CN101281749A - Scalable Speech and Tone Joint Coding Apparatus and Decoding Apparatus - Google Patents
Scalable Speech and Tone Joint Coding Apparatus and Decoding ApparatusDownload PDFInfo
- Publication number
- CN101281749A CN101281749ACNA2008100378274ACN200810037827ACN101281749ACN 101281749 ACN101281749 ACN 101281749ACN A2008100378274 ACNA2008100378274 ACN A2008100378274ACN 200810037827 ACN200810037827 ACN 200810037827ACN 101281749 ACN101281749 ACN 101281749A
- Authority
- CN
- China
- Prior art keywords
- coding
- unit
- class
- signal
- musical sound
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images


Landscapes
- Compression, Expansion, Code Conversion, And Decoders (AREA)
Abstract
Translated fromChineseDescription
Translated fromChinese技术领域technical field
本发明涉及一种数字音频编码技术领域的装置,具体是一种可分级的语音和乐音联合编码装置和解码装置。The invention relates to a device in the technical field of digital audio coding, in particular to a scalable speech and musical sound joint coding device and decoding device.
背景技术Background technique
数字通信业务和数字存储业务的高速增长对数字信号处理技术提出了越来越高的要求。由于多媒体业务的不断扩展,不但需要更高的编码效率和实时性,对语音和乐音信号的普遍适应性的需求也越来越大。同时,在移动音频应用中,由于信道的不稳定性,需要依据信道情况自适应的调整码率,这就要求音频编解码器能够满足自适应多码率性,从而移动音频的可分级编码技术也成为下一代音频数字信号处理需要解决的关键技术。在通常的音频编码中,使用时域和频域混合编码的方式来解决针对语音和乐音信号不同特性进行编码的问题。The rapid growth of digital communication services and digital storage services has put forward higher and higher requirements for digital signal processing technology. Due to the continuous expansion of multimedia services, not only higher coding efficiency and real-time performance are required, but also the demand for universal adaptability of voice and music signals is also increasing. At the same time, in mobile audio applications, due to the instability of the channel, it is necessary to adjust the code rate adaptively according to the channel conditions, which requires the audio codec to be able to meet adaptive multi-bit rates, so that the scalable coding technology of mobile audio It has also become a key technology that needs to be solved in the next generation of audio digital signal processing. In common audio coding, a time-domain and frequency-domain mixed coding method is used to solve the problem of coding different characteristics of speech and musical tone signals.
经对现有技术文献检索发现,第三代合作伙伴计划(The 3rd GenerationPartnership Project,3GPP)组织推荐的AMR-WB+(Adaptive MultiRate WideBandplus,自适应多速率宽带)音频编解码标准和国际电信联盟[InternationalTelecommunication Union,ITU-T]推荐的G.729.1音频编解码标准,这两种标准是主要的能够满足低码率、低复杂度、可分级的语音和乐音联合编码技术。After searching the existing technical documents, it is found that the AMR-WB+ (Adaptive MultiRate WideBandplus, adaptive multi-rate broadband) audio codec standard recommended by the 3rd Generation Partnership Project (The 3rd Generation Partnership Project, 3GPP) organization and the International Telecommunication Union [International Telecommunication Union] Union, ITU-T] recommended G.729.1 audio codec standard, these two standards are mainly able to meet the low bit rate, low complexity, scalable voice and tone joint coding technology.
AMR-WB+是通过采取ACELP(代数码激励线性预测)和TCX(变换域激励编码)两种核心编码器来满足对语音和乐音信号的普遍适应性的,是一种通过对低码率的音频编码扩展而形成的一种混合编码方式。G.729.1采用可分级编码方式,包含了12个嵌入式层,每层均对应不同的码率与不同的编码技术,主要核心编码技术有CELP(码激励线性预测)、TDBE(时域频带扩展技术)和TDAC(时域混叠抵消预测变换编码技术)三种。G.729.1由于分层复杂,计算复杂度也相应增大。此外,由于AMR-WB+与G.729.1都是针对低码率音频编码的,AMR-WB+适应的码率范围为:单声道6~36kbps,立体声8~48kbps,G.729.1适应的码率范围为8~32kbps。当码率高到一定程度时,比如当码率达到64kbps时,这两种编码方案的效果就明显不如同码率下的AAC(Advance Audio Coding,高级音频编)了。这两种编码方式的优点在高码率下便体现不出来了。为此,有必要提出一种既适应于低码率又能随着码率的提高仍然保持高音质的编码方案。AMR-WB+ adopts two core encoders, ACELP (Algebraic Code Excited Linear Prediction) and TCX (Transform Domain Excitation Coding) to meet the general adaptability to speech and musical tone signals. A hybrid encoding method formed by encoding extensions. G.729.1 adopts a scalable coding method, including 12 embedded layers, and each layer corresponds to a different code rate and a different coding technology. The main core coding technologies include CELP (Code Excited Linear Prediction), TDBE (Time Domain Band Extension) Technology) and TDAC (Time Domain Aliasing Cancellation Predictive Transform Coding) three. Due to the complex layering of G.729.1, the computational complexity increases accordingly. In addition, since both AMR-WB+ and G.729.1 are for low-bit-rate audio coding, the bit rate range for AMR-WB+ is: 6-36kbps for mono, 8-48kbps for stereo, and the bit-rate range for G.729.1 It is 8~32kbps. When the bit rate reaches a certain level, for example, when the bit rate reaches 64kbps, the effects of these two encoding schemes are obviously not as good as AAC (Advance Audio Coding) at the bit rate. The advantages of these two encoding methods cannot be reflected at high bit rates. For this reason, it is necessary to propose a coding scheme that is not only suitable for low bit rate but also can maintain high sound quality with the increase of bit rate.
