LLMにやさしい言語SuiはLLMにやさしくなさそう
LLMにやさしい言語という謳い文句の言語、Suiが話題。
けどこれ、LLMにあまりやさしくなんじゃなかろうか。
https://github.com/TakatoHonda/sui-lang
9月にこういうエントリを書いてます。
AI専用のプログラミング言語は現れない - きしだのHatena
ここで理由として挙げたのは、この4点です。
- すでにAIは独自の言語を持っている
- 低レベルな記述にはコストがかかる
- 意味の記述が必要であることに変わりはない
- 作っても学習させるのが大変
この4点にあてはまっていると思います。
追記:
あと、こういうことも10月に書いてます。
AIが読み書きするコードも読みやすいほうがいい(トランスフォーマの特性の考慮やリーダブルコードについて追記) - きしだのHatena
去年の4月ですが、こういうことも書いてました。
AIがコードを書くようになるなら、AIだけに理解できる言語を作ればいい、のかな? - きしだのHatena
ブコメに「永久に流行りのフレームワークもプログラミング言語も変わらないという事になるのでは」とありますが、すでにある程度プログラミング言語は完成しつつユースケースによっての住み分けも行われているので「今のプログラミング言語は1000年残る」ということを書いてます。
そして追記:
本田さんからの背景説明や方向性の説明のブログ出てます。面白かったので今回の話に興味ある方はぜひ。
「LLMにやさしい言語SuiはLLMにやさしくなれそう」|本田崇人(ほんだたかと)
さらに追記(12/14):
SuiにやさしいLLMを作る試みをやってみました。
LLMにやさしいSui言語にやさしいLLMを作る - きしだのHatena
トークンの節約になってない
まず、命令が記号1文字なのでトークンの節約になるということが書かれてますが、プログラム言語で頻出のキーワードはだいたい1トークンになっています。
ここで、.utilや");なども1トークンになっています。また、javaやpublicは前後のスペースも含めて1トークンです。つまり、よくある処理をよくある書き方で書けばトークンが節約されます。
このように、人間が見た通りにAIが扱っているわけではなく、すでに言語を扱いやすく変化させています。
一方で、cx = (px * scale) / width - (scale/2) + centerXに相当するSuiコードは次のようなトークン化がされています。vやaはひとつまえのスペースと共にトークン化されているので1トークンですが、やってる内容の割にトークン数が多いです。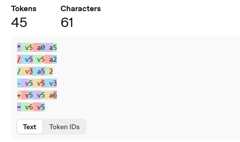
ちなみにcx = (px * scale) / width - (scale/2) + centerXは18トークンです。
命令が細粒度なので、一連の処理のための命令数が増えます。そうするとトークンがかなり増えていきます。
意味の記述が必要であることに変わりはない
実際にChatGPTにマンデルブローを書かせてみた先頭部分がこれです。結局、コメントとして仮コードが埋め込まれてますね。
; 16.16 固定小数点を使ったマンデルブロ集合の 1 ピクセル計算; f0(px, py, width, height, maxIter, scale_fixed, centerX_fixed, centerY_fixed) -> returns iter# 0 8 { ; args: a0=px, a1=py, a2=width, a3=height, a4=maxIter, a5=scale, a6=centerX, a7=centerY = v0 0 ; iter = v1 0 ; x (fixed) = v2 0 ; y (fixed) = v3 0 = v4 0 = v5 0 = v6 0 ; cx = v7 0 ; cy = v8 0 = v9 0 = v10 0 ; cx = (px * scale) / width - (scale/2) + centerX * v5 a0 a5 / v5 v5 a2 / v3 a5 2 - v5 v5 v3 + v5 v5 a6 = v6 v5また、Thinkingで次のような思考が行われています。Thinkingでは結局変数名を使った思考が行われる気がします。
「コメントを書くな」などの指示を行うと、恐らくThinkingでコードを書いてから、そのコードを抜いたものを出力するという挙動にもなりそうです。
と思ったけど、gpt-oss 120bは聞いてくれずコメント書いてた。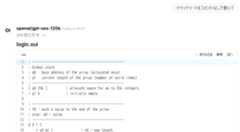
コメントに仮コードを書きながら書き下すのであれば、最初から高級言語を使うほうがトークンも節約できます。
自然言語で要求を与えて、自然言語でThinkingが行われるのであれば、結局のところ自然言語に近い高級言語のほうがLLMにやさしいように思います。
Sui版のマンデルブローは動かなかったので、JavaScriptで書いてもらいました。これは学習不足もあると思うので、言語の問題とは必ずしも言えないと思います。いまのLLMはJavaScriptで書かれたマンデルブローをたくさん学習してるはず。
追記: AIがコードを読むとき変数名などをかなり参考にしているという論文ありました。
https://arxiv.org/abs/2510.03178v1
LLMには実際には厳しいんじゃなかろうか
細粒度の命令を組み合わせて処理を書くと、同じ処理の中では似たような命令列の繰り返しが多くなります。
そうすると、いまのLLMでは繰り返しが発生する可能性が高くなります。
実際、GLM 4.5-Airに「クイックソートをコメントなしで書いて」とやると、不要な処理を繰り返して止まらなくなりました。
LLMに学習させるにしても、頻出する命令列のパターンをたくさん学習させる必要があります。恐らく、現状でもある程度のコードが書けているのはアセンブリに近いからだと思います。けれども配列や関数など使いこなしてもっとうまく書かせようとすると、Suiならではのパターンをたくさん覚えさせる必要があります。
しかしながら、そういうパターンが既存言語の言語機能で表せるのであれば、LLMは既存言語の共通概念を学んでいるので、流用したほうがLLMにやさしいはずです。
また、変数が多くなってv99やv100などになったとき、その役割を覚えることはLLMにとって苦手なことです。特に、v100が必要なくらいコードが長くなって変数定義との距離があいてしまうと、間違いが増えると思います。
実際には、LLMに厳しい言語仕様のように思います。
性能が高いLLMであればこなすだろうけど、それはLLMに厳しいということになります。LLMにやさしいのであれば、サイズが小さく性能の低いLLMにも書きやすい必要があると思います。
プログラミング言語で発展した仕組みを流用したほうがいいのでは
プログラミング言語は、人間がわかりやすいだけではなく、論理を記述します。論理を記述することで、やりたいことを的確に正しく表現できることになります。というか、人間に簡単にわかりやすいものではないので、ある程度の訓練が必要です。
間違いを減らすには冗長性も大事です。v0やv1という名前は、cxとcyという名前より間違いに気付くのが難しくなります。LLMは記号の処理がうまいわけではなく、自然言語のほうが得意なので、自然言語に近い変数名のほうが扱いがうまいです。
LLMに間違いなくプログラムを書かせるには、それなりの型機能をもって自然言語と同じキーワードを持つ言語のほうが適しているように思います。
論理を発展させて計算を記述することがベースになっています。そこに人間が書きやすいような文法を当てはめているだけです。論理構造は既存言語が持つものと共通にしたほうが、LLMに書きやすくなるはずです。また、記号を独自の意味で使うよりも、広く使われる意味に近い使い方のほうがLLMに書きやすくなるはずです。
専用に学習させるにしても、基礎知識として学習させているWikipediaやPythonに近いほうが、知識を転移させやすいと思います。
いまのプログラミング言語は、70年かけて論理による制約と記述の容易さバランスがとられてきたものです。そうすると、ふつうのプログラミング言語が結局はLLMにとっても書きやすくなると思います。
追記Markdownに4文字付け足すだけのコミットもしました🎉。

)")


