,可点击语音训练窗口W上的装置码字段W21,以提醒主机114一使用者已经开始要输入对应数字训练语音T2的训练装置码K1。较佳地,语音训练窗口W还提供确认按键(未绘示)。当步骤S414完成后且经使用者触发此确认按键后,方进入步骤S416。或者,也可在输入完模拟训练语音T1及训练装置码K1后,随即进入步骤S416,不需使用者执行任何的确认操作。Before triggering the keys on the keyboard connected to the
然后,于步骤S416中,主机114可传送代表训练完成的信号(未绘示)给语音识别装置300。在语音识别装置300收到此信号后,语音识别装置300储存训练特征值至语音数据库112,以使训练特征值成为数个模型特征值的一者,且将训练装置码K1通过人机界面102或大量储存界面304储存进语音数据库112,以使训练装置码K1成为数个模型装置码的一者。Then, in step S416 , the
由于语音识别装置300为同时包含操作装置的复合式装置308。故于结束语音训练的操作后,可随时使用语音识别装置300执行语音识别功能,例如可采用图2的第一实施例的操作方法,来进行语音识别操作。Since the voice recognition device 300 is a composite device 308 that also includes an operating device. Therefore, after the speech training operation is finished, the speech recognition device 300 can be used to perform the speech recognition function at any time, for example, the operation method of the first embodiment shown in FIG. 2 can be used to perform the speech recognition operation.
请参照图6,其绘示依照本发明第三实施例的语音识别装置的功能方块图。第三实施例与第一实施例不同之处在于,第三实施例的语音识别装置600的储存单元608储存有应用程序602,应用程序602用以让主机614加载,以进行语音识别功能,且语音识别装置600并无人机界面102,而改以大量储存界面604取代,应用程序602即通过此大量储存界面604被传送至主机614,以让主机614加载。其余相同之处沿用相同标号,在此不再赘述。Please refer to FIG. 6 , which is a functional block diagram of a speech recognition device according to a third embodiment of the present invention. The difference between the third embodiment and the first embodiment is that the storage unit 608 of the speech recognition device 600 of the third embodiment stores an
语音识别装置600,例如是麦克风包括大量储存界面604、语音输入界面616、语音转码单元606、储存单元608及装置处理单元610。The speech recognition device 600 , such as a microphone, includes a mass storage interface 604 , a
大量储存界面604,例如为通用串行总线标准界面,用以向主机614列举语音识别装置600为大量储存装置。大量储存装置例如是含应用程序光盘片的光驱或随身碟,第三实施例的大量储存装置是以光驱为例作说明。The mass storage interface 604 is, for example, a USB standard interface, and is used to enumerate the voice recognition device 600 as a mass storage device to the
语音输入界面616用以撷取模拟指令语音S1。语音转码单元606用以转换模拟指令语音S1为数字指令语音S2。储存单元608储存有应用程序602及语音数据库612,语音数据库612包括数个模型特征值(未绘示)及数个模型装置码(未绘示)。模型特征值对应于模型装置码,模型装置码为键盘码(未绘示)或鼠标码(未绘示)。举例来说,模型特征值包括语音“复制”的特征值及语音“删除”的特征值,而模型装置码包括对应于“复制”的模型特征值的模型装置码及对应于“删除”的模型特征值的模型装置码。The
装置处理单元610用以传送语音数据库612及应用程序602至主机614,以让主机614加载。于语音数据库612及应用程序602被传送完成后,主机614加载应用程序602。之后,主机614用以运算出数字指令语音S2的指令特征值并还用以从多个模型特征值中比对出与指令特征值相似的模型特征值并用以传送多个模型装置码中与相似的模型特征值对应的模型装置码。The
更进一步地说,第一实施例的语音识别装置100及第二实施例的语音识别装置300是以写入装置处理单元110的固件来执行语音识别操作,而第三实施例的语音识别装置600则由主机614加载应用程序602来执行语音识别的操作。由此可知,本发明的语音识别装置的语音识别操作可以多种方式来进行,并不受限于本发明的实施例所描述的内容。Furthermore, the speech recognition device 100 of the first embodiment and the speech recognition device 300 of the second embodiment perform the speech recognition operation by writing the firmware of the
此外,第三实施例是由主机来执行语音识别操作,当主机的处理单元(未绘示)的数据处理速度快于装置处理单元610时,可选择第三实施例的语音识别装置600,以节省执行语音识别操作所需要的时间。In addition, in the third embodiment, the host performs the voice recognition operation. When the data processing speed of the processing unit (not shown) of the host is faster than that of the
请参照图7,其绘示依照本发明第三实施例的语音识别装置的操作流程图。操作方法包括以下步骤。Please refer to FIG. 7 , which shows a flow chart of the operation of the speech recognition device according to the third embodiment of the present invention. The operation method includes the following steps.