此外,在AMR-WB+中提出的ACELP与TCX混合编码技术,将每帧信号分别用ACELP和TCX两种编码方式编码,分别在本地解码后,选取信噪比较高的编码方式编码,编码复杂度高,且由于每帧信号最终只用了一种编码方法编码,在编码过程中损失了不少信息量。In addition, the ACELP and TCX hybrid coding technology proposed in AMR-WB+ uses ACELP and TCX coding methods to encode each frame signal respectively. After local decoding, the coding method with a higher signal-to-noise ratio is selected for coding, which is complicated. The accuracy is high, and because each frame signal is finally encoded by only one encoding method, a lot of information is lost in the encoding process.
发明内容Contents of the invention
本发明针对上述现有技术的不足,提出了一种可分级的语音和乐音联合编码装置和解码装置,使其利用语音和乐音检测技术、类语音信号编码技术、类乐音信号编码技术、残差编码技术等在保证高音质和低计算复杂度的前提下,提高对语音信号和乐音信号的普遍适应性,同时满足对码率的自适应性。Aiming at the deficiencies in the prior art above, the present invention proposes a scalable speech and tone joint encoding device and decoding device, which makes use of speech and tone detection technology, similar speech signal coding technology, similar musical tone signal coding technology, residual On the premise of ensuring high sound quality and low computational complexity, the coding technology improves the general adaptability to speech signals and musical tone signals, and at the same time satisfies the adaptability to the code rate.
本发明是通过以下技术方案实现的:The present invention is achieved through the following technical solutions:
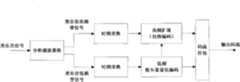
本发明涉及一种可分级的语音和乐音联合编码装置,包括:语音和乐音分类单元、类语音编码单元、本地类语音解码单元、类乐音编码单元、本地类乐音解码单元、残差获取单元、打包输出单元,其中:The present invention relates to a scalable voice and tone joint encoding device, comprising: a voice and tone classification unit, a speech-like encoding unit, a local-like speech decoding unit, a tone-like encoding unit, a local tone-like decoding unit, a residual acquisition unit, Pack output unit, where:
语音和乐音分类单元对输入的音频信号进行分类,根据分类结果将音频信号输入类语音编码单元或类乐音编码单元;The voice and tone classification unit classifies the input audio signal, and inputs the audio signal into the speech-like encoding unit or the tone-like encoding unit according to the classification result;
类语音编码单元负责对语音信号进行编码,获得编码参数,并输出至本地类语音解码单元、残差获取单元和打包输出单元;The speech-like encoding unit is responsible for encoding the speech signal, obtains encoding parameters, and outputs to the local speech-like decoding unit, residual acquisition unit and packaging output unit;
本地类语音解码单元将类语音编码单元编码得到的参数进行本地解码,得到本地重构信号,并输出解码数据至残差获取单元;The local speech-like decoding unit locally decodes the parameters encoded by the speech-like coding unit to obtain a local reconstructed signal, and outputs the decoded data to the residual acquisition unit;
类乐音编码单元负责对乐音信号进行编码,获得编码参数,并输出至本地类乐音解码单元、残差获取单元和打包输出单元;The tone-like encoding unit is responsible for encoding the tone signal, obtaining encoding parameters, and outputting to the local tone-like decoding unit, residual acquisition unit and packaging output unit;
本地类乐音解码单元将类乐音编码单元编码得到的参数进行本地解码,得到本地重构信号,并输出解码数据至残差获取单元;The local tone-like decoding unit locally decodes the parameters encoded by the tone-like encoding unit to obtain a local reconstructed signal, and outputs the decoded data to the residual acquisition unit;
残差获取单元取得输入音频信号与本地重构信号的残差,若本帧信号被判断为类语音信号,则将残差输入到类乐音编码单元;若本帧信号被判断为类乐音信号,则将残差输入到类语音编码单元;The residual acquisition unit obtains the residual of the input audio signal and the local reconstruction signal, and if the frame signal is judged as a speech-like signal, the residual is input to the musical-like coding unit; if the frame signal is judged as a musical-like signal, The residual is then input to the speech-like coding unit;
打包输出单元将类语音编码单元和类乐音编码单元编码得到的参数打包输出。The packing output unit packs and outputs the parameters encoded by the speech-like coding unit and the tone-like coding unit.
所述类语音编码单元,对输入的语音信号的每帧进行线性预测(LP)分析得到线性预测系数,通过将线性预测残差信号通过感知加权滤波器来计算目标信号,同时计算加权合成滤波器的冲激响应,采用目标信号和冲激响应通过在开环基音周期附近搜索闭环基音周期及增益,目标信号通过去除自适应码本的贡献进行更新,得到的新的目标信号用于固定码字搜索分析,计算自适应和固定码本矢量的增益,最后将随机码矢和固定码矢的码矢地址和增益,以及滤波器参数量化编码后打包输出。The speech-like encoding unit performs linear prediction (LP) analysis on each frame of the input speech signal to obtain a linear prediction coefficient, and calculates the target signal by passing the linear prediction residual signal through a perceptual weighting filter, and simultaneously calculates a weighted synthesis filter The impulse response of the target signal and the impulse response are used to search the closed-loop pitch period and gain near the open-loop pitch period. The target signal is updated by removing the contribution of the adaptive codebook, and the new target signal obtained is used for the fixed codeword Search and analyze, calculate the gains of adaptive and fixed codebook vectors, and finally quantize and encode the code vector addresses and gains of random code vectors and fixed code vectors, as well as filter parameters, and then package and output them.
