CN101123723B - Digital Video Decoding Method Based on Graphics Processor - Google Patents
Digital Video Decoding Method Based on Graphics ProcessorDownload PDFInfo
- Publication number
- CN101123723B CN101123723BCN2006100892521ACN200610089252ACN101123723BCN 101123723 BCN101123723 BCN 101123723BCN 2006100892521 ACN2006100892521 ACN 2006100892521ACN 200610089252 ACN200610089252 ACN 200610089252ACN 101123723 BCN101123723 BCN 101123723B
- Authority
- CN
- China
- Prior art keywords
- point
- coefficient
- gpu
- texture
- decoding
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
- 238000000034methodMethods0.000titleclaimsabstractdescription110
- 230000008569processEffects0.000claimsabstractdescription78
- 239000013598vectorSubstances0.000claimsdescription29
- 238000012545processingMethods0.000claimsdescription27
- 238000013139quantizationMethods0.000claimsdescription22
- 239000000872bufferSubstances0.000claimsdescription17
- 238000004364calculation methodMethods0.000claimsdescription11
- 238000001914filtrationMethods0.000claimsdescription9
- 239000011159matrix materialSubstances0.000claimsdescription9
- 230000006870functionEffects0.000claimsdescription7
- 238000002156mixingMethods0.000claimsdescription7
- 238000005070samplingMethods0.000claimsdescription6
- 238000007781pre-processingMethods0.000claims1
- 229920006395saturated elastomerPolymers0.000claims1
- 230000006835compressionEffects0.000abstractdescription14
- 238000007906compressionMethods0.000abstractdescription14
- 230000008901benefitEffects0.000abstractdescription7
- 238000010586diagramMethods0.000description12
- 238000006243chemical reactionMethods0.000description5
- 230000009466transformationEffects0.000description4
- 238000003491arrayMethods0.000description3
- 230000005540biological transmissionEffects0.000description3
- 238000005516engineering processMethods0.000description3
- 230000001133accelerationEffects0.000description2
- 238000009825accumulationMethods0.000description2
- 230000002457bidirectional effectEffects0.000description2
- 238000011161developmentMethods0.000description2
- 241000023320Luma <angiosperm>Species0.000description1
- 238000004458analytical methodMethods0.000description1
- 238000013459approachMethods0.000description1
- 230000008859changeEffects0.000description1
- 239000012141concentrateSubstances0.000description1
- 230000007812deficiencyEffects0.000description1
- 238000012217deletionMethods0.000description1
- 230000037430deletionEffects0.000description1
- 238000013461designMethods0.000description1
- 239000012530fluidSubstances0.000description1
- 239000012634fragmentSubstances0.000description1
- 230000001788irregularEffects0.000description1
- OSWPMRLSEDHDFF-UHFFFAOYSA-Nmethyl salicylateChemical compoundCOC(=O)C1=CC=CC=C1OOSWPMRLSEDHDFF-UHFFFAOYSA-N0.000description1
- 238000012986modificationMethods0.000description1
- 230000004048modificationEffects0.000description1
- 229920001690polydopaminePolymers0.000description1
- 238000009877renderingMethods0.000description1
- 238000004088simulationMethods0.000description1
- 238000006467substitution reactionMethods0.000description1
- 230000002123temporal effectEffects0.000description1
- 238000012546transferMethods0.000description1
Images







Landscapes
- Compression Or Coding Systems Of Tv Signals (AREA)
Abstract
Translated fromChineseDescription
Translated fromChinese技术领域technical field
本发明属于计算机数字视频压缩领域,具体涉及一种利用图形处理器(GraphicsProcessing Unit-GPU)来完成视频解码的方法。The invention belongs to the field of computer digital video compression, in particular to a method for using a Graphics Processing Unit (GPU) to complete video decoding.
背景技术Background technique
数字视频已经广泛应用于人们的日常生活中,涉及数字电视,个人计算机,手持移动设备以及娱乐,教育等各个领域。对于广大用户来讲,最基本的要求就是对视频内容的高质量实时播放(解码)。但是视频压缩标准为了取得高的压缩率和好的图像质量,需要采用高计算复杂度的视频压缩技术,这直接导致其解码过程需要消耗大量的计算资源。Digital video has been widely used in people's daily life, involving various fields such as digital TV, personal computer, handheld mobile equipment, entertainment, and education. For the majority of users, the most basic requirement is high-quality real-time playback (decoding) of video content. However, in order to achieve high compression rate and good image quality, video compression standards need to adopt video compression technology with high computational complexity, which directly leads to the consumption of a large amount of computing resources in the decoding process.
常见的视频压缩标准大多以16×16大小的宏块为基本的处理单元,参考图1,为完成解码过程,需对每个宏块依次完成以下处理环节:变长解码,反量化,逆离散余弦变换(Inverse Discrete Cosine Transform-IDCT),运动补偿和颜色空间转换。变长解码完成视频比特流的解析,恢复视频的熵编码信息,例如每个宏块的参数,系数和运动向量等,该过程为严格串行的位操作。随后的反量化和IDCT作用在构成宏块的每个系数块上,处理稀疏的DCT系数,用来恢复原始的像素块,该变换过程计算复杂度高。运动补偿是减少视频序列中时间冗余的有效方法,以宏块为基本的单位。该过程在编码阶段的基本原理是在参考帧中搜索一个与当前图像中宏块最相似的图像块,即预测块,搜索结果用运动向量来表示,计算当前宏块和预测块之间的差值,然后将此差值和运动向量加以编码。运动补偿就是通过差值和运动向量恢复出编码图像的过程。由于好的预测往往带来更好的编码效率,因此常见的视频编码系统都采用了双向预测(B帧)和子象素精度运动向量等技术来提高运动估计的准确度。虽然提高了预测精度和压缩率,但是却进一步增加了运算的复杂度。最后的颜色空间转换过程针对图像中的每个像素进行颜色向量(RGB)与变换矩形的乘法运算,为典型的计算密集型过程。由此可见,视频的解码过程是由多个耗时的处理环节所共同构成的复杂系统。Most common video compression standards use a 16×16 macroblock as the basic processing unit. Referring to Figure 1, in order to complete the decoding process, the following processing steps must be completed for each macroblock in sequence: variable-length decoding, inverse quantization, and inverse discrete Cosine Transform (Inverse Discrete Cosine Transform-IDCT), motion compensation and color space conversion. Variable-length decoding completes the analysis of the video bit stream and restores the entropy coding information of the video, such as the parameters, coefficients and motion vectors of each macroblock. This process is strictly serial bit operation. Subsequent inverse quantization and IDCT act on each coefficient block constituting the macroblock, and process sparse DCT coefficients to restore the original pixel block. This transformation process has high computational complexity. Motion compensation is an effective method to reduce temporal redundancy in video sequences, and the basic unit is macroblock. The basic principle of this process in the encoding stage is to search for an image block that is most similar to the macroblock in the current image in the reference frame, that is, the prediction block. The search result is represented by a motion vector, and the difference between the current macroblock and the prediction block is calculated. value, and then encode this difference and motion vector. Motion compensation is the process of restoring the coded image through the difference value and the motion vector. Since good prediction often leads to better coding efficiency, common video coding systems use techniques such as bidirectional prediction (B frame) and sub-pixel precision motion vectors to improve the accuracy of motion estimation. Although the prediction accuracy and compression rate are improved, the complexity of the operation is further increased. The final color space conversion process multiplies the color vector (RGB) and the transformation rectangle for each pixel in the image, which is a typical calculation-intensive process. It can be seen that the video decoding process is a complex system composed of multiple time-consuming processing links.