首先,于步骤S702中,电性连接语音识别装置600与主机614,大量储存界面604并向主机614列举语音识别装置600为大量储存装置。Firstly, in step S702, the voice recognition device 600 is electrically connected to the
接着,于步骤S704中,装置处理单元610传送语音数据库612与应用程序602至主机614。Next, in step S704 , the
再来,于步骤S706中,主机614加载装置处理单元610所传来的应用程序602。Next, in step S706 , the
然后,于步骤S708中,语音输入界面616撷取模拟指令语音S1,例如是使用者对着语音输入界面104讲出“复制”。Then, in step S708 , the
然后,于步骤S710中,语音转码单元606转换模拟指令语音S1为数字指令语音S2。然后,于步骤S712中,运算出数字指令语音S2的指令特征值。Then, in step S710 , the
然后,于步骤S714中,主机614从模型特征值中比对出与指令特征值相似的模型特征值。例如,主机614将指令特征值与语音数据库612中“复制”的模型特征值与“删除”的模型特征值进行比对,发现“复制”的模型特征值与指令特征值较接近。Then, in step S714 , the
然后,于步骤S716中,主机614传送模型装置码中与相似的模型特征值对应的模型装置码,即传送对应于“复制”的模型特征值的模型装置码。传送目标例如是主机614所开启的应用程序,如WORD文书处理系统,以对文字进行复制操作。Then, in step S716 , the
此外,请参照图8,其绘示依照本发明第四实施例的语音识别装置的功能方块图。第四实施例与第三实施例不同之处在于,第四实施例的语音识别装置800的应用程序802除了包含应用程序602的语音识别功能外,还包括了语音训练的功能。更进一步地说,主机614加载应用程序后,除了可进行语音识别操作外,还可进行语音训练操作。亦即,语音识别装置800为同时具有语音训练功能及语音识别功能的装置。其余相同之处沿用相同标号,在此不再赘述。In addition, please refer to FIG. 8 , which shows a functional block diagram of a speech recognition device according to a fourth embodiment of the present invention. The difference between the fourth embodiment and the third embodiment is that the
请参照图9,其绘示依照本发明第四实施例的语音识别装置的操作流程图。操作方法包括以下步骤。首先,于步骤S902中,电性连接语音识别装置800与主机614,大量储存界面604并向主机614列举语音识别装置800为大量储存装置。接着,于步骤S904中,语音识别装置800传送应用程序802至主机614,以让主机614加载。由于语音识别装置800被列举成光驱,所以语音识别装置800的储存单元608可储存有自动执行设定文件,例如是文件名为“autorun.inf”的文件,其执行方式如第二实施例的步骤S404所揭露,在此不再赘述。Please refer to FIG. 9 , which is a flowchart illustrating the operation of the voice recognition device according to the fourth embodiment of the present invention. The operation method includes the following steps. Firstly, in step S902, the voice recognition device 800 is electrically connected to the
再来,如图5所示,于步骤S906中,主机614加载装置处理单元610所传来的应用程序802,并开启语音训练窗口W。语音训练过程如第二实施例的步骤S406所揭露,在此不再赘述。然后,于步骤S908中,语音输入界面616撷取模拟训练语音T1,例如是使用者对着语音识别装置300讲出“复制”。然后,于步骤S910中,语音转码单元606转换模拟训练语音T1为数字训练语音T2。Next, as shown in FIG. 5 , in step S906 , the
然后,于步骤S912中,装置处理单元610运算出数字训练语音T2的训练特征值。或者,运算出数字训练语音T2的训练特征值的操作也可以由主机614来完成。更进一步地说,若运算出训练特征值的操作是由主机614来完成的话,应用程序802还包含了语音的特征值的运算功能。较佳地,不管运算特征值的操作是由主机614或装置处理单元610执行,所使用的语音算法是相同的。Then, in step S912, the
然后,于步骤S914中,主机614撷取训练装置码K1,训练装置码K1对应于训练特征值。训练装置码K1例如是使用者触发与主机114相连接的键盘(未绘示)的按键后,由主机614撷取而得。Then, in step S914, the
然后,于步骤S916中,主机614可传送代表训练完成的信号(未绘示)给语音识别装置800。语音识别装置800收到此信号后,语音识别装置800储存训练特征值至语音数据库612,以使训练特征值成为数个模型特征值的一者,且将训练装置码K1通过大量储存界面604储存进语音数据库612,以使训练装置码K1成为数个模型装置码的一者。Then, in step S916 , the
虽然,第四实施例的语音识别装置800在执行语音训练操作时,训练装置码K1通过大量储存界面604储存至语音识别装置800的语音数据库612内。然于其它实施态样中,训练装置码K1也可以通过人机界面储存至语音识别装置800的语音数据库612内。请参照图10,其绘示本发明另一实施例的语音识别装置的功能方块图。语音识别装置900与语音识别装置800不同之处为,语音识别装置900可列举为包含人机界面902及大量储存界面604的复合式装置904。在图10中与图8的相同之处沿用相同标号,在此不再赘述。如此,训练装置码K1也可通过人机界面902储存至语音识别装置800的语音数据库612内。Although, when the speech recognition device 800 of the fourth embodiment performs the speech training operation, the training device code K1 is stored in the