所述类乐音编码单元,将类乐音信号通过分析滤波器组,将信号分成高频带信号和低频带信号两路,对两路信号分别进行时—频变换,将信号变换到频域,得到两个频带的非量化频谱系数,对低频带非量化频谱系数进行基于格型矢量量化的矢量编码,对高频带非量化频谱系数进行基于低频带格型矢量量化的频带扩展,最后将低频带矢量编码码流与高频带扩展编码码流打包并输出。The tone-like encoding unit divides the tone-like signal into two paths, a high-frequency band signal and a low-frequency band signal, through an analysis filter bank, performs time-frequency transformation on the two paths of signals, and transforms the signal into the frequency domain to obtain For the unquantized spectral coefficients of two frequency bands, vector encoding based on lattice vector quantization is performed on the unquantized spectral coefficients in the low frequency band, and the frequency band extension based on lattice vector quantization in the high frequency band is performed on the unquantized spectral coefficients in the high frequency band. Finally, the low frequency band The vector coded code stream and the high frequency band extension coded code stream are packaged and output.
所述残差获取单元,其对类语音信号进行残差编码时,编码过程与类语音编码单元相同,类语音残差编码的比特数分配依据信道和码率情况而定,信道好码率高则分配的比特数多,反之则分配的比特数较少,具有可分级性和对信道与码率的自适应性。The residual acquisition unit, when it performs residual coding on the speech-like signal, the coding process is the same as that of the speech-like coding unit, and the bit number allocation of the speech-like residual coding depends on the channel and the code rate, and the channel is good and the code rate is high The number of allocated bits is large, otherwise, the number of allocated bits is small, which has scalability and adaptability to channels and code rates.
所述残差获取单元,其对类乐音信号进行残差编码时,编码过程与类乐音编码单元相同,类乐音残差编码的比特数分配要依据信道和码率情况而定,信道好码率高则分配的比特数多,反之则分配的比特数较少,它具有对信道和码率的自适应性。The residual acquisition unit, when it carries out residual coding to the musical tone signal, the coding process is the same as the musical tone coding unit, and the bit number distribution of the musical tone residual coding will be determined according to the channel and the code rate, and the code rate of the channel is better than that of the musical tone coding unit. If it is higher, the number of bits allocated will be more, otherwise, the number of bits allocated will be less, and it is adaptive to the channel and code rate.
所述的类乐音编码单元,其基于格型矢量量化的矢量编码还包括:编码器根据码率控制量化部分的比特分配,对量化的质量进行调整,量化是可分级的。The music-like coding unit, whose vector coding based on lattice vector quantization further includes: the coder controls the bit allocation of the quantization part according to the code rate, and adjusts the quality of the quantization, and the quantization is scalable.
所述的类乐音编码单元,其高频带扩展还包括:编码器根据码率控制高频带扩展部分的比特分配,对频带扩展的质量进行调整,频带扩展是可分级的。In the tone-like coding unit, the high frequency band extension further includes: the encoder controls the bit allocation of the high frequency band extension according to the code rate, and adjusts the quality of the frequency band extension, and the frequency band extension is scalable.
本发明还涉及一种可分级的语音和乐音联合解码装置,包括:编码模式获取单元、编码参数获取单元、类语音解码单元、类乐音解码单元、合成输出单元,其中:The present invention also relates to a hierarchical voice and tone joint decoding device, comprising: an encoding mode acquisition unit, an encoding parameter acquisition unit, a speech-like decoding unit, a tone-like decoding unit, and a synthesis output unit, wherein:
编码模式获取单元对码流进行初步解析,将本帧信号所采用的编码模式输入至编码参数获取单元;The encoding mode acquisition unit conducts preliminary analysis on the code stream, and inputs the encoding mode adopted by the frame signal to the encoding parameter acquisition unit;
编码参数获取单元根据不同的编码模式来解析码流,得到各个编码参数输入至类语音解码单元和类乐音解码单元;The encoding parameter acquisition unit parses the code stream according to different encoding modes, and obtains each encoding parameter and inputs it to the speech-like decoding unit and the music-like decoding unit;
类语音解码单元利用类语音编码参数进行解码,得到类语音解码数据,输出解码数据至合成输出单元;The speech-like decoding unit utilizes the speech-like encoding parameters to decode, obtains speech-like decoded data, and outputs the decoded data to the synthesis output unit;
类乐音解码单元利用类乐音编码参数进行解码,得到类乐音解码数据,输出解码数据至合成输出单元;The tone-like decoding unit uses the tone-like encoding parameters to decode, obtains tone-like decoded data, and outputs the decoded data to the synthesis output unit;
合成输出单元将类语音解码单元和类乐音解码单元输出的解码数据进行合成,得到重建的音频信号。The synthesis output unit synthesizes the decoded data output by the speech-like decoding unit and the tone-like decoding unit to obtain a reconstructed audio signal.
所述的类语音解码单元,其通过解析码流,根据固定码矢和自适应码矢的地址找到相应的码矢,将固定码矢和自适应码矢分别与其增益相乘,得到还原的固定码矢和自适应码矢,并将还原的固定码矢和自适应码矢分别通过激励合成滤波器,得到合成语音,最后将合成语音输出。The speech-like decoding unit, by analyzing the code stream, finds the corresponding code vector according to the addresses of the fixed code vector and the adaptive code vector, and multiplies the fixed code vector and the adaptive code vector with their gains respectively to obtain the restored fixed code vector Code vectors and adaptive code vectors, and the restored fixed code vectors and adaptive code vectors are respectively passed through the excitation synthesis filter to obtain synthesized speech, and finally the synthesized speech is output.
