CN101329668A - A method and device for generating information rules, and a method and system for judging information types - Google Patents
A method and device for generating information rules, and a method and system for judging information typesDownload PDFInfo
- Publication number
- CN101329668A CN101329668ACNA2007100493155ACN200710049315ACN101329668ACN 101329668 ACN101329668 ACN 101329668ACN A2007100493155 ACNA2007100493155 ACN A2007100493155ACN 200710049315 ACN200710049315 ACN 200710049315ACN 101329668 ACN101329668 ACN 101329668A
- Authority
- CN
- China
- Prior art keywords
- information
- rule
- content
- feature
- network information
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000000034methodMethods0.000titleclaimsabstractdescription49
- 238000004458analytical methodMethods0.000claimsabstractdescription19
- 238000004364calculation methodMethods0.000claimsabstractdescription17
- 238000000605extractionMethods0.000claimsabstractdescription9
- 238000006243chemical reactionMethods0.000claimsdescription5
- 238000005457optimizationMethods0.000claimsdescription2
- 238000012545processingMethods0.000claimsdescription2
- 230000015572biosynthetic processEffects0.000claims1
- 238000001914filtrationMethods0.000abstractdescription8
- 238000005516engineering processMethods0.000abstractdescription5
- 238000013528artificial neural networkMethods0.000description11
- 238000012549trainingMethods0.000description6
- 238000011161developmentMethods0.000description3
- 238000010586diagramMethods0.000description3
- 238000010801machine learningMethods0.000description3
- 238000012706support-vector machineMethods0.000description3
- 230000007786learning performanceEffects0.000description2
- 210000002569neuronAnatomy0.000description2
- 238000012360testing methodMethods0.000description2
- 206010035148PlagueDiseases0.000description1
- 241000607479Yersinia pestisSpecies0.000description1
- 230000009286beneficial effectEffects0.000description1
- 238000012986modificationMethods0.000description1
- 230000004048modificationEffects0.000description1
- 238000007781pre-processingMethods0.000description1
- 238000011160researchMethods0.000description1
- 239000002699waste materialSubstances0.000description1
Images


Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Data Exchanges In Wide-Area Networks (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明涉及互联网技术,具体涉及一种网络信息特征规则生成方法及装置、网络信息类型判断方法及系统。The invention relates to Internet technology, in particular to a method and device for generating network information characteristic rules, and a method and system for judging network information types.
背景技术Background technique
近年来,随着互连网的发展,垃圾信息问题越来越引起人们的重视。比如不请自来的垃圾邮件问题、垃圾网页问题、垃圾短信问题和日益增多的垃圾即时通信信息问题等,无时无刻的困扰着互连网用户,浪费网络资源,甚至可能引起其他更加严重的社会问题。随着技术的发展,垃圾信息过滤技术也得到了越来越多的关注和发展。In recent years, with the development of the Internet, the problem of spam has attracted more and more attention. For example, the problem of uninvited spam emails, webpage spam, short message spam and instant messaging information that is increasing day by day, etc., plague Internet users all the time, waste network resources, and may even cause other more serious social problems. With the development of technology, spam filtering technology has also received more and more attention and development.
今年来,机器学习方法得到了很大的发展,也成功应用到垃圾信息的过滤上。基于机器学习方法的网络信息内容过滤器是近年来的研究热点。1998年Sahami将朴素贝叶斯NB(Naive Bayes)方法用于垃圾邮件过滤,更是取得了巨大的成功。此后,越来越多的机器学习方法用于垃圾网络信息过滤,特别是很多文本分类的方法可以直接用于垃圾信息的过滤问题中,比如启发式规则、潜在语义索引LSI(Latent Semantic Index)技术、支持向量机SVM(support vector machine)方法、基于实例的学习方法(包括最近邻方法和基于案例的推理)以及最大墒方法等。In recent years, machine learning methods have been greatly developed and successfully applied to spam filtering. Network information content filter based on machine learning method is a research hotspot in recent years. In 1998, Sahami used the Naive Bayesian NB (Naive Bayes) method for spam filtering, and achieved great success. Since then, more and more machine learning methods have been used for spam network information filtering, especially many text classification methods can be directly used in spam filtering problems, such as heuristic rules, latent semantic index LSI (Latent Semantic Index) technology , support vector machine SVM (support vector machine) method, instance-based learning method (including nearest neighbor method and case-based reasoning) and maximum entropy method, etc.