此外,虽然本发明上述实施例的语音识别装置是以麦克风为例作说明,然于其它实施例中,语音识别装置也可以是键盘、鼠标或手机等,其应用范围并不受本发明的实施例所限制。In addition, although the speech recognition device of the above-mentioned embodiment of the present invention is described with a microphone as an example, in other embodiments, the speech recognition device can also be a keyboard, mouse or mobile phone, etc., and its application scope is not limited by the implementation of the present invention. limited by the example.
本发明上述实施例所揭露的语音识别装置及其操作方法,具有多项优点,以下仅列举部分优点说明如下:The speech recognition device and its operating method disclosed in the above-mentioned embodiments of the present invention have many advantages, and only some of the advantages are listed below:
(1).语音数据库与应用程序是储存于语音识别装置内。使用者可随身携带语音识别装置,就算是更换不同的主机,亦不须重新进行语音训练。如此,不但省时且相当便利。(1). The voice database and application program are stored in the voice recognition device. The user can carry the speech recognition device with him, even if he changes to a different host, he does not need to carry out speech training again. This saves time and is quite convenient.
(2).语音识别装置100的装置处理单元110具有语音识别功能的固件,使得主机不需加载任何软件就能进行语音识别操作。也就是说,语音识别装置100不需储存应用程序就能进行语音识别操作。(2). The
(3).语音识别装置600及语音识别装置800的语音识别功能可由主机加载其应用程序602或802来执行。如此,当主机的数据处理速度较快时,可节省语音识别的时间。因此,本发明的语音识别装置具有多种实施态样,可配合不同的环境使语音识别的过程更有效率。(3). The voice recognition function of the voice recognition device 600 and the voice recognition device 800 can be executed by loading its
(4).语音识别装置300、语音识别装置800及语音识别装置900为同时具有语音识别及语音训练的功能。(4). The speech recognition device 300 , the speech recognition device 800 and the speech recognition device 900 have functions of speech recognition and speech training at the same time.
(5).上述实施例的语音识别装置可被列举成光驱,如此,使得应用程序可被自动地传送至主机且主机自动地加载应用程序。如此,节省使用者手动执行应用程序的时间。(5). The voice recognition device of the above embodiment can be enumerated as an optical drive, so that the application program can be automatically transmitted to the host and the host automatically loads the application program. In this way, the user's time of manually executing the application program is saved.
综上所述,虽然本发明已以数组较佳实施例揭露如上,然其并非用以限定本发明。本发明所属技术领域中具有通常知识者,在不脱离本发明的精神和范围内,当可作各种的更动与润饰。因此,本发明的保护范围当视所附的权利要求范围所界定者为准。To sum up, although the present invention has been disclosed above with a number of preferred embodiments, it is not intended to limit the present invention. Those skilled in the art of the present invention can make various changes and modifications without departing from the spirit and scope of the present invention. Therefore, the protection scope of the present invention should be defined by the appended claims.