所述的类乐音解码单元,其通过解析码流,对码流中的低频带量化频谱系数进行格型矢量反量化,得到非量化频谱系数,对码流中的高频带扩展参数进行基于低频格型矢量量化系数的高频带信号重构,得到重构的高频带信号,同时对高低频带分别进行时频反变换,得到时域还原的低频带信号与高频带信号,并将还原的低频带信号与高频带信号通过综合滤波器组,得到还原的类乐音信号,最后将还原的类乐音信号输出。The music-like decoding unit, by parsing the code stream, performs lattice vector inverse quantization on the quantized spectral coefficients in the low frequency band in the code stream to obtain non-quantized spectral coefficients, and performs low frequency based on the high frequency band extension parameters in the code stream. Reconstruct the high-frequency band signal of the lattice vector quantization coefficient to obtain the reconstructed high-frequency band signal, and perform time-frequency inverse transformation on the high and low frequency bands respectively to obtain the low-frequency band signal and high-frequency band signal restored in the time domain, and restore the The low-frequency band signal and the high-frequency band signal pass through the integrated filter bank to obtain a restored musical tone-like signal, and finally output the restored musical-like tone signal.
与现有技术相比,本发明具有如下有益效果Compared with the prior art, the present invention has the following beneficial effects
1.本发明采用语音和乐音联合编码的方式,采用基于CELP的类语音编码单元和基于格型矢量量化的类乐音编码单元分别对类语音信号和类乐音信号编码,具有对语音信号和乐音信号的普遍适应性;1. the present invention adopts the mode of joint coding of speech and musical tone, adopts the similar speech coding unit based on CELP and the similar musical tone coding unit based on lattice vector quantization to class speech signal and class musical tone signal encoding respectively, has the ability to speech signal and musical tone signal universal adaptability;
2.本发明对本地重构信号与输入信号的残差进行编码,减少了编码中信息的损失,提高了编码音质,尤其是在码率提高时,能保持高品质的音质;2. The present invention encodes the residual of the local reconstructed signal and the input signal, which reduces the loss of information in the encoding and improves the encoding sound quality, especially when the code rate is increased, it can maintain high-quality sound quality;
3.通过格型矢量量化的动态比特分配、残差编码的可变比特分配以及高频频带扩展的分级性实现编码的自适应多码率特性,从而使得编码对信道条件具有自适应性。3. Through the dynamic bit allocation of lattice vector quantization, the variable bit allocation of residual coding and the hierarchical nature of high-frequency band extension, the adaptive multi-bit rate characteristics of coding are realized, so that the coding is adaptive to channel conditions.
4.采用语音和乐音分类单元对输入信号进行检测来判断使用类语音编码单元还是类乐音编码单元,相对于在本地分别用语音编码器和乐音编码器进行编码和本地解码,再比较两者效果来选择最终使用何种编码模式的方案,本发明中的方案只需要在本地编码两次,解码一次,所以计算复杂度较低。4. Use the speech and tone classification unit to detect the input signal to determine whether to use a speech-like coding unit or a tone-like coding unit, compared to using a speech encoder and a tone encoder for encoding and local decoding respectively, and then compare the effects of the two To select the solution of which encoding mode to use finally, the solution in the present invention only needs to be encoded twice locally and decoded once, so the computational complexity is relatively low.
附图说明Description of drawings
图1为本发明的编码装置的结构框图;Fig. 1 is the structural block diagram of the encoding device of the present invention;
图 为本发明的类乐音编码单元的工作流程图;The figure is a work flow chart of the class tone coding unit of the present invention;
图3为本发明的解码装置的结构框图;Fig. 3 is a structural block diagram of the decoding device of the present invention;
图4为本发明的类乐音解码单元的工作流程图。Fig. 4 is a working flowchart of the tone-like decoding unit of the present invention.
具体实施方式Detailed ways
下面结合附图对本发明的实施例作详细说明:本实施例在以本发明技术方案为前提下进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。The embodiments of the present invention are described in detail below in conjunction with the accompanying drawings: this embodiment is implemented on the premise of the technical solution of the present invention, and detailed implementation methods and specific operating procedures are provided, but the protection scope of the present invention is not limited to the following the described embodiment.
如图1所示,本实施例涉及一种可分级的语音和乐音联合编码装置,包括:语音和乐音分类单元、类语音编码单元、本地类语音解码单元、类乐音编码单元、本地类乐音解码单元、残差获取单元、打包输出单元,其中:As shown in Figure 1, this embodiment relates to a scalable voice and tone joint encoding device, including: a voice and tone classification unit, a speech-like encoding unit, a local-like speech decoding unit, a tone-like encoding unit, and a local tone-like decoding unit Unit, residual acquisition unit, packing output unit, where:
语音和乐音分类单元对输入的音频信号进行分类,根据分类结果将音频信号输入类语音编码单元或类乐音编码单元,本实施例中输入的音频信号为一帧信号取20ms采样输入,每帧256个采样点。Speech and tone classification unit classifies the audio signal of input, according to classification result, audio signal is input class speech encoding unit or class tone encoding unit, and the audio signal of input among the present embodiment is that a frame signal gets 20ms sampling input, and every frame 256 sampling points.
类语音编码单元负责对语音信号进行编码,获得编码参数,并输出至本地类语音解码单元、残差获取单元和打包输出单元;The speech-like encoding unit is responsible for encoding the speech signal, obtains encoding parameters, and outputs to the local speech-like decoding unit, residual acquisition unit and packaging output unit;
本地类语音解码单元将类语音编码单元编码得到的参数进行本地解码,得到本地重构信号,并输出解码数据至残差获取单元;The local speech-like decoding unit locally decodes the parameters encoded by the speech-like coding unit to obtain a local reconstructed signal, and outputs the decoded data to the residual acquisition unit;
类乐音编码单元负责对乐音信号进行编码,获得编码参数,并输出至本地类乐音解码单元、残差获取单元和打包输出单元;The tone-like encoding unit is responsible for encoding the tone signal, obtaining encoding parameters, and outputting to the local tone-like decoding unit, residual acquisition unit and packaging output unit;
本地类乐音解码单元将类乐音编码单元编码得到的参数进行本地解码,得到本地重构信号,并输出解码数据至残差获取单元;The local tone-like decoding unit locally decodes the parameters encoded by the tone-like encoding unit to obtain a local reconstructed signal, and outputs the decoded data to the residual acquisition unit;
残差获取单元取得输入音频信号与本地重构信号的残差,若本帧信号被判断为类语音信号,则将残差输入到类乐音编码单元;若本帧信号被判断为类乐音信号,则将残差输入到类语音编码单元;The residual acquisition unit obtains the residual of the input audio signal and the local reconstruction signal, and if the frame signal is judged as a speech-like signal, the residual is input to the musical-like coding unit; if the frame signal is judged as a musical-like signal, The residual is then input to the speech-like coding unit;
打包输出单元将类语音编码单元和类乐音编码单元编码得到的参数打包输出。The packing output unit packs and outputs the parameters encoded by the speech-like coding unit and the tone-like coding unit.