面对高质量和高分辨率视频以及新一代压缩标准(例如H.264)所引入的复杂压缩技术,目前计算机系统中单纯利用CPU的软件解码器甚至无法满足实时解码视频的需求。因此,需要其他的子系统来分担部分解码任务从而缓解CPU的压力。近十年来专用的视频解码硬件被引入到计算机系统中,以独立板卡或集成于图形硬件内的形式出现。微软的DirectX Video Acceleration(DXVA)规范的推广使后者成为目前的主流。但是这种专用解码硬件往往只能针对某种特定的视频压缩标准(大部分为MPEG-2)因而具备非常有限的扩展性和可编程性,缺少足够的灵活性来应对目前多样的视频压缩格式。虽然目前图形卡上已经开始集成可编程的视频处理硬件,例如Nvidia的PureVideo和ATI的Avivo等技术,但是它们需要额外的硬件开销和更高的成本,而且目前缺少有效的高级语言和应用程序接口来方便的控制这些底层硬件资源。In the face of high-quality and high-resolution video and the complex compression technology introduced by the new generation of compression standards (such as H.264), software decoders in current computer systems that only use CPU cannot even meet the needs of real-time decoding video. Therefore, other subsystems are needed to share part of the decoding tasks so as to relieve the pressure on the CPU. Dedicated video decoding hardware has been introduced into computer systems over the past decade, either as stand-alone boards or integrated into graphics hardware. The promotion of Microsoft's DirectX Video Acceleration (DXVA) specification has made the latter the mainstream. However, this kind of dedicated decoding hardware can only target a specific video compression standard (mostly MPEG-2), so it has very limited scalability and programmability, and lacks enough flexibility to deal with the current variety of video compression formats. . Although programmable video processing hardware has begun to be integrated on graphics cards, such as Nvidia's PureVideo and ATI's Avivo, they require additional hardware overhead and higher costs, and currently lack effective high-level languages and application programming interfaces. To conveniently control these underlying hardware resources.
另一方面,随着三维图形应用的发展和推广,图形硬件已经演化成为一种兼具高性能和灵活性的图形处理器,也就是GPU,目前主要的可编程部分包括顶点处理器(Vertex Processor)和像素处理器(Fragment Processor)。这两部分处理单元结合光栅和合成器件构成GPU的流水线处理结构。图形处理器大规模并行所带来的高性能,成熟的高级着色语言所带来的可编程性以及高精度数据类型的支持(32位浮点数)使得GPU成为计算机系统中除CPU外的一个极具吸引力的协处理器,并且可被用于解决图形领域之外的很多通用计算问题(GPGPU),例如数值计算,信号处理,流体模拟等。从体系结构的角度来考虑,GPU是以向量操作为基础的高度并行的流处理器,该结构同一些成功的专用多媒体和视频处理器具有很大的相似形。这些都为在GPU上实现高效的视频解码提供了强有力的支持。On the other hand, with the development and promotion of 3D graphics applications, graphics hardware has evolved into a high-performance and flexible graphics processor, that is, GPU. At present, the main programmable part includes vertex processor (Vertex Processor). ) and a pixel processor (Fragment Processor). These two parts of the processing unit combined with the grating and compositing devices constitute the pipeline processing structure of the GPU. The high performance brought by the large-scale parallelism of the graphics processor, the programmability brought by the mature high-level shading language and the support of high-precision data types (32-bit floating point numbers) make the GPU a pole besides the CPU in the computer system. Attractive coprocessor, and can be used to solve many general computing problems (GPGPU) outside the graphics field, such as numerical calculation, signal processing, fluid simulation, etc. From the point of view of architecture, GPU is a highly parallel stream processor based on vector operations. This structure has a great similarity with some successful dedicated multimedia and video processors. These provide strong support for efficient video decoding on GPU.
但是GPU从设计到发展都是为了加速图形计算,处理的数据都是相对规整的顶点和像素,所以并不能直接用于相对复杂和多分支的视频解码过程。除了最后的颜色空间转换环节外,GPGPU领域常用的纹理方法并不适用于该解码过程。主要原因在于目前的大多数视频压缩标准都基于宏块/系数块这种组织结构;每个宏块或系数块都有自己特有的参数和属性,彼此有所不同,不便于用规整的单一纹理来表示。一些以纹理表示法为基础的前人工作,例如利用GPU的DCT/IDCT变换,性能同CPU相比并没有优势,而且还存在相当可观的数据传输开销。文献“Acceleratevideo decoding with generic GPU”(Shen G.等,IEEE Transaction on Circuits andSystems for Video Technology,May 2005)利用小矩形来表示宏块,从而完成解码中的运动补偿过程,虽然有效但仍然存在数据冗余等问题。这些方法没有充分利用GPU的计算资源导致性能偏低,并不适用于实用的视频解码系统。However, the GPU is designed to accelerate graphics calculations from design to development, and the data processed are relatively regular vertices and pixels, so it cannot be directly used for relatively complex and multi-branched video decoding processes. Except for the final color space conversion link, the texture method commonly used in the GPGPU field is not suitable for this decoding process. The main reason is that most of the current video compression standards are based on the organizational structure of macroblocks/coefficient blocks; each macroblock or coefficient block has its own unique parameters and attributes, which are different from each other, and it is not convenient to use a regular single texture To represent. Some previous work based on texture representation, such as DCT/IDCT transformation using GPU, has no advantage in performance compared with CPU, and there is still considerable data transmission overhead. The document "Accelerate video decoding with generic GPU" (Shen G. et al., IEEE Transaction on Circuits and Systems for Video Technology, May 2005) uses small rectangles to represent macroblocks to complete the motion compensation process in decoding. Although it is effective, there is still data redundancy. Other questions. These methods do not make full use of the computing resources of the GPU, resulting in low performance, and are not suitable for practical video decoding systems.
发明内容Contents of the invention
本发明的目的是解决目前软硬件解码方案在性能或灵活性上的不足,提出了一种基于GPU的压缩视频解码方法。该方法兼具硬件的高性能和软件的灵活性,适用于多种视频压缩标准,能用来替代配备GPU的个人计算机,游戏主机,手持移动设备等上的专用解码硬件,提高硬件资源的利用率,降低成本。The purpose of the present invention is to solve the deficiencies in performance or flexibility of current software and hardware decoding schemes, and proposes a compressed video decoding method based on GPU. This method has both the high performance of hardware and the flexibility of software, and is applicable to a variety of video compression standards. It can be used to replace dedicated decoding hardware on personal computers equipped with GPUs, game consoles, handheld mobile devices, etc., and improve the utilization of hardware resources. rate and reduce costs.