贝叶斯过滤器是其中非常简单有效的方法,在商业反垃圾信息软件中得到了广泛的应用。它的本质是一种分类方法,将垃圾信息和非垃圾信息分为两类,通过对训练样本库的分析,得到各特征词在垃圾信息和正常信息中分别出现的初始概率。对于新到信息,首先抽取特征词,根据训练样本库中学习的概率计算新到信息分类为垃圾信息或者非垃圾信息的概率。同时,也将该信息放入训练样本库,以便不断修正初始概率。Bayesian filter is a very simple and effective method among them, and has been widely used in commercial anti-spam software. Its essence is a classification method, which divides spam information and non-spam information into two categories. Through the analysis of the training sample library, the initial probability of each feature word appearing in spam information and normal information is obtained. For newly arrived information, feature words are extracted first, and the probability of new information classified as spam or non-spam is calculated according to the probability learned in the training sample database. At the same time, this information is also put into the training sample library so that the initial probability can be continuously revised.
贝叶斯过滤器的准确性相当高,但是它的缺点是需要维护训练样本库,而这个样本库通常是需要用户的参与。The accuracy of Bayesian filters is quite high, but its disadvantage is that it needs to maintain a training sample library, and this sample library usually requires user participation.
发明内容Contents of the invention
本发明实施例的目的是提供一种网络信息特征规则生成方法及装置、网络信息类型判断方法、装置及系统,使用本发明提供的实施例,可以对网络信息的信息类型进行判断,从而过滤网络垃圾信息。The purpose of the embodiments of the present invention is to provide a method and device for generating network information feature rules, a method, device and system for judging network information types. Using the embodiments provided by the present invention, the information type of network information can be judged, thereby filtering network information. Spam.
为了解决现有技术存在的问题,本发明的实施方式提出了一种网络信息特征规则生成的方法,该方法的步骤包括:In order to solve the problems existing in the prior art, an embodiment of the present invention proposes a method for generating network information feature rules, the steps of which include:
读取分类已知信息的内容;Read the content of classified known information;
将所述信息内容使用预置提取算法得到信息规则库;Obtaining an information rule base by using a preset extraction algorithm for the information content;
采用所述的信息规则库使用预置学习算法进行概率分析得到最终特征集合;Using the information rule library and using a preset learning algorithm to perform probability analysis to obtain the final feature set;
将所述概率使用预置分析算法进行分数优化得到最终分数集。The probability is optimized using a preset analysis algorithm to obtain a final score set.
相应地,本发明的实施方式提出了一种网络信息特征规则生成装置,该装置包括:Correspondingly, the embodiment of the present invention proposes a device for generating network information feature rules, which includes:
网络信息读取单元,用于读取分类已知信息的信息内容;The network information reading unit is used to read the information content of the classified known information;
特征库提取单元,用于从所述信息内容中提取符合预置条件的特征;A feature library extraction unit, configured to extract features meeting preset conditions from the information content;
规则集生成单元,用于将所述特征进行概率分析得到最终的规则集合;a rule set generating unit, configured to perform probability analysis on the features to obtain a final rule set;
规则分数生成单元,用于将所述规则概率进行优化得到最终的分数集合。A rule score generating unit, configured to optimize the rule probability to obtain a final set of scores.
另一方面,本发明的实施方式还提供了一种网络信息类型判断的方法,该方法的步骤包括:On the other hand, the embodiment of the present invention also provides a method for judging the type of network information, and the steps of the method include:
读取分类未知信息的内容Read the contents of the category unknown information
对所述信息内容进行格式解析;Analyzing the format of the information content;
读取所述的网络信息特征规则生成方法得到的规则库和分数集;Reading the rule library and score set obtained by the network information feature rule generation method;
对所述解析后的信息内容使用预置预测算法进行计算;Calculating the analyzed information content using a preset prediction algorithm;
根据计算结果对所述信息类型进行判断。The information type is judged according to the calculation result.
相应地,本发明的实施方式提出了一种网络信息类型判断装置,该装置包括:Correspondingly, the embodiment of the present invention proposes a network information type judging device, which includes:
网络信息读取单元,用于读取分类未知信息的信息内容;The network information reading unit is used to read the information content of the classified unknown information;
信息内容解析单元,用于解析分类未知信息的信息内容;An information content parsing unit for parsing the information content of classified unknown information;
规则与分数集读取单元,用于读取规则集与对应分数集内容;The rule and score set reading unit is used to read the content of the rule set and the corresponding score set;
计算单元,用于以所述解析后的信息内容、规则集和分数集作为输入,采用预置预测算法进行计算;A computing unit, configured to use the parsed information content, rule set and score set as input to perform calculations using a preset prediction algorithm;
判断单元,用于根据所述计算单元的计算结果对所述分类未知信息的信息类型进行判断。A judgment unit, configured to judge the information type of the classified unknown information according to the calculation result of the calculation unit.