所述语音和乐音分类单元,其采用AVS-M(数字音视频编解码技术面向移动的应用标准)中所采用的声音分类器进行语音和乐音的分类检测。根据线性频谱系数和子带能量信息以及开环基音参量等参数,判决输入信号类型,包括类语音信号和类乐音信号两类。The speech and tone classifying unit adopts the sound classifier adopted in AVS-M (digital audio and video codec technology oriented to mobile application standard) to classify and detect speech and tone. According to parameters such as linear spectral coefficients, sub-band energy information, and open-loop fundamental tone parameters, the input signal type is determined, including two types of speech-like signals and musical tone-like signals.
所述类语音编码单元,其采用CELP(码激励线性预测)进行时域上的码激励线性预测编码,经过预处理的语音信号通过高通和预加重,对每帧进行LP分析得到线性预测系数ai,每个语音帧分成4个子帧,每个子帧为64个样本,5ms长,下面的操作按照每个子帧进行:Said speech coding unit, which adopts CELP (code-excited linear prediction) to carry out code-excited linear predictive encoding in the time domain, the preprocessed speech signal is passed through high-pass and pre-emphasized, and LP analysis is performed on each frame to obtain the linear predictive coefficient ai , each speech frame is divided into 4 subframes, each subframe is 64 samples, 5ms long, the following operations are performed according to each subframe:
①通过将LP残差信号通过感知加权滤波器W(z)(其初始状态通过LP残差信号和激励信号的差值进行更新)来计算目标信号x(n);① Calculate the target signal x(n) by passing the LP residual signal through the perceptual weighting filter W(z) (the initial state of which is updated by the difference between the LP residual signal and the excitation signal);
②计算加权合成滤波器的冲激响应h(n);② Calculate the impulse response h(n) of the weighted synthesis filter;
③采用目标信号x(n)和冲激响应h(n)通过在开环基音周期附近搜索闭环基音周期及增益;③ Use the target signal x(n) and the impulse response h(n) to search for the closed-loop pitch period and gain near the open-loop pitch period;
④目标信号x(n)通过去除自适应码本的贡献(滤波后的自适应码本矢量)进行更新。这个新的目标信号为x2(n),用于固定码字搜索分析;④ The target signal x(n) is updated by removing the contribution of the adaptive codebook (filtered adaptive codebook vector). This new target signal is x2 (n) for fixed codeword search analysis;
⑤自适应和固定码本矢量的增益用6或7比特进行量化;⑤ The gain of adaptive and fixed codebook vectors is quantized with 6 or 7 bits;
⑥最后,采用选定的最佳激励信号对滤波器进行更新,用于寻找下一子帧的目标信号;⑥Finally, the filter is updated with the selected best excitation signal to find the target signal of the next subframe;
⑦将量化的LP参数、自适应码矢地址和增益、固定码矢地址和增益打包输出。⑦ The quantized LP parameters, adaptive code vector address and gain, fixed code vector address and gain are packaged and output.
所述本地类乐音解码单元,其采用CELP方法进行基于码激励线性预测解码,获取LP参数、自适应码本矢量、自适应码本增益、固定码本矢量、固定码本增益等参数,然后采用与编码器相同的码本,按照码矢地址找到该码矢并乘上增益,激励合成滤波器,得到合成语音。The local class tone decoding unit adopts the CELP method to perform linear predictive decoding based on code excitation, obtains parameters such as LP parameters, adaptive codebook vectors, adaptive codebook gains, fixed codebook vectors, and fixed codebook gains, and then adopts The codebook is the same as that of the encoder, and the code vector is found according to the code vector address and multiplied by the gain to excite the synthesis filter to obtain the synthesized speech.
如图2所示,所述类乐音编码单元,其使用分析滤波器组将类乐音信号分成高频带信号与低频带信号两类,当采样率为Fs时,低频带信号频率范围为0~Fs/4,高频带信号频率范围为Fs/4~Fs/2,分别对这两个频带信号进行FFT(时频)变换,将信号变换到频域,得到高低两个频带的非量化频谱系数;As shown in Figure 2, the described tone-like encoding unit uses an analysis filter bank to divide the tone-like signal into high-band signals and low-band signals. When the sampling rate is Fs, the frequency range of the low-band signals is 0~ Fs/4, the frequency range of the high-frequency band signal is Fs/4~Fs/2, respectively perform FFT (time-frequency) transformation on the two frequency band signals, transform the signal into the frequency domain, and obtain the unquantized spectrum of the high and low frequency bands coefficient;
对低频带非量化频谱系数,采用格型矢量量化方法进行编码。这里选用8维高斯格RE8,格型矢量码本由低阶基础码本与高阶扩展码本组成,量化时根据信道情况和码率调整量化增益,从而实现对量化比特数的自适应分配,控制量化质量;The unquantized spectral coefficients in the low frequency band are encoded by lattice vector quantization. Here, 8-dimensional Gaussian grid RE8 is selected. The lattice vector codebook is composed of a low-order basic codebook and a high-order extended codebook. During quantization, the quantization gain is adjusted according to the channel condition and code rate, so as to realize the adaptive allocation of the number of quantized bits. control quantification quality;
而对高频带信号进行基于低频矢量量化的频带扩展编码。高频扩展方式为分级扩展,依据当前信道情况和码率决定扩展的级数,分配扩展用比特数,控制频带扩展的质量;On the other hand, band extension coding based on low frequency vector quantization is performed on the high frequency band signal. The high-frequency extension method is hierarchical extension. The number of extension stages is determined according to the current channel situation and code rate, the number of bits for extension is allocated, and the quality of frequency band extension is controlled;
对上述两个频带的编码码流格式化,打包输出。Format the coded streams of the above two frequency bands and package them for output.