本发明的上述目的是通过如下的技术方案予以实现的:Above-mentioned purpose of the present invention is achieved by following technical scheme:
一种基于图形处理器的数字视频解码方法,其步骤包括:A kind of digital video decoding method based on graphic processor, its step comprises:
1)CPU变长解码得到宏块和系数块,并用图形绘制中的基本图元“点”表示,分别生成宏块对应的宏块点集和系数块对应的DCT系数点集;1) The CPU variable-length decoding obtains the macroblock and the coefficient block, and represents it with the basic graphic element "point" in the graphic drawing, and generates the macroblock point set corresponding to the macroblock and the DCT coefficient point set corresponding to the coefficient block;
2)CPU将宏块点集和DCT系数点集以批处理方式分批送入GPU;2) The CPU sends the macroblock point set and the DCT coefficient point set to the GPU in batches;
3)绘制宏块点集和DCT系数点集,GPU执行相应的顶点和像素处理程序完成视频解码过程。3) Draw the macroblock point set and the DCT coefficient point set, and the GPU executes the corresponding vertex and pixel processing programs to complete the video decoding process.
本发明将构成视频的基本单位-“宏块和系数块”用图形绘制中的基本图元-“点”来的表示,从而将传统的视频解码过程映射为点集的绘制过程,继而充分发挥出GPU流水线处理和大规模并行处理的优势,取得更高的解码性能。在绘制点集的过程,通过顶点和像素程序来控制GPU上可编程的顶点处理器和像素处理器来完成解码过程中的主要环节:反量化,IDCT,运动补偿和颜色空间转换,并进一步利用GPU上的合成单元(Blending)和纹理过滤单元来分担部分计算任务。该技术方案具体包括以下几个方面:In the present invention, the basic unit of video - "macroblock and coefficient block" is represented by the basic primitive in graphic drawing - "point", so that the traditional video decoding process is mapped to the drawing process of point set, and then fully utilized Take advantage of GPU pipeline processing and large-scale parallel processing to achieve higher decoding performance. In the process of drawing the point set, the programmable vertex processor and pixel processor on the GPU are controlled by the vertex and pixel programs to complete the main links in the decoding process: dequantization, IDCT, motion compensation and color space conversion, and further use The blending unit (Blending) and the texture filtering unit on the GPU share part of the computing tasks. The technical solution specifically includes the following aspects:
1)利用点图元而不是矩形来表示视频块信息。工作原理在于利用点的属性(四维向量)如位置,法线和纹理坐标等存储视频中的宏块和系数块的类型,位置,参数,系数等信息。其中宏块和系数块分别对应两类不同的点集:宏块点集和DCT系数点集,分别用于运动补偿和IDCT。其中DCT系数点集的生成过程利用了Zigzag扫描来减少点集中点的个数。考虑到GPU低效的分支处理能力和不同类型的宏块或系数块对应的不同操作过程,在生成DCT系数点集和宏块点集的过程中,利用CPU对两类点集做了进一步的细分,对应同类操作的块被分到一类子集中,例如宏块中所有的非预测宏块(Intra)聚为一类,所有的前向预测宏块(forward)聚为另一类。1) Use dot primitives instead of rectangles to represent video block information. The working principle is to use point attributes (four-dimensional vectors) such as position, normal and texture coordinates to store information such as the type, position, parameters and coefficients of macroblocks and coefficient blocks in the video. Among them, macroblocks and coefficient blocks correspond to two different point sets: macroblock point sets and DCT coefficient point sets, which are used for motion compensation and IDCT respectively. The generation process of the DCT coefficient point set utilizes Zigzag scanning to reduce the number of points in the point set. Considering the inefficient branch processing capability of GPU and the different operation processes corresponding to different types of macroblocks or coefficient blocks, in the process of generating DCT coefficient point sets and macroblock point sets, the CPU is used to further refine the two types of point sets. The blocks corresponding to the same type of operation are divided into one type of subset, for example, all non-predicted macroblocks (Intra) in the macroblock are clustered into one category, and all forward-predicted macroblocks (forward) are clustered into another category.
2)解码过程中的反量化和IDCT过程通过一次绘制1)中创建的DCT系数点集来完成。其中反量化完全由GPU的顶点处理器完成,而IDCT主要在像素处理器中完成,两者构成流水线结构提高了执行效率。反量化中的量化参数和DCT系数通过点图元的属性送入顶点处理器而量化矩形通过uniform参数预先设置放入顶点处理器的常量寄存器。IDCT过程通过在像素处理单元中线性组合DCT系数和对应的基图像来完成,基图像经预处理后,以纹理的形式存放在GPU的显存中。对于分布于多个点中的属于同一个系数块的DCT系数,利用GPU中的混合器件(blending)累加多个点图元中的结果到IDCT输出缓存中(残差图像纹理)。2) The inverse quantization and IDCT process in the decoding process is done by drawing the DCT coefficient point set created in 1) at once. Among them, the inverse quantization is completely completed by the vertex processor of the GPU, while the IDCT is mainly completed in the pixel processor. The pipeline structure formed by the two improves the execution efficiency. The quantization parameters and DCT coefficients in dequantization are sent to the vertex processor through the properties of the point primitive, and the quantized rectangle is preset into the constant register of the vertex processor through the uniform parameter. The IDCT process is completed by linearly combining the DCT coefficients and the corresponding base image in the pixel processing unit. After the base image is preprocessed, it is stored in the video memory of the GPU in the form of texture. For the DCT coefficients belonging to the same coefficient block distributed in multiple points, use the blending device (blending) in the GPU to accumulate the results of multiple point primitives into the IDCT output buffer (residual image texture).
3)运动补偿过程通过绘制1)中创建的宏块点集来完成,在像素处理单元中采样参考图像纹理和步骤2)中输出的IDCT输出纹理,累加采样结果并做饱和化运算,完成运动补偿过程。对于子像素精度的运动补偿,利用GPU纹理单元的双线性过滤硬件来实现子像素的插值运算。3) The motion compensation process is completed by drawing the macroblock point set created in 1), sampling the reference image texture and the IDCT output texture output in step 2) in the pixel processing unit, accumulating the sampling results and performing a saturation operation to complete the motion compensation process. For motion compensation with sub-pixel precision, the bilinear filtering hardware of the GPU texture unit is used to realize the sub-pixel interpolation operation.
本发明的优点可以总结为以下几个方面:Advantages of the present invention can be summarized as the following aspects:
1)该方法结合了CPU和GPU各自的优势,使两者并行工作加速视频解码过程,同时具有硬件解码的高性能和软件解码的灵活性,可以处理多样的视频压缩格式和标准。1) This method combines the respective advantages of CPU and GPU to make the two work in parallel to accelerate the video decoding process. It also has the high performance of hardware decoding and the flexibility of software decoding, and can handle various video compression formats and standards.
2)对比专用的视频硬件,该解决方案基于上层的图形API(如OpenGL)和高级着色语言(如CG和GLSL)可以做到平台无关和系统无关,独立于底层的具体硬件实现,适用于各种配有GPU的系统中,如个人计算机,游戏主机,手机和PDA等。GPU的演化速度快,性能增长幅度远远超过摩尔定律,不断增加新的功能和特性带来更灵活的可编程性,从长远看比CPU软解码和专用硬件更具潜力。2) Compared with dedicated video hardware, this solution is based on upper-layer graphics API (such as OpenGL) and advanced shading language (such as CG and GLSL), which can be platform-independent and system-independent, independent of the underlying specific hardware implementation, and is applicable to various In a system equipped with a GPU, such as personal computers, game consoles, mobile phones and PDAs. The evolution speed of the GPU is fast, and the performance growth rate far exceeds Moore's Law. The continuous addition of new functions and features brings more flexible programmability. In the long run, it has more potential than CPU soft decoding and dedicated hardware.