最后,实施本发明具有以下有益效果:Finally, implementing the present invention has the following beneficial effects:
从本发明实施例提供的以上技术方案可以看出,本发明实施例采用分类已知的网络信息的信息特征规则生成方法,并使用生成的特征对分类未知的信息进行判断,由于这些规则可以动态的调整和修改。同时垃圾信息过滤器充分利用了统计技术,可以自动地“学习”接收信息的特点,来调整垃圾信息的分值。除了设置内部的规则之外,垃圾信息过滤器也可以访问其它外部的同类型的垃圾信息库,这样可以进一步增强其适用性。From the above technical solutions provided by the embodiments of the present invention, it can be seen that the embodiments of the present invention adopt the method of generating information feature rules for classifying known network information, and use the generated features to judge information of unknown classification. Since these rules can be dynamically adjustments and modifications. At the same time, the spam filter makes full use of statistical techniques, which can automatically "learn" the characteristics of received information to adjust the score of spam. In addition to setting internal rules, the spam filter can also access other external spam databases of the same type, which can further enhance its applicability.
附图说明Description of drawings
图1为本发明网络信息特征规则生成方法实施例一的具体流程图;Fig. 1 is the specific flowchart of Embodiment 1 of the method for generating network information characteristic rules of the present invention;
图2为本发明网络信息类型判断方法实施例一的具体流程图;Fig. 2 is the specific flow chart of Embodiment 1 of the network information type judging method of the present invention;
图3为本发明网络信息特征规则生成装置实施例一的结构图;FIG. 3 is a structural diagram of Embodiment 1 of a device for generating network information feature rules according to the present invention;
图4为本发明网络信息类型判断装置实施例一的结构图;FIG. 4 is a structural diagram of Embodiment 1 of the network information type judging device of the present invention;
图5为本发明网络信息类型判断系统实施例一的结构图。FIG. 5 is a structural diagram of Embodiment 1 of the network information type judgment system of the present invention.
具体实施方式Detailed ways
为使本发明的目的、技术方案、及优点更加清楚明白,以下参照附图并举实施例,对本发明进一步详细说明。In order to make the object, technical solution, and advantages of the present invention clearer, the present invention will be further described in detail below with reference to the accompanying drawings and examples.
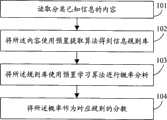
如图1所示,本发明提供的网络信息特征规则生成方法实施例一包括:As shown in Figure 1, Embodiment 1 of the method for generating network information feature rules provided by the present invention includes:
步骤101、读取分类已知网络信息的内容;
此处的网络信息的内容,是指我们要判断的邮件信息、网页信息、短信信息和即时通讯信息等的发送内容,对于接收者可见的部分。分类已知网络信息是指该信息的分类是已知的,也就是该信息是正常信息还是垃圾信息是已经确定的;The content of the network information here refers to the part that is visible to the receiver of the sent content of the email information, web page information, short message information and instant messaging information that we want to judge. Classified known network information means that the classification of the information is known, that is, whether the information is normal information or spam information has been determined;
步骤102、将所述信息内容使用预置提取算法得到信息规则库;
这里所使用的预置提取算法是指将信息的文本内容进行预处理:比如中文的编码转换、全半角字符处理、字符转换,对停用词、标点符合和数学运算符等非识别字符用空格进行转换得到可识别字符集;The preset extraction algorithm used here refers to preprocessing the text content of the information: such as Chinese encoding conversion, full-width character processing, character conversion, and non-recognized characters such as stop words, punctuation, and mathematical operators. Perform conversion to obtain a recognizable character set;
将所述可识别字符集分解成单词和短语形成特征。The set of recognizable characters is decomposed into words and phrases forming features.