所述本地类乐音解码单元,其对类乐音编码单元传过来的码流进行解析,低频带部分进行格型矢量反量化,得到非量化的频谱系数,高频部分通过频带扩展参数在低频非量化频谱系数的基础上重构高频带频谱包络;将两个频带的频谱系数分别进行FFT(时频)反变换,将信号变换到时域;最后将两个频带的时域信号通过综合滤波器组得到输出样值,重构信号。The local tone-like decoding unit analyzes the code stream transmitted from the tone-like encoding unit, performs lattice vector inverse quantization on the low-frequency band part, and obtains unquantized spectral coefficients, and unquantizes the high-frequency part at low frequencies through the band extension parameter On the basis of spectral coefficients, the high-band spectral envelope is reconstructed; the spectral coefficients of the two frequency bands are respectively subjected to FFT (time-frequency) inverse transformation, and the signal is transformed into the time domain; finally, the time-domain signals of the two frequency bands are passed through comprehensive filtering The output sample value is obtained by the filter group, and the signal is reconstructed.
所述残差获取单元,其对类语音信号进行残差编码时,编码过程与类语音编码单元相同,类语音残差编码的比特数分配依据信道和码率情况而定,信道好码率高则分配的比特数多,反之则分配的比特数较少,具有可分级性和对信道与码率的自适应性。The residual acquisition unit, when it performs residual coding on the speech-like signal, the coding process is the same as that of the speech-like coding unit, and the bit number allocation of the speech-like residual coding depends on the channel and the code rate, and the channel is good and the code rate is high The number of allocated bits is large, otherwise, the number of allocated bits is small, which has scalability and adaptability to channels and code rates.
所述残差获取单元,其对类乐音信号进行残差编码时,编码过程与类乐音编码单元相同,类乐音残差编码的比特数分配要依据信道和码率情况而定,信道好码率高则分配的比特数多,反之则分配的比特数较少,它具有对信道和码率的自适应性。The residual acquisition unit, when it carries out residual coding to the musical tone signal, the coding process is the same as the musical tone coding unit, and the bit number distribution of the musical tone residual coding will be determined according to the channel and the code rate, and the code rate of the channel is better than that of the musical tone coding unit. If it is higher, the number of bits allocated will be more, otherwise, the number of bits allocated will be less, and it is adaptive to the channel and code rate.
所述的类乐音编码单元,其基于格型矢量量化的矢量编码还包括:编码器根据码率控制量化部分的比特分配,对量化的质量进行调整,量化是可分级的。The music-like coding unit, whose vector coding based on lattice vector quantization further includes: the coder controls the bit allocation of the quantization part according to the code rate, and adjusts the quality of the quantization, and the quantization is scalable.
所述的类乐音编码单元,其高频带扩展还包括:编码器根据码率控制高频带扩展部分的比特分配,对频带扩展的质量进行调整,频带扩展是可分级的。In the tone-like coding unit, the high frequency band extension further includes: the encoder controls the bit allocation of the high frequency band extension according to the code rate, and adjusts the quality of the frequency band extension, and the frequency band extension is scalable.
如图3所示,本实施例还涉及一种可分级的语音和乐音联合解码装置,包括:编码模式获取单元、编码参数获取单元、类语音解码单元、类乐音解码单元、合成输出单元,其中:As shown in FIG. 3 , this embodiment also relates to a scalable speech and musical tone joint decoding device, including: an encoding mode acquisition unit, an encoding parameter acquisition unit, a speech-like decoding unit, a musical tone decoding unit, and a composite output unit, wherein :
编码模式获取单元对码流进行初步解析,将本帧信号所采用的编码模式输入至编码参数获取单元;The encoding mode acquisition unit conducts preliminary analysis on the code stream, and inputs the encoding mode adopted by the frame signal to the encoding parameter acquisition unit;
编码参数获取单元根据不同的编码模式来解析码流,得到各个编码参数输入至类语音解码单元和类乐音解码单元;The encoding parameter acquisition unit parses the code stream according to different encoding modes, and obtains each encoding parameter and inputs it to the speech-like decoding unit and the music-like decoding unit;
类语音解码单元利用类语音编码参数进行解码,得到类语音解码数据,输出解码数据至合成输出单元;The speech-like decoding unit utilizes the speech-like encoding parameters to decode, obtains speech-like decoded data, and outputs the decoded data to the synthesis output unit;
类乐音解码单元利用类乐音编码参数进行解码,得到类乐音解码数据,输出解码数据至合成输出单元;The tone-like decoding unit uses the tone-like encoding parameters to decode, obtains tone-like decoded data, and outputs the decoded data to the synthesis output unit;
合成输出单元将类语音解码单元和类乐音解码单元输出的解码数据进行合成,得到重建的音频信号。The synthesis output unit synthesizes the decoded data output by the speech-like decoding unit and the tone-like decoding unit to obtain a reconstructed audio signal.