3)该方法用点来表示宏块和系数块,实现简单,控制灵活。对比纹理表示法,基于点的方法仅传输非零系数;对比矩形表示法,消除了矩形中四个顶点的大量冗余数据,从而减少了传输开销,降低了带宽需求。同时,点方法控制灵活,方便剔除未编码块(non-coded block),而且系数块所对应的DCT系数点图元生成过程自动剔除了零系数,减少了不必要的计算。基于点的表示方式,也方便利用GPU处理流水线中的顶点处理器和光栅化硬件,充分挖掘GPU的计算资源。另一方面,利用CPU划分为不同点集的方法,消除了GPU分支处理的瓶颈,提高了性能。3) This method uses dots to represent macroblocks and coefficient blocks, which is simple to implement and flexible to control. Compared with the texture representation, the point-based method only transmits non-zero coefficients; compared with the rectangular representation, a large amount of redundant data for the four vertices in the rectangle is eliminated, thereby reducing transmission overhead and reducing bandwidth requirements. At the same time, the point method is flexible in control, and it is convenient to eliminate non-coded blocks, and the generation process of DCT coefficient point primitives corresponding to coefficient blocks automatically eliminates zero coefficients, reducing unnecessary calculations. The point-based representation method also facilitates the use of the vertex processor and rasterization hardware in the GPU processing pipeline to fully tap the computing resources of the GPU. On the other hand, using the method of dividing the CPU into different point sets eliminates the bottleneck of GPU branch processing and improves performance.
附图说明Description of drawings
下面是对本发明附图的简要说明:Below is a brief description of the accompanying drawings of the present invention:
图1是典型的视频解码过程的主要环节示意图。FIG. 1 is a schematic diagram of main links in a typical video decoding process.
图2是本发明对应的硬件系统结构图。Fig. 2 is a structural diagram of a hardware system corresponding to the present invention.
图3是数字视频的宏块/块结构的示意图。FIG. 3 is a schematic diagram of a macroblock/block structure of digital video.
图4是本发明通过绘制点集来利用GPU进行视频解码的整体流程图。FIG. 4 is an overall flowchart of video decoding using GPU by drawing point sets in the present invention.
图5是本发明中从视频的系数块产生DCT系数点图元的示意图。FIG. 5 is a schematic diagram of generating DCT coefficient point primitives from video coefficient blocks in the present invention.
图6是DCT基图像形成纹理的示意图。FIG. 6 is a schematic diagram of a DCT-based image forming texture.
图7a是IDCT过程的输出缓存的结构示意图。Fig. 7a is a schematic diagram of the structure of the output buffer of the IDCT process.
图7b是运动补偿过程的帧缓存的结构示意图。Fig. 7b is a schematic diagram of the structure of the frame buffer in the motion compensation process.
图8a是子像素精度运动补偿插值过程的示意图。Fig. 8a is a schematic diagram of a sub-pixel precision motion compensation interpolation process.
图8b是纹理过滤单元双线性插值的示意图。Fig. 8b is a schematic diagram of the bilinear interpolation of the texture filtering unit.
图9是绘制DCT系数点集完成反量化和IDCT的过程示意图。Fig. 9 is a schematic diagram of the process of drawing a DCT coefficient point set to complete inverse quantization and IDCT.
图10是绘制宏块点集完成运动补偿的过程示意图。Fig. 10 is a schematic diagram of the process of drawing a macroblock point set to complete motion compensation.
具体实施方式Detailed ways
下面参照本发明的附图,更详细地描述本发明的最佳实施例。DETAILED DESCRIPTION OF THE PREFERRED EMBODIMENTS The preferred embodiments of the present invention will be described in more detail below with reference to the accompanying drawings of the present invention.
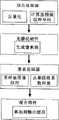
图2说明了本发明所对应的硬件系统的结构图。本发明需要CPU和GPU合作完成整个解码过程,两者可以并行执行,进一步提高效率。CPU和GPU间通过系统总线相连接,例如PCIE或AGP。总线带宽是个有限资源,数据传输开销是影响整体性能的重要因素。本发明对比现有方法的一个重要优势就在于避免了无用或冗余数据,明显降低了数据传输量。CPU将视频中宏块和系数块的解码所需信息封装进绘制用的点集中,以顶点数组或其他形式暂存于系统内存中,然后通过系统总线传入GPU。GPU是本发明中解码任务的主要执行单元,完成主要的解码任务,要求具有可编程性的顶点和像素处理器以及一定容量的显存用于存放计算数据和中间结果。Fig. 2 illustrates the structural diagram of the hardware system corresponding to the present invention. The present invention requires the cooperation of the CPU and the GPU to complete the entire decoding process, and the two can be executed in parallel to further improve efficiency. The CPU and GPU are connected through a system bus, such as PCIE or AGP. Bus bandwidth is a finite resource, and data transfer overhead is an important factor affecting overall performance. An important advantage of the present invention compared with the existing method is that useless or redundant data is avoided, and the amount of data transmission is obviously reduced. The CPU encapsulates the information required for the decoding of macroblocks and coefficient blocks in the video into point sets for drawing, temporarily stores them in the system memory in the form of vertex arrays or other forms, and then transmits them to the GPU through the system bus. The GPU is the main execution unit of the decoding task in the present invention. To complete the main decoding task, a programmable vertex and pixel processor and a certain capacity of video memory are required to store calculation data and intermediate results.
本发明提出了一种用点图元表示视频中宏块和系数块,通过图形硬件GPU绘制对应宏块和系数块所对应的点集来实现视频解码的方法。本发明的处理流程如图4所示。下面结合附图详细的说明本发明实现视频解码的具体步骤:The present invention proposes a method for representing macroblocks and coefficient blocks in video by using dot primitives, and drawing point sets corresponding to corresponding macroblocks and coefficient blocks through graphics hardware GPU to realize video decoding. The processing flow of the present invention is shown in FIG. 4 . The specific steps that the present invention realizes video decoding are described in detail below in conjunction with accompanying drawing:
1)CPU变长解码生成视频中宏块和系数块对应的点集。1) CPU variable-length decoding generates point sets corresponding to macroblocks and coefficient blocks in the video.
首先CPU完成变长解码得到视频中宏块和系数块的信息,然后将视频信息封装进点图元的属性中,并根据宏块和系数块的不同类型或处理过程分类到不同的点集中,处理完所有的视频块后,对应的点集以批处理的方式(如顶点数组)分批送入GPU,提高GPU并行和流水线执行的效率。First, the CPU completes variable-length decoding to obtain the information of macroblocks and coefficient blocks in the video, and then encapsulates the video information into the attributes of point primitives, and classifies them into different point sets according to the different types or processing processes of macroblocks and coefficient blocks. After processing all the video blocks, the corresponding point sets are sent to the GPU in batches (such as vertex arrays) to improve the efficiency of GPU parallel and pipeline execution.