步骤103、采用所述的规则库使用预置学习算法进行概率分析;
首先计算得到的各个特征出现的频度,删除其中频率超过一定值的特征,以去除常见的词汇,如“的”、“了”等,这里的一定值可由用户根据实际情况进行限定,同时删除频率小于一定值的特征,以去掉其中表达不明显的词汇,这里的一定值也可以由用户进行限定,通常为2或3;对剩下的特征采用信息增益方法得到每个特征的信息增益;将该信息增益按照从大到小的顺序进行排序;并对排序后的信息增益选取特定个数得到最终的特征规则集合,这里的特定个数应该由用户根据信息增益的变化趋势来限定特征的选取个数,此时的特征即为最终的规则集合。First, calculate the frequency of occurrence of each feature, and delete the features whose frequency exceeds a certain value to remove common words, such as "的", "了", etc. The certain value here can be limited by the user according to the actual situation, and deleted at the same time Features whose frequency is less than a certain value to remove words that are not obvious in expression, the certain value here can also be limited by the user, usually 2 or 3; use the information gain method to obtain the information gain of each feature for the remaining features; Sort the information gains in order from large to small; and select a specific number of sorted information gains to obtain the final feature rule set, where the specific number should be defined by the user according to the change trend of the information gain. Select the number, the feature at this time is the final rule set.
本发明进一步提供了一种采用贝叶斯学习算法(Bayes)生成网络信息规则方法。The present invention further provides a method for generating network information rules using a Bayesian learning algorithm (Bayes).
步骤104、将所述概率使用预置分析算法进行分数优化;
读入特征规则集合与特征对应的各个特征的信息增益;读入分类已知的网络信息的内容;计算所述各个特征项的分数并得到最终的分数集合。Read in the feature rule set and the information gain of each feature corresponding to the feature; read in the content of the classified and known network information; calculate the score of each feature item and obtain the final score set.
本发明进一步提供了一种采用神经网络优化网络信息规则分数方法。本发明应用的神经网络是一个很简单的单神经元的BP神经网络,采用的是单神经元的感知机学习模型。首先构造神经网络,同时基于特征向量将所有网络信息进行向量表示。将信息分成10份,将其中的九份作为训练数据输入神经网络进行学习,经过学习后,每条规则的分数就得到了优化,就可以用它来判断是否是垃圾信息了。所以,我们将余下一份作为测试数据验证学习性能。The present invention further provides a method for optimizing network information rule scores using a neural network. The neural network applied in the present invention is a very simple single-neuron BP neural network, which adopts a single-neuron perceptron learning model. Firstly, the neural network is constructed, and all network information is expressed as a vector based on the feature vector. The information is divided into 10 parts, and nine of them are input into the neural network as training data for learning. After learning, the score of each rule is optimized, and it can be used to judge whether it is spam. Therefore, we use the remaining one as the test data to verify the learning performance.
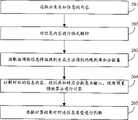
如图2所示,本发明提供的网络信息类型判断的实施例一包括:As shown in Figure 2, Embodiment 1 of network information type judgment provided by the present invention includes:
步骤201、读取分类未知信息的内容;
步骤202、对所述信息内容进行格式解析,这里的格式解析是指将按照该信息协议进行解析,把该信息表示成能够识别的信息文本内容,如对邮件利用因特网邮件扩展协议格式(MIME)形成邮件格式树等;
步骤203、读取网络信息特征规则生成方法得到的规则库和分数集;
读取由网络信息特征规则生成方法得到的规则库和各个规则对应的分数集合;Read the rule library obtained by the network information feature rule generation method and the score set corresponding to each rule;
步骤204、对所述解析后的信息内容使用预置预测算法进行计算;
将读入规则库中的规则按照类型优化形成规则树的形式,并将所述解析后的信息内容按照规则树进行匹配;若所述匹配成功则增加该规则对应分数,最后可以得到该信息的总匹配分数。The rules read into the rule base are optimized according to the type to form a rule tree, and the parsed information content is matched according to the rule tree; if the match is successful, the corresponding score of the rule is increased, and finally the information can be obtained total match score.
步骤205、根据计算结果对所述信息类型进行判断。
如果得到的信息的总匹配分数大于规定的阈值,则判断该信息为垃圾信息,反之为非垃圾信息。这里的阈值为用户自定义,可以根据不断的实验结果得出,在此处我们选择阈值为5。If the total matching score of the obtained information is greater than the specified threshold, it is judged that the information is spam, otherwise it is not spam. The threshold here is user-defined and can be obtained according to continuous experimental results. Here we choose a threshold of 5.