Claims (8)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN2009100063762ACN101807398B (en) | 2009-02-16 | 2009-02-16 | Speech recognition device and operating method thereof |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN2009100063762ACN101807398B (en) | 2009-02-16 | 2009-02-16 | Speech recognition device and operating method thereof |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN101807398A CN101807398A (en) | 2010-08-18 |
| CN101807398Btrue CN101807398B (en) | 2011-12-21 |
Family
ID=42609167
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN2009100063762AExpired - Fee RelatedCN101807398B (en) | 2009-02-16 | 2009-02-16 | Speech recognition device and operating method thereof |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN101807398B (en) |
Families Citing this family (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR102022318B1 (en)* | 2012-01-11 | 2019-09-18 | 삼성전자 주식회사 | Method and apparatus for performing user function by voice recognition |
| CN103869948B (en)* | 2012-12-14 | 2019-01-15 | 联想(北京)有限公司 | Voice command processing method and electronic equipment |
| CN106356057A (en)* | 2016-08-24 | 2017-01-25 | 安徽咪鼠科技有限公司 | Speech recognition system based on semantic understanding of computer application scenario |
| CN107889085A (en)* | 2016-09-30 | 2018-04-06 | 亚旭电脑股份有限公司 | Method for inputting voice signal into intelligent device, electronic device and computer |
| CN106409297A (en)* | 2016-10-18 | 2017-02-15 | 安徽天达网络科技有限公司 | Voice recognition method |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN2428838Y (en)* | 2000-06-23 | 2001-05-02 | 陈振文 | voice recognition device |
| CN2447894Y (en)* | 2000-11-02 | 2001-09-12 | 陈振文 | A voice control identification device |
| CN2724146Y (en)* | 2004-08-27 | 2005-09-07 | 中国科学院自动化研究所 | Non specific person independent word sound identifying device |
| CN1716413A (en)* | 2004-07-02 | 2006-01-04 | 深圳市朗科科技有限公司 | Vehicle carried speech identification audio-video playing device and method |
- 2009
- 2009-02-16CNCN2009100063762Apatent/CN101807398B/ennot_activeExpired - Fee Related
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN2428838Y (en)* | 2000-06-23 | 2001-05-02 | 陈振文 | voice recognition device |
| CN2447894Y (en)* | 2000-11-02 | 2001-09-12 | 陈振文 | A voice control identification device |
| CN1716413A (en)* | 2004-07-02 | 2006-01-04 | 深圳市朗科科技有限公司 | Vehicle carried speech identification audio-video playing device and method |
| CN2724146Y (en)* | 2004-08-27 | 2005-09-07 | 中国科学院自动化研究所 | Non specific person independent word sound identifying device |
Also Published As
| Publication number | Publication date |
|---|---|
| CN101807398A (en) | 2010-08-18 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6811758B2 (en) | Voice interaction methods, devices, devices and storage media | |
| CN101807398B (en) | Speech recognition device and operating method thereof | |
| US20170230318A1 (en) | Return to sender | |
| CN108279839A (en) | Voice-based exchange method, device, electronic equipment and operating system | |
| EP0653701B1 (en) | Method and system for location dependent verbal command execution in a computer based control system | |
| CN103218137B (en) | Automatically method and the device of control is adjusted according to user operation | |
| WO1999063425A1 (en) | Method and apparatus for information processing, and medium for provision of information | |
| CN1790326A (en) | Semantic canvas | |
| CN1763842B (en) | Verb error comeback method and system in speech recognition | |
| US11163377B2 (en) | Remote generation of executable code for a client application based on natural language commands captured at a client device | |
| CN106844028B (en) | System switching method based on dual systems and mobile terminal | |
| CN110211364A (en) | A kind of test macro, test method, electronic equipment and storage medium | |
| WO2014032597A1 (en) | Voice recognition method and electronic device | |
| US11460971B2 (en) | Control method and electronic device | |
| CN105681533A (en) | Call content recording method and apparatus | |
| JP6801539B2 (en) | Information processing system, information processing device, information processing program and information processing method | |
| TWI382400B (en) | Voice recognition device and operating method thereof | |
| CN103973870B (en) | Information processing device and information processing method | |
| CN112542168B (en) | Voice control method and device | |
| US20090304367A1 (en) | System and method for media player device | |
| CN110286940B (en) | Smart television log generation method | |
| WO2025030654A1 (en) | Voice processing method and apparatus, and electronic device and storage medium | |
| CN111108755B (en) | Electronic device control system, audio output device, and method | |
| CN105979371A (en) | Method and system for obtaining audio and video information | |
| US11176096B2 (en) | File system for genomic data |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C14 | Grant of patent or utility model | ||
| GR01 | Patent grant | ||
| CF01 | Termination of patent right due to non-payment of annual fee | ||
| CF01 | Termination of patent right due to non-payment of annual fee | Granted publication date:20111221 |