点集被划分为两个大类:DCT系数点集和宏块点集。这一划分的主要依据是目前压缩视频基于块的构成结构,如图3所示,其中的宏块是运动补偿的基本单位,而构成宏块的系数块是反量化和IDCT的基本单位。两大类点集都可以依据块的类型和特性进一步划分为新的子集。例如DCT系数点集可以根据DCT编码方式的不同进一步划分为场DCT编码点集和帧DCT编码点集;宏块点集可以根据宏块类型细分为非预测宏块(Intra)集,单向预测宏块集和双向预测宏块集等。这些不同类型的视频块往往对应不同的解码处理过程,预先利用CPU分类到子集并分别送入GPU执行,可以避免GPU上耗时的分支操作,提高整体的解码效率。Point sets are divided into two categories: DCT coefficient point sets and macroblock point sets. The main basis for this division is the current block-based structure of compressed video, as shown in Figure 3, where the macroblock is the basic unit of motion compensation, and the coefficient blocks that constitute the macroblock are the basic unit of inverse quantization and IDCT. Both types of point sets can be further divided into new subsets according to the type and characteristics of blocks. For example, the DCT coefficient point set can be further divided into field DCT code point set and frame DCT code point set according to the different DCT coding methods; the macroblock point set can be subdivided into non-predictive macroblock (Intra) set according to the macroblock type, one-way Prediction macroblock set and bidirectional prediction macroblock set etc. These different types of video blocks often correspond to different decoding processes. Using the CPU to classify them into subsets and sending them to the GPU for execution can avoid time-consuming branch operations on the GPU and improve the overall decoding efficiency.
宏块和系数块中的信息封装进点图元的过程有所不同,但是基本思想都是利用点图元的多个向量属性如位置,法线,颜色,纹理坐标等来存储视频块中的类型,参数,系数等有用信息。The process of encapsulating the information in the macroblock and the coefficient block into the point primitive is different, but the basic idea is to use multiple vector attributes of the point primitive such as position, normal, color, texture coordinates, etc. to store the information in the video block. Types, parameters, coefficients and other useful information.
宏块中包含的主要信息为宏块的位置,类型(intra,inter)和运动向量,可以直接放入点图元的向量属性中,从而将宏块转化为点图元。The main information contained in the macroblock is the location, type (intra, inter) and motion vector of the macroblock, which can be directly put into the vector attribute of the point primitive, so as to convert the macroblock into a point primitive.
系数块的主要信息为DCT系数。得益于DCT的能量汇聚特性和量化过程,一个8×8系数块中的64个DCT系数仅有少量非零值分布在低频部分。虽然能够将少量系数直接放入点图元的属性中,但是不同系数块内的系数分布无规律,不利于形成适合GPU处理的规整点集,所以需要对每个系数块中的系数重新组织生成规整的结构。我们利用DCT系数的Zigzag存储形式来生成对应的系数点图元,如图5所示。Zigzag扫描将二维转化为一维形式将非零系数尽可能的集中起来。以Zigzag的一维系数数组为基础,每四个系数为一个组对应点图元中的一个四维属性。为保证点的规整性,每一个或特定多个四维属性放入一个点中,同时装入该组系数在此一维数组中的索引(系数索引),连同系数块的位置,类型,量化参数信息,形成一个DCT系数点图元。该方法的直接结果就是对每个视频块可能产生多个点图元。我们随后利用IDCT过程将分散到不同点中的结果累加起来。The main information of the coefficient block is the DCT coefficient. Thanks to the energy-gathering characteristics of DCT and the quantization process, only a small number of non-zero values of the 64 DCT coefficients in an 8×8 coefficient block are distributed in the low-frequency part. Although a small number of coefficients can be directly put into the attributes of point primitives, the distribution of coefficients in different coefficient blocks is irregular, which is not conducive to forming a regular point set suitable for GPU processing, so it is necessary to reorganize and generate the coefficients in each coefficient block regular structure. We use the Zigzag storage form of DCT coefficients to generate corresponding coefficient point primitives, as shown in Figure 5. Zigzag scanning converts two-dimensional into one-dimensional form and concentrates the non-zero coefficients as much as possible. Based on the one-dimensional coefficient array of Zigzag, every four coefficients are a four-dimensional attribute in a group corresponding to a point primitive. In order to ensure the regularity of points, each or specific four-dimensional attributes are put into a point, and the index (coefficient index) of the set of coefficients in this one-dimensional array is loaded at the same time, together with the position, type, and quantization parameter of the coefficient block information, forming a DCT coefficient point primitive. A direct consequence of this approach is that multiple point primitives may be generated for each video block. We then use the IDCT process to add up the results scattered into different points.
上述点图元的生成方法作用于每帧图像中的所有的宏块和系数块,产生的点集以顶点数组(Vertex Array)的形式存储在系统内存中,然后利用图形API绘制点集,数据以批处理的方式送入GPU完成随后的解码过程。The generation method of the above-mentioned point primitives acts on all the macroblocks and coefficient blocks in each frame image, and the generated point sets are stored in the system memory in the form of vertex arrays (Vertex Array), and then use the graphics API to draw the point sets, and the data It is sent to the GPU in batch processing to complete the subsequent decoding process.
2)初始化图形API绘制环境。2) Initialize the graphics API drawing environment.
a)调用API函数设置点图元光栅化后的大小(例如OpenGL中的glPointSize)。绘制DCT系数点集时大小设置为8并激活点精灵方式的纹理生成(Point Sprite ARBExtension),绘制宏块点集时设置为16。对于可变大小的块结构,可以将块的大小存放在点的属性中,改变GPU的顶点处理器中的PSIZE寄存器来实现不同的光栅化大小。a) Call the API function to set the rasterized size of the point primitive (for example, glPointSize in OpenGL). When drawing the DCT coefficient point set, set the size to 8 and activate the point sprite texture generation (Point Sprite ARBExtension), and set it to 16 when drawing the macroblock point set. For a variable-sized block structure, the block size can be stored in the attribute of the point, and the PSIZE register in the vertex processor of the GPU can be changed to achieve different rasterization sizes.
b)在GPU上分配好离屏缓存(off-screen buffer)空间,存放中间输出结果。我们分配了一个IDCT输出缓存和三个帧缓存。为了保证IDCT运算的精度,IDCT的输出缓存为单通道的16位浮点数格式(fp16),亮度和色度分量如图7a所示。由于运动补偿过程需要保留参考帧,三个帧缓存分别用于保存前向参考帧,后向参考帧和当前帧,帧缓存的结构为8位RGB三通道的Unsigned Byte类型,结构如图7b所示,亮度分量保存在R通道中,两个色度分量经过插值后分别保存在G和B通道中。利用GPU的“渲染到纹理”功能,如OpenGL的render to texture extension或FBO,这些缓存可以在渲染完成后直接作为纹理供采样和访问。对于IDCT输出纹理设置纹理过滤模式为“Nearest”;对于用于运动预测的帧缓存设置纹理过滤为“Bilinear”以便纹理采样时自动激活纹理过滤功能用于子像素精度运动补偿;同时设置纹理寻址模式为“Clamp”用于“非受限的运动向量”所需的对图象边缘的像素填充(padding)。b) Allocate off-screen buffer (off-screen buffer) space on the GPU to store intermediate output results. We allocated one IDCT output buffer and three frame buffers. In order to ensure the accuracy of the IDCT operation, the output buffer of the IDCT is a single-channel 16-bit floating-point number format (fp16), and the luma and chrominance components are shown in Figure 7a. Since the motion compensation process needs to retain the reference frame, the three frame buffers are used to save the forward reference frame, the backward reference frame and the current frame respectively. The structure of the frame buffer is an 8-bit RGB three-channel Unsigned Byte type, as shown in Figure 7b. As shown, the luminance component is stored in the R channel, and the two chrominance components are stored in the G and B channels respectively after interpolation. Using the GPU's "render to texture" capabilities, such as OpenGL's render to texture extension or FBO, these buffers can be sampled and accessed directly as textures after rendering is complete. For the IDCT output texture, set the texture filtering mode to "Nearest"; for the frame buffer used for motion prediction, set the texture filtering to "Bilinear" so that the texture filtering function is automatically activated when texture sampling is used for sub-pixel precision motion compensation; at the same time, set the texture addressing The mode "Clamp" is used for pixel padding to the edges of the image required for "unclamped motion vectors".