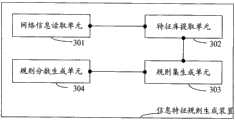
如图3所示,本发明提供的网络信息特征规则生成装置的实施例一包括:As shown in Figure 3, Embodiment 1 of the device for generating network information feature rules provided by the present invention includes:
网络信息读取单元301,用于读取分类已知信息的信息内容;A network
分类已知信息既要有正常同类信息也要有垃圾同类信息,从而可以保证该类型网络信息特征规则的全面性,因而能够保证网络信息特征规则的准确性;Classification of known information requires both normal and spam information, so as to ensure the comprehensiveness and accuracy of network information characteristic rules of this type;
特征库提取单元302,用于从所述信息内容中提取符合预置条件的特征;A feature
这些特征应该是具有同类信息可代表性的词汇,即在总的信息语料库中出现的频率即不过大也不过小。当然也不限于语料中的词汇,用户也可以自行添加或删除。These features should be representative words with similar information, that is, the frequency of occurrence in the total information corpus is neither too large nor too small. Of course, it is not limited to the words in the corpus, and users can also add or delete them by themselves.
规则分数生成单元303,用于将所述特征进行概率分析得到最终的规则集合;A rule
特征规则选取的数量具体应根据特征的信息增益的变化趋势来决定,形成最终的规则集合。The number of feature rules selected should be determined according to the change trend of feature information gain to form the final rule set.
规则分数生成单元304,用于将所述规则概率进行优化得到最终的分数集合;A rule
这里采用很简单的单神经元的BP神经网络,采用的是单神经元的感知机学习模型。首先构造神经网络,同时基于特征向量将所有网络信息进行向量表示。将信息分成10份,将其中的九份作为训练数据利用神经网络进行学习,将所得到的特征作为神经网络神经元的输入,将所得到的特征的信息增益作为神经网络神经元的权重,经过神经网络的递归学习后可以得到新的权重。直到新的权重趋于稳定后,每条规则的分数就得到了优化,就可以用它来判断是否是垃圾信息了。最后,我们将余下一份作为测试数据验证学习性能。A very simple single-neuron BP neural network is used here, and a single-neuron perceptron learning model is used. Firstly, the neural network is constructed, and all network information is expressed as a vector based on the feature vector. The information is divided into 10 parts, and nine of them are used as training data to learn using the neural network, the obtained features are used as the input of the neural network neurons, and the information gain of the obtained features is used as the weight of the neural network neurons. New weights can be obtained after recursive learning of the neural network. After the new weight becomes stable, the score of each rule is optimized, and it can be used to judge whether it is spam. Finally, we use the remaining one as test data to verify the learning performance.
从上可以看出,由于这些规则集合可以动态的调整和修改,同时垃圾信息过滤器充分利用了统计技术,可以自动地“学习”接收信息的特点,来调整垃圾信息的分值。这使得该过滤能根据不同阶段的垃圾信息特点来不断更新,能很好的适应不同阶段不同类型的垃圾信息过滤器的要求。It can be seen from the above that since these rule sets can be dynamically adjusted and modified, and the spam filter makes full use of statistical techniques, it can automatically "learn" the characteristics of received information to adjust the score of spam. This enables the filtering to be continuously updated according to the characteristics of spam information at different stages, and can well adapt to the requirements of different types of spam information filters at different stages.