所述的类语音解码单元,其通过解析码流,根据固定码矢和自适应码矢的地址找到相应的码矢,将固定码矢和自适应码矢分别与其增益相乘,得到还原的固定码矢和自适应码矢,并将还原的固定码矢和自适应码矢分别通过激励合成滤波器,得到合成语音,最后将合成语音输出。The speech-like decoding unit, by analyzing the code stream, finds the corresponding code vector according to the addresses of the fixed code vector and the adaptive code vector, and multiplies the fixed code vector and the adaptive code vector with their gains respectively to obtain the restored fixed code vector Code vectors and adaptive code vectors, and the restored fixed code vectors and adaptive code vectors are respectively passed through the excitation synthesis filter to obtain synthesized speech, and finally the synthesized speech is output.
如图4所示,所述的类乐音解码单元,其通过解析码流,对码流中的低频带量化频谱系数进行格型矢量反量化,得到非量化频谱系数,对码流中的高频带扩展参数进行基于低频格型矢量量化系数的高频带信号重构,得到重构的高频带信号,同时对高低频带分别进行时频反变换,得到时域还原的低频带信号与高频带信号,并将还原的低频带信号与高频带信号通过综合滤波器组,得到还原的类乐音信号,最后将还原的类乐音信号输出。As shown in Figure 4, the described tone-like decoding unit, by analyzing the code stream, carries out lattice vector inverse quantization to the quantized spectral coefficients of the low frequency band in the code stream, obtains unquantized spectral coefficients, and analyzes the high frequency spectrum coefficients in the code stream Reconstruct the high-frequency signal based on low-frequency lattice vector quantization coefficients with extended parameters to obtain the reconstructed high-frequency signal. band signal, and pass the restored low-frequency band signal and high-frequency band signal through a comprehensive filter bank to obtain a restored musical tone-like signal, and finally output the restored musical-like tone signal.
本实施例中,采用语音和乐音联合编码的方式,采用基于CELP的类语音编码单元和基于格型矢量量化的类乐音编码单元分别对类语音信号和类乐音信号编码,具有对语音信号和乐音信号的普遍适应性,减少了编码中信息的损失,提高了编码音质。尤其是在码率提高时,能保持高品质的音质。同时,本实施例中只需要在本地编码两次,解码一次,所以计算复杂度较低。In this embodiment, the way of joint coding of speech and tone is adopted, and the speech-like coding unit based on CELP and the tone-like coding unit based on lattice vector quantization are used to encode the speech-like signal and the tone-like signal respectively, and have the ability to encode the speech signal and the tone The general adaptability of the signal reduces the loss of information in the coding and improves the coding sound quality. Especially when the bit rate is increased, it can maintain high-quality sound quality. At the same time, in this embodiment, only two local encodings and one decoding are required, so the computational complexity is relatively low.
Claims (10)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CNA2008100378274ACN101281749A (en) | 2008-05-22 | 2008-05-22 | Scalable Speech and Tone Joint Coding Apparatus and Decoding Apparatus |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CNA2008100378274ACN101281749A (en) | 2008-05-22 | 2008-05-22 | Scalable Speech and Tone Joint Coding Apparatus and Decoding Apparatus |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN101281749Atrue CN101281749A (en) | 2008-10-08 |
Family
ID=40014177
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CNA2008100378274APendingCN101281749A (en) | 2008-05-22 | 2008-05-22 | Scalable Speech and Tone Joint Coding Apparatus and Decoding Apparatus |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN101281749A (en) |
Cited By (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102576534A (en)* | 2009-09-30 | 2012-07-11 | 松下电器产业株式会社 | Audio decoder, audio encoder, system |
| CN102687200A (en)* | 2009-12-31 | 2012-09-19 | 摩托罗拉移动公司 | Embedded speech and audio coding using a switchable model core |
| CN103369320A (en)* | 2010-06-04 | 2013-10-23 | 索尼公司 | Image processing apparatus and method |
| CN107221334A (en)* | 2016-11-01 | 2017-09-29 | 武汉大学深圳研究院 | The method and expanding unit of a kind of audio bandwidth expansion |
| CN107305770A (en)* | 2016-04-21 | 2017-10-31 | 华为技术有限公司 | A kind of sampling of audio signal and method for reconstructing, apparatus and system |
| CN107886960A (en)* | 2016-09-30 | 2018-04-06 | 华为技术有限公司 | A kind of audio signal method for reconstructing and device |
| CN107895580A (en)* | 2016-09-30 | 2018-04-10 | 华为技术有限公司 | The method for reconstructing and device of a kind of audio signal |
| CN109478407A (en)* | 2016-03-15 | 2019-03-15 | 弗劳恩霍夫应用研究促进协会 | Encoding apparatus for processing an input signal and decoding apparatus for processing an encoded signal |
| CN109887519A (en)* | 2019-03-14 | 2019-06-14 | 北京芯盾集团有限公司 | The method for improving voice channel data transfer accuracy |
| CN111402906A (en)* | 2020-03-06 | 2020-07-10 | 深圳前海微众银行股份有限公司 | Speech decoding method, device, engine and storage medium |
| CN113747236A (en)* | 2021-10-19 | 2021-12-03 | 江下信息科技(惠州)有限公司 | Multithreading-based high-speed audio format conversion method and system |
- 2008
- 2008-05-22CNCNA2008100378274Apatent/CN101281749A/enactivePending
Cited By (21)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8688442B2 (en) | 2009-09-30 | 2014-04-01 | Panasonic Corporation | Audio decoding apparatus, audio coding apparatus, and system comprising the apparatuses |
| CN102576534B (en)* | 2009-09-30 | 2014-10-08 | 松下电器产业株式会社 | Audio decoder, audio encoder, system |