c)处理DCT基图像,合成供GPU采样用的基图像纹理。IDCT变换可以看作是DCT系数和其对应基图像的线性组合,如下列公式所示:c) Process the DCT base image and synthesize the base image texture for GPU sampling. The IDCT transform can be regarded as a linear combination of DCT coefficients and their corresponding base images, as shown in the following formula:
其中的x表示IDCT后的像素块,X(u,v)表示DCT系数块中(u,v)处的系数,T表示DCT变换矩阵,T(u)是该矩阵的第u行,系数(u,v)所应对的基图像通过列向量T(u)T和行向量T(v)的外积生成。上述公式的计算过程为标量和矩阵的乘法运算和矩阵的线性组合运算。该过程的主要优势在于每个系数的计算相对独立,而且可以直接剔除零值系数减少计算量。Among them, x represents the pixel block after IDCT, X(u, v) represents the coefficient at (u, v) in the DCT coefficient block, T represents the DCT transformation matrix, T(u) is the uth row of the matrix, and the coefficient ( The base image corresponding to u, v) is generated by the outer product of the column vector T(u)T and the row vector T(v). The calculation process of the above formula is the multiplication operation of scalar and matrix and the linear combination operation of matrix. The main advantage of this process is that the calculation of each coefficient is relatively independent, and the zero value coefficient can be directly eliminated to reduce the amount of calculation.
基图像纹理生成过程如图7所示。按照Zigzag扫描的次序,每四个系数对应的基图像存放在一个8×8纹理块的RGBA通道中,为了保证IDCT运算的精度,每个颜色通道的数据精度为16位。这样最终可以得到一个32×32大小,16位浮点数精度RGBA格式的纹理。The base image texture generation process is shown in Figure 7. According to the order of Zigzag scanning, the base image corresponding to every four coefficients is stored in the RGBA channel of an 8×8 texture block. In order to ensure the accuracy of IDCT operation, the data accuracy of each color channel is 16 bits. In this way, a 32×32 size, 16-bit floating-point number precision RGBA format texture can be obtained.
d)装入对应于绘制DCT系数点集的顶点处理程序(Vertex Program)和像素处理程序(Fragment Program)。通过Uniform参数将量化矩阵装入顶点处理程序,用于反量化。d) load the vertex processing program (Vertex Program) and the pixel processing program (Fragment Program) corresponding to drawing the DCT coefficient point set. Load the quantization matrix into the vertex handler via the Uniform parameter for dequantization.
3)完成准备工作2)后,开始绘制步骤1)生成的DCT系数点集,在绘制过程中GPU完成反量化和IDCT过程,如图9所示。3) After completing the preparatory work 2), start to draw the DCT coefficient point set generated in step 1). During the drawing process, the GPU completes the dequantization and IDCT process, as shown in FIG. 9 .
a)顶点处理器实现反量化。反量化过程本质上是量化步长和系数的乘法运算。操作过程如下:a) The vertex processor implements dequantization. The dequantization process is essentially a multiplication operation of the quantization step size and the coefficient. The operation process is as follows:
Xiq(u,v)=qp×QM(u,v)×Xq(u,v)Xiq (u, v) = qp × QM (u, v) × Xq (u, v)
其中的Xq(u,v)和Xiq(u,v)分别表示反量化前后的DCT系数,qp所表示的量化参数已经通过步骤1)中系数点图元的生成过程放入点的属性中,QM(u,v)表示量化矩阵的对应项,整个量化矩阵已经在步骤2)d)中装入常量寄存器,对应的项(entry)可以通过步骤1)中引入的系数索引获取。由于系数以向量形式存放,顶点处理程序中一次向量乘法可以完成四个系数的反量化过程。Among them, Xq (u, v) andXiq (u, v) respectively represent the DCT coefficients before and after inverse quantization, and the quantization parameter represented by qp has been put into the attribute of the point through the generation process of the coefficient point primitive in step 1) where QM(u, v) represents the corresponding entry of the quantization matrix, the entire quantization matrix has been loaded into the constant register in step 2)d), and the corresponding entry (entry) can be obtained through the coefficient index introduced in step 1). Since the coefficients are stored in the form of vectors, one vector multiplication in the vertex processing program can complete the inverse quantization process of the four coefficients.
顶点处理程序还可以根据系数索引计算出系数对应的基图像的纹理坐标,并传递到随后的光栅化阶段。The vertex processing program can also calculate the texture coordinates of the base image corresponding to the coefficients according to the coefficient indexes, and pass them to the subsequent rasterization stage.
b)光删化阶段根据步骤2)a)中设定的点的大小和顶点处理器输出的位置,将点图元转化为相应位置上指定大小的像素块。同时像素块所覆盖的每个像素都继承了点图元在顶点处理阶段的输出属性。对于系数点集,激活步骤2)a)点精灵纹理生成后,每个像素会生成对应的块内纹理坐标,范围(0,0)-(1,1)。b) In the stage of light deletion, according to the size of the point set in step 2)a) and the position output by the vertex processor, the point primitive is converted into a pixel block of the specified size at the corresponding position. At the same time, each pixel covered by the pixel block inherits the output attributes of the point primitive in the vertex processing stage. For the coefficient point set, activate step 2) a) After the sprite texture is generated, each pixel will generate the corresponding texture coordinates in the block, ranging from (0, 0)-(1, 1).
c)像素处理器结合a)中输出的基图像纹理坐标和b)中形成的块内纹理坐标,可以精确采样每个像素点对应的基图像纹理值。考虑步骤2)c)中的IDCT计算公式。此时已经将标量与矩阵间的乘法运算转换为了像素间的直接运算形式。由于系数和基图像纹理值都以RGBA四维向量的形式存在,像素处理程序中的一次向量点乘操作就可以完成四个系数的乘法和累加,然后输出结果到缓存中。c) The pixel processor can accurately sample the base image texture value corresponding to each pixel by combining the base image texture coordinates output in a) and the block texture coordinates formed in b). Consider the IDCT calculation formula in step 2)c). At this point, the multiplication operation between the scalar and the matrix has been converted into a direct operation form between pixels. Since both coefficients and base image texture values exist in the form of RGBA four-dimensional vectors, one vector point multiplication operation in the pixel processing program can complete the multiplication and accumulation of four coefficients, and then output the result to the cache.
d)激活GPU硬件的混合功能(Blending),并设置为Add运算。由于步骤1)中每个系数块可能生成的多个系数点图元,通过该步骤每个点图元输出的运算结果可以最终在输出缓存中累加,从而完成步骤2)c)中IDCT计算公式中对所有系数的线性累加。d) Activate the blending function (Blending) of the GPU hardware and set it to Add operation. Since each coefficient block in step 1) may generate multiple coefficient point primitives, the calculation results output by each point primitive in this step can be finally accumulated in the output cache, thereby completing the IDCT calculation formula in step 2) c) Linear accumulation of all coefficients in .