图4描述的是本发明提供的网络信息类型判断装置的实施例一,包括:Figure 4 describes Embodiment 1 of the network information type judging device provided by the present invention, including:
网络信息读取单元401,用于读取分类未知信息的信息内容;A network
信息内容解析单元402,用于解析分类未知信息的信息内容;An information
对所述信息内容进行格式解析,这里的格式解析是指将按照该信息协议进行解析,把该信息表示成能够识别的信息文本内容,如对邮件利用因特网邮件扩展协议格式(MIME)形成邮件格式树等;Carry out format analysis to described information content, format analysis here refers to will be analyzed according to this information protocol, and this information is expressed as the information text content that can be identified, as utilizing Internet mail extension protocol format (MIME) to form mail format to mail tree, etc.;
规则与分数集读取单元403,用于读取规则集与对应分数集内容;A rule and score set reading
读取由网络信息特征规则生成方法得到的规则库和各个规则对应的分数集合;Read the rule library obtained by the network information feature rule generation method and the score set corresponding to each rule;
计算单元404,用于以所述解析后的信息内容、规则集和分数集作为输入,采用预置预测算法进行计算;A
将读入规则库中的规则按照类型优化形成规则树的形式,并将所述解析后的信息内容按照规则树进行匹配;若所述匹配成功则增加该规则对应分数,最后可以得到该信息的总匹配分数;The rules read into the rule base are optimized according to the type to form a rule tree, and the parsed information content is matched according to the rule tree; if the match is successful, the corresponding score of the rule is increased, and finally the information can be obtained total match score;
判断单元405,用于根据所述计算单元的计算结果对所述分类未知信息的信息类型进行判断;A
通过预测算法计算后,就可以得到一个值,一般情况下,这个值是一个可正可负的浮点数。如果得到的信息的这个总匹配分数大于规定的阈值,则判断该信息为垃圾信息,反之为非垃圾信息。这里的阈值为用户预先自定义的,可以根据多次的实验结果得出,在此处我们选择阈值为5。After calculation by the prediction algorithm, a value can be obtained. Generally, this value is a floating point number that can be positive or negative. If the total matching score of the obtained information is greater than the prescribed threshold, it is judged that the information is spam, otherwise it is not spam. The threshold here is pre-defined by the user and can be obtained from multiple experimental results. Here we choose the threshold as 5.
从上可以看出,由于我们在进行匹配的时候预先将信息内容解析成树的形式,同时将规则集合优化成规则树的形式,所以在应用过程中,匹配判断的速度将不会很慢,满足实际的需要。It can be seen from the above that since we pre-parse the information content into the form of a tree when performing matching, and optimize the rule set into the form of a rule tree, the speed of matching judgment will not be very slow during the application process. meet actual needs.
进一步,本发明提供了网络信息类型判断系统的实施例一,如图5所示,包括:Further, the present invention provides Embodiment 1 of the network information type judgment system, as shown in FIG. 5 , including:
信息特征规则生成装置501,用于读取分类已知信息的信息内容;从所述信息内容中提取符合预置条件的特征;将所述特征进行概率分析得到最终的规则集合;将所述规则概率进行优化得到最终的分数集合;The information feature
网络信息类型判断装置502,用于读取分类未知信息的信息内容并进行解析;读取规则集与对应分数集内容;以所述解析后的信息内容、规则集和分数集作为输入,采用预置预测算法进行计算;根据所述计算单元的计算结果对所述分类未知信息的信息类型进行判断。The network information
以上对本发明实施例所提供的网络信息特征规则生成方法及装置、网络信息类型判断方法及系统进行了详细介绍,以上实施例的说明只是用于帮助理解本发明的方法及其思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。The method and device for generating network information characteristic rules provided by the embodiments of the present invention, the method and system for judging network information types and systems are described above in detail, and the descriptions of the above embodiments are only used to help understand the methods and ideas of the present invention; at the same time, for Those skilled in the art will have changes in the specific implementation and scope of application according to the idea of the present invention. In summary, the contents of this specification should not be construed as limiting the present invention.
Claims (10)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CNA2007100493155ACN101329668A (en) | 2007-06-18 | 2007-06-18 | A method and device for generating information rules, and a method and system for judging information types |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CNA2007100493155ACN101329668A (en) | 2007-06-18 | 2007-06-18 | A method and device for generating information rules, and a method and system for judging information types |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN101329668Atrue CN101329668A (en) | 2008-12-24 |
Family
ID=40205481
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CNA2007100493155APendingCN101329668A (en) | 2007-06-18 | 2007-06-18 | A method and device for generating information rules, and a method and system for judging information types |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN101329668A (en) |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102542063A (en)* | 2011-12-30 | 2012-07-04 | 华为技术有限公司 | Content filtering method, device and system |
| CN103455621A (en)* | 2013-09-12 | 2013-12-18 | 金蝶软件(中国)有限公司 | Method, device and system for analyzing physical distribution invoice numbers |
| CN103874033A (en)* | 2012-12-12 | 2014-06-18 | 上海粱江通信系统股份有限公司 | Method for identifying irregular spam short message on the basis of Chinese word segmentation |