| CN102576534A (en)* | 2009-09-30 | 2012-07-11 | 松下电器产业株式会社 | Audio decoder, audio encoder, system |
| CN102687200A (en)* | 2009-12-31 | 2012-09-19 | 摩托罗拉移动公司 | Embedded speech and audio coding using a switchable model core |
| CN102687200B (en)* | 2009-12-31 | 2014-12-10 | 摩托罗拉移动公司 | Embedded speech and audio coding using a switchable model core |
| CN103369320A (en)* | 2010-06-04 | 2013-10-23 | 索尼公司 | Image processing apparatus and method |
| CN103369320B (en)* | 2010-06-04 | 2016-06-22 | 索尼公司 | Image processing equipment and method |
| CN109478407A (en)* | 2016-03-15 | 2019-03-15 | 弗劳恩霍夫应用研究促进协会 | Encoding apparatus for processing an input signal and decoding apparatus for processing an encoded signal |
| CN109478407B (en)* | 2016-03-15 | 2023-11-03 | 弗劳恩霍夫应用研究促进协会 | Encoding device for processing an input signal and decoding device for processing an encoded signal |
| CN107305770B (en)* | 2016-04-21 | 2021-02-09 | 华为技术有限公司 | Method, device and system for sampling and reconstructing audio signal |
| CN107305770A (en)* | 2016-04-21 | 2017-10-31 | 华为技术有限公司 | A kind of sampling of audio signal and method for reconstructing, apparatus and system |
| CN107895580A (en)* | 2016-09-30 | 2018-04-10 | 华为技术有限公司 | The method for reconstructing and device of a kind of audio signal |
| CN107886960A (en)* | 2016-09-30 | 2018-04-06 | 华为技术有限公司 | A kind of audio signal method for reconstructing and device |
| CN107886960B (en)* | 2016-09-30 | 2020-12-01 | 华为技术有限公司 | A kind of audio signal reconstruction method and device |
| CN107895580B (en)* | 2016-09-30 | 2021-06-01 | 华为技术有限公司 | Method and device for reconstructing audio signal |
| CN107221334A (en)* | 2016-11-01 | 2017-09-29 | 武汉大学深圳研究院 | The method and expanding unit of a kind of audio bandwidth expansion |
| CN109887519A (en)* | 2019-03-14 | 2019-06-14 | 北京芯盾集团有限公司 | The method for improving voice channel data transfer accuracy |
| CN109887519B (en)* | 2019-03-14 | 2021-05-11 | 北京芯盾集团有限公司 | Method for improving voice channel data transmission accuracy |
| CN111402906A (en)* | 2020-03-06 | 2020-07-10 | 深圳前海微众银行股份有限公司 | Speech decoding method, device, engine and storage medium |
| CN111402906B (en)* | 2020-03-06 | 2024-05-14 | 深圳前海微众银行股份有限公司 | Speech decoding method, device, engine and storage medium |
| CN113747236A (en)* | 2021-10-19 | 2021-12-03 | 江下信息科技(惠州)有限公司 | Multithreading-based high-speed audio format conversion method and system |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN101281749A (en) | Scalable Speech and Tone Joint Coding Apparatus and Decoding Apparatus | |
| CN102177426B (en) | Multi-resolution switching audio encoding/decoding scheme | |
| AU2008316860B2 (en) | Scalable speech and audio encoding using combinatorial encoding of MDCT spectrum | |
| CN101335000B (en) | Coding method and device | |
| CN102113051B (en) | Audio encoder, decoder, and audio signal encoding and decoding method | |
| CN102089814B (en) | Device and method for decoding encoded audio signal | |
| KR101565634B1 (en) | APPARATUS FOR ENCODING AND DECODING OF INTEGRATed VOICE AND MUSIC | |
| JP5357055B2 (en) | Improved digital audio signal encoding / decoding method | |
| CN105280190B (en) | Bandwidth extension encoding and decoding method and device | |
| CN101025918A (en) | Voice/music dual-mode coding-decoding seamless switching method | |
| CA2697604A1 (en) | Method and device for efficient quantization of transform information in an embedded speech and audio codec | |
| JP2012518194A (en) | Audio signal encoding and decoding method and apparatus using adaptive sinusoidal coding | |
| CN104025189A (en) | Method for encoding voice signal, method for decoding voice signal, and apparatus using same | |
| JP5730860B2 (en) | Audio signal encoding and decoding method and apparatus using hierarchical sinusoidal pulse coding | |
| CN101281748B (en) | Method for filling opening son (sub) tape using encoding index as well as method for generating encoding index | |
| Vaillancourt et al. | ITU-T EV-VBR: A robust 8-32 kbit/s scalable coder for error prone telecommunications channels | |
| US9390722B2 (en) | Method and device for quantizing voice signals in a band-selective manner | |
| CN101651752B (en) | Decoding method and decoding device | |
| CN105280189A (en) | Method and apparatus for high-frequency generation during bandwidth extension coding and decoding | |
| CN102254562B (en) | Method for coding variable speed audio frequency switching between adjacent high/low speed coding modes | |
| Zhang et al. | AVS-M audio: algorithm and implementation | |
| Jung et al. | An embedded variable bit-rate coder based on GSM EFR: EFR-EV | |
| Jeong et al. | Embedded bandwidth scalable wideband codec using hybrid matching pursuit harmonic/CELP scheme | |
| Bao et al. | A 8.32 kb/s embedded wideband speech coding candidate for ITU-t EV-VBR standardization. | |
| Jeong et al. | Bandwidth Scalable Wideband Codec Using Hybrid Matching Pursuit Harmonic/CELP Scheme |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C02 | Deemed withdrawal of patent application after publication (patent law 2001) | ||
| WD01 | Invention patent application deemed withdrawn after publication | Open date:20081008 |