到此,DCT系数点集的绘制完成,视频中系数块反量化和IDCT后的结果保存在IDCT的输出缓存中,作为残差图像纹理用于随后的运动补偿过程。At this point, the drawing of the DCT coefficient point set is completed, and the result of inverse quantization and IDCT of the coefficient block in the video is stored in the output buffer of IDCT, which is used as a residual image texture for the subsequent motion compensation process.
4)装入用于运动补偿的顶点和像素处理程序,设置宏块点的大小(16),绘制宏块点集完成运动补偿过程,如图10所示。4) Load the vertex and pixel processing program for motion compensation, set the size of the macroblock point (16), draw the macroblock point set to complete the motion compensation process, as shown in Figure 10.
a)顶点处理程序主要用于对运动向量进行预处理。根据运动向量的像素精度产生对应的小数部分,以便在纹理采样时利用纹理的双线性过滤硬件自动完成像素的插值。例如对于半像素精度,小数部分为0.5。图8a和图8b简单说明了像素插值和纹理双线性过滤过程。a) The vertex handler is mainly used to preprocess the motion vector. According to the pixel precision of the motion vector, the corresponding fractional part is generated, so that the bilinear filtering hardware of the texture can be used to automatically complete the pixel interpolation when the texture is sampled. For example, for half-pixel precision, the fractional part is 0.5. Figure 8a and Figure 8b briefly illustrate the pixel interpolation and texture bilinear filtering process.
b)光栅化产生宏块大小的像素块,每个像素都继承a)中输出的运动向量。b) Rasterization produces macroblock-sized blocks of pixels, each pixel inheriting the motion vector output in a).
c)像素处理程序中,首先利用WPOS寄存器得到每个像素的位置,然后利用运动向量对该位置进行偏移得出对应参考块的纹理坐标。像素处理程序采样参考帧纹理和IDCT输出的残差图像纹理,累加采样值并做饱和化处理,输出结果到帧缓存中。c) In the pixel processing program, first use the WPOS register to obtain the position of each pixel, and then use the motion vector to offset the position to obtain the texture coordinates of the corresponding reference block. The pixel processing program samples the reference frame texture and the residual image texture output by IDCT, accumulates the sampled values and performs saturation processing, and outputs the result to the frame buffer.
5)帧缓存中的图像如果需要输出到显示设备上,需要进行颜色空间转化。实现过程为绘制一个图像大小的矩形,利用像素处理程序采样步骤4)c)输出的帧缓存,并对每个像素做颜色变化,并将结果输出显示。最终完成整个解码过程。5) If the image in the frame buffer needs to be output to the display device, color space conversion is required. The implementation process is to draw a rectangle with the size of an image, use the pixel processing program to sample the frame buffer output in step 4) c), and change the color of each pixel, and output and display the result. Finally complete the entire decoding process.
上述步骤给出了利用GPU完成视频解码的全部过程,本发明中CPU仅用于生成和组织绘制用的点集,其他所有解码环节都在GPU上完成,最大限度降低了CPU的计算负担;通过将视频中宏块和系数块表示为点图元,整个解码过程高效的映射为点图元的绘制过程,充分发挥了GPU上的计算资源,借助于GPU硬件的并行计算和流水线处理的加速功能,本发明显著提高了视频解码的效率。The above steps have provided the whole process of utilizing the GPU to complete video decoding. In the present invention, the CPU is only used to generate and organize the point sets used for drawing, and all other decoding links are completed on the GPU, which reduces the computational burden of the CPU to the greatest extent; The macroblocks and coefficient blocks in the video are represented as point primitives, and the entire decoding process is efficiently mapped to the drawing process of point primitives, giving full play to the computing resources on the GPU, with the help of GPU hardware parallel computing and pipeline processing acceleration functions , the present invention significantly improves the efficiency of video decoding.
尽管为说明目的公开了本发明的具体实施例和附图,其目的在于帮助理解本发明的内容并据以实施,但是本领域的技术人员可以理解:在不脱离本发明及所附的权利要求的精神和范围内,各种替换、变化和修改都是可能的。因此,本发明不应局限于最佳实施例和附图所公开的内容。Although specific embodiments and drawings of the present invention are disclosed for the purpose of illustration, the purpose is to help understand the content of the present invention and implement it accordingly, but those skilled in the art can understand that: without departing from the present invention and the appended claims Various substitutions, changes and modifications are possible within the spirit and scope of . Therefore, the present invention should not be limited to what is disclosed in the preferred embodiments and drawings.