| WO2015062514A1 (en)* | 2013-10-31 | 2015-05-07 | Tencent Technology (Shenzhen) Company Limited | Web content extracting method, device, and system |
| CN107171948A (en)* | 2017-07-04 | 2017-09-15 | 彩讯科技股份有限公司 | A kind of method, device and the mail server of filtering spam mail |
| CN110913353A (en)* | 2018-09-17 | 2020-03-24 | 阿里巴巴集团控股有限公司 | Short message classification method and device |
- 2007
- 2007-06-18CNCNA2007100493155Apatent/CN101329668A/enactivePending
Cited By (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102542063A (en)* | 2011-12-30 | 2012-07-04 | 华为技术有限公司 | Content filtering method, device and system |
| CN102542063B (en)* | 2011-12-30 | 2015-04-29 | 华为技术有限公司 | Content filtering method, device and system |
| CN103874033A (en)* | 2012-12-12 | 2014-06-18 | 上海粱江通信系统股份有限公司 | Method for identifying irregular spam short message on the basis of Chinese word segmentation |
| CN103874033B (en)* | 2012-12-12 | 2017-11-24 | 上海粱江通信系统股份有限公司 | A kind of method that irregular refuse messages are identified based on Chinese word segmentation |
| CN103455621A (en)* | 2013-09-12 | 2013-12-18 | 金蝶软件(中国)有限公司 | Method, device and system for analyzing physical distribution invoice numbers |
| CN103455621B (en)* | 2013-09-12 | 2018-07-06 | 深圳前海百递网络有限公司 | A kind of analytic method of logistics Air Way Bill No., device and system |
| WO2015062514A1 (en)* | 2013-10-31 | 2015-05-07 | Tencent Technology (Shenzhen) Company Limited | Web content extracting method, device, and system |
| CN107171948A (en)* | 2017-07-04 | 2017-09-15 | 彩讯科技股份有限公司 | A kind of method, device and the mail server of filtering spam mail |
| CN107171948B (en)* | 2017-07-04 | 2020-08-25 | 彩讯科技股份有限公司 | Method, device and mail server for filtering spam |
| CN110913353A (en)* | 2018-09-17 | 2020-03-24 | 阿里巴巴集团控股有限公司 | Short message classification method and device |
| CN110913353B (en)* | 2018-09-17 | 2022-01-18 | 阿里巴巴集团控股有限公司 | Short message classification method and device |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN109446404B (en) | Method and device for analyzing emotion polarity of network public sentiment | |
| CN108874777B (en) | Text anti-spam method and device | |
| US9720901B2 (en) | Automated text-evaluation of user generated text | |
| CN101877837B (en) | Method and device for short message filtration | |
| CN108885623B (en) | Semantic analysis system and method based on knowledge graph | |
| CN103336766B (en) | Short text garbage identification and modeling method and device | |
| CN111753086A (en) | Method and device for identifying spam | |
| CN107239512B (en) | A microblog spam comment identification method combined with comment relationship network graph | |
| CN107515873A (en) | A kind of junk information recognition methods and equipment | |
| CN109947934B (en) | Data mining methods and systems for short texts | |
| CN107291886A (en) | A kind of microblog topic detecting method and system based on incremental clustering algorithm | |
| CN105183715B (en) | A kind of word-based distribution and the comment spam automatic classification method of file characteristics | |
| CN113780007A (en) | Corpus screening method, intention recognition model optimization method, equipment and storage medium | |
| CN104915443B (en) | A kind of abstracting method of Chinese microblogging evaluation object | |
| CN109086355B (en) | Hot-spot association relation analysis method and system based on news subject term | |
| CN112492606B (en) | Classification recognition method and device for spam messages, computer equipment and storage medium | |
| CN110858217A (en) | Method and device for detecting microblog sensitive topics and readable storage medium | |
| CN112232079B (en) | A method and system for classifying microblog comment data | |
| CN110457711A (en) | A topic recognition method for social media events based on keywords | |
| CN110516057A (en) | Method and device for answering petition questions | |
| CN108021582A (en) | Internet public feelings monitoring method and device | |
| CN101329668A (en) | A method and device for generating information rules, and a method and system for judging information types | |
| CN107688630A (en) | A kind of more sentiment dictionary extending methods of Weakly supervised microblogging based on semanteme | |
| CN113010664B (en) | Data processing method, device and computer equipment | |
| CN114065749A (en) | Text-oriented Guangdong language recognition model and training and recognition method of system |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| DD01 | Delivery of document by public notice | Addressee:Zheng Mei Document name:Notification that Application Deemed to be Withdrawn | |
| C02 | Deemed withdrawal of patent application after publication (patent law 2001) | ||
| WD01 | Invention patent application deemed withdrawn after publication | Open date:20081224 |