Claims (9)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN2006100892521ACN101123723B (en) | 2006-08-11 | 2006-08-11 | Digital Video Decoding Method Based on Graphics Processor |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN2006100892521ACN101123723B (en) | 2006-08-11 | 2006-08-11 | Digital Video Decoding Method Based on Graphics Processor |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN101123723A CN101123723A (en) | 2008-02-13 |
| CN101123723Btrue CN101123723B (en) | 2011-01-12 |
Family
ID=39085869
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN2006100892521AExpired - Fee RelatedCN101123723B (en) | 2006-08-11 | 2006-08-11 | Digital Video Decoding Method Based on Graphics Processor |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN101123723B (en) |
Families Citing this family (37)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101577110B (en)* | 2009-05-31 | 2012-04-25 | 腾讯科技(深圳)有限公司 | Method for playing videos and video player |
| CN102164284A (en)* | 2010-02-24 | 2011-08-24 | 富士通株式会社 | Video decoding method and system |
| CN102158694B (en)* | 2010-12-01 | 2012-12-26 | 航天恒星科技有限公司 | Remote-sensing image decompression method based on GPU (Graphics Processing Unit) |
| CN102904857A (en)* | 2011-07-25 | 2013-01-30 | 风网科技(北京)有限公司 | Client video playing system and method thereof |
| CN102404576A (en)* | 2011-11-30 | 2012-04-04 | 国云科技股份有限公司 | Cloud terminal decoder and its load balancing algorithm and GPU decoding algorithm |
| CN102497550A (en)* | 2011-12-05 | 2012-06-13 | 南京大学 | Parallel acceleration method and device for motion compensation interpolation in H.264 encoding |
| CN108924563B (en) | 2011-12-19 | 2022-11-15 | 索尼公司 | Image processing device and method |
| CN102547289B (en)* | 2012-01-17 | 2015-01-28 | 西安电子科技大学 | Fast motion estimation method realized based on GPU (Graphics Processing Unit) parallel |
| CN102932003B (en)* | 2012-09-07 | 2016-05-04 | 上海交通大学 | The acceleration interpretation method of the QC-LDPC code based on GPU framework |
| CN103077688B (en)* | 2013-01-11 | 2015-02-18 | 北京京东方光电科技有限公司 | Source electrode driving device and source electrode driving method of liquid crystal display screen |
| CN103108186A (en)* | 2013-02-21 | 2013-05-15 | 中国对外翻译出版有限公司 | Method of achieving high-definition transmission of videos |
| CN104104958B (en)* | 2013-04-08 | 2017-08-25 | 联发科技(新加坡)私人有限公司 | Picture decoding method and its picture decoding apparatus |
| CN104143334B (en)* | 2013-05-10 | 2017-06-16 | 中国电信股份有限公司 | Programmable graphics processor and its method that audio mixing is carried out to MCVF multichannel voice frequency |
| CN103327413A (en)* | 2013-06-26 | 2013-09-25 | 四川长虹电器股份有限公司 | Method for achieving alpha animation in smart television |
| CN103427844B (en)* | 2013-07-26 | 2016-03-02 | 华中科技大学 | A kind of high-speed lossless data compression method based on GPU and CPU mixing platform |
| CN104519353B (en)* | 2013-09-29 | 2019-02-05 | 联想(北京)有限公司 | Image processing method and electronic equipment |
| CN104702954B (en)* | 2013-12-05 | 2017-11-17 | 华为技术有限公司 | Method for video coding and device |
| US9693077B2 (en)* | 2013-12-13 | 2017-06-27 | Qualcomm Incorporated | Controlling sub prediction unit (sub-PU) motion parameter inheritance (MPI) in three dimensional (3D) HEVC or other 3D coding |
| CN103841389B (en)* | 2014-04-02 | 2015-10-21 | 北京奇艺世纪科技有限公司 | A kind of video broadcasting method and player |
| WO2016076659A1 (en) | 2014-11-14 | 2016-05-19 | 엘지전자(주) | Method and device for performing graph-based transform using generalized graph parameter |
| CN104836970B (en)* | 2015-03-27 | 2018-06-15 | 北京联合大学 | More projection fusion methods and system based on GPU real time video processings |
| CN105120293B (en)* | 2015-08-26 | 2018-07-06 | 中国航空工业集团公司洛阳电光设备研究所 | Image collaboration coding/decoding method and device based on CPU and GPU |
| CN105678681A (en)* | 2015-12-30 | 2016-06-15 | 广东威创视讯科技股份有限公司 | GPU data processing method, GPU, PC architecture processor and GPU data processing system |
| CN105787987B (en)* | 2016-03-15 | 2019-07-30 | 广州爱九游信息技术有限公司 | A kind of Texture Processing Methods and electronic equipment |
| CN107239268A (en)* | 2016-03-29 | 2017-10-10 | 阿里巴巴集团控股有限公司 | A kind of method for processing business, device and intelligent terminal |
| US10237566B2 (en) | 2016-04-01 | 2019-03-19 | Microsoft Technology Licensing, Llc | Video decoding using point sprites |
| US10575007B2 (en) | 2016-04-12 | 2020-02-25 | Microsoft Technology Licensing, Llc | Efficient decoding and rendering of blocks in a graphics pipeline |
| US10157480B2 (en) | 2016-06-24 | 2018-12-18 | Microsoft Technology Licensing, Llc | Efficient decoding and rendering of inter-coded blocks in a graphics pipeline |
| CN106210726A (en)* | 2016-08-08 | 2016-12-07 | 成都佳发安泰科技股份有限公司 | The method that utilization rate according to CPU Yu GPU carries out adaptive decoding to video data |
| CN106331852A (en)* | 2016-09-13 | 2017-01-11 | 武汉斗鱼网络科技有限公司 | Method and system of using WP cell phone for H264 hardware decoding |
| US11197010B2 (en) | 2016-10-07 | 2021-12-07 | Microsoft Technology Licensing, Llc | Browser-based video decoder using multiple CPU threads |
| CN106504185B (en)* | 2016-10-26 | 2020-04-07 | 腾讯科技(深圳)有限公司 | Rendering optimization method and device |
| CN106792066A (en)* | 2016-12-20 | 2017-05-31 | 暴风集团股份有限公司 | The method and system that the video decoding of optimization is played |
| CN107172432A (en)* | 2017-03-23 | 2017-09-15 | 杰发科技(合肥)有限公司 | A kind of method for processing video frequency, device and terminal |
| CN109005160A (en)* | 2018-07-10 | 2018-12-14 | 广州虎牙信息科技有限公司 | Video encoding/decoding method, device and computer readable storage medium, terminal |
| CN109408028B (en)* | 2018-09-21 | 2021-03-05 | 东软集团股份有限公司 | Floating point number operation method and device and storage medium |
| CN111464773A (en)* | 2020-04-08 | 2020-07-28 | 湖南泽天智航电子技术有限公司 | Multi-channel video display method and system |
- 2006
- 2006-08-11CNCN2006100892521Apatent/CN101123723B/ennot_activeExpired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| CN101123723A (en) | 2008-02-13 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN101123723B (en) | Digital Video Decoding Method Based on Graphics Processor | |
| US10783698B2 (en) | Point cloud operations | |
| US10719447B2 (en) | Cache and compression interoperability in a graphics processor pipeline | |
| US7565021B2 (en) | Efficient implementation of block-based transform on graphics processing unit | |
| US10008034B2 (en) | System, method, and computer program product for computing indirect lighting in a cloud network | |
| US20140153635A1 (en) | Method, computer program product, and system for multi-threaded video encoding | |
| US10140732B2 (en) | Method and apparatus for efficient texture compression | |
| CN111402380B (en) | GPU compressed texture processing method | |
| WO2017172053A2 (en) | Method and apparatus for multi format lossless compression | |
| US10397542B2 (en) | Facilitating quantization and compression of three-dimensional graphics data using screen space metrics at computing devices | |
| CN102158694A (en) | Remote-sensing image decompression method based on GPU (Graphics Processing Unit) | |
| WO2017105595A1 (en) | Graphics processor logic for encoding increasing or decreasing values | |
| JP7676447B2 (en) | Delta Triplet Index Compression | |
| CN101754039A (en) | Three-dimensional parameter decoding system for mobile devices | |
| US11978234B2 (en) | Method and apparatus of data compression | |
| CN101415117A (en) | Transmission method for high presence image based on GPGPU | |
| CN102164284A (en) | Video decoding method and system | |
| CN102572436A (en) | Intra-frame compression method based on CUDA (Compute Unified Device Architecture) | |
| US10198850B2 (en) | Method and apparatus for filtering compressed textures | |
| Nagayasu et al. | A decompression pipeline for accelerating out-of-core volume rendering of time-varying data | |
| Datla et al. | Parallelizing motion JPEG 2000 with CUDA | |
| US7911478B2 (en) | Drawing device, drawing method, and drawing program | |
| Kwan et al. | Packing vertex data into hardware-decompressible textures | |
| Han et al. | Efficient video decoding on GPUs by point based rendering | |
| Krajcevski et al. | Compressed coverage masks for path rendering on mobile GPUs |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C14 | Grant of patent or utility model | ||
| GR01 | Patent grant | ||
| C17 | Cessation of patent right | ||
| CF01 | Termination of patent right due to non-payment of annual fee | Granted publication date:20110112 Termination date:20130811 |